
Commit
•
41062fa
1
Parent(s):
cdda9a8
Upload 10 files
Browse files- config.json +37 -0
- finetune_10270700.log +0 -0
- finetuning_wrime_02_optuna.py +274 -0
- history.csv +16 -0
- output.png +0 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +7 -0
- tokenizer_config.json +19 -0
- training_args.bin +3 -0
- vocab.txt +0 -0
config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "cl-tohoku/bert-base-japanese-whole-word-masking",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_dropout_prob": 0.1,
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"id2label": {
|
| 12 |
+
"0": "positive",
|
| 13 |
+
"1": "negative",
|
| 14 |
+
"2": "neutral"
|
| 15 |
+
},
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"intermediate_size": 3072,
|
| 18 |
+
"label2id": {
|
| 19 |
+
"negative": 1,
|
| 20 |
+
"neutral": 2,
|
| 21 |
+
"positive": 0
|
| 22 |
+
},
|
| 23 |
+
"layer_norm_eps": 1e-12,
|
| 24 |
+
"max_position_embeddings": 512,
|
| 25 |
+
"model_type": "bert",
|
| 26 |
+
"num_attention_heads": 12,
|
| 27 |
+
"num_hidden_layers": 12,
|
| 28 |
+
"pad_token_id": 0,
|
| 29 |
+
"position_embedding_type": "absolute",
|
| 30 |
+
"problem_type": "single_label_classification",
|
| 31 |
+
"tokenizer_class": "BertJapaneseTokenizer",
|
| 32 |
+
"torch_dtype": "float32",
|
| 33 |
+
"transformers_version": "4.33.2",
|
| 34 |
+
"type_vocab_size": 2,
|
| 35 |
+
"use_cache": true,
|
| 36 |
+
"vocab_size": 32000
|
| 37 |
+
}
|
finetune_10270700.log
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
finetuning_wrime_02_optuna.py
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# %%
|
| 2 |
+
import torch
|
| 3 |
+
# GPUが使用可能か判断
|
| 4 |
+
if torch.cuda.is_available():
|
| 5 |
+
print('gpu is available')
|
| 6 |
+
else:
|
| 7 |
+
raise Exception('gpu is NOT available')
|
| 8 |
+
|
| 9 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 10 |
+
device
|
| 11 |
+
|
| 12 |
+
# %%
|
| 13 |
+
from datasets import load_dataset, DatasetDict
|
| 14 |
+
from transformers import AutoTokenizer
|
| 15 |
+
from transformers import AutoModelForSequenceClassification
|
| 16 |
+
from transformers import TrainingArguments
|
| 17 |
+
from transformers import Trainer
|
| 18 |
+
from sklearn.metrics import accuracy_score, f1_score
|
| 19 |
+
import numpy as np
|
| 20 |
+
import pandas as pd
|
| 21 |
+
import torch
|
| 22 |
+
import random
|
| 23 |
+
|
| 24 |
+
# %%
|
| 25 |
+
from transformers.trainer_utils import set_seed
|
| 26 |
+
|
| 27 |
+
# 乱数シードを42に固定
|
| 28 |
+
set_seed(42)
|
| 29 |
+
|
| 30 |
+
# %%
|
| 31 |
+
from pprint import pprint
|
| 32 |
+
from datasets import load_dataset
|
| 33 |
+
|
| 34 |
+
# Hugging Face Hub上のllm-book/wrime-sentimentのリポジトリから
|
| 35 |
+
# データを読み込む
|
| 36 |
+
train_dataset = load_dataset("llm-book/wrime-sentiment", split="train", remove_neutral=False)
|
| 37 |
+
valid_dataset = load_dataset("llm-book/wrime-sentiment", split="validation", remove_neutral=False)
|
| 38 |
+
# pprintで見やすく表示する
|
| 39 |
+
