

Updated CSS and app
Browse files
app.py
CHANGED
|
@@ -2,6 +2,7 @@ import gradio as gr
|
|
| 2 |
from haystack.document_stores import FAISSDocumentStore
|
| 3 |
from haystack.nodes import EmbeddingRetriever
|
| 4 |
import openai
|
|
|
|
| 5 |
import os
|
| 6 |
from utils import (
|
| 7 |
make_pairs,
|
|
@@ -13,15 +14,21 @@ import numpy as np
|
|
| 13 |
from datetime import datetime
|
| 14 |
from azure.storage.fileshare import ShareServiceClient
|
| 15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
|
| 17 |
theme = gr.themes.Soft(
|
| 18 |
primary_hue="sky",
|
| 19 |
-
font=[gr.themes.GoogleFont("
|
| 20 |
)
|
| 21 |
|
| 22 |
init_prompt = (
|
| 23 |
"You are ClimateQA, an AI Assistant by Ekimetrics. "
|
| 24 |
-
"You are given a question and extracted parts of IPCC reports.
|
| 25 |
"Provide a clear and structured answer based on the context provided. "
|
| 26 |
"When relevant, use bullet points and lists to structure your answers."
|
| 27 |
)
|
|
@@ -35,7 +42,7 @@ sources_prompt = (
|
|
| 35 |
|
| 36 |
|
| 37 |
def get_reformulation_prompt(query: str) -> str:
|
| 38 |
-
return f"""Reformulate the following user message to be a short standalone question in English, in the context of an
|
| 39 |
---
|
| 40 |
query: La technologie nous sauvera-t-elle ?
|
| 41 |
standalone question: Can technology help humanity mitigate the effects of climate change?
|
|
@@ -45,6 +52,10 @@ query: what are our reserves in fossil fuel?
|
|
| 45 |
standalone question: What are the current reserves of fossil fuels and how long will they last?
|
| 46 |
language: English
|
| 47 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
query: {query}
|
| 49 |
standalone question:"""
|
| 50 |
|
|
@@ -59,24 +70,24 @@ openai.api_key = os.environ["api_key"]
|
|
| 59 |
openai.api_base = os.environ["ressource_endpoint"]
|
| 60 |
openai.api_version = "2022-12-01"
|
| 61 |
|
| 62 |
-
|
| 63 |
document_store=FAISSDocumentStore.load(
|
| 64 |
-
index_path="./
|
| 65 |
-
config_path="./
|
| 66 |
),
|
| 67 |
embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
|
| 68 |
model_format="sentence_transformers",
|
| 69 |
progress_bar=False,
|
| 70 |
)
|
| 71 |
|
| 72 |
-
retrieve_giec = EmbeddingRetriever(
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
)
|
| 80 |
|
| 81 |
credential = {
|
| 82 |
"account_key": os.environ["account_key"],
|
|
@@ -90,11 +101,76 @@ share_client = service.get_share_client(file_share_name)
|
|
| 90 |
user_id = create_user_id(10)
|
| 91 |
|
| 92 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 93 |
def chat(
|
| 94 |
user_id: str,
|
| 95 |
query: str,
|
| 96 |
history: list = [system_template],
|
| 97 |
-
report_type: str = "IPCC
|
| 98 |
threshold: float = 0.555,
|
| 99 |
) -> tuple:
|
| 100 |
"""retrieve relevant documents in the document store then query gpt-turbo
|
|
@@ -109,12 +185,14 @@ def chat(
|
|
| 109 |
tuple: chat gradio format, chat openai format, sources used.
