
Upload 243 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- img/docker_logs.png +0 -0
- img/langchain+chatglm.png +3 -0
- img/langchain+chatglm2.png +0 -0
- img/qr_code_36.jpg +0 -0
- img/qr_code_37.jpg +0 -0
- img/qr_code_38.jpg +0 -0
- img/qr_code_39.jpg +0 -0
- img/vue_0521_0.png +0 -0
- img/vue_0521_1.png +3 -0
- img/vue_0521_2.png +3 -0
- img/webui_0419.png +0 -0
- img/webui_0510_0.png +0 -0
- img/webui_0510_1.png +0 -0
- img/webui_0510_2.png +0 -0
- img/webui_0521_0.png +0 -0
- loader/RSS_loader.py +54 -0
- loader/__init__.py +14 -0
- loader/__pycache__/__init__.cpython-310.pyc +0 -0
- loader/__pycache__/__init__.cpython-311.pyc +0 -0
- loader/__pycache__/dialogue.cpython-310.pyc +0 -0
- loader/__pycache__/image_loader.cpython-310.pyc +0 -0
- loader/__pycache__/image_loader.cpython-311.pyc +0 -0
- loader/__pycache__/pdf_loader.cpython-310.pyc +0 -0
- loader/dialogue.py +131 -0
- loader/image_loader.py +42 -0
- loader/pdf_loader.py +58 -0
- models/__init__.py +4 -0
- models/__pycache__/__init__.cpython-310.pyc +0 -0
- models/__pycache__/chatglm_llm.cpython-310.pyc +0 -0
- models/__pycache__/fastchat_openai_llm.cpython-310.pyc +0 -0
- models/__pycache__/llama_llm.cpython-310.pyc +0 -0
- models/__pycache__/moss_llm.cpython-310.pyc +0 -0
- models/__pycache__/shared.cpython-310.pyc +0 -0
- models/base/__init__.py +13 -0
- models/base/__pycache__/__init__.cpython-310.pyc +0 -0
- models/base/__pycache__/base.cpython-310.pyc +0 -0
- models/base/__pycache__/remote_rpc_model.cpython-310.pyc +0 -0
- models/base/base.py +41 -0
- models/base/lavis_blip2_multimodel.py +26 -0
- models/base/remote_rpc_model.py +33 -0
- models/chatglm_llm.py +83 -0
- models/fastchat_openai_llm.py +137 -0
- models/llama_llm.py +185 -0
- models/loader/__init__.py +2 -0
- models/loader/__pycache__/__init__.cpython-310.pyc +0 -0
- models/loader/__pycache__/args.cpython-310.pyc +0 -0
- models/loader/__pycache__/loader.cpython-310.pyc +0 -0
- models/loader/args.py +55 -0
- models/loader/loader.py +447 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
img/langchain+chatglm.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
img/vue_0521_1.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
img/vue_0521_2.png filter=lfs diff=lfs merge=lfs -text
|
img/docker_logs.png
ADDED
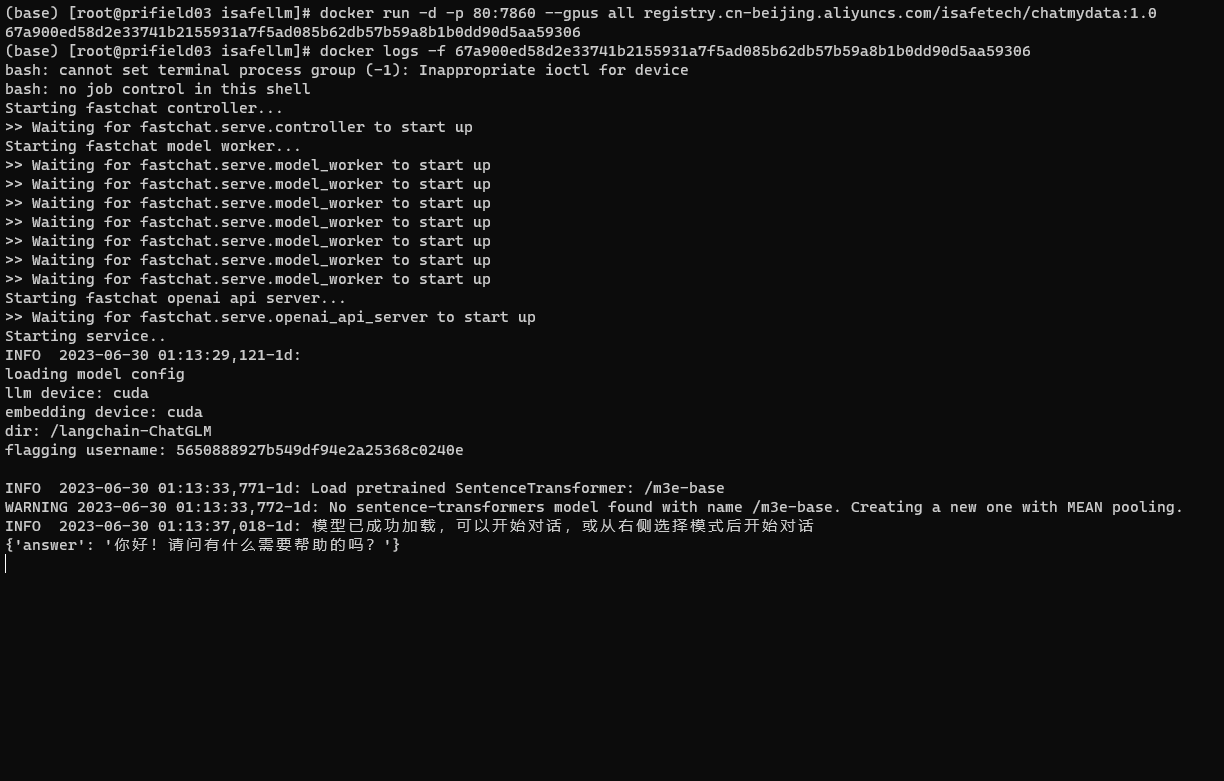
|
img/langchain+chatglm.png
ADDED

|
Git LFS Details
|
img/langchain+chatglm2.png
ADDED

|
img/qr_code_36.jpg
ADDED

|
img/qr_code_37.jpg
ADDED

|
img/qr_code_38.jpg
ADDED

|
img/qr_code_39.jpg
ADDED

|
img/vue_0521_0.png
ADDED
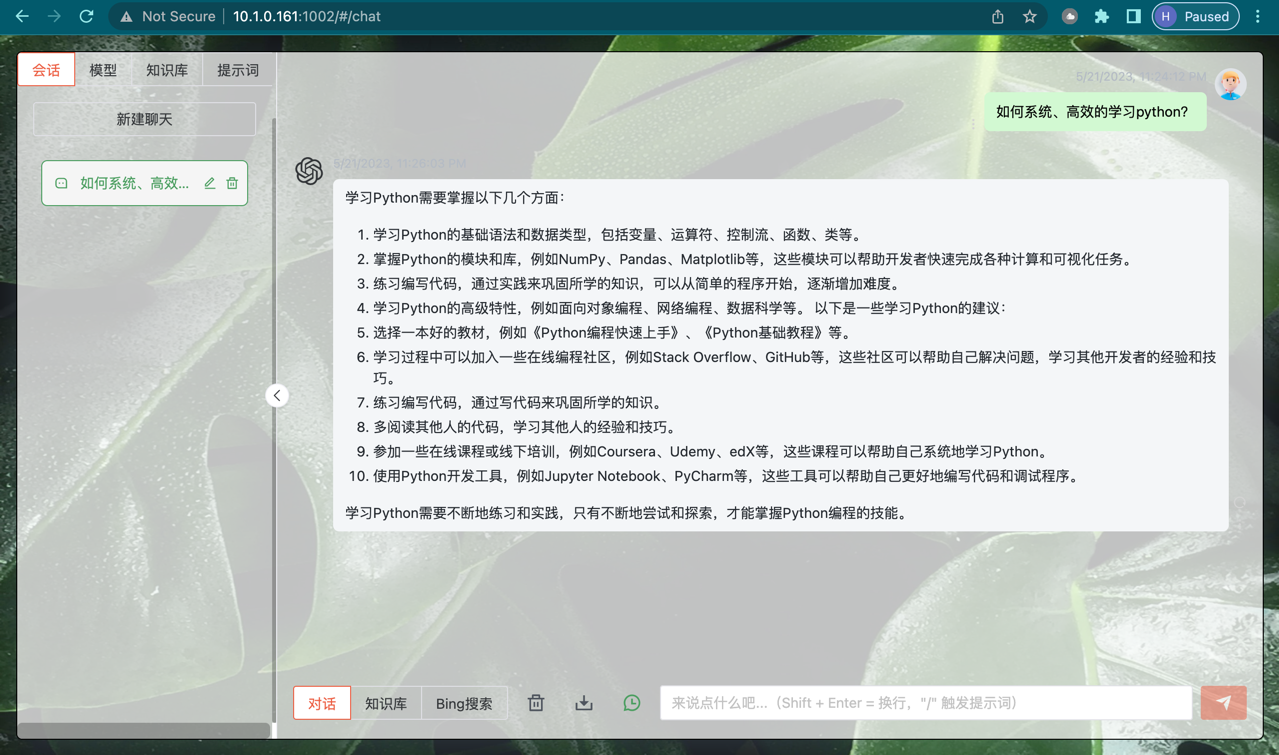
|
img/vue_0521_1.png
ADDED

|
Git LFS Details
|
img/vue_0521_2.png
ADDED

|
Git LFS Details
|
img/webui_0419.png
ADDED

|
img/webui_0510_0.png
ADDED
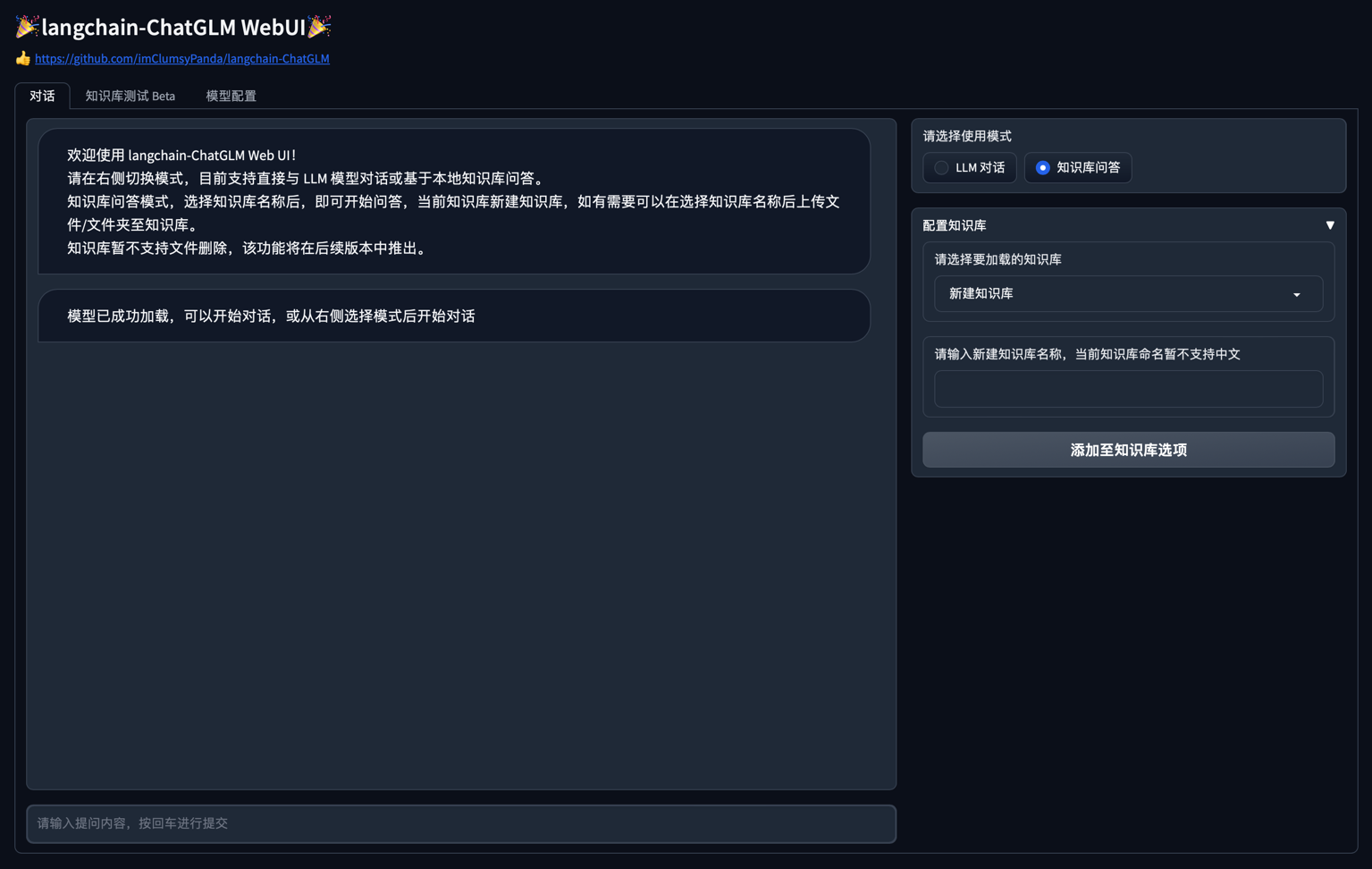
|
img/webui_0510_1.png
ADDED
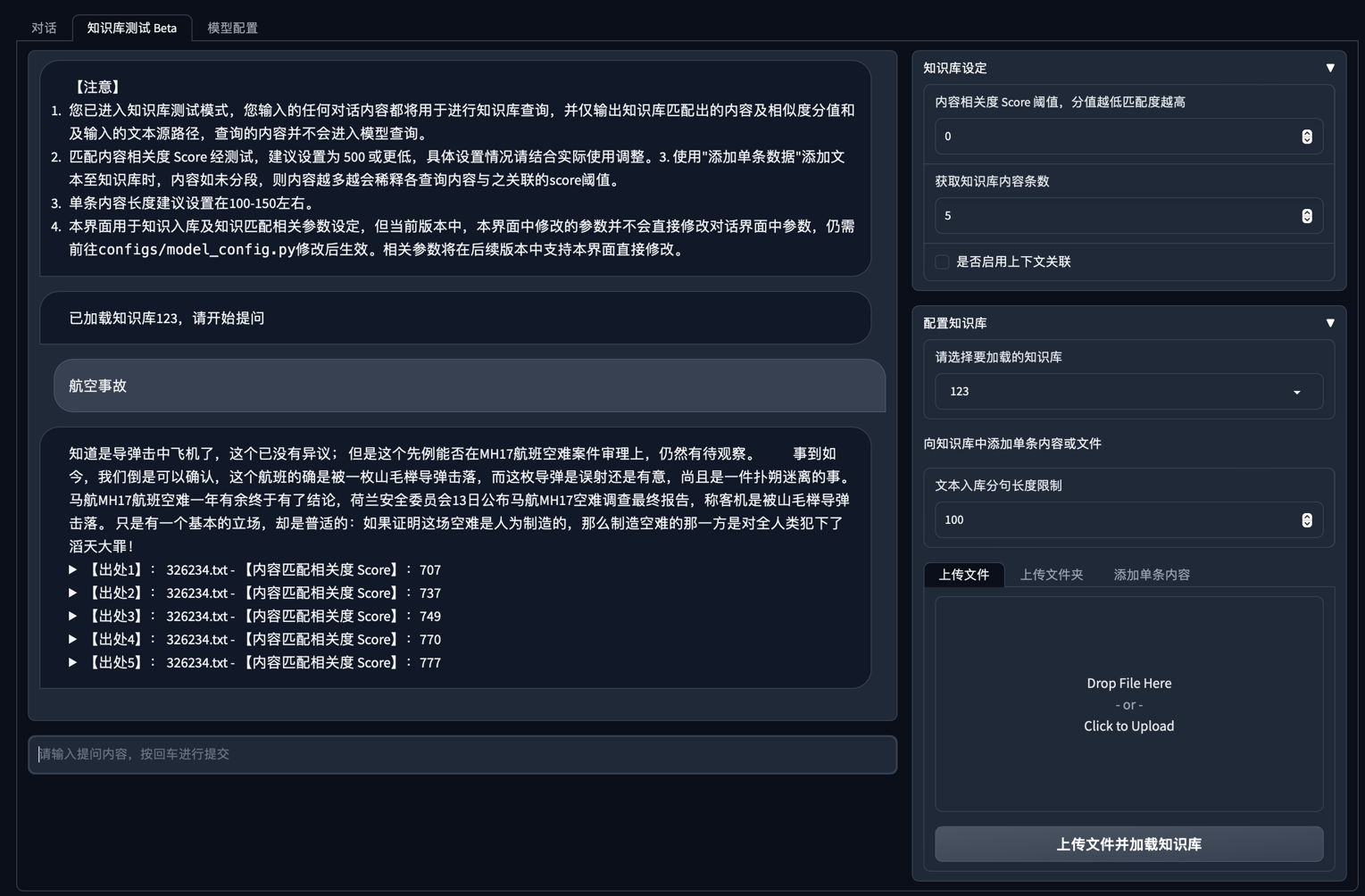
|
img/webui_0510_2.png
ADDED
|
img/webui_0521_0.png
ADDED

|
loader/RSS_loader.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.docstore.document import Document
|
| 2 |
+
import feedparser
|
| 3 |
+
import html2text
|
| 4 |
+
import ssl
|
| 5 |
+
import time
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class RSS_Url_loader:
|
| 9 |
+
def __init__(self, urls=None,interval=60):
