🔗 Try Aria! · 📖 Blog · 📌 Paper · ⭐ GitHub · 🟣 Discord
This checkpoint is one of base models of [Aria](https://huggingface.co/rhymes-ai/Aria), designed for research purposes as well as continue training. Specifically, Aria-Base-8K corresponds to the model checkpoint after the multimodal pre-training stage (boxed in gray).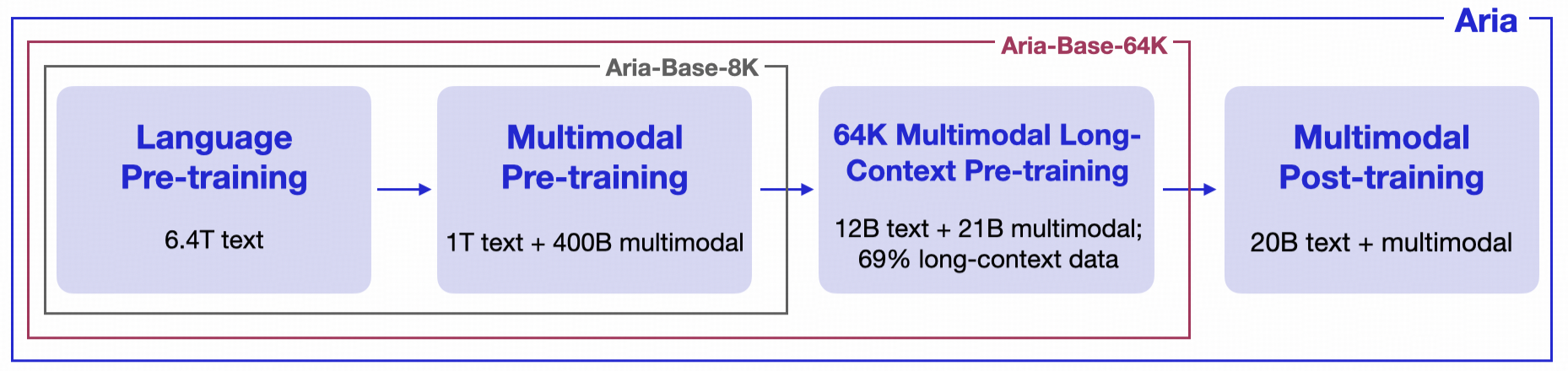 ## Aria-Base-8K
- **Base Model After Pre-training**: This model corresponds to the model checkpoint after the multimodal pre-training stage, with 1.4T tokens (1T language + 400B multimodal) trained in this stage. This stage lasts 43,000 iterations, with all sequences packed to 8192 with Megatron-LM, with global batch size 4096. During this training stage, the learning rate decays from `8.75e-5` to `3.5e-5`.
- **Appropriate for Continue Pre-training**: This model is recommended for continue pre-training, *e.g.* on domain-specific pre-training data (OCR, agent, multi-lingual), while the targeted scenario does not involve long-context inputs. Please consider fine-tuning [Aria-Base-64K](https://huggingface.co/rhymes-ai/Aria-Base-64K) for long-context scenarios.
- **Strong Base Performance on Language and Multimodal Scenarios**: This model shows excellent base performance on knowledge-related evaluations on both pure language and multimodal scenarios (MMLU 70+, MMMU 50+, *etc*).
- ***Limited Ability on Long-context Scenarios***: This model is only trained with 8K context length, and is not expected to show best performance with context length especially longer than 8K (e.g. a video with >100 frames). [Aria-Base-64K](https://huggingface.co/rhymes-ai/Aria-Base-64K) is more appropriate for longer sequence understanding.
- ***Limited Chat Template Availability***: This model is trained with a very low percentage of data (around 3%) re-formatted with the chat template. Hence, it might not be optimal to be directly used for chatting.
## Quick Start
### Installation
```
pip install transformers==4.45.0 accelerate==0.34.1 sentencepiece==0.2.0 torchvision requests torch Pillow
pip install flash-attn --no-build-isolation
# For better inference performance, you can install grouped-gemm, which may take 3-5 minutes to install
pip install grouped_gemm==0.1.6
```
### Inference
You can use the same method as the final [Aria](https://huggingface.co/rhymes-ai/Aria) model to load this checkpoint. However, as the base model, it might not be able to yield optimal chat performance.
```python
import requests
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_id_or_path = "rhymes-ai/Aria-Base-8K"
model = AutoModelForCausalLM.from_pretrained(model_id_or_path, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_id_or_path, trust_remote_code=True)
image_path = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png"
image = Image.open(requests.get(image_path, stream=True).raw)
messages = [
{
"role": "user",
"content": [
{"text": None, "type": "image"},
{"text": "what is the image?", "type": "text"},
],
}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=text, images=image, return_tensors="pt")
inputs["pixel_values"] = inputs["pixel_values"].to(model.dtype)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.inference_mode(), torch.cuda.amp.autocast(dtype=torch.bfloat16):
output = model.generate(
**inputs,
max_new_tokens=500,
stop_strings=["<|im_end|>"],
tokenizer=processor.tokenizer,
do_sample=True,
temperature=0.9,
)
output_ids = output[0][inputs["input_ids"].shape[1]:]
result = processor.decode(output_ids, skip_special_tokens=True)
print(result)
```
### Advanced Inference and Fine-tuning
We provide a [codebase](https://github.com/rhymes-ai/Aria) for more advanced usage of Aria,
including vllm inference, cookbooks, and fine-tuning on custom datasets.
