State-of-the-art compact VLMs for on-device applications: Base, Synthetic, and Instruct

Hugging Face TB Research
Enterprise
community
AI & ML interests
Exploring smol models and high quality web and synthetic datasets, generated by LLMs (TB is for Textbook, as inspired by the "Textbooks are all your need" paper)
Organization Card
HuggingFaceTB
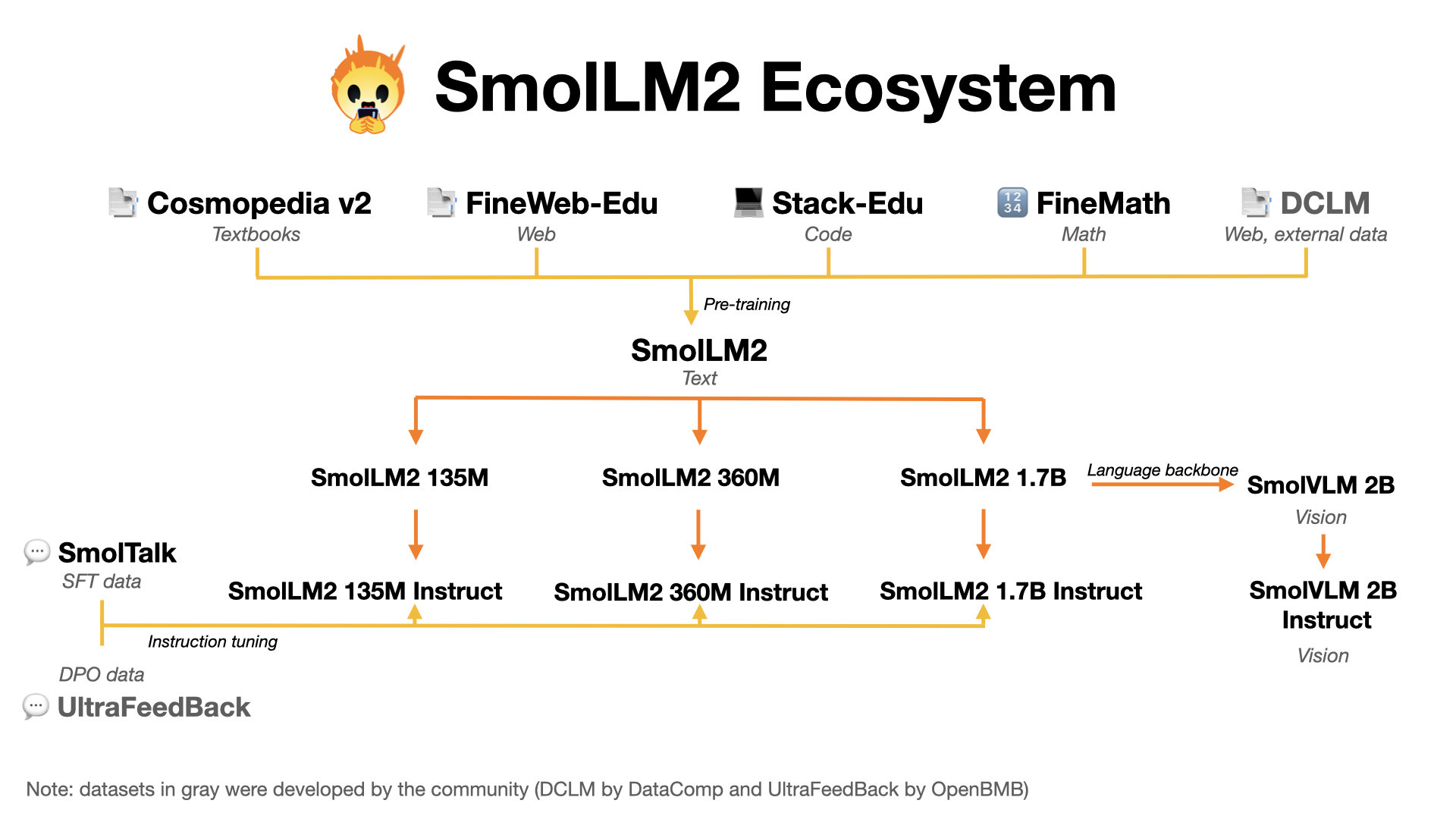
This is the home for smol models (SmolLM) and high quality pre-training datasets. We released:
- FineWeb-Edu: a filtered version of FineWeb dataset for educational content, paper available here.