|
| 10 |
+
'''可用参数urls数组或者是字符串形式的url列表'''
|
| 11 |
+
self.urls = []
|
| 12 |
+
self.interval = interval
|
| 13 |
+
if urls is not None:
|
| 14 |
+
try:
|
| 15 |
+
if isinstance(urls, str):
|
| 16 |
+
urls = [urls]
|
| 17 |
+
elif isinstance(urls, list):
|
| 18 |
+
pass
|
| 19 |
+
else:
|
| 20 |
+
raise TypeError('urls must be a list or a string.')
|
| 21 |
+
self.urls = urls
|
| 22 |
+
except:
|
| 23 |
+
Warning('urls must be a list or a string.')
|
| 24 |
+
|
| 25 |
+
#定时代码还要考虑是不是引入其他类,暂时先不对外开放
|
| 26 |
+
def scheduled_execution(self):
|
| 27 |
+
while True:
|
| 28 |
+
docs = self.load()
|
| 29 |
+
return docs
|
| 30 |
+
time.sleep(self.interval)
|
| 31 |
+
|
| 32 |
+
def load(self):
|
| 33 |
+
if hasattr(ssl, '_create_unverified_context'):
|
| 34 |
+
ssl._create_default_https_context = ssl._create_unverified_context
|
| 35 |
+
documents = []
|
| 36 |
+
for url in self.urls:
|
| 37 |
+
parsed = feedparser.parse(url)
|
| 38 |
+
for entry in parsed.entries:
|
| 39 |
+
if "content" in entry:
|
| 40 |
+
data = entry.content[0].value
|
| 41 |
+
else:
|
| 42 |
+
data = entry.description or entry.summary
|
| 43 |
+
data = html2text.html2text(data)
|
| 44 |
+
metadata = {"title": entry.title, "link": entry.link}
|
| 45 |
+
documents.append(Document(page_content=data, metadata=metadata))
|
| 46 |
+
return documents
|
| 47 |
+
|
| 48 |
+
if __name__=="__main__":
|
| 49 |
+
#需要在配置文件中加入urls的配置,或者是在用户界面上加入urls的配置
|
| 50 |
+
urls = ["https://www.zhihu.com/rss", "https://www.36kr.com/feed"]
|
| 51 |
+
loader = RSS_Url_loader(urls)
|
| 52 |
+
docs = loader.load()
|
| 53 |
+
for doc in docs:
|
| 54 |
+
print(doc)
|
loader/__init__.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .image_loader import UnstructuredPaddleImageLoader
|
| 2 |
+
from .pdf_loader import UnstructuredPaddlePDFLoader
|
| 3 |
+
from .dialogue import (
|
| 4 |
+
Person,
|
| 5 |
+
Dialogue,
|
| 6 |
+
Turn,
|
| 7 |
+
DialogueLoader
|
| 8 |
+
)
|
| 9 |
+
|
| 10 |
+
__all__ = [
|
| 11 |
+
"UnstructuredPaddleImageLoader",
|
| 12 |
+
"UnstructuredPaddlePDFLoader",
|
| 13 |
+
"DialogueLoader",
|
| 14 |
+
]
|
loader/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (414 Bytes). View file
|
|
|
loader/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (531 Bytes). View file
|
|
|
loader/__pycache__/dialogue.cpython-310.pyc
ADDED
|
Binary file (4.95 kB). View file
|
|
|
loader/__pycache__/image_loader.cpython-310.pyc
ADDED
|
Binary file (2.23 kB). View file
|
|
|
loader/__pycache__/image_loader.cpython-311.pyc
ADDED
|
Binary file (3.94 kB). View file
|
|
|
loader/__pycache__/pdf_loader.cpython-310.pyc
ADDED
|
Binary file (2.57 kB). View file
|
|
|
loader/dialogue.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from abc import ABC
|
| 3 |
+
from typing import List
|
| 4 |
+
from langchain.docstore.document import Document
|
| 5 |
+
from langchain.document_loaders.base import BaseLoader
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class Person:
|
| 9 |
+
def __init__(self, name, age):
|
| 10 |
+
self.name = name
|
| 11 |
+
self.age = age
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class Dialogue:
|
| 15 |
+
"""
|
| 16 |
+
Build an abstract dialogue model using classes and methods to represent different dialogue elements.