|
| 110 |
"""
|
| 111 |
|
| 112 |
-
if report_type
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
|
|
|
|
|
|
| 118 |
|
| 119 |
reformulated_query = openai.Completion.create(
|
| 120 |
engine="climateGPT",
|
|
@@ -126,16 +204,29 @@ def chat(
|
|
| 126 |
reformulated_query = reformulated_query["choices"][0]["text"]
|
| 127 |
reformulated_query, language = reformulated_query.split("\n")
|
| 128 |
language = language.split(":")[1].strip()
|
| 129 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 130 |
messages = history + [{"role": "user", "content": query}]
|
| 131 |
|
| 132 |
-
if
|
| 133 |
docs_string = []
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
docs_string.append(f"📃
|
| 137 |
-
|
| 138 |
-
|
|
|
|
|
|
|
|
|
|
| 139 |
|
| 140 |
response = openai.Completion.create(
|
| 141 |
engine="climateGPT",
|
|
@@ -167,14 +258,14 @@ def chat(
|
|
| 167 |
complete_response += chunk_message
|
| 168 |
messages[-1]["content"] = complete_response
|
| 169 |
gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 170 |
-
yield gradio_format, messages,
|
| 171 |
|
| 172 |
else:
|
| 173 |
-
|
| 174 |
-
complete_response = "**⚠️ No relevant passages found in the climate science reports, you may want to ask a more specific question (specifying your question on climate issues).**"
|
| 175 |
messages.append({"role": "assistant", "content": complete_response})
|
| 176 |
gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 177 |
-
yield gradio_format, messages,
|
| 178 |
|
| 179 |
|
| 180 |
def save_feedback(feed: str, user_id):
|
|
@@ -205,35 +296,11 @@ with gr.Blocks(title="🌍 Climate Q&A", css="style.css", theme=theme) as demo:
|
|
| 205 |
# Gradio
|
| 206 |
gr.Markdown("<h1><center>Climate Q&A 🌍</center></h1>")
|
| 207 |
gr.Markdown("<h4><center>Ask climate-related questions to the IPCC reports</center></h4>")
|
| 208 |
-
with gr.Row():
|
| 209 |
-
with gr.Column(scale=1):
|
| 210 |
-
gr.Markdown(
|
| 211 |
-
"""
|
| 212 |
-
<p><b>Climate change and environmental disruptions have become some of the most pressing challenges facing our planet today</b>. As global temperatures rise and ecosystems suffer, it is essential for individuals to understand the gravity of the situation in order to make informed decisions and advocate for appropriate policy changes.</p>
|
| 213 |
-
<p>However, comprehending the vast and complex scientific information can be daunting, as the scientific consensus references, such as <b>the Intergovernmental Panel on Climate Change (IPCC) reports, span thousands of pages</b>. To bridge this gap and make climate science more accessible, we introduce <b>ClimateQ&A as a tool to distill expert-level knowledge into easily digestible insights about climate science.</b></p>
|
| 214 |
-
<div class="tip-box">
|
| 215 |
-
<div class="tip-box-title">
|
| 216 |
-
<span class="light-bulb" role="img" aria-label="Light Bulb">💡</span>
|
| 217 |
-
How does ClimateQ&A work?
|
| 218 |
-
</div>
|
| 219 |
-
ClimateQ&A harnesses modern OCR techniques to parse and preprocess IPCC reports. By leveraging state-of-the-art question-answering algorithms, <i>ClimateQ&A is able to sift through the extensive collection of climate scientific reports and identify relevant passages in response to user inquiries</i>. Furthermore, the integration of the ChatGPT API allows ClimateQ&A to present complex data in a user-friendly manner, summarizing key points and facilitating communication of climate science to a wider audience.
