
Upload 10 files
Browse fileszhongjing reward model
- adapter_config.json +17 -0
- adapter_model.bin +3 -0
- all_results.json +7 -0
- finetuning_args.json +13 -0
- train_results.json +7 -0
- trainer_log.jsonl +22 -0
- trainer_state.json +157 -0
- training_args.bin +3 -0
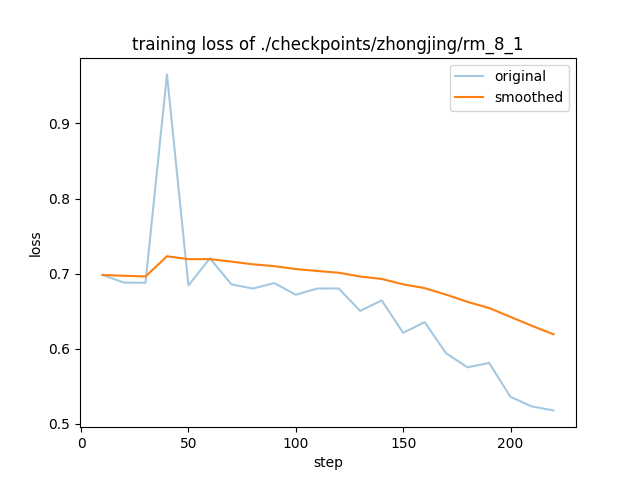
- training_loss.png +0 -0
- value_head.bin +3 -0
adapter_config.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"base_model_name_or_path": "/hy-tmp/Ziya-LLaMA-13B-v1",
|
| 3 |
+
"bias": "none",
|
| 4 |
+
"fan_in_fan_out": false,
|
| 5 |
+
"inference_mode": true,
|
| 6 |
+
"init_lora_weights": true,
|
| 7 |
+
"lora_alpha": 32.0,
|
| 8 |
+
"lora_dropout": 0.1,
|
| 9 |
+
"modules_to_save": null,
|
| 10 |
+
"peft_type": "LORA",
|
| 11 |
+
"r": 8,
|
| 12 |
+
"target_modules": [
|
| 13 |
+
"q_proj",
|
| 14 |
+
"v_proj"
|
| 15 |
+
],
|
| 16 |
+
"task_type": "CAUSAL_LM"
|
| 17 |
+
}
|
adapter_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2a533e443a5e2aeb4ff0e5d64576b70659497d73b9815cadf39ba3b54c2aa181
|
| 3 |
+
size 26269517
|
all_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 9.67,
|
| 3 |
+
"train_loss": 0.6559816967357289,
|
| 4 |
+
"train_runtime": 11143.63,
|
| 5 |
+
"train_samples_per_second": 1.302,
|
| 6 |
+
"train_steps_per_second": 0.02
|
| 7 |
+
}
|
finetuning_args.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"finetuning_type": "lora",
|
| 3 |
+
"lora_alpha": 32.0,
|
| 4 |
+
"lora_dropout": 0.1,
|
| 5 |
+
"lora_rank": 8,
|
| 6 |
+
"lora_target": [
|
| 7 |
+
"q_proj",
|
| 8 |
+
"v_proj"
|
| 9 |
+
],
|
| 10 |
+
"name_module_trainable": "mlp",
|
| 11 |
+
"num_hidden_layers": 32,
|
| 12 |
+
"num_layer_trainable": 3
|
| 13 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 9.67,
|
| 3 |
+
"train_loss": 0.6559816967357289,
|
| 4 |
+
"train_runtime": 11143.63,
|
| 5 |
+
"train_samples_per_second": 1.302,
|
| 6 |
+
"train_steps_per_second": 0.02
|
| 7 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 10, "total_steps": 220, "loss": 0.6983, "reward": null, "learning_rate": 0.0006987161058019419, "epoch": 0.44, "percentage": 4.55, "elapsed_time": "0:08:38", "remaining_time": "3:01:32"}
|
| 2 |
+
{"current_steps": 20, "total_steps": 220, "loss": 0.6882, "reward": null, "learning_rate": 0.0006909041709298167, "epoch": 0.88, "percentage": 9.09, "elapsed_time": "0:17:04", "remaining_time": "2:50:48"}
|
| 3 |
+
{"current_steps": 30, "total_steps": 220, "loss": 0.688, "reward": null, "learning_rate": 0.0006761524102240084, "epoch": 1.32, "percentage": 13.64, "elapsed_time": "0:25:20", "remaining_time": "2:40:26"}
|
| 4 |
+
{"current_steps": 40, "total_steps": 220, "loss": 0.9653, "reward": null, "learning_rate": 0.0006618522834659287, "epoch": 1.76, "percentage": 18.18, "elapsed_time": "0:34:00", "remaining_time": "2:33:03"}
|
| 5 |
+
