 -
-Prepare the conditioning:
-
-```python
-from diffusers.utils import load_image
-from PIL import Image
-import cv2
-import numpy as np
-from diffusers.utils import load_image
-
-canny_image = load_image(
- "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
-)
-canny_image = np.array(canny_image)
-
-low_threshold = 100
-high_threshold = 200
-
-canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
-
-# zero out middle columns of image where pose will be overlayed
-zero_start = canny_image.shape[1] // 4
-zero_end = zero_start + canny_image.shape[1] // 2
-canny_image[:, zero_start:zero_end] = 0
-
-canny_image = canny_image[:, :, None]
-canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
-canny_image = Image.fromarray(canny_image)
-```
-
-
-
-Prepare the conditioning:
-
-```python
-from diffusers.utils import load_image
-from PIL import Image
-import cv2
-import numpy as np
-from diffusers.utils import load_image
-
-canny_image = load_image(
- "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
-)
-canny_image = np.array(canny_image)
-
-low_threshold = 100
-high_threshold = 200
-
-canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
-
-# zero out middle columns of image where pose will be overlayed
-zero_start = canny_image.shape[1] // 4
-zero_end = zero_start + canny_image.shape[1] // 2
-canny_image[:, zero_start:zero_end] = 0
-
-canny_image = canny_image[:, :, None]
-canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
-canny_image = Image.fromarray(canny_image)
-```
-
- -
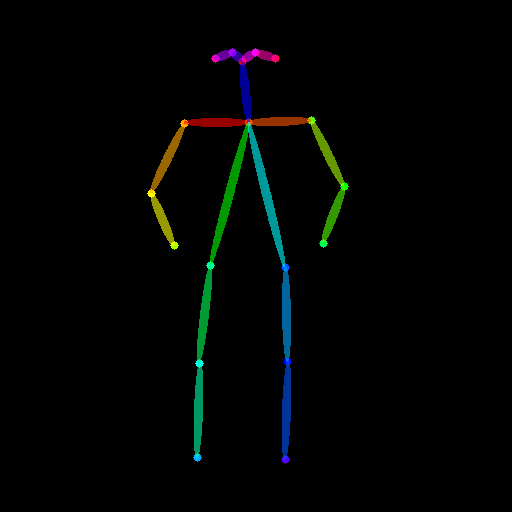
-### Openpose conditioning
-
-The original image:
-
-
-
-### Openpose conditioning
-
-The original image:
-
- -
-Prepare the conditioning:
-
-```python
-from controlnet_aux import OpenposeDetector
-from diffusers.utils import load_image
-
-openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
-
-openpose_image = load_image(
- "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
-)
-openpose_image = openpose(openpose_image)
-```
-
-
-
-Prepare the conditioning:
-
-```python
-from controlnet_aux import OpenposeDetector
-from diffusers.utils import load_image
-
-openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
-
-openpose_image = load_image(
- "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
-)
-openpose_image = openpose(openpose_image)
-```
-
- -
-### Running ControlNet with multiple conditionings
-
-```python
-from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
-import torch
-
-controlnet = [
- ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
- ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
-]
-
-pipe = StableDiffusionControlNetPipeline.from_pretrained(
- "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
-)
-pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
-
-pipe.enable_xformers_memory_efficient_attention()
-pipe.enable_model_cpu_offload()
-
-prompt = "a giant standing in a fantasy landscape, best quality"
-negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
-
-generator = torch.Generator(device="cpu").manual_seed(1)
-
-images = [openpose_image, canny_image]
-
-image = pipe(
- prompt,
- images,
- num_inference_steps=20,
- generator=generator,
- negative_prompt=negative_prompt,
- controlnet_conditioning_scale=[1.0, 0.8],
-).images[0]
-
-image.save("./multi_controlnet_output.png")
-```
-
-
-
-### Running ControlNet with multiple conditionings
-
-```python
-from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
-import torch
-
-controlnet = [
- ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
- ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
-]
-
-pipe = StableDiffusionControlNetPipeline.from_pretrained(
- "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
-)
-pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
-
-pipe.enable_xformers_memory_efficient_attention()
-pipe.enable_model_cpu_offload()
-
-prompt = "a giant standing in a fantasy landscape, best quality"
-negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
-
-generator = torch.Generator(device="cpu").manual_seed(1)
-
-images = [openpose_image, canny_image]
-
-image = pipe(
- prompt,
- images,
- num_inference_steps=20,
- generator=generator,
- negative_prompt=negative_prompt,
- controlnet_conditioning_scale=[1.0, 0.8],
-).images[0]
-
-image.save("./multi_controlnet_output.png")
-```
-
- -
-## Available checkpoints
-
-ControlNet requires a *control image* in addition to the text-to-image *prompt*.
-Each pretrained model is trained using a different conditioning method that requires different images for conditioning the generated outputs. For example, Canny edge conditioning requires the control image to be the output of a Canny filter, while depth conditioning requires the control image to be a depth map. See the overview and image examples below to know more.
-
-All checkpoints can be found under the authors' namespace [lllyasviel](https://huggingface.co/lllyasviel).
-
-### ControlNet with Stable Diffusion 1.5
-
-| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
-|---|---|---|---|
-|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)
-
-## Available checkpoints
-
-ControlNet requires a *control image* in addition to the text-to-image *prompt*.
-Each pretrained model is trained using a different conditioning method that requires different images for conditioning the generated outputs. For example, Canny edge conditioning requires the control image to be the output of a Canny filter, while depth conditioning requires the control image to be a depth map. See the overview and image examples below to know more.
-
-All checkpoints can be found under the authors' namespace [lllyasviel](https://huggingface.co/lllyasviel).
-
-### ControlNet with Stable Diffusion 1.5
-
-| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
-|---|---|---|---|
-|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)*Trained with canny edge detection* | A monochrome image with white edges on a black background.|
 |
| |
-|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)
|
-|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)*Trained with Midas depth estimation* |A grayscale image with black representing deep areas and white representing shallow areas.|
 |
| |
-|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)
|
-|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)*Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.|
 |
| |
-|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)
|
-|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)*Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.|
 |
| |
-|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)
|
-|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)*Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.|
 |
| |
-|[lllyasviel/sd-controlnet-openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)
|
-|[lllyasviel/sd-controlnet-openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)*Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|
 |
| |
-|[lllyasviel/sd-controlnet-scribble](https://huggingface.co/lllyasviel/sd-controlnet_scribble)
|
-|[lllyasviel/sd-controlnet-scribble](https://huggingface.co/lllyasviel/sd-controlnet_scribble)*Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.|
 |
| |
-|[lllyasviel/sd-controlnet-seg](https://huggingface.co/lllyasviel/sd-controlnet_seg)
|
-|[lllyasviel/sd-controlnet-seg](https://huggingface.co/lllyasviel/sd-controlnet_seg)*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.|
 |
| |
-
-## StableDiffusionControlNetPipeline
-[[autodoc]] StableDiffusionControlNetPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
-
-## FlaxStableDiffusionControlNetPipeline
-[[autodoc]] FlaxStableDiffusionControlNetPipeline
- - all
- - __call__
-
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
deleted file mode 100644
index c46576ff288757a316a5efa0ec3b753fd9ce2bd4..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
+++ /dev/null
@@ -1,33 +0,0 @@
-
-
-# Depth-to-Image Generation
-
-## StableDiffusionDepth2ImgPipeline
-
-The depth-guided stable diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. It uses [MiDas](https://github.com/isl-org/MiDaS) to infer depth based on an image.
-
-[`StableDiffusionDepth2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images as well as a `depth_map` to preserve the images’ structure.
-
-The original codebase can be found here:
-- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion)
-
-Available Checkpoints are:
-- *stable-diffusion-2-depth*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth)
-
-[[autodoc]] StableDiffusionDepth2ImgPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
deleted file mode 100644
index 8ca69ff69aec6a74e22beade70b5ef2ef42a0e3c..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
+++ /dev/null
@@ -1,31 +0,0 @@
-
-
-# Image Variation
-
-## StableDiffusionImageVariationPipeline
-
-[`StableDiffusionImageVariationPipeline`] lets you generate variations from an input image using Stable Diffusion. It uses a fine-tuned version of Stable Diffusion model, trained by [Justin Pinkney](https://www.justinpinkney.com/) (@Buntworthy) at [Lambda](https://lambdalabs.com/).
-
-The original codebase can be found here:
-[Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations)
-
-Available Checkpoints are:
-- *sd-image-variations-diffusers*: [lambdalabs/sd-image-variations-diffusers](https://huggingface.co/lambdalabs/sd-image-variations-diffusers)
-
-[[autodoc]] StableDiffusionImageVariationPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
deleted file mode 100644
index 09bfb853f9c9bdce1fbd4b4ae3571557d2a5bfc1..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
+++ /dev/null
@@ -1,36 +0,0 @@
-
-
-# Image-to-Image Generation
-
-## StableDiffusionImg2ImgPipeline
-
-The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images using Stable Diffusion.
-
-The original codebase can be found here: [CampVis/stable-diffusion](https://github.com/CompVis/stable-diffusion/blob/main/scripts/img2img.py)
-
-[`StableDiffusionImg2ImgPipeline`] is compatible with all Stable Diffusion checkpoints for [Text-to-Image](./text2img)
-
-The pipeline uses the diffusion-denoising mechanism proposed by SDEdit ([SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations](https://arxiv.org/abs/2108.01073)
-proposed by Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, Stefano Ermon).
-
-[[autodoc]] StableDiffusionImg2ImgPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
-
-[[autodoc]] FlaxStableDiffusionImg2ImgPipeline
- - all
- - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
deleted file mode 100644
index 33e84a63261fbf9c370e2d5e22ffbf4a1256bbb4..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
+++ /dev/null
@@ -1,37 +0,0 @@
-
-
-# Text-Guided Image Inpainting
-
-## StableDiffusionInpaintPipeline
-
-The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionInpaintPipeline`] lets you edit specific parts of an image by providing a mask and a text prompt using Stable Diffusion.
-
-The original codebase can be found here:
-- *Stable Diffusion V1*: [CampVis/stable-diffusion](https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion)
-- *Stable Diffusion V2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-inpainting-with-stable-diffusion)
-
-Available checkpoints are:
-- *stable-diffusion-inpainting (512x512 resolution)*: [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting)
-- *stable-diffusion-2-inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting)
-
-[[autodoc]] StableDiffusionInpaintPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
-
-[[autodoc]] FlaxStableDiffusionInpaintPipeline
- - all
- - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
deleted file mode 100644
index 61fd2f799114de345400a692c115811fbf222871..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
+++ /dev/null
@@ -1,33 +0,0 @@
-
-
-# Stable Diffusion Latent Upscaler
-
-## StableDiffusionLatentUpscalePipeline
-
-The Stable Diffusion Latent Upscaler model was created by [Katherine Crowson](https://github.com/crowsonkb/k-diffusion) in collaboration with [Stability AI](https://stability.ai/). It can be used on top of any [`StableDiffusionUpscalePipeline`] checkpoint to enhance its output image resolution by a factor of 2.
-
-A notebook that demonstrates the original implementation can be found here:
-- [Stable Diffusion Upscaler Demo](https://colab.research.google.com/drive/1o1qYJcFeywzCIdkfKJy7cTpgZTCM2EI4)
-
-Available Checkpoints are:
-- *stabilityai/latent-upscaler*: [stabilityai/sd-x2-latent-upscaler](https://huggingface.co/stabilityai/sd-x2-latent-upscaler)
-
-
-[[autodoc]] StableDiffusionLatentUpscalePipeline
- - all
- - __call__
- - enable_sequential_cpu_offload
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
deleted file mode 100644
index 7aae35ba2a91774a4297ee7ada6d13a40fed6f32..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
+++ /dev/null
@@ -1,61 +0,0 @@
-
-
-# Editing Implicit Assumptions in Text-to-Image Diffusion Models
-
-## Overview
-
-[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084) by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov.
-
-The abstract of the paper is the following:
-
-*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
-
-Resources:
-
-* [Project Page](https://time-diffusion.github.io/).
