
Commit
•
7c669f0
1
Parent(s):
a42ad9f
Upload folder using huggingface_hub
Browse files- .gitattributes +15 -0
- LMCocktail-10.7B-v1-Q2_K.gguf +3 -0
- LMCocktail-10.7B-v1-Q3_K.gguf +3 -0
- LMCocktail-10.7B-v1-Q3_K_L.gguf +3 -0
- LMCocktail-10.7B-v1-Q3_K_M.gguf +3 -0
- LMCocktail-10.7B-v1-Q3_K_S.gguf +3 -0
- LMCocktail-10.7B-v1-Q4_0.gguf +3 -0
- LMCocktail-10.7B-v1-Q4_1.gguf +3 -0
- LMCocktail-10.7B-v1-Q4_K.gguf +3 -0
- LMCocktail-10.7B-v1-Q4_K_M.gguf +3 -0
- LMCocktail-10.7B-v1-Q4_K_S.gguf +3 -0
- LMCocktail-10.7B-v1-Q5_0.gguf +3 -0
- LMCocktail-10.7B-v1-Q5_1.gguf +3 -0
- LMCocktail-10.7B-v1-Q5_K.gguf +3 -0
- LMCocktail-10.7B-v1-Q5_K_M.gguf +0 -0
- LMCocktail-10.7B-v1-Q5_K_S.gguf +3 -0
- LMCocktail-10.7B-v1-Q6_K.gguf +0 -0
- LMCocktail-10.7B-v1-Q8_0.gguf +0 -0
- LMCocktail-10.7B-v1-f16.gguf +3 -0
- README.md +269 -0
- alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/alpaca_eval_log.txt +0 -0
- alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/annotation_chatgpt_fn.json +0 -0
- alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/leaderboard.csv +15 -0
- alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/model_outputs.json +0 -0
- alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/reference_outputs.json +0 -0
- assets/SOLAR.png +0 -0
- assets/SOLAR_mixed.png +0 -0
- assets/SOLAR_mixed2.png +0 -0
- config.json +29 -0
- generation_config.json +8 -0
- model.safetensors.index.json +442 -0
- sciprts/convert.py +13 -0
- sciprts/merge.log +0 -0
- sciprts/merge.py +22 -0
- sciprts/merge.sh +8 -0
- special_tokens_map.json +30 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +43 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,18 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
LMCocktail-10.7B-v1-Q2_K.gguf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
LMCocktail-10.7B-v1-Q3_K.gguf filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
LMCocktail-10.7B-v1-Q3_K_L.gguf filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
LMCocktail-10.7B-v1-Q3_K_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
LMCocktail-10.7B-v1-Q3_K_S.gguf filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
LMCocktail-10.7B-v1-Q4_0.gguf filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
LMCocktail-10.7B-v1-Q4_1.gguf filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
LMCocktail-10.7B-v1-Q4_K.gguf filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
LMCocktail-10.7B-v1-Q4_K_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
LMCocktail-10.7B-v1-Q4_K_S.gguf filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
LMCocktail-10.7B-v1-Q5_0.gguf filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
LMCocktail-10.7B-v1-Q5_1.gguf filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
LMCocktail-10.7B-v1-Q5_K.gguf filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
LMCocktail-10.7B-v1-Q5_K_S.gguf filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
LMCocktail-10.7B-v1-f16.gguf filter=lfs diff=lfs merge=lfs -text
|
LMCocktail-10.7B-v1-Q2_K.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0a376074a23bd64476c605f07bcb5dfbac1ab6676e522143236a67bf559a372c
