Spaces:
Runtime error

Runtime error
Deploying Agentic RAG
Browse files- AgenticRAG/.chainlit/config.toml +84 -0
- AgenticRAG/.gitattributes +35 -0
- AgenticRAG/.gitignore +1 -0
- AgenticRAG/Agentic RAG.ipynb +428 -0
- AgenticRAG/BuildingAChainlitApp.md +214 -0
- AgenticRAG/Dockerfile +11 -0
- AgenticRAG/README.md +118 -0
- AgenticRAG/agentic_rag.py +0 -0
- AgenticRAG/aimakerspace/__init__.py +0 -0
- AgenticRAG/aimakerspace/openai_utils/__init__.py +0 -0
- AgenticRAG/aimakerspace/openai_utils/chatmodel.py +45 -0
- AgenticRAG/aimakerspace/openai_utils/embedding.py +59 -0
- AgenticRAG/aimakerspace/openai_utils/prompts.py +78 -0
- AgenticRAG/aimakerspace/text_utils.py +77 -0
- AgenticRAG/aimakerspace/vectordatabase.py +81 -0
- AgenticRAG/app.py +137 -0
- AgenticRAG/chainlit.md +3 -0
- AgenticRAG/images/docchain_img.png +0 -0
- AgenticRAG/requirements.txt +7 -0
- AgenticRAG/runtime.txt +1 -0
AgenticRAG/.chainlit/config.toml
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
# Whether to enable telemetry (default: true). No personal data is collected.
|
| 3 |
+
enable_telemetry = true
|
| 4 |
+
|
| 5 |
+
# List of environment variables to be provided by each user to use the app.
|
| 6 |
+
user_env = []
|
| 7 |
+
|
| 8 |
+
# Duration (in seconds) during which the session is saved when the connection is lost
|
| 9 |
+
session_timeout = 3600
|
| 10 |
+
|
| 11 |
+
# Enable third parties caching (e.g LangChain cache)
|
| 12 |
+
cache = false
|
| 13 |
+
|
| 14 |
+
# Follow symlink for asset mount (see https://github.com/Chainlit/chainlit/issues/317)
|
| 15 |
+
follow_symlink = true
|
| 16 |
+
|
| 17 |
+
[features]
|
| 18 |
+
# Show the prompt playground
|
| 19 |
+
prompt_playground = true
|
| 20 |
+
|
| 21 |
+
# Process and display HTML in messages. This can be a security risk (see https://stackoverflow.com/questions/19603097/why-is-it-dangerous-to-render-user-generated-html-or-javascript)
|
| 22 |
+
unsafe_allow_html = false
|
| 23 |
+
|
| 24 |
+
# Process and display mathematical expressions. This can clash with "$" characters in messages.
|
| 25 |
+
latex = false
|
| 26 |
+
|
| 27 |
+
# Authorize users to upload files with messages
|
| 28 |
+
multi_modal = true
|
| 29 |
+
|
| 30 |
+
# Allows user to use speech to text
|
| 31 |
+
[features.speech_to_text]
|
| 32 |
+
enabled = false
|
| 33 |
+
# See all languages here https://github.com/JamesBrill/react-speech-recognition/blob/HEAD/docs/API.md#language-string
|
| 34 |
+
# language = "en-US"
|
| 35 |
+
|
| 36 |
+
[UI]
|
| 37 |
+
# Name of the app and chatbot.
|
| 38 |
+
name = "Chatbot"
|
| 39 |
+
|
| 40 |
+
# Show the readme while the conversation is empty.
|
| 41 |
+
show_readme_as_default = true
|
| 42 |
+
|
| 43 |
+
# Description of the app and chatbot. This is used for HTML tags.
|
| 44 |
+
# description = ""
|
| 45 |
+
|
| 46 |
+
# Large size content are by default collapsed for a cleaner ui
|
| 47 |
+
default_collapse_content = true
|
| 48 |
+
|
| 49 |
+
# The default value for the expand messages settings.
|
| 50 |
+
default_expand_messages = false
|
| 51 |
+
|
| 52 |
+
# Hide the chain of thought details from the user in the UI.
|
| 53 |
+
hide_cot = false
|
| 54 |
+
|
| 55 |
+
# Link to your github repo. This will add a github button in the UI's header.
|
| 56 |
+
# github = ""
|
| 57 |
+
|
| 58 |
+
# Specify a CSS file that can be used to customize the user interface.
|
| 59 |
+
# The CSS file can be served from the public directory or via an external link.
|
| 60 |
+
# custom_css = "/public/test.css"
|
| 61 |
+
|
| 62 |
+
# Override default MUI light theme. (Check theme.ts)
|
| 63 |
+
[UI.theme.light]
|
| 64 |
+
#background = "#FAFAFA"
|
| 65 |
+
#paper = "#FFFFFF"
|
| 66 |
+
|
| 67 |
+
[UI.theme.light.primary]
|
| 68 |
+
#main = "#F80061"
|
| 69 |
+
#dark = "#980039"
|
| 70 |
+
#light = "#FFE7EB"
|
| 71 |
+
|
| 72 |
+
# Override default MUI dark theme. (Check theme.ts)
|
| 73 |
+
[UI.theme.dark]
|
| 74 |
+
#background = "#FAFAFA"
|
| 75 |
+
#paper = "#FFFFFF"
|
| 76 |
+
|
| 77 |
+
[UI.theme.dark.primary]
|
| 78 |
+
#main = "#F80061"
|
| 79 |
+
#dark = "#980039"
|
| 80 |
+
#light = "#FFE7EB"
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
[meta]
|
| 84 |
+
generated_by = "0.7.700"
|
AgenticRAG/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
AgenticRAG/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__pycache__/
|
AgenticRAG/Agentic RAG.ipynb
ADDED
|
@@ -0,0 +1,428 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"name": "stdout",
|
| 10 |
+
"output_type": "stream",
|
| 11 |
+
"text": [
|
| 12 |
+
"^C\n",
|
| 13 |
+
"Note: you may need to restart the kernel to use updated packages.\n"
|
| 14 |
+
]
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"name": "stderr",
|
| 18 |
+
"output_type": "stream",
|
| 19 |
+
"text": [
|
| 20 |
+
"ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
|
| 21 |
+
"grpcio-tools 1.66.1 requires protobuf<6.0dev,>=5.26.1, but you have protobuf 4.25.5 which is incompatible.\n",
|
| 22 |
+
"langchain-chroma 0.1.3 requires langchain-core<0.3,>=0.1.40, but you have langchain-core 0.3.5 which is incompatible.\n",
|
| 23 |
+
"langchain-huggingface 0.0.3 requires langchain-core<0.3,>=0.1.52, but you have langchain-core 0.3.5 which is incompatible.\n",
|
| 24 |
+
"ragas 0.1.20 requires langchain-core<0.3, but you have langchain-core 0.3.5 which is incompatible.\n"
|
| 25 |
+
]
|
| 26 |
+
}
|
| 27 |
+
],
|
| 28 |
+
"source": [
|
| 29 |
+
"%pip install -qU langchain-community tiktoken langchain-openai langchainhub langchain langgraph langchain-text-splitters"
|
| 30 |
+
]
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"cell_type": "code",
|
| 34 |
+
"execution_count": null,
|
| 35 |
+
"metadata": {},
|
| 36 |
+
"outputs": [],
|
| 37 |
+
"source": [
|
| 38 |
+
"%pip install qdrant-client"
|
| 39 |
+
]
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"cell_type": "code",
|
| 43 |
+
"execution_count": 27,
|
| 44 |
+
"metadata": {},
|
| 45 |
+
"outputs": [],
|
| 46 |
+
"source": [
|
| 47 |
+
"import os\n",
|
| 48 |
+
"import getpass\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"OpenAI API Key:\")"
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"cell_type": "code",
|
| 55 |
+
"execution_count": 4,
|
| 56 |
+
"metadata": {},
|
| 57 |
+
"outputs": [],
|
| 58 |
+
"source": [
|
| 59 |
+
"from langchain_community.document_loaders import PyMuPDFLoader\n",
|
| 60 |
+
"from langchain_text_splitters import RecursiveCharacterTextSplitter\n",
|
| 61 |
+
"from langchain_openai import OpenAIEmbeddings\n",
|
| 62 |
+
"from langchain_community.vectorstores import Qdrant\n",
|
| 63 |
+
"\n",
|
| 64 |
+
"pdfs = [\n",
|
| 65 |
+
" \"C:/Users/andre/OneDrive/Documents/AIE4/AIE4/Midterm/Blueprint-for-an-AI-Bill-of-Rights.pdf\",\n",
|
| 66 |
+
" \"C:/Users/andre/OneDrive/Documents/AIE4/AIE4/Midterm/NIST_report.pdf\",\n",
|
| 67 |
+
"]\n",
|
| 68 |
+
"\n",
|
| 69 |
+
"docs = [PyMuPDFLoader(pdf).load() for pdf in pdfs]\n",
|
| 70 |
+
"\n",
|
| 71 |
+
"docs_list = [item for sublist in docs for item in sublist]\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(\n",
