
Add Luminia-8B-RP v0.3
Browse filesSame v0.2 datasets. Update base model from 'NousResearch/Meta-Llama-3.1-8B-Instruct' to 'meta-llama/Meta-Llama-3.1-8B-Instruct', for possible misconfig.
- Luminia-8B-RP-DPO/adapter_config.json +5 -5
- Luminia-8B-RP-DPO/adapter_model.safetensors +1 -1
- Luminia-8B-RP-DPO/all_results.json +4 -4
- Luminia-8B-RP-DPO/train_results.json +4 -4
- Luminia-8B-RP-DPO/trainer_log.jsonl +9 -9
- Luminia-8B-RP-DPO/trainer_state.json +92 -92
- Luminia-8B-RP-DPO/training_args.bin +1 -1
- Luminia-8B-RP-DPO/training_loss.png +0 -0
- Luminia-8B-RP/adapter_config.json +6 -6
- Luminia-8B-RP/adapter_model.safetensors +1 -1
- Luminia-8B-RP/all_results.json +4 -4
- Luminia-8B-RP/train_results.json +4 -4
- Luminia-8B-RP/trainer_log.jsonl +0 -0
- Luminia-8B-RP/trainer_state.json +0 -0
- Luminia-8B-RP/training_args.bin +2 -2
- Luminia-8B-RP/training_loss.png +0 -0
- config.json +1 -1
- model-00001-of-00004.safetensors +1 -1
- model-00002-of-00004.safetensors +1 -1
- model-00003-of-00004.safetensors +1 -1
- model-00004-of-00004.safetensors +1 -1
Luminia-8B-RP-DPO/adapter_config.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
"alpha_pattern": {},
|
| 3 |
"auto_mapping": null,
|
| 4 |
-
"base_model_name_or_path": "
|
| 5 |
"bias": "none",
|
| 6 |
"fan_in_fan_out": false,
|
| 7 |
"inference_mode": true,
|
|
@@ -20,13 +20,13 @@
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
|
|
|
|
|
|
| 23 |
"v_proj",
|
| 24 |
-
"
|
| 25 |
"gate_proj",
|
| 26 |
-
"q_proj",
|
| 27 |
"down_proj",
|
| 28 |
-
"
|
| 29 |
-
"o_proj"
|
| 30 |
],
|
| 31 |
"task_type": "CAUSAL_LM",
|
| 32 |
"use_dora": false,
|
|
|
|
| 1 |
{
|
| 2 |
"alpha_pattern": {},
|
| 3 |
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "meta-llama/Meta-Llama-3.1-8B-Instruct",
|
| 5 |
"bias": "none",
|
| 6 |
"fan_in_fan_out": false,
|
| 7 |
"inference_mode": true,
|
|
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
| 23 |
+
"q_proj",
|
| 24 |
+
"up_proj",
|
| 25 |
"v_proj",
|
| 26 |
+
"o_proj",
|
| 27 |
"gate_proj",
|
|
|
|
| 28 |
"down_proj",
|
| 29 |
+
"k_proj"
|
|
|
|
| 30 |
],
|
| 31 |
"task_type": "CAUSAL_LM",
|
| 32 |
"use_dora": false,
|
Luminia-8B-RP-DPO/adapter_model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 335604696
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a678e1675c3ad8bb2684f7ad23bbe6dbfb5d1c29270f8e13f9b20c28eafeb8f0
|
| 3 |
size 335604696
|
Luminia-8B-RP-DPO/all_results.json
CHANGED
|
@@ -2,8 +2,8 @@
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 75616,
|
| 4 |
"total_flos": 3443013082939392.0,
|
| 5 |
-
"train_loss": 1.
|
| 6 |
-
"train_runtime":
|
| 7 |
-
"train_samples_per_second": 1.
|
| 8 |
-
"train_steps_per_second": 1.
|
| 9 |
}
|
|
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 75616,
|
| 4 |
"total_flos": 3443013082939392.0,
|
| 5 |
+
"train_loss": 1.2913588443434383,
|
| 6 |
+
"train_runtime": 65.9669,
|
| 7 |
+
"train_samples_per_second": 1.258,
|
| 8 |
+
"train_steps_per_second": 1.258
|
| 9 |
}
|
Luminia-8B-RP-DPO/train_results.json
CHANGED
|
@@ -2,8 +2,8 @@
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 75616,
|
| 4 |
"total_flos": 3443013082939392.0,
|
| 5 |
-
"train_loss": 1.
