
Commit
•
92c1291
1
Parent(s):
1a88948
Upload 15 files
Browse files- README.md +714 -1
- README_en.md +747 -0
- images/1-wiki.png +0 -0
- images/2-eval.png +0 -0
- images/2-wiki.png +0 -0
- images/3-wiki.png +0 -0
- images/4-wiki.png +0 -0
- images/5-wiki.png +0 -0
- images/LLM-structure-moe.png +0 -0
- images/LLM-structure.png +0 -0
- images/fastgpt.png +0 -0
- images/gpt3_config.png +0 -0
- images/logger.png +0 -0
- images/logo.png +0 -0
- images/streamlit.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,716 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
<div align="center">
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
[](https://github.com/jingyaogong/minimind/stargazers)
|
| 11 |
+
[](LICENSE)
|
| 12 |
+
[](https://github.com/jingyaogong/minimind/commits/master)
|
| 13 |
+
[](https://github.com/jingyaogong/minimind/pulls)
|
| 14 |
+
[](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
|
| 15 |
+
|
| 16 |
+
</div>
|
| 17 |
+
|
| 18 |
+
<div align="center">
|
| 19 |
+
<h3>"大道至简"</h3>
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
<div align="center">
|
| 23 |
+
|
| 24 |
+
中文 | [English](./README_en.md)
|
| 25 |
+
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
* 本开源项目旨在完全从0开始,最快仅用3小时!即可训练出仅为26M大小的微型语言模型**MiniMind**。
|
| 29 |
+
* **MiniMind**极其轻量,体积约是 GPT3 的 $\frac{1}{7000}$,力求做到最普通的个人GPU也可快速推理甚至训练。
|
| 30 |
+
* **MiniMind**改进自DeepSeek-V2、Llama3结构,项目包含整个数据处理、pretrain、sft、dpo的全部阶段,包含混合专家(MoE)模型。
|
| 31 |
+
* 这是一个既是开源项目,又是入门LLM教程,同时也是一个初具雏形的开源模型,希望能起到抛砖引玉的作用。
|
| 32 |
+
|
| 33 |
---
|
| 34 |
+
|
| 35 |
+
<div align="center">
|
| 36 |
+
|
| 37 |
+
https://github.com/user-attachments/assets/88b98128-636e-43bc-a419-b1b1403c2055
|
| 38 |
+
|
| 39 |
+
[Bilibili视频链接](https://www.bilibili.com/video/BV12dHPeqE72/?share_source=copy_web&vd_source=670c2504f88726f8cf4a21ef6147c0e8)
|
| 40 |
+
|
| 41 |
+
</div>
|
| 42 |
+
|
| 43 |
+
# 📌 Introduction
|
| 44 |
+
|
| 45 |
+
大语言模型(LLM)领域,如 GPT、LLaMA、GLM 等,虽然它们效果惊艳,
|
| 46 |
+
但动辄10 Bilion庞大的模型参数个人设备显存远不够训练,甚至推理困难。
|
| 47 |
+
几乎所有人都不会只满足于用Lora等方案fine-tuing大模型学会一些新的指令,
|
| 48 |
+
这约等于在教牛顿玩21世纪的智能手机,然而,这远远脱离了学习物理本身的奥妙。
|
| 49 |
+
此外,卖课付费订阅的营销号漏洞百出的一知半解讲解AI的教程遍地,
|
| 50 |
+
让理解LLM的优质内容雪上加霜,严重阻碍了学习者。
|
| 51 |
+
|
| 52 |
+
因此,本项目的目标是把上手LLM的门槛无限降低,
|
| 53 |
+
直接从0开始训练一个极其轻量的语言模型。
|
| 54 |
+
|
| 55 |
+
> [!TIP]
|
| 56 |
+
> (截至2024-9-17)minimind训练了3个型号模型,最小仅需26M(0.02B),即可具备流畅的对话能力!
|
| 57 |
+
|
| 58 |
+
| 模型 (大小) | tokenizer长度 | 推理占用 | release | 主观评分(/100) |
|
| 59 |
+
|-------------------------|-------------|--------|------------|------------|
|
| 60 |
+
| minimind-v1-small (26M) | 6400 | 0.5 GB | 2024.08.28 | 50' |
|
| 61 |
+
| minimind-v1-moe (4×26M) | 6400 | 1.0 GB | 2024.09.17 | 55' |
|
| 62 |
+
| minimind-v1 (108M) | 6400 | 1.0 GB | 2024.09.01 | 60' |
|
| 63 |
+
|
| 64 |
+
> 该分析在一个带有Torch 2.1.2、CUDA 12.2和Flash Attention 2的RTX 3090 GPU上运行。
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
项目包含:
|
| 69 |
+
|
| 70 |
+
- 公开MiniMind模型代码(包含Dense和MoE模型)、Pretrain、SFT指令微调、LoRA微调、DPO偏好优化的全过程代码、数据集和来源。
|
| 71 |
+
- 兼容`transformers`、`accelerate`、`trl`、`peft`等流行框架。
|
| 72 |
+
- 训练支持单机单卡、单机多卡(DDP、DeepSpeed)训练。训练过程中支持在任意位置停止,及在任意位置继续训练。
|
| 73 |
+
- 在Ceval数据集上进行模型测试的代码。
|
| 74 |
+
- 实现Openai-Api基本的chat接口,便于集成到第三方ChatUI使用(FastGPT、Open-WebUI等)。
|
| 75 |
+
|
| 76 |
+
希望此开源项目可以帮助LLM初学者快速入门!
|
| 77 |
+
|
| 78 |
+
### 👉**最近更新**
|
| 79 |
+
|
| 80 |
+
<details close>
|
| 81 |
+
<summary> <b>2024-09-17 (new🎉)</b> </summary>
|
| 82 |
+
|
| 83 |
+
- 更新minimind-v1-moe模型
|
| 84 |
+
|
| 85 |
+
- 为了防止歧义,不再使用mistral_tokenizer分词,全部采用自定义的minimind_tokenizer作为分词器。
|
| 86 |
+
|
| 87 |
+
</details>
|
| 88 |
+
|
| 89 |
+
<details close>
|
| 90 |
+
<summary> <b>2024-09-01</b> </summary>
|
| 91 |
+
|
| 92 |
+
- 更新minimind-v1 (108M)模型,采用minimind_tokenizer,预训练轮次3 + SFT轮次10,更充分训练,性能更强。
|
| 93 |
+
|
| 94 |
+
- 项目已部署至ModelScope创空间,可以在此网站上体验:
|
| 95 |
+
|
| 96 |
+
- [ModelScope在线体验](https://www.modelscope.cn/studios/gongjy/minimind)
|
| 97 |
+
|
| 98 |
+
</details>
|
| 99 |
+
|
| 100 |
+
<details close>
|
| 101 |
+
<summary> <b>2024-08-27</b> </summary>
|
| 102 |
+
|
| 103 |
+
- 项目首次开源
|
| 104 |
+
|
| 105 |
+
</details>
|
| 106 |
+
|
| 107 |
+
# 📌 Environment
|
| 108 |
+
|
| 109 |
+
仅是我个人的软硬件环境配置,自行酌情更改:
|
| 110 |
+
|
| 111 |
+
* Ubuntu == 20.04
|
| 112 |
+
* Python == 3.9
|
| 113 |
+
* Pytorch == 2.1.2
|
| 114 |
+
* CUDA == 12.2
|
| 115 |
+
* [requirements.txt](./requirements.txt)
|
| 116 |
+
|
| 117 |
+
# 📌 Quick Inference & Test
|
| 118 |
+
|
| 119 |
+
<div align="center" style="font-size: 1.5em; font-weight: bold;">
|
| 120 |
+
<img src="https://huggingface.co/front/assets/huggingface_logo-noborder.svg" alt="Hugging Face Logo" style="vertical-align: middle; height: 30px;" />
|
| 121 |
+
Hugging Face
|
| 122 |
+
|
| 123 |
+
[MiniMind (HuggingFace)](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
|
| 124 |
+
|
| 125 |
+
<img src="https://g.alicdn.com/sail-web/maas/1.15.0/static/modelscopeIcon.cd89353f.svg" alt="Hugging Face Logo" style="vertical-align: middle; height: 30px;" />
|
| 126 |
+
|
| 127 |
+
[MiniMind (ModelScope)](https://www.modelscope.cn/models/gongjy/minimind-v1)
|
| 128 |
+
|
| 129 |
+
</div>
|
| 130 |
+
|
| 131 |
+
```bash
|
| 132 |
+
# step 1
|
| 133 |
+
git clone https://huggingface.co/jingyaogong/minimind-v1
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
```bash
|
| 137 |
+
# step 2
|
| 138 |
+
python 2-eval.py
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
或者启动streamlit,启动网页聊天界面
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
# or step 3, use streamlit
|
| 145 |
+
streamlit run fast_inference.py
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+

|
| 149 |
+
|
| 150 |
+
<div align="center">
|
| 151 |
+
|
| 152 |
+
项目已部署至ModelScope创空间,可以在此网站上体验:
|
| 153 |
+
|
| 154 |
+
[ModelScope在线体验](https://www.modelscope.cn/studios/gongjy/minimind)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
</div>
|
| 158 |
+
|
| 159 |
+
# 📌 Quick Start
|
| 160 |
+
|
| 161 |
+
* 0、环境安装
|
| 162 |
+
```bash
|
| 163 |
+
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
|
| 164 |
+
```
|
| 165 |
+
* 1、克隆项目代码
|
| 166 |
+
```text
|
| 167 |
+
git clone https://github.com/jingyaogong/minimind.git
|
| 168 |
+
```
|
| 169 |
+
* 2、如果你需要自己训练
|
| 170 |
+
|
| 171 |
+
* 2.1 下载[数据集下载地址](#数据集下载地址)放到`./dataset`目录下
|
| 172 |
+
|
| 173 |
+
* 2.2 `python data_process.py`处理数据集,例如pretrain数据提前进行token-encoder、sft数据集抽离qa到csv文件
|
| 174 |
+
|
| 175 |
+
* 2.3 在`./model/LMConfig.py` 中调整model的参数配置
|
| 176 |
+
* 2.4 `python 1-pretrain.py` 执行预训练
|
| 177 |
+
* 2.5 `python 3-full_sft.py` 执行指令微调
|
| 178 |
+
* 2.6 `python 4-lora_sft.py` 执行lora微调(非必须)
|
| 179 |
+
* 2.7 `python 5-dpo_train.py` 执行DPO人类偏好强化学习对齐(非必须)
|
| 180 |
+
* 3、测试模型推理效果
|
| 181 |
+
* 确保需要使用的,训练完成的参数权重位于`./out/`目录下
|
| 182 |
+
* 也可以直接去[训练完成的模型权重](#训练完成的模型权重)下载使用我训练好的
|
| 183 |
+
```text
|
| 184 |
+
out
|
| 185 |
+
├── multi_chat
|
| 186 |
+
│ ├── full_sft_512.pth
|
| 187 |
+
│ ├── full_sft_512_moe.pth
|
| 188 |
+
│ └── full_sft_768.pth
|
| 189 |
+
├── single_chat
|
| 190 |
+
│ ├── full_sft_512.pth
|
| 191 |
+
│ ├── full_sft_512_moe.pth
|
| 192 |
+
│ └── full_sft_768.pth
|
| 193 |
+
├── pretrain_768.pth
|
| 194 |
+
├── pretrain_512_moe.pth
|
| 195 |
+
├── pretrain_512.pth
|
| 196 |
+
```
|
| 197 |
+
* `python 0-eval_pretrain.py`测试预训练模型的接龙效果
|
| 198 |
+
* `python 2-eval.py`测试模型的对话效果
|
| 199 |
+

