Spaces:
Running

Running
Commit
•
d917a85
1
Parent(s):
5bedb5a
p2t v1.0
Browse files- README.md +8 -9
- app.py +168 -125
- docs/examples/formula1.png +0 -0
- docs/examples/formula2.jpg +0 -0
- docs/examples/hw-formula.png +0 -0
- docs/examples/mixed-ch_sim.jpg +0 -0
- docs/examples/mixed-ch_tra.jpg +0 -0
- docs/examples/mixed-en.jpg +0 -0
- docs/examples/mixed-vietnamese.jpg +0 -0
- docs/examples/pure-text.jpg +0 -0
- requirements.txt +3 -1
README.md
CHANGED
|
@@ -1,10 +1,10 @@
|
|
| 1 |
---
|
| 2 |
title: Pix2Text
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: red
|
| 5 |
colorTo: blue
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 4.
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
|
@@ -12,14 +12,13 @@ license: mit
|
|
| 12 |
|
| 13 |
# Pix2Text (P2T)
|
| 14 |
|
| 15 |
-
[
|
| 16 |
|
| 17 |
-
<div align="center">
|
| 18 |
-
<img src="https://huggingface.co/datasets/breezedeus/cnocr-wx-qr-code/resolve/main/wx-qr-code.JPG" alt="WeChat Group" width="300px"/>
|
| 19 |
-
</div>
|
| 20 |
|
| 21 |
-
|
| 22 |
|
| 23 |
-
|
| 24 |
|
| 25 |
-
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: Pix2Text
|
| 3 |
+
emoji: ♾️
|
| 4 |
colorFrom: red
|
| 5 |
colorTo: blue
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 4.19.2
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
|
|
|
| 12 |
|
| 13 |
# Pix2Text (P2T)
|
| 14 |
|
| 15 |
+
**[Pix2Text (P2T)](https://github.com/breezedeus/pix2text)** aims to be a **free and open-source Python** alternative to **[Mathpix](https://mathpix.com/)**. It can already complete the core functionalities of **Mathpix**. Starting from **V0.2**, **Pix2Text (P2T)** supports recognizing **mixed images containing both text and formulas**, with output similar to **Mathpix**. The core principles of P2T are shown below (text recognition supports both **Chinese** and **English**):
|
| 16 |
|
| 17 |
+
<div align="center"> <img src="https://www.notion.so/image/https%3A%2F%2Fs3-us-west-2.amazonaws.com%2Fsecure.notion-static.com%2F8afb65f8-fd1d-48b9-978a-688554cc759a%2FUntitled.jpeg?table=block&id=39580ae6-09e5-4631-a611-e80e720f3877" alt="Pix2Text workflow" width="600px"/> </div>
|
|
|
|
|
|
|
| 18 |
|
| 19 |
+
**P2T** utilizes the open-source tool **[CnSTD](https://github.com/breezedeus/cnstd)** to detect the locations of **mathematical formulas** in images. These detected areas are then processed by **P2T**'s own **formula recognition engine (LatexOCR)** to recognize the LaTeX representation of each mathematical formula. The remaining parts of the image are processed by a **text recognition engine ([CnOCR](https://github.com/breezedeus/cnocr) or [EasyOCR](https://github.com/JaidedAI/EasyOCR))** for text detection and recognition. Finally, **P2T** merges all recognition results to obtain the final image recognition outcome. Thanks to these great open-source projects!
|
| 20 |
|
| 21 |
+
For beginners who are not familiar with Python, we also provide the **free-to-use** [P2T Online Service](https://p2t.breezedeus.com/). Just upload your image and it will output the P2T parsing results. **The online service uses the latest models and works better than the open-source ones.**
|
| 22 |
|
| 23 |
+
|
| 24 |
+
The author also maintains **Planet of Knowledge** [**P2T/CnOCR/CnSTD Private Group**](https://t.zsxq.com/FEYZRJQ), welcome to join. The **Planet of Knowledge Private Group** will release some P2T/CnOCR/CnSTD related private materials one after another, including **non-public models**, **discount for paid models**, answers to problems encountered during usage, etc. This group also releases the latest research materials related to VIE/OCR/STD.