-* [Paper](https://arxiv.org/abs/2303.08084).
-* [Original Code](https://github.com/bahjat-kawar/time-diffusion).
-* [Demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionModelEditingPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py) | *Text-to-Image Model Editing* | [🤗 Space](https://huggingface.co/spaces/bahjat-kawar/time-diffusion)) |
-
-This pipeline enables editing the diffusion model weights, such that its assumptions on a given concept are changed. The resulting change is expected to take effect in all prompt generations pertaining to the edited concept.
-
-## Usage example
-
-```python
-import torch
-from diffusers import StableDiffusionModelEditingPipeline
-
-model_ckpt = "CompVis/stable-diffusion-v1-4"
-pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt)
-
-pipe = pipe.to("cuda")
-
-source_prompt = "A pack of roses"
-destination_prompt = "A pack of blue roses"
-pipe.edit_model(source_prompt, destination_prompt)
-
-prompt = "A field of roses"
-image = pipe(prompt).images[0]
-image.save("field_of_roses.png")
-```
-
-## StableDiffusionModelEditingPipeline
-[[autodoc]] StableDiffusionModelEditingPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
deleted file mode 100644
index 70731fd294b91c8bca9bb1726c14011507c22a4a..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
+++ /dev/null
@@ -1,82 +0,0 @@
-
-
-# Stable diffusion pipelines
-
-Stable Diffusion is a text-to-image _latent diffusion_ model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/). It's trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and can run on consumer GPUs.
-
-Latent diffusion is the research on top of which Stable Diffusion was built. It was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. You can learn more details about it in the [specific pipeline for latent diffusion](pipelines/latent_diffusion) that is part of 🤗 Diffusers.
-
-For more details about how Stable Diffusion works and how it differs from the base latent diffusion model, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-announcement) and [this section of our own blog post](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work).
-
-*Tips*:
-- To tweak your prompts on a specific result you liked, you can generate your own latents, as demonstrated in the following notebook: [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
-
-*Overview*:
-
-| Pipeline | Tasks | Colab | Demo
-|---|---|:---:|:---:|
-| [StableDiffusionPipeline](./text2img) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb) | [🤗 Stable Diffusion](https://huggingface.co/spaces/stabilityai/stable-diffusion)
-| [StableDiffusionImg2ImgPipeline](./img2img) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb) | [🤗 Diffuse the Rest](https://huggingface.co/spaces/huggingface/diffuse-the-rest)
-| [StableDiffusionInpaintPipeline](./inpaint) | **Experimental** – *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) | Coming soon
-| [StableDiffusionDepth2ImgPipeline](./depth2img) | **Experimental** – *Depth-to-Image Text-Guided Generation * | | Coming soon
-| [StableDiffusionImageVariationPipeline](./image_variation) | **Experimental** – *Image Variation Generation * | | [🤗 Stable Diffusion Image Variations](https://huggingface.co/spaces/lambdalabs/stable-diffusion-image-variations)
-| [StableDiffusionUpscalePipeline](./upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
-| [StableDiffusionLatentUpscalePipeline](./latent_upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
-| [StableDiffusionInstructPix2PixPipeline](./pix2pix) | **Experimental** – *Text-Based Image Editing * | | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/spaces/timbrooks/instruct-pix2pix)
-| [StableDiffusionAttendAndExcitePipeline](./attend_and_excite) | **Experimental** – *Text-to-Image Generation * | | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
-| [StableDiffusionPix2PixZeroPipeline](./pix2pix_zero) | **Experimental** – *Text-Based Image Editing * | | [Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027)
-| [StableDiffusionModelEditingPipeline](./model_editing) | **Experimental** – *Text-to-Image Model Editing * | | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084)
-
-
-
-## Tips
-
-### How to load and use different schedulers.
-
-The stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
-To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
-
-```python
->>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
-
->>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
->>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
-
->>> # or
->>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
->>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=euler_scheduler)
-```
-
-
-### How to convert all use cases with multiple or single pipeline
-
-If you want to use all possible use cases in a single `DiffusionPipeline` you can either:
-- Make use of the [Stable Diffusion Mega Pipeline](https://github.com/huggingface/diffusers/tree/main/examples/community#stable-diffusion-mega) or
-- Make use of the `components` functionality to instantiate all components in the most memory-efficient way:
-
-```python
->>> from diffusers import (
-... StableDiffusionPipeline,
-... StableDiffusionImg2ImgPipeline,
-... StableDiffusionInpaintPipeline,
-... )
-
->>> text2img = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
->>> img2img = StableDiffusionImg2ImgPipeline(**text2img.components)
->>> inpaint = StableDiffusionInpaintPipeline(**text2img.components)
-
->>> # now you can use text2img(...), img2img(...), inpaint(...) just like the call methods of each respective pipeline
-```
-
-## StableDiffusionPipelineOutput
-[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
deleted file mode 100644
index e0c7747a0193013507ccc28e3d48c7ee5ab8ca11..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
+++ /dev/null
@@ -1,58 +0,0 @@
-
-
-# MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
-
-## Overview
-
-[MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation](https://arxiv.org/abs/2302.08113) by Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel.
-
-The abstract of the paper is the following:
-
-*Recent advances in text-to-image generation with diffusion models present transformative capabilities in image quality. However, user controllability of the generated image, and fast adaptation to new tasks still remains an open challenge, currently mostly addressed by costly and long re-training and fine-tuning or ad-hoc adaptations to specific image generation tasks. In this work, we present MultiDiffusion, a unified framework that enables versatile and controllable image generation, using a pre-trained text-to-image diffusion model, without any further training or finetuning. At the center of our approach is a new generation process, based on an optimization task that binds together multiple diffusion generation processes with a shared set of parameters or constraints. We show that MultiDiffusion can be readily applied to generate high quality and diverse images that adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes.
-
-Resources:
-
-* [Project Page](https://multidiffusion.github.io/).
-* [Paper](https://arxiv.org/abs/2302.08113).
-* [Original Code](https://github.com/omerbt/MultiDiffusion).
-* [Demo](https://huggingface.co/spaces/weizmannscience/MultiDiffusion).
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionPanoramaPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py) | *Text-Guided Panorama View Generation* | [🤗 Space](https://huggingface.co/spaces/weizmannscience/MultiDiffusion)) |
-
-
-
-## Usage example
-
-```python
-import torch
-from diffusers import StableDiffusionPanoramaPipeline, DDIMScheduler
-
-model_ckpt = "stabilityai/stable-diffusion-2-base"
-scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
-pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, torch_dtype=torch.float16)
-
-pipe = pipe.to("cuda")
-
-prompt = "a photo of the dolomites"
-image = pipe(prompt).images[0]
-image.save("dolomites.png")
-```
-
-## StableDiffusionPanoramaPipeline
-[[autodoc]] StableDiffusionPanoramaPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
deleted file mode 100644
index 42cd4b896b2e4603aaf826efc7201672c016563f..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
+++ /dev/null
@@ -1,70 +0,0 @@
-
-
-# InstructPix2Pix: Learning to Follow Image Editing Instructions
-
-## Overview
-
-[InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) by Tim Brooks, Aleksander Holynski and Alexei A. Efros.
-
-The abstract of the paper is the following:
-
-*We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.*
-
-Resources:
-
-* [Project Page](https://www.timothybrooks.com/instruct-pix2pix).
-* [Paper](https://arxiv.org/abs/2211.09800).
-* [Original Code](https://github.com/timothybrooks/instruct-pix2pix).
-* [Demo](https://huggingface.co/spaces/timbrooks/instruct-pix2pix).
-
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionInstructPix2PixPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/timbrooks/instruct-pix2pix) |
-
-
-
-## Usage example
-
-```python
-import PIL
-import requests
-import torch
-from diffusers import StableDiffusionInstructPix2PixPipeline
-
-model_id = "timbrooks/instruct-pix2pix"
-pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
-
-url = "https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
-
-
-def download_image(url):
- image = PIL.Image.open(requests.get(url, stream=True).raw)
- image = PIL.ImageOps.exif_transpose(image)
- image = image.convert("RGB")
- return image
-
-
-image = download_image(url)
-
-prompt = "make the mountains snowy"
-images = pipe(prompt, image=image, num_inference_steps=20, image_guidance_scale=1.5, guidance_scale=7).images
-images[0].save("snowy_mountains.png")
-```
-
-## StableDiffusionInstructPix2PixPipeline
-[[autodoc]] StableDiffusionInstructPix2PixPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
deleted file mode 100644
index f04a54f242acade990415a1ed7c240c37a828dd7..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
+++ /dev/null
@@ -1,291 +0,0 @@
-
-
-# Zero-shot Image-to-Image Translation
-
-## Overview
-
-[Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027).
-
-The abstract of the paper is the following:
-
-*Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.*
-
-Resources:
-
-* [Project Page](https://pix2pixzero.github.io/).
-* [Paper](https://arxiv.org/abs/2302.03027).
-* [Original Code](https://github.com/pix2pixzero/pix2pix-zero).
-* [Demo](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo).
-
-## Tips
-
-* The pipeline can be conditioned on real input images. Check out the code examples below to know more.
-* The pipeline exposes two arguments namely `source_embeds` and `target_embeds`
-that let you control the direction of the semantic edits in the final image to be generated. Let's say,
-you wanted to translate from "cat" to "dog". In this case, the edit direction will be "cat -> dog". To reflect
-this in the pipeline, you simply have to set the embeddings related to the phrases including "cat" to
-`source_embeds` and "dog" to `target_embeds`. Refer to the code example below for more details.
-* When you're using this pipeline from a prompt, specify the _source_ concept in the prompt. Taking
-the above example, a valid input prompt would be: "a high resolution painting of a **cat** in the style of van gough".
-* If you wanted to reverse the direction in the example above, i.e., "dog -> cat", then it's recommended to:
- * Swap the `source_embeds` and `target_embeds`.
- * Change the input prompt to include "dog".
-* To learn more about how the source and target embeddings are generated, refer to the [original
-paper](https://arxiv.org/abs/2302.03027). Below, we also provide some directions on how to generate the embeddings.
-* Note that the quality of the outputs generated with this pipeline is dependent on how good the `source_embeds` and `target_embeds` are. Please, refer to [this discussion](#generating-source-and-target-embeddings) for some suggestions on the topic.
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionPix2PixZeroPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo) |
-
-
-
-## Usage example
-
-### Based on an image generated with the input prompt
-
-```python
-import requests
-import torch
-
-from diffusers import DDIMScheduler, StableDiffusionPix2PixZeroPipeline
-
-
-def download(embedding_url, local_filepath):
- r = requests.get(embedding_url)
- with open(local_filepath, "wb") as f:
- f.write(r.content)
-
-
-model_ckpt = "CompVis/stable-diffusion-v1-4"
-pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
- model_ckpt, conditions_input_image=False, torch_dtype=torch.float16
-)
-pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
-pipeline.to("cuda")
-
-prompt = "a high resolution painting of a cat in the style of van gogh"
-src_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/cat.pt"
-target_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/dog.pt"
-
-for url in [src_embs_url, target_embs_url]:
- download(url, url.split("/")[-1])
-
-src_embeds = torch.load(src_embs_url.split("/")[-1])
-target_embeds = torch.load(target_embs_url.split("/")[-1])
-
-images = pipeline(
- prompt,
- source_embeds=src_embeds,
- target_embeds=target_embeds,
- num_inference_steps=50,
- cross_attention_guidance_amount=0.15,
-).images
-images[0].save("edited_image_dog.png")
-```
-
-### Based on an input image
-
-When the pipeline is conditioned on an input image, we first obtain an inverted
-noise from it using a `DDIMInverseScheduler` with the help of a generated caption. Then
-the inverted noise is used to start the generation process.
