initial commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .streamlit/config.toml +2 -0
- VaultChem.png +0 -0
- app.py +662 -0
- chemdata.py +340 -0
- deployment.zip +3 -0
- deployment/FHE_timings.json +1 -0
- deployment/deployment_0/best_params_demo_0.json +1 -0
- deployment/deployment_0/client.zip +3 -0
- deployment/deployment_0/regression_0.png +0 -0
- deployment/deployment_0/server.zip +3 -0
- deployment/deployment_0/task_name.txt +1 -0
- deployment/deployment_0/versions.json +1 -0
- deployment/deployment_1/best_params_demo_1.json +1 -0
- deployment/deployment_1/client.zip +3 -0
- deployment/deployment_1/regression_1.png +0 -0
- deployment/deployment_1/server.zip +3 -0
- deployment/deployment_1/task_name.txt +1 -0
- deployment/deployment_1/versions.json +1 -0
- deployment/deployment_2/best_params_demo_2.json +1 -0
- deployment/deployment_2/client.zip +3 -0
- deployment/deployment_2/regression_2.png +0 -0
- deployment/deployment_2/server.zip +3 -0
- deployment/deployment_2/task_name.txt +1 -0
- deployment/deployment_2/versions.json +1 -0
- deployment/deployment_3/best_params_demo_3.json +1 -0
- deployment/deployment_3/client.zip +3 -0
- deployment/deployment_3/regression_3.png +0 -0
- deployment/deployment_3/server.zip +3 -0
- deployment/deployment_3/task_name.txt +1 -0
- deployment/deployment_3/versions.json +1 -0
- deployment/deployment_4/best_params_demo_4.json +1 -0
- deployment/deployment_4/client.zip +3 -0
- deployment/deployment_4/regression_4.png +0 -0
- deployment/deployment_4/server.zip +3 -0
- deployment/deployment_4/task_name.txt +1 -0
- deployment/deployment_4/versions.json +1 -0
- deployment/deployment_5/best_params_demo_5.json +1 -0
- deployment/deployment_5/client.zip +3 -0
- deployment/deployment_5/regression_5.png +0 -0
- deployment/deployment_5/server.zip +3 -0
- deployment/deployment_5/task_name.txt +1 -0
- deployment/deployment_5/versions.json +1 -0
- description.txt +0 -0
- logo_app.png +0 -0
- regress_utils.py +342 -0
- requirements.txt +18 -0
- run_app.sh +1 -0
- scheme2.png +3 -0
- scheme2.svg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
scheme2.png filter=lfs diff=lfs merge=lfs -text
|
.streamlit/config.toml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[theme]
|
| 2 |
+
base="light"
|
VaultChem.png
ADDED
|
app.py
ADDED
|
@@ -0,0 +1,662 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Uncomment if run locally
|
| 2 |
+
import os
|
| 3 |
+
#import sys
|
| 4 |
+
#sys.path.append(os.path.abspath("../../../molvault"))
|
| 5 |
+
#sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
|
| 6 |
+
|
| 7 |
+
from requests import head
|
| 8 |
+
from concrete.ml.deployment import FHEModelClient
|
| 9 |
+
import numpy
|
| 10 |
+
import os
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
import requests
|
| 13 |
+
import json
|
| 14 |
+
import base64
|
| 15 |
+
import subprocess
|
| 16 |
+
import shutil
|
| 17 |
+
import time
|
| 18 |
+
from chemdata import get_ECFP_AND_FEATURES
|
| 19 |
+
import streamlit as st
|
| 20 |
+
import subprocess
|
| 21 |
+
import cairosvg
|
| 22 |
+
from rdkit import Chem
|
| 23 |
+
from rdkit.Chem import AllChem
|
| 24 |
+
from rdkit.Chem.Draw import rdMolDraw2D
|
| 25 |
+
import pandas as pd
|
| 26 |
+
from st_keyup import st_keyup
|
| 27 |
+
|
| 28 |
+
st.set_page_config(layout="centered", page_title="VaultChem")
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def local_css(file_name):
|
| 32 |
+
with open(file_name) as f:
|
| 33 |
+
st.markdown(f"<style>{f.read()}</style>", unsafe_allow_html=True)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
local_css("style.css")
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def img_to_bytes(img_path):
|
| 40 |
+
img_bytes = Path(img_path).read_bytes()
|
| 41 |
+
encoded = base64.b64encode(img_bytes).decode()
|
| 42 |
+
return encoded
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def img_to_html(img_path, width=None):
|
| 46 |
+
img_bytes = img_to_bytes(img_path)
|
| 47 |
+
if width:
|
| 48 |
+
img_html = "<img src='data:image/png;base64,{}' class='img-fluid' style='width:{};'>".format(
|
| 49 |
+
img_bytes, width
|
| 50 |
+
)
|
| 51 |
+
else:
|
| 52 |
+
img_html = "<img src='data:image/png;base64,{}' class='img-fluid'>".format(
|
| 53 |
+
img_bytes
|
| 54 |
+
)
|
| 55 |
+
return img_html
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
# Start timing
|
| 59 |
+
formatted_text = (
|
| 60 |
+
"<h1 style='text-align: center;'>"
|
| 61 |
+
"<span style='color: red;'>Pharmacokinetics</span>"
|
| 62 |
+
"<span style='color: black;'> of </span>"
|
| 63 |
+
"<span style='color: blue;'>🤫confidential🤫</span>"
|
| 64 |
+
"<span style='color: black;'> molecules</span>"
|
| 65 |
+
"</h1>"
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
st.markdown(formatted_text, unsafe_allow_html=True)
|
| 69 |
+
|
| 70 |
+
interesting_text = """
|
| 71 |
+
Machine learning (**ML**) has become a cornerstone of modern drug discovery. However, the data used to evaluate the ML models is often **confidential**.
|
| 72 |
+
This is especially true for the pharmaceutical industry where new drug candidates are considered as the most valuable asset.
|
| 73 |
+
Therefore chemical companies are reluctant to share their data with third parties, for instance to use ML services provided by other companies.
|
| 74 |
+
We developed an application that allows predicting properties of molecules **without sharing them**.
|
| 75 |
+
That means an organization "A" can use any server - even an untrusted environment - outside of their infrastructure to perform the prediction.
|
| 76 |
+
This way organization "A" can benefit from ML services provided by organization "B" without sharing their confidential data.
|
| 77 |
+
|
| 78 |
+
🪄 **The magic?** 🪄
|
| 79 |
+
|
| 80 |
+
The server on which the prediction is computed will never see the molecule in clear text, but will still compute an encrypted prediction.
|
| 81 |
+
Why is this **magic**? Because this is equivalent to computing the prediction on the molecule in clear text, but without sharing the molecule with the server.
|
| 82 |
+
Even if organization "B" - or in fact any other party - would try to steal the data, they would only see the encrypted molecular data.
|
| 83 |
+
Only the party that has the private key (organization "A") can decrypt the prediction. This is possible using a method called "Fully homomorphic encryption" (FHE).
|
| 84 |
+
This special encryption scheme allows to perform computations on encrypted data.
|
| 85 |
+
The code used for the FHE prediction is available in the open-source library <a href="https://docs.zama.ai/concrete-ml" target="_blank">Concrete ML</a>.
|
| 86 |
+
\n
|
| 87 |
+
**What are the steps involved?**
|
| 88 |
+
\n
|
| 89 |
+
Find out below! 👇
|
| 90 |
+
You can try it out yourself by entering a molecule and clicking on the buttons.
|
| 91 |
+
"""
|
| 92 |
+
|
| 93 |
+
st.markdown(
|
| 94 |
+
f"{interesting_text}",
|
| 95 |
+
unsafe_allow_html=True,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
st.divider()
|
| 99 |
+
|
| 100 |
+
st.markdown(
|
| 101 |
+
"<p style='text-align: center; color: grey;'>"
|
| 102 |
+
+ img_to_html("scheme2.png", width="80%")
|
| 103 |
+
+ "</p>",
|
| 104 |
+
unsafe_allow_html=True,
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
# Define your data
|
| 108 |
+
st.divider()
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
# This repository's directory
|
| 112 |
+
REPO_DIR = Path(__file__).parent
|
| 113 |
+
subprocess.Popen(["uvicorn", "server:app"], cwd=REPO_DIR)
|
| 114 |
+
|
| 115 |
+
# if not exists, create a directory for the FHE keys called .fhe_keys
|
| 116 |
+
if not os.path.exists(".fhe_keys"):
|
| 117 |
+
os.mkdir(".fhe_keys")
|
| 118 |
+
# if not exists, create a directory for the tmp files called tmp
|
| 119 |
+
if not os.path.exists("tmp"):
|
| 120 |
+
os.mkdir("tmp")
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
# Wait 4 sec for the server to start
|
| 124 |
+
time.sleep(4)
|
| 125 |
+
|
| 126 |
+
# Encrypted data limit for the browser to display
|
| 127 |
+
# (encrypted data is too large to display in the browser)
|
| 128 |
+
ENCRYPTED_DATA_BROWSER_LIMIT = 500
|
| 129 |
+
N_USER_KEY_STORED = 20
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def clean_tmp_directory():
|
| 133 |
+
# Allow 20 user keys to be stored.
|
| 134 |
+
# Once that limitation is reached, deleted the oldest.
|
| 135 |
+
path_sub_directories = sorted(
|
| 136 |
+
[f for f in Path(".fhe_keys/").iterdir() if f.is_dir()], key=os.path.getmtime
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
user_ids = []
|
| 140 |
+
if len(path_sub_directories) > N_USER_KEY_STORED:
|
| 141 |
+
n_files_to_delete = len(path_sub_directories) - N_USER_KEY_STORED
|
| 142 |
+
for p in path_sub_directories[:n_files_to_delete]:
|
| 143 |
+
user_ids.append(p.name)
|
| 144 |
+
shutil.rmtree(p)
|
| 145 |
+
|
| 146 |
+
list_files_tmp = Path("tmp/").iterdir()
|
| 147 |
+
# Delete all files related to user_id
|
| 148 |
+
for file in list_files_tmp:
|
| 149 |
+
for user_id in user_ids:
|
| 150 |
+
if file.name.endswith(f"{user_id}.npy"):
|
| 151 |
+
file.unlink()
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def keygen():
|
| 155 |
+
# Clean tmp directory if needed
|
| 156 |
+
clean_tmp_directory()
|
| 157 |
+
|
| 158 |
+
print("Initializing FHEModelClient...")