|
| 200 |
+
|
| 201 |
+
🍭 【Tip】预训练和全参微调pretrain和full_sft均支持多卡加速
|
| 202 |
+
|
| 203 |
+
* 单机N卡启动训练(DDP)
|
| 204 |
+
```bash
|
| 205 |
+
torchrun --nproc_per_node N 1-pretrain.py
|
| 206 |
+
# and
|
| 207 |
+
torchrun --nproc_per_node N 3-full_sft.py
|
| 208 |
+
```
|
| 209 |
+
* 单机N卡启动训练(DeepSpeed)
|
| 210 |
+
```bash
|
| 211 |
+
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
|
| 212 |
+
# and
|
| 213 |
+
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.py
|
| 214 |
+
```
|
| 215 |
+
|
| 216 |
+
# 📌 Data sources
|
| 217 |
+
|
| 218 |
+
- 🤖 分词器:nlp中的Tokenizer类似于词典,将单词从自然语言通过“词典”映射到0,1,36这样的数字,可以理解为数字就代表了单词在“词典”中的页码。
|
| 219 |
+
LLM分词器的构建方式有两种:一种是自己构造词表训练一个分词器,代码可见`train_tokenizer.py`;另一种是选择开源模型训练好的分词器。
|
| 220 |
+
“词典”当然可以直接选择用新华词典或是牛津词典,优点是token转化压缩率很好,但缺点是词表太长,动辄数十万个词汇短语;
|
| 221 |
+
也可以使用自己训练的分词器,优点是词表随意控制,缺点是压缩率不够理想,且生僻词不容易面面俱到。
|
| 222 |
+
当然,“词典”的选择很重要,LLM的输出本质上是SoftMax到词典N个词的多分类问题,然后通过“词典”解码到自然语言。
|
| 223 |
+
因为LLM体积非常小,为了避免模型头重脚轻(词嵌入embedding层参数占整个LLM比太高),所以词表长度需要选择比较小。
|
| 224 |
+
强大的开源模型例如01万物、千问、chatglm、mistral、Llama3等,它们的tokenizer词表长度如下:
|
| 225 |
+
|
| 226 |
+
<table>
|
| 227 |
+
<tr><th>Tokenizer模型</th><th>词表大小</th><th>来源</th></tr>
|
| 228 |
+
<tr><td>yi tokenizer</td><td>64,000</td><td>01万物(中国)</td></tr>
|
| 229 |
+
<tr><td>qwen2 tokenizer</td><td>151,643</td><td>阿里云(中国)</td></tr>
|
| 230 |
+
<tr><td>glm tokenizer</td><td>151,329</td><td>智谱AI(中国)</td></tr>
|
| 231 |
+
<tr><td>mistral tokenizer</td><td>32,000</td><td>Mistral AI(法国)</td></tr>
|
| 232 |
+
<tr><td>llama3 tokenizer</td><td>128,000</td><td>Meta(美国)</td></tr>
|
| 233 |
+
<tr><td>minimind tokenizer</td><td>6,400</td><td>自定义</td></tr>
|
| 234 |
+
</table>
|
| 235 |
+
|
| 236 |
+
> [!TIP]
|
| 237 |
+
> 2024-09-17更新:为了防止过去的版本歧义&控制体积,minimind所有模型均使用minimind_tokenizer分词,废弃所有mistral_tokenizer��本。
|
| 238 |
+
|
| 239 |
+
> 尽管minimind_tokenizer长度很小,编解码效率弱于qwen2、glm等中文友好型分词器。
|
| 240 |
+
> 但minimind模型选择了自己训练的minimind_tokenizer作为分词器,以保持整体参数轻量,避免编码层和计算层占比失衡,头重脚轻,因为minimind的词表大小只有6400。
|
| 241 |
+
> 且minimind在实际测试中没有出现过生僻词汇解码失败的情况,效果良好。
|
| 242 |
+
> 由于自定义词表压缩长度到6400,使得LLM总参数量最低只有26M。
|
| 243 |
+
|
| 244 |
---
|
| 245 |
+
|
| 246 |
+
- 📙【Pretrain数据】:
|
| 247 |
+
[Seq-Monkey通用文本数据集](https://github.com/mobvoi/seq-monkey-data/blob/main/docs/pretrain_open_corpus.md) / [Seq-Monkey百度网盘](https://pan.baidu.com/s/114F1k3eksiWCOQLvaT3RYQ?pwd=6666)
|
| 248 |
+
是由多种公开来源的数据(如网页、百科、博客、开源代码、书籍等)汇总清洗而成。整理成统一的JSONL格式,并经过了严格的筛选和去重,确保数据的全面性、规模、可信性和高质量。总量大约在10B
|
| 249 |
+
token,适合中文大语言模型的预训练。
|
| 250 |
+
|
| 251 |
+
> 第2种选择:[SkyPile-150B数据集](https://hf-mirror.com/datasets/Skywork/SkyPile-150B/tree/main/data)
|
| 252 |
+
的可公开访问部分包含约2.33亿个独立网页,每个网页平均包含1000多个汉字。数据集包括大约1500亿个令牌和620GB的纯文本数据。
|
| 253 |
+
**如果着急的话**,可以尝试只挑选SkyPile-150B的部分jsonl下载(并在./data_process.py中对文本tokenizer生成*
|
| 254 |
+
.bin文件),以便快速跑通预训练流程。
|
| 255 |
+
|
| 256 |
+
---
|
| 257 |
+
|
| 258 |
+
- 📕【SFT数据】:[匠数大模型SFT数据集](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data)
|
| 259 |
+
是一个完整、格式统一、安全的大模型训练和研究资源。
|
| 260 |
+
从网络上的公开数据源收集并整理了大量开源数据集,对其进行了格式统一,数据清洗,
|
| 261 |
+
包含10M条数据的中文数据集和包含2M条数据的英文数据集。
|
| 262 |
+
总量大约在3B token,适合中文大语言模型的SFT。
|
| 263 |
+
数据集整合来源于以下所有数据(仅供参考,因此无需单独下载,仅需下载一个完整的【SFT数据】):
|
| 264 |
+
- [BelleGroup/train_3.5M_CN](https://huggingface.co/datasets/BelleGroup/train_3.5M_CN)
|
| 265 |
+
- [LinkSoul/instruction_merge_set](https://huggingface.co/datasets/LinkSoul/instruction_merge_set)
|
| 266 |
+
- [stingning/ultrachat](https://huggingface.co/datasets/stingning/ultrachat)
|
| 267 |
+
- [BAAI/COIG-PC-core](https://huggingface.co/datasets/BAAI/COIG-PC-core)
|
| 268 |
+
- [shibing624/sharegpt_gpt4](https://huggingface.co/datasets/shibing624/sharegpt_gpt4)
|
| 269 |
+
- [shareAI/ShareGPT-Chinese-English-90k](https://huggingface.co/datasets/shareAI/ShareGPT-Chinese-English-90k)
|
| 270 |
+
- [Tiger Research](https://huggingface.co/TigerResearch/sft_zh)
|
| 271 |
+
- [BelleGroup/school_math_0.25M](https://huggingface.co/datasets/BelleGroup/school_math_0.25M)
|
| 272 |
+
- [YeungNLP/moss-003-sft-data](https://huggingface.co/datasets/YeungNLP/moss-003-sft-data)
|
| 273 |
+
|
| 274 |
+
---
|
| 275 |
+
|
| 276 |
+
- 📘【DPO数据】:大约合并后共8万条dpo数据,人工标注的偏好数据,均来自[活字模型](https://github.com/HIT-SCIR/huozi)
|
| 277 |
+
,可以用于训练奖励模型,优化模型回复质量,使其更加符合人类偏好。
|
| 278 |
+
|
| 279 |
+
---
|
| 280 |
+
|
| 281 |
+
- 【更多数据集】目前已经有[HqWu-HITCS/Awesome-Chinese-LLM](https://github.com/HqWu-HITCS/Awesome-Chinese-LLM)
|
| 282 |
+
在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,并持续更新这方面的最新进展。全面且专业,Respect!
|
| 283 |
+
|
| 284 |
+
---
|
| 285 |
+
|
| 286 |
+
### 数据集下载地址
|
| 287 |
+
|
| 288 |
+
下载到`./dataset/`目录下
|
| 289 |
+
|
| 290 |
+
| MiniMind训练数据集 | 下载地址 |
|
| 291 |
+
|--------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
| 292 |
+
| **【tokenizer训练集】** | [HuggingFace](https://huggingface.co/datasets/jingyaogong/minimind_dataset/tree/main) / [百度网盘](https://pan.baidu.com/s/1yAw1LVTftuhQGAC1Y9RdYQ?pwd=6666) |
|
| 293 |
+
| **【Pretrain数据】** | [Seq-Monkey官方](http://share.mobvoi.com:5000/sharing/O91blwPkY) / [百度网盘](https://pan.baidu.com/s/1-Z8Q37lJD4tOKhyBs1D_6Q?pwd=6666) / [HuggingFace](https://huggingface.co/datasets/jingyaogong/minimind_dataset/tree/main) |
|
| 294 |
+
| **【SFT数据】** | [匠数大模型SFT数据集](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data/resolve/master/sft_data_zh.jsonl) |
|
| 295 |
+
| **【DPO数据1】** | [活字数据集1](https://huggingface.co/datasets/Skepsun/huozi_rlhf_data_json) |
|
| 296 |
+
| **【DPO数据2】** | [活字数据集2](https://huggingface.co/datasets/beyond/rlhf-reward-single-round-trans_chinese) |
|
| 297 |
+
|
| 298 |
+
# 📌 Model
|
| 299 |
+
|
| 300 |
+
MiniMind-Dense(和[Llama3.1](https://ai.meta.com/blog/meta-llama-3-1/)一样)使用了Transformer的Decoder-Only结构,跟GPT-3的区别在于:
|
| 301 |
+
|
| 302 |
+
* 采用了GPT-3的预标准化方法,也就是在每个Transformer子层的输入上进行归一化,而不是在输出上。具体来说,使用的是RMSNorm归一化函数。
|
| 303 |
+
* 用SwiGLU激活函数替代了ReLU,这样做是为了提高性能。
|
| 304 |
+
* 像GPT-Neo一样,去掉了绝对位置嵌入,改用了旋转位置嵌入(RoPE),这样在处理超出训练长度的推理时效果更好。
|
| 305 |
+
|
| 306 |
+
---
|
| 307 |
+
|
| 308 |
+
MiniMind-MoE模型,它的结构基于Llama3和[Deepseek-V2](https://arxiv.org/pdf/2405.04434)中的MixFFN混合专家模块。
|
| 309 |
+
|
| 310 |
+
* DeepSeek-V2在前馈网络(FFN)方面,采用了更细粒度的专家分割和共享的专家隔离技术,以提高Experts的效果。
|
| 311 |
+
|
| 312 |
+
---
|
| 313 |
+
|
| 314 |
+
MiniMind的整体结构一致,只是在RoPE计算、推理函数和FFN层的代码上做了一些小调整。
|
| 315 |
+
其结构如下图(重绘版):
|
| 316 |
+
|
| 317 |
+

|
| 318 |
+

|
| 319 |
+
|
| 320 |
+
修改模型配置见[./model/LMConfig.py](./model/LMConfig.py)。
|
| 321 |
+
minimind目前训练的模型版本见下表:
|
| 322 |
+
|
| 323 |
+
| Model Name | params | len_vocab | n_layers | d_model | kv_heads | q_heads | share+route | TopK |
|
| 324 |
+
|------------------|--------|-----------|----------|---------|----------|---------|-------------|------|
|
| 325 |
+
| minimind-v1-small | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
|
| 326 |
+
| minimind-v1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
|
| 327 |
+
| minimind-v1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
# 📌 Experiment
|
| 331 |
+
|
| 332 |
+
```bash
|
| 333 |
+
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
|
| 334 |
+
内存:128 GB
|
| 335 |
+
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
|
| 336 |
+
环境:python 3.9 + Torch 2.1.2 + DDP多卡训练
|
| 337 |
+
```
|
| 338 |
+
|
| 339 |
+
| Model Name | params | len_vocab | batch_size | pretrain_time | sft_single_time | sft_multi_time |
|
| 340 |
+
|------------------|--------|-----------|------------|-------------------|-------------------|---------------------|
|
| 341 |
+
| minimind-v1-small | 26M | 6400 | 64 | ≈2 hour (1 epoch) | ≈2 hour (1 epoch) | ≈0.5 hour (1 epoch) |
|
| 342 |
+
| minimind-v1-moe | 4×26M | 6400 | 40 | ≈6 hour (1 epoch) | ≈5 hour (1 epoch) | ≈1 hour (1 epoch) |
|
| 343 |
+
| minimind-v1 | 108M | 6400 | 16 | ≈6 hour (1 epoch) | ≈4 hour (1 epoch) | ≈1 hour (1 epoch) |
|
| 344 |
+
|
| 345 |
+
---
|
| 346 |
+
|
| 347 |
+
1. **预训练(Text-to-Text)**:
|
| 348 |
+
- LLM首先要学习的并非直接与人交流,而是让肚子中充满知识的墨水,至于墨水理论上喝的越饱越好,产生大量的对世界的认知积累。
|
| 349 |
+
- 预训练就是让Model先埋头苦学大量基本的知识,例如从维基百科、新闻、常识、书籍等。
|
| 350 |
+
- 它无监督的从大量的文本数据中压缩知识到自己模型的权重,目的是:学会词语接龙。例如我们输入“秦始皇是”四个字,它在大量学习后能预测出下一句话大概率是“中国的第一位皇帝”。
|
| 351 |
+
> pretrain的学习率设置为1e-4到1e-5的动态学习率,预训练epoch数设为5。
|
| 352 |
+
```bash
|
| 353 |
+
torchrun --nproc_per_node 2 1-pretrain.py
|
| 354 |
+
```
|
| 355 |
+
2. **单轮次对话有监督微调(Single dialog Fine-tuning)**:
|
| 356 |
+
- 经过预训练,半成品LLM此时已经掌握了几乎所有的语言知识和百科常识。此时它还不会与人聊天,相反它只会无脑地进行输入词语的接龙,生成下一个词。
|
| 357 |
+
- 此时需要对半成品LLM做限制在聊天模板中进行微调,例如当它遇到这样的模板“<聊天开始>秦始皇是<聊天终止>
|
| 358 |
+
”后不再无脑接龙,而是意识到这是一段完整的对话结束。
|
| 359 |
+
- 我们称这个过程为指令微调,就如同让学富五车的「牛顿」先生适应21世纪的聊天习惯,学习屏幕左侧是对方消息,右侧是本人消息这个规律。
|
| 360 |
+
- 在训练时,MiniMind的指令和回答长度被截断在512,是为了节省显存空间。就像我们学习时,会先从短的文章开始,当学会阅读200字作文后,800字长文章就不需要再单独学习。
|
| 361 |
+
> 在推理时通过调整RoPE线性差值,实现长度外推到1024或2048及以上很方便。学习率设置为1e-5到1e-6的动态学习率,微调epoch数为6。
|
| 362 |
+
|
| 363 |
+
```bash
|
| 364 |
+
# 3-full_sft.py中设置数据集为sft_data_single.csv
|
| 365 |
+
torchrun --nproc_per_node 2 3-full_sft.py
|
| 366 |
+
```
|
| 367 |
+
3. **多轮对话微调(Multi dialog Fine-tuning)**:
|
| 368 |
+
- 在2的基础上,LLM已经学会一个问题->一个回答的聊天模板。此时仅需在具备历史问答的更长聊天模板上进一步微调即可。
|
| 369 |
+
- 我们仅需使用数据集的history_chat 字段,即历史对话,以及history_chat_response字段,即历史对话的回答。
|
| 370 |
+
- 构建【问题->回答,问题->回答,问题->】的新聊天模板,然后使用这个数据集进行微调。
|
| 371 |
+
- 学习完成的模型不仅仅只能回答当前问题,还能根据历史对话进行连贯的对话。
|
| 372 |
+
- 这一步并非必须,因为小模型长上文对话能力很弱,强行对齐多轮问答模板会损失一定程度的单轮SFT效果。
|
| 373 |
+
> 学习率设置为1e-5到1e-6的动态学习率,微调epoch数为5。
|
| 374 |
+
```bash
|
| 375 |
+
# 3-full_sft.py中设置数据集为sft_data.csv
|
| 376 |
+
torchrun --nproc_per_node 2 3-full_sft.py
|
| 377 |
+
```
|
| 378 |
+
4. **直接偏好优化,强化学习微调(Direct Preference Optimization, DPO)**:
|
| 379 |
+
- 在前面的训练中,机器人已经具备了基本的对话能力。但是,我们希望它能够更符合人的偏好,给出更让人满意的回答。
|
| 380 |
+
- 这个过程就像是让机器人参加工作培训,从优秀员工的作为例子,消极员工作为反例,学习如何更好地服务客户。
|
| 381 |
+
> 活字三元组(q,chose,reject)数据集,学习率le-5,半精度fp16,共1个epoch,耗时1h。
|
| 382 |
+
```bash
|
| 383 |
+
python 5-dpo_train.py
|
| 384 |
+
```
|
| 385 |
+
---
|
| 386 |
+
|
| 387 |
+
📋关于LLM的参数配置,有一篇很有意思的论文[MobileLLM](https://arxiv.org/pdf/2402.14905)做了详细的研究和实验。
|
| 388 |
+
scaling law在小模型中有自己独特的规律。
|
| 389 |
+
引起Transformer参数成规模变化的参数几乎只取决于`d_model`和`n_layers`。
|
| 390 |
+
|
| 391 |
+
* `d_model`↑+`n_layers`↓->矮胖子
|
| 392 |
+
* `d_model`↓+`n_layers`↑->瘦高个
|
| 393 |
+
|
| 394 |
+
2020年提出Scaling Law的论文认为,训练数据量、参数量以及训练迭代次数才是决定性能的关键因素,而模型架构的影响几乎可以忽视。
|
| 395 |
+
然而似乎这个定律对小模型并不完全适用。
|
| 396 |
+
MobileLLM提出架构的深度比宽度更重要,「深而窄」的「瘦长」模型可以学习到比「宽而浅」模型更多的抽象概念。
|
| 397 |
+
例如当模型参数固定在125M或者350M时,30~42层的「狭长」模型明显比12层左右的「矮胖」模型有更优越的性能,
|
| 398 |
+
在常识推理、问答、阅读理解等8个基准测试上都有类似的趋势。
|
| 399 |
+
这其实是非常有趣的发现,因为以往为100M左右量级的小模型设计架构时,几乎没人尝试过叠加超过12层。
|
| 400 |
+
这与MiniMind在训练过程中,模型参数量在`d_model`和`n_layers`之间进行调整实验观察到的效果是一致的。
|
| 401 |
+
然而「深而窄」的「窄」也是有维度极限的,当d_model<512时,词嵌入维度坍塌的劣势非常明显,
|
| 402 |
+
增加的layers并不能弥补词嵌入在固定q_head带来d_head不足的劣势。
|
| 403 |
+
当d_model>1536时,layers的增加似乎比d_model的优先级更高,更能带来具有“性价比”的参数->效果增益。
|
| 404 |
+
因此MiniMind设定small模型的d_model=512,n_layers=8来获取的「极小体积<->更好效果」的平衡。
|
| 405 |
+
设定d_model=768,n_layers=16来获取效果的更大收益,更加符合小模型scaling-law的变化曲线。
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
> 作为参考,GPT3的参数设定见下表:
|
| 409 |
+
|
| 410 |
+

