
Upload extensions using SD-Hub extension
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +144 -0
- extensions/1-sd-dynamic-thresholding/.github/FUNDING.yml +1 -0
- extensions/1-sd-dynamic-thresholding/.github/workflows/publish.yml +21 -0
- extensions/1-sd-dynamic-thresholding/.gitignore +1 -0
- extensions/1-sd-dynamic-thresholding/LICENSE.txt +21 -0
- extensions/1-sd-dynamic-thresholding/README.md +120 -0
- extensions/1-sd-dynamic-thresholding/__init__.py +6 -0
- extensions/1-sd-dynamic-thresholding/__pycache__/dynthres_core.cpython-310.pyc +0 -0
- extensions/1-sd-dynamic-thresholding/__pycache__/dynthres_unipc.cpython-310.pyc +0 -0
- extensions/1-sd-dynamic-thresholding/dynthres_comfyui.py +86 -0
- extensions/1-sd-dynamic-thresholding/dynthres_core.py +167 -0
- extensions/1-sd-dynamic-thresholding/dynthres_unipc.py +111 -0
- extensions/1-sd-dynamic-thresholding/github/cat_demo_1.jpg +0 -0
- extensions/1-sd-dynamic-thresholding/github/comfy_node.png +0 -0
- extensions/1-sd-dynamic-thresholding/github/grid_preview.png +0 -0
- extensions/1-sd-dynamic-thresholding/github/ui.png +0 -0
- extensions/1-sd-dynamic-thresholding/javascript/active.js +68 -0
- extensions/1-sd-dynamic-thresholding/pyproject.toml +13 -0
- extensions/1-sd-dynamic-thresholding/scripts/__pycache__/dynamic_thresholding.cpython-310.pyc +0 -0
- extensions/1-sd-dynamic-thresholding/scripts/dynamic_thresholding.py +270 -0
- extensions/ABG_extension/.gitignore +1 -0
- extensions/ABG_extension/README.md +32 -0
- extensions/ABG_extension/install.py +11 -0
- extensions/ABG_extension/scripts/__pycache__/app.cpython-310.pyc +0 -0
- extensions/ABG_extension/scripts/app.py +183 -0
- extensions/Automatic1111-Geeky-Remb/LICENSE +21 -0
- extensions/Automatic1111-Geeky-Remb/README.md +258 -0
- extensions/Automatic1111-Geeky-Remb/__init__.py +4 -0
- extensions/Automatic1111-Geeky-Remb/install.py +7 -0
- extensions/Automatic1111-Geeky-Remb/requirements.txt +6 -0
- extensions/Automatic1111-Geeky-Remb/scripts/__pycache__/geeky-remb.cpython-310.pyc +0 -0
- extensions/Automatic1111-Geeky-Remb/scripts/geeky-remb.py +475 -0
- extensions/CFGRescale_For_Forge/LICENSE +21 -0
- extensions/CFGRescale_For_Forge/README.md +6 -0
- extensions/CFGRescale_For_Forge/extensions-builtin/sd_forge_cfgrescale/scripts/__pycache__/forge_cfgrescale.cpython-310.pyc +0 -0
- extensions/CFGRescale_For_Forge/extensions-builtin/sd_forge_cfgrescale/scripts/forge_cfgrescale.py +45 -0
- extensions/CFGRescale_For_Forge/ldm_patched/contrib/external_cfgrescale.py +44 -0
- extensions/CFG_Rescale_webui/.gitignore +160 -0
- extensions/CFG_Rescale_webui/LICENSE +21 -0
- extensions/CFG_Rescale_webui/README.md +10 -0
- extensions/CFG_Rescale_webui/scripts/CFGRescale.py +225 -0
- extensions/CFG_Rescale_webui/scripts/__pycache__/CFGRescale.cpython-310.pyc +0 -0
- extensions/CharacteristicGuidanceWebUI/CHGextension_pic.PNG +0 -0
- extensions/CharacteristicGuidanceWebUI/LICENSE +201 -0
- extensions/CharacteristicGuidanceWebUI/README.md +184 -0
- extensions/CharacteristicGuidanceWebUI/scripts/CHGextension.py +439 -0
- extensions/CharacteristicGuidanceWebUI/scripts/CharaIte.py +530 -0
- extensions/CharacteristicGuidanceWebUI/scripts/__pycache__/CHGextension.cpython-310.pyc +0 -0
- extensions/CharacteristicGuidanceWebUI/scripts/__pycache__/CharaIte.cpython-310.pyc +0 -0
- extensions/CharacteristicGuidanceWebUI/scripts/__pycache__/forge_CHG.cpython-310.pyc +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,147 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
extensions/advanced_euler_sampler_extension/img/xyz_grid-0000-114514.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
extensions/artjiggler/thesaurus.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
extensions/canvas-zoom/dist/templates/frontend/assets/index-0c8f6dbd.js.map filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
extensions/canvas-zoom/dist/v1_1_v1_5_1/templates/frontend/assets/index-2a280c06.js.map filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
extensions/diffusion-noise-alternatives-webui/images/ColorGrade.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
extensions/diffusion-noise-alternatives-webui/images/GrainCompare.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
extensions/latent-upscale/assets/default.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
extensions/latent-upscale/assets/img2img_latent_upscale_process.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
extensions/latent-upscale/assets/nearest-exact-normal1.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
extensions/latent-upscale/assets/nearest-exact-normal2.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
extensions/latent-upscale/assets/nearest-exact-simple1.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
extensions/latent-upscale/assets/nearest-exact-simple2.png filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
extensions/latent-upscale/assets/nearest-exact-simple8.png filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
extensions/sd-canvas-editor/doc/images/overall.png filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
extensions/sd-canvas-editor/doc/images/panels.png filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
extensions/sd-canvas-editor/doc/images/photos.png filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
extensions/sd-civitai-browser-plus_fix/aria2/lin/aria2 filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
extensions/sd-civitai-browser-plus_fix/aria2/win/aria2.exe filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
extensions/sd-webui-Lora-queue-helper/docs/output_sample.png filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
extensions/sd-webui-agentattention/samples/xyz_grid-2415-1-desk.png filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
extensions/sd-webui-agentattention/samples/xyz_grid-2417-1-goldfinch,[[:space:]]Carduelis[[:space:]]carduelis.png filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
extensions/sd-webui-agentattention/samples/xyz_grid-2418-1-bell[[:space:]]pepper.png filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
extensions/sd-webui-agentattention/samples/xyz_grid-2419-1-bicycle.png filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
extensions/sd-webui-agentattention/samples/xyz_grid-2428-1-desk.jpg filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
extensions/sd-webui-birefnet/sd-webui-birefnet.png filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
extensions/sd-webui-cads/samples/comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
extensions/sd-webui-cads/samples/grid-7069.png filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
extensions/sd-webui-cads/samples/grid-7070.png filter=lfs diff=lfs merge=lfs -text
|
| 64 |
+
extensions/sd-webui-cardmaster/docked-detail-view.png filter=lfs diff=lfs merge=lfs -text
|
| 65 |
+
extensions/sd-webui-cardmaster/preview.gif filter=lfs diff=lfs merge=lfs -text
|
| 66 |
+
extensions/sd-webui-cardmaster/toma-chan[[:space:]]alt.png filter=lfs diff=lfs merge=lfs -text
|
| 67 |
+
extensions/sd-webui-cardmaster/toma-chan.png filter=lfs diff=lfs merge=lfs -text
|
| 68 |
+
extensions/sd-webui-cutoff/images/cover.jpg filter=lfs diff=lfs merge=lfs -text
|
| 69 |
+
extensions/sd-webui-cutoff/images/sample-1.png filter=lfs diff=lfs merge=lfs -text
|
| 70 |
+
extensions/sd-webui-cutoff/images/sample-2.png filter=lfs diff=lfs merge=lfs -text
|
| 71 |
+
extensions/sd-webui-cutoff/images/sample-3.png filter=lfs diff=lfs merge=lfs -text
|
| 72 |
+
extensions/sd-webui-cutoff/images/sample-4.png filter=lfs diff=lfs merge=lfs -text
|
| 73 |
+
extensions/sd-webui-cutoff/images/sample-4_small.png filter=lfs diff=lfs merge=lfs -text
|
| 74 |
+
extensions/sd-webui-cutoff/images/sample-5.png filter=lfs diff=lfs merge=lfs -text
|
| 75 |
+
extensions/sd-webui-cutoff/images/sample-5_small.png filter=lfs diff=lfs merge=lfs -text
|
| 76 |
+
extensions/sd-webui-diffusion-cg/examples/xl_off.jpg filter=lfs diff=lfs merge=lfs -text
|
| 77 |
+
extensions/sd-webui-diffusion-cg/examples/xl_on.jpg filter=lfs diff=lfs merge=lfs -text
|
| 78 |
+
extensions/sd-webui-ditail/assets/Intro-a.png filter=lfs diff=lfs merge=lfs -text
|
| 79 |
+
extensions/sd-webui-ditail/assets/Intro-b.png filter=lfs diff=lfs merge=lfs -text
|
| 80 |
+
extensions/sd-webui-ditail/assets/Intro-vertical.png filter=lfs diff=lfs merge=lfs -text
|
| 81 |
+
extensions/sd-webui-ditail/assets/Intro.png filter=lfs diff=lfs merge=lfs -text
|
| 82 |
+
extensions/sd-webui-dycfg/images/05.png filter=lfs diff=lfs merge=lfs -text
|
| 83 |
+
extensions/sd-webui-dycfg/images/09.png filter=lfs diff=lfs merge=lfs -text
|
| 84 |
+
extensions/sd-webui-fabric/static/example_2_default.png filter=lfs diff=lfs merge=lfs -text
|
| 85 |
+
extensions/sd-webui-fabric/static/example_2_feedback.png filter=lfs diff=lfs merge=lfs -text
|
| 86 |
+
extensions/sd-webui-fabric/static/example_3_10.png filter=lfs diff=lfs merge=lfs -text
|
| 87 |
+
extensions/sd-webui-fabric/static/example_3_feedback.png filter=lfs diff=lfs merge=lfs -text
|
| 88 |
+
extensions/sd-webui-fabric/static/fabric_demo.gif filter=lfs diff=lfs merge=lfs -text
|
| 89 |
+
extensions/sd-webui-image-comparison/tab.gif filter=lfs diff=lfs merge=lfs -text
|
| 90 |
+
extensions/sd-webui-img2txt/sd-webui-img2txt.gif filter=lfs diff=lfs merge=lfs -text
|
| 91 |
+
extensions/sd-webui-incantations/images/xyz_grid-0463-3.jpg filter=lfs diff=lfs merge=lfs -text
|
| 92 |
+
extensions/sd-webui-incantations/images/xyz_grid-0469-4.jpg filter=lfs diff=lfs merge=lfs -text
|
| 93 |
+
extensions/sd-webui-incantations/images/xyz_grid-2652-1419902843-cinematic[[:space:]]4K[[:space:]]photo[[:space:]]of[[:space:]]a[[:space:]]dog[[:space:]]riding[[:space:]]a[[:space:]]bus[[:space:]]and[[:space:]]eating[[:space:]]cake[[:space:]]and[[:space:]]wearing[[:space:]]headphones.png filter=lfs diff=lfs merge=lfs -text
|
| 94 |
+
extensions/sd-webui-incantations/images/xyz_grid-2660-1590472902-A[[:space:]]photo[[:space:]]of[[:space:]]a[[:space:]]lion[[:space:]]and[[:space:]]a[[:space:]]grizzly[[:space:]]bear[[:space:]]and[[:space:]]a[[:space:]]tiger[[:space:]]in[[:space:]]the[[:space:]]woods.jpg filter=lfs diff=lfs merge=lfs -text
|
| 95 |
+
extensions/sd-webui-incantations/images/xyz_grid-3040-1-a[[:space:]]puppy[[:space:]]and[[:space:]]a[[:space:]]kitten[[:space:]]on[[:space:]]the[[:space:]]moon.png filter=lfs diff=lfs merge=lfs -text
|
| 96 |
+
extensions/sd-webui-incantations/images/xyz_grid-3348-1590472902-A[[:space:]]photo[[:space:]]of[[:space:]]a[[:space:]]lion[[:space:]]and[[:space:]]a[[:space:]]grizzly[[:space:]]bear[[:space:]]and[[:space:]]a[[:space:]]tiger[[:space:]]in[[:space:]]the[[:space:]]woods.jpg filter=lfs diff=lfs merge=lfs -text
|
| 97 |
+
extensions/sd-webui-llul/images/llul_yuv420p.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 98 |
+
extensions/sd-webui-llul/images/mask_effect.jpg filter=lfs diff=lfs merge=lfs -text
|
| 99 |
+
extensions/sd-webui-lora-masks/images/example.02.png filter=lfs diff=lfs merge=lfs -text
|
| 100 |
+
extensions/sd-webui-lora-masks/images/example.03.png filter=lfs diff=lfs merge=lfs -text
|
| 101 |
+
extensions/sd-webui-matview/images/sample1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 102 |
+
extensions/sd-webui-panorama-tools/images/example_2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 103 |
+
extensions/sd-webui-panorama-tools/images/example_3.jpg filter=lfs diff=lfs merge=lfs -text
|
| 104 |
+
extensions/sd-webui-panorama-tools/images/panorama_tools_ui_screenshot.jpg filter=lfs diff=lfs merge=lfs -text
|
| 105 |
+
extensions/sd-webui-picbatchwork/bin/ebsynth.dll filter=lfs diff=lfs merge=lfs -text
|
| 106 |
+
extensions/sd-webui-picbatchwork/bin/ebsynth.exe filter=lfs diff=lfs merge=lfs -text
|
| 107 |
+
extensions/sd-webui-picbatchwork/img/2.gif filter=lfs diff=lfs merge=lfs -text
|
| 108 |
+
extensions/sd-webui-pixelart/examples/custom_palette_demo.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 109 |
+
extensions/sd-webui-samplers-scheduler/images/example2.png filter=lfs diff=lfs merge=lfs -text
|
| 110 |
+
extensions/sd-webui-samplers-scheduler/images/example3.png filter=lfs diff=lfs merge=lfs -text
|
| 111 |
+
extensions/sd-webui-semantic-guidance/samples/comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 112 |
+
extensions/sd-webui-semantic-guidance/samples/enhance.jpg filter=lfs diff=lfs merge=lfs -text
|
| 113 |
+
extensions/sd-webui-smea/sample.jpg filter=lfs diff=lfs merge=lfs -text
|
| 114 |
+
extensions/sd-webui-smea/sample2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 115 |
+
extensions/sd-webui-timemachine/images/tm_result.png filter=lfs diff=lfs merge=lfs -text
|
| 116 |
+
extensions/sd-webui-vectorscope-cc/samples/XYZ.jpg filter=lfs diff=lfs merge=lfs -text
|
| 117 |
+
extensions/sd-webui-xl_vec/images/crop_top.png filter=lfs diff=lfs merge=lfs -text
|
| 118 |
+
extensions/sd-webui-xl_vec/images/mult.png filter=lfs diff=lfs merge=lfs -text
|
| 119 |
+
extensions/sd-webui-xl_vec/images/original_size.png filter=lfs diff=lfs merge=lfs -text
|
| 120 |
+
extensions/sd-webui-xyz-addon/img/Extra-Network-Weight.png filter=lfs diff=lfs merge=lfs -text
|
| 121 |
+
extensions/sd-webui-xyz-addon/img/Multi-Axis-2.png filter=lfs diff=lfs merge=lfs -text
|
| 122 |
+
extensions/sd-webui-xyz-addon/img/Multi-Axis-3.png filter=lfs diff=lfs merge=lfs -text
|
| 123 |
+
extensions/sd-webui-xyz-addon/img/Prompt-SR-Combinations.png filter=lfs diff=lfs merge=lfs -text
|
| 124 |
+
extensions/sd-webui-xyz-addon/img/Prompt-SR-P.png filter=lfs diff=lfs merge=lfs -text
|
| 125 |
+
extensions/sd-webui-xyz-addon/img/Prompt-SR-Permutations-1-2.png filter=lfs diff=lfs merge=lfs -text
|
| 126 |
+
extensions/sd-webui-xyz-addon/img/Prompt-SR-Permutations-2.png filter=lfs diff=lfs merge=lfs -text
|
| 127 |
+
extensions/sd-webui-xyz-addon/img/Prompt-SR-Permutations.png filter=lfs diff=lfs merge=lfs -text
|
| 128 |
+
extensions/sd-webui-xyz-addon/img/Prompt-SR.png filter=lfs diff=lfs merge=lfs -text
|
| 129 |
+
extensions/sd_extension-prompt_formatter/Twemoji.Mozilla.ttf filter=lfs diff=lfs merge=lfs -text
|
| 130 |
+
extensions/sd_webui_masactrl/resources/img/xyz_grid-0010-1508457017.png filter=lfs diff=lfs merge=lfs -text
|
| 131 |
+
extensions/sd_webui_masactrl-ash/resources/img/xyz_grid-0010-1508457017.png filter=lfs diff=lfs merge=lfs -text
|
| 132 |
+
extensions/sd_webui_realtime_lcm_canvas/preview.png filter=lfs diff=lfs merge=lfs -text
|
| 133 |
+
extensions/sd_webui_realtime_lcm_canvas/scripts/models/models--Lykon--dreamshaper-7/blobs/6d0f6f2e3f7f0133e7684e8dffd7d0dfb1f2b09ddaf327763214449cc7a36574 filter=lfs diff=lfs merge=lfs -text
|
| 134 |
+
extensions/sd_webui_realtime_lcm_canvas/scripts/models/models--Lykon--dreamshaper-7/blobs/79d051410ce59a337cb358d79a3e81b9e0c691c34fcc7625ecfebf6a5db233a4 filter=lfs diff=lfs merge=lfs -text
|
| 135 |
+
extensions/sd_webui_realtime_lcm_canvas/scripts/models/models--Lykon--dreamshaper-7/blobs/a6f6744cfbcfe4fa9d236a231fd67e248389df7187dc15d52f16d9e9872105ff filter=lfs diff=lfs merge=lfs -text
|
| 136 |
+
extensions/sd_webui_sghm/preview.png filter=lfs diff=lfs merge=lfs -text
|
| 137 |
+
extensions/sd_webui_sghm/sghm/models/SGHM filter=lfs diff=lfs merge=lfs -text
|
| 138 |
+
extensions/ssasd/images/sample.png filter=lfs diff=lfs merge=lfs -text
|
| 139 |
+
extensions/ssasd/images/sample2.png filter=lfs diff=lfs merge=lfs -text
|
| 140 |
+
extensions/ssasd/images/sample3.png filter=lfs diff=lfs merge=lfs -text
|
| 141 |
+
extensions/stable-diffusion-webui-composable-lora/readme/changelog_2023-04-08.png filter=lfs diff=lfs merge=lfs -text
|
| 142 |
+
extensions/stable-diffusion-webui-composable-lora/readme/fig11.png filter=lfs diff=lfs merge=lfs -text
|
| 143 |
+
extensions/stable-diffusion-webui-composable-lora/readme/fig12.png filter=lfs diff=lfs merge=lfs -text
|
| 144 |
+
extensions/stable-diffusion-webui-composable-lora/readme/fig13.png filter=lfs diff=lfs merge=lfs -text
|
| 145 |
+
extensions/stable-diffusion-webui-composable-lora/readme/fig8.png filter=lfs diff=lfs merge=lfs -text
|
| 146 |
+
extensions/stable-diffusion-webui-composable-lora/readme/fig9.png filter=lfs diff=lfs merge=lfs -text
|
| 147 |
+
extensions/stable-diffusion-webui-dumpunet/images/IN00.jpg filter=lfs diff=lfs merge=lfs -text
|
| 148 |
+
extensions/stable-diffusion-webui-dumpunet/images/IN05.jpg filter=lfs diff=lfs merge=lfs -text
|
| 149 |
+
extensions/stable-diffusion-webui-dumpunet/images/OUT06.jpg filter=lfs diff=lfs merge=lfs -text
|
| 150 |
+
extensions/stable-diffusion-webui-dumpunet/images/OUT11.jpg filter=lfs diff=lfs merge=lfs -text
|
| 151 |
+
extensions/stable-diffusion-webui-dumpunet/images/README_00_01_color.png filter=lfs diff=lfs merge=lfs -text
|
| 152 |
+
extensions/stable-diffusion-webui-dumpunet/images/README_00_01_gray.png filter=lfs diff=lfs merge=lfs -text
|
| 153 |
+
extensions/stable-diffusion-webui-dumpunet/images/README_02.png filter=lfs diff=lfs merge=lfs -text
|
| 154 |
+
extensions/stable-diffusion-webui-dumpunet/images/attn-IN01.png filter=lfs diff=lfs merge=lfs -text
|
| 155 |
+
extensions/stable-diffusion-webui-dumpunet/images/attn-OUT10.png filter=lfs diff=lfs merge=lfs -text
|
| 156 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/highres.png filter=lfs diff=lfs merge=lfs -text
|
| 157 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_10x12.png filter=lfs diff=lfs merge=lfs -text
|
| 158 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_1x120.png filter=lfs diff=lfs merge=lfs -text
|
| 159 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_2x60.png filter=lfs diff=lfs merge=lfs -text
|
| 160 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_3x40.png filter=lfs diff=lfs merge=lfs -text
|
| 161 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_4x15.png filter=lfs diff=lfs merge=lfs -text
|
| 162 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_4x23.png filter=lfs diff=lfs merge=lfs -text
|
| 163 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_4x3.png filter=lfs diff=lfs merge=lfs -text
|
| 164 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_4x30.png filter=lfs diff=lfs merge=lfs -text
|
| 165 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_4x5.png filter=lfs diff=lfs merge=lfs -text
|
| 166 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_4x8.png filter=lfs diff=lfs merge=lfs -text
|
| 167 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_6x20.png filter=lfs diff=lfs merge=lfs -text
|
| 168 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/pg_8x15.png filter=lfs diff=lfs merge=lfs -text
|
| 169 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/std_10.png filter=lfs diff=lfs merge=lfs -text
|
| 170 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/std_120.png filter=lfs diff=lfs merge=lfs -text
|
| 171 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/std_20.png filter=lfs diff=lfs merge=lfs -text
|
| 172 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/std_30.png filter=lfs diff=lfs merge=lfs -text
|
| 173 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/std_60.png filter=lfs diff=lfs merge=lfs -text
|
| 174 |
+
extensions/stable-diffusion-webui-hires-fix-progressive/img/std_90.png filter=lfs diff=lfs merge=lfs -text
|
| 175 |
+
extensions/stable-diffusion-webui-intm/images/IMAGE.png filter=lfs diff=lfs merge=lfs -text
|
| 176 |
+
extensions/stable-diffusion-webui-rembg/preview.png filter=lfs diff=lfs merge=lfs -text
|
| 177 |
+
extensions/stable-diffusion-webui-sonar/img/momentum.png filter=lfs diff=lfs merge=lfs -text
|
| 178 |
+
extensions/stable-diffusion-webui-tripclipskip/images/xy_plot.jpg filter=lfs diff=lfs merge=lfs -text
|
| 179 |
+
extensions/stable-diffusion-webui-two-shot/gradio-3.16.2-py3-none-any.whl filter=lfs diff=lfs merge=lfs -text
|
extensions/1-sd-dynamic-thresholding/.github/FUNDING.yml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
github: mcmonkey4eva
|
extensions/1-sd-dynamic-thresholding/.github/workflows/publish.yml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Publish to Comfy registry
|
| 2 |
+
on:
|
| 3 |
+
workflow_dispatch:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- master
|
| 7 |
+
paths:
|
| 8 |
+
- "pyproject.toml"
|
| 9 |
+
|
| 10 |
+
jobs:
|
| 11 |
+
publish-node:
|
| 12 |
+
name: Publish Custom Node to registry
|
| 13 |
+
runs-on: ubuntu-latest
|
| 14 |
+
steps:
|
| 15 |
+
- name: Check out code
|
| 16 |
+
uses: actions/checkout@v4
|
| 17 |
+
- name: Publish Custom Node
|
| 18 |
+
uses: Comfy-Org/publish-node-action@main
|
| 19 |
+
with:
|
| 20 |
+
## Add your own personal access token to your Github Repository secrets and reference it here.
|
| 21 |
+
personal_access_token: ${{ secrets.REGISTRY_ACCESS_TOKEN }}
|
extensions/1-sd-dynamic-thresholding/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__pycache__/
|
extensions/1-sd-dynamic-thresholding/LICENSE.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The MIT License (MIT)
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Alex "mcmonkey" Goodwin
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
extensions/1-sd-dynamic-thresholding/README.md
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Stable Diffusion Dynamic Thresholding (CFG Scale Fix)
|
| 2 |
+
|
| 3 |
+
### Concept
|
| 4 |
+
|
| 5 |
+
Extension for [SwarmUI](https://github.com/mcmonkeyprojects/SwarmUI), [ComfyUI](https://github.com/comfyanonymous/ComfyUI), and [AUTOMATIC1111 Stable Diffusion WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) that enables a way to use higher CFG Scales without color issues.
|
| 6 |
+
|
| 7 |
+
This works by clamping latents between steps. You can read more [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/3962) or [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/3268) or [this tweet](https://twitter.com/Birchlabs/status/1582165379832348672).
|
| 8 |
+
|
| 9 |
+
--------------
|
| 10 |
+
|
| 11 |
+
### Credit
|
| 12 |
+
|
| 13 |
+
The core functionality of this PR was originally developed by [Birch-san](https://github.com/Birch-san) and ported to the WebUI by [dtan3847](https://github.com/dtan3847), then converted to an Auto WebUI extension and given a UI by [mcmonkey4eva](https://github.com/mcmonkey4eva), further development and research done by [mcmonkey4eva](https://github.com/mcmonkey4eva) and JDMLeverton. Ported by ComfyUI by [TwoDukes](https://github.com/TwoDukes) and [mcmonkey4eva](https://github.com/mcmonkey4eva). Ported to SwarmUI by [mcmonkey4eva](https://github.com/mcmonkey4eva).
|
| 14 |
+
|
| 15 |
+
--------------
|
| 16 |
+
|
| 17 |
+
### Examples
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
--------------
|
| 25 |
+
|
| 26 |
+
### Demo Grid
|
| 27 |
+
|
| 28 |
+
View at <https://sd.mcmonkey.org/dynthresh/>.
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
(Was generated via [this YAML config](https://gist.github.com/mcmonkey4eva/fccd29172f44424dfc0217a482c824f6) for the [Infinite Grid Generator](https://github.com/mcmonkeyprojects/sd-infinity-grid-generator-script))
|
| 33 |
+
|
| 34 |
+
--------------
|
| 35 |
+
|
| 36 |
+
### Installation and Usage
|
| 37 |
+
|
| 38 |
+
#### SwarmUI
|
| 39 |
+
|
| 40 |
+
- Supported out-of-the-box on default installations.
|
| 41 |
+
- If using a custom installation, just make sure the backend you use has this repo installed per the instructions specific to the backend as written below.
|
| 42 |
+
- It's under the "Display Advanced Options" parameter checkbox.
|
| 43 |
+
|
| 44 |
+
#### Auto WebUI
|
| 45 |
+
|
| 46 |
+
- You must have the [AUTOMATIC1111 Stable Diffusion WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) already installed and working. Refer to that project's readme for help with that.
|
| 47 |
+
- Open the WebUI, go to the `Extensions` tab
|
| 48 |
+
- -EITHER- Option **A**:
|
| 49 |
+
- go to the `Available` tab with
|
| 50 |
+
- click `Load from` (with the default list)
|
| 51 |
+
- Scroll down to find `Dynamic Thresholding (CFG Scale Fix)`, or use `CTRL+F` to find it
|
| 52 |
+
- -OR- Option **B**:
|
| 53 |
+
- Click on `Install from URL`
|
| 54 |
+
- Copy/paste this project's URL into the `URL for extension's git repository` textbox: `https://github.com/mcmonkeyprojects/sd-dynamic-thresholding`
|
| 55 |
+
- Click `Install`
|
| 56 |
+
- Restart or reload the WebUI
|
| 57 |
+
- Go to txt2img or img2img
|
| 58 |
+
- Check the `Enable Dynamic Thresholding (CFG Scale Fix)` box
|
| 59 |
+
- Read the info on-page and set the sliders where you want em.
|
| 60 |
+
- Click generate.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
#### ComfyUI
|
| 64 |
+
|
| 65 |
+
- Must have [ComfyUI](https://github.com/comfyanonymous/ComfyUI) already installed and working. Refer to that project's readme for help with that.
|
| 66 |
+
- -EITHER- Option **A**: (TODO: Manager install)
|
| 67 |
+
- -OR- Option **B**:
|
| 68 |
+
- `cd ComfyUI/custom_nodes`
|
| 69 |
+
- `git clone https://github.com/mcmonkeyprojects/sd-dynamic-thresholding`
|
| 70 |
+
- restart ComfyUI
|
| 71 |
+
- Add node `advanced/mcmonkey/DynamicThresholdingSimple` (or `Full`)
|
| 72 |
+
- Link your model to the input, and then link the output model to your KSampler's input
|
| 73 |
+
|
| 74 |
+

|
| 75 |
+
|
| 76 |
+
--------------
|
| 77 |
+
|
| 78 |
+
### Supported Auto WebUI Extensions
|
| 79 |
+
|
| 80 |
+
- This can be configured within the [Infinity Grid Generator](https://github.com/mcmonkeyprojects/sd-infinity-grid-generator-script#supported-extensions) extension, see the readme of that project for details.
|
| 81 |
+
|
| 82 |
+
### ComfyUI Compatibility
|
| 83 |
+
|
| 84 |
+
- This would work with any variant of the `KSampler` node, including custom ones, so long as they do not totally override the internal sampling function (most don't).
|
| 85 |
+
|
| 86 |
+
----------------------
|
| 87 |
+
|
| 88 |
+
### Licensing pre-note:
|
| 89 |
+
|
| 90 |
+
This is an open source project, provided entirely freely, for everyone to use and contribute to.
|
| 91 |
+
|
| 92 |
+
If you make any changes that could benefit the community as a whole, please contribute upstream.
|
| 93 |
+
|
| 94 |
+
### The short of the license is:
|
| 95 |
+
|
| 96 |
+
You can do basically whatever you want, except you may not hold any developer liable for what you do with the software.
|
| 97 |
+
|
| 98 |
+
### The long version of the license follows:
|
| 99 |
+
|
| 100 |
+
The MIT License (MIT)
|
| 101 |
+
|
| 102 |
+
Copyright (c) 2023 Alex "mcmonkey" Goodwin
|
| 103 |
+
|
| 104 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 105 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 106 |
+
in the Software without restriction, including without limitation the rights
|
| 107 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 108 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 109 |
+
furnished to do so, subject to the following conditions:
|
| 110 |
+
|
| 111 |
+
The above copyright notice and this permission notice shall be included in all
|
| 112 |
+
copies or substantial portions of the Software.
|
| 113 |
+
|
| 114 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 115 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 116 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 117 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 118 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 119 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 120 |
+
SOFTWARE.