|
| 159 |
+
task = st.session_state["task"]
|
| 160 |
+
# Let's create a user_id
|
| 161 |
+
user_id = numpy.random.randint(0, 2**32)
|
| 162 |
+
fhe_api = FHEModelClient(f"deployment/deployment_{task}", f".fhe_keys/{user_id}")
|
| 163 |
+
fhe_api.load()
|
| 164 |
+
|
| 165 |
+
# Generate a fresh key
|
| 166 |
+
fhe_api.generate_private_and_evaluation_keys(force=True)
|
| 167 |
+
evaluation_key = fhe_api.get_serialized_evaluation_keys()
|
| 168 |
+
|
| 169 |
+
numpy.save(f"tmp/tmp_evaluation_key_{user_id}.npy", evaluation_key)
|
| 170 |
+
|
| 171 |
+
return [list(evaluation_key)[:ENCRYPTED_DATA_BROWSER_LIMIT], user_id]
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
@st.cache_data
|
| 175 |
+
def encode_quantize_encrypt(text, user_id):
|
| 176 |
+
task = st.session_state["task"]
|
| 177 |
+
fhe_api = FHEModelClient(f"deployment/deployment_{task}", f".fhe_keys/{user_id}")
|
| 178 |
+
fhe_api.load()
|
| 179 |
+
|
| 180 |
+
encodings = get_ECFP_AND_FEATURES(text, radius=2, bits=1024).reshape(1, -1)
|
| 181 |
+
|
| 182 |
+
quantized_encodings = fhe_api.model.quantize_input(encodings).astype(numpy.uint8)
|
| 183 |
+
encrypted_quantized_encoding = fhe_api.quantize_encrypt_serialize(encodings)
|
| 184 |
+
|
| 185 |
+
# Save encrypted_quantized_encoding in a file, since too large to pass through regular Gradio
|
| 186 |
+
# buttons, https://github.com/gradio-app/gradio/issues/1877
|
| 187 |
+
numpy.save(
|
| 188 |
+
f"tmp/tmp_encrypted_quantized_encoding_{user_id}.npy",
|
| 189 |
+
encrypted_quantized_encoding,
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
# Compute size
|
| 193 |
+
encrypted_quantized_encoding_shorten = list(encrypted_quantized_encoding)[
|
| 194 |
+
:ENCRYPTED_DATA_BROWSER_LIMIT
|
| 195 |
+
]
|
| 196 |
+
encrypted_quantized_encoding_shorten_hex = "".join(
|
| 197 |
+
f"{i:02x}" for i in encrypted_quantized_encoding_shorten
|
| 198 |
+
)
|
| 199 |
+
return (
|
| 200 |
+
encodings[0],
|
| 201 |
+
quantized_encodings[0],
|
| 202 |
+
encrypted_quantized_encoding_shorten_hex,
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def run_fhe(user_id):
|
| 207 |
+
encoded_data_path = Path(f"tmp/tmp_encrypted_quantized_encoding_{user_id}.npy")
|
| 208 |
+
# if not user_id:
|
| 209 |
+
# print("You need to generate FHE keys first.")
|
| 210 |
+
# if not encoded_data_path.is_file():
|
| 211 |
+
# print("No encrypted data was found. Encrypt the data before trying to predict.")
|
| 212 |
+
|
| 213 |
+
# Read encrypted_quantized_encoding from the file
|
| 214 |
+
|
| 215 |
+
task = st.session_state["task"]
|
| 216 |
+
if st.session_state["fhe_prediction"] == "":
|
| 217 |
+
encrypted_quantized_encoding = numpy.load(encoded_data_path)
|
| 218 |
+
|
| 219 |
+
# Read evaluation_key from the file
|
| 220 |
+
evaluation_key = numpy.load(f"tmp/tmp_evaluation_key_{user_id}.npy")
|
| 221 |
+
|
| 222 |
+
# Use base64 to encode the encodings and evaluation key
|
| 223 |
+
encrypted_quantized_encoding = base64.b64encode(
|
| 224 |
+
encrypted_quantized_encoding
|
| 225 |
+
).decode()
|
| 226 |
+
encoded_evaluation_key = base64.b64encode(evaluation_key).decode()
|
| 227 |
+
|
| 228 |
+
query = {}
|
| 229 |
+
query["evaluation_key"] = encoded_evaluation_key
|
| 230 |
+
query["encrypted_encoding"] = encrypted_quantized_encoding
|
| 231 |
+
headers = {"Content-type": "application/json"}
|
| 232 |
+
# pdb.set_trace()
|
| 233 |
+
if task == "0":
|
| 234 |
+
response = requests.post(
|
| 235 |
+
"http://localhost:8000/predict_HLM",
|
| 236 |
+
data=json.dumps(query),
|
| 237 |
+
headers=headers,
|
| 238 |
+
)
|
| 239 |
+
elif task == "1":
|
| 240 |
+
response = requests.post(
|
| 241 |
+
"http://localhost:8000/predict_MDR1MDCK",
|
| 242 |
+
data=json.dumps(query),
|
| 243 |
+
headers=headers,
|
| 244 |
+
)
|
| 245 |
+
elif task == "2":
|
| 246 |
+
response = requests.post(
|
| 247 |
+
"http://localhost:8000/predict_SOLUBILITY",
|
| 248 |
+
data=json.dumps(query),
|
| 249 |
+
headers=headers,
|
| 250 |
+
)
|
| 251 |
+
elif task == "3":
|
| 252 |
+
response = requests.post(
|
| 253 |
+
"http://localhost:8000/predict_PROTEIN_BINDING_HUMAN",
|
| 254 |
+
data=json.dumps(query),
|
| 255 |
+
headers=headers,
|
| 256 |
+
)
|
| 257 |
+
elif task == "4":
|
| 258 |
+
response = requests.post(
|
| 259 |
+
"http://localhost:8000/predict_PROTEIN_BINDING_RAT",
|
| 260 |
+
data=json.dumps(query),
|
| 261 |
+
headers=headers,
|
| 262 |
+
)
|
| 263 |
+
elif task == "5":
|
| 264 |
+
response = requests.post(
|
| 265 |
+
"http://localhost:8000/predict_RLM_CLint",
|
| 266 |
+
data=json.dumps(query),
|
| 267 |
+
headers=headers,
|
| 268 |
+
)
|
| 269 |
+
else:
|
| 270 |
+
print("Invalid task number")
|
| 271 |
+
# pdb.set_trace()
|
| 272 |
+
encrypted_prediction = base64.b64decode(response.json()["encrypted_prediction"])
|
| 273 |
+
|
| 274 |
+
# Save encrypted_prediction in a file, since too large to pass through regular Gradio
|
| 275 |
+
# buttons, https://github.com/gradio-app/gradio/issues/1877
|
| 276 |
+
numpy.save(f"tmp/tmp_encrypted_prediction_{user_id}.npy", encrypted_prediction)
|
| 277 |
+
encrypted_prediction_shorten = list(encrypted_prediction)[
|
| 278 |
+
:ENCRYPTED_DATA_BROWSER_LIMIT
|
| 279 |
+
]
|
| 280 |
+
encrypted_prediction_shorten_hex = "".join(
|
| 281 |
+
f"{i:02x}" for i in encrypted_prediction_shorten
|
| 282 |
+
)
|
| 283 |
+
st.session_state["fhe_prediction"] = encrypted_prediction_shorten_hex
|
| 284 |
+
|
| 285 |
+
st.session_state["fhe_done"] = True
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
def decrypt_prediction(user_id):
|
| 289 |
+
encoded_data_path = Path(f"tmp/tmp_encrypted_prediction_{user_id}.npy")
|
| 290 |
+
|
| 291 |
+
# Read encrypted_prediction from the file
|
| 292 |
+
task = st.session_state["task"]
|
| 293 |
+
if st.session_state["decryption_done"] == False:
|
| 294 |
+
encrypted_prediction = numpy.load(encoded_data_path).tobytes()
|
| 295 |
+
|
| 296 |
+
fhe_api = FHEModelClient(
|
| 297 |
+
f"deployment/deployment_{task}", f".fhe_keys/{user_id}"
|
| 298 |
+
)
|
| 299 |
+
fhe_api.load()
|
| 300 |
+
|
| 301 |
+
# We need to retrieve the private key that matches the client specs (see issue #18)
|
| 302 |
+
fhe_api.generate_private_and_evaluation_keys(force=False)
|
| 303 |
+
|
| 304 |
+
predictions = fhe_api.deserialize_decrypt_dequantize(encrypted_prediction)
|
| 305 |
+
st.session_state["decryption_done"] = True
|
| 306 |
+
st.session_state["decrypted_prediction"] = predictions
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
def init_session_state():
|
| 310 |
+
if "molecule_submitted" not in st.session_state:
|
| 311 |
+
st.session_state["molecule_submitted"] = False
|
| 312 |
+
|
| 313 |
+
if "input_molecule" not in st.session_state:
|
| 314 |
+
st.session_state["input_molecule"] = ""
|
| 315 |
+
|
| 316 |
+
if "key_generated" not in st.session_state:
|
| 317 |
+
st.session_state["key_generated"] = False
|
| 318 |
+
|
| 319 |
+
if "evaluation_key" not in st.session_state:
|
| 320 |
+
st.session_state["evaluation_key"] = []
|
| 321 |
+
|
| 322 |
+
if "user_id" not in st.session_state:
|
| 323 |
+
st.session_state["user_id"] = -100
|
| 324 |
+
|
| 325 |
+
if "encrypt" not in st.session_state:
|
| 326 |
+
st.session_state["encrypt"] = False
|
| 327 |
+
|
| 328 |
+
if "molecule_info_list" not in st.session_state:
|
| 329 |
+
st.session_state["molecule_info_list"] = []
|
| 330 |
+
|
| 331 |
+
if "encrypt_tuple" not in st.session_state:
|
| 332 |
+
st.session_state["encrypt_tuple"] = ()
|
| 333 |
+
|
| 334 |
+
if "fhe_prediction" not in st.session_state:
|
| 335 |
+
st.session_state["fhe_prediction"] = ""
|
| 336 |
+
|
| 337 |
+
if "fhe_done" not in st.session_state:
|
| 338 |
+
st.session_state["fhe_done"] = False
|
| 339 |
+
|
| 340 |
+
if "decryption_done" not in st.session_state:
|
| 341 |
+
st.session_state["decryption_done"] = False
|
| 342 |
+
if "decrypted_prediction" not in st.session_state:
|
| 343 |
+
st.session_state[
|
| 344 |
+
"decrypted_prediction"
|
| 345 |
+
] = "" # actually a list of list. But python takes care as it is dynamically typed.
