

Commit
•
c4db958
1
Parent(s):
6ec1dec
Carga inicial de archivos
Browse files- 01.TFM_Web_Scraping.ipynb +658 -0
- 02.TFM_CNN_Model.ipynb +0 -0
- 03.TFM_Web_App.ipynb +325 -0
- Images.rar +3 -0
- app.py +125 -0
- app_interface/Agaricus augustus 2 wf.jpg +0 -0
- app_interface/Amanita muscaria 1 wf.jpg +0 -0
- app_interface/Amanita pantherina 11 wf.jpg +0 -0
- app_interface/Amanita torrendii 8 fp.jpg +0 -0
- app_interface/Amanitaphalloides1 mw.jpg +0 -0
- app_interface/Boletus edulis 15 wf.jpg +0 -0
- app_interface/Caloceraviscosa1 mw.jpg +0 -0
- app_interface/Cantharelluscibarius5 mw.jpg +0 -0
- app_interface/Clavulinopsis fusiformis 2 fp.jpg +0 -0
- app_interface/Coprinellus micaceus 8 wf.jpg +0 -0
- app_interface/Lactarius torminosus 6 fp.jpg +0 -0
- app_interface/Russula sanguinea 5 fp.jpg +0 -0
- app_interface/confusion_matrix.png +0 -0
- app_interface/thumbnail.png +0 -0
- model.h5 +3 -0
- requirements.txt +5 -0
01.TFM_Web_Scraping.ipynb
ADDED
|
@@ -0,0 +1,658 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {
|
| 6 |
+
"toc": true
|
| 7 |
+
},
|
| 8 |
+
"source": [
|
| 9 |
+
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
|
| 10 |
+
"<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Web-Scraping\" data-toc-modified-id=\"Web-Scraping-1\"><span class=\"toc-item-num\">1 </span>Web Scraping</a></span><ul class=\"toc-item\"><li><span><a href=\"#Importación-de-librerías\" data-toc-modified-id=\"Importación-de-librerías-1.1\"><span class=\"toc-item-num\">1.1 </span>Importación de librerías</a></span></li><li><span><a href=\"#Definición-de-funciones\" data-toc-modified-id=\"Definición-de-funciones-1.2\"><span class=\"toc-item-num\">1.2 </span>Definición de funciones</a></span><ul class=\"toc-item\"><li><span><a href=\"#HTML-parser\" data-toc-modified-id=\"HTML-parser-1.2.1\"><span class=\"toc-item-num\">1.2.1 </span>HTML parser</a></span></li><li><span><a href=\"#Directory-switcher\" data-toc-modified-id=\"Directory-switcher-1.2.2\"><span class=\"toc-item-num\">1.2.2 </span>Directory switcher</a></span></li><li><span><a href=\"#Image-downloader\" data-toc-modified-id=\"Image-downloader-1.2.3\"><span class=\"toc-item-num\">1.2.3 </span>Image downloader</a></span></li><li><span><a href=\"#Pager\" data-toc-modified-id=\"Pager-1.2.4\"><span class=\"toc-item-num\">1.2.4 </span>Pager</a></span></li></ul></li><li><span><a href=\"#Obtención-de-imágenes\" data-toc-modified-id=\"Obtención-de-imágenes-1.3\"><span class=\"toc-item-num\">1.3 </span>Obtención de imágenes</a></span><ul class=\"toc-item\"><li><span><a href=\"#Mushroom-World\" data-toc-modified-id=\"Mushroom-World-1.3.1\"><span class=\"toc-item-num\">1.3.1 </span>Mushroom World</a></span></li><li><span><a href=\"#Wild-UK-Mushrooms\" data-toc-modified-id=\"Wild-UK-Mushrooms-1.3.2\"><span class=\"toc-item-num\">1.3.2 </span>Wild UK Mushrooms</a></span></li><li><span><a href=\"#Fungipedia\" data-toc-modified-id=\"Fungipedia-1.3.3\"><span class=\"toc-item-num\">1.3.3 </span>Fungipedia</a></span></li></ul></li></ul></li></ul></div>"
|
| 11 |
+
]
|
| 12 |
+
},
|
| 13 |
+
{
|
| 14 |
+
"cell_type": "markdown",
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"source": [
|
| 17 |
+
"# Web Scraping"
|
| 18 |
+
]
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"cell_type": "markdown",
|
| 22 |
+
"metadata": {},
|
| 23 |
+
"source": [
|
| 24 |
+
"La primera parte del proyecto consiste en la obtención, mediantes técnicas de Web Scraping, de:\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"* Un set de imágenes de setas para entrenar un modelo Deep Learning de clasificación multiclase.\n",
|
| 27 |
+
"* Un dataset con los datos asociados a distintas especies de setas, para entrenar un modelo Machine Learning de clasificación multiclase. \n",
|
| 28 |
+
"\n",
|
| 29 |
+
"Toda la información será obtenida de las siguientes páginas web:\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"* https://www.mushroom.world/\n",
|
| 33 |
+
"* https://www.wildfooduk.com/mushroom-guide/\n",
|
| 34 |
+
"* https://www.fungipedia.org/hongos/\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"\n"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "markdown",
|
| 41 |
+
"metadata": {},
|
| 42 |
+
"source": [
|
| 43 |
+
"## Importación de librerías "
|
| 44 |
+
]
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"execution_count": 1,
|
| 49 |
+
"metadata": {
|
| 50 |
+
"ExecuteTime": {
|
| 51 |
+
"end_time": "2022-02-05T11:38:51.241675Z",
|
| 52 |
+
"start_time": "2022-02-05T11:38:50.637941Z"
|
| 53 |
+
}
|
| 54 |
+
},
|
| 55 |
+
"outputs": [],
|
| 56 |
+
"source": [
|
| 57 |
+
"# Importamos librerías\n",
|
| 58 |
+
"import requests # Librería HTTP\n",
|
| 59 |
+
"from bs4 import BeautifulSoup # Extraer datos de archivos HTML y XML\n",
|
| 60 |
+
"import re # Regular Expressions\n",
|
| 61 |
+
"import os # Paths y directorios\n",
|
| 62 |
+
"import pathlib # Paths y directorios\n",
|
| 63 |
+
"import pandas as pd # Tratamiento de DataFrames\n",
|
| 64 |
+
"import numpy as np # Funciones matemáticas, algebraicas y otras\n",
|
| 65 |
+
"from PIL import Image # Edición de imágenes\n",
|
| 66 |
+
"from resizeimage import resizeimage # Reescalado de imágenes"
|
| 67 |
+
]
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"cell_type": "markdown",
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"source": [
|
| 73 |
+
"## Definición de funciones"
|
| 74 |
+
]
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"cell_type": "markdown",
|
| 78 |
+
"metadata": {},
|
| 79 |
+
"source": [
|
| 80 |
+
"Para este ejercicio, definiremos una serie de funciones que nos facilitarán la ejecución y la estructura del mismo:"
|
| 81 |
+
]
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"cell_type": "markdown",
|
| 85 |
+
"metadata": {},
|
| 86 |
+
"source": [
|
| 87 |
+
"### HTML parser\n"
|
| 88 |
+
]