|
extensions/1-sd-dynamic-thresholding/__init__.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from . import dynthres_comfyui
|
| 2 |
+
|
| 3 |
+
NODE_CLASS_MAPPINGS = {
|
| 4 |
+
"DynamicThresholdingSimple": dynthres_comfyui.DynamicThresholdingSimpleComfyNode,
|
| 5 |
+
"DynamicThresholdingFull": dynthres_comfyui.DynamicThresholdingComfyNode,
|
| 6 |
+
}
|
extensions/1-sd-dynamic-thresholding/__pycache__/dynthres_core.cpython-310.pyc
ADDED
|
Binary file (4.49 kB). View file
|
|
|
extensions/1-sd-dynamic-thresholding/__pycache__/dynthres_unipc.cpython-310.pyc
ADDED
|
Binary file (4.92 kB). View file
|
|
|
extensions/1-sd-dynamic-thresholding/dynthres_comfyui.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .dynthres_core import DynThresh
|
| 2 |
+
|
| 3 |
+
class DynamicThresholdingComfyNode:
|
| 4 |
+
|
| 5 |
+
@classmethod
|
| 6 |
+
def INPUT_TYPES(s):
|
| 7 |
+
return {
|
| 8 |
+
"required": {
|
| 9 |
+
"model": ("MODEL",),
|
| 10 |
+
"mimic_scale": ("FLOAT", {"default": 7.0, "min": 0.0, "max": 100.0, "step": 0.5}),
|
| 11 |
+
"threshold_percentile": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 1.0, "step": 0.01}),
|
| 12 |
+
"mimic_mode": (DynThresh.Modes, ),
|
| 13 |
+
"mimic_scale_min": ("FLOAT", {"default": 0.0, "min": 0.0, "max": 100.0, "step": 0.5}),
|
| 14 |
+
"cfg_mode": (DynThresh.Modes, ),
|
| 15 |
+
"cfg_scale_min": ("FLOAT", {"default": 0.0, "min": 0.0, "max": 100.0, "step": 0.5}),
|
| 16 |
+
"sched_val": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 100.0, "step": 0.01}),
|
| 17 |
+
"separate_feature_channels": (["enable", "disable"], ),
|
| 18 |
+
"scaling_startpoint": (DynThresh.Startpoints, ),
|
| 19 |
+
"variability_measure": (DynThresh.Variabilities, ),
|
| 20 |
+
"interpolate_phi": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 1.0, "step": 0.01}),
|
| 21 |
+
}
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
RETURN_TYPES = ("MODEL",)
|
| 25 |
+
FUNCTION = "patch"
|
| 26 |
+
CATEGORY = "advanced/mcmonkey"
|
| 27 |
+
|
| 28 |
+
def patch(self, model, mimic_scale, threshold_percentile, mimic_mode, mimic_scale_min, cfg_mode, cfg_scale_min, sched_val, separate_feature_channels, scaling_startpoint, variability_measure, interpolate_phi):
|
| 29 |
+
|
| 30 |
+
dynamic_thresh = DynThresh(mimic_scale, threshold_percentile, mimic_mode, mimic_scale_min, cfg_mode, cfg_scale_min, sched_val, 0, 999, separate_feature_channels == "enable", scaling_startpoint, variability_measure, interpolate_phi)
|
| 31 |
+
|
| 32 |
+
def sampler_dyn_thresh(args):
|
| 33 |
+
input = args["input"]
|
| 34 |
+
cond = input - args["cond"]
|
| 35 |
+
uncond = input - args["uncond"]
|
| 36 |
+
cond_scale = args["cond_scale"]
|
| 37 |
+
time_step = model.model.model_sampling.timestep(args["sigma"])
|
| 38 |
+
time_step = time_step[0].item()
|
| 39 |
+
dynamic_thresh.step = 999 - time_step
|
| 40 |
+
|
| 41 |
+
if cond_scale == mimic_scale:
|
| 42 |
+
return input - (uncond + (cond - uncond) * cond_scale)
|
| 43 |
+
else:
|
| 44 |
+
return input - dynamic_thresh.dynthresh(cond, uncond, cond_scale, None)
|
| 45 |
+
|
| 46 |
+
m = model.clone()
|
| 47 |
+
m.set_model_sampler_cfg_function(sampler_dyn_thresh)
|
| 48 |
+
return (m, )
|
| 49 |
+
|
| 50 |
+
class DynamicThresholdingSimpleComfyNode:
|
| 51 |
+
|
| 52 |
+
@classmethod
|
| 53 |
+
def INPUT_TYPES(s):
|
| 54 |
+
return {
|
| 55 |
+
"required": {
|
| 56 |
+
"model": ("MODEL",),
|
| 57 |
+
"mimic_scale": ("FLOAT", {"default": 7.0, "min": 0.0, "max": 100.0, "step": 0.5}),
|
| 58 |
+
"threshold_percentile": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 1.0, "step": 0.01}),
|
| 59 |
+
}
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
RETURN_TYPES = ("MODEL",)
|
| 63 |
+
FUNCTION = "patch"
|
| 64 |
+
CATEGORY = "advanced/mcmonkey"
|
| 65 |
+
|
| 66 |
+
def patch(self, model, mimic_scale, threshold_percentile):
|
| 67 |
+
|
| 68 |
+
dynamic_thresh = DynThresh(mimic_scale, threshold_percentile, "CONSTANT", 0, "CONSTANT", 0, 0, 0, 999, False, "MEAN", "AD", 1)
|
| 69 |
+
|
| 70 |
+
def sampler_dyn_thresh(args):
|
| 71 |
+
input = args["input"]
|
| 72 |
+
cond = input - args["cond"]
|
| 73 |
+
uncond = input - args["uncond"]
|
| 74 |
+
cond_scale = args["cond_scale"]
|
| 75 |
+
time_step = model.model.model_sampling.timestep(args["sigma"])
|
| 76 |
+
time_step = time_step[0].item()
|
| 77 |
+
dynamic_thresh.step = 999 - time_step
|
| 78 |
+
|
| 79 |
+
if cond_scale == mimic_scale:
|
| 80 |
+
return input - (uncond + (cond - uncond) * cond_scale)
|
| 81 |
+
else:
|
| 82 |
+
return input - dynamic_thresh.dynthresh(cond, uncond, cond_scale, None)
|
| 83 |
+
|
| 84 |
+
m = model.clone()
|
| 85 |
+
m.set_model_sampler_cfg_function(sampler_dyn_thresh)
|
| 86 |
+
return (m, )
|
extensions/1-sd-dynamic-thresholding/dynthres_core.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch, math
|
| 2 |
+
|
| 3 |
+
######################### DynThresh Core #########################
|
| 4 |
+
|
| 5 |
+
class DynThresh:
|
| 6 |
+
|
| 7 |
+
Modes = ["Constant", "Linear Down", "Cosine Down", "Half Cosine Down", "Linear Up", "Cosine Up", "Half Cosine Up", "Power Up", "Power Down", "Linear Repeating", "Cosine Repeating", "Sawtooth"]
|
| 8 |
+
Startpoints = ["MEAN", "ZERO"]
|
| 9 |
+
Variabilities = ["AD", "STD"]
|
| 10 |
+
|
| 11 |
+
def __init__(self, mimic_scale, threshold_percentile, mimic_mode, mimic_scale_min, cfg_mode, cfg_scale_min, sched_val, experiment_mode, max_steps, separate_feature_channels, scaling_startpoint, variability_measure, interpolate_phi):
|
| 12 |
+
self.mimic_scale = mimic_scale
|
| 13 |
+
self.threshold_percentile = threshold_percentile
|
| 14 |
+
self.mimic_mode = mimic_mode
|
| 15 |
+
self.cfg_mode = cfg_mode
|
| 16 |
+
self.max_steps = max_steps
|
| 17 |
+
self.cfg_scale_min = cfg_scale_min
|
| 18 |
+
self.mimic_scale_min = mimic_scale_min
|
| 19 |
+
self.experiment_mode = experiment_mode
|
| 20 |
+
self.sched_val = sched_val
|
| 21 |
+
self.sep_feat_channels = separate_feature_channels
|
| 22 |
+
self.scaling_startpoint = scaling_startpoint
|
| 23 |
+
self.variability_measure = variability_measure
|
| 24 |
+
self.interpolate_phi = interpolate_phi
|
| 25 |
+
|
| 26 |
+
def interpret_scale(self, scale, mode, min):
|
| 27 |
+
scale -= min
|
| 28 |
+
max = self.max_steps - 1
|
| 29 |
+
frac = self.step / max
|
| 30 |
+
if mode == "Constant":
|
| 31 |
+
pass
|
| 32 |
+
elif mode == "Linear Down":
|
| 33 |
+
scale *= 1.0 - frac
|
| 34 |
+
elif mode == "Half Cosine Down":
|
| 35 |
+
scale *= math.cos(frac)
|
| 36 |
+
elif mode == "Cosine Down":
|
| 37 |
+
scale *= math.cos(frac * 1.5707)
|
| 38 |
+
elif mode == "Linear Up":
|
| 39 |
+
scale *= frac
|
| 40 |
+
elif mode == "Half Cosine Up":
|
| 41 |
+
scale *= 1.0 - math.cos(frac)
|
| 42 |
+
elif mode == "Cosine Up":
|
| 43 |
+
scale *= 1.0 - math.cos(frac * 1.5707)
|
| 44 |
+
elif mode == "Power Up":
|
| 45 |
+
scale *= math.pow(frac, self.sched_val)
|
| 46 |
+
elif mode == "Power Down":
|
| 47 |
+
scale *= 1.0 - math.pow(frac, self.sched_val)
|
| 48 |
+
elif mode == "Linear Repeating":
|
| 49 |
+
portion = (frac * self.sched_val) % 1.0
|
| 50 |
+
scale *= (0.5 - portion) * 2 if portion < 0.5 else (portion - 0.5) * 2
|
| 51 |
+
elif mode == "Cosine Repeating":
|
| 52 |
+
scale *= math.cos(frac * 6.28318 * self.sched_val) * 0.5 + 0.5
|
| 53 |
+
elif mode == "Sawtooth":
|
| 54 |
+
scale *= (frac * self.sched_val) % 1.0
|
| 55 |
+
scale += min
|
| 56 |
+
return scale
|
| 57 |
+
|
| 58 |
+
def dynthresh(self, cond, uncond, cfg_scale, weights):
|
| 59 |
+
mimic_scale = self.interpret_scale(self.mimic_scale, self.mimic_mode, self.mimic_scale_min)
|
| 60 |
+
cfg_scale = self.interpret_scale(cfg_scale, self.cfg_mode, self.cfg_scale_min)
|
| 61 |
+
# uncond shape is (batch, 4, height, width)
|
| 62 |
+
conds_per_batch = cond.shape[0] / uncond.shape[0]
|
| 63 |
+
assert conds_per_batch == int(conds_per_batch), "Expected # of conds per batch to be constant across batches"
|
| 64 |
+
cond_stacked = cond.reshape((-1, int(conds_per_batch)) + uncond.shape[1:])
|
| 65 |
+
|
| 66 |
+
### Normal first part of the CFG Scale logic, basically
|
| 67 |
+
diff = cond_stacked - uncond.unsqueeze(1)
|
| 68 |
+
if weights is not None:
|
| 69 |
+
diff = diff * weights
|
| 70 |
+
relative = diff.sum(1)
|
| 71 |
+
|
| 72 |
+
### Get the normal result for both mimic and normal scale
|
| 73 |
+
mim_target = uncond + relative * mimic_scale
|
| 74 |
+
cfg_target = uncond + relative * cfg_scale
|
| 75 |
+
### If we weren't doing mimic scale, we'd just return cfg_target here
|
| 76 |
+
|
| 77 |
+
### Now recenter the values relative to their average rather than absolute, to allow scaling from average
|
| 78 |
+
mim_flattened = mim_target.flatten(2)
|
| 79 |
+
cfg_flattened = cfg_target.flatten(2)
|
| 80 |
+
mim_means = mim_flattened.mean(dim=2).unsqueeze(2)
|
| 81 |
+
cfg_means = cfg_flattened.mean(dim=2).unsqueeze(2)
|
| 82 |
+
mim_centered = mim_flattened - mim_means
|
| 83 |
+
cfg_centered = cfg_flattened - cfg_means
|
| 84 |
+
|
| 85 |
+
if self.sep_feat_channels:
|
| 86 |
+
if self.variability_measure == 'STD':
|
| 87 |
+
mim_scaleref = mim_centered.std(dim=2).unsqueeze(2)
|
| 88 |
+
cfg_scaleref = cfg_centered.std(dim=2).unsqueeze(2)
|
| 89 |
+
else: # 'AD'
|
| 90 |
+
mim_scaleref = mim_centered.abs().max(dim=2).values.unsqueeze(2)
|
| 91 |
+
cfg_scaleref = torch.quantile(cfg_centered.abs(), self.threshold_percentile, dim=2).unsqueeze(2)
|
| 92 |
+
|
| 93 |
+
else:
|
| 94 |
+
if self.variability_measure == 'STD':
|
| 95 |
+
mim_scaleref = mim_centered.std()
|
| 96 |
+
cfg_scaleref = cfg_centered.std()
|
| 97 |
+
else: # 'AD'
|
| 98 |
+
mim_scaleref = mim_centered.abs().max()
|
| 99 |
+
cfg_scaleref = torch.quantile(cfg_centered.abs(), self.threshold_percentile)
|
| 100 |
+
|
| 101 |
+
if self.scaling_startpoint == 'ZERO':
|
| 102 |
+
scaling_factor = mim_scaleref / cfg_scaleref
|
| 103 |
+
result = cfg_flattened * scaling_factor
|
| 104 |
+
|
| 105 |
+
else: # 'MEAN'
|
| 106 |
+
if self.variability_measure == 'STD':
|
| 107 |
+
cfg_renormalized = (cfg_centered / cfg_scaleref) * mim_scaleref
|
| 108 |
+
else: # 'AD'
|
| 109 |
+
### Get the maximum value of all datapoints (with an optional threshold percentile on the uncond)
|
| 110 |
+
max_scaleref = torch.maximum(mim_scaleref, cfg_scaleref)
|
| 111 |
+
### Clamp to the max
|
| 112 |
+
cfg_clamped = cfg_centered.clamp(-max_scaleref, max_scaleref)
|
| 113 |
+
### Now shrink from the max to normalize and grow to the mimic scale (instead of the CFG scale)
|
| 114 |
+
cfg_renormalized = (cfg_clamped / max_scaleref) * mim_scaleref
|
| 115 |
+
|
| 116 |
+
### Now add it back onto the averages to get into real scale again and return
|
| 117 |
+
result = cfg_renormalized + cfg_means
|
| 118 |
+
|
| 119 |
+
actual_res = result.unflatten(2, mim_target.shape[2:])
|
| 120 |
+
|
| 121 |
+
if self.interpolate_phi != 1.0:
|
| 122 |
+
actual_res = actual_res * self.interpolate_phi + cfg_target * (1.0 - self.interpolate_phi)
|
| 123 |
+
|
| 124 |
+
if self.experiment_mode == 1:
|
| 125 |
+
num = actual_res.cpu().numpy()
|
| 126 |
+
for y in range(0, 64):
|
| 127 |
+
for x in range (0, 64):
|
| 128 |
+
if num[0][0][y][x] > 1.0:
|
| 129 |
+
num[0][1][y][x] *= 0.5
|
| 130 |
+
if num[0][1][y][x] > 1.0:
|
| 131 |
+
num[0][1][y][x] *= 0.5
|
| 132 |
+
if num[0][2][y][x] > 1.5:
|
| 133 |
+
num[0][2][y][x] *= 0.5
|
| 134 |
+
actual_res = torch.from_numpy(num).to(device=uncond.device)
|
| 135 |
+
elif self.experiment_mode == 2:
|
| 136 |
+
num = actual_res.cpu().numpy()
|
| 137 |
+
for y in range(0, 64):
|
| 138 |
+
for x in range (0, 64):
|
| 139 |
+
over_scale = False
|
| 140 |
+
for z in range(0, 4):
|
| 141 |
+
if abs(num[0][z][y][x]) > 1.5:
|
| 142 |
+
over_scale = True
|
| 143 |
+
if over_scale:
|
| 144 |
+
for z in range(0, 4):
|
| 145 |
+
num[0][z][y][x] *= 0.7
|
| 146 |
+
actual_res = torch.from_numpy(num).to(device=uncond.device)
|
| 147 |
+
elif self.experiment_mode == 3:
|
| 148 |
+
coefs = torch.tensor([
|
| 149 |
+
# R G B W
|
| 150 |
+
[0.298, 0.207, 0.208, 0.0], # L1
|
| 151 |
+
[0.187, 0.286, 0.173, 0.0], # L2
|
| 152 |
+
[-0.158, 0.189, 0.264, 0.0], # L3
|
| 153 |
+
[-0.184, -0.271, -0.473, 1.0], # L4
|
| 154 |
+
], device=uncond.device)
|
| 155 |
+
res_rgb = torch.einsum("laxy,ab -> lbxy", actual_res, coefs)
|
| 156 |
+
max_r, max_g, max_b, max_w = res_rgb[0][0].max(), res_rgb[0][1].max(), res_rgb[0][2].max(), res_rgb[0][3].max()
|
| 157 |
+
max_rgb = max(max_r, max_g, max_b)
|
| 158 |
+
print(f"test max = r={max_r}, g={max_g}, b={max_b}, w={max_w}, rgb={max_rgb}")
|
| 159 |
+
if self.step / (self.max_steps - 1) > 0.2:
|
| 160 |
+
if max_rgb < 2.0 and max_w < 3.0:
|
| 161 |
+
res_rgb /= max_rgb / 2.4
|
| 162 |
+
else:
|
| 163 |
+
if max_rgb > 2.4 and max_w > 3.0:
|
| 164 |
+
res_rgb /= max_rgb / 2.4
|
| 165 |
+
actual_res = torch.einsum("laxy,ab -> lbxy", res_rgb, coefs.inverse())
|
| 166 |
+
|
| 167 |
+
return actual_res
|
extensions/1-sd-dynamic-thresholding/dynthres_unipc.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
import math
|
| 4 |
+
import traceback
|
| 5 |
+
from modules import shared
|
| 6 |
+
try:
|
| 7 |
+
from modules.models.diffusion import uni_pc
|
| 8 |
+
except Exception as e:
|
| 9 |
+
from modules import unipc as uni_pc
|
| 10 |
+
|
| 11 |
+
######################### UniPC Implementation logic #########################
|
| 12 |
+
|
| 13 |
+
# The majority of this is straight from modules.models/diffusion/uni_pc/sampler.py
|
| 14 |
+
# Unfortunately that's not an easy middle-injection point, so, just copypasta'd it all
|
| 15 |
+
# It's like they designed it to intentionally be as difficult to inject into as possible :(
|
| 16 |
+
# (It has hooks but not in useful locations)
|
| 17 |
+
# I stripped the original comments for brevity.
|
| 18 |
+
# Some never-used code (scheduler modes, noise modes, guidance modes) have been removed as well for brevity.
|
| 19 |
+
# The actual impl comes down to just the last line in particular, and the `before_sample` insert to track step count.
|
| 20 |
+
|
| 21 |
+
class CustomUniPCSampler(uni_pc.sampler.UniPCSampler):
|
| 22 |
+
def __init__(self, model, **kwargs):
|
| 23 |
+
super().__init__(model, *kwargs)
|
| 24 |
+
@torch.no_grad()
|
| 25 |
+
def sample(self, S, batch_size, shape, conditioning=None, callback=None, normals_sequence=None, img_callback=None,
|
| 26 |
+
quantize_x0=False, eta=0., mask=None, x0=None, temperature=1., noise_dropout=0., score_corrector=None,
|
| 27 |
+
corrector_kwargs=None, verbose=True, x_T=None, log_every_t=100, unconditional_guidance_scale=1.,
|
| 28 |
+
unconditional_conditioning=None, **kwargs):
|
| 29 |
+
if conditioning is not None:
|
| 30 |
+
if isinstance(conditioning, dict):
|
| 31 |
+
ctmp = conditioning[list(conditioning.keys())[0]]
|
| 32 |
+
while isinstance(ctmp, list): ctmp = ctmp[0]
|
| 33 |
+
cbs = ctmp.shape[0]
|
| 34 |
+
if cbs != batch_size:
|
| 35 |
+
print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
|
| 36 |
+
|
| 37 |
+
elif isinstance(conditioning, list):
|
| 38 |
+
for ctmp in conditioning:
|
| 39 |
+
if ctmp.shape[0] != batch_size:
|
| 40 |
+
print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
|
| 41 |
+
else:
|
| 42 |
+
if conditioning.shape[0] != batch_size:
|
| 43 |
+
print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
|
| 44 |
+
C, H, W = shape
|
| 45 |
+
size = (batch_size, C, H, W)
|
| 46 |
+
device = self.model.betas.device
|
| 47 |
+
if x_T is None:
|
| 48 |
+
img = torch.randn(size, device=device)
|
| 49 |
+
else:
|
| 50 |
+
img = x_T
|
| 51 |
+
ns = uni_pc.uni_pc.NoiseScheduleVP('discrete', alphas_cumprod=self.alphas_cumprod)
|
| 52 |
+
model_type = "v" if self.model.parameterization == "v" else "noise"
|
| 53 |
+
model_fn = CustomUniPC_model_wrapper(lambda x, t, c: self.model.apply_model(x, t, c), ns, model_type=model_type, guidance_scale=unconditional_guidance_scale, dt_data=self.main_class)
|
| 54 |
+
self.main_class.step = 0
|
| 55 |
+
def before_sample(x, t, cond, uncond):
|
| 56 |
+
self.main_class.step += 1
|
| 57 |
+
return self.before_sample(x, t, cond, uncond)
|
| 58 |
+
uni_pc_inst = uni_pc.uni_pc.UniPC(model_fn, ns, predict_x0=True, thresholding=False, variant=shared.opts.uni_pc_variant, condition=conditioning, unconditional_condition=unconditional_conditioning, before_sample=before_sample, after_sample=self.after_sample, after_update=self.after_update)
|
| 59 |
+
x = uni_pc_inst.sample(img, steps=S, skip_type=shared.opts.uni_pc_skip_type, method="multistep", order=shared.opts.uni_pc_order, lower_order_final=shared.opts.uni_pc_lower_order_final)
|
| 60 |
+
return x.to(device), None
|
| 61 |
+
|
| 62 |
+
def CustomUniPC_model_wrapper(model, noise_schedule, model_type="noise", model_kwargs={}, guidance_scale=1.0, dt_data=None):
|
| 63 |
+
def expand_dims(v, dims):
|
| 64 |
+
return v[(...,) + (None,)*(dims - 1)]
|
| 65 |
+
def get_model_input_time(t_continuous):
|
| 66 |
+
return (t_continuous - 1. / noise_schedule.total_N) * 1000.
|
| 67 |
+
def noise_pred_fn(x, t_continuous, cond=None):
|
| 68 |
+
if t_continuous.reshape((-1,)).shape[0] == 1:
|
| 69 |
+
t_continuous = t_continuous.expand((x.shape[0]))
|
| 70 |
+
t_input = get_model_input_time(t_continuous)
|
| 71 |
+
if cond is None:
|
| 72 |
+
output = model(x, t_input, None, **model_kwargs)
|
| 73 |
+
else:
|
| 74 |
+
output = model(x, t_input, cond, **model_kwargs)
|
| 75 |
+
if model_type == "noise":
|
| 76 |
+
return output
|
| 77 |
+
elif model_type == "v":
|
| 78 |
+
alpha_t, sigma_t = noise_schedule.marginal_alpha(t_continuous), noise_schedule.marginal_std(t_continuous)
|
| 79 |
+
dims = x.dim()
|
| 80 |
+
return expand_dims(alpha_t, dims) * output + expand_dims(sigma_t, dims) * x
|
| 81 |
+
def model_fn(x, t_continuous, condition, unconditional_condition):
|
| 82 |
+
if t_continuous.reshape((-1,)).shape[0] == 1:
|
| 83 |
+
t_continuous = t_continuous.expand((x.shape[0]))
|
| 84 |
+
if guidance_scale == 1. or unconditional_condition is None:
|
| 85 |
+
return noise_pred_fn(x, t_continuous, cond=condition)
|
| 86 |
+
else:
|
| 87 |
+
x_in = torch.cat([x] * 2)
|
| 88 |
+
t_in = torch.cat([t_continuous] * 2)
|
| 89 |
+
if isinstance(condition, dict):
|
| 90 |
+
assert isinstance(unconditional_condition, dict)
|
| 91 |
+
c_in = dict()
|
| 92 |
+
for k in condition:
|
| 93 |
+
if isinstance(condition[k], list):
|
| 94 |
+
c_in[k] = [torch.cat([
|
| 95 |
+
unconditional_condition[k][i],
|
| 96 |
+
condition[k][i]]) for i in range(len(condition[k]))]
|
| 97 |
+
else:
|
| 98 |
+
c_in[k] = torch.cat([
|
| 99 |
+
unconditional_condition[k],
|
| 100 |
+
condition[k]])
|
| 101 |
+
elif isinstance(condition, list):
|
| 102 |
+
c_in = list()
|
| 103 |
+
assert isinstance(unconditional_condition, list)
|
| 104 |
+
for i in range(len(condition)):
|
| 105 |
+
c_in.append(torch.cat([unconditional_condition[i], condition[i]]))
|
| 106 |
+
else:
|
| 107 |
+
c_in = torch.cat([unconditional_condition, condition])
|
| 108 |
+
noise_uncond, noise = noise_pred_fn(x_in, t_in, cond=c_in).chunk(2)
|
| 109 |
+
#return noise_uncond + guidance_scale * (noise - noise_uncond)
|
| 110 |
+
return dt_data.dynthresh(noise, noise_uncond, guidance_scale, None)
|
| 111 |
+
return model_fn
|
extensions/1-sd-dynamic-thresholding/github/cat_demo_1.jpg
ADDED

|
extensions/1-sd-dynamic-thresholding/github/comfy_node.png
ADDED
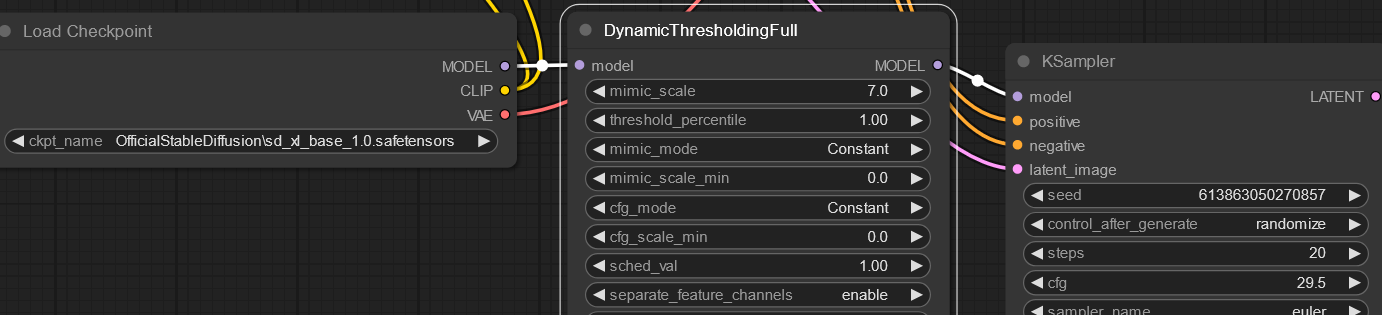
|
extensions/1-sd-dynamic-thresholding/github/grid_preview.png
ADDED

|
extensions/1-sd-dynamic-thresholding/github/ui.png
ADDED
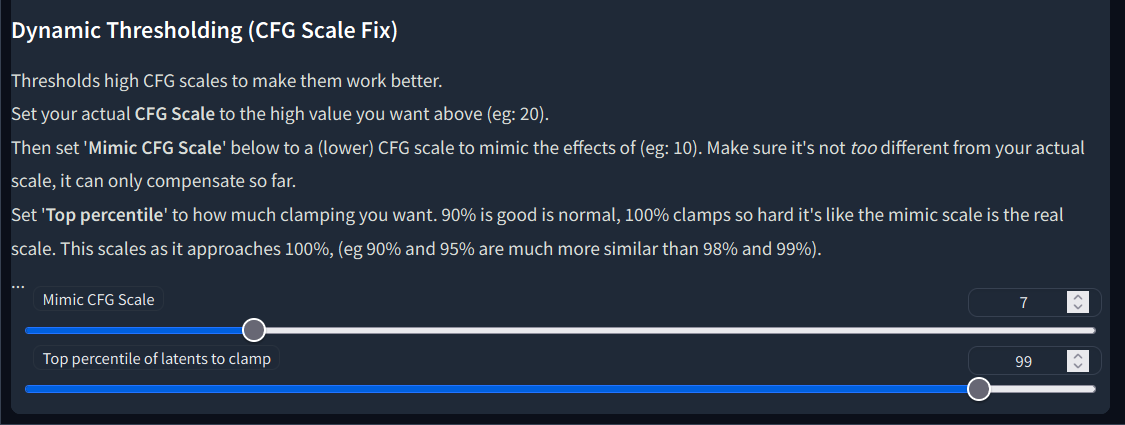
|
extensions/1-sd-dynamic-thresholding/javascript/active.js
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
let dynthres_update_enabled = function() {
|
| 2 |
+
return Array.from(arguments);
|
| 3 |
+
};
|
| 4 |
+
|
| 5 |
+
(function(){
|
| 6 |
+
let accordions = {};
|
| 7 |
+
let enabled = {};
|
| 8 |
+
onUiUpdate(() => {
|
| 9 |
+
let accordion_id_prefix = "#dynthres_";
|
| 10 |
+
let extension_checkbox_class = ".dynthres-enabled";
|
| 11 |
+
|
| 12 |
+
dynthres_update_enabled = function() {
|
| 13 |
+
let res = Array.from(arguments);
|
| 14 |
+
let tabname = res[1] ? "img2img" : "txt2img";
|
| 15 |
+
|
| 16 |
+
let checkbox = accordions[tabname]?.querySelector(extension_checkbox_class + ' input');
|
| 17 |
+
checkbox?.dispatchEvent(new Event('change'));
|
| 18 |
+
|
| 19 |
+
return res;
|
| 20 |
+
};
|
| 21 |
+
|
| 22 |
+
function attachEnabledButtonListener(checkbox, accordion) {
|
| 23 |
+
let span = accordion.querySelector('.label-wrap span');
|
| 24 |
+
let badge = document.createElement('input');
|
| 25 |
+
badge.type = "checkbox";
|
| 26 |
+
badge.checked = checkbox.checked;
|
| 27 |
+
badge.addEventListener('click', (e) => {
|
| 28 |
+
checkbox.checked = !checkbox.checked;
|
| 29 |
+
badge.checked = checkbox.checked;
|
| 30 |
+
checkbox.dispatchEvent(new Event('change'));
|
| 31 |
+
e.stopPropagation();
|
| 32 |
+
});
|
| 33 |
+
|
| 34 |
+
badge.className = checkbox.className;
|
| 35 |
+
badge.classList.add('primary');
|
| 36 |
+
span.insertBefore(badge, span.firstChild);
|
| 37 |
+
let space = document.createElement('span');
|
| 38 |
+
space.innerHTML = " ";
|
| 39 |
+
span.insertBefore(space, badge.nextSibling);
|
| 40 |
+
|
| 41 |
+
checkbox.addEventListener('change', () => {
|
| 42 |
+
let badge = accordion.querySelector('.label-wrap span input');
|
| 43 |
+
badge.checked = checkbox.checked;
|
| 44 |
+
});
|
| 45 |
+
checkbox.parentNode.style.display = "none";
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
if (Object.keys(accordions).length < 2) {
|
| 49 |
+
let accordion = gradioApp().querySelector(accordion_id_prefix + 'txt2img');
|
| 50 |
+
if (accordion) {
|
| 51 |
+
accordions.txt2img = accordion;
|
| 52 |
+
}
|
| 53 |
+
accordion = gradioApp().querySelector(accordion_id_prefix + 'img2img');
|
| 54 |
+
if (accordion) {
|
| 55 |
+
accordions.img2img = accordion;
|
| 56 |
+
}
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
if (Object.keys(accordions).length > 0 && accordions.txt2img && !enabled.txt2img) {
|
| 60 |
+
enabled.txt2img = accordions.txt2img.querySelector(extension_checkbox_class + ' input');
|
| 61 |
+
attachEnabledButtonListener(enabled.txt2img, accordions.txt2img);
|
| 62 |
+
}
|
| 63 |
+
if (Object.keys(accordions).length > 0 && accordions.img2img && !enabled.img2img) {
|
| 64 |
+
enabled.img2img = accordions.img2img.querySelector(extension_checkbox_class + ' input');
|
| 65 |
+
attachEnabledButtonListener(enabled.img2img, accordions.img2img);
|
| 66 |
+
}
|
| 67 |
+
});
|
| 68 |
+
})();
|
extensions/1-sd-dynamic-thresholding/pyproject.toml
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
name = "sd-dynamic-thresholding"
|
| 3 |
+
description = "Adds nodes for Dynamic Thresholding, CFG scheduling, and related techniques"
|
| 4 |
+
version = "1.0.1"
|
| 5 |
+
license = { file = "LICENSE.txt" }
|
| 6 |
+
|
| 7 |
+
[project.urls]
|
| 8 |
+
Repository = "https://github.com/mcmonkeyprojects/sd-dynamic-thresholding"
|
| 9 |
+
|
| 10 |
+
[tool.comfy]
|
| 11 |
+
PublisherId = "mcmonkey"
|
| 12 |
+
DisplayName = "Dynamic Thresholding"
|
| 13 |
+
Icon = ""
|
extensions/1-sd-dynamic-thresholding/scripts/__pycache__/dynamic_thresholding.cpython-310.pyc
ADDED
|
Binary file (12.7 kB). View file
|
|
|
extensions/1-sd-dynamic-thresholding/scripts/dynamic_thresholding.py
ADDED
|
@@ -0,0 +1,270 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##################
