Spaces:
Runtime error

Runtime error

Commit
•
ce955af
1
Parent(s):
b4c7401
Update app.py
Browse files
app.py
CHANGED
|
@@ -3,61 +3,147 @@ import requests
|
|
| 3 |
|
| 4 |
import gradio as gr
|
| 5 |
from languages import LANGUAGES
|
|
|
|
| 6 |
|
| 7 |
-
GLADIA_API_KEY = os.environ.get(
|
| 8 |
|
| 9 |
headers = {
|
| 10 |
-
|
| 11 |
-
|
| 12 |
}
|
| 13 |
|
| 14 |
ACCEPTED_LANGUAGE_BEHAVIOUR = [
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
]
|
| 19 |
|
| 20 |
-
|
| 21 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
files = {
|
| 23 |
-
|
| 24 |
-
'language': (None, language),
|
| 25 |
-
'language_behaviour': (None, language_behaviour),
|
| 26 |
}
|
| 27 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 28 |
response = requests.post(
|
| 29 |
-
|
| 30 |
headers=headers,
|
| 31 |
-
files=files
|
| 32 |
)
|
|
|
|
|
|
|
| 33 |
if response.status_code != 200:
|
| 34 |
print(response.content, response.status_code)
|
| 35 |
|
| 36 |
-
return "Sorry, an error occured with
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
output = response.json()["prediction_raw"]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
del output["metadata"]["original_mediainfo"]
|
| 39 |
-
|
| 40 |
return output
|
| 41 |
|
| 42 |
|
| 43 |
iface = gr.Interface(
|
| 44 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
inputs=[
|
| 46 |
-
gr.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
gr.Dropdown(
|
| 48 |
-
label="Language transcription behaviour
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 49 |
choices=ACCEPTED_LANGUAGE_BEHAVIOUR,
|
| 50 |
-
value=ACCEPTED_LANGUAGE_BEHAVIOUR[1]
|
| 51 |
-
type="value",
|
| 52 |
),
|
| 53 |
gr.Dropdown(
|
| 54 |
-
choices
|
| 55 |
label="Language (only if language behaviour is set to manual)",
|
| 56 |
-
value="english"
|
| 57 |
-
type="value",
|
| 58 |
),
|
| 59 |
],
|
| 60 |
-
outputs="json"
|
| 61 |
)
|
| 62 |
-
|
| 63 |
iface.launch()
|
|
|
|
| 3 |
|
| 4 |
import gradio as gr
|
| 5 |
from languages import LANGUAGES
|
| 6 |
+
from time import time
|
| 7 |
|
| 8 |
+
GLADIA_API_KEY = os.environ.get("GLADIA_API_KEY")
|
| 9 |
|
| 10 |
headers = {
|
| 11 |
+
"accept": "application/json",
|
| 12 |
+
"x-gladia-key": GLADIA_API_KEY,
|
| 13 |
}
|
| 14 |
|
| 15 |
ACCEPTED_LANGUAGE_BEHAVIOUR = [
|
| 16 |
+
"manual",
|
| 17 |
+
"automatic single language",
|
| 18 |
+
"automatic multiple languages",
|
| 19 |
]
|
| 20 |
|
| 21 |
+
|
| 22 |
+
def transcribe(
|
| 23 |
+
audio_url: str = None,
|
| 24 |
+
audio: str = None,
|
| 25 |
+
video: str = None,
|
| 26 |
+
language_behaviour: str = ACCEPTED_LANGUAGE_BEHAVIOUR[2],
|
| 27 |
+
language: str = "english",
|
| 28 |
+
) -> dict:
|
| 29 |
+
"""
|
| 30 |
+
This function transcribes audio to text using the Gladia API.
|
| 31 |
+
It sends a request to the API with the given audio file or audio URL, and returns the transcribed text.
|
| 32 |
+
Find your api key at gladia.io
|
| 33 |
+
|
| 34 |
+
Parameters:
|
| 35 |
+
audio_url (str): The URL of the audio file to transcribe. If audio_url is provided, audio file will be ignored.
|
| 36 |
+
audio (str): The path to the audio file to transcribe.
