Spaces:
Runtime error


Runtime error
update
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +0 -14
- __pycache__/model.cpython-37.pyc +0 -0
- __pycache__/model.cpython-38.pyc +0 -0
- api/61.png +0 -0
- app.py +36 -147
- bird.jpeg +0 -0
- model.py +515 -0
- models/VLE/__init__.py +0 -11
- models/VLE/__pycache__/__init__.cpython-39.pyc +0 -0
- models/VLE/__pycache__/configuration_vle.cpython-39.pyc +0 -0
- models/VLE/__pycache__/modeling_vle.cpython-39.pyc +0 -0
- models/VLE/__pycache__/pipeline_vle.cpython-39.pyc +0 -0
- models/VLE/__pycache__/processing_vle.cpython-39.pyc +0 -0
- models/VLE/configuration_vle.py +0 -143
- models/VLE/modeling_vle.py +0 -709
- models/VLE/pipeline_vle.py +0 -166
- models/VLE/processing_vle.py +0 -149
- qa9.jpg +0 -3
- requirements.txt +1 -4
- timm/__init__.py +4 -0
- timm/__pycache__/__init__.cpython-37.pyc +0 -0
- timm/__pycache__/__init__.cpython-38.pyc +0 -0
- timm/__pycache__/version.cpython-37.pyc +0 -0
- timm/__pycache__/version.cpython-38.pyc +0 -0
- timm/data/__init__.py +12 -0
- timm/data/__pycache__/__init__.cpython-37.pyc +0 -0
- timm/data/__pycache__/__init__.cpython-38.pyc +0 -0
- timm/data/__pycache__/auto_augment.cpython-37.pyc +0 -0
- timm/data/__pycache__/auto_augment.cpython-38.pyc +0 -0
- timm/data/__pycache__/config.cpython-37.pyc +0 -0
- timm/data/__pycache__/config.cpython-38.pyc +0 -0
- timm/data/__pycache__/constants.cpython-37.pyc +0 -0
- timm/data/__pycache__/constants.cpython-38.pyc +0 -0
- timm/data/__pycache__/dataset.cpython-37.pyc +0 -0
- timm/data/__pycache__/dataset.cpython-38.pyc +0 -0
- timm/data/__pycache__/dataset_factory.cpython-37.pyc +0 -0
- timm/data/__pycache__/dataset_factory.cpython-38.pyc +0 -0
- timm/data/__pycache__/distributed_sampler.cpython-37.pyc +0 -0
- timm/data/__pycache__/distributed_sampler.cpython-38.pyc +0 -0
- timm/data/__pycache__/loader.cpython-37.pyc +0 -0
- timm/data/__pycache__/loader.cpython-38.pyc +0 -0
- timm/data/__pycache__/mixup.cpython-37.pyc +0 -0
- timm/data/__pycache__/mixup.cpython-38.pyc +0 -0
- timm/data/__pycache__/random_erasing.cpython-37.pyc +0 -0
- timm/data/__pycache__/random_erasing.cpython-38.pyc +0 -0
- timm/data/__pycache__/real_labels.cpython-37.pyc +0 -0
- timm/data/__pycache__/real_labels.cpython-38.pyc +0 -0
- timm/data/__pycache__/transforms.cpython-37.pyc +0 -0
- timm/data/__pycache__/transforms.cpython-38.pyc +0 -0
- timm/data/__pycache__/transforms_factory.cpython-37.pyc +0 -0
README.md
DELETED
|
@@ -1,14 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: VQA CAP GPT
|
| 3 |
-
emoji: 😻
|
| 4 |
-
colorFrom: gray
|
| 5 |
-
colorTo: red
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.19.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: openrail
|
| 11 |
-
duplicated_from: xxx1/VQA_CAP_GPT
|
| 12 |
-
---
|
| 13 |
-
|
| 14 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
__pycache__/model.cpython-37.pyc
ADDED
|
Binary file (12.1 kB). View file
|
|
|
__pycache__/model.cpython-38.pyc
ADDED
|
Binary file (12.2 kB). View file
|
|
|
api/61.png
ADDED
|
app.py
CHANGED
|
@@ -2,129 +2,47 @@ import string
|
|
| 2 |
import gradio as gr
|
| 3 |
import requests
|
| 4 |
import torch
|
| 5 |
-
from models.VLE import VLEForVQA, VLEProcessor, VLEForVQAPipeline
|
| 6 |
from PIL import Image
|
| 7 |
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
model_vqa = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-capfilt-large").to(device)
|
| 20 |
-
|
| 21 |
-
from transformers import BlipProcessor, BlipForConditionalGeneration
|
| 22 |
-
|
| 23 |
-
cap_processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
|
| 24 |
-
cap_model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large")
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
def caption(input_image):
|
| 29 |
-
inputs = cap_processor(input_image, return_tensors="pt")
|
| 30 |
-
# inputs["num_beams"] = 1
|
| 31 |
-
# inputs['num_return_sequences'] =1
|
| 32 |
-
out = cap_model.generate(**inputs)
|
| 33 |
-
return "\n".join(cap_processor.batch_decode(out, skip_special_tokens=True))
|
| 34 |
-
import openai
|
| 35 |
-
import os
|
| 36 |
-
openai.api_key= os.getenv('openai_appkey')
|
| 37 |
-
def gpt3_short(question,vqa_answer,caption):
|
| 38 |
-
vqa_answer,vqa_score=vqa_answer
|
| 39 |
-
prompt="This is the caption of a picture: "+caption+". Question: "+question+" VQA model predicts:"+"A: "+vqa_answer[0]+", socre:"+str(vqa_score[0])+\
|
| 40 |
-
"; B: "+vqa_answer[1]+", score:"+str(vqa_score[1])+"; C: "+vqa_answer[2]+", score:"+str(vqa_score[2])+\
|
| 41 |
-
"; D: "+vqa_answer[3]+', score:'+str(vqa_score[3])+\
|
| 42 |
-
". Choose A if it is not in conflict with the description of the picture and A's score is bigger than 0.8; otherwise choose the B, C or D based on the description."
|
| 43 |
-
|
| 44 |
-
# prompt=caption+"\n"+question+"\n"+vqa_answer+"\n Tell me the right answer."
|
| 45 |
-
response = openai.Completion.create(
|
| 46 |
-
engine="text-davinci-003",
|
| 47 |
-
prompt=prompt,
|
| 48 |
-
max_tokens=10,
|
| 49 |
-
n=1,
|
| 50 |
-
stop=None,
|
| 51 |
-
temperature=0.7,
|
| 52 |
-
)
|
| 53 |
-
answer = response.choices[0].text.strip()
|
| 54 |
-
|
| 55 |
-
llm_ans=answer
|
| 56 |
-
choice=set(["A","B","C","D"])
|
| 57 |
-
llm_ans=llm_ans.replace("\n"," ").replace(":"," ").replace("."," " ).replace(","," ")
|
| 58 |
-
sllm_ans=llm_ans.split(" ")
|
| 59 |
-
for cho in sllm_ans:
|
| 60 |
-
if cho in choice:
|
| 61 |
-
llm_ans=cho
|
| 62 |
-
break
|
| 63 |
-
if llm_ans not in choice:
|
| 64 |
-
llm_ans="A"
|
| 65 |
-
llm_ans=vqa_answer[ord(llm_ans)-ord("A")]
|
| 66 |
-
answer=llm_ans
|
| 67 |
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
temperature=0.7,
|
| 91 |
-
)
|
| 92 |
-
answer = response.choices[0].text.strip()
|
| 93 |
-
return answer
|
| 94 |
-
def gpt3(question,vqa_answer,caption):
|
| 95 |
-
prompt=caption+"\n"+question+"\n"+vqa_answer+"\n Tell me the right answer."
|
| 96 |
-
response = openai.Completion.create(
|
| 97 |
-
engine="text-davinci-003",
|
| 98 |
-
prompt=prompt,
|
| 99 |
-
max_tokens=30,
|
| 100 |
-
n=1,
|
| 101 |
-
stop=None,
|
| 102 |
-
temperature=0.7,
|
| 103 |
-
)
|
| 104 |
-
answer = response.choices[0].text.strip()
|
| 105 |
-
# return "input_text:\n"+prompt+"\n\n output_answer:\n"+answer
|
| 106 |
-
return answer
|
| 107 |
|
| 108 |
-
def vle(input_image,input_text):
|
| 109 |
-
vqa_answers = vqa_pipeline({"image":input_image, "question":input_text}, top_k=4)
|
| 110 |
-
# return [" ".join([str(value) for key,value in vqa.items()] )for vqa in vqa_answers]
|
| 111 |
-
return [vqa['answer'] for vqa in vqa_answers],[vqa['score'] for vqa in vqa_answers]
|
| 112 |
-
def inference_chat(input_image,input_text):
|
| 113 |
-
cap=caption(input_image)
|
| 114 |
-
print(cap)
|
| 115 |
-
# inputs = processor(images=input_image, text=input_text,return_tensors="pt")
|
| 116 |
-
# inputs["max_length"] = 10
|
| 117 |
-
# inputs["num_beams"] = 5
|
| 118 |
-
# inputs['num_return_sequences'] =4
|
| 119 |
-
# out = model_vqa.generate(**inputs)
|
| 120 |
-
# out=processor.batch_decode(out, skip_special_tokens=True)
|
| 121 |
|
| 122 |
-
out=vle(input_image,input_text)
|
| 123 |
-
# vqa="\n".join(out[0])
|
| 124 |
-
# gpt3_out=gpt3(input_text,vqa,cap)
|
| 125 |
-
gpt3_out=gpt3_long(input_text,out,cap)
|
| 126 |
-
gpt3_out1=gpt3_short(input_text,out,cap)
|
| 127 |
-
return out[0][0], gpt3_out,gpt3_out1
|
| 128 |
title = """# VQA with VLE and LLM"""
|
| 129 |
description = """**VLE** (Visual-Language Encoder) is an image-text multimodal understanding model built on the pre-trained text and image encoders. See https://github.com/iflytek/VLE for more details.
|
| 130 |
We demonstrate visual question answering systems built with VLE and LLM."""
|
|
@@ -169,14 +87,6 @@ with gr.Blocks(
|
|
| 169 |
caption_output_v1 = gr.Textbox(lines=0, label="VQA + LLM (short answer)")
|
| 170 |
gpt3_output_v1 = gr.Textbox(lines=0, label="VQA+LLM (long answer)")
|
| 171 |
|
| 172 |
-
|
| 173 |
-
|
| 174 |
-
# image_input.change(
|
| 175 |
-
# lambda: ("", [],"","",""),
|
| 176 |
-
# [],
|
| 177 |
-
# [ caption_output, state,caption_output,gpt3_output_v1,caption_output_v1],
|
| 178 |
-
# queue=False,
|
| 179 |
-
# )
|
| 180 |
chat_input.submit(
|
| 181 |
inference_chat,
|
| 182 |
[
|
|
@@ -199,28 +109,7 @@ with gr.Blocks(
|
|
| 199 |
],
|
| 200 |
[caption_output,gpt3_output_v1,caption_output_v1],
|
| 201 |
)
|
| 202 |
-
|
| 203 |
-
cap_submit_button.click(
|
| 204 |
-
caption,
|
| 205 |
-
[
|
| 206 |
-
image_input,
|
| 207 |
-
|
| 208 |
-
],
|
| 209 |
-
[caption_output_v1],
|
| 210 |
-
)
|
| 211 |
-
gpt3_submit_button.click(
|
| 212 |
-
gpt3,
|
| 213 |
-
[
|
| 214 |
-
chat_input,
|
| 215 |
-
caption_output ,
|
| 216 |
-
caption_output_v1,
|
| 217 |
-
],
|
| 218 |
-
[gpt3_output_v1],
|
| 219 |
-
)
|
| 220 |
-
'''
|
| 221 |
-
examples=[['bird.jpeg',"How many birds are there in the tree?","2","2","2"],
|
| 222 |
-
['qa9.jpg',"What type of vehicle is being pulled by the horses ?",'carriage','sled','Sled'],
|
| 223 |
-
['upload4.jpg',"What is this old man doing?","fishing","fishing","Fishing"]]
|
| 224 |
examples = gr.Examples(
|
| 225 |
examples=examples,inputs=[image_input, chat_input,caption_output,caption_output_v1,gpt3_output_v1],
|
| 226 |
)
|
|
|
|
| 2 |
import gradio as gr
|
| 3 |
import requests
|
| 4 |
import torch
|
|
|
|
| 5 |
from PIL import Image
|
| 6 |
|
| 7 |
+
rationale_model_dir = "cooelf/MM-CoT-UnifiedQA-Base-Rationale-Joint"
|
| 8 |
+
vit_model = timm.create_model("vit_base_patch16_384", pretrained=True, num_classes=0)
|
| 9 |
+
vit_model.eval()
|
| 10 |
+
config = resolve_data_config({}, model=vit_model)
|
| 11 |
+
transform = create_transform(**config)
|
| 12 |
+
tokenizer = T5Tokenizer.from_pretrained(rationale_model_dir)
|
| 13 |
+
r_model = T5ForMultimodalGeneration.from_pretrained(rationale_model_dir, patch_size=(577, 768))
|
| 14 |
|
| 15 |
+
def inference_chat(input_image,input_text):
|
| 16 |
+
with torch.no_grad():
|
| 17 |
+
img = Image.open(input_image).convert("RGB")
|
| 18 |
+
input = transform(img).unsqueeze(0)
|
| 19 |
+
out = vit_model.forward_features(input)
|
| 20 |
+
image_features = out.detach()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
+
input_ids = tokenizer(input_text, return_tensors='pt', padding=True).input_ids
|
| 23 |
+
source = tokenizer.batch_encode_plus(
|
| 24 |
+
[input_text],
|
| 25 |
+
max_length=512,
|
| 26 |
+
pad_to_max_length=True,
|
| 27 |
+
truncation=True,
|
| 28 |
+
padding="max_length",
|
| 29 |
+
return_tensors="pt",
|
| 30 |
+
)
|
| 31 |
+
source_ids = source["input_ids"]
|
| 32 |
+
source_mask = source["attention_mask"]
|
| 33 |
+
rationale = r_model.generate(
|
| 34 |
+
input_ids=source_ids,
|
| 35 |
+
attention_mask=source_mask,
|
| 36 |
+
image_ids=image_features,
|
| 37 |
+
max_length=512,
|
| 38 |
+
num_beams=1,
|
| 39 |
+
do_sample=False
|
| 40 |
+
)
|
| 41 |
+
gpt3_out = tokenizer.batch_decode(rationale, skip_special_tokens=True)[0]
|
| 42 |
+
gpt3_out1 = gpt3_out
|
| 43 |
+
return out[0][0], gpt3_out,gpt3_out1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 44 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
title = """# VQA with VLE and LLM"""
|
| 47 |
description = """**VLE** (Visual-Language Encoder) is an image-text multimodal understanding model built on the pre-trained text and image encoders. See https://github.com/iflytek/VLE for more details.
