---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- mteb
license: apache-2.0
model-index:
- name: bge-en-icl
results:
- dataset:
config: en
name: MTEB AmazonCounterfactualClassification (en)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 93.1492537313433
- type: ap
value: 72.56132559564212
- type: f1
value: 89.71796898040243
- type: main_score
value: 93.1492537313433
task:
type: Classification
- dataset:
config: default
name: MTEB AmazonPolarityClassification
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
split: test
type: mteb/amazon_polarity
metrics:
- type: accuracy
value: 96.98372499999999
- type: ap
value: 95.62303091773919
- type: f1
value: 96.98308191715637
- type: main_score
value: 96.98372499999999
task:
type: Classification
- dataset:
config: en
name: MTEB AmazonReviewsClassification (en)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 61.461999999999996
- type: f1
value: 60.57257766583118
- type: main_score
value: 61.461999999999996
task:
type: Classification
- dataset:
config: default
name: MTEB ArguAna
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
split: test
type: mteb/arguana
metrics:
- type: main_score
value: 83.07967801208441
- type: ndcg_at_1
value: 66.50071123755335
- type: ndcg_at_3
value: 80.10869593172173
- type: ndcg_at_5
value: 81.89670542467924
- type: ndcg_at_10
value: 83.07967801208441
- type: ndcg_at_100
value: 83.5991349601075
- type: ndcg_at_1000
value: 83.5991349601075
- type: map_at_1
value: 66.50071123755335
- type: map_at_3
value: 76.83736367946898
- type: map_at_5
value: 77.8473210052158
- type: map_at_10
value: 78.35472690735851
- type: map_at_100
value: 78.47388207611678
- type: map_at_1000
value: 78.47388207611678
- type: precision_at_1
value: 66.50071123755335
- type: precision_at_3
value: 29.848269321953076
- type: precision_at_5
value: 18.762446657183045
- type: precision_at_10
value: 9.736842105262909
- type: precision_at_100
value: 0.9964438122332677
- type: precision_at_1000
value: 0.09964438122332549
- type: recall_at_1
value: 66.50071123755335
- type: recall_at_3
value: 89.5448079658606
- type: recall_at_5
value: 93.8122332859175
- type: recall_at_10
value: 97.36842105263158
- type: recall_at_100
value: 99.6443812233286
- type: recall_at_1000
value: 99.6443812233286
task:
type: Retrieval
- dataset:
config: default
name: MTEB ArxivClusteringP2P
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
split: test
type: mteb/arxiv-clustering-p2p
metrics:
- type: main_score
value: 54.43859683357485
- type: v_measure
value: 54.43859683357485
- type: v_measure_std
value: 14.511128158596337
task:
type: Clustering
- dataset:
config: default
name: MTEB ArxivClusteringS2S
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
split: test
type: mteb/arxiv-clustering-s2s
metrics:
- type: main_score
value: 49.33365996236564
- type: v_measure
value: 49.33365996236564
- type: v_measure_std
value: 14.61261944856548
task:
type: Clustering
- dataset:
config: default
name: MTEB AskUbuntuDupQuestions
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
split: test
type: mteb/askubuntudupquestions-reranking
metrics:
- type: main_score
value: 65.15263966490278
- type: map
value: 65.15263966490278
- type: mrr
value: 77.90331090885107
task:
type: Reranking
- dataset:
config: default
name: MTEB BIOSSES
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
split: test
type: mteb/biosses-sts
metrics:
- type: main_score
value: 86.47365710792691
- type: cosine_spearman
value: 86.47365710792691
- type: spearman
value: 86.47365710792691
task:
type: STS
- dataset:
config: default
name: MTEB Banking77Classification
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
split: test
type: mteb/banking77
metrics:
- type: accuracy
value: 91.48701298701299
- type: f1
value: 91.4733869423637
- type: main_score
value: 91.48701298701299
task:
type: Classification
- dataset:
config: default
name: MTEB BiorxivClusteringP2P
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
split: test
type: mteb/biorxiv-clustering-p2p
metrics:
- type: main_score
value: 53.050461108038036
- type: v_measure
value: 53.050461108038036
- type: v_measure_std
value: 0.9436104839012786
task:
type: Clustering
- dataset:
config: default
name: MTEB BiorxivClusteringS2S
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
split: test
type: mteb/biorxiv-clustering-s2s
metrics:
- type: main_score
value: 48.38215568371151
- type: v_measure
value: 48.38215568371151
- type: v_measure_std
value: 0.9104384504649026
task:
type: Clustering
- dataset:
config: default
name: MTEB CQADupstackRetrieval
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
split: test
type: mteb/cqadupstack
metrics:
- type: main_score
value: 47.308084499970704
- type: ndcg_at_1
value: 36.038578730542476
- type: ndcg_at_3
value: 41.931365356453036
- type: ndcg_at_5
value: 44.479015523894994
- type: ndcg_at_10
value: 47.308084499970704
- type: ndcg_at_100
value: 52.498062430513606
- type: ndcg_at_1000
value: 54.2908789514719
- type: map_at_1
value: 30.38821701528966
- type: map_at_3
value: 37.974871761903636
- type: map_at_5
value: 39.85399878507757
- type: map_at_10
value: 41.31456611036795
- type: map_at_100
value: 42.62907836655835
- type: map_at_1000
value: 42.737235870659845
- type: precision_at_1
value: 36.038578730542476
- type: precision_at_3
value: 19.39960180094633
- type: precision_at_5
value: 13.79264655952497
- type: precision_at_10
value: 8.399223517333388
- type: precision_at_100
value: 1.2992373779520896
- type: precision_at_1000
value: 0.16327170951909567
- type: recall_at_1
value: 30.38821701528966
- type: recall_at_3
value: 45.51645512564165
- type: recall_at_5
value: 52.06077167834868
- type: recall_at_10
value: 60.38864106788279
- type: recall_at_100
value: 82.76968509918343
- type: recall_at_1000
value: 94.84170217080344
task:
type: Retrieval
- dataset:
config: default
name: MTEB ClimateFEVER
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
split: test
type: mteb/climate-fever
metrics:
- type: main_score
value: 45.4272998284769
- type: ndcg_at_1
value: 44.36482084690554
- type: ndcg_at_3
