Spaces:
Running
on
L40S

Running
on
L40S
Migrated from GitHub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +11 -0
- LightGlue/.flake8 +4 -0
- LightGlue/LICENSE +201 -0
- LightGlue/README.md +180 -0
- LightGlue/assets/DSC_0410.JPG +0 -0
- LightGlue/assets/DSC_0411.JPG +0 -0
- LightGlue/assets/architecture.svg +0 -0
- LightGlue/assets/benchmark.png +0 -0
- LightGlue/assets/benchmark_cpu.png +0 -0
- LightGlue/assets/easy_hard.jpg +0 -0
- LightGlue/assets/sacre_coeur1.jpg +0 -0
- LightGlue/assets/sacre_coeur2.jpg +0 -0
- LightGlue/assets/teaser.svg +1499 -0
- LightGlue/benchmark.py +255 -0
- LightGlue/demo.ipynb +0 -0
- LightGlue/lightglue/__init__.py +7 -0
- LightGlue/lightglue/aliked.py +758 -0
- LightGlue/lightglue/disk.py +55 -0
- LightGlue/lightglue/dog_hardnet.py +41 -0
- LightGlue/lightglue/lightglue.py +655 -0
- LightGlue/lightglue/sift.py +216 -0
- LightGlue/lightglue/superpoint.py +227 -0
- LightGlue/lightglue/utils.py +165 -0
- LightGlue/lightglue/viz2d.py +185 -0
- LightGlue/pyproject.toml +30 -0
- LightGlue/requirements.txt +6 -0
- ORIGINAL_README.md +115 -0
- cotracker/__init__.py +5 -0
- cotracker/build/lib/datasets/__init__.py +5 -0
- cotracker/build/lib/datasets/dataclass_utils.py +166 -0
- cotracker/build/lib/datasets/dr_dataset.py +161 -0
- cotracker/build/lib/datasets/kubric_movif_dataset.py +441 -0
- cotracker/build/lib/datasets/tap_vid_datasets.py +209 -0
- cotracker/build/lib/datasets/utils.py +106 -0
- cotracker/build/lib/evaluation/__init__.py +5 -0
- cotracker/build/lib/evaluation/core/__init__.py +5 -0
- cotracker/build/lib/evaluation/core/eval_utils.py +138 -0
- cotracker/build/lib/evaluation/core/evaluator.py +253 -0
- cotracker/build/lib/evaluation/evaluate.py +169 -0
- cotracker/build/lib/models/__init__.py +5 -0
- cotracker/build/lib/models/build_cotracker.py +33 -0
- cotracker/build/lib/models/core/__init__.py +5 -0
- cotracker/build/lib/models/core/cotracker/__init__.py +5 -0
- cotracker/build/lib/models/core/cotracker/blocks.py +367 -0
- cotracker/build/lib/models/core/cotracker/cotracker.py +503 -0
- cotracker/build/lib/models/core/cotracker/losses.py +61 -0
- cotracker/build/lib/models/core/embeddings.py +120 -0
- cotracker/build/lib/models/core/model_utils.py +271 -0
- cotracker/build/lib/models/evaluation_predictor.py +104 -0
- cotracker/build/lib/utils/__init__.py +5 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,14 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
figure/showcases/image1.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
figure/showcases/image2.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
figure/showcases/image29.gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
figure/showcases/image3.gif filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
figure/showcases/image30.gif filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
figure/showcases/image31.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
figure/showcases/image33.gif filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
figure/showcases/image34.gif filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
figure/showcases/image35.gif filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
figure/showcases/image4.gif filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
figure/teaser.png filter=lfs diff=lfs merge=lfs -text
|
LightGlue/.flake8
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[flake8]
|
| 2 |
+
max-line-length = 88
|
| 3 |
+
extend-ignore = E203
|
| 4 |
+
exclude = .git,__pycache__,build,.venv/
|
LightGlue/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2023 ETH Zurich
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
LightGlue/README.md
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center">
|
| 2 |
+
<h1 align="center"><ins>LightGlue</ins> ⚡️<br>Local Feature Matching at Light Speed</h1>
|
| 3 |
+
<p align="center">
|
| 4 |
+
<a href="https://www.linkedin.com/in/philipplindenberger/">Philipp Lindenberger</a>
|
| 5 |
+
·
|
| 6 |
+
<a href="https://psarlin.com/">Paul-Edouard Sarlin</a>
|
| 7 |
+
·
|
| 8 |
+
<a href="https://www.microsoft.com/en-us/research/people/mapoll/">Marc Pollefeys</a>
|
| 9 |
+
</p>
|
| 10 |
+
<h2 align="center">
|
| 11 |
+
<p>ICCV 2023</p>
|
| 12 |
+
<a href="https://arxiv.org/pdf/2306.13643.pdf" align="center">Paper</a> |
|
| 13 |
+
<a href="https://colab.research.google.com/github/cvg/LightGlue/blob/main/demo.ipynb" align="center">Colab</a> |
|
| 14 |
+
<a href="https://psarlin.com/assets/LightGlue_ICCV2023_poster_compressed.pdf" align="center">Poster</a> |
|
| 15 |
+
<a href="https://github.com/cvg/glue-factory" align="center">Train your own!</a>
|
| 16 |
+
</h2>
|
| 17 |
+
|
| 18 |
+
</p>
|
| 19 |
+
<p align="center">
|
| 20 |
+
<a href="https://arxiv.org/abs/2306.13643"><img src="assets/easy_hard.jpg" alt="example" width=80%></a>
|
| 21 |
+
<br>
|
| 22 |
+
<em>LightGlue is a deep neural network that matches sparse local features across image pairs.<br>An adaptive mechanism makes it fast for easy pairs (top) and reduces the computational complexity for difficult ones (bottom).</em>
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
##
|
| 26 |
+
|
| 27 |
+
This repository hosts the inference code of LightGlue, a lightweight feature matcher with high accuracy and blazing fast inference. It takes as input a set of keypoints and descriptors for each image and returns the indices of corresponding points. The architecture is based on adaptive pruning techniques, in both network width and depth - [check out the paper for more details](https://arxiv.org/pdf/2306.13643.pdf).
|
| 28 |
+
|
| 29 |
+
We release pretrained weights of LightGlue with [SuperPoint](https://arxiv.org/abs/1712.07629), [DISK](https://arxiv.org/abs/2006.13566), [ALIKED](https://arxiv.org/abs/2304.03608) and [SIFT](https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf) local features.
|
| 30 |
+
The training and evaluation code can be found in our library [glue-factory](https://github.com/cvg/glue-factory/).
|
| 31 |
+
|
| 32 |
+
## Installation and demo [](https://colab.research.google.com/github/cvg/LightGlue/blob/main/demo.ipynb)
|
| 33 |
+
|
| 34 |
+
Install this repo using pip:
|
| 35 |
+
|
| 36 |
+
```bash
|
| 37 |
+
git clone https://github.com/cvg/LightGlue.git && cd LightGlue
|
| 38 |
+
python -m pip install -e .
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
We provide a [demo notebook](demo.ipynb) which shows how to perform feature extraction and matching on an image pair.
|
| 42 |
+
|
| 43 |
+
Here is a minimal script to match two images:
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
from lightglue import LightGlue, SuperPoint, DISK, SIFT, ALIKED, DoGHardNet
|
| 47 |
+
from lightglue.utils import load_image, rbd
|
| 48 |
+
|
| 49 |
+
# SuperPoint+LightGlue
|
| 50 |
+
extractor = SuperPoint(max_num_keypoints=2048).eval().cuda() # load the extractor
|
| 51 |
+
matcher = LightGlue(features='superpoint').eval().cuda() # load the matcher
|
| 52 |
+
|
| 53 |
+
# or DISK+LightGlue, ALIKED+LightGlue or SIFT+LightGlue
|
| 54 |
+
extractor = DISK(max_num_keypoints=2048).eval().cuda() # load the extractor
|
| 55 |
+
matcher = LightGlue(features='disk').eval().cuda() # load the matcher
|
| 56 |
+
|
| 57 |
+
# load each image as a torch.Tensor on GPU with shape (3,H,W), normalized in [0,1]
|
| 58 |
+
image0 = load_image('path/to/image_0.jpg').cuda()
|
| 59 |
+
image1 = load_image('path/to/image_1.jpg').cuda()
|
| 60 |
+
|
| 61 |
+
# extract local features
|
| 62 |
+
feats0 = extractor.extract(image0) # auto-resize the image, disable with resize=None
|
| 63 |
+
feats1 = extractor.extract(image1)
|
| 64 |
+
|
| 65 |
+
# match the features
|
| 66 |
+
matches01 = matcher({'image0': feats0, 'image1': feats1})
|
| 67 |
+
feats0, feats1, matches01 = [rbd(x) for x in [feats0, feats1, matches01]] # remove batch dimension
|
| 68 |
+
matches = matches01['matches'] # indices with shape (K,2)
|
| 69 |
+
points0 = feats0['keypoints'][matches[..., 0]] # coordinates in image #0, shape (K,2)
|
| 70 |
+
points1 = feats1['keypoints'][matches[..., 1]] # coordinates in image #1, shape (K,2)
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
We also provide a convenience method to match a pair of images:
|
| 74 |
+
|
| 75 |
+
```python
|
| 76 |
+
from lightglue import match_pair
|
| 77 |
+
feats0, feats1, matches01 = match_pair(extractor, matcher, image0, image1)
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
##
|
| 81 |
+
|
| 82 |
+
<p align="center">
|
| 83 |
+
<a href="https://arxiv.org/abs/2306.13643"><img src="assets/teaser.svg" alt="Logo" width=50%></a>
|
| 84 |
+
<br>
|
| 85 |
+
<em>LightGlue can adjust its depth (number of layers) and width (number of keypoints) per image pair, with a marginal impact on accuracy.</em>
|
| 86 |
+
</p>
|
| 87 |
+
|
| 88 |
+
## Advanced configuration
|
| 89 |
+
|
| 90 |
+
<details>
|
| 91 |
+
<summary>[Detail of all parameters - click to expand]</summary>
|
| 92 |
+
|
| 93 |
+
- ```n_layers```: Number of stacked self+cross attention layers. Reduce this value for faster inference at the cost of accuracy (continuous red line in the plot above). Default: 9 (all layers).
|
| 94 |
+
- ```flash```: Enable FlashAttention. Significantly increases the speed and reduces the memory consumption without any impact on accuracy. Default: True (LightGlue automatically detects if FlashAttention is available).
|
| 95 |
+
- ```mp```: Enable mixed precision inference. Default: False (off)
|
| 96 |
+
- ```depth_confidence```: Controls the early stopping. A lower values stops more often at earlier layers. Default: 0.95, disable with -1.
|
| 97 |
+
- ```width_confidence```: Controls the iterative point pruning. A lower value prunes more points earlier. Default: 0.99, disable with -1.
|
| 98 |
+
- ```filter_threshold```: Match confidence. Increase this value to obtain less, but stronger matches. Default: 0.1
|
| 99 |
+
|
| 100 |
+
</details>
|
| 101 |
+
|
| 102 |
+
The default values give a good trade-off between speed and accuracy. To maximize the accuracy, use all keypoints and disable the adaptive mechanisms:
|
| 103 |
+
```python
|
| 104 |
+
extractor = SuperPoint(max_num_keypoints=None)
|
| 105 |
+
matcher = LightGlue(features='superpoint', depth_confidence=-1, width_confidence=-1)
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
To increase the speed with a small drop of accuracy, decrease the number of keypoints and lower the adaptive thresholds:
|
| 109 |
+
```python
|
| 110 |
+
extractor = SuperPoint(max_num_keypoints=1024)
|
| 111 |
+
matcher = LightGlue(features='superpoint', depth_confidence=0.9, width_confidence=0.95)
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
The maximum speed is obtained with a combination of:
|
| 115 |
+
- [FlashAttention](https://arxiv.org/abs/2205.14135): automatically used when ```torch >= 2.0``` or if [installed from source](https://github.com/HazyResearch/flash-attention#installation-and-features).
|
| 116 |
+
- PyTorch compilation, available when ```torch >= 2.0```:
|
| 117 |
+
```python
|
| 118 |
+
matcher = matcher.eval().cuda()
|
| 119 |
+
matcher.compile(mode='reduce-overhead')
|
| 120 |
+
```
|
| 121 |
+
For inputs with fewer than 1536 keypoints (determined experimentally), this compiles LightGlue but disables point pruning (large overhead). For larger input sizes, it automatically falls backs to eager mode with point pruning. Adaptive depths is supported for any input size.
|
| 122 |
+
|
| 123 |
+
## Benchmark
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
<p align="center">
|
| 127 |
+
<a><img src="assets/benchmark.png" alt="Logo" width=80%></a>
|
| 128 |
+
<br>
|
| 129 |
+
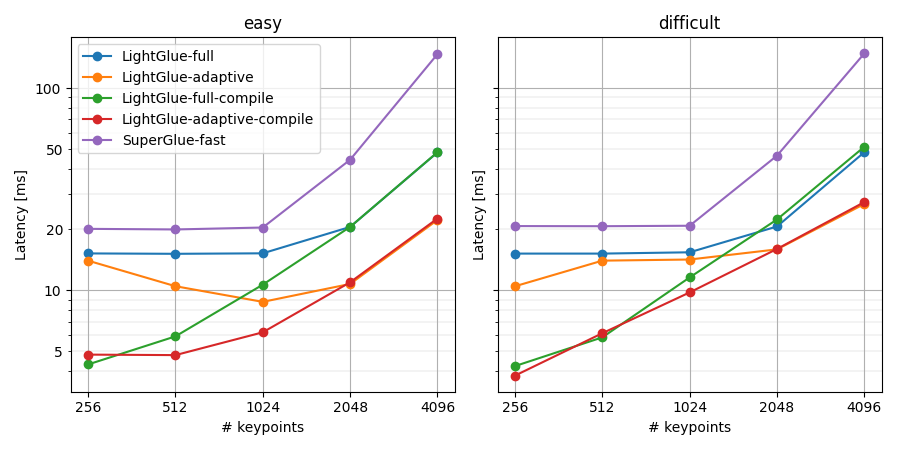
<em>Benchmark results on GPU (RTX 3080). With compilation and adaptivity, LightGlue runs at 150 FPS @ 1024 keypoints and 50 FPS @ 4096 keypoints per image. This is a 4-10x speedup over SuperGlue. </em>
|
| 130 |
+
</p>
|
| 131 |
+
|
| 132 |
+
<p align="center">
|
| 133 |
+
<a><img src="assets/benchmark_cpu.png" alt="Logo" width=80%></a>
|
| 134 |
+
<br>
|
| 135 |
+
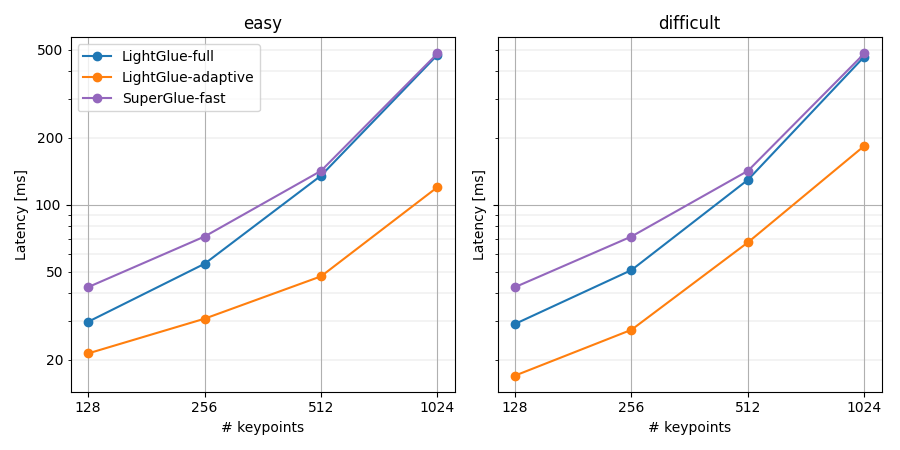
<em>Benchmark results on CPU (Intel i7 10700K). LightGlue runs at 20 FPS @ 512 keypoints. </em>
|
| 136 |
+
</p>
|
| 137 |
+
|
| 138 |
+
Obtain the same plots for your setup using our [benchmark script](benchmark.py):
|
| 139 |
+
```
|
| 140 |
+
python benchmark.py [--device cuda] [--add_superglue] [--num_keypoints 512 1024 2048 4096] [--compile]
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
<details>
|
| 144 |
+
<summary>[Performance tip - click to expand]</summary>
|
| 145 |
+
|
| 146 |
+
Note: **Point pruning** introduces an overhead that sometimes outweighs its benefits.
|
| 147 |
+
Point pruning is thus enabled only when the there are more than N keypoints in an image, where N is hardware-dependent.
|
| 148 |
+
We provide defaults optimized for current hardware (RTX 30xx GPUs).
|
| 149 |
+
We suggest running the benchmark script and adjusting the thresholds for your hardware by updating `LightGlue.pruning_keypoint_thresholds['cuda']`.
|
| 150 |
+
|
| 151 |
+
</details>
|
| 152 |
+
|
| 153 |
+
## Training and evaluation
|
| 154 |
+
|
| 155 |
+
With [Glue Factory](https://github.com/cvg/glue-factory), you can train LightGlue with your own local features, on your own dataset!
|
| 156 |
+
You can also evaluate it and other baselines on standard benchmarks like HPatches and MegaDepth.
|
| 157 |
+
|
| 158 |
+
## Other links
|
| 159 |
+
- [hloc - the visual localization toolbox](https://github.com/cvg/Hierarchical-Localization/): run LightGlue for Structure-from-Motion and visual localization.
|
| 160 |
+
- [LightGlue-ONNX](https://github.com/fabio-sim/LightGlue-ONNX): export LightGlue to the Open Neural Network Exchange (ONNX) format with support for TensorRT and OpenVINO.
|
| 161 |
+
- [Image Matching WebUI](https://github.com/Vincentqyw/image-matching-webui): a web GUI to easily compare different matchers, including LightGlue.
|
| 162 |
+
- [kornia](https://kornia.readthedocs.io) now exposes LightGlue via the interfaces [`LightGlue`](https://kornia.readthedocs.io/en/latest/feature.html#kornia.feature.LightGlue) and [`LightGlueMatcher`](https://kornia.readthedocs.io/en/latest/feature.html#kornia.feature.LightGlueMatcher).
|
| 163 |
+
|
| 164 |
+
## BibTeX citation
|
| 165 |
+
If you use any ideas from the paper or code from this repo, please consider citing:
|
| 166 |
+
|
| 167 |
+
```txt
|
| 168 |
+
@inproceedings{lindenberger2023lightglue,
|
| 169 |
+
author = {Philipp Lindenberger and
|
| 170 |
+
Paul-Edouard Sarlin and
|
| 171 |
+
Marc Pollefeys},
|
| 172 |
+
title = {{LightGlue: Local Feature Matching at Light Speed}},
|
| 173 |
+
booktitle = {ICCV},
|
| 174 |
+
year = {2023}
|
| 175 |
+
}
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
## License
|
| 180 |
+
The pre-trained weights of LightGlue and the code provided in this repository are released under the [Apache-2.0 license](./LICENSE). [DISK](https://github.com/cvlab-epfl/disk) follows this license as well but SuperPoint follows [a different, restrictive license](https://github.com/magicleap/SuperPointPretrainedNetwork/blob/master/LICENSE) (this includes its pre-trained weights and its [inference file](./lightglue/superpoint.py)). [ALIKED](https://github.com/Shiaoming/ALIKED) was published under a BSD-3-Clause license.
|
LightGlue/assets/DSC_0410.JPG
ADDED

|
LightGlue/assets/DSC_0411.JPG
ADDED

|
LightGlue/assets/architecture.svg
ADDED

|
LightGlue/assets/benchmark.png
ADDED
|
LightGlue/assets/benchmark_cpu.png
ADDED
|
LightGlue/assets/easy_hard.jpg
ADDED

|
LightGlue/assets/sacre_coeur1.jpg
ADDED

|
LightGlue/assets/sacre_coeur2.jpg
ADDED

|
LightGlue/assets/teaser.svg
ADDED

|
LightGlue/benchmark.py
ADDED
|
@@ -0,0 +1,255 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Benchmark script for LightGlue on real images
|
| 2 |
+
import argparse
|
| 3 |
+
import time
|
| 4 |
+
from collections import defaultdict
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
|
| 7 |
+
import matplotlib.pyplot as plt
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch._dynamo
|
| 11 |
+
|
| 12 |
+
from lightglue import LightGlue, SuperPoint
|
| 13 |
+
from lightglue.utils import load_image
|
| 14 |
+
|
| 15 |
+
torch.set_grad_enabled(False)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def measure(matcher, data, device="cuda", r=100):
|
| 19 |
+
timings = np.zeros((r, 1))
|
| 20 |
+
if device.type == "cuda":
|
| 21 |
+
starter = torch.cuda.Event(enable_timing=True)
|
| 22 |
+
ender = torch.cuda.Event(enable_timing=True)
|
| 23 |
+
# warmup
|
| 24 |
+
for _ in range(10):
|
| 25 |
+
_ = matcher(data)
|
| 26 |
+
# measurements
|
| 27 |
+
with torch.no_grad():
|
| 28 |
+
for rep in range(r):
|
| 29 |
+
if device.type == "cuda":
|
| 30 |
+
starter.record()
|
| 31 |
+
_ = matcher(data)
|
| 32 |
+
ender.record()
|
| 33 |
+
# sync gpu
|
| 34 |
+
torch.cuda.synchronize()
|
| 35 |
+
curr_time = starter.elapsed_time(ender)
|
| 36 |
+
else:
|
| 37 |
+
start = time.perf_counter()
|
| 38 |
+
_ = matcher(data)
|
| 39 |
+
curr_time = (time.perf_counter() - start) * 1e3
|
| 40 |
+
timings[rep] = curr_time
|
| 41 |
+
mean_syn = np.sum(timings) / r
|
| 42 |
+
std_syn = np.std(timings)
|
| 43 |
+
return {"mean": mean_syn, "std": std_syn}
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def print_as_table(d, title, cnames):
|
| 47 |
+
print()
|
| 48 |
+
header = f"{title:30} " + " ".join([f"{x:>7}" for x in cnames])
|
| 49 |
+
print(header)
|
| 50 |
+
print("-" * len(header))
|
| 51 |
+
for k, l in d.items():
|
| 52 |
+
print(f"{k:30}", " ".join([f"{x:>7.1f}" for x in l]))
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
if __name__ == "__main__":
|
| 56 |
+
parser = argparse.ArgumentParser(description="Benchmark script for LightGlue")
|
| 57 |
+
parser.add_argument(
|
| 58 |
+
"--device",
|
| 59 |
+
choices=["auto", "cuda", "cpu", "mps"],
|
| 60 |
+
default="auto",
|
| 61 |
+
help="device to benchmark on",
|
| 62 |
+
)
|
| 63 |
+
parser.add_argument("--compile", action="store_true", help="Compile LightGlue runs")
|
| 64 |
+
parser.add_argument(
|
| 65 |
+
"--no_flash", action="store_true", help="disable FlashAttention"
|
| 66 |
+
)
|
| 67 |
+
parser.add_argument(
|
| 68 |
+
"--no_prune_thresholds",
|
| 69 |
+
action="store_true",
|
| 70 |
+
help="disable pruning thresholds (i.e. always do pruning)",
|
| 71 |
+
)
|
| 72 |
+
parser.add_argument(
|
| 73 |
+
"--add_superglue",
|
| 74 |
+
action="store_true",
|
| 75 |
+
help="add SuperGlue to the benchmark (requires hloc)",
|
| 76 |
+
)
|
| 77 |
+
parser.add_argument(
|
| 78 |
+
"--measure", default="time", choices=["time", "log-time", "throughput"]
|
| 79 |
+
)
|
| 80 |
+
parser.add_argument(
|
| 81 |
+
"--repeat", "--r", type=int, default=100, help="repetitions of measurements"
|
| 82 |
+
)
|
| 83 |
+
parser.add_argument(
|
| 84 |
+
"--num_keypoints",
|
| 85 |
+
nargs="+",
|
| 86 |
+
type=int,
|
| 87 |
+
default=[256, 512, 1024, 2048, 4096],
|
| 88 |
+
help="number of keypoints (list separated by spaces)",
|
| 89 |
+
)
|
| 90 |
+
parser.add_argument(
|
| 91 |
+
"--matmul_precision", default="highest", choices=["highest", "high", "medium"]
|
| 92 |
+
)
|
| 93 |
+
parser.add_argument(
|
| 94 |
+
"--save", default=None, type=str, help="path where figure should be saved"
|
| 95 |
+
)
|
| 96 |
+
args = parser.parse_intermixed_args()
|
| 97 |
+
|
| 98 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 99 |
+
if args.device != "auto":
|
| 100 |
+
device = torch.device(args.device)
|
| 101 |
+
|
| 102 |
+
print("Running benchmark on device:", device)
|
| 103 |
+
|
| 104 |
+
images = Path("assets")
|
| 105 |
+
inputs = {
|
| 106 |
+
"easy": (
|
| 107 |
+
load_image(images / "DSC_0411.JPG"),
|
| 108 |
+
load_image(images / "DSC_0410.JPG"),
|
| 109 |
+
),
|
| 110 |
+
"difficult": (
|
| 111 |
+
load_image(images / "sacre_coeur1.jpg"),
|
| 112 |
+
load_image(images / "sacre_coeur2.jpg"),
|
| 113 |
+
),
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
configs = {
|
| 117 |
+
"LightGlue-full": {
|
| 118 |
+
"depth_confidence": -1,
|
| 119 |
+
"width_confidence": -1,
|
| 120 |
+
},
|
| 121 |
+
# 'LG-prune': {
|
| 122 |
+
# 'width_confidence': -1,
|
| 123 |
+
# },
|
| 124 |
+
# 'LG-depth': {
|
| 125 |
+
# 'depth_confidence': -1,
|
| 126 |
+
# },
|
| 127 |
+
"LightGlue-adaptive": {},
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
if args.compile:
|
| 131 |
+
configs = {**configs, **{k + "-compile": v for k, v in configs.items()}}
|
| 132 |
+
|
| 133 |
+
sg_configs = {
|
| 134 |
+
# 'SuperGlue': {},
|
| 135 |
+
"SuperGlue-fast": {"sinkhorn_iterations": 5}
|
| 136 |
+
}
|
| 137 |
+
|
| 138 |
+
torch.set_float32_matmul_precision(args.matmul_precision)
|
| 139 |
+
|
| 140 |
+
results = {k: defaultdict(list) for k, v in inputs.items()}
|
| 141 |
+
|
| 142 |
+
extractor = SuperPoint(max_num_keypoints=None, detection_threshold=-1)
|
| 143 |
+
extractor = extractor.eval().to(device)
|
| 144 |
+
figsize = (len(inputs) * 4.5, 4.5)
|
| 145 |
+
fig, axes = plt.subplots(1, len(inputs), sharey=True, figsize=figsize)
|
| 146 |
+
axes = axes if len(inputs) > 1 else [axes]
|
| 147 |
+
fig.canvas.manager.set_window_title(f"LightGlue benchmark ({device.type})")
|
| 148 |
+
|
| 149 |
+
for title, ax in zip(inputs.keys(), axes):
|
| 150 |
+
ax.set_xscale("log", base=2)
|
| 151 |
+
bases = [2**x for x in range(7, 16)]
|
| 152 |
+
ax.set_xticks(bases, bases)
|
| 153 |
+
ax.grid(which="major")
|
| 154 |
+
if args.measure == "log-time":
|
| 155 |
+
ax.set_yscale("log")
|
| 156 |
+
yticks = [10**x for x in range(6)]
|
| 157 |
+
ax.set_yticks(yticks, yticks)
|
| 158 |
+
mpos = [10**x * i for x in range(6) for i in range(2, 10)]
|
| 159 |
+
mlabel = [
|
| 160 |
+
10**x * i if i in [2, 5] else None
|
| 161 |
+
for x in range(6)
|
| 162 |
+
for i in range(2, 10)
|
| 163 |
+
]
|
| 164 |
+
ax.set_yticks(mpos, mlabel, minor=True)
|
| 165 |
+
ax.grid(which="minor", linewidth=0.2)
|
| 166 |
+
ax.set_title(title)
|
| 167 |
+
|
| 168 |
+
ax.set_xlabel("# keypoints")
|
| 169 |
+
if args.measure == "throughput":
|
| 170 |
+
ax.set_ylabel("Throughput [pairs/s]")
|
| 171 |
+
else:
|
| 172 |
+
ax.set_ylabel("Latency [ms]")
|
| 173 |
+
|
| 174 |
+
for name, conf in configs.items():
|
| 175 |
+
print("Run benchmark for:", name)
|
| 176 |
+
torch.cuda.empty_cache()
|
| 177 |
+
matcher = LightGlue(features="superpoint", flash=not args.no_flash, **conf)
|
| 178 |
+
if args.no_prune_thresholds:
|
| 179 |
+
matcher.pruning_keypoint_thresholds = {
|
| 180 |
+
k: -1 for k in matcher.pruning_keypoint_thresholds
|
| 181 |
+
}
|
| 182 |
+
matcher = matcher.eval().to(device)
|
| 183 |
+
if name.endswith("compile"):
|
| 184 |
+
import torch._dynamo
|
| 185 |
+
|
| 186 |
+
torch._dynamo.reset() # avoid buffer overflow
|
| 187 |
+
matcher.compile()
|
| 188 |
+
for pair_name, ax in zip(inputs.keys(), axes):
|
| 189 |
+
image0, image1 = [x.to(device) for x in inputs[pair_name]]
|
| 190 |
+
runtimes = []
|
| 191 |
+
for num_kpts in args.num_keypoints:
|
| 192 |
+
extractor.conf.max_num_keypoints = num_kpts
|
| 193 |
+
feats0 = extractor.extract(image0)
|
| 194 |
+
feats1 = extractor.extract(image1)
|
| 195 |
+
runtime = measure(
|
| 196 |
+
matcher,
|
| 197 |
+
{"image0": feats0, "image1": feats1},
|
| 198 |
+
device=device,
|
| 199 |
+
r=args.repeat,
|
| 200 |
+
)["mean"]
|
| 201 |
+
results[pair_name][name].append(
|
| 202 |
+
1000 / runtime if args.measure == "throughput" else runtime
|
| 203 |
+
)
|
| 204 |
+
ax.plot(
|
| 205 |
+
args.num_keypoints, results[pair_name][name], label=name, marker="o"
|
| 206 |
+
)
|
| 207 |
+
del matcher, feats0, feats1
|
| 208 |
+
|
| 209 |
+
if args.add_superglue:
|
| 210 |
+
from hloc.matchers.superglue import SuperGlue
|
| 211 |
+
|
| 212 |
+
for name, conf in sg_configs.items():
|
| 213 |
+
print("Run benchmark for:", name)
|
| 214 |
+
matcher = SuperGlue(conf)
|
| 215 |
+
matcher = matcher.eval().to(device)
|
| 216 |
+
for pair_name, ax in zip(inputs.keys(), axes):
|
| 217 |
+
image0, image1 = [x.to(device) for x in inputs[pair_name]]
|
| 218 |
+
runtimes = []
|
| 219 |
+
for num_kpts in args.num_keypoints:
|
| 220 |
+
extractor.conf.max_num_keypoints = num_kpts
|
| 221 |
+
feats0 = extractor.extract(image0)
|
| 222 |
+
feats1 = extractor.extract(image1)
|
| 223 |
+
data = {
|
| 224 |
+
"image0": image0[None],
|
| 225 |
+
"image1": image1[None],
|
| 226 |
+
**{k + "0": v for k, v in feats0.items()},
|
| 227 |
+
**{k + "1": v for k, v in feats1.items()},
|
| 228 |
+
}
|
| 229 |
+
data["scores0"] = data["keypoint_scores0"]
|
| 230 |
+
data["scores1"] = data["keypoint_scores1"]
|
| 231 |
+
data["descriptors0"] = (
|
| 232 |
+
data["descriptors0"].transpose(-1, -2).contiguous()
|
| 233 |
+
)
|
| 234 |
+
data["descriptors1"] = (
|
| 235 |
+
data["descriptors1"].transpose(-1, -2).contiguous()
|
| 236 |
+
)
|
| 237 |
+
runtime = measure(matcher, data, device=device, r=args.repeat)[
|
| 238 |
+
"mean"
|
| 239 |
+
]
|
| 240 |
+
results[pair_name][name].append(
|
| 241 |
+
1000 / runtime if args.measure == "throughput" else runtime
|
| 242 |
+
)
|
| 243 |
+
ax.plot(
|
| 244 |
+
args.num_keypoints, results[pair_name][name], label=name, marker="o"
|
| 245 |
+
)
|
| 246 |
+
del matcher, data, image0, image1, feats0, feats1
|
| 247 |
+
|
| 248 |
+
for name, runtimes in results.items():
|
| 249 |
+
print_as_table(runtimes, name, args.num_keypoints)
|
| 250 |
+
|
| 251 |
+
axes[0].legend()
|
| 252 |
+
fig.tight_layout()
|
| 253 |
+
if args.save:
|
| 254 |
+
plt.savefig(args.save, dpi=fig.dpi)
|
| 255 |
+
plt.show()
|
LightGlue/demo.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
LightGlue/lightglue/__init__.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .aliked import ALIKED # noqa