pprint(train_dataset)
|
| 40 |
+
pprint(valid_dataset)
|
| 41 |
+
|
| 42 |
+
# %%
|
| 43 |
+
# トークナイザのロード
|
| 44 |
+
model_name = "cl-tohoku/bert-base-japanese-whole-word-masking"
|
| 45 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 46 |
+
|
| 47 |
+
# %%
|
| 48 |
+
# トークナイズ処理
|
| 49 |
+
def preprocess_text(batch):
|
| 50 |
+
encoded_batch = tokenizer(batch['sentence'], max_length=100)
|
| 51 |
+
encoded_batch['labels'] = batch['label']
|
| 52 |
+
return encoded_batch
|
| 53 |
+
|
| 54 |
+
# %%
|
| 55 |
+
encoded_train_dataset = train_dataset.map(
|
| 56 |
+
preprocess_text,
|
| 57 |
+
remove_columns=train_dataset.column_names,
|
| 58 |
+
)
|
| 59 |
+
encoded_valid_dataset = valid_dataset.map(
|
| 60 |
+
preprocess_text,
|
| 61 |
+
remove_columns=valid_dataset.column_names,
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
# %%
|
| 65 |
+
# ミニバッチ構築
|
| 66 |
+
from transformers import DataCollatorWithPadding
|
| 67 |
+
|
| 68 |
+
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
|
| 69 |
+
|
| 70 |
+
# %%
|
| 71 |
+
# オプティマイザ
|
| 72 |
+
OPTIMIZER_NAME = "adamw_torch"
|
| 73 |
+
|
| 74 |
+
# 最適化するハイパーパラメータ
|
| 75 |
+
def optuna_hp_space(trial):
|
| 76 |
+
return {
|
| 77 |
+
"lr_scheduler_type": trial.suggest_categorical("lr_scheduler_type", ["constant", "linear", "cosine"]),
|
| 78 |
+
"learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
|
| 79 |
+
"per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128, 256]),
|
| 80 |
+
"weight_decay": trial.suggest_float("weight_decay", 1e-6, 1e-1, log=True),
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
# %%
|
| 84 |
+
# モデルの準備
|
| 85 |
+
from transformers import AutoModelForSequenceClassification
|
| 86 |
+
|
| 87 |
+
def model_init(trial):
|
| 88 |
+
class_label = train_dataset.features["label"]
|
| 89 |
+
label2id = {label: id for id, label in enumerate(class_label.names)}
|
| 90 |
+
id2label = {id: label for id, label in enumerate(class_label.names)}
|
| 91 |
+
model = AutoModelForSequenceClassification.from_pretrained(
|
| 92 |
+
model_name,
|
| 93 |
+
num_labels=class_label.num_classes,
|
| 94 |
+
label2id=label2id, # ラベル名からIDへの対応を指定
|
| 95 |
+
id2label=id2label, # IDからラベル名への対応を指定
|
| 96 |
+
)
|
| 97 |
+
return model
|
| 98 |
+
|
| 99 |
+
# %%
|
| 100 |
+
# 訓練の実行
|
| 101 |
+
from transformers import TrainingArguments
|
| 102 |
+
|
| 103 |
+
training_args = TrainingArguments(
|
| 104 |
+
optim=OPTIMIZER_NAME, # オプティマイザの種類
|
| 105 |
+
output_dir="output_wrime", # 結果の保存フォルダ
|
| 106 |
+
# per_device_train_batch_size=32, # 訓練時のバッチサイズ
|
| 107 |
+
# per_device_eval_batch_size=32, # 評価時のバッチサイズ
|
| 108 |
+
# learning_rate=2e-5, # 学習率
|
| 109 |
+
# lr_scheduler_type="constant", # 学習率スケジューラの種類
|
| 110 |
+
warmup_ratio=0.1, # 学習率のウォームアップの長さを指定
|
| 111 |
+
num_train_epochs=3, # エポック数
|
| 112 |
+
save_strategy="epoch", # チェックポイントの保存タイミング
|
| 113 |
+
logging_strategy="epoch", # ロギングのタイミング
|
| 114 |
+
evaluation_strategy="epoch", # 検証セットによる評価のタイミング