|
app.py
CHANGED
|
@@ -1,34 +1,23 @@
|
|
| 1 |
# coding: utf-8
|
| 2 |
-
#
|
| 3 |
-
#
|
| 4 |
-
# or more contributor license agreements. See the NOTICE file
|
| 5 |
-
# distributed with this work for additional information
|
| 6 |
-
# regarding copyright ownership. The ASF licenses this file
|
| 7 |
-
# to you under the Apache License, Version 2.0 (the
|
| 8 |
-
# "License"); you may not use this file except in compliance
|
| 9 |
-
# with the License. You may obtain a copy of the License at
|
| 10 |
-
#
|
| 11 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 12 |
-
#
|
| 13 |
-
# Unless required by applicable law or agreed to in writing,
|
| 14 |
-
# software distributed under the License is distributed on an
|
| 15 |
-
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
| 16 |
-
# KIND, either express or implied. See the License for the
|
| 17 |
-
# specific language governing permissions and limitations
|
| 18 |
-
# under the License.
|
| 19 |
-
# Ref: https://huggingface.co/spaces/hysts/Manga-OCR/blob/main/app.py
|
| 20 |
|
| 21 |
import os
|
| 22 |
import json
|
| 23 |
import functools
|
| 24 |
import random
|
|
|
|
| 25 |
import string
|
|
|
|
| 26 |
import time
|
|
|
|
|
|
|
| 27 |
|
| 28 |
import yaml
|
| 29 |
|
| 30 |
import gradio as gr
|
| 31 |
import numpy as np
|
|
|
|
| 32 |
|
| 33 |
# from cnstd.utils import pil_to_numpy, imsave
|
| 34 |
|
|
@@ -38,10 +27,47 @@ from pix2text.utils import set_logger, merge_line_texts
|
|
| 38 |
logger = set_logger()
|
| 39 |
|
| 40 |
LANGUAGES = yaml.safe_load(open('languages.yaml', 'r', encoding='utf-8'))['languages']
|
|
|
|
|
|
|
| 41 |
|
| 42 |
|
| 43 |
-
def
|
| 44 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
return p2t
|
| 46 |
|
| 47 |
|
|
@@ -50,27 +76,36 @@ def latex_render(latex_str):
|
|
| 50 |
# return latex_str
|
| 51 |
|
| 52 |
|
| 53 |
-
def recognize(
|
|
|
|
|
|
|
| 54 |
lang_list = [LANGUAGES[l] for l in lang_list]
|
| 55 |
-
p2t = get_p2t_model(lang_list)
|
| 56 |
|
| 57 |
-
if rec_type == '
|
| 58 |
suffix = list(string.ascii_letters)
|
| 59 |
random.shuffle(suffix)
|
| 60 |
suffix = ''.join(suffix[:6])
|
| 61 |
out_det_fp = f'out-det-{time.time()}-{suffix}.jpg'
|
| 62 |
-
|
| 63 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
)
|
| 65 |
# To get just the text contents, use:
|
| 66 |
only_text = merge_line_texts(outs, auto_line_break=True)
|
| 67 |
|
| 68 |
# return only_text, latex_render(only_text)
|
| 69 |
-
return only_text, out_det_fp
|
| 70 |
-
elif rec_type == '
|
| 71 |
only_text = p2t.recognize_formula(image_file)
|
| 72 |
return latex_render(only_text), None
|
| 73 |
-
elif rec_type == '
|
| 74 |
only_text = p2t.recognize_text(image_file)
|
| 75 |
return only_text, None
|
| 76 |
|
|
@@ -80,77 +115,71 @@ def main():
|
|
| 80 |
langs.sort(key=lambda x: x.lower())
|
| 81 |
|
| 82 |
title = 'Demo'
