# Come aggiungere un modello a 🤗 Transformers?
Aggiungere un nuovo modello é spesso difficile e richiede una profonda conoscenza della libreria 🤗 Transformers e anche
della repository originale del modello. A Hugging Face cerchiamo di dare alla community sempre piú poteri per aggiungere
modelli independentemente. Quindi, per alcuni nuovi modelli che la community vuole aggiungere a 🤗 Transformers, abbiamo
creato una specifica *call-for-model-addition* che spiega passo dopo passo come aggiungere il modello richiesto. Con
questo *call-for-model-addition* vogliamo insegnare a volenterosi e esperti collaboratori della community come implementare
un modello in 🤗 Transformers.
Se questo é qualcosa che può interessarvi, siete liberi di controllare l'attuale “calls-for-model-addition” [qui](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model/open_model_proposals/README.md)
e contattarci.
Se il modello sarà selezionato, allora potrete lavorare insieme a un membro di Hugging Face per integrare il modello in 🤗
Transformers. Così facendo, ci guadagnerai in una comprensione totale, sia teorica che pratica, del modello proposto. Inoltre,
sarai l'artefice di un importante contributo open-source a 🤗 Transformers. Durante l'implementazione avrai l'opportunità di:
- ottenere più comprensione delle best practices in open-source
- capire i principi di design di una della librerie NLP più popolari
- capire come efficientemente testare complessi modelli NLP
- capire come integrare utilit Python come `black`, `ruff`, `make fix-copies` in una libreria per garantire sempre di avere un codice leggibile e pulito
Siamo anche contenti se vuoi aggiungere un modello che non può essere trovato nella cartella “calls-for-model-addition”.
Le seguenti sezioni spiegano in dettaglio come aggiungere un nuovo modello. Può anche essere molto utile controllare modelli
già aggiunti [qui](https://github.com/huggingface/transformers/pulls?q=is%3Apr+label%3A%22PR+for+Model+Addition%22+is%3Aclosed),
per capire se richiamano il modello che vorreste aggiungere.
Per cominciare, vediamo una panoramica general della libreria Transformers.
## Panoramica generale su 🤗 Transformers
Prima di tutto, vediamo in generale 🤗 Transformers. 🤗 Transformers é una libreria molto strutturata, quindi
puà essere che a volte ci sia un disaccordo con alcune filosofie della libreria o scelte di design. Dalla nostra esperienza,
tuttavia, abbiamo trovato che le scelte fondamentali di design della libreria sono cruciali per usare 🤗 Transformers efficacemente
su larga scala, mantenendo i costi a un livello accettabile.
Un buon primo punto di partenza per capire al meglio la libreria é leggere la [documentazione sulla nostra filosofia](filosofia)
Da qui, ci sono alcune scelte sul modo di lavorare che cerchiamo di applicare a tutti i modelli:
- La composizione é generalmente favorita sulla sovra-astrazione
- Duplicare il codice non é sempre male, soprattutto se migliora notevolmente la leggibilità e accessibilità del modello
- Tutti i files creati per il nuovo modello devono il piu possibile "compatti". Questo vuol dire che quando qualcuno leggerá il codice
di uno specifico modello, potrá vedere solo il corrispettivo file `modeling_....py` senza avere multiple dipendenze.
La cosa piú importante, é che consideriamo la libreria non solo un mezzo per dare un prodotto, *per esempio* dare la possibilità
di usare BERT per inferenza, ma é anche il prodotto reale che noi vogliamo migliorare sempre più. Quindi, quando aggiungi
un modello, non sei solo la persona che userà il modello, ma rappresenti anche tutti coloro che leggeranno,
cercheranno di capire e modificare il tuo modello.
Tenendo questi principi in mente, immergiamoci nel design generale della libreria.
### Panoramica sui modelli
Per aggiungere con successo un modello, é importante capire l'interazione tra il tuo modello e la sua configurazione,
[`PreTrainedModel`], e [`PretrainedConfig`]. Per dare un esempio, chiameremo il modello da aggiungere a 🤗 Transformers
`BrandNewBert`.
Diamo un'occhiata:
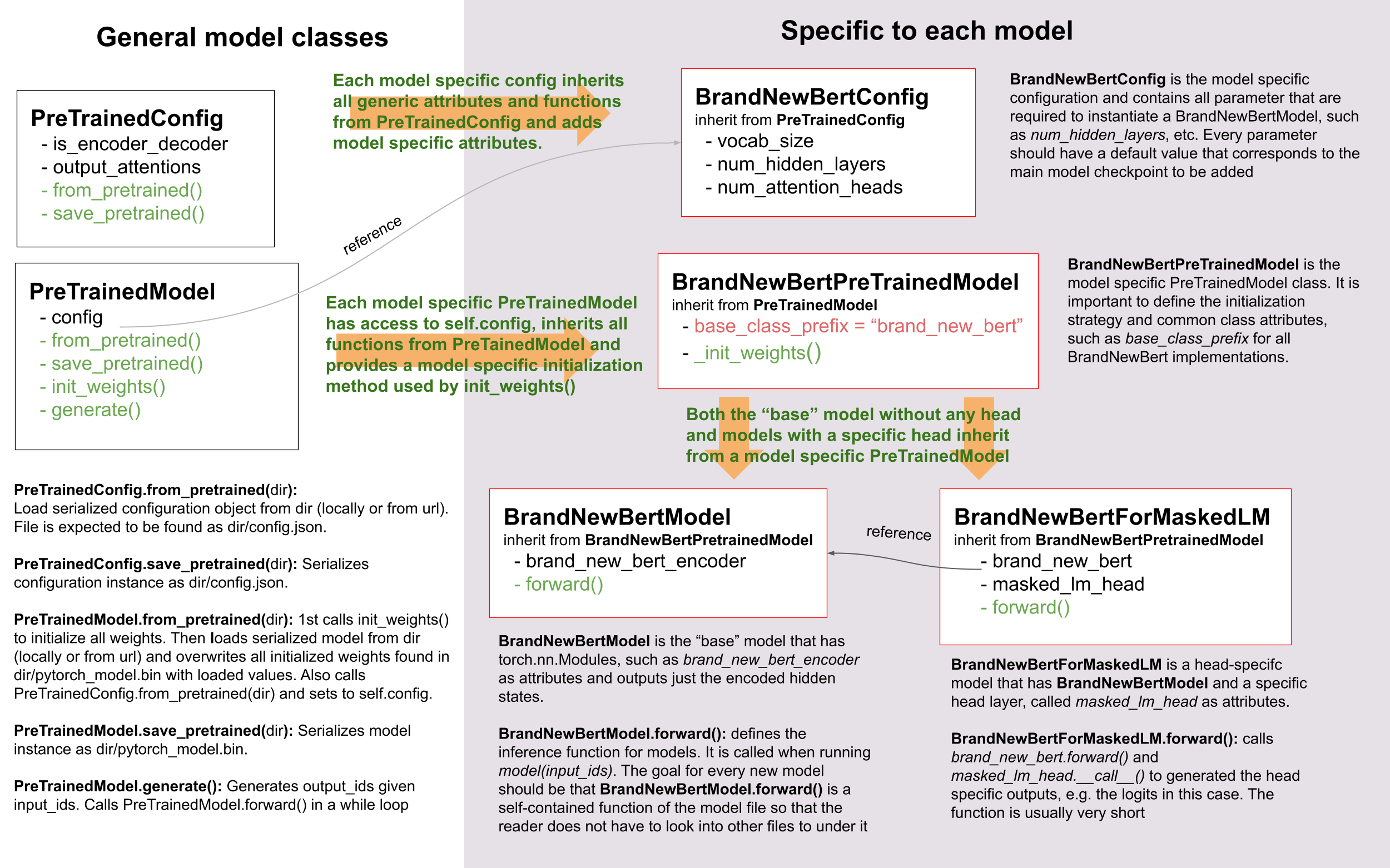 Come potete vedere, ci basiamo sull'ereditarietà in 🤗 Transformers, tenendo però il livello di astrazione a un minimo
assoluto. Non ci sono mai più di due livelli di astrazione per ogni modello nella libreria. `BrandNewBertModel` eredita
da `BrandNewBertPreTrainedModel` che, a sua volta, eredita da [`PreTrainedModel`] - semplice no?
Come regola generale, vogliamo essere sicuri che un nuovo modello dipenda solo da [`PreTrainedModel`]. Le funzionalità
importanti che sono automaticamente conferite a ogni nuovo modello sono [`~PreTrainedModel.from_pretrained`]
e [`~PreTrainedModel.save_pretrained`], che sono usate per serializzazione e deserializzazione. Tutte le altre importanti
funzionalità, come ad esempio `BrandNewBertModel.forward` devono essere definite completamente nel nuovo script
`modeling_brand_new_bert.py`. Inoltre, vogliamo essere sicuri che un modello con uno specifico head layer, come
`BrandNewBertForMaskedLM` non erediti da `BrandNewBertModel`, ma piuttosto usi `BrandNewBertModel`
come componente che può essere chiamata nel passaggio forward per mantenere il livello di astrazione basso. Ogni
nuovo modello richieste una classe di configurazione, chiamata `BrandNewBertConfig`. Questa configurazione é sempre
mantenuta come un attributo in [`PreTrainedModel`], e quindi può essere accessibile tramite l'attributo `config`
per tutte le classi che ereditano da `BrandNewBertPreTrainedModel`:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # il modello ha accesso al suo config
```
Analogamente al modello, la configurazione eredita le funzionalità base di serializzazione e deserializzazione da
[`PretrainedConfig`]. É da notare che la configurazione e il modello sono sempre serializzati in due formati differenti -
il modello é serializzato in un file *pytorch_model.bin* mentre la configurazione con *config.json*. Chiamando
[`~PreTrainedModel.save_pretrained`] automaticamente chiamerà [`~PretrainedConfig.save_pretrained`], cosicché sia il
modello che la configurazione siano salvati.
### Stile per il codice
Quando codifichi un nuovo modello, tieni presente che Transformers ha una sua struttura di fondo come libreria, perciò
ci sono alcuni fatti da considerare su come scrivere un codice :-)
1. Il forward pass del tuo modello dev'essere scritto completamente nel file del modello, mentre dev'essere indipendente
da altri modelli nella libreria. Se vuoi riutilizzare un blocco di codice da un altro modello, copia e incolla il codice con un commento `# Copied from` in cima al codice (guarda [qui](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
per un ottimo esempio).
