
File size: 53,224 Bytes
3567964 8e8fba2 2d325bf 900d017 2d325bf bf5df27 2d325bf 3567964 88c52f5 3567964 c5d8dc2 3567964 f71474a 3567964 ecae910 2645855 3567964 c446b09 3567964 f71474a 3567964 ecae910 88c52f5 039e70d 88c52f5 3567964 c389a96 1b908db f71474a 1b908db 3567964 db62f28 2d325bf a580b1b 3567964 2d325bf 3567964 c389a96 7939a50 dadf36e 2f33adf dadf36e c389a96 ea5d0cd b08541a ea5d0cd 3567964 277b5e2 c446b09 3567964 2e6227d 357996b 2e6227d 357996b 2e6227d 357996b 2e6227d 277b5e2 2e6227d 357996b 2e6227d 3567964 9082859 3567964 9082859 3567964 2e6227d 3567964 2e6227d 3567964 2e6227d 3567964 357996b 3567964 2e6227d 3567964 2e6227d db62f28 3567964 2e6227d 3567964 2e6227d 3567964 2e6227d 3567964 2e6227d 3567964 2e6227d 3567964 9082859 2e6227d 9082859 2e6227d 9082859 2e6227d 9082859 2e6227d 3567964 2e6227d 3567964 2e6227d 3567964 2e6227d 3567964 2e6227d 20758ec c389a96 20758ec c389a96 2e6227d 20758ec 2e6227d 20758ec 9082859 20758ec 2e6227d 3567964 2e6227d 581c716 2e6227d 581c716 21629e3 db62f28 21629e3 bc71a12 db62f28 bc71a12 b08541a bc71a12 db62f28 bc71a12 db62f28 bc71a12 b08541a c446b09 b08541a db62f28 b08541a db62f28 b08541a bb437c0 b08541a db62f28 b08541a db62f28 b08541a bc71a12 b08541a db62f28 b08541a db62f28 b08541a 0223f73 db62f28 0223f73 c446b09 0223f73 c446b09 9c22dd0 c446b09 0223f73 3567964 9c22dd0 3567964 039e70d c446b09 039e70d ecae910 039e70d 9d36290 039e70d c389a96 1b908db f71474a 1b908db db62f28 1b908db 039e70d a580b1b 039e70d b08541a 7939a50 dadf36e 2f33adf dadf36e b08541a ea5d0cd 039e70d ea5d0cd 4012170 bb437c0 4012170 2e6227d c446b09 4012170 21629e3 db62f28 21629e3 b08541a db62f28 b08541a db62f28 b08541a db62f28 b08541a db62f28 b08541a db62f28 b08541a db62f28 bb437c0 b08541a db62f28 b08541a db62f28 b08541a db62f28 b08541a db62f28 b08541a 0223f73 db62f28 0223f73 c446b09 0223f73 c446b09 0223f73 c446b09 9c22dd0 c446b09 039e70d e110c56 039e70d 9082859 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 |
---
license: mit
pipeline_tag: image-text-to-text
library_name: transformers
base_model:
- OpenGVLab/InternViT-300M-448px
- internlm/internlm2_5-7b-chat
base_model_relation: merge
language:
- multilingual
tags:
- internvl
- vision
- ocr
- multi-image
- video
- custom_code
---
# InternVL2-8B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[🆕 Blog\]](https://internvl.github.io/blog/) [\[📜 InternVL 1.0 Paper\]](https://arxiv.org/abs/2312.14238) [\[📜 InternVL 1.5 Report\]](https://arxiv.org/abs/2404.16821)
[\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 中文解读\]](https://zhuanlan.zhihu.com/p/706547971) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
[切换至中文版](#简介)
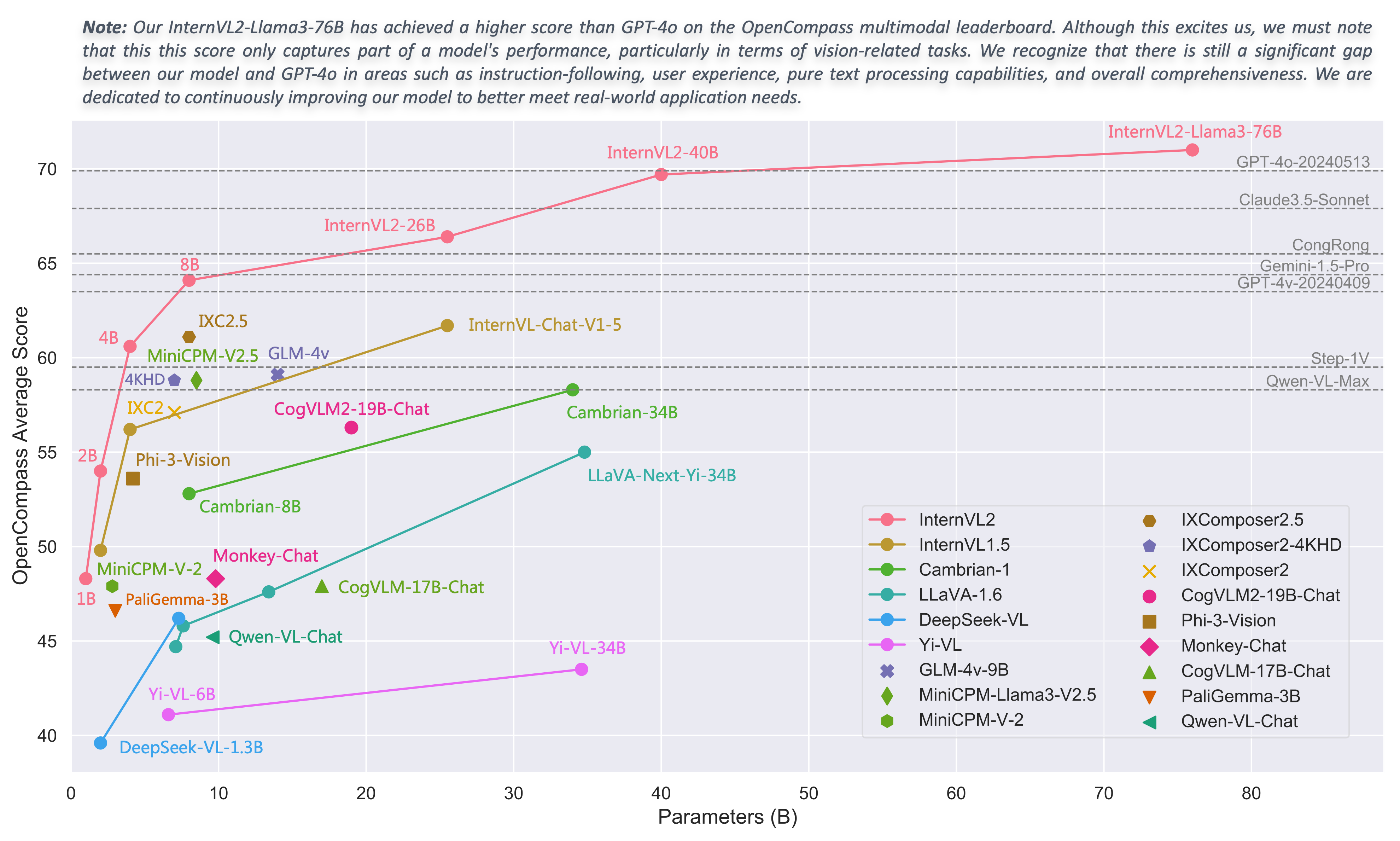