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
# [
|
| 133 |
-
# 'db_shufflenet_v2::pytorch',
|
| 134 |
-
# False,
|
| 135 |
-
# 'densenet_lite_136-gru',
|
| 136 |
-
# True,
|
| 137 |
-
# 'docs/examples/beauty0.jpg',
|
| 138 |
-
# ],
|
| 139 |
-
# ]
|
| 140 |
|
| 141 |
table_desc = """
|
| 142 |
<div align="center">
|
| 143 |
-
<img src="https://www.notion.so/image/https%3A%2F%2Fprod-files-secure.s3.us-west-2.amazonaws.com%2F9341931a-53f0-48e1-b026-0f1ad17b457c%
|
| 144 |
|
| 145 |
-
[](https://discord.gg/H9FmDSMA)
|
| 148 |
|
| 149 |
| | |
|
| 150 |
| ------------------------------- | --------------------------------------- |
|
| 151 |
-
| 🏄 **
|
|
|
|
| 152 |
| 📀 **Code** | [Github](https://github.com/breezedeus/pix2text) |
|
| 153 |
-
|
|
|
|
|
| 154 |
| 👨🏻💻 **Author** | [Breezedeus](https://www.breezedeus.com) |
|
| 155 |
|
| 156 |
If useful, please help to **star 🌟 [Pix2Text](https://github.com/breezedeus/pix2text)** 🙏
|
|
@@ -169,31 +198,38 @@ If useful, please help to **star 🌟 [Pix2Text](https://github.com/breezedeus/p
|
|
| 169 |
choices=langs,
|
| 170 |
value=['English', 'Chinese Simplified'],
|
| 171 |
multiselect=True,
|
| 172 |
-
info='Which languages to be recognized as Texts.',
|
| 173 |
)
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
value='
|
| 178 |
-
info='Which type of image to be recognized.',
|
| 179 |
)
|
| 180 |
-
|
| 181 |
-
label='
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
value=608,
|
| 185 |
-
step=32,
|
| 186 |
)
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
|
| 190 |
-
|
| 191 |
-
|
| 192 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 193 |
|
| 194 |
with gr.Column(scale=6, variant='compact'):
|
| 195 |
gr.Markdown('### Upload Image to be Recognized')
|
| 196 |
-
image_file = gr.Image(
|
|
|
|
|
|
|
| 197 |
sub_btn = gr.Button("Submit", variant="primary")
|
| 198 |
|
| 199 |
with gr.Column(scale=2, variant='compact'):
|
|
@@ -205,9 +241,11 @@ If useful, please help to **star 🌟 [Pix2Text](https://github.com/breezedeus/p
|
|
| 205 |
label='Detection Result', scale=1, show_label=False
|
| 206 |
)
|
| 207 |
with gr.Column(scale=1, variant='compact'):
|
| 208 |
-
gr.Markdown(
|
|
|
|
|
|
|
| 209 |
rec_result = gr.Textbox(
|
| 210 |
-
label=f'Recognition Result',
|
| 211 |
lines=5,
|
| 212 |
value='',
|
| 213 |
scale=1,
|
|
@@ -218,24 +256,29 @@ If useful, please help to **star 🌟 [Pix2Text](https://github.com/breezedeus/p
|
|
| 218 |
# rec_result.change(latex_render, rec_result, render_result)
|
| 219 |
sub_btn.click(
|
| 220 |
recognize,
|
| 221 |
-
inputs=[
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 222 |
outputs=[rec_result, det_result],
|
| 223 |
)
|
| 224 |
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
# cache_examples=os.getenv('CACHE_EXAMPLES') == '1',
|
| 238 |
-
# )
|
| 239 |
|
| 240 |
demo.queue(max_size=10)
|
| 241 |
demo.launch()