2. Il codice dev'essere interamente comprensibile, anche da persone che non parlano in inglese. Questo significa che le
variabili devono avere un nome descrittivo e bisogna evitare abbreviazioni. Per esempio, `activation` é molto meglio
che `act`. Le variabili con una lettera sono da evitare fortemente, almeno che non sia per un indce in un for loop.
3. Generamente é meglio avere un codice esplicito e piú lungo che un codice corto e magico.
4. Evita di subclassare `nn.Sequential` in Pytorch, puoi subclassare `nn.Module` e scrivere il forward pass, cosicché
chiunque può effettuare debug sul tuo codice, aggiungendo print o breaking points.
5. La tua function-signature dev'essere type-annoted. Per il resto, é meglio preferire variabili con un nome accettabile
piuttosto che annotazioni per aumentare la comprensione e leggibilità del codice.
### Panoramica sui tokenizers
Questa sezione sarà creata al piu presto :-(
## Aggiungere un modello a 🤗 Transformers passo dopo passo
Ci sono differenti modi per aggiungere un modello a Hugging Face. Qui trovi una lista di blog posts da parte della community su come aggiungere un modello:
1. [Aggiungere GPT2](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) scritto da [Thomas](https://huggingface.co/thomwolf)
2. [Aggiungere WMT19 MT](https://huggingface.co/blog/porting-fsmt) scritto da [Stas](https://huggingface.co/stas)
Per esperienza, possiamo dirti che quando si aggiunge un modello é meglio tenere a mente le seguenti considerazioni:
- Non sfondare una porta giá aperta! La maggior parte del codice che aggiungerai per un nuovo modello 🤗 Transformers
esiste già da qualche parte in 🤗 Transformers. Prendi un po' di tempo per trovare codici simili in modelli e tokenizers esistenti e fare un copia-incolla. Ricorda che [grep](https://www.gnu.org/software/grep/) e [rg](https://github.com/BurntSushi/ripgrep) sono tuoi buoni amici. Inoltre, ricorda che puó essere molto probabile che il tokenizer per il tuo modello sia basato sull'implementazione di un altro modello, e il codice del tuo modello stesso su un altro ancora. *Per esempio* il modello FSMT é basato su BART, mentre il tokenizer di FSMT é basato su XLM.
- Ricorda che qui é piu una sfida ingegneristica che scientifica. Spendi piú tempo per create un efficiente ambiente di debugging piuttosto che cercare di capire tutti gli aspetti teorici dell'articolo del modello.
- Chiedi aiuto se sei in panne! I modelli sono la parte principale di 🤗 Transformers, perciò qui a Hugging Face siamo più che contenti di aiutarti in ogni passo per aggiungere il tuo modello. Non esitare a chiedere se vedi che non riesci a progredire.
Di seguito, diamo una ricetta generale per aiutare a portare un modello in 🤗 Transformers.
La lista seguente é un sommario di tutto quello che é stato fatto per aggiungere un modello, e può essere usata come To-Do List:
- 1. ☐ (Opzionale) Capire gli aspetti teorici del modello
- 2. ☐ Preparare l'ambiente dev per transformers
- 3. ☐ Preparare l'ambiente debugging della repository originale
- 4. ☐ Create uno script che gestisca con successo il forward pass usando la repository originale e checkpoint
- 5. ☐ Aggiungere con successo lo scheletro del modello a Transformers
- 6. ☐ Convertire i checkpoint original a Transformers checkpoint
- 7. ☐ Effettuare con successo la forward pass in Transformers, di modo che dia un output identico al checkpoint originale
- 8. ☐ Finire i tests per il modello in Transformers
- 9. ☐ Aggiungere con successo Tokenizer in Transformers
- 10. ☐ Testare e provare gli integration tests da capo a fine
- 11. ☐ Completare i docs
- 12. ☐ Caricare i moedl weights all'hub
- 13. ☐ Sottomettere una pull request
- 14. ☐ (Opzionale) Aggiungere un notebook con una demo
Per cominciare di solito consigliamo `BrandNewBert`, partendo dalla teoria, di modo da avere una buona comprensione della teoria generale. TUttavia, se preferisci imparare l'aspetto teorico del modello mentre *lavori* sul modello é ok immergersi direttamente nel codice di `BrandNewBert`. Questa opzione puó essere buona se le tue skills ingegneristiche sono meglio che quelle teoriche, o se il paper `BrandNewBert` ti dá problemi, o se semplicemente ti piace programmare piú che leggere articoli scientifici.
### 1. (Opzionale) Aspetti teorici di BrandNewBert
Allora con calma, prendi un po' di tempo per leggere l'articolo su *BrandNewBert* . Sicuramente, alcune sezioni dell'articolo sono molto complesse, ma non preoccuparti! L'obiettivo non é avere una compresione immensa della teoria alla base, ma estrarre le informazioni necessarie per re-implementare con successo il modello in 🤗 Transformers. Quindi, non impazzire sugli aspetti teorici, ma piuttosto focalizzati su quelli pratici, ossia:
- Che tipo di modello é *brand_new_bert*? É solo un encoder in stile BERT? O tipo decoder come GPT2? O encoder e decoder stile BART? Dai un'occhiata a [model_summary](model_summary) se non sei famigliare con le differenze tra questi modelli
- Quali sono le applicazioni di *brand_new_bert*? Classificazione di testo? Generazione di testo? O per tasks del genere seq2seq?
- Quali sono le nuove aggiunte al modello che lo rendono diverso da BERT/GPT-2/BART?
- Quali modelli estistenti in [🤗 Transformers models](https://huggingface.co/transformers/#contents) sono molto simili a *brand_new_bert*?
- Che tipo di tokenizer si usa in questo caso? Un sentencepiece tokenizer? O un word piece tokenizer? Il tokenizer é lo stesso di BERT o BART?
Una volta che senti che hai avuto una bella overview dell'architettura del modello, puoi scrivere senza problemi al team di Hugging Face per ogni domanda che tu hai. Questo puó includere domande sull'architettura del modello, o sull'attention layer, etc. Saremo molto felici di aiutarti :)
### 2. Prepare il tuo ambiente
1. Forka la [repository](https://github.com/huggingface/transformers) cliccando sul tasto ‘Fork' nella pagina della repository. Questo crea una copia del codice nel tuo account GitHub
2. Clona il tuo fork `transfomers` sul tuo dico locale, e aggiungi la repository base come remota:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Crea un ambiente di sviluppo, per esempio tramite questo comando:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
quindi torna alla directory principale:
```bash
cd ..
```
4. Attenzione, raccomandiamo di aggiungere la versione di PyTorch di *brand_new_bert* a Transfomers. Per installare PyTorch, basta seguire queste istruzioni https://pytorch.org/get-started/locally/.
**Nota bene:** Non c'é bisogno di installare o avere installato CUDA. Il nuovo modello può funzionare senza problemi su una CPU.
5. Per trasferire *brand_new_bert* To port *brand_new_bert* avrai bisogno anche accesso alla sua repository originale:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
Ok, ora hai un ambiente di sviluppo per portare *brand_new_bert* in 🤗 Transformers.
### 3.-4. Provare un pretrained checkpoint usando la repo originale
Per cominciare, comincerai a lavorare sulla repo originale di *brand_new_bert*. Come spesso accade, l'implementazione originale é molto sullo stile "ricerca". Questo significa che a volte la documentazione non é al top, magari manca qualche cosa e il codice puó essere difficile da capire. Tuttavia, questa é e dev'essere la motivazione per reimplementare *brand_new_bert*. In Hugging Face, uno degli obiettivi principali é di *mettere le persone sulle spalle dei giganti*, il che si traduce, in questo contesto, di prendere un modello funzionante e riscriverlo e renderlo il piú possibile **accessibile, user-friendly, e leggibile**. Questa é la top motivazione per re-implementare modelli in 🤗 Transformers - cercare di creare nuove complesse tecnologie NLP accessibili a **chiunque**.
Riuscire a far girare il modello pretrained originale dalla repository ufficiale é spesso il passo **piu arduo**. Dalla nostra esperienza, é molto importante spendere un p' di tempo per diventare familiari con il codice base originale. Come test, prova a capire i seguenti punti:
- Dove si trovano i pretrained weights?
- Come caricare i pretrained weights nel modello corrispondente?
- Come girare un tokenizer independentemente dal modello?
- Prova a tracciare un singolo forward pass, cosicché potrai sapere che classi e funzioni sono richieste per un semplice forward pass. Di solito, dovrai reimplementare queste funzioni e basta
- Prova a localizzare i componenti importanti del modello: Dove si trova la classe del modello? Ci sono sotto classi nel modello *per esempio* EngoderModel, DecoderMOdel? Dove si trova il self-attention layer? Ci sono molteplici differenti layer di attention, *per esempio * *self-attention*, *cross-attention*...?
- Come puoi fare debug sul modello nell'ambiente originale della repo? Devi aggiungere dei *print* o puoi usare *ipdb* come debugger interattivo, o vabene anche un IDE efficiente per debug come PyCharm?
É molto importante che prima di cominciare a trasferire il modello nuovo tu spenda tempo a fare debug del codice originale in maniera **efficiente**! Inoltre, ricorda che tutta la library é open-soruce, quindi non temere di aprire issue o fare una pull request nella repo originale. Tutti coloro che mantengono la repository saranno piú che felici di avere qualcuno che guarda e gioca con i loro codici!
A questo punto, sta a te decidere quale ambiente per debug vuoi usare. Noi consilgiamo di evitare setup con GPU, che potrebbero costare assai, lavorare su una CPU puó essere un ottimo punto di partenza per indagare la repository originale e per cominciare a scrivere il codice per 🤗 Transformers. Solo alla fine, quando il modello é stato portato con successo in 🤗 Transformers, allora si potrá verificare il suo funzionamento su GPU.
In generale ci sono due possibili ambienti di debug per il testare il modello originale:
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Scripts locali in Python
Il vantaggio dei Jupyter notebooks é la possibilità di eseguire cella per cella, il che può essere utile per decomporre tutte le componenti logiche, cosi da a vere un ciclo di debug più rapido, siccome si possono salvare i risultati da steps intermedi. Inoltre, i notebooks spesso sono molto facili da condividere con altri contributors, il che può essere molto utile se vuoi chiedere aiuto al team di Hugging Face. Se sei famigliare con Jupyter notebooks allora racommandiamo di lavorare in questa maniera.
Ovviamente se non siete abituati a lavorare con i notebook, questo può essere uno svantaggio nell'usare questa tecnologia, sprecando un sacco di tempo per setup e portare tutto al nuovo ambiente, siccome non potreste neanche usare dei tools di debug come `ipdb`.