|
| 6 |
-
"train_runtime":
|
| 7 |
-
"train_samples_per_second": 1.
|
| 8 |
-
"train_steps_per_second": 1.
|
| 9 |
}
|
|
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 75616,
|
| 4 |
"total_flos": 3443013082939392.0,
|
| 5 |
+
"train_loss": 1.2913588443434383,
|
| 6 |
+
"train_runtime": 65.9669,
|
| 7 |
+
"train_samples_per_second": 1.258,
|
| 8 |
+
"train_steps_per_second": 1.258
|
| 9 |
}
|
Luminia-8B-RP-DPO/trainer_log.jsonl
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
-
{"current_steps": 10, "total_steps": 83, "loss": 1.
|
| 2 |
-
{"current_steps": 20, "total_steps": 83, "loss": 1.
|
| 3 |
-
{"current_steps": 30, "total_steps": 83, "loss": 1.
|
| 4 |
-
{"current_steps": 40, "total_steps": 83, "loss": 1.
|
| 5 |
-
{"current_steps": 50, "total_steps": 83, "loss": 1.
|
| 6 |
-
{"current_steps": 60, "total_steps": 83, "loss": 1.
|
| 7 |
-
{"current_steps": 70, "total_steps": 83, "loss": 1.
|
| 8 |
-
{"current_steps": 80, "total_steps": 83, "loss": 1.
|
| 9 |
-
{"current_steps": 83, "total_steps": 83, "epoch": 1.0, "percentage": 100.0, "elapsed_time": "0:
|
|
|
|
| 1 |
+
{"current_steps": 10, "total_steps": 83, "loss": 1.4779, "accuracy": 0.8999999761581421, "learning_rate": 4.8230451807939135e-05, "epoch": 0.12048192771084337, "percentage": 12.05, "elapsed_time": "0:00:08", "remaining_time": "0:01:02", "throughput": 1036.63, "total_tokens": 8864}
|
| 2 |
+
{"current_steps": 20, "total_steps": 83, "loss": 1.4745, "accuracy": 1.0, "learning_rate": 4.3172311296078595e-05, "epoch": 0.24096385542168675, "percentage": 24.1, "elapsed_time": "0:00:16", "remaining_time": "0:00:52", "throughput": 1067.18, "total_tokens": 17712}
|
| 3 |
+
{"current_steps": 30, "total_steps": 83, "loss": 1.3135, "accuracy": 1.0, "learning_rate": 3.55416283362546e-05, "epoch": 0.3614457831325301, "percentage": 36.14, "elapsed_time": "0:00:24", "remaining_time": "0:00:43", "throughput": 1117.95, "total_tokens": 27520}
|
| 4 |
+
{"current_steps": 40, "total_steps": 83, "loss": 1.2285, "accuracy": 1.0, "learning_rate": 2.6418631827326857e-05, "epoch": 0.4819277108433735, "percentage": 48.19, "elapsed_time": "0:00:32", "remaining_time": "0:00:34", "throughput": 1122.66, "total_tokens": 36096}
|
| 5 |
+
{"current_steps": 50, "total_steps": 83, "loss": 1.0171, "accuracy": 1.0, "learning_rate": 1.70948083275794e-05, "epoch": 0.6024096385542169, "percentage": 60.24, "elapsed_time": "0:00:38", "remaining_time": "0:00:25", "throughput": 1114.67, "total_tokens": 43456}
|
| 6 |
+
{"current_steps": 60, "total_steps": 83, "loss": 1.4433, "accuracy": 1.0, "learning_rate": 8.890074238378074e-06, "epoch": 0.7228915662650602, "percentage": 72.29, "elapsed_time": "0:00:46", "remaining_time": "0:00:17", "throughput": 1112.96, "total_tokens": 51600}
|
| 7 |
+
{"current_steps": 70, "total_steps": 83, "loss": 1.1624, "accuracy": 1.0, "learning_rate": 2.9659233496337786e-06, "epoch": 0.8433734939759037, "percentage": 84.34, "elapsed_time": "0:00:54", "remaining_time": "0:00:10", "throughput": 1141.19, "total_tokens": 62624}
|
| 8 |
+
{"current_steps": 80, "total_steps": 83, "loss": 1.2645, "accuracy": 1.0, "learning_rate": 1.6100130092037703e-07, "epoch": 0.963855421686747, "percentage": 96.39, "elapsed_time": "0:01:03", "remaining_time": "0:00:02", "throughput": 1158.26, "total_tokens": 73184}
|
| 9 |
+
{"current_steps": 83, "total_steps": 83, "epoch": 1.0, "percentage": 100.0, "elapsed_time": "0:01:05", "remaining_time": "0:00:00", "throughput": 1146.3, "total_tokens": 75616}
|
Luminia-8B-RP-DPO/trainer_state.json
CHANGED
|
@@ -10,146 +10,146 @@
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.12048192771084337,
|
| 13 |
-
"grad_norm": 2.