|
|
|
|
| 1 |
# coding: utf-8
|
| 2 |
+
# [Pix2Text](https://github.com/breezedeus/pix2text): an Open-Source Alternative to Mathpix.
|
| 3 |
+
# Copyright (C) 2022-2024, [Breezedeus](https://www.breezedeus.com).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
|
| 5 |
import os
|
| 6 |
import json
|
| 7 |
import functools
|
| 8 |
import random
|
| 9 |
+
import shutil
|
| 10 |
import string
|
| 11 |
+
import tempfile
|
| 12 |
import time
|
| 13 |
+
import zipfile
|
| 14 |
+
from pathlib import Path
|
| 15 |
|
| 16 |
import yaml
|
| 17 |
|
| 18 |
import gradio as gr
|
| 19 |
import numpy as np
|
| 20 |
+
from huggingface_hub import hf_hub_download
|
| 21 |
|
| 22 |
# from cnstd.utils import pil_to_numpy, imsave
|
| 23 |
|
|
|
|
| 27 |
logger = set_logger()
|
| 28 |
|
| 29 |
LANGUAGES = yaml.safe_load(open('languages.yaml', 'r', encoding='utf-8'))['languages']
|
| 30 |
+
OUTPUT_RESULT_DIR = Path('./output-results')
|
| 31 |
+
OUTPUT_RESULT_DIR.mkdir(exist_ok=True)
|
| 32 |
|
| 33 |
|
| 34 |
+
def prepare_mfd_model():
|
| 35 |
+
target_fp = './yolov7-model/mfd-yolov7-epoch224-20230613.pt'
|
| 36 |
+
if os.path.exists(target_fp):
|
| 37 |
+
return target_fp
|
| 38 |
+
HF_TOKEN = os.environ.get('HF_TOKEN')
|
| 39 |
+
local_path = hf_hub_download(
|
| 40 |
+
repo_id='breezedeus/paid-models',
|
| 41 |
+
subfolder='cnstd/1.2',
|
| 42 |
+
filename='yolov7-model-20230613.zip',
|
| 43 |
+
repo_type="model",
|
| 44 |
+
cache_dir='./',
|
| 45 |
+
token=HF_TOKEN,
|
| 46 |
+
)
|
| 47 |
+
with zipfile.ZipFile(local_path) as zf:
|
| 48 |
+
zf.extractall('./')
|
| 49 |
+
return target_fp
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def get_p2t_model(lan_list: list, mfd_model_name: str, mfr_model_name: str):
|
| 53 |
+
analyzer_config = {}
|
| 54 |
+
if 'yolov7_tiny' not in mfd_model_name:
|
| 55 |
+
mfd_fp = prepare_mfd_model()
|
| 56 |
+
analyzer_config = dict( # 声明 LayoutAnalyzer 的初始化参数
|
| 57 |
+
model_name='mfd',
|
| 58 |
+
model_type='yolov7', # 表示使用的是 YoloV7 模型,而不是 YoloV7_Tiny 模型
|
| 59 |
+
model_fp=mfd_fp, # 注:修改成你的模型文件所存储的路径
|
| 60 |
+
)
|
| 61 |
+
formula_config = {}
|
| 62 |
+
if 'mfr-pro' in mfr_model_name:
|
| 63 |
+
formula_config = dict( # 声明 LayoutAnalyzer 的初始化参数
|
| 64 |
+
model_name='mfr-pro', model_backend='onnx',
|
| 65 |
+
)
|
| 66 |
+
p2t = Pix2Text(
|
| 67 |
+
languages=lan_list,
|
| 68 |
+
analyzer_config=analyzer_config,
|
| 69 |
+
formula_config=formula_config,
|
| 70 |
+
)
|
| 71 |
return p2t
|
