
File size: 14,035 Bytes
e1b32dd 1399c6f e1b32dd 1399c6f e1b32dd 1399c6f e1b32dd |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 |
---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- multimodal
base_model: Qwen/Qwen2-VL-7B-Instruct
---
# Qwen2-VL-7B-Instruct
## Introduction
We're excited to unveil **Qwen2-VL**, the latest iteration of our Qwen-VL model, representing nearly a year of innovation.
### What’s New in Qwen2-VL?
#### Key Enhancements:
* **Enhanced Image Comprehension**: We've significantly improved the model's ability to understand and interpret visual information, setting new benchmarks across key performance metrics.
* **Advanced Video Understanding**: Qwen2-VL now features superior online streaming capabilities, enabling real-time analysis of dynamic video content with remarkable accuracy.
* **Integrated Visual Agent Functionality**: Our model now seamlessly incorporates sophisticated system integration, transforming Qwen2-VL into a powerful visual agent capable of complex reasoning and decision-making.
* **Expanded Multilingual Support**: We've broadened our language capabilities to better serve a diverse global user base, making Qwen2-VL more accessible and effective across different linguistic contexts.
#### Model Architecture Updates:
* **Naive Dynamic Resolution**: Unlike before, Qwen2-VL can handle arbitrary image resolutions, mapping them into a dynamic number of visual tokens, offering a more human-like visual processing experience.
* **Multimodal Rotary Position Embedding (M-ROPE)**: Decomposes positional embedding into parts to capture 1D textual, 2D visual, and 3D video positional information, enhancing its multimodal processing capabilities.
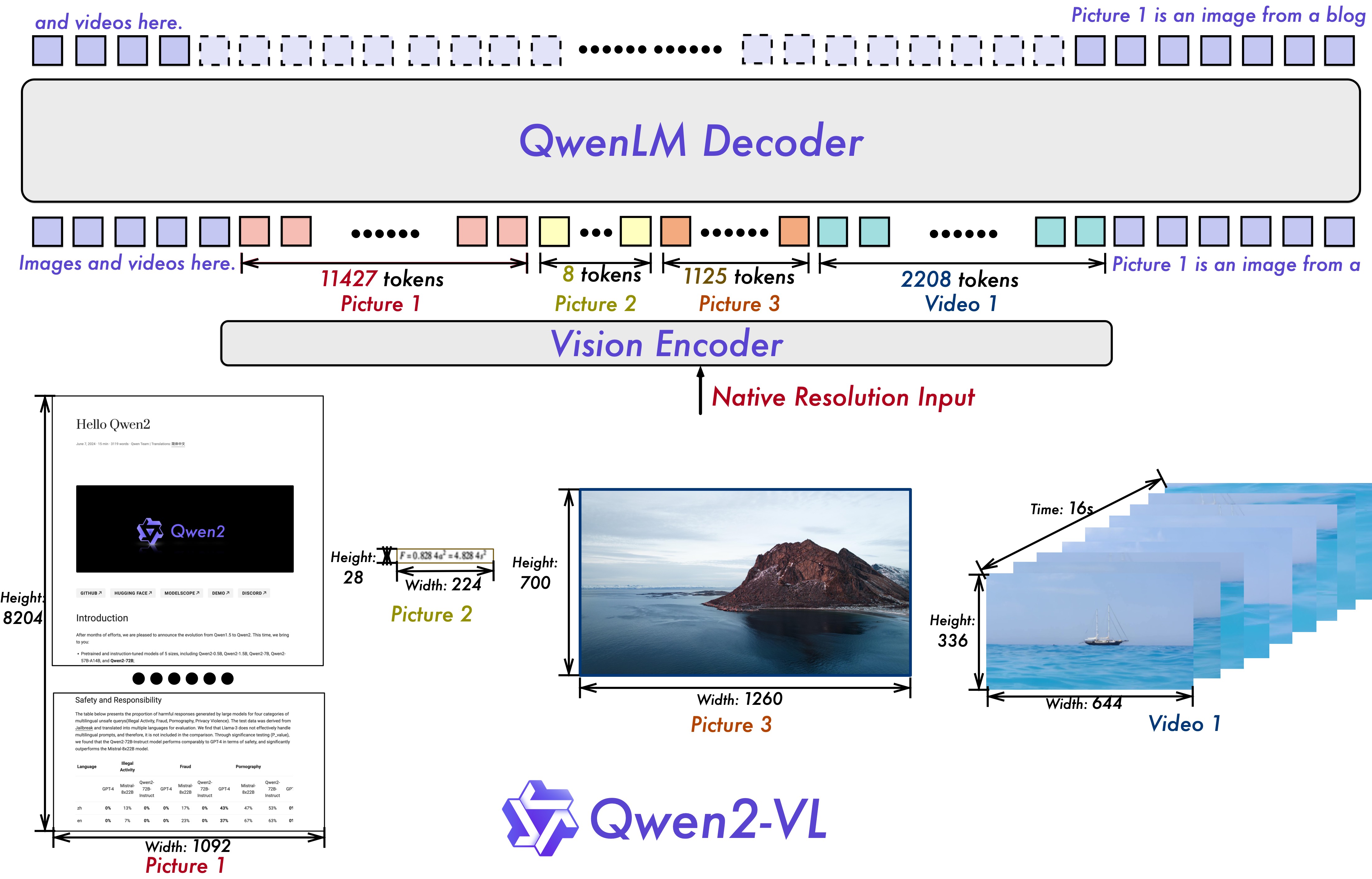
We have three models with 2, 7 and 72 billion parameters. This repo contains the instruction-tuned 7B Qwen2-VL model. For more information, visit our [Blog](https://qwenlm.github.io/blog/qwen2-vl/) and [GitHub](https://github.com/QwenLM/Qwen2-VL).
## Evaluation
### Image Benchmarks
| Benchmark | InternVL2-8B | MiniCPM-V 2.6 | GPT-4o-mini | **Qwen2-VL-7B** |
| :--- | :---: | :---: | :---: | :---: |
| MMMU<sub>val</sub> | 51.8 | 49.8 | **60**| 54.1 |
| DocVQA<sub>test</sub> | 91.6 | 90.8 | - | **94.5** |
| InfoVQA<sub>test</sub> | 74.8 | - | - |**76.5** |
| ChartQA<sub>test</sub> | **83.3** | - |- | 83.0 |
| TextVQA<sub>val</sub> | 77.4 | 80.1 | -| **84.3** |