Per ogni pratica code-base, é sempre meglio come primo step caricare un **piccolo** checkpoint pretrained e cercare di riprodurre un singolo forward pass usando un vettore fittizio di IDs fatti da numeri interi. Un esempio per uno script simile, in pseudocodice é:
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Per quanto riguarda la strategia di debugging, si può scegliere tra:
- Decomporre il modello originario in piccole componenenti e testare ognuna di esse
- Decomporre il modello originario nel *tokenizer* originale e nel *modello* originale, testare un forward pass su questi,
e usare dei print statement o breakpoints intermedi per verificare
Ancora una volta, siete liberi di scegliere quale strategia sia ottimale per voi. Spesso una strategia é piu
avvantaggiosa di un'altra, ma tutto dipende dall'code-base originario.
Se il code-base vi permette di decomporre il modello in piccole sub-componenenti, *per esempio* se il code-base
originario può essere facilmente testato in eager mode, allora vale la pena effettuare un debugging di questo genere.
Ricordate che ci sono dei vantaggi nel decidere di prendere la strada piu impegnativa sin da subito:
- negli stage piu finali, quando bisognerà comparare il modello originario all'implementazione in Hugging Face, potrete verificare
automaticamente ogni componente, individualmente, di modo che ci sia una corrispondenza 1:1
- avrete l'opportunità di decomporre un problema molto grande in piccoli passi, così da strutturare meglio il vostro lavoro
- separare il modello in componenti logiche vi aiuterà ad avere un'ottima overview sul design del modello, quindi una migliore
comprensione del modello stesso
- verso gli stage finali i test fatti componente per componente vi aiuterà ad essere sicuri di non andare avanti e indietro
nell'implementazione, così da continuare la modifica del codice senza interruzione
Un ottimo esempio di come questo può essere fatto é dato da [Lysandre](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
per il modello ELECTRA
Tuttavia, se il code-base originale é molto complesso o le componenti intermedie possono essere testate solo in tramite
compilazione, potrebbe richiedere parecchio tempo o addirittura essere impossibile separare il modello in piccole sotto-componenti.
Un buon esempio é [MeshTensorFlow di T5](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow). Questa libreria
é molto complessa e non offre un metodo semplice di decomposizione in sotto-componenti. Per simili librerie, potrete fare
affidamento ai print statements.
In ogni caso, indipendentemente da quale strategia scegliete, la procedura raccomandata é di cominciare a fare debug dal
primo layer al layer finale.
É consigliato recuperare gli output dai layers, tramite print o sotto-componenti, nel seguente ordine:
1. Recuperare gli IDs di input dati al modello
2. Recuperare i word embeddings
3. Recuperare l'input del primo Transformer layer
4. Recuperare l'output del primo Transformer layer
5. Recuperare l'output dei seguenti `n - 1` Transformer layers
6. Recuperare l'output dell'intero BrandNewBert Model
Gli IDs in input dovrebbero essere un arrary di interi, *per esempio* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
Gli output dei seguenti layer di solito dovrebbero essere degli array di float multi-dimensionali come questo:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
Ci aspettiamo che ogni modello aggiunto a 🤗 Transformers passi con successo un paio di test d'integrazione. Questo
significa che il modello originale e la sua implementazione in 🤗 Transformers abbiano lo stesso output con una precisione
di 0.001! Siccome é normale che lo stesso esatto modello, scritto in librerie diverse, possa dare output leggermente
diversi, la tolleranza accettata é 1e-3 (0.001). Ricordate che i due modelli devono dare output quasi identici. Dunque,
é molto conveniente comparare gli output intermedi di 🤗 Transformers molteplici volte con gli output intermedi del
modello originale di *brand_new_bert*. Di seguito vi diamo alcuni consigli per avere un ambiente di debug il piu efficiente
possibile:
- Trovate la migliore strategia per fare debug dei risultati intermedi. Per esempio, é la repository originale scritta in PyTorch?
Se si, molto probabilmente dovrete dedicare un po' di tempo per scrivere degli script piu lunghi, così da decomporre il
modello originale in piccole sotto-componenti, in modo da poter recuperare i valori intermedi. Oppure, la repo originale
é scritta in Tensorflow 1? Se é così dovrete fare affidamento ai print di Tensorflow [tf.print](https://www.tensorflow.org/api_docs/python/tf/print)
per avere i valori intermedi. Altro caso, la repo é scritta in Jax? Allora assicuratevi che il modello non sia in **jit**
quanto testate il foward pass, *per esempio* controllate [questo link](https://github.com/google/jax/issues/196).
- Usate i più piccoli pretrained checkpoint che potete trovare. Piu piccolo é il checkpoint, piu velocemente sarà il vostro
ciclo di debug. Non é efficiente avere un pretrained model così gigante che per il forward pass impieghi piu di 10 secondi.
Nel caso in cui i checkpoints siano molto grandi, e non si possa trovare di meglio, allora é buona consuetudine ricorrere
a fare un dummy model nel nuovo ambiente, con weights inizializzati random e salvare quei weights per comprare la versione 🤗 Transformers
con il vostro modello
- Accertatevi di usare la via piu semplice per chiamare il forward pass nella repo originale. Sarebbe opportuno trovare
la funzione originaria che chiami **solo** un singolo forward pass, *per esempio* questa funzione spesso viene chiamata
`predict`, `evaluate`, `forward` o `__call__`. Siate sicuri di non fare debug su una funzione che chiami `forward` molteplici
volte, *per esempio* per generare testo, come `autoregressive_sample`, `generate`.
- Cercate di separare la tokenization dal forward pass del modello. Se la repo originaria mostra esempio dove potete dare
come input una stringa, provate a cercare dove nella forward call la stringa viene cambiata in input ids e cominciate il
debug da questo punto. Questo vi garantisce un ottimo punto di partenza per scrivere un piccolo script personale dove dare
gli input al modello, anziche delle stringhe in input.
- Assicuratevi che il debugging **non** sia in training mode. Spesso questo potra il modello a dare degli output random, per
via dei molteplici dropout layers. Assicuratevi che il forward pass nell'ambiente di debug sia **deterministico**, cosicche
i dropout non siano usati. Alternativamente, potete usare *transformers.utils.set_seed* se la vecchia e nuova implementazione
sono nello stesso framework.
La seguente sezione vi da ulteriori dettagli e accorgimenti su come potete fare tutto questo per *brand_new_bert*.
### 5.-14. Trasferire BrandNewBert in 🤗 Transformers
Allora cominciamo ad aggiungere un nuovo codice in 🤗 Transformers. Andate nel vostro fork clone di 🤗 Transformers:
```bash
cd transformers
```
Nel caso speciale in cui stiate aggiungendo un modello, la cui architettura sia identica a una di un modello già esistente,
dovrete solo aggiugnere uno script di conversione, come descritto [qui](#write-a-conversion-script).
In questo caso, potete riutilizzare l'intera architettura del modello gia esistente.
Se questo non é il caso, cominciamo con il generare un nuovo modello. Avrete due opzioni:
- `transformers-cli add-new-model-like` per aggiungere un nuovo modello come uno che gia esiste
- `transformers-cli add-new-model` per aggiungere un nuovo modello da un nostro template (questo assomigliera a BERT o Bart, in base al modello che selezionerete)
In entrambi i casi, l'output vi darà un questionario da riempire con informazioni basi sul modello. Il secondo comando richiede di installare
un `cookiecutter` - maggiori informazioni [qui](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
**Aprire una Pull Request in main huggingface/transformers repo**
Prime di cominciare ad adattare il codice automaticamente generato, aprite una nuova PR come "Work in progress (WIP)",
*per esempio* "[WIP] Aggiungere *brand_new_bert*", cosicché il team di Hugging Face possa lavorare al vostro fianco nell'
integrare il modello in 🤗 Transformers.
Questi sarebbero gli step generali da seguire:
1. Creare un branch dal main branch con un nome descrittivo
```bash
git checkout -b add_brand_new_bert
```
2. Commit del codice automaticamente generato
```bash
git add .
git commit
```
3. Fare fetch e rebase del main esistente
```bash
git fetch upstream
git rebase upstream/main
```
4. Push dei cambiamenti al proprio account:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. Una volte che siete soddisfatti dei nuovi cambiamenti, andate sulla webpage del vostro fork su GitHub. Cliccate "Pull request".
Assiuratevi di aggiungere alcuni membri di Hugging Face come reviewers, nel riguardo alla destra della pagina della PR, cosicche il team
Hugging Face verrà notificato anche per i futuri cambiamenti.
6. Cambiare la PR a draft, cliccando su "Convert to draft" alla destra della pagina della PR
Da quel punto in poi, ricordate di fare commit di ogni progresso e cambiamento, cosicche venga mostrato nella PR. Inoltre,
ricordatevi di tenere aggiornato il vostro lavoro con il main esistente:
```bash
git fetch upstream
git merge upstream/main
```
In generale, tutte le domande che avrete riguardo al modello o l'implementazione dovranno essere fatte nella vostra PR
e discusse/risolte nella PR stessa. In questa maniera, il team di Hugging Face sarà sempre notificato quando farete commit
di un nuovo codice o se avrete qualche domanda. É molto utile indicare al team di Hugging Face il codice a cui fate riferimento
nella domanda, cosicche il team potra facilmente capire il problema o la domanda.
Per fare questo andate sulla tab "Files changed", dove potrete vedere tutti i vostri cambiamenti al codice, andate sulla linea
dove volete chiedere una domanda, e cliccate sul simbolo "+" per aggiungere un commento. Ogni volta che una domanda o problema
é stato risolto, cliccate sul bottone "Resolve".
In questa stessa maniera, Hugging Face aprirà domande o commenti nel rivedere il vostro codice. Mi raccomando, chiedete più
domande possibili nella pagina della vostra PR. Se avete domande molto generali, non molto utili per il pubblico, siete liberi
di chiedere al team Hugging Face direttamente su slack o email.
**5. Adattare i codici per brand_new_bert**
Per prima cosa, ci focalizzeremo sul modello e non sui tokenizer. Tutto il codice relative dovrebbe trovarsi in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` e
`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
Ora potete finalmente cominciare il codice :). Il codice generato in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` avrà sia la stessa architettura di BERT se é un
modello encoder-only o BART se é encoder-decoder. A questo punto, ricordatevi cio che avete imparato all'inizio, riguardo
agli aspetti teorici del modello: *In che maniera il modello che sto implmementando é diverso da BERT o BART?*. Implementare
questi cambi spesso vuol dire cambiare il layer *self-attention*, l'ordine dei layer di normalizzazione e così via...