-
-First, let's load our pipeline:
-
-```py
-import torch
-from transformers import BlipForConditionalGeneration, BlipProcessor
-from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionPix2PixZeroPipeline
-
-captioner_id = "Salesforce/blip-image-captioning-base"
-processor = BlipProcessor.from_pretrained(captioner_id)
-model = BlipForConditionalGeneration.from_pretrained(captioner_id, torch_dtype=torch.float16, low_cpu_mem_usage=True)
-
-sd_model_ckpt = "CompVis/stable-diffusion-v1-4"
-pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
- sd_model_ckpt,
- caption_generator=model,
- caption_processor=processor,
- torch_dtype=torch.float16,
- safety_checker=None,
-)
-pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
-pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
-pipeline.enable_model_cpu_offload()
-```
-
-Then, we load an input image for conditioning and obtain a suitable caption for it:
-
-```py
-import requests
-from PIL import Image
-
-img_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/test_images/cats/cat_6.png"
-raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB").resize((512, 512))
-caption = pipeline.generate_caption(raw_image)
-```
-
-Then we employ the generated caption and the input image to get the inverted noise:
-
-```py
-generator = torch.manual_seed(0)
-inv_latents = pipeline.invert(caption, image=raw_image, generator=generator).latents
-```
-
-Now, generate the image with edit directions:
-
-```py
-# See the "Generating source and target embeddings" section below to
-# automate the generation of these captions with a pre-trained model like Flan-T5 as explained below.
-source_prompts = ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
-target_prompts = ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
-
-source_embeds = pipeline.get_embeds(source_prompts, batch_size=2)
-target_embeds = pipeline.get_embeds(target_prompts, batch_size=2)
-
-
-image = pipeline(
- caption,
- source_embeds=source_embeds,
- target_embeds=target_embeds,
- num_inference_steps=50,
- cross_attention_guidance_amount=0.15,
- generator=generator,
- latents=inv_latents,
- negative_prompt=caption,
-).images[0]
-image.save("edited_image.png")
-```
-
-## Generating source and target embeddings
-
-The authors originally used the [GPT-3 API](https://openai.com/api/) to generate the source and target captions for discovering
-edit directions. However, we can also leverage open source and public models for the same purpose.
-Below, we provide an end-to-end example with the [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5) model
-for generating captions and [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for
-computing embeddings on the generated captions.
-
-**1. Load the generation model**:
-
-```py
-import torch
-from transformers import AutoTokenizer, T5ForConditionalGeneration
-
-tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
-model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xl", device_map="auto", torch_dtype=torch.float16)
-```
-
-**2. Construct a starting prompt**:
-
-```py
-source_concept = "cat"
-target_concept = "dog"
-
-source_text = f"Provide a caption for images containing a {source_concept}. "
-"The captions should be in English and should be no longer than 150 characters."
-
-target_text = f"Provide a caption for images containing a {target_concept}. "
-"The captions should be in English and should be no longer than 150 characters."
-```
-
-Here, we're interested in the "cat -> dog" direction.
-
-**3. Generate captions**:
-
-We can use a utility like so for this purpose.
-
-```py
-def generate_captions(input_prompt):
- input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.to("cuda")
-
- outputs = model.generate(
- input_ids, temperature=0.8, num_return_sequences=16, do_sample=True, max_new_tokens=128, top_k=10
- )
- return tokenizer.batch_decode(outputs, skip_special_tokens=True)
-```
-
-And then we just call it to generate our captions:
-
-```py
-source_captions = generate_captions(source_text)
-target_captions = generate_captions(target_concept)
-```
-
-We encourage you to play around with the different parameters supported by the
-`generate()` method ([documentation](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_tf_utils.TFGenerationMixin.generate)) for the generation quality you are looking for.
-
-**4. Load the embedding model**:
-
-Here, we need to use the same text encoder model used by the subsequent Stable Diffusion model.
-
-```py
-from diffusers import StableDiffusionPix2PixZeroPipeline
-
-pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
- "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
-)
-pipeline = pipeline.to("cuda")
-tokenizer = pipeline.tokenizer
-text_encoder = pipeline.text_encoder
-```
-
-**5. Compute embeddings**:
-
-```py
-import torch
-
-def embed_captions(sentences, tokenizer, text_encoder, device="cuda"):
- with torch.no_grad():
- embeddings = []
- for sent in sentences:
- text_inputs = tokenizer(
- sent,
- padding="max_length",
- max_length=tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
- prompt_embeds = text_encoder(text_input_ids.to(device), attention_mask=None)[0]
- embeddings.append(prompt_embeds)
- return torch.concatenate(embeddings, dim=0).mean(dim=0).unsqueeze(0)
-
-source_embeddings = embed_captions(source_captions, tokenizer, text_encoder)
-target_embeddings = embed_captions(target_captions, tokenizer, text_encoder)
-```
-
-And you're done! [Here](https://colab.research.google.com/drive/1tz2C1EdfZYAPlzXXbTnf-5PRBiR8_R1F?usp=sharing) is a Colab Notebook that you can use to interact with the entire process.
-
-Now, you can use these embeddings directly while calling the pipeline:
-
-```py
-from diffusers import DDIMScheduler
-
-pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
-
-images = pipeline(
- prompt,
- source_embeds=source_embeddings,
- target_embeds=target_embeddings,
- num_inference_steps=50,
- cross_attention_guidance_amount=0.15,
-).images
-images[0].save("edited_image_dog.png")
-```
-
-## StableDiffusionPix2PixZeroPipeline
-[[autodoc]] StableDiffusionPix2PixZeroPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
deleted file mode 100644
index b34c1f51cf668b289ca000719828addb88f6a20e..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
+++ /dev/null
@@ -1,64 +0,0 @@
-
-
-# Self-Attention Guidance (SAG)
-
-## Overview
-
-[Self-Attention Guidance](https://arxiv.org/abs/2210.00939) by Susung Hong et al.
-
-The abstract of the paper is the following:
-
-*Denoising diffusion models (DDMs) have been drawing much attention for their appreciable sample quality and diversity. Despite their remarkable performance, DDMs remain black boxes on which further study is necessary to take a profound step. Motivated by this, we delve into the design of conventional U-shaped diffusion models. More specifically, we investigate the self-attention modules within these models through carefully designed experiments and explore their characteristics. In addition, inspired by the studies that substantiate the effectiveness of the guidance schemes, we present plug-and-play diffusion guidance, namely Self-Attention Guidance (SAG), that can drastically boost the performance of existing diffusion models. Our method, SAG, extracts the intermediate attention map from a diffusion model at every iteration and selects tokens above a certain attention score for masking and blurring to obtain a partially blurred input. Subsequently, we measure the dissimilarity between the predicted noises obtained from feeding the blurred and original input to the diffusion model and leverage it as guidance. With this guidance, we observe apparent improvements in a wide range of diffusion models, e.g., ADM, IDDPM, and Stable Diffusion, and show that the results further improve by combining our method with the conventional guidance scheme. We provide extensive ablation studies to verify our choices.*
-
-Resources:
-
-* [Project Page](https://ku-cvlab.github.io/Self-Attention-Guidance).
-* [Paper](https://arxiv.org/abs/2210.00939).
-* [Original Code](https://github.com/KU-CVLAB/Self-Attention-Guidance).
-* [Demo](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb).
-
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionSAGPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py) | *Text-to-Image Generation* | [Colab](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb) |
-
-## Usage example
-
-```python
-import torch
-from diffusers import StableDiffusionSAGPipeline
-from accelerate.utils import set_seed
-
-pipe = StableDiffusionSAGPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
-pipe = pipe.to("cuda")
-
-seed = 8978
-prompt = "."
-guidance_scale = 7.5
-num_images_per_prompt = 1
-
-sag_scale = 1.0
-
-set_seed(seed)
-images = pipe(
- prompt, num_images_per_prompt=num_images_per_prompt, guidance_scale=guidance_scale, sag_scale=sag_scale
-).images
-images[0].save("example.png")
-```
-
-## StableDiffusionSAGPipeline
-[[autodoc]] StableDiffusionSAGPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
deleted file mode 100644
index 6b8d53bf6510a0b122529170e0de3cbddcc40690..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
+++ /dev/null
@@ -1,45 +0,0 @@
-
-
-# Text-to-Image Generation
-
-## StableDiffusionPipeline
-
-The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionPipeline`] is capable of generating photo-realistic images given any text input using Stable Diffusion.
-
-The original codebase can be found here:
-- *Stable Diffusion V1*: [CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion)
-- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion)
-
-Available Checkpoints are:
-- *stable-diffusion-v1-4 (512x512 resolution)* [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)
-- *stable-diffusion-v1-5 (512x512 resolution)* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
-- *stable-diffusion-2-base (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base)
-- *stable-diffusion-2 (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2)
-- *stable-diffusion-2-1-base (512x512 resolution)* [stabilityai/stable-diffusion-2-1-base](https://huggingface.co/stabilityai/stable-diffusion-2-1-base)
-- *stable-diffusion-2-1 (768x768 resolution)*: [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1)
-
-[[autodoc]] StableDiffusionPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
- - enable_vae_tiling
- - disable_vae_tiling
-
-[[autodoc]] FlaxStableDiffusionPipeline
- - all
- - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
deleted file mode 100644
index f70d8f445fd95fb49e7a92c7566951c40ec74933..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
+++ /dev/null
@@ -1,32 +0,0 @@
-
-
-# Super-Resolution
-
-## StableDiffusionUpscalePipeline
-
-The upscaler diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. [`StableDiffusionUpscalePipeline`] can be used to enhance the resolution of input images by a factor of 4.
-
-The original codebase can be found here:
-- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-upscaling-with-stable-diffusion)
-
-Available Checkpoints are:
-- *stabilityai/stable-diffusion-x4-upscaler (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler)
-
-
-[[autodoc]] StableDiffusionUpscalePipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
deleted file mode 100644
index e922072e4e3185f9de4a0d6e734e0c46a4fe3215..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
+++ /dev/null
@@ -1,176 +0,0 @@
-
-
-# Stable diffusion 2
-
-Stable Diffusion 2 is a text-to-image _latent diffusion_ model built upon the work of [Stable Diffusion 1](https://stability.ai/blog/stable-diffusion-public-release).
-The project to train Stable Diffusion 2 was led by Robin Rombach and Katherine Crowson from [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
-
-*The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases. The text-to-image models in this release can generate images with default resolutions of both 512x512 pixels and 768x768 pixels.
-These models are trained on an aesthetic subset of the [LAION-5B dataset](https://laion.ai/blog/laion-5b/) created by the DeepFloyd team at Stability AI, which is then further filtered to remove adult content using [LAION’s NSFW filter](https://openreview.net/forum?id=M3Y74vmsMcY).*
-
-For more details about how Stable Diffusion 2 works and how it differs from Stable Diffusion 1, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-v2-release).
-
-## Tips
-
-### Available checkpoints:
-
-Note that the architecture is more or less identical to [Stable Diffusion 1](./stable_diffusion/overview) so please refer to [this page](./stable_diffusion/overview) for API documentation.
-
-- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
-- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
-- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
-- *Super-Resolution (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) [`StableDiffusionUpscalePipeline`]
-- *Depth-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) with [`StableDiffusionDepth2ImagePipeline`]
-
-We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest scheduler there is.