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"cell_type": "markdown",
|
| 92 |
+
"metadata": {},
|
| 93 |
+
"source": [
|
| 94 |
+
"Definimos en primer lugar una función general para ***parsear* la información de la URL facilitada**: "
|
| 95 |
+
]
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"cell_type": "code",
|
| 99 |
+
"execution_count": 2,
|
| 100 |
+
"metadata": {
|
| 101 |
+
"ExecuteTime": {
|
| 102 |
+
"end_time": "2022-02-05T11:38:51.257201Z",
|
| 103 |
+
"start_time": "2022-02-05T11:38:51.242692Z"
|
| 104 |
+
}
|
| 105 |
+
},
|
| 106 |
+
"outputs": [],
|
| 107 |
+
"source": [
|
| 108 |
+
"def getdata(url, parser='html.parser'):\n",
|
| 109 |
+
" #Definimos los headers para la request HTTP de manera que el servidor no nos bloquee la respuesta:\n",
|
| 110 |
+
" headers = {\n",
|
| 111 |
+
" 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',\n",
|
| 112 |
+
" 'Accept-Language': 'es-ES,es;q=0.9', \n",
|
| 113 |
+
" 'Cache-Control': 'max-age=0',\n",
|
| 114 |
+
" 'Referer': 'https://google.com',\n",
|
| 115 |
+
" 'DNT': '1',\n",
|
| 116 |
+
" }\n",
|
| 117 |
+
" dir = url\n",
|
| 118 |
+
" r = requests.get(dir, headers = headers)\n",
|
| 119 |
+
" soup = BeautifulSoup(r.text, parser)\n",
|
| 120 |
+
" return soup"
|
| 121 |
+
]
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"cell_type": "markdown",
|
| 125 |
+
"metadata": {},
|
| 126 |
+
"source": [
|
| 127 |
+
"### Directory switcher"
|
| 128 |
+
]
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"cell_type": "markdown",
|
| 132 |
+
"metadata": {},
|
| 133 |
+
"source": [
|
| 134 |
+
"Creamos también una función para crear y cambiar directorios en la carpeta raíz para nuestras imágenes:"
|
| 135 |
+
]
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"cell_type": "code",
|
| 139 |
+
"execution_count": 3,
|
| 140 |
+
"metadata": {
|
| 141 |
+
"ExecuteTime": {
|
| 142 |
+
"end_time": "2022-02-05T11:38:51.273252Z",
|
| 143 |
+
"start_time": "2022-02-05T11:38:51.258172Z"
|
| 144 |
+
}
|
| 145 |
+
},
|
| 146 |
+
"outputs": [],
|
| 147 |
+
"source": [
|
| 148 |
+
"directory = os.getcwd()\n",
|
| 149 |
+
"image_directory = os.path.join(directory + '\\Images')\n",
|
| 150 |
+
"try:\n",
|
| 151 |
+
" os.mkdir(image_directory)\n",
|
| 152 |
+
"except FileExistsError:\n",
|
| 153 |
+
" pass"
|
| 154 |
+
]
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"cell_type": "code",
|
| 158 |
+
"execution_count": 4,
|
| 159 |
+
"metadata": {
|
| 160 |
+
"ExecuteTime": {
|
| 161 |
+
"end_time": "2022-02-05T11:38:51.289268Z",
|
| 162 |
+
"start_time": "2022-02-05T11:38:51.274220Z"
|
| 163 |
+
}
|
| 164 |
+
},
|
| 165 |
+
"outputs": [],
|
| 166 |
+
"source": [
|
| 167 |
+
"def getdirectory(folder):\n",
|
| 168 |
+
" os.chdir(image_directory)\n",
|
| 169 |
+
" try:\n",
|
| 170 |
+
" os.mkdir(os.getcwd() + \"/\" + str(folder))\n",
|
| 171 |
+
" except FileExistsError:\n",
|
| 172 |
+
" pass\n",
|
| 173 |
+
" os.chdir(os.getcwd() + \"/\" + str(folder))"
|
| 174 |
+
]
|
| 175 |
+
},
|
| 176 |
+
{
|
| 177 |
+
"cell_type": "markdown",
|
| 178 |
+
"metadata": {},
|
| 179 |
+
"source": [
|
| 180 |
+
"### Image downloader"
|
| 181 |
+
]
|
| 182 |
+
},
|
| 183 |
+
{
|
| 184 |
+
"cell_type": "markdown",
|
| 185 |
+
"metadata": {},
|
| 186 |
+
"source": [
|
| 187 |
+
"La siguientes funciones sirven para **descargar todas las imágenes de las distintas webs** anteriormente mencionadas:"
|
| 188 |
+
]
|
| 189 |
+
},
|
| 190 |
+
{
|
| 191 |
+
"cell_type": "markdown",
|
| 192 |
+
"metadata": {
|
| 193 |
+
"ExecuteTime": {
|
| 194 |
+
"end_time": "2022-01-21T19:56:14.547984Z",
|
| 195 |
+
"start_time": "2022-01-21T19:56:14.529008Z"
|
| 196 |
+
}
|
| 197 |
+
},
|
| 198 |
+
"source": [
|
| 199 |
+
"1. La **primera función de descarga** es para https://www.mushroom.world/.\n",
|
| 200 |
+
"\n",
|
| 201 |
+
" En ella, usamos las *RE* para obtener los atributos \"href\" de cada imagen y obtener sus URLs. En este caso, todas son de la forma: *https://www.mushroom.world/data/...*. Después, iteraremos sobre este listado y escribiremos cada imagen en el directorio."
|
| 202 |
+
]
|
| 203 |
+
},
|
| 204 |
+
{
|
| 205 |
+
"cell_type": "code",
|
| 206 |
+
"execution_count": 5,
|
| 207 |
+
"metadata": {
|
| 208 |
+
"ExecuteTime": {
|
| 209 |
+
"end_time": "2022-02-05T11:38:51.304866Z",
|
| 210 |
+
"start_time": "2022-02-05T11:38:51.290267Z"
|
| 211 |
+
}
|
| 212 |
+
},
|
| 213 |
+
"outputs": [],
|
| 214 |
+
"source": [
|
| 215 |
+
"def imagedown_1(soup):\n",
|
| 216 |
+
" images = soup.find_all(href=re.compile(\"data\"))\n",
|
| 217 |
+
" for image in images:\n",
|
| 218 |
+
" href = image['href']\n",
|
| 219 |
+
" link = 'https://www.mushroom.world' + image['href'][3:]\n",
|
| 220 |
+
" name = href[15:-4] + ' mw' + '.jpg'\n",
|
| 221 |
+
" name = name.replace('/','-')\n",
|
| 222 |
+
" if not os.path.exists('./' + name): # Solo descargamos aquellas imágenes que no tengamos\n",
|
| 223 |
+
" with open(name, 'wb') as f:\n",
|
| 224 |
+
" im = requests.get(link)\n",
|
| 225 |
+
" f.write(im.content)\n",
|
| 226 |
+
" # Reescalamos la imagen a 512x512 píxeles\n",
|
| 227 |
+
" with open(name, 'r+b') as f:\n",
|
| 228 |
+
" try:\n",
|
| 229 |
+
" with Image.open(f) as image:\n",
|
| 230 |
+
" cover = resizeimage.resize_cover(image, [512, 512])\n",
|
| 231 |
+
" cover.save(name, image.format)\n",
|
| 232 |
+
" except:\n",
|
| 233 |
+
" pass"
|
| 234 |
+
]
|
| 235 |
+
},
|
| 236 |
+
{
|
| 237 |
+
"cell_type": "markdown",
|
| 238 |
+
"metadata": {},
|
| 239 |
+
"source": [
|
| 240 |
+
"2. Creamos ahora una **función para aplicar en la segunda web** utilizada : https://www.wildfooduk.com/mushroom-guide/\n",
|
| 241 |
+
"\n",
|
| 242 |
+
" En este caso, hacemos uso de las utilidades de BS4 y html para obtener las imágenes de cada página. Eso si, previamente necesitaremos un listado con todos los links individuales."