|
| 48 |
We demonstrate visual question answering systems built with VLE and LLM."""
|
|
|
|
| 87 |
caption_output_v1 = gr.Textbox(lines=0, label="VQA + LLM (short answer)")
|
| 88 |
gpt3_output_v1 = gr.Textbox(lines=0, label="VQA+LLM (long answer)")
|
| 89 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 90 |
chat_input.submit(
|
| 91 |
inference_chat,
|
| 92 |
[
|
|
|
|
| 109 |
],
|
| 110 |
[caption_output,gpt3_output_v1,caption_output_v1],
|
| 111 |
)
|
| 112 |
+
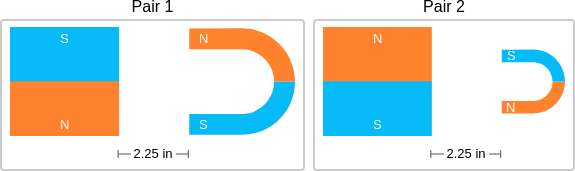
examples=[['api/61.png',"Think about the magnetic force between the magnets in each pair. Which of the following statements is true?","The images below show two pairs of magnets. The magnets in different pairs do not affect each other. All the magnets shown are made of the same material, but some of them are different sizes and shapes.","(A) The magnitude of the magnetic force is the same in both pairs. (B) The magnitude of the magnetic force is smaller in Pair 1. (C) The magnitude of the magnetic force is smaller in Pair 2.","Magnet sizes affect the magnitude of the magnetic force. Imagine magnets that are the same shape and made of the same material. The smaller the magnets, the smaller the magnitude of the magnetic force between them.nMagnet A is the same size in both pairs. But Magnet B is smaller in Pair 2 than in Pair 1. So, the magnitude of the magnetic force is smaller in Pair 2 than in Pair 1."],
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 113 |
examples = gr.Examples(
|
| 114 |
examples=examples,inputs=[image_input, chat_input,caption_output,caption_output_v1,gpt3_output_v1],
|
| 115 |
)
|
bird.jpeg
DELETED
|
Binary file (49.1 kB)
|
|
|
model.py
ADDED
|
@@ -0,0 +1,515 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Adapted from https://github.com/huggingface/transformers
|
| 3 |
+
'''
|
| 4 |
+
|
| 5 |
+
from transformers import T5Config, T5ForConditionalGeneration
|
| 6 |
+
from transformers.models.t5.modeling_t5 import T5Stack, __HEAD_MASK_WARNING_MSG, T5Block, T5LayerNorm
|
| 7 |
+
import copy
|
| 8 |
+
from transformers.modeling_outputs import ModelOutput, BaseModelOutput, BaseModelOutputWithPast, BaseModelOutputWithPastAndCrossAttentions, Seq2SeqLMOutput, Seq2SeqModelOutput
|
| 9 |
+
from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
|
| 10 |
+
import math
|
| 11 |
+
import os
|
| 12 |
+
import warnings
|
| 13 |
+
from typing import Optional, Tuple, Union
|
| 14 |
+
import torch
|
| 15 |
+
from torch import nn
|
| 16 |
+
from torch.nn import CrossEntropyLoss
|
| 17 |
+
from transformers.modeling_outputs import (
|
| 18 |
+
BaseModelOutput,
|
| 19 |
+
Seq2SeqLMOutput,
|
| 20 |
+
)
|
| 21 |
+
from transformers.utils.model_parallel_utils import assert_device_map, get_device_map
|
| 22 |
+
from torch.utils.checkpoint import checkpoint
|
| 23 |
+
|
| 24 |
+
class JointEncoder(T5Stack):
|
| 25 |
+
def __init__(self, config, embed_tokens=None, patch_size=None):
|
| 26 |
+
super().__init__(config)
|
| 27 |
+
|
| 28 |
+
self.embed_tokens = embed_tokens
|
| 29 |
+
self.is_decoder = config.is_decoder
|
| 30 |
+
|
| 31 |
+
self.patch_num, self.patch_dim = patch_size
|
| 32 |
+
self.image_dense = nn.Linear(self.patch_dim, config.d_model)
|
| 33 |
+
self.mha_layer = torch.nn.MultiheadAttention(embed_dim=config.hidden_size, kdim=config.hidden_size, vdim=config.hidden_size, num_heads=1, batch_first=True)
|
| 34 |
+
self.gate_dense = nn.Linear(2*config.hidden_size, config.hidden_size)
|
| 35 |
+
self.sigmoid = nn.Sigmoid()
|
| 36 |
+
|
| 37 |
+
self.block = nn.ModuleList(
|
| 38 |
+
[T5Block(config, has_relative_attention_bias=bool(i == 0)) for i in range(config.num_layers)]
|
| 39 |
+
)
|
| 40 |
+
self.final_layer_norm = T5LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
|
| 41 |
+
self.dropout = nn.Dropout(config.dropout_rate)
|
| 42 |
+
|
| 43 |
+
# Initialize weights and apply final processing
|
| 44 |
+
self.post_init()
|
| 45 |
+
# Model parallel
|
| 46 |
+
self.model_parallel = False
|
| 47 |
+
self.device_map = None
|
| 48 |
+
self.gradient_checkpointing = False
|
| 49 |
+
|
| 50 |
+
def parallelize(self, device_map=None):
|
| 51 |
+
warnings.warn(
|
| 52 |
+
"`T5Stack.parallelize` is deprecated and will be removed in v5 of Transformers, you should load your model"
|
| 53 |
+
" with `device_map='balanced'` in the call to `from_pretrained`. You can also provide your own"
|
| 54 |
+
" `device_map` but it needs to be a dictionary module_name to device, so for instance {'block.0': 0,"
|
| 55 |
+
" 'block.1': 1, ...}",
|
| 56 |
+
FutureWarning,
|
| 57 |
+
)
|
| 58 |
+
# Check validity of device_map
|
| 59 |
+
self.device_map = (
|
| 60 |
+
get_device_map(len(self.block), range(torch.cuda.device_count())) if device_map is None else device_map
|
| 61 |
+
)
|
| 62 |
+
assert_device_map(self.device_map, len(self.block))
|
| 63 |
+
self.model_parallel = True
|
| 64 |
+
self.first_device = "cpu" if "cpu" in self.device_map.keys() else "cuda:" + str(min(self.device_map.keys()))
|
| 65 |
+
self.last_device = "cuda:" + str(max(self.device_map.keys()))
|
| 66 |
+
# Load onto devices
|
| 67 |
+
for k, v in self.device_map.items():
|
| 68 |
+
for layer in v:
|
| 69 |
+
cuda_device = "cuda:" + str(k)
|
| 70 |
+
self.block[layer] = self.block[layer].to(cuda_device)
|
| 71 |
+
|
| 72 |
+
# Set embed_tokens to first layer
|
| 73 |
+
self.embed_tokens = self.embed_tokens.to(self.first_device)
|
| 74 |
+
# Set final layer norm to last device
|
| 75 |
+
self.final_layer_norm = self.final_layer_norm.to(self.last_device)
|
| 76 |
+
|
| 77 |
+
def deparallelize(self):
|
| 78 |
+
warnings.warn(
|
| 79 |
+
"Like `parallelize`, `deparallelize` is deprecated and will be removed in v5 of Transformers.",
|
| 80 |
+
FutureWarning,
|
| 81 |
+
)
|
| 82 |
+
self.model_parallel = False
|
| 83 |
+
self.device_map = None
|
| 84 |
+
self.first_device = "cpu"
|
| 85 |
+
self.last_device = "cpu"
|
| 86 |
+
for i in range(len(self.block)):
|
| 87 |
+
self.block[i] = self.block[i].to("cpu")
|
| 88 |
+
self.embed_tokens = self.embed_tokens.to("cpu")
|
| 89 |
+
self.final_layer_norm = self.final_layer_norm.to("cpu")
|
| 90 |
+
torch.cuda.empty_cache()
|
| 91 |
+
|
| 92 |
+
def get_input_embeddings(self):
|
| 93 |
+
return self.embed_tokens
|
| 94 |
+
|
| 95 |
+
def set_input_embeddings(self, new_embeddings):
|
| 96 |
+
self.embed_tokens = new_embeddings
|
| 97 |
+
|
| 98 |
+
def forward(
|
| 99 |
+
self,
|
| 100 |
+
input_ids=None,
|
| 101 |
+
attention_mask=None,
|
| 102 |
+
encoder_hidden_states=None,
|
| 103 |
+
encoder_attention_mask=None,
|
| 104 |
+
inputs_embeds=None,
|
| 105 |
+
image_ids=None,
|
| 106 |
+
head_mask=None,
|
| 107 |
+
cross_attn_head_mask=None,
|
| 108 |
+
past_key_values=None,
|
| 109 |
+
use_cache=None,
|
| 110 |
+
output_attentions=None,
|
| 111 |
+
output_hidden_states=None,
|
| 112 |
+
return_dict=None,
|
| 113 |
+
):
|
| 114 |
+
# Model parallel
|
| 115 |
+
if self.model_parallel:
|
| 116 |
+
torch.cuda.set_device(self.first_device)
|
| 117 |
+
self.embed_tokens = self.embed_tokens.to(self.first_device)
|
| 118 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 119 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 120 |
+
output_hidden_states = (
|
| 121 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 122 |
+
)
|
| 123 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 124 |
+
|
| 125 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 126 |
+
err_msg_prefix = "decoder_" if self.is_decoder else ""
|
| 127 |
+
raise ValueError(
|
| 128 |
+
f"You cannot specify both {err_msg_prefix}input_ids and {err_msg_prefix}inputs_embeds at the same time"
|
| 129 |
+
)
|
| 130 |
+
elif input_ids is not None:
|
| 131 |
+
input_shape = input_ids.size()
|
| 132 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 133 |
+
elif inputs_embeds is not None:
|
| 134 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 135 |
+
else:
|
| 136 |
+
err_msg_prefix = "decoder_" if self.is_decoder else ""
|
| 137 |
+
raise ValueError(f"You have to specify either {err_msg_prefix}input_ids or {err_msg_prefix}inputs_embeds")
|
| 138 |
+
|
| 139 |
+
if inputs_embeds is None:
|
| 140 |
+
assert self.embed_tokens is not None, "You have to initialize the model with valid token embeddings"
|
| 141 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 142 |
+
|
| 143 |
+
batch_size, seq_length = input_shape
|
| 144 |
+
|
| 145 |
+
# required mask seq length can be calculated via length of past
|
| 146 |
+
mask_seq_length = past_key_values[0][0].shape[2] + seq_length if past_key_values is not None else seq_length
|
| 147 |
+
|
| 148 |
+
if use_cache is True:
|
| 149 |
+
assert self.is_decoder, f"`use_cache` can only be set to `True` if {self} is used as a decoder"
|
| 150 |
+
|
| 151 |
+
if attention_mask is None:
|
| 152 |
+
attention_mask = torch.ones(batch_size, mask_seq_length, device=inputs_embeds.device)
|
| 153 |
+
if self.is_decoder and encoder_attention_mask is None and encoder_hidden_states is not None:
|
| 154 |
+
encoder_seq_length = encoder_hidden_states.shape[1]
|
| 155 |
+
encoder_attention_mask = torch.ones(
|
| 156 |
+
batch_size, encoder_seq_length, device=inputs_embeds.device, dtype=torch.long
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
# initialize past_key_values with `None` if past does not exist
|
| 160 |
+
if past_key_values is None:
|
| 161 |
+
past_key_values = [None] * len(self.block)