|
| 17 |
+
This class serves as a fundamental framework for constructing dialogue models.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def __init__(self, file_path: str):
|
| 21 |
+
self.file_path = file_path
|
| 22 |
+
self.turns = []
|
| 23 |
+
|
| 24 |
+
def add_turn(self, turn):
|
| 25 |
+
"""
|
| 26 |
+
Create an instance of a conversation participant
|
| 27 |
+
:param turn:
|
| 28 |
+
:return:
|
| 29 |
+
"""
|
| 30 |
+
self.turns.append(turn)
|
| 31 |
+
|
| 32 |
+
def parse_dialogue(self):
|
| 33 |
+
"""
|
| 34 |
+
The parse_dialogue function reads the specified dialogue file and parses each dialogue turn line by line.
|
| 35 |
+
For each turn, the function extracts the name of the speaker and the message content from the text,
|
| 36 |
+
creating a Turn instance. If the speaker is not already present in the participants dictionary,
|
| 37 |
+
a new Person instance is created. Finally, the parsed Turn instance is added to the Dialogue object.
|
| 38 |
+
|
| 39 |
+
Please note that this sample code assumes that each line in the file follows a specific format:
|
| 40 |
+
<speaker>:\r\n<message>\r\n\r\n. If your file has a different format or includes other metadata,
|
| 41 |
+
you may need to adjust the parsing logic accordingly.
|
| 42 |
+
"""
|
| 43 |
+
participants = {}
|
| 44 |
+
speaker_name = None
|
| 45 |
+
message = None
|
| 46 |
+
|
| 47 |
+
with open(self.file_path, encoding='utf-8') as file:
|
| 48 |
+
lines = file.readlines()
|
| 49 |
+
for i, line in enumerate(lines):
|
| 50 |
+
line = line.strip()
|
| 51 |
+
if not line:
|
| 52 |
+
continue
|
| 53 |
+
|
| 54 |
+
if speaker_name is None:
|
| 55 |
+
speaker_name, _ = line.split(':', 1)
|
| 56 |
+
elif message is None:
|
| 57 |
+
message = line
|
| 58 |
+
if speaker_name not in participants:
|
| 59 |
+
participants[speaker_name] = Person(speaker_name, None)
|
| 60 |
+
|
| 61 |
+
speaker = participants[speaker_name]
|
| 62 |
+
turn = Turn(speaker, message)
|
| 63 |
+
self.add_turn(turn)
|
| 64 |
+
|
| 65 |
+
# Reset speaker_name and message for the next turn
|
| 66 |
+
speaker_name = None
|
| 67 |
+
message = None
|
| 68 |
+
|
| 69 |
+
def display(self):
|
| 70 |
+
for turn in self.turns:
|
| 71 |
+
print(f"{turn.speaker.name}: {turn.message}")
|
| 72 |
+
|
| 73 |
+
def export_to_file(self, file_path):
|
| 74 |
+
with open(file_path, 'w', encoding='utf-8') as file:
|
| 75 |
+
for turn in self.turns:
|
| 76 |
+
file.write(f"{turn.speaker.name}: {turn.message}\n")
|
| 77 |
+
|
| 78 |
+
def to_dict(self):
|
| 79 |
+
dialogue_dict = {"turns": []}
|
| 80 |
+
for turn in self.turns:
|
| 81 |
+
turn_dict = {
|
| 82 |
+
"speaker": turn.speaker.name,
|
| 83 |
+
"message": turn.message
|
| 84 |
+
}
|
| 85 |
+
dialogue_dict["turns"].append(turn_dict)
|
| 86 |
+
return dialogue_dict
|
| 87 |
+
|
| 88 |
+
def to_json(self):
|
| 89 |
+
dialogue_dict = self.to_dict()
|
| 90 |
+
return json.dumps(dialogue_dict, ensure_ascii=False, indent=2)
|
| 91 |
+
|
| 92 |
+
def participants_to_export(self):
|
| 93 |
+
"""
|
| 94 |
+
participants_to_export
|
| 95 |
+
:return:
|
| 96 |
+
"""
|
| 97 |
+
participants = set()
|
| 98 |
+
for turn in self.turns:
|
| 99 |
+
participants.add(turn.speaker.name)
|
| 100 |
+
return ', '.join(participants)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class Turn:
|
| 104 |
+
def __init__(self, speaker, message):
|
| 105 |
+
self.speaker = speaker
|
| 106 |
+
self.message = message
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class DialogueLoader(BaseLoader, ABC):
|
| 110 |
+
"""Load dialogue."""
|
| 111 |
+
|
| 112 |
+
def __init__(self, file_path: str):
|
| 113 |
+
"""Initialize with dialogue."""
|
| 114 |
+
self.file_path = file_path
|
| 115 |
+
dialogue = Dialogue(file_path=file_path)
|
| 116 |
+
dialogue.parse_dialogue()
|
| 117 |
+
self.dialogue = dialogue
|
| 118 |
+
|
| 119 |
+
def load(self) -> List[Document]:
|
| 120 |
+
"""Load from dialogue."""
|
| 121 |
+
documents = []
|
| 122 |
+
participants = self.dialogue.participants_to_export()
|
| 123 |
+
|
| 124 |
+
for turn in self.dialogue.turns:
|
| 125 |
+
metadata = {"source": f"Dialogue File:{self.dialogue.file_path},"
|
| 126 |
+
f"speaker:{turn.speaker.name},"
|
| 127 |
+
f"participant:{participants}"}
|
| 128 |
+
turn_document = Document(page_content=turn.message, metadata=metadata.copy())
|
| 129 |
+
documents.append(turn_document)
|
| 130 |
+
|
| 131 |
+
return documents
|
loader/image_loader.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Loader that loads image files."""
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
from langchain.document_loaders.unstructured import UnstructuredFileLoader
|
| 5 |
+
from paddleocr import PaddleOCR
|
| 6 |
+
import os
|
| 7 |
+
import nltk
|
| 8 |
+
from configs.model_config import NLTK_DATA_PATH
|
| 9 |
+
|
| 10 |
+
nltk.data.path = [NLTK_DATA_PATH] + nltk.data.path
|
| 11 |
+
|
| 12 |
+
class UnstructuredPaddleImageLoader(UnstructuredFileLoader):
|
| 13 |
+
"""Loader that uses unstructured to load image files, such as PNGs and JPGs."""
|
| 14 |
+
|
| 15 |
+
def _get_elements(self) -> List:
|
| 16 |
+
def image_ocr_txt(filepath, dir_path="tmp_files"):
|
| 17 |
+
full_dir_path = os.path.join(os.path.dirname(filepath), dir_path)
|
| 18 |
+
if not os.path.exists(full_dir_path):
|
| 19 |
+
os.makedirs(full_dir_path)
|
| 20 |
+
filename = os.path.split(filepath)[-1]
|
| 21 |
+
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=False, show_log=False)
|
| 22 |
+
result = ocr.ocr(img=filepath)
|
| 23 |
+
|
| 24 |
+
ocr_result = [i[1][0] for line in result for i in line]
|
| 25 |
+
txt_file_path = os.path.join(full_dir_path, "%s.txt" % (filename))
|
| 26 |
+
with open(txt_file_path, 'w', encoding='utf-8') as fout:
|
| 27 |
+
fout.write("\n".join(ocr_result))
|
| 28 |
+
return txt_file_path
|
| 29 |
+
|
| 30 |
+
txt_file_path = image_ocr_txt(self.file_path)
|
| 31 |
+
from unstructured.partition.text import partition_text
|
| 32 |
+
return partition_text(filename=txt_file_path, **self.unstructured_kwargs)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
if __name__ == "__main__":
|
| 36 |
+
import sys
|
| 37 |
+
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
|
| 38 |
+
filepath = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base", "samples", "content", "test.jpg")
|
| 39 |
+
loader = UnstructuredPaddleImageLoader(filepath, mode="elements")
|
| 40 |
+
docs = loader.load()
|
| 41 |
+
for doc in docs:
|
| 42 |
+
print(doc)
|
loader/pdf_loader.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Loader that loads image files."""
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
from langchain.document_loaders.unstructured import UnstructuredFileLoader
|
| 5 |
+
from paddleocr import PaddleOCR
|
| 6 |
+
import os
|
| 7 |
+
import fitz
|
| 8 |
+
import nltk
|
| 9 |
+
from configs.model_config import NLTK_DATA_PATH
|
| 10 |
+
|
| 11 |
+
nltk.data.path = [NLTK_DATA_PATH] + nltk.data.path
|
| 12 |
+
|
| 13 |
+
class UnstructuredPaddlePDFLoader(UnstructuredFileLoader):
|
| 14 |
+
"""Loader that uses unstructured to load image files, such as PNGs and JPGs."""
|
| 15 |
+
|
| 16 |
+
def _get_elements(self) -> List:
|
| 17 |
+
def pdf_ocr_txt(filepath, dir_path="tmp_files"):
|
| 18 |
+
full_dir_path = os.path.join(os.path.dirname(filepath), dir_path)
|
| 19 |
+
if not os.path.exists(full_dir_path):
|
| 20 |
+
os.makedirs(full_dir_path)
|
| 21 |
+
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=False, show_log=False)
|
| 22 |
+
doc = fitz.open(filepath)
|
| 23 |
+
txt_file_path = os.path.join(full_dir_path, f"{os.path.split(filepath)[-1]}.txt")
|
| 24 |
+
img_name = os.path.join(full_dir_path, 'tmp.png')
|
| 25 |
+
with open(txt_file_path, 'w', encoding='utf-8') as fout:
|
| 26 |
+
for i in range(doc.page_count):
|
| 27 |
+
page = doc[i]
|
| 28 |
+
text = page.get_text("")
|
| 29 |
+
fout.write(text)
|
| 30 |
+
fout.write("\n")
|
| 31 |
+
|
| 32 |
+
img_list = page.get_images()
|
| 33 |
+
for img in img_list:
|
| 34 |
+
pix = fitz.Pixmap(doc, img[0])
|
| 35 |
+
if pix.n - pix.alpha >= 4:
|
| 36 |
+
pix = fitz.Pixmap(fitz.csRGB, pix)
|
| 37 |
+
pix.save(img_name)
|
| 38 |
+
|
| 39 |
+
result = ocr.ocr(img_name)
|
| 40 |
+
ocr_result = [i[1][0] for line in result for i in line]
|
| 41 |
+
fout.write("\n".join(ocr_result))
|
| 42 |
+
if os.path.exists(img_name):
|
| 43 |
+
os.remove(img_name)
|
| 44 |
+
return txt_file_path
|
| 45 |
+
|
| 46 |
+
txt_file_path = pdf_ocr_txt(self.file_path)
|
| 47 |
+
from unstructured.partition.text import partition_text
|
| 48 |
+
return partition_text(filename=txt_file_path, **self.unstructured_kwargs)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
if __name__ == "__main__":
|
| 52 |
+
import sys
|
| 53 |
+
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
|
| 54 |
+
filepath = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base", "samples", "content", "test.pdf")
|
| 55 |
+
loader = UnstructuredPaddlePDFLoader(filepath, mode="elements")
|
| 56 |
+
docs = loader.load()
|
| 57 |
+
for doc in docs:
|
| 58 |
+
print(doc)
|
models/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .chatglm_llm import ChatGLM
|
| 2 |
+
from .llama_llm import LLamaLLM
|
| 3 |
+
from .moss_llm import MOSSLLM
|
| 4 |
+
from .fastchat_openai_llm import FastChatOpenAILLM
|
models/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (338 Bytes). View file
|
|
|
models/__pycache__/chatglm_llm.cpython-310.pyc
ADDED
|
Binary file (2.66 kB). View file
|
|
|
models/__pycache__/fastchat_openai_llm.cpython-310.pyc
ADDED
|
Binary file (4.45 kB). View file
|
|
|
models/__pycache__/llama_llm.cpython-310.pyc
ADDED
|
Binary file (6.45 kB). View file
|
|
|
models/__pycache__/moss_llm.cpython-310.pyc
ADDED
|
Binary file (3.88 kB). View file
|
|
|
models/__pycache__/shared.cpython-310.pyc
ADDED
|
Binary file (1.48 kB). View file
|
|
|
models/base/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from models.base.base import (
|
| 2 |
+
AnswerResult,
|
| 3 |
+
BaseAnswer
|
| 4 |
+
)
|
| 5 |
+
from models.base.remote_rpc_model import (
|
| 6 |
+
RemoteRpcModel
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
__all__ = [
|
| 10 |
+
"AnswerResult",
|
| 11 |
+
"BaseAnswer",
|
| 12 |
+
"RemoteRpcModel",
|
| 13 |
+
]
|
models/base/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (334 Bytes). View file
|
|
|
models/base/__pycache__/base.cpython-310.pyc
ADDED
|
Binary file (1.79 kB). View file
|
|
|
models/base/__pycache__/remote_rpc_model.cpython-310.pyc
ADDED
|
Binary file (1.59 kB). View file
|
|
|
models/base/base.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Optional, List
|
| 3 |
+
import traceback
|
| 4 |
+
from collections import deque
|
| 5 |
+
from queue import Queue
|
| 6 |
+
from threading import Thread
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import transformers
|
| 10 |
+
from models.loader import LoaderCheckPoint
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class AnswerResult:
|
| 14 |
+
"""
|
| 15 |
+
消息实体
|
| 16 |
+
"""
|
| 17 |
+
history: List[List[str]] = []
|
| 18 |
+
llm_output: Optional[dict] = None
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class BaseAnswer(ABC):
|
| 22 |
+
"""上层业务包装器.用于结果生成统一api调用"""
|
| 23 |
+
|
| 24 |
+
@property
|
| 25 |
+
@abstractmethod
|
| 26 |
+
def _check_point(self) -> LoaderCheckPoint:
|
| 27 |
+
"""Return _check_point of llm."""