| OCRBench | 794 | **852** | 785 | 845 |
| MTVQA | - | - | -| **26.3** |
| RealWorldQA | 64.4 | - | - | **70.1** |
| MME<sub>sum</sub> | 2210.3 | **2348.4** | 2003.4| 2326.8 |
| MMBench-EN<sub>test</sub> | 81.7 | - | - | **83.0** |
| MMBench-CN<sub>test</sub> | **81.2** | - | - | 80.5 |
| MMBench-V1.1<sub>test</sub> | 79.4 | 78.0 | 76.0| **80.7** |
| MMT-Bench<sub>test</sub> | - | - | - |**63.7** |
| MMStar | **61.5** | 57.5 | 54.8 | 60.7 |
| MMVet<sub>GPT-4-Turbo</sub> | 54.2 | 60.0 | **66.9** | 62.0 |
| HallBench<sub>avg</sub> | 45.2 | 48.1 | 46.1| **50.6** |
| MathVista<sub>testmini</sub> | 58.3 | **60.6** | 52.4 | 58.2 |
| MathVision | - | - | - | **16.3** |
### Video Benchmarks
| Benchmark | Internvl2-8B | LLaVA-OneVision-7B | MiniCPM-V 2.6 | **Qwen2-VL-7B** |
| :--- | :---: | :---: | :---: | :---: |
| MVBench | 66.4 | 56.7 | - | **67.0** |
| PerceptionTest<sub>test</sub> | - | 57.1 | - | **62.3** |
| EgoSchema<sub>test</sub> | - | 60.1 | - | **66.7** |
| Video-MME<sub>wo/w subs</sub> | 54.0/56.9 | 58.2/- | 60.9/63.6 | **63.3**/**69.0** |
## Requirements
The code of Qwen2-VL has been in the latest Hugging face transformers and we advise you to build from source with command `pip install git+https://github.com/huggingface/transformers`, or you might encounter the following error:
```
KeyError: 'qwen2_vl'
```
## Quickstart
We offer a toolkit to help you handle various types of visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved images and videos. You can install it using the following command:
```bash
pip install qwen-vl-utils
```
Here we show a code snippet to show you how to use the chat model with `transformers` and `qwen_vl_utils`:
```python
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [{"role": "user", "content": [{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}, {"type": "text", "text": "Describe this image."}]}]
# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(output_text)
```
<details>
<summary>Without qwen_vl_utils</summary>
```python
from PIL import Image
import requests
import torch
from torchvision import io
from typing import Dict
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
# Load the model in half-precision on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
# Image
url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
conversation = [
{
"role":"user",
"content":[
{
"type":"image",
},
{
"type":"text",
"text":"Describe this image."
