Spaces:
Runtime error

Runtime error

Upload folder using huggingface_hub
Browse files- .gitignore +119 -0
- README.md +163 -12
- assets/motivation.jpg +0 -0
- assets/the_great_wall.jpg +0 -0
- assets/user_study.jpg +0 -0
- assets/vbench.jpg +0 -0
- diffusion_schedulers/__init__.py +2 -0
- diffusion_schedulers/scheduling_cosine_ddpm.py +137 -0
- diffusion_schedulers/scheduling_flow_matching.py +298 -0
- pyramid_dit/__init__.py +3 -0
- pyramid_dit/modeling_embedding.py +390 -0
- pyramid_dit/modeling_mmdit_block.py +672 -0
- pyramid_dit/modeling_normalization.py +184 -0
- pyramid_dit/modeling_pyramid_mmdit.py +487 -0
- pyramid_dit/modeling_text_encoder.py +140 -0
- pyramid_dit/pyramid_dit_for_video_gen_pipeline.py +665 -0
- requirements.txt +31 -0
- trainer_misc/__init__.py +25 -0
- trainer_misc/communicate.py +58 -0
- trainer_misc/sp_utils.py +98 -0
- trainer_misc/utils.py +382 -0
- utils.py +457 -0
- video_generation_demo.ipynb +179 -0
- video_vae/__init__.py +2 -0
- video_vae/context_parallel_ops.py +172 -0
- video_vae/modeling_block.py +760 -0
- video_vae/modeling_causal_conv.py +139 -0
- video_vae/modeling_causal_vae.py +625 -0
- video_vae/modeling_discriminator.py +122 -0
- video_vae/modeling_enc_dec.py +422 -0
- video_vae/modeling_loss.py +192 -0
- video_vae/modeling_lpips.py +120 -0
- video_vae/modeling_resnet.py +729 -0
.gitignore
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Xcode
|
| 2 |
+
.DS_Store
|
| 3 |
+
.idea
|
| 4 |
+
|
| 5 |
+
# tyte-compiled / optimized / DLL files
|
| 6 |
+
__pycache__/
|
| 7 |
+
*.py[cod]
|
| 8 |
+
*$py.class
|
| 9 |
+
# C extensions
|
| 10 |
+
*.so
|
| 11 |
+
onnx_model/*.onnx
|
| 12 |
+
onnx_model/antelope/*.onnx
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
logs/
|
| 16 |
+
prompts/
|
| 17 |
+
|
| 18 |
+
# Distribution / packaging
|
| 19 |
+
.Python
|
| 20 |
+
build/
|
| 21 |
+
develop-eggs/
|
| 22 |
+
downloads/
|
| 23 |
+
eggs/
|
| 24 |
+
.eggs/
|
| 25 |
+
lib/
|
| 26 |
+
lib64/
|
| 27 |
+
parts/
|
| 28 |
+
sdist/
|
| 29 |
+
wheels/
|
| 30 |
+
share/python-wheels/
|
| 31 |
+
*.egg-info/
|
| 32 |
+
.installed.cfg
|
| 33 |
+
*.egg
|
| 34 |
+
MANIFEST
|
| 35 |
+
|
| 36 |
+
# PyInstaller
|
| 37 |
+
# Usually these files are written by a python script from a template
|
| 38 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 39 |
+
*.manifest
|
| 40 |
+
*.spec
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# Unit test / coverage reports
|
| 44 |
+
htmlcov/
|
| 45 |
+
.tox/
|
| 46 |
+
.nox/
|
| 47 |
+
.coverage
|
| 48 |
+
.coverage.*
|
| 49 |
+
.cache
|
| 50 |
+
nosetests.xml
|
| 51 |
+
coverage.xml
|
| 52 |
+
*.cover
|
| 53 |
+
.hypothesis/
|
| 54 |
+
.pytest_cache/
|
| 55 |
+
|
| 56 |
+
# Translations
|
| 57 |
+
*.mo
|
| 58 |
+
*.pot
|
| 59 |
+
|
| 60 |
+
# Django stuff:
|
| 61 |
+
*.log
|
| 62 |
+
local_settings.py
|
| 63 |
+
db.sqlite3
|
| 64 |
+
|
| 65 |
+
# Flask stuff:
|
| 66 |
+
instance/
|
| 67 |
+
.webassets-cache
|
| 68 |
+
|
| 69 |
+
# Scrapy stuff:
|
| 70 |
+
.scrapy
|
| 71 |
+
|
| 72 |
+
# Sphinx documentation
|
| 73 |
+
docs/_build/
|
| 74 |
+
|
| 75 |
+
# PyBuilder
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
.python-version
|
| 87 |
+
|
| 88 |
+
# celery beat schedule file
|
| 89 |
+
celerybeat-schedule
|
| 90 |
+
|
| 91 |
+
# SageMath parsed files
|
| 92 |
+
*.sage.py
|
| 93 |
+
|
| 94 |
+
# Environments
|
| 95 |
+
.env
|
| 96 |
+
.pt2/
|
| 97 |
+
.venv
|
| 98 |
+
env/
|
| 99 |
+
venv/
|
| 100 |
+
ENV/
|
| 101 |
+
env.bak/
|
| 102 |
+
venv.bak/
|
| 103 |
+
|
| 104 |
+
# Spyder project settings
|
| 105 |
+
.spyderproject
|
| 106 |
+
.spyproject
|
| 107 |
+
|
| 108 |
+
# Rope project settings
|
| 109 |
+
.ropeproject
|
| 110 |
+
|
| 111 |
+
# mkdocs documentation
|
| 112 |
+
/site
|
| 113 |
+
|
| 114 |
+
# mypy
|
| 115 |
+
.mypy_cache/
|
| 116 |
+
.dmypy.json
|
| 117 |
+
dmypy.json
|
| 118 |
+
.bak
|
| 119 |
+
|
README.md
CHANGED
|
@@ -1,12 +1,163 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# ⚡️Pyramid Flow⚡️
|
| 4 |
+
|
| 5 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page ✨]](https://pyramid-flow.github.io) [[Model 🤗]](https://huggingface.co/rain1011/pyramid-flow-sd3)
|
| 6 |
+
|
| 7 |
+
</div>
|
| 8 |
+
|
| 9 |
+
This is the official repository for Pyramid Flow, a training-efficient **Autoregressive Video Generation** method based on **Flow Matching**. By training only on open-source datasets, it can generate high-quality 10-second videos at 768p resolution and 24 FPS, and naturally supports image-to-video generation.
|
| 10 |
+
|
| 11 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 12 |
+
<tr>
|
| 13 |
+
<th>10s, 768p, 24fps</th>
|
| 14 |
+
<th>5s, 768p, 24fps</th>
|
| 15 |
+
<th>Image-to-video</th>
|
| 16 |
+
</tr>
|
| 17 |
+
<tr>
|
| 18 |
+
<td><video src="https://github.com/user-attachments/assets/9935da83-ae56-4672-8747-0f46e90f7b2b" autoplay muted loop playsinline></video></td>
|
| 19 |
+
<td><video src="https://github.com/user-attachments/assets/3412848b-64db-4d9e-8dbf-11403f6d02c5" autoplay muted loop playsinline></video></td>
|
| 20 |
+
<td><video src="https://github.com/user-attachments/assets/3bd7251f-7b2c-4bee-951d-656fdb45f427" autoplay muted loop playsinline></video></td>
|
| 21 |
+
</tr>
|
| 22 |
+
</table>
|
| 23 |
+
|
| 24 |
+
## News
|
| 25 |
+
|
| 26 |
+
* `COMING SOON` ⚡️⚡️⚡️ Training code and new model checkpoints trained from scratch.
|
| 27 |
+
|
| 28 |
+
> We are training Pyramid Flow from scratch to fix human structure issues related to the currently adopted SD3 initialization and hope to release it in the next few days.
|
| 29 |
+
* `2024.10.10` 🚀🚀🚀 We release the [technical report](https://arxiv.org/abs/2410.05954), [project page](https://pyramid-flow.github.io) and [model checkpoint](https://huggingface.co/rain1011/pyramid-flow-sd3) of Pyramid Flow.
|
| 30 |
+
|
| 31 |
+
## Introduction
|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+
Existing video diffusion models operate at full resolution, spending a lot of computation on very noisy latents. By contrast, our method harnesses the flexibility of flow matching ([Lipman et al., 2023](https://openreview.net/forum?id=PqvMRDCJT9t); [Liu et al., 2023](https://openreview.net/forum?id=XVjTT1nw5z); [Albergo & Vanden-Eijnden, 2023](https://openreview.net/forum?id=li7qeBbCR1t)) to interpolate between latents of different resolutions and noise levels, allowing for simultaneous generation and decompression of visual content with better computational efficiency. The entire framework is end-to-end optimized with a single DiT ([Peebles & Xie, 2023](http://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.html)), generating high-quality 10-second videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours.
|
| 36 |
+
|
| 37 |
+
## Usage
|
| 38 |
+
|
| 39 |
+
You can directly download the model from [Huggingface](https://huggingface.co/rain1011/pyramid-flow-sd3). We provide both model checkpoints for 768p and 384p video generation. The 384p checkpoint supports 5-second video generation at 24FPS, while the 768p checkpoint supports up to 10-second video generation at 24FPS.
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
from huggingface_hub import snapshot_download
|
| 43 |
+
|
| 44 |
+
model_path = 'PATH' # The local directory to save downloaded checkpoint
|
| 45 |
+
snapshot_download("rain1011/pyramid-flow-sd3", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
To use our model, please follow the inference code in `video_generation_demo.ipynb` at [this link](https://github.com/jy0205/Pyramid-Flow/blob/main/video_generation_demo.ipynb). We further simplify it into the following two-step procedure. First, load the downloaded model:
|
| 50 |
+
|
| 51 |
+
```python
|
| 52 |
+
import torch
|
| 53 |
+
from PIL import Image
|
| 54 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 55 |
+
from diffusers.utils import load_image, export_to_video
|
| 56 |
+
|
| 57 |
+
torch.cuda.set_device(0)
|
| 58 |
+
model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16, fp16 or fp32
|
| 59 |
+
|
| 60 |
+
model = PyramidDiTForVideoGeneration(
|
| 61 |
+
'PATH', # The downloaded checkpoint dir
|
| 62 |
+
model_dtype,
|
| 63 |
+
model_variant='diffusion_transformer_768p', # 'diffusion_transformer_384p'
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
model.vae.to("cuda")
|
| 67 |
+
model.dit.to("cuda")
|
| 68 |
+
model.text_encoder.to("cuda")
|
| 69 |
+
model.vae.enable_tiling()
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
Then, you can try text-to-video generation on your own prompts:
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
|
| 76 |
+
|
| 77 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 78 |
+
frames = model.generate(
|
| 79 |
+
prompt=prompt,
|
| 80 |
+
num_inference_steps=[20, 20, 20],
|
| 81 |
+
video_num_inference_steps=[10, 10, 10],
|
| 82 |
+
height=768,
|
| 83 |
+
width=1280,
|
| 84 |
+
temp=16, # temp=16: 5s, temp=31: 10s
|
| 85 |
+
guidance_scale=9.0, # The guidance for the first frame
|
| 86 |
+
video_guidance_scale=5.0, # The guidance for the other video latent
|
| 87 |
+
output_type="pil",
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
As an autoregressive model, our model also supports (text conditioned) image-to-video generation:
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((1280, 768))
|
| 97 |
+
prompt = "FPV flying over the Great Wall"
|
| 98 |
+
|
| 99 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 100 |
+
frames = model.generate_i2v(
|
| 101 |
+
prompt=prompt,
|
| 102 |
+
input_image=image,
|
| 103 |
+
num_inference_steps=[10, 10, 10],
|
| 104 |
+
temp=16,
|
| 105 |
+
video_guidance_scale=4.0,
|
| 106 |
+
output_type="pil",
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
Usage tips:
|
| 113 |
+
|
| 114 |
+
* The `guidance_scale` parameter controls the visual quality. We suggest using a guidance within [7, 9] for the 768p checkpoint during text-to-video generation, and 7 for the 384p checkpoint.
|
| 115 |
+
* The `video_guidance_scale` parameter controls the motion. A larger value increases the dynamic degree and mitigates the autoregressive generation degradation, while a smaller value stabilizes the video.
|
| 116 |
+
* For 10-second video generation, we recommend using a guidance scale of 7 and a video guidance scale of 5.
|
| 117 |
+
|
| 118 |
+
## Gallery
|
| 119 |
+
|
| 120 |
+
The following video examples are generated at 5s, 768p, 24fps. For more results, please visit our [project page](https://pyramid-flow.github.io).
|
| 121 |
+
|
| 122 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 123 |
+
<tr>
|
| 124 |
+
<td><video src="https://github.com/user-attachments/assets/5b44a57e-fa08-4554-84a2-2c7a99f2b343" autoplay muted loop playsinline></video></td>
|
| 125 |
+
<td><video src="https://github.com/user-attachments/assets/5afd5970-de72-40e2-900d-a20d18308e8e" autoplay muted loop playsinline></video></td>
|
| 126 |
+
</tr>
|
| 127 |
+
<tr>
|
| 128 |
+
<td><video src="https://github.com/user-attachments/assets/1d44daf8-017f-40e9-bf18-1e19c0a8983b" autoplay muted loop playsinline></video></td>
|
| 129 |
+
<td><video src="https://github.com/user-attachments/assets/7f5dd901-b7d7-48cc-b67a-3c5f9e1546d2" autoplay muted loop playsinline></video></td>
|
| 130 |
+
</tr>
|
| 131 |
+
</table>
|
| 132 |
+
|
| 133 |
+
## Comparison
|
| 134 |
+
|
| 135 |
+
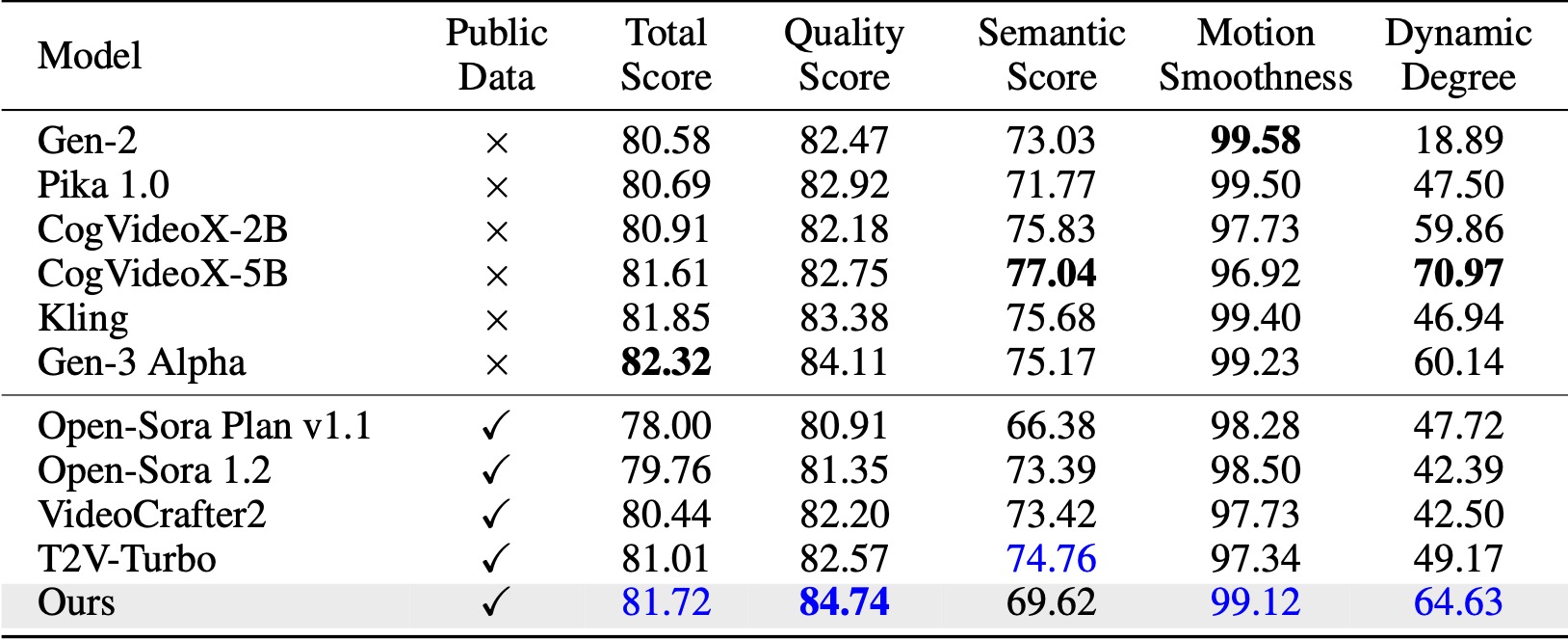
On VBench ([Huang et al., 2024](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard)), our method surpasses all the compared open-source baselines. Even with only public video data, it achieves comparable performance to commercial models like Kling ([Kuaishou, 2024](https://kling.kuaishou.com/en)) and Gen-3 Alpha ([Runway, 2024](https://runwayml.com/research/introducing-gen-3-alpha)), especially in the quality score (84.74 vs. 84.11 of Gen-3) and motion smoothness.
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
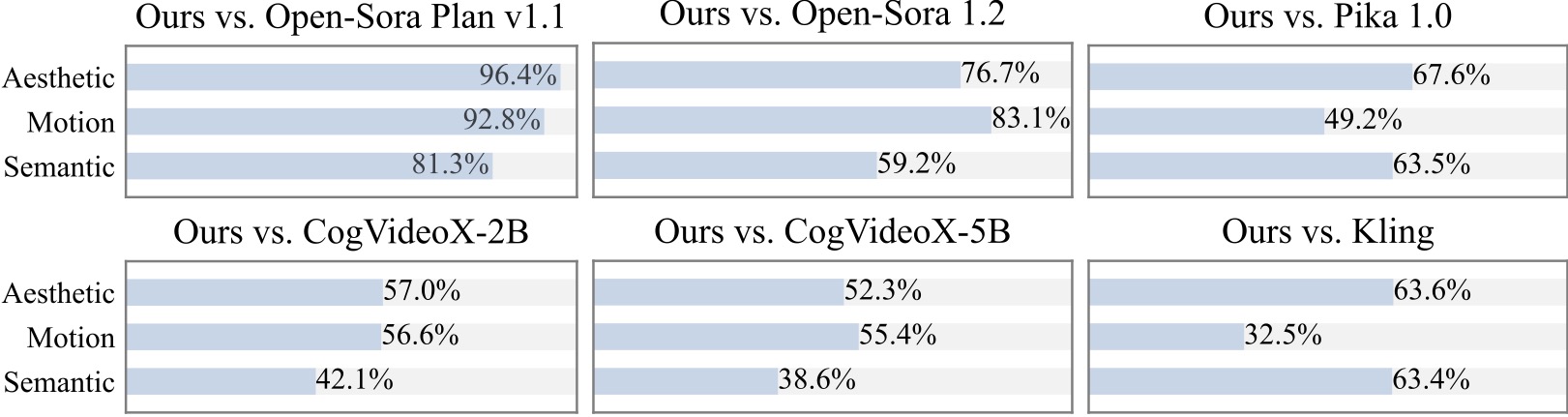
We conduct an additional user study with 20+ participants. As can be seen, our method is preferred over open-source models such as [Open-Sora](https://github.com/hpcaitech/Open-Sora) and [CogVideoX-2B](https://github.com/THUDM/CogVideo) especially in terms of motion smoothness.
|
| 140 |
+
|
| 141 |
+

|
| 142 |
+
|
| 143 |
+
## Acknowledgement
|
| 144 |
+
|
| 145 |
+
We are grateful for the following awesome projects when implementing Pyramid Flow:
|
| 146 |
+
|
| 147 |
+
* [SD3 Medium](https://huggingface.co/stabilityai/stable-diffusion-3-medium) and [Flux 1.0](https://huggingface.co/black-forest-labs/FLUX.1-dev): State-of-the-art image generation models based on flow matching.
|
| 148 |
+
* [Diffusion Forcing](https://boyuan.space/diffusion-forcing) and [GameNGen](https://gamengen.github.io): Next-token prediction meets full-sequence diffusion.
|
| 149 |
+
* [WebVid-10M](https://github.com/m-bain/webvid), [OpenVid-1M](https://github.com/NJU-PCALab/OpenVid-1M) and [Open-Sora Plan](https://github.com/PKU-YuanGroup/Open-Sora-Plan): Large-scale datasets for text-to-video generation.
|
| 150 |
+
* [CogVideoX](https://github.com/THUDM/CogVideo): An open-source text-to-video generation model that shares many training details.
|
| 151 |
+
* [Video-LLaMA2](https://github.com/DAMO-NLP-SG/VideoLLaMA2): An open-source video LLM for our video recaptioning.
|
| 152 |
+
|
| 153 |
+
## Citation
|
| 154 |
+
|
| 155 |
+
Consider giving this repository a star and cite Pyramid Flow in your publications if it helps your research.
|
| 156 |
+
```
|
| 157 |
+
@article{jin2024pyramidal,
|
| 158 |
+
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
|
| 159 |
+
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
|
| 160 |
+
jounal={arXiv preprint arXiv:2410.05954},
|
| 161 |
+
year={2024}
|
| 162 |
+
}
|
| 163 |
+
```
|
assets/motivation.jpg
ADDED

|
assets/the_great_wall.jpg
ADDED

|
assets/user_study.jpg
ADDED
|
assets/vbench.jpg
ADDED
|
diffusion_schedulers/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .scheduling_cosine_ddpm import DDPMCosineScheduler
|
| 2 |
+
from .scheduling_flow_matching import PyramidFlowMatchEulerDiscreteScheduler
|
diffusion_schedulers/scheduling_cosine_ddpm.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import List, Optional, Tuple, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.utils import BaseOutput
|
| 9 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 10 |
+
from diffusers.schedulers.scheduling_utils import SchedulerMixin
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass
|
| 14 |
+
class DDPMSchedulerOutput(BaseOutput):
|
| 15 |
+
"""
|
| 16 |
+
Output class for the scheduler's step function output.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
prev_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 20 |
+
Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
|
| 21 |
+
denoising loop.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
prev_sample: torch.Tensor
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class DDPMCosineScheduler(SchedulerMixin, ConfigMixin):
|
| 28 |
+
|
| 29 |
+
@register_to_config
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
scaler: float = 1.0,
|
| 33 |
+
s: float = 0.008,
|
| 34 |
+
):
|
| 35 |
+
self.scaler = scaler
|
| 36 |
+
self.s = torch.tensor([s])
|
| 37 |
+
self._init_alpha_cumprod = torch.cos(self.s / (1 + self.s) * torch.pi * 0.5) ** 2
|
| 38 |
+
|
| 39 |
+
# standard deviation of the initial noise distribution
|
| 40 |
+
self.init_noise_sigma = 1.0
|
| 41 |
+
|
| 42 |
+
def _alpha_cumprod(self, t, device):
|
| 43 |
+
if self.scaler > 1:
|
| 44 |
+
t = 1 - (1 - t) ** self.scaler
|
| 45 |
+
elif self.scaler < 1:
|
| 46 |
+
t = t**self.scaler
|
| 47 |
+
alpha_cumprod = torch.cos(
|
| 48 |
+
(t + self.s.to(device)) / (1 + self.s.to(device)) * torch.pi * 0.5
|
| 49 |
+
) ** 2 / self._init_alpha_cumprod.to(device)
|
| 50 |
+
return alpha_cumprod.clamp(0.0001, 0.9999)
|
| 51 |
+
|
| 52 |
+
def scale_model_input(self, sample: torch.Tensor, timestep: Optional[int] = None) -> torch.Tensor:
|
| 53 |
+
"""
|
| 54 |
+
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
|
| 55 |
+
current timestep.
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
sample (`torch.Tensor`): input sample
|
| 59 |
+
timestep (`int`, optional): current timestep
|
| 60 |
+
|
| 61 |
+
Returns:
|
| 62 |
+
`torch.Tensor`: scaled input sample
|
| 63 |
+
"""
|
| 64 |
+
return sample
|
| 65 |
+
|
| 66 |
+
def set_timesteps(
|
| 67 |
+
self,
|
| 68 |
+
num_inference_steps: int = None,
|
| 69 |
+
timesteps: Optional[List[int]] = None,
|
| 70 |
+
device: Union[str, torch.device] = None,
|
| 71 |
+
):
|
| 72 |
+
"""
|
| 73 |
+
Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
|
| 74 |
+
|
| 75 |
+
Args:
|
| 76 |
+
num_inference_steps (`Dict[float, int]`):
|
| 77 |
+
the number of diffusion steps used when generating samples with a pre-trained model. If passed, then
|
| 78 |
+
`timesteps` must be `None`.
|
| 79 |
+
device (`str` or `torch.device`, optional):
|
| 80 |
+
the device to which the timesteps are moved to. {2 / 3: 20, 0.0: 10}
|
| 81 |
+
"""
|
| 82 |
+
if timesteps is None:
|
| 83 |
+
timesteps = torch.linspace(1.0, 0.0, num_inference_steps + 1, device=device)
|
| 84 |
+
if not isinstance(timesteps, torch.Tensor):
|
| 85 |
+
timesteps = torch.Tensor(timesteps).to(device)
|
| 86 |
+
self.timesteps = timesteps
|
| 87 |
+
|
| 88 |
+
def step(
|
| 89 |
+
self,
|
| 90 |
+
model_output: torch.Tensor,
|
| 91 |
+
timestep: int,
|
| 92 |
+
sample: torch.Tensor,
|
| 93 |
+
generator=None,
|
| 94 |
+
return_dict: bool = True,
|
| 95 |
+
) -> Union[DDPMSchedulerOutput, Tuple]:
|
| 96 |
+
dtype = model_output.dtype
|
| 97 |
+
device = model_output.device
|
| 98 |
+
t = timestep
|
| 99 |
+
|
| 100 |
+
prev_t = self.previous_timestep(t)
|
| 101 |
+
|
| 102 |
+
alpha_cumprod = self._alpha_cumprod(t, device).view(t.size(0), *[1 for _ in sample.shape[1:]])
|
| 103 |
+
alpha_cumprod_prev = self._alpha_cumprod(prev_t, device).view(prev_t.size(0), *[1 for _ in sample.shape[1:]])
|
| 104 |
+
alpha = alpha_cumprod / alpha_cumprod_prev
|
| 105 |
+
|
| 106 |
+
mu = (1.0 / alpha).sqrt() * (sample - (1 - alpha) * model_output / (1 - alpha_cumprod).sqrt())
|
| 107 |
+
|
| 108 |
+
std_noise = randn_tensor(mu.shape, generator=generator, device=model_output.device, dtype=model_output.dtype)
|
| 109 |
+
std = ((1 - alpha) * (1.0 - alpha_cumprod_prev) / (1.0 - alpha_cumprod)).sqrt() * std_noise
|
| 110 |
+
pred = mu + std * (prev_t != 0).float().view(prev_t.size(0), *[1 for _ in sample.shape[1:]])
|
| 111 |
+
|
| 112 |
+
if not return_dict:
|
| 113 |
+
return (pred.to(dtype),)
|
| 114 |
+
|
| 115 |
+
return DDPMSchedulerOutput(prev_sample=pred.to(dtype))
|
| 116 |
+
|
| 117 |
+
def add_noise(
|
| 118 |
+
self,
|
| 119 |
+
original_samples: torch.Tensor,
|
| 120 |
+
noise: torch.Tensor,
|
| 121 |
+
timesteps: torch.Tensor,
|
| 122 |
+
) -> torch.Tensor:
|
| 123 |
+
device = original_samples.device
|
| 124 |
+
dtype = original_samples.dtype
|
| 125 |
+
alpha_cumprod = self._alpha_cumprod(timesteps, device=device).view(
|
| 126 |
+
timesteps.size(0), *[1 for _ in original_samples.shape[1:]]
|
| 127 |
+
)
|
| 128 |
+
noisy_samples = alpha_cumprod.sqrt() * original_samples + (1 - alpha_cumprod).sqrt() * noise
|
| 129 |
+
return noisy_samples.to(dtype=dtype)
|
| 130 |
+
|
| 131 |
+
def __len__(self):
|
| 132 |
+
return self.config.num_train_timesteps
|
| 133 |
+
|
| 134 |
+
def previous_timestep(self, timestep):
|
| 135 |
+
index = (self.timesteps - timestep[0]).abs().argmin().item()
|
| 136 |
+
prev_t = self.timesteps[index + 1][None].expand(timestep.shape[0])
|
| 137 |
+
return prev_t
|
diffusion_schedulers/scheduling_flow_matching.py
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Optional, Tuple, Union, List
|
| 3 |
+
import math
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.utils import BaseOutput, logging
|
| 9 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 10 |
+
from diffusers.schedulers.scheduling_utils import SchedulerMixin
|
| 11 |
+
from IPython import embed
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@dataclass
|
| 15 |
+
class FlowMatchEulerDiscreteSchedulerOutput(BaseOutput):
|
| 16 |
+
"""
|
| 17 |
+
Output class for the scheduler's `step` function output.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 21 |
+
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
|
| 22 |
+
denoising loop.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
prev_sample: torch.FloatTensor
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class PyramidFlowMatchEulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
|
| 29 |
+
"""
|
| 30 |
+
Euler scheduler.
|
| 31 |
+
|
| 32 |
+
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
|
| 33 |
+
methods the library implements for all schedulers such as loading and saving.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
num_train_timesteps (`int`, defaults to 1000):
|
| 37 |
+
The number of diffusion steps to train the model.
|
| 38 |
+
timestep_spacing (`str`, defaults to `"linspace"`):
|
| 39 |
+
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
|
| 40 |
+
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
|
| 41 |
+
shift (`float`, defaults to 1.0):
|
| 42 |
+
The shift value for the timestep schedule.
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
_compatibles = []
|
| 46 |
+
order = 1
|
| 47 |
+
|
| 48 |
+
@register_to_config
|
| 49 |
+
def __init__(
|
| 50 |
+
self,
|
| 51 |
+
num_train_timesteps: int = 1000,
|
| 52 |
+
shift: float = 1.0, # Following Stable diffusion 3,
|
| 53 |
+
stages: int = 3,
|
| 54 |
+
stage_range: List = [0, 1/3, 2/3, 1],
|
| 55 |
+
gamma: float = 1/3,
|
| 56 |
+
):
|
| 57 |
+
|
| 58 |
+
self.timestep_ratios = {} # The timestep ratio for each stage
|
| 59 |
+
self.timesteps_per_stage = {} # The detailed timesteps per stage
|
| 60 |
+
self.sigmas_per_stage = {}
|
| 61 |
+
self.start_sigmas = {}
|
| 62 |
+
self.end_sigmas = {}
|
| 63 |
+
self.ori_start_sigmas = {}
|
| 64 |
+
|
| 65 |
+
# self.init_sigmas()
|
| 66 |
+
self.init_sigmas_for_each_stage()
|
| 67 |
+
self.sigma_min = self.sigmas[-1].item()
|
| 68 |
+
self.sigma_max = self.sigmas[0].item()
|
| 69 |
+
self.gamma = gamma
|
| 70 |
+
|
| 71 |
+
def init_sigmas(self):
|
| 72 |
+
"""
|
| 73 |
+
initialize the global timesteps and sigmas
|
| 74 |
+
"""
|
| 75 |
+
num_train_timesteps = self.config.num_train_timesteps
|
| 76 |
+
shift = self.config.shift
|
| 77 |
+
|
| 78 |
+
timesteps = np.linspace(1, num_train_timesteps, num_train_timesteps, dtype=np.float32)[::-1].copy()
|
| 79 |
+
timesteps = torch.from_numpy(timesteps).to(dtype=torch.float32)
|
| 80 |
+
|
| 81 |
+
sigmas = timesteps / num_train_timesteps
|
| 82 |
+
sigmas = shift * sigmas / (1 + (shift - 1) * sigmas)
|
| 83 |
+
|
| 84 |
+
self.timesteps = sigmas * num_train_timesteps
|
| 85 |
+
|
| 86 |
+
self._step_index = None
|
| 87 |
+
self._begin_index = None
|
| 88 |
+
|
| 89 |
+
self.sigmas = sigmas.to("cpu") # to avoid too much CPU/GPU communication
|
| 90 |
+
|
| 91 |
+
def init_sigmas_for_each_stage(self):
|
| 92 |
+
"""
|
| 93 |
+
Init the timesteps for each stage
|
| 94 |
+
"""
|
| 95 |
+
self.init_sigmas()
|
| 96 |
+
|
| 97 |
+
stage_distance = []
|
| 98 |
+
stages = self.config.stages
|
| 99 |
+
training_steps = self.config.num_train_timesteps
|
| 100 |
+
stage_range = self.config.stage_range
|
| 101 |
+
|
| 102 |
+
# Init the start and end point of each stage
|
| 103 |
+
for i_s in range(stages):
|
| 104 |
+
# To decide the start and ends point
|
| 105 |
+
start_indice = int(stage_range[i_s] * training_steps)
|
| 106 |
+
start_indice = max(start_indice, 0)
|
| 107 |
+
end_indice = int(stage_range[i_s+1] * training_steps)
|
| 108 |
+
end_indice = min(end_indice, training_steps)
|
| 109 |
+
start_sigma = self.sigmas[start_indice].item()
|
| 110 |
+
end_sigma = self.sigmas[end_indice].item() if end_indice < training_steps else 0.0
|
| 111 |
+
self.ori_start_sigmas[i_s] = start_sigma
|
| 112 |
+
|
| 113 |
+
if i_s != 0:
|
| 114 |
+
ori_sigma = 1 - start_sigma
|
| 115 |
+
gamma = self.config.gamma
|
| 116 |
+
corrected_sigma = (1 / (math.sqrt(1 + (1 / gamma)) * (1 - ori_sigma) + ori_sigma)) * ori_sigma
|
| 117 |
+
# corrected_sigma = 1 / (2 - ori_sigma) * ori_sigma
|
| 118 |
+
start_sigma = 1 - corrected_sigma
|
| 119 |
+
|
| 120 |
+
stage_distance.append(start_sigma - end_sigma)
|
| 121 |
+
self.start_sigmas[i_s] = start_sigma
|
| 122 |
+
self.end_sigmas[i_s] = end_sigma
|
| 123 |
+
|
| 124 |
+
# Determine the ratio of each stage according to flow length
|
| 125 |
+
tot_distance = sum(stage_distance)
|
| 126 |
+
for i_s in range(stages):
|
| 127 |
+
if i_s == 0:
|
| 128 |
+
start_ratio = 0.0
|
| 129 |
+
else:
|
| 130 |
+
start_ratio = sum(stage_distance[:i_s]) / tot_distance
|
| 131 |
+
if i_s == stages - 1:
|
| 132 |
+
end_ratio = 1.0
|
| 133 |
+
else:
|
| 134 |
+
end_ratio = sum(stage_distance[:i_s+1]) / tot_distance
|
| 135 |
+
|
| 136 |
+
self.timestep_ratios[i_s] = (start_ratio, end_ratio)
|
| 137 |
+
|
| 138 |
+
# Determine the timesteps and sigmas for each stage
|
| 139 |
+
for i_s in range(stages):
|
| 140 |
+
timestep_ratio = self.timestep_ratios[i_s]
|
| 141 |
+
timestep_max = self.timesteps[int(timestep_ratio[0] * training_steps)]
|
| 142 |
+
timestep_min = self.timesteps[min(int(timestep_ratio[1] * training_steps), training_steps - 1)]
|
| 143 |
+
timesteps = np.linspace(
|
| 144 |
+
timestep_max, timestep_min, training_steps + 1,
|
| 145 |
+
)
|
| 146 |
+
self.timesteps_per_stage[i_s] = torch.from_numpy(timesteps[:-1])
|
| 147 |
+
stage_sigmas = np.linspace(
|
| 148 |
+
1, 0, training_steps + 1,
|
| 149 |
+
)
|
| 150 |
+
self.sigmas_per_stage[i_s] = torch.from_numpy(stage_sigmas[:-1])
|
| 151 |
+
|
| 152 |
+
@property
|
| 153 |
+
def step_index(self):
|
| 154 |
+
"""
|
| 155 |
+
The index counter for current timestep. It will increase 1 after each scheduler step.
|
| 156 |
+
"""
|
| 157 |
+
return self._step_index
|
| 158 |
+
|
| 159 |
+
@property
|
| 160 |
+
def begin_index(self):
|
| 161 |
+
"""
|
| 162 |
+
The index for the first timestep. It should be set from pipeline with `set_begin_index` method.
|
| 163 |
+
"""
|
| 164 |
+
return self._begin_index
|
| 165 |
+
|
| 166 |
+
# Copied from diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler.set_begin_index
|
| 167 |
+
def set_begin_index(self, begin_index: int = 0):
|
| 168 |
+
"""
|
| 169 |
+
Sets the begin index for the scheduler. This function should be run from pipeline before the inference.
|
| 170 |
+
|
| 171 |
+
Args:
|
| 172 |
+
begin_index (`int`):
|
| 173 |
+
The begin index for the scheduler.
|
| 174 |
+
"""
|
| 175 |
+
self._begin_index = begin_index
|
| 176 |
+
|
| 177 |
+
def _sigma_to_t(self, sigma):
|
| 178 |
+
return sigma * self.config.num_train_timesteps
|
| 179 |
+
|
| 180 |
+
def set_timesteps(self, num_inference_steps: int, stage_index: int, device: Union[str, torch.device] = None):
|
| 181 |
+
"""
|
| 182 |
+
Setting the timesteps and sigmas for each stage
|
| 183 |
+
"""
|
| 184 |
+
self.num_inference_steps = num_inference_steps
|
| 185 |
+
training_steps = self.config.num_train_timesteps
|
| 186 |
+
self.init_sigmas()
|
| 187 |
+
|
| 188 |
+
stage_timesteps = self.timesteps_per_stage[stage_index]
|
| 189 |
+
timestep_max = stage_timesteps[0].item()
|
| 190 |
+
timestep_min = stage_timesteps[-1].item()
|
| 191 |
+
|
| 192 |
+
timesteps = np.linspace(
|
| 193 |
+
timestep_max, timestep_min, num_inference_steps,
|
| 194 |
+
)
|
| 195 |
+
self.timesteps = torch.from_numpy(timesteps).to(device=device)
|
| 196 |
+
|
| 197 |
+
stage_sigmas = self.sigmas_per_stage[stage_index]
|
| 198 |
+
sigma_max = stage_sigmas[0].item()
|
| 199 |
+
sigma_min = stage_sigmas[-1].item()
|
| 200 |
+
|
| 201 |
+
ratios = np.linspace(
|
| 202 |
+
sigma_max, sigma_min, num_inference_steps
|
| 203 |
+
)
|
| 204 |
+
sigmas = torch.from_numpy(ratios).to(device=device)
|
| 205 |
+
self.sigmas = torch.cat([sigmas, torch.zeros(1, device=sigmas.device)])
|
| 206 |
+
|
| 207 |
+
self._step_index = None
|
| 208 |
+
|
| 209 |
+
def index_for_timestep(self, timestep, schedule_timesteps=None):
|
| 210 |
+
if schedule_timesteps is None:
|
| 211 |
+
schedule_timesteps = self.timesteps
|
| 212 |
+
|
| 213 |
+
indices = (schedule_timesteps == timestep).nonzero()
|
| 214 |
+
|
| 215 |
+
# The sigma index that is taken for the **very** first `step`
|
| 216 |
+
# is always the second index (or the last index if there is only 1)
|
| 217 |
+
# This way we can ensure we don't accidentally skip a sigma in
|
| 218 |
+
# case we start in the middle of the denoising schedule (e.g. for image-to-image)
|
| 219 |
+
pos = 1 if len(indices) > 1 else 0
|
| 220 |
+
|
| 221 |
+
return indices[pos].item()
|
| 222 |
+
|
| 223 |
+
def _init_step_index(self, timestep):
|
| 224 |
+
if self.begin_index is None:
|
| 225 |
+
if isinstance(timestep, torch.Tensor):
|
| 226 |
+
timestep = timestep.to(self.timesteps.device)
|
| 227 |
+
self._step_index = self.index_for_timestep(timestep)
|
| 228 |
+
else:
|
| 229 |
+
self._step_index = self._begin_index
|
| 230 |
+
|
| 231 |
+
def step(
|
| 232 |
+
self,
|
| 233 |
+
model_output: torch.FloatTensor,
|
| 234 |
+
timestep: Union[float, torch.FloatTensor],
|
| 235 |
+
sample: torch.FloatTensor,
|
| 236 |
+
generator: Optional[torch.Generator] = None,
|
| 237 |
+
return_dict: bool = True,
|
| 238 |
+
) -> Union[FlowMatchEulerDiscreteSchedulerOutput, Tuple]:
|
| 239 |
+
"""
|
| 240 |
+
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
|
| 241 |
+
process from the learned model outputs (most often the predicted noise).
|
| 242 |
+
|
| 243 |
+
Args:
|
| 244 |
+
model_output (`torch.FloatTensor`):
|
| 245 |
+
The direct output from learned diffusion model.
|
| 246 |
+
timestep (`float`):
|
| 247 |
+
The current discrete timestep in the diffusion chain.
|
| 248 |
+
sample (`torch.FloatTensor`):
|
| 249 |
+
A current instance of a sample created by the diffusion process.
|
| 250 |
+
generator (`torch.Generator`, *optional*):
|
| 251 |
+
A random number generator.
|
| 252 |
+
return_dict (`bool`):
|
| 253 |
+
Whether or not to return a [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or
|
| 254 |
+
tuple.
|
| 255 |
+
|
| 256 |
+
Returns:
|
| 257 |
+
[`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or `tuple`:
|
| 258 |
+
If return_dict is `True`, [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] is
|
| 259 |
+
returned, otherwise a tuple is returned where the first element is the sample tensor.
|
| 260 |
+
"""
|
| 261 |
+
|
| 262 |
+
if (
|
| 263 |
+
isinstance(timestep, int)
|
| 264 |
+
or isinstance(timestep, torch.IntTensor)
|
| 265 |
+
or isinstance(timestep, torch.LongTensor)
|
| 266 |
+
):
|
| 267 |
+
raise ValueError(
|
| 268 |
+
(
|
| 269 |
+
"Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
|
| 270 |
+
" `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
|
| 271 |
+
" one of the `scheduler.timesteps` as a timestep."
|
| 272 |
+
),
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
if self.step_index is None:
|
| 276 |
+
self._step_index = 0
|
| 277 |
+
|
| 278 |
+
# Upcast to avoid precision issues when computing prev_sample
|
| 279 |
+
sample = sample.to(torch.float32)
|
| 280 |
+
|
| 281 |
+
sigma = self.sigmas[self.step_index]
|
| 282 |
+
sigma_next = self.sigmas[self.step_index + 1]
|
| 283 |
+
|
| 284 |
+
prev_sample = sample + (sigma_next - sigma) * model_output
|
| 285 |
+
|
| 286 |
+
# Cast sample back to model compatible dtype
|
| 287 |
+
prev_sample = prev_sample.to(model_output.dtype)
|
| 288 |
+
|
| 289 |
+
# upon completion increase step index by one
|
| 290 |
+
self._step_index += 1
|
| 291 |
+
|
| 292 |
+
if not return_dict:
|
| 293 |
+
return (prev_sample,)
|
| 294 |
+
|
| 295 |
+
return FlowMatchEulerDiscreteSchedulerOutput(prev_sample=prev_sample)
|
| 296 |
+
|
| 297 |
+
def __len__(self):
|
| 298 |
+
return self.config.num_train_timesteps
|
pyramid_dit/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .modeling_pyramid_mmdit import PyramidDiffusionMMDiT
|
| 2 |
+
from .pyramid_dit_for_video_gen_pipeline import PyramidDiTForVideoGeneration
|
| 3 |
+
from .modeling_text_encoder import SD3TextEncoderWithMask
|
pyramid_dit/modeling_embedding.py
ADDED
|
@@ -0,0 +1,390 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, Optional, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import numpy as np
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
from diffusers.models.activations import get_activation
|
| 9 |
+
from einops import rearrange
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_1d_sincos_pos_embed(
|
| 13 |
+
embed_dim, num_frames, cls_token=False, extra_tokens=0,
|
| 14 |
+
):
|
| 15 |
+
t = np.arange(num_frames, dtype=np.float32)
|
| 16 |
+
pos_embed = get_1d_sincos_pos_embed_from_grid(embed_dim, t) # (T, D)
|
| 17 |
+
if cls_token and extra_tokens > 0:
|
| 18 |
+
pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)
|
| 19 |
+
return pos_embed
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def get_2d_sincos_pos_embed(
|
| 23 |
+
embed_dim, grid_size, cls_token=False, extra_tokens=0, interpolation_scale=1.0, base_size=16
|
| 24 |
+
):
|
| 25 |
+
"""
|
| 26 |
+
grid_size: int of the grid height and width return: pos_embed: [grid_size*grid_size, embed_dim] or
|
| 27 |
+
[1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
|
| 28 |
+
"""
|
| 29 |
+
if isinstance(grid_size, int):
|
| 30 |
+
grid_size = (grid_size, grid_size)
|
| 31 |
+
|
| 32 |
+
grid_h = np.arange(grid_size[0], dtype=np.float32) / (grid_size[0] / base_size) / interpolation_scale
|
| 33 |
+
grid_w = np.arange(grid_size[1], dtype=np.float32) / (grid_size[1] / base_size) / interpolation_scale
|
| 34 |
+
grid = np.meshgrid(grid_w, grid_h) # here w goes first
|
| 35 |
+
grid = np.stack(grid, axis=0)
|
| 36 |
+
|
| 37 |
+
grid = grid.reshape([2, 1, grid_size[1], grid_size[0]])
|
| 38 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 39 |
+
if cls_token and extra_tokens > 0:
|
| 40 |
+
pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)
|
| 41 |
+
return pos_embed
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
|
| 45 |
+
if embed_dim % 2 != 0:
|
| 46 |
+
raise ValueError("embed_dim must be divisible by 2")
|
| 47 |
+
|
| 48 |
+
# use half of dimensions to encode grid_h
|
| 49 |
+
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
|
| 50 |
+
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
|
| 51 |
+
|
| 52 |
+
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
|
| 53 |
+
return emb
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
|
| 57 |
+
"""
|
| 58 |
+
embed_dim: output dimension for each position pos: a list of positions to be encoded: size (M,) out: (M, D)
|
| 59 |
+
"""
|
| 60 |
+
if embed_dim % 2 != 0:
|
| 61 |
+
raise ValueError("embed_dim must be divisible by 2")
|
| 62 |
+
|
| 63 |
+
omega = np.arange(embed_dim // 2, dtype=np.float64)
|
| 64 |
+
omega /= embed_dim / 2.0
|
| 65 |
+
omega = 1.0 / 10000**omega # (D/2,)
|
| 66 |
+
|
| 67 |
+
pos = pos.reshape(-1) # (M,)
|
| 68 |
+
out = np.einsum("m,d->md", pos, omega) # (M, D/2), outer product
|
| 69 |
+
|
| 70 |
+
emb_sin = np.sin(out) # (M, D/2)
|
| 71 |
+
emb_cos = np.cos(out) # (M, D/2)
|
| 72 |
+
|
| 73 |
+
emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
|
| 74 |
+
return emb
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def get_timestep_embedding(
|
| 78 |
+
timesteps: torch.Tensor,
|
| 79 |
+
embedding_dim: int,
|
| 80 |
+
flip_sin_to_cos: bool = False,
|
| 81 |
+
downscale_freq_shift: float = 1,
|
| 82 |
+
scale: float = 1,
|
| 83 |
+
max_period: int = 10000,
|
| 84 |
+
):
|
| 85 |
+
"""
|
| 86 |
+
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
| 87 |
+
:param timesteps: a 1-D Tensor of N indices, one per batch element. These may be fractional.
|
| 88 |
+
:param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
|
| 89 |
+
embeddings. :return: an [N x dim] Tensor of positional embeddings.
|
| 90 |
+
"""
|
| 91 |
+
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
|
| 92 |
+
|
| 93 |
+
half_dim = embedding_dim // 2
|
| 94 |
+
exponent = -math.log(max_period) * torch.arange(
|
| 95 |
+
start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
|
| 96 |
+
)
|
| 97 |
+
exponent = exponent / (half_dim - downscale_freq_shift)
|
| 98 |
+
|
| 99 |
+
emb = torch.exp(exponent)
|
| 100 |
+
emb = timesteps[:, None].float() * emb[None, :]
|
| 101 |
+
|
| 102 |
+
# scale embeddings
|
| 103 |
+
emb = scale * emb
|
| 104 |
+
|
| 105 |
+
# concat sine and cosine embeddings
|
| 106 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
| 107 |
+
|
| 108 |
+
# flip sine and cosine embeddings
|
| 109 |
+
if flip_sin_to_cos:
|
| 110 |
+
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
|
| 111 |
+
|
| 112 |
+
# zero pad
|
| 113 |
+
if embedding_dim % 2 == 1:
|
| 114 |
+
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
| 115 |
+
return emb
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class Timesteps(nn.Module):
|
| 119 |
+
def __init__(self, num_channels: int, flip_sin_to_cos: bool, downscale_freq_shift: float):
|
| 120 |
+
super().__init__()
|
| 121 |
+
self.num_channels = num_channels
|
| 122 |
+
self.flip_sin_to_cos = flip_sin_to_cos
|
| 123 |
+
self.downscale_freq_shift = downscale_freq_shift
|
| 124 |
+
|
| 125 |
+
def forward(self, timesteps):
|
| 126 |
+
t_emb = get_timestep_embedding(
|
| 127 |
+
timesteps,
|
| 128 |
+
self.num_channels,
|
| 129 |
+
flip_sin_to_cos=self.flip_sin_to_cos,
|
| 130 |
+
downscale_freq_shift=self.downscale_freq_shift,
|
| 131 |
+
)
|
| 132 |
+
return t_emb
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class TimestepEmbedding(nn.Module):
|
| 136 |
+
def __init__(
|
| 137 |
+
self,
|
| 138 |
+
in_channels: int,
|
| 139 |
+
time_embed_dim: int,
|
| 140 |
+
act_fn: str = "silu",
|
| 141 |
+
out_dim: int = None,
|
| 142 |
+
post_act_fn: Optional[str] = None,
|
| 143 |
+
sample_proj_bias=True,
|
| 144 |
+
):
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.linear_1 = nn.Linear(in_channels, time_embed_dim, sample_proj_bias)
|
| 147 |
+
self.act = get_activation(act_fn)
|
| 148 |
+
self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim, sample_proj_bias)
|
| 149 |
+
|
| 150 |
+
def forward(self, sample):
|
| 151 |
+
sample = self.linear_1(sample)
|
| 152 |
+
sample = self.act(sample)
|
| 153 |
+
sample = self.linear_2(sample)
|
| 154 |
+
return sample
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
class TextProjection(nn.Module):
|
| 158 |
+
def __init__(self, in_features, hidden_size, act_fn="silu"):
|
| 159 |
+
super().__init__()
|
| 160 |
+
self.linear_1 = nn.Linear(in_features=in_features, out_features=hidden_size, bias=True)
|
| 161 |
+
self.act_1 = get_activation(act_fn)
|
| 162 |
+
self.linear_2 = nn.Linear(in_features=hidden_size, out_features=hidden_size, bias=True)
|
| 163 |
+
|
| 164 |
+
def forward(self, caption):
|
| 165 |
+
hidden_states = self.linear_1(caption)
|
| 166 |
+
hidden_states = self.act_1(hidden_states)
|
| 167 |
+
hidden_states = self.linear_2(hidden_states)
|
| 168 |
+
return hidden_states
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
class CombinedTimestepConditionEmbeddings(nn.Module):
|
| 172 |
+
def __init__(self, embedding_dim, pooled_projection_dim):
|
| 173 |
+
super().__init__()
|
| 174 |
+
|
| 175 |
+
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
|
| 176 |
+
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
|
| 177 |
+
self.text_embedder = TextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
|
| 178 |
+
|
| 179 |
+
def forward(self, timestep, pooled_projection):
|
| 180 |
+
timesteps_proj = self.time_proj(timestep)
|
| 181 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
|
| 182 |
+
pooled_projections = self.text_embedder(pooled_projection)
|
| 183 |
+
conditioning = timesteps_emb + pooled_projections
|
| 184 |
+
return conditioning
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class CombinedTimestepEmbeddings(nn.Module):
|
| 188 |
+
def __init__(self, embedding_dim):
|
| 189 |
+
super().__init__()
|
| 190 |
+
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
|
| 191 |
+
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
|
| 192 |
+
|
| 193 |
+
def forward(self, timestep):
|
| 194 |
+
timesteps_proj = self.time_proj(timestep)
|
| 195 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj) # (N, D)
|
| 196 |
+
return timesteps_emb
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
class PatchEmbed3D(nn.Module):
|
| 200 |
+
"""Support the 3D Tensor input"""
|
| 201 |
+
|
| 202 |
+
def __init__(
|
| 203 |
+
self,
|
| 204 |
+
height=128,
|
| 205 |
+
width=128,
|
| 206 |
+
patch_size=2,
|
| 207 |
+
in_channels=16,
|
| 208 |
+
embed_dim=1536,
|
| 209 |
+
layer_norm=False,
|
| 210 |
+
bias=True,
|
| 211 |
+
interpolation_scale=1,
|
| 212 |
+
pos_embed_type="sincos",
|
| 213 |
+
temp_pos_embed_type='rope',
|
| 214 |
+
pos_embed_max_size=192, # For SD3 cropping
|
| 215 |
+
max_num_frames=64,
|
| 216 |
+
add_temp_pos_embed=False,
|
| 217 |
+
interp_condition_pos=False,
|
| 218 |
+
):
|
| 219 |
+
super().__init__()
|
| 220 |
+
|
| 221 |
+
num_patches = (height // patch_size) * (width // patch_size)
|
| 222 |
+
self.layer_norm = layer_norm
|
| 223 |
+
self.pos_embed_max_size = pos_embed_max_size
|
| 224 |
+
|
| 225 |
+
self.proj = nn.Conv2d(
|
| 226 |
+
in_channels, embed_dim, kernel_size=(patch_size, patch_size), stride=patch_size, bias=bias
|
| 227 |
+
)
|
| 228 |
+
if layer_norm:
|
| 229 |
+
self.norm = nn.LayerNorm(embed_dim, elementwise_affine=False, eps=1e-6)
|
| 230 |
+
else:
|
| 231 |
+
self.norm = None
|
| 232 |
+
|
| 233 |
+
self.patch_size = patch_size
|
| 234 |
+
self.height, self.width = height // patch_size, width // patch_size
|
| 235 |
+
self.base_size = height // patch_size
|
| 236 |
+
self.interpolation_scale = interpolation_scale
|
| 237 |
+
self.add_temp_pos_embed = add_temp_pos_embed
|
| 238 |
+
|
| 239 |
+
# Calculate positional embeddings based on max size or default
|
| 240 |
+
if pos_embed_max_size:
|
| 241 |
+
grid_size = pos_embed_max_size
|
| 242 |
+
else:
|
| 243 |
+
grid_size = int(num_patches**0.5)
|
| 244 |
+
|
| 245 |
+
if pos_embed_type is None:
|
| 246 |
+
self.pos_embed = None
|
| 247 |
+
|
| 248 |
+
elif pos_embed_type == "sincos":
|
| 249 |
+
pos_embed = get_2d_sincos_pos_embed(
|
| 250 |
+
embed_dim, grid_size, base_size=self.base_size, interpolation_scale=self.interpolation_scale
|
| 251 |
+
)
|
| 252 |
+
persistent = True if pos_embed_max_size else False
|
| 253 |
+
self.register_buffer("pos_embed", torch.from_numpy(pos_embed).float().unsqueeze(0), persistent=persistent)
|
| 254 |
+
|
| 255 |
+
if add_temp_pos_embed and temp_pos_embed_type == 'sincos':
|
| 256 |
+
time_pos_embed = get_1d_sincos_pos_embed(embed_dim, max_num_frames)
|
| 257 |
+
self.register_buffer("temp_pos_embed", torch.from_numpy(time_pos_embed).float().unsqueeze(0), persistent=True)
|
| 258 |
+
|
| 259 |
+
elif pos_embed_type == "rope":
|
| 260 |
+
print("Using the rotary position embedding")
|
| 261 |
+
|
| 262 |
+
else:
|
| 263 |
+
raise ValueError(f"Unsupported pos_embed_type: {pos_embed_type}")
|
| 264 |
+
|
| 265 |
+
self.pos_embed_type = pos_embed_type
|
| 266 |
+
self.temp_pos_embed_type = temp_pos_embed_type
|
| 267 |
+
self.interp_condition_pos = interp_condition_pos
|
| 268 |
+
|
| 269 |
+
def cropped_pos_embed(self, height, width, ori_height, ori_width):
|
| 270 |
+
"""Crops positional embeddings for SD3 compatibility."""
|
| 271 |
+
if self.pos_embed_max_size is None:
|
| 272 |
+
raise ValueError("`pos_embed_max_size` must be set for cropping.")
|
| 273 |
+
|
| 274 |
+
height = height // self.patch_size
|
| 275 |
+
width = width // self.patch_size
|
| 276 |
+
ori_height = ori_height // self.patch_size
|
| 277 |
+
ori_width = ori_width // self.patch_size
|
| 278 |
+
|
| 279 |
+
assert ori_height >= height, "The ori_height needs >= height"
|
| 280 |
+
assert ori_width >= width, "The ori_width needs >= width"
|
| 281 |
+
|
| 282 |
+
if height > self.pos_embed_max_size:
|
| 283 |
+
raise ValueError(
|
| 284 |
+
f"Height ({height}) cannot be greater than `pos_embed_max_size`: {self.pos_embed_max_size}."
|
| 285 |
+
)
|
| 286 |
+
if width > self.pos_embed_max_size:
|
| 287 |
+
raise ValueError(
|
| 288 |
+
f"Width ({width}) cannot be greater than `pos_embed_max_size`: {self.pos_embed_max_size}."