As it shares the same structure with the final model,
you may just replace the `rhymes-ai/Aria` to this model path for any advanced inference and fine-tuning.
## Citation
If you find our work helpful, please consider citing.
```
@article{aria,
title={Aria: An Open Multimodal Native Mixture-of-Experts Model},
author={Dongxu Li and Yudong Liu and Haoning Wu and Yue Wang and Zhiqi Shen and Bowen Qu and Xinyao Niu and Guoyin Wang and Bei Chen and Junnan Li},
year={2024},
journal={arXiv preprint arXiv:2410.05993},
}
```
## Aria-Base-8K
- **Base Model After Pre-training**: This model corresponds to the model checkpoint after the multimodal pre-training stage, with 1.4T tokens (1T language + 400B multimodal) trained in this stage. This stage lasts 43,000 iterations, with all sequences packed to 8192 with Megatron-LM, with global batch size 4096. During this training stage, the learning rate decays from `8.75e-5` to `3.5e-5`.
- **Appropriate for Continue Pre-training**: This model is recommended for continue pre-training, *e.g.* on domain-specific pre-training data (OCR, agent, multi-lingual), while the targeted scenario does not involve long-context inputs. Please consider fine-tuning [Aria-Base-64K](https://huggingface.co/rhymes-ai/Aria-Base-64K) for long-context scenarios.
- **Strong Base Performance on Language and Multimodal Scenarios**: This model shows excellent base performance on knowledge-related evaluations on both pure language and multimodal scenarios (MMLU 70+, MMMU 50+, *etc*).
- ***Limited Ability on Long-context Scenarios***: This model is only trained with 8K context length, and is not expected to show best performance with context length especially longer than 8K (e.g. a video with >100 frames). [Aria-Base-64K](https://huggingface.co/rhymes-ai/Aria-Base-64K) is more appropriate for longer sequence understanding.
- ***Limited Chat Template Availability***: This model is trained with a very low percentage of data (around 3%) re-formatted with the chat template. Hence, it might not be optimal to be directly used for chatting.
## Quick Start
### Installation
```
pip install transformers==4.45.0 accelerate==0.34.1 sentencepiece==0.2.0 torchvision requests torch Pillow
pip install flash-attn --no-build-isolation
# For better inference performance, you can install grouped-gemm, which may take 3-5 minutes to install
pip install grouped_gemm==0.1.6
```
### Inference
You can use the same method as the final [Aria](https://huggingface.co/rhymes-ai/Aria) model to load this checkpoint. However, as the base model, it might not be able to yield optimal chat performance.
```python
import requests
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_id_or_path = "rhymes-ai/Aria-Base-8K"
model = AutoModelForCausalLM.from_pretrained(model_id_or_path, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_id_or_path, trust_remote_code=True)
image_path = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png"
image = Image.open(requests.get(image_path, stream=True).raw)
messages = [
{
"role": "user",
"content": [
{"text": None, "type": "image"},
{"text": "what is the image?", "type": "text"},
],
}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=text, images=image, return_tensors="pt")
inputs["pixel_values"] = inputs["pixel_values"].to(model.dtype)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.inference_mode(), torch.cuda.amp.autocast(dtype=torch.bfloat16):
output = model.generate(
**inputs,
max_new_tokens=500,
stop_strings=["<|im_end|>"],
tokenizer=processor.tokenizer,
do_sample=True,
temperature=0.9,
)
output_ids = output[0][inputs["input_ids"].shape[1]:]
result = processor.decode(output_ids, skip_special_tokens=True)
print(result)
```
### Advanced Inference and Fine-tuning
We provide a [codebase](https://github.com/rhymes-ai/Aria) for more advanced usage of Aria,
including vllm inference, cookbooks, and fine-tuning on custom datasets.
As it shares the same structure with the final model,
you may just replace the `rhymes-ai/Aria` to this model path for any advanced inference and fine-tuning.
## Citation
If you find our work helpful, please consider citing.
```
@article{aria,
title={Aria: An Open Multimodal Native Mixture-of-Experts Model},
author={Dongxu Li and Yudong Liu and Haoning Wu and Yue Wang and Zhiqi Shen and Bowen Qu and Xinyao Niu and Guoyin Wang and Bei Chen and Junnan Li},
year={2024},
journal={arXiv preprint arXiv:2410.05993},
}
```