Spaces:
Running
on
Zero

Running
on
Zero

Commit
•
e87d958
1
Parent(s):
6b629aa
update to videoscore
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- README.md +9 -41
- app_generation.py +197 -0
- app_high_res.py +236 -0
- app_regression.py +223 -0
- barchart.jpeg +0 -0
- barchart_single_image_vqa.jpeg +0 -0
- examples/1006309.mp4 +3 -0
- examples/1006309/1006309_00.jpg +0 -0
- examples/1006309/1006309_01.jpg +0 -0
- examples/1006309/1006309_02.jpg +0 -0
- examples/1006309/1006309_03.jpg +0 -0
- examples/1006309/1006309_04.jpg +0 -0
- examples/1006309/1006309_05.jpg +0 -0
- examples/1006309/1006309_06.jpg +0 -0
- examples/1006309/1006309_07.jpg +0 -0
- examples/1006309/1006309_08.jpg +0 -0
- examples/1006309/1006309_09.jpg +0 -0
- examples/1006309/1006309_10.jpg +0 -0
- examples/1006309/1006309_11.jpg +0 -0
- examples/1006309/1006309_12.jpg +0 -0
- examples/1006309/1006309_13.jpg +0 -0
- examples/1006309/1006309_14.jpg +0 -0
- examples/1006309/1006309_15.jpg +0 -0
- examples/3005033.mp4 +3 -0
- examples/3005033/3005033_00.jpg +0 -0
- examples/3005033/3005033_01.jpg +0 -0
- examples/3005033/3005033_02.jpg +0 -0
- examples/3005033/3005033_03.jpg +0 -0
- examples/3005033/3005033_04.jpg +0 -0
- examples/3005033/3005033_05.jpg +0 -0
- examples/3005033/3005033_06.jpg +0 -0
- examples/3005033/3005033_07.jpg +0 -0
- examples/3005033/3005033_08.jpg +0 -0
- examples/3005033/3005033_09.jpg +0 -0
- examples/3005033/3005033_10.jpg +0 -0
- examples/3005033/3005033_11.jpg +0 -0
- examples/3005033/3005033_12.jpg +0 -0
- examples/3005033/3005033_13.jpg +0 -0
- examples/3005033/3005033_14.jpg +0 -0
- examples/3005033/3005033_15.jpg +0 -0
- examples/7004180.mp4 +3 -0
- examples/7004180/7004180_00.jpg +0 -0
- examples/7004180/7004180_01.jpg +0 -0
- examples/7004180/7004180_02.jpg +0 -0
- examples/7004180/7004180_03.jpg +0 -0
- examples/7004180/7004180_04.jpg +0 -0
- examples/7004180/7004180_05.jpg +0 -0
- examples/7004180/7004180_06.jpg +0 -0
- examples/7004180/7004180_07.jpg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,46 +1,14 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 4.
|
| 8 |
-
app_file:
|
| 9 |
pinned: false
|
| 10 |
-
license:
|
| 11 |
-
|
| 12 |
-
- arena
|
| 13 |
-
- leaderboard
|
| 14 |
-
short_description: Realtime Image/Video Gen AI Arena
|
| 15 |
---
|
| 16 |
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
- for cuda 11.8
|
| 20 |
-
```bash
|
| 21 |
-
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
|
| 22 |
-
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu118
|
| 23 |
-
pip install -r requirements.txt
|
| 24 |
-
```
|
| 25 |
-
- for cuda 12.1
|
| 26 |
-
```bash
|
| 27 |
-
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
|
| 28 |
-
pip install -r requirements.txt
|
| 29 |
-
```
|
| 30 |
-
|
| 31 |
-
## Start Hugging Face UI
|
| 32 |
-
```bash
|
| 33 |
-
python app.py
|
| 34 |
-
```
|
| 35 |
-
|
| 36 |
-
## Start Log server
|
| 37 |
-
```bash
|
| 38 |
-
uvicorn serve.log_server:app --reload --port 22005 --host 0.0.0.0
|
| 39 |
-
```
|
| 40 |
-
|
| 41 |
-
## Update leaderboard
|
| 42 |
-
```bash
|
| 43 |
-
cd arena_elo && bash update_leaderboard.sh
|
| 44 |
-
```
|
| 45 |
-
|
| 46 |
-
Paper: arxiv.org/abs/2406.04485
|
|
|
|
| 1 |
---
|
| 2 |
+
title: MantisScore
|
| 3 |
+
emoji: 📹
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: yellow
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 4.24.0
|
| 8 |
+
app_file: app_regression.py
|
| 9 |
pinned: false
|
| 10 |
+
license: apache-2.0
|
| 11 |
+
short_description: Multimodal Language Model
|
|
|
|
|
|
|
|
|
|
| 12 |
---
|
| 13 |
|
| 14 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
app_generation.py
ADDED
|
@@ -0,0 +1,197 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import spaces
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
import json
|
| 6 |
+
import numpy as np
|
| 7 |
+
import av
|
| 8 |
+
import torch
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import functools
|
| 11 |
+
from transformers import AutoProcessor, AutoConfig
|
| 12 |
+
from models.idefics2 import Idefics2ForSequenceClassification, Idefics2ForConditionalGeneration
|
| 13 |
+
from models.conversation import conv_templates
|
| 14 |
+
from typing import List
|
| 15 |
+
|
| 16 |
+
processor = AutoProcessor.from_pretrained("Mantis-VL/mantis-8b-idefics2-video-eval-refined-40k_4096_generation")
|
| 17 |
+
model = Idefics2ForConditionalGeneration.from_pretrained("Mantis-VL/mantis-8b-idefics2-video-eval-refined-40k_4096_generation", torch_dtype=torch.bfloat16).eval()
|
| 18 |
+
|