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
if self.interp_condition_pos:
|
| 292 |
+
top = (self.pos_embed_max_size - ori_height) // 2
|
| 293 |
+
left = (self.pos_embed_max_size - ori_width) // 2
|
| 294 |
+
spatial_pos_embed = self.pos_embed.reshape(1, self.pos_embed_max_size, self.pos_embed_max_size, -1)
|
| 295 |
+
spatial_pos_embed = spatial_pos_embed[:, top : top + ori_height, left : left + ori_width, :] # [b h w c]
|
| 296 |
+
if ori_height != height or ori_width != width:
|
| 297 |
+
spatial_pos_embed = spatial_pos_embed.permute(0, 3, 1, 2)
|
| 298 |
+
spatial_pos_embed = torch.nn.functional.interpolate(spatial_pos_embed, size=(height, width), mode='bilinear')
|
| 299 |
+
spatial_pos_embed = spatial_pos_embed.permute(0, 2, 3, 1)
|
| 300 |
+
else:
|
| 301 |
+
top = (self.pos_embed_max_size - height) // 2
|
| 302 |
+
left = (self.pos_embed_max_size - width) // 2
|
| 303 |
+
spatial_pos_embed = self.pos_embed.reshape(1, self.pos_embed_max_size, self.pos_embed_max_size, -1)
|
| 304 |
+
spatial_pos_embed = spatial_pos_embed[:, top : top + height, left : left + width, :]
|
| 305 |
+
|
| 306 |
+
spatial_pos_embed = spatial_pos_embed.reshape(1, -1, spatial_pos_embed.shape[-1])
|
| 307 |
+
|
| 308 |
+
return spatial_pos_embed
|
| 309 |
+
|
| 310 |
+
def forward_func(self, latent, time_index=0, ori_height=None, ori_width=None):
|
| 311 |
+
if self.pos_embed_max_size is not None:
|
| 312 |
+
height, width = latent.shape[-2:]
|
| 313 |
+
else:
|
| 314 |
+
height, width = latent.shape[-2] // self.patch_size, latent.shape[-1] // self.patch_size
|
| 315 |
+
|
| 316 |
+
bs = latent.shape[0]
|
| 317 |
+
temp = latent.shape[2]
|
| 318 |
+
|
| 319 |
+
latent = rearrange(latent, 'b c t h w -> (b t) c h w')
|
| 320 |
+
latent = self.proj(latent)
|
| 321 |
+
latent = latent.flatten(2).transpose(1, 2) # (BT)CHW -> (BT)NC
|
| 322 |
+
|
| 323 |
+
if self.layer_norm:
|
| 324 |
+
latent = self.norm(latent)
|
| 325 |
+
|
| 326 |
+
if self.pos_embed_type == 'sincos':
|
| 327 |
+
# Spatial position embedding, Interpolate or crop positional embeddings as needed
|
| 328 |
+
if self.pos_embed_max_size:
|
| 329 |
+
pos_embed = self.cropped_pos_embed(height, width, ori_height, ori_width)
|
| 330 |
+
else:
|
| 331 |
+
raise NotImplementedError("Not implemented sincos pos embed without sd3 max pos crop")
|
| 332 |
+
if self.height != height or self.width != width:
|
| 333 |
+
pos_embed = get_2d_sincos_pos_embed(
|
| 334 |
+
embed_dim=self.pos_embed.shape[-1],
|
| 335 |
+
grid_size=(height, width),
|
| 336 |
+
base_size=self.base_size,
|
| 337 |
+
interpolation_scale=self.interpolation_scale,
|
| 338 |
+
)
|
| 339 |
+
pos_embed = torch.from_numpy(pos_embed).float().unsqueeze(0).to(latent.device)
|
| 340 |
+
else:
|
| 341 |
+
pos_embed = self.pos_embed
|
| 342 |
+
|
| 343 |
+
if self.add_temp_pos_embed and self.temp_pos_embed_type == 'sincos':
|
| 344 |
+
latent_dtype = latent.dtype
|
| 345 |
+
latent = latent + pos_embed
|
| 346 |
+
latent = rearrange(latent, '(b t) n c -> (b n) t c', t=temp)
|
| 347 |
+
latent = latent + self.temp_pos_embed[:, time_index:time_index + temp, :]
|
| 348 |
+
latent = latent.to(latent_dtype)
|
| 349 |
+
latent = rearrange(latent, '(b n) t c -> b t n c', b=bs)
|
| 350 |
+
else:
|
| 351 |
+
latent = (latent + pos_embed).to(latent.dtype)
|
| 352 |
+
latent = rearrange(latent, '(b t) n c -> b t n c', b=bs, t=temp)
|
| 353 |
+
|
| 354 |
+
else:
|
| 355 |
+
assert self.pos_embed_type == "rope", "Only supporting the sincos and rope embedding"
|
| 356 |
+
latent = rearrange(latent, '(b t) n c -> b t n c', b=bs, t=temp)
|
| 357 |
+
|
| 358 |
+
return latent
|
| 359 |
+
|
| 360 |
+
def forward(self, latent):
|
| 361 |
+
"""
|
| 362 |
+
Arguments:
|
| 363 |
+
past_condition_latents (Torch.FloatTensor): The past latent during the generation
|
| 364 |
+
flatten_input (bool): True indicate flatten the latent into 1D sequence
|
| 365 |
+
"""
|
| 366 |
+
|
| 367 |
+
if isinstance(latent, list):
|
| 368 |
+
output_list = []
|
| 369 |
+
|
| 370 |
+
for latent_ in latent:
|
| 371 |
+
if not isinstance(latent_, list):
|
| 372 |
+
latent_ = [latent_]
|
| 373 |
+
|
| 374 |
+
output_latent = []
|
| 375 |
+
time_index = 0
|
| 376 |
+
ori_height, ori_width = latent_[-1].shape[-2:]
|
| 377 |
+
for each_latent in latent_:
|
| 378 |
+
hidden_state = self.forward_func(each_latent, time_index=time_index, ori_height=ori_height, ori_width=ori_width)
|
| 379 |
+
time_index += each_latent.shape[2]
|
| 380 |
+
hidden_state = rearrange(hidden_state, "b t n c -> b (t n) c")
|
| 381 |
+
output_latent.append(hidden_state)
|
| 382 |
+
|
| 383 |
+
output_latent = torch.cat(output_latent, dim=1)
|
| 384 |
+
output_list.append(output_latent)
|
| 385 |
+
|
| 386 |
+
return output_list
|
| 387 |
+
else:
|
| 388 |
+
hidden_states = self.forward_func(latent)
|
| 389 |
+
hidden_states = rearrange(hidden_states, "b t n c -> b (t n) c")
|
| 390 |
+
return hidden_states
|
pyramid_dit/modeling_mmdit_block.py
ADDED
|
@@ -0,0 +1,672 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, Optional, Tuple, List
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
from diffusers.models.activations import GEGLU, GELU, ApproximateGELU
|
| 7 |
+
|
| 8 |
+
try:
|
| 9 |
+
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
|
| 10 |
+
from flash_attn.bert_padding import pad_input, unpad_input, index_first_axis
|
| 11 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_func
|
| 12 |
+
except:
|
| 13 |
+
flash_attn_func = None
|
| 14 |
+
flash_attn_qkvpacked_func = None
|
| 15 |
+
flash_attn_varlen_func = None
|
| 16 |
+
print("Please install flash attention")
|
| 17 |
+
|
| 18 |
+
from trainer_misc import (
|
| 19 |
+
is_sequence_parallel_initialized,
|
| 20 |
+
get_sequence_parallel_group,
|
| 21 |
+
get_sequence_parallel_world_size,
|
| 22 |
+
all_to_all,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
from .modeling_normalization import AdaLayerNormZero, AdaLayerNormContinuous, RMSNorm
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class FeedForward(nn.Module):
|
| 29 |
+
r"""
|
| 30 |
+
A feed-forward layer.
|
| 31 |
+
|
| 32 |
+
Parameters:
|
| 33 |
+
dim (`int`): The number of channels in the input.
|
| 34 |
+
dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
|
| 35 |
+
mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
|
| 36 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 37 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 38 |
+
final_dropout (`bool` *optional*, defaults to False): Apply a final dropout.
|
| 39 |
+
bias (`bool`, defaults to True): Whether to use a bias in the linear layer.
|
| 40 |
+
"""
|
| 41 |
+
def __init__(
|
| 42 |
+
self,
|
| 43 |
+
dim: int,
|
| 44 |
+
dim_out: Optional[int] = None,
|
| 45 |
+
mult: int = 4,
|
| 46 |
+
dropout: float = 0.0,
|
| 47 |
+
activation_fn: str = "geglu",
|
| 48 |
+
final_dropout: bool = False,
|
| 49 |
+
inner_dim=None,
|
| 50 |
+
bias: bool = True,
|
| 51 |
+
):
|
| 52 |
+
super().__init__()
|
| 53 |
+
if inner_dim is None:
|
| 54 |
+
inner_dim = int(dim * mult)
|
| 55 |
+
dim_out = dim_out if dim_out is not None else dim
|
| 56 |
+
|
| 57 |
+
if activation_fn == "gelu":
|
| 58 |
+
act_fn = GELU(dim, inner_dim, bias=bias)
|
| 59 |
+
if activation_fn == "gelu-approximate":
|
| 60 |
+
act_fn = GELU(dim, inner_dim, approximate="tanh", bias=bias)
|
| 61 |
+
elif activation_fn == "geglu":
|
| 62 |
+
act_fn = GEGLU(dim, inner_dim, bias=bias)
|
| 63 |
+
elif activation_fn == "geglu-approximate":
|
| 64 |
+
act_fn = ApproximateGELU(dim, inner_dim, bias=bias)
|
| 65 |
+
|
| 66 |
+
self.net = nn.ModuleList([])
|
| 67 |
+
# project in
|
| 68 |
+
self.net.append(act_fn)
|
| 69 |
+
# project dropout
|
| 70 |
+
self.net.append(nn.Dropout(dropout))
|
| 71 |
+
# project out
|
| 72 |
+
self.net.append(nn.Linear(inner_dim, dim_out, bias=bias))
|
| 73 |
+
# FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout
|
| 74 |
+
if final_dropout:
|
| 75 |
+
self.net.append(nn.Dropout(dropout))
|
| 76 |
+
|
| 77 |
+
def forward(self, hidden_states: torch.Tensor, *args, **kwargs) -> torch.Tensor:
|
| 78 |
+
if len(args) > 0 or kwargs.get("scale", None) is not None:
|
| 79 |
+
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
|
| 80 |
+
deprecate("scale", "1.0.0", deprecation_message)
|
| 81 |
+
for module in self.net:
|
| 82 |
+
hidden_states = module(hidden_states)
|
| 83 |
+
return hidden_states
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class VarlenFlashSelfAttentionWithT5Mask:
|
| 87 |
+
|
| 88 |
+
def __init__(self):
|
| 89 |
+
pass
|
| 90 |
+
|
| 91 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 92 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 93 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 94 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 95 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 96 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 97 |
+
|
| 98 |
+
def __call__(
|
| 99 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 100 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 101 |
+
):
|
| 102 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 103 |
+
|
| 104 |
+
batch_size = query.shape[0]
|
| 105 |
+
output_hidden = torch.zeros_like(query)
|
| 106 |
+
output_encoder_hidden = torch.zeros_like(encoder_query)
|
| 107 |
+
encoder_length = encoder_query.shape[1]
|
| 108 |
+
|
| 109 |
+
qkv_list = []
|
| 110 |
+
num_stages = len(hidden_length)
|
| 111 |
+
|
| 112 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 113 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 114 |
+
|
| 115 |
+
i_sum = 0
|
| 116 |
+
for i_p, length in enumerate(hidden_length):
|
| 117 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 118 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 119 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 120 |
+
|
| 121 |
+
if image_rotary_emb is not None:
|
| 122 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 123 |
+
|
| 124 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 125 |
+
qkv_list.append(index_first_axis(rearrange(concat_qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 126 |
+
i_sum += length
|
| 127 |
+
|
| 128 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 129 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 130 |
+
query, key, value = qkv.unbind(1)
|
| 131 |
+
|
| 132 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 133 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 134 |
+
max_seqlen_k = max_seqlen_q
|
| 135 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 136 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 137 |
+
|
| 138 |
+
output = flash_attn_varlen_func(
|
| 139 |
+
query,
|
| 140 |
+
key,
|
| 141 |
+
value,
|
| 142 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 143 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 144 |
+
max_seqlen_q=max_seqlen_q,
|
| 145 |
+
max_seqlen_k=max_seqlen_k,
|
| 146 |
+
dropout_p=0.0,
|
| 147 |
+
causal=False,
|
| 148 |
+
softmax_scale=scale,
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
# To merge the tokens
|
| 152 |
+
i_sum = 0;token_sum = 0
|
| 153 |
+
for i_p, length in enumerate(hidden_length):
|
| 154 |
+
tot_token_num = token_lengths[i_p]
|
| 155 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 156 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, encoder_length + length)
|
| 157 |
+
stage_encoder_hidden_output = stage_output[:, :encoder_length]
|
| 158 |
+
stage_hidden_output = stage_output[:, encoder_length:]
|
| 159 |
+
output_hidden[:, i_sum:i_sum+length] = stage_hidden_output
|
| 160 |
+
output_encoder_hidden[i_p::num_stages] = stage_encoder_hidden_output
|
| 161 |
+
token_sum += tot_token_num
|
| 162 |
+
i_sum += length
|
| 163 |
+
|
| 164 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 165 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 166 |
+
|
| 167 |
+
return output_hidden, output_encoder_hidden
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class SequenceParallelVarlenFlashSelfAttentionWithT5Mask:
|
| 171 |
+
|
| 172 |
+
def __init__(self):
|
| 173 |
+
pass
|
| 174 |
+
|
| 175 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 176 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 177 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 178 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 179 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 180 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 181 |
+
|
| 182 |
+
def __call__(
|
| 183 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 184 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 185 |
+
):
|
| 186 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 187 |
+
|
| 188 |
+
batch_size = query.shape[0]
|
| 189 |
+
qkv_list = []
|
| 190 |
+
num_stages = len(hidden_length)
|
| 191 |
+
|
| 192 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 193 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 194 |
+
|
| 195 |
+
# To sync the encoder query, key and values
|
| 196 |
+
sp_group = get_sequence_parallel_group()
|
| 197 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 198 |
+
encoder_qkv = all_to_all(encoder_qkv, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 199 |
+
|
| 200 |
+
output_hidden = torch.zeros_like(qkv[:,:,0])
|
| 201 |
+
output_encoder_hidden = torch.zeros_like(encoder_qkv[:,:,0])
|
| 202 |
+
encoder_length = encoder_qkv.shape[1]
|
| 203 |
+
|
| 204 |
+
i_sum = 0
|
| 205 |
+
for i_p, length in enumerate(hidden_length):
|
| 206 |
+
# get the query, key, value from padding sequence
|
| 207 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 208 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 209 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 210 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, pad_seq, 3, nhead, dim]
|
| 211 |
+
|
| 212 |
+
if image_rotary_emb is not None:
|
| 213 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 214 |
+
|
| 215 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 216 |
+
qkv_list.append(index_first_axis(rearrange(concat_qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 217 |
+
i_sum += length
|
| 218 |
+
|
| 219 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 220 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 221 |
+
query, key, value = qkv.unbind(1)
|
| 222 |
+
|
| 223 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 224 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 225 |
+
max_seqlen_k = max_seqlen_q
|
| 226 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 227 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 228 |
+
|
| 229 |
+
output = flash_attn_varlen_func(
|
| 230 |
+
query,
|
| 231 |
+
key,
|
| 232 |
+
value,
|
| 233 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 234 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 235 |
+
max_seqlen_q=max_seqlen_q,
|
| 236 |
+
max_seqlen_k=max_seqlen_k,
|
| 237 |
+
dropout_p=0.0,
|
| 238 |
+
causal=False,
|
| 239 |
+
softmax_scale=scale,
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
# To merge the tokens
|
| 243 |
+
i_sum = 0;token_sum = 0
|
| 244 |
+
for i_p, length in enumerate(hidden_length):
|
| 245 |
+
tot_token_num = token_lengths[i_p]
|
| 246 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 247 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, encoder_length + length * sp_group_size)
|
| 248 |
+
stage_encoder_hidden_output = stage_output[:, :encoder_length]
|
| 249 |
+
stage_hidden_output = stage_output[:, encoder_length:]
|
| 250 |
+
stage_hidden_output = all_to_all(stage_hidden_output, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 251 |
+
output_hidden[:, i_sum:i_sum+length] = stage_hidden_output
|
| 252 |
+
output_encoder_hidden[i_p::num_stages] = stage_encoder_hidden_output
|
| 253 |
+
token_sum += tot_token_num
|
| 254 |
+
i_sum += length
|
| 255 |
+
|
| 256 |
+
output_encoder_hidden = all_to_all(output_encoder_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 257 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 258 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 259 |
+
|
| 260 |
+
return output_hidden, output_encoder_hidden
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
class VarlenSelfAttentionWithT5Mask:
|
| 264 |
+
|
| 265 |
+
"""
|
| 266 |
+
For chunk stage attention without using flash attention
|
| 267 |
+
"""
|
| 268 |
+
|
| 269 |
+
def __init__(self):
|
| 270 |
+
pass
|
| 271 |
+
|
| 272 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 273 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 274 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 275 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 276 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 277 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 278 |
+
|
| 279 |
+
def __call__(
|
| 280 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 281 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 282 |
+
):
|
| 283 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 284 |
+
|
| 285 |
+
encoder_length = encoder_query.shape[1]
|
| 286 |
+
num_stages = len(hidden_length)
|
| 287 |
+
|
| 288 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 289 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 290 |
+
|
| 291 |
+
i_sum = 0
|
| 292 |
+
output_encoder_hidden_list = []
|
| 293 |
+
output_hidden_list = []
|
| 294 |
+
|
| 295 |
+
for i_p, length in enumerate(hidden_length):
|
| 296 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 297 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 298 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 299 |
+
|
| 300 |
+
if image_rotary_emb is not None:
|
| 301 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 302 |
+
|
| 303 |
+
query, key, value = concat_qkv_tokens.unbind(2) # [bs, tot_seq, nhead, dim]
|
| 304 |
+
query = query.transpose(1, 2)
|
| 305 |
+
key = key.transpose(1, 2)
|
| 306 |
+
value = value.transpose(1, 2)
|
| 307 |
+
|
| 308 |
+
# with torch.backends.cuda.sdp_kernel(enable_math=False, enable_flash=False, enable_mem_efficient=True):
|
| 309 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 310 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 311 |
+
)
|
| 312 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2).flatten(2, 3) # [bs, tot_seq, dim]
|
| 313 |
+
|
| 314 |
+
output_encoder_hidden_list.append(stage_hidden_states[:, :encoder_length])
|
| 315 |
+
output_hidden_list.append(stage_hidden_states[:, encoder_length:])
|
| 316 |
+
i_sum += length
|
| 317 |
+
|
| 318 |
+
output_encoder_hidden = torch.stack(output_encoder_hidden_list, dim=1) # [b n s d]
|
| 319 |
+
output_encoder_hidden = rearrange(output_encoder_hidden, 'b n s d -> (b n) s d')
|
| 320 |
+
output_hidden = torch.cat(output_hidden_list, dim=1)
|
| 321 |
+
|
| 322 |
+
return output_hidden, output_encoder_hidden
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
class SequenceParallelVarlenSelfAttentionWithT5Mask:
|
| 326 |
+
"""
|
| 327 |
+
For chunk stage attention without using flash attention
|
| 328 |
+
"""
|
| 329 |
+
|
| 330 |
+
def __init__(self):
|
| 331 |
+
pass
|
| 332 |
+
|
| 333 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 334 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 335 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 336 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 337 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 338 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 339 |
+
|
| 340 |
+
def __call__(
|
| 341 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 342 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 343 |
+
):
|
| 344 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 345 |
+
|
| 346 |
+
num_stages = len(hidden_length)
|
| 347 |
+
|
| 348 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 349 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 350 |
+
|
| 351 |
+
# To sync the encoder query, key and values
|
| 352 |
+
sp_group = get_sequence_parallel_group()
|
| 353 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 354 |
+
encoder_qkv = all_to_all(encoder_qkv, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 355 |
+
encoder_length = encoder_qkv.shape[1]
|
| 356 |
+
|
| 357 |
+
i_sum = 0
|
| 358 |
+
output_encoder_hidden_list = []
|
| 359 |
+
output_hidden_list = []
|
| 360 |
+
|
| 361 |
+
for i_p, length in enumerate(hidden_length):
|
| 362 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 363 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 364 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 365 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 366 |
+
|
| 367 |
+
if image_rotary_emb is not None:
|
| 368 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 369 |
+
|
| 370 |
+
query, key, value = concat_qkv_tokens.unbind(2) # [bs, tot_seq, nhead, dim]
|
| 371 |
+
query = query.transpose(1, 2)
|
| 372 |
+
key = key.transpose(1, 2)
|
| 373 |
+
value = value.transpose(1, 2)
|
| 374 |
+
|
| 375 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 376 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 377 |
+
)
|
| 378 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2) # [bs, tot_seq, nhead, dim]
|
| 379 |
+
|
| 380 |
+
output_encoder_hidden_list.append(stage_hidden_states[:, :encoder_length])
|
| 381 |
+
|
| 382 |
+
output_hidden = stage_hidden_states[:, encoder_length:]
|
| 383 |
+
output_hidden = all_to_all(output_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 384 |
+
output_hidden_list.append(output_hidden)
|
| 385 |
+
|
| 386 |
+
i_sum += length
|
| 387 |
+
|
| 388 |
+
output_encoder_hidden = torch.stack(output_encoder_hidden_list, dim=1) # [b n s nhead d]
|
| 389 |
+
output_encoder_hidden = rearrange(output_encoder_hidden, 'b n s h d -> (b n) s h d')
|
| 390 |
+
output_encoder_hidden = all_to_all(output_encoder_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 391 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 392 |
+
output_hidden = torch.cat(output_hidden_list, dim=1).flatten(2, 3)
|
| 393 |
+
|
| 394 |
+
return output_hidden, output_encoder_hidden
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
class JointAttention(nn.Module):
|
| 398 |
+
|
| 399 |
+
def __init__(
|
| 400 |
+
self,
|
| 401 |
+
query_dim: int,
|
| 402 |
+
cross_attention_dim: Optional[int] = None,
|
| 403 |
+
heads: int = 8,
|
| 404 |
+
dim_head: int = 64,
|
| 405 |
+
dropout: float = 0.0,
|
| 406 |
+
bias: bool = False,
|
| 407 |
+
qk_norm: Optional[str] = None,
|
| 408 |
+
added_kv_proj_dim: Optional[int] = None,
|
| 409 |
+
out_bias: bool = True,
|
| 410 |
+
eps: float = 1e-5,
|
| 411 |
+
out_dim: int = None,
|
| 412 |
+
context_pre_only=None,
|
| 413 |
+
use_flash_attn=True,
|
| 414 |
+
):
|
| 415 |
+
"""
|
| 416 |
+
Fixing the QKNorm, following the flux, norm the head dimension
|
| 417 |
+
"""
|
| 418 |
+
super().__init__()
|
| 419 |
+
self.inner_dim = out_dim if out_dim is not None else dim_head * heads
|
| 420 |
+
self.query_dim = query_dim
|
| 421 |
+
self.cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
|
| 422 |
+
self.use_bias = bias
|
| 423 |
+
self.dropout = dropout
|
| 424 |
+
|
| 425 |
+
self.out_dim = out_dim if out_dim is not None else query_dim
|
| 426 |
+
self.context_pre_only = context_pre_only
|
| 427 |
+
|
| 428 |
+
self.scale = dim_head**-0.5
|
| 429 |
+
self.heads = out_dim // dim_head if out_dim is not None else heads
|
| 430 |
+
self.added_kv_proj_dim = added_kv_proj_dim
|
| 431 |
+
|
| 432 |
+
if qk_norm is None:
|
| 433 |
+
self.norm_q = None
|
| 434 |
+
self.norm_k = None
|
| 435 |
+
elif qk_norm == "layer_norm":
|
| 436 |
+
self.norm_q = nn.LayerNorm(dim_head, eps=eps)
|
| 437 |
+
self.norm_k = nn.LayerNorm(dim_head, eps=eps)
|
| 438 |
+
elif qk_norm == 'rms_norm':
|
| 439 |
+
self.norm_q = RMSNorm(dim_head, eps=eps)
|
| 440 |
+
self.norm_k = RMSNorm(dim_head, eps=eps)
|
| 441 |
+
else:
|
| 442 |
+
raise ValueError(f"unknown qk_norm: {qk_norm}. Should be None or 'layer_norm'")
|
| 443 |
+
|
| 444 |
+
self.to_q = nn.Linear(query_dim, self.inner_dim, bias=bias)
|
| 445 |
+
self.to_k = nn.Linear(self.cross_attention_dim, self.inner_dim, bias=bias)
|
| 446 |
+
self.to_v = nn.Linear(self.cross_attention_dim, self.inner_dim, bias=bias)
|
| 447 |
+
|
| 448 |
+
if self.added_kv_proj_dim is not None:
|
| 449 |
+
self.add_k_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
|
| 450 |
+
self.add_v_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
|
| 451 |
+
self.add_q_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
|
| 452 |
+
|
| 453 |
+
if qk_norm is None:
|
| 454 |
+
self.norm_add_q = None
|
| 455 |
+
self.norm_add_k = None
|
| 456 |
+
elif qk_norm == "layer_norm":
|
| 457 |
+
self.norm_add_q = nn.LayerNorm(dim_head, eps=eps)
|
| 458 |
+
self.norm_add_k = nn.LayerNorm(dim_head, eps=eps)
|
| 459 |
+
elif qk_norm == 'rms_norm':
|
| 460 |
+
self.norm_add_q = RMSNorm(dim_head, eps=eps)
|
| 461 |
+
self.norm_add_k = RMSNorm(dim_head, eps=eps)
|
| 462 |
+
else:
|
| 463 |
+
raise ValueError(f"unknown qk_norm: {qk_norm}. Should be None or 'layer_norm'")
|
| 464 |
+
|
| 465 |
+
self.to_out = nn.ModuleList([])
|
| 466 |
+
self.to_out.append(nn.Linear(self.inner_dim, self.out_dim, bias=out_bias))
|
| 467 |
+
self.to_out.append(nn.Dropout(dropout))
|
| 468 |
+
|
| 469 |
+
if not self.context_pre_only:
|
| 470 |
+
self.to_add_out = nn.Linear(self.inner_dim, self.out_dim, bias=out_bias)
|
| 471 |
+
|
| 472 |
+
self.use_flash_attn = use_flash_attn
|
| 473 |
+
|
| 474 |
+
if flash_attn_func is None:
|
| 475 |
+
self.use_flash_attn = False
|
| 476 |
+
|
| 477 |
+
# print(f"Using flash-attention: {self.use_flash_attn}")
|
| 478 |
+
if self.use_flash_attn:
|
| 479 |
+
if is_sequence_parallel_initialized():
|
| 480 |
+
self.var_flash_attn = SequenceParallelVarlenFlashSelfAttentionWithT5Mask()
|
| 481 |
+
else:
|
| 482 |
+
self.var_flash_attn = VarlenFlashSelfAttentionWithT5Mask()
|
| 483 |
+
else:
|
| 484 |
+
if is_sequence_parallel_initialized():
|
| 485 |
+
self.var_len_attn = SequenceParallelVarlenSelfAttentionWithT5Mask()
|
| 486 |
+
else:
|
| 487 |
+
self.var_len_attn = VarlenSelfAttentionWithT5Mask()
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
def forward(
|
| 491 |
+
self,
|
| 492 |
+
hidden_states: torch.FloatTensor,
|
| 493 |
+
encoder_hidden_states: torch.FloatTensor = None,
|
| 494 |
+
encoder_attention_mask: torch.FloatTensor = None,
|
| 495 |
+
attention_mask: torch.FloatTensor = None, # [B, L, S]
|
| 496 |
+
hidden_length: torch.Tensor = None,
|
| 497 |
+
image_rotary_emb: torch.Tensor = None,
|
| 498 |
+
**kwargs,
|
| 499 |
+
) -> torch.FloatTensor:
|
| 500 |
+
# This function is only used during training
|
| 501 |
+
# `sample` projections.
|
| 502 |
+
query = self.to_q(hidden_states)
|
| 503 |
+
key = self.to_k(hidden_states)
|
| 504 |
+
value = self.to_v(hidden_states)
|
| 505 |
+
|
| 506 |
+
inner_dim = key.shape[-1]
|
| 507 |
+
head_dim = inner_dim // self.heads
|
| 508 |
+
|
| 509 |
+
query = query.view(query.shape[0], -1, self.heads, head_dim)
|
| 510 |
+
key = key.view(key.shape[0], -1, self.heads, head_dim)
|
| 511 |
+
value = value.view(value.shape[0], -1, self.heads, head_dim)
|
| 512 |
+
|
| 513 |
+
if self.norm_q is not None:
|
| 514 |
+
query = self.norm_q(query)
|
| 515 |
+
|
| 516 |
+
if self.norm_k is not None:
|
| 517 |
+
key = self.norm_k(key)
|
| 518 |
+
|
| 519 |
+
# `context` projections.
|
| 520 |
+
encoder_hidden_states_query_proj = self.add_q_proj(encoder_hidden_states)
|
| 521 |
+
encoder_hidden_states_key_proj = self.add_k_proj(encoder_hidden_states)
|
| 522 |
+
encoder_hidden_states_value_proj = self.add_v_proj(encoder_hidden_states)
|
| 523 |
+
|
| 524 |
+
encoder_hidden_states_query_proj = encoder_hidden_states_query_proj.view(
|
| 525 |
+
encoder_hidden_states_query_proj.shape[0], -1, self.heads, head_dim
|
| 526 |
+
)
|
| 527 |
+
encoder_hidden_states_key_proj = encoder_hidden_states_key_proj.view(
|
| 528 |
+
encoder_hidden_states_key_proj.shape[0], -1, self.heads, head_dim
|
| 529 |
+
)
|
| 530 |
+
encoder_hidden_states_value_proj = encoder_hidden_states_value_proj.view(
|
| 531 |
+
encoder_hidden_states_value_proj.shape[0], -1, self.heads, head_dim
|
| 532 |
+
)
|
| 533 |
+
|
| 534 |
+
if self.norm_add_q is not None:
|
| 535 |
+
encoder_hidden_states_query_proj = self.norm_add_q(encoder_hidden_states_query_proj)
|
| 536 |
+
|
| 537 |
+
if self.norm_add_k is not None:
|
| 538 |
+
encoder_hidden_states_key_proj = self.norm_add_k(encoder_hidden_states_key_proj)
|
| 539 |
+
|
| 540 |
+
# To cat the hidden and encoder hidden, perform attention compuataion, and then split
|
| 541 |
+
if self.use_flash_attn:
|
| 542 |
+
hidden_states, encoder_hidden_states = self.var_flash_attn(
|
| 543 |
+
query, key, value,
|
| 544 |
+
encoder_hidden_states_query_proj, encoder_hidden_states_key_proj,
|
| 545 |
+
encoder_hidden_states_value_proj, self.heads, self.scale, hidden_length,
|
| 546 |
+
image_rotary_emb, encoder_attention_mask,
|
| 547 |
+
)
|
| 548 |
+
else:
|
| 549 |
+
hidden_states, encoder_hidden_states = self.var_len_attn(
|
| 550 |
+
query, key, value,
|
| 551 |
+
encoder_hidden_states_query_proj, encoder_hidden_states_key_proj,
|
| 552 |
+
encoder_hidden_states_value_proj, self.heads, self.scale, hidden_length,
|
| 553 |
+
image_rotary_emb, attention_mask,
|
| 554 |
+
)
|
| 555 |
+
|
| 556 |
+
# linear proj
|
| 557 |
+
hidden_states = self.to_out[0](hidden_states)
|
| 558 |
+
# dropout
|
| 559 |
+
hidden_states = self.to_out[1](hidden_states)
|
| 560 |
+
if not self.context_pre_only:
|
| 561 |
+
encoder_hidden_states = self.to_add_out(encoder_hidden_states)
|
| 562 |
+
|
| 563 |
+
return hidden_states, encoder_hidden_states
|
| 564 |
+
|
| 565 |
+
|
| 566 |
+
class JointTransformerBlock(nn.Module):
|
| 567 |
+
r"""
|
| 568 |
+
A Transformer block following the MMDiT architecture, introduced in Stable Diffusion 3.
|
| 569 |
+
|
| 570 |
+
Reference: https://arxiv.org/abs/2403.03206
|
| 571 |
+
|
| 572 |
+
Parameters:
|
| 573 |
+
dim (`int`): The number of channels in the input and output.
|
| 574 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 575 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 576 |
+
context_pre_only (`bool`): Boolean to determine if we should add some blocks associated with the
|
| 577 |
+
processing of `context` conditions.
|
| 578 |
+
"""
|
| 579 |
+
|
| 580 |
+
def __init__(
|
| 581 |
+
self, dim, num_attention_heads, attention_head_dim, qk_norm=None,
|
| 582 |
+
context_pre_only=False, use_flash_attn=True,
|
| 583 |
+
):
|
| 584 |
+
super().__init__()
|
| 585 |
+
|
| 586 |
+
self.context_pre_only = context_pre_only
|
| 587 |
+
context_norm_type = "ada_norm_continous" if context_pre_only else "ada_norm_zero"
|
| 588 |
+
|
| 589 |
+
self.norm1 = AdaLayerNormZero(dim)
|
| 590 |
+
|
| 591 |
+
if context_norm_type == "ada_norm_continous":
|
| 592 |
+
self.norm1_context = AdaLayerNormContinuous(
|
| 593 |
+
dim, dim, elementwise_affine=False, eps=1e-6, bias=True, norm_type="layer_norm"
|
| 594 |
+
)
|
| 595 |
+
elif context_norm_type == "ada_norm_zero":
|
| 596 |
+
self.norm1_context = AdaLayerNormZero(dim)
|
| 597 |
+
else:
|
| 598 |
+
raise ValueError(
|
| 599 |
+
f"Unknown context_norm_type: {context_norm_type}, currently only support `ada_norm_continous`, `ada_norm_zero`"
|
| 600 |
+
)
|
| 601 |
+
|
| 602 |
+
self.attn = JointAttention(
|
| 603 |
+
query_dim=dim,
|
| 604 |
+
cross_attention_dim=None,
|
| 605 |
+
added_kv_proj_dim=dim,
|
| 606 |
+
dim_head=attention_head_dim // num_attention_heads,
|
| 607 |
+
heads=num_attention_heads,
|
| 608 |
+
out_dim=attention_head_dim,
|
| 609 |
+
qk_norm=qk_norm,
|
| 610 |
+
context_pre_only=context_pre_only,
|
| 611 |
+
bias=True,
|
| 612 |
+
use_flash_attn=use_flash_attn,
|
| 613 |
+
)
|
| 614 |
+
|
| 615 |
+
self.norm2 = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
|
| 616 |
+
self.ff = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
|
| 617 |
+
|
| 618 |
+
if not context_pre_only:
|
| 619 |
+
self.norm2_context = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
|
| 620 |
+
self.ff_context = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
|
| 621 |
+
else:
|
| 622 |
+
self.norm2_context = None
|
| 623 |
+
self.ff_context = None
|
| 624 |
+
|
| 625 |
+
def forward(
|
| 626 |
+
self, hidden_states: torch.FloatTensor, encoder_hidden_states: torch.FloatTensor,
|
| 627 |
+
encoder_attention_mask: torch.FloatTensor, temb: torch.FloatTensor,
|
| 628 |
+
attention_mask: torch.FloatTensor = None, hidden_length: List = None,
|
| 629 |
+
image_rotary_emb: torch.FloatTensor = None,
|
| 630 |
+
):
|
| 631 |
+
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb, hidden_length=hidden_length)
|
| 632 |
+
|
| 633 |
+
if self.context_pre_only:
|
| 634 |
+
norm_encoder_hidden_states = self.norm1_context(encoder_hidden_states, temb)
|
| 635 |
+
else:
|
| 636 |
+
norm_encoder_hidden_states, c_gate_msa, c_shift_mlp, c_scale_mlp, c_gate_mlp = self.norm1_context(
|
| 637 |
+
encoder_hidden_states, emb=temb,
|
| 638 |
+
)
|
| 639 |
+
|
| 640 |
+
# Attention
|
| 641 |
+
attn_output, context_attn_output = self.attn(
|
| 642 |
+
hidden_states=norm_hidden_states, encoder_hidden_states=norm_encoder_hidden_states,
|
| 643 |
+
encoder_attention_mask=encoder_attention_mask, attention_mask=attention_mask,
|
| 644 |
+
hidden_length=hidden_length, image_rotary_emb=image_rotary_emb,
|
| 645 |
+
)
|
| 646 |
+
|
| 647 |
+
# Process attention outputs for the `hidden_states`.
|
| 648 |
+
attn_output = gate_msa * attn_output
|
| 649 |
+
hidden_states = hidden_states + attn_output
|
| 650 |
+
|
| 651 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 652 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_mlp) + shift_mlp
|
| 653 |
+
|
| 654 |
+
ff_output = self.ff(norm_hidden_states)
|
| 655 |
+
ff_output = gate_mlp * ff_output
|
| 656 |
+
|
| 657 |
+
hidden_states = hidden_states + ff_output
|
| 658 |
+
|
| 659 |
+
# Process attention outputs for the `encoder_hidden_states`.
|
| 660 |
+
if self.context_pre_only:
|
| 661 |
+
encoder_hidden_states = None
|
| 662 |
+
else:
|
| 663 |
+
context_attn_output = c_gate_msa.unsqueeze(1) * context_attn_output
|
| 664 |
+
encoder_hidden_states = encoder_hidden_states + context_attn_output
|
| 665 |
+
|
| 666 |
+
norm_encoder_hidden_states = self.norm2_context(encoder_hidden_states)
|
| 667 |
+
norm_encoder_hidden_states = norm_encoder_hidden_states * (1 + c_scale_mlp[:, None]) + c_shift_mlp[:, None]
|
| 668 |
+
|
| 669 |
+
context_ff_output = self.ff_context(norm_encoder_hidden_states)
|
| 670 |
+
encoder_hidden_states = encoder_hidden_states + c_gate_mlp.unsqueeze(1) * context_ff_output
|
| 671 |
+
|
| 672 |
+
return encoder_hidden_states, hidden_states
|
pyramid_dit/modeling_normalization.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numbers
|
| 2 |
+
from typing import Dict, Optional, Tuple
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
from diffusers.utils import is_torch_version
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
if is_torch_version(">=", "2.1.0"):
|
| 12 |
+
LayerNorm = nn.LayerNorm
|
| 13 |
+
else:
|
| 14 |
+
# Has optional bias parameter compared to torch layer norm
|
| 15 |
+
# TODO: replace with torch layernorm once min required torch version >= 2.1
|
| 16 |
+
class LayerNorm(nn.Module):
|
| 17 |
+
def __init__(self, dim, eps: float = 1e-5, elementwise_affine: bool = True, bias: bool = True):
|
| 18 |
+
super().__init__()
|
| 19 |
+
|
| 20 |
+
self.eps = eps
|
| 21 |
+
|
| 22 |
+
if isinstance(dim, numbers.Integral):
|
| 23 |
+
dim = (dim,)
|
| 24 |
+
|
| 25 |
+
self.dim = torch.Size(dim)
|
| 26 |
+
|
| 27 |
+
if elementwise_affine:
|
| 28 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 29 |
+
self.bias = nn.Parameter(torch.zeros(dim)) if bias else None
|
| 30 |
+
else:
|
| 31 |
+
self.weight = None
|
| 32 |
+
self.bias = None
|
| 33 |
+
|
| 34 |
+
def forward(self, input):
|
| 35 |
+
return F.layer_norm(input, self.dim, self.weight, self.bias, self.eps)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class RMSNorm(nn.Module):
|
| 39 |
+
def __init__(self, dim, eps: float, elementwise_affine: bool = True):
|
| 40 |
+
super().__init__()
|
| 41 |
+
|
| 42 |
+
self.eps = eps
|
| 43 |
+
|
| 44 |
+
if isinstance(dim, numbers.Integral):
|
| 45 |
+
dim = (dim,)
|
| 46 |
+
|
| 47 |
+
self.dim = torch.Size(dim)
|
| 48 |
+
|
| 49 |
+
if elementwise_affine:
|
| 50 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 51 |
+
else:
|
| 52 |
+
self.weight = None
|
| 53 |
+
|
| 54 |
+
def forward(self, hidden_states):
|
| 55 |
+
input_dtype = hidden_states.dtype
|
| 56 |
+
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
|
| 57 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
|
| 58 |
+
|
| 59 |
+
if self.weight is not None:
|
| 60 |
+
# convert into half-precision if necessary
|
| 61 |
+
if self.weight.dtype in [torch.float16, torch.bfloat16]:
|
| 62 |
+
hidden_states = hidden_states.to(self.weight.dtype)
|
| 63 |
+
hidden_states = hidden_states * self.weight
|
| 64 |
+
|
| 65 |
+
hidden_states = hidden_states.to(input_dtype)
|
| 66 |
+
|
| 67 |
+
return hidden_states
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class AdaLayerNormContinuous(nn.Module):
|
| 71 |
+
def __init__(
|
| 72 |
+
self,
|
| 73 |
+
embedding_dim: int,
|
| 74 |
+
conditioning_embedding_dim: int,
|
| 75 |
+
# NOTE: It is a bit weird that the norm layer can be configured to have scale and shift parameters
|
| 76 |
+
# because the output is immediately scaled and shifted by the projected conditioning embeddings.
|
| 77 |
+
# Note that AdaLayerNorm does not let the norm layer have scale and shift parameters.
|
| 78 |
+
# However, this is how it was implemented in the original code, and it's rather likely you should
|
| 79 |
+
# set `elementwise_affine` to False.
|
| 80 |
+
elementwise_affine=True,
|
| 81 |
+
eps=1e-5,
|
| 82 |
+
bias=True,
|
| 83 |
+
norm_type="layer_norm",
|
| 84 |
+
):
|
| 85 |
+
super().__init__()
|
| 86 |
+
self.silu = nn.SiLU()
|
| 87 |
+
self.linear = nn.Linear(conditioning_embedding_dim, embedding_dim * 2, bias=bias)
|
| 88 |
+
if norm_type == "layer_norm":
|
| 89 |
+
self.norm = LayerNorm(embedding_dim, eps, elementwise_affine, bias)
|
| 90 |
+
elif norm_type == "rms_norm":
|
| 91 |
+
self.norm = RMSNorm(embedding_dim, eps, elementwise_affine)
|
| 92 |
+
else:
|
| 93 |
+
raise ValueError(f"unknown norm_type {norm_type}")
|
| 94 |
+
|
| 95 |
+
def forward_with_pad(self, x: torch.Tensor, conditioning_embedding: torch.Tensor, hidden_length=None) -> torch.Tensor:
|
| 96 |
+
assert hidden_length is not None
|
| 97 |
+
|
| 98 |
+
emb = self.linear(self.silu(conditioning_embedding).to(x.dtype))
|
| 99 |
+
batch_emb = torch.zeros_like(x).repeat(1, 1, 2)
|
| 100 |
+
|
| 101 |
+
i_sum = 0
|
| 102 |
+
num_stages = len(hidden_length)
|
| 103 |
+
for i_p, length in enumerate(hidden_length):
|
| 104 |
+
batch_emb[:, i_sum:i_sum+length] = emb[i_p::num_stages][:,None]
|
| 105 |
+
i_sum += length
|
| 106 |
+
|
| 107 |
+
batch_scale, batch_shift = torch.chunk(batch_emb, 2, dim=2)
|
| 108 |
+
x = self.norm(x) * (1 + batch_scale) + batch_shift
|
| 109 |
+
return x
|
| 110 |
+
|
| 111 |
+
def forward(self, x: torch.Tensor, conditioning_embedding: torch.Tensor, hidden_length=None) -> torch.Tensor:
|
| 112 |
+
# convert back to the original dtype in case `conditioning_embedding`` is upcasted to float32 (needed for hunyuanDiT)
|
| 113 |
+
if hidden_length is not None:
|
| 114 |
+
return self.forward_with_pad(x, conditioning_embedding, hidden_length)
|
| 115 |
+
emb = self.linear(self.silu(conditioning_embedding).to(x.dtype))
|
| 116 |
+
scale, shift = torch.chunk(emb, 2, dim=1)
|
| 117 |
+
x = self.norm(x) * (1 + scale)[:, None, :] + shift[:, None, :]
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class AdaLayerNormZero(nn.Module):
|
| 122 |
+
r"""
|
| 123 |
+
Norm layer adaptive layer norm zero (adaLN-Zero).
|
| 124 |
+
|
| 125 |
+
Parameters:
|
| 126 |
+
embedding_dim (`int`): The size of each embedding vector.
|
| 127 |
+
num_embeddings (`int`): The size of the embeddings dictionary.