|
| 37 |
+
video (str): The path to the video file. If provided, the audio field will be set to the content of this video.
|
| 38 |
+
language_behaviour (str): Determines how language detection should be performed.
|
| 39 |
+
Must be one of [
|
| 40 |
+
"manual",
|
| 41 |
+
"automatic single language",
|
| 42 |
+
"automatic multiple languages"
|
| 43 |
+
]
|
| 44 |
+
If "manual", the language field must be provided and the API will transcribe the audio in the given language.
|
| 45 |
+
If "automatic single language", the language of the audio will be automatically detected by the API
|
| 46 |
+
but will force the transcription to be in a single language.
|
| 47 |
+
If "automatic multiple languages", the language of the audio will be automatically detected by the API for
|
| 48 |
+
each sentence allowing code-switching over 97 languages.
|
| 49 |
+
|
| 50 |
+
language (str): The language of the audio file. This field is ignored if language_behaviour is set to "automatic*".
|
| 51 |
+
|
| 52 |
+
Returns:
|
| 53 |
+
dict: A dictionary containing the transcribed text and other metadata about the transcription process. If an error occurs, the function returns a string with an error message.
|
| 54 |
+
"""
|
| 55 |
+
|
| 56 |
+
# if video file is there then send the audio field as the content of the video
|
| 57 |
files = {
|
| 58 |
+
"language_behaviour": (None, language_behaviour),
|
|
|
|
|
|
|
| 59 |
}
|
| 60 |
|
| 61 |
+
# priority given to the video
|
| 62 |
+
if video:
|
| 63 |
+
audio = video
|
| 64 |
+
|
| 65 |
+
# priority given to the audio or video
|
| 66 |
+
if audio:
|
| 67 |
+
files["audio"] = (audio, open(audio, "rb"), "audio/wav")
|
| 68 |
+
else:
|
| 69 |
+
files["audio_url"] = ((None, audio_url),)
|
| 70 |
+
|
| 71 |
+
# if language is manual then send the language field
|
| 72 |
+
# if it's there for language_behaviour == automatic*
|
| 73 |
+
# it will ignored anyways
|
| 74 |
+
if language_behaviour == "manual":
|
| 75 |
+
files["language"] = (None, language)
|
| 76 |
+
|
| 77 |
+
start_transfer = time()
|
| 78 |
response = requests.post(
|
| 79 |
+
"https://api.gladia.io/audio/text/audio-transcription/",
|
| 80 |
headers=headers,
|
| 81 |
+
files=files,
|
| 82 |
)
|
| 83 |
+
end_transfer = time()
|
| 84 |
+
|
| 85 |
if response.status_code != 200:
|
| 86 |
print(response.content, response.status_code)
|
| 87 |
|
| 88 |
+
return "Sorry, an error occured with your request :/"
|
| 89 |
+
|
| 90 |
+
# we have 2 outputs:
|
| 91 |
+
# prediction and prediction_raw
|
| 92 |
+
# prediction_raw has more details about the processing
|
| 93 |
+
# and other debugging detailed element you might be
|
| 94 |
+
# interested in
|
| 95 |
+
|
| 96 |
output = response.json()["prediction_raw"]
|
| 97 |
+
|
| 98 |
+
output["metadata"]["client_total_execution_time"] = end_transfer - start_transfer
|
| 99 |
+
output["metadata"]["data_transfer_time"] = output["metadata"]["client_total_execution_time"] -output["metadata"]["total_transcription_time"]
|
| 100 |
+
output["metadata"]["api_server_transcription_time"] = output["metadata"]["total_transcription_time"]
|
| 101 |
+
|
| 102 |
del output["metadata"]["original_mediainfo"]
|
| 103 |
+
|
| 104 |
return output
|
| 105 |
|
| 106 |
|
| 107 |
iface = gr.Interface(
|
| 108 |
+
title="Gladia.io fast audio transcription",
|
| 109 |
+
description="""Gladia.io Whisper large-v2 fast audio transcription API
|
| 110 |
+
is able to perform fast audio transcription for any audio / video or url format.<br/><br/>
|
| 111 |
+
However it's prefered for faster performance to provide <br/>
|
| 112 |
+
wav 16KHz with 16b encoding (pcm_u16be) to avoid further the conversion time.<br/>
|
| 113 |
+
"automatic single language" language discovery behavior may also<br/>
|
| 114 |
+
slow down (just a little bit - talking about ms) the process.