|
| 162 |
+
|
| 163 |
+
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
|
| 164 |
+
# ourselves in which case we just need to make it broadcastable to all heads.
|
| 165 |
+
extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
|
| 166 |
+
|
| 167 |
+
# If a 2D or 3D attention mask is provided for the cross-attention
|
| 168 |
+
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
| 169 |
+
if self.is_decoder and encoder_hidden_states is not None:
|
| 170 |
+
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
|
| 171 |
+
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
|
| 172 |
+
if encoder_attention_mask is None:
|
| 173 |
+
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=inputs_embeds.device)
|
| 174 |
+
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
|
| 175 |
+
else:
|
| 176 |
+
encoder_extended_attention_mask = None
|
| 177 |
+
|
| 178 |
+
# Prepare head mask if needed
|
| 179 |
+
head_mask = self.get_head_mask(head_mask, self.config.num_layers)
|
| 180 |
+
cross_attn_head_mask = self.get_head_mask(cross_attn_head_mask, self.config.num_layers)
|
| 181 |
+
present_key_value_states = () if use_cache else None
|
| 182 |
+
all_hidden_states = () if output_hidden_states else None
|
| 183 |
+
all_attentions = () if output_attentions else None
|
| 184 |
+
all_cross_attentions = () if (output_attentions and self.is_decoder) else None
|
| 185 |
+
position_bias = None
|
| 186 |
+
encoder_decoder_position_bias = None
|
| 187 |
+
|
| 188 |
+
hidden_states = self.dropout(inputs_embeds)
|
| 189 |
+
|
| 190 |
+
for i, (layer_module, past_key_value) in enumerate(zip(self.block, past_key_values)):
|
| 191 |
+
layer_head_mask = head_mask[i]
|
| 192 |
+
cross_attn_layer_head_mask = cross_attn_head_mask[i]
|
| 193 |
+
# Model parallel
|
| 194 |
+
if self.model_parallel:
|
| 195 |
+
torch.cuda.set_device(hidden_states.device)
|
| 196 |
+
# Ensure that attention_mask is always on the same device as hidden_states
|
| 197 |
+
if attention_mask is not None:
|
| 198 |
+
attention_mask = attention_mask.to(hidden_states.device)
|
| 199 |
+
if position_bias is not None:
|
| 200 |
+
position_bias = position_bias.to(hidden_states.device)
|
| 201 |
+
if encoder_hidden_states is not None:
|
| 202 |
+
encoder_hidden_states = encoder_hidden_states.to(hidden_states.device)
|
| 203 |
+
if encoder_extended_attention_mask is not None:
|
| 204 |
+
encoder_extended_attention_mask = encoder_extended_attention_mask.to(hidden_states.device)
|
| 205 |
+
if encoder_decoder_position_bias is not None:
|
| 206 |
+
encoder_decoder_position_bias = encoder_decoder_position_bias.to(hidden_states.device)
|
| 207 |
+
if layer_head_mask is not None:
|
| 208 |
+
layer_head_mask = layer_head_mask.to(hidden_states.device)
|
| 209 |
+
if cross_attn_layer_head_mask is not None:
|
| 210 |
+
cross_attn_layer_head_mask = cross_attn_layer_head_mask.to(hidden_states.device)
|
| 211 |
+
if output_hidden_states:
|
| 212 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 213 |
+
|
| 214 |
+
if self.gradient_checkpointing and self.training:
|
| 215 |
+
if use_cache:
|
| 216 |
+
logger.warning_once(
|
| 217 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 218 |
+
)
|
| 219 |
+
use_cache = False
|
| 220 |
+
|
| 221 |
+
def create_custom_forward(module):
|
| 222 |
+
def custom_forward(*inputs):
|
| 223 |
+
return tuple(module(*inputs, use_cache, output_attentions))
|
| 224 |
+
|
| 225 |
+
return custom_forward
|
| 226 |
+
|
| 227 |
+
layer_outputs = checkpoint(
|
| 228 |
+
create_custom_forward(layer_module),
|
| 229 |
+
hidden_states,
|
| 230 |
+
extended_attention_mask,
|
| 231 |
+
position_bias,
|
| 232 |
+
encoder_hidden_states,
|
| 233 |
+
encoder_extended_attention_mask,
|
| 234 |
+
encoder_decoder_position_bias,
|
| 235 |
+
layer_head_mask,
|
| 236 |
+
cross_attn_layer_head_mask,
|
| 237 |
+
None, # past_key_value is always None with gradient checkpointing
|
| 238 |
+
)
|
| 239 |
+
else:
|
| 240 |
+
layer_outputs = layer_module(
|
| 241 |
+
hidden_states,
|
| 242 |
+
attention_mask=extended_attention_mask,
|
| 243 |
+
position_bias=position_bias,
|
| 244 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 245 |
+
encoder_attention_mask=encoder_extended_attention_mask,
|
| 246 |
+
encoder_decoder_position_bias=encoder_decoder_position_bias,
|
| 247 |
+
layer_head_mask=layer_head_mask,
|
| 248 |
+
cross_attn_layer_head_mask=cross_attn_layer_head_mask,
|
| 249 |
+
past_key_value=past_key_value,
|
| 250 |
+
use_cache=use_cache,
|
| 251 |
+
output_attentions=output_attentions,
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
# layer_outputs is a tuple with:
|
| 255 |
+
# hidden-states, key-value-states, (self-attention position bias), (self-attention weights), (cross-attention position bias), (cross-attention weights)
|
| 256 |
+
if use_cache is False:
|
| 257 |
+
layer_outputs = layer_outputs[:1] + (None,) + layer_outputs[1:]
|
| 258 |
+
|
| 259 |
+
hidden_states, present_key_value_state = layer_outputs[:2]
|
| 260 |
+
|
| 261 |
+
# We share the position biases between the layers - the first layer store them
|
| 262 |
+
# layer_outputs = hidden-states, key-value-states (self-attention position bias), (self-attention weights),
|
| 263 |
+
# (cross-attention position bias), (cross-attention weights)
|
| 264 |
+
position_bias = layer_outputs[2]
|
| 265 |
+
if self.is_decoder and encoder_hidden_states is not None:
|
| 266 |
+
encoder_decoder_position_bias = layer_outputs[4 if output_attentions else 3]
|
| 267 |
+
# append next layer key value states
|
| 268 |
+
if use_cache:
|
| 269 |
+
present_key_value_states = present_key_value_states + (present_key_value_state,)
|
| 270 |
+
|
| 271 |
+
if output_attentions:
|
| 272 |
+
all_attentions = all_attentions + (layer_outputs[3],)
|
| 273 |
+
if self.is_decoder:
|
| 274 |
+
all_cross_attentions = all_cross_attentions + (layer_outputs[5],)
|
| 275 |
+
|
| 276 |
+
# Model Parallel: If it's the last layer for that device, put things on the next device
|
| 277 |
+
if self.model_parallel:
|
| 278 |
+
for k, v in self.device_map.items():
|
| 279 |
+
if i == v[-1] and "cuda:" + str(k) != self.last_device:
|
| 280 |
+
hidden_states = hidden_states.to("cuda:" + str(k + 1))
|
| 281 |
+
|
| 282 |
+
hidden_states = self.final_layer_norm(hidden_states)
|
| 283 |
+
hidden_states = self.dropout(hidden_states)
|
| 284 |
+
|
| 285 |
+
# Add last layer
|
| 286 |
+
if output_hidden_states:
|
| 287 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 288 |
+
|
| 289 |
+
image_embedding = self.image_dense(image_ids)
|
| 290 |
+
image_att, _ = self.mha_layer(hidden_states, image_embedding, image_embedding)
|
| 291 |
+
merge = torch.cat([hidden_states, image_att], dim=-1)
|
| 292 |
+
gate = self.sigmoid(self.gate_dense(merge))
|
| 293 |
+
hidden_states = (1 - gate) * hidden_states + gate * image_att
|
| 294 |
+
|
| 295 |
+
if not return_dict:
|
| 296 |
+
return tuple(
|
| 297 |
+
v
|
| 298 |
+
for v in [
|
| 299 |
+
hidden_states,
|
| 300 |
+
present_key_value_states,
|
| 301 |
+
all_hidden_states,
|
| 302 |
+
all_attentions,
|
| 303 |
+
all_cross_attentions,
|
| 304 |
+
]
|
| 305 |
+
if v is not None
|
| 306 |
+
)
|
| 307 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 308 |
+
last_hidden_state=hidden_states,
|
| 309 |
+
past_key_values=present_key_value_states,
|
| 310 |
+
hidden_states=all_hidden_states,
|
| 311 |
+
attentions=all_attentions,
|
| 312 |
+
cross_attentions=all_cross_attentions,
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
class T5ForMultimodalGeneration(T5ForConditionalGeneration):
|
| 317 |
+
_keys_to_ignore_on_load_missing = [
|
| 318 |
+
r"encoder.embed_tokens.weight",
|
| 319 |
+
r"decoder.embed_tokens.weight",
|
| 320 |
+
r"lm_head.weight",
|
| 321 |
+
]
|
| 322 |
+
_keys_to_ignore_on_load_unexpected = [
|
| 323 |
+
r"decoder.block.0.layer.1.EncDecAttention.relative_attention_bias.weight",
|
| 324 |
+
]
|
| 325 |
+
|
| 326 |
+
def __init__(self, config: T5Config, patch_size):
|
| 327 |
+
super().__init__(config)
|
| 328 |
+
self.model_dim = config.d_model
|
| 329 |
+
|
| 330 |
+
self.shared = nn.Embedding(config.vocab_size, config.d_model)
|
| 331 |
+
|
| 332 |
+
encoder_config = copy.deepcopy(config)
|
| 333 |
+
encoder_config.is_decoder = False
|
| 334 |
+
encoder_config.use_cache = False
|
| 335 |
+
encoder_config.is_encoder_decoder = False
|
| 336 |
+
# self.encoder = T5Stack(encoder_config, self.shared)
|
| 337 |
+
self.encoder = JointEncoder(encoder_config, self.shared, patch_size)
|
| 338 |
+
decoder_config = copy.deepcopy(config)
|
| 339 |
+
decoder_config.is_decoder = True
|
| 340 |
+
decoder_config.is_encoder_decoder = False
|
| 341 |
+
decoder_config.num_layers = config.num_decoder_layers
|
| 342 |
+
self.decoder = T5Stack(decoder_config, self.shared)
|
| 343 |
+
|
| 344 |
+
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
|
| 345 |
+
|
| 346 |
+
# Initialize weights and apply final processing
|
| 347 |
+
self.post_init()
|
| 348 |
+
|
| 349 |
+
# Model parallel
|
| 350 |
+
self.model_parallel = False
|
| 351 |
+
self.device_map = None
|
| 352 |
+
|
| 353 |
+
def forward(
|
| 354 |
+
self,
|
| 355 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 356 |
+
image_ids=None,
|
| 357 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 358 |
+
decoder_input_ids: Optional[torch.LongTensor] = None,
|
| 359 |
+
decoder_attention_mask: Optional[torch.BoolTensor] = None,
|
| 360 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 361 |
+
decoder_head_mask: Optional[torch.FloatTensor] = None,
|
| 362 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 363 |
+
encoder_outputs: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 364 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 365 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 366 |
+
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 367 |
+
labels: Optional[torch.LongTensor] = None,
|
| 368 |
+
use_cache: Optional[bool] = None,
|
| 369 |
+
output_attentions: Optional[bool] = None,
|
| 370 |
+
output_hidden_states: Optional[bool] = None,
|
| 371 |
+
return_dict: Optional[bool] = None,
|
| 372 |
+
) -> Union[Tuple[torch.FloatTensor], Seq2SeqLMOutput]:
|
| 373 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 374 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 375 |
+
|
| 376 |
+
# FutureWarning: head_mask was separated into two input args - head_mask, decoder_head_mask
|
| 377 |
+
if head_mask is not None and decoder_head_mask is None:
|
| 378 |
+
if self.config.num_layers == self.config.num_decoder_layers:
|
| 379 |
+
warnings.warn(__HEAD_MASK_WARNING_MSG, FutureWarning)
|
| 380 |
+
decoder_head_mask = head_mask
|
| 381 |
+
|
| 382 |
+
# Encode if needed (training, first prediction pass)
|
| 383 |
+
if encoder_outputs is None:
|
| 384 |
+
# Convert encoder inputs in embeddings if needed
|
| 385 |
+
encoder_outputs = self.encoder(
|
| 386 |
+
input_ids=input_ids,
|
| 387 |
+
attention_mask=attention_mask,
|
| 388 |
+
inputs_embeds=inputs_embeds,
|
| 389 |
+
image_ids=image_ids,
|
| 390 |
+
head_mask=head_mask,
|
| 391 |
+
output_attentions=output_attentions,
|
| 392 |
+
output_hidden_states=output_hidden_states,
|
| 393 |
+
return_dict=return_dict,
|
| 394 |
+
)
|
| 395 |
+
|
| 396 |
+
elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
|
| 397 |
+
encoder_outputs = BaseModelOutput(
|
| 398 |
+
last_hidden_state=encoder_outputs[0],
|
| 399 |
+
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
|
| 400 |
+
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
|
| 401 |
+
)
|
| 402 |
+
|
| 403 |
+
hidden_states = encoder_outputs[0]
|
| 404 |
+
|
| 405 |
+
if self.model_parallel:
|
| 406 |
+
torch.cuda.set_device(self.decoder.first_device)
|
| 407 |
+
|
| 408 |
+
if labels is not None and decoder_input_ids is None and decoder_inputs_embeds is None:
|
| 409 |
+
# get decoder inputs from shifting lm labels to the right
|
| 410 |
+
decoder_input_ids = self._shift_right(labels)
|
| 411 |
+
|
| 412 |
+
# Set device for model parallelism
|
| 413 |
+
if self.model_parallel:
|
| 414 |
+
torch.cuda.set_device(self.decoder.first_device)
|
| 415 |
+
hidden_states = hidden_states.to(self.decoder.first_device)
|
| 416 |
+
if decoder_input_ids is not None:
|
| 417 |
+
decoder_input_ids = decoder_input_ids.to(self.decoder.first_device)
|
| 418 |
+
if attention_mask is not None:
|
| 419 |
+
attention_mask = attention_mask.to(self.decoder.first_device)
|
| 420 |
+
if decoder_attention_mask is not None:
|
| 421 |
+
decoder_attention_mask = decoder_attention_mask.to(self.decoder.first_device)
|
| 422 |
+
|
| 423 |
+
# Decode
|
| 424 |
+
decoder_outputs = self.decoder(
|
| 425 |
+
input_ids=decoder_input_ids,
|
| 426 |
+
attention_mask=decoder_attention_mask,
|
| 427 |
+
inputs_embeds=decoder_inputs_embeds,
|
| 428 |
+
past_key_values=past_key_values,
|
| 429 |
+
encoder_hidden_states=hidden_states,
|
| 430 |
+
encoder_attention_mask=attention_mask,
|
| 431 |
+
head_mask=decoder_head_mask,
|
| 432 |
+
cross_attn_head_mask=cross_attn_head_mask,
|
| 433 |
+
use_cache=use_cache,
|
| 434 |
+
output_attentions=output_attentions,
|
| 435 |
+
output_hidden_states=output_hidden_states,
|
| 436 |
+
return_dict=return_dict,
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
sequence_output = decoder_outputs[0]
|
| 440 |
+
|
| 441 |
+
# Set device for model parallelism
|
| 442 |
+
if self.model_parallel:
|
| 443 |
+
torch.cuda.set_device(self.encoder.first_device)
|
| 444 |
+
self.lm_head = self.lm_head.to(self.encoder.first_device)
|
| 445 |
+
sequence_output = sequence_output.to(self.lm_head.weight.device)
|
| 446 |
+
|
| 447 |
+
if self.config.tie_word_embeddings:
|
| 448 |
+
# Rescale output before projecting on vocab
|
| 449 |
+
# See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/transformer.py#L586
|
| 450 |
+
sequence_output = sequence_output * (self.model_dim**-0.5)
|
| 451 |
+
|
| 452 |
+
lm_logits = self.lm_head(sequence_output)
|
| 453 |
+
|
| 454 |
+
loss = None
|
| 455 |
+
if labels is not None:
|
| 456 |
+
loss_fct = CrossEntropyLoss(ignore_index=-100)
|
| 457 |
+
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
|
| 458 |
+
# TODO(thom): Add z_loss https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L666
|
| 459 |
+
|
| 460 |
+
if not return_dict:
|
| 461 |
+
output = (lm_logits,) + decoder_outputs[1:] + encoder_outputs
|
| 462 |
+
return ((loss,) + output) if loss is not None else output
|
| 463 |
+
|
| 464 |
+
return Seq2SeqLMOutput(
|
| 465 |
+
loss=loss,
|
| 466 |
+
logits=lm_logits,
|
| 467 |
+
past_key_values=decoder_outputs.past_key_values,
|
| 468 |
+
decoder_hidden_states=decoder_outputs.hidden_states,
|
| 469 |
+
decoder_attentions=decoder_outputs.attentions,
|
| 470 |
+
cross_attentions=decoder_outputs.cross_attentions,
|
| 471 |
+
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
|
| 472 |
+
encoder_hidden_states=encoder_outputs.hidden_states,
|
| 473 |
+
encoder_attentions=encoder_outputs.attentions,
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
def prepare_inputs_for_generation(
|
| 477 |
+
self, decoder_input_ids, past=None, attention_mask=None, use_cache=None, encoder_outputs=None, **kwargs
|
| 478 |
+
):
|
| 479 |
+
# cut decoder_input_ids if past is used
|
| 480 |
+
if past is not None:
|
| 481 |
+
decoder_input_ids = decoder_input_ids[:, -1:]
|
| 482 |
+
|
| 483 |
+
output = {
|
| 484 |
+
"input_ids": None, # encoder_outputs is defined. input_ids not needed
|
| 485 |
+
"encoder_outputs": encoder_outputs,
|
| 486 |
+
"past_key_values": past,
|
| 487 |
+
"decoder_input_ids": decoder_input_ids,
|
| 488 |
+
"attention_mask": attention_mask,
|
| 489 |
+
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
|
| 490 |
+
}
|
| 491 |
+
|
| 492 |
+
if "image_ids" in kwargs:
|
| 493 |
+
output["image_ids"] = kwargs['image_ids']
|
| 494 |
+
|
| 495 |
+
return output
|
| 496 |
+
|
| 497 |
+
def test_step(self, tokenizer, batch, **kwargs):
|
| 498 |
+
device = next(self.parameters()).device
|
| 499 |
+
input_ids = batch['input_ids'].to(device)
|
| 500 |
+
image_ids = batch['image_ids'].to(device)
|
| 501 |
+
|
| 502 |
+
output = self.generate(
|
| 503 |
+
input_ids=input_ids,
|
| 504 |
+
image_ids=image_ids,
|
| 505 |
+
**kwargs
|
| 506 |
+
)
|
| 507 |
+
|
| 508 |
+
generated_sents = tokenizer.batch_decode(output, skip_special_tokens=True)
|
| 509 |
+
targets = tokenizer.batch_decode(batch['labels'], skip_special_tokens=True)
|
| 510 |
+
|
| 511 |
+
result = {}
|
| 512 |
+
result['preds'] = generated_sents
|
| 513 |
+
result['targets'] = targets
|
| 514 |
+
|
| 515 |
+
return result
|
models/VLE/__init__.py
DELETED
|
@@ -1,11 +0,0 @@
|
|
| 1 |
-
from .modeling_vle import (
|
| 2 |
-
VLEModel,
|
| 3 |
-
VLEForVQA,
|
| 4 |
-
VLEForITM,
|
| 5 |
-
VLEForMLM,
|
| 6 |
-
VLEForPBC
|
| 7 |
-
)
|
| 8 |
-
|
| 9 |
-
from .configuration_vle import VLEConfig
|
| 10 |
-
from .processing_vle import VLEProcessor
|
| 11 |
-
from .pipeline_vle import VLEForVQAPipeline, VLEForITMPipeline, VLEForPBCPipeline
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
models/VLE/__pycache__/__init__.cpython-39.pyc
DELETED
|
Binary file (498 Bytes)
|
|
|
models/VLE/__pycache__/configuration_vle.cpython-39.pyc
DELETED
|
Binary file (4.27 kB)
|
|
|
models/VLE/__pycache__/modeling_vle.cpython-39.pyc
DELETED
|
Binary file (18.5 kB)
|
|
|
models/VLE/__pycache__/pipeline_vle.cpython-39.pyc
DELETED
|
Binary file (6.38 kB)
|
|
|
models/VLE/__pycache__/processing_vle.cpython-39.pyc
DELETED
|
Binary file (6.16 kB)
