

Commit
•
2959fde
1
Parent(s):
ecfc0d8
Copying answerdotai/answerai-colbert-small-v1 for demo purposes
Browse files- README.md +188 -3
- artifact.metadata +75 -0
- config.json +31 -0
- model.safetensors +3 -0
- onnx/model.onnx +3 -0
- onnx/model_bnb4.onnx +3 -0
- onnx/model_fp16.onnx +3 -0
- onnx/model_int8.onnx +3 -0
- onnx/model_q4.onnx +3 -0
- onnx/model_q4f16.onnx +3 -0
- onnx/model_quantized.onnx +3 -0
- onnx/model_uint8.onnx +3 -0
- special_tokens_map.json +37 -0
- tokenizer.json +0 -0
- tokenizer_config.json +57 -0
- vespa_colbert.onnx +3 -0
- vocab.txt +0 -0
README.md
CHANGED
|
@@ -1,3 +1,188 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
tags:
|
| 6 |
+
- ColBERT
|
| 7 |
+
- RAGatouille
|
| 8 |
+
- passage-retrieval
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# answerai-colbert-small-v1
|
| 12 |
+
|
| 13 |
+
**answerai-colbert-small-v1** is a new, proof-of-concept model by [Answer.AI](https://answer.ai), showing the strong performance multi-vector models with the new [JaColBERTv2.5 training recipe](https://arxiv.org/abs/2407.20750) and some extra tweaks can reach, even with just **33 million parameters**.
|
| 14 |
+
|
| 15 |
+
While being MiniLM-sized, it outperforms all previous similarly-sized models on common benchmarks, and even outperforms much larger popular models such as e5-large-v2 or bge-base-en-v1.5.
|
| 16 |
+
|
| 17 |
+
For more information about this model or how it was trained, head over to the [announcement blogpost](https://www.answer.ai/posts/2024-08-13-small-but-mighty-colbert.html).
|
| 18 |
+
|
| 19 |
+
## Architecture
|
| 20 |
+
|
| 21 |
+
<iframe
|
| 22 |
+
src="https://brianronan-netron-docker.hf.space?repo_id=brianronan/answerai-colbert-small&filename=model.safetensors"
|
| 23 |
+
style="width: 95%; height: 70vh; border: none;"
|
| 24 |
+
></iframe>
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
## Usage
|
| 28 |
+
|
| 29 |
+
### Installation
|
| 30 |
+
|
| 31 |
+
This model was designed with the upcoming RAGatouille overhaul in mind. However, it's compatible with all recent ColBERT implementations!
|
| 32 |
+
|
| 33 |
+
To use it, you can either use the Stanford ColBERT library, or RAGatouille. You can install both or either by simply running.
|
| 34 |
+
|
| 35 |
+
```sh
|
| 36 |
+
pip install --upgrade ragatouille
|
| 37 |
+
pip install --upgrade colbert-ai
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
If you're interested in using this model as a re-ranker (it vastly outperforms cross-encoders its size!), you can do so via the [rerankers](https://github.com/AnswerDotAI/rerankers) library:
|
| 41 |
+
```sh
|
| 42 |
+
pip install --upgrade rerankers[transformers]
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
### Rerankers
|
| 46 |
+
|
| 47 |
+
```python
|
| 48 |
+
from rerankers import Reranker
|
| 49 |
+
|
| 50 |
+
ranker = Reranker("answerdotai/answerai-colbert-small-v1", model_type='colbert')
|
| 51 |
+
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...]
|
| 52 |
+
query = 'Who directed spirited away?'
|
| 53 |
+
ranker.rank(query=query, docs=docs)
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
### RAGatouille
|
| 57 |
+
|
| 58 |
+
```python
|
| 59 |
+
from ragatouille import RAGPretrainedModel
|
| 60 |
+
|
| 61 |
+
RAG = RAGPretrainedModel.from_pretrained("answerdotai/answerai-colbert-small-v1")
|
| 62 |
+
|
| 63 |
+
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...]
|
| 64 |
+
|
| 65 |
+
RAG.index(documents, index_name="ghibli")
|
| 66 |
+
|
| 67 |
+
query = 'Who directed spirited away?'