value: 38.13005747178844
- type: ndcg_at_5
value: 40.83474510717123
- type: ndcg_at_10
value: 45.4272998284769
- type: ndcg_at_100
value: 52.880220707479516
- type: ndcg_at_1000
value: 55.364753427333
- type: map_at_1
value: 19.200868621064064
- type: map_at_3
value: 28.33785740137525
- type: map_at_5
value: 31.67162504524064
- type: map_at_10
value: 34.417673164090075
- type: map_at_100
value: 36.744753097028976
- type: map_at_1000
value: 36.91262189016135
- type: precision_at_1
value: 44.36482084690554
- type: precision_at_3
value: 29.14223669923975
- type: precision_at_5
value: 22.410423452768388
- type: precision_at_10
value: 14.293159609120309
- type: precision_at_100
value: 2.248859934853431
- type: precision_at_1000
value: 0.2722475570032542
- type: recall_at_1
value: 19.200868621064064
- type: recall_at_3
value: 34.132464712269176
- type: recall_at_5
value: 42.35613463626491
- type: recall_at_10
value: 52.50814332247546
- type: recall_at_100
value: 77.16178067318128
- type: recall_at_1000
value: 90.59174809989138
task:
type: Retrieval
- dataset:
config: default
name: MTEB DBPedia
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
split: test
type: mteb/dbpedia
metrics:
- type: main_score
value: 51.634197691802754
- type: ndcg_at_1
value: 64.375
- type: ndcg_at_3
value: 55.677549598242614
- type: ndcg_at_5
value: 53.44347199908503
- type: ndcg_at_10
value: 51.634197691802754
- type: ndcg_at_100
value: 56.202861267183415
- type: ndcg_at_1000
value: 63.146019108272576
- type: map_at_1
value: 9.789380503780919
- type: map_at_3
value: 16.146582195277016
- type: map_at_5
value: 19.469695222167193
- type: map_at_10
value: 24.163327344766145
- type: map_at_100
value: 35.47047690245571
- type: map_at_1000
value: 37.5147432331838
- type: precision_at_1
value: 76.25
- type: precision_at_3
value: 59.08333333333333
- type: precision_at_5
value: 52.24999999999997
- type: precision_at_10
value: 42.54999999999994
- type: precision_at_100
value: 13.460000000000008
- type: precision_at_1000
value: 2.4804999999999966
- type: recall_at_1
value: 9.789380503780919
- type: recall_at_3
value: 17.48487134027656
- type: recall_at_5
value: 22.312024269698806
- type: recall_at_10
value: 30.305380335237324
- type: recall_at_100
value: 62.172868946596424
- type: recall_at_1000
value: 85.32410301328747
task:
type: Retrieval
- dataset:
config: default
name: MTEB EmotionClassification
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
split: test
type: mteb/emotion
metrics:
- type: accuracy
value: 93.36
- type: f1
value: 89.73665936982262
- type: main_score
value: 93.36
task:
type: Classification
- dataset:
config: default
name: MTEB FEVER
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
split: test
type: mteb/fever
metrics:
- type: main_score
value: 92.82809814626805
- type: ndcg_at_1
value: 88.98889888988899
- type: ndcg_at_3
value: 91.82404417747676
- type: ndcg_at_5
value: 92.41785792357787
- type: ndcg_at_10
value: 92.82809814626805
- type: ndcg_at_100
value: 93.31730867509245
- type: ndcg_at_1000
value: 93.45171203408582
- type: map_at_1
value: 82.64125817343636
- type: map_at_3
value: 89.39970782792554
- type: map_at_5
value: 89.96799501378695
- type: map_at_10
value: 90.27479706587437
- type: map_at_100
value: 90.45185655778057
- type: map_at_1000
value: 90.46130471574544
- type: precision_at_1
value: 88.98889888988899
- type: precision_at_3
value: 34.923492349234245
- type: precision_at_5
value: 21.524152415244043
- type: precision_at_10
value: 11.033603360337315
- type: precision_at_100
value: 1.1521152115211895
- type: precision_at_1000
value: 0.11765676567657675
- type: recall_at_1
value: 82.64125817343636
- type: recall_at_3
value: 94.35195900542428
- type: recall_at_5
value: 95.9071323799047
- type: recall_at_10
value: 97.04234113887586
- type: recall_at_100
value: 98.77282371094255
- type: recall_at_1000
value: 99.5555567461508
task:
type: Retrieval
- dataset:
config: default
name: MTEB FiQA2018
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
split: test
type: mteb/fiqa
metrics:
- type: main_score
value: 59.67151242793314
- type: ndcg_at_1
value: 57.407407407407405
- type: ndcg_at_3
value: 53.79975378289304
- type: ndcg_at_5
value: 56.453379423655406
- type: ndcg_at_10
value: 59.67151242793314
- type: ndcg_at_100
value: 65.34055762539253
- type: ndcg_at_1000
value: 67.07707746043032
- type: map_at_1
value: 30.65887045053714
- type: map_at_3
value: 44.09107110881799
- type: map_at_5
value: 48.18573748068346
- type: map_at_10
value: 51.03680979612876
- type: map_at_100
value: 53.03165194566928
- type: map_at_1000
value: 53.16191096190861
- type: precision_at_1
value: 57.407407407407405
- type: precision_at_3
value: 35.493827160493886
- type: precision_at_5
value: 26.913580246913547
- type: precision_at_10
value: 16.435185185185155
- type: precision_at_100
value: 2.2685185185184986
- type: precision_at_1000
value: 0.25864197530863964
- type: recall_at_1
value: 30.65887045053714
- type: recall_at_3
value: 48.936723427464194
- type: recall_at_5
value: 58.55942925387371
- type: recall_at_10
value: 68.45128551147073
- type: recall_at_100
value: 88.24599311867836
- type: recall_at_1000
value: 98.18121693121691
task:
type: Retrieval
- dataset:
config: default
name: MTEB HotpotQA
revision: ab518f4d6fcca38d87c25209f94beba119d02014
split: test
type: mteb/hotpotqa
metrics:
- type: main_score
value: 85.13780800141961
- type: ndcg_at_1
value: 89.9392302498312
- type: ndcg_at_3
value: 81.2061569376288
- type: ndcg_at_5
value: 83.53311592078133
- type: ndcg_at_10
value: 85.13780800141961
- type: ndcg_at_100
value: 87.02630661625386
- type: ndcg_at_1000
value: 87.47294723601075
- type: map_at_1
value: 44.9696151249156
- type: map_at_3
value: 76.46972766148966
- type: map_at_5
value: 78.47749268512187
- type: map_at_10
value: 79.49792611170005
- type: map_at_100
value: 80.09409086274644
- type: map_at_1000
value: 80.11950878917663
- type: precision_at_1
value: 89.9392302498312
- type: precision_at_3
value: 53.261309925724234
- type: precision_at_5
value: 33.79338284942924
- type: precision_at_10
