Spaces:
Configuration error

Configuration error
Commit
•
3b40f46
1
Parent(s):
8366707
Upload 351 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- .gitignore +3 -0
- CLIP/CLIP.png +0 -0
- CLIP/LICENSE +22 -0
- CLIP/MANIFEST.in +1 -0
- CLIP/README.md +193 -0
- CLIP/__init__.py +0 -0
- CLIP/clip/__init__.py +1 -0
- CLIP/clip/bpe_simple_vocab_16e6.txt.gz +3 -0
- CLIP/clip/clip.py +231 -0
- CLIP/clip/model.py +484 -0
- CLIP/clip/simple_tokenizer.py +132 -0
- CLIP/clip_explainability/__init__.py +1 -0
- CLIP/clip_explainability/auxilary.py +422 -0
- CLIP/clip_explainability/bpe_simple_vocab_16e6.txt.gz +3 -0
- CLIP/clip_explainability/clip.py +196 -0
- CLIP/clip_explainability/model.py +442 -0
- CLIP/clip_explainability/simple_tokenizer.py +132 -0
- CLIP/data/country211.md +12 -0
- CLIP/data/prompts.md +3401 -0
- CLIP/data/rendered-sst2.md +11 -0
- CLIP/data/yfcc100m.md +14 -0
- CLIP/model-card.md +120 -0
- CLIP/requirements.txt +5 -0
- CLIP/setup.py +21 -0
- CLIP/tests/test_consistency.py +25 -0
- LICENSE +21 -0
- README.md +86 -13
- Text2LIVE-main/CLIP/__pycache__/__init__.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip/__pycache__/__init__.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip/__pycache__/clip.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip/__pycache__/model.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip/__pycache__/simple_tokenizer.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip_explainability/__pycache__/__init__.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip_explainability/__pycache__/auxilary.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip_explainability/__pycache__/clip.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip_explainability/__pycache__/model.cpython-37.pyc +0 -0
- Text2LIVE-main/CLIP/clip_explainability/__pycache__/simple_tokenizer.cpython-37.pyc +0 -0
- Text2LIVE-main/README.md +5 -7
- Text2LIVE-main/data/data/images/Thumbs.db +0 -0
- Text2LIVE-main/data/data/images/cake.jpeg +0 -0
- Text2LIVE-main/data/data/images/horse.jpg +0 -0
- Text2LIVE-main/data/data/pretrained_nla_models/blackswan/checkpoint +3 -0
- Text2LIVE-main/data/data/pretrained_nla_models/car-turn/checkpoint +3 -0
- Text2LIVE-main/data/data/pretrained_nla_models/libby/checkpoint +3 -0
- Text2LIVE-main/data/data/videos/blackswan/00000.jpg +0 -0
- Text2LIVE-main/data/data/videos/blackswan/00001.jpg +0 -0
- Text2LIVE-main/data/data/videos/blackswan/00002.jpg +0 -0
- Text2LIVE-main/data/data/videos/blackswan/00003.jpg +0 -0
- Text2LIVE-main/data/data/videos/blackswan/00004.jpg +0 -0
.gitattributes
CHANGED
|
@@ -35,3 +35,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 35 |
Text2LIVE-main/Text2LIVE-main/data/data/pretrained_nla_models/blackswan/checkpoint filter=lfs diff=lfs merge=lfs -text
|
| 36 |
Text2LIVE-main/Text2LIVE-main/data/data/pretrained_nla_models/car-turn/checkpoint filter=lfs diff=lfs merge=lfs -text
|
| 37 |
Text2LIVE-main/Text2LIVE-main/data/data/pretrained_nla_models/libby/checkpoint filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
Text2LIVE-main/Text2LIVE-main/data/data/pretrained_nla_models/blackswan/checkpoint filter=lfs diff=lfs merge=lfs -text
|
| 36 |
Text2LIVE-main/Text2LIVE-main/data/data/pretrained_nla_models/car-turn/checkpoint filter=lfs diff=lfs merge=lfs -text
|
| 37 |
Text2LIVE-main/Text2LIVE-main/data/data/pretrained_nla_models/libby/checkpoint filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
Text2LIVE-main/data/data/pretrained_nla_models/blackswan/checkpoint filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
Text2LIVE-main/data/data/pretrained_nla_models/car-turn/checkpoint filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
Text2LIVE-main/data/data/pretrained_nla_models/libby/checkpoint filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/wandb/
|
| 2 |
+
__pycache__/
|
| 3 |
+
/idea
|
CLIP/CLIP.png
ADDED
|
CLIP/LICENSE
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 OpenAI
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
| 22 |
+
|
CLIP/MANIFEST.in
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
include clip/bpe_simple_vocab_16e6.txt.gz
|
CLIP/README.md
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CLIP
|
| 2 |
+
|
| 3 |
+
[[Blog]](https://openai.com/blog/clip/) [[Paper]](https://arxiv.org/abs/2103.00020) [[Model Card]](model-card.md) [[Colab]](https://colab.research.google.com/github/openai/clip/blob/master/notebooks/Interacting_with_CLIP.ipynb)
|
| 4 |
+
|
| 5 |
+
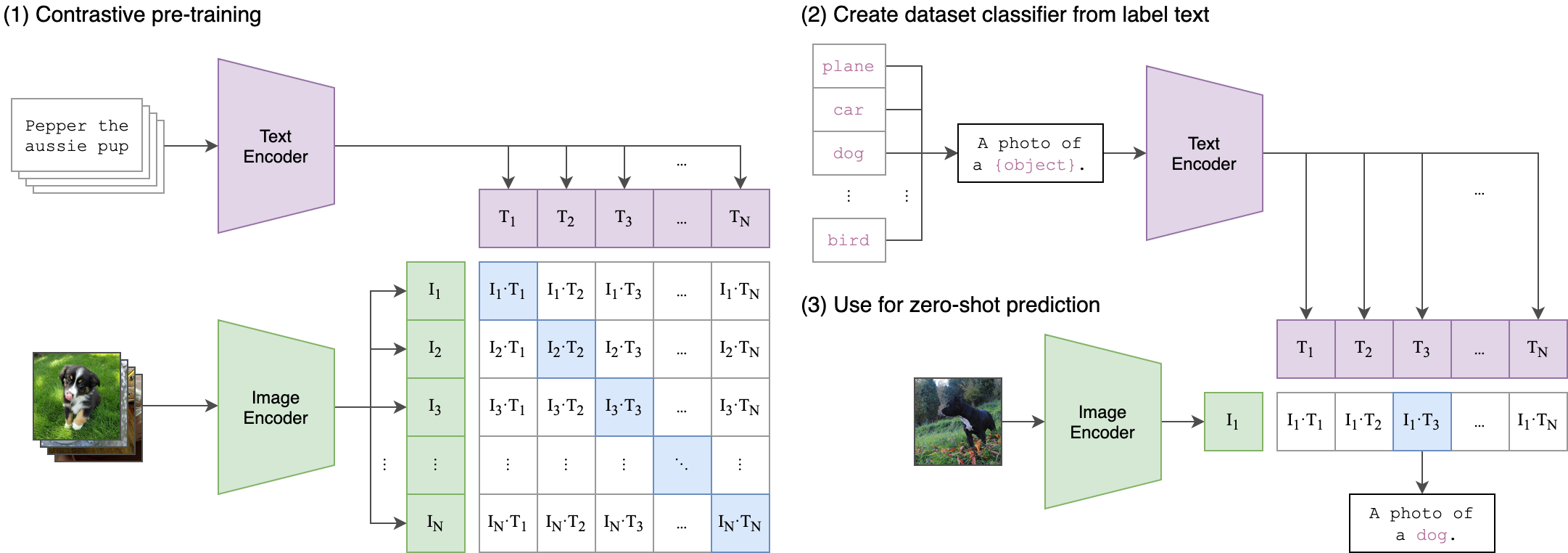
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3. We found CLIP matches the performance of the original ResNet50 on ImageNet “zero-shot” without using any of the original 1.28M labeled examples, overcoming several major challenges in computer vision.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Approach
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
## Usage
|
| 16 |
+
|
| 17 |
+
First, [install PyTorch 1.7.1](https://pytorch.org/get-started/locally/) and torchvision, as well as small additional dependencies, and then install this repo as a Python package. On a CUDA GPU machine, the following will do the trick:
|
| 18 |
+
|
| 19 |
+
```bash
|
| 20 |
+
$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
|
| 21 |
+
$ pip install ftfy regex tqdm
|
| 22 |
+
$ pip install git+https://github.com/openai/CLIP.git
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
Replace `cudatoolkit=11.0` above with the appropriate CUDA version on your machine or `cpuonly` when installing on a machine without a GPU.
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
import torch
|
| 29 |
+
import clip
|
| 30 |
+
from PIL import Image
|
| 31 |
+
|
| 32 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 33 |
+
model, preprocess = clip.load("ViT-B/32", device=device)
|
| 34 |
+
|
| 35 |
+
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
|
| 36 |
+
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
|
| 37 |
+
|
| 38 |
+
with torch.no_grad():
|
| 39 |
+
image_features = model.encode_image(image)
|
| 40 |
+
text_features = model.encode_text(text)
|
| 41 |
+
|
| 42 |
+
logits_per_image, logits_per_text = model(image, text)
|
| 43 |
+
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
|
| 44 |
+
|
| 45 |
+
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## API
|
| 50 |
+
|
| 51 |
+
The CLIP module `clip` provides the following methods:
|
| 52 |
+
|
| 53 |
+
#### `clip.available_models()`
|
| 54 |
+
|
| 55 |
+
Returns the names of the available CLIP models.
|
| 56 |
+
|
| 57 |
+
#### `clip.load(name, device=..., jit=False)`
|
| 58 |
+
|
| 59 |
+
Returns the model and the TorchVision transform needed by the model, specified by the model name returned by `clip.available_models()`. It will download the model as necessary. The `name` argument can also be a path to a local checkpoint.
|
| 60 |
+
|
| 61 |
+
The device to run the model can be optionally specified, and the default is to use the first CUDA device if there is any, otherwise the CPU. When `jit` is `False`, a non-JIT version of the model will be loaded.
|
| 62 |
+
|
| 63 |
+
#### `clip.tokenize(text: Union[str, List[str]], context_length=77)`
|
| 64 |
+
|
| 65 |
+
Returns a LongTensor containing tokenized sequences of given text input(s). This can be used as the input to the model
|
| 66 |
+
|
| 67 |
+
---
|
| 68 |
+
|
| 69 |
+
The model returned by `clip.load()` supports the following methods:
|
| 70 |
+
|
| 71 |
+
#### `model.encode_image(image: Tensor)`
|
| 72 |
+
|
| 73 |
+
Given a batch of images, returns the image features encoded by the vision portion of the CLIP model.
|
| 74 |
+
|
| 75 |
+
#### `model.encode_text(text: Tensor)`
|
| 76 |
+
|
| 77 |
+
Given a batch of text tokens, returns the text features encoded by the language portion of the CLIP model.
|
| 78 |
+
|
| 79 |
+
#### `model(image: Tensor, text: Tensor)`
|
| 80 |
+
|
| 81 |
+
Given a batch of images and a batch of text tokens, returns two Tensors, containing the logit scores corresponding to each image and text input. The values are cosine similarities between the corresponding image and text features, times 100.
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## More Examples
|
| 86 |
+
|
| 87 |
+
### Zero-Shot Prediction
|
| 88 |
+
|
| 89 |
+
The code below performs zero-shot prediction using CLIP, as shown in Appendix B in the paper. This example takes an image from the [CIFAR-100 dataset](https://www.cs.toronto.edu/~kriz/cifar.html), and predicts the most likely labels among the 100 textual labels from the dataset.
|
| 90 |
+
|
| 91 |
+
```python
|
| 92 |
+
import os
|
| 93 |
+
import clip
|
| 94 |
+
import torch
|
| 95 |
+
from torchvision.datasets import CIFAR100
|
| 96 |
+
|
| 97 |
+
# Load the model
|
| 98 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 99 |
+
model, preprocess = clip.load('ViT-B/32', device)
|
| 100 |
+
|
| 101 |
+
# Download the dataset
|
| 102 |
+
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
|
| 103 |
+
|
| 104 |
+
# Prepare the inputs
|
| 105 |
+
image, class_id = cifar100[3637]
|
| 106 |
+
image_input = preprocess(image).unsqueeze(0).to(device)
|
| 107 |
+
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
|
| 108 |
+
|
| 109 |
+
# Calculate features
|
| 110 |
+
with torch.no_grad():
|
| 111 |
+
image_features = model.encode_image(image_input)
|
| 112 |
+
text_features = model.encode_text(text_inputs)
|
| 113 |
+
|
| 114 |
+
# Pick the top 5 most similar labels for the image
|
| 115 |
+
image_features /= image_features.norm(dim=-1, keepdim=True)
|
| 116 |
+
text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 117 |
+
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
|
| 118 |
+
values, indices = similarity[0].topk(5)
|
| 119 |
+
|
| 120 |
+
# Print the result
|
| 121 |
+
print("\nTop predictions:\n")
|
| 122 |
+
for value, index in zip(values, indices):
|
| 123 |
+
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
The output will look like the following (the exact numbers may be slightly different depending on the compute device):
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
Top predictions:
|
| 130 |
+
|
| 131 |
+
snake: 65.31%
|
| 132 |
+
turtle: 12.29%
|
| 133 |
+
sweet_pepper: 3.83%
|
| 134 |
+
lizard: 1.88%
|
| 135 |
+
crocodile: 1.75%
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
Note that this example uses the `encode_image()` and `encode_text()` methods that return the encoded features of given inputs.
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
### Linear-probe evaluation
|
| 142 |
+
|
| 143 |
+
The example below uses [scikit-learn](https://scikit-learn.org/) to perform logistic regression on image features.
|
| 144 |
+
|
| 145 |
+
```python
|
| 146 |
+
import os
|
| 147 |
+
import clip
|
| 148 |
+
import torch
|
| 149 |
+
|
| 150 |
+
import numpy as np
|
| 151 |
+
from sklearn.linear_model import LogisticRegression
|
| 152 |
+
from torch.utils.data import DataLoader
|
| 153 |
+
from torchvision.datasets import CIFAR100
|
| 154 |
+
from tqdm import tqdm
|
| 155 |
+
|
| 156 |
+
# Load the model
|
| 157 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 158 |
+
model, preprocess = clip.load('ViT-B/32', device)
|
| 159 |
+
|
| 160 |
+
# Load the dataset
|
| 161 |
+
root = os.path.expanduser("~/.cache")
|
| 162 |
+
train = CIFAR100(root, download=True, train=True, transform=preprocess)
|
| 163 |
+
test = CIFAR100(root, download=True, train=False, transform=preprocess)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def get_features(dataset):
|
| 167 |
+
all_features = []
|
| 168 |
+
all_labels = []
|
| 169 |
+
|
| 170 |
+
with torch.no_grad():
|
| 171 |
+
for images, labels in tqdm(DataLoader(dataset, batch_size=100)):
|
| 172 |
+
features = model.encode_image(images.to(device))
|
| 173 |
+
|
| 174 |
+
all_features.append(features)
|
| 175 |
+
all_labels.append(labels)
|
| 176 |
+
|
| 177 |
+
return torch.cat(all_features).cpu().numpy(), torch.cat(all_labels).cpu().numpy()
|
| 178 |
+
|
| 179 |
+
# Calculate the image features
|
| 180 |
+
train_features, train_labels = get_features(train)
|
| 181 |
+
test_features, test_labels = get_features(test)
|
| 182 |
+
|
| 183 |
+
# Perform logistic regression
|
| 184 |
+
classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1)
|
| 185 |
+
classifier.fit(train_features, train_labels)
|
| 186 |
+
|
| 187 |
+
# Evaluate using the logistic regression classifier
|
| 188 |
+
predictions = classifier.predict(test_features)
|
| 189 |
+
accuracy = np.mean((test_labels == predictions).astype(np.float)) * 100.
|
| 190 |
+
print(f"Accuracy = {accuracy:.3f}")
|
| 191 |
+
```
|
| 192 |
+
|
| 193 |
+
Note that the `C` value should be determined via a hyperparameter sweep using a validation split.
|
CLIP/__init__.py
ADDED
|
File without changes
|
CLIP/clip/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .clip import *
|
CLIP/clip/bpe_simple_vocab_16e6.txt.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:924691ac288e54409236115652ad4aa250f48203de50a9e4722a6ecd48d6804a
|
| 3 |
+
size 1356917
|
CLIP/clip/clip.py
ADDED
|
@@ -0,0 +1,231 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import hashlib
|
| 2 |
+
import os
|
| 3 |
+
import urllib
|
| 4 |
+
import warnings
|
| 5 |
+
from typing import Any, Union, List
|
| 6 |
+
from pkg_resources import packaging
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
|
| 13 |
+
from .model import build_model
|
| 14 |
+
from .simple_tokenizer import SimpleTokenizer as _Tokenizer
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
from torchvision.transforms import InterpolationMode
|
| 18 |
+
BICUBIC = InterpolationMode.BICUBIC
|
| 19 |
+
except ImportError:
|
| 20 |
+
BICUBIC = Image.BICUBIC
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
if packaging.version.parse(torch.__version__) < packaging.version.parse("1.7.1"):
|
| 24 |
+
warnings.warn("PyTorch version 1.7.1 or higher is recommended")
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
__all__ = ["available_models", "load", "tokenize"]
|
| 28 |
+
_tokenizer = _Tokenizer()
|
| 29 |
+
|
| 30 |
+
_MODELS = {
|
| 31 |
+
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
|
| 32 |
+
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
|
| 33 |
+
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
|
| 34 |
+
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
|
| 35 |
+
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
|
| 36 |
+
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
|
| 37 |
+
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
|
| 38 |
+
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def _download(url: str, root: str):
|
| 43 |
+
os.makedirs(root, exist_ok=True)
|
| 44 |
+
filename = os.path.basename(url)
|
| 45 |
+
|
| 46 |
+
expected_sha256 = url.split("/")[-2]
|
| 47 |
+
download_target = os.path.join(root, filename)
|
| 48 |
+
|
| 49 |
+
if os.path.exists(download_target) and not os.path.isfile(download_target):
|
| 50 |
+
raise RuntimeError(f"{download_target} exists and is not a regular file")
|
| 51 |
+
|
| 52 |
+
if os.path.isfile(download_target):
|
| 53 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:
|
| 54 |
+
return download_target
|
| 55 |
+
else:
|
| 56 |
+
warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
|
| 57 |
+
|
| 58 |
+
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
|
| 59 |
+
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True, unit_divisor=1024) as loop:
|
| 60 |
+
while True:
|
| 61 |
+
buffer = source.read(8192)
|
| 62 |
+
if not buffer:
|
| 63 |
+
break
|
| 64 |
+
|
| 65 |
+
output.write(buffer)
|
| 66 |
+
loop.update(len(buffer))
|
| 67 |
+
|
| 68 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:
|
| 69 |
+
raise RuntimeError(f"Model has been downloaded but the SHA256 checksum does not not match")
|
| 70 |
+
|
| 71 |
+
return download_target
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def _convert_image_to_rgb(image):
|
| 75 |
+
return image.convert("RGB")
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def _transform(n_px):
|
| 79 |
+
return Compose([
|
| 80 |
+
Resize(n_px, interpolation=BICUBIC),
|
| 81 |
+
CenterCrop(n_px),
|
| 82 |
+
_convert_image_to_rgb,
|
| 83 |
+
ToTensor(),
|
| 84 |
+
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
|
| 85 |
+
])
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def available_models() -> List[str]:
|
| 89 |
+
"""Returns the names of available CLIP models"""
|
| 90 |
+
return list(_MODELS.keys())
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit: bool = False, download_root: str = None):
|
| 94 |
+
"""Load a CLIP model
|
| 95 |
+
|
| 96 |
+
Parameters
|
| 97 |
+
----------
|
| 98 |
+
name : str
|
| 99 |
+
A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
|
| 100 |
+
|
| 101 |
+
device : Union[str, torch.device]
|
| 102 |
+
The device to put the loaded model
|
| 103 |
+
|
| 104 |
+
jit : bool
|
| 105 |
+
Whether to load the optimized JIT model or more hackable non-JIT model (default).
|
| 106 |
+
|
| 107 |
+
download_root: str
|
| 108 |
+
path to download the model files; by default, it uses "~/.cache/clip"
|
| 109 |
+
|
| 110 |
+
Returns
|
| 111 |
+
-------
|
| 112 |
+
model : torch.nn.Module
|
| 113 |
+
The CLIP model
|
| 114 |
+
|
| 115 |
+
preprocess : Callable[[PIL.Image], torch.Tensor]
|
| 116 |
+
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
|
| 117 |
+
"""
|
| 118 |
+
if name in _MODELS:
|
| 119 |
+
model_path = _download(_MODELS[name], download_root or os.path.expanduser("~/.cache/clip"))
|
| 120 |
+
elif os.path.isfile(name):
|
| 121 |
+
model_path = name
|
| 122 |
+
else:
|
| 123 |
+
raise RuntimeError(f"Model {name} not found; available models = {available_models()}")
|
| 124 |
+
|
| 125 |
+
try:
|
| 126 |
+
# loading JIT archive
|
| 127 |
+
model = torch.jit.load(model_path, map_location=device if jit else "cpu").eval()
|
| 128 |
+
state_dict = None
|
| 129 |
+
except RuntimeError:
|
| 130 |
+
# loading saved state dict
|
| 131 |
+
if jit:
|
| 132 |
+
warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")
|
| 133 |
+
jit = False
|
| 134 |
+
state_dict = torch.load(model_path, map_location="cpu")
|
| 135 |
+
|
| 136 |
+
if not jit:
|
| 137 |
+
model = build_model(state_dict or model.state_dict()).to(device)
|
| 138 |
+
if str(device) == "cpu":
|
| 139 |
+
model.float()
|
| 140 |
+
return model, _transform(model.visual.input_resolution)
|
| 141 |
+
|
| 142 |
+
# patch the device names
|
| 143 |
+
device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
|
| 144 |
+
device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]
|
| 145 |
+
|
| 146 |
+
def patch_device(module):
|
| 147 |
+
try:
|
| 148 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 149 |
+
except RuntimeError:
|
| 150 |
+
graphs = []
|
| 151 |
+
|
| 152 |
+
if hasattr(module, "forward1"):
|
| 153 |
+
graphs.append(module.forward1.graph)
|
| 154 |
+
|
| 155 |
+
for graph in graphs:
|
| 156 |
+
for node in graph.findAllNodes("prim::Constant"):
|
| 157 |
+
if "value" in node.attributeNames() and str(node["value"]).startswith("cuda"):
|
| 158 |
+
node.copyAttributes(device_node)
|
| 159 |
+
|
| 160 |
+
model.apply(patch_device)
|
| 161 |
+
patch_device(model.encode_image)
|
| 162 |
+
patch_device(model.encode_text)
|
| 163 |
+
|
| 164 |
+
# patch dtype to float32 on CPU
|
| 165 |
+
if str(device) == "cpu":
|
| 166 |
+
float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])
|
| 167 |
+
float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]
|
| 168 |
+
float_node = float_input.node()
|
| 169 |
+
|
| 170 |
+
def patch_float(module):
|
| 171 |
+
try:
|
| 172 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 173 |
+
except RuntimeError:
|
| 174 |
+
graphs = []
|
| 175 |
+
|
| 176 |
+
if hasattr(module, "forward1"):
|
| 177 |
+
graphs.append(module.forward1.graph)
|
| 178 |
+
|
| 179 |
+
for graph in graphs:
|
| 180 |
+
for node in graph.findAllNodes("aten::to"):
|
| 181 |
+
inputs = list(node.inputs())
|
| 182 |
+
for i in [1, 2]: # dtype can be the second or third argument to aten::to()
|
| 183 |
+
if inputs[i].node()["value"] == 5:
|
| 184 |
+
inputs[i].node().copyAttributes(float_node)
|
| 185 |
+
|
| 186 |
+
model.apply(patch_float)
|
| 187 |
+
patch_float(model.encode_image)
|
| 188 |
+
patch_float(model.encode_text)
|
| 189 |
+
|
| 190 |
+
model.float()
|
| 191 |
+
|
| 192 |
+
return model, _transform(model.input_resolution.item())
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def tokenize(texts: Union[str, List[str]], context_length: int = 77, truncate: bool = False) -> torch.LongTensor:
|
| 196 |
+
"""
|
| 197 |
+
Returns the tokenized representation of given input string(s)
|
| 198 |
+
|
| 199 |
+
Parameters
|
| 200 |
+
----------
|
| 201 |
+
texts : Union[str, List[str]]
|
| 202 |
+
An input string or a list of input strings to tokenize
|
| 203 |
+
|
| 204 |
+
context_length : int
|
| 205 |
+
The context length to use; all CLIP models use 77 as the context length
|
| 206 |
+
|
| 207 |
+
truncate: bool
|
| 208 |
+
Whether to truncate the text in case its encoding is longer than the context length
|
| 209 |
+
|
| 210 |
+
Returns
|
| 211 |
+
-------
|
| 212 |
+
A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
|
| 213 |
+
"""
|
| 214 |
+
if isinstance(texts, str):
|
| 215 |
+
texts = [texts]
|
| 216 |
+
|
| 217 |
+
sot_token = _tokenizer.encoder["<|startoftext|>"]
|
| 218 |
+
eot_token = _tokenizer.encoder["<|endoftext|>"]
|
| 219 |
+
all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
|
| 220 |
+
result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
|
| 221 |
+
|
| 222 |
+
for i, tokens in enumerate(all_tokens):
|
| 223 |
+
if len(tokens) > context_length:
|
| 224 |
+
if truncate:
|
| 225 |
+
tokens = tokens[:context_length]
|
| 226 |
+
tokens[-1] = eot_token
|
| 227 |
+
else:
|
| 228 |
+
raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
|
| 229 |
+
result[i, :len(tokens)] = torch.tensor(tokens)
|
| 230 |
+
|
| 231 |
+
return result
|
CLIP/clip/model.py
ADDED
|
@@ -0,0 +1,484 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict
|
| 2 |
+
from typing import Tuple, Union
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import nn
|
| 8 |
+
import math
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class Bottleneck(nn.Module):
|
| 12 |
+
expansion = 4
|
| 13 |
+
|
| 14 |
+
def __init__(self, inplanes, planes, stride=1):
|
| 15 |
+
super().__init__()
|
| 16 |
+
|
| 17 |
+
# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
|
| 18 |
+
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
|
| 19 |
+
self.bn1 = nn.BatchNorm2d(planes)
|
| 20 |
+
|
| 21 |
+
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
|
| 22 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 23 |
+
|
| 24 |
+
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
|
| 25 |
+
|
| 26 |
+
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
|
| 27 |
+
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
|
| 28 |
+
|
| 29 |
+
self.relu = nn.ReLU(inplace=True)
|
| 30 |
+
self.downsample = None
|
| 31 |
+
self.stride = stride
|
| 32 |
+
|
| 33 |
+
if stride > 1 or inplanes != planes * Bottleneck.expansion:
|
| 34 |
+
# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
|
| 35 |
+
self.downsample = nn.Sequential(OrderedDict([
|
| 36 |
+
("-1", nn.AvgPool2d(stride)),
|
| 37 |
+
("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
|
| 38 |
+
("1", nn.BatchNorm2d(planes * self.expansion))
|
| 39 |
+
]))
|
| 40 |
+
|
| 41 |
+
def forward(self, x: torch.Tensor):
|
| 42 |
+
identity = x
|
| 43 |
+
|
| 44 |
+
out = self.relu(self.bn1(self.conv1(x)))
|
| 45 |
+
out = self.relu(self.bn2(self.conv2(out)))
|
| 46 |
+
out = self.avgpool(out)
|
| 47 |
+
out = self.bn3(self.conv3(out))
|
| 48 |
+
|
| 49 |
+
if self.downsample is not None:
|
| 50 |
+
identity = self.downsample(x)
|
| 51 |
+
|
| 52 |
+
out += identity
|
| 53 |
+
out = self.relu(out)
|
| 54 |
+
return out
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class AttentionPool2d(nn.Module):
|
| 58 |
+
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
|
| 59 |
+
super().__init__()
|
| 60 |
+
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
|
| 61 |
+
self.k_proj = nn.Linear(embed_dim, embed_dim)
|
| 62 |
+
self.q_proj = nn.Linear(embed_dim, embed_dim)
|
| 63 |
+
self.v_proj = nn.Linear(embed_dim, embed_dim)
|
| 64 |
+
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
|
| 65 |
+
self.num_heads = num_heads
|
| 66 |
+
|
| 67 |
+
def forward(self, x):
|
| 68 |
+
x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
|
| 69 |
+
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
|
| 70 |
+
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
|
| 71 |
+
x, _ = F.multi_head_attention_forward(
|
| 72 |
+
query=x, key=x, value=x,
|
| 73 |
+
embed_dim_to_check=x.shape[-1],
|
| 74 |
+
num_heads=self.num_heads,
|
| 75 |
+
q_proj_weight=self.q_proj.weight,
|
| 76 |
+
k_proj_weight=self.k_proj.weight,
|
| 77 |
+
v_proj_weight=self.v_proj.weight,
|
| 78 |
+
in_proj_weight=None,
|
| 79 |
+
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
|
| 80 |
+
bias_k=None,
|
| 81 |
+
bias_v=None,
|
| 82 |
+
add_zero_attn=False,
|
| 83 |
+
dropout_p=0,
|
| 84 |
+
out_proj_weight=self.c_proj.weight,
|
| 85 |
+
out_proj_bias=self.c_proj.bias,
|
| 86 |
+
use_separate_proj_weight=True,
|
| 87 |
+
training=self.training,
|
| 88 |
+
need_weights=False
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
return x[0]
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class ModifiedResNet(nn.Module):
|
| 95 |
+
"""
|
| 96 |
+
A ResNet class that is similar to torchvision's but contains the following changes:
|
| 97 |
+
- There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
|
| 98 |
+
- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
|
| 99 |
+
- The final pooling layer is a QKV attention instead of an average pool
|
| 100 |
+
"""
|
| 101 |
+
|
| 102 |
+
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
|
| 103 |
+
super().__init__()
|
| 104 |
+
self.output_dim = output_dim
|
| 105 |
+
self.input_resolution = input_resolution
|
| 106 |
+
|
| 107 |
+
# the 3-layer stem
|
| 108 |
+
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
|
| 109 |
+
self.bn1 = nn.BatchNorm2d(width // 2)
|
| 110 |
+
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
|
| 111 |
+
self.bn2 = nn.BatchNorm2d(width // 2)
|
| 112 |
+
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
|
| 113 |
+
self.bn3 = nn.BatchNorm2d(width)
|
| 114 |
+
self.avgpool = nn.AvgPool2d(2)
|
| 115 |
+
self.relu = nn.ReLU(inplace=True)
|
| 116 |
+
|
| 117 |
+
# residual layers
|
| 118 |
+
self._inplanes = width # this is a *mutable* variable used during construction
|
| 119 |
+
self.layer1 = self._make_layer(width, layers[0])
|
| 120 |
+
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
|
| 121 |
+
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
|
| 122 |
+
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
|
| 123 |
+
|
| 124 |
+
embed_dim = width * 32 # the ResNet feature dimension
|
| 125 |
+
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
|
| 126 |
+
|
| 127 |
+
def _make_layer(self, planes, blocks, stride=1):
|
| 128 |
+
layers = [Bottleneck(self._inplanes, planes, stride)]
|
| 129 |
+
|
| 130 |
+
self._inplanes = planes * Bottleneck.expansion
|
| 131 |
+
for _ in range(1, blocks):
|
| 132 |
+
layers.append(Bottleneck(self._inplanes, planes))
|
| 133 |
+
|
| 134 |
+
return nn.Sequential(*layers)
|
| 135 |
+
|
| 136 |
+
def forward(self, x):
|
| 137 |
+
def stem(x):
|
| 138 |
+
for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
|
| 139 |
+
x = self.relu(bn(conv(x)))
|
| 140 |
+
x = self.avgpool(x)
|
| 141 |
+
return x
|
| 142 |
+
|
| 143 |
+
x = x.type(self.conv1.weight.dtype)
|
| 144 |
+
x = stem(x)
|
| 145 |
+
x = self.layer1(x)
|
| 146 |
+
x = self.layer2(x)
|
| 147 |
+
x = self.layer3(x)
|
| 148 |
+
x = self.layer4(x)
|
| 149 |
+
x = self.attnpool(x)
|
| 150 |
+
|
| 151 |
+
return x
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class LayerNorm(nn.LayerNorm):
|
| 155 |
+
"""Subclass torch's LayerNorm to handle fp16."""
