
End of training
Browse files- all_results.json +15 -15
- egy_training_log.txt +2 -0
- eval_results.json +10 -10
- train_results.json +6 -6
- train_vs_val_loss.png +0 -0
- trainer_state.json +71 -14
all_results.json
CHANGED
|
@@ -1,19 +1,19 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"eval_bleu": 0.
|
| 4 |
-
"eval_loss":
|
| 5 |
-
"eval_rouge1": 0.
|
| 6 |
-
"eval_rouge2": 0.
|
| 7 |
-
"eval_rougeL": 0.
|
| 8 |
-
"eval_runtime": 27.
|
| 9 |
"eval_samples": 847,
|
| 10 |
-
"eval_samples_per_second": 31.
|
| 11 |
-
"eval_steps_per_second": 3.
|
| 12 |
-
"perplexity":
|
| 13 |
-
"total_flos":
|
| 14 |
-
"train_loss":
|
| 15 |
-
"train_runtime":
|
| 16 |
"train_samples": 2552,
|
| 17 |
-
"train_samples_per_second":
|
| 18 |
-
"train_steps_per_second":
|
| 19 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 5.0,
|
| 3 |
+
"eval_bleu": 0.16068905926811505,
|
| 4 |
+
"eval_loss": 2.6229476928710938,
|
| 5 |
+
"eval_rouge1": 0.4264320027787866,
|
| 6 |
+
"eval_rouge2": 0.1630682859845051,
|
| 7 |
+
"eval_rougeL": 0.367472815476786,
|
| 8 |
+
"eval_runtime": 27.1354,
|
| 9 |
"eval_samples": 847,
|
| 10 |
+
"eval_samples_per_second": 31.214,
|
| 11 |
+
"eval_steps_per_second": 3.906,
|
| 12 |
+
"perplexity": 13.77627201236392,
|
| 13 |
+
"total_flos": 5001129492480000.0,
|
| 14 |
+
"train_loss": 2.2704222102150275,
|
| 15 |
+
"train_runtime": 565.3472,
|
| 16 |
"train_samples": 2552,
|
| 17 |
+
"train_samples_per_second": 22.57,
|
| 18 |
+
"train_steps_per_second": 2.821
|
| 19 |
}
|
egy_training_log.txt
CHANGED
|
@@ -440,3 +440,5 @@ INFO:absl:Using default tokenizer.
|
|
| 440 |
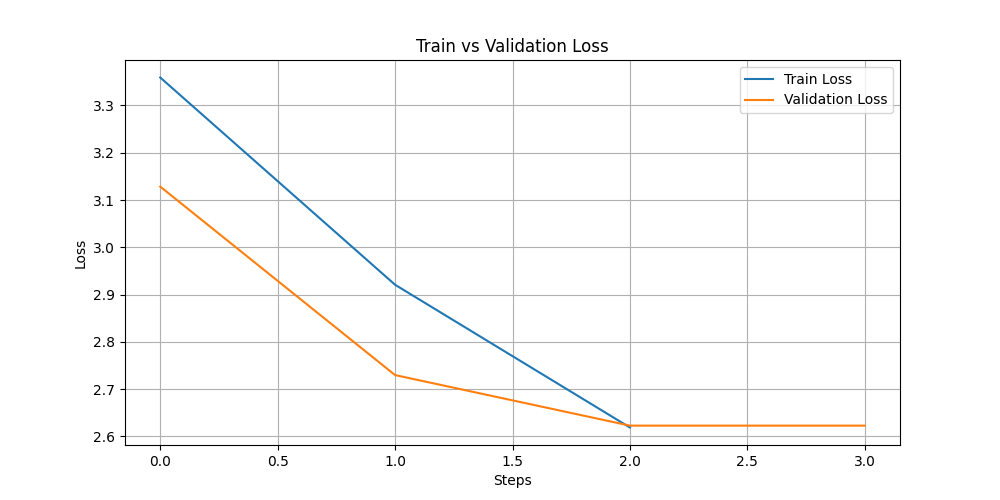
INFO:root:Epoch 4.0: Train Loss = 2.9208, Eval Loss = 2.729825496673584
|
| 441 |
INFO:absl:Using default tokenizer.