|
| 2 |
+
from .disk import DISK # noqa
|
| 3 |
+
from .dog_hardnet import DoGHardNet # noqa
|
| 4 |
+
from .lightglue import LightGlue # noqa
|
| 5 |
+
from .sift import SIFT # noqa
|
| 6 |
+
from .superpoint import SuperPoint # noqa
|
| 7 |
+
from .utils import match_pair # noqa
|
LightGlue/lightglue/aliked.py
ADDED
|
@@ -0,0 +1,758 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
# Copyright (c) 2022, Zhao Xiaoming
|
| 4 |
+
# All rights reserved.
|
| 5 |
+
|
| 6 |
+
# Redistribution and use in source and binary forms, with or without
|
| 7 |
+
# modification, are permitted provided that the following conditions are met:
|
| 8 |
+
|
| 9 |
+
# 1. Redistributions of source code must retain the above copyright notice, this
|
| 10 |
+
# list of conditions and the following disclaimer.
|
| 11 |
+
|
| 12 |
+
# 2. Redistributions in binary form must reproduce the above copyright notice,
|
| 13 |
+
# this list of conditions and the following disclaimer in the documentation
|
| 14 |
+
# and/or other materials provided with the distribution.
|
| 15 |
+
|
| 16 |
+
# 3. Neither the name of the copyright holder nor the names of its
|
| 17 |
+
# contributors may be used to endorse or promote products derived from
|
| 18 |
+
# this software without specific prior written permission.
|
| 19 |
+
|
| 20 |
+
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 21 |
+
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 22 |
+
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 23 |
+
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 24 |
+
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 25 |
+
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 26 |
+
# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 27 |
+
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 28 |
+
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 29 |
+
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 30 |
+
|
| 31 |
+
# Authors:
|
| 32 |
+
# Xiaoming Zhao, Xingming Wu, Weihai Chen, Peter C.Y. Chen, Qingsong Xu, and Zhengguo Li
|
| 33 |
+
# Code from https://github.com/Shiaoming/ALIKED
|
| 34 |
+
|
| 35 |
+
from typing import Callable, Optional
|
| 36 |
+
|
| 37 |
+
import torch
|
| 38 |
+
import torch.nn.functional as F
|
| 39 |
+
import torchvision
|
| 40 |
+
from kornia.color import grayscale_to_rgb
|
| 41 |
+
from torch import nn
|
| 42 |
+
from torch.nn.modules.utils import _pair
|
| 43 |
+
from torchvision.models import resnet
|
| 44 |
+
|
| 45 |
+
from .utils import Extractor
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def get_patches(
|
| 49 |
+
tensor: torch.Tensor, required_corners: torch.Tensor, ps: int
|
| 50 |
+
) -> torch.Tensor:
|
| 51 |
+
c, h, w = tensor.shape
|
| 52 |
+
corner = (required_corners - ps / 2 + 1).long()
|
| 53 |
+
corner[:, 0] = corner[:, 0].clamp(min=0, max=w - 1 - ps)
|
| 54 |
+
corner[:, 1] = corner[:, 1].clamp(min=0, max=h - 1 - ps)
|
| 55 |
+
offset = torch.arange(0, ps)
|
| 56 |
+
|
| 57 |
+
kw = {"indexing": "ij"} if torch.__version__ >= "1.10" else {}
|
| 58 |
+
x, y = torch.meshgrid(offset, offset, **kw)
|
| 59 |
+
patches = torch.stack((x, y)).permute(2, 1, 0).unsqueeze(2)
|
| 60 |
+
patches = patches.to(corner) + corner[None, None]
|
| 61 |
+
pts = patches.reshape(-1, 2)
|
| 62 |
+
sampled = tensor.permute(1, 2, 0)[tuple(pts.T)[::-1]]
|
| 63 |
+
sampled = sampled.reshape(ps, ps, -1, c)
|
| 64 |
+
assert sampled.shape[:3] == patches.shape[:3]
|
| 65 |
+
return sampled.permute(2, 3, 0, 1)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def simple_nms(scores: torch.Tensor, nms_radius: int):
|
| 69 |
+
"""Fast Non-maximum suppression to remove nearby points"""
|
| 70 |
+
|
| 71 |
+
zeros = torch.zeros_like(scores)
|
| 72 |
+
max_mask = scores == torch.nn.functional.max_pool2d(
|
| 73 |
+
scores, kernel_size=nms_radius * 2 + 1, stride=1, padding=nms_radius
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
for _ in range(2):
|
| 77 |
+
supp_mask = (
|
| 78 |
+
torch.nn.functional.max_pool2d(
|
| 79 |
+
max_mask.float(),
|
| 80 |
+
kernel_size=nms_radius * 2 + 1,
|
| 81 |
+
stride=1,
|
| 82 |
+
padding=nms_radius,
|
| 83 |
+
)
|
| 84 |
+
> 0
|
| 85 |
+
)
|
| 86 |
+
supp_scores = torch.where(supp_mask, zeros, scores)
|
| 87 |
+
new_max_mask = supp_scores == torch.nn.functional.max_pool2d(
|
| 88 |
+
supp_scores, kernel_size=nms_radius * 2 + 1, stride=1, padding=nms_radius
|
| 89 |
+
)
|
| 90 |
+
max_mask = max_mask | (new_max_mask & (~supp_mask))
|
| 91 |
+
return torch.where(max_mask, scores, zeros)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class DKD(nn.Module):
|
| 95 |
+
def __init__(
|
| 96 |
+
self,
|
| 97 |
+
radius: int = 2,
|
| 98 |
+
top_k: int = 0,
|
| 99 |
+
scores_th: float = 0.2,
|
| 100 |
+
n_limit: int = 20000,
|
| 101 |
+
):
|
| 102 |
+
"""
|
| 103 |
+
Args:
|
| 104 |
+
radius: soft detection radius, kernel size is (2 * radius + 1)
|
| 105 |
+
top_k: top_k > 0: return top k keypoints
|
| 106 |
+
scores_th: top_k <= 0 threshold mode:
|
| 107 |
+
scores_th > 0: return keypoints with scores>scores_th
|
| 108 |
+
else: return keypoints with scores > scores.mean()
|
| 109 |
+
n_limit: max number of keypoint in threshold mode
|
| 110 |
+
"""
|
| 111 |
+
super().__init__()
|
| 112 |
+
self.radius = radius
|
| 113 |
+
self.top_k = top_k
|
| 114 |
+
self.scores_th = scores_th
|
| 115 |
+
self.n_limit = n_limit
|
| 116 |
+
self.kernel_size = 2 * self.radius + 1
|
| 117 |
+
self.temperature = 0.1 # tuned temperature
|
| 118 |
+
self.unfold = nn.Unfold(kernel_size=self.kernel_size, padding=self.radius)
|
| 119 |
+
# local xy grid
|
| 120 |
+
x = torch.linspace(-self.radius, self.radius, self.kernel_size)
|
| 121 |
+
# (kernel_size*kernel_size) x 2 : (w,h)
|
| 122 |
+
kw = {"indexing": "ij"} if torch.__version__ >= "1.10" else {}
|
| 123 |
+
self.hw_grid = (
|
| 124 |
+
torch.stack(torch.meshgrid([x, x], **kw)).view(2, -1).t()[:, [1, 0]]
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
def forward(
|
| 128 |
+
self,
|
| 129 |
+
scores_map: torch.Tensor,
|
| 130 |
+
sub_pixel: bool = True,
|
| 131 |
+
image_size: Optional[torch.Tensor] = None,
|
| 132 |
+
):
|
| 133 |
+
"""
|
| 134 |
+
:param scores_map: Bx1xHxW
|
| 135 |
+
:param descriptor_map: BxCxHxW
|
| 136 |
+
:param sub_pixel: whether to use sub-pixel keypoint detection
|
| 137 |
+
:return: kpts: list[Nx2,...]; kptscores: list[N,....] normalised position: -1~1
|
| 138 |
+
"""
|
| 139 |
+
b, c, h, w = scores_map.shape
|
| 140 |
+
scores_nograd = scores_map.detach()
|
| 141 |
+
nms_scores = simple_nms(scores_nograd, self.radius)
|
| 142 |
+
|
| 143 |
+
# remove border
|
| 144 |
+
nms_scores[:, :, : self.radius, :] = 0
|
| 145 |
+
nms_scores[:, :, :, : self.radius] = 0
|
| 146 |
+
if image_size is not None:
|
| 147 |
+
for i in range(scores_map.shape[0]):
|
| 148 |
+
w, h = image_size[i].long()
|
| 149 |
+
nms_scores[i, :, h.item() - self.radius :, :] = 0
|
| 150 |
+
nms_scores[i, :, :, w.item() - self.radius :] = 0
|
| 151 |
+
else:
|
| 152 |
+
nms_scores[:, :, -self.radius :, :] = 0
|
| 153 |
+
nms_scores[:, :, :, -self.radius :] = 0
|
| 154 |
+
|
| 155 |
+
# detect keypoints without grad
|
| 156 |
+
if self.top_k > 0:
|
| 157 |
+
topk = torch.topk(nms_scores.view(b, -1), self.top_k)
|
| 158 |
+
indices_keypoints = [topk.indices[i] for i in range(b)] # B x top_k
|
| 159 |
+
else:
|
| 160 |
+
if self.scores_th > 0:
|
| 161 |
+
masks = nms_scores > self.scores_th
|
| 162 |
+
if masks.sum() == 0:
|
| 163 |
+
th = scores_nograd.reshape(b, -1).mean(dim=1) # th = self.scores_th
|
| 164 |
+
masks = nms_scores > th.reshape(b, 1, 1, 1)
|
| 165 |
+
else:
|
| 166 |
+
th = scores_nograd.reshape(b, -1).mean(dim=1) # th = self.scores_th
|
| 167 |
+
masks = nms_scores > th.reshape(b, 1, 1, 1)
|
| 168 |
+
masks = masks.reshape(b, -1)
|
| 169 |
+
|
| 170 |
+
indices_keypoints = [] # list, B x (any size)
|
| 171 |
+
scores_view = scores_nograd.reshape(b, -1)
|
| 172 |
+
for mask, scores in zip(masks, scores_view):
|
| 173 |
+
indices = mask.nonzero()[:, 0]
|
| 174 |
+
if len(indices) > self.n_limit:
|
| 175 |
+
kpts_sc = scores[indices]
|
| 176 |
+
sort_idx = kpts_sc.sort(descending=True)[1]
|
| 177 |
+
sel_idx = sort_idx[: self.n_limit]
|
| 178 |
+
indices = indices[sel_idx]
|
| 179 |
+
indices_keypoints.append(indices)
|
| 180 |
+
|
| 181 |
+
wh = torch.tensor([w - 1, h - 1], device=scores_nograd.device)
|
| 182 |
+
|
| 183 |
+
keypoints = []
|
| 184 |
+
scoredispersitys = []
|
| 185 |
+
kptscores = []
|
| 186 |
+
if sub_pixel:
|
| 187 |
+
# detect soft keypoints with grad backpropagation
|
| 188 |
+
patches = self.unfold(scores_map) # B x (kernel**2) x (H*W)
|
| 189 |
+
self.hw_grid = self.hw_grid.to(scores_map) # to device
|
| 190 |
+
for b_idx in range(b):
|
| 191 |
+
patch = patches[b_idx].t() # (H*W) x (kernel**2)
|
| 192 |
+
indices_kpt = indices_keypoints[
|
| 193 |
+
b_idx
|
| 194 |
+
] # one dimension vector, say its size is M
|
| 195 |
+
patch_scores = patch[indices_kpt] # M x (kernel**2)
|
| 196 |
+
keypoints_xy_nms = torch.stack(
|
| 197 |
+
[indices_kpt % w, torch.div(indices_kpt, w, rounding_mode="trunc")],
|
| 198 |
+
dim=1,
|
| 199 |
+
) # Mx2
|
| 200 |
+
|
| 201 |
+
# max is detached to prevent undesired backprop loops in the graph
|
| 202 |
+
max_v = patch_scores.max(dim=1).values.detach()[:, None]
|
| 203 |
+
x_exp = (
|
| 204 |
+
(patch_scores - max_v) / self.temperature
|
| 205 |
+
).exp() # M * (kernel**2), in [0, 1]
|
| 206 |
+
|
| 207 |
+
# \frac{ \sum{(i,j) \times \exp(x/T)} }{ \sum{\exp(x/T)} }
|
| 208 |
+
xy_residual = (
|
| 209 |
+
x_exp @ self.hw_grid / x_exp.sum(dim=1)[:, None]
|
| 210 |
+
) # Soft-argmax, Mx2
|
| 211 |
+
|
| 212 |
+
hw_grid_dist2 = (
|
| 213 |
+
torch.norm(
|
| 214 |
+
(self.hw_grid[None, :, :] - xy_residual[:, None, :])
|
| 215 |
+
/ self.radius,
|
| 216 |
+
dim=-1,
|
| 217 |
+
)
|
| 218 |
+
** 2
|
| 219 |
+
)
|
| 220 |
+
scoredispersity = (x_exp * hw_grid_dist2).sum(dim=1) / x_exp.sum(dim=1)
|
| 221 |
+
|
| 222 |
+
# compute result keypoints
|
| 223 |
+
keypoints_xy = keypoints_xy_nms + xy_residual
|
| 224 |
+
keypoints_xy = keypoints_xy / wh * 2 - 1 # (w,h) -> (-1~1,-1~1)
|
| 225 |
+
|
| 226 |
+
kptscore = torch.nn.functional.grid_sample(
|
| 227 |
+
scores_map[b_idx].unsqueeze(0),
|
| 228 |
+
keypoints_xy.view(1, 1, -1, 2),
|
| 229 |
+
mode="bilinear",
|
| 230 |
+
align_corners=True,
|
| 231 |
+
)[
|
| 232 |
+
0, 0, 0, :
|
| 233 |
+
] # CxN
|
| 234 |
+
|
| 235 |
+
keypoints.append(keypoints_xy)
|
| 236 |
+
scoredispersitys.append(scoredispersity)
|
| 237 |
+
kptscores.append(kptscore)
|
| 238 |
+
else:
|
| 239 |
+
for b_idx in range(b):
|
| 240 |
+
indices_kpt = indices_keypoints[
|
| 241 |
+
b_idx
|
| 242 |
+
] # one dimension vector, say its size is M
|
| 243 |
+
# To avoid warning: UserWarning: __floordiv__ is deprecated
|
| 244 |
+
keypoints_xy_nms = torch.stack(
|
| 245 |
+
[indices_kpt % w, torch.div(indices_kpt, w, rounding_mode="trunc")],
|
| 246 |
+
dim=1,
|
| 247 |
+
) # Mx2
|
| 248 |
+
keypoints_xy = keypoints_xy_nms / wh * 2 - 1 # (w,h) -> (-1~1,-1~1)
|
| 249 |
+
kptscore = torch.nn.functional.grid_sample(
|
| 250 |
+
scores_map[b_idx].unsqueeze(0),
|
| 251 |
+
keypoints_xy.view(1, 1, -1, 2),
|
| 252 |
+
mode="bilinear",
|
| 253 |
+
align_corners=True,
|
| 254 |
+
)[
|
| 255 |
+
0, 0, 0, :
|
| 256 |
+
] # CxN
|
| 257 |
+
keypoints.append(keypoints_xy)
|
| 258 |
+
scoredispersitys.append(kptscore) # for jit.script compatability
|
| 259 |
+
kptscores.append(kptscore)
|
| 260 |
+
|
| 261 |
+
return keypoints, scoredispersitys, kptscores
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class InputPadder(object):
|
| 265 |
+
"""Pads images such that dimensions are divisible by 8"""
|
| 266 |
+
|
| 267 |
+
def __init__(self, h: int, w: int, divis_by: int = 8):
|
| 268 |
+
self.ht = h
|
| 269 |
+
self.wd = w
|
| 270 |
+
pad_ht = (((self.ht // divis_by) + 1) * divis_by - self.ht) % divis_by
|
| 271 |
+
pad_wd = (((self.wd // divis_by) + 1) * divis_by - self.wd) % divis_by
|
| 272 |
+
self._pad = [
|
| 273 |
+
pad_wd // 2,
|
| 274 |
+
pad_wd - pad_wd // 2,
|
| 275 |
+
pad_ht // 2,
|
| 276 |
+
pad_ht - pad_ht // 2,
|
| 277 |
+
]
|
| 278 |
+
|
| 279 |
+
def pad(self, x: torch.Tensor):
|
| 280 |
+
assert x.ndim == 4
|
| 281 |
+
return F.pad(x, self._pad, mode="replicate")
|
| 282 |
+
|
| 283 |
+
def unpad(self, x: torch.Tensor):
|
| 284 |
+
assert x.ndim == 4
|
| 285 |
+
ht = x.shape[-2]
|
| 286 |
+
wd = x.shape[-1]
|
| 287 |
+
c = [self._pad[2], ht - self._pad[3], self._pad[0], wd - self._pad[1]]
|
| 288 |
+
return x[..., c[0] : c[1], c[2] : c[3]]
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class DeformableConv2d(nn.Module):
|
| 292 |
+
def __init__(
|
| 293 |
+
self,
|
| 294 |
+
in_channels,
|
| 295 |
+
out_channels,
|
| 296 |
+
kernel_size=3,
|
| 297 |
+
stride=1,
|
| 298 |
+
padding=1,
|
| 299 |
+
bias=False,
|
| 300 |
+
mask=False,
|
| 301 |
+
):
|
| 302 |
+
super(DeformableConv2d, self).__init__()
|
| 303 |
+
|
| 304 |
+
self.padding = padding
|
| 305 |
+
self.mask = mask
|
| 306 |
+
|
| 307 |
+
self.channel_num = (
|
| 308 |
+
3 * kernel_size * kernel_size if mask else 2 * kernel_size * kernel_size
|
| 309 |
+
)
|
| 310 |
+
self.offset_conv = nn.Conv2d(
|
| 311 |
+
in_channels,
|
| 312 |
+
self.channel_num,
|
| 313 |
+
kernel_size=kernel_size,
|
| 314 |
+
stride=stride,
|
| 315 |
+
padding=self.padding,
|
| 316 |
+
bias=True,
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
self.regular_conv = nn.Conv2d(
|
| 320 |
+
in_channels=in_channels,
|
| 321 |
+
out_channels=out_channels,
|
| 322 |
+
kernel_size=kernel_size,
|
| 323 |
+
stride=stride,
|
| 324 |
+
padding=self.padding,
|
| 325 |
+
bias=bias,
|
| 326 |
+
)
|
| 327 |
+
|
| 328 |
+
def forward(self, x):
|
| 329 |
+
h, w = x.shape[2:]
|
| 330 |
+
max_offset = max(h, w) / 4.0
|
| 331 |
+
|
| 332 |
+
out = self.offset_conv(x)
|
| 333 |
+
if self.mask:
|
| 334 |
+
o1, o2, mask = torch.chunk(out, 3, dim=1)
|
| 335 |
+
offset = torch.cat((o1, o2), dim=1)
|
| 336 |
+
mask = torch.sigmoid(mask)
|
| 337 |
+
else:
|
| 338 |
+
offset = out
|
| 339 |
+
mask = None
|
| 340 |
+
offset = offset.clamp(-max_offset, max_offset)
|
| 341 |
+
x = torchvision.ops.deform_conv2d(
|
| 342 |
+
input=x,
|
| 343 |
+
offset=offset,
|
| 344 |
+
weight=self.regular_conv.weight,
|
| 345 |
+
bias=self.regular_conv.bias,
|
| 346 |
+
padding=self.padding,
|
| 347 |
+
mask=mask,
|
| 348 |
+
)
|
| 349 |
+
return x
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
def get_conv(
|
| 353 |
+
inplanes,
|
| 354 |
+
planes,
|
| 355 |
+
kernel_size=3,
|
| 356 |
+
stride=1,
|
| 357 |
+
padding=1,
|
| 358 |
+
bias=False,
|
| 359 |
+
conv_type="conv",
|
| 360 |
+
mask=False,
|
| 361 |
+
):
|
| 362 |
+
if conv_type == "conv":
|
| 363 |
+
conv = nn.Conv2d(
|
| 364 |
+
inplanes,
|
| 365 |
+
planes,
|
| 366 |
+
kernel_size=kernel_size,
|
| 367 |
+
stride=stride,
|
| 368 |
+
padding=padding,
|
| 369 |
+
bias=bias,
|
| 370 |
+
)
|
| 371 |
+
elif conv_type == "dcn":
|
| 372 |
+
conv = DeformableConv2d(
|
| 373 |
+
inplanes,
|
| 374 |
+
planes,
|
| 375 |
+
kernel_size=kernel_size,
|
| 376 |
+
stride=stride,
|
| 377 |
+
padding=_pair(padding),
|
| 378 |
+
bias=bias,
|
| 379 |
+
mask=mask,
|
| 380 |
+
)
|
| 381 |
+
else:
|
| 382 |
+
raise TypeError
|
| 383 |
+
return conv
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
class ConvBlock(nn.Module):
|
| 387 |
+
def __init__(
|
| 388 |
+
self,
|
| 389 |
+
in_channels,
|
| 390 |
+
out_channels,
|
| 391 |
+
gate: Optional[Callable[..., nn.Module]] = None,
|
| 392 |
+
norm_layer: Optional[Callable[..., nn.Module]] = None,
|
| 393 |
+
conv_type: str = "conv",
|
| 394 |
+
mask: bool = False,
|
| 395 |
+
):
|
| 396 |
+
super().__init__()
|
| 397 |
+
if gate is None:
|
| 398 |
+
self.gate = nn.ReLU(inplace=True)
|
| 399 |
+
else:
|
| 400 |
+
self.gate = gate
|
| 401 |
+
if norm_layer is None:
|
| 402 |
+
norm_layer = nn.BatchNorm2d
|
| 403 |
+
self.conv1 = get_conv(
|
| 404 |
+
in_channels, out_channels, kernel_size=3, conv_type=conv_type, mask=mask
|
| 405 |
+
)
|
| 406 |
+
self.bn1 = norm_layer(out_channels)
|
| 407 |
+
self.conv2 = get_conv(
|
| 408 |
+
out_channels, out_channels, kernel_size=3, conv_type=conv_type, mask=mask
|
| 409 |
+
)
|
| 410 |
+
self.bn2 = norm_layer(out_channels)
|
| 411 |
+
|
| 412 |
+
def forward(self, x):
|
| 413 |
+
x = self.gate(self.bn1(self.conv1(x))) # B x in_channels x H x W
|
| 414 |
+
x = self.gate(self.bn2(self.conv2(x))) # B x out_channels x H x W
|
| 415 |
+
return x
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
# modified based on torchvision\models\resnet.py#27->BasicBlock
|
| 419 |
+
class ResBlock(nn.Module):
|
| 420 |
+
expansion: int = 1
|
| 421 |
+
|
| 422 |
+
def __init__(
|
| 423 |
+
self,
|
| 424 |
+
inplanes: int,
|
| 425 |
+
planes: int,
|
| 426 |
+
stride: int = 1,
|
| 427 |
+
downsample: Optional[nn.Module] = None,
|
| 428 |
+
groups: int = 1,
|
| 429 |
+
base_width: int = 64,
|
| 430 |
+
dilation: int = 1,
|
| 431 |
+
gate: Optional[Callable[..., nn.Module]] = None,
|
| 432 |
+
norm_layer: Optional[Callable[..., nn.Module]] = None,
|
| 433 |
+
conv_type: str = "conv",
|
| 434 |
+
mask: bool = False,
|
| 435 |
+
) -> None:
|
| 436 |
+
super(ResBlock, self).__init__()
|
| 437 |
+
if gate is None:
|
| 438 |
+
self.gate = nn.ReLU(inplace=True)
|
| 439 |
+
else:
|
| 440 |
+
self.gate = gate
|
| 441 |
+
if norm_layer is None:
|
| 442 |
+
norm_layer = nn.BatchNorm2d
|
| 443 |
+
if groups != 1 or base_width != 64:
|
| 444 |
+
raise ValueError("ResBlock only supports groups=1 and base_width=64")
|
| 445 |
+
if dilation > 1:
|
| 446 |
+
raise NotImplementedError("Dilation > 1 not supported in ResBlock")
|
| 447 |
+
# Both self.conv1 and self.downsample layers
|
| 448 |
+
# downsample the input when stride != 1
|
| 449 |
+
self.conv1 = get_conv(
|
| 450 |
+
inplanes, planes, kernel_size=3, conv_type=conv_type, mask=mask
|
| 451 |
+
)
|
| 452 |
+
self.bn1 = norm_layer(planes)
|
| 453 |
+
self.conv2 = get_conv(
|
| 454 |
+
planes, planes, kernel_size=3, conv_type=conv_type, mask=mask
|
| 455 |
+
)
|
| 456 |
+
self.bn2 = norm_layer(planes)
|
| 457 |
+
self.downsample = downsample
|
| 458 |
+
self.stride = stride
|
| 459 |
+
|
| 460 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 461 |
+
identity = x
|
| 462 |
+
|
| 463 |
+
out = self.conv1(x)
|
| 464 |
+
out = self.bn1(out)
|
| 465 |
+
out = self.gate(out)
|
| 466 |
+
|
| 467 |
+
out = self.conv2(out)
|
| 468 |
+
out = self.bn2(out)
|
| 469 |
+
|
| 470 |
+
if self.downsample is not None:
|
| 471 |
+
identity = self.downsample(x)
|
| 472 |
+
|
| 473 |
+
out += identity
|
| 474 |
+
out = self.gate(out)
|
| 475 |
+
|
| 476 |
+
return out
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
class SDDH(nn.Module):
|
| 480 |
+
def __init__(
|
| 481 |
+
self,
|
| 482 |
+
dims: int,
|
| 483 |
+
kernel_size: int = 3,
|
| 484 |
+
n_pos: int = 8,
|
| 485 |
+
gate=nn.ReLU(),
|
| 486 |
+
conv2D=False,
|
| 487 |
+
mask=False,
|
| 488 |
+
):
|
| 489 |
+
super(SDDH, self).__init__()
|
| 490 |
+
self.kernel_size = kernel_size
|
| 491 |
+
self.n_pos = n_pos
|
| 492 |
+
self.conv2D = conv2D
|
| 493 |
+
self.mask = mask
|
| 494 |
+
|
| 495 |
+
self.get_patches_func = get_patches
|
| 496 |
+
|
| 497 |
+
# estimate offsets
|
| 498 |
+
self.channel_num = 3 * n_pos if mask else 2 * n_pos
|
| 499 |
+
self.offset_conv = nn.Sequential(
|
| 500 |
+
nn.Conv2d(
|
| 501 |
+
dims,
|
| 502 |
+
self.channel_num,
|
| 503 |
+
kernel_size=kernel_size,
|
| 504 |
+
stride=1,
|
| 505 |
+
padding=0,
|
| 506 |
+
bias=True,
|
| 507 |
+
),
|
| 508 |
+
gate,
|
| 509 |
+
nn.Conv2d(
|
| 510 |
+
self.channel_num,
|
| 511 |
+
self.channel_num,
|
| 512 |
+
kernel_size=1,
|
| 513 |
+
stride=1,
|
| 514 |
+
padding=0,
|
| 515 |
+
bias=True,
|
| 516 |
+
),
|
| 517 |
+
)
|
| 518 |
+
|
| 519 |
+
# sampled feature conv
|
| 520 |
+
self.sf_conv = nn.Conv2d(
|
| 521 |
+
dims, dims, kernel_size=1, stride=1, padding=0, bias=False
|
| 522 |
+
)
|
| 523 |
+
|
| 524 |
+
# convM
|
| 525 |
+
if not conv2D:
|
| 526 |
+
# deformable desc weights
|
| 527 |
+
agg_weights = torch.nn.Parameter(torch.rand(n_pos, dims, dims))
|
| 528 |
+
self.register_parameter("agg_weights", agg_weights)
|
| 529 |
+
else:
|
| 530 |
+
self.convM = nn.Conv2d(
|
| 531 |
+
dims * n_pos, dims, kernel_size=1, stride=1, padding=0, bias=False
|
| 532 |
+
)
|
| 533 |
+
|
| 534 |
+
def forward(self, x, keypoints):
|
| 535 |
+
# x: [B,C,H,W]
|
| 536 |
+
# keypoints: list, [[N_kpts,2], ...] (w,h)
|
| 537 |
+
b, c, h, w = x.shape
|
| 538 |
+
wh = torch.tensor([[w - 1, h - 1]], device=x.device)
|
| 539 |
+
max_offset = max(h, w) / 4.0
|
| 540 |
+
|
| 541 |
+
offsets = []
|
| 542 |
+
descriptors = []
|
| 543 |
+
# get offsets for each keypoint
|
| 544 |
+
for ib in range(b):
|
| 545 |
+
xi, kptsi = x[ib], keypoints[ib]
|
| 546 |
+
kptsi_wh = (kptsi / 2 + 0.5) * wh
|
| 547 |
+
N_kpts = len(kptsi)
|
| 548 |
+
|
| 549 |
+
if self.kernel_size > 1:
|
| 550 |
+
patch = self.get_patches_func(
|
| 551 |
+
xi, kptsi_wh.long(), self.kernel_size
|
| 552 |
+
) # [N_kpts, C, K, K]
|
| 553 |
+
else:
|
| 554 |
+
kptsi_wh_long = kptsi_wh.long()
|
| 555 |
+
patch = (
|
| 556 |
+
xi[:, kptsi_wh_long[:, 1], kptsi_wh_long[:, 0]]
|
| 557 |
+
.permute(1, 0)
|
| 558 |
+
.reshape(N_kpts, c, 1, 1)
|
| 559 |
+
)
|
| 560 |
+
|
| 561 |
+
offset = self.offset_conv(patch).clamp(
|
| 562 |
+
-max_offset, max_offset
|
| 563 |
+
) # [N_kpts, 2*n_pos, 1, 1]
|
| 564 |
+
if self.mask:
|
| 565 |
+
offset = (
|
| 566 |
+
offset[:, :, 0, 0].view(N_kpts, 3, self.n_pos).permute(0, 2, 1)
|
| 567 |
+
) # [N_kpts, n_pos, 3]
|
| 568 |
+
offset = offset[:, :, :-1] # [N_kpts, n_pos, 2]
|
| 569 |
+
mask_weight = torch.sigmoid(offset[:, :, -1]) # [N_kpts, n_pos]
|
| 570 |
+
else:
|
| 571 |
+
offset = (
|
| 572 |
+
offset[:, :, 0, 0].view(N_kpts, 2, self.n_pos).permute(0, 2, 1)
|
| 573 |
+
) # [N_kpts, n_pos, 2]
|
| 574 |
+
offsets.append(offset) # for visualization
|
| 575 |
+
|
| 576 |
+
# get sample positions
|
| 577 |
+
pos = kptsi_wh.unsqueeze(1) + offset # [N_kpts, n_pos, 2]
|
| 578 |
+
pos = 2.0 * pos / wh[None] - 1
|
| 579 |
+
pos = pos.reshape(1, N_kpts * self.n_pos, 1, 2)
|
| 580 |
+
|
| 581 |
+
# sample features
|
| 582 |
+
features = F.grid_sample(
|
| 583 |
+
xi.unsqueeze(0), pos, mode="bilinear", align_corners=True
|
| 584 |
+
) # [1,C,(N_kpts*n_pos),1]
|
| 585 |
+
features = features.reshape(c, N_kpts, self.n_pos, 1).permute(
|
| 586 |
+
1, 0, 2, 3
|
| 587 |
+
) # [N_kpts, C, n_pos, 1]
|
| 588 |
+
if self.mask:
|
| 589 |
+
features = torch.einsum("ncpo,np->ncpo", features, mask_weight)
|
| 590 |
+
|
| 591 |
+
features = torch.selu_(self.sf_conv(features)).squeeze(
|
| 592 |
+
-1
|
| 593 |
+
) # [N_kpts, C, n_pos]
|
| 594 |
+
# convM
|
| 595 |
+
if not self.conv2D:
|
| 596 |
+
descs = torch.einsum(
|
| 597 |
+
"ncp,pcd->nd", features, self.agg_weights
|
| 598 |
+
) # [N_kpts, C]
|
| 599 |
+
else:
|
| 600 |
+
features = features.reshape(N_kpts, -1)[
|
| 601 |
+
:, :, None, None
|
| 602 |
+
] # [N_kpts, C*n_pos, 1, 1]
|
| 603 |
+
descs = self.convM(features).squeeze() # [N_kpts, C]
|
| 604 |
+
|
| 605 |
+
# normalize
|
| 606 |
+
descs = F.normalize(descs, p=2.0, dim=1)
|
| 607 |
+
descriptors.append(descs)
|
| 608 |
+
|
| 609 |
+
return descriptors, offsets
|
| 610 |
+
|
| 611 |
+
|
| 612 |
+
class ALIKED(Extractor):
|
| 613 |
+
default_conf = {
|
| 614 |
+
"model_name": "aliked-n16",
|
| 615 |
+
"max_num_keypoints": -1,
|
| 616 |
+
"detection_threshold": 0.2,
|
| 617 |
+
"nms_radius": 2,
|
| 618 |
+
}
|
| 619 |
+
|
| 620 |
+
checkpoint_url = "https://github.com/Shiaoming/ALIKED/raw/main/models/{}.pth"
|
| 621 |
+
|
| 622 |
+
n_limit_max = 20000
|
| 623 |
+
|
| 624 |
+
# c1, c2, c3, c4, dim, K, M
|
| 625 |
+
cfgs = {
|
| 626 |
+
"aliked-t16": [8, 16, 32, 64, 64, 3, 16],
|
| 627 |
+
"aliked-n16": [16, 32, 64, 128, 128, 3, 16],
|
| 628 |
+
"aliked-n16rot": [16, 32, 64, 128, 128, 3, 16],
|
| 629 |
+
"aliked-n32": [16, 32, 64, 128, 128, 3, 32],
|
| 630 |
+
}
|
| 631 |
+
preprocess_conf = {
|
| 632 |
+
"resize": 1024,
|
| 633 |
+
}
|
| 634 |
+
|
| 635 |
+
required_data_keys = ["image"]
|
| 636 |
+
|
| 637 |
+
def __init__(self, **conf):
|
| 638 |
+
super().__init__(**conf) # Update with default configuration.
|
| 639 |
+
conf = self.conf
|
| 640 |
+
c1, c2, c3, c4, dim, K, M = self.cfgs[conf.model_name]
|
| 641 |
+
conv_types = ["conv", "conv", "dcn", "dcn"]
|
| 642 |
+
conv2D = False
|
| 643 |
+
mask = False
|
| 644 |
+
|
| 645 |
+
# build model
|
| 646 |
+
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
|
| 647 |
+
self.pool4 = nn.AvgPool2d(kernel_size=4, stride=4)
|
| 648 |
+
self.norm = nn.BatchNorm2d
|
| 649 |
+
self.gate = nn.SELU(inplace=True)
|
| 650 |
+
self.block1 = ConvBlock(3, c1, self.gate, self.norm, conv_type=conv_types[0])
|
| 651 |
+
self.block2 = self.get_resblock(c1, c2, conv_types[1], mask)
|
| 652 |
+
self.block3 = self.get_resblock(c2, c3, conv_types[2], mask)
|
| 653 |
+
self.block4 = self.get_resblock(c3, c4, conv_types[3], mask)
|
| 654 |
+
|
| 655 |
+
self.conv1 = resnet.conv1x1(c1, dim // 4)
|
| 656 |
+
self.conv2 = resnet.conv1x1(c2, dim // 4)
|
| 657 |
+
self.conv3 = resnet.conv1x1(c3, dim // 4)
|
| 658 |
+
self.conv4 = resnet.conv1x1(dim, dim // 4)
|
| 659 |
+
self.upsample2 = nn.Upsample(
|
| 660 |
+
scale_factor=2, mode="bilinear", align_corners=True
|
| 661 |
+
)
|
| 662 |
+
self.upsample4 = nn.Upsample(
|
| 663 |
+
scale_factor=4, mode="bilinear", align_corners=True
|
| 664 |
+
)
|
| 665 |
+
self.upsample8 = nn.Upsample(
|
| 666 |
+
scale_factor=8, mode="bilinear", align_corners=True
|
| 667 |
+
)
|
| 668 |
+
self.upsample32 = nn.Upsample(
|
| 669 |
+
scale_factor=32, mode="bilinear", align_corners=True
|
| 670 |
+
)
|
| 671 |
+
self.score_head = nn.Sequential(
|
| 672 |
+
resnet.conv1x1(dim, 8),
|
| 673 |
+
self.gate,
|
| 674 |
+
resnet.conv3x3(8, 4),
|
| 675 |
+
self.gate,
|
| 676 |
+
resnet.conv3x3(4, 4),
|
| 677 |
+
self.gate,
|
| 678 |
+
resnet.conv3x3(4, 1),
|
| 679 |
+
)
|
| 680 |
+
self.desc_head = SDDH(dim, K, M, gate=self.gate, conv2D=conv2D, mask=mask)
|
| 681 |
+
self.dkd = DKD(
|
| 682 |
+
radius=conf.nms_radius,
|
| 683 |
+
top_k=-1 if conf.detection_threshold > 0 else conf.max_num_keypoints,
|
| 684 |
+
scores_th=conf.detection_threshold,
|
| 685 |
+
n_limit=conf.max_num_keypoints
|
| 686 |
+
if conf.max_num_keypoints > 0
|
| 687 |
+
else self.n_limit_max,
|
| 688 |
+
)
|
| 689 |
+
|
| 690 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 691 |
+
self.checkpoint_url.format(conf.model_name), map_location="cpu"
|
| 692 |
+
)
|
| 693 |
+
self.load_state_dict(state_dict, strict=True)
|
| 694 |
+
|
| 695 |
+
def get_resblock(self, c_in, c_out, conv_type, mask):
|
| 696 |
+
return ResBlock(
|
| 697 |
+
c_in,
|
| 698 |
+
c_out,
|
| 699 |
+
1,
|
| 700 |
+
nn.Conv2d(c_in, c_out, 1),
|
| 701 |
+
gate=self.gate,
|
| 702 |
+
norm_layer=self.norm,
|
| 703 |
+
conv_type=conv_type,
|
| 704 |
+
mask=mask,
|
| 705 |
+
)
|
| 706 |
+
|
| 707 |
+
def extract_dense_map(self, image):
|
| 708 |
+
# Pads images such that dimensions are divisible by
|
| 709 |
+
div_by = 2**5
|
| 710 |
+
padder = InputPadder(image.shape[-2], image.shape[-1], div_by)
|
| 711 |
+
image = padder.pad(image)
|
| 712 |
+
|
| 713 |
+
# ================================== feature encoder
|
| 714 |
+
x1 = self.block1(image) # B x c1 x H x W
|
| 715 |
+
x2 = self.pool2(x1)
|
| 716 |
+
x2 = self.block2(x2) # B x c2 x H/2 x W/2
|
| 717 |
+
x3 = self.pool4(x2)
|
| 718 |
+
x3 = self.block3(x3) # B x c3 x H/8 x W/8
|
| 719 |
+
x4 = self.pool4(x3)
|
| 720 |
+
x4 = self.block4(x4) # B x dim x H/32 x W/32
|
| 721 |
+
# ================================== feature aggregation
|
| 722 |
+
x1 = self.gate(self.conv1(x1)) # B x dim//4 x H x W
|
| 723 |
+
x2 = self.gate(self.conv2(x2)) # B x dim//4 x H//2 x W//2
|
| 724 |
+
x3 = self.gate(self.conv3(x3)) # B x dim//4 x H//8 x W//8
|
| 725 |
+
x4 = self.gate(self.conv4(x4)) # B x dim//4 x H//32 x W//32
|
| 726 |
+
x2_up = self.upsample2(x2) # B x dim//4 x H x W
|
| 727 |
+
x3_up = self.upsample8(x3) # B x dim//4 x H x W
|
| 728 |
+
x4_up = self.upsample32(x4) # B x dim//4 x H x W
|
| 729 |
+
x1234 = torch.cat([x1, x2_up, x3_up, x4_up], dim=1)
|
| 730 |
+
# ================================== score head
|
| 731 |
+
score_map = torch.sigmoid(self.score_head(x1234))
|
| 732 |
+
feature_map = torch.nn.functional.normalize(x1234, p=2, dim=1)
|
| 733 |
+
|
| 734 |
+
# Unpads images
|
| 735 |
+
feature_map = padder.unpad(feature_map)
|
| 736 |
+
score_map = padder.unpad(score_map)
|
| 737 |
+
|
| 738 |
+
return feature_map, score_map
|
| 739 |
+
|
| 740 |
+
def forward(self, data: dict) -> dict:
|
| 741 |
+
image = data["image"]
|
| 742 |
+
if image.shape[1] == 1:
|
| 743 |
+
image = grayscale_to_rgb(image)
|
| 744 |
+
feature_map, score_map = self.extract_dense_map(image)
|
| 745 |
+
keypoints, kptscores, scoredispersitys = self.dkd(
|
| 746 |
+
score_map, image_size=data.get("image_size")
|
| 747 |
+
)
|
| 748 |
+
descriptors, offsets = self.desc_head(feature_map, keypoints)
|
| 749 |
+
|
| 750 |
+
_, _, h, w = image.shape
|
| 751 |
+
wh = torch.tensor([w - 1, h - 1], device=image.device)
|
| 752 |
+
# no padding required
|
| 753 |
+
# we can set detection_threshold=-1 and conf.max_num_keypoints > 0
|
| 754 |
+
return {
|
| 755 |
+
"keypoints": wh * (torch.stack(keypoints) + 1) / 2.0, # B x N x 2
|
| 756 |
+
"descriptors": torch.stack(descriptors), # B x N x D
|
| 757 |
+
"keypoint_scores": torch.stack(kptscores), # B x N
|
| 758 |
+
}
|
LightGlue/lightglue/disk.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import kornia
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from .utils import Extractor
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class DISK(Extractor):
|
| 8 |
+
default_conf = {
|
| 9 |
+
"weights": "depth",
|
| 10 |
+
"max_num_keypoints": None,
|
| 11 |
+
"desc_dim": 128,
|
| 12 |
+
"nms_window_size": 5,
|
| 13 |
+
"detection_threshold": 0.0,
|
| 14 |
+
"pad_if_not_divisible": True,
|
| 15 |
+
}
|
| 16 |
+
|
| 17 |
+
preprocess_conf = {
|
| 18 |
+
"resize": 1024,
|
| 19 |
+
"grayscale": False,
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
required_data_keys = ["image"]
|
| 23 |
+
|
| 24 |
+
def __init__(self, **conf) -> None:
|
| 25 |
+
super().__init__(**conf) # Update with default configuration.
