InternVL2_5-4B
[📂 GitHub] [📜 InternVL 1.0] [📜 InternVL 1.5] [📜 Mini-InternVL] [📜 InternVL 2.5]
[🆕 Blog] [🗨️ Chat Demo] [🤗 HF Demo] [🚀 Quick Start] [📖 Documents]
Introduction
We are excited to introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality.

InternVL 2.5 Family
In the following table, we provide an overview of the InternVL 2.5 series.
Model Architecture
As shown in the following figure, InternVL 2.5 retains the same model architecture as its predecessors, InternVL 1.5 and 2.0, following the "ViT-MLP-LLM" paradigm. In this new version, we integrate a newly incrementally pre-trained InternViT with various pre-trained LLMs, including InternLM 2.5 and Qwen 2.5, using a randomly initialized MLP projector.

As in the previous version, we applied a pixel unshuffle operation, reducing the number of visual tokens to one-quarter of the original. Besides, we adopted a similar dynamic resolution strategy as InternVL 1.5, dividing images into tiles of 448×448 pixels. The key difference, starting from InternVL 2.0, is that we additionally introduced support for multi-image and video data.
Training Strategy
Dynamic High-Resolution for Multimodal Data
In InternVL 2.0 and 2.5, we extend the dynamic high-resolution training approach, enhancing its capabilities to handle multi-image and video datasets.

For single-image datasets, the total number of tiles n_max are allocated to a single image for maximum resolution. Visual tokens are enclosed in <img> and </img> tags.
For multi-image datasets, the total number of tiles n_max are distributed across all images in a sample. Each image is labeled with auxiliary tags like Image-1 and enclosed in <img> and </img> tags.
For videos, each frame is resized to 448×448. Frames are labeled with tags like Frame-1 and enclosed in <img> and </img> tags, similar to images.
Single Model Training Pipeline
The training pipeline for a single model in InternVL 2.5 is structured across three stages, designed to enhance the model's visual perception and multimodal capabilities.

Stage 1: MLP Warmup. In this stage, only the MLP projector is trained while the vision encoder and language model are frozen. A dynamic high-resolution training strategy is applied for better performance, despite increased cost. This phase ensures robust cross-modal alignment and prepares the model for stable multimodal training.
Stage 1.5: ViT Incremental Learning (Optional). This stage allows incremental training of the vision encoder and MLP projector using the same data as Stage 1. It enhances the encoder’s ability to handle rare domains like multilingual OCR and mathematical charts. Once trained, the encoder can be reused across LLMs without retraining, making this stage optional unless new domains are introduced.
Stage 2: Full Model Instruction Tuning. The entire model is trained on high-quality multimodal instruction datasets. Strict data quality controls are enforced to prevent degradation of the LLM, as noisy data can cause issues like repetitive or incorrect outputs. After this stage, the training process is complete.
Progressive Scaling Strategy
We introduce a progressive scaling strategy to align the vision encoder with LLMs efficiently. This approach trains with smaller LLMs first (e.g., 20B) to optimize foundational visual capabilities and cross-modal alignment before transferring the vision encoder to larger LLMs (e.g., 72B) without retraining. This reuse skips intermediate stages for larger models.

Compared to Qwen2-VL's 1.4 trillion tokens, InternVL2.5-78B uses only 120 billion tokens—less than one-tenth. This strategy minimizes redundancy, maximizes pre-trained component reuse, and enables efficient training for complex vision-language tasks.
Training Enhancements
To improve real-world adaptability and performance, we introduce two key techniques:
Random JPEG Compression: Random JPEG compression with quality levels between 75 and 100 is applied as a data augmentation technique. This simulates image degradation from internet sources, enhancing the model's robustness to noisy images.
Loss Reweighting: To balance the NTP loss across responses of different lengths, we use a reweighting strategy called square averaging. This method balances contributions from responses of varying lengths, mitigating biases toward longer or shorter responses.
Data Organization
Dataset Configuration
In InternVL 2.0 and 2.5, the organization of the training data is controlled by several key parameters to optimize the balance and distribution of datasets during training.

Data Augmentation: JPEG compression is applied conditionally: enabled for image datasets to enhance robustness and disabled for video datasets to maintain consistent frame quality.
Maximum Tile Number: The parameter n_max controls the maximum tiles per dataset. For example, higher values (24–36) are used for multi-image or high-resolution data, lower values (6–12) for standard images, and 1 for videos.
Repeat Factor: The repeat factor r adjusts dataset sampling frequency. Values below 1 reduce a dataset's weight, while values above 1 increase it. This ensures balanced training across tasks and prevents overfitting or underfitting.
Data Filtering Pipeline
During development, we found that LLMs are highly sensitive to data noise, with even small anomalies—like outliers or repetitive data—causing abnormal behavior during inference. Repetitive generation, especially in long-form or CoT reasoning tasks, proved particularly harmful.