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
def molecule_submitted(text: str = st.session_state.get("molecule_to_test", "")):
|
| 349 |
+
msg_to_user = ""
|
| 350 |
+
if len(text) == 0:
|
| 351 |
+
msg_to_user = "Enter a non-empty molecule formula."
|
| 352 |
+
molecule_present = False
|
| 353 |
+
|
| 354 |
+
elif Chem.MolFromSmiles(text) == None:
|
| 355 |
+
msg_to_user = "Invalid Molecule. Please enter a valid molecule. How about trying Aspirin or Ibuprofen?"
|
| 356 |
+
molecule_present = False
|
| 357 |
+
|
| 358 |
+
else:
|
| 359 |
+
st.session_state["molecule_submitted"] = True
|
| 360 |
+
st.session_state["input_molecule"] = text
|
| 361 |
+
molecule_present = True
|
| 362 |
+
msg_to_user = "Molecule Submitted for Prediction"
|
| 363 |
+
|
| 364 |
+
st.session_state["molecule_info_list"].clear()
|
| 365 |
+
st.session_state["molecule_info_list"].append(molecule_present)
|
| 366 |
+
st.session_state["molecule_info_list"].append(msg_to_user)
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
def keygen_util():
|
| 370 |
+
if st.session_state["molecule_submitted"] == False:
|
| 371 |
+
pass
|
| 372 |
+
else:
|
| 373 |
+
if st.session_state["user_id"] == -100:
|
| 374 |
+
(st.session_state["evaluation_key"], st.session_state["user_id"]) = keygen()
|
| 375 |
+
st.session_state["key_generated"] = True
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
def encrpyt_data_util():
|
| 379 |
+
if st.session_state["key_generated"] == False:
|
| 380 |
+
pass
|
| 381 |
+
else:
|
| 382 |
+
if len(st.session_state["encrypt_tuple"]) == 0:
|
| 383 |
+
st.session_state["encrypt_tuple"] = encode_quantize_encrypt(
|
| 384 |
+
st.session_state["input_molecule"], st.session_state["user_id"]
|
| 385 |
+
)
|
| 386 |
+
st.session_state["encrypt"] = True
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
@st.cache_data
|
| 390 |
+
def mol_to_img(mol):
|
| 391 |
+
mol = Chem.MolFromSmiles(mol)
|
| 392 |
+
mol = AllChem.RemoveHs(mol)
|
| 393 |
+
AllChem.Compute2DCoords(mol)
|
| 394 |
+
drawer = rdMolDraw2D.MolDraw2DSVG(300, 300)
|
| 395 |
+
drawer.DrawMolecule(mol)
|
| 396 |
+
drawer.FinishDrawing()
|
| 397 |
+
svg = drawer.GetDrawingText()
|
| 398 |
+
return cairosvg.svg2png(bytestring=svg.encode("utf-8"))
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
def FHE_util():
|
| 402 |
+
run_fhe(st.session_state["user_id"])
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
def decrypt_util():
|
| 406 |
+
decrypt_prediction(st.session_state["user_id"])
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
def clear_session_state():
|
| 410 |
+
st.session_state.clear()
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
# Define global variables outside main function scope.
|
| 414 |
+
|
| 415 |
+
task_options = ["0", "1", "2", "3", "4", "5"]
|
| 416 |
+
task_mapping = {
|
| 417 |
+
"0": "HLM",
|
| 418 |
+
"1": "MDR-1-MDCK-ER",
|
| 419 |
+
"2": "Solubility",
|
| 420 |
+
"3": "Protein bind. human",
|
| 421 |
+
"4": "Protein bind. rat",
|
| 422 |
+
"5": "RLM",
|
| 423 |
+
}
|
| 424 |
+
unit_mapping = {
|
| 425 |
+
"0": "(mL/min/kg)",
|
| 426 |
+
"1": " ",
|
| 427 |
+
"2": "(ug/mL)",
|
| 428 |
+
"3": " (%)",
|
| 429 |
+
"4": " (%)",
|
| 430 |
+
"5": "(mL/min/kg)",
|
| 431 |
+
}
|
| 432 |
+
task_options = list(task_mapping.values())
|
| 433 |
+
|
| 434 |
+
# Create the dropdown menu
|
| 435 |
+
data_dict = {
|
| 436 |
+
"HLM": "Human Liver Microsomes: drug is metabolized by the liver",
|
| 437 |
+
"MDR-1-MDCK-ER": "MDR-1-MDCK-ER: drug is transported by the P-glycoprotein",
|
| 438 |
+
"Solubility": "How soluble a drug is in water",
|
| 439 |
+
"Protein bind. human": "Drug binding to human plasma proteins",
|
| 440 |
+
"Protein bind. rat": "Drug binding to rat plasma proteins",
|
| 441 |
+
"RLM": "Rat Liver Microsomes: Drug metabolism by a rat liver",
|
| 442 |
+
}
|
| 443 |
+
|
| 444 |
+
# Convert the dictionary to a DataFrame
|
| 445 |
+
data = pd.DataFrame(list(data_dict.items()), columns=["Property", "Explanation"])
|
| 446 |
+
|
| 447 |
+
user_id = 0
|
| 448 |
+
|
| 449 |
+
css_styling = """<style>
|
| 450 |
+
.table {
|
| 451 |
+
width: 100%;
|
| 452 |
+
margin: 10px 0 20px 0;
|
| 453 |
+
}
|
| 454 |
+
.table-striped tbody tr:nth-of-type(odd) {
|
| 455 |
+
background-color: rgba(0,0,0,.05);
|
| 456 |
+
}
|
| 457 |
+
.table-hover tbody tr:hover {
|
| 458 |
+
color: #563d7c;
|
| 459 |
+
background-color: rgba(0,0,0,.075);
|
| 460 |
+
}
|
| 461 |
+
.table thead th, .table tbody td {
|
| 462 |
+
text-align: center;
|
| 463 |
+
max-width: 150px; # Adjust this value as needed
|
| 464 |
+
word-wrap: break-word;
|
| 465 |
+
}
|
| 466 |
+
</style>"""
|
| 467 |
+
|
| 468 |
+
|
| 469 |
+
if __name__ == "__main__":
|
| 470 |
+
# Set up the Streamlit interface
|
| 471 |
+
init_session_state()
|
| 472 |
+
|
| 473 |
+
with st.container():
|
| 474 |
+
st.header(":green[Start]")
|
| 475 |
+
st.text(
|
| 476 |
+
"Run all the steps in order to predict the molecule's property. Why not all steps at once? Because we want to show you the steps involved in the process."
|
| 477 |
+
)
|
| 478 |
+
st.subheader("Step 0: Which property do you want to predict?")
|
| 479 |
+
st.text(
|
| 480 |
+
"This app can predict the following properties of confidential molecules:"
|
| 481 |
+
)
|
| 482 |
+
|
| 483 |
+
# Check if 'task' is not already in session_state
|
| 484 |
+
if "task" not in st.session_state:
|
| 485 |
+
# Initialize it with the first value of your options
|
| 486 |
+
st.session_state["task"] = "0"
|
| 487 |
+
|
| 488 |
+
# Custom HTML and CSS styling
|
| 489 |
+
html = data.to_html(index=False, classes="table table-striped table-hover")
|
| 490 |
+
|
| 491 |
+
# Custom styling
|
| 492 |
+
st.markdown(css_styling, unsafe_allow_html=True)
|
| 493 |
+
|
| 494 |
+
# Display the HTML table
|
| 495 |
+
st.write(html, unsafe_allow_html=True)
|
| 496 |
+
st.text("Which to predict?")
|
| 497 |
+
selected_label = st.selectbox(
|
| 498 |
+
"Choose a property",
|
| 499 |
+
task_options,
|
| 500 |
+
index=task_options.index(task_mapping[st.session_state["task"]]),
|
| 501 |
+
)
|
| 502 |
+
st.session_state["task"] = list(task_mapping.keys())[
|
| 503 |
+
task_options.index(selected_label)
|
| 504 |
+
]
|
| 505 |
+
|
| 506 |
+
st.subheader("Step 1: Submit a molecule")
|
| 507 |
+
|
| 508 |
+
x, y, z = st.columns(3)
|
| 509 |
+
|
| 510 |
+
with x:
|
| 511 |
+
st.text("")
|
| 512 |
+
|
| 513 |
+
with y:
|
| 514 |
+
submit_molecule = st.button(
|
| 515 |
+
"Try Aspirin",
|
| 516 |
+
on_click=molecule_submitted,
|
| 517 |
+
args=("CC(=O)OC1=CC=CC=C1C(=O)O",),
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
with z:
|
| 521 |
+
submit_molecule = st.button(
|
| 522 |
+
"Try Ibuprofen",
|
| 523 |
+
on_click=molecule_submitted,
|
| 524 |
+
args=("CC(Cc1ccc(cc1)C(C(=O)O)C)C",),
|
| 525 |
+
)
|
| 526 |
+
|
| 527 |
+
# Use the custom keyup component for text input
|
| 528 |
+
molecule_to_test = st_keyup(
|
| 529 |
+
label="Enter a molecular SMILES string or click on one of the buttons above",
|
| 530 |
+
value=st.session_state.get("molecule_to_test", ""),
|
| 531 |
+
)
|
| 532 |
+
submit_molecule = st.button(
|
| 533 |
+
"Submit",
|
| 534 |
+
on_click=molecule_submitted,
|
| 535 |
+
args=(molecule_to_test,),
|
| 536 |
+
)
|
| 537 |
+
|
| 538 |
+
if len(st.session_state["molecule_info_list"]) != 0:
|
| 539 |
+
if st.session_state["molecule_info_list"][0] == True:
|
| 540 |
+
st.success(st.session_state["molecule_info_list"][1])
|
| 541 |
+
mol_image = mol_to_img(st.session_state["input_molecule"])
|
| 542 |
+
# center the image
|
| 543 |
+
col1, col2, col3 = st.columns([1, 2, 1])
|
| 544 |
+
with col2:
|
| 545 |
+
st.image(mol_image)
|
| 546 |
+
st.caption(f"Input molecule {st.session_state['input_molecule']}")
|
| 547 |
+
|
| 548 |
+
else:
|
| 549 |
+
st.warning(st.session_state["molecule_info_list"][1], icon="⚠️")
|
| 550 |
+
|
| 551 |
+
with st.container():
|
| 552 |
+
st.subheader(
|
| 553 |
+
f"Step 2 : Generate encryption key (private to you) and an evaluation key (public)."
|
| 554 |
+
)
|
| 555 |
+
bullet_points = """
|
| 556 |
+
- Evaluation key is public and accessible by server.
|
| 557 |
+
- Private Keys are solely accessible by client for encrypting the information
|
| 558 |
+
before sending to the server. The same key is used for decryption after FHE inference.