|
| 26 |
+
self.model = kornia.feature.DISK.from_pretrained(self.conf.weights)
|
| 27 |
+
|
| 28 |
+
def forward(self, data: dict) -> dict:
|
| 29 |
+
"""Compute keypoints, scores, descriptors for image"""
|
| 30 |
+
for key in self.required_data_keys:
|
| 31 |
+
assert key in data, f"Missing key {key} in data"
|
| 32 |
+
image = data["image"]
|
| 33 |
+
if image.shape[1] == 1:
|
| 34 |
+
image = kornia.color.grayscale_to_rgb(image)
|
| 35 |
+
features = self.model(
|
| 36 |
+
image,
|
| 37 |
+
n=self.conf.max_num_keypoints,
|
| 38 |
+
window_size=self.conf.nms_window_size,
|
| 39 |
+
score_threshold=self.conf.detection_threshold,
|
| 40 |
+
pad_if_not_divisible=self.conf.pad_if_not_divisible,
|
| 41 |
+
)
|
| 42 |
+
keypoints = [f.keypoints for f in features]
|
| 43 |
+
scores = [f.detection_scores for f in features]
|
| 44 |
+
descriptors = [f.descriptors for f in features]
|
| 45 |
+
del features
|
| 46 |
+
|
| 47 |
+
keypoints = torch.stack(keypoints, 0)
|
| 48 |
+
scores = torch.stack(scores, 0)
|
| 49 |
+
descriptors = torch.stack(descriptors, 0)
|
| 50 |
+
|
| 51 |
+
return {
|
| 52 |
+
"keypoints": keypoints.to(image).contiguous(),
|
| 53 |
+
"keypoint_scores": scores.to(image).contiguous(),
|
| 54 |
+
"descriptors": descriptors.to(image).contiguous(),
|
| 55 |
+
}
|
LightGlue/lightglue/dog_hardnet.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from kornia.color import rgb_to_grayscale
|
| 3 |
+
from kornia.feature import HardNet, LAFDescriptor, laf_from_center_scale_ori
|
| 4 |
+
|
| 5 |
+
from .sift import SIFT
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class DoGHardNet(SIFT):
|
| 9 |
+
required_data_keys = ["image"]
|
| 10 |
+
|
| 11 |
+
def __init__(self, **conf):
|
| 12 |
+
super().__init__(**conf)
|
| 13 |
+
self.laf_desc = LAFDescriptor(HardNet(True)).eval()
|
| 14 |
+
|
| 15 |
+
def forward(self, data: dict) -> dict:
|
| 16 |
+
image = data["image"]
|
| 17 |
+
if image.shape[1] == 3:
|
| 18 |
+
image = rgb_to_grayscale(image)
|
| 19 |
+
device = image.device
|
| 20 |
+
self.laf_desc = self.laf_desc.to(device)
|
| 21 |
+
self.laf_desc.descriptor = self.laf_desc.descriptor.eval()
|
| 22 |
+
pred = []
|
| 23 |
+
if "image_size" in data.keys():
|
| 24 |
+
im_size = data.get("image_size").long()
|
| 25 |
+
else:
|
| 26 |
+
im_size = None
|
| 27 |
+
for k in range(len(image)):
|
| 28 |
+
img = image[k]
|
| 29 |
+
if im_size is not None:
|
| 30 |
+
w, h = data["image_size"][k]
|
| 31 |
+
img = img[:, : h.to(torch.int32), : w.to(torch.int32)]
|
| 32 |
+
p = self.extract_single_image(img)
|
| 33 |
+
lafs = laf_from_center_scale_ori(
|
| 34 |
+
p["keypoints"].reshape(1, -1, 2),
|
| 35 |
+
6.0 * p["scales"].reshape(1, -1, 1, 1),
|
| 36 |
+
torch.rad2deg(p["oris"]).reshape(1, -1, 1),
|
| 37 |
+
).to(device)
|
| 38 |
+
p["descriptors"] = self.laf_desc(img[None], lafs).reshape(-1, 128)
|
| 39 |
+
pred.append(p)
|
| 40 |
+
pred = {k: torch.stack([p[k] for p in pred], 0).to(device) for k in pred[0]}
|
| 41 |
+
return pred
|
LightGlue/lightglue/lightglue.py
ADDED
|
@@ -0,0 +1,655 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
from types import SimpleNamespace
|
| 4 |
+
from typing import Callable, List, Optional, Tuple
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from torch import nn
|
| 10 |
+
|
| 11 |
+
try:
|
| 12 |
+
from flash_attn.modules.mha import FlashCrossAttention
|
| 13 |
+
except ModuleNotFoundError:
|
| 14 |
+
FlashCrossAttention = None
|
| 15 |
+
|
| 16 |
+
if FlashCrossAttention or hasattr(F, "scaled_dot_product_attention"):
|
| 17 |
+
FLASH_AVAILABLE = True
|
| 18 |
+
else:
|
| 19 |
+
FLASH_AVAILABLE = False
|
| 20 |
+
|
| 21 |
+
torch.backends.cudnn.deterministic = True
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
@torch.cuda.amp.custom_fwd(cast_inputs=torch.float32)
|
| 25 |
+
def normalize_keypoints(
|
| 26 |
+
kpts: torch.Tensor, size: Optional[torch.Tensor] = None
|
| 27 |
+
) -> torch.Tensor:
|
| 28 |
+
if size is None:
|
| 29 |
+
size = 1 + kpts.max(-2).values - kpts.min(-2).values
|
| 30 |
+
elif not isinstance(size, torch.Tensor):
|
| 31 |
+
size = torch.tensor(size, device=kpts.device, dtype=kpts.dtype)
|
| 32 |
+
size = size.to(kpts)
|
| 33 |
+
shift = size / 2
|
| 34 |
+
scale = size.max(-1).values / 2
|
| 35 |
+
kpts = (kpts - shift[..., None, :]) / scale[..., None, None]
|
| 36 |
+
return kpts
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def pad_to_length(x: torch.Tensor, length: int) -> Tuple[torch.Tensor]:
|
| 40 |
+
if length <= x.shape[-2]:
|
| 41 |
+
return x, torch.ones_like(x[..., :1], dtype=torch.bool)
|
| 42 |
+
pad = torch.ones(
|
| 43 |
+
*x.shape[:-2], length - x.shape[-2], x.shape[-1], device=x.device, dtype=x.dtype
|
| 44 |
+
)
|
| 45 |
+
y = torch.cat([x, pad], dim=-2)
|
| 46 |
+
mask = torch.zeros(*y.shape[:-1], 1, dtype=torch.bool, device=x.device)
|
| 47 |
+
mask[..., : x.shape[-2], :] = True
|
| 48 |
+
return y, mask
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def rotate_half(x: torch.Tensor) -> torch.Tensor:
|
| 52 |
+
x = x.unflatten(-1, (-1, 2))
|
| 53 |
+
x1, x2 = x.unbind(dim=-1)
|
| 54 |
+
return torch.stack((-x2, x1), dim=-1).flatten(start_dim=-2)
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def apply_cached_rotary_emb(freqs: torch.Tensor, t: torch.Tensor) -> torch.Tensor:
|
| 58 |
+
return (t * freqs[0]) + (rotate_half(t) * freqs[1])
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class LearnableFourierPositionalEncoding(nn.Module):
|
| 62 |
+
def __init__(self, M: int, dim: int, F_dim: int = None, gamma: float = 1.0) -> None:
|
| 63 |
+
super().__init__()
|
| 64 |
+
F_dim = F_dim if F_dim is not None else dim
|
| 65 |
+
self.gamma = gamma
|
| 66 |
+
self.Wr = nn.Linear(M, F_dim // 2, bias=False)
|
| 67 |
+
nn.init.normal_(self.Wr.weight.data, mean=0, std=self.gamma**-2)
|
| 68 |
+
|
| 69 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 70 |
+
"""encode position vector"""
|
| 71 |
+
projected = self.Wr(x)
|
| 72 |
+
cosines, sines = torch.cos(projected), torch.sin(projected)
|
| 73 |
+
emb = torch.stack([cosines, sines], 0).unsqueeze(-3)
|
| 74 |
+
return emb.repeat_interleave(2, dim=-1)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class TokenConfidence(nn.Module):
|
| 78 |
+
def __init__(self, dim: int) -> None:
|
| 79 |
+
super().__init__()
|
| 80 |
+
self.token = nn.Sequential(nn.Linear(dim, 1), nn.Sigmoid())
|
| 81 |
+
|
| 82 |
+
def forward(self, desc0: torch.Tensor, desc1: torch.Tensor):
|
| 83 |
+
"""get confidence tokens"""
|
| 84 |
+
return (
|
| 85 |
+
self.token(desc0.detach()).squeeze(-1),
|
| 86 |
+
self.token(desc1.detach()).squeeze(-1),
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class Attention(nn.Module):
|
| 91 |
+
def __init__(self, allow_flash: bool) -> None:
|
| 92 |
+
super().__init__()
|
| 93 |
+
if allow_flash and not FLASH_AVAILABLE:
|
| 94 |
+
warnings.warn(
|
| 95 |
+
"FlashAttention is not available. For optimal speed, "
|
| 96 |
+
"consider installing torch >= 2.0 or flash-attn.",
|
| 97 |
+
stacklevel=2,
|
| 98 |
+
)
|
| 99 |
+
self.enable_flash = allow_flash and FLASH_AVAILABLE
|
| 100 |
+
self.has_sdp = hasattr(F, "scaled_dot_product_attention")
|
| 101 |
+
if allow_flash and FlashCrossAttention:
|
| 102 |
+
self.flash_ = FlashCrossAttention()
|
| 103 |
+
if self.has_sdp:
|
| 104 |
+
torch.backends.cuda.enable_flash_sdp(allow_flash)
|
| 105 |
+
|
| 106 |
+
def forward(self, q, k, v, mask: Optional[torch.Tensor] = None) -> torch.Tensor:
|
| 107 |
+
if q.shape[-2] == 0 or k.shape[-2] == 0:
|
| 108 |
+
return q.new_zeros((*q.shape[:-1], v.shape[-1]))
|
| 109 |
+
if self.enable_flash and q.device.type == "cuda":
|
| 110 |
+
# use torch 2.0 scaled_dot_product_attention with flash
|
| 111 |
+
if self.has_sdp:
|
| 112 |
+
args = [x.half().contiguous() for x in [q, k, v]]
|
| 113 |
+
v = F.scaled_dot_product_attention(*args, attn_mask=mask).to(q.dtype)
|
| 114 |
+
return v if mask is None else v.nan_to_num()
|
| 115 |
+
else:
|
| 116 |
+
assert mask is None
|
| 117 |
+
q, k, v = [x.transpose(-2, -3).contiguous() for x in [q, k, v]]
|
| 118 |
+
m = self.flash_(q.half(), torch.stack([k, v], 2).half())
|
| 119 |
+
return m.transpose(-2, -3).to(q.dtype).clone()
|
| 120 |
+
elif self.has_sdp:
|
| 121 |
+
args = [x.contiguous() for x in [q, k, v]]
|
| 122 |
+
v = F.scaled_dot_product_attention(*args, attn_mask=mask)
|
| 123 |
+
return v if mask is None else v.nan_to_num()
|
| 124 |
+
else:
|
| 125 |
+
s = q.shape[-1] ** -0.5
|
| 126 |
+
sim = torch.einsum("...id,...jd->...ij", q, k) * s
|
| 127 |
+
if mask is not None:
|
| 128 |
+
sim.masked_fill(~mask, -float("inf"))
|
| 129 |
+
attn = F.softmax(sim, -1)
|
| 130 |
+
return torch.einsum("...ij,...jd->...id", attn, v)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class SelfBlock(nn.Module):
|
| 134 |
+
def __init__(
|
| 135 |
+
self, embed_dim: int, num_heads: int, flash: bool = False, bias: bool = True
|
| 136 |
+
) -> None:
|
| 137 |
+
super().__init__()
|
| 138 |
+
self.embed_dim = embed_dim
|
| 139 |
+
self.num_heads = num_heads
|
| 140 |
+
assert self.embed_dim % num_heads == 0
|
| 141 |
+
self.head_dim = self.embed_dim // num_heads
|
| 142 |
+
self.Wqkv = nn.Linear(embed_dim, 3 * embed_dim, bias=bias)
|
| 143 |
+
self.inner_attn = Attention(flash)
|
| 144 |
+
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
|
| 145 |
+
self.ffn = nn.Sequential(
|
| 146 |
+
nn.Linear(2 * embed_dim, 2 * embed_dim),
|
| 147 |
+
nn.LayerNorm(2 * embed_dim, elementwise_affine=True),
|
| 148 |
+
nn.GELU(),
|
| 149 |
+
nn.Linear(2 * embed_dim, embed_dim),
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
def forward(
|
| 153 |
+
self,
|
| 154 |
+
x: torch.Tensor,
|
| 155 |
+
encoding: torch.Tensor,
|
| 156 |
+
mask: Optional[torch.Tensor] = None,
|
| 157 |
+
) -> torch.Tensor:
|
| 158 |
+
qkv = self.Wqkv(x)
|
| 159 |
+
qkv = qkv.unflatten(-1, (self.num_heads, -1, 3)).transpose(1, 2)
|
| 160 |
+
q, k, v = qkv[..., 0], qkv[..., 1], qkv[..., 2]
|
| 161 |
+
q = apply_cached_rotary_emb(encoding, q)
|
| 162 |
+
k = apply_cached_rotary_emb(encoding, k)
|
| 163 |
+
context = self.inner_attn(q, k, v, mask=mask)
|
| 164 |
+
message = self.out_proj(context.transpose(1, 2).flatten(start_dim=-2))
|
| 165 |
+
return x + self.ffn(torch.cat([x, message], -1))
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
class CrossBlock(nn.Module):
|
| 169 |
+
def __init__(
|
| 170 |
+
self, embed_dim: int, num_heads: int, flash: bool = False, bias: bool = True
|
| 171 |
+
) -> None:
|
| 172 |
+
super().__init__()
|
| 173 |
+
self.heads = num_heads
|
| 174 |
+
dim_head = embed_dim // num_heads
|
| 175 |
+
self.scale = dim_head**-0.5
|
| 176 |
+
inner_dim = dim_head * num_heads
|
| 177 |
+
self.to_qk = nn.Linear(embed_dim, inner_dim, bias=bias)
|
| 178 |
+
self.to_v = nn.Linear(embed_dim, inner_dim, bias=bias)
|
| 179 |
+
self.to_out = nn.Linear(inner_dim, embed_dim, bias=bias)
|
| 180 |
+
self.ffn = nn.Sequential(
|
| 181 |
+
nn.Linear(2 * embed_dim, 2 * embed_dim),
|
| 182 |
+
nn.LayerNorm(2 * embed_dim, elementwise_affine=True),
|
| 183 |
+
nn.GELU(),
|
| 184 |
+
nn.Linear(2 * embed_dim, embed_dim),
|
| 185 |
+
)
|
| 186 |
+
if flash and FLASH_AVAILABLE:
|
| 187 |
+
self.flash = Attention(True)
|
| 188 |
+
else:
|
| 189 |
+
self.flash = None
|
| 190 |
+
|
| 191 |
+
def map_(self, func: Callable, x0: torch.Tensor, x1: torch.Tensor):
|
| 192 |
+
return func(x0), func(x1)
|
| 193 |
+
|
| 194 |
+
def forward(
|
| 195 |
+
self, x0: torch.Tensor, x1: torch.Tensor, mask: Optional[torch.Tensor] = None
|
| 196 |
+
) -> List[torch.Tensor]:
|
| 197 |
+
qk0, qk1 = self.map_(self.to_qk, x0, x1)
|
| 198 |
+
v0, v1 = self.map_(self.to_v, x0, x1)
|
| 199 |
+
qk0, qk1, v0, v1 = map(
|
| 200 |
+
lambda t: t.unflatten(-1, (self.heads, -1)).transpose(1, 2),
|
| 201 |
+
(qk0, qk1, v0, v1),
|
| 202 |
+
)
|
| 203 |
+
if self.flash is not None and qk0.device.type == "cuda":
|
| 204 |
+
m0 = self.flash(qk0, qk1, v1, mask)
|
| 205 |
+
m1 = self.flash(
|
| 206 |
+
qk1, qk0, v0, mask.transpose(-1, -2) if mask is not None else None
|
| 207 |
+
)
|
| 208 |
+
else:
|
| 209 |
+
qk0, qk1 = qk0 * self.scale**0.5, qk1 * self.scale**0.5
|
| 210 |
+
sim = torch.einsum("bhid, bhjd -> bhij", qk0, qk1)
|
| 211 |
+
if mask is not None:
|
| 212 |
+
sim = sim.masked_fill(~mask, -float("inf"))
|
| 213 |
+
attn01 = F.softmax(sim, dim=-1)
|
| 214 |
+
attn10 = F.softmax(sim.transpose(-2, -1).contiguous(), dim=-1)
|
| 215 |
+
m0 = torch.einsum("bhij, bhjd -> bhid", attn01, v1)
|
| 216 |
+
m1 = torch.einsum("bhji, bhjd -> bhid", attn10.transpose(-2, -1), v0)
|
| 217 |
+
if mask is not None:
|
| 218 |
+
m0, m1 = m0.nan_to_num(), m1.nan_to_num()
|
| 219 |
+
m0, m1 = self.map_(lambda t: t.transpose(1, 2).flatten(start_dim=-2), m0, m1)
|
| 220 |
+
m0, m1 = self.map_(self.to_out, m0, m1)
|
| 221 |
+
x0 = x0 + self.ffn(torch.cat([x0, m0], -1))
|
| 222 |
+
x1 = x1 + self.ffn(torch.cat([x1, m1], -1))
|
| 223 |
+
return x0, x1
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
class TransformerLayer(nn.Module):
|
| 227 |
+
def __init__(self, *args, **kwargs):
|
| 228 |
+
super().__init__()
|
| 229 |
+
self.self_attn = SelfBlock(*args, **kwargs)
|
| 230 |
+
self.cross_attn = CrossBlock(*args, **kwargs)
|
| 231 |
+
|
| 232 |
+
def forward(
|
| 233 |
+
self,
|
| 234 |
+
desc0,
|
| 235 |
+
desc1,
|
| 236 |
+
encoding0,
|
| 237 |
+
encoding1,
|
| 238 |
+
mask0: Optional[torch.Tensor] = None,
|
| 239 |
+
mask1: Optional[torch.Tensor] = None,
|
| 240 |
+
):
|
| 241 |
+
if mask0 is not None and mask1 is not None:
|
| 242 |
+
return self.masked_forward(desc0, desc1, encoding0, encoding1, mask0, mask1)
|
| 243 |
+
else:
|
| 244 |
+
desc0 = self.self_attn(desc0, encoding0)
|
| 245 |
+
desc1 = self.self_attn(desc1, encoding1)
|
| 246 |
+
return self.cross_attn(desc0, desc1)
|
| 247 |
+
|
| 248 |
+
# This part is compiled and allows padding inputs
|
| 249 |
+
def masked_forward(self, desc0, desc1, encoding0, encoding1, mask0, mask1):
|
| 250 |
+
mask = mask0 & mask1.transpose(-1, -2)
|
| 251 |
+
mask0 = mask0 & mask0.transpose(-1, -2)
|
| 252 |
+
mask1 = mask1 & mask1.transpose(-1, -2)
|
| 253 |
+
desc0 = self.self_attn(desc0, encoding0, mask0)
|
| 254 |
+
desc1 = self.self_attn(desc1, encoding1, mask1)
|
| 255 |
+
return self.cross_attn(desc0, desc1, mask)
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def sigmoid_log_double_softmax(
|
| 259 |
+
sim: torch.Tensor, z0: torch.Tensor, z1: torch.Tensor
|
| 260 |
+
) -> torch.Tensor:
|
| 261 |
+
"""create the log assignment matrix from logits and similarity"""
|
| 262 |
+
b, m, n = sim.shape
|
| 263 |
+
certainties = F.logsigmoid(z0) + F.logsigmoid(z1).transpose(1, 2)
|
| 264 |
+
scores0 = F.log_softmax(sim, 2)
|
| 265 |
+
scores1 = F.log_softmax(sim.transpose(-1, -2).contiguous(), 2).transpose(-1, -2)
|
| 266 |
+
scores = sim.new_full((b, m + 1, n + 1), 0)
|
| 267 |
+
scores[:, :m, :n] = scores0 + scores1 + certainties
|
| 268 |
+
scores[:, :-1, -1] = F.logsigmoid(-z0.squeeze(-1))
|
| 269 |
+
scores[:, -1, :-1] = F.logsigmoid(-z1.squeeze(-1))
|
| 270 |
+
return scores
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
class MatchAssignment(nn.Module):
|
| 274 |
+
def __init__(self, dim: int) -> None:
|
| 275 |
+
super().__init__()
|
| 276 |
+
self.dim = dim
|
| 277 |
+
self.matchability = nn.Linear(dim, 1, bias=True)
|
| 278 |
+
self.final_proj = nn.Linear(dim, dim, bias=True)
|
| 279 |
+
|
| 280 |
+
def forward(self, desc0: torch.Tensor, desc1: torch.Tensor):
|
| 281 |
+
"""build assignment matrix from descriptors"""
|
| 282 |
+
mdesc0, mdesc1 = self.final_proj(desc0), self.final_proj(desc1)
|
| 283 |
+
_, _, d = mdesc0.shape
|
| 284 |
+
mdesc0, mdesc1 = mdesc0 / d**0.25, mdesc1 / d**0.25
|
| 285 |
+
sim = torch.einsum("bmd,bnd->bmn", mdesc0, mdesc1)
|
| 286 |
+
z0 = self.matchability(desc0)
|
| 287 |
+
z1 = self.matchability(desc1)
|
| 288 |
+
scores = sigmoid_log_double_softmax(sim, z0, z1)
|
| 289 |
+
return scores, sim
|
| 290 |
+
|
| 291 |
+
def get_matchability(self, desc: torch.Tensor):
|
| 292 |
+
return torch.sigmoid(self.matchability(desc)).squeeze(-1)
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
def filter_matches(scores: torch.Tensor, th: float):
|
| 296 |
+
"""obtain matches from a log assignment matrix [Bx M+1 x N+1]"""
|
| 297 |
+
max0, max1 = scores[:, :-1, :-1].max(2), scores[:, :-1, :-1].max(1)
|
| 298 |
+
m0, m1 = max0.indices, max1.indices
|
| 299 |
+
indices0 = torch.arange(m0.shape[1], device=m0.device)[None]
|
| 300 |
+
indices1 = torch.arange(m1.shape[1], device=m1.device)[None]
|
| 301 |
+
mutual0 = indices0 == m1.gather(1, m0)
|
| 302 |
+
mutual1 = indices1 == m0.gather(1, m1)
|
| 303 |
+
max0_exp = max0.values.exp()
|
| 304 |
+
zero = max0_exp.new_tensor(0)
|
| 305 |
+
mscores0 = torch.where(mutual0, max0_exp, zero)
|
| 306 |
+
mscores1 = torch.where(mutual1, mscores0.gather(1, m1), zero)
|
| 307 |
+
valid0 = mutual0 & (mscores0 > th)
|
| 308 |
+
valid1 = mutual1 & valid0.gather(1, m1)
|
| 309 |
+
m0 = torch.where(valid0, m0, -1)
|
| 310 |
+
m1 = torch.where(valid1, m1, -1)
|
| 311 |
+
return m0, m1, mscores0, mscores1
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
class LightGlue(nn.Module):
|
| 315 |
+
default_conf = {
|
| 316 |
+
"name": "lightglue", # just for interfacing
|
| 317 |
+
"input_dim": 256, # input descriptor dimension (autoselected from weights)
|
| 318 |
+
"descriptor_dim": 256,
|
| 319 |
+
"add_scale_ori": False,
|
| 320 |
+
"n_layers": 9,
|
| 321 |
+
"num_heads": 4,
|
| 322 |
+
"flash": True, # enable FlashAttention if available.
|
| 323 |
+
"mp": False, # enable mixed precision
|
| 324 |
+
"depth_confidence": 0.95, # early stopping, disable with -1
|
| 325 |
+
"width_confidence": 0.99, # point pruning, disable with -1
|
| 326 |
+
"filter_threshold": 0.1, # match threshold
|
| 327 |
+
"weights": None,
|
| 328 |
+
}
|
| 329 |
+
|
| 330 |
+
# Point pruning involves an overhead (gather).
|
| 331 |
+
# Therefore, we only activate it if there are enough keypoints.
|
| 332 |
+
pruning_keypoint_thresholds = {
|
| 333 |
+
"cpu": -1,
|
| 334 |
+
"mps": -1,
|
| 335 |
+
"cuda": 1024,
|
| 336 |
+
"flash": 1536,
|
| 337 |
+
}
|
| 338 |
+
|
| 339 |
+
required_data_keys = ["image0", "image1"]
|
| 340 |
+
|
| 341 |
+
version = "v0.1_arxiv"
|
| 342 |
+
url = "https://github.com/cvg/LightGlue/releases/download/{}/{}_lightglue.pth"
|
| 343 |
+
|
| 344 |
+
features = {
|
| 345 |
+
"superpoint": {
|
| 346 |
+
"weights": "superpoint_lightglue",
|
| 347 |
+
"input_dim": 256,
|
| 348 |
+
},
|
| 349 |
+
"disk": {
|
| 350 |
+
"weights": "disk_lightglue",
|
| 351 |
+
"input_dim": 128,
|
| 352 |
+
},
|
| 353 |
+
"aliked": {
|
| 354 |
+
"weights": "aliked_lightglue",
|
| 355 |
+
"input_dim": 128,
|
| 356 |
+
},
|
| 357 |
+
"sift": {
|
| 358 |
+
"weights": "sift_lightglue",
|
| 359 |
+
"input_dim": 128,
|
| 360 |
+
"add_scale_ori": True,
|
| 361 |
+
},
|
| 362 |
+
"doghardnet": {
|
| 363 |
+
"weights": "doghardnet_lightglue",
|
| 364 |
+
"input_dim": 128,
|
| 365 |
+
"add_scale_ori": True,
|
| 366 |
+
},
|
| 367 |
+
}
|
| 368 |
+
|
| 369 |
+
def __init__(self, features="superpoint", **conf) -> None:
|
| 370 |
+
super().__init__()
|
| 371 |
+
self.conf = conf = SimpleNamespace(**{**self.default_conf, **conf})
|
| 372 |
+
if features is not None:
|
| 373 |
+
if features not in self.features:
|
| 374 |
+
raise ValueError(
|
| 375 |
+
f"Unsupported features: {features} not in "
|
| 376 |
+
f"{{{','.join(self.features)}}}"
|
| 377 |
+
)
|
| 378 |
+
for k, v in self.features[features].items():
|
| 379 |
+
setattr(conf, k, v)
|
| 380 |
+
|
| 381 |
+
if conf.input_dim != conf.descriptor_dim:
|
| 382 |
+
self.input_proj = nn.Linear(conf.input_dim, conf.descriptor_dim, bias=True)
|
| 383 |
+
else:
|
| 384 |
+
self.input_proj = nn.Identity()
|
| 385 |
+
|
| 386 |
+
head_dim = conf.descriptor_dim // conf.num_heads
|
| 387 |
+
self.posenc = LearnableFourierPositionalEncoding(
|
| 388 |
+
2 + 2 * self.conf.add_scale_ori, head_dim, head_dim
|
| 389 |
+
)
|
| 390 |
+
|
| 391 |
+
h, n, d = conf.num_heads, conf.n_layers, conf.descriptor_dim
|
| 392 |
+
|
| 393 |
+
self.transformers = nn.ModuleList(
|
| 394 |
+
[TransformerLayer(d, h, conf.flash) for _ in range(n)]
|
| 395 |
+
)
|
| 396 |
+
|
| 397 |
+
self.log_assignment = nn.ModuleList([MatchAssignment(d) for _ in range(n)])
|
| 398 |
+
self.token_confidence = nn.ModuleList(
|
| 399 |
+
[TokenConfidence(d) for _ in range(n - 1)]
|
| 400 |
+
)
|
| 401 |
+
self.register_buffer(
|
| 402 |
+
"confidence_thresholds",
|
| 403 |
+
torch.Tensor(
|
| 404 |
+
[self.confidence_threshold(i) for i in range(self.conf.n_layers)]
|
| 405 |
+
),
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
state_dict = None
|
| 409 |
+
if features is not None:
|
| 410 |
+
fname = f"{conf.weights}_{self.version.replace('.', '-')}.pth"
|
| 411 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 412 |
+
self.url.format(self.version, features), model_dir='./LightGlue/ckpts',file_name="superpoint_lightglue.pth"
|
| 413 |
+
)
|
| 414 |
+
self.load_state_dict(state_dict, strict=False)
|
| 415 |
+
elif conf.weights is not None:
|
| 416 |
+
path = Path(__file__).parent
|
| 417 |
+
path = path / "weights/{}.pth".format(self.conf.weights)
|
| 418 |
+
state_dict = torch.load(str(path), map_location="cpu")
|
| 419 |
+
|
| 420 |
+
if state_dict:
|
| 421 |
+
# rename old state dict entries
|
| 422 |
+
for i in range(self.conf.n_layers):
|
| 423 |
+
pattern = f"self_attn.{i}", f"transformers.{i}.self_attn"
|
| 424 |
+
state_dict = {k.replace(*pattern): v for k, v in state_dict.items()}
|
| 425 |
+
pattern = f"cross_attn.{i}", f"transformers.{i}.cross_attn"
|
| 426 |
+
state_dict = {k.replace(*pattern): v for k, v in state_dict.items()}
|
| 427 |
+
self.load_state_dict(state_dict, strict=False)
|
| 428 |
+
|
| 429 |
+
# static lengths LightGlue is compiled for (only used with torch.compile)
|
| 430 |
+
self.static_lengths = None
|
| 431 |
+
|
| 432 |
+
def compile(
|
| 433 |
+
self, mode="reduce-overhead", static_lengths=[256, 512, 768, 1024, 1280, 1536]
|
| 434 |
+
):
|
| 435 |
+
if self.conf.width_confidence != -1:
|
| 436 |
+
warnings.warn(
|
| 437 |
+
"Point pruning is partially disabled for compiled forward.",
|
| 438 |
+
stacklevel=2,
|
| 439 |
+
)
|
| 440 |
+
|
| 441 |
+
torch._inductor.cudagraph_mark_step_begin()
|
| 442 |
+
for i in range(self.conf.n_layers):
|
| 443 |
+
self.transformers[i].masked_forward = torch.compile(
|
| 444 |
+
self.transformers[i].masked_forward, mode=mode, fullgraph=True
|
| 445 |
+
)
|
| 446 |
+
|
| 447 |
+
self.static_lengths = static_lengths
|
| 448 |
+
|
| 449 |
+
def forward(self, data: dict) -> dict:
|
| 450 |
+
"""
|
| 451 |
+
Match keypoints and descriptors between two images
|
| 452 |
+
|
| 453 |
+
Input (dict):
|
| 454 |
+
image0: dict
|
| 455 |
+
keypoints: [B x M x 2]
|
| 456 |
+
descriptors: [B x M x D]
|
| 457 |
+
image: [B x C x H x W] or image_size: [B x 2]
|
| 458 |
+
image1: dict
|
| 459 |
+
keypoints: [B x N x 2]
|
| 460 |
+
descriptors: [B x N x D]
|
| 461 |
+
image: [B x C x H x W] or image_size: [B x 2]
|
| 462 |
+
Output (dict):
|
| 463 |
+
matches0: [B x M]
|
| 464 |
+
matching_scores0: [B x M]
|
| 465 |
+
matches1: [B x N]
|
| 466 |
+
matching_scores1: [B x N]
|
| 467 |
+
matches: List[[Si x 2]]
|
| 468 |
+
scores: List[[Si]]
|
| 469 |
+
stop: int
|
| 470 |
+
prune0: [B x M]
|
| 471 |
+
prune1: [B x N]
|
| 472 |
+
"""
|
| 473 |
+
with torch.autocast(enabled=self.conf.mp, device_type="cuda"):
|
| 474 |
+
return self._forward(data)
|
| 475 |
+
|
| 476 |
+
def _forward(self, data: dict) -> dict:
|
| 477 |
+
for key in self.required_data_keys:
|
| 478 |
+
assert key in data, f"Missing key {key} in data"
|
| 479 |
+
data0, data1 = data["image0"], data["image1"]
|
| 480 |
+
kpts0, kpts1 = data0["keypoints"], data1["keypoints"]
|
| 481 |
+
b, m, _ = kpts0.shape
|
| 482 |
+
b, n, _ = kpts1.shape
|
| 483 |
+
device = kpts0.device
|
| 484 |
+
size0, size1 = data0.get("image_size"), data1.get("image_size")
|
| 485 |
+
kpts0 = normalize_keypoints(kpts0, size0).clone()
|
| 486 |
+
kpts1 = normalize_keypoints(kpts1, size1).clone()
|
| 487 |
+
|
| 488 |
+
if self.conf.add_scale_ori:
|
| 489 |
+
kpts0 = torch.cat(
|
| 490 |
+
[kpts0] + [data0[k].unsqueeze(-1) for k in ("scales", "oris")], -1
|
| 491 |
+
)
|
| 492 |
+
kpts1 = torch.cat(
|
| 493 |
+
[kpts1] + [data1[k].unsqueeze(-1) for k in ("scales", "oris")], -1
|
| 494 |
+
)
|
| 495 |
+
desc0 = data0["descriptors"].detach().contiguous()
|
| 496 |
+
desc1 = data1["descriptors"].detach().contiguous()
|
| 497 |
+
|
| 498 |
+
assert desc0.shape[-1] == self.conf.input_dim
|
| 499 |
+
assert desc1.shape[-1] == self.conf.input_dim
|
| 500 |
+
|
| 501 |
+
if torch.is_autocast_enabled():
|
| 502 |
+
desc0 = desc0.half()
|
| 503 |
+
desc1 = desc1.half()
|
| 504 |
+
|
| 505 |
+
mask0, mask1 = None, None
|
| 506 |
+
c = max(m, n)
|
| 507 |
+
do_compile = self.static_lengths and c <= max(self.static_lengths)
|
| 508 |
+
if do_compile:
|
| 509 |
+
kn = min([k for k in self.static_lengths if k >= c])
|
| 510 |
+
desc0, mask0 = pad_to_length(desc0, kn)
|
| 511 |
+
desc1, mask1 = pad_to_length(desc1, kn)
|
| 512 |
+
kpts0, _ = pad_to_length(kpts0, kn)
|
| 513 |
+
kpts1, _ = pad_to_length(kpts1, kn)
|
| 514 |
+
desc0 = self.input_proj(desc0)
|
| 515 |
+
desc1 = self.input_proj(desc1)
|
| 516 |
+
# cache positional embeddings
|
| 517 |
+
encoding0 = self.posenc(kpts0)
|
| 518 |
+
encoding1 = self.posenc(kpts1)
|
| 519 |
+
|
| 520 |
+
# GNN + final_proj + assignment
|
| 521 |
+
do_early_stop = self.conf.depth_confidence > 0
|
| 522 |
+
do_point_pruning = self.conf.width_confidence > 0 and not do_compile
|
| 523 |
+
pruning_th = self.pruning_min_kpts(device)
|
| 524 |
+
if do_point_pruning:
|
| 525 |
+
ind0 = torch.arange(0, m, device=device)[None]
|
| 526 |
+
ind1 = torch.arange(0, n, device=device)[None]
|
| 527 |
+
# We store the index of the layer at which pruning is detected.
|
| 528 |
+
prune0 = torch.ones_like(ind0)
|
| 529 |
+
prune1 = torch.ones_like(ind1)
|
| 530 |
+
token0, token1 = None, None
|
| 531 |
+
for i in range(self.conf.n_layers):
|
| 532 |
+
if desc0.shape[1] == 0 or desc1.shape[1] == 0: # no keypoints
|
| 533 |
+
break
|
| 534 |
+
desc0, desc1 = self.transformers[i](
|
| 535 |
+
desc0, desc1, encoding0, encoding1, mask0=mask0, mask1=mask1
|
| 536 |
+
)
|
| 537 |
+
if i == self.conf.n_layers - 1:
|
| 538 |
+
continue # no early stopping or adaptive width at last layer
|
| 539 |
+
|
| 540 |
+
if do_early_stop:
|
| 541 |
+
token0, token1 = self.token_confidence[i](desc0, desc1)
|
| 542 |
+
if self.check_if_stop(token0[..., :m], token1[..., :n], i, m + n):
|
| 543 |
+
break
|
| 544 |
+
if do_point_pruning and desc0.shape[-2] > pruning_th:
|
| 545 |
+
scores0 = self.log_assignment[i].get_matchability(desc0)
|
| 546 |
+
prunemask0 = self.get_pruning_mask(token0, scores0, i)
|
| 547 |
+
keep0 = torch.where(prunemask0)[1]
|
| 548 |
+
ind0 = ind0.index_select(1, keep0)
|
| 549 |
+
desc0 = desc0.index_select(1, keep0)
|
| 550 |
+
encoding0 = encoding0.index_select(-2, keep0)
|
| 551 |
+
prune0[:, ind0] += 1
|
| 552 |
+
if do_point_pruning and desc1.shape[-2] > pruning_th:
|
| 553 |
+
scores1 = self.log_assignment[i].get_matchability(desc1)
|
| 554 |
+
prunemask1 = self.get_pruning_mask(token1, scores1, i)
|
| 555 |
+
keep1 = torch.where(prunemask1)[1]
|
| 556 |
+
ind1 = ind1.index_select(1, keep1)
|
| 557 |
+
desc1 = desc1.index_select(1, keep1)
|
| 558 |
+
encoding1 = encoding1.index_select(-2, keep1)
|
| 559 |
+
prune1[:, ind1] += 1
|
| 560 |
+
|
| 561 |
+
if desc0.shape[1] == 0 or desc1.shape[1] == 0: # no keypoints
|
| 562 |
+
m0 = desc0.new_full((b, m), -1, dtype=torch.long)
|
| 563 |
+
m1 = desc1.new_full((b, n), -1, dtype=torch.long)
|
| 564 |
+
mscores0 = desc0.new_zeros((b, m))
|
| 565 |
+
mscores1 = desc1.new_zeros((b, n))
|
| 566 |
+
matches = desc0.new_empty((b, 0, 2), dtype=torch.long)
|
| 567 |
+
mscores = desc0.new_empty((b, 0))
|
| 568 |
+
if not do_point_pruning:
|
| 569 |
+
prune0 = torch.ones_like(mscores0) * self.conf.n_layers
|
| 570 |
+
prune1 = torch.ones_like(mscores1) * self.conf.n_layers
|
| 571 |
+
return {
|
| 572 |
+
"matches0": m0,
|
| 573 |
+
"matches1": m1,
|
| 574 |
+
"matching_scores0": mscores0,
|
| 575 |
+
"matching_scores1": mscores1,
|
| 576 |
+
"stop": i + 1,
|
| 577 |
+
"matches": matches,
|
| 578 |
+
"scores": mscores,
|
| 579 |
+
"prune0": prune0,
|
| 580 |
+
"prune1": prune1,
|
| 581 |
+
}
|
| 582 |
+
|
| 583 |
+
desc0, desc1 = desc0[..., :m, :], desc1[..., :n, :] # remove padding
|
| 584 |
+
scores, _ = self.log_assignment[i](desc0, desc1)
|
| 585 |
+
m0, m1, mscores0, mscores1 = filter_matches(scores, self.conf.filter_threshold)
|
| 586 |
+
matches, mscores = [], []
|
| 587 |
+
for k in range(b):
|
| 588 |
+
valid = m0[k] > -1
|
| 589 |
+
m_indices_0 = torch.where(valid)[0]
|
| 590 |
+
m_indices_1 = m0[k][valid]
|
| 591 |
+
if do_point_pruning:
|
| 592 |
+
m_indices_0 = ind0[k, m_indices_0]
|
| 593 |
+
m_indices_1 = ind1[k, m_indices_1]
|
| 594 |
+
matches.append(torch.stack([m_indices_0, m_indices_1], -1))
|
| 595 |
+
mscores.append(mscores0[k][valid])
|
| 596 |
+
|
| 597 |
+
# TODO: Remove when hloc switches to the compact format.
|
| 598 |
+
if do_point_pruning:
|
| 599 |
+
m0_ = torch.full((b, m), -1, device=m0.device, dtype=m0.dtype)
|
| 600 |
+
m1_ = torch.full((b, n), -1, device=m1.device, dtype=m1.dtype)
|
| 601 |
+
m0_[:, ind0] = torch.where(m0 == -1, -1, ind1.gather(1, m0.clamp(min=0)))
|
| 602 |
+
m1_[:, ind1] = torch.where(m1 == -1, -1, ind0.gather(1, m1.clamp(min=0)))
|
| 603 |
+
mscores0_ = torch.zeros((b, m), device=mscores0.device)
|
| 604 |
+
mscores1_ = torch.zeros((b, n), device=mscores1.device)
|
| 605 |
+
mscores0_[:, ind0] = mscores0
|
| 606 |
+
mscores1_[:, ind1] = mscores1
|
| 607 |
+
m0, m1, mscores0, mscores1 = m0_, m1_, mscores0_, mscores1_
|
| 608 |
+
else:
|
| 609 |
+
prune0 = torch.ones_like(mscores0) * self.conf.n_layers
|
| 610 |
+
prune1 = torch.ones_like(mscores1) * self.conf.n_layers
|
| 611 |
+
|
| 612 |
+
return {
|
| 613 |
+
"matches0": m0,
|
| 614 |
+
"matches1": m1,
|
| 615 |
+
"matching_scores0": mscores0,
|
| 616 |
+
"matching_scores1": mscores1,
|
| 617 |
+
"stop": i + 1,
|
| 618 |
+
"matches": matches,
|
| 619 |
+
"scores": mscores,
|
| 620 |
+
"prune0": prune0,
|
| 621 |
+
"prune1": prune1,
|
| 622 |
+
}
|
| 623 |
+
|
| 624 |
+
def confidence_threshold(self, layer_index: int) -> float:
|
| 625 |
+
"""scaled confidence threshold"""
|
| 626 |
+
threshold = 0.8 + 0.1 * np.exp(-4.0 * layer_index / self.conf.n_layers)
|
| 627 |
+
return np.clip(threshold, 0, 1)
|
| 628 |
+
|
| 629 |
+
def get_pruning_mask(
|
| 630 |
+
self, confidences: torch.Tensor, scores: torch.Tensor, layer_index: int
|
| 631 |
+
) -> torch.Tensor:
|
| 632 |
+
"""mask points which should be removed"""
|
| 633 |
+
keep = scores > (1 - self.conf.width_confidence)
|
| 634 |
+
if confidences is not None: # Low-confidence points are never pruned.