-
-
-### Text-to-Image
-
-- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
-
-```python
-from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
-import torch
-
-repo_id = "stabilityai/stable-diffusion-2-base"
-pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
-
-pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
-pipe = pipe.to("cuda")
-
-prompt = "High quality photo of an astronaut riding a horse in space"
-image = pipe(prompt, num_inference_steps=25).images[0]
-image.save("astronaut.png")
-```
-
-- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
-
-```python
-from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
-import torch
-
-repo_id = "stabilityai/stable-diffusion-2"
-pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
-
-pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
-pipe = pipe.to("cuda")
-
-prompt = "High quality photo of an astronaut riding a horse in space"
-image = pipe(prompt, guidance_scale=9, num_inference_steps=25).images[0]
-image.save("astronaut.png")
-```
-
-### Image Inpainting
-
-- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
-
-```python
-import PIL
-import requests
-import torch
-from io import BytesIO
-
-from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
-
-
-def download_image(url):
- response = requests.get(url)
- return PIL.Image.open(BytesIO(response.content)).convert("RGB")
-
-
-img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
-mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
-
-init_image = download_image(img_url).resize((512, 512))
-mask_image = download_image(mask_url).resize((512, 512))
-
-repo_id = "stabilityai/stable-diffusion-2-inpainting"
-pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
-
-pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
-pipe = pipe.to("cuda")
-
-prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
-image = pipe(prompt=prompt, image=init_image, mask_image=mask_image, num_inference_steps=25).images[0]
-
-image.save("yellow_cat.png")
-```
-
-### Super-Resolution
-
-- *Image Upscaling (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) with [`StableDiffusionUpscalePipeline`]
-
-
-```python
-import requests
-from PIL import Image
-from io import BytesIO
-from diffusers import StableDiffusionUpscalePipeline
-import torch
-
-# load model and scheduler
-model_id = "stabilityai/stable-diffusion-x4-upscaler"
-pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
-pipeline = pipeline.to("cuda")
-
-# let's download an image
-url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
-response = requests.get(url)
-low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
-low_res_img = low_res_img.resize((128, 128))
-prompt = "a white cat"
-upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
-upscaled_image.save("upsampled_cat.png")
-```
-
-### Depth-to-Image
-
-- *Depth-Guided Text-to-Image*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) [`StableDiffusionDepth2ImagePipeline`]
-
-
-```python
-import torch
-import requests
-from PIL import Image
-
-from diffusers import StableDiffusionDepth2ImgPipeline
-
-pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
- "stabilityai/stable-diffusion-2-depth",
- torch_dtype=torch.float16,
-).to("cuda")
-
-
-url = "http://images.cocodataset.org/val2017/000000039769.jpg"
-init_image = Image.open(requests.get(url, stream=True).raw)
-prompt = "two tigers"
-n_propmt = "bad, deformed, ugly, bad anotomy"
-image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
-```
-
-### How to load and use different schedulers.
-
-The stable diffusion pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
-To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
-
-```python
->>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
-
->>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
->>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
-
->>> # or
->>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("stabilityai/stable-diffusion-2", subfolder="scheduler")
->>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=euler_scheduler)
-```
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
deleted file mode 100644
index 688eb5013c6a287c77722f006eea59bab73343e6..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
+++ /dev/null
@@ -1,90 +0,0 @@
-
-
-# Safe Stable Diffusion
-
-Safe Stable Diffusion was proposed in [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://arxiv.org/abs/2211.05105) and mitigates the well known issue that models like Stable Diffusion that are trained on unfiltered, web-crawled datasets tend to suffer from inappropriate degeneration. For instance Stable Diffusion may unexpectedly generate nudity, violence, images depicting self-harm, or otherwise offensive content.
-Safe Stable Diffusion is an extension to the Stable Diffusion that drastically reduces content like this.
-
-The abstract of the paper is the following:
-
-*Text-conditioned image generation models have recently achieved astonishing results in image quality and text alignment and are consequently employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer, as we demonstrate, from degenerated and biased human behavior. In turn, they may even reinforce such biases. To help combat these undesired side effects, we present safe latent diffusion (SLD). Specifically, to measure the inappropriate degeneration due to unfiltered and imbalanced training sets, we establish a novel image generation test bed-inappropriate image prompts (I2P)-containing dedicated, real-world image-to-text prompts covering concepts such as nudity and violence. As our exhaustive empirical evaluation demonstrates, the introduced SLD removes and suppresses inappropriate image parts during the diffusion process, with no additional training required and no adverse effect on overall image quality or text alignment.*
-
-
-*Overview*:
-
-| Pipeline | Tasks | Colab | Demo
-|---|---|:---:|:---:|
-| [pipeline_stable_diffusion_safe.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb) | [](https://huggingface.co/spaces/AIML-TUDA/unsafe-vs-safe-stable-diffusion)
-
-## Tips
-
-- Safe Stable Diffusion may also be used with weights of [Stable Diffusion](./api/pipelines/stable_diffusion/text2img).
-
-### Run Safe Stable Diffusion
-
-Safe Stable Diffusion can be tested very easily with the [`StableDiffusionPipelineSafe`], and the `"AIML-TUDA/stable-diffusion-safe"` checkpoint exactly in the same way it is shown in the [Conditional Image Generation Guide](./using-diffusers/conditional_image_generation).
-
-### Interacting with the Safety Concept
-
-To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]:
-```python
->>> from diffusers import StableDiffusionPipelineSafe
-
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
->>> pipeline.safety_concept
-```
-For each image generation the active concept is also contained in [`StableDiffusionSafePipelineOutput`].
-
-### Using pre-defined safety configurations
-
-You may use the 4 configurations defined in the [Safe Latent Diffusion paper](https://arxiv.org/abs/2211.05105) as follows:
-
-```python
->>> from diffusers import StableDiffusionPipelineSafe
->>> from diffusers.pipelines.stable_diffusion_safe import SafetyConfig
-
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
->>> prompt = "the four horsewomen of the apocalypse, painting by tom of finland, gaston bussiere, craig mullins, j. c. leyendecker"
->>> out = pipeline(prompt=prompt, **SafetyConfig.MAX)
-```
-
-The following configurations are available: `SafetyConfig.WEAK`, `SafetyConfig.MEDIUM`, `SafetyConfig.STRONG`, and `SafetyConfig.MAX`.
-
-### How to load and use different schedulers
-
-The safe stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
-To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
-
-```python
->>> from diffusers import StableDiffusionPipelineSafe, EulerDiscreteScheduler
-
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
->>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
-
->>> # or
->>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("AIML-TUDA/stable-diffusion-safe", subfolder="scheduler")
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained(
-... "AIML-TUDA/stable-diffusion-safe", scheduler=euler_scheduler
-... )
-```
-
-
-## StableDiffusionSafePipelineOutput
-[[autodoc]] pipelines.stable_diffusion_safe.StableDiffusionSafePipelineOutput
- - all
- - __call__
-
-## StableDiffusionPipelineSafe
-[[autodoc]] StableDiffusionPipelineSafe
- - all
- - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx b/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
deleted file mode 100644
index ee359d0ba486a30fb732fe3d191e7088c6c69a1e..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
+++ /dev/null
@@ -1,175 +0,0 @@
-
-
-# Stable unCLIP
-
-Stable unCLIP checkpoints are finetuned from [stable diffusion 2.1](./stable_diffusion_2) checkpoints to condition on CLIP image embeddings.
-Stable unCLIP also still conditions on text embeddings. Given the two separate conditionings, stable unCLIP can be used
-for text guided image variation. When combined with an unCLIP prior, it can also be used for full text to image generation.
-
-To know more about the unCLIP process, check out the following paper:
-
-[Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen.
-
-## Tips
-
-Stable unCLIP takes a `noise_level` as input during inference. `noise_level` determines how much noise is added
-to the image embeddings. A higher `noise_level` increases variation in the final un-noised images. By default,
-we do not add any additional noise to the image embeddings i.e. `noise_level = 0`.
-
-### Available checkpoints:
-
-* Image variation
- * [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip)
- * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
-* Text-to-image
- * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
-
-### Text-to-Image Generation
-Stable unCLIP can be leveraged for text-to-image generation by pipelining it with the prior model of KakaoBrain's open source DALL-E 2 replication [Karlo](https://huggingface.co/kakaobrain/karlo-v1-alpha)
-
-```python
-import torch
-from diffusers import UnCLIPScheduler, DDPMScheduler, StableUnCLIPPipeline
-from diffusers.models import PriorTransformer
-from transformers import CLIPTokenizer, CLIPTextModelWithProjection
-
-prior_model_id = "kakaobrain/karlo-v1-alpha"
-data_type = torch.float16
-prior = PriorTransformer.from_pretrained(prior_model_id, subfolder="prior", torch_dtype=data_type)
-
-prior_text_model_id = "openai/clip-vit-large-patch14"
-prior_tokenizer = CLIPTokenizer.from_pretrained(prior_text_model_id)
-prior_text_model = CLIPTextModelWithProjection.from_pretrained(prior_text_model_id, torch_dtype=data_type)
-prior_scheduler = UnCLIPScheduler.from_pretrained(prior_model_id, subfolder="prior_scheduler")
-prior_scheduler = DDPMScheduler.from_config(prior_scheduler.config)
-
-stable_unclip_model_id = "stabilityai/stable-diffusion-2-1-unclip-small"
-
-pipe = StableUnCLIPPipeline.from_pretrained(
- stable_unclip_model_id,
- torch_dtype=data_type,
- variant="fp16",
- prior_tokenizer=prior_tokenizer,
- prior_text_encoder=prior_text_model,
- prior=prior,
- prior_scheduler=prior_scheduler,
-)
-
-pipe = pipe.to("cuda")
-wave_prompt = "dramatic wave, the Oceans roar, Strong wave spiral across the oceans as the waves unfurl into roaring crests; perfect wave form; perfect wave shape; dramatic wave shape; wave shape unbelievable; wave; wave shape spectacular"
-
-images = pipe(prompt=wave_prompt).images
-images[0].save("waves.png")
-```
-
|
-
-## StableDiffusionControlNetPipeline
-[[autodoc]] StableDiffusionControlNetPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
-
-## FlaxStableDiffusionControlNetPipeline
-[[autodoc]] FlaxStableDiffusionControlNetPipeline
- - all
- - __call__
-
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
deleted file mode 100644
index c46576ff288757a316a5efa0ec3b753fd9ce2bd4..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
+++ /dev/null
@@ -1,33 +0,0 @@
-
-
-# Depth-to-Image Generation
-
-## StableDiffusionDepth2ImgPipeline
-
-The depth-guided stable diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. It uses [MiDas](https://github.com/isl-org/MiDaS) to infer depth based on an image.
-
-[`StableDiffusionDepth2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images as well as a `depth_map` to preserve the images’ structure.
-
-The original codebase can be found here:
-- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion)
-
-Available Checkpoints are:
-- *stable-diffusion-2-depth*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth)
-
-[[autodoc]] StableDiffusionDepth2ImgPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
deleted file mode 100644
index 8ca69ff69aec6a74e22beade70b5ef2ef42a0e3c..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
+++ /dev/null
@@ -1,31 +0,0 @@
-
-
-# Image Variation
-
-## StableDiffusionImageVariationPipeline
-
-[`StableDiffusionImageVariationPipeline`] lets you generate variations from an input image using Stable Diffusion. It uses a fine-tuned version of Stable Diffusion model, trained by [Justin Pinkney](https://www.justinpinkney.com/) (@Buntworthy) at [Lambda](https://lambdalabs.com/).
-
-The original codebase can be found here:
-[Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations)
-
-Available Checkpoints are:
-- *sd-image-variations-diffusers*: [lambdalabs/sd-image-variations-diffusers](https://huggingface.co/lambdalabs/sd-image-variations-diffusers)
-
-[[autodoc]] StableDiffusionImageVariationPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
deleted file mode 100644
index 09bfb853f9c9bdce1fbd4b4ae3571557d2a5bfc1..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
+++ /dev/null
@@ -1,36 +0,0 @@
-
-
-# Image-to-Image Generation
-
-## StableDiffusionImg2ImgPipeline
-
-The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images using Stable Diffusion.
-
-The original codebase can be found here: [CampVis/stable-diffusion](https://github.com/CompVis/stable-diffusion/blob/main/scripts/img2img.py)
-
-[`StableDiffusionImg2ImgPipeline`] is compatible with all Stable Diffusion checkpoints for [Text-to-Image](./text2img)
-
-The pipeline uses the diffusion-denoising mechanism proposed by SDEdit ([SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations](https://arxiv.org/abs/2108.01073)
-proposed by Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, Stefano Ermon).
-
-[[autodoc]] StableDiffusionImg2ImgPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
-
-[[autodoc]] FlaxStableDiffusionImg2ImgPipeline
- - all
- - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
deleted file mode 100644
index 33e84a63261fbf9c370e2d5e22ffbf4a1256bbb4..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
+++ /dev/null
@@ -1,37 +0,0 @@
-
-
-# Text-Guided Image Inpainting
-
-## StableDiffusionInpaintPipeline
-
-The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionInpaintPipeline`] lets you edit specific parts of an image by providing a mask and a text prompt using Stable Diffusion.