|
| 2 |
+
# Stable Diffusion Dynamic Thresholding (CFG Scale Fix)
|
| 3 |
+
#
|
| 4 |
+
# Author: Alex 'mcmonkey' Goodwin
|
| 5 |
+
# GitHub URL: https://github.com/mcmonkeyprojects/sd-dynamic-thresholding
|
| 6 |
+
# Created: 2022/01/26
|
| 7 |
+
# Last updated: 2023/01/30
|
| 8 |
+
#
|
| 9 |
+
# For usage help, view the README.md file in the extension root, or via the GitHub page.
|
| 10 |
+
#
|
| 11 |
+
##################
|
| 12 |
+
|
| 13 |
+
import gradio as gr
|
| 14 |
+
import torch, traceback
|
| 15 |
+
import dynthres_core
|
| 16 |
+
from modules import scripts, script_callbacks, sd_samplers, sd_samplers_compvis, sd_samplers_common
|
| 17 |
+
try:
|
| 18 |
+
import dynthres_unipc
|
| 19 |
+
except Exception as e:
|
| 20 |
+
print(f"\n\n======\nError! UniPC sampler support failed to load! Is your WebUI up to date?\n(Error: {e})\n======")
|
| 21 |
+
try:
|
| 22 |
+
from modules.sd_samplers_kdiffusion import CFGDenoiserKDiffusion as cfgdenoisekdiff
|
| 23 |
+
IS_AUTO_16 = True
|
| 24 |
+
except Exception as e:
|
| 25 |
+
print(f"\n\n======\nWarning! Using legacy KDiff version! Is your WebUI up to date?\n======")
|
| 26 |
+
from modules.sd_samplers_kdiffusion import CFGDenoiser as cfgdenoisekdiff
|
| 27 |
+
IS_AUTO_16 = False
|
| 28 |
+
|
| 29 |
+
DISABLE_VISIBILITY = True
|
| 30 |
+
|
| 31 |
+
######################### Data values #########################
|
| 32 |
+
MODES_WITH_VALUE = ["Power Up", "Power Down", "Linear Repeating", "Cosine Repeating", "Sawtooth"]
|
| 33 |
+
|
| 34 |
+
######################### Script class entrypoint #########################
|
| 35 |
+
class Script(scripts.Script):
|
| 36 |
+
|
| 37 |
+
def title(self):
|
| 38 |
+
return "Dynamic Thresholding (CFG Scale Fix)"
|
| 39 |
+
|
| 40 |
+
def show(self, is_img2img):
|
| 41 |
+
return scripts.AlwaysVisible
|
| 42 |
+
|
| 43 |
+
def ui(self, is_img2img):
|
| 44 |
+
def vis_change(is_vis):
|
| 45 |
+
return {"visible": is_vis, "__type__": "update"}
|
| 46 |
+
# "Dynamic Thresholding (CFG Scale Fix)"
|
| 47 |
+
dtrue = gr.Checkbox(value=True, visible=False)
|
| 48 |
+
dfalse = gr.Checkbox(value=False, visible=False)
|
| 49 |
+
with gr.Accordion("Dynamic Thresholding (CFG Scale Fix)", open=False, elem_id="dynthres_" + ("img2img" if is_img2img else "txt2img")):
|
| 50 |
+
with gr.Row():
|
| 51 |
+
enabled = gr.Checkbox(value=False, label="Enable Dynamic Thresholding (CFG Scale Fix)", elem_classes=["dynthres-enabled"], elem_id='dynthres_enabled')
|
| 52 |
+
with gr.Group():
|
| 53 |
+
gr.HTML(value=f"View <a style=\"border-bottom: 1px #00ffff dotted;\" href=\"https://github.com/mcmonkeyprojects/sd-dynamic-thresholding/wiki/Usage-Tips\">the wiki for usage tips.</a><br><br>", elem_id='dynthres_wiki_link')
|
| 54 |
+
mimic_scale = gr.Slider(minimum=1.0, maximum=30.0, step=0.5, label='Mimic CFG Scale', value=7.0, elem_id='dynthres_mimic_scale')
|
| 55 |
+
with gr.Accordion("Advanced Options", open=False, elem_id='dynthres_advanced_opts'):
|
| 56 |
+
with gr.Row():
|
| 57 |
+
threshold_percentile = gr.Slider(minimum=90.0, value=100.0, maximum=100.0, step=0.05, label='Top percentile of latents to clamp', elem_id='dynthres_threshold_percentile')
|
| 58 |
+
interpolate_phi = gr.Slider(minimum=0.0, maximum=1.0, step=0.01, label="Interpolate Phi", value=1.0, elem_id='dynthres_interpolate_phi')
|
| 59 |
+
with gr.Row():
|
| 60 |
+
mimic_mode = gr.Dropdown(dynthres_core.DynThresh.Modes, value="Constant", label="Mimic Scale Scheduler", elem_id='dynthres_mimic_mode')
|
| 61 |
+
cfg_mode = gr.Dropdown(dynthres_core.DynThresh.Modes, value="Constant", label="CFG Scale Scheduler", elem_id='dynthres_cfg_mode')
|
| 62 |
+
mimic_scale_min = gr.Slider(minimum=0.0, maximum=30.0, step=0.5, visible=DISABLE_VISIBILITY, label="Minimum value of the Mimic Scale Scheduler", elem_id='dynthres_mimic_scale_min')
|
| 63 |
+
cfg_scale_min = gr.Slider(minimum=0.0, maximum=30.0, step=0.5, visible=DISABLE_VISIBILITY, label="Minimum value of the CFG Scale Scheduler", elem_id='dynthres_cfg_scale_min')
|
| 64 |
+
sched_val = gr.Slider(minimum=0.0, maximum=40.0, step=0.5, value=4.0, visible=DISABLE_VISIBILITY, label="Scheduler Value", info="Value unique to the scheduler mode - for Power Up/Down, this is the power. For Linear/Cosine Repeating, this is the number of repeats per image.", elem_id='dynthres_sched_val')
|
| 65 |
+
with gr.Row():
|
| 66 |
+
separate_feature_channels = gr.Checkbox(value=True, label="Separate Feature Channels", elem_id='dynthres_separate_feature_channels')
|
| 67 |
+
scaling_startpoint = gr.Radio(["ZERO", "MEAN"], value="MEAN", label="Scaling Startpoint")
|
| 68 |
+
variability_measure = gr.Radio(["STD", "AD"], value="AD", label="Variability Measure")
|
| 69 |
+
def should_show_scheduler_value(cfg_mode, mimic_mode):
|
| 70 |
+
sched_vis = cfg_mode in MODES_WITH_VALUE or mimic_mode in MODES_WITH_VALUE or DISABLE_VISIBILITY
|
| 71 |
+
return vis_change(sched_vis), vis_change(mimic_mode != "Constant" or DISABLE_VISIBILITY), vis_change(cfg_mode != "Constant" or DISABLE_VISIBILITY)
|
| 72 |
+
cfg_mode.change(should_show_scheduler_value, inputs=[cfg_mode, mimic_mode], outputs=[sched_val, mimic_scale_min, cfg_scale_min])
|
| 73 |
+
mimic_mode.change(should_show_scheduler_value, inputs=[cfg_mode, mimic_mode], outputs=[sched_val, mimic_scale_min, cfg_scale_min])
|
| 74 |
+
enabled.change(
|
| 75 |
+
_js="dynthres_update_enabled",
|
| 76 |
+
fn=None,
|
| 77 |
+
inputs=[enabled, dtrue if is_img2img else dfalse],
|
| 78 |
+
show_progress = False)
|
| 79 |
+
self.infotext_fields = (
|
| 80 |
+
(enabled, lambda d: gr.Checkbox.update(value="Dynamic thresholding enabled" in d)),
|
| 81 |
+
(mimic_scale, "Mimic scale"),
|
| 82 |
+
(separate_feature_channels, "Separate Feature Channels"),
|
| 83 |
+
(scaling_startpoint, lambda d: gr.Radio.update(value=d.get("Scaling Startpoint", "MEAN"))),
|
| 84 |
+
(variability_measure, lambda d: gr.Radio.update(value=d.get("Variability Measure", "AD"))),
|
| 85 |
+
(interpolate_phi, "Interpolate Phi"),
|
| 86 |
+
(threshold_percentile, "Threshold percentile"),
|
| 87 |
+
(mimic_scale_min, "Mimic scale minimum"),
|
| 88 |
+
(mimic_mode, lambda d: gr.Dropdown.update(value=d.get("Mimic mode", "Constant"))),
|
| 89 |
+
(cfg_mode, lambda d: gr.Dropdown.update(value=d.get("CFG mode", "Constant"))),
|
| 90 |
+
(cfg_scale_min, "CFG scale minimum"),
|
| 91 |
+
(sched_val, "Scheduler value"))
|
| 92 |
+
return [enabled, mimic_scale, threshold_percentile, mimic_mode, mimic_scale_min, cfg_mode, cfg_scale_min, sched_val, separate_feature_channels, scaling_startpoint, variability_measure, interpolate_phi]
|
| 93 |
+
|
| 94 |
+
last_id = 0
|
| 95 |
+
|
| 96 |
+
def process_batch(self, p, enabled, mimic_scale, threshold_percentile, mimic_mode, mimic_scale_min, cfg_mode, cfg_scale_min, sched_val, separate_feature_channels, scaling_startpoint, variability_measure, interpolate_phi, batch_number, prompts, seeds, subseeds):
|
| 97 |
+
enabled = getattr(p, 'dynthres_enabled', enabled)
|
| 98 |
+
if not enabled:
|
| 99 |
+
return
|
| 100 |
+
orig_sampler_name = p.sampler_name
|
| 101 |
+
orig_latent_sampler_name = getattr(p, 'latent_sampler', None)
|
| 102 |
+
if orig_sampler_name in ["DDIM", "PLMS"]:
|
| 103 |
+
raise RuntimeError(f"Cannot use sampler {orig_sampler_name} with Dynamic Thresholding")
|
| 104 |
+
if orig_latent_sampler_name in ["DDIM", "PLMS"]:
|
| 105 |
+
raise RuntimeError(f"Cannot use secondary sampler {orig_latent_sampler_name} with Dynamic Thresholding")
|
| 106 |
+
if 'UniPC' in (orig_sampler_name, orig_latent_sampler_name) and p.enable_hr:
|
| 107 |
+
raise RuntimeError(f"UniPC does not support Hires Fix. Auto WebUI silently swaps to DDIM for this, which DynThresh does not support. Please swap to a sampler capable of img2img processing for HR Fix to work.")
|
| 108 |
+
mimic_scale = getattr(p, 'dynthres_mimic_scale', mimic_scale)
|
| 109 |
+
separate_feature_channels = getattr(p, 'dynthres_separate_feature_channels', separate_feature_channels)
|
| 110 |
+
scaling_startpoint = getattr(p, 'dynthres_scaling_startpoint', scaling_startpoint)
|
| 111 |
+
variability_measure = getattr(p, 'dynthres_variability_measure', variability_measure)
|
| 112 |
+
interpolate_phi = getattr(p, 'dynthres_interpolate_phi', interpolate_phi)
|
| 113 |
+
threshold_percentile = getattr(p, 'dynthres_threshold_percentile', threshold_percentile)
|
| 114 |
+
mimic_mode = getattr(p, 'dynthres_mimic_mode', mimic_mode)
|
| 115 |
+
mimic_scale_min = getattr(p, 'dynthres_mimic_scale_min', mimic_scale_min)
|
| 116 |
+
cfg_mode = getattr(p, 'dynthres_cfg_mode', cfg_mode)
|
| 117 |
+
cfg_scale_min = getattr(p, 'dynthres_cfg_scale_min', cfg_scale_min)
|
| 118 |
+
experiment_mode = getattr(p, 'dynthres_experiment_mode', 0)
|
| 119 |
+
sched_val = getattr(p, 'dynthres_scheduler_val', sched_val)
|
| 120 |
+
p.extra_generation_params["Dynamic thresholding enabled"] = True
|
| 121 |
+
p.extra_generation_params["Mimic scale"] = mimic_scale
|
| 122 |
+
p.extra_generation_params["Separate Feature Channels"] = separate_feature_channels
|
| 123 |
+
p.extra_generation_params["Scaling Startpoint"] = scaling_startpoint
|
| 124 |
+
p.extra_generation_params["Variability Measure"] = variability_measure
|
| 125 |
+
p.extra_generation_params["Interpolate Phi"] = interpolate_phi
|
| 126 |
+
p.extra_generation_params["Threshold percentile"] = threshold_percentile
|
| 127 |
+
p.extra_generation_params["Sampler"] = orig_sampler_name
|
| 128 |
+
if mimic_mode != "Constant":
|
| 129 |
+
p.extra_generation_params["Mimic mode"] = mimic_mode
|
| 130 |
+
p.extra_generation_params["Mimic scale minimum"] = mimic_scale_min
|
| 131 |
+
if cfg_mode != "Constant":
|
| 132 |
+
p.extra_generation_params["CFG mode"] = cfg_mode
|
| 133 |
+
p.extra_generation_params["CFG scale minimum"] = cfg_scale_min
|
| 134 |
+
if cfg_mode in MODES_WITH_VALUE or mimic_mode in MODES_WITH_VALUE:
|
| 135 |
+
p.extra_generation_params["Scheduler value"] = sched_val
|
| 136 |
+
# Note: the ID number is to protect the edge case of multiple simultaneous runs with different settings
|
| 137 |
+
Script.last_id += 1
|
| 138 |
+
# Percentage to portion
|
| 139 |
+
threshold_percentile *= 0.01
|
| 140 |
+
|
| 141 |
+
def make_sampler(orig_sampler_name):
|
| 142 |
+
fixed_sampler_name = f"{orig_sampler_name}_dynthres{Script.last_id}"
|
| 143 |
+
|
| 144 |
+
# Make a placeholder sampler
|
| 145 |
+
sampler = sd_samplers.all_samplers_map[orig_sampler_name]
|
| 146 |
+
dt_data = dynthres_core.DynThresh(mimic_scale, threshold_percentile, mimic_mode, mimic_scale_min, cfg_mode, cfg_scale_min, sched_val, experiment_mode, p.steps, separate_feature_channels, scaling_startpoint, variability_measure, interpolate_phi)
|
| 147 |
+
if orig_sampler_name == "UniPC":
|
| 148 |
+
def unipc_constructor(model):
|
| 149 |
+
return CustomVanillaSDSampler(dynthres_unipc.CustomUniPCSampler, model, dt_data)
|
| 150 |
+
new_sampler = sd_samplers_common.SamplerData(fixed_sampler_name, unipc_constructor, sampler.aliases, sampler.options)
|
| 151 |
+
else:
|
| 152 |
+
def new_constructor(model):
|
| 153 |
+
result = sampler.constructor(model)
|
| 154 |
+
cfg = CustomCFGDenoiser(result if IS_AUTO_16 else result.model_wrap_cfg.inner_model, dt_data)
|
| 155 |
+
result.model_wrap_cfg = cfg
|
| 156 |
+
return result
|
| 157 |
+
new_sampler = sd_samplers_common.SamplerData(fixed_sampler_name, new_constructor, sampler.aliases, sampler.options)
|
| 158 |
+
return fixed_sampler_name, new_sampler
|
| 159 |
+
|
| 160 |
+
# Apply for usage
|
| 161 |
+
p.orig_sampler_name = orig_sampler_name
|
| 162 |
+
p.orig_latent_sampler_name = orig_latent_sampler_name
|
| 163 |
+
p.fixed_samplers = []
|
| 164 |
+
|
| 165 |
+
if orig_latent_sampler_name:
|
| 166 |
+
latent_sampler_name, latent_sampler = make_sampler(orig_latent_sampler_name)
|
| 167 |
+
sd_samplers.all_samplers_map[latent_sampler_name] = latent_sampler
|
| 168 |
+
p.fixed_samplers.append(latent_sampler_name)
|
| 169 |
+
p.latent_sampler = latent_sampler_name
|
| 170 |
+
|
| 171 |
+
if orig_sampler_name != orig_latent_sampler_name:
|
| 172 |
+
p.sampler_name, new_sampler = make_sampler(orig_sampler_name)
|
| 173 |
+
sd_samplers.all_samplers_map[p.sampler_name] = new_sampler
|
| 174 |
+
p.fixed_samplers.append(p.sampler_name)
|
| 175 |
+
else:
|
| 176 |
+
p.sampler_name = p.latent_sampler
|
| 177 |
+
|
| 178 |
+
if p.sampler is not None:
|
| 179 |
+
p.sampler = sd_samplers.create_sampler(p.sampler_name, p.sd_model)
|
| 180 |
+
|
| 181 |
+
def postprocess_batch(self, p, enabled, mimic_scale, threshold_percentile, mimic_mode, mimic_scale_min, cfg_mode, cfg_scale_min, sched_val, separate_feature_channels, scaling_startpoint, variability_measure, interpolate_phi, batch_number, images):
|
| 182 |
+
if not enabled or not hasattr(p, 'orig_sampler_name'):
|
| 183 |
+
return
|
| 184 |
+
p.sampler_name = p.orig_sampler_name
|
| 185 |
+
if p.orig_latent_sampler_name:
|
| 186 |
+
p.latent_sampler = p.orig_latent_sampler_name
|
| 187 |
+
for added_sampler in p.fixed_samplers:
|
| 188 |
+
del sd_samplers.all_samplers_map[added_sampler]
|
| 189 |
+
del p.fixed_samplers
|
| 190 |
+
del p.orig_sampler_name
|
| 191 |
+
del p.orig_latent_sampler_name
|
| 192 |
+
|
| 193 |
+
######################### CompVis Implementation logic #########################
|
| 194 |
+
|
| 195 |
+
class CustomVanillaSDSampler(sd_samplers_compvis.VanillaStableDiffusionSampler):
|
| 196 |
+
def __init__(self, constructor, sd_model, dt_data):
|
| 197 |
+
super().__init__(constructor, sd_model)
|
| 198 |
+
self.sampler.main_class = dt_data
|
| 199 |
+
|
| 200 |
+
######################### K-Diffusion Implementation logic #########################
|
| 201 |
+
|
| 202 |
+
class CustomCFGDenoiser(cfgdenoisekdiff):
|
| 203 |
+
def __init__(self, model, dt_data):
|
| 204 |
+
super().__init__(model)
|
| 205 |
+
self.main_class = dt_data
|
| 206 |
+
|
| 207 |
+
def combine_denoised(self, x_out, conds_list, uncond, cond_scale):
|
| 208 |
+
if isinstance(uncond, dict) and 'crossattn' in uncond:
|
| 209 |
+
uncond = uncond['crossattn']
|
| 210 |
+
denoised_uncond = x_out[-uncond.shape[0]:]
|
| 211 |
+
# conds_list shape is (batch, cond, 2)
|
| 212 |
+
weights = torch.tensor(conds_list, device=uncond.device).select(2, 1)
|
| 213 |
+
weights = weights.reshape(*weights.shape, 1, 1, 1)
|
| 214 |
+
self.main_class.step = self.step
|
| 215 |
+
if hasattr(self, 'total_steps'):
|
| 216 |
+
self.main_class.max_steps = self.total_steps
|
| 217 |
+
|
| 218 |
+
if self.main_class.experiment_mode >= 4 and self.main_class.experiment_mode <= 5:
|
| 219 |
+
# https://arxiv.org/pdf/2305.08891.pdf "Rescale CFG". It's not good, but if you want to test it, just set experiment_mode = 4 + phi.
|
| 220 |
+
denoised = torch.clone(denoised_uncond)
|
| 221 |
+
fi = self.main_class.experiment_mode - 4.0
|
| 222 |
+
for i, conds in enumerate(conds_list):
|
| 223 |
+
for cond_index, weight in conds:
|
| 224 |
+
xcfg = (denoised_uncond[i] + (x_out[cond_index] - denoised_uncond[i]) * (cond_scale * weight))
|
| 225 |
+
xrescaled = xcfg * (torch.std(x_out[cond_index]) / torch.std(xcfg))
|
| 226 |
+
xfinal = fi * xrescaled + (1.0 - fi) * xcfg
|
| 227 |
+
denoised[i] = xfinal
|
| 228 |
+
return denoised
|
| 229 |
+
|
| 230 |
+
return self.main_class.dynthresh(x_out[:-uncond.shape[0]], denoised_uncond, cond_scale, weights)
|
| 231 |
+
|
| 232 |
+
######################### XYZ Plot Script Support logic #########################
|
| 233 |
+
|
| 234 |
+
def make_axis_options():
|
| 235 |
+
xyz_grid = [x for x in scripts.scripts_data if x.script_class.__module__ in ("xyz_grid.py", "scripts.xyz_grid")][0].module
|
| 236 |
+
def apply_mimic_scale(p, x, xs):
|
| 237 |
+
if x != 0:
|
| 238 |
+
setattr(p, "dynthres_enabled", True)
|
| 239 |
+
setattr(p, "dynthres_mimic_scale", x)
|
| 240 |
+
else:
|
| 241 |
+
setattr(p, "dynthres_enabled", False)
|
| 242 |
+
def confirm_scheduler(p, xs):
|
| 243 |
+
for x in xs:
|
| 244 |
+
if x not in dynthres_core.DynThresh.Modes:
|
| 245 |
+
raise RuntimeError(f"Unknown Scheduler: {x}")
|
| 246 |
+
extra_axis_options = [
|
| 247 |
+
xyz_grid.AxisOption("[DynThres] Mimic Scale", float, apply_mimic_scale),
|
| 248 |
+
xyz_grid.AxisOption("[DynThres] Separate Feature Channels", int,
|
| 249 |
+
xyz_grid.apply_field("dynthres_separate_feature_channels")),
|
| 250 |
+
xyz_grid.AxisOption("[DynThres] Scaling Startpoint", str, xyz_grid.apply_field("dynthres_scaling_startpoint"), choices=lambda:['ZERO', 'MEAN']),
|
| 251 |
+
xyz_grid.AxisOption("[DynThres] Variability Measure", str, xyz_grid.apply_field("dynthres_variability_measure"), choices=lambda:['STD', 'AD']),
|
| 252 |
+
xyz_grid.AxisOption("[DynThres] Interpolate Phi", float, xyz_grid.apply_field("dynthres_interpolate_phi")),
|
| 253 |
+
xyz_grid.AxisOption("[DynThres] Threshold Percentile", float, xyz_grid.apply_field("dynthres_threshold_percentile")),
|
| 254 |
+
xyz_grid.AxisOption("[DynThres] Mimic Scheduler", str, xyz_grid.apply_field("dynthres_mimic_mode"), confirm=confirm_scheduler, choices=lambda: dynthres_core.DynThresh.Modes),
|
| 255 |
+
xyz_grid.AxisOption("[DynThres] Mimic minimum", float, xyz_grid.apply_field("dynthres_mimic_scale_min")),
|
| 256 |
+
xyz_grid.AxisOption("[DynThres] CFG Scheduler", str, xyz_grid.apply_field("dynthres_cfg_mode"), confirm=confirm_scheduler, choices=lambda: dynthres_core.DynThresh.Modes),
|
| 257 |
+
xyz_grid.AxisOption("[DynThres] CFG minimum", float, xyz_grid.apply_field("dynthres_cfg_scale_min")),
|
| 258 |
+
xyz_grid.AxisOption("[DynThres] Scheduler value", float, xyz_grid.apply_field("dynthres_scheduler_val"))
|
| 259 |
+
]
|
| 260 |
+
if not any("[DynThres]" in x.label for x in xyz_grid.axis_options):
|
| 261 |
+
xyz_grid.axis_options.extend(extra_axis_options)
|
| 262 |
+
|
| 263 |
+
def callback_before_ui():
|
| 264 |
+
try:
|
| 265 |
+
make_axis_options()
|
| 266 |
+
except Exception as e:
|
| 267 |
+
traceback.print_exc()
|
| 268 |
+
print(f"Failed to add support for X/Y/Z Plot Script because: {e}")
|
| 269 |
+
|
| 270 |
+
script_callbacks.on_before_ui(callback_before_ui)
|
extensions/ABG_extension/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
scripts/__pycache__
|
extensions/ABG_extension/README.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<h3 align="center">
|
| 2 |
+
<b>ABG extension</b>
|
| 3 |
+
</h3>
|
| 4 |
+
|
| 5 |
+
<p align="center">
|
| 6 |
+
<a href="https://github.com/KutsuyaYuki/ABG_extension/stargazers"><img src="https://img.shields.io/github/stars/KutsuyaYuki/ABG_extension?style=for-the-badge"></a>
|
| 7 |
+
<a href="https://github.com/KutsuyaYuki/ABG_extension/issues"><img src="https://img.shields.io/github/issues/KutsuyaYuki/ABG_extension?style=for-the-badge"></a>
|
| 8 |
+
<a href="https://github.com/KutsuyaYuki/ABG_extension/commits/main"><img src="https://img.shields.io/github/last-commit/KutsuyaYuki/ABG_extension?style=for-the-badge"></a>