|
| 635 |
+
keep |= confidences <= self.confidence_thresholds[layer_index]
|
| 636 |
+
return keep
|
| 637 |
+
|
| 638 |
+
def check_if_stop(
|
| 639 |
+
self,
|
| 640 |
+
confidences0: torch.Tensor,
|
| 641 |
+
confidences1: torch.Tensor,
|
| 642 |
+
layer_index: int,
|
| 643 |
+
num_points: int,
|
| 644 |
+
) -> torch.Tensor:
|
| 645 |
+
"""evaluate stopping condition"""
|
| 646 |
+
confidences = torch.cat([confidences0, confidences1], -1)
|
| 647 |
+
threshold = self.confidence_thresholds[layer_index]
|
| 648 |
+
ratio_confident = 1.0 - (confidences < threshold).float().sum() / num_points
|
| 649 |
+
return ratio_confident > self.conf.depth_confidence
|
| 650 |
+
|
| 651 |
+
def pruning_min_kpts(self, device: torch.device):
|
| 652 |
+
if self.conf.flash and FLASH_AVAILABLE and device.type == "cuda":
|
| 653 |
+
return self.pruning_keypoint_thresholds["flash"]
|
| 654 |
+
else:
|
| 655 |
+
return self.pruning_keypoint_thresholds[device.type]
|
LightGlue/lightglue/sift.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
from kornia.color import rgb_to_grayscale
|
| 7 |
+
from packaging import version
|
| 8 |
+
|
| 9 |
+
try:
|
| 10 |
+
import pycolmap
|
| 11 |
+
except ImportError:
|
| 12 |
+
pycolmap = None
|
| 13 |
+
|
| 14 |
+
from .utils import Extractor
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def filter_dog_point(points, scales, angles, image_shape, nms_radius, scores=None):
|
| 18 |
+
h, w = image_shape
|
| 19 |
+
ij = np.round(points - 0.5).astype(int).T[::-1]
|
| 20 |
+
|
| 21 |
+
# Remove duplicate points (identical coordinates).
|
| 22 |
+
# Pick highest scale or score
|
| 23 |
+
s = scales if scores is None else scores
|
| 24 |
+
buffer = np.zeros((h, w))
|
| 25 |
+
np.maximum.at(buffer, tuple(ij), s)
|
| 26 |
+
keep = np.where(buffer[tuple(ij)] == s)[0]
|
| 27 |
+
|
| 28 |
+
# Pick lowest angle (arbitrary).
|
| 29 |
+
ij = ij[:, keep]
|
| 30 |
+
buffer[:] = np.inf
|
| 31 |
+
o_abs = np.abs(angles[keep])
|
| 32 |
+
np.minimum.at(buffer, tuple(ij), o_abs)
|
| 33 |
+
mask = buffer[tuple(ij)] == o_abs
|
| 34 |
+
ij = ij[:, mask]
|
| 35 |
+
keep = keep[mask]
|
| 36 |
+
|
| 37 |
+
if nms_radius > 0:
|
| 38 |
+
# Apply NMS on the remaining points
|
| 39 |
+
buffer[:] = 0
|
| 40 |
+
buffer[tuple(ij)] = s[keep] # scores or scale
|
| 41 |
+
|
| 42 |
+
local_max = torch.nn.functional.max_pool2d(
|
| 43 |
+
torch.from_numpy(buffer).unsqueeze(0),
|
| 44 |
+
kernel_size=nms_radius * 2 + 1,
|
| 45 |
+
stride=1,
|
| 46 |
+
padding=nms_radius,
|
| 47 |
+
).squeeze(0)
|
| 48 |
+
is_local_max = buffer == local_max.numpy()
|
| 49 |
+
keep = keep[is_local_max[tuple(ij)]]
|
| 50 |
+
return keep
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def sift_to_rootsift(x: torch.Tensor, eps=1e-6) -> torch.Tensor:
|
| 54 |
+
x = torch.nn.functional.normalize(x, p=1, dim=-1, eps=eps)
|
| 55 |
+
x.clip_(min=eps).sqrt_()
|
| 56 |
+
return torch.nn.functional.normalize(x, p=2, dim=-1, eps=eps)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def run_opencv_sift(features: cv2.Feature2D, image: np.ndarray) -> np.ndarray:
|
| 60 |
+
"""
|
| 61 |
+
Detect keypoints using OpenCV Detector.
|
| 62 |
+
Optionally, perform description.
|
| 63 |
+
Args:
|
| 64 |
+
features: OpenCV based keypoints detector and descriptor
|
| 65 |
+
image: Grayscale image of uint8 data type
|
| 66 |
+
Returns:
|
| 67 |
+
keypoints: 1D array of detected cv2.KeyPoint
|
| 68 |
+
scores: 1D array of responses
|
| 69 |
+
descriptors: 1D array of descriptors
|
| 70 |
+
"""
|
| 71 |
+
detections, descriptors = features.detectAndCompute(image, None)
|
| 72 |
+
points = np.array([k.pt for k in detections], dtype=np.float32)
|
| 73 |
+
scores = np.array([k.response for k in detections], dtype=np.float32)
|
| 74 |
+
scales = np.array([k.size for k in detections], dtype=np.float32)
|
| 75 |
+
angles = np.deg2rad(np.array([k.angle for k in detections], dtype=np.float32))
|
| 76 |
+
return points, scores, scales, angles, descriptors
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class SIFT(Extractor):
|
| 80 |
+
default_conf = {
|
| 81 |
+
"rootsift": True,
|
| 82 |
+
"nms_radius": 0, # None to disable filtering entirely.
|
| 83 |
+
"max_num_keypoints": 4096,
|
| 84 |
+
"backend": "opencv", # in {opencv, pycolmap, pycolmap_cpu, pycolmap_cuda}
|
| 85 |
+
"detection_threshold": 0.0066667, # from COLMAP
|
| 86 |
+
"edge_threshold": 10,
|
| 87 |
+
"first_octave": -1, # only used by pycolmap, the default of COLMAP
|
| 88 |
+
"num_octaves": 4,
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
preprocess_conf = {
|
| 92 |
+
"resize": 1024,
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
required_data_keys = ["image"]
|
| 96 |
+
|
| 97 |
+
def __init__(self, **conf):
|
| 98 |
+
super().__init__(**conf) # Update with default configuration.
|
| 99 |
+
backend = self.conf.backend
|
| 100 |
+
if backend.startswith("pycolmap"):
|
| 101 |
+
if pycolmap is None:
|
| 102 |
+
raise ImportError(
|
| 103 |
+
"Cannot find module pycolmap: install it with pip"
|
| 104 |
+
"or use backend=opencv."
|
| 105 |
+
)
|
| 106 |
+
options = {
|
| 107 |
+
"peak_threshold": self.conf.detection_threshold,
|
| 108 |
+
"edge_threshold": self.conf.edge_threshold,
|
| 109 |
+
"first_octave": self.conf.first_octave,
|
| 110 |
+
"num_octaves": self.conf.num_octaves,
|
| 111 |
+
"normalization": pycolmap.Normalization.L2, # L1_ROOT is buggy.
|
| 112 |
+
}
|
| 113 |
+
device = (
|
| 114 |
+
"auto" if backend == "pycolmap" else backend.replace("pycolmap_", "")
|
| 115 |
+
)
|
| 116 |
+
if (
|
| 117 |
+
backend == "pycolmap_cpu" or not pycolmap.has_cuda
|
| 118 |
+
) and pycolmap.__version__ < "0.5.0":
|
| 119 |
+
warnings.warn(
|
| 120 |
+
"The pycolmap CPU SIFT is buggy in version < 0.5.0, "
|
| 121 |
+
"consider upgrading pycolmap or use the CUDA version.",
|
| 122 |
+
stacklevel=1,
|
| 123 |
+
)
|
| 124 |
+
else:
|
| 125 |
+
options["max_num_features"] = self.conf.max_num_keypoints
|
| 126 |
+
self.sift = pycolmap.Sift(options=options, device=device)
|
| 127 |
+
elif backend == "opencv":
|
| 128 |
+
self.sift = cv2.SIFT_create(
|
| 129 |
+
contrastThreshold=self.conf.detection_threshold,
|
| 130 |
+
nfeatures=self.conf.max_num_keypoints,
|
| 131 |
+
edgeThreshold=self.conf.edge_threshold,
|
| 132 |
+
nOctaveLayers=self.conf.num_octaves,
|
| 133 |
+
)
|
| 134 |
+
else:
|
| 135 |
+
backends = {"opencv", "pycolmap", "pycolmap_cpu", "pycolmap_cuda"}
|
| 136 |
+
raise ValueError(
|
| 137 |
+
f"Unknown backend: {backend} not in " f"{{{','.join(backends)}}}."
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
def extract_single_image(self, image: torch.Tensor):
|
| 141 |
+
image_np = image.cpu().numpy().squeeze(0)
|
| 142 |
+
|
| 143 |
+
if self.conf.backend.startswith("pycolmap"):
|
| 144 |
+
if version.parse(pycolmap.__version__) >= version.parse("0.5.0"):
|
| 145 |
+
detections, descriptors = self.sift.extract(image_np)
|
| 146 |
+
scores = None # Scores are not exposed by COLMAP anymore.
|
| 147 |
+
else:
|
| 148 |
+
detections, scores, descriptors = self.sift.extract(image_np)
|
| 149 |
+
keypoints = detections[:, :2] # Keep only (x, y).
|
| 150 |
+
scales, angles = detections[:, -2:].T
|
| 151 |
+
if scores is not None and (
|
| 152 |
+
self.conf.backend == "pycolmap_cpu" or not pycolmap.has_cuda
|
| 153 |
+
):
|
| 154 |
+
# Set the scores as a combination of abs. response and scale.
|
| 155 |
+
scores = np.abs(scores) * scales
|
| 156 |
+
elif self.conf.backend == "opencv":
|
| 157 |
+
# TODO: Check if opencv keypoints are already in corner convention
|
| 158 |
+
keypoints, scores, scales, angles, descriptors = run_opencv_sift(
|
| 159 |
+
self.sift, (image_np * 255.0).astype(np.uint8)
|
| 160 |
+
)
|
| 161 |
+
pred = {
|
| 162 |
+
"keypoints": keypoints,
|
| 163 |
+
"scales": scales,
|
| 164 |
+
"oris": angles,
|
| 165 |
+
"descriptors": descriptors,
|
| 166 |
+
}
|
| 167 |
+
if scores is not None:
|
| 168 |
+
pred["keypoint_scores"] = scores
|
| 169 |
+
|
| 170 |
+
# sometimes pycolmap returns points outside the image. We remove them
|
| 171 |
+
if self.conf.backend.startswith("pycolmap"):
|
| 172 |
+
is_inside = (
|
| 173 |
+
pred["keypoints"] + 0.5 < np.array([image_np.shape[-2:][::-1]])
|
| 174 |
+
).all(-1)
|
| 175 |
+
pred = {k: v[is_inside] for k, v in pred.items()}
|
| 176 |
+
|
| 177 |
+
if self.conf.nms_radius is not None:
|
| 178 |
+
keep = filter_dog_point(
|
| 179 |
+
pred["keypoints"],
|
| 180 |
+
pred["scales"],
|
| 181 |
+
pred["oris"],
|
| 182 |
+
image_np.shape,
|
| 183 |
+
self.conf.nms_radius,
|
| 184 |
+
scores=pred.get("keypoint_scores"),
|
| 185 |
+
)
|
| 186 |
+
pred = {k: v[keep] for k, v in pred.items()}
|
| 187 |
+
|
| 188 |
+
pred = {k: torch.from_numpy(v) for k, v in pred.items()}
|
| 189 |
+
if scores is not None:
|
| 190 |
+
# Keep the k keypoints with highest score
|
| 191 |
+
num_points = self.conf.max_num_keypoints
|
| 192 |
+
if num_points is not None and len(pred["keypoints"]) > num_points:
|
| 193 |
+
indices = torch.topk(pred["keypoint_scores"], num_points).indices
|
| 194 |
+
pred = {k: v[indices] for k, v in pred.items()}
|
| 195 |
+
|
| 196 |
+
return pred
|
| 197 |
+
|
| 198 |
+
def forward(self, data: dict) -> dict:
|
| 199 |
+
image = data["image"]
|
| 200 |
+
if image.shape[1] == 3:
|
| 201 |
+
image = rgb_to_grayscale(image)
|
| 202 |
+
device = image.device
|
| 203 |
+
image = image.cpu()
|
| 204 |
+
pred = []
|
| 205 |
+
for k in range(len(image)):
|
| 206 |
+
img = image[k]
|
| 207 |
+
if "image_size" in data.keys():
|
| 208 |
+
# avoid extracting points in padded areas
|
| 209 |
+
w, h = data["image_size"][k]
|
| 210 |
+
img = img[:, :h, :w]
|
| 211 |
+
p = self.extract_single_image(img)
|
| 212 |
+
pred.append(p)
|
| 213 |
+
pred = {k: torch.stack([p[k] for p in pred], 0).to(device) for k in pred[0]}
|
| 214 |
+
if self.conf.rootsift:
|
| 215 |
+
pred["descriptors"] = sift_to_rootsift(pred["descriptors"])
|
| 216 |
+
return pred
|
LightGlue/lightglue/superpoint.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# %BANNER_BEGIN%
|
| 2 |
+
# ---------------------------------------------------------------------
|
| 3 |
+
# %COPYRIGHT_BEGIN%
|
| 4 |
+
#
|
| 5 |
+
# Magic Leap, Inc. ("COMPANY") CONFIDENTIAL
|
| 6 |
+
#
|
| 7 |
+
# Unpublished Copyright (c) 2020
|
| 8 |
+
# Magic Leap, Inc., All Rights Reserved.
|
| 9 |
+
#
|
| 10 |
+
# NOTICE: All information contained herein is, and remains the property
|
| 11 |
+
# of COMPANY. The intellectual and technical concepts contained herein
|
| 12 |
+
# are proprietary to COMPANY and may be covered by U.S. and Foreign
|
| 13 |
+
# Patents, patents in process, and are protected by trade secret or
|
| 14 |
+
# copyright law. Dissemination of this information or reproduction of
|
| 15 |
+
# this material is strictly forbidden unless prior written permission is
|
| 16 |
+
# obtained from COMPANY. Access to the source code contained herein is
|
| 17 |
+
# hereby forbidden to anyone except current COMPANY employees, managers
|
| 18 |
+
# or contractors who have executed Confidentiality and Non-disclosure
|
| 19 |
+
# agreements explicitly covering such access.
|
| 20 |
+
#
|
| 21 |
+
# The copyright notice above does not evidence any actual or intended
|
| 22 |
+
# publication or disclosure of this source code, which includes
|
| 23 |
+
# information that is confidential and/or proprietary, and is a trade
|
| 24 |
+
# secret, of COMPANY. ANY REPRODUCTION, MODIFICATION, DISTRIBUTION,
|
| 25 |
+
# PUBLIC PERFORMANCE, OR PUBLIC DISPLAY OF OR THROUGH USE OF THIS
|
| 26 |
+
# SOURCE CODE WITHOUT THE EXPRESS WRITTEN CONSENT OF COMPANY IS
|
| 27 |
+
# STRICTLY PROHIBITED, AND IN VIOLATION OF APPLICABLE LAWS AND
|
| 28 |
+
# INTERNATIONAL TREATIES. THE RECEIPT OR POSSESSION OF THIS SOURCE
|
| 29 |
+
# CODE AND/OR RELATED INFORMATION DOES NOT CONVEY OR IMPLY ANY RIGHTS
|
| 30 |
+
# TO REPRODUCE, DISCLOSE OR DISTRIBUTE ITS CONTENTS, OR TO MANUFACTURE,
|
| 31 |
+
# USE, OR SELL ANYTHING THAT IT MAY DESCRIBE, IN WHOLE OR IN PART.
|
| 32 |
+
#
|
| 33 |
+
# %COPYRIGHT_END%
|
| 34 |
+
# ----------------------------------------------------------------------
|
| 35 |
+
# %AUTHORS_BEGIN%
|
| 36 |
+
#
|
| 37 |
+
# Originating Authors: Paul-Edouard Sarlin
|
| 38 |
+
#
|
| 39 |
+
# %AUTHORS_END%
|
| 40 |
+
# --------------------------------------------------------------------*/
|
| 41 |
+
# %BANNER_END%
|
| 42 |
+
|
| 43 |
+
# Adapted by Remi Pautrat, Philipp Lindenberger
|
| 44 |
+
|
| 45 |
+
import torch
|
| 46 |
+
from kornia.color import rgb_to_grayscale
|
| 47 |
+
from torch import nn
|
| 48 |
+
|
| 49 |
+
from .utils import Extractor
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def simple_nms(scores, nms_radius: int):
|
| 53 |
+
"""Fast Non-maximum suppression to remove nearby points"""
|
| 54 |
+
assert nms_radius >= 0
|
| 55 |
+
|
| 56 |
+
def max_pool(x):
|
| 57 |
+
return torch.nn.functional.max_pool2d(
|
| 58 |
+
x, kernel_size=nms_radius * 2 + 1, stride=1, padding=nms_radius
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
zeros = torch.zeros_like(scores)
|
| 62 |
+
max_mask = scores == max_pool(scores)
|
| 63 |
+
for _ in range(2):
|
| 64 |
+
supp_mask = max_pool(max_mask.float()) > 0
|
| 65 |
+
supp_scores = torch.where(supp_mask, zeros, scores)
|
| 66 |
+
new_max_mask = supp_scores == max_pool(supp_scores)
|
| 67 |
+
max_mask = max_mask | (new_max_mask & (~supp_mask))
|
| 68 |
+
return torch.where(max_mask, scores, zeros)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def top_k_keypoints(keypoints, scores, k):
|
| 72 |
+
if k >= len(keypoints):
|
| 73 |
+
return keypoints, scores
|
| 74 |
+
scores, indices = torch.topk(scores, k, dim=0, sorted=True)
|
| 75 |
+
return keypoints[indices], scores
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def sample_descriptors(keypoints, descriptors, s: int = 8):
|
| 79 |
+
"""Interpolate descriptors at keypoint locations"""
|
| 80 |
+
b, c, h, w = descriptors.shape
|
| 81 |
+
keypoints = keypoints - s / 2 + 0.5
|
| 82 |
+
keypoints /= torch.tensor(
|
| 83 |
+
[(w * s - s / 2 - 0.5), (h * s - s / 2 - 0.5)],
|
| 84 |
+
).to(
|
| 85 |
+
keypoints
|
| 86 |
+
)[None]
|
| 87 |
+
keypoints = keypoints * 2 - 1 # normalize to (-1, 1)
|
| 88 |
+
args = {"align_corners": True} if torch.__version__ >= "1.3" else {}
|
| 89 |
+
descriptors = torch.nn.functional.grid_sample(
|
| 90 |
+
descriptors, keypoints.view(b, 1, -1, 2), mode="bilinear", **args
|
| 91 |
+
)
|
| 92 |
+
descriptors = torch.nn.functional.normalize(
|
| 93 |
+
descriptors.reshape(b, c, -1), p=2, dim=1
|
| 94 |
+
)
|
| 95 |
+
return descriptors
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class SuperPoint(Extractor):
|
| 99 |
+
"""SuperPoint Convolutional Detector and Descriptor
|
| 100 |
+
|
| 101 |
+
SuperPoint: Self-Supervised Interest Point Detection and
|
| 102 |
+
Description. Daniel DeTone, Tomasz Malisiewicz, and Andrew
|
| 103 |
+
Rabinovich. In CVPRW, 2019. https://arxiv.org/abs/1712.07629
|
| 104 |
+
|
| 105 |
+
"""
|
| 106 |
+
|
| 107 |
+
default_conf = {
|
| 108 |
+
"descriptor_dim": 256,
|
| 109 |
+
"nms_radius": 4,
|
| 110 |
+
"max_num_keypoints": None,
|
| 111 |
+
"detection_threshold": 0.0005,
|
| 112 |
+
"remove_borders": 4,
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
preprocess_conf = {
|
| 116 |
+
"resize": 1024,
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
required_data_keys = ["image"]
|
| 120 |
+
|
| 121 |
+
def __init__(self, **conf):
|
| 122 |
+
super().__init__(**conf) # Update with default configuration.
|
| 123 |
+
self.relu = nn.ReLU(inplace=True)
|
| 124 |
+
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
|
| 125 |
+
c1, c2, c3, c4, c5 = 64, 64, 128, 128, 256
|
| 126 |
+
|
| 127 |
+
self.conv1a = nn.Conv2d(1, c1, kernel_size=3, stride=1, padding=1)
|
| 128 |
+
self.conv1b = nn.Conv2d(c1, c1, kernel_size=3, stride=1, padding=1)
|
| 129 |
+
self.conv2a = nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1)
|
| 130 |
+
self.conv2b = nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1)
|
| 131 |
+
self.conv3a = nn.Conv2d(c2, c3, kernel_size=3, stride=1, padding=1)
|
| 132 |
+
self.conv3b = nn.Conv2d(c3, c3, kernel_size=3, stride=1, padding=1)
|
| 133 |
+
self.conv4a = nn.Conv2d(c3, c4, kernel_size=3, stride=1, padding=1)
|
| 134 |
+
self.conv4b = nn.Conv2d(c4, c4, kernel_size=3, stride=1, padding=1)
|
| 135 |
+
|
| 136 |
+
self.convPa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
|
| 137 |
+
self.convPb = nn.Conv2d(c5, 65, kernel_size=1, stride=1, padding=0)
|
| 138 |
+
|
| 139 |
+
self.convDa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
|
| 140 |
+
self.convDb = nn.Conv2d(
|
| 141 |
+
c5, self.conf.descriptor_dim, kernel_size=1, stride=1, padding=0
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
url = "https://github.com/cvg/LightGlue/releases/download/v0.1_arxiv/superpoint_v1.pth" # noqa
|
| 145 |
+
self.load_state_dict(torch.hub.load_state_dict_from_url(url,model_dir='./LightGlue/ckpts/',file_name='superpoint_v1.pth'))
|
| 146 |
+
|
| 147 |
+
if self.conf.max_num_keypoints is not None and self.conf.max_num_keypoints <= 0:
|
| 148 |
+
raise ValueError("max_num_keypoints must be positive or None")
|
| 149 |
+
|
| 150 |
+
def forward(self, data: dict) -> dict:
|
| 151 |
+
"""Compute keypoints, scores, descriptors for image"""
|
| 152 |
+
for key in self.required_data_keys:
|
| 153 |
+
assert key in data, f"Missing key {key} in data"
|
| 154 |
+
image = data["image"]
|
| 155 |
+
if image.shape[1] == 3:
|
| 156 |
+
image = rgb_to_grayscale(image)
|
| 157 |
+
|
| 158 |
+
# Shared Encoder
|
| 159 |
+
x = self.relu(self.conv1a(image))
|
| 160 |
+
x = self.relu(self.conv1b(x))
|
| 161 |
+
x = self.pool(x)
|
| 162 |
+
x = self.relu(self.conv2a(x))
|
| 163 |
+
x = self.relu(self.conv2b(x))
|
| 164 |
+
x = self.pool(x)
|
| 165 |
+
x = self.relu(self.conv3a(x))
|
| 166 |
+
x = self.relu(self.conv3b(x))
|
| 167 |
+
x = self.pool(x)
|
| 168 |
+
x = self.relu(self.conv4a(x))
|
| 169 |
+
x = self.relu(self.conv4b(x))
|
| 170 |
+
|
| 171 |
+
# Compute the dense keypoint scores
|
| 172 |
+
cPa = self.relu(self.convPa(x))
|
| 173 |
+
scores = self.convPb(cPa)
|
| 174 |
+
scores = torch.nn.functional.softmax(scores, 1)[:, :-1]
|
| 175 |
+
b, _, h, w = scores.shape
|
| 176 |
+
scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8)
|
| 177 |
+
scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h * 8, w * 8)
|
| 178 |
+
scores = simple_nms(scores, self.conf.nms_radius)
|
| 179 |
+
|
| 180 |
+
# Discard keypoints near the image borders
|
| 181 |
+
if self.conf.remove_borders:
|
| 182 |
+
pad = self.conf.remove_borders
|
| 183 |
+
scores[:, :pad] = -1
|
| 184 |
+
scores[:, :, :pad] = -1
|
| 185 |
+
scores[:, -pad:] = -1
|
| 186 |
+
scores[:, :, -pad:] = -1
|
| 187 |
+
|
| 188 |
+
# Extract keypoints
|
| 189 |
+
best_kp = torch.where(scores > self.conf.detection_threshold)
|
| 190 |
+
scores = scores[best_kp]
|
| 191 |
+
|
| 192 |
+
# Separate into batches
|
| 193 |
+
keypoints = [
|
| 194 |
+
torch.stack(best_kp[1:3], dim=-1)[best_kp[0] == i] for i in range(b)
|
| 195 |
+
]
|
| 196 |
+
scores = [scores[best_kp[0] == i] for i in range(b)]
|
| 197 |
+
|
| 198 |
+
# Keep the k keypoints with highest score
|
| 199 |
+
if self.conf.max_num_keypoints is not None:
|
| 200 |
+
keypoints, scores = list(
|
| 201 |
+
zip(
|
| 202 |
+
*[
|
| 203 |
+
top_k_keypoints(k, s, self.conf.max_num_keypoints)
|
| 204 |
+
for k, s in zip(keypoints, scores)
|
| 205 |
+
]
|
| 206 |
+
)
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
# Convert (h, w) to (x, y)
|
| 210 |
+
keypoints = [torch.flip(k, [1]).float() for k in keypoints]
|
| 211 |
+
|
| 212 |
+
# Compute the dense descriptors
|
| 213 |
+
cDa = self.relu(self.convDa(x))
|
| 214 |
+
descriptors = self.convDb(cDa)
|
| 215 |
+
descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1)
|
| 216 |
+
|
| 217 |
+
# Extract descriptors
|
| 218 |
+
descriptors = [
|
| 219 |
+
sample_descriptors(k[None], d[None], 8)[0]
|
| 220 |
+
for k, d in zip(keypoints, descriptors)
|
| 221 |
+
]
|
| 222 |
+
|
| 223 |
+
return {
|
| 224 |
+
"keypoints": torch.stack(keypoints, 0),
|
| 225 |
+
"keypoint_scores": torch.stack(scores, 0),
|
| 226 |
+
"descriptors": torch.stack(descriptors, 0).transpose(-1, -2).contiguous(),
|
| 227 |
+
}
|
LightGlue/lightglue/utils.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import collections.abc as collections
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
from types import SimpleNamespace
|
| 4 |
+
from typing import Callable, List, Optional, Tuple, Union
|
| 5 |
+
|
| 6 |
+
import cv2
|
| 7 |
+
import kornia
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class ImagePreprocessor:
|
| 13 |
+
default_conf = {
|
| 14 |
+
"resize": None, # target edge length, None for no resizing
|
| 15 |
+
"side": "long",
|
| 16 |
+
"interpolation": "bilinear",
|
| 17 |
+
"align_corners": None,
|
| 18 |
+
"antialias": True,
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
def __init__(self, **conf) -> None:
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.conf = {**self.default_conf, **conf}
|
| 24 |
+
self.conf = SimpleNamespace(**self.conf)
|
| 25 |
+
|
| 26 |
+
def __call__(self, img: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 27 |
+
"""Resize and preprocess an image, return image and resize scale"""
|
| 28 |
+
h, w = img.shape[-2:]
|
| 29 |
+
if self.conf.resize is not None:
|
| 30 |
+
img = kornia.geometry.transform.resize(
|
| 31 |
+
img,
|
| 32 |
+
self.conf.resize,
|
| 33 |
+
side=self.conf.side,
|
| 34 |
+
antialias=self.conf.antialias,
|
| 35 |
+
align_corners=self.conf.align_corners,
|
| 36 |
+
)
|
| 37 |
+
scale = torch.Tensor([img.shape[-1] / w, img.shape[-2] / h]).to(img)
|
| 38 |
+
return img, scale
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def map_tensor(input_, func: Callable):
|
| 42 |
+
string_classes = (str, bytes)
|
| 43 |
+
if isinstance(input_, string_classes):
|
| 44 |
+
return input_
|
| 45 |
+
elif isinstance(input_, collections.Mapping):
|
| 46 |
+
return {k: map_tensor(sample, func) for k, sample in input_.items()}
|
| 47 |
+
elif isinstance(input_, collections.Sequence):
|
| 48 |
+
return [map_tensor(sample, func) for sample in input_]
|
| 49 |
+
elif isinstance(input_, torch.Tensor):
|
| 50 |
+
return func(input_)
|
| 51 |
+
else:
|
| 52 |
+
return input_
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def batch_to_device(batch: dict, device: str = "cpu", non_blocking: bool = True):
|
| 56 |
+
"""Move batch (dict) to device"""
|
| 57 |
+
|
| 58 |
+
def _func(tensor):
|
| 59 |
+
return tensor.to(device=device, non_blocking=non_blocking).detach()
|
| 60 |
+
|
| 61 |
+
return map_tensor(batch, _func)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def rbd(data: dict) -> dict:
|
| 65 |
+
"""Remove batch dimension from elements in data"""
|
| 66 |
+
return {
|
| 67 |
+
k: v[0] if isinstance(v, (torch.Tensor, np.ndarray, list)) else v
|
| 68 |
+
for k, v in data.items()
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def read_image(path: Path, grayscale: bool = False) -> np.ndarray:
|
| 73 |
+
"""Read an image from path as RGB or grayscale"""
|
| 74 |
+
if not Path(path).exists():
|
| 75 |
+
raise FileNotFoundError(f"No image at path {path}.")
|
| 76 |
+
mode = cv2.IMREAD_GRAYSCALE if grayscale else cv2.IMREAD_COLOR
|
| 77 |
+
image = cv2.imread(str(path), mode)
|
| 78 |
+
if image is None:
|
| 79 |
+
raise IOError(f"Could not read image at {path}.")
|
| 80 |
+
if not grayscale:
|
| 81 |
+
image = image[..., ::-1]
|
| 82 |
+
return image
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def numpy_image_to_torch(image: np.ndarray) -> torch.Tensor:
|
| 86 |
+
"""Normalize the image tensor and reorder the dimensions."""
|
| 87 |
+
if image.ndim == 3:
|
| 88 |
+
image = image.transpose((2, 0, 1)) # HxWxC to CxHxW
|
| 89 |
+
elif image.ndim == 2:
|
| 90 |
+
image = image[None] # add channel axis
|
| 91 |
+
else:
|
| 92 |
+
raise ValueError(f"Not an image: {image.shape}")
|
| 93 |
+
return torch.tensor(image / 255.0, dtype=torch.float)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def resize_image(
|
| 97 |
+
image: np.ndarray,
|
| 98 |
+
size: Union[List[int], int],
|
| 99 |
+
fn: str = "max",
|
| 100 |
+
interp: Optional[str] = "area",
|
| 101 |
+
) -> np.ndarray:
|
| 102 |
+
"""Resize an image to a fixed size, or according to max or min edge."""
|
| 103 |
+
h, w = image.shape[:2]
|
| 104 |
+
|
| 105 |
+
fn = {"max": max, "min": min}[fn]
|
| 106 |
+
if isinstance(size, int):
|
| 107 |
+
scale = size / fn(h, w)
|
| 108 |
+
h_new, w_new = int(round(h * scale)), int(round(w * scale))
|
| 109 |
+
scale = (w_new / w, h_new / h)
|
| 110 |
+
elif isinstance(size, (tuple, list)):
|
| 111 |
+
h_new, w_new = size
|
| 112 |
+
scale = (w_new / w, h_new / h)
|
| 113 |
+
else:
|
| 114 |
+
raise ValueError(f"Incorrect new size: {size}")
|
| 115 |
+
mode = {
|
| 116 |
+
"linear": cv2.INTER_LINEAR,
|
| 117 |
+
"cubic": cv2.INTER_CUBIC,
|
| 118 |
+
"nearest": cv2.INTER_NEAREST,
|
| 119 |
+
"area": cv2.INTER_AREA,
|
| 120 |
+
}[interp]
|
| 121 |
+
return cv2.resize(image, (w_new, h_new), interpolation=mode), scale
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def load_image(path: Path, resize: int = None, **kwargs) -> torch.Tensor:
|
| 125 |
+
image = read_image(path)
|
| 126 |
+
if resize is not None:
|
| 127 |
+
image, _ = resize_image(image, resize, **kwargs)
|
| 128 |
+
return numpy_image_to_torch(image)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
class Extractor(torch.nn.Module):
|
| 132 |
+
def __init__(self, **conf):
|
| 133 |
+
super().__init__()
|
| 134 |
+
self.conf = SimpleNamespace(**{**self.default_conf, **conf})
|
| 135 |
+
|
| 136 |
+
@torch.no_grad()
|
| 137 |
+
def extract(self, img: torch.Tensor, **conf) -> dict:
|
| 138 |
+
"""Perform extraction with online resizing"""
|
| 139 |
+
if img.dim() == 3:
|
| 140 |
+
img = img[None] # add batch dim
|
| 141 |
+
assert img.dim() == 4 and img.shape[0] == 1
|
| 142 |
+
shape = img.shape[-2:][::-1]
|
| 143 |
+
img, scales = ImagePreprocessor(**{**self.preprocess_conf, **conf})(img)
|
| 144 |
+
feats = self.forward({"image": img})
|
| 145 |
+
feats["image_size"] = torch.tensor(shape)[None].to(img).float()
|
| 146 |
+
feats["keypoints"] = (feats["keypoints"] + 0.5) / scales[None] - 0.5
|
| 147 |
+
return feats
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def match_pair(
|
| 151 |
+
extractor,
|
| 152 |
+
matcher,
|
| 153 |
+
image0: torch.Tensor,
|
| 154 |
+
image1: torch.Tensor,
|
| 155 |
+
device: str = "cpu",
|
| 156 |
+
**preprocess,
|
| 157 |
+
):
|
| 158 |
+
"""Match a pair of images (image0, image1) with an extractor and matcher"""
|
| 159 |
+
feats0 = extractor.extract(image0, **preprocess)
|
| 160 |
+
feats1 = extractor.extract(image1, **preprocess)
|
| 161 |
+
matches01 = matcher({"image0": feats0, "image1": feats1})
|
| 162 |
+
data = [feats0, feats1, matches01]
|
| 163 |
+
# remove batch dim and move to target device
|
| 164 |
+
feats0, feats1, matches01 = [batch_to_device(rbd(x), device) for x in data]
|
| 165 |
+
return feats0, feats1, matches01
|
LightGlue/lightglue/viz2d.py
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
2D visualization primitives based on Matplotlib.
|
| 3 |
+
1) Plot images with `plot_images`.
|
| 4 |
+
2) Call `plot_keypoints` or `plot_matches` any number of times.
|
| 5 |
+
3) Optionally: save a .png or .pdf plot (nice in papers!) with `save_plot`.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import matplotlib
|
| 9 |
+
import matplotlib.patheffects as path_effects
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def cm_RdGn(x):
|
| 16 |
+
"""Custom colormap: red (0) -> yellow (0.5) -> green (1)."""
|
| 17 |
+
x = np.clip(x, 0, 1)[..., None] * 2
|
| 18 |
+
c = x * np.array([[0, 1.0, 0]]) + (2 - x) * np.array([[1.0, 0, 0]])
|
| 19 |
+
return np.clip(c, 0, 1)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def cm_BlRdGn(x_):
|
| 23 |
+
"""Custom colormap: blue (-1) -> red (0.0) -> green (1)."""
|
| 24 |
+
x = np.clip(x_, 0, 1)[..., None] * 2
|
| 25 |
+
c = x * np.array([[0, 1.0, 0, 1.0]]) + (2 - x) * np.array([[1.0, 0, 0, 1.0]])
|
| 26 |
+
|
| 27 |
+
xn = -np.clip(x_, -1, 0)[..., None] * 2
|
| 28 |
+
cn = xn * np.array([[0, 0.1, 1, 1.0]]) + (2 - xn) * np.array([[1.0, 0, 0, 1.0]])
|
| 29 |
+
out = np.clip(np.where(x_[..., None] < 0, cn, c), 0, 1)
|
| 30 |
+
return out
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def cm_prune(x_):
|
| 34 |
+
"""Custom colormap to visualize pruning"""
|
| 35 |
+
if isinstance(x_, torch.Tensor):
|
| 36 |
+
x_ = x_.cpu().numpy()
|
| 37 |
+
max_i = max(x_)
|
| 38 |
+
norm_x = np.where(x_ == max_i, -1, (x_ - 1) / 9)
|
| 39 |
+
return cm_BlRdGn(norm_x)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def plot_images(imgs, titles=None, cmaps="gray", dpi=100, pad=0.5, adaptive=True):
|
| 43 |
+
"""Plot a set of images horizontally.
