---
tags:
- RUDOLPH
- text-image
- image-text
- decoder
---
# RUDOLPH-1.3B (Large)
RUDOLPH: One Hyper-Tasking Transformer Can be Creative as DALL-E and GPT-3 and Smart as CLIP
 Model was trained by [Sber AI](https://github.com/sberbank-ai) team.
# Model Description
**RU**ssian **D**ecoder **O**n **L**anguage **P**icture **H**yper-tasking (**RUDOLPH**) **1.3B** is a large text-image-text transformer designed for an easy fine-tuning for a range of tasks: from generating images by text description and image classification to visual question answering and more. This model demonstrates the power of Hyper-tasking Transformers.
*Hyper-tasking model is a generalized multi-tasking model, i.e., the model that can solve almost all tasks within supported modalities, mandatory including mutual pairwise translations between modalities (two modalities in case of RUDOLPH: images and Russian texts).*
* Tasks: ` text2image generation, self reranking, text ranking, image ranking, image2text generation, zero-shot image classification, text2text generation, text-qa, math-qa, image captioning, image generation, text-in-the-wild, vqa, and so on`
* Language: ` Russian`
* Type: ` decoder`
* Num Parameters: ` 1.3B`
* Training Data Volume: ` 119 million text-image pairs, 60 million text paragraphs`
# Details of architecture
### Parameters
Model was trained by [Sber AI](https://github.com/sberbank-ai) team.
# Model Description
**RU**ssian **D**ecoder **O**n **L**anguage **P**icture **H**yper-tasking (**RUDOLPH**) **1.3B** is a large text-image-text transformer designed for an easy fine-tuning for a range of tasks: from generating images by text description and image classification to visual question answering and more. This model demonstrates the power of Hyper-tasking Transformers.
*Hyper-tasking model is a generalized multi-tasking model, i.e., the model that can solve almost all tasks within supported modalities, mandatory including mutual pairwise translations between modalities (two modalities in case of RUDOLPH: images and Russian texts).*
* Tasks: ` text2image generation, self reranking, text ranking, image ranking, image2text generation, zero-shot image classification, text2text generation, text-qa, math-qa, image captioning, image generation, text-in-the-wild, vqa, and so on`
* Language: ` Russian`
* Type: ` decoder`
* Num Parameters: ` 1.3B`
* Training Data Volume: ` 119 million text-image pairs, 60 million text paragraphs`
# Details of architecture
### Parameters
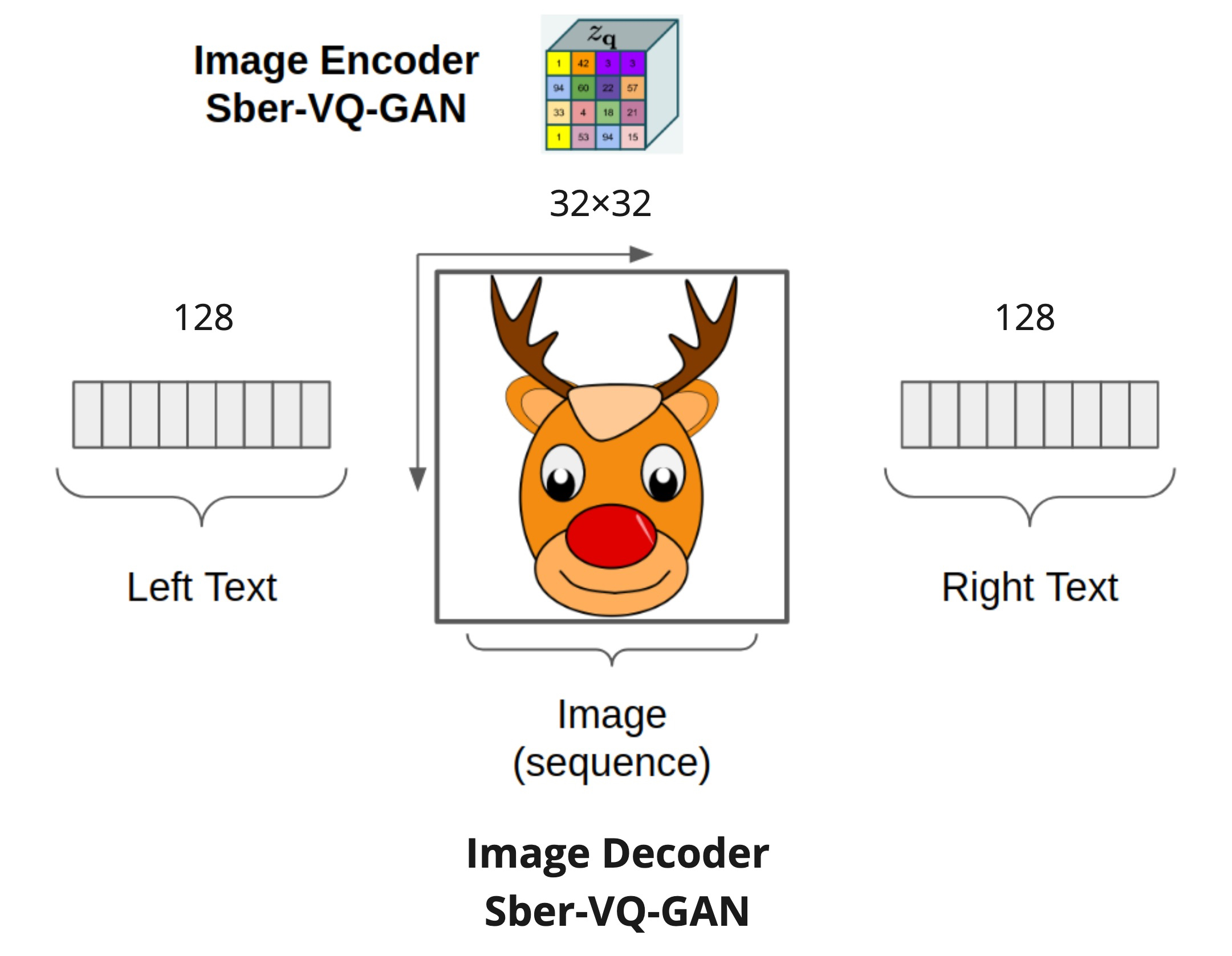 The maximum sequence length that this model may be used with depends on the modality and stands for 128 - 1024 - 128 for the left text tokens, image tokens, and right text tokens, respectively.