## Introduction
We are excited to announce the release of InternVL 2.0, the latest addition to the InternVL series of multimodal large language models. InternVL 2.0 features a variety of **instruction-tuned models**, ranging from 1 billion to 108 billion parameters. This repository contains the instruction-tuned InternVL2-8B model.
Compared to the state-of-the-art open-source multimodal large language models, InternVL 2.0 surpasses most open-source models. It demonstrates competitive performance on par with proprietary commercial models across various capabilities, including document and chart comprehension, infographics QA, scene text understanding and OCR tasks, scientific and mathematical problem solving, as well as cultural understanding and integrated multimodal capabilities.
InternVL 2.0 is trained with an 8k context window and utilizes training data consisting of long texts, multiple images, and videos, significantly improving its ability to handle these types of inputs compared to InternVL 1.5. For more details, please refer to our [blog](https://internvl.github.io/blog/2024-07-02-InternVL-2.0/) and [GitHub](https://github.com/OpenGVLab/InternVL).
| Model Name | Vision Part | Language Part | HF Link | MS Link |
| :------------------: | :---------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: | :--------------------------------------------------------------------: |
| InternVL2-1B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-1B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-1B) |
| InternVL2-2B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-2B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-2B) |
| InternVL2-4B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Phi-3-mini-128k-instruct](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-4B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-4B) |
| InternVL2-8B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-8B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-8B) |
| InternVL2-26B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [internlm2-chat-20b](https://huggingface.co/internlm/internlm2-chat-20b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-26B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-26B) |
| InternVL2-40B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-40B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-40B) |
| InternVL2-Llama3-76B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-Llama3-76B) |
## Model Details
InternVL 2.0 is a multimodal large language model series, featuring models of various sizes. For each size, we release instruction-tuned models optimized for multimodal tasks. InternVL2-8B consists of [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px), an MLP projector, and [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat).