|
| 442 |
INFO:root:Epoch 5.0: Train Loss = 2.619, Eval Loss = 2.6229476928710938
|
|
|
|
|
|
|
|
|
| 440 |
INFO:root:Epoch 4.0: Train Loss = 2.9208, Eval Loss = 2.729825496673584
|
| 441 |
INFO:absl:Using default tokenizer.
|
| 442 |
INFO:root:Epoch 5.0: Train Loss = 2.619, Eval Loss = 2.6229476928710938
|
| 443 |
+
INFO:__main__:*** Evaluate ***
|
| 444 |
+
INFO:absl:Using default tokenizer.
|
eval_results.json
CHANGED
|
@@ -1,13 +1,13 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"eval_bleu": 0.
|
| 4 |
-
"eval_loss":
|
| 5 |
-
"eval_rouge1": 0.
|
| 6 |
-
"eval_rouge2": 0.
|
| 7 |
-
"eval_rougeL": 0.
|
| 8 |
-
"eval_runtime": 27.
|
| 9 |
"eval_samples": 847,
|
| 10 |
-
"eval_samples_per_second": 31.
|
| 11 |
-
"eval_steps_per_second": 3.
|
| 12 |
-
"perplexity":
|
| 13 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 5.0,
|
| 3 |
+
"eval_bleu": 0.16068905926811505,
|
| 4 |
+
"eval_loss": 2.6229476928710938,
|
| 5 |
+
"eval_rouge1": 0.4264320027787866,
|
| 6 |
+
"eval_rouge2": 0.1630682859845051,
|
| 7 |
+
"eval_rougeL": 0.367472815476786,
|
| 8 |
+
"eval_runtime": 27.1354,
|
| 9 |
"eval_samples": 847,
|
| 10 |
+
"eval_samples_per_second": 31.214,
|
| 11 |
+
"eval_steps_per_second": 3.906,
|
| 12 |
+
"perplexity": 13.77627201236392
|
| 13 |
}
|
train_results.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss":
|
| 5 |
-
"train_runtime":
|
| 6 |
"train_samples": 2552,
|
| 7 |
-
"train_samples_per_second":
|
| 8 |
-
"train_steps_per_second":
|
| 9 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 5.0,
|
| 3 |
+
"total_flos": 5001129492480000.0,
|
| 4 |
+
"train_loss": 2.2704222102150275,
|
| 5 |
+
"train_runtime": 565.3472,
|
| 6 |
"train_samples": 2552,
|
| 7 |
+
"train_samples_per_second": 22.57,
|
| 8 |
+
"train_steps_per_second": 2.821
|
| 9 |
}
|
train_vs_val_loss.png
ADDED
|
trainer_state.json
CHANGED
|
@@ -1,27 +1,84 @@
|
|
| 1 |
{
|
| 2 |
-
"best_metric":
|
| 3 |
-
"best_model_checkpoint":
|
| 4 |
-
"epoch":
|
| 5 |
"eval_steps": 500,
|
| 6 |
-
"global_step":
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
-
"epoch": 1.
