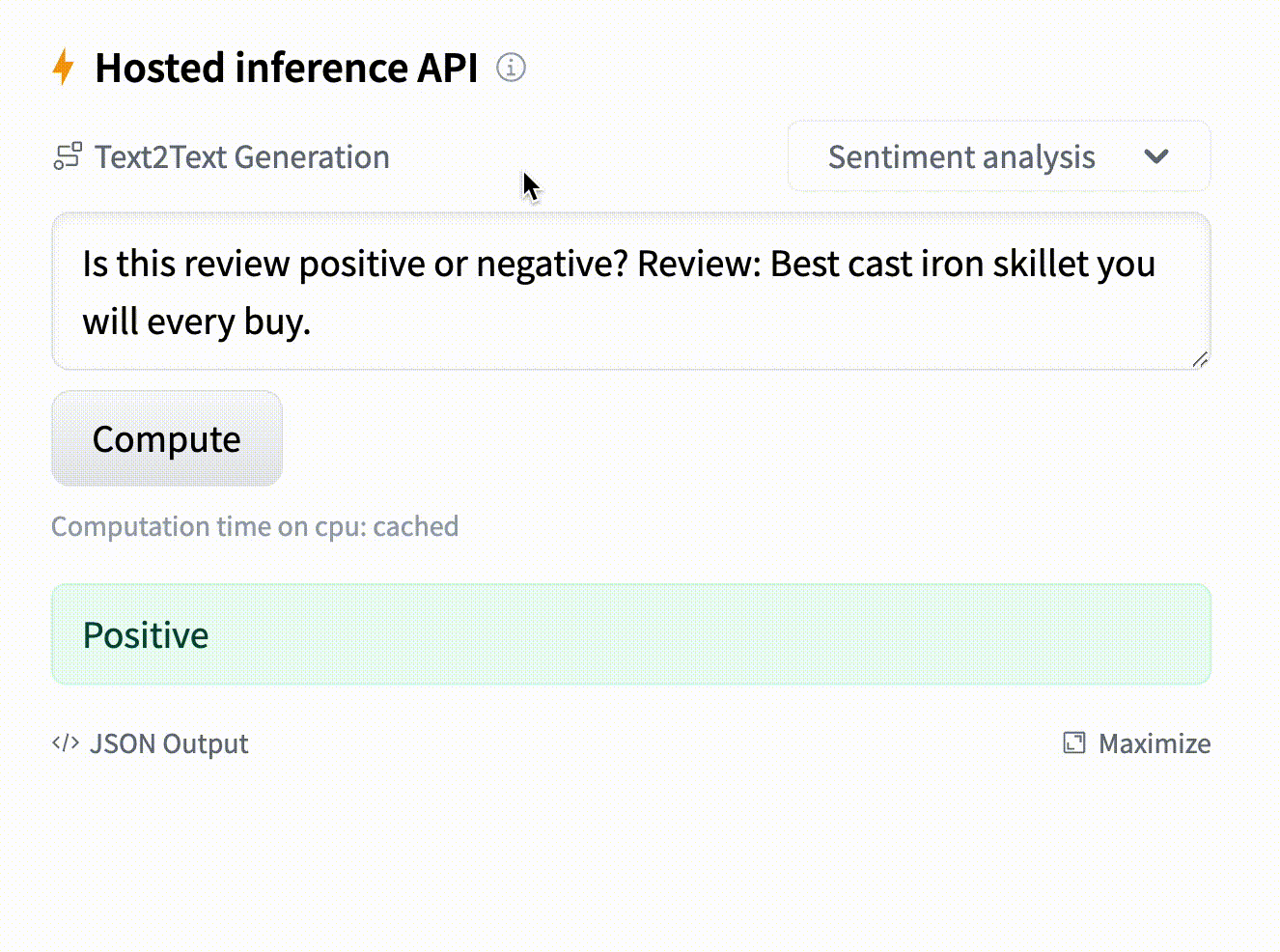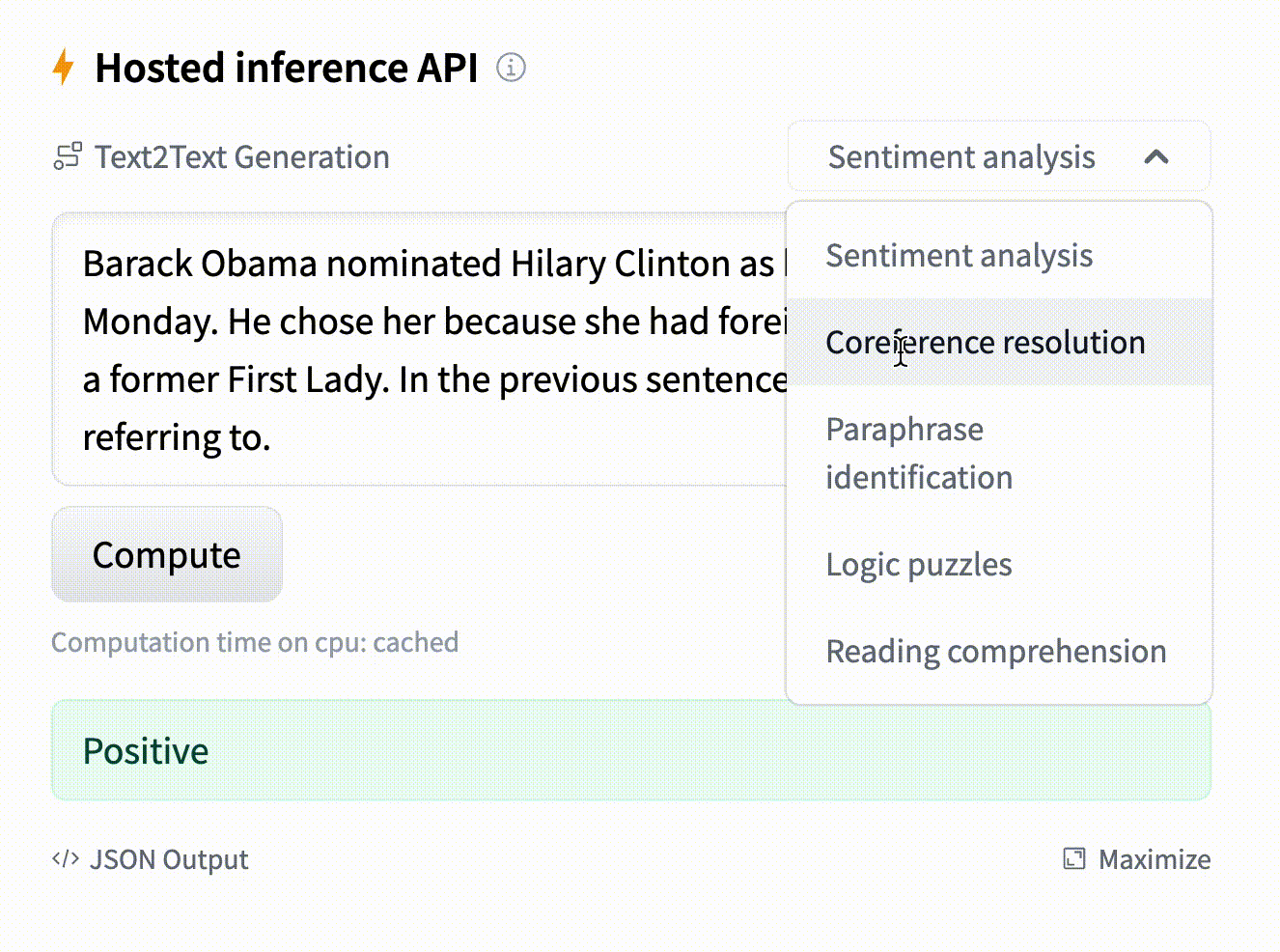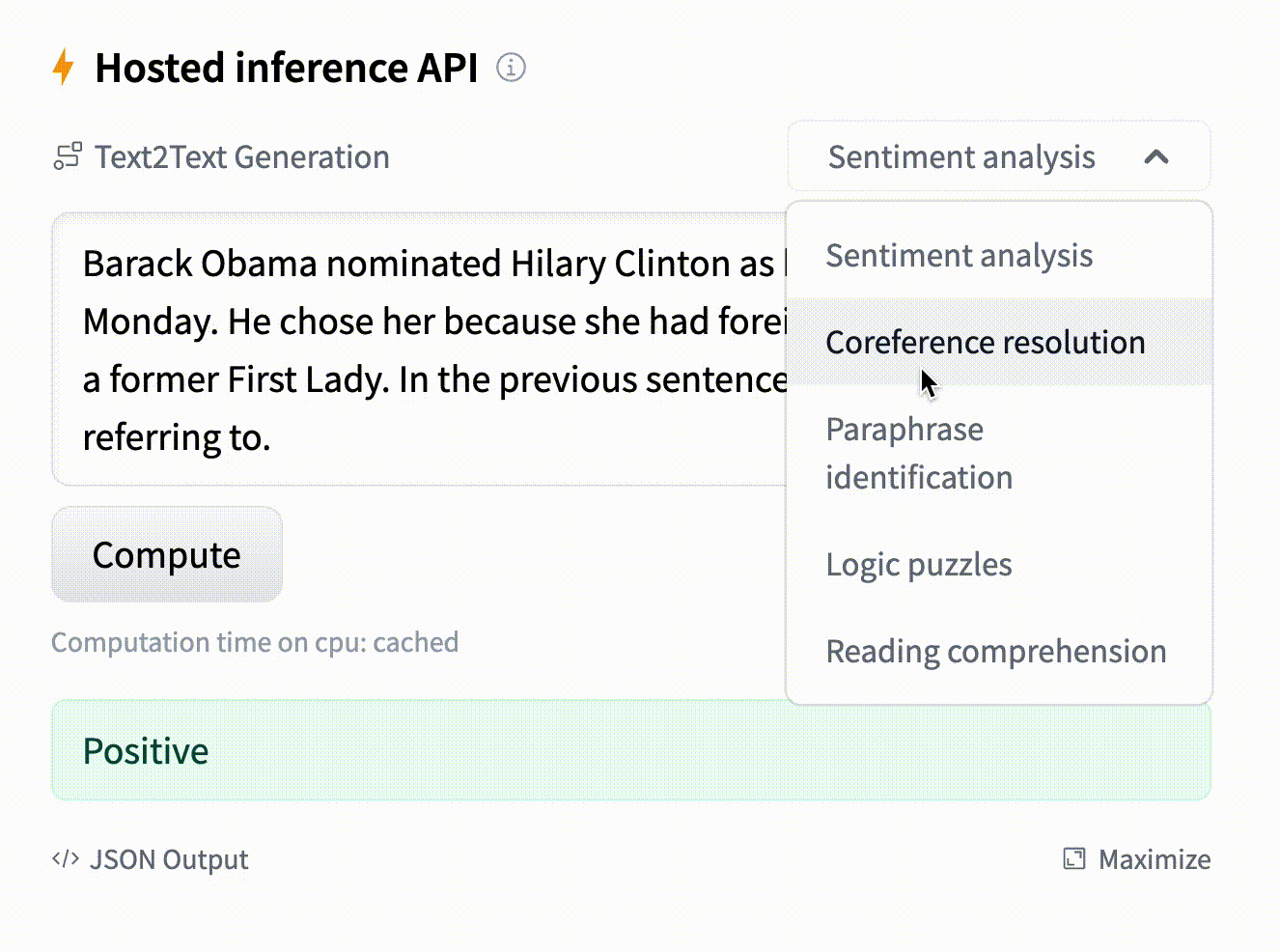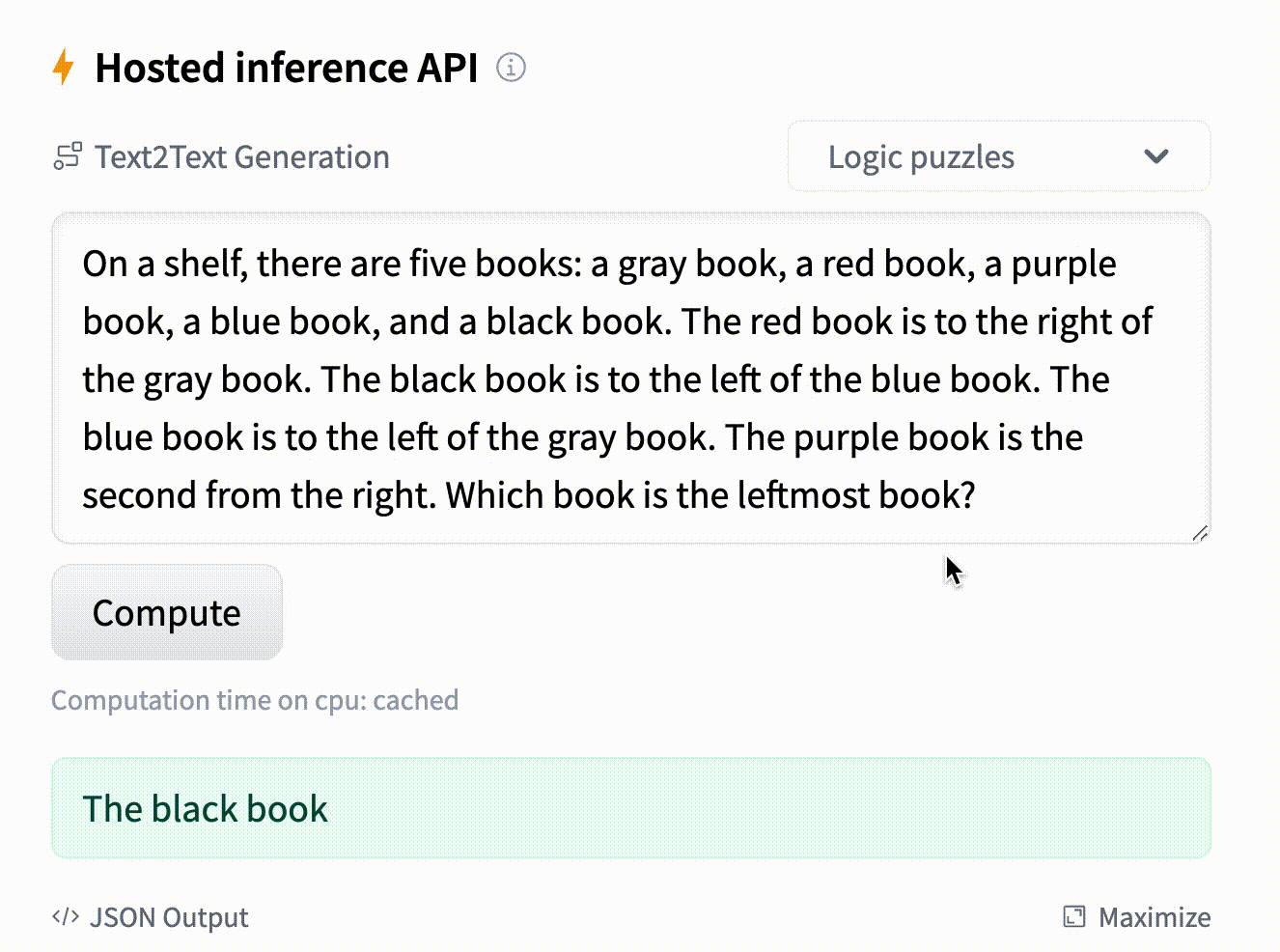
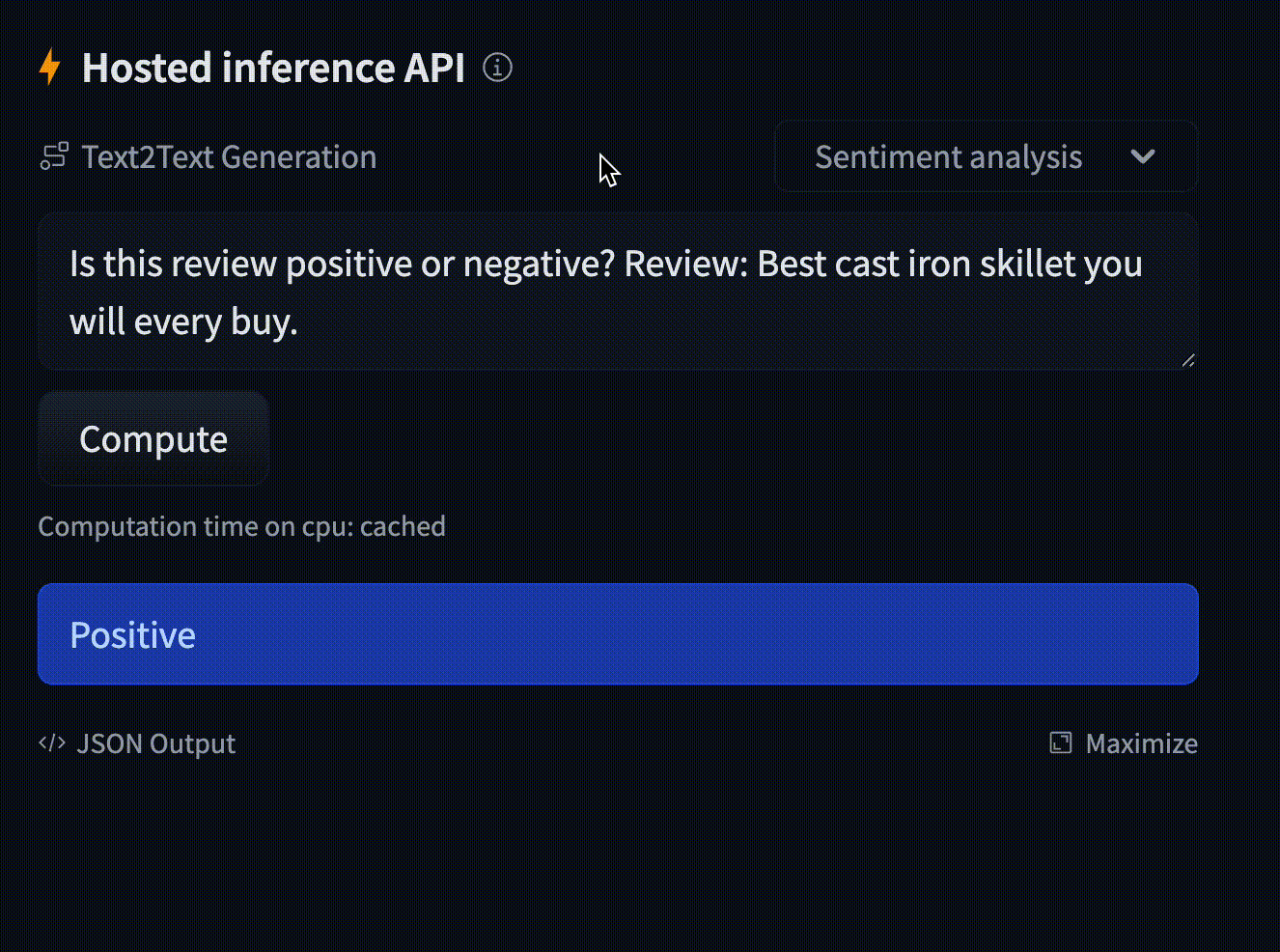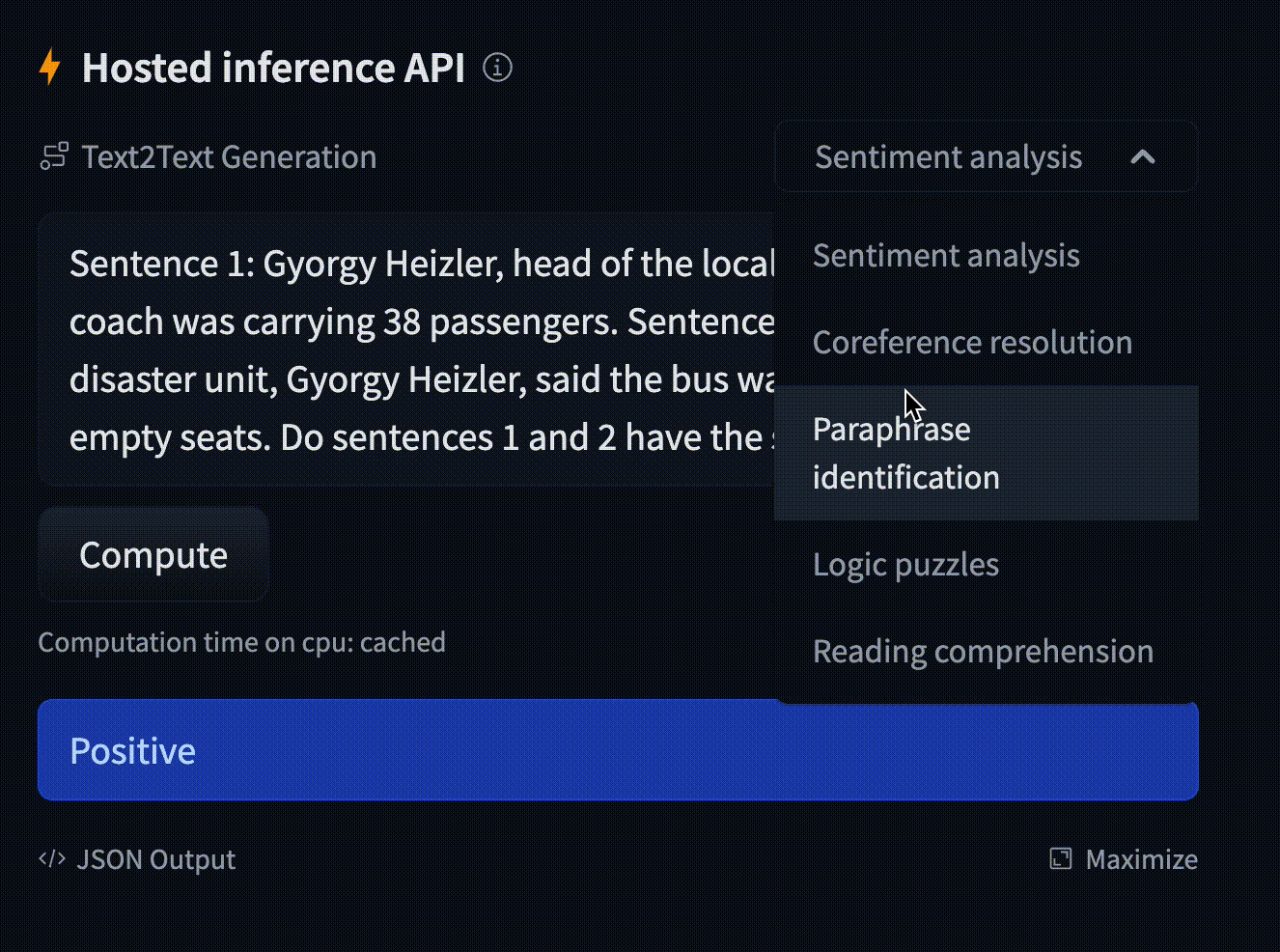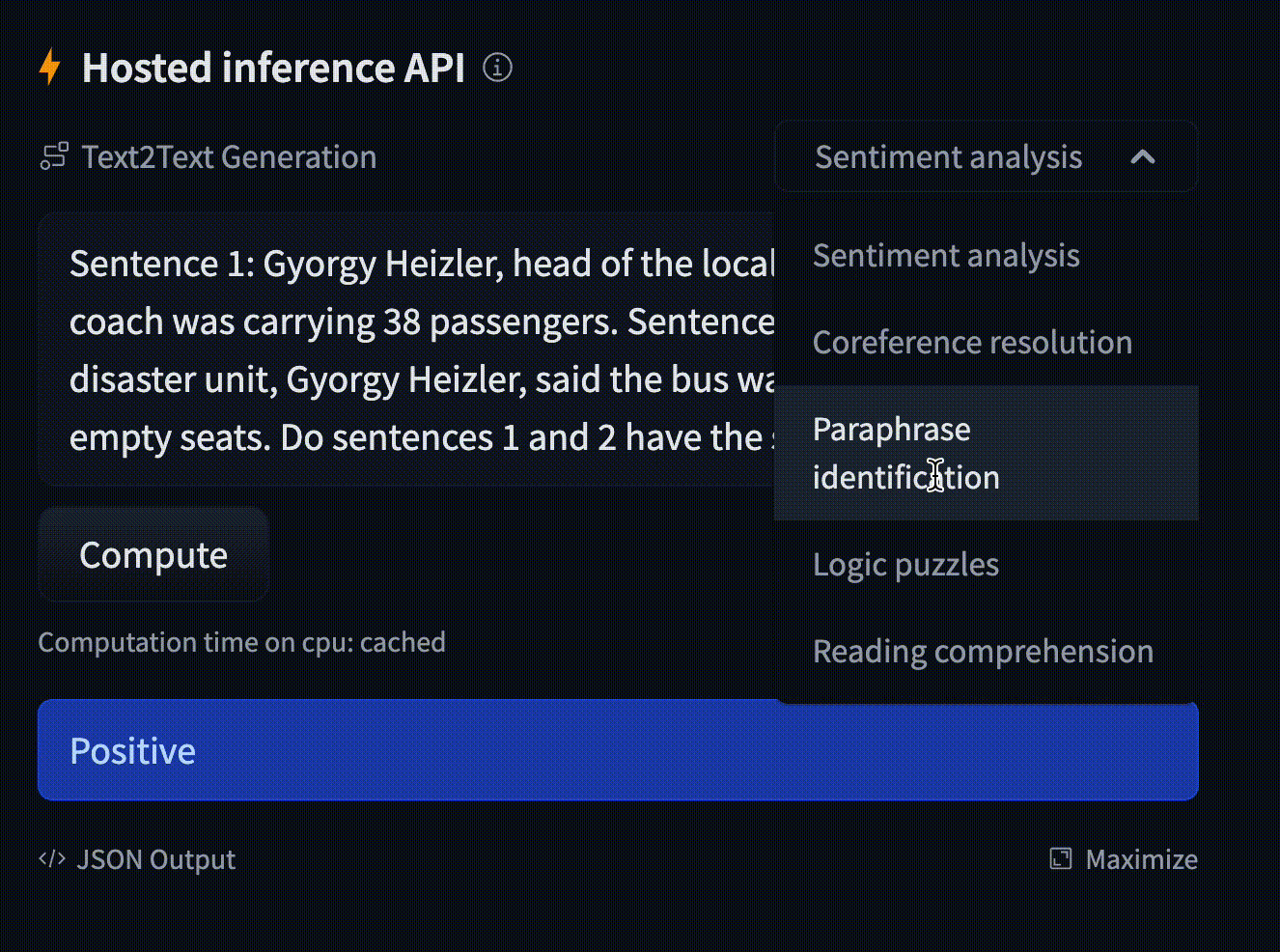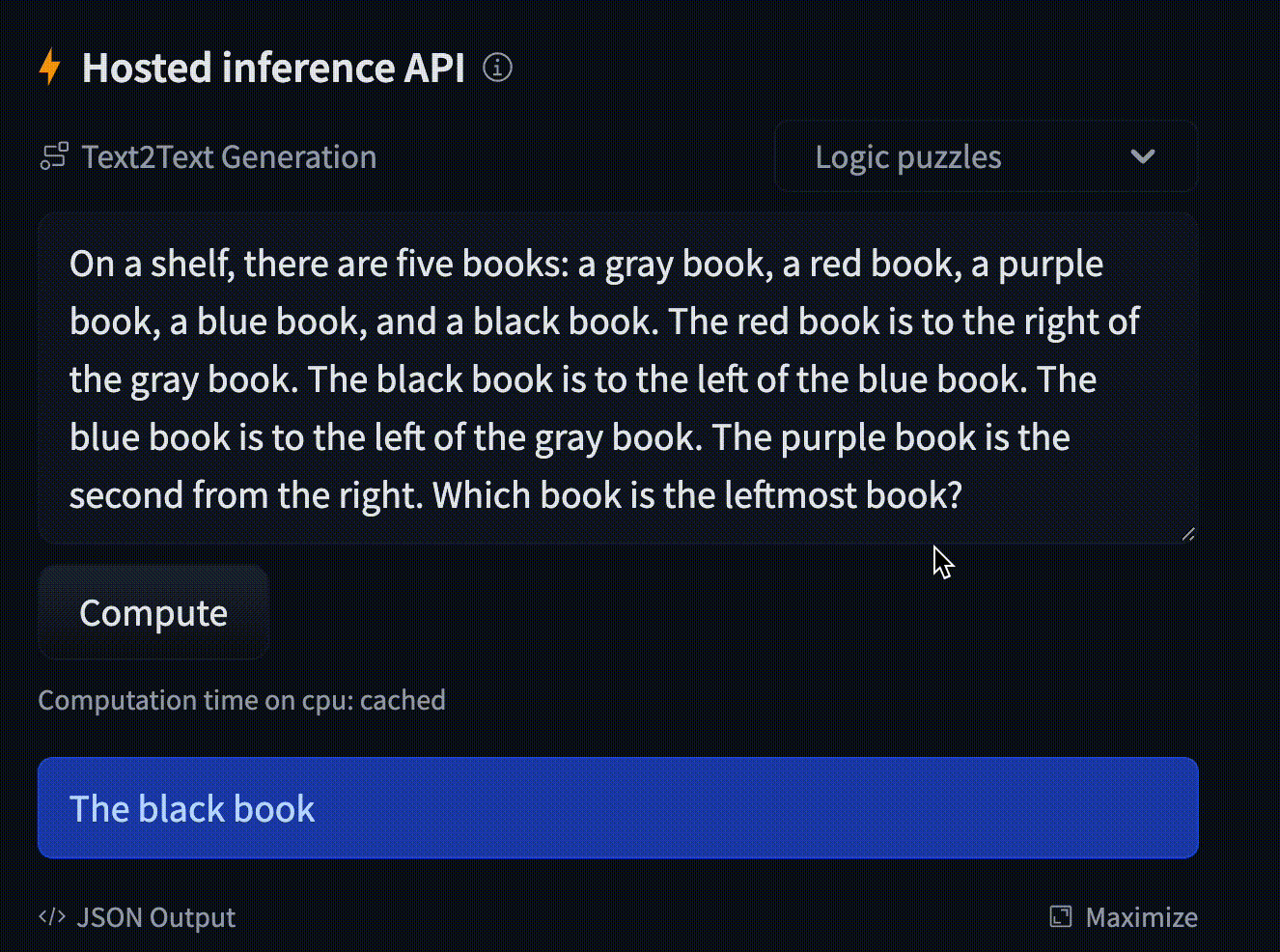
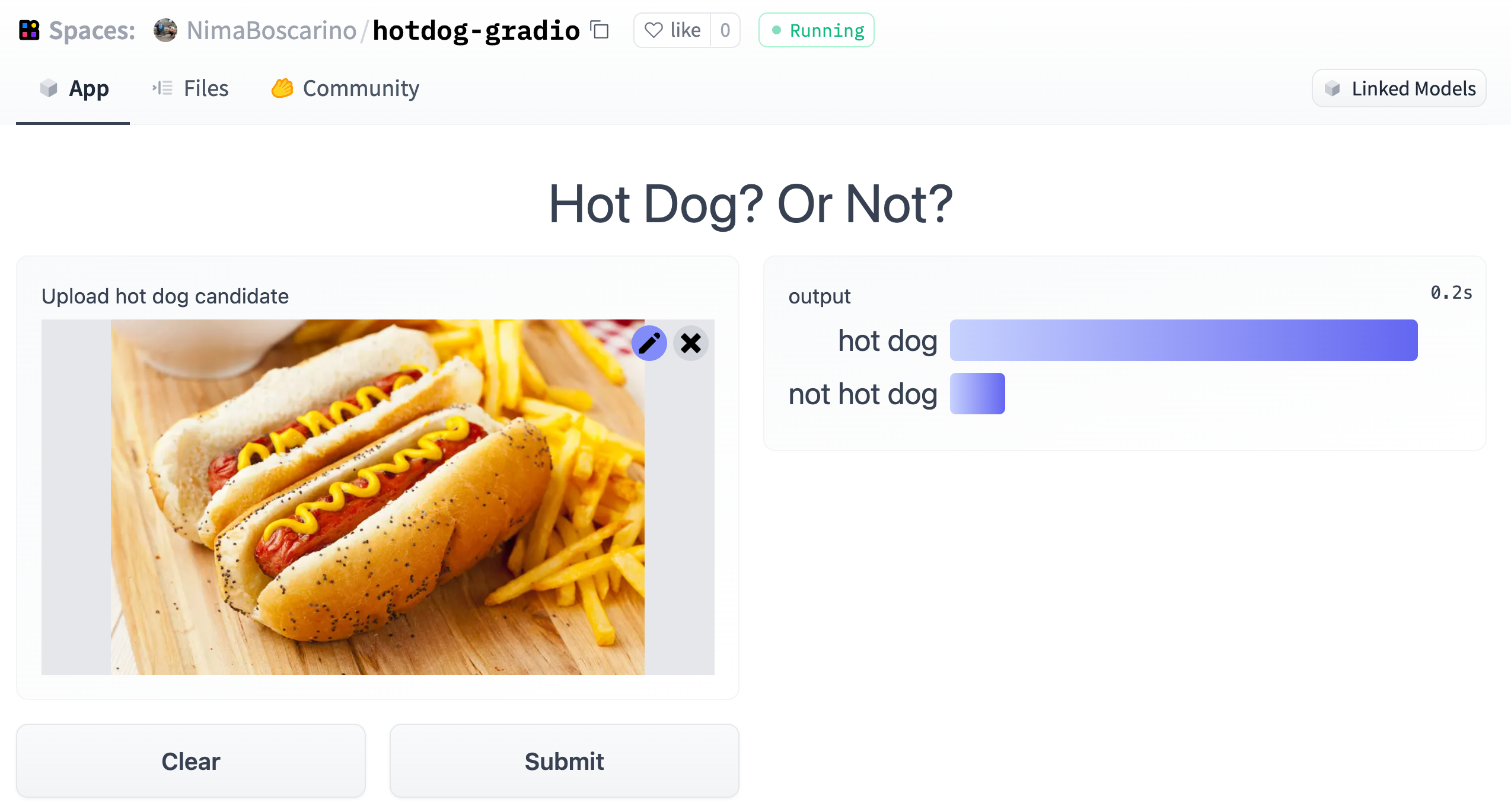
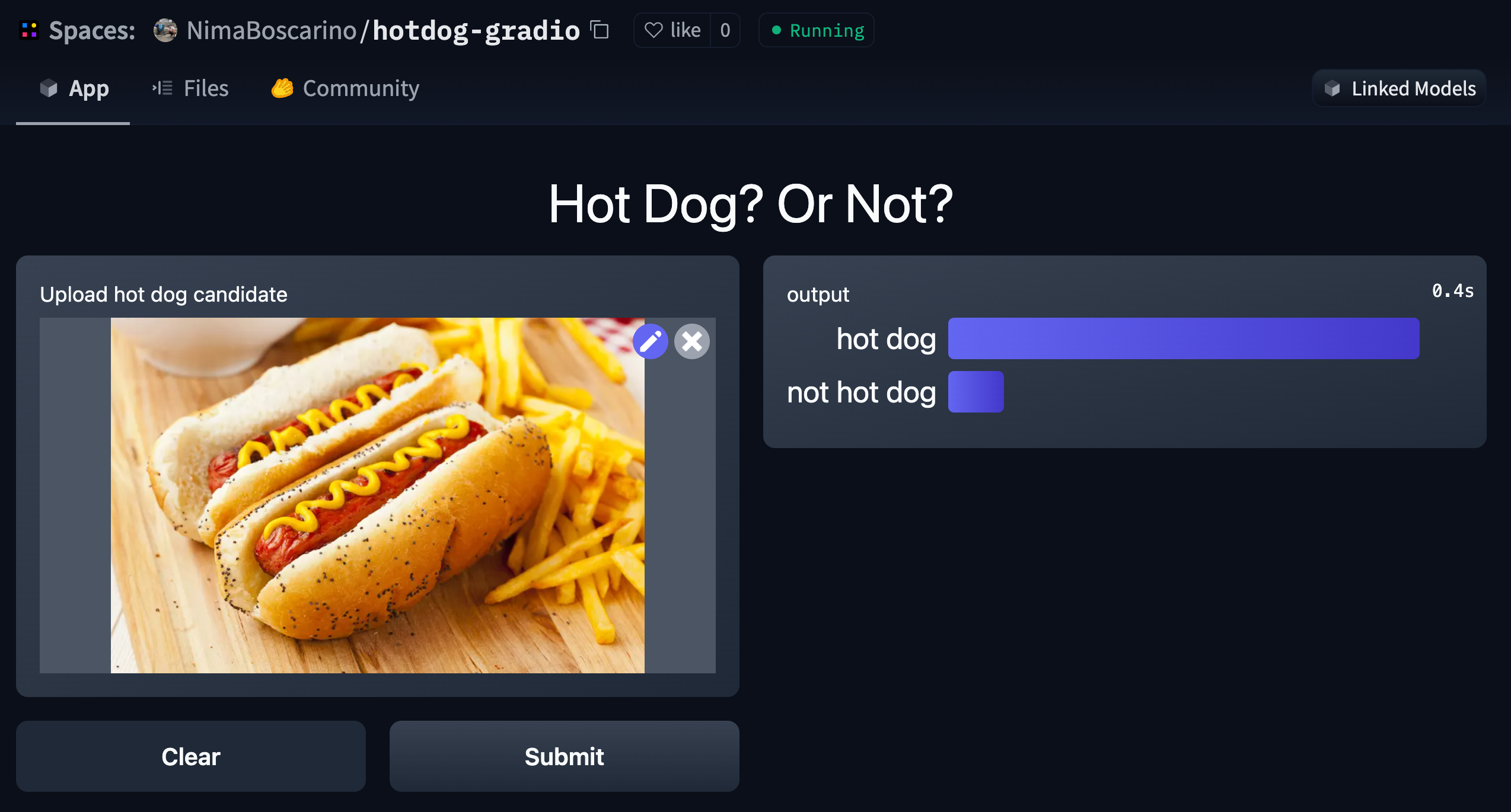
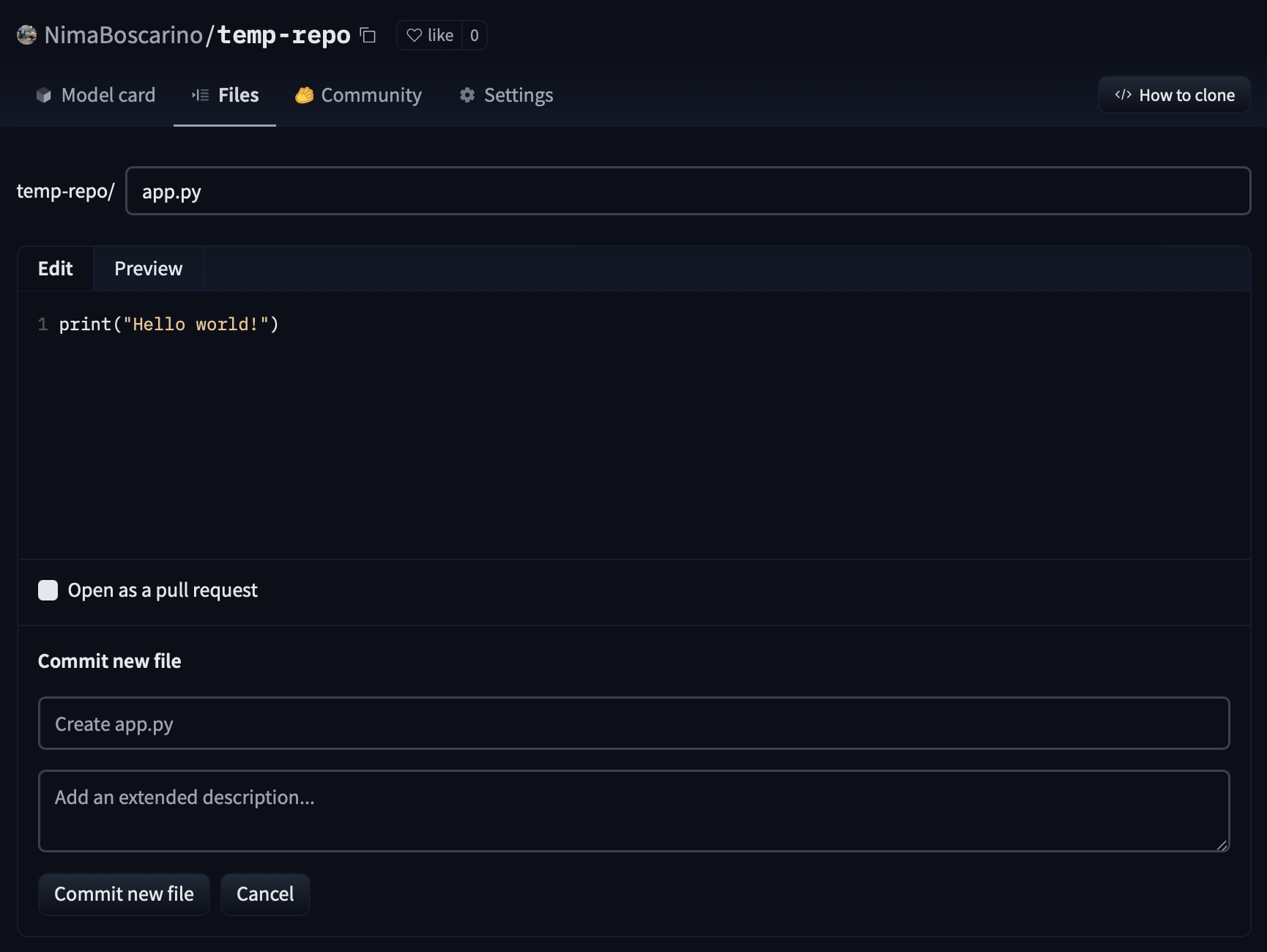
Text generation using Flan T5
Model: google/flan-t5-small


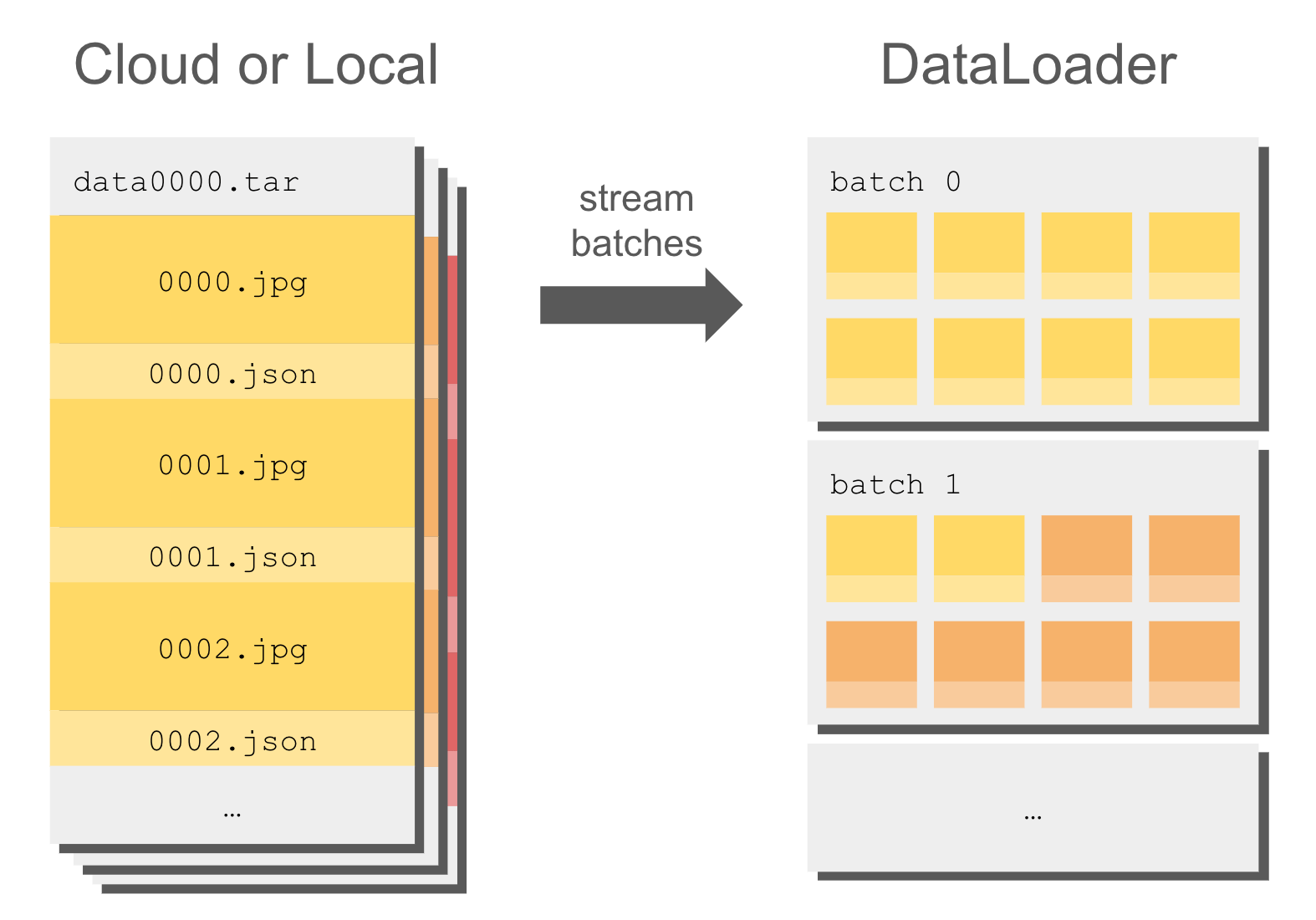
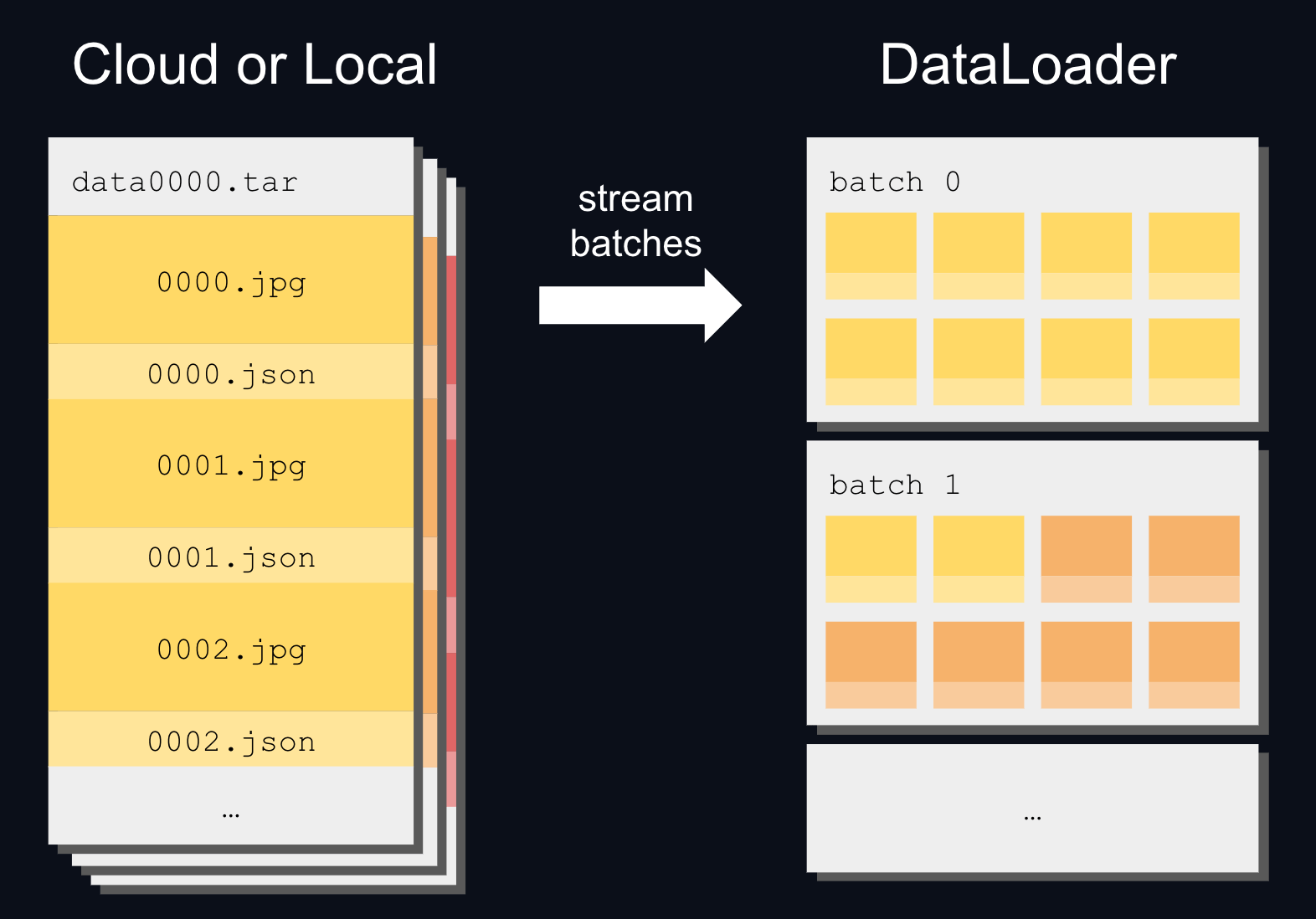
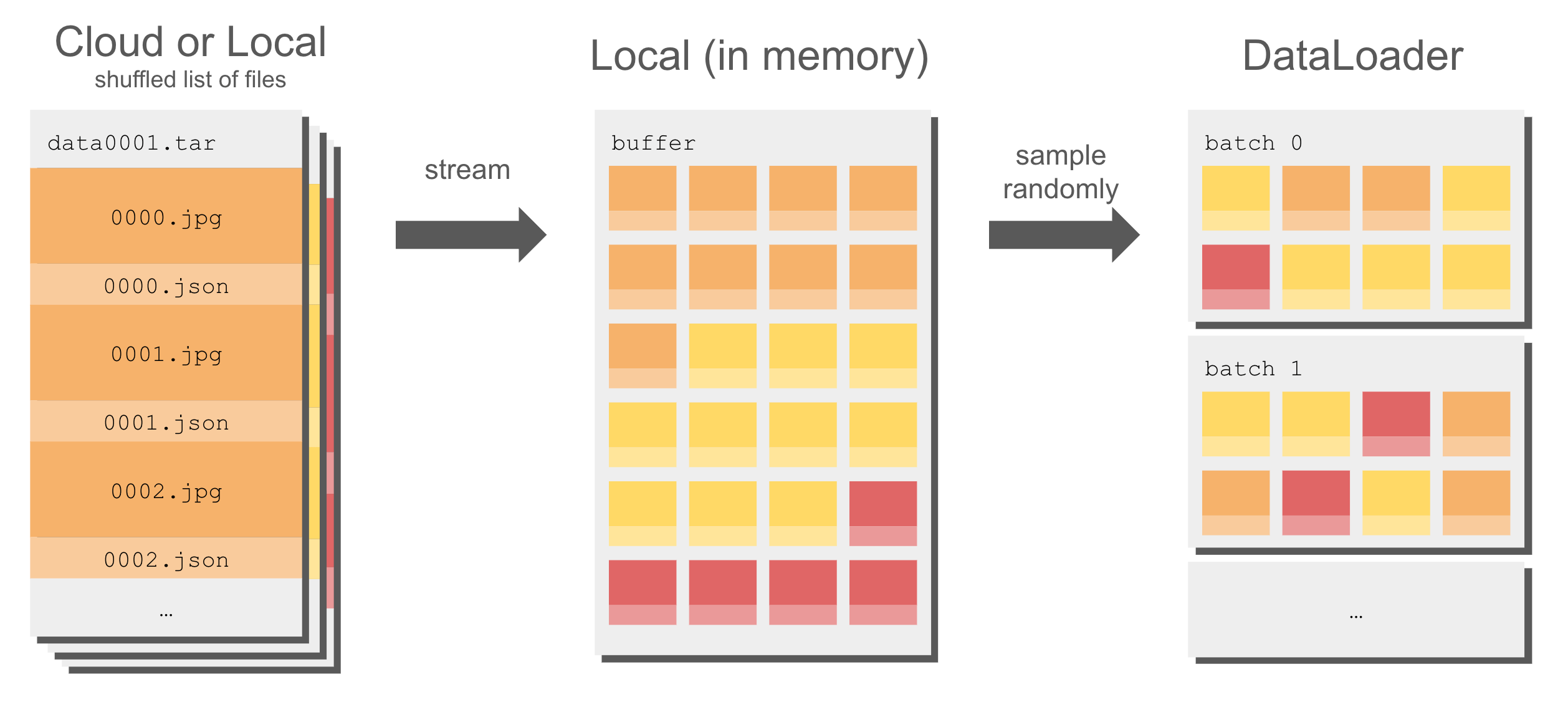
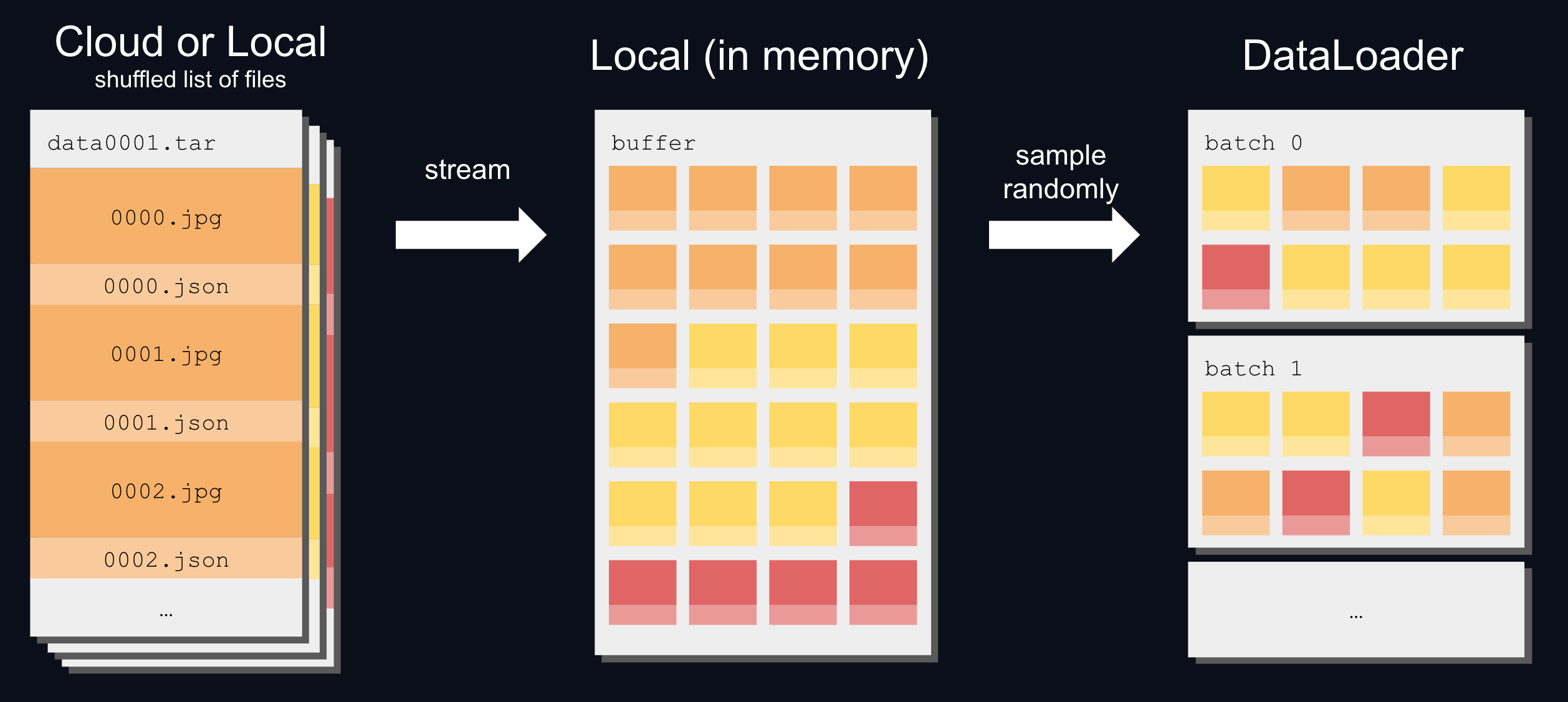
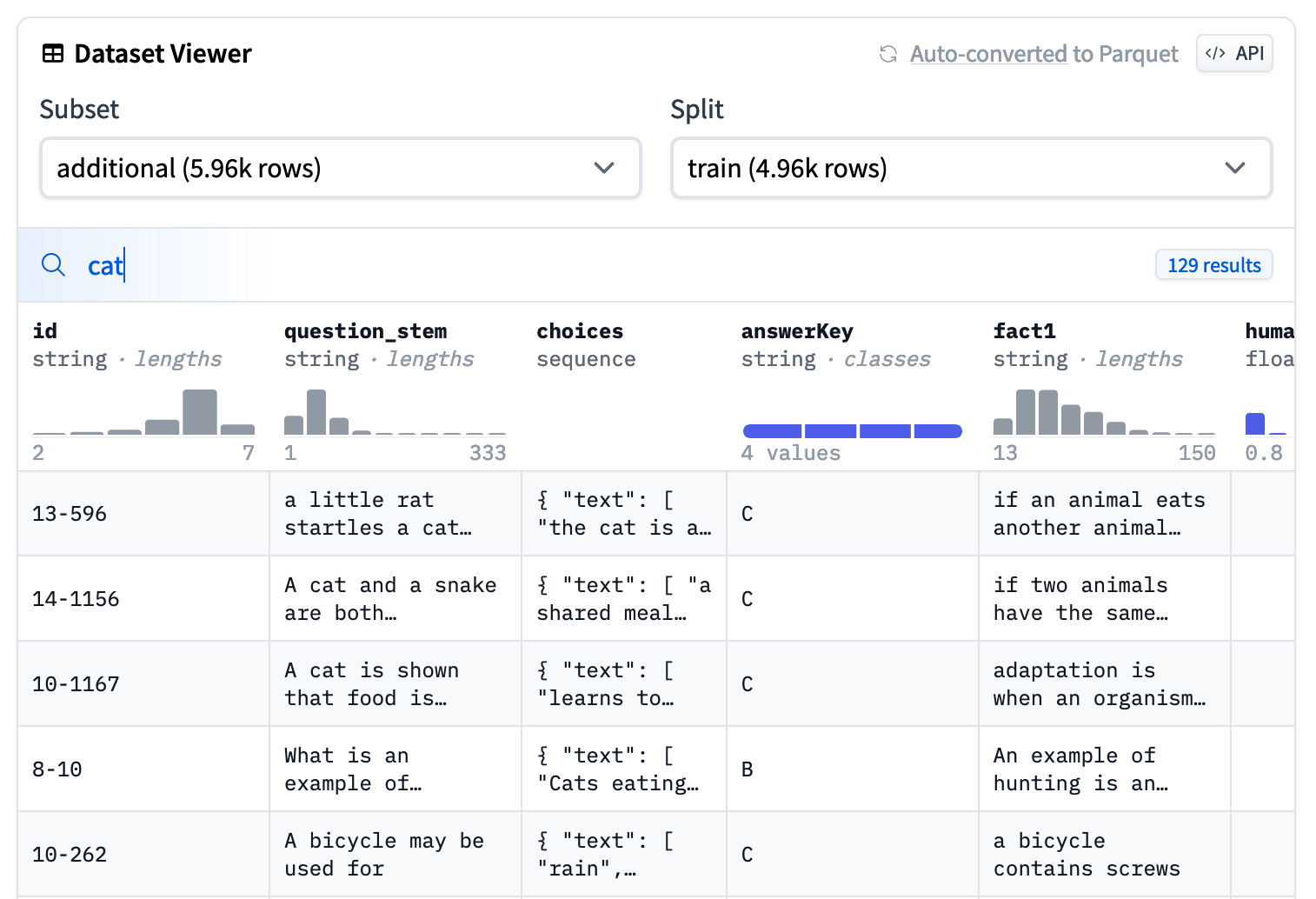
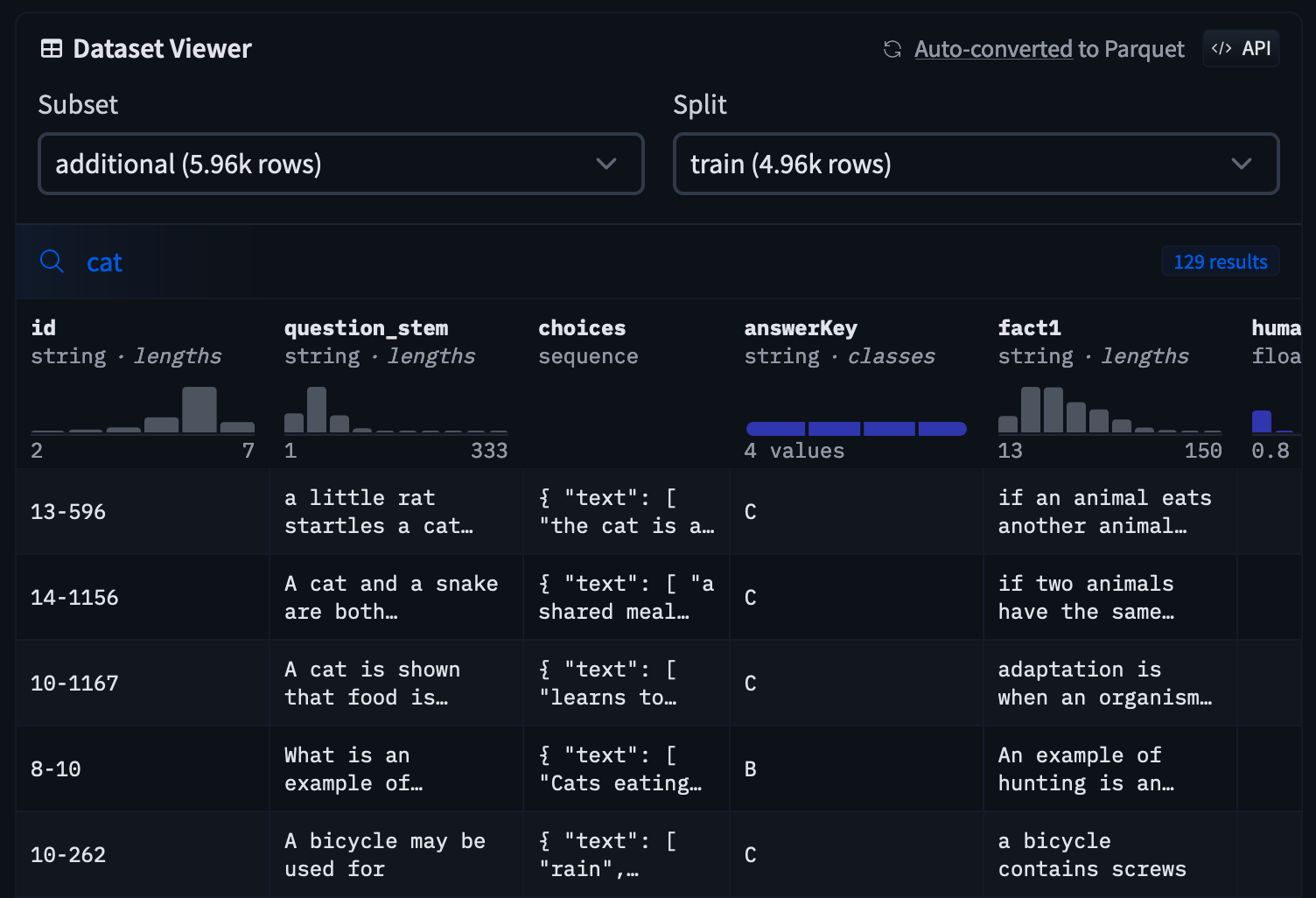
 _app.py_
This file defines your app's logic. To learn more about how to modify this file, see [the Shiny for Python documentation](https://shiny.rstudio.com/py/docs/overview.html).
As your app gets more complex, it's a good idea to break your application logic up into [modules](https://shiny.rstudio.com/py/docs/workflow-modules.html).
_Dockerfile_
The Dockerfile for a Shiny for Python app is very minimal because the library doesn't have many system dependencies, but you may need to modify this file if your application has additional system dependencies.
The one essential feature of this file is that it exposes and runs the app on the port specified in the space README file (which is 7860 by default).
__requirements.txt__
The Space will automatically install dependencies listed in the requirements.txt file.
Note that you must include shiny in this file.
## Shiny for R
[Shiny for R](https://shiny.rstudio.com/) is a popular and well-established application framework in the R community and is a great choice if you want to host an R app on Hugging Face infrastructure or make use of some of the great [Shiny R extensions](https://github.com/nanxstats/awesome-shiny-extensions).
To integrate Hugging Face tools into an R app, you can either use [httr2](https://httr2.r-lib.org/) to call Hugging Face APIs, or [reticulate](https://rstudio.github.io/reticulate/) to call one of the Hugging Face Python SDKs.
To deploy an R Shiny Space, click this button and fill out the space metadata.
This will populate the Space with all the files you need to get started.
_app.R_
This file contains all of your application logic. If you prefer, you can break this file up into `ui.R` and `server.R`.
_Dockerfile_
The Dockerfile builds off of the the [rocker shiny](https://hub.docker.com/r/rocker/shiny) image. You'll need to modify this file to use additional packages.
If you are using a lot of tidyverse packages we recommend switching the base image to [rocker/shinyverse](https://hub.docker.com/r/rocker/shiny-verse).
You can install additional R packages by adding them under the `RUN install2.r` section of the dockerfile, and github packages can be installed by adding the repository under `RUN installGithub.r`.
There are two main requirements for this Dockerfile:
- First, the file must expose the port that you have listed in the README. The default is 7860 and we recommend not changing this port unless you have a reason to.
- Second, for the moment you must use the development version of [httpuv](https://github.com/rstudio/httpuv) which resolves an issue with app timeouts on Hugging Face.
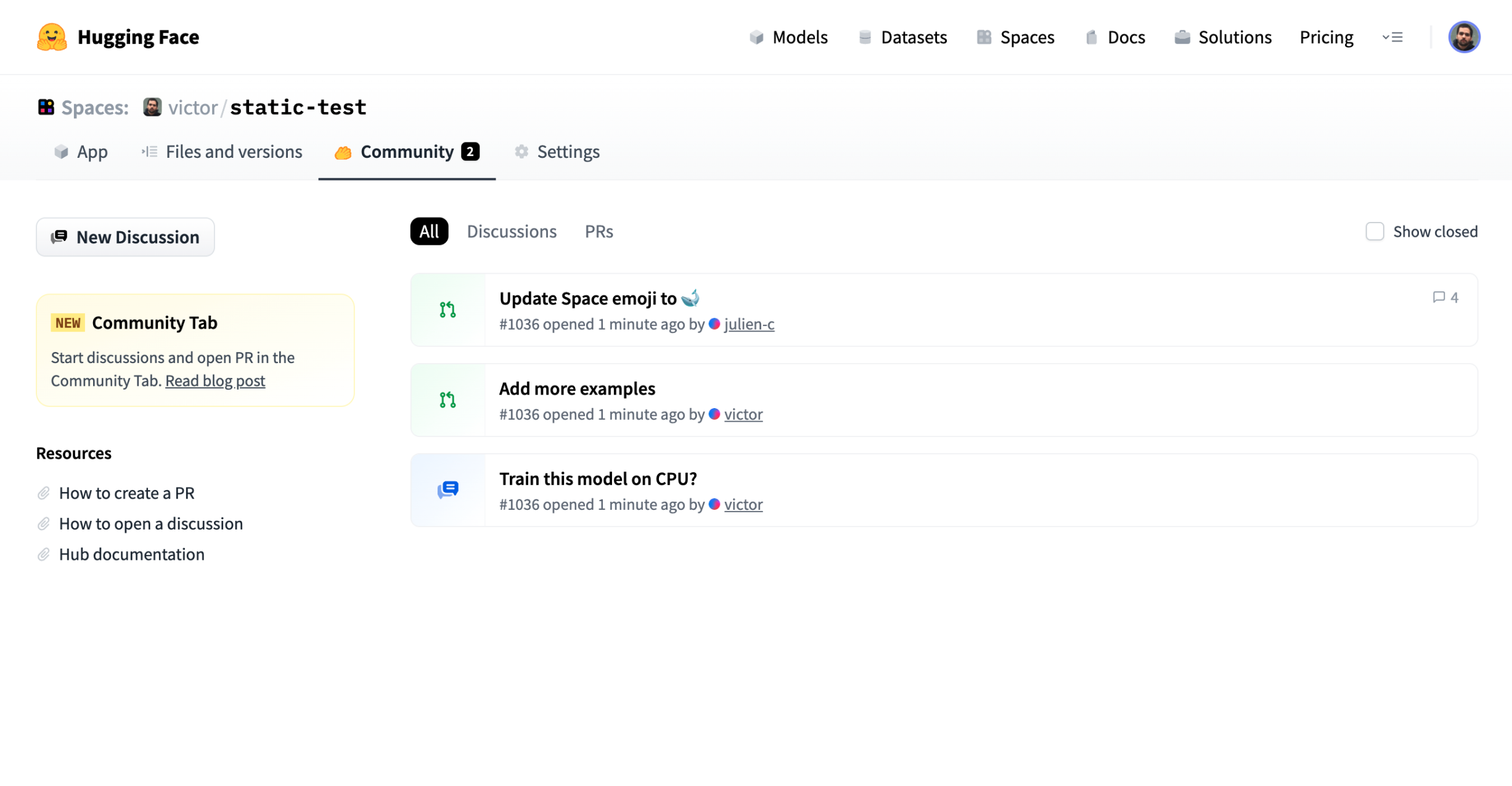
# Malware Scanning
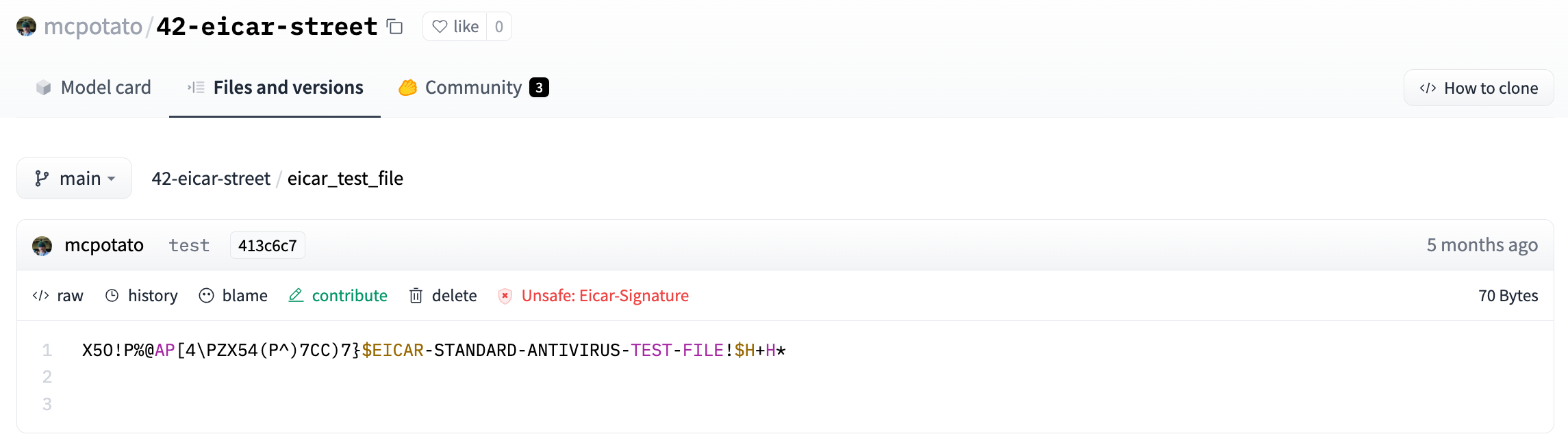
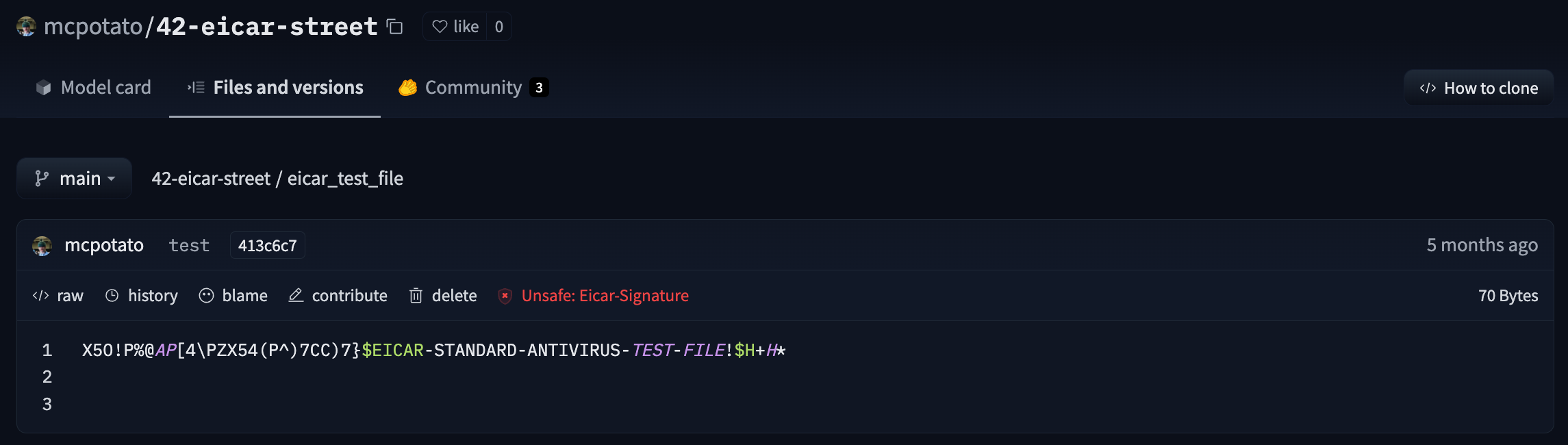
We run every file of your repositories through a [malware scanner](https://www.clamav.net/).
Scanning is triggered at each commit or when you visit a repository page.
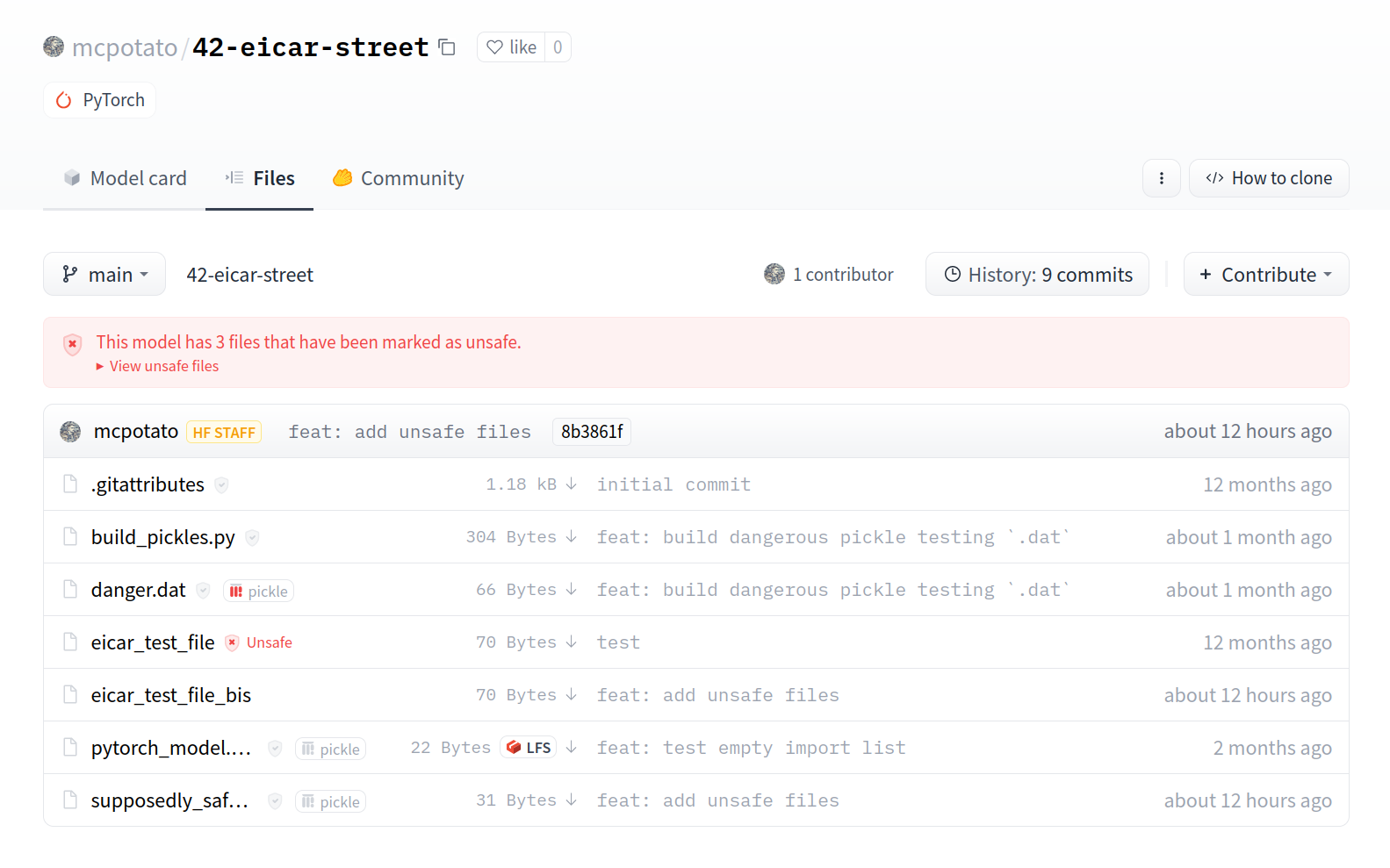
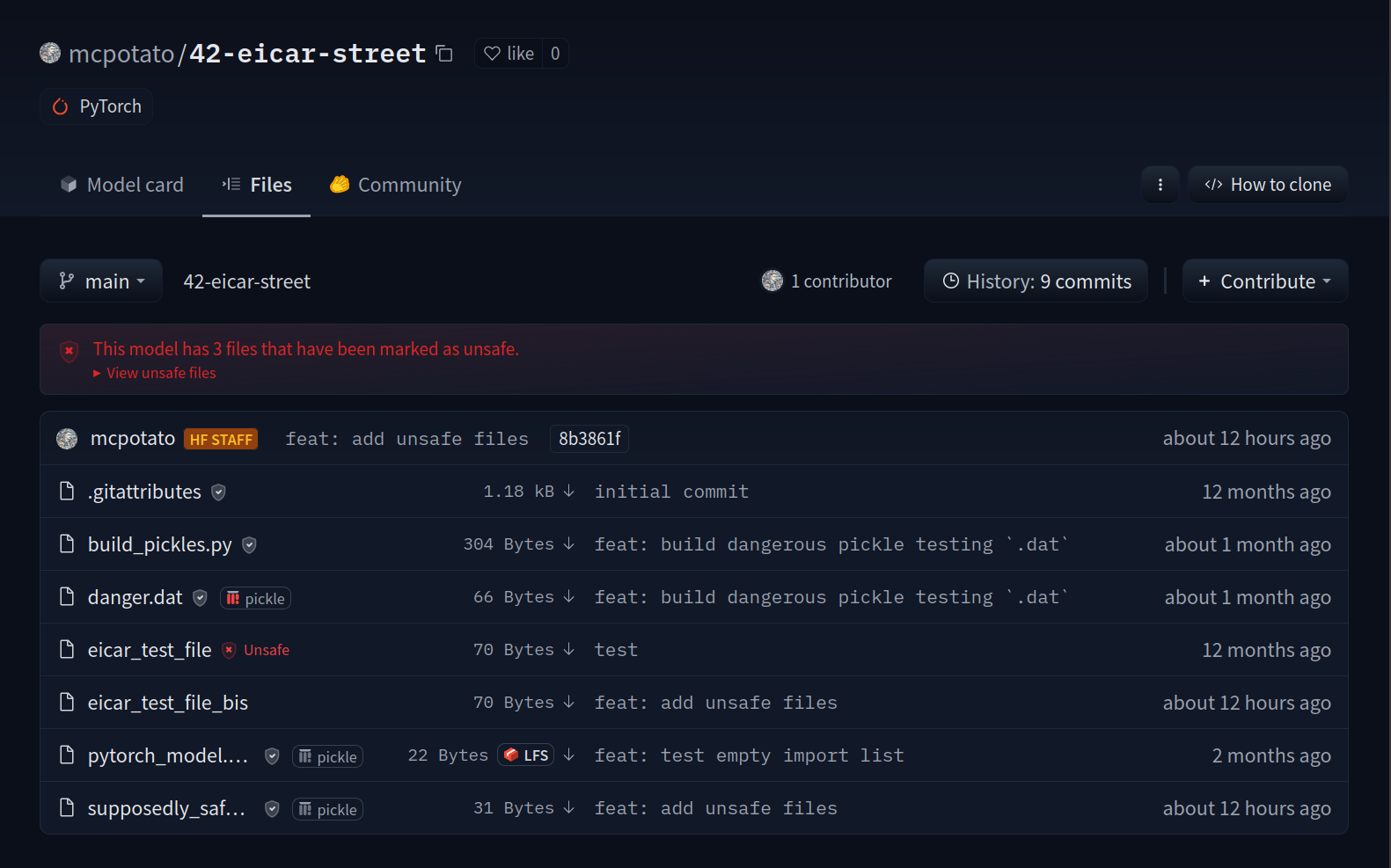
Here is an [example view](https://huggingface.co/mcpotato/42-eicar-street/tree/main) of an infected file:
_app.py_
This file defines your app's logic. To learn more about how to modify this file, see [the Shiny for Python documentation](https://shiny.rstudio.com/py/docs/overview.html).
As your app gets more complex, it's a good idea to break your application logic up into [modules](https://shiny.rstudio.com/py/docs/workflow-modules.html).
_Dockerfile_
The Dockerfile for a Shiny for Python app is very minimal because the library doesn't have many system dependencies, but you may need to modify this file if your application has additional system dependencies.
The one essential feature of this file is that it exposes and runs the app on the port specified in the space README file (which is 7860 by default).
__requirements.txt__
The Space will automatically install dependencies listed in the requirements.txt file.
Note that you must include shiny in this file.
## Shiny for R
[Shiny for R](https://shiny.rstudio.com/) is a popular and well-established application framework in the R community and is a great choice if you want to host an R app on Hugging Face infrastructure or make use of some of the great [Shiny R extensions](https://github.com/nanxstats/awesome-shiny-extensions).
To integrate Hugging Face tools into an R app, you can either use [httr2](https://httr2.r-lib.org/) to call Hugging Face APIs, or [reticulate](https://rstudio.github.io/reticulate/) to call one of the Hugging Face Python SDKs.
To deploy an R Shiny Space, click this button and fill out the space metadata.
This will populate the Space with all the files you need to get started.
_app.R_
This file contains all of your application logic. If you prefer, you can break this file up into `ui.R` and `server.R`.
_Dockerfile_
The Dockerfile builds off of the the [rocker shiny](https://hub.docker.com/r/rocker/shiny) image. You'll need to modify this file to use additional packages.
If you are using a lot of tidyverse packages we recommend switching the base image to [rocker/shinyverse](https://hub.docker.com/r/rocker/shiny-verse).
You can install additional R packages by adding them under the `RUN install2.r` section of the dockerfile, and github packages can be installed by adding the repository under `RUN installGithub.r`.
There are two main requirements for this Dockerfile:
- First, the file must expose the port that you have listed in the README. The default is 7860 and we recommend not changing this port unless you have a reason to.
- Second, for the moment you must use the development version of [httpuv](https://github.com/rstudio/httpuv) which resolves an issue with app timeouts on Hugging Face.
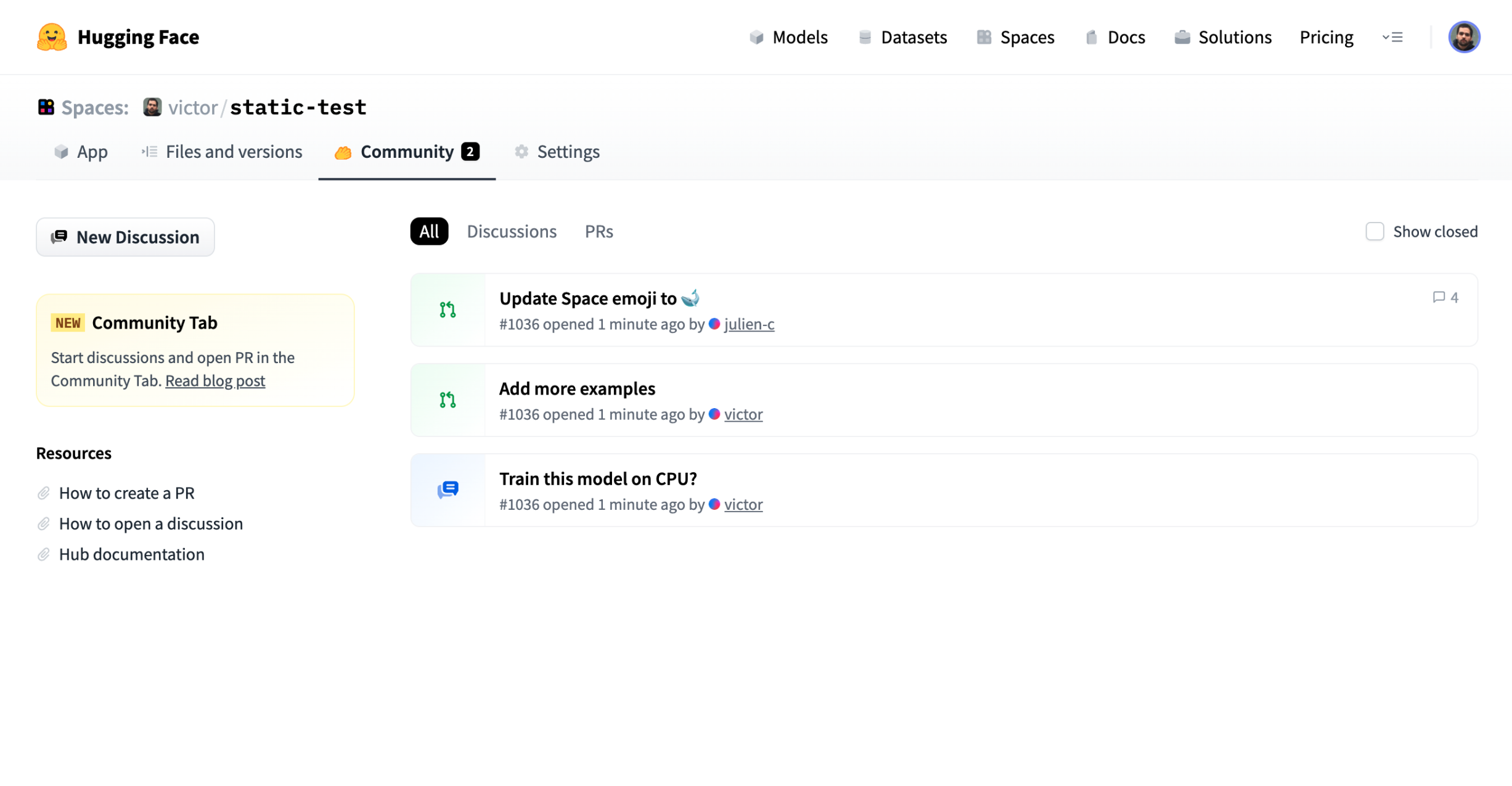
# Malware Scanning
We run every file of your repositories through a [malware scanner](https://www.clamav.net/).
Scanning is triggered at each commit or when you visit a repository page.
Here is an [example view](https://huggingface.co/mcpotato/42-eicar-street/tree/main) of an infected file:



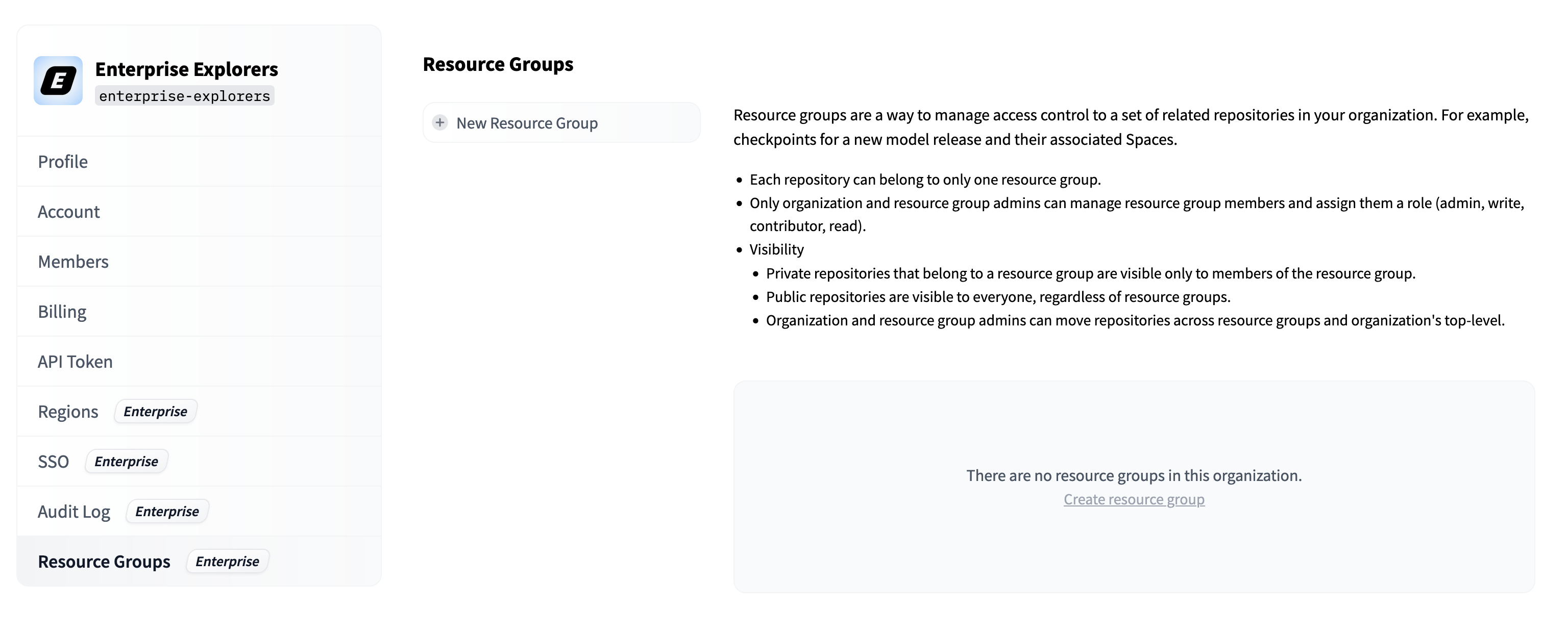
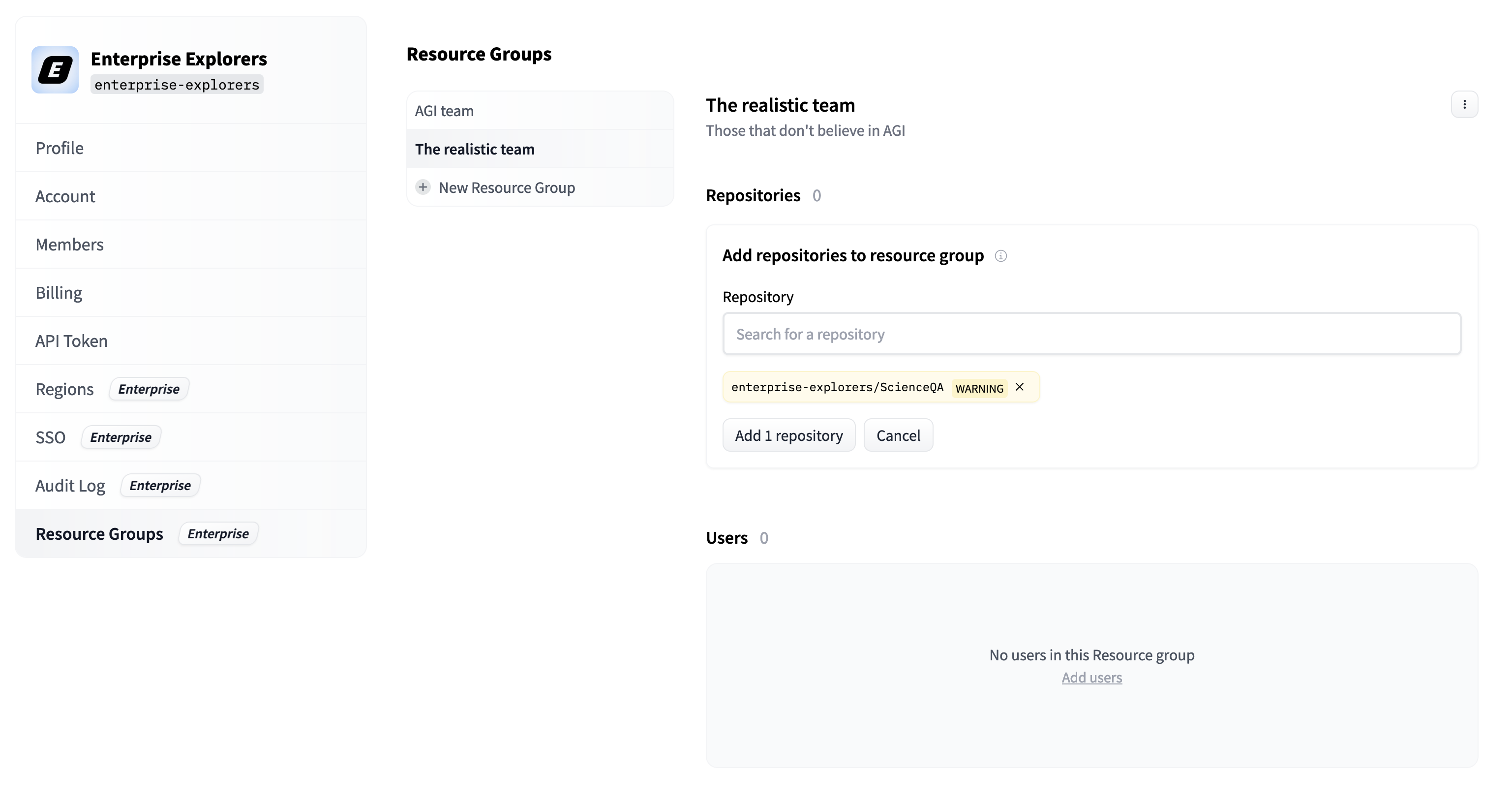
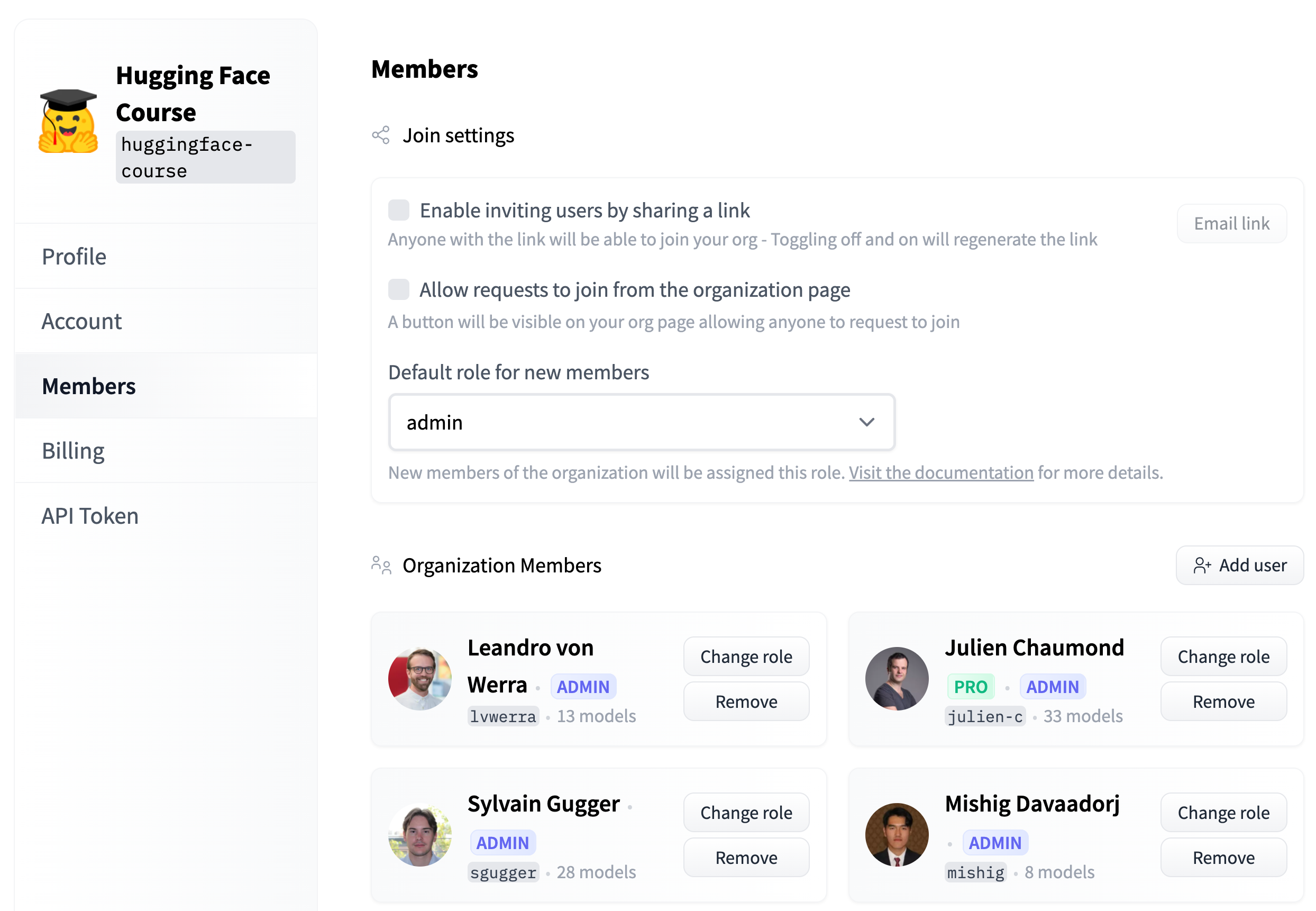
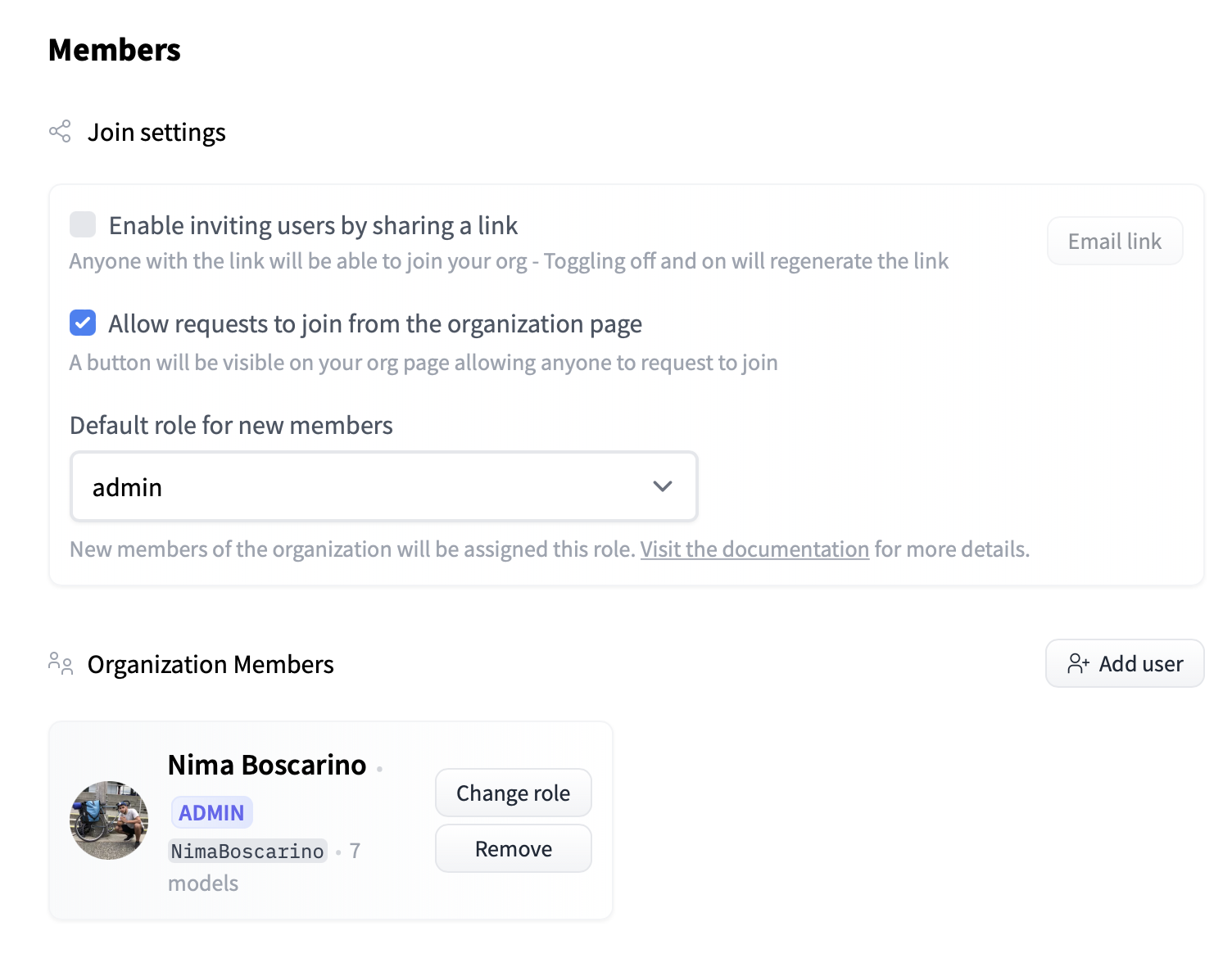
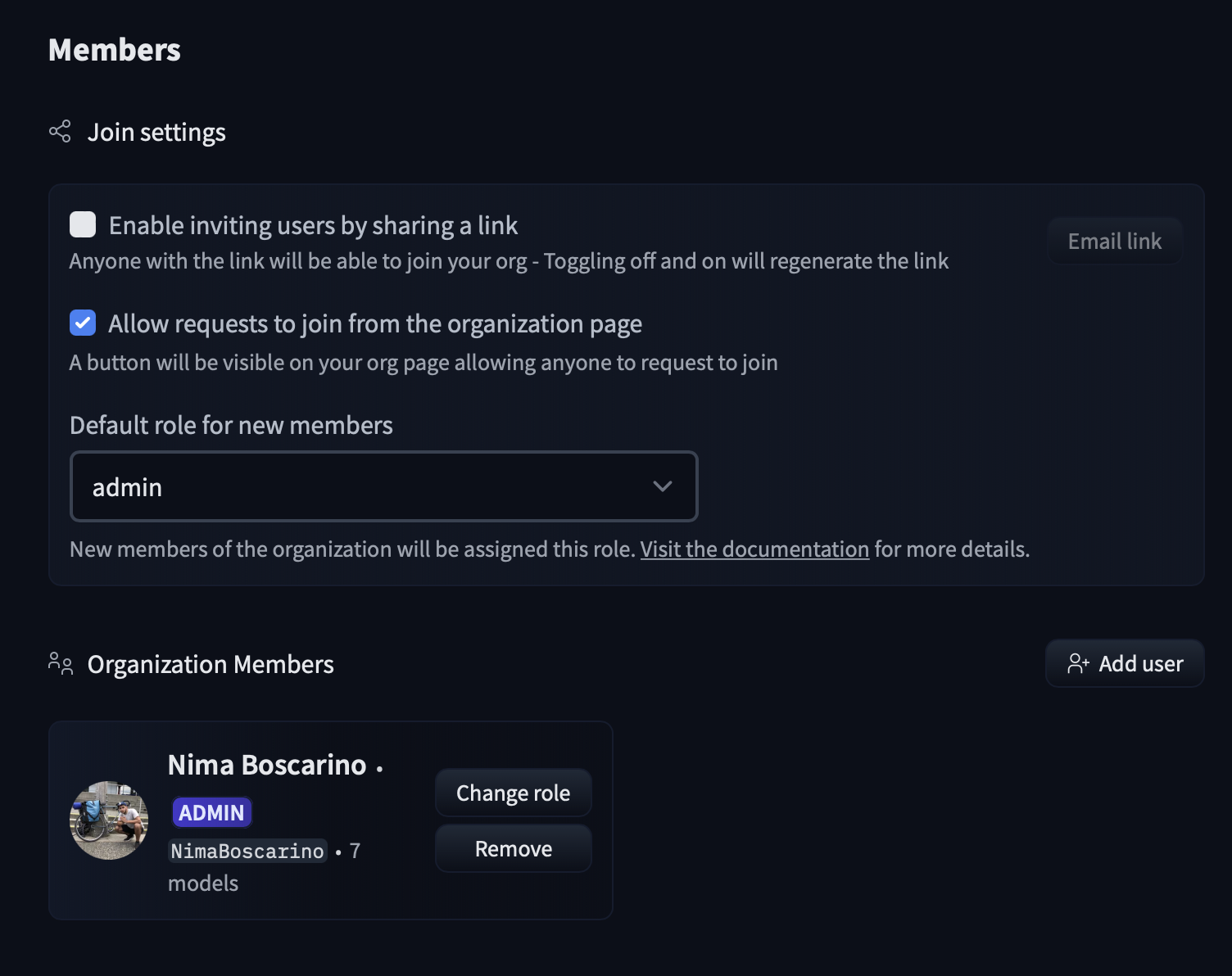
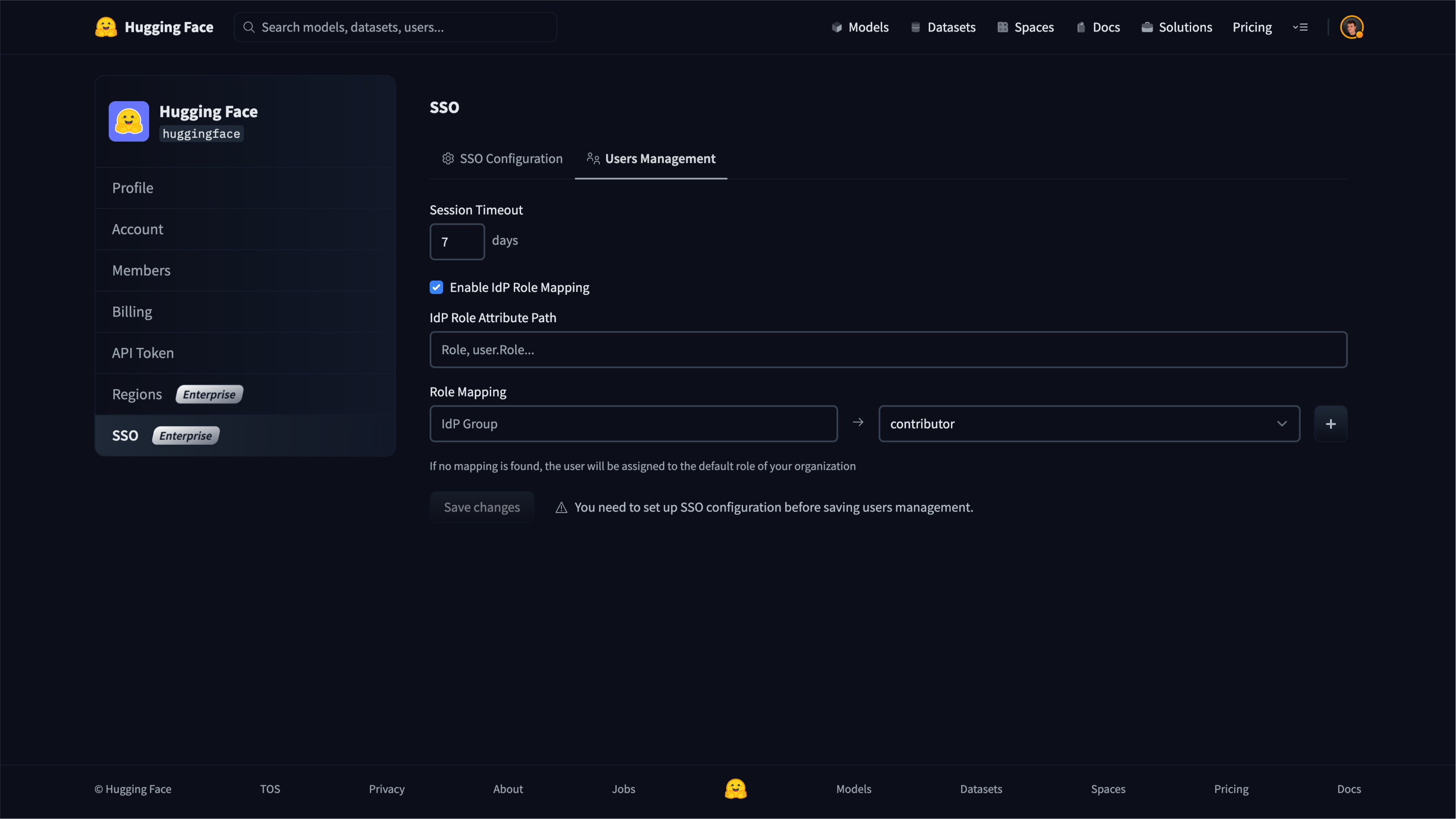
 In this section we will document the following Enterprise Hub features:
- [Single Sign-On (SSO)](./enterprise-sso)
- [Audit Logs](./audit-logs)
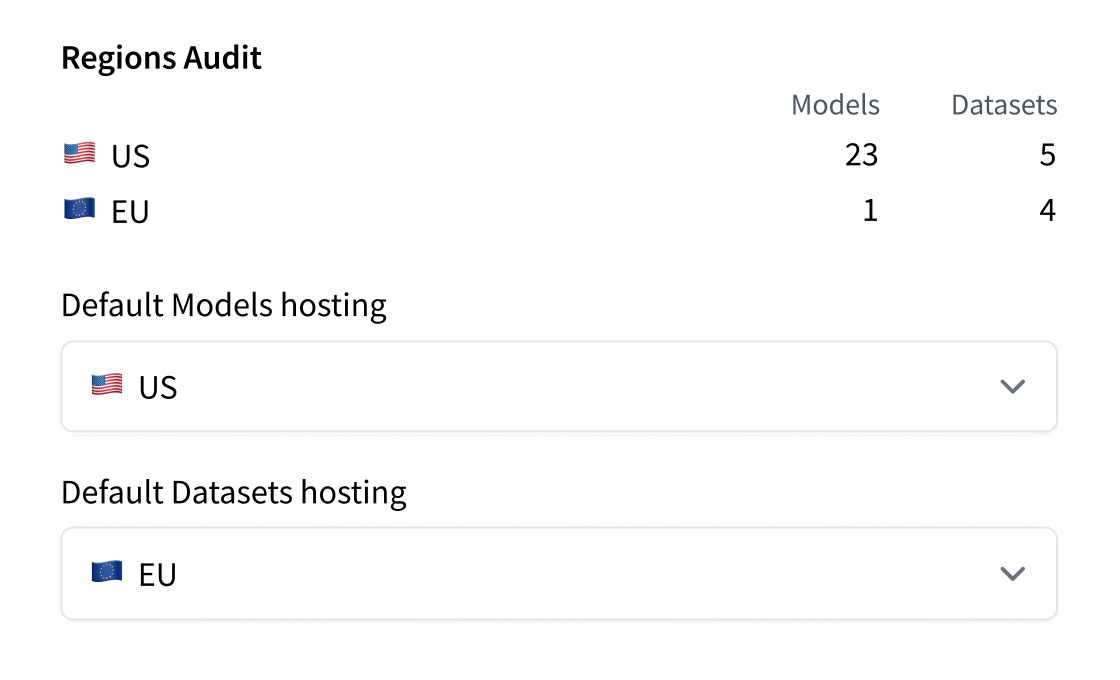
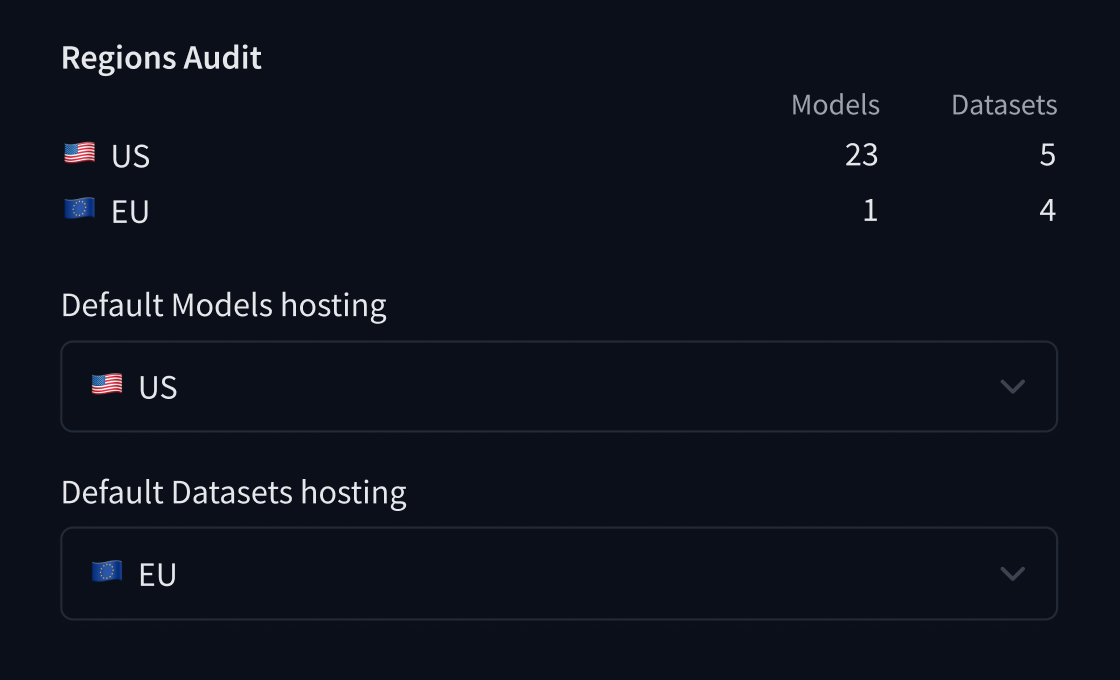
- [Storage Regions](./storage-regions)
- [Dataset viewer for Private datasets](./enterprise-hub-datasets)
- [Resource Groups](./security-resource-groups)
- [Advanced Compute Options](./advanced-compute-options)
- [Advanced Security](./enterprise-hub-advanced-security)
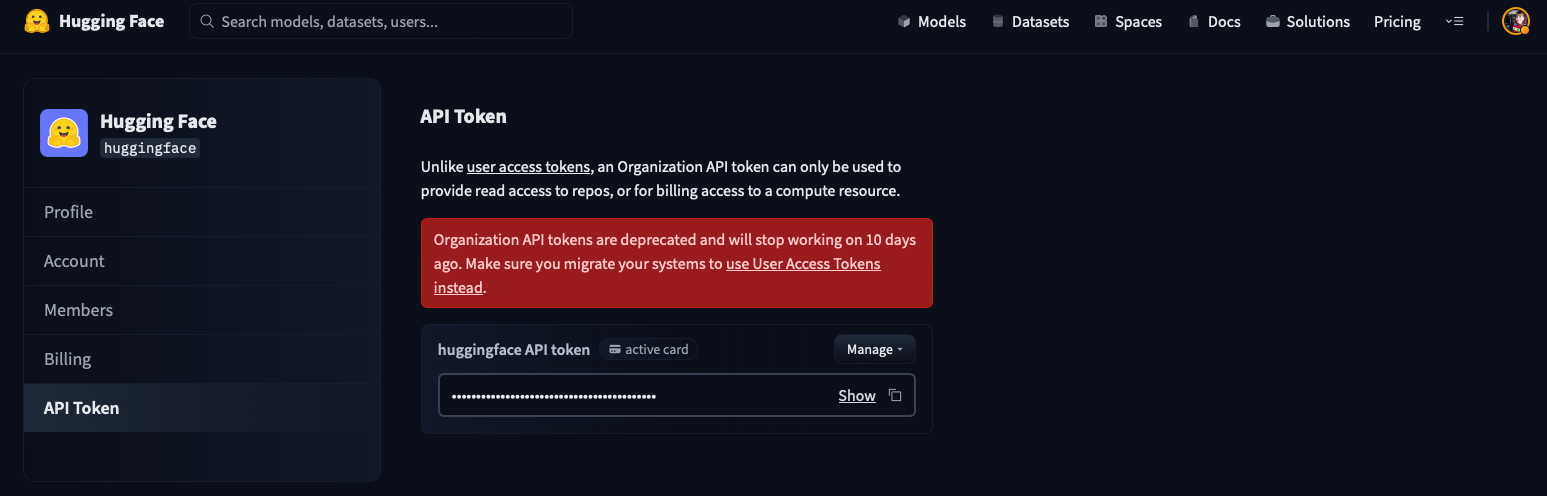
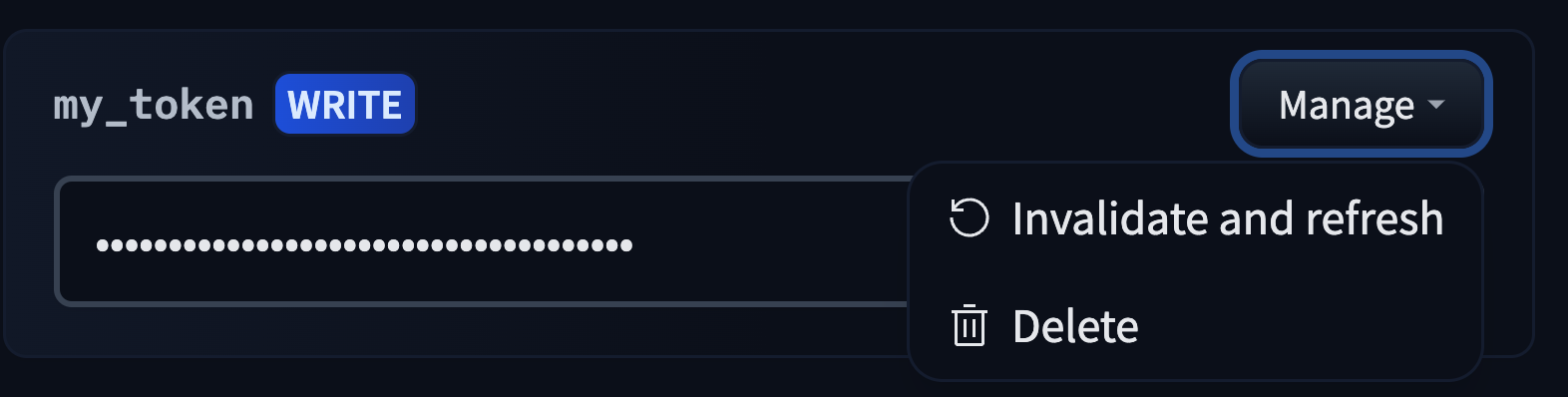
- [Tokens Management](./enterprise-hub-tokens-management)
- [Analytics](./enterprise-hub-analytics)
# Adding a Sign-In with HF button to your Space
You can enable a built-in sign-in flow in your Space by seamlessly creating and associating an [OAuth/OpenID connect](https://developer.okta.com/blog/2019/10/21/illustrated-guide-to-oauth-and-oidc) app so users can log in with their HF account.
This enables new use cases for your Space. For instance, when combined with [Persistent Storage](https://huggingface.co/docs/hub/spaces-storage), a generative AI Space could allow users to log in to access their previous generations, only accessible to them.
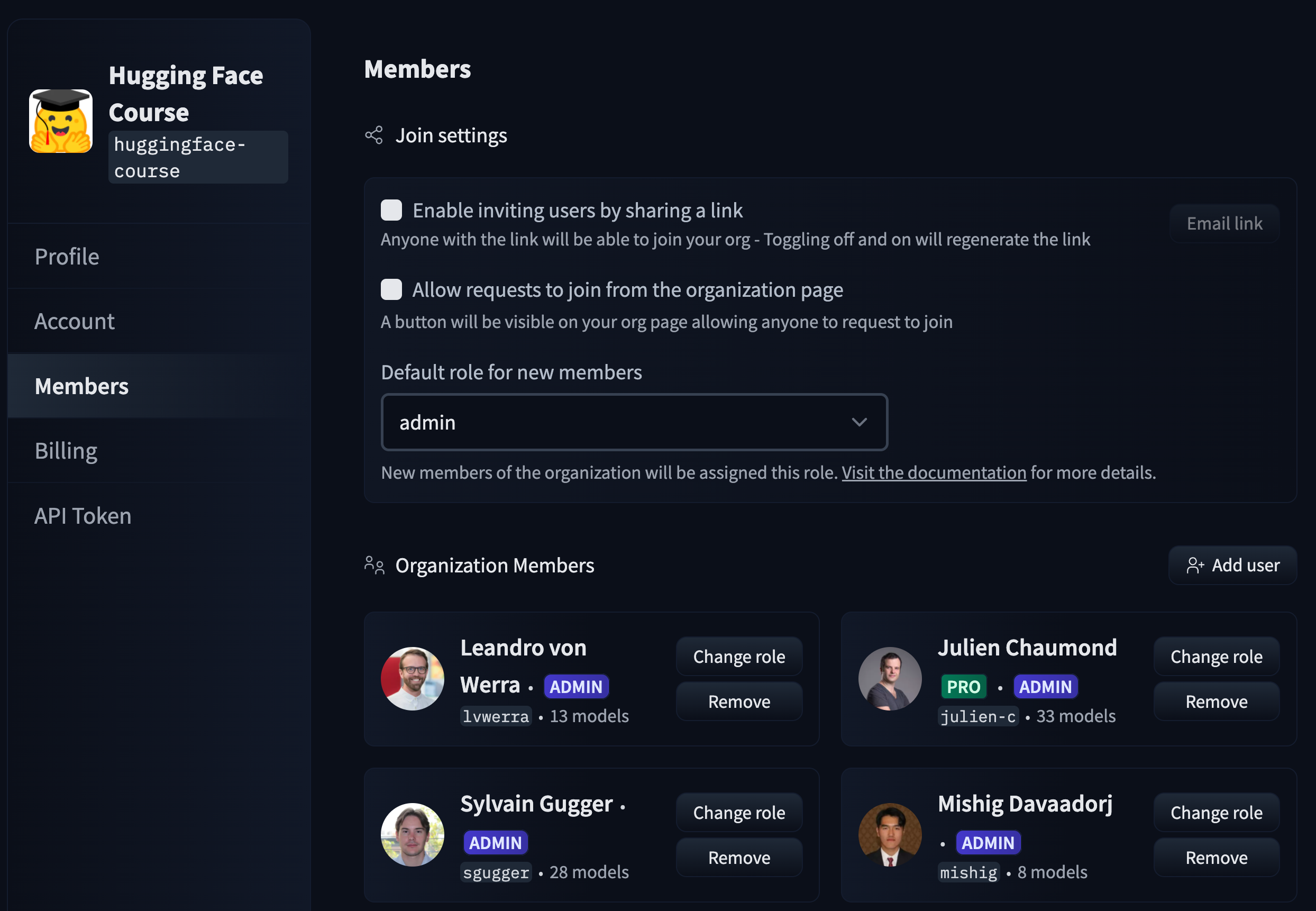
In this section we will document the following Enterprise Hub features:
- [Single Sign-On (SSO)](./enterprise-sso)
- [Audit Logs](./audit-logs)
- [Storage Regions](./storage-regions)
- [Dataset viewer for Private datasets](./enterprise-hub-datasets)
- [Resource Groups](./security-resource-groups)
- [Advanced Compute Options](./advanced-compute-options)
- [Advanced Security](./enterprise-hub-advanced-security)
- [Tokens Management](./enterprise-hub-tokens-management)
- [Analytics](./enterprise-hub-analytics)
# Adding a Sign-In with HF button to your Space
You can enable a built-in sign-in flow in your Space by seamlessly creating and associating an [OAuth/OpenID connect](https://developer.okta.com/blog/2019/10/21/illustrated-guide-to-oauth-and-oidc) app so users can log in with their HF account.
This enables new use cases for your Space. For instance, when combined with [Persistent Storage](https://huggingface.co/docs/hub/spaces-storage), a generative AI Space could allow users to log in to access their previous generations, only accessible to them.

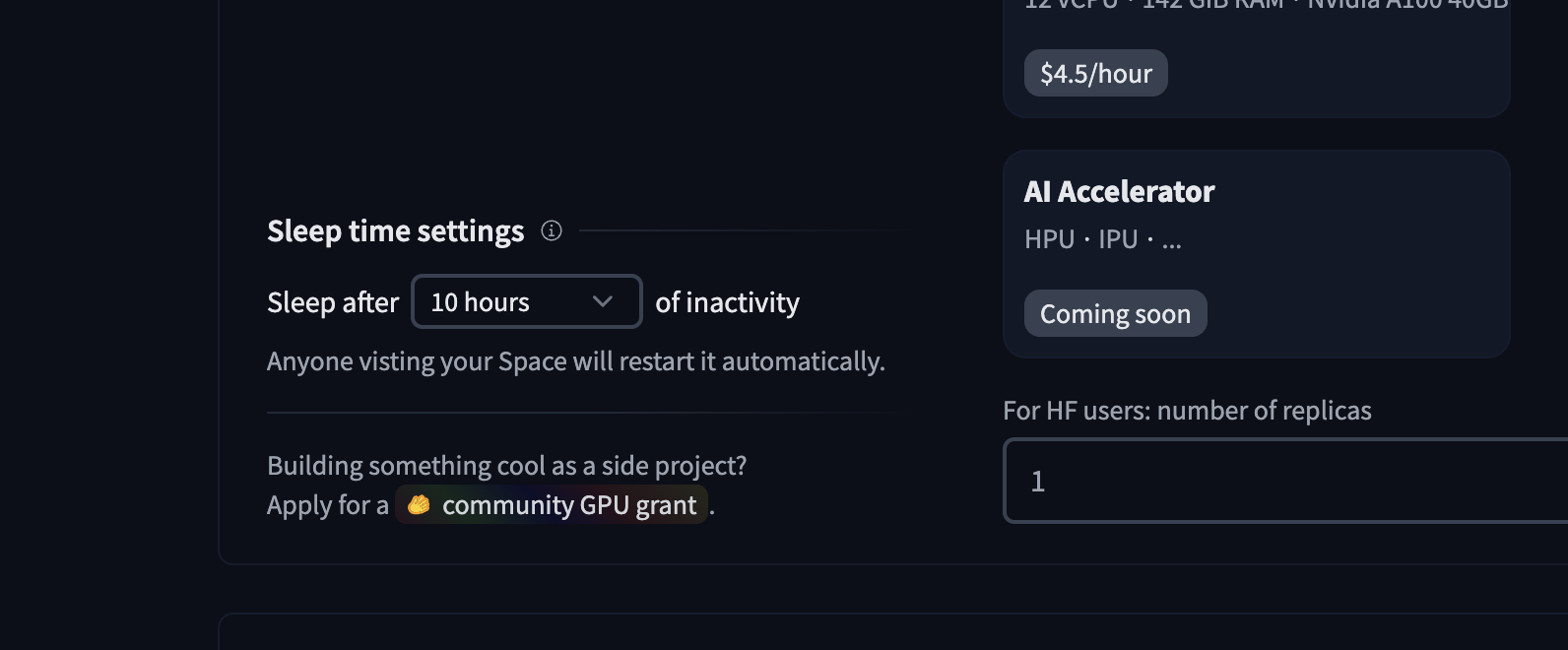
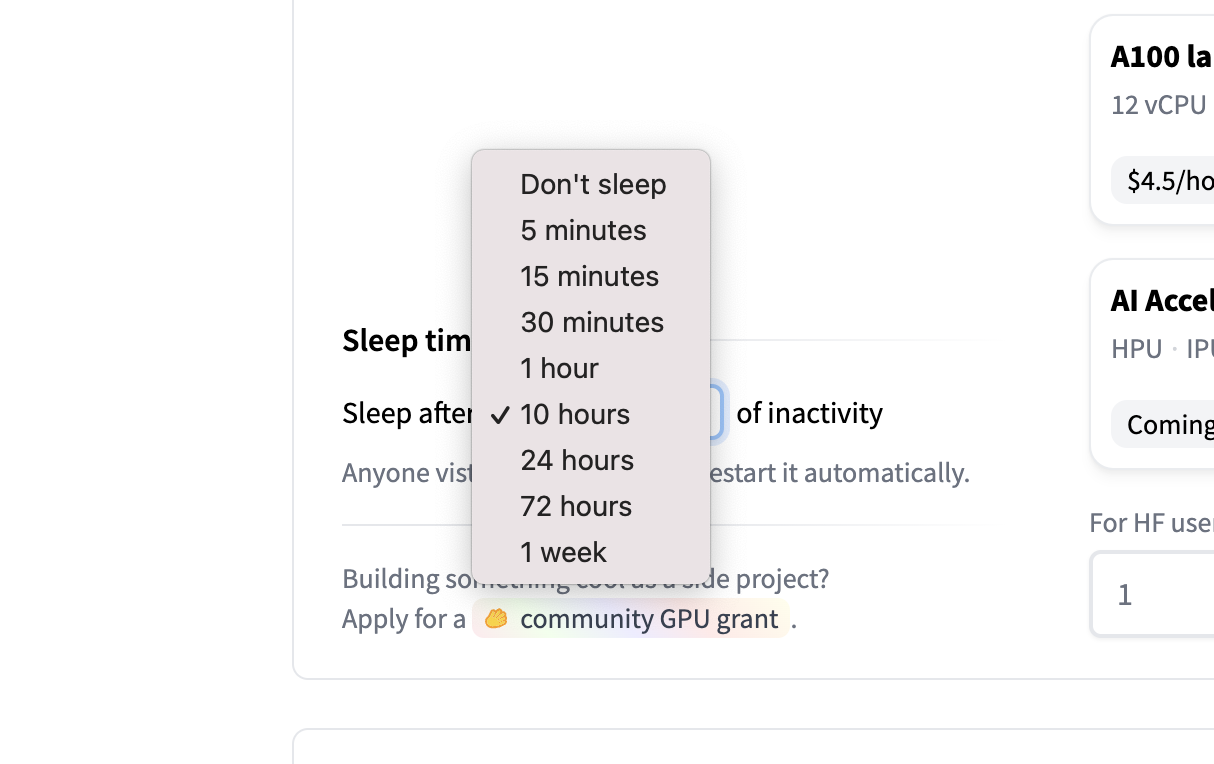
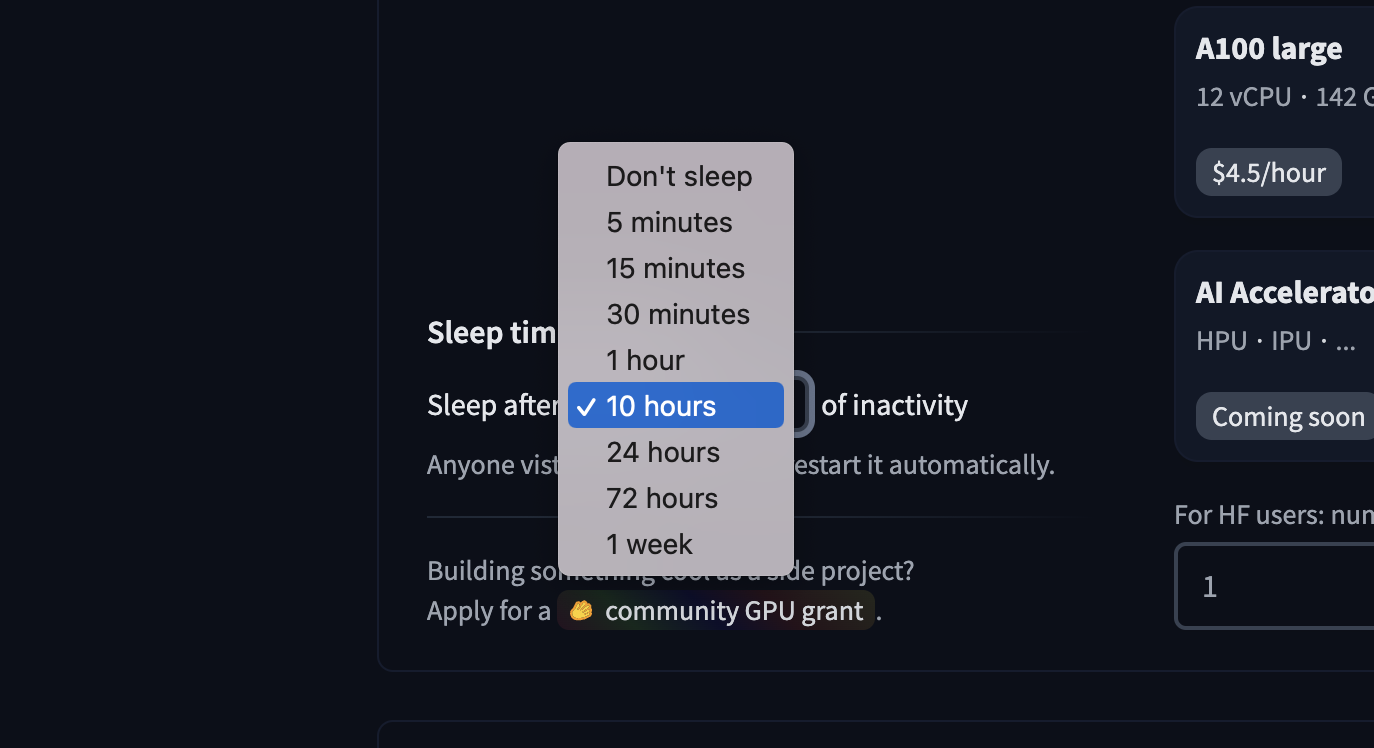 Once you have created the Space, you'll see the `Building` status, and once it becomes `Running,` your Space is ready to go!
Once you have created the Space, you'll see the `Building` status, and once it becomes `Running,` your Space is ready to go!
 Now, when you navigate to your Space's **App** section, you can access the Aim UI.
## Compare your experiments with Aim on Spaces
Let's use a quick example of a PyTorch CNN trained on MNIST to demonstrate end-to-end Aim on Spaces deployment.
The full example is in the [Aim repo examples folder](https://github.com/aimhubio/aim/blob/main/examples/pytorch_track.py).
```python
from aim import Run
from aim.pytorch import track_gradients_dists, track_params_dists
# Initialize a new Run
aim_run = Run()
...
items = {'accuracy': acc, 'loss': loss}
aim_run.track(items, epoch=epoch, context={'subset': 'train'})
# Track weights and gradients distributions
track_params_dists(model, aim_run)
track_gradients_dists(model, aim_run)
```
The experiments tracked by Aim are stored in the `.aim` folder. **To display the logs with the Aim UI in your Space, you need to compress the `.aim` folder to a `tar.gz` file and upload it to your Space using `git` or the Files and Versions sections of your Space.**
Here's a bash command for that:
```bash
tar -czvf aim_repo.tar.gz .aim
```
That’s it! Now open the App section of your Space and the Aim UI is available with your logs.
Here is what to expect:
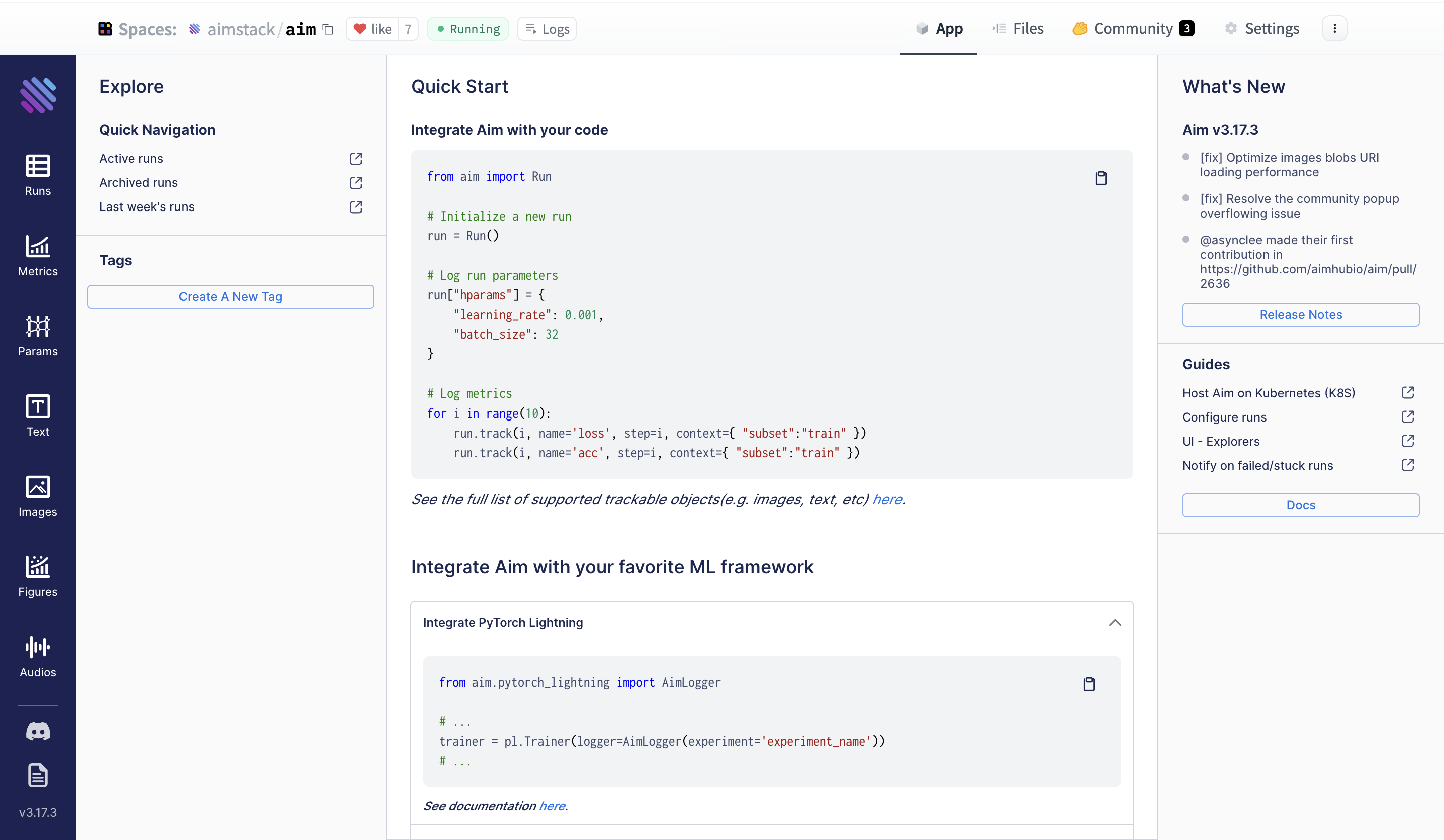
Filter your runs using Aim’s Pythonic search. You can write pythonic [queries against](https://aimstack.readthedocs.io/en/latest/using/search.html) EVERYTHING you have tracked - metrics, hyperparams etc. Check out some [examples](https://huggingface.co/aimstack) on HF Hub Spaces.
Now, when you navigate to your Space's **App** section, you can access the Aim UI.
## Compare your experiments with Aim on Spaces
Let's use a quick example of a PyTorch CNN trained on MNIST to demonstrate end-to-end Aim on Spaces deployment.
The full example is in the [Aim repo examples folder](https://github.com/aimhubio/aim/blob/main/examples/pytorch_track.py).
```python
from aim import Run
from aim.pytorch import track_gradients_dists, track_params_dists
# Initialize a new Run
aim_run = Run()
...
items = {'accuracy': acc, 'loss': loss}
aim_run.track(items, epoch=epoch, context={'subset': 'train'})
# Track weights and gradients distributions
track_params_dists(model, aim_run)
track_gradients_dists(model, aim_run)
```
The experiments tracked by Aim are stored in the `.aim` folder. **To display the logs with the Aim UI in your Space, you need to compress the `.aim` folder to a `tar.gz` file and upload it to your Space using `git` or the Files and Versions sections of your Space.**
Here's a bash command for that:
```bash
tar -czvf aim_repo.tar.gz .aim
```
That’s it! Now open the App section of your Space and the Aim UI is available with your logs.
Here is what to expect:

Filter your runs using Aim’s Pythonic search. You can write pythonic [queries against](https://aimstack.readthedocs.io/en/latest/using/search.html) EVERYTHING you have tracked - metrics, hyperparams etc. Check out some [examples](https://huggingface.co/aimstack) on HF Hub Spaces.


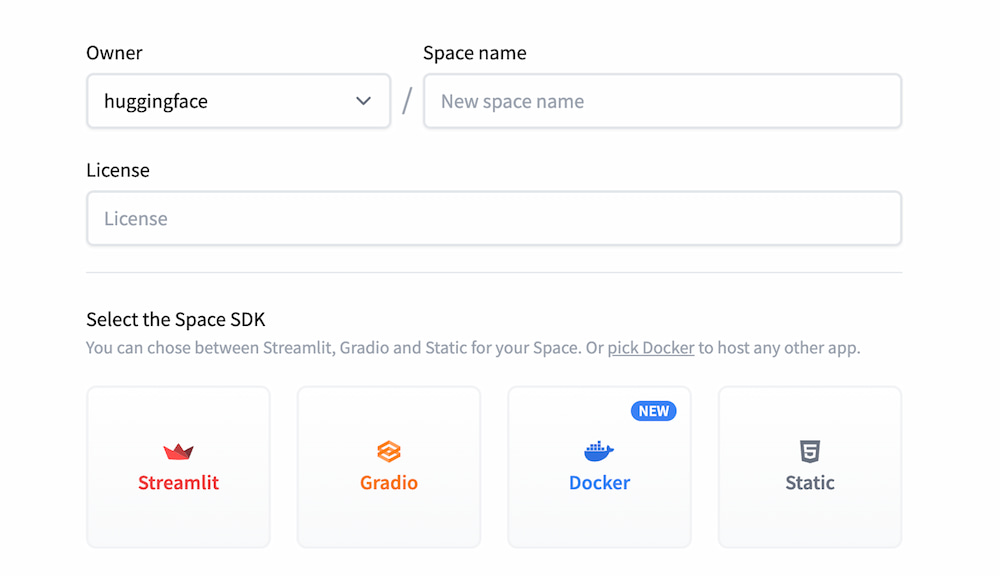
 To set up your ZenML app, you need to specify three main components: the Owner
(either your personal account or an organization), a Space name, and the
Visibility (a bit lower down the page). Note that the space visibility needs to
be set to 'Public' if you wish to connect to the ZenML server from your local
machine.
You have the option here to select a higher tier machine to use for your server.
The advantage of selecting a paid CPU instance is that it is not subject to
auto-shutdown policies and thus will stay up as long as you leave it up. In
order to make use of a persistent CPU, you'll likely want to create and set up a
MySQL database to connect to (see below).
To personalize your Space's appearance, such as the title, emojis, and colors,
navigate to "Files and Versions" and modify the metadata in your README.md file.
Full information on Spaces configuration parameters can be found on the
HuggingFace [documentation reference guide](https://huggingface.co/docs/hub/spaces-config-reference).
After creating your Space, you'll notice a 'Building' status along with logs
displayed on the screen. When this switches to 'Running', your Space is ready for use. If the
ZenML login UI isn't visible, try refreshing the page.
In the upper-right hand corner of your space you'll see a button with three dots
which, when you click on it, will offer you a menu option to "Embed this Space".
(See [the HuggingFace
documentation](https://huggingface.co/docs/hub/spaces-embed) for more details on
this feature.) Copy the "Direct URL" shown in the box that you can now see on
the screen. This should look something like this:
`https://
To set up your ZenML app, you need to specify three main components: the Owner
(either your personal account or an organization), a Space name, and the
Visibility (a bit lower down the page). Note that the space visibility needs to
be set to 'Public' if you wish to connect to the ZenML server from your local
machine.