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
def __init__(self, embedding_dim: int, num_embeddings: Optional[int] = None):
|
| 131 |
+
super().__init__()
|
| 132 |
+
if num_embeddings is not None:
|
| 133 |
+
self.emb = CombinedTimestepLabelEmbeddings(num_embeddings, embedding_dim)
|
| 134 |
+
else:
|
| 135 |
+
self.emb = None
|
| 136 |
+
|
| 137 |
+
self.silu = nn.SiLU()
|
| 138 |
+
self.linear = nn.Linear(embedding_dim, 6 * embedding_dim, bias=True)
|
| 139 |
+
self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False, eps=1e-6)
|
| 140 |
+
|
| 141 |
+
def forward_with_pad(
|
| 142 |
+
self,
|
| 143 |
+
x: torch.Tensor,
|
| 144 |
+
timestep: Optional[torch.Tensor] = None,
|
| 145 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 146 |
+
hidden_dtype: Optional[torch.dtype] = None,
|
| 147 |
+
emb: Optional[torch.Tensor] = None,
|
| 148 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 149 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 150 |
+
# hidden_length: [[20, 30], [30, 40], [50, 60]]
|
| 151 |
+
# x: [bs, seq_len, dim]
|
| 152 |
+
if self.emb is not None:
|
| 153 |
+
emb = self.emb(timestep, class_labels, hidden_dtype=hidden_dtype)
|
| 154 |
+
|
| 155 |
+
emb = self.linear(self.silu(emb))
|
| 156 |
+
batch_emb = torch.zeros_like(x).repeat(1, 1, 6)
|
| 157 |
+
|
| 158 |
+
i_sum = 0
|
| 159 |
+
num_stages = len(hidden_length)
|
| 160 |
+
for i_p, length in enumerate(hidden_length):
|
| 161 |
+
batch_emb[:, i_sum:i_sum+length] = emb[i_p::num_stages][:,None]
|
| 162 |
+
i_sum += length
|
| 163 |
+
|
| 164 |
+
batch_shift_msa, batch_scale_msa, batch_gate_msa, batch_shift_mlp, batch_scale_mlp, batch_gate_mlp = batch_emb.chunk(6, dim=2)
|
| 165 |
+
x = self.norm(x) * (1 + batch_scale_msa) + batch_shift_msa
|
| 166 |
+
return x, batch_gate_msa, batch_shift_mlp, batch_scale_mlp, batch_gate_mlp
|
| 167 |
+
|
| 168 |
+
def forward(
|
| 169 |
+
self,
|
| 170 |
+
x: torch.Tensor,
|
| 171 |
+
timestep: Optional[torch.Tensor] = None,
|
| 172 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 173 |
+
hidden_dtype: Optional[torch.dtype] = None,
|
| 174 |
+
emb: Optional[torch.Tensor] = None,
|
| 175 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 176 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 177 |
+
if hidden_length is not None:
|
| 178 |
+
return self.forward_with_pad(x, timestep, class_labels, hidden_dtype, emb, hidden_length)
|
| 179 |
+
if self.emb is not None:
|
| 180 |
+
emb = self.emb(timestep, class_labels, hidden_dtype=hidden_dtype)
|
| 181 |
+
emb = self.linear(self.silu(emb))
|
| 182 |
+
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = emb.chunk(6, dim=1)
|
| 183 |
+
x = self.norm(x) * (1 + scale_msa[:, None]) + shift_msa[:, None]
|
| 184 |
+
return x, gate_msa, shift_mlp, scale_mlp, gate_mlp
|
pyramid_dit/modeling_pyramid_mmdit.py
ADDED
|
@@ -0,0 +1,487 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import os
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 8 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 9 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 10 |
+
from diffusers.utils import is_torch_version
|
| 11 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
from .modeling_embedding import PatchEmbed3D, CombinedTimestepConditionEmbeddings
|
| 15 |
+
from .modeling_normalization import AdaLayerNormContinuous
|
| 16 |
+
from .modeling_mmdit_block import JointTransformerBlock
|
| 17 |
+
|
| 18 |
+
from trainer_misc import (
|
| 19 |
+
is_sequence_parallel_initialized,
|
| 20 |
+
get_sequence_parallel_group,
|
| 21 |
+
get_sequence_parallel_world_size,
|
| 22 |
+
get_sequence_parallel_rank,
|
| 23 |
+
all_to_all,
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
from IPython import embed
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def rope(pos: torch.Tensor, dim: int, theta: int) -> torch.Tensor:
|
| 30 |
+
assert dim % 2 == 0, "The dimension must be even."
|
| 31 |
+
|
| 32 |
+
scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
|
| 33 |
+
omega = 1.0 / (theta**scale)
|
| 34 |
+
|
| 35 |
+
batch_size, seq_length = pos.shape
|
| 36 |
+
out = torch.einsum("...n,d->...nd", pos, omega)
|
| 37 |
+
cos_out = torch.cos(out)
|
| 38 |
+
sin_out = torch.sin(out)
|
| 39 |
+
|
| 40 |
+
stacked_out = torch.stack([cos_out, -sin_out, sin_out, cos_out], dim=-1)
|
| 41 |
+
out = stacked_out.view(batch_size, -1, dim // 2, 2, 2)
|
| 42 |
+
return out.float()
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class EmbedNDRoPE(nn.Module):
|
| 46 |
+
def __init__(self, dim: int, theta: int, axes_dim: List[int]):
|
| 47 |
+
super().__init__()
|
| 48 |
+
self.dim = dim
|
| 49 |
+
self.theta = theta
|
| 50 |
+
self.axes_dim = axes_dim
|
| 51 |
+
|
| 52 |
+
def forward(self, ids: torch.Tensor) -> torch.Tensor:
|
| 53 |
+
n_axes = ids.shape[-1]
|
| 54 |
+
emb = torch.cat(
|
| 55 |
+
[rope(ids[..., i], self.axes_dim[i], self.theta) for i in range(n_axes)],
|
| 56 |
+
dim=-3,
|
| 57 |
+
)
|
| 58 |
+
return emb.unsqueeze(2)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class PyramidDiffusionMMDiT(ModelMixin, ConfigMixin):
|
| 62 |
+
_supports_gradient_checkpointing = True
|
| 63 |
+
|
| 64 |
+
@register_to_config
|
| 65 |
+
def __init__(
|
| 66 |
+
self,
|
| 67 |
+
sample_size: int = 128,
|
| 68 |
+
patch_size: int = 2,
|
| 69 |
+
in_channels: int = 16,
|
| 70 |
+
num_layers: int = 24,
|
| 71 |
+
attention_head_dim: int = 64,
|
| 72 |
+
num_attention_heads: int = 24,
|
| 73 |
+
caption_projection_dim: int = 1152,
|
| 74 |
+
pooled_projection_dim: int = 2048,
|
| 75 |
+
pos_embed_max_size: int = 192,
|
| 76 |
+
max_num_frames: int = 200,
|
| 77 |
+
qk_norm: str = 'rms_norm',
|
| 78 |
+
pos_embed_type: str = 'rope',
|
| 79 |
+
temp_pos_embed_type: str = 'sincos',
|
| 80 |
+
joint_attention_dim: int = 4096,
|
| 81 |
+
use_gradient_checkpointing: bool = False,
|
| 82 |
+
use_flash_attn: bool = True,
|
| 83 |
+
use_temporal_causal: bool = False,
|
| 84 |
+
use_t5_mask: bool = False,
|
| 85 |
+
add_temp_pos_embed: bool = False,
|
| 86 |
+
interp_condition_pos: bool = False,
|
| 87 |
+
):
|
| 88 |
+
super().__init__()
|
| 89 |
+
|
| 90 |
+
self.out_channels = in_channels
|
| 91 |
+
self.inner_dim = num_attention_heads * attention_head_dim
|
| 92 |
+
assert temp_pos_embed_type in ['rope', 'sincos']
|
| 93 |
+
|
| 94 |
+
# The input latent embeder, using the name pos_embed to remain the same with SD#
|
| 95 |
+
self.pos_embed = PatchEmbed3D(
|
| 96 |
+
height=sample_size,
|
| 97 |
+
width=sample_size,
|
| 98 |
+
patch_size=patch_size,
|
| 99 |
+
in_channels=in_channels,
|
| 100 |
+
embed_dim=self.inner_dim,
|
| 101 |
+
pos_embed_max_size=pos_embed_max_size, # hard-code for now.
|
| 102 |
+
max_num_frames=max_num_frames,
|
| 103 |
+
pos_embed_type=pos_embed_type,
|
| 104 |
+
temp_pos_embed_type=temp_pos_embed_type,
|
| 105 |
+
add_temp_pos_embed=add_temp_pos_embed,
|
| 106 |
+
interp_condition_pos=interp_condition_pos,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
# The RoPE EMbedding
|
| 110 |
+
if pos_embed_type == 'rope':
|
| 111 |
+
self.rope_embed = EmbedNDRoPE(self.inner_dim, 10000, axes_dim=[16, 24, 24])
|
| 112 |
+
else:
|
| 113 |
+
self.rope_embed = None
|
| 114 |
+
|
| 115 |
+
if temp_pos_embed_type == 'rope':
|
| 116 |
+
self.temp_rope_embed = EmbedNDRoPE(self.inner_dim, 10000, axes_dim=[attention_head_dim])
|
| 117 |
+
else:
|
| 118 |
+
self.temp_rope_embed = None
|
| 119 |
+
|
| 120 |
+
self.time_text_embed = CombinedTimestepConditionEmbeddings(
|
| 121 |
+
embedding_dim=self.inner_dim, pooled_projection_dim=self.config.pooled_projection_dim,
|
| 122 |
+
)
|
| 123 |
+
self.context_embedder = nn.Linear(self.config.joint_attention_dim, self.config.caption_projection_dim)
|
| 124 |
+
|
| 125 |
+
self.transformer_blocks = nn.ModuleList(
|
| 126 |
+
[
|
| 127 |
+
JointTransformerBlock(
|
| 128 |
+
dim=self.inner_dim,
|
| 129 |
+
num_attention_heads=num_attention_heads,
|
| 130 |
+
attention_head_dim=self.inner_dim,
|
| 131 |
+
qk_norm=qk_norm,
|
| 132 |
+
context_pre_only=i == num_layers - 1,
|
| 133 |
+
use_flash_attn=use_flash_attn,
|
| 134 |
+
)
|
| 135 |
+
for i in range(num_layers)
|
| 136 |
+
]
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
self.norm_out = AdaLayerNormContinuous(self.inner_dim, self.inner_dim, elementwise_affine=False, eps=1e-6)
|
| 140 |
+
self.proj_out = nn.Linear(self.inner_dim, patch_size * patch_size * self.out_channels, bias=True)
|
| 141 |
+
self.gradient_checkpointing = use_gradient_checkpointing
|
| 142 |
+
self.patch_size = patch_size
|
| 143 |
+
self.use_flash_attn = use_flash_attn
|
| 144 |
+
self.use_temporal_causal = use_temporal_causal
|
| 145 |
+
self.pos_embed_type = pos_embed_type
|
| 146 |
+
self.temp_pos_embed_type = temp_pos_embed_type
|
| 147 |
+
self.add_temp_pos_embed = add_temp_pos_embed
|
| 148 |
+
|
| 149 |
+
if self.use_temporal_causal:
|
| 150 |
+
print("Using temporal causal attention")
|
| 151 |
+
assert self.use_flash_attn is False, "The flash attention does not support temporal causal"
|
| 152 |
+
|
| 153 |
+
if interp_condition_pos:
|
| 154 |
+
print("We interp the position embedding of condition latents")
|
| 155 |
+
|
| 156 |
+
# init weights
|
| 157 |
+
self.initialize_weights()
|
| 158 |
+
|
| 159 |
+
def initialize_weights(self):
|
| 160 |
+
# Initialize transformer layers:
|
| 161 |
+
def _basic_init(module):
|
| 162 |
+
if isinstance(module, (nn.Linear, nn.Conv2d, nn.Conv3d)):
|
| 163 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 164 |
+
if module.bias is not None:
|
| 165 |
+
nn.init.constant_(module.bias, 0)
|
| 166 |
+
self.apply(_basic_init)
|
| 167 |
+
|
| 168 |
+
# Initialize patch_embed like nn.Linear (instead of nn.Conv2d):
|
| 169 |
+
w = self.pos_embed.proj.weight.data
|
| 170 |
+
nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 171 |
+
nn.init.constant_(self.pos_embed.proj.bias, 0)
|
| 172 |
+
|
| 173 |
+
# Initialize all the conditioning to normal init
|
| 174 |
+
nn.init.normal_(self.time_text_embed.timestep_embedder.linear_1.weight, std=0.02)
|
| 175 |
+
nn.init.normal_(self.time_text_embed.timestep_embedder.linear_2.weight, std=0.02)
|
| 176 |
+
nn.init.normal_(self.time_text_embed.text_embedder.linear_1.weight, std=0.02)
|
| 177 |
+
nn.init.normal_(self.time_text_embed.text_embedder.linear_2.weight, std=0.02)
|
| 178 |
+
nn.init.normal_(self.context_embedder.weight, std=0.02)
|
| 179 |
+
|
| 180 |
+
# Zero-out adaLN modulation layers in DiT blocks:
|
| 181 |
+
for block in self.transformer_blocks:
|
| 182 |
+
nn.init.constant_(block.norm1.linear.weight, 0)
|
| 183 |
+
nn.init.constant_(block.norm1.linear.bias, 0)
|
| 184 |
+
nn.init.constant_(block.norm1_context.linear.weight, 0)
|
| 185 |
+
nn.init.constant_(block.norm1_context.linear.bias, 0)
|
| 186 |
+
|
| 187 |
+
# Zero-out output layers:
|
| 188 |
+
nn.init.constant_(self.norm_out.linear.weight, 0)
|
| 189 |
+
nn.init.constant_(self.norm_out.linear.bias, 0)
|
| 190 |
+
nn.init.constant_(self.proj_out.weight, 0)
|
| 191 |
+
nn.init.constant_(self.proj_out.bias, 0)
|
| 192 |
+
|
| 193 |
+
@torch.no_grad()
|
| 194 |
+
def _prepare_latent_image_ids(self, batch_size, temp, height, width, device):
|
| 195 |
+
latent_image_ids = torch.zeros(temp, height, width, 3)
|
| 196 |
+
latent_image_ids[..., 0] = latent_image_ids[..., 0] + torch.arange(temp)[:, None, None]
|
| 197 |
+
latent_image_ids[..., 1] = latent_image_ids[..., 1] + torch.arange(height)[None, :, None]
|
| 198 |
+
latent_image_ids[..., 2] = latent_image_ids[..., 2] + torch.arange(width)[None, None, :]
|
| 199 |
+
|
| 200 |
+
latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1, 1)
|
| 201 |
+
latent_image_ids = rearrange(latent_image_ids, 'b t h w c -> b (t h w) c')
|
| 202 |
+
return latent_image_ids.to(device=device)
|
| 203 |
+
|
| 204 |
+
@torch.no_grad()
|
| 205 |
+
def _prepare_pyramid_latent_image_ids(self, batch_size, temp_list, height_list, width_list, device):
|
| 206 |
+
base_width = width_list[-1]; base_height = height_list[-1]
|
| 207 |
+
assert base_width == max(width_list)
|
| 208 |
+
assert base_height == max(height_list)
|
| 209 |
+
|
| 210 |
+
image_ids_list = []
|
| 211 |
+
for temp, height, width in zip(temp_list, height_list, width_list):
|
| 212 |
+
latent_image_ids = torch.zeros(temp, height, width, 3)
|
| 213 |
+
|
| 214 |
+
if height != base_height:
|
| 215 |
+
height_pos = F.interpolate(torch.arange(base_height)[None, None, :].float(), height, mode='linear').squeeze(0, 1)
|
| 216 |
+
else:
|
| 217 |
+
height_pos = torch.arange(base_height).float()
|
| 218 |
+
if width != base_width:
|
| 219 |
+
width_pos = F.interpolate(torch.arange(base_width)[None, None, :].float(), width, mode='linear').squeeze(0, 1)
|
| 220 |
+
else:
|
| 221 |
+
width_pos = torch.arange(base_width).float()
|
| 222 |
+
|
| 223 |
+
latent_image_ids[..., 0] = latent_image_ids[..., 0] + torch.arange(temp)[:, None, None]
|
| 224 |
+
latent_image_ids[..., 1] = latent_image_ids[..., 1] + height_pos[None, :, None]
|
| 225 |
+
latent_image_ids[..., 2] = latent_image_ids[..., 2] + width_pos[None, None, :]
|
| 226 |
+
latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1, 1)
|
| 227 |
+
latent_image_ids = rearrange(latent_image_ids, 'b t h w c -> b (t h w) c').to(device)
|
| 228 |
+
image_ids_list.append(latent_image_ids)
|
| 229 |
+
|
| 230 |
+
return image_ids_list
|
| 231 |
+
|
| 232 |
+
@torch.no_grad()
|
| 233 |
+
def _prepare_temporal_rope_ids(self, batch_size, temp, height, width, device, start_time_stamp=0):
|
| 234 |
+
latent_image_ids = torch.zeros(temp, height, width, 1)
|
| 235 |
+
latent_image_ids[..., 0] = latent_image_ids[..., 0] + torch.arange(start_time_stamp, start_time_stamp + temp)[:, None, None]
|
| 236 |
+
latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1, 1)
|
| 237 |
+
latent_image_ids = rearrange(latent_image_ids, 'b t h w c -> b (t h w) c')
|
| 238 |
+
return latent_image_ids.to(device=device)
|
| 239 |
+
|
| 240 |
+
@torch.no_grad()
|
| 241 |
+
def _prepare_pyramid_temporal_rope_ids(self, sample, batch_size, device):
|
| 242 |
+
image_ids_list = []
|
| 243 |
+
|
| 244 |
+
for i_b, sample_ in enumerate(sample):
|
| 245 |
+
if not isinstance(sample_, list):
|
| 246 |
+
sample_ = [sample_]
|
| 247 |
+
|
| 248 |
+
cur_image_ids = []
|
| 249 |
+
start_time_stamp = 0
|
| 250 |
+
|
| 251 |
+
for clip_ in sample_:
|
| 252 |
+
_, _, temp, height, width = clip_.shape
|
| 253 |
+
height = height // self.patch_size
|
| 254 |
+
width = width // self.patch_size
|
| 255 |
+
cur_image_ids.append(self._prepare_temporal_rope_ids(batch_size, temp, height, width, device, start_time_stamp=start_time_stamp))
|
| 256 |
+
start_time_stamp += temp
|
| 257 |
+
|
| 258 |
+
cur_image_ids = torch.cat(cur_image_ids, dim=1)
|
| 259 |
+
image_ids_list.append(cur_image_ids)
|
| 260 |
+
|
| 261 |
+
return image_ids_list
|
| 262 |
+
|
| 263 |
+
def merge_input(self, sample, encoder_hidden_length, encoder_attention_mask):
|
| 264 |
+
"""
|
| 265 |
+
Merge the input video with different resolutions into one sequence
|
| 266 |
+
Sample: From low resolution to high resolution
|
| 267 |
+
"""
|
| 268 |
+
if isinstance(sample[0], list):
|
| 269 |
+
device = sample[0][-1].device
|
| 270 |
+
pad_batch_size = sample[0][-1].shape[0]
|
| 271 |
+
else:
|
| 272 |
+
device = sample[0].device
|
| 273 |
+
pad_batch_size = sample[0].shape[0]
|
| 274 |
+
|
| 275 |
+
num_stages = len(sample)
|
| 276 |
+
height_list = [];width_list = [];temp_list = []
|
| 277 |
+
trainable_token_list = []
|
| 278 |
+
|
| 279 |
+
for i_b, sample_ in enumerate(sample):
|
| 280 |
+
if isinstance(sample_, list):
|
| 281 |
+
sample_ = sample_[-1]
|
| 282 |
+
_, _, temp, height, width = sample_.shape
|
| 283 |
+
height = height // self.patch_size
|
| 284 |
+
width = width // self.patch_size
|
| 285 |
+
temp_list.append(temp)
|
| 286 |
+
height_list.append(height)
|
| 287 |
+
width_list.append(width)
|
| 288 |
+
trainable_token_list.append(height * width * temp)
|
| 289 |
+
|
| 290 |
+
# prepare the RoPE embedding if needed
|
| 291 |
+
if self.pos_embed_type == 'rope':
|
| 292 |
+
# TODO: support the 3D Rope for video
|
| 293 |
+
raise NotImplementedError("Not compatible with video generation now")
|
| 294 |
+
text_ids = torch.zeros(pad_batch_size, encoder_hidden_length, 3).to(device=device)
|
| 295 |
+
image_ids_list = self._prepare_pyramid_latent_image_ids(pad_batch_size, temp_list, height_list, width_list, device)
|
| 296 |
+
input_ids_list = [torch.cat([text_ids, image_ids], dim=1) for image_ids in image_ids_list]
|
| 297 |
+
image_rotary_emb = [self.rope_embed(input_ids) for input_ids in input_ids_list] # [bs, seq_len, 1, head_dim // 2, 2, 2]
|
| 298 |
+
else:
|
| 299 |
+
if self.temp_pos_embed_type == 'rope' and self.add_temp_pos_embed:
|
| 300 |
+
image_ids_list = self._prepare_pyramid_temporal_rope_ids(sample, pad_batch_size, device)
|
| 301 |
+
text_ids = torch.zeros(pad_batch_size, encoder_attention_mask.shape[1], 1).to(device=device)
|
| 302 |
+
input_ids_list = [torch.cat([text_ids, image_ids], dim=1) for image_ids in image_ids_list]
|
| 303 |
+
image_rotary_emb = [self.temp_rope_embed(input_ids) for input_ids in input_ids_list] # [bs, seq_len, 1, head_dim // 2, 2, 2]
|
| 304 |
+
|
| 305 |
+
if is_sequence_parallel_initialized():
|
| 306 |
+
sp_group = get_sequence_parallel_group()
|
| 307 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 308 |
+
image_rotary_emb = [all_to_all(x_.repeat(1, 1, sp_group_size, 1, 1, 1), sp_group, sp_group_size, scatter_dim=2, gather_dim=0) for x_ in image_rotary_emb]
|
| 309 |
+
input_ids_list = [all_to_all(input_ids.repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0) for input_ids in input_ids_list]
|
| 310 |
+
|
| 311 |
+
else:
|
| 312 |
+
image_rotary_emb = None
|
| 313 |
+
|
| 314 |
+
hidden_states = self.pos_embed(sample) # hidden states is a list of [b c t h w] b = real_b // num_stages
|
| 315 |
+
hidden_length = []
|
| 316 |
+
|
| 317 |
+
for i_b in range(num_stages):
|
| 318 |
+
hidden_length.append(hidden_states[i_b].shape[1])
|
| 319 |
+
|
| 320 |
+
# prepare the attention mask
|
| 321 |
+
if self.use_flash_attn:
|
| 322 |
+
attention_mask = None
|
| 323 |
+
indices_list = []
|
| 324 |
+
for i_p, length in enumerate(hidden_length):
|
| 325 |
+
pad_attention_mask = torch.ones((pad_batch_size, length), dtype=encoder_attention_mask.dtype).to(device)
|
| 326 |
+
pad_attention_mask = torch.cat([encoder_attention_mask[i_p::num_stages], pad_attention_mask], dim=1)
|
| 327 |
+
|
| 328 |
+
if is_sequence_parallel_initialized():
|
| 329 |
+
sp_group = get_sequence_parallel_group()
|
| 330 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 331 |
+
pad_attention_mask = all_to_all(pad_attention_mask.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0)
|
| 332 |
+
pad_attention_mask = pad_attention_mask.squeeze(2)
|
| 333 |
+
|
| 334 |
+
seqlens_in_batch = pad_attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 335 |
+
indices = torch.nonzero(pad_attention_mask.flatten(), as_tuple=False).flatten()
|
| 336 |
+
|
| 337 |
+
indices_list.append(
|
| 338 |
+
{
|
| 339 |
+
'indices': indices,
|
| 340 |
+
'seqlens_in_batch': seqlens_in_batch,
|
| 341 |
+
}
|
| 342 |
+
)
|
| 343 |
+
encoder_attention_mask = indices_list
|
| 344 |
+
else:
|
| 345 |
+
assert encoder_attention_mask.shape[1] == encoder_hidden_length
|
| 346 |
+
real_batch_size = encoder_attention_mask.shape[0]
|
| 347 |
+
# prepare text ids
|
| 348 |
+
text_ids = torch.arange(1, real_batch_size + 1, dtype=encoder_attention_mask.dtype).unsqueeze(1).repeat(1, encoder_hidden_length)
|
| 349 |
+
text_ids = text_ids.to(device)
|
| 350 |
+
text_ids[encoder_attention_mask == 0] = 0
|
| 351 |
+
|
| 352 |
+
# prepare image ids
|
| 353 |
+
image_ids = torch.arange(1, real_batch_size + 1, dtype=encoder_attention_mask.dtype).unsqueeze(1).repeat(1, max(hidden_length))
|
| 354 |
+
image_ids = image_ids.to(device)
|
| 355 |
+
image_ids_list = []
|
| 356 |
+
for i_p, length in enumerate(hidden_length):
|
| 357 |
+
image_ids_list.append(image_ids[i_p::num_stages][:, :length])
|
| 358 |
+
|
| 359 |
+
if is_sequence_parallel_initialized():
|
| 360 |
+
sp_group = get_sequence_parallel_group()
|
| 361 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 362 |
+
text_ids = all_to_all(text_ids.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0).squeeze(2)
|
| 363 |
+
image_ids_list = [all_to_all(image_ids_.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0).squeeze(2) for image_ids_ in image_ids_list]
|
| 364 |
+
|
| 365 |
+
attention_mask = []
|
| 366 |
+
for i_p in range(len(hidden_length)):
|
| 367 |
+
image_ids = image_ids_list[i_p]
|
| 368 |
+
token_ids = torch.cat([text_ids[i_p::num_stages], image_ids], dim=1)
|
| 369 |
+
stage_attention_mask = rearrange(token_ids, 'b i -> b 1 i 1') == rearrange(token_ids, 'b j -> b 1 1 j') # [bs, 1, q_len, k_len]
|
| 370 |
+
if self.use_temporal_causal:
|
| 371 |
+
input_order_ids = input_ids_list[i_p].squeeze(2)
|
| 372 |
+
temporal_causal_mask = rearrange(input_order_ids, 'b i -> b 1 i 1') >= rearrange(input_order_ids, 'b j -> b 1 1 j')
|
| 373 |
+
stage_attention_mask = stage_attention_mask & temporal_causal_mask
|
| 374 |
+
attention_mask.append(stage_attention_mask)
|
| 375 |
+
|
| 376 |
+
return hidden_states, hidden_length, temp_list, height_list, width_list, trainable_token_list, encoder_attention_mask, attention_mask, image_rotary_emb
|
| 377 |
+
|
| 378 |
+
def split_output(self, batch_hidden_states, hidden_length, temps, heights, widths, trainable_token_list):
|
| 379 |
+
# To split the hidden states
|
| 380 |
+
batch_size = batch_hidden_states.shape[0]
|
| 381 |
+
output_hidden_list = []
|
| 382 |
+
batch_hidden_states = torch.split(batch_hidden_states, hidden_length, dim=1)
|
| 383 |
+
|
| 384 |
+
if is_sequence_parallel_initialized():
|
| 385 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 386 |
+
batch_size = batch_size // sp_group_size
|
| 387 |
+
|
| 388 |
+
for i_p, length in enumerate(hidden_length):
|
| 389 |
+
width, height, temp = widths[i_p], heights[i_p], temps[i_p]
|
| 390 |
+
trainable_token_num = trainable_token_list[i_p]
|
| 391 |
+
hidden_states = batch_hidden_states[i_p]
|
| 392 |
+
|
| 393 |
+
if is_sequence_parallel_initialized():
|
| 394 |
+
sp_group = get_sequence_parallel_group()
|
| 395 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 396 |
+
hidden_states = all_to_all(hidden_states, sp_group, sp_group_size, scatter_dim=0, gather_dim=1)
|
| 397 |
+
|
| 398 |
+
# only the trainable token are taking part in loss computation
|
| 399 |
+
hidden_states = hidden_states[:, -trainable_token_num:]
|
| 400 |
+
|
| 401 |
+
# unpatchify
|
| 402 |
+
hidden_states = hidden_states.reshape(
|
| 403 |
+
shape=(batch_size, temp, height, width, self.patch_size, self.patch_size, self.out_channels)
|
| 404 |
+
)
|
| 405 |
+
hidden_states = rearrange(hidden_states, "b t h w p1 p2 c -> b t (h p1) (w p2) c")
|
| 406 |
+
hidden_states = rearrange(hidden_states, "b t h w c -> b c t h w")
|
| 407 |
+
output_hidden_list.append(hidden_states)
|
| 408 |
+
|
| 409 |
+
return output_hidden_list
|
| 410 |
+
|
| 411 |
+
def forward(
|
| 412 |
+
self,
|
| 413 |
+
sample: torch.FloatTensor, # [num_stages]
|
| 414 |
+
encoder_hidden_states: torch.FloatTensor = None,
|
| 415 |
+
encoder_attention_mask: torch.FloatTensor = None,
|
| 416 |
+
pooled_projections: torch.FloatTensor = None,
|
| 417 |
+
timestep_ratio: torch.FloatTensor = None,
|
| 418 |
+
):
|
| 419 |
+
# Get the timestep embedding
|
| 420 |
+
temb = self.time_text_embed(timestep_ratio, pooled_projections)
|
| 421 |
+
encoder_hidden_states = self.context_embedder(encoder_hidden_states)
|
| 422 |
+
encoder_hidden_length = encoder_hidden_states.shape[1]
|
| 423 |
+
|
| 424 |
+
# Get the input sequence
|
| 425 |
+
hidden_states, hidden_length, temps, heights, widths, trainable_token_list, encoder_attention_mask, \
|
| 426 |
+
attention_mask, image_rotary_emb = self.merge_input(sample, encoder_hidden_length, encoder_attention_mask)
|
| 427 |
+
|
| 428 |
+
# split the long latents if necessary
|
| 429 |
+
if is_sequence_parallel_initialized():
|
| 430 |
+
sp_group = get_sequence_parallel_group()
|
| 431 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 432 |
+
|
| 433 |
+
# sync the input hidden states
|
| 434 |
+
batch_hidden_states = []
|
| 435 |
+
for i_p, hidden_states_ in enumerate(hidden_states):
|
| 436 |
+
assert hidden_states_.shape[1] % sp_group_size == 0, "The sequence length should be divided by sequence parallel size"
|
| 437 |
+
hidden_states_ = all_to_all(hidden_states_, sp_group, sp_group_size, scatter_dim=1, gather_dim=0)
|
| 438 |
+
hidden_length[i_p] = hidden_length[i_p] // sp_group_size
|
| 439 |
+
batch_hidden_states.append(hidden_states_)
|
| 440 |
+
|
| 441 |
+
# sync the encoder hidden states
|
| 442 |
+
hidden_states = torch.cat(batch_hidden_states, dim=1)
|
| 443 |
+
encoder_hidden_states = all_to_all(encoder_hidden_states, sp_group, sp_group_size, scatter_dim=1, gather_dim=0)
|
| 444 |
+
temb = all_to_all(temb.unsqueeze(1).repeat(1, sp_group_size, 1), sp_group, sp_group_size, scatter_dim=1, gather_dim=0)
|
| 445 |
+
temb = temb.squeeze(1)
|
| 446 |
+
else:
|
| 447 |
+
hidden_states = torch.cat(hidden_states, dim=1)
|
| 448 |
+
|
| 449 |
+
# print(hidden_length)
|
| 450 |
+
for i_b, block in enumerate(self.transformer_blocks):
|
| 451 |
+
if self.training and self.gradient_checkpointing and (i_b >= 2):
|
| 452 |
+
def create_custom_forward(module):
|
| 453 |
+
def custom_forward(*inputs):
|
| 454 |
+
return module(*inputs)
|
| 455 |
+
|
| 456 |
+
return custom_forward
|
| 457 |
+
|
| 458 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 459 |
+
encoder_hidden_states, hidden_states = torch.utils.checkpoint.checkpoint(
|
| 460 |
+
create_custom_forward(block),
|
| 461 |
+
hidden_states,
|
| 462 |
+
encoder_hidden_states,
|
| 463 |
+
encoder_attention_mask,
|
| 464 |
+
temb,
|
| 465 |
+
attention_mask,
|
| 466 |
+
hidden_length,
|
| 467 |
+
image_rotary_emb,
|
| 468 |
+
**ckpt_kwargs,
|
| 469 |
+
)
|
| 470 |
+
|
| 471 |
+
else:
|
| 472 |
+
encoder_hidden_states, hidden_states = block(
|
| 473 |
+
hidden_states=hidden_states,
|
| 474 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 475 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 476 |
+
temb=temb,
|
| 477 |
+
attention_mask=attention_mask,
|
| 478 |
+
hidden_length=hidden_length,
|
| 479 |
+
image_rotary_emb=image_rotary_emb,
|
| 480 |
+
)
|
| 481 |
+
|
| 482 |
+
hidden_states = self.norm_out(hidden_states, temb, hidden_length=hidden_length)
|
| 483 |
+
hidden_states = self.proj_out(hidden_states)
|
| 484 |
+
|
| 485 |
+
output = self.split_output(hidden_states, hidden_length, temps, heights, widths, trainable_token_list)
|
| 486 |
+
|
| 487 |
+
return output
|
pyramid_dit/modeling_text_encoder.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
from transformers import (
|
| 6 |
+
CLIPTextModelWithProjection,
|
| 7 |
+
CLIPTokenizer,
|
| 8 |
+
T5EncoderModel,
|
| 9 |
+
T5TokenizerFast,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class SD3TextEncoderWithMask(nn.Module):
|
| 16 |
+
def __init__(self, model_path, torch_dtype):
|
| 17 |
+
super().__init__()
|
| 18 |
+
# CLIP-L
|
| 19 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(os.path.join(model_path, 'tokenizer'))
|
| 20 |
+
self.tokenizer_max_length = self.tokenizer.model_max_length
|
| 21 |
+
self.text_encoder = CLIPTextModelWithProjection.from_pretrained(os.path.join(model_path, 'text_encoder'), torch_dtype=torch_dtype)
|
| 22 |
+
|
| 23 |
+
# CLIP-G
|
| 24 |
+
self.tokenizer_2 = CLIPTokenizer.from_pretrained(os.path.join(model_path, 'tokenizer_2'))
|
| 25 |
+
self.text_encoder_2 = CLIPTextModelWithProjection.from_pretrained(os.path.join(model_path, 'text_encoder_2'), torch_dtype=torch_dtype)
|
| 26 |
+
|
| 27 |
+
# T5
|
| 28 |
+
self.tokenizer_3 = T5TokenizerFast.from_pretrained(os.path.join(model_path, 'tokenizer_3'))
|
| 29 |
+
self.text_encoder_3 = T5EncoderModel.from_pretrained(os.path.join(model_path, 'text_encoder_3'), torch_dtype=torch_dtype)
|
| 30 |
+
|
| 31 |
+
self._freeze()
|
| 32 |
+
|
| 33 |
+
def _freeze(self):
|
| 34 |
+
for param in self.parameters():
|
| 35 |
+
param.requires_grad = False
|
| 36 |
+
|
| 37 |
+
def _get_t5_prompt_embeds(
|
| 38 |
+
self,
|
| 39 |
+
prompt: Union[str, List[str]] = None,
|
| 40 |
+
num_images_per_prompt: int = 1,
|
| 41 |
+
device: Optional[torch.device] = None,
|
| 42 |
+
max_sequence_length: int = 128,
|
| 43 |
+
):
|
| 44 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 45 |
+
batch_size = len(prompt)
|
| 46 |
+
|
| 47 |
+
text_inputs = self.tokenizer_3(
|
| 48 |
+
prompt,
|
| 49 |
+
padding="max_length",
|
| 50 |
+
max_length=max_sequence_length,
|
| 51 |
+
truncation=True,
|
| 52 |
+
add_special_tokens=True,
|
| 53 |
+
return_tensors="pt",
|
| 54 |
+
)
|
| 55 |
+
text_input_ids = text_inputs.input_ids
|
| 56 |
+
prompt_attention_mask = text_inputs.attention_mask
|
| 57 |
+
prompt_attention_mask = prompt_attention_mask.to(device)
|
| 58 |
+
prompt_embeds = self.text_encoder_3(text_input_ids.to(device), attention_mask=prompt_attention_mask)[0]
|
| 59 |
+
dtype = self.text_encoder_3.dtype
|
| 60 |
+
prompt_embeds = prompt_embeds.to(dtype=dtype, device=device)
|
| 61 |
+
|
| 62 |
+
_, seq_len, _ = prompt_embeds.shape
|
| 63 |
+
|
| 64 |
+
# duplicate text embeddings and attention mask for each generation per prompt, using mps friendly method
|
| 65 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 66 |
+
prompt_embeds = prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
|
| 67 |
+
prompt_attention_mask = prompt_attention_mask.view(batch_size, -1)
|
| 68 |
+
prompt_attention_mask = prompt_attention_mask.repeat(num_images_per_prompt, 1)
|
| 69 |
+
|
| 70 |
+
return prompt_embeds, prompt_attention_mask
|
| 71 |
+
|
| 72 |
+
def _get_clip_prompt_embeds(
|
| 73 |
+
self,
|
| 74 |
+
prompt: Union[str, List[str]],
|
| 75 |
+
num_images_per_prompt: int = 1,
|
| 76 |
+
device: Optional[torch.device] = None,
|
| 77 |
+
clip_skip: Optional[int] = None,
|
| 78 |
+
clip_model_index: int = 0,
|
| 79 |
+
):
|
| 80 |
+
|
| 81 |
+
clip_tokenizers = [self.tokenizer, self.tokenizer_2]
|
| 82 |
+
clip_text_encoders = [self.text_encoder, self.text_encoder_2]
|
| 83 |
+
|
| 84 |
+
tokenizer = clip_tokenizers[clip_model_index]
|
| 85 |
+
text_encoder = clip_text_encoders[clip_model_index]
|
| 86 |
+
|
| 87 |
+
batch_size = len(prompt)
|
| 88 |
+
|
| 89 |
+
text_inputs = tokenizer(
|
| 90 |
+
prompt,
|
| 91 |
+
padding="max_length",
|
| 92 |
+
max_length=self.tokenizer_max_length,
|
| 93 |
+
truncation=True,
|
| 94 |
+
return_tensors="pt",
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
text_input_ids = text_inputs.input_ids
|
| 98 |
+
prompt_embeds = text_encoder(text_input_ids.to(device), output_hidden_states=True)
|
| 99 |
+
pooled_prompt_embeds = prompt_embeds[0]
|
| 100 |
+
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 101 |
+
pooled_prompt_embeds = pooled_prompt_embeds.view(batch_size * num_images_per_prompt, -1)
|
| 102 |
+
|
| 103 |
+
return pooled_prompt_embeds
|
| 104 |
+
|
| 105 |
+
def encode_prompt(self,
|
| 106 |
+
prompt,
|
| 107 |
+
num_images_per_prompt=1,
|
| 108 |
+
clip_skip: Optional[int] = None,
|
| 109 |
+
device=None,
|
| 110 |
+
):
|
| 111 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 112 |
+
|
| 113 |
+
pooled_prompt_embed = self._get_clip_prompt_embeds(
|
| 114 |
+
prompt=prompt,
|
| 115 |
+
device=device,
|
| 116 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 117 |
+
clip_skip=clip_skip,
|
| 118 |
+
clip_model_index=0,
|
| 119 |
+
)
|
| 120 |
+
pooled_prompt_2_embed = self._get_clip_prompt_embeds(
|
| 121 |
+
prompt=prompt,
|
| 122 |
+
device=device,
|
| 123 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 124 |
+
clip_skip=clip_skip,
|
| 125 |
+
clip_model_index=1,
|
| 126 |
+
)
|
| 127 |
+
pooled_prompt_embeds = torch.cat([pooled_prompt_embed, pooled_prompt_2_embed], dim=-1)
|
| 128 |
+
|
| 129 |
+
prompt_embeds, prompt_attention_mask = self._get_t5_prompt_embeds(
|
| 130 |
+
prompt=prompt,
|
| 131 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 132 |
+
device=device,
|
| 133 |
+
)
|
| 134 |
+
return prompt_embeds, prompt_attention_mask, pooled_prompt_embeds
|
| 135 |
+
|
| 136 |
+
def forward(self, input_prompts, device):
|
| 137 |
+
with torch.no_grad():
|
| 138 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.encode_prompt(input_prompts, 1, clip_skip=None, device=device)
|
| 139 |
+
|
| 140 |
+
return prompt_embeds, prompt_attention_mask, pooled_prompt_embeds
|
pyramid_dit/pyramid_dit_for_video_gen_pipeline.py
ADDED
|
@@ -0,0 +1,665 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
from collections import OrderedDict
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 10 |
+
import numpy as np
|
| 11 |
+
import math
|
| 12 |
+
import random
|
| 13 |
+
import PIL
|
| 14 |
+
from PIL import Image
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
from torchvision import transforms
|
| 17 |
+
from copy import deepcopy
|
| 18 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 19 |
+
from accelerate import Accelerator
|
| 20 |
+
from diffusion_schedulers import PyramidFlowMatchEulerDiscreteScheduler
|
| 21 |
+
from video_vae.modeling_causal_vae import CausalVideoVAE
|
| 22 |
+
|
| 23 |
+
from trainer_misc import (
|
| 24 |
+
all_to_all,
|
| 25 |
+
is_sequence_parallel_initialized,
|
| 26 |
+
get_sequence_parallel_group,
|
| 27 |
+
get_sequence_parallel_group_rank,
|
| 28 |
+
get_sequence_parallel_rank,
|
| 29 |
+
get_sequence_parallel_world_size,
|
| 30 |
+
get_rank,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
from .modeling_pyramid_mmdit import PyramidDiffusionMMDiT
|
| 34 |
+
from .modeling_text_encoder import SD3TextEncoderWithMask
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def compute_density_for_timestep_sampling(
|
| 38 |
+
weighting_scheme: str, batch_size: int, logit_mean: float = None, logit_std: float = None, mode_scale: float = None
|
| 39 |
+
):
|
| 40 |
+
if weighting_scheme == "logit_normal":
|
| 41 |
+
# See 3.1 in the SD3 paper ($rf/lognorm(0.00,1.00)$).
|
| 42 |
+
u = torch.normal(mean=logit_mean, std=logit_std, size=(batch_size,), device="cpu")
|
| 43 |
+
u = torch.nn.functional.sigmoid(u)
|
| 44 |
+
elif weighting_scheme == "mode":
|
| 45 |
+
u = torch.rand(size=(batch_size,), device="cpu")
|
| 46 |
+
u = 1 - u - mode_scale * (torch.cos(math.pi * u / 2) ** 2 - 1 + u)
|
| 47 |
+
else:
|
| 48 |
+
u = torch.rand(size=(batch_size,), device="cpu")
|
| 49 |
+
return u
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class PyramidDiTForVideoGeneration:
|
| 53 |
+
"""
|
| 54 |
+
The pyramid dit for both image and video generation, The running class wrapper
|
| 55 |
+
This class is mainly for fixed unit implementation: 1 + n + n + n
|
| 56 |
+
"""
|
| 57 |
+
def __init__(self, model_path, model_dtype='bf16', use_gradient_checkpointing=False, return_log=True,
|
| 58 |
+
model_variant="diffusion_transformer_768p", timestep_shift=1.0, stage_range=[0, 1/3, 2/3, 1],
|
| 59 |
+
sample_ratios=[1, 1, 1], scheduler_gamma=1/3, use_mixed_training=False, use_flash_attn=False,
|
| 60 |
+
load_text_encoder=True, load_vae=True, max_temporal_length=31, frame_per_unit=1, use_temporal_causal=True,
|
| 61 |
+
corrupt_ratio=1/3, interp_condition_pos=True, stages=[1, 2, 4], **kwargs,
|
| 62 |
+
):
|
| 63 |
+
super().__init__()
|
| 64 |
+
|
| 65 |
+
if model_dtype == 'bf16':
|
| 66 |
+
torch_dtype = torch.bfloat16
|
| 67 |
+
elif model_dtype == 'fp16':
|
| 68 |
+
torch_dtype = torch.float16
|
| 69 |
+
else:
|
| 70 |
+
torch_dtype = torch.float32
|
| 71 |
+
|
| 72 |
+
self.stages = stages
|
| 73 |
+
self.sample_ratios = sample_ratios
|
| 74 |
+
self.corrupt_ratio = corrupt_ratio
|
| 75 |
+
|
| 76 |
+
dit_path = os.path.join(model_path, model_variant)
|
| 77 |
+
|
| 78 |
+
# The dit
|
| 79 |
+
if use_mixed_training:
|
| 80 |
+
print("using mixed precision training, do not explicitly casting models")
|
| 81 |
+
self.dit = PyramidDiffusionMMDiT.from_pretrained(
|
| 82 |
+
dit_path, use_gradient_checkpointing=use_gradient_checkpointing,
|
| 83 |
+
use_flash_attn=use_flash_attn, use_t5_mask=True,
|
| 84 |
+
add_temp_pos_embed=True, temp_pos_embed_type='rope',
|
| 85 |
+
use_temporal_causal=use_temporal_causal, interp_condition_pos=interp_condition_pos,
|
| 86 |
+
)
|
| 87 |
+
else:
|
| 88 |
+
print("using half precision")
|
| 89 |
+
self.dit = PyramidDiffusionMMDiT.from_pretrained(
|
| 90 |
+
dit_path, torch_dtype=torch_dtype,
|
| 91 |
+
use_gradient_checkpointing=use_gradient_checkpointing,
|
| 92 |
+
use_flash_attn=use_flash_attn, use_t5_mask=True,
|
| 93 |
+
add_temp_pos_embed=True, temp_pos_embed_type='rope',
|
| 94 |
+
use_temporal_causal=use_temporal_causal, interp_condition_pos=interp_condition_pos,
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
# The text encoder
|
| 98 |
+
if load_text_encoder:
|
| 99 |
+
self.text_encoder = SD3TextEncoderWithMask(model_path, torch_dtype=torch_dtype)
|
| 100 |
+
else:
|
| 101 |
+
self.text_encoder = None
|
| 102 |
+
|
| 103 |
+
# The base video vae decoder
|
| 104 |
+
if load_vae:
|
| 105 |
+
self.vae = CausalVideoVAE.from_pretrained(os.path.join(model_path, 'causal_video_vae'), torch_dtype=torch_dtype, interpolate=False)
|
| 106 |
+
# Freeze vae
|
| 107 |
+
for parameter in self.vae.parameters():
|
| 108 |
+
parameter.requires_grad = False
|
| 109 |
+
else:
|
| 110 |
+
self.vae = None
|
| 111 |
+
|
| 112 |
+
# For the image latent
|
| 113 |
+
self.vae_shift_factor = 0.1490
|
| 114 |
+
self.vae_scale_factor = 1 / 1.8415
|
| 115 |
+
|
| 116 |
+
# For the video latent
|
| 117 |
+
self.vae_video_shift_factor = -0.2343
|
| 118 |
+
self.vae_video_scale_factor = 1 / 3.0986
|
| 119 |
+
|
| 120 |
+
self.downsample = 8
|
| 121 |
+
|
| 122 |
+
# Configure the video training hyper-parameters
|
| 123 |
+
# The video sequence: one frame + N * unit
|
| 124 |
+
self.frame_per_unit = frame_per_unit
|
| 125 |
+
self.max_temporal_length = max_temporal_length
|
| 126 |
+
assert (max_temporal_length - 1) % frame_per_unit == 0, "The frame number should be divided by the frame number per unit"
|
| 127 |
+
self.num_units_per_video = 1 + ((max_temporal_length - 1) // frame_per_unit) + int(sum(sample_ratios))
|
| 128 |
+
|
| 129 |
+
self.scheduler = PyramidFlowMatchEulerDiscreteScheduler(
|
| 130 |
+
shift=timestep_shift, stages=len(self.stages),
|
| 131 |
+
stage_range=stage_range, gamma=scheduler_gamma,
|
| 132 |
+
)
|
| 133 |
+
print(f"The start sigmas and end sigmas of each stage is Start: {self.scheduler.start_sigmas}, End: {self.scheduler.end_sigmas}, Ori_start: {self.scheduler.ori_start_sigmas}")
|
| 134 |
+
|
| 135 |
+
self.cfg_rate = 0.1
|
| 136 |
+
self.return_log = return_log
|
| 137 |
+
self.use_flash_attn = use_flash_attn
|
| 138 |
+
|
| 139 |
+
def load_checkpoint(self, checkpoint_path, model_key='model', **kwargs):
|
| 140 |
+
checkpoint = torch.load(checkpoint_path, map_location='cpu')
|
| 141 |
+
dit_checkpoint = OrderedDict()
|
| 142 |
+
for key in checkpoint:
|
| 143 |
+
if key.startswith('vae') or key.startswith('text_encoder'):
|
| 144 |
+
continue
|
| 145 |
+
if key.startswith('dit'):
|
| 146 |
+
new_key = key.split('.')
|
| 147 |
+
new_key = '.'.join(new_key[1:])
|
| 148 |
+
dit_checkpoint[new_key] = checkpoint[key]
|
| 149 |
+
else:
|
| 150 |
+
dit_checkpoint[key] = checkpoint[key]
|
| 151 |
+
|
| 152 |
+
load_result = self.dit.load_state_dict(dit_checkpoint, strict=True)
|
| 153 |
+
print(f"Load checkpoint from {checkpoint_path}, load result: {load_result}")
|
| 154 |
+
|
| 155 |
+
def load_vae_checkpoint(self, vae_checkpoint_path, model_key='model'):
|
| 156 |
+
checkpoint = torch.load(vae_checkpoint_path, map_location='cpu')
|
| 157 |
+
checkpoint = checkpoint[model_key]
|
| 158 |
+
loaded_checkpoint = OrderedDict()
|
| 159 |
+
|
| 160 |
+
for key in checkpoint.keys():
|
| 161 |
+
if key.startswith('vae.'):
|
| 162 |
+
new_key = key.split('.')