|
| 74 |
+
" chunk_size=500, chunk_overlap=50\n",
|
| 75 |
+
")\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"doc_splits = text_splitter.split_documents(docs_list)\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"embeddings = OpenAIEmbeddings(model=\"text-embedding-3-small\")\n",
|
| 80 |
+
"\n",
|
| 81 |
+
"vectorstore = Qdrant.from_documents(\n",
|
| 82 |
+
" documents=doc_splits,\n",
|
| 83 |
+
" embedding=embeddings,\n",
|
| 84 |
+
" location=\":memory:\",\n",
|
| 85 |
+
" collection_name=\"rag-agentic\"\n",
|
| 86 |
+
")\n",
|
| 87 |
+
"\n",
|
| 88 |
+
"retriever = vectorstore.as_retriever()"
|
| 89 |
+
]
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"cell_type": "code",
|
| 93 |
+
"execution_count": 32,
|
| 94 |
+
"metadata": {},
|
| 95 |
+
"outputs": [],
|
| 96 |
+
"source": [
|
| 97 |
+
"from langchain.tools.retriever import create_retriever_tool\n",
|
| 98 |
+
"\n",
|
| 99 |
+
"retriever_tool = create_retriever_tool(\n",
|
| 100 |
+
" retriever,\n",
|
| 101 |
+
" \"retrieve_blog_posts\",\n",
|
| 102 |
+
" \"Search and return information about the responsible and ethical use of AI along with the development of policies and practices to protect civil rights and promote democratic values in the building, deployment, and government of automated systems.\",\n",
|
| 103 |
+
")\n",
|
| 104 |
+
"\n",
|
| 105 |
+
"tools = [retriever_tool]"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": 33,
|
| 111 |
+
"metadata": {},
|
| 112 |
+
"outputs": [],
|
| 113 |
+
"source": [
|
| 114 |
+
"from typing import Annotated, Sequence, TypedDict\n",
|
| 115 |
+
"\n",
|
| 116 |
+
"from langchain_core.messages import BaseMessage\n",
|
| 117 |
+
"\n",
|
| 118 |
+
"from langgraph.graph.message import add_messages\n",
|
| 119 |
+
"\n",
|
| 120 |
+
"\n",
|
| 121 |
+
"class AgentState(TypedDict):\n",
|
| 122 |
+
" # The add_messages function defines how an update should be processed\n",
|
| 123 |
+
" # Default is to replace. add_messages says \"append\"\n",
|
| 124 |
+
" messages: Annotated[Sequence[BaseMessage], add_messages]"
|
| 125 |
+
]
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"cell_type": "code",
|
| 129 |
+
"execution_count": 34,
|
| 130 |
+
"metadata": {},
|
| 131 |
+
"outputs": [],
|
| 132 |
+
"source": [
|
| 133 |
+
"from typing import Annotated, Literal, Sequence, TypedDict\n",
|
| 134 |
+
"\n",
|
| 135 |
+
"from langchain import hub\n",
|
| 136 |
+
"from langchain_core.messages import BaseMessage, HumanMessage\n",
|
| 137 |
+
"from langchain_core.output_parsers import StrOutputParser\n",
|
| 138 |
+
"from langchain_core.prompts import PromptTemplate\n",
|
| 139 |
+
"from langchain_openai import ChatOpenAI\n",
|
| 140 |
+
"# NOTE: you must use langchain-core >= 0.3 with Pydantic v2\n",
|
| 141 |
+
"from pydantic import BaseModel, Field\n",
|
| 142 |
+
"from langgraph.prebuilt import tools_condition\n"
|
| 143 |
+
]
|
| 144 |
+
},
|
| 145 |
+
{
|
| 146 |
+
"cell_type": "code",
|
| 147 |
+
"execution_count": 35,
|
| 148 |
+
"metadata": {},
|
| 149 |
+
"outputs": [],
|
| 150 |
+
"source": [
|
| 151 |
+
"\n",
|
| 152 |
+
"### Edges\n",
|
| 153 |
+
"\n",
|
| 154 |
+
"\n",
|
| 155 |
+
"def grade_documents(state) -> Literal[\"generate\", \"rewrite\"]:\n",
|
| 156 |
+
" \"\"\"\n",
|
| 157 |
+
" Determines whether the retrieved documents are relevant to the question.\n",
|
| 158 |
+
"\n",
|
| 159 |
+
" Args:\n",
|
| 160 |
+
" state (messages): The current state\n",
|
| 161 |
+
"\n",
|
| 162 |
+
" Returns:\n",
|
| 163 |
+
" str: A decision for whether the documents are relevant or not\n",
|
| 164 |
+
" \"\"\"\n",
|
| 165 |
+
"\n",
|
| 166 |
+
" print(\"---CHECK RELEVANCE---\")\n",
|
| 167 |
+
"\n",
|
| 168 |
+
" # Data model\n",
|
| 169 |
+
" class grade(BaseModel):\n",
|
| 170 |
+
" \"\"\"Binary score for relevance check.\"\"\"\n",
|
| 171 |
+
"\n",
|
| 172 |
+
" binary_score: str = Field(description=\"Relevance score 'yes' or 'no'\")\n",
|
| 173 |
+
"\n",
|
| 174 |
+
" # LLM\n",
|
| 175 |
+
" model = ChatOpenAI(temperature=0, model=\"gpt-4o-mini\", streaming=True)\n",
|
| 176 |
+
"\n",
|
| 177 |
+
" # LLM with tool and validation\n",
|
| 178 |
+
" llm_with_tool = model.with_structured_output(grade)\n",
|
| 179 |
+
"\n",
|
| 180 |
+
" # Prompt\n",
|
| 181 |
+
" prompt = PromptTemplate(\n",
|
| 182 |
+
" template=\"\"\"You are a grader assessing relevance of a retrieved document to a user question. \\n \n",
|
| 183 |
+
" Here is the retrieved document: \\n\\n {context} \\n\\n\n",
|
| 184 |
+
" Here is the user question: {question} \\n\n",
|
| 185 |
+
" If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \\n\n",
|
| 186 |
+
" Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.\"\"\",\n",
|
| 187 |
+
" input_variables=[\"context\", \"question\"],\n",
|
| 188 |
+
" )\n",
|
| 189 |
+
"\n",
|
| 190 |
+
" # Chain\n",
|
| 191 |
+
" chain = prompt | llm_with_tool\n",
|
| 192 |
+
"\n",
|
| 193 |
+
" messages = state[\"messages\"]\n",
|
| 194 |
+
" last_message = messages[-1]\n",
|
| 195 |
+
"\n",
|
| 196 |
+
" question = messages[0].content\n",
|
| 197 |
+
" docs = last_message.content\n",
|
| 198 |
+
"\n",
|
| 199 |
+
" scored_result = chain.invoke({\"question\": question, \"context\": docs})\n",
|
| 200 |
+
"\n",
|
| 201 |
+
" score = scored_result.binary_score\n",
|
| 202 |
+
"\n",
|
| 203 |
+
" if score == \"yes\":\n",
|
| 204 |
+
" print(\"---DECISION: DOCS RELEVANT---\")\n",
|
| 205 |
+
" return \"generate\"\n",
|
| 206 |
+
"\n",
|
| 207 |
+
" else:\n",
|
| 208 |
+
" print(\"---DECISION: DOCS NOT RELEVANT---\")\n",
|
| 209 |
+
" print(score)\n",
|
| 210 |
+
" return \"rewrite\"\n"
|
| 211 |
+
]
|
| 212 |
+
},
|
| 213 |
+
{
|
| 214 |
+
"cell_type": "code",
|
| 215 |
+
"execution_count": 37,
|
| 216 |
+
"metadata": {},
|
| 217 |
+
"outputs": [],
|
| 218 |
+
"source": [
|
| 219 |
+
"os.environ[\"LANGCHAIN_API_KEY\"] = getpass.getpass(\"LangChain API Key:\")"
|
| 220 |
+
]
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"cell_type": "code",
|
| 224 |
+
"execution_count": 67,
|
| 225 |
+
"metadata": {},
|
| 226 |
+
"outputs": [],
|
| 227 |
+
"source": [
|
| 228 |
+
"### Nodes\n",
|
| 229 |
+
"\n",
|
| 230 |
+
"\n",
|
| 231 |
+
"def agent(state):\n",
|
| 232 |
+
" \"\"\"\n",
|
| 233 |
+
" Invokes the agent model to generate a response based on the current state. Given\n",
|
| 234 |
+
" the question, it will decide to retrieve using the retriever tool, or simply end.\n",
|
| 235 |
+
"\n",
|
| 236 |
+
" Args:\n",
|
| 237 |
+
" state (messages): The current state\n",
|
| 238 |
+
"\n",
|
| 239 |
+
" Returns:\n",
|
| 240 |
+
" dict: The updated state with the agent response appended to messages\n",
|
| 241 |
+
" \"\"\"\n",
|
| 242 |
+
" print(\"---CALL AGENT---\")\n",
|
| 243 |
+
" messages = state[\"messages\"]\n",
|
| 244 |
+
" model = ChatOpenAI(temperature=0, streaming=True, model=\"gpt-4o-mini\")\n",
|
| 245 |
+
" model = model.bind_tools(tools)\n",
|
| 246 |
+
" response = model.invoke(messages)\n",
|
| 247 |
+
" # We return a list, because this will get added to the existing list\n",