|
| 156 |
+
|
| 157 |
+
def forward(self, x: torch.Tensor):
|
| 158 |
+
orig_type = x.dtype
|
| 159 |
+
ret = super().forward(x.type(torch.float32))
|
| 160 |
+
return ret.type(orig_type)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
class QuickGELU(nn.Module):
|
| 164 |
+
def forward(self, x: torch.Tensor):
|
| 165 |
+
return x * torch.sigmoid(1.702 * x)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
class ResidualAttentionBlock(nn.Module):
|
| 169 |
+
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
|
| 170 |
+
super().__init__()
|
| 171 |
+
|
| 172 |
+
self.attn = nn.MultiheadAttention(d_model, n_head)
|
| 173 |
+
self.ln_1 = LayerNorm(d_model)
|
| 174 |
+
self.mlp = nn.Sequential(OrderedDict([
|
| 175 |
+
("c_fc", nn.Linear(d_model, d_model * 4)),
|
| 176 |
+
("gelu", QuickGELU()),
|
| 177 |
+
("c_proj", nn.Linear(d_model * 4, d_model))
|
| 178 |
+
]))
|
| 179 |
+
self.ln_2 = LayerNorm(d_model)
|
| 180 |
+
self.attn_mask = attn_mask
|
| 181 |
+
|
| 182 |
+
def attention(self, x: torch.Tensor):
|
| 183 |
+
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
|
| 184 |
+
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
|
| 185 |
+
|
| 186 |
+
def forward(self, x: torch.Tensor):
|
| 187 |
+
x = x + self.attention(self.ln_1(x))
|
| 188 |
+
x = x + self.mlp(self.ln_2(x))
|
| 189 |
+
return x
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
class Transformer(nn.Module):
|
| 193 |
+
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
|
| 194 |
+
super().__init__()
|
| 195 |
+
self.width = width
|
| 196 |
+
self.layers = layers
|
| 197 |
+
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
|
| 198 |
+
|
| 199 |
+
def forward(self, x: torch.Tensor):
|
| 200 |
+
return self.resblocks(x)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
class VisionTransformer(nn.Module):
|
| 204 |
+
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
|
| 205 |
+
super().__init__()
|
| 206 |
+
self.input_resolution = input_resolution
|
| 207 |
+
self.output_dim = output_dim
|
| 208 |
+
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
|
| 209 |
+
|
| 210 |
+
scale = width ** -0.5
|
| 211 |
+
self.class_embedding = nn.Parameter(scale * torch.randn(width))
|
| 212 |
+
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
|
| 213 |
+
self.ln_pre = LayerNorm(width)
|
| 214 |
+
|
| 215 |
+
self.transformer = Transformer(width, layers, heads)
|
| 216 |
+
|
| 217 |
+
self.ln_post = LayerNorm(width)
|
| 218 |
+
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
|
| 219 |
+
|
| 220 |
+
# https://github.com/facebookresearch/dino
|
| 221 |
+
def interpolate_pos_encoding(self, x, w, h):
|
| 222 |
+
positional_embedding = self.positional_embedding.unsqueeze(0)
|
| 223 |
+
patch_size = self.conv1.kernel_size[0]
|
| 224 |
+
|
| 225 |
+
npatch = x.shape[1] - 1
|
| 226 |
+
N = positional_embedding.shape[1] - 1
|
| 227 |
+
if npatch == N and w == h:
|
| 228 |
+
return positional_embedding
|
| 229 |
+
class_pos_embed = positional_embedding[:, 0]
|
| 230 |
+
patch_pos_embed = positional_embedding[:, 1:]
|
| 231 |
+
dim = x.shape[-1]
|
| 232 |
+
|
| 233 |
+
w0 = w // patch_size
|
| 234 |
+
h0 = h // patch_size
|
| 235 |
+
|
| 236 |
+
# we add a small number to avoid floating point error in the interpolation
|
| 237 |
+
# see discussion at https://github.com/facebookresearch/dino/issues/8
|
| 238 |
+
w0, h0 = w0 + 0.1, h0 + 0.1
|
| 239 |
+
patch_pos_embed = nn.functional.interpolate(
|
| 240 |
+
patch_pos_embed.reshape(1, int(math.sqrt(N)), int(math.sqrt(N)), dim).permute(0, 3, 1, 2),
|
| 241 |
+
scale_factor=(w0 / math.sqrt(N), h0 / math.sqrt(N)),
|
| 242 |
+
mode='bicubic',
|
| 243 |
+
)
|
| 244 |
+
assert int(w0) == patch_pos_embed.shape[-2] and int(h0) == patch_pos_embed.shape[-1]
|
| 245 |
+
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
|
| 246 |
+
return torch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1)
|
| 247 |
+
|
| 248 |
+
def forward(self, x: torch.Tensor):
|
| 249 |
+
x = self.transformer_first_blocks_forward(x)
|
| 250 |
+
x = self.transformer.resblocks[-1](x)
|
| 251 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 252 |
+
x = self.ln_post(x[:, 0, :])
|
| 253 |
+
|
| 254 |
+
if self.proj is not None:
|
| 255 |
+
x = x @ self.proj
|
| 256 |
+
|
| 257 |
+
return x
|
| 258 |
+
|
| 259 |
+
def transformer_first_blocks_forward(self, x):
|
| 260 |
+
h, w = x.shape[-2:]
|
| 261 |
+
x = self.conv1(x) # shape = [*, width, grid, grid]
|
| 262 |
+
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
|
| 263 |
+
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
|
| 264 |
+
x = torch.cat(
|
| 265 |
+
[self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device),
|
| 266 |
+
x], dim=1) # shape = [*, grid ** 2 + 1, width]
|
| 267 |
+
positional_embedding = self.interpolate_pos_encoding(x, w, h)
|
| 268 |
+
x = x + positional_embedding.to(x.dtype)
|
| 269 |
+
# x = x + self.positional_embedding.to(x.dtype)
|
| 270 |
+
x = self.ln_pre(x)
|
| 271 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 272 |
+
x = self.transformer.resblocks[:-1](x)
|
| 273 |
+
return x
|
| 274 |
+
|
| 275 |
+
@staticmethod
|
| 276 |
+
def attn_cosine_sim(x, eps=1e-08):
|
| 277 |
+
norm = x.norm(dim=2, keepdim=True)
|
| 278 |
+
factor = torch.clamp(norm @ norm.permute(0, 2, 1), min=eps) # shape [1, t, t]
|
| 279 |
+
sim_matrix = (x @ x.permute(0, 2, 1)) / factor # shape [1, t, t]
|
| 280 |
+
return sim_matrix
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
class CLIP(nn.Module):
|
| 284 |
+
def __init__(self,
|
| 285 |
+
embed_dim: int,
|
| 286 |
+
# vision
|
| 287 |
+
image_resolution: int,
|
| 288 |
+
vision_layers: Union[Tuple[int, int, int, int], int],
|
| 289 |
+
vision_width: int,
|
| 290 |
+
vision_patch_size: int,
|
| 291 |
+
# text
|
| 292 |
+
context_length: int,
|
| 293 |
+
vocab_size: int,
|
| 294 |
+
transformer_width: int,
|
| 295 |
+
transformer_heads: int,
|
| 296 |
+
transformer_layers: int
|
| 297 |
+
):
|
| 298 |
+
super().__init__()
|
| 299 |
+
|
| 300 |
+
self.context_length = context_length
|
| 301 |
+
|
| 302 |
+
if isinstance(vision_layers, (tuple, list)):
|
| 303 |
+
vision_heads = vision_width * 32 // 64
|
| 304 |
+
self.visual = ModifiedResNet(
|
| 305 |
+
layers=vision_layers,
|
| 306 |
+
output_dim=embed_dim,
|
| 307 |
+
heads=vision_heads,
|
| 308 |
+
input_resolution=image_resolution,
|
| 309 |
+
width=vision_width
|
| 310 |
+
)
|
| 311 |
+
else:
|
| 312 |
+
vision_heads = vision_width // 64
|
| 313 |
+
self.visual = VisionTransformer(
|
| 314 |
+
input_resolution=image_resolution,
|
| 315 |
+
patch_size=vision_patch_size,
|
| 316 |
+
width=vision_width,
|
| 317 |
+
layers=vision_layers,
|
| 318 |
+
heads=vision_heads,
|
| 319 |
+
output_dim=embed_dim
|
| 320 |
+
)
|
| 321 |
+
|
| 322 |
+
self.transformer = Transformer(
|
| 323 |
+
width=transformer_width,
|
| 324 |
+
layers=transformer_layers,
|
| 325 |
+
heads=transformer_heads,
|
| 326 |
+
attn_mask=self.build_attention_mask()
|
| 327 |
+
)
|
| 328 |
+
|
| 329 |
+
self.vocab_size = vocab_size
|
| 330 |
+
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
|
| 331 |
+
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
|
| 332 |
+
self.ln_final = LayerNorm(transformer_width)
|
| 333 |
+
|
| 334 |
+
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
|
| 335 |
+
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
|
| 336 |
+
|
| 337 |
+
self.initialize_parameters()
|
| 338 |
+
|
| 339 |
+
def initialize_parameters(self):
|
| 340 |
+
nn.init.normal_(self.token_embedding.weight, std=0.02)
|
| 341 |
+
nn.init.normal_(self.positional_embedding, std=0.01)
|
| 342 |
+
|
| 343 |
+
if isinstance(self.visual, ModifiedResNet):
|
| 344 |
+
if self.visual.attnpool is not None:
|
| 345 |
+
std = self.visual.attnpool.c_proj.in_features ** -0.5
|
| 346 |
+
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
|
| 347 |
+
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
|
| 348 |
+
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
|
| 349 |
+
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
|
| 350 |
+
|
| 351 |
+
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
|
| 352 |
+
for name, param in resnet_block.named_parameters():
|
| 353 |
+
if name.endswith("bn3.weight"):
|
| 354 |
+
nn.init.zeros_(param)
|
| 355 |
+
|
| 356 |
+
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
|
| 357 |
+
attn_std = self.transformer.width ** -0.5
|
| 358 |
+
fc_std = (2 * self.transformer.width) ** -0.5
|
| 359 |
+
for block in self.transformer.resblocks:
|
| 360 |
+
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
|
| 361 |
+
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
|
| 362 |
+
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
|
| 363 |
+
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
|
| 364 |
+
|
| 365 |
+
if self.text_projection is not None:
|
| 366 |
+
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
|
| 367 |
+
|
| 368 |
+
def build_attention_mask(self):
|
| 369 |
+
# lazily create causal attention mask, with full attention between the vision tokens
|
| 370 |
+
# pytorch uses additive attention mask; fill with -inf
|
| 371 |
+
mask = torch.empty(self.context_length, self.context_length)
|
| 372 |
+
mask.fill_(float("-inf"))
|
| 373 |
+
mask.triu_(1) # zero out the lower diagonal
|
| 374 |
+
return mask
|
| 375 |
+
|
| 376 |
+
@property
|
| 377 |
+
def dtype(self):
|
| 378 |
+
return self.visual.conv1.weight.dtype
|
| 379 |
+
|
| 380 |
+
def calculate_self_sim(self, x: torch.Tensor):
|
| 381 |
+
tokens = self.visual.transformer_first_blocks_forward(
|
| 382 |
+
x.type(self.dtype)) # shape = [batch, tokens, emb_dim] tokens include class token
|
| 383 |
+
tokens = tokens.permute(1, 0, 2)
|
| 384 |
+
ssim = self.visual.attn_cosine_sim(tokens) # shape = [batch, tokens, tokens]
|
| 385 |
+
return ssim
|
| 386 |
+
|
| 387 |
+
def encode_image(self, image):
|
| 388 |
+
return self.visual(image.type(self.dtype))
|
| 389 |
+
|
| 390 |
+
def encode_text(self, text):
|
| 391 |
+
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
|
| 392 |
+
x = x + self.positional_embedding.type(self.dtype)
|
| 393 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 394 |
+
x = self.transformer(x)
|
| 395 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 396 |
+
x = self.ln_final(x).type(self.dtype)
|
| 397 |
+
|
| 398 |
+
# x.shape = [batch_size, n_ctx, transformer.width]
|
| 399 |
+
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
| 400 |
+
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
|
| 401 |
+
|
| 402 |
+
return x
|
| 403 |
+
|
| 404 |
+
def forward(self, image, text):
|
| 405 |
+
image_features = self.encode_image(image)
|
| 406 |
+
text_features = self.encode_text(text)
|
| 407 |
+
|
| 408 |
+
# normalized features
|
| 409 |
+
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
|
| 410 |
+
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
|
| 411 |
+
|
| 412 |
+
# cosine similarity as logits
|
| 413 |
+
logit_scale = self.logit_scale.exp()
|
| 414 |
+
logits_per_image = logit_scale * image_features @ text_features.t()
|
| 415 |
+
logits_per_text = logits_per_image.t()
|
| 416 |
+
|
| 417 |
+
# shape = [global_batch_size, global_batch_size]
|
| 418 |
+
return logits_per_image, logits_per_text
|
| 419 |
+
|
| 420 |
+
|
| 421 |
+
def convert_weights(model: nn.Module):
|
| 422 |
+
"""Convert applicable model parameters to fp16"""
|
| 423 |
+
|
| 424 |
+
def _convert_weights_to_fp16(l):
|
| 425 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
|
| 426 |
+
l.weight.data = l.weight.data.half()
|
| 427 |
+
if l.bias is not None:
|
| 428 |
+
l.bias.data = l.bias.data.half()
|
| 429 |
+
|
| 430 |
+
if isinstance(l, nn.MultiheadAttention):
|
| 431 |
+
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
|
| 432 |
+
tensor = getattr(l, attr)
|
| 433 |
+
if tensor is not None:
|
| 434 |
+
tensor.data = tensor.data.half()
|
| 435 |
+
|
| 436 |
+
for name in ["text_projection", "proj"]:
|
| 437 |
+
if hasattr(l, name):
|
| 438 |
+
attr = getattr(l, name)
|
| 439 |
+
if attr is not None:
|
| 440 |
+
attr.data = attr.data.half()
|
| 441 |
+
|
| 442 |
+
model.apply(_convert_weights_to_fp16)
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
def build_model(state_dict: dict):
|
| 446 |
+
vit = "visual.proj" in state_dict
|
| 447 |
+
|
| 448 |
+
if vit:
|
| 449 |
+
vision_width = state_dict["visual.conv1.weight"].shape[0]
|
| 450 |
+
vision_layers = len(
|
| 451 |
+
[k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
|
| 452 |
+
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
|
| 453 |
+
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 454 |
+
image_resolution = vision_patch_size * grid_size
|
| 455 |
+
else:
|
| 456 |
+
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in
|
| 457 |
+
[1, 2, 3, 4]]
|
| 458 |
+
vision_layers = tuple(counts)
|
| 459 |
+
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
|
| 460 |
+
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 461 |
+
vision_patch_size = None
|
| 462 |
+
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
|
| 463 |
+
image_resolution = output_width * 32
|
| 464 |
+
|
| 465 |
+
embed_dim = state_dict["text_projection"].shape[1]
|
| 466 |
+
context_length = state_dict["positional_embedding"].shape[0]
|
| 467 |
+
vocab_size = state_dict["token_embedding.weight"].shape[0]
|
| 468 |
+
transformer_width = state_dict["ln_final.weight"].shape[0]
|
| 469 |
+
transformer_heads = transformer_width // 64
|
| 470 |
+
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
|
| 471 |
+
|
| 472 |
+
model = CLIP(
|
| 473 |
+
embed_dim,
|
| 474 |
+
image_resolution, vision_layers, vision_width, vision_patch_size,
|
| 475 |
+
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
|
| 476 |
+
)
|
| 477 |
+
|
| 478 |
+
for key in ["input_resolution", "context_length", "vocab_size"]:
|
| 479 |
+
if key in state_dict:
|
| 480 |
+
del state_dict[key]
|
| 481 |
+
|
| 482 |
+
convert_weights(model)
|
| 483 |
+
model.load_state_dict(state_dict)
|
| 484 |
+
return model.eval()
|
CLIP/clip/simple_tokenizer.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gzip
|
| 2 |
+
import html
|
| 3 |
+
import os
|
| 4 |
+
from functools import lru_cache
|
| 5 |
+
|
| 6 |
+
import ftfy
|
| 7 |
+
import regex as re
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@lru_cache()
|
| 11 |
+
def default_bpe():
|
| 12 |
+
return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@lru_cache()
|
| 16 |
+
def bytes_to_unicode():
|
| 17 |
+
"""
|
| 18 |
+
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
| 19 |
+
The reversible bpe codes work on unicode strings.
|
| 20 |
+
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
| 21 |
+
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
| 22 |
+
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
| 23 |
+
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
| 24 |
+
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
| 25 |
+
"""
|
| 26 |
+
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
| 27 |
+
cs = bs[:]
|
| 28 |
+
n = 0
|
| 29 |
+
for b in range(2**8):
|
| 30 |
+
if b not in bs:
|
| 31 |
+
bs.append(b)
|
| 32 |
+
cs.append(2**8+n)
|
| 33 |
+
n += 1
|
| 34 |
+
cs = [chr(n) for n in cs]
|
| 35 |
+
return dict(zip(bs, cs))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_pairs(word):
|
| 39 |
+
"""Return set of symbol pairs in a word.
|
| 40 |
+
Word is represented as tuple of symbols (symbols being variable-length strings).
|
| 41 |
+
"""
|
| 42 |
+
pairs = set()
|
| 43 |
+
prev_char = word[0]
|
| 44 |
+
for char in word[1:]:
|
| 45 |
+
pairs.add((prev_char, char))
|
| 46 |
+
prev_char = char
|
| 47 |
+
return pairs
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def basic_clean(text):
|
| 51 |
+
text = ftfy.fix_text(text)
|
| 52 |
+
text = html.unescape(html.unescape(text))
|
| 53 |
+
return text.strip()
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def whitespace_clean(text):
|
| 57 |
+
text = re.sub(r'\s+', ' ', text)
|
| 58 |
+
text = text.strip()
|
| 59 |
+
return text
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class SimpleTokenizer(object):
|
| 63 |
+
def __init__(self, bpe_path: str = default_bpe()):
|
| 64 |
+
self.byte_encoder = bytes_to_unicode()
|
| 65 |
+
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
|
| 66 |
+
merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
|
| 67 |
+
merges = merges[1:49152-256-2+1]
|
| 68 |
+
merges = [tuple(merge.split()) for merge in merges]
|
| 69 |
+
vocab = list(bytes_to_unicode().values())
|
| 70 |
+
vocab = vocab + [v+'</w>' for v in vocab]
|
| 71 |
+
for merge in merges:
|
| 72 |
+
vocab.append(''.join(merge))
|
| 73 |
+
vocab.extend(['<|startoftext|>', '<|endoftext|>'])
|
| 74 |
+
self.encoder = dict(zip(vocab, range(len(vocab))))
|
| 75 |
+
self.decoder = {v: k for k, v in self.encoder.items()}
|
| 76 |
+
self.bpe_ranks = dict(zip(merges, range(len(merges))))
|
| 77 |
+
self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
|
| 78 |
+
self.pat = re.compile(r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)
|
| 79 |
+
|
| 80 |
+
def bpe(self, token):
|
| 81 |
+
if token in self.cache:
|
| 82 |
+
return self.cache[token]
|
| 83 |
+
word = tuple(token[:-1]) + ( token[-1] + '</w>',)
|
| 84 |
+
pairs = get_pairs(word)
|
| 85 |
+
|
| 86 |
+
if not pairs:
|
| 87 |
+
return token+'</w>'
|
| 88 |
+
|
| 89 |
+
while True:
|
| 90 |
+
bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
|
| 91 |
+
if bigram not in self.bpe_ranks:
|
| 92 |
+
break
|
| 93 |
+
first, second = bigram
|
| 94 |
+
new_word = []
|
| 95 |
+
i = 0
|
| 96 |
+
while i < len(word):
|
| 97 |
+
try:
|
| 98 |
+
j = word.index(first, i)
|
| 99 |
+
new_word.extend(word[i:j])
|
| 100 |
+
i = j
|
| 101 |
+
except:
|
| 102 |
+
new_word.extend(word[i:])
|
| 103 |
+
break
|
| 104 |
+
|
| 105 |
+
if word[i] == first and i < len(word)-1 and word[i+1] == second:
|
| 106 |
+
new_word.append(first+second)
|
| 107 |
+
i += 2
|
| 108 |
+
else:
|
| 109 |
+
new_word.append(word[i])
|
| 110 |
+
i += 1
|
| 111 |
+
new_word = tuple(new_word)
|
| 112 |
+
word = new_word
|
| 113 |
+
if len(word) == 1:
|
| 114 |
+
break
|
| 115 |
+
else:
|
| 116 |
+
pairs = get_pairs(word)
|
| 117 |
+
word = ' '.join(word)
|
| 118 |
+
self.cache[token] = word
|
| 119 |
+
return word
|
| 120 |
+
|
| 121 |
+
def encode(self, text):
|
| 122 |
+
bpe_tokens = []
|
| 123 |
+
text = whitespace_clean(basic_clean(text)).lower()
|
| 124 |
+
for token in re.findall(self.pat, text):
|
| 125 |
+
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
|
| 126 |
+
bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
|
| 127 |
+
return bpe_tokens
|
| 128 |
+
|
| 129 |
+
def decode(self, tokens):
|
| 130 |
+
text = ''.join([self.decoder[token] for token in tokens])
|
| 131 |
+
text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('</w>', ' ')
|
| 132 |
+
return text
|
CLIP/clip_explainability/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .clip import *
|
CLIP/clip_explainability/auxilary.py
ADDED
|
@@ -0,0 +1,422 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import warnings
|
| 3 |
+
from typing import Tuple, Optional
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from torch import Tensor
|
| 7 |
+
from torch.nn.init import xavier_uniform_
|
| 8 |
+
from torch.nn.init import constant_
|
| 9 |
+
from torch.nn.init import xavier_normal_
|
| 10 |
+
from torch.nn.parameter import Parameter
|
| 11 |
+
from torch.nn import functional as F
|
| 12 |
+
|
| 13 |
+
# We define this function as _pad because it takes an argument
|
| 14 |
+
# named pad, which clobbers the recursive reference to the pad
|
| 15 |
+
# function needed for __torch_function__ support
|
| 16 |
+
pad = F._pad
|
| 17 |
+
|
| 18 |
+
# This class exists solely for Transformer; it has an annotation stating
|
| 19 |
+
# that bias is never None, which appeases TorchScript
|
| 20 |
+
class _LinearWithBias(torch.nn.Linear):
|
| 21 |
+
bias: Tensor
|
| 22 |
+
|
| 23 |
+
def __init__(self, in_features: int, out_features: int) -> None:
|
| 24 |
+
super().__init__(in_features, out_features, bias=True)
|
| 25 |
+
|
| 26 |
+
def multi_head_attention_forward(query: Tensor,
|
| 27 |
+
key: Tensor,
|
| 28 |
+
value: Tensor,
|
| 29 |
+
embed_dim_to_check: int,
|
| 30 |
+
num_heads: int,
|
| 31 |
+
in_proj_weight: Tensor,
|
| 32 |
+
in_proj_bias: Tensor,
|
| 33 |
+
bias_k: Optional[Tensor],
|
| 34 |
+
bias_v: Optional[Tensor],
|
| 35 |
+
add_zero_attn: bool,
|
| 36 |
+
dropout_p: float,
|
| 37 |
+
out_proj_weight: Tensor,
|
| 38 |
+
out_proj_bias: Tensor,
|
| 39 |
+
training: bool = True,
|
| 40 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 41 |
+
need_weights: bool = True,
|
| 42 |
+
attn_mask: Optional[Tensor] = None,
|
| 43 |
+
use_separate_proj_weight: bool = False,
|
| 44 |
+
q_proj_weight: Optional[Tensor] = None,
|
| 45 |
+
k_proj_weight: Optional[Tensor] = None,
|
| 46 |
+
v_proj_weight: Optional[Tensor] = None,
|
| 47 |
+
static_k: Optional[Tensor] = None,
|
| 48 |
+
static_v: Optional[Tensor] = None,
|
| 49 |
+
attention_probs_forward_hook = None,
|
| 50 |
+
attention_probs_backwards_hook = None,
|
| 51 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 52 |
+
if not torch.jit.is_scripting():
|
| 53 |
+
tens_ops = (query, key, value, in_proj_weight, in_proj_bias, bias_k, bias_v,
|
| 54 |
+
out_proj_weight, out_proj_bias)
|
| 55 |
+
if any([type(t) is not Tensor for t in tens_ops]) and F.has_torch_function(tens_ops):
|
| 56 |
+
return F.handle_torch_function(
|
| 57 |
+
multi_head_attention_forward, tens_ops, query, key, value,
|
| 58 |
+
embed_dim_to_check, num_heads, in_proj_weight, in_proj_bias,
|
| 59 |
+
bias_k, bias_v, add_zero_attn, dropout_p, out_proj_weight,
|
| 60 |
+
out_proj_bias, training=training, key_padding_mask=key_padding_mask,
|
| 61 |
+
need_weights=need_weights, attn_mask=attn_mask,
|
| 62 |
+
use_separate_proj_weight=use_separate_proj_weight,
|
| 63 |
+
q_proj_weight=q_proj_weight, k_proj_weight=k_proj_weight,
|
| 64 |
+
v_proj_weight=v_proj_weight, static_k=static_k, static_v=static_v)
|
| 65 |
+
tgt_len, bsz, embed_dim = query.size()
|
| 66 |
+
assert embed_dim == embed_dim_to_check
|
| 67 |
+
# allow MHA to have different sizes for the feature dimension
|
| 68 |
+
assert key.size(0) == value.size(0) and key.size(1) == value.size(1)
|
| 69 |
+
|
| 70 |
+
head_dim = embed_dim // num_heads
|
| 71 |
+
assert head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
|
| 72 |
+
scaling = float(head_dim) ** -0.5
|
| 73 |
+
|
| 74 |
+
if not use_separate_proj_weight:
|
| 75 |
+
if torch.equal(query, key) and torch.equal(key, value):
|
| 76 |
+
# self-attention
|
| 77 |
+
q, k, v = F.linear(query, in_proj_weight, in_proj_bias).chunk(3, dim=-1)
|
| 78 |
+
|
| 79 |
+
elif torch.equal(key, value):
|
| 80 |
+
# encoder-decoder attention
|
| 81 |
+
# This is inline in_proj function with in_proj_weight and in_proj_bias
|
| 82 |
+
_b = in_proj_bias
|
| 83 |
+
_start = 0
|
| 84 |
+
_end = embed_dim
|
| 85 |
+
_w = in_proj_weight[_start:_end, :]
|
| 86 |
+
if _b is not None:
|
| 87 |
+
_b = _b[_start:_end]
|
| 88 |
+
q = F.linear(query, _w, _b)
|
| 89 |
+
|
| 90 |
+
if key is None:
|
| 91 |
+
assert value is None
|
| 92 |
+
k = None
|
| 93 |
+
v = None
|
| 94 |
+
else:
|
| 95 |
+
|
| 96 |
+
# This is inline in_proj function with in_proj_weight and in_proj_bias
|
| 97 |
+
_b = in_proj_bias
|
| 98 |
+
_start = embed_dim
|
| 99 |
+
_end = None
|
| 100 |
+
_w = in_proj_weight[_start:, :]
|
| 101 |
+
if _b is not None:
|
| 102 |
+
_b = _b[_start:]
|
| 103 |
+
k, v = F.linear(key, _w, _b).chunk(2, dim=-1)
|
| 104 |
+
|
| 105 |
+
else:
|
| 106 |
+
# This is inline in_proj function with in_proj_weight and in_proj_bias
|
| 107 |
+
_b = in_proj_bias
|
| 108 |
+
_start = 0
|
| 109 |
+
_end = embed_dim
|
| 110 |
+
_w = in_proj_weight[_start:_end, :]
|
| 111 |
+
if _b is not None:
|
| 112 |
+
_b = _b[_start:_end]
|
| 113 |
+
q = F.linear(query, _w, _b)
|
| 114 |
+
|
| 115 |
+
# This is inline in_proj function with in_proj_weight and in_proj_bias
|
| 116 |
+
_b = in_proj_bias
|
| 117 |
+
_start = embed_dim
|
| 118 |
+
_end = embed_dim * 2
|
| 119 |
+
_w = in_proj_weight[_start:_end, :]
|
| 120 |
+
if _b is not None:
|
| 121 |
+
_b = _b[_start:_end]
|
| 122 |
+
k = F.linear(key, _w, _b)
|
| 123 |
+
|
| 124 |
+
# This is inline in_proj function with in_proj_weight and in_proj_bias
|
| 125 |
+
_b = in_proj_bias
|
| 126 |
+
_start = embed_dim * 2
|
| 127 |
+
_end = None
|
| 128 |
+
_w = in_proj_weight[_start:, :]
|
| 129 |
+
if _b is not None:
|
| 130 |
+
_b = _b[_start:]
|
| 131 |
+
v = F.linear(value, _w, _b)
|
| 132 |
+
else:
|
| 133 |
+
q_proj_weight_non_opt = torch.jit._unwrap_optional(q_proj_weight)
|
| 134 |
+
len1, len2 = q_proj_weight_non_opt.size()
|
| 135 |
+
assert len1 == embed_dim and len2 == query.size(-1)
|
| 136 |
+
|
| 137 |
+
k_proj_weight_non_opt = torch.jit._unwrap_optional(k_proj_weight)
|
| 138 |
+
len1, len2 = k_proj_weight_non_opt.size()
|
| 139 |
+
assert len1 == embed_dim and len2 == key.size(-1)
|
| 140 |
+
|
| 141 |
+
v_proj_weight_non_opt = torch.jit._unwrap_optional(v_proj_weight)
|
| 142 |
+
len1, len2 = v_proj_weight_non_opt.size()
|
| 143 |
+
assert len1 == embed_dim and len2 == value.size(-1)
|
| 144 |
+
|
| 145 |
+
if in_proj_bias is not None:
|
| 146 |
+
q = F.linear(query, q_proj_weight_non_opt, in_proj_bias[0:embed_dim])
|
| 147 |
+
k = F.linear(key, k_proj_weight_non_opt, in_proj_bias[embed_dim:(embed_dim * 2)])
|
| 148 |
+
v = F.linear(value, v_proj_weight_non_opt, in_proj_bias[(embed_dim * 2):])
|
| 149 |
+
else:
|
| 150 |
+
q = F.linear(query, q_proj_weight_non_opt, in_proj_bias)
|
| 151 |
+
k = F.linear(key, k_proj_weight_non_opt, in_proj_bias)
|
| 152 |
+
v = F.linear(value, v_proj_weight_non_opt, in_proj_bias)
|
| 153 |
+
q = q * scaling
|
| 154 |
+
|
| 155 |
+
if attn_mask is not None:
|
| 156 |
+
assert attn_mask.dtype == torch.float32 or attn_mask.dtype == torch.float64 or \
|
| 157 |
+
attn_mask.dtype == torch.float16 or attn_mask.dtype == torch.uint8 or attn_mask.dtype == torch.bool, \
|
| 158 |
+
'Only float, byte, and bool types are supported for attn_mask, not {}'.format(attn_mask.dtype)
|
| 159 |
+
if attn_mask.dtype == torch.uint8:
|
| 160 |
+
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
|
| 161 |
+
attn_mask = attn_mask.to(torch.bool)
|
| 162 |
+
|
| 163 |
+
if attn_mask.dim() == 2:
|
| 164 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 165 |
+
if list(attn_mask.size()) != [1, query.size(0), key.size(0)]:
|
| 166 |
+
raise RuntimeError('The size of the 2D attn_mask is not correct.')
|
| 167 |
+
elif attn_mask.dim() == 3:
|
| 168 |
+
if list(attn_mask.size()) != [bsz * num_heads, query.size(0), key.size(0)]:
|
| 169 |
+
raise RuntimeError('The size of the 3D attn_mask is not correct.')
|
| 170 |
+
else:
|
| 171 |
+
raise RuntimeError("attn_mask's dimension {} is not supported".format(attn_mask.dim()))
|
| 172 |
+
# attn_mask's dim is 3 now.
|
| 173 |
+
|
| 174 |
+
# convert ByteTensor key_padding_mask to bool
|
| 175 |
+
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
|
| 176 |
+
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
|
| 177 |
+
key_padding_mask = key_padding_mask.to(torch.bool)
|
| 178 |
+
|
| 179 |
+
if bias_k is not None and bias_v is not None:
|
| 180 |
+
if static_k is None and static_v is None:
|
| 181 |
+
k = torch.cat([k, bias_k.repeat(1, bsz, 1)])
|
| 182 |
+
v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
|
| 183 |
+
if attn_mask is not None:
|
| 184 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 185 |
+
if key_padding_mask is not None:
|
| 186 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 187 |
+
else:
|
| 188 |
+
assert static_k is None, "bias cannot be added to static key."
|
| 189 |
+
assert static_v is None, "bias cannot be added to static value."
|
| 190 |
+
else:
|
| 191 |
+
assert bias_k is None
|
| 192 |
+
assert bias_v is None
|
| 193 |
+
|
| 194 |
+
q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
|
| 195 |
+
if k is not None:
|
| 196 |
+
k = k.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
|
| 197 |
+
if v is not None:
|
| 198 |
+
v = v.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
|
| 199 |
+
|
| 200 |
+
if static_k is not None:
|
| 201 |
+
assert static_k.size(0) == bsz * num_heads
|
| 202 |
+
assert static_k.size(2) == head_dim
|
| 203 |
+
k = static_k
|
| 204 |
+
|
| 205 |
+
if static_v is not None:
|
| 206 |
+
assert static_v.size(0) == bsz * num_heads
|
| 207 |
+
assert static_v.size(2) == head_dim
|
| 208 |
+
v = static_v
|
| 209 |
+
|
| 210 |
+
src_len = k.size(1)
|
| 211 |
+
|
| 212 |
+
if key_padding_mask is not None:
|
| 213 |
+
assert key_padding_mask.size(0) == bsz
|
| 214 |
+
assert key_padding_mask.size(1) == src_len
|
| 215 |
+
|
| 216 |
+
if add_zero_attn:
|
| 217 |
+
src_len += 1
|
| 218 |
+
k = torch.cat([k, torch.zeros((k.size(0), 1) + k.size()[2:], dtype=k.dtype, device=k.device)], dim=1)
|
| 219 |
+
v = torch.cat([v, torch.zeros((v.size(0), 1) + v.size()[2:], dtype=v.dtype, device=v.device)], dim=1)
|
| 220 |
+
if attn_mask is not None:
|
| 221 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 222 |
+
if key_padding_mask is not None:
|
| 223 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 224 |
+
|
| 225 |
+
attn_output_weights = torch.bmm(q, k.transpose(1, 2))
|
| 226 |
+
assert list(attn_output_weights.size()) == [bsz * num_heads, tgt_len, src_len]
|
| 227 |
+
|
| 228 |
+
if attn_mask is not None:
|
| 229 |
+
if attn_mask.dtype == torch.bool:
|
| 230 |
+
attn_output_weights.masked_fill_(attn_mask, float('-inf'))
|
| 231 |
+
else:
|
| 232 |
+
attn_output_weights += attn_mask
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
if key_padding_mask is not None:
|
| 236 |
+
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
|
| 237 |
+
attn_output_weights = attn_output_weights.masked_fill(
|
| 238 |
+
key_padding_mask.unsqueeze(1).unsqueeze(2),
|
| 239 |
+
float('-inf'),
|
| 240 |
+
)
|
| 241 |
+
attn_output_weights = attn_output_weights.view(bsz * num_heads, tgt_len, src_len)
|
| 242 |
+
|
| 243 |
+
attn_output_weights = F.softmax(
|
| 244 |
+
attn_output_weights, dim=-1)
|
| 245 |
+
attn_output_weights = F.dropout(attn_output_weights, p=dropout_p, training=training)
|
| 246 |
+
|
| 247 |
+
# use hooks for the attention weights if necessary
|
| 248 |
+
if attention_probs_forward_hook is not None and attention_probs_backwards_hook is not None:
|
| 249 |
+
attention_probs_forward_hook(attn_output_weights)
|
| 250 |
+
attn_output_weights.register_hook(attention_probs_backwards_hook)
|
| 251 |
+
|
| 252 |
+
attn_output = torch.bmm(attn_output_weights, v)
|
| 253 |
+
assert list(attn_output.size()) == [bsz * num_heads, tgt_len, head_dim]
|
| 254 |
+
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
|
| 255 |
+
attn_output = F.linear(attn_output, out_proj_weight, out_proj_bias)
|
| 256 |
+
|
| 257 |
+
if need_weights:
|
| 258 |
+
# average attention weights over heads
|
| 259 |
+
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
|
| 260 |
+
return attn_output, attn_output_weights.sum(dim=1) / num_heads
|
| 261 |
+
else:
|
| 262 |
+
return attn_output, None
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
class MultiheadAttention(torch.nn.Module):
|
| 266 |
+
r"""Allows the model to jointly attend to information
|
| 267 |
+
from different representation subspaces.
|
| 268 |
+
See reference: Attention Is All You Need
|
| 269 |
+
|
| 270 |
+
.. math::
|
| 271 |
+
\text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
|
| 272 |
+
\text{where} head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
|
| 273 |
+
|
| 274 |
+
Args:
|
| 275 |
+
embed_dim: total dimension of the model.
|
| 276 |
+
num_heads: parallel attention heads.
|
| 277 |
+
dropout: a Dropout layer on attn_output_weights. Default: 0.0.
|
| 278 |
+
bias: add bias as module parameter. Default: True.
|
| 279 |
+
add_bias_kv: add bias to the key and value sequences at dim=0.
|
| 280 |
+
add_zero_attn: add a new batch of zeros to the key and
|
| 281 |
+
value sequences at dim=1.
|
| 282 |
+
kdim: total number of features in key. Default: None.
|
| 283 |
+
vdim: total number of features in value. Default: None.
|
| 284 |
+
|
| 285 |
+
Note: if kdim and vdim are None, they will be set to embed_dim such that
|
| 286 |
+
query, key, and value have the same number of features.
|
| 287 |
+
|
| 288 |
+
Examples::
|
| 289 |
+
|
| 290 |
+
>>> multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
|
| 291 |
+
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
|
| 292 |
+
"""
|
| 293 |
+
bias_k: Optional[torch.Tensor]
|
| 294 |
+
bias_v: Optional[torch.Tensor]
|
| 295 |
+
|
| 296 |
+
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None):
|
| 297 |
+
super(MultiheadAttention, self).__init__()
|
| 298 |
+
self.embed_dim = embed_dim
|
| 299 |
+
self.kdim = kdim if kdim is not None else embed_dim
|
| 300 |
+
self.vdim = vdim if vdim is not None else embed_dim
|
| 301 |
+
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
|
| 302 |
+
|
| 303 |
+
self.num_heads = num_heads
|
| 304 |
+
self.dropout = dropout
|
| 305 |
+
self.head_dim = embed_dim // num_heads
|
| 306 |
+
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
|
| 307 |
+
|
| 308 |
+
if self._qkv_same_embed_dim is False:
|
| 309 |
+
self.q_proj_weight = Parameter(torch.Tensor(embed_dim, embed_dim))
|
| 310 |
+
self.k_proj_weight = Parameter(torch.Tensor(embed_dim, self.kdim))
|
| 311 |
+
self.v_proj_weight = Parameter(torch.Tensor(embed_dim, self.vdim))
|
| 312 |
+
self.register_parameter('in_proj_weight', None)
|
| 313 |
+
else:
|
| 314 |
+
self.in_proj_weight = Parameter(torch.empty(3 * embed_dim, embed_dim))
|
| 315 |
+
self.register_parameter('q_proj_weight', None)
|
| 316 |
+
self.register_parameter('k_proj_weight', None)
|
| 317 |
+
self.register_parameter('v_proj_weight', None)
|
| 318 |
+
|
| 319 |
+
if bias:
|
| 320 |
+
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
|
| 321 |
+
else:
|
| 322 |
+
self.register_parameter('in_proj_bias', None)
|
| 323 |
+
self.out_proj = _LinearWithBias(embed_dim, embed_dim)
|
| 324 |
+
|
| 325 |
+
if add_bias_kv:
|
| 326 |
+
self.bias_k = Parameter(torch.empty(1, 1, embed_dim))
|
| 327 |
+
self.bias_v = Parameter(torch.empty(1, 1, embed_dim))
|
| 328 |
+
else:
|
| 329 |
+
self.bias_k = self.bias_v = None
|
| 330 |
+
|
| 331 |
+
self.add_zero_attn = add_zero_attn
|
| 332 |
+
|
| 333 |
+
self._reset_parameters()
|
| 334 |
+
|
| 335 |
+
def _reset_parameters(self):
|
| 336 |
+
if self._qkv_same_embed_dim:
|
| 337 |
+
xavier_uniform_(self.in_proj_weight)
|
| 338 |
+
else:
|
| 339 |
+
xavier_uniform_(self.q_proj_weight)
|
| 340 |
+
xavier_uniform_(self.k_proj_weight)
|
| 341 |
+
xavier_uniform_(self.v_proj_weight)
|
| 342 |
+
|
| 343 |
+
if self.in_proj_bias is not None:
|
| 344 |
+
constant_(self.in_proj_bias, 0.)