|
| 220 |
-
</div>
|
| 221 |
-
|
| 222 |
-
<div class="warning-box">
|
| 223 |
-
Version 0.2-beta - This tool is under active development
|
| 224 |
-
</div>
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
"""
|
| 228 |
-
)
|
| 229 |
|
| 230 |
-
with gr.Column(scale=1):
|
| 231 |
-
gr.Markdown("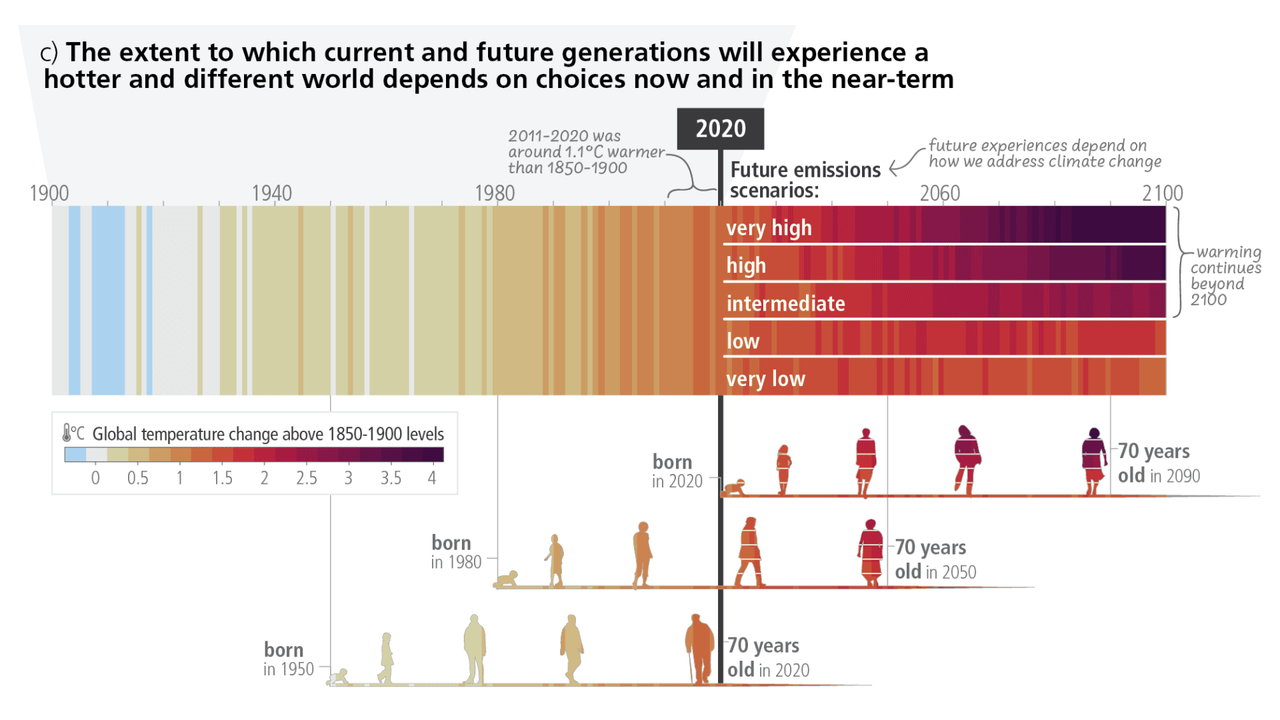")
|
| 232 |
-
gr.Markdown("*Source : IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6)*")
|
| 233 |
|
| 234 |
with gr.Row():
|
| 235 |
with gr.Column(scale=2):
|
| 236 |
-
chatbot = gr.Chatbot(elem_id="chatbot", label="ClimateQ&A chatbot")
|
| 237 |
state = gr.State([system_template])
|
| 238 |
|
| 239 |
with gr.Row():
|
|
@@ -245,15 +312,15 @@ Version 0.2-beta - This tool is under active development
|
|
| 245 |
|
| 246 |
examples_questions = gr.Examples(
|
| 247 |
[
|
| 248 |
-
"
|
|
|
|
| 249 |
"What are the impacts of climate change?",
|
| 250 |
"Can climate change be reversed?",
|
| 251 |
"What is the difference between climate change and global warming?",
|
| 252 |
-
"What can individuals do to address climate change?
|
| 253 |
-
"What
|
| 254 |
"What is the Paris Agreement and why is it important?",
|
| 255 |
"Which industries have the highest GHG emissions?",
|
| 256 |
-
"Is climate change caused by humans?",
|
| 257 |
"Is climate change a hoax created by the government or environmental organizations?",
|
| 258 |
"What is the relationship between climate change and biodiversity loss?",
|
| 259 |
"What is the link between gender equality and climate change?",
|
|
@@ -284,19 +351,21 @@ Version 0.2-beta - This tool is under active development
|
|
| 284 |
|
| 285 |
with gr.Column(scale=1, variant="panel"):
|
| 286 |
gr.Markdown("### Sources")
|
| 287 |
-
sources_textbox = gr.
|
| 288 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 289 |
ask.submit(
|
| 290 |
fn=chat,
|
| 291 |
inputs=[
|
| 292 |
user_id_state,
|
| 293 |
ask,
|
| 294 |
state,
|
| 295 |
-
|
| 296 |
-
|
| 297 |
-
default="IPCC only",
|
| 298 |
-
label="Select reports",
|
| 299 |
-
),
|
| 300 |
],
|
| 301 |
outputs=[chatbot, state, sources_textbox],
|
| 302 |
)
|
|
@@ -308,10 +377,38 @@ Version 0.2-beta - This tool is under active development
|
|
| 308 |
user_id_state,
|
| 309 |
ask_examples_hidden,
|
| 310 |
state,
|
|
|
|
| 311 |
],
|
| 312 |
outputs=[chatbot, state, sources_textbox],
|
| 313 |
)
|
| 314 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 315 |
gr.Markdown("## How to use ClimateQ&A")
|
| 316 |
with gr.Row():
|
| 317 |
with gr.Column(scale=1):
|
|
@@ -322,7 +419,7 @@ Version 0.2-beta - This tool is under active development
|
|
| 322 |
- ClimateQ&A retrieves specific passages from the IPCC reports to help answer your question accurately.
|
| 323 |
- Source information, including page numbers and passages, is displayed on the right side of the screen for easy verification.
|
| 324 |
- Feel free to ask follow-up questions within the chatbot for a more in-depth understanding.
|
| 325 |
-
- ClimateQ&A integrates multiple sources (IPCC
|
| 326 |
"""
|
| 327 |
)
|
| 328 |
with gr.Column(scale=1):
|
|
@@ -342,24 +439,26 @@ Version 0.2-beta - This tool is under active development
|
|
| 342 |
"""
|
| 343 |
### Beta test
|
| 344 |
- ClimateQ&A welcomes community contributions. To participate, head over to the Community Tab and create a "New Discussion" to ask questions and share your insights.
