 +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+ +
 +
+---
+
+
+
+---
+
+
+
+
+
+
+
+
+
![]() +
+
+
+
+
+
+
+
 +
+```bash
+python tools/visualization.py \
+ --config_path config/visual.yaml \
+ --output_path {ckpt_dir}/outputs.jsonl
+```
+Visualization configuration can be set as below:
+```yaml
+host: 127.0.0.1
+port: 7861
+is_push_to_public: true # whether to push to gradio platform(public network)
+output_path: save/stack/outputs.jsonl # output prediction file path
+page-size: 2 # the number of instances of each page in instance anlysis.
+```
+### 2. Deployment
+
+We provide an script to deploy your model automatically. You are only needed to run the command as below to deploy your own model:
+
+```bash
+python app.py --config_path config/reproduction/atis/bi-model.yaml
+```
+
+
+
+```bash
+python tools/visualization.py \
+ --config_path config/visual.yaml \
+ --output_path {ckpt_dir}/outputs.jsonl
+```
+Visualization configuration can be set as below:
+```yaml
+host: 127.0.0.1
+port: 7861
+is_push_to_public: true # whether to push to gradio platform(public network)
+output_path: save/stack/outputs.jsonl # output prediction file path
+page-size: 2 # the number of instances of each page in instance anlysis.
+```
+### 2. Deployment
+
+We provide an script to deploy your model automatically. You are only needed to run the command as below to deploy your own model:
+
+```bash
+python app.py --config_path config/reproduction/atis/bi-model.yaml
+```
+
+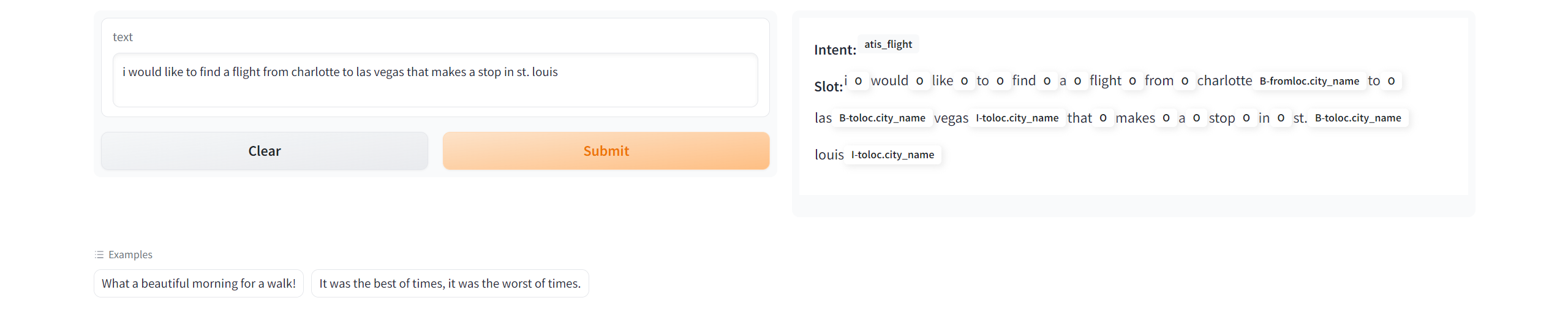 +
+### 3. Publish your model to hugging face
+
+We also offer an script to transfer models trained by OpenSLU to hugging face format automatically. And you can upload the model to your `Model` space.
+
+```shell
+python tools/parse_to_hugging_face.py -cp config/reproduction/atis/bi-model.yaml -op save/temp
+```
+
+It will generate 5 files, and you should only need to upload `config.json`, `pytorch_model.bin` and `tokenizer.pkl`.
+After that, others can reproduction your model just by adjust `_from_pretrained_` parameters in Configuration.
+
+##
+
+### 3. Publish your model to hugging face
+
+We also offer an script to transfer models trained by OpenSLU to hugging face format automatically. And you can upload the model to your `Model` space.
+
+```shell
+python tools/parse_to_hugging_face.py -cp config/reproduction/atis/bi-model.yaml -op save/temp
+```
+
+It will generate 5 files, and you should only need to upload `config.json`, `pytorch_model.bin` and `tokenizer.pkl`.
+After that, others can reproduction your model just by adjust `_from_pretrained_` parameters in Configuration.
+
+## +
+