|
| 115 |
+
load_best_model_at_end=True, # 訓練後に開発セットで最良のモデルをロード
|
| 116 |
+
metric_for_best_model="accuracy", # 最良のモデルを決定する評価指標
|
| 117 |
+
gradient_checkpointing=True, # 勾配チェックポイント
|
| 118 |
+
fp16=True, # 自動混合精度演算の有効化
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
# %%
|
| 122 |
+
# メトリクスの定義
|
| 123 |
+
def compute_metrics(pred):
|
| 124 |
+
labels = pred.label_ids
|
| 125 |
+
preds = pred.predictions.argmax(-1)
|
| 126 |
+
f1 = f1_score(labels, preds, average="weighted")
|
| 127 |
+
acc = accuracy_score(labels, preds)
|
| 128 |
+
return {"accuracy": acc, "f1": f1}
|
| 129 |
+
|
| 130 |
+
# %%
|
| 131 |
+
from transformers import Trainer
|
| 132 |
+
|
| 133 |
+
trainer = Trainer(
|
| 134 |
+
model=None,
|
| 135 |
+
train_dataset=encoded_train_dataset,
|
| 136 |
+
eval_dataset=encoded_valid_dataset,
|
| 137 |
+
data_collator=data_collator,
|
| 138 |
+
args=training_args,
|
| 139 |
+
compute_metrics=compute_metrics,
|
| 140 |
+
model_init=model_init,
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
# %%
|
| 144 |
+
def compute_objective(metrics):
|
| 145 |
+
return metrics["eval_f1"]
|
| 146 |
+
|
| 147 |
+
# %%
|
| 148 |
+
best_trial = trainer.hyperparameter_search(
|
| 149 |
+
direction="maximize",
|
| 150 |
+
backend="optuna",
|
| 151 |
+
hp_space=optuna_hp_space,
|
| 152 |
+
n_trials=50,
|
| 153 |
+
# n_trials=3, # TEST
|
| 154 |
+
compute_objective=compute_objective,
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
# %%
|
| 158 |
+
print('-'*80)
|
| 159 |
+
# ベスト-ハイパーパラメータ
|
| 160 |
+
print('optimizer:',OPTIMIZER_NAME)
|
| 161 |
+
print(best_trial)
|
| 162 |
+
|
| 163 |
+
## 最適化されたハイパーパラメータでFineTuning
|
| 164 |
+
|
| 165 |
+
# %%
|
| 166 |
+
# モデルの準備
|
| 167 |
+
from transformers import AutoModelForSequenceClassification
|
| 168 |
+
|
| 169 |
+
class_label = train_dataset.features["label"]
|
| 170 |
+
label2id = {label: id for id, label in enumerate(class_label.names)}
|
| 171 |
+
id2label = {id: label for id, label in enumerate(class_label.names)}
|
| 172 |
+
model = AutoModelForSequenceClassification.from_pretrained(
|
| 173 |
+
model_name,
|
| 174 |
+
num_labels=class_label.num_classes,
|
| 175 |
+
label2id=label2id, # ラベル名からIDへの対応を指定
|
| 176 |
+
id2label=id2label, # IDからラベル名への対応を指定
|
| 177 |
+
)
|
| 178 |
+
print(type(model).__name__)
|
| 179 |
+
|
| 180 |
+
# %%
|
| 181 |
+
# 訓練用の設定
|
| 182 |
+
from transformers import TrainingArguments
|
| 183 |
+
|
| 184 |
+
# ベストパラメータ
|
| 185 |
+
best_lr_type = best_trial.hyperparameters['lr_scheduler_type']
|
| 186 |
+
best_lr = best_trial.hyperparameters['learning_rate']
|
| 187 |
+
best_batch_size = best_trial.hyperparameters['per_device_train_batch_size']
|
| 188 |
+
best_weight_decay = best_trial.hyperparameters['weight_decay']
|
| 189 |
+
# 保存ディレクトリ
|
| 190 |
+
save_dir = f'bert-finetuned-wrime-{OPTIMIZER_NAME}'
|
| 191 |
+
|
| 192 |
+
training_args = TrainingArguments(
|
| 193 |
+
output_dir=save_dir, # 結果の保存フォルダ
|
| 194 |
+