|
| 3 |
+
size 4549952480
|
LMCocktail-10.7B-v1-Q3_K.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d1b515c11ae967ff5988d6403d1ecb468ee080ce4e9182a98404d2d55483bff
|
| 3 |
+
size 5189264352
|
LMCocktail-10.7B-v1-Q3_K_L.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:474fed3c57841874113aef0146abadfd60c99cf4cf1a925c6c11db0c7d412e8d
|
| 3 |
+
size 5651686368
|
LMCocktail-10.7B-v1-Q3_K_M.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d1b515c11ae967ff5988d6403d1ecb468ee080ce4e9182a98404d2d55483bff
|
| 3 |
+
size 5189264352
|
LMCocktail-10.7B-v1-Q3_K_S.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2ea5bddfe4831a7bbd0e3763a2b18ef27333d074d4810ec0d85a2b93e823ef1f
|
| 3 |
+
size 4665500640
|
LMCocktail-10.7B-v1-Q4_0.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ad3e6ac133e210f422661cc4a6c51e528a5f156dd588770d00eec811144deb3
|
| 3 |
+
size 6073320416
|
LMCocktail-10.7B-v1-Q4_1.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f4c6d57be881e8e33c5d885a452c12695b76d961683ee19bc8e8431f011fc584
|
| 3 |
+
size 6735823840
|
LMCocktail-10.7B-v1-Q4_K.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7ee01b82909c660b69b6bd7ce437fd5cb471558aaeed8b3dc061bd5355242ac1
|
| 3 |
+
size 6462604256
|
LMCocktail-10.7B-v1-Q4_K_M.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7ee01b82909c660b69b6bd7ce437fd5cb471558aaeed8b3dc061bd5355242ac1
|
| 3 |
+
size 6462604256
|
LMCocktail-10.7B-v1-Q4_K_S.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:baeecfc95a51e3cd150c4a3acd925ddd6fa7eb17d6dec903219fdb989a633baa
|
| 3 |
+
size 6104777696
|
LMCocktail-10.7B-v1-Q5_0.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fa81bc151d54adc659b1d37c532ce45971ffad72994af36c15588eed1133dffe
|
| 3 |
+
size 7398327264
|
LMCocktail-10.7B-v1-Q5_1.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9ae11fd24ca2f6322d0c3ca14dcf576b544a307dba72ceb6b1de63aa497ce87e
|
| 3 |
+
size 8060830688
|
LMCocktail-10.7B-v1-Q5_K.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:996b88ab8db934027aeeea793d03cb341359f9239252b1126382c96034cbc5d0
|
| 3 |
+
size 7598867424
|
LMCocktail-10.7B-v1-Q5_K_M.gguf
ADDED
|
File without changes
|
LMCocktail-10.7B-v1-Q5_K_S.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:71cdf7756b60d208ac8503c5c8bcaf23399874e014fc6411ae86208c598fdb8c
|
| 3 |
+
size 1706242048
|
LMCocktail-10.7B-v1-Q6_K.gguf
ADDED
|
File without changes
|
LMCocktail-10.7B-v1-Q8_0.gguf
ADDED
|
File without changes
|
LMCocktail-10.7B-v1-f16.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:74b0ffd2f8edb4a4c3ef0f6d110506d958aff00df9f6645bbf5c5d2324a3c3da
|
| 3 |
+
size 21465523136
|
README.md
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama2
|
| 3 |
+
tags:
|
| 4 |
+
- GGUF
|
| 5 |
+
quantized_by: andrijdavid
|
| 6 |
+
---
|
| 7 |
+
# LMCocktail-10.7B-v1-GGUF
|
| 8 |
+
- Original model: [LMCocktail-10.7B-v1](https://huggingface.co/Yhyu13/LMCocktail-10.7B-v1)
|
| 9 |
+
|
| 10 |
+
<!-- description start -->
|
| 11 |
+
## Description
|
| 12 |
+
|
| 13 |
+
This repo contains GGUF format model files for [LMCocktail-10.7B-v1](https://huggingface.co/Yhyu13/LMCocktail-10.7B-v1).
