---
language:
- en
library_name: transformers
license: apache-2.0
tags:
- gpt
- llm
- multimodal large language model
thumbnail: >-
https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
pipeline_tag: text-generation
---
# Model Card
The H2OVL-Mississippi-2B is a high-performing, general-purpose vision-language model developed by H2O.ai to handle a wide range of multimodal tasks. This model, with 2 billion parameters, excels in tasks such as image captioning, visual question answering (VQA), and document understanding, while maintaining efficiency for real-world applications.
The Mississippi-2B model builds on the strong foundations of our H2O-Danube language models, now extended to integrate vision and language tasks. It competes with larger models across various benchmarks, offering a versatile and scalable solution for document AI, OCR, and multimodal reasoning.
## Key Features:
- 2 Billion Parameters: Balance between performance and efficiency, making it suitable for document processing, OCR, VQA, and more.
- Optimized for Vision-Language Tasks: Achieves high performance across a wide range of applications, including document AI, OCR, and multimodal reasoning.
- Comprehensive Dataset: Trained on 17M image-text pairs, ensuring broad coverage and strong task generalization.
## Usage
### Install dependencies:
```bash
pip install transformers torch torchvision einops timm peft sentencepiece
```
If you have ampere GPUs, install flash-attention to speed up inference:
```bash
pip install flash_attn
```
### Sample demo:
```python
import torch
from transformers import AutoModel, AutoTokenizer
# Set up the model and tokenizer
model_path = 'h2oai/h2ovl-mississippi-2b'
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# Example for single image
image_file = './examples/image1.jpg'
question = '\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, image_file, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# Example for multiple images - multiround conversation
image_files = ['./examples/image1.jpg', './examples/image2.jpg']
question = 'Image-1: \nImage-2: \nDescribe the Image-1 and Image-2 in detail.'