| 19 |
+
MAX_NUM_FRAMES = 24
|
| 20 |
+
conv_template = conv_templates["idefics_2"]
|
| 21 |
+
|
| 22 |
+
with open("./examples/all_subsets.json", 'r') as f:
|
| 23 |
+
examples = json.load(f)
|
| 24 |
+
|
| 25 |
+
for item in examples:
|
| 26 |
+
video_id = item['images'][0].split("_")[0]
|
| 27 |
+
item['images'] = [os.path.join("./examples", video_id, x) for x in item['images']]
|
| 28 |
+
item['video'] = os.path.join("./examples", item['video'])
|
| 29 |
+
|
| 30 |
+
with open("./examples/hd.json", 'r') as f:
|
| 31 |
+
hd_examples = json.load(f)
|
| 32 |
+
|
| 33 |
+
for item in hd_examples:
|
| 34 |
+
item['video'] = os.path.join("./examples", item['video'])
|
| 35 |
+
|
| 36 |
+
examples = hd_examples + examples
|
| 37 |
+
|
| 38 |
+
VIDEO_EVAL_PROMPT = """
|
| 39 |
+
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
|
| 40 |
+
please watch the following frames of a given video and see the text prompt for generating the video,
|
| 41 |
+
then give scores from 5 different dimensions:
|
| 42 |
+
(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color
|
| 43 |
+
(2) temporal consistency, the consistency of objects or humans in video
|
| 44 |
+
(3) dynamic degree, the degree of dynamic changes
|
| 45 |
+
(4) text-to-video alignment, the alignment between the text prompt and the video content
|
| 46 |
+
(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge
|
| 47 |
+
|
| 48 |
+
For each dimension, output a number from [1,2,3,4],
|
| 49 |
+
in which '1' means 'Bad', '2' means 'Average', '3' means 'Good',
|
| 50 |
+
'4' means 'Real' or 'Perfect' (the video is like a real video)
|
| 51 |
+
Here is an output example:
|
| 52 |
+
visual quality: 4
|
| 53 |
+
temporal consistency: 4
|
| 54 |
+
dynamic degree: 3
|
| 55 |
+
text-to-video alignment: 1
|
| 56 |
+
factual consistency: 2
|
| 57 |
+
|
| 58 |
+
For this video, the text prompt is "{text_prompt}",
|
| 59 |
+
all the frames of video are as follows:
|
| 60 |
+
|
| 61 |
+
"""
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
aspect_mapping= [
|
| 65 |
+
"visual quality",
|
| 66 |
+
"temporal consistency",
|
| 67 |
+
"dynamic degree",
|
| 68 |
+
"text-to-video alignment",
|
| 69 |
+
"factual consistency",
|
| 70 |
+
]
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
@spaces.GPU(duration=60)
|
| 74 |
+
def score(prompt:str, images:List[Image.Image]):
|
| 75 |
+
if not prompt:
|
| 76 |
+
raise gr.Error("Please provide a prompt")
|
| 77 |
+
model.to("cuda")
|
| 78 |
+
if not images:
|
| 79 |
+
images = None
|
| 80 |
+
|
| 81 |
+
flatten_images = []
|
| 82 |
+
for x in images:
|
| 83 |
+
if isinstance(x, list):
|
| 84 |
+
flatten_images.extend(x)
|
| 85 |
+
else:
|
| 86 |
+
flatten_images.append(x)
|
| 87 |
+
|
| 88 |
+
messages = [{"role": "User", "content": [{"type": "text", "text": prompt}]}]
|
| 89 |
+
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
|
| 90 |
+
print(prompt)
|
| 91 |
+
|
| 92 |
+
flatten_images = [Image.open(x) if isinstance(x, str) else x for x in flatten_images]
|
| 93 |
+
inputs = processor(text=prompt, images=flatten_images, return_tensors="pt")
|
| 94 |
+
inputs = {k: v.to(model.device) for k, v in inputs.items()}
|
| 95 |
+
|
| 96 |
+
outputs = model.generate(**inputs, max_new_tokens=1024)
|
| 97 |
+
generated_text = processor.decode(outputs[0, inputs["input_ids"].shape[-1]:], skip_special_tokens=True)
|
| 98 |
+
return generated_text
|
| 99 |
+
|
| 100 |
+
def read_video_pyav(container, indices):
|
| 101 |
+
'''
|
| 102 |
+
Decode the video with PyAV decoder.
|
| 103 |
+
|
| 104 |
+
Args:
|
| 105 |
+
container (av.container.input.InputContainer): PyAV container.
|
| 106 |
+
indices (List[int]): List of frame indices to decode.
|
| 107 |
+
|
| 108 |
+
Returns:
|
| 109 |
+
np.ndarray: np array of decoded frames of shape (num_frames, height, width, 3).
|
| 110 |
+
'''
|
| 111 |
+
frames = []
|
| 112 |
+
container.seek(0)
|
| 113 |
+
start_index = indices[0]
|
| 114 |
+
end_index = indices[-1]
|
| 115 |
+
for i, frame in enumerate(container.decode(video=0)):
|
| 116 |
+
if i > end_index:
|
| 117 |
+
break
|
| 118 |
+
if i >= start_index and i in indices:
|
| 119 |
+
frames.append(frame)
|
| 120 |
+
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
|
| 121 |
+
|
| 122 |
+
def eval_video(prompt, video:str):
|
| 123 |
+
container = av.open(video)
|
| 124 |
+
|
| 125 |
+
# sample uniformly 8 frames from the video
|
| 126 |
+
total_frames = container.streams.video[0].frames
|
| 127 |
+
if total_frames > MAX_NUM_FRAMES:
|
| 128 |
+
indices = np.arange(0, total_frames, total_frames / MAX_NUM_FRAMES).astype(int)