|
|
|
models/VLE/configuration_vle.py
DELETED
|
@@ -1,143 +0,0 @@
|
|
| 1 |
-
# coding=utf-8
|
| 2 |
-
# Copyright The HuggingFace Inc. team. All rights reserved.
|
| 3 |
-
#
|
| 4 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
# you may not use this file except in compliance with the License.
|
| 6 |
-
# You may obtain a copy of the License at
|
| 7 |
-
#
|
| 8 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
#
|
| 10 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
# See the License for the specific language governing permissions and
|
| 14 |
-
# limitations under the License.
|
| 15 |
-
""" VLE model configuration"""
|
| 16 |
-
|
| 17 |
-
import copy
|
| 18 |
-
|
| 19 |
-
from transformers.configuration_utils import PretrainedConfig
|
| 20 |
-
from transformers.utils import logging
|
| 21 |
-
from transformers.models.auto.configuration_auto import AutoConfig
|
| 22 |
-
from transformers.models.clip.configuration_clip import CLIPVisionConfig
|
| 23 |
-
from typing import Union, Dict
|
| 24 |
-
|
| 25 |
-
logger = logging.get_logger(__name__)
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
class VLEConfig(PretrainedConfig):
|
| 29 |
-
r"""
|
| 30 |
-
[`VLEConfig`] is the configuration class to store the configuration of a
|
| 31 |
-
[`VLEModel`]. It is used to instantiate [`VLEModel`] model according to the
|
| 32 |
-
specified arguments, defining the text model and vision model configs.
|
| 33 |
-
|
| 34 |
-
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 35 |
-
documentation from [`PretrainedConfig`] for more information.
|
| 36 |
-
|
| 37 |
-
Args:
|
| 38 |
-
text_config (`dict`):
|
| 39 |
-
Dictionary of configuration options that defines text model config.
|
| 40 |
-
vision_config (`dict`):
|
| 41 |
-
Dictionary of configuration options that defines vison model config.
|
| 42 |
-
#TODO
|
| 43 |
-
logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
|
| 44 |
-
The inital value of the *logit_scale* paramter. Default is used as per the original CLIP implementation.
|
| 45 |
-
kwargs (*optional*):
|
| 46 |
-
Dictionary of keyword arguments.
|
| 47 |
-
|
| 48 |
-
Examples:
|
| 49 |
-
|
| 50 |
-
```python
|
| 51 |
-
>>> from transformers import ViTConfig, BertConfig
|
| 52 |
-
>>> from configuration_vle import VLEconfig
|
| 53 |
-
>>> from modeling_vle import VLEModel
|
| 54 |
-
>>> # Initializing a BERT and ViT configuration
|
| 55 |
-
>>> config_vision = ViTConfig()
|
| 56 |
-
>>> config_text = BertConfig()
|
| 57 |
-
|
| 58 |
-
>>> config = VLEConfig.from_vision_text_configs(config_vision, config_text) #TODO
|
| 59 |
-
|
| 60 |
-
>>> # Initializing a BERT and ViT model (with random weights)
|
| 61 |
-
>>> model = VLEModel(config=config)
|
| 62 |
-
|
| 63 |
-
>>> # Accessing the model configuration
|
| 64 |
-
>>> config_vision = model.config.vision_config
|
| 65 |
-
>>> config_text = model.config.text_config
|
| 66 |
-
|
| 67 |
-
>>> # Saving the model, including its configuration
|
| 68 |
-
>>> model.save_pretrained("vit-bert")
|
| 69 |
-
|
| 70 |
-
>>> # loading model and config from pretrained folder
|
| 71 |
-
>>> vision_text_config = VLEConfig.from_pretrained("vit-bert")
|
| 72 |
-
>>> model = VLEModel.from_pretrained("vit-bert", config=vision_text_config)
|
| 73 |
-
```"""
|
| 74 |
-
|
| 75 |
-
model_type = "vle"
|
| 76 |
-
is_composition = True
|
| 77 |
-
|
| 78 |
-
def __init__(
|
| 79 |
-
self,
|
| 80 |
-
text_config: Union[PretrainedConfig, Dict],
|
| 81 |
-
vision_config: Union[PretrainedConfig, Dict],
|
| 82 |
-
num_token_types=2,
|
| 83 |
-
hidden_size=768,
|
| 84 |
-
num_hidden_layers=6,
|
| 85 |
-
num_attention_heads=12,
|
| 86 |
-
intermediate_size=3072,
|
| 87 |
-
hidden_act="gelu",
|
| 88 |
-
hidden_dropout_prob=0.1,
|
| 89 |
-
attention_probs_dropout_prob=0.1,
|
| 90 |
-
initializer_range=0.02,
|
| 91 |
-
layer_norm_eps=1e-12,
|
| 92 |
-
classifier_dropout=None,
|
| 93 |
-
**kwargs):
|
| 94 |
-
super().__init__(**kwargs)
|
| 95 |
-
|
| 96 |
-
if not isinstance(text_config,PretrainedConfig):
|
| 97 |
-
text_model_type = text_config.pop('model_type')
|
| 98 |
-
text_config = AutoConfig.for_model(text_model_type, **text_config)
|
| 99 |
-
self.text_config = text_config
|
| 100 |
-
|
| 101 |
-
if not isinstance(vision_config, PretrainedConfig):
|
| 102 |
-
vision_model_type = vision_config.pop('model_type')
|
| 103 |
-
if vision_model_type == "clip":
|
| 104 |
-
vision_config = AutoConfig.for_model(vision_model_type, **vision_config).vision_config
|
| 105 |
-
elif vision_model_type == "clip_vision_model":
|
| 106 |
-
vision_config = CLIPVisionConfig(**vision_config)
|
| 107 |
-
else:
|
| 108 |
-
vision_config = AutoConfig.for_model(vision_model_type, **vision_config)
|
| 109 |
-
self.vision_config = vision_config
|
| 110 |
-
else:
|
| 111 |
-
vision_model_type = vision_config.model_type
|
| 112 |
-
if vision_model_type== "clip":
|
| 113 |
-
vision_config = vision_config.vision_config
|
| 114 |
-
self.vision_config = vision_config
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
# co-attention
|
| 119 |
-
self.num_token_types=num_token_types
|
| 120 |
-
self.hidden_size=hidden_size
|
| 121 |
-
self.num_hidden_layers=num_hidden_layers
|
| 122 |
-
self.num_attention_heads=num_attention_heads
|
| 123 |
-
self.intermediate_size=intermediate_size
|
| 124 |
-
self.hidden_act=hidden_act
|
| 125 |
-
self.hidden_dropout_prob=hidden_dropout_prob
|
| 126 |
-
self.attention_probs_dropout_prob=attention_probs_dropout_prob
|
| 127 |
-
self.initializer_range=initializer_range
|
| 128 |
-
self.layer_norm_eps=layer_norm_eps
|
| 129 |
-
self.classifier_dropout=classifier_dropout
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
def to_dict(self):
|
| 133 |
-
"""
|
| 134 |
-
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 135 |
-
|
| 136 |
-
Returns:
|
| 137 |
-
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 138 |
-
"""
|
| 139 |
-
output = copy.deepcopy(self.__dict__)
|
| 140 |
-
output["vision_config"] = self.vision_config.to_dict()
|
| 141 |
-
output["text_config"] = self.text_config.to_dict()
|
| 142 |
-
output["model_type"] = self.__class__.model_type
|
| 143 |
-
return output
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
models/VLE/modeling_vle.py
DELETED
|
@@ -1,709 +0,0 @@
|
|
| 1 |
-
# coding=utf-8
|
| 2 |
-
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
|
| 3 |
-
#
|
| 4 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
# you may not use this file except in compliance with the License.
|
| 6 |
-
# You may obtain a copy of the License at
|
| 7 |
-
#
|
| 8 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
#
|
| 10 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
# See the License for the specific language governing permissions and
|
| 14 |
-
# limitations under the License.
|
| 15 |
-
""" PyTorch VLE model."""
