

Update README.md
Browse files
README.md
CHANGED
|
@@ -9,12 +9,15 @@ datasets:
|
|
| 9 |
- emozilla/yarn-train-tokenized-8k-llama
|
| 10 |
---
|
| 11 |
|
| 12 |
-
# Model Card:
|
| 13 |
|
| 14 |
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
|
| 15 |
[GitHub](https://github.com/jquesnelle/yarn)
|
| 16 |
|
| 17 |
|
|
|
|
|
|
|
|
|
|
| 18 |
## Model Description
|
| 19 |
|
| 20 |
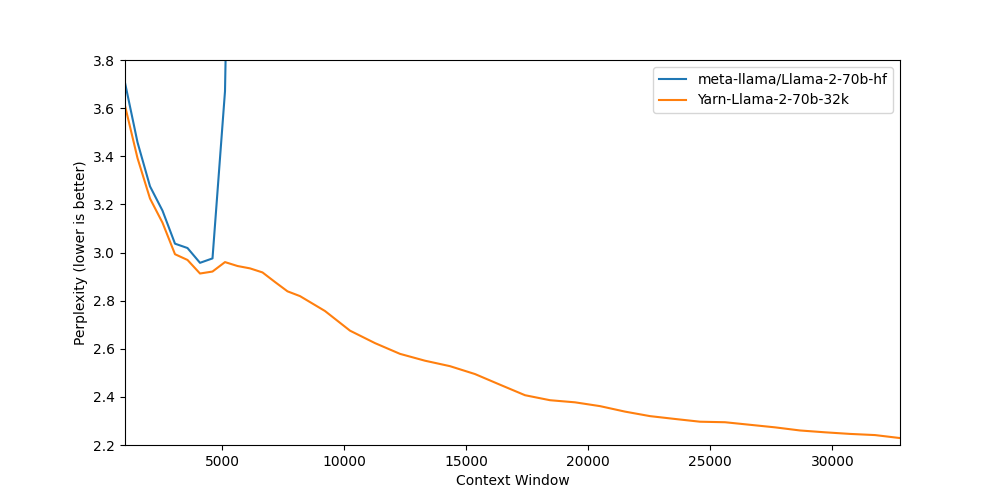
Nous-Yarn-Llama-2-70b-32k is a state-of-the-art language model for long context, further pretrained on long context data for 400 steps using the YaRN extension method.
|
|
@@ -55,6 +58,3 @@ Short context benchmarks showing that quality degradation is minimal:
|
|
| 55 |
- [@theemozilla](https://twitter.com/theemozilla): Methods, paper, model training, and evals
|
| 56 |
- [@EnricoShippole](https://twitter.com/EnricoShippole): Model training
|
| 57 |
- [honglu2875](https://github.com/honglu2875): Paper and evals
|
| 58 |
-
|
| 59 |
-
The authors would like to thank LAION AI for their support of compute for this model.
|
| 60 |
-
It was trained on the [JUWELS](https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels) supercomputer.
|
|
|
|
| 9 |
- emozilla/yarn-train-tokenized-8k-llama
|
| 10 |
---
|
| 11 |
|
| 12 |
+
# Model Card: Yarn-Llama-2-70b-32k
|
| 13 |
|
| 14 |
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
|
| 15 |
[GitHub](https://github.com/jquesnelle/yarn)
|
| 16 |

|
| 17 |
|
| 18 |
+
The authors would like to thank [LAION AI](https://laion.ai/) for their support of compute for this model.
|
| 19 |
+
It was trained on the [JUWELS](https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels) supercomputer.
|
| 20 |
+
|
| 21 |
## Model Description
|
| 22 |
|
| 23 |
Nous-Yarn-Llama-2-70b-32k is a state-of-the-art language model for long context, further pretrained on long context data for 400 steps using the YaRN extension method.
|
|
|
|
| 58 |
- [@theemozilla](https://twitter.com/theemozilla): Methods, paper, model training, and evals
|
| 59 |
- [@EnricoShippole](https://twitter.com/EnricoShippole): Model training
|
| 60 |
- [honglu2875](https://github.com/honglu2875): Paper and evals
|
|
|
|
|
|
|
|
|