value: 17.69750168805041
- type: precision_at_100
value: 1.9141120864280805
- type: precision_at_1000
value: 0.19721809588118133
- type: recall_at_1
value: 44.9696151249156
- type: recall_at_3
value: 79.8919648885888
- type: recall_at_5
value: 84.48345712356516
- type: recall_at_10
value: 88.48750844024308
- type: recall_at_100
value: 95.70560432140446
- type: recall_at_1000
value: 98.60904794058068
task:
type: Retrieval
- dataset:
config: default
name: MTEB ImdbClassification
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
split: test
type: mteb/imdb
metrics:
- type: accuracy
value: 96.9144
- type: ap
value: 95.45276911068486
- type: f1
value: 96.91412729455966
- type: main_score
value: 96.9144
task:
type: Classification
- dataset:
config: default
name: MTEB MSMARCO
revision: c5a29a104738b98a9e76336939199e264163d4a0
split: dev
type: mteb/msmarco
metrics:
- type: main_score
value: 46.78865753107054
- type: ndcg_at_1
value: 26.63323782234957
- type: ndcg_at_3
value: 38.497585804985754
- type: ndcg_at_5
value: 42.72761631631636
- type: ndcg_at_10
value: 46.78865753107054
- type: ndcg_at_100
value: 51.96170786623209
- type: ndcg_at_1000
value: 52.82713901970963
- type: map_at_1
value: 25.89063992359121
- type: map_at_3
value: 35.299466730340654
- type: map_at_5
value: 37.68771887933786
- type: map_at_10
value: 39.40908074468253
- type: map_at_100
value: 40.53444082323405
- type: map_at_1000
value: 40.57183037649452
- type: precision_at_1
value: 26.63323782234957
- type: precision_at_3
value: 16.265520534861793
- type: precision_at_5
value: 11.902578796562304
- type: precision_at_10
value: 7.262177650430416
- type: precision_at_100
value: 0.9819484240687512
- type: precision_at_1000
value: 0.10571633237823287
- type: recall_at_1
value: 25.89063992359121
- type: recall_at_3
value: 46.99737344794652
- type: recall_at_5
value: 57.160936007640906
- type: recall_at_10
value: 69.43409742120343
- type: recall_at_100
value: 92.86413562559697
- type: recall_at_1000
value: 99.3230659025788
task:
type: Retrieval
- dataset:
config: en
name: MTEB MTOPDomainClassification (en)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 98.42225262197901
- type: f1
value: 98.31652547061115
- type: main_score
value: 98.42225262197901
task:
type: Classification
- dataset:
config: en
name: MTEB MTOPIntentClassification (en)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 94.00136798905609
- type: f1
value: 82.7022316533099
- type: main_score
value: 94.00136798905609
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveIntentClassification (en)
revision: 4672e20407010da34463acc759c162ca9734bca6
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 82.92535305985204
- type: f1
value: 79.885538231847
- type: main_score
value: 82.92535305985204
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveScenarioClassification (en)
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 85.60188298587758
- type: f1
value: 84.87416963499224
- type: main_score
value: 85.60188298587758
task:
type: Classification
- dataset:
config: default
name: MTEB MedrxivClusteringP2P
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
split: test
type: mteb/medrxiv-clustering-p2p
metrics:
- type: main_score
value: 45.86171497327639
- type: v_measure
value: 45.86171497327639
- type: v_measure_std
value: 1.551347259003324
task:
type: Clustering
- dataset:
config: default
name: MTEB MedrxivClusteringS2S
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
split: test
type: mteb/medrxiv-clustering-s2s
metrics:
- type: main_score
value: 44.33336692345644
- type: v_measure
value: 44.33336692345644
- type: v_measure_std
value: 1.5931408596404715
task:
type: Clustering
- dataset:
config: default
name: MTEB MindSmallReranking
revision: 59042f120c80e8afa9cdbb224f67076cec0fc9a7
split: test
type: mteb/mind_small
metrics:
- type: main_score
value: 30.597409734750503
- type: map
value: 30.597409734750503
- type: mrr
value: 31.397041548018457
task:
type: Reranking
- dataset:
config: default
name: MTEB NFCorpus
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
split: test
type: mteb/nfcorpus
metrics:
- type: main_score
value: 41.850870119787835
- type: ndcg_at_1
value: 52.47678018575851
- type: ndcg_at_3
value: 47.43993801247414
- type: ndcg_at_5
value: 45.08173173082719
- type: ndcg_at_10
value: 41.850870119787835
- type: ndcg_at_100
value: 37.79284946590978
- type: ndcg_at_1000
value: 46.58046062123418
- type: map_at_1
value: 6.892464464226138
- type: map_at_3
value: 12.113195798233127
- type: map_at_5
value: 13.968475602788812
- type: map_at_10
value: 16.47564069781326
- type: map_at_100
value: 20.671726065190025
- type: map_at_1000
value: 22.328875914012006
- type: precision_at_1
value: 53.86996904024768
- type: precision_at_3
value: 43.96284829721363
- type: precision_at_5
value: 38.69969040247682
- type: precision_at_10
value: 30.928792569659457
- type: precision_at_100
value: 9.507739938080498
- type: precision_at_1000
value: 2.25882352941176
- type: recall_at_1
value: 6.892464464226138
- type: recall_at_3
value: 13.708153358278407
- type: recall_at_5
value: 16.651919797359145
- type: recall_at_10
value: 21.01801714352559
- type: recall_at_100
value: 37.01672102843443
- type: recall_at_1000
value: 69.8307270724072
task:
type: Retrieval
- dataset:
config: default
name: MTEB NQ
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
split: test
type: mteb/nq
metrics:
- type: main_score
value: 73.88350836507092
- type: ndcg_at_1
value: 57.0683661645423
- type: ndcg_at_3
value: 67.89935813080585
- type: ndcg_at_5
value: 71.47769719452941
- type: ndcg_at_10
value: 73.88350836507092
- type: ndcg_at_100
value: 75.76561068060907
- type: ndcg_at_1000
value: 75.92437662684215
- type: map_at_1
value: 51.00424874468904
- type: map_at_3
value: 63.87359984550011
- type: map_at_5
value: 66.23696407879494
- type: map_at_10
value: 67.42415446608673
- type: map_at_100
value: 67.92692839842621
- type: map_at_1000
value: 67.93437922640133
- type: precision_at_1
value: 57.0683661645423
- type: precision_at_3
value: 29.692931633836416
- type: precision_at_5