|
| 14 |
+
|
| 15 |
+
<!-- description end -->
|
| 16 |
+
<!-- README_GGUF.md-about-gguf start -->
|
| 17 |
+
### About GGUF
|
| 18 |
+
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
|
| 19 |
+
Here is an incomplete list of clients and libraries that are known to support GGUF:
|
| 20 |
+
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
|
| 21 |
+
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
|
| 22 |
+
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
|
| 23 |
+
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
|
| 24 |
+
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
|
| 25 |
+
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
|
| 26 |
+
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
|
| 27 |
+
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
|
| 28 |
+
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
|
| 29 |
+
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
|
| 30 |
+
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
|
| 31 |
+
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
|
| 32 |
+
<!-- README_GGUF.md-about-gguf end -->
|
| 33 |
+
|
| 34 |
+
<!-- compatibility_gguf start -->
|
| 35 |
+
## Explanation of quantisation methods
|
| 36 |
+
<details>
|
| 37 |
+
<summary>Click to see details</summary>
|
| 38 |
+
The new methods available are:
|
| 39 |
+
|
| 40 |
+
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
|
| 41 |
+
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
|
| 42 |
+
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
|
| 43 |
+
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
|
| 44 |
+
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
|
| 45 |
+
</details>
|
| 46 |
+
<!-- compatibility_gguf end -->
|
| 47 |
+
|
| 48 |
+
<!-- README_GGUF.md-how-to-download start -->
|
| 49 |
+
## How to download GGUF files
|
| 50 |
+
|
| 51 |
+
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
|
| 52 |
+
|
| 53 |
+
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
|
| 54 |
+
|
| 55 |
+
* LM Studio
|
| 56 |
+
* LoLLMS Web UI
|
| 57 |
+
* Faraday.dev
|
| 58 |
+
|
| 59 |
+
### In `text-generation-webui`
|
| 60 |
+
|
| 61 |
+
Under Download Model, you can enter the model repo: andrijdavid/LMCocktail-10.7B-v1-GGUF and below it, a specific filename to download, such as: LMCocktail-10.7B-v1-f16.gguf.
|
| 62 |
+
|
| 63 |
+
Then click Download.
|
| 64 |
+
|
| 65 |
+
### On the command line, including multiple files at once
|
| 66 |
+
|
| 67 |
+
I recommend using the `huggingface-hub` Python library:
|
| 68 |
+
|
| 69 |
+
```shell
|
| 70 |
+
pip3 install huggingface-hub
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
Then you can download any individual model file to the current directory, at high speed, with a command like this:
|
| 74 |
+
|
| 75 |
+
```shell
|
| 76 |
+
huggingface-cli download andrijdavid/LMCocktail-10.7B-v1-GGUF LMCocktail-10.7B-v1-f16.gguf --local-dir . --local-dir-use-symlinks False
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
<details>
|
| 80 |
+
<summary>More advanced huggingface-cli download usage (click to read)</summary>
|
| 81 |
+
|
| 82 |
+
You can also download multiple files at once with a pattern:
|
| 83 |
+
|
| 84 |
+
```shell
|
| 85 |
+
huggingface-cli download andrijdavid/LMCocktail-10.7B-v1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
|
| 89 |
+
|
| 90 |
+
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
