
Commit
•
dd4a118
1
Parent(s):
27ebf4c
Upload 6 files
Browse files- README.md +137 -0
- config.json +53 -0
- generation_config.json +4 -0
- model.safetensors +3 -0
- patchtst_architecture.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- generated_from_trainer
|
| 4 |
+
license: cdla-permissive-2.0
|
| 5 |
+
model-index:
|
| 6 |
+
- name: patchtst_etth1_forecast
|
| 7 |
+
results: []
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# PatchTST model pre-trained on ETTh1 dataset
|
| 11 |
+
|
| 12 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 13 |
+
|
| 14 |
+
[`PatchTST`](https://huggingface.co/docs/transformers/model_doc/patchtst) is a transformer-based model for time series modeling tasks, including forecasting, regression, and classification. This repository contains a pre-trained `PatchTST` model encompassing all seven channels of the `ETTh1` dataset.
|
| 15 |
+
This particular pre-trained model produces a Mean Squared Error (MSE) of 0.3881 on the `test` split of the `ETTh1` dataset when forecasting 96 hours into the future with a historical data window of 512 hours.
|
| 16 |
+
|
| 17 |
+
For training and evaluating a `PatchTST` model, you can refer to this [demo notebook](https://github.com/IBM/tsfm/blob/main/notebooks/hfdemo/patch_tst_getting_started.ipynb).
|
| 18 |
+
|
| 19 |
+
## Model Details
|
| 20 |
+
|
| 21 |
+
### Model Description
|
| 22 |
+
|
| 23 |
+
The `PatchTST` model was proposed in A Time Series is Worth [64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
| 24 |
+
|
| 25 |
+
At a high level the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head.
|
| 26 |
+
|
| 27 |
+
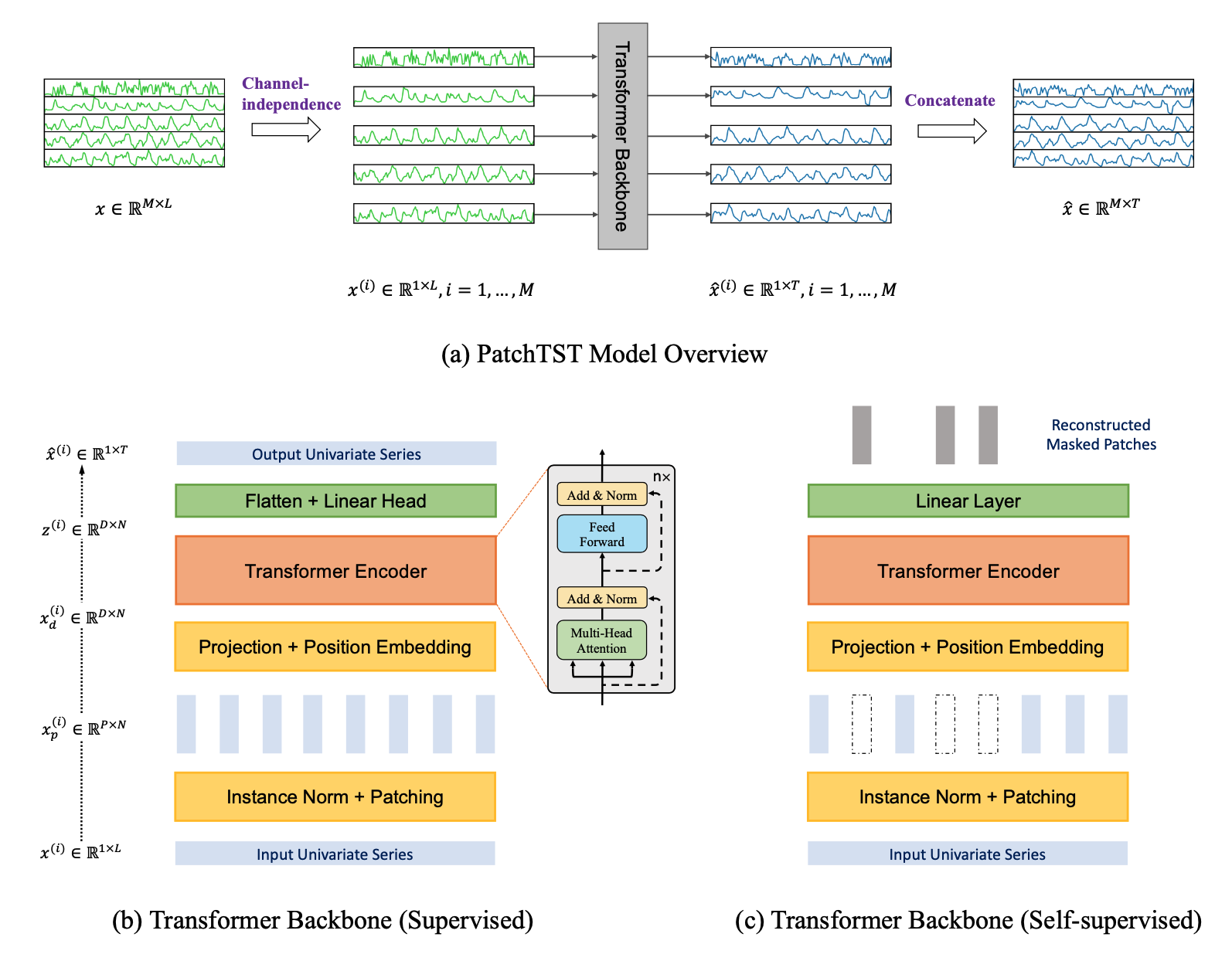
The model is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. The patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models.