- Cosmopedia: the largest open synthetic dataset, with 25B tokens and 30M samples. It contains synthetic textbooks, blog posts, and stories, posts generated by Mixtral. Blog post available here.
- Smollm-Corpus: the pre-training corpus of SmolLM: Cosmopedia v0.2, FineWeb-Edu dedup and Python-Edu. Blog post available here.
- SmolLM models and SmolLM2 models: a series of strong small models in three sizes: 135M, 360M and 1.7B
- SmolVLM: a 2 billion Vision Language Model (VLM) built for on-device inference. It uses SmolLM2-1.7B as a language backbone. Blog post available here.
News 🗞️
- SmolLM2: you can find our most capable model SmolLM2-1.7B here: https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct and our training and evaluation toolkit at: https://github.com/huggingface/smollm
- We released our SFT mix SmolTalk, a 1M samples synthetic dataset to improve instruction following, chat and reasoning: https://hf.co/datasets/HuggingFaceTB/smoltalk
- SmolVLM: a lightweight 2B Vision Language Model available here https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct
spaces
5
Running
on
Zero
68
📊
SmolVLM
Running
8
🚀
SmolLM2 1.7B Instruct WebGPU
A blazingly fast & powerful AI chatbot that runs in-browser!
Running
122
🚀
SmolLM 360M Instruct WebGPU
A blazingly fast and powerful AI chatbot that runs locally.
Running
49
🤏
Instant SmolLM
Run SmolLM-360M-Instruct in realtime with MLC WebLLM
Running
6
🕸️
Web clusters
models
34
HuggingFaceTB/SmolLM2-nanotron-ckpt
Updated
HuggingFaceTB/SmolVLM-Base
Image-Text-to-Text
•
Updated
•
1.02k
•
12
HuggingFaceTB/SmolVLM-Instruct
Image-Text-to-Text
•
Updated
•
14.7k
•
173
HuggingFaceTB/SmolLM2-1.7B-Instruct-Q8-mlx
Text Generation
•
Updated
•
10
HuggingFaceTB/SmolLM2-135M-Instruct-Q8-mlx
Text Generation
•
Updated
•
12
HuggingFaceTB/SmolLM2-360M-Instruct-Q8-mlx
Text Generation
•
Updated
•
12
HuggingFaceTB/SmolVLM-Synthetic
Image-Text-to-Text
•
Updated
•
89
•
5
HuggingFaceTB/SmolVLM-Instruct-DPO
Image-Text-to-Text
•
Updated
•
172
•
9
HuggingFaceTB/SmolLM2-1.7B-Instruct
Text Generation
•
Updated
•
90.9k
•
•
393
HuggingFaceTB/SmolLM2-135M-Instruct
Text Generation
•
Updated
•
25k
•
64
datasets
31
HuggingFaceTB/smoltalk
Viewer
•
Updated
•
2.2M
•
2.5k
•
183
HuggingFaceTB/smol-smoltalk
Viewer
•
Updated
•
485k
•
545
•
17
HuggingFaceTB/MATH
Updated
•
82
•
2
HuggingFaceTB/smollm-corpus
Viewer
•
Updated
•
237M
•
37.4k
•
250
HuggingFaceTB/everyday-conversations-llama3.1-2k
Viewer
•
Updated
•
2.38k
•
628
•
79
HuggingFaceTB/instruct-data-basics-smollm-H4
Viewer
•
Updated
•
767
•
174
HuggingFaceTB/self-oss-instruct-sc2-H4
Viewer
•
Updated
•
50.7k
•
284
•
2
HuggingFaceTB/Magpie-Pro-300K-Filtered-H4
Viewer
•
Updated
•
300k
•
170
•
2
HuggingFaceTB/OpenHermes-2.5-H4
Viewer
•
Updated
•
1M
•
216
•
2
HuggingFaceTB/bisac_expanded_topics
Viewer
•
Updated
•
34.2k
•
33