value: 20.046349942062854
- type: precision_at_10
value: 10.950173812283
- type: precision_at_100
value: 1.1995944380069687
- type: precision_at_1000
value: 0.12146581691772171
- type: recall_at_1
value: 51.00424874468904
- type: recall_at_3
value: 75.93665507918116
- type: recall_at_5
value: 83.95133256083433
- type: recall_at_10
value: 90.78794901506375
- type: recall_at_100
value: 98.61915797605253
- type: recall_at_1000
value: 99.7827346465817
task:
type: Retrieval
- dataset:
config: default
name: MTEB QuoraRetrieval
revision: e4e08e0b7dbe3c8700f0daef558ff32256715259
split: test
type: mteb/quora
metrics:
- type: main_score
value: 90.95410848372035
- type: ndcg_at_1
value: 84.61999999999999
- type: ndcg_at_3
value: 88.57366734033212
- type: ndcg_at_5
value: 89.89804048972175
- type: ndcg_at_10
value: 90.95410848372035
- type: ndcg_at_100
value: 91.83227134455773
- type: ndcg_at_1000
value: 91.88368412611601
- type: map_at_1
value: 73.4670089207039
- type: map_at_3
value: 84.87862925508942
- type: map_at_5
value: 86.68002324701408
- type: map_at_10
value: 87.7165466015312
- type: map_at_100
value: 88.28718809614146
- type: map_at_1000
value: 88.29877148480672
- type: precision_at_1
value: 84.61999999999999
- type: precision_at_3
value: 38.82333333333838
- type: precision_at_5
value: 25.423999999998642
- type: precision_at_10
value: 13.787999999998583
- type: precision_at_100
value: 1.5442999999999767
- type: precision_at_1000
value: 0.15672999999997972
- type: recall_at_1
value: 73.4670089207039
- type: recall_at_3
value: 89.98389854832143
- type: recall_at_5
value: 93.88541046010576
- type: recall_at_10
value: 96.99779417520634
- type: recall_at_100
value: 99.80318763957743
- type: recall_at_1000
value: 99.99638888888889
task:
type: Retrieval
- dataset:
config: default
name: MTEB RedditClustering
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
split: test
type: mteb/reddit-clustering
metrics:
- type: main_score
value: 72.33008348681277
- type: v_measure
value: 72.33008348681277
- type: v_measure_std
value: 2.9203215463933008
task:
type: Clustering
- dataset:
config: default
name: MTEB RedditClusteringP2P
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
split: test
type: mteb/reddit-clustering-p2p
metrics:
- type: main_score
value: 72.72079657828903
- type: v_measure
value: 72.72079657828903
- type: v_measure_std
value: 11.930271663428735
task:
type: Clustering
- dataset:
config: default
name: MTEB SCIDOCS
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
split: test
type: mteb/scidocs
metrics:
- type: main_score
value: 25.25865384510787
- type: ndcg_at_1
value: 28.7
- type: ndcg_at_3
value: 23.61736427940938
- type: ndcg_at_5
value: 20.845690325673885
- type: ndcg_at_10
value: 25.25865384510787
- type: ndcg_at_100
value: 36.18596641088721
- type: ndcg_at_1000
value: 41.7166868935345
- type: map_at_1
value: 5.828333333333361
- type: map_at_3
value: 10.689166666666676
- type: map_at_5
value: 13.069916666666668
- type: map_at_10
value: 15.4901164021164
- type: map_at_100
value: 18.61493245565425
- type: map_at_1000
value: 18.99943478016456
- type: precision_at_1
value: 28.7
- type: precision_at_3
value: 22.30000000000006
- type: precision_at_5
value: 18.55999999999997
- type: precision_at_10
value: 13.289999999999946
- type: precision_at_100
value: 2.905000000000005
- type: precision_at_1000
value: 0.4218999999999946
- type: recall_at_1
value: 5.828333333333361
- type: recall_at_3
value: 13.548333333333387
- type: recall_at_5
value: 18.778333333333308
- type: recall_at_10
value: 26.939999999999902
- type: recall_at_100
value: 58.91333333333344
- type: recall_at_1000
value: 85.57499999999972
task:
type: Retrieval
- dataset:
config: default
name: MTEB SICK-R
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
split: test
type: mteb/sickr-sts
metrics:
- type: main_score
value: 83.86733787791422
- type: cosine_spearman
value: 83.86733787791422
- type: spearman
value: 83.86733787791422
task:
type: STS
- dataset:
config: default
name: MTEB STS12
revision: a0d554a64d88156834ff5ae9920b964011b16384
split: test
type: mteb/sts12-sts
metrics:
- type: main_score
value: 78.14269330480724
- type: cosine_spearman
value: 78.14269330480724
- type: spearman
value: 78.14269330480724
task:
type: STS
- dataset:
config: default
name: MTEB STS13
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
split: test
type: mteb/sts13-sts
metrics:
- type: main_score
value: 86.58640009300751
- type: cosine_spearman
value: 86.58640009300751
- type: spearman
value: 86.58640009300751
task:
type: STS
- dataset:
config: default
name: MTEB STS14
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
split: test
type: mteb/sts14-sts
metrics:
- type: main_score
value: 82.8292579957437
- type: cosine_spearman
value: 82.8292579957437
- type: spearman
value: 82.8292579957437
task:
type: STS
- dataset:
config: default
name: MTEB STS15
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
split: test
type: mteb/sts15-sts
metrics:
- type: main_score
value: 87.77203714228862
- type: cosine_spearman
value: 87.77203714228862
- type: spearman
value: 87.77203714228862
task:
type: STS
- dataset:
config: default
name: MTEB STS16
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
split: test
type: mteb/sts16-sts
metrics:
- type: main_score
value: 87.0439304006969
- type: cosine_spearman
value: 87.0439304006969
- type: spearman
value: 87.0439304006969
task:
type: STS
- dataset:
config: en-en
name: MTEB STS17 (en-en)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: main_score
value: 91.24736138013424
- type: cosine_spearman
value: 91.24736138013424
- type: spearman
value: 91.24736138013424
task:
type: STS
- dataset:
config: en
name: MTEB STS22 (en)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: main_score
value: 70.07326214706
- type: cosine_spearman
value: 70.07326214706
- type: spearman
value: 70.07326214706
task:
type: STS
- dataset:
config: default
name: MTEB STSBenchmark
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
split: test
type: mteb/stsbenchmark-sts
metrics:
- type: main_score
value: 88.42076443255168