|
| 411 |
+
|
| 412 |
+
---
|
| 413 |
+
### 训练完成的模型权重
|
| 414 |
+
|
| 415 |
+
| Model Name | params | Config | pretrain_model | single_sft_model | multi_sft_model |
|
| 416 |
+
|-------------------|--------|-----------------------------|----------------|----------------------------------------------------------------|----------------------------------------------------------------|
|
| 417 |
+
| minimind-v1-small | 26M | d_model=512<br/>n_layers=8 | - | [链接](https://pan.baidu.com/s/1_COe0FQRDmeapSsvArahCA?pwd=6666) | [链接](https://pan.baidu.com/s/1GsGsWSL0Dckl0YPRXiBIFQ?pwd=6666) |
|
| 418 |
+
| minimind-v1-moe | 4×26M | d_model=512<br/>n_layers=8 | - | - | - |
|
| 419 |
+
| minimind-v1 | 108M | d_model=768<br/>n_layers=16 | - | [链接](https://pan.baidu.com/s/1p713loS7EfwHQf3G9eYI3Q?pwd=6666) | [链接](https://pan.baidu.com/s/12iHGpAs6R0kqsOnGtgK6vQ?pwd=6666) |
|
| 420 |
+
|
| 421 |
+
---
|
| 422 |
+
|
| 423 |
+
|
| 424 |
+
# 📌 Eval
|
| 425 |
+
|
| 426 |
+
> [!TIP]
|
| 427 |
+
> 以下测试于2024-09-17完成,此日期后发布的新模型,无特殊需要时将不加入测试。
|
| 428 |
+
|
| 429 |
+
[A] [minimind-v1-small(0.02B)](https://pan.baidu.com/s/1_COe0FQRDmeapSsvArahCA?pwd=6666)<br/>
|
| 430 |
+
[B] minimind-v1-moe(0.1B)<br/>
|
| 431 |
+
[C] [minimind-v1(0.1B)](https://pan.baidu.com/s/1p713loS7EfwHQf3G9eYI3Q?pwd=6666)<br/>
|
| 432 |
+
[D] [baby-llama2-chinese(0.2B)](https://github.com/DLLXW/baby-llama2-chinese)<br/>
|
| 433 |
+
[E] [chatlm-mini-chinese(0.2B)](https://github.com/charent/ChatLM-mini-Chinese)<br/>
|
| 434 |
+
|
| 435 |
+
```text
|
| 436 |
+
[Q]: 你知道长江吗?
|
| 437 |
+
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
|
| 438 |
+
[B]: 是的,长江是中国最长的河流,全长约7100公里。它的流域面积约为3328万平方公里,是中国最大的河流之一,也是世界第三大河流,总长度约为6300千米。
|
| 439 |
+
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
|
| 440 |
+
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
|
| 441 |
+
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
|
| 442 |
+
|
| 443 |
+
|
| 444 |
+
[Q]: 第一颗人造卫星是哪个国家发射的?
|
| 445 |
+
[A]: 第一颗人造卫星是斯普特尼克1号。
|
| 446 |
+
[B]: 第一颗人造卫星是美国发射的。
|
| 447 |
+
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
|
| 448 |
+
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
|
| 449 |
+
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
[Q]: 你知道泰山在哪里吗?
|
| 453 |
+
[A]: 泰山位于中国东部地区,是中国五岳之一。
|
| 454 |
+
[B]: 泰山位于山东省泰安市,是中国五岳之一。
|
| 455 |
+
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
|
| 456 |
+
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
|
| 457 |
+
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
|
| 458 |
+
|
| 459 |
+
|
| 460 |
+
[Q]: 世界上最高的山峰是什么?
|
| 461 |
+
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
|
| 462 |
+
[B]: 珠穆朗玛峰是世界上最高的山峰,位于喜马拉雅山脉,海拔8848米。
|
| 463 |
+
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
|
| 464 |
+
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
|
| 465 |
+
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
|
| 466 |
+
|
| 467 |
+
|
| 468 |
+
[Q]: 万有引力是谁提出的?
|
| 469 |
+
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
|
| 470 |
+
[B]: 万有引力是由牛顿发现的,它是由英国物理学家詹姆斯·瓦特于1879年提出的。
|
| 471 |
+
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
|
| 472 |
+
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
|
| 473 |
+
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
|
| 474 |
+
|
| 475 |
+
|
| 476 |
+
[Q]: 你知道大熊猫的主要食物是什么吗?
|
| 477 |
+
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
|
| 478 |
+
[B]: 大熊猫主要是竹子,它们的主要食物是竹子。大熊猫的消化系统比较特殊,它们每天需要消化大量的竹子才能维持其生存需要。除了竹子外,大熊猫还在野外生存。
|
| 479 |
+
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
|
| 480 |
+
[D]: 大熊猫的主要食物是竹子。
|
| 481 |
+
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
|
| 482 |
+
|
| 483 |
+
|
| 484 |
+
[Q]: 海水为什么是咸的?
|
| 485 |
+
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
|
| 486 |
+
[B]: 海水中含有丰富的钙、磷、钾和磷等元素,这些元素在海洋中的数量和分布非常有限。此外,海水中还含有各种生物和微生物的营养物质,如贝壳和海藻等。
|
| 487 |
+
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
|
| 488 |
+
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
|
| 489 |
+
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
|
| 490 |
+
```
|
| 491 |
+
|
| 492 |
+
> [!NOTE]
|
| 493 |
+
> 🙋♂️直接把上述模型的回答丢给GPT-4o,让它帮忙打个分:
|
| 494 |
+
|
| 495 |
+
---
|
| 496 |
+
|
| 497 |
+
### 模型表现点评:
|
| 498 |
+
|
| 499 |
+
1. **模型A**:
|
| 500 |
+
- **表现**:模型A的回答通常简洁明了,但在某些问题上缺乏详细信息和准确性。例如,在长江的长度问题上,模型A的回答是错误的。
|
| 501 |
+
- **评分**:60
|
| 502 |
+
|
| 503 |
+
2. **模型B**:
|
| 504 |
+
- **表现**:模型B的回答在某些问题上提供了额外的信息,但这些信息有时是不准确的或多余的。例如,在长江的长度问题上,模型B提供了不准确的长度和流域面积。
|
| 505 |
+
- **评分**:65
|
| 506 |
+
|
| 507 |
+
3. **模型C**:
|
| 508 |
+
- **表现**:模型C的回答通常较为详细,且在大多数问题上提供了准确的信息。例如,在长江和泰山的问题上,模型C的回答是准确的。
|
| 509 |
+
- **评分**:75
|
| 510 |
+
|
| 511 |
+
4. **模型D**:
|
| 512 |
+
- **表现**:模型D的回答在某些问题上显得混乱,且缺乏准确性。例如,在泰山的问题上,模型D的回答完全偏离了主题。
|
| 513 |
+
- **评分**:50
|
| 514 |
+
|
| 515 |
+
5. **模型E**:
|
| 516 |
+
- **表现**:模型E的回答通常非常详细,但在某些问题上过于冗长,且包含了一些不必要的信息。例如,在万有引力的问题上,模型E的回答过于复杂。
|
| 517 |
+
- **评分**:70
|
| 518 |
+
|
| 519 |
+
#### 排序(从高到低):
|
| 520 |
+
|
| 521 |
+
| 模型 | C | E | B | A | D |
|
| 522 |
+
|----|----|----|----|----|----|
|
| 523 |
+
| 分数 | 75 | 70 | 65 | 60 | 50 |
|
| 524 |
+
|
| 525 |
+
---
|
| 526 |
+
|
| 527 |
+
## 👉效果总结
|
| 528 |
+
|
| 529 |
+
* minimind系列(ABC)的排序符合直觉,minimind-v1(0.1B)评分最高,常识性问题的回答基本没有错误和幻觉。
|
| 530 |
+
* 出乎意料的是,minimind-v1-small(0.02B)仅有26M参数,却可以接近minimind-v1(0.1B)的表现。
|
| 531 |
+
* minimind-v1(0.1B)的sft轮数`epochs`仅有不到2,偷懒提前kill腾出资源给小模型,0.1B没有得到充分训练的情况下依然做到了最强,其实还是底大一级压死人。
|
| 532 |
+
* minimind-v1-moe(0.1B)
|
| 533 |
+
表现很差,同样是因为偷懒提前kill腾出资源给小模型,但是MoE模型多专家模式需要的训练轮次本来就需要酌情更高,在epochs设置为2时训练的极其不充分。minimind不久前实验阶段在Yi
|
| 534 |
+
tokenizer上试验过moe的充分训练版本,可以做到比dense表现肉眼可见的更好。日后腾出服务器再训练更新v2、v3版本。
|
| 535 |
+
|
| 536 |
+
|
| 537 |
+
* E模型的回答看起来是这里最完美的,尽管存在些许幻觉瞎编的情况。但GPT-4o和Deepseek的评分都一致认为它“信息过度冗长,且有重复内容,存在幻觉”。
|
| 538 |
+
其实这种评价太严格了,100个字中有10个字是幻觉,就很容易把它归到0分。由于F模型训练文本默认长度更长,数据集大得多,所以回答的看起来很完备,在体积近似的情况下,数据比模型更重要得多。
|
| 539 |
+
|
| 540 |
+
> 🙋♂️个人主观评价:E>C>B≈A>D
|
| 541 |
+
|
| 542 |
+
> 🤖 GPT-4o 评价:C>E>B>A>D
|
| 543 |
+
|
| 544 |
+
Scaling Law:模型参数越大,训练数据越多模型的性能越强。
|
| 545 |
+
|
| 546 |
+
# 📌 Objective dataset: C-Eval
|
| 547 |
+
|
| 548 |
+
C-Eval评测代码见:`./eval_ceval.py`,
|
| 549 |
+
小模型的测评通常为了避免回复格式的难以固定的特点,
|
| 550 |
+
而直接判断`A`,`B`,`C`,`D`四个字母对应token预测概率,取最大的作为回答答案,与标准答案计算正确率。
|
| 551 |
+
minimind模型本身没有使用较大的数据集训练,也没有针对回答选择题的指令做微调,测评结果可以当个参考。
|
| 552 |
+
|
| 553 |
+
> 例如minimind-small的结果细项:
|
| 554 |
+
|
| 555 |
+
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|
| 556 |
+
|------|----------------------------|-----|-----------------------|-----------------------|---------------------|--------------------|---------------------|---------------------|----------------|------------------------|-----------------------|-----------------------|----------------|------------------|-------|---------------------|---------------|---------------------------------|---------------------|------------|------------------|-------------------------|--------------------|---------------------|---------|----------------------|-------------------------|-------------------------|--------------------|-----------------------------------|-------------------|-------------------------|------------------------------------------|-----------------------|-------------------------|-----------------|---------------------------|----------------------|-----------|-------------------|---------------------|-----------------------|------------------------|-------------------|------------------|----------------|-------------|-----------------------|----------------------|-------------------|---------------|-------------------------|
|
| 557 |
+
| Data | probability_and_statistics | law | middle_school_biology | high_school_chemistry | high_school_physics | legal_professional | high_school_chinese | high_school_history | tax_accountant | modern_chinese_history | middle_school_physics | middle_school_history | basic_medicine | operating_system | logic | electrical_engineer | civil_servant | chinese_language_and_literature | college_programming | accountant | plant_protection | middle_school_chemistry | metrology_engineer | veterinary_medicine | marxism | advanced_mathematics | high_school_mathematics | business_administration | mao_zedong_thought | ideological_and_moral_cultivation | college_economics | professional_tour_guide | environmental_impact_assessment_engineer | computer_architecture | urban_and_rural_planner | college_physics | middle_school_mathematics | high_school_politics | physician | college_chemistry | high_school_biology | high_school_geography | middle_school_politics | clinical_medicine | computer_network | sports_science | art_studies | teacher_qualification | discrete_mathematics | education_science | fire_engineer | middle_school_geography |
|
| 558 |
+
|
| 559 |
+
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|
| 560 |
+
|----------|--------|--------|--------|--------|--------|-------|--------|--------|--------|--------|--------|--------|-------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|-------|
|
| 561 |
+
| T/A | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 7/31 | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 9/31 | 1/12 |
|
| 562 |
+
| Accuracy | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
|
| 563 |
+
|
| 564 |
+
```text
|
| 565 |
+
总题数: 1346
|
| 566 |
+
总正确数: 316
|
| 567 |
+
总正确率: 23.48%
|
| 568 |
+
```
|
| 569 |
+
|
| 570 |
+
---
|
| 571 |
+
|
| 572 |
+
#### 结果汇总:
|
| 573 |
+
|
| 574 |
+
| category | correct | question_count | accuracy |
|
| 575 |
+
|:------------------|:--------:|:--------------:|:--------:|
|
| 576 |
+
| minimind-v1-small | 344 | 1346 | 25.56% |
|
| 577 |
+
| minimind-v1 | 351 | 1346 | 26.08% |
|
| 578 |
+
|
| 579 |
+
#### 以下来自GPT-4o对minimind表现的瞎猜:
|
| 580 |
+
|
| 581 |
+
```text
|
| 582 |
+
### 模型擅长的领域:
|
| 583 |
+
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
|
| 584 |
+
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
|
| 585 |
+
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
|
| 586 |
+
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
|
| 587 |
+
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
|
| 588 |
+
|
| 589 |
+
### 模型不擅长的领域:
|
| 590 |
+
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
|
| 591 |
+
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
|
| 592 |
+
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
|
| 593 |
+
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体���结构(9.52%),在这些计算机专业课程上的表现也不够好。
|
| 594 |
+
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
|
| 595 |
+
|
| 596 |
+
### 总结:
|
| 597 |
+
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
|
| 598 |
+
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
|
| 599 |
+
|
| 600 |
+
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
|
| 601 |
+
```
|
| 602 |
+
|
| 603 |
+
# 📌 Others
|
| 604 |
+
|
| 605 |
+
### 推理与导出
|
| 606 |
+
|
| 607 |
+
* [./export_model.py](./export_model.py)可以导出模型到transformers格式,推送到huggingface
|
| 608 |
+
|
| 609 |
+
* MiniMind的huggingface集合地址:
|
| 610 |
+
[MiniMind](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
|
| 611 |
+
|
| 612 |
+
---
|
| 613 |
+
|
| 614 |
+
### API推理
|
| 615 |
+
|
| 616 |
+
* [my_openai_api.py](./my_openai_api.py)完成了openai_api的聊天接口,方便将自己的模型接入第三方UI
|
| 617 |
+
例如fastgpt、OpenWebUI等
|
| 618 |
+
|
| 619 |
+
* 从[Huggingface](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)下载模型权重文件
|
| 620 |
+
```
|
| 621 |
+
minimind (root dir)
|
| 622 |
+
├─minimind
|
| 623 |
+
| ├── config.json
|
| 624 |
+
| ├── generation_config.json
|
| 625 |
+
| ├── LMConfig.py
|
| 626 |
+
| ├── model.py
|
| 627 |
+
| ├── pytorch_model.bin
|
| 628 |
+
| ├── special_tokens_map.json
|
| 629 |
+
| ├── tokenizer_config.json
|
| 630 |
+
| ├── tokenizer.json
|
| 631 |
+
```
|
| 632 |
+
|
| 633 |
+
* 启动聊天服务端
|
| 634 |
+
```bash
|
| 635 |
+
python my_openai_api.py
|
| 636 |
+
```
|
| 637 |
+
* 测试服务接口
|
| 638 |
+
```bash
|
| 639 |
+
python chat_openai_api.py
|
| 640 |
+
```
|
| 641 |
+
* API接口示例,兼容openai api格式
|
| 642 |
+
```bash
|
| 643 |
+
curl http://ip:port/v1/chat/completions \
|
| 644 |
+
-H "Content-Type: application/json" \
|
| 645 |
+
-d '{
|
| 646 |
+
"model": "model-identifier",
|
| 647 |
+
"messages": [
|
| 648 |
+
{ "role": "user", "content": "世界上最高的山是什么?" }
|
| 649 |
+
],
|
| 650 |
+
"temperature": 0.7,
|
| 651 |
+
"max_tokens": -1,
|
| 652 |
+
"stream": true
|
| 653 |
+
}'
|
| 654 |
+
```
|
| 655 |
+
|
| 656 |
+

|
| 657 |
+
|
| 658 |
+
### 在fastgpt中接入使用minimind api
|
| 659 |
+
|
| 660 |
+

|
| 661 |
+
|
| 662 |
+
# 📌 Acknowledge
|
| 663 |
+
|
| 664 |
+
> [!NOTE]
|
| 665 |
+
> 如果您觉得 `MiniMind`对您有所帮助,请在 GitHub 上给一个⭐<br/>
|
| 666 |
+
> 您的支持是我们持续改进项目的动力!篇幅不短水平有限难免纰漏,欢迎在issue交流和指正。
|
| 667 |
+
|
| 668 |
+
## 🤝[贡献者](https://github.com/jingyaogong/minimind/graphs/contributors)
|
| 669 |
+
|
| 670 |
+
<!--
|
| 671 |
+
<a href="https://github.com/jingyaogong/minimind/graphs/contributors">
|
| 672 |
+
<img src="https://contrib.rocks/image?repo=jingyaogong/minimind&v3" />
|
| 673 |
+
</a>
|
| 674 |
+
-->
|
| 675 |
+
|
| 676 |
+
<a href="https://github.com/jingyaogong"><img src="https://avatars.githubusercontent.com/u/62287848" width="70px" height="70px"/></a>
|
| 677 |
+
|
| 678 |
+
<a href="https://github.com/MuWinds"><img src="https://avatars.githubusercontent.com/u/93832089" width="70px" height="70px"/></a>
|
| 679 |
+
|
| 680 |
+
<a href="https://github.com/chuanzhubin"><img src="https://avatars.githubusercontent.com/u/2813798" width="70px" height="70px"/></a>
|
| 681 |
+
|
| 682 |
+
|
| 683 |
+
## 😊鸣谢
|
| 684 |
+
|
| 685 |
+
<a href="https://github.com/ipfgao"><b>@ipfgao</b></a>:
|
| 686 |
+
<a href="https://github.com/jingyaogong/minimind/issues/26">🔗训练步骤记录</a>
|
| 687 |
+
|
| 688 |
+
## 🫶支持者
|
| 689 |
+
|
| 690 |
+
<a href="https://github.com/jingyaogong/minimind/stargazers">
|
| 691 |
+
<picture>
|
| 692 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/stars/dark/jingyaogong/minimind"/>
|
| 693 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/stars/jingyaogong/minimind"/>
|
| 694 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/stars/jingyaogong/minimind"/>
|
| 695 |
+
</picture>
|
| 696 |
+
</a>
|
| 697 |
+
|
| 698 |
+
<a href="https://github.com/jingyaogong/minimind/network/members">
|
| 699 |
+
<picture>
|
| 700 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/forks/dark/jingyaogong/minimind"/>
|
| 701 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/forks/jingyaogong/minimind"/>
|
| 702 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/forks/jingyaogong/minimind"/>
|
| 703 |
+
</picture>
|
| 704 |
+
</a>
|
| 705 |
+
|
| 706 |
+
<picture>
|
| 707 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind&type=Date&theme=dark"/>
|
| 708 |
+
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind&type=Date"/>
|
| 709 |
+
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=jingyaogong/minimind&type=Date"/>
|
| 710 |
+
</picture>
|
| 711 |
+
|
| 712 |
+
# License
|
| 713 |
+
|
| 714 |
+
This repository is licensed under the [Apache-2.0 License](LICENSE).
|
| 715 |
+
|
| 716 |
+
|
README_en.md
ADDED
|
@@ -0,0 +1,747 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
<div align="center">
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
[](https://github.com/jingyaogong/minimind/stargazers)
|
| 11 |
+
[](LICENSE)
|
| 12 |
+
[](https://github.com/jingyaogong/minimind/commits/master)
|
| 13 |
+
[](https://github.com/jingyaogong/minimind/pulls)
|
| 14 |
+
[](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
<div align="center">
|
| 20 |
+
<h3>"The Greatest Path is the Simplest"</h3>
|
| 21 |
+
</div>
|
| 22 |
+
|
| 23 |
+
<div align="center">
|
| 24 |
+
|
| 25 |
+
[中文](./README.md) | English
|
| 26 |
+
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
* This open-source project aims to train a miniature language model **MiniMind** from scratch, with a size of just 26MB.
|
| 30 |
+
* **MiniMind** is extremely lightweight, approximately $\frac{1}{7000}$ the size of GPT-3, designed to enable fast
|
| 31 |
+
inference and even training on CPUs.
|
| 32 |
+
* **MiniMind** is an improvement on the DeepSeek-V2 and Llama3 architectures. The project includes all stages of data
|
| 33 |
+
processing, pretraining, SFT, and DPO, and features a Mixture of Experts (MoE) model.
|
| 34 |
+
* This project is not only an open-source initiative but also a beginner's tutorial for LLMs, and serves as a nascent
|
| 35 |
+
open-source model with the hope of inspiring further development.
|
| 36 |
+
|
| 37 |
+
---
|
| 38 |
+
|
| 39 |
+
<div align="center">
|
| 40 |
+
|
| 41 |
+
https://github.com/user-attachments/assets/88b98128-636e-43bc-a419-b1b1403c2055
|
| 42 |
+
|
| 43 |
+
[Bilibili Video](https://www.bilibili.com/video/BV12dHPeqE72/?share_source=copy_web&vd_source=670c2504f88726f8cf4a21ef6147c0e8)
|
| 44 |
+
|
| 45 |
+
</div>
|
| 46 |
+
|
| 47 |
+
# 📌 Introduction
|
| 48 |
+
|
| 49 |
+
In the field of large language models (LLMs) such as GPT, LLaMA, GLM, etc., while their performance is impressive, the
|
| 50 |
+
massive model parameters—often in the range of 10 billion—make them difficult to train or even infer on personal devices
|
| 51 |
+
with limited memory. Most users do not settle for merely fine-tuning large models using methods like LoRA to learn a few
|
| 52 |
+
new instructions. It's akin to teaching Newton to use a 21st-century smartphone, which is far removed from the essence
|
| 53 |
+
of learning physics itself.
|
| 54 |
+
|
| 55 |
+
Additionally, the abundance of flawed, superficial AI tutorials offered by subscription-based marketing accounts
|
| 56 |
+
exacerbates the problem of finding quality content to understand LLMs, severely hindering learners.
|
| 57 |
+
|
| 58 |
+
Therefore, the goal of this project is to lower the barrier to entry for working with LLMs as much as possible, by
|
| 59 |
+
training an extremely lightweight language model from scratch.
|
| 60 |
+
|
| 61 |
+
> [!CAUTION]
|
| 62 |
+
> As of 2024-09-17, MiniMind has trained three model versions, with the smallest model requiring only 26M (0.02B) parameters to achieve smooth conversational abilities!
|
| 63 |
+
|
| 64 |
+
| Model (Size) | Tokenizer Length | Inference Memory Usage | Release Date | Subjective Rating (/100) |
|
| 65 |
+
|-------------------------------|------------------|------------------------|--------------|--------------------------|
|
| 66 |
+
| minimind-v1-small (26M) | 6400 | 0.5 GB | 2024.08.28 | 50' |
|
| 67 |
+
| minimind-v1-moe (4×26M) | 6400 | 1.0 GB | 2024.09.17 | 55' |
|
| 68 |
+
| MiniMind-V1 (108M) | 6400 | 1.0 GB | 2024.09.01 | 60' |
|
| 69 |
+
|
| 70 |
+
> This analysis was run on an RTX 3090 GPU with Torch 2.1.2, CUDA 12.2, and Flash Attention 2.
|
| 71 |
+
|
| 72 |
+
The project includes:
|
| 73 |
+
|
| 74 |
+
- Public MiniMind model code (including Dense and MoE models), code for Pretrain, SFT instruction fine-tuning, LoRA
|
| 75 |
+
fine-tuning, and DPO preference optimization, along with datasets and sources.
|
| 76 |
+
- Compatibility with popular frameworks such as `transformers`, `accelerate`, `trl`, and `peft`.
|
| 77 |
+
- Training support for single-GPU and multi-GPU setups(DDP、DeepSpeed). The training process allows for stopping and
|
| 78 |
+
resuming at any
|
| 79 |
+
point.
|
| 80 |
+
- Code for testing the model on the Ceval dataset.
|
| 81 |
+
- Implementation of a basic chat interface compatible with OpenAI's API, facilitating integration into third-party Chat
|
| 82 |
+
UIs (such as FastGPT, Open-WebUI, etc.).
|
| 83 |
+
|
| 84 |
+
We hope this open-source project helps LLM beginners get started quickly!
|
| 85 |
+
|
| 86 |
+
### 👉**Recent Updates**
|
| 87 |
+
<details close>
|
| 88 |
+
<summary> <b>2024-09-17 (new🎉)</b> </summary>
|
| 89 |
+
|
| 90 |
+
- Updated the minimind-v1-moe model
|
| 91 |
+
- To prevent ambiguity, all mistral_tokenizer versions have been removed, and a custom minimind_tokenizer is now used as the tokenizer.
|
| 92 |
+
|
| 93 |
+
</details>
|
| 94 |
+
|
| 95 |
+
<details close>
|
| 96 |
+
<summary> <b>2024-09-01</b> </summary>
|
| 97 |
+
|
| 98 |
+
- Updated the MiniMind-V1 (108M) model, using minimind_tokenizer with 3 pre-training epochs and 10 SFT epochs for more thorough training and improved performance.
|
| 99 |
+
|
| 100 |
+
- The project has been deployed to ModelScope's Creative Space and can be experienced on the website:
|
| 101 |
+
|
| 102 |
+
- [ModelScope Online Experience](https://www.modelscope.cn/studios/gongjy/minimind)
|
| 103 |
+
|
| 104 |
+
</details>
|
| 105 |
+
|
| 106 |
+
<details close>
|
| 107 |
+
<summary> <b>2024-08-27</b> </summary>
|
| 108 |
+
|
| 109 |
+
- The project was open-sourced for the first time.
|
| 110 |
+
|
| 111 |
+
</details>
|
| 112 |
+
|
| 113 |
+
# 📌 Environment
|
| 114 |
+
|
| 115 |
+
These are my personal software and hardware environment configurations. Please adjust according to your own setup:
|
| 116 |
+
|
| 117 |
+
* Ubuntu == 20.04
|
| 118 |
+
* Python == 3.9
|
| 119 |
+
* Pytorch == 2.1.2
|
| 120 |
+
* CUDA == 12.2
|
| 121 |
+
* [requirements.txt](./requirements.txt)
|
| 122 |
+
|
| 123 |
+
# 📌 Quick Inference & Test
|
| 124 |
+
|
| 125 |
+
<div align="center" style="font-size: 1.5em; font-weight: bold;">
|
| 126 |
+
<img src="https://huggingface.co/front/assets/huggingface_logo-noborder.svg" alt="Hugging Face Logo" style="vertical-align: middle; height: 30px;" />
|
| 127 |
+
Hugging Face
|
| 128 |
+
|
| 129 |
+
[MiniMind (HuggingFace)](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
|
| 130 |
+
|
| 131 |
+
<img src="https://g.alicdn.com/sail-web/maas/1.15.0/static/modelscopeIcon.cd89353f.svg" alt="Hugging Face Logo" style="vertical-align: middle; height: 30px;" />
|
| 132 |
+
|
| 133 |
+
[MiniMind (ModelScope)](https://www.modelscope.cn/models/gongjy/MiniMind-V1)
|
| 134 |
+
|
| 135 |
+
</div>
|
| 136 |
+
|
| 137 |
+
```bash
|
| 138 |
+
# step 1
|
| 139 |
+
git clone https://huggingface.co/jingyaogong/minimind-v1
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
```bash
|
| 143 |
+
# step 2
|
| 144 |
+
python 2-eval.py
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
or you can run streamlit, launch a web page to chat with minimind-v1
|
| 148 |
+
|
| 149 |
+
```bash
|
| 150 |
+
# or step 3, use streamlit
|
| 151 |
+
streamlit run fast_inference.py
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+

|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
<div align="center">
|
| 158 |
+
|
| 159 |
+
The project has been deployed to ModelScope makerspace, where you can experience:
|
| 160 |
+
|
| 161 |
+
[ModelScope Online](https://www.modelscope.cn/studios/gongjy/minimind)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
</div>
|
| 165 |
+
|
| 166 |
+
# 📌 Quick Start
|
| 167 |
+
|
| 168 |
+
*
|
| 169 |
+
0. Install the required dependencies
|
| 170 |
+
```bash
|
| 171 |
+
pip install -r requirements.txt
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
*
|
| 175 |
+
1. Clone the project code
|
| 176 |
+
|
| 177 |
+
```text
|
| 178 |
+
git clone https://github.com/jingyaogong/minimind.git
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
*
|
| 182 |
+
2. If you need to train the model yourself
|
| 183 |
+
|
| 184 |
+
* 2.1 Download the [dataset download link](#dataset-download-links) and place it in the `./dataset` directory.
|
| 185 |
+
|
| 186 |
+
* 2.2 Run `python data_process.py` to process the dataset, such as token-encoding pretrain data and extracting QA
|
| 187 |
+
data to CSV files for the SFT dataset.
|
| 188 |
+
|
| 189 |
+
* 2.3 Adjust the model parameter configuration in `./model/LMConfig.py`.
|
| 190 |
+
* 2.4 Execute pretraining with `python 1-pretrain.py`.
|
| 191 |
+
* 2.5 Perform instruction fine-tuning with `python 3-full_sft.py`.
|
| 192 |
+
* 2.6 Perform LoRA fine-tuning (optional) with `python 4-lora_sft.py`.
|
| 193 |
+
* 2.7 Execute DPO human preference reinforcement learning alignment (optional) with `python 5-dpo_train.py`.
|
| 194 |
+
|
| 195 |
+
*
|
| 196 |
+
3. Test model inference performance
|
| 197 |
+
|
| 198 |
+
* Ensure that the required trained parameter weights are located in the `./out/` directory.
|
| 199 |
+
* You can also directly download and use the trained model weights from [Trained Model Weights](#Trained Model Weights).
|
| 200 |
+
```text
|
| 201 |
+
out
|
| 202 |
+
├── multi_chat
|
| 203 |
+
│ ├── full_sft_512.pth
|
| 204 |
+
│ ├── full_sft_512_moe.pth
|
| 205 |
+
│ └── full_sft_768.pth
|
| 206 |
+
├── single_chat
|
| 207 |
+
│ ├── full_sft_512.pth
|
| 208 |
+
│ ├── full_sft_512_moe.pth
|
| 209 |
+
│ └── full_sft_768.pth
|
| 210 |
+
├── pretrain_768.pth
|
| 211 |
+
├── pretrain_512_moe.pth
|
| 212 |
+
├── pretrain_512.pth
|
| 213 |
+
```
|
| 214 |
+
|
| 215 |
+
* Test the pretraining model's chain effect with `python 0-eval_pretrain.py`
|
| 216 |
+
* Test the model's conversational effect with `python 2-eval.py`
|
| 217 |
+

|
| 218 |
+
|
| 219 |
+
🍭 **Tip**: Pretraining and full parameter fine-tuning (`pretrain` and `full_sft`) support DDP multi-GPU acceleration.
|
| 220 |
+
|
| 221 |
+
* Start training on a single machine with N GPUs(DDP)
|
| 222 |
+
```bash
|
| 223 |
+
torchrun --nproc_per_node N 1-pretrain.py
|
| 224 |
+
# and
|
| 225 |
+
torchrun --nproc_per_node N 3-full_sft.py
|
| 226 |
+
```
|
| 227 |
+
* Start training on a single machine with N GPUs(DeepSpeed)
|
| 228 |
+
```bash
|
| 229 |
+
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
|
| 230 |
+
# and
|
| 231 |
+
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.py
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
# 📌 Data sources
|
| 235 |
+
|
| 236 |
+
- 🤖 Tokenizer: In NLP, a Tokenizer is similar to a dictionary, mapping words from natural language to numbers like 0, 1,
|
| 237 |
+
36, etc., which can be understood as page numbers in the "dictionary" representing words. There are two ways to build
|
| 238 |
+
an LLM tokenizer: one is to create a vocabulary and train a tokenizer yourself, as seen in `train_tokenizer.py`; the
|
| 239 |
+
other is to use a pre-trained tokenizer from an open-source model.
|
| 240 |
+
|
| 241 |
+
You can use a standard dictionary like Xinhua or Oxford. The advantage is that token conversion has a good compression
|
| 242 |
+
rate, but the downside is that the vocabulary can be very large, with tens of thousands of words and phrases.
|
| 243 |
+
Alternatively, you can use a custom-trained tokenizer. The advantage is that you can control the vocabulary size, but
|
| 244 |
+
the compression rate may not be ideal, and rare words might be missed.
|
| 245 |
+
|
| 246 |
+
The choice of "dictionary" is crucial. The output of an LLM is essentially a multi-class classification problem over N
|
| 247 |
+
words in the dictionary, which is then decoded back into natural language. Because LLMs are very small, to avoid the
|
| 248 |
+
model being top-heavy (with the embedding layer's parameters taking up too much of the model), the vocabulary length
|
| 249 |
+
should be kept relatively small.
|
| 250 |
+
|
| 251 |
+
Powerful open-source models like 01万物, 千问, chatglm, mistral, and Llama3 have the following tokenizer vocabulary
|
| 252 |
+
sizes:
|
| 253 |
+
<table>
|
| 254 |
+
<tr><th>Tokenizer Model</th><th>Vocabulary Size</th><th>Come from</th></tr>
|
| 255 |
+
<tr><td>yi tokenizer</td><td>64,000</td><td>01-AI(China)</td></tr>
|
| 256 |
+
<tr><td>qwen2 tokenizer</td><td>151,643</td><td>Alibaba Cloud(China)</td></tr>
|
| 257 |
+
<tr><td>glm tokenizer</td><td>151,329</td><td>Zhipu AI(China)</td></tr>
|
| 258 |
+
<tr><td>mistral tokenizer</td><td>32,000</td><td>Mistral AI(China)</td></tr>
|
| 259 |
+
<tr><td>llama3 tokenizer</td><td>128,000</td><td>Meta(China)</td></tr>
|
| 260 |
+
<tr><td>minimind tokenizer</td><td>6,400</td><td>Custom</td></tr>
|
| 261 |
+
</table>
|
| 262 |
+
|
| 263 |
+
> [!IMPORTANT]
|
| 264 |
+
> Update on 2024-09-17: To avoid ambiguity from previous versions and control the model size, all Minimind models now use the Minimind_tokenizer for tokenization, and all versions of the Mistral_tokenizer have been deprecated.
|
| 265 |
+
|
| 266 |
+
> Although the Minimind_tokenizer has a small length and its encoding/decoding efficiency is weaker compared to Chinese-friendly tokenizers like Qwen2 and GLM, the Minimind models have opted for their custom-trained Minimind_tokenizer to maintain a lightweight parameter structure and prevent an imbalance between encoding and computation layers. This is because the Minimind vocabulary size is only 6,400.
|
| 267 |
+
> Moreover, Minimind has not encountered any issues with decoding rare words in practical tests, and the performance has been satisfactory. Due to the custom vocabulary being compressed to 6,400 tokens, the total parameter size of the LLM is minimized to only 26M.
|
| 268 |
+
|
| 269 |
+
---
|
| 270 |
+
|
| 271 |
+
- 📙 **[Pretrain Data](https://github.com/mobvoi/seq-monkey-data/blob/main/docs/pretrain_open_corpus.md)**:
|
| 272 |
+
The [Seq-Monkey General Text Dataset](https://github.com/mobvoi/seq-monkey-data/blob/main/docs/pretrain_open_corpus.md) / [Baidu](https://pan.baidu.com/s/114F1k3eksiWCOQLvaT3RYQ?pwd=6666)
|
| 273 |
+
is a collection of data from various public sources such as websites, encyclopedias, blogs, open-source code, books,
|
| 274 |
+
etc. It has been compiled, cleaned, and organized into a unified JSONL format, with rigorous filtering and
|
| 275 |
+
deduplication to ensure data comprehensiveness, scale, reliability, and high quality. The total amount is
|
| 276 |
+
approximately 10B tokens, suitable for pretraining Chinese large language models.
|
| 277 |
+
|
| 278 |
+
---
|
| 279 |
+
|
| 280 |
+
- 📕 **[SFT Data](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data)**:
|
| 281 |
+
The [Jiangshu Large Model SFT Dataset](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data) is a
|
| 282 |
+
comprehensive, uniformly formatted, and secure resource for large model training and research. It includes a large
|
| 283 |
+
amount of open-source data collected and organized from publicly available online sources, with format unification and
|
| 284 |
+
data cleaning. It comprises a Chinese dataset with 10M entries and an English dataset with 2M entries. The total
|
| 285 |
+
amount is approximately 3B tokens, suitable for SFT of Chinese large language models. The dataset integration includes
|
| 286 |
+
all data from the following sources (for reference only, no need to download separately, just download the
|
| 287 |
+
complete [SFT Data]):
|
| 288 |
+
|
| 289 |
+
- [BelleGroup/train_3.5M_CN](https://huggingface.co/datasets/BelleGroup/train_3.5M_CN)
|
| 290 |
+
- [LinkSoul/instruction_merge_set](https://huggingface.co/datasets/LinkSoul/instruction_merge_set)
|
| 291 |
+
- [stingning/ultrachat](https://huggingface.co/datasets/stingning/ultrachat)
|
| 292 |
+
- [BAAI/COIG-PC-core](https://huggingface.co/datasets/BAAI/COIG-PC-core)
|
| 293 |
+
- [shibing624/sharegpt_gpt4](https://huggingface.co/datasets/shibing624/sharegpt_gpt4)
|
| 294 |
+
- [shareAI/ShareGPT-Chinese-English-90k](https://huggingface.co/datasets/shareAI/ShareGPT-Chinese-English-90k)
|
| 295 |
+
- [Tiger Research](https://huggingface.co/TigerResearch/sft_zh)
|
| 296 |
+
- [BelleGroup/school_math_0.25M](https://huggingface.co/datasets/BelleGroup/school_math_0.25M)
|
| 297 |
+
- [YeungNLP/moss-003-sft-data](https://huggingface.co/datasets/YeungNLP/moss-003-sft-data)
|
| 298 |
+
- 📘 **DPO Data**: Approximately 80,000 DPO (Direct Preference Optimization) data entries, which are manually labeled
|
| 299 |
+
preference data, come from [Huozi Model](https://github.com/HIT-SCIR/huozi). These can be used to train reward models
|
| 300 |
+
to optimize response quality and align more closely with human preferences.
|
| 301 |
+
|
| 302 |
+
---
|
| 303 |
+
|
| 304 |
+
- **More Datasets**: [HqWu-HITCS/Awesome-Chinese-LLM](https://github.com/HqWu-HITCS/Awesome-Chinese-LLM) is currently
|
| 305 |
+
collecting and organizing open-source models, applications, datasets, and tutorials related to Chinese LLMs, with
|
| 306 |
+
continuous updates on the latest developments in this field. Comprehensive and professional, respect!
|
| 307 |
+
|
| 308 |
+
---
|
| 309 |
+
|
| 310 |
+
### Dataset Download Links
|
| 311 |
+
|
| 312 |
+
| MiniMind Training Dataset | Download Link |
|
| 313 |
+
|---------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------|
|
| 314 |
+
| **[tokenizer Data]** | [HuggingFace](https://huggingface.co/datasets/jingyaogong/minimind_dataset/tree/main) / [Baidu](https://pan.baidu.com/s/1yAw1LVTftuhQGAC1Y9RdYQ?pwd=6666) |
|
| 315 |
+
| **[Pretrain Data]** | [Seq-Monkey General Text Dataset](http://share.mobvoi.com:5000/sharing/O91blwPkY) / [Baidu](https://pan.baidu.com/s/114F1k3eksiWCOQLvaT3RYQ?pwd=6666) |
|
| 316 |
+
| **[SFT Data]** | [Jiangshu Large Model SFT Dataset](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data/resolve/master/sft_data_zh.jsonl) |
|
| 317 |
+
| **[DPO Data]** | [Huozi Dataset 1](https://huggingface.co/datasets/Skepsun/huozi_rlhf_data_json) |
|
| 318 |
+
| **[DPO Data]** | [Huozi Dataset 2](https://huggingface.co/datasets/beyond/rlhf-reward-single-round-trans_chinese) |
|
| 319 |
+
|
| 320 |
+
# 📌 Model
|
| 321 |
+
|
| 322 |
+
MiniMind-Dense (like [Llama3.1](https://ai.meta.com/blog/meta-llama-3-1/)) uses a Transformer Decoder-Only architecture.
|
| 323 |
+
The differences from GPT-3 are:
|
| 324 |
+
|
| 325 |
+
* It employs GPT-3's pre-normalization method, which normalizes the input of each Transformer sub-layer rather than the
|
| 326 |
+
output. Specifically, it uses the RMSNorm normalization function.
|
| 327 |
+
* It replaces ReLU with the SwiGLU activation function to enhance performance.
|
| 328 |
+
* Like GPT-Neo, it omits absolute position embeddings in favor of Rotary Position Embeddings (RoPE), which improves
|
| 329 |
+
performance for inference beyond the training length.
|
| 330 |
+
|
| 331 |
+
---
|
| 332 |
+
|
| 333 |
+
The MiniMind-MoE model is based on the MixFFN mixture-of-experts module from Llama3
|
| 334 |
+
and [DeepSeek-V2](https://arxiv.org/pdf/2405.04434).
|
| 335 |
+
|
| 336 |
+
* DeepSeek-V2 adopts more granular expert partitioning and shared expert isolation techniques in the feed-forward
|
| 337 |
+
network (FFN) to improve the performance of experts.
|
| 338 |
+
|
| 339 |
+
---
|
| 340 |
+
|
| 341 |
+
The overall structure of MiniMind remains consistent, with minor adjustments in RoPE calculations, inference functions,
|
| 342 |
+
and FFN layer code. The structure is illustrated in the figure below (redrawn):
|
| 343 |
+
|
| 344 |
+

|
| 345 |
+

|
| 346 |
+
Model configurations can be found in [./model/LMConfig.py](./model/LMConfig.py). The model types and parameters are
|
| 347 |
+
shown in the table below:
|
| 348 |
+
|
| 349 |
+
| Model Name | params | len_vocab | n_layers | d_model | kv_heads | q_heads | share+route | TopK |
|
| 350 |
+
|------------------|--------|-----------|----------|---------|----------|---------|-------------|------|
|
| 351 |
+
| minimind-v1-small | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
|
| 352 |
+
| minimind-v1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
|
| 353 |
+
| minimind-v1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
# 📌 Experiment
|
| 357 |
+
|
| 358 |
+
```bash
|
| 359 |
+
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
|
| 360 |
+
Memory: 128 GB
|
| 361 |
+
GPU: NVIDIA GeForce RTX 3090 (24GB) * 2
|
| 362 |
+
Environment: python 3.9 + Torch 2.1.2 + DDP multi-GPU training
|
| 363 |
+
```
|
| 364 |
+
|
| 365 |
+
| Model Name | params | len_vocab | batch_size | pretrain_time | sft_single_time | sft_multi_time |
|
| 366 |
+
|------------------|--------|-----------|------------|-------------------|-------------------|---------------------|
|
| 367 |
+
| minimind-v1-small | 26M | 6400 | 64 | ≈2 hour (1 epoch) | ≈2 hour (1 epoch) | ≈0.5 hour (1 epoch) |
|
| 368 |
+
| minimind-v1-moe | 4×26M | 6400 | 40 | ≈6 hour (1 epoch) | ≈5 hour (1 epoch) | ≈1 hour (1 epoch) |
|
| 369 |
+
| minimind-v1 | 108M | 6400 | 16 | ≈6 hour (1 epoch) | ≈4 hour (1 epoch) | ≈1 hour (1 epoch) |
|
| 370 |
+
|
| 371 |
+
---
|
| 372 |
+
|
| 373 |
+
1. **Pretraining (Text-to-Text)**:
|
| 374 |
+
- LLMs first need to absorb a vast amount of knowledge, much like filling a well with ink. The more "ink" it has,
|
| 375 |
+
the better its understanding of the world will be.
|
| 376 |
+
- Pretraining involves the model learning a large amount of basic knowledge from sources such as Wikipedia, news
|
| 377 |
+
articles, common knowledge, books, etc.
|
| 378 |
+
- It unsupervisedly compresses knowledge from vast text data into its model weights with the aim of learning word
|
| 379 |
+
sequences. For instance, if we input “Qin Shi Huang is,” after extensive training, the model can predict that the
|
| 380 |
+
next probable sentence is “the first emperor of China.”
|
| 381 |
+
> The learning rate for pretraining is set dynamically between 1e-4 and 1e-5, with 2 epochs and a training time of
|
| 382 |
+
less than one day.
|
| 383 |
+
```bash
|
| 384 |
+
torchrun --nproc_per_node 2 1-pretrain.py
|
| 385 |
+
```
|
| 386 |
+
|
| 387 |
+
2. **Single Dialog Fine-Tuning**:
|
| 388 |
+
- After pretraining, the semi-finished LLM has almost all language knowledge and encyclopedic common sense. At this
|
| 389 |
+
stage, it only performs word sequences without understanding how to chat with humans.
|
| 390 |
+
- The model needs fine-tuning to adapt to chat templates. For example, it should recognize that a template
|
| 391 |
+
like “<chat start> Qin Shi Huang is <chat end>” indicates the end of a complete conversation, rather than just
|
| 392 |
+
generating the next word.
|
| 393 |
+
- This process is known as instruction fine-tuning, akin to teaching a knowledgeable person like Newton to adapt to
|
| 394 |
+
21st-century chat habits, learning the pattern of messages on the left and responses on the right.
|
| 395 |
+
- During training, MiniMind’s instruction and response lengths are truncated to 512 to save memory. Just as we start
|
| 396 |
+
with shorter texts when learning, we don’t need to separately learn longer articles once we master shorter ones.
|
| 397 |
+
> During inference, RoPE can be linearly interpolated to extend lengths to 1024 or 2048 or more. The learning rate is
|
| 398 |
+
set dynamically between 1e-5 and 1e-6, with 5 epochs for fine-tuning.
|
| 399 |
+
```bash
|
| 400 |
+
# Set dataset to sft_data_single.csv in 3-full_sft.py
|
| 401 |
+
torchrun --nproc_per_node 2 3-full_sft.py
|
| 402 |
+
```
|
| 403 |
+
|
| 404 |
+
3. **Multi-Dialog Fine-Tuning**:
|
| 405 |
+
- Building on step 2, the LLM has learned a single-question-to-answer chat template. Now, it only needs further
|
| 406 |
+
fine-tuning on longer chat templates with historical question-and-answer pairs.
|
| 407 |
+
- Use the `history_chat` field for historical dialogues and `history_chat_response` for historical responses in the
|
| 408 |
+
dataset.
|
| 409 |
+
- Construct new chat templates like [question->answer, question->answer, question->] and use this dataset for
|
| 410 |
+
fine-tuning.
|
| 411 |
+
- The trained model will not only answer the current question but also conduct coherent dialogues based on
|
| 412 |
+
historical interactions.
|
| 413 |
+
- This step is not strictly necessary, as small models have weak long-context dialogue abilities, and forcing
|
| 414 |
+
multi-turn Q&A templates may slightly compromise single-turn SFT performance.
|
| 415 |
+
> The learning rate is set dynamically between 1e-5 and 1e-6, with 2 epochs for fine-tuning.
|
| 416 |
+
```bash
|
| 417 |
+
# Set dataset to sft_data.csv in 3-full_sft.py
|
| 418 |
+
torchrun --nproc_per_node 2 3-full_sft.py
|
| 419 |
+
```
|
| 420 |
+
|
| 421 |
+
4. **Direct Preference Optimization (DPO)**:
|
| 422 |
+
- After the previous training steps, the model has basic conversational abilities. However, we want it to align more
|
| 423 |
+
closely with human preferences and provide more satisfactory responses.
|
| 424 |
+
- This process is similar to workplace training for the model, where it learns from examples of excellent employees
|
| 425 |
+
and negative examples to better serve customers.
|
| 426 |
+
> For the Huozi trio (q, chose, reject) dataset, the learning rate is set to 1e-5, with half-precision fp16, 1 epoch,
|
| 427 |
+
and it takes about 1 hour.
|
| 428 |
+
```bash
|
| 429 |
+
python 5-dpo_train.py
|
| 430 |
+
```
|
| 431 |
+
---
|
| 432 |
+
📋 Regarding LLM parameter configuration, an interesting paper [MobileLLM](https://arxiv.org/pdf/2402.14905) provides detailed research and experiments.
|
| 433 |
+
The scaling law exhibits unique patterns in small models. The parameters that significantly influence the scaling of Transformer models are primarily `d_model` and `n_layers`.
|
| 434 |
+
|
| 435 |
+
* `d_model`↑ + `n_layers`↓ -> Short and wide models
|
| 436 |
+
* `d_model`↓ + `n_layers`↑ -> Tall and narrow models
|
| 437 |
+
|
| 438 |
+
The Scaling Law proposed in 2020 posits that the amount of training data, parameter count, and training iterations are the key factors determining performance, with the influence of model architecture being nearly negligible. However, this law seems not to fully apply to small models.
|
| 439 |
+
MobileLLM suggests that the depth of the architecture is more important than its width. A "deep and narrow" model can learn more abstract concepts compared to a "wide and shallow" model. For instance, when the model parameters are fixed at 125M or 350M, a 30–42 layer "narrow" model significantly outperforms a 12-layer "short and wide" model. This trend is observed across eight benchmark tests, including common sense reasoning, question answering, and reading comprehension.
|
| 440 |
+
This is a fascinating discovery, as previously, few attempts were made to stack more than 12 layers when designing architectures for small models around the 100M parameter range. This aligns with the observations from MiniMind, where adjusting parameters between `d_model` and `n_layers` during training produced similar effects.
|
| 441 |
+
However, "deep and narrow" has its limitations. When `d_model` < 512, the disadvantages of collapsing word embedding dimensions become very pronounced, and increasing layers does not compensate for the shortcomings in `d_head` caused by fixed `q_head`. Conversely, when `d_model` > 1536, increasing layers seems to have a higher priority than `d_model`, providing a better "cost-performance" ratio and effect gain.
|
| 442 |
+
Therefore, MiniMind sets `d_model = 512` and `n_layers = 8` for the small model to achieve a balance between "minimal size <-> better performance." For greater performance gains, `d_model = 768` and `n_layers = 16` are set, aligning better with the scaling law for small models.
|
| 443 |
+
|
| 444 |
+
> For reference, the configuration details for GPT-3 are shown in the table below:
|
| 445 |
+
|
| 446 |
+