|
| 13 |
-
"
|
| 14 |
-
"
|
| 15 |
-
"
|
| 16 |
-
"
|
| 17 |
-
|
| 18 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
}
|
| 20 |
],
|
| 21 |
"logging_steps": 500,
|
| 22 |
-
"max_steps":
|
| 23 |
"num_input_tokens_seen": 0,
|
| 24 |
-
"num_train_epochs":
|
| 25 |
"save_steps": 500,
|
| 26 |
"stateful_callbacks": {
|
| 27 |
"EarlyStoppingCallback": {
|
|
@@ -44,7 +101,7 @@
|
|
| 44 |
"attributes": {}
|
| 45 |
}
|
| 46 |
},
|
| 47 |
-
"total_flos":
|
| 48 |
"train_batch_size": 8,
|
| 49 |
"trial_name": null,
|
| 50 |
"trial_params": null
|
|
|
|
| 1 |
{
|
| 2 |
+
"best_metric": 2.6229476928710938,
|
| 3 |
+
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/results/checkpoint-1500",
|
| 4 |
+
"epoch": 5.0,
|
| 5 |
"eval_steps": 500,
|
| 6 |
+
"global_step": 1595,
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
+
"epoch": 1.567398119122257,
|
| 13 |
+
"grad_norm": 1.353641152381897,
|
| 14 |
+
"learning_rate": 5e-05,
|
| 15 |
+
"loss": 3.359,
|
| 16 |
+
"step": 500
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 1.567398119122257,
|
| 20 |
+
"eval_bleu": 0.11424038411303619,
|
| 21 |
+
"eval_loss": 3.128293514251709,
|
| 22 |
+
"eval_rouge1": 0.3297614987151056,
|
| 23 |
+
"eval_rouge2": 0.08429294540985294,
|
| 24 |
+
"eval_rougeL": 0.2561476738686219,
|
| 25 |
+
"eval_runtime": 26.8133,
|
| 26 |
+
"eval_samples_per_second": 31.589,
|
| 27 |
+
"eval_steps_per_second": 3.953,
|
| 28 |
+
"step": 500
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"epoch": 3.134796238244514,
|
| 32 |
+
"grad_norm": 1.156111717224121,
|
| 33 |
+
"learning_rate": 2.71689497716895e-05,
|
| 34 |
+
"loss": 2.9208,
|
| 35 |
+
"step": 1000
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"epoch": 3.134796238244514,
|
| 39 |
+
"eval_bleu": 0.1490666503828191,
|
| 40 |
+
"eval_loss": 2.729825496673584,
|
| 41 |
+
"eval_rouge1": 0.40409071928626966,
|
| 42 |
+
"eval_rouge2": 0.14297878002377568,
|
| 43 |
+
"eval_rougeL": 0.34083403761346187,
|
| 44 |
+
"eval_runtime": 27.234,
|
| 45 |
+
"eval_samples_per_second": 31.101,
|
| 46 |
+
"eval_steps_per_second": 3.892,
|
| 47 |
+
"step": 1000
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"epoch": 4.702194357366771,
|
| 51 |
+
"grad_norm": 1.1165863275527954,
|
| 52 |
+
"learning_rate": 4.337899543378996e-06,
|
| 53 |
+
"loss": 2.619,
|
| 54 |
+
"step": 1500
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"epoch": 4.702194357366771,
|
| 58 |
+
"eval_bleu": 0.16068905926811505,
|
| 59 |
+
"eval_loss": 2.6229476928710938,
|
| 60 |
+
"eval_rouge1": 0.4264320027787866,
|
| 61 |
+
"eval_rouge2": 0.1630682859845051,
|
| 62 |
+
"eval_rougeL": 0.367472815476786,
|
| 63 |
+
"eval_runtime": 27.3027,
|
| 64 |
+
"eval_samples_per_second": 31.023,
|
| 65 |
+
"eval_steps_per_second": 3.882,
|
| 66 |
+
"step": 1500
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"epoch": 5.0,
|
| 70 |
+
"step": 1595,
|
| 71 |
+
"total_flos": 5001129492480000.0,
|
| 72 |
+
"train_loss": 2.2704222102150275,
|
| 73 |
+
"train_runtime": 565.3472,
|
| 74 |
+
"train_samples_per_second": 22.57,
|
| 75 |
+
"train_steps_per_second": 2.821
|
| 76 |
}
|
| 77 |
],
|
| 78 |
"logging_steps": 500,
|
| 79 |
+
"max_steps": 1595,
|
| 80 |
"num_input_tokens_seen": 0,
|
| 81 |
+
"num_train_epochs": 5,
|
| 82 |
"save_steps": 500,
|
| 83 |
"stateful_callbacks": {
|
| 84 |
"EarlyStoppingCallback": {
|
|
|
|
| 101 |
"attributes": {}
|
| 102 |
}
|
| 103 |
},
|
| 104 |
+
"total_flos": 5001129492480000.0,
|
| 105 |
"train_batch_size": 8,
|
| 106 |
"trial_name": null,
|
| 107 |
"trial_params": null
|