- type: cosine_spearman
value: 88.42076443255168
- type: spearman
value: 88.42076443255168
task:
type: STS
- dataset:
config: default
name: MTEB SciDocsRR
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
split: test
type: mteb/scidocs-reranking
metrics:
- type: main_score
value: 86.9584489124583
- type: map
value: 86.9584489124583
- type: mrr
value: 96.59475328592976
task:
type: Reranking
- dataset:
config: default
name: MTEB SciFact
revision: 0228b52cf27578f30900b9e5271d331663a030d7
split: test
type: mteb/scifact
metrics:
- type: main_score
value: 79.09159079425369
- type: ndcg_at_1
value: 66.0
- type: ndcg_at_3
value: 74.98853481223065
- type: ndcg_at_5
value: 77.29382051205019
- type: ndcg_at_10
value: 79.09159079425369
- type: ndcg_at_100
value: 80.29692802526776
- type: ndcg_at_1000
value: 80.55210036585547
- type: map_at_1
value: 62.994444444444454
- type: map_at_3
value: 71.7425925925926
- type: map_at_5
value: 73.6200925925926
- type: map_at_10
value: 74.50223544973547
- type: map_at_100
value: 74.82438594015447
- type: map_at_1000
value: 74.83420474892468
- type: precision_at_1
value: 66.0
- type: precision_at_3
value: 29.44444444444439
- type: precision_at_5
value: 19.40000000000008
- type: precision_at_10
value: 10.366666666666715
- type: precision_at_100
value: 1.0999999999999928
- type: precision_at_1000
value: 0.11200000000000007
- type: recall_at_1
value: 62.994444444444454
- type: recall_at_3
value: 80.89999999999998
- type: recall_at_5
value: 86.72777777777779
- type: recall_at_10
value: 91.88888888888887
- type: recall_at_100
value: 97.0
- type: recall_at_1000
value: 99.0
task:
type: Retrieval
- dataset:
config: default
name: MTEB SprintDuplicateQuestions
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
split: test
type: mteb/sprintduplicatequestions-pairclassification
metrics:
- type: main_score
value: 97.26819027722253
- type: cos_sim_accuracy
value: 99.88019801980198
- type: cos_sim_accuracy_threshold
value: 76.67685151100159
- type: cos_sim_ap
value: 97.23260568085786
- type: cos_sim_f1
value: 93.91824526420737
- type: cos_sim_f1_threshold
value: 75.82710981369019
- type: cos_sim_precision
value: 93.63817097415506
- type: cos_sim_recall
value: 94.19999999999999
- type: dot_accuracy
value: 99.88019801980198
- type: dot_accuracy_threshold
value: 76.67686343193054
- type: dot_ap
value: 97.23260568085786
- type: dot_f1
value: 93.91824526420737
- type: dot_f1_threshold
value: 75.8271336555481
- type: dot_precision
value: 93.63817097415506
- type: dot_recall
value: 94.19999999999999
- type: euclidean_accuracy
value: 99.88019801980198
- type: euclidean_accuracy_threshold
value: 68.29807758331299
- type: euclidean_ap
value: 97.23259982599497
- type: euclidean_f1
value: 93.91824526420737
- type: euclidean_f1_threshold
value: 69.53110694885254
- type: euclidean_precision
value: 93.63817097415506
- type: euclidean_recall
value: 94.19999999999999
- type: manhattan_accuracy
value: 99.87821782178217
- type: manhattan_accuracy_threshold
value: 3482.6908111572266
- type: manhattan_ap
value: 97.26819027722253
- type: manhattan_f1
value: 93.92592592592592
- type: manhattan_f1_threshold
value: 3555.5641174316406
- type: manhattan_precision
value: 92.78048780487805
- type: manhattan_recall
value: 95.1
- type: max_accuracy
value: 99.88019801980198
- type: max_ap
value: 97.26819027722253
- type: max_f1
value: 93.92592592592592
task:
type: PairClassification
- dataset:
config: default
name: MTEB StackExchangeClustering
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
split: test
type: mteb/stackexchange-clustering
metrics:
- type: main_score
value: 81.32419328350603
- type: v_measure
value: 81.32419328350603
- type: v_measure_std
value: 2.666861121694755
task:
type: Clustering
- dataset:
config: default
name: MTEB StackExchangeClusteringP2P
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
split: test
type: mteb/stackexchange-clustering-p2p
metrics:
- type: main_score
value: 46.048387963107565
- type: v_measure
value: 46.048387963107565
- type: v_measure_std
value: 1.4102848576321703
task:
type: Clustering
- dataset:
config: default
name: MTEB StackOverflowDupQuestions
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
split: test
type: mteb/stackoverflowdupquestions-reranking
metrics:
- type: main_score
value: 56.70574900554072
- type: map
value: 56.70574900554072
- type: mrr
value: 57.517109116373824
task:
type: Reranking
- dataset:
config: default
name: MTEB SummEval
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
split: test
type: mteb/summeval
metrics:
- type: main_score
value: 30.76932903185174
- type: cosine_spearman
value: 30.76932903185174
- type: spearman
value: 30.76932903185174
task:
type: Summarization
- dataset:
config: default
name: MTEB TRECCOVID
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
split: test
type: mteb/trec-covid
metrics:
- type: main_score
value: 79.07987651251462
- type: ndcg_at_1
value: 83.0
- type: ndcg_at_3
value: 79.86598407528447
- type: ndcg_at_5
value: 79.27684428714952
- type: ndcg_at_10
value: 79.07987651251462
- type: ndcg_at_100
value: 64.55029164391163
- type: ndcg_at_1000
value: 59.42333857860492
- type: map_at_1
value: 0.226053732680979
- type: map_at_3
value: 0.644034626013194
- type: map_at_5
value: 1.045196967937728
- type: map_at_10
value: 2.0197496659905085
- type: map_at_100
value: 13.316018005224159
- type: map_at_1000
value: 33.784766957424104
- type: precision_at_1
value: 88.0
- type: precision_at_3
value: 86.66666666666667
- type: precision_at_5
value: 85.20000000000002
- type: precision_at_10
value: 84.19999999999997
- type: precision_at_100
value: 67.88000000000001
- type: precision_at_1000
value: 26.573999999999998
- type: recall_at_1
value: 0.226053732680979
- type: recall_at_3
value: 0.6754273711472734
- type: recall_at_5
value: 1.1168649828059245
- type: recall_at_10
value: 2.2215081031265207
- type: recall_at_100
value: 16.694165236664727
- type: recall_at_1000
value: 56.7022214857503
task:
type: Retrieval
- dataset:
config: default
name: MTEB Touche2020
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