Ancora una volta ripetiamo, é molto utile vedere architetture simili di modelli gia esistenti in Transformers per avere
un'idea migliore su come implementare il modello.
**Notate** che a questo punto non dovete avere subito un codice tutto corretto o pulito. Piuttosto, é consigliato cominciare con un
codice poco pulito, con copia-incolla del codice originale in `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`
fino a che non avrete tutto il codice necessario. In base alla nostra esperienza, é molto meglio aggiungere una prima bozza
del codice richiesto e poi correggere e migliorare iterativamente. L'unica cosa essenziale che deve funzionare qui é la seguente
instanza:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
Questo comando creerà un modello con i parametri di default definiti in `BrandNewBergConfig()` e weights random. Questo garantisce
che `init()` di tutte le componenti funzioni correttamente.
**6. Scrivere uno script di conversione**
Il prossimo step é scrivere uno script per convertire il checkpoint che avete usato per fare debug su *brand_new_berts* nella
repo originale in un checkpoint per la nuova implementazione di *brand_new_bert* in 🤗 Transformers. Non é consigliato scrivere
lo script di conversione da zero, ma piuttosto cercate e guardate script gia esistenti in 🤗 Transformers, così da trovarne
uno simile al vostro modello. Di solito basta fare una copia di uno script gia esistente e adattarlo al vostro caso.
Non esistate a chiedre al team di Hugging Face a riguardo.
- Se state convertendo un modello da TensorFlow a PyTorch, un ottimo inizio é vedere [questo script di conversione per BERT](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- Se state convertendo un modello da PyTorch a PyTorch, [lo script di conversione di BART può esservi utile](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
Qui di seguito spiegheremo come i modelli PyTorch salvano i weights per ogni layer e come i nomi dei layer sono definiti. In PyTorch,
il nomde del layer é definito dal nome della class attribute che date al layer. Definiamo un modello dummy in PyTorch,
chiamato `SimpleModel`:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Ora possiamo creare un'instanza di questa definizione di modo da inizializzare a random weights: `dense`, `intermediate`, `layer_norm`.
Possiamo usare print per vedere l'architettura del modello:
```python
model = SimpleModel()
print(model)
```
Da cui si ottiene:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
Si può vedere come i nomi dei layers siano definiti dal nome della class attribute in PyTorch. I valori dei weights di uno
specifico layer possono essere visualizzati:
```python
print(model.dense.weight.data)
```
ad esempio:
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
Nello script di conversione, dovreste riempire quei valori di inizializzazione random con gli stessi weights del corrispondente
layer nel checkpoint. *Per esempio*
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
Così facendo, dovete verificare che ogni inizializzazione random di un peso del modello PyTorch e il suo corrispondente peso nel pretrained checkpoint
siano esattamente gli stessi e uguali in **dimensione/shape e nome**. Per fare questo, é **necessario** aggiungere un `assert`
per la dimensione/shape e nome:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Inoltre, dovrete fare il print sia dei nomi che dei weights per essere sicuri che siano gli stessi:
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
Se la dimensione o il nome non sono uguali, probabilmente avete sbagliato ad assegnare il peso nel checkpoint o nel layer costrutture di
🤗 Transformers.
Una dimensione sbagliata può essere dovuta ad un errore nei parameteri in `BrandNewBertConfig()`. Tuttavia, può essere anche
che l'implementazione del layer in PyTorch richieda di fare una transposizione della matrice dei weights.
Infine, controllate **tutti** che tutti i weights inizializzati e fate print di tutti i weights del checkpoint che non sono stati
usati per l'inizializzazione, di modo da essere sicuri che il modello sia correttamente convertito. É normale che ci siano
errori nel test di conversione, fai per un errore in `BrandNewBertConfig()`, o un errore nell'architettura in 🤗 Transformers,
o un bug in `init()`.
Questo step dev'essere fatto tramite iterazioni fino a che non si raggiungano gli stessi valori per i weights. Una volta che
il checkpoint é stato correttamente caricato in 🤗 Transformers, potete salvare il modello in una cartella di vostra scelta
`/path/to/converted/checkpoint/folder` che contenga sia
`pytorch_model.bin` che `config.json`:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implementare il forward pass**
Una volta che i weights pretrained sono stati correttamente caricati in 🤗 Transformers, dovrete assicurarvi che il forward pass
sia correttamente implementato. [Qui](#provare-un-pretrained-checkpoint-usando-la-repo-originale), avete give creato e provato
uno script che testi il forward pass del modello usando la repo originaria. Ora dovrete fare lo stesso con uno script analogo
usando l'implementazione in 🤗 Transformers anziché l'originale. Piu o meno lo script dovrebbe essere:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
Di solito l'output da 🤗 Transformers non é uguale uguale all'output originario, sopratto la prima volta. Non vi abbattete -
é normale! Prima di tutto assicuratevi che non ci siano errori o che non vengano segnalati degli errori nella forward pass.
Spesso capita che ci siano dimensioni sbagliate o data type sbagliati, *ad esempio* `torch.long` anziche `torch.float32`.
Non esistate a chiedere al team Hugging Face!
Nella parte finale assicuratevi che l'implementazione 🤗 Transformers funzioni correttamente cosi da testare che gli output
siano equivalenti a una precisione di `1e-3`. Controllate che `outputs.shape` siano le stesse tra 🤗 Transformers e l'implementazione
originaria. Poi, controllate che i valori in output siano identici. Questa é sicuramente la parte più difficile, qui una serie
di errori comuni quando gli output non sono uguali:
- Alcuni layers non sono stati aggiunti, *ad esempio* un *activation* layer non é stato aggiunto, o ci si é scordati di una connessione
- La matrice del word embedding non é stata ripareggiata
- Ci sono degli embeddings posizionali sbagliati perché l'implementazione originaria ha un offset
- Il dropout é in azione durante il forward pass. Per sistemare questo errore controllate che *model.training = False* e che
il dropout non sia stato attivato nel forward pass, * per esempio * passate *self.training* a [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
La miglior maniera per sistemare il problema é di vedere all'implementazione originaria del forward pass e in 🤗 Transformers
fianco a fianco e vedere se ci sono delle differenze. In teoria, con debug e print degli output intermedie di entrambe le
implementazioni nel forward pass nell'esatta posizione del network dovrebbe aiutarvi a vedere dove ci sono differenze tra
i due frameworks. Come prima mossa controllate che `input_ids` siano identici in entrambi gli scripts. Da lì andate fino
all'ultimo layer. Potrete notare una differenza tra le due implementazioni a quel punto.
Una volta che lo stesso output é stato ragguingi, verificate gli output con `torch.allclose(original_output, output, atol=1e-3)`.
A questo punto se é tutto a posto: complimenti! Le parti seguenti saranno una passeggiata 😊.
**8. Aggiungere i test necessari per il modello**
A questo punto avete aggiunto con successo il vostro nuovo modello. Tuttavia, é molto probabile che il modello non sia
del tutto ok con il design richiesto. Per essere sicuri che l'implementazione sia consona e compatibile con 🤗 Transformers é
necessario implementare dei tests. Il Cookiecutter dovrebbe fornire automaticamente dei file per test per il vostro modello,
di solito nella folder `tests/test_modeling_brand_new_bert.py`. Provate questo per verificare l'ok nei test piu comuni:
```bash
pytest tests/test_modeling_brand_new_bert.py
```
Una volta sistemati i test comuni, bisogna assicurarsi che il vostro lavoro sia correttamente testato cosicchè:
- a) La community puo capire in maniera semplice il vostro lavoro controllando tests specifici del modello *brand_new_bert*,
- b) Implementazioni future del vostro modello non rompano alcune feature importante del modello.
Per prima cosa agguingete dei test d'integrazione. Questi sono essenziali perche fanno la stessa funzione degli scripts di
debug usati precedentemente. Un template per questi tests esiste gia nel Cookiecutter ed é sotto il nome di `BrandNewBertModelIntegrationTests`,
voi dovrete solo completarlo. Una volta che questi tests sono OK, provate:
```bash
RUN_SLOW=1 pytest -sv tests/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
Nel caso siate su Windows, sostituite `RUN_SLOW=1` con `SET RUN_SLOW=1`
Di seguito, tutte le features che sono utili e necessarire per *brand_new_bert* devono essere testate in test separati,
contenuti in `BrandNewBertModelTester`/ `BrandNewBertModelTest`. spesso la gente si scorda questi test, ma ricordate che sono utili per:
- Aiuta gli utenti a capire il vostro codice meglio, richiamando l'attenzione su queste nuove features
- Developers e contributors futuri potranno velocemente testare nuove implementazioni del modello testanto questi casi speciali.
**9. Implementare il tokenizer**
A questo punto avremo bisogno un tokenizer per *brand_new_bert*. Di solito il tokenizer é uguale ad altri modelli in 🤗 Transformers.
É importante che troviate il file con il tokenizer originale e che lo carichiate in 🤗 Transformers.
Per controllare che il tokenizer funzioni in modo corretto, create uno script nella repo originaria che riceva come input
una stringa e ritorni gli `input_ids`. Piu o meno questo potrebbe essere il codice:
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
Potrebbe richiedere un po' di tempo, ma guardate ancora alla repo originaria per trovare la funzione corretta del tokenizer.
A volte capita di dover riscrivere il tokenizer nella repo originaria, di modo da avere come output gli `input_ids`.
A quel punto uno script analogo é necessario in 🤗 Transformers:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
Una volta che `input_ids` sono uguali, bisogna aggiungere un test per il tokenizer.
Il file test per tokenizer di *brand_new_brand* dovrebbe avere un paio di hard-coded test d'integrazione.
**10. Test end-to-end**
Ora che avete il tokenizer, dovrete aggiungere dei test d'integrazione per l'intero workflow in `tests/test_modeling_brand_new_bert.py` in 🤗 Transformer.
Questi test devono mostrare che un significante campione text-to-text funzioni come ci si aspetta nell'implementazione di 🤗 Transformers.
*Per esempio* potreste usare dei source-to-target-translation, o un sommario di un articolo, o un domanda-risposta e cosi via.
Se nessuno dei checkpoints é stato ultra parametrizzato per task simili, allora i tests per il modello sono piu che sufficienti.
Nello step finale dovete assicurarvi che il modello sia totalmente funzionale, e consigliamo anche di provare a testare su GPU.