|
| 163 |
+
new_key = '.'.join(new_key[1:])
|
| 164 |
+
loaded_checkpoint[new_key] = checkpoint[key]
|
| 165 |
+
|
| 166 |
+
load_result = self.vae.load_state_dict(loaded_checkpoint)
|
| 167 |
+
print(f"Load the VAE from {vae_checkpoint_path}, load result: {load_result}")
|
| 168 |
+
|
| 169 |
+
@torch.no_grad()
|
| 170 |
+
def get_pyramid_latent(self, x, stage_num):
|
| 171 |
+
# x is the origin vae latent
|
| 172 |
+
vae_latent_list = []
|
| 173 |
+
vae_latent_list.append(x)
|
| 174 |
+
|
| 175 |
+
temp, height, width = x.shape[-3], x.shape[-2], x.shape[-1]
|
| 176 |
+
for _ in range(stage_num):
|
| 177 |
+
height //= 2
|
| 178 |
+
width //= 2
|
| 179 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 180 |
+
x = torch.nn.functional.interpolate(x, size=(height, width), mode='bilinear')
|
| 181 |
+
x = rearrange(x, '(b t) c h w -> b c t h w', t=temp)
|
| 182 |
+
vae_latent_list.append(x)
|
| 183 |
+
|
| 184 |
+
vae_latent_list = list(reversed(vae_latent_list))
|
| 185 |
+
return vae_latent_list
|
| 186 |
+
|
| 187 |
+
def prepare_latents(
|
| 188 |
+
self,
|
| 189 |
+
batch_size,
|
| 190 |
+
num_channels_latents,
|
| 191 |
+
temp,
|
| 192 |
+
height,
|
| 193 |
+
width,
|
| 194 |
+
dtype,
|
| 195 |
+
device,
|
| 196 |
+
generator,
|
| 197 |
+
):
|
| 198 |
+
shape = (
|
| 199 |
+
batch_size,
|
| 200 |
+
num_channels_latents,
|
| 201 |
+
int(temp),
|
| 202 |
+
int(height) // self.downsample,
|
| 203 |
+
int(width) // self.downsample,
|
| 204 |
+
)
|
| 205 |
+
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 206 |
+
return latents
|
| 207 |
+
|
| 208 |
+
def sample_block_noise(self, bs, ch, temp, height, width):
|
| 209 |
+
gamma = self.scheduler.config.gamma
|
| 210 |
+
dist = torch.distributions.multivariate_normal.MultivariateNormal(torch.zeros(4), torch.eye(4) * (1 + gamma) - torch.ones(4, 4) * gamma)
|
| 211 |
+
block_number = bs * ch * temp * (height // 2) * (width // 2)
|
| 212 |
+
noise = torch.stack([dist.sample() for _ in range(block_number)]) # [block number, 4]
|
| 213 |
+
noise = rearrange(noise, '(b c t h w) (p q) -> b c t (h p) (w q)',b=bs,c=ch,t=temp,h=height//2,w=width//2,p=2,q=2)
|
| 214 |
+
return noise
|
| 215 |
+
|
| 216 |
+
@torch.no_grad()
|
| 217 |
+
def generate_one_unit(
|
| 218 |
+
self,
|
| 219 |
+
latents,
|
| 220 |
+
past_conditions, # List of past conditions, contains the conditions of each stage
|
| 221 |
+
prompt_embeds,
|
| 222 |
+
prompt_attention_mask,
|
| 223 |
+
pooled_prompt_embeds,
|
| 224 |
+
num_inference_steps,
|
| 225 |
+
height,
|
| 226 |
+
width,
|
| 227 |
+
temp,
|
| 228 |
+
device,
|
| 229 |
+
dtype,
|
| 230 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 231 |
+
is_first_frame: bool = False,
|
| 232 |
+
):
|
| 233 |
+
stages = self.stages
|
| 234 |
+
intermed_latents = []
|
| 235 |
+
|
| 236 |
+
for i_s in range(len(stages)):
|
| 237 |
+
self.scheduler.set_timesteps(num_inference_steps[i_s], i_s, device=device)
|
| 238 |
+
timesteps = self.scheduler.timesteps
|
| 239 |
+
|
| 240 |
+
if i_s > 0:
|
| 241 |
+
height *= 2; width *= 2
|
| 242 |
+
latents = rearrange(latents, 'b c t h w -> (b t) c h w')
|
| 243 |
+
latents = F.interpolate(latents, size=(height, width), mode='nearest')
|
| 244 |
+
latents = rearrange(latents, '(b t) c h w -> b c t h w', t=temp)
|
| 245 |
+
# Fix the stage
|
| 246 |
+
ori_sigma = 1 - self.scheduler.ori_start_sigmas[i_s] # the original coeff of signal
|
| 247 |
+
gamma = self.scheduler.config.gamma
|
| 248 |
+
alpha = 1 / (math.sqrt(1 + (1 / gamma)) * (1 - ori_sigma) + ori_sigma)
|
| 249 |
+
beta = alpha * (1 - ori_sigma) / math.sqrt(gamma)
|
| 250 |
+
|
| 251 |
+
bs, ch, temp, height, width = latents.shape
|
| 252 |
+
noise = self.sample_block_noise(bs, ch, temp, height, width)
|
| 253 |
+
noise = noise.to(device=device, dtype=dtype)
|
| 254 |
+
latents = alpha * latents + beta * noise # To fix the block artifact
|
| 255 |
+
|
| 256 |
+
for idx, t in enumerate(timesteps):
|
| 257 |
+
# expand the latents if we are doing classifier free guidance
|
| 258 |
+
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
|
| 259 |
+
|
| 260 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 261 |
+
timestep = t.expand(latent_model_input.shape[0]).to(latent_model_input.dtype)
|
| 262 |
+
|
| 263 |
+
latent_model_input = past_conditions[i_s] + [latent_model_input]
|
| 264 |
+
|
| 265 |
+
noise_pred = self.dit(
|
| 266 |
+
sample=[latent_model_input],
|
| 267 |
+
timestep_ratio=timestep,
|
| 268 |
+
encoder_hidden_states=prompt_embeds,
|
| 269 |
+
encoder_attention_mask=prompt_attention_mask,
|
| 270 |
+
pooled_projections=pooled_prompt_embeds,
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
noise_pred = noise_pred[0]
|
| 274 |
+
|
| 275 |
+
# perform guidance
|
| 276 |
+
if self.do_classifier_free_guidance:
|
| 277 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 278 |
+
if is_first_frame:
|
| 279 |
+
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 280 |
+
else:
|
| 281 |
+
noise_pred = noise_pred_uncond + self.video_guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 282 |
+
|
| 283 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 284 |
+
latents = self.scheduler.step(
|
| 285 |
+
model_output=noise_pred,
|
| 286 |
+
timestep=timestep,
|
| 287 |
+
sample=latents,
|
| 288 |
+
generator=generator,
|
| 289 |
+
).prev_sample
|
| 290 |
+
|
| 291 |
+
intermed_latents.append(latents)
|
| 292 |
+
|
| 293 |
+
return intermed_latents
|
| 294 |
+
|
| 295 |
+
@torch.no_grad()
|
| 296 |
+
def generate_i2v(
|
| 297 |
+
self,
|
| 298 |
+
prompt: Union[str, List[str]] = '',
|
| 299 |
+
input_image: PIL.Image = None,
|
| 300 |
+
temp: int = 1,
|
| 301 |
+
num_inference_steps: Optional[Union[int, List[int]]] = 28,
|
| 302 |
+
guidance_scale: float = 7.0,
|
| 303 |
+
video_guidance_scale: float = 4.0,
|
| 304 |
+
min_guidance_scale: float = 2.0,
|
| 305 |
+
use_linear_guidance: bool = False,
|
| 306 |
+
alpha: float = 0.5,
|
| 307 |
+
negative_prompt: Optional[Union[str, List[str]]]="cartoon style, worst quality, low quality, blurry, absolute black, absolute white, low res, extra limbs, extra digits, misplaced objects, mutated anatomy, monochrome, horror",
|
| 308 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 309 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 310 |
+
output_type: Optional[str] = "pil",
|
| 311 |
+
):
|
| 312 |
+
device = self.device
|
| 313 |
+
dtype = self.dtype
|
| 314 |
+
|
| 315 |
+
width = input_image.width
|
| 316 |
+
height = input_image.height
|
| 317 |
+
|
| 318 |
+
assert temp % self.frame_per_unit == 0, "The frames should be divided by frame_per unit"
|
| 319 |
+
|
| 320 |
+
if isinstance(prompt, str):
|
| 321 |
+
batch_size = 1
|
| 322 |
+
prompt = prompt + ", hyper quality, Ultra HD, 8K" # adding this prompt to improve aesthetics
|
| 323 |
+
else:
|
| 324 |
+
assert isinstance(prompt, list)
|
| 325 |
+
batch_size = len(prompt)
|
| 326 |
+
prompt = [_ + ", hyper quality, Ultra HD, 8K" for _ in prompt]
|
| 327 |
+
|
| 328 |
+
if isinstance(num_inference_steps, int):
|
| 329 |
+
num_inference_steps = [num_inference_steps] * len(self.stages)
|
| 330 |
+
|
| 331 |
+
negative_prompt = negative_prompt or ""
|
| 332 |
+
|
| 333 |
+
# Get the text embeddings
|
| 334 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.text_encoder(prompt, device)
|
| 335 |
+
negative_prompt_embeds, negative_prompt_attention_mask, negative_pooled_prompt_embeds = self.text_encoder(negative_prompt, device)
|
| 336 |
+
|
| 337 |
+
if use_linear_guidance:
|
| 338 |
+
max_guidance_scale = guidance_scale
|
| 339 |
+
guidance_scale_list = [max(max_guidance_scale - alpha * t_, min_guidance_scale) for t_ in range(temp+1)]
|
| 340 |
+
print(guidance_scale_list)
|
| 341 |
+
|
| 342 |
+
self._guidance_scale = guidance_scale
|
| 343 |
+
self._video_guidance_scale = video_guidance_scale
|
| 344 |
+
|
| 345 |
+
if self.do_classifier_free_guidance:
|
| 346 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 347 |
+
pooled_prompt_embeds = torch.cat([negative_pooled_prompt_embeds, pooled_prompt_embeds], dim=0)
|
| 348 |
+
prompt_attention_mask = torch.cat([negative_prompt_attention_mask, prompt_attention_mask], dim=0)
|
| 349 |
+
|
| 350 |
+
# Create the initial random noise
|
| 351 |
+
num_channels_latents = self.dit.config.in_channels
|
| 352 |
+
latents = self.prepare_latents(
|
| 353 |
+
batch_size * num_images_per_prompt,
|
| 354 |
+
num_channels_latents,
|
| 355 |
+
temp,
|
| 356 |
+
height,
|
| 357 |
+
width,
|
| 358 |
+
prompt_embeds.dtype,
|
| 359 |
+
device,
|
| 360 |
+
generator,
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
temp, height, width = latents.shape[-3], latents.shape[-2], latents.shape[-1]
|
| 364 |
+
|
| 365 |
+
latents = rearrange(latents, 'b c t h w -> (b t) c h w')
|
| 366 |
+
# by defalut, we needs to start from the block noise
|
| 367 |
+
for _ in range(len(self.stages)-1):
|
| 368 |
+
height //= 2;width //= 2
|
| 369 |
+
latents = F.interpolate(latents, size=(height, width), mode='bilinear') * 2
|
| 370 |
+
|
| 371 |
+
latents = rearrange(latents, '(b t) c h w -> b c t h w', t=temp)
|
| 372 |
+
|
| 373 |
+
num_units = temp // self.frame_per_unit
|
| 374 |
+
stages = self.stages
|
| 375 |
+
|
| 376 |
+
# encode the image latents
|
| 377 |
+
image_transform = transforms.Compose([
|
| 378 |
+
transforms.ToTensor(),
|
| 379 |
+
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
|
| 380 |
+
])
|
| 381 |
+
input_image_tensor = image_transform(input_image).unsqueeze(0).unsqueeze(2) # [b c 1 h w]
|
| 382 |
+
input_image_latent = (self.vae.encode(input_image_tensor.to(device)).latent_dist.sample() - self.vae_shift_factor) * self.vae_scale_factor # [b c 1 h w]
|
| 383 |
+
|
| 384 |
+
generated_latents_list = [input_image_latent] # The generated results
|
| 385 |
+
last_generated_latents = input_image_latent
|
| 386 |
+
|
| 387 |
+
for unit_index in tqdm(range(1, num_units + 1)):
|
| 388 |
+
if use_linear_guidance:
|
| 389 |
+
self._guidance_scale = guidance_scale_list[unit_index]
|
| 390 |
+
self._video_guidance_scale = guidance_scale_list[unit_index]
|
| 391 |
+
|
| 392 |
+
# prepare the condition latents
|
| 393 |
+
past_condition_latents = []
|
| 394 |
+
clean_latents_list = self.get_pyramid_latent(torch.cat(generated_latents_list, dim=2), len(stages) - 1)
|
| 395 |
+
|
| 396 |
+
for i_s in range(len(stages)):
|
| 397 |
+
last_cond_latent = clean_latents_list[i_s][:,:,-self.frame_per_unit:]
|
| 398 |
+
|
| 399 |
+
stage_input = [torch.cat([last_cond_latent] * 2) if self.do_classifier_free_guidance else last_cond_latent]
|
| 400 |
+
|
| 401 |
+
# pad the past clean latents
|
| 402 |
+
cur_unit_num = unit_index
|
| 403 |
+
cur_stage = i_s
|
| 404 |
+
cur_unit_ptx = 1
|
| 405 |
+
|
| 406 |
+
while cur_unit_ptx < cur_unit_num:
|
| 407 |
+
cur_stage = max(cur_stage - 1, 0)
|
| 408 |
+
if cur_stage == 0:
|
| 409 |
+
break
|
| 410 |
+
cur_unit_ptx += 1
|
| 411 |
+
cond_latents = clean_latents_list[cur_stage][:, :, -(cur_unit_ptx * self.frame_per_unit) : -((cur_unit_ptx - 1) * self.frame_per_unit)]
|
| 412 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 413 |
+
|
| 414 |
+
if cur_stage == 0 and cur_unit_ptx < cur_unit_num:
|
| 415 |
+
cond_latents = clean_latents_list[0][:, :, :-(cur_unit_ptx * self.frame_per_unit)]
|
| 416 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 417 |
+
|
| 418 |
+
stage_input = list(reversed(stage_input))
|
| 419 |
+
past_condition_latents.append(stage_input)
|
| 420 |
+
|
| 421 |
+
intermed_latents = self.generate_one_unit(
|
| 422 |
+
latents[:,:,(unit_index - 1) * self.frame_per_unit:unit_index * self.frame_per_unit],
|
| 423 |
+
past_condition_latents,
|
| 424 |
+
prompt_embeds,
|
| 425 |
+
prompt_attention_mask,
|
| 426 |
+
pooled_prompt_embeds,
|
| 427 |
+
num_inference_steps,
|
| 428 |
+
height,
|
| 429 |
+
width,
|
| 430 |
+
self.frame_per_unit,
|
| 431 |
+
device,
|
| 432 |
+
dtype,
|
| 433 |
+
generator,
|
| 434 |
+
is_first_frame=False,
|
| 435 |
+
)
|
| 436 |
+
|
| 437 |
+
generated_latents_list.append(intermed_latents[-1])
|
| 438 |
+
last_generated_latents = intermed_latents
|
| 439 |
+
|
| 440 |
+
generated_latents = torch.cat(generated_latents_list, dim=2)
|
| 441 |
+
|
| 442 |
+
if output_type == "latent":
|
| 443 |
+
image = generated_latents
|
| 444 |
+
else:
|
| 445 |
+
image = self.decode_latent(generated_latents)
|
| 446 |
+
|
| 447 |
+
return image
|
| 448 |
+
|
| 449 |
+
@torch.no_grad()
|
| 450 |
+
def generate(
|
| 451 |
+
self,
|
| 452 |
+
prompt: Union[str, List[str]] = None,
|
| 453 |
+
height: Optional[int] = None,
|
| 454 |
+
width: Optional[int] = None,
|
| 455 |
+
temp: int = 1,
|
| 456 |
+
num_inference_steps: Optional[Union[int, List[int]]] = 28,
|
| 457 |
+
video_num_inference_steps: Optional[Union[int, List[int]]] = 28,
|
| 458 |
+
guidance_scale: float = 7.0,
|
| 459 |
+
video_guidance_scale: float = 7.0,
|
| 460 |
+
min_guidance_scale: float = 2.0,
|
| 461 |
+
use_linear_guidance: bool = False,
|
| 462 |
+
alpha: float = 0.5,
|
| 463 |
+
negative_prompt: Optional[Union[str, List[str]]]="cartoon style, worst quality, low quality, blurry, absolute black, absolute white, low res, extra limbs, extra digits, misplaced objects, mutated anatomy, monochrome, horror",
|
| 464 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 465 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 466 |
+
output_type: Optional[str] = "pil",
|
| 467 |
+
):
|
| 468 |
+
device = self.device
|
| 469 |
+
dtype = self.dtype
|
| 470 |
+
|
| 471 |
+
assert (temp - 1) % self.frame_per_unit == 0, "The frames should be divided by frame_per unit"
|
| 472 |
+
|
| 473 |
+
if isinstance(prompt, str):
|
| 474 |
+
batch_size = 1
|
| 475 |
+
prompt = prompt + ", hyper quality, Ultra HD, 8K" # adding this prompt to improve aesthetics
|
| 476 |
+
else:
|
| 477 |
+
assert isinstance(prompt, list)
|
| 478 |
+
batch_size = len(prompt)
|
| 479 |
+
prompt = [_ + ", hyper quality, Ultra HD, 8K" for _ in prompt]
|
| 480 |
+
|
| 481 |
+
if isinstance(num_inference_steps, int):
|
| 482 |
+
num_inference_steps = [num_inference_steps] * len(self.stages)
|
| 483 |
+
|
| 484 |
+
if isinstance(video_num_inference_steps, int):
|
| 485 |
+
video_num_inference_steps = [video_num_inference_steps] * len(self.stages)
|
| 486 |
+
|
| 487 |
+
negative_prompt = negative_prompt or ""
|
| 488 |
+
|
| 489 |
+
# Get the text embeddings
|
| 490 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.text_encoder(prompt, device)
|
| 491 |
+
negative_prompt_embeds, negative_prompt_attention_mask, negative_pooled_prompt_embeds = self.text_encoder(negative_prompt, device)
|
| 492 |
+
|
| 493 |
+
if use_linear_guidance:
|
| 494 |
+
max_guidance_scale = guidance_scale
|
| 495 |
+
# guidance_scale_list = torch.linspace(max_guidance_scale, min_guidance_scale, temp).tolist()
|
| 496 |
+
guidance_scale_list = [max(max_guidance_scale - alpha * t_, min_guidance_scale) for t_ in range(temp)]
|
| 497 |
+
print(guidance_scale_list)
|
| 498 |
+
|
| 499 |
+
self._guidance_scale = guidance_scale
|
| 500 |
+
self._video_guidance_scale = video_guidance_scale
|
| 501 |
+
|
| 502 |
+
if self.do_classifier_free_guidance:
|
| 503 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 504 |
+
pooled_prompt_embeds = torch.cat([negative_pooled_prompt_embeds, pooled_prompt_embeds], dim=0)
|
| 505 |
+
prompt_attention_mask = torch.cat([negative_prompt_attention_mask, prompt_attention_mask], dim=0)
|
| 506 |
+
|
| 507 |
+
# Create the initial random noise
|
| 508 |
+
num_channels_latents = self.dit.config.in_channels
|
| 509 |
+
latents = self.prepare_latents(
|
| 510 |
+
batch_size * num_images_per_prompt,
|
| 511 |
+
num_channels_latents,
|
| 512 |
+
temp,
|
| 513 |
+
height,
|
| 514 |
+
width,
|
| 515 |
+
prompt_embeds.dtype,
|
| 516 |
+
device,
|
| 517 |
+
generator,
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
temp, height, width = latents.shape[-3], latents.shape[-2], latents.shape[-1]
|
| 521 |
+
|
| 522 |
+
latents = rearrange(latents, 'b c t h w -> (b t) c h w')
|
| 523 |
+
# by defalut, we needs to start from the block noise
|
| 524 |
+
for _ in range(len(self.stages)-1):
|
| 525 |
+
height //= 2;width //= 2
|
| 526 |
+
latents = F.interpolate(latents, size=(height, width), mode='bilinear') * 2
|
| 527 |
+
|
| 528 |
+
latents = rearrange(latents, '(b t) c h w -> b c t h w', t=temp)
|
| 529 |
+
|
| 530 |
+
num_units = 1 + (temp - 1) // self.frame_per_unit
|
| 531 |
+
stages = self.stages
|
| 532 |
+
|
| 533 |
+
generated_latents_list = [] # The generated results
|
| 534 |
+
last_generated_latents = None
|
| 535 |
+
|
| 536 |
+
for unit_index in tqdm(range(num_units)):
|
| 537 |
+
if use_linear_guidance:
|
| 538 |
+
self._guidance_scale = guidance_scale_list[unit_index]
|
| 539 |
+
self._video_guidance_scale = guidance_scale_list[unit_index]
|
| 540 |
+
|
| 541 |
+
if unit_index == 0:
|
| 542 |
+
past_condition_latents = [[] for _ in range(len(stages))]
|
| 543 |
+
intermed_latents = self.generate_one_unit(
|
| 544 |
+
latents[:,:,:1],
|
| 545 |
+
past_condition_latents,
|
| 546 |
+
prompt_embeds,
|
| 547 |
+
prompt_attention_mask,
|
| 548 |
+
pooled_prompt_embeds,
|
| 549 |
+
num_inference_steps,
|
| 550 |
+
height,
|
| 551 |
+
width,
|
| 552 |
+
1,
|
| 553 |
+
device,
|
| 554 |
+
dtype,
|
| 555 |
+
generator,
|
| 556 |
+
is_first_frame=True,
|
| 557 |
+
)
|
| 558 |
+
else:
|
| 559 |
+
# prepare the condition latents
|
| 560 |
+
past_condition_latents = []
|
| 561 |
+
clean_latents_list = self.get_pyramid_latent(torch.cat(generated_latents_list, dim=2), len(stages) - 1)
|
| 562 |
+
|
| 563 |
+
for i_s in range(len(stages)):
|
| 564 |
+
last_cond_latent = clean_latents_list[i_s][:,:,-(self.frame_per_unit):]
|
| 565 |
+
|
| 566 |
+
stage_input = [torch.cat([last_cond_latent] * 2) if self.do_classifier_free_guidance else last_cond_latent]
|
| 567 |
+
|
| 568 |
+
# pad the past clean latents
|
| 569 |
+
cur_unit_num = unit_index
|
| 570 |
+
cur_stage = i_s
|
| 571 |
+
cur_unit_ptx = 1
|
| 572 |
+
|
| 573 |
+
while cur_unit_ptx < cur_unit_num:
|
| 574 |
+
cur_stage = max(cur_stage - 1, 0)
|
| 575 |
+
if cur_stage == 0:
|
| 576 |
+
break
|
| 577 |
+
cur_unit_ptx += 1
|
| 578 |
+
cond_latents = clean_latents_list[cur_stage][:, :, -(cur_unit_ptx * self.frame_per_unit) : -((cur_unit_ptx - 1) * self.frame_per_unit)]
|
| 579 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 580 |
+
|
| 581 |
+
if cur_stage == 0 and cur_unit_ptx < cur_unit_num:
|
| 582 |
+
cond_latents = clean_latents_list[0][:, :, :-(cur_unit_ptx * self.frame_per_unit)]
|
| 583 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 584 |
+
|
| 585 |
+
stage_input = list(reversed(stage_input))
|
| 586 |
+
past_condition_latents.append(stage_input)
|
| 587 |
+
|
| 588 |
+
intermed_latents = self.generate_one_unit(
|
| 589 |
+
latents[:,:, 1 + (unit_index - 1) * self.frame_per_unit:1 + unit_index * self.frame_per_unit],
|
| 590 |
+
past_condition_latents,
|
| 591 |
+
prompt_embeds,
|
| 592 |
+
prompt_attention_mask,
|
| 593 |
+
pooled_prompt_embeds,
|
| 594 |
+
video_num_inference_steps,
|
| 595 |
+
height,
|
| 596 |
+
width,
|
| 597 |
+
self.frame_per_unit,
|
| 598 |
+
device,
|
| 599 |
+
dtype,
|
| 600 |
+
generator,
|
| 601 |
+
is_first_frame=False,
|
| 602 |
+
)
|
| 603 |
+
|
| 604 |
+
generated_latents_list.append(intermed_latents[-1])
|
| 605 |
+
last_generated_latents = intermed_latents
|
| 606 |
+
|
| 607 |
+
generated_latents = torch.cat(generated_latents_list, dim=2)
|
| 608 |
+
|
| 609 |
+
if output_type == "latent":
|
| 610 |
+
image = generated_latents
|
| 611 |
+
else:
|
| 612 |
+
image = self.decode_latent(generated_latents)
|
| 613 |
+
|
| 614 |
+
return image
|
| 615 |
+
|
| 616 |
+
def decode_latent(self, latents):
|
| 617 |
+
if latents.shape[2] == 1:
|
| 618 |
+
latents = (latents / self.vae_scale_factor) + self.vae_shift_factor
|
| 619 |
+
else:
|
| 620 |
+
latents[:, :, :1] = (latents[:, :, :1] / self.vae_scale_factor) + self.vae_shift_factor
|
| 621 |
+
latents[:, :, 1:] = (latents[:, :, 1:] / self.vae_video_scale_factor) + self.vae_video_shift_factor
|
| 622 |
+
|
| 623 |
+
image = self.vae.decode(latents, temporal_chunk=True, window_size=2, tile_sample_min_size=512).sample
|
| 624 |
+
image = image.float()
|
| 625 |
+
image = (image / 2 + 0.5).clamp(0, 1)
|
| 626 |
+
image = rearrange(image, "B C T H W -> (B T) C H W")
|
| 627 |
+
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
| 628 |
+
image = self.numpy_to_pil(image)
|
| 629 |
+
return image
|
| 630 |
+
|
| 631 |
+
@staticmethod
|
| 632 |
+
def numpy_to_pil(images):
|
| 633 |
+
"""
|
| 634 |
+
Convert a numpy image or a batch of images to a PIL image.
|
| 635 |
+
"""
|
| 636 |
+
if images.ndim == 3:
|
| 637 |
+
images = images[None, ...]
|
| 638 |
+
images = (images * 255).round().astype("uint8")
|
| 639 |
+
if images.shape[-1] == 1:
|
| 640 |
+
# special case for grayscale (single channel) images
|
| 641 |
+
pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
|
| 642 |
+
else:
|
| 643 |
+
pil_images = [Image.fromarray(image) for image in images]
|
| 644 |
+
|
| 645 |
+
return pil_images
|
| 646 |
+
|
| 647 |
+
@property
|
| 648 |
+
def device(self):
|
| 649 |
+
return next(self.dit.parameters()).device
|
| 650 |
+
|
| 651 |
+
@property
|
| 652 |
+
def dtype(self):
|
| 653 |
+
return next(self.dit.parameters()).dtype
|
| 654 |
+
|
| 655 |
+
@property
|
| 656 |
+
def guidance_scale(self):
|
| 657 |
+
return self._guidance_scale
|
| 658 |
+
|
| 659 |
+
@property
|
| 660 |
+
def video_guidance_scale(self):
|
| 661 |
+
return self._video_guidance_scale
|
| 662 |
+
|
| 663 |
+
@property
|
| 664 |
+
def do_classifier_free_guidance(self):
|
| 665 |
+
return self._guidance_scale > 0
|
requirements.txt
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
contexttimer
|
| 2 |
+
decord
|
| 3 |
+
diffusers>=0.30.1
|
| 4 |
+
accelerate==0.30.0
|
| 5 |
+
torch==2.1.2
|
| 6 |
+
torchvision==0.16.2
|
| 7 |
+
einops
|
| 8 |
+
ftfy
|
| 9 |
+
ipython
|
| 10 |
+
opencv-python-headless==4.10.0.84
|
| 11 |
+
imageio==2.33.1
|
| 12 |
+
imageio-ffmpeg==0.5.1
|
| 13 |
+
packaging
|
| 14 |
+
pandas
|
| 15 |
+
plotly
|
| 16 |
+
pre-commit
|
| 17 |
+
pycocoevalcap
|
| 18 |
+
pycocotools
|
| 19 |
+
python-magic
|
| 20 |
+
scikit-image
|
| 21 |
+
sentencepiece
|
| 22 |
+
spacy
|
| 23 |
+
streamlit
|
| 24 |
+
timm==0.6.12
|
| 25 |
+
tqdm
|
| 26 |
+
transformers==4.39.3
|
| 27 |
+
wheel
|
| 28 |
+
torchmetrics
|
| 29 |
+
tiktoken
|
| 30 |
+
jsonlines
|
| 31 |
+
tensorboardX
|
trainer_misc/__init__.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .utils import (
|
| 2 |
+
create_optimizer,
|
| 3 |
+
get_rank,
|
| 4 |
+
get_world_size,
|
| 5 |
+
is_main_process,
|
| 6 |
+
is_dist_avail_and_initialized,
|
| 7 |
+
init_distributed_mode,
|
| 8 |
+
setup_for_distributed,
|
| 9 |
+
cosine_scheduler,
|
| 10 |
+
constant_scheduler,
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
from .sp_utils import (
|
| 14 |
+
is_sequence_parallel_initialized,
|
| 15 |
+
init_sequence_parallel_group,
|
| 16 |
+
get_sequence_parallel_group,
|
| 17 |
+
get_sequence_parallel_world_size,
|
| 18 |
+
get_sequence_parallel_rank,
|
| 19 |
+
get_sequence_parallel_group_rank,
|
| 20 |
+
get_sequence_parallel_proc_num,
|
| 21 |
+
init_sync_input_group,
|
| 22 |
+
get_sync_input_group,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
from .communicate import all_to_all
|
trainer_misc/communicate.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import math
|
| 4 |
+
import torch.distributed as dist
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def _all_to_all(
|
| 8 |
+
input_: torch.Tensor,
|
| 9 |
+
world_size: int,
|
| 10 |
+
group: dist.ProcessGroup,
|
| 11 |
+
scatter_dim: int,
|
| 12 |
+
gather_dim: int,
|
| 13 |
+
):
|
| 14 |
+
if world_size == 1:
|
| 15 |
+
return input_
|
| 16 |
+
input_list = [t.contiguous() for t in torch.tensor_split(input_, world_size, scatter_dim)]
|
| 17 |
+
output_list = [torch.empty_like(input_list[0]) for _ in range(world_size)]
|
| 18 |
+
dist.all_to_all(output_list, input_list, group=group)
|
| 19 |
+
return torch.cat(output_list, dim=gather_dim).contiguous()
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class _AllToAll(torch.autograd.Function):
|
| 23 |
+
|
| 24 |
+
@staticmethod
|
| 25 |
+
def forward(ctx, input_, process_group, world_size, scatter_dim, gather_dim):
|
| 26 |
+
ctx.process_group = process_group
|
| 27 |
+
ctx.scatter_dim = scatter_dim
|
| 28 |
+
ctx.gather_dim = gather_dim
|
| 29 |
+
ctx.world_size = world_size
|
| 30 |
+
output = _all_to_all(input_, ctx.world_size, process_group, scatter_dim, gather_dim)
|
| 31 |
+
return output
|
| 32 |
+
|
| 33 |
+
@staticmethod
|
| 34 |
+
def backward(ctx, grad_output):
|
| 35 |
+
grad_output = _all_to_all(
|
| 36 |
+
grad_output,
|
| 37 |
+
ctx.world_size,
|
| 38 |
+
ctx.process_group,
|
| 39 |
+
ctx.gather_dim,
|
| 40 |
+
ctx.scatter_dim,
|
| 41 |
+
)
|
| 42 |
+
return (
|
| 43 |
+
grad_output,
|
| 44 |
+
None,
|
| 45 |
+
None,
|
| 46 |
+
None,
|
| 47 |
+
None,
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def all_to_all(
|
| 52 |
+
input_: torch.Tensor,
|
| 53 |
+
process_group: dist.ProcessGroup,
|
| 54 |
+
world_size: int = 1,
|
| 55 |
+
scatter_dim: int = 2,
|
| 56 |
+
gather_dim: int = 1,
|
| 57 |
+
):
|
| 58 |
+
return _AllToAll.apply(input_, process_group, world_size, scatter_dim, gather_dim)
|
trainer_misc/sp_utils.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import torch.distributed as dist
|
| 4 |
+
from .utils import is_dist_avail_and_initialized, get_rank
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
SEQ_PARALLEL_GROUP = None
|
| 8 |
+
SEQ_PARALLEL_SIZE = None
|
| 9 |
+
SEQ_PARALLEL_PROC_NUM = None # using how many process for sequence parallel
|
| 10 |
+
|
| 11 |
+
SYNC_INPUT_GROUP = None
|
| 12 |
+
SYNC_INPUT_SIZE = None
|
| 13 |
+
|
| 14 |
+
def is_sequence_parallel_initialized():
|
| 15 |
+
if SEQ_PARALLEL_GROUP is None:
|
| 16 |
+
return False
|
| 17 |
+
else:
|
| 18 |
+
return True
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def init_sequence_parallel_group(args):
|
| 22 |
+
global SEQ_PARALLEL_GROUP
|
| 23 |
+
global SEQ_PARALLEL_SIZE
|
| 24 |
+
global SEQ_PARALLEL_PROC_NUM
|
| 25 |
+
|
| 26 |
+
assert SEQ_PARALLEL_GROUP is None, "sequence parallel group is already initialized"
|
| 27 |
+
assert is_dist_avail_and_initialized(), "The pytorch distributed should be initialized"
|
| 28 |
+
SEQ_PARALLEL_SIZE = args.sp_group_size
|
| 29 |
+
|
| 30 |
+
print(f"Setting the Sequence Parallel Size {SEQ_PARALLEL_SIZE}")
|
| 31 |
+
|
| 32 |
+
rank = torch.distributed.get_rank()
|
| 33 |
+
world_size = torch.distributed.get_world_size()
|
| 34 |
+
|
| 35 |
+
if args.sp_proc_num == -1:
|
| 36 |
+
SEQ_PARALLEL_PROC_NUM = world_size
|
| 37 |
+
else:
|
| 38 |
+
SEQ_PARALLEL_PROC_NUM = args.sp_proc_num
|
| 39 |
+
|
| 40 |
+
assert SEQ_PARALLEL_PROC_NUM % SEQ_PARALLEL_SIZE == 0, "The process needs to be evenly divided"
|
| 41 |
+
|
| 42 |
+
for i in range(0, SEQ_PARALLEL_PROC_NUM, SEQ_PARALLEL_SIZE):
|
| 43 |
+
ranks = list(range(i, i + SEQ_PARALLEL_SIZE))
|
| 44 |
+
group = torch.distributed.new_group(ranks)
|
| 45 |
+
if rank in ranks:
|
| 46 |
+
SEQ_PARALLEL_GROUP = group
|
| 47 |
+
break
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def init_sync_input_group(args):
|
| 51 |
+
global SYNC_INPUT_GROUP
|
| 52 |
+
global SYNC_INPUT_SIZE
|
| 53 |
+
|
| 54 |
+
assert SYNC_INPUT_GROUP is None, "parallel group is already initialized"
|
| 55 |
+
assert is_dist_avail_and_initialized(), "The pytorch distributed should be initialized"
|
| 56 |
+
SYNC_INPUT_SIZE = args.max_frames
|
| 57 |
+
|
| 58 |
+
rank = torch.distributed.get_rank()
|
| 59 |
+
world_size = torch.distributed.get_world_size()
|
| 60 |
+
|
| 61 |
+
for i in range(0, world_size, SYNC_INPUT_SIZE):
|
| 62 |
+
ranks = list(range(i, i + SYNC_INPUT_SIZE))
|
| 63 |
+
group = torch.distributed.new_group(ranks)
|
| 64 |
+
if rank in ranks:
|
| 65 |
+
SYNC_INPUT_GROUP = group
|
| 66 |
+
break
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def get_sequence_parallel_group():
|
| 70 |
+
assert SEQ_PARALLEL_GROUP is not None, "sequence parallel group is not initialized"
|
| 71 |
+
return SEQ_PARALLEL_GROUP
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def get_sync_input_group():
|
| 75 |
+
return SYNC_INPUT_GROUP
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def get_sequence_parallel_world_size():
|
| 79 |
+
assert SEQ_PARALLEL_SIZE is not None, "sequence parallel size is not initialized"
|
| 80 |
+
return SEQ_PARALLEL_SIZE
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def get_sequence_parallel_rank():
|
| 84 |
+
assert SEQ_PARALLEL_SIZE is not None, "sequence parallel size is not initialized"
|
| 85 |
+
rank = get_rank()
|
| 86 |
+
cp_rank = rank % SEQ_PARALLEL_SIZE
|
| 87 |
+
return cp_rank
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def get_sequence_parallel_group_rank():
|
| 91 |
+
assert SEQ_PARALLEL_SIZE is not None, "sequence parallel size is not initialized"
|
| 92 |
+
rank = get_rank()
|
| 93 |
+
cp_group_rank = rank // SEQ_PARALLEL_SIZE
|
| 94 |
+
return cp_group_rank
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def get_sequence_parallel_proc_num():
|
| 98 |
+
return SEQ_PARALLEL_PROC_NUM
|
trainer_misc/utils.py
ADDED
|
@@ -0,0 +1,382 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import io
|
| 2 |
+
import os
|
| 3 |
+
import math
|
| 4 |
+
import time
|
| 5 |
+
import json
|
| 6 |
+
import glob
|
| 7 |
+
from collections import defaultdict, deque, OrderedDict
|
| 8 |
+
import datetime
|
| 9 |
+
import numpy as np
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
from pathlib import Path
|
| 13 |
+
import argparse
|
| 14 |
+
|
| 15 |
+
import torch
|
| 16 |
+
from torch import optim as optim
|
| 17 |
+
import torch.distributed as dist
|
| 18 |
+
from tensorboardX import SummaryWriter
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def is_dist_avail_and_initialized():
|
| 22 |
+
if not dist.is_available():
|
| 23 |
+
return False
|
| 24 |
+
if not dist.is_initialized():
|
| 25 |
+
return False
|
| 26 |
+
return True
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_world_size():
|
| 30 |
+
if not is_dist_avail_and_initialized():
|
| 31 |
+
return 1
|
| 32 |
+
return dist.get_world_size()
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def get_rank():
|
| 36 |
+
if not is_dist_avail_and_initialized():
|
| 37 |
+
return 0
|
| 38 |
+
return dist.get_rank()
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def is_main_process():
|
| 42 |
+
return get_rank() == 0
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def save_on_master(*args, **kwargs):
|
| 46 |
+
if is_main_process():
|
| 47 |
+
torch.save(*args, **kwargs)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def setup_for_distributed(is_master):
|
| 51 |
+
"""
|
| 52 |
+
This function disables printing when not in master process
|
| 53 |
+
"""
|
| 54 |
+
import builtins as __builtin__
|
| 55 |
+
builtin_print = __builtin__.print
|
| 56 |
+
|
| 57 |
+
def print(*args, **kwargs):
|
| 58 |
+
force = kwargs.pop('force', False)
|
| 59 |
+
if is_master or force:
|
| 60 |
+
builtin_print(*args, **kwargs)
|
| 61 |
+
|
| 62 |
+
__builtin__.print = print
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def init_distributed_mode(args):
|
| 66 |
+
if int(os.getenv('OMPI_COMM_WORLD_SIZE', '0')) > 0:
|
| 67 |
+
rank = int(os.environ['OMPI_COMM_WORLD_RANK'])
|
| 68 |
+
local_rank = int(os.environ['OMPI_COMM_WORLD_LOCAL_RANK'])
|
| 69 |
+
world_size = int(os.environ['OMPI_COMM_WORLD_SIZE'])
|
| 70 |
+
|
| 71 |
+
os.environ["LOCAL_RANK"] = os.environ['OMPI_COMM_WORLD_LOCAL_RANK']
|
| 72 |
+
os.environ["RANK"] = os.environ['OMPI_COMM_WORLD_RANK']
|
| 73 |
+
os.environ["WORLD_SIZE"] = os.environ['OMPI_COMM_WORLD_SIZE']
|
| 74 |
+
|
| 75 |
+
args.rank = int(os.environ["RANK"])
|
| 76 |
+
args.world_size = int(os.environ["WORLD_SIZE"])
|
| 77 |
+
args.gpu = int(os.environ["LOCAL_RANK"])
|
| 78 |
+
|
| 79 |
+
elif 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
|
| 80 |
+
args.rank = int(os.environ["RANK"])
|
| 81 |
+
args.world_size = int(os.environ['WORLD_SIZE'])
|
| 82 |
+
args.gpu = int(os.environ['LOCAL_RANK'])
|
| 83 |
+
|
| 84 |
+
else:
|
| 85 |
+
print('Not using distributed mode')
|
| 86 |
+
args.distributed = False
|
| 87 |
+
return
|
| 88 |
+
|
| 89 |
+
args.distributed = True
|
| 90 |
+
args.dist_backend = 'nccl'
|
| 91 |
+
args.dist_url = "env://"
|
| 92 |
+
print('| distributed init (rank {}): {}, gpu {}'.format(
|
| 93 |
+
args.rank, args.dist_url, args.gpu), flush=True)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def cosine_scheduler(base_value, final_value, epochs, niter_per_ep, warmup_epochs=0,
|
| 97 |
+
start_warmup_value=0, warmup_steps=-1):
|
| 98 |
+
warmup_schedule = np.array([])
|
| 99 |
+
warmup_iters = warmup_epochs * niter_per_ep
|
| 100 |
+
if warmup_steps > 0:
|
| 101 |
+
warmup_iters = warmup_steps
|
| 102 |
+
print("Set warmup steps = %d" % warmup_iters)
|
| 103 |
+
if warmup_epochs > 0:
|
| 104 |
+
warmup_schedule = np.linspace(start_warmup_value, base_value, warmup_iters)
|
| 105 |
+
|
| 106 |
+
iters = np.arange(epochs * niter_per_ep - warmup_iters)
|
| 107 |
+
schedule = np.array(
|
| 108 |
+
[final_value + 0.5 * (base_value - final_value) * (1 + math.cos(math.pi * i / (len(iters)))) for i in iters])
|
| 109 |
+
|
| 110 |
+
schedule = np.concatenate((warmup_schedule, schedule))
|
| 111 |
+
|
| 112 |
+
assert len(schedule) == epochs * niter_per_ep
|
| 113 |
+
return schedule
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def constant_scheduler(base_value, epochs, niter_per_ep, warmup_epochs=0,
|
| 117 |
+
start_warmup_value=1e-6, warmup_steps=-1):
|
| 118 |
+
warmup_schedule = np.array([])
|
| 119 |
+
warmup_iters = warmup_epochs * niter_per_ep
|
| 120 |
+
if warmup_steps > 0:
|
| 121 |
+
warmup_iters = warmup_steps
|
| 122 |
+
print("Set warmup steps = %d" % warmup_iters)
|
| 123 |
+
if warmup_iters > 0:
|
| 124 |
+
warmup_schedule = np.linspace(start_warmup_value, base_value, warmup_iters)
|
| 125 |
+
|
| 126 |
+
iters = epochs * niter_per_ep - warmup_iters
|
| 127 |
+
schedule = np.array([base_value] * iters)
|
| 128 |
+
|
| 129 |
+
schedule = np.concatenate((warmup_schedule, schedule))
|
| 130 |
+
|
| 131 |
+
assert len(schedule) == epochs * niter_per_ep
|
| 132 |
+
return schedule
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def get_parameter_groups(model, weight_decay=1e-5, base_lr=1e-4, skip_list=(), get_num_layer=None, get_layer_scale=None, **kwargs):
|
| 136 |
+
parameter_group_names = {}
|
| 137 |
+
parameter_group_vars = {}
|
| 138 |
+
|
| 139 |
+
for name, param in model.named_parameters():
|
| 140 |
+
if not param.requires_grad:
|
| 141 |
+
continue # frozen weights
|
| 142 |
+
if len(kwargs.get('filter_name', [])) > 0:
|
| 143 |
+
flag = False
|
| 144 |
+
for filter_n in kwargs.get('filter_name', []):
|
| 145 |
+
if filter_n in name:
|
| 146 |
+
print(f"filter {name} because of the pattern {filter_n}")
|
| 147 |
+
flag = True
|
| 148 |
+
if flag:
|
| 149 |
+
continue
|
| 150 |
+
|
| 151 |
+
default_scale=1.
|
| 152 |
+
|
| 153 |
+
if param.ndim <= 1 or name.endswith(".bias") or name in skip_list: # param.ndim <= 1 len(param.shape) == 1
|
| 154 |
+
group_name = "no_decay"
|
| 155 |
+
this_weight_decay = 0.
|
| 156 |
+
else:
|
| 157 |
+
group_name = "decay"
|
| 158 |
+
this_weight_decay = weight_decay
|
| 159 |
+
|
| 160 |
+
if get_num_layer is not None:
|
| 161 |
+
layer_id = get_num_layer(name)
|
| 162 |
+
group_name = "layer_%d_%s" % (layer_id, group_name)
|
| 163 |
+
else:
|
| 164 |
+
layer_id = None
|
| 165 |
+
|
| 166 |
+
if group_name not in parameter_group_names:
|
| 167 |
+
if get_layer_scale is not None:
|
| 168 |
+
scale = get_layer_scale(layer_id)
|
| 169 |
+
else:
|
| 170 |
+
scale = default_scale
|
| 171 |
+
|
| 172 |
+
parameter_group_names[group_name] = {
|
| 173 |
+
"weight_decay": this_weight_decay,
|
| 174 |
+
"params": [],
|
| 175 |
+
"lr": base_lr,
|
| 176 |
+
"lr_scale": scale,
|
| 177 |
+
}
|
| 178 |
+
|
| 179 |
+
parameter_group_vars[group_name] = {
|
| 180 |
+
"weight_decay": this_weight_decay,
|
| 181 |
+
"params": [],
|
| 182 |
+
"lr": base_lr,
|
| 183 |
+
"lr_scale": scale,
|
| 184 |
+
}
|
| 185 |
+
|
| 186 |
+
parameter_group_vars[group_name]["params"].append(param)
|
| 187 |
+
parameter_group_names[group_name]["params"].append(name)
|
| 188 |
+
|
| 189 |
+
print("Param groups = %s" % json.dumps(parameter_group_names, indent=2))
|
| 190 |
+
return list(parameter_group_vars.values())
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def create_optimizer(args, model, get_num_layer=None, get_layer_scale=None, filter_bias_and_bn=True, skip_list=None, **kwargs):
|
| 194 |
+
opt_lower = args.opt.lower()
|
| 195 |
+
weight_decay = args.weight_decay
|
| 196 |
+
|
| 197 |
+
skip = {}
|
| 198 |
+
if skip_list is not None:
|
| 199 |
+
skip = skip_list
|
| 200 |
+
elif hasattr(model, 'no_weight_decay'):
|
| 201 |
+
skip = model.no_weight_decay()
|
| 202 |
+
print(f"Skip weight decay name marked in model: {skip}")
|
| 203 |
+
parameters = get_parameter_groups(model, weight_decay, args.lr, skip, get_num_layer, get_layer_scale, **kwargs)
|
| 204 |
+
weight_decay = 0.
|
| 205 |
+
|
| 206 |
+
if 'fused' in opt_lower:
|
| 207 |
+
assert has_apex and torch.cuda.is_available(), 'APEX and CUDA required for fused optimizers'
|
| 208 |
+
|
| 209 |
+
opt_args = dict(lr=args.lr, weight_decay=weight_decay)
|
| 210 |
+
if hasattr(args, 'opt_eps') and args.opt_eps is not None:
|
| 211 |
+
opt_args['eps'] = args.opt_eps
|
| 212 |
+
if hasattr(args, 'opt_beta1') and args.opt_beta1 is not None:
|
| 213 |
+
opt_args['betas'] = (args.opt_beta1, args.opt_beta2)
|
| 214 |
+
|
| 215 |
+
print('Optimizer config:', opt_args)
|
| 216 |
+
opt_split = opt_lower.split('_')
|
| 217 |
+
opt_lower = opt_split[-1]
|
| 218 |
+
if opt_lower == 'sgd' or opt_lower == 'nesterov':
|
| 219 |
+
opt_args.pop('eps', None)
|
| 220 |
+
optimizer = optim.SGD(parameters, momentum=args.momentum, nesterov=True, **opt_args)
|
| 221 |
+
elif opt_lower == 'momentum':
|
| 222 |
+
opt_args.pop('eps', None)
|
| 223 |
+
optimizer = optim.SGD(parameters, momentum=args.momentum, nesterov=False, **opt_args)
|
| 224 |
+
elif opt_lower == 'adam':
|
| 225 |
+
optimizer = optim.Adam(parameters, **opt_args)
|
| 226 |
+
elif opt_lower == 'adamw':
|
| 227 |
+
optimizer = optim.AdamW(parameters, **opt_args)
|
| 228 |
+
elif opt_lower == 'adadelta':
|
| 229 |
+
optimizer = optim.Adadelta(parameters, **opt_args)
|
| 230 |
+
elif opt_lower == 'rmsprop':
|
| 231 |
+
optimizer = optim.RMSprop(parameters, alpha=0.9, momentum=args.momentum, **opt_args)
|
| 232 |
+
else:
|
| 233 |
+
assert False and "Invalid optimizer"
|
| 234 |
+
raise ValueError
|
| 235 |
+
|
| 236 |
+
return optimizer
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
class SmoothedValue(object):
|
| 240 |
+
"""Track a series of values and provide access to smoothed values over a
|
| 241 |
+
window or the global series average.
|
| 242 |
+
"""
|
| 243 |
+
|
| 244 |
+
def __init__(self, window_size=20, fmt=None):
|
| 245 |
+
if fmt is None:
|
| 246 |
+
fmt = "{median:.4f} ({global_avg:.4f})"
|
| 247 |
+
self.deque = deque(maxlen=window_size)
|
| 248 |
+
self.total = 0.0
|
| 249 |
+
self.count = 0
|
| 250 |
+
self.fmt = fmt
|
| 251 |
+
|
| 252 |
+
def update(self, value, n=1):
|
| 253 |
+
self.deque.append(value)
|
| 254 |
+
self.count += n
|
| 255 |
+
self.total += value * n
|
| 256 |
+
|
| 257 |
+
def synchronize_between_processes(self):
|
| 258 |
+
"""
|
| 259 |
+
Warning: does not synchronize the deque!