|
| 243 |
+
]
|
| 244 |
+
},
|
| 245 |
+
{
|
| 246 |
+
"cell_type": "code",
|
| 247 |
+
"execution_count": 6,
|
| 248 |
+
"metadata": {
|
| 249 |
+
"ExecuteTime": {
|
| 250 |
+
"end_time": "2022-02-05T11:38:51.319987Z",
|
| 251 |
+
"start_time": "2022-02-05T11:38:51.305866Z"
|
| 252 |
+
}
|
| 253 |
+
},
|
| 254 |
+
"outputs": [],
|
| 255 |
+
"source": [
|
| 256 |
+
"def imagedown_2(soup):\n",
|
| 257 |
+
" image_set = soup.find('ul', {'class': 'mush-thumbs'})\n",
|
| 258 |
+
" images = image_set.find_all('a', {'id': re.compile(\"image-\")})\n",
|
| 259 |
+
" contador = 0\n",
|
| 260 |
+
" for image in images:\n",
|
| 261 |
+
" contador += 1\n",
|
| 262 |
+
" link = image['href']\n",
|
| 263 |
+
" name = soup.find('table').find_all('td')[5].string.strip() + \" \" + str(contador) + ' wf' + '.jpg'\n",
|
| 264 |
+
" name = name.replace('/','-')\n",
|
| 265 |
+
" if not os.path.exists('./' + name): # Solo descargamos aquellas imágenes que no tengamos\n",
|
| 266 |
+
" with open(name, 'wb') as f:\n",
|
| 267 |
+
" im = requests.get(link)\n",
|
| 268 |
+
" f.write(im.content)\n",
|
| 269 |
+
" # Reescalamos la imagen a 512x512 píxeles\n",
|
| 270 |
+
" with open(name, 'r+b') as f:\n",
|
| 271 |
+
" try:\n",
|
| 272 |
+
" with Image.open(f) as image:\n",
|
| 273 |
+
" cover = resizeimage.resize_cover(image, [512, 512])\n",
|
| 274 |
+
" cover.save(name, image.format)\n",
|
| 275 |
+
" except:\n",
|
| 276 |
+
" pass\n"
|
| 277 |
+
]
|
| 278 |
+
},
|
| 279 |
+
{
|
| 280 |
+
"cell_type": "markdown",
|
| 281 |
+
"metadata": {},
|
| 282 |
+
"source": [
|
| 283 |
+
"3. Creamos ahora una función para aplicar en la **tercera y última web utilizada**: https://www.fungipedia.org/hongos.html\n",
|
| 284 |
+
"\n",
|
| 285 |
+
" En este caso utilizaremos CSS Selectors para obtener las imágenes, pues las imágenes se encuentran dentro de un plugin \"Simple Image Gallery Pro\". Al igual que en caso anterior, previamente necesitaremos un listado con todos los links individuales:"
|
| 286 |
+
]
|
| 287 |
+
},
|
| 288 |
+
{
|
| 289 |
+
"cell_type": "code",
|
| 290 |
+
"execution_count": 7,
|
| 291 |
+
"metadata": {
|
| 292 |
+
"ExecuteTime": {
|
| 293 |
+
"end_time": "2022-02-05T11:38:51.335814Z",
|
| 294 |
+
"start_time": "2022-02-05T11:38:51.320673Z"
|
| 295 |
+
}
|
| 296 |
+
},
|
| 297 |
+
"outputs": [],
|
| 298 |
+
"source": [
|
| 299 |
+
"def imagedown_3(soup):\n",
|
| 300 |
+
" # Utilizamos nuevamente headers, de lo contrario el servidor nos devuelve un codigo 403 Forbidden error.\n",
|
| 301 |
+
" headers = {\n",
|
| 302 |
+
" 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',\n",
|
| 303 |
+
" 'Accept-Language': 'es-ES,es;q=0.9', \n",
|
| 304 |
+
" 'Cache-Control': 'max-age=0',\n",
|
| 305 |
+
" 'Referer': 'https://google.com',\n",
|
| 306 |
+
" 'DNT': '1',\n",
|
| 307 |
+
" }\n",
|
| 308 |
+
" images = soup.select('.sigProLinkWrapper a[href]:not([href=\"\"])')\n",
|
| 309 |
+
" domain = 'https://www.fungipedia.org'\n",
|
| 310 |
+
" contador = 0\n",
|
| 311 |
+
" for image in images:\n",
|
| 312 |
+
" contador += 1\n",
|
| 313 |
+
" link = image.attrs.get('href')\n",
|
| 314 |
+
" name = soup.find('h1', {'class': 'itemTitle'}).string.strip() + \" \" + str(contador) + ' fp' + '.jpg'\n",
|
| 315 |
+
" name = name.replace('/','-')\n",
|
| 316 |
+
" if not os.path.exists('./' + name): # Solo descargamos aquellas imágenes que no tengamos\n",
|
| 317 |
+
" with open(name, 'wb') as f: \n",
|
| 318 |
+
" im = requests.get(domain + link, allow_redirects = True, headers = headers)\n",
|
| 319 |
+
" f.write(im.content)\n",
|
| 320 |
+
" # Reescalamos la imagen a 512x512 píxeles\n",
|
| 321 |
+
" with open(name, 'r+b') as f:\n",
|
| 322 |
+
" try:\n",
|
| 323 |
+
" with Image.open(f) as image:\n",
|
| 324 |
+
" cover = resizeimage.resize_cover(image, [512, 512])\n",
|
| 325 |
+
" cover.save(name, image.format)\n",
|
| 326 |
+
" except:\n",
|
| 327 |
+
" pass"
|
| 328 |
+
]
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"cell_type": "markdown",
|
| 332 |
+
"metadata": {},
|
| 333 |
+
"source": [
|
| 334 |
+
"### Pager"
|
| 335 |
+
]
|
| 336 |
+
},
|
| 337 |
+
{
|
| 338 |
+
"cell_type": "markdown",
|
| 339 |
+
"metadata": {},
|
| 340 |
+
"source": [
|
| 341 |
+
"En último lugar, definimos las funciones para **pasar de página** en las distintas estructuras de las webs:"
|
| 342 |
+
]
|
| 343 |
+
},
|
| 344 |
+
{
|
| 345 |
+
"cell_type": "markdown",
|
| 346 |
+
"metadata": {
|
| 347 |
+
"ExecuteTime": {
|
| 348 |
+
"end_time": "2022-01-21T20:00:04.349396Z",
|
| 349 |
+
"start_time": "2022-01-21T20:00:04.339424Z"
|
| 350 |
+
}
|
| 351 |
+
},
|
| 352 |
+
"source": [
|
| 353 |
+
"1. Para https://www.mushroom.world:"
|
| 354 |
+
]
|
| 355 |
+
},
|
| 356 |
+
{
|
| 357 |
+
"cell_type": "code",
|
| 358 |
+
"execution_count": 8,
|
| 359 |
+
"metadata": {
|
| 360 |
+
"ExecuteTime": {
|
| 361 |
+
"end_time": "2022-02-05T11:38:51.351406Z",
|
| 362 |
+
"start_time": "2022-02-05T11:38:51.336529Z"
|
| 363 |
+
}
|
| 364 |
+
},
|
| 365 |
+
"outputs": [],
|
| 366 |
+
"source": [
|
| 367 |
+
"def getnextpage_1(soup):\n",
|
| 368 |
+
" page = soup.find('div', {'id': 'pager'}) # A partir de la etiqueta de división div del paginador (id=pager), podemos pasar de página iterando en un bucle:\n",
|
| 369 |
+
" if page.find(string=re.compile(\"Next Page\")):\n",
|
| 370 |
+
" url = 'https://www.mushroom.world' + str(page.find('a', string=re.compile(\"Next Page\"))['href'])\n",
|
| 371 |
+
" return url\n",
|
| 372 |
+
" else:\n",
|
| 373 |
+
" return"
|
| 374 |
+
]
|
| 375 |
+
},
|
| 376 |
+
{
|
| 377 |
+
"cell_type": "markdown",
|
| 378 |
+
"metadata": {},
|
| 379 |
+
"source": [
|
| 380 |
+
"2. Para https://www.wildfooduk.com/mushroom-guide/: en este caso encontramos todos los links en una única URL, luego no hará falta."