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
from typing import Optional, Tuple, Union
|
| 19 |
-
|
| 20 |
-
import torch
|
| 21 |
-
from torch import nn
|
| 22 |
-
|
| 23 |
-
from transformers.modeling_utils import PreTrainedModel
|
| 24 |
-
from transformers.utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings, ModelOutput
|
| 25 |
-
from transformers.models.auto.configuration_auto import AutoConfig
|
| 26 |
-
from transformers.models.auto.modeling_auto import AutoModel
|
| 27 |
-
|
| 28 |
-
from transformers.models.bert.modeling_bert import BertAttention, BertIntermediate, BertOutput, apply_chunking_to_forward
|
| 29 |
-
from transformers.models.clip.modeling_clip import CLIPOutput, CLIPVisionConfig, CLIPVisionModel
|
| 30 |
-
from transformers.models.deberta_v2.modeling_deberta_v2 import DebertaV2OnlyMLMHead
|
| 31 |
-
from .configuration_vle import VLEConfig
|
| 32 |
-
from dataclasses import dataclass
|
| 33 |
-
|
| 34 |
-
logger = logging.get_logger(__name__)
|
| 35 |
-
|
| 36 |
-
_CONFIG_FOR_DOC = "VLEConfig"
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
@dataclass
|
| 40 |
-
class VLEModelOutput(ModelOutput):
|
| 41 |
-
|
| 42 |
-
pooler_output: torch.FloatTensor = None
|
| 43 |
-
text_embeds: torch.FloatTensor = None
|
| 44 |
-
image_embeds: torch.FloatTensor = None
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
@dataclass
|
| 48 |
-
class VLEForITMOutput(ModelOutput):
|
| 49 |
-
|
| 50 |
-
loss: torch.FloatTensor = None
|
| 51 |
-
logits: torch.FloatTensor = None
|
| 52 |
-
|
| 53 |
-
@dataclass
|
| 54 |
-
class VLEForPBCOutput(ModelOutput):
|
| 55 |
-
|
| 56 |
-
loss: torch.FloatTensor = None
|
| 57 |
-
logits: torch.FloatTensor = None
|
| 58 |
-
|
| 59 |
-
@dataclass
|
| 60 |
-
class VLEForMLMOutput(ModelOutput):
|
| 61 |
-
|
| 62 |
-
loss: torch.FloatTensor = None
|
| 63 |
-
logits: torch.FloatTensor = None
|
| 64 |
-
|
| 65 |
-
@dataclass
|
| 66 |
-
class VLEForVQAOutput(ModelOutput):
|
| 67 |
-
|
| 68 |
-
loss : torch.FloatTensor = None
|
| 69 |
-
logits: torch.FloatTensor = None
|
| 70 |
-
|
| 71 |
-
class ITMHead(nn.Module):
|
| 72 |
-
def __init__(self, hidden_size):
|
| 73 |
-
super().__init__()
|
| 74 |
-
self.fc = nn.Linear(hidden_size, 2)
|
| 75 |
-
|
| 76 |
-
def forward(self, x):
|
| 77 |
-
x = self.fc(x)
|
| 78 |
-
return x
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
def extend_position_embedding(state_dict, patch_size, after):
|
| 82 |
-
"""
|
| 83 |
-
modify state_dict in-place for longer position embeddings
|
| 84 |
-
"""
|
| 85 |
-
keys = {}
|
| 86 |
-
for k,v in state_dict.items():
|
| 87 |
-
if k.endswith('vision_model.embeddings.position_embedding.weight'):
|
| 88 |
-
assert k not in keys
|
| 89 |
-
keys['pe'] = (k,v)
|
| 90 |
-
if k.endswith('vision_model.embeddings.position_ids'):
|
| 91 |
-
assert k not in keys
|
| 92 |
-
keys['pi'] = (k,v)
|
| 93 |
-
|
| 94 |
-
pe_weight = keys['pe'][1]
|
| 95 |
-
position_length_before = pe_weight.shape[0]
|
| 96 |
-
embed_dim = pe_weight.shape[1]
|
| 97 |
-
grid_before = position_length_before - 1
|
| 98 |
-
position_length_after = (after // patch_size) ** 2 + 1
|
| 99 |
-
grid_after = position_length_after - 1
|
| 100 |
-
|
| 101 |
-
new_pe_weight = pe_weight[1:].reshape((grid_before,grid_before,-1))
|
| 102 |
-
new_pe_weight = torch.nn.functional.interpolate(
|
| 103 |
-
new_pe_weight.permute(2,0,1).unsqueeze(0),
|
| 104 |
-
size = (grid_after,grid_after), mode = 'bicubic')
|
| 105 |
-
new_pe_weight = new_pe_weight.squeeze(0).permute(1,2,0).reshape(grid_after*grid_after, -1)
|
| 106 |
-
new_pe_weight = torch.cat((pe_weight[0:1],new_pe_weight), dim=0)
|
| 107 |
-
assert new_pe_weight.shape == (grid_after*grid_after + 1, embed_dim)
|
| 108 |
-
|
| 109 |
-
state_dict[keys['pe'][0]] = new_pe_weight
|
| 110 |
-
state_dict[keys['pi'][0]] = torch.arange(grid_after*grid_after + 1).unsqueeze(0)
|
| 111 |
-
return state_dict
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
class Pooler(nn.Module):
|
| 115 |
-
def __init__(self, hidden_size):
|
| 116 |
-
super().__init__()
|
| 117 |
-
self.dense = nn.Linear(hidden_size, hidden_size)
|
| 118 |
-
self.activation = nn.Tanh()
|
| 119 |
-
|
| 120 |
-
def forward(self, hidden_states):
|
| 121 |
-
first_token_tensor = hidden_states[:, 0]
|
| 122 |
-
pooled_output = self.dense(first_token_tensor)
|
| 123 |
-
pooled_output = self.activation(pooled_output)
|
| 124 |
-
return pooled_output
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
class BertCrossLayer(nn.Module):
|
| 128 |
-
def __init__(self, config):
|
| 129 |
-
super().__init__()
|
| 130 |
-
self.chunk_size_feed_forward = config.chunk_size_feed_forward
|
| 131 |
-
self.seq_len_dim = 1
|
| 132 |
-
self.attention = BertAttention(config)
|
| 133 |
-
self.is_decoder = config.is_decoder
|
| 134 |
-
self.add_cross_attention = config.add_cross_attention
|
| 135 |
-
self.crossattention = BertAttention(config)
|
| 136 |
-
self.intermediate = BertIntermediate(config)
|
| 137 |
-
self.output = BertOutput(config)
|
| 138 |
-
|
| 139 |
-
def forward(
|
| 140 |
-
self,
|
| 141 |
-
hidden_states,
|
| 142 |
-
encoder_hidden_states,
|
| 143 |
-
attention_mask=None,
|
| 144 |
-
encoder_attention_mask=None,
|
| 145 |
-
output_attentions=False,
|
| 146 |
-
):
|
| 147 |
-
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
|
| 148 |
-
self_attn_past_key_value = None #past_key_value[:2] if past_key_value is not None else None
|
| 149 |
-
self_attention_outputs = self.attention(
|
| 150 |
-
hidden_states,
|
| 151 |
-
attention_mask,
|
| 152 |
-
head_mask=None,
|
| 153 |
-
output_attentions=output_attentions,
|
| 154 |
-
past_key_value=None,
|
| 155 |
-
)
|
| 156 |
-
attention_output = self_attention_outputs[0]
|
| 157 |
-
|
| 158 |
-
# if decoder, the last output is tuple of self-attn cache
|
| 159 |
-
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
|
| 160 |
-
|
| 161 |
-
cross_attn_present_key_value = None
|
| 162 |
-
cross_attention_outputs = self.crossattention(
|
| 163 |
-
attention_output,
|
| 164 |
-
attention_mask,
|
| 165 |
-
None,
|
| 166 |
-
encoder_hidden_states,
|
| 167 |
-
encoder_attention_mask,
|
| 168 |
-
None,
|
| 169 |
-
output_attentions,
|
| 170 |
-
)
|
| 171 |
-
attention_output = cross_attention_outputs[0]
|
| 172 |
-
outputs = outputs + cross_attention_outputs[1:] # add cross attentions if we output attention weights
|
| 173 |
-
|
| 174 |
-
layer_output = apply_chunking_to_forward(
|
| 175 |
-
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
|
| 176 |
-
)
|
| 177 |
-
outputs = (layer_output,) + outputs
|
| 178 |
-
|
| 179 |
-
return outputs
|
| 180 |
-
|
| 181 |
-
def feed_forward_chunk(self, attention_output):
|
| 182 |
-
intermediate_output = self.intermediate(attention_output)
|
| 183 |
-
layer_output = self.output(intermediate_output, attention_output)
|
| 184 |
-
return layer_output
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
class VLEPreTrainedModel(PreTrainedModel):
|
| 188 |
-
"""
|
| 189 |
-
An abstract class to handle weights initialization.
|
| 190 |
-
"""
|
| 191 |
-
|
| 192 |
-
config_class = VLEConfig
|
| 193 |
-
base_model_prefix = "vle"
|
| 194 |
-
supports_gradient_checkpointing = False
|
| 195 |
-
_keys_to_ignore_on_load_missing = [r"position_ids"]
|
| 196 |
-
|
| 197 |
-
def _init_weights(self, module):
|
| 198 |
-
"""Initialize the weights"""
|
| 199 |
-
if isinstance(module, nn.Linear):
|
| 200 |
-
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 201 |
-
if module.bias is not None:
|
| 202 |
-
module.bias.data.zero_()
|
| 203 |
-
elif isinstance(module, nn.Embedding):
|
| 204 |
-
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 205 |
-
if module.padding_idx is not None:
|
| 206 |
-
module.weight.data[module.padding_idx].zero_()
|
| 207 |
-
elif isinstance(module, nn.LayerNorm):
|
| 208 |
-
module.bias.data.zero_()
|
| 209 |
-
module.weight.data.fill_(1.0)
|
| 210 |
-
''' TODO checkpointing
|
| 211 |
-
def _set_gradient_checkpointing(self, module, value=False):
|
| 212 |
-
if isinstance(module, BertEncoder):
|
| 213 |
-
module.gradient_checkpointing = value
|
| 214 |
-
'''
|
| 215 |
-
|
| 216 |
-
class VLEModel(VLEPreTrainedModel):
|
| 217 |
-
def __init__(
|
| 218 |
-
self,
|
| 219 |
-
config: Optional[VLEConfig] = None,
|
| 220 |
-
vision_model: Optional[PreTrainedModel] = None,
|
| 221 |
-
text_model: Optional[PreTrainedModel] = None,
|
| 222 |
-
):
|
| 223 |
-
|
| 224 |
-
if config is None and (vision_model is None or text_model is None):
|
| 225 |
-
raise ValueError("Either a configuration or an vision and a text model has to be provided")
|
| 226 |
-
|
| 227 |
-
if config is None:
|
| 228 |
-
config = VLEConfig(vision_model.config, text_model.config)
|
| 229 |
-
else:
|
| 230 |
-
if not isinstance(config, self.config_class):
|
| 231 |
-
raise ValueError(f"config: {config} has to be of type {self.config_class}")
|
| 232 |
-
|
| 233 |
-
# initialize with config
|
| 234 |
-
super().__init__(config)
|
| 235 |
-
|
| 236 |
-
if vision_model is None:
|
| 237 |
-
if isinstance(config.vision_config, CLIPVisionConfig):
|
| 238 |
-
vision_model = CLIPVisionModel(config.vision_config)
|
| 239 |
-
else:
|
| 240 |
-
vision_model = AutoModel.from_config(config.vision_config)
|
| 241 |
-
|
| 242 |
-
if text_model is None:
|
| 243 |
-
text_model = AutoModel.from_config(config.text_config)
|
| 244 |
-
|
| 245 |
-
self.vision_model = vision_model
|
| 246 |
-
self.text_model = text_model
|
| 247 |
-
|
| 248 |
-
# make sure that the individual model's config refers to the shared config
|
| 249 |
-
# so that the updates to the config will be synced
|
| 250 |
-
self.vision_model.config = self.config.vision_config
|
| 251 |
-
self.text_model.config = self.config.text_config
|
| 252 |
-
|
| 253 |
-
self.vision_embed_dim = config.vision_config.hidden_size
|
| 254 |
-
self.text_embed_dim = config.text_config.hidden_size
|
| 255 |
-
self.coattention_dim = config.hidden_size
|
| 256 |
-
|
| 257 |
-
# add projection layers
|
| 258 |
-
self.text_projection_layer = nn.Linear(self.text_embed_dim, self.coattention_dim)
|
| 259 |
-
self.image_projection_layer = nn.Linear(self.vision_embed_dim, self.coattention_dim)
|
| 260 |
-
|
| 261 |
-
#self.logit_scale = nn.Parameter(torch.ones([]) * self.config.logit_scale_init_value)
|
| 262 |
-
self.token_type_embeddings = nn.Embedding(config.num_token_types, config.hidden_size)
|
| 263 |
-
|
| 264 |
-
self.cross_modal_image_layers = nn.ModuleList([BertCrossLayer(config) for _ in range(config.num_hidden_layers)])
|
| 265 |
-
self.cross_modal_text_layers = nn.ModuleList([BertCrossLayer(config) for _ in range(config.num_hidden_layers)])
|
| 266 |
-
self.cross_modal_image_pooler = Pooler(config.hidden_size)
|
| 267 |
-
self.cross_modal_text_pooler = Pooler(config.hidden_size)
|
| 268 |
-
|
| 269 |
-
# Initialize weights and apply final processing
|
| 270 |
-
self.token_type_embeddings.apply(self._init_weights)
|
| 271 |
-
self.cross_modal_image_layers.apply(self._init_weights)
|
| 272 |
-
self.cross_modal_text_layers.apply(self._init_weights)
|
| 273 |
-
self.cross_modal_image_pooler.apply(self._init_weights)
|
| 274 |
-
self.cross_modal_text_pooler.apply(self._init_weights)
|
| 275 |
-
if hasattr(self,"text_projection_layer"):
|
| 276 |
-
self.text_projection_layer.apply(self._init_weights)
|
| 277 |
-
if hasattr(self,"image_projection_layer"):
|
| 278 |
-
self.image_projection_layer.apply(self._init_weights)
|
| 279 |
-
|
| 280 |
-
|
| 281 |
-
def forward(
|
| 282 |
-
self,
|
| 283 |
-
input_ids: Optional[torch.LongTensor] = None,
|
| 284 |
-
pixel_values: Optional[torch.FloatTensor] = None,
|
| 285 |
-
attention_mask: Optional[torch.Tensor] = None,
|
| 286 |
-
position_ids: Optional[torch.LongTensor] = None,
|
| 287 |
-
token_type_ids: Optional[torch.LongTensor] = None,
|
| 288 |
-
patch_ids = None,
|
| 289 |
-
return_loss: Optional[bool] = None,
|
| 290 |
-
return_dict: Optional[bool] = None,
|
| 291 |
-
) -> Union[Tuple[torch.Tensor], VLEModelOutput]:
|
| 292 |
-
|
| 293 |
-
return_dict = return_dict if return_dict is not None else self.config.return_dict
|
| 294 |
-
|
| 295 |
-
vision_outputs = self.vision_model(
|
| 296 |
-
pixel_values=pixel_values,
|
| 297 |
-
return_dict=return_dict,
|
| 298 |
-
)
|
| 299 |
-
|
| 300 |
-
text_outputs = self.text_model(
|
| 301 |
-
input_ids=input_ids,
|
| 302 |
-
attention_mask=attention_mask,
|
| 303 |
-
token_type_ids=token_type_ids,
|
| 304 |
-
position_ids=position_ids,
|
| 305 |
-
return_dict=return_dict,