You have the option here to select a higher tier machine to use for your server.
The advantage of selecting a paid CPU instance is that it is not subject to
auto-shutdown policies and thus will stay up as long as you leave it up. In
order to make use of a persistent CPU, you'll likely want to create and set up a
MySQL database to connect to (see below).
To personalize your Space's appearance, such as the title, emojis, and colors,
navigate to "Files and Versions" and modify the metadata in your README.md file.
Full information on Spaces configuration parameters can be found on the
HuggingFace [documentation reference guide](https://huggingface.co/docs/hub/spaces-config-reference).
After creating your Space, you'll notice a 'Building' status along with logs
displayed on the screen. When this switches to 'Running', your Space is ready for use. If the
ZenML login UI isn't visible, try refreshing the page.
In the upper-right hand corner of your space you'll see a button with three dots
which, when you click on it, will offer you a menu option to "Embed this Space".
(See [the HuggingFace
documentation](https://huggingface.co/docs/hub/spaces-embed) for more details on
this feature.) Copy the "Direct URL" shown in the box that you can now see on
the screen. This should look something like this:
`https://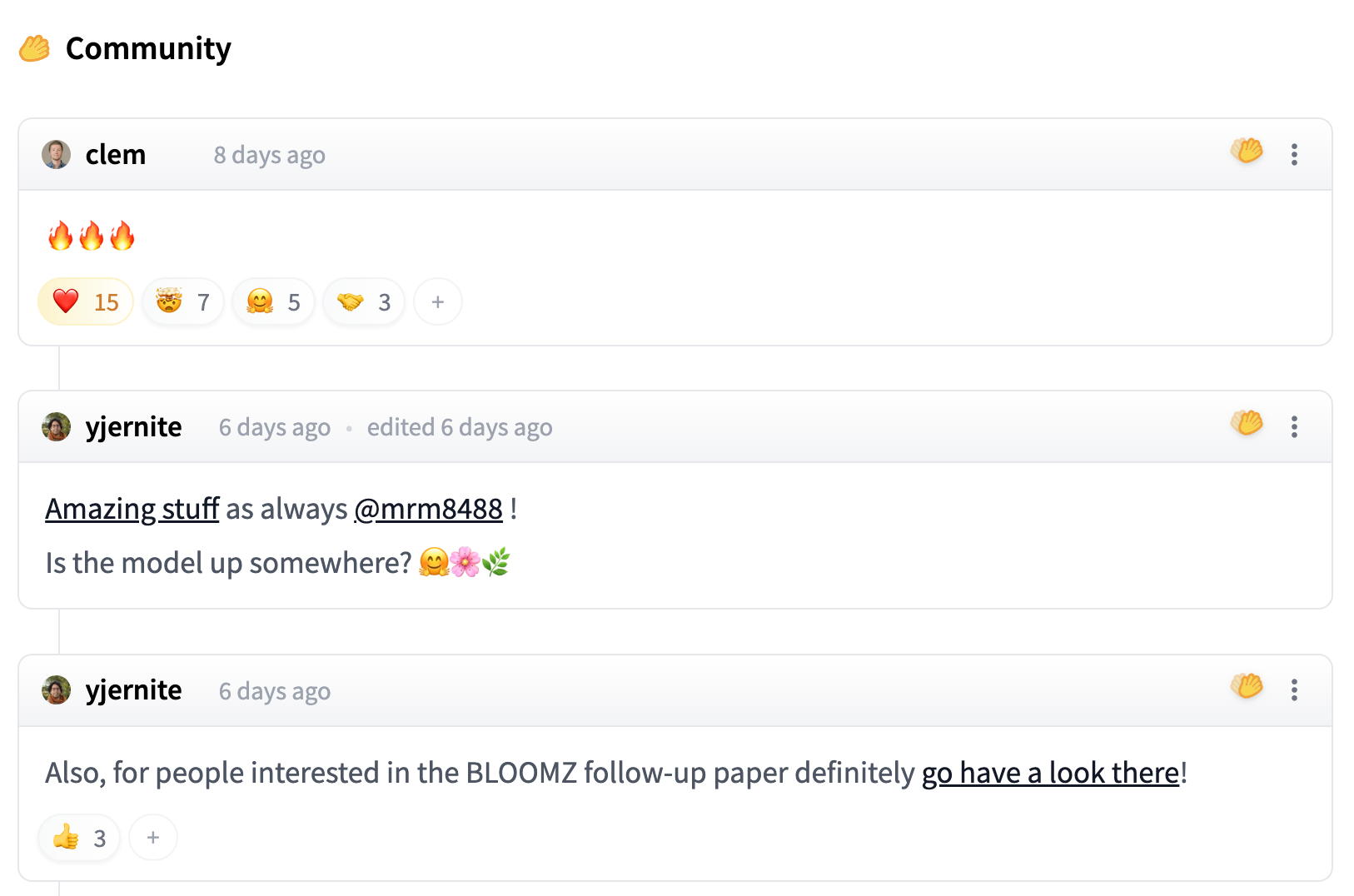







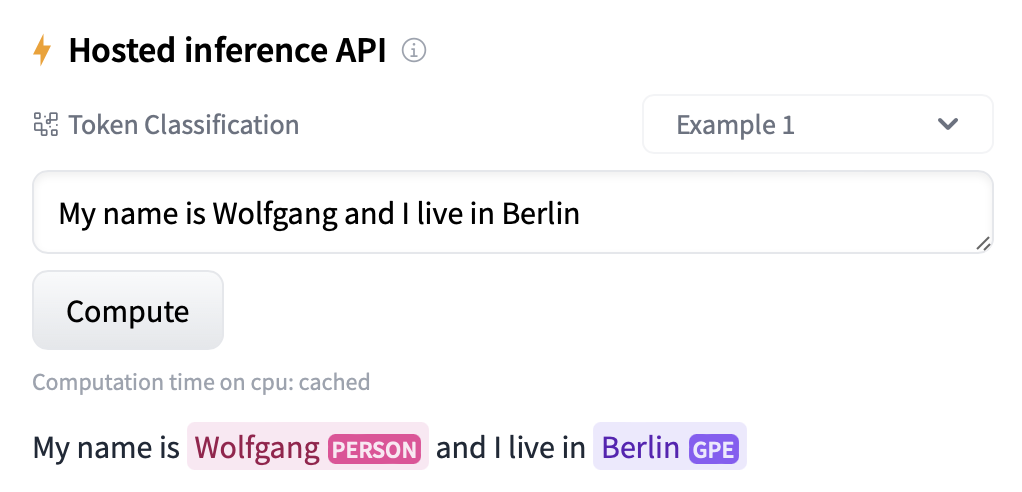
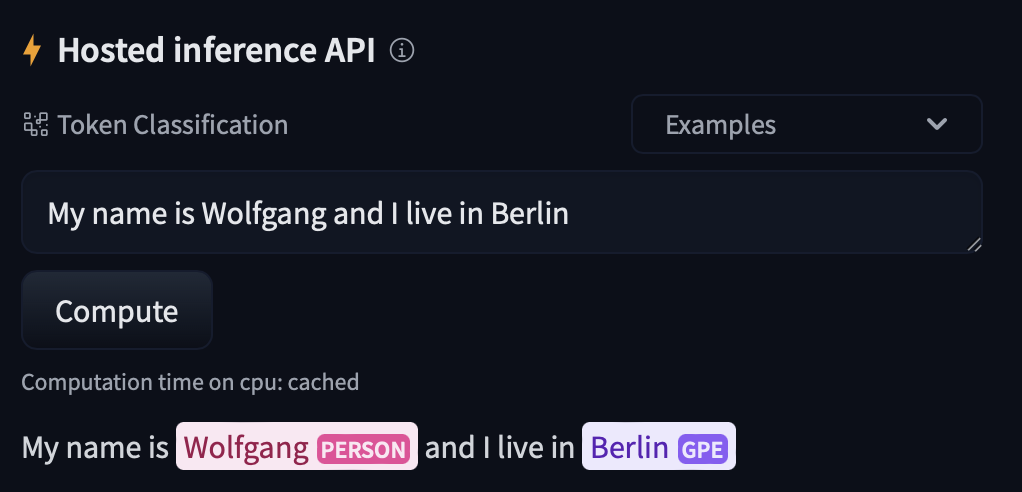

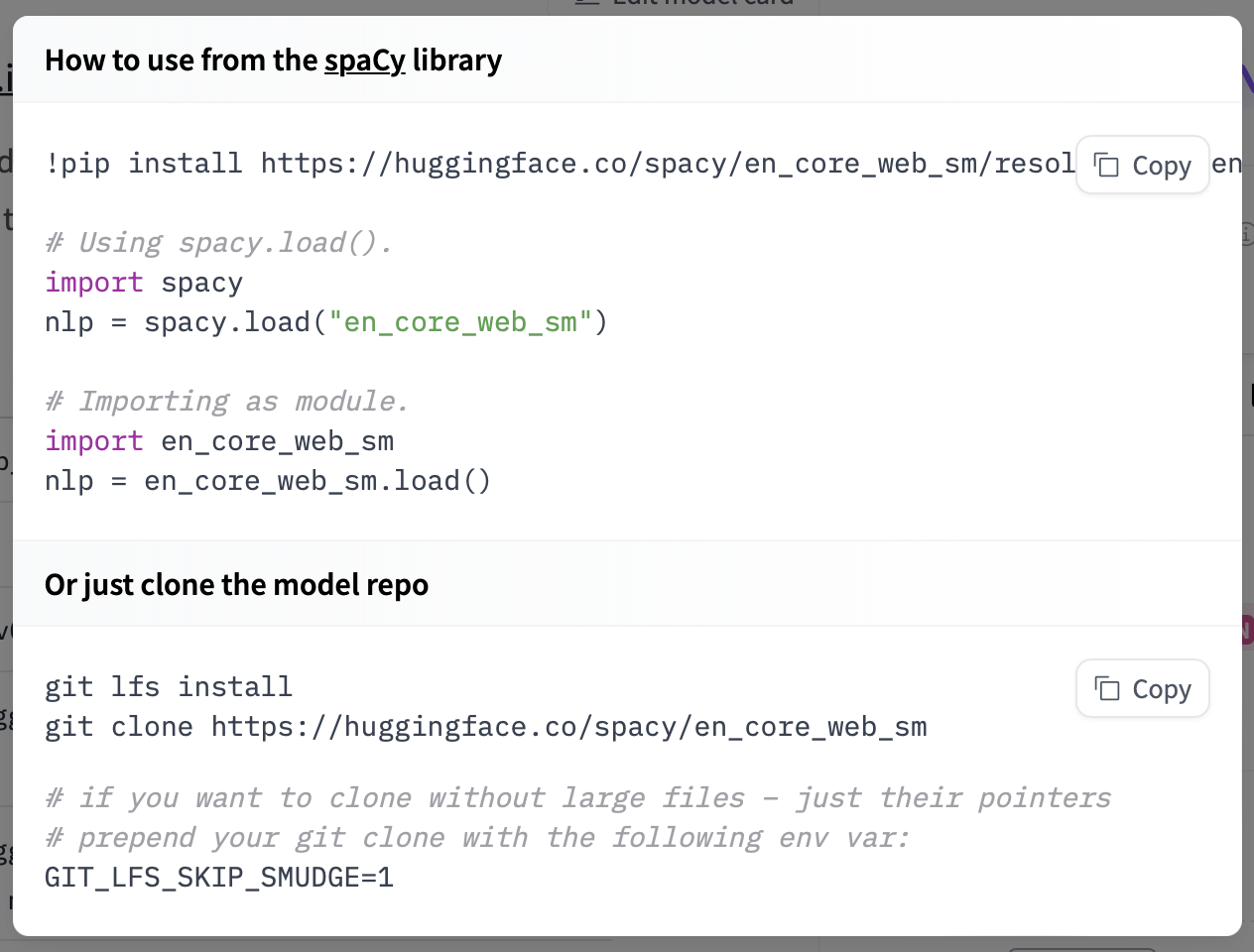
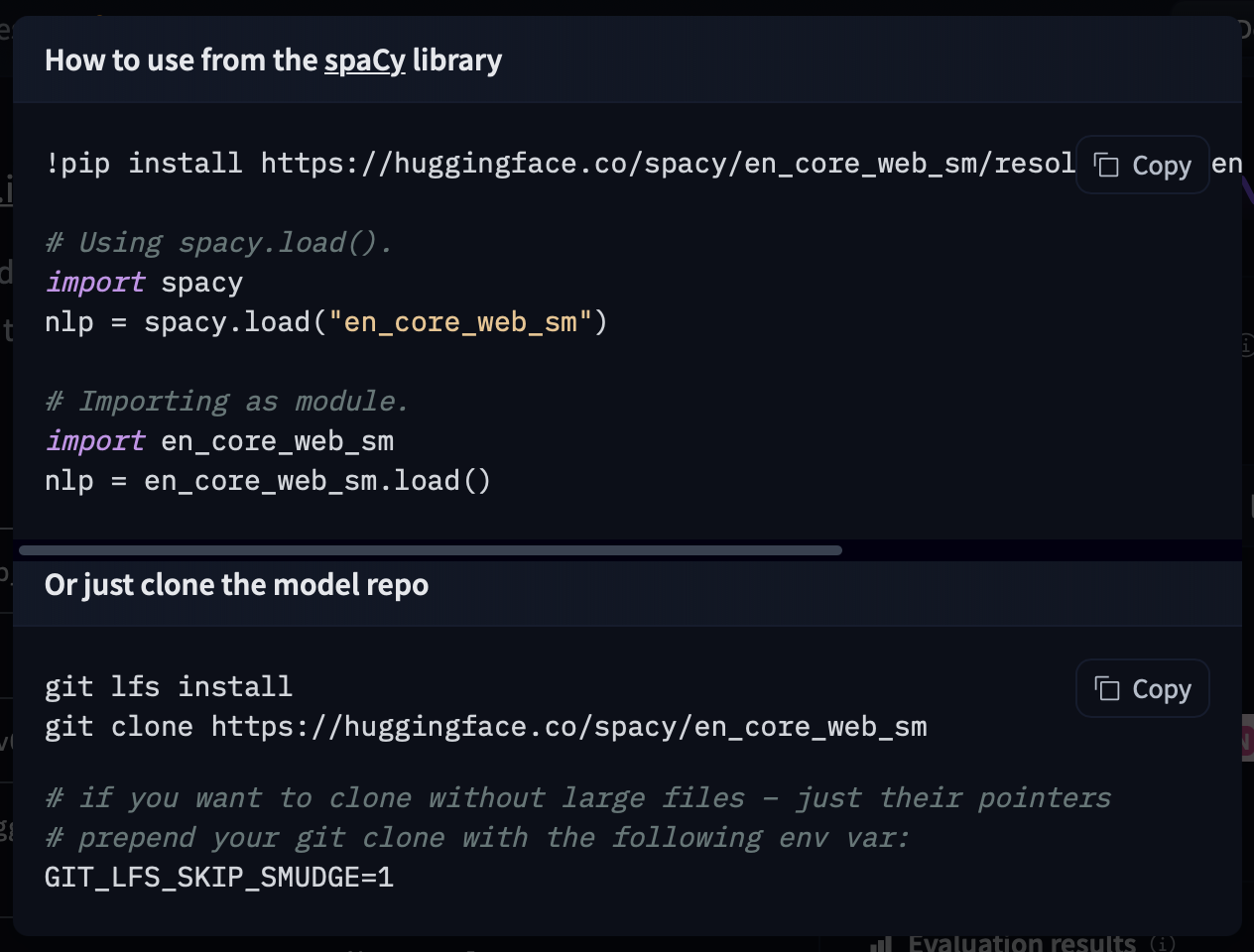


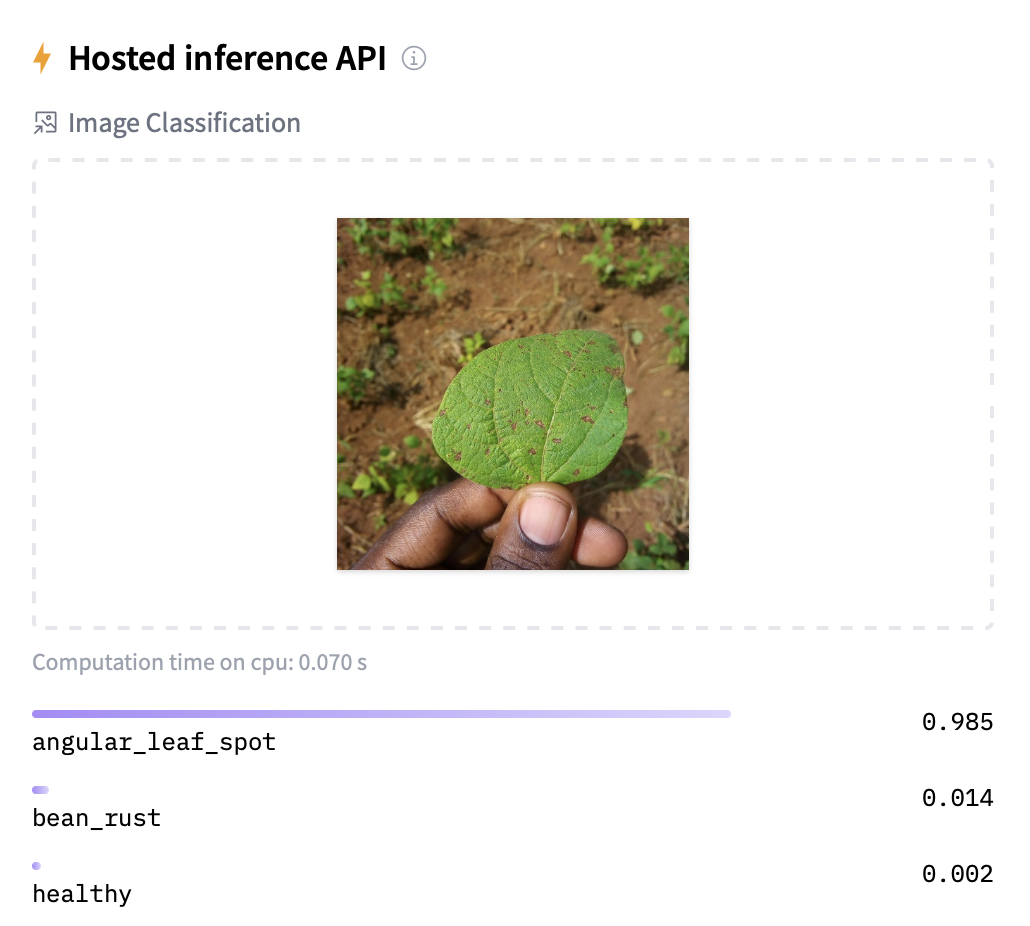
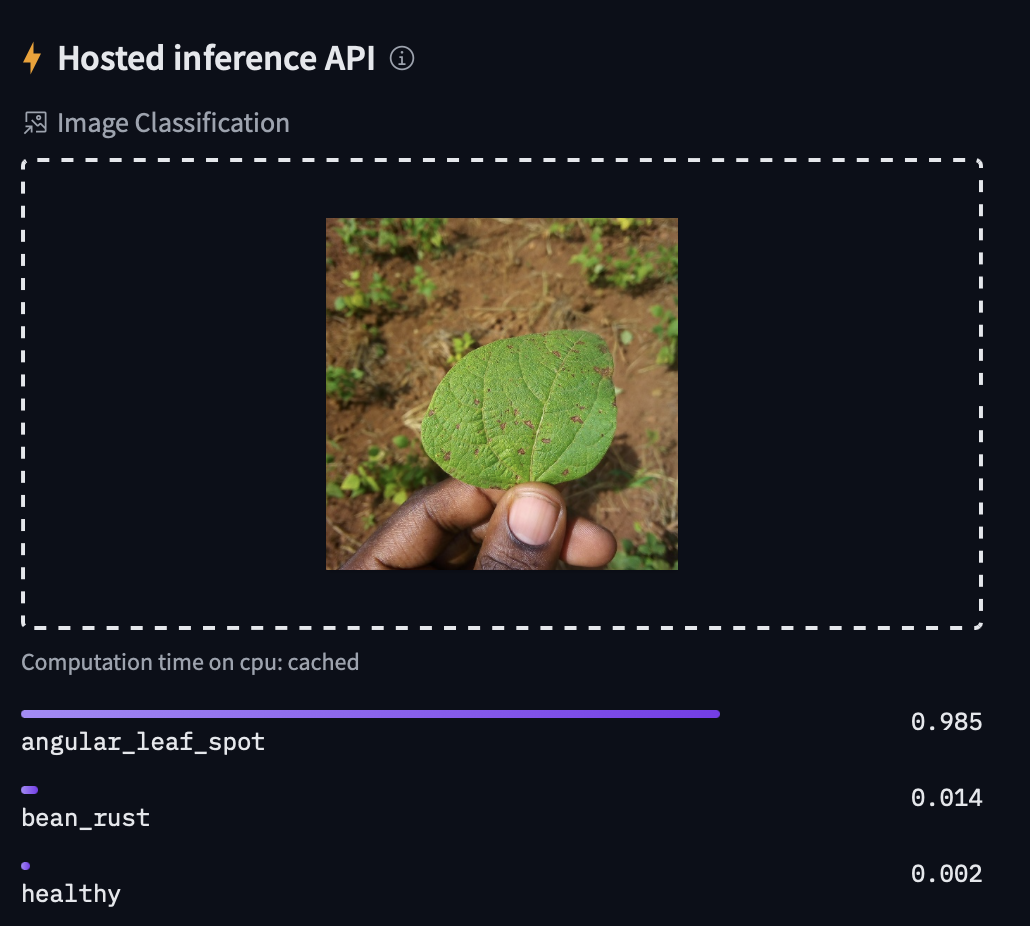


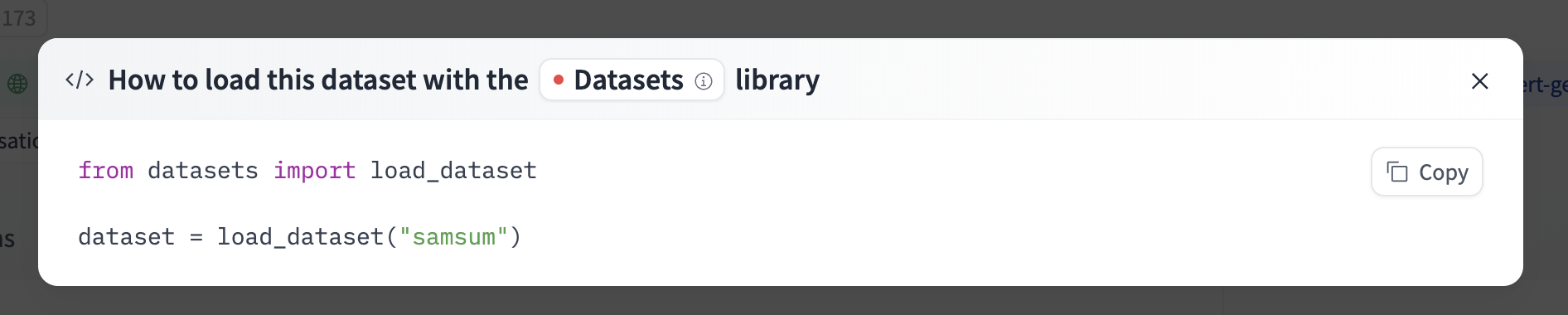
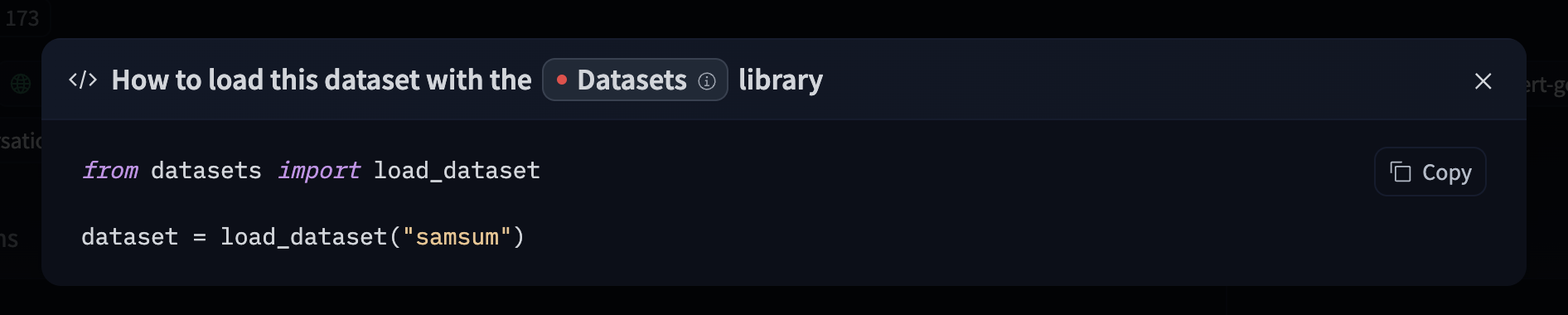


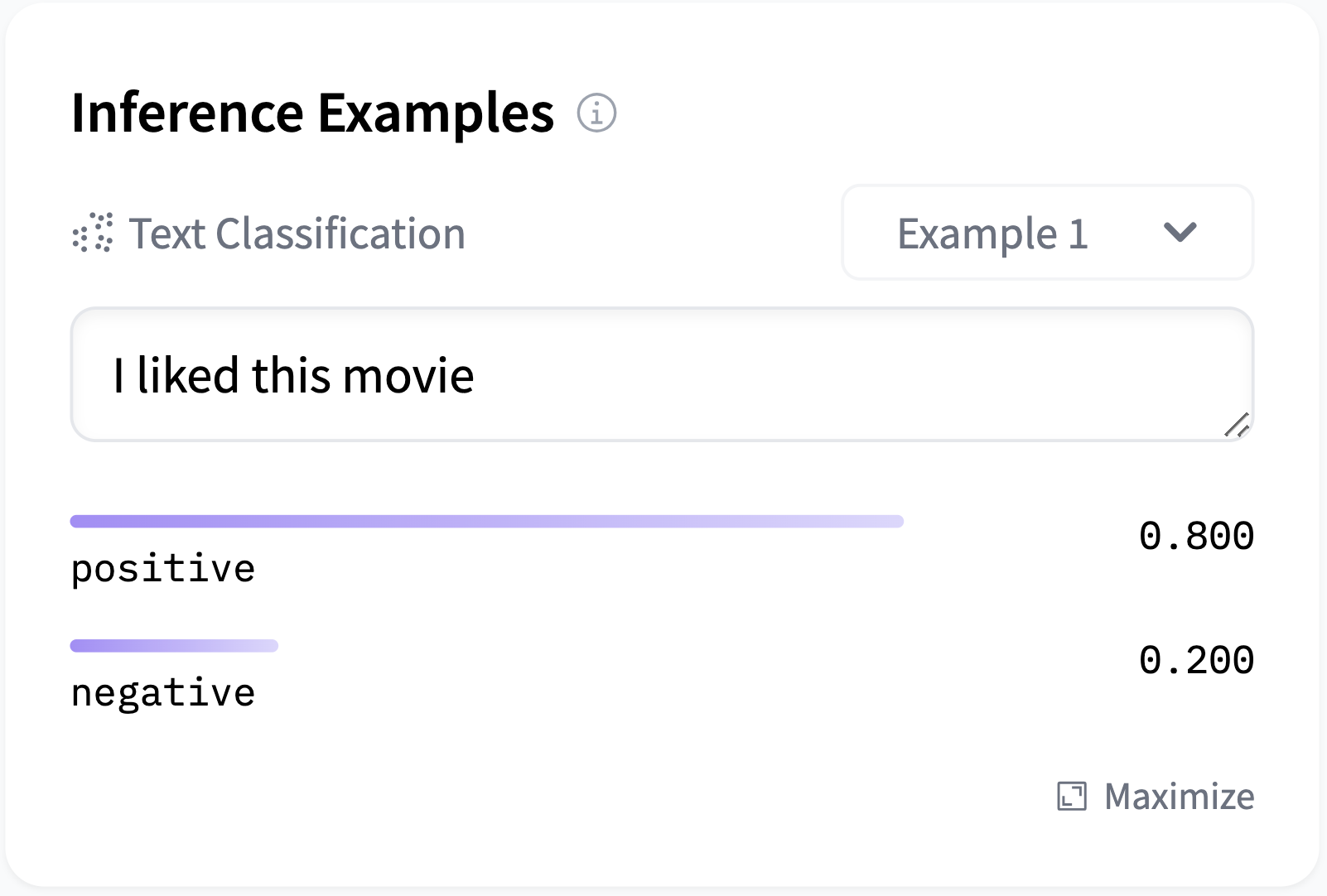
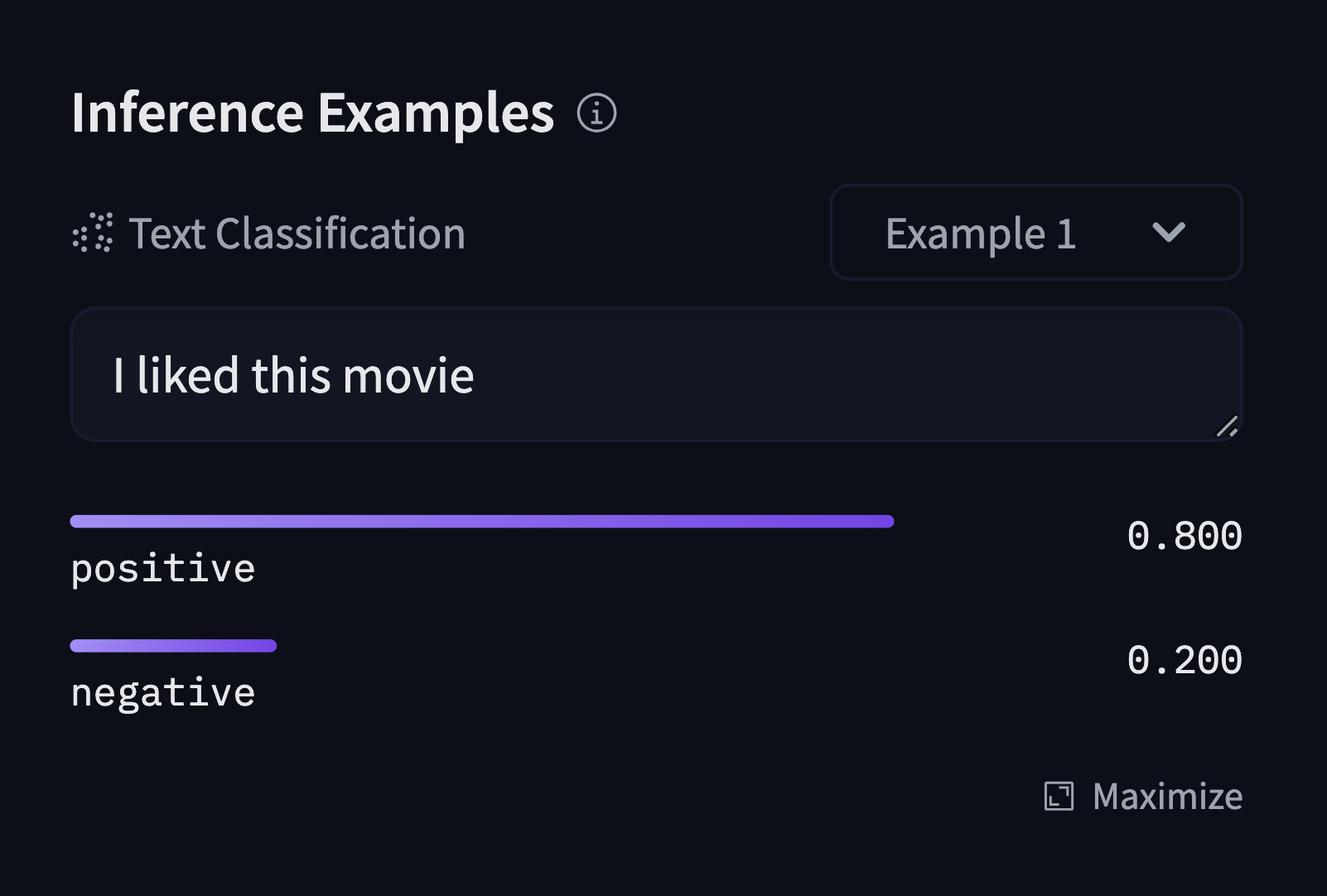
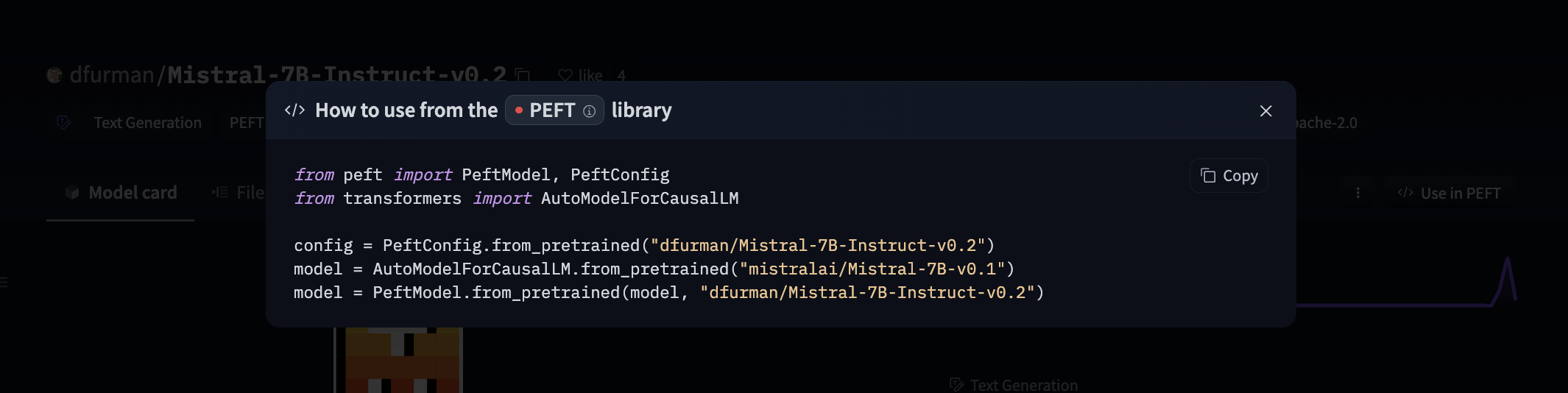
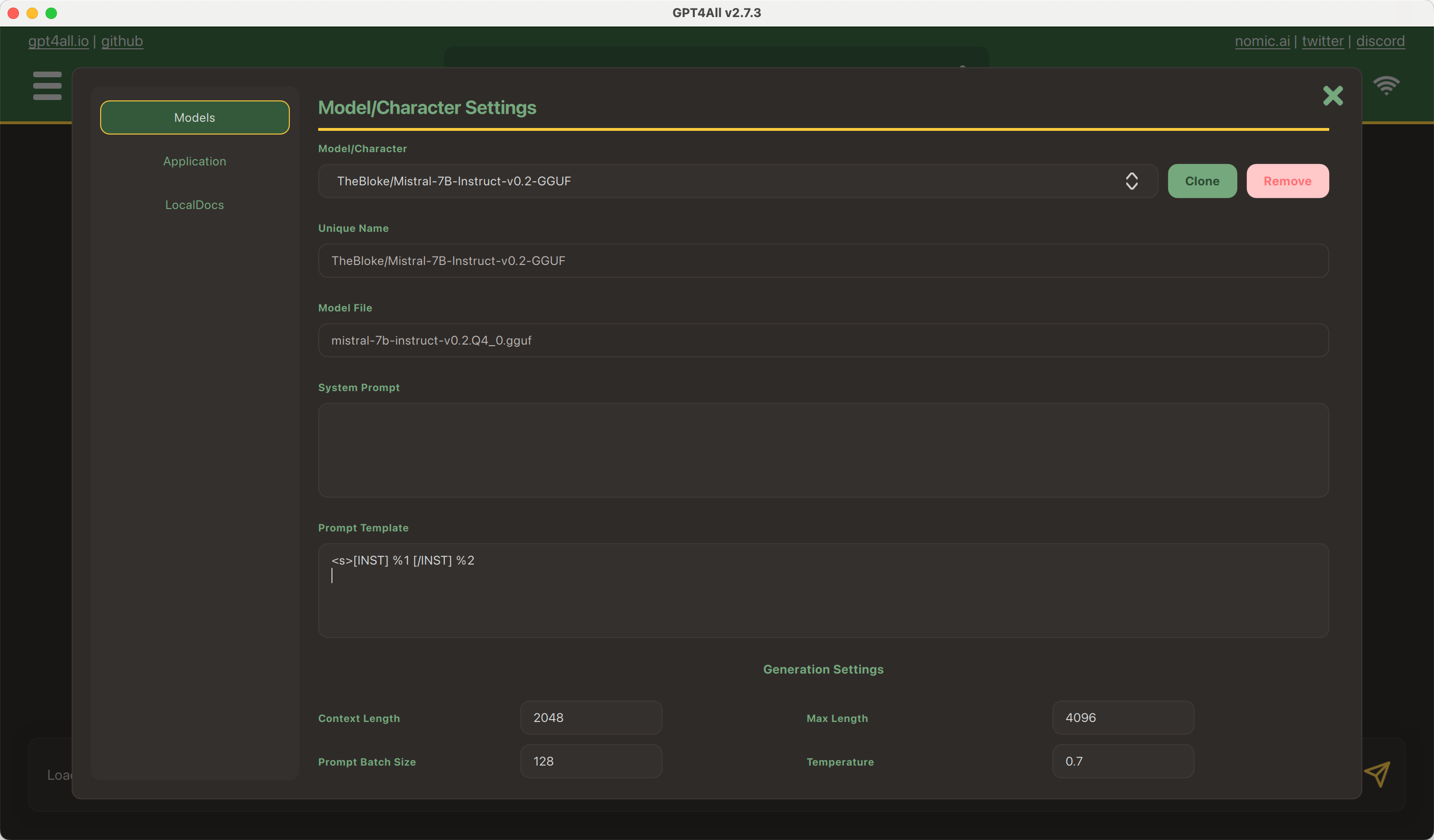
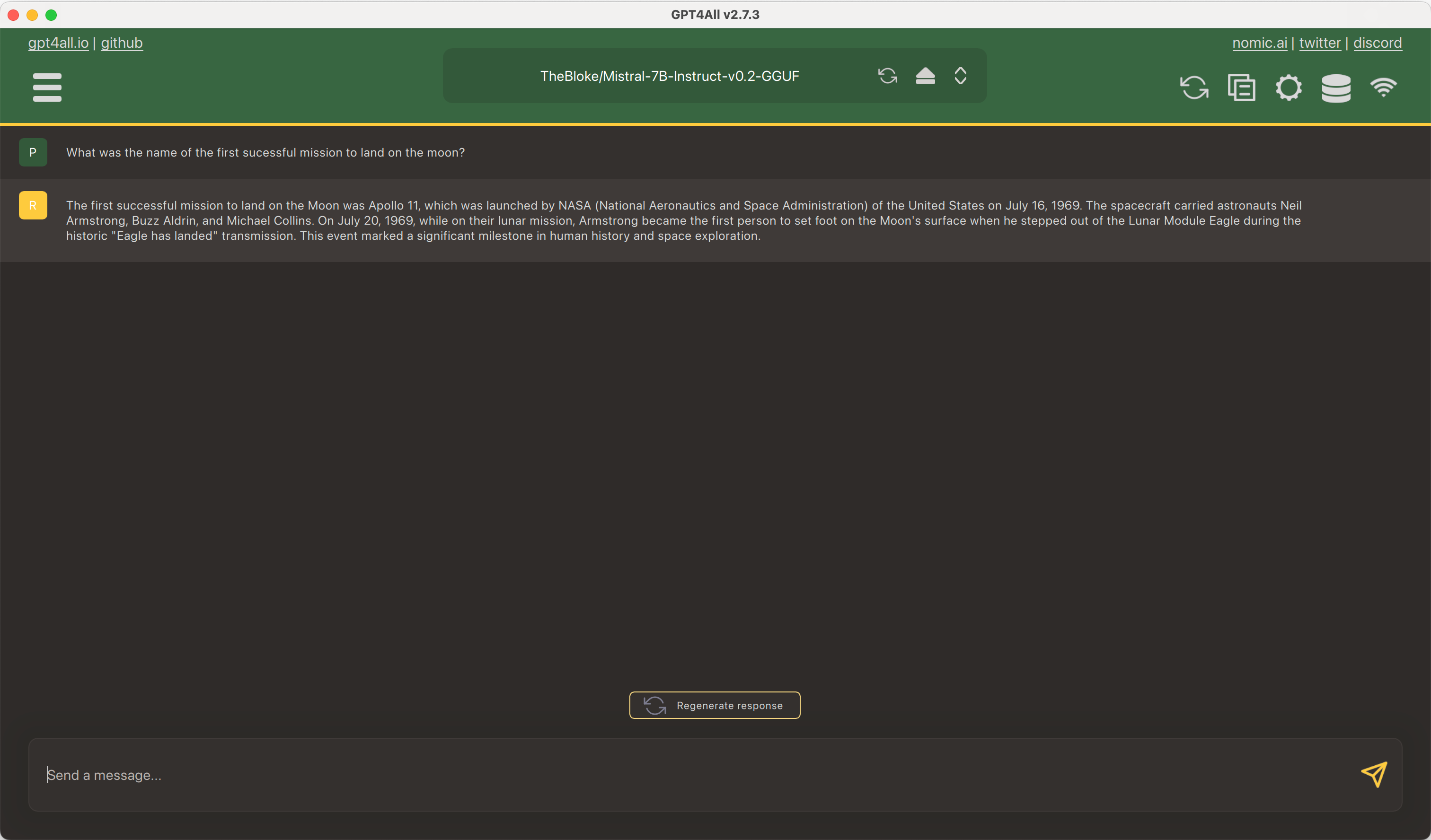
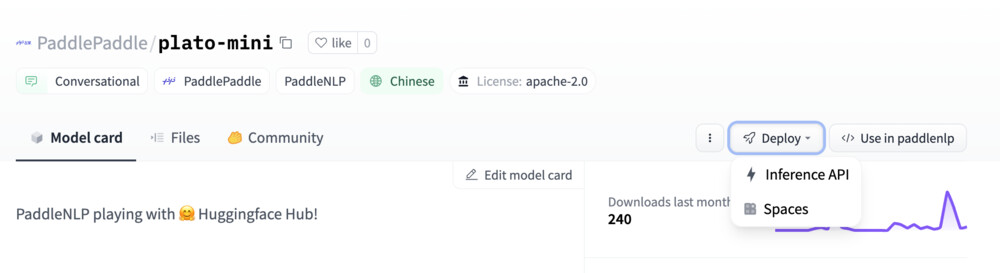
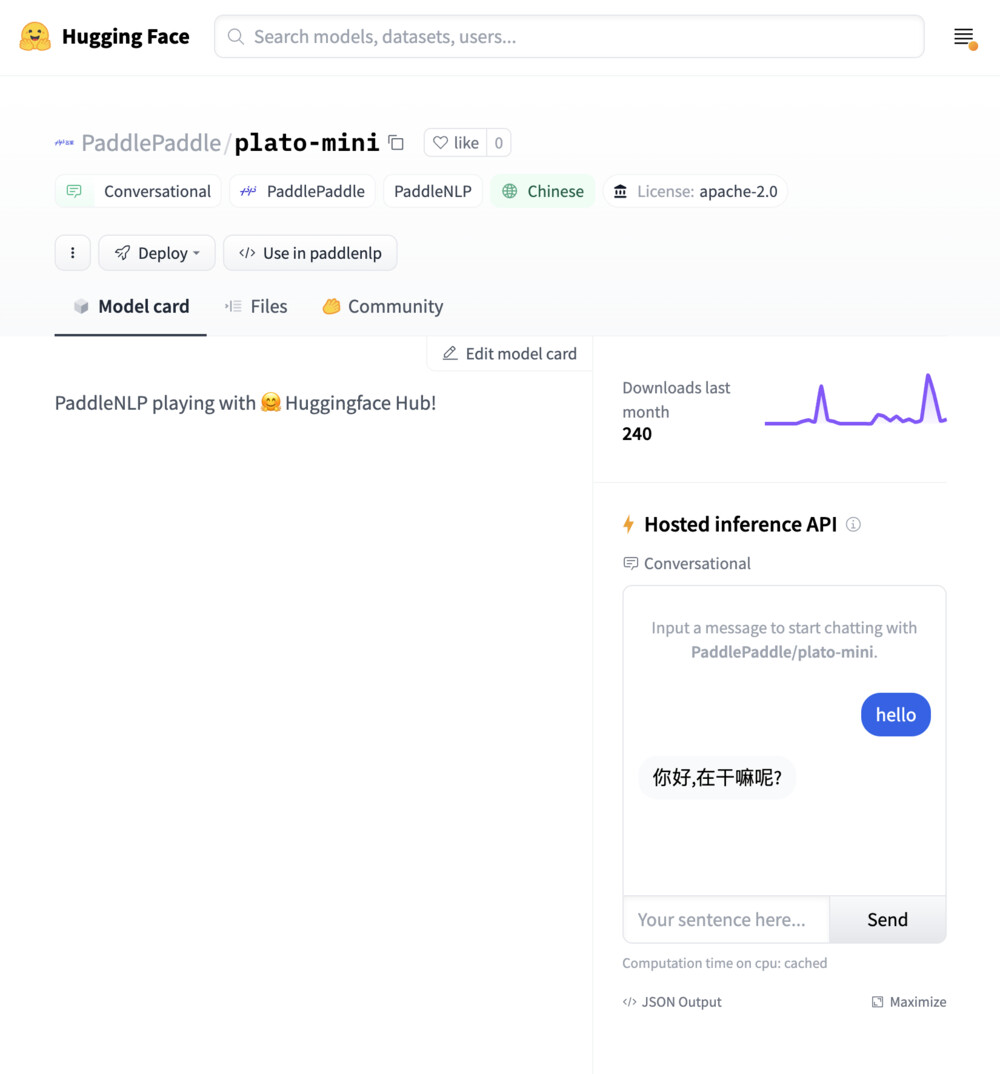
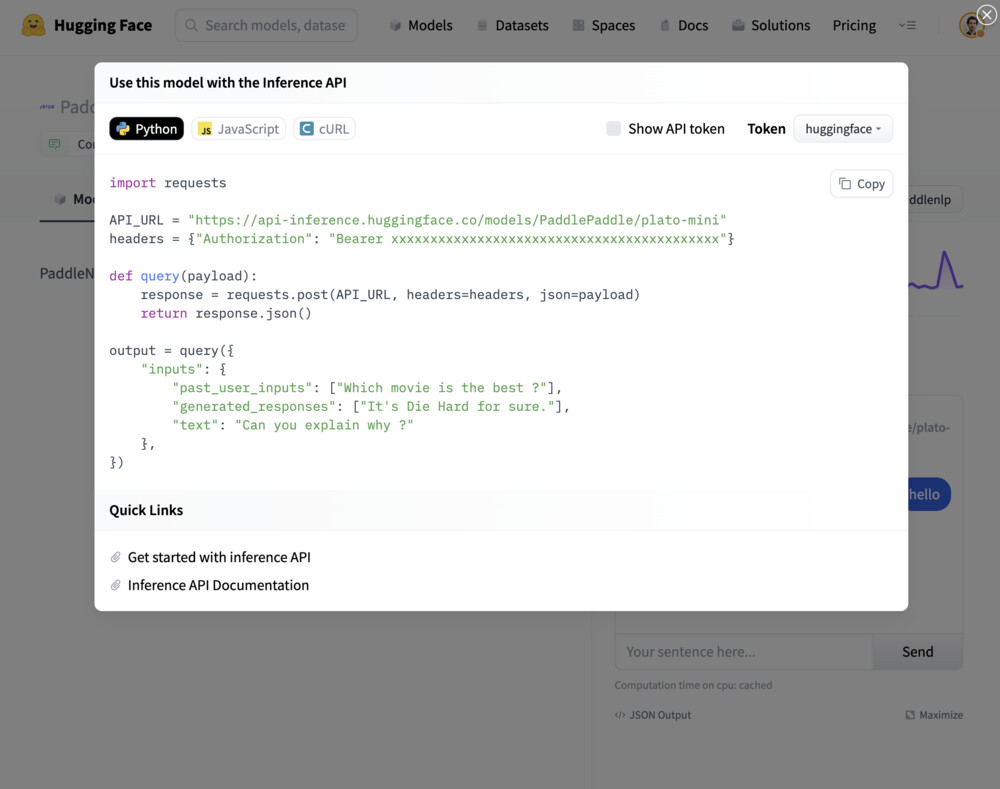
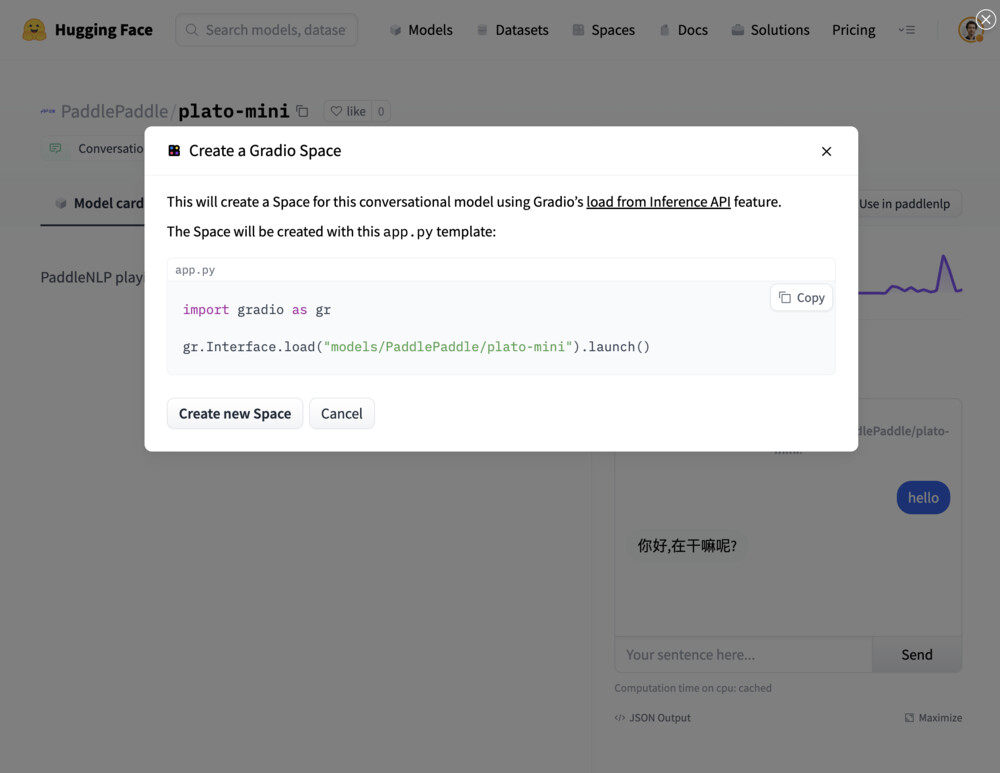
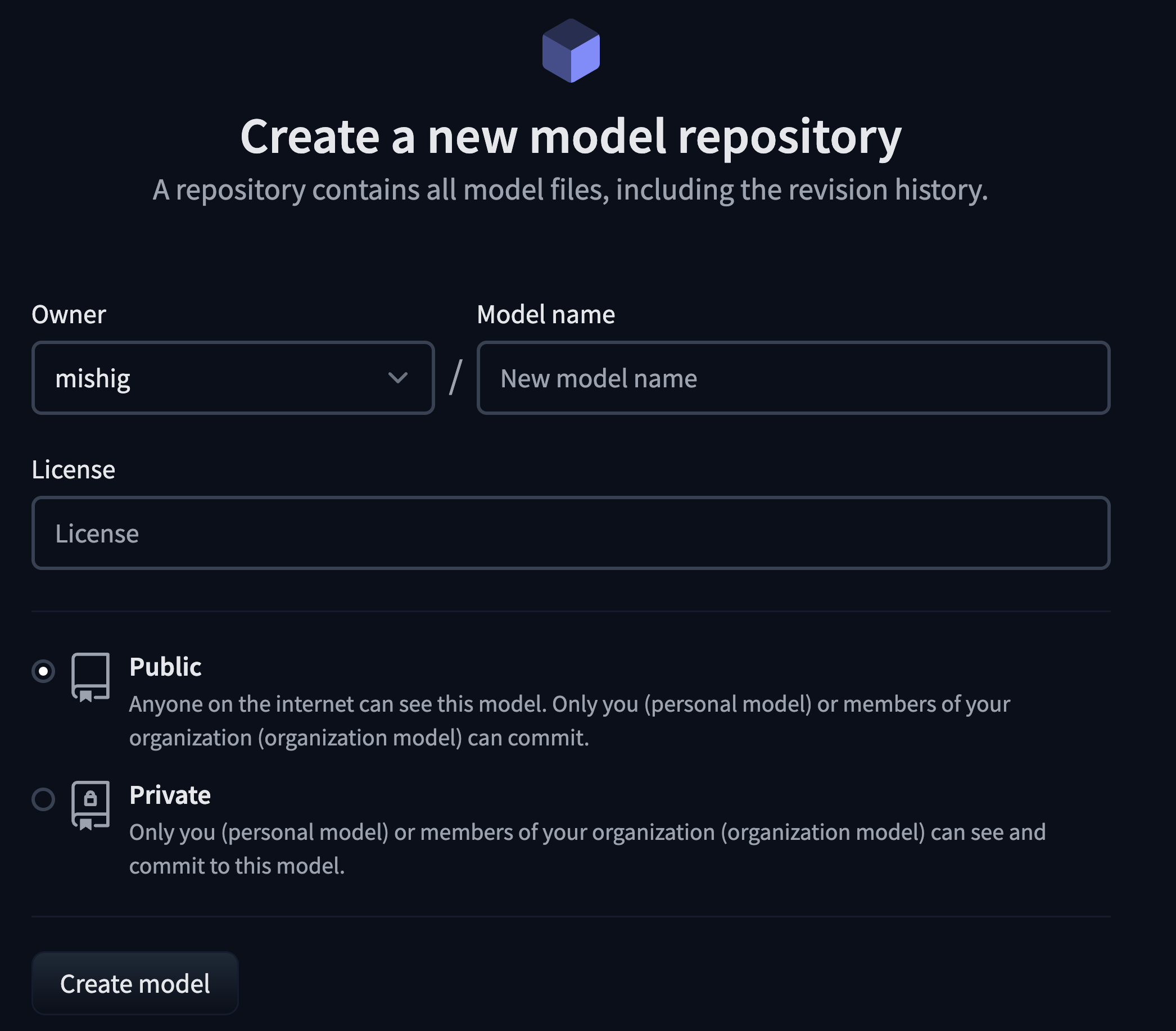
Model: google/flan-t5-small
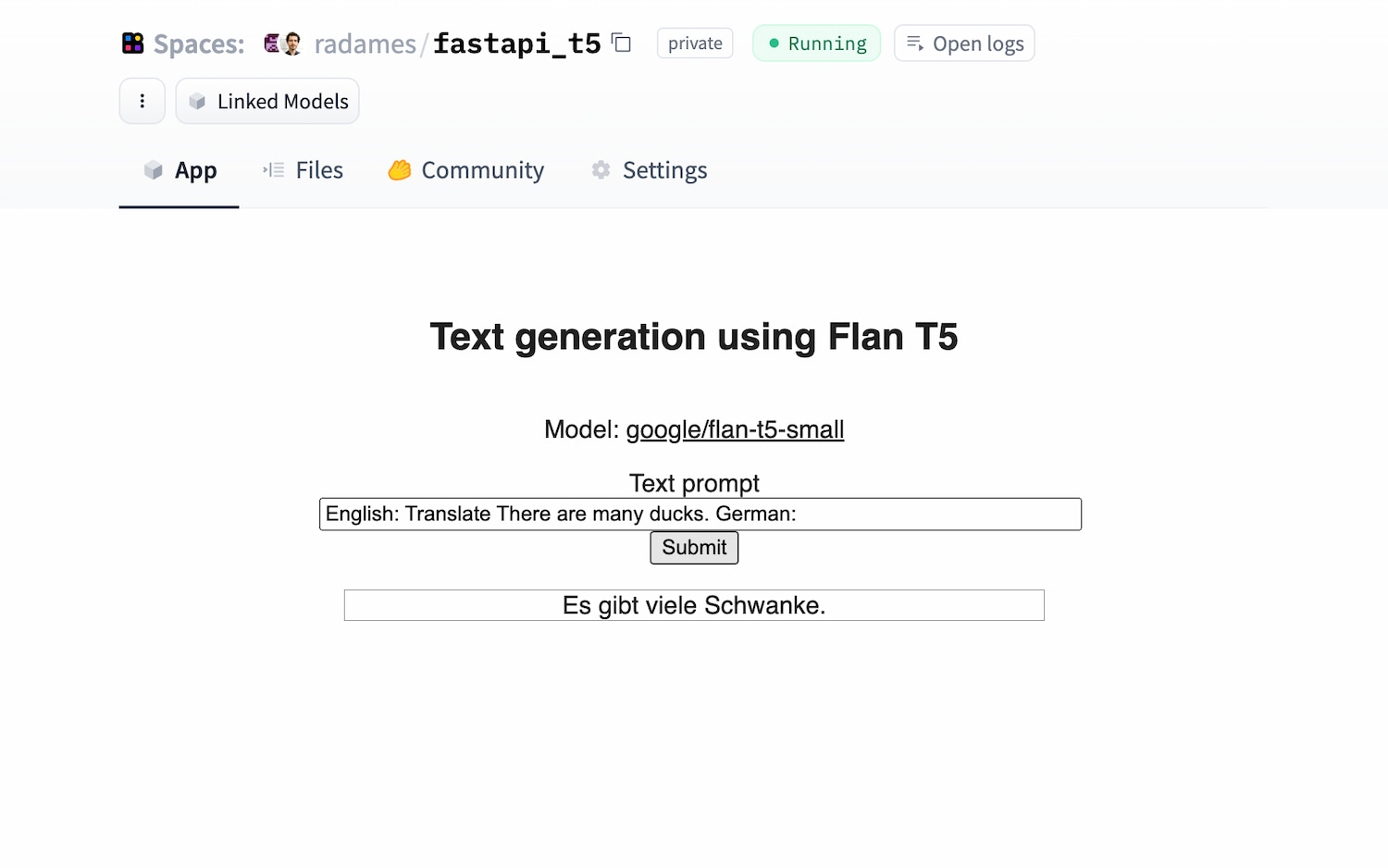
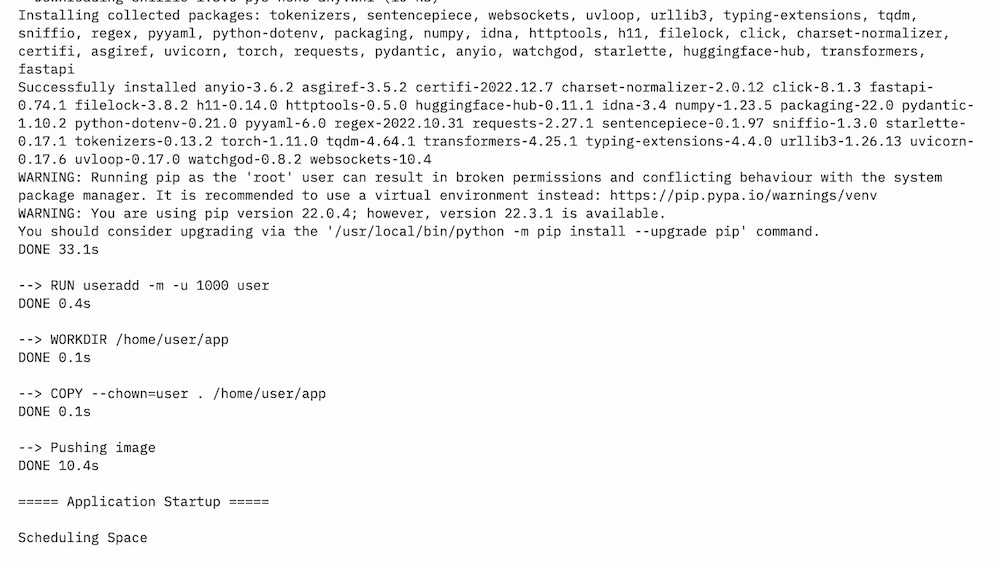