|
| 14 |
"learning_rate": 4.8230451807939135e-05,
|
| 15 |
-
"logits/chosen": -0.
|
| 16 |
-
"logits/rejected": -3.
|
| 17 |
-
"logps/chosen": -1.
|
| 18 |
-
"logps/rejected": -3.
|
| 19 |
-
"loss": 1.
|
| 20 |
"num_input_tokens_seen": 8864,
|
| 21 |
-
"odds_ratio_loss": 14.
|
| 22 |
"rewards/accuracies": 0.8999999761581421,
|
| 23 |
-
"rewards/chosen": -0.
|
| 24 |
-
"rewards/margins": 0.
|
| 25 |
-
"rewards/rejected": -0.
|
| 26 |
-
"sft_loss": 0.
|
| 27 |
"step": 10
|
| 28 |
},
|
| 29 |
{
|
| 30 |
"epoch": 0.24096385542168675,
|
| 31 |
-
"grad_norm":
|
| 32 |
"learning_rate": 4.3172311296078595e-05,
|
| 33 |
-
"logits/chosen": -0.
|
| 34 |
-
"logits/rejected": -3.
|
| 35 |
-
"logps/chosen": -1.
|
| 36 |
-
"logps/rejected": -5.
|
| 37 |
-
"loss": 1.
|
| 38 |
"num_input_tokens_seen": 17712,
|
| 39 |
-
"odds_ratio_loss": 14.
|
| 40 |
"rewards/accuracies": 1.0,
|
| 41 |
-
"rewards/chosen": -0.
|
| 42 |
-
"rewards/margins": 0.
|
| 43 |
-
"rewards/rejected": -0.
|
| 44 |
-
"sft_loss": 0.
|
| 45 |
"step": 20
|
| 46 |
},
|
| 47 |
{
|
| 48 |
"epoch": 0.3614457831325301,
|
| 49 |
-
"grad_norm": 2.
|
| 50 |
"learning_rate": 3.55416283362546e-05,
|
| 51 |
-
"logits/chosen": -0.
|
| 52 |
-
"logits/rejected": -3.
|
| 53 |
-
"logps/chosen": -1.
|
| 54 |
-
"logps/rejected": -6.
|
| 55 |
-
"loss": 1.
|
| 56 |
"num_input_tokens_seen": 27520,
|
| 57 |
-
"odds_ratio_loss": 13.
|
| 58 |
"rewards/accuracies": 1.0,
|
| 59 |
-
"rewards/chosen": -0.
|
| 60 |
-
"rewards/margins": 0.
|
| 61 |
-
"rewards/rejected": -0.
|
| 62 |
-
"sft_loss": 0.
|
| 63 |
"step": 30
|
| 64 |
},
|
| 65 |
{
|
| 66 |
"epoch": 0.4819277108433735,
|
| 67 |
-
"grad_norm": 2.
|
| 68 |
"learning_rate": 2.6418631827326857e-05,
|
| 69 |
-
"logits/chosen": -0.
|
| 70 |
-
"logits/rejected": -3.
|
| 71 |
-
"logps/chosen": -1.
|
| 72 |
-
"logps/rejected": -6.
|
| 73 |
-
"loss": 1.
|
| 74 |
"num_input_tokens_seen": 36096,
|
| 75 |
-
"odds_ratio_loss": 12.
|
| 76 |
"rewards/accuracies": 1.0,
|
| 77 |
-
"rewards/chosen": -0.
|
| 78 |
-
"rewards/margins": 0.
|
| 79 |
-
"rewards/rejected": -0.
|
| 80 |
-
"sft_loss": 0.
|
| 81 |
"step": 40
|
| 82 |
},
|
| 83 |
{
|
| 84 |
"epoch": 0.6024096385542169,
|
| 85 |
-
"grad_norm": 2.
