

Commit
•
a3507d1
1
Parent(s):
d8398e0
up
Browse files- + +52 -0
- README.md +52 -0
- config.json +22 -0
- diffusion_model.pt +3 -0
- model_index.json +12 -0
- modeling_ddim.py +71 -0
- scheduler_config.json +8 -0
+
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- ddim_diffusion
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Denoising Diffusion Implicit Models (DDIM)
|
| 7 |
+
|
| 8 |
+
**Paper**: [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502)
|
| 9 |
+
|
| 10 |
+
**Abstract**:
|
| 11 |
+
|
| 12 |
+
*Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.*
|
| 13 |
+
|
| 14 |
+
**Explanation on `eta` and `num_inference_steps`**
|
| 15 |
+
|
| 16 |
+
- `num_inference_steps` is called *S* in the following table
|
| 17 |
+
- `eta` is called *η* in the following table
|
| 18 |
+
|
| 19 |
+
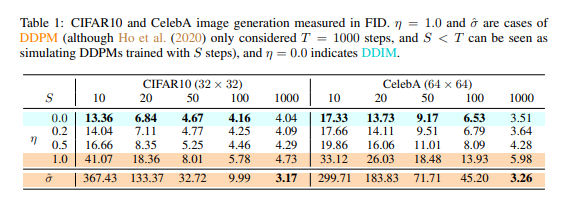
|
| 20 |
+
|
| 21 |
+
## Usage
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
# !pip install diffusers
|
| 25 |
+
from diffusers import DiffusionPipeline
|
| 26 |
+
import PIL.Image
|
| 27 |
+
import numpy as np
|
| 28 |
+
|
| 29 |
+
model_id = "fusing/ddim-lsun-bedroom"
|
| 30 |
+
|
| 31 |
+
# load model and scheduler
|
| 32 |
+
ddpm = DiffusionPipeline.from_pretrained(model_id)
|
| 33 |
+
|
| 34 |
+
# run pipeline in inference (sample random noise and denoise)
|
| 35 |
+
image = ddpm()
|
| 36 |
+
|
| 37 |
+
# process image to PIL
|
| 38 |
+
image_processed = image.cpu().permute(0, 2, 3, 1)
|
| 39 |
+
image_processed = (image_processed + 1.0) * 127.5
|
| 40 |
+
image_processed = image_processed.numpy().astype(np.uint8)
|
| 41 |
+
image_pil = PIL.Image.fromarray(image_processed[0])
|
| 42 |
+
|
| 43 |
+
# save image
|
| 44 |
+
image_pil.save("test.png")
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
## Samples
|
| 48 |
+
|
| 49 |
+
1. 
|
| 50 |
+
2. 
|
| 51 |
+
3. 
|
| 52 |
+
4. 
|
README.md
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- ddim_diffusion
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Denoising Diffusion Implicit Models (DDIM)
|
| 7 |
+
|
| 8 |
+
**Paper**: [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502)
|
| 9 |
+
|
| 10 |
+
**Abstract**:
|
| 11 |
+
|
| 12 |
+
*Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.*
|
| 13 |
+
|
| 14 |
+
**Explanation on `eta` and `num_inference_steps`**
|
| 15 |
+
|
| 16 |
+
- `num_inference_steps` is called *S* in the following table
|
| 17 |
+
- `eta` is called *η* in the following table
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
## Usage
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
# !pip install diffusers
|
| 25 |
+
from diffusers import DiffusionPipeline
|
| 26 |
+
import PIL.Image
|
| 27 |
+
import numpy as np
|
| 28 |
+
|
| 29 |
+
model_id = "fusing/ddim-lsun-bedroom"
|
| 30 |
+
|
| 31 |
+
# load model and scheduler
|
| 32 |
+
ddpm = DiffusionPipeline.from_pretrained(model_id)
|
| 33 |
+
|
| 34 |
+
# run pipeline in inference (sample random noise and denoise)
|
| 35 |
+
image = ddpm(eta=0.0, num_inference_steps=50)
|
| 36 |
+
|
| 37 |
+
# process image to PIL
|
| 38 |
+
image_processed = image.cpu().permute(0, 2, 3, 1)
|
| 39 |
+
image_processed = (image_processed + 1.0) * 127.5
|
| 40 |
+
image_processed = image_processed.numpy().astype(np.uint8)
|
| 41 |
+
image_pil = PIL.Image.fromarray(image_processed[0])
|
| 42 |
+
|
| 43 |
+
# save image
|
| 44 |
+
image_pil.save("test.png")
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
## Samples
|
| 48 |
+
|
| 49 |
+
1. 
|
| 50 |
+
2. 
|
| 51 |
+
3. 
|
| 52 |
+
4. 