| 72 |
|
| 73 |
|
|
|
|
| 76 |
# return latex_str
|
| 77 |
|
| 78 |
|
| 79 |
+
def recognize(
|
| 80 |
+
lang_list, mfd_model_name, mfr_model_name, rec_type, resized_shape, image_file
|
| 81 |
+
):
|
| 82 |
lang_list = [LANGUAGES[l] for l in lang_list]
|
| 83 |
+
p2t = get_p2t_model(lang_list, mfd_model_name, mfr_model_name)
|
| 84 |
|
| 85 |
+
if rec_type == 'mixed':
|
| 86 |
suffix = list(string.ascii_letters)
|
| 87 |
random.shuffle(suffix)
|
| 88 |
suffix = ''.join(suffix[:6])
|
| 89 |
out_det_fp = f'out-det-{time.time()}-{suffix}.jpg'
|
| 90 |
+
# 如果 OUTPUT_RESULT_DIR 文件数量超过 1000,按时间删除最早的 1000 个文件
|
| 91 |
+
if len(os.listdir(OUTPUT_RESULT_DIR)) > 1000:
|
| 92 |
+
for fp in sorted(os.listdir(OUTPUT_RESULT_DIR))[:1000]:
|
| 93 |
+
os.remove(OUTPUT_RESULT_DIR / fp)
|
| 94 |
+
|
| 95 |
+
outs = p2t.recognize(
|
| 96 |
+
image_file,
|
| 97 |
+
resized_shape=resized_shape,
|
| 98 |
+
save_analysis_res=OUTPUT_RESULT_DIR / out_det_fp,
|
| 99 |
)
|
| 100 |
# To get just the text contents, use:
|
| 101 |
only_text = merge_line_texts(outs, auto_line_break=True)
|
| 102 |
|
| 103 |
# return only_text, latex_render(only_text)
|
| 104 |
+
return only_text, str(OUTPUT_RESULT_DIR / out_det_fp)
|
| 105 |
+
elif rec_type == 'formula':
|
| 106 |
only_text = p2t.recognize_formula(image_file)
|
| 107 |
return latex_render(only_text), None
|
| 108 |
+
elif rec_type == 'text':
|
| 109 |
only_text = p2t.recognize_text(image_file)
|
| 110 |
return only_text, None
|
| 111 |
|
|
|
|
| 115 |
langs.sort(key=lambda x: x.lower())
|
| 116 |
|
| 117 |
title = 'Demo'
|
| 118 |
+
example_func = functools.partial(
|
| 119 |
+
recognize,
|
| 120 |
+
mfd_model_name='yolov7 (paid)',
|
| 121 |
+
mfr_model_name='mfr-pro',
|
| 122 |
+
rec_type='mixed',
|
| 123 |
+
resized_shape=768,
|
| 124 |
+
)
|
| 125 |
+
examples = [
|
| 126 |
+
[
|
| 127 |
+
['English'],
|
| 128 |
+
'mixed',
|
| 129 |
+
'docs/examples/mixed-en.jpg',
|
| 130 |
+
],
|
| 131 |
+
[
|
| 132 |
+
['English', 'Chinese Simplified'],
|
| 133 |
+
'mixed',
|
| 134 |
+
'docs/examples/mixed-ch_sim.jpg',
|
| 135 |
+
],
|
| 136 |
+
[
|
| 137 |
+
['English', 'Chinese Traditional'],
|
| 138 |
+
'mixed',
|
| 139 |
+
'docs/examples/mixed-ch_tra.jpg',
|
| 140 |
+
],
|
| 141 |
+
[
|
| 142 |
+
['English', 'Vietnamese'],
|
| 143 |
+
'mixed',
|
| 144 |
+
'docs/examples/mixed-vietnamese.jpg',
|
| 145 |
+
],
|
| 146 |
+
[
|
| 147 |
+
['English'],
|
| 148 |
+
'formula',
|
| 149 |
+
'docs/examples/formula1.png'