Puo succedere che ci si scordi un `.to(self.device)` ad esempio. Se non avete accesso a GPU, il team Hugging Face puo provvedere
a testare questo aspetto per voi.
**11. Aggiungere una Docstring**
Siete quasi alla fine! L'ultima cosa rimasta é avere una bella docstring e una pagina doc. Il Cookiecutter dovrebbe provvedere già
un template chiamato `docs/source/model_doc/brand_new_bert.rst`, che dovrete compilare. La prima cosa che un utente farà
per usare il vostro modello sarà dare una bella lettura al doc. Quindi proponete una documentazione chiara e concisa. É molto
utile per la community avere anche delle *Tips* per mostrare come il modello puo' essere usato. Non esitate a chiedere a Hugging Face
riguardo alle docstirng.
Quindi, assicuratevi che la docstring sia stata aggiunta a `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`.
Assicuratevi che la docstring sia corretta e che includa tutti i necessari input e output. Abbiamo una guida dettagliata per
scrivere la documentazione e docstring.
**Rifattorizzare il codice**
Perfetto! Ora che abbiamo tutto per *brand_new_bert* controllate che lo stile del codice sia ok:
```bash
make style
```
E che il codice passi i quality check:
```bash
make quality
```
A volte capita che manchino delle informazioninella docstring o alcuni nomi sbagliati, questo farà fallire i tests sopra.
Ripetiamo: chiedete pure a Hugging Face, saremo lieti di aiutarvi.
Per ultimo, fare del refactoring del codice una volta che é stato creato.
Avete finito con il codice, congratulazioni! 🎉 Siete fantasticiiiiiii! 😎
**12. Caricare il modello sul model hub**
In questa ultima parte dovrete convertire e caricare il modello, con tutti i checkpoints, nel model hub e aggiungere una
model card per ogni checkpoint caricato. Leggete la nostra guida [Model sharing and uploading Page](model_sharing) per
avere familiarità con l'hub. Di solito in questa parte lavorate a fianco di Hugging face per decidere un nome che sia ok
per ogni checkpoint, per ottenere i permessi necessari per caricare il modello nell'organizzazione dell'autore di *brand_new_bert*.
Il metodo `push_to_hub`, presente in tutti i modelli `transformers`, é una maniera rapida e indolore per caricare il vostro checkpoint sull'hub:
```python
brand_new_bert.push_to_hub(
repo_path_or_name="brand_new_bert",
# Uncomment the following line to push to an organization
# organization="",
commit_message="Add model",
use_temp_dir=True,
)
```
Vale la pena spendere un po' di tempo per creare una model card ad-hoc per ogni checkpoint. Le model cards dovrebbero
suggerire le caratteristiche specifiche del checkpoint, *per esempio* su che dataset il checkpoint é stato pretrained o fine-tuned.
O che su che genere di task il modello lavoro? E anche buona pratica includere del codice su come usare il modello correttamente.
**13. (Opzionale) Aggiungere un notebook**
É molto utile aggiungere un notebook, che dimostri in dettaglio come *brand_new_bert* si utilizzi per fare inferenza e/o
fine-tuned su specifiche task. Non é una cosa obbligatoria da avere nella vostra PR, ma é molto utile per la community.
**14. Sottomettere la PR**
L'ultimissimo step! Ovvero il merge della PR nel main. Di solito il team Hugging face a questo punto vi avrà gia aiutato,
ma é ok prendere un po' di tempo per pulire la descirzione e commenti nel codice.
### Condividete il vostro lavoro!!
É ora tempo di prendere un po' di credito dalla communità per il vostro lavoro! Caricare e implementare un nuovo modello
é un grandissimo contributo per Transformers e l'intera community NLP. Il codice e la conversione dei modelli pre-trained sara
sicuramente utilizzato da centinaia o migliaia di sviluppatori e ricercatori. Siate fieri e orgogliosi di condividere il vostro
traguardo con l'intera community :)
** Avete create un altro modello che é super facile da usare per tutti quanti nella community! 🤯**
Come potete vedere, ci basiamo sull'ereditarietà in 🤗 Transformers, tenendo però il livello di astrazione a un minimo
assoluto. Non ci sono mai più di due livelli di astrazione per ogni modello nella libreria. `BrandNewBertModel` eredita
da `BrandNewBertPreTrainedModel` che, a sua volta, eredita da [`PreTrainedModel`] - semplice no?
Come regola generale, vogliamo essere sicuri che un nuovo modello dipenda solo da [`PreTrainedModel`]. Le funzionalità
importanti che sono automaticamente conferite a ogni nuovo modello sono [`~PreTrainedModel.from_pretrained`]
e [`~PreTrainedModel.save_pretrained`], che sono usate per serializzazione e deserializzazione. Tutte le altre importanti
funzionalità, come ad esempio `BrandNewBertModel.forward` devono essere definite completamente nel nuovo script
`modeling_brand_new_bert.py`. Inoltre, vogliamo essere sicuri che un modello con uno specifico head layer, come
`BrandNewBertForMaskedLM` non erediti da `BrandNewBertModel`, ma piuttosto usi `BrandNewBertModel`
come componente che può essere chiamata nel passaggio forward per mantenere il livello di astrazione basso. Ogni
nuovo modello richieste una classe di configurazione, chiamata `BrandNewBertConfig`. Questa configurazione é sempre
mantenuta come un attributo in [`PreTrainedModel`], e quindi può essere accessibile tramite l'attributo `config`
per tutte le classi che ereditano da `BrandNewBertPreTrainedModel`:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # il modello ha accesso al suo config
```
Analogamente al modello, la configurazione eredita le funzionalità base di serializzazione e deserializzazione da
[`PretrainedConfig`]. É da notare che la configurazione e il modello sono sempre serializzati in due formati differenti -
il modello é serializzato in un file *pytorch_model.bin* mentre la configurazione con *config.json*. Chiamando
[`~PreTrainedModel.save_pretrained`] automaticamente chiamerà [`~PretrainedConfig.save_pretrained`], cosicché sia il
modello che la configurazione siano salvati.
### Stile per il codice
Quando codifichi un nuovo modello, tieni presente che Transformers ha una sua struttura di fondo come libreria, perciò
ci sono alcuni fatti da considerare su come scrivere un codice :-)
1. Il forward pass del tuo modello dev'essere scritto completamente nel file del modello, mentre dev'essere indipendente
da altri modelli nella libreria. Se vuoi riutilizzare un blocco di codice da un altro modello, copia e incolla il codice con un commento `# Copied from` in cima al codice (guarda [qui](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
per un ottimo esempio).
2. Il codice dev'essere interamente comprensibile, anche da persone che non parlano in inglese. Questo significa che le
variabili devono avere un nome descrittivo e bisogna evitare abbreviazioni. Per esempio, `activation` é molto meglio
che `act`. Le variabili con una lettera sono da evitare fortemente, almeno che non sia per un indce in un for loop.
3. Generamente é meglio avere un codice esplicito e piú lungo che un codice corto e magico.
4. Evita di subclassare `nn.Sequential` in Pytorch, puoi subclassare `nn.Module` e scrivere il forward pass, cosicché
chiunque può effettuare debug sul tuo codice, aggiungendo print o breaking points.
5. La tua function-signature dev'essere type-annoted. Per il resto, é meglio preferire variabili con un nome accettabile
piuttosto che annotazioni per aumentare la comprensione e leggibilità del codice.
### Panoramica sui tokenizers
Questa sezione sarà creata al piu presto :-(
## Aggiungere un modello a 🤗 Transformers passo dopo passo
Ci sono differenti modi per aggiungere un modello a Hugging Face. Qui trovi una lista di blog posts da parte della community su come aggiungere un modello:
1. [Aggiungere GPT2](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) scritto da [Thomas](https://huggingface.co/thomwolf)
2. [Aggiungere WMT19 MT](https://huggingface.co/blog/porting-fsmt) scritto da [Stas](https://huggingface.co/stas)
Per esperienza, possiamo dirti che quando si aggiunge un modello é meglio tenere a mente le seguenti considerazioni:
- Non sfondare una porta giá aperta! La maggior parte del codice che aggiungerai per un nuovo modello 🤗 Transformers
esiste già da qualche parte in 🤗 Transformers. Prendi un po' di tempo per trovare codici simili in modelli e tokenizers esistenti e fare un copia-incolla. Ricorda che [grep](https://www.gnu.org/software/grep/) e [rg](https://github.com/BurntSushi/ripgrep) sono tuoi buoni amici. Inoltre, ricorda che puó essere molto probabile che il tokenizer per il tuo modello sia basato sull'implementazione di un altro modello, e il codice del tuo modello stesso su un altro ancora. *Per esempio* il modello FSMT é basato su BART, mentre il tokenizer di FSMT é basato su XLM.
- Ricorda che qui é piu una sfida ingegneristica che scientifica. Spendi piú tempo per create un efficiente ambiente di debugging piuttosto che cercare di capire tutti gli aspetti teorici dell'articolo del modello.
- Chiedi aiuto se sei in panne! I modelli sono la parte principale di 🤗 Transformers, perciò qui a Hugging Face siamo più che contenti di aiutarti in ogni passo per aggiungere il tuo modello. Non esitare a chiedere se vedi che non riesci a progredire.
Di seguito, diamo una ricetta generale per aiutare a portare un modello in 🤗 Transformers.
La lista seguente é un sommario di tutto quello che é stato fatto per aggiungere un modello, e può essere usata come To-Do List:
- 1. ☐ (Opzionale) Capire gli aspetti teorici del modello
- 2. ☐ Preparare l'ambiente dev per transformers
- 3. ☐ Preparare l'ambiente debugging della repository originale
- 4. ☐ Create uno script che gestisca con successo il forward pass usando la repository originale e checkpoint
- 5. ☐ Aggiungere con successo lo scheletro del modello a Transformers
- 6. ☐ Convertire i checkpoint original a Transformers checkpoint
- 7. ☐ Effettuare con successo la forward pass in Transformers, di modo che dia un output identico al checkpoint originale
- 8. ☐ Finire i tests per il modello in Transformers
- 9. ☐ Aggiungere con successo Tokenizer in Transformers
- 10. ☐ Testare e provare gli integration tests da capo a fine
- 11. ☐ Completare i docs
- 12. ☐ Caricare i moedl weights all'hub
- 13. ☐ Sottomettere una pull request
- 14. ☐ (Opzionale) Aggiungere un notebook con una demo
Per cominciare di solito consigliamo `BrandNewBert`, partendo dalla teoria, di modo da avere una buona comprensione della teoria generale. TUttavia, se preferisci imparare l'aspetto teorico del modello mentre *lavori* sul modello é ok immergersi direttamente nel codice di `BrandNewBert`. Questa opzione puó essere buona se le tue skills ingegneristiche sono meglio che quelle teoriche, o se il paper `BrandNewBert` ti dá problemi, o se semplicemente ti piace programmare piú che leggere articoli scientifici.