|
| 129 |
+
else:
|
| 130 |
+
indices = np.arange(total_frames)
|
| 131 |
+
video_frames = read_video_pyav(container, indices)
|
| 132 |
+
|
| 133 |
+
frames = [Image.fromarray(x) for x in video_frames]
|
| 134 |
+
|
| 135 |
+
eval_prompt = VIDEO_EVAL_PROMPT.format(text_prompt=prompt)
|
| 136 |
+
|
| 137 |
+
num_image_token = eval_prompt.count("<image>")
|
| 138 |
+
if num_image_token < len(frames):
|
| 139 |
+
eval_prompt += "<image> " * (len(frames) - num_image_token)
|
| 140 |
+
|
| 141 |
+
aspect_scores = score(eval_prompt, [frames])
|
| 142 |
+
return aspect_scores
|
| 143 |
+
|
| 144 |
+
def build_demo():
|
| 145 |
+
with gr.Blocks() as demo:
|
| 146 |
+
gr.Markdown("""
|
| 147 |
+
## Video Evaluation
|
| 148 |
+
upload a video along with a text prompt when generating the video, this model will evaluate the video's quality from 7 different dimensions.
|
| 149 |
+
""")
|
| 150 |
+
with gr.Row():
|
| 151 |
+
video = gr.Video(width=500, label="Video")
|
| 152 |
+
with gr.Column():
|
| 153 |
+
eval_prompt_template = gr.Textbox(VIDEO_EVAL_PROMPT.strip(' \n'), label="Evaluation Prompt Template", interactive=False, max_lines=26)
|
| 154 |
+
video_prompt = gr.Textbox(label="Text Prompt", lines=1)
|
| 155 |
+
with gr.Row():
|
| 156 |
+
eval_button = gr.Button("Evaluate Video")
|
| 157 |
+
clear_button = gr.ClearButton([video, video_prompt])
|
| 158 |
+
eval_result = gr.Textbox(label="Evaluation result", interactive=False, lines=7)
|
| 159 |
+
# eval_result = gr.Json(label="Evaluation result")
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
eval_button.click(
|
| 163 |
+
eval_video, [video_prompt, video], [eval_result]
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
dummy_id = gr.Textbox("id", label="id", visible=False, min_width=50)
|
| 167 |
+
dummy_output = gr.Textbox("reference score", label="reference scores", visible=False, lines=7)
|
| 168 |
+
|
| 169 |
+
gr.Examples(
|
| 170 |
+
examples=
|
| 171 |
+
[
|
| 172 |
+
[
|
| 173 |
+
item['id'],
|
| 174 |
+
item['prompt'],
|
| 175 |
+
item['video'],
|
| 176 |
+
item['conversations'][1]['value']
|
| 177 |
+
] for item in examples
|
| 178 |
+
],
|
| 179 |
+
inputs=[dummy_id, video_prompt, video, dummy_output],
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
# gr.Markdown("""
|
| 183 |
+
# ## Citation
|
| 184 |
+
# ```
|
| 185 |
+
# @article{jiang2024mantis,
|
| 186 |
+
# title={MANTIS: Interleaved Multi-Image Instruction Tuning},
|
| 187 |
+
# author={Jiang, Dongfu and He, Xuan and Zeng, Huaye and Wei, Con and Ku, Max and Liu, Qian and Chen, Wenhu},
|
| 188 |
+
# journal={arXiv preprint arXiv:2405.01483},
|
| 189 |
+
# year={2024}
|
| 190 |
+
# }
|
| 191 |
+
# ```""")
|
| 192 |
+
return demo
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
if __name__ == "__main__":
|
| 196 |
+
demo = build_demo()
|
| 197 |
+
demo.launch(share=True)
|
app_high_res.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import spaces
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
import json
|
| 6 |
+
import numpy as np
|
| 7 |
+
import av
|
| 8 |
+
import torch
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import functools
|
| 11 |
+
from transformers import AutoProcessor, Idefics2ForConditionalGeneration
|
| 12 |
+
from models.conversation import conv_templates
|
| 13 |
+
from typing import List
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
processor = AutoProcessor.from_pretrained("Mantis-VL/mantis-8b-idefics2-video-eval-refined-40k_4096_generation")
|
| 17 |
+
model = Idefics2ForConditionalGeneration.from_pretrained("Mantis-VL/mantis-8b-idefics2-video-eval-refined-40k_4096_generation", device_map="auto", torch_dtype=torch.bfloat16).eval()
|
| 18 |
+
MAX_NUM_FRAMES = 24
|
| 19 |
+
conv_template = conv_templates["idefics_2"]
|
| 20 |
+
|
| 21 |
+
with open("./examples/all_subsets.json", 'r') as f:
|
| 22 |
+
examples = json.load(f)
|
| 23 |
+
|
| 24 |
+
for item in examples:
|
| 25 |
+
video_id = item['images'][0].split("_")[0]
|
| 26 |
+
item['images'] = [os.path.join("./examples", video_id, x) for x in item['images']]
|
| 27 |
+
item['video'] = os.path.join("./examples", item['video'])
|
| 28 |
+
|
| 29 |
+
with open("./examples/hd.json", 'r') as f:
|
| 30 |
+
hd_examples = json.load(f)
|
| 31 |
+
|
| 32 |
+
for item in hd_examples:
|
| 33 |
+
item['video'] = os.path.join("./examples", item['video'])
|
| 34 |
+
|
| 35 |
+
examples = hd_examples + examples
|
| 36 |
+
|
| 37 |
+
VIDEO_EVAL_PROMPT = """
|
| 38 |
+
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
|