|
| 381 |
+
]
|
| 382 |
+
},
|
| 383 |
+
{
|
| 384 |
+
"cell_type": "markdown",
|
| 385 |
+
"metadata": {},
|
| 386 |
+
"source": [
|
| 387 |
+
"3. Para https://www.fungipedia.org/':"
|
| 388 |
+
]
|
| 389 |
+
},
|
| 390 |
+
{
|
| 391 |
+
"cell_type": "code",
|
| 392 |
+
"execution_count": 9,
|
| 393 |
+
"metadata": {
|
| 394 |
+
"ExecuteTime": {
|
| 395 |
+
"end_time": "2022-02-05T11:38:51.366585Z",
|
| 396 |
+
"start_time": "2022-02-05T11:38:51.352439Z"
|
| 397 |
+
}
|
| 398 |
+
},
|
| 399 |
+
"outputs": [],
|
| 400 |
+
"source": [
|
| 401 |
+
"def getnextpage_2(soup):\n",
|
| 402 |
+
" pager = soup.find('div', {'class': 'pagination'})\n",
|
| 403 |
+
" if pager.find('a', {'class': 'next'}):\n",
|
| 404 |
+
" url = 'https://www.fungipedia.org/' + str(pager.find('a', {'class': 'next'})['href'])\n",
|
| 405 |
+
" return url\n",
|
| 406 |
+
" else:\n",
|
| 407 |
+
" return"
|
| 408 |
+
]
|
| 409 |
+
},
|
| 410 |
+
{
|
| 411 |
+
"cell_type": "markdown",
|
| 412 |
+
"metadata": {},
|
| 413 |
+
"source": [
|
| 414 |
+
"## Obtención de imágenes"
|
| 415 |
+
]
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"cell_type": "markdown",
|
| 419 |
+
"metadata": {},
|
| 420 |
+
"source": [
|
| 421 |
+
"### Mushroom World "
|
| 422 |
+
]
|
| 423 |
+
},
|
| 424 |
+
{
|
| 425 |
+
"cell_type": "markdown",
|
| 426 |
+
"metadata": {},
|
| 427 |
+
"source": [
|
| 428 |
+
"Las distintas URLs del siguiente diccionario hacen referencia a las clases en las que dividiremos las imágenes de las setas:\n",
|
| 429 |
+
"\n",
|
| 430 |
+
"* **Edible** *(Comestibles)*\n",
|
| 431 |
+
"* **Inedible** *(No Comestibles)*\n",
|
| 432 |
+
"* **Poisonous** *(Venenosas)*\n",
|
| 433 |
+
"\n",
|
| 434 |
+
"Cada una de ellas se guardará en una carpeta en nuestro directorio."
|
| 435 |
+
]
|
| 436 |
+
},
|
| 437 |
+
{
|
| 438 |
+
"cell_type": "code",
|
| 439 |
+
"execution_count": 10,
|
| 440 |
+
"metadata": {
|
| 441 |
+
"ExecuteTime": {
|
| 442 |
+
"end_time": "2022-02-05T11:38:51.381814Z",
|
| 443 |
+
"start_time": "2022-02-05T11:38:51.368582Z"
|
| 444 |
+
}
|
| 445 |
+
},
|
| 446 |
+
"outputs": [],
|
| 447 |
+
"source": [
|
| 448 |
+
"edibility = {\"Edible\" : 'https://www.mushroom.world/mushrooms/edible', \n",
|
| 449 |
+
" \"Inedible\": 'https://www.mushroom.world/mushrooms/inedible', \n",
|
| 450 |
+
" \"Poisonous\": 'https://www.mushroom.world/mushrooms/poisonous'}"
|
| 451 |
+
]
|
| 452 |
+
},
|
| 453 |
+
{
|
| 454 |
+
"cell_type": "markdown",
|
| 455 |
+
"metadata": {},
|
| 456 |
+
"source": [
|
| 457 |
+
"Con las funciones anteriormente definidas, simplemente planteamos el siguiente bucle para descargar todas las imágenes:"
|
| 458 |
+
]
|
| 459 |
+
},
|
| 460 |
+
{
|
| 461 |
+
"cell_type": "code",
|
| 462 |
+
"execution_count": 11,
|
| 463 |
+
"metadata": {
|
| 464 |
+
"ExecuteTime": {
|
| 465 |
+
"end_time": "2022-02-05T11:48:33.300282Z",
|
| 466 |
+
"start_time": "2022-02-05T11:38:51.382815Z"
|
| 467 |
+
}
|
| 468 |
+
},
|
| 469 |
+
"outputs": [],
|
| 470 |
+
"source": [
|
| 471 |
+
"for i in edibility:\n",
|
| 472 |
+
" url = edibility[i]\n",
|
| 473 |
+
" getdirectory(i)\n",
|
| 474 |
+
" while type(url) == str:\n",
|
| 475 |
+
" soup = getdata(url,'html.parser')\n",
|
| 476 |
+
" imagedown_1(soup)\n",
|
| 477 |
+
" url = getnextpage_1(soup)"
|
| 478 |
+
]
|
| 479 |
+
},
|
| 480 |
+
{
|
| 481 |
+
"cell_type": "markdown",
|
| 482 |
+
"metadata": {},
|
| 483 |
+
"source": [
|
| 484 |
+
"### Wild UK Mushrooms"
|
| 485 |
+
]
|
| 486 |
+
},
|
| 487 |
+
{
|
| 488 |
+
"cell_type": "markdown",
|
| 489 |
+
"metadata": {},
|
| 490 |
+
"source": [
|
| 491 |
+
"Fijamos las URLs nuevamente:"
|
| 492 |
+
]
|
| 493 |
+
},
|
| 494 |
+
{
|
| 495 |
+
"cell_type": "code",
|
| 496 |
+
"execution_count": 12,
|
| 497 |
+
"metadata": {
|
| 498 |
+
"ExecuteTime": {
|
| 499 |
+
"end_time": "2022-02-05T11:48:33.316268Z",
|
| 500 |
+
"start_time": "2022-02-05T11:48:33.301281Z"
|
| 501 |
+
}
|
| 502 |
+
},
|
| 503 |
+
"outputs": [],
|
| 504 |
+
"source": [
|
| 505 |
+
"edibility = {\"Edible\" : 'https://www.wildfooduk.com/mushroom-guide/?mushroom_type=edible', \n",
|
| 506 |
+
" \"Inedible\": 'https://www.wildfooduk.com/mushroom-guide/?mushroom_type=inedible', \n",
|
| 507 |
+
" \"Poisonous\": 'https://www.wildfooduk.com/mushroom-guide/?mushroom_type=poisonous'} "
|
| 508 |
+
]
|
| 509 |
+
},
|
| 510 |
+
{
|
| 511 |
+
"cell_type": "markdown",
|
| 512 |
+
"metadata": {},
|
| 513 |
+
"source": [
|
| 514 |
+
"Planteamos el bucle para recorrer la estructura de la web y descargar las imágenes:"
|
| 515 |
+
]
|
| 516 |
+
},
|
| 517 |
+
{
|
| 518 |
+
"cell_type": "code",
|
| 519 |
+
"execution_count": 13,
|
| 520 |
+
"metadata": {
|
| 521 |
+
"ExecuteTime": {
|
| 522 |
+
"end_time": "2022-02-05T12:13:26.101999Z",
|
| 523 |
+
"start_time": "2022-02-05T11:48:33.317238Z"
|
| 524 |
+
}
|
| 525 |
+
},
|
| 526 |
+
"outputs": [],
|
| 527 |
+
"source": [
|
| 528 |
+
"for i in edibility:\n",
|
| 529 |
+
" url = edibility[i]\n",
|
| 530 |
+
" getdirectory(i)\n",
|
| 531 |
+
" soup = getdata(url)\n",
|
| 532 |
+
" mushroom_table = soup.find_all('td', {'class': 'mushroom-image'})\n",
|
| 533 |
+
" mushroom_links = []\n",
|
| 534 |
+
" for mushroom in mushroom_table:\n",
|
| 535 |
+
" mushroom_links.append(mushroom.find('a')['href'])\n",
|
| 536 |
+
" for link in mushroom_links:\n",
|
| 537 |
+
" soup = getdata(link,'html.parser')\n",
|
| 538 |
+
" imagedown_2(soup)"
|
| 539 |
+
]
|
| 540 |
+
},
|
| 541 |
+
{
|
| 542 |
+
"cell_type": "markdown",
|
| 543 |
+
"metadata": {},
|
| 544 |
+
"source": [
|
| 545 |
+
"### Fungipedia "
|
| 546 |
+
]
|
| 547 |
+
},
|
| 548 |
+
{
|
| 549 |
+
"cell_type": "markdown",
|
| 550 |
+
"metadata": {},
|
| 551 |
+
"source": [
|
| 552 |
+
"Fijamos las URLs nuevamente, en este caso al aplicando los filtros correspondientes en la web, estos se reflejan directamente en las URLs."