|
| 44 |
+
Args:
|
| 45 |
+
imgs: list of NumPy RGB (H, W, 3) or PyTorch RGB (3, H, W) or mono (H, W).
|
| 46 |
+
titles: a list of strings, as titles for each image.
|
| 47 |
+
cmaps: colormaps for monochrome images.
|
| 48 |
+
adaptive: whether the figure size should fit the image aspect ratios.
|
| 49 |
+
"""
|
| 50 |
+
# conversion to (H, W, 3) for torch.Tensor
|
| 51 |
+
imgs = [
|
| 52 |
+
img.permute(1, 2, 0).cpu().numpy()
|
| 53 |
+
if (isinstance(img, torch.Tensor) and img.dim() == 3)
|
| 54 |
+
else img
|
| 55 |
+
for img in imgs
|
| 56 |
+
]
|
| 57 |
+
|
| 58 |
+
n = len(imgs)
|
| 59 |
+
if not isinstance(cmaps, (list, tuple)):
|
| 60 |
+
cmaps = [cmaps] * n
|
| 61 |
+
|
| 62 |
+
if adaptive:
|
| 63 |
+
ratios = [i.shape[1] / i.shape[0] for i in imgs] # W / H
|
| 64 |
+
else:
|
| 65 |
+
ratios = [4 / 3] * n
|
| 66 |
+
figsize = [sum(ratios) * 4.5, 4.5]
|
| 67 |
+
fig, ax = plt.subplots(
|
| 68 |
+
1, n, figsize=figsize, dpi=dpi, gridspec_kw={"width_ratios": ratios}
|
| 69 |
+
)
|
| 70 |
+
if n == 1:
|
| 71 |
+
ax = [ax]
|
| 72 |
+
for i in range(n):
|
| 73 |
+
ax[i].imshow(imgs[i], cmap=plt.get_cmap(cmaps[i]))
|
| 74 |
+
ax[i].get_yaxis().set_ticks([])
|
| 75 |
+
ax[i].get_xaxis().set_ticks([])
|
| 76 |
+
ax[i].set_axis_off()
|
| 77 |
+
for spine in ax[i].spines.values(): # remove frame
|
| 78 |
+
spine.set_visible(False)
|
| 79 |
+
if titles:
|
| 80 |
+
ax[i].set_title(titles[i])
|
| 81 |
+
fig.tight_layout(pad=pad)
|
| 82 |
+
return fig, ax
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def plot_keypoints(kpts, colors="lime", ps=4, axes=None, a=1.0):
|
| 86 |
+
"""Plot keypoints for existing images.
|
| 87 |
+
Args:
|
| 88 |
+
kpts: list of ndarrays of size (N, 2).
|
| 89 |
+
colors: string, or list of list of tuples (one for each keypoints).
|
| 90 |
+
ps: size of the keypoints as float.
|
| 91 |
+
"""
|
| 92 |
+
if not isinstance(colors, list):
|
| 93 |
+
colors = [colors] * len(kpts)
|
| 94 |
+
if not isinstance(a, list):
|
| 95 |
+
a = [a] * len(kpts)
|
| 96 |
+
if axes is None:
|
| 97 |
+
axes = plt.gcf().axes
|
| 98 |
+
for ax, k, c, alpha in zip(axes, kpts, colors, a):
|
| 99 |
+
if isinstance(k, torch.Tensor):
|
| 100 |
+
k = k.cpu().numpy()
|
| 101 |
+
ax.scatter(k[:, 0], k[:, 1], c=c, s=ps, linewidths=0, alpha=alpha)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def plot_matches(kpts0, kpts1, color=None, lw=1.5, ps=4, a=1.0, labels=None, axes=None):
|
| 105 |
+
"""Plot matches for a pair of existing images.
|
| 106 |
+
Args:
|
| 107 |
+
kpts0, kpts1: corresponding keypoints of size (N, 2).
|
| 108 |
+
color: color of each match, string or RGB tuple. Random if not given.
|
| 109 |
+
lw: width of the lines.
|
| 110 |
+
ps: size of the end points (no endpoint if ps=0)
|
| 111 |
+
indices: indices of the images to draw the matches on.
|
| 112 |
+
a: alpha opacity of the match lines.
|
| 113 |
+
"""
|
| 114 |
+
fig = plt.gcf()
|
| 115 |
+
if axes is None:
|
| 116 |
+
ax = fig.axes
|
| 117 |
+
ax0, ax1 = ax[0], ax[1]
|
| 118 |
+
else:
|
| 119 |
+
ax0, ax1 = axes
|
| 120 |
+
if isinstance(kpts0, torch.Tensor):
|
| 121 |
+
kpts0 = kpts0.cpu().numpy()
|
| 122 |
+
if isinstance(kpts1, torch.Tensor):
|
| 123 |
+
kpts1 = kpts1.cpu().numpy()
|
| 124 |
+
assert len(kpts0) == len(kpts1)
|
| 125 |
+
if color is None:
|
| 126 |
+
color = matplotlib.cm.hsv(np.random.rand(len(kpts0))).tolist()
|
| 127 |
+
elif len(color) > 0 and not isinstance(color[0], (tuple, list)):
|
| 128 |
+
color = [color] * len(kpts0)
|
| 129 |
+
|
| 130 |
+
if lw > 0:
|
| 131 |
+
for i in range(len(kpts0)):
|
| 132 |
+
line = matplotlib.patches.ConnectionPatch(
|
| 133 |
+
xyA=(kpts0[i, 0], kpts0[i, 1]),
|
| 134 |
+
xyB=(kpts1[i, 0], kpts1[i, 1]),
|
| 135 |
+
coordsA=ax0.transData,
|
| 136 |
+
coordsB=ax1.transData,
|
| 137 |
+
axesA=ax0,
|
| 138 |
+
axesB=ax1,
|
| 139 |
+
zorder=1,
|
| 140 |
+
color=color[i],
|
| 141 |
+
linewidth=lw,
|
| 142 |
+
clip_on=True,
|
| 143 |
+
alpha=a,
|
| 144 |
+
label=None if labels is None else labels[i],
|
| 145 |
+
picker=5.0,
|
| 146 |
+
)
|
| 147 |
+
line.set_annotation_clip(True)
|
| 148 |
+
fig.add_artist(line)
|
| 149 |
+
|
| 150 |
+
# freeze the axes to prevent the transform to change
|
| 151 |
+
ax0.autoscale(enable=False)
|
| 152 |
+
ax1.autoscale(enable=False)
|
| 153 |
+
|
| 154 |
+
if ps > 0:
|
| 155 |
+
ax0.scatter(kpts0[:, 0], kpts0[:, 1], c=color, s=ps)
|
| 156 |
+
ax1.scatter(kpts1[:, 0], kpts1[:, 1], c=color, s=ps)
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def add_text(
|
| 160 |
+
idx,
|
| 161 |
+
text,
|
| 162 |
+
pos=(0.01, 0.99),
|
| 163 |
+
fs=15,
|
| 164 |
+
color="w",
|
| 165 |
+
lcolor="k",
|
| 166 |
+
lwidth=2,
|
| 167 |
+
ha="left",
|
| 168 |
+
va="top",
|
| 169 |
+
):
|
| 170 |
+
ax = plt.gcf().axes[idx]
|
| 171 |
+
t = ax.text(
|
| 172 |
+
*pos, text, fontsize=fs, ha=ha, va=va, color=color, transform=ax.transAxes
|
| 173 |
+
)
|
| 174 |
+
if lcolor is not None:
|
| 175 |
+
t.set_path_effects(
|
| 176 |
+
[
|
| 177 |
+
path_effects.Stroke(linewidth=lwidth, foreground=lcolor),
|
| 178 |
+
path_effects.Normal(),
|
| 179 |
+
]
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def save_plot(path, **kw):
|
| 184 |
+
"""Save the current figure without any white margin."""
|
| 185 |
+
plt.savefig(path, bbox_inches="tight", pad_inches=0, **kw)
|
LightGlue/pyproject.toml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
name = "lightglue"
|
| 3 |
+
description = "LightGlue: Local Feature Matching at Light Speed"
|
| 4 |
+
version = "0.0"
|
| 5 |
+
authors = [
|
| 6 |
+
{name = "Philipp Lindenberger"},
|
| 7 |
+
{name = "Paul-Edouard Sarlin"},
|
| 8 |
+
]
|
| 9 |
+
readme = "README.md"
|
| 10 |
+
requires-python = ">=3.6"
|
| 11 |
+
license = {file = "LICENSE"}
|
| 12 |
+
classifiers = [
|
| 13 |
+
"Programming Language :: Python :: 3",
|
| 14 |
+
"License :: OSI Approved :: Apache Software License",
|
| 15 |
+
"Operating System :: OS Independent",
|
| 16 |
+
]
|
| 17 |
+
urls = {Repository = "https://github.com/cvg/LightGlue/"}
|
| 18 |
+
dynamic = ["dependencies"]
|
| 19 |
+
|
| 20 |
+
[project.optional-dependencies]
|
| 21 |
+
dev = ["black==23.12.1", "flake8", "isort"]
|
| 22 |
+
|
| 23 |
+
[tool.setuptools]
|
| 24 |
+
packages = ["lightglue"]
|
| 25 |
+
|
| 26 |
+
[tool.setuptools.dynamic]
|
| 27 |
+
dependencies = {file = ["requirements.txt"]}
|
| 28 |
+
|
| 29 |
+
[tool.isort]
|
| 30 |
+
profile = "black"
|
LightGlue/requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# torch>=1.9.1
|
| 2 |
+
# torchvision>=0.3
|
| 3 |
+
# numpy
|
| 4 |
+
# opencv-python
|
| 5 |
+
# matplotlib
|
| 6 |
+
# kornia>=0.6.11
|
ORIGINAL_README.md
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AniDoc: Animation Creation Made Easier
|
| 2 |
+
<a href="https://yihao-meng.github.io/AniDoc_demo/"><img src="https://img.shields.io/static/v1?label=Project&message=Website&color=blue"></a>
|
| 3 |
+
<a href="https://arxiv.org/pdf/2412.14173"><img src="https://img.shields.io/badge/arXiv-2404.12.14173-b31b1b.svg"></a>
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
https://github.com/user-attachments/assets/99e1e52a-f0e1-49f5-b81f-e787857901e4
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
> <a href="https://yihao-meng.github.io/AniDoc_demo">**AniDoc: Animation Creation Made Easier**</a>
|
| 13 |
+
>
|
| 14 |
+
|
| 15 |
+
[Yihao Meng](https://yihao-meng.github.io/)<sup>1,2</sup>, [Hao Ouyang](https://ken-ouyang.github.io/)<sup>2</sup>, [Hanlin Wang](https://openreview.net/profile?id=~Hanlin_Wang2)<sup>3,2</sup>, [Qiuyu Wang](https://github.com/qiuyu96)<sup>2</sup>, [Wen Wang](https://github.com/encounter1997)<sup>4,2</sup>, [Ka Leong Cheng](https://felixcheng97.github.io/)<sup>1,2</sup> , [Zhiheng Liu](https://johanan528.github.io/)<sup>5</sup>, [Yujun Shen](https://shenyujun.github.io/)<sup>2</sup>, [Huamin Qu](http://www.huamin.org/index.htm/)<sup>†,2</sup><br>
|
| 16 |
+
<sup>1</sup>HKUST <sup>2</sup>Ant Group <sup>3</sup>NJU <sup>4</sup>ZJU <sup>5</sup>HKU <sup>†</sup>corresponding author
|
| 17 |
+
|
| 18 |
+
> AniDoc colorizes a sequence of sketches based on a character design reference with high fidelity, even when the sketches significantly differ in pose and scale.
|
| 19 |
+
</p>
|
| 20 |
+
|
| 21 |
+
**Strongly recommend seeing our [demo page](https://yihao-meng.github.io/AniDoc_demo).**
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## Showcases:
|
| 25 |
+
<p style="text-align: center;">
|
| 26 |
+
<img src="figure/showcases/image1.gif" alt="GIF" />
|
| 27 |
+
</p>
|
| 28 |
+
<p style="text-align: center;">
|
| 29 |
+
<img src="figure/showcases/image2.gif" alt="GIF" />
|
| 30 |
+
</p>
|
| 31 |
+
<p style="text-align: center;">
|
| 32 |
+
<img src="figure/showcases/image3.gif" alt="GIF" />
|
| 33 |
+
</p>
|
| 34 |
+
<p style="text-align: center;">
|
| 35 |
+
<img src="figure/showcases/image4.gif" alt="GIF" />
|
| 36 |
+
</p>
|
| 37 |
+
|
| 38 |
+
## Flexible Usage:
|
| 39 |
+
### Same Reference with Varying Sketches
|
| 40 |
+
<div style="display: flex; flex-direction: column; align-items: center; gap: 20px;">
|
| 41 |
+
<img src="figure/showcases/image29.gif" alt="GIF Animation">
|
| 42 |
+
<img src="figure/showcases/image30.gif" alt="GIF Animation">
|
| 43 |
+
<img src="figure/showcases/image31.gif" alt="GIF Animation" style="margin-bottom: 40px;">
|
| 44 |
+
<div style="text-align:center; margin-top: -50px; margin-bottom: 70px;font-size: 18px; letter-spacing: 0.2px;">
|
| 45 |
+
<em>Satoru Gojo from Jujutsu Kaisen</em>
|
| 46 |
+
</div>
|
| 47 |
+
</div>
|
| 48 |
+
|
| 49 |
+
### Same Sketch with Different References.
|
| 50 |
+
|
| 51 |
+
<div style="display: flex; flex-direction: column; align-items: center; gap: 20px;">
|
| 52 |
+
<img src="figure/showcases/image33.gif" alt="GIF Animation" >
|
| 53 |
+
|
| 54 |
+
<img src="figure/showcases/image34.gif" alt="GIF Animation" >
|
| 55 |
+
<img src="figure/showcases/image35.gif" alt="GIF Animation" style="margin-bottom: 40px;">
|
| 56 |
+
<div style="text-align:center; margin-top: -50px; margin-bottom: 70px;font-size: 18px; letter-spacing: 0.2px;">
|
| 57 |
+
<em>Anya Forger from Spy x Family</em>
|
| 58 |
+
</div>
|
| 59 |
+
</div>
|
| 60 |
+
|
| 61 |
+
## TODO List
|
| 62 |
+
|
| 63 |
+
- [x] Release the paper and demo page. Visit [https://yihao-meng.github.io/AniDoc_demo/](https://yihao-meng.github.io/AniDoc_demo/)
|
| 64 |
+
- [x] Release the inference code.
|
| 65 |
+
- [ ] Build Gradio Demo
|
| 66 |
+
- [ ] Release the training code.
|
| 67 |
+
- [ ] Release the sparse sketch setting interpolation code.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
## Requirements:
|
| 71 |
+
The training is conducted on 8 A100 GPUs (80GB VRAM), the inference is tested on RTX 5000 (32GB VRAM). In our test, the inference requires about 14GB VRAM.
|
| 72 |
+
## Setup
|
| 73 |
+
```
|
| 74 |
+
git clone https://github.com/yihao-meng/AniDoc.git
|
| 75 |
+
cd AniDoc
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
## Environment
|
| 79 |
+
All the tests are conducted in Linux. We suggest running our code in Linux. To set up our environment in Linux, please run:
|
| 80 |
+
```
|
| 81 |
+
conda create -n anidoc python=3.8 -y
|
| 82 |
+
conda activate anidoc
|
| 83 |
+
|
| 84 |
+
bash install.sh
|
| 85 |
+
```
|
| 86 |
+
## Checkpoints
|
| 87 |
+
1. please download the pre-trained stable video diffusion (SVD) checkpoints from [here](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/tree/main), and put the whole folder under `pretrained_weight`, it should look like `./pretrained_weights/stable-video-diffusion-img2vid-xt`
|
| 88 |
+
2. please download the checkpoint for our Unet and ControlNet from [here](https://huggingface.co/Yhmeng1106/anidoc/tree/main), and put the whole folder as `./pretrained_weights/anidoc`.
|
| 89 |
+
3. please download the co_tracker checkpoint from [here](https://huggingface.co/facebook/cotracker/blob/main/cotracker2.pth) and put it as `./pretrained_weights/cotracker2.pth`.
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
## Generate Your Animation!
|
| 95 |
+
To colorize the target lineart sequence with a specific character design, you can run the following command:
|
| 96 |
+
```
|
| 97 |
+
bash scripts_infer/anidoc_inference.sh
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
We provide some test cases in `data_test` folder. You can also try our model with your own data. You can change the lineart sequence and corresponding character design in the script `anidoc_inference.sh`, where `--control_image` refers to the lineart sequence and `--ref_image` refers to the character design.
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
## Citation:
|
| 106 |
+
Don't forget to cite this source if it proves useful in your research!
|
| 107 |
+
```bibtex
|
| 108 |
+
@article{meng2024anidoc,
|
| 109 |
+
title={AniDoc: Animation Creation Made Easier},
|
| 110 |
+
author={Yihao Meng and Hao Ouyang and Hanlin Wang and Qiuyu Wang and Wen Wang and Ka Leong Cheng and Zhiheng Liu and Yujun Shen and Huamin Qu},
|
| 111 |
+
journal={arXiv preprint arXiv:2412.14173},
|
| 112 |
+
year={2024}
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
```
|
cotracker/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
cotracker/build/lib/datasets/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
cotracker/build/lib/datasets/dataclass_utils.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import json
|
| 9 |
+
import dataclasses
|
| 10 |
+
import numpy as np
|
| 11 |
+
from dataclasses import Field, MISSING
|
| 12 |
+
from typing import IO, TypeVar, Type, get_args, get_origin, Union, Any, Tuple
|
| 13 |
+
|
| 14 |
+
_X = TypeVar("_X")
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def load_dataclass(f: IO, cls: Type[_X], binary: bool = False) -> _X:
|
| 18 |
+
"""
|
| 19 |
+
Loads to a @dataclass or collection hierarchy including dataclasses
|
| 20 |
+
from a json recursively.
|
| 21 |
+
Call it like load_dataclass(f, typing.List[FrameAnnotationAnnotation]).
|
| 22 |
+
raises KeyError if json has keys not mapping to the dataclass fields.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
f: Either a path to a file, or a file opened for writing.
|
| 26 |
+
cls: The class of the loaded dataclass.
|
| 27 |
+
binary: Set to True if `f` is a file handle, else False.
|
| 28 |
+
"""
|
| 29 |
+
if binary:
|
| 30 |
+
asdict = json.loads(f.read().decode("utf8"))
|
| 31 |
+
else:
|
| 32 |
+
asdict = json.load(f)
|
| 33 |
+
|
| 34 |
+
# in the list case, run a faster "vectorized" version
|
| 35 |
+
cls = get_args(cls)[0]
|
| 36 |
+
res = list(_dataclass_list_from_dict_list(asdict, cls))
|
| 37 |
+
|
| 38 |
+
return res
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def _resolve_optional(type_: Any) -> Tuple[bool, Any]:
|
| 42 |
+
"""Check whether `type_` is equivalent to `typing.Optional[T]` for some T."""
|
| 43 |
+
if get_origin(type_) is Union:
|
| 44 |
+
args = get_args(type_)
|
| 45 |
+
if len(args) == 2 and args[1] == type(None): # noqa E721
|
| 46 |
+
return True, args[0]
|
| 47 |
+
if type_ is Any:
|
| 48 |
+
return True, Any
|
| 49 |
+
|
| 50 |
+
return False, type_
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def _unwrap_type(tp):
|
| 54 |
+
# strips Optional wrapper, if any
|
| 55 |
+
if get_origin(tp) is Union:
|
| 56 |
+
args = get_args(tp)
|
| 57 |
+
if len(args) == 2 and any(a is type(None) for a in args): # noqa: E721
|
| 58 |
+
# this is typing.Optional
|
| 59 |
+
return args[0] if args[1] is type(None) else args[1] # noqa: E721
|
| 60 |
+
return tp
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def _get_dataclass_field_default(field: Field) -> Any:
|
| 64 |
+
if field.default_factory is not MISSING:
|
| 65 |
+
# pyre-fixme[29]: `Union[dataclasses._MISSING_TYPE,
|
| 66 |
+
# dataclasses._DefaultFactory[typing.Any]]` is not a function.
|
| 67 |
+
return field.default_factory()
|
| 68 |
+
elif field.default is not MISSING:
|
| 69 |
+
return field.default
|
| 70 |
+
else:
|
| 71 |
+
return None
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def _dataclass_list_from_dict_list(dlist, typeannot):
|
| 75 |
+
"""
|
| 76 |
+
Vectorised version of `_dataclass_from_dict`.
|
| 77 |
+
The output should be equivalent to
|
| 78 |
+
`[_dataclass_from_dict(d, typeannot) for d in dlist]`.
|
| 79 |
+
|
| 80 |
+
Args:
|
| 81 |
+
dlist: list of objects to convert.
|
| 82 |
+
typeannot: type of each of those objects.
|
| 83 |
+
Returns:
|
| 84 |
+
iterator or list over converted objects of the same length as `dlist`.
|
| 85 |
+
|
| 86 |
+
Raises:
|
| 87 |
+
ValueError: it assumes the objects have None's in consistent places across
|
| 88 |
+
objects, otherwise it would ignore some values. This generally holds for
|
| 89 |
+
auto-generated annotations, but otherwise use `_dataclass_from_dict`.
|
| 90 |
+
"""
|
| 91 |
+
|
| 92 |
+
cls = get_origin(typeannot) or typeannot
|
| 93 |
+
|
| 94 |
+
if typeannot is Any:
|
| 95 |
+
return dlist
|
| 96 |
+
if all(obj is None for obj in dlist): # 1st recursion base: all None nodes
|
| 97 |
+
return dlist
|
| 98 |
+
if any(obj is None for obj in dlist):
|
| 99 |
+
# filter out Nones and recurse on the resulting list
|
| 100 |
+
idx_notnone = [(i, obj) for i, obj in enumerate(dlist) if obj is not None]
|
| 101 |
+
idx, notnone = zip(*idx_notnone)
|
| 102 |
+
converted = _dataclass_list_from_dict_list(notnone, typeannot)
|
| 103 |
+
res = [None] * len(dlist)
|
| 104 |
+
for i, obj in zip(idx, converted):
|
| 105 |
+
res[i] = obj
|
| 106 |
+
return res
|
| 107 |
+
|
| 108 |
+
is_optional, contained_type = _resolve_optional(typeannot)
|
| 109 |
+
if is_optional:
|
| 110 |
+
return _dataclass_list_from_dict_list(dlist, contained_type)
|
| 111 |
+
|
| 112 |
+
# otherwise, we dispatch by the type of the provided annotation to convert to
|
| 113 |
+
if issubclass(cls, tuple) and hasattr(cls, "_fields"): # namedtuple
|
| 114 |
+
# For namedtuple, call the function recursively on the lists of corresponding keys
|
| 115 |
+
types = cls.__annotations__.values()
|
| 116 |
+
dlist_T = zip(*dlist)
|
| 117 |
+
res_T = [
|
| 118 |
+
_dataclass_list_from_dict_list(key_list, tp) for key_list, tp in zip(dlist_T, types)
|
| 119 |
+
]
|
| 120 |
+
return [cls(*converted_as_tuple) for converted_as_tuple in zip(*res_T)]
|
| 121 |
+
elif issubclass(cls, (list, tuple)):
|
| 122 |
+
# For list/tuple, call the function recursively on the lists of corresponding positions
|
| 123 |
+
types = get_args(typeannot)
|
| 124 |
+
if len(types) == 1: # probably List; replicate for all items
|
| 125 |
+
types = types * len(dlist[0])
|
| 126 |
+
dlist_T = zip(*dlist)
|
| 127 |
+
res_T = (
|
| 128 |
+
_dataclass_list_from_dict_list(pos_list, tp) for pos_list, tp in zip(dlist_T, types)
|
| 129 |
+
)
|
| 130 |
+
if issubclass(cls, tuple):
|
| 131 |
+
return list(zip(*res_T))
|
| 132 |
+
else:
|
| 133 |
+
return [cls(converted_as_tuple) for converted_as_tuple in zip(*res_T)]
|
| 134 |
+
elif issubclass(cls, dict):
|
| 135 |
+
# For the dictionary, call the function recursively on concatenated keys and vertices
|
| 136 |
+
key_t, val_t = get_args(typeannot)
|
| 137 |
+
all_keys_res = _dataclass_list_from_dict_list(
|
| 138 |
+
[k for obj in dlist for k in obj.keys()], key_t
|
| 139 |
+
)
|
| 140 |
+
all_vals_res = _dataclass_list_from_dict_list(
|
| 141 |
+
[k for obj in dlist for k in obj.values()], val_t
|
| 142 |
+
)
|
| 143 |
+
indices = np.cumsum([len(obj) for obj in dlist])
|
| 144 |
+
assert indices[-1] == len(all_keys_res)
|
| 145 |
+
|
| 146 |
+
keys = np.split(list(all_keys_res), indices[:-1])
|
| 147 |
+
all_vals_res_iter = iter(all_vals_res)
|
| 148 |
+
return [cls(zip(k, all_vals_res_iter)) for k in keys]
|
| 149 |
+
elif not dataclasses.is_dataclass(typeannot):
|
| 150 |
+
return dlist
|
| 151 |
+
|
| 152 |
+
# dataclass node: 2nd recursion base; call the function recursively on the lists
|
| 153 |
+
# of the corresponding fields
|
| 154 |
+
assert dataclasses.is_dataclass(cls)
|
| 155 |
+
fieldtypes = {
|
| 156 |
+
f.name: (_unwrap_type(f.type), _get_dataclass_field_default(f))
|
| 157 |
+
for f in dataclasses.fields(typeannot)
|
| 158 |
+
}
|
| 159 |
+
|
| 160 |
+
# NOTE the default object is shared here
|
| 161 |
+
key_lists = (
|
| 162 |
+
_dataclass_list_from_dict_list([obj.get(k, default) for obj in dlist], type_)
|
| 163 |
+
for k, (type_, default) in fieldtypes.items()
|
| 164 |
+
)
|
| 165 |
+
transposed = zip(*key_lists)
|
| 166 |
+
return [cls(*vals_as_tuple) for vals_as_tuple in transposed]
|
cotracker/build/lib/datasets/dr_dataset.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import gzip
|
| 10 |
+
import torch
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch.utils.data as data
|
| 13 |
+
from collections import defaultdict
|
| 14 |
+
from dataclasses import dataclass
|
| 15 |
+
from typing import List, Optional, Any, Dict, Tuple
|
| 16 |
+
|
| 17 |
+
from cotracker.datasets.utils import CoTrackerData
|
| 18 |
+
from cotracker.datasets.dataclass_utils import load_dataclass
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@dataclass
|
| 22 |
+
class ImageAnnotation:
|
| 23 |
+
# path to jpg file, relative w.r.t. dataset_root
|
| 24 |
+
path: str
|
| 25 |
+
# H x W
|
| 26 |
+
size: Tuple[int, int]
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
@dataclass
|
| 30 |
+
class DynamicReplicaFrameAnnotation:
|
| 31 |
+
"""A dataclass used to load annotations from json."""