-
-The original codebase can be found here:
-- *Stable Diffusion V1*: [CampVis/stable-diffusion](https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion)
-- *Stable Diffusion V2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-inpainting-with-stable-diffusion)
-
-Available checkpoints are:
-- *stable-diffusion-inpainting (512x512 resolution)*: [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting)
-- *stable-diffusion-2-inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting)
-
-[[autodoc]] StableDiffusionInpaintPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
-
-[[autodoc]] FlaxStableDiffusionInpaintPipeline
- - all
- - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
deleted file mode 100644
index 61fd2f799114de345400a692c115811fbf222871..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
+++ /dev/null
@@ -1,33 +0,0 @@
-
-
-# Stable Diffusion Latent Upscaler
-
-## StableDiffusionLatentUpscalePipeline
-
-The Stable Diffusion Latent Upscaler model was created by [Katherine Crowson](https://github.com/crowsonkb/k-diffusion) in collaboration with [Stability AI](https://stability.ai/). It can be used on top of any [`StableDiffusionUpscalePipeline`] checkpoint to enhance its output image resolution by a factor of 2.
-
-A notebook that demonstrates the original implementation can be found here:
-- [Stable Diffusion Upscaler Demo](https://colab.research.google.com/drive/1o1qYJcFeywzCIdkfKJy7cTpgZTCM2EI4)
-
-Available Checkpoints are:
-- *stabilityai/latent-upscaler*: [stabilityai/sd-x2-latent-upscaler](https://huggingface.co/stabilityai/sd-x2-latent-upscaler)
-
-
-[[autodoc]] StableDiffusionLatentUpscalePipeline
- - all
- - __call__
- - enable_sequential_cpu_offload
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
deleted file mode 100644
index 7aae35ba2a91774a4297ee7ada6d13a40fed6f32..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
+++ /dev/null
@@ -1,61 +0,0 @@
-
-
-# Editing Implicit Assumptions in Text-to-Image Diffusion Models
-
-## Overview
-
-[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084) by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov.
-
-The abstract of the paper is the following:
-
-*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
-
-Resources:
-
-* [Project Page](https://time-diffusion.github.io/).
-* [Paper](https://arxiv.org/abs/2303.08084).
-* [Original Code](https://github.com/bahjat-kawar/time-diffusion).
-* [Demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionModelEditingPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py) | *Text-to-Image Model Editing* | [🤗 Space](https://huggingface.co/spaces/bahjat-kawar/time-diffusion)) |
-
-This pipeline enables editing the diffusion model weights, such that its assumptions on a given concept are changed. The resulting change is expected to take effect in all prompt generations pertaining to the edited concept.
-
-## Usage example
-
-```python
-import torch
-from diffusers import StableDiffusionModelEditingPipeline
-
-model_ckpt = "CompVis/stable-diffusion-v1-4"
-pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt)
-
-pipe = pipe.to("cuda")
-
-source_prompt = "A pack of roses"
-destination_prompt = "A pack of blue roses"
-pipe.edit_model(source_prompt, destination_prompt)
-
-prompt = "A field of roses"
-image = pipe(prompt).images[0]
-image.save("field_of_roses.png")
-```
-
-## StableDiffusionModelEditingPipeline
-[[autodoc]] StableDiffusionModelEditingPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
deleted file mode 100644
index 70731fd294b91c8bca9bb1726c14011507c22a4a..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
+++ /dev/null
@@ -1,82 +0,0 @@
-
-
-# Stable diffusion pipelines
-
-Stable Diffusion is a text-to-image _latent diffusion_ model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/). It's trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and can run on consumer GPUs.
-
-Latent diffusion is the research on top of which Stable Diffusion was built. It was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. You can learn more details about it in the [specific pipeline for latent diffusion](pipelines/latent_diffusion) that is part of 🤗 Diffusers.
-
-For more details about how Stable Diffusion works and how it differs from the base latent diffusion model, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-announcement) and [this section of our own blog post](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work).
-
-*Tips*:
-- To tweak your prompts on a specific result you liked, you can generate your own latents, as demonstrated in the following notebook: [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
-
-*Overview*:
-
-| Pipeline | Tasks | Colab | Demo
-|---|---|:---:|:---:|
-| [StableDiffusionPipeline](./text2img) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb) | [🤗 Stable Diffusion](https://huggingface.co/spaces/stabilityai/stable-diffusion)
-| [StableDiffusionImg2ImgPipeline](./img2img) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb) | [🤗 Diffuse the Rest](https://huggingface.co/spaces/huggingface/diffuse-the-rest)
-| [StableDiffusionInpaintPipeline](./inpaint) | **Experimental** – *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) | Coming soon
-| [StableDiffusionDepth2ImgPipeline](./depth2img) | **Experimental** – *Depth-to-Image Text-Guided Generation * | | Coming soon
-| [StableDiffusionImageVariationPipeline](./image_variation) | **Experimental** – *Image Variation Generation * | | [🤗 Stable Diffusion Image Variations](https://huggingface.co/spaces/lambdalabs/stable-diffusion-image-variations)
-| [StableDiffusionUpscalePipeline](./upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
-| [StableDiffusionLatentUpscalePipeline](./latent_upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
-| [StableDiffusionInstructPix2PixPipeline](./pix2pix) | **Experimental** – *Text-Based Image Editing * | | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/spaces/timbrooks/instruct-pix2pix)
-| [StableDiffusionAttendAndExcitePipeline](./attend_and_excite) | **Experimental** – *Text-to-Image Generation * | | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
-| [StableDiffusionPix2PixZeroPipeline](./pix2pix_zero) | **Experimental** – *Text-Based Image Editing * | | [Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027)
-| [StableDiffusionModelEditingPipeline](./model_editing) | **Experimental** – *Text-to-Image Model Editing * | | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084)
-
-
-
-## Tips
-
-### How to load and use different schedulers.
-
-The stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
-To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
-
-```python
->>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
-
->>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
->>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
-
->>> # or
->>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
->>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=euler_scheduler)
-```
-
-
-### How to convert all use cases with multiple or single pipeline
-
-If you want to use all possible use cases in a single `DiffusionPipeline` you can either:
-- Make use of the [Stable Diffusion Mega Pipeline](https://github.com/huggingface/diffusers/tree/main/examples/community#stable-diffusion-mega) or
-- Make use of the `components` functionality to instantiate all components in the most memory-efficient way:
-
-```python
->>> from diffusers import (
-... StableDiffusionPipeline,
-... StableDiffusionImg2ImgPipeline,
-... StableDiffusionInpaintPipeline,
-... )
-
->>> text2img = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
->>> img2img = StableDiffusionImg2ImgPipeline(**text2img.components)
->>> inpaint = StableDiffusionInpaintPipeline(**text2img.components)
-
->>> # now you can use text2img(...), img2img(...), inpaint(...) just like the call methods of each respective pipeline
-```
-
-## StableDiffusionPipelineOutput
-[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
deleted file mode 100644
index e0c7747a0193013507ccc28e3d48c7ee5ab8ca11..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
+++ /dev/null
@@ -1,58 +0,0 @@
-
-
-# MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
-
-## Overview
-
-[MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation](https://arxiv.org/abs/2302.08113) by Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel.
-
-The abstract of the paper is the following:
-
-*Recent advances in text-to-image generation with diffusion models present transformative capabilities in image quality. However, user controllability of the generated image, and fast adaptation to new tasks still remains an open challenge, currently mostly addressed by costly and long re-training and fine-tuning or ad-hoc adaptations to specific image generation tasks. In this work, we present MultiDiffusion, a unified framework that enables versatile and controllable image generation, using a pre-trained text-to-image diffusion model, without any further training or finetuning. At the center of our approach is a new generation process, based on an optimization task that binds together multiple diffusion generation processes with a shared set of parameters or constraints. We show that MultiDiffusion can be readily applied to generate high quality and diverse images that adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes.
-
-Resources:
-
-* [Project Page](https://multidiffusion.github.io/).
-* [Paper](https://arxiv.org/abs/2302.08113).
-* [Original Code](https://github.com/omerbt/MultiDiffusion).
-* [Demo](https://huggingface.co/spaces/weizmannscience/MultiDiffusion).
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionPanoramaPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py) | *Text-Guided Panorama View Generation* | [🤗 Space](https://huggingface.co/spaces/weizmannscience/MultiDiffusion)) |
-
-
-
-## Usage example
-
-```python
-import torch
-from diffusers import StableDiffusionPanoramaPipeline, DDIMScheduler
-
-model_ckpt = "stabilityai/stable-diffusion-2-base"
-scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
-pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, torch_dtype=torch.float16)
-
-pipe = pipe.to("cuda")
-
-prompt = "a photo of the dolomites"
-image = pipe(prompt).images[0]
-image.save("dolomites.png")
-```
-
-## StableDiffusionPanoramaPipeline
-[[autodoc]] StableDiffusionPanoramaPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
deleted file mode 100644
index 42cd4b896b2e4603aaf826efc7201672c016563f..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
+++ /dev/null
@@ -1,70 +0,0 @@
-
-
-# InstructPix2Pix: Learning to Follow Image Editing Instructions
-
-## Overview
-
-[InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) by Tim Brooks, Aleksander Holynski and Alexei A. Efros.
-
-The abstract of the paper is the following:
-
-*We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.*
-
-Resources:
-
-* [Project Page](https://www.timothybrooks.com/instruct-pix2pix).
-* [Paper](https://arxiv.org/abs/2211.09800).
-* [Original Code](https://github.com/timothybrooks/instruct-pix2pix).
-* [Demo](https://huggingface.co/spaces/timbrooks/instruct-pix2pix).
-
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionInstructPix2PixPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/timbrooks/instruct-pix2pix) |
-
-
-
-## Usage example
-
-```python
-import PIL
-import requests
-import torch
-from diffusers import StableDiffusionInstructPix2PixPipeline
-
-model_id = "timbrooks/instruct-pix2pix"
-pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
-
-url = "https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
-
-
-def download_image(url):
- image = PIL.Image.open(requests.get(url, stream=True).raw)
- image = PIL.ImageOps.exif_transpose(image)
- image = image.convert("RGB")
- return image
-
-
-image = download_image(url)
-
-prompt = "make the mountains snowy"
-images = pipe(prompt, image=image, num_inference_steps=20, image_guidance_scale=1.5, guidance_scale=7).images
-images[0].save("snowy_mountains.png")
-```
-
-## StableDiffusionInstructPix2PixPipeline
-[[autodoc]] StableDiffusionInstructPix2PixPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
deleted file mode 100644
index f04a54f242acade990415a1ed7c240c37a828dd7..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
+++ /dev/null
@@ -1,291 +0,0 @@
-
-
-# Zero-shot Image-to-Image Translation
-
-## Overview
-
-[Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027).
-
-The abstract of the paper is the following:
-
-*Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.*
-
-Resources:
-
-* [Project Page](https://pix2pixzero.github.io/).
-* [Paper](https://arxiv.org/abs/2302.03027).
-* [Original Code](https://github.com/pix2pixzero/pix2pix-zero).
-* [Demo](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo).
-
-## Tips
-
-* The pipeline can be conditioned on real input images. Check out the code examples below to know more.
-* The pipeline exposes two arguments namely `source_embeds` and `target_embeds`
-that let you control the direction of the semantic edits in the final image to be generated. Let's say,
-you wanted to translate from "cat" to "dog". In this case, the edit direction will be "cat -> dog". To reflect
-this in the pipeline, you simply have to set the embeddings related to the phrases including "cat" to
-`source_embeds` and "dog" to `target_embeds`. Refer to the code example below for more details.
-* When you're using this pipeline from a prompt, specify the _source_ concept in the prompt. Taking
-the above example, a valid input prompt would be: "a high resolution painting of a **cat** in the style of van gough".
-* If you wanted to reverse the direction in the example above, i.e., "dog -> cat", then it's recommended to:
- * Swap the `source_embeds` and `target_embeds`.
- * Change the input prompt to include "dog".
-* To learn more about how the source and target embeddings are generated, refer to the [original
-paper](https://arxiv.org/abs/2302.03027). Below, we also provide some directions on how to generate the embeddings.