|
| 553 |
+
]
|
| 554 |
+
},
|
| 555 |
+
{
|
| 556 |
+
"cell_type": "code",
|
| 557 |
+
"execution_count": 14,
|
| 558 |
+
"metadata": {
|
| 559 |
+
"ExecuteTime": {
|
| 560 |
+
"end_time": "2022-02-05T12:13:26.117978Z",
|
| 561 |
+
"start_time": "2022-02-05T12:13:26.102991Z"
|
| 562 |
+
}
|
| 563 |
+
},
|
| 564 |
+
"outputs": [],
|
| 565 |
+
"source": [
|
| 566 |
+
"edibility = {\"Edible\" : 'https://www.fungipedia.org/hongos/itemlist/filter.html?array12%5B%5D=buen-comestible&array12%5B%5D=buen-comestible-precaucion&array12%5B%5D=comestible&array12%5B%5D=comestible-precaucion&array12%5B%5D=excelente-comestible&array12%5B%5D=excelente-comestible-precaucion&moduleId=95&Itemid=337', \n",
|
| 567 |
+
" \"Inedible\": 'https://www.fungipedia.org/hongos/itemlist/filter.html?array12%5B%5D=no-comestible&array12%5B%5D=sin-valor&moduleId=95&Itemid=337', \n",
|
| 568 |
+
" \"Poisonous\": 'https://www.fungipedia.org/hongos/itemlist/filter.html?array12%5B%5D=mortal&array12%5B%5D=toxica&moduleId=95&Itemid=337'} "
|
| 569 |
+
]
|
| 570 |
+
},
|
| 571 |
+
{
|
| 572 |
+
"cell_type": "markdown",
|
| 573 |
+
"metadata": {},
|
| 574 |
+
"source": [
|
| 575 |
+
"Planteamos el bucle para recorrer la estructura de la web y descargar las imágenes:"
|
| 576 |
+
]
|
| 577 |
+
},
|
| 578 |
+
{
|
| 579 |
+
"cell_type": "code",
|
| 580 |
+
"execution_count": 15,
|
| 581 |
+
"metadata": {
|
| 582 |
+
"ExecuteTime": {
|
| 583 |
+
"end_time": "2022-02-05T12:36:46.899216Z",
|
| 584 |
+
"start_time": "2022-02-05T12:13:26.118948Z"
|
| 585 |
+
}
|
| 586 |
+
},
|
| 587 |
+
"outputs": [],
|
| 588 |
+
"source": [
|
| 589 |
+
"for i in edibility:\n",
|
| 590 |
+
" url_main = edibility[i]\n",
|
| 591 |
+
" getdirectory(i)\n",
|
| 592 |
+
" while True:\n",
|
| 593 |
+
" soup_main = getdata(url_main,'html.parser')\n",
|
| 594 |
+
" mushroom_elements = soup_main.find_all('a', {'class': 'gris'})\n",
|
| 595 |
+
" mushroom_links = []\n",
|
| 596 |
+
" for element in mushroom_elements:\n",
|
| 597 |
+
" mushroom_links.append('https://www.fungipedia.org' + element['href'])\n",
|
| 598 |
+
" for link in mushroom_links:\n",
|
| 599 |
+
" soup_link = getdata(link,'html.parser')\n",
|
| 600 |
+
" imagedown_3(soup_link)\n",
|
| 601 |
+
" url_main = getnextpage_2(soup_main)\n",
|
| 602 |
+
" if not url_main:\n",
|
| 603 |
+
" break"
|
| 604 |
+
]
|
| 605 |
+
}
|
| 606 |
+
],
|
| 607 |
+
"metadata": {
|
| 608 |
+
"accelerator": "GPU",
|
| 609 |
+
"colab": {
|
| 610 |
+
"collapsed_sections": [
|
| 611 |
+
"eRTY-COfOwwD",
|
| 612 |
+
"ip1P14xN-uSX",
|
| 613 |
+
"VaNHXO2N_Hv-",
|
| 614 |
+
"mhPpAK2bMyQZ",
|
| 615 |
+
"rEI-mXrkU4ku"
|
| 616 |
+
],
|
| 617 |
+
"name": "PrevioTFM3.ipynb",
|
| 618 |
+
"provenance": []
|
| 619 |
+
},
|
| 620 |
+
"kernelspec": {
|
| 621 |
+
"display_name": "Python 3 (ipykernel)",
|
| 622 |
+
"language": "python",
|
| 623 |
+
"name": "python3"
|
| 624 |
+
},
|
| 625 |
+
"language_info": {
|
| 626 |
+
"codemirror_mode": {
|
| 627 |
+
"name": "ipython",
|
| 628 |
+
"version": 3
|
| 629 |
+
},
|
| 630 |
+
"file_extension": ".py",
|
| 631 |
+
"mimetype": "text/x-python",
|
| 632 |
+
"name": "python",
|
| 633 |
+
"nbconvert_exporter": "python",
|
| 634 |
+
"pygments_lexer": "ipython3",
|
| 635 |
+
"version": "3.8.12"
|
| 636 |
+
},
|
| 637 |
+
"toc": {
|
| 638 |
+
"base_numbering": 1,
|
| 639 |
+
"nav_menu": {},
|
| 640 |
+
"number_sections": true,
|
| 641 |
+
"sideBar": true,
|
| 642 |
+
"skip_h1_title": false,
|
| 643 |
+
"title_cell": "Table of Contents",
|
| 644 |
+
"title_sidebar": "Contents",
|
| 645 |
+
"toc_cell": true,
|
| 646 |
+
"toc_position": {
|
| 647 |
+
"height": "877px",
|
| 648 |
+
"left": "70px",
|
| 649 |
+
"top": "111.125px",
|
| 650 |
+
"width": "165px"
|
| 651 |
+
},
|
| 652 |
+
"toc_section_display": true,
|
| 653 |
+
"toc_window_display": true
|
| 654 |
+
}
|
| 655 |
+
},
|
| 656 |
+
"nbformat": 4,
|
| 657 |
+
"nbformat_minor": 1
|
| 658 |
+
}
|
02.TFM_CNN_Model.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
03.TFM_Web_App.ipynb
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {
|
| 6 |
+
"toc": true
|
| 7 |
+
},
|
| 8 |
+
"source": [
|
| 9 |
+
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
|
| 10 |
+
"<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Implementación-del-modelo-como-una-Web-App\" data-toc-modified-id=\"Implementación-del-modelo-como-una-Web-App-1\"><span class=\"toc-item-num\">1 </span>Implementación del modelo como una Web App</a></span></li></ul></div>"
|
| 11 |
+
]
|
| 12 |
+
},
|
| 13 |
+
{
|
| 14 |
+
"cell_type": "markdown",
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"source": [
|
| 17 |
+
"# Implementación del modelo como una Web App"
|
| 18 |
+
]
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"cell_type": "code",
|
| 22 |
+
"execution_count": 1,
|
| 23 |
+
"metadata": {
|
| 24 |
+
"ExecuteTime": {
|
| 25 |
+
"end_time": "2022-02-06T22:40:31.231371Z",
|
| 26 |
+
"start_time": "2022-02-06T22:40:25.856446Z"
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"outputs": [],
|
| 30 |
+
"source": [
|
| 31 |
+
"import gradio as gr\n",
|
| 32 |
+
"import matplotlib.pyplot as plt\n",
|
| 33 |
+
"import numpy as np\n",
|
| 34 |
+
"import PIL\n",
|
| 35 |
+
"import tensorflow as tf"
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "markdown",
|
| 40 |
+
"metadata": {
|
| 41 |
+