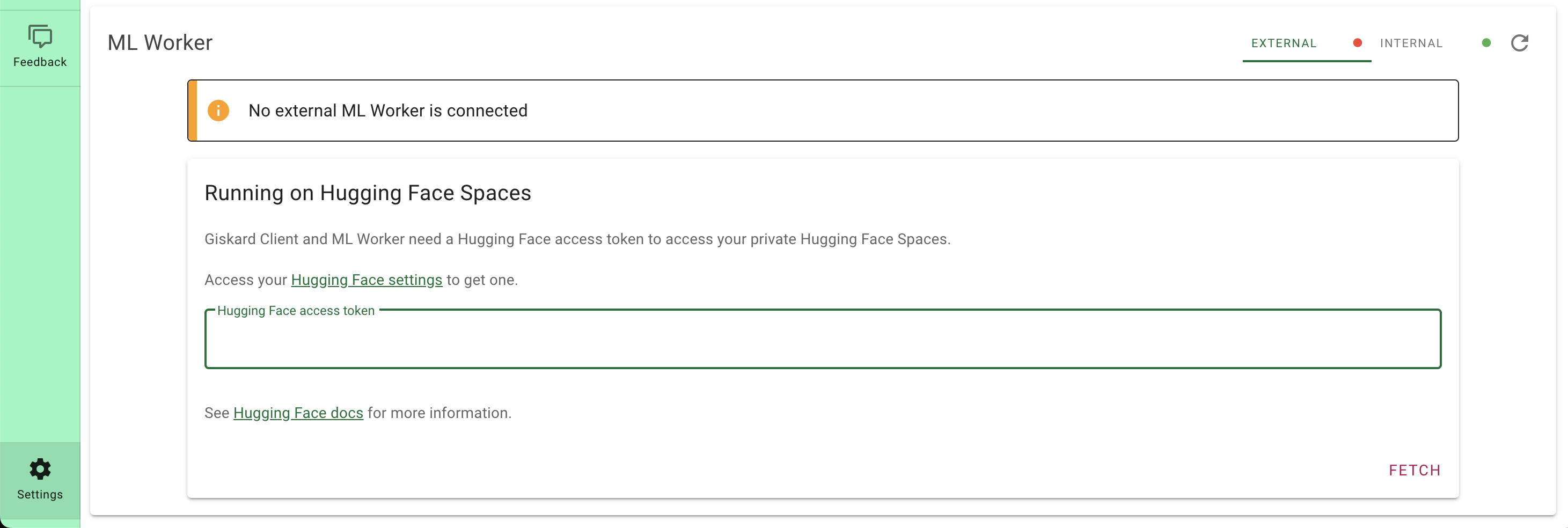
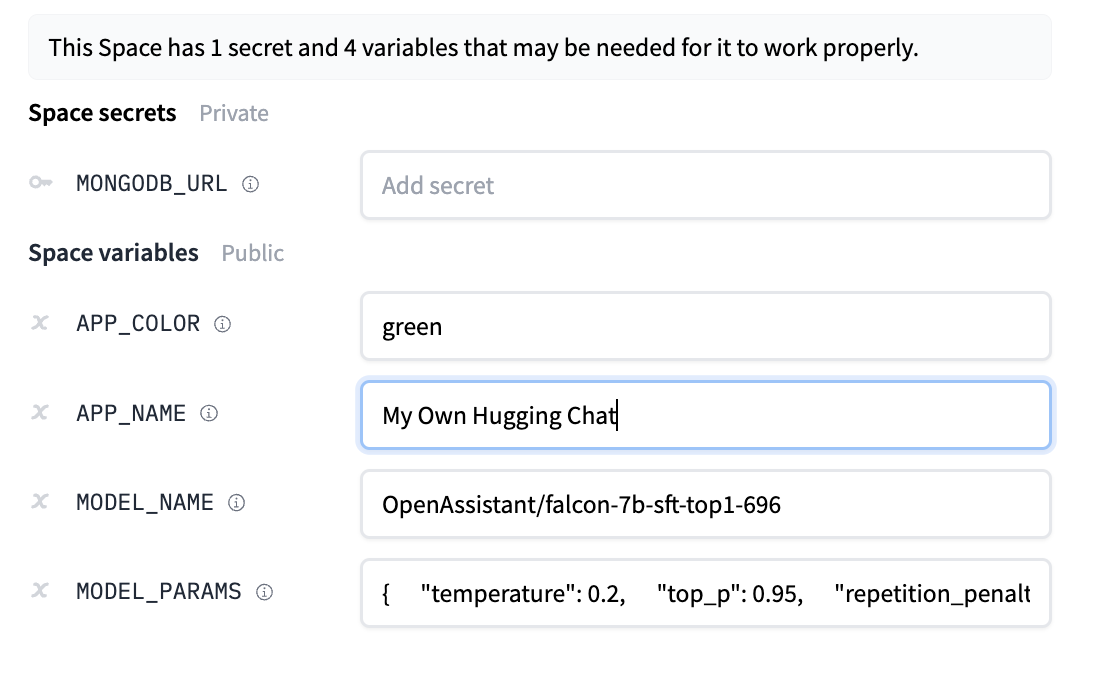
 You should provide a MongoDB endpoint where your chats will be written. If you leave this section blank, your logs will be persisted to a database inside the Space. Note that Hugging Face does not have access to your chats. You can configure the name and the theme of the Space by providing the application name and application color parameters.
Below this, you can select the Hugging Face Hub ID of the model you wish to serve. You can also change the generation hyperparameters in the dictionary below in JSON format.
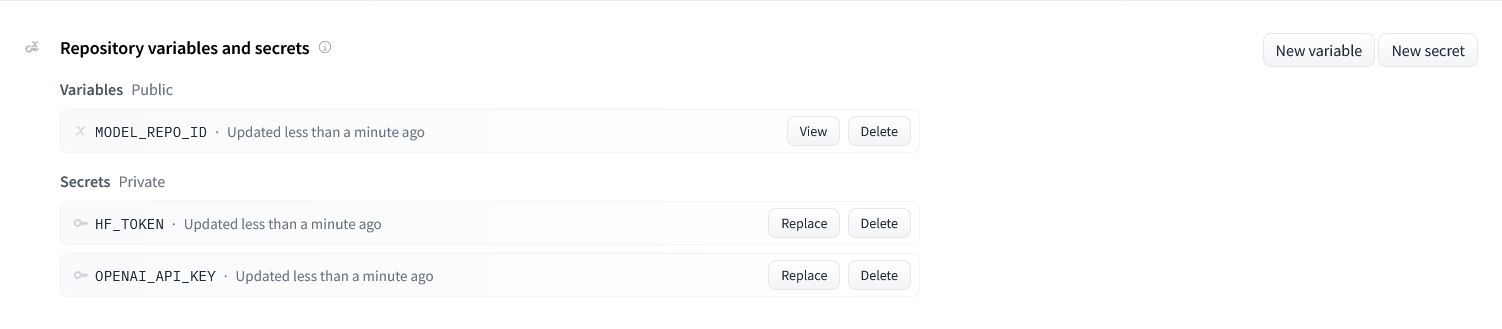
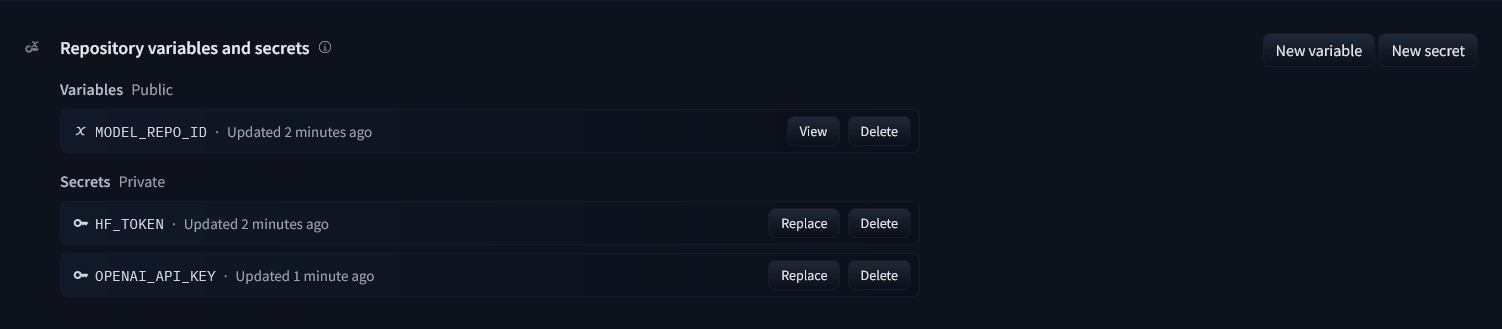
_Note_: If you'd like to deploy a model with gated access or a model in a private repository, you can simply provide `HF_TOKEN` in repository secrets. You need to set its value to an access token you can get from [here](https://huggingface.co/settings/tokens).
You should provide a MongoDB endpoint where your chats will be written. If you leave this section blank, your logs will be persisted to a database inside the Space. Note that Hugging Face does not have access to your chats. You can configure the name and the theme of the Space by providing the application name and application color parameters.
Below this, you can select the Hugging Face Hub ID of the model you wish to serve. You can also change the generation hyperparameters in the dictionary below in JSON format.
_Note_: If you'd like to deploy a model with gated access or a model in a private repository, you can simply provide `HF_TOKEN` in repository secrets. You need to set its value to an access token you can get from [here](https://huggingface.co/settings/tokens).
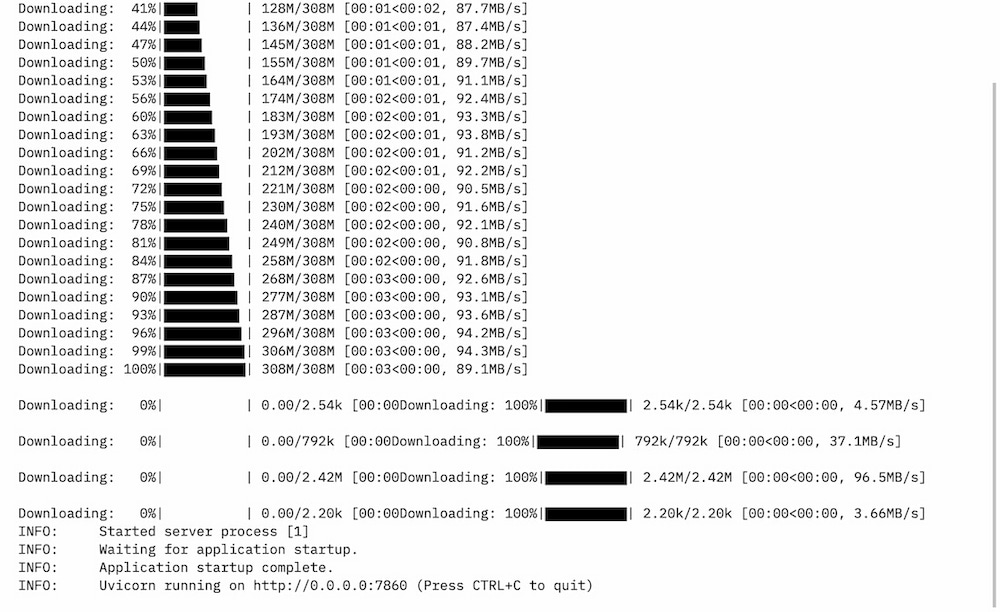
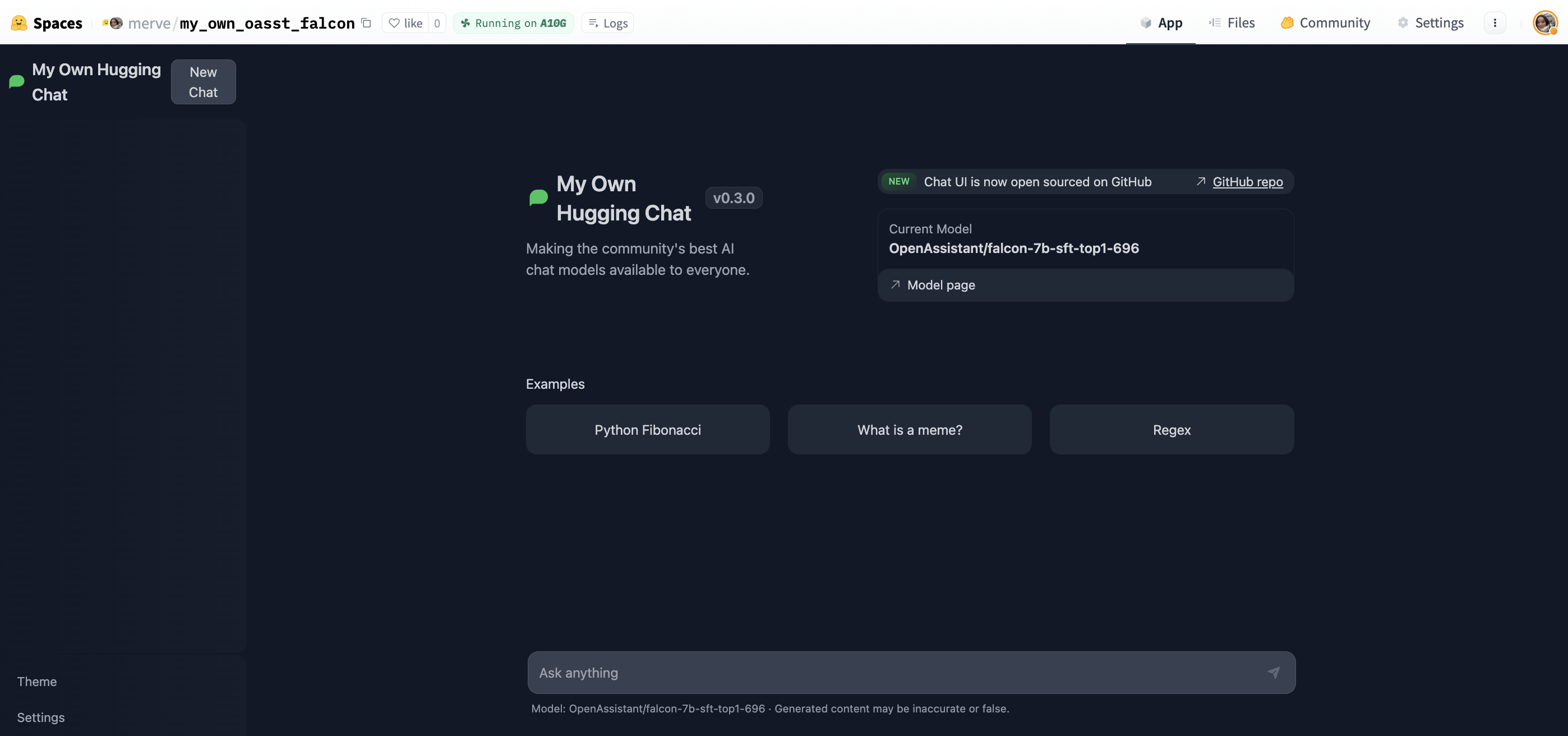
 Once the creation is complete, you will see `Building` on your Space. Once built, you can try your own HuggingChat!
Once the creation is complete, you will see `Building` on your Space. Once built, you can try your own HuggingChat!
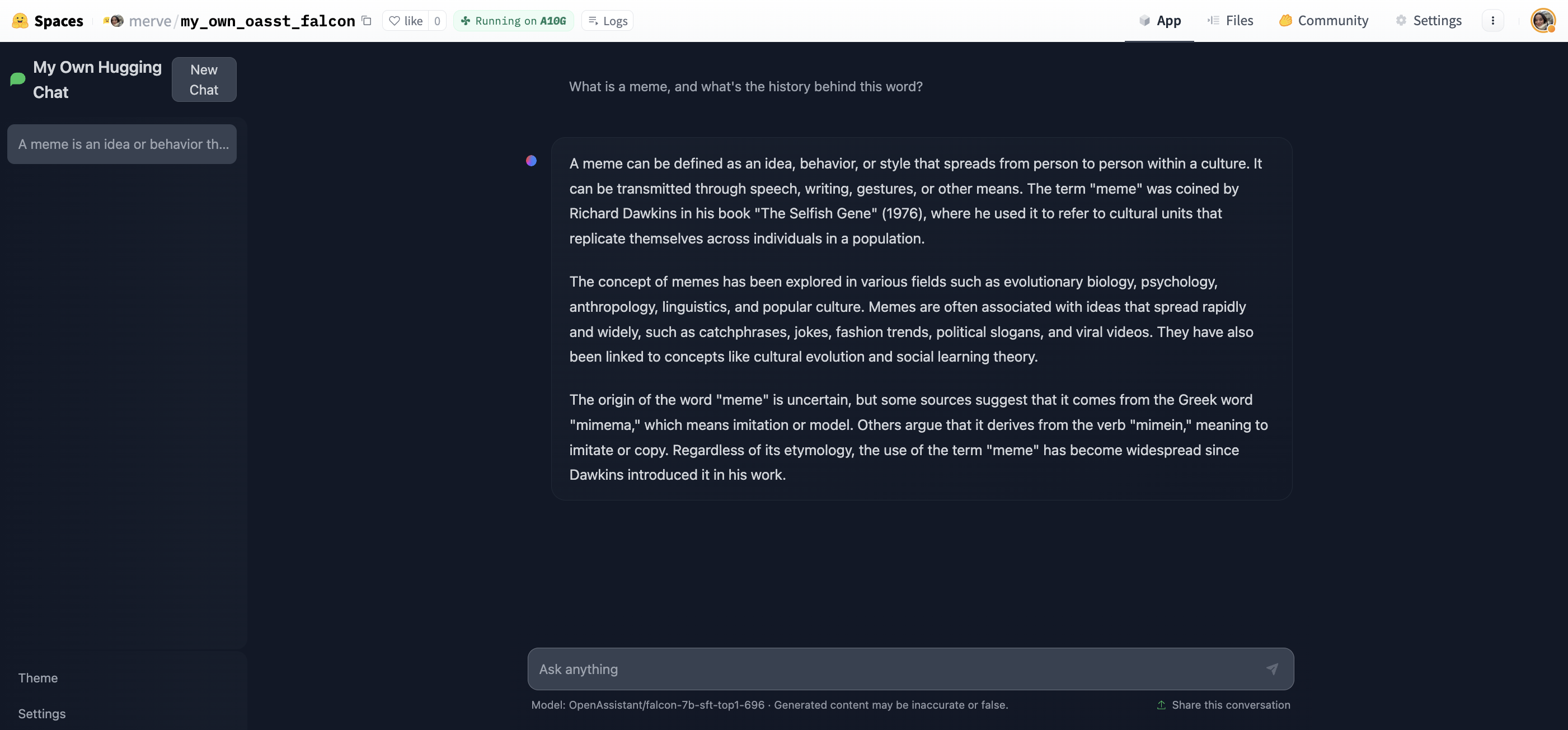
 Start chatting!
Start chatting!
 ## Read more
- [HF Docker Spaces](https://huggingface.co/docs/hub/spaces-sdks-docker)
- [chat-ui GitHub Repository](https://github.com/huggingface/chat-ui)
- [text-generation-inference GitHub repository](https://github.com/huggingface/text-generation-inference)
# Managing Spaces with Github Actions
You can keep your app in sync with your GitHub repository with **Github Actions**. Remember that for files larger than 10MB, Spaces requires Git-LFS. If you don't want to use Git-LFS, you may need to review your files and check your history. Use a tool like [BFG Repo-Cleaner](https://rtyley.github.io/bfg-repo-cleaner/) to remove any large files from your history. BFG Repo-Cleaner will keep a local copy of your repository as a backup.
First, you should set up your GitHub repository and Spaces app together. Add your Spaces app as an additional remote to your existing Git repository.
```bash
git remote add space https://huggingface.co/spaces/HF_USERNAME/SPACE_NAME
```
Then force push to sync everything for the first time:
```bash
git push --force space main
```
Next, set up a GitHub Action to push your main branch to Spaces. In the example below:
* Replace `HF_USERNAME` with your username and `SPACE_NAME` with your Space name.
* Create a [Github secret](https://docs.github.com/en/actions/security-guides/encrypted-secrets#creating-encrypted-secrets-for-an-environment) with your `HF_TOKEN`. You can find your Hugging Face API token under **API Tokens** on your Hugging Face profile.
```yaml
name: Sync to Hugging Face hub
on:
push:
branches: [main]
# to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
sync-to-hub:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
fetch-depth: 0
lfs: true
- name: Push to hub
env:
HF_TOKEN: ${{ secrets.HF_TOKEN }}
run: git push https://HF_USERNAME:$HF_TOKEN@huggingface.co/spaces/HF_USERNAME/SPACE_NAME main
```
Finally, create an Action that automatically checks the file size of any new pull request:
```yaml
name: Check file size
on: # or directly `on: [push]` to run the action on every push on any branch
pull_request:
branches: [main]
# to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
sync-to-hub:
runs-on: ubuntu-latest
steps:
- name: Check large files
uses: ActionsDesk/lfs-warning@v2.0
with:
filesizelimit: 10485760 # this is 10MB so we can sync to HF Spaces
```
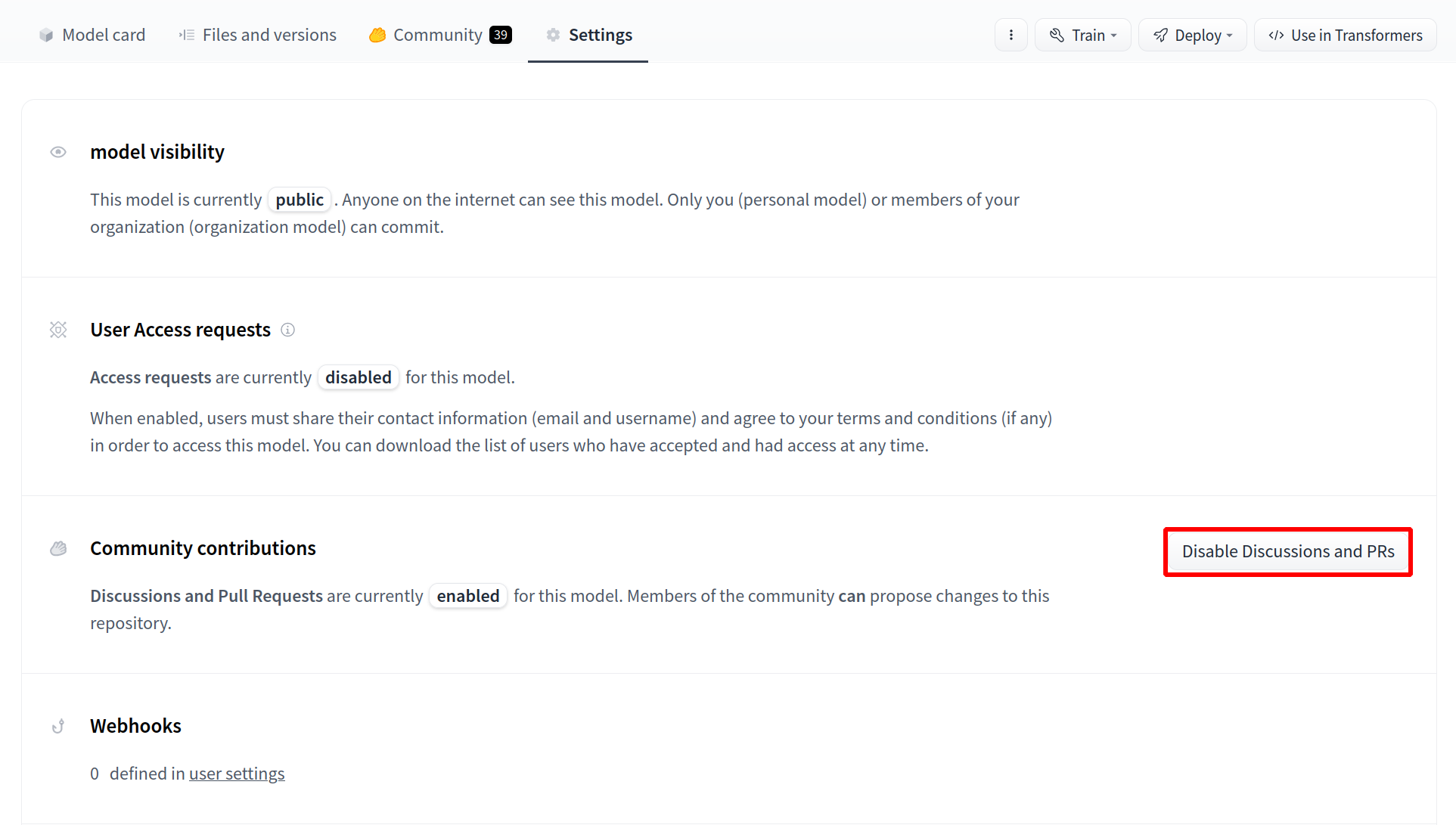
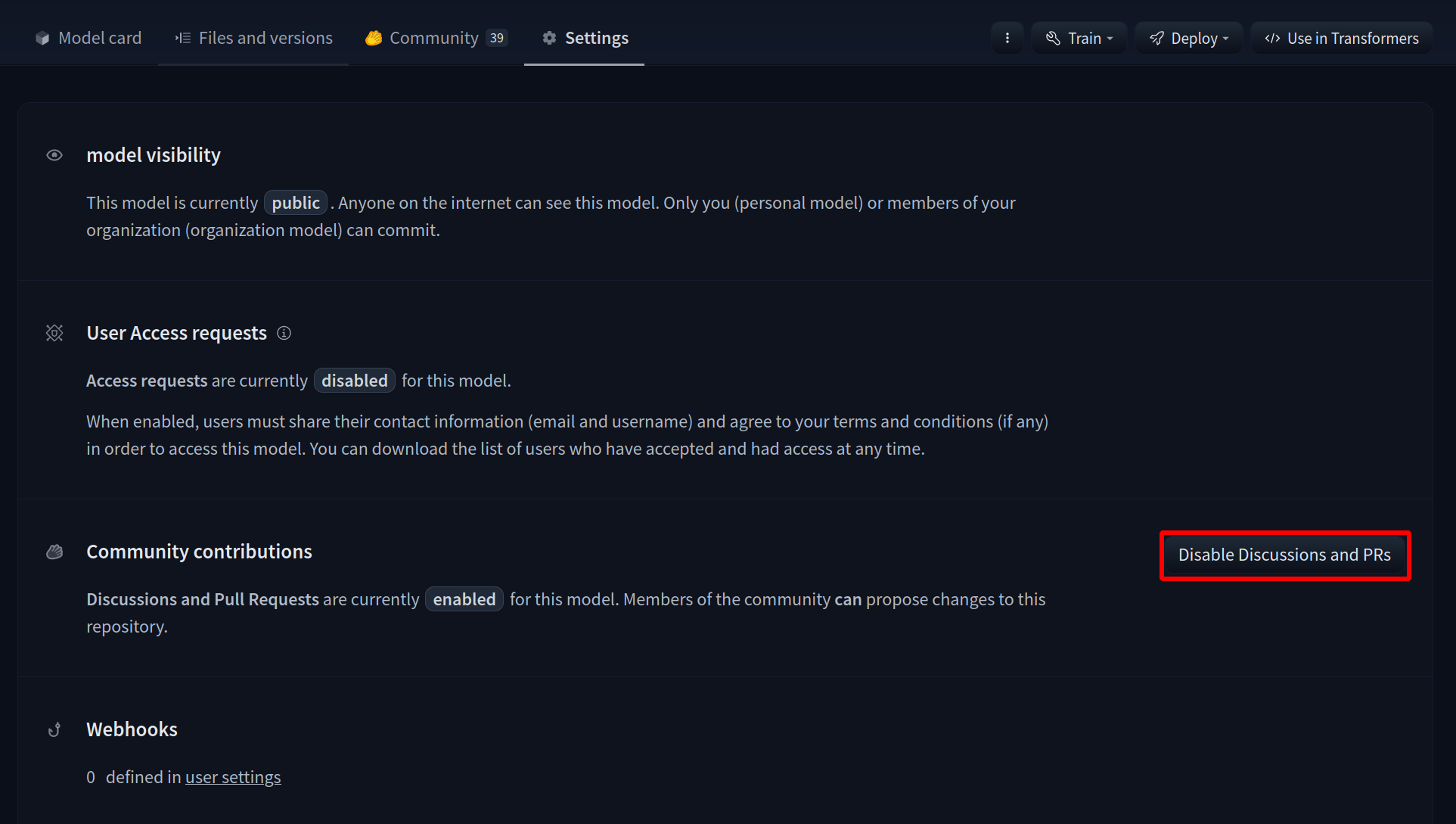
# Gated datasets
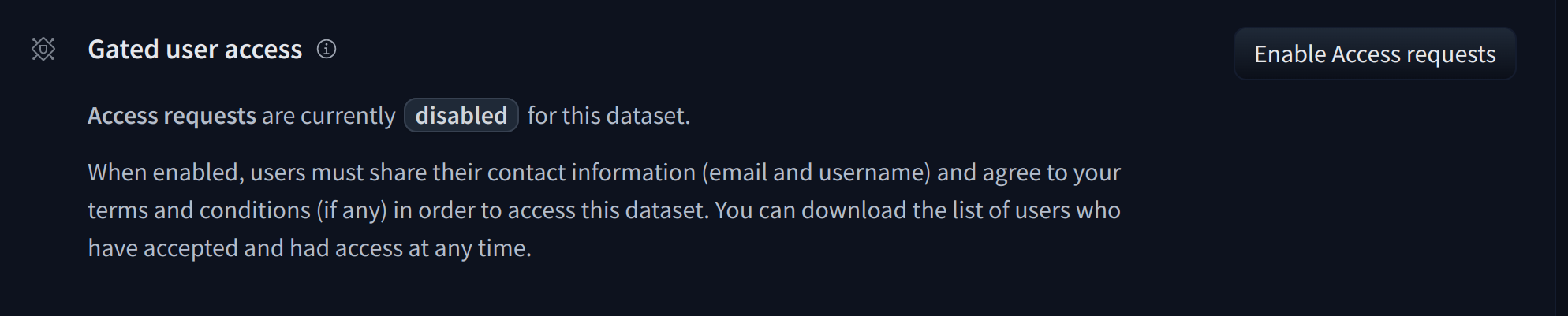
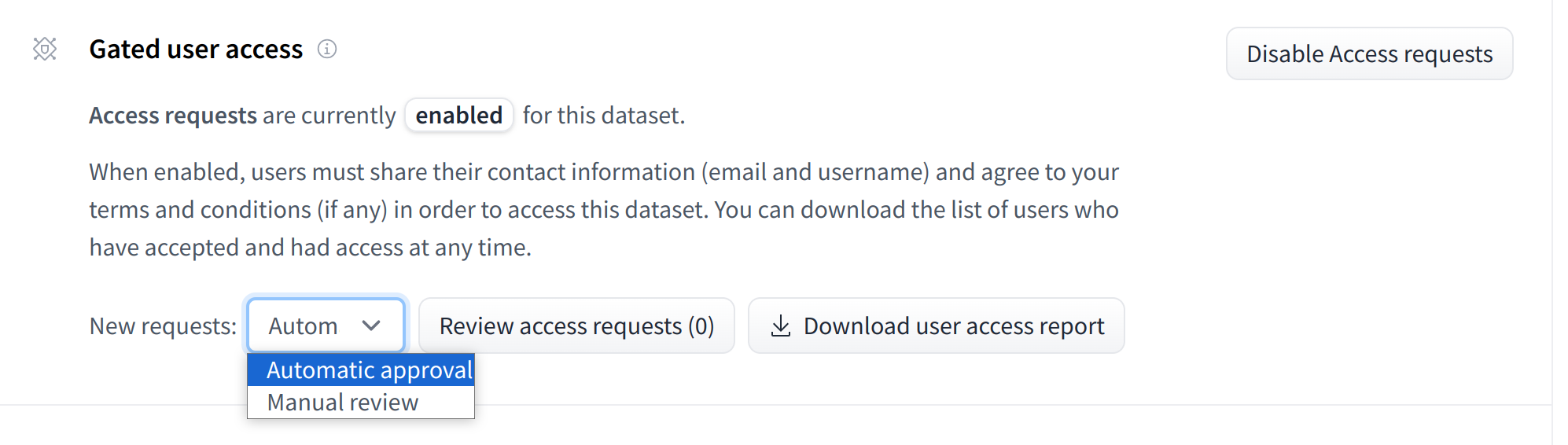
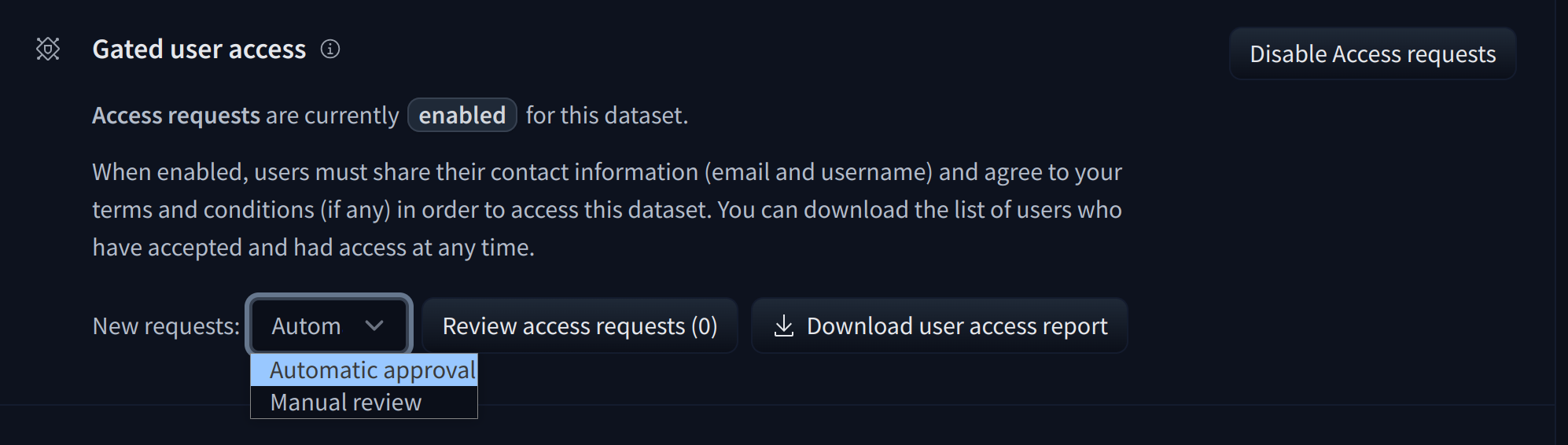
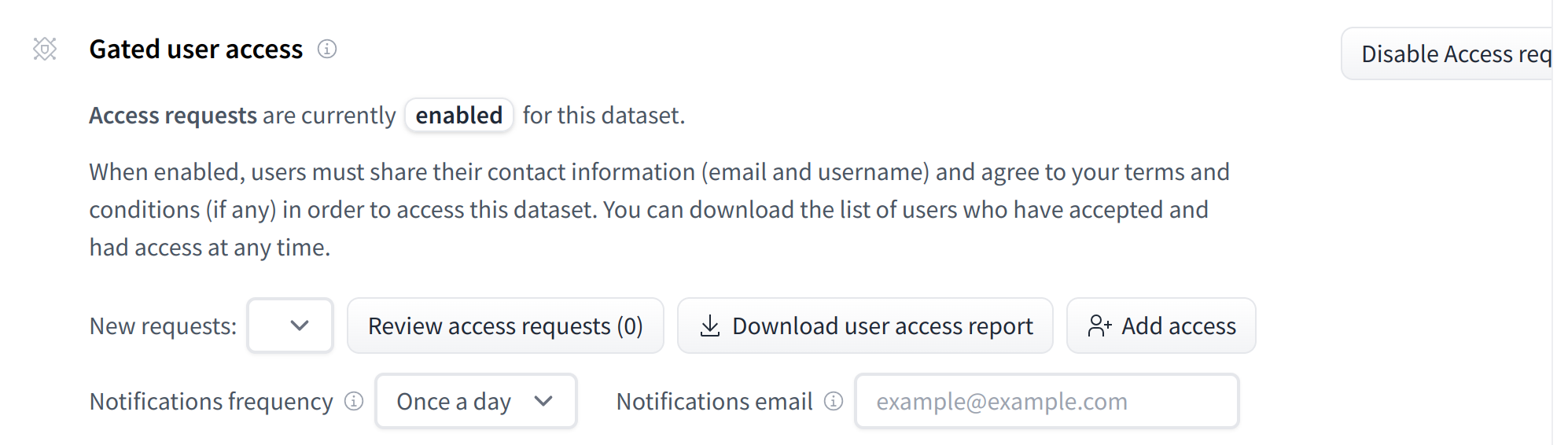
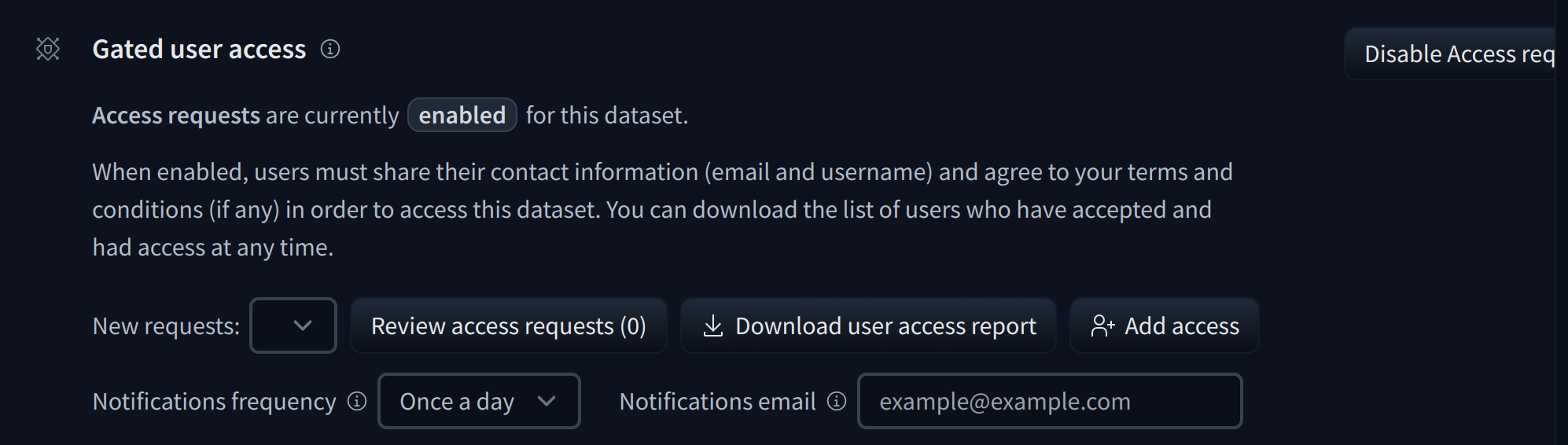
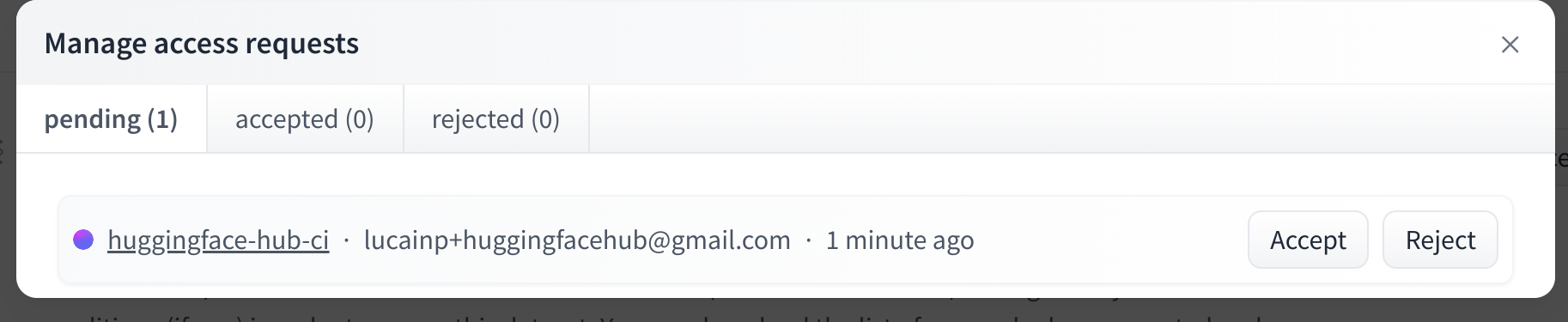
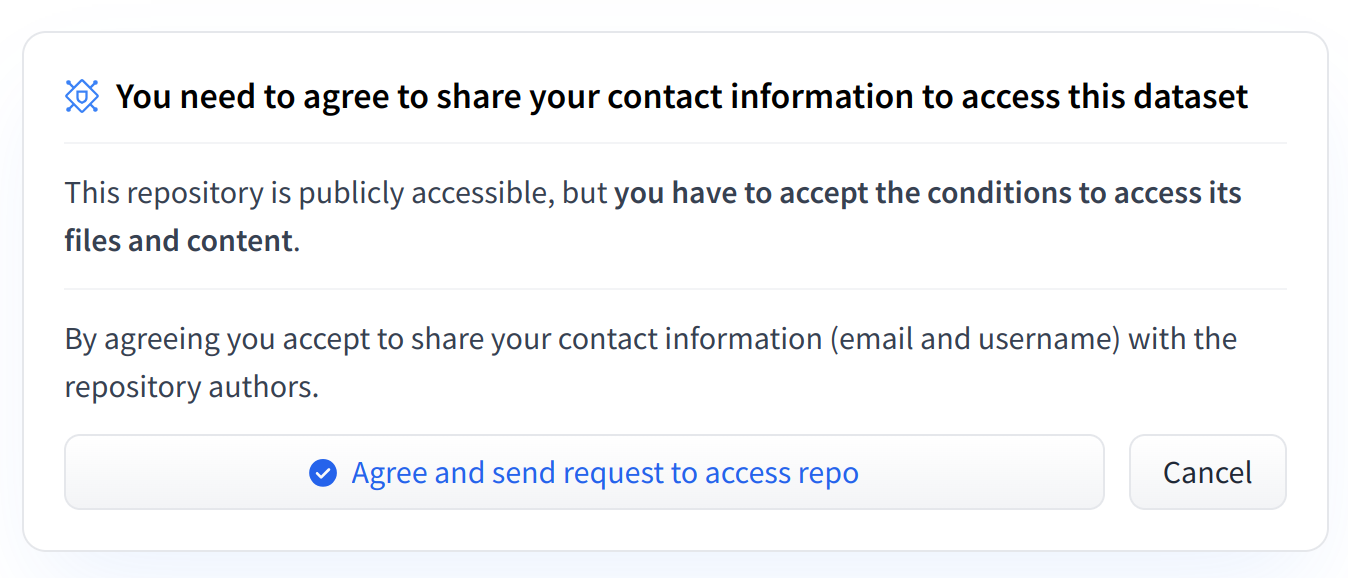
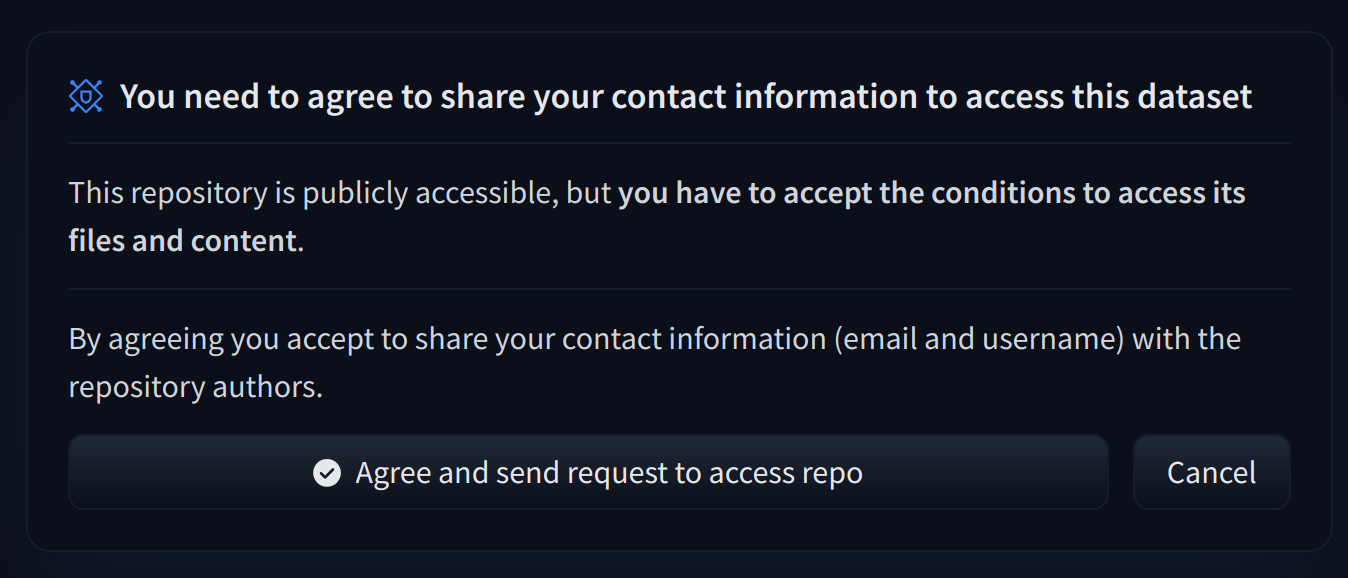
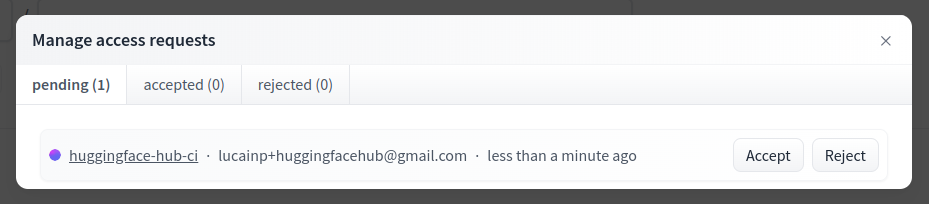
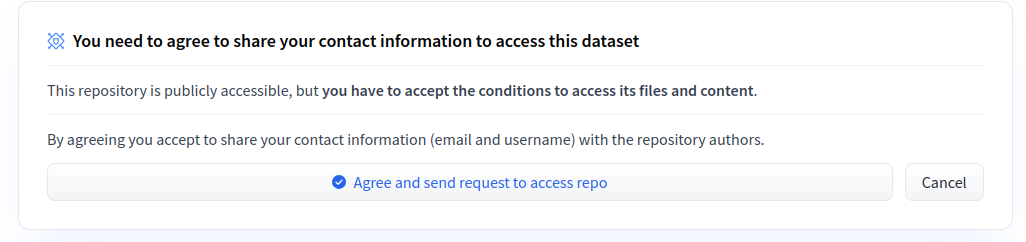
To give more control over how datasets are used, the Hub allows datasets authors to enable **access requests** for their datasets. Users must agree to share their contact information (username and email address) with the datasets authors to access the datasets files when enabled. Datasets authors can configure this request with additional fields. A dataset with access requests enabled is called a **gated dataset**. Access requests are always granted to individual users rather than to entire organizations. A common use case of gated datasets is to provide access to early research datasets before the wider release.
## Manage gated datasets as a dataset author
To enable access requests, go to the dataset settings page. By default, the dataset is not gated. Click on **Enable Access request** in the top-right corner.
## Read more
- [HF Docker Spaces](https://huggingface.co/docs/hub/spaces-sdks-docker)
- [chat-ui GitHub Repository](https://github.com/huggingface/chat-ui)
- [text-generation-inference GitHub repository](https://github.com/huggingface/text-generation-inference)
# Managing Spaces with Github Actions
You can keep your app in sync with your GitHub repository with **Github Actions**. Remember that for files larger than 10MB, Spaces requires Git-LFS. If you don't want to use Git-LFS, you may need to review your files and check your history. Use a tool like [BFG Repo-Cleaner](https://rtyley.github.io/bfg-repo-cleaner/) to remove any large files from your history. BFG Repo-Cleaner will keep a local copy of your repository as a backup.
First, you should set up your GitHub repository and Spaces app together. Add your Spaces app as an additional remote to your existing Git repository.
```bash
git remote add space https://huggingface.co/spaces/HF_USERNAME/SPACE_NAME
```
Then force push to sync everything for the first time:
```bash
git push --force space main
```
Next, set up a GitHub Action to push your main branch to Spaces. In the example below:
* Replace `HF_USERNAME` with your username and `SPACE_NAME` with your Space name.
* Create a [Github secret](https://docs.github.com/en/actions/security-guides/encrypted-secrets#creating-encrypted-secrets-for-an-environment) with your `HF_TOKEN`. You can find your Hugging Face API token under **API Tokens** on your Hugging Face profile.
```yaml
name: Sync to Hugging Face hub
on:
push:
branches: [main]
# to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
sync-to-hub:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
fetch-depth: 0
lfs: true
- name: Push to hub
env:
HF_TOKEN: ${{ secrets.HF_TOKEN }}
run: git push https://HF_USERNAME:$HF_TOKEN@huggingface.co/spaces/HF_USERNAME/SPACE_NAME main
```
Finally, create an Action that automatically checks the file size of any new pull request:
```yaml
name: Check file size
on: # or directly `on: [push]` to run the action on every push on any branch
pull_request:
branches: [main]
# to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
sync-to-hub:
runs-on: ubuntu-latest
steps:
- name: Check large files
uses: ActionsDesk/lfs-warning@v2.0
with:
filesizelimit: 10485760 # this is 10MB so we can sync to HF Spaces
```
# Gated datasets
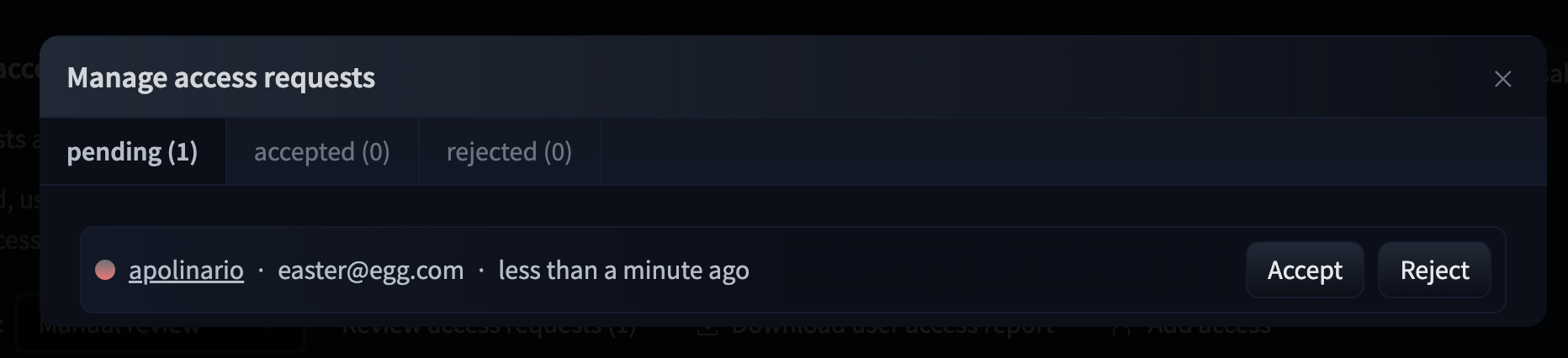
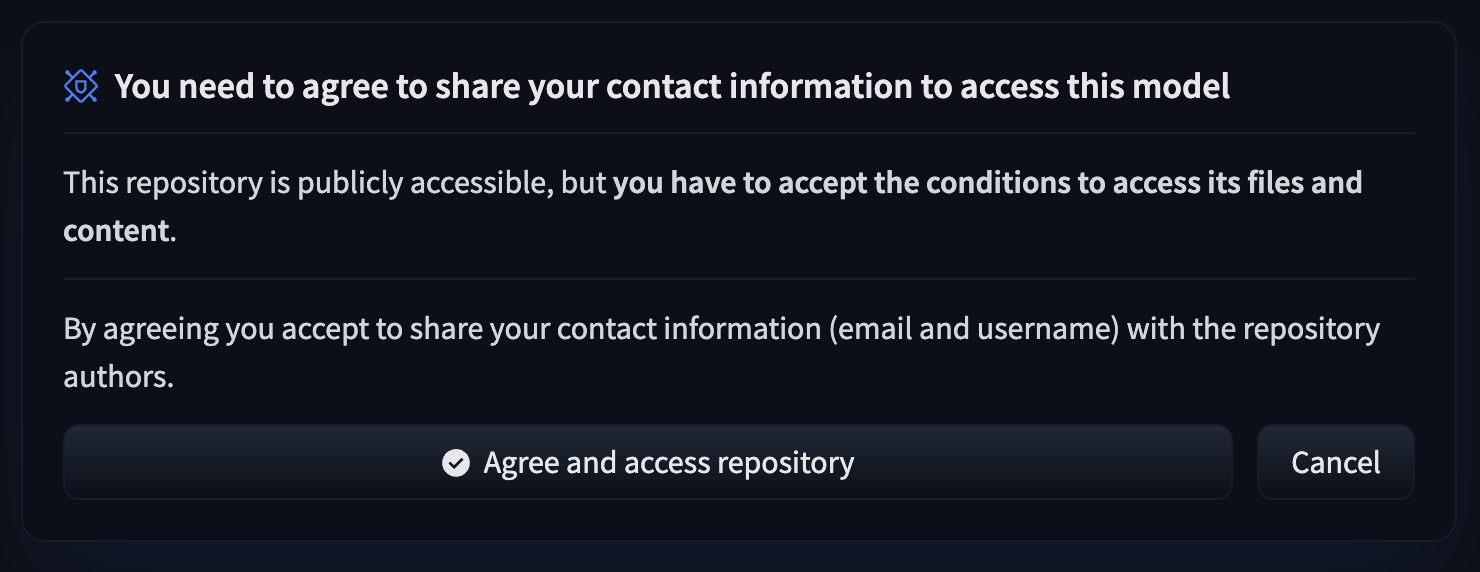
To give more control over how datasets are used, the Hub allows datasets authors to enable **access requests** for their datasets. Users must agree to share their contact information (username and email address) with the datasets authors to access the datasets files when enabled. Datasets authors can configure this request with additional fields. A dataset with access requests enabled is called a **gated dataset**. Access requests are always granted to individual users rather than to entire organizations. A common use case of gated datasets is to provide access to early research datasets before the wider release.
## Manage gated datasets as a dataset author
To enable access requests, go to the dataset settings page. By default, the dataset is not gated. Click on **Enable Access request** in the top-right corner.


 For any other security questions, please feel free to send us an email at security@huggingface.co.
## Contents
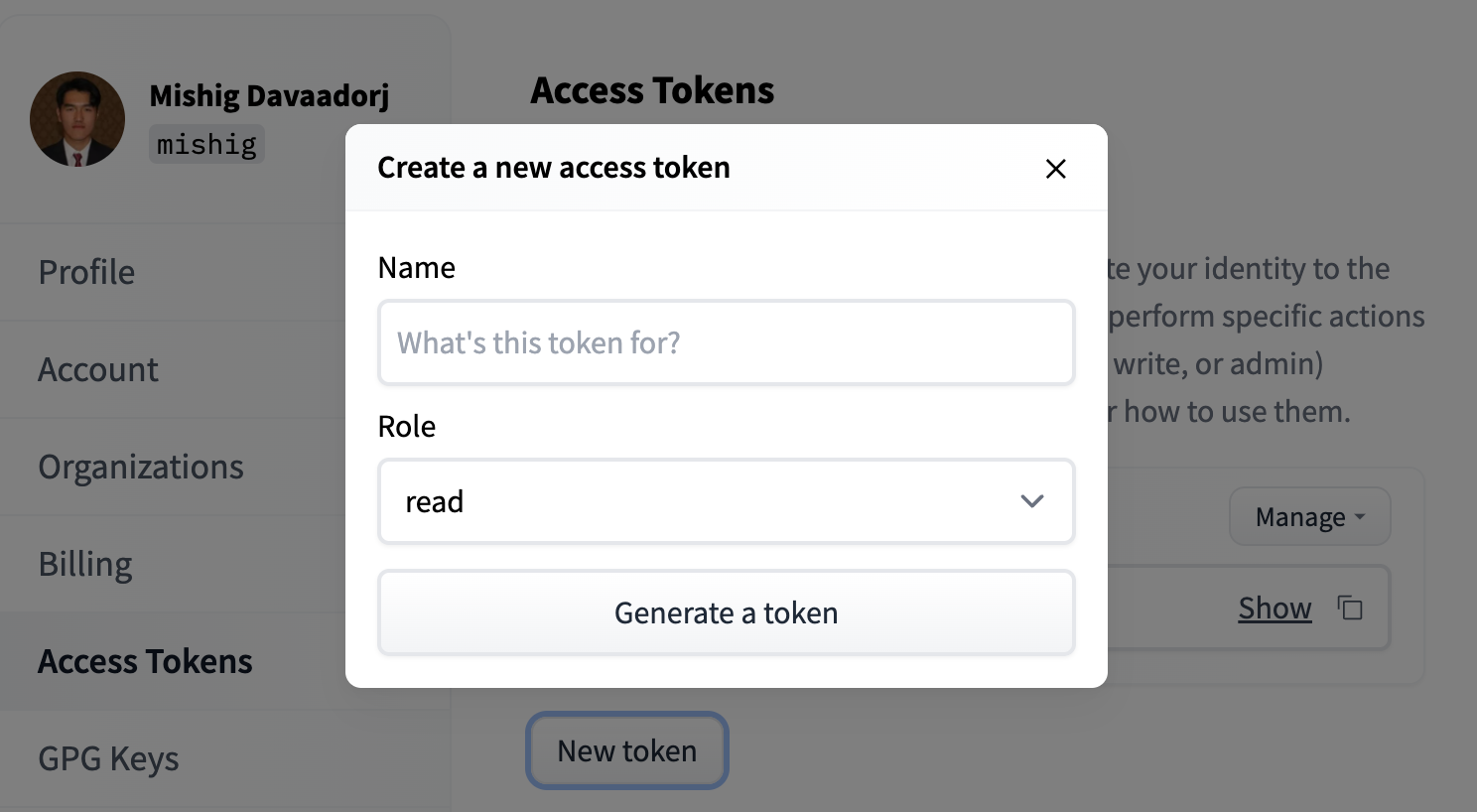
- [User Access Tokens](./security-tokens)
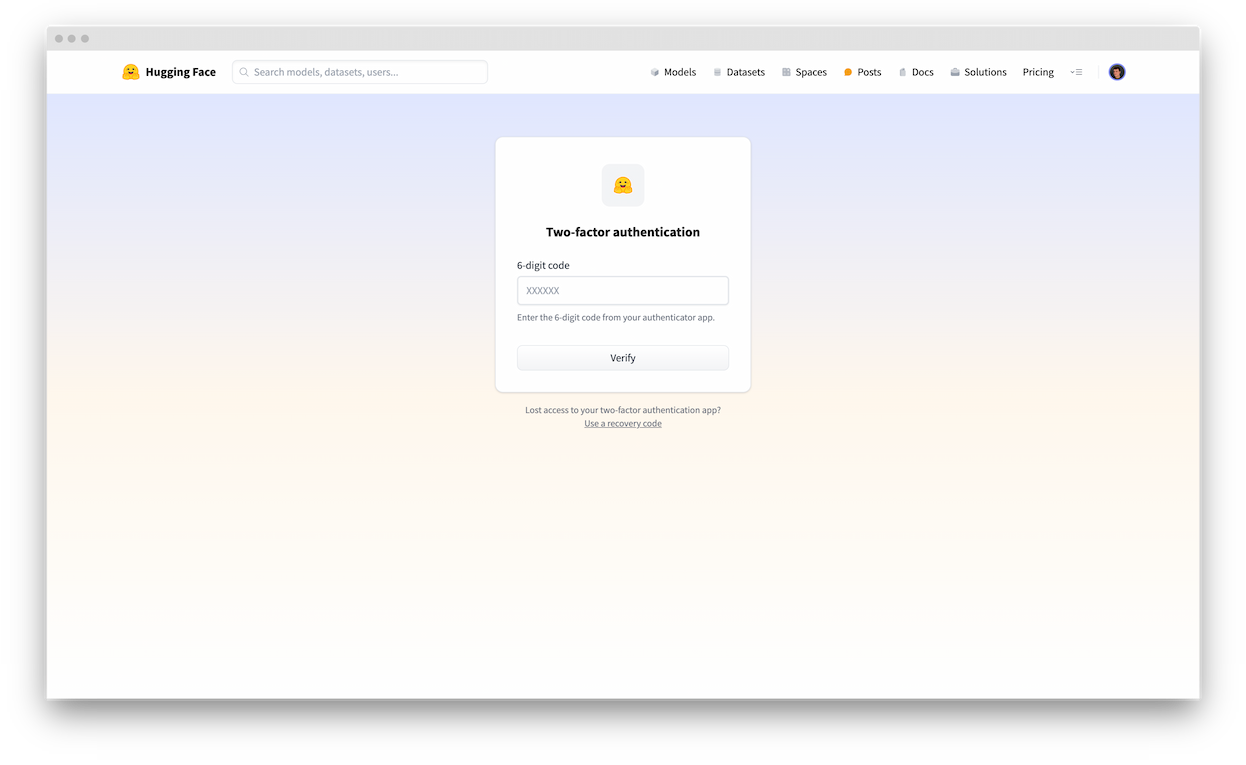
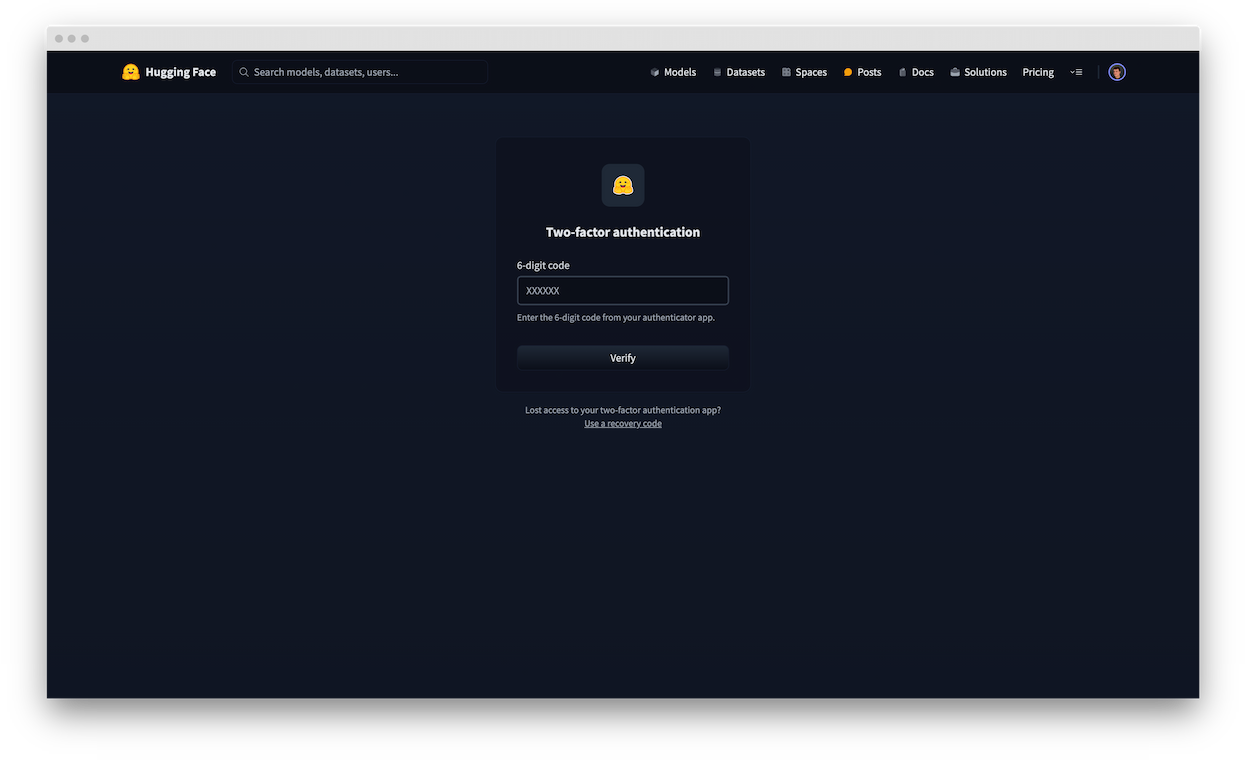
- [Two-Factor Authentication (2FA)](./security-2fa)
- [Git over SSH](./security-git-ssh)
- [Signing commits with GPG](./security-gpg)
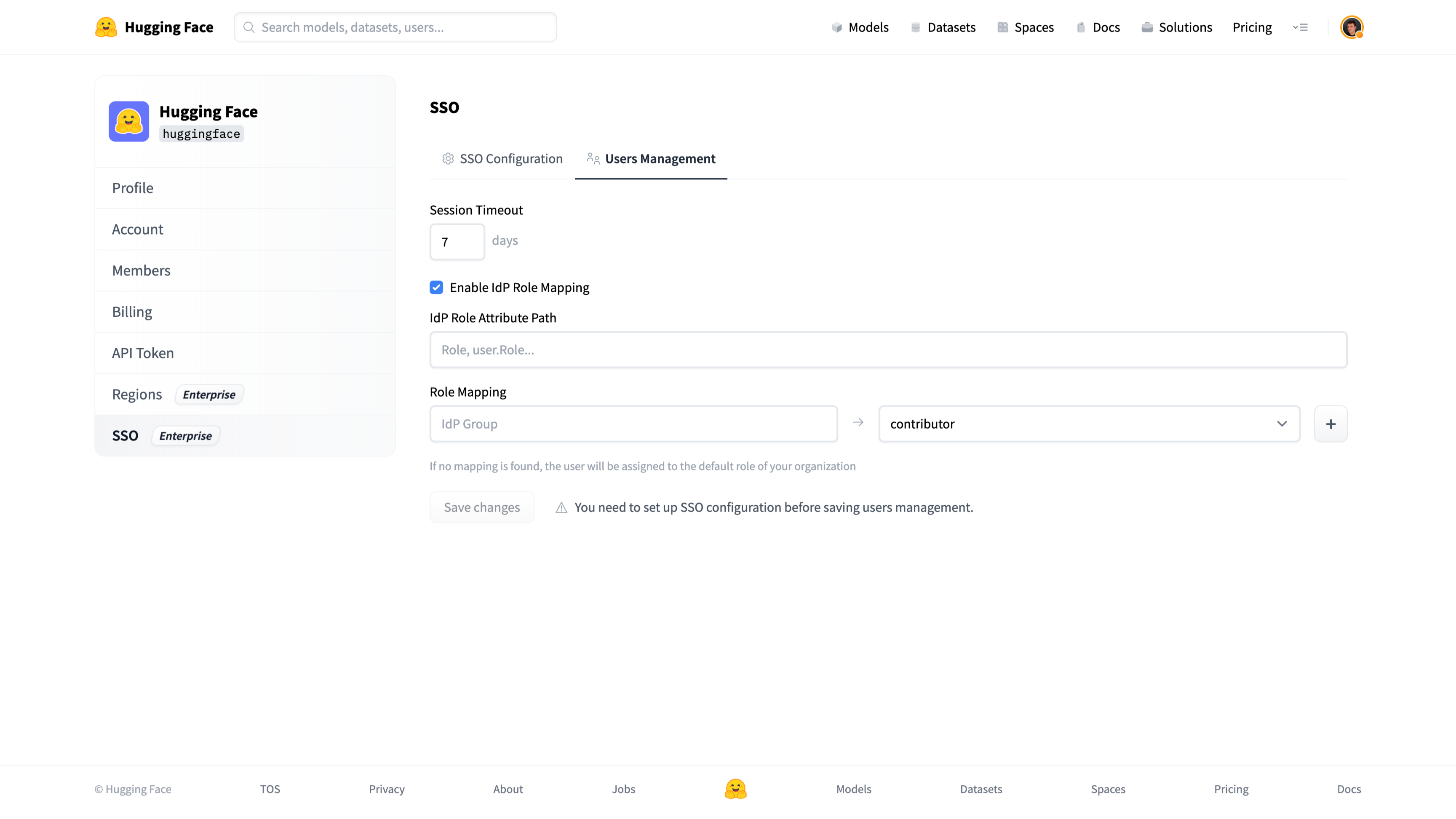
- [Single Sign-On (SSO)](./security-sso)
- [Malware Scanning](./security-malware)
- [Pickle Scanning](./security-pickle)
- [Secrets Scanning](./security-secrets)
- [Third-party scanner: Protect AI](./security-protectai)
- [Resource Groups](./security-resource-groups)
# Using sample-factory at Hugging Face
[`sample-factory`](https://github.com/alex-petrenko/sample-factory) is a codebase for high throughput asynchronous reinforcement learning. It has integrations with the Hugging Face Hub to share models with evaluation results and training metrics.
## Exploring sample-factory in the Hub
You can find `sample-factory` models by filtering at the left of the [models page](https://huggingface.co/models?library=sample-factory).
All models on the Hub come up with useful features:
1. An automatically generated model card with a description, a training configuration, and more.
2. Metadata tags that help for discoverability.
3. Evaluation results to compare with other models.
4. A video widget where you can watch your agent performing.
## Install the library
To install the `sample-factory` library, you need to install the package:
`pip install sample-factory`
SF is known to work on Linux and MacOS. There is no Windows support at this time.
## Loading models from the Hub
### Using load_from_hub
To download a model from the Hugging Face Hub to use with Sample-Factory, use the `load_from_hub` script:
```
python -m sample_factory.huggingface.load_from_hub -r
For any other security questions, please feel free to send us an email at security@huggingface.co.
## Contents
- [User Access Tokens](./security-tokens)
- [Two-Factor Authentication (2FA)](./security-2fa)
- [Git over SSH](./security-git-ssh)
- [Signing commits with GPG](./security-gpg)
- [Single Sign-On (SSO)](./security-sso)
- [Malware Scanning](./security-malware)
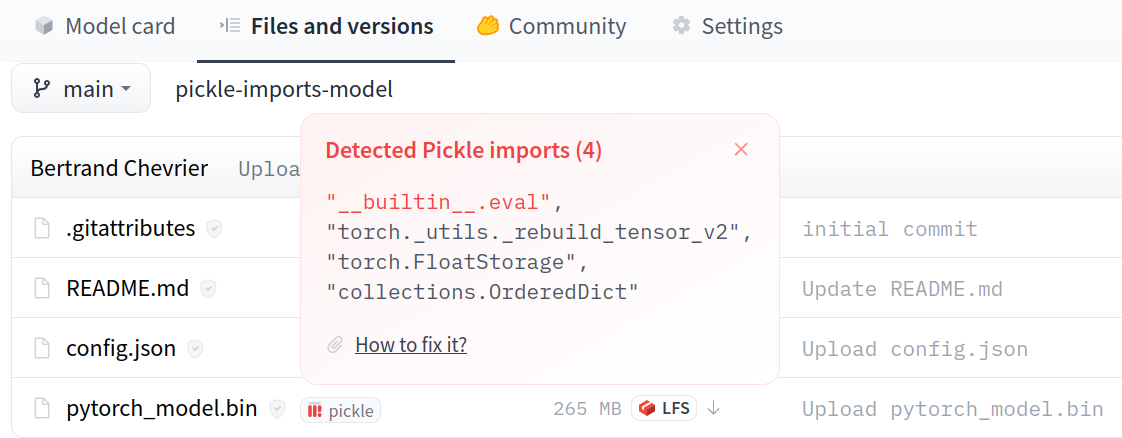
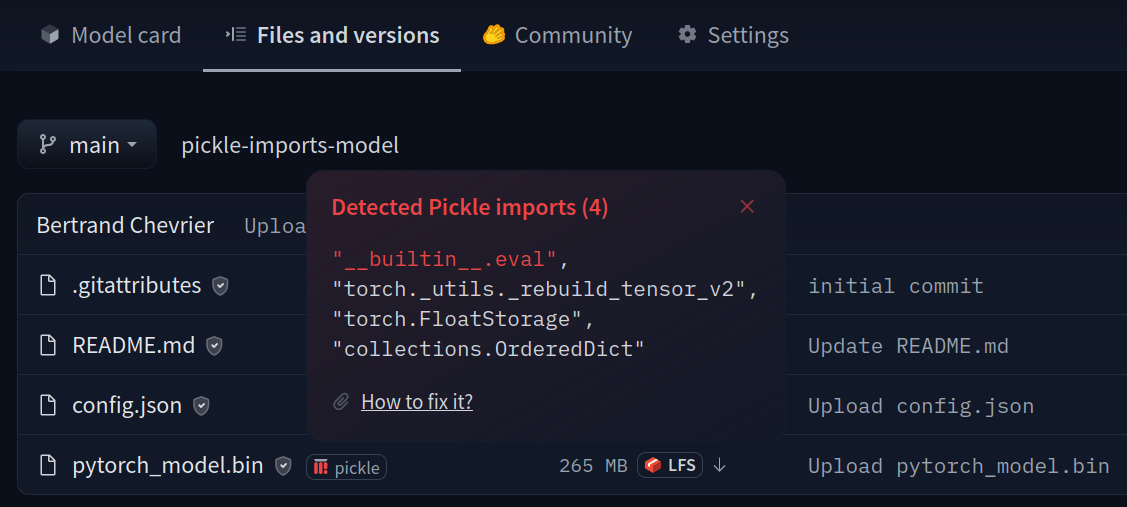
- [Pickle Scanning](./security-pickle)
- [Secrets Scanning](./security-secrets)
- [Third-party scanner: Protect AI](./security-protectai)
- [Resource Groups](./security-resource-groups)
# Using sample-factory at Hugging Face
[`sample-factory`](https://github.com/alex-petrenko/sample-factory) is a codebase for high throughput asynchronous reinforcement learning. It has integrations with the Hugging Face Hub to share models with evaluation results and training metrics.
## Exploring sample-factory in the Hub
You can find `sample-factory` models by filtering at the left of the [models page](https://huggingface.co/models?library=sample-factory).
All models on the Hub come up with useful features:
1. An automatically generated model card with a description, a training configuration, and more.
2. Metadata tags that help for discoverability.
3. Evaluation results to compare with other models.
4. A video widget where you can watch your agent performing.
## Install the library
To install the `sample-factory` library, you need to install the package:
`pip install sample-factory`
SF is known to work on Linux and MacOS. There is no Windows support at this time.
## Loading models from the Hub
### Using load_from_hub
To download a model from the Hugging Face Hub to use with Sample-Factory, use the `load_from_hub` script:
```
python -m sample_factory.huggingface.load_from_hub -r 
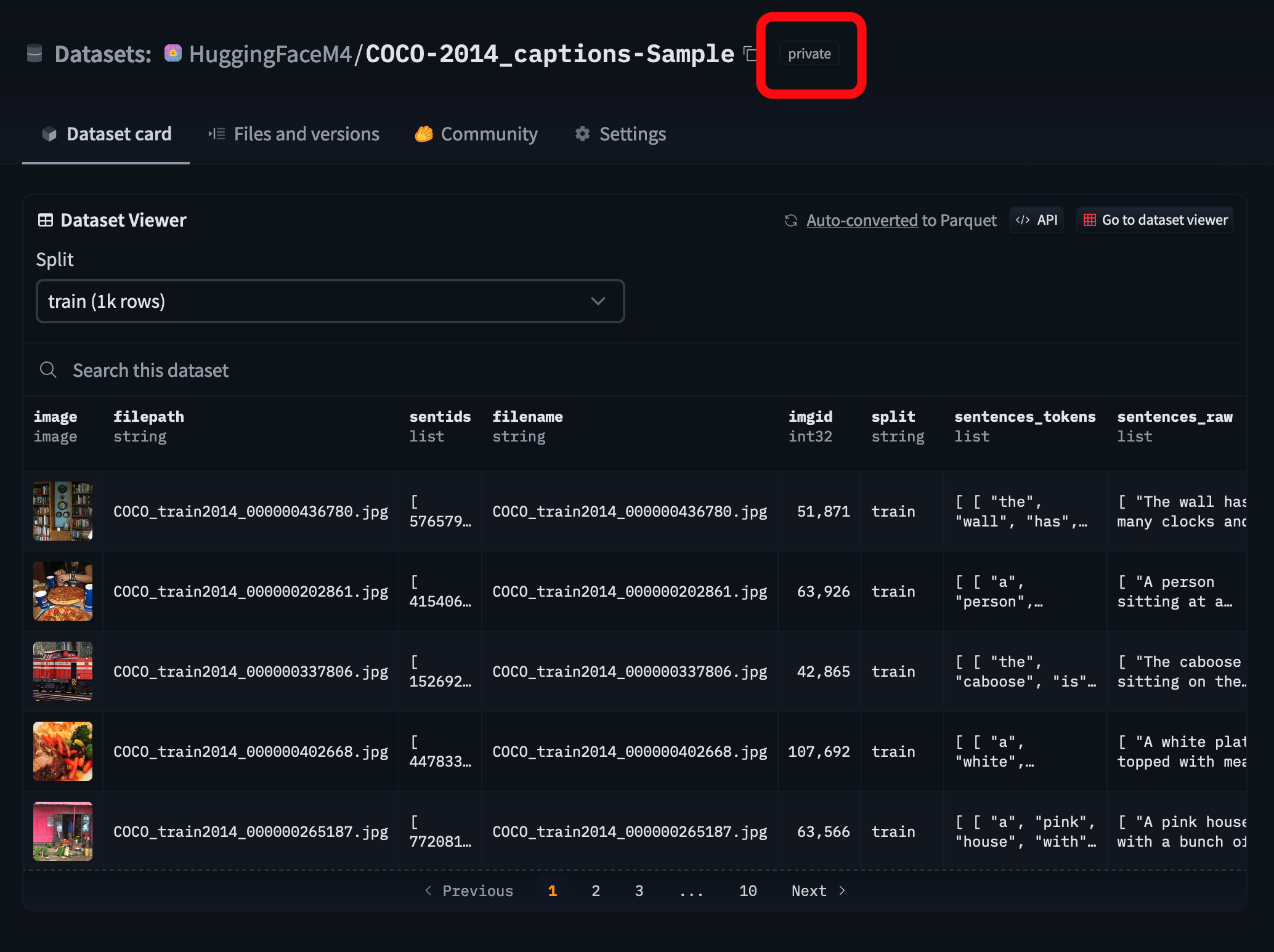














To learn more about the SQL Console, see the SQL Console blog post.
Through the SQL Console, you can: - Run [DuckDB SQL queries](https://duckdb.org/docs/sql/query_syntax/select) on the dataset (_checkout [SQL Snippets](https://huggingface.co/spaces/cfahlgren1/sql-snippets) for useful queries_) - Share results of the query with others via a link (_check out [this example](https://huggingface.co/datasets/gretelai/synthetic-gsm8k-reflection-405b?sql_console=true&sql=FROM+histogram%28%0A++train%2C%0A++topic%2C%0A++bin_count+%3A%3D+10%0A%29)_) - Download the results of the query to a parquet file - Embed the results of the query in your own webpage using an iframe



Learn more about the `histogram` function and parameters here.
```sql FROM histogram(train, len(reasoning_chains)) ``` ### Regex Matching One of the most powerful features of DuckDB is the deep support for regular expressions. You can use the `regexp` function to match patterns in your data. Using the [regexp_matches](https://duckdb.org/docs/sql/functions/char.html#regexp_matchesstring-pattern) function, we can filter the `SkunkworksAI/reasoning-0.01` dataset for instructions that contain markdown code blocks.

Learn more about the DuckDB regex functions here.
```sql SELECT * FROM train WHERE regexp_matches(instruction, '```[a-z]*\n') limit 100 ``` ### Leakage Detection Leakage detection is the process of identifying whether data in a dataset is present in multiple splits, for example, whether the test set is present in the training set.