{"current_steps": 50, "total_steps": 220, "loss": 0.6844, "reward": null, "learning_rate": 0.0006360647222822923, "epoch": 2.2, "percentage": 22.73, "elapsed_time": "0:42:17", "remaining_time": "2:23:48"}
|
| 6 |
+
{"current_steps": 60, "total_steps": 220, "loss": 0.7206, "reward": null, "learning_rate": 0.0006044537082955259, "epoch": 2.64, "percentage": 27.27, "elapsed_time": "0:50:50", "remaining_time": "2:15:33"}
|
| 7 |
+
{"current_steps": 70, "total_steps": 220, "loss": 0.6859, "reward": null, "learning_rate": 0.0005676627505917628, "epoch": 3.08, "percentage": 31.82, "elapsed_time": "0:59:19", "remaining_time": "2:07:07"}
|
| 8 |
+
{"current_steps": 80, "total_steps": 220, "loss": 0.6803, "reward": null, "learning_rate": 0.0005264408069734912, "epoch": 3.52, "percentage": 36.36, "elapsed_time": "1:07:45", "remaining_time": "1:58:34"}
|
| 9 |
+
{"current_steps": 90, "total_steps": 220, "loss": 0.6876, "reward": null, "learning_rate": 0.00048162703733850993, "epoch": 3.96, "percentage": 40.91, "elapsed_time": "1:16:13", "remaining_time": "1:50:06"}
|
| 10 |
+
{"current_steps": 100, "total_steps": 220, "loss": 0.672, "reward": null, "learning_rate": 0.0004341337208043474, "epoch": 4.4, "percentage": 45.45, "elapsed_time": "1:24:39", "remaining_time": "1:41:35"}
|
| 11 |
+
{"current_steps": 110, "total_steps": 220, "loss": 0.6803, "reward": null, "learning_rate": 0.00038492768433622394, "epoch": 4.84, "percentage": 50.0, "elapsed_time": "1:33:09", "remaining_time": "1:33:09"}
|
| 12 |
+
{"current_steps": 120, "total_steps": 220, "loss": 0.6804, "reward": null, "learning_rate": 0.0003350106209381392, "epoch": 5.27, "percentage": 54.55, "elapsed_time": "1:41:31", "remaining_time": "1:24:36"}
|
| 13 |
+
{"current_steps": 130, "total_steps": 220, "loss": 0.6505, "reward": null, "learning_rate": 0.00028539869807195416, "epoch": 5.71, "percentage": 59.09, "elapsed_time": "1:50:02", "remaining_time": "1:16:11"}
|
| 14 |
+
{"current_steps": 140, "total_steps": 220, "loss": 0.6645, "reward": null, "learning_rate": 0.00023710187141825318, "epoch": 6.15, "percentage": 63.64, "elapsed_time": "1:58:18", "remaining_time": "1:07:36"}
|
| 15 |
+
{"current_steps": 150, "total_steps": 220, "loss": 0.6214, "reward": null, "learning_rate": 0.00019110332509115864, "epoch": 6.59, "percentage": 68.18, "elapsed_time": "2:06:59", "remaining_time": "0:59:15"}
|
| 16 |
+
{"current_steps": 160, "total_steps": 220, "loss": 0.6356, "reward": null, "learning_rate": 0.00014833945684503654, "epoch": 7.03, "percentage": 72.73, "elapsed_time": "2:15:11", "remaining_time": "0:50:41"}
|
| 17 |
+
{"current_steps": 170, "total_steps": 220, "loss": 0.5941, "reward": null, "learning_rate": 0.00010968081571656524, "epoch": 7.47, "percentage": 77.27, "elapsed_time": "2:23:43", "remaining_time": "0:42:16"}
|
| 18 |
+
