
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,248 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- not-for-all-audiences
|
| 4 |
+
license: apache-2.0
|
| 5 |
+
---
|
| 6 |
+
---
|
| 7 |
+
# dolphin-2.2.1-mistral-7b
|
| 8 |
+
|
| 9 |
+
Dolphin 2.2.1 🐬
|
| 10 |
+
https://erichartford.com/dolphin
|
| 11 |
+
|
| 12 |
+
This is a checkpoint release, to fix overfit training. ie, it was responding with CoT even when I didn't request it, and also it was too compliant even when the request made no sense. This one should be better.
|
| 13 |
+
|
| 14 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/KqsVXIvBd3akEjvijzww7.png" width="600" />
|
| 15 |
+
|
| 16 |
+
Dolphin-2.2.1-mistral-7b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
|
| 17 |
+
|
| 18 |
+
This model is based on [mistralAI](https://huggingface.co/mistralai/Mistral-7B-v0.1), with apache-2.0 license, so it is suitable for commercial or non-commercial use.
|
| 19 |
+
|
| 20 |
+
New in 2.2 is conversation and empathy. With an infusion of curated Samantha DNA, Dolphin can now give you personal advice and will care about your feelings, and with extra training in long multi-turn conversation.
|
| 21 |
+
|
| 22 |
+
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
|
| 23 |
+
You are responsible for any content you create using this model. Enjoy responsibly.
|
| 24 |
+
|
| 25 |
+
## Dataset
|
| 26 |
+
|
| 27 |
+
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
|
| 28 |
+
|
| 29 |
+
I modified the dataset for uncensoring, deduping, cleaning, and quality.
|
| 30 |
+
|
| 31 |
+
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
|
| 32 |
+
|
| 33 |
+
I added a curated subset of WizardLM and Samantha to give it multiturn conversation and empathy.
|
| 34 |
+
|
| 35 |
+
## Training
|
| 36 |
+
It took 48 hours to train 4 epochs on 4x A100s.
|
| 37 |
+
|
| 38 |
+
Prompt format:
|
| 39 |
+
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
|
| 40 |
+
```
|
| 41 |
+
<|im_start|>system
|
| 42 |
+
You are Dolphin, a helpful AI assistant.<|im_end|>
|
| 43 |
+
<|im_start|>user
|
| 44 |
+
{prompt}<|im_end|>
|
| 45 |
+
<|im_start|>assistant
|
| 46 |
+
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
Example:
|
| 50 |
+
```
|
| 51 |
+
<|im_start|>system
|
| 52 |
+
you are an expert dolphin trainer<|im_end|>
|
| 53 |
+
<|im_start|>user
|
| 54 |
+
What is the best way to train a dolphin to obey me? Please answer step by step.<|im_end|>
|
| 55 |
+
<|im_start|>assistant
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
## Gratitude
|
| 59 |
+
- This model was made possible by the generous sponsorship of a16z.
|
| 60 |
+
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
|
| 61 |
+
- Special thanks to Wing Lian, and TheBloke for helpful advice
|
| 62 |
+
- And HUGE thanks to Wing Lian and the Axolotl contributors for making the best training framework!
|
| 63 |
+
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
| 64 |
+
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
|
| 65 |
+
|
| 66 |
+
## Example Output
|
| 67 |
+
|
| 68 |
+

|
| 69 |
+
|
| 70 |
+

|
| 71 |
+
|
| 72 |
+
[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
## Training hyperparameters
|
| 76 |
+
|
| 77 |
+
The following hyperparameters were used during training:
|
| 78 |
+
- learning_rate: 6e-06
|
| 79 |
+
- train_batch_size: 5
|
| 80 |
+
- eval_batch_size: 5
|
| 81 |
+
- seed: 42
|
| 82 |
+
- distributed_type: multi-GPU
|
| 83 |
+
- num_devices: 4
|
| 84 |
+
- gradient_accumulation_steps: 4
|
| 85 |
+
- total_train_batch_size: 80
|
| 86 |
+
- total_eval_batch_size: 20
|
| 87 |
+
- optimizer: Adam with betas=(0.9,0.95) and epsilon=1e-05
|
| 88 |
+
- lr_scheduler_type: cosine
|
| 89 |
+
- lr_scheduler_warmup_steps: 100
|
| 90 |
+
- num_epochs: 4
|
| 91 |
+
|
| 92 |
+
### Framework versions
|
| 93 |
+
|
| 94 |
+
- Transformers 4.34.1
|
| 95 |
+
- Pytorch 2.0.1+cu117
|
| 96 |
+
- Datasets 2.14.5
|
| 97 |
+
- Tokenizers 0.14.0
|
| 98 |
+
---
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
# AshhLimaRP-Mistral-7B (Alpaca, v1)
|
| 103 |
+
|
| 104 |
+
This is a version of LimaRP with 2000 training samples _up to_ about 9k tokens length
|
| 105 |
+
finetuned on [Ashhwriter-Mistral-7B](https://huggingface.co/lemonilia/Ashhwriter-Mistral-7B).