|
| 86 |
"learning_rate": 1.70948083275794e-05,
|
| 87 |
-
"logits/chosen": -0.
|
| 88 |
-
"logits/rejected": -3.
|
| 89 |
-
"logps/chosen": -1.
|
| 90 |
-
"logps/rejected": -6.
|
| 91 |
-
"loss": 1.
|
| 92 |
"num_input_tokens_seen": 43456,
|
| 93 |
-
"odds_ratio_loss": 10.
|
| 94 |
"rewards/accuracies": 1.0,
|
| 95 |
-
"rewards/chosen": -0.
|
| 96 |
-
"rewards/margins": 0.
|
| 97 |
-
"rewards/rejected": -0.
|
| 98 |
-
"sft_loss": 0.
|
| 99 |
"step": 50
|
| 100 |
},
|
| 101 |
{
|
| 102 |
"epoch": 0.7228915662650602,
|
| 103 |
-
"grad_norm": 2.
|
| 104 |
"learning_rate": 8.890074238378074e-06,
|
| 105 |
-
"logits/chosen": -0.
|
| 106 |
-
"logits/rejected": -3.
|
| 107 |
-
"logps/chosen": -1.
|
| 108 |
-
"logps/rejected": -6.
|
| 109 |
-
"loss": 1.
|
| 110 |
"num_input_tokens_seen": 51600,
|
| 111 |
-
"odds_ratio_loss": 14.
|
| 112 |
"rewards/accuracies": 1.0,
|
| 113 |
-
"rewards/chosen": -0.
|
| 114 |
-
"rewards/margins": 0.
|
| 115 |
-
"rewards/rejected": -0.
|
| 116 |
-
"sft_loss": 0.
|
| 117 |
"step": 60
|
| 118 |
},
|
| 119 |
{
|
| 120 |
"epoch": 0.8433734939759037,
|
| 121 |
-
"grad_norm": 2.
|
| 122 |
"learning_rate": 2.9659233496337786e-06,
|
| 123 |
-
"logits/chosen": -0.
|
| 124 |
-
"logits/rejected": -3.
|
| 125 |
-
"logps/chosen": -1.
|
| 126 |
-
"logps/rejected": -6.
|
| 127 |
-
"loss": 1.
|
| 128 |
"num_input_tokens_seen": 62624,
|
| 129 |
-
"odds_ratio_loss": 11.
|
| 130 |
"rewards/accuracies": 1.0,
|
| 131 |
-
"rewards/chosen": -0.
|
| 132 |
-
"rewards/margins": 0.
|
| 133 |
-
"rewards/rejected": -0.
|
| 134 |
-
"sft_loss": 0.
|
| 135 |
"step": 70
|
| 136 |
},
|
| 137 |
{
|
| 138 |
"epoch": 0.963855421686747,
|
| 139 |
-
"grad_norm": 1.
|
| 140 |
"learning_rate": 1.6100130092037703e-07,
|
| 141 |
-
"logits/chosen": -0.
|
| 142 |
-
"logits/rejected": -3.
|
| 143 |
-
"logps/chosen": -1.
|
| 144 |
-
"logps/rejected": -6.
|
| 145 |
-
"loss": 1.
|
| 146 |
"num_input_tokens_seen": 73184,
|
| 147 |
-
"odds_ratio_loss": 12.
|
| 148 |
"rewards/accuracies": 1.0,
|
| 149 |
-
"rewards/chosen": -0.
|
| 150 |
-
"rewards/margins": 0.
|
| 151 |
-
"rewards/rejected": -0.
|
| 152 |
-
"sft_loss": 0.
|
| 153 |
"step": 80
|
| 154 |
},
|
| 155 |
{
|
|
@@ -157,10 +157,10 @@
|
|
| 157 |
"num_input_tokens_seen": 75616,
|
| 158 |
"step": 83,
|
| 159 |
"total_flos": 3443013082939392.0,
|
| 160 |
-
"train_loss": 1.
|
| 161 |
-
"train_runtime":
|
| 162 |
-
"train_samples_per_second": 1.
|
| 163 |
-
"train_steps_per_second": 1.