|
| 260 |
+
"""
|
| 261 |
+
if not is_dist_avail_and_initialized():
|
| 262 |
+
return
|
| 263 |
+
t = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')
|
| 264 |
+
dist.barrier()
|
| 265 |
+
dist.all_reduce(t)
|
| 266 |
+
t = t.tolist()
|
| 267 |
+
self.count = int(t[0])
|
| 268 |
+
self.total = t[1]
|
| 269 |
+
|
| 270 |
+
@property
|
| 271 |
+
def median(self):
|
| 272 |
+
d = torch.tensor(list(self.deque))
|
| 273 |
+
return d.median().item()
|
| 274 |
+
|
| 275 |
+
@property
|
| 276 |
+
def avg(self):
|
| 277 |
+
d = torch.tensor(list(self.deque), dtype=torch.float32)
|
| 278 |
+
return d.mean().item()
|
| 279 |
+
|
| 280 |
+
@property
|
| 281 |
+
def global_avg(self):
|
| 282 |
+
return self.total / self.count
|
| 283 |
+
|
| 284 |
+
@property
|
| 285 |
+
def max(self):
|
| 286 |
+
return max(self.deque)
|
| 287 |
+
|
| 288 |
+
@property
|
| 289 |
+
def value(self):
|
| 290 |
+
return self.deque[-1]
|
| 291 |
+
|
| 292 |
+
def __str__(self):
|
| 293 |
+
return self.fmt.format(
|
| 294 |
+
median=self.median,
|
| 295 |
+
avg=self.avg,
|
| 296 |
+
global_avg=self.global_avg,
|
| 297 |
+
max=self.max,
|
| 298 |
+
value=self.value)
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class MetricLogger(object):
|
| 302 |
+
def __init__(self, delimiter="\t"):
|
| 303 |
+
self.meters = defaultdict(SmoothedValue)
|
| 304 |
+
self.delimiter = delimiter
|
| 305 |
+
|
| 306 |
+
def update(self, **kwargs):
|
| 307 |
+
for k, v in kwargs.items():
|
| 308 |
+
if v is None:
|
| 309 |
+
continue
|
| 310 |
+
if isinstance(v, torch.Tensor):
|
| 311 |
+
v = v.item()
|
| 312 |
+
assert isinstance(v, (float, int))
|
| 313 |
+
self.meters[k].update(v)
|
| 314 |
+
|
| 315 |
+
def __getattr__(self, attr):
|
| 316 |
+
if attr in self.meters:
|
| 317 |
+
return self.meters[attr]
|
| 318 |
+
if attr in self.__dict__:
|
| 319 |
+
return self.__dict__[attr]
|
| 320 |
+
raise AttributeError("'{}' object has no attribute '{}'".format(
|
| 321 |
+
type(self).__name__, attr))
|
| 322 |
+
|
| 323 |
+
def __str__(self):
|
| 324 |
+
loss_str = []
|
| 325 |
+
for name, meter in self.meters.items():
|
| 326 |
+
loss_str.append(
|
| 327 |
+
"{}: {}".format(name, str(meter))
|
| 328 |
+
)
|
| 329 |
+
return self.delimiter.join(loss_str)
|
| 330 |
+
|
| 331 |
+
def synchronize_between_processes(self):
|
| 332 |
+
for meter in self.meters.values():
|
| 333 |
+
meter.synchronize_between_processes()
|
| 334 |
+
|
| 335 |
+
def add_meter(self, name, meter):
|
| 336 |
+
self.meters[name] = meter
|
| 337 |
+
|
| 338 |
+
def log_every(self, iterable, print_freq, header=None):
|
| 339 |
+
i = 0
|
| 340 |
+
if not header:
|
| 341 |
+
header = ''
|
| 342 |
+
start_time = time.time()
|
| 343 |
+
end = time.time()
|
| 344 |
+
iter_time = SmoothedValue(fmt='{avg:.4f}')
|
| 345 |
+
data_time = SmoothedValue(fmt='{avg:.4f}')
|
| 346 |
+
space_fmt = ':' + str(len(str(len(iterable)))) + 'd'
|
| 347 |
+
log_msg = [
|
| 348 |
+
header,
|
| 349 |
+
'[{0' + space_fmt + '}/{1}]',
|
| 350 |
+
'eta: {eta}',
|
| 351 |
+
'{meters}',
|
| 352 |
+
'time: {time}',
|
| 353 |
+
'data: {data}'
|
| 354 |
+
]
|
| 355 |
+
if torch.cuda.is_available():
|
| 356 |
+
log_msg.append('max mem: {memory:.0f}')
|
| 357 |
+
log_msg = self.delimiter.join(log_msg)
|
| 358 |
+
MB = 1024.0 * 1024.0
|
| 359 |
+
for obj in iterable:
|
| 360 |
+
data_time.update(time.time() - end)
|
| 361 |
+
yield obj
|
| 362 |
+
iter_time.update(time.time() - end)
|
| 363 |
+
if i % print_freq == 0 or i == len(iterable) - 1:
|
| 364 |
+
eta_seconds = iter_time.global_avg * (len(iterable) - i)
|
| 365 |
+
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
|
| 366 |
+
if torch.cuda.is_available():
|
| 367 |
+
print(log_msg.format(
|
| 368 |
+
i, len(iterable), eta=eta_string,
|
| 369 |
+
meters=str(self),
|
| 370 |
+
time=str(iter_time), data=str(data_time),
|
| 371 |
+
memory=torch.cuda.max_memory_allocated() / MB))
|
| 372 |
+
else:
|
| 373 |
+
print(log_msg.format(
|
| 374 |
+
i, len(iterable), eta=eta_string,
|
| 375 |
+
meters=str(self),
|
| 376 |
+
time=str(iter_time), data=str(data_time)))
|
| 377 |
+
i += 1
|
| 378 |
+
end = time.time()
|
| 379 |
+
total_time = time.time() - start_time
|
| 380 |
+
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
|
| 381 |
+
print('{} Total time: {} ({:.4f} s / it)'.format(
|
| 382 |
+
header, total_time_str, total_time / len(iterable)))
|
utils.py
ADDED
|
@@ -0,0 +1,457 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import PIL.Image
|
| 4 |
+
import numpy as np
|
| 5 |
+
from torch import nn
|
| 6 |
+
import torch.distributed as dist
|
| 7 |
+
import timm.models.hub as timm_hub
|
| 8 |
+
|
| 9 |
+
"""Modified from https://github.com/CompVis/taming-transformers.git"""
|
| 10 |
+
|
| 11 |
+
import hashlib
|
| 12 |
+
import requests
|
| 13 |
+
from tqdm import tqdm
|
| 14 |
+
try:
|
| 15 |
+
import piq
|
| 16 |
+
except:
|
| 17 |
+
pass
|
| 18 |
+
|
| 19 |
+
_CONTEXT_PARALLEL_GROUP = None
|
| 20 |
+
_CONTEXT_PARALLEL_SIZE = None
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def is_dist_avail_and_initialized():
|
| 24 |
+
if not dist.is_available():
|
| 25 |
+
return False
|
| 26 |
+
if not dist.is_initialized():
|
| 27 |
+
return False
|
| 28 |
+
return True
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def get_world_size():
|
| 32 |
+
if not is_dist_avail_and_initialized():
|
| 33 |
+
return 1
|
| 34 |
+
return dist.get_world_size()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def get_rank():
|
| 38 |
+
if not is_dist_avail_and_initialized():
|
| 39 |
+
return 0
|
| 40 |
+
return dist.get_rank()
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def is_main_process():
|
| 44 |
+
return get_rank() == 0
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def is_context_parallel_initialized():
|
| 48 |
+
if _CONTEXT_PARALLEL_GROUP is None:
|
| 49 |
+
return False
|
| 50 |
+
else:
|
| 51 |
+
return True
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def set_context_parallel_group(size, group):
|
| 55 |
+
global _CONTEXT_PARALLEL_GROUP
|
| 56 |
+
global _CONTEXT_PARALLEL_SIZE
|
| 57 |
+
_CONTEXT_PARALLEL_GROUP = group
|
| 58 |
+
_CONTEXT_PARALLEL_SIZE = size
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def initialize_context_parallel(context_parallel_size):
|
| 62 |
+
global _CONTEXT_PARALLEL_GROUP
|
| 63 |
+
global _CONTEXT_PARALLEL_SIZE
|
| 64 |
+
|
| 65 |
+
assert _CONTEXT_PARALLEL_GROUP is None, "context parallel group is already initialized"
|
| 66 |
+
_CONTEXT_PARALLEL_SIZE = context_parallel_size
|
| 67 |
+
|
| 68 |
+
rank = torch.distributed.get_rank()
|
| 69 |
+
world_size = torch.distributed.get_world_size()
|
| 70 |
+
|
| 71 |
+
for i in range(0, world_size, context_parallel_size):
|
| 72 |
+
ranks = range(i, i + context_parallel_size)
|
| 73 |
+
group = torch.distributed.new_group(ranks)
|
| 74 |
+
if rank in ranks:
|
| 75 |
+
_CONTEXT_PARALLEL_GROUP = group
|
| 76 |
+
break
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def get_context_parallel_group():
|
| 80 |
+
assert _CONTEXT_PARALLEL_GROUP is not None, "context parallel group is not initialized"
|
| 81 |
+
|
| 82 |
+
return _CONTEXT_PARALLEL_GROUP
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def get_context_parallel_world_size():
|
| 86 |
+
assert _CONTEXT_PARALLEL_SIZE is not None, "context parallel size is not initialized"
|
| 87 |
+
|
| 88 |
+
return _CONTEXT_PARALLEL_SIZE
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def get_context_parallel_rank():
|
| 92 |
+
assert _CONTEXT_PARALLEL_SIZE is not None, "context parallel size is not initialized"
|
| 93 |
+
|
| 94 |
+
rank = get_rank()
|
| 95 |
+
cp_rank = rank % _CONTEXT_PARALLEL_SIZE
|
| 96 |
+
return cp_rank
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def get_context_parallel_group_rank():
|
| 100 |
+
assert _CONTEXT_PARALLEL_SIZE is not None, "context parallel size is not initialized"
|
| 101 |
+
|
| 102 |
+
rank = get_rank()
|
| 103 |
+
cp_group_rank = rank // _CONTEXT_PARALLEL_SIZE
|
| 104 |
+
|
| 105 |
+
return cp_group_rank
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def download_cached_file(url, check_hash=True, progress=False):
|
| 109 |
+
"""
|
| 110 |
+
Download a file from a URL and cache it locally. If the file already exists, it is not downloaded again.
|
| 111 |
+
If distributed, only the main process downloads the file, and the other processes wait for the file to be downloaded.
|
| 112 |
+
"""
|
| 113 |
+
|
| 114 |
+
def get_cached_file_path():
|
| 115 |
+
# a hack to sync the file path across processes
|
| 116 |
+
parts = torch.hub.urlparse(url)
|
| 117 |
+
filename = os.path.basename(parts.path)
|
| 118 |
+
cached_file = os.path.join(timm_hub.get_cache_dir(), filename)
|
| 119 |
+
|
| 120 |
+
return cached_file
|
| 121 |
+
|
| 122 |
+
if is_main_process():
|
| 123 |
+
timm_hub.download_cached_file(url, check_hash, progress)
|
| 124 |
+
|
| 125 |
+
if is_dist_avail_and_initialized():
|
| 126 |
+
dist.barrier()
|
| 127 |
+
|
| 128 |
+
return get_cached_file_path()
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def convert_weights_to_fp16(model: nn.Module):
|
| 132 |
+
"""Convert applicable model parameters to fp16"""
|
| 133 |
+
|
| 134 |
+
def _convert_weights_to_fp16(l):
|
| 135 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d, nn.Linear)):
|
| 136 |
+
l.weight.data = l.weight.data.to(torch.float16)
|
| 137 |
+
if l.bias is not None:
|
| 138 |
+
l.bias.data = l.bias.data.to(torch.float16)
|
| 139 |
+
|
| 140 |
+
model.apply(_convert_weights_to_fp16)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def convert_weights_to_bf16(model: nn.Module):
|
| 144 |
+
"""Convert applicable model parameters to fp16"""
|
| 145 |
+
|
| 146 |
+
def _convert_weights_to_bf16(l):
|
| 147 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d, nn.Linear)):
|
| 148 |
+
l.weight.data = l.weight.data.to(torch.bfloat16)
|
| 149 |
+
if l.bias is not None:
|
| 150 |
+
l.bias.data = l.bias.data.to(torch.bfloat16)
|
| 151 |
+
|
| 152 |
+
model.apply(_convert_weights_to_bf16)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def save_result(result, result_dir, filename, remove_duplicate="", save_format='json'):
|
| 156 |
+
import json
|
| 157 |
+
import jsonlines
|
| 158 |
+
print("Dump result")
|
| 159 |
+
|
| 160 |
+
# Make the temp dir for saving results
|
| 161 |
+
if not os.path.exists(result_dir):
|
| 162 |
+
if is_main_process():
|
| 163 |
+
os.makedirs(result_dir)
|
| 164 |
+
if is_dist_avail_and_initialized():
|
| 165 |
+
torch.distributed.barrier()
|
| 166 |
+
|
| 167 |
+
result_file = os.path.join(
|
| 168 |
+
result_dir, "%s_rank%d.json" % (filename, get_rank())
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
final_result_file = os.path.join(result_dir, f"{filename}.{save_format}")
|
| 172 |
+
|
| 173 |
+
json.dump(result, open(result_file, "w"))
|
| 174 |
+
|
| 175 |
+
if is_dist_avail_and_initialized():
|
| 176 |
+
torch.distributed.barrier()
|
| 177 |
+
|
| 178 |
+
if is_main_process():
|
| 179 |
+
# print("rank %d starts merging results." % get_rank())
|
| 180 |
+
# combine results from all processes
|
| 181 |
+
result = []
|
| 182 |
+
|
| 183 |
+
for rank in range(get_world_size()):
|
| 184 |
+
result_file = os.path.join(result_dir, "%s_rank%d.json" % (filename, rank))
|
| 185 |
+
res = json.load(open(result_file, "r"))
|
| 186 |
+
result += res
|
| 187 |
+
|
| 188 |
+
# print("Remove duplicate")
|
| 189 |
+
if remove_duplicate:
|
| 190 |
+
result_new = []
|
| 191 |
+
id_set = set()
|
| 192 |
+
for res in result:
|
| 193 |
+
if res[remove_duplicate] not in id_set:
|
| 194 |
+
id_set.add(res[remove_duplicate])
|
| 195 |
+
result_new.append(res)
|
| 196 |
+
result = result_new
|
| 197 |
+
|
| 198 |
+
if save_format == 'json':
|
| 199 |
+
json.dump(result, open(final_result_file, "w"))
|
| 200 |
+
else:
|
| 201 |
+
assert save_format == 'jsonl', "Only support json adn jsonl format"
|
| 202 |
+
with jsonlines.open(final_result_file, "w") as writer:
|
| 203 |
+
writer.write_all(result)
|
| 204 |
+
|
| 205 |
+
# print("result file saved to %s" % final_result_file)
|
| 206 |
+
|
| 207 |
+
return final_result_file
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
# resizing utils
|
| 211 |
+
# TODO: clean up later
|
| 212 |
+
def _resize_with_antialiasing(input, size, interpolation="bicubic", align_corners=True):
|
| 213 |
+
h, w = input.shape[-2:]
|
| 214 |
+
factors = (h / size[0], w / size[1])
|
| 215 |
+
|
| 216 |
+
# First, we have to determine sigma
|
| 217 |
+
# Taken from skimage: https://github.com/scikit-image/scikit-image/blob/v0.19.2/skimage/transform/_warps.py#L171
|
| 218 |
+
sigmas = (
|
| 219 |
+
max((factors[0] - 1.0) / 2.0, 0.001),
|
| 220 |
+
max((factors[1] - 1.0) / 2.0, 0.001),
|
| 221 |
+
)
|
| 222 |
+
|
| 223 |
+
# Now kernel size. Good results are for 3 sigma, but that is kind of slow. Pillow uses 1 sigma
|
| 224 |
+
# https://github.com/python-pillow/Pillow/blob/master/src/libImaging/Resample.c#L206
|
| 225 |
+
# But they do it in the 2 passes, which gives better results. Let's try 2 sigmas for now
|
| 226 |
+
ks = int(max(2.0 * 2 * sigmas[0], 3)), int(max(2.0 * 2 * sigmas[1], 3))
|
| 227 |
+
|
| 228 |
+
# Make sure it is odd
|
| 229 |
+
if (ks[0] % 2) == 0:
|
| 230 |
+
ks = ks[0] + 1, ks[1]
|
| 231 |
+
|
| 232 |
+
if (ks[1] % 2) == 0:
|
| 233 |
+
ks = ks[0], ks[1] + 1
|
| 234 |
+
|
| 235 |
+
input = _gaussian_blur2d(input, ks, sigmas)
|
| 236 |
+
|
| 237 |
+
output = torch.nn.functional.interpolate(input, size=size, mode=interpolation, align_corners=align_corners)
|
| 238 |
+
return output
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def _compute_padding(kernel_size):
|
| 242 |
+
"""Compute padding tuple."""
|
| 243 |
+
# 4 or 6 ints: (padding_left, padding_right,padding_top,padding_bottom)
|
| 244 |
+
# https://pytorch.org/docs/stable/nn.html#torch.nn.functional.pad
|
| 245 |
+
if len(kernel_size) < 2:
|
| 246 |
+
raise AssertionError(kernel_size)
|
| 247 |
+
computed = [k - 1 for k in kernel_size]
|
| 248 |
+
|
| 249 |
+
# for even kernels we need to do asymmetric padding :(
|
| 250 |
+
out_padding = 2 * len(kernel_size) * [0]
|
| 251 |
+
|
| 252 |
+
for i in range(len(kernel_size)):
|
| 253 |
+
computed_tmp = computed[-(i + 1)]
|
| 254 |
+
|
| 255 |
+
pad_front = computed_tmp // 2
|
| 256 |
+
pad_rear = computed_tmp - pad_front
|
| 257 |
+
|
| 258 |
+
out_padding[2 * i + 0] = pad_front
|
| 259 |
+
out_padding[2 * i + 1] = pad_rear
|
| 260 |
+
|
| 261 |
+
return out_padding
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def _filter2d(input, kernel):
|
| 265 |
+
# prepare kernel
|
| 266 |
+
b, c, h, w = input.shape
|
| 267 |
+
tmp_kernel = kernel[:, None, ...].to(device=input.device, dtype=input.dtype)
|
| 268 |
+
|
| 269 |
+
tmp_kernel = tmp_kernel.expand(-1, c, -1, -1)
|
| 270 |
+
|
| 271 |
+
height, width = tmp_kernel.shape[-2:]
|
| 272 |
+
|
| 273 |
+
padding_shape: list[int] = _compute_padding([height, width])
|
| 274 |
+
input = torch.nn.functional.pad(input, padding_shape, mode="reflect")
|
| 275 |
+
|
| 276 |
+
# kernel and input tensor reshape to align element-wise or batch-wise params
|
| 277 |
+
tmp_kernel = tmp_kernel.reshape(-1, 1, height, width)
|
| 278 |
+
input = input.view(-1, tmp_kernel.size(0), input.size(-2), input.size(-1))
|
| 279 |
+
|
| 280 |
+
# convolve the tensor with the kernel.
|
| 281 |
+
output = torch.nn.functional.conv2d(input, tmp_kernel, groups=tmp_kernel.size(0), padding=0, stride=1)
|
| 282 |
+
|
| 283 |
+
out = output.view(b, c, h, w)
|
| 284 |
+
return out
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
def _gaussian(window_size: int, sigma):
|
| 288 |
+
if isinstance(sigma, float):
|
| 289 |
+
sigma = torch.tensor([[sigma]])
|
| 290 |
+
|
| 291 |
+
batch_size = sigma.shape[0]
|
| 292 |
+
|
| 293 |
+
x = (torch.arange(window_size, device=sigma.device, dtype=sigma.dtype) - window_size // 2).expand(batch_size, -1)
|
| 294 |
+
|
| 295 |
+
if window_size % 2 == 0:
|
| 296 |
+
x = x + 0.5
|
| 297 |
+
|
| 298 |
+
gauss = torch.exp(-x.pow(2.0) / (2 * sigma.pow(2.0)))
|
| 299 |
+
|
| 300 |
+
return gauss / gauss.sum(-1, keepdim=True)
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def _gaussian_blur2d(input, kernel_size, sigma):
|
| 304 |
+
if isinstance(sigma, tuple):
|
| 305 |
+
sigma = torch.tensor([sigma], dtype=input.dtype)
|
| 306 |
+
else:
|
| 307 |
+
sigma = sigma.to(dtype=input.dtype)
|
| 308 |
+
|
| 309 |
+
ky, kx = int(kernel_size[0]), int(kernel_size[1])
|
| 310 |
+
bs = sigma.shape[0]
|
| 311 |
+
kernel_x = _gaussian(kx, sigma[:, 1].view(bs, 1))
|
| 312 |
+
kernel_y = _gaussian(ky, sigma[:, 0].view(bs, 1))
|
| 313 |
+
out_x = _filter2d(input, kernel_x[..., None, :])
|
| 314 |
+
out = _filter2d(out_x, kernel_y[..., None])
|
| 315 |
+
|
| 316 |
+
return out
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
URL_MAP = {
|
| 320 |
+
"vgg_lpips": "https://heibox.uni-heidelberg.de/f/607503859c864bc1b30b/?dl=1"
|
| 321 |
+
}
|
| 322 |
+
|
| 323 |
+
CKPT_MAP = {
|
| 324 |
+
"vgg_lpips": "vgg.pth"
|
| 325 |
+
}
|
| 326 |
+
|
| 327 |
+
MD5_MAP = {
|
| 328 |
+
"vgg_lpips": "d507d7349b931f0638a25a48a722f98a"
|
| 329 |
+
}
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
def download(url, local_path, chunk_size=1024):
|
| 333 |
+
os.makedirs(os.path.split(local_path)[0], exist_ok=True)
|
| 334 |
+
with requests.get(url, stream=True) as r:
|
| 335 |
+
total_size = int(r.headers.get("content-length", 0))
|
| 336 |
+
with tqdm(total=total_size, unit="B", unit_scale=True) as pbar:
|
| 337 |
+
with open(local_path, "wb") as f:
|
| 338 |
+
for data in r.iter_content(chunk_size=chunk_size):
|
| 339 |
+
if data:
|
| 340 |
+
f.write(data)
|
| 341 |
+
pbar.update(chunk_size)
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
def md5_hash(path):
|
| 345 |
+
with open(path, "rb") as f:
|
| 346 |
+
content = f.read()
|
| 347 |
+
return hashlib.md5(content).hexdigest()
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
def get_ckpt_path(name, root, check=False):
|
| 351 |
+
assert name in URL_MAP
|
| 352 |
+
path = os.path.join(root, CKPT_MAP[name])
|
| 353 |
+
print(md5_hash(path))
|
| 354 |
+
if not os.path.exists(path) or (check and not md5_hash(path) == MD5_MAP[name]):
|
| 355 |
+
print("Downloading {} model from {} to {}".format(name, URL_MAP[name], path))
|
| 356 |
+
download(URL_MAP[name], path)
|
| 357 |
+
md5 = md5_hash(path)
|
| 358 |
+
assert md5 == MD5_MAP[name], md5
|
| 359 |
+
return path
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
class KeyNotFoundError(Exception):
|
| 363 |
+
def __init__(self, cause, keys=None, visited=None):
|
| 364 |
+
self.cause = cause
|
| 365 |
+
self.keys = keys
|
| 366 |
+
self.visited = visited
|
| 367 |
+
messages = list()
|
| 368 |
+
if keys is not None:
|
| 369 |
+
messages.append("Key not found: {}".format(keys))
|
| 370 |
+
if visited is not None:
|
| 371 |
+
messages.append("Visited: {}".format(visited))
|
| 372 |
+
messages.append("Cause:\n{}".format(cause))
|
| 373 |
+
message = "\n".join(messages)
|
| 374 |
+
super().__init__(message)
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
def retrieve(
|
| 378 |
+
list_or_dict, key, splitval="/", default=None, expand=True, pass_success=False
|
| 379 |
+
):
|
| 380 |
+
"""Given a nested list or dict return the desired value at key expanding
|
| 381 |
+
callable nodes if necessary and :attr:`expand` is ``True``. The expansion
|
| 382 |
+
is done in-place.
|
| 383 |
+
|
| 384 |
+
Parameters
|
| 385 |
+
----------
|
| 386 |
+
list_or_dict : list or dict
|
| 387 |
+
Possibly nested list or dictionary.
|
| 388 |
+
key : str
|
| 389 |
+
key/to/value, path like string describing all keys necessary to
|
| 390 |
+
consider to get to the desired value. List indices can also be
|
| 391 |
+
passed here.
|
| 392 |
+
splitval : str
|
| 393 |
+
String that defines the delimiter between keys of the
|
| 394 |
+
different depth levels in `key`.
|
| 395 |
+
default : obj
|
| 396 |
+
Value returned if :attr:`key` is not found.
|
| 397 |
+
expand : bool
|
| 398 |
+
Whether to expand callable nodes on the path or not.
|
| 399 |
+
|
| 400 |
+
Returns
|
| 401 |
+
-------
|
| 402 |
+
The desired value or if :attr:`default` is not ``None`` and the
|
| 403 |
+
:attr:`key` is not found returns ``default``.
|
| 404 |
+
|
| 405 |
+
Raises
|
| 406 |
+
------
|
| 407 |
+
Exception if ``key`` not in ``list_or_dict`` and :attr:`default` is
|
| 408 |
+
``None``.
|
| 409 |
+
"""
|
| 410 |
+
|
| 411 |
+
keys = key.split(splitval)
|
| 412 |
+
|
| 413 |
+
success = True
|
| 414 |
+
try:
|
| 415 |
+
visited = []
|
| 416 |
+
parent = None
|
| 417 |
+
last_key = None
|
| 418 |
+
for key in keys:
|
| 419 |
+
if callable(list_or_dict):
|
| 420 |
+
if not expand:
|
| 421 |
+
raise KeyNotFoundError(
|
| 422 |
+
ValueError(
|
| 423 |
+
"Trying to get past callable node with expand=False."
|
| 424 |
+
),
|
| 425 |
+
keys=keys,
|
| 426 |
+
visited=visited,
|
| 427 |
+
)
|
| 428 |
+
list_or_dict = list_or_dict()
|
| 429 |
+
parent[last_key] = list_or_dict
|
| 430 |
+
|
| 431 |
+
last_key = key
|
| 432 |
+
parent = list_or_dict
|
| 433 |
+
|
| 434 |
+
try:
|
| 435 |
+
if isinstance(list_or_dict, dict):
|
| 436 |
+
list_or_dict = list_or_dict[key]
|
| 437 |
+
else:
|
| 438 |
+
list_or_dict = list_or_dict[int(key)]
|
| 439 |
+
except (KeyError, IndexError, ValueError) as e:
|
| 440 |
+
raise KeyNotFoundError(e, keys=keys, visited=visited)
|
| 441 |
+
|
| 442 |
+
visited += [key]
|
| 443 |
+
# final expansion of retrieved value
|
| 444 |
+
if expand and callable(list_or_dict):
|
| 445 |
+
list_or_dict = list_or_dict()
|
| 446 |
+
parent[last_key] = list_or_dict
|
| 447 |
+
except KeyNotFoundError as e:
|
| 448 |
+
if default is None:
|
| 449 |
+
raise e
|
| 450 |
+
else:
|
| 451 |
+
list_or_dict = default
|
| 452 |
+
success = False
|
| 453 |
+
|
| 454 |
+
if not pass_success:
|
| 455 |
+
return list_or_dict
|
| 456 |
+
else:
|
| 457 |
+
return list_or_dict, success
|
video_generation_demo.ipynb
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import os\n",
|
| 10 |
+
"import json\n",
|
| 11 |
+
"import torch\n",
|
| 12 |
+
"import numpy as np\n",
|
| 13 |
+
"import PIL\n",
|
| 14 |
+
"from PIL import Image\n",
|
| 15 |
+
"from IPython.display import HTML\n",
|
| 16 |
+
"from pyramid_dit import PyramidDiTForVideoGeneration\n",
|
| 17 |
+
"from IPython.display import Image as ipython_image\n",
|
| 18 |
+
"from diffusers.utils import load_image, export_to_video, export_to_gif"
|
| 19 |
+
]
|
| 20 |
+
},
|
| 21 |
+
{
|
| 22 |
+
"cell_type": "code",
|
| 23 |
+
"execution_count": null,
|
| 24 |
+
"metadata": {},
|
| 25 |
+
"outputs": [],
|
| 26 |
+
"source": [
|
| 27 |
+
"variant='diffusion_transformer_768p' # For high resolution\n",
|
| 28 |
+
"# variant='diffusion_transformer_384p' # For low resolution\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"model_path = \"/home/jinyang06/models/pyramid-flow\" # The downloaded checkpoint dir\n",
|
| 31 |
+
"model_dtype = 'bf16'\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"device_id = 0\n",
|
| 34 |
+
"torch.cuda.set_device(device_id)\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"model = PyramidDiTForVideoGeneration(\n",
|
| 37 |
+
" model_path,\n",
|
| 38 |
+
" model_dtype,\n",
|
| 39 |
+
" model_variant=variant,\n",
|
| 40 |
+
")\n",
|
| 41 |
+
"\n",
|
| 42 |
+
"model.vae.to(\"cuda\")\n",
|
| 43 |
+
"model.dit.to(\"cuda\")\n",
|
| 44 |
+
"model.text_encoder.to(\"cuda\")\\\n",
|
| 45 |
+
"\n",
|
| 46 |
+
"if model_dtype == \"bf16\":\n",
|
| 47 |
+
" torch_dtype = torch.bfloat16 \n",
|
| 48 |
+
"elif model_dtype == \"fp16\":\n",
|
| 49 |
+
" torch_dtype = torch.float16\n",
|
| 50 |
+
"else:\n",
|
| 51 |
+
" torch_dtype = torch.float32\n",
|
| 52 |
+
"\n",
|
| 53 |
+
"\n",
|
| 54 |
+
"def show_video(ori_path, rec_path, width=\"100%\"):\n",
|
| 55 |
+
" html = ''\n",
|
| 56 |
+
" if ori_path is not None:\n",
|
| 57 |
+
" html += f\"\"\"<video controls=\"\" name=\"media\" data-fullscreen-container=\"true\" width=\"{width}\">\n",
|
| 58 |
+
" <source src=\"{ori_path}\" type=\"video/mp4\">\n",
|
| 59 |
+
" </video>\n",
|
| 60 |
+
" \"\"\"\n",
|
| 61 |
+
" \n",
|
| 62 |
+
" html += f\"\"\"<video controls=\"\" name=\"media\" data-fullscreen-container=\"true\" width=\"{width}\">\n",
|
| 63 |
+
" <source src=\"{rec_path}\" type=\"video/mp4\">\n",
|
| 64 |
+
" </video>\n",
|
| 65 |
+
" \"\"\"\n",
|
| 66 |
+
" return HTML(html)"
|
| 67 |
+
]
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"attachments": {},
|
| 71 |
+
"cell_type": "markdown",
|
| 72 |
+
"metadata": {},
|
| 73 |
+
"source": [
|
| 74 |
+
"#### Text-to-Video"
|
| 75 |
+
]
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"cell_type": "code",
|
| 79 |
+
"execution_count": null,
|
| 80 |
+
"metadata": {},
|
| 81 |
+
"outputs": [],
|
| 82 |
+
"source": [
|
| 83 |
+
"prompt = \"A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors\"\n",
|
| 84 |
+
"\n",
|
| 85 |
+
"# used for 384p model variant\n",
|
| 86 |
+
"# width = 640\n",
|
| 87 |
+
"# height = 384\n",
|
| 88 |
+
"\n",
|
| 89 |
+
"# used for 768p model variant\n",
|
| 90 |
+
"width = 1280\n",
|
| 91 |
+
"height = 768\n",
|
| 92 |
+
"\n",
|
| 93 |
+
"temp = 16 # temp in [1, 31] <=> frame in [1, 241] <=> duration in [0, 10s]\n",
|
| 94 |
+
"\n",
|
| 95 |
+
"model.vae.enable_tiling()\n",
|
| 96 |
+
"\n",
|
| 97 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):\n",
|
| 98 |
+
" frames = model.generate(\n",
|
| 99 |
+
" prompt=prompt,\n",
|
| 100 |
+
" num_inference_steps=[20, 20, 20],\n",
|
| 101 |
+
" video_num_inference_steps=[10, 10, 10],\n",
|
| 102 |
+
" height=height,\n",
|
| 103 |
+
" width=width,\n",
|
| 104 |
+
" temp=temp,\n",
|
| 105 |
+
" guidance_scale=9.0, # The guidance for the first frame\n",
|
| 106 |
+
" video_guidance_scale=5.0, # The guidance for the other video latent\n",
|
| 107 |
+
" output_type=\"pil\",\n",
|
| 108 |
+
" )\n",
|
| 109 |
+
"\n",
|
| 110 |
+
"export_to_video(frames, \"./text_to_video_sample.mp4\", fps=24)\n",
|
| 111 |
+
"show_video(None, \"./text_to_video_sample.mp4\", \"70%\")"
|
| 112 |
+
]
|
| 113 |
+
},
|
| 114 |
+
{
|
| 115 |
+
"attachments": {},
|
| 116 |
+
"cell_type": "markdown",
|
| 117 |
+
"metadata": {},
|
| 118 |
+
"source": [
|
| 119 |
+
"#### Image-to-Video"
|
| 120 |
+
]
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"cell_type": "code",
|
| 124 |
+
"execution_count": null,
|
| 125 |
+
"metadata": {},
|
| 126 |
+
"outputs": [],
|
| 127 |
+
"source": [
|
| 128 |
+
"image_path = 'assets/the_great_wall.jpg'\n",
|
| 129 |
+
"image = Image.open(image_path).convert(\"RGB\")\n",
|
| 130 |
+
"\n",
|
| 131 |
+
"width = 1280\n",
|
| 132 |
+
"height = 768\n",
|
| 133 |
+
"temp = 16\n",
|
| 134 |
+
"\n",
|
| 135 |
+
"image = image.resize((width, height))\n",
|
| 136 |
+
"\n",
|
| 137 |
+
"display(image)\n",
|
| 138 |
+
"\n",
|
| 139 |
+
"prompt = \"FPV flying over the Great Wall\"\n",
|
| 140 |
+
"\n",
|
| 141 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):\n",
|
| 142 |
+
" frames = model.generate_i2v(\n",
|
| 143 |
+
" prompt=prompt,\n",
|
| 144 |
+
" input_image=image,\n",
|
| 145 |
+
" num_inference_steps=[10, 10, 10],\n",
|
| 146 |
+
" temp=temp,\n",
|
| 147 |
+
" guidance_scale=7.0,\n",
|
| 148 |
+
" video_guidance_scale=4.0,\n",
|
| 149 |
+
" output_type=\"pil\",\n",
|
| 150 |
+
" )\n",
|
| 151 |
+
"\n",
|
| 152 |
+
"export_to_video(frames, \"./image_to_video_sample.mp4\", fps=24)\n",
|
| 153 |
+
"show_video(None, \"./image_to_video_sample.mp4\", \"70%\")"
|
| 154 |
+
]
|
| 155 |
+
}
|
| 156 |
+
],
|
| 157 |
+
"metadata": {
|
| 158 |
+
"kernelspec": {
|
| 159 |
+
"display_name": "Python 3",
|
| 160 |
+
"language": "python",
|
| 161 |
+
"name": "python3"
|
| 162 |
+
},
|
| 163 |
+
"language_info": {
|
| 164 |
+
"codemirror_mode": {
|
| 165 |
+
"name": "ipython",
|
| 166 |
+
"version": 3
|
| 167 |
+
},
|
| 168 |
+
"file_extension": ".py",
|
| 169 |
+
"mimetype": "text/x-python",
|
| 170 |
+
"name": "python",
|
| 171 |
+
"nbconvert_exporter": "python",
|
| 172 |
+
"pygments_lexer": "ipython3",
|
| 173 |
+
"version": "3.8.10"
|
| 174 |
+
},
|
| 175 |
+
"orig_nbformat": 4
|
| 176 |
+
},
|
| 177 |
+
"nbformat": 4,
|
| 178 |
+
"nbformat_minor": 2
|
| 179 |
+
}
|
video_vae/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .modeling_loss import LPIPSWithDiscriminator
|
| 2 |
+
from .modeling_causal_vae import CausalVideoVAE
|
video_vae/context_parallel_ops.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# from cogvideoX
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
from utils import (
|
| 7 |
+
get_context_parallel_group,
|
| 8 |
+
get_context_parallel_rank,
|
| 9 |
+
get_context_parallel_world_size,
|
| 10 |
+
get_context_parallel_group_rank,
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def _conv_split(input_, dim=2, kernel_size=1):
|
| 15 |
+
cp_world_size = get_context_parallel_world_size()
|
| 16 |
+
|
| 17 |
+
# Bypass the function if context parallel is 1
|
| 18 |
+
if cp_world_size == 1:
|
| 19 |
+
return input_
|
| 20 |
+
|
| 21 |
+
# print('in _conv_split, cp_rank:', cp_rank, 'input_size:', input_.shape)
|
| 22 |
+
|
| 23 |
+
cp_rank = get_context_parallel_rank()
|
| 24 |
+
|
| 25 |
+
dim_size = (input_.size()[dim] - kernel_size) // cp_world_size
|
| 26 |
+
|
| 27 |
+
if cp_rank == 0:
|
| 28 |
+
output = input_.transpose(dim, 0)[: dim_size + kernel_size].transpose(dim, 0)
|
| 29 |
+
else:
|
| 30 |
+
# output = input_.transpose(dim, 0)[cp_rank * dim_size + 1:(cp_rank + 1) * dim_size + kernel_size].transpose(dim, 0)
|
| 31 |
+
output = input_.transpose(dim, 0)[
|
| 32 |
+
cp_rank * dim_size + kernel_size : (cp_rank + 1) * dim_size + kernel_size
|
| 33 |
+
].transpose(dim, 0)
|
| 34 |
+
output = output.contiguous()
|
| 35 |
+
|
| 36 |
+
# print('out _conv_split, cp_rank:', cp_rank, 'input_size:', output.shape)
|
| 37 |
+
|
| 38 |
+
return output
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def _conv_gather(input_, dim=2, kernel_size=1):
|
| 42 |
+
cp_world_size = get_context_parallel_world_size()
|
| 43 |
+
|
| 44 |
+
# Bypass the function if context parallel is 1
|
| 45 |
+
if cp_world_size == 1:
|
| 46 |
+
return input_
|
| 47 |
+
|
| 48 |
+
group = get_context_parallel_group()
|
| 49 |
+
cp_rank = get_context_parallel_rank()
|
| 50 |
+
|
| 51 |
+
# print('in _conv_gather, cp_rank:', cp_rank, 'input_size:', input_.shape)
|
| 52 |
+
|
| 53 |
+
input_first_kernel_ = input_.transpose(0, dim)[:kernel_size].transpose(0, dim).contiguous()
|
| 54 |
+
if cp_rank == 0:
|
| 55 |
+
input_ = input_.transpose(0, dim)[kernel_size:].transpose(0, dim).contiguous()
|
| 56 |
+
else:
|
| 57 |
+
input_ = input_.transpose(0, dim)[max(kernel_size - 1, 0) :].transpose(0, dim).contiguous()
|
| 58 |
+
|
| 59 |
+
tensor_list = [torch.empty_like(torch.cat([input_first_kernel_, input_], dim=dim))] + [
|
| 60 |
+
torch.empty_like(input_) for _ in range(cp_world_size - 1)
|
| 61 |
+
]
|
| 62 |
+
if cp_rank == 0:
|
| 63 |
+
input_ = torch.cat([input_first_kernel_, input_], dim=dim)
|
| 64 |
+
|
| 65 |
+
tensor_list[cp_rank] = input_
|
| 66 |
+
torch.distributed.all_gather(tensor_list, input_, group=group)
|
| 67 |
+
|
| 68 |
+
# Note: torch.cat already creates a contiguous tensor.
|
| 69 |
+
output = torch.cat(tensor_list, dim=dim).contiguous()
|
| 70 |
+
|
| 71 |
+
# print('out _conv_gather, cp_rank:', cp_rank, 'input_size:', output.shape)
|
| 72 |
+
|
| 73 |
+
return output
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def _cp_pass_from_previous_rank(input_, dim, kernel_size):
|
| 77 |
+
# Bypass the function if kernel size is 1
|
| 78 |
+
if kernel_size == 1:
|
| 79 |
+
return input_
|
| 80 |
+
|
| 81 |
+
group = get_context_parallel_group()
|
| 82 |
+
cp_rank = get_context_parallel_rank()
|
| 83 |
+
cp_group_rank = get_context_parallel_group_rank()
|
| 84 |
+
cp_world_size = get_context_parallel_world_size()
|
| 85 |
+
|
| 86 |
+
# print('in _pass_from_previous_rank, cp_rank:', cp_rank, 'input_size:', input_.shape)
|
| 87 |
+
|
| 88 |
+
global_rank = torch.distributed.get_rank()
|
| 89 |
+
global_world_size = torch.distributed.get_world_size()
|
| 90 |
+
|
| 91 |
+
input_ = input_.transpose(0, dim)
|
| 92 |
+
|
| 93 |
+
# pass from last rank
|
| 94 |
+
send_rank = global_rank + 1
|
| 95 |
+
recv_rank = global_rank - 1
|
| 96 |
+
if send_rank % cp_world_size == 0:
|
| 97 |
+
send_rank -= cp_world_size
|
| 98 |
+
if recv_rank % cp_world_size == cp_world_size - 1:
|
| 99 |
+
recv_rank += cp_world_size
|
| 100 |
+
|
| 101 |
+
recv_buffer = torch.empty_like(input_[-kernel_size + 1 :]).contiguous()
|
| 102 |
+
if cp_rank < cp_world_size - 1:
|
| 103 |
+
req_send = torch.distributed.isend(input_[-kernel_size + 1 :].contiguous(), send_rank, group=group)
|
| 104 |
+
if cp_rank > 0:
|
| 105 |
+
req_recv = torch.distributed.irecv(recv_buffer, recv_rank, group=group)
|
| 106 |
+
|
| 107 |
+
if cp_rank == 0:
|
| 108 |
+
input_ = torch.cat([torch.zeros_like(input_[:1])] * (kernel_size - 1) + [input_], dim=0)
|
| 109 |
+
else:
|
| 110 |
+
req_recv.wait()
|
| 111 |
+
input_ = torch.cat([recv_buffer, input_], dim=0)
|
| 112 |
+
|
| 113 |
+
input_ = input_.transpose(0, dim).contiguous()
|
| 114 |
+
return input_
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def _drop_from_previous_rank(input_, dim, kernel_size):
|
| 118 |
+
input_ = input_.transpose(0, dim)[kernel_size - 1 :].transpose(0, dim)
|
| 119 |
+
return input_
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
class _ConvolutionScatterToContextParallelRegion(torch.autograd.Function):
|
| 123 |
+
@staticmethod
|
| 124 |
+
def forward(ctx, input_, dim, kernel_size):
|
| 125 |
+
ctx.dim = dim
|
| 126 |
+
ctx.kernel_size = kernel_size
|
| 127 |
+
return _conv_split(input_, dim, kernel_size)
|
| 128 |
+
|
| 129 |
+
@staticmethod
|
| 130 |
+
def backward(ctx, grad_output):
|
| 131 |
+
return _conv_gather(grad_output, ctx.dim, ctx.kernel_size), None, None
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
class _ConvolutionGatherFromContextParallelRegion(torch.autograd.Function):
|
| 135 |
+
@staticmethod
|
| 136 |
+
def forward(ctx, input_, dim, kernel_size):
|
| 137 |
+
ctx.dim = dim
|
| 138 |
+
ctx.kernel_size = kernel_size
|
| 139 |
+
return _conv_gather(input_, dim, kernel_size)
|
| 140 |
+
|
| 141 |
+
@staticmethod
|
| 142 |
+
def backward(ctx, grad_output):
|
| 143 |
+
return _conv_split(grad_output, ctx.dim, ctx.kernel_size), None, None
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
class _CPConvolutionPassFromPreviousRank(torch.autograd.Function):
|
| 147 |
+
@staticmethod
|
| 148 |
+
def forward(ctx, input_, dim, kernel_size):
|
| 149 |
+
ctx.dim = dim
|
| 150 |
+
ctx.kernel_size = kernel_size
|
| 151 |
+
return _cp_pass_from_previous_rank(input_, dim, kernel_size)
|
| 152 |
+
|
| 153 |
+
@staticmethod
|
| 154 |
+
def backward(ctx, grad_output):
|
| 155 |
+
return _drop_from_previous_rank(grad_output, ctx.dim, ctx.kernel_size), None, None
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def conv_scatter_to_context_parallel_region(input_, dim, kernel_size):
|
| 159 |
+
return _ConvolutionScatterToContextParallelRegion.apply(input_, dim, kernel_size)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def conv_gather_from_context_parallel_region(input_, dim, kernel_size):
|
| 163 |
+
return _ConvolutionGatherFromContextParallelRegion.apply(input_, dim, kernel_size)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def cp_pass_from_previous_rank(input_, dim, kernel_size):
|
| 167 |
+
return _CPConvolutionPassFromPreviousRank.apply(input_, dim, kernel_size)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
|
video_vae/modeling_block.py
ADDED
|
@@ -0,0 +1,760 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from typing import Any, Dict, Optional, Tuple, Union
|
| 15 |
+
|
| 16 |
+
import numpy as np
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn.functional as F
|
| 19 |
+
from torch import nn
|
| 20 |
+
from einops import rearrange
|
| 21 |
+
|
| 22 |
+
from diffusers.utils import logging
|
| 23 |
+
from diffusers.models.attention_processor import Attention
|
| 24 |
+
from .modeling_resnet import (
|
| 25 |
+
Downsample2D, ResnetBlock2D, CausalResnetBlock3D, Upsample2D,
|
| 26 |
+
TemporalDownsample2x, TemporalUpsample2x,
|
| 27 |
+
CausalDownsample2x, CausalTemporalDownsample2x,
|
| 28 |
+
CausalUpsample2x, CausalTemporalUpsample2x,
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_input_layer(
|
| 35 |
+
in_channels: int,
|
| 36 |
+
out_channels: int,
|
| 37 |
+
norm_num_groups: int,
|
| 38 |
+
layer_type: str,
|
| 39 |
+
norm_type: str = 'group',
|
| 40 |
+
affine: bool = True,
|
| 41 |
+
):
|
| 42 |
+
if layer_type == 'conv':
|
| 43 |
+
input_layer = nn.Conv3d(
|
| 44 |
+
in_channels,
|
| 45 |
+
out_channels,
|
| 46 |
+
kernel_size=3,
|
| 47 |
+
stride=1,
|
| 48 |
+
padding=1,
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
elif layer_type == 'pixel_shuffle':
|
| 52 |
+
input_layer = nn.Sequential(
|
| 53 |
+
nn.PixelUnshuffle(2),
|
| 54 |
+
nn.Conv2d(in_channels * 4, out_channels, kernel_size=1),
|
| 55 |
+
)
|
| 56 |
+
else:
|
| 57 |
+
raise NotImplementedError(f"Not support input layer {layer_type}")
|
| 58 |
+
|
| 59 |
+
return input_layer
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def get_output_layer(
|
| 63 |
+
in_channels: int,
|
| 64 |
+
out_channels: int,
|
| 65 |
+
norm_num_groups: int,
|
| 66 |
+
layer_type: str,
|
| 67 |
+
norm_type: str = 'group',
|
| 68 |
+
affine: bool = True,
|
| 69 |
+
):
|
| 70 |
+
if layer_type == 'norm_act_conv':
|
| 71 |
+
output_layer = nn.Sequential(
|
| 72 |
+
nn.GroupNorm(num_channels=in_channels, num_groups=norm_num_groups, eps=1e-6, affine=affine),
|
| 73 |
+
nn.SiLU(),
|
| 74 |
+
nn.Conv3d(in_channels, out_channels, 3, stride=1, padding=1),
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
elif layer_type == 'pixel_shuffle':
|
| 78 |
+
output_layer = nn.Sequential(
|
| 79 |
+
nn.Conv2d(in_channels, out_channels * 4, kernel_size=1),
|
| 80 |
+
nn.PixelShuffle(2),
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
else:
|
| 84 |
+
raise NotImplementedError(f"Not support output layer {layer_type}")
|
| 85 |
+
|
| 86 |
+
return output_layer
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def get_down_block(
|
| 90 |
+
down_block_type: str,
|
| 91 |
+
num_layers: int,
|
| 92 |
+
in_channels: int,
|
| 93 |
+
out_channels: int = None,
|
| 94 |
+
temb_channels: int = None,
|
| 95 |
+
add_spatial_downsample: bool = None,
|
| 96 |
+
add_temporal_downsample: bool = None,
|
| 97 |
+
resnet_eps: float = 1e-6,
|
| 98 |
+
resnet_act_fn: str = 'silu',
|
| 99 |
+
resnet_groups: Optional[int] = None,
|
| 100 |
+
downsample_padding: Optional[int] = None,
|
| 101 |
+
resnet_time_scale_shift: str = "default",
|
| 102 |
+
attention_head_dim: Optional[int] = None,
|
| 103 |
+
dropout: float = 0.0,
|
| 104 |
+
norm_affline: bool = True,
|
| 105 |
+
norm_layer: str = 'layer',
|
| 106 |
+
):
|
| 107 |
+
|
| 108 |
+
if down_block_type == "DownEncoderBlock2D":
|
| 109 |
+
return DownEncoderBlock2D(
|
| 110 |
+
num_layers=num_layers,
|
| 111 |
+
in_channels=in_channels,
|
| 112 |
+
out_channels=out_channels,
|
| 113 |
+
dropout=dropout,
|
| 114 |
+
add_spatial_downsample=add_spatial_downsample,
|
| 115 |
+
add_temporal_downsample=add_temporal_downsample,
|
| 116 |
+
resnet_eps=resnet_eps,
|
| 117 |
+
resnet_act_fn=resnet_act_fn,
|
| 118 |
+
resnet_groups=resnet_groups,
|
| 119 |
+
downsample_padding=downsample_padding,
|
| 120 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
elif down_block_type == "DownEncoderBlockCausal3D":
|
| 124 |
+
return DownEncoderBlockCausal3D(
|
| 125 |
+
num_layers=num_layers,
|
| 126 |
+
in_channels=in_channels,
|
| 127 |
+
out_channels=out_channels,
|
| 128 |
+
dropout=dropout,
|
| 129 |
+
add_spatial_downsample=add_spatial_downsample,
|
| 130 |
+
add_temporal_downsample=add_temporal_downsample,
|
| 131 |
+
resnet_eps=resnet_eps,
|
| 132 |
+
resnet_act_fn=resnet_act_fn,
|
| 133 |
+
resnet_groups=resnet_groups,
|
| 134 |
+
downsample_padding=downsample_padding,
|
| 135 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
raise ValueError(f"{down_block_type} does not exist.")