|
| 28 |
+
|
| 29 |
+
In addition, PatchTST has a modular design to seamlessly support masked time series pre-training as well as direct time series forecasting, classification, and regression.
|
| 30 |
+
|
| 31 |
+
<img src="patchtst_architecture.png" alt="Architecture" width="600" />
|
| 32 |
+
|
| 33 |
+
### Model Sources
|
| 34 |
+
|
| 35 |
+
<!-- Provide the basic links for the model. -->
|
| 36 |
+
|
| 37 |
+
- **Repository:** [PatchTST Hugging Face](https://huggingface.co/docs/transformers/model_doc/patchtst)
|
| 38 |
+
- **Paper:** [PatchTST ICLR 2023 paper](https://dl.acm.org/doi/abs/10.1145/3580305.3599533)
|
| 39 |
+
- **Demo:** [Get started with PatchTST](https://github.com/IBM/tsfm/blob/main/notebooks/hfdemo/patch_tst_getting_started.ipynb)
|
| 40 |
+
|
| 41 |
+
## Uses
|
| 42 |
+
|
| 43 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 44 |
+
This pre-trained model can be employed for fine-tuning or evaluation using any Electrical Transformer dataset that has the same channels as the `ETTh1` dataset, specifically: `HUFL, HULL, MUFL, MULL, LUFL, LULL, OT`. The model is designed to predict the next 96 hours based on the input values from the preceding 512 hours. It is crucial to normalize the data. For a more comprehensive understanding of data pre-processing, please consult the paper or the demo.
|
| 45 |
+
|
| 46 |
+
## How to Get Started with the Model
|
| 47 |
+
|
| 48 |
+
Use the code below to get started with the model.
|
| 49 |
+
|
| 50 |
+
[Demo](https://github.com/IBM/tsfm/blob/main/notebooks/hfdemo/patch_tst_getting_started.ipynb)
|
| 51 |
+
|
| 52 |
+
## Training Details
|
| 53 |
+
|
| 54 |
+
### Training Data
|
| 55 |
+
|
| 56 |
+
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 57 |
+
|
| 58 |
+
[`ETTh1`/train split](https://github.com/zhouhaoyi/ETDataset/blob/main/ETT-small/ETTh1.csv).
|
| 59 |
+
Train/validation/test splits are shown in the [demo](https://github.com/IBM/tsfm/blob/main/notebooks/hfdemo/patch_tst_getting_started.ipynb).
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
### Training hyperparameters
|
| 63 |
+
|
| 64 |
+
The following hyperparameters were used during training:
|
| 65 |
+
- learning_rate: 5e-05
|
| 66 |
+
- train_batch_size: 8
|
| 67 |
+
- eval_batch_size: 8
|
| 68 |
+
- seed: 42
|
| 69 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 70 |
+
- lr_scheduler_type: linear
|
| 71 |
+
- num_epochs: 10
|
| 72 |
+
|
| 73 |
+
### Training Results
|
| 74 |
+
|
| 75 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 76 |
+
|:-------------:|:-----:|:-----:|:---------------:|
|
| 77 |
+
| 0.4306 | 1.0 | 1005 | 0.7268 |
|
| 78 |
+
| 0.3641 | 2.0 | 2010 | 0.7456 |
|
| 79 |
+
| 0.348 | 3.0 | 3015 | 0.7161 |
|
| 80 |
+
| 0.3379 | 4.0 | 4020 | 0.7428 |
|
| 81 |
+
| 0.3284 | 5.0 | 5025 | 0.7681 |
|
| 82 |
+
| 0.321 | 6.0 | 6030 | 0.7842 |
|
| 83 |
+
| 0.314 | 7.0 | 7035 | 0.7991 |
|
| 84 |
+
| 0.3088 | 8.0 | 8040 | 0.8021 |
|
| 85 |
+
| 0.3053 | 9.0 | 9045 | 0.8199 |
|
| 86 |
+
| 0.3019 | 10.0 | 10050 | 0.8173 |
|
| 87 |
+
|
| 88 |
+
## Evaluation
|
| 89 |
+
|
| 90 |
+
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 91 |
+
|
| 92 |
+
### Testing Data
|
| 93 |
+
|
| 94 |
+
[`ETTh1`/test split](https://github.com/zhouhaoyi/ETDataset/blob/main/ETT-small/ETTh1.csv).