|
| 9 |
+
</p>
|
| 10 |
+
|
| 11 |
+
## Installation
|
| 12 |
+
|
| 13 |
+
1. Install extension by going to Extensions tab -> Install from URL -> Paste github URL and click Install.
|
| 14 |
+
2. After it's installed, go back to the Installed tab in Extensions and press Apply and restart UI.
|
| 15 |
+
3. Installation finished.
|
| 16 |
+
4. If the script does not show up or work, please restart the WebUI.
|
| 17 |
+
|
| 18 |
+
## Usage
|
| 19 |
+
|
| 20 |
+
### txt2img
|
| 21 |
+
|
| 22 |
+
1. In the bottom of the WebUI in Script, select **ABG Remover**.
|
| 23 |
+
2. Select the desired options: **Only save background free pictures** or **Do not auto save**.
|
| 24 |
+
3. Generate an image and you will see the result in the output area.
|
| 25 |
+
|
| 26 |
+
### img2img
|
| 27 |
+
|
| 28 |
+
1. In the bottom of the WebUI in Script, select **ABG Remover**.
|
| 29 |
+
2. Select the desired options: **Only save background free pictures** or **Do not auto save**.
|
| 30 |
+
3. **IMPORTANT**: Set **Denoising strength** to a low value, like **0.01**
|
| 31 |
+
|
| 32 |
+
Based on https://huggingface.co/spaces/skytnt/anime-remove-background
|
extensions/ABG_extension/install.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import launch
|
| 2 |
+
|
| 3 |
+
for dep in ['onnx', 'onnxruntime', 'numpy']:
|
| 4 |
+
if not launch.is_installed(dep):
|
| 5 |
+
launch.run_pip(f"install {dep}", f"{dep} for ABG_extension")
|
| 6 |
+
|
| 7 |
+
if not launch.is_installed("cv2"):
|
| 8 |
+
launch.run_pip("install opencv-python", "opencv-python")
|
| 9 |
+
|
| 10 |
+
if not launch.is_installed("PIL"):
|
| 11 |
+
launch.run_pip("install Pillow", "Pillow")
|
extensions/ABG_extension/scripts/__pycache__/app.cpython-310.pyc
ADDED
|
Binary file (4.23 kB). View file
|
|
|
extensions/ABG_extension/scripts/app.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import modules.scripts as scripts
|
| 3 |
+
from modules import images
|
| 4 |
+
from modules.processing import process_images, Processed
|
| 5 |
+
from modules.processing import Processed
|
| 6 |
+
from modules.shared import opts, cmd_opts, state
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
import huggingface_hub
|
| 10 |
+
import onnxruntime as rt
|
| 11 |
+
import copy
|
| 12 |
+
import numpy as np
|
| 13 |
+
import cv2
|
| 14 |
+
from PIL import Image as im, ImageDraw
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# Declare Execution Providers
|
| 18 |
+
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
|
| 19 |
+
|
| 20 |
+
# Download and host the model
|
| 21 |
+
model_path = huggingface_hub.hf_hub_download(
|
| 22 |
+
"skytnt/anime-seg", "isnetis.onnx")
|
| 23 |
+
rmbg_model = rt.InferenceSession(model_path, providers=providers)
|
| 24 |
+
|
| 25 |
+
# Function to get mask
|
| 26 |
+
def get_mask(img, s=1024):
|
| 27 |
+
# Resize the img to a square shape with dimension s
|
| 28 |
+
# Convert img pixel values from integers 0-255 to float 0-1
|
| 29 |
+
img = (img / 255).astype(np.float32)
|
| 30 |
+
# get the amount of dimensions of img
|
| 31 |
+
dim = img.shape[2]
|
| 32 |
+
# Convert the input image to RGB format if it has an alpha channel
|
| 33 |
+
if dim == 4:
|
| 34 |
+
img = img[..., :3]
|
| 35 |
+
dim = 3
|
| 36 |
+
# Get height and width of the image
|
| 37 |
+
h, w = h0, w0 = img.shape[:-1]
|
| 38 |
+
# IF height is greater than width, set h as s and w as s*width/height
|
| 39 |
+
# ELSE, set w as s and h as s*height/width
|
| 40 |
+
h, w = (s, int(s * w / h)) if h > w else (int(s * h / w), s)
|
| 41 |
+
# Calculate padding for height and width
|
| 42 |
+
ph, pw = s - h, s - w
|
| 43 |
+
# Create a 1024x1024x3 array of 0's
|
| 44 |
+
img_input = np.zeros([s, s, dim], dtype=np.float32)
|
| 45 |
+
# Resize the original image to (w,h) and then pad with the calculated ph,pw
|
| 46 |
+
img_input[ph // 2:ph // 2 + h, pw //
|
| 47 |
+
2:pw // 2 + w] = cv2.resize(img, (w, h))
|
| 48 |
+
# Change the axes
|
| 49 |
+
img_input = np.transpose(img_input, (2, 0, 1))
|
| 50 |
+
# Add an extra axis (1,0)
|
| 51 |
+
img_input = img_input[np.newaxis, :]
|
| 52 |
+
# Run the model to get the mask
|
| 53 |
+
mask = rmbg_model.run(None, {'img': img_input})[0][0]
|
| 54 |
+
# Transpose axis
|
| 55 |
+
mask = np.transpose(mask, (1, 2, 0))
|
| 56 |
+
# Crop it to the images original dimensions (h0,w0)
|
| 57 |
+
mask = mask[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w]
|
| 58 |
+
# Resize the mask to original image size (h0,w0)
|
| 59 |
+
mask = cv2.resize(mask, (w0, h0))[:, :, np.newaxis]
|
| 60 |
+
return mask
|
| 61 |
+
|
| 62 |
+
### Function to remove background
|
| 63 |
+
def rmbg_fn(img):
|
| 64 |
+
# Call get_mask() to get the mask
|
| 65 |
+
mask = get_mask(img)
|
| 66 |
+
# Multiply the image and the mask together to get the output image
|
| 67 |
+
img = (mask * img + 255 * (1 - mask)).astype(np.uint8)
|
| 68 |
+
# Convert mask value back to int 0-255
|
| 69 |
+
mask = (mask * 255).astype(np.uint8)
|
| 70 |
+
# Concatenate the output image and mask
|
| 71 |
+
img = np.concatenate([img, mask], axis=2, dtype=np.uint8)
|
| 72 |
+
# Stacking 3 identical copies of the mask for displaying
|
| 73 |
+
mask = mask.repeat(3, axis=2)
|
| 74 |
+
return mask, img
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class Script(scripts.Script):
|
| 78 |
+
is_txt2img = False
|
| 79 |
+
|
| 80 |
+
# Function to set title
|
| 81 |
+
def title(self):
|
| 82 |
+
return "ABG Remover"
|
| 83 |
+
|
| 84 |
+
def ui(self, is_img2img):
|
| 85 |
+
|
| 86 |
+
with gr.Column():
|
| 87 |
+
only_save_background_free_pictures = gr.Checkbox(
|
| 88 |
+
label='Only save background free pictures')
|
| 89 |
+
do_not_auto_save = gr.Checkbox(label='Do not auto save')
|
| 90 |
+
with gr.Row():
|
| 91 |
+
custom_background = gr.Checkbox(label='Custom Background')
|
| 92 |
+
custom_background_color = gr.ColorPicker(
|
| 93 |
+
label='Background Color', default='#ff0000')
|
| 94 |
+
custom_background_random = gr.Checkbox(
|
| 95 |
+
label='Random Custom Background')
|
| 96 |
+
|
| 97 |
+
return [only_save_background_free_pictures, do_not_auto_save, custom_background, custom_background_color, custom_background_random]
|
| 98 |
+
|
| 99 |
+
# Function to show the script
|
| 100 |
+
def show(self, is_img2img):
|
| 101 |
+
return True
|
| 102 |
+
|
| 103 |
+
# Function to run the script
|
| 104 |
+
def run(self, p, only_save_background_free_pictures, do_not_auto_save, custom_background, custom_background_color, custom_background_random):
|
| 105 |
+
# If only_save_background_free_pictures is true, set do_not_save_samples to true
|
| 106 |
+
if only_save_background_free_pictures:
|
| 107 |
+
p.do_not_save_samples = True
|
| 108 |
+
|
| 109 |
+
# Create a process_images object
|
| 110 |
+
proc = process_images(p)
|
| 111 |
+
|
| 112 |
+
has_grid = False
|
| 113 |
+
|
| 114 |
+
unwanted_grid_because_of_img_count = len(
|
| 115 |
+
proc.images) < 2 and opts.grid_only_if_multiple
|
| 116 |
+
if (opts.return_grid or opts.grid_save) and not p.do_not_save_grid and not unwanted_grid_because_of_img_count:
|
| 117 |
+
has_grid = True
|
| 118 |
+
|
| 119 |
+
# Loop through all the images in proc
|
| 120 |
+
for i in range(len(proc.images)):
|
| 121 |
+
# Separate the background from the foreground
|
| 122 |
+
nmask, nimg = rmbg_fn(np.array(proc.images[i]))
|
| 123 |
+
|
| 124 |
+
# Check the number of channels in the nimg array, select only the first 3 or 4 channels
|
| 125 |
+
num_channels = nimg.shape[2]
|
| 126 |
+
if num_channels > 4:
|
| 127 |
+
nimg = nimg[:, :, :4]
|
| 128 |
+
|
| 129 |
+
# Ensure the data type is uint8 and convert the image back to a format that can be saved
|
| 130 |
+
nimg = nimg.astype(np.uint8)
|
| 131 |
+
img = im.fromarray(nimg)
|
| 132 |
+
|
| 133 |
+
# If only_save_background_free_pictures is true, check if the image has a background
|
| 134 |
+
if custom_background or custom_background_random:
|
| 135 |
+
# If custom_background_random is true, set the background color to a random color
|
| 136 |
+
if custom_background_random:
|
| 137 |
+
custom_background_color = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
|
| 138 |
+
|
| 139 |
+
# Create a new image with the same size as the original image
|
| 140 |
+
background = im.new('RGBA', img.size, custom_background_color)
|
| 141 |
+
|
| 142 |
+
# Draw a colored rectangle onto the new image
|
| 143 |
+
draw = ImageDraw.Draw(background)
|
| 144 |
+
draw.rectangle([(0, 0), img.size],
|
| 145 |
+
fill=custom_background_color)
|
| 146 |
+
|
| 147 |
+
# Merge the two images
|
| 148 |
+
img = im.alpha_composite(background, img)
|
| 149 |
+
|
| 150 |
+
# determine output path
|
| 151 |
+
outpath = p.outpath_grids if has_grid and i == 0 else p.outpath_samples
|
| 152 |
+
|
| 153 |
+
# If we are saving all images, save the mask and the image
|
| 154 |
+
if not only_save_background_free_pictures:
|
| 155 |
+
mask = im.fromarray(nmask)
|
| 156 |
+
# Dot not save the new images if checkbox is checked
|
| 157 |
+
if not do_not_auto_save:
|
| 158 |
+
# Save the new images
|
| 159 |
+
images.save_image(
|
| 160 |
+
mask, outpath, "mask_", proc.seed + i, proc.prompt, "png", info=proc.info, p=p)
|
| 161 |
+
images.save_image(
|
| 162 |
+
img, outpath, "img_", proc.seed + i, proc.prompt, "png", info=proc.info, p=p)
|
| 163 |
+
# Add the images to the proc object
|
| 164 |
+
proc.images.append(mask)
|
| 165 |
+
proc.images.append(img)
|
| 166 |
+
# If we are only saving background-free images, save the image and replace it in the proc object
|
| 167 |
+
else:
|
| 168 |
+
proc.images[i] = img
|
| 169 |
+
|
| 170 |
+
# Check if automatic saving is enabled
|
| 171 |
+
if not do_not_auto_save:
|
| 172 |
+
# Check if the image is the first one and has a grid
|
| 173 |
+
if has_grid and i == 0:
|
| 174 |
+
# Save the image
|
| 175 |
+
images.save_image(img, p.outpath_grids, "grid", p.all_seeds[0], p.all_prompts[0],
|
| 176 |
+
opts.grid_format, info=proc.info, short_filename=not opts.grid_extended_filename, p=p)
|
| 177 |
+
else:
|
| 178 |
+
# Save the image
|
| 179 |
+
images.save_image(img, outpath, "", proc.seed,
|
| 180 |
+
proc.prompt, "png", info=proc.info, p=p)
|
| 181 |
+
|
| 182 |
+
# Return the proc object
|
| 183 |
+
return proc
|
extensions/Automatic1111-Geeky-Remb/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 GeekyGhost
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
extensions/Automatic1111-Geeky-Remb/README.md
ADDED
|
@@ -0,0 +1,258 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GeekyRemB: Advanced Background Removal for Automatic1111 Web UI
|
| 2 |
+
|
| 3 |
+
update 8/18/2024
|
| 4 |
+
|
| 5 |
+
Key Updates to the Code:
|
| 6 |
+
|
| 7 |
+
New Methods in GeekyRemB Class:
|
| 8 |
+
a) parse_aspect_ratio(self, aspect_ratio_input):
|
| 9 |
+
This method interprets the user's aspect ratio input. It can handle:
|
| 10 |
+
|
| 11 |
+
Ratio strings (e.g., "16:9")
|
| 12 |
+
Decimal values (e.g., "1.77")
|
| 13 |
+
Standard terms (e.g., "portrait", "landscape")
|
| 14 |
+
|
| 15 |
+
b) calculate_new_dimensions(self, orig_width, orig_height, scale, aspect_ratio):
|
| 16 |
+
This method calculates the new dimensions based on the original size, scale, and aspect ratio.
|
| 17 |
+
Updated remove_background Method:
|
| 18 |
+
The method now uses parse_aspect_ratio and calculate_new_dimensions to determine the new image dimensions.
|
| 19 |
+
UI Changes:
|
| 20 |
+
The foreground_aspect_ratio input is now a gr.Textbox with a more descriptive placeholder, allowing for more flexible input.
|
| 21 |
+
|
| 22 |
+
How to Use the New Aspect Ratio Feature:
|
| 23 |
+
|
| 24 |
+
Basic Usage:
|
| 25 |
+
In the "Foreground Adjustments" section, you'll find an input field labeled "Aspect Ratio". Here are the ways you can use it:
|
| 26 |
+
a) Leave it blank: This will maintain the original aspect ratio of your image.
|
| 27 |
+
b) Enter a ratio: You can input ratios like "16:9", "4:3", "1:1", etc. The format is "width:height".
|
| 28 |
+
c) Use decimal values: You can enter a single number representing width divided by height, e.g., "1.77" for 16:9.
|
| 29 |
+
d) Use standard terms: You can enter "portrait", "landscape", or "square".
|
| 30 |
+
Examples:
|
| 31 |
+
|
| 32 |
+
For a widescreen format, enter "16:9"
|
| 33 |
+
For a traditional TV format, enter "4:3"
|
| 34 |
+
For a square image, enter "1:1" or "square"
|
| 35 |
+
For a vertical video format, you might enter "9:16"
|
| 36 |
+
For a slight landscape format, you could enter "1.2" (which is equivalent to 6:5)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
Combining with Scale:
|
| 40 |
+
The aspect ratio works in conjunction with the "Scale" slider. Here's how they interact:
|
| 41 |
+
|
| 42 |
+
Scale determines the overall size of the image relative to its original size.
|
| 43 |
+
Aspect ratio determines the shape of the image.
|
| 44 |
+
|
| 45 |
+
For example:
|
| 46 |
+
|
| 47 |
+
If you set scale to 1.5 and aspect ratio to "16:9", the image will be enlarged by 50% and shaped to a 16:9 ratio.
|
| 48 |
+
If you set scale to 0.5 and aspect ratio to "1:1", the image will be shrunk by 50% and made square.
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
Special Considerations:
|
| 52 |
+
|
| 53 |
+
If you enter an invalid aspect ratio, the script will default to maintaining the original aspect ratio.
|
| 54 |
+
The aspect ratio is applied before other transformations like rotation or flipping.
|
| 55 |
+
When using custom terms like "portrait" or "landscape", the script uses preset ratios (3:4 for portrait, 4:3 for landscape).
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
Tips for Best Results:
|
| 59 |
+
|
| 60 |
+
For precise control, use numeric ratios (like "16:9") rather than terms like "landscape".
|
| 61 |
+
If you're targeting a specific output size, you may need to experiment with both the scale and aspect ratio settings.
|
| 62 |
+
Remember that extreme changes in aspect ratio might distort your image, especially if it contains people or recognizable objects.
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
Interaction with Other Features:
|
| 66 |
+
|
| 67 |
+
The aspect ratio is applied before positioning (X and Y position) and rotation.
|
| 68 |
+
If you're using a background image, you might want to consider its aspect ratio when setting the foreground aspect ratio for a cohesive look.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
<img width="1249" alt="Screenshot 2024-08-18 230754" src="https://github.com/user-attachments/assets/a876427e-30b1-42fa-b0d0-ff1d41cb6aa6">
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+

|
| 77 |
+
|
| 78 |
+
## Overview
|
| 79 |
+
|
| 80 |
+
GeekyRemB is a powerful extension for Automatic1111 that provides advanced background removal and image/video manipulation capabilities. It is a port of the ComfyUI node, bringing its functionality to the Automatic1111 environment. The extension allows users to remove backgrounds from images and videos, apply various effects, and manipulate foreground elements with precision.
|
| 81 |
+
|
| 82 |
+
## Key Features
|
| 83 |
+
|
| 84 |
+
- Background removal for images and videos
|
| 85 |
+
- Support for multiple background removal models
|
| 86 |
+
- Chroma key functionality
|
| 87 |
+
- Foreground manipulation (scaling, rotation, positioning)
|
| 88 |
+
- Various image effects (edge detection, shadow, color adjustments)
|
| 89 |
+
- Mask processing options
|
| 90 |
+
- Custom output dimensions
|
| 91 |
+
- Video background support
|
| 92 |
+
|
| 93 |
+
## How to Use
|
| 94 |
+
|
| 95 |
+
1. Install the extension by placing the `geeky_remb.py` file in the `scripts` folder of your Automatic1111 installation.
|
| 96 |
+
2. Restart Automatic1111 or reload the UI.
|
| 97 |
+
3. Navigate to the "GeekyRemB" tab in the Automatic1111 interface.
|
| 98 |
+
4. Choose your input type (Image or Video) and upload your content.
|
| 99 |
+
5. Adjust the settings as needed (described in detail below).
|
| 100 |
+
6. Click the "Run GeekyRemB" button to process your input.
|
| 101 |
+
|
| 102 |
+
## UI Settings and Their Functions
|
| 103 |
+
|
| 104 |
+
### Input/Output Settings
|
| 105 |
+
|
| 106 |
+
- **Input Type**: Choose between "Image" or "Video" as your input source.
|
| 107 |
+
- **Foreground Image/Video**: Upload your image or video file to be processed.
|
| 108 |
+
- **Output Type**: Select whether you want the output to be an "Image" or "Video".
|
| 109 |
+
|
| 110 |
+
### Foreground Adjustments
|
| 111 |
+
|
| 112 |
+
- **Scale**: Adjust the size of the foreground element (0.1 to 5.0).
|
| 113 |
+
- **Aspect Ratio**: Modify the aspect ratio of the foreground (0.1 to 10.0).
|
| 114 |
+
- **X Position**: Move the foreground horizontally (-1000 to 1000 pixels).
|
| 115 |
+
- **Y Position**: Move the foreground vertically (-1000 to 1000 pixels).
|
| 116 |
+
- **Rotation**: Rotate the foreground (-360 to 360 degrees).
|
| 117 |
+
- **Opacity**: Adjust the transparency of the foreground (0.0 to 1.0).
|
| 118 |
+
- **Flip Horizontal**: Mirror the foreground horizontally.
|
| 119 |
+
- **Flip Vertical**: Mirror the foreground vertically.
|
| 120 |
+
|
| 121 |
+
### Background Options
|
| 122 |
+
|
| 123 |
+
- **Remove Background**: Toggle background removal on/off.
|
| 124 |
+
- **Background Mode**: Choose between "transparent", "color", "image", or "video" backgrounds.
|
| 125 |
+
- **Background Color**: Select a color when "color" mode is chosen.
|
| 126 |
+
- **Background Image**: Upload an image to use as the background.
|
| 127 |
+
- **Background Video**: Upload a video to use as the background.
|
| 128 |
+
|
| 129 |
+
### Advanced Settings
|
| 130 |
+
|
| 131 |
+
#### Removal Settings
|
| 132 |
+
|
| 133 |
+
- **Model**: Select the background removal model (e.g., "u2net", "isnet-general-use").
|
| 134 |
+
- **Output Format**: Choose between "RGBA" (with transparency) or "RGB".
|
| 135 |
+
- **Alpha Matting**: Enable for improved edge detection in complex images.
|
| 136 |
+
- **Alpha Matting Foreground Threshold**: Adjust sensitivity for foreground detection (0-255).
|
| 137 |
+
- **Alpha Matting Background Threshold**: Adjust sensitivity for background detection (0-255).
|
| 138 |
+
- **Post Process Mask**: Apply additional processing to the generated mask.
|
| 139 |
+
|
| 140 |
+
#### Chroma Key Settings
|
| 141 |
+
|
| 142 |
+
- **Chroma Key**: Choose a color ("none", "green", "blue", "red") for chroma keying.
|
| 143 |
+
- **Chroma Threshold**: Adjust the sensitivity of the chroma key effect (0-255).
|
| 144 |
+
- **Color Tolerance**: Set the range of colors to be considered part of the chroma key (0-255).
|
| 145 |
+
|
| 146 |
+
#### Effects
|
| 147 |
+
|
| 148 |
+
- **Invert Mask**: Invert the generated mask.
|
| 149 |
+
- **Feather Amount**: Soften the edges of the mask (0-100).
|
| 150 |
+
- **Edge Detection**: Apply an edge detection effect.
|
| 151 |
+
- **Edge Thickness**: Adjust the thickness of detected edges (1-10).
|
| 152 |
+
- **Edge Color**: Choose the color for detected edges.
|
| 153 |
+
- **Shadow**: Add a shadow effect to the foreground.
|
| 154 |
+
- **Shadow Blur**: Adjust the blurriness of the shadow (0-20).
|
| 155 |
+
- **Shadow Opacity**: Set the transparency of the shadow (0.0-1.0).
|
| 156 |
+
- **Color Adjustment**: Enable color adjustments for the result.
|
| 157 |
+
- **Brightness**: Adjust the brightness of the result (0.0-2.0).
|
| 158 |
+
- **Contrast**: Adjust the contrast of the result (0.0-2.0).
|
| 159 |
+
- **Saturation**: Adjust the color saturation of the result (0.0-2.0).
|
| 160 |
+
- **Mask Blur**: Apply blur to the mask (0-100).
|
| 161 |
+
- **Mask Expansion**: Expand or contract the mask (-100 to 100).
|
| 162 |
+
|
| 163 |
+
### Output Settings
|
| 164 |
+
|
| 165 |
+
- **Image Format**: Choose the output format for images (PNG, JPEG, WEBP).
|
| 166 |
+
- **Video Format**: Select the output format for videos (MP4, AVI, MOV).
|
| 167 |
+
- **Video Quality**: Adjust the quality of the output video (0-100).
|
| 168 |
+
- **Use Custom Dimensions**: Enable to specify custom output dimensions.
|
| 169 |
+
- **Custom Width**: Set a custom width for the output.
|
| 170 |
+
- **Custom Height**: Set a custom height for the output.
|
| 171 |
+
|
| 172 |
+
## Technical Implementation for Developers
|
| 173 |
+
|
| 174 |
+
The GeekyRemB extension is implemented as a Python class (`GeekyRemB`) with several key methods:
|
| 175 |
+
|
| 176 |
+
1. `__init__`: Initializes the class and prepares for background removal sessions.
|
| 177 |
+
|
| 178 |
+
2. `apply_chroma_key`: Implements chroma key functionality using OpenCV.
|
| 179 |
+
|
| 180 |
+
3. `process_mask`: Handles mask processing operations like inversion, feathering, and expansion.
|
| 181 |
+
|
| 182 |
+
4. `remove_background`: The core method that processes images, removing backgrounds and applying effects.
|
| 183 |
+
|
| 184 |
+
5. `process_frame`: Processes individual video frames.
|
| 185 |
+
|
| 186 |
+
6. `process_video`: Handles video processing, including background video integration.
|
| 187 |
+
|
| 188 |
+
The UI is built using Gradio components, with the `on_ui_tabs` function setting up the interface. Key functions include:
|
| 189 |
+
|
| 190 |
+
- `update_input_type`, `update_output_type`, `update_background_mode`, `update_custom_dimensions`: Dynamic UI updates based on user selections.
|
| 191 |
+
- `process_image` and `process_video`: Wrapper functions for image and video processing.
|
| 192 |
+
- `run_geeky_remb`: The main function that orchestrates the entire process based on user inputs.
|
| 193 |
+
|
| 194 |
+
The extension uses libraries like `rembg` for background removal, `PIL` for image processing, `cv2` for video handling, and `numpy` for array operations.
|
| 195 |
+
|
| 196 |
+
Developers can extend the functionality by adding new background removal models, implementing additional effects, or enhancing video processing capabilities. The modular structure allows for easy integration of new features.
|
| 197 |
+
|
| 198 |
+
## Performance Considerations
|
| 199 |
+
|
| 200 |
+
- Background removal and video processing can be computationally intensive. Consider implementing progress bars or asynchronous processing for better user experience with large files.
|
| 201 |
+
- The extension currently processes videos frame-by-frame. For longer videos, consider implementing batch processing or multi-threading for improved performance.
|
| 202 |
+
- Memory usage can be high when processing large images or videos. Implement memory management techniques for handling large files.
|
| 203 |
+
|
| 204 |
+
## Future Enhancements
|
| 205 |
+
|
| 206 |
+
Potential areas for improvement include:
|
| 207 |
+
- Support for more background removal models
|
| 208 |
+
- Advanced video editing features (e.g., keyframe animation for foreground properties)
|
| 209 |
+
- Integration with other Automatic1111 extensions or workflows
|
| 210 |
+
- GPU acceleration for video processing
|
| 211 |
+
- Real-time preview for adjustments
|
| 212 |
+
|
| 213 |
+
This extension provides a powerful set of tools for background removal and image/video manipulation, bringing the capabilities of the ComfyUI node to the Automatic1111 environment.
|
| 214 |
+
|
| 215 |
+
## Troubleshooting
|
| 216 |
+
|
| 217 |
+
- If the background removal is imperfect, try adjusting the alpha matting thresholds or using a different model.
|
| 218 |
+
- For subjects with similar colors to the background, experiment with the chroma key feature in combination with AI removal.
|
| 219 |
+
- If the resulting image looks unnatural, play with the shadow and color adjustment settings to better integrate the subject with the new background.
|
| 220 |
+
|
| 221 |
+
## Contributing
|
| 222 |
+
|
| 223 |
+
We welcome contributions to GeekyRemB! If you have ideas for improvements or new features, feel free to open an issue or submit a pull request.
|
| 224 |
+
|
| 225 |
+
## License
|
| 226 |
+
|
| 227 |
+
GeekyRemB is released under the MIT License. Feel free to use, modify, and distribute it as you see fit.
|
| 228 |
+
|
| 229 |
+
## Acknowledgments
|
| 230 |
+
|
| 231 |
+
GeekyRemB is built upon the excellent [rembg](https://github.com/danielgatis/rembg) library and integrates seamlessly with the Automatic1111 Stable Diffusion Web UI. We're grateful to the developers of these projects for their fantastic work.
|
| 232 |
+
|
| 233 |
+
---
|
| 234 |
+
|
| 235 |
+
<img width="1247" alt="Screenshot 2024-08-08 123752" src="https://github.com/user-attachments/assets/2491ce81-09a7-4d8a-9bdc-58d48f82dfaf">
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
<img width="1235" alt="Screenshot 2024-08-08 124700" src="https://github.com/user-attachments/assets/cd672db7-97fe-4c1b-b8a3-2b50fb152d04">
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
<img width="1238" alt="Screenshot 2024-08-08 123732" src="https://github.com/user-attachments/assets/f7b91764-041e-4ae6-a46a-a81eaa8692c9">
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
We hope you enjoy using GeekyRemB to create stunning images with ease! If you find it useful, consider starring the repository and sharing it with your friends and colleagues.
|
| 247 |
+
|
| 248 |
+
The gap that allows for full and free rotation will become important later, for right now it's a fun and useful ediging feature, in the future it's going to allow for something pretty neat with animation.
|
| 249 |
+
|
| 250 |
+

|
| 251 |
+
|
| 252 |
+
To things that may come
|
| 253 |
+
|
| 254 |
+
<img width="1245" alt="Screenshot 2024-08-18 234435" src="https://github.com/user-attachments/assets/86a720ad-a0e3-4c86-8fed-d90e60d62a50">
|
| 255 |
+
|
| 256 |
+
<img width="1256" alt="Screenshot 2024-08-18 234617" src="https://github.com/user-attachments/assets/d92bc8a8-1393-4b49-9de3-a4375239613f">
|
| 257 |
+
<img width="1234" alt="Screenshot 2024-08-18 234630" src="https://github.com/user-attachments/assets/5c2e8039-94b5-4d2a-904a-7b87b07ac578">
|
| 258 |
+
|
extensions/Automatic1111-Geeky-Remb/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .geeky_remb import GeekyRemBExtras
|
| 2 |
+
|
| 3 |
+
def __init__():
|
| 4 |
+
return [GeekyRemBExtras()]
|
extensions/Automatic1111-Geeky-Remb/install.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import launch
|
| 2 |
+
|
| 3 |
+
if not launch.is_installed("rembg"):
|
| 4 |
+
launch.run_pip("install rembg", "requirement for Geeky RemB")
|
| 5 |
+
|
| 6 |
+
if not launch.is_installed("opencv-python"):
|
| 7 |
+
launch.run_pip("install opencv-python", "requirement for Geeky RemB")
|
extensions/Automatic1111-Geeky-Remb/requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
rembg
|
| 2 |
+
numpy
|
| 3 |
+
opencv-python
|
| 4 |
+
Pillow
|
| 5 |
+
onnxruntime-gpu
|
| 6 |
+
onnxruntime
|
extensions/Automatic1111-Geeky-Remb/scripts/__pycache__/geeky-remb.cpython-310.pyc
ADDED
|
Binary file (15.6 kB). View file
|
|
|
extensions/Automatic1111-Geeky-Remb/scripts/geeky-remb.py
ADDED
|
@@ -0,0 +1,475 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
from rembg import remove, new_session
|
| 4 |
+
from PIL import Image, ImageOps, ImageFilter, ImageEnhance
|
| 5 |
+
import cv2
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import gradio as gr
|
| 8 |
+
from modules import script_callbacks, shared
|
| 9 |
+
import torch
|
| 10 |
+
import tempfile
|
| 11 |
+
|
| 12 |
+
class GeekyRemB:
|
| 13 |
+
def __init__(self):
|
| 14 |
+
self.session = None
|
| 15 |
+
|
| 16 |
+
def apply_chroma_key(self, image, color, threshold, color_tolerance=20):
|
| 17 |
+
hsv = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
|
| 18 |
+
if color == "green":
|
| 19 |
+
lower = np.array([40 - color_tolerance, 40, 40])
|
| 20 |
+
upper = np.array([80 + color_tolerance, 255, 255])
|
| 21 |
+
elif color == "blue":
|
| 22 |
+
lower = np.array([90 - color_tolerance, 40, 40])
|
| 23 |
+
upper = np.array([130 + color_tolerance, 255, 255])
|
| 24 |
+
elif color == "red":
|
| 25 |
+
lower = np.array([0, 40, 40])
|
| 26 |
+
upper = np.array([20 + color_tolerance, 255, 255])
|
| 27 |
+
else:
|
| 28 |
+
return np.zeros(image.shape[:2], dtype=np.uint8)
|
| 29 |
+
|
| 30 |
+
mask = cv2.inRange(hsv, lower, upper)
|
| 31 |
+
mask = 255 - cv2.threshold(mask, threshold, 255, cv2.THRESH_BINARY)[1]
|
| 32 |
+
return mask
|
| 33 |
+
|
| 34 |
+
def process_mask(self, mask, invert_mask, feather_amount, mask_blur, mask_expansion):
|
| 35 |
+
if invert_mask:
|
| 36 |
+
mask = 255 - mask
|
| 37 |
+
|
| 38 |
+
if mask_expansion != 0:
|
| 39 |
+
kernel = np.ones((abs(mask_expansion), abs(mask_expansion)), np.uint8)
|
| 40 |
+
if mask_expansion > 0:
|
| 41 |
+
mask = cv2.dilate(mask, kernel, iterations=1)
|
| 42 |
+
else:
|
| 43 |
+
mask = cv2.erode(mask, kernel, iterations=1)
|
| 44 |
+
|
| 45 |
+
if feather_amount > 0:
|
| 46 |
+
mask = cv2.GaussianBlur(mask, (0, 0), sigmaX=feather_amount)
|
| 47 |
+
|
| 48 |
+
if mask_blur > 0:
|
| 49 |
+
mask = cv2.GaussianBlur(mask, (0, 0), sigmaX=mask_blur)
|
| 50 |
+
|
| 51 |
+
return mask
|
| 52 |
+
|
| 53 |
+
def parse_aspect_ratio(self, aspect_ratio_input):
|
| 54 |
+