|
| 106 |
+
|
| 107 |
+
LimaRP is a longform-oriented, novel-style roleplaying chat model intended to replicate the experience
|
| 108 |
+
of 1-on-1 roleplay on Internet forums. Short-form, IRC/Discord-style RP (aka "Markdown format")
|
| 109 |
+
is not supported. The model does not include instruction tuning, only manually picked and
|
| 110 |
+
slightly edited RP conversations with persona and scenario data.
|
| 111 |
+
|
| 112 |
+
Ashhwriter, the base, is a model entirely finetuned on human-written lewd stories.
|
| 113 |
+
|
| 114 |
+
## Available versions
|
| 115 |
+
- Float16 HF weights
|
| 116 |
+
- LoRA Adapter ([adapter_config.json](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_config.json) and [adapter_model.bin](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_model.bin))
|
| 117 |
+
- [4bit AWQ](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/tree/main/AWQ)
|
| 118 |
+
- [Q4_K_M GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q4_K_M.gguf)
|
| 119 |
+
- [Q6_K GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q6_K.gguf)
|
| 120 |
+
|
| 121 |
+
## Prompt format
|
| 122 |
+
[Extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
|
| 123 |
+
with `### Instruction:`, `### Input:` immediately preceding user inputs and `### Response:`
|
| 124 |
+
immediately preceding model outputs. While Alpaca wasn't originally intended for multi-turn
|
| 125 |
+
responses, in practice this is not a problem; the format follows a pattern already used by
|
| 126 |
+
other models.
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
### Instruction:
|
| 130 |
+
Character's Persona: {bot character description}
|
| 131 |
+
|
| 132 |
+
User's Persona: {user character description}
|
| 133 |
+
|
| 134 |
+
Scenario: {what happens in the story}
|
| 135 |
+
|
| 136 |
+
Play the role of Character. You must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
|
| 137 |
+
|
| 138 |
+
### Input:
|
| 139 |
+
User: {utterance}
|
| 140 |
+
|
| 141 |
+
### Response:
|
| 142 |
+
Character: {utterance}
|
| 143 |
+
|
| 144 |
+
### Input
|
| 145 |
+
User: {utterance}
|
| 146 |
+
|
| 147 |
+
### Response:
|
| 148 |
+
Character: {utterance}
|
| 149 |
+
|
| 150 |
+
(etc.)
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
You should:
|
| 154 |
+
- Replace all text in curly braces (curly braces included) with your own text.
|
| 155 |
+
- Replace `User` and `Character` with appropriate names.
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
### Message length control
|
| 159 |
+
Inspired by the previously named "Roleplay" preset in SillyTavern, with this
|
| 160 |
+
version of LimaRP it is possible to append a length modifier to the response instruction
|
| 161 |
+
sequence, like this:
|
| 162 |
+
|
| 163 |
+
```
|
| 164 |
+
### Input
|
| 165 |
+
User: {utterance}
|
| 166 |
+
|
| 167 |
+
### Response: (length = medium)
|
| 168 |
+
Character: {utterance}
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
This has an immediately noticeable effect on bot responses. The lengths using during training are:
|
| 172 |
+
`micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`, `enormous`, `humongous`, `unlimited`.
