
Commit
•
64d01aa
1
Parent(s):
35eab02
Upload 7 files
Browse files- .gitattributes +3 -0
- README.md +86 -3
- images/Screen_recording-2024-07-03_16-39-54.mp4 +3 -0
- images/data.png +0 -0
- images/generateTraj.png +0 -0
- images/hook.png +0 -0
- images/leaderboard.png +3 -0
- images/main.png +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/leaderboard.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/main.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
images/Screen_recording-2024-07-03_16-39-54.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,86 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<h1 align="center"> PyBench: Evaluate LLM Agent on Real World Tasks </h1>
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
<a href="comming soon">📃 Paper</a>
|
| 5 |
+
•
|
| 6 |
+
<a href="https://huggingface.co/datasets/Mercury7353/PyInstruct" >🤗 Data (PyInstruct)</a>
|
| 7 |
+
•
|
| 8 |
+
<a href="https://huggingface.co/Mercury7353/PyLlama3" >🤗 Model (PyLlama3)</a>
|
| 9 |
+
•
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
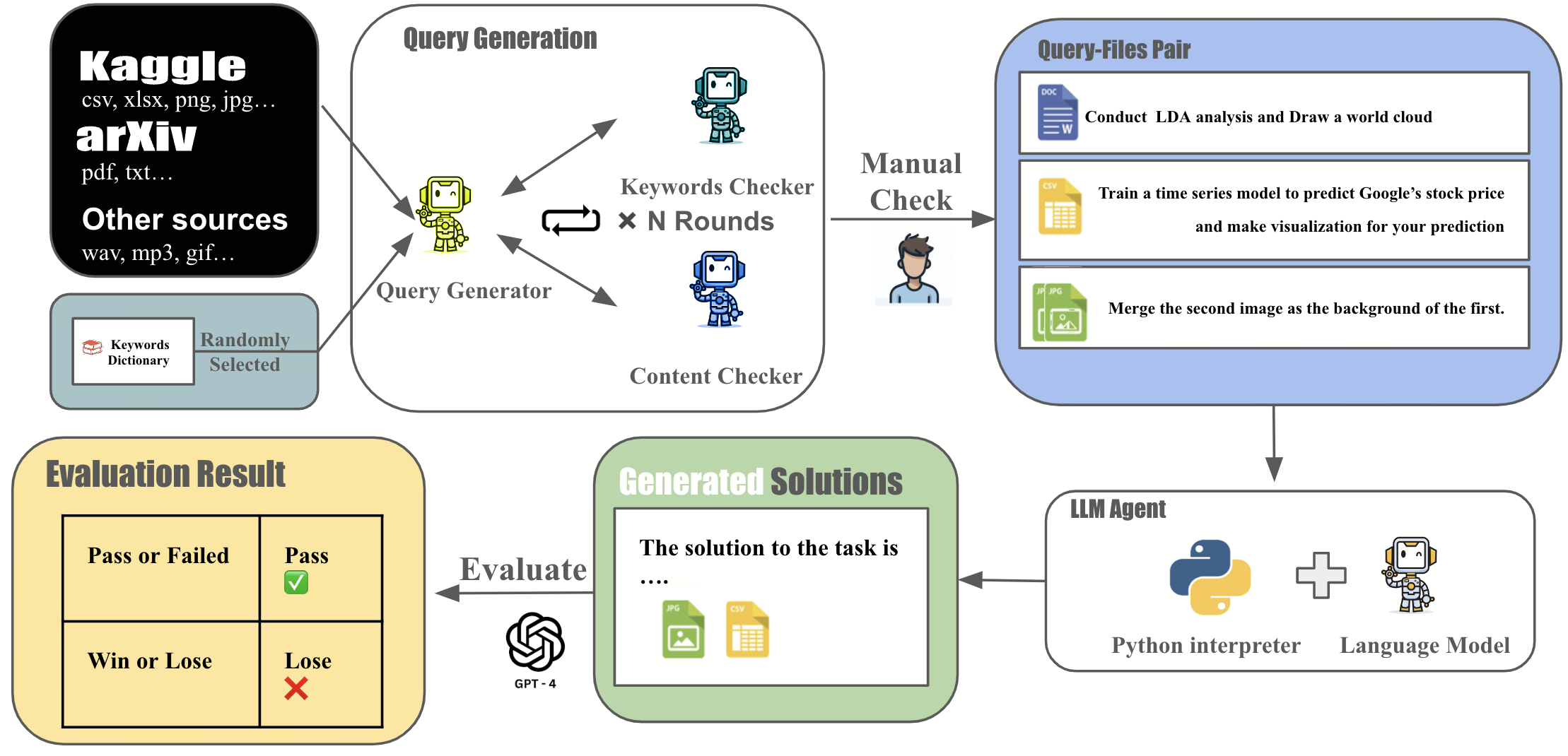
PyBench is a comprehensive benchmark evaluating LLM on real-world coding tasks including **chart analysis**, **text analysis**, **image/ audio editing**, **complex math** and **software/website development**.
|
| 14 |
+
We collect files from Kaggle, arXiv, and other sources and automatically generate queries according to the type and content of each file.