if not aspect_ratio_input:
|
| 55 |
+
return None
|
| 56 |
+
|
| 57 |
+
if ':' in aspect_ratio_input:
|
| 58 |
+
try:
|
| 59 |
+
w, h = map(float, aspect_ratio_input.split(':'))
|
| 60 |
+
return w / h
|
| 61 |
+
except ValueError:
|
| 62 |
+
return None
|
| 63 |
+
|
| 64 |
+
try:
|
| 65 |
+
return float(aspect_ratio_input)
|
| 66 |
+
except ValueError:
|
| 67 |
+
pass
|
| 68 |
+
|
| 69 |
+
standard_ratios = {
|
| 70 |
+
'4:3': 4/3,
|
| 71 |
+
'16:9': 16/9,
|
| 72 |
+
'21:9': 21/9,
|
| 73 |
+
'1:1': 1,
|
| 74 |
+
'square': 1,
|
| 75 |
+
'portrait': 3/4,
|
| 76 |
+
'landscape': 4/3
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
return standard_ratios.get(aspect_ratio_input.lower())
|
| 80 |
+
|
| 81 |
+
def calculate_new_dimensions(self, orig_width, orig_height, scale, aspect_ratio):
|
| 82 |
+
new_width = int(orig_width * scale)
|
| 83 |
+
|
| 84 |
+
if aspect_ratio is None:
|
| 85 |
+
new_height = int(orig_height * scale)
|
| 86 |
+
else:
|
| 87 |
+
new_height = int(new_width / aspect_ratio)
|
| 88 |
+
|
| 89 |
+
return new_width, new_height
|
| 90 |
+
|
| 91 |
+
def remove_background(self, image, background_image, model, alpha_matting, alpha_matting_foreground_threshold,
|
| 92 |
+
alpha_matting_background_threshold, post_process_mask, chroma_key, chroma_threshold,
|
| 93 |
+
color_tolerance, background_mode, background_color, output_format="RGBA",
|
| 94 |
+
invert_mask=False, feather_amount=0, edge_detection=False,
|
| 95 |
+
edge_thickness=1, edge_color="#FFFFFF", shadow=False, shadow_blur=5,
|
| 96 |
+
shadow_opacity=0.5, color_adjustment=False, brightness=1.0, contrast=1.0,
|
| 97 |
+
saturation=1.0, x_position=0, y_position=0, rotation=0, opacity=1.0,
|
| 98 |
+
flip_horizontal=False, flip_vertical=False, mask_blur=0, mask_expansion=0,
|
| 99 |
+
foreground_scale=1.0, foreground_aspect_ratio=None, remove_bg=True,
|
| 100 |
+
use_custom_dimensions=False, custom_width=None, custom_height=None,
|
| 101 |
+
output_dimension_source="Foreground"):
|
| 102 |
+
if self.session is None or self.session.model_name != model:
|
| 103 |
+
self.session = new_session(model)
|
| 104 |
+
|
| 105 |
+
bg_color = tuple(int(background_color.lstrip('#')[i:i+2], 16) for i in (0, 2, 4)) + (255,)
|
| 106 |
+
edge_color = tuple(int(edge_color.lstrip('#')[i:i+2], 16) for i in (0, 2, 4))
|
| 107 |
+
|
| 108 |
+
pil_image = image if isinstance(image, Image.Image) else Image.fromarray(np.clip(255. * image[0].cpu().numpy(), 0, 255).astype(np.uint8))
|
| 109 |
+
original_image = np.array(pil_image)
|
| 110 |
+
|
| 111 |
+
if chroma_key != "none":
|
| 112 |
+
chroma_mask = self.apply_chroma_key(original_image, chroma_key, chroma_threshold, color_tolerance)
|
| 113 |
+
input_mask = chroma_mask
|
| 114 |
+
else:
|
| 115 |
+
input_mask = None
|
| 116 |
+
|
| 117 |
+
if remove_bg:
|
| 118 |
+
removed_bg = remove(
|
| 119 |
+
pil_image,
|
| 120 |
+
session=self.session,
|
| 121 |
+
alpha_matting=alpha_matting,
|
| 122 |
+
alpha_matting_foreground_threshold=alpha_matting_foreground_threshold,
|
| 123 |
+
alpha_matting_background_threshold=alpha_matting_background_threshold,
|
| 124 |
+
post_process_mask=post_process_mask,
|
| 125 |
+
)
|
| 126 |
+
rembg_mask = np.array(removed_bg)[:, :, 3]
|
| 127 |
+
else:
|
| 128 |
+
removed_bg = pil_image.convert("RGBA")
|
| 129 |
+
rembg_mask = np.full(pil_image.size[::-1], 255, dtype=np.uint8)
|
| 130 |
+
|
| 131 |
+
if input_mask is not None:
|
| 132 |
+
final_mask = cv2.bitwise_and(rembg_mask, input_mask)
|
| 133 |
+
else:
|
| 134 |
+
final_mask = rembg_mask
|
| 135 |
+
|
| 136 |
+
final_mask = self.process_mask(final_mask, invert_mask, feather_amount, mask_blur, mask_expansion)
|
| 137 |
+
|
| 138 |
+
orig_width, orig_height = pil_image.size
|
| 139 |
+
bg_width, bg_height = background_image.size if background_image else (orig_width, orig_height)
|
| 140 |
+
|
| 141 |
+
if use_custom_dimensions and custom_width and custom_height:
|
| 142 |
+
output_width, output_height = int(custom_width), int(custom_height)
|
| 143 |
+
elif output_dimension_source == "Background" and background_image:
|
| 144 |
+
output_width, output_height = bg_width, bg_height
|
| 145 |
+
else:
|
| 146 |
+
output_width, output_height = orig_width, orig_height
|
| 147 |
+
|
| 148 |
+
aspect_ratio = self.parse_aspect_ratio(foreground_aspect_ratio)
|
| 149 |
+
new_width, new_height = self.calculate_new_dimensions(orig_width, orig_height, foreground_scale, aspect_ratio)
|
| 150 |
+
|
| 151 |
+
fg_image = pil_image.resize((new_width, new_height), Image.LANCZOS)
|
| 152 |
+
fg_mask = Image.fromarray(final_mask).resize((new_width, new_height), Image.LANCZOS)
|
| 153 |
+
|
| 154 |
+
if background_mode == "transparent":
|
| 155 |
+
result = Image.new("RGBA", (output_width, output_height), (0, 0, 0, 0))
|
| 156 |
+
elif background_mode == "color":
|
| 157 |
+
result = Image.new("RGBA", (output_width, output_height), bg_color)
|
| 158 |
+
else: # background_mode == "image"
|
| 159 |
+
if background_image is not None:
|
| 160 |
+
result = background_image.resize((output_width, output_height), Image.LANCZOS).convert("RGBA")
|
| 161 |
+
else:
|
| 162 |
+
result = Image.new("RGBA", (output_width, output_height), (0, 0, 0, 0))
|
| 163 |
+
|
| 164 |
+
if flip_horizontal:
|
| 165 |
+
fg_image = fg_image.transpose(Image.FLIP_LEFT_RIGHT)
|
| 166 |
+
fg_mask = fg_mask.transpose(Image.FLIP_LEFT_RIGHT)
|
| 167 |
+
if flip_vertical:
|
| 168 |
+
fg_image = fg_image.transpose(Image.FLIP_TOP_BOTTOM)
|
| 169 |
+
fg_mask = fg_mask.transpose(Image.FLIP_TOP_BOTTOM)
|
| 170 |
+
|
| 171 |
+
fg_image = fg_image.rotate(rotation, resample=Image.BICUBIC, expand=True)
|
| 172 |
+
fg_mask = fg_mask.rotate(rotation, resample=Image.BICUBIC, expand=True)
|
| 173 |
+
|
| 174 |
+
paste_x = x_position + (output_width - fg_image.width) // 2
|
| 175 |
+
paste_y = y_position + (output_height - fg_image.height) // 2
|
| 176 |
+
|
| 177 |
+
fg_rgba = fg_image.convert("RGBA")
|
| 178 |
+
fg_with_opacity = Image.new("RGBA", fg_rgba.size, (0, 0, 0, 0))
|
| 179 |
+
for x in range(fg_rgba.width):
|
| 180 |
+
for y in range(fg_rgba.height):
|
| 181 |
+
r, g, b, a = fg_rgba.getpixel((x, y))
|
| 182 |
+
fg_with_opacity.putpixel((x, y), (r, g, b, int(a * opacity)))
|
| 183 |
+
|
| 184 |
+
fg_mask_with_opacity = fg_mask.point(lambda p: int(p * opacity))
|
| 185 |
+
|
| 186 |
+
result.paste(fg_with_opacity, (paste_x, paste_y), fg_mask_with_opacity)
|
| 187 |
+
|
| 188 |
+
if edge_detection:
|
| 189 |
+
edge_mask = cv2.Canny(np.array(fg_mask), 100, 200)
|
| 190 |
+
edge_mask = cv2.dilate(edge_mask, np.ones((edge_thickness, edge_thickness), np.uint8), iterations=1)
|
| 191 |
+
edge_overlay = Image.new("RGBA", (output_width, output_height), (0, 0, 0, 0))
|
| 192 |
+
edge_overlay.paste(Image.new("RGB", fg_image.size, edge_color), (paste_x, paste_y), Image.fromarray(edge_mask))
|
| 193 |
+
result = Image.alpha_composite(result, edge_overlay)
|
| 194 |
+
|
| 195 |
+
if shadow:
|
| 196 |
+
shadow_mask = fg_mask.filter(ImageFilter.GaussianBlur(shadow_blur))
|
| 197 |
+
shadow_image = Image.new("RGBA", (output_width, output_height), (0, 0, 0, 0))
|
| 198 |
+
shadow_image.paste((0, 0, 0, int(255 * shadow_opacity)), (paste_x, paste_y), shadow_mask)
|
| 199 |
+
result = Image.alpha_composite(result, shadow_image.filter(ImageFilter.GaussianBlur(shadow_blur)))
|
| 200 |
+
|
| 201 |
+
if color_adjustment:
|
| 202 |
+
enhancer = ImageEnhance.Brightness(result)
|
| 203 |
+
result = enhancer.enhance(brightness)
|
| 204 |
+
enhancer = ImageEnhance.Contrast(result)
|
| 205 |
+
result = enhancer.enhance(contrast)
|
| 206 |
+
enhancer = ImageEnhance.Color(result)
|
| 207 |
+
result = enhancer.enhance(saturation)
|
| 208 |
+
|
| 209 |
+
if output_format == "RGB":
|
| 210 |
+
result = result.convert("RGB")
|
| 211 |
+
|
| 212 |
+
return result, fg_mask
|
| 213 |
+
|
| 214 |
+
def process_frame(self, frame, *args):
|
| 215 |
+
pil_frame = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
|
| 216 |
+
processed_frame, _ = self.remove_background(pil_frame, *args)
|
| 217 |
+
return cv2.cvtColor(np.array(processed_frame), cv2.COLOR_RGB2BGR)
|
| 218 |
+
|
| 219 |
+
def process_video(self, input_path, output_path, background_video_path, *args):
|
| 220 |
+
cap = cv2.VideoCapture(input_path)
|
| 221 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 222 |
+
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 223 |
+
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 224 |
+
|
| 225 |
+
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
|
| 226 |
+
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
|
| 227 |
+
|
| 228 |
+
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 229 |
+
|
| 230 |
+
if background_video_path:
|
| 231 |
+
bg_cap = cv2.VideoCapture(background_video_path)
|
| 232 |
+
bg_total_frames = int(bg_cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 233 |
+
|
| 234 |
+
for frame_num in tqdm(range(total_frames), desc="Processing video"):
|
| 235 |
+
ret, frame = cap.read()
|
| 236 |
+
if not ret:
|
| 237 |
+
break
|
| 238 |
+
|
| 239 |
+
if background_video_path:
|
| 240 |
+
bg_frame_num = frame_num % bg_total_frames
|
| 241 |
+
bg_cap.set(cv2.CAP_PROP_POS_FRAMES, bg_frame_num)
|
| 242 |
+
bg_ret, bg_frame = bg_cap.read()
|
| 243 |
+
if bg_ret:
|
| 244 |
+
bg_frame_resized = cv2.resize(bg_frame, (width, height))
|
| 245 |
+
args = list(args)
|
| 246 |
+
args[1] = Image.fromarray(cv2.cvtColor(bg_frame_resized, cv2.COLOR_BGR2RGB))
|
| 247 |
+
args = tuple(args)
|
| 248 |
+
|
| 249 |
+
processed_frame = self.process_frame(frame, *args)
|
| 250 |
+
out.write(processed_frame)
|
| 251 |
+
|
| 252 |
+
cap.release()
|
| 253 |
+
if background_video_path:
|
| 254 |
+
bg_cap.release()
|
| 255 |
+
out.release()
|
| 256 |
+
|
| 257 |
+
# Convert output video to MP4 container
|
| 258 |
+
temp_output = output_path + "_temp.mp4"
|
| 259 |
+
os.rename(output_path, temp_output)
|
| 260 |
+
os.system(f"ffmpeg -i {temp_output} -c copy {output_path}")
|
| 261 |
+
os.remove(temp_output)
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def on_ui_tabs():
|
| 265 |
+
with gr.Blocks(analytics_enabled=False) as geeky_remb_tab:
|
| 266 |
+
gr.Markdown("# GeekyRemB: Background Removal and Image/Video Manipulation")
|
| 267 |
+
|
| 268 |
+
with gr.Row():
|
| 269 |
+
with gr.Column(scale=1):
|
| 270 |
+
input_type = gr.Radio(["Image", "Video"], label="Input Type", value="Image")
|
| 271 |
+
foreground_input = gr.Image(label="Foreground Image", type="pil", visible=True)
|
| 272 |
+
foreground_video = gr.Video(label="Foreground Video", visible=False)
|
| 273 |
+
run_button = gr.Button(label="Run GeekyRemB")
|
| 274 |
+
|
| 275 |
+
with gr.Group():
|
| 276 |
+
gr.Markdown("### Foreground Adjustments")
|
| 277 |
+
foreground_scale = gr.Slider(label="Scale", minimum=0.1, maximum=5.0, value=1.0, step=0.1)
|
| 278 |
+
foreground_aspect_ratio = gr.Textbox(
|
| 279 |
+
label="Aspect Ratio",
|
| 280 |
+
placeholder="e.g., 16:9, 4:3, 1:1, portrait, landscape, or leave blank for original",
|
| 281 |
+
value=""
|
| 282 |
+
)
|
| 283 |
+
x_position = gr.Slider(label="X Position", minimum=-1000, maximum=1000, value=0, step=1)
|
| 284 |
+
y_position = gr.Slider(label="Y Position", minimum=-1000, maximum=1000, value=0, step=1)
|
| 285 |
+
rotation = gr.Slider(label="Rotation", minimum=-360, maximum=360, value=0, step=0.1)
|
| 286 |
+
opacity = gr.Slider(label="Opacity", minimum=0.0, maximum=1.0, value=1.0, step=0.01)
|
| 287 |
+
flip_horizontal = gr.Checkbox(label="Flip Horizontal", value=False)
|
| 288 |
+
flip_vertical = gr.Checkbox(label="Flip Vertical", value=False)
|
| 289 |
+
|
| 290 |
+
with gr.Column(scale=1):
|
| 291 |
+
result_type = gr.Radio(["Image", "Video"], label="Output Type", value="Image")
|
| 292 |
+
result_image = gr.Image(label="Result Image", type="pil", visible=True)
|
| 293 |
+
result_video = gr.Video(label="Result Video", visible=False)
|
| 294 |
+
|
| 295 |
+
with gr.Group():
|
| 296 |
+
gr.Markdown("### Background Options")
|
| 297 |
+
remove_background = gr.Checkbox(label="Remove Background", value=True)
|
| 298 |
+
background_mode = gr.Radio(label="Background Mode", choices=["transparent", "color", "image", "video"], value="transparent")
|
| 299 |
+
background_color = gr.ColorPicker(label="Background Color", value="#000000", visible=False)
|
| 300 |
+
background_image = gr.Image(label="Background Image", type="pil", visible=False)
|
| 301 |
+
background_video = gr.Video(label="Background Video", visible=False)
|
| 302 |
+
|
| 303 |
+
with gr.Accordion("Advanced Settings", open=False):
|
| 304 |
+
with gr.Row():
|
| 305 |
+
with gr.Column():
|
| 306 |
+
gr.Markdown("### Removal Settings")
|
| 307 |
+
model = gr.Dropdown(label="Model", choices=["u2net", "u2netp", "u2net_human_seg", "u2net_cloth_seg", "silueta", "isnet-general-use", "isnet-anime"], value="u2net")
|
| 308 |
+
output_format = gr.Radio(label="Output Format", choices=["RGBA", "RGB"], value="RGBA")
|
| 309 |
+
alpha_matting = gr.Checkbox(label="Alpha Matting", value=False)
|
| 310 |
+
alpha_matting_foreground_threshold = gr.Slider(label="Alpha Matting Foreground Threshold", minimum=0, maximum=255, value=240, step=1)
|
| 311 |
+
alpha_matting_background_threshold = gr.Slider(label="Alpha Matting Background Threshold", minimum=0, maximum=255, value=10, step=1)
|
| 312 |
+
post_process_mask = gr.Checkbox(label="Post Process Mask", value=False)
|
| 313 |
+
|
| 314 |
+
with gr.Column():
|
| 315 |
+
gr.Markdown("### Chroma Key Settings")
|
| 316 |
+
chroma_key = gr.Dropdown(label="Chroma Key", choices=["none", "green", "blue", "red"], value="none")
|
| 317 |
+
chroma_threshold = gr.Slider(label="Chroma Threshold", minimum=0, maximum=255, value=30, step=1)
|
| 318 |
+
color_tolerance = gr.Slider(label="Color Tolerance", minimum=0, maximum=255, value=20, step=1)
|
| 319 |
+
|
| 320 |
+
with gr.Column():
|
| 321 |
+
gr.Markdown("### Effects")
|
| 322 |
+
invert_mask = gr.Checkbox(label="Invert Mask", value=False)
|
| 323 |
+
feather_amount = gr.Slider(label="Feather Amount", minimum=0, maximum=100, value=0, step=1)
|
| 324 |
+
edge_detection = gr.Checkbox(label="Edge Detection", value=False)
|
| 325 |
+
edge_thickness = gr.Slider(label="Edge Thickness", minimum=1, maximum=10, value=1, step=1)
|
| 326 |
+
edge_color = gr.ColorPicker(label="Edge Color", value="#FFFFFF")
|
| 327 |
+
shadow = gr.Checkbox(label="Shadow", value=False)
|
| 328 |
+
shadow_blur = gr.Slider(label="Shadow Blur", minimum=0, maximum=20, value=5, step=1)
|
| 329 |
+
shadow_opacity = gr.Slider(label="Shadow Opacity", minimum=0.0, maximum=1.0, value=0.5, step=0.1)
|
| 330 |
+
color_adjustment = gr.Checkbox(label="Color Adjustment", value=False)
|
| 331 |
+
brightness = gr.Slider(label="Brightness", minimum=0.0, maximum=2.0, value=1.0, step=0.1)
|
| 332 |
+
contrast = gr.Slider(label="Contrast", minimum=0.0, maximum=2.0, value=1.0, step=0.1)
|
| 333 |
+
saturation = gr.Slider(label="Saturation", minimum=0.0, maximum=2.0, value=1.0, step=0.1)
|
| 334 |
+
mask_blur = gr.Slider(label="Mask Blur", minimum=0, maximum=100, value=0, step=1)
|
| 335 |
+
mask_expansion = gr.Slider(label="Mask Expansion", minimum=-100, maximum=100, value=0, step=1)
|
| 336 |
+
|
| 337 |
+
with gr.Row():
|
| 338 |
+
gr.Markdown("### Output Settings")
|
| 339 |
+
image_format = gr.Dropdown(label="Image Format", choices=["PNG", "JPEG", "WEBP"], value="PNG")
|
| 340 |
+
video_format = gr.Dropdown(label="Video Format", choices=["MP4", "AVI", "MOV"], value="MP4")
|
| 341 |
+
video_quality = gr.Slider(label="Video Quality", minimum=0, maximum=100, value=95, step=1)
|
| 342 |
+
use_custom_dimensions = gr.Checkbox(label="Use Custom Dimensions", value=False)
|
| 343 |
+
custom_width = gr.Number(label="Custom Width", value=512, visible=False)
|
| 344 |
+
custom_height = gr.Number(label="Custom Height", value=512, visible=False)
|
| 345 |
+
output_dimension_source = gr.Radio(
|
| 346 |
+
label="Output Dimension Source",
|
| 347 |
+
choices=["Foreground", "Background"],
|
| 348 |
+
value="Foreground",
|
| 349 |
+
visible=True
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
def update_input_type(choice):
|
| 353 |
+
return {
|
| 354 |
+
foreground_input: gr.update(visible=choice == "Image"),
|
| 355 |
+
foreground_video: gr.update(visible=choice == "Video"),
|
| 356 |
+
}
|
| 357 |
+
|
| 358 |
+
def update_output_type(choice):
|
| 359 |
+
return {
|
| 360 |
+
result_image: gr.update(visible=choice == "Image"),
|
| 361 |
+
result_video: gr.update(visible=choice == "Video"),
|
| 362 |
+
}
|
| 363 |
+
|
| 364 |
+
def update_background_mode(mode):
|
| 365 |
+
return {
|
| 366 |
+
background_color: gr.update(visible=mode == "color"),
|
| 367 |
+
background_image: gr.update(visible=mode == "image"),
|
| 368 |
+
background_video: gr.update(visible=mode == "video"),
|
| 369 |
+
}
|
| 370 |
+
|
| 371 |
+
def update_custom_dimensions(use_custom):
|
| 372 |
+
return {
|
| 373 |
+
custom_width: gr.update(visible=use_custom),
|
| 374 |
+
custom_height: gr.update(visible=use_custom),
|
| 375 |
+
output_dimension_source: gr.update(visible=not use_custom)
|
| 376 |
+
}
|
| 377 |
+
|
| 378 |
+
def process_image(image, background_image, *args):
|
| 379 |
+
geeky_remb = GeekyRemB()
|
| 380 |
+
result, _ = geeky_remb.remove_background(image, background_image, *args)
|
| 381 |
+
return result
|
| 382 |
+
|
| 383 |
+
def process_video(video_path, background_video_path, *args):
|
| 384 |
+
geeky_remb = GeekyRemB()
|
| 385 |
+
with tempfile.NamedTemporaryFile(delete=False, suffix=".mp4") as temp_file:
|
| 386 |
+
output_path = temp_file.name
|
| 387 |
+
geeky_remb.process_video(video_path, output_path, background_video_path, *args)
|
| 388 |
+
return output_path
|
| 389 |
+
|
| 390 |
+
def run_geeky_remb(input_type, foreground_input, foreground_video, result_type, model, output_format,
|
| 391 |
+
alpha_matting, alpha_matting_foreground_threshold, alpha_matting_background_threshold,
|
| 392 |
+
post_process_mask, chroma_key, chroma_threshold, color_tolerance, background_mode,
|
| 393 |
+
background_color, background_image, background_video, invert_mask, feather_amount,
|
| 394 |
+
edge_detection, edge_thickness, edge_color, shadow, shadow_blur, shadow_opacity,
|
| 395 |
+
color_adjustment, brightness, contrast, saturation, x_position, y_position, rotation,
|
| 396 |
+
opacity, flip_horizontal, flip_vertical, mask_blur, mask_expansion, foreground_scale,
|
| 397 |
+
foreground_aspect_ratio, remove_background, image_format, video_format, video_quality,
|
| 398 |
+
use_custom_dimensions, custom_width, custom_height, output_dimension_source):
|
| 399 |
+
|
| 400 |
+
args = (model, alpha_matting, alpha_matting_foreground_threshold,
|
| 401 |
+
alpha_matting_background_threshold, post_process_mask, chroma_key, chroma_threshold,
|
| 402 |
+
color_tolerance, background_mode, background_color, output_format,
|
| 403 |
+
invert_mask, feather_amount, edge_detection, edge_thickness, edge_color, shadow, shadow_blur,
|
| 404 |
+
shadow_opacity, color_adjustment, brightness, contrast, saturation, x_position,
|
| 405 |
+
y_position, rotation, opacity, flip_horizontal, flip_vertical, mask_blur,
|
| 406 |
+
mask_expansion, foreground_scale, foreground_aspect_ratio, remove_background,
|
| 407 |
+
use_custom_dimensions, custom_width, custom_height, output_dimension_source)
|
| 408 |
+
|
| 409 |
+
if input_type == "Image" and result_type == "Image":
|
| 410 |
+
result = process_image(foreground_input, background_image, *args)
|
| 411 |
+
if image_format != "PNG":
|
| 412 |
+
result = result.convert("RGB")
|
| 413 |
+
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{image_format.lower()}") as temp_file:
|
| 414 |
+
result.save(temp_file.name, format=image_format, quality=95 if image_format == "JPEG" else None)
|
| 415 |
+
return temp_file.name, None
|
| 416 |
+
elif input_type == "Video" and result_type == "Video":
|
| 417 |
+
output_video = process_video(foreground_video, background_video if background_mode == "video" else None, *args)
|
| 418 |
+
if video_format != "MP4":
|
| 419 |
+
temp_output = output_video + f"_temp.{video_format.lower()}"
|
| 420 |
+
os.system(f"ffmpeg -i {output_video} -c:v libx264 -crf {int(20 - (video_quality / 5))} {temp_output}")
|
| 421 |
+
os.remove(output_video)
|
| 422 |
+
output_video = temp_output
|
| 423 |
+
return None, output_video
|
| 424 |
+
elif input_type == "Image" and result_type == "Video":
|
| 425 |
+
with tempfile.NamedTemporaryFile(delete=False, suffix=".mp4") as temp_file:
|
| 426 |
+
output_path = temp_file.name
|
| 427 |
+
frame = cv2.cvtColor(np.array(foreground_input), cv2.COLOR_RGB2BGR)
|
| 428 |
+
height, width = frame.shape[:2]
|
| 429 |
+
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
|
| 430 |
+
out = cv2.VideoWriter(output_path, fourcc, 24, (width, height))
|
| 431 |
+
for _ in range(24 * 5): # 5 seconds at 24 fps
|
| 432 |
+
out.write(frame)
|
| 433 |
+
out.release()
|
| 434 |
+
return None, process_video(output_path, background_video if background_mode == "video" else None, *args)
|
| 435 |
+
elif input_type == "Video" and result_type == "Image":
|
| 436 |
+
cap = cv2.VideoCapture(foreground_video)
|
| 437 |
+
ret, frame = cap.read()
|
| 438 |
+
cap.release()
|
| 439 |
+
if ret:
|
| 440 |
+
pil_frame = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
|
| 441 |
+
result = process_image(pil_frame, background_image, *args)
|
| 442 |
+
if image_format != "PNG":
|
| 443 |
+
result = result.convert("RGB")
|
| 444 |
+
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{image_format.lower()}") as temp_file:
|
| 445 |
+
result.save(temp_file.name, format=image_format, quality=95 if image_format == "JPEG" else None)
|
| 446 |
+
return temp_file.name, None
|
| 447 |
+
else:
|
| 448 |
+
return None, None
|
| 449 |
+
|
| 450 |
+
input_type.change(update_input_type, inputs=[input_type], outputs=[foreground_input, foreground_video])
|
| 451 |
+
result_type.change(update_output_type, inputs=[result_type], outputs=[result_image, result_video])
|
| 452 |
+
background_mode.change(update_background_mode, inputs=[background_mode], outputs=[background_color, background_image, background_video])
|
| 453 |
+
use_custom_dimensions.change(update_custom_dimensions, inputs=[use_custom_dimensions], outputs=[custom_width, custom_height, output_dimension_source])
|
| 454 |
+
|
| 455 |
+
run_button.click(
|
| 456 |
+
fn=run_geeky_remb,
|
| 457 |
+
inputs=[
|
| 458 |
+
input_type, foreground_input, foreground_video, result_type,
|
| 459 |
+
model, output_format, alpha_matting, alpha_matting_foreground_threshold,
|
| 460 |
+
alpha_matting_background_threshold, post_process_mask, chroma_key, chroma_threshold,
|
| 461 |
+
color_tolerance, background_mode, background_color, background_image, background_video,
|
| 462 |
+
invert_mask, feather_amount, edge_detection, edge_thickness, edge_color,
|
| 463 |
+
shadow, shadow_blur, shadow_opacity, color_adjustment, brightness, contrast,
|
| 464 |
+
saturation, x_position, y_position, rotation, opacity, flip_horizontal,
|
| 465 |
+
flip_vertical, mask_blur, mask_expansion, foreground_scale, foreground_aspect_ratio,
|
| 466 |
+
remove_background, image_format, video_format, video_quality,
|
| 467 |
+
use_custom_dimensions, custom_width, custom_height, output_dimension_source
|
| 468 |
+
],
|
| 469 |
+
outputs=[result_image, result_video]
|
| 470 |
+
)
|
| 471 |
+
|
| 472 |
+
return [(geeky_remb_tab, "GeekyRemB", "geeky_remb_tab")]
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
script_callbacks.on_ui_tabs(on_ui_tabs)
|
extensions/CFGRescale_For_Forge/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 MythicalChu
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
extensions/CFGRescale_For_Forge/README.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CFGRescale_For_Forge
|
| 2 |
+
The CFGRescale extension from A1111, adjusted for Forge.
|
| 3 |
+
|
| 4 |
+
Taken from https://github.com/Seshelle/CFG_Rescale_webui and modified to be integrated in forge (https://github.com/lllyasviel/stable-diffusion-webui-forge).
|
| 5 |
+
|
| 6 |
+
Just drop the folders in your Forge folder and enable it in the web interface. Defaulted to 0.7 rescale. Personally, I like using Cfg at 3.0 with LCM Lora.
|
extensions/CFGRescale_For_Forge/extensions-builtin/sd_forge_cfgrescale/scripts/__pycache__/forge_cfgrescale.cpython-310.pyc
ADDED
|
Binary file (1.66 kB). View file
|
|
|
extensions/CFGRescale_For_Forge/extensions-builtin/sd_forge_cfgrescale/scripts/forge_cfgrescale.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
from modules import scripts
|
| 4 |
+
from ldm_patched.contrib.external_cfgrescale import RescaleCFG
|
| 5 |
+
|
| 6 |
+
opRescaleCFG = RescaleCFG()
|
| 7 |
+
|
| 8 |
+
class CFGRescaleForForge(scripts.Script):
|
| 9 |
+
def title(self):
|
| 10 |
+
return "CFGRescale Integrated"
|
| 11 |
+
|
| 12 |
+
def show(self, is_img2img):
|
| 13 |
+
# make this extension visible in both txt2img and img2img tab.
|
| 14 |
+
return scripts.AlwaysVisible
|
| 15 |
+
|
| 16 |
+
def ui(self, *args, **kwargs):
|
| 17 |
+
with gr.Accordion(open=False, label=self.title()):
|
| 18 |
+
cfgrescale_enabled = gr.Checkbox(label='Enabled', value=True)
|
| 19 |
+
multiplier = gr.Slider(label='Multiplier', minimum=0, maximum=1, step=0.01, value=0.7)
|
| 20 |
+
|
| 21 |
+
return cfgrescale_enabled, multiplier
|
| 22 |
+
|
| 23 |
+
def process_before_every_sampling(self, p, *script_args, **kwargs):
|
| 24 |
+
# This will be called before every sampling.
|
| 25 |
+
# If you use highres fix, this will be called twice.
|
| 26 |
+
|
| 27 |
+
cfgrescale_enabled, multiplier = script_args
|
| 28 |
+
|
| 29 |
+
if not cfgrescale_enabled:
|
| 30 |
+
return
|
| 31 |
+
|
| 32 |
+
unet = p.sd_model.forge_objects.unet
|
| 33 |
+
|
| 34 |
+
unet = opRescaleCFG.patch(unet, multiplier)[0]
|
| 35 |
+
|
| 36 |
+
p.sd_model.forge_objects.unet = unet
|
| 37 |
+
|
| 38 |
+
# Below codes will add some logs to the texts below the image outputs on UI.
|
| 39 |
+
# The extra_generation_params does not influence results.
|
| 40 |
+
p.extra_generation_params.update(dict(
|
| 41 |
+
cfgrescale_enabled=cfgrescale_enabled,
|
| 42 |
+
multiplier=multiplier,
|
| 43 |
+
))
|
| 44 |
+
|
| 45 |
+
return
|
extensions/CFGRescale_For_Forge/ldm_patched/contrib/external_cfgrescale.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
class RescaleCFG:
|
| 4 |
+
@classmethod
|
| 5 |
+
def INPUT_TYPES(s):
|
| 6 |
+
return {"required": { "model": ("MODEL",),
|
| 7 |
+
"multiplier": ("FLOAT", {"default": 0.7, "min": 0.0, "max": 1.0, "step": 0.01}),
|
| 8 |
+
}}
|
| 9 |
+
RETURN_TYPES = ("MODEL",)
|
| 10 |
+
FUNCTION = "patch"
|
| 11 |
+
|
| 12 |
+
CATEGORY = "advanced/model"
|
| 13 |
+
|
| 14 |
+
def patch(self, model, multiplier):
|
| 15 |
+
def rescale_cfg(args):
|
| 16 |
+
cond = args["cond"]
|
| 17 |
+
uncond = args["uncond"]
|
| 18 |
+
cond_scale = args["cond_scale"]
|
| 19 |
+
sigma = args["sigma"]
|
| 20 |
+
sigma = sigma.view(sigma.shape[:1] + (1,) * (cond.ndim - 1))
|
| 21 |
+
x_orig = args["input"]
|
| 22 |
+
|
| 23 |
+
#rescale cfg has to be done on v-pred model output
|
| 24 |
+
x = x_orig / (sigma * sigma + 1.0)
|
| 25 |
+
cond = ((x - (x_orig - cond)) * (sigma ** 2 + 1.0) ** 0.5) / (sigma)
|
| 26 |
+
uncond = ((x - (x_orig - uncond)) * (sigma ** 2 + 1.0) ** 0.5) / (sigma)
|
| 27 |
+
|
| 28 |
+
#rescalecfg
|
| 29 |
+
x_cfg = uncond + cond_scale * (cond - uncond)
|
| 30 |
+
ro_pos = torch.std(cond, dim=(1,2,3), keepdim=True)
|
| 31 |
+
ro_cfg = torch.std(x_cfg, dim=(1,2,3), keepdim=True)
|
| 32 |
+
|
| 33 |
+
x_rescaled = x_cfg * (ro_pos / ro_cfg)
|
| 34 |
+
x_final = multiplier * x_rescaled + (1.0 - multiplier) * x_cfg
|
| 35 |
+
|
| 36 |
+
return x_orig - (x - x_final * sigma / (sigma * sigma + 1.0) ** 0.5)
|
| 37 |
+
|
| 38 |
+
m = model.clone()
|
| 39 |
+
m.set_model_sampler_cfg_function(rescale_cfg)
|
| 40 |
+
return (m, )
|
| 41 |
+
|
| 42 |
+
NODE_CLASS_MAPPINGS = {
|
| 43 |
+
"RescaleCFG": RescaleCFG,
|
| 44 |
+
}
|
extensions/CFG_Rescale_webui/.gitignore
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea/
|
extensions/CFG_Rescale_webui/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 CartUniverse
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
extensions/CFG_Rescale_webui/README.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CFG_Rescale_webui
|
| 2 |
+
Adds a CFG rescale option to A1111 webui for vpred models. Implements features described in https://arxiv.org/pdf/2305.08891.pdf
|
| 3 |
+
|
| 4 |
+
When installed, you will see a CFG slider below appear below the seed selection.
|
| 5 |
+
|
| 6 |
+
The recommended settings from the paper is 0.7 CFG rescale. The paper recommends using it at 7.5 CFG, but I find that the default 7.0 CFG works just fine as well.
|
| 7 |
+
If you notice your images are dull or muddy, try setting CFG Rescale to 0.5 and/or turning on color fix.
|
| 8 |
+
|
| 9 |
+
# Extra Features
|
| 10 |
+
Auto color fix: CFG rescale can result in the color palette of the image becoming smaller, resulting in muddy or brown images. Turning this on attempts to return the image colors to full range again, making it appear more vibrant and natural.