|
| 32 |
+
|
| 33 |
+
# can be used to join with `SequenceAnnotation`
|
| 34 |
+
sequence_name: str
|
| 35 |
+
# 0-based, continuous frame number within sequence
|
| 36 |
+
frame_number: int
|
| 37 |
+
# timestamp in seconds from the video start
|
| 38 |
+
frame_timestamp: float
|
| 39 |
+
|
| 40 |
+
image: ImageAnnotation
|
| 41 |
+
meta: Optional[Dict[str, Any]] = None
|
| 42 |
+
|
| 43 |
+
camera_name: Optional[str] = None
|
| 44 |
+
trajectories: Optional[str] = None
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class DynamicReplicaDataset(data.Dataset):
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
root,
|
| 51 |
+
split="valid",
|
| 52 |
+
traj_per_sample=256,
|
| 53 |
+
crop_size=None,
|
| 54 |
+
sample_len=-1,
|
| 55 |
+
only_first_n_samples=-1,
|
| 56 |
+
rgbd_input=False,
|
| 57 |
+
):
|
| 58 |
+
super(DynamicReplicaDataset, self).__init__()
|
| 59 |
+
self.root = root
|
| 60 |
+
self.sample_len = sample_len
|
| 61 |
+
self.split = split
|
| 62 |
+
self.traj_per_sample = traj_per_sample
|
| 63 |
+
self.rgbd_input = rgbd_input
|
| 64 |
+
self.crop_size = crop_size
|
| 65 |
+
frame_annotations_file = f"frame_annotations_{split}.jgz"
|
| 66 |
+
self.sample_list = []
|
| 67 |
+
with gzip.open(
|
| 68 |
+
os.path.join(root, split, frame_annotations_file), "rt", encoding="utf8"
|
| 69 |
+
) as zipfile:
|
| 70 |
+
frame_annots_list = load_dataclass(zipfile, List[DynamicReplicaFrameAnnotation])
|
| 71 |
+
seq_annot = defaultdict(list)
|
| 72 |
+
for frame_annot in frame_annots_list:
|
| 73 |
+
if frame_annot.camera_name == "left":
|
| 74 |
+
seq_annot[frame_annot.sequence_name].append(frame_annot)
|
| 75 |
+
|
| 76 |
+
for seq_name in seq_annot.keys():
|
| 77 |
+
seq_len = len(seq_annot[seq_name])
|
| 78 |
+
|
| 79 |
+
step = self.sample_len if self.sample_len > 0 else seq_len
|
| 80 |
+
counter = 0
|
| 81 |
+
|
| 82 |
+
for ref_idx in range(0, seq_len, step):
|
| 83 |
+
sample = seq_annot[seq_name][ref_idx : ref_idx + step]
|
| 84 |
+
self.sample_list.append(sample)
|
| 85 |
+
counter += 1
|
| 86 |
+
if only_first_n_samples > 0 and counter >= only_first_n_samples:
|
| 87 |
+
break
|
| 88 |
+
|
| 89 |
+
def __len__(self):
|
| 90 |
+
return len(self.sample_list)
|
| 91 |
+
|
| 92 |
+
def crop(self, rgbs, trajs):
|
| 93 |
+
T, N, _ = trajs.shape
|
| 94 |
+
|
| 95 |
+
S = len(rgbs)
|
| 96 |
+
H, W = rgbs[0].shape[:2]
|
| 97 |
+
assert S == T
|
| 98 |
+
|
| 99 |
+
H_new = H
|
| 100 |
+
W_new = W
|
| 101 |
+
|
| 102 |
+
# simple random crop
|
| 103 |
+
y0 = 0 if self.crop_size[0] >= H_new else (H_new - self.crop_size[0]) // 2
|
| 104 |
+
x0 = 0 if self.crop_size[1] >= W_new else (W_new - self.crop_size[1]) // 2
|
| 105 |
+
rgbs = [rgb[y0 : y0 + self.crop_size[0], x0 : x0 + self.crop_size[1]] for rgb in rgbs]
|
| 106 |
+
|
| 107 |
+
trajs[:, :, 0] -= x0
|
| 108 |
+
trajs[:, :, 1] -= y0
|
| 109 |
+
|
| 110 |
+
return rgbs, trajs
|
| 111 |
+
|
| 112 |
+
def __getitem__(self, index):
|
| 113 |
+
sample = self.sample_list[index]
|
| 114 |
+
T = len(sample)
|
| 115 |
+
rgbs, visibilities, traj_2d = [], [], []
|
| 116 |
+
|
| 117 |
+
H, W = sample[0].image.size
|
| 118 |
+
image_size = (H, W)
|
| 119 |
+
|
| 120 |
+
for i in range(T):
|
| 121 |
+
traj_path = os.path.join(self.root, self.split, sample[i].trajectories["path"])
|
| 122 |
+
traj = torch.load(traj_path)
|
| 123 |
+
|
| 124 |
+
visibilities.append(traj["verts_inds_vis"].numpy())
|
| 125 |
+
|
| 126 |
+
rgbs.append(traj["img"].numpy())
|
| 127 |
+
traj_2d.append(traj["traj_2d"].numpy()[..., :2])
|
| 128 |
+
|
| 129 |
+
traj_2d = np.stack(traj_2d)
|
| 130 |
+
visibility = np.stack(visibilities)
|
| 131 |
+
T, N, D = traj_2d.shape
|
| 132 |
+
# subsample trajectories for augmentations
|
| 133 |
+
visible_inds_sampled = torch.randperm(N)[: self.traj_per_sample]
|
| 134 |
+
|
| 135 |
+
traj_2d = traj_2d[:, visible_inds_sampled]
|
| 136 |
+
visibility = visibility[:, visible_inds_sampled]
|
| 137 |
+
|
| 138 |
+
if self.crop_size is not None:
|
| 139 |
+
rgbs, traj_2d = self.crop(rgbs, traj_2d)
|
| 140 |
+
H, W, _ = rgbs[0].shape
|
| 141 |
+
image_size = self.crop_size
|
| 142 |
+
|
| 143 |
+
visibility[traj_2d[:, :, 0] > image_size[1] - 1] = False
|
| 144 |
+
visibility[traj_2d[:, :, 0] < 0] = False
|
| 145 |
+
visibility[traj_2d[:, :, 1] > image_size[0] - 1] = False
|
| 146 |
+
visibility[traj_2d[:, :, 1] < 0] = False
|
| 147 |
+
|
| 148 |
+
# filter out points that're visible for less than 10 frames
|
| 149 |
+
visible_inds_resampled = visibility.sum(0) > 10
|
| 150 |
+
traj_2d = torch.from_numpy(traj_2d[:, visible_inds_resampled])
|
| 151 |
+
visibility = torch.from_numpy(visibility[:, visible_inds_resampled])
|
| 152 |
+
|
| 153 |
+
rgbs = np.stack(rgbs, 0)
|
| 154 |
+
video = torch.from_numpy(rgbs).reshape(T, H, W, 3).permute(0, 3, 1, 2).float()
|
| 155 |
+
return CoTrackerData(
|
| 156 |
+
video=video,
|
| 157 |
+
trajectory=traj_2d,
|
| 158 |
+
visibility=visibility,
|
| 159 |
+
valid=torch.ones(T, N),
|
| 160 |
+
seq_name=sample[0].sequence_name,
|
| 161 |
+
)
|
cotracker/build/lib/datasets/kubric_movif_dataset.py
ADDED
|
@@ -0,0 +1,441 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import torch
|
| 9 |
+
import cv2
|
| 10 |
+
|
| 11 |
+
import imageio
|
| 12 |
+
import numpy as np
|
| 13 |
+
|
| 14 |
+
from cotracker.datasets.utils import CoTrackerData
|
| 15 |
+
from torchvision.transforms import ColorJitter, GaussianBlur
|
| 16 |
+
from PIL import Image
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class CoTrackerDataset(torch.utils.data.Dataset):
|
| 20 |
+
def __init__(
|
| 21 |
+
self,
|
| 22 |
+
data_root,
|
| 23 |
+
crop_size=(384, 512),
|
| 24 |
+
seq_len=24,
|
| 25 |
+
traj_per_sample=768,
|
| 26 |
+
sample_vis_1st_frame=False,
|
| 27 |
+
use_augs=False,
|
| 28 |
+
):
|
| 29 |
+
super(CoTrackerDataset, self).__init__()
|
| 30 |
+
np.random.seed(0)
|
| 31 |
+
torch.manual_seed(0)
|
| 32 |
+
self.data_root = data_root
|
| 33 |
+
self.seq_len = seq_len
|
| 34 |
+
self.traj_per_sample = traj_per_sample
|
| 35 |
+
self.sample_vis_1st_frame = sample_vis_1st_frame
|
| 36 |
+
self.use_augs = use_augs
|
| 37 |
+
self.crop_size = crop_size
|
| 38 |
+
|
| 39 |
+
# photometric augmentation
|
| 40 |
+
self.photo_aug = ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.25 / 3.14)
|
| 41 |
+
self.blur_aug = GaussianBlur(11, sigma=(0.1, 2.0))
|
| 42 |
+
|
| 43 |
+
self.blur_aug_prob = 0.25
|
| 44 |
+
self.color_aug_prob = 0.25
|
| 45 |
+
|
| 46 |
+
# occlusion augmentation
|
| 47 |
+
self.eraser_aug_prob = 0.5
|
| 48 |
+
self.eraser_bounds = [2, 100]
|
| 49 |
+
self.eraser_max = 10
|
| 50 |
+
|
| 51 |
+
# occlusion augmentation
|
| 52 |
+
self.replace_aug_prob = 0.5
|
| 53 |
+
self.replace_bounds = [2, 100]
|
| 54 |
+
self.replace_max = 10
|
| 55 |
+
|
| 56 |
+
# spatial augmentations
|
| 57 |
+
self.pad_bounds = [0, 100]
|
| 58 |
+
self.crop_size = crop_size
|
| 59 |
+
self.resize_lim = [0.25, 2.0] # sample resizes from here
|
| 60 |
+
self.resize_delta = 0.2
|
| 61 |
+
self.max_crop_offset = 50
|
| 62 |
+
|
| 63 |
+
self.do_flip = True
|
| 64 |
+
self.h_flip_prob = 0.5
|
| 65 |
+
self.v_flip_prob = 0.5
|
| 66 |
+
|
| 67 |
+
def getitem_helper(self, index):
|
| 68 |
+
return NotImplementedError
|
| 69 |
+
|
| 70 |
+
def __getitem__(self, index):
|
| 71 |
+
gotit = False
|
| 72 |
+
|
| 73 |
+
sample, gotit = self.getitem_helper(index)
|
| 74 |
+
if not gotit:
|
| 75 |
+
print("warning: sampling failed")
|
| 76 |
+
# fake sample, so we can still collate
|
| 77 |
+
sample = CoTrackerData(
|
| 78 |
+
video=torch.zeros((self.seq_len, 3, self.crop_size[0], self.crop_size[1])),
|
| 79 |
+
trajectory=torch.zeros((self.seq_len, self.traj_per_sample, 2)),
|
| 80 |
+
visibility=torch.zeros((self.seq_len, self.traj_per_sample)),
|
| 81 |
+
valid=torch.zeros((self.seq_len, self.traj_per_sample)),
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
return sample, gotit
|
| 85 |
+
|
| 86 |
+
def add_photometric_augs(self, rgbs, trajs, visibles, eraser=True, replace=True):
|
| 87 |
+
T, N, _ = trajs.shape
|
| 88 |
+
|
| 89 |
+
S = len(rgbs)
|
| 90 |
+
H, W = rgbs[0].shape[:2]
|
| 91 |
+
assert S == T
|
| 92 |
+
|
| 93 |
+
if eraser:
|
| 94 |
+
############ eraser transform (per image after the first) ############
|
| 95 |
+
rgbs = [rgb.astype(np.float32) for rgb in rgbs]
|
| 96 |
+
for i in range(1, S):
|
| 97 |
+
if np.random.rand() < self.eraser_aug_prob:
|
| 98 |
+
for _ in range(
|
| 99 |
+
np.random.randint(1, self.eraser_max + 1)
|
| 100 |
+
): # number of times to occlude
|
| 101 |
+
xc = np.random.randint(0, W)
|
| 102 |
+
yc = np.random.randint(0, H)
|
| 103 |
+
dx = np.random.randint(self.eraser_bounds[0], self.eraser_bounds[1])
|
| 104 |
+
dy = np.random.randint(self.eraser_bounds[0], self.eraser_bounds[1])
|
| 105 |
+
x0 = np.clip(xc - dx / 2, 0, W - 1).round().astype(np.int32)
|
| 106 |
+
x1 = np.clip(xc + dx / 2, 0, W - 1).round().astype(np.int32)
|
| 107 |
+
y0 = np.clip(yc - dy / 2, 0, H - 1).round().astype(np.int32)
|
| 108 |
+
y1 = np.clip(yc + dy / 2, 0, H - 1).round().astype(np.int32)
|
| 109 |
+
|
| 110 |
+
mean_color = np.mean(rgbs[i][y0:y1, x0:x1, :].reshape(-1, 3), axis=0)
|
| 111 |
+
rgbs[i][y0:y1, x0:x1, :] = mean_color
|
| 112 |
+
|
| 113 |
+
occ_inds = np.logical_and(
|
| 114 |
+
np.logical_and(trajs[i, :, 0] >= x0, trajs[i, :, 0] < x1),
|
| 115 |
+
np.logical_and(trajs[i, :, 1] >= y0, trajs[i, :, 1] < y1),
|
| 116 |
+
)
|
| 117 |
+
visibles[i, occ_inds] = 0
|
| 118 |
+
rgbs = [rgb.astype(np.uint8) for rgb in rgbs]
|
| 119 |
+
|
| 120 |
+
if replace:
|
| 121 |
+
rgbs_alt = [
|
| 122 |
+
np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs
|
| 123 |
+
]
|
| 124 |
+
rgbs_alt = [
|
| 125 |
+
np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs_alt
|
| 126 |
+
]
|
| 127 |
+
|
| 128 |
+
############ replace transform (per image after the first) ############
|
| 129 |
+
rgbs = [rgb.astype(np.float32) for rgb in rgbs]
|
| 130 |
+
rgbs_alt = [rgb.astype(np.float32) for rgb in rgbs_alt]
|
| 131 |
+
for i in range(1, S):
|
| 132 |
+
if np.random.rand() < self.replace_aug_prob:
|
| 133 |
+
for _ in range(
|
| 134 |
+
np.random.randint(1, self.replace_max + 1)
|
| 135 |
+
): # number of times to occlude
|
| 136 |
+
xc = np.random.randint(0, W)
|
| 137 |
+
yc = np.random.randint(0, H)
|
| 138 |
+
dx = np.random.randint(self.replace_bounds[0], self.replace_bounds[1])
|
| 139 |
+
dy = np.random.randint(self.replace_bounds[0], self.replace_bounds[1])
|
| 140 |
+
x0 = np.clip(xc - dx / 2, 0, W - 1).round().astype(np.int32)
|
| 141 |
+
x1 = np.clip(xc + dx / 2, 0, W - 1).round().astype(np.int32)
|
| 142 |
+
y0 = np.clip(yc - dy / 2, 0, H - 1).round().astype(np.int32)
|
| 143 |
+
y1 = np.clip(yc + dy / 2, 0, H - 1).round().astype(np.int32)
|
| 144 |
+
|
| 145 |
+
wid = x1 - x0
|
| 146 |
+
hei = y1 - y0
|
| 147 |
+
y00 = np.random.randint(0, H - hei)
|
| 148 |
+
x00 = np.random.randint(0, W - wid)
|
| 149 |
+
fr = np.random.randint(0, S)
|
| 150 |
+
rep = rgbs_alt[fr][y00 : y00 + hei, x00 : x00 + wid, :]
|
| 151 |
+
rgbs[i][y0:y1, x0:x1, :] = rep
|
| 152 |
+
|
| 153 |
+
occ_inds = np.logical_and(
|
| 154 |
+
np.logical_and(trajs[i, :, 0] >= x0, trajs[i, :, 0] < x1),
|
| 155 |
+
np.logical_and(trajs[i, :, 1] >= y0, trajs[i, :, 1] < y1),
|
| 156 |
+
)
|
| 157 |
+
visibles[i, occ_inds] = 0
|
| 158 |
+
rgbs = [rgb.astype(np.uint8) for rgb in rgbs]
|
| 159 |
+
|
| 160 |
+
############ photometric augmentation ############
|
| 161 |
+
if np.random.rand() < self.color_aug_prob:
|
| 162 |
+
# random per-frame amount of aug
|
| 163 |
+
rgbs = [np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
|
| 164 |
+
|
| 165 |
+
if np.random.rand() < self.blur_aug_prob:
|
| 166 |
+
# random per-frame amount of blur
|
| 167 |
+
rgbs = [np.array(self.blur_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
|
| 168 |
+
|
| 169 |
+
return rgbs, trajs, visibles
|
| 170 |
+
|
| 171 |
+
def add_spatial_augs(self, rgbs, trajs, visibles):
|
| 172 |
+
T, N, __ = trajs.shape
|
| 173 |
+
|
| 174 |
+
S = len(rgbs)
|
| 175 |
+
H, W = rgbs[0].shape[:2]
|
| 176 |
+
assert S == T
|
| 177 |
+
|
| 178 |
+
rgbs = [rgb.astype(np.float32) for rgb in rgbs]
|
| 179 |
+
|
| 180 |
+
############ spatial transform ############
|
| 181 |
+
|
| 182 |
+
# padding
|
| 183 |
+
pad_x0 = np.random.randint(self.pad_bounds[0], self.pad_bounds[1])
|
| 184 |
+
pad_x1 = np.random.randint(self.pad_bounds[0], self.pad_bounds[1])
|
| 185 |
+
pad_y0 = np.random.randint(self.pad_bounds[0], self.pad_bounds[1])
|
| 186 |
+
pad_y1 = np.random.randint(self.pad_bounds[0], self.pad_bounds[1])
|
| 187 |
+
|
| 188 |
+
rgbs = [np.pad(rgb, ((pad_y0, pad_y1), (pad_x0, pad_x1), (0, 0))) for rgb in rgbs]
|
| 189 |
+
trajs[:, :, 0] += pad_x0
|
| 190 |
+
trajs[:, :, 1] += pad_y0
|
| 191 |
+
H, W = rgbs[0].shape[:2]
|
| 192 |
+
|
| 193 |
+
# scaling + stretching
|
| 194 |
+
scale = np.random.uniform(self.resize_lim[0], self.resize_lim[1])
|
| 195 |
+
scale_x = scale
|
| 196 |
+
scale_y = scale
|
| 197 |
+
H_new = H
|
| 198 |
+
W_new = W
|
| 199 |
+
|
| 200 |
+
scale_delta_x = 0.0
|
| 201 |
+
scale_delta_y = 0.0
|
| 202 |
+
|
| 203 |
+
rgbs_scaled = []
|
| 204 |
+
for s in range(S):
|
| 205 |
+
if s == 1:
|
| 206 |
+
scale_delta_x = np.random.uniform(-self.resize_delta, self.resize_delta)
|
| 207 |
+
scale_delta_y = np.random.uniform(-self.resize_delta, self.resize_delta)
|
| 208 |
+
elif s > 1:
|
| 209 |
+
scale_delta_x = (
|
| 210 |
+
scale_delta_x * 0.8
|
| 211 |
+
+ np.random.uniform(-self.resize_delta, self.resize_delta) * 0.2
|
| 212 |
+
)
|
| 213 |
+
scale_delta_y = (
|
| 214 |
+
scale_delta_y * 0.8
|
| 215 |
+
+ np.random.uniform(-self.resize_delta, self.resize_delta) * 0.2
|
| 216 |
+
)
|
| 217 |
+
scale_x = scale_x + scale_delta_x
|
| 218 |
+
scale_y = scale_y + scale_delta_y
|
| 219 |
+
|
| 220 |
+
# bring h/w closer
|
| 221 |
+
scale_xy = (scale_x + scale_y) * 0.5
|
| 222 |
+
scale_x = scale_x * 0.5 + scale_xy * 0.5
|
| 223 |
+
scale_y = scale_y * 0.5 + scale_xy * 0.5
|
| 224 |
+
|
| 225 |
+
# don't get too crazy
|
| 226 |
+
scale_x = np.clip(scale_x, 0.2, 2.0)
|
| 227 |
+
scale_y = np.clip(scale_y, 0.2, 2.0)
|
| 228 |
+
|
| 229 |
+
H_new = int(H * scale_y)
|
| 230 |
+
W_new = int(W * scale_x)
|
| 231 |
+
|
| 232 |
+
# make it at least slightly bigger than the crop area,
|
| 233 |
+
# so that the random cropping can add diversity
|
| 234 |
+
H_new = np.clip(H_new, self.crop_size[0] + 10, None)
|
| 235 |
+
W_new = np.clip(W_new, self.crop_size[1] + 10, None)
|
| 236 |
+
# recompute scale in case we clipped
|
| 237 |
+
scale_x = (W_new - 1) / float(W - 1)
|
| 238 |
+
scale_y = (H_new - 1) / float(H - 1)
|
| 239 |
+
rgbs_scaled.append(cv2.resize(rgbs[s], (W_new, H_new), interpolation=cv2.INTER_LINEAR))
|
| 240 |
+
trajs[s, :, 0] *= scale_x
|
| 241 |
+
trajs[s, :, 1] *= scale_y
|
| 242 |
+
rgbs = rgbs_scaled
|
| 243 |
+
|
| 244 |
+
ok_inds = visibles[0, :] > 0
|
| 245 |
+
vis_trajs = trajs[:, ok_inds] # S,?,2
|
| 246 |
+
|
| 247 |
+
if vis_trajs.shape[1] > 0:
|
| 248 |
+
mid_x = np.mean(vis_trajs[0, :, 0])
|
| 249 |
+
mid_y = np.mean(vis_trajs[0, :, 1])
|
| 250 |
+
else:
|
| 251 |
+
mid_y = self.crop_size[0]
|
| 252 |
+
mid_x = self.crop_size[1]
|
| 253 |
+
|
| 254 |
+
x0 = int(mid_x - self.crop_size[1] // 2)
|
| 255 |
+
y0 = int(mid_y - self.crop_size[0] // 2)
|
| 256 |
+
|
| 257 |
+
offset_x = 0
|
| 258 |
+
offset_y = 0
|
| 259 |
+
|
| 260 |
+
for s in range(S):
|
| 261 |
+
# on each frame, shift a bit more
|
| 262 |
+
if s == 1:
|
| 263 |
+
offset_x = np.random.randint(-self.max_crop_offset, self.max_crop_offset)
|
| 264 |
+
offset_y = np.random.randint(-self.max_crop_offset, self.max_crop_offset)
|
| 265 |
+
elif s > 1:
|
| 266 |
+
offset_x = int(
|
| 267 |
+
offset_x * 0.8
|
| 268 |
+
+ np.random.randint(-self.max_crop_offset, self.max_crop_offset + 1) * 0.2
|
| 269 |
+
)
|
| 270 |
+
offset_y = int(
|
| 271 |
+
offset_y * 0.8
|
| 272 |
+
+ np.random.randint(-self.max_crop_offset, self.max_crop_offset + 1) * 0.2
|
| 273 |
+
)
|
| 274 |
+
x0 = x0 + offset_x
|
| 275 |
+
y0 = y0 + offset_y
|
| 276 |
+
|
| 277 |
+
H_new, W_new = rgbs[s].shape[:2]
|
| 278 |
+
if H_new == self.crop_size[0]:
|
| 279 |
+
y0 = 0
|
| 280 |
+
else:
|
| 281 |
+
y0 = min(max(0, y0), H_new - self.crop_size[0] - 1)
|
| 282 |
+
|
| 283 |
+
if W_new == self.crop_size[1]:
|
| 284 |
+
x0 = 0
|
| 285 |
+
else:
|
| 286 |
+
x0 = min(max(0, x0), W_new - self.crop_size[1] - 1)
|
| 287 |
+
|
| 288 |
+
rgbs[s] = rgbs[s][y0 : y0 + self.crop_size[0], x0 : x0 + self.crop_size[1]]
|
| 289 |
+
trajs[s, :, 0] -= x0
|
| 290 |
+
trajs[s, :, 1] -= y0
|
| 291 |
+
|
| 292 |
+
H_new = self.crop_size[0]
|
| 293 |
+
W_new = self.crop_size[1]
|
| 294 |
+
|
| 295 |
+
# flip
|
| 296 |
+
h_flipped = False
|
| 297 |
+
v_flipped = False
|
| 298 |
+
if self.do_flip:
|
| 299 |
+
# h flip
|
| 300 |
+
if np.random.rand() < self.h_flip_prob:
|
| 301 |
+
h_flipped = True
|
| 302 |
+
rgbs = [rgb[:, ::-1] for rgb in rgbs]
|
| 303 |
+
# v flip
|
| 304 |
+
if np.random.rand() < self.v_flip_prob:
|
| 305 |
+
v_flipped = True
|
| 306 |
+
rgbs = [rgb[::-1] for rgb in rgbs]
|
| 307 |
+
if h_flipped:
|
| 308 |
+
trajs[:, :, 0] = W_new - trajs[:, :, 0]
|
| 309 |
+
if v_flipped:
|
| 310 |
+
trajs[:, :, 1] = H_new - trajs[:, :, 1]
|
| 311 |
+
|
| 312 |
+
return rgbs, trajs
|
| 313 |
+
|
| 314 |
+
def crop(self, rgbs, trajs):
|
| 315 |
+
T, N, _ = trajs.shape
|
| 316 |
+
|
| 317 |
+
S = len(rgbs)
|
| 318 |
+
H, W = rgbs[0].shape[:2]
|
| 319 |
+
assert S == T
|
| 320 |
+
|
| 321 |
+
############ spatial transform ############
|
| 322 |
+
|
| 323 |
+
H_new = H
|
| 324 |
+
W_new = W
|
| 325 |
+
|
| 326 |
+
# simple random crop
|
| 327 |
+
y0 = 0 if self.crop_size[0] >= H_new else np.random.randint(0, H_new - self.crop_size[0])
|
| 328 |
+
x0 = 0 if self.crop_size[1] >= W_new else np.random.randint(0, W_new - self.crop_size[1])
|
| 329 |
+
rgbs = [rgb[y0 : y0 + self.crop_size[0], x0 : x0 + self.crop_size[1]] for rgb in rgbs]
|
| 330 |
+
|
| 331 |
+
trajs[:, :, 0] -= x0
|
| 332 |
+
trajs[:, :, 1] -= y0
|
| 333 |
+
|
| 334 |
+
return rgbs, trajs
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
class KubricMovifDataset(CoTrackerDataset):
|
| 338 |
+
def __init__(
|
| 339 |
+
self,
|
| 340 |
+
data_root,
|
| 341 |
+
crop_size=(384, 512),
|
| 342 |
+
seq_len=24,
|
| 343 |
+
traj_per_sample=768,
|
| 344 |
+
sample_vis_1st_frame=False,
|
| 345 |
+
use_augs=False,
|
| 346 |
+
):
|
| 347 |
+
super(KubricMovifDataset, self).__init__(
|
| 348 |
+
data_root=data_root,
|
| 349 |
+
crop_size=crop_size,
|
| 350 |
+
seq_len=seq_len,
|
| 351 |
+
traj_per_sample=traj_per_sample,
|
| 352 |
+
sample_vis_1st_frame=sample_vis_1st_frame,
|
| 353 |
+
use_augs=use_augs,
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
self.pad_bounds = [0, 25]
|
| 357 |
+
self.resize_lim = [0.75, 1.25] # sample resizes from here
|
| 358 |
+
self.resize_delta = 0.05
|
| 359 |
+
self.max_crop_offset = 15
|
| 360 |
+
self.seq_names = [
|
| 361 |
+
fname
|
| 362 |
+
for fname in os.listdir(data_root)
|
| 363 |
+
if os.path.isdir(os.path.join(data_root, fname))
|
| 364 |
+
]
|
| 365 |
+
print("found %d unique videos in %s" % (len(self.seq_names), self.data_root))
|
| 366 |
+
|
| 367 |
+
def getitem_helper(self, index):
|
| 368 |
+
gotit = True
|
| 369 |
+
seq_name = self.seq_names[index]
|
| 370 |
+
|
| 371 |
+
npy_path = os.path.join(self.data_root, seq_name, seq_name + ".npy")
|
| 372 |
+
rgb_path = os.path.join(self.data_root, seq_name, "frames")
|
| 373 |
+
|
| 374 |
+
img_paths = sorted(os.listdir(rgb_path))
|
| 375 |
+
rgbs = []
|
| 376 |
+
for i, img_path in enumerate(img_paths):
|
| 377 |
+
rgbs.append(imageio.v2.imread(os.path.join(rgb_path, img_path)))
|
| 378 |
+
|
| 379 |
+
rgbs = np.stack(rgbs)
|
| 380 |
+
annot_dict = np.load(npy_path, allow_pickle=True).item()
|
| 381 |
+
traj_2d = annot_dict["coords"]
|
| 382 |
+
visibility = annot_dict["visibility"]
|
| 383 |
+
|
| 384 |
+
# random crop
|
| 385 |
+
assert self.seq_len <= len(rgbs)
|
| 386 |
+
if self.seq_len < len(rgbs):
|
| 387 |
+
start_ind = np.random.choice(len(rgbs) - self.seq_len, 1)[0]
|
| 388 |
+
|
| 389 |
+
rgbs = rgbs[start_ind : start_ind + self.seq_len]
|
| 390 |
+
traj_2d = traj_2d[:, start_ind : start_ind + self.seq_len]
|
| 391 |
+
visibility = visibility[:, start_ind : start_ind + self.seq_len]
|
| 392 |
+
|
| 393 |
+
traj_2d = np.transpose(traj_2d, (1, 0, 2))
|
| 394 |
+
visibility = np.transpose(np.logical_not(visibility), (1, 0))
|
| 395 |
+
if self.use_augs:
|
| 396 |
+
rgbs, traj_2d, visibility = self.add_photometric_augs(rgbs, traj_2d, visibility)
|
| 397 |
+
rgbs, traj_2d = self.add_spatial_augs(rgbs, traj_2d, visibility)
|
| 398 |
+
else:
|
| 399 |
+
rgbs, traj_2d = self.crop(rgbs, traj_2d)
|
| 400 |
+
|
| 401 |
+
visibility[traj_2d[:, :, 0] > self.crop_size[1] - 1] = False
|
| 402 |
+
visibility[traj_2d[:, :, 0] < 0] = False
|
| 403 |
+
visibility[traj_2d[:, :, 1] > self.crop_size[0] - 1] = False
|
| 404 |
+
visibility[traj_2d[:, :, 1] < 0] = False
|
| 405 |
+
|
| 406 |
+
visibility = torch.from_numpy(visibility)
|
| 407 |
+
traj_2d = torch.from_numpy(traj_2d)
|
| 408 |
+
|
| 409 |
+
visibile_pts_first_frame_inds = (visibility[0]).nonzero(as_tuple=False)[:, 0]
|
| 410 |
+
|
| 411 |
+
if self.sample_vis_1st_frame:
|
| 412 |
+
visibile_pts_inds = visibile_pts_first_frame_inds
|
| 413 |
+
else:
|
| 414 |
+
visibile_pts_mid_frame_inds = (visibility[self.seq_len // 2]).nonzero(as_tuple=False)[
|
| 415 |
+
:, 0
|
| 416 |
+
]
|
| 417 |
+
visibile_pts_inds = torch.cat(
|
| 418 |
+
(visibile_pts_first_frame_inds, visibile_pts_mid_frame_inds), dim=0
|
| 419 |
+
)
|
| 420 |
+
point_inds = torch.randperm(len(visibile_pts_inds))[: self.traj_per_sample]
|
| 421 |
+
if len(point_inds) < self.traj_per_sample:
|
| 422 |
+
gotit = False
|
| 423 |
+
|
| 424 |
+
visible_inds_sampled = visibile_pts_inds[point_inds]
|
| 425 |
+
|
| 426 |
+
trajs = traj_2d[:, visible_inds_sampled].float()
|
| 427 |
+
visibles = visibility[:, visible_inds_sampled]
|
| 428 |
+
valids = torch.ones((self.seq_len, self.traj_per_sample))
|
| 429 |
+
|
| 430 |
+
rgbs = torch.from_numpy(np.stack(rgbs)).permute(0, 3, 1, 2).float()
|
| 431 |
+
sample = CoTrackerData(
|
| 432 |
+
video=rgbs,
|
| 433 |
+
trajectory=trajs,
|
| 434 |
+
visibility=visibles,
|
| 435 |
+
valid=valids,
|
| 436 |
+
seq_name=seq_name,
|
| 437 |
+
)
|
| 438 |
+
return sample, gotit
|
| 439 |
+
|
| 440 |
+
def __len__(self):
|
| 441 |
+
return len(self.seq_names)
|
cotracker/build/lib/datasets/tap_vid_datasets.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import io
|
| 9 |
+
import glob
|
| 10 |
+
import torch
|
| 11 |
+
import pickle
|
| 12 |
+
import numpy as np
|
| 13 |
+
import mediapy as media
|
| 14 |
+
|
| 15 |
+
from PIL import Image
|
| 16 |
+
from typing import Mapping, Tuple, Union
|
| 17 |
+
|
| 18 |
+
from cotracker.datasets.utils import CoTrackerData
|
| 19 |
+
|
| 20 |
+
DatasetElement = Mapping[str, Mapping[str, Union[np.ndarray, str]]]
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def resize_video(video: np.ndarray, output_size: Tuple[int, int]) -> np.ndarray:
|
| 24 |
+
"""Resize a video to output_size."""
|
| 25 |
+
# If you have a GPU, consider replacing this with a GPU-enabled resize op,
|
| 26 |
+
# such as a jitted jax.image.resize. It will make things faster.
|
| 27 |
+
return media.resize_video(video, output_size)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def sample_queries_first(
|
| 31 |
+
target_occluded: np.ndarray,
|
| 32 |
+
target_points: np.ndarray,
|
| 33 |
+
frames: np.ndarray,
|
| 34 |
+
) -> Mapping[str, np.ndarray]:
|
| 35 |
+
"""Package a set of frames and tracks for use in TAPNet evaluations.
|
| 36 |
+
Given a set of frames and tracks with no query points, use the first
|
| 37 |
+
visible point in each track as the query.
|
| 38 |
+
Args:
|
| 39 |
+
target_occluded: Boolean occlusion flag, of shape [n_tracks, n_frames],
|
| 40 |
+
where True indicates occluded.
|
| 41 |
+
target_points: Position, of shape [n_tracks, n_frames, 2], where each point
|
| 42 |
+
is [x,y] scaled between 0 and 1.
|
| 43 |
+
frames: Video tensor, of shape [n_frames, height, width, 3]. Scaled between
|
| 44 |
+
-1 and 1.
|
| 45 |
+
Returns:
|
| 46 |
+
A dict with the keys:
|
| 47 |
+
video: Video tensor of shape [1, n_frames, height, width, 3]
|
| 48 |
+
query_points: Query points of shape [1, n_queries, 3] where
|
| 49 |
+
each point is [t, y, x] scaled to the range [-1, 1]
|
| 50 |
+
target_points: Target points of shape [1, n_queries, n_frames, 2] where
|
| 51 |
+
each point is [x, y] scaled to the range [-1, 1]
|
| 52 |
+
"""
|
| 53 |
+
valid = np.sum(~target_occluded, axis=1) > 0
|
| 54 |
+
target_points = target_points[valid, :]
|
| 55 |
+
target_occluded = target_occluded[valid, :]
|
| 56 |
+
|
| 57 |
+
query_points = []
|
| 58 |
+
for i in range(target_points.shape[0]):
|
| 59 |
+
index = np.where(target_occluded[i] == 0)[0][0]
|
| 60 |
+
x, y = target_points[i, index, 0], target_points[i, index, 1]
|
| 61 |
+
query_points.append(np.array([index, y, x])) # [t, y, x]
|
| 62 |
+
query_points = np.stack(query_points, axis=0)
|
| 63 |
+
|
| 64 |
+
return {
|
| 65 |
+
"video": frames[np.newaxis, ...],
|
| 66 |
+
"query_points": query_points[np.newaxis, ...],
|
| 67 |
+
"target_points": target_points[np.newaxis, ...],
|
| 68 |
+
"occluded": target_occluded[np.newaxis, ...],
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def sample_queries_strided(
|
| 73 |
+
target_occluded: np.ndarray,
|
| 74 |
+
target_points: np.ndarray,
|
| 75 |
+
frames: np.ndarray,
|
| 76 |
+
query_stride: int = 5,
|
| 77 |
+
) -> Mapping[str, np.ndarray]:
|
| 78 |
+
"""Package a set of frames and tracks for use in TAPNet evaluations.
|
| 79 |
+
|
| 80 |
+
Given a set of frames and tracks with no query points, sample queries
|
| 81 |
+
strided every query_stride frames, ignoring points that are not visible
|
| 82 |
+
at the selected frames.
|
| 83 |
+
|
| 84 |
+
Args:
|
| 85 |
+
target_occluded: Boolean occlusion flag, of shape [n_tracks, n_frames],
|
| 86 |
+
where True indicates occluded.
|
| 87 |
+
target_points: Position, of shape [n_tracks, n_frames, 2], where each point
|
| 88 |
+
is [x,y] scaled between 0 and 1.
|
| 89 |
+
frames: Video tensor, of shape [n_frames, height, width, 3]. Scaled between
|
| 90 |
+
-1 and 1.
|
| 91 |
+
query_stride: When sampling query points, search for un-occluded points
|
| 92 |
+
every query_stride frames and convert each one into a query.
|
| 93 |
+
|
| 94 |
+
Returns:
|
| 95 |
+
A dict with the keys:
|
| 96 |
+
video: Video tensor of shape [1, n_frames, height, width, 3]. The video
|
| 97 |
+
has floats scaled to the range [-1, 1].
|
| 98 |
+
query_points: Query points of shape [1, n_queries, 3] where
|
| 99 |
+
each point is [t, y, x] scaled to the range [-1, 1].
|
| 100 |
+
target_points: Target points of shape [1, n_queries, n_frames, 2] where
|
| 101 |
+
each point is [x, y] scaled to the range [-1, 1].
|
| 102 |
+
trackgroup: Index of the original track that each query point was
|
| 103 |
+
sampled from. This is useful for visualization.
|
| 104 |
+
"""
|
| 105 |
+
tracks = []
|
| 106 |
+
occs = []
|
| 107 |
+
queries = []
|
| 108 |
+
trackgroups = []
|
| 109 |
+
total = 0
|
| 110 |
+
trackgroup = np.arange(target_occluded.shape[0])
|
| 111 |
+
for i in range(0, target_occluded.shape[1], query_stride):
|
| 112 |
+
mask = target_occluded[:, i] == 0
|
| 113 |
+
query = np.stack(
|
| 114 |
+
[
|
| 115 |
+
i * np.ones(target_occluded.shape[0:1]),
|
| 116 |
+
target_points[:, i, 1],
|
| 117 |
+
target_points[:, i, 0],
|
| 118 |
+
],
|
| 119 |
+
axis=-1,
|
| 120 |
+
)
|
| 121 |
+
queries.append(query[mask])
|
| 122 |
+
tracks.append(target_points[mask])
|
| 123 |
+
occs.append(target_occluded[mask])
|
| 124 |
+
trackgroups.append(trackgroup[mask])
|
| 125 |
+
total += np.array(np.sum(target_occluded[:, i] == 0))
|
| 126 |
+
|
| 127 |
+
return {
|
| 128 |
+
"video": frames[np.newaxis, ...],
|
| 129 |
+
"query_points": np.concatenate(queries, axis=0)[np.newaxis, ...],
|
| 130 |
+
"target_points": np.concatenate(tracks, axis=0)[np.newaxis, ...],
|
| 131 |
+
"occluded": np.concatenate(occs, axis=0)[np.newaxis, ...],
|
| 132 |
+
"trackgroup": np.concatenate(trackgroups, axis=0)[np.newaxis, ...],
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class TapVidDataset(torch.utils.data.Dataset):
|
| 137 |
+
def __init__(
|
| 138 |
+
self,
|
| 139 |
+
data_root,
|
| 140 |
+
dataset_type="davis",
|
| 141 |
+
resize_to_256=True,
|
| 142 |
+
queried_first=True,
|
| 143 |
+
):
|
| 144 |
+
self.dataset_type = dataset_type
|
| 145 |
+
self.resize_to_256 = resize_to_256
|
| 146 |
+
self.queried_first = queried_first
|
| 147 |
+
if self.dataset_type == "kinetics":
|
| 148 |
+
all_paths = glob.glob(os.path.join(data_root, "*_of_0010.pkl"))
|
| 149 |
+
points_dataset = []
|
| 150 |
+
for pickle_path in all_paths:
|
| 151 |
+
with open(pickle_path, "rb") as f:
|
| 152 |
+
data = pickle.load(f)
|
| 153 |
+
points_dataset = points_dataset + data
|
| 154 |
+
self.points_dataset = points_dataset
|
| 155 |
+
else:
|
| 156 |
+
with open(data_root, "rb") as f:
|
| 157 |
+
self.points_dataset = pickle.load(f)
|
| 158 |
+
if self.dataset_type == "davis":
|
| 159 |
+
self.video_names = list(self.points_dataset.keys())
|
| 160 |
+
print("found %d unique videos in %s" % (len(self.points_dataset), data_root))
|
| 161 |
+
|
| 162 |
+
def __getitem__(self, index):
|
| 163 |
+
if self.dataset_type == "davis":
|
| 164 |
+
video_name = self.video_names[index]
|
| 165 |
+
else:
|
| 166 |
+
video_name = index
|
| 167 |
+
video = self.points_dataset[video_name]
|
| 168 |
+
frames = video["video"]
|
| 169 |
+
|
| 170 |
+
if isinstance(frames[0], bytes):
|
| 171 |
+
# TAP-Vid is stored and JPEG bytes rather than `np.ndarray`s.
|
| 172 |
+
def decode(frame):
|
| 173 |
+
byteio = io.BytesIO(frame)
|
| 174 |
+
img = Image.open(byteio)
|
| 175 |
+
return np.array(img)
|
| 176 |
+
|
| 177 |
+
frames = np.array([decode(frame) for frame in frames])
|
| 178 |
+
|
| 179 |
+
target_points = self.points_dataset[video_name]["points"]
|
| 180 |
+
if self.resize_to_256:
|
| 181 |
+
frames = resize_video(frames, [256, 256])
|
| 182 |
+
target_points *= np.array([255, 255]) # 1 should be mapped to 256-1
|
| 183 |
+
else:
|
| 184 |
+
target_points *= np.array([frames.shape[2] - 1, frames.shape[1] - 1])
|
| 185 |
+
|
| 186 |
+
target_occ = self.points_dataset[video_name]["occluded"]
|
| 187 |
+
if self.queried_first:
|
| 188 |
+
converted = sample_queries_first(target_occ, target_points, frames)
|
| 189 |
+
else:
|
| 190 |
+
converted = sample_queries_strided(target_occ, target_points, frames)
|
| 191 |
+
assert converted["target_points"].shape[1] == converted["query_points"].shape[1]
|
| 192 |
+
|
| 193 |
+
trajs = torch.from_numpy(converted["target_points"])[0].permute(1, 0, 2).float() # T, N, D
|
| 194 |
+
|
| 195 |
+
rgbs = torch.from_numpy(frames).permute(0, 3, 1, 2).float()
|
| 196 |
+
visibles = torch.logical_not(torch.from_numpy(converted["occluded"]))[0].permute(
|
| 197 |
+
1, 0
|
| 198 |
+
) # T, N
|
| 199 |
+
query_points = torch.from_numpy(converted["query_points"])[0] # T, N
|
| 200 |
+
return CoTrackerData(
|
| 201 |
+
rgbs,
|
| 202 |
+
trajs,
|
| 203 |
+
visibles,
|
| 204 |
+
seq_name=str(video_name),
|
| 205 |
+
query_points=query_points,
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
def __len__(self):
|
| 209 |
+
return len(self.points_dataset)
|
cotracker/build/lib/datasets/utils.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import dataclasses
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
from dataclasses import dataclass
|
| 12 |
+
from typing import Any, Optional
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@dataclass(eq=False)
|
| 16 |
+
class CoTrackerData:
|
| 17 |
+
"""
|
| 18 |
+
Dataclass for storing video tracks data.
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
video: torch.Tensor # B, S, C, H, W
|
| 22 |
+
trajectory: torch.Tensor # B, S, N, 2
|
| 23 |
+
visibility: torch.Tensor # B, S, N
|
| 24 |
+
# optional data
|
| 25 |
+
valid: Optional[torch.Tensor] = None # B, S, N
|
| 26 |
+
segmentation: Optional[torch.Tensor] = None # B, S, 1, H, W
|
| 27 |
+
seq_name: Optional[str] = None
|
| 28 |
+
query_points: Optional[torch.Tensor] = None # TapVID evaluation format
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def collate_fn(batch):
|
| 32 |
+
"""
|
| 33 |
+
Collate function for video tracks data.
|
| 34 |
+
"""
|
| 35 |
+
video = torch.stack([b.video for b in batch], dim=0)
|
| 36 |
+
trajectory = torch.stack([b.trajectory for b in batch], dim=0)
|
| 37 |
+
visibility = torch.stack([b.visibility for b in batch], dim=0)
|
| 38 |
+
query_points = segmentation = None
|
| 39 |
+
if batch[0].query_points is not None:
|
| 40 |
+
query_points = torch.stack([b.query_points for b in batch], dim=0)
|
| 41 |
+
if batch[0].segmentation is not None:
|
| 42 |
+
segmentation = torch.stack([b.segmentation for b in batch], dim=0)
|
| 43 |
+
seq_name = [b.seq_name for b in batch]
|
| 44 |
+
|
| 45 |
+
return CoTrackerData(
|
| 46 |
+
video=video,
|
| 47 |
+
trajectory=trajectory,
|
| 48 |
+
visibility=visibility,
|
| 49 |
+
segmentation=segmentation,
|
| 50 |
+
seq_name=seq_name,
|
| 51 |
+
query_points=query_points,
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def collate_fn_train(batch):
|
| 56 |
+
"""
|
| 57 |
+
Collate function for video tracks data during training.
|
| 58 |
+
"""
|
| 59 |
+
gotit = [gotit for _, gotit in batch]
|
| 60 |
+
video = torch.stack([b.video for b, _ in batch], dim=0)
|
| 61 |
+
trajectory = torch.stack([b.trajectory for b, _ in batch], dim=0)
|
| 62 |
+
visibility = torch.stack([b.visibility for b, _ in batch], dim=0)
|
| 63 |
+
valid = torch.stack([b.valid for b, _ in batch], dim=0)
|
| 64 |
+
seq_name = [b.seq_name for b, _ in batch]
|
| 65 |
+
return (
|
| 66 |
+
CoTrackerData(
|
| 67 |
+
video=video,
|
| 68 |
+
trajectory=trajectory,
|
| 69 |
+
visibility=visibility,
|
| 70 |
+
valid=valid,
|
| 71 |
+
seq_name=seq_name,
|
| 72 |
+
),
|
| 73 |
+
gotit,
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def try_to_cuda(t: Any) -> Any:
|
| 78 |
+
"""
|
| 79 |
+
Try to move the input variable `t` to a cuda device.
|
| 80 |
+
|
| 81 |
+
Args:
|
| 82 |
+
t: Input.
|
| 83 |
+
|
| 84 |
+
Returns:
|
| 85 |
+
t_cuda: `t` moved to a cuda device, if supported.
|
| 86 |
+
"""
|
| 87 |
+
try:
|
| 88 |
+
t = t.float().cuda()
|
| 89 |
+
except AttributeError:
|
| 90 |
+
pass
|
| 91 |
+
return t
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def dataclass_to_cuda_(obj):
|
| 95 |
+
"""
|
| 96 |
+
Move all contents of a dataclass to cuda inplace if supported.
|
| 97 |
+
|
| 98 |
+
Args:
|
| 99 |
+
batch: Input dataclass.