| 39 |
+
please watch the following frames of a given video and see the text prompt for generating the video,
|
| 40 |
+
then give scores from 5 different dimensions:
|
| 41 |
+
(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color
|
| 42 |
+
(2) temporal consistency, the consistency of objects or humans in video
|
| 43 |
+
(3) dynamic degree, the degree of dynamic changes
|
| 44 |
+
(4) text-to-video alignment, the alignment between the text prompt and the video content
|
| 45 |
+
(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge
|
| 46 |
+
|
| 47 |
+
For each dimension, output a number from [1,2,3,4],
|
| 48 |
+
in which '1' means 'Bad', '2' means 'Average', '3' means 'Good',
|
| 49 |
+
'4' means 'Real' or 'Perfect' (the video is like a real video)
|
| 50 |
+
Here is an output example:
|
| 51 |
+
visual quality: 4
|
| 52 |
+
temporal consistency: 4
|
| 53 |
+
dynamic degree: 3
|
| 54 |
+
text-to-video alignment: 1
|
| 55 |
+
factual consistency: 2
|
| 56 |
+
|
| 57 |
+
For this video, the text prompt is "{text_prompt}",
|
| 58 |
+
all the frames of video are as follows:
|
| 59 |
+
|
| 60 |
+
"""
|
| 61 |
+
@spaces.GPU(duration=60)
|
| 62 |
+
def generate(text:str, images:List[Image.Image], history: List[dict], **kwargs):
|
| 63 |
+
model.to("cuda")
|
| 64 |
+
if not images:
|
| 65 |
+
images = None
|
| 66 |
+
|
| 67 |
+
user_role = conv_template.roles[0]
|
| 68 |
+
assistant_role = conv_template.roles[1]
|
| 69 |
+
|
| 70 |
+
idefics_2_message = []
|
| 71 |
+
cur_img_idx = 0
|
| 72 |
+
cur_vid_idx = 0
|
| 73 |
+
all_videos = [x for x in images if isinstance(x, list)]
|
| 74 |
+
flatten_images = []
|
| 75 |
+
for x in images:
|
| 76 |
+
if isinstance(x, list):
|
| 77 |
+
flatten_images.extend(x)
|
| 78 |
+
else:
|
| 79 |
+
flatten_images.append(x)
|
| 80 |
+
|
| 81 |
+
print(history)
|
| 82 |
+
for i, message in enumerate(history):
|
| 83 |
+
if message["role"] == user_role:
|
| 84 |
+
idefics_2_message.append({
|
| 85 |
+
"role": user_role,
|
| 86 |
+
"content": []
|
| 87 |
+
})
|
| 88 |
+
message_text = message["text"]
|
| 89 |
+
num_video_tokens_in_text = message_text.count("<video>")
|
| 90 |
+
if num_video_tokens_in_text > 0:
|
| 91 |
+
for _ in range(num_video_tokens_in_text):
|
| 92 |
+
message_text = message_text.replace("<video>", "<image> " * len(all_videos[cur_vid_idx]), 1)
|
| 93 |
+
cur_vid_idx += 1
|
| 94 |
+
num_image_tokens_in_text = message_text.count("<image>")
|
| 95 |
+
if num_image_tokens_in_text > 0:
|
| 96 |
+
sub_texts = [x.strip() for x in message_text.split("<image>")]
|
| 97 |
+
if sub_texts[0]:
|
| 98 |
+
idefics_2_message[-1]["content"].append({"type": "text", "text": sub_texts[0]})
|
| 99 |
+
for sub_text in sub_texts[1:]:
|
| 100 |
+
idefics_2_message[-1]["content"].append({"type": "image"})
|
| 101 |
+
if sub_text:
|
| 102 |
+
idefics_2_message.append({
|
| 103 |
+
"role": user_role,
|
| 104 |
+
"content": [{"type": "text", "text": sub_text}]
|
| 105 |
+
})
|
| 106 |
+
else:
|
| 107 |
+
idefics_2_message[-1]["content"].append({"type": "text", "text": message_text})
|
| 108 |
+
elif message["role"] == assistant_role:
|
| 109 |
+
if i == len(history) - 1 and not message["text"]:
|
| 110 |
+
break
|
| 111 |
+
idefics_2_message.append({
|
| 112 |
+
"role": assistant_role,
|
| 113 |
+
"content": [{"type": "text", "text": message["text"]}]
|
| 114 |
+
})
|
| 115 |
+
if text:
|
| 116 |
+
assert idefics_2_message[-1]["role"] == assistant_role and not idefics_2_message[-1]["content"], "Internal error"
|
| 117 |
+
idefics_2_message.append({
|
| 118 |
+
"role": user_role,
|
| 119 |
+
"content": [{"type": "text", "text": text}]
|
| 120 |
+
})
|
| 121 |
+
|
| 122 |
+
print(idefics_2_message)
|
| 123 |
+
prompt = processor.apply_chat_template(idefics_2_message, add_generation_prompt=True)
|
| 124 |
+
|
| 125 |
+
images = [Image.open(x) if isinstance(x, str) else x for x in flatten_images]
|
| 126 |
+
inputs = processor(text=prompt, images=images, return_tensors="pt")
|
| 127 |
+
inputs = {k: v.to(model.device) for k, v in inputs.items()}
|
| 128 |
+
outputs = model.generate(**inputs, max_new_tokens=1024)
|
| 129 |
+
generated_text = processor.decode(outputs[0, inputs["input_ids"].shape[-1]:], skip_special_tokens=True)
|
| 130 |
+
return generated_text
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def read_video_pyav(container, indices):
|
| 134 |
+
'''
|
| 135 |
+
Decode the video with PyAV decoder.
|
| 136 |
+
|
| 137 |
+
Args:
|
| 138 |
+
container (av.container.input.InputContainer): PyAV container.
|
| 139 |
+