optim=OPTIMIZER_NAME, # オプティマイザの種類
|
| 195 |
+
per_device_train_batch_size=best_batch_size, # 訓練時のバッチサイズ
|
| 196 |
+
per_device_eval_batch_size=best_batch_size, # 評価時のバッチサイズ
|
| 197 |
+
learning_rate=best_lr, # 学習率
|
| 198 |
+
lr_scheduler_type=best_lr_type, # 学習率スケジューラの種類
|
| 199 |
+
weight_decay=best_weight_decay, # 正則化
|
| 200 |
+
warmup_ratio=0.1, # 学習率のウォームアップの長さを指定
|
| 201 |
+
num_train_epochs=100, # エポック数
|
| 202 |
+
# num_train_epochs=3, # エポック数 TEST
|
| 203 |
+
save_strategy="epoch", # チェックポイントの保存タイミング
|
| 204 |
+
logging_strategy="epoch", # ロギングのタイミング
|
| 205 |
+
evaluation_strategy="epoch", # 検証セットによる評価のタイミング
|
| 206 |
+
load_best_model_at_end=True, # 訓練後に開発セットで最良のモデルをロード
|
| 207 |
+
metric_for_best_model="accuracy", # 最良のモデルを決定する評価指標
|
| 208 |
+
fp16=True, # 自動混合精度演算の有効化
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
# %%
|
| 212 |
+
# 訓練の実施
|
| 213 |
+
from transformers import Trainer
|
| 214 |
+
from transformers import EarlyStoppingCallback
|
| 215 |
+
|
| 216 |
+
trainer = Trainer(
|
| 217 |
+
model=model,
|
| 218 |
+
train_dataset=encoded_train_dataset,
|
| 219 |
+
eval_dataset=encoded_valid_dataset,
|
| 220 |
+
data_collator=data_collator,
|
| 221 |
+
args=training_args,
|
| 222 |
+
compute_metrics=compute_metrics,
|
| 223 |
+
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)],
|
| 224 |
+
)
|
| 225 |
+
trainer.train()
|
| 226 |
+
|
| 227 |
+
# %%
|
| 228 |
+
# モデルの保存
|
| 229 |
+
trainer.save_model(save_dir)
|
| 230 |
+
tokenizer.save_pretrained(save_dir)
|
| 231 |
+
|
| 232 |
+
# %%
|
| 233 |
+
# 結果描画用関数
|
| 234 |
+
import matplotlib.pyplot as plt
|
| 235 |
+
from sklearn.linear_model import LinearRegression
|
| 236 |
+
|
| 237 |
+
def show_graph(df, suptitle, output='output.png'):
|
| 238 |
+
suptitle_size = 23
|
| 239 |
+
graph_title_size = 20
|
| 240 |
+
legend_size = 18
|
| 241 |
+
ticks_size = 13
|
| 242 |
+
# 学習曲線
|
| 243 |
+
fig = plt.figure(figsize=(20, 5))
|
| 244 |
+
plt.suptitle(suptitle, fontsize=suptitle_size)
|
| 245 |
+
# Train Loss
|
| 246 |
+
plt.subplot(131)
|
| 247 |
+
plt.title('Train Loss', fontsize=graph_title_size)
|
| 248 |
+
plt.plot(df['loss'].dropna(), label='train')
|
| 249 |
+
plt.legend(fontsize=legend_size)
|
| 250 |
+
plt.yticks(fontsize=ticks_size)
|
| 251 |
+
# Validation Loss
|
| 252 |
+
plt.subplot(132)
|
| 253 |
+
plt.title(f'Val Loss', fontsize=graph_title_size)
|
| 254 |
+
y = df['eval_loss'].dropna().values
|
| 255 |
+
x = np.arange(len(y)).reshape(-1, 1)
|
| 256 |
+
plt.plot(y, color='tab:orange', label='val')
|
| 257 |
+
plt.legend(fontsize=legend_size)
|
| 258 |
+
plt.yticks(fontsize=ticks_size)
|
| 259 |
+
# Accuracy/F1
|
| 260 |
+
plt.subplot(133)
|
| 261 |
+
plt.title('eval Accuracy/F1', fontsize=graph_title_size)
|
| 262 |
+
plt.plot(df['eval_accuracy'].dropna(), label='accuracy')
|
| 263 |
+
plt.plot(df['eval_f1'].dropna(), label='F1')
|
| 264 |
+
plt.legend(fontsize=legend_size)
|
| 265 |
+
plt.yticks(fontsize=ticks_size)
|
| 266 |
+
plt.tight_layout()