|
| 115 |
+
<br/>
|
| 116 |
+
Here is a benchmark ran on multiple Speech-To-Text providers
|
| 117 |
+
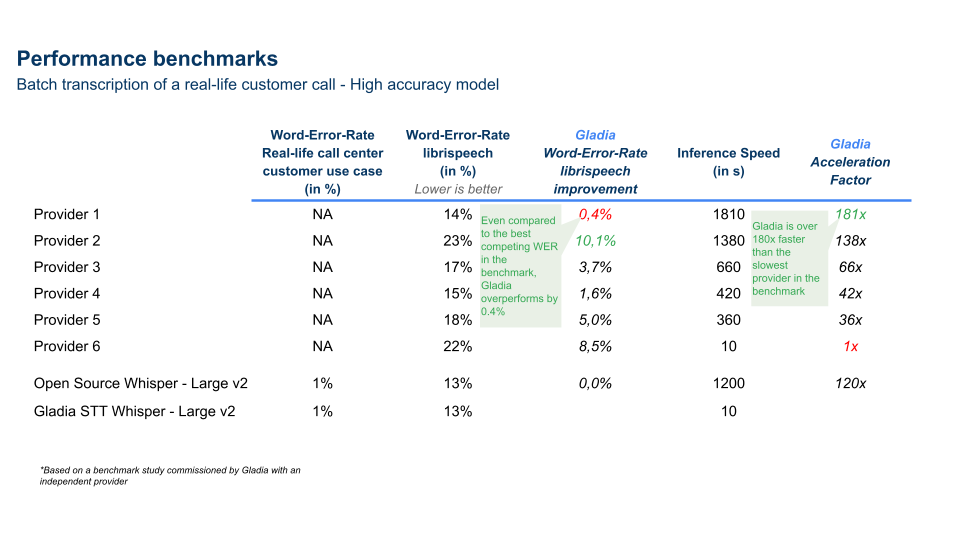<br/>
|
| 118 |
+
Join our [Slack](https://gladia-io.slack.com) to discuss with us.<br/><br/>
|
| 119 |
+
Get your own API key on [Gladia.io](https://gladia.io/) during free alpha
|
| 120 |
+
""",
|
| 121 |
+
fn=transcribe,
|
| 122 |
inputs=[
|
| 123 |
+
gr.Textbox(
|
| 124 |
+
lines=1,
|
| 125 |
+
label="Audio/Video url to transcribe",
|
| 126 |
+
),
|
| 127 |
+
gr.Audio(label="or Audio file to transcribe", source="upload", type="filepath"),
|
| 128 |
+
gr.Video(label="or Video file to transcribe", source="upload", type="filepath"),
|
| 129 |
gr.Dropdown(
|
| 130 |
+
label="""Language transcription behaviour:\n
|
| 131 |
+
If "manual", the language field must be provided and the API will transcribe the audio in the given language.
|
| 132 |
+
If "automatic single language", the language of the audio will be automatically detected by the API
|
| 133 |
+
but will force the transcription to be in a single language.
|
| 134 |
+
If "automatic multiple languages", the language of the audio will be automatically detected by the API for
|
| 135 |
+
each sentence allowing code-switching over 97 languages.
|
| 136 |
+
""",
|
| 137 |
choices=ACCEPTED_LANGUAGE_BEHAVIOUR,
|
| 138 |
+
value=ACCEPTED_LANGUAGE_BEHAVIOUR[1]
|
|
|
|
| 139 |
),
|
| 140 |
gr.Dropdown(
|
| 141 |
+
choices=sorted([language_name for language_name in LANGUAGES.keys()]),
|
| 142 |
label="Language (only if language behaviour is set to manual)",
|
| 143 |
+
value="english"
|
|
|
|
| 144 |
),
|
| 145 |
],
|
| 146 |
+
outputs="json",
|
| 147 |
)
|
| 148 |
+
iface.queue()
|
| 149 |
iface.launch()
|