
update readme
Browse files- README.md +63 -4
- figures/evaluation.png +0 -0
README.md
CHANGED
|
@@ -5,7 +5,66 @@ library_name: peft
|
|
| 5 |
|
| 6 |
---
|
| 7 |
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
|
| 6 |
---
|
| 7 |
|
| 8 |
+
# OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection
|
| 9 |
+
|
| 10 |
+
### Introduction
|
| 11 |
+
OriGen is a fine-tuned lora model designed for Verilog code generation. It is trained on top of DeepSeek Coder 7B using datasets generated from code-to-code augmentation and self-reflection.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
**Repository:** [pku-liang/OriGen](https://github.com/pku-liang/OriGen)
|
| 15 |
+
|
| 16 |
+
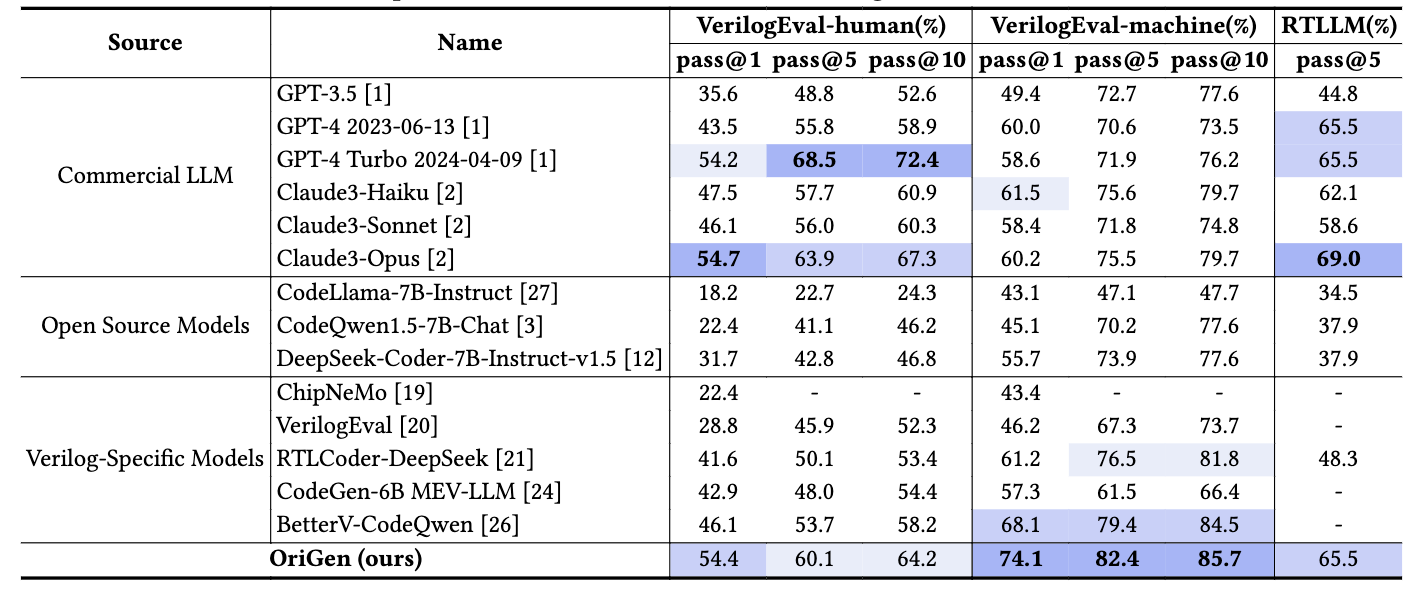
### Evaluation Results
|
| 17 |
+
<img src="figures/evaluation.png" alt="evaluation" width="1000"/>
|
| 18 |
+
|
| 19 |
+
### Quick Start
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
|
| 23 |
+
import torch
|
| 24 |
+
from peft import PeftModel
|
| 25 |
+
|
| 26 |
+
model_name = "deepseek-ai/deepseek-coder-7b-instruct-v1.5"
|
| 27 |
+
|
| 28 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 29 |
+
|
| 30 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 31 |
+
model_name,
|
| 32 |
+
low_cpu_mem_usage=True,
|
| 33 |
+
torch_dtype=torch.float16,
|
| 34 |
+
attn_implementation="flash_attention_2",
|
| 35 |
+
device_map="auto",
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
model = PeftModel.from_pretrained(model, model_id="henryen/OriGen")
|
| 39 |
+
model.eval()
|
| 40 |
+
|
| 41 |
+
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
| 42 |
+
|
| 43 |
+
prompt = "### Instruction: Please act as a professional Verilog designer. and provide Verilog code based on the given instruction. Generate a concise Verilog module for a 8 bit full adder, don't include any unnecessary code.\n### Response: "
|
| 44 |
+
|
| 45 |
+
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
|
| 46 |
+
|
| 47 |
+
outputs = model.generate(
|
| 48 |
+
**inputs,
|
| 49 |
+
max_new_tokens=1000,
|
| 50 |
+
do_sample=False,
|
| 51 |
+
temperature=0,
|
| 52 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 53 |
+
pad_token_id=tokenizer.pad_token_id,
|
| 54 |
+
streamer=streamer
|
| 55 |
+
)
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
### Paper
|
| 59 |
+
**Arxiv:** https://arxiv.org/abs/2407.16237
|
| 60 |
+
|
| 61 |
+
Please cite our paper if you use this model.
|
| 62 |
+
|
| 63 |
+
```
|
| 64 |
+
@article{2024origen,
|
| 65 |
+
title={OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection},
|
| 66 |
+
author={Cui, Fan and Yin, Chenyang and Zhou, Kexing and Xiao, Youwei and Sun, Guangyu and Xu, Qiang and Guo, Qipeng and Song, Demin and Lin, Dahua and Zhang, Xingcheng and others},
|
| 67 |
+
journal={arXiv preprint arXiv:2407.16237},
|
| 68 |
+
year={2024}
|
| 69 |
+
}
|
| 70 |
+
```
|
figures/evaluation.png
ADDED
|