|
| 248 |
+
" return {\"messages\": [response]}\n",
|
| 249 |
+
"\n",
|
| 250 |
+
"\n",
|
| 251 |
+
"def rewrite(state):\n",
|
| 252 |
+
" \"\"\"\n",
|
| 253 |
+
" Transform the query to produce a better question.\n",
|
| 254 |
+
"\n",
|
| 255 |
+
" Args:\n",
|
| 256 |
+
" state (messages): The current state\n",
|
| 257 |
+
"\n",
|
| 258 |
+
" Returns:\n",
|
| 259 |
+
" dict: The updated state with re-phrased question\n",
|
| 260 |
+
" \"\"\"\n",
|
| 261 |
+
"\n",
|
| 262 |
+
" print(\"---TRANSFORM QUERY---\")\n",
|
| 263 |
+
" messages = state[\"messages\"]\n",
|
| 264 |
+
" question = messages[0].content\n",
|
| 265 |
+
"\n",
|
| 266 |
+
" msg = [\n",
|
| 267 |
+
" HumanMessage(\n",
|
| 268 |
+
" content=f\"\"\" \\n \n",
|
| 269 |
+
" Look at the input and try to reason about the underlying semantic intent / meaning. \\n \n",
|
| 270 |
+
" Here is the initial question:\n",
|
| 271 |
+
" \\n ------- \\n\n",
|
| 272 |
+
" {question} \n",
|
| 273 |
+
" \\n ------- \\n\n",
|
| 274 |
+
" Formulate an improved question: \"\"\",\n",
|
| 275 |
+
" )\n",
|
| 276 |
+
" ]\n",
|
| 277 |
+
"\n",
|
| 278 |
+
" # Grader\n",
|
| 279 |
+
" model = ChatOpenAI(temperature=0, model=\"gpt-4o-mini\", streaming=True)\n",
|
| 280 |
+
" response = model.invoke(msg)\n",
|
| 281 |
+
" return {\"messages\": [response]}\n",
|
| 282 |
+
"\n",
|
| 283 |
+
"\n",
|
| 284 |
+
"def generate(state):\n",
|
| 285 |
+
" \"\"\"\n",
|
| 286 |
+
" Generate answer\n",
|
| 287 |
+
"\n",
|
| 288 |
+
" Args:\n",
|
| 289 |
+
" state (messages): The current state\n",
|
| 290 |
+
"\n",
|
| 291 |
+
" Returns:\n",
|
| 292 |
+
" dict: The updated state with re-phrased question\n",
|
| 293 |
+
" \"\"\"\n",
|
| 294 |
+
" print(\"---GENERATE---\")\n",
|
| 295 |
+
" messages = state[\"messages\"]\n",
|
| 296 |
+
" question = messages[0].content\n",
|
| 297 |
+
" last_message = messages[-1]\n",
|
| 298 |
+
"\n",
|
| 299 |
+
" docs = last_message.content\n",
|
| 300 |
+
"\n",
|
| 301 |
+
" # Prompt\n",
|
| 302 |
+
" prompt = hub.pull(\"rlm/rag-prompt\")\n",
|
| 303 |
+
"\n",
|
| 304 |
+
" # LLM\n",
|
| 305 |
+
" llm = ChatOpenAI(model_name=\"gpt-4o-mini\", temperature=0, streaming=True)\n",
|
| 306 |
+
"\n",
|
| 307 |
+
" # Post-processing\n",
|
| 308 |
+
" def format_docs(docs):\n",
|
| 309 |
+
" return \"\\n\\n\".join(doc.page_content for doc in docs)\n",
|
| 310 |
+
"\n",
|
| 311 |
+
" # Chain\n",
|
| 312 |
+
" rag_chain = prompt | llm | StrOutputParser()\n",
|
| 313 |
+
"\n",
|
| 314 |
+
" # Run\n",
|
| 315 |
+
" response = rag_chain.invoke({\"context\": docs, \"question\": question})\n",
|
| 316 |
+
" return {\"messages\": [response]}"
|
| 317 |
+
]
|
| 318 |
+
},
|
| 319 |
+
{
|
| 320 |
+
"cell_type": "code",
|
| 321 |
+
"execution_count": 39,
|
| 322 |
+
"metadata": {},
|
| 323 |
+
"outputs": [],
|
| 324 |
+
"source": [
|
| 325 |
+
"from langgraph.graph import END, StateGraph, START\n",
|
| 326 |
+
"from langgraph.prebuilt import ToolNode\n",
|
| 327 |
+
"\n",
|
| 328 |
+
"# Define a new graph\n",
|
| 329 |
+
"workflow = StateGraph(AgentState)\n",
|
| 330 |
+
"\n",
|
| 331 |
+
"# Define the nodes we will cycle between\n",
|
| 332 |
+
"workflow.add_node(\"agent\", agent) # agent\n",
|
| 333 |
+
"retrieve = ToolNode([retriever_tool])\n",
|
| 334 |
+
"workflow.add_node(\"retrieve\", retrieve) # retrieval\n",
|
| 335 |
+
"workflow.add_node(\"rewrite\", rewrite) # Re-writing the question\n",
|
| 336 |
+
"workflow.add_node(\n",
|
| 337 |
+
" \"generate\", generate\n",
|
| 338 |
+
") # Generating a response after we know the documents are relevant\n",
|
| 339 |
+
"# Call agent node to decide to retrieve or not\n",
|
| 340 |
+
"workflow.add_edge(START, \"agent\")\n",
|
| 341 |
+
"\n",
|
| 342 |
+
"# Decide whether to retrieve\n",
|
| 343 |
+
"workflow.add_conditional_edges(\n",
|
| 344 |
+
" \"agent\",\n",
|
| 345 |
+
" # Assess agent decision\n",
|
| 346 |
+
" tools_condition,\n",
|
| 347 |
+
" {\n",
|
| 348 |
+
" # Translate the condition outputs to nodes in our graph\n",
|
| 349 |
+
" \"tools\": \"retrieve\",\n",
|
| 350 |
+
" END: END,\n",
|
| 351 |
+
" },\n",
|
| 352 |
+
")\n",
|
| 353 |
+
"\n",
|
| 354 |
+
"# Edges taken after the `action` node is called.\n",
|
| 355 |
+
"workflow.add_conditional_edges(\n",
|
| 356 |
+
" \"retrieve\",\n",
|
| 357 |
+
" # Assess agent decision\n",
|
| 358 |
+
" grade_documents,\n",
|
| 359 |
+
")\n",
|
| 360 |
+
"workflow.add_edge(\"generate\", END)\n",
|
| 361 |
+
"workflow.add_edge(\"rewrite\", \"agent\")\n",
|
| 362 |
+
"\n",
|
| 363 |
+
"# Compile\n",
|
| 364 |
+
"graph = workflow.compile()"
|
| 365 |
+
]
|
| 366 |
+
},
|
| 367 |
+
{
|
| 368 |
+
"cell_type": "code",
|
| 369 |
+
"execution_count": 66,
|
| 370 |
+
"metadata": {},
|
| 371 |
+
"outputs": [
|
| 372 |
+
{
|
| 373 |
+
"name": "stdout",
|
| 374 |
+
"output_type": "stream",
|
| 375 |
+
"text": [
|
| 376 |
+
"---CALL AGENT---\n",
|
| 377 |
+
"\"Output from node 'agent':\"\n",
|
| 378 |
+
"'---'\n",
|
| 379 |
+
"('Some problems with AI include biases in algorithms that can lead to unfair '\n",
|
| 380 |
+
" 'treatment of individuals and the potential for job displacement as '\n",
|
| 381 |
+
" 'automation increases. Additionally, concerns about privacy, security, and '\n",
|
| 382 |
+
" 'the ethical implications of decision-making by AI systems pose significant '\n",
|
| 383 |
+
" 'challenges.')\n",
|
| 384 |
+
"'\\n---\\n'\n"
|
| 385 |
+
]
|
| 386 |
+
}
|
| 387 |
+
],
|
| 388 |
+
"source": [
|
| 389 |
+
"import pprint\n",
|
| 390 |
+
"\n",
|
| 391 |
+
"inputs = {\n",
|
| 392 |
+
" \"messages\": [\n",
|
| 393 |
+
" (\"user\", \"What are some problems with AI? Give me a response in two sentences or less\"),\n",
|
| 394 |
+
" ]\n",
|
| 395 |
+
"}\n",
|
| 396 |
+
"\n",
|
| 397 |
+
"\n",
|
| 398 |
+
"for output in graph.stream(inputs):\n",
|
| 399 |
+
" for key, value in output.items():\n",
|
| 400 |
+
" pprint.pprint(f\"Output from node '{key}':\")\n",
|
| 401 |
+
" pprint.pprint(\"---\")\n",
|
| 402 |
+
" pprint.pprint(value['messages'][0].content, indent=2, width=80, depth=None)\n",
|
| 403 |
+
" pprint.pprint(\"\\n---\\n\")"
|
| 404 |
+
]
|
| 405 |
+
}
|
| 406 |
+
],
|
| 407 |
+
"metadata": {
|
| 408 |
+
"kernelspec": {
|
| 409 |
+
"display_name": "llm-ops",
|
| 410 |
+
"language": "python",
|
| 411 |
+
"name": "python3"
|
| 412 |
+
},
|
| 413 |
+
"language_info": {
|
| 414 |
+
"codemirror_mode": {
|
| 415 |
+
"name": "ipython",
|
| 416 |
+
"version": 3
|
| 417 |
+
},
|
| 418 |
+
"file_extension": ".py",
|
| 419 |
+
"mimetype": "text/x-python",
|
| 420 |
+
"name": "python",
|
| 421 |
+
"nbconvert_exporter": "python",
|
| 422 |
+
"pygments_lexer": "ipython3",
|
| 423 |
+
"version": "3.11.9"
|
| 424 |
+
}
|
| 425 |
+
},
|
| 426 |
+
"nbformat": 4,
|
| 427 |
+
"nbformat_minor": 2
|
| 428 |
+
}
|
AgenticRAG/BuildingAChainlitApp.md
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Building a Chainlit App
|
| 2 |
+
|
| 3 |
+
What if we want to take our Week 1 Day 2 assignment - [Pythonic RAG](https://github.com/AI-Maker-Space/AIE4/tree/main/Week%201/Day%202) - and bring it out of the notebook?