RUDOLPH 1.3B is a Transformer-based decoder model with the following parameters:
* num\_layers (24) — Number of hidden layers in the Transformer decoder.
* hidden\_size (2048) — Dimensionality of the hidden layers.
* num\_attention\_heads (16) — Number of attention heads for each attention layer.
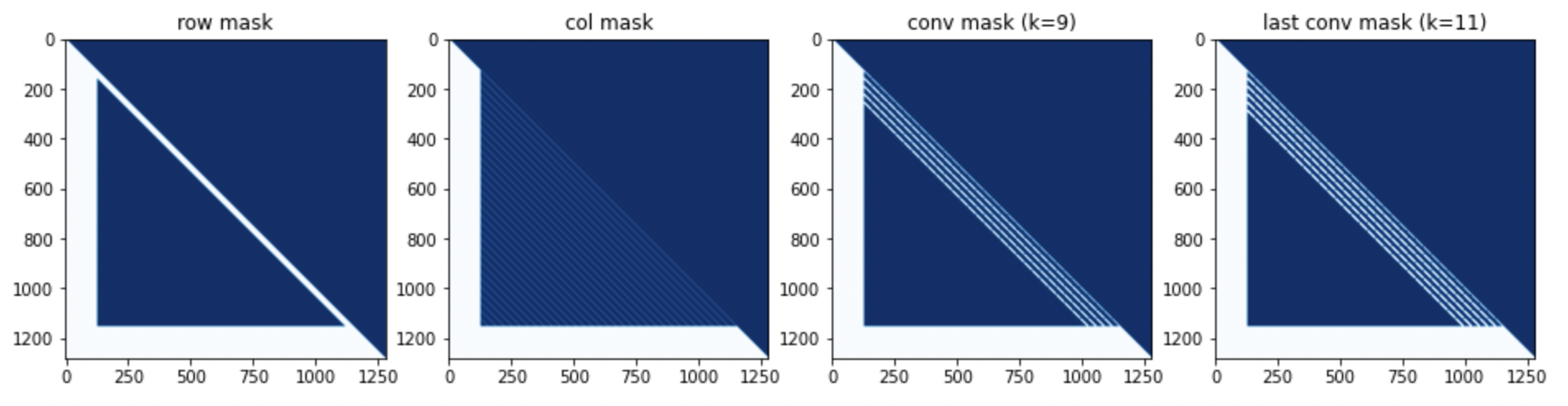
# Sparse Attention Mask
The primary proposed method is to modify the sparse transformer's attention mask to better control multi-modalities and up to the next level with "hyper-modality". It allows us to calculate the transitions of modalities in both directions, unlike another similar work DALL-E Transformer, which used only one direction, "text to image". The proposed "image to right text" direction is achieved by extension sparse attention mask to the right for auto-repressively text generation with both image and left text condition.
The maximum sequence length that this model may be used with depends on the modality and stands for 128 - 1024 - 128 for the left text tokens, image tokens, and right text tokens, respectively.
RUDOLPH 1.3B is a Transformer-based decoder model with the following parameters:
* num\_layers (24) — Number of hidden layers in the Transformer decoder.
* hidden\_size (2048) — Dimensionality of the hidden layers.
* num\_attention\_heads (16) — Number of attention heads for each attention layer.
# Sparse Attention Mask
The primary proposed method is to modify the sparse transformer's attention mask to better control multi-modalities and up to the next level with "hyper-modality". It allows us to calculate the transitions of modalities in both directions, unlike another similar work DALL-E Transformer, which used only one direction, "text to image". The proposed "image to right text" direction is achieved by extension sparse attention mask to the right for auto-repressively text generation with both image and left text condition.
 # Authors
+ Alex Shonenkov: [Github](https://github.com/shonenkov), [Kaggle GM](https://www.kaggle.com/shonenkov)
# Authors
+ Alex Shonenkov: [Github](https://github.com/shonenkov), [Kaggle GM](https://www.kaggle.com/shonenkov)