Spaces:
Sleeping

Sleeping
Commit
•
841b1aa
1
Parent(s):
fb0ec99
Upload 3 files
Browse files- app.py +10 -6
- best_rf.joblib +1 -1
- mmr-corr.png +0 -0
app.py
CHANGED
|
@@ -4,6 +4,7 @@ import numpy as np
|
|
| 4 |
import pandas as pd
|
| 5 |
import plotly.express as px
|
| 6 |
|
|
|
|
| 7 |
# Load the models
|
| 8 |
scaler = joblib.load('scaler.joblib')
|
| 9 |
model = joblib.load('best_rf.joblib')
|
|
@@ -44,7 +45,11 @@ def scale_output(prediction_matrix):
|
|
| 44 |
|
| 45 |
# Streamlit App
|
| 46 |
def main():
|
| 47 |
-
st.title("
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
|
| 49 |
col1, col2, col3 = st.columns(3)
|
| 50 |
|
|
@@ -91,12 +96,11 @@ def main():
|
|
| 91 |
handout_pred_df.columns = [str(i) for i in range(1,10)]
|
| 92 |
handout_pred_df['prod'] = 'prediction'
|
| 93 |
handout_pred_df = handout_pred_df.melt('prod')
|
| 94 |
-
|
|
|
|
|
|
|
|
|
|
| 95 |
|
| 96 |
-
# st.write(f"select data: {data_input }")
|
| 97 |
-
# st.write(f"scaled select data: {scaled_data_input }")
|
| 98 |
-
st.write(f"prediction: {handout_prediction }")
|
| 99 |
-
st.write(f"sum of probability: {handout_prediction.sum()}")
|
| 100 |
|
| 101 |
fig = px.histogram(data_frame=handout_pred_df, x= 'variable',y='value', nbins= 9,
|
| 102 |
text_auto=True, title="Probability prediction of liking score from sensory attributes",
|
|
|
|
| 4 |
import pandas as pd
|
| 5 |
import plotly.express as px
|
| 6 |
|
| 7 |
+
|
| 8 |
# Load the models
|
| 9 |
scaler = joblib.load('scaler.joblib')
|
| 10 |
model = joblib.load('best_rf.joblib')
|
|
|
|
| 45 |
|
| 46 |
# Streamlit App
|
| 47 |
def main():
|
| 48 |
+
st.title("Consumer liking score distribution prediction")
|
| 49 |
+
st.markdown("Please adjust the values of 21 sensory attributes (assumed to have the range from 1 - 10), and see the liking score distribution below")
|
| 50 |
+
|
| 51 |
+
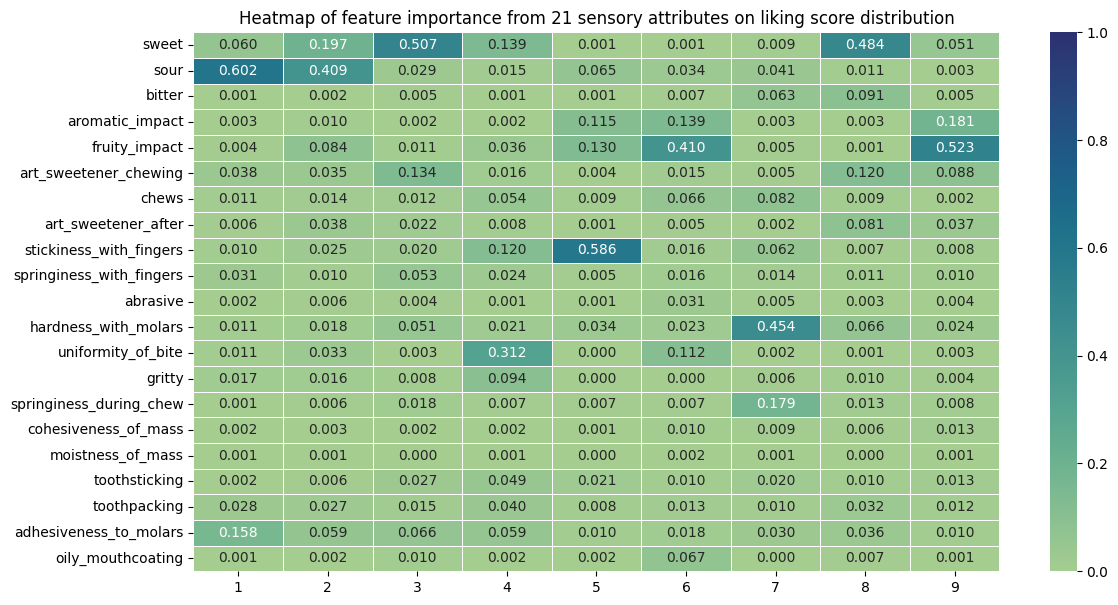
with st.expander("Feature importance heatmap of sensory attributes on liking score"):
|
| 52 |
+
st.image("/Users/carlosito/Documents/vsCode/exercise-MMR/mmr-corr.png")
|
| 53 |
|
| 54 |
col1, col2, col3 = st.columns(3)
|
| 55 |
|
|
|
|
| 96 |
handout_pred_df.columns = [str(i) for i in range(1,10)]
|
| 97 |
handout_pred_df['prod'] = 'prediction'
|
| 98 |
handout_pred_df = handout_pred_df.melt('prod')
|
| 99 |
+
|
| 100 |
+
# st.write(f"prediction: {handout_prediction }")
|
| 101 |
+
st.write(f"sum of probability: {np.round(handout_prediction.sum(), 2)}")
|
| 102 |
+
|
| 103 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 104 |
|
| 105 |
fig = px.histogram(data_frame=handout_pred_df, x= 'variable',y='value', nbins= 9,
|
| 106 |
text_auto=True, title="Probability prediction of liking score from sensory attributes",
|
best_rf.joblib
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1775335
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ac8b3eb99b91d7c52fe16cc49c678835f36ede0fece460be9d8e3a7eed228c08
|
| 3 |
size 1775335
|
mmr-corr.png
ADDED
|