indices (List[int]): List of frame indices to decode.
|
| 140 |
+
|
| 141 |
+
Returns:
|
| 142 |
+
np.ndarray: np array of decoded frames of shape (num_frames, height, width, 3).
|
| 143 |
+
'''
|
| 144 |
+
frames = []
|
| 145 |
+
container.seek(0)
|
| 146 |
+
start_index = indices[0]
|
| 147 |
+
end_index = indices[-1]
|
| 148 |
+
for i, frame in enumerate(container.decode(video=0)):
|
| 149 |
+
if i > end_index:
|
| 150 |
+
break
|
| 151 |
+
if i >= start_index and i in indices:
|
| 152 |
+
frames.append(frame)
|
| 153 |
+
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
|
| 154 |
+
|
| 155 |
+
def eval_video(prompt, video:str):
|
| 156 |
+
container = av.open(video)
|
| 157 |
+
|
| 158 |
+
# sample uniformly 8 frames from the video
|
| 159 |
+
total_frames = container.streams.video[0].frames
|
| 160 |
+
if total_frames > MAX_NUM_FRAMES:
|
| 161 |
+
indices = np.arange(0, total_frames, total_frames / MAX_NUM_FRAMES).astype(int)
|
| 162 |
+
else:
|
| 163 |
+
indices = np.arange(total_frames)
|
| 164 |
+
video_frames = read_video_pyav(container, indices)
|
| 165 |
+
|
| 166 |
+
frames = [Image.fromarray(x) for x in video_frames]
|
| 167 |
+
|
| 168 |
+
eval_prompt = VIDEO_EVAL_PROMPT.format(text_prompt=prompt)
|
| 169 |
+
eval_prompt += "<video>"
|
| 170 |
+
user_role = conv_template.roles[0]
|
| 171 |
+
assistant_role = conv_template.roles[1]
|
| 172 |
+
chat_messages = [
|
| 173 |
+
{
|
| 174 |
+
"role": user_role,
|
| 175 |
+
"text": eval_prompt
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"role": assistant_role,
|
| 179 |
+
"text": ""
|
| 180 |
+
}
|
| 181 |
+
]
|
| 182 |
+
response = generate(None, [frames], chat_messages)
|
| 183 |
+
return response
|
| 184 |
+
|
| 185 |
+
def build_demo():
|
| 186 |
+
with gr.Blocks() as demo:
|
| 187 |
+
gr.Markdown("""
|
| 188 |
+
## Video Evaluation
|
| 189 |
+
upload a video along with a text prompt when generating the video, this model will evaluate the video's quality from 7 different dimensions.
|
| 190 |
+
""")
|
| 191 |
+
with gr.Row():
|
| 192 |
+
video = gr.Video(width=500, label="Video")
|
| 193 |
+
with gr.Column():
|
| 194 |
+
eval_prompt_template = gr.Textbox(VIDEO_EVAL_PROMPT.strip(' \n'), label="Evaluation Prompt Template", interactive=False, max_lines=26)
|
| 195 |
+
video_prompt = gr.Textbox(label="Text Prompt", lines=1)
|
| 196 |
+
with gr.Row():
|
| 197 |
+
eval_button = gr.Button("Evaluate Video")
|
| 198 |
+
clear_button = gr.ClearButton([video, video_prompt])
|
| 199 |
+
eval_result = gr.Textbox(label="Evaluation result", interactive=False, lines=7)
|
| 200 |
+
|
| 201 |
+
eval_button.click(
|
| 202 |
+
eval_video, [video_prompt, video], [eval_result]
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
dummy_id = gr.Textbox("id", label="id", visible=False, min_width=50)
|
| 206 |
+
dummy_output = gr.Textbox("reference score", label="reference scores", visible=False, lines=7)
|
| 207 |
+
|
| 208 |
+
gr.Examples(
|
| 209 |
+
examples=
|
| 210 |
+
[
|
| 211 |
+
[
|
| 212 |
+
item['id'],
|
| 213 |
+
item['prompt'],
|
| 214 |
+
item['video'],
|
| 215 |
+
item['conversations'][1]['value']
|
| 216 |
+
] for item in examples
|
| 217 |
+
],
|
| 218 |
+
inputs=[dummy_id, video_prompt, video, dummy_output],
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
# gr.Markdown("""
|
| 222 |
+
# ## Citation
|
| 223 |
+
# ```
|
| 224 |
+
# @article{jiang2024mantis,
|
| 225 |
+
# title={MANTIS: Interleaved Multi-Image Instruction Tuning},
|
| 226 |
+
# author={Jiang, Dongfu and He, Xuan and Zeng, Huaye and Wei, Con and Ku, Max and Liu, Qian and Chen, Wenhu},
|
| 227 |
+
# journal={arXiv preprint arXiv:2405.01483},
|
| 228 |
+
# year={2024}
|
| 229 |
+
# }
|
| 230 |
+
# ```""")
|
| 231 |
+
return demo
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
if __name__ == "__main__":
|
| 235 |
+
demo = build_demo()
|
| 236 |
+
demo.launch(share=True)
|
app_regression.py
ADDED
|
@@ -0,0 +1,223 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import spaces
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
import json
|
| 6 |
+
import numpy as np
|
| 7 |
+
import av
|
| 8 |
+
import torch
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import functools
|
| 11 |
+
from transformers import AutoProcessor, AutoConfig
|
| 12 |
+
from models.idefics2 import Idefics2ForSequenceClassification
|
| 13 |
+
from models.conversation import conv_templates
|
| 14 |
+
from typing import List
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
processor = AutoProcessor.from_pretrained("TIGER-Lab/VideoScore")
|
| 18 |
+