### 1. (Opzionale) Aspetti teorici di BrandNewBert
Allora con calma, prendi un po' di tempo per leggere l'articolo su *BrandNewBert* . Sicuramente, alcune sezioni dell'articolo sono molto complesse, ma non preoccuparti! L'obiettivo non é avere una compresione immensa della teoria alla base, ma estrarre le informazioni necessarie per re-implementare con successo il modello in 🤗 Transformers. Quindi, non impazzire sugli aspetti teorici, ma piuttosto focalizzati su quelli pratici, ossia:
- Che tipo di modello é *brand_new_bert*? É solo un encoder in stile BERT? O tipo decoder come GPT2? O encoder e decoder stile BART? Dai un'occhiata a [model_summary](model_summary) se non sei famigliare con le differenze tra questi modelli
- Quali sono le applicazioni di *brand_new_bert*? Classificazione di testo? Generazione di testo? O per tasks del genere seq2seq?
- Quali sono le nuove aggiunte al modello che lo rendono diverso da BERT/GPT-2/BART?
- Quali modelli estistenti in [🤗 Transformers models](https://huggingface.co/transformers/#contents) sono molto simili a *brand_new_bert*?
- Che tipo di tokenizer si usa in questo caso? Un sentencepiece tokenizer? O un word piece tokenizer? Il tokenizer é lo stesso di BERT o BART?
Una volta che senti che hai avuto una bella overview dell'architettura del modello, puoi scrivere senza problemi al team di Hugging Face per ogni domanda che tu hai. Questo puó includere domande sull'architettura del modello, o sull'attention layer, etc. Saremo molto felici di aiutarti :)
### 2. Prepare il tuo ambiente
1. Forka la [repository](https://github.com/huggingface/transformers) cliccando sul tasto ‘Fork' nella pagina della repository. Questo crea una copia del codice nel tuo account GitHub
2. Clona il tuo fork `transfomers` sul tuo dico locale, e aggiungi la repository base come remota:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Crea un ambiente di sviluppo, per esempio tramite questo comando:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
quindi torna alla directory principale:
```bash
cd ..
```
4. Attenzione, raccomandiamo di aggiungere la versione di PyTorch di *brand_new_bert* a Transfomers. Per installare PyTorch, basta seguire queste istruzioni https://pytorch.org/get-started/locally/.
**Nota bene:** Non c'é bisogno di installare o avere installato CUDA. Il nuovo modello può funzionare senza problemi su una CPU.
5. Per trasferire *brand_new_bert* To port *brand_new_bert* avrai bisogno anche accesso alla sua repository originale:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
Ok, ora hai un ambiente di sviluppo per portare *brand_new_bert* in 🤗 Transformers.
### 3.-4. Provare un pretrained checkpoint usando la repo originale
Per cominciare, comincerai a lavorare sulla repo originale di *brand_new_bert*. Come spesso accade, l'implementazione originale é molto sullo stile "ricerca". Questo significa che a volte la documentazione non é al top, magari manca qualche cosa e il codice puó essere difficile da capire. Tuttavia, questa é e dev'essere la motivazione per reimplementare *brand_new_bert*. In Hugging Face, uno degli obiettivi principali é di *mettere le persone sulle spalle dei giganti*, il che si traduce, in questo contesto, di prendere un modello funzionante e riscriverlo e renderlo il piú possibile **accessibile, user-friendly, e leggibile**. Questa é la top motivazione per re-implementare modelli in 🤗 Transformers - cercare di creare nuove complesse tecnologie NLP accessibili a **chiunque**.
Riuscire a far girare il modello pretrained originale dalla repository ufficiale é spesso il passo **piu arduo**. Dalla nostra esperienza, é molto importante spendere un p' di tempo per diventare familiari con il codice base originale. Come test, prova a capire i seguenti punti:
- Dove si trovano i pretrained weights?
- Come caricare i pretrained weights nel modello corrispondente?
- Come girare un tokenizer independentemente dal modello?
- Prova a tracciare un singolo forward pass, cosicché potrai sapere che classi e funzioni sono richieste per un semplice forward pass. Di solito, dovrai reimplementare queste funzioni e basta
- Prova a localizzare i componenti importanti del modello: Dove si trova la classe del modello? Ci sono sotto classi nel modello *per esempio* EngoderModel, DecoderMOdel? Dove si trova il self-attention layer? Ci sono molteplici differenti layer di attention, *per esempio * *self-attention*, *cross-attention*...?
- Come puoi fare debug sul modello nell'ambiente originale della repo? Devi aggiungere dei *print* o puoi usare *ipdb* come debugger interattivo, o vabene anche un IDE efficiente per debug come PyCharm?
É molto importante che prima di cominciare a trasferire il modello nuovo tu spenda tempo a fare debug del codice originale in maniera **efficiente**! Inoltre, ricorda che tutta la library é open-soruce, quindi non temere di aprire issue o fare una pull request nella repo originale. Tutti coloro che mantengono la repository saranno piú che felici di avere qualcuno che guarda e gioca con i loro codici!
A questo punto, sta a te decidere quale ambiente per debug vuoi usare. Noi consilgiamo di evitare setup con GPU, che potrebbero costare assai, lavorare su una CPU puó essere un ottimo punto di partenza per indagare la repository originale e per cominciare a scrivere il codice per 🤗 Transformers. Solo alla fine, quando il modello é stato portato con successo in 🤗 Transformers, allora si potrá verificare il suo funzionamento su GPU.
In generale ci sono due possibili ambienti di debug per il testare il modello originale:
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Scripts locali in Python
Il vantaggio dei Jupyter notebooks é la possibilità di eseguire cella per cella, il che può essere utile per decomporre tutte le componenti logiche, cosi da a vere un ciclo di debug più rapido, siccome si possono salvare i risultati da steps intermedi. Inoltre, i notebooks spesso sono molto facili da condividere con altri contributors, il che può essere molto utile se vuoi chiedere aiuto al team di Hugging Face. Se sei famigliare con Jupyter notebooks allora racommandiamo di lavorare in questa maniera.
Ovviamente se non siete abituati a lavorare con i notebook, questo può essere uno svantaggio nell'usare questa tecnologia, sprecando un sacco di tempo per setup e portare tutto al nuovo ambiente, siccome non potreste neanche usare dei tools di debug come `ipdb`.
Per ogni pratica code-base, é sempre meglio come primo step caricare un **piccolo** checkpoint pretrained e cercare di riprodurre un singolo forward pass usando un vettore fittizio di IDs fatti da numeri interi. Un esempio per uno script simile, in pseudocodice é:
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Per quanto riguarda la strategia di debugging, si può scegliere tra:
- Decomporre il modello originario in piccole componenenti e testare ognuna di esse
- Decomporre il modello originario nel *tokenizer* originale e nel *modello* originale, testare un forward pass su questi,
e usare dei print statement o breakpoints intermedi per verificare
Ancora una volta, siete liberi di scegliere quale strategia sia ottimale per voi. Spesso una strategia é piu
avvantaggiosa di un'altra, ma tutto dipende dall'code-base originario.
Se il code-base vi permette di decomporre il modello in piccole sub-componenenti, *per esempio* se il code-base
originario può essere facilmente testato in eager mode, allora vale la pena effettuare un debugging di questo genere.
Ricordate che ci sono dei vantaggi nel decidere di prendere la strada piu impegnativa sin da subito:
- negli stage piu finali, quando bisognerà comparare il modello originario all'implementazione in Hugging Face, potrete verificare
automaticamente ogni componente, individualmente, di modo che ci sia una corrispondenza 1:1
- avrete l'opportunità di decomporre un problema molto grande in piccoli passi, così da strutturare meglio il vostro lavoro
- separare il modello in componenti logiche vi aiuterà ad avere un'ottima overview sul design del modello, quindi una migliore
comprensione del modello stesso
- verso gli stage finali i test fatti componente per componente vi aiuterà ad essere sicuri di non andare avanti e indietro
nell'implementazione, così da continuare la modifica del codice senza interruzione
Un ottimo esempio di come questo può essere fatto é dato da [Lysandre](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
per il modello ELECTRA
Tuttavia, se il code-base originale é molto complesso o le componenti intermedie possono essere testate solo in tramite
compilazione, potrebbe richiedere parecchio tempo o addirittura essere impossibile separare il modello in piccole sotto-componenti.
Un buon esempio é [MeshTensorFlow di T5](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow). Questa libreria
é molto complessa e non offre un metodo semplice di decomposizione in sotto-componenti. Per simili librerie, potrete fare
affidamento ai print statements.
In ogni caso, indipendentemente da quale strategia scegliete, la procedura raccomandata é di cominciare a fare debug dal
primo layer al layer finale.
É consigliato recuperare gli output dai layers, tramite print o sotto-componenti, nel seguente ordine:
1. Recuperare gli IDs di input dati al modello
2. Recuperare i word embeddings
3. Recuperare l'input del primo Transformer layer
4. Recuperare l'output del primo Transformer layer
5. Recuperare l'output dei seguenti `n - 1` Transformer layers
6. Recuperare l'output dell'intero BrandNewBert Model
Gli IDs in input dovrebbero essere un arrary di interi, *per esempio* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
Gli output dei seguenti layer di solito dovrebbero essere degli array di float multi-dimensionali come questo:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
Ci aspettiamo che ogni modello aggiunto a 🤗 Transformers passi con successo un paio di test d'integrazione. Questo
significa che il modello originale e la sua implementazione in 🤗 Transformers abbiano lo stesso output con una precisione
di 0.001! Siccome é normale che lo stesso esatto modello, scritto in librerie diverse, possa dare output leggermente
diversi, la tolleranza accettata é 1e-3 (0.001). Ricordate che i due modelli devono dare output quasi identici. Dunque,
é molto conveniente comparare gli output intermedi di 🤗 Transformers molteplici volte con gli output intermedi del
modello originale di *brand_new_bert*. Di seguito vi diamo alcuni consigli per avere un ambiente di debug il piu efficiente
possibile:
- Trovate la migliore strategia per fare debug dei risultati intermedi. Per esempio, é la repository originale scritta in PyTorch?
