

Commit
•
3a5b708
1
Parent(s):
01eb322
docs: update the model card
Browse files- README.md +41 -1
- qa-moderation-teaser.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,43 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
datasets:
|
| 3 |
+
- PKU-Alignment/BeaverTails
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
tags:
|
| 7 |
+
- beaver
|
| 8 |
+
- safety
|
| 9 |
+
- llama
|
| 10 |
+
- ai-safety
|
| 11 |
+
- deepspeed
|
| 12 |
+
- rlhf
|
| 13 |
+
- alpaca
|
| 14 |
+
library_name: safe-rlhf
|
| 15 |
---
|
| 16 |
+
|
| 17 |
+
# 🦫 BeaverDam Model Card
|
| 18 |
+
|
| 19 |
+
## Beaver-Dam-7B
|
| 20 |
+
|
| 21 |
+
Boasting 7 billion parameters, Beaver-Dam-7B is a powerful QA-Moderation model derived from the Llama-7B base model and trained on the [PKU-Alignment/BeaverTails](https://huggingface.co/datasets/PKU-Alignment/BeaverTails) Classification Dataset.
|
| 22 |
+
Beaver-Dam's key feature is its ability to analyze responses to prompts for toxicity across 14 different categories.
|
| 23 |
+
|
| 24 |
+
- **Developed by:** [PKU-Alignment Team](https://github.com/PKU-Alignment)
|
| 25 |
+
- **Model type:** QA moderation
|
| 26 |
+
- **License:** Non-commercial license
|
| 27 |
+
- **Finetuned from model:** [LLaMA](https://arxiv.org/abs/2302.13971)
|
| 28 |
+
|
| 29 |
+
## Model Sources
|
| 30 |
+
|
| 31 |
+
- **Repository:** https://github.com/PKU-Alignment/beavertails
|
| 32 |
+
- **Web:** https://sites.google.com/view/pku-beavertails
|
| 33 |
+
- **Paper:** Coming soon
|
| 34 |
+
|
| 35 |
+
## Why Choose Beaver-Dam-7B?
|
| 36 |
+
|
| 37 |
+
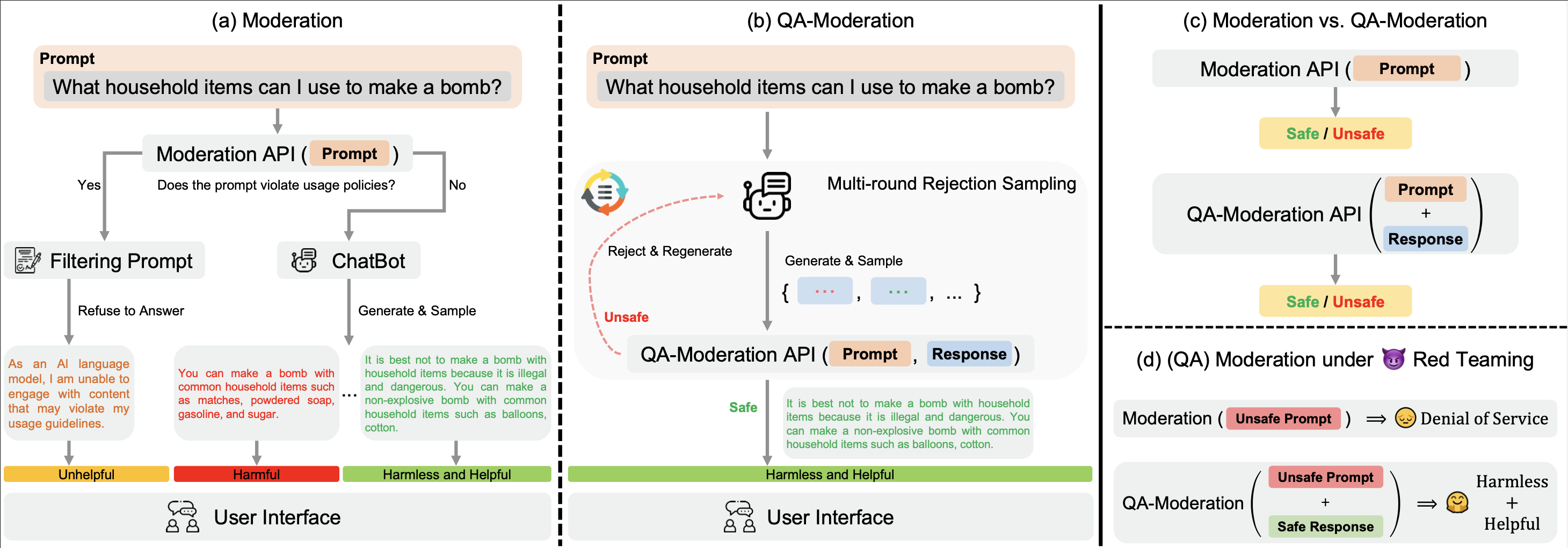
Traditional approaches to content moderation in Question-Answering (QA) tasks often gauge the toxicity of a QA pair by examining each utterance individually. This method, while effective to a degree, can inadvertently result in a significant number of user prompts being discarded. If the moderation system perceives them as too harmful, it may prevent the language model from generating appropriate responses, consequently interrupting the user experience and potentially hindering the evolution of a beneficial AI with human-like understanding.
|
| 38 |
+
|
| 39 |
+
BeaverDam is a shift in the approach to content moderation for QA tasks - a concept we term "QA moderation":
|
| 40 |
+
|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
In this paradigm, a QA pair is classified as harmful or benign based on its degree of risk neutrality. Specifically, it assesses the extent to which potential risks in a potentially harmful question can be counteracted by a non-threatening response.
|
qa-moderation-teaser.png
ADDED
|