|
extensions/CFG_Rescale_webui/scripts/CFGRescale.py
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import re
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import numpy as np
|
| 6 |
+
import modules.scripts as scripts
|
| 7 |
+
import modules.images as saving
|
| 8 |
+
from modules import devices, processing, shared, sd_samplers_kdiffusion, sd_samplers_compvis, script_callbacks
|
| 9 |
+
from modules.processing import Processed
|
| 10 |
+
from modules.shared import opts, state
|
| 11 |
+
from ldm.models.diffusion import ddim
|
| 12 |
+
from PIL import Image
|
| 13 |
+
|
| 14 |
+
from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, noise_like
|
| 15 |
+
|
| 16 |
+
re_prompt_cfgr = re.compile(r"<cfg_rescale:([^>]+)>")
|
| 17 |
+
|
| 18 |
+
class Script(scripts.Script):
|
| 19 |
+
|
| 20 |
+
def __init__(self):
|
| 21 |
+
self.old_denoising = sd_samplers_kdiffusion.CFGDenoiser.combine_denoised
|
| 22 |
+
self.old_schedule = ddim.DDIMSampler.make_schedule
|
| 23 |
+
self.old_sample = ddim.DDIMSampler.p_sample_ddim
|
| 24 |
+
globals()['enable_furry_cocks'] = True
|
| 25 |
+
|
| 26 |
+
def find_module(module_names):
|
| 27 |
+
if isinstance(module_names, str):
|
| 28 |
+
module_names = [s.strip() for s in module_names.split(",")]
|
| 29 |
+
for data in scripts.scripts_data:
|
| 30 |
+
if data.script_class.__module__ in module_names and hasattr(data, "module"):
|
| 31 |
+
return data.module
|
| 32 |
+
return None
|
| 33 |
+
|
| 34 |
+
def rescale_opt(p, x, xs):
|
| 35 |
+
globals()['cfg_rescale_fi'] = x
|
| 36 |
+
globals()['enable_furry_cocks'] = False
|
| 37 |
+
|
| 38 |
+
xyz_grid = find_module("xyz_grid.py, xy_grid.py")
|
| 39 |
+
if xyz_grid:
|
| 40 |
+
extra_axis_options = [xyz_grid.AxisOption("Rescale CFG", float, rescale_opt)]
|
| 41 |
+
xyz_grid.axis_options.extend(extra_axis_options)
|
| 42 |
+
|
| 43 |
+
def title(self):
|
| 44 |
+
return "CFG Rescale Extension"
|
| 45 |
+
|
| 46 |
+
def show(self, is_img2img):
|
| 47 |
+
return scripts.AlwaysVisible
|
| 48 |
+
|
| 49 |
+
def ui(self, is_img2img):
|
| 50 |
+
with gr.Accordion("CFG Rescale", open=True, elem_id="cfg_rescale"):
|
| 51 |
+
rescale = gr.Slider(label="CFG Rescale", show_label=False, minimum=0.0, maximum=1.0, step=0.01, value=0.0)
|
| 52 |
+
with gr.Row():
|
| 53 |
+
recolor = gr.Checkbox(label="Auto Color Fix", default=False)
|
| 54 |
+
rec_strength = gr.Slider(label="Fix Strength", interactive=True, visible=False,
|
| 55 |
+
elem_id=self.elem_id("rec_strength"), minimum=0.1, maximum=10.0, step=0.1,
|
| 56 |
+
value=1.0)
|
| 57 |
+
show_original = gr.Checkbox(label="Keep Original Images", elem_id=self.elem_id("show_original"), visible=False, default=False)
|
| 58 |
+
|
| 59 |
+
def show_recolor_strength(rec_checked):
|
| 60 |
+
return [gr.update(visible=rec_checked), gr.update(visible=rec_checked)]
|
| 61 |
+
|
| 62 |
+
recolor.change(
|
| 63 |
+
fn=show_recolor_strength,
|
| 64 |
+
inputs=recolor,
|
| 65 |
+
outputs=[rec_strength, show_original]
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
self.infotext_fields = [
|
| 69 |
+
(rescale, "CFG Rescale"),
|
| 70 |
+
(recolor, "Auto Color Fix")
|
| 71 |
+
]
|
| 72 |
+
self.paste_field_names = []
|
| 73 |
+
for _, field_name in self.infotext_fields:
|
| 74 |
+
self.paste_field_names.append(field_name)
|
| 75 |
+
return [rescale, recolor, rec_strength, show_original]
|
| 76 |
+
|
| 77 |
+
def cfg_replace(self, x_out, conds_list, uncond, cond_scale):
|
| 78 |
+
denoised_uncond = x_out[-uncond.shape[0]:]
|
| 79 |
+
denoised = torch.clone(denoised_uncond)
|
| 80 |
+
fi = globals()['cfg_rescale_fi']
|
| 81 |
+
|
| 82 |
+
for i, conds in enumerate(conds_list):
|
| 83 |
+
for cond_index, weight in conds:
|
| 84 |
+
if fi == 0:
|
| 85 |
+
denoised[i] += (x_out[cond_index] - denoised_uncond[i]) * (weight * cond_scale)
|
| 86 |
+
else:
|
| 87 |
+
xcfg = (denoised_uncond[i] + (x_out[cond_index] - denoised_uncond[i]) * (cond_scale * weight))
|
| 88 |
+
xrescaled = (torch.std(x_out[cond_index]) / torch.std(xcfg))
|
| 89 |
+
xfinal = fi * xrescaled + (1.0 - fi)
|
| 90 |
+
denoised[i] = xfinal * xcfg
|
| 91 |
+
|
| 92 |
+
return denoised
|
| 93 |
+
|
| 94 |
+
def process(self, p, rescale, recolor, rec_strength, show_original):
|
| 95 |
+
|
| 96 |
+
if globals()['enable_furry_cocks']:
|
| 97 |
+
# parse <cfg_rescale:[number]> from prompt for override
|
| 98 |
+
rescale_override = None
|
| 99 |
+
def found(m):
|
| 100 |
+
nonlocal rescale_override
|
| 101 |
+
try:
|
| 102 |
+
rescale_override = float(m.group(1))
|
| 103 |
+
except ValueError:
|
| 104 |
+
rescale_override = None
|
| 105 |
+
return ""
|
| 106 |
+
p.prompt = re.sub(re_prompt_cfgr, found, p.prompt)
|
| 107 |
+
if rescale_override is not None:
|
| 108 |
+
rescale = rescale_override
|
| 109 |
+
|
| 110 |
+
globals()['cfg_rescale_fi'] = rescale
|
| 111 |
+
else:
|
| 112 |
+
# rescale value is being set from xyz_grid
|
| 113 |
+
rescale = globals()['cfg_rescale_fi']
|
| 114 |
+
globals()['enable_furry_cocks'] = True
|
| 115 |
+
|
| 116 |
+
sd_samplers_kdiffusion.CFGDenoiser.combine_denoised = self.cfg_replace
|
| 117 |
+
|
| 118 |
+
if rescale > 0:
|
| 119 |
+
p.extra_generation_params["CFG Rescale"] = rescale
|
| 120 |
+
|
| 121 |
+
if recolor:
|
| 122 |
+
p.extra_generation_params["Auto Color Fix Strength"] = rec_strength
|
| 123 |
+
p.do_not_save_samples = True
|
| 124 |
+
|
| 125 |
+
def postprocess_batch_list(self, p, pp, rescale, recolor, rec_strength, show_original, batch_number):
|
| 126 |
+
if recolor and show_original:
|
| 127 |
+
num = len(pp.images)
|
| 128 |
+
for i in range(num):
|
| 129 |
+
pp.images.append(pp.images[i])
|
| 130 |
+
p.prompts.append(p.prompts[i])
|
| 131 |
+
p.negative_prompts.append(p.negative_prompts[i])
|
| 132 |
+
p.seeds.append(p.seeds[i])
|
| 133 |
+
p.subseeds.append(p.subseeds[i])
|
| 134 |
+
|
| 135 |
+
def postprocess(self, p, processed, rescale, recolor, rec_strength, show_original):
|
| 136 |
+
sd_samplers_kdiffusion.CFGDenoiser.combine_denoised = self.old_denoising
|
| 137 |
+
|
| 138 |
+
def postfix(img, rec_strength):
|
| 139 |
+
prec = 0.0005 * rec_strength
|
| 140 |
+
r, g, b = img.split()
|
| 141 |
+
|
| 142 |
+
# softer effect
|
| 143 |
+
# r_min, r_max = np.percentile(r, p), np.percentile(r, 100.0 - p)
|
| 144 |
+
# g_min, g_max = np.percentile(g, p), np.percentile(g, 100.0 - p)
|
| 145 |
+
# b_min, b_max = np.percentile(b, p), np.percentile(b, 100.0 - p)
|
| 146 |
+
|
| 147 |
+
rh, rbins = np.histogram(r, 256, (0, 256))
|
| 148 |
+
tmp = np.where(rh > rh.sum() * prec)[0]
|
| 149 |
+
r_min = tmp.min()
|
| 150 |
+
r_max = tmp.max()
|
| 151 |
+
|
| 152 |
+
gh, gbins = np.histogram(g, 256, (0, 256))
|
| 153 |
+
tmp = np.where(gh > gh.sum() * prec)[0]
|
| 154 |
+
g_min = tmp.min()
|
| 155 |
+
g_max = tmp.max()
|
| 156 |
+
|
| 157 |
+
bh, bbins = np.histogram(b, 256, (0, 256))
|
| 158 |
+
tmp = np.where(bh > bh.sum() * prec)[0]
|
| 159 |
+
b_min = tmp.min()
|
| 160 |
+
b_max = tmp.max()
|
| 161 |
+
|
| 162 |
+
r = r.point(lambda i: int(255 * (min(max(i, r_min), r_max) - r_min) / (r_max - r_min)))
|
| 163 |
+
g = g.point(lambda i: int(255 * (min(max(i, g_min), g_max) - g_min) / (g_max - g_min)))
|
| 164 |
+
b = b.point(lambda i: int(255 * (min(max(i, b_min), b_max) - b_min) / (b_max - b_min)))
|
| 165 |
+
|
| 166 |
+
new_img = Image.merge("RGB", (r, g, b))
|
| 167 |
+
|
| 168 |
+
return new_img
|
| 169 |
+
|
| 170 |
+
if recolor:
|
| 171 |
+
grab = 0
|
| 172 |
+
n_img = len(processed.images)
|
| 173 |
+
for i in range(n_img):
|
| 174 |
+
doit = False
|
| 175 |
+
|
| 176 |
+
if show_original:
|
| 177 |
+
check = i
|
| 178 |
+
if opts.return_grid:
|
| 179 |
+
if i == 0:
|
| 180 |
+
continue
|
| 181 |
+
else:
|
| 182 |
+
check = check - 1
|
| 183 |
+
doit = check % (p.batch_size * 2) >= p.batch_size
|
| 184 |
+
else:
|
| 185 |
+
if n_img > 1 and i != 0:
|
| 186 |
+
doit = True
|
| 187 |
+
elif n_img == 1 or not opts.return_grid:
|
| 188 |
+
doit = True
|
| 189 |
+
|
| 190 |
+
if doit:
|
| 191 |
+
res_img = postfix(processed.images[i], rec_strength)
|
| 192 |
+
if opts.samples_save:
|
| 193 |
+
ind = grab
|
| 194 |
+
grab += 1
|
| 195 |
+
prompt_infotext = processing.create_infotext(p, p.all_prompts, p.all_seeds, p.all_subseeds,
|
| 196 |
+
index=ind)
|
| 197 |
+
# Save images to disk
|
| 198 |
+
if opts.samples_save:
|
| 199 |
+
saving.save_image(processed.images[i], p.outpath_samples, "", seed=p.all_seeds[ind],
|
| 200 |
+
prompt=p.all_prompts[ind],
|
| 201 |
+
info=prompt_infotext, p=p, suffix="colorfix")
|
| 202 |
+
saving.save_image(res_img, p.outpath_samples, "", seed=p.all_seeds[ind],
|
| 203 |
+
prompt=p.all_prompts[ind],
|
| 204 |
+
info=prompt_infotext, p=p, suffix="colorfix")
|
| 205 |
+
|
| 206 |
+
processed.images[i] = res_img
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def on_infotext_pasted(infotext, params):
|
| 210 |
+
if "CFG Rescale" not in params:
|
| 211 |
+
params["CFG Rescale"] = 0
|
| 212 |
+
|
| 213 |
+
if "CFG Rescale φ" in params:
|
| 214 |
+
params["CFG Rescale"] = params["CFG Rescale φ"]
|
| 215 |
+
del params["CFG Rescale φ"]
|
| 216 |
+
|
| 217 |
+
if "CFG Rescale phi" in params and scripts.scripts_txt2img.script("Neutral Prompt") is None:
|
| 218 |
+
params["CFG Rescale"] = params["CFG Rescale phi"]
|
| 219 |
+
del params["CFG Rescale phi"]
|
| 220 |
+
|
| 221 |
+
if "DDIM Trailing" not in params:
|
| 222 |
+
params["DDIM Trailing"] = False
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
script_callbacks.on_infotext_pasted(on_infotext_pasted)
|
extensions/CFG_Rescale_webui/scripts/__pycache__/CFGRescale.cpython-310.pyc
ADDED
|
Binary file (7.39 kB). View file
|
|
|
extensions/CharacteristicGuidanceWebUI/CHGextension_pic.PNG
ADDED
|
extensions/CharacteristicGuidanceWebUI/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
extensions/CharacteristicGuidanceWebUI/README.md
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Characteristic Guidance Web UI (enhanced sampling for high CFG scale)
|
| 2 |
+
|
| 3 |
+
## About
|
| 4 |
+
Characteristic Guidance Web UI is an extension of for the Stable Diffusion web UI (AUTOMATIC1111). It offers a theory-backed guidance sampling method with improved sample and control quality at high CFG scale (10-30).
|
| 5 |
+
|
| 6 |
+
This is the official implementation of [Characteristic Guidance: Non-linear Correction for Diffusion Model at Large Guidance Scale](https://arxiv.org/abs/2312.07586). We are happy to announce that this work has been accepted by ICML 2024.
|
| 7 |
+
|
| 8 |
+
## News
|
| 9 |
+
|
| 10 |
+
We release the Turbo version of characteristic guidance.
|
| 11 |
+
- Easier to use: much fewer parameters to choose
|
| 12 |
+
- Speed optimization (~2x faster)
|
| 13 |
+
- Stability improvement (better convergence at initial steps)
|
| 14 |
+
|
| 15 |
+
Please try the Turbo version by swiching to the branch Turbo_dev. (If you are forge user, please use Karras schedule or unipic to avoid artifacts)
|
| 16 |
+
|
| 17 |
+
## Features
|
| 18 |
+
Characteristic guidance offers improved sample generation and control at high CFG scale. Try characteristic guidance for
|
| 19 |
+
- Detail refinement
|
| 20 |
+
- Fixing quality issues, like
|
| 21 |
+
- Weird colors and styles
|
| 22 |
+
- Bad anatomy (not guaranteed :rofl:, works better on Stable Diffusion XL)
|
| 23 |
+
- Strange backgrounds
|
| 24 |
+
|
| 25 |
+
Characteristic guidance is compatible with every existing sampling methods in Stable Diffusion WebUI. It now have preliminary support for **Forge UI** and ControlNet.
|
| 26 |
+

|
| 27 |
+

|
| 28 |
+

|
| 29 |
+

|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
For more information and previews, please visit our project website: [Characteristic Guidance Project Website](https://scraed.github.io/CharacteristicGuidance/).
|
| 33 |
+
|
| 34 |
+
Q&A: What's the difference with [Dynamical Thresholding](https://github.com/mcmonkeyprojects/sd-dynamic-thresholding)?
|
| 35 |
+
|
| 36 |
+
They are distinct and independent methods, can be used either independently or in conjunction.
|
| 37 |
+
|
| 38 |
+
- **Characteristic Guidance**: Corrects both context and color, works at the given CFG scale, iteratively corrects **input** of the U-net according to the Fokker-Planck equation.
|
| 39 |
+
- **Dynamical Thresholding**: Mainly focusing on color, works to mimic lower CFG scales, clips and rescales **output** of the U-net.
|
| 40 |
+
|
| 41 |
+
Using [Characteristic Guidance](#) and Dynamical Thresholding simutaneously may further reduce saturation.
|
| 42 |
+
|
| 43 |
+

|
| 44 |
+
|
| 45 |
+
## Prerequisites
|
| 46 |
+
Before installing and using the Characteristic Guidance Web UI, ensure that you have the following prerequisites met:
|
| 47 |
+
|
| 48 |
+
- **Stable Diffusion WebUI (AUTOMATIC1111)**: Your system must have the [Stable Diffusion WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) by AUTOMATIC1111 installed. This interface is the foundation on which the Characteristic Guidance Web UI operates.
|
| 49 |
+
- **Version Requirement**: The extension is developed for Stable Diffusion WebUI **v1.6.0 or higher**. It may works for previous versions but not guaranteed.
|
| 50 |
+
|
| 51 |
+
## Installation
|
| 52 |
+
Follow these steps to install the Characteristic Guidance Web UI extension:
|
| 53 |
+
|
| 54 |
+
1. Navigate to the "Extensions" tab in the Stable Diffusion web UI.
|
| 55 |
+
2. In the "Extensions" tab, select the "Install from URL" option.
|
| 56 |
+
3. Enter the URL `https://github.com/scraed/CharacteristicGuidanceWebUI.git` into the "URL for extension's git repository" field.
|
| 57 |
+
4. Click on the "Install" button.
|
| 58 |
+
5. After waiting for several seconds, a confirmation message should appear indicating successful installation: "Installed into stable-diffusion-webui\extensions\CharacteristicGuidanceWebUI. Use the Installed tab to restart".
|
| 59 |
+
6. Proceed to the "Installed" tab. Here, click "Check for updates", followed by "Apply and restart UI" for the changes to take effect. Note: Use these buttons for future updates to the CharacteristicGuidanceWebUI as well.
|
| 60 |
+
|
| 61 |
+
## Usage
|
| 62 |
+
The Characteristic Guidance Web UI features an interactive interface for both txt2img and img2img mode.
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
**The characteristic guidance is slow compared to classifier-free guidance. We recommend the user to generate image with classifier-free guidance at first, then try characteristic guidance with the same prompt and seed to enhance the image.**
|
| 66 |
+
|
| 67 |
+
### Activation
|
| 68 |
+
- `Enable` Checkbox: Toggles the activation of the Characteristic Guidance features.
|
| 69 |
+
|
| 70 |
+
### Visualization and Testing
|
| 71 |
+
- `Check Convergence` Button: Allows users to test and visualize the convergence of their settings. Adjust the regularization parameters if the convergence is not satisfactory.
|
| 72 |
+
|
| 73 |
+
In practice, convergence is not always guaranteed. **If characteristic guidance fails to converge at a certain time step, classifier-free guidance will be adopted at that time step**.
|
| 74 |
+
|
| 75 |
+
Below are the parameters you can adjust to customize the behavior of the guidance correction:
|
| 76 |
+
|
| 77 |
+
### Basic Parameters
|
| 78 |
+
- `Regularization Strength`: Range 0.0 to 10.0 (default: 1). Adjusts the strength of regularization at the beginning of sampling, larger regularization means easier convergence and closer alignment with CFG (Classifier Free Guidance).
|
| 79 |
+
- `Regularization Range Over Time`: Range 0.01 to 10.0 (default: 1). Modifies the range of time being regularized, larger time means slow decay in regularization strength hence more time steps being regularized, affecting convergence difficulty and the extent of correction.
|
| 80 |
+
- `Max Num. Characteristic Iteration`: Range 1 to 50 (default: 50). Determines the maximum number of characteristic iterations per sampling time step.
|
| 81 |
+
- `Num. Basis for Correction`: Range 0 to 10 (default: 0). Sets the number of bases for correction, influencing the amount of correction and convergence behavior. More basis means better quality but harder convergence. Basis number = 0 means batch-wise correction, > 0 means channel-wise correction.
|
| 82 |
+
- `CHG Start Step`: Range 0 to 0.25 (default: 0). Characteristic guidance begins to influence the process from the specified percentage of steps, indicated by `CHG Start Step`.
|
| 83 |
+
- `CHG End Step`: Range 0.25 to 1 (default: 0). Characteristic guidance ceases to have an effect from the specified percentage of steps, denoted by `CHG End Step`. Setting this value to approximately 0.4 can significantly speed up the generation process without substantially altering the outcome.
|
| 84 |
+
- `ControlNet Compatible Mode`
|
| 85 |
+
- `More Prompt`: Controlnet is turned off when iteratively solving characteristic guidance correction.
|
| 86 |
+
- `More ControlNet`: Controlnet is turned on when iteratively solving characteristic guidance correction.
|
| 87 |
+
|
| 88 |
+
### Advanced Parameters
|
| 89 |
+
- `Reuse Correction of Previous Iteration`: Range 0.0 to 1.0 (default: 1.0). Controls the reuse of correction from previous iterations to reduce abrupt changes during generation.
|
| 90 |
+
- `Log 10 Tolerance for Iteration Convergence`: Range -6 to -2 (default: -4). Adjusts the tolerance for iteration convergence, trading off between speed and image quality.
|
| 91 |
+
- `Iteration Step Size`: Range 0 to 1 (default: 1.0). Sets the step size for each iteration, affecting the speed of convergence.
|
| 92 |
+
- `Regularization Annealing Speed`: Range 0.0 to 1.0 (default: 0.4). How fast the regularization strength decay to desired rate. Smaller value potentially easing convergence.
|
| 93 |
+
- `Regularization Annealing Strength`: Range 0.0 to 5 (default: 0.5). Determines the how important regularization annealing is in characteristic guidance interations. Higher value means higher priority to bring regularization level to specified regularization strength. Affecting the balance between annealing and convergence.
|
| 94 |
+
- `AA Iteration Memory Size`: Range 1 to 10 (default: 2). Specifies the memory size for AA (Anderson Acceleration) iterations, influencing convergence speed and stability.
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
Please experiment with different settings, especially **regularization strength and time range**, to achieve better convergence for your specific use case. (According to my experience, high CFG scale need relatively large regularization strength and time range for convergence, while low CFG scale prefers lower regularization strength and time range for more guidance correction.)
|
| 98 |
+
|
| 99 |
+
### How to Set Parameters (Preliminary Guide)
|
| 100 |
+
Here is my recommended approach for parameter setting:
|
| 101 |
+
|
| 102 |
+
1. Start by running characteristic guidance with the default parameters (Use `Regularization Strength`=5 for Stable Diffusion XL).
|
| 103 |
+
2. Verify convergence by clicking the `Check Convergence` button.
|
| 104 |
+
3. If convergence is achieved easily:
|
| 105 |
+
- Decrease the `Regularization Strength` and `Regularization Range Over Time` to enhance correction.
|
| 106 |
+
- If the `Regularization Strength` is already minimal, consider increasing the `Num. Basis for Correction` for improved performance.
|
| 107 |
+
4. If convergence is not reached:
|
| 108 |
+
- Increment the `Max Num. Characteristic Iteration` to allow for additional iterations.
|
| 109 |
+
- Should convergence still not occur, raise the `Regularization Strength` and `Regularization Range Over Time` for increased regularization.
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
## Updates
|
| 114 |
+
### July 9, 2024: Release Turbo_dev branch.
|
| 115 |
+
- New technique to stablize the iteration at beginning steps
|
| 116 |
+
- Avoid redundant iteration steps to accelerate generation.
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
### June 24, 2024: Preliminary Support for Forge.
|
| 120 |
+
- **Thanks to our team member [@charrywhite](https://github.com/charrywhite)**: The UI now have preliminary supports [forge](https://github.com/lllyasviel/stable-diffusion-webui-forge).
|
| 121 |
+
- Fixed minor incompatibility with WebUI v1.9
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
### February 3, 2024: New parameters accelerating the generation.
|
| 125 |
+
- **Thanks to [@v0xie](https://github.com/v0xie)**: The UI now supports two more parameters.
|
| 126 |
+
- `CHG Start Step`: Range 0 to 0.25 (default: 0). Characteristic guidance begins to influence the process from the specified percentage of steps, indicated by `CHG Start Step`.
|
| 127 |
+
- `CHG End Step`: Range 0.25 to 1 (default: 0). Characteristic guidance ceases to have an effect from the specified percentage of steps, denoted by `CHG End Step`. Setting this value to approximately 0.4 can significantly **speed up** the generation process without substantially altering the outcome.
|
| 128 |
+
|
| 129 |
+
### January 28, 2024: Modify how parameter `Reuse Correction of Previous Iteration` works
|
| 130 |
+
- **Effect**: Move parameter `Reuse Correction of Previous Iteration` to advanced parameters. Its default value is set to 1 to accelerate convergence. It is now using the same update direction as the case `Reuse Correction of Previous Iteration` = 0 regardless of its value.
|
| 131 |
+
- **User Action Required**: Please delete "ui-config.json" from the stable diffusion WebUI root directory for the update to take effect.
|
| 132 |
+
- **Issue**: Infotext with `Reuse Correction of Previous Iteration` > 0 may not generate the same image as previous version.
|
| 133 |
+
|
| 134 |
+
### January 28, 2024: Allow Num. Basis for Correction = 0
|
| 135 |
+
- **Effect**: Now the Num. Basis for Correction can takes value 0 which means batch-wise correction instead of channel-wise correction. It is a more suitable default value since it converges faster.
|
| 136 |
+
- **User Action Required**: Please delete "ui-config.json" from the stable diffusion WebUI root directory for the update to take effect.
|
| 137 |
+
|
| 138 |
+
### January 14, 2024: Bug fix: allow prompts with more than 75 tokens
|
| 139 |
+
- **Effect**: Now the extension still works if the prompt have more than 75 tokens.
|
| 140 |
+
|
| 141 |
+
### January 13, 2024: Add support for V-Prediction model
|
| 142 |
+
- **Effect**: Now the extension supports models trained in V-prediction mode.
|
| 143 |
+
|
| 144 |
+
### January 12, 2024: Add support for 'AND' prompt combination
|
| 145 |
+
- **Effect**: Now the extension supports the 'AND' word in positive prompt.
|
| 146 |
+
- **Current Limitations**: Note that characteristic guidance only give correction between positive and negative prompt. Therefore positive prompts combined by 'AND' will be averaged when computing the correction.
|
| 147 |
+
|
| 148 |
+
### January 8, 2024: Improved Guidance Settings
|
| 149 |
+
- **Extended Settings Range**: `Regularization Strength` & `Regularization Range Over Time` can now go up to 10.
|
| 150 |
+
- **Effect**: Reproduce classifier-free guidance results at high values of `Regularization Strength` & `Regularization Range Over Time`.
|
| 151 |
+
- **User Action Required**: Please delete "ui-config.json" from the stable diffusion WebUI root directory for the update to take effect.
|
| 152 |
+
|
| 153 |
+
### January 6, 2024: Integration of ControlNet
|
| 154 |
+
- **Early Support**: We're excited to announce preliminary support for ControlNet.
|
| 155 |
+
- **Current Limitations**: As this is an early stage, expect some developmental issues. The integration of ControlNet and characteristic guidance remains a scientific open problem (which I am investigating). Known issues include:
|
| 156 |
+
- Iterations failing to converge when ControlNet is in reference mode.
|
| 157 |
+
|
| 158 |
+
### January 3, 2024: UI Enhancement for Infotext
|
| 159 |
+
- **Thanks to [@w-e-w](https://github.com/w-e-w)**: The UI now supports infotext reading.
|
| 160 |
+
- **How to Use**: Check out this [PR](https://github.com/scraed/CharacteristicGuidanceWebUI/pull/1) for detailed instructions.
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
## Compatibility and Issues
|
| 164 |
+
|
| 165 |
+
### July 9, 2024: Bad Turbo_dev branch output on Forge.
|
| 166 |
+
- Sometimes the generated images has wierd artifacts on Forge Turbo_dev. Please use Karras schedule to avoid it.
|
| 167 |
+
|
| 168 |
+
### June 24, 2024: Inconsistent Forge Implementation.
|
| 169 |
+
- Note that the current forge implementation of CHG does not always generate the same image as CHG on WebUI. See this [pull request](https://github.com/scraed/CharacteristicGuidanceWebUI/pull/13). We are still investigating why it happends.