{"current_steps": 180, "total_steps": 220, "loss": 0.5754, "reward": null, "learning_rate": 7.591438015680559e-05, "epoch": 7.91, "percentage": 81.82, "elapsed_time": "2:32:13", "remaining_time": "0:33:49"}
|
| 19 |
+
{"current_steps": 190, "total_steps": 220, "loss": 0.5813, "reward": null, "learning_rate": 4.7727537419395036e-05, "epoch": 8.35, "percentage": 86.36, "elapsed_time": "2:40:41", "remaining_time": "0:25:22"}
|
| 20 |
+
{"current_steps": 200, "total_steps": 220, "loss": 0.5361, "reward": null, "learning_rate": 2.5694090338324998e-05, "epoch": 8.79, "percentage": 90.91, "elapsed_time": "2:49:07", "remaining_time": "0:16:54"}
|
| 21 |
+
{"current_steps": 210, "total_steps": 220, "loss": 0.5233, "reward": null, "learning_rate": 1.0262576356951625e-05, "epoch": 9.23, "percentage": 95.45, "elapsed_time": "2:57:21", "remaining_time": "0:08:26"}
|
| 22 |
+
{"current_steps": 220, "total_steps": 220, "loss": 0.5181, "reward": null, "learning_rate": 1.7471365991241382e-06, "epoch": 9.67, "percentage": 100.0, "elapsed_time": "3:05:51", "remaining_time": "0:00:00"}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 9.67032967032967,
|
| 5 |
+
"global_step": 220,
|
| 6 |
+
"is_hyper_param_search": false,
|
| 7 |
+
"is_local_process_zero": true,
|
| 8 |
+
"is_world_process_zero": true,
|
| 9 |
+
"log_history": [
|
| 10 |
+
{
|
| 11 |
+
"epoch": 0.44,
|
| 12 |
+
"learning_rate": 0.0006987161058019419,
|
| 13 |
+
"loss": 0.6983,
|
| 14 |
+
"step": 10
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"epoch": 0.88,
|
| 18 |
+
"learning_rate": 0.0006909041709298167,
|
| 19 |
+
"loss": 0.6882,
|
| 20 |
+
"step": 20
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"epoch": 1.32,
|
| 24 |
+
"learning_rate": 0.0006761524102240084,
|
| 25 |
+
"loss": 0.688,
|
| 26 |
+
"step": 30
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"epoch": 1.76,
|
| 30 |
+
"learning_rate": 0.0006618522834659287,
|
| 31 |
+
"loss": 0.9653,
|
| 32 |
+
"step": 40
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"epoch": 2.2,
|
| 36 |
+
"learning_rate": 0.0006360647222822923,
|
| 37 |
+
"loss": 0.6844,
|
| 38 |
+
"step": 50
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 2.64,
|
| 42 |
+
"learning_rate": 0.0006044537082955259,
|
| 43 |
+
"loss": 0.7206,
|
| 44 |
+
"step": 60
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 3.08,
|
| 48 |
+
"learning_rate": 0.0005676627505917628,
|
| 49 |
+
"loss": 0.6859,
|
| 50 |
+
"step": 70
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"epoch": 3.52,
|
| 54 |
+
"learning_rate": 0.0005264408069734912,
|
| 55 |
+
"loss": 0.6803,
|
| 56 |
+
"step": 80
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"epoch": 3.96,
|
| 60 |
+
"learning_rate": 0.00048162703733850993,
|
| 61 |
+
"loss": 0.6876,
|
| 62 |
+
"step": 90
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
"epoch": 4.4,
|
| 66 |
+
"learning_rate": 0.0004341337208043474,
|
| 67 |
+
"loss": 0.672,
|
| 68 |
+
"step": 100