model = Idefics2ForSequenceClassification.from_pretrained("TIGER-Lab/VideoScore", torch_dtype=torch.bfloat16).eval()
|
| 19 |
+
|
| 20 |
+
MAX_NUM_FRAMES = 24
|
| 21 |
+
conv_template = conv_templates["idefics_2"]
|
| 22 |
+
|
| 23 |
+
with open("./examples/all_subsets.json", 'r') as f:
|
| 24 |
+
examples = json.load(f)
|
| 25 |
+
|
| 26 |
+
for item in examples:
|
| 27 |
+
video_id = item['images'][0].split("_")[0]
|
| 28 |
+
item['images'] = [os.path.join("./examples", video_id, x) for x in item['images']]
|
| 29 |
+
item['video'] = os.path.join("./examples", item['video'])
|
| 30 |
+
|
| 31 |
+
with open("./examples/hd.json", 'r') as f:
|
| 32 |
+
hd_examples = json.load(f)
|
| 33 |
+
|
| 34 |
+
for item in hd_examples:
|
| 35 |
+
item['video'] = os.path.join("./examples", item['video'])
|
| 36 |
+
|
| 37 |
+
examples = hd_examples + examples
|
| 38 |
+
|
| 39 |
+
VIDEO_EVAL_PROMPT = """
|
| 40 |
+
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
|
| 41 |
+
please watch the following frames of a given video and see the text prompt for generating the video,
|
| 42 |
+
then give scores from 5 different dimensions:
|
| 43 |
+
(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color
|
| 44 |
+
(2) temporal consistency, the consistency of objects or humans in video
|
| 45 |
+
(3) dynamic degree, the degree of dynamic changes
|
| 46 |
+
(4) text-to-video alignment, the alignment between the text prompt and the video content
|
| 47 |
+
(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge
|
| 48 |
+
|
| 49 |
+
For each dimension, output a number from [1,2,3,4],
|
| 50 |
+
in which '1' means 'Bad', '2' means 'Average', '3' means 'Good',
|
| 51 |
+
'4' means 'Real' or 'Perfect' (the video is like a real video)
|
| 52 |
+
Here is an output example:
|
| 53 |
+
visual quality: 4
|
| 54 |
+
temporal consistency: 4
|
| 55 |
+
dynamic degree: 3
|
| 56 |
+
text-to-video alignment: 1
|
| 57 |
+
factual consistency: 2
|
| 58 |
+
|
| 59 |
+
For this video, the text prompt is "{text_prompt}",
|
| 60 |
+
all the frames of video are as follows:
|
| 61 |
+
|
| 62 |
+
"""
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
space_description="""\
|
| 67 |
+
[📃Paper](https://arxiv.org/abs/2406.15252) | [🌐Website](https://tiger-ai-lab.github.io/VideoScore/) | [💻Github](https://github.com/TIGER-AI-Lab/VideoScore) | [🛢️Datasets](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback) | [🤗Model](https://huggingface.co/TIGER-Lab/VideoScore) | [🤗Demo](https://huggingface.co/spaces/TIGER-Lab/VideoScore)
|
| 68 |
+
|
| 69 |
+
- VideoScore is a video quality evaluation model, taking [Mantis-8B-Idefics2](https://huggingface.co/TIGER-Lab/Mantis-8B-Idefics2) as base-model
|
| 70 |
+
and trained on [VideoFeedback](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback),
|
| 71 |
+
a large video evaluation dataset with multi-aspect human scores.
|
| 72 |
+
|
| 73 |
+
- VideoScore can reach 75+ Spearman correlation with humans on VideoEval-test, surpassing all the MLLM-prompting methods and feature-based metrics.
|
| 74 |
+
|
| 75 |
+
- VideoScore also beat the best baselines on other three benchmarks EvalCrafter, GenAI-Bench and VBench, showing high alignment with human evaluations.
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
aspect_mapping= [
|
| 80 |
+
"visual quality",
|
| 81 |
+
"temporal consistency",
|
| 82 |
+
"dynamic degree",
|
| 83 |
+
"text-to-video alignment",
|
| 84 |
+
"factual consistency",
|
| 85 |
+
]
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
@spaces.GPU(duration=60)
|
| 89 |
+
def score(prompt:str, images:List[Image.Image]):
|
| 90 |
+
if not prompt:
|
| 91 |
+
raise gr.Error("Please provide a prompt")
|
| 92 |
+
model.to("cuda")
|
| 93 |
+
if not images:
|
| 94 |
+
images = None
|
| 95 |
+
|
| 96 |
+
flatten_images = []
|
| 97 |
+
for x in images:
|
| 98 |
+
if isinstance(x, list):
|
| 99 |
+
flatten_images.extend(x)
|
| 100 |
+
else:
|
| 101 |
+
flatten_images.append(x)
|
| 102 |
+
|
| 103 |
+
flatten_images = [Image.open(x) if isinstance(x, str) else x for x in flatten_images]
|
| 104 |
+
inputs = processor(text=prompt, images=flatten_images, return_tensors="pt")
|
| 105 |
+
inputs = {k: v.to(model.device) for k, v in inputs.items()}
|
| 106 |
+
with torch.no_grad():
|
| 107 |
+
outputs = model(**inputs)
|
| 108 |
+
|
| 109 |
+
logits = outputs.logits
|
| 110 |
+
num_aspects = logits.shape[-1]
|
| 111 |
+
aspects = [aspect_mapping[i] for i in range(num_aspects)]
|
| 112 |
+
|
| 113 |
+
aspect_scores = {}
|
| 114 |
+
for i, aspect in enumerate(aspects):
|
| 115 |
