
Commit
•
1bf62f5
1
Parent(s):
7ce2554
Update README.md
Browse files
README.md
CHANGED
|
@@ -36,11 +36,11 @@ This is one of the models produced by the paper ["LEVER: Learning to Verify Lang
|
|
| 36 |
**Authors:** [Ansong Ni](https://niansong1996.github.io), Srini Iyer, Dragomir Radev, Ves Stoyanov, Wen-tau Yih, Sida I. Wang*, Xi Victoria Lin*
|
| 37 |
|
| 38 |
**Note**: This specific model is for Codex on the [GSM8K](https://github.com/openai/grade-school-math) dataset, for the models pretrained on other datasets, please see:
|
| 39 |
-
* [lever-spider-codex](https://huggingface.co/
|
| 40 |
-
* [lever-wikitq-codex](https://huggingface.co/
|
| 41 |
-
* [lever-mbpp-codex](https://huggingface.co/
|
| 42 |
|
| 43 |
-
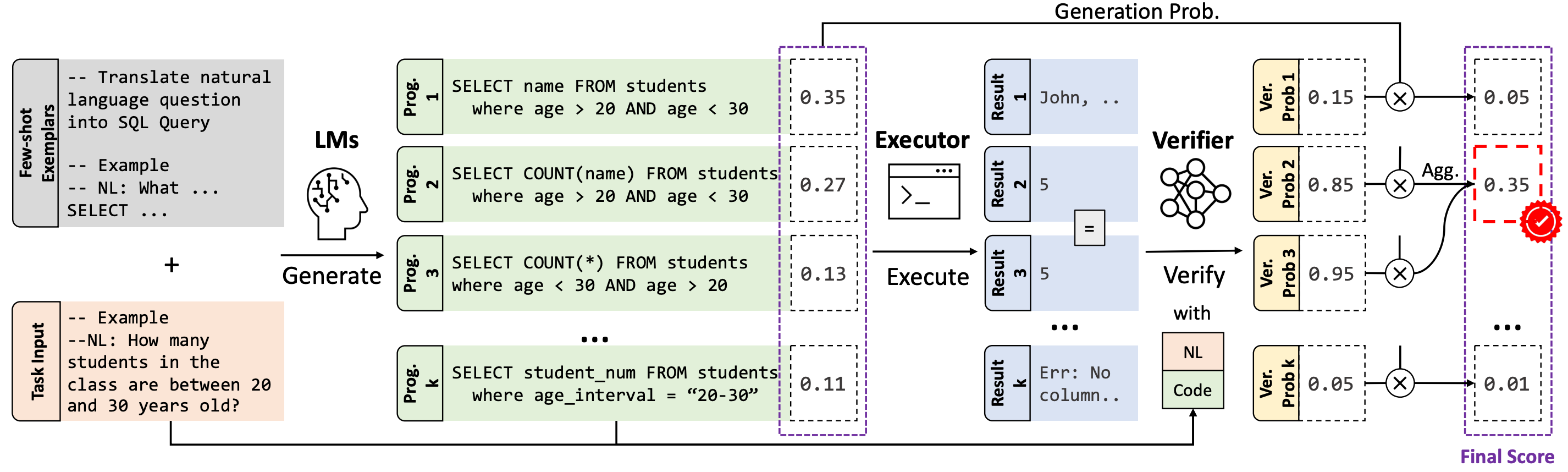
 has led to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
|
| 50 |
|
| 51 |
|
| 52 |
-
- **Developed by:** Yale
|
| 53 |
-
- **Shared by
|
| 54 |
|
| 55 |
- **Model type:** Text Classification
|
| 56 |
- **Language(s) (NLP):** More information needed
|
|
|
|
| 36 |
**Authors:** [Ansong Ni](https://niansong1996.github.io), Srini Iyer, Dragomir Radev, Ves Stoyanov, Wen-tau Yih, Sida I. Wang*, Xi Victoria Lin*
|
| 37 |
|
| 38 |
**Note**: This specific model is for Codex on the [GSM8K](https://github.com/openai/grade-school-math) dataset, for the models pretrained on other datasets, please see:
|
| 39 |
+
* [lever-spider-codex](https://huggingface.co/niansong1996/lever-spider-codex)
|
| 40 |
+
* [lever-wikitq-codex](https://huggingface.co/niansong1996/lever-wikitq-codex)
|
| 41 |
+
* [lever-mbpp-codex](https://huggingface.co/niansong1996/lever-mbpp-codex)
|
| 42 |
|
| 43 |
+
|
| 44 |
|
| 45 |
# Model Details
|
| 46 |
|
|
|
|
| 49 |
The advent of pre-trained code language models (Code LLMs) has led to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
|
| 50 |
|
| 51 |
|
| 52 |
+
- **Developed by:** Yale University and Meta AI
|
| 53 |
+
- **Shared by:** Ansong Ni
|
| 54 |
|
| 55 |
- **Model type:** Text Classification
|
| 56 |
- **Language(s) (NLP):** More information needed
|