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
## Citation
|
| 173 |
+
If you utilize characteristic guidance in your research or projects, please consider citing our paper:
|
| 174 |
+
```bibtex
|
| 175 |
+
@misc{zheng2023characteristic,
|
| 176 |
+
title={Characteristic Guidance: Non-linear Correction for DDPM at Large Guidance Scale},
|
| 177 |
+
author={Candi Zheng and Yuan Lan},
|
| 178 |
+
year={2023},
|
| 179 |
+
eprint={2312.07586},
|
| 180 |
+
archivePrefix={arXiv},
|
| 181 |
+
primaryClass={cs.CV}
|
| 182 |
+
}
|
| 183 |
+
|
| 184 |
+
|
extensions/CharacteristicGuidanceWebUI/scripts/CHGextension.py
ADDED
|
@@ -0,0 +1,439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import modules.scripts as scripts
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
import io
|
| 5 |
+
import json
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import numpy as np
|
| 9 |
+
import inspect
|
| 10 |
+
import torch
|
| 11 |
+
from modules import prompt_parser, devices, sd_samplers_common
|
| 12 |
+
import re
|
| 13 |
+
from modules.shared import opts, state
|
| 14 |
+
import modules.shared as shared
|
| 15 |
+
from modules.script_callbacks import CFGDenoiserParams, cfg_denoiser_callback
|
| 16 |
+
from modules.script_callbacks import CFGDenoisedParams, cfg_denoised_callback
|
| 17 |
+
from modules.script_callbacks import AfterCFGCallbackParams, cfg_after_cfg_callback
|
| 18 |
+
import k_diffusion.utils as utils
|
| 19 |
+
from k_diffusion.external import CompVisVDenoiser, CompVisDenoiser
|
| 20 |
+
from modules.sd_samplers_timesteps import CompVisTimestepsDenoiser, CompVisTimestepsVDenoiser
|
| 21 |
+
from modules.sd_samplers_cfg_denoiser import CFGDenoiser, catenate_conds, subscript_cond, pad_cond
|
| 22 |
+
from modules import script_callbacks
|
| 23 |
+
from scripts.CharaIte import Chara_iteration
|
| 24 |
+
|
| 25 |
+
try:
|
| 26 |
+
from modules_forge import forge_sampler
|
| 27 |
+
isForge = True
|
| 28 |
+
except Exception:
|
| 29 |
+
isForge = False
|
| 30 |
+
|
| 31 |
+
######## Infotext processing ##########
|
| 32 |
+
quote_swap = str.maketrans('\'"', '"\'')
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def pares_infotext(infotext, params):
|
| 36 |
+
# parse infotext decode json string
|
| 37 |
+
try:
|
| 38 |
+
params['CHG'] = json.loads(params['CHG'].translate(quote_swap))
|
| 39 |
+
except Exception:
|
| 40 |
+
pass
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
script_callbacks.on_infotext_pasted(pares_infotext)
|
| 44 |
+
#######################################
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if not isForge:
|
| 48 |
+
from scripts.webui_CHG import CHGdenoiserConstruct
|
| 49 |
+
exec( CHGdenoiserConstruct() )
|
| 50 |
+
else:
|
| 51 |
+
from scripts.forge_CHG import CHGdenoiserConstruct
|
| 52 |
+
import scripts.forge_CHG as forge_CHG
|
| 53 |
+
exec( CHGdenoiserConstruct() )
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class ExtensionTemplateScript(scripts.Script):
|
| 58 |
+
# Extension title in menu UI
|
| 59 |
+
def title(self):
|
| 60 |
+
return "Characteristic Guidance"
|
| 61 |
+
|
| 62 |
+
# Decide to show menu in txt2img or img2img
|
| 63 |
+
# - in "txt2img" -> is_img2img is `False`
|
| 64 |
+
# - in "img2img" -> is_img2img is `True`
|
| 65 |
+
#
|
| 66 |
+
# below code always show extension menu
|
| 67 |
+
def show(self, is_img2img):
|
| 68 |
+
return scripts.AlwaysVisible
|
| 69 |
+
|
| 70 |
+
def update_plot(self):
|
| 71 |
+
from modules.sd_samplers_cfg_denoiser import CFGDenoiser
|
| 72 |
+
try:
|
| 73 |
+
res, ite_num, reg = CFGDenoiser.ite_infos
|
| 74 |
+
res = np.array([r[:, 0, 0, 0].cpu().numpy() for r in res]).T
|
| 75 |
+
ite_num = np.array([r.cpu().numpy() for r in ite_num]).T
|
| 76 |
+
reg = np.array([r.cpu().numpy() for r in reg]).T
|
| 77 |
+
if len(res) == 0:
|
| 78 |
+
raise Exception('res has not been written yet')
|
| 79 |
+
except Exception as e:
|
| 80 |
+
res, ite_num, reg = [np.linspace(1, 0., 50)], [np.ones(50) * 10], [np.linspace(1, 0., 50)]
|
| 81 |
+
print("The following exception occured when reading iteration info, demo plot is returned")
|
| 82 |
+
print(e)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
try:
|
| 86 |
+
res_thres = CFGDenoiser.res_thres
|
| 87 |
+
reg_ini = CFGDenoiser.reg_ini
|
| 88 |
+
reg_range = CFGDenoiser.reg_range
|
| 89 |
+
noise_base = CFGDenoiser.noise_base
|
| 90 |
+
start_step = CFGDenoiser.chg_start_step
|
| 91 |
+
except:
|
| 92 |
+
res_thres = 0.1
|
| 93 |
+
reg_ini=1
|
| 94 |
+
reg_range=1
|
| 95 |
+
noise_base = 1
|
| 96 |
+
start_step = 0
|
| 97 |
+
# Create legend
|
| 98 |
+
from matplotlib.patches import Patch
|
| 99 |
+
legend_elements = [Patch(facecolor='green', label='Converged'),
|
| 100 |
+
Patch(facecolor='yellow', label='Barely Converged'),
|
| 101 |
+
Patch(facecolor='red', label='Not Converged')]
|
| 102 |
+
def get_title(reg_ini, reg_range, noise_base, num_no_converge, pos_no_converge):
|
| 103 |
+
title = ""
|
| 104 |
+
prompts = ["Nice! All iterations converged.\n ",
|
| 105 |
+
"Lowering the regularization strength may be better.\n ",
|
| 106 |
+
"One iteration not converge, but it is OK.\n ",
|
| 107 |
+
"Two or more iteration not converge, maybe you should increase regularization strength.\n ",
|
| 108 |
+
"Steps in the middle didn't converge, maybe you should increase regularization time range.\n ",
|
| 109 |
+
"The regularization strength is already small. Increasing the number of basis worth a try.\n ",
|
| 110 |
+
"If you think context changed too much, increase the regularization strength. \n ",
|
| 111 |
+
"Increase the regularization strength may be better.\n ",
|
| 112 |
+
"If you think context changed too little, lower the regularization strength. \n ",
|
| 113 |
+
"If you think context changed too little, lower the regularization time range. \n ",
|
| 114 |
+
"Number of Basis maybe too high, try lowering it. \n "
|
| 115 |
+
]
|
| 116 |
+
if num_no_converge <=0:
|
| 117 |
+
title += prompts[0]
|
| 118 |
+
if num_no_converge <=0 and reg_ini > 0.5:
|
| 119 |
+
title += prompts[1]
|
| 120 |
+
if num_no_converge == 1:
|
| 121 |
+
title += prompts[2]
|
| 122 |
+
title += prompts[7]
|
| 123 |
+
if num_no_converge >1:
|
| 124 |
+
title += prompts[3]
|
| 125 |
+
title += prompts[7]
|
| 126 |
+
if pos_no_converge > 0.3:
|
| 127 |
+
title += prompts[4]
|
| 128 |
+
if num_no_converge <=0 and reg_ini <= 0.5:
|
| 129 |
+
title += prompts[5]
|
| 130 |
+
if num_no_converge <=0 and reg_ini < 5:
|
| 131 |
+
title += prompts[6]
|
| 132 |
+
if num_no_converge <=0 and reg_ini >= 5:
|
| 133 |
+
title += prompts[8]
|
| 134 |
+
title += prompts[9]
|
| 135 |
+
if num_no_converge >=2 and noise_base >2:
|
| 136 |
+
title += prompts[10]
|
| 137 |
+
alltitles = title.split("\n")[:-1]
|
| 138 |
+
n = np.random.randint(len(alltitles))
|
| 139 |
+
return alltitles[n]
|
| 140 |
+
# Create bar plot
|
| 141 |
+
fig, axs = plt.subplots(len(res), 1, figsize=(10, 4.5 * len(res)))
|
| 142 |
+
if len(res) > 1:
|
| 143 |
+
# Example plotting code
|
| 144 |
+
for i in range(len(res)):
|
| 145 |
+
num_no_converge = 0
|
| 146 |
+
pos_no_converge = 0
|
| 147 |
+
for j, r in enumerate(res[i]):
|
| 148 |
+
if r >= res_thres:
|
| 149 |
+
num_no_converge+=1
|
| 150 |
+
pos_no_converge = max(j,pos_no_converge)
|
| 151 |
+
pos_no_converge = pos_no_converge/(len(res[i])+1)
|
| 152 |
+
# Categorize each result and assign colors
|
| 153 |
+
colors = ['green' if r < res_thres else 'yellow' if r < 10 * res_thres else 'red' for r in res[i]]
|
| 154 |
+
axs[i].bar(np.arange(len(ite_num[i]))+start_step, ite_num[i], color=colors)
|
| 155 |
+
# Create legend
|
| 156 |
+
axs[i].legend(handles=legend_elements, loc='upper right')
|
| 157 |
+
|
| 158 |
+
# Add labels and title
|
| 159 |
+
axs[i].set_xlabel('Diffusion Step')
|
| 160 |
+
axs[i].set_ylabel('Num. Characteristic Iteration')
|
| 161 |
+
ax2 = axs[i].twinx()
|
| 162 |
+
ax2.plot(np.arange(len(ite_num[i]))+start_step, reg[i], linewidth=4, color='C1', label='Regularization Level')
|
| 163 |
+
ax2.set_ylabel('Regularization Level')
|
| 164 |
+
ax2.set_ylim(bottom=0.)
|
| 165 |
+
ax2.legend(loc='upper left')
|
| 166 |
+
title = get_title(reg_ini, reg_range, noise_base, num_no_converge, pos_no_converge)
|
| 167 |
+
ax2.set_title(title)
|
| 168 |
+
ax2.autoscale()
|
| 169 |
+
# axs[i].set_title('Convergence Status of Iterations for Each Step')
|
| 170 |
+
elif len(res) == 1:
|
| 171 |
+
num_no_converge = 0
|
| 172 |
+
pos_no_converge = 0
|
| 173 |
+
for j, r in enumerate(res[0]):
|
| 174 |
+
if r >= res_thres:
|
| 175 |
+
num_no_converge+=1
|
| 176 |
+
pos_no_converge = max(j,pos_no_converge)
|
| 177 |
+
pos_no_converge = pos_no_converge/(len(res[0])+1)
|
| 178 |
+
colors = ['green' if r < res_thres else 'yellow' if r < 10 * res_thres else 'red' for r in res[0]]
|
| 179 |
+
axs.bar(np.arange(len(ite_num[0]))+start_step, ite_num[0], color=colors)
|
| 180 |
+
# Create legend
|
| 181 |
+
axs.legend(handles=legend_elements, loc='upper right')
|
| 182 |
+
|
| 183 |
+
# Add labels and title
|
| 184 |
+
axs.set_xlabel('Diffusion Step')
|
| 185 |
+
axs.set_ylabel('Num. Characteristic Iteration')
|
| 186 |
+
ax2 = axs.twinx()
|
| 187 |
+
title = get_title(reg_ini, reg_range, noise_base, num_no_converge, pos_no_converge)
|
| 188 |
+
ax2.plot(np.arange(len(ite_num[0]))+start_step, reg[0], linewidth=4, color='C1', label='Regularization Level')
|
| 189 |
+
ax2.set_ylabel('Regularization Level')
|
| 190 |
+
ax2.set_ylim(bottom=0.)
|
| 191 |
+
ax2.legend(loc='upper left')
|
| 192 |
+
ax2.set_title(title)
|
| 193 |
+
ax2.autoscale()
|
| 194 |
+
else:
|
| 195 |
+
pass
|
| 196 |
+
# axs.set_title('Convergence Status of Iterations for Each Step')
|
| 197 |
+
# Convert the Matplotlib plot to a PIL Image
|
| 198 |
+
buf = io.BytesIO()
|
| 199 |
+
plt.savefig(buf, format='png')
|
| 200 |
+
buf.seek(0)
|
| 201 |
+
img = Image.open(buf)
|
| 202 |
+
|
| 203 |
+
plt.close() # Close the plot
|
| 204 |
+
return img
|
| 205 |
+
|
| 206 |
+
# Setup menu ui detail
|
| 207 |
+
def ui(self, is_img2img):
|
| 208 |
+
with gr.Accordion('Characteristic Guidance (CHG)', open=False):
|
| 209 |
+
reg_ini = gr.Slider(
|
| 210 |
+
minimum=0.0,
|
| 211 |
+
maximum=10.,
|
| 212 |
+
step=0.1,
|
| 213 |
+
value=1.,
|
| 214 |
+
label="Regularization Strength ( → Easier Convergence, Closer to Classfier-Free. Please try various values)",
|
| 215 |
+
)
|
| 216 |
+
reg_range = gr.Slider(
|
| 217 |
+
minimum=0.01,
|
| 218 |
+
maximum=10.,
|
| 219 |
+
step=0.01,
|
| 220 |
+
value=1.,
|
| 221 |
+
label="Regularization Range Over Time ( ← Harder Convergence, More Correction. Please try various values)",
|
| 222 |
+
)
|
| 223 |
+
ite = gr.Slider(
|
| 224 |
+
minimum=1,
|
| 225 |
+
maximum=50,
|
| 226 |
+
step=1,
|
| 227 |
+
value=50,
|
| 228 |
+
label="Max Num. Characteristic Iteration ( → Slow but Better Convergence)",
|
| 229 |
+
)
|
| 230 |
+
noise_base = gr.Slider(
|
| 231 |
+
minimum=0,
|
| 232 |
+
maximum=10,
|
| 233 |
+
step=1,
|
| 234 |
+
value=0,
|
| 235 |
+
label="Num. Basis for Correction ( ← Less Correction, Better Convergence)",
|
| 236 |
+
)
|
| 237 |
+
with gr.Row(open=True):
|
| 238 |
+
start_step = gr.Slider(
|
| 239 |
+
minimum=0.0,
|
| 240 |
+
maximum=0.25,
|
| 241 |
+
step=0.01,
|
| 242 |
+
value=0.0,
|
| 243 |
+
label="CHG Start Step ( Use CFG before Percent of Steps. )",
|
| 244 |
+
)
|
| 245 |
+
stop_step = gr.Slider(
|
| 246 |
+
minimum=0.25,
|
| 247 |
+
maximum=1.0,
|
| 248 |
+
step=0.01,
|
| 249 |
+
value=1.0,
|
| 250 |
+
label="CHG End Step ( Use CFG after Percent of Steps. )",
|
| 251 |
+
)
|
| 252 |
+
with gr.Accordion('Advanced', open=False):
|
| 253 |
+
chara_decay = gr.Slider(
|
| 254 |
+
minimum=0.,
|
| 255 |
+
maximum=1.,
|
| 256 |
+
step=0.01,
|
| 257 |
+
value=1.,
|
| 258 |
+
label="Reuse Correction of Previous Iteration ( → Suppress Abrupt Changes During Generation )",
|
| 259 |
+
)
|
| 260 |
+
res = gr.Slider(
|
| 261 |
+
minimum=-6,
|
| 262 |
+
maximum=-2,
|
| 263 |
+
step=0.1,
|
| 264 |
+
value=-4.,
|
| 265 |
+
label="Log 10 Tolerance for Iteration Convergence ( → Faster Convergence, Lower Quality)",
|
| 266 |
+
)
|
| 267 |
+
lr = gr.Slider(
|
| 268 |
+
minimum=0,
|
| 269 |
+
maximum=1,
|
| 270 |
+
step=0.01,
|
| 271 |
+
value=1.,
|
| 272 |
+
label="Iteration Step Size ( → Faster Convergence)",
|
| 273 |
+
)
|
| 274 |
+
reg_size = gr.Slider(
|
| 275 |
+
minimum=0.0,
|
| 276 |
+
maximum=1.,
|
| 277 |
+
step=0.1,
|
| 278 |
+
value=0.4,
|
| 279 |
+
label="Regularization Annealing Speed ( ← Slower, Maybe Easier Convergence)",
|
| 280 |
+
)
|
| 281 |
+
reg_w = gr.Slider(
|
| 282 |
+
minimum=0.0,
|
| 283 |
+
maximum=5,
|
| 284 |
+
step=0.01,
|
| 285 |
+
value=0.5,
|
| 286 |
+
label="Regularization Annealing Strength ( ← Stronger Annealing, Slower, Maybe Better Convergence )",
|
| 287 |
+
)
|
| 288 |
+
aa_dim = gr.Slider(
|
| 289 |
+
minimum=1,
|
| 290 |
+
maximum=10,
|
| 291 |
+
step=1,
|
| 292 |
+
value=2,
|
| 293 |
+
label="AA Iteration Memory Size ( → Faster Convergence, Maybe Unstable)",
|
| 294 |
+
)
|
| 295 |
+
with gr.Row():
|
| 296 |
+
checkbox = gr.Checkbox(
|
| 297 |
+
False,
|
| 298 |
+
label="Enable"
|
| 299 |
+
)
|
| 300 |
+
markdown = gr.Markdown("[How to set parameters? Check our github!](https://github.com/scraed/CharacteristicGuidanceWebUI/tree/main)")
|
| 301 |
+
radio = gr.Radio(
|
| 302 |
+
choices=["More Prompt", "More ControlNet"],
|
| 303 |
+
label="ControlNet Compatible Mode",
|
| 304 |
+
value = "More ControlNet"
|
| 305 |
+
)
|
| 306 |
+
with gr.Blocks() as demo:
|
| 307 |
+
image = gr.Image()
|
| 308 |
+
button = gr.Button("Check Convergence (Please Adjust Regularization Strength & Range Over Time If Not Converged)")
|
| 309 |
+
|
| 310 |
+
button.click(fn=self.update_plot, outputs=image)
|
| 311 |
+
# with gr.Blocks(show_footer=False) as blocks:
|
| 312 |
+
# image = gr.Image(show_label=False)
|
| 313 |
+
# blocks.load(fn=self.update_plot, inputs=None, outputs=image,
|
| 314 |
+
# show_progress=False, every=5)
|
| 315 |
+
|
| 316 |
+
def get_chg_parameter(key, default=None):
|
| 317 |
+
def get_parameters(d):
|
| 318 |
+
return d.get('CHG', {}).get(key, default)
|
| 319 |
+
return get_parameters
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
self.infotext_fields = [
|
| 323 |
+
(checkbox, lambda d: 'CHG' in d),
|
| 324 |
+
(reg_ini, get_chg_parameter('RegS')),
|
| 325 |
+
(reg_range, get_chg_parameter('RegR')),
|
| 326 |
+
(ite, get_chg_parameter('MaxI')),
|
| 327 |
+
(noise_base, get_chg_parameter('NBasis')),
|
| 328 |
+
(chara_decay, get_chg_parameter('Reuse')),
|
| 329 |
+
(res, get_chg_parameter('Tol')),
|
| 330 |
+
(lr, get_chg_parameter('IteSS')),
|
| 331 |
+
(reg_size, get_chg_parameter('ASpeed')),
|
| 332 |
+
(reg_w, get_chg_parameter('AStrength')),
|
| 333 |
+
(aa_dim, get_chg_parameter('AADim')),
|
| 334 |
+
(radio, get_chg_parameter('CMode')),
|
| 335 |
+
(start_step, get_chg_parameter('StartStep')),
|
| 336 |
+
(stop_step, get_chg_parameter('StopStep'))
|
| 337 |
+
]
|
| 338 |
+
|
| 339 |
+
# TODO: add more UI components (cf. https://gradio.app/docs/#components)
|
| 340 |
+
return [reg_ini, reg_range, ite, noise_base, chara_decay, res, lr, reg_size, reg_w, aa_dim, checkbox, markdown, radio, start_step, stop_step]
|
| 341 |
+
|
| 342 |
+
def process(self, p, reg_ini, reg_range, ite, noise_base, chara_decay, res, lr, reg_size, reg_w, aa_dim,
|
| 343 |
+
checkbox, markdown, radio, start_step, stop_step, **kwargs):
|
| 344 |
+
if checkbox:
|
| 345 |
+
# info text will have to be written hear otherwise params.txt will not have the infotext of CHG
|
| 346 |
+
# write parameters to extra_generation_params["CHG"] as json dict with double and single quotes swapped
|
| 347 |
+
parameters = {
|
| 348 |
+
'RegS': reg_ini,
|
| 349 |
+
'RegR': reg_range,
|
| 350 |
+
'MaxI': ite,
|
| 351 |
+
'NBasis': noise_base,
|
| 352 |
+
'Reuse': chara_decay,
|
| 353 |
+
'Tol': res,
|
| 354 |
+
'IteSS': lr,
|
| 355 |
+
'ASpeed': reg_size,
|
| 356 |
+
'AStrength': reg_w,
|
| 357 |
+
'AADim': aa_dim,
|
| 358 |
+
'CMode': radio,
|
| 359 |
+
'StartStep': start_step,
|
| 360 |
+
'StopStep': stop_step,
|
| 361 |
+
}
|
| 362 |
+
p.extra_generation_params["CHG"] = json.dumps(parameters).translate(quote_swap)
|
| 363 |
+
print("Characteristic Guidance parameters registered")
|
| 364 |
+
|
| 365 |
+
# Extension main process
|
| 366 |
+
# Type: (StableDiffusionProcessing, List<UI>) -> (Processed)
|
| 367 |
+
# args is [StableDiffusionProcessing, UI1, UI2, ...]
|
| 368 |
+
def process_batch(self, p, reg_ini, reg_range, ite, noise_base, chara_decay, res, lr, reg_size, reg_w, aa_dim,
|
| 369 |
+
checkbox, markdown, radio, start_step, stop_step, **kwargs):
|
| 370 |
+
def modified_sample(sample):
|
| 371 |
+
def wrapper(self, conditioning, unconditional_conditioning, seeds, subseeds, subseed_strength, prompts):
|
| 372 |
+
# modules = sys.modules
|
| 373 |
+
if checkbox:
|
| 374 |
+
# from ssd_samplers_chg_denoiser import CFGDenoiser as CHGDenoiser
|
| 375 |
+
print("Characteristic Guidance modifying the CFGDenoiser")
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
original_forward = CFGDenoiser.forward
|
| 379 |
+
def _call_forward(self, *args, **kwargs):
|
| 380 |
+
if self.chg_start_step <= self.step < self.chg_stop_step:
|
| 381 |
+
return CHGDenoiser.forward(self, *args, **kwargs)
|
| 382 |
+
else:
|
| 383 |
+
return original_forward(self, *args, **kwargs)
|
| 384 |
+
CFGDenoiser.forward = _call_forward
|
| 385 |
+
#CFGDenoiser.Chara_iteration = Chara_iteration
|
| 386 |
+
print('*********cfg denoiser res thres def ************')
|
| 387 |
+
CFGDenoiser.res_thres = 10 ** res
|
| 388 |
+
CFGDenoiser.noise_base = noise_base
|
| 389 |
+
CFGDenoiser.lr_chara = lr
|
| 390 |
+
CFGDenoiser.ite = ite
|
| 391 |
+
CFGDenoiser.reg_size = reg_size
|
| 392 |
+
if reg_ini<=5:
|
| 393 |
+
CFGDenoiser.reg_ini = reg_ini
|
| 394 |
+
else:
|
| 395 |
+
k = 0.8898
|
| 396 |
+
CFGDenoiser.reg_ini = np.exp(k*(reg_ini-5))/np.exp(0)/k + 5 - 1/k
|
| 397 |
+
if reg_range<=5:
|
| 398 |
+
CFGDenoiser.reg_range = reg_range
|
| 399 |
+
else:
|
| 400 |
+
k = 0.8898
|
| 401 |
+
CFGDenoiser.reg_range = np.exp(k*(reg_range-5))/np.exp(0)/k + 5 - 1/k
|
| 402 |
+
CFGDenoiser.reg_w = reg_w
|
| 403 |
+
CFGDenoiser.ite_infos = [[], [], []]
|
| 404 |
+
CFGDenoiser.dxs_buffer = None
|
| 405 |
+
CFGDenoiser.abt_buffer = None
|
| 406 |
+
CFGDenoiser.aa_dim = aa_dim
|
| 407 |
+
CFGDenoiser.chara_decay = chara_decay
|
| 408 |
+
CFGDenoiser.process_p = p
|
| 409 |
+
CFGDenoiser.radio_controlnet = radio
|
| 410 |
+
constrain_step = lambda total_step, step_pct: max(0, min(round(total_step * step_pct), total_step))
|
| 411 |
+
CFGDenoiser.chg_start_step = constrain_step(p.steps, start_step)
|
| 412 |
+
CFGDenoiser.chg_stop_step = constrain_step(p.steps, stop_step)
|
| 413 |
+
# CFGDenoiser.CFGdecayS = CFGdecayS
|
| 414 |
+
try:
|
| 415 |
+
print("Characteristic Guidance sampling:")
|
| 416 |
+
result = sample(conditioning, unconditional_conditioning, seeds, subseeds, subseed_strength,
|
| 417 |
+
prompts)
|
| 418 |
+
|
| 419 |
+
except Exception as e:
|
| 420 |
+
raise e
|
| 421 |
+
finally:
|
| 422 |
+
print("Characteristic Guidance recorded iterations info for " + str(len(CFGDenoiser.ite_infos[0])) + " steps" )
|
| 423 |
+
print("Characteristic Guidance recovering the CFGDenoiser")
|
| 424 |
+
CFGDenoiser.forward = original_forward
|
| 425 |
+
# del CFGDenoiser.CFGdecayS
|
| 426 |
+
else:
|
| 427 |
+
result = sample(conditioning, unconditional_conditioning, seeds, subseeds, subseed_strength,
|
| 428 |
+
prompts)
|
| 429 |
+
return result
|
| 430 |
+
|
| 431 |
+
return wrapper
|
| 432 |
+
|
| 433 |
+
# TODO: get UI info through UI object angle, checkbox
|
| 434 |
+
if checkbox:
|
| 435 |
+
print("Characteristic Guidance enabled, warpping the sample method")
|
| 436 |
+
p.sample = modified_sample(p.sample).__get__(p)
|
| 437 |
+
|
| 438 |
+
# print(p.sampler_name)
|
| 439 |
+
|
extensions/CharacteristicGuidanceWebUI/scripts/CharaIte.py
ADDED
|
@@ -0,0 +1,530 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import modules.scripts as scripts
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
import io
|
| 5 |
+
import json
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import numpy as np
|
| 9 |
+
import inspect
|
| 10 |
+
import torch
|
| 11 |
+
from modules import prompt_parser, devices, sd_samplers_common
|
| 12 |
+
import re
|
| 13 |
+
from modules.shared import opts, state
|
| 14 |
+
import modules.shared as shared
|
| 15 |
+
from modules.script_callbacks import CFGDenoiserParams, cfg_denoiser_callback
|
| 16 |
+
from modules.script_callbacks import CFGDenoisedParams, cfg_denoised_callback
|
| 17 |
+
from modules.script_callbacks import AfterCFGCallbackParams, cfg_after_cfg_callback
|
| 18 |
+
import k_diffusion.utils as utils
|
| 19 |
+
from k_diffusion.external import CompVisVDenoiser, CompVisDenoiser
|
| 20 |
+
from modules.sd_samplers_timesteps import CompVisTimestepsDenoiser, CompVisTimestepsVDenoiser
|
| 21 |
+
from modules.sd_samplers_cfg_denoiser import CFGDenoiser, catenate_conds, subscript_cond, pad_cond
|
| 22 |
+
from modules import script_callbacks
|
| 23 |
+
import copy
|
| 24 |
+
|
| 25 |
+
try:
|
| 26 |
+
from modules_forge import forge_sampler
|
| 27 |
+
isForge = True
|
| 28 |
+
except Exception:
|
| 29 |
+
isForge = False
|
| 30 |
+
|
| 31 |
+
def solve_least_squares(A, B):
|
| 32 |
+
# print(A.shape)
|
| 33 |
+
# print(B.shape)
|
| 34 |
+
# Compute C = A^T A
|
| 35 |
+
# min_eigenvalues = torch.min( torch.linalg.eigvalsh(C), dim=-1 )
|
| 36 |
+
# eps_e = torch.maximum( min_eigenvalues, min_eigenvalues.new_ones(min_eigenvalues.shape)*1e-3 )[...,]
|
| 37 |
+
C = torch.matmul(A.transpose(-2, -1), A) # + eps_e*torch.eye(A.shape[-1], device=A.device)
|
| 38 |
+
# Compute the pseudo-inverse of C
|
| 39 |
+
U, S, Vh = torch.linalg.svd(C.float(), full_matrices=False)
|
| 40 |
+
D_inv = torch.diag_embed(1.0 / torch.maximum(S, torch.ones_like(S) * 1e-4))
|
| 41 |
+
C_inv = Vh.transpose(-1,-2).matmul(D_inv).matmul(U.transpose(-1,-2))
|
| 42 |
+
|
| 43 |
+
# Compute X = C_inv A^T B
|
| 44 |
+
X = torch.matmul(torch.matmul(C_inv, A.transpose(-2, -1)), B)
|
| 45 |
+
return X
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def split_basis(g, n):
|
| 49 |
+
# Define the number of quantiles, n
|
| 50 |
+
|
| 51 |
+
# Flatten the last two dimensions of g for easier processing
|
| 52 |
+
g_flat = g.view(g.shape[0], g.shape[1], -1) # Shape will be (6, 4, 64*64)
|
| 53 |
+
|
| 54 |
+
# Calculate quantiles
|
| 55 |
+
quantiles = torch.quantile(g_flat, torch.linspace(0, 1, n + 1, device=g.device), dim=-1).permute(1, 2, 0)
|
| 56 |
+
|
| 57 |
+
# Initialize an empty tensor for the output
|
| 58 |
+
output = torch.zeros(*g.shape, n, device=g.device)
|
| 59 |
+
|
| 60 |
+
# Use broadcasting and comparisons to fill the output tensor
|
| 61 |
+
for i in range(n):
|
| 62 |
+
lower = quantiles[..., i][..., None, None]
|
| 63 |
+
upper = quantiles[..., i + 1][..., None, None]
|
| 64 |
+
if i < n - 1:
|
| 65 |
+
mask = (g >= lower) & (g < upper)
|
| 66 |
+
else:
|
| 67 |
+
mask = (g >= lower) & (g <= upper)
|
| 68 |
+
output[..., i] = g * mask
|
| 69 |
+
|
| 70 |
+
# Reshape output to the desired shape
|
| 71 |
+
output = output.view(*g.shape, n)
|
| 72 |
+
return output
|
| 73 |
+
|
| 74 |
+
def proj_least_squares(A, B, reg):
|
| 75 |
+
# print(A.shape)
|
| 76 |
+
# print(B.shape)
|
| 77 |
+
# Compute C = A^T A
|
| 78 |
+
C = torch.matmul(A.transpose(-2, -1), A) + reg * torch.eye(A.shape[-1], device=A.device)
|
| 79 |
+
|
| 80 |
+
# Compute the eigenvalues and eigenvectors of C
|
| 81 |
+
eigenvalues, eigenvectors = torch.linalg.eigh(C)
|
| 82 |
+
# eigenvalues = torch.maximum( eigenvalues,eigenvalues*0+1e-3 )
|
| 83 |
+
|
| 84 |
+
# Diagonal matrix with non-zero eigenvalues in the diagonal
|
| 85 |
+
D_inv = torch.diag_embed(1.0 / torch.maximum(eigenvalues, torch.ones_like(eigenvalues) * 1e-4))
|
| 86 |
+
|
| 87 |
+
# Compute the pseudo-inverse of C
|
| 88 |
+
C_inv = torch.matmul(torch.matmul(eigenvectors, D_inv), eigenvectors.transpose(-2, -1))
|
| 89 |
+
|
| 90 |
+
# Compute X = C_inv A^T B
|
| 91 |
+
B_proj = torch.matmul(A, torch.matmul(torch.matmul(C_inv, A.transpose(-2, -1)), B))
|
| 92 |
+
return B_proj
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def Chara_iteration(self, *args, **kwargs):
|
| 96 |
+
# print('Chara_iteration Working')
|
| 97 |
+
if not isForge:
|
| 98 |
+
dxs, x_in, sigma_in, tensor, uncond, cond_scale, image_cond_in, is_edit_model, skip_uncond, make_condition_dict, batch_cond_uncond, batch_size = args
|
| 99 |
+
cond_in=kwargs["cond_in"]
|
| 100 |
+
x_out = kwargs["x_out"]
|
| 101 |
+
# function being evaluated must have x_in and cond_in as first and second input
|
| 102 |
+
def x_out_evaluation(x_in, cond_in, sigma_in, image_cond_in):
|
| 103 |
+
return self.inner_model(x_in, sigma_in, cond=make_condition_dict(cond_in, image_cond_in))
|
| 104 |
+
def eps_evaluation(x_in, cond_in, t_in, image_cond_in):
|
| 105 |
+
return self.inner_model.get_eps(x_in, t_in, cond=make_condition_dict(cond_in, image_cond_in))
|
| 106 |
+
def v_evaluation(x_in, cond_in, t_in, image_cond_in):
|
| 107 |
+
return self.inner_model.get_v(x_in, t_in, cond=make_condition_dict(cond_in, image_cond_in))
|
| 108 |
+
def eps_legacy_evaluation(x_in, cond_in, t_in, image_cond_in):
|
| 109 |
+
return self.inner_model(x_in, t_in, cond=make_condition_dict(cond_in, image_cond_in))
|
| 110 |
+
if tensor.shape[1] == uncond.shape[1] or skip_uncond:
|
| 111 |
+
if batch_cond_uncond:
|
| 112 |
+
def evaluation(func, x_in, conds, *args, **kwargs):
|
| 113 |
+
tensor, uncond, cond_in = conds
|
| 114 |
+
return func(x_in, cond_in, *args, **kwargs)
|
| 115 |
+
else:
|
| 116 |
+
def evaluation(func, x_in, conds, *args, **kwargs):
|
| 117 |
+
x_out = torch.zeros_like(x_in)
|
| 118 |
+
tensor, uncond, cond_in = conds
|
| 119 |
+
for batch_offset in range(0, x_out.shape[0], batch_size):
|
| 120 |
+
a = batch_offset
|
| 121 |
+
b = a + batch_size
|
| 122 |
+
x_out[a:b] = func(x_in[a:b],subscript_cond(cond_in, a, b), *[arg[a:b] for arg in args], **kwargs)
|
| 123 |
+
return x_out
|
| 124 |
+
else:
|
| 125 |
+
def evaluation(func, x_in, conds, *args, **kwargs):
|
| 126 |
+
x_out = torch.zeros_like(x_in)
|
| 127 |
+
tensor, uncond, cond_in = conds
|
| 128 |
+
batch_Size = batch_size*2 if batch_cond_uncond else batch_size
|
| 129 |
+
for batch_offset in range(0, tensor.shape[0], batch_Size):
|
| 130 |
+
a = batch_offset
|
| 131 |
+
b = min(a + batch_Size, tensor.shape[0])
|
| 132 |
+
|
| 133 |
+
if not is_edit_model:
|
| 134 |
+
c_crossattn = subscript_cond(tensor, a, b)
|
| 135 |
+
else:
|
| 136 |
+
c_crossattn = torch.cat([tensor[a:b]], uncond)
|
| 137 |
+
|
| 138 |
+
x_out[a:b] = func(x_in[a:b], c_crossattn, *[arg[a:b] for arg in args], **kwargs)
|
| 139 |
+
|
| 140 |
+
if not skip_uncond:
|
| 141 |
+
x_out[-uncond.shape[0]:] = func(x_in[-uncond.shape[0]:], uncond, *[arg[-uncond.shape[0]:] for arg in args], **kwargs)
|
| 142 |
+
|
| 143 |
+
return x_out
|
| 144 |
+
if is_edit_model or skip_uncond:
|
| 145 |
+
return evaluation(x_out_evaluation, x_in, (tensor, uncond, cond_in), sigma_in, image_cond_in)
|
| 146 |
+
else:
|
| 147 |
+
evaluations = [eps_evaluation, v_evaluation, eps_legacy_evaluation, evaluation]
|
| 148 |
+
ite_paras = [dxs, x_in, sigma_in, tensor, uncond, cond_scale, image_cond_in, is_edit_model, skip_uncond, make_condition_dict, batch_cond_uncond, batch_size, cond_in, x_out]
|
| 149 |
+
dxs_add = chara_ite_inner_loop(self, evaluations, ite_paras)
|
| 150 |
+
return evaluation(x_out_evaluation, x_in + dxs_add, (tensor, uncond, cond_in), sigma_in, image_cond_in)
|
| 151 |
+
else:
|
| 152 |
+
model,dxs,x_in, sigma_in,cond_scale,uncond, c = args
|
| 153 |
+
# print('dxs', dxs)
|
| 154 |
+
# print('x_in', (x_in.dtype))
|
| 155 |
+
# print('x_in',(x_in))
|
| 156 |
+
# print('sigma_in',sigma_in)
|
| 157 |
+
# print('cond_scale',cond_scale)
|
| 158 |
+
# print('uncond',uncond)
|
| 159 |
+
def evaluation(func, x_in, t_in, c):
|
| 160 |
+
# tensor, uncond, cond_in = conds
|
| 161 |
+
# print('x_in eval',x_in.shape)
|
| 162 |
+
return func(x_in, t_in, c)
|
| 163 |
+
|
| 164 |
+
def eps_evaluation(x_in, t_in, c):
|
| 165 |
+
# print('x_in',x_in.dtype)
|
| 166 |
+
# print('t_in',t_in.dtype)
|
| 167 |
+
x_out = model.apply_model(x_in,t_in,**c)
|
| 168 |
+
# print('x_out',x_out.dtype)
|
| 169 |
+
t_in_expand = t_in.view(t_in.shape[:1] + (1,) * (x_in.ndim - 1))
|
| 170 |
+
eps_out = (x_in - x_out)#/t_in_expand.half() # t_in_expand = ((1- abt)/abt)**0.5
|
| 171 |
+
# This eps_out here is actually ((1- abt)/abt)**0.5*eps
|
| 172 |
+
return eps_out
|
| 173 |
+
|
| 174 |
+
def v_evaluation(x_in, t_in, c):
|
| 175 |
+
#print('model v evaluation')
|
| 176 |
+
x_out = model.apply_model(x_in, t_in, **c)
|
| 177 |
+
t_in_expand = t_in.view(t_in.shape[:1] + (1,) * (x_in.ndim - 1))
|
| 178 |
+
sigma_data = model.model_sampling.sigma_data
|
| 179 |
+
v_out = (x_in* sigma_data**2 - (sigma_data**2 + t_in_expand**2)*x_out)/(t_in_expand*sigma_data*(t_in_expand**2+sigma_data**2)** 0.5)
|
| 180 |
+
return v_out
|
| 181 |
+
|
| 182 |
+
def x_out_evaluation(x_in, t_in, c):
|
| 183 |
+
# t_in_expand = t_in.view(t_in.shape[:1] + (1,) * (x_in.ndim - 1))
|
| 184 |
+
# x_in = x_in*((t_in_expand ** 2 + 1 ** 2) ** 0.5)
|
| 185 |
+
# print('x out evaluation control', c['control']['middle'])
|
| 186 |
+
x_out = model.apply_model(x_in, t_in,**c)
|
| 187 |
+
return x_out
|
| 188 |
+
|
| 189 |
+
def eps_legacy_evaluation(x_in, t_in, c):
|
| 190 |
+
return self.inner_model(x_in, t_in, **c)
|
| 191 |
+
# return self.inner_model.get_eps(x_in, t_in, cond=make_condition_dict(cond_in, image_cond_in))
|
| 192 |
+
evaluations = [eps_evaluation, v_evaluation, None, evaluation]
|
| 193 |
+
ite_paras = [model,dxs,x_in, sigma_in,cond_scale,uncond, c]
|
| 194 |
+
dxs_add = chara_ite_inner_loop(self, evaluations, ite_paras)
|
| 195 |
+
# print('dxs_add',dxs_add)
|
| 196 |
+
return evaluation(x_out_evaluation, x_in + dxs_add, sigma_in, c)
|
| 197 |
+
|
| 198 |
+
def chara_ite_inner_loop(self, evaluations, ite_paras):
|
| 199 |
+
eps_evaluation, v_evaluation, eps_legacy_evaluation, evaluation = evaluations
|
| 200 |
+
if isForge:
|
| 201 |
+
model,dxs,x_in, sigma_in,cond_scale,uncond, c = ite_paras
|
| 202 |
+
# print('inside inner loop control',c['control']['middle'])
|
| 203 |
+
sigma_in = sigma_in.to(x_in.device)
|
| 204 |
+
else:
|
| 205 |
+
dxs, x_in, sigma_in, tensor, uncond, cond_scale, image_cond_in, is_edit_model, skip_uncond, make_condition_dict, batch_cond_uncond, batch_size, cond_in, x_out = ite_paras
|
| 206 |
+
if dxs is None:
|
| 207 |
+
dxs = torch.zeros_like(x_in[-uncond.shape[0]:])
|
| 208 |
+
if self.radio_controlnet == "More Prompt":
|
| 209 |
+
control_net_weights = []
|
| 210 |
+
for script in self.process_p.scripts.scripts:
|
| 211 |
+
if script.title() == "ControlNet":
|
| 212 |
+
try:
|
| 213 |
+
for param in script.latest_network.control_params:
|
| 214 |
+
control_net_weights.append(param.weight)
|
| 215 |
+
param.weight = 0.