|
| 345 |
-
- Provide feedback through
|
| 346 |
-
- Only a few sources (see below) are integrated (all IPCC, IPBES
|
|
|
|
|
|
|
| 347 |
"""
|
| 348 |
)
|
| 349 |
-
with gr.Row():
|
| 350 |
-
|
| 351 |
-
|
| 352 |
-
|
| 353 |
-
|
| 354 |
-
|
| 355 |
-
|
| 356 |
-
|
| 357 |
-
|
| 358 |
-
|
| 359 |
-
|
| 360 |
-
|
| 361 |
-
|
| 362 |
-
|
| 363 |
|
| 364 |
# with gr.Column(scale=1):
|
| 365 |
# gr.Markdown("### OpenAI API")
|
|
@@ -451,4 +550,4 @@ For developers, the methodology used is detailed below :
|
|
| 451 |
|
| 452 |
demo.queue(concurrency_count=16)
|
| 453 |
|
| 454 |
-
demo.launch()
|
|
|
|
| 2 |
from haystack.document_stores import FAISSDocumentStore
|
| 3 |
from haystack.nodes import EmbeddingRetriever
|
| 4 |
import openai
|
| 5 |
+
import pandas as pd
|
| 6 |
import os
|
| 7 |
from utils import (
|
| 8 |
make_pairs,
|
|
|
|
| 14 |
from datetime import datetime
|
| 15 |
from azure.storage.fileshare import ShareServiceClient
|
| 16 |
|
| 17 |
+
try:
|
| 18 |
+
from dotenv import load_dotenv
|
| 19 |
+
load_dotenv()
|
| 20 |
+
except:
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
|
| 24 |
theme = gr.themes.Soft(
|
| 25 |
primary_hue="sky",
|
| 26 |
+
font=[gr.themes.GoogleFont("Poppins"), "ui-sans-serif", "system-ui", "sans-serif"],
|
| 27 |
)
|
| 28 |
|
| 29 |
init_prompt = (
|
| 30 |
"You are ClimateQA, an AI Assistant by Ekimetrics. "
|
| 31 |
+
"You are given a question and extracted parts of the IPCC and IPBES reports."
|
| 32 |
"Provide a clear and structured answer based on the context provided. "
|
| 33 |
"When relevant, use bullet points and lists to structure your answers."
|
| 34 |
)
|
|
|
|
| 42 |
|
| 43 |
|
| 44 |
def get_reformulation_prompt(query: str) -> str:
|
| 45 |
+
return f"""Reformulate the following user message to be a short standalone question in English, in the context of an educational discussion about climate change.
|
| 46 |
---
|
| 47 |
query: La technologie nous sauvera-t-elle ?
|
| 48 |
standalone question: Can technology help humanity mitigate the effects of climate change?
|
|
|
|
| 52 |
standalone question: What are the current reserves of fossil fuels and how long will they last?
|
| 53 |
language: English
|
| 54 |
---
|
| 55 |
+
query: what are the main causes of climate change?
|
| 56 |
+
standalone question: What are the main causes of climate change in the last century?
|
| 57 |
+
language: English
|
| 58 |
+
---
|
| 59 |
query: {query}
|
| 60 |
standalone question:"""
|
| 61 |
|
|
|
|
| 70 |
openai.api_base = os.environ["ressource_endpoint"]
|
| 71 |
openai.api_version = "2022-12-01"
|
| 72 |
|
| 73 |
+
retriever = EmbeddingRetriever(
|
| 74 |
document_store=FAISSDocumentStore.load(
|
| 75 |
+
index_path="./climateqa_v3.faiss",
|
| 76 |
+
config_path="./climateqa_v3.json",
|
| 77 |
),
|
| 78 |
embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
|
| 79 |
model_format="sentence_transformers",
|
| 80 |
progress_bar=False,
|
| 81 |
)
|
| 82 |
|
| 83 |
+
# retrieve_giec = EmbeddingRetriever(
|
| 84 |
+
# document_store=FAISSDocumentStore.load(
|
| 85 |
+
# index_path="./documents/climate_gpt_v2_only_giec.faiss",
|
| 86 |
+
# config_path="./documents/climate_gpt_v2_only_giec.json",
|
| 87 |
+
# ),
|
| 88 |
+
# embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
|