-* Note that the quality of the outputs generated with this pipeline is dependent on how good the `source_embeds` and `target_embeds` are. Please, refer to [this discussion](#generating-source-and-target-embeddings) for some suggestions on the topic.
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionPix2PixZeroPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo) |
-
-
-
-## Usage example
-
-### Based on an image generated with the input prompt
-
-```python
-import requests
-import torch
-
-from diffusers import DDIMScheduler, StableDiffusionPix2PixZeroPipeline
-
-
-def download(embedding_url, local_filepath):
- r = requests.get(embedding_url)
- with open(local_filepath, "wb") as f:
- f.write(r.content)
-
-
-model_ckpt = "CompVis/stable-diffusion-v1-4"
-pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
- model_ckpt, conditions_input_image=False, torch_dtype=torch.float16
-)
-pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
-pipeline.to("cuda")
-
-prompt = "a high resolution painting of a cat in the style of van gogh"
-src_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/cat.pt"
-target_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/dog.pt"
-
-for url in [src_embs_url, target_embs_url]:
- download(url, url.split("/")[-1])
-
-src_embeds = torch.load(src_embs_url.split("/")[-1])
-target_embeds = torch.load(target_embs_url.split("/")[-1])
-
-images = pipeline(
- prompt,
- source_embeds=src_embeds,
- target_embeds=target_embeds,
- num_inference_steps=50,
- cross_attention_guidance_amount=0.15,
-).images
-images[0].save("edited_image_dog.png")
-```
-
-### Based on an input image
-
-When the pipeline is conditioned on an input image, we first obtain an inverted
-noise from it using a `DDIMInverseScheduler` with the help of a generated caption. Then
-the inverted noise is used to start the generation process.
-
-First, let's load our pipeline:
-
-```py
-import torch
-from transformers import BlipForConditionalGeneration, BlipProcessor
-from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionPix2PixZeroPipeline
-
-captioner_id = "Salesforce/blip-image-captioning-base"
-processor = BlipProcessor.from_pretrained(captioner_id)
-model = BlipForConditionalGeneration.from_pretrained(captioner_id, torch_dtype=torch.float16, low_cpu_mem_usage=True)
-
-sd_model_ckpt = "CompVis/stable-diffusion-v1-4"
-pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
- sd_model_ckpt,
- caption_generator=model,
- caption_processor=processor,
- torch_dtype=torch.float16,
- safety_checker=None,
-)
-pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
-pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
-pipeline.enable_model_cpu_offload()
-```
-
-Then, we load an input image for conditioning and obtain a suitable caption for it:
-
-```py
-import requests
-from PIL import Image
-
-img_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/test_images/cats/cat_6.png"
-raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB").resize((512, 512))
-caption = pipeline.generate_caption(raw_image)
-```
-
-Then we employ the generated caption and the input image to get the inverted noise:
-
-```py
-generator = torch.manual_seed(0)
-inv_latents = pipeline.invert(caption, image=raw_image, generator=generator).latents
-```
-
-Now, generate the image with edit directions:
-
-```py
-# See the "Generating source and target embeddings" section below to
-# automate the generation of these captions with a pre-trained model like Flan-T5 as explained below.
-source_prompts = ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
-target_prompts = ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
-
-source_embeds = pipeline.get_embeds(source_prompts, batch_size=2)
-target_embeds = pipeline.get_embeds(target_prompts, batch_size=2)
-
-
-image = pipeline(
- caption,
- source_embeds=source_embeds,
- target_embeds=target_embeds,
- num_inference_steps=50,
- cross_attention_guidance_amount=0.15,
- generator=generator,
- latents=inv_latents,
- negative_prompt=caption,
-).images[0]
-image.save("edited_image.png")
-```
-
-## Generating source and target embeddings
-
-The authors originally used the [GPT-3 API](https://openai.com/api/) to generate the source and target captions for discovering
-edit directions. However, we can also leverage open source and public models for the same purpose.
-Below, we provide an end-to-end example with the [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5) model
-for generating captions and [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for
-computing embeddings on the generated captions.
-
-**1. Load the generation model**:
-
-```py
-import torch
-from transformers import AutoTokenizer, T5ForConditionalGeneration
-
-tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
-model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xl", device_map="auto", torch_dtype=torch.float16)
-```
-
-**2. Construct a starting prompt**:
-
-```py
-source_concept = "cat"
-target_concept = "dog"
-
-source_text = f"Provide a caption for images containing a {source_concept}. "
-"The captions should be in English and should be no longer than 150 characters."
-
-target_text = f"Provide a caption for images containing a {target_concept}. "
-"The captions should be in English and should be no longer than 150 characters."
-```
-
-Here, we're interested in the "cat -> dog" direction.
-
-**3. Generate captions**:
-
-We can use a utility like so for this purpose.
-
-```py
-def generate_captions(input_prompt):
- input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.to("cuda")
-
- outputs = model.generate(
- input_ids, temperature=0.8, num_return_sequences=16, do_sample=True, max_new_tokens=128, top_k=10
- )
- return tokenizer.batch_decode(outputs, skip_special_tokens=True)
-```
-
-And then we just call it to generate our captions:
-
-```py
-source_captions = generate_captions(source_text)
-target_captions = generate_captions(target_concept)
-```
-
-We encourage you to play around with the different parameters supported by the
-`generate()` method ([documentation](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_tf_utils.TFGenerationMixin.generate)) for the generation quality you are looking for.
-
-**4. Load the embedding model**:
-
-Here, we need to use the same text encoder model used by the subsequent Stable Diffusion model.
-
-```py
-from diffusers import StableDiffusionPix2PixZeroPipeline
-
-pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
- "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
-)
-pipeline = pipeline.to("cuda")
-tokenizer = pipeline.tokenizer
-text_encoder = pipeline.text_encoder
-```
-
-**5. Compute embeddings**:
-
-```py
-import torch
-
-def embed_captions(sentences, tokenizer, text_encoder, device="cuda"):
- with torch.no_grad():
- embeddings = []
- for sent in sentences:
- text_inputs = tokenizer(
- sent,
- padding="max_length",
- max_length=tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
- prompt_embeds = text_encoder(text_input_ids.to(device), attention_mask=None)[0]
- embeddings.append(prompt_embeds)
- return torch.concatenate(embeddings, dim=0).mean(dim=0).unsqueeze(0)
-
-source_embeddings = embed_captions(source_captions, tokenizer, text_encoder)
-target_embeddings = embed_captions(target_captions, tokenizer, text_encoder)
-```
-
-And you're done! [Here](https://colab.research.google.com/drive/1tz2C1EdfZYAPlzXXbTnf-5PRBiR8_R1F?usp=sharing) is a Colab Notebook that you can use to interact with the entire process.
-
-Now, you can use these embeddings directly while calling the pipeline:
-
-```py
-from diffusers import DDIMScheduler
-
-pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
-
-images = pipeline(
- prompt,
- source_embeds=source_embeddings,
- target_embeds=target_embeddings,
- num_inference_steps=50,
- cross_attention_guidance_amount=0.15,
-).images
-images[0].save("edited_image_dog.png")
-```
-
-## StableDiffusionPix2PixZeroPipeline
-[[autodoc]] StableDiffusionPix2PixZeroPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
deleted file mode 100644
index b34c1f51cf668b289ca000719828addb88f6a20e..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
+++ /dev/null
@@ -1,64 +0,0 @@
-
-
-# Self-Attention Guidance (SAG)
-
-## Overview
-
-[Self-Attention Guidance](https://arxiv.org/abs/2210.00939) by Susung Hong et al.
-
-The abstract of the paper is the following:
-
-*Denoising diffusion models (DDMs) have been drawing much attention for their appreciable sample quality and diversity. Despite their remarkable performance, DDMs remain black boxes on which further study is necessary to take a profound step. Motivated by this, we delve into the design of conventional U-shaped diffusion models. More specifically, we investigate the self-attention modules within these models through carefully designed experiments and explore their characteristics. In addition, inspired by the studies that substantiate the effectiveness of the guidance schemes, we present plug-and-play diffusion guidance, namely Self-Attention Guidance (SAG), that can drastically boost the performance of existing diffusion models. Our method, SAG, extracts the intermediate attention map from a diffusion model at every iteration and selects tokens above a certain attention score for masking and blurring to obtain a partially blurred input. Subsequently, we measure the dissimilarity between the predicted noises obtained from feeding the blurred and original input to the diffusion model and leverage it as guidance. With this guidance, we observe apparent improvements in a wide range of diffusion models, e.g., ADM, IDDPM, and Stable Diffusion, and show that the results further improve by combining our method with the conventional guidance scheme. We provide extensive ablation studies to verify our choices.*
-
-Resources:
-
-* [Project Page](https://ku-cvlab.github.io/Self-Attention-Guidance).
-* [Paper](https://arxiv.org/abs/2210.00939).
-* [Original Code](https://github.com/KU-CVLAB/Self-Attention-Guidance).
-* [Demo](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb).
-
-
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionSAGPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py) | *Text-to-Image Generation* | [Colab](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb) |
-
-## Usage example
-
-```python
-import torch
-from diffusers import StableDiffusionSAGPipeline
-from accelerate.utils import set_seed
-
-pipe = StableDiffusionSAGPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
-pipe = pipe.to("cuda")
-
-seed = 8978
-prompt = "."
-guidance_scale = 7.5
-num_images_per_prompt = 1
-
-sag_scale = 1.0
-
-set_seed(seed)
-images = pipe(
- prompt, num_images_per_prompt=num_images_per_prompt, guidance_scale=guidance_scale, sag_scale=sag_scale
-).images
-images[0].save("example.png")
-```
-
-## StableDiffusionSAGPipeline
-[[autodoc]] StableDiffusionSAGPipeline
- - __call__
- - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
deleted file mode 100644
index 6b8d53bf6510a0b122529170e0de3cbddcc40690..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
+++ /dev/null
@@ -1,45 +0,0 @@
-
-
-# Text-to-Image Generation
-
-## StableDiffusionPipeline
-
-The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionPipeline`] is capable of generating photo-realistic images given any text input using Stable Diffusion.
-
-The original codebase can be found here:
-- *Stable Diffusion V1*: [CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion)
-- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion)
-
-Available Checkpoints are:
-- *stable-diffusion-v1-4 (512x512 resolution)* [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)
-- *stable-diffusion-v1-5 (512x512 resolution)* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
-- *stable-diffusion-2-base (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base)
-- *stable-diffusion-2 (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2)
-- *stable-diffusion-2-1-base (512x512 resolution)* [stabilityai/stable-diffusion-2-1-base](https://huggingface.co/stabilityai/stable-diffusion-2-1-base)
-- *stable-diffusion-2-1 (768x768 resolution)*: [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1)
-
-[[autodoc]] StableDiffusionPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
- - enable_vae_tiling
- - disable_vae_tiling
-
-[[autodoc]] FlaxStableDiffusionPipeline
- - all
- - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
deleted file mode 100644
index f70d8f445fd95fb49e7a92c7566951c40ec74933..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
+++ /dev/null
@@ -1,32 +0,0 @@
-
-
-# Super-Resolution
-
-## StableDiffusionUpscalePipeline
-
-The upscaler diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. [`StableDiffusionUpscalePipeline`] can be used to enhance the resolution of input images by a factor of 4.
-
-The original codebase can be found here:
-- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-upscaling-with-stable-diffusion)
-
-Available Checkpoints are:
-- *stabilityai/stable-diffusion-x4-upscaler (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler)
-
-
-[[autodoc]] StableDiffusionUpscalePipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
deleted file mode 100644
index e922072e4e3185f9de4a0d6e734e0c46a4fe3215..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
+++ /dev/null
@@ -1,176 +0,0 @@
-
-
-# Stable diffusion 2
-
-Stable Diffusion 2 is a text-to-image _latent diffusion_ model built upon the work of [Stable Diffusion 1](https://stability.ai/blog/stable-diffusion-public-release).