Learn more about leakage detection here.
```sql WITH overlapping_rows AS ( SELECT COALESCE( (SELECT COUNT(*) AS overlap_count FROM train INTERSECT SELECT COUNT(*) AS overlap_count FROM test), 0 ) AS overlap_count ), total_unique_rows AS ( SELECT COUNT(*) AS total_count FROM ( SELECT * FROM train UNION SELECT * FROM test ) combined ) SELECT overlap_count, total_count, CASE WHEN total_count > 0 THEN (overlap_count * 100.0 / total_count) ELSE 0 END AS overlap_percentage FROM overlapping_rows, total_unique_rows; ``` # Docker Spaces Examples We gathered some example demos in the [Spaces Examples](https://huggingface.co/SpacesExamples) organization. Please check them out! * Dummy FastAPI app: https://huggingface.co/spaces/DockerTemplates/fastapi_dummy * FastAPI app serving a static site and using `transformers`: https://huggingface.co/spaces/DockerTemplates/fastapi_t5 * Phoenix app for https://huggingface.co/spaces/DockerTemplates/single_file_phx_bumblebee_ml * HTTP endpoint in Go with query parameters https://huggingface.co/spaces/XciD/test-docker-go?q=Adrien * Shiny app written in Python https://huggingface.co/spaces/elonmuskceo/shiny-orbit-simulation * Genie.jl app in Julia https://huggingface.co/spaces/nooji/GenieOnHuggingFaceSpaces * Argilla app for data labelling and curation: https://huggingface.co/spaces/argilla/live-demo and [write-up about hosting Argilla on Spaces](./spaces-sdks-docker-argilla) by [@dvilasuero](https://huggingface.co/dvilasuero) 🎉 * JupyterLab and VSCode: https://huggingface.co/spaces/DockerTemplates/docker-examples by [@camenduru](https://twitter.com/camenduru) and [@nateraw](https://hf.co/nateraw). * Zeno app for interactive model evaluation: https://huggingface.co/spaces/zeno-ml/diffusiondb and [instructions for setup](https://zenoml.com/docs/deployment#hugging-face-spaces) * Gradio App: https://huggingface.co/spaces/sayakpaul/demo-docker-gradio # Livebook on Spaces **Livebook** is an open-source tool for writing interactive code notebooks in [Elixir](https://elixir-lang.org/). It's part of a growing collection of Elixir tools for [numerical computing](https://github.com/elixir-nx/nx), [data science](https://github.com/elixir-nx/explorer), and [Machine Learning](https://github.com/elixir-nx/bumblebee). Some of Livebook's most exciting features are: - **Reproducible workflows**: Livebook runs your code in a predictable order, all the way down to package management - **Smart cells**: perform complex tasks, such as data manipulation and running machine learning models, with a few clicks using Livebook's extensible notebook cells - **Elixir powered**: use the power of the Elixir programming language to write concurrent and distributed notebooks that scale beyond your machine To learn more about it, watch this [15-minute video](https://www.youtube.com/watch?v=EhSNXWkji6o). Or visit [Livebook's website](https://livebook.dev/). Or follow its [Twitter](https://twitter.com/livebookdev) and [blog](https://news.livebook.dev/) to keep up with new features and updates. ## Your first Livebook Space You can get Livebook up and running in a Space with just a few clicks. Click the button below to start creating a new Space using Livebook's Docker template:
Then:
1. Give your Space a name
2. Set the password of your Livebook
3. Set its visibility to public
4. Create your Space
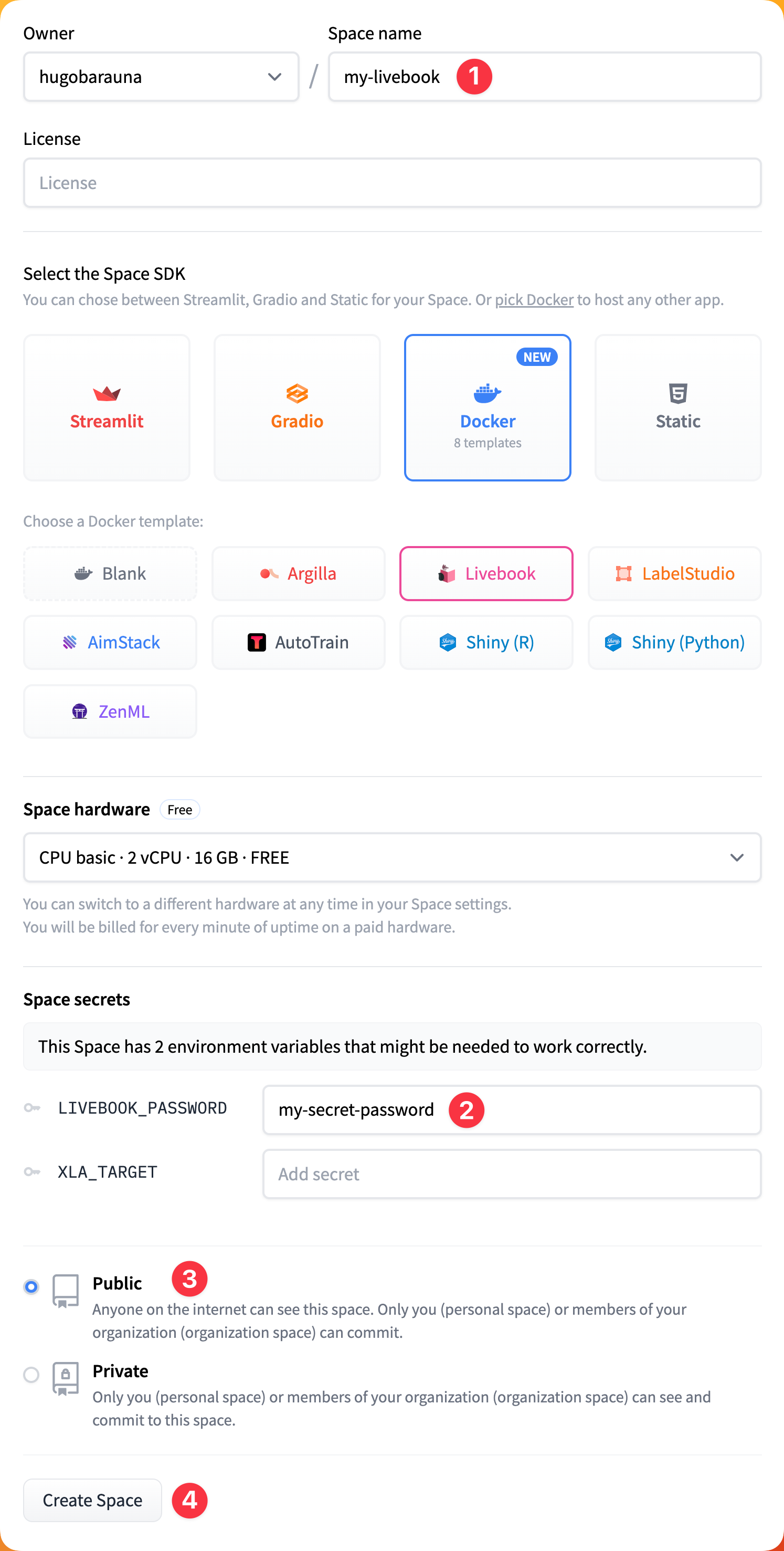
This will start building your Space using Livebook's Docker image.
The visibility of the Space must be set to public for the Smart cells feature in Livebook to function properly. However, your Livebook instance will be protected by Livebook authentication.








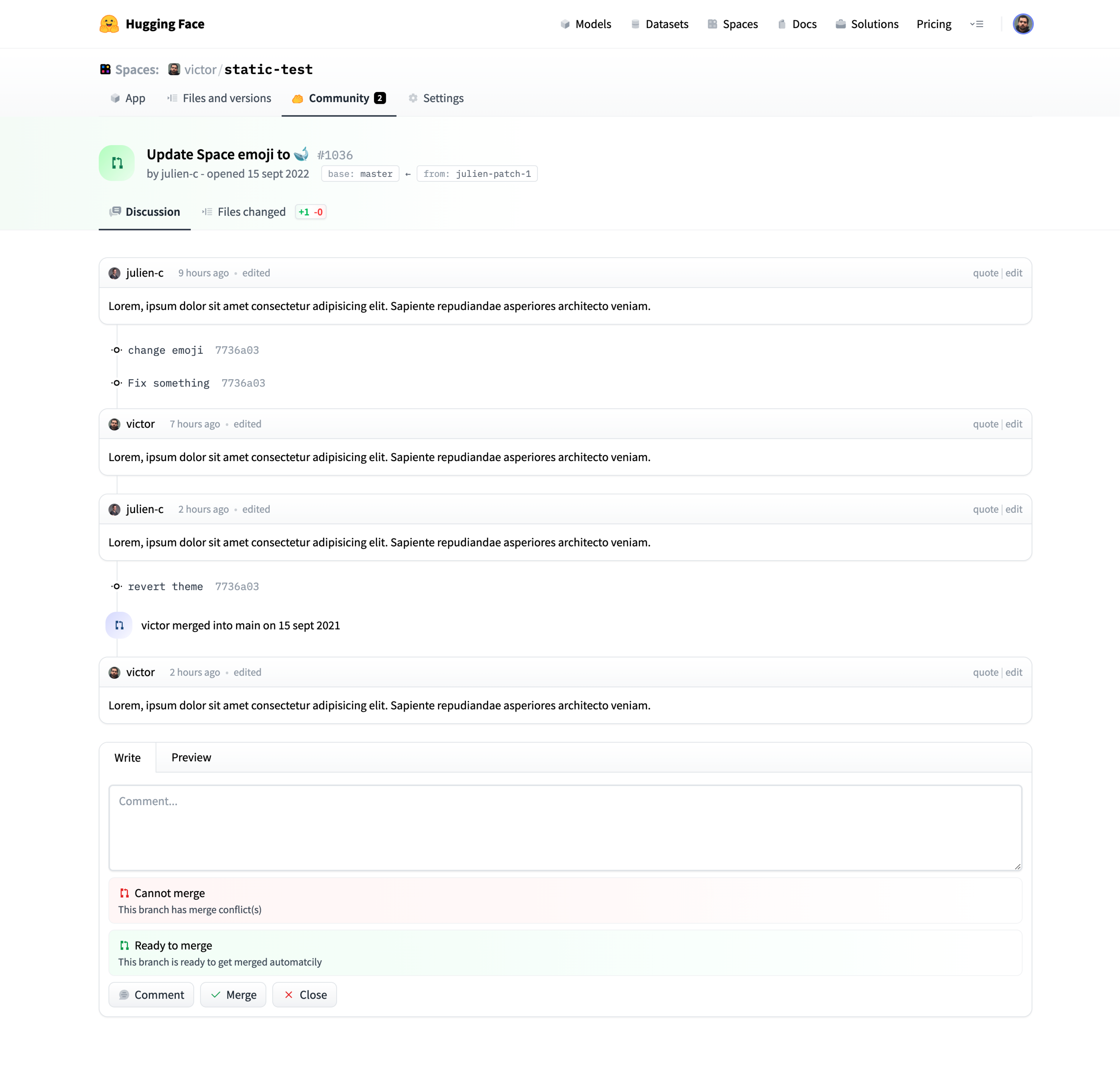
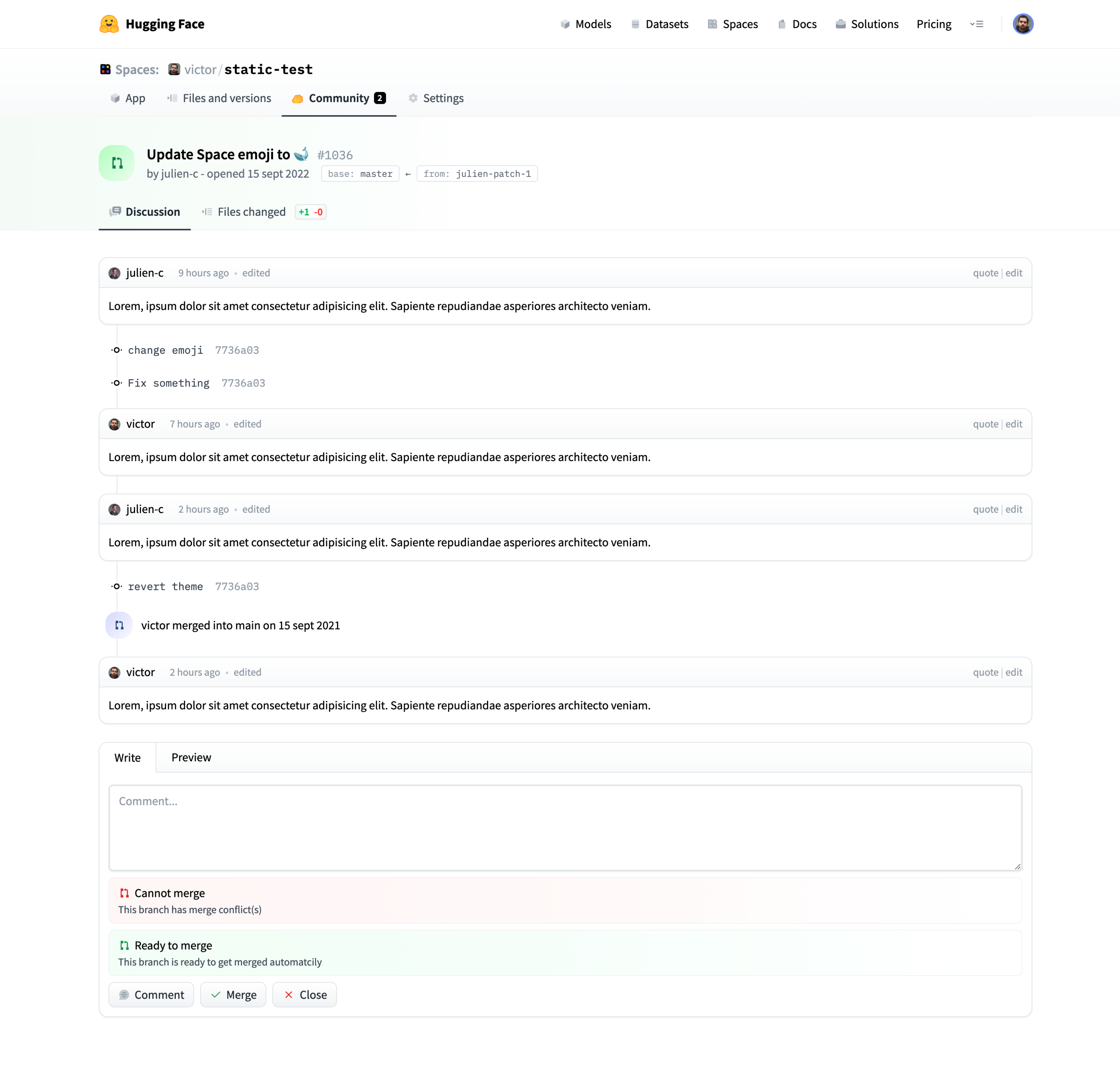
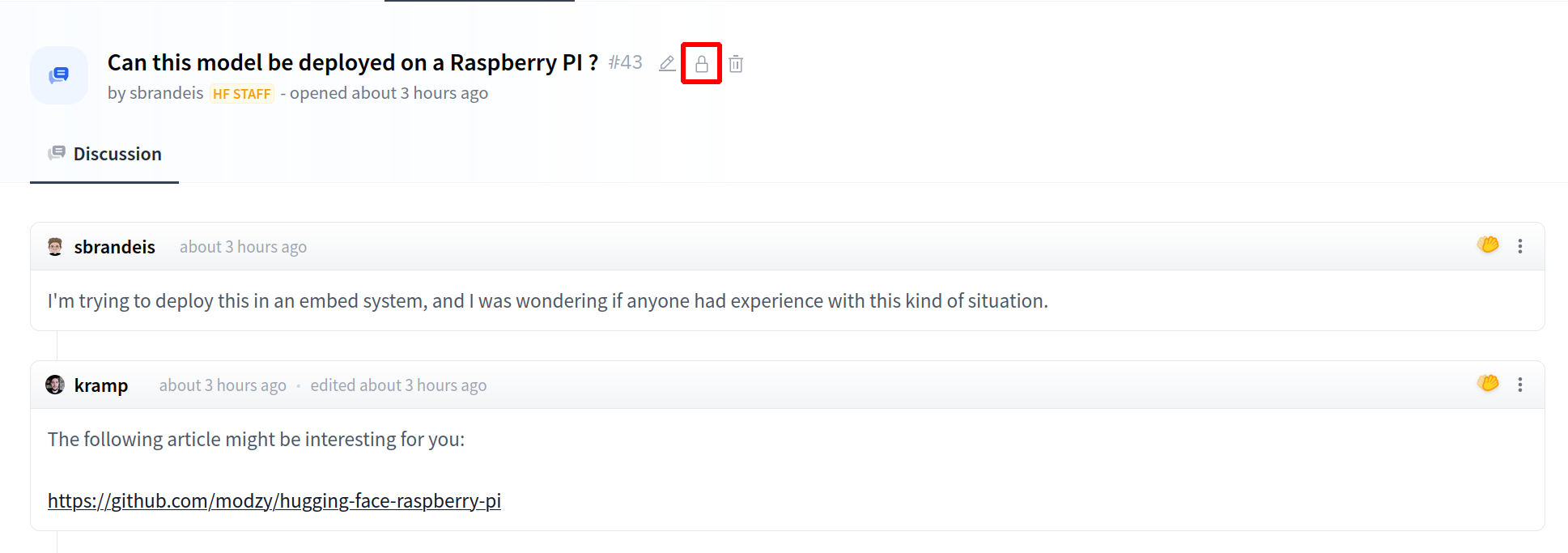
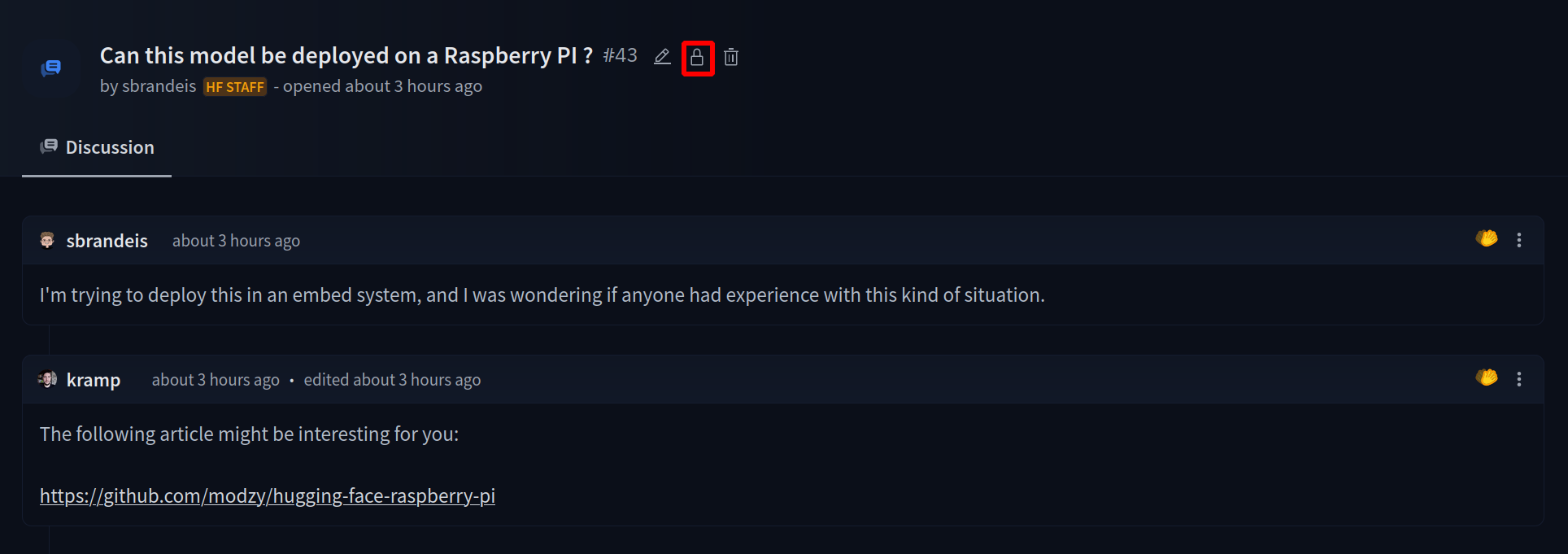
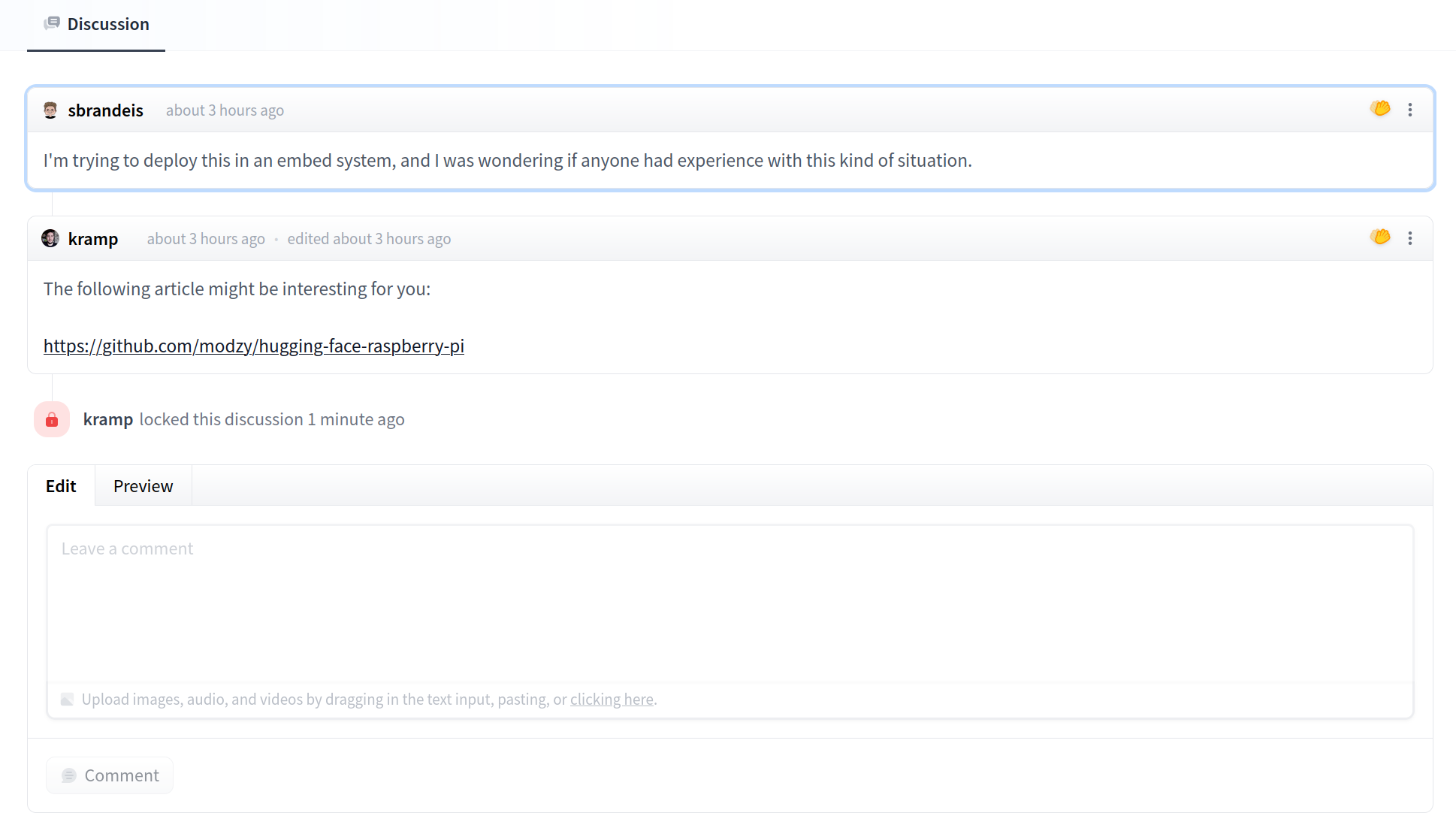
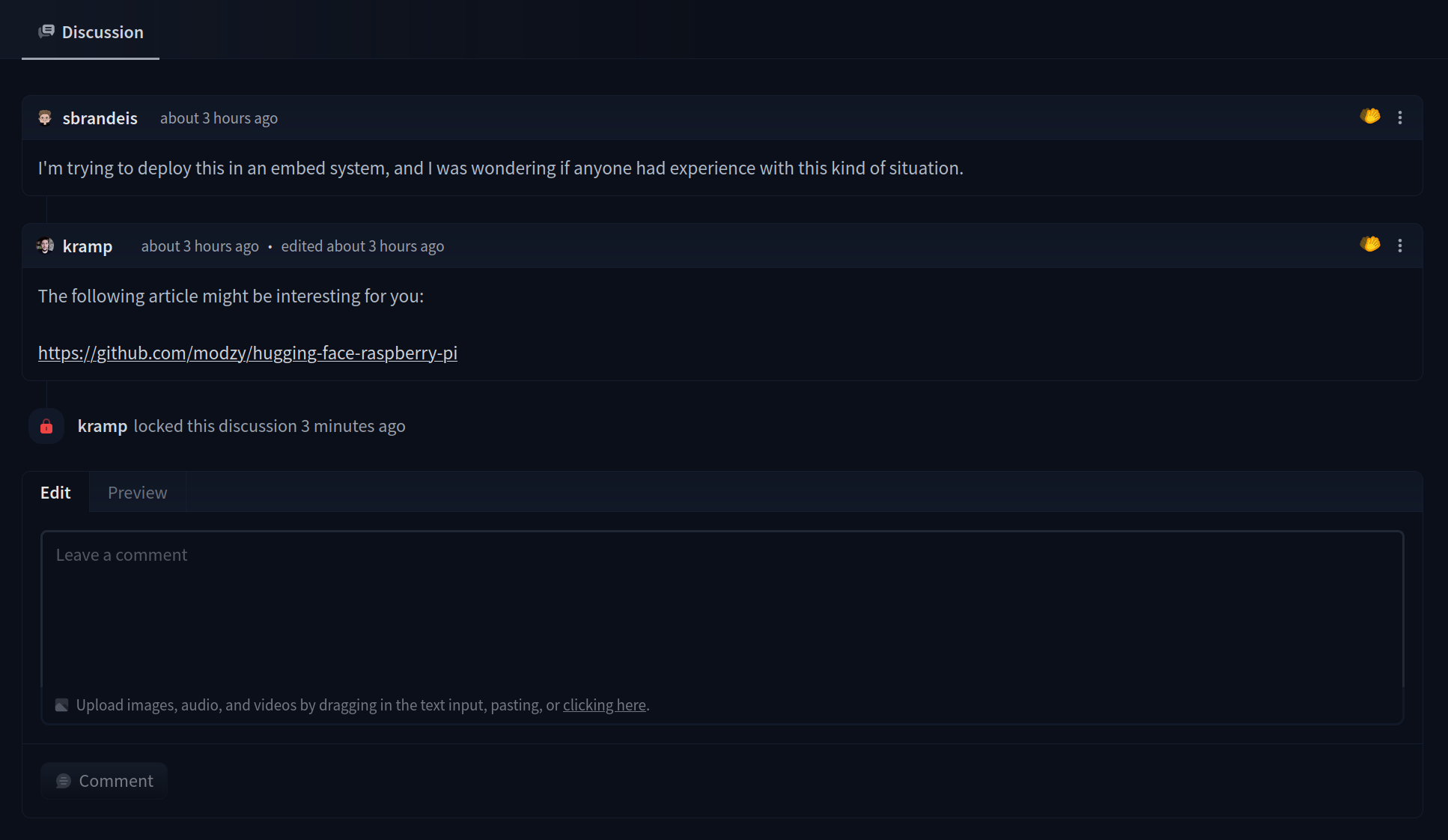
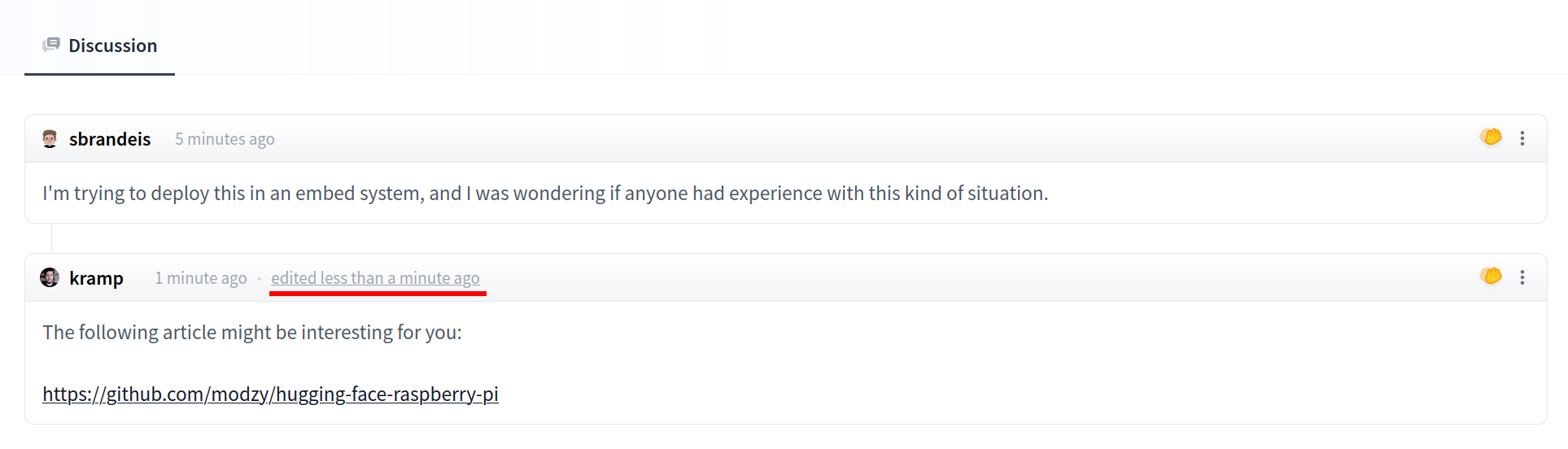
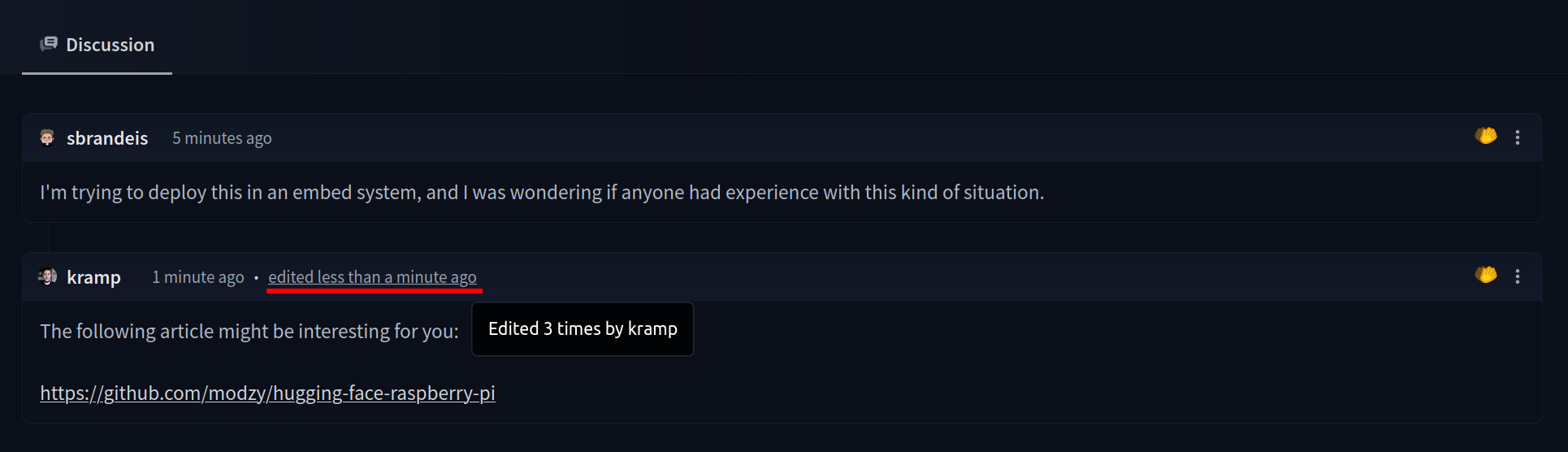
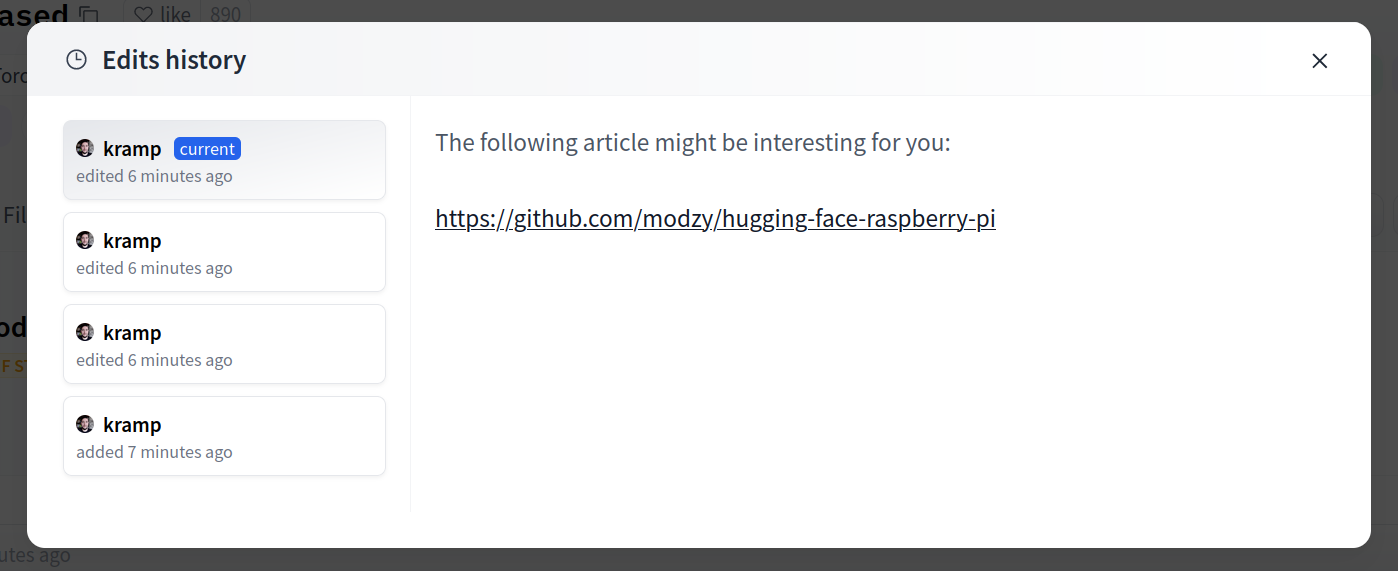
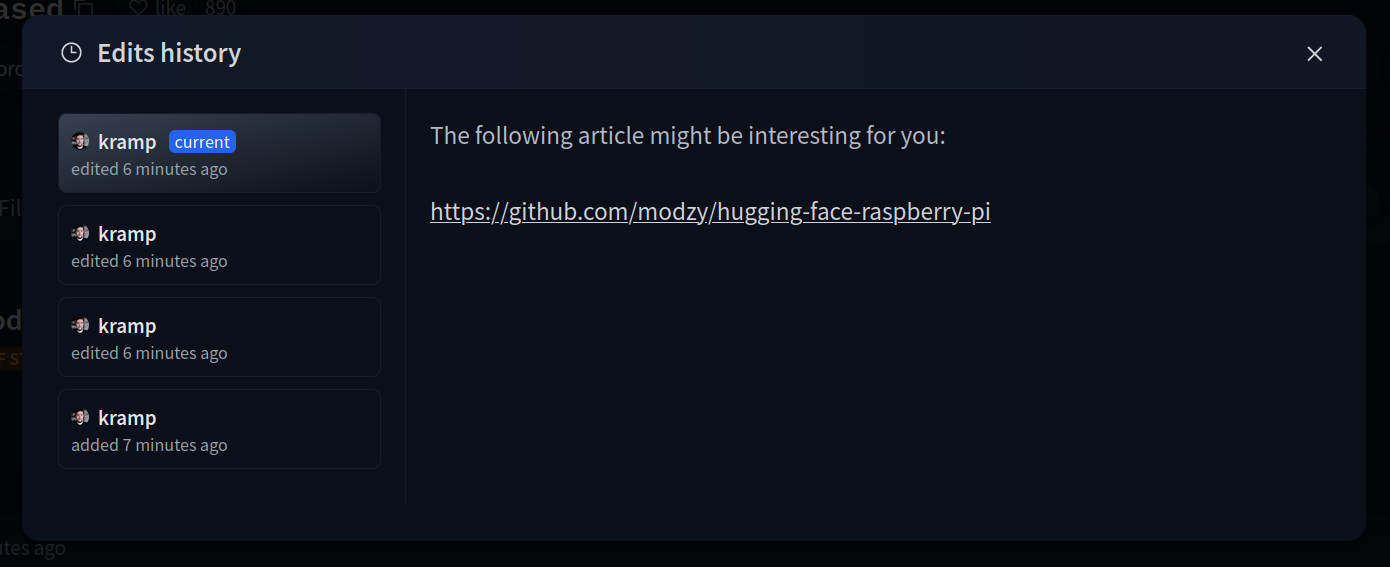




 Once created, the Space will display `Building` status. Refresh the page if the status doesn't automatically update to `Running`.
Your Evidence app will automatically be deployed on Hugging Face Spaces.
## Editing your Evidence app from the CLI
To edit your app, clone the Space and edit the files locally.
```bash
git clone https://huggingface.co/spaces/your-username/your-space-name
cd your-space-name
npm install
npm run sources
npm run dev
```
You can then modify pages/index.md to change the content of your app.
## Editing your Evidence app from VS Code
The easiest way to develop with Evidence is using the [VS Code Extension](https://marketplace.visualstudio.com/items?itemName=Evidence.evidence-vscode):
1. Install the extension from the VS Code Marketplace
2. Open the Command Palette (Ctrl/Cmd + Shift + P) and enter `Evidence: Copy Existing Project`
3. Paste the URL of the Hugging Face Spaces Evidence app you'd like to copy (e.g. `https://huggingface.co/spaces/your-username/your-space-name`) and press Enter
4. Select the folder you'd like to clone the project to and press Enter
5. Press `Start Evidence` in the bottom status bar
Check out the docs for [alternative install methods](https://docs.evidence.dev/getting-started/install-evidence), Github Codespaces, and alongside dbt.
## Learning More
- [Docs](https://docs.evidence.dev/)
- [Github](https://github.com/evidence-dev/evidence)
- [Slack Community](https://slack.evidence.dev/)
- [Evidence Home Page](https://www.evidence.dev)
# Libraries
The Datasets Hub has support for several libraries in the Open Source ecosystem.
Thanks to the [huggingface_hub Python library](/docs/huggingface_hub), it's easy to enable sharing your datasets on the Hub.
We're happy to welcome to the Hub a set of Open Source libraries that are pushing Machine Learning forward.
The table below summarizes the supported libraries and their level of integration.
| Library | Description | Download from Hub | Push to Hub |
|-----------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------|---|----|
| [Argilla](./datasets-argilla) | Collaboration tool for AI engineers and domain experts that value high quality data. | ✅ | ✅ |
| [Dask](./datasets-dask) | Parallel and distributed computing library that scales the existing Python and PyData ecosystem. | ✅ | ✅ |
| [Datasets](./datasets-usage) | 🤗 Datasets is a library for accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP). | ✅ | ✅ |
| [Distilabel](./datasets-distilabel) | The framework for synthetic data generation and AI feedback. | ✅ | ✅ |
| [DuckDB](./datasets-duckdb) | In-process SQL OLAP database management system. | ✅ | ✅ |
| [FiftyOne](./datasets-fiftyone) | FiftyOne is a library for curation and visualization of image, video, and 3D data. | ✅ | ✅ |
| [Pandas](./datasets-pandas) | Python data analysis toolkit. | ✅ | ✅ |
| [Polars](./datasets-polars) | A DataFrame library on top of an OLAP query engine. | ✅ | ✅ |
| [Spark](./datasets-spark) | Real-time, large-scale data processing tool in a distributed environment. | ✅ | ✅ |
| [WebDataset](./datasets-webdataset) | Library to write I/O pipelines for large datasets. | ✅ | ❌ |
# How to Add a Space to ArXiv
Demos on Hugging Face Spaces allow a wide audience to try out state-of-the-art machine
learning research without writing any code. [Hugging Face and ArXiv have collaborated](https://huggingface.co/blog/arxiv)
to embed these demos directly along side papers on ArXiv!
Thanks to this integration, users can now find the most popular demos for a paper on its arXiv abstract page. For example, if you want to try out demos of the LayoutLM document classification model, you can go to [the LayoutLM paper's arXiv page](https://arxiv.org/abs/1912.13318), and navigate to the demo tab. You will see open-source demos built by the machine learning community for this model, which you can try out immediately in your browser:
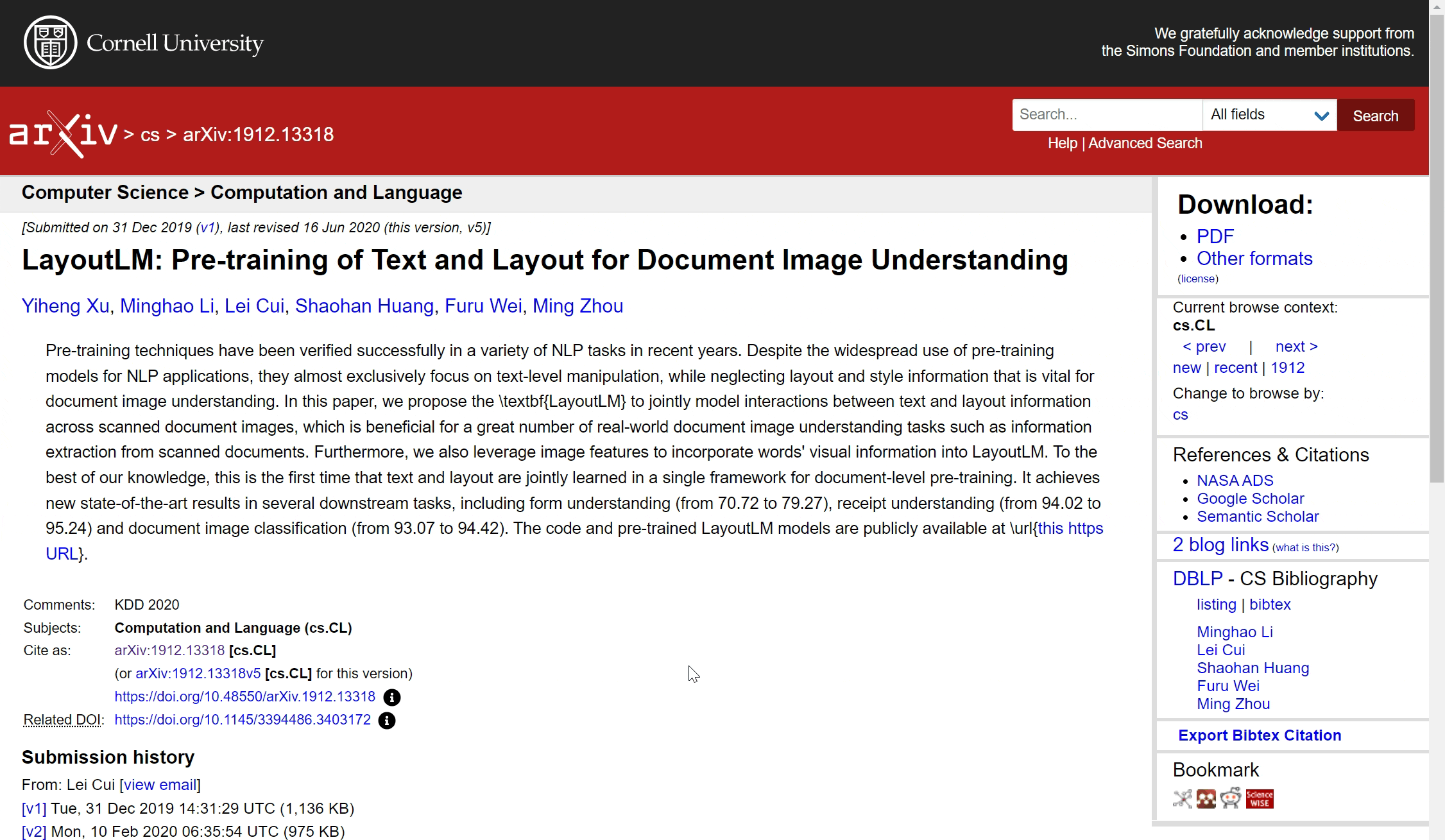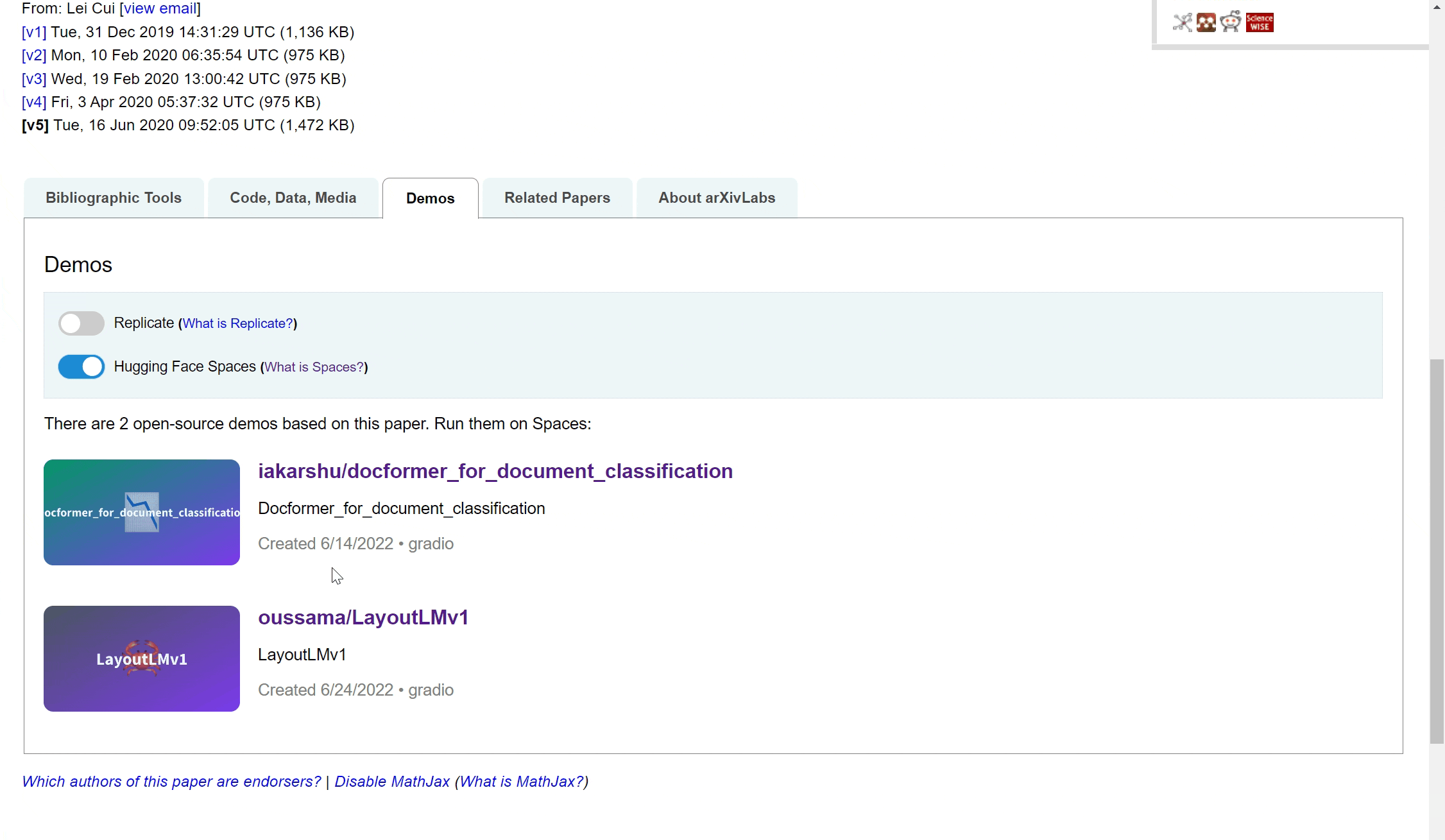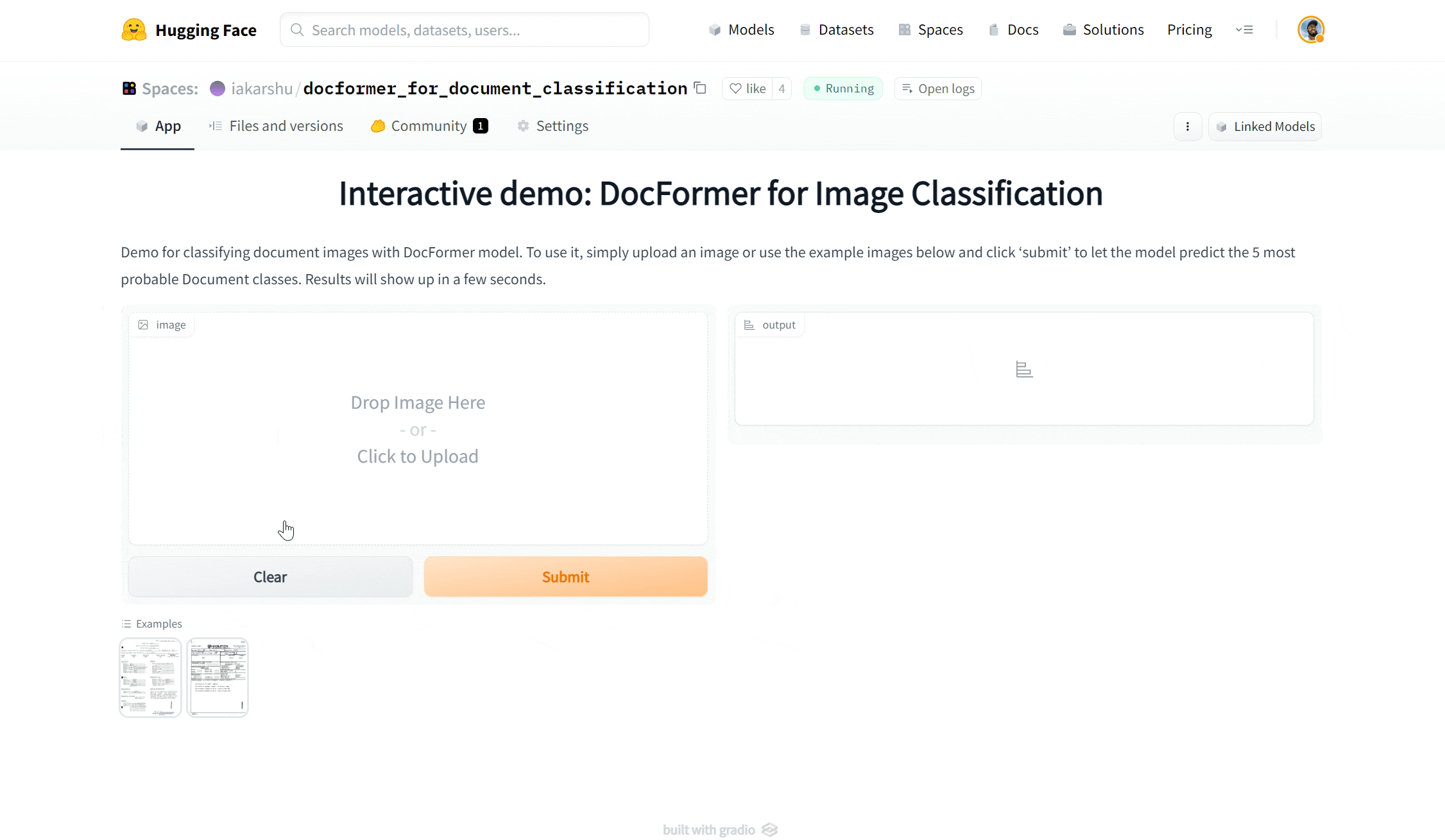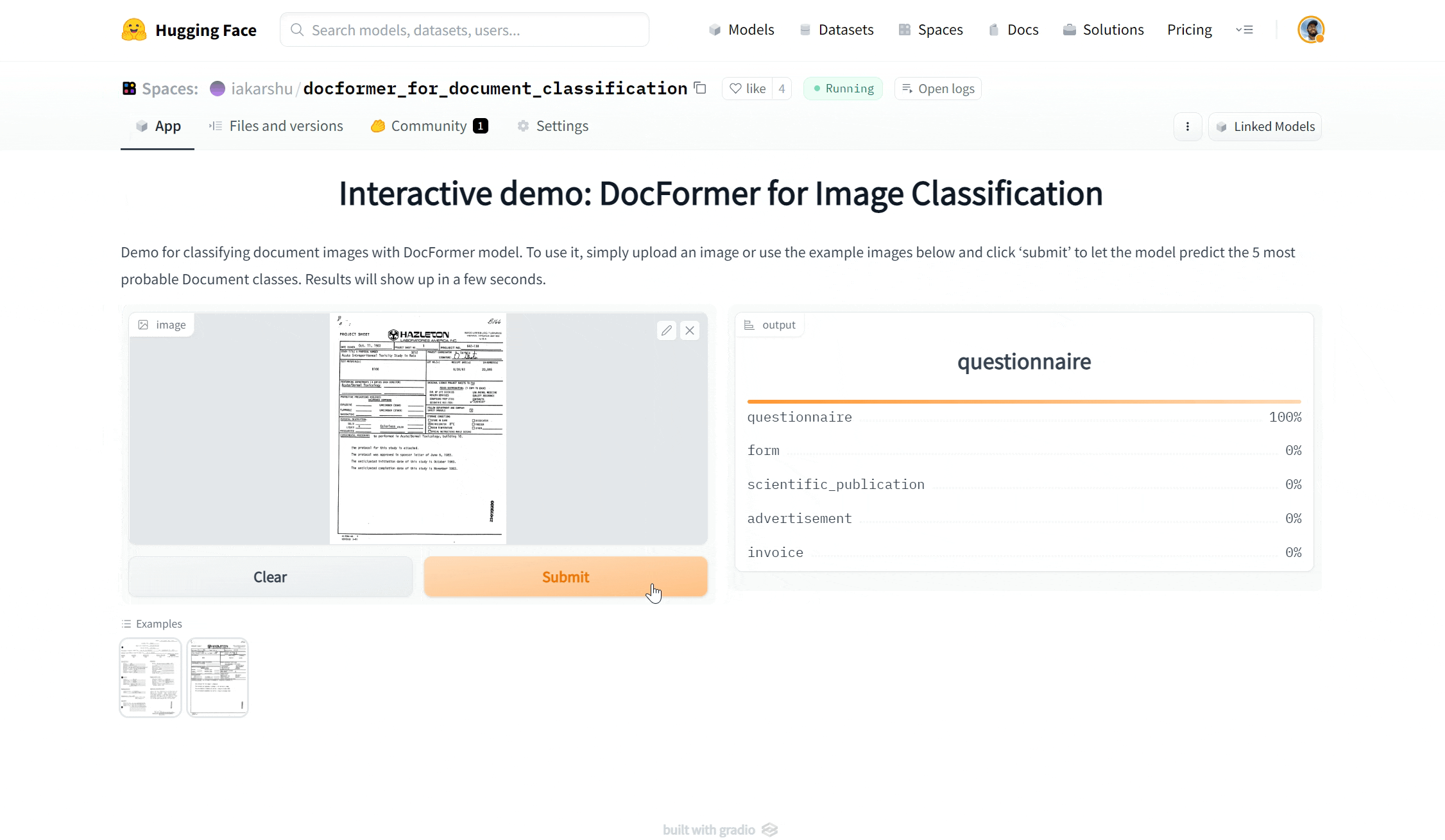
We'll cover two different ways to add your Space to ArXiv and have it show up in the Demos tab.
**Prerequisites**
* There's an existing paper on ArXiv that you'd like to create a demo for
* You have built or (can build) a demo for the model on Spaces
**Method 1 (Recommended): Linking from the Space README**
The simplest way to add a Space to an ArXiv paper is to include the link to the paper in the Space README file (`README.md`). It's good practice to include a full citation as well. You can see an example of a link and a citation on this [Echocardiogram Segmentation Space README](https://huggingface.co/spaces/abidlabs/echocardiogram-arxiv/blob/main/README.md).
And that's it! Your Space should appear in the Demo tab next to the paper on ArXiv in a few minutes 🤗
**Method 2: Linking a Related Model**
An alternative approach can be used to link Spaces to papers by linking an intermediate model to the Space. This requires that the paper is **associated with a model** that is on the Hugging Face Hub (or can be uploaded there)
1. First, upload the model associated with the ArXiv paper onto the Hugging Face Hub if it is not already there. ([Detailed instructions are here](./models-uploading))
2. When writing the model card (README.md) for the model, include a link to the ArXiv paper. It's good practice to include a full citation as well. You can see an example of a link and a citation on the [LayoutLM model card](https://huggingface.co/microsoft/layoutlm-base-uncased)
*Note*: you can verify this step has been carried out successfully by seeing if an ArXiv button appears above the model card. In the case of LayoutLM, the button says: "arxiv:1912.13318" and links to the LayoutLM paper on ArXiv.

3. Then, create a demo on Spaces that loads this model. Somewhere within the code, the model name must be included in order for Hugging Face to detect that a Space is associated with it.
For example, the [docformer_for_document_classification](https://huggingface.co/spaces/iakarshu/docformer_for_document_classification) Space loads the LayoutLM [like this](https://huggingface.co/spaces/iakarshu/docformer_for_document_classification/blob/main/modeling.py#L484) and include the string `"microsoft/layoutlm-base-uncased"`:
```py
from transformers import LayoutLMForTokenClassification
layoutlm_dummy = LayoutLMForTokenClassification.from_pretrained("microsoft/layoutlm-base-uncased", num_labels=1)
```
*Note*: Here's an [overview on building demos on Hugging Face Spaces](./spaces-overview) and here are more specific instructions for [Gradio](./spaces-sdks-gradio) and [Streamlit](./spaces-sdks-streamlit).
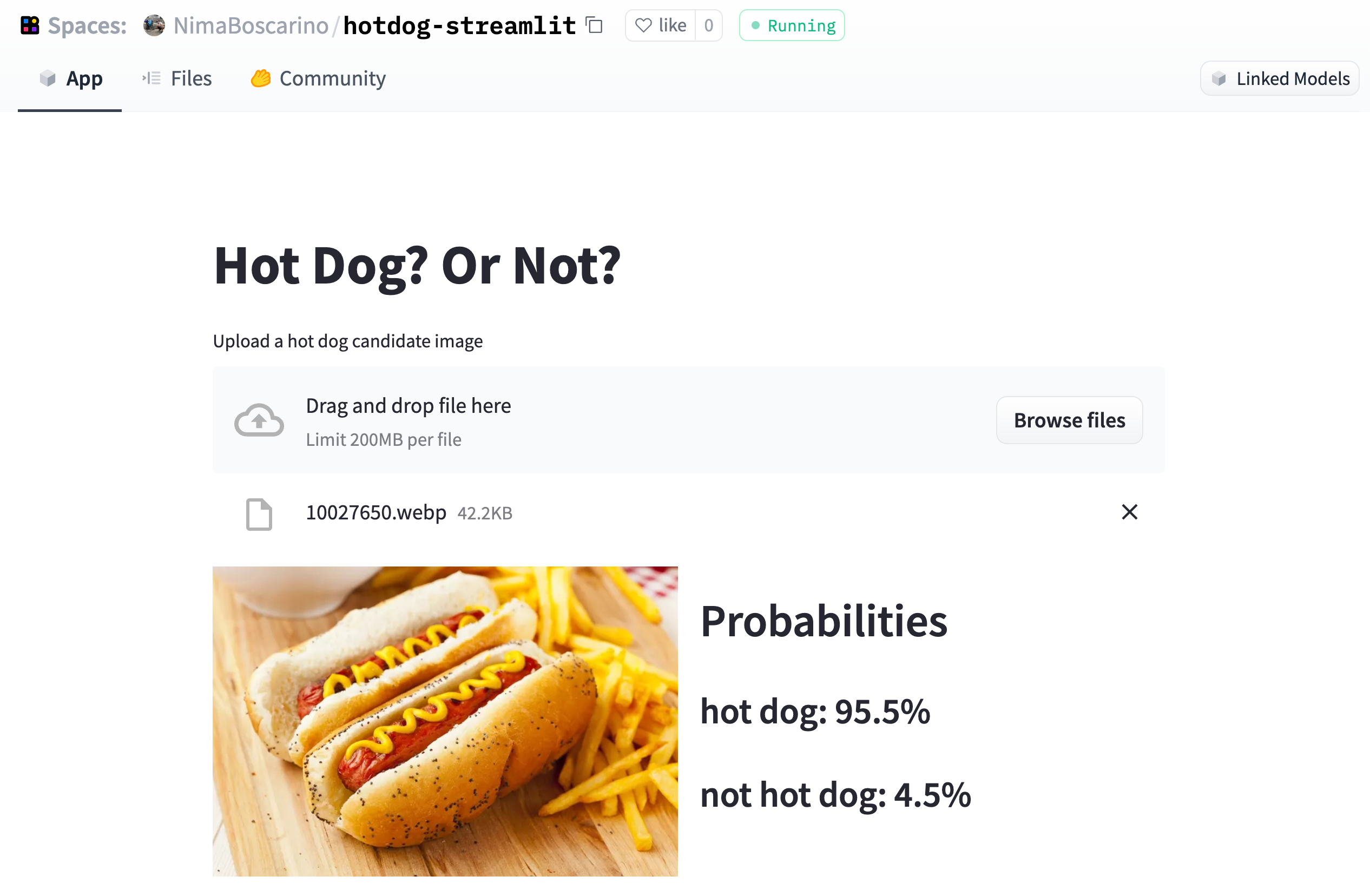
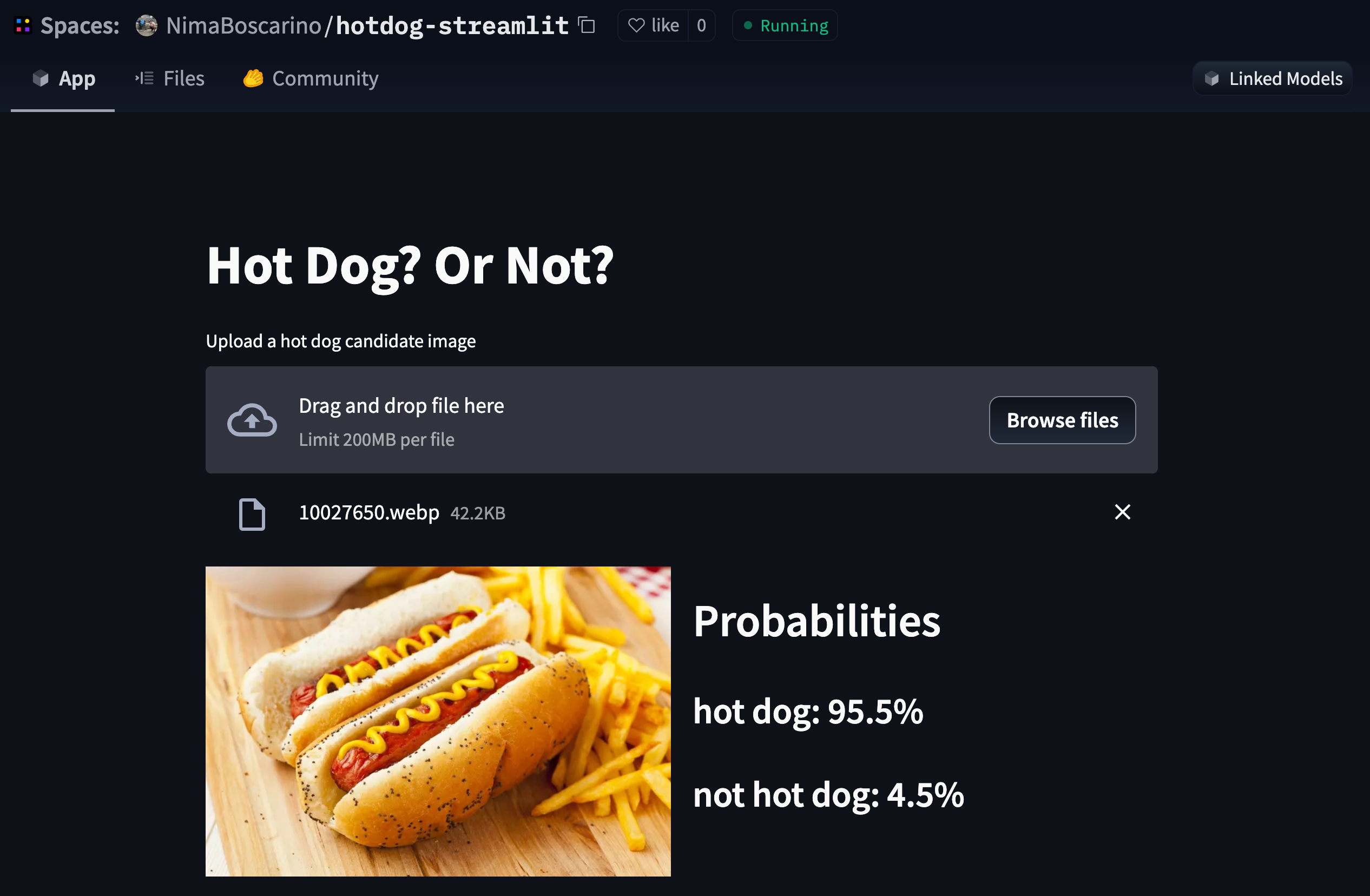
4. As soon as your Space is built, Hugging Face will detect that it is associated with the model. A "Linked Models" button should appear in the top right corner of the Space, as shown here:

*Note*: You can also add linked models manually by explicitly updating them in the [README metadata for the Space, as described here](https://huggingface.co/docs/hub/spaces-config-reference).
Your Space should appear in the Demo tab next to the paper on ArXiv in a few minutes 🤗
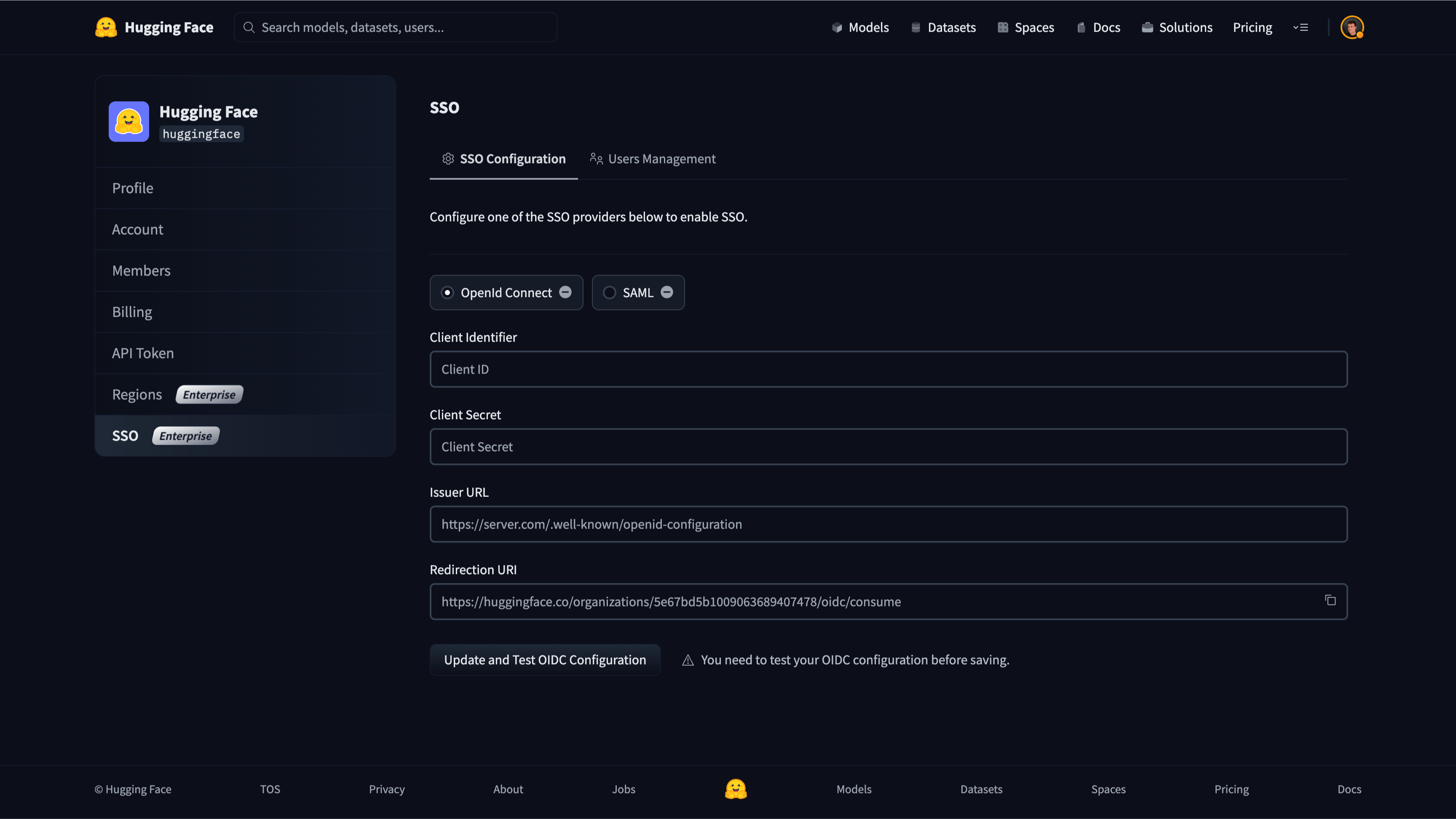
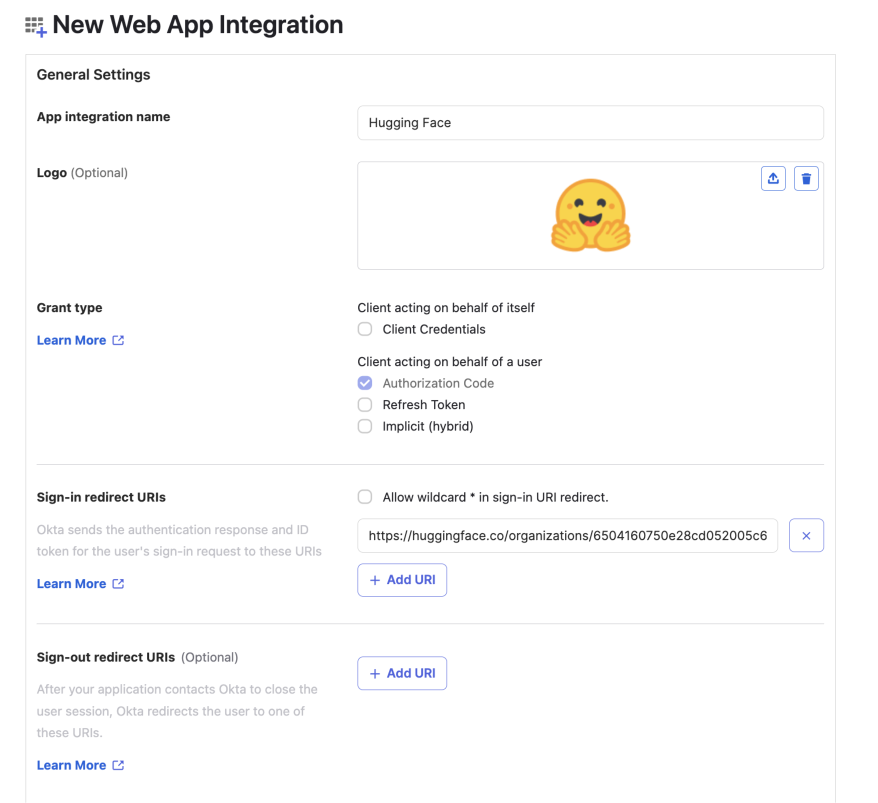
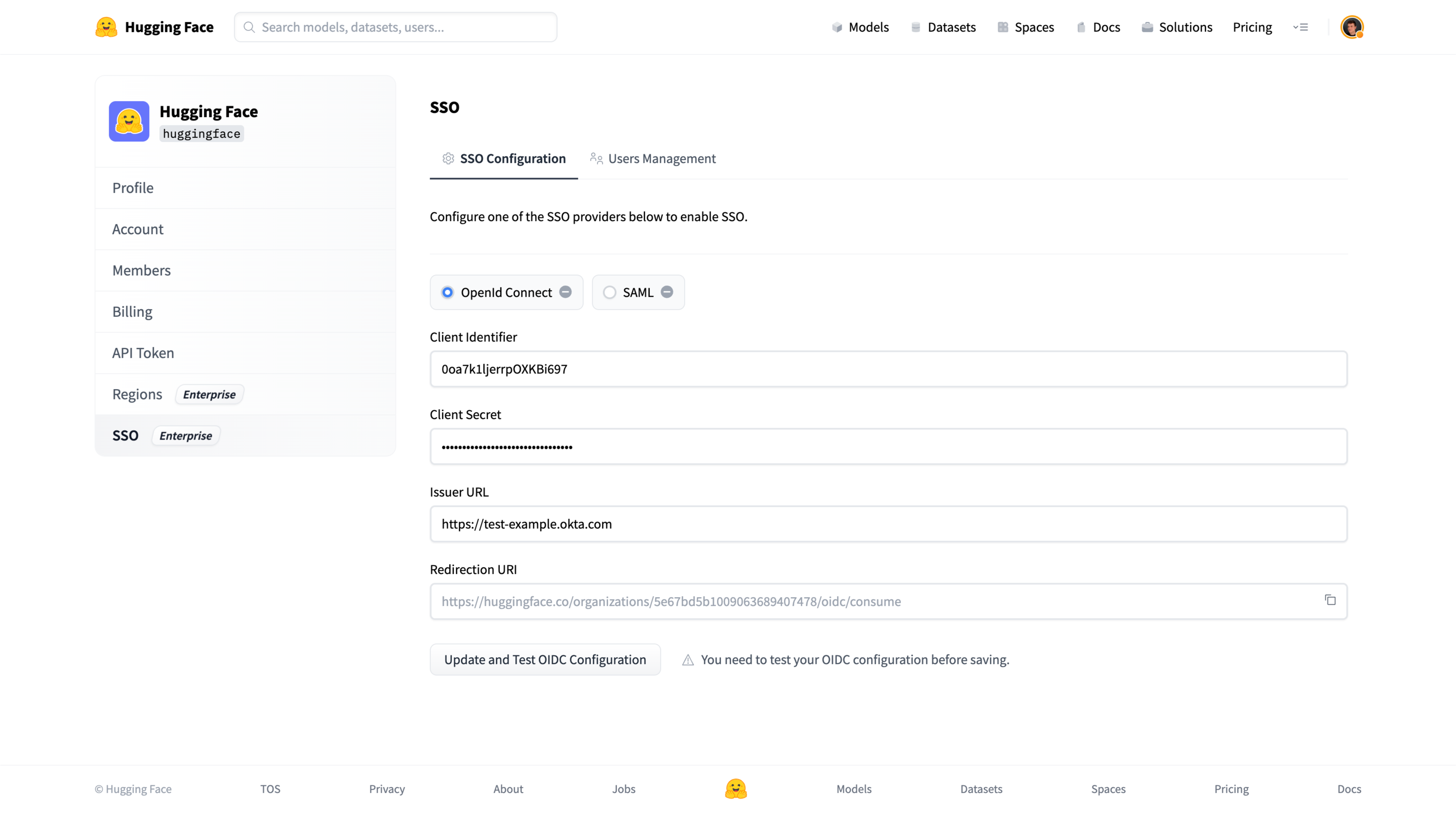
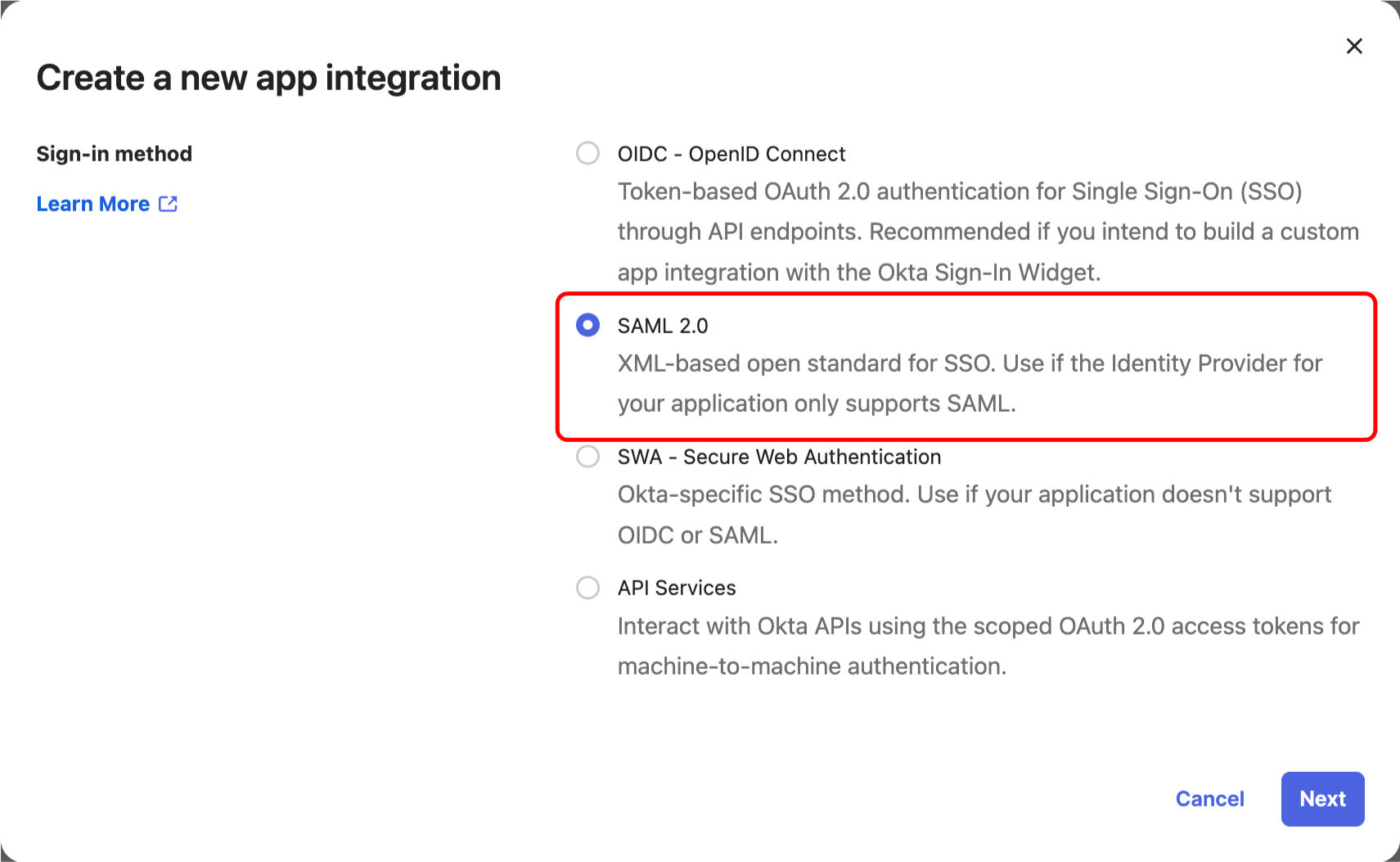
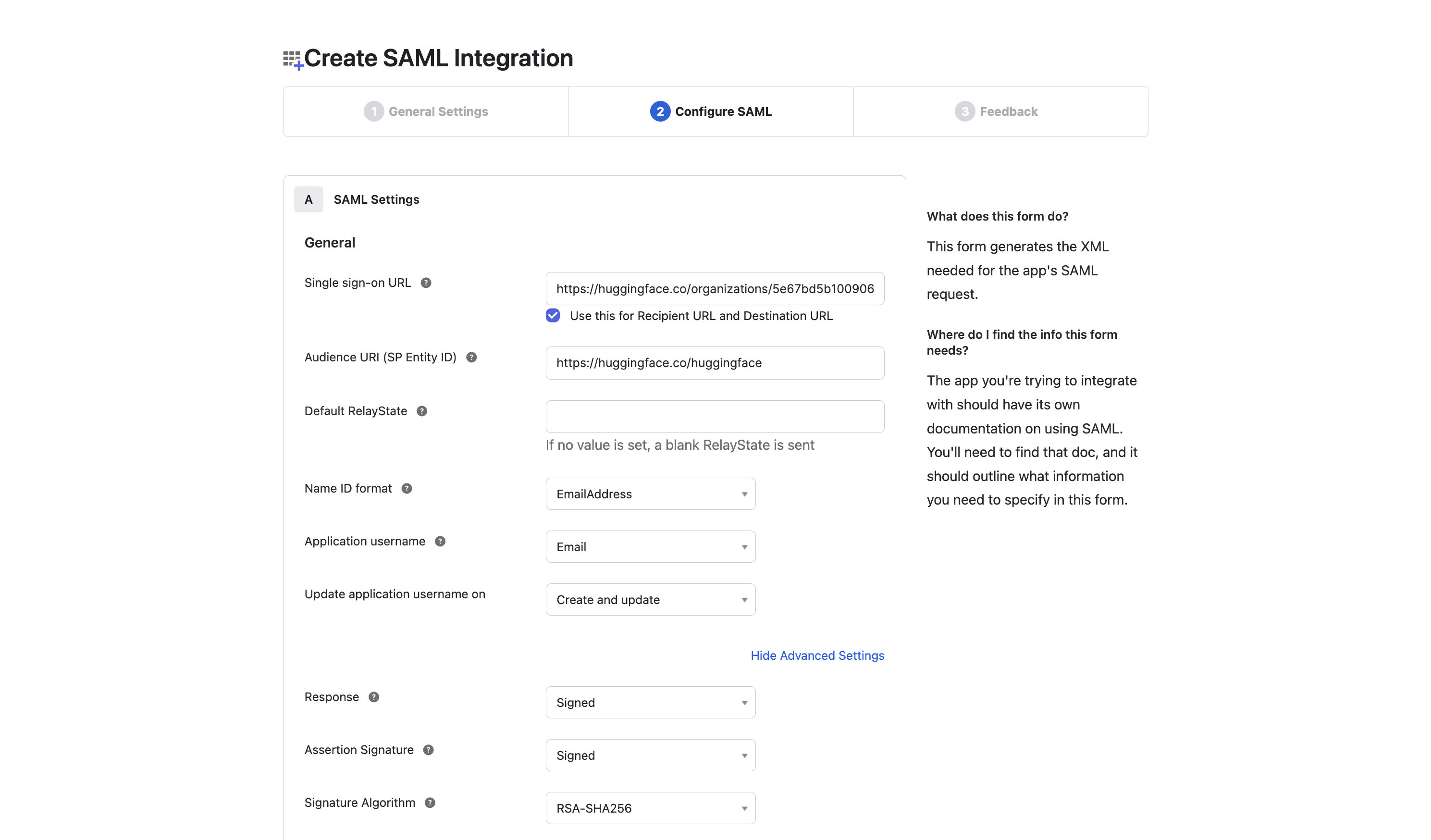
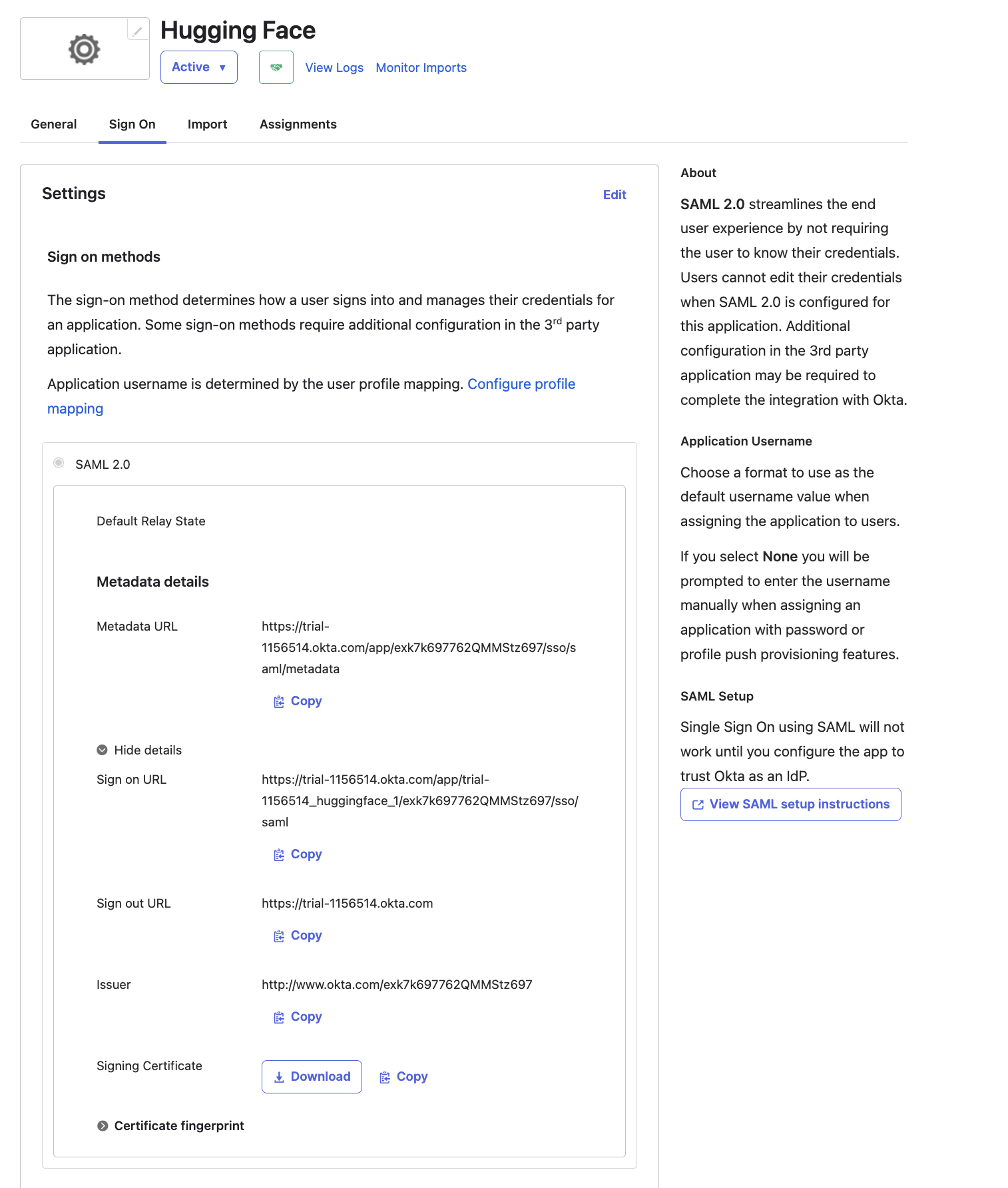
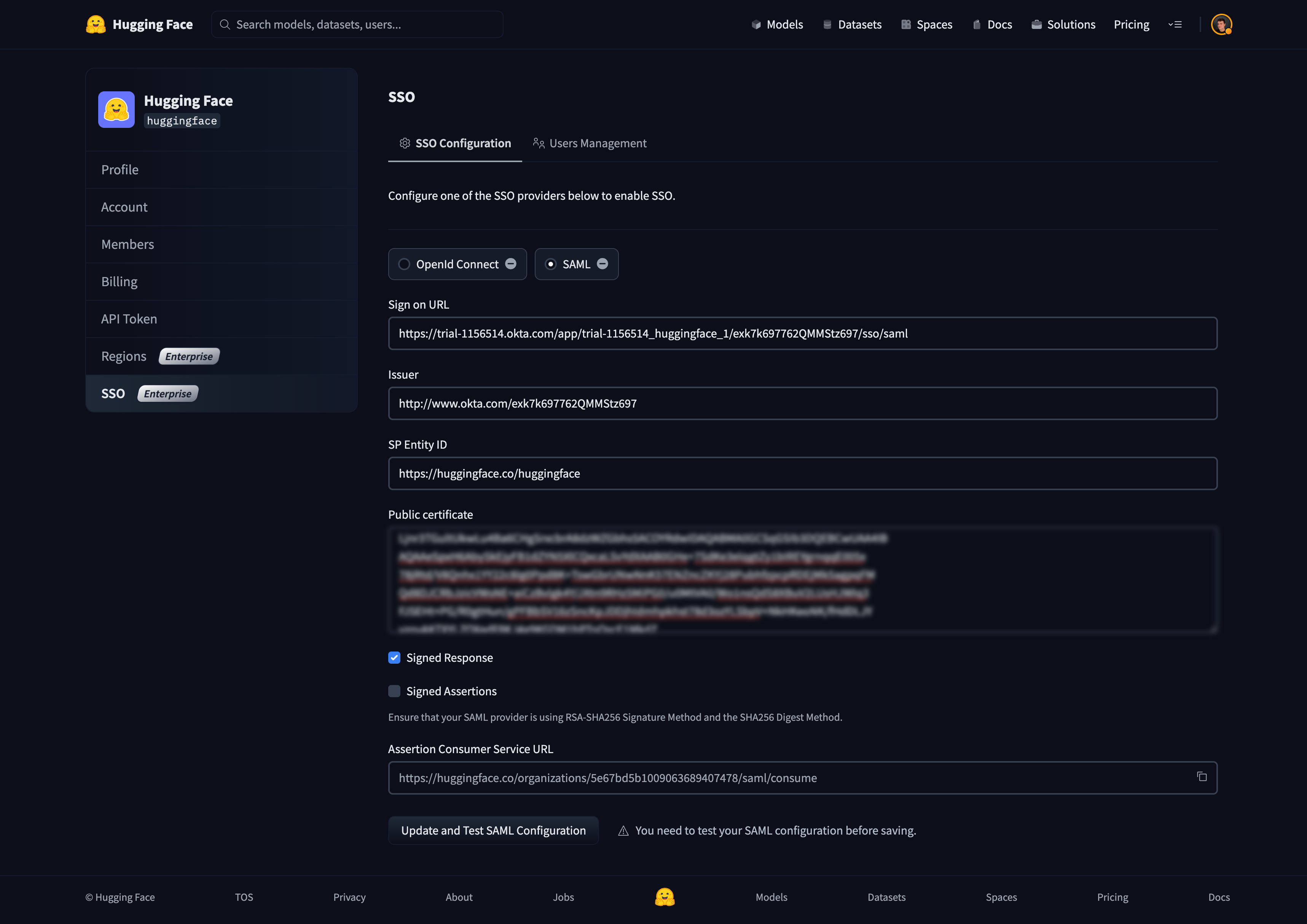
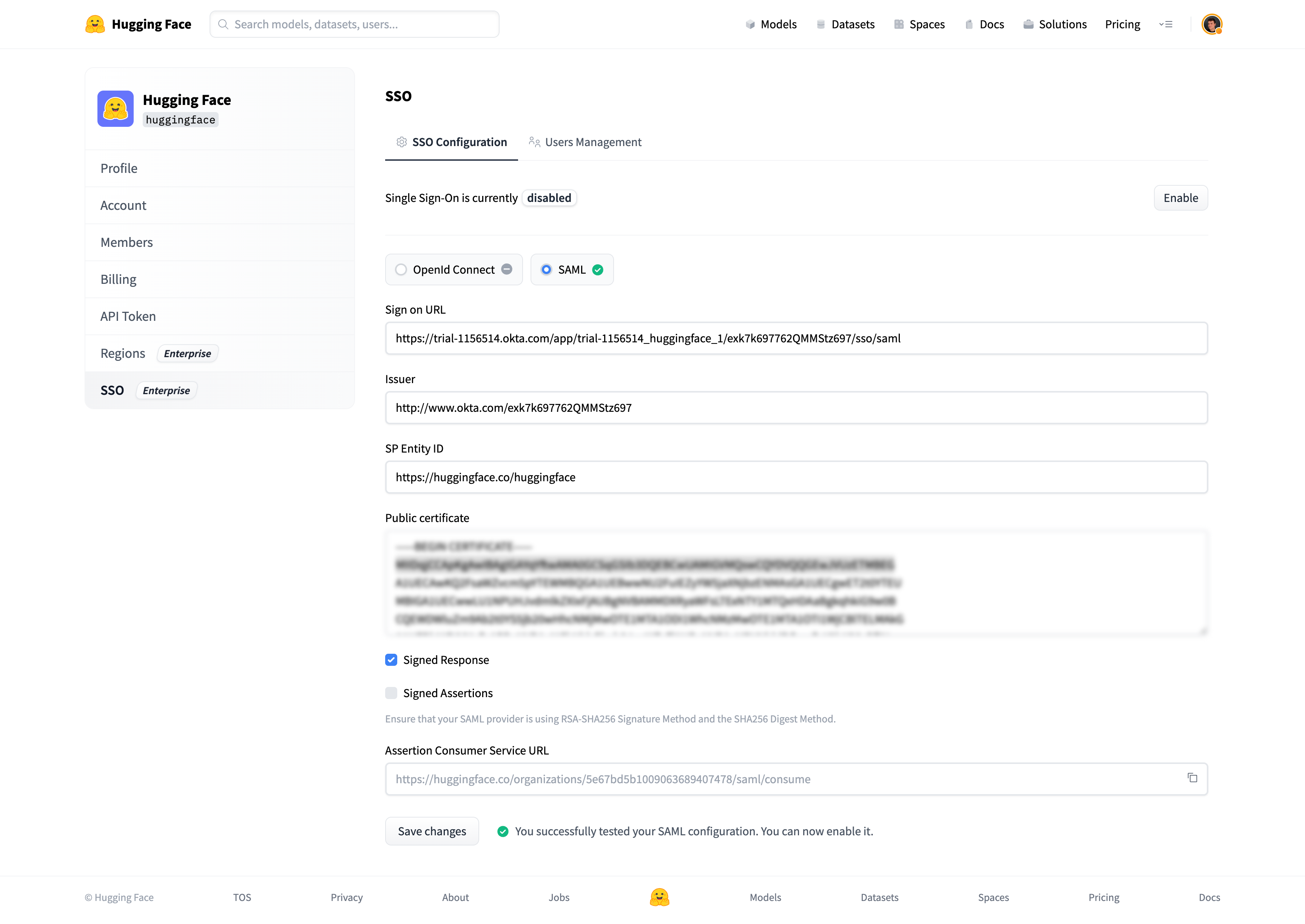
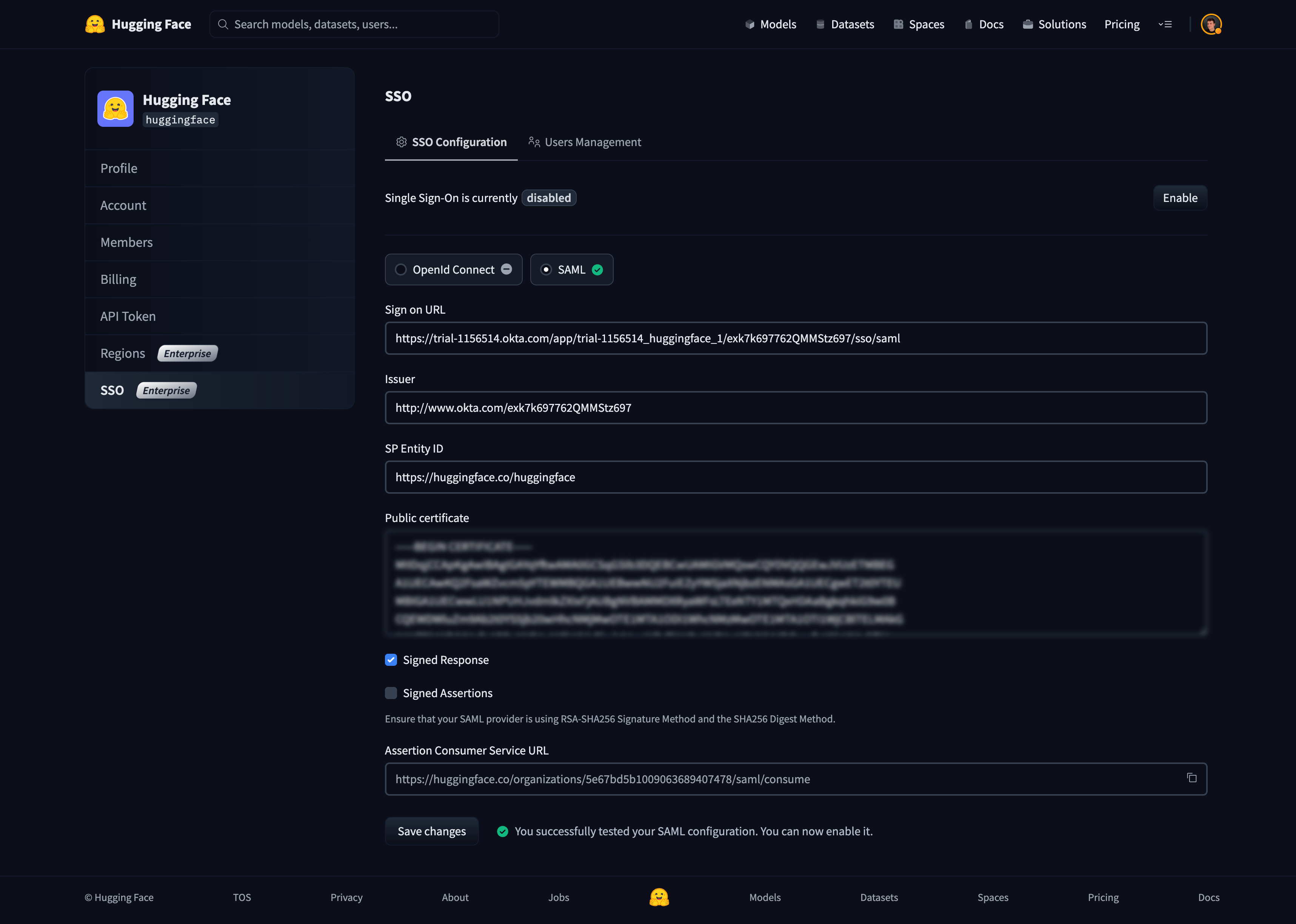
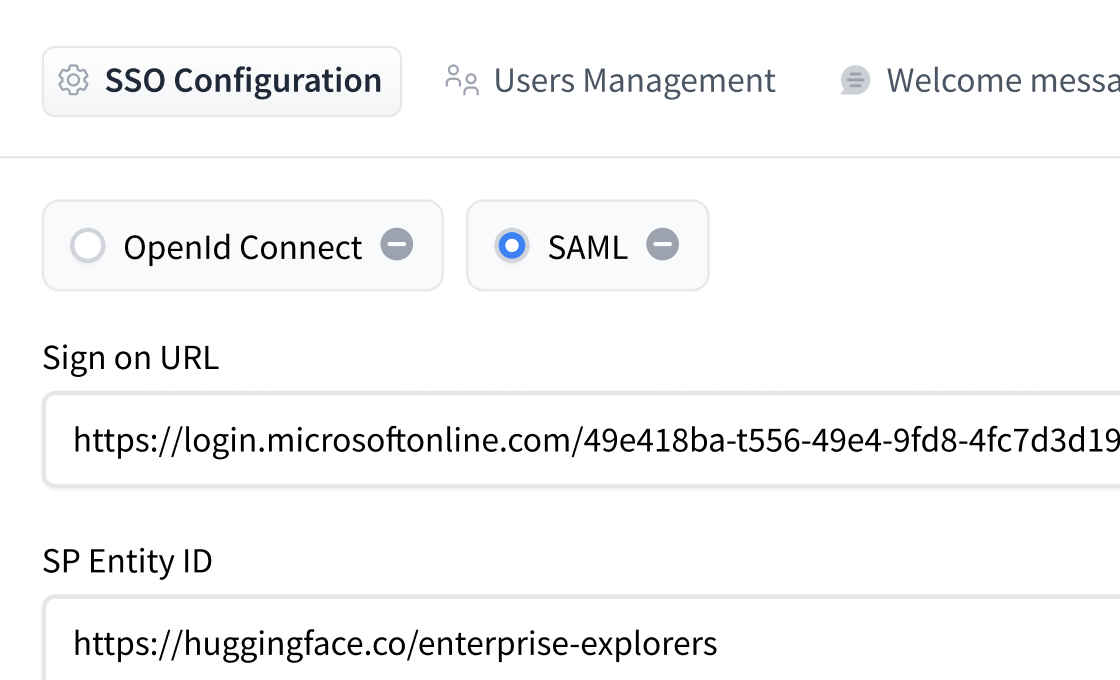
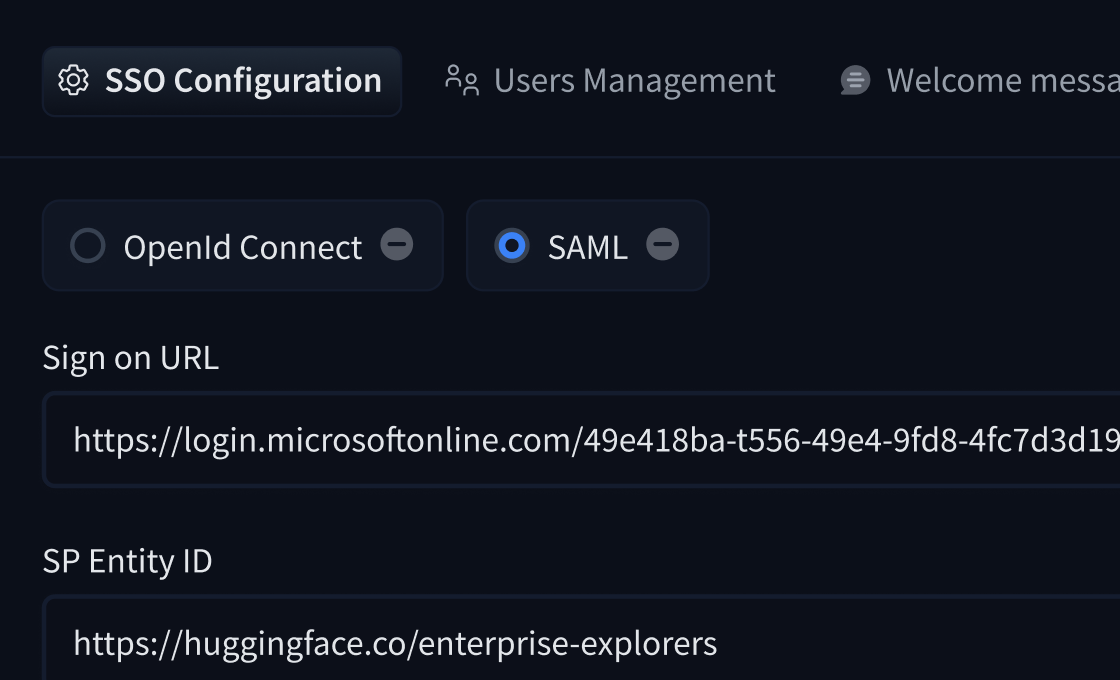
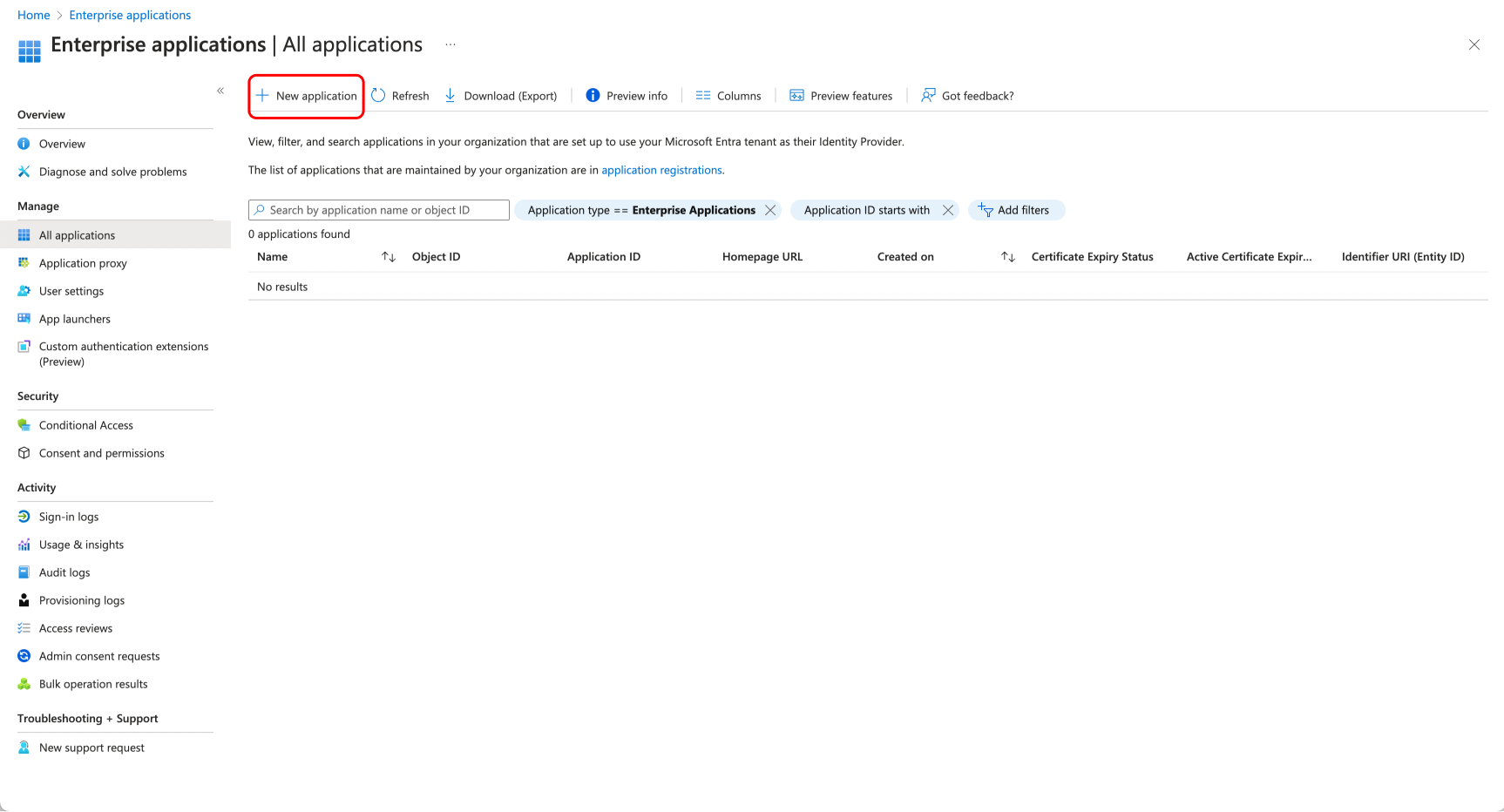
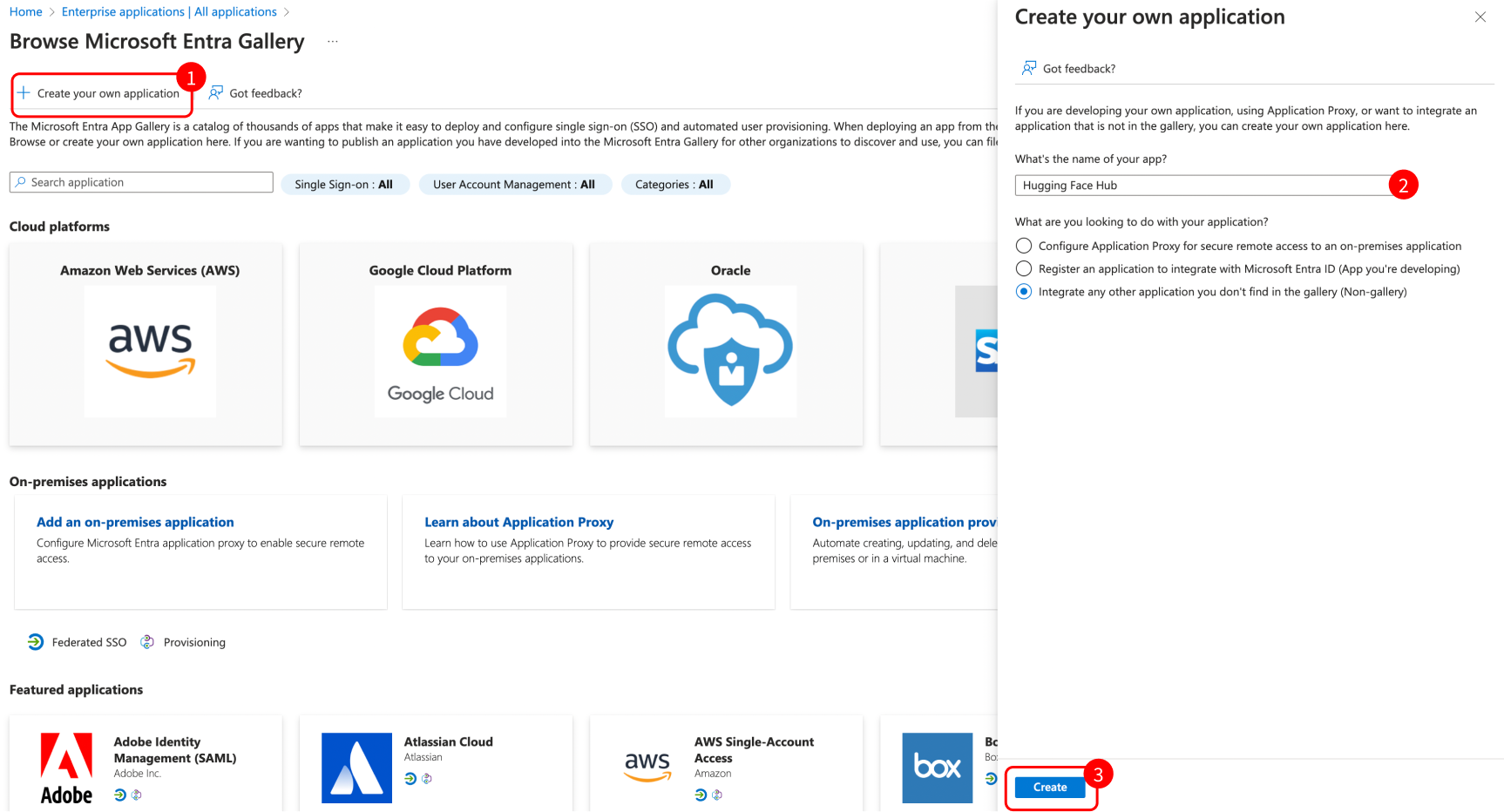
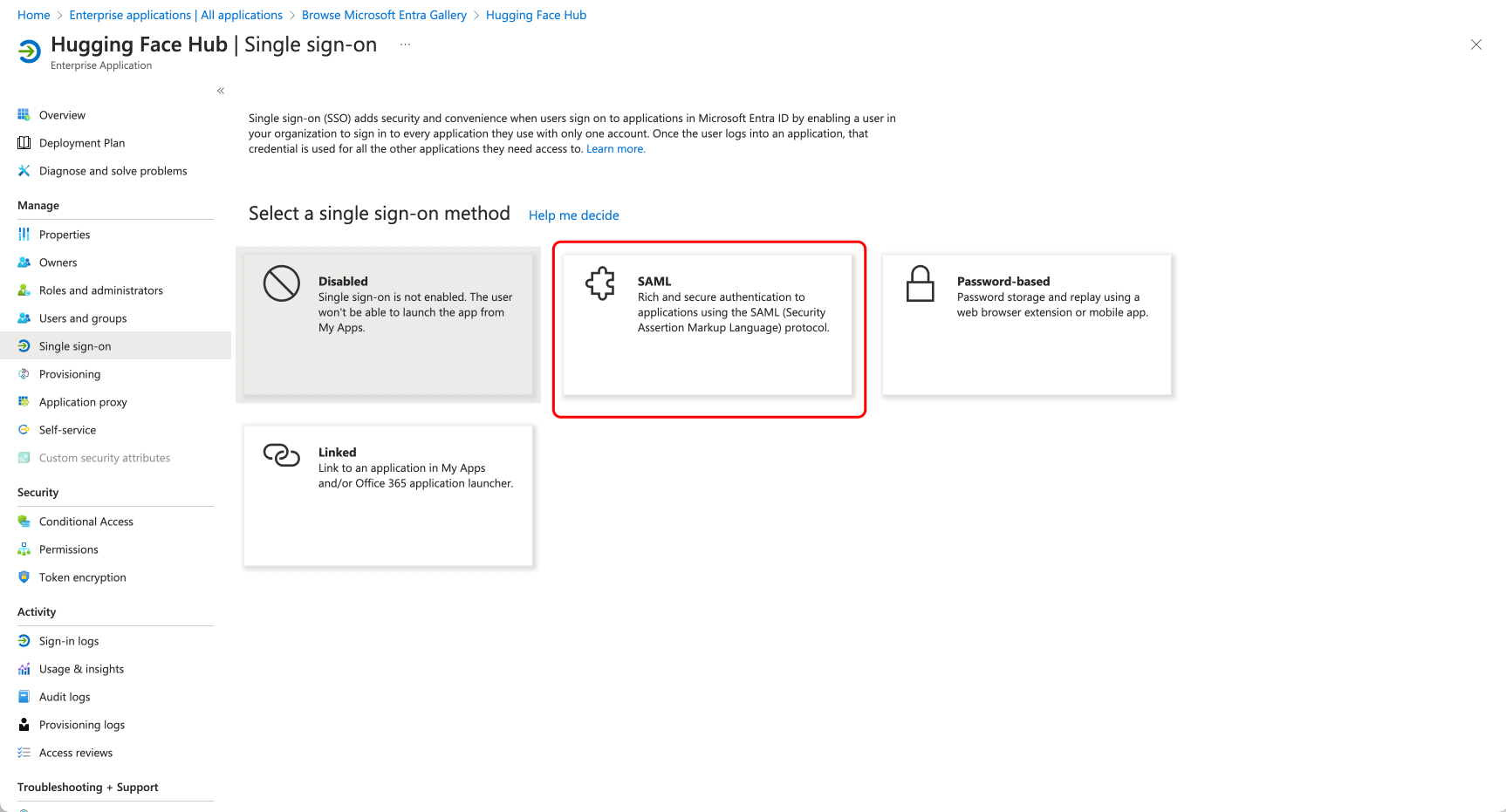
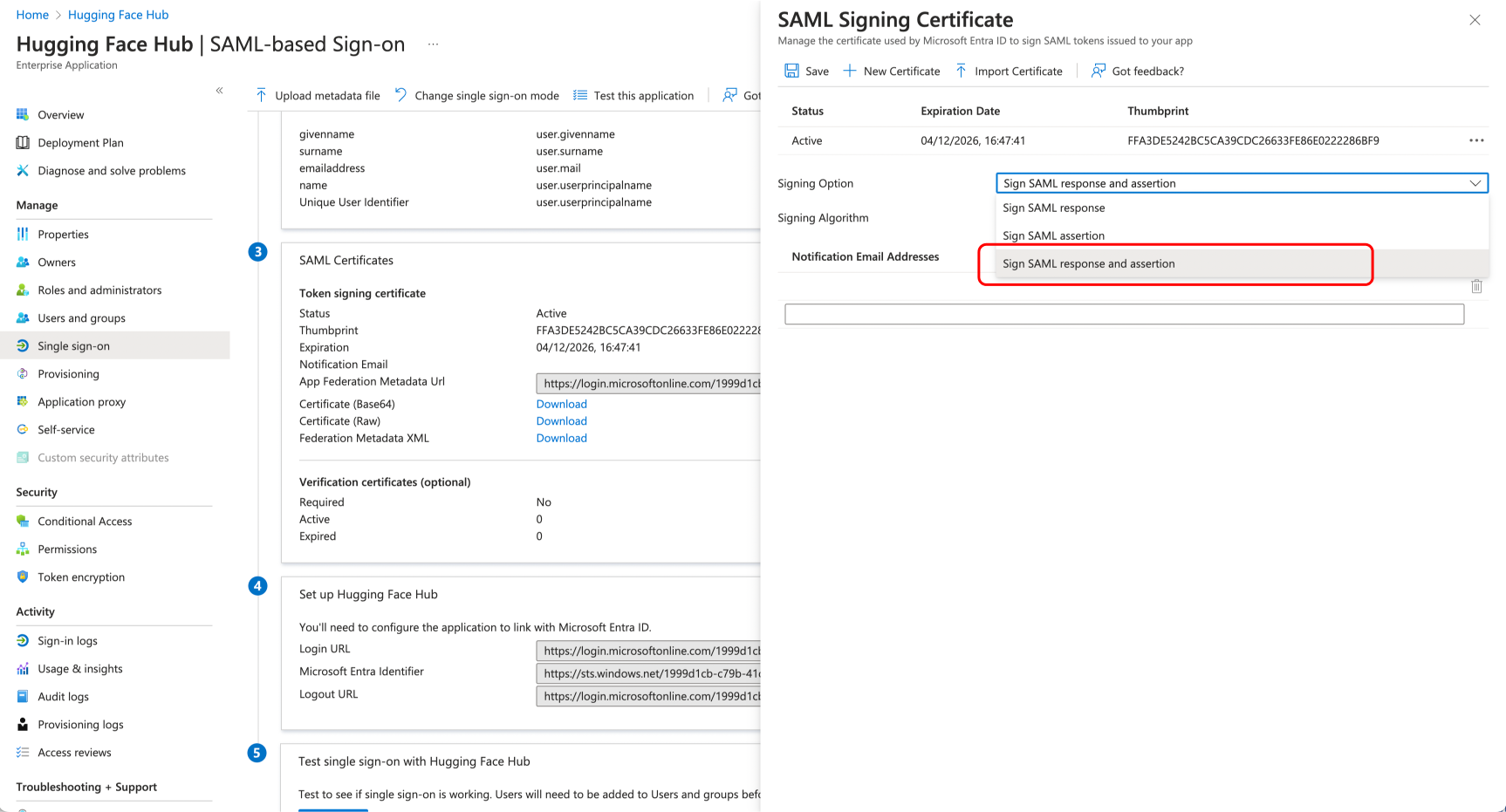
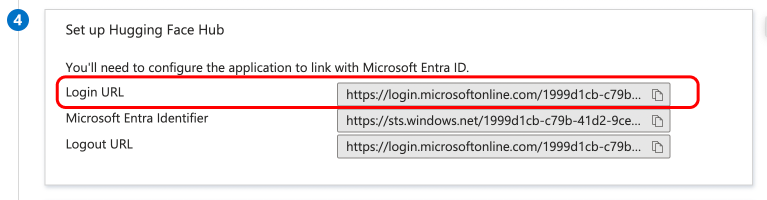
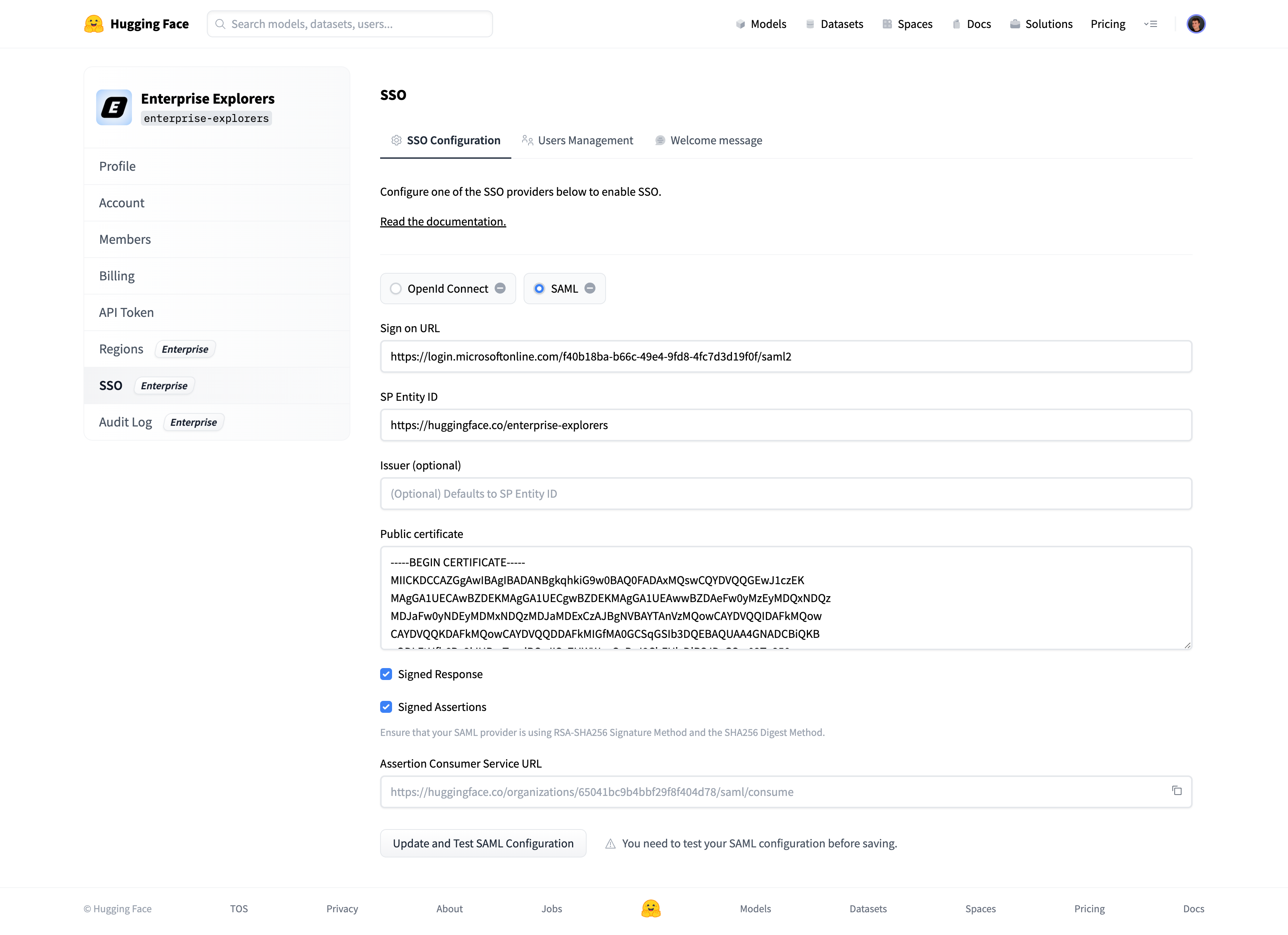
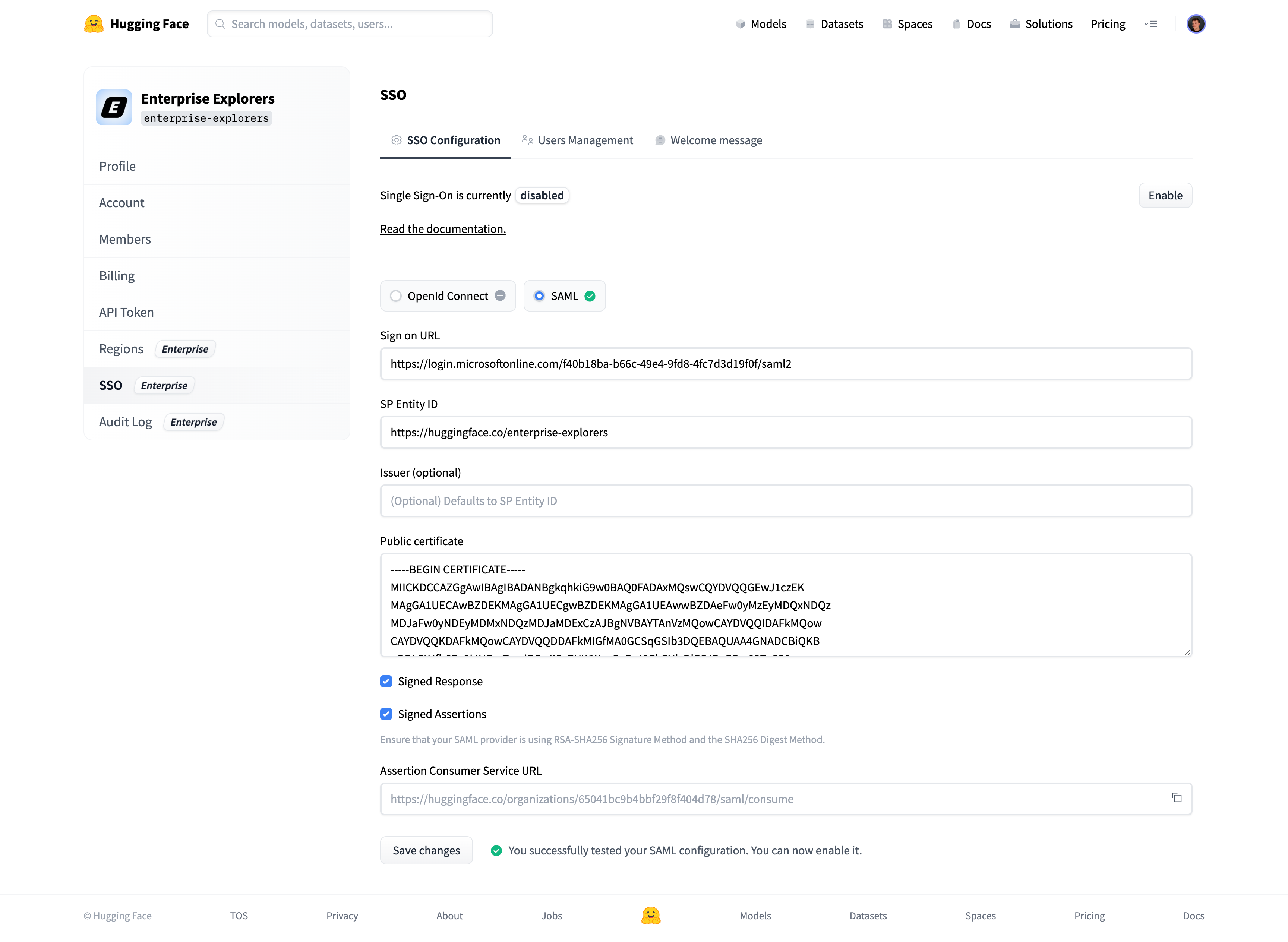
# How to configure SAML SSO with Azure
In this guide, we will use Azure as the SSO provider and with the Security Assertion Markup Language (SAML) protocol as our preferred identity protocol.
We currently support SP-initiated and IdP-initiated authentication. User provisioning is not yet supported at this time.
Once created, the Space will display `Building` status. Refresh the page if the status doesn't automatically update to `Running`.
Your Evidence app will automatically be deployed on Hugging Face Spaces.
## Editing your Evidence app from the CLI
To edit your app, clone the Space and edit the files locally.
```bash
git clone https://huggingface.co/spaces/your-username/your-space-name
cd your-space-name
npm install
npm run sources
npm run dev
```
You can then modify pages/index.md to change the content of your app.
## Editing your Evidence app from VS Code
The easiest way to develop with Evidence is using the [VS Code Extension](https://marketplace.visualstudio.com/items?itemName=Evidence.evidence-vscode):
1. Install the extension from the VS Code Marketplace
2. Open the Command Palette (Ctrl/Cmd + Shift + P) and enter `Evidence: Copy Existing Project`
3. Paste the URL of the Hugging Face Spaces Evidence app you'd like to copy (e.g. `https://huggingface.co/spaces/your-username/your-space-name`) and press Enter
4. Select the folder you'd like to clone the project to and press Enter
5. Press `Start Evidence` in the bottom status bar
Check out the docs for [alternative install methods](https://docs.evidence.dev/getting-started/install-evidence), Github Codespaces, and alongside dbt.
## Learning More
- [Docs](https://docs.evidence.dev/)
- [Github](https://github.com/evidence-dev/evidence)
- [Slack Community](https://slack.evidence.dev/)
- [Evidence Home Page](https://www.evidence.dev)
# Libraries
The Datasets Hub has support for several libraries in the Open Source ecosystem.
Thanks to the [huggingface_hub Python library](/docs/huggingface_hub), it's easy to enable sharing your datasets on the Hub.
We're happy to welcome to the Hub a set of Open Source libraries that are pushing Machine Learning forward.
The table below summarizes the supported libraries and their level of integration.
| Library | Description | Download from Hub | Push to Hub |
|-----------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------|---|----|
| [Argilla](./datasets-argilla) | Collaboration tool for AI engineers and domain experts that value high quality data. | ✅ | ✅ |
| [Dask](./datasets-dask) | Parallel and distributed computing library that scales the existing Python and PyData ecosystem. | ✅ | ✅ |
| [Datasets](./datasets-usage) | 🤗 Datasets is a library for accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP). | ✅ | ✅ |
| [Distilabel](./datasets-distilabel) | The framework for synthetic data generation and AI feedback. | ✅ | ✅ |
| [DuckDB](./datasets-duckdb) | In-process SQL OLAP database management system. | ✅ | ✅ |
| [FiftyOne](./datasets-fiftyone) | FiftyOne is a library for curation and visualization of image, video, and 3D data. | ✅ | ✅ |
| [Pandas](./datasets-pandas) | Python data analysis toolkit. | ✅ | ✅ |
| [Polars](./datasets-polars) | A DataFrame library on top of an OLAP query engine. | ✅ | ✅ |
| [Spark](./datasets-spark) | Real-time, large-scale data processing tool in a distributed environment. | ✅ | ✅ |
| [WebDataset](./datasets-webdataset) | Library to write I/O pipelines for large datasets. | ✅ | ❌ |
# How to Add a Space to ArXiv
Demos on Hugging Face Spaces allow a wide audience to try out state-of-the-art machine
learning research without writing any code. [Hugging Face and ArXiv have collaborated](https://huggingface.co/blog/arxiv)
to embed these demos directly along side papers on ArXiv!