To address this challenge and support future research, we designed an efficient data filtering pipeline to remove low-quality samples.

The pipeline includes two modules, for pure-text data, three key strategies are used:
- LLM-Based Quality Scoring: Each sample is scored (0–10) using a pre-trained LLM with domain-specific prompts. Samples scoring below a threshold (e.g., 7) are removed to ensure high-quality data.
- Repetition Detection: Repetitive samples are flagged using LLM-based prompts and manually reviewed. Samples scoring below a stricter threshold (e.g., 3) are excluded to avoid repetitive patterns.
- Heuristic Rule-Based Filtering: Anomalies like abnormal sentence lengths or duplicate lines are detected using rules. Flagged samples undergo manual verification to ensure accuracy before removal.
For multimodal data, two strategies are used:
- Repetition Detection: Repetitive samples in non-academic datasets are flagged and manually reviewed to prevent pattern loops. High-quality datasets are exempt from this process.
- Heuristic Rule-Based Filtering: Similar rules are applied to detect visual anomalies, with flagged data verified manually to maintain integrity.
Training Data
As shown in the following figure, from InternVL 1.5 to 2.0 and then to 2.5, the fine-tuning data mixture has undergone iterative improvements in scale, quality, and diversity. For more information about the training data, please refer to our technical report.

Evaluation on Multimodal Capability
Multimodal Reasoning and Mathematics


OCR, Chart, and Document Understanding

Multi-Image & Real-World Comprehension

Comprehensive Multimodal & Hallucination Evaluation

Visual Grounding

Multimodal Multilingual Understanding

Video Understanding

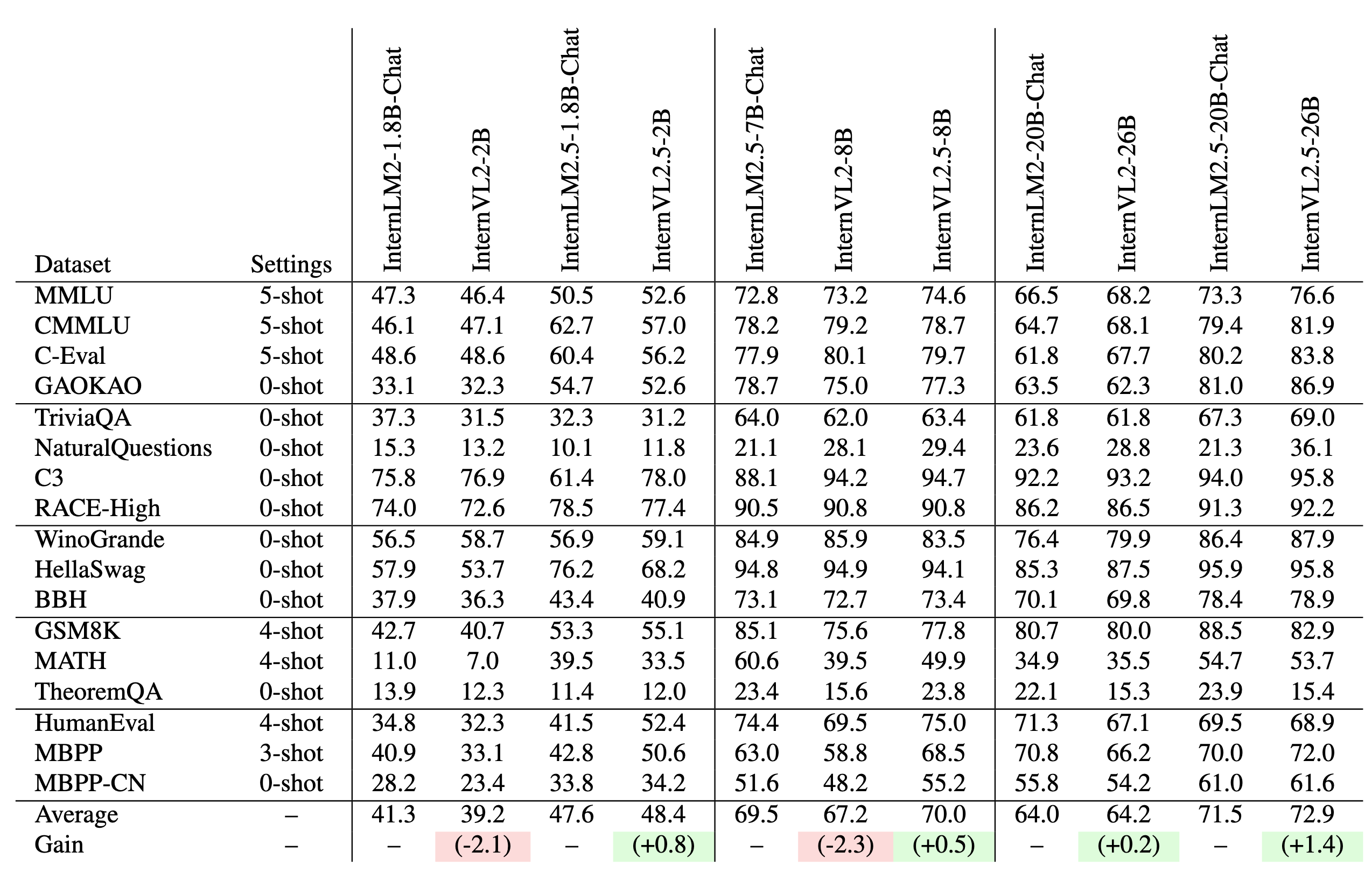
Evaluation on Language Capability
Training InternVL 2.0 models led to a decline in pure language capabilities. InternVL 2.5 addresses this by collecting more high-quality open-source data and filtering out low-quality data, achieving better preservation of pure language performance.
Quick Start
We provide an example code to run InternVL2_5-4B using transformers.
Please use transformers>=4.37.2 to ensure the model works normally.
Model Loading
16-bit (bf16 / fp16)
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2_5-4B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
BNB 8-bit Quantization
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL2_5-4B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
Multiple GPUs
The reason for writing the code this way is to avoid errors that occur during multi-GPU inference due to tensors not being on the same device. By ensuring that the first and last layers of the large language model (LLM) are on the same device, we prevent such errors.
import math
import torch
from transformers import AutoTokenizer, AutoModel
def split_model(model_name):
device_map = {}
world_size = torch.cuda.device_count()
num_layers = {
'InternVL2_5-1B': 24, 'InternVL2_5-2B': 24, 'InternVL2_5-4B': 36, 'InternVL2_5-8B': 32,
'InternVL2_5-26B': 48, 'InternVL2_5-38B': 64, 'InternVL2_5-78B': 80}[model_name]