|
| 345 |
+
constant_(self.out_proj.bias, 0.)
|
| 346 |
+
if self.bias_k is not None:
|
| 347 |
+
xavier_normal_(self.bias_k)
|
| 348 |
+
if self.bias_v is not None:
|
| 349 |
+
xavier_normal_(self.bias_v)
|
| 350 |
+
|
| 351 |
+
def __setstate__(self, state):
|
| 352 |
+
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
|
| 353 |
+
if '_qkv_same_embed_dim' not in state:
|
| 354 |
+
state['_qkv_same_embed_dim'] = True
|
| 355 |
+
|
| 356 |
+
super(MultiheadAttention, self).__setstate__(state)
|
| 357 |
+
|
| 358 |
+
def forward(self, query, key, value, key_padding_mask=None,
|
| 359 |
+
need_weights=True, attn_mask=None, attention_probs_forward_hook=None, attention_probs_backwards_hook=None):
|
| 360 |
+
r"""
|
| 361 |
+
Args:
|
| 362 |
+
query, key, value: map a query and a set of key-value pairs to an output.
|
| 363 |
+
See "Attention Is All You Need" for more details.
|
| 364 |
+
key_padding_mask: if provided, specified padding elements in the key will
|
| 365 |
+
be ignored by the attention. When given a binary mask and a value is True,
|
| 366 |
+
the corresponding value on the attention layer will be ignored. When given
|
| 367 |
+
a byte mask and a value is non-zero, the corresponding value on the attention
|
| 368 |
+
layer will be ignored
|
| 369 |
+
need_weights: output attn_output_weights.
|
| 370 |
+
attn_mask: 2D or 3D mask that prevents attention to certain positions. A 2D mask will be broadcasted for all
|
| 371 |
+
the batches while a 3D mask allows to specify a different mask for the entries of each batch.
|
| 372 |
+
|
| 373 |
+
Shape:
|
| 374 |
+
- Inputs:
|
| 375 |
+
- query: :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
|
| 376 |
+
the embedding dimension.
|
| 377 |
+
- key: :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
|
| 378 |
+
the embedding dimension.
|
| 379 |
+
- value: :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
|
| 380 |
+
the embedding dimension.
|
| 381 |
+
- key_padding_mask: :math:`(N, S)` where N is the batch size, S is the source sequence length.
|
| 382 |
+
If a ByteTensor is provided, the non-zero positions will be ignored while the position
|
| 383 |
+
with the zero positions will be unchanged. If a BoolTensor is provided, the positions with the
|
| 384 |
+
value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
|
| 385 |
+
- attn_mask: 2D mask :math:`(L, S)` where L is the target sequence length, S is the source sequence length.
|
| 386 |
+
3D mask :math:`(N*num_heads, L, S)` where N is the batch size, L is the target sequence length,
|
| 387 |
+
S is the source sequence length. attn_mask ensure that position i is allowed to attend the unmasked
|
| 388 |
+
positions. If a ByteTensor is provided, the non-zero positions are not allowed to attend
|
| 389 |
+
while the zero positions will be unchanged. If a BoolTensor is provided, positions with ``True``
|
| 390 |
+
is not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
|
| 391 |
+
is provided, it will be added to the attention weight.
|
| 392 |
+
|
| 393 |
+
- Outputs:
|
| 394 |
+
- attn_output: :math:`(L, N, E)` where L is the target sequence length, N is the batch size,
|
| 395 |
+
E is the embedding dimension.
|
| 396 |
+
- attn_output_weights: :math:`(N, L, S)` where N is the batch size,
|
| 397 |
+
L is the target sequence length, S is the source sequence length.
|
| 398 |
+
"""
|
| 399 |
+
if not self._qkv_same_embed_dim:
|
| 400 |
+
return multi_head_attention_forward(
|
| 401 |
+
query, key, value, self.embed_dim, self.num_heads,
|
| 402 |
+
self.in_proj_weight, self.in_proj_bias,
|
| 403 |
+
self.bias_k, self.bias_v, self.add_zero_attn,
|
| 404 |
+
self.dropout, self.out_proj.weight, self.out_proj.bias,
|
| 405 |
+
training=self.training,
|
| 406 |
+
key_padding_mask=key_padding_mask, need_weights=need_weights,
|
| 407 |
+
attn_mask=attn_mask, use_separate_proj_weight=True,
|
| 408 |
+
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
|
| 409 |
+
v_proj_weight=self.v_proj_weight,
|
| 410 |
+
attention_probs_forward_hook=attention_probs_forward_hook,
|
| 411 |
+
attention_probs_backwards_hook=attention_probs_backwards_hook)
|
| 412 |
+
else:
|
| 413 |
+
return multi_head_attention_forward(
|
| 414 |
+
query, key, value, self.embed_dim, self.num_heads,
|
| 415 |
+
self.in_proj_weight, self.in_proj_bias,
|
| 416 |
+
self.bias_k, self.bias_v, self.add_zero_attn,
|
| 417 |
+
self.dropout, self.out_proj.weight, self.out_proj.bias,
|
| 418 |
+
training=self.training,
|
| 419 |
+
key_padding_mask=key_padding_mask, need_weights=need_weights,
|
| 420 |
+
attn_mask=attn_mask,
|
| 421 |
+
attention_probs_forward_hook=attention_probs_forward_hook,
|
| 422 |
+
attention_probs_backwards_hook=attention_probs_backwards_hook)
|
CLIP/clip_explainability/bpe_simple_vocab_16e6.txt.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:924691ac288e54409236115652ad4aa250f48203de50a9e4722a6ecd48d6804a
|
| 3 |
+
size 1356917
|
CLIP/clip_explainability/clip.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import hashlib
|
| 2 |
+
import os
|
| 3 |
+
import urllib
|
| 4 |
+
import warnings
|
| 5 |
+
from typing import Union, List
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from PIL import Image
|
| 9 |
+
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
from .model import build_model
|
| 13 |
+
from .simple_tokenizer import SimpleTokenizer as _Tokenizer
|
| 14 |
+
|
| 15 |
+
__all__ = ["available_models", "load", "tokenize"]
|
| 16 |
+
_tokenizer = _Tokenizer()
|
| 17 |
+
|
| 18 |
+
_MODELS = {
|
| 19 |
+
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
|
| 20 |
+
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
|
| 21 |
+
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
|
| 22 |
+
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
|
| 23 |
+
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
|
| 24 |
+
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
|
| 25 |
+
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
|
| 26 |
+
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
def _download(url: str, root: str = os.path.expanduser("~/.cache/clip")):
|
| 30 |
+
os.makedirs(root, exist_ok=True)
|
| 31 |
+
filename = os.path.basename(url)
|
| 32 |
+
|
| 33 |
+
expected_sha256 = url.split("/")[-2]
|
| 34 |
+
download_target = os.path.join(root, filename)
|
| 35 |
+
|
| 36 |
+
if os.path.exists(download_target) and not os.path.isfile(download_target):
|
| 37 |
+
raise RuntimeError(f"{download_target} exists and is not a regular file")
|
| 38 |
+
|
| 39 |
+
if os.path.isfile(download_target):
|
| 40 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:
|
| 41 |
+
return download_target
|
| 42 |
+
else:
|
| 43 |
+
warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
|
| 44 |
+
|
| 45 |
+
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
|
| 46 |
+
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True) as loop:
|
| 47 |
+
while True:
|
| 48 |
+
buffer = source.read(8192)
|
| 49 |
+
if not buffer:
|
| 50 |
+
break
|
| 51 |
+
|
| 52 |
+
output.write(buffer)
|
| 53 |
+
loop.update(len(buffer))
|
| 54 |
+
|
| 55 |
+
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:
|
| 56 |
+
raise RuntimeError(f"Model has been downloaded but the SHA256 checksum does not not match")
|
| 57 |
+
|
| 58 |
+
return download_target
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def _transform(n_px):
|
| 62 |
+
return Compose([
|
| 63 |
+
Resize(n_px, interpolation=Image.BICUBIC),
|
| 64 |
+
CenterCrop(n_px),
|
| 65 |
+
lambda image: image.convert("RGB"),
|
| 66 |
+
ToTensor(),
|
| 67 |
+
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
|
| 68 |
+
])
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def available_models() -> List[str]:
|
| 72 |
+
"""Returns the names of available CLIP models"""
|
| 73 |
+
return list(_MODELS.keys())
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit=True):
|
| 77 |
+
"""Load a CLIP model
|
| 78 |
+
|
| 79 |
+
Parameters
|
| 80 |
+
----------
|
| 81 |
+
name : str
|
| 82 |
+
A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
|
| 83 |
+
|
| 84 |
+
device : Union[str, torch.device]
|
| 85 |
+
The device to put the loaded model
|
| 86 |
+
|
| 87 |
+
jit : bool
|
| 88 |
+
Whether to load the optimized JIT model (default) or more hackable non-JIT model.
|
| 89 |
+
|
| 90 |
+
Returns
|
| 91 |
+
-------
|
| 92 |
+
model : torch.nn.Module
|
| 93 |
+
The CLIP model
|
| 94 |
+
|
| 95 |
+
preprocess : Callable[[PIL.Image], torch.Tensor]
|
| 96 |
+
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
|
| 97 |
+
"""
|
| 98 |
+
if name in _MODELS:
|
| 99 |
+
model_path = _download(_MODELS[name])
|
| 100 |
+
elif os.path.isfile(name):
|
| 101 |
+
model_path = name
|
| 102 |
+
else:
|
| 103 |
+
raise RuntimeError(f"Model {name} not found; available models = {available_models()}")
|
| 104 |
+
|
| 105 |
+
try:
|
| 106 |
+
# loading JIT archive
|
| 107 |
+
model = torch.jit.load(model_path, map_location=device if jit else "cpu").eval()
|
| 108 |
+
state_dict = None
|
| 109 |
+
except RuntimeError:
|
| 110 |
+
# loading saved state dict
|
| 111 |
+
if jit:
|
| 112 |
+
warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")
|
| 113 |
+
jit = False
|
| 114 |
+
state_dict = torch.load(model_path, map_location="cpu")
|
| 115 |
+
|
| 116 |
+
if not jit:
|
| 117 |
+
model = build_model(state_dict or model.state_dict()).to(device)
|
| 118 |
+
if str(device) == "cpu":
|
| 119 |
+
model.float()
|
| 120 |
+
return model, _transform(model.visual.input_resolution)
|
| 121 |
+
|
| 122 |
+
# patch the device names
|
| 123 |
+
device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
|
| 124 |
+
device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]
|
| 125 |
+
|
| 126 |
+
def patch_device(module):
|
| 127 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 128 |
+
if hasattr(module, "forward1"):
|
| 129 |
+
graphs.append(module.forward1.graph)
|
| 130 |
+
|
| 131 |
+
for graph in graphs:
|
| 132 |
+
for node in graph.findAllNodes("prim::Constant"):
|
| 133 |
+
if "value" in node.attributeNames() and str(node["value"]).startswith("cuda"):
|
| 134 |
+
node.copyAttributes(device_node)
|
| 135 |
+
|
| 136 |
+
model.apply(patch_device)
|
| 137 |
+
patch_device(model.encode_image)
|
| 138 |
+
patch_device(model.encode_text)
|
| 139 |
+
|
| 140 |
+
# patch dtype to float32 on CPU
|
| 141 |
+
if str(device) == "cpu":
|
| 142 |
+
float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])
|
| 143 |
+
float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]
|
| 144 |
+
float_node = float_input.node()
|
| 145 |
+
|
| 146 |
+
def patch_float(module):
|
| 147 |
+
graphs = [module.graph] if hasattr(module, "graph") else []
|
| 148 |
+
if hasattr(module, "forward1"):
|
| 149 |
+
graphs.append(module.forward1.graph)
|
| 150 |
+
|
| 151 |
+
for graph in graphs:
|
| 152 |
+
for node in graph.findAllNodes("aten::to"):
|
| 153 |
+
inputs = list(node.inputs())
|
| 154 |
+
for i in [1, 2]: # dtype can be the second or third argument to aten::to()
|
| 155 |
+
if inputs[i].node()["value"] == 5:
|
| 156 |
+
inputs[i].node().copyAttributes(float_node)
|
| 157 |
+
|
| 158 |
+
model.apply(patch_float)
|
| 159 |
+
patch_float(model.encode_image)
|
| 160 |
+
patch_float(model.encode_text)
|
| 161 |
+
|
| 162 |
+
model.float()
|
| 163 |
+
|
| 164 |
+
return model, _transform(model.input_resolution.item())
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def tokenize(texts: Union[str, List[str]], context_length: int = 77) -> torch.LongTensor:
|
| 168 |
+
"""
|
| 169 |
+
Returns the tokenized representation of given input string(s)
|
| 170 |
+
|
| 171 |
+
Parameters
|
| 172 |
+
----------
|
| 173 |
+
texts : Union[str, List[str]]
|
| 174 |
+
An input string or a list of input strings to tokenize
|
| 175 |
+
|
| 176 |
+
context_length : int
|
| 177 |
+
The context length to use; all CLIP models use 77 as the context length
|
| 178 |
+
|
| 179 |
+
Returns
|
| 180 |
+
-------
|
| 181 |
+
A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
|
| 182 |
+
"""
|
| 183 |
+
if isinstance(texts, str):
|
| 184 |
+
texts = [texts]
|
| 185 |
+
|
| 186 |
+
sot_token = _tokenizer.encoder["<|startoftext|>"]
|
| 187 |
+
eot_token = _tokenizer.encoder["<|endoftext|>"]
|
| 188 |
+
all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
|
| 189 |
+
result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
|
| 190 |
+
|
| 191 |
+
for i, tokens in enumerate(all_tokens):
|
| 192 |
+
if len(tokens) > context_length:
|
| 193 |
+
raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
|
| 194 |
+
result[i, :len(tokens)] = torch.tensor(tokens)
|
| 195 |
+
|
| 196 |
+
return result
|
CLIP/clip_explainability/model.py
ADDED
|
@@ -0,0 +1,442 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict
|
| 2 |
+
from typing import Tuple, Union
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import nn
|
| 8 |
+
from .auxilary import *
|
| 9 |
+
|
| 10 |
+
class Bottleneck(nn.Module):
|
| 11 |
+
expansion = 4
|
| 12 |
+
|
| 13 |
+
def __init__(self, inplanes, planes, stride=1):
|
| 14 |
+
super().__init__()
|
| 15 |
+
|
| 16 |
+
# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
|
| 17 |
+
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
|
| 18 |
+
self.bn1 = nn.BatchNorm2d(planes)
|
| 19 |
+
|
| 20 |
+
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
|
| 21 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 22 |
+
|
| 23 |
+
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
|
| 24 |
+
|
| 25 |
+
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
|
| 26 |
+
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
|
| 27 |
+
|
| 28 |
+
self.relu = nn.ReLU(inplace=True)
|
| 29 |
+
self.downsample = None
|
| 30 |
+
self.stride = stride
|
| 31 |
+
|
| 32 |
+
if stride > 1 or inplanes != planes * Bottleneck.expansion:
|
| 33 |
+
# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
|
| 34 |
+
self.downsample = nn.Sequential(OrderedDict([
|
| 35 |
+
("-1", nn.AvgPool2d(stride)),
|
| 36 |
+
("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
|
| 37 |
+
("1", nn.BatchNorm2d(planes * self.expansion))
|
| 38 |
+
]))
|
| 39 |
+
|
| 40 |
+
def forward(self, x: torch.Tensor):
|
| 41 |
+
identity = x
|
| 42 |
+
|
| 43 |
+
out = self.relu(self.bn1(self.conv1(x)))
|
| 44 |
+
out = self.relu(self.bn2(self.conv2(out)))
|
| 45 |
+
out = self.avgpool(out)
|
| 46 |
+
out = self.bn3(self.conv3(out))
|
| 47 |
+
|
| 48 |
+
if self.downsample is not None:
|
| 49 |
+
identity = self.downsample(x)
|
| 50 |
+
|
| 51 |
+
out += identity
|
| 52 |
+
out = self.relu(out)
|
| 53 |
+
return out
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class AttentionPool2d(nn.Module):
|
| 57 |
+
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
|
| 58 |
+
super().__init__()
|
| 59 |
+
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
|
| 60 |
+
self.k_proj = nn.Linear(embed_dim, embed_dim)
|
| 61 |
+
self.q_proj = nn.Linear(embed_dim, embed_dim)
|
| 62 |
+
self.v_proj = nn.Linear(embed_dim, embed_dim)
|
| 63 |
+
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
|
| 64 |
+
self.num_heads = num_heads
|
| 65 |
+
|
| 66 |
+
def forward(self, x):
|
| 67 |
+
x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
|
| 68 |
+
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
|
| 69 |
+
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
|
| 70 |
+
x, _ = multi_head_attention_forward(
|
| 71 |
+
query=x, key=x, value=x,
|
| 72 |
+
embed_dim_to_check=x.shape[-1],
|
| 73 |
+
num_heads=self.num_heads,
|
| 74 |
+
q_proj_weight=self.q_proj.weight,
|
| 75 |
+
k_proj_weight=self.k_proj.weight,
|
| 76 |
+
v_proj_weight=self.v_proj.weight,
|
| 77 |
+
in_proj_weight=None,
|
| 78 |
+
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
|
| 79 |
+
bias_k=None,
|
| 80 |
+
bias_v=None,
|
| 81 |
+
add_zero_attn=False,
|
| 82 |
+
dropout_p=0,
|
| 83 |
+
out_proj_weight=self.c_proj.weight,
|
| 84 |
+
out_proj_bias=self.c_proj.bias,
|
| 85 |
+
use_separate_proj_weight=True,
|
| 86 |
+
training=self.training,
|
| 87 |
+
need_weights=False
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
return x[0]
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class ModifiedResNet(nn.Module):
|
| 94 |
+
"""
|
| 95 |
+
A ResNet class that is similar to torchvision's but contains the following changes:
|
| 96 |
+
- There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
|
| 97 |
+
- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
|
| 98 |
+
- The final pooling layer is a QKV attention instead of an average pool
|
| 99 |
+
"""
|
| 100 |
+
|
| 101 |
+
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
|
| 102 |
+
super().__init__()
|
| 103 |
+
self.output_dim = output_dim
|
| 104 |
+
self.input_resolution = input_resolution
|
| 105 |
+
|
| 106 |
+
# the 3-layer stem
|
| 107 |
+
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
|
| 108 |
+
self.bn1 = nn.BatchNorm2d(width // 2)
|
| 109 |
+
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
|
| 110 |
+
self.bn2 = nn.BatchNorm2d(width // 2)
|
| 111 |
+
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
|
| 112 |
+
self.bn3 = nn.BatchNorm2d(width)
|
| 113 |
+
self.avgpool = nn.AvgPool2d(2)
|
| 114 |
+
self.relu = nn.ReLU(inplace=True)
|
| 115 |
+
|
| 116 |
+
# residual layers
|
| 117 |
+
self._inplanes = width # this is a *mutable* variable used during construction
|
| 118 |
+
self.layer1 = self._make_layer(width, layers[0])
|
| 119 |
+
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
|
| 120 |
+
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
|
| 121 |
+
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
|
| 122 |
+
|
| 123 |
+
embed_dim = width * 32 # the ResNet feature dimension
|
| 124 |
+
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
|
| 125 |
+
|
| 126 |
+
def _make_layer(self, planes, blocks, stride=1):
|
| 127 |
+
layers = [Bottleneck(self._inplanes, planes, stride)]
|
| 128 |
+
|
| 129 |
+
self._inplanes = planes * Bottleneck.expansion
|
| 130 |
+
for _ in range(1, blocks):
|
| 131 |
+
layers.append(Bottleneck(self._inplanes, planes))
|
| 132 |
+
|
| 133 |
+
return nn.Sequential(*layers)
|
| 134 |
+
|
| 135 |
+
def forward(self, x):
|
| 136 |
+
def stem(x):
|
| 137 |
+
for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
|
| 138 |
+
x = self.relu(bn(conv(x)))
|
| 139 |
+
x = self.avgpool(x)
|
| 140 |
+
return x
|
| 141 |
+
|
| 142 |
+
x = x.type(self.conv1.weight.dtype)
|
| 143 |
+
x = stem(x)
|
| 144 |
+
x = self.layer1(x)
|
| 145 |
+
x = self.layer2(x)
|
| 146 |
+
x = self.layer3(x)
|
| 147 |
+
x = self.layer4(x)
|
| 148 |
+
x = self.attnpool(x)
|
| 149 |
+
|
| 150 |
+
return x
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class LayerNorm(nn.LayerNorm):
|
| 154 |
+
"""Subclass torch's LayerNorm to handle fp16."""
|
| 155 |
+
|
| 156 |
+
def forward(self, x: torch.Tensor):
|
| 157 |
+
orig_type = x.dtype
|
| 158 |
+
ret = super().forward(x.type(torch.float32))
|
| 159 |
+
return ret.type(orig_type)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class QuickGELU(nn.Module):
|
| 163 |
+
def forward(self, x: torch.Tensor):
|
| 164 |
+
return x * torch.sigmoid(1.702 * x)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class ResidualAttentionBlock(nn.Module):
|
| 168 |
+
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
|
| 169 |
+
super().__init__()
|
| 170 |
+
|
| 171 |
+
self.attn = MultiheadAttention(d_model, n_head)
|
| 172 |
+
self.ln_1 = LayerNorm(d_model)
|
| 173 |
+
self.mlp = nn.Sequential(OrderedDict([
|
| 174 |
+
("c_fc", nn.Linear(d_model, d_model * 4)),
|
| 175 |
+
("gelu", QuickGELU()),
|
| 176 |
+
("c_proj", nn.Linear(d_model * 4, d_model))
|
| 177 |
+
]))
|
| 178 |
+
self.ln_2 = LayerNorm(d_model)
|
| 179 |
+
self.attn_mask = attn_mask
|
| 180 |
+
|
| 181 |
+
self.attn_probs = None
|
| 182 |
+
self.attn_grad = None
|
| 183 |
+
|
| 184 |
+
def set_attn_probs(self, attn_probs):
|
| 185 |
+
self.attn_probs = attn_probs
|
| 186 |
+
|
| 187 |
+
def set_attn_grad(self, attn_grad):
|
| 188 |
+
self.attn_grad = attn_grad
|
| 189 |
+
|
| 190 |
+
def attention(self, x: torch.Tensor):
|
| 191 |
+
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
|
| 192 |
+
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask, attention_probs_forward_hook=self.set_attn_probs,
|
| 193 |
+
attention_probs_backwards_hook=self.set_attn_grad)[0]
|
| 194 |
+
|
| 195 |
+
def forward(self, x: torch.Tensor):
|
| 196 |
+
x = x + self.attention(self.ln_1(x))
|
| 197 |
+
x = x + self.mlp(self.ln_2(x))
|
| 198 |
+
return x
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
class Transformer(nn.Module):
|
| 202 |
+
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
|
| 203 |
+
super().__init__()
|
| 204 |
+
self.width = width
|
| 205 |
+
self.layers = layers
|
| 206 |
+
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
|
| 207 |
+
|
| 208 |
+
def forward(self, x: torch.Tensor):
|
| 209 |
+
return self.resblocks(x)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class VisualTransformer(nn.Module):
|
| 213 |
+
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
|
| 214 |
+
super().__init__()
|
| 215 |
+
self.input_resolution = input_resolution
|
| 216 |
+
self.output_dim = output_dim
|
| 217 |
+
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
|
| 218 |
+
|
| 219 |
+
scale = width ** -0.5
|
| 220 |
+
self.class_embedding = nn.Parameter(scale * torch.randn(width))
|
| 221 |
+
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
|
| 222 |
+
self.ln_pre = LayerNorm(width)
|
| 223 |
+
|
| 224 |
+
self.transformer = Transformer(width, layers, heads)
|
| 225 |
+
|
| 226 |
+
self.ln_post = LayerNorm(width)
|
| 227 |
+
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
|
| 228 |
+
|
| 229 |
+
def forward(self, x: torch.Tensor):
|
| 230 |
+
x = self.conv1(x) # shape = [*, width, grid, grid]
|
| 231 |
+
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
|
| 232 |
+
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
|
| 233 |
+
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
|
| 234 |
+
x = x + self.positional_embedding.to(x.dtype)
|
| 235 |
+
x = self.ln_pre(x)
|
| 236 |
+
|
| 237 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 238 |
+
x = self.transformer(x)
|
| 239 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 240 |
+
|
| 241 |
+
x = self.ln_post(x[:, 0, :])
|
| 242 |
+
|
| 243 |
+
if self.proj is not None:
|
| 244 |
+
x = x @ self.proj
|
| 245 |
+
|
| 246 |
+
return x
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
class CLIP(nn.Module):
|
| 250 |
+
def __init__(self,
|
| 251 |
+
embed_dim: int,
|
| 252 |
+
# vision
|
| 253 |
+
image_resolution: int,
|
| 254 |
+
vision_layers: Union[Tuple[int, int, int, int], int],
|
| 255 |
+
vision_width: int,
|
| 256 |
+
vision_patch_size: int,
|
| 257 |
+
# text
|
| 258 |
+
context_length: int,
|
| 259 |
+
vocab_size: int,
|
| 260 |
+
transformer_width: int,
|
| 261 |
+
transformer_heads: int,
|
| 262 |
+
transformer_layers: int
|
| 263 |
+
):
|
| 264 |
+
super().__init__()
|
| 265 |
+
|
| 266 |
+
self.context_length = context_length
|
| 267 |
+
|
| 268 |
+
if isinstance(vision_layers, (tuple, list)):
|
| 269 |
+
vision_heads = vision_width * 32 // 64
|
| 270 |
+
self.visual = ModifiedResNet(
|
| 271 |
+
layers=vision_layers,
|
| 272 |
+
output_dim=embed_dim,
|
| 273 |
+
heads=vision_heads,
|
| 274 |
+
input_resolution=image_resolution,
|
| 275 |
+
width=vision_width
|
| 276 |
+
)
|
| 277 |
+
else:
|
| 278 |
+
vision_heads = vision_width // 64
|
| 279 |
+
self.visual = VisualTransformer(
|
| 280 |
+
input_resolution=image_resolution,
|
| 281 |
+
patch_size=vision_patch_size,
|
| 282 |
+
width=vision_width,
|
| 283 |
+
layers=vision_layers,
|
| 284 |
+
heads=vision_heads,
|
| 285 |
+
output_dim=embed_dim
|
| 286 |
+
)
|
| 287 |
+
|
| 288 |
+
self.transformer = Transformer(
|
| 289 |
+
width=transformer_width,
|
| 290 |
+
layers=transformer_layers,
|
| 291 |
+
heads=transformer_heads,
|
| 292 |
+
attn_mask=self.build_attention_mask()
|
| 293 |
+
)
|
| 294 |
+
|
| 295 |
+
self.vocab_size = vocab_size
|
| 296 |
+
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
|
| 297 |
+
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
|
| 298 |
+
self.ln_final = LayerNorm(transformer_width)
|
| 299 |
+
|
| 300 |
+
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
|
| 301 |
+
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
|
| 302 |
+
|
| 303 |
+
self.initialize_parameters()
|
| 304 |
+
|
| 305 |
+
def initialize_parameters(self):
|
| 306 |
+
nn.init.normal_(self.token_embedding.weight, std=0.02)
|
| 307 |
+
nn.init.normal_(self.positional_embedding, std=0.01)
|
| 308 |
+
|
| 309 |
+
if isinstance(self.visual, ModifiedResNet):
|
| 310 |
+
if self.visual.attnpool is not None:
|
| 311 |
+
std = self.visual.attnpool.c_proj.in_features ** -0.5
|
| 312 |
+
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
|
| 313 |
+
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
|
| 314 |
+
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
|
| 315 |
+
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
|
| 316 |
+
|
| 317 |
+
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
|
| 318 |
+
for name, param in resnet_block.named_parameters():
|
| 319 |
+
if name.endswith("bn3.weight"):
|
| 320 |
+
nn.init.zeros_(param)
|
| 321 |
+
|
| 322 |
+
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
|
| 323 |
+
attn_std = self.transformer.width ** -0.5
|
| 324 |
+
fc_std = (2 * self.transformer.width) ** -0.5
|
| 325 |
+
for block in self.transformer.resblocks:
|
| 326 |
+
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
|
| 327 |
+
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
|
| 328 |
+
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
|
| 329 |
+
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
|
| 330 |
+
|
| 331 |
+
if self.text_projection is not None:
|
| 332 |
+
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
|
| 333 |
+
|
| 334 |
+
def build_attention_mask(self):
|
| 335 |
+
# lazily create causal attention mask, with full attention between the vision tokens
|
| 336 |
+
# pytorch uses additive attention mask; fill with -inf
|
| 337 |
+
mask = torch.empty(self.context_length, self.context_length)
|
| 338 |
+
mask.fill_(float("-inf"))
|
| 339 |
+
mask.triu_(1) # zero out the lower diagonal
|
| 340 |
+
return mask
|
| 341 |
+
|
| 342 |
+
@property
|
| 343 |
+
def dtype(self):
|
| 344 |
+
return self.visual.conv1.weight.dtype
|
| 345 |
+
|
| 346 |
+
def encode_image(self, image):
|
| 347 |
+
return self.visual(image.type(self.dtype))
|
| 348 |
+
|
| 349 |
+
def encode_text(self, text):
|
| 350 |
+
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
|
| 351 |
+
|
| 352 |
+
x = x + self.positional_embedding.type(self.dtype)
|
| 353 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 354 |
+
x = self.transformer(x)
|
| 355 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 356 |
+
x = self.ln_final(x).type(self.dtype)
|
| 357 |
+
|
| 358 |
+
# x.shape = [batch_size, n_ctx, transformer.width]
|
| 359 |
+
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
| 360 |
+
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
|
| 361 |
+
|
| 362 |
+
return x
|
| 363 |
+
|
| 364 |
+
def forward(self, image, text):
|
| 365 |
+
image_features = self.encode_image(image)
|
| 366 |
+
text_features = self.encode_text(text)
|
| 367 |
+
|
| 368 |
+
# normalized features
|
| 369 |
+
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
|
| 370 |
+
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
|
| 371 |
+
|
| 372 |
+
# cosine similarity as logits
|
| 373 |
+
logit_scale = self.logit_scale.exp()
|
| 374 |
+
logits_per_image = logit_scale * image_features @ text_features.t()
|
| 375 |
+
logits_per_text = logit_scale * text_features @ image_features.t()
|
| 376 |
+
|
| 377 |
+
# shape = [global_batch_size, global_batch_size]
|
| 378 |
+
return logits_per_image, logits_per_text
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
def convert_weights(model: nn.Module):
|
| 382 |
+
"""Convert applicable model parameters to fp16"""
|
| 383 |
+
|
| 384 |
+
def _convert_weights_to_fp16(l):
|
| 385 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
|
| 386 |
+
l.weight.data = l.weight.data.half()
|
| 387 |
+
if l.bias is not None:
|
| 388 |
+
l.bias.data = l.bias.data.half()
|
| 389 |
+
|
| 390 |
+
if isinstance(l, MultiheadAttention):
|
| 391 |
+
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
|
| 392 |
+
tensor = getattr(l, attr)
|
| 393 |
+
if tensor is not None:
|
| 394 |
+
tensor.data = tensor.data.half()
|
| 395 |
+
|
| 396 |
+
for name in ["text_projection", "proj"]:
|
| 397 |
+
if hasattr(l, name):
|
| 398 |
+
attr = getattr(l, name)
|
| 399 |
+
if attr is not None:
|
| 400 |
+
attr.data = attr.data.half()
|
| 401 |
+
|
| 402 |
+
model.apply(_convert_weights_to_fp16)
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
def build_model(state_dict: dict):
|
| 406 |
+
vit = "visual.proj" in state_dict
|
| 407 |
+
|
| 408 |
+
if vit:
|
| 409 |
+
vision_width = state_dict["visual.conv1.weight"].shape[0]
|
| 410 |
+
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
|
| 411 |
+
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
|
| 412 |
+
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 413 |
+
image_resolution = vision_patch_size * grid_size
|
| 414 |
+
else:
|
| 415 |
+
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
|
| 416 |
+
vision_layers = tuple(counts)
|
| 417 |
+
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
|
| 418 |
+
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 419 |
+
vision_patch_size = None
|
| 420 |
+
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
|
| 421 |
+
image_resolution = output_width * 32
|
| 422 |
+
|
| 423 |
+
embed_dim = state_dict["text_projection"].shape[1]
|
| 424 |
+
context_length = state_dict["positional_embedding"].shape[0]
|
| 425 |
+
vocab_size = state_dict["token_embedding.weight"].shape[0]
|
| 426 |
+
transformer_width = state_dict["ln_final.weight"].shape[0]
|
| 427 |
+
transformer_heads = transformer_width // 64
|
| 428 |
+
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
|
| 429 |
+
|
| 430 |
+
model = CLIP(
|
| 431 |
+
embed_dim,
|
| 432 |
+
image_resolution, vision_layers, vision_width, vision_patch_size,
|
| 433 |
+
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
|
| 434 |
+
)
|
| 435 |
+
|
| 436 |
+
for key in ["input_resolution", "context_length", "vocab_size"]:
|
| 437 |
+
if key in state_dict:
|
| 438 |
+
del state_dict[key]
|
| 439 |
+
|
| 440 |
+
convert_weights(model)
|
| 441 |
+
model.load_state_dict(state_dict)
|
| 442 |
+
return model.eval()
|
CLIP/clip_explainability/simple_tokenizer.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gzip
|
| 2 |
+
import html
|
| 3 |
+
import os
|
| 4 |
+
from functools import lru_cache
|
| 5 |
+
|
| 6 |
+
import ftfy
|
| 7 |
+
import regex as re
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@lru_cache()
|
| 11 |
+
def default_bpe():
|
| 12 |
+
return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@lru_cache()
|
| 16 |
+
def bytes_to_unicode():
|
| 17 |
+
"""
|
| 18 |
+
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
| 19 |
+
The reversible bpe codes work on unicode strings.
|
| 20 |
+
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
| 21 |
+
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
| 22 |
+
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
| 23 |
+
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
| 24 |
+
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
| 25 |
+
"""
|
| 26 |
+
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
| 27 |
+
cs = bs[:]
|
| 28 |
+
n = 0
|
| 29 |
+
for b in range(2**8):
|
| 30 |
+
if b not in bs:
|
| 31 |
+
bs.append(b)
|
| 32 |
+
cs.append(2**8+n)
|
| 33 |
+
n += 1
|
| 34 |
+
cs = [chr(n) for n in cs]
|
| 35 |
+
return dict(zip(bs, cs))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_pairs(word):
|
| 39 |
+
"""Return set of symbol pairs in a word.
|
| 40 |
+
Word is represented as tuple of symbols (symbols being variable-length strings).