Thanks to this integration, users can now find the most popular demos for a paper on its arXiv abstract page. For example, if you want to try out demos of the LayoutLM document classification model, you can go to [the LayoutLM paper's arXiv page](https://arxiv.org/abs/1912.13318), and navigate to the demo tab. You will see open-source demos built by the machine learning community for this model, which you can try out immediately in your browser:

We'll cover two different ways to add your Space to ArXiv and have it show up in the Demos tab.
**Prerequisites**
* There's an existing paper on ArXiv that you'd like to create a demo for
* You have built or (can build) a demo for the model on Spaces
**Method 1 (Recommended): Linking from the Space README**
The simplest way to add a Space to an ArXiv paper is to include the link to the paper in the Space README file (`README.md`). It's good practice to include a full citation as well. You can see an example of a link and a citation on this [Echocardiogram Segmentation Space README](https://huggingface.co/spaces/abidlabs/echocardiogram-arxiv/blob/main/README.md).
And that's it! Your Space should appear in the Demo tab next to the paper on ArXiv in a few minutes 🤗
**Method 2: Linking a Related Model**
An alternative approach can be used to link Spaces to papers by linking an intermediate model to the Space. This requires that the paper is **associated with a model** that is on the Hugging Face Hub (or can be uploaded there)
1. First, upload the model associated with the ArXiv paper onto the Hugging Face Hub if it is not already there. ([Detailed instructions are here](./models-uploading))
2. When writing the model card (README.md) for the model, include a link to the ArXiv paper. It's good practice to include a full citation as well. You can see an example of a link and a citation on the [LayoutLM model card](https://huggingface.co/microsoft/layoutlm-base-uncased)
*Note*: you can verify this step has been carried out successfully by seeing if an ArXiv button appears above the model card. In the case of LayoutLM, the button says: "arxiv:1912.13318" and links to the LayoutLM paper on ArXiv.

3. Then, create a demo on Spaces that loads this model. Somewhere within the code, the model name must be included in order for Hugging Face to detect that a Space is associated with it.
For example, the [docformer_for_document_classification](https://huggingface.co/spaces/iakarshu/docformer_for_document_classification) Space loads the LayoutLM [like this](https://huggingface.co/spaces/iakarshu/docformer_for_document_classification/blob/main/modeling.py#L484) and include the string `"microsoft/layoutlm-base-uncased"`:
```py
from transformers import LayoutLMForTokenClassification
layoutlm_dummy = LayoutLMForTokenClassification.from_pretrained("microsoft/layoutlm-base-uncased", num_labels=1)
```
*Note*: Here's an [overview on building demos on Hugging Face Spaces](./spaces-overview) and here are more specific instructions for [Gradio](./spaces-sdks-gradio) and [Streamlit](./spaces-sdks-streamlit).
4. As soon as your Space is built, Hugging Face will detect that it is associated with the model. A "Linked Models" button should appear in the top right corner of the Space, as shown here:

*Note*: You can also add linked models manually by explicitly updating them in the [README metadata for the Space, as described here](https://huggingface.co/docs/hub/spaces-config-reference).
Your Space should appear in the Demo tab next to the paper on ArXiv in a few minutes 🤗
# How to configure SAML SSO with Azure
In this guide, we will use Azure as the SSO provider and with the Security Assertion Markup Language (SAML) protocol as our preferred identity protocol.
We currently support SP-initiated and IdP-initiated authentication. User provisioning is not yet supported at this time.





createdAt attribute indicates the time when the respective repository was created. It's important to note that there is a unique value, 2022-03-02T23:29:04.000Z assigned to all repositories that were created before we began storing creation dates.
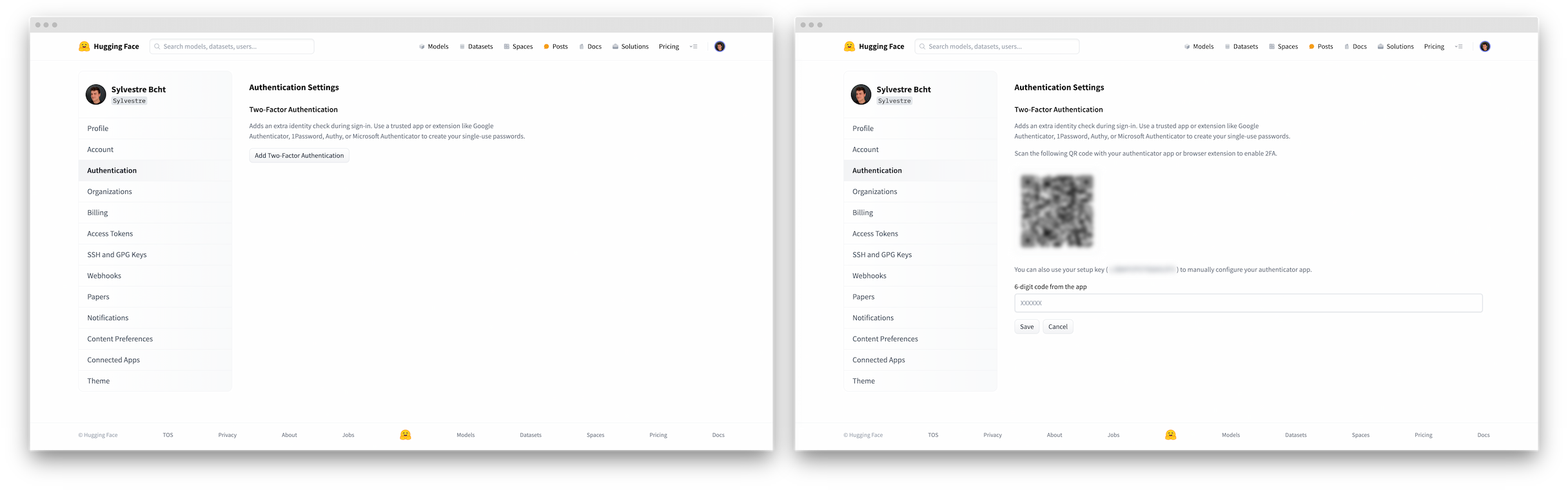
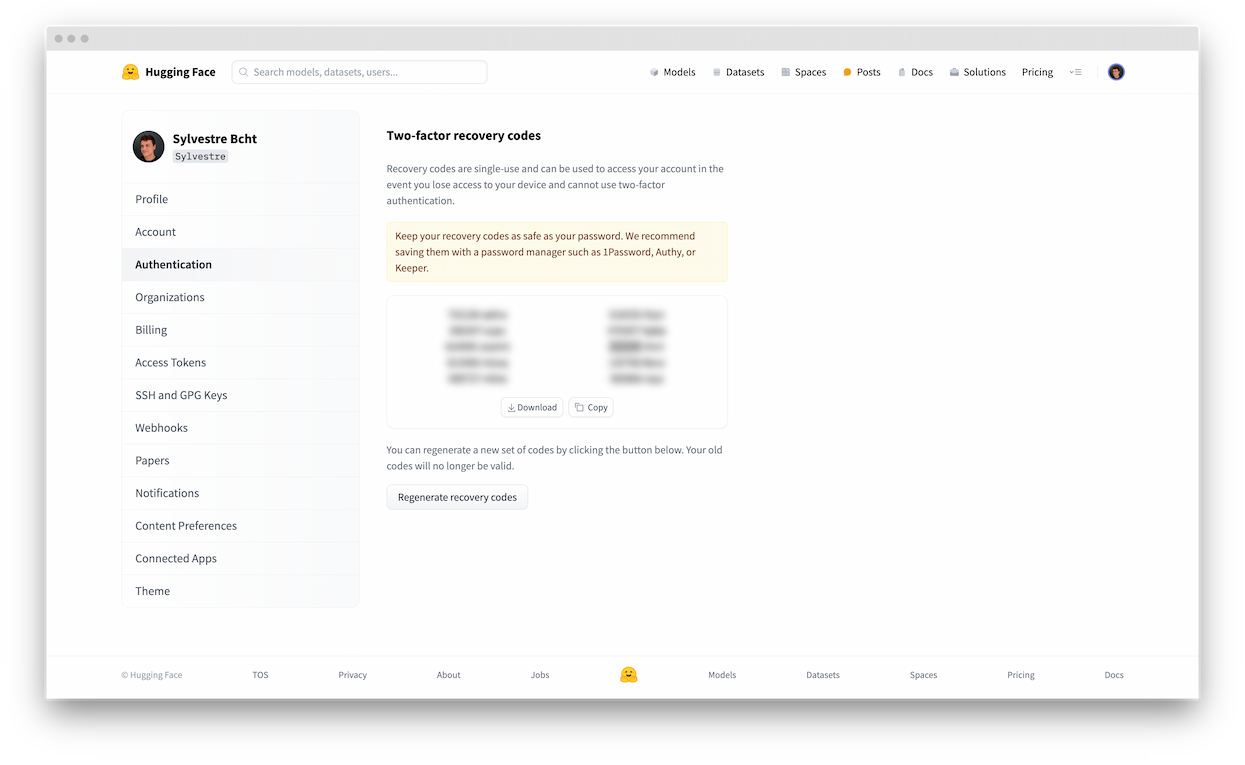
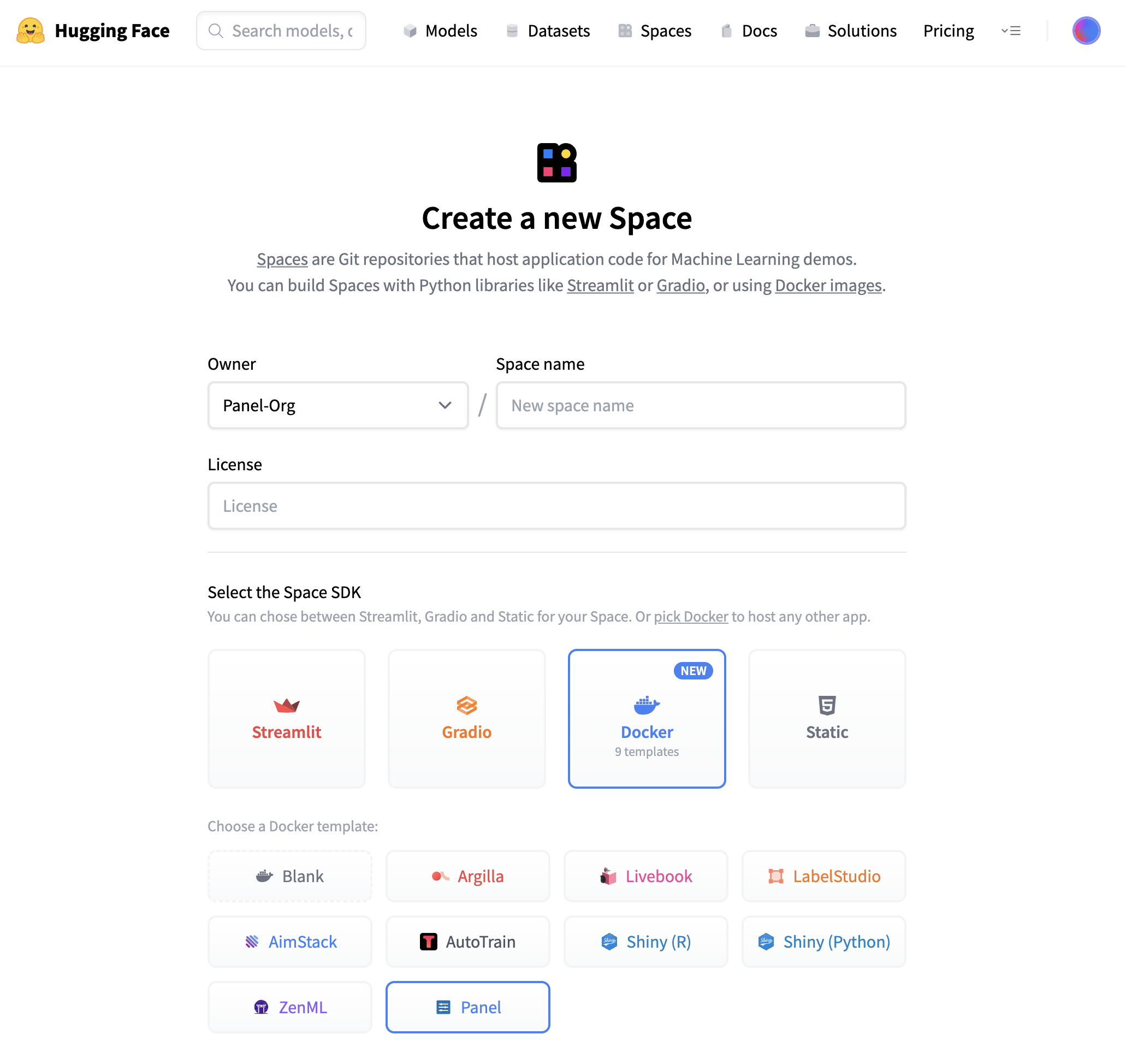
 There are a few key parameters you need to define: the Owner (either your personal account or an organization), a Space name, and Visibility. In case you intend to execute computationally intensive deep learning models, consider upgrading to a GPU to boost performance.
There are a few key parameters you need to define: the Owner (either your personal account or an organization), a Space name, and Visibility. In case you intend to execute computationally intensive deep learning models, consider upgrading to a GPU to boost performance.
 Once you have created the Space, it will start out in “Building” status, which will change to “Running” once your Space is ready to go.
## ⚡️ What will you see?
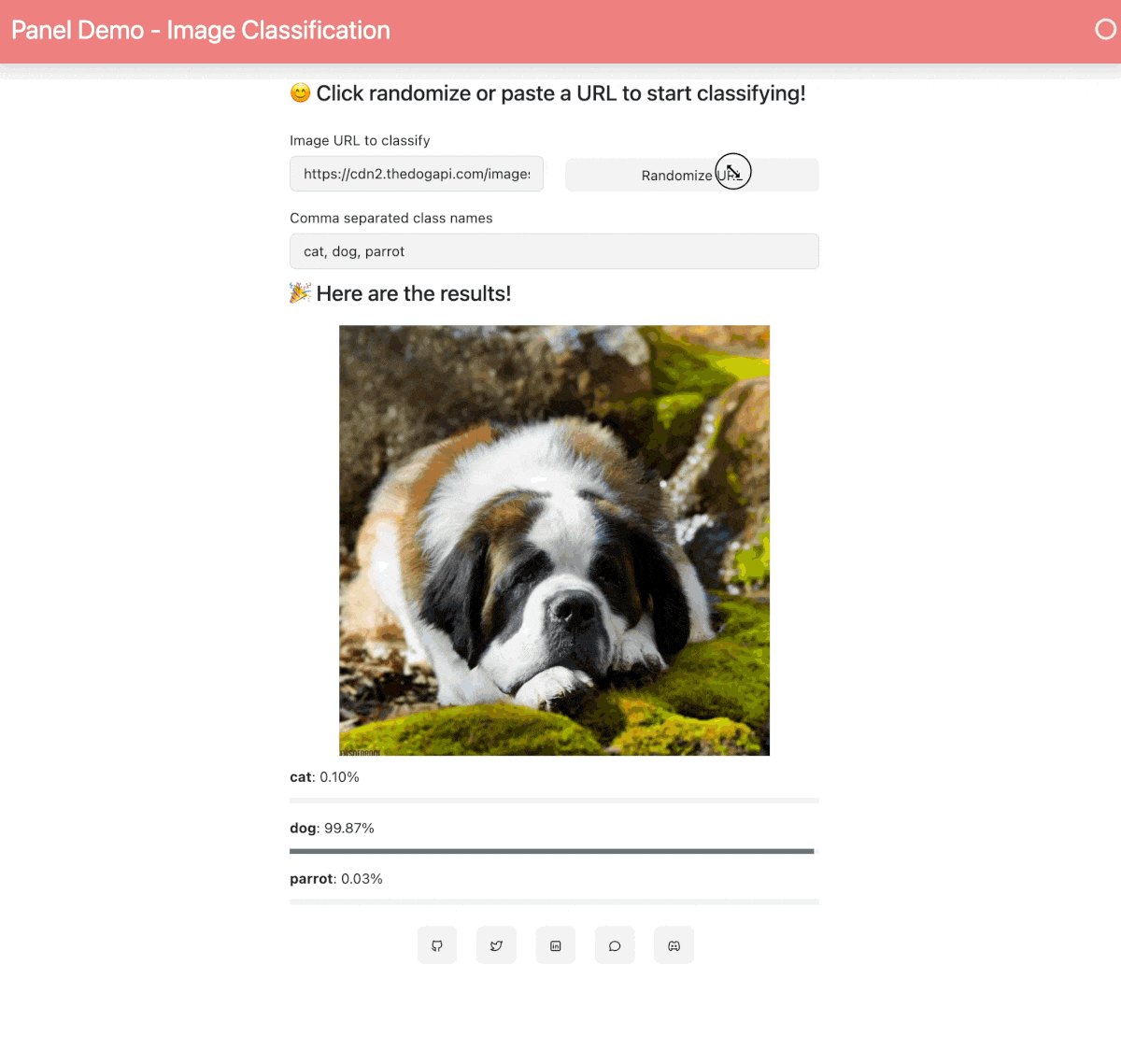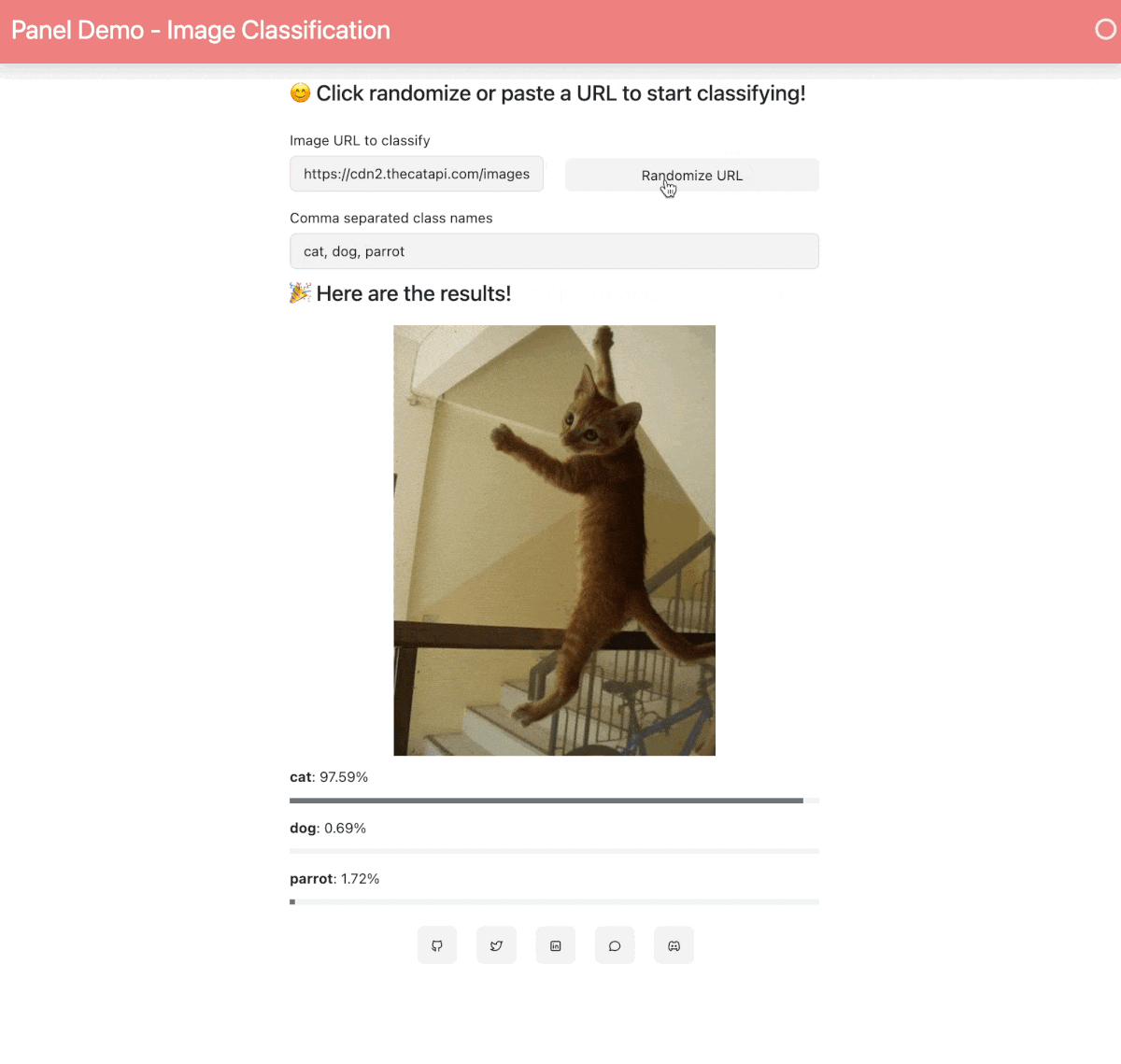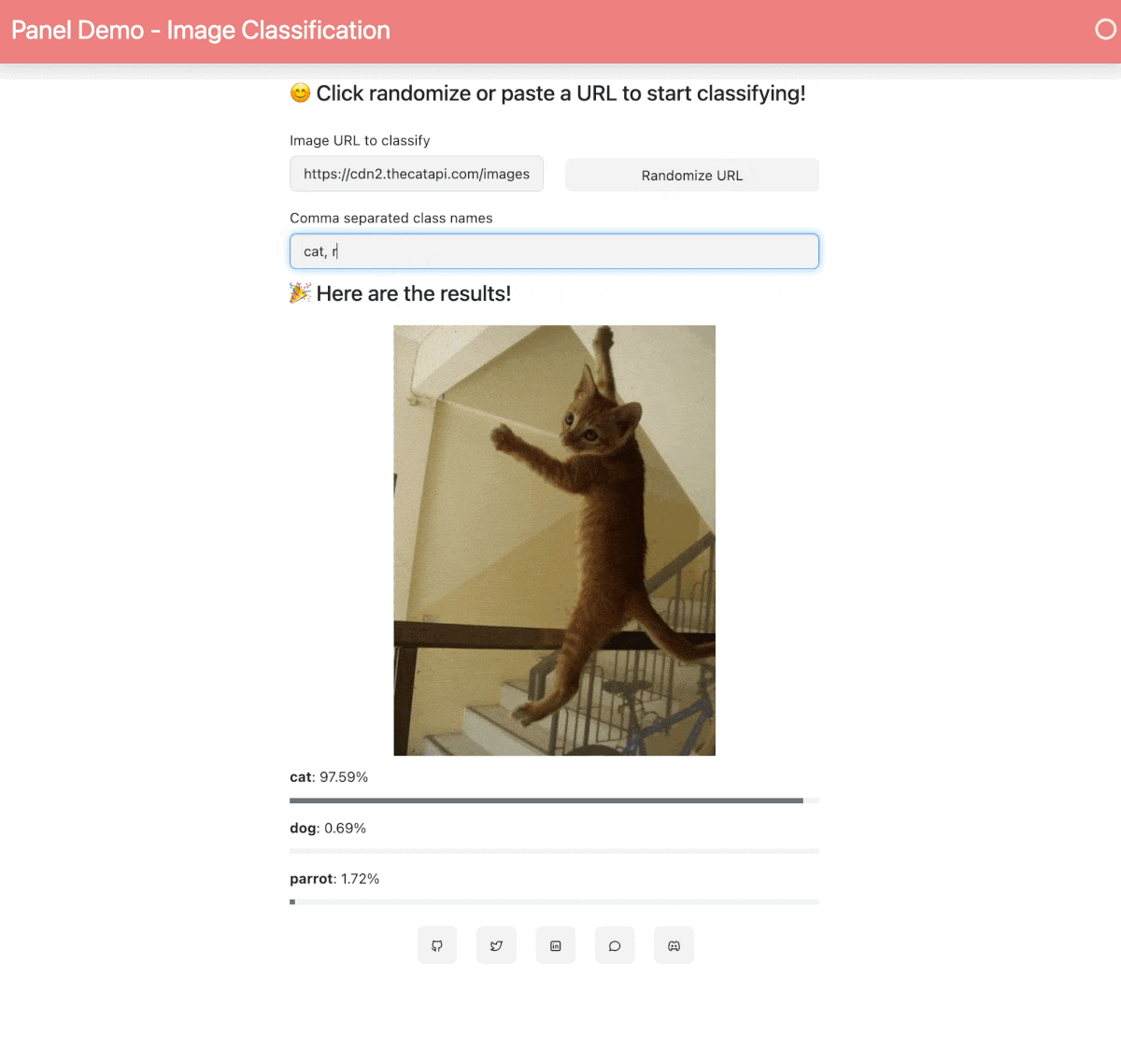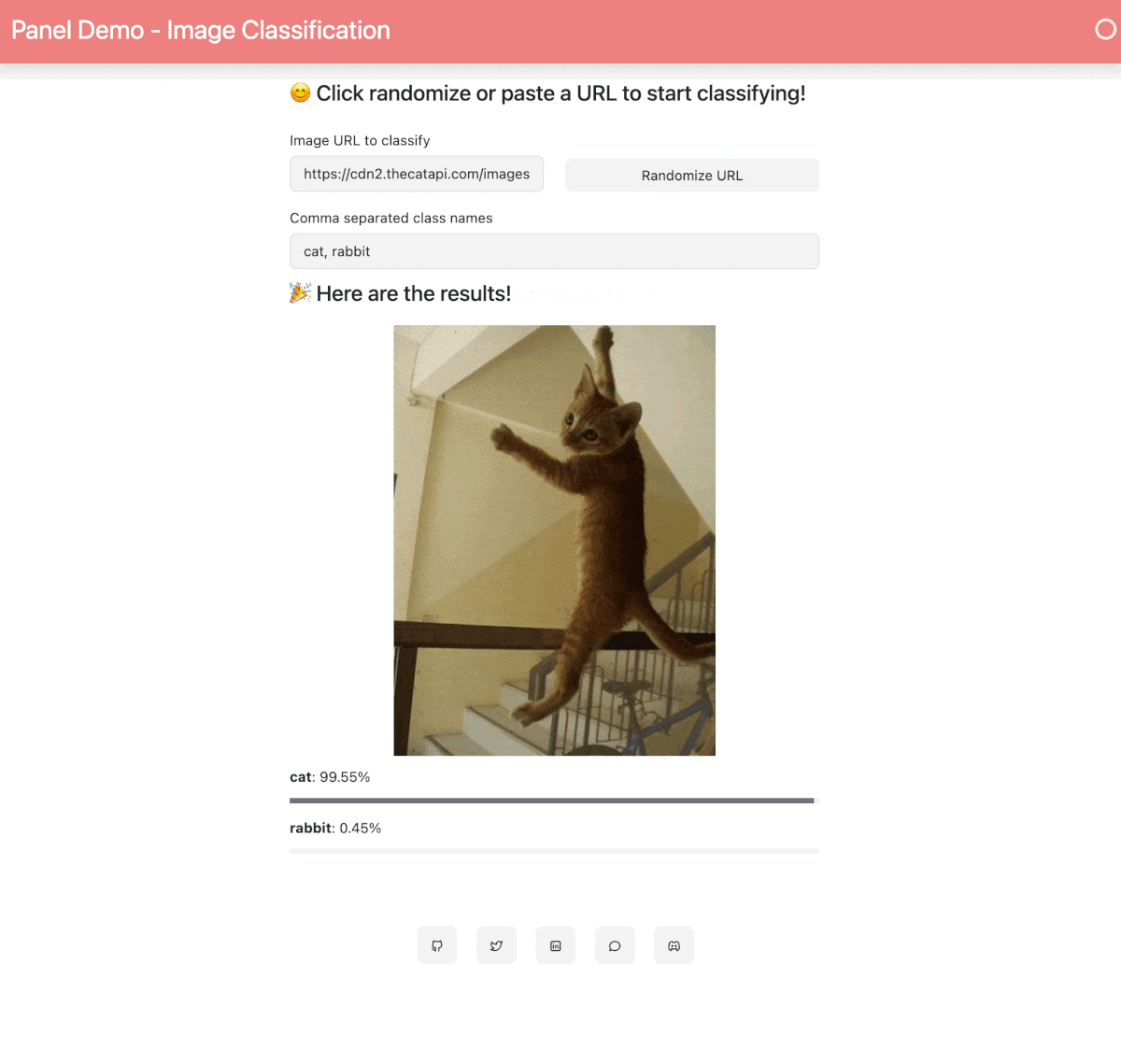
When your Space is built and ready, you will see this image classification Panel app which will let you fetch a random image and run the OpenAI CLIP classifier model on it. Check out our [blog post](https://blog.holoviz.org/building_an_interactive_ml_dashboard_in_panel.html) for a walkthrough of this app.
Once you have created the Space, it will start out in “Building” status, which will change to “Running” once your Space is ready to go.
## ⚡️ What will you see?
When your Space is built and ready, you will see this image classification Panel app which will let you fetch a random image and run the OpenAI CLIP classifier model on it. Check out our [blog post](https://blog.holoviz.org/building_an_interactive_ml_dashboard_in_panel.html) for a walkthrough of this app.
 ## 🛠️ How to customize and make your own app?
The Space template will populate a few files to get your app started:
## 🛠️ How to customize and make your own app?
The Space template will populate a few files to get your app started:
 Three files are important:
### 1. app.py
This file defines your Panel application code. You can start by modifying the existing application or replace it entirely to build your own application. To learn more about writing your own Panel app, refer to the [Panel documentation](https://panel.holoviz.org/).
### 2. Dockerfile
The Dockerfile contains a sequence of commands that Docker will execute to construct and launch an image as a container that your Panel app will run in. Typically, to serve a Panel app, we use the command `panel serve app.py`. In this specific file, we divide the command into a list of strings. Furthermore, we must define the address and port because Hugging Face will expect to serve your application on port 7860. Additionally, we need to specify the `allow-websocket-origin` flag to enable the connection to the server's websocket.
### 3. requirements.txt
This file defines the required packages for our Panel app. When using Space, dependencies listed in the requirements.txt file will be automatically installed. You have the freedom to modify this file by removing unnecessary packages or adding additional ones that are required for your application. Feel free to make the necessary changes to ensure your app has the appropriate packages installed.
## 🌐 Join Our Community
The Panel community is vibrant and supportive, with experienced developers and data scientists eager to help and share their knowledge. Join us and connect with us:
- [Discord](https://discord.gg/aRFhC3Dz9w)
- [Discourse](https://discourse.holoviz.org/)
- [Twitter](https://twitter.com/Panel_Org)
- [LinkedIn](https://www.linkedin.com/company/panel-org)
- [Github](https://github.com/holoviz/panel)
# Datasets Overview
## Datasets on the Hub
The Hugging Face Hub hosts a [large number of community-curated datasets](https://huggingface.co/datasets) for a diverse range of tasks such as translation, automatic speech recognition, and image classification. Alongside the information contained in the [dataset card](./datasets-cards), many datasets, such as [GLUE](https://huggingface.co/datasets/nyu-mll/glue), include a [Dataset Viewer](./datasets-viewer) to showcase the data.
Each dataset is a [Git repository](./repositories) that contains the data required to generate splits for training, evaluation, and testing. For information on how a dataset repository is structured, refer to the [Data files Configuration page](./datasets-data-files-configuration). Following the supported repo structure will ensure that the dataset page on the Hub will have a Viewer.
## Search for datasets
Like models and spaces, you can search the Hub for datasets using the search bar in the top navigation or on the [main datasets page](https://huggingface.co/datasets). There's a large number of languages, tasks, and licenses that you can use to filter your results to find a dataset that's right for you.
Three files are important:
### 1. app.py
This file defines your Panel application code. You can start by modifying the existing application or replace it entirely to build your own application. To learn more about writing your own Panel app, refer to the [Panel documentation](https://panel.holoviz.org/).
### 2. Dockerfile
The Dockerfile contains a sequence of commands that Docker will execute to construct and launch an image as a container that your Panel app will run in. Typically, to serve a Panel app, we use the command `panel serve app.py`. In this specific file, we divide the command into a list of strings. Furthermore, we must define the address and port because Hugging Face will expect to serve your application on port 7860. Additionally, we need to specify the `allow-websocket-origin` flag to enable the connection to the server's websocket.
### 3. requirements.txt
This file defines the required packages for our Panel app. When using Space, dependencies listed in the requirements.txt file will be automatically installed. You have the freedom to modify this file by removing unnecessary packages or adding additional ones that are required for your application. Feel free to make the necessary changes to ensure your app has the appropriate packages installed.
## 🌐 Join Our Community
The Panel community is vibrant and supportive, with experienced developers and data scientists eager to help and share their knowledge. Join us and connect with us:
- [Discord](https://discord.gg/aRFhC3Dz9w)
- [Discourse](https://discourse.holoviz.org/)
- [Twitter](https://twitter.com/Panel_Org)
- [LinkedIn](https://www.linkedin.com/company/panel-org)
- [Github](https://github.com/holoviz/panel)
# Datasets Overview
## Datasets on the Hub
The Hugging Face Hub hosts a [large number of community-curated datasets](https://huggingface.co/datasets) for a diverse range of tasks such as translation, automatic speech recognition, and image classification. Alongside the information contained in the [dataset card](./datasets-cards), many datasets, such as [GLUE](https://huggingface.co/datasets/nyu-mll/glue), include a [Dataset Viewer](./datasets-viewer) to showcase the data.
Each dataset is a [Git repository](./repositories) that contains the data required to generate splits for training, evaluation, and testing. For information on how a dataset repository is structured, refer to the [Data files Configuration page](./datasets-data-files-configuration). Following the supported repo structure will ensure that the dataset page on the Hub will have a Viewer.
## Search for datasets
Like models and spaces, you can search the Hub for datasets using the search bar in the top navigation or on the [main datasets page](https://huggingface.co/datasets). There's a large number of languages, tasks, and licenses that you can use to filter your results to find a dataset that's right for you.
git config --global commit.gpgsign true.






| Python (original) | Javascript (ours) |
|---|---|
| ```python from transformers import pipeline # Allocate a pipeline for sentiment-analysis pipe = pipeline('sentiment-analysis') out = pipe('I love transformers!') # [{'label': 'POSITIVE', 'score': 0.999806941}] ``` | ```javascript import { pipeline } from '@xenova/transformers'; // Allocate a pipeline for sentiment-analysis let pipe = await pipeline('sentiment-analysis'); let out = await pipe('I love transformers!'); // [{'label': 'POSITIVE', 'score': 0.999817686}] ``` |



 Spaces requires you to define:
* An **Owner**: either your personal account or an organization you're a
part of.
* A **Space name**: the name of the Space within the account
you're creating the Space.
* The **Visibility**: _private_ if you want the
Space to be visible only to you or your organization, or _public_ if you want
it to be visible to other users or applications using the Label Studio API
(suggested).
## 🚀 Using the Default Configuration
By default, Label Studio is installed in Spaces with a configuration that uses
local storage for the application database to store configuration, account
credentials, and project information. Labeling tasks and data items are also held
in local storage.
Spaces requires you to define:
* An **Owner**: either your personal account or an organization you're a
part of.
* A **Space name**: the name of the Space within the account
you're creating the Space.
* The **Visibility**: _private_ if you want the
Space to be visible only to you or your organization, or _public_ if you want
it to be visible to other users or applications using the Label Studio API
(suggested).
## 🚀 Using the Default Configuration
By default, Label Studio is installed in Spaces with a configuration that uses
local storage for the application database to store configuration, account
credentials, and project information. Labeling tasks and data items are also held
in local storage.




























 # Model Card Guidebook
Model cards are an important documentation and transparency framework for machine learning models. We believe that model cards have the potential to serve as *boundary objects*, a single artefact that is accessible to users who have different backgrounds and goals when interacting with model cards – including developers, students, policymakers, ethicists, those impacted by machine learning models, and other stakeholders. We recognize that developing a single artefact to serve such multifaceted purposes is difficult and requires careful consideration of potential users and use cases. Our goal as part of the Hugging Face science team over the last several months has been to help operationalize model cards towards that vision, taking into account these challenges, both at Hugging Face and in the broader ML community.
To work towards that goal, it is important to recognize the thoughtful, dedicated efforts that have helped model cards grow into what they are today, from the adoption of model cards as a standard practice at many large organisations to the development of sophisticated tools for hosting and generating model cards. Since model cards were proposed by Mitchell et al. (2018), the landscape of machine learning documentation has expanded and evolved. A plethora of documentation tools and templates for data, models, and ML systems have been proposed and have developed – reflecting the incredible work of hundreds of researchers, impacted community members, advocates, and other stakeholders. Important discussions about the relationship between ML documentation and theories of change in responsible AI have created continued important discussions, and at times, divergence. We also recognize the challenges facing model cards, which in some ways mirror the challenges facing machine learning documentation and responsible AI efforts more generally, and we see opportunities ahead to help shape both model cards and the ecosystems in which they function positively in the months and years ahead.
