📃 Paper • 🤗 Data (PyInstruct) • 🤗 Model (PyLlama3) • 🚗Code •
This is the PyLlama3 model, fine-tuned for PyBench . PyBench is a comprehensive benchmark evaluating LLM on real-world coding tasks including **chart analysis**, **text analysis**, **image/ audio editing**, **complex math** and **software/website development**. We collect files from Kaggle, arXiv, and other sources and automatically generate queries according to the type and content of each file. As for evaluation, we design unit tests for each tasks.  ## Why PyBench? The LLM Agent, equipped with a code interpreter, is capable of automatically solving real-world coding tasks, such as data analysis and image processing. However, existing benchmarks primarily focus on either simplistic tasks, such as completing a few lines of code, or on extremely complex and specific tasks at the repository level, neither of which are representative of various daily coding tasks. To address this gap, we introduce **PyBench**, a benchmark that encompasses 5 main categories of real-world tasks, covering more than 10 types of files. 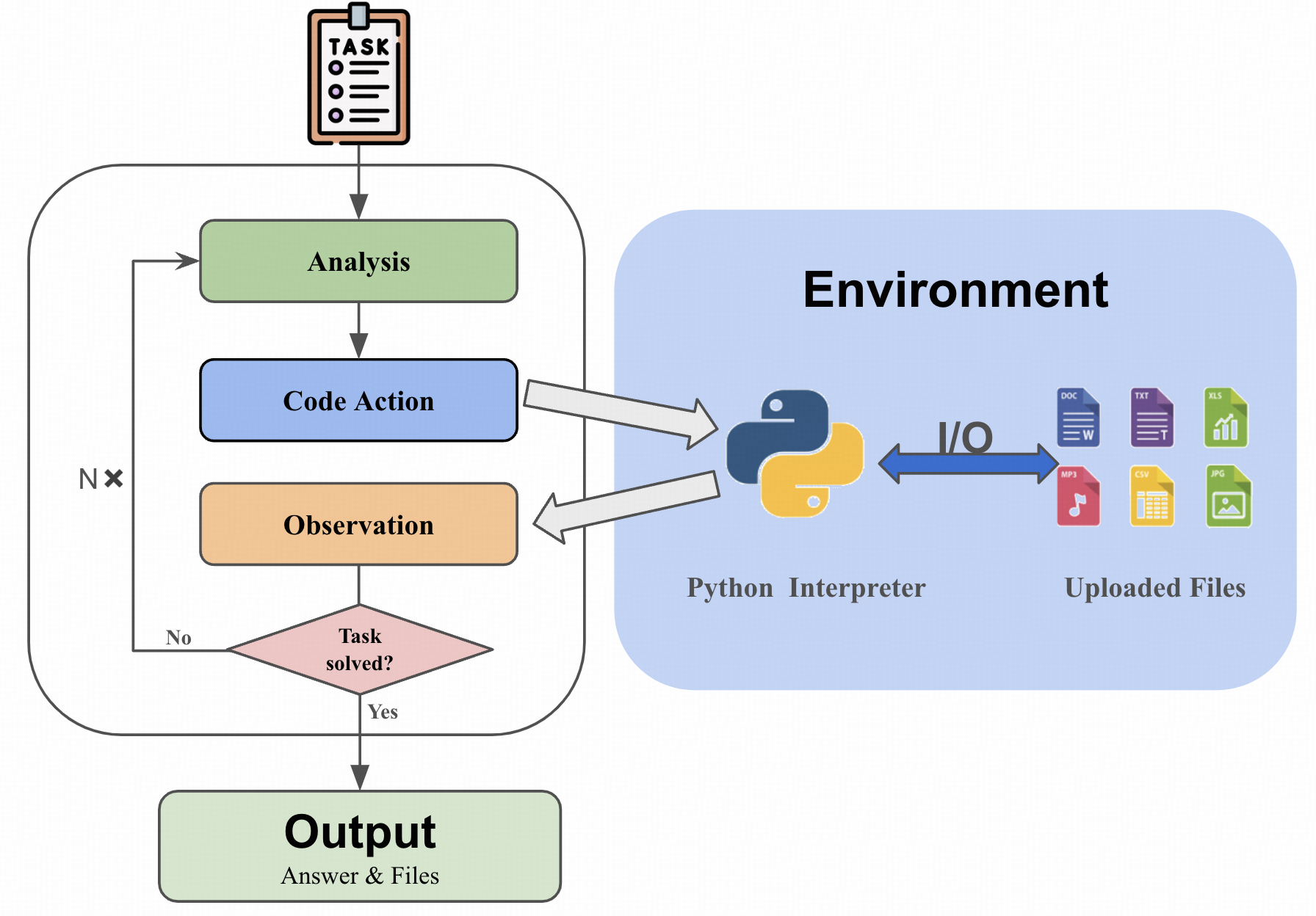 ## 📁 PyInstruct To figure out a way to enhance the model's ability on PyBench, we generate a homologous dataset: **PyInstruct**. The PyInstruct contains multi-turn interaction between the model and files, stimulating the model's capability on coding, debugging and multi-turn complex task solving. Compare to other Datasets focus on multi-turn coding ability, PyInstruct has longer turns and tokens per trajectory. 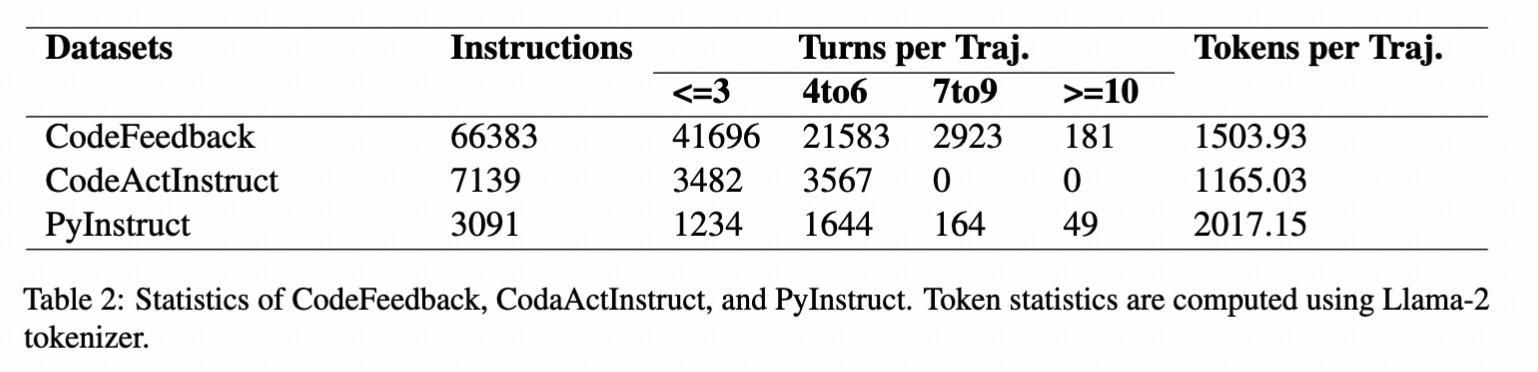 *Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.* ## 🪄 PyLlama We trained Llama3-8B-base on PyInstruct, CodeActInstruct, CodeFeedback, and Jupyter Notebook Corpus to get PyLlama3, achieving an outstanding performance on PyBench ## 🚀 Model Evaluation with PyBench! *Demonstration of the chat interface.* - Detailed in 🚗Github ## 📊 LeaderBoard  # 📚 Citation ```bibtex @misc{zhang2024pybenchevaluatingllmagent, title={PyBench: Evaluating LLM Agent on various real-world coding tasks}, author={Yaolun Zhang and Yinxu Pan and Yudong Wang and Jie Cai and Zhi Zheng and Guoyang Zeng and Zhiyuan Liu}, year={2024}, eprint={2407.16732}, archivePrefix={arXiv}, primaryClass={cs.SE}, url={https://arxiv.org/abs/2407.16732}, } ```