|
| 41 |
+
"""
|
| 42 |
+
pairs = set()
|
| 43 |
+
prev_char = word[0]
|
| 44 |
+
for char in word[1:]:
|
| 45 |
+
pairs.add((prev_char, char))
|
| 46 |
+
prev_char = char
|
| 47 |
+
return pairs
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def basic_clean(text):
|
| 51 |
+
text = ftfy.fix_text(text)
|
| 52 |
+
text = html.unescape(html.unescape(text))
|
| 53 |
+
return text.strip()
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def whitespace_clean(text):
|
| 57 |
+
text = re.sub(r'\s+', ' ', text)
|
| 58 |
+
text = text.strip()
|
| 59 |
+
return text
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class SimpleTokenizer(object):
|
| 63 |
+
def __init__(self, bpe_path: str = default_bpe()):
|
| 64 |
+
self.byte_encoder = bytes_to_unicode()
|
| 65 |
+
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
|
| 66 |
+
merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
|
| 67 |
+
merges = merges[1:49152-256-2+1]
|
| 68 |
+
merges = [tuple(merge.split()) for merge in merges]
|
| 69 |
+
vocab = list(bytes_to_unicode().values())
|
| 70 |
+
vocab = vocab + [v+'</w>' for v in vocab]
|
| 71 |
+
for merge in merges:
|
| 72 |
+
vocab.append(''.join(merge))
|
| 73 |
+
vocab.extend(['<|startoftext|>', '<|endoftext|>'])
|
| 74 |
+
self.encoder = dict(zip(vocab, range(len(vocab))))
|
| 75 |
+
self.decoder = {v: k for k, v in self.encoder.items()}
|
| 76 |
+
self.bpe_ranks = dict(zip(merges, range(len(merges))))
|
| 77 |
+
self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
|
| 78 |
+
self.pat = re.compile(r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)
|
| 79 |
+
|
| 80 |
+
def bpe(self, token):
|
| 81 |
+
if token in self.cache:
|
| 82 |
+
return self.cache[token]
|
| 83 |
+
word = tuple(token[:-1]) + ( token[-1] + '</w>',)
|
| 84 |
+
pairs = get_pairs(word)
|
| 85 |
+
|
| 86 |
+
if not pairs:
|
| 87 |
+
return token+'</w>'
|
| 88 |
+
|
| 89 |
+
while True:
|
| 90 |
+
bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
|
| 91 |
+
if bigram not in self.bpe_ranks:
|
| 92 |
+
break
|
| 93 |
+
first, second = bigram
|
| 94 |
+
new_word = []
|
| 95 |
+
i = 0
|
| 96 |
+
while i < len(word):
|
| 97 |
+
try:
|
| 98 |
+
j = word.index(first, i)
|
| 99 |
+
new_word.extend(word[i:j])
|
| 100 |
+
i = j
|
| 101 |
+
except:
|
| 102 |
+
new_word.extend(word[i:])
|
| 103 |
+
break
|
| 104 |
+
|
| 105 |
+
if word[i] == first and i < len(word)-1 and word[i+1] == second:
|
| 106 |
+
new_word.append(first+second)
|
| 107 |
+
i += 2
|
| 108 |
+
else:
|
| 109 |
+
new_word.append(word[i])
|
| 110 |
+
i += 1
|
| 111 |
+
new_word = tuple(new_word)
|
| 112 |
+
word = new_word
|
| 113 |
+
if len(word) == 1:
|
| 114 |
+
break
|
| 115 |
+
else:
|
| 116 |
+
pairs = get_pairs(word)
|
| 117 |
+
word = ' '.join(word)
|
| 118 |
+
self.cache[token] = word
|
| 119 |
+
return word
|
| 120 |
+
|
| 121 |
+
def encode(self, text):
|
| 122 |
+
bpe_tokens = []
|
| 123 |
+
text = whitespace_clean(basic_clean(text)).lower()
|
| 124 |
+
for token in re.findall(self.pat, text):
|
| 125 |
+
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
|
| 126 |
+
bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
|
| 127 |
+
return bpe_tokens
|
| 128 |
+
|
| 129 |
+
def decode(self, tokens):
|
| 130 |
+
text = ''.join([self.decoder[token] for token in tokens])
|
| 131 |
+
text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('</w>', ' ')
|
| 132 |
+
return text
|
CLIP/data/country211.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# The Country211 Dataset
|
| 2 |
+
|
| 3 |
+
In the paper, we used an image classification dataset called Country211, to evaluate the model's capability on geolocation. To do so, we filtered the YFCC100m dataset that have GPS coordinate corresponding to a [ISO-3166 country code](https://en.wikipedia.org/wiki/List_of_ISO_3166_country_codes) and created a balanced dataset by sampling 150 train images, 50 validation images, and 100 test images images for each country.
|
| 4 |
+
|
| 5 |
+
The following command will download an 11GB archive countaining the images and extract into a subdirectory `country211`:
|
| 6 |
+
|
| 7 |
+
```bash
|
| 8 |
+
wget https://openaipublic.azureedge.net/clip/data/country211.tgz
|
| 9 |
+
tar zxvf country211.tgz
|
| 10 |
+
```
|
| 11 |
+
|
| 12 |
+
These images are a subset of the YFCC100m dataset. Use of the underlying media files is subject to the Creative Commons licenses chosen by their creators/uploaders. For more information about the YFCC100M dataset, visit [the official website](https://multimediacommons.wordpress.com/yfcc100m-core-dataset/).
|
CLIP/data/prompts.md
ADDED
|
@@ -0,0 +1,3401 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Prompts for Image Classification
|
| 2 |
+
|
| 3 |
+
Below are the class names and templates that are used for collecting the zero-shot classification scores in the paper. Each dataset has two lists `classes` and `templates`, where the string `{}` in the template is to be replaced with the corresponding class names. For the Facial Emotion Recognition 2013 dataset specifically, we used multiple class names for certain classes.
|
| 4 |
+
|
| 5 |
+
This file contains prompt data for 26 of the 27 datasets shown in Table 9 of the paper; the text prompts for ImageNet (as well as other [ImageNet Testbed](https://modestyachts.github.io/imagenet-testbed/) datasets in Figure 13) can be found in [this notebook](https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb), as well as how to ensemble predictions from multiple prompts using these templates.
|
| 6 |
+
|
| 7 |
+
If you are viewing this document on GitHub, use the table of contents icon at the upper left to browse the datasets.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Birdsnap
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
classes = [
|
| 14 |
+
'Acadian Flycatcher',
|
| 15 |
+
'Acorn Woodpecker',
|
| 16 |
+
'Alder Flycatcher',
|
| 17 |
+
'Allens Hummingbird',
|
| 18 |
+
'Altamira Oriole',
|
| 19 |
+
'American Avocet',
|
| 20 |
+
'American Bittern',
|
| 21 |
+
'American Black Duck',
|
| 22 |
+
'American Coot',
|
| 23 |
+
'American Crow',
|
| 24 |
+
'American Dipper',
|
| 25 |
+
'American Golden Plover',
|
| 26 |
+
'American Goldfinch',
|
| 27 |
+
'American Kestrel',
|
| 28 |
+
'American Oystercatcher',
|
| 29 |
+
'American Pipit',
|
| 30 |
+
'American Redstart',
|
| 31 |
+
'American Robin',
|
| 32 |
+
'American Three toed Woodpecker',
|
| 33 |
+
'American Tree Sparrow',
|
| 34 |
+
'American White Pelican',
|
| 35 |
+
'American Wigeon',
|
| 36 |
+
'American Woodcock',
|
| 37 |
+
'Anhinga',
|
| 38 |
+
'Annas Hummingbird',
|
| 39 |
+
'Arctic Tern',
|
| 40 |
+
'Ash throated Flycatcher',
|
| 41 |
+
'Audubons Oriole',
|
| 42 |
+
'Bairds Sandpiper',
|
| 43 |
+
'Bald Eagle',
|
| 44 |
+
'Baltimore Oriole',
|
| 45 |
+
'Band tailed Pigeon',
|
| 46 |
+
'Barn Swallow',
|
| 47 |
+
'Barred Owl',
|
| 48 |
+
'Barrows Goldeneye',
|
| 49 |
+
'Bay breasted Warbler',
|
| 50 |
+
'Bells Vireo',
|
| 51 |
+
'Belted Kingfisher',
|
| 52 |
+
'Bewicks Wren',
|
| 53 |
+
'Black Guillemot',
|
| 54 |
+
'Black Oystercatcher',
|
| 55 |
+
'Black Phoebe',
|
| 56 |
+
'Black Rosy Finch',
|
| 57 |
+
'Black Scoter',
|
| 58 |
+
'Black Skimmer',
|
| 59 |
+
'Black Tern',
|
| 60 |
+
'Black Turnstone',
|
| 61 |
+
'Black Vulture',
|
| 62 |
+
'Black and white Warbler',
|
| 63 |
+
'Black backed Woodpecker',
|
| 64 |
+
'Black bellied Plover',
|
| 65 |
+
'Black billed Cuckoo',
|
| 66 |
+
'Black billed Magpie',
|
| 67 |
+
'Black capped Chickadee',
|
| 68 |
+
'Black chinned Hummingbird',
|
| 69 |
+
'Black chinned Sparrow',
|
| 70 |
+
'Black crested Titmouse',
|
| 71 |
+
'Black crowned Night Heron',
|
| 72 |
+
'Black headed Grosbeak',
|
| 73 |
+
'Black legged Kittiwake',
|
| 74 |
+
'Black necked Stilt',
|
| 75 |
+
'Black throated Blue Warbler',
|
| 76 |
+
'Black throated Gray Warbler',
|
| 77 |
+
'Black throated Green Warbler',
|
| 78 |
+
'Black throated Sparrow',
|
| 79 |
+
'Blackburnian Warbler',
|
| 80 |
+
'Blackpoll Warbler',
|
| 81 |
+
'Blue Grosbeak',
|
| 82 |
+
'Blue Jay',
|
| 83 |
+
'Blue gray Gnatcatcher',
|
| 84 |
+
'Blue headed Vireo',
|
| 85 |
+
'Blue winged Teal',
|
| 86 |
+
'Blue winged Warbler',
|
| 87 |
+
'Boat tailed Grackle',
|
| 88 |
+
'Bobolink',
|
| 89 |
+
'Bohemian Waxwing',
|
| 90 |
+
'Bonapartes Gull',
|
| 91 |
+
'Boreal Chickadee',
|
| 92 |
+
'Brandts Cormorant',
|
| 93 |
+
'Brant',
|
| 94 |
+
'Brewers Blackbird',
|
| 95 |
+
'Brewers Sparrow',
|
| 96 |
+
'Bridled Titmouse',
|
| 97 |
+
'Broad billed Hummingbird',
|
| 98 |
+
'Broad tailed Hummingbird',
|
| 99 |
+
'Broad winged Hawk',
|
| 100 |
+
'Bronzed Cowbird',
|
| 101 |
+
'Brown Creeper',
|
| 102 |
+
'Brown Pelican',
|
| 103 |
+
'Brown Thrasher',
|
| 104 |
+
'Brown capped Rosy Finch',
|
| 105 |
+
'Brown crested Flycatcher',
|
| 106 |
+
'Brown headed Cowbird',
|
| 107 |
+
'Brown headed Nuthatch',
|
| 108 |
+
'Bufflehead',
|
| 109 |
+
'Bullocks Oriole',
|
| 110 |
+
'Burrowing Owl',
|
| 111 |
+
'Bushtit',
|
| 112 |
+
'Cackling Goose',
|
| 113 |
+
'Cactus Wren',
|
| 114 |
+
'California Gull',
|
| 115 |
+
'California Quail',
|
| 116 |
+
'California Thrasher',
|
| 117 |
+
'California Towhee',
|
| 118 |
+
'Calliope Hummingbird',
|
| 119 |
+
'Canada Goose',
|
| 120 |
+
'Canada Warbler',
|
| 121 |
+
'Canvasback',
|
| 122 |
+
'Canyon Towhee',
|
| 123 |
+
'Canyon Wren',
|
| 124 |
+
'Cape May Warbler',
|
| 125 |
+
'Carolina Chickadee',
|
| 126 |
+
'Carolina Wren',
|
| 127 |
+
'Caspian Tern',
|
| 128 |
+
'Cassins Finch',
|
| 129 |
+
'Cassins Kingbird',
|
| 130 |
+
'Cassins Sparrow',
|
| 131 |
+
'Cassins Vireo',
|
| 132 |
+
'Cattle Egret',
|
| 133 |
+
'Cave Swallow',
|
| 134 |
+
'Cedar Waxwing',
|
| 135 |
+
'Cerulean Warbler',
|
| 136 |
+
'Chestnut backed Chickadee',
|
| 137 |
+
'Chestnut collared Longspur',
|
| 138 |
+
'Chestnut sided Warbler',
|
| 139 |
+
'Chihuahuan Raven',
|
| 140 |
+
'Chimney Swift',
|
| 141 |
+
'Chipping Sparrow',
|
| 142 |
+
'Cinnamon Teal',
|
| 143 |
+
'Clapper Rail',
|
| 144 |
+
'Clarks Grebe',
|
| 145 |
+
'Clarks Nutcracker',
|
| 146 |
+
'Clay colored Sparrow',
|
| 147 |
+
'Cliff Swallow',
|
| 148 |
+
'Common Black Hawk',
|
| 149 |
+
'Common Eider',
|
| 150 |
+
'Common Gallinule',
|
| 151 |
+
'Common Goldeneye',
|
| 152 |
+
'Common Grackle',
|
| 153 |
+
'Common Ground Dove',
|
| 154 |
+
'Common Loon',
|
| 155 |
+
'Common Merganser',
|
| 156 |
+
'Common Murre',
|
| 157 |
+
'Common Nighthawk',
|
| 158 |
+
'Common Raven',
|
| 159 |
+
'Common Redpoll',
|
| 160 |
+
'Common Tern',
|
| 161 |
+
'Common Yellowthroat',
|
| 162 |
+
'Connecticut Warbler',
|
| 163 |
+
'Coopers Hawk',
|
| 164 |
+
'Cordilleran Flycatcher',
|
| 165 |
+
'Costas Hummingbird',
|
| 166 |
+
'Couchs Kingbird',
|
| 167 |
+
'Crested Caracara',
|
| 168 |
+
'Curve billed Thrasher',
|
| 169 |
+
'Dark eyed Junco',
|
| 170 |
+
'Dickcissel',
|
| 171 |
+
'Double crested Cormorant',
|
| 172 |
+
'Downy Woodpecker',
|
| 173 |
+
'Dunlin',
|
| 174 |
+
'Dusky Flycatcher',
|
| 175 |
+
'Dusky Grouse',
|
| 176 |
+
'Eared Grebe',
|
| 177 |
+
'Eastern Bluebird',
|
| 178 |
+
'Eastern Kingbird',
|
| 179 |
+
'Eastern Meadowlark',
|
| 180 |
+
'Eastern Phoebe',
|
| 181 |
+
'Eastern Screech Owl',
|
| 182 |
+
'Eastern Towhee',
|
| 183 |
+
'Eastern Wood Pewee',
|
| 184 |
+
'Elegant Trogon',
|
| 185 |
+
'Elf Owl',
|
| 186 |
+
'Eurasian Collared Dove',
|
| 187 |
+
'Eurasian Wigeon',
|
| 188 |
+
'European Starling',
|
| 189 |
+
'Evening Grosbeak',
|
| 190 |
+
'Ferruginous Hawk',
|
| 191 |
+
'Ferruginous Pygmy Owl',
|
| 192 |
+
'Field Sparrow',
|
| 193 |
+
'Fish Crow',
|
| 194 |
+
'Florida Scrub Jay',
|
| 195 |
+
'Forsters Tern',
|
| 196 |
+
'Fox Sparrow',
|
| 197 |
+
'Franklins Gull',
|
| 198 |
+
'Fulvous Whistling Duck',
|
| 199 |
+
'Gadwall',
|
| 200 |
+
'Gambels Quail',
|
| 201 |
+
'Gila Woodpecker',
|
| 202 |
+
'Glaucous Gull',
|
| 203 |
+
'Glaucous winged Gull',
|
| 204 |
+
'Glossy Ibis',
|
| 205 |
+
'Golden Eagle',
|
| 206 |
+
'Golden crowned Kinglet',
|
| 207 |
+
'Golden crowned Sparrow',
|
| 208 |
+
'Golden fronted Woodpecker',
|
| 209 |
+
'Golden winged Warbler',
|
| 210 |
+
'Grasshopper Sparrow',
|
| 211 |
+
'Gray Catbird',
|
| 212 |
+
'Gray Flycatcher',
|
| 213 |
+
'Gray Jay',
|
| 214 |
+
'Gray Kingbird',
|
| 215 |
+
'Gray cheeked Thrush',
|
| 216 |
+
'Gray crowned Rosy Finch',
|
| 217 |
+
'Great Black backed Gull',
|
| 218 |
+
'Great Blue Heron',
|
| 219 |
+
'Great Cormorant',
|
| 220 |
+
'Great Crested Flycatcher',
|
| 221 |
+
'Great Egret',
|
| 222 |
+
'Great Gray Owl',
|
| 223 |
+
'Great Horned Owl',
|
| 224 |
+
'Great Kiskadee',
|
| 225 |
+
'Great tailed Grackle',
|
| 226 |
+
'Greater Prairie Chicken',
|
| 227 |
+
'Greater Roadrunner',
|
| 228 |
+
'Greater Sage Grouse',
|
| 229 |
+
'Greater Scaup',
|
| 230 |
+
'Greater White fronted Goose',
|
| 231 |
+
'Greater Yellowlegs',
|
| 232 |
+
'Green Jay',
|
| 233 |
+
'Green tailed Towhee',
|
| 234 |
+
'Green winged Teal',
|
| 235 |
+
'Groove billed Ani',
|
| 236 |
+
'Gull billed Tern',
|
| 237 |
+
'Hairy Woodpecker',
|
| 238 |
+
'Hammonds Flycatcher',
|
| 239 |
+
'Harlequin Duck',
|
| 240 |
+
'Harriss Hawk',
|
| 241 |
+
'Harriss Sparrow',
|
| 242 |
+
'Heermanns Gull',
|
| 243 |
+
'Henslows Sparrow',
|
| 244 |
+
'Hepatic Tanager',
|
| 245 |
+
'Hermit Thrush',
|
| 246 |
+
'Herring Gull',
|
| 247 |
+
'Hoary Redpoll',
|
| 248 |
+
'Hooded Merganser',
|
| 249 |
+
'Hooded Oriole',
|
| 250 |
+
'Hooded Warbler',
|
| 251 |
+
'Horned Grebe',
|
| 252 |
+
'Horned Lark',
|
| 253 |
+
'House Finch',
|
| 254 |
+
'House Sparrow',
|
| 255 |
+
'House Wren',
|
| 256 |
+
'Huttons Vireo',
|
| 257 |
+
'Iceland Gull',
|
| 258 |
+
'Inca Dove',
|
| 259 |
+
'Indigo Bunting',
|
| 260 |
+
'Killdeer',
|
| 261 |
+
'King Rail',
|
| 262 |
+
'Ladder backed Woodpecker',
|
| 263 |
+
'Lapland Longspur',
|
| 264 |
+
'Lark Bunting',
|
| 265 |
+
'Lark Sparrow',
|
| 266 |
+
'Laughing Gull',
|
| 267 |
+
'Lazuli Bunting',
|
| 268 |
+
'Le Contes Sparrow',
|
| 269 |
+
'Least Bittern',
|
| 270 |
+
'Least Flycatcher',
|
| 271 |
+
'Least Grebe',
|
| 272 |
+
'Least Sandpiper',
|
| 273 |
+
'Least Tern',
|
| 274 |
+
'Lesser Goldfinch',
|
| 275 |
+
'Lesser Nighthawk',
|
| 276 |
+
'Lesser Scaup',
|
| 277 |
+
'Lesser Yellowlegs',
|
| 278 |
+
'Lewiss Woodpecker',
|
| 279 |
+
'Limpkin',
|
| 280 |
+
'Lincolns Sparrow',
|
| 281 |
+
'Little Blue Heron',
|
| 282 |
+
'Loggerhead Shrike',
|
| 283 |
+
'Long billed Curlew',
|
| 284 |
+
'Long billed Dowitcher',
|
| 285 |
+
'Long billed Thrasher',
|
| 286 |
+
'Long eared Owl',
|
| 287 |
+
'Long tailed Duck',
|
| 288 |
+
'Louisiana Waterthrush',
|
| 289 |
+
'Magnificent Frigatebird',
|
| 290 |
+
'Magnolia Warbler',
|
| 291 |
+
'Mallard',
|
| 292 |
+
'Marbled Godwit',
|
| 293 |
+
'Marsh Wren',
|
| 294 |
+
'Merlin',
|
| 295 |
+
'Mew Gull',
|
| 296 |
+
'Mexican Jay',
|
| 297 |
+
'Mississippi Kite',
|
| 298 |
+
'Monk Parakeet',
|
| 299 |
+
'Mottled Duck',
|
| 300 |
+
'Mountain Bluebird',
|
| 301 |
+
'Mountain Chickadee',
|
| 302 |
+
'Mountain Plover',
|
| 303 |
+
'Mourning Dove',
|
| 304 |
+
'Mourning Warbler',
|
| 305 |
+
'Muscovy Duck',
|
| 306 |
+
'Mute Swan',
|
| 307 |
+
'Nashville Warbler',
|
| 308 |
+
'Nelsons Sparrow',
|
| 309 |
+
'Neotropic Cormorant',
|
| 310 |
+
'Northern Bobwhite',
|
| 311 |
+
'Northern Cardinal',
|
| 312 |
+
'Northern Flicker',
|
| 313 |
+
'Northern Gannet',
|
| 314 |
+
'Northern Goshawk',
|
| 315 |
+
'Northern Harrier',
|
| 316 |
+
'Northern Hawk Owl',
|
| 317 |
+
'Northern Mockingbird',
|
| 318 |
+
'Northern Parula',
|
| 319 |
+
'Northern Pintail',
|
| 320 |
+
'Northern Rough winged Swallow',
|
| 321 |
+
'Northern Saw whet Owl',
|
| 322 |
+
'Northern Shrike',
|
| 323 |
+
'Northern Waterthrush',
|
| 324 |
+
'Nuttalls Woodpecker',
|
| 325 |
+
'Oak Titmouse',
|
| 326 |
+
'Olive Sparrow',
|
| 327 |
+
'Olive sided Flycatcher',
|
| 328 |
+
'Orange crowned Warbler',
|
| 329 |
+
'Orchard Oriole',
|
| 330 |
+
'Osprey',
|
| 331 |
+
'Ovenbird',
|
| 332 |
+
'Pacific Golden Plover',
|
| 333 |
+
'Pacific Loon',
|
| 334 |
+
'Pacific Wren',
|
| 335 |
+
'Pacific slope Flycatcher',
|
| 336 |
+
'Painted Bunting',
|
| 337 |
+
'Painted Redstart',
|
| 338 |
+
'Palm Warbler',
|
| 339 |
+
'Pectoral Sandpiper',
|
| 340 |
+
'Peregrine Falcon',
|
| 341 |
+
'Phainopepla',
|
| 342 |
+
'Philadelphia Vireo',
|
| 343 |
+
'Pied billed Grebe',
|
| 344 |
+
'Pigeon Guillemot',
|
| 345 |
+
'Pileated Woodpecker',
|
| 346 |
+
'Pine Grosbeak',
|
| 347 |
+
'Pine Siskin',
|
| 348 |
+
'Pine Warbler',
|
| 349 |
+
'Piping Plover',
|
| 350 |
+
'Plumbeous Vireo',
|
| 351 |
+
'Prairie Falcon',
|
| 352 |
+
'Prairie Warbler',
|
| 353 |
+
'Prothonotary Warbler',
|
| 354 |
+
'Purple Finch',
|
| 355 |
+
'Purple Gallinule',
|
| 356 |
+
'Purple Martin',
|
| 357 |
+
'Purple Sandpiper',
|
| 358 |
+
'Pygmy Nuthatch',
|
| 359 |
+
'Pyrrhuloxia',
|
| 360 |
+
'Red Crossbill',
|
| 361 |
+
'Red Knot',
|
| 362 |
+
'Red Phalarope',
|
| 363 |
+
'Red bellied Woodpecker',
|
| 364 |
+
'Red breasted Merganser',
|
| 365 |
+
'Red breasted Nuthatch',
|
| 366 |
+
'Red breasted Sapsucker',
|
| 367 |
+
'Red cockaded Woodpecker',
|
| 368 |
+
'Red eyed Vireo',
|
| 369 |
+
'Red headed Woodpecker',
|
| 370 |
+
'Red naped Sapsucker',
|
| 371 |
+
'Red necked Grebe',
|
| 372 |
+
'Red necked Phalarope',
|
| 373 |
+
'Red shouldered Hawk',
|
| 374 |
+
'Red tailed Hawk',
|
| 375 |
+
'Red throated Loon',
|
| 376 |
+
'Red winged Blackbird',
|
| 377 |
+
'Reddish Egret',
|
| 378 |
+
'Redhead',
|
| 379 |
+
'Ring billed Gull',
|
| 380 |
+
'Ring necked Duck',
|
| 381 |
+
'Ring necked Pheasant',
|
| 382 |
+
'Rock Pigeon',
|
| 383 |
+
'Rock Ptarmigan',
|
| 384 |
+
'Rock Sandpiper',
|
| 385 |
+
'Rock Wren',
|
| 386 |
+
'Rose breasted Grosbeak',
|
| 387 |
+
'Roseate Tern',
|
| 388 |
+
'Rosss Goose',
|
| 389 |
+
'Rough legged Hawk',
|
| 390 |
+
'Royal Tern',
|
| 391 |
+
'Ruby crowned Kinglet',
|
| 392 |
+
'Ruby throated Hummingbird',
|
| 393 |
+
'Ruddy Duck',
|
| 394 |
+
'Ruddy Turnstone',
|
| 395 |
+
'Ruffed Grouse',
|
| 396 |
+
'Rufous Hummingbird',
|
| 397 |
+
'Rufous crowned Sparrow',
|
| 398 |
+
'Rusty Blackbird',
|
| 399 |
+
'Sage Thrasher',
|
| 400 |
+
'Saltmarsh Sparrow',
|
| 401 |
+
'Sanderling',
|
| 402 |
+
'Sandhill Crane',
|
| 403 |
+
'Sandwich Tern',
|
| 404 |
+
'Says Phoebe',
|
| 405 |
+
'Scaled Quail',
|
| 406 |
+
'Scarlet Tanager',
|
| 407 |
+
'Scissor tailed Flycatcher',
|
| 408 |
+
'Scotts Oriole',
|
| 409 |
+
'Seaside Sparrow',
|
| 410 |
+
'Sedge Wren',
|
| 411 |
+
'Semipalmated Plover',
|
| 412 |
+
'Semipalmated Sandpiper',
|
| 413 |
+
'Sharp shinned Hawk',
|
| 414 |
+
'Sharp tailed Grouse',
|
| 415 |
+
'Short billed Dowitcher',
|
| 416 |
+
'Short eared Owl',
|
| 417 |
+
'Snail Kite',
|
| 418 |
+
'Snow Bunting',
|
| 419 |
+
'Snow Goose',
|
| 420 |
+
'Snowy Egret',
|
| 421 |
+
'Snowy Owl',
|
| 422 |
+
'Snowy Plover',
|
| 423 |
+
'Solitary Sandpiper',
|
| 424 |
+
'Song Sparrow',
|
| 425 |
+
'Sooty Grouse',
|
| 426 |
+
'Sora',
|
| 427 |
+
'Spotted Owl',
|
| 428 |
+
'Spotted Sandpiper',
|
| 429 |
+
'Spotted Towhee',
|
| 430 |
+
'Spruce Grouse',
|
| 431 |
+
'Stellers Jay',
|
| 432 |
+
'Stilt Sandpiper',
|
| 433 |
+
'Summer Tanager',
|
| 434 |
+
'Surf Scoter',
|
| 435 |
+
'Surfbird',
|
| 436 |
+
'Swainsons Hawk',
|
| 437 |
+
'Swainsons Thrush',
|
| 438 |
+
'Swallow tailed Kite',
|
| 439 |
+
'Swamp Sparrow',
|
| 440 |
+
'Tennessee Warbler',
|
| 441 |
+
'Thayers Gull',
|
| 442 |
+
'Townsends Solitaire',
|
| 443 |
+
'Townsends Warbler',
|
| 444 |
+
'Tree Swallow',
|
| 445 |
+
'Tricolored Heron',
|
| 446 |
+
'Tropical Kingbird',
|
| 447 |
+
'Trumpeter Swan',
|
| 448 |
+
'Tufted Titmouse',
|
| 449 |
+
'Tundra Swan',
|
| 450 |
+
'Turkey Vulture',
|
| 451 |
+
'Upland Sandpiper',
|
| 452 |
+
'Varied Thrush',
|
| 453 |
+
'Veery',
|
| 454 |
+
'Verdin',
|
| 455 |
+
'Vermilion Flycatcher',
|
| 456 |
+
'Vesper Sparrow',
|
| 457 |
+
'Violet green Swallow',
|
| 458 |
+
'Virginia Rail',
|
| 459 |
+
'Wandering Tattler',
|
| 460 |
+
'Warbling Vireo',
|
| 461 |
+
'Western Bluebird',
|
| 462 |
+
'Western Grebe',
|
| 463 |
+
'Western Gull',
|
| 464 |
+
'Western Kingbird',
|
| 465 |
+
'Western Meadowlark',
|
| 466 |
+
'Western Sandpiper',
|
| 467 |
+
'Western Screech Owl',
|
| 468 |
+
'Western Scrub Jay',
|
| 469 |
+
'Western Tanager',
|
| 470 |
+
'Western Wood Pewee',
|
| 471 |
+
'Whimbrel',
|
| 472 |
+
'White Ibis',
|
| 473 |
+
'White breasted Nuthatch',
|
| 474 |
+
'White crowned Sparrow',
|
| 475 |
+
'White eyed Vireo',
|
| 476 |
+
'White faced Ibis',
|
| 477 |
+
'White headed Woodpecker',
|
| 478 |
+
'White rumped Sandpiper',
|
| 479 |
+
'White tailed Hawk',
|
| 480 |
+
'White tailed Kite',
|
| 481 |
+
'White tailed Ptarmigan',
|
| 482 |
+
'White throated Sparrow',
|
| 483 |
+
'White throated Swift',
|
| 484 |
+
'White winged Crossbill',
|
| 485 |
+
'White winged Dove',
|
| 486 |
+
'White winged Scoter',
|
| 487 |
+
'Wild Turkey',
|
| 488 |
+
'Willet',
|
| 489 |
+
'Williamsons Sapsucker',
|
| 490 |
+
'Willow Flycatcher',
|
| 491 |
+
'Willow Ptarmigan',
|
| 492 |
+
'Wilsons Phalarope',
|
| 493 |
+
'Wilsons Plover',
|
| 494 |
+
'Wilsons Snipe',
|
| 495 |
+
'Wilsons Warbler',
|
| 496 |
+
'Winter Wren',
|
| 497 |
+
'Wood Stork',
|
| 498 |
+
'Wood Thrush',
|
| 499 |
+
'Worm eating Warbler',
|
| 500 |
+
'Wrentit',
|
| 501 |
+
'Yellow Warbler',
|
| 502 |
+
'Yellow bellied Flycatcher',
|
| 503 |
+
'Yellow bellied Sapsucker',
|
| 504 |
+
'Yellow billed Cuckoo',
|
| 505 |
+
'Yellow billed Magpie',
|
| 506 |
+
'Yellow breasted Chat',
|
| 507 |
+
'Yellow crowned Night Heron',
|
| 508 |
+
'Yellow eyed Junco',
|
| 509 |
+
'Yellow headed Blackbird',
|
| 510 |
+
'Yellow rumped Warbler',
|
| 511 |
+
'Yellow throated Vireo',
|
| 512 |
+
'Yellow throated Warbler',
|
| 513 |
+
'Zone tailed Hawk',
|
| 514 |
+
]
|
| 515 |
+
|
| 516 |
+
templates = [
|
| 517 |
+
'a photo of a {}, a type of bird.',
|
| 518 |
+
]
|
| 519 |
+
```
|
| 520 |
+
|
| 521 |
+
|
| 522 |
+
|
| 523 |
+
## CIFAR10
|
| 524 |
+
|
| 525 |
+
```bash
|
| 526 |
+
classes = [
|
| 527 |
+
'airplane',
|
| 528 |
+
'automobile',
|
| 529 |
+
'bird',
|
| 530 |
+
'cat',
|
| 531 |
+
'deer',
|
| 532 |
+
'dog',
|
| 533 |
+
'frog',
|
| 534 |
+
'horse',
|
| 535 |
+
'ship',
|
| 536 |
+
'truck',
|
| 537 |
+
]
|
| 538 |
+
|
| 539 |
+
templates = [
|
| 540 |
+
'a photo of a {}.',
|
| 541 |
+
'a blurry photo of a {}.',
|
| 542 |
+
'a black and white photo of a {}.',
|
| 543 |
+
'a low contrast photo of a {}.',
|
| 544 |
+
'a high contrast photo of a {}.',
|
| 545 |
+
'a bad photo of a {}.',
|
| 546 |
+
'a good photo of a {}.',
|
| 547 |
+
'a photo of a small {}.',
|
| 548 |
+
'a photo of a big {}.',
|
| 549 |
+
'a photo of the {}.',
|
| 550 |
+
'a blurry photo of the {}.',
|
| 551 |
+
'a black and white photo of the {}.',
|
| 552 |
+
'a low contrast photo of the {}.',
|
| 553 |
+
'a high contrast photo of the {}.',
|
| 554 |
+
'a bad photo of the {}.',
|
| 555 |
+
'a good photo of the {}.',
|
| 556 |
+
'a photo of the small {}.',
|
| 557 |
+
'a photo of the big {}.',
|
| 558 |
+
]
|
| 559 |
+
```
|
| 560 |
+
|
| 561 |
+
|
| 562 |
+
|
| 563 |
+
## CIFAR100
|
| 564 |
+
|
| 565 |
+
```bash
|
| 566 |
+
classes = [
|
| 567 |
+
'apple',
|
| 568 |
+
'aquarium fish',
|
| 569 |
+
'baby',
|
| 570 |
+
'bear',
|
| 571 |
+
'beaver',
|
| 572 |
+
'bed',
|
| 573 |
+
'bee',
|
| 574 |
+
'beetle',
|
| 575 |
+
'bicycle',
|
| 576 |
+
'bottle',
|
| 577 |
+
'bowl',
|
| 578 |
+
'boy',
|
| 579 |
+
'bridge',
|
| 580 |
+
'bus',
|
| 581 |
+
'butterfly',
|
| 582 |
+
'camel',
|
| 583 |
+
'can',
|
| 584 |
+
'castle',
|
| 585 |
+
'caterpillar',
|
| 586 |
+
'cattle',
|
| 587 |
+
'chair',
|
| 588 |
+
'chimpanzee',
|
| 589 |
+
'clock',
|
| 590 |
+
'cloud',
|
| 591 |
+
'cockroach',
|
| 592 |
+
'couch',
|
| 593 |
+
'crab',
|
| 594 |
+
'crocodile',
|
| 595 |
+
'cup',
|
| 596 |
+
'dinosaur',
|
| 597 |
+
'dolphin',
|
| 598 |
+
'elephant',
|
| 599 |
+
'flatfish',
|
| 600 |
+
'forest',
|
| 601 |
+
'fox',
|
| 602 |
+
'girl',
|
| 603 |
+
'hamster',
|
| 604 |
+
'house',
|
| 605 |
+
'kangaroo',
|
| 606 |
+
'keyboard',
|
| 607 |
+
'lamp',
|
| 608 |
+
'lawn mower',
|
| 609 |
+
'leopard',
|
| 610 |
+
'lion',
|
| 611 |
+
'lizard',
|
| 612 |
+
'lobster',
|
| 613 |
+
'man',
|
| 614 |
+
'maple tree',
|
| 615 |
+
'motorcycle',
|
| 616 |
+
'mountain',
|
| 617 |
+
'mouse',
|
| 618 |
+
'mushroom',
|
| 619 |
+
'oak tree',
|
| 620 |
+
'orange',
|
| 621 |
+
'orchid',
|
| 622 |
+
'otter',
|
| 623 |
+
'palm tree',
|
| 624 |
+
'pear',
|
| 625 |
+
'pickup truck',
|
| 626 |
+
'pine tree',
|
| 627 |
+
'plain',
|
| 628 |
+
'plate',
|
| 629 |
+
'poppy',
|
| 630 |
+
'porcupine',
|
| 631 |
+
'possum',
|
| 632 |
+
'rabbit',
|
| 633 |
+
'raccoon',
|
| 634 |
+
'ray',
|
| 635 |
+
'road',
|
| 636 |
+
'rocket',
|
| 637 |
+
'rose',
|
| 638 |
+
'sea',
|
| 639 |
+
'seal',
|
| 640 |
+
'shark',
|
| 641 |
+
'shrew',
|
| 642 |
+
'skunk',
|
| 643 |
+
'skyscraper',
|
| 644 |
+
'snail',
|
| 645 |
+
'snake',
|
| 646 |
+
'spider',
|
| 647 |
+
'squirrel',
|
| 648 |
+
'streetcar',
|
| 649 |
+
'sunflower',
|
| 650 |
+
'sweet pepper',
|
| 651 |
+