|
| 28 |
+
|
| 29 |
+
@property
|
| 30 |
+
@abstractmethod
|
| 31 |
+
def _history_len(self) -> int:
|
| 32 |
+
"""Return _history_len of llm."""
|
| 33 |
+
|
| 34 |
+
@abstractmethod
|
| 35 |
+
def set_history_len(self, history_len: int) -> None:
|
| 36 |
+
"""Return _history_len of llm."""
|
| 37 |
+
|
| 38 |
+
def generatorAnswer(self, prompt: str,
|
| 39 |
+
history: List[List[str]] = [],
|
| 40 |
+
streaming: bool = False):
|
| 41 |
+
pass
|
models/base/lavis_blip2_multimodel.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from models.base import (BaseAnswer,
|
| 5 |
+
AnswerResult)
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class MultimodalAnswerResult(AnswerResult):
|
| 9 |
+
image: str = None
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class LavisBlip2Multimodal(BaseAnswer, ABC):
|
| 13 |
+
|
| 14 |
+
@property
|
| 15 |
+
@abstractmethod
|
| 16 |
+
def _blip2_instruct(self) -> any:
|
| 17 |
+
"""Return _blip2_instruct of blip2."""
|
| 18 |
+
|
| 19 |
+
@property
|
| 20 |
+
@abstractmethod
|
| 21 |
+
def _image_blip2_vis_processors(self) -> dict:
|
| 22 |
+
"""Return _image_blip2_vis_processors of blip2 image processors."""
|
| 23 |
+
|
| 24 |
+
@abstractmethod
|
| 25 |
+
def set_image_path(self, image_path: str):
|
| 26 |
+
"""set set_image_path"""
|
models/base/remote_rpc_model.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from models.base import (BaseAnswer,
|
| 5 |
+
AnswerResult)
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class MultimodalAnswerResult(AnswerResult):
|
| 9 |
+
image: str = None
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class RemoteRpcModel(BaseAnswer, ABC):
|
| 13 |
+
|
| 14 |
+
@property
|
| 15 |
+
@abstractmethod
|
| 16 |
+
def _api_key(self) -> str:
|
| 17 |
+
"""Return _api_key of client."""
|
| 18 |
+
|
| 19 |
+
@property
|
| 20 |
+
@abstractmethod
|
| 21 |
+
def _api_base_url(self) -> str:
|
| 22 |
+
"""Return _api_base of client host bash url."""
|
| 23 |
+
|
| 24 |
+
@abstractmethod
|
| 25 |
+
def set_api_key(self, api_key: str):
|
| 26 |
+
"""set set_api_key"""
|
| 27 |
+
|
| 28 |
+
@abstractmethod
|
| 29 |
+
def set_api_base_url(self, api_base_url: str):
|
| 30 |
+
"""set api_base_url"""
|
| 31 |
+
@abstractmethod
|
| 32 |
+
def call_model_name(self, model_name):
|
| 33 |
+
"""call model name of client"""
|
models/chatglm_llm.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC
|
| 2 |
+
from langchain.llms.base import LLM
|
| 3 |
+
from typing import Optional, List
|
| 4 |
+
from models.loader import LoaderCheckPoint
|
| 5 |
+
from models.base import (BaseAnswer,
|
| 6 |
+
AnswerResult)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class ChatGLM(BaseAnswer, LLM, ABC):
|
| 10 |
+
max_token: int = 10000
|
| 11 |
+
temperature: float = 0.01
|
| 12 |
+
top_p = 0.9
|
| 13 |
+
checkPoint: LoaderCheckPoint = None
|
| 14 |
+
# history = []
|
| 15 |
+
history_len: int = 10
|
| 16 |
+
|
| 17 |
+
def __init__(self, checkPoint: LoaderCheckPoint = None):
|
| 18 |
+
super().__init__()
|
| 19 |
+
self.checkPoint = checkPoint
|
| 20 |
+
|
| 21 |
+
@property
|
| 22 |
+
def _llm_type(self) -> str:
|
| 23 |
+
return "ChatGLM"
|
| 24 |
+
|
| 25 |
+
@property
|
| 26 |
+
def _check_point(self) -> LoaderCheckPoint:
|
| 27 |
+
return self.checkPoint
|
| 28 |
+
|
| 29 |
+
@property
|
| 30 |
+
def _history_len(self) -> int:
|
| 31 |
+
return self.history_len
|
| 32 |
+
|
| 33 |
+
def set_history_len(self, history_len: int = 10) -> None:
|
| 34 |
+
self.history_len = history_len
|
| 35 |
+
|
| 36 |
+
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
|
| 37 |
+
print(f"__call:{prompt}")
|
| 38 |
+
response, _ = self.checkPoint.model.chat(
|
| 39 |
+
self.checkPoint.tokenizer,
|
| 40 |
+
prompt,
|
| 41 |
+
history=[],
|
| 42 |
+
max_length=self.max_token,
|
| 43 |
+
temperature=self.temperature
|
| 44 |
+
)
|
| 45 |
+
print(f"response:{response}")
|
| 46 |
+
print(f"+++++++++++++++++++++++++++++++++++")
|
| 47 |
+
return response
|
| 48 |
+
|
| 49 |
+
def generatorAnswer(self, prompt: str,
|
| 50 |
+
history: List[List[str]] = [],
|
| 51 |
+
streaming: bool = False):
|
| 52 |
+
|
| 53 |
+
if streaming:
|
| 54 |
+
history += [[]]
|
| 55 |
+
for inum, (stream_resp, _) in enumerate(self.checkPoint.model.stream_chat(
|
| 56 |
+
self.checkPoint.tokenizer,
|
| 57 |
+
prompt,
|
| 58 |
+
history=history[-self.history_len:-1] if self.history_len > 1 else [],
|
| 59 |
+
max_length=self.max_token,
|
| 60 |
+
temperature=self.temperature
|
| 61 |
+
)):
|
| 62 |
+
# self.checkPoint.clear_torch_cache()
|
| 63 |
+
history[-1] = [prompt, stream_resp]
|
| 64 |
+
answer_result = AnswerResult()
|
| 65 |
+
answer_result.history = history
|
| 66 |
+
answer_result.llm_output = {"answer": stream_resp}
|
| 67 |
+
yield answer_result
|
| 68 |
+
else:
|
| 69 |
+
response, _ = self.checkPoint.model.chat(
|
| 70 |
+
self.checkPoint.tokenizer,
|
| 71 |
+
prompt,
|
| 72 |
+
history=history[-self.history_len:] if self.history_len > 0 else [],
|
| 73 |
+
max_length=self.max_token,
|
| 74 |
+
temperature=self.temperature
|
| 75 |
+
)
|
| 76 |
+
self.checkPoint.clear_torch_cache()
|
| 77 |
+
history += [[prompt, response]]
|
| 78 |
+
answer_result = AnswerResult()
|
| 79 |
+
answer_result.history = history
|
| 80 |
+
answer_result.llm_output = {"answer": response}
|
| 81 |
+
yield answer_result
|
| 82 |
+
|
| 83 |
+
|
models/fastchat_openai_llm.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC
|
| 2 |
+
import requests
|
| 3 |
+
from typing import Optional, List
|
| 4 |
+
from langchain.llms.base import LLM
|
| 5 |
+
|
| 6 |
+
from models.loader import LoaderCheckPoint
|
| 7 |
+
from models.base import (RemoteRpcModel,
|
| 8 |
+
AnswerResult)
|
| 9 |
+
from typing import (
|
| 10 |
+
Collection,
|
| 11 |
+
Dict
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def _build_message_template() -> Dict[str, str]:
|
| 16 |
+
"""
|
| 17 |
+
:return: 结构
|
| 18 |
+
"""
|
| 19 |
+
return {
|
| 20 |
+
"role": "",
|
| 21 |
+
"content": "",
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class FastChatOpenAILLM(RemoteRpcModel, LLM, ABC):
|
| 26 |
+
api_base_url: str = "http://localhost:8000/v1"
|
| 27 |
+
model_name: str = "chatglm-6b"
|
| 28 |
+
max_token: int = 10000
|
| 29 |
+
temperature: float = 0.01
|
| 30 |
+
top_p = 0.9
|
| 31 |
+
checkPoint: LoaderCheckPoint = None
|
| 32 |
+
history = []
|
| 33 |
+
history_len: int = 10
|
| 34 |
+
|
| 35 |
+
def __init__(self, checkPoint: LoaderCheckPoint = None):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.checkPoint = checkPoint
|
| 38 |
+
|
| 39 |
+
@property
|
| 40 |
+
def _llm_type(self) -> str:
|
| 41 |
+
return "FastChat"
|
| 42 |
+
|
| 43 |
+
@property
|
| 44 |
+
def _check_point(self) -> LoaderCheckPoint:
|
| 45 |
+
return self.checkPoint
|
| 46 |
+
|
| 47 |
+
@property
|
| 48 |
+
def _history_len(self) -> int:
|
| 49 |
+
return self.history_len
|
| 50 |
+
|
| 51 |
+
def set_history_len(self, history_len: int = 10) -> None:
|
| 52 |
+
self.history_len = history_len
|
| 53 |
+
|
| 54 |
+
@property
|
| 55 |
+
def _api_key(self) -> str:
|
| 56 |
+
pass
|
| 57 |
+
|
| 58 |
+
@property
|
| 59 |
+
def _api_base_url(self) -> str:
|
| 60 |
+
return self.api_base_url
|
| 61 |
+
|
| 62 |
+
def set_api_key(self, api_key: str):
|
| 63 |
+
pass
|
| 64 |
+
|
| 65 |
+
def set_api_base_url(self, api_base_url: str):
|
| 66 |
+
self.api_base_url = api_base_url
|
| 67 |
+
|
| 68 |
+
def call_model_name(self, model_name):
|
| 69 |
+
self.model_name = model_name
|
| 70 |
+
|
| 71 |
+
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
|
| 72 |
+
print(f"__call:{prompt}")
|
| 73 |
+
try:
|
| 74 |
+
import openai
|
| 75 |
+
# Not support yet
|
| 76 |
+
openai.api_key = "EMPTY"
|
| 77 |
+
openai.api_base = self.api_base_url
|
| 78 |
+
except ImportError:
|
| 79 |
+
raise ValueError(
|
| 80 |
+
"Could not import openai python package. "
|
| 81 |
+
"Please install it with `pip install openai`."