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
batch_cuda: `batch` moved to a cuda device, if supported.
|
| 103 |
+
"""
|
| 104 |
+
for f in dataclasses.fields(obj):
|
| 105 |
+
setattr(obj, f.name, try_to_cuda(getattr(obj, f.name)))
|
| 106 |
+
return obj
|
cotracker/build/lib/evaluation/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
cotracker/build/lib/evaluation/core/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
cotracker/build/lib/evaluation/core/eval_utils.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
from typing import Iterable, Mapping, Tuple, Union
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def compute_tapvid_metrics(
|
| 13 |
+
query_points: np.ndarray,
|
| 14 |
+
gt_occluded: np.ndarray,
|
| 15 |
+
gt_tracks: np.ndarray,
|
| 16 |
+
pred_occluded: np.ndarray,
|
| 17 |
+
pred_tracks: np.ndarray,
|
| 18 |
+
query_mode: str,
|
| 19 |
+
) -> Mapping[str, np.ndarray]:
|
| 20 |
+
"""Computes TAP-Vid metrics (Jaccard, Pts. Within Thresh, Occ. Acc.)
|
| 21 |
+
See the TAP-Vid paper for details on the metric computation. All inputs are
|
| 22 |
+
given in raster coordinates. The first three arguments should be the direct
|
| 23 |
+
outputs of the reader: the 'query_points', 'occluded', and 'target_points'.
|
| 24 |
+
The paper metrics assume these are scaled relative to 256x256 images.
|
| 25 |
+
pred_occluded and pred_tracks are your algorithm's predictions.
|
| 26 |
+
This function takes a batch of inputs, and computes metrics separately for
|
| 27 |
+
each video. The metrics for the full benchmark are a simple mean of the
|
| 28 |
+
metrics across the full set of videos. These numbers are between 0 and 1,
|
| 29 |
+
but the paper multiplies them by 100 to ease reading.
|
| 30 |
+
Args:
|
| 31 |
+
query_points: The query points, an in the format [t, y, x]. Its size is
|
| 32 |
+
[b, n, 3], where b is the batch size and n is the number of queries
|
| 33 |
+
gt_occluded: A boolean array of shape [b, n, t], where t is the number
|
| 34 |
+
of frames. True indicates that the point is occluded.
|
| 35 |
+
gt_tracks: The target points, of shape [b, n, t, 2]. Each point is
|
| 36 |
+
in the format [x, y]
|
| 37 |
+
pred_occluded: A boolean array of predicted occlusions, in the same
|
| 38 |
+
format as gt_occluded.
|
| 39 |
+
pred_tracks: An array of track predictions from your algorithm, in the
|
| 40 |
+
same format as gt_tracks.
|
| 41 |
+
query_mode: Either 'first' or 'strided', depending on how queries are
|
| 42 |
+
sampled. If 'first', we assume the prior knowledge that all points
|
| 43 |
+
before the query point are occluded, and these are removed from the
|
| 44 |
+
evaluation.
|
| 45 |
+
Returns:
|
| 46 |
+
A dict with the following keys:
|
| 47 |
+
occlusion_accuracy: Accuracy at predicting occlusion.
|
| 48 |
+
pts_within_{x} for x in [1, 2, 4, 8, 16]: Fraction of points
|
| 49 |
+
predicted to be within the given pixel threshold, ignoring occlusion
|
| 50 |
+
prediction.
|
| 51 |
+
jaccard_{x} for x in [1, 2, 4, 8, 16]: Jaccard metric for the given
|
| 52 |
+
threshold
|
| 53 |
+
average_pts_within_thresh: average across pts_within_{x}
|
| 54 |
+
average_jaccard: average across jaccard_{x}
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
metrics = {}
|
| 58 |
+
# Fixed bug is described in:
|
| 59 |
+
# https://github.com/facebookresearch/co-tracker/issues/20
|
| 60 |
+
eye = np.eye(gt_tracks.shape[2], dtype=np.int32)
|
| 61 |
+
|
| 62 |
+
if query_mode == "first":
|
| 63 |
+
# evaluate frames after the query frame
|
| 64 |
+
query_frame_to_eval_frames = np.cumsum(eye, axis=1) - eye
|
| 65 |
+
elif query_mode == "strided":
|
| 66 |
+
# evaluate all frames except the query frame
|
| 67 |
+
query_frame_to_eval_frames = 1 - eye
|
| 68 |
+
else:
|
| 69 |
+
raise ValueError("Unknown query mode " + query_mode)
|
| 70 |
+
|
| 71 |
+
query_frame = query_points[..., 0]
|
| 72 |
+
query_frame = np.round(query_frame).astype(np.int32)
|
| 73 |
+
evaluation_points = query_frame_to_eval_frames[query_frame] > 0
|
| 74 |
+
|
| 75 |
+
# Occlusion accuracy is simply how often the predicted occlusion equals the
|
| 76 |
+
# ground truth.
|
| 77 |
+
occ_acc = np.sum(
|
| 78 |
+
np.equal(pred_occluded, gt_occluded) & evaluation_points,
|
| 79 |
+
axis=(1, 2),
|
| 80 |
+
) / np.sum(evaluation_points)
|
| 81 |
+
metrics["occlusion_accuracy"] = occ_acc
|
| 82 |
+
|
| 83 |
+
# Next, convert the predictions and ground truth positions into pixel
|
| 84 |
+
# coordinates.
|
| 85 |
+
visible = np.logical_not(gt_occluded)
|
| 86 |
+
pred_visible = np.logical_not(pred_occluded)
|
| 87 |
+
all_frac_within = []
|
| 88 |
+
all_jaccard = []
|
| 89 |
+
for thresh in [1, 2, 4, 8, 16]:
|
| 90 |
+
# True positives are points that are within the threshold and where both
|
| 91 |
+
# the prediction and the ground truth are listed as visible.
|
| 92 |
+
within_dist = np.sum(
|
| 93 |
+
np.square(pred_tracks - gt_tracks),
|
| 94 |
+
axis=-1,
|
| 95 |
+
) < np.square(thresh)
|
| 96 |
+
is_correct = np.logical_and(within_dist, visible)
|
| 97 |
+
|
| 98 |
+
# Compute the frac_within_threshold, which is the fraction of points
|
| 99 |
+
# within the threshold among points that are visible in the ground truth,
|
| 100 |
+
# ignoring whether they're predicted to be visible.
|
| 101 |
+
count_correct = np.sum(
|
| 102 |
+
is_correct & evaluation_points,
|
| 103 |
+
axis=(1, 2),
|
| 104 |
+
)
|
| 105 |
+
count_visible_points = np.sum(visible & evaluation_points, axis=(1, 2))
|
| 106 |
+
frac_correct = count_correct / count_visible_points
|
| 107 |
+
metrics["pts_within_" + str(thresh)] = frac_correct
|
| 108 |
+
all_frac_within.append(frac_correct)
|
| 109 |
+
|
| 110 |
+
true_positives = np.sum(
|
| 111 |
+
is_correct & pred_visible & evaluation_points, axis=(1, 2)
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
# The denominator of the jaccard metric is the true positives plus
|
| 115 |
+
# false positives plus false negatives. However, note that true positives
|
| 116 |
+
# plus false negatives is simply the number of points in the ground truth
|
| 117 |
+
# which is easier to compute than trying to compute all three quantities.
|
| 118 |
+
# Thus we just add the number of points in the ground truth to the number
|
| 119 |
+
# of false positives.
|
| 120 |
+
#
|
| 121 |
+
# False positives are simply points that are predicted to be visible,
|
| 122 |
+
# but the ground truth is not visible or too far from the prediction.
|
| 123 |
+
gt_positives = np.sum(visible & evaluation_points, axis=(1, 2))
|
| 124 |
+
false_positives = (~visible) & pred_visible
|
| 125 |
+
false_positives = false_positives | ((~within_dist) & pred_visible)
|
| 126 |
+
false_positives = np.sum(false_positives & evaluation_points, axis=(1, 2))
|
| 127 |
+
jaccard = true_positives / (gt_positives + false_positives)
|
| 128 |
+
metrics["jaccard_" + str(thresh)] = jaccard
|
| 129 |
+
all_jaccard.append(jaccard)
|
| 130 |
+
metrics["average_jaccard"] = np.mean(
|
| 131 |
+
np.stack(all_jaccard, axis=1),
|
| 132 |
+
axis=1,
|
| 133 |
+
)
|
| 134 |
+
metrics["average_pts_within_thresh"] = np.mean(
|
| 135 |
+
np.stack(all_frac_within, axis=1),
|
| 136 |
+
axis=1,
|
| 137 |
+
)
|
| 138 |
+
return metrics
|
cotracker/build/lib/evaluation/core/evaluator.py
ADDED
|
@@ -0,0 +1,253 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from collections import defaultdict
|
| 8 |
+
import os
|
| 9 |
+
from typing import Optional
|
| 10 |
+
import torch
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
import numpy as np
|
| 13 |
+
|
| 14 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 15 |
+
from cotracker.datasets.utils import dataclass_to_cuda_
|
| 16 |
+
from cotracker.utils.visualizer import Visualizer
|
| 17 |
+
from cotracker.models.core.model_utils import reduce_masked_mean
|
| 18 |
+
from cotracker.evaluation.core.eval_utils import compute_tapvid_metrics
|
| 19 |
+
|
| 20 |
+
import logging
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class Evaluator:
|
| 24 |
+
"""
|
| 25 |
+
A class defining the CoTracker evaluator.
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
def __init__(self, exp_dir) -> None:
|
| 29 |
+
# Visualization
|
| 30 |
+
self.exp_dir = exp_dir
|
| 31 |
+
os.makedirs(exp_dir, exist_ok=True)
|
| 32 |
+
self.visualization_filepaths = defaultdict(lambda: defaultdict(list))
|
| 33 |
+
self.visualize_dir = os.path.join(exp_dir, "visualisations")
|
| 34 |
+
|
| 35 |
+
def compute_metrics(self, metrics, sample, pred_trajectory, dataset_name):
|
| 36 |
+
if isinstance(pred_trajectory, tuple):
|
| 37 |
+
pred_trajectory, pred_visibility = pred_trajectory
|
| 38 |
+
else:
|
| 39 |
+
pred_visibility = None
|
| 40 |
+
if "tapvid" in dataset_name:
|
| 41 |
+
B, T, N, D = sample.trajectory.shape
|
| 42 |
+
traj = sample.trajectory.clone()
|
| 43 |
+
thr = 0.9
|
| 44 |
+
|
| 45 |
+
if pred_visibility is None:
|
| 46 |
+
logging.warning("visibility is NONE")
|
| 47 |
+
pred_visibility = torch.zeros_like(sample.visibility)
|
| 48 |
+
|
| 49 |
+
if not pred_visibility.dtype == torch.bool:
|
| 50 |
+
pred_visibility = pred_visibility > thr
|
| 51 |
+
|
| 52 |
+
query_points = sample.query_points.clone().cpu().numpy()
|
| 53 |
+
|
| 54 |
+
pred_visibility = pred_visibility[:, :, :N]
|
| 55 |
+
pred_trajectory = pred_trajectory[:, :, :N]
|
| 56 |
+
|
| 57 |
+
gt_tracks = traj.permute(0, 2, 1, 3).cpu().numpy()
|
| 58 |
+
gt_occluded = (
|
| 59 |
+
torch.logical_not(sample.visibility.clone().permute(0, 2, 1)).cpu().numpy()
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
pred_occluded = (
|
| 63 |
+
torch.logical_not(pred_visibility.clone().permute(0, 2, 1)).cpu().numpy()
|
| 64 |
+
)
|
| 65 |
+
pred_tracks = pred_trajectory.permute(0, 2, 1, 3).cpu().numpy()
|
| 66 |
+
|
| 67 |
+
out_metrics = compute_tapvid_metrics(
|
| 68 |
+
query_points,
|
| 69 |
+
gt_occluded,
|
| 70 |
+
gt_tracks,
|
| 71 |
+
pred_occluded,
|
| 72 |
+
pred_tracks,
|
| 73 |
+
query_mode="strided" if "strided" in dataset_name else "first",
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
metrics[sample.seq_name[0]] = out_metrics
|
| 77 |
+
for metric_name in out_metrics.keys():
|
| 78 |
+
if "avg" not in metrics:
|
| 79 |
+
metrics["avg"] = {}
|
| 80 |
+
metrics["avg"][metric_name] = np.mean(
|
| 81 |
+
[v[metric_name] for k, v in metrics.items() if k != "avg"]
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
logging.info(f"Metrics: {out_metrics}")
|
| 85 |
+
logging.info(f"avg: {metrics['avg']}")
|
| 86 |
+
print("metrics", out_metrics)
|
| 87 |
+
print("avg", metrics["avg"])
|
| 88 |
+
elif dataset_name == "dynamic_replica" or dataset_name == "pointodyssey":
|
| 89 |
+
*_, N, _ = sample.trajectory.shape
|
| 90 |
+
B, T, N = sample.visibility.shape
|
| 91 |
+
H, W = sample.video.shape[-2:]
|
| 92 |
+
device = sample.video.device
|
| 93 |
+
|
| 94 |
+
out_metrics = {}
|
| 95 |
+
|
| 96 |
+
d_vis_sum = d_occ_sum = d_sum_all = 0.0
|
| 97 |
+
thrs = [1, 2, 4, 8, 16]
|
| 98 |
+
sx_ = (W - 1) / 255.0
|
| 99 |
+
sy_ = (H - 1) / 255.0
|
| 100 |
+
sc_py = np.array([sx_, sy_]).reshape([1, 1, 2])
|
| 101 |
+
sc_pt = torch.from_numpy(sc_py).float().to(device)
|
| 102 |
+
__, first_visible_inds = torch.max(sample.visibility, dim=1)
|
| 103 |
+
|
| 104 |
+
frame_ids_tensor = torch.arange(T, device=device)[None, :, None].repeat(B, 1, N)
|
| 105 |
+
start_tracking_mask = frame_ids_tensor > (first_visible_inds.unsqueeze(1))
|
| 106 |
+
|
| 107 |
+
for thr in thrs:
|
| 108 |
+
d_ = (
|
| 109 |
+
torch.norm(
|
| 110 |
+
pred_trajectory[..., :2] / sc_pt - sample.trajectory[..., :2] / sc_pt,
|
| 111 |
+
dim=-1,
|
| 112 |
+
)
|
| 113 |
+
< thr
|
| 114 |
+
).float() # B,S-1,N
|
| 115 |
+
d_occ = (
|
| 116 |
+
reduce_masked_mean(d_, (1 - sample.visibility) * start_tracking_mask).item()
|
| 117 |
+
* 100.0
|
| 118 |
+
)
|
| 119 |
+
d_occ_sum += d_occ
|
| 120 |
+
out_metrics[f"accuracy_occ_{thr}"] = d_occ
|
| 121 |
+
|
| 122 |
+
d_vis = (
|
| 123 |
+
reduce_masked_mean(d_, sample.visibility * start_tracking_mask).item() * 100.0
|
| 124 |
+
)
|
| 125 |
+
d_vis_sum += d_vis
|
| 126 |
+
out_metrics[f"accuracy_vis_{thr}"] = d_vis
|
| 127 |
+
|
| 128 |
+
d_all = reduce_masked_mean(d_, start_tracking_mask).item() * 100.0
|
| 129 |
+
d_sum_all += d_all
|
| 130 |
+
out_metrics[f"accuracy_{thr}"] = d_all
|
| 131 |
+
|
| 132 |
+
d_occ_avg = d_occ_sum / len(thrs)
|
| 133 |
+
d_vis_avg = d_vis_sum / len(thrs)
|
| 134 |
+
d_all_avg = d_sum_all / len(thrs)
|
| 135 |
+
|
| 136 |
+
sur_thr = 50
|
| 137 |
+
dists = torch.norm(
|
| 138 |
+
pred_trajectory[..., :2] / sc_pt - sample.trajectory[..., :2] / sc_pt,
|
| 139 |
+
dim=-1,
|
| 140 |
+
) # B,S,N
|
| 141 |
+
dist_ok = 1 - (dists > sur_thr).float() * sample.visibility # B,S,N
|
| 142 |
+
survival = torch.cumprod(dist_ok, dim=1) # B,S,N
|
| 143 |
+
out_metrics["survival"] = torch.mean(survival).item() * 100.0
|
| 144 |
+
|
| 145 |
+
out_metrics["accuracy_occ"] = d_occ_avg
|
| 146 |
+
out_metrics["accuracy_vis"] = d_vis_avg
|
| 147 |
+
out_metrics["accuracy"] = d_all_avg
|
| 148 |
+
|
| 149 |
+
metrics[sample.seq_name[0]] = out_metrics
|
| 150 |
+
for metric_name in out_metrics.keys():
|
| 151 |
+
if "avg" not in metrics:
|
| 152 |
+
metrics["avg"] = {}
|
| 153 |
+
metrics["avg"][metric_name] = float(
|
| 154 |
+
np.mean([v[metric_name] for k, v in metrics.items() if k != "avg"])
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
logging.info(f"Metrics: {out_metrics}")
|
| 158 |
+
logging.info(f"avg: {metrics['avg']}")
|
| 159 |
+
print("metrics", out_metrics)
|
| 160 |
+
print("avg", metrics["avg"])
|
| 161 |
+
|
| 162 |
+
@torch.no_grad()
|
| 163 |
+
def evaluate_sequence(
|
| 164 |
+
self,
|
| 165 |
+
model,
|
| 166 |
+
test_dataloader: torch.utils.data.DataLoader,
|
| 167 |
+
dataset_name: str,
|
| 168 |
+
train_mode=False,
|
| 169 |
+
visualize_every: int = 1,
|
| 170 |
+
writer: Optional[SummaryWriter] = None,
|
| 171 |
+
step: Optional[int] = 0,
|
| 172 |
+
):
|
| 173 |
+
metrics = {}
|
| 174 |
+
|
| 175 |
+
vis = Visualizer(
|
| 176 |
+
save_dir=self.exp_dir,
|
| 177 |
+
fps=7,
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
for ind, sample in enumerate(tqdm(test_dataloader)):
|
| 181 |
+
if isinstance(sample, tuple):
|
| 182 |
+
sample, gotit = sample
|
| 183 |
+
if not all(gotit):
|
| 184 |
+
print("batch is None")
|
| 185 |
+
continue
|
| 186 |
+
if torch.cuda.is_available():
|
| 187 |
+
dataclass_to_cuda_(sample)
|
| 188 |
+
device = torch.device("cuda")
|
| 189 |
+
else:
|
| 190 |
+
device = torch.device("cpu")
|
| 191 |
+
|
| 192 |
+
if (
|
| 193 |
+
not train_mode
|
| 194 |
+
and hasattr(model, "sequence_len")
|
| 195 |
+
and (sample.visibility[:, : model.sequence_len].sum() == 0)
|
| 196 |
+
):
|
| 197 |
+
print(f"skipping batch {ind}")
|
| 198 |
+
continue
|
| 199 |
+
|
| 200 |
+
if "tapvid" in dataset_name:
|
| 201 |
+
queries = sample.query_points.clone().float()
|
| 202 |
+
|
| 203 |
+
queries = torch.stack(
|
| 204 |
+
[
|
| 205 |
+
queries[:, :, 0],
|
| 206 |
+
queries[:, :, 2],
|
| 207 |
+
queries[:, :, 1],
|
| 208 |
+
],
|
| 209 |
+
dim=2,
|
| 210 |
+
).to(device)
|
| 211 |
+
else:
|
| 212 |
+
queries = torch.cat(
|
| 213 |
+
[
|
| 214 |
+
torch.zeros_like(sample.trajectory[:, 0, :, :1]),
|
| 215 |
+
sample.trajectory[:, 0],
|
| 216 |
+
],
|
| 217 |
+
dim=2,
|
| 218 |
+
).to(device)
|
| 219 |
+
|
| 220 |
+
pred_tracks = model(sample.video, queries)
|
| 221 |
+
if "strided" in dataset_name:
|
| 222 |
+
inv_video = sample.video.flip(1).clone()
|
| 223 |
+
inv_queries = queries.clone()
|
| 224 |
+
inv_queries[:, :, 0] = inv_video.shape[1] - inv_queries[:, :, 0] - 1
|
| 225 |
+
|
| 226 |
+
pred_trj, pred_vsb = pred_tracks
|
| 227 |
+
inv_pred_trj, inv_pred_vsb = model(inv_video, inv_queries)
|
| 228 |
+
|
| 229 |
+
inv_pred_trj = inv_pred_trj.flip(1)
|
| 230 |
+
inv_pred_vsb = inv_pred_vsb.flip(1)
|
| 231 |
+
|
| 232 |
+
mask = pred_trj == 0
|
| 233 |
+
|
| 234 |
+
pred_trj[mask] = inv_pred_trj[mask]
|
| 235 |
+
pred_vsb[mask[:, :, :, 0]] = inv_pred_vsb[mask[:, :, :, 0]]
|
| 236 |
+
|
| 237 |
+
pred_tracks = pred_trj, pred_vsb
|
| 238 |
+
|
| 239 |
+
if dataset_name == "badja" or dataset_name == "fastcapture":
|
| 240 |
+
seq_name = sample.seq_name[0]
|
| 241 |
+
else:
|
| 242 |
+
seq_name = str(ind)
|
| 243 |
+
if ind % visualize_every == 0:
|
| 244 |
+
vis.visualize(
|
| 245 |
+
sample.video,
|
| 246 |
+
pred_tracks[0] if isinstance(pred_tracks, tuple) else pred_tracks,
|
| 247 |
+
filename=dataset_name + "_" + seq_name,
|
| 248 |
+
writer=writer,
|
| 249 |
+
step=step,
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
self.compute_metrics(metrics, sample, pred_tracks, dataset_name)
|
| 253 |
+
return metrics
|
cotracker/build/lib/evaluation/evaluate.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import json
|
| 8 |
+
import os
|
| 9 |
+
from dataclasses import dataclass, field
|
| 10 |
+
|
| 11 |
+
import hydra
|
| 12 |
+
import numpy as np
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
from omegaconf import OmegaConf
|
| 16 |
+
|
| 17 |
+
from cotracker.datasets.tap_vid_datasets import TapVidDataset
|
| 18 |
+
from cotracker.datasets.dr_dataset import DynamicReplicaDataset
|
| 19 |
+
from cotracker.datasets.utils import collate_fn
|
| 20 |
+
|
| 21 |
+
from cotracker.models.evaluation_predictor import EvaluationPredictor
|
| 22 |
+
|
| 23 |
+
from cotracker.evaluation.core.evaluator import Evaluator
|
| 24 |
+
from cotracker.models.build_cotracker import (
|
| 25 |
+
build_cotracker,
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
@dataclass(eq=False)
|
| 30 |
+
class DefaultConfig:
|
| 31 |
+
# Directory where all outputs of the experiment will be saved.
|
| 32 |
+
exp_dir: str = "./outputs"
|
| 33 |
+
|
| 34 |
+
# Name of the dataset to be used for the evaluation.
|
| 35 |
+
dataset_name: str = "tapvid_davis_first"
|
| 36 |
+
# The root directory of the dataset.
|
| 37 |
+
dataset_root: str = "./"
|
| 38 |
+
|
| 39 |
+
# Path to the pre-trained model checkpoint to be used for the evaluation.
|
| 40 |
+
# The default value is the path to a specific CoTracker model checkpoint.
|
| 41 |
+
checkpoint: str = "./checkpoints/cotracker2.pth"
|
| 42 |
+
|
| 43 |
+
# EvaluationPredictor parameters
|
| 44 |
+
# The size (N) of the support grid used in the predictor.
|
| 45 |
+
# The total number of points is (N*N).
|
| 46 |
+
grid_size: int = 5
|
| 47 |
+
# The size (N) of the local support grid.
|
| 48 |
+
local_grid_size: int = 8
|
| 49 |
+
# A flag indicating whether to evaluate one ground truth point at a time.
|
| 50 |
+
single_point: bool = True
|
| 51 |
+
# The number of iterative updates for each sliding window.
|
| 52 |
+
n_iters: int = 6
|
| 53 |
+
|
| 54 |
+
seed: int = 0
|
| 55 |
+
gpu_idx: int = 0
|
| 56 |
+
|
| 57 |
+
# Override hydra's working directory to current working dir,
|
| 58 |
+
# also disable storing the .hydra logs:
|
| 59 |
+
hydra: dict = field(
|
| 60 |
+
default_factory=lambda: {
|
| 61 |
+
"run": {"dir": "."},
|
| 62 |
+
"output_subdir": None,
|
| 63 |
+
}
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def run_eval(cfg: DefaultConfig):
|
| 68 |
+
"""
|
| 69 |
+
The function evaluates CoTracker on a specified benchmark dataset based on a provided configuration.
|
| 70 |
+
|
| 71 |
+
Args:
|
| 72 |
+
cfg (DefaultConfig): An instance of DefaultConfig class which includes:
|
| 73 |
+
- exp_dir (str): The directory path for the experiment.
|
| 74 |
+
- dataset_name (str): The name of the dataset to be used.
|
| 75 |
+
- dataset_root (str): The root directory of the dataset.
|
| 76 |
+
- checkpoint (str): The path to the CoTracker model's checkpoint.
|
| 77 |
+
- single_point (bool): A flag indicating whether to evaluate one ground truth point at a time.
|
| 78 |
+
- n_iters (int): The number of iterative updates for each sliding window.
|
| 79 |
+
- seed (int): The seed for setting the random state for reproducibility.
|
| 80 |
+
- gpu_idx (int): The index of the GPU to be used.
|
| 81 |
+
"""
|
| 82 |
+
# Creating the experiment directory if it doesn't exist
|
| 83 |
+
os.makedirs(cfg.exp_dir, exist_ok=True)
|
| 84 |
+
|
| 85 |
+
# Saving the experiment configuration to a .yaml file in the experiment directory
|
| 86 |
+
cfg_file = os.path.join(cfg.exp_dir, "expconfig.yaml")
|
| 87 |
+
with open(cfg_file, "w") as f:
|
| 88 |
+
OmegaConf.save(config=cfg, f=f)
|
| 89 |
+
|
| 90 |
+
evaluator = Evaluator(cfg.exp_dir)
|
| 91 |
+
cotracker_model = build_cotracker(cfg.checkpoint)
|
| 92 |
+
|
| 93 |
+
# Creating the EvaluationPredictor object
|
| 94 |
+
predictor = EvaluationPredictor(
|
| 95 |
+
cotracker_model,
|
| 96 |
+
grid_size=cfg.grid_size,
|
| 97 |
+
local_grid_size=cfg.local_grid_size,
|
| 98 |
+
single_point=cfg.single_point,
|
| 99 |
+
n_iters=cfg.n_iters,
|
| 100 |
+
)
|
| 101 |
+
if torch.cuda.is_available():
|
| 102 |
+
predictor.model = predictor.model.cuda()
|
| 103 |
+
|
| 104 |
+
# Setting the random seeds
|
| 105 |
+
torch.manual_seed(cfg.seed)
|
| 106 |
+
np.random.seed(cfg.seed)
|
| 107 |
+
|
| 108 |
+
# Constructing the specified dataset
|
| 109 |
+
curr_collate_fn = collate_fn
|
| 110 |
+
if "tapvid" in cfg.dataset_name:
|
| 111 |
+
dataset_type = cfg.dataset_name.split("_")[1]
|
| 112 |
+
if dataset_type == "davis":
|
| 113 |
+
data_root = os.path.join(cfg.dataset_root, "tapvid_davis", "tapvid_davis.pkl")
|
| 114 |
+
elif dataset_type == "kinetics":
|
| 115 |
+
data_root = os.path.join(
|
| 116 |
+
cfg.dataset_root, "/kinetics/kinetics-dataset/k700-2020/tapvid_kinetics"
|
| 117 |
+
)
|
| 118 |
+
test_dataset = TapVidDataset(
|
| 119 |
+
dataset_type=dataset_type,
|
| 120 |
+
data_root=data_root,
|
| 121 |
+
queried_first=not "strided" in cfg.dataset_name,
|
| 122 |
+
)
|
| 123 |
+
elif cfg.dataset_name == "dynamic_replica":
|
| 124 |
+
test_dataset = DynamicReplicaDataset(sample_len=300, only_first_n_samples=1)
|
| 125 |
+
|
| 126 |
+
# Creating the DataLoader object
|
| 127 |
+
test_dataloader = torch.utils.data.DataLoader(
|
| 128 |
+
test_dataset,
|
| 129 |
+
batch_size=1,
|
| 130 |
+
shuffle=False,
|
| 131 |
+
num_workers=14,
|
| 132 |
+
collate_fn=curr_collate_fn,
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
# Timing and conducting the evaluation
|
| 136 |
+
import time
|
| 137 |
+
|
| 138 |
+
start = time.time()
|
| 139 |
+
evaluate_result = evaluator.evaluate_sequence(
|
| 140 |
+
predictor,
|
| 141 |
+
test_dataloader,
|
| 142 |
+
dataset_name=cfg.dataset_name,
|
| 143 |
+
)
|
| 144 |
+
end = time.time()
|
| 145 |
+
print(end - start)
|
| 146 |
+
|
| 147 |
+
# Saving the evaluation results to a .json file
|
| 148 |
+
evaluate_result = evaluate_result["avg"]
|
| 149 |
+
print("evaluate_result", evaluate_result)
|
| 150 |
+
result_file = os.path.join(cfg.exp_dir, f"result_eval_.json")
|
| 151 |
+
evaluate_result["time"] = end - start
|
| 152 |
+
print(f"Dumping eval results to {result_file}.")