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"epoch": 4.84,
|
| 72 |
+
"learning_rate": 0.00038492768433622394,
|
| 73 |
+
"loss": 0.6803,
|
| 74 |
+
"step": 110
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"epoch": 5.27,
|
| 78 |
+
"learning_rate": 0.0003350106209381392,
|
| 79 |
+
"loss": 0.6804,
|
| 80 |
+
"step": 120
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"epoch": 5.71,
|
| 84 |
+
"learning_rate": 0.00028539869807195416,
|
| 85 |
+
"loss": 0.6505,
|
| 86 |
+
"step": 130
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"epoch": 6.15,
|
| 90 |
+
"learning_rate": 0.00023710187141825318,
|
| 91 |
+
"loss": 0.6645,
|
| 92 |
+
"step": 140
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 6.59,
|
| 96 |
+
"learning_rate": 0.00019110332509115864,
|
| 97 |
+
"loss": 0.6214,
|
| 98 |
+
"step": 150
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"epoch": 7.03,
|
| 102 |
+
"learning_rate": 0.00014833945684503654,
|
| 103 |
+
"loss": 0.6356,
|
| 104 |
+
"step": 160
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"epoch": 7.47,
|
| 108 |
+
"learning_rate": 0.00010968081571656524,
|
| 109 |
+
"loss": 0.5941,
|
| 110 |
+
"step": 170
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"epoch": 7.91,
|
| 114 |
+
"learning_rate": 7.591438015680559e-05,
|
| 115 |
+
"loss": 0.5754,
|
| 116 |
+
"step": 180
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"epoch": 8.35,
|
| 120 |
+
"learning_rate": 4.7727537419395036e-05,
|
| 121 |
+
"loss": 0.5813,
|
| 122 |
+
"step": 190
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
"epoch": 8.79,
|
| 126 |
+
"learning_rate": 2.5694090338324998e-05,
|
| 127 |
+
"loss": 0.5361,
|
| 128 |
+
"step": 200
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"epoch": 9.23,
|
| 132 |
+
"learning_rate": 1.0262576356951625e-05,
|
| 133 |
+
"loss": 0.5233,
|
| 134 |
+
"step": 210
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"epoch": 9.67,
|
| 138 |
+
"learning_rate": 1.7471365991241382e-06,
|
| 139 |
+
"loss": 0.5181,
|
| 140 |
+
"step": 220
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"epoch": 9.67,
|
| 144 |
+
"step": 220,
|
| 145 |
+
"total_flos": 0.0,
|
| 146 |
+
"train_loss": 0.6559816967357289,
|
| 147 |
+
"train_runtime": 11143.63,
|
| 148 |
+
"train_samples_per_second": 1.302,
|
| 149 |
+
"train_steps_per_second": 0.02
|
| 150 |
+
}
|
| 151 |
+
],
|
| 152 |
+
"max_steps": 220,
|
| 153 |
+
"num_train_epochs": 10,
|
| 154 |
+
"total_flos": 0.0,
|
| 155 |
+
"trial_name": null,
|
| 156 |
+
"trial_params": null
|
| 157 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dc5956f44bfde99c8ebe9bb481abd02e2ba3e19a283191698d44b72c86d833f1
|
| 3 |
+
size 3363
|
training_loss.png
ADDED
|
value_head.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:72bc7d2eab94d00ff621713cc857191d0de7b14b1a8bfb22cbae58ac38fa5a1d
|
| 3 |
+
size 21491
|