|
| 82 |
+
)
|
| 83 |
+
# create a chat completion
|
| 84 |
+
completion = openai.ChatCompletion.create(
|
| 85 |
+
model=self.model_name,
|
| 86 |
+
messages=self.build_message_list(prompt)
|
| 87 |
+
)
|
| 88 |
+
print(f"response:{completion.choices[0].message.content}")
|
| 89 |
+
print(f"+++++++++++++++++++++++++++++++++++")
|
| 90 |
+
return completion.choices[0].message.content
|
| 91 |
+
|
| 92 |
+
# 将历史对话数组转换为文本格式
|
| 93 |
+
def build_message_list(self, query) -> Collection[Dict[str, str]]:
|
| 94 |
+
build_message_list: Collection[Dict[str, str]] = []
|
| 95 |
+
history = self.history[-self.history_len:] if self.history_len > 0 else []
|
| 96 |
+
for i, (old_query, response) in enumerate(history):
|
| 97 |
+
user_build_message = _build_message_template()
|
| 98 |
+
user_build_message['role'] = 'user'
|
| 99 |
+
user_build_message['content'] = old_query
|
| 100 |
+
system_build_message = _build_message_template()
|
| 101 |
+
system_build_message['role'] = 'system'
|
| 102 |
+
system_build_message['content'] = response
|
| 103 |
+
build_message_list.append(user_build_message)
|
| 104 |
+
build_message_list.append(system_build_message)
|
| 105 |
+
|
| 106 |
+
user_build_message = _build_message_template()
|
| 107 |
+
user_build_message['role'] = 'user'
|
| 108 |
+
user_build_message['content'] = query
|
| 109 |
+
build_message_list.append(user_build_message)
|
| 110 |
+
return build_message_list
|
| 111 |
+
|
| 112 |
+
def generatorAnswer(self, prompt: str,
|
| 113 |
+
history: List[List[str]] = [],
|
| 114 |
+
streaming: bool = False):
|
| 115 |
+
|
| 116 |
+
try:
|
| 117 |
+
import openai
|
| 118 |
+
# Not support yet
|
| 119 |
+
openai.api_key = "EMPTY"
|
| 120 |
+
openai.api_base = self.api_base_url
|
| 121 |
+
except ImportError:
|
| 122 |
+
raise ValueError(
|
| 123 |
+
"Could not import openai python package. "
|
| 124 |
+
"Please install it with `pip install openai`."
|
| 125 |
+
)
|
| 126 |
+
# create a chat completion
|
| 127 |
+
completion = openai.ChatCompletion.create(
|
| 128 |
+
model=self.model_name,
|
| 129 |
+
messages=self.build_message_list(prompt)
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
history += [[prompt, completion.choices[0].message.content]]
|
| 133 |
+
answer_result = AnswerResult()
|
| 134 |
+
answer_result.history = history
|
| 135 |
+
answer_result.llm_output = {"answer": completion.choices[0].message.content}
|
| 136 |
+
|
| 137 |
+
yield answer_result
|
models/llama_llm.py
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC
|
| 2 |
+
|
| 3 |
+
from langchain.llms.base import LLM
|
| 4 |
+
import random
|
| 5 |
+
import torch
|
| 6 |
+
import transformers
|
| 7 |
+
from transformers.generation.logits_process import LogitsProcessor
|
| 8 |
+
from transformers.generation.utils import LogitsProcessorList, StoppingCriteriaList
|
| 9 |
+
from typing import Optional, List, Dict, Any
|
| 10 |
+
from models.loader import LoaderCheckPoint
|
| 11 |
+
from models.base import (BaseAnswer,
|
| 12 |
+
AnswerResult)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class InvalidScoreLogitsProcessor(LogitsProcessor):
|
| 16 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
|
| 17 |
+
if torch.isnan(scores).any() or torch.isinf(scores).any():
|
| 18 |
+
scores.zero_()
|
| 19 |
+
scores[..., 5] = 5e4
|
| 20 |
+
return scores
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class LLamaLLM(BaseAnswer, LLM, ABC):
|
| 24 |
+
checkPoint: LoaderCheckPoint = None
|
| 25 |
+
# history = []
|
| 26 |
+
history_len: int = 3
|
| 27 |
+
max_new_tokens: int = 500
|
| 28 |
+
num_beams: int = 1
|
| 29 |
+
temperature: float = 0.5
|
| 30 |
+
top_p: float = 0.4
|
| 31 |
+
top_k: int = 10
|
| 32 |
+
repetition_penalty: float = 1.2
|
| 33 |
+
encoder_repetition_penalty: int = 1
|
| 34 |
+
min_length: int = 0
|
| 35 |
+
logits_processor: LogitsProcessorList = None
|
| 36 |
+
stopping_criteria: Optional[StoppingCriteriaList] = None
|
| 37 |
+
eos_token_id: Optional[int] = [2]
|
| 38 |
+
|
| 39 |
+
state: object = {'max_new_tokens': 50,
|
| 40 |
+
'seed': 1,
|
| 41 |
+
'temperature': 0, 'top_p': 0.1,
|
| 42 |
+
'top_k': 40, 'typical_p': 1,
|
| 43 |
+
'repetition_penalty': 1.2,
|
| 44 |
+
'encoder_repetition_penalty': 1,
|
| 45 |
+
'no_repeat_ngram_size': 0,
|
| 46 |
+
'min_length': 0,
|
| 47 |
+
'penalty_alpha': 0,
|
| 48 |
+
'num_beams': 1,
|
| 49 |
+
'length_penalty': 1,
|
| 50 |
+
'early_stopping': False, 'add_bos_token': True, 'ban_eos_token': False,
|
| 51 |
+
'truncation_length': 2048, 'custom_stopping_strings': '',
|
| 52 |
+
'cpu_memory': 0, 'auto_devices': False, 'disk': False, 'cpu': False, 'bf16': False,
|
| 53 |
+
'load_in_8bit': False, 'wbits': 'None', 'groupsize': 'None', 'model_type': 'None',
|
| 54 |
+
'pre_layer': 0, 'gpu_memory_0': 0}
|
| 55 |
+
|
| 56 |
+
def __init__(self, checkPoint: LoaderCheckPoint = None):
|
| 57 |
+
super().__init__()
|
| 58 |
+
self.checkPoint = checkPoint
|
| 59 |
+
|
| 60 |
+
@property
|
| 61 |
+
def _llm_type(self) -> str:
|
| 62 |
+
return "LLamaLLM"
|
| 63 |
+
|
| 64 |
+
@property
|
| 65 |
+
def _check_point(self) -> LoaderCheckPoint:
|
| 66 |
+
return self.checkPoint
|
| 67 |
+
|
| 68 |
+
def encode(self, prompt, add_special_tokens=True, add_bos_token=True, truncation_length=None):
|
| 69 |
+
input_ids = self.checkPoint.tokenizer.encode(str(prompt), return_tensors='pt',
|
| 70 |
+
add_special_tokens=add_special_tokens)