'table',
|
| 652 |
+
'tank',
|
| 653 |
+
'telephone',
|
| 654 |
+
'television',
|
| 655 |
+
'tiger',
|
| 656 |
+
'tractor',
|
| 657 |
+
'train',
|
| 658 |
+
'trout',
|
| 659 |
+
'tulip',
|
| 660 |
+
'turtle',
|
| 661 |
+
'wardrobe',
|
| 662 |
+
'whale',
|
| 663 |
+
'willow tree',
|
| 664 |
+
'wolf',
|
| 665 |
+
'woman',
|
| 666 |
+
'worm',
|
| 667 |
+
]
|
| 668 |
+
|
| 669 |
+
templates = [
|
| 670 |
+
'a photo of a {}.',
|
| 671 |
+
'a blurry photo of a {}.',
|
| 672 |
+
'a black and white photo of a {}.',
|
| 673 |
+
'a low contrast photo of a {}.',
|
| 674 |
+
'a high contrast photo of a {}.',
|
| 675 |
+
'a bad photo of a {}.',
|
| 676 |
+
'a good photo of a {}.',
|
| 677 |
+
'a photo of a small {}.',
|
| 678 |
+
'a photo of a big {}.',
|
| 679 |
+
'a photo of the {}.',
|
| 680 |
+
'a blurry photo of the {}.',
|
| 681 |
+
'a black and white photo of the {}.',
|
| 682 |
+
'a low contrast photo of the {}.',
|
| 683 |
+
'a high contrast photo of the {}.',
|
| 684 |
+
'a bad photo of the {}.',
|
| 685 |
+
'a good photo of the {}.',
|
| 686 |
+
'a photo of the small {}.',
|
| 687 |
+
'a photo of the big {}.',
|
| 688 |
+
]
|
| 689 |
+
```
|
| 690 |
+
|
| 691 |
+
|
| 692 |
+
|
| 693 |
+
## CLEVRCounts
|
| 694 |
+
|
| 695 |
+
```bash
|
| 696 |
+
classes = [
|
| 697 |
+
'10',
|
| 698 |
+
'3',
|
| 699 |
+
'4',
|
| 700 |
+
'5',
|
| 701 |
+
'6',
|
| 702 |
+
'7',
|
| 703 |
+
'8',
|
| 704 |
+
'9',
|
| 705 |
+
]
|
| 706 |
+
|
| 707 |
+
templates = [
|
| 708 |
+
'a photo of {} objects.',
|
| 709 |
+
]
|
| 710 |
+
```
|
| 711 |
+
|
| 712 |
+
|
| 713 |
+
|
| 714 |
+
## Caltech101
|
| 715 |
+
|
| 716 |
+
```bash
|
| 717 |
+
classes = [
|
| 718 |
+
'background',
|
| 719 |
+
'off-center face',
|
| 720 |
+
'centered face',
|
| 721 |
+
'leopard',
|
| 722 |
+
'motorbike',
|
| 723 |
+
'accordion',
|
| 724 |
+
'airplane',
|
| 725 |
+
'anchor',
|
| 726 |
+
'ant',
|
| 727 |
+
'barrel',
|
| 728 |
+
'bass',
|
| 729 |
+
'beaver',
|
| 730 |
+
'binocular',
|
| 731 |
+
'bonsai',
|
| 732 |
+
'brain',
|
| 733 |
+
'brontosaurus',
|
| 734 |
+
'buddha',
|
| 735 |
+
'butterfly',
|
| 736 |
+
'camera',
|
| 737 |
+
'cannon',
|
| 738 |
+
'side of a car',
|
| 739 |
+
'ceiling fan',
|
| 740 |
+
'cellphone',
|
| 741 |
+
'chair',
|
| 742 |
+
'chandelier',
|
| 743 |
+
'body of a cougar cat',
|
| 744 |
+
'face of a cougar cat',
|
| 745 |
+
'crab',
|
| 746 |
+
'crayfish',
|
| 747 |
+
'crocodile',
|
| 748 |
+
'head of a crocodile',
|
| 749 |
+
'cup',
|
| 750 |
+
'dalmatian',
|
| 751 |
+
'dollar bill',
|
| 752 |
+
'dolphin',
|
| 753 |
+
'dragonfly',
|
| 754 |
+
'electric guitar',
|
| 755 |
+
'elephant',
|
| 756 |
+
'emu',
|
| 757 |
+
'euphonium',
|
| 758 |
+
'ewer',
|
| 759 |
+
'ferry',
|
| 760 |
+
'flamingo',
|
| 761 |
+
'head of a flamingo',
|
| 762 |
+
'garfield',
|
| 763 |
+
'gerenuk',
|
| 764 |
+
'gramophone',
|
| 765 |
+
'grand piano',
|
| 766 |
+
'hawksbill',
|
| 767 |
+
'headphone',
|
| 768 |
+
'hedgehog',
|
| 769 |
+
'helicopter',
|
| 770 |
+
'ibis',
|
| 771 |
+
'inline skate',
|
| 772 |
+
'joshua tree',
|
| 773 |
+
'kangaroo',
|
| 774 |
+
'ketch',
|
| 775 |
+
'lamp',
|
| 776 |
+
'laptop',
|
| 777 |
+
'llama',
|
| 778 |
+
'lobster',
|
| 779 |
+
'lotus',
|
| 780 |
+
'mandolin',
|
| 781 |
+
'mayfly',
|
| 782 |
+
'menorah',
|
| 783 |
+
'metronome',
|
| 784 |
+
'minaret',
|
| 785 |
+
'nautilus',
|
| 786 |
+
'octopus',
|
| 787 |
+
'okapi',
|
| 788 |
+
'pagoda',
|
| 789 |
+
'panda',
|
| 790 |
+
'pigeon',
|
| 791 |
+
'pizza',
|
| 792 |
+
'platypus',
|
| 793 |
+
'pyramid',
|
| 794 |
+
'revolver',
|
| 795 |
+
'rhino',
|
| 796 |
+
'rooster',
|
| 797 |
+
'saxophone',
|
| 798 |
+
'schooner',
|
| 799 |
+
'scissors',
|
| 800 |
+
'scorpion',
|
| 801 |
+
'sea horse',
|
| 802 |
+
'snoopy (cartoon beagle)',
|
| 803 |
+
'soccer ball',
|
| 804 |
+
'stapler',
|
| 805 |
+
'starfish',
|
| 806 |
+
'stegosaurus',
|
| 807 |
+
'stop sign',
|
| 808 |
+
'strawberry',
|
| 809 |
+
'sunflower',
|
| 810 |
+
'tick',
|
| 811 |
+
'trilobite',
|
| 812 |
+
'umbrella',
|
| 813 |
+
'watch',
|
| 814 |
+
'water lilly',
|
| 815 |
+
'wheelchair',
|
| 816 |
+
'wild cat',
|
| 817 |
+
'windsor chair',
|
| 818 |
+
'wrench',
|
| 819 |
+
'yin and yang symbol',
|
| 820 |
+
]
|
| 821 |
+
|
| 822 |
+
templates = [
|
| 823 |
+
'a photo of a {}.',
|
| 824 |
+
'a painting of a {}.',
|
| 825 |
+
'a plastic {}.',
|
| 826 |
+
'a sculpture of a {}.',
|
| 827 |
+
'a sketch of a {}.',
|
| 828 |
+
'a tattoo of a {}.',
|
| 829 |
+
'a toy {}.',
|
| 830 |
+
'a rendition of a {}.',
|
| 831 |
+
'a embroidered {}.',
|
| 832 |
+
'a cartoon {}.',
|
| 833 |
+
'a {} in a video game.',
|
| 834 |
+
'a plushie {}.',
|
| 835 |
+
'a origami {}.',
|
| 836 |
+
'art of a {}.',
|
| 837 |
+
'graffiti of a {}.',
|
| 838 |
+
'a drawing of a {}.',
|
| 839 |
+
'a doodle of a {}.',
|
| 840 |
+
'a photo of the {}.',
|
| 841 |
+
'a painting of the {}.',
|
| 842 |
+
'the plastic {}.',
|
| 843 |
+
'a sculpture of the {}.',
|
| 844 |
+
'a sketch of the {}.',
|
| 845 |
+
'a tattoo of the {}.',
|
| 846 |
+
'the toy {}.',
|
| 847 |
+
'a rendition of the {}.',
|
| 848 |
+
'the embroidered {}.',
|
| 849 |
+
'the cartoon {}.',
|
| 850 |
+
'the {} in a video game.',
|
| 851 |
+
'the plushie {}.',
|
| 852 |
+
'the origami {}.',
|
| 853 |
+
'art of the {}.',
|
| 854 |
+
'graffiti of the {}.',
|
| 855 |
+
'a drawing of the {}.',
|
| 856 |
+
'a doodle of the {}.',
|
| 857 |
+
]
|
| 858 |
+
```
|
| 859 |
+
|
| 860 |
+
|
| 861 |
+
|
| 862 |
+
## Country211
|
| 863 |
+
|
| 864 |
+
```bash
|
| 865 |
+
classes = [
|
| 866 |
+
'Andorra',
|
| 867 |
+
'United Arab Emirates',
|
| 868 |
+
'Afghanistan',
|
| 869 |
+
'Antigua and Barbuda',
|
| 870 |
+
'Anguilla',
|
| 871 |
+
'Albania',
|
| 872 |
+
'Armenia',
|
| 873 |
+
'Angola',
|
| 874 |
+
'Antarctica',
|
| 875 |
+
'Argentina',
|
| 876 |
+
'Austria',
|
| 877 |
+
'Australia',
|
| 878 |
+
'Aruba',
|
| 879 |
+
'Aland Islands',
|
| 880 |
+
'Azerbaijan',
|
| 881 |
+
'Bosnia and Herzegovina',
|
| 882 |
+
'Barbados',
|
| 883 |
+
'Bangladesh',
|
| 884 |
+
'Belgium',
|
| 885 |
+
'Burkina Faso',
|
| 886 |
+
'Bulgaria',
|
| 887 |
+
'Bahrain',
|
| 888 |
+
'Benin',
|
| 889 |
+
'Bermuda',
|
| 890 |
+
'Brunei Darussalam',
|
| 891 |
+
'Bolivia',
|
| 892 |
+
'Bonaire, Saint Eustatius and Saba',
|
| 893 |
+
'Brazil',
|
| 894 |
+
'Bahamas',
|
| 895 |
+
'Bhutan',
|
| 896 |
+
'Botswana',
|
| 897 |
+
'Belarus',
|
| 898 |
+
'Belize',
|
| 899 |
+
'Canada',
|
| 900 |
+
'DR Congo',
|
| 901 |
+
'Central African Republic',
|
| 902 |
+
'Switzerland',
|
| 903 |
+
"Cote d'Ivoire",
|
| 904 |
+
'Cook Islands',
|
| 905 |
+
'Chile',
|
| 906 |
+
'Cameroon',
|
| 907 |
+
'China',
|
| 908 |
+
'Colombia',
|
| 909 |
+
'Costa Rica',
|
| 910 |
+
'Cuba',
|
| 911 |
+
'Cabo Verde',
|
| 912 |
+
'Curacao',
|
| 913 |
+
'Cyprus',
|
| 914 |
+
'Czech Republic',
|
| 915 |
+
'Germany',
|
| 916 |
+
'Denmark',
|
| 917 |
+
'Dominica',
|
| 918 |
+
'Dominican Republic',
|
| 919 |
+
'Algeria',
|
| 920 |
+
'Ecuador',
|
| 921 |
+
'Estonia',
|
| 922 |
+
'Egypt',
|
| 923 |
+
'Spain',
|
| 924 |
+
'Ethiopia',
|
| 925 |
+
'Finland',
|
| 926 |
+
'Fiji',
|
| 927 |
+
'Falkland Islands',
|
| 928 |
+
'Faeroe Islands',
|
| 929 |
+
'France',
|
| 930 |
+
'Gabon',
|
| 931 |
+
'United Kingdom',
|
| 932 |
+
'Grenada',
|
| 933 |
+
'Georgia',
|
| 934 |
+
'French Guiana',
|
| 935 |
+
'Guernsey',
|
| 936 |
+
'Ghana',
|
| 937 |
+
'Gibraltar',
|
| 938 |
+
'Greenland',
|
| 939 |
+
'Gambia',
|
| 940 |
+
'Guadeloupe',
|
| 941 |
+
'Greece',
|
| 942 |
+
'South Georgia and South Sandwich Is.',
|
| 943 |
+
'Guatemala',
|
| 944 |
+
'Guam',
|
| 945 |
+
'Guyana',
|
| 946 |
+
'Hong Kong',
|
| 947 |
+
'Honduras',
|
| 948 |
+
'Croatia',
|
| 949 |
+
'Haiti',
|
| 950 |
+
'Hungary',
|
| 951 |
+
'Indonesia',
|
| 952 |
+
'Ireland',
|
| 953 |
+
'Israel',
|
| 954 |
+
'Isle of Man',
|
| 955 |
+
'India',
|
| 956 |
+
'Iraq',
|
| 957 |
+
'Iran',
|
| 958 |
+
'Iceland',
|
| 959 |
+
'Italy',
|
| 960 |
+
'Jersey',
|
| 961 |
+
'Jamaica',
|
| 962 |
+
'Jordan',
|
| 963 |
+
'Japan',
|
| 964 |
+
'Kenya',
|
| 965 |
+
'Kyrgyz Republic',
|
| 966 |
+
'Cambodia',
|
| 967 |
+
'St. Kitts and Nevis',
|
| 968 |
+
'North Korea',
|
| 969 |
+
'South Korea',
|
| 970 |
+
'Kuwait',
|
| 971 |
+
'Cayman Islands',
|
| 972 |
+
'Kazakhstan',
|
| 973 |
+
'Laos',
|
| 974 |
+
'Lebanon',
|
| 975 |
+
'St. Lucia',
|
| 976 |
+
'Liechtenstein',
|
| 977 |
+
'Sri Lanka',
|
| 978 |
+
'Liberia',
|
| 979 |
+
'Lithuania',
|
| 980 |
+
'Luxembourg',
|
| 981 |
+
'Latvia',
|
| 982 |
+
'Libya',
|
| 983 |
+
'Morocco',
|
| 984 |
+
'Monaco',
|
| 985 |
+
'Moldova',
|
| 986 |
+
'Montenegro',
|
| 987 |
+
'Saint-Martin',
|
| 988 |
+
'Madagascar',
|
| 989 |
+
'Macedonia',
|
| 990 |
+
'Mali',
|
| 991 |
+
'Myanmar',
|
| 992 |
+
'Mongolia',
|
| 993 |
+
'Macau',
|
| 994 |
+
'Martinique',
|
| 995 |
+
'Mauritania',
|
| 996 |
+
'Malta',
|
| 997 |
+
'Mauritius',
|
| 998 |
+
'Maldives',
|
| 999 |
+
'Malawi',
|
| 1000 |
+
'Mexico',
|
| 1001 |
+
'Malaysia',
|
| 1002 |
+
'Mozambique',
|
| 1003 |
+
'Namibia',
|
| 1004 |
+
'New Caledonia',
|
| 1005 |
+
'Nigeria',
|
| 1006 |
+
'Nicaragua',
|
| 1007 |
+
'Netherlands',
|
| 1008 |
+
'Norway',
|
| 1009 |
+
'Nepal',
|
| 1010 |
+
'New Zealand',
|
| 1011 |
+
'Oman',
|
| 1012 |
+
'Panama',
|
| 1013 |
+
'Peru',
|
| 1014 |
+
'French Polynesia',
|
| 1015 |
+
'Papua New Guinea',
|
| 1016 |
+
'Philippines',
|
| 1017 |
+
'Pakistan',
|
| 1018 |
+
'Poland',
|
| 1019 |
+
'Puerto Rico',
|
| 1020 |
+
'Palestine',
|
| 1021 |
+
'Portugal',
|
| 1022 |
+
'Palau',
|
| 1023 |
+
'Paraguay',
|
| 1024 |
+
'Qatar',
|
| 1025 |
+
'Reunion',
|
| 1026 |
+
'Romania',
|
| 1027 |
+
'Serbia',
|
| 1028 |
+
'Russia',
|
| 1029 |
+
'Rwanda',
|
| 1030 |
+
'Saudi Arabia',
|
| 1031 |
+
'Solomon Islands',
|
| 1032 |
+
'Seychelles',
|
| 1033 |
+
'Sudan',
|
| 1034 |
+
'Sweden',
|
| 1035 |
+
'Singapore',
|
| 1036 |
+
'St. Helena',
|
| 1037 |
+
'Slovenia',
|
| 1038 |
+
'Svalbard and Jan Mayen Islands',
|
| 1039 |
+
'Slovakia',
|
| 1040 |
+
'Sierra Leone',
|
| 1041 |
+
'San Marino',
|
| 1042 |
+
'Senegal',
|
| 1043 |
+
'Somalia',
|
| 1044 |
+
'South Sudan',
|
| 1045 |
+
'El Salvador',
|
| 1046 |
+
'Sint Maarten',
|
| 1047 |
+
'Syria',
|
| 1048 |
+
'Eswatini',
|
| 1049 |
+
'Togo',
|
| 1050 |
+
'Thailand',
|
| 1051 |
+
'Tajikistan',
|
| 1052 |
+
'Timor-Leste',
|
| 1053 |
+
'Turkmenistan',
|
| 1054 |
+
'Tunisia',
|
| 1055 |
+
'Tonga',
|
| 1056 |
+
'Turkey',
|
| 1057 |
+
'Trinidad and Tobago',
|
| 1058 |
+
'Taiwan',
|
| 1059 |
+
'Tanzania',
|
| 1060 |
+
'Ukraine',
|
| 1061 |
+
'Uganda',
|
| 1062 |
+
'United States',
|
| 1063 |
+
'Uruguay',
|
| 1064 |
+
'Uzbekistan',
|
| 1065 |
+
'Vatican',
|
| 1066 |
+
'Venezuela',
|
| 1067 |
+
'British Virgin Islands',
|
| 1068 |
+
'United States Virgin Islands',
|
| 1069 |
+
'Vietnam',
|
| 1070 |
+
'Vanuatu',
|
| 1071 |
+
'Samoa',
|
| 1072 |
+
'Kosovo',
|
| 1073 |
+
'Yemen',
|
| 1074 |
+
'South Africa',
|
| 1075 |
+
'Zambia',
|
| 1076 |
+
'Zimbabwe',
|
| 1077 |
+
]
|
| 1078 |
+
|
| 1079 |
+
templates = [
|
| 1080 |
+
'a photo i took in {}.',
|
| 1081 |
+
'a photo i took while visiting {}.',
|
| 1082 |
+
'a photo from my home country of {}.',
|
| 1083 |
+
'a photo from my visit to {}.',
|
| 1084 |
+
'a photo showing the country of {}.',
|
| 1085 |
+
]
|
| 1086 |
+
```
|
| 1087 |
+
|
| 1088 |
+
|
| 1089 |
+
|
| 1090 |
+
## DescribableTextures
|
| 1091 |
+
|
| 1092 |
+
```bash
|
| 1093 |
+
classes = [
|
| 1094 |
+
'banded',
|
| 1095 |
+
'blotchy',
|
| 1096 |
+
'braided',
|
| 1097 |
+
'bubbly',
|
| 1098 |
+
'bumpy',
|
| 1099 |
+
'chequered',
|
| 1100 |
+
'cobwebbed',
|
| 1101 |
+
'cracked',
|
| 1102 |
+
'crosshatched',
|
| 1103 |
+
'crystalline',
|
| 1104 |
+
'dotted',
|
| 1105 |
+
'fibrous',
|
| 1106 |
+
'flecked',
|
| 1107 |
+
'freckled',
|
| 1108 |
+
'frilly',
|
| 1109 |
+
'gauzy',
|
| 1110 |
+
'grid',
|
| 1111 |
+
'grooved',
|
| 1112 |
+
'honeycombed',
|
| 1113 |
+
'interlaced',
|
| 1114 |
+
'knitted',
|
| 1115 |
+
'lacelike',
|
| 1116 |
+
'lined',
|
| 1117 |
+
'marbled',
|
| 1118 |
+
'matted',
|
| 1119 |
+
'meshed',
|
| 1120 |
+
'paisley',
|
| 1121 |
+
'perforated',
|
| 1122 |
+
'pitted',
|
| 1123 |
+
'pleated',
|
| 1124 |
+
'polka-dotted',
|
| 1125 |
+
'porous',
|
| 1126 |
+
'potholed',
|
| 1127 |
+
'scaly',
|
| 1128 |
+
'smeared',
|
| 1129 |
+
'spiralled',
|
| 1130 |
+
'sprinkled',
|
| 1131 |
+
'stained',
|
| 1132 |
+
'stratified',
|
| 1133 |
+
'striped',
|
| 1134 |
+
'studded',
|
| 1135 |
+
'swirly',
|
| 1136 |
+
'veined',
|
| 1137 |
+
'waffled',
|
| 1138 |
+
'woven',
|
| 1139 |
+
'wrinkled',
|
| 1140 |
+
'zigzagged',
|
| 1141 |
+
]
|
| 1142 |
+
|
| 1143 |
+
templates = [
|
| 1144 |
+
'a photo of a {} texture.',
|
| 1145 |
+
'a photo of a {} pattern.',
|
| 1146 |
+
'a photo of a {} thing.',
|
| 1147 |
+
'a photo of a {} object.',
|
| 1148 |
+
'a photo of the {} texture.',
|
| 1149 |
+
'a photo of the {} pattern.',
|
| 1150 |
+
'a photo of the {} thing.',
|
| 1151 |
+
'a photo of the {} object.',
|
| 1152 |
+
]
|
| 1153 |
+
```
|
| 1154 |
+
|
| 1155 |
+
|
| 1156 |
+
|
| 1157 |
+
## EuroSAT
|
| 1158 |
+
|
| 1159 |
+
```bash
|
| 1160 |
+
classes = [
|
| 1161 |
+
'forest',
|
| 1162 |
+
'permanent crop land',
|
| 1163 |
+
'residential buildings or homes or apartments',
|
| 1164 |
+
'river',
|
| 1165 |
+
'pasture land',
|
| 1166 |
+
'lake or sea',
|
| 1167 |
+
'brushland or shrubland',
|
| 1168 |
+
'annual crop land',
|
| 1169 |
+
'industrial buildings or commercial buildings',
|
| 1170 |
+
'highway or road',
|
| 1171 |
+
]
|
| 1172 |
+
|
| 1173 |
+
templates = [
|
| 1174 |
+
'a centered satellite photo of {}.',
|
| 1175 |
+
'a centered satellite photo of a {}.',
|
| 1176 |
+
'a centered satellite photo of the {}.',
|
| 1177 |
+
]
|
| 1178 |
+
```
|
| 1179 |
+
|
| 1180 |
+
|
| 1181 |
+
|
| 1182 |
+
## FGVCAircraft
|
| 1183 |
+
|
| 1184 |
+
```bash
|
| 1185 |
+
classes = [
|
| 1186 |
+
'707-320',
|
| 1187 |
+
'727-200',
|
| 1188 |
+
'737-200',
|
| 1189 |
+
'737-300',
|
| 1190 |
+
'737-400',
|
| 1191 |
+
'737-500',
|
| 1192 |
+
'737-600',
|
| 1193 |
+
'737-700',
|
| 1194 |
+
'737-800',
|
| 1195 |
+
'737-900',
|
| 1196 |
+
'747-100',
|
| 1197 |
+
'747-200',
|
| 1198 |
+
'747-300',
|
| 1199 |
+
'747-400',
|
| 1200 |
+
'757-200',
|
| 1201 |
+
'757-300',
|
| 1202 |
+
'767-200',
|
| 1203 |
+
'767-300',
|
| 1204 |
+
'767-400',
|
| 1205 |
+
'777-200',
|
| 1206 |
+
'777-300',
|
| 1207 |
+
'A300B4',
|
| 1208 |
+
'A310',
|
| 1209 |
+
'A318',
|
| 1210 |
+
'A319',
|
| 1211 |
+
'A320',
|
| 1212 |
+
'A321',
|
| 1213 |
+
'A330-200',
|
| 1214 |
+
'A330-300',
|
| 1215 |
+
'A340-200',
|
| 1216 |
+
'A340-300',
|
| 1217 |
+
'A340-500',
|
| 1218 |
+
'A340-600',
|
| 1219 |
+
'A380',
|
| 1220 |
+
'ATR-42',
|
| 1221 |
+
'ATR-72',
|
| 1222 |
+
'An-12',
|
| 1223 |
+
'BAE 146-200',
|
| 1224 |
+
'BAE 146-300',
|
| 1225 |
+
'BAE-125',
|
| 1226 |
+
'Beechcraft 1900',
|
| 1227 |
+
'Boeing 717',
|
| 1228 |
+
'C-130',
|
| 1229 |
+
'C-47',
|
| 1230 |
+
'CRJ-200',
|
| 1231 |
+
'CRJ-700',
|
| 1232 |
+
'CRJ-900',
|
| 1233 |
+
'Cessna 172',
|
| 1234 |
+
'Cessna 208',
|
| 1235 |
+
'Cessna 525',
|
| 1236 |
+
'Cessna 560',
|
| 1237 |
+
'Challenger 600',
|
| 1238 |
+
'DC-10',
|
| 1239 |
+
'DC-3',
|
| 1240 |
+
'DC-6',
|
| 1241 |
+
'DC-8',
|
| 1242 |
+
'DC-9-30',
|
| 1243 |
+
'DH-82',
|
| 1244 |
+
'DHC-1',
|
| 1245 |
+
'DHC-6',
|
| 1246 |
+
'DHC-8-100',
|
| 1247 |
+
'DHC-8-300',
|
| 1248 |
+
'DR-400',
|
| 1249 |
+
'Dornier 328',
|
| 1250 |
+
'E-170',
|
| 1251 |
+
'E-190',
|
| 1252 |
+
'E-195',
|
| 1253 |
+
'EMB-120',
|
| 1254 |
+
'ERJ 135',
|
| 1255 |
+
'ERJ 145',
|
| 1256 |
+
'Embraer Legacy 600',
|
| 1257 |
+
'Eurofighter Typhoon',
|
| 1258 |
+
'F-16A/B',
|
| 1259 |
+
'F/A-18',
|
| 1260 |
+
'Falcon 2000',
|
| 1261 |
+
'Falcon 900',
|
| 1262 |
+
'Fokker 100',
|
| 1263 |
+
'Fokker 50',
|
| 1264 |
+
'Fokker 70',
|
| 1265 |
+
'Global Express',
|
| 1266 |
+
'Gulfstream IV',
|
| 1267 |
+
'Gulfstream V',
|
| 1268 |
+
'Hawk T1',
|
| 1269 |
+
'Il-76',
|
| 1270 |
+
'L-1011',
|
| 1271 |
+
'MD-11',
|
| 1272 |
+
'MD-80',
|
| 1273 |
+
'MD-87',
|
| 1274 |
+
'MD-90',
|
| 1275 |
+
'Metroliner',
|
| 1276 |
+
'Model B200',
|
| 1277 |
+
'PA-28',
|
| 1278 |
+
'SR-20',
|
| 1279 |
+
'Saab 2000',
|
| 1280 |
+
'Saab 340',
|
| 1281 |
+
'Spitfire',
|
| 1282 |
+
'Tornado',
|
| 1283 |
+
'Tu-134',
|
| 1284 |
+
'Tu-154',
|
| 1285 |
+
'Yak-42',
|
| 1286 |
+
]
|
| 1287 |
+
|
| 1288 |
+
templates = [
|
| 1289 |
+
'a photo of a {}, a type of aircraft.',
|
| 1290 |
+
'a photo of the {}, a type of aircraft.',
|
| 1291 |
+
]
|
| 1292 |
+
```
|
| 1293 |
+
|
| 1294 |
+
|
| 1295 |
+
|
| 1296 |
+
## FacialEmotionRecognition2013
|
| 1297 |
+
|
| 1298 |
+
```bash
|
| 1299 |
+
classes = [
|
| 1300 |
+
['angry'],
|
| 1301 |
+
['disgusted'],
|
| 1302 |
+
['fearful'],
|
| 1303 |
+
['happy', 'smiling'],
|
| 1304 |
+
['sad', 'depressed'],
|
| 1305 |
+
['surprised', 'shocked', 'spooked'],
|
| 1306 |
+
['neutral', 'bored'],
|
| 1307 |
+
]
|
| 1308 |
+
|
| 1309 |
+
templates = [
|
| 1310 |
+
'a photo of a {} looking face.',
|
| 1311 |
+
'a photo of a face showing the emotion: {}.',
|
| 1312 |
+
'a photo of a face looking {}.',
|
| 1313 |
+
'a face that looks {}.',
|
| 1314 |
+
'they look {}.',
|
| 1315 |
+
'look at how {} they are.',
|
| 1316 |
+
]
|
| 1317 |
+
```
|
| 1318 |
+
|
| 1319 |
+
|
| 1320 |
+
|
| 1321 |
+
## Flowers102
|
| 1322 |
+
|
| 1323 |
+
```bash
|
| 1324 |
+
classes = [
|
| 1325 |
+
'pink primrose',
|
| 1326 |
+
'hard-leaved pocket orchid',
|
| 1327 |
+
'canterbury bells',
|
| 1328 |
+
'sweet pea',
|
| 1329 |
+
'english marigold',
|
| 1330 |
+
'tiger lily',
|
| 1331 |
+
'moon orchid',
|
| 1332 |
+
'bird of paradise',
|
| 1333 |
+
'monkshood',
|
| 1334 |
+
'globe thistle',
|
| 1335 |
+
'snapdragon',
|
| 1336 |
+
"colt's foot",
|
| 1337 |
+
'king protea',
|
| 1338 |
+
'spear thistle',
|
| 1339 |
+
'yellow iris',
|
| 1340 |
+
'globe flower',
|
| 1341 |
+
'purple coneflower',
|
| 1342 |
+
'peruvian lily',
|
| 1343 |
+
'balloon flower',
|
| 1344 |
+
'giant white arum lily',
|
| 1345 |
+
'fire lily',
|
| 1346 |
+
'pincushion flower',
|
| 1347 |
+
'fritillary',
|
| 1348 |
+
'red ginger',
|
| 1349 |
+
'grape hyacinth',
|
| 1350 |
+
'corn poppy',
|
| 1351 |
+
'prince of wales feathers',
|
| 1352 |
+
'stemless gentian',
|
| 1353 |
+
'artichoke',
|
| 1354 |
+
'sweet william',
|
| 1355 |
+
'carnation',
|
| 1356 |
+
'garden phlox',
|
| 1357 |
+
'love in the mist',
|
| 1358 |
+
'mexican aster',
|
| 1359 |
+
'alpine sea holly',
|
| 1360 |
+
'ruby-lipped cattleya',
|
| 1361 |
+
'cape flower',
|
| 1362 |
+
'great masterwort',
|
| 1363 |
+
'siam tulip',
|
| 1364 |
+
'lenten rose',
|
| 1365 |
+
'barbeton daisy',
|
| 1366 |
+
'daffodil',
|
| 1367 |
+
'sword lily',
|
| 1368 |
+
'poinsettia',
|
| 1369 |
+
'bolero deep blue',
|
| 1370 |
+
'wallflower',
|
| 1371 |
+
'marigold',
|
| 1372 |
+
'buttercup',
|
| 1373 |
+
'oxeye daisy',
|
| 1374 |
+
'common dandelion',
|
| 1375 |
+
'petunia',
|
| 1376 |
+
'wild pansy',
|
| 1377 |
+
'primula',
|
| 1378 |
+
'sunflower',
|
| 1379 |
+
'pelargonium',
|
| 1380 |
+
'bishop of llandaff',
|
| 1381 |
+
'gaura',
|
| 1382 |
+
'geranium',
|
| 1383 |
+
'orange dahlia',
|
| 1384 |
+
'pink and yellow dahlia',
|
| 1385 |
+
'cautleya spicata',
|
| 1386 |
+
'japanese anemone',
|
| 1387 |
+
'black-eyed susan',
|
| 1388 |
+
'silverbush',
|
| 1389 |
+
'californian poppy',
|
| 1390 |
+
'osteospermum',
|
| 1391 |
+
'spring crocus',
|
| 1392 |
+
'bearded iris',
|
| 1393 |
+
'windflower',
|
| 1394 |
+
'tree poppy',
|
| 1395 |
+
'gazania',
|
| 1396 |
+
'azalea',
|
| 1397 |
+
'water lily',
|
| 1398 |
+
'rose',
|
| 1399 |
+
'thorn apple',
|
| 1400 |
+
'morning glory',
|
| 1401 |
+
'passion flower',
|
| 1402 |
+
'lotus',
|
| 1403 |
+
'toad lily',
|
| 1404 |
+
'anthurium',
|
| 1405 |
+
'frangipani',
|
| 1406 |
+
'clematis',
|
| 1407 |
+
'hibiscus',
|
| 1408 |
+
'columbine',
|
| 1409 |
+
'desert-rose',
|
| 1410 |
+
'tree mallow',
|
| 1411 |
+
'magnolia',
|
| 1412 |
+
'cyclamen',
|
| 1413 |
+
'watercress',
|
| 1414 |
+
'canna lily',
|
| 1415 |
+
'hippeastrum',
|
| 1416 |
+
'bee balm',
|
| 1417 |
+
'air plant',
|
| 1418 |
+
'foxglove',
|
| 1419 |
+
'bougainvillea',
|
| 1420 |
+
'camellia',
|
| 1421 |
+
'mallow',
|
| 1422 |
+
'mexican petunia',
|
| 1423 |
+
'bromelia',
|
| 1424 |
+
'blanket flower',
|
| 1425 |
+
'trumpet creeper',
|
| 1426 |
+
'blackberry lily',
|
| 1427 |
+
]
|
| 1428 |
+
|
| 1429 |
+
templates = [
|
| 1430 |
+
'a photo of a {}, a type of flower.',
|
| 1431 |
+
]
|
| 1432 |
+
```
|
| 1433 |
+
|
| 1434 |
+
|
| 1435 |
+
|
| 1436 |
+
## Food101
|
| 1437 |
+
|
| 1438 |
+
```bash
|
| 1439 |
+
classes = [
|
| 1440 |
+
'apple pie',
|
| 1441 |
+
'baby back ribs',
|
| 1442 |
+
'baklava',
|
| 1443 |
+
'beef carpaccio',
|
| 1444 |
+
'beef tartare',
|
| 1445 |
+
'beet salad',
|
| 1446 |
+
'beignets',
|
| 1447 |
+
'bibimbap',
|
| 1448 |
+
'bread pudding',
|
| 1449 |
+
'breakfast burrito',
|
| 1450 |
+
'bruschetta',
|
| 1451 |
+
'caesar salad',
|
| 1452 |
+
'cannoli',
|
| 1453 |
+
'caprese salad',
|
| 1454 |
+
'carrot cake',
|
| 1455 |
+
'ceviche',
|
| 1456 |
+
'cheese plate',
|
| 1457 |
+
'cheesecake',
|
| 1458 |
+
'chicken curry',
|
| 1459 |
+
'chicken quesadilla',
|
| 1460 |
+
'chicken wings',
|
| 1461 |
+
'chocolate cake',
|
| 1462 |
+
'chocolate mousse',
|
| 1463 |
+
'churros',
|
| 1464 |
+
'clam chowder',
|
| 1465 |
+
'club sandwich',
|
| 1466 |
+
'crab cakes',
|
| 1467 |
+
'creme brulee',
|
| 1468 |
+
'croque madame',
|
| 1469 |
+
'cup cakes',
|
| 1470 |
+
'deviled eggs',
|
| 1471 |
+
'donuts',
|
| 1472 |
+
'dumplings',
|
| 1473 |
+
'edamame',
|
| 1474 |
+
'eggs benedict',
|
| 1475 |
+
'escargots',
|
| 1476 |
+
'falafel',
|
| 1477 |
+
'filet mignon',
|
| 1478 |
+
'fish and chips',
|
| 1479 |
+
'foie gras',
|
| 1480 |
+
'french fries',
|
| 1481 |
+
'french onion soup',
|
| 1482 |
+
'french toast',
|
| 1483 |
+
'fried calamari',
|
| 1484 |
+
'fried rice',
|
| 1485 |
+
'frozen yogurt',
|
| 1486 |
+
'garlic bread',
|
| 1487 |
+
'gnocchi',
|
| 1488 |
+
'greek salad',
|
| 1489 |
+
'grilled cheese sandwich',
|
| 1490 |
+
'grilled salmon',
|
| 1491 |
+
'guacamole',
|
| 1492 |
+
'gyoza',
|
| 1493 |
+
'hamburger',
|
| 1494 |
+
'hot and sour soup',
|
| 1495 |
+
'hot dog',
|
| 1496 |
+
'huevos rancheros',
|
| 1497 |
+
'hummus',
|
| 1498 |
+
'ice cream',
|
| 1499 |
+
'lasagna',
|
| 1500 |
+
'lobster bisque',
|
| 1501 |
+
'lobster roll sandwich',
|
| 1502 |
+
'macaroni and cheese',
|
| 1503 |
+
'macarons',
|
| 1504 |
+
'miso soup',
|
| 1505 |
+
'mussels',
|
| 1506 |
+
'nachos',
|
| 1507 |
+
'omelette',
|
| 1508 |
+
'onion rings',
|
| 1509 |
+
'oysters',
|
| 1510 |
+
'pad thai',
|
| 1511 |
+
'paella',
|
| 1512 |
+
'pancakes',
|
| 1513 |
+
'panna cotta',
|
| 1514 |
+
'peking duck',
|
| 1515 |
+
'pho',
|
| 1516 |
+
'pizza',
|
| 1517 |
+
'pork chop',
|
| 1518 |
+
'poutine',
|
| 1519 |
+
'prime rib',
|
| 1520 |
+
'pulled pork sandwich',
|
| 1521 |
+
'ramen',
|
| 1522 |
+
'ravioli',
|
| 1523 |
+
'red velvet cake',
|
| 1524 |
+
'risotto',
|
| 1525 |
+
'samosa',
|
| 1526 |
+
'sashimi',
|
| 1527 |
+
'scallops',
|
| 1528 |
+
'seaweed salad',
|
| 1529 |
+
'shrimp and grits',
|
| 1530 |
+
'spaghetti bolognese',
|
| 1531 |
+
'spaghetti carbonara',
|
| 1532 |
+
'spring rolls',
|
| 1533 |
+
'steak',
|
| 1534 |
+
'strawberry shortcake',
|
| 1535 |
+
'sushi',
|
| 1536 |
+
'tacos',
|
| 1537 |
+
'takoyaki',
|
| 1538 |
+
'tiramisu',
|
| 1539 |
+
'tuna tartare',
|
| 1540 |
+
'waffles',
|
| 1541 |
+
]
|
| 1542 |
+
|
| 1543 |
+
templates = [
|
| 1544 |
+
'a photo of {}, a type of food.',
|
| 1545 |
+
]
|
| 1546 |
+
```
|
| 1547 |
+
|
| 1548 |
+
|
| 1549 |
+
|
| 1550 |
+
## GTSRB
|
| 1551 |
+
|
| 1552 |
+
```bash
|
| 1553 |
+
classes = [
|
| 1554 |
+
'red and white circle 20 kph speed limit',
|
| 1555 |
+
'red and white circle 30 kph speed limit',
|
| 1556 |
+
'red and white circle 50 kph speed limit',
|
| 1557 |
+
'red and white circle 60 kph speed limit',
|
| 1558 |
+
'red and white circle 70 kph speed limit',
|
| 1559 |
+
'red and white circle 80 kph speed limit',
|
| 1560 |
+
'end / de-restriction of 80 kph speed limit',
|
| 1561 |
+
'red and white circle 100 kph speed limit',
|
| 1562 |
+
'red and white circle 120 kph speed limit',
|
| 1563 |
+
'red and white circle red car and black car no passing',
|
| 1564 |
+
'red and white circle red truck and black car no passing',
|
| 1565 |
+
'red and white triangle road intersection warning',
|
| 1566 |
+
'white and yellow diamond priority road',
|
| 1567 |
+
'red and white upside down triangle yield right-of-way',
|
| 1568 |
+
'stop',
|
| 1569 |
+
'empty red and white circle',
|
| 1570 |
+
'red and white circle no truck entry',
|
| 1571 |
+
'red circle with white horizonal stripe no entry',
|
| 1572 |
+
'red and white triangle with exclamation mark warning',
|
| 1573 |
+
'red and white triangle with black left curve approaching warning',
|
| 1574 |
+
'red and white triangle with black right curve approaching warning',
|
| 1575 |
+
'red and white triangle with black double curve approaching warning',
|
| 1576 |
+
'red and white triangle rough / bumpy road warning',
|
| 1577 |
+