split: test
type: mteb/touche2020
metrics:
- type: main_score
value: 30.47934263207554
- type: ndcg_at_1
value: 33.6734693877551
- type: ndcg_at_3
value: 34.36843900446739
- type: ndcg_at_5
value: 32.21323786731918
- type: ndcg_at_10
value: 30.47934263207554
- type: ndcg_at_100
value: 41.49598869753928
- type: ndcg_at_1000
value: 52.32963949183662
- type: map_at_1
value: 3.0159801678718168
- type: map_at_3
value: 7.13837927642557
- type: map_at_5
value: 9.274004610363466
- type: map_at_10
value: 12.957368366814324
- type: map_at_100
value: 19.3070585127604
- type: map_at_1000
value: 20.809777161133532
- type: precision_at_1
value: 34.69387755102041
- type: precision_at_3
value: 36.054421768707485
- type: precision_at_5
value: 32.24489795918368
- type: precision_at_10
value: 27.142857142857146
- type: precision_at_100
value: 8.326530612244898
- type: precision_at_1000
value: 1.5755102040816336
- type: recall_at_1
value: 3.0159801678718168
- type: recall_at_3
value: 8.321771388428257
- type: recall_at_5
value: 11.737532394366069
- type: recall_at_10
value: 19.49315139822179
- type: recall_at_100
value: 50.937064145519685
- type: recall_at_1000
value: 83.4358283484675
task:
type: Retrieval
- dataset:
config: default
name: MTEB ToxicConversationsClassification
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
split: test
type: mteb/toxic_conversations_50k
metrics:
- type: accuracy
value: 93.173828125
- type: ap
value: 46.040184641424396
- type: f1
value: 80.77280549412752
- type: main_score
value: 93.173828125
task:
type: Classification
- dataset:
config: default
name: MTEB TweetSentimentExtractionClassification
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
split: test
type: mteb/tweet_sentiment_extraction
metrics:
- type: accuracy
value: 79.9320882852292
- type: f1
value: 80.22638685975485
- type: main_score
value: 79.9320882852292
task:
type: Classification
- dataset:
config: default
name: MTEB TwentyNewsgroupsClustering
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
split: test
type: mteb/twentynewsgroups-clustering
metrics:
- type: main_score
value: 68.98152919711418
- type: v_measure
value: 68.98152919711418
- type: v_measure_std
value: 1.2519720970652428
task:
type: Clustering
- dataset:
config: default
name: MTEB TwitterSemEval2015
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
split: test
type: mteb/twittersemeval2015-pairclassification
metrics:
- type: main_score
value: 79.34189681158234
- type: cos_sim_accuracy
value: 87.68552184538356
- type: cos_sim_accuracy_threshold
value: 76.06316804885864
- type: cos_sim_ap
value: 79.34189149773933
- type: cos_sim_f1
value: 72.16386554621849
- type: cos_sim_f1_threshold
value: 73.62890243530273
- type: cos_sim_precision
value: 71.82435964453737
- type: cos_sim_recall
value: 72.5065963060686
- type: dot_accuracy
value: 87.68552184538356
- type: dot_accuracy_threshold
value: 76.06316208839417
- type: dot_ap
value: 79.34189231911259
- type: dot_f1
value: 72.16386554621849
- type: dot_f1_threshold
value: 73.62889647483826
- type: dot_precision
value: 71.82435964453737
- type: dot_recall
value: 72.5065963060686
- type: euclidean_accuracy
value: 87.68552184538356
- type: euclidean_accuracy_threshold
value: 69.19080018997192
- type: euclidean_ap
value: 79.34189681158234
- type: euclidean_f1
value: 72.16386554621849
- type: euclidean_f1_threshold
value: 72.62383103370667
- type: euclidean_precision
value: 71.82435964453737
- type: euclidean_recall
value: 72.5065963060686
- type: manhattan_accuracy
value: 87.661679680515
- type: manhattan_accuracy_threshold
value: 3408.807373046875
- type: manhattan_ap
value: 79.29617544165136
- type: manhattan_f1
value: 72.1957671957672
- type: manhattan_f1_threshold
value: 3597.7684020996094
- type: manhattan_precision
value: 72.38726790450929
- type: manhattan_recall
value: 72.00527704485488
- type: max_accuracy
value: 87.68552184538356
- type: max_ap
value: 79.34189681158234
- type: max_f1
value: 72.1957671957672
task:
type: PairClassification
- dataset:
config: default
name: MTEB TwitterURLCorpus
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
split: test
type: mteb/twitterurlcorpus-pairclassification
metrics:
- type: main_score
value: 87.8635519535718
- type: cos_sim_accuracy
value: 89.80672953778088
- type: cos_sim_accuracy_threshold
value: 73.09532165527344
- type: cos_sim_ap
value: 87.84251379545145
- type: cos_sim_f1
value: 80.25858884373845
- type: cos_sim_f1_threshold
value: 70.57080268859863
- type: cos_sim_precision
value: 77.14103110353643
- type: cos_sim_recall
value: 83.63874345549738
- type: dot_accuracy
value: 89.80672953778088
- type: dot_accuracy_threshold
value: 73.09532761573792
- type: dot_ap
value: 87.84251881260793
- type: dot_f1
value: 80.25858884373845
- type: dot_f1_threshold
value: 70.57079076766968
- type: dot_precision
value: 77.14103110353643
- type: dot_recall
value: 83.63874345549738
- type: euclidean_accuracy
value: 89.80672953778088
- type: euclidean_accuracy_threshold
value: 73.3548641204834
- type: euclidean_ap
value: 87.84251335039049
- type: euclidean_f1
value: 80.25858884373845
- type: euclidean_f1_threshold
value: 76.71923041343689
- type: euclidean_precision
value: 77.14103110353643
- type: euclidean_recall
value: 83.63874345549738
- type: manhattan_accuracy
value: 89.78150347343501
- type: manhattan_accuracy_threshold
value: 3702.7603149414062
- type: manhattan_ap
value: 87.8635519535718
- type: manhattan_f1
value: 80.27105660516332
- type: manhattan_f1_threshold
value: 3843.5962677001953
- type: manhattan_precision
value: 76.9361101306036
- type: manhattan_recall
value: 83.90822297505389
- type: max_accuracy
value: 89.80672953778088
- type: max_ap
value: 87.8635519535718
- type: max_f1
value: 80.27105660516332
task:
type: PairClassification
---
FlagEmbedding
For more details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
**BGE-EN-ICL** primarily demonstrates the following capabilities:
- In-context learning ability: By providing few-shot examples in the query, it can significantly enhance the model's ability to handle new tasks.