| 89 |
+
# model_format="sentence_transformers",
|
| 90 |
+
# )
|
| 91 |
|
| 92 |
credential = {
|
| 93 |
"account_key": os.environ["account_key"],
|
|
|
|
| 101 |
user_id = create_user_id(10)
|
| 102 |
|
| 103 |
|
| 104 |
+
|
| 105 |
+
def filter_sources(df,k_summary = 3,k_total = 10,source = "ipcc"):
|
| 106 |
+
assert source in ["ipcc","ipbes","all"]
|
| 107 |
+
|
| 108 |
+
# Filter by source
|
| 109 |
+
if source == "ipcc":
|
| 110 |
+
df = df.loc[df["source"]=="IPCC"]
|
| 111 |
+
elif source == "ipbes":
|
| 112 |
+
df = df.loc[df["source"]=="IPBES"]
|
| 113 |
+
else:
|
| 114 |
+
pass
|
| 115 |
+
|
| 116 |
+
# Separate summaries and full reports
|
| 117 |
+
df_summaries = df.loc[df["report_type"].isin(["SPM","TS"])]
|
| 118 |
+
df_full = df.loc[~df["report_type"].isin(["SPM","TS"])]
|
| 119 |
+
|
| 120 |
+
# Find passages from summaries dataset
|
| 121 |
+
passages_summaries = df_summaries.head(k_summary)
|
| 122 |
+
|
| 123 |
+
# Find passages from full reports dataset
|
| 124 |
+
passages_fullreports = df_full.head(k_total - len(passages_summaries))
|
| 125 |
+
|
| 126 |
+
# Concatenate passages
|
| 127 |
+
passages = pd.concat([passages_summaries,passages_fullreports],axis = 0,ignore_index = True)
|
| 128 |
+
return passages
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def retrieve_with_summaries(query,retriever,k_summary = 3,k_total = 10,source = "ipcc",max_k = 100,threshold = 0.555,as_dict = True):
|
| 132 |
+
assert max_k > k_total
|
| 133 |
+
docs = retriever.retrieve(query,top_k = max_k)
|
| 134 |
+
docs = [{**x.meta,"score":x.score,"content":x.content} for x in docs if x.score > threshold]
|
| 135 |
+
if len(docs) == 0:
|
| 136 |
+
return []
|
| 137 |
+
res = pd.DataFrame(docs)
|
| 138 |
+
passages_df = filter_sources(res,k_summary,k_total,source)
|
| 139 |
+
if as_dict:
|
| 140 |
+
contents = passages_df["content"].tolist()
|
| 141 |
+
meta = passages_df.drop(columns = ["content"]).to_dict(orient = "records")
|
| 142 |
+
passages = []
|
| 143 |
+
for i in range(len(contents)):
|
| 144 |
+
passages.append({"content":contents[i],"meta":meta[i]})
|
| 145 |
+
return passages
|
| 146 |
+
else:
|
| 147 |
+
return passages_df
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def make_html_source(source,i):
|
| 151 |
+
meta = source['meta']
|
| 152 |
+
return f"""
|
| 153 |
+
<div class="card">
|
| 154 |
+
<div class="card-content">
|
| 155 |
+
<h2>Doc {i} - {meta['short_name']} - Page {meta['page_number']}</h2>
|
| 156 |
+
<p>{source['content']}</p>
|
| 157 |
+
</div>
|
| 158 |
+
<div class="card-footer">
|
| 159 |
+
<span>{meta['name']}</span>
|
| 160 |
+
<a href="{meta['url']}#page={meta['page_number']}" target="_blank" class="pdf-link">
|
| 161 |
+
<span role="img" aria-label="Open PDF">🔗</span>
|
| 162 |
+
</a>
|
| 163 |
+
</div>
|
| 164 |
+
</div>
|
| 165 |
+
"""
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
|
| 169 |
def chat(
|
| 170 |
user_id: str,
|
| 171 |
query: str,
|
| 172 |
history: list = [system_template],
|
| 173 |
+
report_type: str = "IPCC",
|
| 174 |
threshold: float = 0.555,
|
| 175 |
) -> tuple:
|
| 176 |
"""retrieve relevant documents in the document store then query gpt-turbo
|
|
|
|
| 185 |
tuple: chat gradio format, chat openai format, sources used.