|
| 306 |
-
)
|
| 307 |
-
|
| 308 |
-
image_embeds = self.vision_model.vision_model.post_layernorm(vision_outputs[0]) # last_hidden_state
|
| 309 |
-
image_embeds = self.image_projection_layer(image_embeds)
|
| 310 |
-
|
| 311 |
-
text_embeds = text_outputs[0] # last_hidden_state
|
| 312 |
-
text_embeds = self.text_projection_layer(text_embeds)
|
| 313 |
-
|
| 314 |
-
if patch_ids is not None:
|
| 315 |
-
raise NotImplementedError #TODO
|
| 316 |
-
|
| 317 |
-
image_masks = torch.ones((image_embeds.size(0), image_embeds.size(1)), dtype=torch.long, device=image_embeds.device)
|
| 318 |
-
extend_image_masks = self.text_model.get_extended_attention_mask(image_masks, image_masks.size())
|
| 319 |
-
image_embeds = image_embeds + self.token_type_embeddings(torch.full_like(image_masks, 1)) # image_token_type_idx=1 TODO use_vcr_token_type_embedding
|
| 320 |
-
|
| 321 |
-
extend_text_masks = self.text_model.get_extended_attention_mask(attention_mask, attention_mask.size())
|
| 322 |
-
text_embeds = text_embeds + self.token_type_embeddings(torch.zeros_like(attention_mask))
|
| 323 |
-
|
| 324 |
-
x, y = text_embeds, image_embeds
|
| 325 |
-
for text_layer, image_layer in zip(self.cross_modal_text_layers, self.cross_modal_image_layers):
|
| 326 |
-
x1 = text_layer(x, y, extend_text_masks, extend_image_masks)
|
| 327 |
-
y1 = image_layer(y, x, extend_image_masks, extend_text_masks)
|
| 328 |
-
x, y = x1[0], y1[0]
|
| 329 |
-
|
| 330 |
-
text_embeds, image_embeds = x, y
|
| 331 |
-
text_pooler_output = self.cross_modal_text_pooler(x)
|
| 332 |
-
image_pooler_output = self.cross_modal_image_pooler(y)
|
| 333 |
-
pooler_output = torch.cat([text_pooler_output, image_pooler_output], dim=-1)
|
| 334 |
-
|
| 335 |
-
if not return_dict:
|
| 336 |
-
output = (pooler_output, text_embeds, image_embeds)
|
| 337 |
-
return output
|
| 338 |
-
return VLEModelOutput(
|
| 339 |
-
pooler_output = pooler_output,
|
| 340 |
-
text_embeds = text_embeds,
|
| 341 |
-
image_embeds = image_embeds
|
| 342 |
-
)
|
| 343 |
-
|
| 344 |
-
|
| 345 |
-
@classmethod
|
| 346 |
-
def from_pretrained(cls, *args, **kwargs):
|
| 347 |
-
# At the moment fast initialization is not supported
|
| 348 |
-
# for composite models
|
| 349 |
-
kwargs["_fast_init"] = False
|
| 350 |
-
return super().from_pretrained(*args, **kwargs)
|
| 351 |
-
|
| 352 |
-
@classmethod
|
| 353 |
-
def from_vision_text_pretrained(
|
| 354 |
-
cls,
|
| 355 |
-
vision_model_name_or_path: str = None,
|
| 356 |
-
text_model_name_or_path: str = None,
|
| 357 |
-
*model_args,
|
| 358 |
-
**kwargs,
|
| 359 |
-
) -> PreTrainedModel:
|
| 360 |
-
|
| 361 |
-
kwargs_vision = {
|
| 362 |
-
argument[len("vision_") :]: value for argument, value in kwargs.items() if argument.startswith("vision_")
|
| 363 |
-
}
|
| 364 |
-
|
| 365 |
-
kwargs_text = {
|
| 366 |
-
argument[len("text_") :]: value for argument, value in kwargs.items() if argument.startswith("text_")
|
| 367 |
-
}
|
| 368 |
-
|
| 369 |
-
# remove vision, text kwargs from kwargs
|
| 370 |
-
for key in kwargs_vision.keys():
|
| 371 |
-
del kwargs["vision_" + key]
|
| 372 |
-
for key in kwargs_text.keys():
|
| 373 |
-
del kwargs["text_" + key]
|
| 374 |
-
|
| 375 |
-
# Load and initialize the vision and text model
|
| 376 |
-
vision_model = kwargs_vision.pop("model", None)
|
| 377 |
-
if vision_model is None:
|
| 378 |
-
if vision_model_name_or_path is None:
|
| 379 |
-
raise ValueError(
|
| 380 |
-
"If `vision_model` is not defined as an argument, a `vision_model_name_or_path` has to be defined"
|
| 381 |
-
)
|
| 382 |
-
|
| 383 |
-
if "config" not in kwargs_vision:
|
| 384 |
-
vision_config = AutoConfig.from_pretrained(vision_model_name_or_path)
|
| 385 |
-
|
| 386 |
-
if vision_config.model_type == "clip":
|
| 387 |
-
kwargs_vision["config"] = vision_config.vision_config
|
| 388 |
-
vision_model = CLIPVisionModel.from_pretrained(vision_model_name_or_path, *model_args, **kwargs_vision)
|
| 389 |
-
else:
|
| 390 |
-
kwargs_vision["config"] = vision_config
|
| 391 |
-
vision_model = AutoModel.from_pretrained(vision_model_name_or_path, *model_args, **kwargs_vision)
|
| 392 |
-
|
| 393 |
-
text_model = kwargs_text.pop("model", None)
|
| 394 |
-
if text_model is None:
|
| 395 |
-
if text_model_name_or_path is None:
|
| 396 |
-
raise ValueError(
|
| 397 |
-
"If `text_model` is not defined as an argument, a `text_model_name_or_path` has to be defined"
|
| 398 |
-
)
|
| 399 |
-
|
| 400 |
-
if "config" not in kwargs_text:
|
| 401 |
-
text_config = AutoConfig.from_pretrained(text_model_name_or_path)
|
| 402 |
-
kwargs_text["config"] = text_config
|
| 403 |
-
|
| 404 |
-
text_model = AutoModel.from_pretrained(text_model_name_or_path, *model_args, **kwargs_text)
|
| 405 |
-
|
| 406 |
-
# instantiate config with corresponding kwargs
|
| 407 |
-
config = VLEConfig(vision_model.config, text_model.config, **kwargs)
|
| 408 |
-
|
| 409 |
-
# init model
|
| 410 |
-
model = cls(config=config, vision_model=vision_model, text_model=text_model)
|
| 411 |
-
|
| 412 |
-
# the projection layers are always newly initialized when loading the model
|
| 413 |
-
# using pre-trained vision and text model.
|
| 414 |
-
logger.warning(
|
| 415 |
-
"The coattention layers and projection layers are newly initialized. You should probably TRAIN this model on a down-stream task to be"
|
| 416 |
-
" able to use it for predictions and inference."
|
| 417 |
-
)
|
| 418 |
-
return model
|
| 419 |
-
|
| 420 |
-
|
| 421 |
-
def get_text_features(
|
| 422 |
-
self,
|
| 423 |
-
input_ids=None,
|
| 424 |
-
attention_mask=None,
|
| 425 |
-
position_ids=None,
|
| 426 |
-
token_type_ids=None,
|
| 427 |
-
output_attentions=None,
|
| 428 |
-
output_hidden_states=None,
|
| 429 |
-
return_dict=None,
|
| 430 |
-
):
|
| 431 |
-
text_outputs = self.text_model(
|
| 432 |
-
input_ids=input_ids,
|
| 433 |
-
attention_mask=attention_mask,
|
| 434 |
-
position_ids=position_ids,
|
| 435 |
-
token_type_ids=token_type_ids,
|
| 436 |
-
#output_attentions=output_attentions,
|
| 437 |
-
#output_hidden_states=output_hidden_states,
|
| 438 |
-
return_dict=return_dict,
|
| 439 |
-
)
|
| 440 |
-
return text_outputs[0] # last_hidden_state
|
| 441 |
-
|
| 442 |
-
def get_image_features(
|
| 443 |
-
self,
|
| 444 |
-
pixel_values=None,
|
| 445 |
-
output_attentions=None,
|
| 446 |
-
output_hidden_states=None,
|
| 447 |
-
return_dict=None,
|
| 448 |
-
):
|
| 449 |
-
r"""
|
| 450 |
-
Returns:
|
| 451 |
-
image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
|
| 452 |
-
applying the projection layer to the pooled output of [`CLIPVisionModel`].
|
| 453 |
-
|
| 454 |
-
Examples:
|
| 455 |
-
|
| 456 |
-
```python
|
| 457 |
-
>>> from PIL import Image
|
| 458 |
-
>>> import requests
|
| 459 |
-
>>> from transformers import VLEModel, AutoImageProcessor
|
| 460 |
-
|
| 461 |
-
>>> model = VLEModel.from_pretrained("clip-italian/clip-italian")
|
| 462 |
-
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
|
| 463 |
-
|
| 464 |
-
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 465 |
-
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 466 |
-
|
| 467 |
-
>>> inputs = image_processor(images=image, return_tensors="pt")
|
| 468 |
-
|
| 469 |
-
>>> image_features = model.get_image_features(**inputs)
|
| 470 |
-
```"""
|
| 471 |
-
vision_outputs = self.vision_model(
|
| 472 |
-
pixel_values=pixel_values,
|
| 473 |
-
#output_attentions=output_attentions,
|
| 474 |
-
#output_hidden_states=output_hidden_states,
|
| 475 |
-
return_dict=return_dict,
|
| 476 |
-
)
|
| 477 |
-
last_hidden_state = self.vision_model.vision_model.post_layernorm(vision_outputs[0])
|
| 478 |
-
return last_hidden_state
|
| 479 |
-
def get_input_embeddings(self):
|
| 480 |
-
return self.text_model.embeddings.word_embeddings
|
| 481 |
-
|
| 482 |
-
def set_input_embeddings(self, new_embeddings):
|
| 483 |
-
self.text_model.embeddings.word_embeddings = new_embeddings
|
| 484 |
-
|
| 485 |
-
class VLEForVQA(VLEPreTrainedModel):
|
| 486 |
-
def __init__(
|
| 487 |
-
self,
|
| 488 |
-
config: Optional[VLEConfig] = None,
|
| 489 |
-
vision_model: Optional[PreTrainedModel] = None,
|
| 490 |
-
text_model: Optional[PreTrainedModel] = None,
|
| 491 |
-
):
|
| 492 |
-
super().__init__(config)
|
| 493 |
-
self.vle = VLEModel(config, vision_model, text_model)
|
| 494 |
-
|
| 495 |
-
hidden_size = config.hidden_size
|
| 496 |
-
self.num_vqa_labels = len(self.config.id2label)
|
| 497 |
-
self.vqa_classifier = nn.Sequential(
|
| 498 |
-
nn.Linear(hidden_size * 2, hidden_size * 2),
|
| 499 |
-
nn.LayerNorm(hidden_size * 2),
|
| 500 |
-
nn.GELU(),
|
| 501 |
-
nn.Linear(hidden_size * 2, self.num_vqa_labels),
|
| 502 |
-
)
|
| 503 |
-
self.vqa_classifier.apply(self._init_weights)
|
| 504 |
-
|
| 505 |
-
def forward(self,
|
| 506 |
-
input_ids: Optional[torch.LongTensor],
|
| 507 |
-
pixel_values: Optional[torch.FloatTensor],
|
| 508 |
-
attention_mask: Optional[torch.Tensor] = None,
|
| 509 |
-
position_ids: Optional[torch.LongTensor] = None,
|
| 510 |
-
token_type_ids: Optional[torch.LongTensor] = None,
|
| 511 |
-
patch_ids = None,
|
| 512 |
-
vqa_labels = None,
|
| 513 |
-
vqa_scores = None,
|
| 514 |
-
return_loss: Optional[bool] = None,
|
| 515 |
-
return_dict: Optional[bool] = None,
|
| 516 |
-
) -> Union[Tuple[torch.Tensor], VLEForVQAOutput]:
|
| 517 |
-
|
| 518 |
-
return_dict = return_dict if return_dict is not None else self.config.return_dict
|
| 519 |
-
|
| 520 |
-
vle_output = self.vle(
|
| 521 |
-
input_ids = input_ids,
|
| 522 |
-
pixel_values = pixel_values,
|
| 523 |
-
attention_mask = attention_mask,
|
| 524 |
-
position_ids = position_ids,
|
| 525 |
-
token_type_ids = token_type_ids,
|
| 526 |
-
patch_ids = patch_ids,)
|
| 527 |
-
pooler_output = vle_output[0]
|
| 528 |
-
vqa_logits = self.vqa_classifier(pooler_output)
|
| 529 |
-
|
| 530 |
-
|
| 531 |
-
vqa_loss = None
|
| 532 |
-
if return_loss and vqa_labels is not None and vqa_scores is not None:
|
| 533 |
-
vqa_targets = torch.zeros(len(vqa_logits), self.num_vqa_labels,device=vqa_logits.device)
|
| 534 |
-
for i, (_label, _score) in enumerate(zip(vqa_labels, vqa_scores)):
|
| 535 |
-
for l, s in zip(_label, _score):
|
| 536 |
-
vqa_targets[i, l] = s
|
| 537 |
-
vqa_loss = F.binary_cross_entropy_with_logits(vqa_logits, vqa_targets) * vqa_targets.shape[1]
|
| 538 |
-
# https://github.com/jnhwkim/ban-vqa/blob/master/train.py#L19
|
| 539 |
-
|
| 540 |
-
if not return_dict:
|
| 541 |
-
output = (vqa_logits,)
|
| 542 |
-
return ((vqa_loss,) + output) if vqa_loss is not None else output
|
| 543 |
-
return VLEForVQAOutput(
|
| 544 |
-
loss = vqa_loss,
|
| 545 |
-
logits = vqa_logits
|
| 546 |
-
)
|
| 547 |
-
|
| 548 |
-
|
| 549 |
-
class VLEForITM(VLEPreTrainedModel):
|
| 550 |
-
def __init__(
|
| 551 |
-
self,
|
| 552 |
-
config: Optional[VLEConfig] = None,
|
| 553 |
-
vision_model: Optional[PreTrainedModel] = None,
|
| 554 |
-
text_model: Optional[PreTrainedModel] = None,
|
| 555 |
-
):
|
| 556 |
-
super().__init__(config)
|
| 557 |
-
self.vle = VLEModel(config, vision_model, text_model)
|
| 558 |
-
|
| 559 |
-
hidden_size = config.hidden_size
|
| 560 |
-
self.itm_score = ITMHead(hidden_size*2)
|
| 561 |
-
self.itm_score.apply(self._init_weights)
|
| 562 |
-
|
| 563 |
-
def forward(self,
|
| 564 |
-
input_ids: Optional[torch.LongTensor],
|
| 565 |
-
pixel_values: Optional[torch.FloatTensor],
|
| 566 |
-
attention_mask: Optional[torch.Tensor] = None,
|
| 567 |
-
position_ids: Optional[torch.LongTensor] = None,
|
| 568 |
-
token_type_ids: Optional[torch.LongTensor] = None,
|
| 569 |
-
patch_ids = None,
|
| 570 |
-
itm_labels = None,
|
| 571 |
-
return_loss: Optional[bool] = None,
|
| 572 |
-
return_dict: Optional[bool] = None,
|
| 573 |
-
) -> Union[Tuple[torch.Tensor], VLEForITMOutput]:
|
| 574 |
-
|
| 575 |
-
return_dict = return_dict if return_dict is not None else self.config.return_dict
|
| 576 |
-
|
| 577 |
-
vle_output = self.vle(
|
| 578 |
-
input_ids = input_ids,
|
| 579 |
-
pixel_values = pixel_values,
|
| 580 |
-
attention_mask = attention_mask,
|
| 581 |
-
position_ids = position_ids,
|
| 582 |
-
token_type_ids = token_type_ids,
|
| 583 |
-
patch_ids = patch_ids,)
|
| 584 |
-
pooler_output = vle_output[0]
|
| 585 |
-
|
| 586 |
-
itm_logits = self.itm_score(pooler_output)
|
| 587 |
-
itm_loss = None
|
| 588 |
-
if return_loss and itm_labels is not None:
|
| 589 |
-
itm_loss = nn.functional.cross_entropy(itm_logits, torch.tensor(itm_labels).long().to(itm_logits.device))
|
| 590 |
-