- Outstanding performance: The model has achieved state-of-the-art (SOTA) performance on both BEIR and AIR-Bench.
## 📑 Open-source Plan
- [x] Checkpoint
- [ ] Training Data
- [ ] Evaluation Pipeline
- [ ] Technical Report
We will release the technical report and training data for **BGE-EN-ICL** in the future.
## Usage
### Using FlagEmbedding
```
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .
```
```python
from FlagEmbedding import FlagICLModel
queries = ["how much protein should a female eat", "summit define"]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
examples = [
{'instruct': 'Given a web search query, retrieve relevant passages that answer the query.',
'query': 'what is a virtual interface',
'response': "A virtual interface is a software-defined abstraction that mimics the behavior and characteristics of a physical network interface. It allows multiple logical network connections to share the same physical network interface, enabling efficient utilization of network resources. Virtual interfaces are commonly used in virtualization technologies such as virtual machines and containers to provide network connectivity without requiring dedicated hardware. They facilitate flexible network configurations and help in isolating network traffic for security and management purposes."},
{'instruct': 'Given a web search query, retrieve relevant passages that answer the query.',
'query': 'causes of back pain in female for a week',
'response': "Back pain in females lasting a week can stem from various factors. Common causes include muscle strain due to lifting heavy objects or improper posture, spinal issues like herniated discs or osteoporosis, menstrual cramps causing referred pain, urinary tract infections, or pelvic inflammatory disease. Pregnancy-related changes can also contribute. Stress and lack of physical activity may exacerbate symptoms. Proper diagnosis by a healthcare professional is crucial for effective treatment and management."}
]
model = FlagICLModel('BAAI/bge-en-icl',
query_instruction_for_retrieval="Given a web search query, retrieve relevant passages that answer the query.",
examples_for_task=examples, # set `examples_for_task=None` to use model without examples
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode_queries(queries)
embeddings_2 = model.encode_corpus(documents)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
By default, FlagICLModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'{task_description}\n{query}'
def get_detailed_example(task_description: str, query: str, response: str) -> str:
return f'{task_description}\n{query}\n{response}'
def get_new_queries(queries, query_max_len, examples_prefix, tokenizer):
inputs = tokenizer(
queries,
max_length=query_max_len - len(tokenizer('', add_special_tokens=False)['input_ids']) - len(
tokenizer('\n', add_special_tokens=False)['input_ids']),
return_token_type_ids=False,
truncation=True,
return_tensors=None,
add_special_tokens=False
)
prefix_ids = tokenizer(examples_prefix, add_special_tokens=False)['input_ids']
suffix_ids = tokenizer('\n', add_special_tokens=False)['input_ids']
new_max_length = (len(prefix_ids) + len(suffix_ids) + query_max_len + 8) // 8 * 8 + 8
new_queries = tokenizer.batch_decode(inputs['input_ids'])
for i in range(len(new_queries)):
new_queries[i] = examples_prefix + new_queries[i] + '\n'
return new_max_length, new_queries
task = 'Given a web search query, retrieve relevant passages that answer the query.'
examples = [
{'instruct': 'Given a web search query, retrieve relevant passages that answer the query.',
'query': 'what is a virtual interface',
'response': "A virtual interface is a software-defined abstraction that mimics the behavior and characteristics of a physical network interface. It allows multiple logical network connections to share the same physical network interface, enabling efficient utilization of network resources. Virtual interfaces are commonly used in virtualization technologies such as virtual machines and containers to provide network connectivity without requiring dedicated hardware. They facilitate flexible network configurations and help in isolating network traffic for security and management purposes."},
{'instruct': 'Given a web search query, retrieve relevant passages that answer the query.',
'query': 'causes of back pain in female for a week',