|
| 150 |
+
],
|
| 151 |
+
[
|
| 152 |
+
['English'],
|
| 153 |
+
'formula',
|
| 154 |
+
'docs/examples/formula2.jpg'
|
| 155 |
+
],
|
| 156 |
+
[
|
| 157 |
+
['English'],
|
| 158 |
+
'formula',
|
| 159 |
+
'docs/examples/hw-formula.png'
|
| 160 |
+
],
|
| 161 |
+
[
|
| 162 |
+
['English', 'Chinese Simplified'],
|
| 163 |
+
'text',
|
| 164 |
+
'docs/examples/pure-text.jpg',
|
| 165 |
+
],
|
| 166 |
+
]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 167 |
|
| 168 |
table_desc = """
|
| 169 |
<div align="center">
|
| 170 |
+
<img src="https://www.notion.so/image/https%3A%2F%2Fprod-files-secure.s3.us-west-2.amazonaws.com%2F9341931a-53f0-48e1-b026-0f1ad17b457c%2Fd0e55da8-36a5-482c-bea6-c389e2fcacea%2FUntitled.png?table=block&id=caebb37a-e23f-49ab-9687-2cba3801992e" width="120px"/>
|
| 171 |
|
| 172 |
+
[](https://visitorbadge.io/status?path=https%3A%2F%2Fhuggingface.co%2Fspaces%2Fbreezedeus%2FCnOCR-Demo)
|
| 173 |
|
| 174 |
[](https://discord.gg/H9FmDSMA)
|
| 175 |
|
| 176 |
| | |
|
| 177 |
| ------------------------------- | --------------------------------------- |
|
| 178 |
+
| 🏄 **Online Service** | [p2t.breezedeus.com](https://p2t.breezedeus.com) |
|
| 179 |
+
| 💬 **Discord** | [Pix2Text @ Discord](https://discord.gg/tGuFEybd) |
|
| 180 |
| 📀 **Code** | [Github](https://github.com/breezedeus/pix2text) |
|
| 181 |
+
| 🤗 **MFR Model** | [breezedeus/pix2text-mfr](https://huggingface.co/breezedeus/pix2text-mfr) |
|
| 182 |
+
| 📄 **More Infos** | [breezedeus.com/pix2text](https://www.breezedeus.com/pix2text) |
|
| 183 |
| 👨🏻💻 **Author** | [Breezedeus](https://www.breezedeus.com) |
|
| 184 |
|
| 185 |
If useful, please help to **star 🌟 [Pix2Text](https://github.com/breezedeus/pix2text)** 🙏
|
|
|
|
| 198 |
choices=langs,
|
| 199 |
value=['English', 'Chinese Simplified'],
|
| 200 |
multiselect=True,
|
| 201 |
+
# info='Which languages to be recognized as Texts.',
|
| 202 |
)
|
| 203 |
+
mfd_model_name = gr.Dropdown(
|
| 204 |
+
label='MFD Models',
|
| 205 |
+
choices=['yolov7_tiny (free)', 'yolov7 (paid)'],
|
| 206 |
+
value='yolov7 (paid)',
|
|
|
|
| 207 |
)
|
| 208 |
+
mfr_model_name = gr.Dropdown(
|
| 209 |
+
label='MFR Models',
|
| 210 |
+
choices=['mfr (free)', 'mfr-pro (paid)'],
|
| 211 |
+
value='mfr-pro (paid)',
|
|
|
|
|
|
|
| 212 |
)
|
| 213 |
+
rec_type = gr.Dropdown(
|
| 214 |
+
label='Image Type',
|
| 215 |
+
choices=['mixed', 'formula', 'text'],
|
| 216 |
+
value='mixed',
|
| 217 |
+