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def get_up_block(
|
| 142 |
+
up_block_type: str,
|
| 143 |
+
num_layers: int,
|
| 144 |
+
in_channels: int,
|
| 145 |
+
out_channels: int,
|
| 146 |
+
prev_output_channel: int = None,
|
| 147 |
+
temb_channels: int = None,
|
| 148 |
+
add_spatial_upsample: bool = None,
|
| 149 |
+
add_temporal_upsample: bool = None,
|
| 150 |
+
resnet_eps: float = 1e-6,
|
| 151 |
+
resnet_act_fn: str = 'silu',
|
| 152 |
+
resolution_idx: Optional[int] = None,
|
| 153 |
+
resnet_groups: Optional[int] = None,
|
| 154 |
+
resnet_time_scale_shift: str = "default",
|
| 155 |
+
attention_head_dim: Optional[int] = None,
|
| 156 |
+
dropout: float = 0.0,
|
| 157 |
+
interpolate: bool = True,
|
| 158 |
+
norm_affline: bool = True,
|
| 159 |
+
norm_layer: str = 'layer',
|
| 160 |
+
) -> nn.Module:
|
| 161 |
+
|
| 162 |
+
if up_block_type == "UpDecoderBlock2D":
|
| 163 |
+
return UpDecoderBlock2D(
|
| 164 |
+
num_layers=num_layers,
|
| 165 |
+
in_channels=in_channels,
|
| 166 |
+
out_channels=out_channels,
|
| 167 |
+
resolution_idx=resolution_idx,
|
| 168 |
+
dropout=dropout,
|
| 169 |
+
add_spatial_upsample=add_spatial_upsample,
|
| 170 |
+
add_temporal_upsample=add_temporal_upsample,
|
| 171 |
+
resnet_eps=resnet_eps,
|
| 172 |
+
resnet_act_fn=resnet_act_fn,
|
| 173 |
+
resnet_groups=resnet_groups,
|
| 174 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 175 |
+
temb_channels=temb_channels,
|
| 176 |
+
interpolate=interpolate,
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
elif up_block_type == "UpDecoderBlockCausal3D":
|
| 180 |
+
return UpDecoderBlockCausal3D(
|
| 181 |
+
num_layers=num_layers,
|
| 182 |
+
in_channels=in_channels,
|
| 183 |
+
out_channels=out_channels,
|
| 184 |
+
resolution_idx=resolution_idx,
|
| 185 |
+
dropout=dropout,
|
| 186 |
+
add_spatial_upsample=add_spatial_upsample,
|
| 187 |
+
add_temporal_upsample=add_temporal_upsample,
|
| 188 |
+
resnet_eps=resnet_eps,
|
| 189 |
+
resnet_act_fn=resnet_act_fn,
|
| 190 |
+
resnet_groups=resnet_groups,
|
| 191 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 192 |
+
temb_channels=temb_channels,
|
| 193 |
+
interpolate=interpolate,
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
raise ValueError(f"{up_block_type} does not exist.")
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
class UNetMidBlock2D(nn.Module):
|
| 201 |
+
"""
|
| 202 |
+
A 2D UNet mid-block [`UNetMidBlock2D`] with multiple residual blocks and optional attention blocks.
|
| 203 |
+
|
| 204 |
+
Args:
|
| 205 |
+
in_channels (`int`): The number of input channels.
|
| 206 |
+
temb_channels (`int`): The number of temporal embedding channels.
|
| 207 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout rate.
|
| 208 |
+
num_layers (`int`, *optional*, defaults to 1): The number of residual blocks.
|
| 209 |
+
resnet_eps (`float`, *optional*, 1e-6 ): The epsilon value for the resnet blocks.
|
| 210 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `default`):
|
| 211 |
+
The type of normalization to apply to the time embeddings. This can help to improve the performance of the
|
| 212 |
+
model on tasks with long-range temporal dependencies.
|
| 213 |
+
resnet_act_fn (`str`, *optional*, defaults to `swish`): The activation function for the resnet blocks.
|
| 214 |
+
resnet_groups (`int`, *optional*, defaults to 32):
|
| 215 |
+
The number of groups to use in the group normalization layers of the resnet blocks.
|
| 216 |
+
attn_groups (`Optional[int]`, *optional*, defaults to None): The number of groups for the attention blocks.
|
| 217 |
+
resnet_pre_norm (`bool`, *optional*, defaults to `True`):
|
| 218 |
+
Whether to use pre-normalization for the resnet blocks.
|
| 219 |
+
add_attention (`bool`, *optional*, defaults to `True`): Whether to add attention blocks.
|
| 220 |
+
attention_head_dim (`int`, *optional*, defaults to 1):
|
| 221 |
+
Dimension of a single attention head. The number of attention heads is determined based on this value and
|
| 222 |
+
the number of input channels.
|
| 223 |
+
output_scale_factor (`float`, *optional*, defaults to 1.0): The output scale factor.
|
| 224 |
+
|
| 225 |
+
Returns:
|
| 226 |
+
`torch.FloatTensor`: The output of the last residual block, which is a tensor of shape `(batch_size,
|
| 227 |
+
in_channels, height, width)`.
|
| 228 |
+
|
| 229 |
+
"""
|
| 230 |
+
|
| 231 |
+
def __init__(
|
| 232 |
+
self,
|
| 233 |
+
in_channels: int,
|
| 234 |
+
temb_channels: int,
|
| 235 |
+
dropout: float = 0.0,
|
| 236 |
+
num_layers: int = 1,
|
| 237 |
+
resnet_eps: float = 1e-6,
|
| 238 |
+
resnet_time_scale_shift: str = "default", # default, spatial
|
| 239 |
+
resnet_act_fn: str = "swish",
|
| 240 |
+
resnet_groups: int = 32,
|
| 241 |
+
attn_groups: Optional[int] = None,
|
| 242 |
+
resnet_pre_norm: bool = True,
|
| 243 |
+
add_attention: bool = True,
|
| 244 |
+
attention_head_dim: int = 1,
|
| 245 |
+
output_scale_factor: float = 1.0,
|
| 246 |
+
):
|
| 247 |
+
super().__init__()
|
| 248 |
+
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
|
| 249 |
+
self.add_attention = add_attention
|
| 250 |
+
|
| 251 |
+
if attn_groups is None:
|
| 252 |
+
attn_groups = resnet_groups if resnet_time_scale_shift == "default" else None
|
| 253 |
+
|
| 254 |
+
# there is always at least one resnet
|
| 255 |
+
resnets = [
|
| 256 |
+
ResnetBlock2D(
|
| 257 |
+
in_channels=in_channels,
|
| 258 |
+
out_channels=in_channels,
|
| 259 |
+
temb_channels=temb_channels,
|
| 260 |
+
eps=resnet_eps,
|
| 261 |
+
groups=resnet_groups,
|
| 262 |
+
dropout=dropout,
|
| 263 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 264 |
+
non_linearity=resnet_act_fn,
|
| 265 |
+
output_scale_factor=output_scale_factor,
|
| 266 |
+
pre_norm=resnet_pre_norm,
|
| 267 |
+
)
|
| 268 |
+
]
|
| 269 |
+
attentions = []
|
| 270 |
+
|
| 271 |
+
if attention_head_dim is None:
|
| 272 |
+
logger.warn(
|
| 273 |
+
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {in_channels}."
|
| 274 |
+
)
|
| 275 |
+
attention_head_dim = in_channels
|
| 276 |
+
|
| 277 |
+
for _ in range(num_layers):
|
| 278 |
+
if self.add_attention:
|
| 279 |
+
# Spatial attention
|
| 280 |
+
attentions.append(
|
| 281 |
+
Attention(
|
| 282 |
+
in_channels,
|
| 283 |
+
heads=in_channels // attention_head_dim,
|
| 284 |
+
dim_head=attention_head_dim,
|
| 285 |
+
rescale_output_factor=output_scale_factor,
|
| 286 |
+
eps=resnet_eps,
|
| 287 |
+
norm_num_groups=attn_groups,
|
| 288 |
+
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
|
| 289 |
+
residual_connection=True,
|
| 290 |
+
bias=True,
|
| 291 |
+
upcast_softmax=True,
|
| 292 |
+
_from_deprecated_attn_block=True,
|
| 293 |
+
)
|
| 294 |
+
)
|
| 295 |
+
else:
|
| 296 |
+
attentions.append(None)
|
| 297 |
+
|
| 298 |
+
resnets.append(
|
| 299 |
+
ResnetBlock2D(
|
| 300 |
+
in_channels=in_channels,
|
| 301 |
+
out_channels=in_channels,
|
| 302 |
+
temb_channels=temb_channels,
|
| 303 |
+
eps=resnet_eps,
|
| 304 |
+
groups=resnet_groups,
|
| 305 |
+
dropout=dropout,
|
| 306 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 307 |
+
non_linearity=resnet_act_fn,
|
| 308 |
+
output_scale_factor=output_scale_factor,
|
| 309 |
+
pre_norm=resnet_pre_norm,
|
| 310 |
+
)
|
| 311 |
+
)
|
| 312 |
+
|
| 313 |
+
self.attentions = nn.ModuleList(attentions)
|
| 314 |
+
self.resnets = nn.ModuleList(resnets)
|
| 315 |
+
|
| 316 |
+
def forward(self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None) -> torch.FloatTensor:
|
| 317 |
+
hidden_states = self.resnets[0](hidden_states, temb)
|
| 318 |
+
t = hidden_states.shape[2]
|
| 319 |
+
|
| 320 |
+
for attn, resnet in zip(self.attentions, self.resnets[1:]):
|
| 321 |
+
if attn is not None:
|
| 322 |
+
hidden_states = rearrange(hidden_states, 'b c t h w -> b t c h w')
|
| 323 |
+
hidden_states = rearrange(hidden_states, 'b t c h w -> (b t) c h w')
|
| 324 |
+
hidden_states = attn(hidden_states, temb=temb)
|
| 325 |
+
hidden_states = rearrange(hidden_states, '(b t) c h w -> b t c h w', t=t)
|
| 326 |
+
hidden_states = rearrange(hidden_states, 'b t c h w -> b c t h w')
|
| 327 |
+
|
| 328 |
+
hidden_states = resnet(hidden_states, temb)
|
| 329 |
+
|
| 330 |
+
return hidden_states
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
class CausalUNetMidBlock2D(nn.Module):
|
| 334 |
+
"""
|
| 335 |
+
A 2D UNet mid-block [`UNetMidBlock2D`] with multiple residual blocks and optional attention blocks.
|
| 336 |
+
|
| 337 |
+
Args:
|
| 338 |
+
in_channels (`int`): The number of input channels.
|
| 339 |
+
temb_channels (`int`): The number of temporal embedding channels.
|
| 340 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout rate.
|
| 341 |
+
num_layers (`int`, *optional*, defaults to 1): The number of residual blocks.
|
| 342 |
+
resnet_eps (`float`, *optional*, 1e-6 ): The epsilon value for the resnet blocks.
|
| 343 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `default`):
|
| 344 |
+
The type of normalization to apply to the time embeddings. This can help to improve the performance of the
|
| 345 |
+
model on tasks with long-range temporal dependencies.
|
| 346 |
+
resnet_act_fn (`str`, *optional*, defaults to `swish`): The activation function for the resnet blocks.
|
| 347 |
+
resnet_groups (`int`, *optional*, defaults to 32):
|
| 348 |
+
The number of groups to use in the group normalization layers of the resnet blocks.
|
| 349 |
+
attn_groups (`Optional[int]`, *optional*, defaults to None): The number of groups for the attention blocks.
|
| 350 |
+
resnet_pre_norm (`bool`, *optional*, defaults to `True`):
|
| 351 |
+
Whether to use pre-normalization for the resnet blocks.
|
| 352 |
+
add_attention (`bool`, *optional*, defaults to `True`): Whether to add attention blocks.
|
| 353 |
+
attention_head_dim (`int`, *optional*, defaults to 1):
|
| 354 |
+
Dimension of a single attention head. The number of attention heads is determined based on this value and
|
| 355 |
+
the number of input channels.
|
| 356 |
+
output_scale_factor (`float`, *optional*, defaults to 1.0): The output scale factor.
|
| 357 |
+
|
| 358 |
+
Returns:
|
| 359 |
+
`torch.FloatTensor`: The output of the last residual block, which is a tensor of shape `(batch_size,
|
| 360 |
+
in_channels, height, width)`.
|
| 361 |
+
|
| 362 |
+
"""
|
| 363 |
+
|
| 364 |
+
def __init__(
|
| 365 |
+
self,
|
| 366 |
+
in_channels: int,
|
| 367 |
+
temb_channels: int,
|
| 368 |
+
dropout: float = 0.0,
|
| 369 |
+
num_layers: int = 1,
|
| 370 |
+
resnet_eps: float = 1e-6,
|
| 371 |
+
resnet_time_scale_shift: str = "default", # default, spatial
|
| 372 |
+
resnet_act_fn: str = "swish",
|
| 373 |
+
resnet_groups: int = 32,
|
| 374 |
+
attn_groups: Optional[int] = None,
|
| 375 |
+
resnet_pre_norm: bool = True,
|
| 376 |
+
add_attention: bool = True,
|
| 377 |
+
attention_head_dim: int = 1,
|
| 378 |
+
output_scale_factor: float = 1.0,
|
| 379 |
+
):
|
| 380 |
+
super().__init__()
|
| 381 |
+
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
|
| 382 |
+
self.add_attention = add_attention
|
| 383 |
+
|
| 384 |
+
if attn_groups is None:
|
| 385 |
+
attn_groups = resnet_groups if resnet_time_scale_shift == "default" else None
|
| 386 |
+
|
| 387 |
+
# there is always at least one resnet
|
| 388 |
+
resnets = [
|
| 389 |
+
CausalResnetBlock3D(
|
| 390 |
+
in_channels=in_channels,
|
| 391 |
+
out_channels=in_channels,
|
| 392 |
+
temb_channels=temb_channels,
|
| 393 |
+
eps=resnet_eps,
|
| 394 |
+
groups=resnet_groups,
|
| 395 |
+
dropout=dropout,
|
| 396 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 397 |
+
non_linearity=resnet_act_fn,
|
| 398 |
+
output_scale_factor=output_scale_factor,
|
| 399 |
+
pre_norm=resnet_pre_norm,
|
| 400 |
+
)
|
| 401 |
+
]
|
| 402 |
+
attentions = []
|
| 403 |
+
|
| 404 |
+
if attention_head_dim is None:
|
| 405 |
+
logger.warn(
|
| 406 |
+
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {in_channels}."
|
| 407 |
+
)
|
| 408 |
+
attention_head_dim = in_channels
|
| 409 |
+
|
| 410 |
+
for _ in range(num_layers):
|
| 411 |
+
if self.add_attention:
|
| 412 |
+
# Spatial attention
|
| 413 |
+
attentions.append(
|
| 414 |
+
Attention(
|
| 415 |
+
in_channels,
|
| 416 |
+
heads=in_channels // attention_head_dim,
|
| 417 |
+
dim_head=attention_head_dim,
|
| 418 |
+
rescale_output_factor=output_scale_factor,
|
| 419 |
+
eps=resnet_eps,
|
| 420 |
+
norm_num_groups=attn_groups,
|
| 421 |
+
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
|
| 422 |
+
residual_connection=True,
|
| 423 |
+
bias=True,
|
| 424 |
+
upcast_softmax=True,
|
| 425 |
+
_from_deprecated_attn_block=True,
|
| 426 |
+
)
|
| 427 |
+
)
|
| 428 |
+
else:
|
| 429 |
+
attentions.append(None)
|
| 430 |
+
|
| 431 |
+
resnets.append(
|
| 432 |
+
CausalResnetBlock3D(
|
| 433 |
+
in_channels=in_channels,
|
| 434 |
+
out_channels=in_channels,
|
| 435 |
+
temb_channels=temb_channels,
|
| 436 |
+
eps=resnet_eps,
|
| 437 |
+
groups=resnet_groups,
|
| 438 |
+
dropout=dropout,
|
| 439 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 440 |
+
non_linearity=resnet_act_fn,
|
| 441 |
+
output_scale_factor=output_scale_factor,
|
| 442 |
+
pre_norm=resnet_pre_norm,
|
| 443 |
+
)
|
| 444 |
+
)
|
| 445 |
+
|
| 446 |
+
self.attentions = nn.ModuleList(attentions)
|
| 447 |
+
self.resnets = nn.ModuleList(resnets)
|
| 448 |
+
|
| 449 |
+
def forward(self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None,
|
| 450 |
+
is_init_image=True, temporal_chunk=False) -> torch.FloatTensor:
|
| 451 |
+
hidden_states = self.resnets[0](hidden_states, temb, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 452 |
+
t = hidden_states.shape[2]
|
| 453 |
+
|
| 454 |
+
for attn, resnet in zip(self.attentions, self.resnets[1:]):
|
| 455 |
+
if attn is not None:
|
| 456 |
+
hidden_states = rearrange(hidden_states, 'b c t h w -> b t c h w')
|
| 457 |
+
hidden_states = rearrange(hidden_states, 'b t c h w -> (b t) c h w')
|
| 458 |
+
hidden_states = attn(hidden_states, temb=temb)
|
| 459 |
+
hidden_states = rearrange(hidden_states, '(b t) c h w -> b t c h w', t=t)
|
| 460 |
+
hidden_states = rearrange(hidden_states, 'b t c h w -> b c t h w')
|
| 461 |
+
|
| 462 |
+
hidden_states = resnet(hidden_states, temb, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 463 |
+
|
| 464 |
+
return hidden_states
|
| 465 |
+
|
| 466 |
+
|
| 467 |
+
class DownEncoderBlockCausal3D(nn.Module):
|
| 468 |
+
def __init__(
|
| 469 |
+
self,
|
| 470 |
+
in_channels: int,
|
| 471 |
+
out_channels: int,
|
| 472 |
+
dropout: float = 0.0,
|
| 473 |
+
num_layers: int = 1,
|
| 474 |
+
resnet_eps: float = 1e-6,
|
| 475 |
+
resnet_time_scale_shift: str = "default",
|
| 476 |
+
resnet_act_fn: str = "swish",
|
| 477 |
+
resnet_groups: int = 32,
|
| 478 |
+
resnet_pre_norm: bool = True,
|
| 479 |
+
output_scale_factor: float = 1.0,
|
| 480 |
+
add_spatial_downsample: bool = True,
|
| 481 |
+
add_temporal_downsample: bool = False,
|
| 482 |
+
downsample_padding: int = 1,
|
| 483 |
+
):
|
| 484 |
+
super().__init__()
|
| 485 |
+
resnets = []
|
| 486 |
+
|
| 487 |
+
for i in range(num_layers):
|
| 488 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 489 |
+
resnets.append(
|
| 490 |
+
CausalResnetBlock3D(
|
| 491 |
+
in_channels=in_channels,
|
| 492 |
+
out_channels=out_channels,
|
| 493 |
+
temb_channels=None,
|
| 494 |
+
eps=resnet_eps,
|
| 495 |
+
groups=resnet_groups,
|
| 496 |
+
dropout=dropout,
|
| 497 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 498 |
+
non_linearity=resnet_act_fn,
|
| 499 |
+
output_scale_factor=output_scale_factor,
|
| 500 |
+
pre_norm=resnet_pre_norm,
|
| 501 |
+
)
|
| 502 |
+
)
|
| 503 |
+
|
| 504 |
+
self.resnets = nn.ModuleList(resnets)
|
| 505 |
+
|
| 506 |
+
if add_spatial_downsample:
|
| 507 |
+
self.downsamplers = nn.ModuleList(
|
| 508 |
+
[
|
| 509 |
+
CausalDownsample2x(
|
| 510 |
+
out_channels, use_conv=True, out_channels=out_channels,
|
| 511 |
+
)
|
| 512 |
+
]
|
| 513 |
+
)
|
| 514 |
+
else:
|
| 515 |
+
self.downsamplers = None
|
| 516 |
+
|
| 517 |
+
if add_temporal_downsample:
|
| 518 |
+
self.temporal_downsamplers = nn.ModuleList(
|
| 519 |
+
[
|
| 520 |
+
CausalTemporalDownsample2x(
|
| 521 |
+
out_channels, use_conv=True, out_channels=out_channels,
|
| 522 |
+
)
|
| 523 |
+
]
|
| 524 |
+
)
|
| 525 |
+
else:
|
| 526 |
+
self.temporal_downsamplers = None
|
| 527 |
+
|
| 528 |
+
def forward(self, hidden_states: torch.FloatTensor, is_init_image=True, temporal_chunk=False) -> torch.FloatTensor:
|
| 529 |
+
for resnet in self.resnets:
|
| 530 |
+
hidden_states = resnet(hidden_states, temb=None, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 531 |
+
|
| 532 |
+
if self.downsamplers is not None:
|
| 533 |
+
for downsampler in self.downsamplers:
|
| 534 |
+
hidden_states = downsampler(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 535 |
+
|
| 536 |
+
if self.temporal_downsamplers is not None:
|
| 537 |
+
for temporal_downsampler in self.temporal_downsamplers:
|
| 538 |
+
hidden_states = temporal_downsampler(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 539 |
+
|
| 540 |
+
return hidden_states
|
| 541 |
+
|
| 542 |
+
|
| 543 |
+
class DownEncoderBlock2D(nn.Module):
|
| 544 |
+
def __init__(
|
| 545 |
+
self,
|
| 546 |
+
in_channels: int,
|
| 547 |
+
out_channels: int,
|
| 548 |
+
dropout: float = 0.0,
|
| 549 |
+
num_layers: int = 1,
|
| 550 |
+
resnet_eps: float = 1e-6,
|
| 551 |
+
resnet_time_scale_shift: str = "default",
|
| 552 |
+
resnet_act_fn: str = "swish",
|
| 553 |
+
resnet_groups: int = 32,
|
| 554 |
+
resnet_pre_norm: bool = True,
|
| 555 |
+
output_scale_factor: float = 1.0,
|
| 556 |
+
add_spatial_downsample: bool = True,
|
| 557 |
+
add_temporal_downsample: bool = False,
|
| 558 |
+
downsample_padding: int = 1,
|
| 559 |
+
):
|
| 560 |
+
super().__init__()
|
| 561 |
+
resnets = []
|
| 562 |
+
|
| 563 |
+
for i in range(num_layers):
|
| 564 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 565 |
+
resnets.append(
|
| 566 |
+
ResnetBlock2D(
|
| 567 |
+
in_channels=in_channels,
|
| 568 |
+
out_channels=out_channels,
|
| 569 |
+
temb_channels=None,
|
| 570 |
+
eps=resnet_eps,
|
| 571 |
+
groups=resnet_groups,
|
| 572 |
+
dropout=dropout,
|
| 573 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 574 |
+
non_linearity=resnet_act_fn,
|
| 575 |
+
output_scale_factor=output_scale_factor,
|
| 576 |
+
pre_norm=resnet_pre_norm,
|
| 577 |
+
)
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
self.resnets = nn.ModuleList(resnets)
|
| 581 |
+
|
| 582 |
+
if add_spatial_downsample:
|
| 583 |
+
self.downsamplers = nn.ModuleList(
|
| 584 |
+
[
|
| 585 |
+
Downsample2D(
|
| 586 |
+
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
|
| 587 |
+
)
|
| 588 |
+
]
|
| 589 |
+
)
|
| 590 |
+
else:
|
| 591 |
+
self.downsamplers = None
|
| 592 |
+
|
| 593 |
+
if add_temporal_downsample:
|
| 594 |
+
self.temporal_downsamplers = nn.ModuleList(
|
| 595 |
+
[
|
| 596 |
+
TemporalDownsample2x(
|
| 597 |
+
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding,
|
| 598 |
+
)
|
| 599 |
+
]
|
| 600 |
+
)
|
| 601 |
+
else:
|
| 602 |
+
self.temporal_downsamplers = None
|
| 603 |
+
|
| 604 |
+
def forward(self, hidden_states: torch.FloatTensor) -> torch.FloatTensor:
|
| 605 |
+
for resnet in self.resnets:
|
| 606 |
+
hidden_states = resnet(hidden_states, temb=None)
|
| 607 |
+
|
| 608 |
+
if self.downsamplers is not None:
|
| 609 |
+
for downsampler in self.downsamplers:
|
| 610 |
+
hidden_states = downsampler(hidden_states)
|
| 611 |
+
|
| 612 |
+
if self.temporal_downsamplers is not None:
|
| 613 |
+
for temporal_downsampler in self.temporal_downsamplers:
|
| 614 |
+
hidden_states = temporal_downsampler(hidden_states)
|
| 615 |
+
|
| 616 |
+
return hidden_states
|
| 617 |
+
|
| 618 |
+
|
| 619 |
+
class UpDecoderBlock2D(nn.Module):
|
| 620 |
+
def __init__(
|
| 621 |
+
self,
|
| 622 |
+
in_channels: int,
|
| 623 |
+
out_channels: int,
|
| 624 |
+
resolution_idx: Optional[int] = None,
|
| 625 |
+
dropout: float = 0.0,
|
| 626 |
+
num_layers: int = 1,
|
| 627 |
+
resnet_eps: float = 1e-6,
|
| 628 |
+
resnet_time_scale_shift: str = "default", # default, spatial
|
| 629 |
+
resnet_act_fn: str = "swish",
|
| 630 |
+
resnet_groups: int = 32,
|
| 631 |
+
resnet_pre_norm: bool = True,
|
| 632 |
+
output_scale_factor: float = 1.0,
|
| 633 |
+
add_spatial_upsample: bool = True,
|
| 634 |
+
add_temporal_upsample: bool = False,
|
| 635 |
+
temb_channels: Optional[int] = None,
|
| 636 |
+
interpolate: bool = True,
|
| 637 |
+
):
|
| 638 |
+
super().__init__()
|
| 639 |
+
resnets = []
|
| 640 |
+
|
| 641 |
+
for i in range(num_layers):
|
| 642 |
+
input_channels = in_channels if i == 0 else out_channels
|
| 643 |
+
|
| 644 |
+
resnets.append(
|
| 645 |
+
ResnetBlock2D(
|
| 646 |
+
in_channels=input_channels,
|
| 647 |
+
out_channels=out_channels,
|
| 648 |
+
temb_channels=temb_channels,
|
| 649 |
+
eps=resnet_eps,
|
| 650 |
+
groups=resnet_groups,
|
| 651 |
+
dropout=dropout,
|
| 652 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 653 |
+
non_linearity=resnet_act_fn,
|
| 654 |
+
output_scale_factor=output_scale_factor,
|
| 655 |
+
pre_norm=resnet_pre_norm,
|
| 656 |
+
)
|
| 657 |
+
)
|
| 658 |
+
|
| 659 |
+
self.resnets = nn.ModuleList(resnets)
|
| 660 |
+
|
| 661 |
+
if add_spatial_upsample:
|
| 662 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels, interpolate=interpolate)])
|
| 663 |
+
else:
|
| 664 |
+
self.upsamplers = None
|
| 665 |
+
|
| 666 |
+
if add_temporal_upsample:
|
| 667 |
+
self.temporal_upsamplers = nn.ModuleList([TemporalUpsample2x(out_channels, use_conv=True, out_channels=out_channels, interpolate=interpolate)])
|
| 668 |
+
else:
|
| 669 |
+
self.temporal_upsamplers = None
|
| 670 |
+
|
| 671 |
+
self.resolution_idx = resolution_idx
|
| 672 |
+
|
| 673 |
+
def forward(
|
| 674 |
+
self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None, scale: float = 1.0, is_image: bool = False,
|
| 675 |
+
) -> torch.FloatTensor:
|
| 676 |
+
for resnet in self.resnets:
|
| 677 |
+
hidden_states = resnet(hidden_states, temb=temb, scale=scale)
|
| 678 |
+
|
| 679 |
+
if self.upsamplers is not None:
|
| 680 |
+
for upsampler in self.upsamplers:
|
| 681 |
+
hidden_states = upsampler(hidden_states)
|
| 682 |
+
|
| 683 |
+
if self.temporal_upsamplers is not None:
|
| 684 |
+
for temporal_upsampler in self.temporal_upsamplers:
|
| 685 |
+
hidden_states = temporal_upsampler(hidden_states, is_image=is_image)
|
| 686 |
+
|
| 687 |
+
return hidden_states
|
| 688 |
+
|
| 689 |
+
|
| 690 |
+
class UpDecoderBlockCausal3D(nn.Module):
|
| 691 |
+
def __init__(
|
| 692 |
+
self,
|
| 693 |
+
in_channels: int,
|
| 694 |
+
out_channels: int,
|
| 695 |
+
resolution_idx: Optional[int] = None,
|
| 696 |
+
dropout: float = 0.0,
|
| 697 |
+
num_layers: int = 1,
|
| 698 |
+
resnet_eps: float = 1e-6,
|
| 699 |
+
resnet_time_scale_shift: str = "default", # default, spatial
|
| 700 |
+
resnet_act_fn: str = "swish",
|
| 701 |
+
resnet_groups: int = 32,
|
| 702 |
+
resnet_pre_norm: bool = True,
|
| 703 |
+
output_scale_factor: float = 1.0,
|
| 704 |
+
add_spatial_upsample: bool = True,
|
| 705 |
+
add_temporal_upsample: bool = False,
|
| 706 |
+
temb_channels: Optional[int] = None,
|
| 707 |
+
interpolate: bool = True,
|
| 708 |
+
):
|
| 709 |
+
super().__init__()
|
| 710 |
+
resnets = []
|
| 711 |
+
|
| 712 |
+
for i in range(num_layers):
|
| 713 |
+
input_channels = in_channels if i == 0 else out_channels
|
| 714 |
+
|
| 715 |
+
resnets.append(
|
| 716 |
+
CausalResnetBlock3D(
|
| 717 |
+
in_channels=input_channels,
|
| 718 |
+
out_channels=out_channels,
|
| 719 |
+
temb_channels=temb_channels,
|
| 720 |
+
eps=resnet_eps,
|
| 721 |
+
groups=resnet_groups,
|
| 722 |
+
dropout=dropout,
|
| 723 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 724 |
+
non_linearity=resnet_act_fn,
|
| 725 |
+
output_scale_factor=output_scale_factor,
|
| 726 |
+
pre_norm=resnet_pre_norm,
|
| 727 |
+
)
|
| 728 |
+
)
|
| 729 |
+
|
| 730 |
+
self.resnets = nn.ModuleList(resnets)
|
| 731 |
+
|
| 732 |
+
if add_spatial_upsample:
|
| 733 |
+
self.upsamplers = nn.ModuleList([CausalUpsample2x(out_channels, use_conv=True, out_channels=out_channels, interpolate=interpolate)])
|
| 734 |
+
else:
|
| 735 |
+
self.upsamplers = None
|
| 736 |
+
|
| 737 |
+
if add_temporal_upsample:
|
| 738 |
+
self.temporal_upsamplers = nn.ModuleList([CausalTemporalUpsample2x(out_channels, use_conv=True, out_channels=out_channels, interpolate=interpolate)])
|
| 739 |
+
else:
|
| 740 |
+
self.temporal_upsamplers = None
|
| 741 |
+
|
| 742 |
+
self.resolution_idx = resolution_idx
|
| 743 |
+
|
| 744 |
+
def forward(
|
| 745 |
+
self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None,
|
| 746 |
+
is_init_image=True, temporal_chunk=False,
|
| 747 |
+
) -> torch.FloatTensor:
|
| 748 |
+
for resnet in self.resnets:
|
| 749 |
+
hidden_states = resnet(hidden_states, temb=temb, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 750 |
+
|
| 751 |
+
if self.upsamplers is not None:
|
| 752 |
+
for upsampler in self.upsamplers:
|
| 753 |
+
hidden_states = upsampler(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 754 |
+
|
| 755 |
+
if self.temporal_upsamplers is not None:
|
| 756 |
+
for temporal_upsampler in self.temporal_upsamplers:
|
| 757 |
+
hidden_states = temporal_upsampler(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 758 |
+
|
| 759 |
+
return hidden_states
|
| 760 |
+
|
video_vae/modeling_causal_conv.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Tuple, Union
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
from torch.utils.checkpoint import checkpoint
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from collections import deque
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
from timm.models.layers import trunc_normal_
|
| 9 |
+
from IPython import embed
|
| 10 |
+
from torch import Tensor
|
| 11 |
+
|
| 12 |
+
from utils import (
|
| 13 |
+
is_context_parallel_initialized,
|
| 14 |
+
get_context_parallel_group,
|
| 15 |
+
get_context_parallel_world_size,
|
| 16 |
+
get_context_parallel_rank,
|
| 17 |
+
get_context_parallel_group_rank,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
from .context_parallel_ops import (
|
| 21 |
+
conv_scatter_to_context_parallel_region,
|
| 22 |
+
conv_gather_from_context_parallel_region,
|
| 23 |
+
cp_pass_from_previous_rank,
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def divisible_by(num, den):
|
| 28 |
+
return (num % den) == 0
|
| 29 |
+
|
| 30 |
+
def cast_tuple(t, length = 1):
|
| 31 |
+
return t if isinstance(t, tuple) else ((t,) * length)
|
| 32 |
+
|
| 33 |
+
def is_odd(n):
|
| 34 |
+
return not divisible_by(n, 2)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class CausalGroupNorm(nn.GroupNorm):
|
| 38 |
+
|
| 39 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 40 |
+
t = x.shape[2]
|
| 41 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 42 |
+
x = super().forward(x)
|
| 43 |
+
x = rearrange(x, '(b t) c h w -> b c t h w', t=t)
|
| 44 |
+
return x
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class CausalConv3d(nn.Module):
|
| 48 |
+
|
| 49 |
+
def __init__(
|
| 50 |
+
self,
|
| 51 |
+
in_channels,
|
| 52 |
+
out_channels,
|
| 53 |
+
kernel_size: Union[int, Tuple[int, int, int]],
|
| 54 |
+
stride: Union[int, Tuple[int, int, int]] = 1,
|
| 55 |
+
pad_mode: str ='constant',
|
| 56 |
+
**kwargs
|
| 57 |
+
):
|
| 58 |
+
super().__init__()
|
| 59 |
+
if isinstance(kernel_size, int):
|
| 60 |
+
kernel_size = cast_tuple(kernel_size, 3)
|
| 61 |
+
|
| 62 |
+
time_kernel_size, height_kernel_size, width_kernel_size = kernel_size
|
| 63 |
+
self.time_kernel_size = time_kernel_size
|
| 64 |
+
assert is_odd(height_kernel_size) and is_odd(width_kernel_size)
|
| 65 |
+
dilation = kwargs.pop('dilation', 1)
|
| 66 |
+
self.pad_mode = pad_mode
|
| 67 |
+
|
| 68 |
+
if isinstance(stride, int):
|
| 69 |
+
stride = (stride, 1, 1)
|
| 70 |
+
|
| 71 |
+
time_pad = dilation * (time_kernel_size - 1)
|
| 72 |
+
height_pad = height_kernel_size // 2
|
| 73 |
+
width_pad = width_kernel_size // 2
|
| 74 |
+
|
| 75 |
+
self.temporal_stride = stride[0]
|
| 76 |
+
self.time_pad = time_pad
|
| 77 |
+
self.time_causal_padding = (width_pad, width_pad, height_pad, height_pad, time_pad, 0)
|
| 78 |
+
self.time_uncausal_padding = (width_pad, width_pad, height_pad, height_pad, 0, 0)
|
| 79 |
+
|
| 80 |
+
self.conv = nn.Conv3d(in_channels, out_channels, kernel_size, stride=stride, padding=0, dilation=dilation, **kwargs)
|
| 81 |
+
self.cache_front_feat = deque()
|
| 82 |
+
|
| 83 |
+
def _clear_context_parallel_cache(self):
|
| 84 |
+
del self.cache_front_feat
|
| 85 |
+
self.cache_front_feat = deque()
|
| 86 |
+
|
| 87 |
+
def _init_weights(self, m):
|
| 88 |
+
if isinstance(m, (nn.Linear, nn.Conv2d, nn.Conv3d)):
|
| 89 |
+
trunc_normal_(m.weight, std=.02)
|
| 90 |
+
if m.bias is not None:
|
| 91 |
+
nn.init.constant_(m.bias, 0)
|
| 92 |
+
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm)):
|
| 93 |
+
nn.init.constant_(m.bias, 0)
|
| 94 |
+
nn.init.constant_(m.weight, 1.0)
|
| 95 |
+
|
| 96 |
+
def context_parallel_forward(self, x):
|
| 97 |
+
x = cp_pass_from_previous_rank(x, dim=2, kernel_size=self.time_kernel_size)
|
| 98 |
+
|
| 99 |
+
x = F.pad(x, self.time_uncausal_padding, mode='constant')
|
| 100 |
+
|
| 101 |
+
cp_rank = get_context_parallel_rank()
|
| 102 |
+
if cp_rank != 0:
|
| 103 |
+
if self.temporal_stride == 2 and self.time_kernel_size == 3:
|
| 104 |
+
x = x[:,:,1:]
|
| 105 |
+
|
| 106 |
+
x = self.conv(x)
|
| 107 |
+
return x
|
| 108 |
+
|
| 109 |
+
def forward(self, x, is_init_image=True, temporal_chunk=False):
|
| 110 |
+
# temporal_chunk: whether to use the temporal chunk
|
| 111 |
+
|
| 112 |
+
if is_context_parallel_initialized():
|
| 113 |
+
return self.context_parallel_forward(x)
|
| 114 |
+
|
| 115 |
+
pad_mode = self.pad_mode if self.time_pad < x.shape[2] else 'constant'
|
| 116 |
+
|
| 117 |
+
if not temporal_chunk:
|
| 118 |
+
x = F.pad(x, self.time_causal_padding, mode=pad_mode)
|
| 119 |
+
else:
|
| 120 |
+
assert not self.training, "The feature cache should not be used in training"
|
| 121 |
+
if is_init_image:
|
| 122 |
+
# Encode the first chunk
|
| 123 |
+
x = F.pad(x, self.time_causal_padding, mode=pad_mode)
|
| 124 |
+
self._clear_context_parallel_cache()
|
| 125 |
+
self.cache_front_feat.append(x[:, :, -2:].clone().detach())
|
| 126 |
+
else:
|
| 127 |
+
x = F.pad(x, self.time_uncausal_padding, mode=pad_mode)
|
| 128 |
+
video_front_context = self.cache_front_feat.pop()
|
| 129 |
+
self._clear_context_parallel_cache()
|
| 130 |
+
|
| 131 |
+
if self.temporal_stride == 1 and self.time_kernel_size == 3:
|
| 132 |
+
x = torch.cat([video_front_context, x], dim=2)
|
| 133 |
+
elif self.temporal_stride == 2 and self.time_kernel_size == 3:
|
| 134 |
+
x = torch.cat([video_front_context[:,:,-1:], x], dim=2)
|
| 135 |
+
|
| 136 |
+
self.cache_front_feat.append(x[:, :, -2:].clone().detach())
|
| 137 |
+
|
| 138 |
+
x = self.conv(x)
|
| 139 |
+
return x
|
video_vae/modeling_causal_vae.py
ADDED
|
@@ -0,0 +1,625 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, Optional, Tuple, Union
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 6 |
+
from diffusers.models.attention_processor import (
|
| 7 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 8 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 9 |
+
Attention,
|
| 10 |
+
AttentionProcessor,
|
| 11 |
+
AttnAddedKVProcessor,
|
| 12 |
+
AttnProcessor,
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
from diffusers.models.modeling_outputs import AutoencoderKLOutput
|
| 16 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 17 |
+
|
| 18 |
+
from timm.models.layers import drop_path, to_2tuple, trunc_normal_
|
| 19 |
+
from .modeling_enc_dec import (
|
| 20 |
+
DecoderOutput, DiagonalGaussianDistribution,
|
| 21 |
+
CausalVaeDecoder, CausalVaeEncoder,
|
| 22 |
+
)
|
| 23 |
+
from .modeling_causal_conv import CausalConv3d
|
| 24 |
+
from IPython import embed
|
| 25 |
+
|
| 26 |
+
from utils import (
|
| 27 |
+
is_context_parallel_initialized,
|
| 28 |
+
get_context_parallel_group,
|
| 29 |
+
get_context_parallel_world_size,
|
| 30 |
+
get_context_parallel_rank,
|
| 31 |
+
get_context_parallel_group_rank,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
from .context_parallel_ops import (
|
| 35 |
+
conv_scatter_to_context_parallel_region,
|
| 36 |
+
conv_gather_from_context_parallel_region,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class CausalVideoVAE(ModelMixin, ConfigMixin):
|
| 41 |
+
r"""
|
| 42 |
+
A VAE model with KL loss for encoding images into latents and decoding latent representations into images.
|
| 43 |
+
|
| 44 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 45 |
+
for all models (such as downloading or saving).
|
| 46 |
+
|
| 47 |
+
Parameters:
|
| 48 |
+
in_channels (int, *optional*, defaults to 3): Number of channels in the input image.
|
| 49 |
+
out_channels (int, *optional*, defaults to 3): Number of channels in the output.
|
| 50 |
+
down_block_types (`Tuple[str]`, *optional*, defaults to `("DownEncoderBlock2D",)`):
|
| 51 |
+
Tuple of downsample block types.
|
| 52 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpDecoderBlock2D",)`):
|
| 53 |
+
Tuple of upsample block types.
|
| 54 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(64,)`):
|
| 55 |
+
Tuple of block output channels.
|
| 56 |
+
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
| 57 |
+
latent_channels (`int`, *optional*, defaults to 4): Number of channels in the latent space.
|
| 58 |
+
sample_size (`int`, *optional*, defaults to `32`): Sample input size.
|
| 59 |
+
scaling_factor (`float`, *optional*, defaults to 0.18215):
|
| 60 |
+
The component-wise standard deviation of the trained latent space computed using the first batch of the
|
| 61 |
+
training set. This is used to scale the latent space to have unit variance when training the diffusion
|
| 62 |
+
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
|
| 63 |
+
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
|
| 64 |
+
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
|
| 65 |
+
Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
|
| 66 |
+
force_upcast (`bool`, *optional*, default to `True`):
|
| 67 |
+
If enabled it will force the VAE to run in float32 for high image resolution pipelines, such as SD-XL. VAE
|
| 68 |
+
can be fine-tuned / trained to a lower range without loosing too much precision in which case
|
| 69 |
+
`force_upcast` can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
|
| 70 |
+
"""
|
| 71 |
+
|
| 72 |
+
_supports_gradient_checkpointing = True
|
| 73 |
+
|
| 74 |
+
@register_to_config
|
| 75 |
+
def __init__(
|
| 76 |
+
self,
|
| 77 |
+
# encoder related parameters
|
| 78 |
+
encoder_in_channels: int = 3,
|
| 79 |
+
encoder_out_channels: int = 4,
|
| 80 |
+
encoder_layers_per_block: Tuple[int, ...] = (2, 2, 2, 2),
|
| 81 |
+
encoder_down_block_types: Tuple[str, ...] = (
|
| 82 |
+
"DownEncoderBlockCausal3D",
|
| 83 |
+
"DownEncoderBlockCausal3D",
|
| 84 |
+
"DownEncoderBlockCausal3D",
|
| 85 |
+
"DownEncoderBlockCausal3D",
|
| 86 |
+
),
|
| 87 |
+
encoder_block_out_channels: Tuple[int, ...] = (128, 256, 512, 512),
|
| 88 |
+
encoder_spatial_down_sample: Tuple[bool, ...] = (True, True, True, False),
|
| 89 |
+
encoder_temporal_down_sample: Tuple[bool, ...] = (True, True, True, False),
|
| 90 |
+
encoder_block_dropout: Tuple[int, ...] = (0.0, 0.0, 0.0, 0.0),
|
| 91 |
+
encoder_act_fn: str = "silu",
|
| 92 |
+
encoder_norm_num_groups: int = 32,
|
| 93 |
+
encoder_double_z: bool = True,
|
| 94 |
+
encoder_type: str = 'causal_vae_conv',
|
| 95 |
+
# decoder related
|
| 96 |
+
decoder_in_channels: int = 4,
|
| 97 |
+
decoder_out_channels: int = 3,
|
| 98 |
+
decoder_layers_per_block: Tuple[int, ...] = (3, 3, 3, 3),
|
| 99 |
+
decoder_up_block_types: Tuple[str, ...] = (
|
| 100 |
+
"UpDecoderBlockCausal3D",
|
| 101 |
+
"UpDecoderBlockCausal3D",
|
| 102 |
+
"UpDecoderBlockCausal3D",
|
| 103 |
+
"UpDecoderBlockCausal3D",
|
| 104 |
+
),
|
| 105 |
+
decoder_block_out_channels: Tuple[int, ...] = (128, 256, 512, 512),
|
| 106 |
+
decoder_spatial_up_sample: Tuple[bool, ...] = (True, True, True, False),
|
| 107 |
+
decoder_temporal_up_sample: Tuple[bool, ...] = (True, True, True, False),
|
| 108 |
+
decoder_block_dropout: Tuple[int, ...] = (0.0, 0.0, 0.0, 0.0),
|
| 109 |
+
decoder_act_fn: str = "silu",
|
| 110 |
+
decoder_norm_num_groups: int = 32,
|
| 111 |
+
decoder_type: str = 'causal_vae_conv',
|
| 112 |
+
sample_size: int = 256,
|
| 113 |
+
scaling_factor: float = 0.18215,
|
| 114 |
+
add_post_quant_conv: bool = True,
|
| 115 |
+
interpolate: bool = False,
|
| 116 |
+
downsample_scale: int = 8,
|
| 117 |
+
):
|
| 118 |
+
super().__init__()
|
| 119 |
+
|
| 120 |
+
print(f"The latent dimmension channes is {encoder_out_channels}")
|
| 121 |
+
# pass init params to Encoder
|
| 122 |
+
|
| 123 |
+
self.encoder = CausalVaeEncoder(
|
| 124 |
+
in_channels=encoder_in_channels,
|
| 125 |
+
out_channels=encoder_out_channels,
|
| 126 |
+
down_block_types=encoder_down_block_types,
|
| 127 |
+
spatial_down_sample=encoder_spatial_down_sample,
|
| 128 |
+
temporal_down_sample=encoder_temporal_down_sample,
|
| 129 |
+
block_out_channels=encoder_block_out_channels,
|
| 130 |
+
layers_per_block=encoder_layers_per_block,
|
| 131 |
+
act_fn=encoder_act_fn,
|
| 132 |
+
norm_num_groups=encoder_norm_num_groups,
|
| 133 |
+
double_z=True,
|
| 134 |
+
block_dropout=encoder_block_dropout,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
# pass init params to Decoder
|
| 138 |
+
self.decoder = CausalVaeDecoder(
|
| 139 |
+
in_channels=decoder_in_channels,
|
| 140 |
+
out_channels=decoder_out_channels,
|
| 141 |
+
up_block_types=decoder_up_block_types,
|
| 142 |
+
spatial_up_sample=decoder_spatial_up_sample,
|
| 143 |
+
temporal_up_sample=decoder_temporal_up_sample,
|
| 144 |
+
block_out_channels=decoder_block_out_channels,
|
| 145 |
+
layers_per_block=decoder_layers_per_block,
|
| 146 |
+
norm_num_groups=decoder_norm_num_groups,
|
| 147 |
+
act_fn=decoder_act_fn,
|
| 148 |
+
interpolate=interpolate,
|
| 149 |
+
block_dropout=decoder_block_dropout,
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
self.quant_conv = CausalConv3d(2 * encoder_out_channels, 2 * encoder_out_channels, kernel_size=1, stride=1)
|
| 153 |
+
self.post_quant_conv = CausalConv3d(encoder_out_channels, encoder_out_channels, kernel_size=1, stride=1)
|
| 154 |
+
self.use_tiling = False
|
| 155 |
+
|
| 156 |
+
# only relevant if vae tiling is enabled
|
| 157 |
+
self.tile_sample_min_size = self.config.sample_size
|
| 158 |
+
|
| 159 |
+
sample_size = (
|
| 160 |
+
self.config.sample_size[0]
|
| 161 |
+
if isinstance(self.config.sample_size, (list, tuple))
|
| 162 |
+
else self.config.sample_size
|
| 163 |
+
)
|
| 164 |
+
self.tile_latent_min_size = int(sample_size / downsample_scale)
|
| 165 |
+
self.encode_tile_overlap_factor = 1 / 8
|
| 166 |
+
self.decode_tile_overlap_factor = 1 / 8
|
| 167 |
+
self.downsample_scale = downsample_scale
|
| 168 |
+
|
| 169 |
+
self.apply(self._init_weights)
|
| 170 |
+
|
| 171 |
+
def _init_weights(self, m):
|
| 172 |
+
if isinstance(m, (nn.Linear, nn.Conv2d, nn.Conv3d)):
|
| 173 |
+
trunc_normal_(m.weight, std=.02)
|
| 174 |
+
if m.bias is not None:
|
| 175 |
+
nn.init.constant_(m.bias, 0)
|
| 176 |
+
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm)):
|
| 177 |
+
nn.init.constant_(m.bias, 0)
|
| 178 |
+
nn.init.constant_(m.weight, 1.0)
|
| 179 |
+
|
| 180 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 181 |
+
if isinstance(module, (Encoder, Decoder)):
|
| 182 |
+
module.gradient_checkpointing = value
|
| 183 |
+
|
| 184 |
+
def enable_tiling(self, use_tiling: bool = True):
|
| 185 |
+
r"""
|
| 186 |
+
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
|
| 187 |
+
compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
|
| 188 |
+
processing larger images.
|
| 189 |
+
"""
|
| 190 |
+
self.use_tiling = use_tiling
|
| 191 |
+
|
| 192 |
+
def disable_tiling(self):
|
| 193 |
+
r"""
|
| 194 |
+
Disable tiled VAE decoding. If `enable_tiling` was previously enabled, this method will go back to computing
|
| 195 |
+
decoding in one step.
|
| 196 |
+
"""
|
| 197 |
+
self.enable_tiling(False)
|
| 198 |
+
|
| 199 |
+
@property
|
| 200 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.attn_processors
|
| 201 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 202 |
+
r"""
|
| 203 |
+
Returns:
|
| 204 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 205 |
+
indexed by its weight name.
|
| 206 |
+
"""
|
| 207 |
+
# set recursively
|
| 208 |
+
processors = {}
|
| 209 |
+
|
| 210 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 211 |
+
if hasattr(module, "get_processor"):
|
| 212 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 213 |
+
|
| 214 |
+
for sub_name, child in module.named_children():
|
| 215 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 216 |
+
|
| 217 |
+
return processors
|
| 218 |
+
|
| 219 |
+
for name, module in self.named_children():
|
| 220 |
+
fn_recursive_add_processors(name, module, processors)
|
| 221 |
+
|
| 222 |
+
return processors
|
| 223 |
+
|
| 224 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
| 225 |
+
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
| 226 |
+
r"""
|
| 227 |
+
Sets the attention processor to use to compute attention.
