
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,34 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
pipeline_tag: text-to-video
|
| 3 |
+
license: other
|
| 4 |
+
license_link: LICENSE
|
| 5 |
---
|
| 6 |
+
|
| 7 |
+
# TrackDiffusion Model Card
|
| 8 |
+
|
| 9 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 10 |
+
TrackDiffusion is a diffusion model that takes in tracklets as conditions, and generates a video from it.
|
| 11 |
+
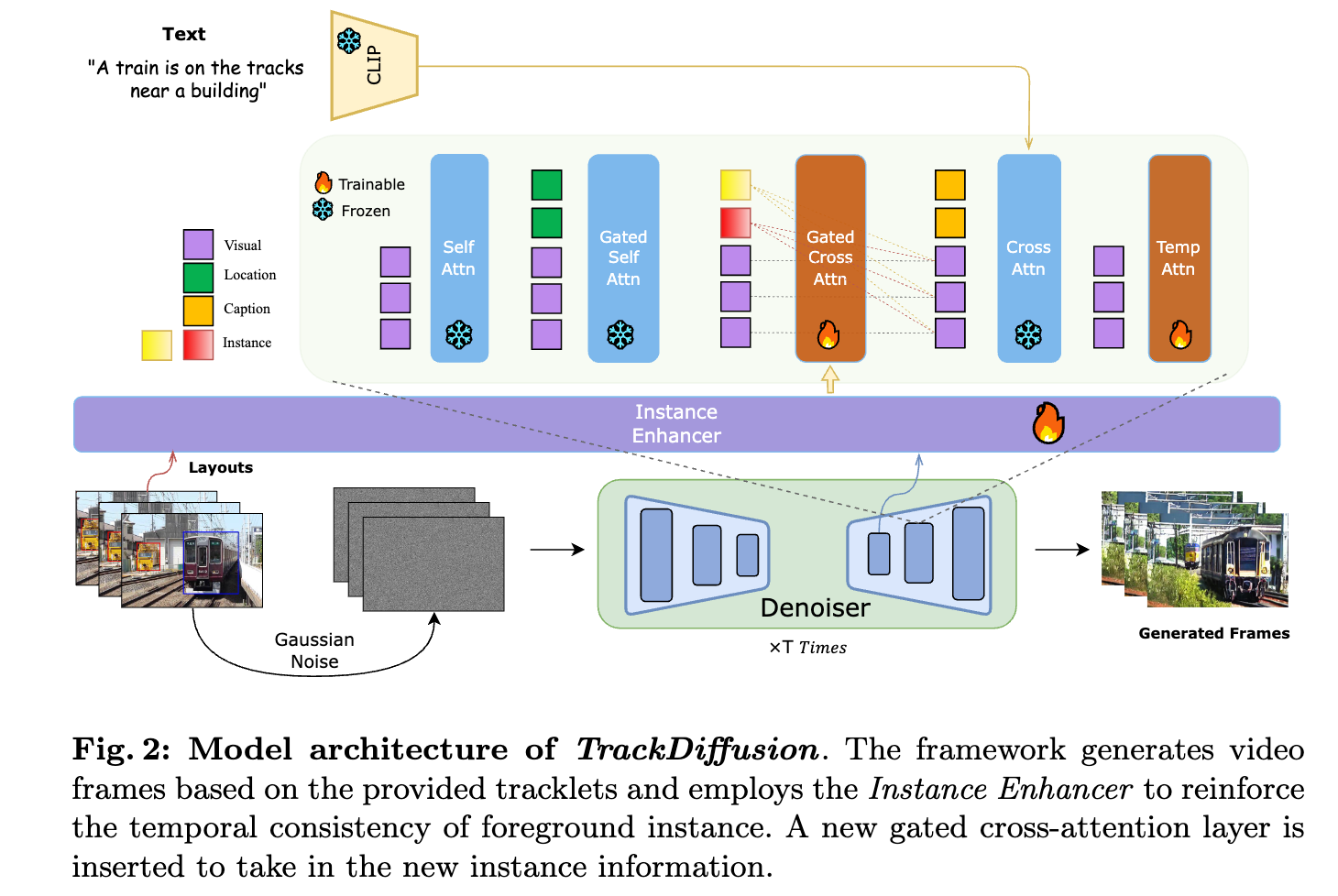
|
| 12 |
+
|
| 13 |
+
## Model Details
|
| 14 |
+
|
| 15 |
+
### Model Description
|
| 16 |
+
|
| 17 |
+
TrackDiffusion is a novel video generation framework that enables fine-grained control over complex dynamics in video synthesis by conditioning the generation process on object trajectories.
|
| 18 |
+
This approach allows for precise manipulation of object trajectories and interactions, addressing the challenges of managing appearance, disappearance, scale changes, and ensuring consistency across frames.
|
| 19 |
+
## Uses
|
| 20 |
+
|
| 21 |
+
### Direct Use
|
| 22 |
+
|
| 23 |
+
We provide the weights for the entire unet, so you can replace it in diffusers pipeline, for example:
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
pretrained_model_path = "stabilityai/stable-video-diffusion-img2vid"
|
| 27 |
+
unet = UNetSpatioTemporalConditionModel.from_pretrained("/path/to/unet", torch_dtype=torch.float16,)
|
| 28 |
+
pipe = StableVideoDiffusionPipeline.from_pretrained(
|
| 29 |
+
pretrained_model_path,
|
| 30 |
+
unet=unet,
|
| 31 |
+
torch_dtype=torch.float16,
|
| 32 |
+
variant="fp16",
|
| 33 |
+
low_cpu_mem_usage=True)
|
| 34 |
+
```
|