|
| 71 |
+
# This is a hack for making replies more creative.
|
| 72 |
+
if not add_bos_token and input_ids[0][0] == self.checkPoint.tokenizer.bos_token_id:
|
| 73 |
+
input_ids = input_ids[:, 1:]
|
| 74 |
+
|
| 75 |
+
# Llama adds this extra token when the first character is '\n', and this
|
| 76 |
+
# compromises the stopping criteria, so we just remove it
|
| 77 |
+
if type(self.checkPoint.tokenizer) is transformers.LlamaTokenizer and input_ids[0][0] == 29871:
|
| 78 |
+
input_ids = input_ids[:, 1:]
|
| 79 |
+
|
| 80 |
+
# Handling truncation
|
| 81 |
+
if truncation_length is not None:
|
| 82 |
+
input_ids = input_ids[:, -truncation_length:]
|
| 83 |
+
|
| 84 |
+
return input_ids.cuda()
|
| 85 |
+
|
| 86 |
+
def decode(self, output_ids):
|
| 87 |
+
reply = self.checkPoint.tokenizer.decode(output_ids, skip_special_tokens=True)
|
| 88 |
+
return reply
|
| 89 |
+
|
| 90 |
+
# 将历史对话数组转换为文本格式
|
| 91 |
+
def history_to_text(self, query, history):
|
| 92 |
+
"""
|
| 93 |
+
历史对话软提示
|
| 94 |
+
这段代码首先定义了一个名为 history_to_text 的函数,用于将 self.history
|
| 95 |
+
数组转换为所需的文本格式。然后,我们将格式化后的历史文本
|
| 96 |
+
再用 self.encode 将其转换为向量表示。最后,将历史对话向量与当前输入的对话向量拼接在一起。
|
| 97 |
+
:return:
|
| 98 |
+
"""
|
| 99 |
+
formatted_history = ''
|
| 100 |
+
history = history[-self.history_len:] if self.history_len > 0 else []
|
| 101 |
+
if len(history) > 0:
|
| 102 |
+
for i, (old_query, response) in enumerate(history):
|
| 103 |
+
formatted_history += "### Human:{}\n### Assistant:{}\n".format(old_query, response)
|
| 104 |
+
formatted_history += "### Human:{}\n### Assistant:".format(query)
|
| 105 |
+
return formatted_history
|
| 106 |
+
|
| 107 |
+
def prepare_inputs_for_generation(self,
|
| 108 |
+
input_ids: torch.LongTensor):
|
| 109 |
+
"""
|
| 110 |
+
预生成注意力掩码和 输入序列中每个位置的索引的张量
|
| 111 |
+
# TODO 没有思路
|
| 112 |
+
:return:
|
| 113 |
+
"""
|
| 114 |
+
|
| 115 |
+
mask_positions = torch.zeros((1, input_ids.shape[1]), dtype=input_ids.dtype).to(self.checkPoint.model.device)
|
| 116 |
+
|
| 117 |
+
attention_mask = self.get_masks(input_ids, input_ids.device)
|
| 118 |
+
|
| 119 |
+
position_ids = self.get_position_ids(
|
| 120 |
+
input_ids,
|
| 121 |
+
device=input_ids.device,
|
| 122 |
+
mask_positions=mask_positions
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
return input_ids, position_ids, attention_mask
|
| 126 |
+
|
| 127 |
+
@property
|
| 128 |
+
def _history_len(self) -> int:
|
| 129 |
+
return self.history_len
|
| 130 |
+
|
| 131 |
+
def set_history_len(self, history_len: int = 10) -> None:
|
| 132 |
+
self.history_len = history_len
|
| 133 |
+
|
| 134 |
+
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
|
| 135 |
+
print(f"__call:{prompt}")
|
| 136 |
+
if self.logits_processor is None:
|
| 137 |
+
self.logits_processor = LogitsProcessorList()
|
| 138 |
+
self.logits_processor.append(InvalidScoreLogitsProcessor())
|
| 139 |
+
|
| 140 |
+
gen_kwargs = {
|
| 141 |
+
"max_new_tokens": self.max_new_tokens,
|
| 142 |
+
"num_beams": self.num_beams,
|
| 143 |
+
"top_p": self.top_p,
|
| 144 |
+
"do_sample": True,
|
| 145 |
+
"top_k": self.top_k,
|
| 146 |
+
"repetition_penalty": self.repetition_penalty,
|
| 147 |
+
"encoder_repetition_penalty": self.encoder_repetition_penalty,
|
| 148 |
+
"min_length": self.min_length,
|
| 149 |
+
"temperature": self.temperature,
|
| 150 |
+
"eos_token_id": self.checkPoint.tokenizer.eos_token_id,
|
| 151 |
+
"logits_processor": self.logits_processor}
|
| 152 |
+
|
| 153 |
+
# 向量转换
|
| 154 |
+
input_ids = self.encode(prompt, add_bos_token=self.state['add_bos_token'], truncation_length=self.max_new_tokens)
|
| 155 |
+
# input_ids, position_ids, attention_mask = self.prepare_inputs_for_generation(input_ids=filler_input_ids)
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
gen_kwargs.update({'inputs': input_ids})
|
| 159 |
+
# 注意力掩码
|
| 160 |
+
# gen_kwargs.update({'attention_mask': attention_mask})
|
| 161 |
+
# gen_kwargs.update({'position_ids': position_ids})
|
| 162 |
+
if self.stopping_criteria is None:
|
| 163 |
+
self.stopping_criteria = transformers.StoppingCriteriaList()
|
| 164 |
+
# 观测输出
|
| 165 |
+
gen_kwargs.update({'stopping_criteria': self.stopping_criteria})
|
| 166 |
+
|
| 167 |
+
output_ids = self.checkPoint.model.generate(**gen_kwargs)
|
| 168 |
+
new_tokens = len(output_ids[0]) - len(input_ids[0])
|
| 169 |
+
reply = self.decode(output_ids[0][-new_tokens:])
|
| 170 |
+
print(f"response:{reply}")
|
| 171 |
+
print(f"+++++++++++++++++++++++++++++++++++")
|
| 172 |
+
return reply
|
| 173 |
+
|
| 174 |
+
def generatorAnswer(self, prompt: str,
|
| 175 |
+
history: List[List[str]] = [],
|
| 176 |
+
streaming: bool = False):
|
| 177 |
+
|
| 178 |
+
# TODO 需要实现chat对话模块和注意力模型,目前_call为langchain的LLM拓展的api,默认为无提示词模式,如果需要操作注意力模型,可以参考chat_glm的实现
|
| 179 |
+
softprompt = self.history_to_text(prompt,history=history)
|
| 180 |
+
response = self._call(prompt=softprompt, stop=['\n###'])
|
| 181 |
+
|
| 182 |
+
answer_result = AnswerResult()
|
| 183 |
+
answer_result.history = history + [[prompt, response]]
|
| 184 |
+
answer_result.llm_output = {"answer": response}
|
| 185 |
+
yield answer_result
|
models/loader/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from .loader import *
|
models/loader/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (182 Bytes). View file
|
|
|
models/loader/__pycache__/args.cpython-310.pyc
ADDED
|
Binary file (1.73 kB). View file
|
|
|
models/loader/__pycache__/loader.cpython-310.pyc
ADDED
|
Binary file (11.1 kB). View file
|
|
|
models/loader/args.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
from configs.model_config import *
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# Additional argparse types
|
| 7 |
+
def path(string):
|
| 8 |
+
if not string:
|
| 9 |
+
return ''
|
| 10 |
+
s = os.path.expanduser(string)
|
| 11 |
+
if not os.path.exists(s):
|
| 12 |
+
raise argparse.ArgumentTypeError(f'No such file or directory: "{string}"')
|
| 13 |
+
return s
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def file_path(string):
|
| 17 |
+
if not string:
|
| 18 |
+
return ''
|
| 19 |
+
s = os.path.expanduser(string)
|
| 20 |
+
if not os.path.isfile(s):
|
| 21 |
+
raise argparse.ArgumentTypeError(f'No such file: "{string}"')
|
| 22 |
+
return s
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def dir_path(string):
|
| 26 |
+
if not string:
|
| 27 |
+
return ''
|
| 28 |
+
s = os.path.expanduser(string)
|
| 29 |
+
if not os.path.isdir(s):
|
| 30 |
+
raise argparse.ArgumentTypeError(f'No such directory: "{string}"')
|
| 31 |
+
return s
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
parser = argparse.ArgumentParser(prog='langchain-ChatGLM',
|
| 35 |
+
description='About langchain-ChatGLM, local knowledge based ChatGLM with langchain | '
|
| 36 |
+
'基于本地知识库的 ChatGLM 问答')
|
| 37 |
+
|
| 38 |
+
parser.add_argument('--no-remote-model', action='store_true', help='remote in the model on '
|
| 39 |
+
'loader checkpoint, '
|
| 40 |
+
'if your load local '
|
| 41 |
+
'model to add the ` '
|
| 42 |
+
'--no-remote-model`')
|
| 43 |
+
parser.add_argument('--model-name', type=str, default=LLM_MODEL, help='Name of the model to load by default.')
|
| 44 |
+
parser.add_argument('--lora', type=str, help='Name of the LoRA to apply to the model by default.')
|
| 45 |
+
parser.add_argument("--lora-dir", type=str, default=LORA_DIR, help="Path to directory with all the loras")
|
| 46 |
+
|
| 47 |
+
# Accelerate/transformers
|
| 48 |
+
parser.add_argument('--load-in-8bit', action='store_true', default=LOAD_IN_8BIT,
|
| 49 |
+
help='Load the model with 8-bit precision.')
|
| 50 |
+
parser.add_argument('--bf16', action='store_true', default=BF16,
|
| 51 |
+
help='Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.')
|
| 52 |
+
|
| 53 |
+
args = parser.parse_args([])
|
| 54 |
+
# Generares dict with a default value for each argument
|
| 55 |
+
DEFAULT_ARGS = vars(args)
|
models/loader/loader.py
ADDED
|
@@ -0,0 +1,447 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gc
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import time
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
from typing import Optional, List, Dict, Tuple, Union
|
| 8 |
+
import torch
|
| 9 |
+
import transformers
|
| 10 |
+
from transformers import (AutoConfig, AutoModel, AutoModelForCausalLM,
|
| 11 |
+
AutoTokenizer, LlamaTokenizer)
|
| 12 |
+
from configs.model_config import LLM_DEVICE
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class LoaderCheckPoint:
|
| 16 |
+
"""
|
| 17 |
+
加载自定义 model CheckPoint
|
| 18 |
+
"""
|
| 19 |
+
# remote in the model on loader checkpoint
|
| 20 |
+
no_remote_model: bool = False
|
| 21 |
+
# 模型名称
|
| 22 |
+
model_name: str = None
|
| 23 |
+
tokenizer: object = None
|
| 24 |
+
# 模型全路径
|
| 25 |
+
model_path: str = None
|
| 26 |
+
model: object = None
|
| 27 |
+
model_config: object = None
|
| 28 |
+
lora_names: set = []
|
| 29 |
+
lora_dir: str = None
|
| 30 |
+
ptuning_dir: str = None
|
| 31 |
+
use_ptuning_v2: bool = False
|
| 32 |
+
# 如果开启了8bit量化加载,项目无法启动,参考此位置,选择合适的cuda版本,https://github.com/TimDettmers/bitsandbytes/issues/156
|
| 33 |
+
# 另一个原因可能是由于bitsandbytes安装时选择了系统环境变量里不匹配的cuda版本,
|
| 34 |
+
# 例如PATH下存在cuda10.2和cuda11.2,bitsandbytes安装时选择了10.2,而torch等安装依赖的版本是11.2
|
| 35 |
+
# 因此主要的解决思路是清理环境变量里PATH下的不匹配的cuda版本,一劳永逸的方法是:
|
| 36 |
+
# 0. 在终端执行`pip uninstall bitsandbytes`
|
| 37 |
+
# 1. 删除.bashrc文件下关于PATH的条目
|
| 38 |
+
# 2. 在终端执行 `echo $PATH >> .bashrc`
|
| 39 |
+
# 3. 删除.bashrc文件下PATH中关于不匹配的cuda版本路径
|
| 40 |
+
# 4. 在终端执行`source .bashrc`
|
| 41 |
+
# 5. 再执行`pip install bitsandbytes`
|
| 42 |
+
|
| 43 |
+
load_in_8bit: bool = False
|
| 44 |
+
is_llamacpp: bool = False
|
| 45 |
+
bf16: bool = False
|
| 46 |
+
params: object = None
|
| 47 |
+
# 自定义设备网络
|
| 48 |
+
device_map: Optional[Dict[str, int]] = None
|
| 49 |
+
# 默认 cuda ,如果不支持cuda使用多卡, 如果不支持多卡 使用cpu
|
| 50 |
+
llm_device = LLM_DEVICE
|
| 51 |
+
|
| 52 |
+
def __init__(self, params: dict = None):
|
| 53 |
+
"""
|
| 54 |
+
模型初始化
|
| 55 |
+
:param params:
|
| 56 |
+
"""
|
| 57 |
+
self.model = None
|
| 58 |
+
self.tokenizer = None
|
| 59 |
+
self.params = params or {}
|
| 60 |
+
self.model_name = params.get('model_name', False)
|
| 61 |
+
self.model_path = params.get('model_path', None)
|
| 62 |
+
self.no_remote_model = params.get('no_remote_model', False)
|
| 63 |
+
self.lora = params.get('lora', '')
|
| 64 |
+
self.use_ptuning_v2 = params.get('use_ptuning_v2', False)
|
| 65 |
+
self.lora_dir = params.get('lora_dir', '')
|
| 66 |
+
self.ptuning_dir = params.get('ptuning_dir', 'ptuning-v2')
|
| 67 |
+
self.load_in_8bit = params.get('load_in_8bit', False)
|
| 68 |
+
self.bf16 = params.get('bf16', False)
|
| 69 |
+
|
| 70 |
+
def _load_model_config(self, model_name):
|
| 71 |
+
|
| 72 |
+
if self.model_path:
|
| 73 |
+
checkpoint = Path(f'{self.model_path}')
|
| 74 |
+
else:
|
| 75 |
+
if not self.no_remote_model:
|
| 76 |
+
checkpoint = model_name
|
| 77 |
+
else:
|
| 78 |
+
raise ValueError(
|
| 79 |
+
"本地模型local_model_path未配置路径"
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
model_config = AutoConfig.from_pretrained(checkpoint, trust_remote_code=True)
|
| 83 |
+
|
| 84 |
+
return model_config
|
| 85 |
+
|
| 86 |
+
def _load_model(self, model_name):
|
| 87 |
+
"""
|
| 88 |
+
加载自定义位置的model
|
| 89 |
+
:param model_name:
|
| 90 |
+
:return:
|
| 91 |
+
"""
|
| 92 |
+
print(f"Loading {model_name}...")