|
| 228 |
+
|
| 229 |
+
Parameters:
|
| 230 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 231 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 232 |
+
for **all** `Attention` layers.
|
| 233 |
+
|
| 234 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 235 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 236 |
+
|
| 237 |
+
"""
|
| 238 |
+
count = len(self.attn_processors.keys())
|
| 239 |
+
|
| 240 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 241 |
+
raise ValueError(
|
| 242 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 243 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 247 |
+
if hasattr(module, "set_processor"):
|
| 248 |
+
if not isinstance(processor, dict):
|
| 249 |
+
module.set_processor(processor)
|
| 250 |
+
else:
|
| 251 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 252 |
+
|
| 253 |
+
for sub_name, child in module.named_children():
|
| 254 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 255 |
+
|
| 256 |
+
for name, module in self.named_children():
|
| 257 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 258 |
+
|
| 259 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
|
| 260 |
+
def set_default_attn_processor(self):
|
| 261 |
+
"""
|
| 262 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 263 |
+
"""
|
| 264 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 265 |
+
processor = AttnAddedKVProcessor()
|
| 266 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 267 |
+
processor = AttnProcessor()
|
| 268 |
+
else:
|
| 269 |
+
raise ValueError(
|
| 270 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
self.set_attn_processor(processor)
|
| 274 |
+
|
| 275 |
+
def encode(
|
| 276 |
+
self, x: torch.FloatTensor, return_dict: bool = True,
|
| 277 |
+
is_init_image=True, temporal_chunk=False, window_size=16, tile_sample_min_size=256,
|
| 278 |
+
) -> Union[AutoencoderKLOutput, Tuple[DiagonalGaussianDistribution]]:
|
| 279 |
+
"""
|
| 280 |
+
Encode a batch of images into latents.
|
| 281 |
+
|
| 282 |
+
Args:
|
| 283 |
+
x (`torch.FloatTensor`): Input batch of images.
|
| 284 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 285 |
+
Whether to return a [`~models.autoencoder_kl.AutoencoderKLOutput`] instead of a plain tuple.
|
| 286 |
+
|
| 287 |
+
Returns:
|
| 288 |
+
The latent representations of the encoded images. If `return_dict` is True, a
|
| 289 |
+
[`~models.autoencoder_kl.AutoencoderKLOutput`] is returned, otherwise a plain `tuple` is returned.
|
| 290 |
+
"""
|
| 291 |
+
self.tile_sample_min_size = tile_sample_min_size
|
| 292 |
+
self.tile_latent_min_size = int(tile_sample_min_size / self.downsample_scale)
|
| 293 |
+
|
| 294 |
+
if self.use_tiling and (x.shape[-1] > self.tile_sample_min_size or x.shape[-2] > self.tile_sample_min_size):
|
| 295 |
+
return self.tiled_encode(x, return_dict=return_dict, is_init_image=is_init_image,
|
| 296 |
+
temporal_chunk=temporal_chunk, window_size=window_size)
|
| 297 |
+
|
| 298 |
+
if temporal_chunk:
|
| 299 |
+
moments = self.chunk_encode(x, window_size=window_size)
|
| 300 |
+
else:
|
| 301 |
+
h = self.encoder(x, is_init_image=is_init_image, temporal_chunk=False)
|
| 302 |
+
moments = self.quant_conv(h, is_init_image=is_init_image, temporal_chunk=False)
|
| 303 |
+
|
| 304 |
+
posterior = DiagonalGaussianDistribution(moments)
|
| 305 |
+
|
| 306 |
+
if not return_dict:
|
| 307 |
+
return (posterior,)
|
| 308 |
+
|
| 309 |
+
return AutoencoderKLOutput(latent_dist=posterior)
|
| 310 |
+
|
| 311 |
+
@torch.no_grad()
|
| 312 |
+
def chunk_encode(self, x: torch.FloatTensor, window_size=16):
|
| 313 |
+
# Only used during inference
|
| 314 |
+
# Encode a long video clips through sliding window
|
| 315 |
+
num_frames = x.shape[2]
|
| 316 |
+
assert (num_frames - 1) % self.downsample_scale == 0
|
| 317 |
+
init_window_size = window_size + 1
|
| 318 |
+
frame_list = [x[:,:,:init_window_size]]
|
| 319 |
+
|
| 320 |
+
# To chunk the long video
|
| 321 |
+
full_chunk_size = (num_frames - init_window_size) // window_size
|
| 322 |
+
fid = init_window_size
|
| 323 |
+
for idx in range(full_chunk_size):
|
| 324 |
+
frame_list.append(x[:, :, fid:fid+window_size])
|
| 325 |
+
fid += window_size
|
| 326 |
+
|
| 327 |
+
if fid < num_frames:
|
| 328 |
+
frame_list.append(x[:, :, fid:])
|
| 329 |
+
|
| 330 |
+
latent_list = []
|
| 331 |
+
for idx, frames in enumerate(frame_list):
|
| 332 |
+
if idx == 0:
|
| 333 |
+
h = self.encoder(frames, is_init_image=True, temporal_chunk=True)
|
| 334 |
+
moments = self.quant_conv(h, is_init_image=True, temporal_chunk=True)
|
| 335 |
+
else:
|
| 336 |
+
h = self.encoder(frames, is_init_image=False, temporal_chunk=True)
|
| 337 |
+
moments = self.quant_conv(h, is_init_image=False, temporal_chunk=True)
|
| 338 |
+
|
| 339 |
+
latent_list.append(moments)
|
| 340 |
+
|
| 341 |
+
latent = torch.cat(latent_list, dim=2)
|
| 342 |
+
return latent
|
| 343 |
+
|
| 344 |
+
def get_last_layer(self):
|
| 345 |
+
return self.decoder.conv_out.conv.weight
|
| 346 |
+
|
| 347 |
+
@torch.no_grad()
|
| 348 |
+
def chunk_decode(self, z: torch.FloatTensor, window_size=2):
|
| 349 |
+
num_frames = z.shape[2]
|
| 350 |
+
init_window_size = window_size + 1
|
| 351 |
+
frame_list = [z[:,:,:init_window_size]]
|
| 352 |
+
|
| 353 |
+
# To chunk the long video
|
| 354 |
+
full_chunk_size = (num_frames - init_window_size) // window_size
|
| 355 |
+
fid = init_window_size
|
| 356 |
+
for idx in range(full_chunk_size):
|
| 357 |
+
frame_list.append(z[:, :, fid:fid+window_size])
|
| 358 |
+
fid += window_size
|
| 359 |
+
|
| 360 |
+
if fid < num_frames:
|
| 361 |
+
frame_list.append(z[:, :, fid:])
|
| 362 |
+
|
| 363 |
+
dec_list = []
|
| 364 |
+
for idx, frames in enumerate(frame_list):
|
| 365 |
+
if idx == 0:
|
| 366 |
+
z_h = self.post_quant_conv(frames, is_init_image=True, temporal_chunk=True)
|
| 367 |
+
dec = self.decoder(z_h, is_init_image=True, temporal_chunk=True)
|
| 368 |
+
else:
|
| 369 |
+
z_h = self.post_quant_conv(frames, is_init_image=False, temporal_chunk=True)
|
| 370 |
+
dec = self.decoder(z_h, is_init_image=False, temporal_chunk=True)
|
| 371 |
+
|
| 372 |
+
dec_list.append(dec)
|
| 373 |
+
|
| 374 |
+
dec = torch.cat(dec_list, dim=2)
|
| 375 |
+
return dec
|
| 376 |
+
|
| 377 |
+
def decode(self, z: torch.FloatTensor, is_init_image=True, temporal_chunk=False,
|
| 378 |
+
return_dict: bool = True, window_size: int = 2, tile_sample_min_size: int = 256,) -> Union[DecoderOutput, torch.FloatTensor]:
|
| 379 |
+
|
| 380 |
+
self.tile_sample_min_size = tile_sample_min_size
|
| 381 |
+
self.tile_latent_min_size = int(tile_sample_min_size / self.downsample_scale)
|
| 382 |
+
|
| 383 |
+
if self.use_tiling and (z.shape[-1] > self.tile_latent_min_size or z.shape[-2] > self.tile_latent_min_size):
|
| 384 |
+
return self.tiled_decode(z, is_init_image=is_init_image,
|
| 385 |
+
temporal_chunk=temporal_chunk, window_size=window_size, return_dict=return_dict)
|
| 386 |
+
|
| 387 |
+
if temporal_chunk:
|
| 388 |
+
dec = self.chunk_decode(z, window_size=window_size)
|
| 389 |
+
else:
|
| 390 |
+
z = self.post_quant_conv(z, is_init_image=is_init_image, temporal_chunk=False)
|
| 391 |
+
dec = self.decoder(z, is_init_image=is_init_image, temporal_chunk=False)
|
| 392 |
+
|
| 393 |
+
if not return_dict:
|
| 394 |
+
return (dec,)
|
| 395 |
+
|
| 396 |
+
return DecoderOutput(sample=dec)
|
| 397 |
+
|
| 398 |
+
def blend_v(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
| 399 |
+
blend_extent = min(a.shape[3], b.shape[3], blend_extent)
|
| 400 |
+
for y in range(blend_extent):
|
| 401 |
+
b[:, :, :, y, :] = a[:, :, :, -blend_extent + y, :] * (1 - y / blend_extent) + b[:, :, :, y, :] * (y / blend_extent)
|
| 402 |
+
return b
|
| 403 |
+
|
| 404 |
+
def blend_h(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
| 405 |
+
blend_extent = min(a.shape[4], b.shape[4], blend_extent)
|
| 406 |
+
for x in range(blend_extent):
|
| 407 |
+
b[:, :, :, :, x] = a[:, :, :, :, -blend_extent + x] * (1 - x / blend_extent) + b[:, :, :, :, x] * (x / blend_extent)
|
| 408 |
+
return b
|
| 409 |
+
|
| 410 |
+
def tiled_encode(self, x: torch.FloatTensor, return_dict: bool = True,
|
| 411 |
+
is_init_image=True, temporal_chunk=False, window_size=16,) -> AutoencoderKLOutput:
|
| 412 |
+
r"""Encode a batch of images using a tiled encoder.
|
| 413 |
+
|
| 414 |
+
When this option is enabled, the VAE will split the input tensor into tiles to compute encoding in several
|
| 415 |
+
steps. This is useful to keep memory use constant regardless of image size. The end result of tiled encoding is
|
| 416 |
+
different from non-tiled encoding because each tile uses a different encoder. To avoid tiling artifacts, the
|
| 417 |
+
tiles overlap and are blended together to form a smooth output. You may still see tile-sized changes in the
|
| 418 |
+
output, but they should be much less noticeable.
|
| 419 |
+
|
| 420 |
+
Args:
|
| 421 |
+
x (`torch.FloatTensor`): Input batch of images.
|
| 422 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 423 |
+
Whether or not to return a [`~models.autoencoder_kl.AutoencoderKLOutput`] instead of a plain tuple.
|
| 424 |
+
|
| 425 |
+
Returns:
|
| 426 |
+
[`~models.autoencoder_kl.AutoencoderKLOutput`] or `tuple`:
|
| 427 |
+
If return_dict is True, a [`~models.autoencoder_kl.AutoencoderKLOutput`] is returned, otherwise a plain
|
| 428 |
+
`tuple` is returned.
|
| 429 |
+
"""
|
| 430 |
+
overlap_size = int(self.tile_sample_min_size * (1 - self.encode_tile_overlap_factor))
|
| 431 |
+
blend_extent = int(self.tile_latent_min_size * self.encode_tile_overlap_factor)
|
| 432 |
+
row_limit = self.tile_latent_min_size - blend_extent
|
| 433 |
+
|
| 434 |
+
# Split the image into 512x512 tiles and encode them separately.
|
| 435 |
+
rows = []
|
| 436 |
+
for i in range(0, x.shape[3], overlap_size):
|
| 437 |
+
row = []
|
| 438 |
+
for j in range(0, x.shape[4], overlap_size):
|
| 439 |
+
tile = x[:, :, :, i : i + self.tile_sample_min_size, j : j + self.tile_sample_min_size]
|
| 440 |
+
if temporal_chunk:
|
| 441 |
+
tile = self.chunk_encode(tile, window_size=window_size)
|
| 442 |
+
else:
|
| 443 |
+
tile = self.encoder(tile, is_init_image=True, temporal_chunk=False)
|
| 444 |
+
tile = self.quant_conv(tile, is_init_image=True, temporal_chunk=False)
|
| 445 |
+
row.append(tile)
|
| 446 |
+
rows.append(row)
|
| 447 |
+
result_rows = []
|
| 448 |
+
for i, row in enumerate(rows):
|
| 449 |
+
result_row = []
|
| 450 |
+
for j, tile in enumerate(row):
|
| 451 |
+
# blend the above tile and the left tile
|
| 452 |
+
# to the current tile and add the current tile to the result row
|
| 453 |
+
if i > 0:
|
| 454 |
+
tile = self.blend_v(rows[i - 1][j], tile, blend_extent)
|
| 455 |
+
if j > 0:
|
| 456 |
+
tile = self.blend_h(row[j - 1], tile, blend_extent)
|
| 457 |
+
result_row.append(tile[:, :, :, :row_limit, :row_limit])
|
| 458 |
+
result_rows.append(torch.cat(result_row, dim=4))
|
| 459 |
+
|
| 460 |
+
moments = torch.cat(result_rows, dim=3)
|
| 461 |
+
|
| 462 |
+
posterior = DiagonalGaussianDistribution(moments)
|
| 463 |
+
|
| 464 |
+
if not return_dict:
|
| 465 |
+
return (posterior,)
|
| 466 |
+
|
| 467 |
+
return AutoencoderKLOutput(latent_dist=posterior)
|
| 468 |
+
|
| 469 |
+
def tiled_decode(self, z: torch.FloatTensor, is_init_image=True,
|
| 470 |
+
temporal_chunk=False, window_size=2, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
|
| 471 |
+
r"""
|
| 472 |
+
Decode a batch of images using a tiled decoder.
|
| 473 |
+
|
| 474 |
+
Args:
|
| 475 |
+
z (`torch.FloatTensor`): Input batch of latent vectors.
|
| 476 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 477 |
+
Whether or not to return a [`~models.vae.DecoderOutput`] instead of a plain tuple.
|
| 478 |
+
|
| 479 |
+
Returns:
|
| 480 |
+
[`~models.vae.DecoderOutput`] or `tuple`:
|
| 481 |
+
If return_dict is True, a [`~models.vae.DecoderOutput`] is returned, otherwise a plain `tuple` is
|
| 482 |
+
returned.
|
| 483 |
+
"""
|
| 484 |
+
overlap_size = int(self.tile_latent_min_size * (1 - self.decode_tile_overlap_factor))
|
| 485 |
+
blend_extent = int(self.tile_sample_min_size * self.decode_tile_overlap_factor)
|
| 486 |
+
row_limit = self.tile_sample_min_size - blend_extent
|
| 487 |
+
|
| 488 |
+
# Split z into overlapping 64x64 tiles and decode them separately.
|
| 489 |
+
# The tiles have an overlap to avoid seams between tiles.
|
| 490 |
+
rows = []
|
| 491 |
+
for i in range(0, z.shape[3], overlap_size):
|
| 492 |
+
row = []
|
| 493 |
+
for j in range(0, z.shape[4], overlap_size):
|
| 494 |
+
tile = z[:, :, :, i : i + self.tile_latent_min_size, j : j + self.tile_latent_min_size]
|
| 495 |
+
if temporal_chunk:
|
| 496 |
+
decoded = self.chunk_decode(tile, window_size=window_size)
|
| 497 |
+
else:
|
| 498 |
+
tile = self.post_quant_conv(tile, is_init_image=True, temporal_chunk=False)
|
| 499 |
+
decoded = self.decoder(tile, is_init_image=True, temporal_chunk=False)
|
| 500 |
+
row.append(decoded)
|
| 501 |
+
rows.append(row)
|
| 502 |
+
result_rows = []
|
| 503 |
+
|
| 504 |
+
for i, row in enumerate(rows):
|
| 505 |
+
result_row = []
|
| 506 |
+
for j, tile in enumerate(row):
|
| 507 |
+
# blend the above tile and the left tile
|
| 508 |
+
# to the current tile and add the current tile to the result row
|
| 509 |
+
if i > 0:
|
| 510 |
+
tile = self.blend_v(rows[i - 1][j], tile, blend_extent)
|
| 511 |
+
if j > 0:
|
| 512 |
+
tile = self.blend_h(row[j - 1], tile, blend_extent)
|
| 513 |
+
result_row.append(tile[:, :, :, :row_limit, :row_limit])
|
| 514 |
+
result_rows.append(torch.cat(result_row, dim=4))
|
| 515 |
+
|
| 516 |
+
dec = torch.cat(result_rows, dim=3)
|
| 517 |
+
if not return_dict:
|
| 518 |
+
return (dec,)
|
| 519 |
+
|
| 520 |
+
return DecoderOutput(sample=dec)
|
| 521 |
+
|
| 522 |
+
def forward(
|
| 523 |
+
self,
|
| 524 |
+
sample: torch.FloatTensor,
|
| 525 |
+
sample_posterior: bool = True,
|
| 526 |
+
generator: Optional[torch.Generator] = None,
|
| 527 |
+
freeze_encoder: bool = False,
|
| 528 |
+
is_init_image=True,
|
| 529 |
+
temporal_chunk=False,
|
| 530 |
+
) -> Union[DecoderOutput, torch.FloatTensor]:
|
| 531 |
+
r"""
|
| 532 |
+
Args:
|
| 533 |
+
sample (`torch.FloatTensor`): Input sample.
|
| 534 |
+
sample_posterior (`bool`, *optional*, defaults to `False`):
|
| 535 |
+
Whether to sample from the posterior.
|
| 536 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 537 |
+
Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
|
| 538 |
+
"""
|
| 539 |
+
x = sample
|
| 540 |
+
|
| 541 |
+
if is_context_parallel_initialized():
|
| 542 |
+
assert self.training, "Only supports during training now"
|
| 543 |
+
|
| 544 |
+
if freeze_encoder:
|
| 545 |
+
with torch.no_grad():
|
| 546 |
+
h = self.encoder(x, is_init_image=True, temporal_chunk=False)
|
| 547 |
+
moments = self.quant_conv(h, is_init_image=True, temporal_chunk=False)
|
| 548 |
+
posterior = DiagonalGaussianDistribution(moments)
|
| 549 |
+
global_posterior = posterior
|
| 550 |
+
else:
|
| 551 |
+
h = self.encoder(x, is_init_image=True, temporal_chunk=False)
|
| 552 |
+
moments = self.quant_conv(h, is_init_image=True, temporal_chunk=False)
|
| 553 |
+
posterior = DiagonalGaussianDistribution(moments)
|
| 554 |
+
global_moments = conv_gather_from_context_parallel_region(moments, dim=2, kernel_size=1)
|
| 555 |
+
global_posterior = DiagonalGaussianDistribution(global_moments)
|
| 556 |
+
|
| 557 |
+
if sample_posterior:
|
| 558 |
+
z = posterior.sample(generator=generator)
|
| 559 |
+
else:
|
| 560 |
+
z = posterior.mode()
|
| 561 |
+
|
| 562 |
+
if get_context_parallel_rank() == 0:
|
| 563 |
+
dec = self.decode(z, is_init_image=True).sample
|
| 564 |
+
else:
|
| 565 |
+
# Do not drop the first upsampled frame
|
| 566 |
+
dec = self.decode(z, is_init_image=False).sample
|
| 567 |
+
|
| 568 |
+
return global_posterior, dec
|
| 569 |
+
|
| 570 |
+
else:
|
| 571 |
+
# The normal training
|
| 572 |
+
if freeze_encoder:
|
| 573 |
+
with torch.no_grad():
|
| 574 |
+
posterior = self.encode(x, is_init_image=is_init_image,
|
| 575 |
+
temporal_chunk=temporal_chunk).latent_dist
|
| 576 |
+
else:
|
| 577 |
+
posterior = self.encode(x, is_init_image=is_init_image,
|
| 578 |
+
temporal_chunk=temporal_chunk).latent_dist
|
| 579 |
+
|
| 580 |
+
if sample_posterior:
|
| 581 |
+
z = posterior.sample(generator=generator)
|
| 582 |
+
else:
|
| 583 |
+
z = posterior.mode()
|
| 584 |
+
|
| 585 |
+
dec = self.decode(z, is_init_image=is_init_image, temporal_chunk=temporal_chunk).sample
|
| 586 |
+
|
| 587 |
+
return posterior, dec
|
| 588 |
+
|
| 589 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.fuse_qkv_projections
|
| 590 |
+
def fuse_qkv_projections(self):
|
| 591 |
+
"""
|
| 592 |
+
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
| 593 |
+
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
| 594 |
+
|
| 595 |
+
<Tip warning={true}>
|
| 596 |
+
|
| 597 |
+
This API is 🧪 experimental.
|
| 598 |
+
|
| 599 |
+
</Tip>
|
| 600 |
+
"""
|
| 601 |
+
self.original_attn_processors = None
|
| 602 |
+
|
| 603 |
+
for _, attn_processor in self.attn_processors.items():
|
| 604 |
+
if "Added" in str(attn_processor.__class__.__name__):
|
| 605 |
+
raise ValueError("`fuse_qkv_projections()` is not supported for models having added KV projections.")
|
| 606 |
+
|
| 607 |
+
self.original_attn_processors = self.attn_processors
|
| 608 |
+
|
| 609 |
+
for module in self.modules():
|
| 610 |
+
if isinstance(module, Attention):
|
| 611 |
+
module.fuse_projections(fuse=True)
|
| 612 |
+
|
| 613 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.unfuse_qkv_projections
|
| 614 |
+
def unfuse_qkv_projections(self):
|
| 615 |
+
"""Disables the fused QKV projection if enabled.
|
| 616 |
+
|
| 617 |
+
<Tip warning={true}>
|
| 618 |
+
|
| 619 |
+
This API is 🧪 experimental.
|
| 620 |
+
|
| 621 |
+
</Tip>
|
| 622 |
+
|
| 623 |
+
"""
|
| 624 |
+
if self.original_attn_processors is not None:
|
| 625 |
+
self.set_attn_processor(self.original_attn_processors)
|
video_vae/modeling_discriminator.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import functools
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from einops import rearrange
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def weights_init(m):
|
| 8 |
+
classname = m.__class__.__name__
|
| 9 |
+
if classname.find('Conv') != -1:
|
| 10 |
+
nn.init.normal_(m.weight.data, 0.0, 0.02)
|
| 11 |
+
nn.init.constant_(m.bias.data, 0)
|
| 12 |
+
elif classname.find('BatchNorm') != -1:
|
| 13 |
+
nn.init.normal_(m.weight.data, 1.0, 0.02)
|
| 14 |
+
nn.init.constant_(m.bias.data, 0)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class NLayerDiscriminator(nn.Module):
|
| 18 |
+
"""Defines a PatchGAN discriminator as in Pix2Pix
|
| 19 |
+
--> see https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/networks.py
|
| 20 |
+
"""
|
| 21 |
+
def __init__(self, input_nc=3, ndf=64, n_layers=4):
|
| 22 |
+
"""Construct a PatchGAN discriminator
|
| 23 |
+
Parameters:
|
| 24 |
+
input_nc (int) -- the number of channels in input images
|
| 25 |
+
ndf (int) -- the number of filters in the last conv layer
|
| 26 |
+
n_layers (int) -- the number of conv layers in the discriminator
|
| 27 |
+
norm_layer -- normalization layer
|
| 28 |
+
"""
|
| 29 |
+
super(NLayerDiscriminator, self).__init__()
|
| 30 |
+
|
| 31 |
+
# norm_layer = nn.BatchNorm2d
|
| 32 |
+
norm_layer = nn.InstanceNorm2d
|
| 33 |
+
|
| 34 |
+
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
|
| 35 |
+
use_bias = norm_layer.func != nn.BatchNorm2d
|
| 36 |
+
else:
|
| 37 |
+
use_bias = norm_layer != nn.BatchNorm2d
|
| 38 |
+
|
| 39 |
+
kw = 4
|
| 40 |
+
padw = 1
|
| 41 |
+
sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
|
| 42 |
+
nf_mult = 1
|
| 43 |
+
nf_mult_prev = 1
|
| 44 |
+
for n in range(1, n_layers): # gradually increase the number of filters
|
| 45 |
+
nf_mult_prev = nf_mult
|
| 46 |
+
nf_mult = min(2 ** n, 8)
|
| 47 |
+
sequence += [
|
| 48 |
+
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
|
| 49 |
+
norm_layer(ndf * nf_mult),
|
| 50 |
+
nn.LeakyReLU(0.2, True)
|
| 51 |
+
]
|
| 52 |
+
|
| 53 |
+
nf_mult_prev = nf_mult
|
| 54 |
+
nf_mult = min(2 ** n_layers, 8)
|
| 55 |
+
sequence += [
|
| 56 |
+
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
|
| 57 |
+
norm_layer(ndf * nf_mult),
|
| 58 |
+
nn.LeakyReLU(0.2, True)
|
| 59 |
+
]
|
| 60 |
+
|
| 61 |
+
sequence += [
|
| 62 |
+
nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
|
| 63 |
+
self.main = nn.Sequential(*sequence)
|
| 64 |
+
|
| 65 |
+
def forward(self, input):
|
| 66 |
+
"""Standard forward."""
|
| 67 |
+
return self.main(input)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class NLayerDiscriminator3D(nn.Module):
|
| 71 |
+
"""Defines a 3D PatchGAN discriminator as in Pix2Pix but for 3D inputs."""
|
| 72 |
+
def __init__(self, input_nc=3, ndf=64, n_layers=3, use_actnorm=False):
|
| 73 |
+
"""
|
| 74 |
+
Construct a 3D PatchGAN discriminator
|
| 75 |
+
|
| 76 |
+
Parameters:
|
| 77 |
+
input_nc (int) -- the number of channels in input volumes
|
| 78 |
+
ndf (int) -- the number of filters in the last conv layer
|
| 79 |
+
n_layers (int) -- the number of conv layers in the discriminator
|
| 80 |
+
use_actnorm (bool) -- flag to use actnorm instead of batchnorm
|
| 81 |
+
"""
|
| 82 |
+
super(NLayerDiscriminator3D, self).__init__()
|
| 83 |
+
# if not use_actnorm:
|
| 84 |
+
# norm_layer = nn.BatchNorm3d
|
| 85 |
+
# else:
|
| 86 |
+
# raise NotImplementedError("Not implemented.")
|
| 87 |
+
|
| 88 |
+
norm_layer = nn.InstanceNorm3d
|
| 89 |
+
|
| 90 |
+
if type(norm_layer) == functools.partial:
|
| 91 |
+
use_bias = norm_layer.func != nn.BatchNorm3d
|
| 92 |
+
else:
|
| 93 |
+
use_bias = norm_layer != nn.BatchNorm3d
|
| 94 |
+
|
| 95 |
+
kw = 4
|
| 96 |
+
padw = 1
|
| 97 |
+
sequence = [nn.Conv3d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
|
| 98 |
+
nf_mult = 1
|
| 99 |
+
nf_mult_prev = 1
|
| 100 |
+
for n in range(1, n_layers): # gradually increase the number of filters
|
| 101 |
+
nf_mult_prev = nf_mult
|
| 102 |
+
nf_mult = min(2 ** n, 8)
|
| 103 |
+
sequence += [
|
| 104 |
+
nn.Conv3d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=(kw, kw, kw), stride=(1,2,2), padding=padw, bias=use_bias),
|
| 105 |
+
norm_layer(ndf * nf_mult),
|
| 106 |
+
nn.LeakyReLU(0.2, True)
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
nf_mult_prev = nf_mult
|
| 110 |
+
nf_mult = min(2 ** n_layers, 8)
|
| 111 |
+
sequence += [
|
| 112 |
+
nn.Conv3d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=(kw, kw, kw), stride=1, padding=padw, bias=use_bias),
|
| 113 |
+
norm_layer(ndf * nf_mult),
|
| 114 |
+
nn.LeakyReLU(0.2, True)
|
| 115 |
+
]
|
| 116 |
+
|
| 117 |
+
sequence += [nn.Conv3d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
|
| 118 |
+
self.main = nn.Sequential(*sequence)
|
| 119 |
+
|
| 120 |
+
def forward(self, input):
|
| 121 |
+
"""Standard forward."""
|
| 122 |
+
return self.main(input)
|
video_vae/modeling_enc_dec.py
ADDED
|
@@ -0,0 +1,422 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from dataclasses import dataclass
|
| 15 |
+
from typing import Optional, Tuple
|
| 16 |
+
|
| 17 |
+
import numpy as np
|
| 18 |
+
import torch
|
| 19 |
+
import torch.nn as nn
|
| 20 |
+
from einops import rearrange
|
| 21 |
+
|
| 22 |
+
from diffusers.utils import BaseOutput, is_torch_version
|
| 23 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 24 |
+
from diffusers.models.attention_processor import SpatialNorm
|
| 25 |
+
from .modeling_block import (
|
| 26 |
+
UNetMidBlock2D,
|
| 27 |
+
CausalUNetMidBlock2D,
|
| 28 |
+
get_down_block,
|
| 29 |
+
get_up_block,
|
| 30 |
+
get_input_layer,
|
| 31 |
+
get_output_layer,
|
| 32 |
+
)
|
| 33 |
+
from .modeling_resnet import (
|
| 34 |
+
Downsample2D,
|
| 35 |
+
Upsample2D,
|
| 36 |
+
TemporalDownsample2x,
|
| 37 |
+
TemporalUpsample2x,
|
| 38 |
+
)
|
| 39 |
+
from .modeling_causal_conv import CausalConv3d, CausalGroupNorm
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
@dataclass
|
| 43 |
+
class DecoderOutput(BaseOutput):
|
| 44 |
+
r"""
|
| 45 |
+
Output of decoding method.
|
| 46 |
+
|
| 47 |
+
Args:
|
| 48 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 49 |
+
The decoded output sample from the last layer of the model.
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
sample: torch.FloatTensor
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class CausalVaeEncoder(nn.Module):
|
| 56 |
+
r"""
|
| 57 |
+
The `Encoder` layer of a variational autoencoder that encodes its input into a latent representation.
|
| 58 |
+
|
| 59 |
+
Args:
|
| 60 |
+
in_channels (`int`, *optional*, defaults to 3):
|
| 61 |
+
The number of input channels.
|
| 62 |
+
out_channels (`int`, *optional*, defaults to 3):
|
| 63 |
+
The number of output channels.
|
| 64 |
+
down_block_types (`Tuple[str, ...]`, *optional*, defaults to `("DownEncoderBlock2D",)`):
|
| 65 |
+
The types of down blocks to use. See `~diffusers.models.unet_2d_blocks.get_down_block` for available
|
| 66 |
+
options.
|
| 67 |
+
block_out_channels (`Tuple[int, ...]`, *optional*, defaults to `(64,)`):
|
| 68 |
+
The number of output channels for each block.
|
| 69 |
+
layers_per_block (`int`, *optional*, defaults to 2):
|
| 70 |
+
The number of layers per block.
|
| 71 |
+
norm_num_groups (`int`, *optional*, defaults to 32):
|
| 72 |
+
The number of groups for normalization.
|
| 73 |
+
act_fn (`str`, *optional*, defaults to `"silu"`):
|
| 74 |
+
The activation function to use. See `~diffusers.models.activations.get_activation` for available options.
|
| 75 |
+
double_z (`bool`, *optional*, defaults to `True`):
|
| 76 |
+
Whether to double the number of output channels for the last block.
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
def __init__(
|
| 80 |
+
self,
|
| 81 |
+
in_channels: int = 3,
|
| 82 |
+
out_channels: int = 3,
|
| 83 |
+
down_block_types: Tuple[str, ...] = ("DownEncoderBlockCausal3D",),
|
| 84 |
+
spatial_down_sample: Tuple[bool, ...] = (True,),
|
| 85 |
+
temporal_down_sample: Tuple[bool, ...] = (False,),
|
| 86 |
+
block_out_channels: Tuple[int, ...] = (64,),
|
| 87 |
+
layers_per_block: Tuple[int, ...] = (2,),
|
| 88 |
+
norm_num_groups: int = 32,
|
| 89 |
+
act_fn: str = "silu",
|
| 90 |
+
double_z: bool = True,
|
| 91 |
+
block_dropout: Tuple[int, ...] = (0.0,),
|
| 92 |
+
mid_block_add_attention=True,
|
| 93 |
+
):
|
| 94 |
+
super().__init__()
|
| 95 |
+
self.layers_per_block = layers_per_block
|
| 96 |
+
|
| 97 |
+
self.conv_in = CausalConv3d(
|
| 98 |
+
in_channels,
|
| 99 |
+
block_out_channels[0],
|
| 100 |
+
kernel_size=3,
|
| 101 |
+
stride=1,
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
self.mid_block = None
|
| 105 |
+
self.down_blocks = nn.ModuleList([])
|
| 106 |
+
|
| 107 |
+
# down
|
| 108 |
+
output_channel = block_out_channels[0]
|
| 109 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 110 |
+
input_channel = output_channel
|
| 111 |
+
output_channel = block_out_channels[i]
|
| 112 |
+
|
| 113 |
+
down_block = get_down_block(
|
| 114 |
+
down_block_type,
|
| 115 |
+
num_layers=self.layers_per_block[i],
|
| 116 |
+
in_channels=input_channel,
|
| 117 |
+
out_channels=output_channel,
|
| 118 |
+
add_spatial_downsample=spatial_down_sample[i],
|
| 119 |
+
add_temporal_downsample=temporal_down_sample[i],
|
| 120 |
+
resnet_eps=1e-6,
|
| 121 |
+
downsample_padding=0,
|
| 122 |
+
resnet_act_fn=act_fn,
|
| 123 |
+
resnet_groups=norm_num_groups,
|
| 124 |
+
attention_head_dim=output_channel,
|
| 125 |
+
temb_channels=None,
|
| 126 |
+
dropout=block_dropout[i],
|
| 127 |
+
)
|
| 128 |
+
self.down_blocks.append(down_block)
|
| 129 |
+
|
| 130 |
+
# mid
|
| 131 |
+
self.mid_block = CausalUNetMidBlock2D(
|
| 132 |
+
in_channels=block_out_channels[-1],
|
| 133 |
+
resnet_eps=1e-6,
|
| 134 |
+
resnet_act_fn=act_fn,
|
| 135 |
+
output_scale_factor=1,
|
| 136 |
+
resnet_time_scale_shift="default",
|
| 137 |
+
attention_head_dim=block_out_channels[-1],
|
| 138 |
+
resnet_groups=norm_num_groups,
|
| 139 |
+
temb_channels=None,
|
| 140 |
+
add_attention=mid_block_add_attention,
|
| 141 |
+
dropout=block_dropout[-1],
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
# out
|
| 145 |
+
|
| 146 |
+
self.conv_norm_out = CausalGroupNorm(num_channels=block_out_channels[-1], num_groups=norm_num_groups, eps=1e-6)
|
| 147 |
+
self.conv_act = nn.SiLU()
|
| 148 |
+
|
| 149 |
+
conv_out_channels = 2 * out_channels if double_z else out_channels
|
| 150 |
+
self.conv_out = CausalConv3d(block_out_channels[-1], conv_out_channels, kernel_size=3, stride=1)
|
| 151 |
+
|
| 152 |
+
self.gradient_checkpointing = False
|
| 153 |
+
|
| 154 |
+
def forward(self, sample: torch.FloatTensor, is_init_image=True, temporal_chunk=False) -> torch.FloatTensor:
|
| 155 |
+
r"""The forward method of the `Encoder` class."""
|
| 156 |
+
|
| 157 |
+
sample = self.conv_in(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 158 |
+
|
| 159 |
+
if self.training and self.gradient_checkpointing:
|
| 160 |
+
|
| 161 |
+
def create_custom_forward(module):
|
| 162 |
+
def custom_forward(*inputs):
|
| 163 |
+
return module(*inputs)
|
| 164 |
+
|
| 165 |
+
return custom_forward
|
| 166 |
+
|
| 167 |
+
# down
|
| 168 |
+
if is_torch_version(">=", "1.11.0"):
|
| 169 |
+
for down_block in self.down_blocks:
|
| 170 |
+
sample = torch.utils.checkpoint.checkpoint(
|
| 171 |
+
create_custom_forward(down_block), sample, is_init_image,
|
| 172 |
+
temporal_chunk, use_reentrant=False
|
| 173 |
+
)
|
| 174 |
+
# middle
|
| 175 |
+
sample = torch.utils.checkpoint.checkpoint(
|
| 176 |
+
create_custom_forward(self.mid_block), sample, is_init_image,
|
| 177 |
+
temporal_chunk, use_reentrant=False
|
| 178 |
+
)
|
| 179 |
+
else:
|
| 180 |
+
for down_block in self.down_blocks:
|
| 181 |
+
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(down_block), sample, is_init_image, temporal_chunk)
|
| 182 |
+
# middle
|
| 183 |
+
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(self.mid_block), sample, is_init_image, temporal_chunk)
|
| 184 |
+
|
| 185 |
+
else:
|
| 186 |
+
# down
|
| 187 |
+
for down_block in self.down_blocks:
|
| 188 |
+
sample = down_block(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 189 |
+
|
| 190 |
+
# middle
|
| 191 |
+
sample = self.mid_block(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 192 |
+
|
| 193 |
+
# post-process
|
| 194 |
+
sample = self.conv_norm_out(sample)
|
| 195 |
+
sample = self.conv_act(sample)
|
| 196 |
+
sample = self.conv_out(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 197 |
+
|
| 198 |
+
return sample
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
class CausalVaeDecoder(nn.Module):
|
| 202 |
+
r"""
|
| 203 |
+
The `Decoder` layer of a variational autoencoder that decodes its latent representation into an output sample.
|
| 204 |
+
|
| 205 |
+
Args:
|
| 206 |
+
in_channels (`int`, *optional*, defaults to 3):
|
| 207 |
+
The number of input channels.
|
| 208 |
+
out_channels (`int`, *optional*, defaults to 3):
|
| 209 |
+
The number of output channels.
|
| 210 |
+
up_block_types (`Tuple[str, ...]`, *optional*, defaults to `("UpDecoderBlock2D",)`):
|
| 211 |
+
The types of up blocks to use. See `~diffusers.models.unet_2d_blocks.get_up_block` for available options.
|
| 212 |
+
block_out_channels (`Tuple[int, ...]`, *optional*, defaults to `(64,)`):
|
| 213 |
+
The number of output channels for each block.
|
| 214 |
+
layers_per_block (`int`, *optional*, defaults to 2):
|
| 215 |
+
The number of layers per block.
|
| 216 |
+
norm_num_groups (`int`, *optional*, defaults to 32):
|
| 217 |
+
The number of groups for normalization.
|
| 218 |
+
act_fn (`str`, *optional*, defaults to `"silu"`):
|
| 219 |
+
The activation function to use. See `~diffusers.models.activations.get_activation` for available options.
|
| 220 |
+
norm_type (`str`, *optional*, defaults to `"group"`):
|
| 221 |
+
The normalization type to use. Can be either `"group"` or `"spatial"`.
|
| 222 |
+
"""
|
| 223 |
+
|
| 224 |
+
def __init__(
|
| 225 |
+
self,
|
| 226 |
+
in_channels: int = 3,
|
| 227 |
+
out_channels: int = 3,
|
| 228 |
+
up_block_types: Tuple[str, ...] = ("UpDecoderBlockCausal3D",),
|
| 229 |
+
spatial_up_sample: Tuple[bool, ...] = (True,),
|
| 230 |
+
temporal_up_sample: Tuple[bool, ...] = (False,),
|
| 231 |
+
block_out_channels: Tuple[int, ...] = (64,),
|
| 232 |
+
layers_per_block: Tuple[int, ...] = (2,),
|
| 233 |
+
norm_num_groups: int = 32,
|
| 234 |
+
act_fn: str = "silu",
|
| 235 |
+
mid_block_add_attention=True,
|
| 236 |
+
interpolate: bool = True,
|
| 237 |
+
block_dropout: Tuple[int, ...] = (0.0,),
|
| 238 |
+
):
|
| 239 |
+
super().__init__()
|
| 240 |
+
self.layers_per_block = layers_per_block
|
| 241 |
+
|
| 242 |
+
self.conv_in = CausalConv3d(
|
| 243 |
+
in_channels,
|
| 244 |
+
block_out_channels[-1],
|
| 245 |
+
kernel_size=3,
|
| 246 |
+
stride=1,
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
self.mid_block = None
|
| 250 |
+
self.up_blocks = nn.ModuleList([])
|
| 251 |
+
|
| 252 |
+
# mid
|
| 253 |
+
self.mid_block = CausalUNetMidBlock2D(
|
| 254 |
+
in_channels=block_out_channels[-1],
|
| 255 |
+
resnet_eps=1e-6,
|
| 256 |
+
resnet_act_fn=act_fn,
|
| 257 |
+
output_scale_factor=1,
|
| 258 |
+
resnet_time_scale_shift="default",
|
| 259 |
+
attention_head_dim=block_out_channels[-1],
|
| 260 |
+
resnet_groups=norm_num_groups,
|
| 261 |
+
temb_channels=None,
|
| 262 |
+
add_attention=mid_block_add_attention,
|
| 263 |
+
dropout=block_dropout[-1],
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
# up
|
| 267 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 268 |
+
output_channel = reversed_block_out_channels[0]
|
| 269 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 270 |
+
prev_output_channel = output_channel
|
| 271 |
+
output_channel = reversed_block_out_channels[i]
|
| 272 |
+
|
| 273 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 274 |
+
|
| 275 |
+
up_block = get_up_block(
|
| 276 |
+
up_block_type,
|
| 277 |
+
num_layers=self.layers_per_block[i],
|
| 278 |
+
in_channels=prev_output_channel,
|
| 279 |
+
out_channels=output_channel,
|
| 280 |
+
prev_output_channel=None,
|
| 281 |
+
add_spatial_upsample=spatial_up_sample[i],
|
| 282 |
+
add_temporal_upsample=temporal_up_sample[i],
|
| 283 |
+
resnet_eps=1e-6,
|
| 284 |
+
resnet_act_fn=act_fn,
|
| 285 |
+
resnet_groups=norm_num_groups,
|
| 286 |
+
attention_head_dim=output_channel,
|
| 287 |
+
temb_channels=None,
|
| 288 |
+
resnet_time_scale_shift='default',
|
| 289 |
+
interpolate=interpolate,
|
| 290 |
+
dropout=block_dropout[i],
|
| 291 |
+
)
|
| 292 |
+
self.up_blocks.append(up_block)
|
| 293 |
+
prev_output_channel = output_channel
|
| 294 |
+
|
| 295 |
+
# out
|
| 296 |
+
self.conv_norm_out = CausalGroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=1e-6)
|
| 297 |
+
self.conv_act = nn.SiLU()
|
| 298 |
+
self.conv_out = CausalConv3d(block_out_channels[0], out_channels, kernel_size=3, stride=1)
|
| 299 |
+
|
| 300 |
+
self.gradient_checkpointing = False
|
| 301 |
+
|
| 302 |
+
def forward(
|
| 303 |
+
self,
|
| 304 |
+
sample: torch.FloatTensor,
|
| 305 |
+
is_init_image=True,
|
| 306 |
+
temporal_chunk=False,
|
| 307 |
+
) -> torch.FloatTensor:
|
| 308 |
+
r"""The forward method of the `Decoder` class."""