+
aspect_scores[aspect] = round(logits[0, i].item(), 2)
|
| 116 |
+
return aspect_scores
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def read_video_pyav(container, indices):
|
| 120 |
+
'''
|
| 121 |
+
Decode the video with PyAV decoder.
|
| 122 |
+
|
| 123 |
+
Args:
|
| 124 |
+
container (av.container.input.InputContainer): PyAV container.
|
| 125 |
+
indices (List[int]): List of frame indices to decode.
|
| 126 |
+
|
| 127 |
+
Returns:
|
| 128 |
+
np.ndarray: np array of decoded frames of shape (num_frames, height, width, 3).
|
| 129 |
+
'''
|
| 130 |
+
frames = []
|
| 131 |
+
container.seek(0)
|
| 132 |
+
start_index = indices[0]
|
| 133 |
+
end_index = indices[-1]
|
| 134 |
+
for i, frame in enumerate(container.decode(video=0)):
|
| 135 |
+
if i > end_index:
|
| 136 |
+
break
|
| 137 |
+
if i >= start_index and i in indices:
|
| 138 |
+
frames.append(frame)
|
| 139 |
+
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
|
| 140 |
+
|
| 141 |
+
def eval_video(prompt, video:str):
|
| 142 |
+
container = av.open(video)
|
| 143 |
+
|
| 144 |
+
# sample uniformly 8 frames from the video
|
| 145 |
+
total_frames = container.streams.video[0].frames
|
| 146 |
+
if total_frames > MAX_NUM_FRAMES:
|
| 147 |
+
indices = np.arange(0, total_frames, total_frames / MAX_NUM_FRAMES).astype(int)
|
| 148 |
+
else:
|
| 149 |
+
indices = np.arange(total_frames)
|
| 150 |
+
video_frames = read_video_pyav(container, indices)
|
| 151 |
+
|
| 152 |
+
frames = [Image.fromarray(x) for x in video_frames]
|
| 153 |
+
|
| 154 |
+
eval_prompt = VIDEO_EVAL_PROMPT.format(text_prompt=prompt)
|
| 155 |
+
|
| 156 |
+
num_image_token = eval_prompt.count("<image>")
|
| 157 |
+
if num_image_token < len(frames):
|
| 158 |
+
eval_prompt += "<image> " * (len(frames) - num_image_token)
|
| 159 |
+
|
| 160 |
+
aspect_scores = score(eval_prompt, [frames])
|
| 161 |
+
return aspect_scores
|
| 162 |
+
|
| 163 |
+
def build_demo():
|
| 164 |
+
with gr.Blocks() as demo:
|
| 165 |
+
|
| 166 |
+
gr.Markdown("## VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation")
|
| 167 |
+
with gr.Row():
|
| 168 |
+
gr.Markdown(space_description)
|
| 169 |
+
gr.Image("https://tiger-ai-lab.github.io/VideoScore/static/images/teaser.png", label="Teaser")
|
| 170 |
+
|
| 171 |
+
gr.Markdown("### Try VideoScore (Regression) with your own text prompt and videos.")
|
| 172 |
+
with gr.Row():
|
| 173 |
+
video = gr.Video(width=500, label="Video")
|
| 174 |
+
with gr.Column():
|
| 175 |
+
eval_prompt_template = gr.Textbox(VIDEO_EVAL_PROMPT.strip(' \n'), label="Evaluation Prompt Template", interactive=False, max_lines=26)
|
| 176 |
+
video_prompt = gr.Textbox(label="Text Prompt", lines=1)
|
| 177 |
+
with gr.Row():
|
| 178 |
+
eval_button = gr.Button("Evaluate Video")
|
| 179 |
+
clear_button = gr.ClearButton([video, video_prompt])
|
| 180 |
+
# eval_result = gr.Textbox(label="Evaluation result", interactive=False, lines=7)
|
| 181 |
+
eval_result = gr.Json(label="Evaluation result")
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
eval_button.click(
|
| 185 |
+
eval_video, [video_prompt, video], [eval_result]
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
dummy_id = gr.Textbox("id", label="id", visible=False, min_width=50)
|
| 189 |
+
# dummy_output = gr.Textbox("reference score", label="reference scores", visible=False, lines=7)
|
| 190 |
+
|
| 191 |
+
gr.Examples(
|
| 192 |
+
examples=
|
| 193 |
+
[
|
| 194 |
+
[
|
| 195 |
+
# item['id'],
|
| 196 |
+
item['prompt'],
|
| 197 |
+
item['video'],
|
| 198 |
+
# item['conversations'][1]['value']
|
| 199 |
+
] for item in examples if item['prompt']
|
| 200 |
+
],
|
| 201 |
+
inputs=[video_prompt, video],
|
| 202 |
+
# inputs=[dummy_id, video_prompt, video, dummy_output],
|
| 203 |
+
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
gr.Markdown("""
|
| 207 |
+
## Citation
|
| 208 |
+
```
|
| 209 |
+
@article{he2024videoscore,
|
| 210 |
+
title = {VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation},
|
| 211 |
+
author = {He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Yuchen and Chen, Wenhu},
|
| 212 |
+
journal = {ArXiv},
|
| 213 |
+
year = {2024},
|
| 214 |
+
volume={abs/2406.15252},
|
| 215 |
+
url = {https://arxiv.org/abs/2406.15252},
|
| 216 |
+
}
|
| 217 |
+
```""")
|
| 218 |
+
return demo
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
if __name__ == "__main__":
|
| 222 |
+
demo = build_demo()
|
| 223 |
+
demo.launch(share=True)
|
barchart.jpeg
ADDED
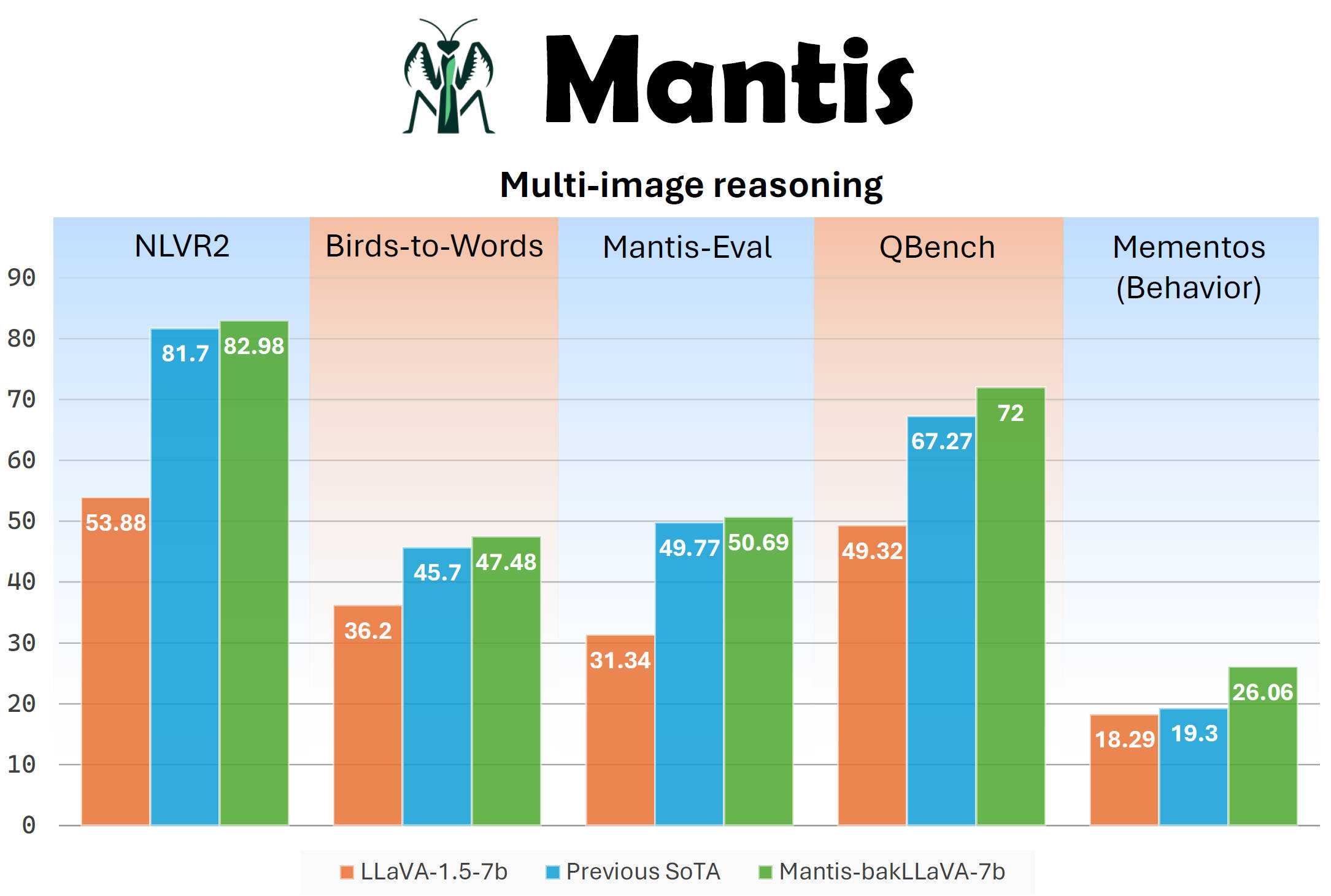
|
barchart_single_image_vqa.jpeg
ADDED