|
| 267 |
+
plt.savefig(output)
|
| 268 |
+
|
| 269 |
+
# %%
|
| 270 |
+
history_df = pd.DataFrame(trainer.state.log_history)
|
| 271 |
+
history_df.to_csv(f'{save_dir}/history.csv')
|
| 272 |
+
# 結果を表示
|
| 273 |
+
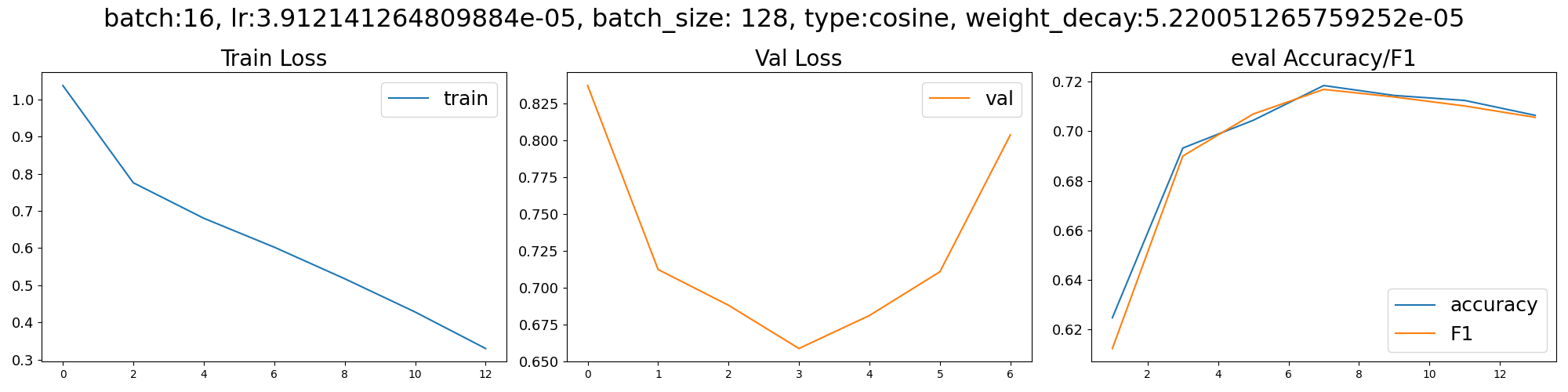
suptitle = f'batch:16, lr:{best_lr}, batch_size: {best_batch_size}, type:{best_lr_type}, weight_decay:{best_weight_decay}'
|
| 274 |
+
show_graph(history_df, suptitle, f'{save_dir}/output.png')
|
history.csv
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,loss,learning_rate,epoch,step,eval_loss,eval_accuracy,eval_f1,eval_runtime,eval_samples_per_second,eval_steps_per_second,train_runtime,train_samples_per_second,train_steps_per_second,total_flos,train_loss
|
| 2 |
+
0,1.0375,3.912141264809884e-06,1.0,235,,,,,,,,,,,
|
| 3 |
+
1,,,1.0,235,0.836928129196167,0.6248,0.612402481155663,1.266,1974.649,15.797,,,,,
|
| 4 |
+
2,0.7758,7.807635119982278e-06,2.0,470,,,,,,,,,,,
|
| 5 |
+
3,,,2.0,470,0.7121442556381226,0.6932,0.6899832814917121,1.2656,1975.323,15.803,,,,,
|
| 6 |
+
4,0.6803,1.1719776384792164e-05,3.0,705,,,,,,,,,,,
|
| 7 |
+
5,,,3.0,705,0.6878911852836609,0.7044,0.7069424431108294,1.2664,1974.166,15.793,,,,,
|
| 8 |
+
6,0.6025,1.5631917649602047e-05,4.0,940,,,,,,,,,,,
|
| 9 |
+
7,,,4.0,940,0.6585601568222046,0.7184,0.7168436594753593,1.266,1974.74,15.798,,,,,
|
| 10 |
+
8,0.5176,1.9544058914411928e-05,5.0,1175,,,,,,,,,,,
|
| 11 |
+
9,,,5.0,1175,0.6809464693069458,0.7144,0.7137994849164195,1.2678,1971.987,15.776,,,,,
|
| 12 |
+
10,0.428,2.3456200179221815e-05,6.0,1410,,,,,,,,,,,
|
| 13 |
+
11,,,6.0,1410,0.7105868458747864,0.7124,0.710171369539371,1.2665,1973.953,15.792,,,,,
|
| 14 |
+
12,0.3298,2.7368341444031695e-05,7.0,1645,,,,,,,,,,,
|
| 15 |
+
13,,,7.0,1645,0.8034451603889465,0.7064,0.7055785145607243,1.2652,1975.987,15.808,,,,,
|
| 16 |
+
14,,,7.0,1645,,,,,,,350.5605,8557.724,67.036,1.0289189979256608e+16,0.6244962929954645
|
output.png
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:efdd6075ce117dba5e3e90a9ad4c91ae0e4afd442b7ca1ca4425801cf6fba919
|
| 3 |
+
size 442545135
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"clean_up_tokenization_spaces": true,
|
| 3 |
+
"cls_token": "[CLS]",
|
| 4 |
+
"do_lower_case": false,
|
| 5 |
+
"do_subword_tokenize": true,
|
| 6 |
+
"do_word_tokenize": true,
|
| 7 |
+
"jumanpp_kwargs": null,
|
| 8 |
+
"mask_token": "[MASK]",
|
| 9 |
+
"mecab_kwargs": null,
|
| 10 |
+
"model_max_length": 512,
|
| 11 |
+
"never_split": null,
|
| 12 |
+
"pad_token": "[PAD]",
|
| 13 |
+
"sep_token": "[SEP]",
|
| 14 |
+
"subword_tokenizer_type": "wordpiece",
|
| 15 |
+
"sudachi_kwargs": null,
|
| 16 |
+
"tokenizer_class": "BertJapaneseTokenizer",
|
| 17 |
+
"unk_token": "[UNK]",
|
| 18 |
+
"word_tokenizer_type": "mecab"
|
| 19 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bb597867864797b851a8d6370f8aa51772a7873cd0502bb132e78471f0fa7d4b
|
| 3 |
+
size 4015
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|