|
| 95 |
+
Train/validation/test splits are shown in the [demo](https://github.com/IBM/tsfm/blob/main/notebooks/hfdemo/patch_tst_getting_started.ipynb).
|
| 96 |
+
|
| 97 |
+
### Metrics
|
| 98 |
+
|
| 99 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 100 |
+
|
| 101 |
+
Mean Squared Error (MSE).
|
| 102 |
+
|
| 103 |
+
### Results
|
| 104 |
+
It achieves a MSE of 0.3881 on the evaluation dataset.
|
| 105 |
+
|
| 106 |
+
#### Hardware
|
| 107 |
+
|
| 108 |
+
1 NVIDIA A100 GPU
|
| 109 |
+
|
| 110 |
+
#### Framework versions
|
| 111 |
+
|
| 112 |
+
- Transformers 4.36.0.dev0
|
| 113 |
+
- Pytorch 2.0.1
|
| 114 |
+
- Datasets 2.14.4
|
| 115 |
+
- Tokenizers 0.14.1
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
## Citation
|
| 119 |
+
|
| 120 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 121 |
+
|
| 122 |
+
**BibTeX:**
|
| 123 |
+
```
|
| 124 |
+
@misc{nie2023time,
|
| 125 |
+
title={A Time Series is Worth 64 Words: Long-term Forecasting with Transformers},
|
| 126 |
+
author={Yuqi Nie and Nam H. Nguyen and Phanwadee Sinthong and Jayant Kalagnanam},
|
| 127 |
+
year={2023},
|
| 128 |
+
eprint={2211.14730},
|
| 129 |
+
archivePrefix={arXiv},
|
| 130 |
+
primaryClass={cs.LG}
|
| 131 |
+
}
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
**APA:**
|
| 135 |
+
```
|
| 136 |
+
Nie, Y., Nguyen, N., Sinthong, P., & Kalagnanam, J. (2023). A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. arXiv preprint arXiv:2211.14730.
|
| 137 |
+
```
|
config.json
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "namctin/patchtst_etth1_forecast",
|
| 3 |
+
"activation_function": "gelu",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"PatchTSTForPrediction"
|
| 6 |
+
],
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"bias": true,
|
| 9 |
+
"channel_attention": false,
|
| 10 |
+
"channel_consistent_masking": false,
|
| 11 |
+
"context_length": 512,
|
| 12 |
+
"d_model": 128,
|
| 13 |
+
"distribution_output": "student_t",
|
| 14 |
+
"do_mask_input": null,
|
| 15 |
+
"dropout": 0.2,
|
| 16 |
+
"ff_dropout": 0.0,
|
| 17 |
+
"ffn_dim": 512,
|
| 18 |
+
"head_dropout": 0.2,
|
| 19 |
+
"init_std": 0.02,
|
| 20 |
+
"loss": "mse",
|
| 21 |
+
"mask_input": null,
|
| 22 |
+
"mask_type": "random",
|
| 23 |
+
"mask_value": 0,
|
| 24 |
+
"model_type": "patchtst",
|
| 25 |
+
"norm_eps": 1e-05,
|
| 26 |
+
"norm_type": "batchnorm",
|
| 27 |
+
"num_attention_heads": 16,
|
| 28 |
+
"num_forecast_mask_patches": [
|
| 29 |
+
2
|
| 30 |
+
],
|
| 31 |
+
"num_hidden_layers": 3,
|
| 32 |
+
"num_input_channels": 2,
|
| 33 |
+
"num_parallel_samples": 100,
|
| 34 |
+
"num_targets": 1,
|
| 35 |
+
"output_range": null,
|
| 36 |
+
"patch_length": 12,
|
| 37 |
+
"patch_stride": 12,
|
| 38 |
+
"path_dropout": 0.0,
|
| 39 |
+
"pooling_type": null,
|
| 40 |
+
"positional_dropout": 0.0,
|
| 41 |
+
"positional_encoding_type": "sincos",
|
| 42 |
+
"pre_norm": true,
|
| 43 |
+
"prediction_length": 96,
|
| 44 |
+
"random_mask_ratio": 0.5,
|
| 45 |
+
"scaling": "std",
|
| 46 |
+
"seed_number": null,
|
| 47 |
+
"share_embedding": true,
|
| 48 |
+
"share_projection": true,
|
| 49 |
+
"torch_dtype": "float32",
|
| 50 |
+
"transformers_version": "4.36.0.dev0",
|
| 51 |
+
"unmasked_channel_indices": null,
|
| 52 |
+
"use_cls_token": true
|
| 53 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.36.0.dev0"
|
| 4 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c7fca6ed95f1b0c2be80f421f100ad744b0334b598b1fbacd4f5a5e01afdcc4f
|
| 3 |
+
size 2472368
|
patchtst_architecture.png
ADDED
|