|
| 68 |
+
results = RAG.search(query)
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
### Stanford ColBERT
|
| 72 |
+
|
| 73 |
+
#### Indexing
|
| 74 |
+
|
| 75 |
+
```python
|
| 76 |
+
from colbert import Indexer
|
| 77 |
+
from colbert.infra import Run, RunConfig, ColBERTConfig
|
| 78 |
+
|
| 79 |
+
INDEX_NAME = "DEFINE_HERE"
|
| 80 |
+
|
| 81 |
+
if __name__ == "__main__":
|
| 82 |
+
config = ColBERTConfig(
|
| 83 |
+
doc_maxlen=512,
|
| 84 |
+
nbits=2
|
| 85 |
+
)
|
| 86 |
+
indexer = Indexer(
|
| 87 |
+
checkpoint="answerdotai/answerai-colbert-small-v1",
|
| 88 |
+
config=config,
|
| 89 |
+
)
|
| 90 |
+
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...]
|
| 91 |
+
|
| 92 |
+
indexer.index(name=INDEX_NAME, collection=docs)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
#### Querying
|
| 96 |
+
|
| 97 |
+
```python
|
| 98 |
+
from colbert import Searcher
|
| 99 |
+
from colbert.infra import Run, RunConfig, ColBERTConfig
|
| 100 |
+
|
| 101 |
+
INDEX_NAME = "THE_INDEX_YOU_CREATED"
|
| 102 |
+
k = 10
|
| 103 |
+
|
| 104 |
+
if __name__ == "__main__":
|
| 105 |
+
config = ColBERTConfig(
|
| 106 |
+
query_maxlen=32 # Adjust as needed, we recommend the nearest higher multiple of 16 to your query
|
| 107 |
+
)
|
| 108 |
+
searcher = Searcher(
|
| 109 |
+
index=index_name,
|
| 110 |
+
config=config
|
| 111 |
+
)
|
| 112 |
+
query = 'Who directed spirited away?'
|
| 113 |
+
results = searcher.search(query, k=k)
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
#### Extracting Vectors
|
| 118 |
+
|
| 119 |
+
Finally, if you want to extract individula vectors, you can use the model this way:
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
```python
|
| 123 |
+
from colbert.modeling.checkpoint import Checkpoint
|
| 124 |
+
|
| 125 |
+
ckpt = Checkpoint("answerdotai/answerai-colbert-small-v1", colbert_config=ColBERTConfig())
|
| 126 |
+
embedded_query = ckpt.queryFromText(["Who dubs Howl's in English?"], bsize=16)
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
## Results
|
| 131 |
+
|
| 132 |
+
### Against single-vector models
|
| 133 |
+
|
| 134 |
+
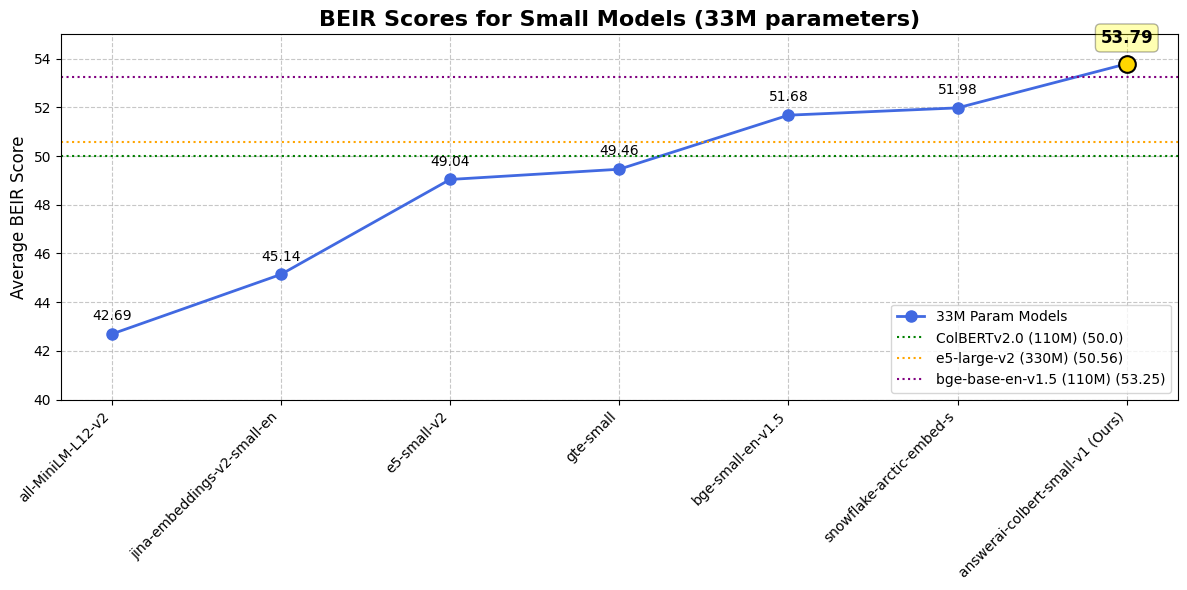
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
| Dataset / Model | answer-colbert-s | snowflake-s | bge-small-en | bge-base-en |
|
| 138 |
+
|:-----------------|:-----------------:|:-------------:|:-------------:|:-------------:|
|
| 139 |
+
| **Size** | 33M (1x) | 33M (1x) | 33M (1x) | **109M (3.3x)** |
|
| 140 |
+
| **BEIR AVG** | **53.79** | 51.99 | 51.68 | 53.25 |
|
| 141 |
+
| **FiQA2018** | **41.15** | 40.65 | 40.34 | 40.65 |
|
| 142 |
+
| **HotpotQA** | **76.11** | 66.54 | 69.94 | 72.6 |
|
| 143 |
+
| **MSMARCO** | **43.5** | 40.23 | 40.83 | 41.35 |
|
| 144 |
+
| **NQ** | **59.1** | 50.9 | 50.18 | 54.15 |
|
| 145 |
+
| **TRECCOVID** | **84.59** | 80.12 | 75.9 | 78.07 |
|
| 146 |
+
| **ArguAna** | 50.09 | 57.59 | 59.55 | **63.61** |
|
| 147 |
+
| **ClimateFEVER**| 33.07 | **35.2** | 31.84 | 31.17 |