|
| 559 |
+
"""
|
| 560 |
+
st.markdown(bullet_points, unsafe_allow_html=True)
|
| 561 |
+
button_gen_key = st.button(
|
| 562 |
+
"Click Here to generate Keys for this session", on_click=keygen_util
|
| 563 |
+
)
|
| 564 |
+
if st.session_state["key_generated"] == True:
|
| 565 |
+
st.success("Keys generated successfully", icon="🙌")
|
| 566 |
+
st.code(f'The user id for this session is {st.session_state["user_id"]} ')
|
| 567 |
+
else:
|
| 568 |
+
task = st.session_state["task"]
|
| 569 |
+
task_label = task_mapping[task]
|
| 570 |
+
st.warning(
|
| 571 |
+
f"Please submit the molecule first to test its {task_label} value",
|
| 572 |
+
icon="⚠️",
|
| 573 |
+
)
|
| 574 |
+
|
| 575 |
+
with st.container():
|
| 576 |
+
st.subheader(
|
| 577 |
+
f"Step 3 : Encrypt molecule using private key and send it to server."
|
| 578 |
+
)
|
| 579 |
+
encrypt_button = st.button("Click to Encrypt", on_click=encrpyt_data_util)
|
| 580 |
+
if st.session_state["encrypt"] == True:
|
| 581 |
+
st.success("Successfully Encrypted Data", icon="🙌")
|
| 582 |
+
st.text("The server can only see the encrypted data:")
|
| 583 |
+
st.code(
|
| 584 |
+
f"The encrypted quantized encoding is \n {st.session_state['encrypt_tuple'][2]}..."
|
| 585 |
+
)
|
| 586 |
+
else:
|
| 587 |
+
st.warning(
|
| 588 |
+
"Keys Not Yet Generated. Encryption can be done only after you generate keys."
|
| 589 |
+
)
|
| 590 |
+
|
| 591 |
+
with st.container():
|
| 592 |
+
st.subheader(f"Step 4 : Run encrypted prediction on server side.")
|
| 593 |
+
fhe_button = st.button("Click to Predict in FHE domain", on_click=FHE_util)
|
| 594 |
+
if st.session_state["fhe_done"]:
|
| 595 |
+
st.success("Prediction Done Successfuly in FHE domain", icon="🙌")
|
| 596 |
+
st.code(
|
| 597 |
+
f"The encrypted prediction is {st.session_state['fhe_prediction']}..."
|
| 598 |
+
)
|
| 599 |
+
else:
|
| 600 |
+
st.warning("Check if you have generated keys correctly.")
|
| 601 |
+
|
| 602 |
+
with st.container():
|
| 603 |
+
st.subheader(f"Step 5 : Decrypt the predictions with your private key.")
|
| 604 |
+
decrypt_button = st.button(
|
| 605 |
+
"Perform Decryption on FHE inferred prediction", on_click=decrypt_util
|
| 606 |
+
)
|
| 607 |
+
if st.session_state["decryption_done"]:
|
| 608 |
+
st.success("Decryption Done successfully!", icon="🙌")
|
| 609 |
+
value = st.session_state["decrypted_prediction"][0][0]
|
| 610 |
+
# 2 digit precision
|
| 611 |
+
value = round(value, 2)
|
| 612 |
+
unit = unit_mapping[st.session_state["task"]]
|
| 613 |
+
task_label = task_mapping[st.session_state["task"]]
|
| 614 |
+
st.code(
|
| 615 |
+
f"The Molecule {st.session_state['input_molecule']} has a {task_label} value of {value} {unit}"
|
| 616 |
+
)
|
| 617 |
+
st.toast("Session successfully completed!!!")
|
| 618 |
+
else:
|
| 619 |
+
st.warning("Check if FHE computation has been done.")
|
| 620 |
+
|
| 621 |
+
with st.container():
|
| 622 |
+
st.subheader(f"Step 6 : Reset to predict a new molecule")
|
| 623 |
+
reset_button = st.button("Click Here to Reset", on_click=clear_session_state)
|
| 624 |
+
x, y, z = st.columns(3)
|
| 625 |
+
with x:
|
| 626 |
+
st.write("")
|
| 627 |
+
with y:
|
| 628 |
+
st.markdown(
|
| 629 |
+
"<p style='text-align: center; color: grey;'>"
|
| 630 |
+
+ img_to_html("VaultChem.png", width="50%")
|
| 631 |
+
+ "</p>",
|
| 632 |
+
unsafe_allow_html=True,
|
| 633 |
+
)
|
| 634 |
+
st.markdown(
|
| 635 |
+
"<h6 style='text-align: center; color: grey;'>Visit our website : <a href='https://vaultchem.com/'>VaultChem</a></h6>",
|
| 636 |
+
unsafe_allow_html=True,
|
| 637 |
+
)
|
| 638 |
+
st.markdown(
|
| 639 |
+
"<h6 style='text-align: center; color: grey;'>Visit our Github Repo : <a href='https://github.com/vaultchem'>Github</a></h6>",
|
| 640 |
+
unsafe_allow_html=True,
|
| 641 |
+
)
|
| 642 |
+
st.markdown(
|
| 643 |
+
"<h6 style='text-align: center; color: grey;'>Built with <a href='https://streamlit.io/'>Streamlit</a>🎈</h6>",
|
| 644 |
+
unsafe_allow_html=True,
|
| 645 |
+
)
|
| 646 |
+
with z:
|
| 647 |
+
st.write("")
|
| 648 |
+
|
| 649 |
+
|
| 650 |
+
st.markdown(
|
| 651 |
+
"""
|
| 652 |
+
<div style="width: 100%; text-align: center; padding: 10px;">
|
| 653 |
+
The app was built with <a href="https://docs.zama.ai/concrete-ml" target="_blank">Concrete ML</a>,
|
| 654 |
+
an open-source library by <a href="https://www.zama.ai/" target="_blank">Zama</a>.
|
| 655 |
+
</div>
|
| 656 |
+
""",
|
| 657 |
+
unsafe_allow_html=True,
|
| 658 |
+
)
|
| 659 |
+
|
| 660 |
+
st.write(
|
| 661 |
+
":red[Please Note]: The content of your app is purely for educational and illustrative purposes and is not intended for the management of sensitive information. We disclaim any liability for potential financial or other damages. This platform is not a substitute for professional health advice, diagnosis, or treatment. Health-related inquiries should be directed to qualified medical professionals. Use of this app implies acknowledgment of these terms and understanding of its intended educational use."
|
| 662 |
+
)
|
chemdata.py
ADDED
|
@@ -0,0 +1,340 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gzip
|
| 2 |
+
import numpy as np
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import requests
|
| 5 |
+
from io import BytesIO
|
| 6 |
+
from concrete.ml.deployment import FHEModelClient, FHEModelDev, FHEModelServer
|
| 7 |
+
from concrete.ml.sklearn.svm import LinearSVR as LinearSVRZAMA
|
| 8 |
+
from concrete.ml.sklearn import XGBClassifier as XGBClassifierZAMA
|
| 9 |
+
from concrete.ml.sklearn import XGBRegressor as XGBRegressorZAMA
|
| 10 |
+
from concrete.ml.sklearn import LogisticRegression as LogisticRegressionZAMA
|
| 11 |
+
|
| 12 |
+
from sklearn.svm import LinearSVR as LinearSVR
|
| 13 |
+
import time
|
| 14 |
+
from shutil import copyfile
|
| 15 |
+
from tempfile import TemporaryDirectory
|
| 16 |
+
import pickle
|
| 17 |
+
import os
|
| 18 |
+
import time
|
| 19 |
+
from rdkit import Chem
|
| 20 |
+
from rdkit.Chem import AllChem
|
| 21 |
+
from rdkit.Chem import Lipinski
|
| 22 |
+
import numpy as np
|
| 23 |
+
from rdkit.Chem import rdMolDescriptors
|
| 24 |
+
from sklearn.model_selection import train_test_split
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def convert_numpy(obj):
|
| 28 |
+
if isinstance(obj, np.integer):
|
| 29 |
+
return int(obj)
|
| 30 |
+
elif isinstance(obj, np.floating):
|
| 31 |
+
return float(obj)
|
| 32 |
+
elif isinstance(obj, np.ndarray):
|
| 33 |
+
return obj.tolist()
|
| 34 |
+
else:
|
| 35 |
+
return obj
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class OnDiskNetwork:
|
| 39 |
+
"""Simulate a network on disk."""
|
| 40 |
+
|
| 41 |
+
def __init__(self):
|
| 42 |
+
# Create 3 temporary folder for server, client and dev with tempfile
|
| 43 |
+
self.server_dir = TemporaryDirectory()
|
| 44 |
+
self.client_dir = TemporaryDirectory()
|
| 45 |
+
self.dev_dir = TemporaryDirectory()
|
| 46 |
+
|
| 47 |
+
def client_send_evaluation_key_to_server(self, serialized_evaluation_keys):
|
| 48 |
+
"""Send the public key to the server."""
|
| 49 |
+
with open(self.server_dir.name + "/serialized_evaluation_keys.ekl", "wb") as f:
|
| 50 |
+
f.write(serialized_evaluation_keys)
|
| 51 |
+
|
| 52 |
+
def client_send_input_to_server_for_prediction(self, encrypted_input):
|
| 53 |
+
"""Send the input to the server and execute on the server in FHE."""
|
| 54 |
+
with open(self.server_dir.name + "/serialized_evaluation_keys.ekl", "rb") as f:
|
| 55 |
+
serialized_evaluation_keys = f.read()
|
| 56 |
+
time_begin = time.time()
|
| 57 |
+
encrypted_prediction = FHEModelServer(self.server_dir.name).run(
|
| 58 |
+
encrypted_input, serialized_evaluation_keys
|
| 59 |
+
)
|
| 60 |
+
time_end = time.time()
|
| 61 |
+
with open(self.server_dir.name + "/encrypted_prediction.enc", "wb") as f:
|
| 62 |
+
f.write(encrypted_prediction)
|
| 63 |
+
return time_end - time_begin
|
| 64 |
+
|
| 65 |
+
def dev_send_model_to_server(self):
|
| 66 |
+
"""Send the model to the server."""
|
| 67 |
+
copyfile(
|
| 68 |
+
self.dev_dir.name + "/server.zip", self.server_dir.name + "/server.zip"
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
def server_send_encrypted_prediction_to_client(self):
|
| 72 |
+
"""Send the encrypted prediction to the client."""
|
| 73 |
+
with open(self.server_dir.name + "/encrypted_prediction.enc", "rb") as f:
|
| 74 |
+
encrypted_prediction = f.read()
|
| 75 |
+
return encrypted_prediction
|
| 76 |
+
|
| 77 |
+
def dev_send_clientspecs_and_modelspecs_to_client(self):
|
| 78 |
+
"""Send the clientspecs and evaluation key to the client."""