|
| 216 |
+
except:
|
| 217 |
+
pass
|
| 218 |
+
|
| 219 |
+
res_thres = self.res_thres
|
| 220 |
+
|
| 221 |
+
num_x_in_cond = len(x_in[:-uncond.shape[0]])//len(dxs)
|
| 222 |
+
# print('x_in',x_in.shape)
|
| 223 |
+
# print('uncond',uncond.shape[0])
|
| 224 |
+
h = cond_scale*num_x_in_cond
|
| 225 |
+
|
| 226 |
+
if isinstance(self.inner_model, CompVisDenoiser):
|
| 227 |
+
# print('sigma_in',sigma_in.device)
|
| 228 |
+
# print('inner model log sigma',self.inner_model.log_sigmas.device)
|
| 229 |
+
t_in = self.inner_model.sigma_to_t(sigma_in.to(self.inner_model.log_sigmas.device),quantize=True)
|
| 230 |
+
abt = self.inner_model.inner_model.alphas_cumprod.to(t_in.device)[t_in.long()]
|
| 231 |
+
c_out, c_in = [utils.append_dims(x, x_in.ndim) for x in self.inner_model.get_scalings(sigma_in)]
|
| 232 |
+
elif isinstance(self.inner_model, CompVisVDenoiser):
|
| 233 |
+
t_in = self.inner_model.sigma_to_t(sigma_in.to(self.inner_model.log_sigmas.device),quantize=True)
|
| 234 |
+
abt = self.inner_model.inner_model.alphas_cumprod.to(t_in.device)[t_in.long()]
|
| 235 |
+
c_skip, c_out, c_in = [utils.append_dims(x, x_in.ndim) for x in self.inner_model.get_scalings(sigma_in)]
|
| 236 |
+
elif isinstance(self.inner_model, CompVisTimestepsDenoiser) or isinstance(self.inner_model,
|
| 237 |
+
CompVisTimestepsVDenoiser):
|
| 238 |
+
if isForge:
|
| 239 |
+
abt_table = self.alphas
|
| 240 |
+
def timestep(sigma,abt_table):
|
| 241 |
+
abt = (1/(1+sigma**2)).to(sigma.device)
|
| 242 |
+
dists = abt - abt_table.to(sigma.device)[:, None]
|
| 243 |
+
return dists.abs().argmin(dim=0).view(sigma.shape).to(sigma.device)
|
| 244 |
+
t_in = timestep(sigma_in,abt_table)
|
| 245 |
+
print('timestep t_in',t_in)
|
| 246 |
+
else:
|
| 247 |
+
t_in = sigma_in
|
| 248 |
+
abt = self.alphas.to(t_in.device)[t_in.long()]
|
| 249 |
+
else:
|
| 250 |
+
raise NotImplementedError()
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
scale = ((1 - abt) ** 0.5)[-uncond.shape[0]:, None, None, None].to(x_in.device)
|
| 254 |
+
scale_f = ((abt) ** 0.5)[-uncond.shape[0]:, None, None, None].to(x_in.device)
|
| 255 |
+
abt_current = abt[-uncond.shape[0]:, None, None, None].to(x_in.device)
|
| 256 |
+
abt_smallest = self.inner_model.inner_model.alphas_cumprod[-1].to(x_in.device)
|
| 257 |
+
# x_in_cond = x_in[:-uncond.shape[0]]
|
| 258 |
+
# x_in_uncond = x_in[-uncond.shape[0]:]
|
| 259 |
+
# print("alphas_cumprod",-torch.log(self.inner_model.inner_model.alphas_cumprod))
|
| 260 |
+
# print("betas",torch.sum(self.inner_model.inner_model.betas))
|
| 261 |
+
|
| 262 |
+
dxs_Anderson = []
|
| 263 |
+
g_Anderson = []
|
| 264 |
+
|
| 265 |
+
def AndersonAccR(dxs, g, reg_level, reg_target, pre_condition=None, m=3):
|
| 266 |
+
batch = dxs.shape[0]
|
| 267 |
+
x_shape = dxs.shape[1:]
|
| 268 |
+
reg_residual_form = reg_level
|
| 269 |
+
g_flat = g.reshape(batch, -1)
|
| 270 |
+
dxs_flat = dxs.reshape(batch, -1)
|
| 271 |
+
res_g = self.reg_size * (reg_residual_form[:, None] - reg_target[:, None])
|
| 272 |
+
res_dxs = reg_residual_form[:, None]
|
| 273 |
+
g_Anderson.append(torch.cat((g_flat, res_g), dim=-1))
|
| 274 |
+
dxs_Anderson.append(torch.cat((dxs_flat, res_dxs), dim=-1))
|
| 275 |
+
|
| 276 |
+
if len(g_Anderson) < 2:
|
| 277 |
+
return dxs, g, res_dxs[:, 0], res_g[:, 0]
|
| 278 |
+
else:
|
| 279 |
+
g_Anderson[-2] = g_Anderson[-1] - g_Anderson[-2]
|
| 280 |
+
dxs_Anderson[-2] = dxs_Anderson[-1] - dxs_Anderson[-2]
|
| 281 |
+
if len(g_Anderson) > m:
|
| 282 |
+
del dxs_Anderson[0]
|
| 283 |
+
del g_Anderson[0]
|
| 284 |
+
gA = torch.cat([g[..., None] for g in g_Anderson[:-1]], dim=-1)
|
| 285 |
+
gB = g_Anderson[-1][..., None]
|
| 286 |
+
|
| 287 |
+
gA_norm = torch.maximum(torch.sum(gA ** 2, dim=-2, keepdim=True) ** 0.5, torch.ones_like(gA) * 1e-4)
|
| 288 |
+
# print("gA_norm ",gA_norm.shape)
|
| 289 |
+
# gB_norm = torch.sum( gB**2, dim = -2 , keepdim=True )**0.5 + 1e-6
|
| 290 |
+
# gamma = solve_least_squares(gA/gA_norm, gB)
|
| 291 |
+
gamma = torch.linalg.lstsq(gA / gA_norm, gB).solution
|
| 292 |
+
if torch.sum( torch.isnan(gamma) ) > 0:
|
| 293 |
+
gamma = solve_least_squares(gA/gA_norm, gB)
|
| 294 |
+
xA = torch.cat([x[..., None] for x in dxs_Anderson[:-1]], dim=-1)
|
| 295 |
+
xB = dxs_Anderson[-1][..., None]
|
| 296 |
+
# print("xO print",xB.shape, xA.shape, gA_norm.shape, gamma.shape)
|
| 297 |
+
xO = xB - (xA / gA_norm).matmul(gamma)
|
| 298 |
+
gO = gB - (gA / gA_norm).matmul(gamma)
|
| 299 |
+
dxsO = xO[:, :-1].reshape(batch, *x_shape)
|
| 300 |
+
dgO = gO[:, :-1].reshape(batch, *x_shape)
|
| 301 |
+
resxO = xO[:, -1, 0]
|
| 302 |
+
resgO = gO[:, -1, 0]
|
| 303 |
+
# print("xO",xO.shape)
|
| 304 |
+
# print("gO",gO.shape)
|
| 305 |
+
# print("gamma",gamma.shape)
|
| 306 |
+
return dxsO, dgO, resxO, resgO
|
| 307 |
+
|
| 308 |
+
def downsample_reg_g(dx, g_1, reg):
|
| 309 |
+
# DDec_dx = DDec(dx)
|
| 310 |
+
# down_DDec_dx = downsample(DDec_dx, factor=factor)
|
| 311 |
+
# DEnc_dx = DEnc(down_DDec_dx)
|
| 312 |
+
# return DEnc_dx
|
| 313 |
+
|
| 314 |
+
if g_1 is None:
|
| 315 |
+
return dx
|
| 316 |
+
elif self.noise_base >= 1:
|
| 317 |
+
# return g_1*torch.sum(g_1*dx, dim = (-1,-2), keepdim=True )/torch.sum( g_1**2, dim = (-1,-2) , keepdim=True )
|
| 318 |
+
A = g_1.reshape(g_1.shape[0] * g_1.shape[1], g_1.shape[2] * g_1.shape[3], g_1.shape[4])
|
| 319 |
+
B = dx.reshape(dx.shape[0] * dx.shape[1], -1, 1)
|
| 320 |
+
regl = reg[:, None].expand(-1, dx.shape[1]).reshape(dx.shape[0] * dx.shape[1], 1, 1)
|
| 321 |
+
dx_proj = proj_least_squares(A, B, regl)
|
| 322 |
+
|
| 323 |
+
return dx_proj.reshape(*dx.shape)
|
| 324 |
+
else:
|
| 325 |
+
# return g_1*torch.sum(g_1*dx, dim = (-1,-2), keepdim=True )/torch.sum( g_1**2, dim = (-1,-2) , keepdim=True )
|
| 326 |
+
A = g_1.reshape(g_1.shape[0], g_1.shape[1]* g_1.shape[2] * g_1.shape[3], g_1.shape[4])
|
| 327 |
+
B = dx.reshape(dx.shape[0], -1, 1)
|
| 328 |
+
regl = reg[:, None].reshape(dx.shape[0], 1, 1)
|
| 329 |
+
dx_proj = proj_least_squares(A, B, regl)
|
| 330 |
+
|
| 331 |
+
return dx_proj.reshape(*dx.shape)
|
| 332 |
+
g_1 = None
|
| 333 |
+
|
| 334 |
+
reg_level = torch.zeros(dxs.shape[0], device=dxs.device) + max(5,self.reg_ini)
|
| 335 |
+
reg_target_level = self.reg_ini * (abt_smallest / abt_current[:, 0, 0, 0]) ** (1 / self.reg_range)
|
| 336 |
+
Converged = False
|
| 337 |
+
eps0_ch, eps1_ch = torch.zeros_like(dxs), torch.zeros_like(dxs)
|
| 338 |
+
best_res_el = torch.mean(dxs, dim=(-1, -2, -3), keepdim=True) + 100
|
| 339 |
+
best_res = 100
|
| 340 |
+
best_dxs = torch.zeros_like(dxs)
|
| 341 |
+
res_max = torch.zeros(dxs.shape[0], device=dxs.device)
|
| 342 |
+
n_iterations = self.ite
|
| 343 |
+
|
| 344 |
+
if self.dxs_buffer is not None:
|
| 345 |
+
abt_prev = self.abt_buffer
|
| 346 |
+
dxs = self.dxs_buffer
|
| 347 |
+
# if self.CFGdecayS:
|
| 348 |
+
dxs = dxs * ((abt_prev - abt_current * abt_prev) / (abt_current - abt_current * abt_prev))
|
| 349 |
+
# print(abt_prev.shape, abt_current.shape, self.dxs_buffer.shape)
|
| 350 |
+
dxs = self.chara_decay * dxs
|
| 351 |
+
iteration_counts = 0
|
| 352 |
+
for iteration in range(n_iterations):
|
| 353 |
+
# print(f'********* ite {iteration} *********')
|
| 354 |
+
# important to keep iteration content consistent
|
| 355 |
+
# Supoort AND prompt combination by using multiple dxs for condition part
|
| 356 |
+
def compute_correction_direction(dxs):
|
| 357 |
+
if isForge:
|
| 358 |
+
c_copy = copy.deepcopy(c)
|
| 359 |
+
# print('num_x_in_cond',num_x_in_cond)
|
| 360 |
+
# print('(h - 1) * dxs[:,None,...]', ((h - 1) * dxs[:,None,...]).shape)
|
| 361 |
+
dxs_cond_part = torch.cat( [*( [(h - 1) * dxs[:,None,...]]*num_x_in_cond )], axis=1 ).view( (dxs.shape[0]*num_x_in_cond, *dxs.shape[1:]) )
|
| 362 |
+
dxs_add = torch.cat([ dxs_cond_part, h * dxs], axis=0)
|
| 363 |
+
if isinstance(self.inner_model, CompVisDenoiser):
|
| 364 |
+
if isForge:
|
| 365 |
+
eps_out = evaluation(eps_evaluation, x_in + dxs_add, sigma_in,c_copy)
|
| 366 |
+
pred_eps_uncond = eps_out[:-uncond.shape[0]] # forge: c_crossatten[0]: uncondition
|
| 367 |
+
eps_cond_batch = eps_out[-uncond.shape[0]:] # forge: c_crossatten[1]: condition
|
| 368 |
+
# print('pred_eps_uncond', pred_eps_uncond.dtype)
|
| 369 |
+
# print('eps_cond_batch', eps_cond_batch.dtype)
|
| 370 |
+
eps_cond_batch_target_shape = ( len(eps_cond_batch)//num_x_in_cond, num_x_in_cond, *(eps_cond_batch.shape[1:]) )
|
| 371 |
+
pred_eps_cond = torch.mean( eps_cond_batch.view(eps_cond_batch_target_shape), dim=1, keepdim=False )
|
| 372 |
+
# print("scale_f", scale_f)
|
| 373 |
+
# print('(pred_eps_uncond - pred_eps_cond)',(pred_eps_uncond - pred_eps_cond))
|
| 374 |
+
# print('pred_eps_cond', pred_eps_cond)
|
| 375 |
+
# print('scale/c_in',scale / c_in[-uncond.shape[0]:])
|
| 376 |
+
# print("c_in", c_in[-uncond.shape[0]:])
|
| 377 |
+
ggg = (pred_eps_uncond - pred_eps_cond) #* (scale / c_in[-uncond.shape[0]:])
|
| 378 |
+
# print('ggg',ggg)
|
| 379 |
+
else:
|
| 380 |
+
eps_out = evaluation(eps_evaluation, x_in * c_in + dxs_add * c_in, (tensor, uncond, cond_in), t_in, image_cond_in)
|
| 381 |
+
pred_eps_uncond = eps_out[-uncond.shape[0]:]
|
| 382 |
+
eps_cond_batch = eps_out[:-uncond.shape[0]]
|
| 383 |
+
eps_cond_batch_target_shape = ( len(eps_cond_batch)//num_x_in_cond, num_x_in_cond, *(eps_cond_batch.shape[1:]) )
|
| 384 |
+
pred_eps_cond = torch.mean( eps_cond_batch.view(eps_cond_batch_target_shape), dim=1, keepdim=False )
|
| 385 |
+
ggg = (pred_eps_uncond - pred_eps_cond) * scale / c_in[-uncond.shape[0]:]
|
| 386 |
+
elif isinstance(self.inner_model, CompVisVDenoiser):
|
| 387 |
+
if isForge:
|
| 388 |
+
v_out = evaluation(v_evaluation, x_in+dxs_add,sigma_in,c_copy)
|
| 389 |
+
eps_out = -c_out*x_in + c_skip**0.5*v_out
|
| 390 |
+
pred_eps_uncond = eps_out[:-uncond.shape[0]] # forge: c_crossatten[0]: uncondition
|
| 391 |
+
eps_cond_batch = eps_out[-uncond.shape[0]:] # forge: c_crossatten[1]: condition
|
| 392 |
+
else:
|
| 393 |
+
v_out = evaluation(v_evaluation, x_in * c_in + dxs_add * c_in, (tensor, uncond, cond_in), t_in, image_cond_in)
|
| 394 |
+
eps_out = -c_out*x_in + c_skip**0.5*v_out
|
| 395 |
+
pred_eps_uncond = eps_out[-uncond.shape[0]:]
|
| 396 |
+
eps_cond_batch = eps_out[:-uncond.shape[0]]
|
| 397 |
+
eps_cond_batch_target_shape = ( len(eps_cond_batch)//num_x_in_cond, num_x_in_cond, *(eps_cond_batch.shape[1:]) )
|
| 398 |
+
pred_eps_cond = torch.mean( eps_cond_batch.view(eps_cond_batch_target_shape), dim=1, keepdim=False )
|
| 399 |
+
ggg = (pred_eps_uncond - pred_eps_cond) * scale / c_in[-uncond.shape[0]:]
|
| 400 |
+
elif isinstance(self.inner_model, CompVisTimestepsDenoiser) or isinstance(self.inner_model,
|
| 401 |
+
CompVisTimestepsVDenoiser):
|
| 402 |
+
#eps_out = self.inner_model(x_in + dxs_add, t_in, cond=cond)
|
| 403 |
+
if isForge:
|
| 404 |
+
eps_out = evaluation(eps_evaluation, x_in + dxs_add, sigma_in, c_copy)
|
| 405 |
+
pred_eps_uncond = eps_out[:-uncond.shape[0]] # forge: c_crossatten[0]: uncondition
|
| 406 |
+
eps_cond_batch = eps_out[-uncond.shape[0]:] # forge: c_crossatten[1]: condition
|
| 407 |
+
# print('pred_eps_uncond', pred_eps_uncond.dtype)
|
| 408 |
+
# print('eps_cond_batch', eps_cond_batch.dtype)
|
| 409 |
+
eps_cond_batch_target_shape = (
|
| 410 |
+
len(eps_cond_batch) // num_x_in_cond, num_x_in_cond, *(eps_cond_batch.shape[1:]))
|
| 411 |
+
pred_eps_cond = torch.mean(eps_cond_batch.view(eps_cond_batch_target_shape), dim=1, keepdim=False)
|
| 412 |
+
ggg = (pred_eps_uncond - pred_eps_cond) # * (scale / c_in[-uncond.shape[0]:])
|
| 413 |
+
else:
|
| 414 |
+
eps_out = evaluation(eps_legacy_evaluation, x_in + dxs_add, (tensor, uncond, cond_in), t_in, image_cond_in)
|
| 415 |
+
pred_eps_uncond = eps_out[-uncond.shape[0]:]
|
| 416 |
+
eps_cond_batch = eps_out[:-uncond.shape[0]]
|
| 417 |
+
eps_cond_batch_target_shape = ( len(eps_cond_batch)//num_x_in_cond, num_x_in_cond, *(eps_cond_batch.shape[1:]) )
|
| 418 |
+
pred_eps_cond = torch.mean( eps_cond_batch.view(eps_cond_batch_target_shape), dim=1, keepdim=False )
|
| 419 |
+
ggg = (pred_eps_uncond - pred_eps_cond) * scale
|
| 420 |
+
else:
|
| 421 |
+
raise NotImplementedError()
|
| 422 |
+
return ggg
|
| 423 |
+
|
| 424 |
+
# dxs = 0*dxs # for debug, need to command
|
| 425 |
+
ggg = compute_correction_direction(dxs)
|
| 426 |
+
# print('ggg',ggg)
|
| 427 |
+
# print("print(reg_level.shape)", reg_level.shape)
|
| 428 |
+
g = dxs - downsample_reg_g(ggg, g_1, reg_level)
|
| 429 |
+
if g_1 is None:
|
| 430 |
+
g_basis = -compute_correction_direction(dxs*0)
|
| 431 |
+
g_1 = split_basis(g_basis, max( self.noise_base,1 ) )
|
| 432 |
+
# if self.Projg:
|
| 433 |
+
# g_1 = split_basis( g, self.noise_base)
|
| 434 |
+
# else:
|
| 435 |
+
# g_1 = split_basis( ggg, self.noise_base)
|
| 436 |
+
# if self.CFGdecayS and self.dxs_buffer is not None:
|
| 437 |
+
# g_1 = torch.cat( [g_1, self.dxs_buffer[:,:,:,:,None]], dim=-1 )
|
| 438 |
+
# if self.noise_base > 0:
|
| 439 |
+
# noise_base = torch.randn(g_1.shape[0],g_1.shape[1],g_1.shape[2],g_1.shape[3],self.noise_base, device=g_1.device)
|
| 440 |
+
# g_1 = torch.cat([g_1, noise_base], dim=-1)
|
| 441 |
+
if self.noise_base >=1:
|
| 442 |
+
g_1_norm = torch.sum(g_1 ** 2, dim=(-2, -3), keepdim=True) ** 0.5
|
| 443 |
+
g_1 = g_1 / torch.maximum(g_1_norm, torch.ones_like(
|
| 444 |
+
g_1_norm) * 1e-4) # + self.noise_level*noise/torch.sum( noise**2, dim = (-1,-2) , keepdim=True )
|
| 445 |
+
else:
|
| 446 |
+
g_1_norm = torch.sum(g_1 ** 2, dim=(-2, -3, -4), keepdim=True) ** 0.5
|
| 447 |
+
g_1 = g_1 / torch.maximum(g_1_norm, torch.ones_like(
|
| 448 |
+
g_1_norm) * 1e-4) # + self.noise_level*noise/torch.sum( noise**2, dim = (-1,-2) , keepdim=True )
|
| 449 |
+
# Compute regularization level
|
| 450 |
+
reg_Acc = (reg_level * self.reg_w) ** 0.5
|
| 451 |
+
reg_target = (reg_target_level * self.reg_w) ** 0.5
|
| 452 |
+
# Compute residual
|
| 453 |
+
g_flat_res = g.reshape(dxs.shape[0], -1)
|
| 454 |
+
reg_g = self.reg_size * (reg_Acc[:, None] - reg_target[:, None])
|
| 455 |
+
g_flat_res_reg = torch.cat((g_flat_res, reg_g), dim=-1)
|
| 456 |
+
|
| 457 |
+
res_x = ((torch.mean((g_flat_res) ** 2, dim=(-1), keepdim=False)) ** 0.5)[:, None, None, None]
|
| 458 |
+
res_el = ((torch.mean((g_flat_res_reg) ** 2, dim=(-1), keepdim=False)) ** 0.5)[:, None, None, None]
|
| 459 |
+
# reg_res = torch.mean( (self.reg_size*torch.abs(reg_level - reg_target))**2 )**0.5
|
| 460 |
+
# reg_res = torch.mean( self.reg_size*torch.abs(reg_level - self.reg_level)/g.shape[-1]/g.shape[-2] )**0.5
|
| 461 |
+
|
| 462 |
+
res = torch.mean(res_el) # + reg_res
|
| 463 |
+
# if res < best_res:
|
| 464 |
+
# best_res = res
|
| 465 |
+
# best_dxs = dxs
|
| 466 |
+
|
| 467 |
+
if iteration == 0:
|
| 468 |
+
best_res_el = res_el
|
| 469 |
+
best_dxs = dxs
|
| 470 |
+
not_converged = torch.ones_like(res_el).bool()
|
| 471 |
+
# update eps if residual is better
|
| 472 |
+
res_mask = torch.logical_and(res_el < best_res_el, not_converged).int()
|
| 473 |
+
best_res_el = res_mask * res_el + (1 - res_mask) * best_res_el
|
| 474 |
+
# print(res_mask.shape, dxs.shape, best_dxs.shape)
|
| 475 |
+
best_dxs = res_mask * dxs + (1 - res_mask) * best_dxs
|
| 476 |
+
# eps0_ch, eps1_ch = res_mask*pred_eps_uncond + (1-res_mask)*eps0_ch, res_mask*pred_eps_cond + (1-res_mask)*eps1_ch
|
| 477 |
+
|
| 478 |
+
res_max = torch.max(best_res_el)
|
| 479 |
+
# print("res_x", torch.max( res_x ), "reg", torch.max( reg_level), "reg_target", reg_target, "res", res_max )
|
| 480 |
+
not_converged = torch.logical_and(res_el >= res_thres, not_converged)
|
| 481 |
+
# print("not_converged", not_converged.shape)
|
| 482 |
+
# torch._dynamo.graph_break()
|
| 483 |
+
if res_max < res_thres:
|
| 484 |
+
Converged = True
|
| 485 |
+
break
|
| 486 |
+
# v = beta*v + (1-beta)*g**2
|
| 487 |
+
# m = beta_m*m + (1-beta_m)*g
|
| 488 |
+
# g/(v**0.5+eps_delta)
|
| 489 |
+
if self.noise_base >=1:
|
| 490 |
+
aa_dim = self.aa_dim
|
| 491 |
+
else:
|
| 492 |
+
aa_dim = 1
|
| 493 |
+
dxs_Acc, g_Acc, reg_dxs_Acc, reg_g_Acc = AndersonAccR(dxs, g, reg_Acc, reg_target, pre_condition=None,
|
| 494 |
+
m=aa_dim + 1)
|
| 495 |
+
# print(Accout)
|
| 496 |
+
#
|
| 497 |
+
dxs = dxs_Acc - self.lr_chara * g_Acc
|
| 498 |
+
reg_Acc = reg_dxs_Acc - self.lr_chara * reg_g_Acc
|
| 499 |
+
reg_level = reg_Acc ** 2 / self.reg_w
|
| 500 |
+
|
| 501 |
+
# reg_target_level = (1+self.reg_level)**( iteration//int(5/self.lr_chara) ) - 1
|
| 502 |
+
# reg_level_mask = (reg_level >= reg_target_level).long()
|
| 503 |
+
# reg_level = reg_level_mask*reg_level + (1-reg_level_mask)*reg_target_level
|
| 504 |
+
# if iteration%int(5) == 0:
|
| 505 |
+
# dxs_Anderson = []
|
| 506 |
+
# g_Anderson = []
|
| 507 |
+
iteration_counts = iteration_counts * (1 - not_converged.long()) + iteration * not_converged.long()
|
| 508 |
+
self.ite_infos[0].append(best_res_el)
|
| 509 |
+
# print(iteration_counts[:,0,0,0].shape)
|
| 510 |
+
self.ite_infos[1].append(iteration_counts[:, 0, 0, 0])
|
| 511 |
+
self.ite_infos[2].append(reg_target_level)
|
| 512 |
+
print("Characteristic iteration happens", iteration_counts[:, 0, 0, 0] , "times")
|
| 513 |
+
final_dxs = best_dxs * (1 - not_converged.long())
|
| 514 |
+
dxs_cond_part = torch.cat( [*( [(h - 1) * final_dxs[:,None,...]]*num_x_in_cond )], axis=1 ).view( (dxs.shape[0]*num_x_in_cond, *dxs.shape[1:]) )
|
| 515 |
+
dxs_add = torch.cat([ dxs_cond_part, h * final_dxs], axis=0)
|
| 516 |
+
#dxs_add = torch.cat([ *( [(h - 1) * final_dxs,]*num_x_in_cond ), h * final_dxs], axis=0)
|
| 517 |
+
self.dxs_buffer = final_dxs
|
| 518 |
+
self.abt_buffer = abt_current
|
| 519 |
+
|
| 520 |
+
if self.radio_controlnet == "More Prompt":
|
| 521 |
+
controlnet_count = 0
|
| 522 |
+
for script in self.process_p.scripts.scripts:
|
| 523 |
+
if script.title() == "ControlNet":
|
| 524 |
+
try:
|
| 525 |
+
for param in script.latest_network.control_params:
|
| 526 |
+
param.weight = control_net_weights[controlnet_count]
|
| 527 |
+
controlnet_count += 1
|
| 528 |
+
except:
|
| 529 |
+
pass
|
| 530 |
+
return dxs_add
|
extensions/CharacteristicGuidanceWebUI/scripts/__pycache__/CHGextension.cpython-310.pyc
ADDED
|
Binary file (13.3 kB). View file
|
|
|
extensions/CharacteristicGuidanceWebUI/scripts/__pycache__/CharaIte.cpython-310.pyc
ADDED
|
Binary file (14.3 kB). View file
|
|
|
extensions/CharacteristicGuidanceWebUI/scripts/__pycache__/forge_CHG.cpython-310.pyc
ADDED
|
Binary file (9.14 kB). View file
|
|
|