|
| 148 |
+
| **CQADupstackRetrieval** | 38.75 | 39.65 | 39.05 | **42.35** |
|
| 149 |
+
| **DBPedia** | **45.58** | 41.02 | 40.03 | 40.77 |
|
| 150 |
+
| **FEVER** | **90.96** | 87.13 | 86.64 | 86.29 |
|
| 151 |
+
| **NFCorpus** | 37.3 | 34.92 | 34.3 | **37.39** |
|
| 152 |
+
| **QuoraRetrieval** | 87.72 | 88.41 | 88.78 | **88.9** |
|
| 153 |
+
| **SCIDOCS** | 18.42 | **21.82** | 20.52 | 21.73 |
|
| 154 |
+
| **SciFact** | **74.77** | 72.22 | 71.28 | 74.04 |
|
| 155 |
+
| **Touche2020** | 25.69 | 23.48 | **26.04** | 25.7 |
|
| 156 |
+
|
| 157 |
+
### Against ColBERTv2.0
|
| 158 |
+
|
| 159 |
+
| Dataset / Model | answerai-colbert-small-v1 | ColBERTv2.0 |
|
| 160 |
+
|:-----------------|:-----------------------:|:------------:|
|
| 161 |
+
| **BEIR AVG** | **53.79** | 50.02 |
|
| 162 |
+
| **DBPedia** | **45.58** | 44.6 |
|
| 163 |
+
| **FiQA2018** | **41.15** | 35.6 |
|
| 164 |
+
| **NQ** | **59.1** | 56.2 |
|
| 165 |
+
| **HotpotQA** | **76.11** | 66.7 |
|
| 166 |
+
| **NFCorpus** | **37.3** | 33.8 |
|
| 167 |
+
| **TRECCOVID** | **84.59** | 73.3 |
|
| 168 |
+
| **Touche2020** | 25.69 | **26.3** |
|
| 169 |
+
| **ArguAna** | **50.09** | 46.3 |
|
| 170 |
+
| **ClimateFEVER**| **33.07** | 17.6 |
|
| 171 |
+
| **FEVER** | **90.96** | 78.5 |
|
| 172 |
+
| **QuoraRetrieval** | **87.72** | 85.2 |
|
| 173 |
+
| **SCIDOCS** | **18.42** | 15.4 |
|
| 174 |
+
| **SciFact** | **74.77** | 69.3 |
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
## Referencing
|
| 178 |
+
|
| 179 |
+
We'll most likely eventually release a technical report. In the meantime, if you use this model or other models following the JaColBERTv2.5 recipe and would like to give us credit, please cite the JaColBERTv2.5 journal pre-print:
|
| 180 |
+
|
| 181 |
+
```
|
| 182 |
+
@article{clavie2024jacolbertv2,
|
| 183 |
+
title={JaColBERTv2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources},
|
| 184 |
+
author={Clavi{\'e}, Benjamin},
|
| 185 |
+
journal={arXiv preprint arXiv:2407.20750},
|
| 186 |
+
year={2024}
|
| 187 |
+
}
|
| 188 |
+
```
|
artifact.metadata
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"query_token_id": "[unused0]",
|
| 3 |
+
"doc_token_id": "[unused1]",
|
| 4 |
+
"query_token": "[Q]",
|
| 5 |
+
"doc_token": "[D]",
|
| 6 |
+
"ncells": null,
|
| 7 |
+
"centroid_score_threshold": null,
|
| 8 |
+
"ndocs": null,
|
| 9 |
+
"load_index_with_mmap": false,
|
| 10 |
+
"index_path": null,
|
| 11 |
+
"index_bsize": 64,
|
| 12 |
+
"nbits": 1,
|
| 13 |
+
"kmeans_niters": 4,
|
| 14 |
+
"resume": false,
|
| 15 |
+
"pool_factor": 1,
|
| 16 |
+
"clustering_mode": "hierarchical",
|
| 17 |
+
"protected_tokens": 0,
|
| 18 |
+
"similarity": "cosine",
|
| 19 |
+
"bsize": 32,
|
| 20 |
+
"accumsteps": 1,
|
| 21 |
+
"lr": 1e-5,
|
| 22 |
+
"maxsteps": 15626,
|
| 23 |
+
"save_every": null,
|
| 24 |
+
"warmup": 781,
|
| 25 |
+
"warmup_bert": null,
|
| 26 |
+
"relu": false,
|
| 27 |
+
"nway": 32,
|
| 28 |
+