|
| 91 |
+
|
| 92 |
+
```shell
|
| 93 |
+
pip3 install hf_transfer
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
|
| 97 |
+
|
| 98 |
+
```shell
|
| 99 |
+
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download andrijdavid/LMCocktail-10.7B-v1-GGUF LMCocktail-10.7B-v1-f16.gguf --local-dir . --local-dir-use-symlinks False
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
|
| 103 |
+
</details>
|
| 104 |
+
<!-- README_GGUF.md-how-to-download end -->
|
| 105 |
+
<!-- README_GGUF.md-how-to-run start -->
|
| 106 |
+
## Example `llama.cpp` command
|
| 107 |
+
|
| 108 |
+
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
|
| 109 |
+
|
| 110 |
+
```shell
|
| 111 |
+
./main -ngl 35 -m LMCocktail-10.7B-v1-f16.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
|
| 115 |
+
|
| 116 |
+
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
|
| 117 |
+
|
| 118 |
+
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
|
| 119 |
+
|
| 120 |
+
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
|
| 121 |
+
|
| 122 |
+
## How to run in `text-generation-webui`
|
| 123 |
+
|
| 124 |
+
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
|
| 125 |
+
|
| 126 |
+
## How to run from Python code
|
| 127 |
+
|
| 128 |
+
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
|
| 129 |
+
|
| 130 |
+
### How to load this model in Python code, using llama-cpp-python
|
| 131 |
+
|
| 132 |
+
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
|
| 133 |
+
|
| 134 |
+
#### First install the package
|
| 135 |
+
|
| 136 |
+
Run one of the following commands, according to your system:
|
| 137 |
+
|
| 138 |
+
```shell
|
| 139 |
+
# Base ctransformers with no GPU acceleration
|
| 140 |
+
pip install llama-cpp-python
|
| 141 |
+
# With NVidia CUDA acceleration
|
| 142 |
+
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
|
| 143 |
+
# Or with OpenBLAS acceleration
|
| 144 |
+
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
|
| 145 |
+
# Or with CLBLast acceleration
|
| 146 |
+
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
|
| 147 |
+
# Or with AMD ROCm GPU acceleration (Linux only)
|
| 148 |
+
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
|
| 149 |
+
# Or with Metal GPU acceleration for macOS systems only
|
| 150 |
+
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
|
| 151 |
+
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
|
| 152 |
+
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
|
| 153 |
+
pip install llama-cpp-python
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
#### Simple llama-cpp-python example code
|
| 157 |
+
|
| 158 |
+
```python
|
| 159 |
+
from llama_cpp import Llama
|
| 160 |
+
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
|
| 161 |
+
llm = Llama(
|
| 162 |
+
model_path="./LMCocktail-10.7B-v1-f16.gguf", # Download the model file first
|
| 163 |
+
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
|
| 164 |
+
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
|
| 165 |
+
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
|
| 166 |
+
)
|
| 167 |
+
# Simple inference example
|
| 168 |
+
output = llm(
|
| 169 |
+
"<PROMPT>", # Prompt
|
| 170 |
+
max_tokens=512, # Generate up to 512 tokens
|
| 171 |
+
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
|
| 172 |
+
echo=True # Whether to echo the prompt
|
| 173 |
+
)
|
| 174 |
+
# Chat Completion API
|
| 175 |
+