if not return_dict:
|
| 591 |
-
output = (itm_logits,)
|
| 592 |
-
return ((itm_loss,) + output) if itm_loss is not None else output
|
| 593 |
-
return VLEForITMOutput(loss = itm_loss, logits = itm_logits)
|
| 594 |
-
|
| 595 |
-
|
| 596 |
-
class VLEForPBC(VLEPreTrainedModel):
|
| 597 |
-
def __init__(
|
| 598 |
-
self,
|
| 599 |
-
config: Optional[VLEConfig] = None,
|
| 600 |
-
vision_model: Optional[PreTrainedModel] = None,
|
| 601 |
-
text_model: Optional[PreTrainedModel] = None,
|
| 602 |
-
):
|
| 603 |
-
super().__init__(config)
|
| 604 |
-
self.vle = VLEModel(config, vision_model, text_model)
|
| 605 |
-
|
| 606 |
-
hidden_size = config.hidden_size
|
| 607 |
-
self.pbc_classifier = nn.Sequential(
|
| 608 |
-
nn.Linear(hidden_size, hidden_size),
|
| 609 |
-
nn.LayerNorm(hidden_size),
|
| 610 |
-
nn.GELU(),
|
| 611 |
-
nn.Linear(hidden_size, 2),
|
| 612 |
-
)
|
| 613 |
-
self.pbc_classifier.apply(self._init_weights)
|
| 614 |
-
|
| 615 |
-
def forward(self,
|
| 616 |
-
input_ids: Optional[torch.LongTensor],
|
| 617 |
-
pixel_values: Optional[torch.FloatTensor],
|
| 618 |
-
attention_mask: Optional[torch.Tensor] = None,
|
| 619 |
-
position_ids: Optional[torch.LongTensor] = None,
|
| 620 |
-
token_type_ids: Optional[torch.LongTensor] = None,
|
| 621 |
-
patch_ids = None,
|
| 622 |
-
pbc_labels = None,
|
| 623 |
-
return_loss: Optional[bool] = None,
|
| 624 |
-
return_dict: Optional[bool] = None,
|
| 625 |
-
) -> Union[Tuple[torch.Tensor], VLEForPBCOutput]:
|
| 626 |
-
|
| 627 |
-
return_dict = return_dict if return_dict is not None else self.config.return_dict
|
| 628 |
-
|
| 629 |
-
vle_output = self.vle(
|
| 630 |
-
input_ids = input_ids,
|
| 631 |
-
pixel_values = pixel_values,
|
| 632 |
-
attention_mask = attention_mask,
|
| 633 |
-
position_ids = position_ids,
|
| 634 |
-
token_type_ids = token_type_ids,
|
| 635 |
-
patch_ids = patch_ids,)
|
| 636 |
-
image_embeds = vle_output['image_embeds']
|
| 637 |
-
pbc_logits = self.pbc_classifier(image_embeds[:,1:,:])
|
| 638 |
-
|
| 639 |
-
pbc_loss = None
|
| 640 |
-
if return_loss and pbc_labels is not None:
|
| 641 |
-
pbc_loss = F.cross_entropy(pbc_logits, torch.tensor(pbc_labels).long().to(pbc_logits.device))
|
| 642 |
-
|
| 643 |
-
if not return_dict:
|
| 644 |
-
output = (pbc_logits,)
|
| 645 |
-
return ((pbc_loss,) + output) if pbc_loss is not None else output
|
| 646 |
-
return VLEForPBCOutput(loss = pbc_loss, logits = pbc_logits)
|
| 647 |
-
|
| 648 |
-
|
| 649 |
-
class VLEForMLM(VLEPreTrainedModel):
|
| 650 |
-
_keys_to_ignore_on_load_missing = [r"mlm_score.1.predictions.decoder.weight",r"mlm_score.1.predictions.decoder.bias"]
|
| 651 |
-
def __init__(
|
| 652 |
-
self,
|
| 653 |
-
config: Optional[VLEConfig] = None,
|
| 654 |
-
vision_model: Optional[PreTrainedModel] = None,
|
| 655 |
-
text_model: Optional[PreTrainedModel] = None,
|
| 656 |
-
):
|
| 657 |
-
super().__init__(config)
|
| 658 |
-
self.vle = VLEModel(config, vision_model, text_model)
|
| 659 |
-
|
| 660 |
-
hidden_size = config.hidden_size
|
| 661 |
-
mlm_head = DebertaV2OnlyMLMHead(self.config.text_config)
|
| 662 |
-
mlm_transform = nn.Linear(hidden_size, self.config.text_config.hidden_size)
|
| 663 |
-
self.mlm_score = nn.Sequential(
|
| 664 |
-
mlm_transform,
|
| 665 |
-
mlm_head,
|
| 666 |
-
)
|
| 667 |
-
|
| 668 |
-
def forward(self,
|
| 669 |
-
input_ids: Optional[torch.LongTensor],
|
| 670 |
-
pixel_values: Optional[torch.FloatTensor],
|
| 671 |
-
attention_mask: Optional[torch.Tensor] = None,
|
| 672 |
-
position_ids: Optional[torch.LongTensor] = None,
|
| 673 |
-
token_type_ids: Optional[torch.LongTensor] = None,
|
| 674 |
-
patch_ids = None,
|
| 675 |
-
mlm_labels = None,
|
| 676 |
-
return_loss: Optional[bool] = None,
|
| 677 |
-
return_dict: Optional[bool] = None,
|
| 678 |
-
) -> Union[Tuple[torch.Tensor], VLEForMLMOutput]:
|
| 679 |
-
|
| 680 |
-
return_dict = return_dict if return_dict is not None else self.config.return_dict
|
| 681 |
-
|
| 682 |
-
vle_output = self.vle(
|
| 683 |
-
input_ids = input_ids,
|
| 684 |
-
pixel_values = pixel_values,
|
| 685 |
-
attention_mask = attention_mask,
|
| 686 |
-
position_ids = position_ids,
|
| 687 |
-
token_type_ids = token_type_ids,
|
| 688 |
-
patch_ids = patch_ids,)
|
| 689 |
-
text_feats = vle_output.text_embeds
|
| 690 |
-
|
| 691 |
-
mlm_logits = self.mlm_score(text_feats)
|
| 692 |
-
mlm_loss = None
|
| 693 |
-
if return_loss and mlm_labels is not None:
|
| 694 |
-
mlm_loss = F.cross_entropy(
|
| 695 |
-
mlm_logits.view(-1, self.config.text_config.vocab_size),
|
| 696 |
-
mlm_labels.view(-1),
|
| 697 |
-
ignore_index=-100,
|
| 698 |
-
)
|
| 699 |
-
if not return_dict:
|
| 700 |
-
output = (mlm_logits,)
|
| 701 |
-
return ((mlm_loss,) + output) if mlm_loss is not None else output
|
| 702 |
-
return VLEForMLMOutput(loss = mlm_loss, logits = mlm_logits)
|
| 703 |
-
|
| 704 |
-
|
| 705 |
-
def get_output_embeddings(self):
|
| 706 |
-
return self.mlm_score[1].predictions.decoder
|
| 707 |
-
|
| 708 |
-
def set_output_embeddings(self, new_embeddings):
|
| 709 |
-
self.mlm_score[1].predictions.decoder = new_embeddings
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
models/VLE/pipeline_vle.py
DELETED
|
@@ -1,166 +0,0 @@
|
|
| 1 |
-
import torch
|
| 2 |
-
from transformers import Pipeline
|
| 3 |
-
from PIL import Image
|
| 4 |
-
from typing import Union
|
| 5 |
-
from copy import deepcopy
|
| 6 |
-
import matplotlib.pyplot as plt
|
| 7 |
-
import io
|
| 8 |
-
|
| 9 |
-
class VLEForVQAPipeline(Pipeline):
|
| 10 |
-
|
| 11 |
-
def __init__(self, vle_processor, *args, **kwargs):
|
| 12 |
-
self.vle_processor = vle_processor
|
| 13 |
-
super().__init__(*args, **kwargs)
|
| 14 |
-
|
| 15 |
-
def _sanitize_parameters(self, top_k=None, **kwargs):
|
| 16 |
-
preprocess_params, forward_params, postprocess_params = {}, {}, {}
|
| 17 |
-
if top_k is not None:
|
| 18 |
-
postprocess_params["top_k"] = top_k
|
| 19 |
-
return preprocess_params, forward_params, postprocess_params
|
| 20 |
-
|
| 21 |
-
def __call__(self, image: Union["Image.Image", str], question: str = None, **kwargs):
|
| 22 |
-
|
| 23 |
-
if isinstance(image, (Image.Image, str)) and isinstance(question, str):
|
| 24 |
-
inputs = {"image": image, "question": question}
|
| 25 |
-
else:
|
| 26 |
-
"""
|
| 27 |
-
Supports the following format
|
| 28 |
-
- {"image": image, "question": question}
|
| 29 |
-
- [{"image": image, "question": question}]
|
| 30 |
-
- Generator and datasets
|
| 31 |
-
"""
|
| 32 |
-
inputs = image
|
| 33 |
-
results = super().__call__(inputs, **kwargs)
|
| 34 |
-
return results
|
| 35 |
-
|
| 36 |
-
def preprocess(self, inputs):
|
| 37 |
-
model_inputs = self.vle_processor(text=inputs['question'], images=inputs['image'], return_tensors="pt",padding=True)
|
| 38 |
-
return model_inputs
|
| 39 |
-
|
| 40 |
-
def _forward(self, model_inputs):
|
| 41 |
-
model_outputs = self.model(**model_inputs)
|
| 42 |
-
return model_outputs
|
| 43 |
-
|
| 44 |
-
def postprocess(self, model_outputs, top_k=1):
|
| 45 |
-
if top_k > self.model.num_vqa_labels:
|
| 46 |
-
top_k = self.model.num_vqa_labels
|
| 47 |
-
probs = torch.softmax(model_outputs['logits'], dim=-1)
|
| 48 |
-
probs, preds = torch.sort(probs, descending=True)
|
| 49 |
-
probs = probs[:,:top_k].tolist()[0]
|
| 50 |
-
preds = preds[:,:top_k].tolist()[0]
|
| 51 |
-
|
| 52 |
-
return [{"score": score, "answer": self.model.config.id2label[pred]} for score, pred in zip(probs, preds)]
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
class VLEForPBCPipeline(Pipeline):
|
| 57 |
-
def __init__(self, vle_processor, *args, **kwargs):
|
| 58 |
-
self.vle_processor = vle_processor
|
| 59 |
-
self.id2label = {0:"False",1:"True"}
|
| 60 |
-
super().__init__(*args, **kwargs)
|
| 61 |
-
|
| 62 |
-
def _sanitize_parameters(self, **kwargs):
|
| 63 |
-
preprocess_params, forward_params, postprocess_params = {}, {}, {}
|
| 64 |
-
return preprocess_params, forward_params, postprocess_params
|
| 65 |
-
|
| 66 |
-
def __call__(self, image: Union["Image.Image", str], text: str = None, **kwargs):
|
| 67 |
-
if isinstance(image, (Image.Image, str)) and isinstance(text, str):
|
| 68 |
-
inputs = {"image": image, "text": text}
|
| 69 |
-
else:
|
| 70 |
-
"""
|
| 71 |
-
Supports the following format
|
| 72 |
-
- {"image": image, "text": text}
|
| 73 |
-
- [{"image": image, "text": text}]
|
| 74 |
-
- Generator and datasets
|
| 75 |
-
"""
|
| 76 |
-
inputs = image
|
| 77 |
-
results = super().__call__(inputs, **kwargs)
|
| 78 |
-
return results
|
| 79 |
-
|
| 80 |
-
def preprocess(self, inputs):
|
| 81 |
-
model_inputs = self.vle_processor(text=inputs['text'], images=inputs['image'], return_tensors="pt",padding=True)
|
| 82 |
-
return model_inputs, inputs['image']
|
| 83 |
-
|
| 84 |
-
def _forward(self, model_inputs):
|
| 85 |
-
model_outputs = self.model(**model_inputs[0])
|
| 86 |
-
return model_outputs, model_inputs[1]
|
| 87 |
-
|
| 88 |
-
def postprocess(self, model_outputs):
|
| 89 |
-
probs = torch.softmax(model_outputs[0]['logits'], dim=-1)
|
| 90 |
-
probs = probs.tolist()[0]
|
| 91 |
-
new_image = self.paint_in_image(model_outputs[0]['logits'], model_outputs[1])
|
| 92 |
-
return {"score": probs, "image": new_image}
|
| 93 |
-
|
| 94 |
-
def paint_in_image(self, logits, raw_image):
|
| 95 |
-
image_back = deepcopy(raw_image)
|
| 96 |
-
raw_image_size = image_back.size
|
| 97 |
-
resized_image_size = self.model.config.vision_config.image_size
|
| 98 |
-
patch_size = self.model.config.vision_config.patch_size
|
| 99 |
-
probs = torch.softmax(logits.detach()[0,:,1].to('cpu'),dim=-1).numpy().reshape(-1, resized_image_size//patch_size)
|
| 100 |
-
|
| 101 |
-
plt.close('all')
|
| 102 |
-
plt.axis('off')
|
| 103 |
-
plt.imshow(probs, cmap='gray', interpolation='None', vmin=(probs.max()-probs.min())*2/5+probs.min(),alpha=0.7)
|
| 104 |
-
plt.xticks([])
|
| 105 |
-
plt.yticks([])
|
| 106 |
-
buf = io.BytesIO()
|
| 107 |
-
plt.savefig(buf, dpi=100, transparent=True, bbox_inches='tight', pad_inches=0)
|
| 108 |
-
image_front = Image.open(buf)
|
| 109 |
-
|
| 110 |
-
def filter_image_front(img: Image.Image):
|
| 111 |
-
width, height = img.width, img.height
|
| 112 |
-
for x in range(width):
|
| 113 |
-
for y in range(height):
|
| 114 |
-
r,g,b,a = img.getpixel((x,y))
|
| 115 |
-
a = int (a * (1-r/255))
|
| 116 |
-
img.putpixel((x,y), (r,g,b,a))
|
| 117 |
-
return img
|
| 118 |
-
|
| 119 |
-
image_front = filter_image_front(image_front).resize(raw_image_size)
|
| 120 |
-
image_back.paste(image_front, (0,0), image_front)
|
| 121 |
-
mixed_image = image_back.resize(raw_image_size)
|
| 122 |
-
buf.close()
|
| 123 |
-
|
| 124 |
-
return mixed_image
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
class VLEForITMPipeline(Pipeline):
|
| 129 |
-
def __init__(self, vle_processor, *args, **kwargs):
|
| 130 |
-
self.vle_processor = vle_processor
|
| 131 |
-
self.id2label = {0:"False",1:"True"}
|
| 132 |
-
super().__init__(*args, **kwargs)
|
| 133 |
-
|
| 134 |
-
def _sanitize_parameters(self, **kwargs):
|
| 135 |
-
preprocess_params, forward_params, postprocess_params = {}, {}, {}
|
| 136 |
-
return preprocess_params, forward_params, postprocess_params
|
| 137 |
-
|
| 138 |
-
def __call__(self, image: Union["Image.Image", str], text: str = None, **kwargs):
|
| 139 |
-
if isinstance(image, (Image.Image, str)) and isinstance(text, str):
|
| 140 |
-
inputs = {"image": image, "text": text}
|
| 141 |
-
else:
|
| 142 |
-
"""
|
| 143 |
-
Supports the following format
|
| 144 |
-
- {"image": image, "text": text}
|
| 145 |
-
- [{"image": image, "text": text}]
|
| 146 |
-
- Generator and datasets
|
| 147 |
-
"""
|
| 148 |
-
inputs = image
|
| 149 |
-
results = super().__call__(inputs, **kwargs)
|
| 150 |
-
return results
|
| 151 |
-
|
| 152 |
-
def preprocess(self, inputs):
|
| 153 |
-
model_inputs = self.vle_processor(text=inputs['text'], images=inputs['image'], return_tensors="pt",padding=True)
|
| 154 |
-
return model_inputs
|
| 155 |
-
|
| 156 |
-
def _forward(self, model_inputs):
|
| 157 |
-
model_outputs = self.model(**model_inputs)
|
| 158 |
-
return model_outputs
|
| 159 |
-
|
| 160 |
-
def postprocess(self, model_outputs):
|
| 161 |
-
probs = torch.softmax(model_outputs['logits'], dim=-1)
|
| 162 |
-
preds = torch.argmax(probs, dim=-1)
|
| 163 |
-
probs = probs.tolist()[0]
|
| 164 |
-
preds = self.id2label[preds.tolist()[0]]
|
| 165 |
-
|
| 166 |
-
return {"score": probs, "match": preds}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