'red and white triangle car skidding / slipping warning',
|
| 1578 |
+
'red and white triangle with merging / narrow lanes warning',
|
| 1579 |
+
'red and white triangle with person digging / construction / road work warning',
|
| 1580 |
+
'red and white triangle with traffic light approaching warning',
|
| 1581 |
+
'red and white triangle with person walking warning',
|
| 1582 |
+
'red and white triangle with child and person walking warning',
|
| 1583 |
+
'red and white triangle with bicyle warning',
|
| 1584 |
+
'red and white triangle with snowflake / ice warning',
|
| 1585 |
+
'red and white triangle with deer warning',
|
| 1586 |
+
'white circle with gray strike bar no speed limit',
|
| 1587 |
+
'blue circle with white right turn arrow mandatory',
|
| 1588 |
+
'blue circle with white left turn arrow mandatory',
|
| 1589 |
+
'blue circle with white forward arrow mandatory',
|
| 1590 |
+
'blue circle with white forward or right turn arrow mandatory',
|
| 1591 |
+
'blue circle with white forward or left turn arrow mandatory',
|
| 1592 |
+
'blue circle with white keep right arrow mandatory',
|
| 1593 |
+
'blue circle with white keep left arrow mandatory',
|
| 1594 |
+
'blue circle with white arrows indicating a traffic circle',
|
| 1595 |
+
'white circle with gray strike bar indicating no passing for cars has ended',
|
| 1596 |
+
'white circle with gray strike bar indicating no passing for trucks has ended',
|
| 1597 |
+
]
|
| 1598 |
+
|
| 1599 |
+
templates = [
|
| 1600 |
+
'a zoomed in photo of a "{}" traffic sign.',
|
| 1601 |
+
'a centered photo of a "{}" traffic sign.',
|
| 1602 |
+
'a close up photo of a "{}" traffic sign.',
|
| 1603 |
+
]
|
| 1604 |
+
```
|
| 1605 |
+
|
| 1606 |
+
|
| 1607 |
+
|
| 1608 |
+
## HatefulMemes
|
| 1609 |
+
|
| 1610 |
+
```bash
|
| 1611 |
+
classes = [
|
| 1612 |
+
'meme',
|
| 1613 |
+
'hatespeech meme',
|
| 1614 |
+
]
|
| 1615 |
+
|
| 1616 |
+
templates = [
|
| 1617 |
+
'a {}.',
|
| 1618 |
+
]
|
| 1619 |
+
```
|
| 1620 |
+
|
| 1621 |
+
|
| 1622 |
+
|
| 1623 |
+
## KITTI
|
| 1624 |
+
|
| 1625 |
+
```bash
|
| 1626 |
+
classes = [
|
| 1627 |
+
'a photo i took of a car on my left or right side.',
|
| 1628 |
+
'a photo i took with a car nearby.',
|
| 1629 |
+
'a photo i took with a car in the distance.',
|
| 1630 |
+
'a photo i took with no car.',
|
| 1631 |
+
]
|
| 1632 |
+
|
| 1633 |
+
templates = [
|
| 1634 |
+
'{}',
|
| 1635 |
+
]
|
| 1636 |
+
```
|
| 1637 |
+
|
| 1638 |
+
|
| 1639 |
+
|
| 1640 |
+
## Kinetics700
|
| 1641 |
+
|
| 1642 |
+
```bash
|
| 1643 |
+
classes = [
|
| 1644 |
+
'abseiling',
|
| 1645 |
+
'acting in play',
|
| 1646 |
+
'adjusting glasses',
|
| 1647 |
+
'air drumming',
|
| 1648 |
+
'alligator wrestling',
|
| 1649 |
+
'answering questions',
|
| 1650 |
+
'applauding',
|
| 1651 |
+
'applying cream',
|
| 1652 |
+
'archaeological excavation',
|
| 1653 |
+
'archery',
|
| 1654 |
+
'arguing',
|
| 1655 |
+
'arm wrestling',
|
| 1656 |
+
'arranging flowers',
|
| 1657 |
+
'arresting',
|
| 1658 |
+
'assembling bicycle',
|
| 1659 |
+
'assembling computer',
|
| 1660 |
+
'attending conference',
|
| 1661 |
+
'auctioning',
|
| 1662 |
+
'baby waking up',
|
| 1663 |
+
'backflip (human)',
|
| 1664 |
+
'baking cookies',
|
| 1665 |
+
'bandaging',
|
| 1666 |
+
'barbequing',
|
| 1667 |
+
'bartending',
|
| 1668 |
+
'base jumping',
|
| 1669 |
+
'bathing dog',
|
| 1670 |
+
'battle rope training',
|
| 1671 |
+
'beatboxing',
|
| 1672 |
+
'bee keeping',
|
| 1673 |
+
'being excited',
|
| 1674 |
+
'being in zero gravity',
|
| 1675 |
+
'belly dancing',
|
| 1676 |
+
'bench pressing',
|
| 1677 |
+
'bending back',
|
| 1678 |
+
'bending metal',
|
| 1679 |
+
'biking through snow',
|
| 1680 |
+
'blasting sand',
|
| 1681 |
+
'blending fruit',
|
| 1682 |
+
'blowdrying hair',
|
| 1683 |
+
'blowing bubble gum',
|
| 1684 |
+
'blowing glass',
|
| 1685 |
+
'blowing leaves',
|
| 1686 |
+
'blowing nose',
|
| 1687 |
+
'blowing out candles',
|
| 1688 |
+
'bobsledding',
|
| 1689 |
+
'bodysurfing',
|
| 1690 |
+
'bookbinding',
|
| 1691 |
+
'bottling',
|
| 1692 |
+
'bouncing ball (not juggling)',
|
| 1693 |
+
'bouncing on bouncy castle',
|
| 1694 |
+
'bouncing on trampoline',
|
| 1695 |
+
'bowling',
|
| 1696 |
+
'braiding hair',
|
| 1697 |
+
'breading or breadcrumbing',
|
| 1698 |
+
'breakdancing',
|
| 1699 |
+
'breaking boards',
|
| 1700 |
+
'breaking glass',
|
| 1701 |
+
'breathing fire',
|
| 1702 |
+
'brush painting',
|
| 1703 |
+
'brushing floor',
|
| 1704 |
+
'brushing hair',
|
| 1705 |
+
'brushing teeth',
|
| 1706 |
+
'building cabinet',
|
| 1707 |
+
'building lego',
|
| 1708 |
+
'building sandcastle',
|
| 1709 |
+
'building shed',
|
| 1710 |
+
'bulldozing',
|
| 1711 |
+
'bungee jumping',
|
| 1712 |
+
'burping',
|
| 1713 |
+
'busking',
|
| 1714 |
+
'calculating',
|
| 1715 |
+
'calligraphy',
|
| 1716 |
+
'canoeing or kayaking',
|
| 1717 |
+
'capoeira',
|
| 1718 |
+
'capsizing',
|
| 1719 |
+
'card stacking',
|
| 1720 |
+
'card throwing',
|
| 1721 |
+
'carrying baby',
|
| 1722 |
+
'carrying weight',
|
| 1723 |
+
'cartwheeling',
|
| 1724 |
+
'carving ice',
|
| 1725 |
+
'carving marble',
|
| 1726 |
+
'carving pumpkin',
|
| 1727 |
+
'carving wood with a knife',
|
| 1728 |
+
'casting fishing line',
|
| 1729 |
+
'catching fish',
|
| 1730 |
+
'catching or throwing baseball',
|
| 1731 |
+
'catching or throwing frisbee',
|
| 1732 |
+
'catching or throwing softball',
|
| 1733 |
+
'celebrating',
|
| 1734 |
+
'changing gear in car',
|
| 1735 |
+
'changing oil',
|
| 1736 |
+
'changing wheel (not on bike)',
|
| 1737 |
+
'chasing',
|
| 1738 |
+
'checking tires',
|
| 1739 |
+
'checking watch',
|
| 1740 |
+
'cheerleading',
|
| 1741 |
+
'chewing gum',
|
| 1742 |
+
'chiseling stone',
|
| 1743 |
+
'chiseling wood',
|
| 1744 |
+
'chopping meat',
|
| 1745 |
+
'chopping wood',
|
| 1746 |
+
'clam digging',
|
| 1747 |
+
'clapping',
|
| 1748 |
+
'clay pottery making',
|
| 1749 |
+
'clean and jerk',
|
| 1750 |
+
'cleaning gutters',
|
| 1751 |
+
'cleaning pool',
|
| 1752 |
+
'cleaning shoes',
|
| 1753 |
+
'cleaning toilet',
|
| 1754 |
+
'cleaning windows',
|
| 1755 |
+
'climbing a rope',
|
| 1756 |
+
'climbing ladder',
|
| 1757 |
+
'climbing tree',
|
| 1758 |
+
'closing door',
|
| 1759 |
+
'coloring in',
|
| 1760 |
+
'combing hair',
|
| 1761 |
+
'contact juggling',
|
| 1762 |
+
'contorting',
|
| 1763 |
+
'cooking chicken',
|
| 1764 |
+
'cooking egg',
|
| 1765 |
+
'cooking on campfire',
|
| 1766 |
+
'cooking sausages (not on barbeque)',
|
| 1767 |
+
'cooking scallops',
|
| 1768 |
+
'cosplaying',
|
| 1769 |
+
'coughing',
|
| 1770 |
+
'counting money',
|
| 1771 |
+
'country line dancing',
|
| 1772 |
+
'cracking back',
|
| 1773 |
+
'cracking knuckles',
|
| 1774 |
+
'cracking neck',
|
| 1775 |
+
'crawling baby',
|
| 1776 |
+
'crocheting',
|
| 1777 |
+
'crossing eyes',
|
| 1778 |
+
'crossing river',
|
| 1779 |
+
'crying',
|
| 1780 |
+
'cumbia',
|
| 1781 |
+
'curling (sport)',
|
| 1782 |
+
'curling eyelashes',
|
| 1783 |
+
'curling hair',
|
| 1784 |
+
'cutting apple',
|
| 1785 |
+
'cutting cake',
|
| 1786 |
+
'cutting nails',
|
| 1787 |
+
'cutting orange',
|
| 1788 |
+
'cutting pineapple',
|
| 1789 |
+
'cutting watermelon',
|
| 1790 |
+
'dancing ballet',
|
| 1791 |
+
'dancing charleston',
|
| 1792 |
+
'dancing gangnam style',
|
| 1793 |
+
'dancing macarena',
|
| 1794 |
+
'deadlifting',
|
| 1795 |
+
'dealing cards',
|
| 1796 |
+
'decorating the christmas tree',
|
| 1797 |
+
'decoupage',
|
| 1798 |
+
'delivering mail',
|
| 1799 |
+
'digging',
|
| 1800 |
+
'dining',
|
| 1801 |
+
'directing traffic',
|
| 1802 |
+
'disc golfing',
|
| 1803 |
+
'diving cliff',
|
| 1804 |
+
'docking boat',
|
| 1805 |
+
'dodgeball',
|
| 1806 |
+
'doing aerobics',
|
| 1807 |
+
'doing jigsaw puzzle',
|
| 1808 |
+
'doing laundry',
|
| 1809 |
+
'doing nails',
|
| 1810 |
+
'doing sudoku',
|
| 1811 |
+
'drawing',
|
| 1812 |
+
'dribbling basketball',
|
| 1813 |
+
'drinking shots',
|
| 1814 |
+
'driving car',
|
| 1815 |
+
'driving tractor',
|
| 1816 |
+
'drooling',
|
| 1817 |
+
'drop kicking',
|
| 1818 |
+
'drumming fingers',
|
| 1819 |
+
'dumpster diving',
|
| 1820 |
+
'dunking basketball',
|
| 1821 |
+
'dyeing eyebrows',
|
| 1822 |
+
'dyeing hair',
|
| 1823 |
+
'eating burger',
|
| 1824 |
+
'eating cake',
|
| 1825 |
+
'eating carrots',
|
| 1826 |
+
'eating chips',
|
| 1827 |
+
'eating doughnuts',
|
| 1828 |
+
'eating hotdog',
|
| 1829 |
+
'eating ice cream',
|
| 1830 |
+
'eating nachos',
|
| 1831 |
+
'eating spaghetti',
|
| 1832 |
+
'eating watermelon',
|
| 1833 |
+
'egg hunting',
|
| 1834 |
+
'embroidering',
|
| 1835 |
+
'entering church',
|
| 1836 |
+
'exercising arm',
|
| 1837 |
+
'exercising with an exercise ball',
|
| 1838 |
+
'extinguishing fire',
|
| 1839 |
+
'faceplanting',
|
| 1840 |
+
'falling off bike',
|
| 1841 |
+
'falling off chair',
|
| 1842 |
+
'feeding birds',
|
| 1843 |
+
'feeding fish',
|
| 1844 |
+
'feeding goats',
|
| 1845 |
+
'fencing (sport)',
|
| 1846 |
+
'fidgeting',
|
| 1847 |
+
'filling cake',
|
| 1848 |
+
'filling eyebrows',
|
| 1849 |
+
'finger snapping',
|
| 1850 |
+
'fixing bicycle',
|
| 1851 |
+
'fixing hair',
|
| 1852 |
+
'flint knapping',
|
| 1853 |
+
'flipping bottle',
|
| 1854 |
+
'flipping pancake',
|
| 1855 |
+
'fly tying',
|
| 1856 |
+
'flying kite',
|
| 1857 |
+
'folding clothes',
|
| 1858 |
+
'folding napkins',
|
| 1859 |
+
'folding paper',
|
| 1860 |
+
'front raises',
|
| 1861 |
+
'frying vegetables',
|
| 1862 |
+
'gargling',
|
| 1863 |
+
'geocaching',
|
| 1864 |
+
'getting a haircut',
|
| 1865 |
+
'getting a piercing',
|
| 1866 |
+
'getting a tattoo',
|
| 1867 |
+
'giving or receiving award',
|
| 1868 |
+
'gold panning',
|
| 1869 |
+
'golf chipping',
|
| 1870 |
+
'golf driving',
|
| 1871 |
+
'golf putting',
|
| 1872 |
+
'gospel singing in church',
|
| 1873 |
+
'grinding meat',
|
| 1874 |
+
'grooming cat',
|
| 1875 |
+
'grooming dog',
|
| 1876 |
+
'grooming horse',
|
| 1877 |
+
'gymnastics tumbling',
|
| 1878 |
+
'hammer throw',
|
| 1879 |
+
'hand washing clothes',
|
| 1880 |
+
'head stand',
|
| 1881 |
+
'headbanging',
|
| 1882 |
+
'headbutting',
|
| 1883 |
+
'helmet diving',
|
| 1884 |
+
'herding cattle',
|
| 1885 |
+
'high fiving',
|
| 1886 |
+
'high jump',
|
| 1887 |
+
'high kick',
|
| 1888 |
+
'historical reenactment',
|
| 1889 |
+
'hitting baseball',
|
| 1890 |
+
'hockey stop',
|
| 1891 |
+
'holding snake',
|
| 1892 |
+
'home roasting coffee',
|
| 1893 |
+
'hopscotch',
|
| 1894 |
+
'hoverboarding',
|
| 1895 |
+
'huddling',
|
| 1896 |
+
'hugging (not baby)',
|
| 1897 |
+
'hugging baby',
|
| 1898 |
+
'hula hooping',
|
| 1899 |
+
'hurdling',
|
| 1900 |
+
'hurling (sport)',
|
| 1901 |
+
'ice climbing',
|
| 1902 |
+
'ice fishing',
|
| 1903 |
+
'ice skating',
|
| 1904 |
+
'ice swimming',
|
| 1905 |
+
'inflating balloons',
|
| 1906 |
+
'installing carpet',
|
| 1907 |
+
'ironing',
|
| 1908 |
+
'ironing hair',
|
| 1909 |
+
'javelin throw',
|
| 1910 |
+
'jaywalking',
|
| 1911 |
+
'jetskiing',
|
| 1912 |
+
'jogging',
|
| 1913 |
+
'juggling balls',
|
| 1914 |
+
'juggling fire',
|
| 1915 |
+
'juggling soccer ball',
|
| 1916 |
+
'jumping bicycle',
|
| 1917 |
+
'jumping into pool',
|
| 1918 |
+
'jumping jacks',
|
| 1919 |
+
'jumping sofa',
|
| 1920 |
+
'jumpstyle dancing',
|
| 1921 |
+
'karaoke',
|
| 1922 |
+
'kicking field goal',
|
| 1923 |
+
'kicking soccer ball',
|
| 1924 |
+
'kissing',
|
| 1925 |
+
'kitesurfing',
|
| 1926 |
+
'knitting',
|
| 1927 |
+
'krumping',
|
| 1928 |
+
'land sailing',
|
| 1929 |
+
'laughing',
|
| 1930 |
+
'lawn mower racing',
|
| 1931 |
+
'laying bricks',
|
| 1932 |
+
'laying concrete',
|
| 1933 |
+
'laying decking',
|
| 1934 |
+
'laying stone',
|
| 1935 |
+
'laying tiles',
|
| 1936 |
+
'leatherworking',
|
| 1937 |
+
'letting go of balloon',
|
| 1938 |
+
'licking',
|
| 1939 |
+
'lifting hat',
|
| 1940 |
+
'lighting candle',
|
| 1941 |
+
'lighting fire',
|
| 1942 |
+
'listening with headphones',
|
| 1943 |
+
'lock picking',
|
| 1944 |
+
'long jump',
|
| 1945 |
+
'longboarding',
|
| 1946 |
+
'looking at phone',
|
| 1947 |
+
'looking in mirror',
|
| 1948 |
+
'luge',
|
| 1949 |
+
'lunge',
|
| 1950 |
+
'making a cake',
|
| 1951 |
+
'making a sandwich',
|
| 1952 |
+
'making balloon shapes',
|
| 1953 |
+
'making bubbles',
|
| 1954 |
+
'making cheese',
|
| 1955 |
+
'making horseshoes',
|
| 1956 |
+
'making jewelry',
|
| 1957 |
+
'making latte art',
|
| 1958 |
+
'making paper aeroplanes',
|
| 1959 |
+
'making pizza',
|
| 1960 |
+
'making slime',
|
| 1961 |
+
'making snowman',
|
| 1962 |
+
'making sushi',
|
| 1963 |
+
'making tea',
|
| 1964 |
+
'making the bed',
|
| 1965 |
+
'marching',
|
| 1966 |
+
'marriage proposal',
|
| 1967 |
+
'massaging back',
|
| 1968 |
+
'massaging feet',
|
| 1969 |
+
'massaging legs',
|
| 1970 |
+
'massaging neck',
|
| 1971 |
+
"massaging person's head",
|
| 1972 |
+
'metal detecting',
|
| 1973 |
+
'milking cow',
|
| 1974 |
+
'milking goat',
|
| 1975 |
+
'mixing colours',
|
| 1976 |
+
'moon walking',
|
| 1977 |
+
'mopping floor',
|
| 1978 |
+
'mosh pit dancing',
|
| 1979 |
+
'motorcycling',
|
| 1980 |
+
'mountain climber (exercise)',
|
| 1981 |
+
'moving baby',
|
| 1982 |
+
'moving child',
|
| 1983 |
+
'moving furniture',
|
| 1984 |
+
'mowing lawn',
|
| 1985 |
+
'mushroom foraging',
|
| 1986 |
+
'needle felting',
|
| 1987 |
+
'news anchoring',
|
| 1988 |
+
'opening bottle (not wine)',
|
| 1989 |
+
'opening coconuts',
|
| 1990 |
+
'opening door',
|
| 1991 |
+
'opening present',
|
| 1992 |
+
'opening refrigerator',
|
| 1993 |
+
'opening wine bottle',
|
| 1994 |
+
'packing',
|
| 1995 |
+
'paragliding',
|
| 1996 |
+
'parasailing',
|
| 1997 |
+
'parkour',
|
| 1998 |
+
'passing American football (in game)',
|
| 1999 |
+
'passing American football (not in game)',
|
| 2000 |
+
'passing soccer ball',
|
| 2001 |
+
'peeling apples',
|
| 2002 |
+
'peeling banana',
|
| 2003 |
+
'peeling potatoes',
|
| 2004 |
+
'person collecting garbage',
|
| 2005 |
+
'petting animal (not cat)',
|
| 2006 |
+
'petting cat',
|
| 2007 |
+
'petting horse',
|
| 2008 |
+
'photobombing',
|
| 2009 |
+
'photocopying',
|
| 2010 |
+
'picking apples',
|
| 2011 |
+
'picking blueberries',
|
| 2012 |
+
'pillow fight',
|
| 2013 |
+
'pinching',
|
| 2014 |
+
'pirouetting',
|
| 2015 |
+
'planing wood',
|
| 2016 |
+
'planting trees',
|
| 2017 |
+
'plastering',
|
| 2018 |
+
'playing accordion',
|
| 2019 |
+
'playing american football',
|
| 2020 |
+
'playing badminton',
|
| 2021 |
+
'playing bagpipes',
|
| 2022 |
+
'playing basketball',
|
| 2023 |
+
'playing bass guitar',
|
| 2024 |
+
'playing beer pong',
|
| 2025 |
+
'playing billiards',
|
| 2026 |
+
'playing blackjack',
|
| 2027 |
+
'playing cards',
|
| 2028 |
+
'playing cello',
|
| 2029 |
+
'playing checkers',
|
| 2030 |
+
'playing chess',
|
| 2031 |
+
'playing clarinet',
|
| 2032 |
+
'playing controller',
|
| 2033 |
+
'playing cricket',
|
| 2034 |
+
'playing cymbals',
|
| 2035 |
+
'playing darts',
|
| 2036 |
+
'playing didgeridoo',
|
| 2037 |
+
'playing dominoes',
|
| 2038 |
+
'playing drums',
|
| 2039 |
+
'playing field hockey',
|
| 2040 |
+
'playing flute',
|
| 2041 |
+
'playing gong',
|
| 2042 |
+
'playing guitar',
|
| 2043 |
+
'playing hand clapping games',
|
| 2044 |
+
'playing harmonica',
|
| 2045 |
+
'playing harp',
|
| 2046 |
+
'playing ice hockey',
|
| 2047 |
+
'playing keyboard',
|
| 2048 |
+
'playing kickball',
|
| 2049 |
+
'playing laser tag',
|
| 2050 |
+
'playing lute',
|
| 2051 |
+
'playing mahjong',
|
| 2052 |
+
'playing maracas',
|
| 2053 |
+
'playing marbles',
|
| 2054 |
+
'playing monopoly',
|
| 2055 |
+
'playing netball',
|
| 2056 |
+
'playing nose flute',
|
| 2057 |
+
'playing oboe',
|
| 2058 |
+
'playing ocarina',
|
| 2059 |
+
'playing organ',
|
| 2060 |
+
'playing paintball',
|
| 2061 |
+
'playing pan pipes',
|
| 2062 |
+
'playing piano',
|
| 2063 |
+
'playing piccolo',
|
| 2064 |
+
'playing pinball',
|
| 2065 |
+
'playing ping pong',
|
| 2066 |
+
'playing poker',
|
| 2067 |
+
'playing polo',
|
| 2068 |
+
'playing recorder',
|
| 2069 |
+
'playing road hockey',
|
| 2070 |
+
'playing rounders',
|
| 2071 |
+
'playing rubiks cube',
|
| 2072 |
+
'playing saxophone',
|
| 2073 |
+
'playing scrabble',
|
| 2074 |
+
'playing shuffleboard',
|
| 2075 |
+
'playing slot machine',
|
| 2076 |
+
'playing squash or racquetball',
|
| 2077 |
+
'playing tennis',
|
| 2078 |
+
'playing trombone',
|
| 2079 |
+
'playing trumpet',
|
| 2080 |
+
'playing ukulele',
|
| 2081 |
+
'playing violin',
|
| 2082 |
+
'playing volleyball',
|
| 2083 |
+
'playing with trains',
|
| 2084 |
+
'playing xylophone',
|
| 2085 |
+
'poaching eggs',
|
| 2086 |
+
'poking bellybutton',
|
| 2087 |
+
'pole vault',
|
| 2088 |
+
'polishing furniture',
|
| 2089 |
+
'polishing metal',
|
| 2090 |
+
'popping balloons',
|
| 2091 |
+
'pouring beer',
|
| 2092 |
+
'pouring milk',
|
| 2093 |
+
'pouring wine',
|
| 2094 |
+
'preparing salad',
|
| 2095 |
+
'presenting weather forecast',
|
| 2096 |
+
'pretending to be a statue',
|
| 2097 |
+
'pull ups',
|
| 2098 |
+
'pulling espresso shot',
|
| 2099 |
+
'pulling rope (game)',
|
| 2100 |
+
'pumping fist',
|
| 2101 |
+
'pumping gas',
|
| 2102 |
+
'punching bag',
|
| 2103 |
+
'punching person (boxing)',
|
| 2104 |
+
'push up',
|
| 2105 |
+
'pushing car',
|
| 2106 |
+
'pushing cart',
|
| 2107 |
+
'pushing wheelbarrow',
|
| 2108 |
+
'pushing wheelchair',
|
| 2109 |
+
'putting in contact lenses',
|
| 2110 |
+
'putting on eyeliner',
|
| 2111 |
+
'putting on foundation',
|
| 2112 |
+
'putting on lipstick',
|
| 2113 |
+
'putting on mascara',
|
| 2114 |
+
'putting on sari',
|
| 2115 |
+
'putting on shoes',
|
| 2116 |
+
'putting wallpaper on wall',
|
| 2117 |
+
'raising eyebrows',
|
| 2118 |
+
'reading book',
|
| 2119 |
+
'reading newspaper',
|
| 2120 |
+
'recording music',
|
| 2121 |
+
'repairing puncture',
|
| 2122 |
+
'riding a bike',
|
| 2123 |
+
'riding camel',
|
| 2124 |
+
'riding elephant',
|
| 2125 |
+
'riding mechanical bull',
|
| 2126 |
+
'riding mule',
|
| 2127 |
+
'riding or walking with horse',
|
| 2128 |
+
'riding scooter',
|
| 2129 |
+
'riding snow blower',
|
| 2130 |
+
'riding unicycle',
|
| 2131 |
+
'ripping paper',
|
| 2132 |
+
'roasting marshmallows',
|
| 2133 |
+
'roasting pig',
|
| 2134 |
+
'robot dancing',
|
| 2135 |
+
'rock climbing',
|
| 2136 |
+
'rock scissors paper',
|
| 2137 |
+
'roller skating',
|
| 2138 |
+
'rolling eyes',
|
| 2139 |
+
'rolling pastry',
|
| 2140 |
+
'rope pushdown',
|
| 2141 |
+
'running on treadmill',
|
| 2142 |
+
'sailing',
|
| 2143 |
+
'salsa dancing',
|
| 2144 |
+
'saluting',
|
| 2145 |
+
'sanding floor',
|
| 2146 |
+
'sanding wood',
|
| 2147 |
+
'sausage making',
|
| 2148 |
+
'sawing wood',
|
| 2149 |
+
'scrambling eggs',
|
| 2150 |
+
'scrapbooking',
|
| 2151 |
+
'scrubbing face',
|
| 2152 |
+
'scuba diving',
|
| 2153 |
+
'seasoning food',
|
| 2154 |
+
'separating eggs',
|
| 2155 |
+
'setting table',
|
| 2156 |
+
'sewing',
|
| 2157 |
+
'shaking hands',
|
| 2158 |
+
'shaking head',
|
| 2159 |
+
'shaping bread dough',
|
| 2160 |
+
'sharpening knives',
|
| 2161 |
+
'sharpening pencil',
|
| 2162 |
+
'shaving head',
|
| 2163 |
+
'shaving legs',
|
| 2164 |
+
'shearing sheep',
|
| 2165 |
+
'shining flashlight',
|
| 2166 |
+
'shining shoes',
|
| 2167 |
+
'shoot dance',
|
| 2168 |
+
'shooting basketball',
|
| 2169 |
+
'shooting goal (soccer)',
|
| 2170 |
+
'shooting off fireworks',
|
| 2171 |
+
'shopping',
|
| 2172 |
+
'shot put',
|
| 2173 |
+
'shouting',
|
| 2174 |
+
'shoveling snow',
|
| 2175 |
+
'shredding paper',
|
| 2176 |
+
'shucking oysters',
|
| 2177 |
+
'shuffling cards',
|
| 2178 |
+
'shuffling feet',
|
| 2179 |
+
'side kick',
|
| 2180 |
+
'sieving',
|
| 2181 |
+
'sign language interpreting',
|
| 2182 |
+
'silent disco',
|
| 2183 |
+
'singing',
|
| 2184 |
+
'sipping cup',
|
| 2185 |
+
'situp',
|
| 2186 |
+
'skateboarding',
|
| 2187 |
+
'ski ballet',
|
| 2188 |
+
'ski jumping',
|
| 2189 |
+
'skiing crosscountry',
|
| 2190 |
+
'skiing mono',
|
| 2191 |
+
'skiing slalom',
|
| 2192 |
+
'skipping rope',
|
| 2193 |
+
'skipping stone',
|
| 2194 |
+
'skydiving',
|
| 2195 |
+
'slacklining',
|
| 2196 |
+
'slapping',
|
| 2197 |
+
'sled dog racing',
|
| 2198 |
+
'sleeping',
|
| 2199 |
+
'slicing onion',
|
| 2200 |
+
'smashing',
|
| 2201 |
+
'smelling feet',
|
| 2202 |
+
'smoking',
|
| 2203 |
+
'smoking hookah',
|
| 2204 |
+
'smoking pipe',
|
| 2205 |
+
'snatch weight lifting',
|
| 2206 |
+
'sneezing',
|
| 2207 |
+
'snorkeling',
|
| 2208 |
+
'snowboarding',
|
| 2209 |
+
'snowkiting',
|
| 2210 |
+
'snowmobiling',
|
| 2211 |
+
'somersaulting',
|
| 2212 |
+
'spelunking',
|
| 2213 |
+
'spinning plates',
|
| 2214 |
+
'spinning poi',
|
| 2215 |
+
'splashing water',
|
| 2216 |
+
'spray painting',
|
| 2217 |
+
'spraying',
|
| 2218 |
+
'springboard diving',
|
| 2219 |
+
'square dancing',
|
| 2220 |
+
'squat',
|
| 2221 |
+
'squeezing orange',
|
| 2222 |
+
'stacking cups',
|
| 2223 |
+
'stacking dice',
|
| 2224 |
+
'standing on hands',
|
| 2225 |
+
'staring',
|
| 2226 |
+
'steer roping',
|
| 2227 |
+
'steering car',
|
| 2228 |
+
'sticking tongue out',
|
| 2229 |
+
'stomping grapes',
|
| 2230 |
+
'stretching arm',
|
| 2231 |
+
'stretching leg',
|
| 2232 |
+
'sucking lolly',
|
| 2233 |
+
'surfing crowd',
|
| 2234 |
+
'surfing water',
|
| 2235 |
+
'surveying',
|
| 2236 |
+
'sweeping floor',
|
| 2237 |
+
'swimming backstroke',
|
| 2238 |
+
'swimming breast stroke',
|
| 2239 |
+
'swimming butterfly stroke',
|
| 2240 |
+
'swimming front crawl',
|
| 2241 |
+
'swimming with dolphins',
|
| 2242 |
+
'swimming with sharks',
|
| 2243 |
+
'swing dancing',
|
| 2244 |
+
'swinging baseball bat',
|
| 2245 |
+
'swinging on something',
|
| 2246 |
+
'sword fighting',
|
| 2247 |
+
'sword swallowing',
|
| 2248 |
+
'tackling',
|
| 2249 |
+
'tagging graffiti',
|
| 2250 |
+
'tai chi',
|
| 2251 |
+
'taking photo',
|
| 2252 |
+
'talking on cell phone',
|
| 2253 |
+
'tango dancing',
|
| 2254 |
+
'tap dancing',
|
| 2255 |
+
'tapping guitar',
|
| 2256 |
+
'tapping pen',
|
| 2257 |
+
'tasting beer',
|
| 2258 |
+
'tasting food',
|
| 2259 |
+
'tasting wine',
|
| 2260 |
+
'testifying',
|
| 2261 |
+
'texting',
|
| 2262 |
+
'threading needle',
|
| 2263 |
+
'throwing axe',
|
| 2264 |
+
'throwing ball (not baseball or American football)',
|
| 2265 |
+
'throwing discus',
|
| 2266 |
+
'throwing knife',
|
| 2267 |
+
'throwing snowballs',
|
| 2268 |
+
'throwing tantrum',
|
| 2269 |
+
'throwing water balloon',
|
| 2270 |
+
'tickling',
|
| 2271 |
+
'tie dying',
|
| 2272 |
+
'tightrope walking',
|
| 2273 |
+
'tiptoeing',
|
| 2274 |
+
'tobogganing',
|
| 2275 |
+
'tossing coin',
|
| 2276 |
+
'tossing salad',
|
| 2277 |
+
'training dog',
|
| 2278 |
+
'trapezing',
|
| 2279 |
+
'treating wood',
|
| 2280 |
+
'trimming or shaving beard',
|
| 2281 |
+
'trimming shrubs',
|
| 2282 |
+
'trimming trees',
|
| 2283 |
+
'triple jump',
|
| 2284 |
+
'twiddling fingers',
|
| 2285 |
+
'tying bow tie',
|
| 2286 |
+
'tying knot (not on a tie)',
|
| 2287 |
+
'tying necktie',
|
| 2288 |
+
'tying shoe laces',
|
| 2289 |
+
'unboxing',
|
| 2290 |
+
'uncorking champagne',
|
| 2291 |
+
'unloading truck',
|
| 2292 |
+
'using a microscope',
|
| 2293 |
+
'using a paint roller',
|
| 2294 |
+
'using a power drill',
|
| 2295 |
+
'using a sledge hammer',
|
| 2296 |
+
'using a wrench',
|
| 2297 |
+
'using atm',
|
| 2298 |
+
'using bagging machine',
|
| 2299 |
+
'using circular saw',
|
| 2300 |
+
'using inhaler',
|
| 2301 |
+
'using megaphone',
|
| 2302 |
+
'using puppets',
|
| 2303 |
+
'using remote controller (not gaming)',
|
| 2304 |
+
'using segway',
|
| 2305 |
+
'vacuuming car',
|
| 2306 |
+
'vacuuming floor',
|
| 2307 |
+
'visiting the zoo',
|
| 2308 |
+
'wading through mud',
|
| 2309 |
+
'wading through water',
|
| 2310 |
+
'waiting in line',
|
| 2311 |
+
'waking up',
|
| 2312 |
+
'walking on stilts',
|
| 2313 |
+
'walking the dog',
|
| 2314 |
+
'walking through snow',
|
| 2315 |
+
'walking with crutches',
|
| 2316 |
+
'washing dishes',
|
| 2317 |
+
'washing feet',
|
| 2318 |
+
'washing hair',
|
| 2319 |
+
'washing hands',
|
| 2320 |
+
'watching tv',
|
| 2321 |
+
'water skiing',
|
| 2322 |
+
'water sliding',
|
| 2323 |
+
'watering plants',
|
| 2324 |
+
'waving hand',
|
| 2325 |
+
'waxing armpits',
|
| 2326 |
+
'waxing back',
|
| 2327 |
+
'waxing chest',
|
| 2328 |
+
'waxing eyebrows',
|
| 2329 |
+
'waxing legs',
|
| 2330 |
+
'weaving basket',
|
| 2331 |
+
'weaving fabric',
|
| 2332 |
+
'welding',
|
| 2333 |
+
'whistling',
|
| 2334 |
+
'windsurfing',
|
| 2335 |
+
'winking',
|
| 2336 |
+
'wood burning (art)',
|
| 2337 |
+
'wrapping present',
|
| 2338 |
+
'wrestling',
|
| 2339 |
+
'writing',
|
| 2340 |
+
'yarn spinning',
|
| 2341 |
+
'yawning',
|
| 2342 |
+
'yoga',
|
| 2343 |
+
'zumba'
|
| 2344 |
+
]
|
| 2345 |
+
|
| 2346 |
+
templates = [
|
| 2347 |
+
'a photo of {}.',
|
| 2348 |
+
'a photo of a person {}.',
|
| 2349 |
+
'a photo of a person using {}.',
|
| 2350 |
+
'a photo of a person doing {}.',
|
| 2351 |
+
'a photo of a person during {}.',
|
| 2352 |
+
'a photo of a person performing {}.',
|
| 2353 |
+
