
Update model with 2x training data and more efficient vocabulary
Browse files- README.md +12 -6
- all_results.json +8 -0
- config.json +5 -4
- model.safetensors +2 -2
- runs/May14_00-15-56_coconut/events.out.tfevents.1715616965.coconut.1514196.0 +3 -0
- special_tokens_map.json +1 -0
- tokenizer.json +0 -0
- tokenizer.model +2 -2
- tokenizer_config.json +4 -1
- train_results.json +8 -0
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
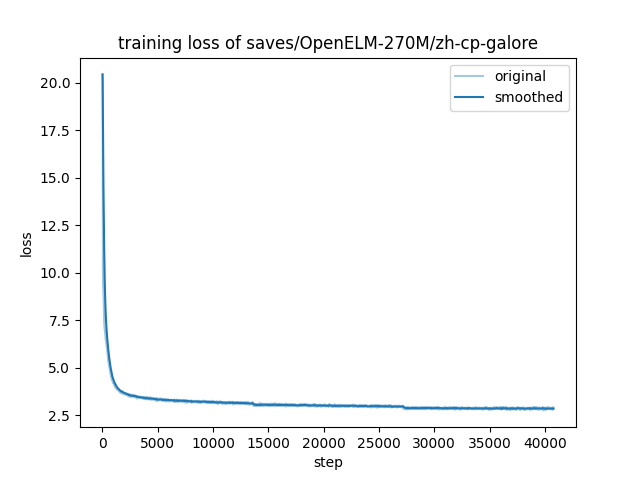
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -2,16 +2,22 @@
|
|
| 2 |
library_name: transformers
|
| 3 |
license: apache-2.0
|
| 4 |
datasets:
|
| 5 |
-
-
|
| 6 |
-
|
| 7 |
language:
|
| 8 |
- zh
|
| 9 |
---
|
| 10 |
|
| 11 |
# Model Card for Chinese-OpenELM-270M
|
| 12 |
|
| 13 |
-
|
| 14 |
|
| 15 |
-
* Extended vocabulary from 32000 to
|
| 16 |
-
*
|
| 17 |
-
*
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
library_name: transformers
|
| 3 |
license: apache-2.0
|
| 4 |
datasets:
|
| 5 |
+
- liswei/zhtw-news-and-articles-2B
|
| 6 |
+
base_model: apple/OpenELM-270M
|
| 7 |
language:
|
| 8 |
- zh
|
| 9 |
---
|
| 10 |
|
| 11 |
# Model Card for Chinese-OpenELM-270M
|
| 12 |
|
| 13 |
+
Continual pre-trained from [apple/OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) with [liswei/zhtw-news-and-articles-2B](https://huggingface.co/datasets/liswei/zhtw-news-and-articles-2B):
|
| 14 |
|
| 15 |
+
* Extended vocabulary from 32000 to 61758 tokens with additional Traditional Chinese characters.
|
| 16 |
+
* Tokenizer is trained on [liswei/zhtw-news-and-articles-2B](https://huggingface.co/datasets/liswei/zhtw-news-and-articles-2B) and pruned from 96000 to 61758 tokens while maintaining 95% coverage on the pre-training dataset.
|
| 17 |
+
* Additional token embeddings are initialized with the mean vector of existing embeddings.
|
| 18 |
+
* Traditional Chinese perplexity = 1.6871 on held-out evaluation dataset.