"use_ib_negatives": false,
|
| 29 |
+
"reranker": false,
|
| 30 |
+
"distillation_alpha": 1.0,
|
| 31 |
+
"ignore_scores": false,
|
| 32 |
+
"model_name": "answerdotai/AnswerAI-ColBERTv2.5-small",
|
| 33 |
+
"schedule_free": false,
|
| 34 |
+
"schedule_free_wd": 0.0,
|
| 35 |
+
"kldiv_loss": true,
|
| 36 |
+
"marginmse_loss": false,
|
| 37 |
+
"kldiv_weight": 1.0,
|
| 38 |
+
"marginmse_weight": 0.05,
|
| 39 |
+
"ib_loss_weight": 1.0,
|
| 40 |
+
"normalise_training_scores": true,
|
| 41 |
+
"normalization_method": "minmax",
|
| 42 |
+
"quant_aware": false,
|
| 43 |
+
"highest_quant_level": 8,
|
| 44 |
+
"lowest_quant_level": 2,
|
| 45 |
+
"query_maxlen": 32,
|
| 46 |
+
"attend_to_mask_tokens": false,
|
| 47 |
+
"interaction": "colbert",
|
| 48 |
+
"cap_padding": 0,
|
| 49 |
+
"dynamic_query_maxlen": false,
|
| 50 |
+
"dynamic_querylen_multiples": 32,
|
| 51 |
+
"dim": 96,
|
| 52 |
+
"doc_maxlen": 300,
|
| 53 |
+
"mask_punctuation": true,
|
| 54 |
+
"checkpoint": "answerdotai/AnswerAI-ColBERTv2.5-small",
|
| 55 |
+
"triples": "\/home\/bclavie\/colbertv2.5_en\/data\/msmarco\/triplets.jsonl",
|
| 56 |
+
"collection": "\/home\/bclavie\/colbertv2.5_en\/data\/msmarco\/collection.tsv",
|
| 57 |
+
"queries": "\/home\/bclavie\/colbertv2.5_en\/data\/msmarco\/queries.tsv",
|
| 58 |
+
"index_name": null,
|
| 59 |
+
"overwrite": false,
|
| 60 |
+
"root": "\/home\/bclavie\/colbertv2.5_en\/experiments",
|
| 61 |
+
"experiment": "minicolbertv2.5",
|
| 62 |
+
"index_root": null,
|
| 63 |
+
"name": "2024-08\/07\/08.16.20",
|
| 64 |
+
"rank": 0,
|
| 65 |
+
"nranks": 4,
|
| 66 |
+
"amp": true,
|
| 67 |
+
"gpus": 4,
|
| 68 |
+
"avoid_fork_if_possible": false,
|
| 69 |
+
"meta": {
|
| 70 |
+
"hostname": "a100-80-4x",
|
| 71 |
+
"current_datetime": "Aug 07, 2024 ; 12:13PM UTC (+0000)",
|
| 72 |
+
"cmd": "train_v2.5_mini.py",
|
| 73 |
+
"version": "colbert-v0.4"
|
| 74 |
+
}
|
| 75 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "bclavie/mini-base",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"HF_ColBERT"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_dropout_prob": 0.1,
|
| 10 |
+
"hidden_size": 384,
|
| 11 |
+
"id2label": {
|
| 12 |
+
"0": "LABEL_0"
|
| 13 |
+
},
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"intermediate_size": 1536,
|
| 16 |
+
"label2id": {
|
| 17 |
+
"LABEL_0": 0
|
| 18 |
+
},
|
| 19 |
+
"layer_norm_eps": 1e-12,
|
| 20 |
+
"max_position_embeddings": 512,
|
| 21 |
+
"model_type": "bert",
|
| 22 |
+
"num_attention_heads": 12,
|
| 23 |
+
"num_hidden_layers": 12,
|
| 24 |
+
"pad_token_id": 0,
|
| 25 |
+
"position_embedding_type": "absolute",
|
| 26 |
+
"torch_dtype": "float32",
|
| 27 |
+
"transformers_version": "4.42.4",
|
| 28 |
+
"type_vocab_size": 2,
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"vocab_size": 30522
|
| 31 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:35bb6ef696cc88b3d18b7520273dfd25315f6c47d265142ba13bba38678c92b6
|
| 3 |
+
size 133610664
|