|
examples/1006309.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:14852166b4443cb90576de69b439b92b88770fb29dc30fb5fafcb8a497d79ac5
|
| 3 |
+
size 101215
|
examples/1006309/1006309_00.jpg
ADDED

|
examples/1006309/1006309_01.jpg
ADDED

|
examples/1006309/1006309_02.jpg
ADDED

|
examples/1006309/1006309_03.jpg
ADDED

|
examples/1006309/1006309_04.jpg
ADDED

|
examples/1006309/1006309_05.jpg
ADDED

|
examples/1006309/1006309_06.jpg
ADDED

|
examples/1006309/1006309_07.jpg
ADDED

|
examples/1006309/1006309_08.jpg
ADDED

|
examples/1006309/1006309_09.jpg
ADDED

|
examples/1006309/1006309_10.jpg
ADDED

|
examples/1006309/1006309_11.jpg
ADDED

|
examples/1006309/1006309_12.jpg
ADDED

|
examples/1006309/1006309_13.jpg
ADDED

|
examples/1006309/1006309_14.jpg
ADDED

|
examples/1006309/1006309_15.jpg
ADDED

|
examples/3005033.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:090465f03d91787ae683591248d5aefd48b4412da8f09a950749bfab72a5c394
|
| 3 |
+
size 42856
|
examples/3005033/3005033_00.jpg
ADDED

|
examples/3005033/3005033_01.jpg
ADDED

|
examples/3005033/3005033_02.jpg
ADDED

|
examples/3005033/3005033_03.jpg
ADDED

|
examples/3005033/3005033_04.jpg
ADDED

|
examples/3005033/3005033_05.jpg
ADDED

|
examples/3005033/3005033_06.jpg
ADDED

|
examples/3005033/3005033_07.jpg
ADDED

|
examples/3005033/3005033_08.jpg
ADDED

|
examples/3005033/3005033_09.jpg
ADDED

|
examples/3005033/3005033_10.jpg
ADDED

|
examples/3005033/3005033_11.jpg
ADDED

|
examples/3005033/3005033_12.jpg
ADDED

|
examples/3005033/3005033_13.jpg
ADDED

|
examples/3005033/3005033_14.jpg
ADDED

|
examples/3005033/3005033_15.jpg
ADDED

|
examples/7004180.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2d255b025443ac89854e9529341767aea3039c1b5df2d6d37cf6fc8d01410b67
|
| 3 |
+
size 19932
|
examples/7004180/7004180_00.jpg
ADDED

|
examples/7004180/7004180_01.jpg
ADDED

|
examples/7004180/7004180_02.jpg
ADDED

|
examples/7004180/7004180_03.jpg
ADDED

|
examples/7004180/7004180_04.jpg
ADDED

|
examples/7004180/7004180_05.jpg
ADDED

|
examples/7004180/7004180_06.jpg
ADDED

|
examples/7004180/7004180_07.jpg
ADDED

|