"ExecuteTime": {
|
| 42 |
+
"end_time": "2022-01-24T14:01:13.298437Z",
|
| 43 |
+
"start_time": "2022-01-24T14:01:13.293451Z"
|
| 44 |
+
}
|
| 45 |
+
},
|
| 46 |
+
"source": [
|
| 47 |
+
"En primer lugar, creamos la función sobre la que envolveremos la interfaz de Gradio. Para ello, cargamos el modelo:"
|
| 48 |
+
]
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"cell_type": "code",
|
| 52 |
+
"execution_count": 2,
|
| 53 |
+
"metadata": {
|
| 54 |
+
"ExecuteTime": {
|
| 55 |
+
"end_time": "2022-02-06T22:40:32.997510Z",
|
| 56 |
+
"start_time": "2022-02-06T22:40:31.232369Z"
|
| 57 |
+
}
|
| 58 |
+
},
|
| 59 |
+
"outputs": [],
|
| 60 |
+
"source": [
|
| 61 |
+
"model = tf.keras.models.load_model('model.h5')"
|
| 62 |
+
]
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
"cell_type": "code",
|
| 66 |
+
"execution_count": 3,
|
| 67 |
+
"metadata": {
|
| 68 |
+
"ExecuteTime": {
|
| 69 |
+
"end_time": "2022-02-06T22:40:33.013563Z",
|
| 70 |
+
"start_time": "2022-02-06T22:40:32.998484Z"
|
| 71 |
+
}
|
| 72 |
+
},
|
| 73 |
+
"outputs": [],
|
| 74 |
+
"source": [
|
| 75 |
+
"class_name_list = ['Edible', 'Inedible', 'Poisonous']"
|
| 76 |
+
]
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
"cell_type": "code",
|
| 80 |
+
"execution_count": 4,
|
| 81 |
+
"metadata": {
|
| 82 |
+
"ExecuteTime": {
|
| 83 |
+
"end_time": "2022-02-06T22:40:33.028866Z",
|
| 84 |
+
"start_time": "2022-02-06T22:40:33.014537Z"
|
| 85 |
+
}
|
| 86 |
+
},
|
| 87 |
+
"outputs": [],
|
| 88 |
+
"source": [
|
| 89 |
+
"def predict_image(img):\n",
|
| 90 |
+
" # Reescalamos la imagen en 4 dimensiones\n",
|
| 91 |
+
" img_4d = img.reshape(-1,224,224,3)\n",
|
| 92 |
+
" # Predicción del modelo\n",
|
| 93 |
+
" prediction = model.predict(img_4d)[0]\n",
|
| 94 |
+
" # Diccionario con todas las clases y las probabilidades correspondientes\n",
|
| 95 |
+
" return {class_name_list[i]: float(prediction[i]) for i in range(3)}"
|
| 96 |
+
]
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"cell_type": "code",
|
| 100 |
+
"execution_count": 5,
|
| 101 |
+
"metadata": {
|
| 102 |
+
"ExecuteTime": {
|
| 103 |
+
"end_time": "2022-02-06T22:40:36.372549Z",
|
| 104 |
+
"start_time": "2022-02-06T22:40:33.029834Z"
|
| 105 |
+
},
|
| 106 |
+
"scrolled": true
|
| 107 |
+
},
|
| 108 |
+
"outputs": [
|
| 109 |
+
{
|
| 110 |
+
"name": "stderr",
|
| 111 |
+
"output_type": "stream",
|
| 112 |
+
"text": [
|
| 113 |
+
"C:\\Users\\Usuario\\anaconda3\\envs\\python38gpu\\lib\\site-packages\\gradio\\interface.py:272: UserWarning: 'darkpeach' theme name is deprecated, using dark-peach instead.\n",
|
| 114 |
+
" warnings.warn(\n",
|
| 115 |
+
"C:\\Users\\Usuario\\anaconda3\\envs\\python38gpu\\lib\\site-packages\\gradio\\interface.py:338: UserWarning: The `allow_flagging` parameter in `Interface` nowtakes a string value ('auto', 'manual', or 'never'), not a boolean. Setting parameter to: 'never'.\n",
|
| 116 |
+
" warnings.warn(\n"
|
| 117 |
+
]
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"name": "stdout",
|
| 121 |
+
"output_type": "stream",
|
| 122 |
+
"text": [
|
| 123 |
+
"Running on local URL: http://127.0.0.1:7860/\n",
|
| 124 |
+
"\n",
|
| 125 |
+
"To create a public link, set `share=True` in `launch()`.\n"
|
| 126 |
+
]
|
| 127 |
+
},
|
| 128 |
+
{
|
| 129 |
+
"data": {
|
| 130 |
+
"text/html": [
|
| 131 |
+
"\n",
|
| 132 |
+
" <iframe\n",
|
| 133 |
+
" width=\"900\"\n",
|
| 134 |
+
" height=\"500\"\n",
|
| 135 |
+
" src=\"http://127.0.0.1:7860/\"\n",
|
| 136 |
+
" frameborder=\"0\"\n",
|
| 137 |
+
" allowfullscreen\n",
|
| 138 |
+
" \n",
|
| 139 |
+
" ></iframe>\n",
|
| 140 |
+
" "
|
| 141 |
+
],
|
| 142 |
+
"text/plain": [
|
| 143 |
+
"<IPython.lib.display.IFrame at 0x1875520e790>"
|
| 144 |
+
]
|
| 145 |
+
},
|
| 146 |
+
"metadata": {},
|
| 147 |
+
"output_type": "display_data"
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"data": {
|
| 151 |
+
"text/plain": [
|
| 152 |
+
"(<fastapi.applications.FastAPI at 0x1873512db50>,\n",
|
| 153 |
+
" 'http://127.0.0.1:7860/',\n",
|
| 154 |
+
" None)"
|
| 155 |
+
]
|
| 156 |
+
},
|
| 157 |
+
"execution_count": 5,
|
| 158 |
+
"metadata": {},
|
| 159 |
+
"output_type": "execute_result"
|
| 160 |
+
}
|
| 161 |
+
],
|
| 162 |
+
"source": [
|
| 163 |
+
"image = gr.inputs.Image(shape=(224,224))\n",
|
| 164 |
+
"label = gr.outputs.Label(num_top_classes=3)\n",
|
| 165 |
+
"title = 'Mushroom Edibility Classifier'\n",
|
| 166 |
+
"description = 'Get the edibility classification for the input mushroom image'\n",
|
| 167 |
+
"examples=[['app_interface/Boletus edulis 15 wf.jpg'],\n",
|
| 168 |
+
" ['app_interface/Cantharelluscibarius5 mw.jpg'],\n",
|
| 169 |
+
" ['app_interface/Agaricus augustus 2 wf.jpg'],\n",
|
| 170 |
+
" ['app_interface/Coprinellus micaceus 8 wf.jpg'],\n",
|
| 171 |
+
" ['app_interface/Clavulinopsis fusiformis 2 fp.jpg'],\n",
|
| 172 |
+
" ['app_interface/Amanita torrendii 8 fp.jpg'],\n",
|
| 173 |
+
" ['app_interface/Russula sanguinea 5 fp.jpg'],\n",
|
| 174 |
+
" ['app_interface/Caloceraviscosa1 mw.jpg'],\n",
|
| 175 |
+
" ['app_interface/Amanita muscaria 1 wf.jpg'],\n",
|
| 176 |
+
" ['app_interface/Amanita pantherina 11 wf.jpg'],\n",
|
| 177 |
+
" ['app_interface/Lactarius torminosus 6 fp.jpg'],\n",
|
| 178 |
+
" ['app_interface/Amanitaphalloides1 mw.jpg']]\n",
|
| 179 |
+
"thumbnail = 'app_interface/thumbnail.png'\n",
