

3de11075ae493d18300247d74446187e9d9bbd9c3911d8c24edaa79c53c0d5dd
Browse files- README.md +1 -1
- model/optimized_model.pkl +1 -1
- model/smash_config.json +1 -1
- plots.png +0 -0
README.md
CHANGED
|
@@ -36,7 +36,7 @@ metrics:
|
|
| 36 |

|
| 37 |
|
| 38 |
**Frequently Asked Questions**
|
| 39 |
-
- ***How does the compression work?*** The model is compressed by combining quantization, jit, cuda graphs.
|
| 40 |
- ***How does the model quality change?*** The quality of the model output might slightly vary compared to the base model.
|
| 41 |
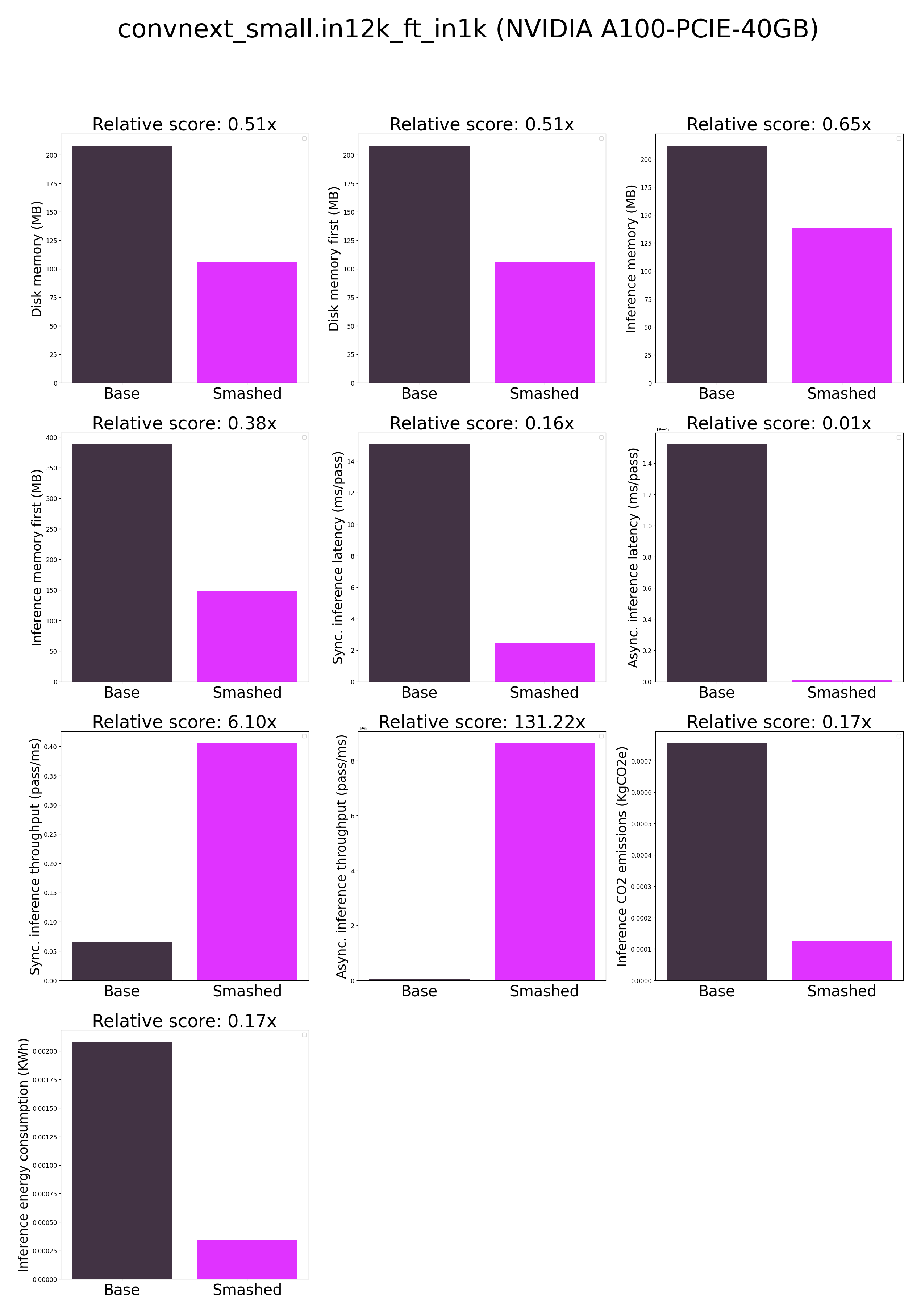
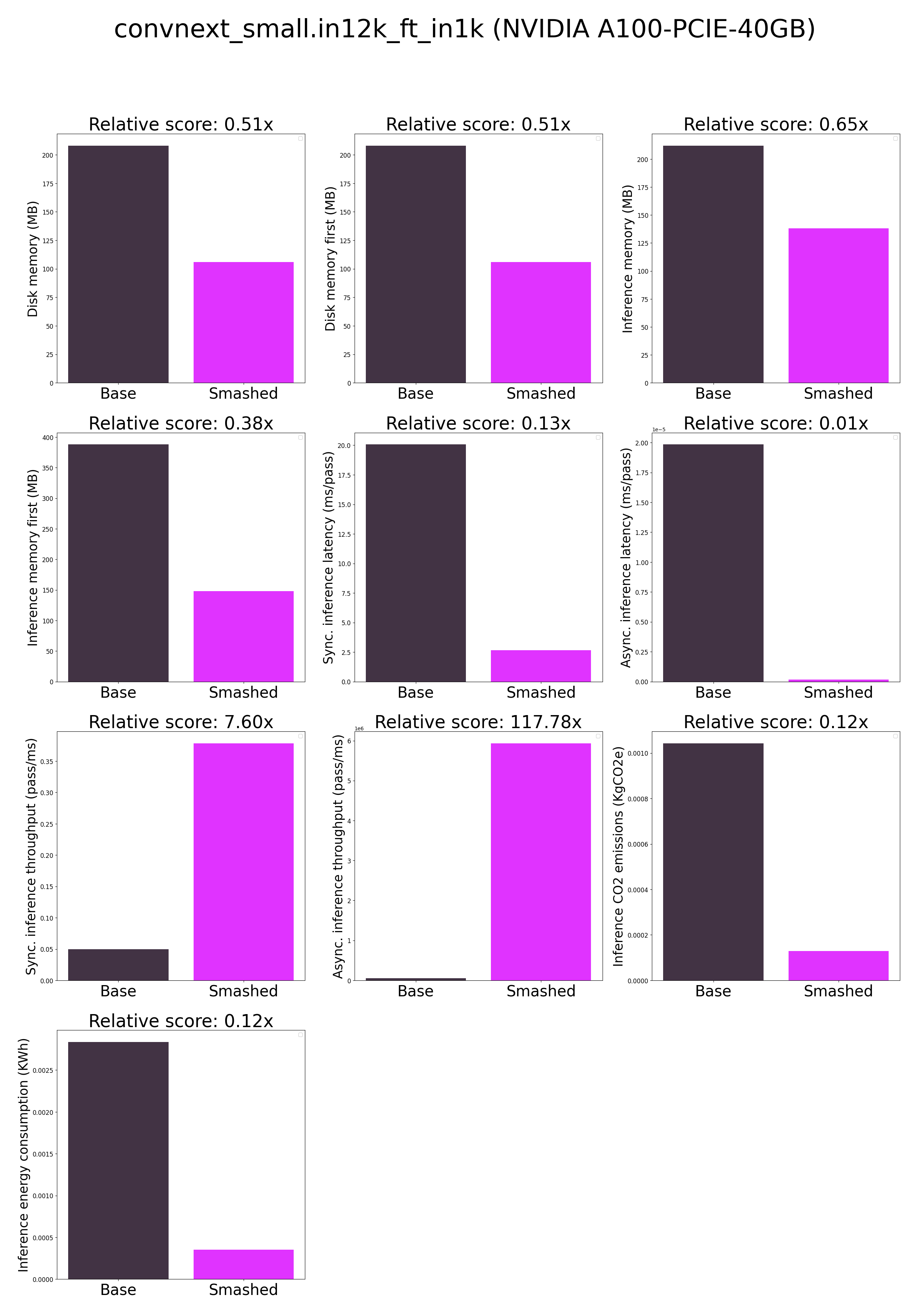
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 42 |
- ***What is the model format?*** We used a custom Pruna model format based on pickle to make models compatible with the compression methods. We provide a tutorial to run models in dockers in the documentation [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/) if needed.
|
|
|
|
| 36 |

|
| 37 |
|
| 38 |
**Frequently Asked Questions**
|
| 39 |
+
- ***How does the compression work?*** The model is compressed by combining quantization, xformers, jit, cuda graphs, triton.
|
| 40 |
- ***How does the model quality change?*** The quality of the model output might slightly vary compared to the base model.
|
| 41 |
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 42 |
- ***What is the model format?*** We used a custom Pruna model format based on pickle to make models compatible with the compression methods. We provide a tutorial to run models in dockers in the documentation [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/) if needed.
|
model/optimized_model.pkl
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 100618063
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:941f8a127725f383a13f5117569db2c34a4aa93fc42d19dada856e6f5175e834
|
| 3 |
size 100618063
|
model/smash_config.json
CHANGED
|
@@ -14,7 +14,7 @@
|
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "convnext_small.in12k_ft_in1k",
|
| 20 |
"max_batch_size": 1,
|
|
|
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsjfy03sg0",
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "convnext_small.in12k_ft_in1k",
|
| 20 |
"max_batch_size": 1,
|
plots.png
CHANGED
|
|