'response': "Back pain in females lasting a week can stem from various factors. Common causes include muscle strain due to lifting heavy objects or improper posture, spinal issues like herniated discs or osteoporosis, menstrual cramps causing referred pain, urinary tract infections, or pelvic inflammatory disease. Pregnancy-related changes can also contribute. Stress and lack of physical activity may exacerbate symptoms. Proper diagnosis by a healthcare professional is crucial for effective treatment and management."}
]
examples = [get_detailed_example(e['instruct'], e['query'], e['response']) for e in examples]
examples_prefix = '\n\n'.join(examples) + '\n\n' # if there not exists any examples, just set examples_prefix = ''
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, 'summit define')
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
query_max_len, doc_max_len = 512, 512
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-en-icl')
model = AutoModel.from_pretrained('BAAI/bge-en-icl')
model.eval()
new_query_max_len, new_queries = get_new_queries(queries, query_max_len, examples_prefix, tokenizer)
query_batch_dict = tokenizer(new_queries, max_length=new_query_max_len, padding=True, truncation=True, return_tensors='pt')
doc_batch_dict = tokenizer(documents, max_length=doc_max_len, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
query_outputs = model(**query_batch_dict)
query_embeddings = last_token_pool(query_outputs.last_hidden_state, query_batch_dict['attention_mask'])
doc_outputs = model(**doc_batch_dict)
doc_embeddings = last_token_pool(doc_outputs.last_hidden_state, doc_batch_dict['attention_mask'])
# normalize embeddings
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
doc_embeddings = F.normalize(doc_embeddings, p=2, dim=1)
scores = (query_embeddings @ doc_embeddings.T) * 100
print(scores.tolist())
```
## Evaluation
`bge-en-icl` achieve **state-of-the-art performance on both MTEB and AIR-Bench leaderboard!**
- **[MTEB](https://huggingface.co/spaces/mteb/leaderboard)**:

- **[BEIR](https://huggingface.co/spaces/mteb/leaderboard)**:
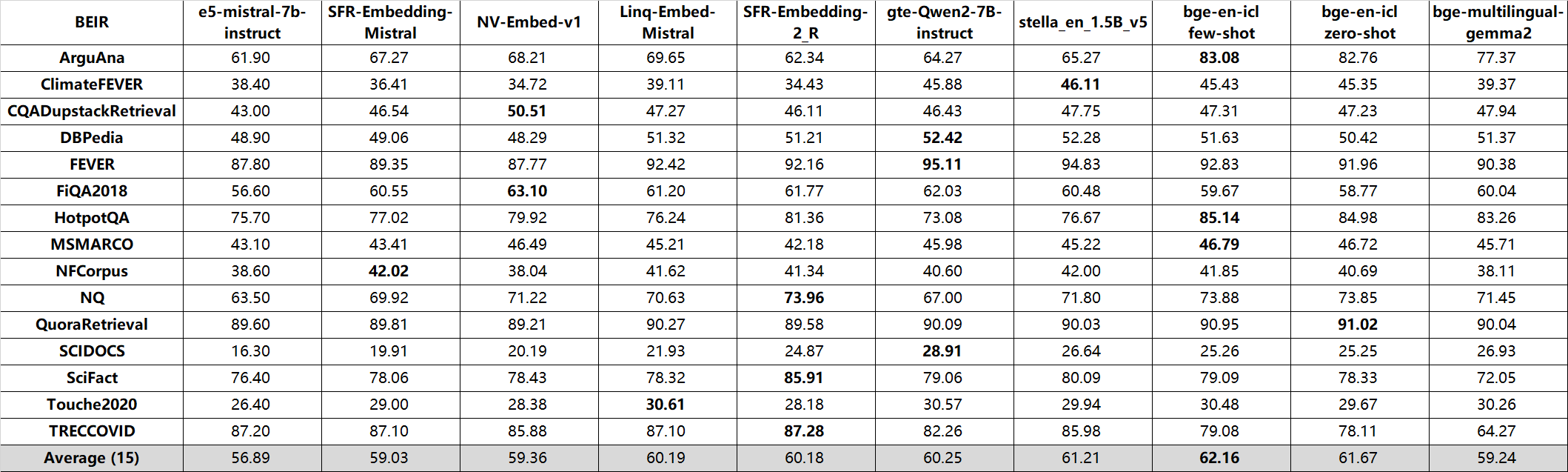
- **[AIR-Bench](https://huggingface.co/spaces/AIR-Bench/leaderboard)**:
**QA (en, nDCG@10):**
| AIR-Bench_24.04 | wiki | web | news | healthcare | law | finance | arxiv | msmarco | ALL (8) |
| :--------------------------: | :-------: | :-------: | :-------: | :--------: | :-------: | :-------: | :-------: | :-------: | :-------: |
| **e5-mistral-7b-instruct** | 61.67 | 44.41 | 48.18 | 56.32 | 19.32 | 54.79 | 44.78 | 59.03 | 48.56 |
| **SFR-Embedding-Mistral** | 63.46 | 51.27 | 52.21 | 58.76 | 23.27 | 56.94 | 47.75 | 58.99 | 51.58 |
| **NV-Embed-v1** | 62.84 | 50.42 | 51.46 | 58.53 | 20.65 | 49.89 | 46.10 | 60.27 | 50.02 |
| **Linq-Embed-Mistral** | 61.04 | 48.41 | 49.44 | **60.18** | 20.34 | 50.04 | 47.56 | 60.50 | 49.69 |
| **gte-Qwen2-7B-instruct** | 63.46 | 51.20 | 54.07 | 54.20 | 22.31 | **58.20** | 40.27 | 58.39 | 50.26 |
| **stella_en_1.5B_v5** | 61.99 | 50.88 | 53.87 | 58.81 | 23.22 | 57.26 | 44.81 | 61.38 | 51.53 |
| **bge-en-icl zero-shot** | 64.61 | 54.40 | 55.11 | 57.25 | 25.10 | 54.81 | 48.46 | 63.71 | 52.93 |
| **bge-en-icl few-shot** | **64.94** | **55.11** | **56.02** | 58.85 | **28.29** | 57.16 | **50.04** | **64.50** | **54.36** |
**Long-Doc (en, Recall@10):**
| AIR-Bench_24.04 | arxiv (4) | book (2) | healthcare (5) | law (4) | ALL (15) |
| :--------------------------: | :-------: | :-------: | :------------: | :-------: | :-------: |
| **text-embedding-3-large** | 74.53 | 73.16 | 65.83 | 64.47 | 68.77 |
| **e5-mistral-7b-instruct** | 72.14 | 72.44 | 68.44 | 62.92 | 68.49 |
| **SFR-Embedding-Mistral** | 72.79 | 72.41 | 67.94 | 64.83 | 69.00 |
| **NV-Embed-v1** | 77.65 | 75.49 | 72.38 | **69.55** | 73.45 |
| **Linq-Embed-Mistral** | 75.46 | 73.81 | 71.58 | 68.58 | 72.11 |
| **gte-Qwen2-7B-instruct** | 63.93 | 68.51 | 65.59 | 65.26 | 65.45 |
| **stella_en_1.5B_v5** | 73.17 | 74.38 | 70.02 | 69.32 | 71.25 |
| **bge-en-icl zero-shot** | 78.30 | 78.21 | 73.65 | 67.09 | 73.75 |
| **bge-en-icl few-shot** | **79.63** | **79.36** | **74.80** | 67.79 | **74.83** |
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:--------------------------------------------------------------------------|:-------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------:|:--------:|
| [BAAI/bge-en-icl](https://huggingface.co/BAAI/bge-en-icl) | English | - | A LLM-based embedding model with in-context learning capabilities, which can fully leverage the model's potential based on a few shot examples | Provide instructions and few-shot examples freely based on the given task. |
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [Inference](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3#usage) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3) | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE).