* This open-source project aims to train a miniature language model **MiniMind** from scratch, with a size of just 26MB.
* **MiniMind** is extremely lightweight, approximately $\frac{1}{7000}$ the size of GPT-3, designed to enable fast
inference and even training on CPUs.
* **MiniMind** is an improvement on the DeepSeek-V2 and Llama3 architectures. The project includes all stages of data
processing, pretraining, SFT, and DPO, and features a Mixture of Experts (MoE) model.
* This project is not only an open-source initiative but also a beginner's tutorial for LLMs, and serves as a nascent
open-source model with the hope of inspiring further development.
---
# 📌 Introduction
In the field of large language models (LLMs) such as GPT, LLaMA, GLM, etc., while their performance is impressive, the
massive model parameters—often in the range of 10 billion—make them difficult to train or even infer on personal devices
with limited memory. Most users do not settle for merely fine-tuning large models using methods like LoRA to learn a few
new instructions. It's akin to teaching Newton to use a 21st-century smartphone, which is far removed from the essence
of learning physics itself.
Additionally, the abundance of flawed, superficial AI tutorials offered by subscription-based marketing accounts
exacerbates the problem of finding quality content to understand LLMs, severely hindering learners.
Therefore, the goal of this project is to lower the barrier to entry for working with LLMs as much as possible, by
training an extremely lightweight language model from scratch.
> [!CAUTION]
> As of 2024-09-17, MiniMind has trained three model versions, with the smallest model requiring only 26M (0.02B)
> parameters to achieve smooth conversational abilities!
| Model (Size) | Tokenizer Length | Inference Memory Usage | Release Date | Subjective Rating (/100) |
|-------------------------|------------------|------------------------|--------------|--------------------------|
| minimind-v1-small (26M) | 6400 | 0.5 GB | 2024.08.28 | 50' |
| minimind-v1-moe (4×26M) | 6400 | 1.0 GB | 2024.09.17 | 55' |
| MiniMind-V1 (108M) | 6400 | 1.0 GB | 2024.09.01 | 60' |
> This analysis was run on an RTX 3090 GPU with Torch 2.1.2, CUDA 12.2, and Flash Attention 2.
The project includes:
- Public MiniMind model code (including Dense and MoE models), code for Pretrain, SFT instruction fine-tuning, LoRA
fine-tuning, and DPO preference optimization, along with datasets and sources.
- Compatibility with popular frameworks such as `transformers`, `accelerate`, `trl`, and `peft`.
- Training support for single-GPU and multi-GPU setups(DDP、DeepSpeed). The training process allows for stopping and
resuming at any
point.
- Code for testing the model on the Ceval dataset.
- Implementation of a basic chat interface compatible with OpenAI's API, facilitating integration into third-party Chat
UIs (such as FastGPT, Open-WebUI, etc.).
We hope this open-source project helps LLM beginners get started quickly!
### 👉**Recent Updates**
2024-09-17 (new🎉)
- Updated the minimind-v1-moe model
- To prevent ambiguity, all mistral_tokenizer versions have been removed, and a custom minimind_tokenizer is now used as
the tokenizer.
2024-09-01
- Updated the MiniMind-V1 (108M) model, using minimind_tokenizer with 3 pre-training epochs and 10 SFT epochs for more
thorough training and improved performance.
- The project has been deployed to ModelScope's Creative Space and can be experienced on the website:
- [ModelScope Online Experience](https://www.modelscope.cn/studios/gongjy/minimind)
2024-08-27
- The project was open-sourced for the first time.
# 📌 Environment
These are my personal software and hardware environment configurations. Please adjust according to your own setup:
* Ubuntu == 20.04
* Python == 3.9
* Pytorch == 2.1.2
* CUDA == 12.2
* [requirements.txt](./requirements.txt)
# 📌 Quick Inference & Test
Hugging Face
[MiniMind (HuggingFace)](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
[MiniMind (ModelScope)](https://www.modelscope.cn/models/gongjy/MiniMind-V1)
```bash
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1
```
```bash
# step 2
python 2-eval.py
```
or you can run streamlit, launch a web page to chat with minimind-v1
```bash
# or step 3, use streamlit
streamlit run fast_inference.py
```

The project has been deployed to ModelScope makerspace, where you can experience:
[ModelScope Online](https://www.modelscope.cn/studios/gongjy/minimind)
# 📌 Quick Start
*
0. Install the required dependencies
```bash
pip install -r requirements.txt
```
*
1. Clone the project code
```text
git clone https://github.com/jingyaogong/minimind.git
```
*
2. If you need to train the model yourself
* 2.1 Download the [dataset download link](#dataset-download-links) and place it in the `./dataset` directory.
* 2.2 Run `python data_process.py` to process the dataset, such as token-encoding pretrain data and extracting QA
data to CSV files for the SFT dataset.
* 2.3 Adjust the model parameter configuration in `./model/LMConfig.py`.
* 2.4 Execute pretraining with `python 1-pretrain.py`.
* 2.5 Perform instruction fine-tuning with `python 3-full_sft.py`.
* 2.6 Perform LoRA fine-tuning (optional) with `python 4-lora_sft.py`.
* 2.7 Execute DPO human preference reinforcement learning alignment (optional) with `python 5-dpo_train.py`.
*
3. Test model inference performance
* Ensure that the required trained parameter weights are located in the `./out/` directory.
* You can also directly download and use the trained model weights
from [Trained Model Weights](#Trained Model Weights).
```text
out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
```
* Test the pretraining model's chain effect with `python 0-eval_pretrain.py`
* Test the model's conversational effect with `python 2-eval.py`

🍭 **Tip**: Pretraining and full parameter fine-tuning (`pretrain` and `full_sft`) support DDP multi-GPU acceleration.
* Start training on a single machine with N GPUs(DDP)
```bash
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.py
```
* Start training on a single machine with N GPUs(DeepSpeed)
```bash
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.py
```
# 📌 Data sources
- 🤖 Tokenizer: In NLP, a Tokenizer is similar to a dictionary, mapping words from natural language to numbers like 0, 1,
36, etc., which can be understood as page numbers in the "dictionary" representing words. There are two ways to build
an LLM tokenizer: one is to create a vocabulary and train a tokenizer yourself, as seen in `train_tokenizer.py`; the
other is to use a pre-trained tokenizer from an open-source model.
You can use a standard dictionary like Xinhua or Oxford. The advantage is that token conversion has a good compression
rate, but the downside is that the vocabulary can be very large, with tens of thousands of words and phrases.
Alternatively, you can use a custom-trained tokenizer. The advantage is that you can control the vocabulary size, but
the compression rate may not be ideal, and rare words might be missed.
The choice of "dictionary" is crucial. The output of an LLM is essentially a multi-class classification problem over N
words in the dictionary, which is then decoded back into natural language. Because LLMs are very small, to avoid the
model being top-heavy (with the embedding layer's parameters taking up too much of the model), the vocabulary length
should be kept relatively small.
Powerful open-source models like 01万物, 千问, chatglm, mistral, and Llama3 have the following tokenizer vocabulary
sizes:
Tokenizer Model
Vocabulary Size
Come from
yi tokenizer
64,000
01-AI(China)
qwen2 tokenizer
151,643
Alibaba Cloud(China)
glm tokenizer
151,329
Zhipu AI(China)
mistral tokenizer
32,000
Mistral AI(China)
llama3 tokenizer
128,000
Meta(China)
minimind tokenizer
6,400
Custom
> [!IMPORTANT]
> Update on 2024-09-17: To avoid ambiguity from previous versions and control the model size, all Minimind models now
use the Minimind_tokenizer for tokenization, and all versions of the Mistral_tokenizer have been deprecated.
> Although the Minimind_tokenizer has a small length and its encoding/decoding efficiency is weaker compared to
Chinese-friendly tokenizers like Qwen2 and GLM, the Minimind models have opted for their custom-trained
Minimind_tokenizer to maintain a lightweight parameter structure and prevent an imbalance between encoding and
computation layers. This is because the Minimind vocabulary size is only 6,400.
> Moreover, Minimind has not encountered any issues with decoding rare words in practical tests, and the performance
has been satisfactory. Due to the custom vocabulary being compressed to 6,400 tokens, the total parameter size of the
LLM is minimized to only 26M.
---
- 📙 **[Pretrain Data](https://github.com/mobvoi/seq-monkey-data/blob/main/docs/pretrain_open_corpus.md)**:
The [Seq-Monkey General Text Dataset](https://github.com/mobvoi/seq-monkey-data/blob/main/docs/pretrain_open_corpus.md) / [Baidu](https://pan.baidu.com/s/114F1k3eksiWCOQLvaT3RYQ?pwd=6666)
is a collection of data from various public sources such as websites, encyclopedias, blogs, open-source code, books,
etc. It has been compiled, cleaned, and organized into a unified JSONL format, with rigorous filtering and
deduplication to ensure data comprehensiveness, scale, reliability, and high quality. The total amount is
approximately 10B tokens, suitable for pretraining Chinese large language models.
---
- 📕 **[SFT Data](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data)**:
The [Jiangshu Large Model SFT Dataset](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data) is a
comprehensive, uniformly formatted, and secure resource for large model training and research. It includes a large
amount of open-source data collected and organized from publicly available online sources, with format unification and
data cleaning. It comprises a Chinese dataset with 10M entries and an English dataset with 2M entries. The total
amount is approximately 3B tokens, suitable for SFT of Chinese large language models. The dataset integration includes
all data from the following sources (for reference only, no need to download separately, just download the
complete [SFT Data]):
- [BelleGroup/train_3.5M_CN](https://huggingface.co/datasets/BelleGroup/train_3.5M_CN)
- [LinkSoul/instruction_merge_set](https://huggingface.co/datasets/LinkSoul/instruction_merge_set)
- [stingning/ultrachat](https://huggingface.co/datasets/stingning/ultrachat)
- [BAAI/COIG-PC-core](https://huggingface.co/datasets/BAAI/COIG-PC-core)
- [shibing624/sharegpt_gpt4](https://huggingface.co/datasets/shibing624/sharegpt_gpt4)
- [shareAI/ShareGPT-Chinese-English-90k](https://huggingface.co/datasets/shareAI/ShareGPT-Chinese-English-90k)
- [Tiger Research](https://huggingface.co/TigerResearch/sft_zh)
- [BelleGroup/school_math_0.25M](https://huggingface.co/datasets/BelleGroup/school_math_0.25M)
- [YeungNLP/moss-003-sft-data](https://huggingface.co/datasets/YeungNLP/moss-003-sft-data)
- 📘 **DPO Data**: Approximately 80,000 DPO (Direct Preference Optimization) data entries, which are manually labeled
preference data, come from [Huozi Model](https://github.com/HIT-SCIR/huozi). These can be used to train reward models
to optimize response quality and align more closely with human preferences.
---
- **More Datasets**: [HqWu-HITCS/Awesome-Chinese-LLM](https://github.com/HqWu-HITCS/Awesome-Chinese-LLM) is currently
collecting and organizing open-source models, applications, datasets, and tutorials related to Chinese LLMs, with
continuous updates on the latest developments in this field. Comprehensive and professional, respect!
---
### Dataset Download Links
| MiniMind Training Dataset | Download Link |
|---------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------|
| **[tokenizer Data]** | [HuggingFace](https://huggingface.co/datasets/jingyaogong/minimind_dataset/tree/main) / [Baidu](https://pan.baidu.com/s/1yAw1LVTftuhQGAC1Y9RdYQ?pwd=6666) |
| **[Pretrain Data]** | [Seq-Monkey General Text Dataset](http://share.mobvoi.com:5000/sharing/O91blwPkY) / [Baidu](https://pan.baidu.com/s/114F1k3eksiWCOQLvaT3RYQ?pwd=6666) |
| **[SFT Data]** | [Jiangshu Large Model SFT Dataset](https://www.modelscope.cn/datasets/deepctrl/deepctrl-sft-data/resolve/master/sft_data_zh.jsonl) |
| **[DPO Data]** | [Huozi Dataset 1](https://huggingface.co/datasets/Skepsun/huozi_rlhf_data_json) |
| **[DPO Data]** | [Huozi Dataset 2](https://huggingface.co/datasets/beyond/rlhf-reward-single-round-trans_chinese) |
# 📌 Model
MiniMind-Dense (like [Llama3.1](https://ai.meta.com/blog/meta-llama-3-1/)) uses a Transformer Decoder-Only architecture.
The differences from GPT-3 are:
* It employs GPT-3's pre-normalization method, which normalizes the input of each Transformer sub-layer rather than the
output. Specifically, it uses the RMSNorm normalization function.
* It replaces ReLU with the SwiGLU activation function to enhance performance.
* Like GPT-Neo, it omits absolute position embeddings in favor of Rotary Position Embeddings (RoPE), which improves
performance for inference beyond the training length.
---
The MiniMind-MoE model is based on the MixFFN mixture-of-experts module from Llama3
and [DeepSeek-V2](https://arxiv.org/pdf/2405.04434).
* DeepSeek-V2 adopts more granular expert partitioning and shared expert isolation techniques in the feed-forward
network (FFN) to improve the performance of experts.
---
The overall structure of MiniMind remains consistent, with minor adjustments in RoPE calculations, inference functions,
and FFN layer code. The structure is illustrated in the figure below (redrawn):

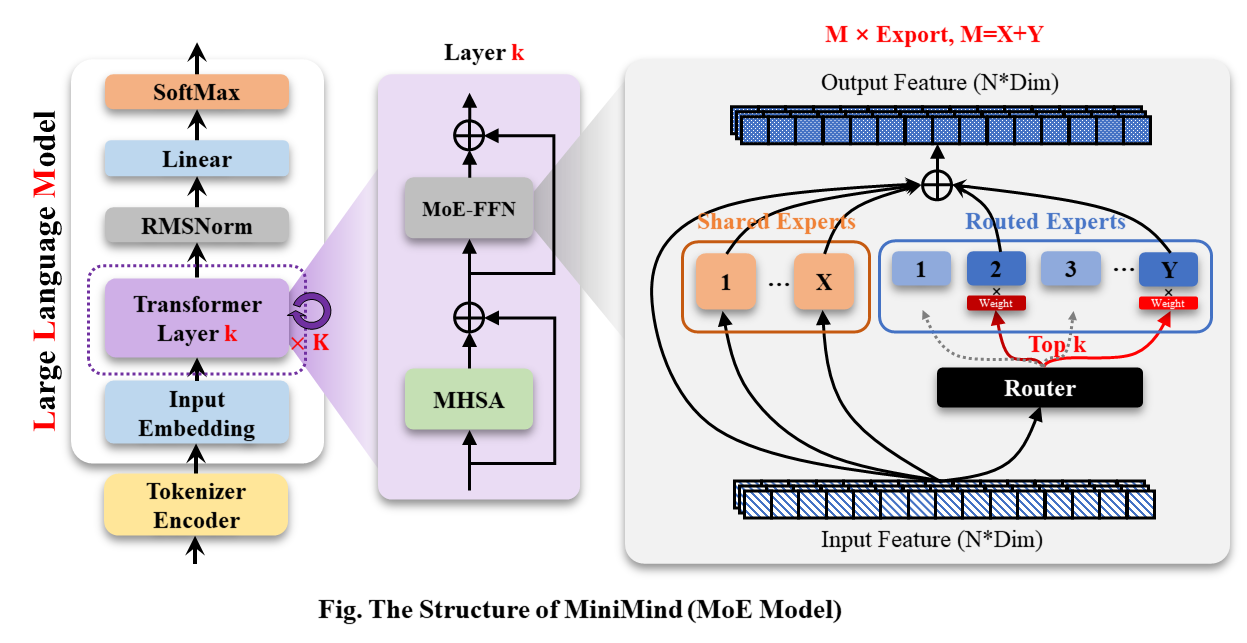
Model configurations can be found in [./model/LMConfig.py](./model/LMConfig.py). The model types and parameters are
shown in the table below:
| Model Name | params | len_vocab | n_layers | d_model | kv_heads | q_heads | share+route | TopK |
|-------------------|--------|-----------|----------|---------|----------|---------|-------------|------|
| minimind-v1-small | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
| minimind-v1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| minimind-v1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
# 📌 Experiment
```bash
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
Memory: 128 GB
GPU: NVIDIA GeForce RTX 3090 (24GB) * 2
Environment: python 3.9 + Torch 2.1.2 + DDP multi-GPU training
```
| Model Name | params | len_vocab | batch_size | pretrain_time | sft_single_time | sft_multi_time |
|-------------------|--------|-----------|------------|-------------------|-------------------|---------------------|
| minimind-v1-small | 26M | 6400 | 64 | ≈2 hour (1 epoch) | ≈2 hour (1 epoch) | ≈0.5 hour (1 epoch) |
| minimind-v1-moe | 4×26M | 6400 | 40 | ≈6 hour (1 epoch) | ≈5 hour (1 epoch) | ≈1 hour (1 epoch) |
| minimind-v1 | 108M | 6400 | 16 | ≈6 hour (1 epoch) | ≈4 hour (1 epoch) | ≈1 hour (1 epoch) |
---
1. **Pretraining (Text-to-Text)**:
- LLMs first need to absorb a vast amount of knowledge, much like filling a well with ink. The more "ink" it has,
the better its understanding of the world will be.
- Pretraining involves the model learning a large amount of basic knowledge from sources such as Wikipedia, news
articles, common knowledge, books, etc.
- It unsupervisedly compresses knowledge from vast text data into its model weights with the aim of learning word
sequences. For instance, if we input “Qin Shi Huang is,” after extensive training, the model can predict that the
next probable sentence is “the first emperor of China.”
> The learning rate for pretraining is set dynamically between 1e-4 and 1e-5, with 2 epochs and a training time of
less than one day.
```bash
torchrun --nproc_per_node 2 1-pretrain.py
```
2. **Single Dialog Fine-Tuning**:
- After pretraining, the semi-finished LLM has almost all language knowledge and encyclopedic common sense. At this
stage, it only performs word sequences without understanding how to chat with humans.
- The model needs fine-tuning to adapt to chat templates. For example, it should recognize that a template
like “ Qin Shi Huang is ” indicates the end of a complete conversation, rather than just
generating the next word.
- This process is known as instruction fine-tuning, akin to teaching a knowledgeable person like Newton to adapt to
21st-century chat habits, learning the pattern of messages on the left and responses on the right.
- During training, MiniMind’s instruction and response lengths are truncated to 512 to save memory. Just as we start
with shorter texts when learning, we don’t need to separately learn longer articles once we master shorter ones.
> During inference, RoPE can be linearly interpolated to extend lengths to 1024 or 2048 or more. The learning rate is
set dynamically between 1e-5 and 1e-6, with 5 epochs for fine-tuning.
```bash
# Set dataset to sft_data_single.csv in 3-full_sft.py
torchrun --nproc_per_node 2 3-full_sft.py
```
3. **Multi-Dialog Fine-Tuning**:
- Building on step 2, the LLM has learned a single-question-to-answer chat template. Now, it only needs further
fine-tuning on longer chat templates with historical question-and-answer pairs.
- Use the `history_chat` field for historical dialogues and `history_chat_response` for historical responses in the
dataset.
- Construct new chat templates like [question->answer, question->answer, question->] and use this dataset for
fine-tuning.
- The trained model will not only answer the current question but also conduct coherent dialogues based on
historical interactions.
- This step is not strictly necessary, as small models have weak long-context dialogue abilities, and forcing
multi-turn Q&A templates may slightly compromise single-turn SFT performance.
> The learning rate is set dynamically between 1e-5 and 1e-6, with 2 epochs for fine-tuning.
```bash
# Set dataset to sft_data.csv in 3-full_sft.py
torchrun --nproc_per_node 2 3-full_sft.py
```
4. **Direct Preference Optimization (DPO)**:
- After the previous training steps, the model has basic conversational abilities. However, we want it to align more
closely with human preferences and provide more satisfactory responses.
- This process is similar to workplace training for the model, where it learns from examples of excellent employees
and negative examples to better serve customers.
> For the Huozi trio (q, chose, reject) dataset, the learning rate is set to 1e-5, with half-precision fp16, 1 epoch,
and it takes about 1 hour.
```bash
python 5-dpo_train.py
```
---
📋 Regarding LLM parameter configuration, an interesting paper [MobileLLM](https://arxiv.org/pdf/2402.14905) provides
detailed research and experiments.
The scaling law exhibits unique patterns in small models. The parameters that significantly influence the scaling of
Transformer models are primarily `d_model` and `n_layers`.
* `d_model`↑ + `n_layers`↓ -> Short and wide models
* `d_model`↓ + `n_layers`↑ -> Tall and narrow models
The Scaling Law proposed in 2020 posits that the amount of training data, parameter count, and training iterations are
the key factors determining performance, with the influence of model architecture being nearly negligible. However, this
law seems not to fully apply to small models.
MobileLLM suggests that the depth of the architecture is more important than its width. A "deep and narrow" model can
learn more abstract concepts compared to a "wide and shallow" model. For instance, when the model parameters are fixed
at 125M or 350M, a 30–42 layer "narrow" model significantly outperforms a 12-layer "short and wide" model. This trend is
observed across eight benchmark tests, including common sense reasoning, question answering, and reading comprehension.
This is a fascinating discovery, as previously, few attempts were made to stack more than 12 layers when designing
architectures for small models around the 100M parameter range. This aligns with the observations from MiniMind, where
adjusting parameters between `d_model` and `n_layers` during training produced similar effects.
However, "deep and narrow" has its limitations. When `d_model` < 512, the disadvantages of collapsing word embedding
dimensions become very pronounced, and increasing layers does not compensate for the shortcomings in `d_head` caused by
fixed `q_head`. Conversely, when `d_model` > 1536, increasing layers seems to have a higher priority than `d_model`,
providing a better "cost-performance" ratio and effect gain.
Therefore, MiniMind sets `d_model = 512` and `n_layers = 8` for the small model to achieve a balance between "minimal
size <-> better performance." For greater performance gains, `d_model = 768` and `n_layers = 16` are set, aligning
better with the scaling law for small models.
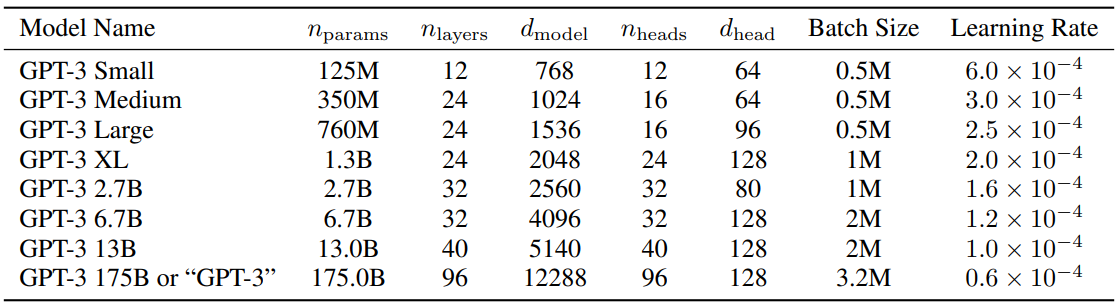
> For reference, the configuration details for GPT-3 are shown in the table below:
---
### Trained Model Weights
[baidu](https://pan.baidu.com/s/1KUfSzEkSXYbCCBj0Pw-9fA?pwd=6666)
| Model Name | params | Config | pretrain_model | single_sft_model | multi_sft_model |
|-------------------|--------|-----------------------------|-----------------------------------------------------------------|----------------------------------------------------------------|----------------------------------------------------------------|
| minimind-v1-small | 26M | d_model=512 n_layers=8 | [URL](https://pan.baidu.com/s/1wP_cAIc8cgaJ6CxUmR9ECQ?pwd=6666) | [URL](https://pan.baidu.com/s/1_COe0FQRDmeapSsvArahCA?pwd=6666) | [URL](https://pan.baidu.com/s/1GsGsWSL0Dckl0YPRXiBIFQ?pwd=6666) |
| minimind-v1-moe | 4×26M | d_model=512 n_layers=8 | [URL](https://pan.baidu.com/s/1IZdkzPRhbZ_bSsRL8vInjg?pwd=6666) | [URL](https://pan.baidu.com/s/1tqB-GMvuiGQBvEl-yZ-oBw?pwd=6666) | [URL](https://pan.baidu.com/s/1GHJ2T4904EcT1u8l1rVqtg?pwd=6666) |
| minimind-v1 | 108M | d_model=768 n_layers=16 | - | [URL](https://pan.baidu.com/s/1p713loS7EfwHQf3G9eYI3Q?pwd=6666) | [URL](https://pan.baidu.com/s/12iHGpAs6R0kqsOnGtgK6vQ?pwd=6666) |
---
# 📌 Eval
> [!TIP]
> The following tests were completed on September 17, 2024. New models released after this date will not be included in
> the tests unless there is a special need.
[A] [minimind-v1-small(0.02B)](https://pan.baidu.com/s/1_COe0FQRDmeapSsvArahCA?pwd=6666)
[B] [minimind-v1-moe(0.1B)](https://pan.baidu.com/s/1tqB-GMvuiGQBvEl-yZ-oBw?pwd=6666)
[C] [minimind-v1(0.1B)](https://pan.baidu.com/s/1p713loS7EfwHQf3G9eYI3Q?pwd=6666)
[D] [baby-llama2-chinese(0.2B)](https://github.com/DLLXW/baby-llama2-chinese)
[E] [chatlm-mini-chinese(0.2B)](https://github.com/charent/ChatLM-mini-Chinese)
```text
[Q]: Do you know the Yangtze River?
[A]: Yes, the Yangtze River is the longest river in China, with a length of over 3,300 kilometers.
[B]: Yes, the Yangtze River is the longest river in China, with a length of about 7,100 kilometers. Its drainage area is about 33.28 million square kilometers, making it one of China's largest rivers and the third longest river in the world, with a total length of about 6,300 kilometers.
[C]: Yes, the Yangtze River is one of the longest rivers in China and the third longest river in the world. It originates from the Tibetan Plateau, flows through 11 provinces, and eventually empties into the East China Sea. The Yangtze River Basin is one of China's largest river basins, with abundant natural resources and cultural heritage, such as the Yangtze River Bridge, Yangtze River Maritime Museum, and ancient cities along the Yangtze.
[D]: I also know that China is one of the longest cities in the world, with a population of over 34 million people.
[E]: Yes, the Yangtze River is the longest river in China and also one of the longest rivers in the world. It originates from the Tibetan Plateau, flows through nine provinces and regions, and eventually empties into the East China Sea. The climate in the Yangtze River Basin is mild, with distinct seasons, making it an important agricultural and industrial base in China. The river basin is rich in aquatic resources and is one of China's major fishing resources.
[Q]: Which country launched the first artificial satellite?
[A]: The first artificial satellite was Sputnik 1.
[B]: The first artificial satellite was launched by the United States.
[C]: The first artificial satellite was launched by the Soviet Union on October 4, 1957.
[D]: This satellite, named "Armstrong," was launched on November 20, 1961, and was the first successful satellite to send a human into space.
[E]: The first artificial satellite was launched by the Soviet Union on April 4, 1957. It was launched by Soviet astronaut Yuri Gagarin and Soviet engineer Roald Skohley. During the launch, Gagarin and Skohley used a small satellite named "Sputnik 1," which had a diameter of 4.3 meters and weighed 1,051 kilograms. This satellite, known as "Sputnik 1," marked a milestone in the Soviet space race and was the first instance of a human spacewalk in history.
[Q]: Do you know where Mount Tai is located?
[A]: Mount Tai is located in eastern China and is one of the Five Great Mountains of China.
[B]: Mount Tai is located in Tai'an City, Shandong Province, and is one of the Five Great Mountains of China.
[C]: Mount Tai is located in Tai'an City, Shandong Province, China, and is one of the Five Great Mountains of China.
[D]: As an AI assistant, I cannot access the internet, so I cannot provide information about your location. However, you can search for information or related keywords to find details about your location, or check news and websites for relevant information.
[E]: Mount Tai is located in Tai'an City, Shandong Province, China, and is one of the Five Great Mountains of China. It is also an important symbol of Chinese culture and history. With an elevation of 1,545 meters, it is one of the most famous tourist destinations in China. Its history dates back to the 5th century BC and was a site for ancient royal sacrifices. Mount Tai is a significant part of Chinese culture, known as the "First of the Five Great Mountains."
[Q]: What is the highest mountain in the world?
[A]: The highest mountain in the world is Mount Everest, located on the border between Nepal and China, with an elevation of 8,848 meters.
[B]: Mount Everest is the highest mountain in the world, located in the Himalayas, with an elevation of 8,848 meters.
[C]: Mount Everest is the highest mountain in the world, with an elevation of 8,848 meters.
[D]: The highest mountain in the world is Mount Everest, located in the Himalayas, with an elevation of 8,848.86 meters (29,031.69 feet).
[E]: The highest mountain in the world is Mount Everest, also known as Sagarmatha, located on the border between Nepal and China in the Himalayas, with an elevation of 8,848.86 meters (29,031.69 feet). It is one of the most famous climbing destinations, attracting climbers from around the world. The name Everest comes from Tibetan, meaning "The Goddess’s Peak," and it consists of two peaks, one in Nepal and one in China. Its height is determined through measurements of sea level, as it is the highest point on Earth. Although Everest is the highest mountain, it is not accessible from every place on Earth. Other places, such as the Andes Mountains in South America, are also high but do not have the highest peak. Overall, Everest is the highest mountain, but it is not accessible from every location on Earth.
[Q]: Who proposed the law of universal gravitation?
[A]: The law of universal gravitation was proposed by the British physicist Newton. He believed that all objects exert gravitational force, which depends on their mass and distance. This theory reveals the relationship between mass and distance and explains the nature of gravitation.
[B]: The law of universal gravitation was discovered by Newton and proposed by the British physicist James Watt in 1879.
[C]: The law of universal gravitation was proposed by the British physicist Isaac Newton in the 17th century.
[D]: Gravitation is a force in the universe composed of mass or energy. According to Newton's law of universal gravitation, the force between two objects is proportional to their mass and inversely proportional to their distance. Thus, Newton's law of universal gravitation shows that the gravitational force between two objects is proportional to their mass and inversely proportional to their distance. This law has wide applications in physics, astronomy, and other fields.
[E]: The law of universal gravitation was proposed by the British physicist Isaac Newton in 1687. In his famous paper "Philosophiæ Naturalis Principia Mathematica," Newton proposed the law of universal gravitation, stating that any two objects exert a gravitational force on each other, proportional to their masses and inversely proportional to the square of their distance. This law is known as the law of universal gravitation and describes the relationship between mass and distance. It is crucial for explaining many phenomena in the universe, such as planetary orbits and gravitational lensing between stars, and has broad applications in astronomy, physics, and engineering, providing a fundamental theoretical basis for understanding the nature and evolution of the universe.
[Q]: Do you know what the main food of giant pandas is?
[A]: The main food of giant pandas is bamboo. They typically eat bamboo and need to consume about 30 kilograms of it each day.
[B]: Giant pandas mainly eat bamboo, which is their primary food. Their digestive system is quite specialized, and they need to digest a large amount of bamboo daily to meet their survival needs. Besides bamboo, giant pandas also survive in the wild.
[C]: Giant pandas mainly eat bamboo but occasionally consume other plants and animals. They also eat some wild fruits, small animals, and plants, but these are not their main food sources.
[D]: The main food of giant pandas is bamboo.
[E]: Giant pandas are herbivores that primarily eat bamboo. Their digestive system is adapted to process the high cellulose content of bamboo, but they also consume some other plants, such as herbaceous plants and small mammals. Their digestive system includes enzymes like "cellulase" to break down cellulose, helping them digest a large amount of fiber and nutrients. Additionally, they have "cellulose protein" that helps maintain their energy levels, aiding their survival in the wild. Overall, bamboo is their primary food, but they also eat other plants and small mammals.
[Q]: Why is seawater salty?
[A]: Seawater contains many salts, which increase its salinity. The salts in seawater mainly come from the dissolved salts and form hydrogen bonds with water molecules, increasing the salinity.
[B]: Seawater contains abundant elements like calcium, phosphorus, potassium, and phosphorus, which are limited in quantity and distribution in the ocean. Additionally, seawater contains nutrients from various organisms and microorganisms, such as shells and seaweeds.
[C]: Seawater contains many dissolved salts, with the most common being sodium chloride. When salt is added to water, its molecules react with water molecules to form sodium hydroxide, which is a type of salt.
[D]: Water is essential for many organisms, as it can absorb and release carbon dioxide, release oxygen,
```
> [!NOTE]
> 🙋♂️Directly throw the answer of the above model to GPT-4o and ask it to help score it:
---
### Model Performance Review:
1. **Model A**:
- **Performance**: Model A's responses are usually concise and clear but lack detail and accuracy in some cases. For
example, Model A provided incorrect information about the length of the Yangtze River.
- **Score**: 60
2. **Model B**:
- **Performance**: Model B provides additional information in some cases, but this information can sometimes be
inaccurate or excessive. For instance, Model B gave incorrect figures for the length and drainage area of the
Yangtze River.
- **Score**: 65
3. **Model C**:
- **Performance**: Model C typically provides detailed and accurate answers for most questions. For example,
responses about the Yangtze River and Mount Tai were accurate.
- **Score**: 75
4. **Model D**:
- **Performance**: Model D’s responses sometimes appear disorganized and lack accuracy. For example, the answer
about Mount Tai was completely off-topic.
- **Score**: 50
5. **Model E**:
- **Performance**: Model E’s responses are usually very detailed, but they can be overly verbose and contain
unnecessary information. For instance, the answer on gravity was overly complex.
- **Score**: 70
#### Ranking (from highest to lowest):
| Model | C | E | B | A | D |
|-------|----|----|----|----|----|
| Score | 75 | 70 | 65 | 60 | 50 |
---
## 👉 Summary of Effects
* The ranking of the minimind series (ABC) is intuitive, with minimind-v1(0.1B) scoring the highest and providing mostly
accurate answers to common knowledge questions.
* Surprisingly, minimind-v1-small (0.02B) with only 26M parameters performs close to minimind-v1(0.1B).
* Despite having less than 2 epochs of training, minimind-v1(0.1B) performed the best. This suggests that a larger
model often yields better performance, even with limited training.
* minimind-v1-moe (0.1B) performed poorly, likely because it was terminated early to free up resources for smaller
models. MoE models require more training epochs, and with only 2 epochs, it was under-trained. Previous
experiments with a fully trained MoE model on Yi tokenizer showed visible improvements. Future versions, v2 and
v3, will be updated with better training.
* Model E’s responses appear the most complete, despite some instances of hallucination and overly verbose content.
However, GPT-4o and Deepseek's evaluations suggest it is "overly verbose and repetitive, with some hallucinations."
This strict evaluation might penalize models with some hallucinations heavily. Due to F models having longer default
text lengths and much larger datasets, the quality of responses depends significantly on the data rather than the
model size alone.
> 🙋♂️ Personal Subjective Evaluation: E>C>B≈A>D
> 🤖 GPT-4o Evaluation: C>E>B>A>D
Scaling Law: Larger model parameters and more training data generally lead to better model performance.
# 📌 Objective Dataset: C-Eval
C-Eval evaluation code is located at: `./eval_ceval.py`.
For small models, to avoid issues with fixed response formatting, we directly judge the prediction probabilities of the
four tokens `A`, `B`, `C`, `D`, and choose the one with the highest probability as the answer, then calculate accuracy
against the standard answer. Note that minimind models were not trained on larger datasets or fine-tuned for question
answering, so results should be considered as reference only.
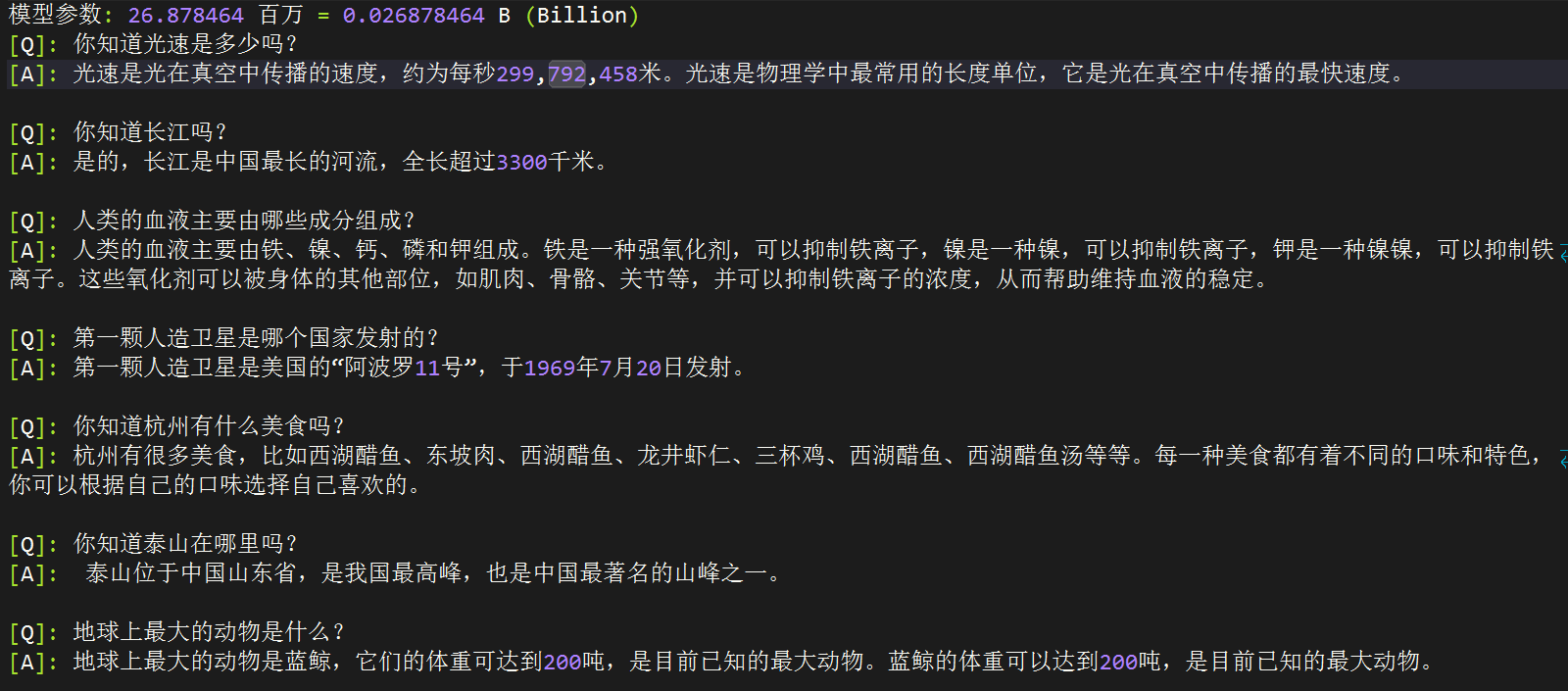
> For example, detailed results for minimind-small:
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|------|----------------------------|-----|-----------------------|-----------------------|---------------------|--------------------|---------------------|---------------------|----------------|------------------------|-----------------------|-----------------------|----------------|------------------|-------|---------------------|---------------|---------------------------------|---------------------|------------|------------------|-------------------------|--------------------|---------------------|---------|----------------------|-------------------------|-------------------------|--------------------|-----------------------------------|-------------------|-------------------------|------------------------------------------|-----------------------|-------------------------|-----------------|---------------------------|----------------------|-----------|-------------------|---------------------|-----------------------|------------------------|-------------------|------------------|----------------|-------------|-----------------------|----------------------|-------------------|---------------|-------------------------|
| Data | probability_and_statistics | law | middle_school_biology | high_school_chemistry | high_school_physics | legal_professional | high_school_chinese | high_school_history | tax_accountant | modern_chinese_history | middle_school_physics | middle_school_history | basic_medicine | operating_system | logic | electrical_engineer | civil_servant | chinese_language_and_literature | college_programming | accountant | plant_protection | middle_school_chemistry | metrology_engineer | veterinary_medicine | marxism | advanced_mathematics | high_school_mathematics | business_administration | mao_zedong_thought | ideological_and_moral_cultivation | college_economics | professional_tour_guide | environmental_impact_assessment_engineer | computer_architecture | urban_and_rural_planner | college_physics | middle_school_mathematics | high_school_politics | physician | college_chemistry | high_school_biology | high_school_geography | middle_school_politics | clinical_medicine | computer_network | sports_science | art_studies | teacher_qualification | discrete_mathematics | education_science | fire_engineer | middle_school_geography |
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|----------|--------|--------|--------|--------|--------|-------|--------|--------|--------|--------|--------|--------|-------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|-------|
| T/A | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 7/31 | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 9/31 | 1/12 |
| Accuracy | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
**Total number of questions**: 1346
**Total confirmed number**: 316
**Total accuracy rate**: 23.48%
---
#### Results summary:
| category | correct | question_count | accuracy |
|:------------------|:--------:|:--------------:|:--------:|
| minimind-v1-small | 344 | 1346 | 25.56% |
| minimind-v1 | 351 | 1346 | 26.08% |
### Model Performance Insights from GPT-4o
```text
### Areas Where the Model Excels:
1. **High School Chemistry**: With an accuracy of 42.11%, this is the strongest area for the model, suggesting a solid grasp of chemistry-related knowledge.
2. **Discrete Mathematics**: Achieving an accuracy of 37.50%, the model performs well in mathematics-related fields.
3. **Education Science**: The model shows good performance in education-related topics with a 37.93% accuracy.
4. **Basic Medicine**: The accuracy of 36.84% indicates strong performance in foundational medical knowledge.
5. **Operating Systems**: With a 36.84% accuracy, the model demonstrates reliable performance in computer operating systems.
### Areas Where the Model Struggles:
1. **Legal Topics**: The model performs poorly in legal-related areas such as Legal Professional (8.70%) and Tax Accountant (20.41%).
2. **Physics**: Both high school (26.32%) and college-level (21.05%) physics topics are challenging for the model.
3. **High School Politics and Geography**: The model shows low accuracy in these areas, with High School Politics at 15.79% and High School Geography at 21.05%.
4. **Computer Networking and Architecture**: The model struggles with Computer Networking (21.05%) and Computer Architecture (9.52%).
5. **Environmental Impact Assessment Engineering**: The accuracy is only 12.90%, indicating weak performance in environmental science.
### Summary:
- **Strengths**: Chemistry, Mathematics (especially Discrete Mathematics), Education Science, Basic Medicine, and Operating Systems.
- **Weaknesses**: Legal Topics, Physics, Politics, Geography, Computer Networking and Architecture, and Environmental Science.
This suggests that the model performs well in logical reasoning, foundational sciences, and some engineering disciplines but is weaker in humanities, social sciences, and certain specialized fields (such as law and taxation). To improve the model's performance, additional training in humanities, physics, law, and environmental science may be beneficial.
```
# 📌 Others
### Inference and Export
* [./export_model.py](./export_model.py) can export the model to the transformers format and push it to Hugging Face.
* MiniMind's Hugging Face collection
address: [MiniMind](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5)
---
### API Inference
[./my_openai_api.py](./my_openai_api.py) provides a chat interface for the OpenAI API, making it easier to integrate
your model with third-party UIs, such as fastgpt, OpenWebUI, etc.
* Download the model weight files
from [Hugging Face](https://huggingface.co/collections/jingyaogong/minimind-66caf8d999f5c7fa64f399e5):
```
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
```
* Start the chat server:
```bash
python my_openai_api.py
```
* Test the service interface:
```bash
python chat_openai_api.py
```
* API interface example, compatible with the OpenAI API format:
```bash
curl http://ip:port/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "What is the highest mountain in the world?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'
```
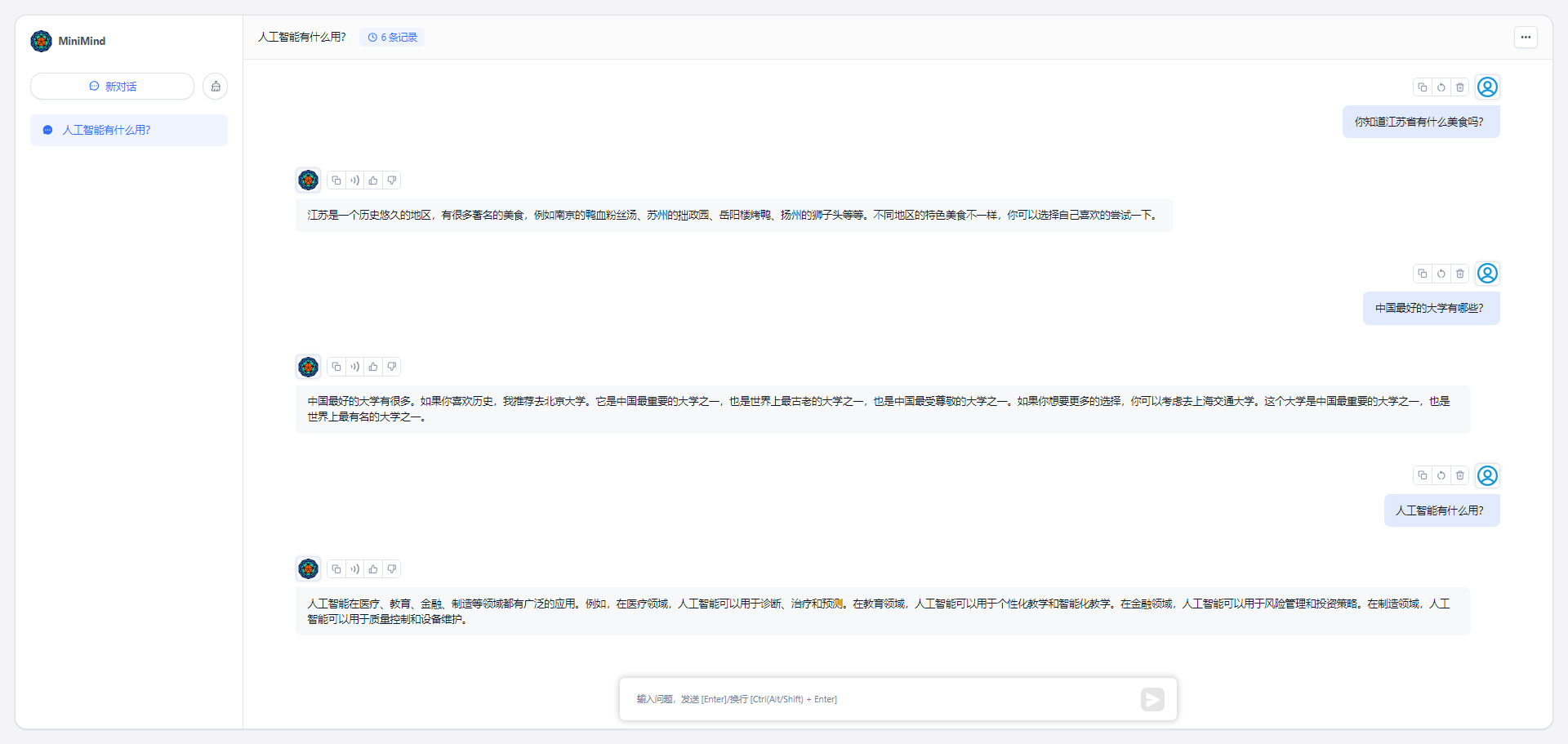
### Integrating MiniMind API in FastGPT
---
# 📌 Acknowledgement
> [!NOTE]
> If you find `MiniMind` helpful, please give us a ⭐️ on GitHub. Your support is the driving force behind our continuous
> efforts to improve the project! Due to the length and limited expertise, there may be some errors. We welcome any
> issues
> for discussion and correction.
## 🤝[Contributors](https://github.com/jingyaogong/minimind/graphs/contributors)
## 😊Thanks for
@ipfgao:
🔗训练步骤记录
## 🫶Supporter
# License
This repository is licensed under the [Apache-2.0 License](LICENSE).
 [MiniMind (ModelScope)](https://www.modelscope.cn/models/gongjy/MiniMind-V1)
[MiniMind (ModelScope)](https://www.modelscope.cn/models/gongjy/MiniMind-V1)


 ## 😊Thanks for
@ipfgao:
🔗训练步骤记录
## 🫶Supporter
## 😊Thanks for
@ipfgao:
🔗训练步骤记录
## 🫶Supporter