|
| 79 |
+
copyfile(
|
| 80 |
+
self.dev_dir.name + "/client.zip", self.client_dir.name + "/client.zip"
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
def cleanup(self):
|
| 84 |
+
"""Clean up the temporary folders."""
|
| 85 |
+
self.server_dir.cleanup()
|
| 86 |
+
self.client_dir.cleanup()
|
| 87 |
+
self.dev_dir.cleanup()
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def generate_fingerprint(smiles, radius=2, bits=512):
|
| 91 |
+
mol = Chem.MolFromSmiles(smiles)
|
| 92 |
+
if mol is None:
|
| 93 |
+
return np.nan
|
| 94 |
+
|
| 95 |
+
fp = AllChem.GetMorganFingerprintAsBitVect(mol, radius=radius, nBits=bits)
|
| 96 |
+
|
| 97 |
+
return np.array(fp)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def compute_descriptors_from_smiles(smiles):
|
| 101 |
+
mol = Chem.MolFromSmiles(smiles)
|
| 102 |
+
MDlist = []
|
| 103 |
+
|
| 104 |
+
MDlist.append(rdMolDescriptors.CalcTPSA(mol))
|
| 105 |
+
MDlist.append(rdMolDescriptors.CalcFractionCSP3(mol))
|
| 106 |
+
MDlist.append(rdMolDescriptors.CalcNumAliphaticCarbocycles(mol))
|
| 107 |
+
MDlist.append(rdMolDescriptors.CalcNumAliphaticHeterocycles(mol))
|
| 108 |
+
MDlist.append(rdMolDescriptors.CalcNumAliphaticRings(mol))
|
| 109 |
+
MDlist.append(rdMolDescriptors.CalcNumAmideBonds(mol))
|
| 110 |
+
MDlist.append(rdMolDescriptors.CalcNumAromaticCarbocycles(mol))
|
| 111 |
+
MDlist.append(rdMolDescriptors.CalcNumAromaticHeterocycles(mol))
|
| 112 |
+
MDlist.append(rdMolDescriptors.CalcNumAromaticRings(mol))
|
| 113 |
+
MDlist.append(rdMolDescriptors.CalcNumLipinskiHBA(mol))
|
| 114 |
+
MDlist.append(rdMolDescriptors.CalcNumLipinskiHBD(mol))
|
| 115 |
+
MDlist.append(rdMolDescriptors.CalcNumHeteroatoms(mol))
|
| 116 |
+
MDlist.append(rdMolDescriptors.CalcNumHeterocycles(mol))
|
| 117 |
+
MDlist.append(rdMolDescriptors.CalcNumRings(mol))
|
| 118 |
+
MDlist.append(rdMolDescriptors.CalcNumRotatableBonds(mol))
|
| 119 |
+
MDlist.append(rdMolDescriptors.CalcNumSaturatedCarbocycles(mol))
|
| 120 |
+
MDlist.append(rdMolDescriptors.CalcNumSaturatedHeterocycles(mol))
|
| 121 |
+
MDlist.append(rdMolDescriptors.CalcNumSaturatedRings(mol))
|
| 122 |
+
MDlist.append(rdMolDescriptors.CalcHallKierAlpha(mol))
|
| 123 |
+
MDlist.append(rdMolDescriptors.CalcKappa1(mol))
|
| 124 |
+
MDlist.append(rdMolDescriptors.CalcKappa2(mol))
|
| 125 |
+
MDlist.append(rdMolDescriptors.CalcKappa3(mol))
|
| 126 |
+
MDlist.append(rdMolDescriptors.CalcChi0n(mol))
|
| 127 |
+
MDlist.append(rdMolDescriptors.CalcChi0v(mol))
|
| 128 |
+
MDlist.append(rdMolDescriptors.CalcChi1n(mol))
|
| 129 |
+
MDlist.append(rdMolDescriptors.CalcChi1v(mol))
|
| 130 |
+
MDlist.append(rdMolDescriptors.CalcChi2n(mol))
|
| 131 |
+
MDlist.append(rdMolDescriptors.CalcChi2v(mol))
|
| 132 |
+
MDlist.append(rdMolDescriptors.CalcChi3n(mol))
|
| 133 |
+
MDlist.append(rdMolDescriptors.CalcChi3v(mol))
|
| 134 |
+
MDlist.append(rdMolDescriptors.CalcChi4n(mol))
|
| 135 |
+
MDlist.append(rdMolDescriptors.CalcChi4v(mol))
|
| 136 |
+
MDlist.append(rdMolDescriptors.CalcExactMolWt(mol) / 100)
|
| 137 |
+
MDlist.append(Lipinski.HeavyAtomCount(mol))
|
| 138 |
+
MDlist.append(Lipinski.NumHAcceptors(mol))
|
| 139 |
+
MDlist.append(Lipinski.NumHDonors(mol))
|
| 140 |
+
MDlist.append(Lipinski.NOCount(mol))
|
| 141 |
+
|
| 142 |
+
return MDlist
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def get_ECFP_AND_FEATURES(smiles, radius=2, bits=512):
|
| 146 |
+
fp = generate_fingerprint(smiles, radius=radius, bits=bits)
|
| 147 |
+
MDlist = np.array(compute_descriptors_from_smiles(smiles))
|
| 148 |
+
return np.hstack([MDlist, fp])
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def compute_descriptors_from_smiles_list(SMILES):
|
| 152 |
+
X = [compute_descriptors_from_smiles(smi) for smi in SMILES]
|
| 153 |
+
return np.array(X)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
class ProcessToxChemData:
|
| 157 |
+
def __init__(self, bits=256):
|
| 158 |
+
self.bits = int(bits)
|
| 159 |
+
if not os.path.exists("data"):
|
| 160 |
+
os.makedirs("data")
|
| 161 |
+
self.save_file = "data/" + "save_file_Tox" + str(self.bits) + ".pkl"
|
| 162 |
+
|
| 163 |
+
if os.path.exists(self.save_file):
|
| 164 |
+
with open(self.save_file, "rb") as file:
|
| 165 |
+
self.adjusted_valid_entries_per_task = pickle.load(file)
|
| 166 |
+
else:
|
| 167 |
+
url = "https://github.com/deepchem/deepchem/blob/master/datasets/tox21.csv.gz?raw=true"
|
| 168 |
+
response = requests.get(url)
|
| 169 |
+
content = gzip.decompress(response.content)
|
| 170 |
+
self.df = pd.read_csv(BytesIO(content))
|
| 171 |
+
self.process()
|
| 172 |
+
self.save_adjusted_data()
|
| 173 |
+
|
| 174 |
+
def process(self):
|
| 175 |
+
self.adjusted_valid_entries_per_task = {}
|
| 176 |
+
|
| 177 |
+
# Iterating through each task column and extracting valid entries
|
| 178 |
+
for task in self.df.columns[
|
| 179 |
+
:-2
|
| 180 |
+
]: # Excluding mol_id and smiles from the iteration
|
| 181 |
+
valid_entries = self.df.dropna(subset=[task])[["mol_id", "smiles", task]]
|
| 182 |
+
|
| 183 |
+
valid_entries["fps"] = valid_entries["smiles"].apply(
|
| 184 |
+
lambda x: generate_fingerprint(x, radius=2, bits=self.bits)
|
| 185 |
+
)
|
| 186 |
+
valid_entries = valid_entries.dropna(subset=["fps"])
|
| 187 |
+
valid_entries["descriptors"] = valid_entries["smiles"].apply(
|
| 188 |
+
lambda x: compute_descriptors_from_smiles_list([x])[0]
|
| 189 |
+
)
|
| 190 |
+
valid_entries = valid_entries.dropna(subset=["descriptors"])
|
| 191 |
+
# Shuffle the rows
|
| 192 |
+
valid_entries = valid_entries.sample(frac=1, random_state=42).reset_index(
|
| 193 |
+
drop=True
|
| 194 |
+
)
|
| 195 |
+
self.adjusted_valid_entries_per_task[task] = valid_entries
|
| 196 |
+
self.adjusted_valid_entries_per_task[
|
| 197 |
+
task
|
| 198 |
+
] = self.adjusted_valid_entries_per_task[task].rename(columns={task: "y"})
|
| 199 |
+
|
| 200 |
+
def save_adjusted_data(self):
|
| 201 |
+
with open(self.save_file, "wb") as file:
|
| 202 |
+
pickle.dump(self.adjusted_valid_entries_per_task, file)
|
| 203 |
+
|
| 204 |
+
def get_X_y(self, task):
|
| 205 |
+
X = np.float_(np.stack(self.adjusted_valid_entries_per_task[task].fps.values))
|
| 206 |
+
y = self.adjusted_valid_entries_per_task[task].y.values.astype(int)
|
| 207 |
+
return X, y
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
class ProcessADMEChemData:
|
| 211 |
+
def __init__(self, bits=512, radius=2):
|
| 212 |
+
self.bits = int(bits)
|
| 213 |
+
self.radius = int(radius)
|
| 214 |
+
if not os.path.exists("data"):
|
| 215 |
+
os.makedirs("data")
|
| 216 |
+
self.save_file = "data/" + "save_file_ADME_{}_{}.pkl".format(
|
| 217 |
+
self.bits, self.radius
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
if os.path.exists(self.save_file):
|
| 221 |
+
with open(self.save_file, "rb") as file:
|
| 222 |
+
self.adjusted_valid_entries_per_task = pickle.load(file)
|
| 223 |
+
else:
|
| 224 |
+
url = "https://raw.githubusercontent.com/molecularinformatics/Computational-ADME/main/ADME_public_set_3521.csv"
|
| 225 |
+
self.df = pd.read_csv(url)
|
| 226 |
+
self.all_tasks = self.df.columns[4:].values
|
| 227 |
+
self.process()
|
| 228 |
+
self.save_adjusted_data()
|
| 229 |
+
|
| 230 |
+
def process(self):
|
| 231 |
+
SMILES = self.df["SMILES"].values
|
| 232 |
+
MOLS = [Chem.MolFromSmiles(smi) for smi in SMILES]
|
| 233 |
+
self.df["MOL"] = MOLS
|
| 234 |
+
self.df["smiles"] = [Chem.MolToSmiles(mol) for mol in MOLS]
|
| 235 |
+
self.adjusted_valid_entries_per_task = {}
|
| 236 |
+
|
| 237 |
+
# Iterating through each task column and extracting valid entries
|
| 238 |
+
for task in self.all_tasks: # Excluding mol_id and smiles from the iteration
|
| 239 |
+
valid_entries = self.df.dropna(subset=[task])[["Vendor ID", "smiles", task]]
|
| 240 |
+
|
| 241 |
+
valid_entries["fps"] = valid_entries["smiles"].apply(
|
| 242 |
+
lambda x: generate_fingerprint(x, radius=self.radius, bits=self.bits)
|
| 243 |
+
)
|
| 244 |
+
valid_entries = valid_entries.dropna(subset=["fps"])
|
| 245 |
+
|
| 246 |
+
valid_entries["descriptors"] = valid_entries["smiles"].apply(
|
| 247 |
+
lambda x: compute_descriptors_from_smiles_list([x])[0]
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
valid_entries = valid_entries.dropna(subset=["descriptors"])
|
| 251 |
+
|
| 252 |
+
## now stack the fps and descriptors
|
| 253 |
+
valid_entries["combined"] = valid_entries.apply(
|
| 254 |
+
lambda row: np.hstack([row["descriptors"], row["fps"]]), axis=1
|
| 255 |
+
)
|
| 256 |
+
valid_entries = valid_entries.sample(frac=1, random_state=42).reset_index(
|
| 257 |
+
drop=True
|
| 258 |
+
)
|
| 259 |
+
self.adjusted_valid_entries_per_task[task] = valid_entries
|
| 260 |
+
self.adjusted_valid_entries_per_task[
|
| 261 |
+
task
|
| 262 |
+
] = self.adjusted_valid_entries_per_task[task].rename(columns={task: "y"})
|
| 263 |
+
|
| 264 |
+
def save_adjusted_data(self):
|
| 265 |
+
with open(self.save_file, "wb") as file:
|
| 266 |
+
pickle.dump(self.adjusted_valid_entries_per_task, file)
|
| 267 |
+
|
| 268 |
+
def get_X_y(self, task):
|
| 269 |
+
X = np.float_(
|
| 270 |
+
np.stack(self.adjusted_valid_entries_per_task[task].combined.values)
|
| 271 |
+
)
|
| 272 |
+
y = self.adjusted_valid_entries_per_task[task].y.values.astype(float)
|
| 273 |
+
return X, y
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
def load_ADME_data(task, bits=256, radius=2):
|
| 277 |
+
"""
|
| 278 |
+
Load and split data for a specified task in cheminformatics.