llm = Llama(model_path="./LMCocktail-10.7B-v1-f16.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
|
| 176 |
+
llm.create_chat_completion(
|
| 177 |
+
messages = [
|
| 178 |
+
{"role": "system", "content": "You are a story writing assistant."},
|
| 179 |
+
{
|
| 180 |
+
"role": "user",
|
| 181 |
+
"content": "Write a story about llamas."
|
| 182 |
+
}
|
| 183 |
+
]
|
| 184 |
+
)
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
## How to use with LangChain
|
| 188 |
+
|
| 189 |
+
Here are guides on using llama-cpp-python and ctransformers with LangChain:
|
| 190 |
+
|
| 191 |
+
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
|
| 192 |
+
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
|
| 193 |
+
|
| 194 |
+
<!-- README_GGUF.md-how-to-run end -->
|
| 195 |
+
|
| 196 |
+
<!-- footer end -->
|
| 197 |
+
|
| 198 |
+
<!-- original-model-card start -->
|
| 199 |
+
# Original model card: LMCocktail-10.7B-v1
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
# LM-cocktail 10.7B v1
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
This is a 50%-50% model of the SOLAR model and meow.
|
| 206 |
+
|
| 207 |
+
https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0
|
| 208 |
+
|
| 209 |
+
https://huggingface.co/rishiraj/meow
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
who rank #1 and #2 among models <13B in the https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard by 2023/12/20.
|
| 213 |
+
|
| 214 |
+
# Alpaca Eval
|
| 215 |
+
|
| 216 |
+
I am thrilled to announce that ChatGPT has ranked LMCocktail 10.7B as the second best model next to GPT4 on AlpcaEval in my local community run. You can also check the leaderboard at [./alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/](./alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/)
|
| 217 |
+
|
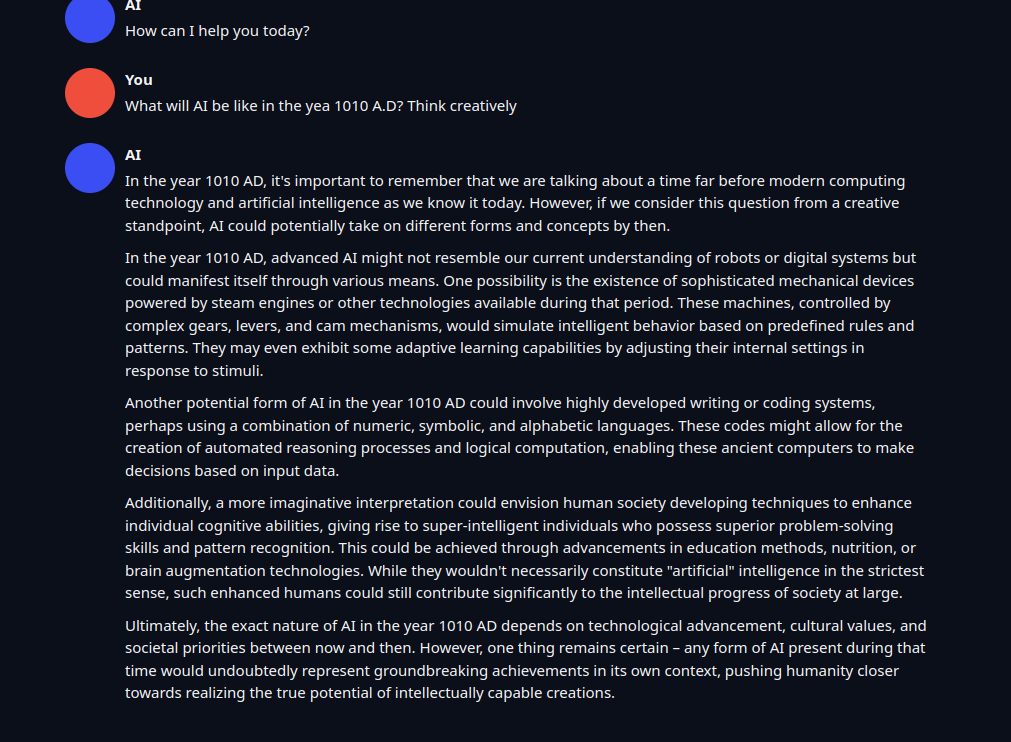
| 218 |
+
```
|
| 219 |
+
win_rate standard_error n_total avg_length
|
| 220 |
+
gpt4 73.79 1.54 805 1365
|
| 221 |
+
SOLAR-10.7B-LMCocktail(new)73.45 1.56 804 1203
|
| 222 |
+
claude 70.37 1.60 805 1082
|
| 223 |
+
chatgpt 66.09 1.66 805 811
|
| 224 |
+
wizardlm-13b 65.16 1.67 805 985
|
| 225 |
+
vicuna-13b 64.10 1.69 805 1037
|
| 226 |
+
guanaco-65b 62.36 1.71 805 1249
|
| 227 |
+
oasst-rlhf-llama-33b 62.05 1.71 805 1079
|
| 228 |
+
alpaca-farm-ppo-human 60.25 1.72 805 803
|
| 229 |
+
falcon-40b-instruct 56.52 1.74 805 662
|
| 230 |
+
text_davinci_003 50.00 0.00 805 307
|
| 231 |
+
alpaca-7b 45.22 1.74 805 396
|
| 232 |
+
text_davinci_001 28.07 1.56 805 296
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
# Code
|
| 237 |
+
|
| 238 |
+
The LM-cocktail is novel technique for merging multiple models https://arxiv.org/abs/2311.13534
|
| 239 |
+
|
| 240 |
+
Code is backed up by this repo https://github.com/FlagOpen/FlagEmbedding.git
|
| 241 |
+
|
| 242 |
+
Merging scripts available under the [./scripts](./scripts) folder
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
# Result
|
| 246 |
+
|
| 247 |
+
The SOLAR model is the first model <30B that can answer this question from my test:
|
| 248 |
+
|
| 249 |
+
```
|
| 250 |
+
What will AI be like in the year 1010 A.D?
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
without hullicinating into 1010 A.D is a future time (like other llama2 models)
|
| 254 |
+
|
| 255 |
+
Models greater than that, like Yi-34B could answer this paradoxic question correctly as well, since it is huge enough.