-The project to train Stable Diffusion 2 was led by Robin Rombach and Katherine Crowson from [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
-
-*The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases. The text-to-image models in this release can generate images with default resolutions of both 512x512 pixels and 768x768 pixels.
-These models are trained on an aesthetic subset of the [LAION-5B dataset](https://laion.ai/blog/laion-5b/) created by the DeepFloyd team at Stability AI, which is then further filtered to remove adult content using [LAION’s NSFW filter](https://openreview.net/forum?id=M3Y74vmsMcY).*
-
-For more details about how Stable Diffusion 2 works and how it differs from Stable Diffusion 1, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-v2-release).
-
-## Tips
-
-### Available checkpoints:
-
-Note that the architecture is more or less identical to [Stable Diffusion 1](./stable_diffusion/overview) so please refer to [this page](./stable_diffusion/overview) for API documentation.
-
-- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
-- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
-- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
-- *Super-Resolution (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) [`StableDiffusionUpscalePipeline`]
-- *Depth-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) with [`StableDiffusionDepth2ImagePipeline`]
-
-We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest scheduler there is.
-
-
-### Text-to-Image
-
-- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
-
-```python
-from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
-import torch
-
-repo_id = "stabilityai/stable-diffusion-2-base"
-pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
-
-pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
-pipe = pipe.to("cuda")
-
-prompt = "High quality photo of an astronaut riding a horse in space"
-image = pipe(prompt, num_inference_steps=25).images[0]
-image.save("astronaut.png")
-```
-
-- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
-
-```python
-from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
-import torch
-
-repo_id = "stabilityai/stable-diffusion-2"
-pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
-
-pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
-pipe = pipe.to("cuda")
-
-prompt = "High quality photo of an astronaut riding a horse in space"
-image = pipe(prompt, guidance_scale=9, num_inference_steps=25).images[0]
-image.save("astronaut.png")
-```
-
-### Image Inpainting
-
-- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
-
-```python
-import PIL
-import requests
-import torch
-from io import BytesIO
-
-from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
-
-
-def download_image(url):
- response = requests.get(url)
- return PIL.Image.open(BytesIO(response.content)).convert("RGB")
-
-
-img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
-mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
-
-init_image = download_image(img_url).resize((512, 512))
-mask_image = download_image(mask_url).resize((512, 512))
-
-repo_id = "stabilityai/stable-diffusion-2-inpainting"
-pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
-
-pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
-pipe = pipe.to("cuda")
-
-prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
-image = pipe(prompt=prompt, image=init_image, mask_image=mask_image, num_inference_steps=25).images[0]
-
-image.save("yellow_cat.png")
-```
-
-### Super-Resolution
-
-- *Image Upscaling (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) with [`StableDiffusionUpscalePipeline`]
-
-
-```python
-import requests
-from PIL import Image
-from io import BytesIO
-from diffusers import StableDiffusionUpscalePipeline
-import torch
-
-# load model and scheduler
-model_id = "stabilityai/stable-diffusion-x4-upscaler"
-pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
-pipeline = pipeline.to("cuda")
-
-# let's download an image
-url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
-response = requests.get(url)
-low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
-low_res_img = low_res_img.resize((128, 128))
-prompt = "a white cat"
-upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
-upscaled_image.save("upsampled_cat.png")
-```
-
-### Depth-to-Image
-
-- *Depth-Guided Text-to-Image*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) [`StableDiffusionDepth2ImagePipeline`]
-
-
-```python
-import torch
-import requests
-from PIL import Image
-
-from diffusers import StableDiffusionDepth2ImgPipeline
-
-pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
- "stabilityai/stable-diffusion-2-depth",
- torch_dtype=torch.float16,
-).to("cuda")
-
-
-url = "http://images.cocodataset.org/val2017/000000039769.jpg"
-init_image = Image.open(requests.get(url, stream=True).raw)
-prompt = "two tigers"
-n_propmt = "bad, deformed, ugly, bad anotomy"
-image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
-```
-
-### How to load and use different schedulers.
-
-The stable diffusion pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
-To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
-
-```python
->>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
-
->>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
->>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
-
->>> # or
->>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("stabilityai/stable-diffusion-2", subfolder="scheduler")
->>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=euler_scheduler)
-```
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
deleted file mode 100644
index 688eb5013c6a287c77722f006eea59bab73343e6..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
+++ /dev/null
@@ -1,90 +0,0 @@
-
-
-# Safe Stable Diffusion
-
-Safe Stable Diffusion was proposed in [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://arxiv.org/abs/2211.05105) and mitigates the well known issue that models like Stable Diffusion that are trained on unfiltered, web-crawled datasets tend to suffer from inappropriate degeneration. For instance Stable Diffusion may unexpectedly generate nudity, violence, images depicting self-harm, or otherwise offensive content.
-Safe Stable Diffusion is an extension to the Stable Diffusion that drastically reduces content like this.
-
-The abstract of the paper is the following:
-
-*Text-conditioned image generation models have recently achieved astonishing results in image quality and text alignment and are consequently employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer, as we demonstrate, from degenerated and biased human behavior. In turn, they may even reinforce such biases. To help combat these undesired side effects, we present safe latent diffusion (SLD). Specifically, to measure the inappropriate degeneration due to unfiltered and imbalanced training sets, we establish a novel image generation test bed-inappropriate image prompts (I2P)-containing dedicated, real-world image-to-text prompts covering concepts such as nudity and violence. As our exhaustive empirical evaluation demonstrates, the introduced SLD removes and suppresses inappropriate image parts during the diffusion process, with no additional training required and no adverse effect on overall image quality or text alignment.*
-
-
-*Overview*:
-
-| Pipeline | Tasks | Colab | Demo
-|---|---|:---:|:---:|
-| [pipeline_stable_diffusion_safe.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb) | [](https://huggingface.co/spaces/AIML-TUDA/unsafe-vs-safe-stable-diffusion)
-
-## Tips
-
-- Safe Stable Diffusion may also be used with weights of [Stable Diffusion](./api/pipelines/stable_diffusion/text2img).
-
-### Run Safe Stable Diffusion
-
-Safe Stable Diffusion can be tested very easily with the [`StableDiffusionPipelineSafe`], and the `"AIML-TUDA/stable-diffusion-safe"` checkpoint exactly in the same way it is shown in the [Conditional Image Generation Guide](./using-diffusers/conditional_image_generation).
-
-### Interacting with the Safety Concept
-
-To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]:
-```python
->>> from diffusers import StableDiffusionPipelineSafe
-
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
->>> pipeline.safety_concept
-```
-For each image generation the active concept is also contained in [`StableDiffusionSafePipelineOutput`].
-
-### Using pre-defined safety configurations
-
-You may use the 4 configurations defined in the [Safe Latent Diffusion paper](https://arxiv.org/abs/2211.05105) as follows:
-
-```python
->>> from diffusers import StableDiffusionPipelineSafe
->>> from diffusers.pipelines.stable_diffusion_safe import SafetyConfig
-
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
->>> prompt = "the four horsewomen of the apocalypse, painting by tom of finland, gaston bussiere, craig mullins, j. c. leyendecker"
->>> out = pipeline(prompt=prompt, **SafetyConfig.MAX)
-```
-
-The following configurations are available: `SafetyConfig.WEAK`, `SafetyConfig.MEDIUM`, `SafetyConfig.STRONG`, and `SafetyConfig.MAX`.
-
-### How to load and use different schedulers
-
-The safe stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
-To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
-
-```python
->>> from diffusers import StableDiffusionPipelineSafe, EulerDiscreteScheduler
-
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
->>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
-
->>> # or
->>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("AIML-TUDA/stable-diffusion-safe", subfolder="scheduler")
->>> pipeline = StableDiffusionPipelineSafe.from_pretrained(
-... "AIML-TUDA/stable-diffusion-safe", scheduler=euler_scheduler
-... )
-```
-
-
-## StableDiffusionSafePipelineOutput
-[[autodoc]] pipelines.stable_diffusion_safe.StableDiffusionSafePipelineOutput
- - all
- - __call__
-
-## StableDiffusionPipelineSafe
-[[autodoc]] StableDiffusionPipelineSafe
- - all
- - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx b/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
deleted file mode 100644
index ee359d0ba486a30fb732fe3d191e7088c6c69a1e..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
+++ /dev/null
@@ -1,175 +0,0 @@
-
-
-# Stable unCLIP
-
-Stable unCLIP checkpoints are finetuned from [stable diffusion 2.1](./stable_diffusion_2) checkpoints to condition on CLIP image embeddings.
-Stable unCLIP also still conditions on text embeddings. Given the two separate conditionings, stable unCLIP can be used
-for text guided image variation. When combined with an unCLIP prior, it can also be used for full text to image generation.
-
-To know more about the unCLIP process, check out the following paper:
-
-[Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen.
-
-## Tips
-
-Stable unCLIP takes a `noise_level` as input during inference. `noise_level` determines how much noise is added
-to the image embeddings. A higher `noise_level` increases variation in the final un-noised images. By default,
-we do not add any additional noise to the image embeddings i.e. `noise_level = 0`.
-
-### Available checkpoints:
-
-* Image variation
- * [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip)
- * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
-* Text-to-image
- * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
-
-### Text-to-Image Generation
-Stable unCLIP can be leveraged for text-to-image generation by pipelining it with the prior model of KakaoBrain's open source DALL-E 2 replication [Karlo](https://huggingface.co/kakaobrain/karlo-v1-alpha)
-
-```python
-import torch
-from diffusers import UnCLIPScheduler, DDPMScheduler, StableUnCLIPPipeline
-from diffusers.models import PriorTransformer
-from transformers import CLIPTokenizer, CLIPTextModelWithProjection
-
-prior_model_id = "kakaobrain/karlo-v1-alpha"
-data_type = torch.float16
-prior = PriorTransformer.from_pretrained(prior_model_id, subfolder="prior", torch_dtype=data_type)
-
-prior_text_model_id = "openai/clip-vit-large-patch14"
-prior_tokenizer = CLIPTokenizer.from_pretrained(prior_text_model_id)
-prior_text_model = CLIPTextModelWithProjection.from_pretrained(prior_text_model_id, torch_dtype=data_type)
-prior_scheduler = UnCLIPScheduler.from_pretrained(prior_model_id, subfolder="prior_scheduler")
-prior_scheduler = DDPMScheduler.from_config(prior_scheduler.config)
-
-stable_unclip_model_id = "stabilityai/stable-diffusion-2-1-unclip-small"
-
-pipe = StableUnCLIPPipeline.from_pretrained(
- stable_unclip_model_id,
- torch_dtype=data_type,
- variant="fp16",
- prior_tokenizer=prior_tokenizer,
- prior_text_encoder=prior_text_model,
- prior=prior,
- prior_scheduler=prior_scheduler,
-)
-
-pipe = pipe.to("cuda")
-wave_prompt = "dramatic wave, the Oceans roar, Strong wave spiral across the oceans as the waves unfurl into roaring crests; perfect wave form; perfect wave shape; dramatic wave shape; wave shape unbelievable; wave; wave shape spectacular"
-
-images = pipe(prompt=wave_prompt).images
-images[0].save("waves.png")
-```
--  -
- |
- -  -
- |
-
 -
-Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
-
-We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
-
-## Overview
-
-You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
-the core library.
-
-In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
-
-* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
-* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
-* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
-* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
-* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
-* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
-* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
-* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
-* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
-
-As said before, **all contributions are valuable to the community**.
-In the following, we will explain each contribution a bit more in detail.
-
-For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
-
-### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
-
-Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
-- Reports of training or inference experiments in an attempt to share knowledge
-- Presentation of personal projects
-- Questions to non-official training examples
-- Project proposals
-- General feedback
-- Paper summaries
-- Asking for help on personal projects that build on top of the Diffusers library
-- General questions
-- Ethical questions regarding diffusion models
-- ...
-
-Every question that is asked on the forum or on Discord actively encourages the community to publicly
-share knowledge and might very well help a beginner in the future that has the same question you're
-having. Please do pose any questions you might have.
-In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
-
-**Please** keep in mind that the more effort you put into asking or answering a question, the higher
-the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
-In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
-
-**NOTE about channels**:
-[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
-In addition, questions and answers posted in the forum can easily be linked to.