|
| 279 |
+
|
| 280 |
+
This function processes chemical data for a given task using specified parameters for bits and radius.
|
| 281 |
+
It then splits the data into training and test sets.
|
| 282 |
+
|
| 283 |
+
Parameters:
|
| 284 |
+
task (str): The specific ADME task for which data needs to be processed.
|
| 285 |
+
bits (int, optional): The number of bits to be used in the fingerprint representation. Default is 256.
|
| 286 |
+
radius (int, optional): The radius parameter for the fingerprint calculation. Default is 2.
|
| 287 |
+
|
| 288 |
+
Returns:
|
| 289 |
+
tuple: A tuple containing the split data in the form (X_train, X_test, y_train, y_test),
|
| 290 |
+
where X_train and X_test are the features and y_train and y_test are the labels.
|
| 291 |
+
"""
|
| 292 |
+
data = ProcessADMEChemData(bits=bits, radius=radius)
|
| 293 |
+
X, y = data.get_X_y(task)
|
| 294 |
+
return train_test_split(X, y, test_size=0.2, random_state=42)
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
class ProcessGenericChemData:
|
| 298 |
+
def __init__(self, source_file, target="y", bits=512, radius=2):
|
| 299 |
+
self.source_file = source_file
|
| 300 |
+
self.target = target
|
| 301 |
+
|
| 302 |
+
self.bits = int(bits)
|
| 303 |
+
self.radius = int(radius)
|
| 304 |
+
|
| 305 |
+
self.df = pd.read_csv(self.source_file)
|
| 306 |
+
# check if a column called y exists in the csv file
|
| 307 |
+
if self.target not in self.df.columns:
|
| 308 |
+
raise ValueError(
|
| 309 |
+
"The target column {} does not exist in the source file {}".format(
|
| 310 |
+
self.target, self.source_file
|
| 311 |
+
)
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
self.process()
|
| 315 |
+
|
| 316 |
+
def process(self):
|
| 317 |
+
self.df = self.df.dropna()
|
| 318 |
+
SMILES = self.df["SMILES"].values
|
| 319 |
+
MOLS = [Chem.MolFromSmiles(smi) for smi in SMILES]
|
| 320 |
+
self.df["MOL"] = MOLS
|
| 321 |
+
self.df["smiles"] = [Chem.MolToSmiles(mol) for mol in MOLS]
|
| 322 |
+
self.df["fps"] = self.df["SMILES"].apply(
|
| 323 |
+
lambda x: generate_fingerprint(x, radius=self.radius, bits=self.bits)
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
def get_X_y(self):
|
| 327 |
+
X = np.float_(np.stack(self.df.fps.values))
|
| 328 |
+
y = self.df[self.target].values.astype(float)
|
| 329 |
+
|
| 330 |
+
return X, y
|
| 331 |
+
|
| 332 |
+
def get_split(self):
|
| 333 |
+
X, y = self.get_X_y()
|
| 334 |
+
return train_test_split(X, y, test_size=0.2, random_state=42)
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
# main function
|
| 338 |
+
if __name__ == "__main__":
|
| 339 |
+
data = ProcessGenericChemData(source_file="output.csv")
|
| 340 |
+
X_train, X_test, y_train, y_test = data.get_split()
|
deployment.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2f4e7563dfeeacbbef70dc9424940dd30c443bd1d893bbc2007bc8e39f6034de
|
| 3 |
+
size 253119
|
deployment/FHE_timings.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"XGB": [[[105, 6, 37.20693778991699], [105, 6, 35.34428858757019], [105, 6, 37.2830650806427], [85, 4, 13.173798084259033], [105, 2, 8.542397499084473], [105, 4, 17.998249530792236]], [[0.1559704232119744, 0.897851328230143], [0.10341718047857285, 0.9527195157697248], [0.11609367605659277, 0.8871980130370078], [0.10565379210897993, 0.9779407437173467], [0.07268084826007966, 0.9827499128733256], [0.12880629277037042, 0.9271080623278181]]], "SVR": [[[0.01, 0.1, 0.06072878837585449], [0.01, 0.0001, 0.054338932037353516], [0.01, 0.0001, 0.05757784843444824], [0.01, 0.1, 0.05663704872131348], [0.1, 0.001, 0.05373835563659668], [0.01, 0.001, 0.0582423210144043]], [[0.007699720908722056, 0.9999179907416972], [0.007754743773992465, 0.9999489939862338], [0.00954305425996474, 0.99978037179889], [0.010820483885872187, 0.9999680481558468], [0.01654155882523093, 0.9998339795155747], [0.01875583579391918, 0.9997520156670396]]]}
|
deployment/deployment_0/best_params_demo_0.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"C": 0.01, "dual": true, "epsilon": 0.1, "loss": "squared_epsilon_insensitive", "max_iter": 40000, "tol": 0.001}
|
deployment/deployment_0/client.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58f74c6723ec14f0fd154aa2b5397ef0127e06a0a117dab7db05b380ec8a8f6d
|
| 3 |
+
size 28720
|
deployment/deployment_0/regression_0.png
ADDED

|
deployment/deployment_0/server.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9938bd8f6443d8c3973297f890e6991e905bf36a622ed37991713b4e3bea0730
|
| 3 |
+
size 7025
|
deployment/deployment_0/task_name.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LOG HLM_CLint (mL/min/kg)
|
deployment/deployment_0/versions.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"concrete-python": "2.5.0rc1", "concrete-ml": "1.3.0", "python": "3.10.13"}
|
deployment/deployment_1/best_params_demo_1.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"C": 0.01, "dual": true, "epsilon": 0.0001, "loss": "squared_epsilon_insensitive", "max_iter": 40000, "tol": 0.001}
|
deployment/deployment_1/client.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:97aadb6ede59e5f091d6d03c212440fbaebde15c3f374874e4e983a78407f4aa
|
| 3 |
+
size 27721
|
deployment/deployment_1/regression_1.png
ADDED

|
deployment/deployment_1/server.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0c48867580228e736cfab70e3e5625342327f2b4e5ec4b90d816ee003aeeff3
|
| 3 |
+
size 6774
|
deployment/deployment_1/task_name.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LOG MDR1-MDCK ER (B-A/A-B)
|
deployment/deployment_1/versions.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"concrete-python": "2.5.0rc1", "concrete-ml": "1.3.0", "python": "3.10.13"}
|
deployment/deployment_2/best_params_demo_2.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"C": 0.01, "dual": true, "epsilon": 0.0001, "loss": "squared_epsilon_insensitive", "max_iter": 40000, "tol": 0.001}
|
deployment/deployment_2/client.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6373f54dd345625c75f944504ce57eaa8b0e37ef961ddda84b0e0b2718b23d45
|
| 3 |
+
size 25495
|
deployment/deployment_2/regression_2.png
ADDED
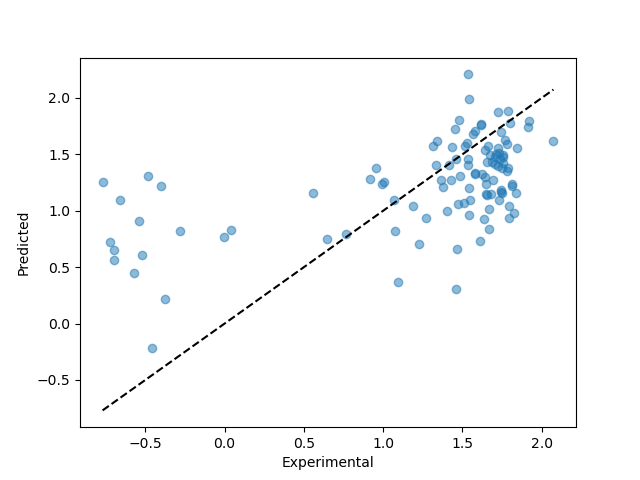
|
deployment/deployment_2/server.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b7cb19bb334f6cc51c3d53218dd87568b05c7d8020dcb71d032321ef63104fb3
|
| 3 |
+
size 6905
|
deployment/deployment_2/task_name.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LOG SOLUBILITY PH 6.8 (ug/mL)
|
deployment/deployment_2/versions.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"concrete-python": "2.5.0rc1", "concrete-ml": "1.3.0", "python": "3.10.13"}
|
deployment/deployment_3/best_params_demo_3.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"C": 0.01, "dual": true, "epsilon": 0.1, "loss": "epsilon_insensitive", "max_iter": 40000, "tol": 5e-05}
|
deployment/deployment_3/client.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3ff25ea5a4058f9c9618371d442bc308ef7c34b2f7fbf6a19fc1c0a53e9d8af3
|
| 3 |
+
size 11838
|
deployment/deployment_3/regression_3.png
ADDED

|
deployment/deployment_3/server.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d1b3b1c9fd778e1cada09edd9fef7d5c31b7204cf4479f36590705c2362db9ee
|
| 3 |
+
size 6651
|
deployment/deployment_3/task_name.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LOG PLASMA PROTEIN BINDING (HUMAN) (% unbound)
|
deployment/deployment_3/versions.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"concrete-python": "2.5.0rc1", "concrete-ml": "1.3.0", "python": "3.10.13"}
|
