
File size: 3,130 Bytes
38dcdc6 dd940c5 8c552ca 38dcdc6 f50b9cf c90a617 dbee730 994b9ce bc27f14 f2a235f f50b9cf e340ff1 f50b9cf e340ff1 f50b9cf e340ff1 f50b9cf 2e4196f e340ff1 96258fc 8a044c2 96258fc f50b9cf bc27f14 f50b9cf bc27f14 ad12092 f50b9cf a5b5284 8bf3e7d f50b9cf b1ddc90 f50b9cf b65cbf8 2ac5533 aedd7d8 2ac5533 e618bed dbee730 4ad4c6e 1661948 0c15322 06e3e8d 06a1b19 92a7ba6 c342086 ef08ef8 dbee730 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 |
---
language:
- sv
- da
- 'no'
license: llama3
tags:
- pytorch
- llama
- llama-3
- ai-sweden
base_model: meta-llama/Meta-Llama-3-8B
pipeline_tag: text-generation
inference:
parameters:
temperature: 0.6
---
# AI-Sweden-Models/Llama-3-8B

### Intended usage:
This is a base model, it can be finetuned to a particular use case.
[**-----> instruct version here <-----**](https://huggingface.co/AI-Sweden-Models/Llama-3-8B-instruct)
### Use with transformers
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "AI-Sweden-Models/Llama-3-8B"
pipeline = transformers.pipeline(
task="text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto"
)
pipeline(
text_inputs="Sommar och sol är det bästa jag vet",
max_length=128,
repetition_penalty=1.03
)
```
```python
>>> "Sommar och sol är det bästa jag vet!
Och nu när jag har fått lite extra semester så ska jag njuta till max av allt som våren och sommaren har att erbjuda.
Jag har redan börjat med att sitta ute på min altan och ta en kopp kaffe och läsa i tidningen, det är så skönt att bara sitta där och njuta av livet.
Ikväll blir det grillat och det ser jag fram emot!"
```
## Training information
`AI-Sweden-Models/Llama-3-8B` is a continuation of the pretraining process from `meta-llama/Meta-Llama-3-8B`.
It was trained on a subset from [The Nordic Pile](https://arxiv.org/abs/2303.17183) containing Swedish, Norwegian and Danish. The training is done on all model parameters, it is a full finetune.
The training dataset consists of 227 105 079 296 tokens. It was trained on the Rattler supercomputer at the Dell Technologies Edge Innovation Center in Austin, Texas. The training used 23 nodes of a duration of 30 days, where one node contained 4X Nvidia A100 GPUs, yielding 92 GPUs.
## trainer.yaml:
```yaml
learning_rate: 2e-5
warmup_steps: 100
lr_scheduler: cosine
optimizer: adamw_torch_fused
max_grad_norm: 1.0
gradient_accumulation_steps: 16
micro_batch_size: 1
num_epochs: 1
sequence_len: 8192
```
## deepspeed_zero2.json:
```json
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
},
"contiguous_gradients": true,
"overlap_comm": true
},
"bf16": {
"enabled": "auto"
},
"fp16": {
"enabled": "auto",
"auto_cast": false,
"loss_scale": 0,
"initial_scale_power": 32,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
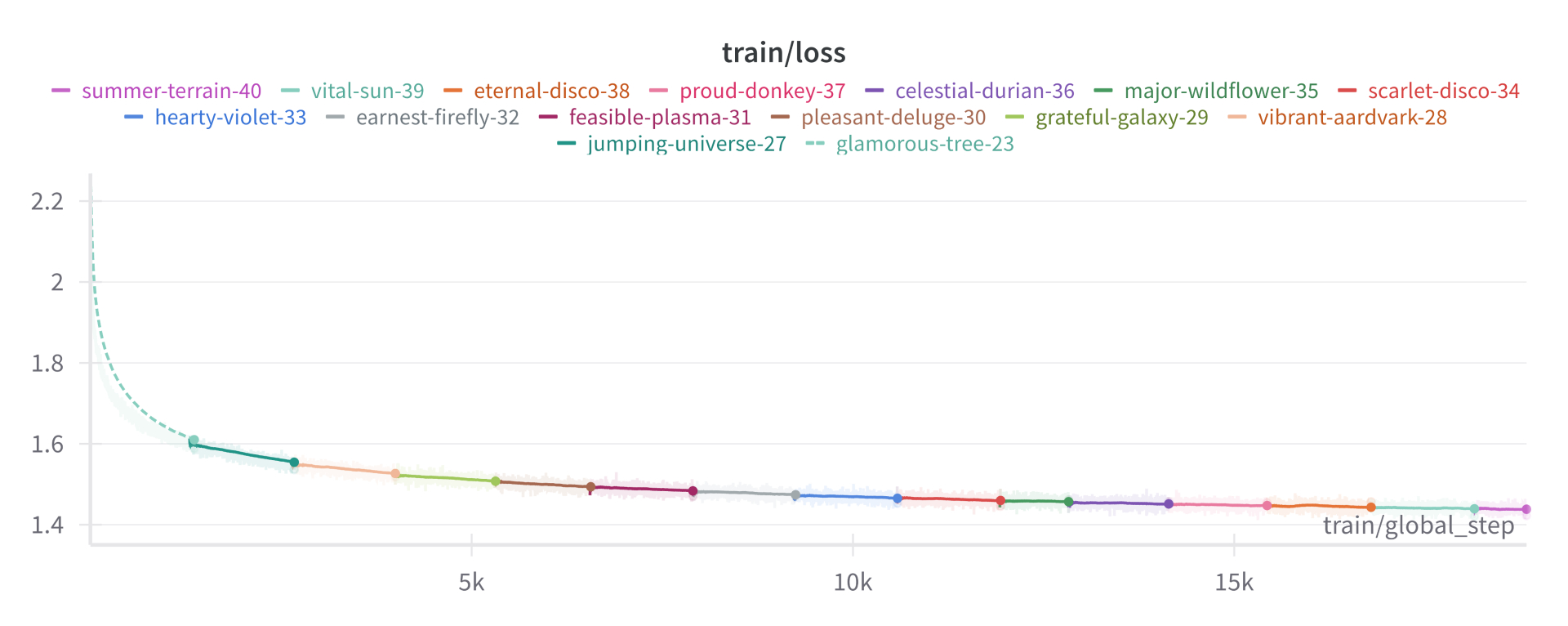
## Checkpoints
* 15/6/2024 (18833) => 1 epoch
* 11/6/2024 (16000)
* 07/6/2024 (14375)
* 03/6/2024 (11525)
* 29/5/2024 (8200)
* 26/5/2024 (6550)
* 24/5/2024 (5325)
* 22/5/2024 (3900)
* 20/5/2024 (2700)
* 13/5/2024 (1500) |