|
| 164 |
}
|
| 165 |
],
|
| 166 |
"logging_steps": 10,
|
|
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.12048192771084337,
|
| 13 |
+
"grad_norm": 2.8577072620391846,
|
| 14 |
"learning_rate": 4.8230451807939135e-05,
|
| 15 |
+
"logits/chosen": -0.11954045295715332,
|
| 16 |
+
"logits/rejected": -3.3223273754119873,
|
| 17 |
+
"logps/chosen": -1.4568630456924438,
|
| 18 |
+
"logps/rejected": -3.726320266723633,
|
| 19 |
+
"loss": 1.4779,
|
| 20 |
"num_input_tokens_seen": 8864,
|
| 21 |
+
"odds_ratio_loss": 14.732812881469727,
|
| 22 |
"rewards/accuracies": 0.8999999761581421,
|
| 23 |
+
"rewards/chosen": -0.1456862986087799,
|
| 24 |
+
"rewards/margins": 0.22694571316242218,
|
| 25 |
+
"rewards/rejected": -0.3726319968700409,
|
| 26 |
+
"sft_loss": 0.0046242037788033485,
|
| 27 |
"step": 10
|
| 28 |
},
|
| 29 |
{
|
| 30 |
"epoch": 0.24096385542168675,
|
| 31 |
+
"grad_norm": 1.9434715509414673,
|
| 32 |
"learning_rate": 4.3172311296078595e-05,
|
| 33 |
+
"logits/chosen": -0.2733025550842285,
|
| 34 |
+
"logits/rejected": -3.2514376640319824,
|
| 35 |
+
"logps/chosen": -1.4726128578186035,
|
| 36 |
+
"logps/rejected": -5.625662803649902,
|
| 37 |
+
"loss": 1.4745,
|
| 38 |
"num_input_tokens_seen": 17712,
|
| 39 |
+
"odds_ratio_loss": 14.662857055664062,
|
| 40 |
"rewards/accuracies": 1.0,
|
| 41 |
+
"rewards/chosen": -0.14726129174232483,
|
| 42 |
+
"rewards/margins": 0.4153049886226654,
|
| 43 |
+
"rewards/rejected": -0.562566339969635,
|
| 44 |
+
"sft_loss": 0.008168135769665241,
|
| 45 |
"step": 20
|
| 46 |
},
|
| 47 |
{
|
| 48 |
"epoch": 0.3614457831325301,
|
| 49 |
+
"grad_norm": 2.154024124145508,
|
| 50 |
"learning_rate": 3.55416283362546e-05,
|
| 51 |
+
"logits/chosen": -0.20305636525154114,
|
| 52 |
+
"logits/rejected": -3.410961627960205,
|
| 53 |
+
"logps/chosen": -1.3130009174346924,
|
| 54 |
+
"logps/rejected": -6.4230146408081055,
|
| 55 |
+
"loss": 1.3135,
|
| 56 |
"num_input_tokens_seen": 27520,
|
| 57 |
+
"odds_ratio_loss": 13.098909378051758,
|
| 58 |
"rewards/accuracies": 1.0,
|
| 59 |
+
"rewards/chosen": -0.13130010664463043,
|
| 60 |
+
"rewards/margins": 0.5110014081001282,
|
| 61 |
+
"rewards/rejected": -0.6423014998435974,
|
| 62 |
+
"sft_loss": 0.0035836666356772184,
|
| 63 |
"step": 30
|
| 64 |
},
|
| 65 |
{
|
| 66 |
"epoch": 0.4819277108433735,
|
| 67 |
+
"grad_norm": 2.372204303741455,
|
| 68 |
"learning_rate": 2.6418631827326857e-05,
|
| 69 |
+
"logits/chosen": -0.2755209803581238,
|
| 70 |
+
"logits/rejected": -3.2902603149414062,
|
| 71 |
+
"logps/chosen": -1.2280548810958862,
|
| 72 |
+
"logps/rejected": -6.585225582122803,
|
| 73 |
+
"loss": 1.2285,
|
| 74 |
"num_input_tokens_seen": 36096,
|
| 75 |
+
"odds_ratio_loss": 12.17691707611084,