deployment/deployment_4/best_params_demo_4.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"C": 0.1, "dual": true, "epsilon": 0.001, "loss": "squared_epsilon_insensitive", "max_iter": 40000, "tol": 0.001}
|
deployment/deployment_4/client.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:64ab22745e787c42a0f384e9ebf5630b37587682f140d46b2f6dfcf7d4b65f3e
|
| 3 |
+
size 11193
|
deployment/deployment_4/regression_4.png
ADDED

|
deployment/deployment_4/server.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a3f7e5ab94371bdbf80f1bafe407dd5bc379d05e794b5ba32acded405fbdd29
|
| 3 |
+
size 6816
|
deployment/deployment_4/task_name.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LOG PLASMA PROTEIN BINDING (RAT) (% unbound)
|
deployment/deployment_4/versions.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"concrete-python": "2.5.0rc1", "concrete-ml": "1.3.0", "python": "3.10.13"}
|
deployment/deployment_5/best_params_demo_5.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"C": 0.01, "dual": true, "epsilon": 0.001, "loss": "squared_epsilon_insensitive", "max_iter": 40000, "tol": 1e-05}
|
deployment/deployment_5/client.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:60e08a87fb72835e8312ff4bd8122b3efb60bcd497481a08155fecc4b6ea0faa
|
| 3 |
+
size 28427
|
deployment/deployment_5/regression_5.png
ADDED

|
deployment/deployment_5/server.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:13634a17a986453da8459c352581c79a5f3bc431a418494266be464c680aeff3
|
| 3 |
+
size 7025
|
deployment/deployment_5/task_name.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LOG RLM_CLint (mL/min/kg)
|
deployment/deployment_5/versions.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"concrete-python": "2.5.0rc1", "concrete-ml": "1.3.0", "python": "3.10.13"}
|
description.txt
ADDED
|
File without changes
|
logo_app.png
ADDED
|
|
regress_utils.py
ADDED
|
@@ -0,0 +1,342 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import random
|
| 6 |
+
import json
|
| 7 |
+
import shutil
|
| 8 |
+
import time
|
| 9 |
+
from scipy.stats import pearsonr
|
| 10 |
+
from sklearn.model_selection import GridSearchCV
|
| 11 |
+
from sklearn.svm import LinearSVR as LinearSVR
|
| 12 |
+
from sklearn.model_selection import KFold
|
| 13 |
+
from chemdata import (
|
| 14 |
+
convert_numpy,
|
| 15 |
+
LinearSVRZAMA,
|
| 16 |
+
XGBRegressorZAMA,
|
| 17 |
+
OnDiskNetwork,
|
| 18 |
+
FHEModelDev,
|
| 19 |
+
FHEModelClient,
|
| 20 |
+
get_ECFP_AND_FEATURES,
|
| 21 |
+
)
|
| 22 |
+
import matplotlib.pyplot as plt
|
| 23 |
+
import xgboost as xgb
|
| 24 |
+
|
| 25 |
+
random.seed(42)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def hyper_opt(X_train, y_train, param_grid, regressor, verbose=10):
|
| 29 |
+
if regressor == "SVR":
|
| 30 |
+
if param_grid is None:
|
| 31 |
+
param_grid = {
|
| 32 |
+
"epsilon": [1e-2, 1e-1, 0.5],
|
| 33 |
+
"C": [1e-4,1e-3, 1e-2, 1e-1],
|
| 34 |
+
"loss": ["squared_epsilon_insensitive"],
|
| 35 |
+
"tol": [0.0001],
|
| 36 |
+
"max_iter": [50000],
|
| 37 |
+
"dual": [True],
|
| 38 |
+
}
|
| 39 |
+
regressor_fct = LinearSVR()
|
| 40 |
+
elif regressor == "XGB":
|
| 41 |
+
if param_grid is None:
|
| 42 |
+
param_grid = {
|
| 43 |
+
"max_depth": [3, 6, 10],
|
| 44 |
+
"learning_rate": [0.01, 0.1, 0.2],
|
| 45 |
+
"n_estimators": [10, 20, 50, 100],
|
| 46 |
+
"colsample_bytree": [0.3, 0.7],
|
| 47 |
+
}
|
| 48 |
+
regressor_fct = xgb.XGBRegressor(objective="reg:squarederror")
|
| 49 |
+
else:
|
| 50 |
+
raise ValueError("Unknown regressor type")
|
| 51 |
+
|
| 52 |
+
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
|
| 53 |
+
grid_search = GridSearchCV(
|
| 54 |
+
estimator=regressor_fct,
|
| 55 |
+
param_grid=param_grid,
|
| 56 |
+
cv=kfold,
|
| 57 |
+
verbose=verbose,
|
| 58 |
+
n_jobs=-1,
|
| 59 |
+
)
|
| 60 |
+
grid_search.fit(X_train, y_train)
|
| 61 |
+
return (
|
| 62 |
+
grid_search.best_params_,
|
| 63 |
+
grid_search.best_score_,
|
| 64 |
+
grid_search.best_estimator_,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def train_xgb_regressor(X_train, y_train, param_grid=None, verbose=10):
|
| 69 |
+
if param_grid is None:
|
| 70 |
+
param_grid = {
|
| 71 |
+
"max_depth": [3, 6],
|
| 72 |
+
"learning_rate": [0.01, 0.1, 0.2],
|
| 73 |
+
"n_estimators": [20],
|
| 74 |
+
"colsample_bytree": [0.3, 0.7],
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
xgb_regressor = xgb.XGBRegressor(objective="reg:squarederror")
|
| 78 |
+
|
| 79 |
+
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
|
| 80 |
+
grid_search = GridSearchCV(
|
| 81 |
+
estimator=xgb_regressor,
|
| 82 |
+
param_grid=param_grid,
|
| 83 |
+
cv=kfold,
|
| 84 |
+
verbose=verbose,
|
| 85 |
+
n_jobs=-1,
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
grid_search.fit(X_train, y_train)
|
| 89 |
+
return (
|
| 90 |
+
grid_search.best_params_,
|
| 91 |
+
grid_search.best_score_,
|
| 92 |
+
grid_search.best_estimator_,
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def evaluate_model(model, X_test, y_test):
|
| 97 |
+
y_pred = model.predict(X_test)
|
| 98 |
+
pearsonr_score = pearsonr(y_test, y_pred).statistic
|
| 99 |
+
return pearsonr_score
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def performance_bits():
|
| 103 |
+
"""
|
| 104 |
+
Test the model performance for different number of bits = feature vector length
|
| 105 |
+
"""
|
| 106 |
+
bits = np.array([2**i for i in range(4, 12)])
|
| 107 |
+
plt.close("all")
|
| 108 |
+
fig, ax = plt.subplots()
|
| 109 |
+
|
| 110 |
+
for r in [2, 3, 4]:
|
| 111 |
+
performance = []
|
| 112 |
+
for bit in bits:
|
| 113 |
+
X_train, X_test, y_train, y_test = load_data(
|
| 114 |
+
"LOG HLM_CLint (mL/min/kg)", bits=bit, radius=r
|
| 115 |
+
)
|
| 116 |
+
param_grid = {
|
| 117 |
+
"epsilon": [0.0, 0.1, 0.2, 0.5, 1.0],
|
| 118 |
+
"C": [0.1, 1, 10, 100],
|
| 119 |
+
"loss": ["epsilon_insensitive", "squared_epsilon_insensitive"],
|
| 120 |
+
"tol": [1e-4, 1e-3, 1e-2],
|
| 121 |
+
"max_iter": [1000, 5000, 10000],
|
| 122 |
+
}
|
| 123 |
+
best_params, best_score, best_model = hyper_opt(
|
| 124 |
+
X_train, y_train, param_grid, regressor="SVR", verbose=10
|
| 125 |
+
)
|
| 126 |
+
if not os.path.exists("data"):
|
| 127 |
+
os.makedirs("data")
|
| 128 |
+
|
| 129 |
+
with open("data/best_params_{}.json".format(bit), "w") as fp:
|
| 130 |
+
json.dump(best_params, fp, default=convert_numpy)
|
| 131 |
+
|
| 132 |
+
pearsonr_score = evaluate_model(best_model, X_test, y_test)
|
| 133 |
+
performance.append(pearsonr_score)
|
| 134 |
+
|
| 135 |
+
performance = np.array(performance)
|
| 136 |
+
ax.plot(bits, performance, marker="o", label=f"radius={r}")
|
| 137 |
+
|
| 138 |
+
ax.set_xlabel("Number of Bits")
|
| 139 |
+
ax.set_ylabel("Pearson's r Correlation Coefficient")
|
| 140 |
+
ax.legend()
|
| 141 |
+
plt.grid(True)
|
| 142 |
+
if not os.path.exists("figures"):
|
| 143 |
+
os.makedirs("figures")
|
| 144 |
+
plt.savefig("figures/performance_bits.png")
|
| 145 |
+
|
| 146 |
+
return bits, performance
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def predict_fhe(model, X_test):
|
| 150 |
+
y_pred_fhe = model.predict(X_test, fhe="execute")
|
| 151 |
+
return y_pred_fhe
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def setup_network(model_dev):
|
| 155 |
+
network = OnDiskNetwork()
|
| 156 |
+
fhemodel_dev = FHEModelDev(network.dev_dir.name, model_dev)
|
| 157 |
+
fhemodel_dev.save()
|
| 158 |
+
return network, fhemodel_dev
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def copy_directory(source, destination="deployment"):
|
| 162 |
+
try:
|
| 163 |
+
# Check if the source directory exists
|
| 164 |
+
if not os.path.exists(source):
|
| 165 |
+
return False, "Source directory does not exist."