|
| 447 |
+
|
| 448 |
+
---
|
| 449 |
+
### Trained Model Weights
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
| Model Name | params | Config | pretrain_model | single_sft_model | multi_sft_model |
|
| 453 |
+
|-------------------|--------|-----------------------------|----------------|-----------------------------------------------------------------|----------------------------------------------------------------|
|
| 454 |
+
| minimind-v1-small | 26M | d_model=512<br/>n_layers=8 | - | [URL](https://pan.baidu.com/s/1_COe0FQRDmeapSsvArahCA?pwd=6666) | [URL](https://pan.baidu.com/s/1GsGsWSL0Dckl0YPRXiBIFQ?pwd=6666) |
|
| 455 |
+
| minimind-v1-moe | 4×26M | d_model=512<br/>n_layers=8 | - | - | - |
|
| 456 |
+
| minimind-v1 | 108M | d_model=768<br/>n_layers=16 | - | [URL](https://pan.baidu.com/s/1p713loS7EfwHQf3G9eYI3Q?pwd=6666) | [URL](https://pan.baidu.com/s/12iHGpAs6R0kqsOnGtgK6vQ?pwd=6666) |
|
| 457 |
+
|
| 458 |
+
---
|
| 459 |
+
|
| 460 |
+
|
| 461 |
+
# 📌 Eval
|
| 462 |
+
|
| 463 |
+
> [!TIP]
|
| 464 |
+
> The following tests were completed on September 17, 2024. New models released after this date will not be included in the tests unless there is a special need.
|
| 465 |
+
|
| 466 |
+
[A] [minimind-v1-small(0.02B)](https://pan.baidu.com/s/1_COe0FQRDmeapSsvArahCA?pwd=6666)<br/>
|
| 467 |
+
[B] minimind-v1-moe(0.1B)<br/>
|
| 468 |
+
[C] [minimind-v1(0.1B)](https://pan.baidu.com/s/1p713loS7EfwHQf3G9eYI3Q?pwd=6666)<br/>
|
| 469 |
+
[D] [baby-llama2-chinese(0.2B)](https://github.com/DLLXW/baby-llama2-chinese)<br/>
|
| 470 |
+
[E] [chatlm-mini-chinese(0.2B)](https://github.com/charent/ChatLM-mini-Chinese)<br/>
|
| 471 |
+
|
| 472 |
+
```text
|
| 473 |
+
[Q]: Do you know the Yangtze River?
|
| 474 |
+
[A]: Yes, the Yangtze River is the longest river in China, with a length of over 3,300 kilometers.
|
| 475 |
+
[B]: Yes, the Yangtze River is the longest river in China, with a length of about 7,100 kilometers. Its drainage area is about 33.28 million square kilometers, making it one of China's largest rivers and the third longest river in the world, with a total length of about 6,300 kilometers.
|
| 476 |
+
[C]: Yes, the Yangtze River is one of the longest rivers in China and the third longest river in the world. It originates from the Tibetan Plateau, flows through 11 provinces, and eventually empties into the East China Sea. The Yangtze River Basin is one of China's largest river basins, with abundant natural resources and cultural heritage, such as the Yangtze River Bridge, Yangtze River Maritime Museum, and ancient cities along the Yangtze.
|
| 477 |
+
[D]: I also know that China is one of the longest cities in the world, with a population of over 34 million people.
|
| 478 |
+
[E]: Yes, the Yangtze River is the longest river in China and also one of the longest rivers in the world. It originates from the Tibetan Plateau, flows through nine provinces and regions, and eventually empties into the East China Sea. The climate in the Yangtze River Basin is mild, with distinct seasons, making it an important agricultural and industrial base in China. The river basin is rich in aquatic resources and is one of China's major fishing resources.
|
| 479 |
+
|
| 480 |
+
[Q]: Which country launched the first artificial satellite?
|
| 481 |
+
[A]: The first artificial satellite was Sputnik 1.
|
| 482 |
+
[B]: The first artificial satellite was launched by the United States.
|
| 483 |
+
[C]: The first artificial satellite was launched by the Soviet Union on October 4, 1957.
|
| 484 |
+
[D]: This satellite, named "Armstrong," was launched on November 20, 1961, and was the first successful satellite to send a human into space.
|
| 485 |
+
[E]: The first artificial satellite was launched by the Soviet Union on April 4, 1957. It was launched by Soviet astronaut Yuri Gagarin and Soviet engineer Roald Skohley. During the launch, Gagarin and Skohley used a small satellite named "Sputnik 1," which had a diameter of 4.3 meters and weighed 1,051 kilograms. This satellite, known as "Sputnik 1," marked a milestone in the Soviet space race and was the first instance of a human spacewalk in history.
|
| 486 |
+
|
| 487 |
+
[Q]: Do you know where Mount Tai is located?
|
| 488 |
+
[A]: Mount Tai is located in eastern China and is one of the Five Great Mountains of China.
|
| 489 |
+
[B]: Mount Tai is located in Tai'an City, Shandong Province, and is one of the Five Great Mountains of China.
|
| 490 |
+
[C]: Mount Tai is located in Tai'an City, Shandong Province, China, and is one of the Five Great Mountains of China.
|
| 491 |
+
[D]: As an AI assistant, I cannot access the internet, so I cannot provide information about your location. However, you can search for information or related keywords to find details about your location, or check news and websites for relevant information.
|
| 492 |
+
[E]: Mount Tai is located in Tai'an City, Shandong Province, China, and is one of the Five Great Mountains of China. It is also an important symbol of Chinese culture and history. With an elevation of 1,545 meters, it is one of the most famous tourist destinations in China. Its history dates back to the 5th century BC and was a site for ancient royal sacrifices. Mount Tai is a significant part of Chinese culture, known as the "First of the Five Great Mountains."
|
| 493 |
+
|
| 494 |
+
[Q]: What is the highest mountain in the world?
|
| 495 |
+
[A]: The highest mountain in the world is Mount Everest, located on the border between Nepal and China, with an elevation of 8,848 meters.
|
| 496 |
+
[B]: Mount Everest is the highest mountain in the world, located in the Himalayas, with an elevation of 8,848 meters.
|
| 497 |
+
[C]: Mount Everest is the highest mountain in the world, with an elevation of 8,848 meters.
|
| 498 |
+
[D]: The highest mountain in the world is Mount Everest, located in the Himalayas, with an elevation of 8,848.86 meters (29,031.69 feet).
|
| 499 |
+
[E]: The highest mountain in the world is Mount Everest, also known as Sagarmatha, located on the border between Nepal and China in the Himalayas, with an elevation of 8,848.86 meters (29,031.69 feet). It is one of the most famous climbing destinations, attracting climbers from around the world. The name Everest comes from Tibetan, meaning "The Goddess’s Peak," and it consists of two peaks, one in Nepal and one in China. Its height is determined through measurements of sea level, as it is the highest point on Earth. Although Everest is the highest mountain, it is not accessible from every place on Earth. Other places, such as the Andes Mountains in South America, are also high but do not have the highest peak. Overall, Everest is the highest mountain, but it is not accessible from every location on Earth.
|
| 500 |
+
|
| 501 |
+
[Q]: Who proposed the law of universal gravitation?
|
| 502 |
+
[A]: The law of universal gravitation was proposed by the British physicist Newton. He believed that all objects exert gravitational force, which depends on their mass and distance. This theory reveals the relationship between mass and distance and explains the nature of gravitation.
|
| 503 |
+
[B]: The law of universal gravitation was discovered by Newton and proposed by the British physicist James Watt in 1879.
|
| 504 |
+
[C]: The law of universal gravitation was proposed by the British physicist Isaac Newton in the 17th century.
|
| 505 |
+
[D]: Gravitation is a force in the universe composed of mass or energy. According to Newton's law of universal gravitation, the force between two objects is proportional to their mass and inversely proportional to their distance. Thus, Newton's law of universal gravitation shows that the gravitational force between two objects is proportional to their mass and inversely proportional to their distance. This law has wide applications in physics, astronomy, and other fields.
|
| 506 |
+
[E]: The law of universal gravitation was proposed by the British physicist Isaac Newton in 1687. In his famous paper "Philosophiæ Naturalis Principia Mathematica," Newton proposed the law of universal gravitation, stating that any two objects exert a gravitational force on each other, proportional to their masses and inversely proportional to the square of their distance. This law is known as the law of universal gravitation and describes the relationship between mass and distance. It is crucial for explaining many phenomena in the universe, such as planetary orbits and gravitational lensing between stars, and has broad applications in astronomy, physics, and engineering, providing a fundamental theoretical basis for understanding the nature and evolution of the universe.
|
| 507 |
+
|
| 508 |
+
[Q]: Do you know what the main food of giant pandas is?
|
| 509 |
+
[A]: The main food of giant pandas is bamboo. They typically eat bamboo and need to consume about 30 kilograms of it each day.
|
| 510 |
+
[B]: Giant pandas mainly eat bamboo, which is their primary food. Their digestive system is quite specialized, and they need to digest a large amount of bamboo daily to meet their survival needs. Besides bamboo, giant pandas also survive in the wild.
|
| 511 |
+
[C]: Giant pandas mainly eat bamboo but occasionally consume other plants and animals. They also eat some wild fruits, small animals, and plants, but these are not their main food sources.
|
| 512 |
+
[D]: The main food of giant pandas is bamboo.
|
| 513 |
+
[E]: Giant pandas are herbivores that primarily eat bamboo. Their digestive system is adapted to process the high cellulose content of bamboo, but they also consume some other plants, such as herbaceous plants and small mammals. Their digestive system includes enzymes like "cellulase" to break down cellulose, helping them digest a large amount of fiber and nutrients. Additionally, they have "cellulose protein" that helps maintain their energy levels, aiding their survival in the wild. Overall, bamboo is their primary food, but they also eat other plants and small mammals.
|
| 514 |
+
|
| 515 |
+
[Q]: Why is seawater salty?
|
| 516 |
+
[A]: Seawater contains many salts, which increase its salinity. The salts in seawater mainly come from the dissolved salts and form hydrogen bonds with water molecules, increasing the salinity.
|
| 517 |
+
[B]: Seawater contains abundant elements like calcium, phosphorus, potassium, and phosphorus, which are limited in quantity and distribution in the ocean. Additionally, seawater contains nutrients from various organisms and microorganisms, such as shells and seaweeds.
|
| 518 |
+
[C]: Seawater contains many dissolved salts, with the most common being sodium chloride. When salt is added to water, its molecules react with water molecules to form sodium hydroxide, which is a type of salt.
|
| 519 |
+
[D]: Water is essential for many organisms, as it can absorb and release carbon dioxide, release oxygen,
|
| 520 |
+
```
|
| 521 |
+
|
| 522 |
+
> [!NOTE]
|
| 523 |
+
> 🙋♂️Directly throw the answer of the above model to GPT-4o and ask it to help score it:
|
| 524 |
+
|
| 525 |
+
---
|
| 526 |
+
### Model Performance Review:
|
| 527 |
+
|
| 528 |
+
1. **Model A**:
|
| 529 |
+
- **Performance**: Model A's responses are usually concise and clear but lack detail and accuracy in some cases. For example, Model A provided incorrect information about the length of the Yangtze River.
|
| 530 |
+
- **Score**: 60
|
| 531 |
+
|
| 532 |
+
2. **Model B**:
|
| 533 |
+
- **Performance**: Model B provides additional information in some cases, but this information can sometimes be inaccurate or excessive. For instance, Model B gave incorrect figures for the length and drainage area of the Yangtze River.
|
| 534 |
+
- **Score**: 65
|
| 535 |
+
|
| 536 |
+
3. **Model C**:
|
| 537 |
+
- **Performance**: Model C typically provides detailed and accurate answers for most questions. For example, responses about the Yangtze River and Mount Tai were accurate.
|
| 538 |
+
- **Score**: 75
|
| 539 |
+
|
| 540 |
+
4. **Model D**:
|
| 541 |
+
- **Performance**: Model D’s responses sometimes appear disorganized and lack accuracy. For example, the answer about Mount Tai was completely off-topic.
|
| 542 |
+
- **Score**: 50
|
| 543 |
+
|
| 544 |
+
5. **Model E**:
|
| 545 |
+
- **Performance**: Model E’s responses are usually very detailed, but they can be overly verbose and contain unnecessary information. For instance, the answer on gravity was overly complex.
|
| 546 |
+
- **Score**: 70
|
| 547 |
+
|
| 548 |
+
#### Ranking (from highest to lowest):
|
| 549 |
+
|
| 550 |
+
| Model | C | E | B | A | D |
|
| 551 |
+
|-------|----|----|----|----|----|
|
| 552 |
+
| Score | 75 | 70 | 65 | 60 | 50 |
|
| 553 |
+
|
| 554 |
+
---
|
| 555 |
+
|
| 556 |
+
## 👉 Summary of Effects
|
| 557 |
+
|
| 558 |
+
* The ranking of the minimind series (ABC) is intuitive, with minimind-v1(0.1B) scoring the highest and providing mostly accurate answers to common knowledge questions.
|
| 559 |
+
* Surprisingly, minimind-v1-small (0.02B) with only 26M parameters performs close to minimind-v1(0.1B).
|
| 560 |
+
* Despite having less than 2 epochs of training, minimind-v1(0.1B) performed the best. This suggests that a larger model often yields better performance, even with limited training.
|
| 561 |
+
* minimind-v1-moe (0.1B) performed poorly, likely because it was terminated early to free up resources for smaller models. MoE models require more training epochs, and with only 2 epochs, it was under-trained. Previous experiments with a fully trained MoE model on Yi tokenizer showed visible improvements. Future versions, v2 and v3, will be updated with better training.
|
| 562 |
+
|
| 563 |
+
* Model E’s responses appear the most complete, despite some instances of hallucination and overly verbose content. However, GPT-4o and Deepseek's evaluations suggest it is "overly verbose and repetitive, with some hallucinations."
|
| 564 |
+
This strict evaluation might penalize models with some hallucinations heavily. Due to F models having longer default text lengths and much larger datasets, the quality of responses depends significantly on the data rather than the model size alone.
|
| 565 |
+
|
| 566 |
+
> 🙋♂️ Personal Subjective Evaluation: E>C>B≈A>D
|
| 567 |
+
|
| 568 |
+
> 🤖 GPT-4o Evaluation: C>E>B>A>D
|
| 569 |
+
|
| 570 |
+
Scaling Law: Larger model parameters and more training data generally lead to better model performance.
|
| 571 |
+
|
| 572 |
+
# 📌 Objective Dataset: C-Eval
|
| 573 |
+
|
| 574 |
+
C-Eval evaluation code is located at: `./eval_ceval.py`.
|
| 575 |
+
|
| 576 |
+
For small models, to avoid issues with fixed response formatting, we directly judge the prediction probabilities of the
|
| 577 |
+
four tokens `A`, `B`, `C`, `D`, and choose the one with the highest probability as the answer, then calculate accuracy
|
| 578 |
+
against the standard answer. Note that minimind models were not trained on larger datasets or fine-tuned for question
|
| 579 |
+
answering, so results should be considered as reference only.
|
| 580 |
+
|
| 581 |
+
> For example, detailed results for minimind-small:
|
| 582 |
+
|
| 583 |
+
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|
| 584 |
+
|------|----------------------------|-----|-----------------------|-----------------------|---------------------|--------------------|---------------------|---------------------|----------------|------------------------|-----------------------|-----------------------|----------------|------------------|-------|---------------------|---------------|---------------------------------|---------------------|------------|------------------|-------------------------|--------------------|---------------------|---------|----------------------|-------------------------|-------------------------|--------------------|-----------------------------------|-------------------|-------------------------|------------------------------------------|-----------------------|-------------------------|-----------------|---------------------------|----------------------|-----------|-------------------|---------------------|-----------------------|------------------------|-------------------|------------------|----------------|-------------|-----------------------|----------------------|-------------------|---------------|-------------------------|
|
| 585 |
+
| Data | probability_and_statistics | law | middle_school_biology | high_school_chemistry | high_school_physics | legal_professional | high_school_chinese | high_school_history | tax_accountant | modern_chinese_history | middle_school_physics | middle_school_history | basic_medicine | operating_system | logic | electrical_engineer | civil_servant | chinese_language_and_literature | college_programming | accountant | plant_protection | middle_school_chemistry | metrology_engineer | veterinary_medicine | marxism | advanced_mathematics | high_school_mathematics | business_administration | mao_zedong_thought | ideological_and_moral_cultivation | college_economics | professional_tour_guide | environmental_impact_assessment_engineer | computer_architecture | urban_and_rural_planner | college_physics | middle_school_mathematics | high_school_politics | physician | college_chemistry | high_school_biology | high_school_geography | middle_school_politics | clinical_medicine | computer_network | sports_science | art_studies | teacher_qualification | discrete_mathematics | education_science | fire_engineer | middle_school_geography |
|
| 586 |
+
|
| 587 |
+
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|
| 588 |
+
|----------|--------|--------|--------|--------|--------|-------|--------|--------|--------|--------|--------|--------|-------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|-------|
|
| 589 |
+
| T/A | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 7/31 | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 9/31 | 1/12 |
|
| 590 |
+
| Accuracy | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
|
| 591 |
+
|
| 592 |
+
**Total number of questions**: 1346
|
| 593 |
+
|
| 594 |
+
**Total confirmed number**: 316
|
| 595 |
+
|
| 596 |
+
**Total accuracy rate**: 23.48%
|
| 597 |
+
|
| 598 |
+
---
|
| 599 |
+
|
| 600 |
+
#### Results summary:
|
| 601 |
+
|
| 602 |
+
| category | correct | question_count | accuracy |
|
| 603 |
+
|:------------------|:--------:|:--------------:|:--------:|
|
| 604 |
+
| minimind-v1-small | 344 | 1346 | 25.56% |
|
| 605 |
+
| minimind-v1 | 351 | 1346 | 26.08% |
|
| 606 |
+
|
| 607 |
+
|
| 608 |
+
### Model Performance Insights from GPT-4o
|
| 609 |
+
|
| 610 |
+
```text
|
| 611 |
+
### Areas Where the Model Excels:
|
| 612 |
+
1. **High School Chemistry**: With an accuracy of 42.11%, this is the strongest area for the model, suggesting a solid grasp of chemistry-related knowledge.
|
| 613 |
+
2. **Discrete Mathematics**: Achieving an accuracy of 37.50%, the model performs well in mathematics-related fields.
|
| 614 |
+
3. **Education Science**: The model shows good performance in education-related topics with a 37.93% accuracy.
|
| 615 |
+
4. **Basic Medicine**: The accuracy of 36.84% indicates strong performance in foundational medical knowledge.
|
| 616 |
+
5. **Operating Systems**: With a 36.84% accuracy, the model demonstrates reliable performance in computer operating systems.
|
| 617 |
+
|
| 618 |
+
### Areas Where the Model Struggles:
|
| 619 |
+
1. **Legal Topics**: The model performs poorly in legal-related areas such as Legal Professional (8.70%) and Tax Accountant (20.41%).
|
| 620 |
+
2. **Physics**: Both high school (26.32%) and college-level (21.05%) physics topics are challenging for the model.
|
| 621 |
+
3. **High School Politics and Geography**: The model shows low accuracy in these areas, with High School Politics at 15.79% and High School Geography at 21.05%.
|
| 622 |
+
4. **Computer Networking and Architecture**: The model struggles with Computer Networking (21.05%) and Computer Architecture (9.52%).
|
| 623 |
+
5. **Environmental Impact Assessment Engineering**: The accuracy is only 12.90%, indicating weak performance in environmental science.
|
| 624 |
+
|
| 625 |
+
### Summary:
|
| 626 |
+
- **Strengths**: Chemistry, Mathematics (especially Discrete Mathematics), Education Science, Basic Medicine, and Operating Systems.
|
| 627 |
+
- **Weaknesses**: Legal Topics, Physics, Politics, Geography, Computer Networking and Architecture, and Environmental Science.
|
| 628 |
+
|
| 629 |
+
This suggests that the model performs well in logical reasoning, foundational sciences, and some engineering disciplines but is weaker in humanities, social sciences, and certain specialized fields (such as law and taxation). To improve the model's performance, additional training in humanities, physics, law, and environmental science may be beneficial.
|
| 630 |
+
```
|
| 631 |
+
|
| 632 |
+
# 📌 Others
|
| 633 |
+
|
| 634 |
+
### Inference and Export
|
| 635 |
+
|
| 636 |
+
* [./export_model.py](./export_model.py) can export the model to the transformers format and push it to Hugging Face.
|
| 637 |
+
|
| 638 |
+
* MiniMind's Hugging Face collection
|
| 639 |
+
address: [MiniMind](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
|
| 640 |
+
|
| 641 |
+
---
|
| 642 |
+
|
| 643 |
+
### API Inference
|
| 644 |
+
|
| 645 |
+
[./my_openai_api.py](./my_openai_api.py) provides a chat interface for the OpenAI API, making it easier to integrate
|
| 646 |
+
your model with third-party UIs, such as fastgpt, OpenWebUI, etc.
|
| 647 |
+
|
| 648 |
+
* Download the model weight files
|
| 649 |
+
from [Hugging Face](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5):
|
| 650 |
+
```
|
| 651 |
+
minimind (root dir)
|
| 652 |
+
├─minimind
|
| 653 |
+
| ├── config.json
|
| 654 |
+
| ├── generation_config.json
|
| 655 |
+
| ├── LMConfig.py
|
| 656 |
+
| ├── model.py
|
| 657 |
+
| ├── pytorch_model.bin
|
| 658 |
+
| ├── special_tokens_map.json
|
| 659 |
+
| ├── tokenizer_config.json
|
| 660 |
+
| ├── tokenizer.json
|
| 661 |
+
```
|
| 662 |
+
|
| 663 |
+
* Start the chat server:
|
| 664 |
+
```bash
|
| 665 |
+
python my_openai_api.py
|
| 666 |
+
```
|
| 667 |
+
* Test the service interface:
|
| 668 |
+
```bash
|
| 669 |
+
python chat_openai_api.py
|
| 670 |
+
```
|
| 671 |
+
* API interface example, compatible with the OpenAI API format:
|
| 672 |
+
```bash
|
| 673 |
+
curl http://ip:port/v1/chat/completions \
|
| 674 |
+
-H "Content-Type: application/json" \
|
| 675 |
+
-d '{
|
| 676 |
+
"model": "model-identifier",
|
| 677 |
+
"messages": [
|
| 678 |
+
{ "role": "user", "content": "What is the highest mountain in the world?" }
|
| 679 |
+
],
|
| 680 |
+
"temperature": 0.7,
|
| 681 |
+
"max_tokens": -1,
|
| 682 |
+
"stream": true
|
| 683 |
+
}'
|
| 684 |
+
```
|
| 685 |
+
|
| 686 |
+