|
| 76 |
"rewards/accuracies": 1.0,
|
| 77 |
+
"rewards/chosen": -0.12280547618865967,
|
| 78 |
+
"rewards/margins": 0.5357170104980469,
|
| 79 |
+
"rewards/rejected": -0.6585224866867065,
|
| 80 |
+
"sft_loss": 0.010825484991073608,
|
| 81 |
"step": 40
|
| 82 |
},
|
| 83 |
{
|
| 84 |
"epoch": 0.6024096385542169,
|
| 85 |
+
"grad_norm": 2.4067399501800537,
|
| 86 |
"learning_rate": 1.70948083275794e-05,
|
| 87 |
+
"logits/chosen": -0.1695922613143921,
|
| 88 |
+
"logits/rejected": -3.419903516769409,
|
| 89 |
+
"logps/chosen": -1.0168521404266357,
|
| 90 |
+
"logps/rejected": -6.722726345062256,
|
| 91 |
+
"loss": 1.0171,
|
| 92 |
"num_input_tokens_seen": 43456,
|
| 93 |
+
"odds_ratio_loss": 10.138498306274414,
|
| 94 |
"rewards/accuracies": 1.0,
|
| 95 |
+
"rewards/chosen": -0.10168520361185074,
|
| 96 |
+
"rewards/margins": 0.5705875158309937,
|
| 97 |
+
"rewards/rejected": -0.6722726821899414,
|
| 98 |
+
"sft_loss": 0.0032351273111999035,
|
| 99 |
"step": 50
|
| 100 |
},
|
| 101 |
{
|
| 102 |
"epoch": 0.7228915662650602,
|
| 103 |
+
"grad_norm": 2.4104135036468506,
|
| 104 |
"learning_rate": 8.890074238378074e-06,
|
| 105 |
+
"logits/chosen": -0.2158750295639038,
|
| 106 |
+
"logits/rejected": -3.261337995529175,
|
| 107 |
+
"logps/chosen": -1.4426627159118652,
|
| 108 |
+
"logps/rejected": -6.552022457122803,
|
| 109 |
+
"loss": 1.4433,
|
| 110 |
"num_input_tokens_seen": 51600,
|
| 111 |
+
"odds_ratio_loss": 14.290933609008789,
|
| 112 |
"rewards/accuracies": 1.0,
|
| 113 |
+
"rewards/chosen": -0.144266277551651,
|
| 114 |
+
"rewards/margins": 0.5109359622001648,
|
| 115 |
+
"rewards/rejected": -0.6552022695541382,
|
| 116 |
+
"sft_loss": 0.01422051526606083,
|
| 117 |
"step": 60
|
| 118 |
},
|
| 119 |
{
|
| 120 |
"epoch": 0.8433734939759037,
|
| 121 |
+
"grad_norm": 2.4223577976226807,
|
| 122 |
"learning_rate": 2.9659233496337786e-06,
|
| 123 |
+
"logits/chosen": -0.14738118648529053,
|
| 124 |
+
"logits/rejected": -3.434018611907959,
|
| 125 |
+
"logps/chosen": -1.1621037721633911,
|
| 126 |
+
"logps/rejected": -6.5490217208862305,
|
| 127 |
+
"loss": 1.1624,
|
| 128 |
"num_input_tokens_seen": 62624,
|
| 129 |
+
"odds_ratio_loss": 11.598767280578613,
|
| 130 |
"rewards/accuracies": 1.0,
|
| 131 |
+
"rewards/chosen": -0.11621036380529404,
|
| 132 |
+
"rewards/margins": 0.5386918783187866,
|
| 133 |
+
"rewards/rejected": -0.6549022197723389,
|
| 134 |
+
"sft_loss": 0.0025552159640938044,
|
| 135 |
"step": 70
|
| 136 |
},
|
| 137 |
{
|
| 138 |
"epoch": 0.963855421686747,
|
| 139 |
+
"grad_norm": 1.6316858530044556,
|
| 140 |
"learning_rate": 1.6100130092037703e-07,
|
| 141 |
+
"logits/chosen": -0.22155144810676575,
|
| 142 |
+
"logits/rejected": -3.4224212169647217,
|
| 143 |