|
| 166 |
+
|
| 167 |
+
# Check if the destination directory exists
|
| 168 |
+
if not os.path.exists(destination):
|
| 169 |
+
os.makedirs(destination)
|
| 170 |
+
|
| 171 |
+
# Copy each item in the source directory
|
| 172 |
+
for item in os.listdir(source):
|
| 173 |
+
s = os.path.join(source, item)
|
| 174 |
+
d = os.path.join(destination, item)
|
| 175 |
+
if os.path.isdir(s):
|
| 176 |
+
shutil.copytree(
|
| 177 |
+
s, d, dirs_exist_ok=True
|
| 178 |
+
) # dirs_exist_ok is available from Python 3.8
|
| 179 |
+
else:
|
| 180 |
+
shutil.copy2(s, d)
|
| 181 |
+
|
| 182 |
+
return True, None
|
| 183 |
+
|
| 184 |
+
except Exception as e:
|
| 185 |
+
return False, str(e)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def client_server_interaction(network, fhemodel_client, X_client):
|
| 189 |
+
decrypted_predictions = []
|
| 190 |
+
execution_time = []
|
| 191 |
+
for i in range(X_client.shape[0]):
|
| 192 |
+
clear_input = X_client[[i], :]
|
| 193 |
+
encrypted_input = fhemodel_client.quantize_encrypt_serialize(clear_input)
|
| 194 |
+
execution_time.append(
|
| 195 |
+
network.client_send_input_to_server_for_prediction(encrypted_input)
|
| 196 |
+
)
|
| 197 |
+
encrypted_prediction = network.server_send_encrypted_prediction_to_client()
|
| 198 |
+
decrypted_prediction = fhemodel_client.deserialize_decrypt_dequantize(
|
| 199 |
+
encrypted_prediction
|
| 200 |
+
)[0]
|
| 201 |
+
decrypted_predictions.append(decrypted_prediction)
|
| 202 |
+
return decrypted_predictions, execution_time
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def train_zama(X_train, y_train, best_params, regressor="SVR"):
|
| 206 |
+
if regressor == "SVR":
|
| 207 |
+
best_params["n_bits"] = 12
|
| 208 |
+
model_dev = LinearSVRZAMA(**best_params)
|
| 209 |
+
elif regressor == "XGB":
|
| 210 |
+
best_params["n_bits"] = 6
|
| 211 |
+
model_dev = XGBRegressorZAMA(**best_params)
|
| 212 |
+
|
| 213 |
+
print("Training Zama model...")
|
| 214 |
+
model_dev.fit(X_train, y_train)
|
| 215 |
+
print("compiling model...")
|
| 216 |
+
model_dev.compile(X_train)
|
| 217 |
+
print("done")
|
| 218 |
+
|
| 219 |
+
return model_dev
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def time_prediction(model, X_sample):
|
| 223 |
+
time_begin = time.time()
|
| 224 |
+
y_pred_fhe = model.predict(X_sample, fhe="execute")
|
| 225 |
+
time_end = time.time()
|
| 226 |
+
return time_end - time_begin
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def setup_client(network, key_dir):
|
| 230 |
+
fhemodel_client = FHEModelClient(network.client_dir.name, key_dir=key_dir)
|
| 231 |
+
fhemodel_client.generate_private_and_evaluation_keys()
|
| 232 |
+
serialized_evaluation_keys = fhemodel_client.get_serialized_evaluation_keys()
|
| 233 |
+
return fhemodel_client, serialized_evaluation_keys
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def compare_predictions(network, fhemodel_client, sklearn_model, X_client):
|
| 237 |
+
fhe_predictions_decrypted, _ = client_server_interaction(
|
| 238 |
+
network, fhemodel_client, X_client
|
| 239 |
+
)
|
| 240 |
+
fhe_predictions_decrypted = [
|
| 241 |
+
item for sublist in fhe_predictions_decrypted for item in sublist
|
| 242 |
+
]
|
| 243 |
+
fhe_predictions_decrypted = np.array(fhe_predictions_decrypted)
|
| 244 |
+
|
| 245 |
+
sklearn_predictions = sklearn_model.predict(X_client)
|
| 246 |
+
|
| 247 |
+
# try:
|
| 248 |
+
mae = np.mean(
|
| 249 |
+
np.abs(sklearn_predictions.flatten() - fhe_predictions_decrypted.flatten())
|
| 250 |
+
)
|
| 251 |
+
# and pearson correlation
|
| 252 |
+
pearsonr_score = pearsonr(
|
| 253 |
+
sklearn_predictions.flatten(), fhe_predictions_decrypted.flatten()
|
| 254 |
+
).statistic
|
| 255 |
+
# pearsons r
|
| 256 |
+
print("sklearn_predictions")
|
| 257 |
+
print(sklearn_predictions)
|
| 258 |
+
print("fhe_predictions_decrypted:")
|
| 259 |
+
print(fhe_predictions_decrypted)
|
| 260 |
+
|
| 261 |
+
print("Pearson's r between sklearn and fhe predictions: " f"{pearsonr_score:.2f}")
|
| 262 |
+
|
| 263 |
+
return mae, pearsonr_score
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def predict_ADME(network, fhemodel_client, molecule, bits=256, radius=2):
|
| 267 |
+
encodings = get_ECFP_AND_FEATURES(molecule, bits=bits, radius=radius).reshape(1, -1)
|
| 268 |
+
# generate_fingerprint(molecule, radius=radius, bits=bits).reshape(1, -1)
|
| 269 |
+
enc_inp = fhemodel_client.quantize_encrypt_serialize(encodings)
|
| 270 |
+
network.client_send_input_to_server_for_prediction(enc_inp)
|
| 271 |
+
encrypted_prediction = network.server_send_encrypted_prediction_to_client()
|
| 272 |
+
decrypted_prediction = fhemodel_client.deserialize_decrypt_dequantize(
|
| 273 |
+
encrypted_prediction
|
| 274 |
+
)
|
| 275 |
+
return np.array([decrypted_prediction])
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def fit_final_model(HYPER=True):
|
| 279 |
+
task = "LOG HLM_CLint (mL/min/kg)"
|
| 280 |
+
bits, radius = 1024, 2
|
| 281 |
+
X_train, X_test, y_train, y_test = load_data(task, bits=bits, radius=radius)
|
| 282 |
+
|
| 283 |
+
if HYPER:
|
| 284 |
+
param_grid = {
|
| 285 |
+
"epsilon": [0.0, 0.05, 0.1, 0.15, 0.2, 0.25, 0.5, 0.75, 1.0],
|
| 286 |
+
"C": [0.1, 0.5, 1, 5, 10, 50, 100],
|
| 287 |
+
"loss": ["epsilon_insensitive", "squared_epsilon_insensitive"],
|
| 288 |
+
"tol": [1e-5, 5e-5, 1e-4, 5e-4, 1e-3, 5e-3, 1e-2],
|
| 289 |
+
"max_iter": [5000, 1e4, 2e4],
|
| 290 |
+
}
|
| 291 |
+
best_params, best_score, best_model = hyper_opt(
|
| 292 |
+
X_train, y_train, param_grid, regressor="SVR", verbose=10
|
| 293 |
+
)
|
| 294 |
+
with open("best_params.json", "w") as fp:
|
| 295 |
+
json.dump(best_params, fp, default=convert_numpy)
|
| 296 |
+
print(best_params)
|
| 297 |
+
pearsonr_score = evaluate_model(best_model, X_test, y_test)
|
| 298 |
+
print(pearsonr_score)
|
| 299 |
+
|
| 300 |
+
try:
|
| 301 |
+
with open("best_params.json", "r") as fp:
|
| 302 |
+
best_params = json.load(fp)
|
| 303 |
+
print(best_params)
|
| 304 |
+
except:
|
| 305 |
+
print(
|
| 306 |
+
"No hyperparameter file found. Please run function with HYPER=True first."
|
| 307 |
+
)
|
| 308 |
+
exit()
|
| 309 |
+
|
| 310 |
+
model_dev = train_zama(X_train, y_train, best_params)
|
| 311 |
+
|
| 312 |
+
prediction_time = time_prediction(model_dev, X_test[0])
|
| 313 |
+
print(f"Time to predict one sample: {prediction_time:.2f} seconds")
|
| 314 |
+
|
| 315 |
+
network, fhemodel_dev = setup_network(model_dev)
|
| 316 |
+
copied, error_message = copy_directory(network.dev_dir.name)
|
| 317 |
+
if not copied:
|
| 318 |
+
print(f"Error copying directory: {error_message}")
|
| 319 |
+
|
| 320 |
+
network.dev_send_model_to_server()
|
| 321 |
+
network.dev_send_clientspecs_and_modelspecs_to_client()
|
| 322 |
+
|
| 323 |
+
fhemodel_client, serialized_evaluation_keys = setup_client(
|
| 324 |
+
network, network.client_dir.name
|
| 325 |
+
)
|
| 326 |
+
print(f"Evaluation keys size: {len(serialized_evaluation_keys) / (10**6):.2f} MB")
|
| 327 |
+
|
| 328 |
+
network.client_send_evaluation_key_to_server(serialized_evaluation_keys)
|
| 329 |
+
|
| 330 |
+
mae_fhe, pearsonr_score_fhe = compare_predictions(
|
| 331 |
+
network, fhemodel_client, best_model, X_test[-10:]
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
pred = predict_with_fingerprint(
|
| 335 |
+
network, fhemodel_client, "CC(=O)OC1=CC=CC=C1C(=O)O", bits=1024, radius=2
|
| 336 |
+
)
|
| 337 |
+
print(f"Prediction: {pred}")
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
if __name__ == "__main__":
|
| 341 |
+
fit_final_model(HYPER=True)
|
| 342 |
+
bits, performance = performance_bits()
|
requirements.txt
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
concrete-ml==1.3.0
|
| 2 |
+
pandas==1.4.3
|
| 3 |
+
streamlit==1.29.0
|
| 4 |
+
streamlit-camera-input-live==0.2.0
|
| 5 |
+
streamlit-card==1.0.0
|
| 6 |
+
streamlit-embedcode==0.1.2
|
| 7 |
+
streamlit-extras==0.3.6
|
| 8 |
+
streamlit-faker==0.0.3
|
| 9 |
+
streamlit-image-coordinates==0.1.6
|
| 10 |
+
streamlit-keyup==0.2.2
|
| 11 |
+
streamlit-scrollable-textbox==0.0.3
|
| 12 |
+
streamlit-toggle-switch==1.0.2
|
| 13 |
+
streamlit-vertical-slider==1.0.2
|
| 14 |
+
st-annotated-text==4.0.1
|
| 15 |
+
CairoSVG==2.7.1
|
| 16 |
+
rdkit-pypi==2022.9.5
|
| 17 |
+
uvicorn==0.21.1
|
| 18 |
+
streamlit-keyup==0.2.2
|
run_app.sh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
streamlit run app.py --server.headless=False
|
scheme2.png
ADDED

|
Git LFS Details
|
scheme2.svg
ADDED

|