# info='Which type of image to be recognized.',
|
| 218 |
+
)
|
| 219 |
+
with gr.Accordion('More Options', open=False):
|
| 220 |
+
resized_shape = gr.Slider(
|
| 221 |
+
label='resized_shape',
|
| 222 |
+
minimum=512,
|
| 223 |
+
maximum=2048,
|
| 224 |
+
value=768,
|
| 225 |
+
step=32,
|
| 226 |
+
)
|
| 227 |
|
| 228 |
with gr.Column(scale=6, variant='compact'):
|
| 229 |
gr.Markdown('### Upload Image to be Recognized')
|
| 230 |
+
image_file = gr.Image(
|
| 231 |
+
label='Image', type="pil", image_mode='RGB', show_label=False
|
| 232 |
+
)
|
| 233 |
sub_btn = gr.Button("Submit", variant="primary")
|
| 234 |
|
| 235 |
with gr.Column(scale=2, variant='compact'):
|
|
|
|
| 241 |
label='Detection Result', scale=1, show_label=False
|
| 242 |
)
|
| 243 |
with gr.Column(scale=1, variant='compact'):
|
| 244 |
+
gr.Markdown(
|
| 245 |
+
'**Recognition Results (Paste them into the [P2T Online Service](https://p2t.breezedeus.com) to view rendered outcomes)**'
|
| 246 |
+
)
|
| 247 |
rec_result = gr.Textbox(
|
| 248 |
+
label=f'Recognition Result ',
|
| 249 |
lines=5,
|
| 250 |
value='',
|
| 251 |
scale=1,
|
|
|
|
| 256 |
# rec_result.change(latex_render, rec_result, render_result)
|
| 257 |
sub_btn.click(
|
| 258 |
recognize,
|
| 259 |
+
inputs=[
|
| 260 |
+
lang_list,
|
| 261 |
+
mfd_model_name,
|
| 262 |
+
mfr_model_name,
|
| 263 |
+
rec_type,
|
| 264 |
+
resized_shape,
|
| 265 |
+
image_file,
|
| 266 |
+
],
|
| 267 |
outputs=[rec_result, det_result],
|
| 268 |
)
|
| 269 |
|
| 270 |
+
gr.Examples(
|
| 271 |
+
label='Examples',
|
| 272 |
+
examples=examples,
|
| 273 |
+
inputs=[
|
| 274 |
+
lang_list,
|
| 275 |
+
rec_type,
|
| 276 |
+
image_file,
|
| 277 |
+
],
|
| 278 |
+
outputs=[rec_result, det_result],
|
| 279 |
+
fn=example_func,
|
| 280 |
+
cache_examples=os.getenv('CACHE_EXAMPLES') == '1',
|
| 281 |
+
)
|
|
|
|
|
|
|
| 282 |
|
| 283 |
demo.queue(max_size=10)
|
| 284 |
demo.launch()
|
docs/examples/formula1.png
ADDED

|
docs/examples/formula2.jpg
ADDED

|
docs/examples/hw-formula.png
ADDED
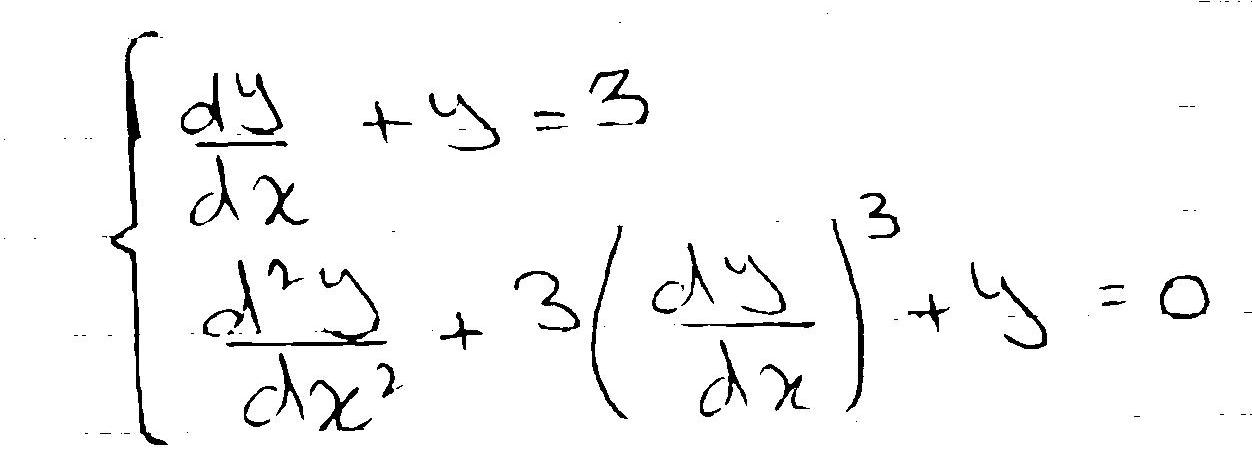
|
docs/examples/mixed-ch_sim.jpg
ADDED

|
docs/examples/mixed-ch_tra.jpg
ADDED

|
docs/examples/mixed-en.jpg
ADDED

|
docs/examples/mixed-vietnamese.jpg
ADDED

|
docs/examples/pure-text.jpg
ADDED

|
requirements.txt
CHANGED
|
@@ -1,2 +1,4 @@
|
|
|
|
|
|
|
|
| 1 |
pyyaml
|
| 2 |
-
pix2text
|
|
|
|
| 1 |
+
--extra-index-url https://pypi.org/simple
|
| 2 |
+
|
| 3 |
pyyaml
|
| 4 |
+
pix2text[multilingual]>=1.0
|