|
| 19 |
+
* Applied [GaLore](https://arxiv.org/abs/2403.03507) for efficient training with following hyperparameters:
|
| 20 |
+
* Rank: 1024
|
| 21 |
+
* Scale: 4.0
|
| 22 |
+
* Update interval: 200
|
| 23 |
+
* Layer-wise training: False
|
all_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.999944821497545,
|
| 3 |
+
"total_flos": 3.6968537365004943e+18,
|
| 4 |
+
"train_loss": 3.121767396105489,
|
| 5 |
+
"train_runtime": 856366.0469,
|
| 6 |
+
"train_samples_per_second": 3.047,
|
| 7 |
+
"train_steps_per_second": 0.048
|
| 8 |
+
}
|
config.json
CHANGED
|
@@ -1,12 +1,13 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "
|
| 3 |
"activation_fn_name": "swish",
|
| 4 |
"architectures": [
|
| 5 |
"OpenELMForCausalLM"
|
| 6 |
],
|
| 7 |
"auto_map": {
|
| 8 |
"AutoConfig": "configuration_openelm.OpenELMConfig",
|
| 9 |
-
"
|
|
|
|
| 10 |
},
|
| 11 |
"bos_token_id": 1,
|
| 12 |
"eos_token_id": 2,
|
|
@@ -84,6 +85,6 @@
|
|
| 84 |
"share_input_output_layers": true,
|
| 85 |
"torch_dtype": "float32",
|
| 86 |
"transformers_version": "4.40.1",
|
| 87 |
-
"use_cache":
|
| 88 |
-
"vocab_size":
|
| 89 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "saves/OpenELM-270M/zh-base",
|
| 3 |
"activation_fn_name": "swish",
|
| 4 |
"architectures": [
|
| 5 |
"OpenELMForCausalLM"
|
| 6 |
],
|
| 7 |
"auto_map": {
|
| 8 |
"AutoConfig": "configuration_openelm.OpenELMConfig",
|
| 9 |
+
"AutoModel": "modeling_openelm.OpenELMForCausalLM",
|
| 10 |
+
"AutoModelForCausalLM": "apple/OpenELM-270M--modeling_openelm.OpenELMForCausalLM"
|
| 11 |
},
|
| 12 |
"bos_token_id": 1,
|
| 13 |
"eos_token_id": 2,
|
|
|
|
| 85 |
"share_input_output_layers": true,
|
| 86 |
"torch_dtype": "float32",
|
| 87 |
"transformers_version": "4.40.1",
|
| 88 |
+
"use_cache": false,
|
| 89 |
+
"vocab_size": 61758
|
| 90 |
}
|
model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:45254a3c27ee9d76e391ca4117b11f8e9bf7fb627abb882c67e421dfbbafbad6
|
| 3 |
+
size 1238484144
|
runs/May14_00-15-56_coconut/events.out.tfevents.1715616965.coconut.1514196.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:74bc86dfc2d4bd97da6ae6ee4e20f61c7371c346902086624e7ee9d4fe426e99
|
| 3 |
+
size 875943
|
special_tokens_map.json
CHANGED
|
@@ -13,6 +13,7 @@
|
|
| 13 |
"rstrip": false,
|
| 14 |
"single_word": false
|
| 15 |
},
|
|
|
|
| 16 |
"unk_token": {
|
| 17 |
"content": "<unk>",
|
| 18 |
"lstrip": false,
|
|
|
|
| 13 |
"rstrip": false,
|
| 14 |
"single_word": false
|
| 15 |
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
"unk_token": {
|
| 18 |
"content": "<unk>",
|
| 19 |
"lstrip": false,
|
tokenizer.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:489162c61bf22fed27ac6d11033cb270715cb83b4de4409569e7858c6c56b844
|
| 3 |
+
size 966919
|
tokenizer_config.json
CHANGED
|
@@ -29,13 +29,16 @@
|
|
| 29 |
}
|
| 30 |
},
|
| 31 |
"bos_token": "<s>",
|
|
|
|
| 32 |
"clean_up_tokenization_spaces": false,
|
| 33 |
"eos_token": "</s>",
|
| 34 |
"legacy": true,
|
| 35 |
"model_max_length": 1000000000000000019884624838656,
|
| 36 |
-
"pad_token":
|
|
|
|
| 37 |
"sp_model_kwargs": {},
|
| 38 |
"spaces_between_special_tokens": false,
|
|
|
|
| 39 |
"tokenizer_class": "LlamaTokenizer",
|
| 40 |
"unk_token": "<unk>",
|
| 41 |
"use_default_system_prompt": false
|
|
|
|
| 29 |
}
|
| 30 |
},
|
| 31 |
"bos_token": "<s>",
|
| 32 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ content }}{% elif message['role'] == 'assistant' %}{{ content }}{% endif %}{% endfor %}",
|
| 33 |
"clean_up_tokenization_spaces": false,
|
| 34 |
"eos_token": "</s>",
|
| 35 |
"legacy": true,
|
| 36 |
"model_max_length": 1000000000000000019884624838656,
|
| 37 |
+
"pad_token": "</s>",
|
| 38 |
+
"padding_side": "right",
|
| 39 |
"sp_model_kwargs": {},
|
| 40 |
"spaces_between_special_tokens": false,
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
"tokenizer_class": "LlamaTokenizer",
|
| 43 |
"unk_token": "<unk>",
|
| 44 |
"use_default_system_prompt": false
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.999944821497545,
|
| 3 |
+
"total_flos": 3.6968537365004943e+18,
|
| 4 |
+
"train_loss": 3.121767396105489,
|
| 5 |
+
"train_runtime": 856366.0469,
|
| 6 |
+
"train_samples_per_second": 3.047,
|
| 7 |
+
"train_steps_per_second": 0.048
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:45616b1f1573d940ede26d5d97433d9906cce9b27c89a1c73b999deb5426836b
|
| 3 |
+
size 5176
|
training_loss.png
ADDED
|