|
| 4 |
+
|
| 5 |
+
Well - we'll cover exactly that here!
|
| 6 |
+
|
| 7 |
+
## Anatomy of a Chainlit Application
|
| 8 |
+
|
| 9 |
+
[Chainlit](https://docs.chainlit.io/get-started/overview) is a Python package similar to Streamlit that lets users write a backend and a front end in a single (or multiple) Python file(s). It is mainly used for prototyping LLM-based Chat Style Applications - though it is used in production in some settings with 1,000,000s of MAUs (Monthly Active Users).
|
| 10 |
+
|
| 11 |
+
The primary method of customizing and interacting with the Chainlit UI is through a few critical [decorators](https://blog.hubspot.com/website/decorators-in-python).
|
| 12 |
+
|
| 13 |
+
> NOTE: Simply put, the decorators (in Chainlit) are just ways we can "plug-in" to the functionality in Chainlit.
|
| 14 |
+
|
| 15 |
+
We'll be concerning ourselves with three main scopes:
|
| 16 |
+
|
| 17 |
+
1. On application start - when we start the Chainlit application with a command like `chainlit run app.py`
|
| 18 |
+
2. On chat start - when a chat session starts (a user opens the web browser to the address hosting the application)
|
| 19 |
+
3. On message - when the users sends a message through the input text box in the Chainlit UI
|
| 20 |
+
|
| 21 |
+
Let's dig into each scope and see what we're doing!
|
| 22 |
+
|
| 23 |
+
## On Application Start:
|
| 24 |
+
|
| 25 |
+
The first thing you'll notice is that we have the traditional "wall of imports" this is to ensure we have everything we need to run our application.
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
import os
|
| 29 |
+
from typing import List
|
| 30 |
+
from chainlit.types import AskFileResponse
|
| 31 |
+
from aimakerspace.text_utils import CharacterTextSplitter, TextFileLoader
|
| 32 |
+
from aimakerspace.openai_utils.prompts import (
|
| 33 |
+
UserRolePrompt,
|
| 34 |
+
SystemRolePrompt,
|
| 35 |
+
AssistantRolePrompt,
|
| 36 |
+
)
|
| 37 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 38 |
+
from aimakerspace.vectordatabase import VectorDatabase
|
| 39 |
+
from aimakerspace.openai_utils.chatmodel import ChatOpenAI
|
| 40 |
+
import chainlit as cl
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
Next up, we have some prompt templates. As all sessions will use the same prompt templates without modification, and we don't need these templates to be specific per template - we can set them up here - at the application scope.
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
system_template = """\
|
| 47 |
+
Use the following context to answer a users question. If you cannot find the answer in the context, say you don't know the answer."""
|
| 48 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 49 |
+
|
| 50 |
+
user_prompt_template = """\
|
| 51 |
+
Context:
|
| 52 |
+
{context}
|
| 53 |
+
|
| 54 |
+
Question:
|
| 55 |
+
{question}
|
| 56 |
+
"""
|
| 57 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
> NOTE: You'll notice that these are the exact same prompt templates we used from the Pythonic RAG Notebook in Week 1 Day 2!
|
| 61 |
+
|
| 62 |
+
Following that - we can create the Python Class definition for our RAG pipeline - or *chain*, as we'll refer to it in the rest of this walkthrough.
|
| 63 |
+
|
| 64 |
+
Let's look at the definition first:
|
| 65 |
+
|
| 66 |
+
```python
|
| 67 |
+
class RetrievalAugmentedQAPipeline:
|
| 68 |
+
def __init__(self, llm: ChatOpenAI(), vector_db_retriever: VectorDatabase) -> None:
|
| 69 |
+
self.llm = llm
|
| 70 |
+
self.vector_db_retriever = vector_db_retriever
|
| 71 |
+
|
| 72 |
+
async def arun_pipeline(self, user_query: str):
|
| 73 |
+
### RETRIEVAL
|
| 74 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 75 |
+
|
| 76 |
+
context_prompt = ""
|
| 77 |
+
for context in context_list:
|
| 78 |
+
context_prompt += context[0] + "\n"
|
| 79 |
+
|
| 80 |
+
### AUGMENTED
|
| 81 |
+
formatted_system_prompt = system_role_prompt.create_message()
|
| 82 |
+
|
| 83 |
+
formatted_user_prompt = user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
### GENERATION
|
| 87 |
+
async def generate_response():
|
| 88 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 89 |
+
yield chunk
|
| 90 |
+
|
| 91 |
+
return {"response": generate_response(), "context": context_list}
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
Notice a few things:
|
| 95 |
+
|
| 96 |
+
1. We have modified this `RetrievalAugmentedQAPipeline` from the initial notebook to support streaming.
|
| 97 |
+
2. In essence, our pipeline is *chaining* a few events together:
|
| 98 |
+
1. We take our user query, and chain it into our Vector Database to collect related chunks
|
| 99 |
+
2. We take those contexts and our user's questions and chain them into the prompt templates
|
| 100 |
+
3. We take that prompt template and chain it into our LLM call
|
| 101 |
+
4. We chain the response of the LLM call to the user
|
| 102 |
+
3. We are using a lot of `async` again!
|
| 103 |
+
|
| 104 |
+
Now, we're going to create a helper function for processing uploaded text files.
|
| 105 |
+
|
| 106 |
+
First, we'll instantiate a shared `CharacterTextSplitter`.
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
text_splitter = CharacterTextSplitter()
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
Now we can define our helper.
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
def process_text_file(file: AskFileResponse):
|
| 116 |
+
import tempfile
|
| 117 |
+
|
| 118 |
+
with tempfile.NamedTemporaryFile(mode="w", delete=False, suffix=".txt") as temp_file:
|
| 119 |
+
temp_file_path = temp_file.name
|
| 120 |
+
|
| 121 |
+
with open(temp_file_path, "wb") as f:
|
| 122 |
+
f.write(file.content)
|
| 123 |
+
|
| 124 |
+
text_loader = TextFileLoader(temp_file_path)
|
| 125 |
+
documents = text_loader.load_documents()
|
| 126 |
+
texts = text_splitter.split_texts(documents)
|
| 127 |
+
return texts
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
Simply put, this downloads the file as a temp file, we load it in with `TextFileLoader` and then split it with our `TextSplitter`, and returns that list of strings!
|
| 131 |
+
|
| 132 |
+
#### QUESTION #1:
|
| 133 |
+
|
| 134 |
+
Why do we want to support streaming? What about streaming is important, or useful?
|
| 135 |
+
|
| 136 |
+
## On Chat Start:
|
| 137 |
+
|
| 138 |
+
The next scope is where "the magic happens". On Chat Start is when a user begins a chat session. This will happen whenever a user opens a new chat window, or refreshes an existing chat window.
|
| 139 |
+
|
| 140 |
+
You'll see that our code is set-up to immediately show the user a chat box requesting them to upload a file.