## Performance
### Image Benchmarks
| Benchmark | MiniCPM-Llama3-V-2_5 | InternVL-Chat-V1-5 | InternVL2-8B |
| :--------------------------: | :------------------: | :----------------: | :----------: |
| Model Size | 8.5B | 25.5B | 8.1B |
| | | | |
| DocVQA<sub>test</sub> | 84.8 | 90.9 | 91.6 |
| ChartQA<sub>test</sub> | - | 83.8 | 83.3 |
| InfoVQA<sub>test</sub> | - | 72.5 | 74.8 |
| TextVQA<sub>val</sub> | 76.6 | 80.6 | 77.4 |
| OCRBench | 725 | 724 | 794 |
| MME<sub>sum</sub> | 2024.6 | 2187.8 | 2210.3 |
| RealWorldQA | 63.5 | 66.0 | 64.4 |
| AI2D<sub>test</sub> | 78.4 | 80.7 | 83.8 |
| MMMU<sub>val</sub> | 45.8 | 45.2 / 46.8 | 49.3 / 51.8 |
| MMBench-EN<sub>test</sub> | 77.2 | 82.2 | 81.7 |
| MMBench-CN<sub>test</sub> | 74.2 | 82.0 | 81.2 |
| CCBench<sub>dev</sub> | 45.9 | 69.8 | 75.9 |
| MMVet<sub>GPT-4-0613</sub> | - | 62.8 | 60.0 |
| MMVet<sub>GPT-4-Turbo</sub> | 52.8 | 55.4 | 54.2 |
| SEED-Image | 72.3 | 76.0 | 76.2 |
| HallBench<sub>avg</sub> | 42.4 | 49.3 | 45.2 |
| MathVista<sub>testmini</sub> | 54.3 | 53.5 | 58.3 |
| OpenCompass<sub>avg</sub> | 58.8 | 61.7 | 64.1 |
- For more details and evaluation reproduction, please refer to our [Evaluation Guide](https://internvl.readthedocs.io/en/latest/internvl2.0/evaluation.html).
- We simultaneously use [InternVL](https://github.com/OpenGVLab/InternVL) and [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) repositories for model evaluation. Specifically, the results reported for DocVQA, ChartQA, InfoVQA, TextVQA, MME, AI2D, MMBench, CCBench, MMVet, and SEED-Image were tested using the InternVL repository. OCRBench, RealWorldQA, HallBench, and MathVista were evaluated using the VLMEvalKit.
- For MMMU, we report both the original scores (left side: evaluated using the InternVL codebase for InternVL series models, and sourced from technical reports or webpages for other models) and the VLMEvalKit scores (right side: collected from the OpenCompass leaderboard).
- Please note that evaluating the same model using different testing toolkits like [InternVL](https://github.com/OpenGVLab/InternVL) and [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) can result in slight differences, which is normal. Updates to code versions and variations in environment and hardware can also cause minor discrepancies in results.
### Video Benchmarks
| Benchmark | VideoChat2-HD-Mistral | Video-CCAM-9B | InternVL2-4B | InternVL2-8B |
| :-------------------------: | :-------------------: | :-----------: | :----------: | :----------: |
| Model Size | 7B | 9B | 4.2B | 8.1B |
| | | | | |
| MVBench | 60.4 | 60.7 | 63.7 | 66.4 |
| MMBench-Video<sub>8f</sub> | - | - | 1.10 | 1.19 |
| MMBench-Video<sub>16f</sub> | - | - | 1.18 | 1.28 |
| Video-MME<br>w/o subs | 42.3 | 50.6 | 51.4 | 54.0 |
| Video-MME<br>w subs | 54.6 | 54.9 | 53.4 | 56.9 |
- We evaluate our models on MVBench and Video-MME by extracting 16 frames from each video, and each frame was resized to a 448x448 image.