'a photo of a person practicing {}.',
|
| 2354 |
+
'a video of {}.',
|
| 2355 |
+
'a video of a person {}.',
|
| 2356 |
+
'a video of a person using {}.',
|
| 2357 |
+
'a video of a person doing {}.',
|
| 2358 |
+
'a video of a person during {}.',
|
| 2359 |
+
'a video of a person performing {}.',
|
| 2360 |
+
'a video of a person practicing {}.',
|
| 2361 |
+
'a example of {}.',
|
| 2362 |
+
'a example of a person {}.',
|
| 2363 |
+
'a example of a person using {}.',
|
| 2364 |
+
'a example of a person doing {}.',
|
| 2365 |
+
'a example of a person during {}.',
|
| 2366 |
+
'a example of a person performing {}.',
|
| 2367 |
+
'a example of a person practicing {}.',
|
| 2368 |
+
'a demonstration of {}.',
|
| 2369 |
+
'a demonstration of a person {}.',
|
| 2370 |
+
'a demonstration of a person using {}.',
|
| 2371 |
+
'a demonstration of a person doing {}.',
|
| 2372 |
+
'a demonstration of a person during {}.',
|
| 2373 |
+
'a demonstration of a person performing {}.',
|
| 2374 |
+
'a demonstration of a person practicing {}.',
|
| 2375 |
+
]
|
| 2376 |
+
```
|
| 2377 |
+
|
| 2378 |
+
|
| 2379 |
+
|
| 2380 |
+
## MNIST
|
| 2381 |
+
|
| 2382 |
+
```bash
|
| 2383 |
+
classes = [
|
| 2384 |
+
'0',
|
| 2385 |
+
'1',
|
| 2386 |
+
'2',
|
| 2387 |
+
'3',
|
| 2388 |
+
'4',
|
| 2389 |
+
'5',
|
| 2390 |
+
'6',
|
| 2391 |
+
'7',
|
| 2392 |
+
'8',
|
| 2393 |
+
'9',
|
| 2394 |
+
]
|
| 2395 |
+
|
| 2396 |
+
templates = [
|
| 2397 |
+
'a photo of the number: "{}".',
|
| 2398 |
+
]
|
| 2399 |
+
```
|
| 2400 |
+
|
| 2401 |
+
|
| 2402 |
+
|
| 2403 |
+
## OxfordPets
|
| 2404 |
+
|
| 2405 |
+
```bash
|
| 2406 |
+
classes = [
|
| 2407 |
+
'Abyssinian',
|
| 2408 |
+
'Bengal',
|
| 2409 |
+
'Birman',
|
| 2410 |
+
'Bombay',
|
| 2411 |
+
'British Shorthair',
|
| 2412 |
+
'Egyptian Mau',
|
| 2413 |
+
'Maine Coon',
|
| 2414 |
+
'Persian',
|
| 2415 |
+
'Ragdoll',
|
| 2416 |
+
'Russian Blue',
|
| 2417 |
+
'Siamese',
|
| 2418 |
+
'Sphynx',
|
| 2419 |
+
'american bulldog',
|
| 2420 |
+
'american pit bull terrier',
|
| 2421 |
+
'basset hound',
|
| 2422 |
+
'beagle',
|
| 2423 |
+
'boxer',
|
| 2424 |
+
'chihuahua',
|
| 2425 |
+
'english cocker spaniel',
|
| 2426 |
+
'english setter',
|
| 2427 |
+
'german shorthaired',
|
| 2428 |
+
'great pyrenees',
|
| 2429 |
+
'havanese',
|
| 2430 |
+
'japanese chin',
|
| 2431 |
+
'keeshond',
|
| 2432 |
+
'leonberger',
|
| 2433 |
+
'miniature pinscher',
|
| 2434 |
+
'newfoundland',
|
| 2435 |
+
'pomeranian',
|
| 2436 |
+
'pug',
|
| 2437 |
+
'saint bernard',
|
| 2438 |
+
'samoyed',
|
| 2439 |
+
'scottish terrier',
|
| 2440 |
+
'shiba inu',
|
| 2441 |
+
'staffordshire bull terrier',
|
| 2442 |
+
'wheaten terrier',
|
| 2443 |
+
'yorkshire terrier',
|
| 2444 |
+
]
|
| 2445 |
+
|
| 2446 |
+
templates = [
|
| 2447 |
+
'a photo of a {}, a type of pet.',
|
| 2448 |
+
]
|
| 2449 |
+
```
|
| 2450 |
+
|
| 2451 |
+
|
| 2452 |
+
|
| 2453 |
+
## PascalVOC2007
|
| 2454 |
+
|
| 2455 |
+
```bash
|
| 2456 |
+
classes = [
|
| 2457 |
+
'aeroplane',
|
| 2458 |
+
'bicycle',
|
| 2459 |
+
'bird',
|
| 2460 |
+
'boat',
|
| 2461 |
+
'bottle',
|
| 2462 |
+
'bus',
|
| 2463 |
+
'car',
|
| 2464 |
+
'cat',
|
| 2465 |
+
'chair',
|
| 2466 |
+
'cow',
|
| 2467 |
+
'dog',
|
| 2468 |
+
'horse',
|
| 2469 |
+
'motorbike',
|
| 2470 |
+
'person',
|
| 2471 |
+
'sheep',
|
| 2472 |
+
'sofa',
|
| 2473 |
+
'diningtable',
|
| 2474 |
+
'pottedplant',
|
| 2475 |
+
'train',
|
| 2476 |
+
'tvmonitor',
|
| 2477 |
+
]
|
| 2478 |
+
|
| 2479 |
+
templates = [
|
| 2480 |
+
'a photo of a {}.',
|
| 2481 |
+
]
|
| 2482 |
+
```
|
| 2483 |
+
|
| 2484 |
+
|
| 2485 |
+
|
| 2486 |
+
## PatchCamelyon
|
| 2487 |
+
|
| 2488 |
+
```bash
|
| 2489 |
+
classes = [
|
| 2490 |
+
'lymph node',
|
| 2491 |
+
'lymph node containing metastatic tumor tissue',
|
| 2492 |
+
]
|
| 2493 |
+
|
| 2494 |
+
templates = [
|
| 2495 |
+
'this is a photo of {}',
|
| 2496 |
+
]
|
| 2497 |
+
```
|
| 2498 |
+
|
| 2499 |
+
|
| 2500 |
+
|
| 2501 |
+
## RESISC45
|
| 2502 |
+
|
| 2503 |
+
```bash
|
| 2504 |
+
classes = [
|
| 2505 |
+
'airplane',
|
| 2506 |
+
'airport',
|
| 2507 |
+
'baseball diamond',
|
| 2508 |
+
'basketball court',
|
| 2509 |
+
'beach',
|
| 2510 |
+
'bridge',
|
| 2511 |
+
'chaparral',
|
| 2512 |
+
'church',
|
| 2513 |
+
'circular farmland',
|
| 2514 |
+
'cloud',
|
| 2515 |
+
'commercial area',
|
| 2516 |
+
'dense residential',
|
| 2517 |
+
'desert',
|
| 2518 |
+
'forest',
|
| 2519 |
+
'freeway',
|
| 2520 |
+
'golf course',
|
| 2521 |
+
'ground track field',
|
| 2522 |
+
'harbor',
|
| 2523 |
+
'industrial area',
|
| 2524 |
+
'intersection',
|
| 2525 |
+
'island',
|
| 2526 |
+
'lake',
|
| 2527 |
+
'meadow',
|
| 2528 |
+
'medium residential',
|
| 2529 |
+
'mobile home park',
|
| 2530 |
+
'mountain',
|
| 2531 |
+
'overpass',
|
| 2532 |
+
'palace',
|
| 2533 |
+
'parking lot',
|
| 2534 |
+
'railway',
|
| 2535 |
+
'railway station',
|
| 2536 |
+
'rectangular farmland',
|
| 2537 |
+
'river',
|
| 2538 |
+
'roundabout',
|
| 2539 |
+
'runway',
|
| 2540 |
+
'sea ice',
|
| 2541 |
+
'ship',
|
| 2542 |
+
'snowberg',
|
| 2543 |
+
'sparse residential',
|
| 2544 |
+
'stadium',
|
| 2545 |
+
'storage tank',
|
| 2546 |
+
'tennis court',
|
| 2547 |
+
'terrace',
|
| 2548 |
+
'thermal power station',
|
| 2549 |
+
'wetland',
|
| 2550 |
+
]
|
| 2551 |
+
|
| 2552 |
+
templates = [
|
| 2553 |
+
'satellite imagery of {}.',
|
| 2554 |
+
'aerial imagery of {}.',
|
| 2555 |
+
'satellite photo of {}.',
|
| 2556 |
+
'aerial photo of {}.',
|
| 2557 |
+
'satellite view of {}.',
|
| 2558 |
+
'aerial view of {}.',
|
| 2559 |
+
'satellite imagery of a {}.',
|
| 2560 |
+
'aerial imagery of a {}.',
|
| 2561 |
+
'satellite photo of a {}.',
|
| 2562 |
+
'aerial photo of a {}.',
|
| 2563 |
+
'satellite view of a {}.',
|
| 2564 |
+
'aerial view of a {}.',
|
| 2565 |
+
'satellite imagery of the {}.',
|
| 2566 |
+
'aerial imagery of the {}.',
|
| 2567 |
+
'satellite photo of the {}.',
|
| 2568 |
+
'aerial photo of the {}.',
|
| 2569 |
+
'satellite view of the {}.',
|
| 2570 |
+
'aerial view of the {}.',
|
| 2571 |
+
]
|
| 2572 |
+
```
|
| 2573 |
+
|
| 2574 |
+
|
| 2575 |
+
|
| 2576 |
+
## SST2
|
| 2577 |
+
|
| 2578 |
+
```bash
|
| 2579 |
+
classes = [
|
| 2580 |
+
'negative',
|
| 2581 |
+
'positive',
|
| 2582 |
+
]
|
| 2583 |
+
|
| 2584 |
+
templates = [
|
| 2585 |
+
'a {} review of a movie.',
|
| 2586 |
+
]
|
| 2587 |
+
```
|
| 2588 |
+
|
| 2589 |
+
|
| 2590 |
+
|
| 2591 |
+
## STL10
|
| 2592 |
+
|
| 2593 |
+
```bash
|
| 2594 |
+
classes = [
|
| 2595 |
+
'airplane',
|
| 2596 |
+
'bird',
|
| 2597 |
+
'car',
|
| 2598 |
+
'cat',
|
| 2599 |
+
'deer',
|
| 2600 |
+
'dog',
|
| 2601 |
+
'horse',
|
| 2602 |
+
'monkey',
|
| 2603 |
+
'ship',
|
| 2604 |
+
'truck',
|
| 2605 |
+
]
|
| 2606 |
+
|
| 2607 |
+
templates = [
|
| 2608 |
+
'a photo of a {}.',
|
| 2609 |
+
'a photo of the {}.',
|
| 2610 |
+
]
|
| 2611 |
+
```
|
| 2612 |
+
|
| 2613 |
+
|
| 2614 |
+
|
| 2615 |
+
## SUN397
|
| 2616 |
+
|
| 2617 |
+
```bash
|
| 2618 |
+
classes = [
|
| 2619 |
+
'abbey',
|
| 2620 |
+
'airplane cabin',
|
| 2621 |
+
'airport terminal',
|
| 2622 |
+
'alley',
|
| 2623 |
+
'amphitheater',
|
| 2624 |
+
'amusement arcade',
|
| 2625 |
+
'amusement park',
|
| 2626 |
+
'anechoic chamber',
|
| 2627 |
+
'apartment building outdoor',
|
| 2628 |
+
'apse indoor',
|
| 2629 |
+
'aquarium',
|
| 2630 |
+
'aqueduct',
|
| 2631 |
+
'arch',
|
| 2632 |
+
'archive',
|
| 2633 |
+
'arrival gate outdoor',
|
| 2634 |
+
'art gallery',
|
| 2635 |
+
'art school',
|
| 2636 |
+
'art studio',
|
| 2637 |
+
'assembly line',
|
| 2638 |
+
'athletic field outdoor',
|
| 2639 |
+
'atrium public',
|
| 2640 |
+
'attic',
|
| 2641 |
+
'auditorium',
|
| 2642 |
+
'auto factory',
|
| 2643 |
+
'badlands',
|
| 2644 |
+
'badminton court indoor',
|
| 2645 |
+
'baggage claim',
|
| 2646 |
+
'bakery shop',
|
| 2647 |
+
'balcony exterior',
|
| 2648 |
+
'balcony interior',
|
| 2649 |
+
'ball pit',
|
| 2650 |
+
'ballroom',
|
| 2651 |
+
'bamboo forest',
|
| 2652 |
+
'banquet hall',
|
| 2653 |
+
'bar',
|
| 2654 |
+
'barn',
|
| 2655 |
+
'barndoor',
|
| 2656 |
+
'baseball field',
|
| 2657 |
+
'basement',
|
| 2658 |
+
'basilica',
|
| 2659 |
+
'basketball court outdoor',
|
| 2660 |
+
'bathroom',
|
| 2661 |
+
'batters box',
|
| 2662 |
+
'bayou',
|
| 2663 |
+
'bazaar indoor',
|
| 2664 |
+
'bazaar outdoor',
|
| 2665 |
+
'beach',
|
| 2666 |
+
'beauty salon',
|
| 2667 |
+
'bedroom',
|
| 2668 |
+
'berth',
|
| 2669 |
+
'biology laboratory',
|
| 2670 |
+
'bistro indoor',
|
| 2671 |
+
'boardwalk',
|
| 2672 |
+
'boat deck',
|
| 2673 |
+
'boathouse',
|
| 2674 |
+
'bookstore',
|
| 2675 |
+
'booth indoor',
|
| 2676 |
+
'botanical garden',
|
| 2677 |
+
'bow window indoor',
|
| 2678 |
+
'bow window outdoor',
|
| 2679 |
+
'bowling alley',
|
| 2680 |
+
'boxing ring',
|
| 2681 |
+
'brewery indoor',
|
| 2682 |
+
'bridge',
|
| 2683 |
+
'building facade',
|
| 2684 |
+
'bullring',
|
| 2685 |
+
'burial chamber',
|
| 2686 |
+
'bus interior',
|
| 2687 |
+
'butchers shop',
|
| 2688 |
+
'butte',
|
| 2689 |
+
'cabin outdoor',
|
| 2690 |
+
'cafeteria',
|
| 2691 |
+
'campsite',
|
| 2692 |
+
'campus',
|
| 2693 |
+
'canal natural',
|
| 2694 |
+
'canal urban',
|
| 2695 |
+
'candy store',
|
| 2696 |
+
'canyon',
|
| 2697 |
+
'car interior backseat',
|
| 2698 |
+
'car interior frontseat',
|
| 2699 |
+
'carrousel',
|
| 2700 |
+
'casino indoor',
|
| 2701 |
+
'castle',
|
| 2702 |
+
'catacomb',
|
| 2703 |
+
'cathedral indoor',
|
| 2704 |
+
'cathedral outdoor',
|
| 2705 |
+
'cavern indoor',
|
| 2706 |
+
'cemetery',
|
| 2707 |
+
'chalet',
|
| 2708 |
+
'cheese factory',
|
| 2709 |
+
'chemistry lab',
|
| 2710 |
+
'chicken coop indoor',
|
| 2711 |
+
'chicken coop outdoor',
|
| 2712 |
+
'childs room',
|
| 2713 |
+
'church indoor',
|
| 2714 |
+
'church outdoor',
|
| 2715 |
+
'classroom',
|
| 2716 |
+
'clean room',
|
| 2717 |
+
'cliff',
|
| 2718 |
+
'cloister indoor',
|
| 2719 |
+
'closet',
|
| 2720 |
+
'clothing store',
|
| 2721 |
+
'coast',
|
| 2722 |
+
'cockpit',
|
| 2723 |
+
'coffee shop',
|
| 2724 |
+
'computer room',
|
| 2725 |
+
'conference center',
|
| 2726 |
+
'conference room',
|
| 2727 |
+
'construction site',
|
| 2728 |
+
'control room',
|
| 2729 |
+
'control tower outdoor',
|
| 2730 |
+
'corn field',
|
| 2731 |
+
'corral',
|
| 2732 |
+
'corridor',
|
| 2733 |
+
'cottage garden',
|
| 2734 |
+
'courthouse',
|
| 2735 |
+
'courtroom',
|
| 2736 |
+
'courtyard',
|
| 2737 |
+
'covered bridge exterior',
|
| 2738 |
+
'creek',
|
| 2739 |
+
'crevasse',
|
| 2740 |
+
'crosswalk',
|
| 2741 |
+
'cubicle office',
|
| 2742 |
+
'dam',
|
| 2743 |
+
'delicatessen',
|
| 2744 |
+
'dentists office',
|
| 2745 |
+
'desert sand',
|
| 2746 |
+
'desert vegetation',
|
| 2747 |
+
'diner indoor',
|
| 2748 |
+
'diner outdoor',
|
| 2749 |
+
'dinette home',
|
| 2750 |
+
'dinette vehicle',
|
| 2751 |
+
'dining car',
|
| 2752 |
+
'dining room',
|
| 2753 |
+
'discotheque',
|
| 2754 |
+
'dock',
|
| 2755 |
+
'doorway outdoor',
|
| 2756 |
+
'dorm room',
|
| 2757 |
+
'driveway',
|
| 2758 |
+
'driving range outdoor',
|
| 2759 |
+
'drugstore',
|
| 2760 |
+
'electrical substation',
|
| 2761 |
+
'elevator door',
|
| 2762 |
+
'elevator interior',
|
| 2763 |
+
'elevator shaft',
|
| 2764 |
+
'engine room',
|
| 2765 |
+
'escalator indoor',
|
| 2766 |
+
'excavation',
|
| 2767 |
+
'factory indoor',
|
| 2768 |
+
'fairway',
|
| 2769 |
+
'fastfood restaurant',
|
| 2770 |
+
'field cultivated',
|
| 2771 |
+
'field wild',
|
| 2772 |
+
'fire escape',
|
| 2773 |
+
'fire station',
|
| 2774 |
+
'firing range indoor',
|
| 2775 |
+
'fishpond',
|
| 2776 |
+
'florist shop indoor',
|
| 2777 |
+
'food court',
|
| 2778 |
+
'forest broadleaf',
|
| 2779 |
+
'forest needleleaf',
|
| 2780 |
+
'forest path',
|
| 2781 |
+
'forest road',
|
| 2782 |
+
'formal garden',
|
| 2783 |
+
'fountain',
|
| 2784 |
+
'galley',
|
| 2785 |
+
'game room',
|
| 2786 |
+
'garage indoor',
|
| 2787 |
+
'garbage dump',
|
| 2788 |
+
'gas station',
|
| 2789 |
+
'gazebo exterior',
|
| 2790 |
+
'general store indoor',
|
| 2791 |
+
'general store outdoor',
|
| 2792 |
+
'gift shop',
|
| 2793 |
+
'golf course',
|
| 2794 |
+
'greenhouse indoor',
|
| 2795 |
+
'greenhouse outdoor',
|
| 2796 |
+
'gymnasium indoor',
|
| 2797 |
+
'hangar indoor',
|
| 2798 |
+
'hangar outdoor',
|
| 2799 |
+
'harbor',
|
| 2800 |
+
'hayfield',
|
| 2801 |
+
'heliport',
|
| 2802 |
+
'herb garden',
|
| 2803 |
+
'highway',
|
| 2804 |
+
'hill',
|
| 2805 |
+
'home office',
|
| 2806 |
+
'hospital',
|
| 2807 |
+
'hospital room',
|
| 2808 |
+
'hot spring',
|
| 2809 |
+
'hot tub outdoor',
|
| 2810 |
+
'hotel outdoor',
|
| 2811 |
+
'hotel room',
|
| 2812 |
+
'house',
|
| 2813 |
+
'hunting lodge outdoor',
|
| 2814 |
+
'ice cream parlor',
|
| 2815 |
+
'ice floe',
|
| 2816 |
+
'ice shelf',
|
| 2817 |
+
'ice skating rink indoor',
|
| 2818 |
+
'ice skating rink outdoor',
|
| 2819 |
+
'iceberg',
|
| 2820 |
+
'igloo',
|
| 2821 |
+
'industrial area',
|
| 2822 |
+
'inn outdoor',
|
| 2823 |
+
'islet',
|
| 2824 |
+
'jacuzzi indoor',
|
| 2825 |
+
'jail cell',
|
| 2826 |
+
'jail indoor',
|
| 2827 |
+
'jewelry shop',
|
| 2828 |
+
'kasbah',
|
| 2829 |
+
'kennel indoor',
|
| 2830 |
+
'kennel outdoor',
|
| 2831 |
+
'kindergarden classroom',
|
| 2832 |
+
'kitchen',
|
| 2833 |
+
'kitchenette',
|
| 2834 |
+
'labyrinth outdoor',
|
| 2835 |
+
'lake natural',
|
| 2836 |
+
'landfill',
|
| 2837 |
+
'landing deck',
|
| 2838 |
+
'laundromat',
|
| 2839 |
+
'lecture room',
|
| 2840 |
+
'library indoor',
|
| 2841 |
+
'library outdoor',
|
| 2842 |
+
'lido deck outdoor',
|
| 2843 |
+
'lift bridge',
|
| 2844 |
+
'lighthouse',
|
| 2845 |
+
'limousine interior',
|
| 2846 |
+
'living room',
|
| 2847 |
+
'lobby',
|
| 2848 |
+
'lock chamber',
|
| 2849 |
+
'locker room',
|
| 2850 |
+
'mansion',
|
| 2851 |
+
'manufactured home',
|
| 2852 |
+
'market indoor',
|
| 2853 |
+
'market outdoor',
|
| 2854 |
+
'marsh',
|
| 2855 |
+
'martial arts gym',
|
| 2856 |
+
'mausoleum',
|
| 2857 |
+
'medina',
|
| 2858 |
+
'moat water',
|
| 2859 |
+
'monastery outdoor',
|
| 2860 |
+
'mosque indoor',
|
| 2861 |
+
'mosque outdoor',
|
| 2862 |
+
'motel',
|
| 2863 |
+
'mountain',
|
| 2864 |
+
'mountain snowy',
|
| 2865 |
+
'movie theater indoor',
|
| 2866 |
+
'museum indoor',
|
| 2867 |
+
'music store',
|
| 2868 |
+
'music studio',
|
| 2869 |
+
'nuclear power plant outdoor',
|
| 2870 |
+
'nursery',
|
| 2871 |
+
'oast house',
|
| 2872 |
+
'observatory outdoor',
|
| 2873 |
+
'ocean',
|
| 2874 |
+
'office',
|
| 2875 |
+
'office building',
|
| 2876 |
+
'oil refinery outdoor',
|
| 2877 |
+
'oilrig',
|
| 2878 |
+
'operating room',
|
| 2879 |
+
'orchard',
|
| 2880 |
+
'outhouse outdoor',
|
| 2881 |
+
'pagoda',
|
| 2882 |
+
'palace',
|
| 2883 |
+
'pantry',
|
| 2884 |
+
'park',
|
| 2885 |
+
'parking garage indoor',
|
| 2886 |
+
'parking garage outdoor',
|
| 2887 |
+
'parking lot',
|
| 2888 |
+
'parlor',
|
| 2889 |
+
'pasture',
|
| 2890 |
+
'patio',
|
| 2891 |
+
'pavilion',
|
| 2892 |
+
'pharmacy',
|
| 2893 |
+
'phone booth',
|
| 2894 |
+
'physics laboratory',
|
| 2895 |
+
'picnic area',
|
| 2896 |
+
'pilothouse indoor',
|
| 2897 |
+
'planetarium outdoor',
|
| 2898 |
+
'playground',
|
| 2899 |
+
'playroom',
|
| 2900 |
+
'plaza',
|
| 2901 |
+
'podium indoor',
|
| 2902 |
+
'podium outdoor',
|
| 2903 |
+
'pond',
|
| 2904 |
+
'poolroom establishment',
|
| 2905 |
+
'poolroom home',
|
| 2906 |
+
'power plant outdoor',
|
| 2907 |
+
'promenade deck',
|
| 2908 |
+
'pub indoor',
|
| 2909 |
+
'pulpit',
|
| 2910 |
+
'putting green',
|
| 2911 |
+
'racecourse',
|
| 2912 |
+
'raceway',
|
| 2913 |
+
'raft',
|
| 2914 |
+
'railroad track',
|
| 2915 |
+
'rainforest',
|
| 2916 |
+
'reception',
|
| 2917 |
+
'recreation room',
|
| 2918 |
+
'residential neighborhood',
|
| 2919 |
+
'restaurant',
|
| 2920 |
+
'restaurant kitchen',
|
| 2921 |
+
'restaurant patio',
|
| 2922 |
+
'rice paddy',
|
| 2923 |
+
'riding arena',
|
| 2924 |
+
'river',
|
| 2925 |
+
'rock arch',
|
| 2926 |
+
'rope bridge',
|
| 2927 |
+
'ruin',
|
| 2928 |
+
'runway',
|
| 2929 |
+
'sandbar',
|
| 2930 |
+
'sandbox',
|
| 2931 |
+
'sauna',
|
| 2932 |
+
'schoolhouse',
|
| 2933 |
+
'sea cliff',
|
| 2934 |
+
'server room',
|
| 2935 |
+
'shed',
|
| 2936 |
+
'shoe shop',
|
| 2937 |
+
'shopfront',
|
| 2938 |
+
'shopping mall indoor',
|
| 2939 |
+
'shower',
|
| 2940 |
+
'skatepark',
|
| 2941 |
+
'ski lodge',
|
| 2942 |
+
'ski resort',
|
| 2943 |
+
'ski slope',
|
| 2944 |
+
'sky',
|
| 2945 |
+
'skyscraper',
|
| 2946 |
+
'slum',
|
| 2947 |
+
'snowfield',
|
| 2948 |
+
'squash court',
|
| 2949 |
+
'stable',
|
| 2950 |
+
'stadium baseball',
|
| 2951 |
+
'stadium football',
|
| 2952 |
+
'stage indoor',
|
| 2953 |
+
'staircase',
|
| 2954 |
+
'street',
|
| 2955 |
+
'subway interior',
|
| 2956 |
+
'subway station platform',
|
| 2957 |
+
'supermarket',
|
| 2958 |
+
'sushi bar',
|
| 2959 |
+
'swamp',
|
| 2960 |
+
'swimming pool indoor',
|
| 2961 |
+
'swimming pool outdoor',
|
| 2962 |
+
'synagogue indoor',
|
| 2963 |
+
'synagogue outdoor',
|
| 2964 |
+
'television studio',
|
| 2965 |
+
'temple east asia',
|
| 2966 |
+
'temple south asia',
|
| 2967 |
+
'tennis court indoor',
|
| 2968 |
+
'tennis court outdoor',
|
| 2969 |
+
'tent outdoor',
|
| 2970 |
+
'theater indoor procenium',
|
| 2971 |
+
'theater indoor seats',
|
| 2972 |
+
'thriftshop',
|
| 2973 |
+
'throne room',
|
| 2974 |
+
'ticket booth',
|
| 2975 |
+
'toll plaza',
|
| 2976 |
+
'topiary garden',
|
| 2977 |
+
'tower',
|
| 2978 |
+
'toyshop',
|
| 2979 |
+
'track outdoor',
|
| 2980 |
+
'train railway',
|
| 2981 |
+
'train station platform',
|
| 2982 |
+
'tree farm',
|
| 2983 |
+
'tree house',
|
| 2984 |
+
'trench',
|
| 2985 |
+
'underwater coral reef',
|
| 2986 |
+
'utility room',
|
| 2987 |
+
'valley',
|
| 2988 |
+
'van interior',
|
| 2989 |
+
'vegetable garden',
|
| 2990 |
+
'veranda',
|
| 2991 |
+
'veterinarians office',
|
| 2992 |
+
'viaduct',
|
| 2993 |
+
'videostore',
|
| 2994 |
+
'village',
|
| 2995 |
+
'vineyard',
|
| 2996 |
+
'volcano',
|
| 2997 |
+
'volleyball court indoor',
|
| 2998 |
+
'volleyball court outdoor',
|
| 2999 |
+
'waiting room',
|
| 3000 |
+
'warehouse indoor',
|
| 3001 |
+
'water tower',
|
| 3002 |
+
'waterfall block',
|
| 3003 |
+
'waterfall fan',
|
| 3004 |
+
'waterfall plunge',
|
| 3005 |
+
'watering hole',
|
| 3006 |
+
'wave',
|
| 3007 |
+
'wet bar',
|
| 3008 |
+
'wheat field',
|
| 3009 |
+
'wind farm',
|
| 3010 |
+
'windmill',
|
| 3011 |
+
'wine cellar barrel storage',
|
| 3012 |
+
'wine cellar bottle storage',
|
| 3013 |
+
'wrestling ring indoor',
|
| 3014 |
+
'yard',
|
| 3015 |
+
'youth hostel',
|
| 3016 |
+
]
|
| 3017 |
+
|
| 3018 |
+
templates = [
|
| 3019 |
+
'a photo of a {}.',
|
| 3020 |
+
'a photo of the {}.',
|
| 3021 |
+
]
|
| 3022 |
+
```
|
| 3023 |
+
|
| 3024 |
+
|
| 3025 |
+
|
| 3026 |
+
## StanfordCars
|
| 3027 |
+
|
| 3028 |
+
```bash
|
| 3029 |
+
classes = [
|
| 3030 |
+
'AM General Hummer SUV 2000',
|
| 3031 |
+
'Acura RL Sedan 2012',
|
| 3032 |
+
'Acura TL Sedan 2012',
|
| 3033 |
+
'Acura TL Type-S 2008',
|
| 3034 |
+
'Acura TSX Sedan 2012',
|
| 3035 |
+
'Acura Integra Type R 2001',
|
| 3036 |
+
'Acura ZDX Hatchback 2012',
|
| 3037 |
+
'Aston Martin V8 Vantage Convertible 2012',
|
| 3038 |
+
'Aston Martin V8 Vantage Coupe 2012',
|
| 3039 |
+
'Aston Martin Virage Convertible 2012',
|
| 3040 |
+
'Aston Martin Virage Coupe 2012',
|
| 3041 |
+
'Audi RS 4 Convertible 2008',
|
| 3042 |
+
'Audi A5 Coupe 2012',
|
| 3043 |
+
'Audi TTS Coupe 2012',
|
| 3044 |
+
'Audi R8 Coupe 2012',
|
| 3045 |
+
'Audi V8 Sedan 1994',
|
| 3046 |
+
'Audi 100 Sedan 1994',
|
| 3047 |
+
'Audi 100 Wagon 1994',
|
| 3048 |
+
'Audi TT Hatchback 2011',
|
| 3049 |
+
'Audi S6 Sedan 2011',
|
| 3050 |
+
'Audi S5 Convertible 2012',
|
| 3051 |
+
'Audi S5 Coupe 2012',
|
| 3052 |
+
'Audi S4 Sedan 2012',
|
| 3053 |
+
'Audi S4 Sedan 2007',
|
| 3054 |
+
'Audi TT RS Coupe 2012',
|
| 3055 |
+
'BMW ActiveHybrid 5 Sedan 2012',
|
| 3056 |
+
'BMW 1 Series Convertible 2012',
|
| 3057 |
+
'BMW 1 Series Coupe 2012',
|
| 3058 |
+
'BMW 3 Series Sedan 2012',
|
| 3059 |
+
'BMW 3 Series Wagon 2012',
|
| 3060 |
+
'BMW 6 Series Convertible 2007',
|
| 3061 |
+
'BMW X5 SUV 2007',
|
| 3062 |
+
'BMW X6 SUV 2012',
|
| 3063 |
+
'BMW M3 Coupe 2012',
|
| 3064 |
+
'BMW M5 Sedan 2010',
|
| 3065 |
+
'BMW M6 Convertible 2010',
|
| 3066 |
+
'BMW X3 SUV 2012',
|
| 3067 |
+
'BMW Z4 Convertible 2012',
|
| 3068 |
+
'Bentley Continental Supersports Conv. Convertible 2012',
|
| 3069 |
+
'Bentley Arnage Sedan 2009',
|
| 3070 |
+
'Bentley Mulsanne Sedan 2011',
|
| 3071 |
+
'Bentley Continental GT Coupe 2012',
|
| 3072 |
+
'Bentley Continental GT Coupe 2007',
|
| 3073 |
+
'Bentley Continental Flying Spur Sedan 2007',
|
| 3074 |
+
'Bugatti Veyron 16.4 Convertible 2009',
|
| 3075 |
+
'Bugatti Veyron 16.4 Coupe 2009',
|
| 3076 |
+
'Buick Regal GS 2012',
|
| 3077 |
+
'Buick Rainier SUV 2007',
|
| 3078 |
+
'Buick Verano Sedan 2012',
|
| 3079 |
+
'Buick Enclave SUV 2012',
|
| 3080 |
+
'Cadillac CTS-V Sedan 2012',
|
| 3081 |
+
'Cadillac SRX SUV 2012',
|
| 3082 |
+
'Cadillac Escalade EXT Crew Cab 2007',
|
| 3083 |
+
'Chevrolet Silverado 1500 Hybrid Crew Cab 2012',
|
| 3084 |
+
'Chevrolet Corvette Convertible 2012',
|
| 3085 |
+
'Chevrolet Corvette ZR1 2012',
|
| 3086 |
+
'Chevrolet Corvette Ron Fellows Edition Z06 2007',
|
| 3087 |
+
'Chevrolet Traverse SUV 2012',
|
| 3088 |
+
'Chevrolet Camaro Convertible 2012',
|
| 3089 |
+
'Chevrolet HHR SS 2010',
|
| 3090 |
+
'Chevrolet Impala Sedan 2007',
|
| 3091 |
+
'Chevrolet Tahoe Hybrid SUV 2012',
|
| 3092 |
+
'Chevrolet Sonic Sedan 2012',
|
| 3093 |
+
'Chevrolet Express Cargo Van 2007',
|
| 3094 |
+
'Chevrolet Avalanche Crew Cab 2012',
|
| 3095 |
+
'Chevrolet Cobalt SS 2010',
|
| 3096 |
+
'Chevrolet Malibu Hybrid Sedan 2010',
|
| 3097 |
+
'Chevrolet TrailBlazer SS 2009',
|
| 3098 |
+
'Chevrolet Silverado 2500HD Regular Cab 2012',
|
| 3099 |
+
'Chevrolet Silverado 1500 Classic Extended Cab 2007',
|
| 3100 |
+
'Chevrolet Express Van 2007',
|
| 3101 |
+
'Chevrolet Monte Carlo Coupe 2007',
|
| 3102 |
+
'Chevrolet Malibu Sedan 2007',
|
| 3103 |
+
'Chevrolet Silverado 1500 Extended Cab 2012',
|
| 3104 |
+
'Chevrolet Silverado 1500 Regular Cab 2012',
|
| 3105 |
+
'Chrysler Aspen SUV 2009',
|
| 3106 |
+
'Chrysler Sebring Convertible 2010',
|
| 3107 |
+
'Chrysler Town and Country Minivan 2012',
|
| 3108 |
+
'Chrysler 300 SRT-8 2010',
|
| 3109 |
+
'Chrysler Crossfire Convertible 2008',
|
| 3110 |
+
'Chrysler PT Cruiser Convertible 2008',
|
| 3111 |
+
'Daewoo Nubira Wagon 2002',
|
| 3112 |
+
'Dodge Caliber Wagon 2012',
|
| 3113 |
+
'Dodge Caliber Wagon 2007',
|
| 3114 |
+
'Dodge Caravan Minivan 1997',
|
| 3115 |
+
'Dodge Ram Pickup 3500 Crew Cab 2010',
|
| 3116 |
+
'Dodge Ram Pickup 3500 Quad Cab 2009',
|
| 3117 |
+
'Dodge Sprinter Cargo Van 2009',
|
| 3118 |
+
'Dodge Journey SUV 2012',
|
| 3119 |
+
'Dodge Dakota Crew Cab 2010',
|
| 3120 |
+
'Dodge Dakota Club Cab 2007',
|
| 3121 |
+
'Dodge Magnum Wagon 2008',
|
| 3122 |
+
'Dodge Challenger SRT8 2011',
|
| 3123 |
+
'Dodge Durango SUV 2012',
|
| 3124 |
+
'Dodge Durango SUV 2007',
|
| 3125 |
+
'Dodge Charger Sedan 2012',
|
| 3126 |
+
'Dodge Charger SRT-8 2009',
|
| 3127 |
+
'Eagle Talon Hatchback 1998',
|
| 3128 |
+
'FIAT 500 Abarth 2012',
|
| 3129 |
+
'FIAT 500 Convertible 2012',
|
| 3130 |
+
'Ferrari FF Coupe 2012',
|
| 3131 |
+
'Ferrari California Convertible 2012',
|
| 3132 |
+
'Ferrari 458 Italia Convertible 2012',
|
| 3133 |
+
'Ferrari 458 Italia Coupe 2012',
|
| 3134 |
+
'Fisker Karma Sedan 2012',
|
| 3135 |
+
'Ford F-450 Super Duty Crew Cab 2012',
|
| 3136 |
+
'Ford Mustang Convertible 2007',
|
| 3137 |
+
'Ford Freestar Minivan 2007',
|
| 3138 |
+
'Ford Expedition EL SUV 2009',
|
| 3139 |
+
'Ford Edge SUV 2012',
|
| 3140 |
+
'Ford Ranger SuperCab 2011',
|
| 3141 |
+
'Ford GT Coupe 2006',
|
| 3142 |
+
'Ford F-150 Regular Cab 2012',
|
| 3143 |
+
'Ford F-150 Regular Cab 2007',
|
| 3144 |
+
'Ford Focus Sedan 2007',
|
| 3145 |
+
'Ford E-Series Wagon Van 2012',
|
| 3146 |
+
'Ford Fiesta Sedan 2012',
|
| 3147 |
+
'GMC Terrain SUV 2012',
|
| 3148 |
+
'GMC Savana Van 2012',
|
| 3149 |
+
'GMC Yukon Hybrid SUV 2012',
|
| 3150 |
+
'GMC Acadia SUV 2012',
|
| 3151 |
+
'GMC Canyon Extended Cab 2012',
|
| 3152 |
+
'Geo Metro Convertible 1993',
|
| 3153 |
+
'HUMMER H3T Crew Cab 2010',
|
| 3154 |
+
'HUMMER H2 SUT Crew Cab 2009',
|
| 3155 |
+
'Honda Odyssey Minivan 2012',
|
| 3156 |
+
'Honda Odyssey Minivan 2007',
|
| 3157 |
+
'Honda Accord Coupe 2012',
|
| 3158 |
+
'Honda Accord Sedan 2012',
|
| 3159 |
+
'Hyundai Veloster Hatchback 2012',
|
| 3160 |
+
'Hyundai Santa Fe SUV 2012',
|
| 3161 |
+
'Hyundai Tucson SUV 2012',
|
| 3162 |
+
'Hyundai Veracruz SUV 2012',
|
| 3163 |
+
'Hyundai Sonata Hybrid Sedan 2012',
|
| 3164 |
+
'Hyundai Elantra Sedan 2007',
|
| 3165 |
+
'Hyundai Accent Sedan 2012',
|
| 3166 |
+
'Hyundai Genesis Sedan 2012',
|
| 3167 |
+
'Hyundai Sonata Sedan 2012',
|
| 3168 |
+
'Hyundai Elantra Touring Hatchback 2012',
|
| 3169 |
+
'Hyundai Azera Sedan 2012',
|
| 3170 |
+
'Infiniti G Coupe IPL 2012',
|
| 3171 |
+