Our work presents a view of where we think model cards stand right now and where they could go in the future, at Hugging Face and beyond. This work is a “snapshot” of the current state of model cards, informed by a landscape analysis of the many ways ML documentation artefacts have been instantiated. It represents one perspective amongst multiple about both the current state and more aspirational visions of model cards. In this blog post, we summarise our work, including a discussion of the broader, growing landscape of ML documentation tools, the diverse audiences for and opinions about model cards, and potential new templates for model card content. We also explore and develop model cards for machine learning models in the context of the Hugging Face Hub, using the Hub’s features to collaboratively create, discuss, and disseminate model cards for ML models.
With the launch of this Guidebook, we introduce several new resources and connect together previous work on Model Cards:
1) An updated Model Card template, released in the `huggingface_hub` library [modelcard_template.md file](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md), drawing together Model Card work in academia and throughout the industry.
2) An [Annotated Model Card Template](./model-card-annotated), which details how to fill the card out.
3) A [Model Card Creator Tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool), to ease card creation without needing to program, and to help teams share the work of different sections.
4) A [User Study](./model-cards-user-studies) on Model Card usage at Hugging Face
5) A [Landscape Analysis and Literature Review](./model-card-landscape-analysis) of the state of the art in model documentation.
We also include an [Appendix](./model-card-appendix) with further details from this work.
---
**Please cite as:**
Ozoani, Ezi and Gerchick, Marissa and Mitchell, Margaret. Model Card Guidebook. Hugging Face, 2022. https://huggingface.co/docs/hub/en/model-card-guidebook
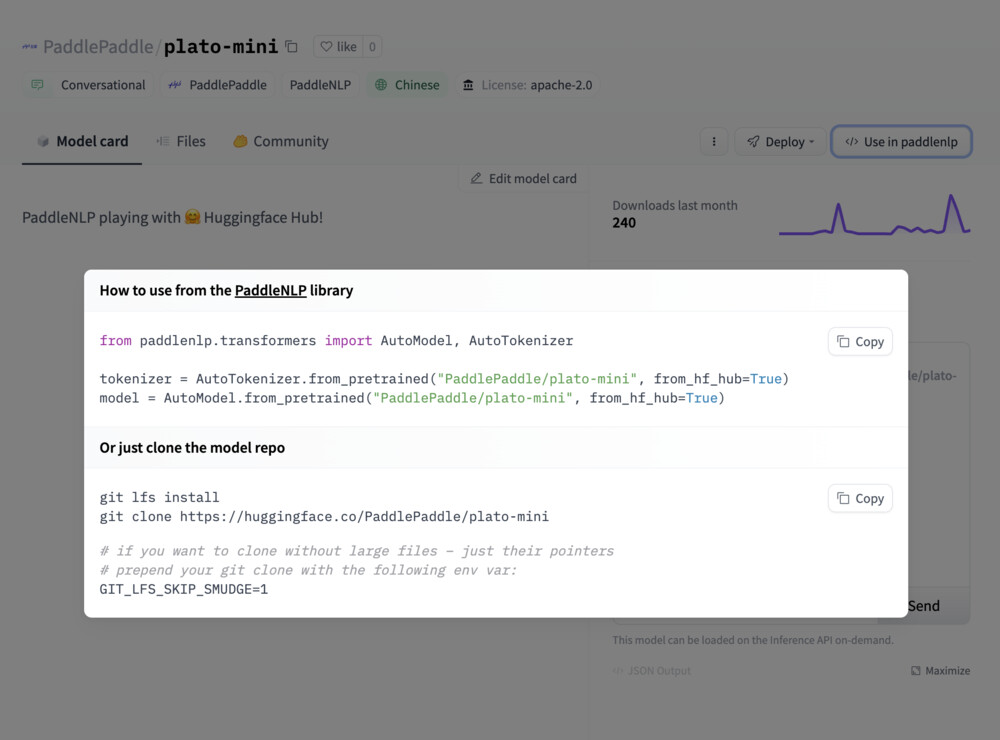
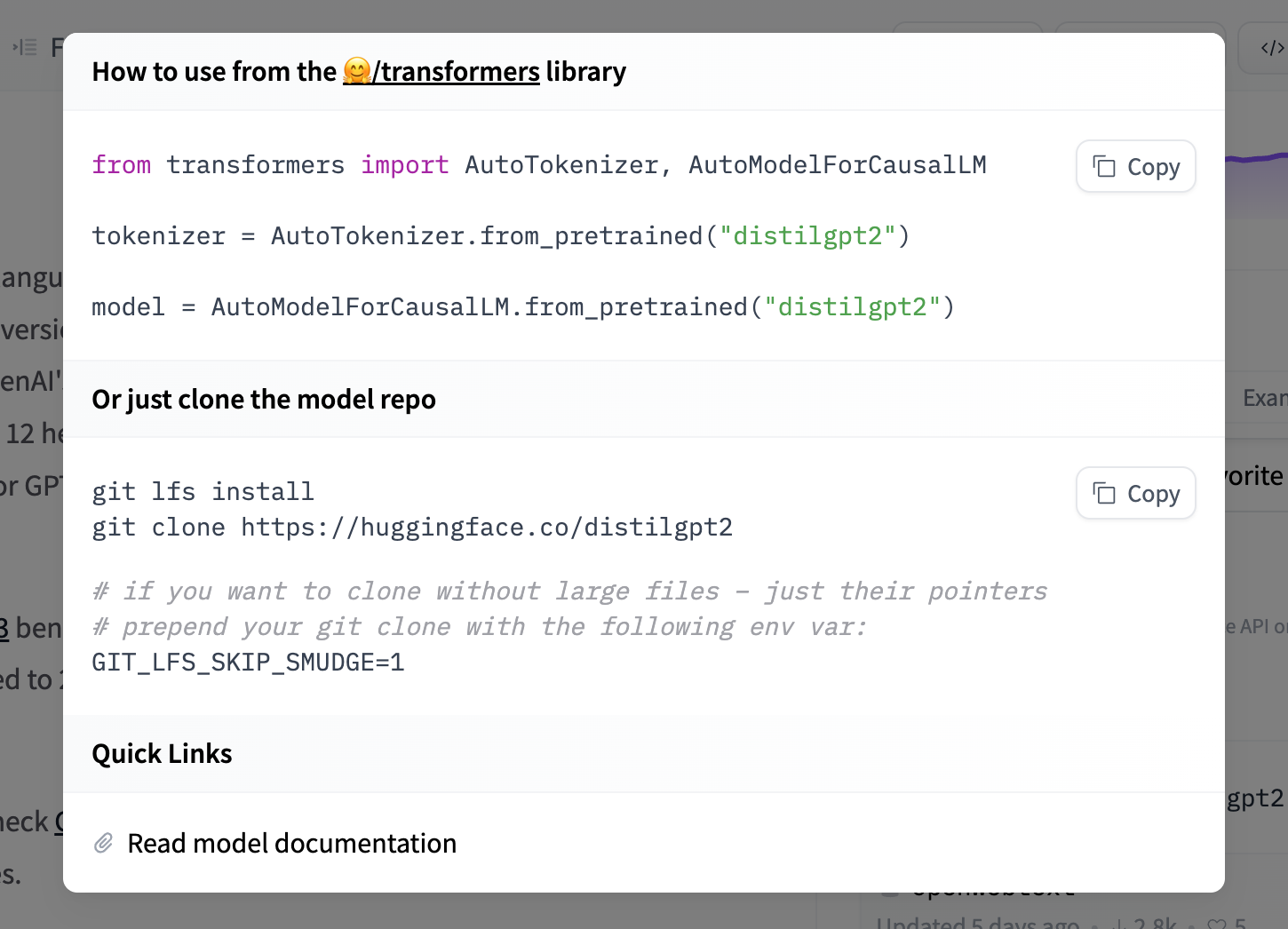
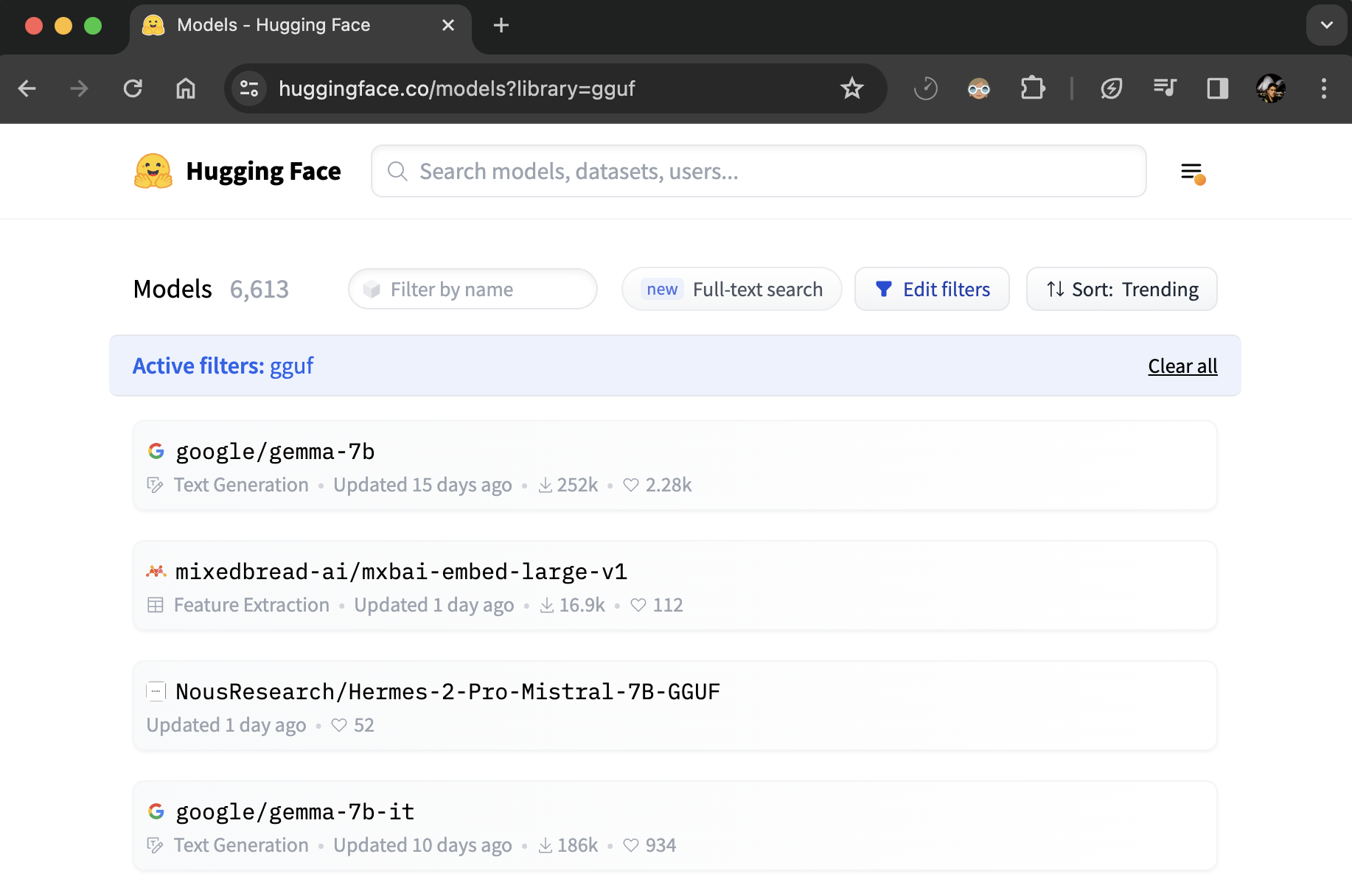
# Downloading models
## Integrated libraries
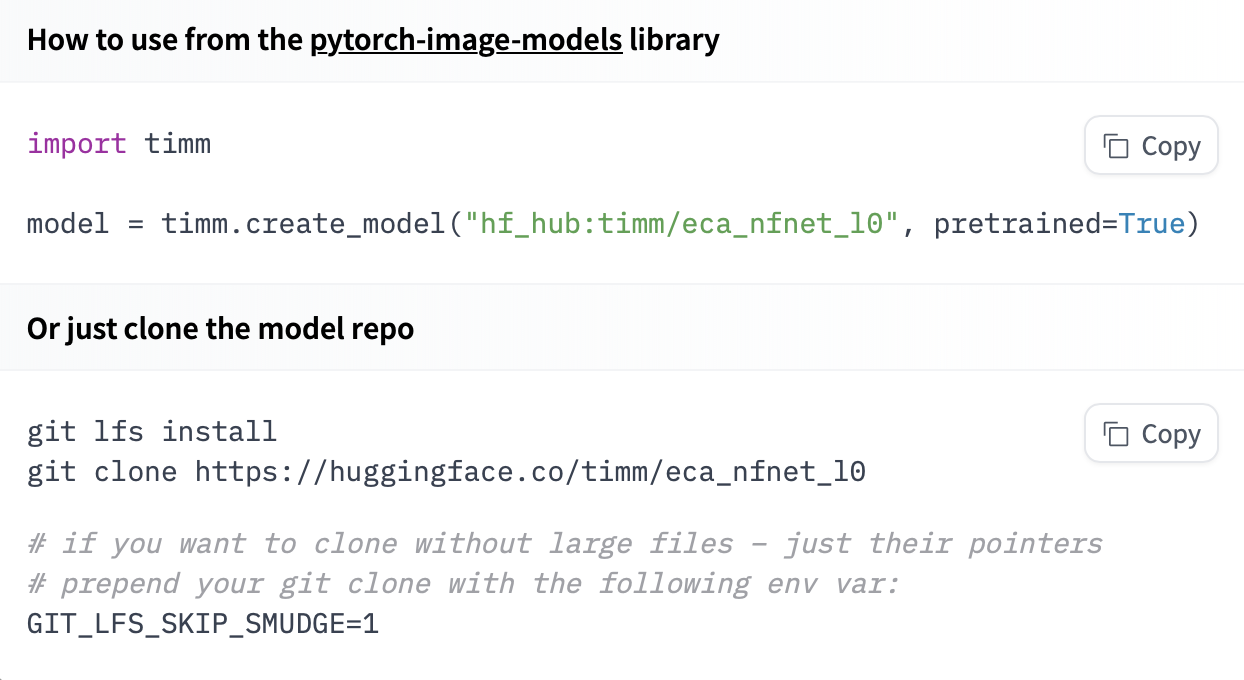
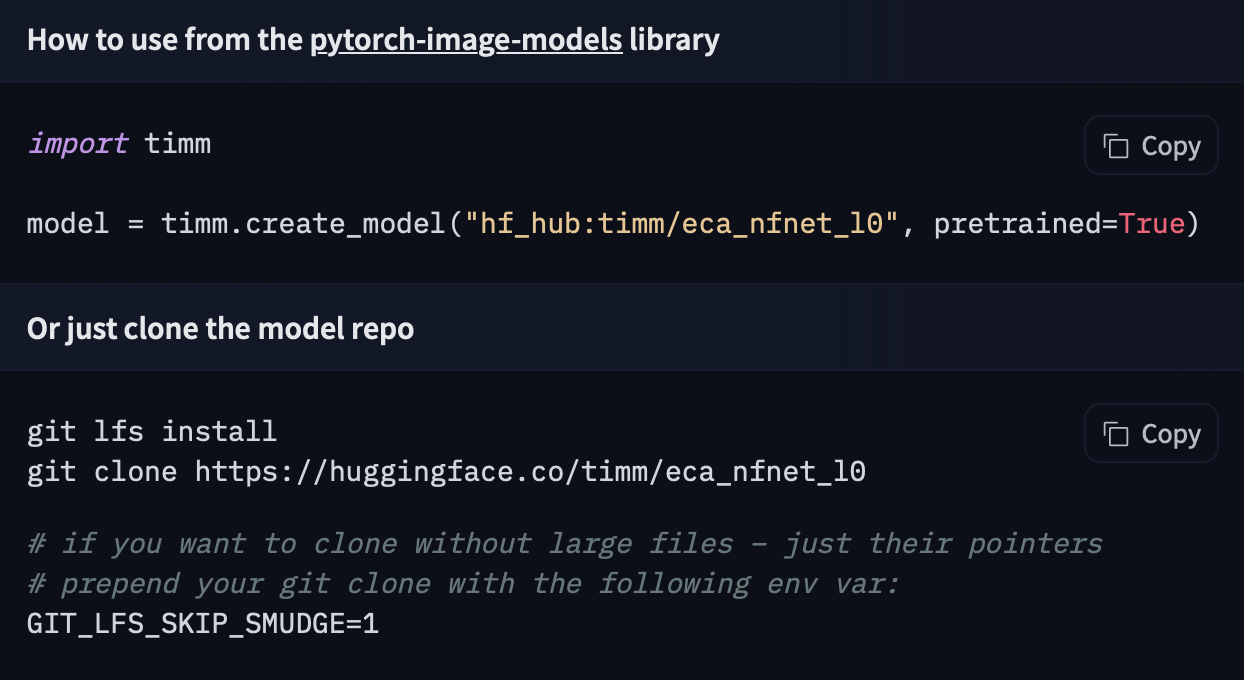
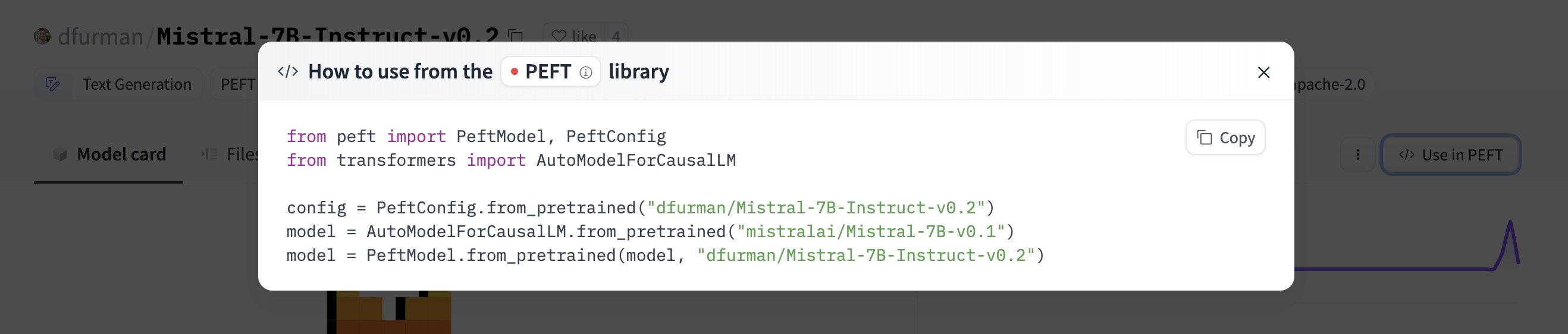
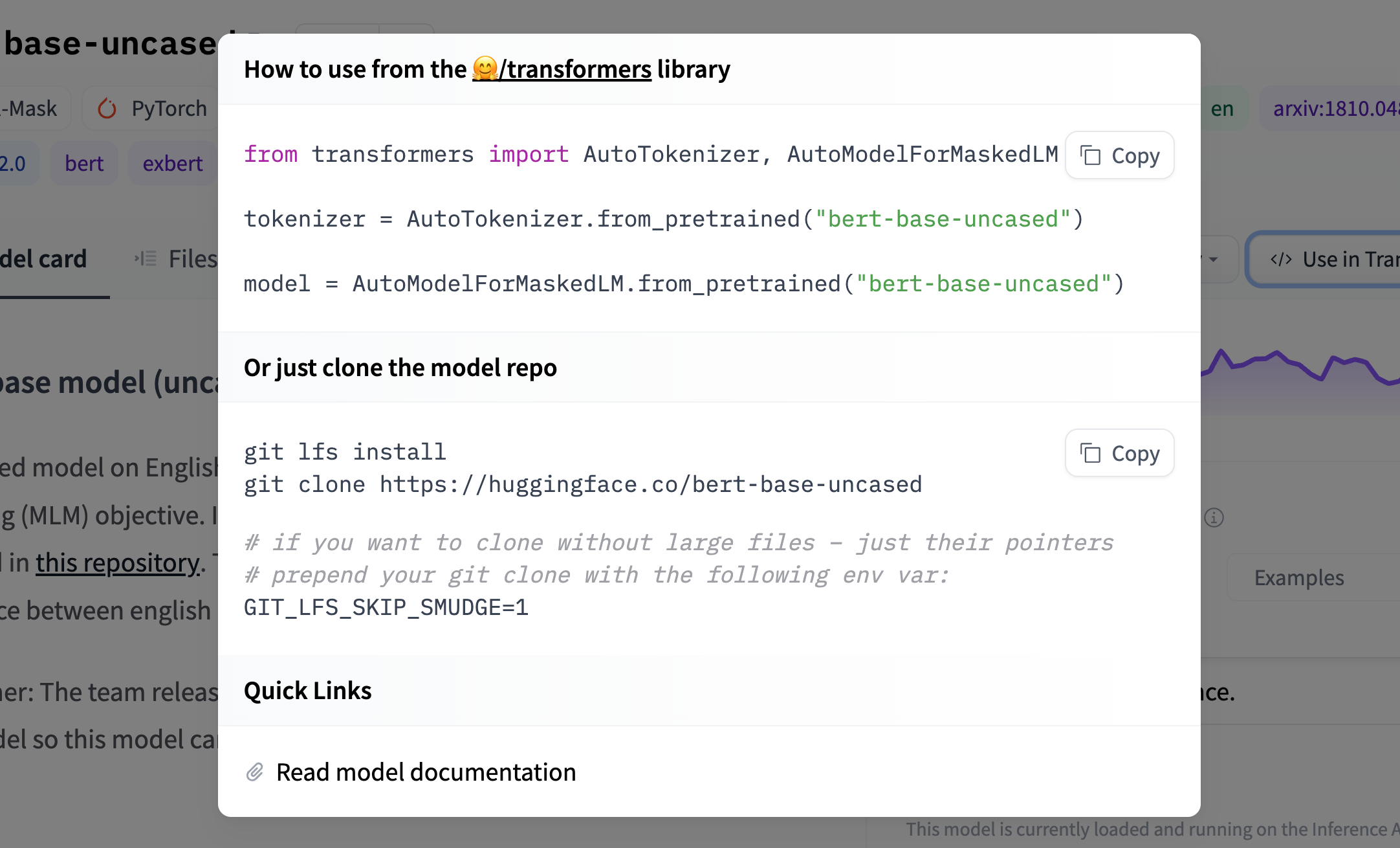
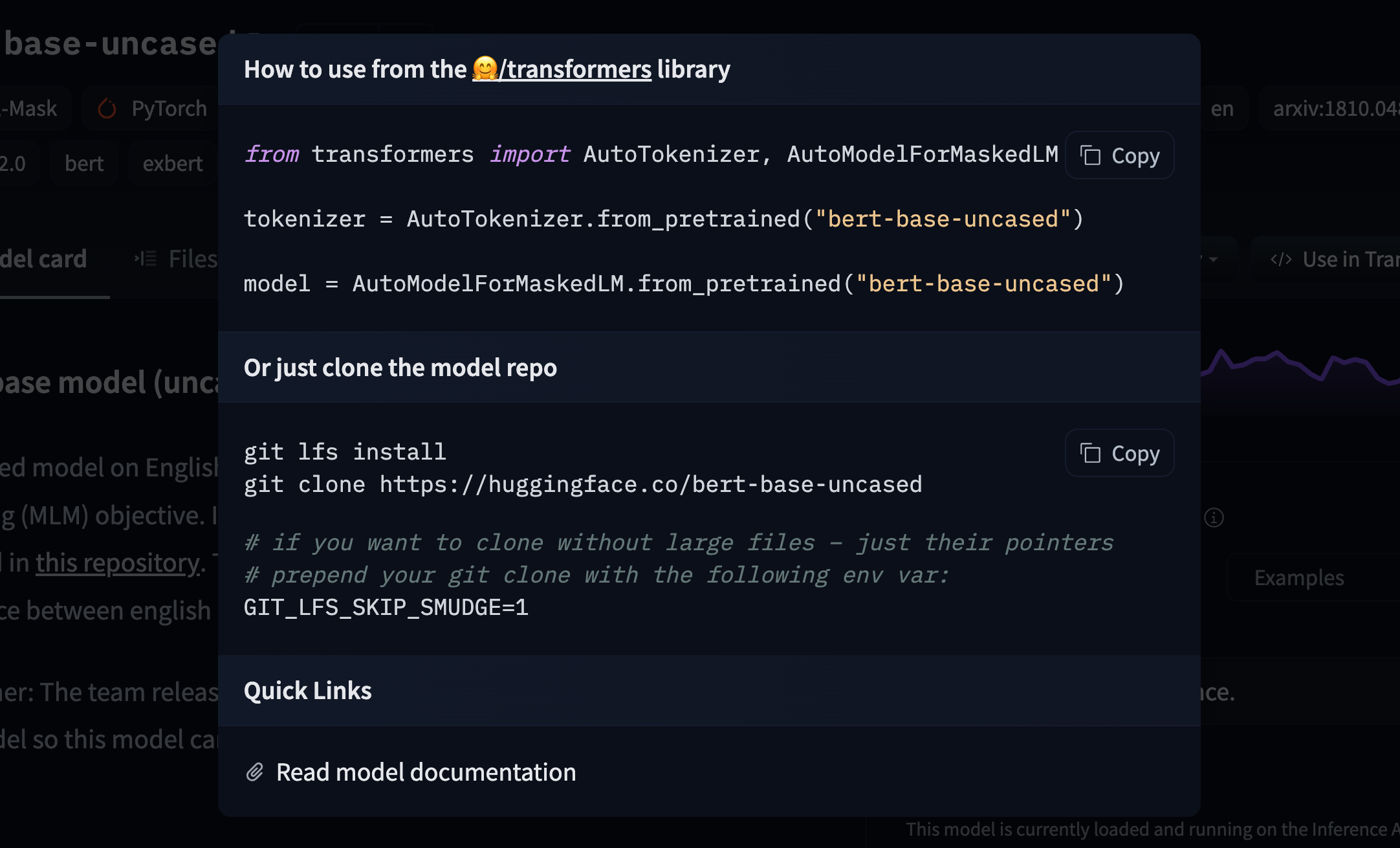
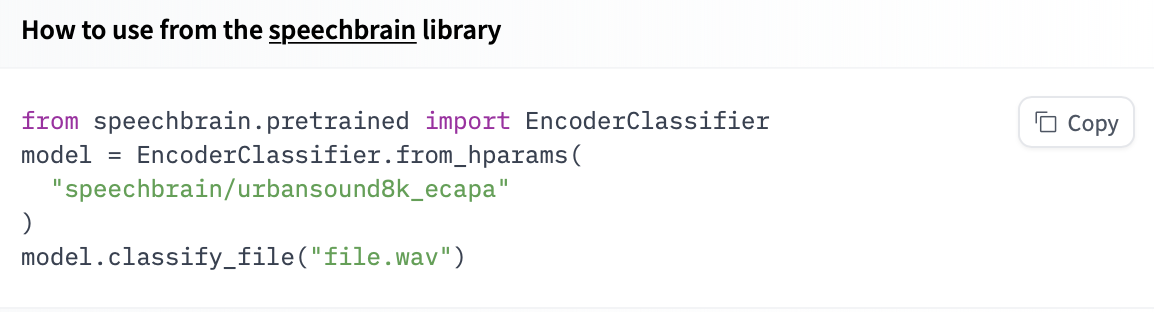
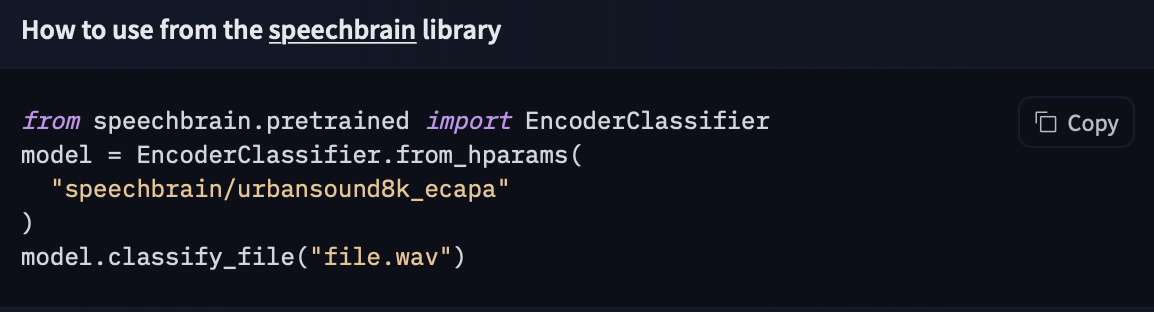
If a model on the Hub is tied to a [supported library](./models-libraries), loading the model can be done in just a few lines. For information on accessing the model, you can click on the "Use in _Library_" button on the model page to see how to do so. For example, `distilbert/distilgpt2` shows how to do so with 🤗 Transformers below.
# Model Card Guidebook
Model cards are an important documentation and transparency framework for machine learning models. We believe that model cards have the potential to serve as *boundary objects*, a single artefact that is accessible to users who have different backgrounds and goals when interacting with model cards – including developers, students, policymakers, ethicists, those impacted by machine learning models, and other stakeholders. We recognize that developing a single artefact to serve such multifaceted purposes is difficult and requires careful consideration of potential users and use cases. Our goal as part of the Hugging Face science team over the last several months has been to help operationalize model cards towards that vision, taking into account these challenges, both at Hugging Face and in the broader ML community.
To work towards that goal, it is important to recognize the thoughtful, dedicated efforts that have helped model cards grow into what they are today, from the adoption of model cards as a standard practice at many large organisations to the development of sophisticated tools for hosting and generating model cards. Since model cards were proposed by Mitchell et al. (2018), the landscape of machine learning documentation has expanded and evolved. A plethora of documentation tools and templates for data, models, and ML systems have been proposed and have developed – reflecting the incredible work of hundreds of researchers, impacted community members, advocates, and other stakeholders. Important discussions about the relationship between ML documentation and theories of change in responsible AI have created continued important discussions, and at times, divergence. We also recognize the challenges facing model cards, which in some ways mirror the challenges facing machine learning documentation and responsible AI efforts more generally, and we see opportunities ahead to help shape both model cards and the ecosystems in which they function positively in the months and years ahead.
Our work presents a view of where we think model cards stand right now and where they could go in the future, at Hugging Face and beyond. This work is a “snapshot” of the current state of model cards, informed by a landscape analysis of the many ways ML documentation artefacts have been instantiated. It represents one perspective amongst multiple about both the current state and more aspirational visions of model cards. In this blog post, we summarise our work, including a discussion of the broader, growing landscape of ML documentation tools, the diverse audiences for and opinions about model cards, and potential new templates for model card content. We also explore and develop model cards for machine learning models in the context of the Hugging Face Hub, using the Hub’s features to collaboratively create, discuss, and disseminate model cards for ML models.
With the launch of this Guidebook, we introduce several new resources and connect together previous work on Model Cards:
1) An updated Model Card template, released in the `huggingface_hub` library [modelcard_template.md file](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md), drawing together Model Card work in academia and throughout the industry.
2) An [Annotated Model Card Template](./model-card-annotated), which details how to fill the card out.
3) A [Model Card Creator Tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool), to ease card creation without needing to program, and to help teams share the work of different sections.
4) A [User Study](./model-cards-user-studies) on Model Card usage at Hugging Face
5) A [Landscape Analysis and Literature Review](./model-card-landscape-analysis) of the state of the art in model documentation.
We also include an [Appendix](./model-card-appendix) with further details from this work.
---
**Please cite as:**
Ozoani, Ezi and Gerchick, Marissa and Mitchell, Margaret. Model Card Guidebook. Hugging Face, 2022. https://huggingface.co/docs/hub/en/model-card-guidebook
# Downloading models
## Integrated libraries
If a model on the Hub is tied to a [supported library](./models-libraries), loading the model can be done in just a few lines. For information on accessing the model, you can click on the "Use in _Library_" button on the model page to see how to do so. For example, `distilbert/distilgpt2` shows how to do so with 🤗 Transformers below.


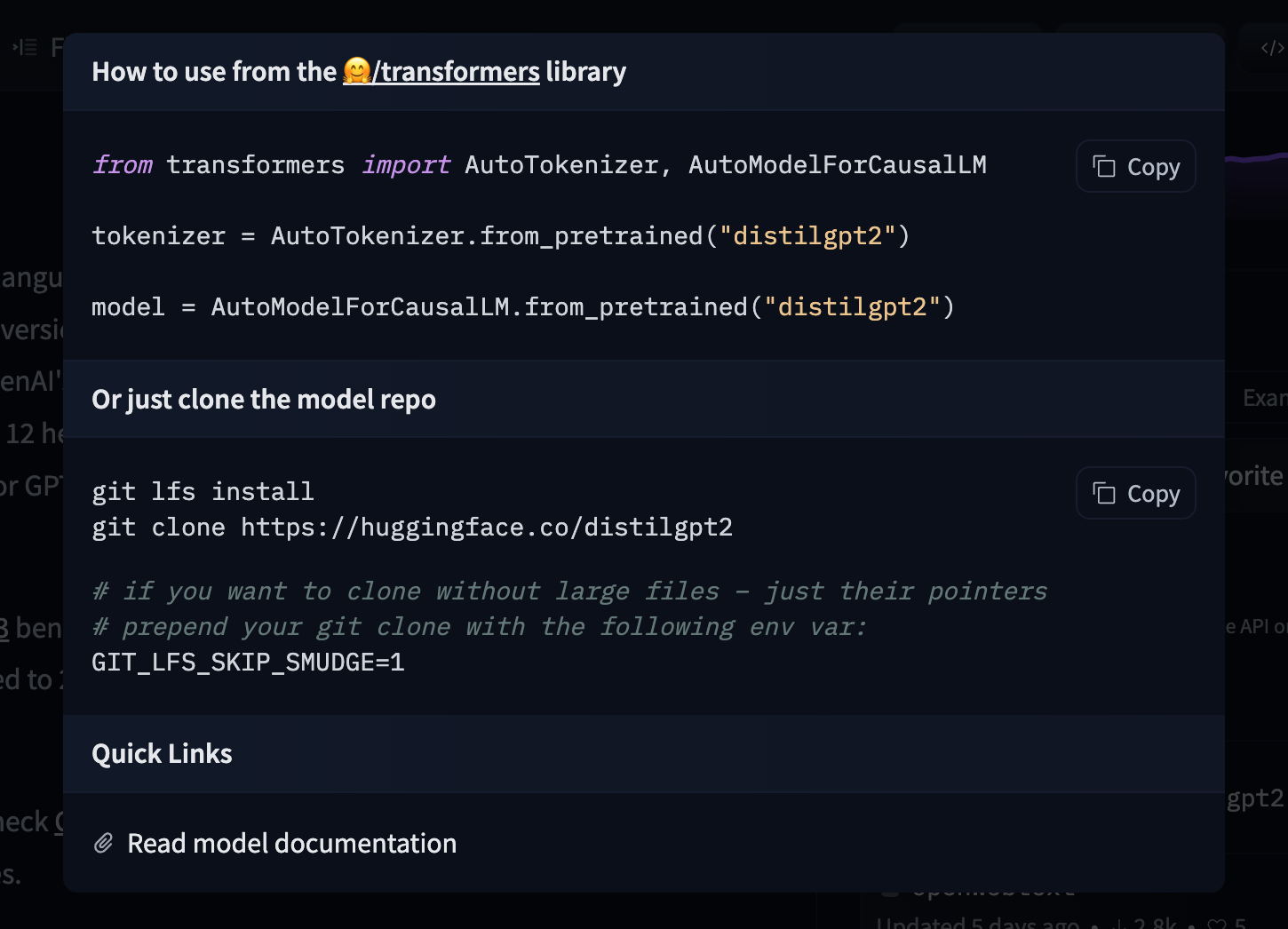

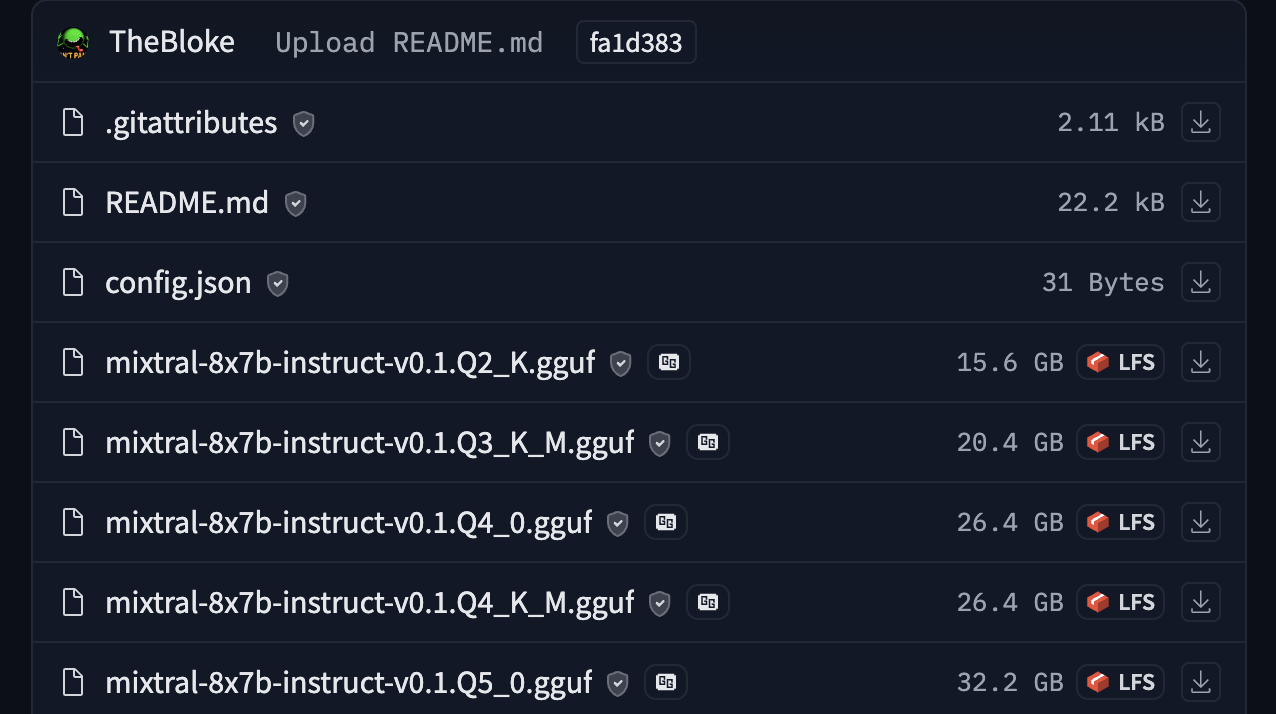
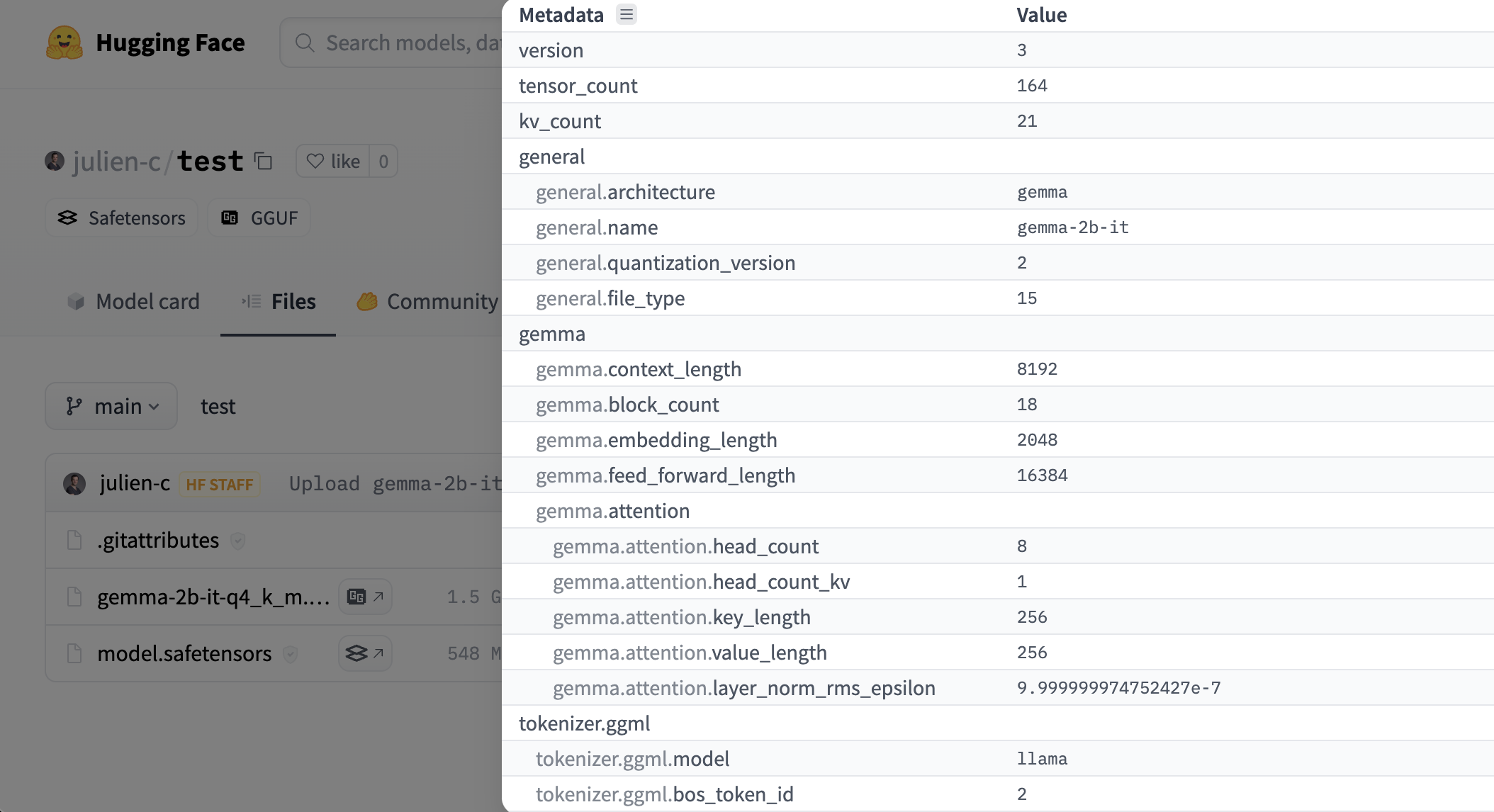
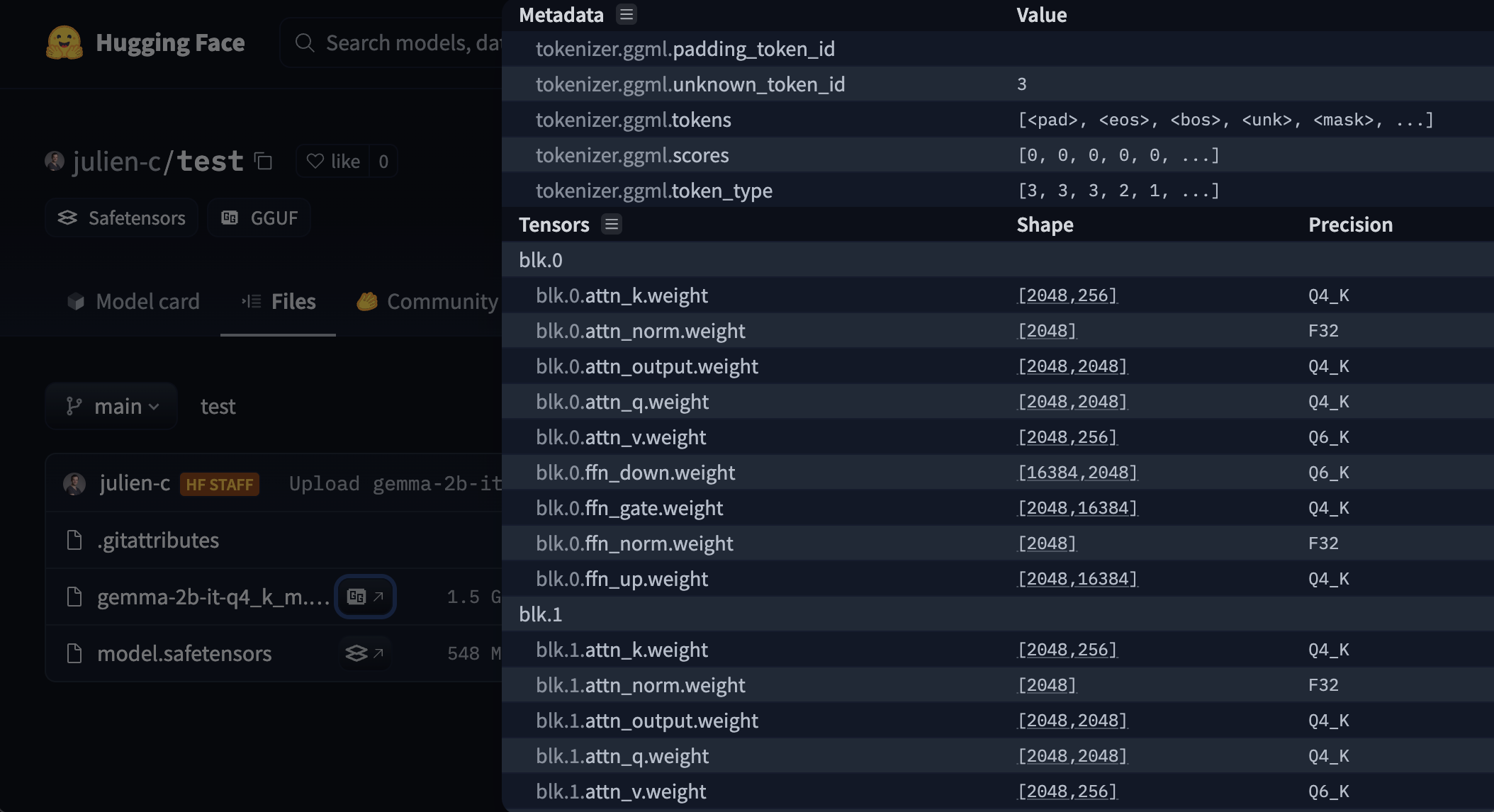

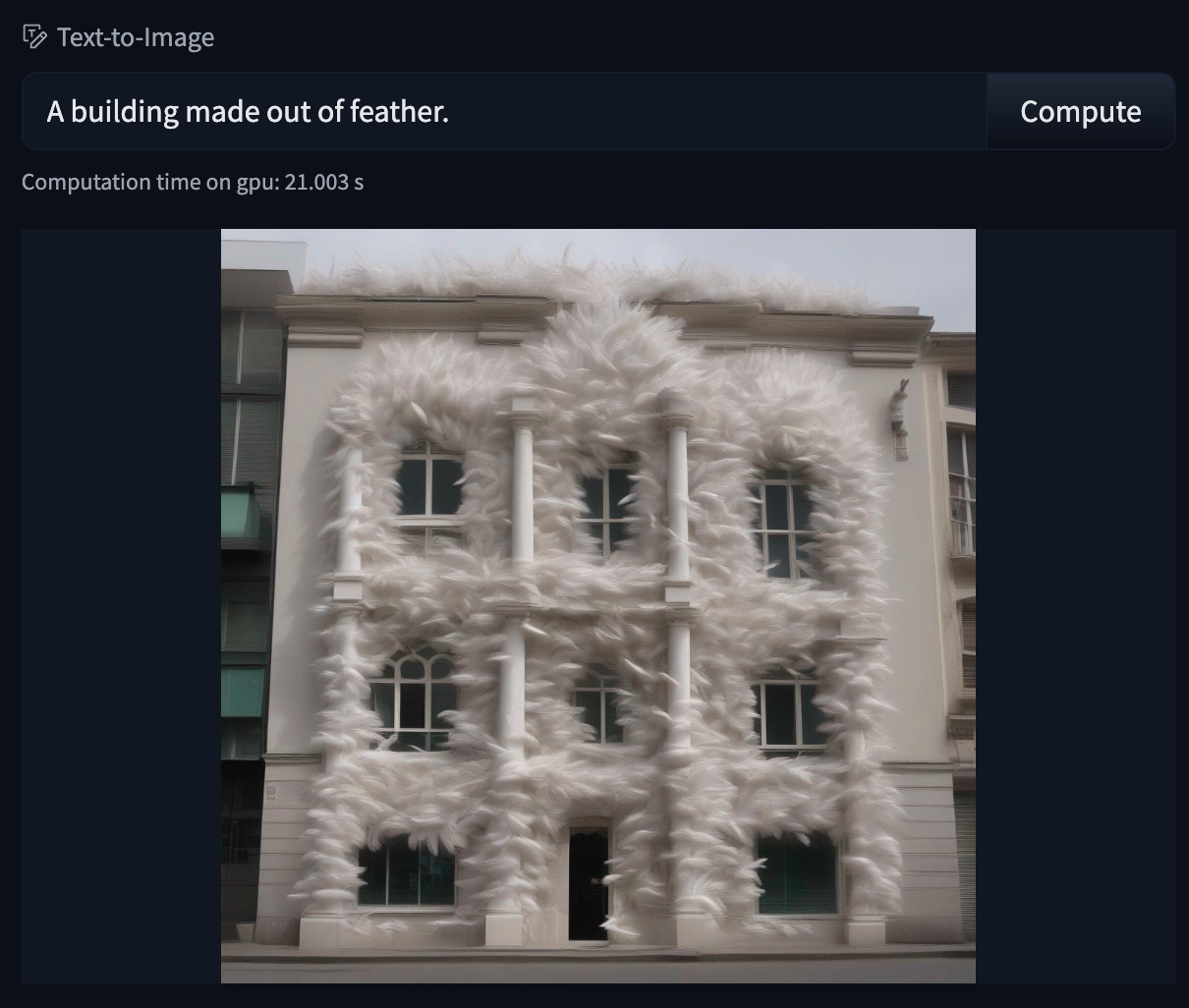





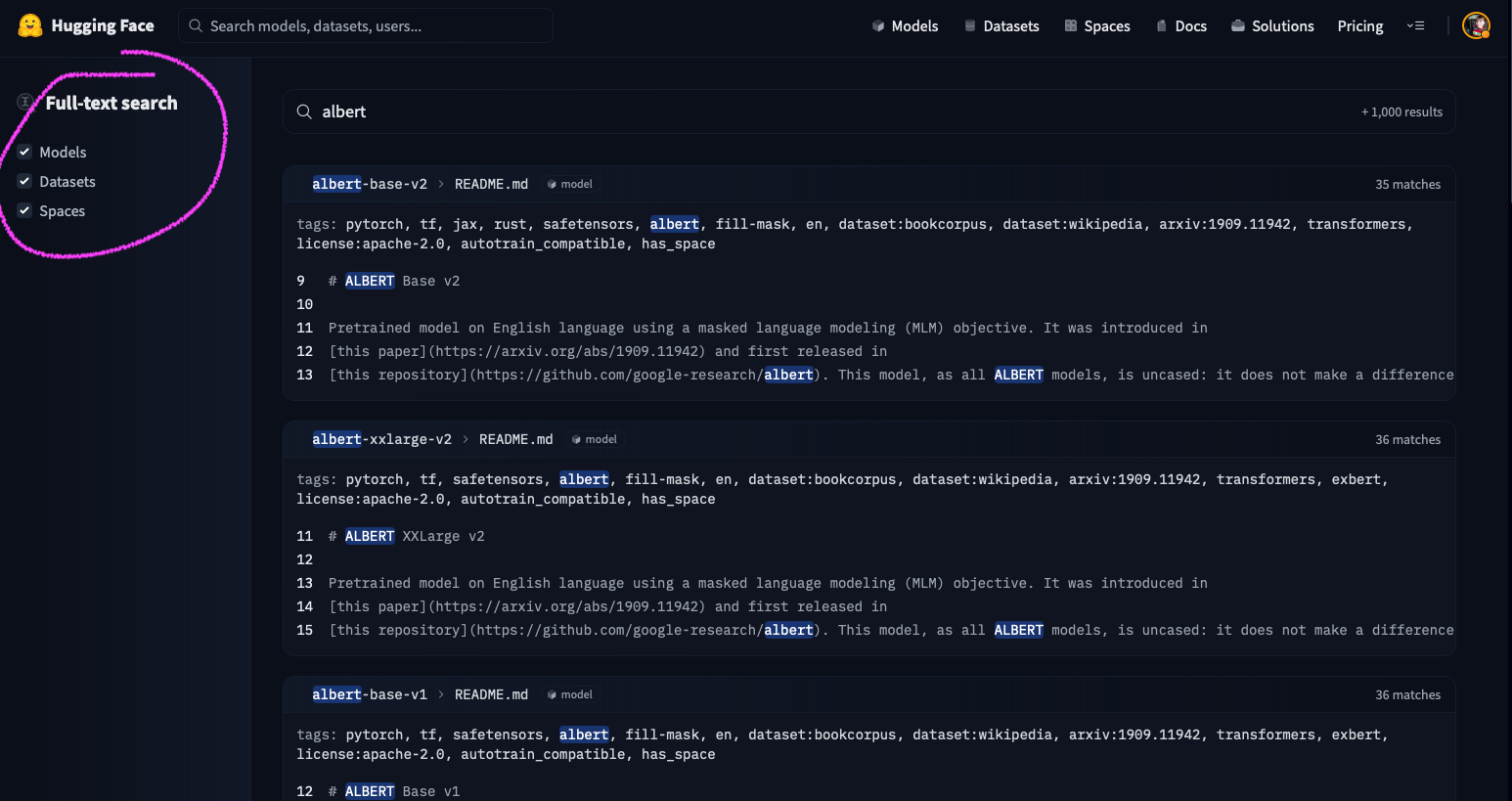
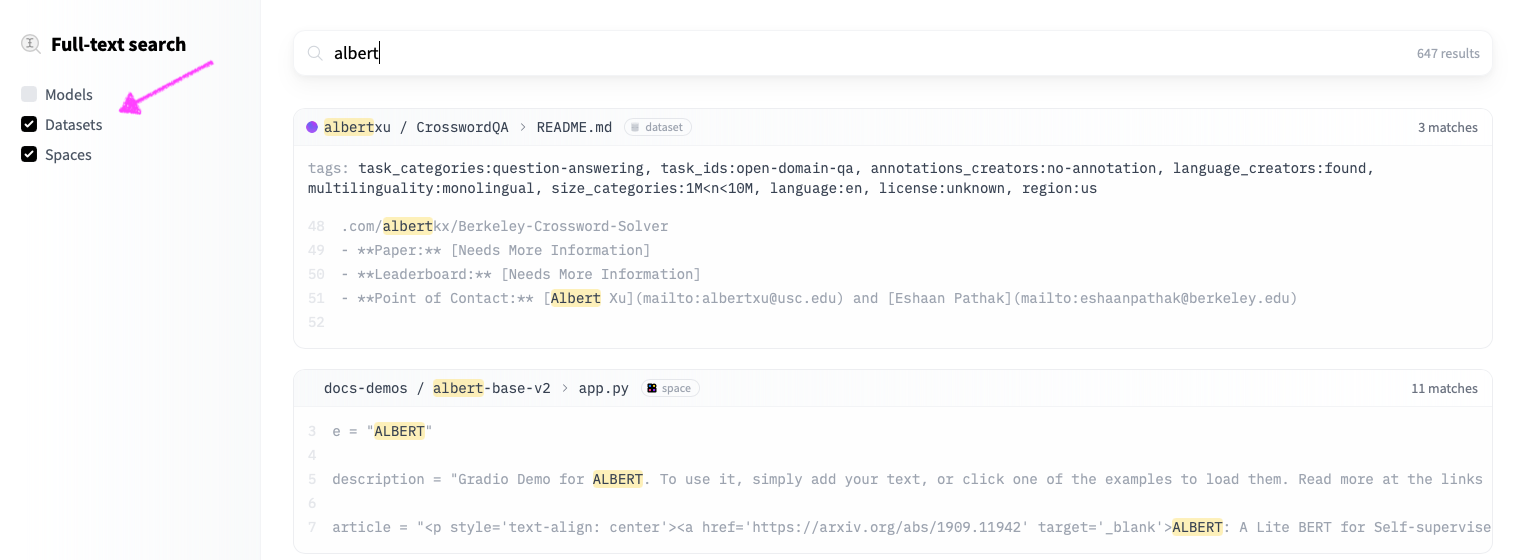
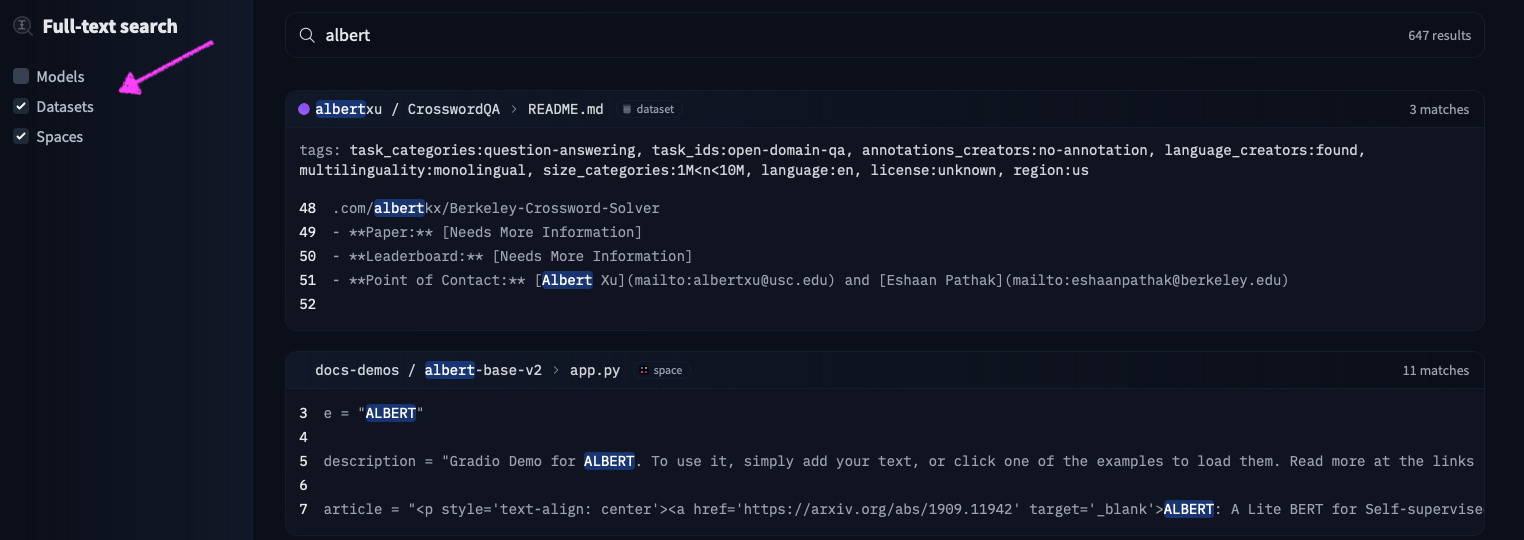



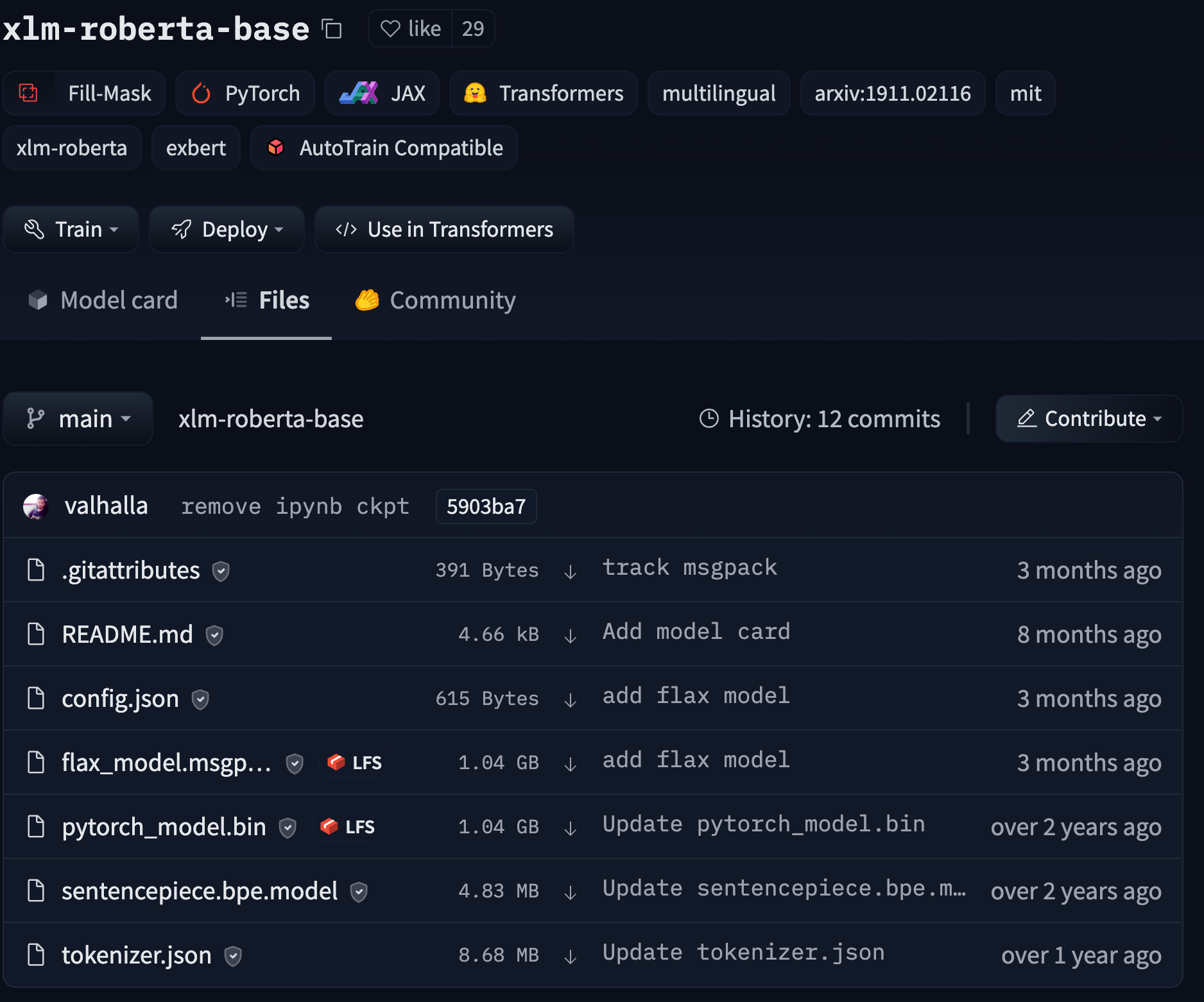


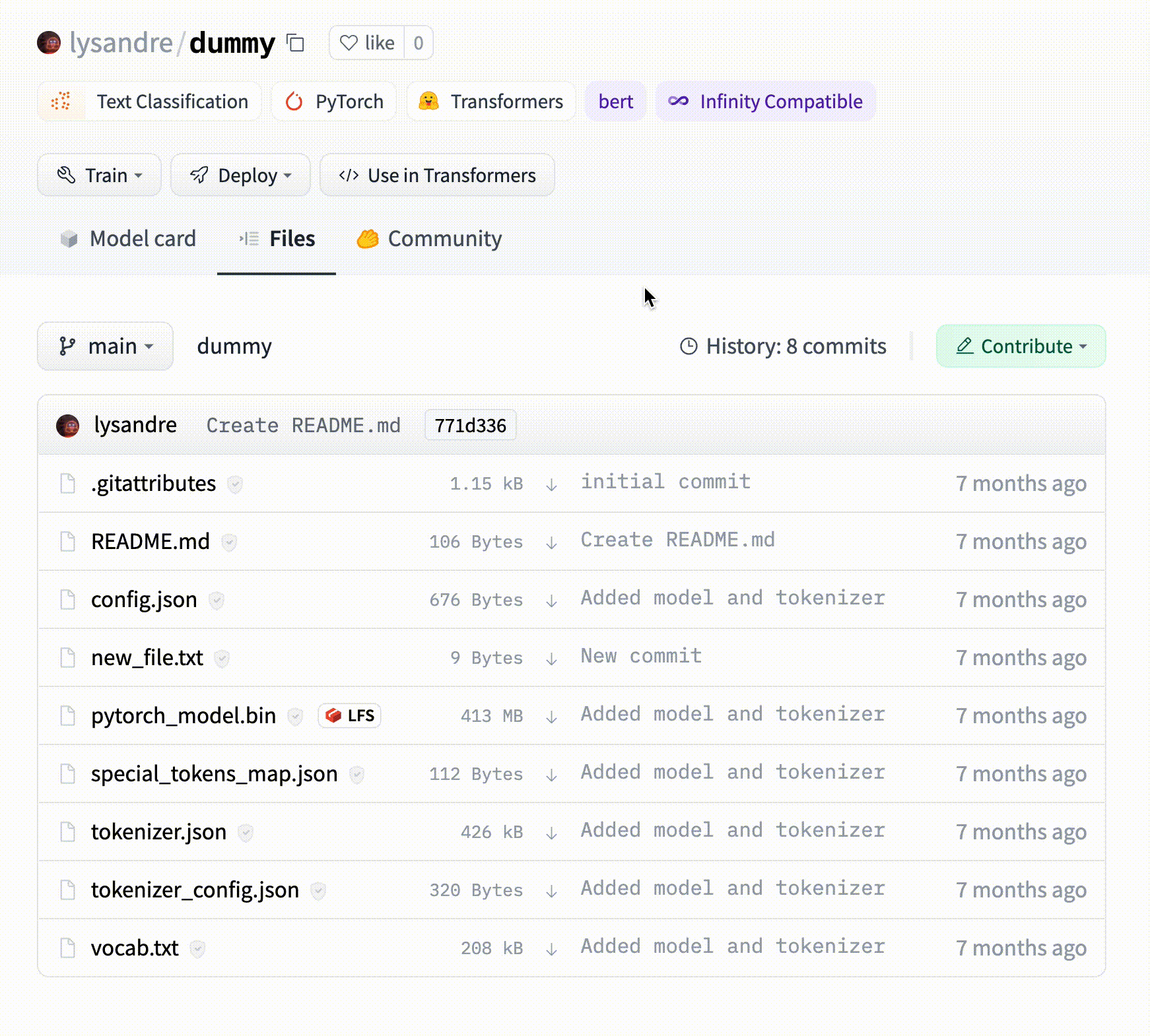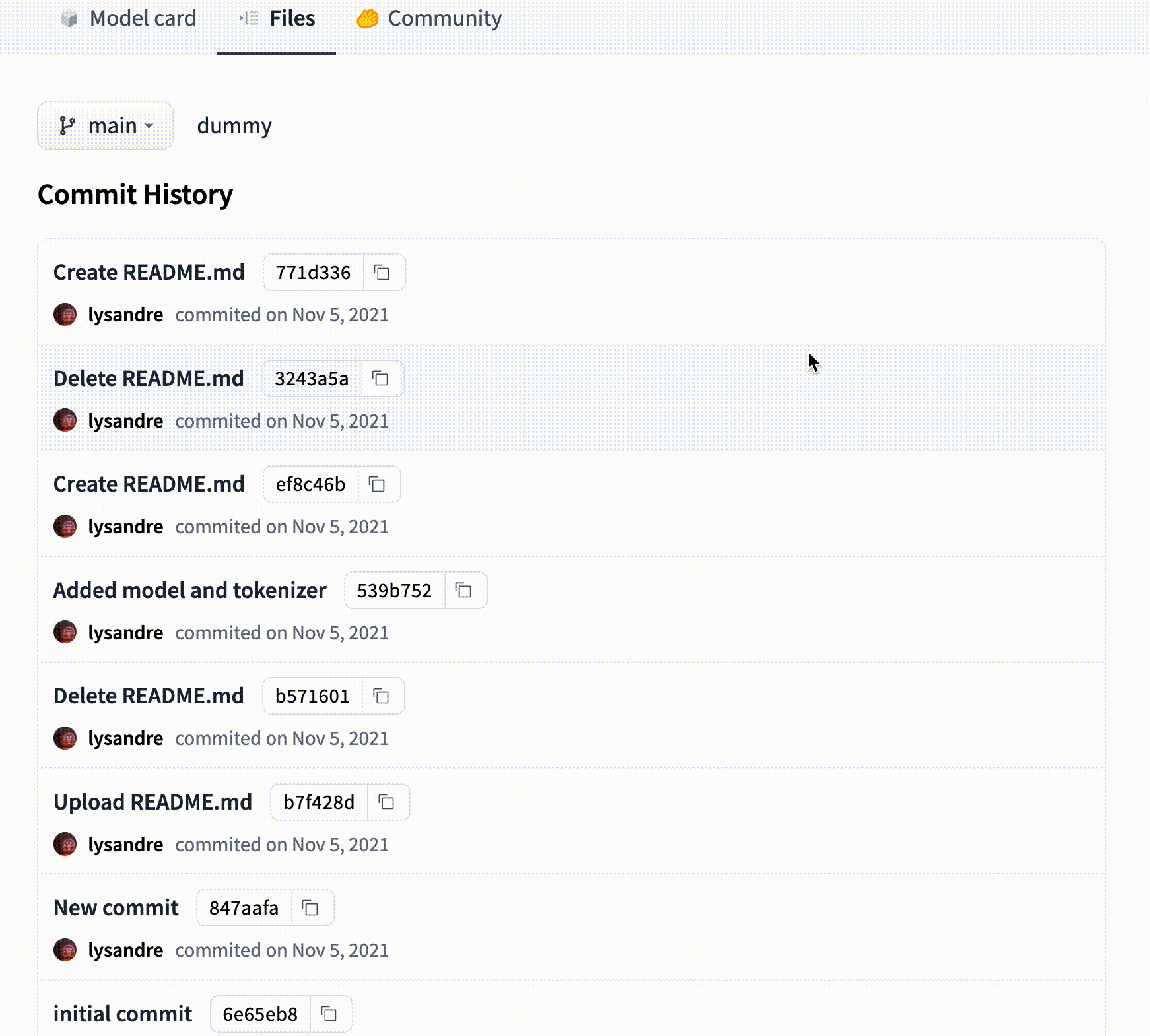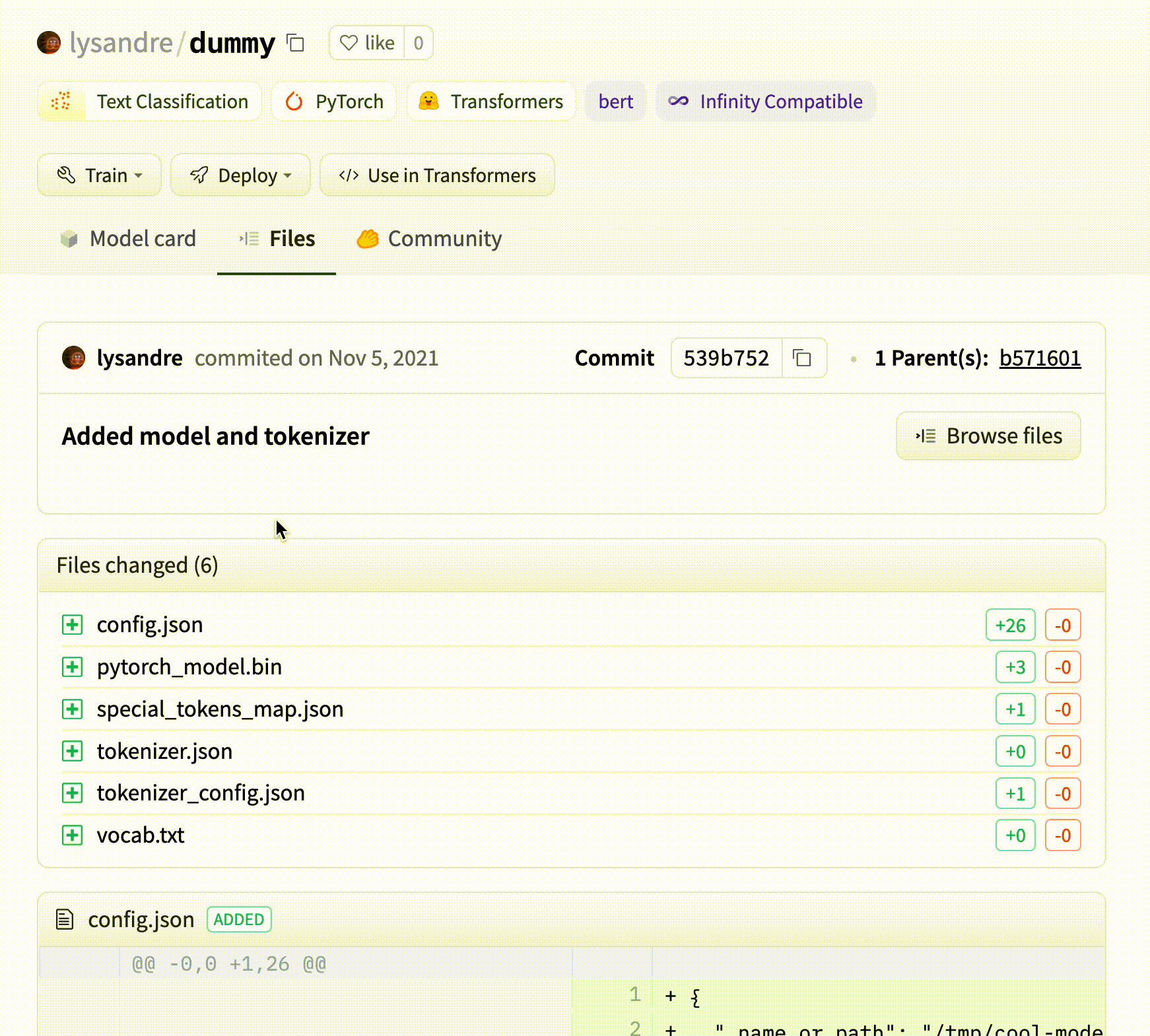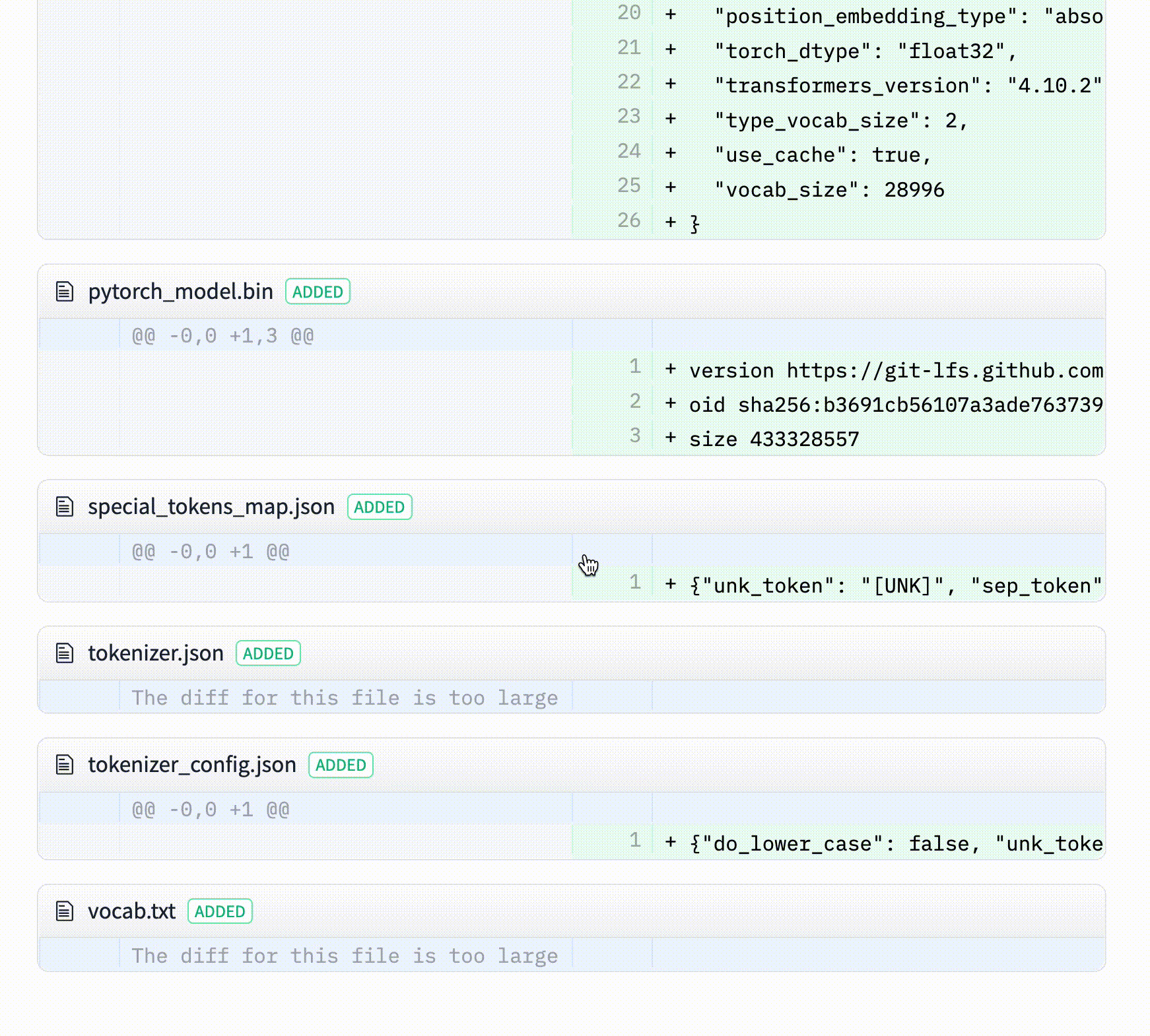




 # Models
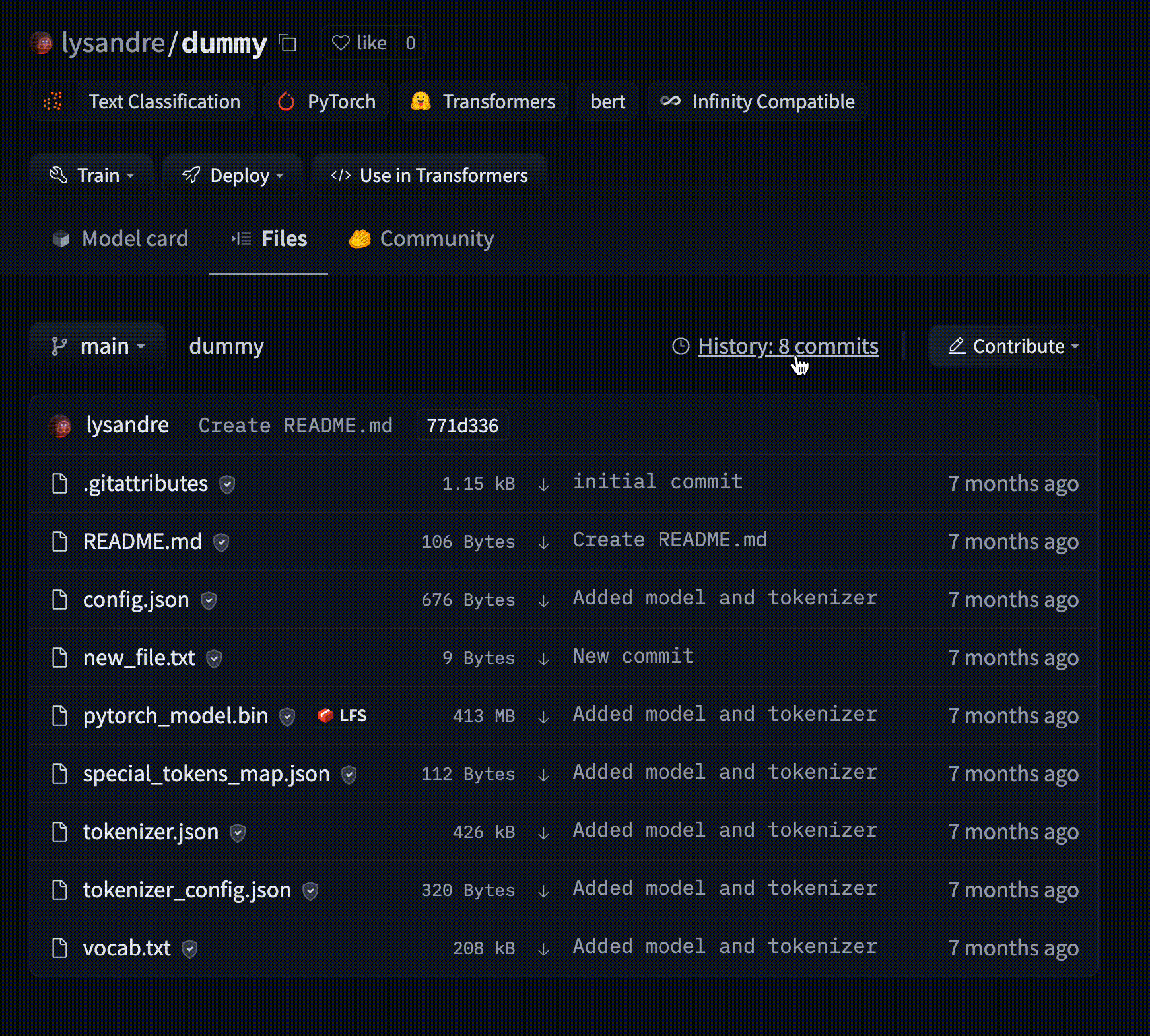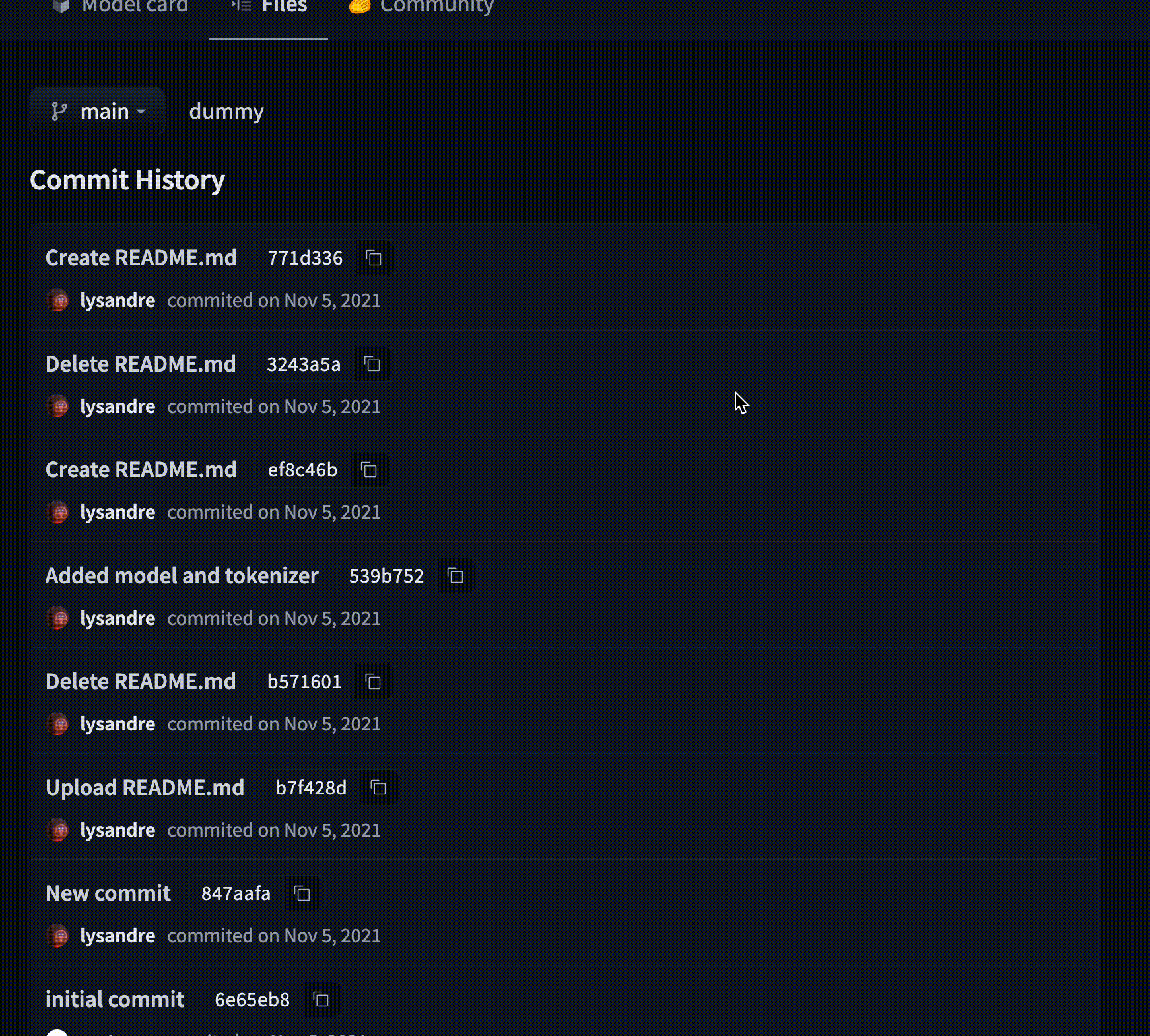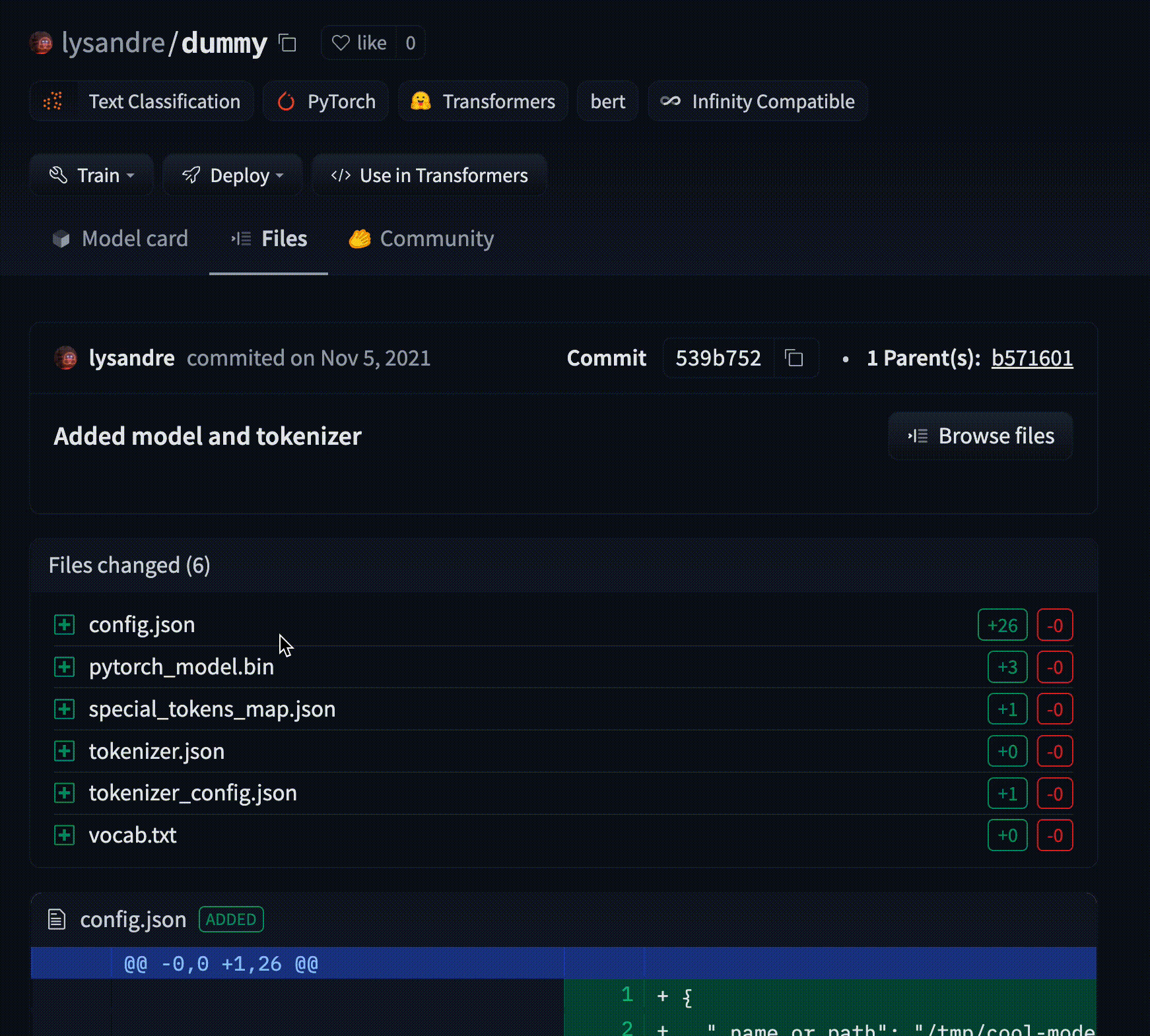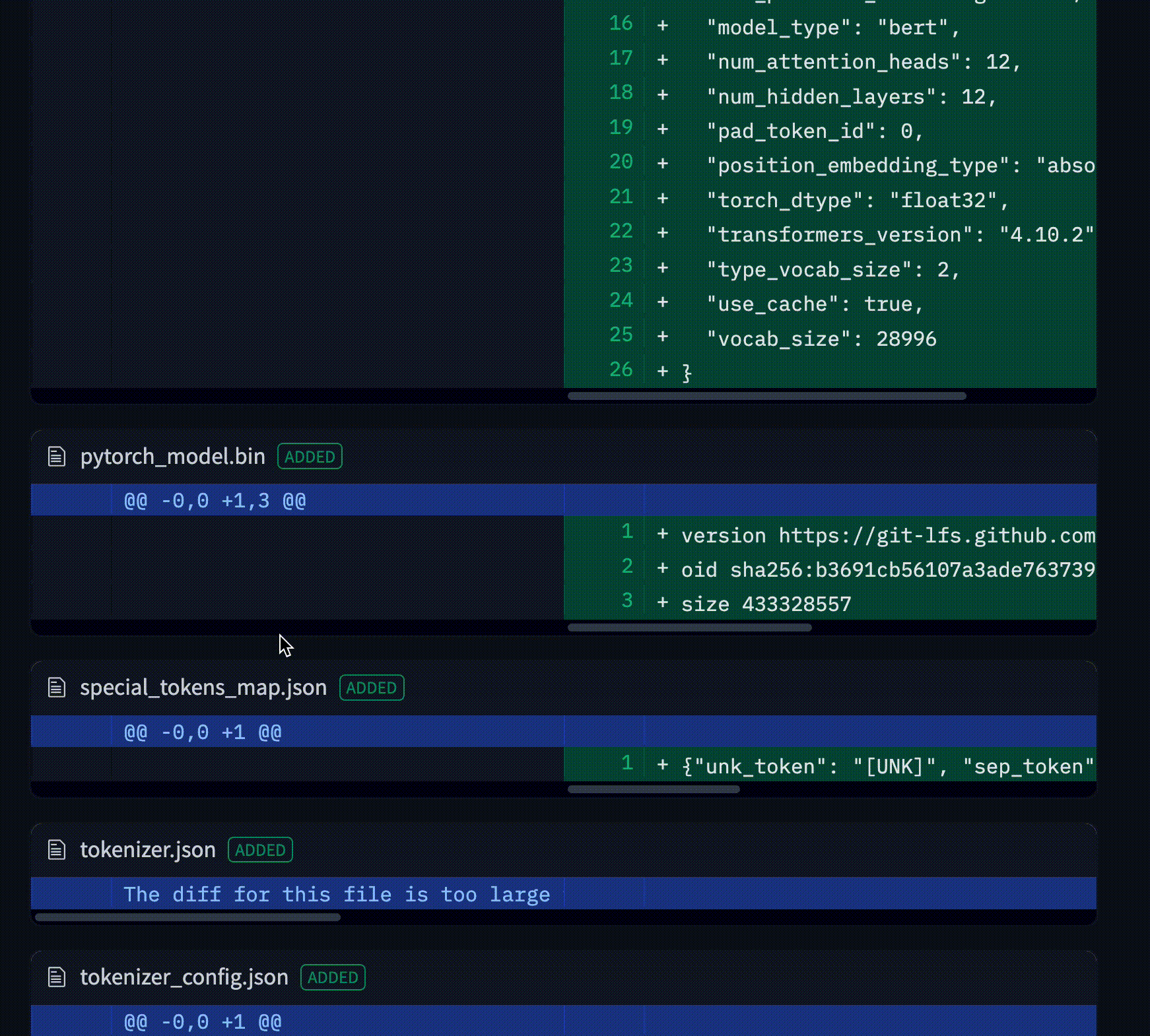
The Hugging Face Hub hosts many models for a [variety of machine learning tasks](https://huggingface.co/tasks). Models are stored in repositories, so they benefit from [all the features](./repositories) possessed by every repo on the Hugging Face Hub. Additionally, model repos have attributes that make exploring and using models as easy as possible. These docs will take you through everything you'll need to know to find models on the Hub, upload your models, and make the most of everything the Model Hub offers!
## Contents
- [The Model Hub](./models-the-hub)
- [Model Cards](./model-cards)
- [CO2 emissions](./model-cards-co2)
- [Gated models](./models-gated)
- [Libraries](./models-libraries)
- [Uploading Models](./models-uploading)
- [Downloading Models](./models-downloading)
- [Widgets](./models-widgets)
- [Widget Examples](./models-widgets-examples)
- [Inference API](./models-inference)
- [Frequently Asked Questions](./models-faq)
- [Advanced Topics](./models-advanced)
- [Integrating libraries with the Hub](./models-adding-libraries)
- [Tasks](./models-tasks)
# Third-party scanner: Protect AI
# Models
The Hugging Face Hub hosts many models for a [variety of machine learning tasks](https://huggingface.co/tasks). Models are stored in repositories, so they benefit from [all the features](./repositories) possessed by every repo on the Hugging Face Hub. Additionally, model repos have attributes that make exploring and using models as easy as possible. These docs will take you through everything you'll need to know to find models on the Hub, upload your models, and make the most of everything the Model Hub offers!
## Contents
- [The Model Hub](./models-the-hub)
- [Model Cards](./model-cards)
- [CO2 emissions](./model-cards-co2)
- [Gated models](./models-gated)
- [Libraries](./models-libraries)
- [Uploading Models](./models-uploading)
- [Downloading Models](./models-downloading)
- [Widgets](./models-widgets)
- [Widget Examples](./models-widgets-examples)
- [Inference API](./models-inference)
- [Frequently Asked Questions](./models-faq)
- [Advanced Topics](./models-advanced)
- [Integrating libraries with the Hub](./models-adding-libraries)
- [Tasks](./models-tasks)
# Third-party scanner: Protect AI
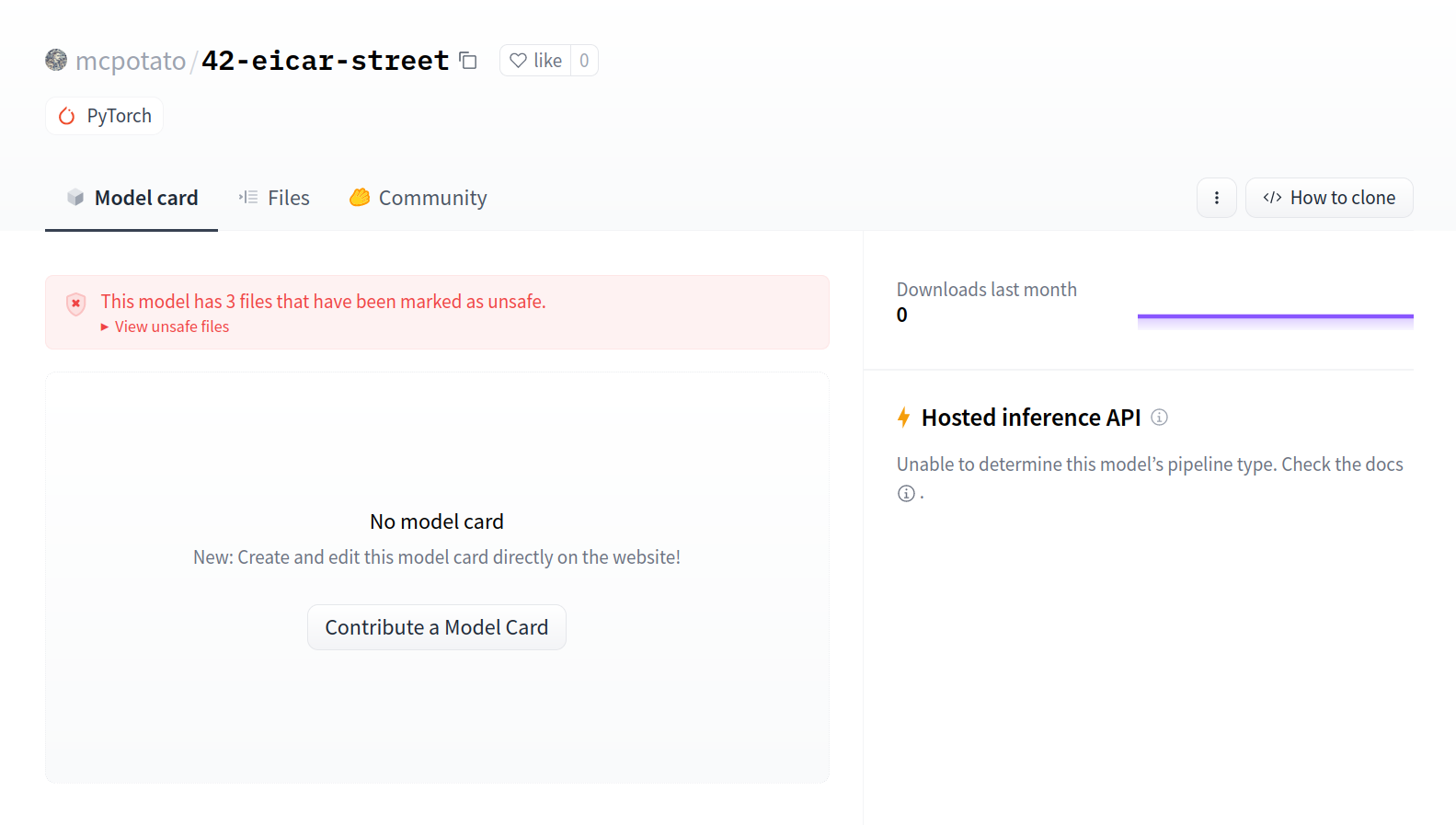
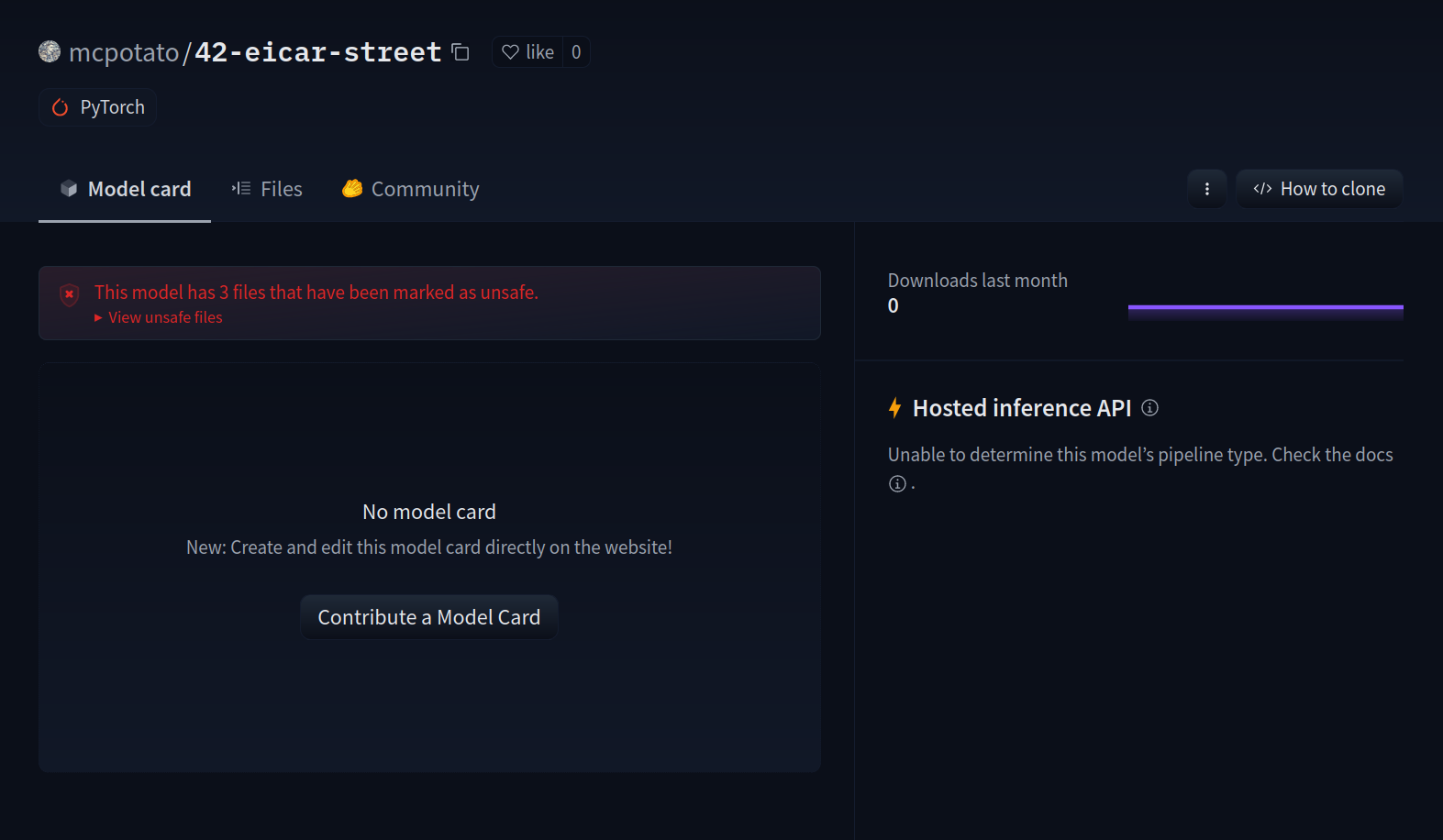
 Here is an example repository you can check out to see the feature in action: [mcpotato/42-eicar-street](https://huggingface.co/mcpotato/42-eicar-street).
## Model security refresher
To share models, we serialize the data structures we use to interact with the models, in order to facilitate storage and transport. Some serialization formats are vulnerable to nasty exploits, such as arbitrary code execution (looking at you pickle), making sharing models potentially dangerous.
As Hugging Face has become a popular platform for model sharing, we’d like to protect the community from this, hence why we have developed tools like [picklescan](https://github.com/mmaitre314/picklescan) and why we integrate third party scanners.
Pickle is not the only exploitable format out there, [see for reference](https://github.com/Azure/counterfit/wiki/Abusing-ML-model-file-formats-to-create-malware-on-AI-systems:-A-proof-of-concept) how one can exploit Keras Lambda layers to achieve arbitrary code execution.
# JupyterLab on Spaces
[JupyterLab](https://jupyter.org/) is a web-based interactive development environment for Jupyter notebooks, code, and data. It is a great tool for data science and machine learning, and it is widely used by the community. With Hugging Face Spaces, you can deploy your own JupyterLab instance and use it for development directly from the Hugging Face website.
## ⚡️ Deploy a JupyterLab instance on Spaces
You can deploy JupyterLab on Spaces with just a few clicks. First, go to [this link](https://huggingface.co/new-space?template=SpacesExamples/jupyterlab) or click the button below:
Spaces requires you to define:
* An **Owner**: either your personal account or an organization you're a
part of.
* A **Space name**: the name of the Space within the account
you're creating the Space.
* The **Visibility**: _private_ if you want the
Space to be visible only to you or your organization, or _public_ if you want
it to be visible to other users.
* The **Hardware**: the hardware you want to use for your JupyterLab instance. This goes from CPUs to H100s.
* You can optionally configure a `JUPYTER_TOKEN` password to protect your JupyterLab workspace. When unspecified, defaults to `huggingface`. We strongly recommend setting this up if your Space is public or if the Space is in an organization.
Here is an example repository you can check out to see the feature in action: [mcpotato/42-eicar-street](https://huggingface.co/mcpotato/42-eicar-street).
## Model security refresher
To share models, we serialize the data structures we use to interact with the models, in order to facilitate storage and transport. Some serialization formats are vulnerable to nasty exploits, such as arbitrary code execution (looking at you pickle), making sharing models potentially dangerous.
As Hugging Face has become a popular platform for model sharing, we’d like to protect the community from this, hence why we have developed tools like [picklescan](https://github.com/mmaitre314/picklescan) and why we integrate third party scanners.
Pickle is not the only exploitable format out there, [see for reference](https://github.com/Azure/counterfit/wiki/Abusing-ML-model-file-formats-to-create-malware-on-AI-systems:-A-proof-of-concept) how one can exploit Keras Lambda layers to achieve arbitrary code execution.
# JupyterLab on Spaces
[JupyterLab](https://jupyter.org/) is a web-based interactive development environment for Jupyter notebooks, code, and data. It is a great tool for data science and machine learning, and it is widely used by the community. With Hugging Face Spaces, you can deploy your own JupyterLab instance and use it for development directly from the Hugging Face website.
## ⚡️ Deploy a JupyterLab instance on Spaces
You can deploy JupyterLab on Spaces with just a few clicks. First, go to [this link](https://huggingface.co/new-space?template=SpacesExamples/jupyterlab) or click the button below:
Spaces requires you to define:
* An **Owner**: either your personal account or an organization you're a
part of.
* A **Space name**: the name of the Space within the account
you're creating the Space.
* The **Visibility**: _private_ if you want the
Space to be visible only to you or your organization, or _public_ if you want
it to be visible to other users.
* The **Hardware**: the hardware you want to use for your JupyterLab instance. This goes from CPUs to H100s.
* You can optionally configure a `JUPYTER_TOKEN` password to protect your JupyterLab workspace. When unspecified, defaults to `huggingface`. We strongly recommend setting this up if your Space is public or if the Space is in an organization.





 ZeroGPU is a shared infrastructure that optimizes GPU usage for AI models and demos on Hugging Face Spaces. It dynamically allocates and releases NVIDIA A100 GPUs as needed, offering:
1. **Free GPU Access**: Enables cost-effective GPU usage for Spaces.
2. **Multi-GPU Support**: Allows Spaces to leverage multiple GPUs concurrently on a single application.
Unlike traditional single-GPU allocations, ZeroGPU's efficient system lowers barriers for developers, researchers, and organizations to deploy AI models by maximizing resource utilization and power efficiency.
## Using and hosting ZeroGPU Spaces
- **Using existing ZeroGPU Spaces**
- ZeroGPU Spaces are available to use for free to all users. (Visit [the curated list](https://huggingface.co/spaces/enzostvs/zero-gpu-spaces)).
- [PRO users](https://huggingface.co/subscribe/pro) get x5 more daily usage quota and highest priority in GPU queues when using any ZeroGPU Spaces.
- **Hosting your own ZeroGPU Spaces**
- Personal accounts: [Subscribe to PRO](https://huggingface.co/settings/billing/subscription) to access ZeroGPU in the hardware options when creating a new Gradio SDK Space.