+
"logps/chosen": -1.2641386985778809,
|
| 144 |
+
"logps/rejected": -6.619866371154785,
|
| 145 |
+
"loss": 1.2645,
|
| 146 |
"num_input_tokens_seen": 73184,
|
| 147 |
+
"odds_ratio_loss": 12.610678672790527,
|
| 148 |
"rewards/accuracies": 1.0,
|
| 149 |
+
"rewards/chosen": -0.12641386687755585,
|
| 150 |
+
"rewards/margins": 0.5355727672576904,
|
| 151 |
+
"rewards/rejected": -0.6619867086410522,
|
| 152 |
+
"sft_loss": 0.003463461296632886,
|
| 153 |
"step": 80
|
| 154 |
},
|
| 155 |
{
|
|
|
|
| 157 |
"num_input_tokens_seen": 75616,
|
| 158 |
"step": 83,
|
| 159 |
"total_flos": 3443013082939392.0,
|
| 160 |
+
"train_loss": 1.2913588443434383,
|
| 161 |
+
"train_runtime": 65.9669,
|
| 162 |
+
"train_samples_per_second": 1.258,
|
| 163 |
+
"train_steps_per_second": 1.258
|
| 164 |
}
|
| 165 |
],
|
| 166 |
"logging_steps": 10,
|
Luminia-8B-RP-DPO/training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 5368
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0fe52b7fade73dd088cdcd69b8c8544dc5dd90b1cf4621e2065f7741b1c16551
|
| 3 |
size 5368
|
Luminia-8B-RP-DPO/training_loss.png
CHANGED
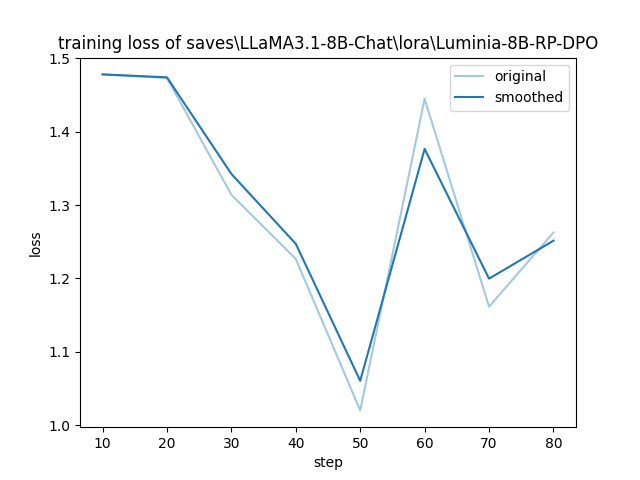
|
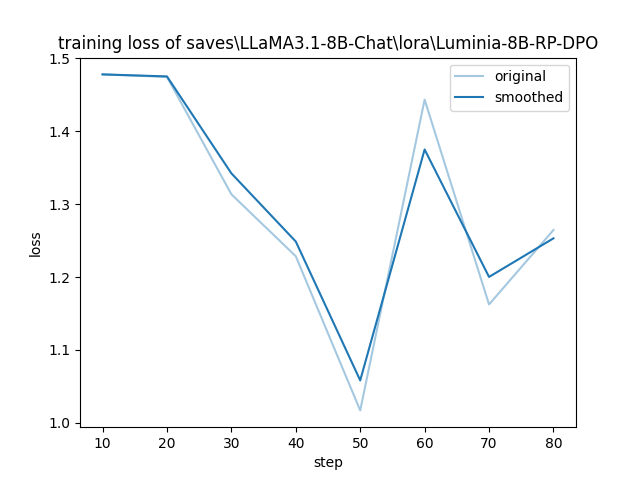
|
Luminia-8B-RP/adapter_config.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
"alpha_pattern": {},
|
| 3 |
"auto_mapping": null,
|
| 4 |
-
"base_model_name_or_path": "
|
| 5 |
"bias": "none",
|
| 6 |
"fan_in_fan_out": false,
|
| 7 |
"inference_mode": true,
|
|
@@ -20,13 +20,13 @@
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
| 23 |
-
"down_proj",
|
| 24 |
-
"up_proj",
|
| 25 |
-
"o_proj",
|
| 26 |
"gate_proj",
|
| 27 |
-
"
|
| 28 |
"k_proj",
|
| 29 |
-
"
|
|
|
|
|
|
|
|
|
|
| 30 |
],
|
| 31 |
"task_type": "CAUSAL_LM",
|
| 32 |
"use_dora": false,
|
|
|
|
| 1 |
{
|
| 2 |
"alpha_pattern": {},
|
| 3 |
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "meta-llama/Meta-Llama-3.1-8B-Instruct",
|
| 5 |
"bias": "none",
|
| 6 |
"fan_in_fan_out": false,
|
| 7 |
"inference_mode": true,
|
|
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
|
|
|
|
|
|
|
|
|
| 23 |
"gate_proj",
|
| 24 |
+
"o_proj",
|
| 25 |
"k_proj",
|
| 26 |
+
"down_proj",
|
| 27 |
+
"q_proj",
|
| 28 |
+
"up_proj",
|
| 29 |
+
"v_proj"
|
| 30 |
],
|
| 31 |
"task_type": "CAUSAL_LM",
|
| 32 |
"use_dora": false,
|
Luminia-8B-RP/adapter_model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 335604696
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f4d4d536113e7ed7303f3655a0294f5b72393f72ce8d11a17ac4b868ac83e1cf
|
| 3 |
size 335604696
|
Luminia-8B-RP/all_results.json
CHANGED
|
@@ -2,8 +2,8 @@
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 170598400,
|
| 4 |
"total_flos": 7.767833833163981e+18,
|
| 5 |
-
"train_loss": 0.