|
| 93 |
+
t0 = time.time()
|
| 94 |
+
|
| 95 |
+
if self.model_path:
|
| 96 |
+
checkpoint = Path(f'{self.model_path}')
|
| 97 |
+
else:
|
| 98 |
+
if not self.no_remote_model:
|
| 99 |
+
checkpoint = model_name
|
| 100 |
+
else:
|
| 101 |
+
raise ValueError(
|
| 102 |
+
"本地模型local_model_path未配置路径"
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
self.is_llamacpp = len(list(Path(f'{checkpoint}').glob('ggml*.bin'))) > 0
|
| 106 |
+
if 'chatglm' in model_name.lower():
|
| 107 |
+
LoaderClass = AutoModel
|
| 108 |
+
else:
|
| 109 |
+
LoaderClass = AutoModelForCausalLM
|
| 110 |
+
|
| 111 |
+
# Load the model in simple 16-bit mode by default
|
| 112 |
+
# 如果加载没问题,但在推理时报错RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
|
| 113 |
+
# 那还是因为显存不够,此时只能考虑--load-in-8bit,或者配置默认模型为`chatglm-6b-int8`
|
| 114 |
+
if not any([self.llm_device.lower() == "cpu",
|
| 115 |
+
self.load_in_8bit, self.is_llamacpp]):
|
| 116 |
+
|
| 117 |
+
if torch.cuda.is_available() and self.llm_device.lower().startswith("cuda"):
|
| 118 |
+
# 根据当前设备GPU数量决定是否进行多卡部署
|
| 119 |
+
num_gpus = torch.cuda.device_count()
|
| 120 |
+
if num_gpus < 2 and self.device_map is None:
|
| 121 |
+
model = (
|
| 122 |
+
LoaderClass.from_pretrained(checkpoint,
|
| 123 |
+
config=self.model_config,
|
| 124 |
+
torch_dtype=torch.bfloat16 if self.bf16 else torch.float16,
|
| 125 |
+
trust_remote_code=True)
|
| 126 |
+
.half()
|
| 127 |
+
.cuda()
|
| 128 |
+
)
|
| 129 |
+
else:
|
| 130 |
+
from accelerate import dispatch_model
|
| 131 |
+
|
| 132 |
+
model = LoaderClass.from_pretrained(checkpoint,
|
| 133 |
+
config=self.model_config,
|
| 134 |
+
torch_dtype=torch.bfloat16 if self.bf16 else torch.float16,
|
| 135 |
+
trust_remote_code=True).half()
|
| 136 |
+
# 可传入device_map自定义每张卡的部署情况
|
| 137 |
+
if self.device_map is None:
|
| 138 |
+
if 'chatglm' in model_name.lower():
|
| 139 |
+
self.device_map = self.chatglm_auto_configure_device_map(num_gpus)
|
| 140 |
+
elif 'moss' in model_name.lower():
|
| 141 |
+
self.device_map = self.moss_auto_configure_device_map(num_gpus, model_name)
|
| 142 |
+
else:
|
| 143 |
+
self.device_map = self.chatglm_auto_configure_device_map(num_gpus)
|
| 144 |
+
|
| 145 |
+
model = dispatch_model(model, device_map=self.device_map)
|
| 146 |
+
else:
|
| 147 |
+
model = (
|
| 148 |
+
LoaderClass.from_pretrained(
|
| 149 |
+
checkpoint,
|
| 150 |
+
config=self.model_config,
|
| 151 |
+
trust_remote_code=True)
|
| 152 |
+
.float()
|
| 153 |
+
.to(self.llm_device)
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
elif self.is_llamacpp:
|
| 157 |
+
|
| 158 |
+
try:
|
| 159 |
+
from models.extensions.llamacpp_model_alternative import LlamaCppModel
|
| 160 |
+
|
| 161 |
+
except ImportError as exc:
|
| 162 |
+
raise ValueError(
|
| 163 |
+
"Could not import depend python package "
|
| 164 |
+
"Please install it with `pip install llama-cpp-python`."
|
| 165 |
+
) from exc
|
| 166 |
+
|
| 167 |
+
model_file = list(checkpoint.glob('ggml*.bin'))[0]
|
| 168 |
+
print(f"llama.cpp weights detected: {model_file}\n")
|
| 169 |
+
|
| 170 |
+
model, tokenizer = LlamaCppModel.from_pretrained(model_file)
|
| 171 |
+
return model, tokenizer
|
| 172 |
+
|
| 173 |
+
elif self.load_in_8bit:
|
| 174 |
+
try:
|
| 175 |
+
from accelerate import init_empty_weights
|
| 176 |
+
from accelerate.utils import get_balanced_memory, infer_auto_device_map
|
| 177 |
+
from transformers import BitsAndBytesConfig
|
| 178 |
+
|
| 179 |
+
except ImportError as exc:
|
| 180 |
+
raise ValueError(
|
| 181 |
+
"Could not import depend python package "
|
| 182 |
+
"Please install it with `pip install transformers` "
|
| 183 |
+
"`pip install bitsandbytes``pip install accelerate`."
|
| 184 |
+
) from exc
|
| 185 |
+
|
| 186 |
+
params = {"low_cpu_mem_usage": True}
|
| 187 |
+
|
| 188 |
+
if not self.llm_device.lower().startswith("cuda"):
|
| 189 |
+
raise SystemError("8bit 模型需要 CUDA 支持,或者改用量化后模型!")
|
| 190 |
+
else:
|
| 191 |
+
params["device_map"] = 'auto'
|
| 192 |
+
params["trust_remote_code"] = True
|
| 193 |
+
params['quantization_config'] = BitsAndBytesConfig(load_in_8bit=True,
|
| 194 |
+
llm_int8_enable_fp32_cpu_offload=False)
|
| 195 |
+
|
| 196 |
+
with init_empty_weights():
|
| 197 |
+
model = LoaderClass.from_config(self.model_config,trust_remote_code = True)
|
| 198 |
+
model.tie_weights()
|
| 199 |
+
if self.device_map is not None:
|
| 200 |
+
params['device_map'] = self.device_map
|
| 201 |
+
else:
|
| 202 |
+
params['device_map'] = infer_auto_device_map(
|
| 203 |
+
model,
|
| 204 |
+
dtype=torch.int8,
|
| 205 |
+
no_split_module_classes=model._no_split_modules
|
| 206 |
+
)
|
| 207 |
+
try:
|
| 208 |
+
|
| 209 |
+
model = LoaderClass.from_pretrained(checkpoint, **params)
|
| 210 |
+
except ImportError as exc:
|
| 211 |
+
raise ValueError(
|
| 212 |
+
"如果开启了8bit量化加载,项目无法启动,参考此位置,选择合适的cuda版本,https://github.com/TimDettmers/bitsandbytes/issues/156"
|
| 213 |
+
) from exc
|
| 214 |
+
# Custom
|
| 215 |
+
else:
|
| 216 |
+
|
| 217 |
+
print(
|
| 218 |
+
"Warning: self.llm_device is False.\nThis means that no use GPU bring to be load CPU mode\n")
|
| 219 |
+
params = {"low_cpu_mem_usage": True, "torch_dtype": torch.float32, "trust_remote_code": True}
|
| 220 |
+
model = LoaderClass.from_pretrained(checkpoint, **params).to(self.llm_device, dtype=float)
|
| 221 |
+
|
| 222 |
+
# Loading the tokenizer
|
| 223 |
+
if type(model) is transformers.LlamaForCausalLM:
|
| 224 |
+
tokenizer = LlamaTokenizer.from_pretrained(checkpoint, clean_up_tokenization_spaces=True)
|
| 225 |
+
# Leaving this here until the LLaMA tokenizer gets figured out.
|
| 226 |
+
# For some people this fixes things, for others it causes an error.
|
| 227 |
+
try:
|
| 228 |
+
tokenizer.eos_token_id = 2
|
| 229 |
+
tokenizer.bos_token_id = 1
|
| 230 |
+
tokenizer.pad_token_id = 0
|
| 231 |
+
except Exception as e:
|
| 232 |
+
print(e)
|
| 233 |
+
pass
|
| 234 |
+
else:
|
| 235 |
+
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
|
| 236 |
+
|
| 237 |
+
print(f"Loaded the model in {(time.time() - t0):.2f} seconds.")