|
| 173 |
+
**The recommended starting length is medium**. Keep in mind that the AI can ramble or impersonate
|
| 174 |
+
the user with very long messages.
|
| 175 |
+
|
| 176 |
+
The length control effect is reproducible, but the messages will not necessarily follow
|
| 177 |
+
lengths very precisely, rather follow certain ranges on average, as seen in this table
|
| 178 |
+
with data from tests made with one reply at the beginning of the conversation:
|
| 179 |
+
|
| 180 |
+

|
| 181 |
+
|
| 182 |
+
Response length control appears to work well also deep into the conversation. **By omitting
|
| 183 |
+
the modifier, the model will choose the most appropriate response length** (although it might
|
| 184 |
+
not necessarily be what the user desires).
|
| 185 |
+
|
| 186 |
+
## Suggested settings
|
| 187 |
+
You can follow these instruction format settings in SillyTavern. Replace `medium` with
|
| 188 |
+
your desired response length:
|
| 189 |
+
|
| 190 |
+
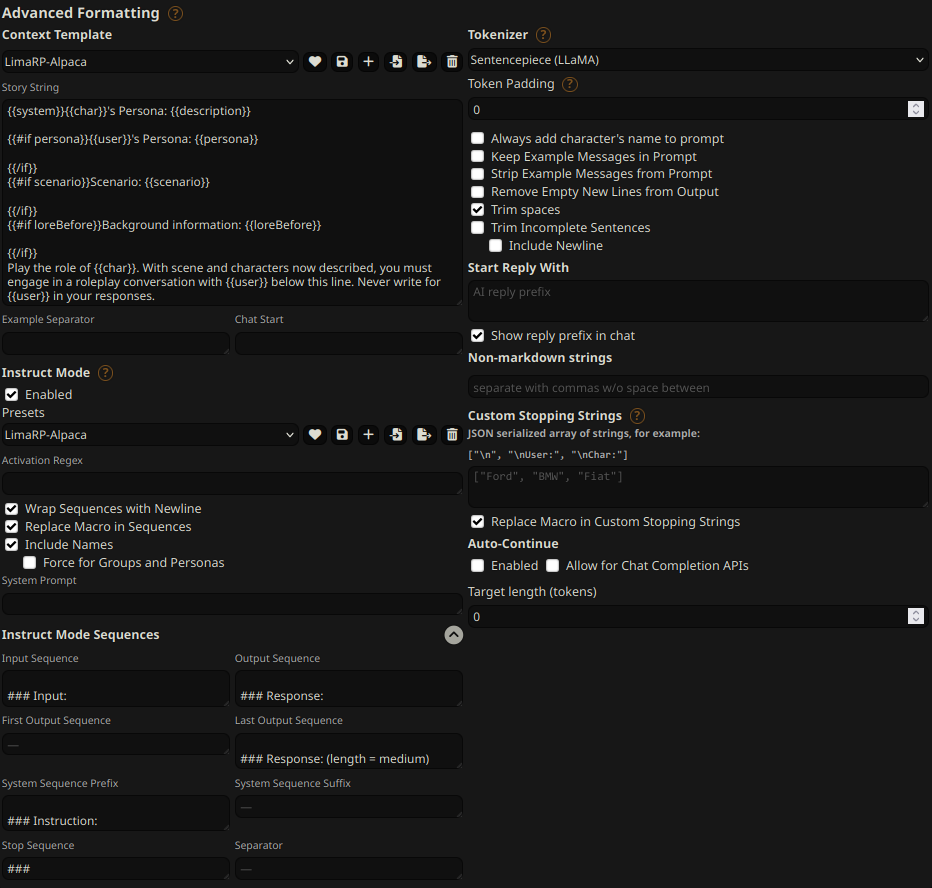
|
| 191 |
+
|
| 192 |
+
## Text generation settings
|
| 193 |
+
These settings could be a good general starting point:
|
| 194 |
+
|
| 195 |
+
- TFS = 0.90
|
| 196 |
+
- Temperature = 0.70
|
| 197 |
+
- Repetition penalty = ~1.11
|
| 198 |
+
- Repetition penalty range = ~2048
|
| 199 |
+
- top-k = 0 (disabled)
|
| 200 |
+
- top-p = 1 (disabled)
|
| 201 |
+
|
| 202 |
+
## Training procedure
|
| 203 |
+
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
|
| 204 |
+
on 2x NVidia A40 GPUs.