Se si, molto probabilmente dovrete dedicare un po' di tempo per scrivere degli script piu lunghi, così da decomporre il
modello originale in piccole sotto-componenti, in modo da poter recuperare i valori intermedi. Oppure, la repo originale
é scritta in Tensorflow 1? Se é così dovrete fare affidamento ai print di Tensorflow [tf.print](https://www.tensorflow.org/api_docs/python/tf/print)
per avere i valori intermedi. Altro caso, la repo é scritta in Jax? Allora assicuratevi che il modello non sia in **jit**
quanto testate il foward pass, *per esempio* controllate [questo link](https://github.com/google/jax/issues/196).
- Usate i più piccoli pretrained checkpoint che potete trovare. Piu piccolo é il checkpoint, piu velocemente sarà il vostro
ciclo di debug. Non é efficiente avere un pretrained model così gigante che per il forward pass impieghi piu di 10 secondi.
Nel caso in cui i checkpoints siano molto grandi, e non si possa trovare di meglio, allora é buona consuetudine ricorrere
a fare un dummy model nel nuovo ambiente, con weights inizializzati random e salvare quei weights per comprare la versione 🤗 Transformers
con il vostro modello
- Accertatevi di usare la via piu semplice per chiamare il forward pass nella repo originale. Sarebbe opportuno trovare
la funzione originaria che chiami **solo** un singolo forward pass, *per esempio* questa funzione spesso viene chiamata
`predict`, `evaluate`, `forward` o `__call__`. Siate sicuri di non fare debug su una funzione che chiami `forward` molteplici
volte, *per esempio* per generare testo, come `autoregressive_sample`, `generate`.
- Cercate di separare la tokenization dal forward pass del modello. Se la repo originaria mostra esempio dove potete dare
come input una stringa, provate a cercare dove nella forward call la stringa viene cambiata in input ids e cominciate il
debug da questo punto. Questo vi garantisce un ottimo punto di partenza per scrivere un piccolo script personale dove dare
gli input al modello, anziche delle stringhe in input.
- Assicuratevi che il debugging **non** sia in training mode. Spesso questo potra il modello a dare degli output random, per
via dei molteplici dropout layers. Assicuratevi che il forward pass nell'ambiente di debug sia **deterministico**, cosicche
i dropout non siano usati. Alternativamente, potete usare *transformers.utils.set_seed* se la vecchia e nuova implementazione
sono nello stesso framework.
La seguente sezione vi da ulteriori dettagli e accorgimenti su come potete fare tutto questo per *brand_new_bert*.
### 5.-14. Trasferire BrandNewBert in 🤗 Transformers
Allora cominciamo ad aggiungere un nuovo codice in 🤗 Transformers. Andate nel vostro fork clone di 🤗 Transformers:
```bash
cd transformers
```
Nel caso speciale in cui stiate aggiungendo un modello, la cui architettura sia identica a una di un modello già esistente,
dovrete solo aggiugnere uno script di conversione, come descritto [qui](#write-a-conversion-script).
In questo caso, potete riutilizzare l'intera architettura del modello gia esistente.
Se questo non é il caso, cominciamo con il generare un nuovo modello. Avrete due opzioni:
- `transformers-cli add-new-model-like` per aggiungere un nuovo modello come uno che gia esiste
- `transformers-cli add-new-model` per aggiungere un nuovo modello da un nostro template (questo assomigliera a BERT o Bart, in base al modello che selezionerete)
In entrambi i casi, l'output vi darà un questionario da riempire con informazioni basi sul modello. Il secondo comando richiede di installare
un `cookiecutter` - maggiori informazioni [qui](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
**Aprire una Pull Request in main huggingface/transformers repo**
Prime di cominciare ad adattare il codice automaticamente generato, aprite una nuova PR come "Work in progress (WIP)",
*per esempio* "[WIP] Aggiungere *brand_new_bert*", cosicché il team di Hugging Face possa lavorare al vostro fianco nell'
integrare il modello in 🤗 Transformers.
Questi sarebbero gli step generali da seguire:
1. Creare un branch dal main branch con un nome descrittivo
```bash
git checkout -b add_brand_new_bert
```
2. Commit del codice automaticamente generato
```bash
git add .
git commit
```
3. Fare fetch e rebase del main esistente
```bash
git fetch upstream
git rebase upstream/main
```
4. Push dei cambiamenti al proprio account:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. Una volte che siete soddisfatti dei nuovi cambiamenti, andate sulla webpage del vostro fork su GitHub. Cliccate "Pull request".
Assiuratevi di aggiungere alcuni membri di Hugging Face come reviewers, nel riguardo alla destra della pagina della PR, cosicche il team
Hugging Face verrà notificato anche per i futuri cambiamenti.
6. Cambiare la PR a draft, cliccando su "Convert to draft" alla destra della pagina della PR
Da quel punto in poi, ricordate di fare commit di ogni progresso e cambiamento, cosicche venga mostrato nella PR. Inoltre,
ricordatevi di tenere aggiornato il vostro lavoro con il main esistente:
```bash
git fetch upstream
git merge upstream/main
```
In generale, tutte le domande che avrete riguardo al modello o l'implementazione dovranno essere fatte nella vostra PR
e discusse/risolte nella PR stessa. In questa maniera, il team di Hugging Face sarà sempre notificato quando farete commit
di un nuovo codice o se avrete qualche domanda. É molto utile indicare al team di Hugging Face il codice a cui fate riferimento
nella domanda, cosicche il team potra facilmente capire il problema o la domanda.
Per fare questo andate sulla tab "Files changed", dove potrete vedere tutti i vostri cambiamenti al codice, andate sulla linea
dove volete chiedere una domanda, e cliccate sul simbolo "+" per aggiungere un commento. Ogni volta che una domanda o problema
é stato risolto, cliccate sul bottone "Resolve".
In questa stessa maniera, Hugging Face aprirà domande o commenti nel rivedere il vostro codice. Mi raccomando, chiedete più
domande possibili nella pagina della vostra PR. Se avete domande molto generali, non molto utili per il pubblico, siete liberi
di chiedere al team Hugging Face direttamente su slack o email.
**5. Adattare i codici per brand_new_bert**
Per prima cosa, ci focalizzeremo sul modello e non sui tokenizer. Tutto il codice relative dovrebbe trovarsi in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` e
`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
Ora potete finalmente cominciare il codice :). Il codice generato in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` avrà sia la stessa architettura di BERT se é un
modello encoder-only o BART se é encoder-decoder. A questo punto, ricordatevi cio che avete imparato all'inizio, riguardo
agli aspetti teorici del modello: *In che maniera il modello che sto implmementando é diverso da BERT o BART?*. Implementare
questi cambi spesso vuol dire cambiare il layer *self-attention*, l'ordine dei layer di normalizzazione e così via...
Ancora una volta ripetiamo, é molto utile vedere architetture simili di modelli gia esistenti in Transformers per avere
un'idea migliore su come implementare il modello.
**Notate** che a questo punto non dovete avere subito un codice tutto corretto o pulito. Piuttosto, é consigliato cominciare con un
codice poco pulito, con copia-incolla del codice originale in `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`
fino a che non avrete tutto il codice necessario. In base alla nostra esperienza, é molto meglio aggiungere una prima bozza
del codice richiesto e poi correggere e migliorare iterativamente. L'unica cosa essenziale che deve funzionare qui é la seguente
instanza:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
Questo comando creerà un modello con i parametri di default definiti in `BrandNewBergConfig()` e weights random. Questo garantisce
che `init()` di tutte le componenti funzioni correttamente.
**6. Scrivere uno script di conversione**
Il prossimo step é scrivere uno script per convertire il checkpoint che avete usato per fare debug su *brand_new_berts* nella
repo originale in un checkpoint per la nuova implementazione di *brand_new_bert* in 🤗 Transformers. Non é consigliato scrivere
lo script di conversione da zero, ma piuttosto cercate e guardate script gia esistenti in 🤗 Transformers, così da trovarne
uno simile al vostro modello. Di solito basta fare una copia di uno script gia esistente e adattarlo al vostro caso.
Non esistate a chiedre al team di Hugging Face a riguardo.
- Se state convertendo un modello da TensorFlow a PyTorch, un ottimo inizio é vedere [questo script di conversione per BERT](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- Se state convertendo un modello da PyTorch a PyTorch, [lo script di conversione di BART può esservi utile](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
Qui di seguito spiegheremo come i modelli PyTorch salvano i weights per ogni layer e come i nomi dei layer sono definiti. In PyTorch,
il nomde del layer é definito dal nome della class attribute che date al layer. Definiamo un modello dummy in PyTorch,
chiamato `SimpleModel`:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Ora possiamo creare un'instanza di questa definizione di modo da inizializzare a random weights: `dense`, `intermediate`, `layer_norm`.
Possiamo usare print per vedere l'architettura del modello:
```python
model = SimpleModel()
print(model)
```
Da cui si ottiene:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
Si può vedere come i nomi dei layers siano definiti dal nome della class attribute in PyTorch. I valori dei weights di uno
specifico layer possono essere visualizzati:
```python
print(model.dense.weight.data)
```
ad esempio:
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
Nello script di conversione, dovreste riempire quei valori di inizializzazione random con gli stessi weights del corrispondente
layer nel checkpoint. *Per esempio*
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
Così facendo, dovete verificare che ogni inizializzazione random di un peso del modello PyTorch e il suo corrispondente peso nel pretrained checkpoint
siano esattamente gli stessi e uguali in **dimensione/shape e nome**. Per fare questo, é **necessario** aggiungere un `assert`
per la dimensione/shape e nome:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Inoltre, dovrete fare il print sia dei nomi che dei weights per essere sicuri che siano gli stessi:
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
Se la dimensione o il nome non sono uguali, probabilmente avete sbagliato ad assegnare il peso nel checkpoint o nel layer costrutture di
🤗 Transformers.
Una dimensione sbagliata può essere dovuta ad un errore nei parameteri in `BrandNewBertConfig()`. Tuttavia, può essere anche
che l'implementazione del layer in PyTorch richieda di fare una transposizione della matrice dei weights.
Infine, controllate **tutti** che tutti i weights inizializzati e fate print di tutti i weights del checkpoint che non sono stati
usati per l'inizializzazione, di modo da essere sicuri che il modello sia correttamente convertito. É normale che ci siano
errori nel test di conversione, fai per un errore in `BrandNewBertConfig()`, o un errore nell'architettura in 🤗 Transformers,
o un bug in `init()`.