- Organizations: [Subscribe to the Enterprise Hub](https://huggingface.co/enterprise) to enable ZeroGPU Spaces for all organization members.
## Technical Specifications
- **GPU Type**: Nvidia A100
- **Available VRAM**: 40GB per workload
## Compatibility
ZeroGPU Spaces are designed to be compatible with most PyTorch-based GPU Spaces. While compatibility is enhanced for high-level Hugging Face libraries like `transformers` and `diffusers`, users should be aware that:
- Currently, ZeroGPU Spaces are exclusively compatible with the **Gradio SDK**.
- ZeroGPU Spaces may have limited compatibility compared to standard GPU Spaces.
- Unexpected issues may arise in some scenarios.
### Supported Versions
- Gradio: 4+
- PyTorch: 2.0.1, 2.1.2, 2.2.2, 2.4.0 (Note: 2.3.x is not supported due to a [PyTorch bug](https://github.com/pytorch/pytorch/issues/122085))
- Python: 3.10.13
## Getting started with ZeroGPU
To utilize ZeroGPU in your Space, follow these steps:
1. Make sure the ZeroGPU hardware is selected in your Space settings.
2. Import the `spaces` module.
3. Decorate GPU-dependent functions with `@spaces.GPU`.
This decoration process allows the Space to request a GPU when the function is called and release it upon completion.
### Example Usage
```python
import spaces
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(...)
pipe.to('cuda')
@spaces.GPU
def generate(prompt):
return pipe(prompt).images
gr.Interface(
fn=generate,
inputs=gr.Text(),
outputs=gr.Gallery(),
).launch()
```
Note: The `@spaces.GPU` decorator is designed to be effect-free in non-ZeroGPU environments, ensuring compatibility across different setups.
## Duration Management
For functions expected to exceed the default 60-second of GPU runtime, you can specify a custom duration:
```python
@spaces.GPU(duration=120)
def generate(prompt):
return pipe(prompt).images
```
This sets the maximum function runtime to 120 seconds. Specifying shorter durations for quicker functions will improve queue priority for Space visitors.
## Hosting Limitations
- **Personal accounts ([PRO subscribers](https://huggingface.co/subscribe/pro))**: Maximum of 10 ZeroGPU Spaces.
- **Organization accounts ([Enterprise Hub](https://huggingface.co/enterprise))**: Maximum of 50 ZeroGPU Spaces.
By leveraging ZeroGPU, developers can create more efficient and scalable Spaces, maximizing GPU utilization while minimizing costs.
## Feedback
You can share your feedback on Spaces ZeroGPU directly on the HF Hub: https://huggingface.co/spaces/zero-gpu-explorers/README/discussions
# Billing
At Hugging Face, we build a collaboration platform for the ML community (i.e., the Hub) and monetize by providing simple access to compute for AI.
Any feedback or support request related to billing is welcome at billing@huggingface.co
## Cloud providers partnerships
We partner with cloud providers like [AWS](https://huggingface.co/blog/aws-partnership), [Azure](https://huggingface.co/blog/hugging-face-endpoints-on-azure), and [Google Cloud](https://huggingface.co/blog/llama31-on-vertex-ai) to make it easy for customers to use Hugging Face directly in their cloud of choice. These solutions and usage are billed directly by the cloud provider. Ultimately, we want people to have great options for using Hugging Face wherever they build ML-powered products.
## Compute Services on the Hub
We also directly provide compute services with [Spaces](./spaces), [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) and the [Serverless Inference API](https://huggingface.co/docs/api-inference/index).
While most of our compute services have a comprehensive free tier, users and organizations can pay to access more powerful hardware accelerators.
The billing for our compute services is usage-based, meaning you only pay for what you use. You can monitor your usage at any time from your billing dashboard, located in your user's or organization's settings menu.
ZeroGPU is a shared infrastructure that optimizes GPU usage for AI models and demos on Hugging Face Spaces. It dynamically allocates and releases NVIDIA A100 GPUs as needed, offering:
1. **Free GPU Access**: Enables cost-effective GPU usage for Spaces.
2. **Multi-GPU Support**: Allows Spaces to leverage multiple GPUs concurrently on a single application.
Unlike traditional single-GPU allocations, ZeroGPU's efficient system lowers barriers for developers, researchers, and organizations to deploy AI models by maximizing resource utilization and power efficiency.
## Using and hosting ZeroGPU Spaces
- **Using existing ZeroGPU Spaces**
- ZeroGPU Spaces are available to use for free to all users. (Visit [the curated list](https://huggingface.co/spaces/enzostvs/zero-gpu-spaces)).
- [PRO users](https://huggingface.co/subscribe/pro) get x5 more daily usage quota and highest priority in GPU queues when using any ZeroGPU Spaces.
- **Hosting your own ZeroGPU Spaces**
- Personal accounts: [Subscribe to PRO](https://huggingface.co/settings/billing/subscription) to access ZeroGPU in the hardware options when creating a new Gradio SDK Space.
- Organizations: [Subscribe to the Enterprise Hub](https://huggingface.co/enterprise) to enable ZeroGPU Spaces for all organization members.
## Technical Specifications
- **GPU Type**: Nvidia A100
- **Available VRAM**: 40GB per workload
## Compatibility
ZeroGPU Spaces are designed to be compatible with most PyTorch-based GPU Spaces. While compatibility is enhanced for high-level Hugging Face libraries like `transformers` and `diffusers`, users should be aware that:
- Currently, ZeroGPU Spaces are exclusively compatible with the **Gradio SDK**.
- ZeroGPU Spaces may have limited compatibility compared to standard GPU Spaces.
- Unexpected issues may arise in some scenarios.
### Supported Versions
- Gradio: 4+
- PyTorch: 2.0.1, 2.1.2, 2.2.2, 2.4.0 (Note: 2.3.x is not supported due to a [PyTorch bug](https://github.com/pytorch/pytorch/issues/122085))
- Python: 3.10.13
## Getting started with ZeroGPU
To utilize ZeroGPU in your Space, follow these steps:
1. Make sure the ZeroGPU hardware is selected in your Space settings.
2. Import the `spaces` module.
3. Decorate GPU-dependent functions with `@spaces.GPU`.
This decoration process allows the Space to request a GPU when the function is called and release it upon completion.
### Example Usage
```python
import spaces
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(...)
pipe.to('cuda')
@spaces.GPU
def generate(prompt):
return pipe(prompt).images
gr.Interface(
fn=generate,
inputs=gr.Text(),
outputs=gr.Gallery(),
).launch()
```
Note: The `@spaces.GPU` decorator is designed to be effect-free in non-ZeroGPU environments, ensuring compatibility across different setups.
## Duration Management
For functions expected to exceed the default 60-second of GPU runtime, you can specify a custom duration:
```python
@spaces.GPU(duration=120)
def generate(prompt):
return pipe(prompt).images
```
This sets the maximum function runtime to 120 seconds. Specifying shorter durations for quicker functions will improve queue priority for Space visitors.
## Hosting Limitations
- **Personal accounts ([PRO subscribers](https://huggingface.co/subscribe/pro))**: Maximum of 10 ZeroGPU Spaces.
- **Organization accounts ([Enterprise Hub](https://huggingface.co/enterprise))**: Maximum of 50 ZeroGPU Spaces.
By leveraging ZeroGPU, developers can create more efficient and scalable Spaces, maximizing GPU utilization while minimizing costs.
## Feedback
You can share your feedback on Spaces ZeroGPU directly on the HF Hub: https://huggingface.co/spaces/zero-gpu-explorers/README/discussions
# Billing
At Hugging Face, we build a collaboration platform for the ML community (i.e., the Hub) and monetize by providing simple access to compute for AI.
Any feedback or support request related to billing is welcome at billing@huggingface.co
## Cloud providers partnerships
We partner with cloud providers like [AWS](https://huggingface.co/blog/aws-partnership), [Azure](https://huggingface.co/blog/hugging-face-endpoints-on-azure), and [Google Cloud](https://huggingface.co/blog/llama31-on-vertex-ai) to make it easy for customers to use Hugging Face directly in their cloud of choice. These solutions and usage are billed directly by the cloud provider. Ultimately, we want people to have great options for using Hugging Face wherever they build ML-powered products.
## Compute Services on the Hub
We also directly provide compute services with [Spaces](./spaces), [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) and the [Serverless Inference API](https://huggingface.co/docs/api-inference/index).
While most of our compute services have a comprehensive free tier, users and organizations can pay to access more powerful hardware accelerators.
The billing for our compute services is usage-based, meaning you only pay for what you use. You can monitor your usage at any time from your billing dashboard, located in your user's or organization's settings menu.









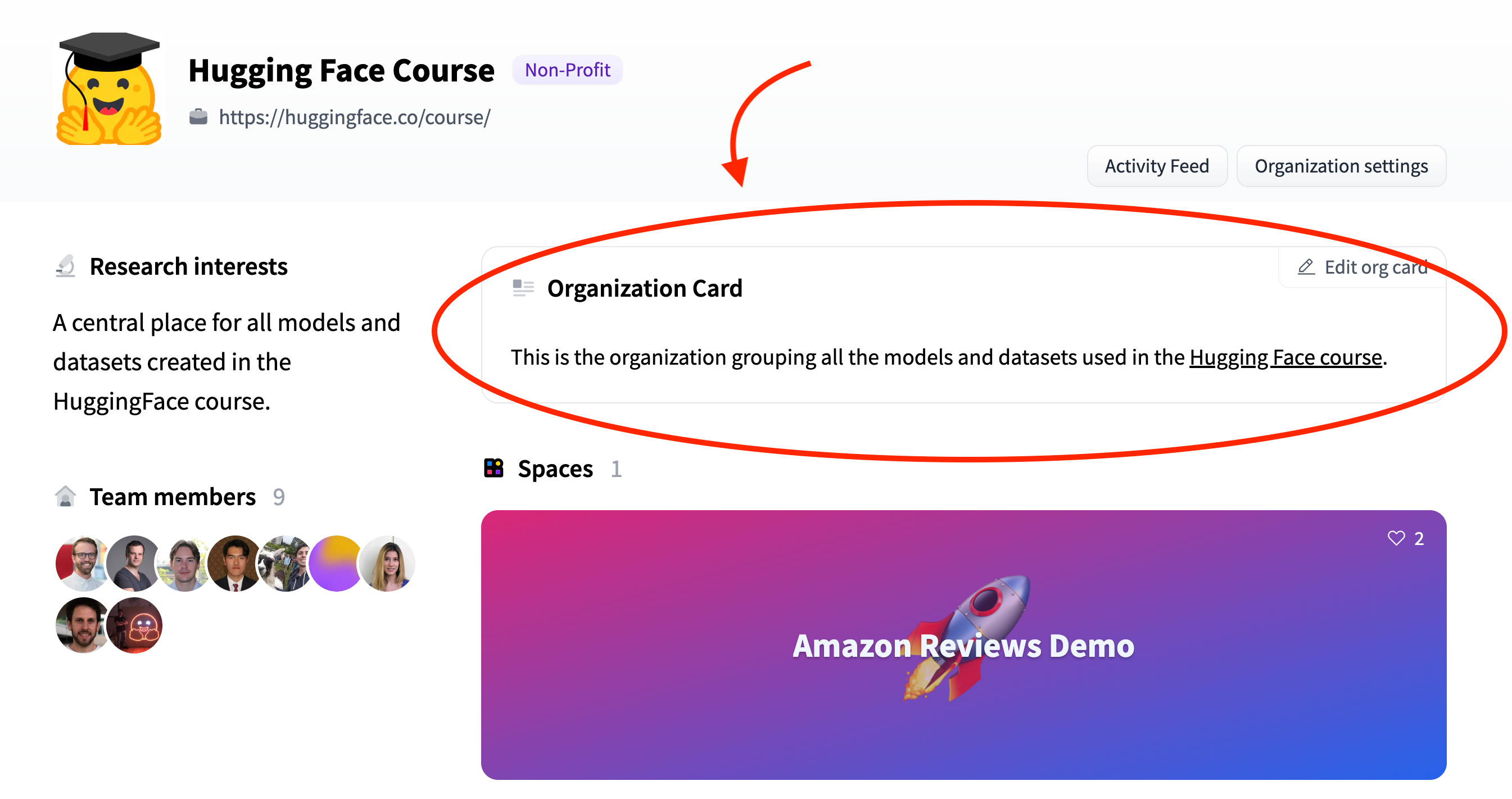
This is the organization grouping all the models and datasets used in the Hugging Face course.
``` For more examples, take a look at: * [Amazon's](https://huggingface.co/spaces/amazon/README/blob/main/README.md) organization card source code * [spaCy's](https://huggingface.co/spaces/spacy/README/blob/main/README.md) organization card source code. # Distilabel Distilabel is a framework for synthetic data and AI feedback for engineers who need fast, reliable and scalable pipelines based on verified research papers. Distilabel can be used for generating synthetic data and AI feedback for a wide variety of projects including traditional predictive NLP (classification, extraction, etc.), or generative and large language model scenarios (instruction following, dialogue generation, judging etc.). Distilabel's programmatic approach allows you to build scalable pipelines data generation and AI feedback. The goal of distilabel is to accelerate your AI development by quickly generating high-quality, diverse datasets based on verified research methodologies for generating and judging with AI feedback. ## What do people build with distilabel? The Argilla community uses distilabel to create amazing [datasets](https://huggingface.co/datasets?other=distilabel) and [models](https://huggingface.co/models?other=distilabel). - The [1M OpenHermesPreference](https://huggingface.co/datasets/argilla/OpenHermesPreferences) is a dataset of ~1 million AI preferences that have been generated using the [teknium/OpenHermes-2.5](https://huggingface.co/datasets/teknium/OpenHermes-2.5) LLM. It is a great example on how you can use distilabel to scale and increase dataset development. - [distilabeled Intel Orca DPO dataset](https://huggingface.co/datasets/argilla/distilabel-intel-orca-dpo-pairs) used to fine-tune the [improved OpenHermes model](https://huggingface.co/argilla/distilabeled-OpenHermes-2.5-Mistral-7B). This dataset was built by combining human curation in Argilla with AI feedback from distilabel, leading to an improved version of the Intel Orca dataset and outperforming models fine-tuned on the original dataset. - The [haiku DPO data](https://github.com/davanstrien/haiku-dpo) is an example how anyone can create a synthetic dataset for a specific task, which after curation and evaluation can be used for fine-tuning custom LLMs. ## Prerequisites First [login with your Hugging Face account](/docs/huggingface_hub/quick-start#login): ```bash huggingface-cli login ``` Make sure you have `distilabel` installed: ```bash pip install -U distilabel[vllm] ``` ## Distilabel pipelines Distilabel pipelines can be built with any number of interconnected steps or tasks. The output of one step or task is fed as input to another. A series of steps can be chained together to build complex data processing and generation pipelines with LLMs. The input of each step is a batch of data, containing a list of dictionaries, where each dictionary represents a row of the dataset, and the keys are the column names. To feed data from and to the Hugging Face hub, we've defined a `Distiset` class as an abstraction of a `datasets.DatasetDict`. ## Distiset as dataset object A Pipeline in distilabel returns a special type of Hugging Face `datasets.DatasetDict` which is called `Distiset`. The Pipeline can output multiple subsets in the Distiset, which is a dictionary-like object with one entry per subset. A Distiset can then be pushed seamlessly to the Hugging face Hub, with all the subsets in the same repository. ## Load data from the Hub to a Distiset To showcase an example of loading data from the Hub, we will reproduce the [Prometheus 2 paper](https://arxiv.org/pdf/2405.01535) and use the PrometheusEval task implemented in distilabel. The Prometheus 2 and Prometheuseval task direct assessment and pairwise ranking tasks i.e. assessing the quality of a single isolated response for a given instruction with or without a reference answer, and assessing the quality of one response against another one for a given instruction with or without a reference answer, respectively. We will use these task on a dataset loaded from the Hub, which was created by the Hugging Face H4 team named [HuggingFaceH4/instruction-dataset](https://huggingface.co/datasets/HuggingFaceH4/instruction-dataset). ```python from distilabel.llms import vLLM from distilabel.pipeline import Pipeline from distilabel.steps import KeepColumns, LoadDataFromHub from distilabel.steps.tasks import PrometheusEval if __name__ == "__main__": with Pipeline(name="prometheus") as pipeline: load_dataset = LoadDataFromHub( name="load_dataset", repo_id="HuggingFaceH4/instruction-dataset", split="test", output_mappings={"prompt": "instruction", "completion": "generation"}, ) task = PrometheusEval( name="task", llm=vLLM( model="prometheus-eval/prometheus-7b-v2.0", chat_template="[INST] {{ messages[0]['content'] }}\n{{ messages[1]['content'] }}[/INST]", ), mode="absolute", rubric="factual-validity", reference=False, num_generations=1, group_generations=False, ) keep_columns = KeepColumns( name="keep_columns", columns=["instruction", "generation", "feedback", "result", "model_name"], ) load_dataset >> task >> keep_columns ``` Then we need to call `pipeline.run` with the runtime parameters so that the pipeline can be launched and data can be stores in the `Distiset` object. ```python distiset = pipeline.run( parameters={ task.name: { "llm": { "generation_kwargs": { "max_new_tokens": 1024, "temperature": 0.7, }, }, }, }, ) ``` ## Push a distilabel Distiset to the Hub Push the `Distiset` to a Hugging Face repository, where each one of the subsets will correspond to a different configuration: ```python distiset.push_to_hub( "my-org/my-dataset", commit_message="Initial commit", private=False, token=os.getenv("HF_TOKEN"), ) ``` ## 📚 Resources - [🚀 Distilabel Docs](https://distilabel.argilla.io/latest/) - [🚀 Distilabel Docs - distiset](https://distilabel.argilla.io/latest/sections/how_to_guides/advanced/distiset/) - [🚀 Distilabel Docs - prometheus](https://distilabel.argilla.io/1.2.0/sections/pipeline_samples/papers/prometheus/) - [🆕 Introducing distilabel](https://argilla.io/blog/introducing-distilabel-1/) # Sign in with Hugging Face You can use the HF OAuth / OpenID connect flow to create a **"Sign in with HF"** flow in any website or App. This will allow users to sign in to your website or app using their HF account, by clicking a button similar to this one:  After clicking this button your users will be presented with a permissions modal to authorize your app: 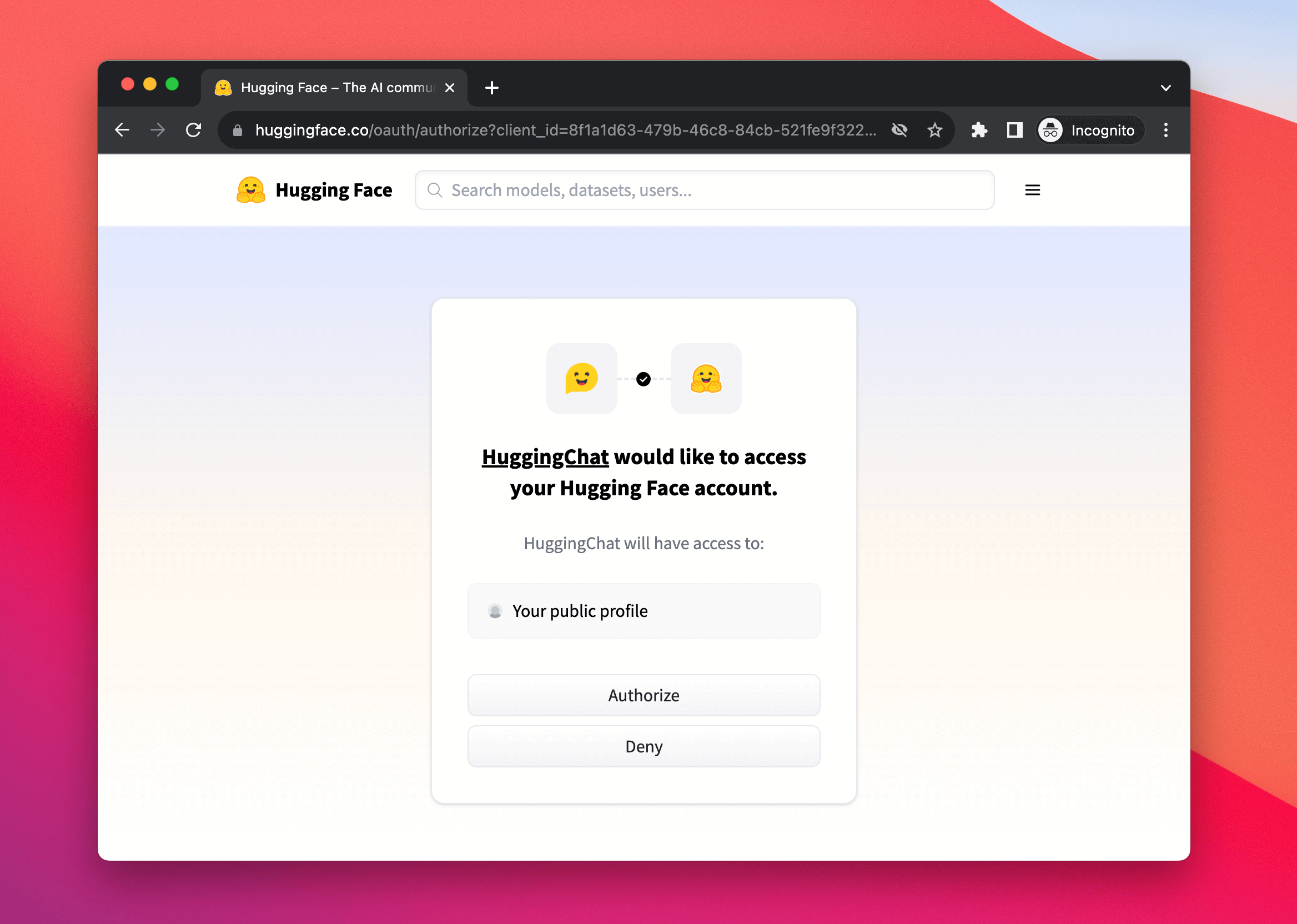 ## Creating an oauth app You can create your application in your [settings](https://huggingface.co/settings/applications/new): 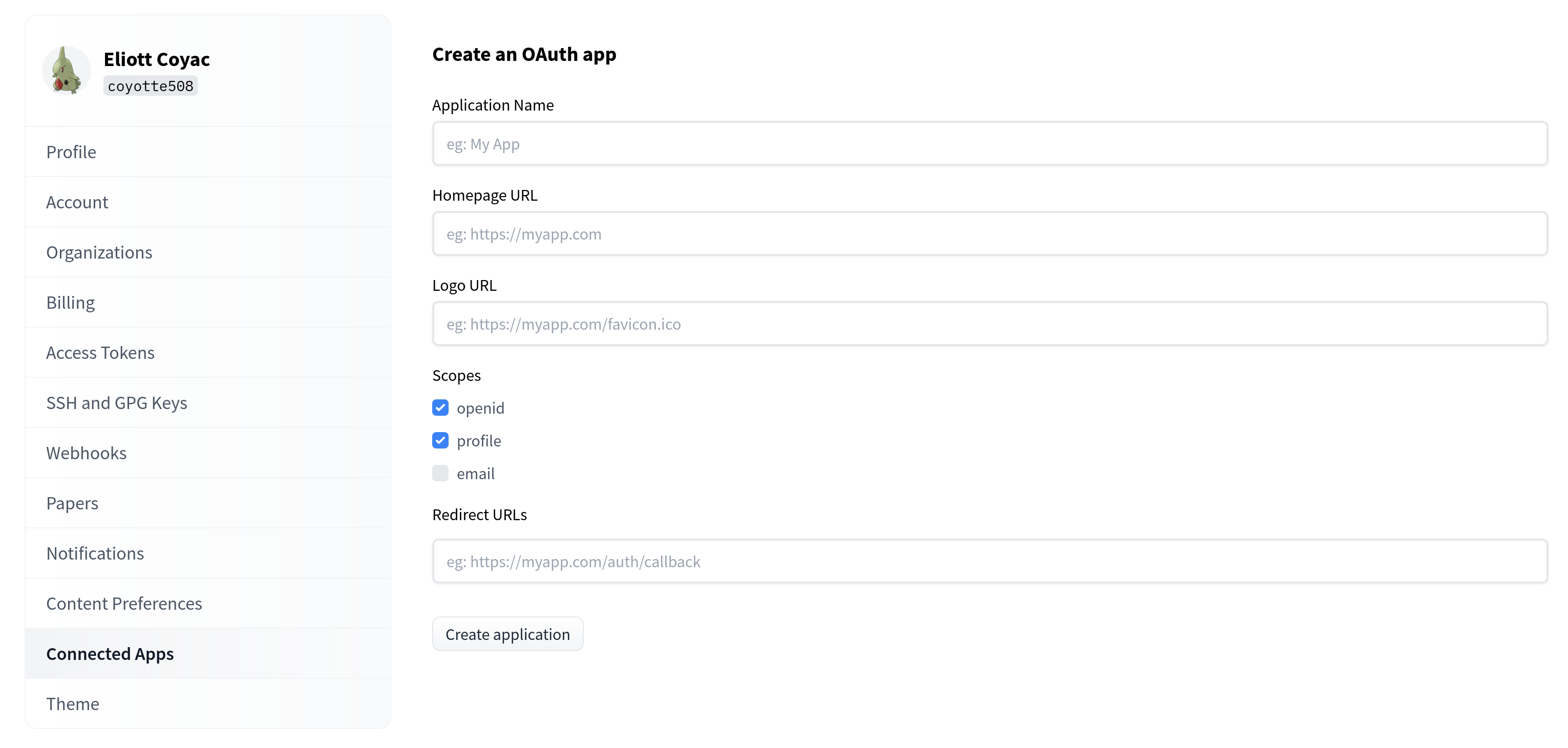 ### If you are hosting in Spaces




