
File size: 1,985 Bytes
d822113 4d3249f d822113 4d3249f c64b253 4d3249f c64b253 4d3249f c64b253 4d3249f 94d242d 4d3249f |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
---
license: cc-by-4.0
datasets:
- cdminix/libritts-aligned
language:
- en
tags:
- speech recognition, speech synthesis, text-to-speech
---
[](https://vocex-demo.streamlit.app)
This model requires the Vocex library, which is available using
```pip install vocex```
Vocex extracts several measures (as well as d-vectors) from audio.
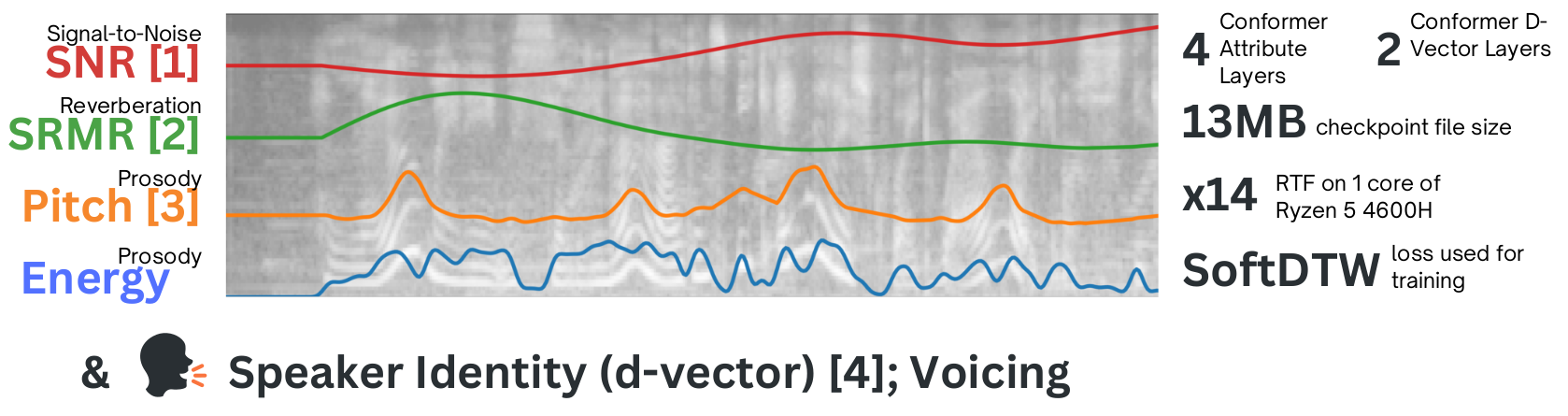
You can read more here:
https://github.com/minixc/vocex
## Usage
```python
from vocex import Vocex
import torchaudio # or any other audio loading library
model = Vocex.from_pretrained('cdminix/vocex') # an fp16 model is loaded by default
model = Vocex.from_pretrained('cdminix/vocex', fp16=False) # to load a fp32 model
model = Vocex.from_pretrained('some/path/model.ckpt') # to load local checkpoint
audio = ... # a numpy or torch array is required with shape [batch_size, length_in_samples] or just [length_in_samples]
sample_rate = ... # we need to specify a sample rate if the audio is not sampled at 22050
outputs = model(audio, sample_rate)
pitch, energy, snr, srmr = (
outputs["measures"]["pitch"],
outputs["measures"]["energy"],
outputs["measures"]["snr"],
outputs["measures"]["srmr"],
)
d_vector = outputs["d_vector"] # a torch tensor with shape [batch_size, 256]
# you can also get activations and attention weights at all layers of the model
outputs = model(audio, sample_rate, return_activations=True, return_attention=True)
activations = outputs["activations"] # a list of torch tensors with shape [batch_size, layers, ...]
attention = outputs["attention"] # a list of torch tensors with shape [batch_size, layers, ...]
# there are also speaker avatars, which are a 2D representation of the speaker's voice
outputs = model(audio, sample_rate, return_avatar=True)
avatar = outputs["avatars"] # a torch tensor with shape [batch_size, 256, 256]
``` |