Questo step dev'essere fatto tramite iterazioni fino a che non si raggiungano gli stessi valori per i weights. Una volta che
il checkpoint é stato correttamente caricato in 🤗 Transformers, potete salvare il modello in una cartella di vostra scelta
`/path/to/converted/checkpoint/folder` che contenga sia
`pytorch_model.bin` che `config.json`:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implementare il forward pass**
Una volta che i weights pretrained sono stati correttamente caricati in 🤗 Transformers, dovrete assicurarvi che il forward pass
sia correttamente implementato. [Qui](#provare-un-pretrained-checkpoint-usando-la-repo-originale), avete give creato e provato
uno script che testi il forward pass del modello usando la repo originaria. Ora dovrete fare lo stesso con uno script analogo
usando l'implementazione in 🤗 Transformers anziché l'originale. Piu o meno lo script dovrebbe essere:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
Di solito l'output da 🤗 Transformers non é uguale uguale all'output originario, sopratto la prima volta. Non vi abbattete -
é normale! Prima di tutto assicuratevi che non ci siano errori o che non vengano segnalati degli errori nella forward pass.
Spesso capita che ci siano dimensioni sbagliate o data type sbagliati, *ad esempio* `torch.long` anziche `torch.float32`.
Non esistate a chiedere al team Hugging Face!
Nella parte finale assicuratevi che l'implementazione 🤗 Transformers funzioni correttamente cosi da testare che gli output
siano equivalenti a una precisione di `1e-3`. Controllate che `outputs.shape` siano le stesse tra 🤗 Transformers e l'implementazione
originaria. Poi, controllate che i valori in output siano identici. Questa é sicuramente la parte più difficile, qui una serie
di errori comuni quando gli output non sono uguali:
- Alcuni layers non sono stati aggiunti, *ad esempio* un *activation* layer non é stato aggiunto, o ci si é scordati di una connessione
- La matrice del word embedding non é stata ripareggiata
- Ci sono degli embeddings posizionali sbagliati perché l'implementazione originaria ha un offset
- Il dropout é in azione durante il forward pass. Per sistemare questo errore controllate che *model.training = False* e che
il dropout non sia stato attivato nel forward pass, * per esempio * passate *self.training* a [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
La miglior maniera per sistemare il problema é di vedere all'implementazione originaria del forward pass e in 🤗 Transformers
fianco a fianco e vedere se ci sono delle differenze. In teoria, con debug e print degli output intermedie di entrambe le
implementazioni nel forward pass nell'esatta posizione del network dovrebbe aiutarvi a vedere dove ci sono differenze tra
i due frameworks. Come prima mossa controllate che `input_ids` siano identici in entrambi gli scripts. Da lì andate fino
all'ultimo layer. Potrete notare una differenza tra le due implementazioni a quel punto.
Una volta che lo stesso output é stato ragguingi, verificate gli output con `torch.allclose(original_output, output, atol=1e-3)`.
A questo punto se é tutto a posto: complimenti! Le parti seguenti saranno una passeggiata 😊.
**8. Aggiungere i test necessari per il modello**
A questo punto avete aggiunto con successo il vostro nuovo modello. Tuttavia, é molto probabile che il modello non sia
del tutto ok con il design richiesto. Per essere sicuri che l'implementazione sia consona e compatibile con 🤗 Transformers é
necessario implementare dei tests. Il Cookiecutter dovrebbe fornire automaticamente dei file per test per il vostro modello,
di solito nella folder `tests/test_modeling_brand_new_bert.py`. Provate questo per verificare l'ok nei test piu comuni:
```bash
pytest tests/test_modeling_brand_new_bert.py
```
Una volta sistemati i test comuni, bisogna assicurarsi che il vostro lavoro sia correttamente testato cosicchè:
- a) La community puo capire in maniera semplice il vostro lavoro controllando tests specifici del modello *brand_new_bert*,
- b) Implementazioni future del vostro modello non rompano alcune feature importante del modello.
Per prima cosa agguingete dei test d'integrazione. Questi sono essenziali perche fanno la stessa funzione degli scripts di
debug usati precedentemente. Un template per questi tests esiste gia nel Cookiecutter ed é sotto il nome di `BrandNewBertModelIntegrationTests`,
voi dovrete solo completarlo. Una volta che questi tests sono OK, provate:
```bash
RUN_SLOW=1 pytest -sv tests/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
Nel caso siate su Windows, sostituite `RUN_SLOW=1` con `SET RUN_SLOW=1`
Di seguito, tutte le features che sono utili e necessarire per *brand_new_bert* devono essere testate in test separati,
contenuti in `BrandNewBertModelTester`/ `BrandNewBertModelTest`. spesso la gente si scorda questi test, ma ricordate che sono utili per:
- Aiuta gli utenti a capire il vostro codice meglio, richiamando l'attenzione su queste nuove features
- Developers e contributors futuri potranno velocemente testare nuove implementazioni del modello testanto questi casi speciali.
**9. Implementare il tokenizer**
A questo punto avremo bisogno un tokenizer per *brand_new_bert*. Di solito il tokenizer é uguale ad altri modelli in 🤗 Transformers.
É importante che troviate il file con il tokenizer originale e che lo carichiate in 🤗 Transformers.
Per controllare che il tokenizer funzioni in modo corretto, create uno script nella repo originaria che riceva come input
una stringa e ritorni gli `input_ids`. Piu o meno questo potrebbe essere il codice:
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
Potrebbe richiedere un po' di tempo, ma guardate ancora alla repo originaria per trovare la funzione corretta del tokenizer.
A volte capita di dover riscrivere il tokenizer nella repo originaria, di modo da avere come output gli `input_ids`.
A quel punto uno script analogo é necessario in 🤗 Transformers:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
Una volta che `input_ids` sono uguali, bisogna aggiungere un test per il tokenizer.
Il file test per tokenizer di *brand_new_brand* dovrebbe avere un paio di hard-coded test d'integrazione.
**10. Test end-to-end**
Ora che avete il tokenizer, dovrete aggiungere dei test d'integrazione per l'intero workflow in `tests/test_modeling_brand_new_bert.py` in 🤗 Transformer.
Questi test devono mostrare che un significante campione text-to-text funzioni come ci si aspetta nell'implementazione di 🤗 Transformers.
*Per esempio* potreste usare dei source-to-target-translation, o un sommario di un articolo, o un domanda-risposta e cosi via.
Se nessuno dei checkpoints é stato ultra parametrizzato per task simili, allora i tests per il modello sono piu che sufficienti.
Nello step finale dovete assicurarvi che il modello sia totalmente funzionale, e consigliamo anche di provare a testare su GPU.
Puo succedere che ci si scordi un `.to(self.device)` ad esempio. Se non avete accesso a GPU, il team Hugging Face puo provvedere
a testare questo aspetto per voi.
**11. Aggiungere una Docstring**
Siete quasi alla fine! L'ultima cosa rimasta é avere una bella docstring e una pagina doc. Il Cookiecutter dovrebbe provvedere già
un template chiamato `docs/source/model_doc/brand_new_bert.rst`, che dovrete compilare. La prima cosa che un utente farà
per usare il vostro modello sarà dare una bella lettura al doc. Quindi proponete una documentazione chiara e concisa. É molto
utile per la community avere anche delle *Tips* per mostrare come il modello puo' essere usato. Non esitate a chiedere a Hugging Face
riguardo alle docstirng.
Quindi, assicuratevi che la docstring sia stata aggiunta a `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`.
Assicuratevi che la docstring sia corretta e che includa tutti i necessari input e output. Abbiamo una guida dettagliata per
scrivere la documentazione e docstring.
**Rifattorizzare il codice**
Perfetto! Ora che abbiamo tutto per *brand_new_bert* controllate che lo stile del codice sia ok:
```bash
make style
```
E che il codice passi i quality check:
```bash
make quality
```
A volte capita che manchino delle informazioninella docstring o alcuni nomi sbagliati, questo farà fallire i tests sopra.
Ripetiamo: chiedete pure a Hugging Face, saremo lieti di aiutarvi.
Per ultimo, fare del refactoring del codice una volta che é stato creato.
Avete finito con il codice, congratulazioni! 🎉 Siete fantasticiiiiiii! 😎
**12. Caricare il modello sul model hub**
In questa ultima parte dovrete convertire e caricare il modello, con tutti i checkpoints, nel model hub e aggiungere una
model card per ogni checkpoint caricato. Leggete la nostra guida [Model sharing and uploading Page](model_sharing) per
avere familiarità con l'hub. Di solito in questa parte lavorate a fianco di Hugging face per decidere un nome che sia ok
per ogni checkpoint, per ottenere i permessi necessari per caricare il modello nell'organizzazione dell'autore di *brand_new_bert*.
Il metodo `push_to_hub`, presente in tutti i modelli `transformers`, é una maniera rapida e indolore per caricare il vostro checkpoint sull'hub:
```python
brand_new_bert.push_to_hub(
repo_path_or_name="brand_new_bert",
# Uncomment the following line to push to an organization
# organization="",
commit_message="Add model",
use_temp_dir=True,
)
```
Vale la pena spendere un po' di tempo per creare una model card ad-hoc per ogni checkpoint. Le model cards dovrebbero
suggerire le caratteristiche specifiche del checkpoint, *per esempio* su che dataset il checkpoint é stato pretrained o fine-tuned.
O che su che genere di task il modello lavoro? E anche buona pratica includere del codice su come usare il modello correttamente.
**13. (Opzionale) Aggiungere un notebook**
É molto utile aggiungere un notebook, che dimostri in dettaglio come *brand_new_bert* si utilizzi per fare inferenza e/o
fine-tuned su specifiche task. Non é una cosa obbligatoria da avere nella vostra PR, ma é molto utile per la community.
**14. Sottomettere la PR**
L'ultimissimo step! Ovvero il merge della PR nel main. Di solito il team Hugging face a questo punto vi avrà gia aiutato,
ma é ok prendere un po' di tempo per pulire la descirzione e commenti nel codice.
### Condividete il vostro lavoro!!
É ora tempo di prendere un po' di credito dalla communità per il vostro lavoro! Caricare e implementare un nuovo modello
é un grandissimo contributo per Transformers e l'intera community NLP. Il codice e la conversione dei modelli pre-trained sara
sicuramente utilizzato da centinaia o migliaia di sviluppatori e ricercatori. Siate fieri e orgogliosi di condividere il vostro
traguardo con l'intera community :)
** Avete create un altro modello che é super facile da usare per tutti quanti nella community! 🤯**