|
| 141 |
+
|
| 142 |
+
```python
|
| 143 |
+
while files == None:
|
| 144 |
+
files = await cl.AskFileMessage(
|
| 145 |
+
content="Please upload a Text File file to begin!",
|
| 146 |
+
accept=["text/plain"],
|
| 147 |
+
max_size_mb=2,
|
| 148 |
+
timeout=180,
|
| 149 |
+
).send()
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
Once we've obtained the text file - we'll use our processing helper function to process our text!
|
| 153 |
+
|
| 154 |
+
After we have processed our text file - we'll need to create a `VectorDatabase` and populate it with our processed chunks and their related embeddings!
|
| 155 |
+
|
| 156 |
+
```python
|
| 157 |
+
vector_db = VectorDatabase()
|
| 158 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
Once we have that piece completed - we can create the chain we'll be using to respond to user queries!
|
| 162 |
+
|
| 163 |
+
```python
|
| 164 |
+
retrieval_augmented_qa_pipeline = RetrievalAugmentedQAPipeline(
|
| 165 |
+
vector_db_retriever=vector_db,
|
| 166 |
+
llm=chat_openai
|
| 167 |
+
)
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
Now, we'll save that into our user session!
|
| 171 |
+
|
| 172 |
+
> NOTE: Chainlit has some great documentation about [User Session](https://docs.chainlit.io/concepts/user-session).
|
| 173 |
+
|
| 174 |
+
### QUESTION #2:
|
| 175 |
+
|
| 176 |
+
Why are we using User Session here? What about Python makes us need to use this? Why not just store everything in a global variable?
|
| 177 |
+
|
| 178 |
+
## On Message
|
| 179 |
+
|
| 180 |
+
First, we load our chain from the user session:
|
| 181 |
+
|
| 182 |
+
```python
|
| 183 |
+
chain = cl.user_session.get("chain")
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
Then, we run the chain on the content of the message - and stream it to the front end - that's it!
|
| 187 |
+
|
| 188 |
+
```python
|
| 189 |
+
msg = cl.Message(content="")
|
| 190 |
+
result = await chain.arun_pipeline(message.content)
|
| 191 |
+
|
| 192 |
+
async for stream_resp in result["response"]:
|
| 193 |
+
await msg.stream_token(stream_resp)
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
## 🎉
|
| 197 |
+
|
| 198 |
+
With that - you've created a Chainlit application that moves our Pythonic RAG notebook to a Chainlit application!
|
| 199 |
+
|
| 200 |
+
## 🚧 CHALLENGE MODE 🚧
|
| 201 |
+
|
| 202 |
+
For an extra challenge - modify the behaviour of your applciation by integrating changes you made to your Pythonic RAG notebook (using new retrieval methods, etc.)
|
| 203 |
+
|
| 204 |
+
If you're still looking for a challenge, or didn't make any modifications to your Pythonic RAG notebook:
|
| 205 |
+
|
| 206 |
+
1) Allow users to upload PDFs (this will require you to build a PDF parser as well)
|
| 207 |
+
2) Modify the VectorStore to leverage [Qdrant](https://python-client.qdrant.tech/)
|
| 208 |
+
|
| 209 |
+
> NOTE: The motivation for these challenges is simple - the beginning of the course is extremely information dense, and people come from all kinds of different technical backgrounds. In order to ensure that all learners are able to engage with the content confidently and comfortably, we want to focus on the basic units of technical competency required. This leads to a situation where some learners, who came in with more robust technical skills, find the introductory material to be too simple - and these open-ended challenges help us do this!
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
|
AgenticRAG/Dockerfile
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.9
|
| 2 |
+
RUN useradd -m -u 1000 user
|
| 3 |
+
USER user
|
| 4 |
+
ENV HOME=/home/user \
|
| 5 |
+
PATH=/home/user/.local/bin:$PATH
|
| 6 |
+
WORKDIR $HOME/app
|
| 7 |
+
COPY --chown=user . $HOME/app
|
| 8 |
+
COPY ./requirements.txt ~/app/requirements.txt
|
| 9 |
+
RUN pip install -r requirements.txt
|
| 10 |
+
COPY . .
|
| 11 |
+
CMD ["chainlit", "run", "app.py", "--port", "7860"]
|
AgenticRAG/README.md
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: MidtermTask2
|
| 3 |
+
emoji: 📉
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: purple
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: false
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# Deploying Pythonic Chat With Your Text File Application
|
| 12 |
+
|
| 13 |
+
In today's breakout rooms, we will be following the processed that you saw during the challenge - for reference, the instructions for that are available [here](https://github.com/AI-Maker-Space/Beyond-ChatGPT/tree/main).
|
| 14 |
+
|
| 15 |
+
Today, we will repeat the same process - but powered by our Pythonic RAG implementation we created last week.
|
| 16 |
+
|
| 17 |
+
You'll notice a few differences in the `app.py` logic - as well as a few changes to the `aimakerspace` package to get things working smoothly with Chainlit.
|
| 18 |
+
|
| 19 |
+
## Reference Diagram (It's Busy, but it works)
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## Deploying the Application to Hugging Face Space
|
| 24 |
+
|
| 25 |
+
Due to the way the repository is created - it should be straightforward to deploy this to a Hugging Face Space!
|
| 26 |
+
|
| 27 |
+
> NOTE: If you wish to go through the local deployments using `chainlit run app.py` and Docker - please feel free to do so!
|
| 28 |
+
|
| 29 |
+
<details>
|
| 30 |
+
<summary>Creating a Hugging Face Space</summary>
|
| 31 |
+
|
| 32 |
+
1. Navigate to the `Spaces` tab.
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
2. Click on `Create new Space`
|
| 37 |
+
|
| 38 |
+

|
| 39 |
+
|
| 40 |
+
3. Create the Space by providing values in the form. Make sure you've selected "Docker" as your Space SDK.
|
| 41 |
+
|
| 42 |
+

|
| 43 |
+
|
| 44 |
+
</details>
|
| 45 |
+
|
| 46 |
+
<details>
|
| 47 |
+
<summary>Adding this Repository to the Newly Created Space</summary>
|
| 48 |
+
|
| 49 |
+
1. Collect the SSH address from the newly created Space.
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
> NOTE: The address is the component that starts with `git@hf.co:spaces/`.
|
| 54 |
+
|
| 55 |
+
2. Use the command:
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
git remote add hf HF_SPACE_SSH_ADDRESS_HERE
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
3. Use the command:
|
| 62 |
+
|
| 63 |
+
```bash
|
| 64 |
+
git pull hf main --no-rebase --allow-unrelated-histories -X ours
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
4. Use the command:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
git add .
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
5. Use the command:
|
| 74 |
+
|
| 75 |
+
```bash
|
| 76 |
+
git commit -m "Deploying Pythonic RAG"
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
6. Use the command:
|
| 80 |
+
|
| 81 |
+
```bash
|
| 82 |
+
git push hf main
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
7. The Space should automatically build as soon as the push is completed!
|
| 86 |
+
|
| 87 |
+
> NOTE: The build will fail before you complete the following steps!
|
| 88 |
+
|
| 89 |
+
</details>
|
| 90 |
+
|
| 91 |
+
<details>
|
| 92 |
+
<summary>Adding OpenAI Secrets to the Space</summary>
|
| 93 |
+
|
| 94 |
+
1. Navigate to your Space settings.
|
| 95 |
+
|
| 96 |
+

|
| 97 |
+
|
| 98 |
+
2. Navigate to `Variables and secrets` on the Settings page and click `New secret`:
|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+
3. In the `Name` field - input `OPENAI_API_KEY` in the `Value (private)` field, put your OpenAI API Key.
|
| 103 |
+
|
| 104 |
+

|
| 105 |
+
|
| 106 |
+
4. The Space will begin rebuilding!
|
| 107 |
+
|
| 108 |
+
</details>
|
| 109 |
+
|
| 110 |
+
## 🎉
|
| 111 |
+
|
| 112 |
+
You just deployed Pythonic RAG!
|
| 113 |
+
|
| 114 |
+
Try uploading a text file and asking some questions!
|
| 115 |
+
|
| 116 |
+
## 🚧CHALLENGE MODE 🚧
|
| 117 |
+
|
| 118 |
+
For more of a challenge, please reference [Building a Chainlit App](./BuildingAChainlitApp.md)!