|
| 309 |
+
|
| 310 |
+
sample = self.conv_in(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 311 |
+
|
| 312 |
+
upscale_dtype = next(iter(self.up_blocks.parameters())).dtype
|
| 313 |
+
if self.training and self.gradient_checkpointing:
|
| 314 |
+
|
| 315 |
+
def create_custom_forward(module):
|
| 316 |
+
def custom_forward(*inputs):
|
| 317 |
+
return module(*inputs)
|
| 318 |
+
|
| 319 |
+
return custom_forward
|
| 320 |
+
|
| 321 |
+
if is_torch_version(">=", "1.11.0"):
|
| 322 |
+
# middle
|
| 323 |
+
sample = torch.utils.checkpoint.checkpoint(
|
| 324 |
+
create_custom_forward(self.mid_block),
|
| 325 |
+
sample,
|
| 326 |
+
is_init_image=is_init_image,
|
| 327 |
+
temporal_chunk=temporal_chunk,
|
| 328 |
+
use_reentrant=False,
|
| 329 |
+
)
|
| 330 |
+
sample = sample.to(upscale_dtype)
|
| 331 |
+
|
| 332 |
+
# up
|
| 333 |
+
for up_block in self.up_blocks:
|
| 334 |
+
sample = torch.utils.checkpoint.checkpoint(
|
| 335 |
+
create_custom_forward(up_block),
|
| 336 |
+
sample,
|
| 337 |
+
is_init_image=is_init_image,
|
| 338 |
+
temporal_chunk=temporal_chunk,
|
| 339 |
+
use_reentrant=False,
|
| 340 |
+
)
|
| 341 |
+
else:
|
| 342 |
+
# middle
|
| 343 |
+
sample = torch.utils.checkpoint.checkpoint(
|
| 344 |
+
create_custom_forward(self.mid_block), sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk,
|
| 345 |
+
)
|
| 346 |
+
sample = sample.to(upscale_dtype)
|
| 347 |
+
|
| 348 |
+
# up
|
| 349 |
+
for up_block in self.up_blocks:
|
| 350 |
+
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(up_block), sample,
|
| 351 |
+
is_init_image=is_init_image, temporal_chunk=temporal_chunk,)
|
| 352 |
+
else:
|
| 353 |
+
# middle
|
| 354 |
+
sample = self.mid_block(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 355 |
+
sample = sample.to(upscale_dtype)
|
| 356 |
+
|
| 357 |
+
# up
|
| 358 |
+
for up_block in self.up_blocks:
|
| 359 |
+
sample = up_block(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk,)
|
| 360 |
+
|
| 361 |
+
# post-process
|
| 362 |
+
sample = self.conv_norm_out(sample)
|
| 363 |
+
sample = self.conv_act(sample)
|
| 364 |
+
sample = self.conv_out(sample, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 365 |
+
|
| 366 |
+
return sample
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
class DiagonalGaussianDistribution(object):
|
| 370 |
+
def __init__(self, parameters: torch.Tensor, deterministic: bool = False):
|
| 371 |
+
self.parameters = parameters
|
| 372 |
+
self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
|
| 373 |
+
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
|
| 374 |
+
self.deterministic = deterministic
|
| 375 |
+
self.std = torch.exp(0.5 * self.logvar)
|
| 376 |
+
self.var = torch.exp(self.logvar)
|
| 377 |
+
if self.deterministic:
|
| 378 |
+
self.var = self.std = torch.zeros_like(
|
| 379 |
+
self.mean, device=self.parameters.device, dtype=self.parameters.dtype
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
def sample(self, generator: Optional[torch.Generator] = None) -> torch.FloatTensor:
|
| 383 |
+
# make sure sample is on the same device as the parameters and has same dtype
|
| 384 |
+
sample = randn_tensor(
|
| 385 |
+
self.mean.shape,
|
| 386 |
+
generator=generator,
|
| 387 |
+
device=self.parameters.device,
|
| 388 |
+
dtype=self.parameters.dtype,
|
| 389 |
+
)
|
| 390 |
+
x = self.mean + self.std * sample
|
| 391 |
+
return x
|
| 392 |
+
|
| 393 |
+
def kl(self, other: "DiagonalGaussianDistribution" = None) -> torch.Tensor:
|
| 394 |
+
if self.deterministic:
|
| 395 |
+
return torch.Tensor([0.0])
|
| 396 |
+
else:
|
| 397 |
+
if other is None:
|
| 398 |
+
return 0.5 * torch.sum(
|
| 399 |
+
torch.pow(self.mean, 2) + self.var - 1.0 - self.logvar,
|
| 400 |
+
dim=[2, 3, 4],
|
| 401 |
+
)
|
| 402 |
+
else:
|
| 403 |
+
return 0.5 * torch.sum(
|
| 404 |
+
torch.pow(self.mean - other.mean, 2) / other.var
|
| 405 |
+
+ self.var / other.var
|
| 406 |
+
- 1.0
|
| 407 |
+
- self.logvar
|
| 408 |
+
+ other.logvar,
|
| 409 |
+
dim=[2, 3, 4],
|
| 410 |
+
)
|
| 411 |
+
|
| 412 |
+
def nll(self, sample: torch.Tensor, dims: Tuple[int, ...] = [1, 2, 3]) -> torch.Tensor:
|
| 413 |
+
if self.deterministic:
|
| 414 |
+
return torch.Tensor([0.0])
|
| 415 |
+
logtwopi = np.log(2.0 * np.pi)
|
| 416 |
+
return 0.5 * torch.sum(
|
| 417 |
+
logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
|
| 418 |
+
dim=dims,
|
| 419 |
+
)
|
| 420 |
+
|
| 421 |
+
def mode(self) -> torch.Tensor:
|
| 422 |
+
return self.mean
|
video_vae/modeling_loss.py
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
from .modeling_lpips import LPIPS
|
| 7 |
+
from .modeling_discriminator import NLayerDiscriminator, NLayerDiscriminator3D, weights_init
|
| 8 |
+
from IPython import embed
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class AdaptiveLossWeight:
|
| 12 |
+
def __init__(self, timestep_range=[0, 1], buckets=300, weight_range=[1e-7, 1e7]):
|
| 13 |
+
self.bucket_ranges = torch.linspace(timestep_range[0], timestep_range[1], buckets-1)
|
| 14 |
+
self.bucket_losses = torch.ones(buckets)
|
| 15 |
+
self.weight_range = weight_range
|
| 16 |
+
|
| 17 |
+
def weight(self, timestep):
|
| 18 |
+
indices = torch.searchsorted(self.bucket_ranges.to(timestep.device), timestep)
|
| 19 |
+
return (1/self.bucket_losses.to(timestep.device)[indices]).clamp(*self.weight_range)
|
| 20 |
+
|
| 21 |
+
def update_buckets(self, timestep, loss, beta=0.99):
|
| 22 |
+
indices = torch.searchsorted(self.bucket_ranges.to(timestep.device), timestep).cpu()
|
| 23 |
+
self.bucket_losses[indices] = self.bucket_losses[indices]*beta + loss.detach().cpu() * (1-beta)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def hinge_d_loss(logits_real, logits_fake):
|
| 27 |
+
loss_real = torch.mean(F.relu(1.0 - logits_real))
|
| 28 |
+
loss_fake = torch.mean(F.relu(1.0 + logits_fake))
|
| 29 |
+
d_loss = 0.5 * (loss_real + loss_fake)
|
| 30 |
+
return d_loss
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def vanilla_d_loss(logits_real, logits_fake):
|
| 34 |
+
d_loss = 0.5 * (
|
| 35 |
+
torch.mean(torch.nn.functional.softplus(-logits_real))
|
| 36 |
+
+ torch.mean(torch.nn.functional.softplus(logits_fake))
|
| 37 |
+
)
|
| 38 |
+
return d_loss
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def adopt_weight(weight, global_step, threshold=0, value=0.0):
|
| 42 |
+
if global_step < threshold:
|
| 43 |
+
weight = value
|
| 44 |
+
return weight
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class LPIPSWithDiscriminator(nn.Module):
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
disc_start,
|
| 51 |
+
logvar_init=0.0,
|
| 52 |
+
kl_weight=1.0,
|
| 53 |
+
pixelloss_weight=1.0,
|
| 54 |
+
perceptual_weight=1.0,
|
| 55 |
+
# --- Discriminator Loss ---
|
| 56 |
+
disc_num_layers=4,
|
| 57 |
+
disc_in_channels=3,
|
| 58 |
+
disc_factor=1.0,
|
| 59 |
+
disc_weight=0.5,
|
| 60 |
+
disc_loss="hinge",
|
| 61 |
+
add_discriminator=True,
|
| 62 |
+
using_3d_discriminator=False,
|
| 63 |
+
):
|
| 64 |
+
|
| 65 |
+
super().__init__()
|
| 66 |
+
assert disc_loss in ["hinge", "vanilla"]
|
| 67 |
+
self.kl_weight = kl_weight
|
| 68 |
+
self.pixel_weight = pixelloss_weight
|
| 69 |
+
self.perceptual_loss = LPIPS().eval()
|
| 70 |
+
self.perceptual_weight = perceptual_weight
|
| 71 |
+
self.logvar = nn.Parameter(torch.ones(size=()) * logvar_init)
|
| 72 |
+
|
| 73 |
+
if add_discriminator:
|
| 74 |
+
disc_cls = NLayerDiscriminator3D if using_3d_discriminator else NLayerDiscriminator
|
| 75 |
+
self.discriminator = disc_cls(
|
| 76 |
+
input_nc=disc_in_channels, n_layers=disc_num_layers,
|
| 77 |
+
).apply(weights_init)
|
| 78 |
+
else:
|
| 79 |
+
self.discriminator = None
|
| 80 |
+
|
| 81 |
+
self.discriminator_iter_start = disc_start
|
| 82 |
+
self.disc_loss = hinge_d_loss if disc_loss == "hinge" else vanilla_d_loss
|
| 83 |
+
self.disc_factor = disc_factor
|
| 84 |
+
self.discriminator_weight = disc_weight
|
| 85 |
+
self.using_3d_discriminator = using_3d_discriminator
|
| 86 |
+
|
| 87 |
+
def calculate_adaptive_weight(self, nll_loss, g_loss, last_layer=None):
|
| 88 |
+
if last_layer is not None:
|
| 89 |
+
nll_grads = torch.autograd.grad(nll_loss, last_layer, retain_graph=True)[0]
|
| 90 |
+
g_grads = torch.autograd.grad(g_loss, last_layer, retain_graph=True)[0]
|
| 91 |
+
else:
|
| 92 |
+
nll_grads = torch.autograd.grad(
|
| 93 |
+
nll_loss, self.last_layer[0], retain_graph=True
|
| 94 |
+
)[0]
|
| 95 |
+
g_grads = torch.autograd.grad(
|
| 96 |
+
g_loss, self.last_layer[0], retain_graph=True
|
| 97 |
+
)[0]
|
| 98 |
+
|
| 99 |
+
d_weight = torch.norm(nll_grads) / (torch.norm(g_grads) + 1e-4)
|
| 100 |
+
d_weight = torch.clamp(d_weight, 0.0, 1e4).detach()
|
| 101 |
+
d_weight = d_weight * self.discriminator_weight
|
| 102 |
+
return d_weight
|
| 103 |
+
|
| 104 |
+
def forward(
|
| 105 |
+
self,
|
| 106 |
+
inputs,
|
| 107 |
+
reconstructions,
|
| 108 |
+
posteriors,
|
| 109 |
+
optimizer_idx,
|
| 110 |
+
global_step,
|
| 111 |
+
split="train",
|
| 112 |
+
last_layer=None,
|
| 113 |
+
):
|
| 114 |
+
t = reconstructions.shape[2]
|
| 115 |
+
inputs = rearrange(inputs, "b c t h w -> (b t) c h w").contiguous()
|
| 116 |
+
reconstructions = rearrange(reconstructions, "b c t h w -> (b t) c h w").contiguous()
|
| 117 |
+
|
| 118 |
+
if optimizer_idx == 0:
|
| 119 |
+
# rec_loss = torch.mean(torch.abs(inputs - reconstructions), dim=(1,2,3), keepdim=True)
|
| 120 |
+
rec_loss = torch.mean(F.mse_loss(inputs, reconstructions, reduction='none'), dim=(1,2,3), keepdim=True)
|
| 121 |
+
|
| 122 |
+
if self.perceptual_weight > 0:
|
| 123 |
+
p_loss = self.perceptual_loss(inputs, reconstructions)
|
| 124 |
+
nll_loss = self.pixel_weight * rec_loss + self.perceptual_weight * p_loss
|
| 125 |
+
|
| 126 |
+
nll_loss = nll_loss / torch.exp(self.logvar) + self.logvar
|
| 127 |
+
weighted_nll_loss = nll_loss
|
| 128 |
+
weighted_nll_loss = torch.sum(weighted_nll_loss) / weighted_nll_loss.shape[0]
|
| 129 |
+
nll_loss = torch.sum(nll_loss) / nll_loss.shape[0]
|
| 130 |
+
|
| 131 |
+
kl_loss = posteriors.kl()
|
| 132 |
+
kl_loss = torch.mean(kl_loss)
|
| 133 |
+
|
| 134 |
+
disc_factor = adopt_weight(
|
| 135 |
+
self.disc_factor, global_step, threshold=self.discriminator_iter_start
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
if disc_factor > 0.0:
|
| 139 |
+
if self.using_3d_discriminator:
|
| 140 |
+
reconstructions = rearrange(reconstructions, '(b t) c h w -> b c t h w', t=t)
|
| 141 |
+
|
| 142 |
+
logits_fake = self.discriminator(reconstructions.contiguous())
|
| 143 |
+
g_loss = -torch.mean(logits_fake)
|
| 144 |
+
try:
|
| 145 |
+
d_weight = self.calculate_adaptive_weight(
|
| 146 |
+
nll_loss, g_loss, last_layer=last_layer
|
| 147 |
+
)
|
| 148 |
+
except RuntimeError:
|
| 149 |
+
assert not self.training
|
| 150 |
+
d_weight = torch.tensor(0.0)
|
| 151 |
+
else:
|
| 152 |
+
d_weight = torch.tensor(0.0)
|
| 153 |
+
g_loss = torch.tensor(0.0)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
loss = (
|
| 157 |
+
weighted_nll_loss
|
| 158 |
+
+ self.kl_weight * kl_loss
|
| 159 |
+
+ d_weight * disc_factor * g_loss
|
| 160 |
+
)
|
| 161 |
+
log = {
|
| 162 |
+
"{}/total_loss".format(split): loss.clone().detach().mean(),
|
| 163 |
+
"{}/logvar".format(split): self.logvar.detach(),
|
| 164 |
+
"{}/kl_loss".format(split): kl_loss.detach().mean(),
|
| 165 |
+
"{}/nll_loss".format(split): nll_loss.detach().mean(),
|
| 166 |
+
"{}/rec_loss".format(split): rec_loss.detach().mean(),
|
| 167 |
+
"{}/perception_loss".format(split): p_loss.detach().mean(),
|
| 168 |
+
"{}/d_weight".format(split): d_weight.detach(),
|
| 169 |
+
"{}/disc_factor".format(split): torch.tensor(disc_factor),
|
| 170 |
+
"{}/g_loss".format(split): g_loss.detach().mean(),
|
| 171 |
+
}
|
| 172 |
+
return loss, log
|
| 173 |
+
|
| 174 |
+
if optimizer_idx == 1:
|
| 175 |
+
if self.using_3d_discriminator:
|
| 176 |
+
inputs = rearrange(inputs, '(b t) c h w -> b c t h w', t=t)
|
| 177 |
+
reconstructions = rearrange(reconstructions, '(b t) c h w -> b c t h w', t=t)
|
| 178 |
+
|
| 179 |
+
logits_real = self.discriminator(inputs.contiguous().detach())
|
| 180 |
+
logits_fake = self.discriminator(reconstructions.contiguous().detach())
|
| 181 |
+
|
| 182 |
+
disc_factor = adopt_weight(
|
| 183 |
+
self.disc_factor, global_step, threshold=self.discriminator_iter_start
|
| 184 |
+
)
|
| 185 |
+
d_loss = disc_factor * self.disc_loss(logits_real, logits_fake)
|
| 186 |
+
|
| 187 |
+
log = {
|
| 188 |
+
"{}/disc_loss".format(split): d_loss.clone().detach().mean(),
|
| 189 |
+
"{}/logits_real".format(split): logits_real.detach().mean(),
|
| 190 |
+
"{}/logits_fake".format(split): logits_fake.detach().mean(),
|
| 191 |
+
}
|
| 192 |
+
return d_loss, log
|
video_vae/modeling_lpips.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Stripped version of https://github.com/richzhang/PerceptualSimilarity/tree/master/models"""
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from torchvision import models
|
| 6 |
+
from collections import namedtuple
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class LPIPS(nn.Module):
|
| 10 |
+
# Learned perceptual metric
|
| 11 |
+
def __init__(self, use_dropout=True):
|
| 12 |
+
super().__init__()
|
| 13 |
+
self.scaling_layer = ScalingLayer()
|
| 14 |
+
self.chns = [64, 128, 256, 512, 512] # vg16 features
|
| 15 |
+
self.net = vgg16(pretrained=False, requires_grad=False)
|
| 16 |
+
self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
|
| 17 |
+
self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
|
| 18 |
+
self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
|
| 19 |
+
self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
|
| 20 |
+
self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
|
| 21 |
+
self.load_from_pretrained()
|
| 22 |
+
for param in self.parameters():
|
| 23 |
+
param.requires_grad = False
|
| 24 |
+
|
| 25 |
+
def load_from_pretrained(self):
|
| 26 |
+
ckpt = "/home/jinyang/models/vae/video_vae_baseline/vgg_lpips.pth" # replace with your lpips
|
| 27 |
+
self.load_state_dict(torch.load(ckpt, map_location=torch.device("cpu")), strict=True)
|
| 28 |
+
print("loaded pretrained LPIPS loss from {}".format(ckpt))
|
| 29 |
+
|
| 30 |
+
def forward(self, input, target):
|
| 31 |
+
in0_input, in1_input = (self.scaling_layer(input), self.scaling_layer(target))
|
| 32 |
+
outs0, outs1 = self.net(in0_input), self.net(in1_input)
|
| 33 |
+
feats0, feats1, diffs = {}, {}, {}
|
| 34 |
+
lins = [self.lin0, self.lin1, self.lin2, self.lin3, self.lin4]
|
| 35 |
+
for kk in range(len(self.chns)):
|
| 36 |
+
feats0[kk], feats1[kk] = normalize_tensor(outs0[kk]), normalize_tensor(outs1[kk])
|
| 37 |
+
diffs[kk] = (feats0[kk] - feats1[kk]) ** 2
|
| 38 |
+
|
| 39 |
+
res = [spatial_average(lins[kk].model(diffs[kk]), keepdim=True) for kk in range(len(self.chns))]
|
| 40 |
+
val = res[0]
|
| 41 |
+
for l in range(1, len(self.chns)):
|
| 42 |
+
val += res[l]
|
| 43 |
+
return val
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class ScalingLayer(nn.Module):
|
| 47 |
+
def __init__(self):
|
| 48 |
+
super(ScalingLayer, self).__init__()
|
| 49 |
+
self.register_buffer('shift', torch.Tensor([-.030, -.088, -.188])[None, :, None, None])
|
| 50 |
+
self.register_buffer('scale', torch.Tensor([.458, .448, .450])[None, :, None, None])
|
| 51 |
+
|
| 52 |
+
def forward(self, inp):
|
| 53 |
+
return (inp - self.shift) / self.scale
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class NetLinLayer(nn.Module):
|
| 57 |
+
""" A single linear layer which does a 1x1 conv """
|
| 58 |
+
def __init__(self, chn_in, chn_out=1, use_dropout=False):
|
| 59 |
+
super(NetLinLayer, self).__init__()
|
| 60 |
+
layers = [nn.Dropout(), ] if (use_dropout) else []
|
| 61 |
+
layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False), ]
|
| 62 |
+
self.model = nn.Sequential(*layers)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class vgg16(torch.nn.Module):
|
| 66 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 67 |
+
super(vgg16, self).__init__()
|
| 68 |
+
vgg_pretrained_features = models.vgg16(pretrained=pretrained).features
|
| 69 |
+
self.slice1 = torch.nn.Sequential()
|
| 70 |
+
self.slice2 = torch.nn.Sequential()
|
| 71 |
+
self.slice3 = torch.nn.Sequential()
|
| 72 |
+
self.slice4 = torch.nn.Sequential()
|
| 73 |
+
self.slice5 = torch.nn.Sequential()
|
| 74 |
+
self.N_slices = 5
|
| 75 |
+
for x in range(4):
|
| 76 |
+
self.slice1.add_module(str(x), vgg_pretrained_features[x])
|
| 77 |
+
for x in range(4, 9):
|
| 78 |
+
self.slice2.add_module(str(x), vgg_pretrained_features[x])
|
| 79 |
+
for x in range(9, 16):
|
| 80 |
+
self.slice3.add_module(str(x), vgg_pretrained_features[x])
|
| 81 |
+
for x in range(16, 23):
|
| 82 |
+
self.slice4.add_module(str(x), vgg_pretrained_features[x])
|
| 83 |
+
for x in range(23, 30):
|
| 84 |
+
self.slice5.add_module(str(x), vgg_pretrained_features[x])
|
| 85 |
+
if not requires_grad:
|
| 86 |
+
for param in self.parameters():
|
| 87 |
+
param.requires_grad = False
|
| 88 |
+
|
| 89 |
+
def forward(self, X):
|
| 90 |
+
h = self.slice1(X)
|
| 91 |
+
h_relu1_2 = h
|
| 92 |
+
h = self.slice2(h)
|
| 93 |
+
h_relu2_2 = h
|
| 94 |
+
h = self.slice3(h)
|
| 95 |
+
h_relu3_3 = h
|
| 96 |
+
h = self.slice4(h)
|
| 97 |
+
h_relu4_3 = h
|
| 98 |
+
h = self.slice5(h)
|
| 99 |
+
h_relu5_3 = h
|
| 100 |
+
vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3', 'relu5_3'])
|
| 101 |
+
out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
|
| 102 |
+
return out
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def normalize_tensor(x,eps=1e-10):
|
| 106 |
+
norm_factor = torch.sqrt(torch.sum(x**2,dim=1,keepdim=True))
|
| 107 |
+
return x/(norm_factor+eps)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def spatial_average(x, keepdim=True):
|
| 111 |
+
return x.mean([2,3],keepdim=keepdim)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
if __name__ == "__main__":
|
| 115 |
+
model = LPIPS().eval()
|
| 116 |
+
_ = torch.manual_seed(123)
|
| 117 |
+
img1 = (torch.rand(10, 3, 100, 100) * 2) - 1
|
| 118 |
+
img2 = (torch.rand(10, 3, 100, 100) * 2) - 1
|
| 119 |
+
print(model(img1, img2).shape)
|
| 120 |
+
# embed()
|
video_vae/modeling_resnet.py
ADDED
|
@@ -0,0 +1,729 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from typing import Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
from diffusers.models.activations import get_activation
|
| 9 |
+
from diffusers.models.attention_processor import SpatialNorm
|
| 10 |
+
from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
|
| 11 |
+
from diffusers.models.normalization import AdaGroupNorm
|
| 12 |
+
from timm.models.layers import drop_path, to_2tuple, trunc_normal_
|
| 13 |
+
from .modeling_causal_conv import CausalConv3d, CausalGroupNorm
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class CausalResnetBlock3D(nn.Module):
|
| 17 |
+
r"""
|
| 18 |
+
A Resnet block.
|
| 19 |
+
|
| 20 |
+
Parameters:
|
| 21 |
+
in_channels (`int`): The number of channels in the input.
|
| 22 |
+
out_channels (`int`, *optional*, default to be `None`):
|
| 23 |
+
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
|
| 24 |
+
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
|
| 25 |
+
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
|
| 26 |
+
groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
|
| 27 |
+
groups_out (`int`, *optional*, default to None):
|
| 28 |
+
The number of groups to use for the second normalization layer. if set to None, same as `groups`.
|
| 29 |
+
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
|
| 30 |
+
non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
|
| 31 |
+
time_embedding_norm (`str`, *optional*, default to `"default"` ): Time scale shift config.
|
| 32 |
+
By default, apply timestep embedding conditioning with a simple shift mechanism. Choose "scale_shift" or
|
| 33 |
+
"ada_group" for a stronger conditioning with scale and shift.
|
| 34 |
+
kernel (`torch.FloatTensor`, optional, default to None): FIR filter, see
|
| 35 |
+
[`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
|
| 36 |
+
output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
|
| 37 |
+
use_in_shortcut (`bool`, *optional*, default to `True`):
|
| 38 |
+
If `True`, add a 1x1 nn.conv2d layer for skip-connection.
|
| 39 |
+
up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
|
| 40 |
+
down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
|
| 41 |
+
conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
|
| 42 |
+
`conv_shortcut` output.
|
| 43 |
+
conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
|
| 44 |
+
If None, same as `out_channels`.
|
| 45 |
+
"""
|
| 46 |
+
|
| 47 |
+
def __init__(
|
| 48 |
+
self,
|
| 49 |
+
*,
|
| 50 |
+
in_channels: int,
|
| 51 |
+
out_channels: Optional[int] = None,
|
| 52 |
+
conv_shortcut: bool = False,
|
| 53 |
+
dropout: float = 0.0,
|
| 54 |
+
temb_channels: int = 512,
|
| 55 |
+
groups: int = 32,
|
| 56 |
+
groups_out: Optional[int] = None,
|
| 57 |
+
pre_norm: bool = True,
|
| 58 |
+
eps: float = 1e-6,
|
| 59 |
+
non_linearity: str = "swish",
|
| 60 |
+
time_embedding_norm: str = "default", # default, scale_shift, ada_group, spatial
|
| 61 |
+
output_scale_factor: float = 1.0,
|
| 62 |
+
use_in_shortcut: Optional[bool] = None,
|
| 63 |
+
conv_shortcut_bias: bool = True,
|
| 64 |
+
conv_2d_out_channels: Optional[int] = None,
|
| 65 |
+
):
|
| 66 |
+
super().__init__()
|
| 67 |
+
self.pre_norm = pre_norm
|
| 68 |
+
self.pre_norm = True
|
| 69 |
+
self.in_channels = in_channels
|
| 70 |
+
out_channels = in_channels if out_channels is None else out_channels
|
| 71 |
+
self.out_channels = out_channels
|
| 72 |
+
self.use_conv_shortcut = conv_shortcut
|
| 73 |
+
self.output_scale_factor = output_scale_factor
|
| 74 |
+
self.time_embedding_norm = time_embedding_norm
|
| 75 |
+
|
| 76 |
+
linear_cls = nn.Linear
|
| 77 |
+
|
| 78 |
+
if groups_out is None:
|
| 79 |
+
groups_out = groups
|
| 80 |
+
|
| 81 |
+
if self.time_embedding_norm == "ada_group":
|
| 82 |
+
self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
|
| 83 |
+
elif self.time_embedding_norm == "spatial":
|
| 84 |
+
self.norm1 = SpatialNorm(in_channels, temb_channels)
|
| 85 |
+
else:
|
| 86 |
+
self.norm1 = CausalGroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
| 87 |
+
|
| 88 |
+
self.conv1 = CausalConv3d(in_channels, out_channels, kernel_size=3, stride=1)
|
| 89 |
+
|
| 90 |
+
if self.time_embedding_norm == "ada_group":
|
| 91 |
+
self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
|
| 92 |
+
elif self.time_embedding_norm == "spatial":
|
| 93 |
+
self.norm2 = SpatialNorm(out_channels, temb_channels)
|
| 94 |
+
else:
|
| 95 |
+
self.norm2 = CausalGroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
| 96 |
+
|
| 97 |
+
self.dropout = torch.nn.Dropout(dropout)
|
| 98 |
+
conv_2d_out_channels = conv_2d_out_channels or out_channels
|
| 99 |
+
self.conv2 = CausalConv3d(out_channels, conv_2d_out_channels, kernel_size=3, stride=1)
|
| 100 |
+
|
| 101 |
+
self.nonlinearity = get_activation(non_linearity)
|
| 102 |
+
self.upsample = self.downsample = None
|
| 103 |
+
self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
|
| 104 |
+
|
| 105 |
+
self.conv_shortcut = None
|
| 106 |
+
if self.use_in_shortcut:
|
| 107 |
+
self.conv_shortcut = CausalConv3d(
|
| 108 |
+
in_channels,
|
| 109 |
+
conv_2d_out_channels,
|
| 110 |
+
kernel_size=1,
|
| 111 |
+
stride=1,
|
| 112 |
+
bias=conv_shortcut_bias,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
def forward(
|
| 116 |
+
self,
|
| 117 |
+
input_tensor: torch.FloatTensor,
|
| 118 |
+
temb: torch.FloatTensor = None,
|
| 119 |
+
is_init_image=True,
|
| 120 |
+
temporal_chunk=False,
|
| 121 |
+
) -> torch.FloatTensor:
|
| 122 |
+
hidden_states = input_tensor
|
| 123 |
+
|
| 124 |
+
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
| 125 |
+
hidden_states = self.norm1(hidden_states, temb)
|
| 126 |
+
else:
|
| 127 |
+
hidden_states = self.norm1(hidden_states)
|
| 128 |
+
|
| 129 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 130 |
+
|
| 131 |
+
hidden_states = self.conv1(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 132 |
+
|
| 133 |
+
if temb is not None and self.time_embedding_norm == "default":
|
| 134 |
+
hidden_states = hidden_states + temb
|
| 135 |
+
|
| 136 |
+
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
| 137 |
+
hidden_states = self.norm2(hidden_states, temb)
|
| 138 |
+
else:
|
| 139 |
+
hidden_states = self.norm2(hidden_states)
|
| 140 |
+
|
| 141 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 142 |
+
hidden_states = self.dropout(hidden_states)
|
| 143 |
+
hidden_states = self.conv2(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 144 |
+
|
| 145 |
+
if self.conv_shortcut is not None:
|
| 146 |
+
input_tensor = self.conv_shortcut(input_tensor, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 147 |
+
|
| 148 |
+
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
|
| 149 |
+
|
| 150 |
+
return output_tensor
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class ResnetBlock2D(nn.Module):
|
| 154 |
+
r"""
|
| 155 |
+
A Resnet block.
|
| 156 |
+
|
| 157 |
+
Parameters:
|
| 158 |
+
in_channels (`int`): The number of channels in the input.
|
| 159 |
+
out_channels (`int`, *optional*, default to be `None`):
|
| 160 |
+
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
|
| 161 |
+
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
|
| 162 |
+
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
|
| 163 |
+
groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
|
| 164 |
+
groups_out (`int`, *optional*, default to None):
|
| 165 |
+
The number of groups to use for the second normalization layer. if set to None, same as `groups`.
|
| 166 |
+
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
|
| 167 |
+
non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
|
| 168 |
+
time_embedding_norm (`str`, *optional*, default to `"default"` ): Time scale shift config.
|
| 169 |
+
By default, apply timestep embedding conditioning with a simple shift mechanism. Choose "scale_shift" or
|
| 170 |
+
"ada_group" for a stronger conditioning with scale and shift.
|
| 171 |
+
kernel (`torch.FloatTensor`, optional, default to None): FIR filter, see
|
| 172 |
+
[`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
|
| 173 |
+
output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
|
| 174 |
+
use_in_shortcut (`bool`, *optional*, default to `True`):
|
| 175 |
+
If `True`, add a 1x1 nn.conv2d layer for skip-connection.
|
| 176 |
+
up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
|
| 177 |
+
down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
|
| 178 |
+
conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
|
| 179 |
+
`conv_shortcut` output.
|
| 180 |
+
conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
|
| 181 |
+
If None, same as `out_channels`.
|
| 182 |
+
"""
|
| 183 |
+
|
| 184 |
+
def __init__(
|
| 185 |
+
self,
|
| 186 |
+
*,
|
| 187 |
+
in_channels: int,
|
| 188 |
+
out_channels: Optional[int] = None,
|
| 189 |
+
conv_shortcut: bool = False,
|
| 190 |
+
dropout: float = 0.0,
|
| 191 |
+
temb_channels: int = 512,
|
| 192 |
+
groups: int = 32,
|
| 193 |
+
groups_out: Optional[int] = None,
|
| 194 |
+
pre_norm: bool = True,
|
| 195 |
+
eps: float = 1e-6,
|
| 196 |
+
non_linearity: str = "swish",
|
| 197 |
+
time_embedding_norm: str = "default", # default, scale_shift, ada_group, spatial
|
| 198 |
+
output_scale_factor: float = 1.0,
|
| 199 |
+
use_in_shortcut: Optional[bool] = None,
|
| 200 |
+
conv_shortcut_bias: bool = True,
|
| 201 |
+
conv_2d_out_channels: Optional[int] = None,
|
| 202 |
+
):
|
| 203 |
+
super().__init__()
|
| 204 |
+
self.pre_norm = pre_norm
|
| 205 |
+
self.pre_norm = True
|
| 206 |
+
self.in_channels = in_channels
|
| 207 |
+
out_channels = in_channels if out_channels is None else out_channels
|
| 208 |
+
self.out_channels = out_channels
|
| 209 |
+
self.use_conv_shortcut = conv_shortcut
|
| 210 |
+
self.output_scale_factor = output_scale_factor
|
| 211 |
+
self.time_embedding_norm = time_embedding_norm
|
| 212 |
+
|
| 213 |
+
linear_cls = nn.Linear
|
| 214 |
+
conv_cls = nn.Conv3d
|
| 215 |
+
|
| 216 |
+
if groups_out is None:
|
| 217 |
+
groups_out = groups
|
| 218 |
+
|
| 219 |
+
if self.time_embedding_norm == "ada_group":
|
| 220 |
+
self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
|
| 221 |
+
elif self.time_embedding_norm == "spatial":
|
| 222 |
+
self.norm1 = SpatialNorm(in_channels, temb_channels)
|
| 223 |
+
else:
|
| 224 |
+
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
| 225 |
+
|
| 226 |
+
self.conv1 = conv_cls(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
| 227 |
+
|
| 228 |
+
if self.time_embedding_norm == "ada_group":
|
| 229 |
+
self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
|
| 230 |
+
elif self.time_embedding_norm == "spatial":
|
| 231 |
+
self.norm2 = SpatialNorm(out_channels, temb_channels)
|
| 232 |
+
else:
|
| 233 |
+
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
| 234 |
+
|
| 235 |
+
self.dropout = torch.nn.Dropout(dropout)
|
| 236 |
+
conv_2d_out_channels = conv_2d_out_channels or out_channels
|
| 237 |
+
self.conv2 = conv_cls(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
|
| 238 |
+
|
| 239 |
+
self.nonlinearity = get_activation(non_linearity)
|
| 240 |
+
self.upsample = self.downsample = None
|
| 241 |
+
self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
|
| 242 |
+
|
| 243 |
+
self.conv_shortcut = None
|
| 244 |
+
if self.use_in_shortcut:
|
| 245 |
+
self.conv_shortcut = conv_cls(
|
| 246 |
+
in_channels,
|
| 247 |
+
conv_2d_out_channels,
|
| 248 |
+
kernel_size=1,
|
| 249 |
+
stride=1,
|
| 250 |
+
padding=0,
|
| 251 |
+
bias=conv_shortcut_bias,
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
def forward(
|
| 255 |
+
self,
|
| 256 |
+
input_tensor: torch.FloatTensor,
|
| 257 |
+
temb: torch.FloatTensor = None,
|
| 258 |
+
scale: float = 1.0,
|
| 259 |
+
) -> torch.FloatTensor:
|
| 260 |
+
hidden_states = input_tensor
|
| 261 |
+
|
| 262 |
+
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
| 263 |
+
hidden_states = self.norm1(hidden_states, temb)
|
| 264 |
+
else:
|
| 265 |
+
hidden_states = self.norm1(hidden_states)
|
| 266 |
+
|
| 267 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 268 |
+
|
| 269 |
+
hidden_states = self.conv1(hidden_states)
|
| 270 |
+
|
| 271 |
+
if temb is not None and self.time_embedding_norm == "default":
|
| 272 |
+
hidden_states = hidden_states + temb
|
| 273 |
+
|
| 274 |
+
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
| 275 |
+
hidden_states = self.norm2(hidden_states, temb)
|
| 276 |
+
else:
|
| 277 |
+
hidden_states = self.norm2(hidden_states)
|
| 278 |
+
|
| 279 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 280 |
+
hidden_states = self.dropout(hidden_states)
|
| 281 |
+
hidden_states = self.conv2(hidden_states)
|
| 282 |
+
|
| 283 |
+
if self.conv_shortcut is not None:
|
| 284 |
+
input_tensor = self.conv_shortcut(input_tensor)
|
| 285 |
+
|
| 286 |
+
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
|
| 287 |
+
|
| 288 |
+
return output_tensor
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class CausalDownsample2x(nn.Module):
|
| 292 |
+
"""A 2D downsampling layer with an optional convolution.
|
| 293 |
+
|
| 294 |
+
Parameters:
|
| 295 |
+
channels (`int`):
|
| 296 |
+
number of channels in the inputs and outputs.
|
| 297 |
+
use_conv (`bool`, default `False`):
|
| 298 |
+
option to use a convolution.
|
| 299 |
+
out_channels (`int`, optional):
|
| 300 |
+
number of output channels. Defaults to `channels`.
|
| 301 |
+
padding (`int`, default `1`):
|
| 302 |
+
padding for the convolution.
|
| 303 |
+
name (`str`, default `conv`):
|
| 304 |
+
name of the downsampling 2D layer.
|
| 305 |
+
"""
|
| 306 |
+
|
| 307 |
+
def __init__(
|
| 308 |
+
self,
|
| 309 |
+
channels: int,
|
| 310 |
+
use_conv: bool = True,
|
| 311 |
+
out_channels: Optional[int] = None,
|
| 312 |
+
name: str = "conv",
|
| 313 |
+
kernel_size=3,
|
| 314 |
+
bias=True,
|
| 315 |
+
):
|
| 316 |
+
super().__init__()
|
| 317 |
+
self.channels = channels
|
| 318 |
+
self.out_channels = out_channels or channels
|
| 319 |
+
self.use_conv = use_conv
|
| 320 |
+
stride = (1, 2, 2)
|
| 321 |
+
self.name = name
|
| 322 |
+
|
| 323 |
+
if use_conv:
|
| 324 |
+
conv = CausalConv3d(
|
| 325 |
+
self.channels, self.out_channels, kernel_size=kernel_size, stride=stride, bias=bias
|
| 326 |
+
)
|
| 327 |
+
else:
|
| 328 |
+
assert self.channels == self.out_channels
|
| 329 |
+
conv = nn.AvgPool3d(kernel_size=stride, stride=stride)
|
| 330 |
+
|
| 331 |
+
self.conv = conv
|
| 332 |
+
|
| 333 |
+
def forward(self, hidden_states: torch.FloatTensor, is_init_image=True, temporal_chunk=False) -> torch.FloatTensor:
|
| 334 |
+
assert hidden_states.shape[1] == self.channels
|
| 335 |
+
hidden_states = self.conv(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 336 |
+
return hidden_states
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
class Downsample2D(nn.Module):
|
| 340 |
+
"""A 2D downsampling layer with an optional convolution.
|
| 341 |
+
|
| 342 |
+
Parameters:
|
| 343 |
+
channels (`int`):
|
| 344 |
+
number of channels in the inputs and outputs.
|
| 345 |
+
use_conv (`bool`, default `False`):
|
| 346 |
+
option to use a convolution.
|
| 347 |
+
out_channels (`int`, optional):
|
| 348 |
+
number of output channels. Defaults to `channels`.
|
| 349 |
+
padding (`int`, default `1`):
|
| 350 |
+
padding for the convolution.
|
| 351 |
+
name (`str`, default `conv`):
|
| 352 |
+
name of the downsampling 2D layer.
|
| 353 |
+
"""
|
| 354 |
+
|
| 355 |
+
def __init__(
|
| 356 |
+
self,
|
| 357 |
+
channels: int,
|
| 358 |
+
use_conv: bool = True,
|
| 359 |
+
out_channels: Optional[int] = None,
|
| 360 |
+
padding: int = 0,
|
| 361 |
+
name: str = "conv",
|
| 362 |
+
kernel_size=3,
|
| 363 |
+
bias=True,
|
| 364 |
+
):
|
| 365 |
+
super().__init__()
|
| 366 |
+
self.channels = channels
|
| 367 |
+
self.out_channels = out_channels or channels
|
| 368 |
+
self.use_conv = use_conv
|
| 369 |
+
self.padding = padding
|
| 370 |
+
stride = (1, 2, 2)
|
| 371 |
+
self.name = name
|
| 372 |
+
conv_cls = nn.Conv3d
|
| 373 |
+
|
| 374 |
+
if use_conv:
|
| 375 |
+
conv = conv_cls(
|
| 376 |
+
self.channels, self.out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias
|
| 377 |
+
)
|
| 378 |
+
else:
|
| 379 |
+
assert self.channels == self.out_channels
|
| 380 |
+
conv = nn.AvgPool2d(kernel_size=stride, stride=stride)
|
| 381 |
+
|
| 382 |
+
self.conv = conv
|
| 383 |
+
|
| 384 |
+
def forward(self, hidden_states: torch.FloatTensor) -> torch.FloatTensor:
|
| 385 |
+
assert hidden_states.shape[1] == self.channels
|
| 386 |
+
|
| 387 |
+
if self.use_conv and self.padding == 0:
|
| 388 |
+
pad = (0, 1, 0, 1, 1, 1)
|
| 389 |
+
hidden_states = F.pad(hidden_states, pad, mode="constant", value=0)
|
| 390 |
+
|
| 391 |
+
assert hidden_states.shape[1] == self.channels
|
| 392 |
+
|
| 393 |
+
hidden_states = self.conv(hidden_states)
|
| 394 |
+
|
| 395 |
+
return hidden_states
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
class TemporalDownsample2x(nn.Module):
|
| 399 |
+
"""A Temporal downsampling layer with an optional convolution.
|
| 400 |
+
|
| 401 |
+
Parameters:
|
| 402 |
+
channels (`int`):
|
| 403 |
+
number of channels in the inputs and outputs.
|
| 404 |
+
use_conv (`bool`, default `False`):
|
| 405 |
+
option to use a convolution.
|
| 406 |
+
out_channels (`int`, optional):
|
| 407 |
+
number of output channels. Defaults to `channels`.
|
| 408 |
+
padding (`int`, default `1`):
|
| 409 |
+
padding for the convolution.
|
| 410 |
+
name (`str`, default `conv`):
|
| 411 |
+
name of the downsampling 2D layer.
|
| 412 |
+
"""
|
| 413 |
+
|
| 414 |
+
def __init__(
|
| 415 |
+
self,
|
| 416 |
+
channels: int,
|
| 417 |
+
use_conv: bool = False,
|
| 418 |
+
out_channels: Optional[int] = None,
|
| 419 |
+
padding: int = 0,
|
| 420 |
+
kernel_size=3,
|
| 421 |
+
bias=True,
|
| 422 |
+
):
|
| 423 |
+
super().__init__()
|
| 424 |
+
self.channels = channels
|
| 425 |
+
self.out_channels = out_channels or channels
|
| 426 |
+
self.use_conv = use_conv
|
| 427 |
+
self.padding = padding
|
| 428 |
+
stride = (2, 1, 1)
|
| 429 |
+
|
| 430 |
+
conv_cls = nn.Conv3d
|
| 431 |
+
|
| 432 |
+
if use_conv:
|
| 433 |
+
conv = conv_cls(
|
| 434 |
+
self.channels, self.out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias
|
| 435 |
+
)
|
| 436 |
+
else:
|
| 437 |
+
raise NotImplementedError("Not implemented for temporal downsample without")
|
| 438 |
+
|
| 439 |
+
self.conv = conv
|
| 440 |
+
|
| 441 |
+
def forward(self, hidden_states: torch.FloatTensor) -> torch.FloatTensor:
|
| 442 |
+
assert hidden_states.shape[1] == self.channels
|
| 443 |
+
|
| 444 |
+
if self.use_conv and self.padding == 0:
|
| 445 |
+
if hidden_states.shape[2] == 1:
|
| 446 |
+
# image
|
| 447 |
+
pad = (1, 1, 1, 1, 1, 1)
|
| 448 |
+
else:
|
| 449 |
+
# video
|
| 450 |
+
pad = (1, 1, 1, 1, 0, 1)
|
| 451 |
+
|
| 452 |
+
hidden_states = F.pad(hidden_states, pad, mode="constant", value=0)
|
| 453 |
+
|
| 454 |
+
hidden_states = self.conv(hidden_states)
|
| 455 |
+
return hidden_states
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
class CausalTemporalDownsample2x(nn.Module):
|
| 459 |
+
"""A Temporal downsampling layer with an optional convolution.
|
| 460 |
+
|
| 461 |
+
Parameters:
|
| 462 |
+
channels (`int`):
|
| 463 |
+
number of channels in the inputs and outputs.
|
| 464 |
+
use_conv (`bool`, default `False`):
|
| 465 |
+
option to use a convolution.
|
| 466 |
+
out_channels (`int`, optional):
|
| 467 |
+
number of output channels. Defaults to `channels`.
|
| 468 |
+
padding (`int`, default `1`):
|
| 469 |
+
padding for the convolution.
|
| 470 |
+
name (`str`, default `conv`):
|
| 471 |
+
name of the downsampling 2D layer.
|
| 472 |
+
"""
|
| 473 |
+
|
| 474 |
+
def __init__(
|
| 475 |
+
self,
|
| 476 |
+
channels: int,
|
| 477 |
+
use_conv: bool = False,
|
| 478 |
+
out_channels: Optional[int] = None,
|
| 479 |
+
kernel_size=3,
|
| 480 |
+
bias=True,
|
| 481 |
+
):
|
| 482 |
+
super().__init__()
|
| 483 |
+
self.channels = channels
|
| 484 |
+
self.out_channels = out_channels or channels
|
| 485 |
+
self.use_conv = use_conv
|
| 486 |
+
stride = (2, 1, 1)
|
| 487 |
+
|
| 488 |
+
conv_cls = nn.Conv3d
|
| 489 |
+
|
| 490 |
+
if use_conv:
|
| 491 |
+
conv = CausalConv3d(
|
| 492 |
+
self.channels, self.out_channels, kernel_size=kernel_size, stride=stride, bias=bias
|
| 493 |
+
)
|
| 494 |
+
else:
|
| 495 |
+
raise NotImplementedError("Not implemented for temporal downsample without")
|
| 496 |
+
|
| 497 |
+
self.conv = conv
|
| 498 |
+
|
| 499 |
+
def forward(self, hidden_states: torch.FloatTensor, is_init_image=True, temporal_chunk=False) -> torch.FloatTensor:
|
| 500 |
+
assert hidden_states.shape[1] == self.channels
|
| 501 |
+
hidden_states = self.conv(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 502 |
+
return hidden_states
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
class Upsample2D(nn.Module):
|
| 506 |
+
"""A 2D upsampling layer with an optional convolution.
|
| 507 |
+
|
| 508 |
+
Parameters:
|
| 509 |
+
channels (`int`):
|
| 510 |
+
number of channels in the inputs and outputs.
|
| 511 |
+
use_conv (`bool`, default `False`):
|
| 512 |
+
option to use a convolution.
|
| 513 |
+
out_channels (`int`, optional):
|
| 514 |
+
number of output channels. Defaults to `channels`.
|
| 515 |
+
name (`str`, default `conv`):
|
| 516 |
+
name of the upsampling 2D layer.
|
| 517 |
+
"""
|
| 518 |
+
|
| 519 |
+
def __init__(
|
| 520 |
+
self,
|
| 521 |
+
channels: int,
|
| 522 |
+
use_conv: bool = False,
|
| 523 |
+
out_channels: Optional[int] = None,
|
| 524 |
+
name: str = "conv",
|
| 525 |
+
kernel_size: Optional[int] = None,
|
| 526 |
+
padding=1,
|
| 527 |
+
bias=True,
|
| 528 |
+
interpolate=False,
|
| 529 |
+
):
|
| 530 |
+
super().__init__()
|
| 531 |
+
self.channels = channels
|
| 532 |
+
self.out_channels = out_channels or channels
|
| 533 |
+
self.use_conv = use_conv
|
| 534 |
+
self.name = name
|
| 535 |
+
self.interpolate = interpolate
|
| 536 |
+
conv_cls = nn.Conv3d
|
| 537 |
+
conv = None
|
| 538 |
+
|
| 539 |
+
if interpolate:
|
| 540 |
+
raise NotImplementedError("Not implemented for spatial upsample with interpolate")
|
| 541 |
+
else:
|
| 542 |
+
if kernel_size is None:
|
| 543 |
+
kernel_size = 3
|
| 544 |
+
conv = conv_cls(self.channels, self.out_channels * 4, kernel_size=kernel_size, padding=padding, bias=bias)
|
| 545 |
+
|
| 546 |
+
self.conv = conv
|
| 547 |
+
self.conv.apply(self._init_weights)
|
| 548 |
+
|
| 549 |
+
def _init_weights(self, m):
|
| 550 |
+
if isinstance(m, (nn.Linear, nn.Conv2d, nn.Conv3d)):
|
| 551 |
+
trunc_normal_(m.weight, std=.02)
|
| 552 |
+
if m.bias is not None:
|
| 553 |
+
nn.init.constant_(m.bias, 0)
|
| 554 |
+
elif isinstance(m, nn.LayerNorm):
|
| 555 |
+
nn.init.constant_(m.bias, 0)
|
| 556 |
+
nn.init.constant_(m.weight, 1.0)
|
| 557 |
+
|
| 558 |
+
def forward(
|
| 559 |
+
self,
|
| 560 |
+
hidden_states: torch.FloatTensor,
|
| 561 |
+
) -> torch.FloatTensor:
|
| 562 |
+
assert hidden_states.shape[1] == self.channels
|
| 563 |
+
|
| 564 |
+
hidden_states = self.conv(hidden_states)
|
| 565 |
+
hidden_states = rearrange(hidden_states, 'b (c p1 p2) t h w -> b c t (h p1) (w p2)', p1=2, p2=2)
|
| 566 |
+
|
| 567 |
+
return hidden_states
|
| 568 |
+
|
| 569 |
+
|
| 570 |
+
class CausalUpsample2x(nn.Module):
|
| 571 |
+
"""A 2D upsampling layer with an optional convolution.
|
| 572 |
+
|
| 573 |
+
Parameters:
|
| 574 |
+
channels (`int`):
|
| 575 |
+
number of channels in the inputs and outputs.
|
| 576 |
+
use_conv (`bool`, default `False`):
|
| 577 |
+
option to use a convolution.
|
| 578 |
+
out_channels (`int`, optional):
|
| 579 |
+
number of output channels. Defaults to `channels`.
|
| 580 |
+
name (`str`, default `conv`):
|
| 581 |
+
name of the upsampling 2D layer.
|
| 582 |
+
"""
|
| 583 |
+
|
| 584 |
+
def __init__(
|
| 585 |
+
self,
|
| 586 |
+
channels: int,
|
| 587 |
+
use_conv: bool = False,
|
| 588 |
+
out_channels: Optional[int] = None,
|
| 589 |
+
name: str = "conv",
|
| 590 |
+
kernel_size: Optional[int] = 3,
|
| 591 |
+
bias=True,
|
| 592 |
+
interpolate=False,
|
| 593 |
+
):
|
| 594 |
+
super().__init__()
|
| 595 |
+
self.channels = channels
|
| 596 |
+
self.out_channels = out_channels or channels
|
| 597 |
+
self.use_conv = use_conv
|
| 598 |
+
self.name = name
|
| 599 |
+
self.interpolate = interpolate
|
| 600 |
+
conv = None
|
| 601 |
+
|
| 602 |
+
if interpolate:
|
| 603 |
+
raise NotImplementedError("Not implemented for spatial upsample with interpolate")
|
| 604 |
+
else:
|
| 605 |
+
conv = CausalConv3d(self.channels, self.out_channels * 4, kernel_size=kernel_size, stride=1, bias=bias)
|
| 606 |
+
|
| 607 |
+
self.conv = conv
|
| 608 |
+
|
| 609 |
+
def forward(
|
| 610 |
+
self,
|
| 611 |
+
hidden_states: torch.FloatTensor,
|
| 612 |
+
is_init_image=True, temporal_chunk=False,
|
| 613 |
+
) -> torch.FloatTensor:
|
| 614 |
+
assert hidden_states.shape[1] == self.channels
|
| 615 |
+
hidden_states = self.conv(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 616 |
+
hidden_states = rearrange(hidden_states, 'b (c p1 p2) t h w -> b c t (h p1) (w p2)', p1=2, p2=2)
|
| 617 |
+
return hidden_states
|
| 618 |
+
|
| 619 |
+
|
| 620 |
+
class TemporalUpsample2x(nn.Module):
|
| 621 |
+
"""A 2D upsampling layer with an optional convolution.
|
| 622 |
+
|
| 623 |
+
Parameters:
|
| 624 |
+
channels (`int`):
|
| 625 |
+
number of channels in the inputs and outputs.
|
| 626 |
+
use_conv (`bool`, default `False`):
|
| 627 |
+
option to use a convolution.
|
| 628 |
+
out_channels (`int`, optional):
|
| 629 |
+
number of output channels. Defaults to `channels`.
|
| 630 |
+
name (`str`, default `conv`):
|
| 631 |
+
name of the upsampling 2D layer.
|
| 632 |
+
"""
|
| 633 |
+
|
| 634 |
+
def __init__(
|
| 635 |
+
self,
|
| 636 |
+
channels: int,
|
| 637 |
+
use_conv: bool = True,
|
| 638 |
+
out_channels: Optional[int] = None,
|
| 639 |
+
kernel_size: Optional[int] = None,
|
| 640 |
+
padding=1,
|
| 641 |
+
bias=True,
|
| 642 |
+
interpolate=False,
|
| 643 |
+
):
|
| 644 |
+
super().__init__()
|
| 645 |
+
self.channels = channels
|
| 646 |
+
self.out_channels = out_channels or channels
|
| 647 |
+
self.use_conv = use_conv
|
| 648 |
+
self.interpolate = interpolate
|
| 649 |
+
conv_cls = nn.Conv3d
|
| 650 |
+
|
| 651 |
+
conv = None
|
| 652 |
+
if interpolate:
|
| 653 |
+
raise NotImplementedError("Not implemented for spatial upsample with interpolate")
|
| 654 |
+
else:
|
| 655 |
+
# depth to space operator
|
| 656 |
+
if kernel_size is None:
|
| 657 |
+
kernel_size = 3
|
| 658 |
+
conv = conv_cls(self.channels, self.out_channels * 2, kernel_size=kernel_size, padding=padding, bias=bias)
|
| 659 |
+
|
| 660 |
+
self.conv = conv
|
| 661 |
+
|
| 662 |
+
def forward(
|
| 663 |
+
self,
|
| 664 |
+
hidden_states: torch.FloatTensor,
|
| 665 |
+
is_image: bool = False,
|
| 666 |
+
) -> torch.FloatTensor:
|
| 667 |
+
assert hidden_states.shape[1] == self.channels
|
| 668 |
+
t = hidden_states.shape[2]
|
| 669 |
+
hidden_states = self.conv(hidden_states)
|
| 670 |
+
hidden_states = rearrange(hidden_states, 'b (c p) t h w -> b c (p t) h w', p=2)
|
| 671 |
+
|
| 672 |
+
if t == 1 and is_image:
|
| 673 |
+
hidden_states = hidden_states[:, :, 1:]
|
| 674 |
+
|
| 675 |
+
return hidden_states
|
| 676 |
+
|
| 677 |
+
|
| 678 |
+
class CausalTemporalUpsample2x(nn.Module):
|
| 679 |
+
"""A 2D upsampling layer with an optional convolution.
|
| 680 |
+
|
| 681 |
+
Parameters:
|
| 682 |
+
channels (`int`):
|
| 683 |
+
number of channels in the inputs and outputs.
|
| 684 |
+
use_conv (`bool`, default `False`):
|
| 685 |
+
option to use a convolution.
|
| 686 |
+
out_channels (`int`, optional):
|
| 687 |
+
number of output channels. Defaults to `channels`.
|
| 688 |
+
name (`str`, default `conv`):
|
| 689 |
+
name of the upsampling 2D layer.
|
| 690 |
+
"""
|
| 691 |
+
|
| 692 |
+
def __init__(
|
| 693 |
+
self,
|
| 694 |
+
channels: int,
|
| 695 |
+
use_conv: bool = True,
|
| 696 |
+
out_channels: Optional[int] = None,
|
| 697 |
+
kernel_size: Optional[int] = 3,
|
| 698 |
+
bias=True,
|
| 699 |
+
interpolate=False,
|
| 700 |
+
):
|
| 701 |
+
super().__init__()
|
| 702 |
+
self.channels = channels
|
| 703 |
+
self.out_channels = out_channels or channels
|
| 704 |
+
self.use_conv = use_conv
|
| 705 |
+
self.interpolate = interpolate
|
| 706 |
+
|
| 707 |
+
conv = None
|
| 708 |
+
if interpolate:
|
| 709 |
+
raise NotImplementedError("Not implemented for spatial upsample with interpolate")
|
| 710 |
+
else:
|
| 711 |
+
# depth to space operator
|
| 712 |
+
conv = CausalConv3d(self.channels, self.out_channels * 2, kernel_size=kernel_size, stride=1, bias=bias)
|
| 713 |
+
|
| 714 |
+
self.conv = conv
|
| 715 |
+
|
| 716 |
+
def forward(
|
| 717 |
+
self,
|
| 718 |
+
hidden_states: torch.FloatTensor,
|
| 719 |
+
is_init_image=True, temporal_chunk=False,
|
| 720 |
+
) -> torch.FloatTensor:
|
| 721 |
+
assert hidden_states.shape[1] == self.channels
|
| 722 |
+
t = hidden_states.shape[2]
|
| 723 |
+
hidden_states = self.conv(hidden_states, is_init_image=is_init_image, temporal_chunk=temporal_chunk)
|
| 724 |
+
hidden_states = rearrange(hidden_states, 'b (c p) t h w -> b c (t p) h w', p=2)
|
| 725 |
+
|
| 726 |
+
if is_init_image:
|
| 727 |
+
hidden_states = hidden_states[:, :, 1:]
|
| 728 |
+
|
| 729 |
+
return hidden_states
|