'Infiniti QX56 SUV 2011',
|
| 3172 |
+
'Isuzu Ascender SUV 2008',
|
| 3173 |
+
'Jaguar XK XKR 2012',
|
| 3174 |
+
'Jeep Patriot SUV 2012',
|
| 3175 |
+
'Jeep Wrangler SUV 2012',
|
| 3176 |
+
'Jeep Liberty SUV 2012',
|
| 3177 |
+
'Jeep Grand Cherokee SUV 2012',
|
| 3178 |
+
'Jeep Compass SUV 2012',
|
| 3179 |
+
'Lamborghini Reventon Coupe 2008',
|
| 3180 |
+
'Lamborghini Aventador Coupe 2012',
|
| 3181 |
+
'Lamborghini Gallardo LP 570-4 Superleggera 2012',
|
| 3182 |
+
'Lamborghini Diablo Coupe 2001',
|
| 3183 |
+
'Land Rover Range Rover SUV 2012',
|
| 3184 |
+
'Land Rover LR2 SUV 2012',
|
| 3185 |
+
'Lincoln Town Car Sedan 2011',
|
| 3186 |
+
'MINI Cooper Roadster Convertible 2012',
|
| 3187 |
+
'Maybach Landaulet Convertible 2012',
|
| 3188 |
+
'Mazda Tribute SUV 2011',
|
| 3189 |
+
'McLaren MP4-12C Coupe 2012',
|
| 3190 |
+
'Mercedes-Benz 300-Class Convertible 1993',
|
| 3191 |
+
'Mercedes-Benz C-Class Sedan 2012',
|
| 3192 |
+
'Mercedes-Benz SL-Class Coupe 2009',
|
| 3193 |
+
'Mercedes-Benz E-Class Sedan 2012',
|
| 3194 |
+
'Mercedes-Benz S-Class Sedan 2012',
|
| 3195 |
+
'Mercedes-Benz Sprinter Van 2012',
|
| 3196 |
+
'Mitsubishi Lancer Sedan 2012',
|
| 3197 |
+
'Nissan Leaf Hatchback 2012',
|
| 3198 |
+
'Nissan NV Passenger Van 2012',
|
| 3199 |
+
'Nissan Juke Hatchback 2012',
|
| 3200 |
+
'Nissan 240SX Coupe 1998',
|
| 3201 |
+
'Plymouth Neon Coupe 1999',
|
| 3202 |
+
'Porsche Panamera Sedan 2012',
|
| 3203 |
+
'Ram C/V Cargo Van Minivan 2012',
|
| 3204 |
+
'Rolls-Royce Phantom Drophead Coupe Convertible 2012',
|
| 3205 |
+
'Rolls-Royce Ghost Sedan 2012',
|
| 3206 |
+
'Rolls-Royce Phantom Sedan 2012',
|
| 3207 |
+
'Scion xD Hatchback 2012',
|
| 3208 |
+
'Spyker C8 Convertible 2009',
|
| 3209 |
+
'Spyker C8 Coupe 2009',
|
| 3210 |
+
'Suzuki Aerio Sedan 2007',
|
| 3211 |
+
'Suzuki Kizashi Sedan 2012',
|
| 3212 |
+
'Suzuki SX4 Hatchback 2012',
|
| 3213 |
+
'Suzuki SX4 Sedan 2012',
|
| 3214 |
+
'Tesla Model S Sedan 2012',
|
| 3215 |
+
'Toyota Sequoia SUV 2012',
|
| 3216 |
+
'Toyota Camry Sedan 2012',
|
| 3217 |
+
'Toyota Corolla Sedan 2012',
|
| 3218 |
+
'Toyota 4Runner SUV 2012',
|
| 3219 |
+
'Volkswagen Golf Hatchback 2012',
|
| 3220 |
+
'Volkswagen Golf Hatchback 1991',
|
| 3221 |
+
'Volkswagen Beetle Hatchback 2012',
|
| 3222 |
+
'Volvo C30 Hatchback 2012',
|
| 3223 |
+
'Volvo 240 Sedan 1993',
|
| 3224 |
+
'Volvo XC90 SUV 2007',
|
| 3225 |
+
'smart fortwo Convertible 2012',
|
| 3226 |
+
]
|
| 3227 |
+
|
| 3228 |
+
templates = [
|
| 3229 |
+
'a photo of a {}.',
|
| 3230 |
+
'a photo of the {}.',
|
| 3231 |
+
'a photo of my {}.',
|
| 3232 |
+
'i love my {}!',
|
| 3233 |
+
'a photo of my dirty {}.',
|
| 3234 |
+
'a photo of my clean {}.',
|
| 3235 |
+
'a photo of my new {}.',
|
| 3236 |
+
'a photo of my old {}.',
|
| 3237 |
+
]
|
| 3238 |
+
```
|
| 3239 |
+
|
| 3240 |
+
|
| 3241 |
+
|
| 3242 |
+
## UCF101
|
| 3243 |
+
|
| 3244 |
+
```bash
|
| 3245 |
+
classes = [
|
| 3246 |
+
'Apply Eye Makeup',
|
| 3247 |
+
'Apply Lipstick',
|
| 3248 |
+
'Archery',
|
| 3249 |
+
'Baby Crawling',
|
| 3250 |
+
'Balance Beam',
|
| 3251 |
+
'Band Marching',
|
| 3252 |
+
'Baseball Pitch',
|
| 3253 |
+
'Basketball',
|
| 3254 |
+
'Basketball Dunk',
|
| 3255 |
+
'Bench Press',
|
| 3256 |
+
'Biking',
|
| 3257 |
+
'Billiards',
|
| 3258 |
+
'Blow Dry Hair',
|
| 3259 |
+
'Blowing Candles',
|
| 3260 |
+
'Body Weight Squats',
|
| 3261 |
+
'Bowling',
|
| 3262 |
+
'Boxing Punching Bag',
|
| 3263 |
+
'Boxing Speed Bag',
|
| 3264 |
+
'Breast Stroke',
|
| 3265 |
+
'Brushing Teeth',
|
| 3266 |
+
'Clean And Jerk',
|
| 3267 |
+
'Cliff Diving',
|
| 3268 |
+
'Cricket Bowling',
|
| 3269 |
+
'Cricket Shot',
|
| 3270 |
+
'Cutting In Kitchen',
|
| 3271 |
+
'Diving',
|
| 3272 |
+
'Drumming',
|
| 3273 |
+
'Fencing',
|
| 3274 |
+
'Field Hockey Penalty',
|
| 3275 |
+
'Floor Gymnastics',
|
| 3276 |
+
'Frisbee Catch',
|
| 3277 |
+
'Front Crawl',
|
| 3278 |
+
'Golf Swing',
|
| 3279 |
+
'Haircut',
|
| 3280 |
+
'Hammer Throw',
|
| 3281 |
+
'Hammering',
|
| 3282 |
+
'Hand Stand Pushups',
|
| 3283 |
+
'Handstand Walking',
|
| 3284 |
+
'Head Massage',
|
| 3285 |
+
'High Jump',
|
| 3286 |
+
'Horse Race',
|
| 3287 |
+
'Horse Riding',
|
| 3288 |
+
'Hula Hoop',
|
| 3289 |
+
'Ice Dancing',
|
| 3290 |
+
'Javelin Throw',
|
| 3291 |
+
'Juggling Balls',
|
| 3292 |
+
'Jump Rope',
|
| 3293 |
+
'Jumping Jack',
|
| 3294 |
+
'Kayaking',
|
| 3295 |
+
'Knitting',
|
| 3296 |
+
'Long Jump',
|
| 3297 |
+
'Lunges',
|
| 3298 |
+
'Military Parade',
|
| 3299 |
+
'Mixing',
|
| 3300 |
+
'Mopping Floor',
|
| 3301 |
+
'Nunchucks',
|
| 3302 |
+
'Parallel Bars',
|
| 3303 |
+
'Pizza Tossing',
|
| 3304 |
+
'Playing Cello',
|
| 3305 |
+
'Playing Daf',
|
| 3306 |
+
'Playing Dhol',
|
| 3307 |
+
'Playing Flute',
|
| 3308 |
+
'Playing Guitar',
|
| 3309 |
+
'Playing Piano',
|
| 3310 |
+
'Playing Sitar',
|
| 3311 |
+
'Playing Tabla',
|
| 3312 |
+
'Playing Violin',
|
| 3313 |
+
'Pole Vault',
|
| 3314 |
+
'Pommel Horse',
|
| 3315 |
+
'Pull Ups',
|
| 3316 |
+
'Punch',
|
| 3317 |
+
'Push Ups',
|
| 3318 |
+
'Rafting',
|
| 3319 |
+
'Rock Climbing Indoor',
|
| 3320 |
+
'Rope Climbing',
|
| 3321 |
+
'Rowing',
|
| 3322 |
+
'Salsa Spin',
|
| 3323 |
+
'Shaving Beard',
|
| 3324 |
+
'Shotput',
|
| 3325 |
+
'Skate Boarding',
|
| 3326 |
+
'Skiing',
|
| 3327 |
+
'Skijet',
|
| 3328 |
+
'Sky Diving',
|
| 3329 |
+
'Soccer Juggling',
|
| 3330 |
+
'Soccer Penalty',
|
| 3331 |
+
'Still Rings',
|
| 3332 |
+
'Sumo Wrestling',
|
| 3333 |
+
'Surfing',
|
| 3334 |
+
'Swing',
|
| 3335 |
+
'Table Tennis Shot',
|
| 3336 |
+
'Tai Chi',
|
| 3337 |
+
'Tennis Swing',
|
| 3338 |
+
'Throw Discus',
|
| 3339 |
+
'Trampoline Jumping',
|
| 3340 |
+
'Typing',
|
| 3341 |
+
'Uneven Bars',
|
| 3342 |
+
'Volleyball Spiking',
|
| 3343 |
+
'Walking With Dog',
|
| 3344 |
+
'Wall Pushups',
|
| 3345 |
+
'Writing On Board',
|
| 3346 |
+
'Yo Yo',
|
| 3347 |
+
]
|
| 3348 |
+
|
| 3349 |
+
templates = [
|
| 3350 |
+
'a photo of a person {}.',
|
| 3351 |
+
'a video of a person {}.',
|
| 3352 |
+
'a example of a person {}.',
|
| 3353 |
+
'a demonstration of a person {}.',
|
| 3354 |
+
'a photo of the person {}.',
|
| 3355 |
+
'a video of the person {}.',
|
| 3356 |
+
'a example of the person {}.',
|
| 3357 |
+
'a demonstration of the person {}.',
|
| 3358 |
+
'a photo of a person using {}.',
|
| 3359 |
+
'a video of a person using {}.',
|
| 3360 |
+
'a example of a person using {}.',
|
| 3361 |
+
'a demonstration of a person using {}.',
|
| 3362 |
+
'a photo of the person using {}.',
|
| 3363 |
+
'a video of the person using {}.',
|
| 3364 |
+
'a example of the person using {}.',
|
| 3365 |
+
'a demonstration of the person using {}.',
|
| 3366 |
+
'a photo of a person doing {}.',
|
| 3367 |
+
'a video of a person doing {}.',
|
| 3368 |
+
'a example of a person doing {}.',
|
| 3369 |
+
'a demonstration of a person doing {}.',
|
| 3370 |
+
'a photo of the person doing {}.',
|
| 3371 |
+
'a video of the person doing {}.',
|
| 3372 |
+
'a example of the person doing {}.',
|
| 3373 |
+
'a demonstration of the person doing {}.',
|
| 3374 |
+
'a photo of a person during {}.',
|
| 3375 |
+
'a video of a person during {}.',
|
| 3376 |
+
'a example of a person during {}.',
|
| 3377 |
+
'a demonstration of a person during {}.',
|
| 3378 |
+
'a photo of the person during {}.',
|
| 3379 |
+
'a video of the person during {}.',
|
| 3380 |
+
'a example of the person during {}.',
|
| 3381 |
+
'a demonstration of the person during {}.',
|
| 3382 |
+
'a photo of a person performing {}.',
|
| 3383 |
+
'a video of a person performing {}.',
|
| 3384 |
+
'a example of a person performing {}.',
|
| 3385 |
+
'a demonstration of a person performing {}.',
|
| 3386 |
+
'a photo of the person performing {}.',
|
| 3387 |
+
'a video of the person performing {}.',
|
| 3388 |
+
'a example of the person performing {}.',
|
| 3389 |
+
'a demonstration of the person performing {}.',
|
| 3390 |
+
'a photo of a person practicing {}.',
|
| 3391 |
+
'a video of a person practicing {}.',
|
| 3392 |
+
'a example of a person practicing {}.',
|
| 3393 |
+
'a demonstration of a person practicing {}.',
|
| 3394 |
+
'a photo of the person practicing {}.',
|
| 3395 |
+
'a video of the person practicing {}.',
|
| 3396 |
+
'a example of the person practicing {}.',
|
| 3397 |
+
'a demonstration of the person practicing {}.',
|
| 3398 |
+
]
|
| 3399 |
+
```
|
| 3400 |
+
|
| 3401 |
+
|
CLIP/data/rendered-sst2.md
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# The Rendered SST2 Dataset
|
| 2 |
+
|
| 3 |
+
In the paper, we used an image classification dataset called Rendered SST2, to evaluate the model's capability on optical character recognition. To do so, we rendered the sentences in the [Standford Sentiment Treebank v2](https://nlp.stanford.edu/sentiment/treebank.html) dataset and used those as the input to the CLIP image encoder.
|
| 4 |
+
|
| 5 |
+
The following command will download a 131MB archive countaining the images and extract into a subdirectory `rendered-sst2`:
|
| 6 |
+
|
| 7 |
+
```bash
|
| 8 |
+
wget https://openaipublic.azureedge.net/clip/data/rendered-sst2.tgz
|
| 9 |
+
tar zxvf rendered-sst2.tgz
|
| 10 |
+
```
|
| 11 |
+
|
CLIP/data/yfcc100m.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# The YFCC100M Subset
|
| 2 |
+
|
| 3 |
+
In the paper, we performed a dataset ablation using a subset of the YFCC100M dataset and showed that the performance remained largely similar.
|
| 4 |
+
|
| 5 |
+
The subset contains 14,829,396 images, about 15% of the full dataset, which have been filtered to only keep those with natural languag titles and/or descriptions in English.
|
| 6 |
+
|
| 7 |
+
We provide the list of (line number, photo identifier, photo hash) of each image contained in this subset. These correspond to the first three columns in the dataset's metadata TSV file.
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
wget https://openaipublic.azureedge.net/clip/data/yfcc100m_subset_data.tsv.bz2
|
| 11 |
+
bunzip2 yfcc100m_subset_data.tsv.bz2
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
Use of the underlying media files is subject to the Creative Commons licenses chosen by their creators/uploaders. For more information about the YFCC100M dataset, visit [the official website](https://multimediacommons.wordpress.com/yfcc100m-core-dataset/).
|
CLIP/model-card.md
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Card: CLIP
|
| 2 |
+
|
| 3 |
+
Inspired by [Model Cards for Model Reporting (Mitchell et al.)](https://arxiv.org/abs/1810.03993) and [Lessons from Archives (Jo & Gebru)](https://arxiv.org/pdf/1912.10389.pdf), we’re providing some accompanying information about the multimodal model.
|
| 4 |
+
|
| 5 |
+
## Model Details
|
| 6 |
+
|
| 7 |
+
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
|
| 8 |
+
|
| 9 |
+
### Model Date
|
| 10 |
+
|
| 11 |
+
January 2021
|
| 12 |
+
|
| 13 |
+
### Model Type
|
| 14 |
+
|
| 15 |
+
The base model uses a ResNet50 with several modifications as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss. There is also a variant of the model where the ResNet image encoder is replaced with a Vision Transformer.
|
| 16 |
+
|
| 17 |
+
### Model Versions
|
| 18 |
+
|
| 19 |
+
Initially, we’ve released one CLIP model based on the Vision Transformer architecture equivalent to ViT-B/32, along with the RN50 model, using the architecture equivalent to ResNet-50.
|
| 20 |
+
|
| 21 |
+
As part of the staged release process, we have also released the RN101 model, as well as RN50x4, a RN50 scaled up 4x according to the [EfficientNet](https://arxiv.org/abs/1905.11946) scaling rule. In July 2021, we additionally released the RN50x16 and ViT-B/16 models, and In January 2022, the RN50x64 and ViT-L/14 models were released.
|
| 22 |
+
|
| 23 |
+
Please see the paper linked below for further details about their specification.
|
| 24 |
+
|
| 25 |
+
### Documents
|
| 26 |
+
|
| 27 |
+
- [Blog Post](https://openai.com/blog/clip/)
|
| 28 |
+
- [CLIP Paper](https://arxiv.org/abs/2103.00020)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
## Model Use
|
| 33 |
+
|
| 34 |
+
### Intended Use
|
| 35 |
+
|
| 36 |
+
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
|
| 37 |
+
|
| 38 |
+
#### Primary intended uses
|
| 39 |
+
|
| 40 |
+
The primary intended users of these models are AI researchers.
|
| 41 |
+
|
| 42 |
+
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
|
| 43 |
+
|
| 44 |
+
### Out-of-Scope Use Cases
|
| 45 |
+
|
| 46 |
+
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
|
| 47 |
+
|
| 48 |
+
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
|
| 49 |
+
|
| 50 |
+
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
## Data
|
| 55 |
+
|
| 56 |
+
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
|
| 57 |
+
|
| 58 |
+
### Data Mission Statement
|
| 59 |
+
|
| 60 |
+
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
## Performance and Limitations
|
| 65 |
+
|
| 66 |
+
### Performance
|
| 67 |
+
|
| 68 |
+
We have evaluated the performance of CLIP on a wide range of benchmarks across a variety of computer vision datasets such as OCR to texture recognition to fine-grained classification. The paper describes model performance on the following datasets:
|
| 69 |
+
|
| 70 |
+
- Food101
|
| 71 |
+
- CIFAR10
|
| 72 |
+
- CIFAR100
|
| 73 |
+
- Birdsnap
|
| 74 |
+
- SUN397
|
| 75 |
+
- Stanford Cars
|
| 76 |
+
- FGVC Aircraft
|
| 77 |
+
- VOC2007
|
| 78 |
+
- DTD
|
| 79 |
+
- Oxford-IIIT Pet dataset
|
| 80 |
+
- Caltech101
|
| 81 |
+
- Flowers102
|
| 82 |
+
- MNIST
|
| 83 |
+
- SVHN
|
| 84 |
+
- IIIT5K
|
| 85 |
+
- Hateful Memes
|
| 86 |
+
- SST-2
|
| 87 |
+
- UCF101
|
| 88 |
+
- Kinetics700
|
| 89 |
+
- Country211
|
| 90 |
+
- CLEVR Counting
|
| 91 |
+
- KITTI Distance
|
| 92 |
+
- STL-10
|
| 93 |
+
- RareAct
|
| 94 |
+
- Flickr30
|
| 95 |
+
- MSCOCO
|
| 96 |
+
- ImageNet
|
| 97 |
+
- ImageNet-A
|
| 98 |
+
- ImageNet-R
|
| 99 |
+
- ImageNet Sketch
|
| 100 |
+
- ObjectNet (ImageNet Overlap)
|
| 101 |
+
- Youtube-BB
|
| 102 |
+
- ImageNet-Vid
|
| 103 |
+
|
| 104 |
+
## Limitations
|
| 105 |
+
|
| 106 |
+
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
|
| 107 |
+
|
| 108 |
+
### Bias and Fairness
|
| 109 |
+
|
| 110 |
+
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
|
| 111 |
+
|
| 112 |
+
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
## Feedback
|
| 117 |
+
|
| 118 |
+
### Where to send questions or comments about the model
|
| 119 |
+
|
| 120 |
+
Please use [this Google Form](https://forms.gle/Uv7afRH5dvY34ZEs9)
|
CLIP/requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ftfy
|
| 2 |
+
regex
|
| 3 |
+
tqdm
|
| 4 |
+
torch
|
| 5 |
+
torchvision
|
CLIP/setup.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import pkg_resources
|
| 4 |
+
from setuptools import setup, find_packages
|
| 5 |
+
|
| 6 |
+
setup(
|
| 7 |
+
name="clip",
|
| 8 |
+
py_modules=["clip"],
|
| 9 |
+
version="1.0",
|
| 10 |
+
description="",
|
| 11 |
+
author="OpenAI",
|
| 12 |
+
packages=find_packages(exclude=["tests*"]),
|
| 13 |
+
install_requires=[
|
| 14 |
+
str(r)
|
| 15 |
+
for r in pkg_resources.parse_requirements(
|
| 16 |
+
open(os.path.join(os.path.dirname(__file__), "requirements.txt"))
|
| 17 |
+
)
|
| 18 |
+
],
|
| 19 |
+
include_package_data=True,
|
| 20 |
+
extras_require={'dev': ['pytest']},
|
| 21 |
+
)
|
CLIP/tests/test_consistency.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pytest
|
| 3 |
+
import torch
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
import clip
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@pytest.mark.parametrize('model_name', clip.available_models())
|
| 10 |
+
def test_consistency(model_name):
|
| 11 |
+
device = "cpu"
|
| 12 |
+
jit_model, transform = clip.load(model_name, device=device, jit=True)
|
| 13 |
+
py_model, _ = clip.load(model_name, device=device, jit=False)
|
| 14 |
+
|
| 15 |
+
image = transform(Image.open("CLIP.png")).unsqueeze(0).to(device)
|
| 16 |
+
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
|
| 17 |
+
|
| 18 |
+
with torch.no_grad():
|
| 19 |
+
logits_per_image, _ = jit_model(image, text)
|
| 20 |
+
jit_probs = logits_per_image.softmax(dim=-1).cpu().numpy()
|
| 21 |
+
|
| 22 |
+
logits_per_image, _ = py_model(image, text)
|
| 23 |
+
py_probs = logits_per_image.softmax(dim=-1).cpu().numpy()
|
| 24 |
+
|
| 25 |
+
assert np.allclose(jit_probs, py_probs, atol=0.01, rtol=0.1)
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,13 +1,86 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Text2LIVE: Text-Driven Layered Image and Video Editing (ECCV 2022 - Oral)
|
| 2 |
+
## [<a href="https://text2live.github.io/" target="_blank">Project Page</a>]
|
| 3 |
+
|
| 4 |
+
[](https://arxiv.org/abs/2204.02491)
|
| 5 |
+

|
| 6 |
+
[](https://huggingface.co/spaces/weizmannscience/text2live)
|
| 7 |
+
|
| 8 |
+

|
| 9 |
+
|
| 10 |
+
**Text2LIVE** is a method for text-driven editing of real-world images and videos, as described in <a href="https://arxiv.org/abs/2204.02491" target="_blank">(link to paper)</a>.
|
| 11 |
+
|
| 12 |
+
[//]: # (. It can be used for localized and global edits that change the texture of existing objects or augment the scene with semi-transparent effects (e.g. smoke, fire, snow).)
|
| 13 |
+
|
| 14 |
+
[//]: # (### Abstract)
|
| 15 |
+
>We present a method for zero-shot, text-driven appearance manipulation in natural images and videos. Specifically, given an input image or video and a target text prompt, our goal is to edit the appearance of existing objects (e.g., object's texture) or augment the scene with new visual effects (e.g., smoke, fire) in a semantically meaningful manner. Our framework trains a generator using an internal dataset of training examples, extracted from a single input (image or video and target text prompt), while leveraging an external pre-trained CLIP model to establish our losses. Rather than directly generating the edited output, our key idea is to generate an edit layer (color+opacity) that is composited over the original input. This allows us to constrain the generation process and maintain high fidelity to the original input via novel text-driven losses that are applied directly to the edit layer. Our method neither relies on a pre-trained generator nor requires user-provided edit masks. Thus, it can perform localized, semantic edits on high-resolution natural images and videos across a variety of objects and scenes.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## Getting Started
|
| 19 |
+
### Installation
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
git clone https://github.com/omerbt/Text2LIVE.git
|
| 23 |
+
conda create --name text2live python=3.9
|
| 24 |
+
conda activate text2live
|
| 25 |
+
pip install -r requirements.txt
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
### Download sample images and videos
|
| 29 |
+
Download sample images and videos from the DAVIS dataset:
|
| 30 |
+
```
|
| 31 |
+
cd Text2LIVE
|
| 32 |
+
gdown https://drive.google.com/uc?id=1osN4PlPkY9uk6pFqJZo8lhJUjTIpa80J&export=download
|
| 33 |
+
unzip data.zip
|
| 34 |
+
```
|
| 35 |
+
It will create a folder `data`:
|
| 36 |
+
```
|
| 37 |
+
Text2LIVE
|
| 38 |
+
├── ...
|
| 39 |
+
├── data
|
| 40 |
+
│ ├── pretrained_nla_models # NLA models are stored here
|
| 41 |
+
│ ├── images # sample images
|
| 42 |
+
│ └── videos # sample videos from DAVIS dataset
|
| 43 |
+
│ ├── car-turn # contains video frames
|
| 44 |
+
│ ├── ...
|
| 45 |
+
└── ...
|
| 46 |
+
```
|
| 47 |
+
To enforce temporal consistency in video edits, we utilize the Neural Layered Atlases (NLA). Pretrained NLA models are taken from <a href="https://layered-neural-atlases.github.io">here</a>, and are already inside the `data` folder.
|
| 48 |
+
|
| 49 |
+
### Run examples
|
| 50 |
+
* Our method is designed to change textures of existing objects / augment the scene with semi-transparent effects (e.g., smoke, fire). It is not designed for adding new objects or significantly deviating from the original spatial layout.
|
| 51 |
+
* Training **Text2LIVE** multiple times with the same inputs can lead to slightly different results.
|
| 52 |
+
* CLIP sometimes exhibits bias towards specific solutions (see figure 9 in the paper), thus slightly different text prompts may lead to different flavors of edits.
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
The required GPU memory depends on the input image/video size, but you should be good with a Tesla V100 32GB :).
|
| 56 |
+
Currently mixed precision introduces some instability in the training process, but it could be added later.
|
| 57 |
+
|
| 58 |
+
#### Video Editing
|
| 59 |
+
Run the following command to start training
|
| 60 |
+
```
|
| 61 |
+
python train_video.py --example_config car-turn_winter.yaml
|
| 62 |
+
```
|
| 63 |
+
#### Image Editing
|
| 64 |
+
Run the following command to start training
|
| 65 |
+
```
|
| 66 |
+
python train_image.py --example_config golden_horse.yaml
|
| 67 |
+
```
|
| 68 |
+
Intermediate results will be saved to `results` during optimization. The frequency of saving intermediate results is indicated in the `log_images_freq` flag of the configuration.
|
| 69 |
+
|
| 70 |
+
## Sample Results
|
| 71 |
+
https://user-images.githubusercontent.com/22198039/179797381-983e0453-2e5d-40e8-983d-578217b358e4.mov
|
| 72 |
+
|
| 73 |
+
For more see the [supplementary material](https://text2live.github.io/sm/index.html).
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
## Citation
|
| 77 |
+
```
|
| 78 |
+
@inproceedings{bar2022text2live,
|
| 79 |
+
title={Text2live: Text-driven layered image and video editing},
|
| 80 |
+
author={Bar-Tal, Omer and Ofri-Amar, Dolev and Fridman, Rafail and Kasten, Yoni and Dekel, Tali},
|
| 81 |
+
booktitle={European Conference on Computer Vision},
|
| 82 |
+
pages={707--723},
|
| 83 |
+
year={2022},
|
| 84 |
+
organization={Springer}
|
| 85 |
+
}
|
| 86 |
+
```
|
Text2LIVE-main/CLIP/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (158 Bytes). View file
|
|
|
Text2LIVE-main/CLIP/clip/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (184 Bytes). View file
|
|
|
Text2LIVE-main/CLIP/clip/__pycache__/clip.cpython-37.pyc
ADDED
|
Binary file (8.28 kB). View file
|
|
|
Text2LIVE-main/CLIP/clip/__pycache__/model.cpython-37.pyc
ADDED
|
Binary file (16.6 kB). View file
|
|
|
Text2LIVE-main/CLIP/clip/__pycache__/simple_tokenizer.cpython-37.pyc
ADDED
|
Binary file (5.78 kB). View file
|
|
|
Text2LIVE-main/CLIP/clip_explainability/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (199 Bytes). View file
|
|
|
Text2LIVE-main/CLIP/clip_explainability/__pycache__/auxilary.cpython-37.pyc
ADDED
|
Binary file (12 kB). View file
|
|
|
Text2LIVE-main/CLIP/clip_explainability/__pycache__/clip.cpython-37.pyc
ADDED
|
Binary file (7.59 kB). View file
|
|
|
Text2LIVE-main/CLIP/clip_explainability/__pycache__/model.cpython-37.pyc
ADDED
|
Binary file (15.4 kB). View file
|
|
|
Text2LIVE-main/CLIP/clip_explainability/__pycache__/simple_tokenizer.cpython-37.pyc
ADDED
|
Binary file (5.79 kB). View file
|
|
|
Text2LIVE-main/README.md
CHANGED
|
@@ -75,12 +75,10 @@ For more see the [supplementary material](https://text2live.github.io/sm/index.h
|
|
| 75 |
|
| 76 |
## Citation
|
| 77 |
```
|
| 78 |
-
@
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
year={2022},
|
| 84 |
-
organization={Springer}
|
| 85 |
}
|
| 86 |
```
|
|
|
|
| 75 |
|
| 76 |
## Citation
|
| 77 |
```
|
| 78 |
+
@article{bar2022text2live,
|
| 79 |
+
title = {Text2LIVE: Text-Driven Layered Image and Video Editing},
|
| 80 |
+
author = {Bar-Tal, Omer and Ofri-Amar, Dolev and Fridman, Rafail and Kasten, Yoni and Dekel, Tali},
|
| 81 |
+
journal = {arXiv preprint arXiv:2204.02491},
|
| 82 |
+
year = {2022}
|
|
|
|
|
|
|
| 83 |
}
|
| 84 |
```
|
Text2LIVE-main/data/data/images/Thumbs.db
ADDED
|
Binary file (13.8 kB). View file
|
|
|
Text2LIVE-main/data/data/images/cake.jpeg
ADDED

|
Text2LIVE-main/data/data/images/horse.jpg
ADDED

|
Text2LIVE-main/data/data/pretrained_nla_models/blackswan/checkpoint
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f50895f39815de243cb8166001771260d9720e6d1bda6289088a0366c7c70f2
|
| 3 |
+
size 14657387
|
Text2LIVE-main/data/data/pretrained_nla_models/car-turn/checkpoint
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:973953ed6f0f742df9ab3fd21e7369db541689c40a8cd22ddb12f912c2e84b95
|
| 3 |
+
size 14657387
|
Text2LIVE-main/data/data/pretrained_nla_models/libby/checkpoint
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2095f38eacee144175b08fdaaffd52e97991c08f0825be0d8cf836a5297ae535
|
| 3 |
+
size 14657387
|
Text2LIVE-main/data/data/videos/blackswan/00000.jpg
ADDED

|
Text2LIVE-main/data/data/videos/blackswan/00001.jpg
ADDED

|
Text2LIVE-main/data/data/videos/blackswan/00002.jpg
ADDED

|
Text2LIVE-main/data/data/videos/blackswan/00003.jpg
ADDED

|
Text2LIVE-main/data/data/videos/blackswan/00004.jpg
ADDED

|