Hugging Face Machine Learning Demos on arXiv



We’re very excited to announce that Hugging Face has collaborated with arXiv to make papers more accessible, discoverable, and fun! Starting today, Hugging Face Spaces is integrated with arXivLabs through a Demo tab that includes links to demos created by the community or the authors themselves. By going to the Demos tab of your favorite paper, you can find links to open-source demos and try them out immediately 🔥
Since its launch in October 2021, Hugging Face Spaces has been used to build and share over 12,000 open-source machine learning demos crafted by the community. With Spaces, Hugging Face users can share, explore, discuss models, and build interactive applications that enable anyone with a browser to try them out without having to run any code. These demos are built using open-source tools such as the Gradio and Streamlit Python libraries, and leverage models and datasets available on the Hugging Face Hub.
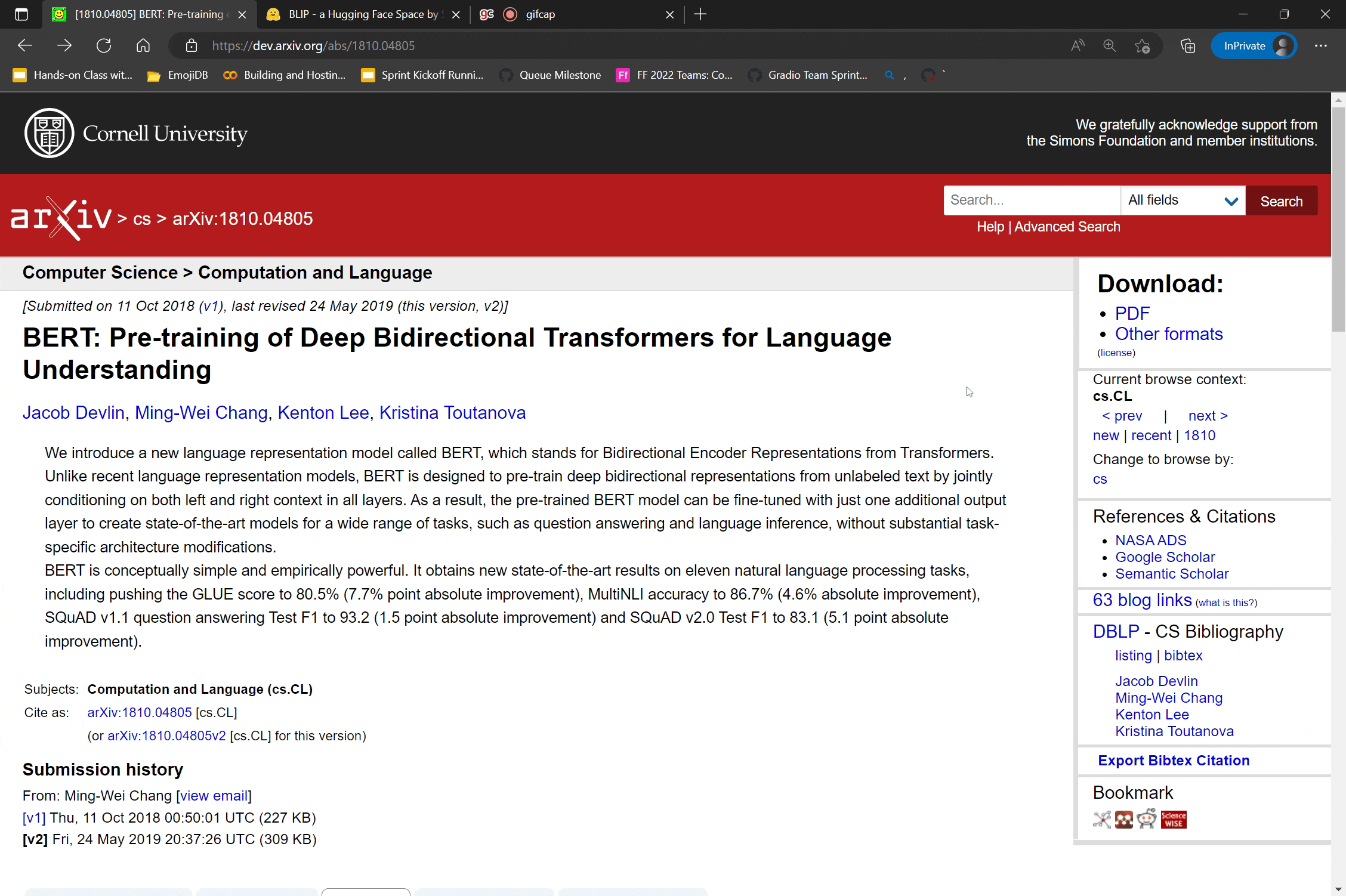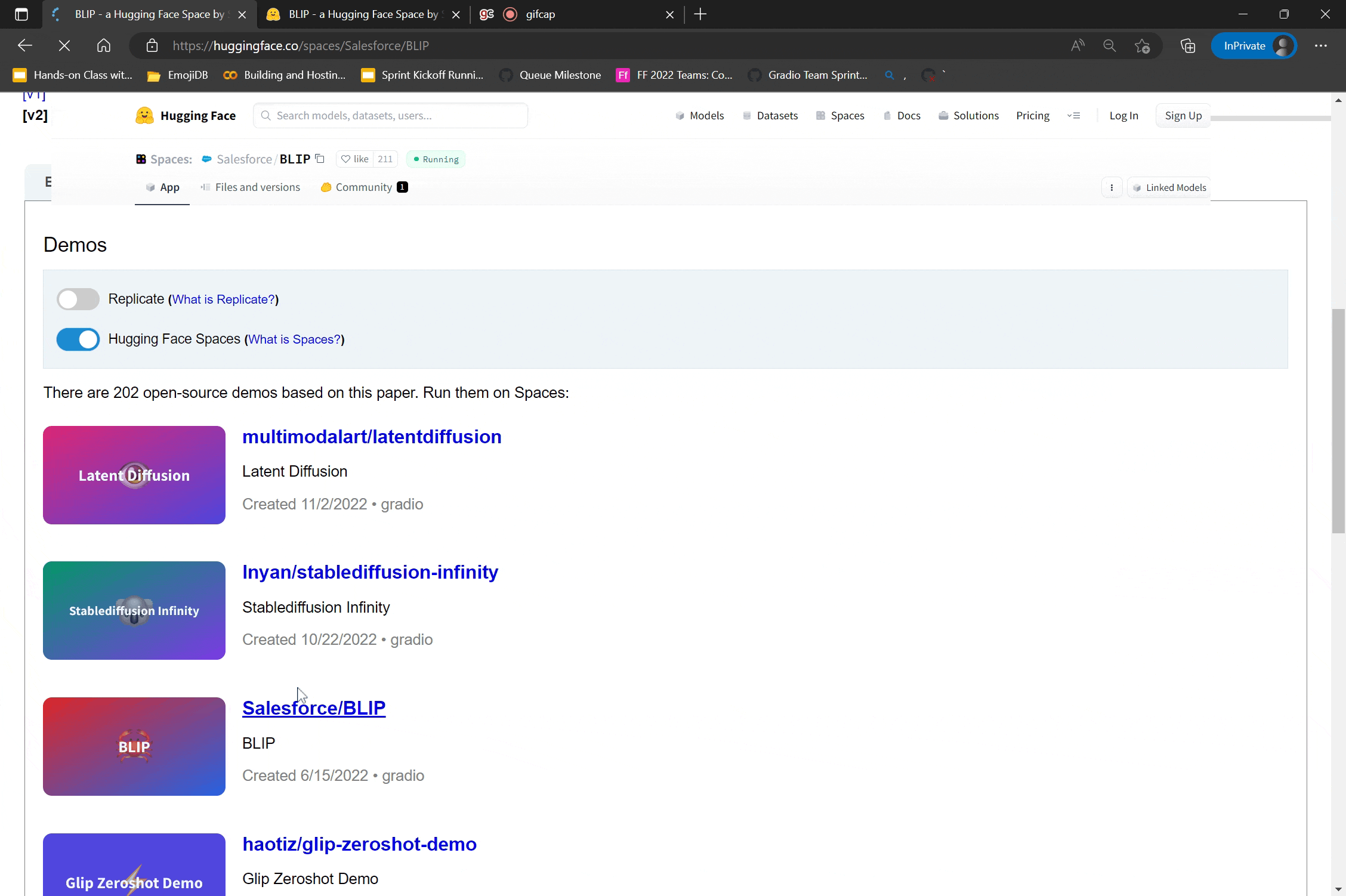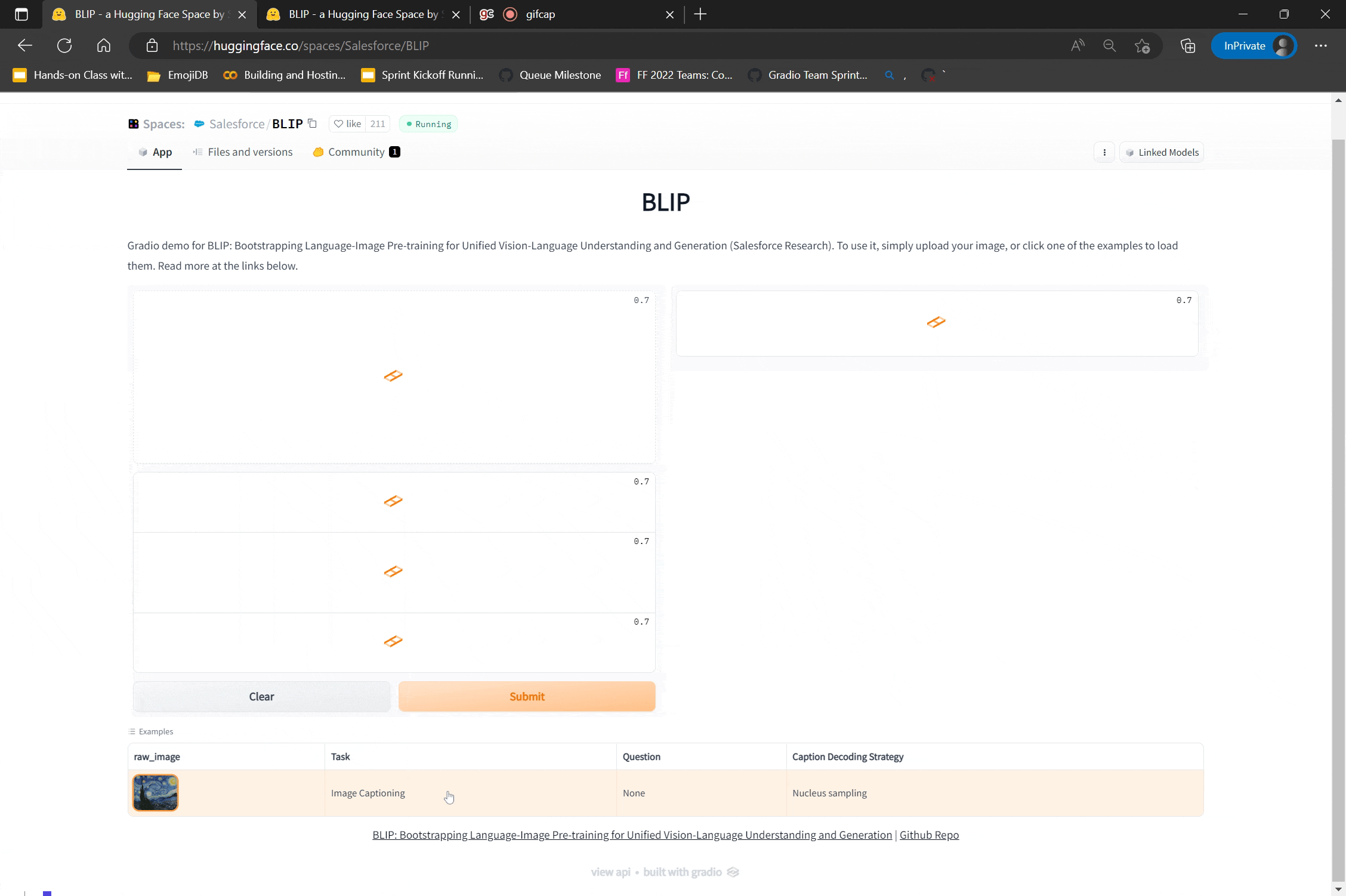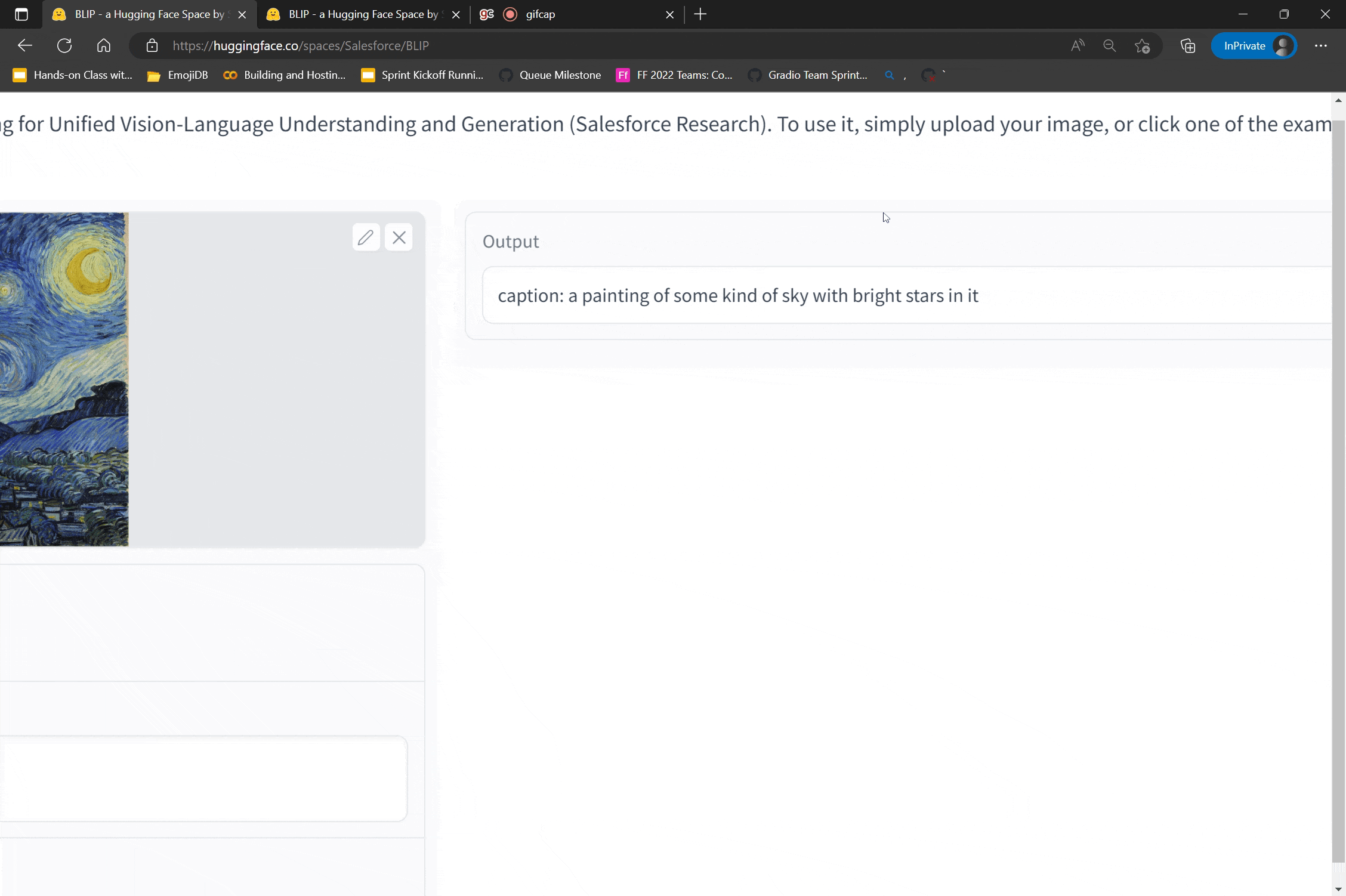
Thanks to the latest arXiv integration, users can now find the most popular demos for a paper on its arXiv abstract page. For example, if you want to try out demos of the BERT language model, you can go to the BERT paper’s arXiv page, and navigate to the demo tab. You will see more than 200 demos built by the open-source community -- some demos simply showcase the BERT model, while others showcase related applications that modify or use BERT as part of larger pipelines, such as the demo shown above.
Demos allow a much wider audience to explore machine learning as well as other fields in which computational models are built, such as biology, chemistry, astronomy, and economics. They help increase the awareness and understanding of how models work, amplify the visibility of researchers' work, and allow a more diverse audience to identify and debug biases and other issues. The demos increase the reproducibility of research by enabling others to explore the paper's results without having to write a single line of code! We are thrilled about this integration with arXiv and can’t wait to see how the research community will use it to improve communication, dissemination and interpretability.