|
| 186 |
"""
|
| 187 |
|
| 188 |
+
if report_type not in ["IPCC","IPBES"]: report_type = "all"
|
| 189 |
+
print("Searching in ",report_type," reports")
|
| 190 |
+
# if report_type == "All available":
|
| 191 |
+
# retriever = retrieve_all
|
| 192 |
+
# elif report_type == "IPCC only":
|
| 193 |
+
# retriever = retrieve_giec
|
| 194 |
+
# else:
|
| 195 |
+
# raise Exception("report_type arg should be in (All available, IPCC only)")
|
| 196 |
|
| 197 |
reformulated_query = openai.Completion.create(
|
| 198 |
engine="climateGPT",
|
|
|
|
| 204 |
reformulated_query = reformulated_query["choices"][0]["text"]
|
| 205 |
reformulated_query, language = reformulated_query.split("\n")
|
| 206 |
language = language.split(":")[1].strip()
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
sources = retrieve_with_summaries(reformulated_query,retriever,k_total = 10,k_summary = 3,as_dict = True,source = report_type.lower(),threshold = threshold)
|
| 210 |
+
response_retriever = {
|
| 211 |
+
"language":language,
|
| 212 |
+
"reformulated_query":reformulated_query,
|
| 213 |
+
"query":query,
|
| 214 |
+
"sources":sources,
|
| 215 |
+
}
|
| 216 |
+
|
| 217 |
+
# docs = [d for d in retriever.retrieve(query=reformulated_query, top_k=10) if d.score > threshold]
|
| 218 |
messages = history + [{"role": "user", "content": query}]
|
| 219 |
|
| 220 |
+
if len(sources) > 0:
|
| 221 |
docs_string = []
|
| 222 |
+
docs_html = []
|
| 223 |
+
for i, d in enumerate(sources, 1):
|
| 224 |
+
docs_string.append(f"📃 Doc {i}: {d['meta']['short_name']} page {d['meta']['page_number']}\n{d['content']}")
|
| 225 |
+
docs_html.append(make_html_source(d,i))
|
| 226 |
+
docs_string = "\n\n".join([f"Query used for retrieval:\n{reformulated_query}"] + docs_string)
|
| 227 |
+
docs_html = "\n\n".join([f"Query used for retrieval:\n{reformulated_query}"] + docs_html)
|
| 228 |
+
messages.append({"role": "system", "content": f"{sources_prompt}\n\n{docs_string}\n\nAnswer in {language}:"})
|
| 229 |
+
|
| 230 |
|
| 231 |
response = openai.Completion.create(
|
| 232 |
engine="climateGPT",
|
|
|
|
| 258 |
complete_response += chunk_message
|
| 259 |
messages[-1]["content"] = complete_response
|
| 260 |
gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 261 |
+
yield gradio_format, messages, docs_html
|
| 262 |
|
| 263 |
else:
|
| 264 |
+
docs_string = "⚠️ No relevant passages found in the climate science reports (IPCC and IPBES)"
|
| 265 |
+
complete_response = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate issues).**"
|
| 266 |
messages.append({"role": "assistant", "content": complete_response})
|
| 267 |
gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 268 |
+
yield gradio_format, messages, docs_string
|
| 269 |
|
| 270 |
|
| 271 |
def save_feedback(feed: str, user_id):
|
|
|
|
| 296 |
# Gradio
|
| 297 |
gr.Markdown("<h1><center>Climate Q&A 🌍</center></h1>")
|
| 298 |
gr.Markdown("<h4><center>Ask climate-related questions to the IPCC reports</center></h4>")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 299 |
|
|
|
|
|
|
|
|
|
|
| 300 |
|
| 301 |
with gr.Row():
|
| 302 |
with gr.Column(scale=2):
|
| 303 |
+
chatbot = gr.Chatbot(elem_id="chatbot", label="ClimateQ&A chatbot",show_label = False)
|
| 304 |
state = gr.State([system_template])
|
| 305 |
|
| 306 |
with gr.Row():
|
|
|
|
| 312 |
|
| 313 |
examples_questions = gr.Examples(
|
| 314 |
[
|
| 315 |
+
"Is climate change caused by humans?",
|
| 316 |
+
"What evidence do we have of climate change?",
|
| 317 |
"What are the impacts of climate change?",
|
| 318 |
"Can climate change be reversed?",
|
| 319 |
"What is the difference between climate change and global warming?",
|
| 320 |
+
"What can individuals do to address climate change?",
|
| 321 |
+
"What are the main causes of climate change?",
|
| 322 |
"What is the Paris Agreement and why is it important?",
|
| 323 |
"Which industries have the highest GHG emissions?",
|
|
|
|
| 324 |
"Is climate change a hoax created by the government or environmental organizations?",
|
| 325 |
"What is the relationship between climate change and biodiversity loss?",
|
| 326 |
"What is the link between gender equality and climate change?",
|
|
|
|
| 351 |
|
| 352 |
with gr.Column(scale=1, variant="panel"):
|
| 353 |
gr.Markdown("### Sources")
|
| 354 |
+
sources_textbox = gr.Markdown(show_label=False)
|
| 355 |
|
| 356 |
+
dropdown_sources = gr.inputs.Dropdown(
|
| 357 |
+
["IPCC", "IPBES","IPCC and IPBES"],
|
| 358 |
+
default="IPCC",
|
| 359 |
+
label="Select reports",
|
| 360 |
+
)
|
| 361 |
ask.submit(
|
| 362 |
fn=chat,
|
| 363 |
inputs=[
|
| 364 |
user_id_state,
|
| 365 |
ask,
|
| 366 |
state,
|
| 367 |
+
dropdown_sources
|
| 368 |
+
|
|
|
|
|
|
|
|
|
|
| 369 |
],
|
| 370 |
outputs=[chatbot, state, sources_textbox],
|
| 371 |
)
|
|
|
|
| 377 |
user_id_state,
|
| 378 |
ask_examples_hidden,
|
| 379 |
state,
|
| 380 |
+
dropdown_sources
|
| 381 |
],
|
| 382 |
outputs=[chatbot, state, sources_textbox],
|
| 383 |
)
|
| 384 |
|
| 385 |
+
|
| 386 |
+
with gr.Row():
|
| 387 |
+
with gr.Column(scale=1):
|
| 388 |
+
gr.Markdown(
|
| 389 |
+
"""
|
| 390 |
+
<p><b>Climate change and environmental disruptions have become some of the most pressing challenges facing our planet today</b>. As global temperatures rise and ecosystems suffer, it is essential for individuals to understand the gravity of the situation in order to make informed decisions and advocate for appropriate policy changes.</p>
|
| 391 |
+
<p>However, comprehending the vast and complex scientific information can be daunting, as the scientific consensus references, such as <b>the Intergovernmental Panel on Climate Change (IPCC) reports, span thousands of pages</b>. To bridge this gap and make climate science more accessible, we introduce <b>ClimateQ&A as a tool to distill expert-level knowledge into easily digestible insights about climate science.</b></p>
|
| 392 |
+
<div class="tip-box">
|
| 393 |
+
<div class="tip-box-title">
|
| 394 |
+
<span class="light-bulb" role="img" aria-label="Light Bulb">💡</span>
|
| 395 |
+
How does ClimateQ&A work?