|
| 687 |
+
|
| 688 |
+
### Integrating MiniMind API in FastGPT
|
| 689 |
+
|
| 690 |
+

|
| 691 |
+
|
| 692 |
+
|
| 693 |
+
---
|
| 694 |
+
|
| 695 |
+
# 📌 Acknowledgement
|
| 696 |
+
|
| 697 |
+
> [!NOTE]
|
| 698 |
+
> If you find `MiniMind` helpful, please give us a ⭐️ on GitHub. Your support is the driving force behind our continuous
|
| 699 |
+
> efforts to improve the project! Due to the length and limited expertise, there may be some errors. We welcome any
|
| 700 |
+
> issues
|
| 701 |
+
> for discussion and correction.
|
| 702 |
+
|
| 703 |
+
## 🤝[Contributors](https://github.com/jingyaogong/minimind/graphs/contributors)
|
| 704 |
+
|
| 705 |
+
<!--
|
| 706 |
+
<a href="https://github.com/jingyaogong/minimind/graphs/contributors">
|
| 707 |
+
<img src="https://contrib.rocks/image?repo=jingyaogong/minimind&v3" />
|
| 708 |
+
</a>
|
| 709 |
+
-->
|
| 710 |
+
|
| 711 |
+
<a href="https://github.com/jingyaogong"><img src="https://avatars.githubusercontent.com/u/62287848" width="70px" height="70px"/></a>
|
| 712 |
+
<a href="https://github.com/MuWinds"><img src="https://avatars.githubusercontent.com/u/93832089" width="70px" height="70px"/></a>
|
| 713 |
+
<a href="https://github.com/chuanzhubin"><img src="https://avatars.githubusercontent.com/u/2813798" width="70px" height="70px"/></a>
|
| 714 |
+
|
| 715 |
+
|
| 716 |
+
## 😊Thanks for
|
| 717 |
+
|
| 718 |
+
<a href="https://github.com/ipfgao"><b>@ipfgao</b></a>:
|
| 719 |
+
<a href="https://github.com/jingyaogong/minimind/issues/26">🔗训练步骤记录</a>
|
| 720 |
+
|
| 721 |
+
## 🫶Supporter
|
| 722 |
+
|
| 723 |
+
<a href="https://github.com/jingyaogong/minimind/stargazers">
|
| 724 |
+
<picture>
|
| 725 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/stars/dark/jingyaogong/minimind"/>
|
| 726 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/stars/jingyaogong/minimind"/>
|
| 727 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/stars/jingyaogong/minimind"/>
|
| 728 |
+
</picture>
|
| 729 |
+
</a>
|
| 730 |
+
|
| 731 |
+
<a href="https://github.com/jingyaogong/minimind/network/members">
|
| 732 |
+
<picture>
|
| 733 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://reporoster.com/forks/dark/jingyaogong/minimind"/>
|
| 734 |
+
<source media="(prefers-color-scheme: light)" srcset="https://reporoster.com/forks/jingyaogong/minimind"/>
|
| 735 |
+
<img alt="github contribution grid snake animation" src="https://reporoster.com/forks/jingyaogong/minimind"/>
|
| 736 |
+
</picture>
|
| 737 |
+
</a>
|
| 738 |
+
|
| 739 |
+
<picture>
|
| 740 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind&type=Date&theme=dark"/>
|
| 741 |
+
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=jingyaogong/minimind&type=Date"/>
|
| 742 |
+
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=jingyaogong/minimind&type=Date"/>
|
| 743 |
+
</picture>
|
| 744 |
+
|
| 745 |
+
# License
|
| 746 |
+
|
| 747 |
+
This repository is licensed under the [Apache-2.0 License](LICENSE).
|
images/1-wiki.png
ADDED

|
images/2-eval.png
ADDED

|
images/2-wiki.png
ADDED
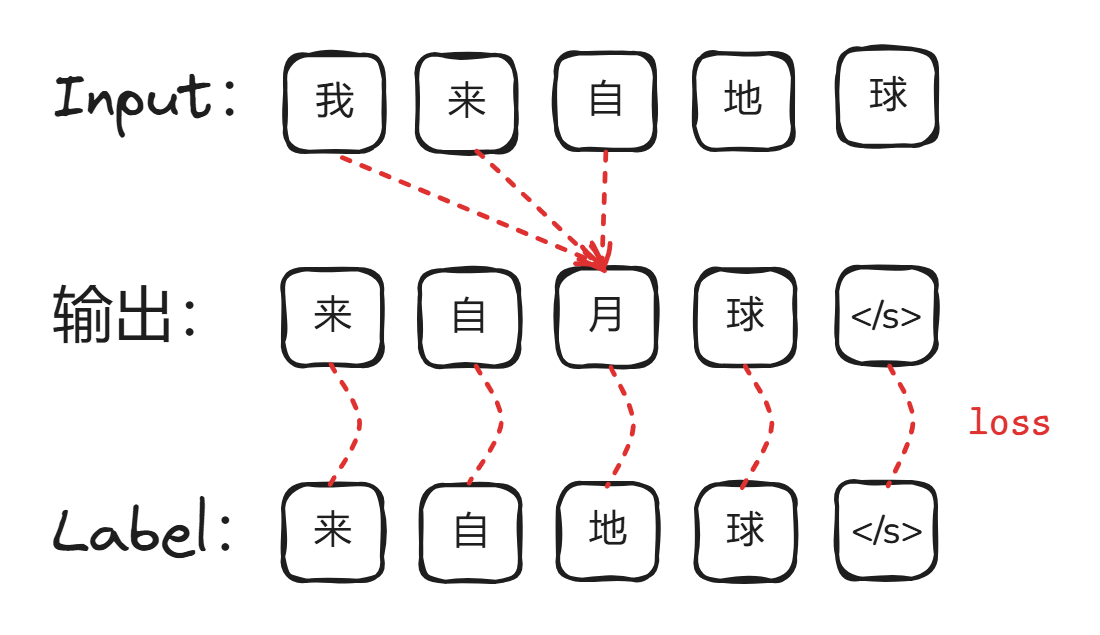
|
images/3-wiki.png
ADDED
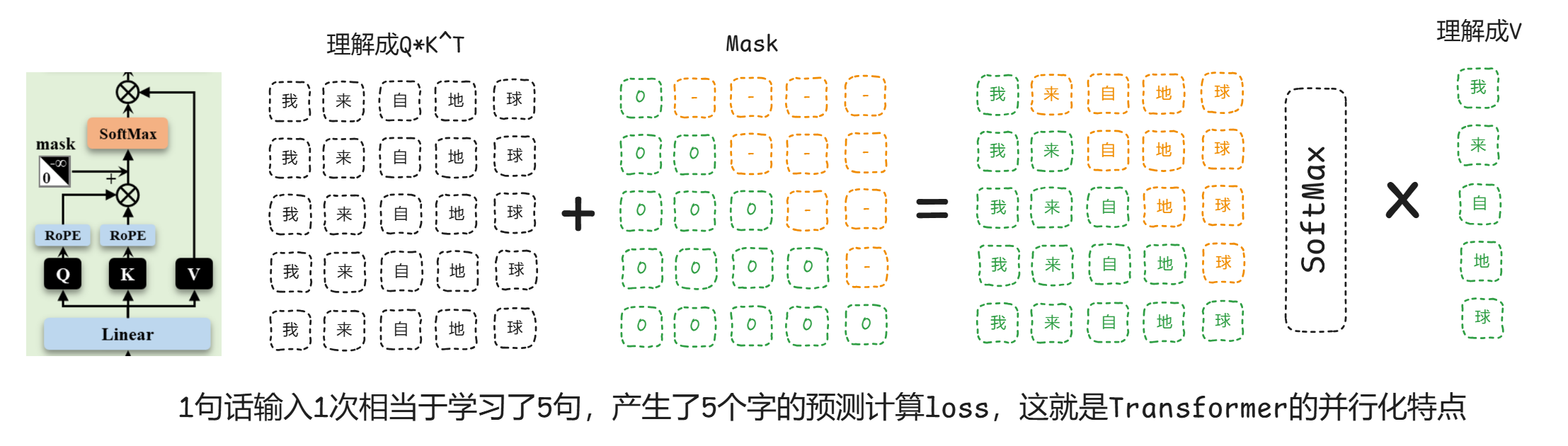
|
images/4-wiki.png
ADDED

|
images/5-wiki.png
ADDED

|
images/LLM-structure-moe.png
ADDED

|
images/LLM-structure.png
ADDED
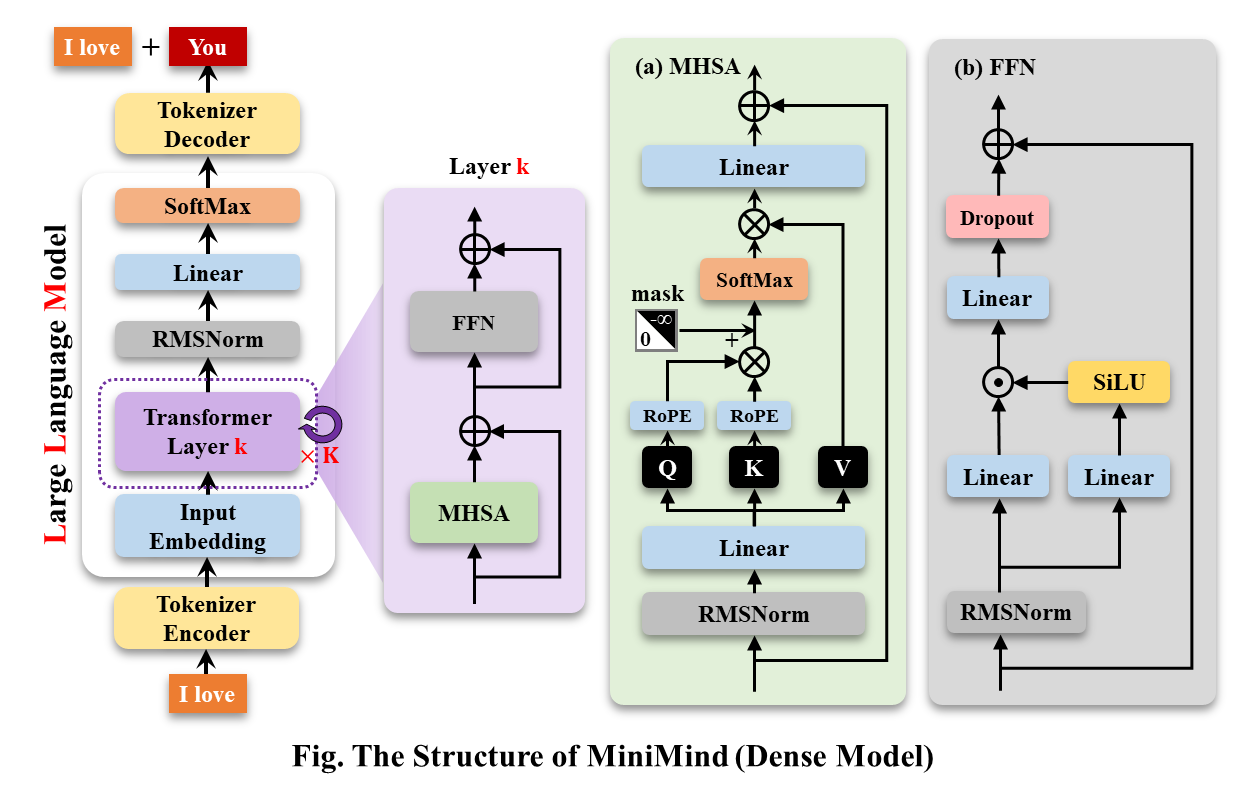
|
images/fastgpt.png
ADDED

|
images/gpt3_config.png
ADDED
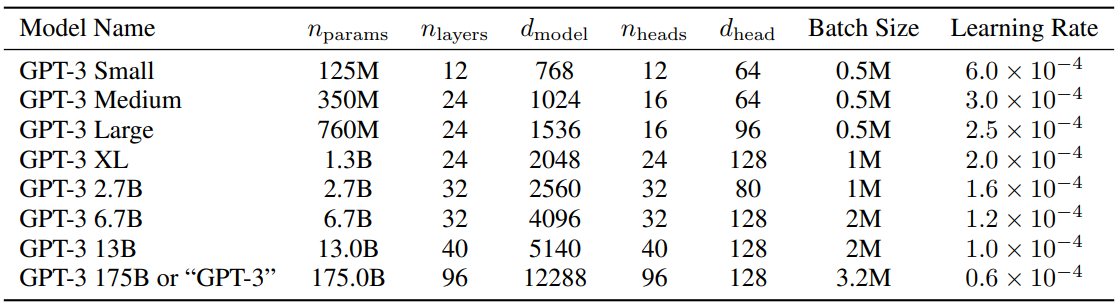
|
images/logger.png
ADDED

|
images/logo.png
ADDED
|
|
images/streamlit.png
ADDED

|