}
]
}
]
# Preprocess the inputs
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe this image.<|im_end|>\n<|im_start|>assistant\n'
inputs = processor(text=[text_prompt], images=[image], padding=True, return_tensors="pt")
inputs = inputs.to('cuda')
# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(output_text)
```
</details>
<details>
<summary>Multi image inference</summary>
```python
# Messages containing multiple images and a text query
messages = [{"role": "user", "content": [{"type": "image", "image": "file:///path/to/image1.jpg"}, {"type": "image", "image": "file:///path/to/image2.jpg"}, {"type": "text", "text": "Identify the similarities between these images."}]}]
# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(output_text)
```
</details>
<details>
<summary>Video inference</summary>
```python
# Messages containing a images list as a video and a text query
messages = [{"role": "user", "content": [{"type": "video", "video": ["file:///path/to/frame1.jpg", "file:///path/to/frame2.jpg", "file:///path/to/frame3.jpg", "file:///path/to/frame4.jpg"], 'fps': 1.0}, {"type": "text", "text": "Describe this video."}]}]
# Messages containing a video and a text query
messages = [{"role": "user", "content": [{"type": "video", "video": "file:///path/to/video1.mp4", 'max_pixels': 360*420, 'fps': 1.0}, {"type": "text", "text": "Describe this video."}]}]
# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(output_text)
```
</details>
<details>
<summary>Batch inference</summary>
```python
# Sample messages for batch inference
messages1 = [{"role": "user", "content": [{"type": "image", "image": "file:///path/to/image1.jpg"}, {"type": "image", "image": "file:///path/to/image2.jpg"}, {"type": "text", "text": "What are the common elements in these pictures?"}]}]
messages2 = [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Who are you?"}]
# Combine messages for batch processing
messages = [messages1, messages1]
# Preparation for batch inference
texts = [processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True) for msg in messages]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=texts, images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt")
# Batch Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_texts = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(output_texts)
```
</details>
### More Usage Tips
For input images, we support local files, base64, and URLs. For videos, we currently only support local files.
```python
# You can directly insert a local file path, a URL, or a base64-encoded image into the position where you want in the text.
## Local file path
messages = [{"role": "user", "content": [{"type": "image", "image": "file:///path/to/your/image.jpg"}, {"type": "text", "text": "Describe this image."}]}]
## Image URL
messages = [{"role": "user", "content": [{"type": "image", "image": "http://path/to/your/image.jpg"}, {"type": "text", "text": "Describe this image."}]}]
## Base64 encoded image
messages = [{"role": "user", "content": [{"type": "image", "image": "data:image;base64,/9j/..."}, {"type": "text", "text": "Describe this image."}]}]
```
#### Image Resolution for performance boost
The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs, such as a token count range of 256-1280, to balance speed and memory usage.
```python
min_pixels = 256*28*28
max_pixels = 1280*28*28
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
```
Besides, We provide two methods for fine-grained control over the image size input to the model:
1. Define min_pixels and max_pixels: Images will be resized to maintain their aspect ratio within the range of min_pixels and max_pixels.
2. Specify exact dimensions: Directly set `resized_height` and `resized_width`. These values will be rounded to the nearest multiple of 28.
```python
# min_pixels and max_pixels
messages = [{"role": "user", "content": [{"type": "image", "image": "file:///path/to/your/image.jpg", "resized_height": 280, "resized_width": 420}, {"type": "text", "text": "Describe this image."}]}]
# resized_height and resized_width
messages = [{"role": "user", "content": [{"type": "image", "image": "file:///path/to/your/image.jpg", "min_pixels": 50176, "max_pixels": 50176}, {"type": "text", "text": "Describe this image."}]}]
```
**Limitations:**
1. Does not support audio extraction from videos.
2. Limited to data available up until June 2023.
3. Limited coverage of character/IP recognition.
4. Complex instruction following capabilities need enhancement.
5. Counting abilities, particularly in complex scenarios, require improvement.
6. Handling of complex charts by the model still needs refinement.
7. The model performs poorly in spatial relationship reasoning, especially in reasoning about object positions in a 3D space.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2vl,
title={Qwen2-VL Technical Report},
year={2024}
}
``` |