|
| 180 |
+
"article = '''\n",
|
| 181 |
+
"<!DOCTYPE html>\n",
|
| 182 |
+
"<html>\n",
|
| 183 |
+
"<body>\n",
|
| 184 |
+
"<p>The Mushroom Edibility Classifier is an MVP for CNN multiclass classification model.<br>\n",
|
| 185 |
+
"It has been trained after gathering <b>5500 mushroom images</b> through Web Scraping techniques from the following web sites:</p>\n",
|
| 186 |
+
"<br>\n",
|
| 187 |
+
"<p>\n",
|
| 188 |
+
"<a href=\"https://www.mushroom.world/\">- Mushroom World</a><br>\n",
|
| 189 |
+
"<a href=\"https://www.wildfooduk.com/mushroom-guide/\">- Wild Food UK</a> <br>\n",
|
| 190 |
+
"<a href=\"https://www.fungipedia.org/hongos\">- Fungipedia</a><\n",
|
| 191 |
+
"</p>\n",
|
| 192 |
+
"<br>\n",
|
| 193 |
+
"<p style=\"color:Orange;\">Note: <i>model created solely and exclusively for academic purposes. The results provided by the model should never be considered definitive as the accuracy of the model is not guaranteed.</i></p>\n",
|
| 194 |
+
"\n",
|
| 195 |
+
"<br>\n",
|
| 196 |
+
"<p><b>MODEL METRICS:</b></p> \n",
|
| 197 |
+
"<table>\n",
|
| 198 |
+
" <tr>\n",
|
| 199 |
+
" <th> </th>\n",
|
| 200 |
+
" <th>precision</th>\n",
|
| 201 |
+
" <th>recall</th>\n",
|
| 202 |
+
" <th>f1-score</th>\n",
|
| 203 |
+
" <th>support</th>\n",
|
| 204 |
+
" </tr>\n",
|
| 205 |
+
" <tr>\n",
|
| 206 |
+
" <th>Edible</th>\n",
|
| 207 |
+
" <th>0.61</th>\n",
|
| 208 |
+
" <th>0.70</th>\n",
|
| 209 |
+
" <th>0.65</th>\n",
|
| 210 |
+
" <th>481</th>\n",
|
| 211 |
+
" </tr>\n",
|
| 212 |
+
" <tr>\n",
|
| 213 |
+
" <th>Inedible</th>\n",
|
| 214 |
+
" <th>0.67</th>\n",
|
| 215 |
+
" <th>0.69</th>\n",
|
| 216 |
+
" <th>0.68</th>\n",
|
| 217 |
+
" <th>439</th>\n",
|
| 218 |
+
" </tr>\n",
|
| 219 |
+
" <tr>\n",
|
| 220 |
+
" <th>Poisonous</th>\n",
|
| 221 |
+
" <th>0.52</th>\n",
|
| 222 |
+
" <th>0.28</th>\n",
|
| 223 |
+
" <th>0.36</th>\n",
|
| 224 |
+
" <th>192</th>\n",
|
| 225 |
+
" </tr>\n",
|
| 226 |
+
" <tr>\n",
|
| 227 |
+
" <th></th>\n",
|
| 228 |
+
" </tr>\n",
|
| 229 |
+
" <tr>\n",
|
| 230 |
+
" <th>Global Accuracy</th>\n",
|
| 231 |
+
" <th></th>\n",
|
| 232 |
+
" <th></th>\n",
|
| 233 |
+
" <th>0.63</th>\n",
|
| 234 |
+
" <th>1112</th>\n",
|
| 235 |
+
" </tr>\n",
|
| 236 |
+
" <tr>\n",
|
| 237 |
+
" <th>Macro Average</th>\n",
|
| 238 |
+
" <th>0.60</th>\n",
|
| 239 |
+
" <th>0.56</th>\n",
|
| 240 |
+
" <th>0.57</th>\n",
|
| 241 |
+
" <th>1112</th>\n",
|
| 242 |
+
" </tr>\n",
|
| 243 |
+
" <tr>\n",
|
| 244 |
+
" <th>Weighted Average</th>\n",
|
| 245 |
+
" <th>0.62</th>\n",
|
| 246 |
+
" <th>0.63</th>\n",
|
| 247 |
+
" <th>0.61</th>\n",
|
| 248 |
+
" <th>1112</th>\n",
|
| 249 |
+
" </tr>\n",
|
| 250 |
+
"</table>\n",
|
| 251 |
+
"<br>\n",
|
| 252 |
+
"<p><i>Author: Íñigo Sarralde Alzórriz</i></p> \n",
|
| 253 |
+
"</body>\n",
|
| 254 |
+
"</html>\n",
|
| 255 |
+
"'''\n",
|
| 256 |
+
"\n",
|
| 257 |
+
"iface = gr.Interface(fn=predict_image, \n",
|
| 258 |
+
" inputs=image, \n",
|
| 259 |
+
" outputs=label,\n",
|
| 260 |
+
" interpretation='default',\n",
|
| 261 |
+
" title = title,\n",
|
| 262 |
+
" description = description,\n",
|
| 263 |
+
" theme = 'darkpeach',\n",
|
| 264 |
+
" examples = examples,\n",
|
| 265 |
+
" thumbnail = thumbnail,\n",
|
| 266 |
+
" article = article,\n",
|
| 267 |
+
" allow_flagging = False,\n",
|
| 268 |
+
" allow_screenshot = False, \n",
|
| 269 |
+
" )\n",
|
| 270 |
+
"iface.launch()"
|
| 271 |
+
]
|
| 272 |
+
}
|
| 273 |
+
],
|
| 274 |
+
"metadata": {
|
| 275 |
+
"accelerator": "GPU",
|
| 276 |
+
"colab": {
|
| 277 |
+
"collapsed_sections": [
|
| 278 |
+
"eRTY-COfOwwD",
|
| 279 |
+
"ip1P14xN-uSX",
|
| 280 |
+
"VaNHXO2N_Hv-",
|
| 281 |
+
"mhPpAK2bMyQZ",
|
| 282 |
+
"rEI-mXrkU4ku"
|
| 283 |
+
],
|
| 284 |
+
"name": "PrevioTFM3.ipynb",
|
| 285 |
+
"provenance": []
|
| 286 |
+
},
|
| 287 |
+
"kernelspec": {
|
| 288 |
+
"display_name": "Python 3 (ipykernel)",
|
| 289 |
+
"language": "python",
|
| 290 |
+
"name": "python3"
|
| 291 |
+
},
|
| 292 |
+
"language_info": {
|
| 293 |
+
"codemirror_mode": {
|
| 294 |
+
"name": "ipython",
|
| 295 |
+
"version": 3
|
| 296 |
+
},
|
| 297 |
+
"file_extension": ".py",
|
| 298 |
+
"mimetype": "text/x-python",
|
| 299 |
+
"name": "python",
|
| 300 |
+
"nbconvert_exporter": "python",
|
| 301 |
+
"pygments_lexer": "ipython3",
|
| 302 |
+
"version": "3.8.12"
|
| 303 |
+
},
|
| 304 |
+
"toc": {
|
| 305 |
+
"base_numbering": 1,
|
| 306 |
+
"nav_menu": {},
|
| 307 |
+
"number_sections": true,
|
| 308 |
+
"sideBar": true,
|
| 309 |
+
"skip_h1_title": false,
|
| 310 |
+
"title_cell": "Table of Contents",
|
| 311 |
+
"title_sidebar": "Contents",
|
| 312 |
+
"toc_cell": true,
|
| 313 |
+
"toc_position": {
|
| 314 |
+
"height": "877px",
|
| 315 |
+
"left": "70px",
|
| 316 |
+
"top": "111.125px",
|
| 317 |
+
"width": "316.771px"
|
| 318 |
+
},
|
| 319 |
+
"toc_section_display": true,
|
| 320 |
+
"toc_window_display": false
|
| 321 |
+
}
|
| 322 |
+
},
|
| 323 |
+
"nbformat": 4,
|
| 324 |
+
"nbformat_minor": 1
|
| 325 |
+
}
|
Images.rar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:be1b81d1226d506d35e4f0e4f3ef903a797b3b46266af3b2b2f6ab11430c8cf5
|
| 3 |
+
size 277969255
|
app.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
import numpy as np
|
| 4 |
+
import PIL
|
| 5 |
+
import tensorflow as tf
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