|
| 396 |
+
</div>
|
| 397 |
+
ClimateQ&A harnesses modern OCR techniques to parse and preprocess IPCC reports. By leveraging state-of-the-art question-answering algorithms, <i>ClimateQ&A is able to sift through the extensive collection of climate scientific reports and identify relevant passages in response to user inquiries</i>. Furthermore, the integration of the ChatGPT API allows ClimateQ&A to present complex data in a user-friendly manner, summarizing key points and facilitating communication of climate science to a wider audience.
|
| 398 |
+
</div>
|
| 399 |
+
|
| 400 |
+
<div class="warning-box">
|
| 401 |
+
Version 0.2-beta - This tool is under active development
|
| 402 |
+
</div>
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
"""
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
with gr.Column(scale=1):
|
| 409 |
+
gr.Markdown("")
|
| 410 |
+
gr.Markdown("*Source : IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6)*")
|
| 411 |
+
|
| 412 |
gr.Markdown("## How to use ClimateQ&A")
|
| 413 |
with gr.Row():
|
| 414 |
with gr.Column(scale=1):
|
|
|
|
| 419 |
- ClimateQ&A retrieves specific passages from the IPCC reports to help answer your question accurately.
|
| 420 |
- Source information, including page numbers and passages, is displayed on the right side of the screen for easy verification.
|
| 421 |
- Feel free to ask follow-up questions within the chatbot for a more in-depth understanding.
|
| 422 |
+
- ClimateQ&A integrates multiple sources (IPCC and IPBES, … ) to cover various aspects of environmental science, such as climate change and biodiversity. See all sources used below.
|
| 423 |
"""
|
| 424 |
)
|
| 425 |
with gr.Column(scale=1):
|
|
|
|
| 439 |
"""
|
| 440 |
### Beta test
|
| 441 |
- ClimateQ&A welcomes community contributions. To participate, head over to the Community Tab and create a "New Discussion" to ask questions and share your insights.
|
| 442 |
+
- Provide feedback through email, letting us know which insights you found accurate, useful, or not. Your input will help us improve the platform.
|
| 443 |
+
- Only a few sources (see below) are integrated (all IPCC, IPBES), if you are a climate science researcher and net to sift through another report, please let us know.