|
config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "UNetModel",
|
| 3 |
+
"attn_resolutions": [
|
| 4 |
+
16
|
| 5 |
+
],
|
| 6 |
+
"ch": 128,
|
| 7 |
+
"ch_mult": [
|
| 8 |
+
1,
|
| 9 |
+
1,
|
| 10 |
+
2,
|
| 11 |
+
2,
|
| 12 |
+
4,
|
| 13 |
+
4
|
| 14 |
+
],
|
| 15 |
+
"dropout": 0.0,
|
| 16 |
+
"in_channels": 3,
|
| 17 |
+
"name_or_path": "./ddpm-lsun-church/",
|
| 18 |
+
"num_res_blocks": 2,
|
| 19 |
+
"out_ch": 3,
|
| 20 |
+
"resamp_with_conv": true,
|
| 21 |
+
"resolution": 256
|
| 22 |
+
}
|
diffusion_model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:23f0ba2284af43b85ced80d2af6338a9875dcf5ec97af93dfa97788fb6e41261
|
| 3 |
+
size 454849341
|
model_index.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "DDIM",
|
| 3 |
+
"_module": "modeling_ddim.py",
|
| 4 |
+
"noise_scheduler": [
|
| 5 |
+
"diffusers",
|
| 6 |
+
"GaussianDDPMScheduler"
|
| 7 |
+
],
|
| 8 |
+
"unet": [
|
| 9 |
+
"diffusers",
|
| 10 |
+
"UNetModel"
|
| 11 |
+
]
|
| 12 |
+
}
|
modeling_ddim.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
from diffusers import DiffusionPipeline
|
| 18 |
+
import tqdm
|
| 19 |
+
import torch
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class DDIM(DiffusionPipeline):
|
| 23 |
+
|
| 24 |
+
def __init__(self, unet, noise_scheduler):
|
| 25 |
+
super().__init__()
|
| 26 |
+
self.register_modules(unet=unet, noise_scheduler=noise_scheduler)
|
| 27 |
+
|
| 28 |
+
def __call__(self, batch_size=1, generator=None, torch_device=None, eta=0.0, num_inference_steps=50):
|
| 29 |
+
# eta corresponds to η in paper and should be between [0, 1]
|
| 30 |
+
if torch_device is None:
|
| 31 |
+
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 32 |
+
|
| 33 |
+
num_trained_timesteps = self.noise_scheduler.num_timesteps
|
| 34 |
+
inference_step_times = range(0, num_trained_timesteps, num_trained_timesteps // num_inference_steps)
|
| 35 |
+
|
| 36 |
+
self.unet.to(torch_device)
|
| 37 |
+
image = self.noise_scheduler.sample_noise((batch_size, self.unet.in_channels, self.unet.resolution, self.unet.resolution), device=torch_device, generator=generator)
|
| 38 |
+
|
| 39 |
+
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
|
| 40 |
+
# get actual t and t-1
|
| 41 |
+
train_step = inference_step_times[t]
|
| 42 |
+
prev_train_step = inference_step_times[t - 1] if t > 0 else - 1
|
| 43 |
+
|
| 44 |
+
# compute alphas
|
| 45 |
+
alpha_prod_t = self.noise_scheduler.get_alpha_prod(train_step)
|
| 46 |
+
alpha_prod_t_prev = self.noise_scheduler.get_alpha_prod(prev_train_step)
|
| 47 |
+
alpha_prod_t_rsqrt = 1 / alpha_prod_t.sqrt()
|
| 48 |
+
alpha_prod_t_prev_rsqrt = 1 / alpha_prod_t_prev.sqrt()
|
| 49 |
+
beta_prod_t_sqrt = (1 - alpha_prod_t).sqrt()
|
| 50 |
+
beta_prod_t_prev_sqrt = (1 - alpha_prod_t_prev).sqrt()
|
| 51 |
+
|
| 52 |
+
# compute relevant coefficients
|
| 53 |
+
coeff_1 = (alpha_prod_t_prev - alpha_prod_t).sqrt() * alpha_prod_t_prev_rsqrt * beta_prod_t_prev_sqrt / beta_prod_t_sqrt * eta
|
| 54 |
+
coeff_2 = ((1 - alpha_prod_t_prev) - coeff_1 ** 2).sqrt()
|
| 55 |
+
|
| 56 |
+
# model forward
|
| 57 |
+
with torch.no_grad():
|
| 58 |
+
noise_residual = self.unet(image, train_step)
|
| 59 |
+
|
| 60 |
+
# predict mean of prev image
|
| 61 |
+
pred_mean = alpha_prod_t_rsqrt * (image - beta_prod_t_sqrt * noise_residual)
|
| 62 |
+
pred_mean = (1 / alpha_prod_t_prev_rsqrt) * pred_mean + coeff_2 * noise_residual
|
| 63 |
+
|
| 64 |
+
# if eta > 0.0 add noise. Note eta = 1.0 essentially corresponds to DDPM
|
| 65 |
+
if eta > 0.0:
|
| 66 |
+
noise = self.noise_scheduler.sample_noise(image.shape, device=image.device, generator=generator)
|
| 67 |
+
image = pred_mean + coeff_1 * noise
|
| 68 |
+
else:
|
| 69 |
+
image = pred_mean
|
| 70 |
+
|
| 71 |
+
return image
|
scheduler_config.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "GaussianDDPMScheduler",
|
| 3 |
+
"beta_end": 0.02,
|
| 4 |
+
"beta_schedule": "linear",
|
| 5 |
+
"beta_start": 0.0001,
|
| 6 |
+
"timesteps": 1000,
|
| 7 |
+
"variance_type": "fixed_small"
|
| 8 |
+
}
|