### Grounding Benchmarks
| Model | avg. | RefCOCO<br>(val) | RefCOCO<br>(testA) | RefCOCO<br>(testB) | RefCOCO+<br>(val) | RefCOCO+<br>(testA) | RefCOCO+<br>(testB) | RefCOCO‑g<br>(val) | RefCOCO‑g<br>(test) |
| :----------------------------: | :--: | :--------------: | :----------------: | :----------------: | :---------------: | :-----------------: | :-----------------: | :----------------: | :-----------------: |
| UNINEXT-H<br>(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
| | | | | | | | | | |
| Mini-InternVL-<br>Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
| Mini-InternVL-<br>Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
| | | | | | | | | | |
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
| InternVL2-<br>Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 |
- We use the following prompt to evaluate InternVL's grounding ability: `Please provide the bounding box coordinates of the region this sentence describes: <ref>{}</ref>`
Limitations: Although we have made efforts to ensure the safety of the model during the training process and to encourage the model to generate text that complies with ethical and legal requirements, the model may still produce unexpected outputs due to its size and probabilistic generation paradigm. For example, the generated responses may contain biases, discrimination, or other harmful content. Please do not propagate such content. We are not responsible for any consequences resulting from the dissemination of harmful information.
### Invitation to Evaluate InternVL
We welcome MLLM benchmark developers to assess our InternVL1.5 and InternVL2 series models. If you need to add your evaluation results here, please contact me at [wztxy89@163.com](mailto:wztxy89@163.com).
## Quick Start
We provide an example code to run InternVL2-8B using `transformers`.
We also welcome you to experience the InternVL2 series models in our [online demo](https://internvl.opengvlab.com/).
> Please use transformers==4.37.2 to ensure the model works normally.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### BNB 4-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_4bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
The reason for writing the code this way is to avoid errors that occur during multi-GPU inference due to tensors not being on the same device. By ensuring that the first and last layers of the large language model (LLM) are on the same device, we prevent such errors.
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
def split_model(model_name):
device_map = {}
world_size = torch.cuda.device_count()
num_layers = {
'InternVL2-1B': 24, 'InternVL2-2B': 24, 'InternVL2-4B': 32, 'InternVL2-8B': 32,
'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80}[model_name]
# Since the first GPU will be used for ViT, treat it as half a GPU.
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
num_layers_per_gpu = [num_layers_per_gpu] * world_size
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
layer_cnt = 0
for i, num_layer in enumerate(num_layers_per_gpu):
for j in range(num_layer):
device_map[f'language_model.model.layers.{layer_cnt}'] = i
layer_cnt += 1
device_map['vision_model'] = 0
device_map['mlp1'] = 0
device_map['language_model.model.tok_embeddings'] = 0
device_map['language_model.model.embed_tokens'] = 0
device_map['language_model.output'] = 0
device_map['language_model.model.norm'] = 0
device_map['language_model.lm_head'] = 0
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
return device_map
path = "OpenGVLab/InternVL2-8B"
device_map = split_model('InternVL2-8B')
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map=device_map).eval()
```
### Inference with Transformers
```python
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# If you want to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
path = 'OpenGVLab/InternVL2-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail. Don\'t repeat.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTurner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams.
```sh
pip install lmdeploy==0.5.3
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' example
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-8B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
response = pipe(('describe this image', image))
print(response.text)
```
If `ImportError` occurs while executing this case, please install the required dependency packages as prompted.
#### Multi-images inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
> Warning: Due to the scarcity of multi-image conversation data, the performance on multi-image tasks may be unstable, and it may require multiple attempts to achieve satisfactory results.