-In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
-While it will most likely take less time for you to get an answer to your question on Discord, your
-question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
-
-### 2. Opening new issues on the GitHub issues tab
-
-The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
-the problems they encounter. So thank you for reporting an issue.
-
-Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
-
-In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
-
-**Please consider the following guidelines when opening a new issue**:
-- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
-- Please never report a new issue on another (related) issue. If another issue is highly related, please
-open a new issue nevertheless and link to the related issue.
-- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
-- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
-- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
-
-New issues usually include the following.
-
-#### 2.1. Reproducible, minimal bug reports.
-
-A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
-This means in more detail:
-- Narrow the bug down as much as you can, **do not just dump your whole code file**
-- Format your code
-- Do not include any external libraries except for Diffusers depending on them.
-- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
-- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
-- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
-- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
-
-For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
-
-You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
-
-#### 2.2. Feature requests.
-
-A world-class feature request addresses the following points:
-
-1. Motivation first:
-* Is it related to a problem/frustration with the library? If so, please explain
-why. Providing a code snippet that demonstrates the problem is best.
-* Is it related to something you would need for a project? We'd love to hear
-about it!
-* Is it something you worked on and think could benefit the community?
-Awesome! Tell us what problem it solved for you.
-2. Write a *full paragraph* describing the feature;
-3. Provide a **code snippet** that demonstrates its future use;
-4. In case this is related to a paper, please attach a link;
-5. Attach any additional information (drawings, screenshots, etc.) you think may help.
-
-You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
-
-#### 2.3 Feedback.
-
-Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
-If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
-
-You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
-
-#### 2.4 Technical questions.
-
-Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
-why this part of the code is difficult to understand.
-
-You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
-
-#### 2.5 Proposal to add a new model, scheduler, or pipeline.
-
-If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
-
-* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
-* Link to any of its open-source implementation.
-* Link to the model weights if they are available.
-
-If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
-to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
-
-You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
-
-### 3. Answering issues on the GitHub issues tab
-
-Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
-Some tips to give a high-quality answer to an issue:
-- Be as concise and minimal as possible
-- Stay on topic. An answer to the issue should concern the issue and only the issue.
-- Provide links to code, papers, or other sources that prove or encourage your point.
-- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
-
-Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
-help to the maintainers if you can answer such issues, encouraging the author of the issue to be
-more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
-
-If you have verified that the issued bug report is correct and requires a correction in the source code,
-please have a look at the next sections.
-
-For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
-
-### 4. Fixing a "Good first issue"
-
-*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
-explains how a potential solution should look so that it is easier to fix.
-If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
-- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
-- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
-- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
-
-
-### 5. Contribute to the documentation
-
-A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
-valuable contribution**.
-
-Contributing to the library can have many forms:
-
-- Correcting spelling or grammatical errors.
-- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
-- Correct the shape or dimensions of a docstring input or output tensor.
-- Clarify documentation that is hard to understand or incorrect.
-- Update outdated code examples.
-- Translating the documentation to another language.
-
-Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
-
-Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
-
-
-### 6. Contribute a community pipeline
-
-[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
-Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
-We support two types of pipelines:
-
-- Official Pipelines
-- Community Pipelines
-
-Both official and community pipelines follow the same design and consist of the same type of components.
-
-Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
-resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
-In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
-They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
-
-The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
-possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
-Officially released diffusion pipelines,
-such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
-high quality of maintenance, no backward-breaking code changes, and testing.
-More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
-
-To add a community pipeline, one should add a
-
-Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
-
-We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
-
-## Overview
-
-You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
-the core library.
-
-In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
-
-* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
-* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
-* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
-* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
-* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
-* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
-* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
-* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
-* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
-
-As said before, **all contributions are valuable to the community**.
-In the following, we will explain each contribution a bit more in detail.
-
-For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
-
-### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
-
-Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
-- Reports of training or inference experiments in an attempt to share knowledge
-- Presentation of personal projects
-- Questions to non-official training examples
-- Project proposals
-- General feedback
-- Paper summaries
-- Asking for help on personal projects that build on top of the Diffusers library
-- General questions
-- Ethical questions regarding diffusion models
-- ...
-
-Every question that is asked on the forum or on Discord actively encourages the community to publicly
-share knowledge and might very well help a beginner in the future that has the same question you're
-having. Please do pose any questions you might have.
-In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
-
-**Please** keep in mind that the more effort you put into asking or answering a question, the higher
-the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
-In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
-
-**NOTE about channels**:
-[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
-In addition, questions and answers posted in the forum can easily be linked to.
-In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
-While it will most likely take less time for you to get an answer to your question on Discord, your
-question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
-
-### 2. Opening new issues on the GitHub issues tab
-
-The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
-the problems they encounter. So thank you for reporting an issue.
-
-Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
-
-In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
-
-**Please consider the following guidelines when opening a new issue**:
-- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
-- Please never report a new issue on another (related) issue. If another issue is highly related, please
-open a new issue nevertheless and link to the related issue.
-- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
-- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
-- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
-
-New issues usually include the following.
-
-#### 2.1. Reproducible, minimal bug reports.
-
-A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
-This means in more detail:
-- Narrow the bug down as much as you can, **do not just dump your whole code file**
-- Format your code
-- Do not include any external libraries except for Diffusers depending on them.
-- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
-- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
-- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
-- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
-
-For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
-
-You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
-
-#### 2.2. Feature requests.
-
-A world-class feature request addresses the following points:
-
-1. Motivation first:
-* Is it related to a problem/frustration with the library? If so, please explain
-why. Providing a code snippet that demonstrates the problem is best.
-* Is it related to something you would need for a project? We'd love to hear
-about it!
-* Is it something you worked on and think could benefit the community?
-Awesome! Tell us what problem it solved for you.
-2. Write a *full paragraph* describing the feature;
-3. Provide a **code snippet** that demonstrates its future use;
-4. In case this is related to a paper, please attach a link;
-5. Attach any additional information (drawings, screenshots, etc.) you think may help.
-
-You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
-
-#### 2.3 Feedback.
-
-Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
-If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
-
-You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
-
-#### 2.4 Technical questions.
-
-Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
-why this part of the code is difficult to understand.
-
-You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
-
-#### 2.5 Proposal to add a new model, scheduler, or pipeline.
-
-If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
-
-* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
-* Link to any of its open-source implementation.
-* Link to the model weights if they are available.
-
-If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
-to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
-
-You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
-
-### 3. Answering issues on the GitHub issues tab
-
-Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
-Some tips to give a high-quality answer to an issue:
-- Be as concise and minimal as possible
-- Stay on topic. An answer to the issue should concern the issue and only the issue.
-- Provide links to code, papers, or other sources that prove or encourage your point.
-- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
-
-Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
-help to the maintainers if you can answer such issues, encouraging the author of the issue to be
-more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
-
-If you have verified that the issued bug report is correct and requires a correction in the source code,
-please have a look at the next sections.
-
-For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
-
-### 4. Fixing a "Good first issue"
-
-*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
-explains how a potential solution should look so that it is easier to fix.
-If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
-- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
-- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
-- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
-
-
-### 5. Contribute to the documentation
-
-A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
-valuable contribution**.
-
-Contributing to the library can have many forms:
-
-- Correcting spelling or grammatical errors.
-- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
-- Correct the shape or dimensions of a docstring input or output tensor.
-- Clarify documentation that is hard to understand or incorrect.
-- Update outdated code examples.
-- Translating the documentation to another language.
-
-Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
-
-Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
-
-
-### 6. Contribute a community pipeline
-
-[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
-Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
-We support two types of pipelines:
-
-- Official Pipelines
-- Community Pipelines
-
-Both official and community pipelines follow the same design and consist of the same type of components.
-
-Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
-resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
-In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
-They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
-
-The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
-possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
-Officially released diffusion pipelines,
-such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
-high quality of maintenance, no backward-breaking code changes, and testing.
-More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
-
-To add a community pipeline, one should add a
- 
- Real images.
-
- 
- Fake images.
-
-
-  -
-
-
Learn the fundamental skills you need to start generating outputs, build your own diffusion system, and train a diffusion model. We recommend starting here if you're using 🤗 Diffusers for the first time!
- -Practical guides for helping you load pipelines, models, and schedulers. You'll also learn how to use pipelines for specific tasks, control how outputs are generated, optimize for inference speed, and different training techniques.
- -Understand why the library was designed the way it was, and learn more about the ethical guidelines and safety implementations for using the library.
- -Technical descriptions of how 🤗 Diffusers classes and methods work.
- - -
- -
- -
- -
- -
- -
- -
- -
- -
-
-  -
-
-  -
-
 -
- -
- -
- -
- -
- |
|  |
-
-Play around with the Spaces below and see if you notice a difference between generated images with and without a depth map!
-
-
diff --git a/diffusers/docs/source/en/using-diffusers/img2img.mdx b/diffusers/docs/source/en/using-diffusers/img2img.mdx
deleted file mode 100644
index 71540fbf5dd9ef203158bf5531e327b27915d5a4..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/using-diffusers/img2img.mdx
+++ /dev/null
@@ -1,99 +0,0 @@
-
-
-# Text-guided image-to-image generation
-
-[[open-in-colab]]
-
-The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images.
-
-Before you begin, make sure you have all the necessary libraries installed:
-
-```bash
-!pip install diffusers transformers ftfy accelerate
-```
-
-Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model like [`nitrosocke/Ghibli-Diffusion`](https://huggingface.co/nitrosocke/Ghibli-Diffusion).
-
-```python
-import torch
-import requests
-from PIL import Image
-from io import BytesIO
-from diffusers import StableDiffusionImg2ImgPipeline
-
-device = "cuda"
-pipe = StableDiffusionImg2ImgPipeline.from_pretrained("nitrosocke/Ghibli-Diffusion", torch_dtype=torch.float16).to(
- device
-)
-```
-
-Download and preprocess an initial image so you can pass it to the pipeline:
-
-```python
-url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
-
-response = requests.get(url)
-init_image = Image.open(BytesIO(response.content)).convert("RGB")
-init_image.thumbnail((768, 768))
-init_image
-```
-
-
|
-
-Play around with the Spaces below and see if you notice a difference between generated images with and without a depth map!
-
-
diff --git a/diffusers/docs/source/en/using-diffusers/img2img.mdx b/diffusers/docs/source/en/using-diffusers/img2img.mdx
deleted file mode 100644
index 71540fbf5dd9ef203158bf5531e327b27915d5a4..0000000000000000000000000000000000000000
--- a/diffusers/docs/source/en/using-diffusers/img2img.mdx
+++ /dev/null
@@ -1,99 +0,0 @@
-
-
-# Text-guided image-to-image generation
-
-[[open-in-colab]]
-
-The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images.
-
-Before you begin, make sure you have all the necessary libraries installed:
-
-```bash
-!pip install diffusers transformers ftfy accelerate
-```
-
-Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model like [`nitrosocke/Ghibli-Diffusion`](https://huggingface.co/nitrosocke/Ghibli-Diffusion).
-
-```python
-import torch
-import requests
-from PIL import Image
-from io import BytesIO
-from diffusers import StableDiffusionImg2ImgPipeline
-
-device = "cuda"
-pipe = StableDiffusionImg2ImgPipeline.from_pretrained("nitrosocke/Ghibli-Diffusion", torch_dtype=torch.float16).to(
- device
-)
-```
-
-Download and preprocess an initial image so you can pass it to the pipeline:
-
-```python
-url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
-
-response = requests.get(url)
-init_image = Image.open(BytesIO(response.content)).convert("RGB")
-init_image.thumbnail((768, 768))
-init_image
-```
-
- -
- -
- -
- |
|  | ***Face of a yellow cat, high resolution, sitting on a park bench*** |
| ***Face of a yellow cat, high resolution, sitting on a park bench*** |  |
-
-
-
|
-
-
- -
- -
- -
- -
- -
- -
- -
-
-
-  -
-
-
-
-  -
-
-
-
-  -
-
-
-
-  -
-
-
-
-  -
-
-
-
-  -
-
-
 -
- -
-
-
-
-
-
-
-
-
-
-
-