response, history = model.chat(tokenizer, image_files, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, image_files, question, generation_config=generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
## Benchmarks
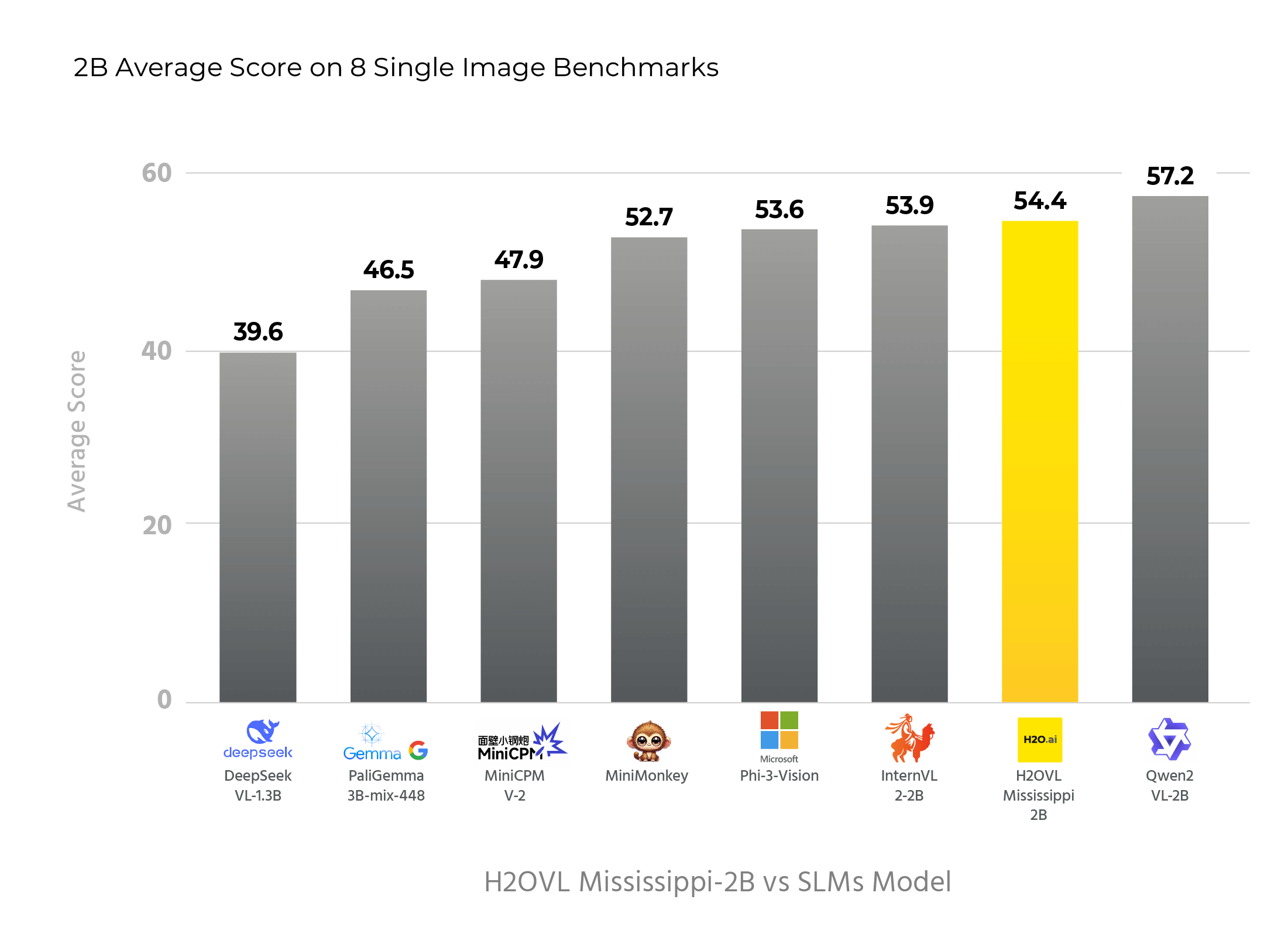
### Performance Comparison of Similar Sized Models Across Multiple Benchmarks - OpenVLM Leaderboard
| **Models** | **Params (B)** | **Avg. Score** | **MMBench** | **MMStar** | **MMMUVAL** | **Math Vista** | **Hallusion** | **AI2DTEST** | **OCRBench** | **MMVet** |
|----------------------------|----------------|----------------|-------------|------------|-----------------------|----------------|---------------|-------------------------|--------------|-----------|
| Qwen2-VL-2B | 2.1 | **57.2** | **72.2** | 47.5 | 42.2 | 47.8 | **42.4** | 74.7 | **797** | **51.5** |
| **H2OVL-Mississippi-2B** | 2.1 | 54.4 | 64.8 | 49.6 | 35.2 | **56.8** | 36.4 | 69.9 | 782 | 44.7 |
| InternVL2-2B | 2.1 | 53.9 | 69.6 | **49.8** | 36.3 | 46.0 | 38.0 | 74.1 | 781 | 39.7 |
| Phi-3-Vision | 4.2 | 53.6 | 65.2 | 47.7 | **46.1** | 44.6 | 39.0 | **78.4** | 637 | 44.1 |
| MiniMonkey | 2.2 | 52.7 | 68.9 | 48.1 | 35.7 | 45.3 | 30.9 | 73.7 | **794** | 39.8 |
| MiniCPM-V-2 | 2.8 | 47.9 | 65.8 | 39.1 | 38.2 | 39.8 | 36.1 | 62.9 | 605 | 41.0 |
| InternVL2-1B | 0.8 | 48.3 | 59.7 | 45.6 | 36.7 | 39.4 | 34.3 | 63.8 | 755 | 31.5 |
| PaliGemma-3B-mix-448 | 2.9 | 46.5 | 65.6 | 48.3 | 34.9 | 28.7 | 32.2 | 68.3 | 614 | 33.1 |
| **H2OVL-Mississippi-0.8B** | 0.8 | 43.5 | 47.7 | 39.1 | 34.0 | 39.0 | 29.6 | 53.6 | 751 | 30.0 |
| DeepSeek-VL-1.3B | 2.0 | 39.6 | 63.8 | 39.9 | 33.8 | 29.8 | 27.6 | 51.5 | 413 | 29.2 |
## Acknowledgments
We would like to express our gratitude to the [InternVL team at OpenGVLab](https://github.com/OpenGVLab/InternVL) for their research and codebases, upon which we have built and expanded. We also acknowledge the work of the [LLaVA team](https://github.com/haotian-liu/LLaVA) and the [Monkey team](https://github.com/Yuliang-Liu/Monkey/tree/main/project/mini_monkey) for their insights and techniques used in improving multimodal models.
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it.