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
model = 'OpenGVLab/InternVL2-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch prompts inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL2-8B --backend turbomind --server-port 23333
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the MIT license, while InternLM2 is licensed under the Apache-2.0 license.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
```
## 简介
我们很高兴宣布 InternVL 2.0 的发布,这是 InternVL 系列多模态大语言模型的最新版本。InternVL 2.0 提供了多种**指令微调**的模型,参数从 10 亿到 1080 亿不等。此仓库包含经过指令微调的 InternVL2-8B 模型。
与最先进的开源多模态大语言模型相比,InternVL 2.0 超越了大多数开源模型。它在各种能力上表现出与闭源商业模型相媲美的竞争力,包括文档和图表理解、信息图表问答、场景文本理解和 OCR 任务、科学和数学问题解决,以及文化理解和综合多模态能力。
InternVL 2.0 使用 8k 上下文窗口进行训练,训练数据包含长文本、多图和视频数据,与 InternVL 1.5 相比,其处理这些类型输入的能力显著提高。更多详细信息,请参阅我们的博客和 GitHub。
| 模型名称 | 视觉部分 | 语言部分 | HF 链接 | MS 链接 |
| :------------------: | :---------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: | :--------------------------------------------------------------------: |
| InternVL2-1B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-1B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-1B) |
| InternVL2-2B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-2B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-2B) |
| InternVL2-4B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Phi-3-mini-128k-instruct](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-4B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-4B) |
| InternVL2-8B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-8B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-8B) |
| InternVL2-26B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [internlm2-chat-20b](https://huggingface.co/internlm/internlm2-chat-20b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-26B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-26B) |
| InternVL2-40B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-40B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-40B) |
| InternVL2-Llama3-76B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-Llama3-76B) |
## 模型细节
InternVL 2.0 是一个多模态大语言模型系列,包含各种规模的模型。对于每个规模的模型,我们都会发布针对多模态任务优化的指令微调模型。InternVL2-8B 包含 [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px)、一个 MLP 投影器和 [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat)。
## 性能测试
### 图像相关评测
| 评测数据集 | MiniCPM-Llama3-V-2_5 | InternVL-Chat-V1-5 | InternVL2-8B |
| :--------------------------: | :------------------: | :----------------: | :----------: |
| 模型大小 | 8.5B | 25.5B | 8.1B |
| | | | |
| DocVQA<sub>test</sub> | 84.8 | 90.9 | 91.6 |
| ChartQA<sub>test</sub> | - | 83.8 | 83.3 |
| InfoVQA<sub>test</sub> | - | 72.5 | 74.8 |
| TextVQA<sub>val</sub> | 76.6 | 80.6 | 77.4 |
| OCRBench | 725 | 724 | 794 |
| MME<sub>sum</sub> | 2024.6 | 2187.8 | 2210.3 |
| RealWorldQA | 63.5 | 66.0 | 64.4 |
| AI2D<sub>test</sub> | 78.4 | 80.7 | 83.8 |
| MMMU<sub>val</sub> | 45.8 | 45.2 / 46.8 | 49.3 / 51.8 |
| MMBench-EN<sub>test</sub> | 77.2 | 82.2 | 81.7 |
| MMBench-CN<sub>test</sub> | 74.2 | 82.0 | 81.2 |
| CCBench<sub>dev</sub> | 45.9 | 69.8 | 75.9 |
| MMVet<sub>GPT-4-0613</sub> | - | 62.8 | 60.0 |
| MMVet<sub>GPT-4-Turbo</sub> | 52.8 | 55.4 | 54.2 |
| SEED-Image | 72.3 | 76.0 | 76.2 |
| HallBench<sub>avg</sub> | 42.4 | 49.3 | 45.2 |
| MathVista<sub>testmini</sub> | 54.3 | 53.5 | 58.3 |
| OpenCompass<sub>avg</sub> | 58.8 | 61.7 | 64.1 |
- 关于更多的细节以及评测复现,请看我们的[评测指南](https://internvl.readthedocs.io/en/latest/internvl2.0/evaluation.html)。
- 我们同时使用 InternVL 和 VLMEvalKit 仓库进行模型评估。具体来说,DocVQA、ChartQA、InfoVQA、TextVQA、MME、AI2D、MMBench、CCBench、MMVet 和 SEED-Image 的结果是使用 InternVL 仓库测试的。OCRBench、RealWorldQA、HallBench 和 MathVista 是使用 VLMEvalKit 进行评估的。