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
num_layers_per_gpu = [num_layers_per_gpu] * world_size
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
layer_cnt = 0
for i, num_layer in enumerate(num_layers_per_gpu):
for j in range(num_layer):
device_map[f'language_model.model.layers.{layer_cnt}'] = i
layer_cnt += 1
device_map['vision_model'] = 0
device_map['mlp1'] = 0
device_map['language_model.model.tok_embeddings'] = 0
device_map['language_model.model.embed_tokens'] = 0
device_map['language_model.output'] = 0
device_map['language_model.model.norm'] = 0
device_map['language_model.lm_head'] = 0
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
return device_map
path = "OpenGVLab/InternVL2_5-4B"
device_map = split_model('InternVL2_5-4B')
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map=device_map).eval()
Inference with Transformers
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
path = 'OpenGVLab/InternVL2_5-4B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
Streaming Output
Besides this method, you can also use the following code to get streamed output.
from transformers import TextIteratorStreamer
from threading import Thread
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
generated_text = ''
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True)
Finetune
Many repositories now support fine-tuning of the InternVL series models, including InternVL, SWIFT, XTurner, and others. Please refer to their documentation for more details on fine-tuning.
Deployment
LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams.
pip install lmdeploy>=0.5.3
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
A 'Hello, world' Example
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2_5-4B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
response = pipe(('describe this image', image))
print(response.text)
If ImportError occurs while executing this case, please install the required dependency packages as prompted.
Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
question = 'Describe this video in detail.'
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
model = 'OpenGVLab/InternVL2_5-4B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2_5-4B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the pipeline.chat interface.
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL2_5-4B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
Service
LMDeploy's api_server enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
lmdeploy serve api_server OpenGVLab/InternVL2_5-4B --backend turbomind --server-port 23333
To use the OpenAI-style interface, you need to install OpenAI:
pip install openai
Then, use the code below to make the API call:
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
License
This project is released under the MIT License. This project uses the pre-trained Qwen2.5-3B-Instruct as a component, which is licensed under the Apache License 2.0.
Citation
If you find this project useful in your research, please consider citing:
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}