|
AgenticRAG/agentic_rag.py
ADDED
|
File without changes
|
AgenticRAG/aimakerspace/__init__.py
ADDED
|
File without changes
|
AgenticRAG/aimakerspace/openai_utils/__init__.py
ADDED
|
File without changes
|
AgenticRAG/aimakerspace/openai_utils/chatmodel.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from openai import OpenAI, AsyncOpenAI
|
| 2 |
+
from dotenv import load_dotenv
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
load_dotenv()
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class ChatOpenAI:
|
| 9 |
+
def __init__(self, model_name: str = "gpt-4o-mini"):
|
| 10 |
+
self.model_name = model_name
|
| 11 |
+
self.openai_api_key = os.getenv("OPENAI_API_KEY")
|
| 12 |
+
if self.openai_api_key is None:
|
| 13 |
+
raise ValueError("OPENAI_API_KEY is not set")
|
| 14 |
+
|
| 15 |
+
def run(self, messages, text_only: bool = True, **kwargs):
|
| 16 |
+
if not isinstance(messages, list):
|
| 17 |
+
raise ValueError("messages must be a list")
|
| 18 |
+
|
| 19 |
+
client = OpenAI()
|
| 20 |
+
response = client.chat.completions.create(
|
| 21 |
+
model=self.model_name, messages=messages, **kwargs
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
if text_only:
|
| 25 |
+
return response.choices[0].message.content
|
| 26 |
+
|
| 27 |
+
return response
|
| 28 |
+
|
| 29 |
+
async def astream(self, messages, **kwargs):
|
| 30 |
+
if not isinstance(messages, list):
|
| 31 |
+
raise ValueError("messages must be a list")
|
| 32 |
+
|
| 33 |
+
client = AsyncOpenAI()
|
| 34 |
+
|
| 35 |
+
stream = await client.chat.completions.create(
|
| 36 |
+
model=self.model_name,
|
| 37 |
+
messages=messages,
|
| 38 |
+
stream=True,
|
| 39 |
+
**kwargs
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
async for chunk in stream:
|
| 43 |
+
content = chunk.choices[0].delta.content
|
| 44 |
+
if content is not None:
|
| 45 |
+
yield content
|
AgenticRAG/aimakerspace/openai_utils/embedding.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dotenv import load_dotenv
|
| 2 |
+
from openai import AsyncOpenAI, OpenAI
|
| 3 |
+
import openai
|
| 4 |
+
from typing import List
|
| 5 |
+
import os
|
| 6 |
+
import asyncio
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class EmbeddingModel:
|
| 10 |
+
def __init__(self, embeddings_model_name: str = "text-embedding-3-small"):
|
| 11 |
+
load_dotenv()
|
| 12 |
+
self.openai_api_key = os.getenv("OPENAI_API_KEY")
|
| 13 |
+
self.async_client = AsyncOpenAI()
|
| 14 |
+
self.client = OpenAI()
|
| 15 |
+
|
| 16 |
+
if self.openai_api_key is None:
|
| 17 |
+
raise ValueError(
|
| 18 |
+
"OPENAI_API_KEY environment variable is not set. Please set it to your OpenAI API key."
|
| 19 |
+
)
|
| 20 |
+
openai.api_key = self.openai_api_key
|
| 21 |
+
self.embeddings_model_name = embeddings_model_name
|
| 22 |
+
|
| 23 |
+
async def async_get_embeddings(self, list_of_text: List[str]) -> List[List[float]]:
|
| 24 |
+
embedding_response = await self.async_client.embeddings.create(
|
| 25 |
+
input=list_of_text, model=self.embeddings_model_name
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
return [embeddings.embedding for embeddings in embedding_response.data]
|
| 29 |
+
|
| 30 |
+
async def async_get_embedding(self, text: str) -> List[float]:
|
| 31 |
+
embedding = await self.async_client.embeddings.create(
|
| 32 |
+
input=text, model=self.embeddings_model_name
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
return embedding.data[0].embedding
|
| 36 |
+
|
| 37 |
+
def get_embeddings(self, list_of_text: List[str]) -> List[List[float]]:
|
| 38 |
+
embedding_response = self.client.embeddings.create(
|
| 39 |
+
input=list_of_text, model=self.embeddings_model_name
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
return [embeddings.embedding for embeddings in embedding_response.data]
|
| 43 |
+
|
| 44 |
+
def get_embedding(self, text: str) -> List[float]:
|
| 45 |
+
embedding = self.client.embeddings.create(
|
| 46 |
+
input=text, model=self.embeddings_model_name
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
return embedding.data[0].embedding
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == "__main__":
|
| 53 |
+
embedding_model = EmbeddingModel()
|
| 54 |
+
print(asyncio.run(embedding_model.async_get_embedding("Hello, world!")))
|
| 55 |
+
print(
|
| 56 |
+
asyncio.run(
|
| 57 |
+
embedding_model.async_get_embeddings(["Hello, world!", "Goodbye, world!"])
|
| 58 |
+
)
|
| 59 |
+
)
|
AgenticRAG/aimakerspace/openai_utils/prompts.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BasePrompt:
|
| 5 |
+
def __init__(self, prompt):
|
| 6 |
+
"""
|
| 7 |
+
Initializes the BasePrompt object with a prompt template.
|
| 8 |
+
|
| 9 |
+
:param prompt: A string that can contain placeholders within curly braces
|
| 10 |
+
"""
|
| 11 |
+
self.prompt = prompt
|
| 12 |
+
self._pattern = re.compile(r"\{([^}]+)\}")
|
| 13 |
+
|
| 14 |
+
def format_prompt(self, **kwargs):
|
| 15 |
+
"""
|
| 16 |
+
Formats the prompt string using the keyword arguments provided.
|
| 17 |
+
|
| 18 |
+
:param kwargs: The values to substitute into the prompt string
|
| 19 |
+
:return: The formatted prompt string
|
| 20 |
+
"""
|
| 21 |
+
matches = self._pattern.findall(self.prompt)
|
| 22 |
+
return self.prompt.format(**{match: kwargs.get(match, "") for match in matches})
|
| 23 |
+
|
| 24 |
+
def get_input_variables(self):
|
| 25 |
+
"""
|
| 26 |
+
Gets the list of input variable names from the prompt string.
|
| 27 |
+
|
| 28 |
+
:return: List of input variable names
|
| 29 |
+
"""
|
| 30 |
+
return self._pattern.findall(self.prompt)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class RolePrompt(BasePrompt):
|
| 34 |
+
def __init__(self, prompt, role: str):
|
| 35 |
+
"""
|
| 36 |
+
Initializes the RolePrompt object with a prompt template and a role.
|
| 37 |
+
|
| 38 |
+
:param prompt: A string that can contain placeholders within curly braces
|
| 39 |
+
:param role: The role for the message ('system', 'user', or 'assistant')
|
| 40 |
+
"""
|
| 41 |
+
super().__init__(prompt)
|
| 42 |
+
self.role = role
|
| 43 |
+
|
| 44 |
+
def create_message(self, format=True, **kwargs):
|
| 45 |
+
"""
|
| 46 |
+
Creates a message dictionary with a role and a formatted message.
|
| 47 |
+
|
| 48 |
+
:param kwargs: The values to substitute into the prompt string
|
| 49 |
+
:return: Dictionary containing the role and the formatted message
|
| 50 |
+
"""
|
| 51 |
+
if format:
|
| 52 |
+
return {"role": self.role, "content": self.format_prompt(**kwargs)}
|
| 53 |
+
|
| 54 |
+
return {"role": self.role, "content": self.prompt}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class SystemRolePrompt(RolePrompt):
|
| 58 |
+
def __init__(self, prompt: str):
|
| 59 |
+
super().__init__(prompt, "system")
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class UserRolePrompt(RolePrompt):
|
| 63 |
+
def __init__(self, prompt: str):
|
| 64 |
+
super().__init__(prompt, "user")
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class AssistantRolePrompt(RolePrompt):
|
| 68 |
+
def __init__(self, prompt: str):
|
| 69 |
+
super().__init__(prompt, "assistant")
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
if __name__ == "__main__":
|
| 73 |
+
prompt = BasePrompt("Hello {name}, you are {age} years old")
|
| 74 |
+
print(prompt.format_prompt(name="John", age=30))
|
| 75 |
+
|
| 76 |
+
prompt = SystemRolePrompt("Hello {name}, you are {age} years old")
|
| 77 |
+
print(prompt.create_message(name="John", age=30))
|
| 78 |
+
print(prompt.get_input_variables())
|
AgenticRAG/aimakerspace/text_utils.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class TextFileLoader:
|
| 6 |
+
def __init__(self, path: str, encoding: str = "utf-8"):
|
| 7 |
+
self.documents = []
|
| 8 |
+
self.path = path
|
| 9 |
+
self.encoding = encoding
|
| 10 |
+
|
| 11 |
+
def load(self):
|
| 12 |
+
if os.path.isdir(self.path):
|
| 13 |
+
self.load_directory()
|
| 14 |
+
elif os.path.isfile(self.path) and self.path.endswith(".txt"):
|
| 15 |
+
self.load_file()
|
| 16 |
+
else:
|
| 17 |
+
raise ValueError(
|
| 18 |
+
"Provided path is neither a valid directory nor a .txt file."