|
| 256 |
+
|
| 257 |
+
### SOLAR 10.7B output
|
| 258 |
+
|
| 259 |
+

|
| 260 |
+
|
| 261 |
+
### LMCocktail 10.7B output1
|
| 262 |
+
|
| 263 |
+

|
| 264 |
+
|
| 265 |
+
### LMCocktail 10.7B output2
|
| 266 |
+
|
| 267 |
+

|
| 268 |
+
|
| 269 |
+
<!-- original-model-card end -->
|
alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/alpaca_eval_log.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/annotation_chatgpt_fn.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/leaderboard.csv
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,win_rate,standard_error,n_wins,n_wins_base,n_draws,n_total,mode,avg_length
|
| 2 |
+
gpt4,73.7888198757764,1.5359801545073597,588,205,12,805,minimal,1365
|
| 3 |
+
SOLAR-10.7B-LMCocktail,73.44527363184079,1.5572150363643398,590,213,1,804,community,1203
|
| 4 |
+
claude,70.37267080745342,1.599519507147828,562,234,9,805,minimal,1082
|
| 5 |
+
chatgpt,66.08695652173913,1.6626479994330317,529,270,6,805,minimal,811
|
| 6 |
+
wizardlm-13b,65.15527950310559,1.670034107787565,520,276,9,805,minimal,985
|
| 7 |
+
vicuna-13b,64.09937888198758,1.6895185863153146,515,288,2,805,minimal,1037
|
| 8 |
+
guanaco-65b,62.36024844720497,1.7086348811605765,502,303,0,805,minimal,1249
|
| 9 |
+
oasst-rlhf-llama-33b,62.0496894409938,1.7080028976103514,498,304,3,805,minimal,1079
|
| 10 |
+
alpaca-farm-ppo-human,60.24844720496895,1.7169496733548772,481,316,8,805,minimal,803
|
| 11 |
+
falcon-40b-instruct,56.52173913043478,1.7438750520312944,453,348,4,805,minimal,662
|
| 12 |
+
phi-2-alpaca-gpt4-dpo,55.59701492537313,1.7533719245384989,447,357,0,804,community,4532
|
| 13 |
+
text_davinci_003,50.0,0.0,0,0,805,805,minimal,307
|
| 14 |
+
alpaca-7b,45.21739130434783,1.7375846781579476,356,433,16,805,minimal,396
|
| 15 |
+
text_davinci_001,28.07453416149068,1.5602183426587484,216,569,20,805,minimal,296
|
alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/model_outputs.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
alpaca_eval/chatgpt_fn_--SOLAR-10-7B-LMCocktail/reference_outputs.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
assets/SOLAR.png
ADDED

|
assets/SOLAR_mixed.png
ADDED
|
assets/SOLAR_mixed2.png
ADDED

|
config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "./mixed_llm",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlamaForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_bias": false,
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"bos_token_id": 1,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"hidden_act": "silu",
|
| 11 |
+
"hidden_size": 4096,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 14336,
|
| 14 |
+
"max_position_embeddings": 4096,
|
| 15 |
+
"model_type": "llama",
|
| 16 |
+
"num_attention_heads": 32,
|
| 17 |
+
"num_hidden_layers": 48,
|
| 18 |
+
"num_key_value_heads": 8,
|
| 19 |
+
"pad_token_id": 2,
|
| 20 |
+
"pretraining_tp": 1,
|
| 21 |
+
"rms_norm_eps": 1e-05,
|
| 22 |
+
"rope_scaling": null,
|
| 23 |
+
"rope_theta": 10000.0,
|
| 24 |
+
"tie_word_embeddings": false,
|
| 25 |
+
"torch_dtype": "float16",
|
| 26 |
+
"transformers_version": "4.36.2",
|
| 27 |
+
"use_cache": true,
|
| 28 |
+
"vocab_size": 32000
|
| 29 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 2,
|
| 6 |
+
"transformers_version": "4.36.2",
|
| 7 |
+
"use_cache": false
|
| 8 |
+
}
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,442 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 21463048192
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00005-of-00005.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00005.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 242 |
+
"model.layers.32.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 243 |
+
"model.layers.32.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 244 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 245 |
+
"model.layers.32.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 246 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 247 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 248 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 249 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 250 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 251 |
+
"model.layers.33.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 252 |
+
"model.layers.33.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 253 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 254 |
+
"model.layers.33.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 255 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 256 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 257 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 258 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 259 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 260 |
+
"model.layers.34.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 261 |
+
"model.layers.34.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 262 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 263 |
+
"model.layers.34.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 264 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 265 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 266 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 267 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 268 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 269 |
+
"model.layers.35.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 270 |
+
"model.layers.35.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 271 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 272 |
+
"model.layers.35.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 273 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 274 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 275 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 276 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 277 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 278 |
+
"model.layers.36.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 279 |
+
"model.layers.36.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 280 |
+
"model.layers.36.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 281 |
+
"model.layers.36.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 282 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 283 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 284 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 285 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 286 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 287 |
+
"model.layers.37.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 288 |
+
"model.layers.37.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 289 |
+
"model.layers.37.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 290 |
+