- 对于MMMU,我们报告了原始分数(左侧:InternVL系列模型使用InternVL代码库评测,其他模型的分数来自其技术报告或网页)和VLMEvalKit分数(右侧:从OpenCompass排行榜收集)。
- 请注意,使用不同的测试工具包(如 InternVL 和 VLMEvalKit)评估同一模型可能会导致细微差异,这是正常的。代码版本的更新、环境和硬件的变化也可能导致结果的微小差异。
### 视频相关评测
| 评测数据集 | VideoChat2-HD-Mistral | Video-CCAM-9B | InternVL2-4B | InternVL2-8B |
| :-------------------------: | :-------------------: | :-----------: | :----------: | :----------: |
| 模型大小 | 7B | 9B | 4.2B | 8.1B |
| | | | | |
| MVBench | 60.4 | 60.7 | 63.7 | 66.4 |
| MMBench-Video<sub>8f</sub> | - | - | 1.10 | 1.19 |
| MMBench-Video<sub>16f</sub> | - | - | 1.18 | 1.28 |
| Video-MME<br>w/o subs | 42.3 | 50.6 | 51.4 | 54.0 |
| Video-MME<br>w subs | 54.6 | 54.9 | 53.4 | 56.9 |
- 我们通过从每个视频中提取 16 帧来评估我们的模型在 MVBench 和 Video-MME 上的性能,每个视频帧被调整为 448x448 的图像。
### 定位相关评测
| 模型 | avg. | RefCOCO<br>(val) | RefCOCO<br>(testA) | RefCOCO<br>(testB) | RefCOCO+<br>(val) | RefCOCO+<br>(testA) | RefCOCO+<br>(testB) | RefCOCO‑g<br>(val) | RefCOCO‑g<br>(test) |
| :----------------------------: | :--: | :--------------: | :----------------: | :----------------: | :---------------: | :-----------------: | :-----------------: | :----------------: | :-----------------: |
| UNINEXT-H<br>(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
| | | | | | | | | | |
| Mini-InternVL-<br>Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
| Mini-InternVL-<br>Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
| | | | | | | | | | |
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
| InternVL2-<br>Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 |
- 我们使用以下 Prompt 来评测 InternVL 的 Grounding 能力: `Please provide the bounding box coordinates of the region this sentence describes: <ref>{}</ref>`
限制:尽管在训练过程中我们非常注重模型的安全性,尽力促使模型输出符合伦理和法律要求的文本,但受限于模型大小以及概率生成范式,模型可能会产生各种不符合预期的输出,例如回复内容包含偏见、歧视等有害内容,请勿传播这些内容。由于传播不良信息导致的任何后果,本项目不承担责任。
### 邀请评测 InternVL
我们欢迎各位 MLLM benchmark 的开发者对我们的 InternVL1.5 以及 InternVL2 系列模型进行评测。如果需要在此处添加评测结果,请与我联系([wztxy89@163.com](mailto:wztxy89@163.com))。
## 快速启动
我们提供了一个示例代码,用于使用 `transformers` 运行 InternVL2-8B。
我们也欢迎你在我们的[在线demo](https://internvl.opengvlab.com/)中体验InternVL2的系列模型。
> 请使用 transformers==4.37.2 以确保模型正常运行。
示例代码请[点击这里](#quick-start)。
## 微调
许多仓库现在都支持 InternVL 系列模型的微调,包括 [InternVL](https://github.com/OpenGVLab/InternVL)、[SWIFT](https://github.com/modelscope/ms-swift)、[XTurner](https://github.com/InternLM/xtuner) 等。请参阅它们的文档以获取更多微调细节。
## 部署
### LMDeploy
LMDeploy 是由 MMRazor 和 MMDeploy 团队开发的用于压缩、部署和服务大语言模型(LLM)的工具包。
```sh
pip install lmdeploy==0.5.3
```
LMDeploy 将多模态视觉-语言模型(VLM)的复杂推理过程抽象为一个易于使用的管道,类似于大语言模型(LLM)的推理管道。
#### 一个“你好,世界”示例
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-8B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
response = pipe(('describe this image', image))
print(response.text)
```
如果在执行此示例时出现 `ImportError`,请按照提示安装所需的依赖包。
#### 多图像推理
在处理多张图像时,可以将它们全部放入一个列表中。请注意,多张图像会导致输入 token 数量增加,因此通常需要增加上下文窗口的大小。
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
model = 'OpenGVLab/InternVL2-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### 批量Prompt推理
使用批量Prompt进行推理非常简单;只需将它们放在一个列表结构中:
```python
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### 多轮对话
使用管道进行多轮对话有两种方法。一种是根据 OpenAI 的格式构建消息并使用上述方法,另一种是使用 `pipeline.chat` 接口。
```python
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### API部署
LMDeploy 的 `api_server` 使模型能够通过一个命令轻松打包成服务。提供的 RESTful API 与 OpenAI 的接口兼容。以下是服务启动的示例:
```shell
lmdeploy serve api_server OpenGVLab/InternVL2-8B --backend turbomind --server-port 23333
```
为了使用OpenAI风格的API接口,您需要安装OpenAI:
```shell
pip install openai
```
然后,使用下面的代码进行API调用:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## 开源许可证
该项目采用 MIT 许可证发布,而 InternLM2 则采用 Apache-2.0 许可证。
## 引用
如果您发现此项目对您的研究有用,可以考虑引用我们的论文:
```BibTeX
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
```
|