|
| 6 |
-
"train_runtime":
|
| 7 |
-
"train_samples_per_second": 0.
|
| 8 |
-
"train_steps_per_second": 0.
|
| 9 |
}
|
|
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 170598400,
|
| 4 |
"total_flos": 7.767833833163981e+18,
|
| 5 |
+
"train_loss": 0.2516314516834566,
|
| 6 |
+
"train_runtime": 26805.2364,
|
| 7 |
+
"train_samples_per_second": 0.777,
|
| 8 |
+
"train_steps_per_second": 0.777
|
| 9 |
}
|
Luminia-8B-RP/train_results.json
CHANGED
|
@@ -2,8 +2,8 @@
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 170598400,
|
| 4 |
"total_flos": 7.767833833163981e+18,
|
| 5 |
-
"train_loss": 0.
|
| 6 |
-
"train_runtime":
|
| 7 |
-
"train_samples_per_second": 0.
|
| 8 |
-
"train_steps_per_second": 0.
|
| 9 |
}
|
|
|
|
| 2 |
"epoch": 1.0,
|
| 3 |
"num_input_tokens_seen": 170598400,
|
| 4 |
"total_flos": 7.767833833163981e+18,
|
| 5 |
+
"train_loss": 0.2516314516834566,
|
| 6 |
+
"train_runtime": 26805.2364,
|
| 7 |
+
"train_samples_per_second": 0.777,
|
| 8 |
+
"train_steps_per_second": 0.777
|
| 9 |
}
|
Luminia-8B-RP/trainer_log.jsonl
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Luminia-8B-RP/trainer_state.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Luminia-8B-RP/training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3c4e993a9ca7f914dcb5321f549e6a90cf5f5ce8708dfcfa54902b8f3c7ea7e6
|
| 3 |
+
size 5432
|
Luminia-8B-RP/training_loss.png
CHANGED

|
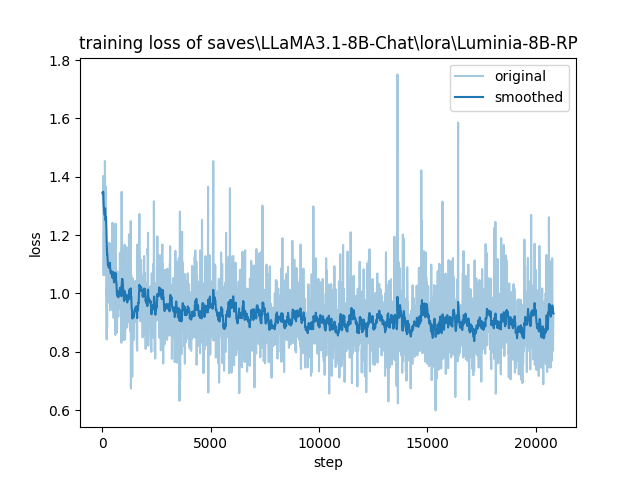
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "meta-llama/Meta-Llama-3.1-8B-Instruct",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
model-00001-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4976698672
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e3c08b21643e94b5ce74a199dd69bec58c068d31a3cab5f08ea62093f0dac2b7
|
| 3 |
size 4976698672
|
model-00002-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4999802720
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1e098f89af9d5a9068f6a336957cc648bbd3b6ae96d2f63f52526dea45f5eadd
|
| 3 |
size 4999802720
|
model-00003-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4915916176
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b128dbc253b1cab6210be96bae6070ebe7039f1f50d22e97a75efb59693800e4
|
| 3 |
size 4915916176
|
model-00004-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1168138808
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:527189a1ceebada68fa13b52c6bf6a1c97ac92c9a0de0b76185de397f4399516
|
| 3 |
size 1168138808
|