"model.layers.37.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 291 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 292 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 293 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 294 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 295 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 296 |
+
"model.layers.38.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 297 |
+
"model.layers.38.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 298 |
+
"model.layers.38.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 299 |
+
"model.layers.38.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 300 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 301 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 302 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 303 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 304 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 305 |
+
"model.layers.39.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 306 |
+
"model.layers.39.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 307 |
+
"model.layers.39.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 308 |
+
"model.layers.39.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 309 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 310 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 311 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 312 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 313 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 314 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 315 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 316 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 317 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 318 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 319 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 320 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 321 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 322 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 323 |
+
"model.layers.40.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 324 |
+
"model.layers.40.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 325 |
+
"model.layers.40.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 326 |
+
"model.layers.40.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 327 |
+
"model.layers.40.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 328 |
+
"model.layers.40.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 329 |
+
"model.layers.40.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 330 |
+
"model.layers.40.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 331 |
+
"model.layers.40.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 332 |
+
"model.layers.41.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 333 |
+
"model.layers.41.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 334 |
+
"model.layers.41.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 335 |
+
"model.layers.41.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 336 |
+
"model.layers.41.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 337 |
+
"model.layers.41.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 338 |
+
"model.layers.41.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 339 |
+
"model.layers.41.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 340 |
+
"model.layers.41.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 341 |
+
"model.layers.42.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 342 |
+
"model.layers.42.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 343 |
+
"model.layers.42.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 344 |
+
"model.layers.42.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 345 |
+
"model.layers.42.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 346 |
+
"model.layers.42.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 347 |
+
"model.layers.42.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 348 |
+
"model.layers.42.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 349 |
+
"model.layers.42.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 350 |
+
"model.layers.43.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 351 |
+
"model.layers.43.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 352 |
+
"model.layers.43.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 353 |
+
"model.layers.43.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 354 |
+
"model.layers.43.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 355 |
+
"model.layers.43.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 356 |
+
"model.layers.43.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 357 |
+
"model.layers.43.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 358 |
+
"model.layers.43.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 359 |
+
"model.layers.44.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 360 |
+
"model.layers.44.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
| 361 |
+
"model.layers.44.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 362 |
+
"model.layers.44.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 363 |
+
"model.layers.44.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 364 |
+
"model.layers.44.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 365 |
+
"model.layers.44.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 366 |
+
"model.layers.44.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 367 |
+
"model.layers.44.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 368 |
+
"model.layers.45.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 369 |
+
"model.layers.45.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
| 370 |
+
"model.layers.45.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
| 371 |
+
"model.layers.45.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
| 372 |
+
"model.layers.45.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 373 |
+
"model.layers.45.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
| 374 |
+
"model.layers.45.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
| 375 |
+
"model.layers.45.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
| 376 |
+
"model.layers.45.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
| 377 |
+
"model.layers.46.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 378 |
+
"model.layers.46.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
| 379 |
+
"model.layers.46.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
| 380 |
+
"model.layers.46.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
| 381 |
+
"model.layers.46.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 382 |
+
"model.layers.46.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
| 383 |
+
"model.layers.46.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
| 384 |
+
"model.layers.46.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
| 385 |
+