|
| 444 |
+
|
| 445 |
+
If you need us to ask another climate science report or ask any question, contact us at <b>theo.alvesdacosta@ekimetrics.com</b>
|
| 446 |
"""
|
| 447 |
)
|
| 448 |
+
# with gr.Row():
|
| 449 |
+
# with gr.Column(scale=1):
|
| 450 |
+
# gr.Markdown("### Feedbacks")
|
| 451 |
+
# feedback = gr.Textbox(label="Write your feedback here")
|
| 452 |
+
# feedback_output = gr.Textbox(label="Submit status")
|
| 453 |
+
# feedback_save = gr.Button(value="submit feedback")
|
| 454 |
+
# feedback_save.click(
|
| 455 |
+
# save_feedback,
|
| 456 |
+
# inputs=[feedback, user_id_state],
|
| 457 |
+
# outputs=feedback_output,
|
| 458 |
+
# )
|
| 459 |
+
# gr.Markdown(
|
| 460 |
+
# "If you need us to ask another climate science report or ask any question, contact us at <b>theo.alvesdacosta@ekimetrics.com</b>"
|
| 461 |
+
# )
|
| 462 |
|
| 463 |
# with gr.Column(scale=1):
|
| 464 |
# gr.Markdown("### OpenAI API")
|
|
|
|
| 550 |
|
| 551 |
demo.queue(concurrency_count=16)
|
| 552 |
|
| 553 |
+
demo.launch(server_port = 8080)
|
style.css
CHANGED
|
@@ -1,3 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
.warning-box {
|
| 2 |
background-color: #fff3cd;
|
| 3 |
border: 1px solid #ffeeba;
|
|
@@ -42,4 +47,118 @@
|
|
| 42 |
|
| 43 |
.message{
|
| 44 |
font-size:14px !important;
|
| 45 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
:root {
|
| 3 |
+
--user-image: url('https://ih1.redbubble.net/image.4776899543.6215/st,small,507x507-pad,600x600,f8f8f8.jpg');
|
| 4 |
+
}
|
| 5 |
+
|
| 6 |
.warning-box {
|
| 7 |
background-color: #fff3cd;
|
| 8 |
border: 1px solid #ffeeba;
|
|
|
|
| 47 |
|
| 48 |
.message{
|
| 49 |
font-size:14px !important;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
a {
|
| 54 |
+
text-decoration: none;
|
| 55 |
+
color: inherit;
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
.card {
|
| 59 |
+
background-color: white;
|
| 60 |
+
border-radius: 10px;
|
| 61 |
+
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
|
| 62 |
+
overflow: hidden;
|
| 63 |
+
display: flex;
|
| 64 |
+
flex-direction: column;
|
| 65 |
+
margin:20px;
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
.card-content {
|
| 69 |
+
padding: 20px;
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
.card-content h2 {
|
| 73 |
+
font-size: 14px !important;
|
| 74 |
+
font-weight: bold;
|
| 75 |
+
margin-bottom: 10px;
|
| 76 |
+
margin-top:0px !important;
|
| 77 |
+
color:#577b9b!important;;
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
.card-content p {
|
| 81 |
+
font-size: 12px;
|
| 82 |
+
margin-bottom: 0;
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
.card-footer {
|
| 86 |
+
background-color: #f4f4f4;
|
| 87 |
+
font-size: 10px;
|
| 88 |
+
padding: 10px;
|
| 89 |
+
display: flex;
|
| 90 |
+
justify-content: space-between;
|
| 91 |
+
align-items: center;
|
| 92 |
+
}
|
| 93 |
+
|
| 94 |
+
.card-footer span {
|
| 95 |
+
flex-grow: 1;
|
| 96 |
+
text-align: left;
|
| 97 |
+
color: #999 !important;
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
.pdf-link {
|
| 101 |
+
display: inline-flex;
|
| 102 |
+
align-items: center;
|
| 103 |
+
margin-left: auto;
|
| 104 |
+
text-decoration: none!important;
|
| 105 |
+
font-size: 14px;
|
| 106 |
+
}
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
.message.user{
|
| 111 |
+
background-color:#7494b0 !important;
|
| 112 |
+
border:none;
|
| 113 |
+
color:white!important;
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
.message.bot{
|
| 117 |
+
background-color:#f2f2f7 !important;
|
| 118 |
+
border:none;
|
| 119 |
+
}
|
| 120 |
+
|
| 121 |
+
.gallery-item > div:hover{
|
| 122 |
+
background-color:#7494b0 !important;
|
| 123 |
+
color:white!important;
|
| 124 |
+
}
|
| 125 |
+
|
| 126 |
+
.gallery-item:hover{
|
| 127 |
+
border:#7494b0 !important;
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
.gallery-item > div{
|
| 131 |
+
background-color:white !important;
|
| 132 |
+
color:#577b9b!important;
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
.label{
|
| 136 |
+
color:#577b9b!important;
|
| 137 |
+
}
|
| 138 |
+
|
| 139 |
+
.paginate{
|
| 140 |
+
color:#577b9b!important;
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
label > span{
|
| 145 |
+
background-color:white !important;
|
| 146 |
+
color:#577b9b!important;
|
| 147 |
+
}
|
| 148 |
+
|
| 149 |
+
/* Pseudo-element for the circularly cropped picture */
|
| 150 |
+
.message.bot::before {
|
| 151 |
+
content: '';
|
| 152 |
+
position: absolute;
|
| 153 |
+
top: -10px;
|
| 154 |
+
left: -10px;
|
| 155 |
+
width: 30px;
|
| 156 |
+
height: 30px;
|
| 157 |
+
background-image: var(--user-image);
|
| 158 |
+
background-size: cover;
|
| 159 |
+
background-position: center;
|
| 160 |
+
border-radius: 50%;
|
| 161 |
+
z-index: 10;
|
| 162 |
+
}
|
| 163 |
+
|
| 164 |
+
|