model = tf.keras.models.load_model('model.h5')
|
| 9 |
+
class_name_list = ['Edible', 'Inedible', 'Poisonous']
|
| 10 |
+
|
| 11 |
+
def predict_image(img):
|
| 12 |
+
# Reescalamos la imagen en 4 dimensiones
|
| 13 |
+
img_4d = img.reshape(-1,224,224,3)
|
| 14 |
+
# Predicción del modelo
|
| 15 |
+
prediction = model.predict(img_4d)[0]
|
| 16 |
+
# Diccionario con todas las clases y las probabilidades correspondientes
|
| 17 |
+
return {class_name_list[i]: float(prediction[i]) for i in range(3)}
|
| 18 |
+
image = gr.inputs.Image(shape=(224,224))
|
| 19 |
+
label = gr.outputs.Label(num_top_classes=3)
|
| 20 |
+
title = 'Mushroom Edibility Classifier'
|
| 21 |
+
description = 'Get the edibility classification for the input mushroom image'
|
| 22 |
+
examples=[['app_interface/Boletus edulis 15 wf.jpg'],
|
| 23 |
+
['app_interface/Cantharelluscibarius5 mw.jpg'],
|
| 24 |
+
['app_interface/Agaricus augustus 2 wf.jpg'],
|
| 25 |
+
['app_interface/Coprinellus micaceus 8 wf.jpg'],
|
| 26 |
+
['app_interface/Clavulinopsis fusiformis 2 fp.jpg'],
|
| 27 |
+
['app_interface/Amanita torrendii 8 fp.jpg'],
|
| 28 |
+
['app_interface/Russula sanguinea 5 fp.jpg'],
|
| 29 |
+
['app_interface/Caloceraviscosa1 mw.jpg'],
|
| 30 |
+
['app_interface/Amanita muscaria 1 wf.jpg'],
|
| 31 |
+
['app_interface/Amanita pantherina 11 wf.jpg'],
|
| 32 |
+
['app_interface/Lactarius torminosus 6 fp.jpg'],
|
| 33 |
+
['app_interface/Amanitaphalloides1 mw.jpg']]
|
| 34 |
+
thumbnail = 'app_interface/thumbnail.png'
|
| 35 |
+
article = '''
|
| 36 |
+
<!DOCTYPE html>
|
| 37 |
+
<html>
|
| 38 |
+
<body>
|
| 39 |
+
<p>The Mushroom Edibility Classifier is an MVP for CNN multiclass classification model.<br>
|
| 40 |
+
It has been trained after gathering <b>5500 mushroom images</b> through Web Scraping techniques from the following web sites:</p>
|
| 41 |
+
<br>
|
| 42 |
+
<p>
|
| 43 |
+
<a href="https://www.mushroom.world/">- Mushroom World</a><br>
|
| 44 |
+
<a href="https://www.wildfooduk.com/mushroom-guide/">- Wild Food UK</a> <br>
|
| 45 |
+
<a href="https://www.fungipedia.org/hongos">- Fungipedia</a>
|
| 46 |
+
</p>
|
| 47 |
+
<br>
|
| 48 |
+
<p style="color:Orange;">Note: <i>model created solely and exclusively for academic purposes. The results provided by the model should never be considered definitive as the accuracy of the model is not guaranteed.</i></p>
|
| 49 |
+
|
| 50 |
+
<br>
|
| 51 |
+
<p><b>MODEL METRICS:</b></p>
|
| 52 |
+
<table>
|
| 53 |
+
<tr>
|
| 54 |
+
<th> </th>
|
| 55 |
+
<th>precision</th>
|
| 56 |
+
<th>recall</th>
|
| 57 |
+
<th>f1-score</th>
|
| 58 |
+
<th>support</th>
|
| 59 |
+
</tr>
|
| 60 |
+
<tr>
|
| 61 |
+
<th>Edible</th>
|
| 62 |
+
<th>0.61</th>
|
| 63 |
+
<th>0.70</th>
|
| 64 |
+
<th>0.65</th>
|
| 65 |
+
<th>481</th>
|
| 66 |
+
</tr>
|
| 67 |
+
<tr>
|
| 68 |
+
<th>Inedible</th>
|
| 69 |
+
<th>0.67</th>
|
| 70 |
+
<th>0.69</th>
|
| 71 |
+
<th>0.68</th>
|
| 72 |
+
<th>439</th>
|
| 73 |
+
</tr>
|
| 74 |
+
<tr>
|
| 75 |
+
<th>Poisonous</th>
|
| 76 |
+
<th>0.52</th>
|
| 77 |
+
<th>0.28</th>
|
| 78 |
+
<th>0.36</th>
|
| 79 |
+
<th>192</th>
|
| 80 |
+
</tr>
|
| 81 |
+
<tr>
|
| 82 |
+
<th></th>
|
| 83 |
+
</tr>
|
| 84 |
+
<tr>
|
| 85 |
+
<th>Global Accuracy</th>
|
| 86 |
+
<th></th>
|
| 87 |
+
<th></th>
|
| 88 |
+
<th>0.63</th>
|
| 89 |
+
<th>1112</th>
|
| 90 |
+
</tr>
|
| 91 |
+
<tr>
|
| 92 |
+
<th>Macro Average</th>
|
| 93 |
+
<th>0.60</th>
|
| 94 |
+
<th>0.56</th>
|
| 95 |
+
<th>0.57</th>
|
| 96 |
+
<th>1112</th>
|
| 97 |
+
</tr>
|
| 98 |
+
<tr>
|
| 99 |
+
<th>Weighted Average</th>
|
| 100 |
+
<th>0.62</th>
|
| 101 |
+
<th>0.63</th>
|
| 102 |
+
<th>0.61</th>
|
| 103 |
+
<th>1112</th>
|
| 104 |
+
</tr>
|
| 105 |
+
</table>
|
| 106 |
+
<br>
|
| 107 |
+
<p><i>Author: Íñigo Sarralde Alzórriz</i></p>
|
| 108 |
+
</body>
|
| 109 |
+
</html>
|
| 110 |
+
'''
|
| 111 |
+
|
| 112 |
+
iface = gr.Interface(fn=predict_image,
|
| 113 |
+
inputs=image,
|
| 114 |
+
outputs=label,
|
| 115 |
+
interpretation='default',
|
| 116 |
+
title = title,
|
| 117 |
+
description = description,
|
| 118 |
+
theme = 'darkpeach',
|
| 119 |
+
examples = examples,
|
| 120 |
+
thumbnail = thumbnail,
|
| 121 |
+
article = article,
|
| 122 |
+
allow_flagging = False,
|
| 123 |
+
allow_screenshot = False,
|
| 124 |
+
)
|
| 125 |
+
iface.launch()
|
app_interface/Agaricus augustus 2 wf.jpg
ADDED

|
app_interface/Amanita muscaria 1 wf.jpg
ADDED

|
app_interface/Amanita pantherina 11 wf.jpg
ADDED

|
app_interface/Amanita torrendii 8 fp.jpg
ADDED

|
app_interface/Amanitaphalloides1 mw.jpg
ADDED

|
app_interface/Boletus edulis 15 wf.jpg
ADDED

|
app_interface/Caloceraviscosa1 mw.jpg
ADDED

|
app_interface/Cantharelluscibarius5 mw.jpg
ADDED

|
app_interface/Clavulinopsis fusiformis 2 fp.jpg
ADDED

|
app_interface/Coprinellus micaceus 8 wf.jpg
ADDED

|
app_interface/Lactarius torminosus 6 fp.jpg
ADDED

|
app_interface/Russula sanguinea 5 fp.jpg
ADDED

|
app_interface/confusion_matrix.png
ADDED
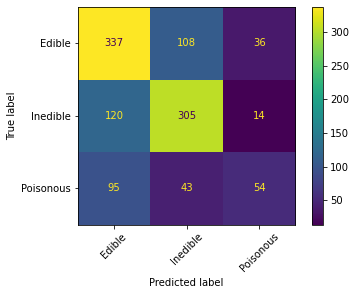
|
app_interface/thumbnail.png
ADDED

|
model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9082514a060a21889095037be1a417104443e5227e06f361e121e81fd8113d2c
|
| 3 |
+
size 126050640
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio==2.7.5.2
|
| 2 |
+
matplotlib==3.5.1
|
| 3 |
+
numpy==1.22.1
|
| 4 |
+
Pillow==9.0.0
|
| 5 |
+
tensorflow==2.7.0
|