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
def load_file(self):
|
| 22 |
+
with open(self.path, "r", encoding=self.encoding) as f:
|
| 23 |
+
self.documents.append(f.read())
|
| 24 |
+
|
| 25 |
+
def load_directory(self):
|
| 26 |
+
for root, _, files in os.walk(self.path):
|
| 27 |
+
for file in files:
|
| 28 |
+
if file.endswith(".txt"):
|
| 29 |
+
with open(
|
| 30 |
+
os.path.join(root, file), "r", encoding=self.encoding
|
| 31 |
+
) as f:
|
| 32 |
+
self.documents.append(f.read())
|
| 33 |
+
|
| 34 |
+
def load_documents(self):
|
| 35 |
+
self.load()
|
| 36 |
+
return self.documents
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class CharacterTextSplitter:
|
| 40 |
+
def __init__(
|
| 41 |
+
self,
|
| 42 |
+
chunk_size: int = 1000,
|
| 43 |
+
chunk_overlap: int = 200,
|
| 44 |
+
):
|
| 45 |
+
assert (
|
| 46 |
+
chunk_size > chunk_overlap
|
| 47 |
+
), "Chunk size must be greater than chunk overlap"
|
| 48 |
+
|
| 49 |
+
self.chunk_size = chunk_size
|
| 50 |
+
self.chunk_overlap = chunk_overlap
|
| 51 |
+
|
| 52 |
+
def split(self, text: str) -> List[str]:
|
| 53 |
+
chunks = []
|
| 54 |
+
for i in range(0, len(text), self.chunk_size - self.chunk_overlap):
|
| 55 |
+
chunks.append(text[i : i + self.chunk_size])
|
| 56 |
+
return chunks
|
| 57 |
+
|
| 58 |
+
def split_texts(self, texts: List[str]) -> List[str]:
|
| 59 |
+
chunks = []
|
| 60 |
+
for text in texts:
|
| 61 |
+
chunks.extend(self.split(text))
|
| 62 |
+
return chunks
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
if __name__ == "__main__":
|
| 66 |
+
loader = TextFileLoader("data/KingLear.txt")
|
| 67 |
+
loader.load()
|
| 68 |
+
splitter = CharacterTextSplitter()
|
| 69 |
+
chunks = splitter.split_texts(loader.documents)
|
| 70 |
+
print(len(chunks))
|
| 71 |
+
print(chunks[0])
|
| 72 |
+
print("--------")
|
| 73 |
+
print(chunks[1])
|
| 74 |
+
print("--------")
|
| 75 |
+
print(chunks[-2])
|
| 76 |
+
print("--------")
|
| 77 |
+
print(chunks[-1])
|
AgenticRAG/aimakerspace/vectordatabase.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from collections import defaultdict
|
| 3 |
+
from typing import List, Tuple, Callable
|
| 4 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 5 |
+
import asyncio
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def cosine_similarity(vector_a: np.array, vector_b: np.array) -> float:
|
| 9 |
+
"""Computes the cosine similarity between two vectors."""
|
| 10 |
+
dot_product = np.dot(vector_a, vector_b)
|
| 11 |
+
norm_a = np.linalg.norm(vector_a)
|
| 12 |
+
norm_b = np.linalg.norm(vector_b)
|
| 13 |
+
return dot_product / (norm_a * norm_b)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class VectorDatabase:
|
| 17 |
+
def __init__(self, embedding_model: EmbeddingModel = None):
|
| 18 |
+
self.vectors = defaultdict(np.array)
|
| 19 |
+
self.embedding_model = embedding_model or EmbeddingModel()
|
| 20 |
+
|
| 21 |
+
def insert(self, key: str, vector: np.array) -> None:
|
| 22 |
+
self.vectors[key] = vector
|
| 23 |
+
|
| 24 |
+
def search(
|
| 25 |
+
self,
|
| 26 |
+
query_vector: np.array,
|
| 27 |
+
k: int,
|
| 28 |
+
distance_measure: Callable = cosine_similarity,
|
| 29 |
+
) -> List[Tuple[str, float]]:
|
| 30 |
+
scores = [
|
| 31 |
+
(key, distance_measure(query_vector, vector))
|
| 32 |
+
for key, vector in self.vectors.items()
|
| 33 |
+
]
|
| 34 |
+
return sorted(scores, key=lambda x: x[1], reverse=True)[:k]
|
| 35 |
+
|
| 36 |
+
def search_by_text(
|
| 37 |
+
self,
|
| 38 |
+
query_text: str,
|
| 39 |
+
k: int,
|
| 40 |
+
distance_measure: Callable = cosine_similarity,
|
| 41 |
+
return_as_text: bool = False,
|
| 42 |
+
) -> List[Tuple[str, float]]:
|
| 43 |
+
query_vector = self.embedding_model.get_embedding(query_text)
|
| 44 |
+
results = self.search(query_vector, k, distance_measure)
|
| 45 |
+
return [result[0] for result in results] if return_as_text else results
|
| 46 |
+
|
| 47 |
+
def retrieve_from_key(self, key: str) -> np.array:
|
| 48 |
+
return self.vectors.get(key, None)
|
| 49 |
+
|
| 50 |
+
async def abuild_from_list(self, list_of_text: List[str]) -> "VectorDatabase":
|
| 51 |
+
embeddings = await self.embedding_model.async_get_embeddings(list_of_text)
|
| 52 |
+
for text, embedding in zip(list_of_text, embeddings):
|
| 53 |
+
self.insert(text, np.array(embedding))
|
| 54 |
+
return self
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
if __name__ == "__main__":
|
| 58 |
+
list_of_text = [
|
| 59 |
+
"I like to eat broccoli and bananas.",
|
| 60 |
+
"I ate a banana and spinach smoothie for breakfast.",
|
| 61 |
+
"Chinchillas and kittens are cute.",
|
| 62 |
+
"My sister adopted a kitten yesterday.",
|
| 63 |
+
"Look at this cute hamster munching on a piece of broccoli.",
|
| 64 |
+
]
|
| 65 |
+
|
| 66 |
+
vector_db = VectorDatabase()
|
| 67 |
+
vector_db = asyncio.run(vector_db.abuild_from_list(list_of_text))
|
| 68 |
+
k = 2
|
| 69 |
+
|
| 70 |
+
searched_vector = vector_db.search_by_text("I think fruit is awesome!", k=k)
|
| 71 |
+
print(f"Closest {k} vector(s):", searched_vector)
|
| 72 |
+
|
| 73 |
+
retrieved_vector = vector_db.retrieve_from_key(
|
| 74 |
+
"I like to eat broccoli and bananas."
|
| 75 |
+
)
|
| 76 |
+
print("Retrieved vector:", retrieved_vector)
|
| 77 |
+
|
| 78 |
+
relevant_texts = vector_db.search_by_text(
|
| 79 |
+
"I think fruit is awesome!", k=k, return_as_text=True
|
| 80 |
+
)
|
| 81 |
+
print(f"Closest {k} text(s):", relevant_texts)
|
AgenticRAG/app.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
from chainlit.types import AskFileResponse
|
| 4 |
+
from aimakerspace.text_utils import CharacterTextSplitter, TextFileLoader
|
| 5 |
+
from aimakerspace.openai_utils.prompts import (
|
| 6 |
+
UserRolePrompt,
|
| 7 |
+
SystemRolePrompt,
|
| 8 |
+
AssistantRolePrompt,
|
| 9 |
+
)
|
| 10 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 11 |
+
from aimakerspace.vectordatabase import VectorDatabase
|
| 12 |
+
from aimakerspace.openai_utils.chatmodel import ChatOpenAI
|
| 13 |
+
import chainlit as cl
|
| 14 |
+
from langchain_text_splitters import RecursiveCharacterTextSplitter
|
| 15 |
+
# from langchain_experimental.text_splitter import SemanticChunker
|
| 16 |
+
# from langchain_openai.embeddings import OpenAIEmbeddings
|
| 17 |
+
|
| 18 |
+
system_template = """\
|
| 19 |
+
Use the following context to answer a users question. If you cannot find the answer in the context, say you don't know the answer."""