onnx/model.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b078342c7af055851eb25e599c7e362674e266aa52fe2d87d7bd325d3e3420e0
|
| 3 |
+
size 133159107
|
onnx/model_bnb4.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9b664122c834ea2dfabb3fdc961b7f59ccd51c8bf9d051300cf1e3deb8a8e146
|
| 3 |
+
size 60179566
|
onnx/model_fp16.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2165cdb0057d0812db7c7b248286c4d9a22b292c7beb88282d63a2241a9fac5f
|
| 3 |
+
size 66734665
|
onnx/model_int8.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:250889c5550969a1f0aaf6f9dcc01db39044fe3998fa9c95ef731af23f737b7b
|
| 3 |
+
size 34000578
|
onnx/model_q4.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e8a2fcc60df4d32698aae409fce597b49e46938ef1e79e7489497e3dd4c9620
|
| 3 |
+
size 61506214
|
onnx/model_q4f16.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a5286e7efbc215bac95dfb42f8c46054ed8d73828dfe69dc59bd0529c82c51d2
|
| 3 |
+
size 36221948
|
onnx/model_quantized.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:250889c5550969a1f0aaf6f9dcc01db39044fe3998fa9c95ef731af23f737b7b
|
| 3 |
+
size 34000578
|
onnx/model_uint8.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb1967fe95a4e180b4be4174d1c17596dfb932450d730cc599804e540ad1a7c7
|
| 3 |
+
size 34000575
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": {
|
| 3 |
+
"content": "[CLS]",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"mask_token": {
|
| 10 |
+
"content": "[MASK]",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "[PAD]",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"sep_token": {
|
| 24 |
+
"content": "[SEP]",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
},
|
| 30 |
+
"unk_token": {
|
| 31 |
+
"content": "[UNK]",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false
|
| 36 |
+
}
|
| 37 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "[PAD]",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"100": {
|
| 12 |
+
"content": "[UNK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"101": {
|
| 20 |
+
"content": "[CLS]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"102": {
|
| 28 |
+
"content": "[SEP]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"103": {
|
| 36 |
+
"content": "[MASK]",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"clean_up_tokenization_spaces": true,
|
| 45 |
+
"cls_token": "[CLS]",
|
| 46 |
+
"do_basic_tokenize": true,
|
| 47 |
+
"do_lower_case": true,
|
| 48 |
+
"mask_token": "[MASK]",
|
| 49 |
+
"model_max_length": 512,
|
| 50 |
+
"never_split": null,
|
| 51 |
+
"pad_token": "[PAD]",
|
| 52 |
+
"sep_token": "[SEP]",
|
| 53 |
+
"strip_accents": null,
|
| 54 |
+
"tokenize_chinese_chars": true,
|
| 55 |
+
"tokenizer_class": "BertTokenizer",
|
| 56 |
+
"unk_token": "[UNK]"
|
| 57 |
+
}
|
vespa_colbert.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9161e64cab96fe5a5366782578e20da3409b26bd171a2a8bc6b9168777950903
|
| 3 |
+
size 133257413
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|