models/VLE/processing_vle.py
DELETED
|
@@ -1,149 +0,0 @@
|
|
| 1 |
-
# coding=utf-8
|
| 2 |
-
# Copyright 2021 The HuggingFace Inc. team.
|
| 3 |
-
#
|
| 4 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
# you may not use this file except in compliance with the License.
|
| 6 |
-
# You may obtain a copy of the License at
|
| 7 |
-
#
|
| 8 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
#
|
| 10 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
# See the License for the specific language governing permissions and
|
| 14 |
-
# limitations under the License.
|
| 15 |
-
"""
|
| 16 |
-
Processor class for VLE
|
| 17 |
-
"""
|
| 18 |
-
|
| 19 |
-
import warnings
|
| 20 |
-
|
| 21 |
-
from transformers.processing_utils import ProcessorMixin
|
| 22 |
-
from transformers.tokenization_utils_base import BatchEncoding
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
class VLEProcessor(ProcessorMixin):
|
| 26 |
-
r"""
|
| 27 |
-
Constructs a VLE processor which wraps an image processor and a tokenizer into a single
|
| 28 |
-
processor.
|
| 29 |
-
|
| 30 |
-
[`VLEProcessor`] offers all the functionalities of [`AutoImageProcessor`] and [`AutoTokenizer`].
|
| 31 |
-
See the [`~VLEProcessor.__call__`] and [`~VLEProcessor.decode`] for more
|
| 32 |
-
information.
|
| 33 |
-
|
| 34 |
-
Args:
|
| 35 |
-
image_processor ([`AutoImageProcessor`]):
|
| 36 |
-
The image processor is a required input.
|
| 37 |
-
tokenizer ([`PreTrainedTokenizer`]):
|
| 38 |
-
The tokenizer is a required input.
|
| 39 |
-
"""
|
| 40 |
-
attributes = ["image_processor", "tokenizer"]
|
| 41 |
-
image_processor_class = "CLIPImageProcessor"
|
| 42 |
-
tokenizer_class = "DebertaV2Tokenizer"
|
| 43 |
-
|
| 44 |
-
def __init__(self, image_processor=None, tokenizer=None, **kwargs):
|
| 45 |
-
if "feature_extractor" in kwargs:
|
| 46 |
-
warnings.warn(
|
| 47 |
-
"The `feature_extractor` argument is deprecated and will be removed in v5, use `image_processor`"
|
| 48 |
-
" instead.",
|
| 49 |
-
FutureWarning,
|
| 50 |
-
)
|
| 51 |
-
feature_extractor = kwargs.pop("feature_extractor")
|
| 52 |
-
|
| 53 |
-
image_processor = image_processor if image_processor is not None else feature_extractor
|
| 54 |
-
if image_processor is None:
|
| 55 |
-
raise ValueError("You need to specify an `image_processor`.")
|
| 56 |
-
if tokenizer is None:
|
| 57 |
-
raise ValueError("You need to specify a `tokenizer`.")
|
| 58 |
-
|
| 59 |
-
super().__init__(image_processor, tokenizer)
|
| 60 |
-
self.current_processor = self.image_processor
|
| 61 |
-
|
| 62 |
-
def __call__(self, text=None, images=None, return_tensors=None, **kwargs): #TODO more specific args?
|
| 63 |
-
"""
|
| 64 |
-
Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
|
| 65 |
-
and `kwargs` arguments to VLETokenizer's [`~PreTrainedTokenizer.__call__`] if `text` is not
|
| 66 |
-
`None` to encode the text. To prepare the image(s), this method forwards the `images` and `kwrags` arguments to
|
| 67 |
-
AutoImageProcessor's [`~AutoImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
|
| 68 |
-
of the above two methods for more information.
|
| 69 |
-
|
| 70 |
-
Args:
|
| 71 |
-
text (`str`, `List[str]`, `List[List[str]]`):
|
| 72 |
-
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
|
| 73 |
-
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
|
| 74 |
-
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
|
| 75 |
-
images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
|
| 76 |
-
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
|
| 77 |
-
tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
|
| 78 |
-
number of channels, H and W are image height and width.
|
| 79 |
-
|
| 80 |
-
return_tensors (`str` or [`~utils.TensorType`], *optional*):
|
| 81 |
-
If set, will return tensors of a particular framework. Acceptable values are:
|
| 82 |
-
|
| 83 |
-
- `'tf'`: Return TensorFlow `tf.constant` objects.
|
| 84 |
-
- `'pt'`: Return PyTorch `torch.Tensor` objects.
|
| 85 |
-
- `'np'`: Return NumPy `np.ndarray` objects.
|
| 86 |
-
- `'jax'`: Return JAX `jnp.ndarray` objects.
|
| 87 |
-
|
| 88 |
-
Returns:
|
| 89 |
-
[`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
|
| 90 |
-
|
| 91 |
-
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
|
| 92 |
-
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
|
| 93 |
-
`return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
|
| 94 |
-
`None`).
|
| 95 |
-
- **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
|
| 96 |
-
"""
|
| 97 |
-
|
| 98 |
-
if text is None and images is None:
|
| 99 |
-
raise ValueError("You have to specify either text or images. Both cannot be none.")
|
| 100 |
-
|
| 101 |
-
if text is not None:
|
| 102 |
-
encoding = self.tokenizer(text, return_tensors=return_tensors, **kwargs)
|
| 103 |
-
|
| 104 |
-
if images is not None:
|
| 105 |
-
image_features = self.image_processor(images, return_tensors=return_tensors, **kwargs)
|
| 106 |
-
|
| 107 |
-
if text is not None and images is not None:
|
| 108 |
-
encoding["pixel_values"] = image_features.pixel_values
|
| 109 |
-
return encoding
|
| 110 |
-
elif text is not None:
|
| 111 |
-
return encoding
|
| 112 |
-
else:
|
| 113 |
-
return BatchEncoding(data=dict(**image_features), tensor_type=return_tensors)
|
| 114 |
-
|
| 115 |
-
def batch_decode(self, *args, **kwargs):
|
| 116 |
-
"""
|
| 117 |
-
This method forwards all its arguments to VLETokenizer's
|
| 118 |
-
[`~PreTrainedTokenizer.batch_decode`]. Please refer to the docstring of this method for more information.
|
| 119 |
-
"""
|
| 120 |
-
return self.tokenizer.batch_decode(*args, **kwargs)
|
| 121 |
-
|
| 122 |
-
def decode(self, *args, **kwargs):
|
| 123 |
-
"""
|
| 124 |
-
This method forwards all its arguments to VLETokenizer's [`~PreTrainedTokenizer.decode`].
|
| 125 |
-
Please refer to the docstring of this method for more information.
|
| 126 |
-
"""
|
| 127 |
-
return self.tokenizer.decode(*args, **kwargs)
|
| 128 |
-
|
| 129 |
-
@property
|
| 130 |
-
def model_input_names(self):
|
| 131 |
-
tokenizer_input_names = self.tokenizer.model_input_names
|
| 132 |
-
image_processor_input_names = self.image_processor.model_input_names
|
| 133 |
-
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
|
| 134 |
-
|
| 135 |
-
@property
|
| 136 |
-
def feature_extractor_class(self):
|
| 137 |
-
warnings.warn(
|
| 138 |
-
"`feature_extractor_class` is deprecated and will be removed in v5. Use `image_processor_class` instead.",
|
| 139 |
-
FutureWarning,
|
| 140 |
-
)
|
| 141 |
-
return self.image_processor_class
|
| 142 |
-
|
| 143 |
-
@property
|
| 144 |
-
def feature_extractor(self):
|
| 145 |
-
warnings.warn(
|
| 146 |
-
"`feature_extractor` is deprecated and will be removed in v5. Use `image_processor` instead.",
|
| 147 |
-
FutureWarning,
|
| 148 |
-
)
|
| 149 |
-
return self.image_processor
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qa9.jpg
DELETED
Git LFS Details
|
requirements.txt
CHANGED
|
@@ -1,4 +1 @@
|
|
| 1 |
-
git+https://github.com/huggingface/transformers.git
|
| 2 |
-
torch
|
| 3 |
-
openai
|
| 4 |
-
sentencepiece
|
|
|
|
| 1 |
+
git+https://github.com/huggingface/transformers.git
|
|
|
|
|
|
|
|
|
timm/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .version import __version__
|
| 2 |
+
from .models import create_model, list_models, is_model, list_modules, model_entrypoint, \
|
| 3 |
+
is_scriptable, is_exportable, set_scriptable, set_exportable, has_model_default_key, is_model_default_key, \
|
| 4 |
+
get_model_default_value, is_model_pretrained
|
timm/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (537 Bytes). View file
|
|
|
timm/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (541 Bytes). View file
|
|
|
timm/__pycache__/version.cpython-37.pyc
ADDED
|
Binary file (156 Bytes). View file
|
|
|
timm/__pycache__/version.cpython-38.pyc
ADDED
|
Binary file (160 Bytes). View file
|
|
|
timm/data/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .auto_augment import RandAugment, AutoAugment, rand_augment_ops, auto_augment_policy,\
|
| 2 |
+
rand_augment_transform, auto_augment_transform
|
| 3 |
+
from .config import resolve_data_config
|
| 4 |
+
from .constants import *
|
| 5 |
+
from .dataset import ImageDataset, IterableImageDataset, AugMixDataset
|
| 6 |
+
from .dataset_factory import create_dataset
|
| 7 |
+
from .loader import create_loader
|
| 8 |
+
from .mixup import Mixup, FastCollateMixup
|
| 9 |
+
from .parsers import create_parser
|
| 10 |
+
from .real_labels import RealLabelsImagenet
|
| 11 |
+
from .transforms import *
|
| 12 |
+
from .transforms_factory import create_transform
|
timm/data/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (848 Bytes). View file
|
|
|
timm/data/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (852 Bytes). View file
|
|
|
timm/data/__pycache__/auto_augment.cpython-37.pyc
ADDED
|
Binary file (25.2 kB). View file
|
|
|
timm/data/__pycache__/auto_augment.cpython-38.pyc
ADDED
|
Binary file (23.3 kB). View file
|
|
|
timm/data/__pycache__/config.cpython-37.pyc
ADDED
|
Binary file (1.59 kB). View file
|
|
|
timm/data/__pycache__/config.cpython-38.pyc
ADDED
|
Binary file (1.6 kB). View file
|
|
|
timm/data/__pycache__/constants.cpython-37.pyc
ADDED
|
Binary file (483 Bytes). View file
|
|
|
timm/data/__pycache__/constants.cpython-38.pyc
ADDED
|
Binary file (479 Bytes). View file
|
|
|
timm/data/__pycache__/dataset.cpython-37.pyc
ADDED
|
Binary file (5 kB). View file
|
|
|
timm/data/__pycache__/dataset.cpython-38.pyc
ADDED
|
Binary file (5.06 kB). View file
|
|
|
timm/data/__pycache__/dataset_factory.cpython-37.pyc
ADDED
|
Binary file (938 Bytes). View file
|
|
|
timm/data/__pycache__/dataset_factory.cpython-38.pyc
ADDED
|
Binary file (966 Bytes). View file
|
|
|
timm/data/__pycache__/distributed_sampler.cpython-37.pyc
ADDED
|
Binary file (2.06 kB). View file
|
|
|
timm/data/__pycache__/distributed_sampler.cpython-38.pyc
ADDED
|
Binary file (2.08 kB). View file
|
|
|
timm/data/__pycache__/loader.cpython-37.pyc
ADDED
|
Binary file (7.09 kB). View file
|
|
|
timm/data/__pycache__/loader.cpython-38.pyc
ADDED
|
Binary file (7.13 kB). View file
|
|
|
timm/data/__pycache__/mixup.cpython-37.pyc
ADDED
|
Binary file (11.5 kB). View file
|
|
|
timm/data/__pycache__/mixup.cpython-38.pyc
ADDED
|
Binary file (11.4 kB). View file
|
|
|
timm/data/__pycache__/random_erasing.cpython-37.pyc
ADDED
|
Binary file (3.66 kB). View file
|
|
|
timm/data/__pycache__/random_erasing.cpython-38.pyc
ADDED
|
Binary file (3.69 kB). View file
|
|
|
timm/data/__pycache__/real_labels.cpython-37.pyc
ADDED
|
Binary file (2.37 kB). View file
|
|
|
timm/data/__pycache__/real_labels.cpython-38.pyc
ADDED
|
Binary file (2.4 kB). View file
|
|
|
timm/data/__pycache__/transforms.cpython-37.pyc
ADDED
|
Binary file (5.66 kB). View file
|
|
|
timm/data/__pycache__/transforms.cpython-38.pyc
ADDED
|
Binary file (5.7 kB). View file
|
|
|
timm/data/__pycache__/transforms_factory.cpython-37.pyc
ADDED
|
Binary file (5.01 kB). View file
|
|
|