|
| 20 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 21 |
+
|
| 22 |
+
user_prompt_template = """\
|
| 23 |
+
Context:
|
| 24 |
+
{context}
|
| 25 |
+
Question:
|
| 26 |
+
{question}
|
| 27 |
+
"""
|
| 28 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 29 |
+
|
| 30 |
+
class RetrievalAugmentedQAPipeline:
|
| 31 |
+
def __init__(self, llm: ChatOpenAI(), vector_db_retriever: VectorDatabase) -> None:
|
| 32 |
+
self.llm = llm
|
| 33 |
+
self.vector_db_retriever = vector_db_retriever
|
| 34 |
+
|
| 35 |
+
async def arun_pipeline(self, user_query: str):
|
| 36 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 37 |
+
|
| 38 |
+
context_prompt = ""
|
| 39 |
+
for context in context_list:
|
| 40 |
+
context_prompt += context[0] + "\n"
|
| 41 |
+
|
| 42 |
+
formatted_system_prompt = system_role_prompt.create_message()
|
| 43 |
+
|
| 44 |
+
formatted_user_prompt = user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 45 |
+
|
| 46 |
+
async def generate_response():
|
| 47 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 48 |
+
yield chunk
|
| 49 |
+
|
| 50 |
+
return {"response": generate_response(), "context": context_list}
|
| 51 |
+
|
| 52 |
+
text_splitter = RecursiveCharacterTextSplitter()
|
| 53 |
+
# try:
|
| 54 |
+
# api_key = os.environ["OPENAI_API_KEY"]
|
| 55 |
+
# except KeyError:
|
| 56 |
+
# print("Environment variable OPENAI_API_KEY not found")
|
| 57 |
+
# text_splitter = SemanticChunker(OpenAIEmbeddings(api_key=api_key), breakpoint_threshold_type="standard_deviation")
|
| 58 |
+
|
| 59 |
+
def process_text_file(file: AskFileResponse):
|
| 60 |
+
import tempfile
|
| 61 |
+
from langchain_community.document_loaders.pdf import PyPDFLoader
|
| 62 |
+
|
| 63 |
+
with tempfile.NamedTemporaryFile(mode="w", delete=False, suffix=file.name) as temp_file:
|
| 64 |
+
temp_file_path = temp_file.name
|
| 65 |
+
|
| 66 |
+
with open(temp_file_path, "wb") as f:
|
| 67 |
+
f.write(file.content)
|
| 68 |
+
|
| 69 |
+
if file.type == 'text/plain':
|
| 70 |
+
text_loader = TextFileLoader(temp_file_path)
|
| 71 |
+
documents = text_loader.load_documents()
|
| 72 |
+
elif file.type == 'application/pdf':
|
| 73 |
+
pdf_loader = PyPDFLoader(temp_file_path)
|
| 74 |
+
documents = pdf_loader.load()
|
| 75 |
+
else:
|
| 76 |
+
raise ValueError("Provide a .txt or .pdf file")
|
| 77 |
+
texts = [x.page_content for x in text_splitter.transform_documents(documents)]
|
| 78 |
+
# texts = [x.page_content for x in text_splitter.split_documents(documents)]
|
| 79 |
+
return texts
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
@cl.on_chat_start
|
| 84 |
+
async def on_chat_start():
|
| 85 |
+
files = None
|
| 86 |
+
|
| 87 |
+
# Wait for the user to upload a file
|
| 88 |
+
while files == None:
|
| 89 |
+
files = await cl.AskFileMessage(
|
| 90 |
+
content="Please upload a Text file or a PDF to begin!",
|
| 91 |
+
accept=["text/plain", "application/pdf"],
|
| 92 |
+
max_size_mb=12,
|
| 93 |
+
timeout=180,
|
| 94 |
+
).send()
|
| 95 |
+
|
| 96 |
+
file = files[0]
|
| 97 |
+
|
| 98 |
+
msg = cl.Message(
|
| 99 |
+
content=f"Processing `{file.name}`...", disable_human_feedback=True
|
| 100 |
+
)
|
| 101 |
+
await msg.send()
|
| 102 |
+
|
| 103 |
+
# load the file
|
| 104 |
+
texts = process_text_file(file)
|
| 105 |
+
|
| 106 |
+
print(f"Processing {len(texts)} text chunks")
|
| 107 |
+
|
| 108 |
+
# Create a dict vector store
|
| 109 |
+
vector_db = VectorDatabase()
|
| 110 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 111 |
+
|
| 112 |
+
chat_openai = ChatOpenAI()
|
| 113 |
+
|
| 114 |
+
# Create a chain
|
| 115 |
+
retrieval_augmented_qa_pipeline = RetrievalAugmentedQAPipeline(
|
| 116 |
+
vector_db_retriever=vector_db,
|
| 117 |
+
llm=chat_openai
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
# Let the user know that the system is ready
|
| 121 |
+
msg.content = f"Processing `{file.name}` done. You can now ask questions!"
|
| 122 |
+
await msg.update()
|
| 123 |
+
|
| 124 |
+
cl.user_session.set("chain", retrieval_augmented_qa_pipeline)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
@cl.on_message
|
| 128 |
+
async def main(message):
|
| 129 |
+
chain = cl.user_session.get("chain")
|
| 130 |
+
|
| 131 |
+
msg = cl.Message(content="")
|
| 132 |
+
result = await chain.arun_pipeline(message.content)
|
| 133 |
+
|
| 134 |
+
async for stream_resp in result["response"]:
|
| 135 |
+
await msg.stream_token(stream_resp)
|
| 136 |
+
|
| 137 |
+
await msg.send()
|
AgenticRAG/chainlit.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Welcome to Chat with Your Text File
|
| 2 |
+
|
| 3 |
+
With this application, you can chat with an uploaded text file that is smaller than 2MB!
|
AgenticRAG/images/docchain_img.png
ADDED
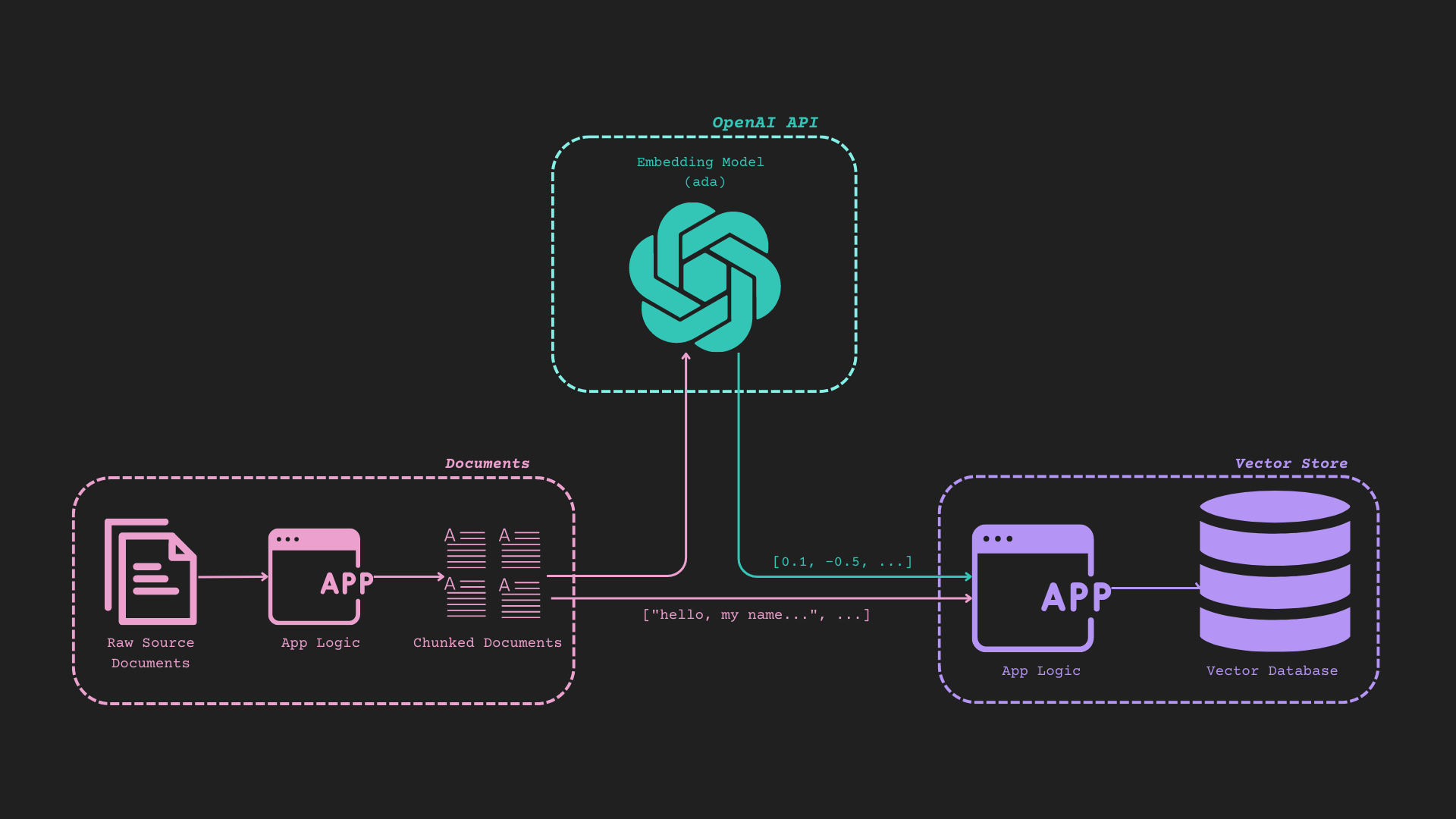
|
AgenticRAG/requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
chainlit==0.7.700
|
| 3 |
+
openai
|
| 4 |
+
langchain_community
|
| 5 |
+
langchain_experimental
|
| 6 |
+
langchain_openai
|
| 7 |
+
pypdf
|
AgenticRAG/runtime.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
python-3.11.9
|