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Why PyBench?
|
| 22 |
+
|
| 23 |
+
The LLM Agent, equipped with a code interpreter, is capable of automatically solving real-world coding tasks, such as data analysis and image processing.
|
| 24 |
+
%
|
| 25 |
+
However, existing benchmarks primarily focus on either simplistic tasks, such as completing a few lines of code, or on extremely complex and specific tasks at the repository level, neither of which are representative of various daily coding tasks.
|
| 26 |
+
%
|
| 27 |
+
To address this gap, we introduce **PyBench**, a benchmark that encompasses 6 main categories of real-world tasks, covering more than 10 types of files.
|
| 28 |
+

|
| 29 |
+
|
| 30 |
+
## 📁 PyInstruct
|
| 31 |
+
|
| 32 |
+
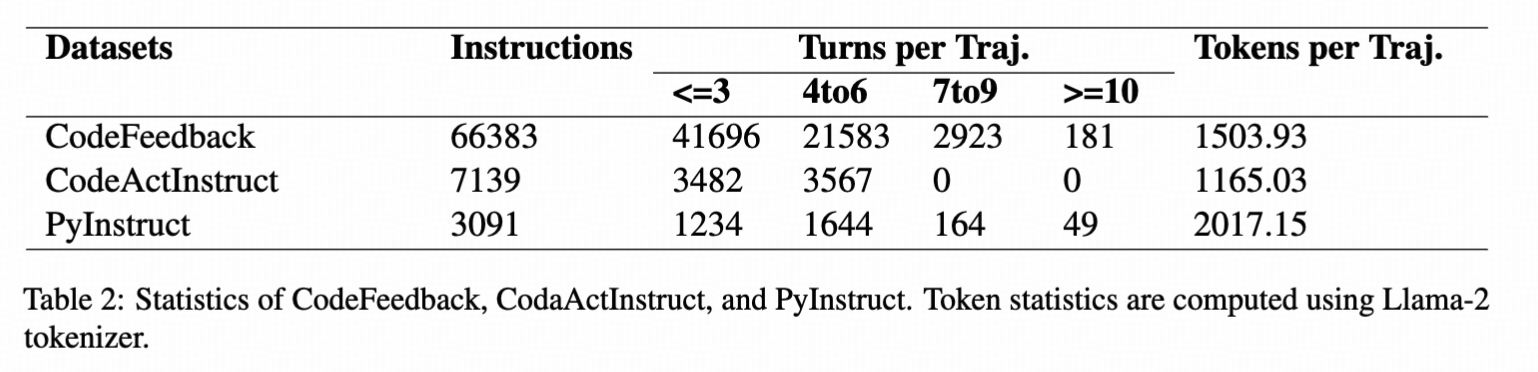
To figure out a way to enhance the model's ability on PyBench, we generate a homologous dataset: **PyInstruct**. The PyInstruct contains multi-turn interaction between the model and files, stimulating the model's capability on coding, debugging and multi-turn complex task solving. Compare to other Datasets focus on multi-turn coding ability, PyInstruct has longer turns and tokens per trajectory.
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+
*Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.*
|
| 36 |
+
|
| 37 |
+
## 🪄 PyLlama
|
| 38 |
+
|
| 39 |
+
We trained Llama3-8B-base on PyInstruct, CodeActInstruct, CodeFeedback, and Jupyter Notebook Corpus to get PyLlama3, achieving an outstanding performance on PyBench
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
## 🚀 Model Evaluation with PyBench!
|
| 43 |
+
<video src="https://github.com/Mercury7353/PyBench/assets/103104011/fef85310-55a3-4ee8-a441-612e7dbbaaab"> </video>
|
| 44 |
+
*Demonstration of the chat interface.*
|
| 45 |
+
### Environment Setup:
|
| 46 |
+
Begin by establishing the required environment:
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
conda env create -f environment.yml
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
### Model Configuration
|
| 53 |
+
Initialize a local server using the vllm framework, which defaults to port "8001":
|
| 54 |
+
|
| 55 |
+
```bash
|
| 56 |
+
bash SetUpModel.sh
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
A Jinja template is necessary to launch a vllm server. Commonly used templates can be located in the `./jinja/` directory.
|
| 61 |
+
Prior to starting the vllm server, specify the model path and Jinja template path in `SetUpModel.sh`.
|
| 62 |
+
### Configuration Adjustments
|
| 63 |
+
Specify your model's path and the server port in `./config/model.yaml`. This configuration file also allows for customization of the system prompts.
|
| 64 |
+
### Execution on PyBench
|
| 65 |
+
Ensure to update the output trajectory file path in the script before execution:
|
| 66 |
+
|
| 67 |
+
```bash
|
| 68 |
+
python /data/zyl7353/codeinterpreterbenchmark/inference.py --config_path ./config/<your config>.yaml --task_path ./data/meta/task.json --output_path <your trajectory.jsonl path>
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
### Unit Testing Procedure
|
| 73 |
+
- **Step 1:** Store the output files in `./output`.
|
| 74 |
+
- **Step 2:** Define the trajectory file path in
|
| 75 |
+
`./data/unit_test/enter_point.py`.
|
| 76 |
+
- **Step 3:** Execute the unit test script:
|
| 77 |
+
```bash
|
| 78 |
+
python data/unit_test/enter_point.py
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## 📊 LeaderBoard
|
| 82 |
+

|
| 83 |
+
# 📚 Citation
|
| 84 |
+
```bibtex
|
| 85 |
+
TBD
|
| 86 |
+
```
|
images/Screen_recording-2024-07-03_16-39-54.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:43692e7d0a6925a082f33d4ae2c5326fdd3af118e37849c8d858c0a8a7fde029
|
| 3 |
+
size 5153739
|
images/data.png
ADDED
|
images/generateTraj.png
ADDED

|
images/hook.png
ADDED
|
images/leaderboard.png
ADDED

|
Git LFS Details
|
images/main.png
ADDED

|
Git LFS Details
|