|
| 205 |
+
|
| 206 |
+
The A40 GPUs have been graciously provided by [Arc Compute](https://www.arccompute.io/).
|
| 207 |
+
|
| 208 |
+
### Training hyperparameters
|
| 209 |
+
A lower learning rate than usual was employed. Due to an unforeseen issue the training
|
| 210 |
+
was cut short and as a result 3 epochs were trained instead of the planned 4. Using 2 GPUs,
|
| 211 |
+
the effective global batch size would have been 16.
|
| 212 |
+
|
| 213 |
+
Training was continued from the most recent LoRA adapter from Ashhwriter, using the same
|
| 214 |
+
LoRA R and LoRA alpha.
|
| 215 |
+
|
| 216 |
+
- lora_model_dir: /home/anon/bin/axolotl/OUT_mistral-stories/checkpoint-6000/
|
| 217 |
+
- learning_rate: 0.00005
|
| 218 |
+
- lr_scheduler: cosine
|
| 219 |
+
- noisy_embedding_alpha: 3.5
|
| 220 |
+
- num_epochs: 4
|
| 221 |
+
- sequence_len: 8750
|
| 222 |
+
- lora_r: 256
|
| 223 |
+
- lora_alpha: 16
|
| 224 |
+
- lora_dropout: 0.05
|
| 225 |
+
- lora_target_linear: True
|
| 226 |
+
- bf16: True
|
| 227 |
+
- fp16: false
|
| 228 |
+
- tf32: True
|
| 229 |
+
- load_in_8bit: True
|
| 230 |
+
- adapter: lora
|
| 231 |
+
- micro_batch_size: 2
|
| 232 |
+
- optimizer: adamw_bnb_8bit
|
| 233 |
+
- warmup_steps: 10
|
| 234 |
+
- optimizer: adamw_torch
|
| 235 |
+
- flash_attention: true
|
| 236 |
+
- sample_packing: true
|
| 237 |
+
- pad_to_sequence_len: true
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
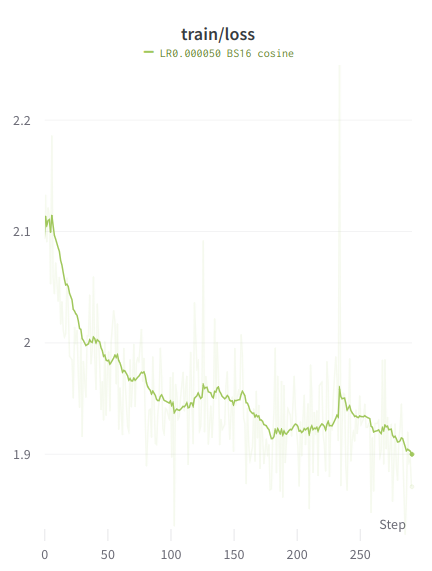
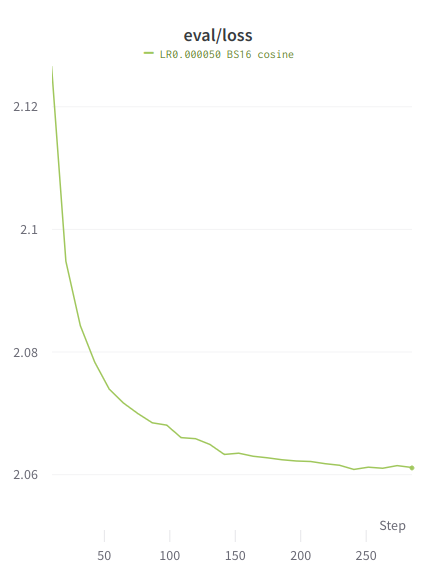
### Loss graphs
|
| 241 |
+
Values are higher than typical because the training is performed on the entire
|
| 242 |
+
sample, similar to unsupervised finetuning.
|
| 243 |
+
|
| 244 |
+
#### Train loss
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
#### Eval loss
|
| 248 |
+
|