"model.layers.46.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
| 386 |
+
"model.layers.47.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 387 |
+
"model.layers.47.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
| 388 |
+
"model.layers.47.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
| 389 |
+
"model.layers.47.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
| 390 |
+
"model.layers.47.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 391 |
+
"model.layers.47.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
| 392 |
+
"model.layers.47.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
| 393 |
+
"model.layers.47.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
| 394 |
+
"model.layers.47.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
| 395 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 396 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 397 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 398 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 399 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 400 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 401 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 402 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 403 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 404 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 405 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 406 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 407 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 408 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 409 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 410 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 411 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 412 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 413 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 414 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 415 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 416 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 417 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 418 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 419 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 420 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 421 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 422 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 423 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 424 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 425 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 426 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 427 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 428 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 429 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 430 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 431 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 432 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 433 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 434 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 435 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 436 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 437 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 438 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 439 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 440 |
+
"model.norm.weight": "model-00005-of-00005.safetensors"
|
| 441 |
+
}
|
| 442 |
+
}
|
sciprts/convert.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoModelForCausalLM
|
| 2 |
+
import torch
|
| 3 |
+
import torch.utils.dlpack
|
| 4 |
+
|
| 5 |
+
# Load the original model
|
| 6 |
+
model_name = "./mixed_llm"
|
| 7 |
+
model = AutoModelForCausalLM.from_pretrained(model_name)
|
| 8 |
+
|
| 9 |
+
# Convert the model to a different precision
|
| 10 |
+
model = model.half()
|
| 11 |
+
|
| 12 |
+
# Save the model as a safetensor
|
| 13 |
+
model.save_pretrained(f"./mixed_llm_half", safetensors=True)
|
sciprts/merge.log
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
sciprts/merge.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from LM_Cocktail import mix_models_by_layers
|
| 2 |
+
import argparse
|
| 3 |
+
|
| 4 |
+
if __name__ == "__main__":
|
| 5 |
+
|
| 6 |
+
parser = argparse.ArgumentParser()
|
| 7 |
+
parser.add_argument("--model_type", type=str, default="decoder", help="Type of model to be mixed")
|
| 8 |
+
parser.add_argument("--output_path", type=str, default="./mixed_llm", help="Path to save the mixed model")
|
| 9 |
+
parser.add_argument("--max_length", type=int, default=100, help="Maximum length of the sequence to be generated")
|
| 10 |
+
parser.add_argument("--models", type=str, nargs='+', default=["meta-llama/Llama-2-7b-chat-hf", "Shitao/llama2-ag-news"], help="Path to the models to be mixed")
|
| 11 |
+
parser.add_argument("--weights", type=float, nargs='+', default=[0.7, 0.3], help="Weights of the models to be mixed")
|
| 12 |
+
parser.add_argument("--save_precision", type=str, default='float32', help="mixed model saved format")
|
| 13 |
+
args = parser.parse_args()
|
| 14 |
+
|
| 15 |
+
# Mix Large Language Models (LLMs) and save the combined model to the path: ./mixed_llm
|
| 16 |
+
model = mix_models_by_layers(
|
| 17 |
+
model_names_or_paths=args.models,
|
| 18 |
+
model_type=args.model_type,
|
| 19 |
+
weights=args.weights,
|
| 20 |
+
output_path=args.output_path)
|
| 21 |
+
|
| 22 |
+
print(model)
|
sciprts/merge.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
eval "$(conda shell.bash hook)"
|
| 3 |
+
conda activate llmcocktail
|
| 4 |
+
|
| 5 |
+
CUDA_VISIBLE_DEVICES=1 python merge.py \
|
| 6 |
+
--models /media/hangyu5/Home/Documents/Hugging-Face/LM_cocktail/meow /media/hangyu5/Home/Documents/Hugging-Face/LM_cocktail/SOLAR-10.7B-Instruct-v1.0 \
|
| 7 |
+
--weights 0.5 0.5 \
|
| 8 |
+
|& tee ./merge.log
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "</s>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"additional_special_tokens": [],
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"chat_template": "{% for message in messages %}{% if message['role'] == 'system' %}{% if message['content']%}{{'### System:\n' + message['content']+'\n\n'}}{% endif %}{% elif message['role'] == 'user' %}{{'### User:\n' + message['content']+'\n\n'}}{% elif message['role'] == 'assistant' %}{{'### Assistant:\n' + message['content']}}{% endif %}{% if loop.last and add_generation_prompt %}{{ '### Assistant:\n' }}{% endif %}{% endfor %}",
|
| 33 |
+
"clean_up_tokenization_spaces": false,
|
| 34 |
+
"eos_token": "</s>",
|
| 35 |
+
"legacy": true,
|
| 36 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 37 |
+
"pad_token": "</s>",
|
| 38 |
+
"sp_model_kwargs": {},
|
| 39 |
+
"spaces_between_special_tokens": false,
|
| 40 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 41 |
+
"unk_token": "<unk>",
|
| 42 |
+
"use_default_system_prompt": true
|
| 43 |
+
}
|