|
| 238 |
+
return model, tokenizer
|
| 239 |
+
|
| 240 |
+
def chatglm_auto_configure_device_map(self, num_gpus: int) -> Dict[str, int]:
|
| 241 |
+
# transformer.word_embeddings 占用1层
|
| 242 |
+
# transformer.final_layernorm 和 lm_head 占用1层
|
| 243 |
+
# transformer.layers 占用 28 层
|
| 244 |
+
# 总共30层分配到num_gpus张卡上
|
| 245 |
+
num_trans_layers = 28
|
| 246 |
+
per_gpu_layers = 30 / num_gpus
|
| 247 |
+
|
| 248 |
+
# bugfix: PEFT加载lora模型出现的层命名不同
|
| 249 |
+
if self.lora:
|
| 250 |
+
layer_prefix = 'base_model.model.transformer'
|
| 251 |
+
else:
|
| 252 |
+
layer_prefix = 'transformer'
|
| 253 |
+
|
| 254 |
+
# bugfix: 在linux中调用torch.embedding传入的weight,input不在同一device上,导致RuntimeError
|
| 255 |
+
# windows下 model.device 会被设置成 transformer.word_embeddings.device
|
| 256 |
+
# linux下 model.device 会被设置成 lm_head.device
|
| 257 |
+
# 在调用chat或者stream_chat时,input_ids会被放到model.device上
|
| 258 |
+
# 如果transformer.word_embeddings.device和model.device不同,则会导致RuntimeError
|
| 259 |
+
# 因此这里将transformer.word_embeddings,transformer.final_layernorm,lm_head都放到第一张卡上
|
| 260 |
+
|
| 261 |
+
encode = ""
|
| 262 |
+
if 'chatglm2' in self.model_name:
|
| 263 |
+
device_map = {
|
| 264 |
+
f"{layer_prefix}.embedding.word_embeddings": 0,
|
| 265 |
+
f"{layer_prefix}.rotary_pos_emb": 0,
|
| 266 |
+
f"{layer_prefix}.output_layer": 0,
|
| 267 |
+
f"{layer_prefix}.encoder.final_layernorm": 0,
|
| 268 |
+
f"base_model.model.output_layer": 0
|
| 269 |
+
}
|
| 270 |
+
encode = ".encoder"
|
| 271 |
+
else:
|
| 272 |
+
device_map = {f'{layer_prefix}.word_embeddings': 0,
|
| 273 |
+
f'{layer_prefix}.final_layernorm': 0, 'lm_head': 0,
|
| 274 |
+
f'base_model.model.lm_head': 0, }
|
| 275 |
+
used = 2
|
| 276 |
+
gpu_target = 0
|
| 277 |
+
for i in range(num_trans_layers):
|
| 278 |
+
if used >= per_gpu_layers:
|
| 279 |
+
gpu_target += 1
|
| 280 |
+
used = 0
|
| 281 |
+
assert gpu_target < num_gpus
|
| 282 |
+
device_map[f'{layer_prefix}{encode}.layers.{i}'] = gpu_target
|
| 283 |
+
used += 1
|
| 284 |
+
|
| 285 |
+
return device_map
|
| 286 |
+
|
| 287 |
+
def moss_auto_configure_device_map(self, num_gpus: int, model_name) -> Dict[str, int]:
|
| 288 |
+
try:
|
| 289 |
+
|
| 290 |
+
from accelerate import init_empty_weights
|
| 291 |
+
from accelerate.utils import get_balanced_memory, infer_auto_device_map
|
| 292 |
+
from transformers.dynamic_module_utils import get_class_from_dynamic_module
|
| 293 |
+
from transformers.modeling_utils import no_init_weights
|
| 294 |
+
from transformers.utils import ContextManagers
|
| 295 |
+
except ImportError as exc:
|
| 296 |
+
raise ValueError(
|
| 297 |
+
"Could not import depend python package "
|
| 298 |
+
"Please install it with `pip install transformers` "
|
| 299 |
+
"`pip install bitsandbytes``pip install accelerate`."
|
| 300 |
+
) from exc
|
| 301 |
+
|
| 302 |
+
if self.model_path:
|
| 303 |
+
checkpoint = Path(f'{self.model_path}')
|
| 304 |
+
else:
|
| 305 |
+
if not self.no_remote_model:
|
| 306 |
+
checkpoint = model_name
|
| 307 |
+
else:
|
| 308 |
+
raise ValueError(
|
| 309 |
+
"本地模型local_model_path未配置路径"
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
cls = get_class_from_dynamic_module(class_reference="fnlp/moss-moon-003-sft--modeling_moss.MossForCausalLM",
|
| 313 |
+
pretrained_model_name_or_path=checkpoint)
|
| 314 |
+
|
| 315 |
+
with ContextManagers([no_init_weights(_enable=True), init_empty_weights()]):
|
| 316 |
+
model = cls(self.model_config)
|
| 317 |
+
max_memory = get_balanced_memory(model, dtype=torch.int8 if self.load_in_8bit else None,
|
| 318 |
+
low_zero=False, no_split_module_classes=model._no_split_modules)
|
| 319 |
+
device_map = infer_auto_device_map(
|
| 320 |
+
model, dtype=torch.float16 if not self.load_in_8bit else torch.int8, max_memory=max_memory,
|
| 321 |
+
no_split_module_classes=model._no_split_modules)
|
| 322 |
+
device_map["transformer.wte"] = 0
|
| 323 |
+
device_map["transformer.drop"] = 0
|
| 324 |
+
device_map["transformer.ln_f"] = 0
|
| 325 |
+
device_map["lm_head"] = 0
|
| 326 |
+
return device_map
|
| 327 |
+
|
| 328 |
+
def _add_lora_to_model(self, lora_names):
|
| 329 |
+
|
| 330 |
+
try:
|
| 331 |
+
|
| 332 |
+
from peft import PeftModel
|
| 333 |
+
|
| 334 |
+
except ImportError as exc:
|
| 335 |
+
raise ValueError(
|
| 336 |
+
"Could not import depend python package. "
|
| 337 |
+
"Please install it with `pip install peft``pip install accelerate`."
|
| 338 |
+
) from exc
|
| 339 |
+
# 目前加载的lora
|
| 340 |
+
prior_set = set(self.lora_names)
|
| 341 |
+
# 需要加载的
|
| 342 |
+
added_set = set(lora_names) - prior_set
|
| 343 |
+
# 删除的lora
|
| 344 |
+
removed_set = prior_set - set(lora_names)
|
| 345 |
+
self.lora_names = list(lora_names)
|
| 346 |
+
|
| 347 |
+
# Nothing to do = skip.
|
| 348 |
+
if len(added_set) == 0 and len(removed_set) == 0:
|
| 349 |
+
return
|
| 350 |
+
|
| 351 |
+
# Only adding, and already peft? Do it the easy way.
|
| 352 |
+
if len(removed_set) == 0 and len(prior_set) > 0:
|
| 353 |
+
print(f"Adding the LoRA(s) named {added_set} to the model...")
|
| 354 |
+
for lora in added_set:
|
| 355 |
+
self.model.load_adapter(Path(f"{self.lora_dir}/{lora}"), lora)
|
| 356 |
+
return
|
| 357 |
+
|
| 358 |
+
# If removing anything, disable all and re-add.
|
| 359 |
+
if len(removed_set) > 0:
|
| 360 |
+
self.model.disable_adapter()
|
| 361 |
+
|
| 362 |
+
if len(lora_names) > 0:
|
| 363 |
+
print("Applying the following LoRAs to {}: {}".format(self.model_name, ', '.join(lora_names)))
|
| 364 |
+
params = {}
|
| 365 |
+
if self.llm_device.lower() != "cpu":
|
| 366 |
+
params['dtype'] = self.model.dtype
|
| 367 |
+
if hasattr(self.model, "hf_device_map"):
|
| 368 |
+
params['device_map'] = {"base_model.model." + k: v for k, v in self.model.hf_device_map.items()}
|
| 369 |
+
elif self.load_in_8bit:
|
| 370 |
+
params['device_map'] = {'': 0}
|
| 371 |
+
self.model.resize_token_embeddings(len(self.tokenizer))
|
| 372 |
+
|
| 373 |
+
self.model = PeftModel.from_pretrained(self.model, Path(f"{self.lora_dir}/{lora_names[0]}"), **params)
|
| 374 |
+
|
| 375 |
+
for lora in lora_names[1:]:
|
| 376 |
+
self.model.load_adapter(Path(f"{self.lora_dir}/{lora}"), lora)
|
| 377 |
+
|
| 378 |
+
if not self.load_in_8bit and self.llm_device.lower() != "cpu":
|
| 379 |
+
|
| 380 |
+
if not hasattr(self.model, "hf_device_map"):
|
| 381 |
+
if torch.has_mps:
|
| 382 |
+
device = torch.device('mps')
|
| 383 |
+
self.model = self.model.to(device)
|
| 384 |
+
else:
|
| 385 |
+
self.model = self.model.cuda()
|
| 386 |
+
|
| 387 |
+
def clear_torch_cache(self):
|
| 388 |
+
gc.collect()
|
| 389 |
+
if self.llm_device.lower() != "cpu":
|
| 390 |
+
if torch.has_mps:
|
| 391 |
+
try:
|
| 392 |
+
from torch.mps import empty_cache
|
| 393 |
+
empty_cache()
|
| 394 |
+
except Exception as e:
|
| 395 |
+
print(e)
|
| 396 |
+
print(
|
| 397 |
+
"如果您使用的是 macOS 建议将 pytorch 版本升级至 2.0.0 或更高版本,以支持及时清理 torch 产生的内存占用。")
|
| 398 |
+
elif torch.has_cuda:
|
| 399 |
+
device_id = "0" if torch.cuda.is_available() else None
|
| 400 |
+
CUDA_DEVICE = f"{self.llm_device}:{device_id}" if device_id else self.llm_device
|
| 401 |
+
with torch.cuda.device(CUDA_DEVICE):
|
| 402 |
+
torch.cuda.empty_cache()
|
| 403 |
+
torch.cuda.ipc_collect()
|
| 404 |
+
else:
|
| 405 |
+
print("未检测到 cuda 或 mps,暂不支持清理显存")
|
| 406 |
+
|
| 407 |
+
def unload_model(self):
|
| 408 |
+
del self.model
|
| 409 |
+
del self.tokenizer
|
| 410 |
+
self.model = self.tokenizer = None
|
| 411 |
+
self.clear_torch_cache()
|
| 412 |
+
|
| 413 |
+
def set_model_path(self, model_path):
|
| 414 |
+
self.model_path = model_path
|
| 415 |
+
|
| 416 |
+
def reload_model(self):
|
| 417 |
+
self.unload_model()
|
| 418 |
+
self.model_config = self._load_model_config(self.model_name)
|
| 419 |
+
|
| 420 |
+
if self.use_ptuning_v2:
|
| 421 |
+
try:
|
| 422 |
+
prefix_encoder_file = open(Path(f'{self.ptuning_dir}/config.json'), 'r')
|
| 423 |
+
prefix_encoder_config = json.loads(prefix_encoder_file.read())
|
| 424 |
+
prefix_encoder_file.close()
|
| 425 |
+
self.model_config.pre_seq_len = prefix_encoder_config['pre_seq_len']
|
| 426 |
+
self.model_config.prefix_projection = prefix_encoder_config['prefix_projection']
|
| 427 |
+
except Exception as e:
|
| 428 |
+
print("加载PrefixEncoder config.json失败")
|
| 429 |
+
|
| 430 |
+
self.model, self.tokenizer = self._load_model(self.model_name)
|
| 431 |
+
|
| 432 |
+
if self.lora:
|
| 433 |
+
self._add_lora_to_model([self.lora])
|
| 434 |
+
|
| 435 |
+
if self.use_ptuning_v2:
|
| 436 |
+
try:
|
| 437 |
+
prefix_state_dict = torch.load(Path(f'{self.ptuning_dir}/pytorch_model.bin'))
|
| 438 |
+
new_prefix_state_dict = {}
|
| 439 |
+
for k, v in prefix_state_dict.items():
|
| 440 |
+
if k.startswith("transformer.prefix_encoder."):
|
| 441 |
+
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
|
| 442 |
+
self.model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
|
| 443 |
+
self.model.transformer.prefix_encoder.float()
|
| 444 |
+
except Exception as e:
|
| 445 |
+
print("加载PrefixEncoder模型参数失败")
|
| 446 |
+
|
| 447 |
+
self.model = self.model.eval()
|