|
| 153 |
+
with open(result_file, "w") as f:
|
| 154 |
+
json.dump(evaluate_result, f)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
cs = hydra.core.config_store.ConfigStore.instance()
|
| 158 |
+
cs.store(name="default_config_eval", node=DefaultConfig)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
@hydra.main(config_path="./configs/", config_name="default_config_eval")
|
| 162 |
+
def evaluate(cfg: DefaultConfig) -> None:
|
| 163 |
+
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
|
| 164 |
+
os.environ["CUDA_VISIBLE_DEVICES"] = str(cfg.gpu_idx)
|
| 165 |
+
run_eval(cfg)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
if __name__ == "__main__":
|
| 169 |
+
evaluate()
|
cotracker/build/lib/models/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
cotracker/build/lib/models/build_cotracker.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from cotracker.models.core.cotracker.cotracker import CoTracker2
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def build_cotracker(
|
| 13 |
+
checkpoint: str,
|
| 14 |
+
):
|
| 15 |
+
if checkpoint is None:
|
| 16 |
+
return build_cotracker()
|
| 17 |
+
model_name = checkpoint.split("/")[-1].split(".")[0]
|
| 18 |
+
if model_name == "cotracker":
|
| 19 |
+
return build_cotracker(checkpoint=checkpoint)
|
| 20 |
+
else:
|
| 21 |
+
raise ValueError(f"Unknown model name {model_name}")
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def build_cotracker(checkpoint=None):
|
| 25 |
+
cotracker = CoTracker2(stride=4, window_len=8, add_space_attn=True)
|
| 26 |
+
|
| 27 |
+
if checkpoint is not None:
|
| 28 |
+
with open(checkpoint, "rb") as f:
|
| 29 |
+
state_dict = torch.load(f, map_location="cpu")
|
| 30 |
+
if "model" in state_dict:
|
| 31 |
+
state_dict = state_dict["model"]
|
| 32 |
+
cotracker.load_state_dict(state_dict)
|
| 33 |
+
return cotracker
|
cotracker/build/lib/models/core/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
cotracker/build/lib/models/core/cotracker/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
cotracker/build/lib/models/core/cotracker/blocks.py
ADDED
|
@@ -0,0 +1,367 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from functools import partial
|
| 11 |
+
from typing import Callable
|
| 12 |
+
import collections
|
| 13 |
+
from torch import Tensor
|
| 14 |
+
from itertools import repeat
|
| 15 |
+
|
| 16 |
+
from cotracker.models.core.model_utils import bilinear_sampler
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# From PyTorch internals
|
| 20 |
+
def _ntuple(n):
|
| 21 |
+
def parse(x):
|
| 22 |
+
if isinstance(x, collections.abc.Iterable) and not isinstance(x, str):
|
| 23 |
+
return tuple(x)
|
| 24 |
+
return tuple(repeat(x, n))
|
| 25 |
+
|
| 26 |
+
return parse
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def exists(val):
|
| 30 |
+
return val is not None
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def default(val, d):
|
| 34 |
+
return val if exists(val) else d
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
to_2tuple = _ntuple(2)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class Mlp(nn.Module):
|
| 41 |
+
"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""
|
| 42 |
+
|
| 43 |
+
def __init__(
|
| 44 |
+
self,
|
| 45 |
+
in_features,
|
| 46 |
+
hidden_features=None,
|
| 47 |
+
out_features=None,
|
| 48 |
+
act_layer=nn.GELU,
|
| 49 |
+
norm_layer=None,
|
| 50 |
+
bias=True,
|
| 51 |
+
drop=0.0,
|
| 52 |
+
use_conv=False,
|
| 53 |
+
):
|
| 54 |
+
super().__init__()
|
| 55 |
+
out_features = out_features or in_features
|
| 56 |
+
hidden_features = hidden_features or in_features
|
| 57 |
+
bias = to_2tuple(bias)
|
| 58 |
+
drop_probs = to_2tuple(drop)
|
| 59 |
+
linear_layer = partial(nn.Conv2d, kernel_size=1) if use_conv else nn.Linear
|
| 60 |
+
|
| 61 |
+
self.fc1 = linear_layer(in_features, hidden_features, bias=bias[0])
|
| 62 |
+
self.act = act_layer()
|
| 63 |
+
self.drop1 = nn.Dropout(drop_probs[0])
|
| 64 |
+
self.norm = norm_layer(hidden_features) if norm_layer is not None else nn.Identity()
|
| 65 |
+
self.fc2 = linear_layer(hidden_features, out_features, bias=bias[1])
|
| 66 |
+
self.drop2 = nn.Dropout(drop_probs[1])
|
| 67 |
+
|
| 68 |
+
def forward(self, x):
|
| 69 |
+
x = self.fc1(x)
|
| 70 |
+
x = self.act(x)
|
| 71 |
+
x = self.drop1(x)
|
| 72 |
+
x = self.fc2(x)
|
| 73 |
+
x = self.drop2(x)
|
| 74 |
+
return x
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class ResidualBlock(nn.Module):
|
| 78 |
+
def __init__(self, in_planes, planes, norm_fn="group", stride=1):
|
| 79 |
+
super(ResidualBlock, self).__init__()
|
| 80 |
+
|
| 81 |
+
self.conv1 = nn.Conv2d(
|
| 82 |
+
in_planes,
|
| 83 |
+
planes,
|
| 84 |
+
kernel_size=3,
|
| 85 |
+
padding=1,
|
| 86 |
+
stride=stride,
|
| 87 |
+
padding_mode="zeros",
|
| 88 |
+
)
|
| 89 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1, padding_mode="zeros")
|
| 90 |
+
self.relu = nn.ReLU(inplace=True)
|
| 91 |
+
|
| 92 |
+
num_groups = planes // 8
|
| 93 |
+
|
| 94 |
+
if norm_fn == "group":
|
| 95 |
+
self.norm1 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 96 |
+
self.norm2 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 97 |
+
if not stride == 1:
|
| 98 |
+
self.norm3 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 99 |
+
|
| 100 |
+
elif norm_fn == "batch":
|
| 101 |
+
self.norm1 = nn.BatchNorm2d(planes)
|
| 102 |
+
self.norm2 = nn.BatchNorm2d(planes)
|
| 103 |
+
if not stride == 1:
|
| 104 |
+
self.norm3 = nn.BatchNorm2d(planes)
|
| 105 |
+
|
| 106 |
+
elif norm_fn == "instance":
|
| 107 |
+
self.norm1 = nn.InstanceNorm2d(planes)
|
| 108 |
+
self.norm2 = nn.InstanceNorm2d(planes)
|
| 109 |
+
if not stride == 1:
|
| 110 |
+
self.norm3 = nn.InstanceNorm2d(planes)
|
| 111 |
+
|
| 112 |
+
elif norm_fn == "none":
|
| 113 |
+
self.norm1 = nn.Sequential()
|
| 114 |
+
self.norm2 = nn.Sequential()
|
| 115 |
+
if not stride == 1:
|
| 116 |
+
self.norm3 = nn.Sequential()
|
| 117 |
+
|
| 118 |
+
if stride == 1:
|
| 119 |
+
self.downsample = None
|
| 120 |
+
|
| 121 |
+
else:
|
| 122 |
+
self.downsample = nn.Sequential(
|
| 123 |
+
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride), self.norm3
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
def forward(self, x):
|
| 127 |
+
y = x
|
| 128 |
+
y = self.relu(self.norm1(self.conv1(y)))
|
| 129 |
+
y = self.relu(self.norm2(self.conv2(y)))
|
| 130 |
+
|
| 131 |
+
if self.downsample is not None:
|
| 132 |
+
x = self.downsample(x)
|
| 133 |
+
|
| 134 |
+
return self.relu(x + y)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class BasicEncoder(nn.Module):
|
| 138 |
+
def __init__(self, input_dim=3, output_dim=128, stride=4):
|
| 139 |
+
super(BasicEncoder, self).__init__()
|
| 140 |
+
self.stride = stride
|
| 141 |
+
self.norm_fn = "instance"
|
| 142 |
+
self.in_planes = output_dim // 2
|
| 143 |
+
|
| 144 |
+
self.norm1 = nn.InstanceNorm2d(self.in_planes)
|
| 145 |
+
self.norm2 = nn.InstanceNorm2d(output_dim * 2)
|
| 146 |
+
|
| 147 |
+
self.conv1 = nn.Conv2d(
|
| 148 |
+
input_dim,
|
| 149 |
+
self.in_planes,
|
| 150 |
+
kernel_size=7,
|
| 151 |
+
stride=2,
|
| 152 |
+
padding=3,
|
| 153 |
+
padding_mode="zeros",
|
| 154 |
+
)
|
| 155 |
+
self.relu1 = nn.ReLU(inplace=True)
|
| 156 |
+
self.layer1 = self._make_layer(output_dim // 2, stride=1)
|
| 157 |
+
self.layer2 = self._make_layer(output_dim // 4 * 3, stride=2)
|
| 158 |
+
self.layer3 = self._make_layer(output_dim, stride=2)
|
| 159 |
+
self.layer4 = self._make_layer(output_dim, stride=2)
|
| 160 |
+
|
| 161 |
+
self.conv2 = nn.Conv2d(
|
| 162 |
+
output_dim * 3 + output_dim // 4,
|
| 163 |
+
output_dim * 2,
|
| 164 |
+
kernel_size=3,
|
| 165 |
+
padding=1,
|
| 166 |
+
padding_mode="zeros",
|
| 167 |
+
)
|
| 168 |
+
self.relu2 = nn.ReLU(inplace=True)
|
| 169 |
+
self.conv3 = nn.Conv2d(output_dim * 2, output_dim, kernel_size=1)
|
| 170 |
+
for m in self.modules():
|
| 171 |
+
if isinstance(m, nn.Conv2d):
|
| 172 |
+
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
|
| 173 |
+
elif isinstance(m, (nn.InstanceNorm2d)):
|
| 174 |
+
if m.weight is not None:
|
| 175 |
+
nn.init.constant_(m.weight, 1)
|
| 176 |
+
if m.bias is not None:
|
| 177 |
+
nn.init.constant_(m.bias, 0)
|
| 178 |
+
|
| 179 |
+
def _make_layer(self, dim, stride=1):
|
| 180 |
+
layer1 = ResidualBlock(self.in_planes, dim, self.norm_fn, stride=stride)
|
| 181 |
+
layer2 = ResidualBlock(dim, dim, self.norm_fn, stride=1)
|
| 182 |
+
layers = (layer1, layer2)
|
| 183 |
+
|
| 184 |
+
self.in_planes = dim
|
| 185 |
+
return nn.Sequential(*layers)
|
| 186 |
+
|
| 187 |
+
def forward(self, x):
|
| 188 |
+
_, _, H, W = x.shape
|
| 189 |
+
|
| 190 |
+
x = self.conv1(x)
|
| 191 |
+
x = self.norm1(x)
|
| 192 |
+
x = self.relu1(x)
|
| 193 |
+
|
| 194 |
+
a = self.layer1(x)
|
| 195 |
+
b = self.layer2(a)
|
| 196 |
+
c = self.layer3(b)
|
| 197 |
+
d = self.layer4(c)
|
| 198 |
+
|
| 199 |
+
def _bilinear_intepolate(x):
|
| 200 |
+
return F.interpolate(
|
| 201 |
+
x,
|
| 202 |
+
(H // self.stride, W // self.stride),
|
| 203 |
+
mode="bilinear",
|
| 204 |
+
align_corners=True,
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
a = _bilinear_intepolate(a)
|
| 208 |
+
b = _bilinear_intepolate(b)
|
| 209 |
+
c = _bilinear_intepolate(c)
|
| 210 |
+
d = _bilinear_intepolate(d)
|
| 211 |
+
|
| 212 |
+
x = self.conv2(torch.cat([a, b, c, d], dim=1))
|
| 213 |
+
x = self.norm2(x)
|
| 214 |
+
x = self.relu2(x)
|
| 215 |
+
x = self.conv3(x)
|
| 216 |
+
return x
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
class CorrBlock:
|
| 220 |
+
def __init__(
|
| 221 |
+
self,
|
| 222 |
+
fmaps,
|
| 223 |
+
num_levels=4,
|
| 224 |
+
radius=4,
|
| 225 |
+
multiple_track_feats=False,
|
| 226 |
+
padding_mode="zeros",
|
| 227 |
+
):
|
| 228 |
+
B, S, C, H, W = fmaps.shape
|
| 229 |
+
self.S, self.C, self.H, self.W = S, C, H, W
|
| 230 |
+
self.padding_mode = padding_mode
|
| 231 |
+
self.num_levels = num_levels
|
| 232 |
+
self.radius = radius
|
| 233 |
+
self.fmaps_pyramid = []
|
| 234 |
+
self.multiple_track_feats = multiple_track_feats
|
| 235 |
+
|
| 236 |
+
self.fmaps_pyramid.append(fmaps)
|
| 237 |
+
for i in range(self.num_levels - 1):
|
| 238 |
+
fmaps_ = fmaps.reshape(B * S, C, H, W)
|
| 239 |
+
fmaps_ = F.avg_pool2d(fmaps_, 2, stride=2)
|
| 240 |
+
_, _, H, W = fmaps_.shape
|
| 241 |
+
fmaps = fmaps_.reshape(B, S, C, H, W)
|
| 242 |
+
self.fmaps_pyramid.append(fmaps)
|
| 243 |
+
|
| 244 |
+
def sample(self, coords):
|
| 245 |
+
r = self.radius
|
| 246 |
+
B, S, N, D = coords.shape
|
| 247 |
+
assert D == 2
|
| 248 |
+
|
| 249 |
+
H, W = self.H, self.W
|
| 250 |
+
out_pyramid = []
|
| 251 |
+
for i in range(self.num_levels):
|
| 252 |
+
corrs = self.corrs_pyramid[i] # B, S, N, H, W
|
| 253 |
+
*_, H, W = corrs.shape
|
| 254 |
+
|
| 255 |
+
dx = torch.linspace(-r, r, 2 * r + 1)
|
| 256 |
+
dy = torch.linspace(-r, r, 2 * r + 1)
|
| 257 |
+
delta = torch.stack(torch.meshgrid(dy, dx, indexing="ij"), axis=-1).to(coords.device)
|
| 258 |
+
|
| 259 |
+
centroid_lvl = coords.reshape(B * S * N, 1, 1, 2) / 2**i
|
| 260 |
+
delta_lvl = delta.view(1, 2 * r + 1, 2 * r + 1, 2)
|
| 261 |
+
coords_lvl = centroid_lvl + delta_lvl
|
| 262 |
+
|
| 263 |
+
corrs = bilinear_sampler(
|
| 264 |
+
corrs.reshape(B * S * N, 1, H, W),
|
| 265 |
+
coords_lvl,
|
| 266 |
+
padding_mode=self.padding_mode,
|
| 267 |
+
)
|
| 268 |
+
corrs = corrs.view(B, S, N, -1)
|
| 269 |
+
out_pyramid.append(corrs)
|
| 270 |
+
|
| 271 |
+
out = torch.cat(out_pyramid, dim=-1) # B, S, N, LRR*2
|
| 272 |
+
out = out.permute(0, 2, 1, 3).contiguous().view(B * N, S, -1).float()
|
| 273 |
+
return out
|
| 274 |
+
|
| 275 |
+
def corr(self, targets):
|
| 276 |
+
B, S, N, C = targets.shape
|
| 277 |
+
if self.multiple_track_feats:
|
| 278 |
+
targets_split = targets.split(C // self.num_levels, dim=-1)
|
| 279 |
+
B, S, N, C = targets_split[0].shape
|
| 280 |
+
|
| 281 |
+
assert C == self.C
|
| 282 |
+
assert S == self.S
|
| 283 |
+
|
| 284 |
+
fmap1 = targets
|
| 285 |
+
|
| 286 |
+
self.corrs_pyramid = []
|
| 287 |
+
for i, fmaps in enumerate(self.fmaps_pyramid):
|
| 288 |
+
*_, H, W = fmaps.shape
|
| 289 |
+
fmap2s = fmaps.view(B, S, C, H * W) # B S C H W -> B S C (H W)
|
| 290 |
+
if self.multiple_track_feats:
|
| 291 |
+
fmap1 = targets_split[i]
|
| 292 |
+
corrs = torch.matmul(fmap1, fmap2s)
|
| 293 |
+
corrs = corrs.view(B, S, N, H, W) # B S N (H W) -> B S N H W
|
| 294 |
+
corrs = corrs / torch.sqrt(torch.tensor(C).float())
|
| 295 |
+
self.corrs_pyramid.append(corrs)
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class Attention(nn.Module):
|
| 299 |
+
def __init__(self, query_dim, context_dim=None, num_heads=8, dim_head=48, qkv_bias=False):
|
| 300 |
+
super().__init__()
|
| 301 |
+
inner_dim = dim_head * num_heads
|
| 302 |
+
context_dim = default(context_dim, query_dim)
|
| 303 |
+
self.scale = dim_head**-0.5
|
| 304 |
+
self.heads = num_heads
|
| 305 |
+
|
| 306 |
+
self.to_q = nn.Linear(query_dim, inner_dim, bias=qkv_bias)
|
| 307 |
+
self.to_kv = nn.Linear(context_dim, inner_dim * 2, bias=qkv_bias)
|
| 308 |
+
self.to_out = nn.Linear(inner_dim, query_dim)
|
| 309 |
+
|
| 310 |
+
def forward(self, x, context=None, attn_bias=None):
|
| 311 |
+
B, N1, C = x.shape
|
| 312 |
+
h = self.heads
|
| 313 |
+
|
| 314 |
+
q = self.to_q(x).reshape(B, N1, h, C // h).permute(0, 2, 1, 3)
|
| 315 |
+
context = default(context, x)
|
| 316 |
+
k, v = self.to_kv(context).chunk(2, dim=-1)
|
| 317 |
+
|
| 318 |
+
N2 = context.shape[1]
|
| 319 |
+
k = k.reshape(B, N2, h, C // h).permute(0, 2, 1, 3)
|
| 320 |
+
v = v.reshape(B, N2, h, C // h).permute(0, 2, 1, 3)
|
| 321 |
+
|
| 322 |
+
sim = (q @ k.transpose(-2, -1)) * self.scale
|
| 323 |
+
|
| 324 |
+
if attn_bias is not None:
|
| 325 |
+
sim = sim + attn_bias
|
| 326 |
+
attn = sim.softmax(dim=-1)
|
| 327 |
+
|
| 328 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N1, C)
|
| 329 |
+
return self.to_out(x)
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
class AttnBlock(nn.Module):
|
| 333 |
+
def __init__(
|
| 334 |
+
self,
|
| 335 |
+
hidden_size,
|
| 336 |
+
num_heads,
|
| 337 |
+
attn_class: Callable[..., nn.Module] = Attention,
|
| 338 |
+
mlp_ratio=4.0,
|
| 339 |
+
**block_kwargs
|
| 340 |
+
):
|
| 341 |
+
super().__init__()
|
| 342 |
+
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 343 |
+
self.attn = attn_class(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
|
| 344 |
+
|
| 345 |
+
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 346 |
+
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
| 347 |
+
approx_gelu = lambda: nn.GELU(approximate="tanh")
|
| 348 |
+
self.mlp = Mlp(
|
| 349 |
+
in_features=hidden_size,
|
| 350 |
+
hidden_features=mlp_hidden_dim,
|
| 351 |
+
act_layer=approx_gelu,
|
| 352 |
+
drop=0,
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
def forward(self, x, mask=None):
|
| 356 |
+
attn_bias = mask
|
| 357 |
+
if mask is not None:
|
| 358 |
+
mask = (
|
| 359 |
+
(mask[:, None] * mask[:, :, None])
|
| 360 |
+
.unsqueeze(1)
|
| 361 |
+
.expand(-1, self.attn.num_heads, -1, -1)
|
| 362 |
+
)
|
| 363 |
+
max_neg_value = -torch.finfo(x.dtype).max
|
| 364 |
+
attn_bias = (~mask) * max_neg_value
|
| 365 |
+
x = x + self.attn(self.norm1(x), attn_bias=attn_bias)
|
| 366 |
+
x = x + self.mlp(self.norm2(x))
|
| 367 |
+
return x
|
cotracker/build/lib/models/core/cotracker/cotracker.py
ADDED
|
@@ -0,0 +1,503 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
from cotracker.models.core.model_utils import sample_features4d, sample_features5d
|
| 12 |
+
from cotracker.models.core.embeddings import (
|
| 13 |
+
get_2d_embedding,
|
| 14 |
+
get_1d_sincos_pos_embed_from_grid,
|
| 15 |
+
get_2d_sincos_pos_embed,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
from cotracker.models.core.cotracker.blocks import (
|
| 19 |
+
Mlp,
|
| 20 |
+
BasicEncoder,
|
| 21 |
+
AttnBlock,
|
| 22 |
+
CorrBlock,
|
| 23 |
+
Attention,
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
torch.manual_seed(0)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class CoTracker2(nn.Module):
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
window_len=8,
|
| 33 |
+
stride=4,
|
| 34 |
+
add_space_attn=True,
|
| 35 |
+
num_virtual_tracks=64,
|
| 36 |
+
model_resolution=(384, 512),
|
| 37 |
+
):
|
| 38 |
+
super(CoTracker2, self).__init__()
|
| 39 |
+
self.window_len = window_len
|
| 40 |
+
self.stride = stride
|
| 41 |
+
self.hidden_dim = 256
|
| 42 |
+
self.latent_dim = 128
|
| 43 |
+
self.add_space_attn = add_space_attn
|
| 44 |
+
self.fnet = BasicEncoder(output_dim=self.latent_dim)
|
| 45 |
+
self.num_virtual_tracks = num_virtual_tracks
|
| 46 |
+
self.model_resolution = model_resolution
|
| 47 |
+
self.input_dim = 456
|
| 48 |
+
self.updateformer = EfficientUpdateFormer(
|
| 49 |
+
space_depth=6,
|
| 50 |
+
time_depth=6,
|
| 51 |
+
input_dim=self.input_dim,
|
| 52 |
+
hidden_size=384,
|
| 53 |
+
output_dim=self.latent_dim + 2,
|
| 54 |
+
mlp_ratio=4.0,
|
| 55 |
+
add_space_attn=add_space_attn,
|
| 56 |
+
num_virtual_tracks=num_virtual_tracks,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
time_grid = torch.linspace(0, window_len - 1, window_len).reshape(1, window_len, 1)
|
| 60 |
+
|
| 61 |
+
self.register_buffer(
|
| 62 |
+
"time_emb", get_1d_sincos_pos_embed_from_grid(self.input_dim, time_grid[0])
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
self.register_buffer(
|
| 66 |
+
"pos_emb",
|
| 67 |
+
get_2d_sincos_pos_embed(
|
| 68 |
+
embed_dim=self.input_dim,
|
| 69 |
+
grid_size=(
|
| 70 |
+
model_resolution[0] // stride,
|
| 71 |
+
model_resolution[1] // stride,
|
| 72 |
+
),
|
| 73 |
+
),
|
| 74 |
+
)
|
| 75 |
+
self.norm = nn.GroupNorm(1, self.latent_dim)
|
| 76 |
+
self.track_feat_updater = nn.Sequential(
|
| 77 |
+
nn.Linear(self.latent_dim, self.latent_dim),
|
| 78 |
+
nn.GELU(),
|
| 79 |
+
)
|
| 80 |
+
self.vis_predictor = nn.Sequential(
|
| 81 |
+
nn.Linear(self.latent_dim, 1),
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
def forward_window(
|
| 85 |
+
self,
|
| 86 |
+
fmaps,
|
| 87 |
+
coords,
|
| 88 |
+
track_feat=None,
|
| 89 |
+
vis=None,
|
| 90 |
+
track_mask=None,
|
| 91 |
+
attention_mask=None,
|
| 92 |
+
iters=4,
|
| 93 |
+
):
|
| 94 |
+
# B = batch size
|
| 95 |
+
# S = number of frames in the window)
|
| 96 |
+
# N = number of tracks
|
| 97 |
+
# C = channels of a point feature vector
|
| 98 |
+
# E = positional embedding size
|
| 99 |
+
# LRR = local receptive field radius
|
| 100 |
+
# D = dimension of the transformer input tokens
|
| 101 |
+
|
| 102 |
+
# track_feat = B S N C
|
| 103 |
+
# vis = B S N 1
|
| 104 |
+
# track_mask = B S N 1
|
| 105 |
+
# attention_mask = B S N
|
| 106 |
+
|
| 107 |
+
B, S_init, N, __ = track_mask.shape
|
| 108 |
+
B, S, *_ = fmaps.shape
|
| 109 |
+
|
| 110 |
+
track_mask = F.pad(track_mask, (0, 0, 0, 0, 0, S - S_init), "constant")
|
| 111 |
+
track_mask_vis = (
|
| 112 |
+
torch.cat([track_mask, vis], dim=-1).permute(0, 2, 1, 3).reshape(B * N, S, 2)
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
corr_block = CorrBlock(
|
| 116 |
+
fmaps,
|
| 117 |
+
num_levels=4,
|
| 118 |
+
radius=3,
|
| 119 |
+
padding_mode="border",
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
sampled_pos_emb = (
|
| 123 |
+
sample_features4d(self.pos_emb.repeat(B, 1, 1, 1), coords[:, 0])
|
| 124 |
+
.reshape(B * N, self.input_dim)
|
| 125 |
+
.unsqueeze(1)
|
| 126 |
+
) # B E N -> (B N) 1 E
|
| 127 |
+
|
| 128 |
+
coord_preds = []
|
| 129 |
+
for __ in range(iters):
|
| 130 |
+
coords = coords.detach() # B S N 2
|
| 131 |
+
corr_block.corr(track_feat)
|
| 132 |
+
|
| 133 |
+
# Sample correlation features around each point
|
| 134 |
+
fcorrs = corr_block.sample(coords) # (B N) S LRR
|
| 135 |
+
|
| 136 |
+
# Get the flow embeddings
|
| 137 |
+
flows = (coords - coords[:, 0:1]).permute(0, 2, 1, 3).reshape(B * N, S, 2)
|
| 138 |
+
flow_emb = get_2d_embedding(flows, 64, cat_coords=True) # N S E
|
| 139 |
+
|
| 140 |
+
track_feat_ = track_feat.permute(0, 2, 1, 3).reshape(B * N, S, self.latent_dim)
|
| 141 |
+
|
| 142 |
+
transformer_input = torch.cat([flow_emb, fcorrs, track_feat_, track_mask_vis], dim=2)
|
| 143 |
+
x = transformer_input + sampled_pos_emb + self.time_emb
|
| 144 |
+
x = x.view(B, N, S, -1) # (B N) S D -> B N S D
|
| 145 |
+
|
| 146 |
+
delta = self.updateformer(
|
| 147 |
+
x,
|
| 148 |
+
attention_mask.reshape(B * S, N), # B S N -> (B S) N
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
delta_coords = delta[..., :2].permute(0, 2, 1, 3)
|
| 152 |
+
coords = coords + delta_coords
|
| 153 |
+
coord_preds.append(coords * self.stride)
|
| 154 |
+
|
| 155 |
+
delta_feats_ = delta[..., 2:].reshape(B * N * S, self.latent_dim)
|
| 156 |
+
track_feat_ = track_feat.permute(0, 2, 1, 3).reshape(B * N * S, self.latent_dim)
|
| 157 |
+
track_feat_ = self.track_feat_updater(self.norm(delta_feats_)) + track_feat_
|
| 158 |
+
track_feat = track_feat_.reshape(B, N, S, self.latent_dim).permute(
|
| 159 |
+
0, 2, 1, 3
|
| 160 |
+
) # (B N S) C -> B S N C
|
| 161 |
+
|
| 162 |
+
vis_pred = self.vis_predictor(track_feat).reshape(B, S, N)
|
| 163 |
+
return coord_preds, vis_pred
|
| 164 |
+
|
| 165 |
+
def get_track_feat(self, fmaps, queried_frames, queried_coords):
|
| 166 |
+
sample_frames = queried_frames[:, None, :, None]
|
| 167 |
+
sample_coords = torch.cat(
|
| 168 |
+
[
|
| 169 |
+
sample_frames,
|
| 170 |
+
queried_coords[:, None],
|
| 171 |
+
],
|
| 172 |
+
dim=-1,
|
| 173 |
+
)
|
| 174 |
+
sample_track_feats = sample_features5d(fmaps, sample_coords)
|
| 175 |
+
return sample_track_feats
|
| 176 |
+
|
| 177 |
+
def init_video_online_processing(self):
|
| 178 |
+
self.online_ind = 0
|
| 179 |
+
self.online_track_feat = None
|
| 180 |
+
self.online_coords_predicted = None
|
| 181 |
+
self.online_vis_predicted = None
|
| 182 |
+
|
| 183 |
+
def forward(self, video, queries, iters=4, is_train=False, is_online=False):
|
| 184 |
+
"""Predict tracks
|
| 185 |
+
|
| 186 |
+
Args:
|
| 187 |
+
video (FloatTensor[B, T, 3]): input videos.
|
| 188 |
+
queries (FloatTensor[B, N, 3]): point queries.
|
| 189 |
+
iters (int, optional): number of updates. Defaults to 4.
|
| 190 |
+
is_train (bool, optional): enables training mode. Defaults to False.
|
| 191 |
+
is_online (bool, optional): enables online mode. Defaults to False. Before enabling, call model.init_video_online_processing().
|
| 192 |
+
|
| 193 |
+
Returns:
|
| 194 |
+
- coords_predicted (FloatTensor[B, T, N, 2]):
|
| 195 |
+
- vis_predicted (FloatTensor[B, T, N]):
|
| 196 |
+
- train_data: `None` if `is_train` is false, otherwise:
|
| 197 |
+
- all_vis_predictions (List[FloatTensor[B, S, N, 1]]):
|
| 198 |
+
- all_coords_predictions (List[FloatTensor[B, S, N, 2]]):
|
| 199 |
+
- mask (BoolTensor[B, T, N]):
|
| 200 |
+
"""
|
| 201 |
+
B, T, C, H, W = video.shape
|
| 202 |
+
B, N, __ = queries.shape
|
| 203 |
+
S = self.window_len
|
| 204 |
+
device = queries.device
|
| 205 |
+
|
| 206 |
+
# B = batch size
|
| 207 |
+
# S = number of frames in the window of the padded video
|
| 208 |
+
# S_trimmed = actual number of frames in the window
|
| 209 |
+
# N = number of tracks
|
| 210 |
+
# C = color channels (3 for RGB)
|
| 211 |
+
# E = positional embedding size
|
| 212 |
+
# LRR = local receptive field radius
|
| 213 |
+
# D = dimension of the transformer input tokens
|
| 214 |
+
|
| 215 |
+
# video = B T C H W
|
| 216 |
+
# queries = B N 3
|
| 217 |
+
# coords_init = B S N 2
|
| 218 |
+
# vis_init = B S N 1
|
| 219 |
+
|
| 220 |
+
assert S >= 2 # A tracker needs at least two frames to track something
|
| 221 |
+
if is_online:
|
| 222 |
+
assert T <= S, "Online mode: video chunk must be <= window size."
|
| 223 |
+
assert self.online_ind is not None, "Call model.init_video_online_processing() first."
|
| 224 |
+
assert not is_train, "Training not supported in online mode."
|
| 225 |
+
step = S // 2 # How much the sliding window moves at every step
|
| 226 |
+
video = 2 * (video / 255.0) - 1.0
|
| 227 |
+
|
| 228 |
+
# The first channel is the frame number
|
| 229 |
+
# The rest are the coordinates of points we want to track
|
| 230 |
+
queried_frames = queries[:, :, 0].long()
|
| 231 |
+
|
| 232 |
+
queried_coords = queries[..., 1:]
|
| 233 |
+
queried_coords = queried_coords / self.stride
|
| 234 |
+
|
| 235 |
+
# We store our predictions here
|
| 236 |
+
coords_predicted = torch.zeros((B, T, N, 2), device=device)
|
| 237 |
+
vis_predicted = torch.zeros((B, T, N), device=device)
|
| 238 |
+
if is_online:
|
| 239 |
+
if self.online_coords_predicted is None:
|
| 240 |
+
# Init online predictions with zeros
|
| 241 |
+
self.online_coords_predicted = coords_predicted
|
| 242 |
+
self.online_vis_predicted = vis_predicted
|
| 243 |
+
else:
|
| 244 |
+
# Pad online predictions with zeros for the current window
|
| 245 |
+
pad = min(step, T - step)
|
| 246 |
+
coords_predicted = F.pad(
|
| 247 |
+
self.online_coords_predicted, (0, 0, 0, 0, 0, pad), "constant"
|
| 248 |
+
)
|
| 249 |
+
vis_predicted = F.pad(self.online_vis_predicted, (0, 0, 0, pad), "constant")
|
| 250 |
+
all_coords_predictions, all_vis_predictions = [], []
|
| 251 |
+
|
| 252 |
+
# Pad the video so that an integer number of sliding windows fit into it
|
| 253 |
+
# TODO: we may drop this requirement because the transformer should not care
|
| 254 |
+
# TODO: pad the features instead of the video
|
| 255 |
+
pad = S - T if is_online else (S - T % S) % S # We don't want to pad if T % S == 0
|
| 256 |
+
video = F.pad(video.reshape(B, 1, T, C * H * W), (0, 0, 0, pad), "replicate").reshape(
|
| 257 |
+
B, -1, C, H, W
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
# Compute convolutional features for the video or for the current chunk in case of online mode
|
| 261 |
+
fmaps = self.fnet(video.reshape(-1, C, H, W)).reshape(
|
| 262 |
+
B, -1, self.latent_dim, H // self.stride, W // self.stride
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
# We compute track features
|
| 266 |
+
track_feat = self.get_track_feat(
|
| 267 |
+
fmaps,
|
| 268 |
+
queried_frames - self.online_ind if is_online else queried_frames,
|
| 269 |
+
queried_coords,
|
| 270 |
+
).repeat(1, S, 1, 1)
|
| 271 |
+
if is_online:
|
| 272 |
+
# We update track features for the current window
|
| 273 |
+
sample_frames = queried_frames[:, None, :, None] # B 1 N 1
|
| 274 |
+
left = 0 if self.online_ind == 0 else self.online_ind + step
|
| 275 |
+
right = self.online_ind + S
|
| 276 |
+
sample_mask = (sample_frames >= left) & (sample_frames < right)
|
| 277 |
+
if self.online_track_feat is None:
|
| 278 |
+
self.online_track_feat = torch.zeros_like(track_feat, device=device)
|
| 279 |
+
self.online_track_feat += track_feat * sample_mask
|
| 280 |
+
track_feat = self.online_track_feat.clone()
|
| 281 |
+
# We process ((num_windows - 1) * step + S) frames in total, so there are
|
| 282 |
+
# (ceil((T - S) / step) + 1) windows
|
| 283 |
+
num_windows = (T - S + step - 1) // step + 1
|
| 284 |
+
# We process only the current video chunk in the online mode
|
| 285 |
+
indices = [self.online_ind] if is_online else range(0, step * num_windows, step)
|
| 286 |
+
|
| 287 |
+
coords_init = queried_coords.reshape(B, 1, N, 2).expand(B, S, N, 2).float()
|
| 288 |
+
vis_init = torch.ones((B, S, N, 1), device=device).float() * 10
|
| 289 |
+
for ind in indices:
|
| 290 |
+
# We copy over coords and vis for tracks that are queried
|
| 291 |
+
# by the end of the previous window, which is ind + overlap
|
| 292 |
+
if ind > 0:
|
| 293 |
+
overlap = S - step
|
| 294 |
+
copy_over = (queried_frames < ind + overlap)[:, None, :, None] # B 1 N 1
|
| 295 |
+
coords_prev = torch.nn.functional.pad(
|
| 296 |
+
coords_predicted[:, ind : ind + overlap] / self.stride,
|
| 297 |
+
(0, 0, 0, 0, 0, step),
|
| 298 |
+
"replicate",
|
| 299 |
+
) # B S N 2
|
| 300 |
+
vis_prev = torch.nn.functional.pad(
|
| 301 |
+
vis_predicted[:, ind : ind + overlap, :, None].clone(),
|
| 302 |
+
(0, 0, 0, 0, 0, step),
|
| 303 |
+
"replicate",
|
| 304 |
+
) # B S N 1
|
| 305 |
+
coords_init = torch.where(
|
| 306 |
+
copy_over.expand_as(coords_init), coords_prev, coords_init
|
| 307 |
+
)
|
| 308 |
+
vis_init = torch.where(copy_over.expand_as(vis_init), vis_prev, vis_init)
|
| 309 |
+
|
| 310 |
+
# The attention mask is 1 for the spatio-temporal points within
|
| 311 |
+
# a track which is updated in the current window
|
| 312 |
+
attention_mask = (queried_frames < ind + S).reshape(B, 1, N).repeat(1, S, 1) # B S N
|
| 313 |
+
|
| 314 |
+
# The track mask is 1 for the spatio-temporal points that actually
|
| 315 |
+
# need updating: only after begin queried, and not if contained
|
| 316 |
+
# in a previous window
|
| 317 |
+
track_mask = (
|
| 318 |
+
queried_frames[:, None, :, None]
|
| 319 |
+
<= torch.arange(ind, ind + S, device=device)[None, :, None, None]
|
| 320 |
+
).contiguous() # B S N 1
|
| 321 |
+
|
| 322 |
+
if ind > 0:
|
| 323 |
+
track_mask[:, :overlap, :, :] = False
|
| 324 |
+
|
| 325 |
+
# Predict the coordinates and visibility for the current window
|
| 326 |
+
coords, vis = self.forward_window(
|
| 327 |
+
fmaps=fmaps if is_online else fmaps[:, ind : ind + S],
|
| 328 |
+
coords=coords_init,
|
| 329 |
+
track_feat=attention_mask.unsqueeze(-1) * track_feat,
|
| 330 |
+
vis=vis_init,
|
| 331 |
+
track_mask=track_mask,
|
| 332 |
+
attention_mask=attention_mask,
|
| 333 |
+
iters=iters,
|
| 334 |
+
)
|
| 335 |
+
|
| 336 |
+
S_trimmed = T if is_online else min(T - ind, S) # accounts for last window duration
|
| 337 |
+
coords_predicted[:, ind : ind + S] = coords[-1][:, :S_trimmed]
|
| 338 |
+
vis_predicted[:, ind : ind + S] = vis[:, :S_trimmed]
|
| 339 |
+
if is_train:
|
| 340 |
+
all_coords_predictions.append([coord[:, :S_trimmed] for coord in coords])
|
| 341 |
+
all_vis_predictions.append(torch.sigmoid(vis[:, :S_trimmed]))
|
| 342 |
+
|
| 343 |
+
if is_online:
|
| 344 |
+
self.online_ind += step
|
| 345 |
+
self.online_coords_predicted = coords_predicted
|
| 346 |
+
self.online_vis_predicted = vis_predicted
|
| 347 |
+
vis_predicted = torch.sigmoid(vis_predicted)
|
| 348 |
+
|
| 349 |
+
if is_train:
|
| 350 |
+
mask = queried_frames[:, None] <= torch.arange(0, T, device=device)[None, :, None]
|
| 351 |
+
train_data = (all_coords_predictions, all_vis_predictions, mask)
|
| 352 |
+
else:
|
| 353 |
+
train_data = None
|
| 354 |
+
|
| 355 |
+
return coords_predicted, vis_predicted, train_data
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
class EfficientUpdateFormer(nn.Module):
|
| 359 |
+
"""
|
| 360 |
+
Transformer model that updates track estimates.
|
| 361 |
+
"""
|
| 362 |
+
|
| 363 |
+
def __init__(
|
| 364 |
+
self,
|
| 365 |
+
space_depth=6,
|
| 366 |
+
time_depth=6,
|
| 367 |
+
input_dim=320,
|
| 368 |
+
hidden_size=384,
|
| 369 |
+
num_heads=8,
|
| 370 |
+
output_dim=130,
|
| 371 |
+
mlp_ratio=4.0,
|
| 372 |
+
add_space_attn=True,
|
| 373 |
+
num_virtual_tracks=64,
|
| 374 |
+
):
|
| 375 |
+
super().__init__()
|
| 376 |
+
self.out_channels = 2
|
| 377 |
+
self.num_heads = num_heads
|
| 378 |
+
self.hidden_size = hidden_size
|
| 379 |
+
self.add_space_attn = add_space_attn
|
| 380 |
+
self.input_transform = torch.nn.Linear(input_dim, hidden_size, bias=True)
|
| 381 |
+
self.flow_head = torch.nn.Linear(hidden_size, output_dim, bias=True)
|
| 382 |
+
self.num_virtual_tracks = num_virtual_tracks
|
| 383 |
+
self.virual_tracks = nn.Parameter(torch.randn(1, num_virtual_tracks, 1, hidden_size))
|
| 384 |
+
self.time_blocks = nn.ModuleList(
|
| 385 |
+
[
|
| 386 |
+
AttnBlock(
|
| 387 |
+
hidden_size,
|
| 388 |
+
num_heads,
|
| 389 |
+
mlp_ratio=mlp_ratio,
|
| 390 |
+
attn_class=Attention,
|
| 391 |
+
)
|
| 392 |
+
for _ in range(time_depth)
|
| 393 |
+
]
|
| 394 |
+
)
|
| 395 |
+
|
| 396 |
+
if add_space_attn:
|
| 397 |
+
self.space_virtual_blocks = nn.ModuleList(
|
| 398 |
+
[
|
| 399 |
+
AttnBlock(
|
| 400 |
+
hidden_size,
|
| 401 |
+
num_heads,
|
| 402 |
+
mlp_ratio=mlp_ratio,
|
| 403 |
+
attn_class=Attention,
|
| 404 |
+
)
|
| 405 |
+
for _ in range(space_depth)
|
| 406 |
+
]
|
| 407 |
+
)
|
| 408 |
+
self.space_point2virtual_blocks = nn.ModuleList(
|
| 409 |
+
[
|
| 410 |
+
CrossAttnBlock(hidden_size, hidden_size, num_heads, mlp_ratio=mlp_ratio)
|
| 411 |
+
for _ in range(space_depth)
|
| 412 |
+
]
|
| 413 |
+
)
|
| 414 |
+
self.space_virtual2point_blocks = nn.ModuleList(
|
| 415 |
+
[
|
| 416 |
+
CrossAttnBlock(hidden_size, hidden_size, num_heads, mlp_ratio=mlp_ratio)
|
| 417 |
+
for _ in range(space_depth)
|
| 418 |
+
]
|
| 419 |
+
)
|
| 420 |
+
assert len(self.time_blocks) >= len(self.space_virtual2point_blocks)
|
| 421 |
+
self.initialize_weights()
|
| 422 |
+
|
| 423 |
+
def initialize_weights(self):
|
| 424 |
+
def _basic_init(module):
|
| 425 |
+
if isinstance(module, nn.Linear):
|
| 426 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 427 |
+
if module.bias is not None:
|
| 428 |
+
nn.init.constant_(module.bias, 0)
|
| 429 |
+
|
| 430 |
+
self.apply(_basic_init)
|
| 431 |
+
|
| 432 |
+
def forward(self, input_tensor, mask=None):
|
| 433 |
+
tokens = self.input_transform(input_tensor)
|
| 434 |
+
B, _, T, _ = tokens.shape
|
| 435 |
+
virtual_tokens = self.virual_tracks.repeat(B, 1, T, 1)
|
| 436 |
+
tokens = torch.cat([tokens, virtual_tokens], dim=1)
|
| 437 |
+
_, N, _, _ = tokens.shape
|
| 438 |
+
|
| 439 |
+
j = 0
|
| 440 |
+
for i in range(len(self.time_blocks)):
|
| 441 |
+
time_tokens = tokens.contiguous().view(B * N, T, -1) # B N T C -> (B N) T C
|
| 442 |
+
time_tokens = self.time_blocks[i](time_tokens)
|
| 443 |
+
|
| 444 |
+
tokens = time_tokens.view(B, N, T, -1) # (B N) T C -> B N T C
|
| 445 |
+
if self.add_space_attn and (
|
| 446 |
+
i % (len(self.time_blocks) // len(self.space_virtual_blocks)) == 0
|
| 447 |
+
):
|
| 448 |
+
space_tokens = (
|
| 449 |
+
tokens.permute(0, 2, 1, 3).contiguous().view(B * T, N, -1)
|
| 450 |
+
) # B N T C -> (B T) N C
|
| 451 |
+
point_tokens = space_tokens[:, : N - self.num_virtual_tracks]
|
| 452 |
+
virtual_tokens = space_tokens[:, N - self.num_virtual_tracks :]
|
| 453 |
+
|
| 454 |
+
virtual_tokens = self.space_virtual2point_blocks[j](
|
| 455 |
+
virtual_tokens, point_tokens, mask=mask
|
| 456 |
+
)
|
| 457 |
+
virtual_tokens = self.space_virtual_blocks[j](virtual_tokens)
|
| 458 |
+
point_tokens = self.space_point2virtual_blocks[j](
|
| 459 |
+
point_tokens, virtual_tokens, mask=mask
|
| 460 |
+
)
|
| 461 |
+
space_tokens = torch.cat([point_tokens, virtual_tokens], dim=1)
|
| 462 |
+
tokens = space_tokens.view(B, T, N, -1).permute(0, 2, 1, 3) # (B T) N C -> B N T C
|
| 463 |
+
j += 1
|
| 464 |
+
tokens = tokens[:, : N - self.num_virtual_tracks]
|
| 465 |
+
flow = self.flow_head(tokens)
|
| 466 |
+
return flow
|
| 467 |
+
|
| 468 |
+
|
| 469 |
+
class CrossAttnBlock(nn.Module):
|
| 470 |
+
def __init__(self, hidden_size, context_dim, num_heads=1, mlp_ratio=4.0, **block_kwargs):
|
| 471 |
+
super().__init__()
|
| 472 |
+
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 473 |
+
self.norm_context = nn.LayerNorm(hidden_size)
|
| 474 |
+
self.cross_attn = Attention(
|
| 475 |
+
hidden_size, context_dim=context_dim, num_heads=num_heads, qkv_bias=True, **block_kwargs
|
| 476 |
+
)
|
| 477 |
+
|
| 478 |
+
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 479 |
+
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
| 480 |
+
approx_gelu = lambda: nn.GELU(approximate="tanh")
|
| 481 |
+
self.mlp = Mlp(
|
| 482 |
+
in_features=hidden_size,
|
| 483 |
+
hidden_features=mlp_hidden_dim,
|
| 484 |
+
act_layer=approx_gelu,
|
| 485 |
+
drop=0,
|
| 486 |
+
)
|
| 487 |
+
|
| 488 |
+
def forward(self, x, context, mask=None):
|
| 489 |
+
if mask is not None:
|
| 490 |
+
if mask.shape[1] == x.shape[1]:
|
| 491 |
+
mask = mask[:, None, :, None].expand(
|
| 492 |
+
-1, self.cross_attn.heads, -1, context.shape[1]
|
| 493 |
+
)
|
| 494 |
+
else:
|
| 495 |
+
mask = mask[:, None, None].expand(-1, self.cross_attn.heads, x.shape[1], -1)
|
| 496 |
+
|
| 497 |
+
max_neg_value = -torch.finfo(x.dtype).max
|
| 498 |
+
attn_bias = (~mask) * max_neg_value
|
| 499 |
+
x = x + self.cross_attn(
|
| 500 |
+
self.norm1(x), context=self.norm_context(context), attn_bias=attn_bias
|
| 501 |
+
)
|
| 502 |
+
x = x + self.mlp(self.norm2(x))
|
| 503 |
+
return x
|
cotracker/build/lib/models/core/cotracker/losses.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from cotracker.models.core.model_utils import reduce_masked_mean
|
| 10 |
+
|
| 11 |
+
EPS = 1e-6
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def balanced_ce_loss(pred, gt, valid=None):
|
| 15 |
+
total_balanced_loss = 0.0
|
| 16 |
+
for j in range(len(gt)):
|
| 17 |
+
B, S, N = gt[j].shape
|
| 18 |
+
# pred and gt are the same shape
|
| 19 |
+
for (a, b) in zip(pred[j].size(), gt[j].size()):
|
| 20 |
+
assert a == b # some shape mismatch!
|
| 21 |
+
# if valid is not None:
|
| 22 |
+
for (a, b) in zip(pred[j].size(), valid[j].size()):
|
| 23 |
+
assert a == b # some shape mismatch!
|
| 24 |
+
|
| 25 |
+
pos = (gt[j] > 0.95).float()
|
| 26 |
+
neg = (gt[j] < 0.05).float()
|
| 27 |
+
|
| 28 |
+
label = pos * 2.0 - 1.0
|
| 29 |
+
a = -label * pred[j]
|
| 30 |
+
b = F.relu(a)
|
| 31 |
+
loss = b + torch.log(torch.exp(-b) + torch.exp(a - b))
|
| 32 |
+
|
| 33 |
+
pos_loss = reduce_masked_mean(loss, pos * valid[j])
|
| 34 |
+
neg_loss = reduce_masked_mean(loss, neg * valid[j])
|
| 35 |
+
|
| 36 |
+
balanced_loss = pos_loss + neg_loss
|
| 37 |
+
total_balanced_loss += balanced_loss / float(N)
|
| 38 |
+
return total_balanced_loss
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def sequence_loss(flow_preds, flow_gt, vis, valids, gamma=0.8):
|
| 42 |
+
"""Loss function defined over sequence of flow predictions"""
|
| 43 |
+
total_flow_loss = 0.0
|
| 44 |
+
for j in range(len(flow_gt)):
|
| 45 |
+
B, S, N, D = flow_gt[j].shape
|
| 46 |
+
assert D == 2
|
| 47 |
+
B, S1, N = vis[j].shape
|
| 48 |
+
B, S2, N = valids[j].shape
|
| 49 |
+
assert S == S1
|
| 50 |
+
assert S == S2
|
| 51 |
+
n_predictions = len(flow_preds[j])
|
| 52 |
+
flow_loss = 0.0
|
| 53 |
+
for i in range(n_predictions):
|
| 54 |
+
i_weight = gamma ** (n_predictions - i - 1)
|
| 55 |
+
flow_pred = flow_preds[j][i]
|
| 56 |
+
i_loss = (flow_pred - flow_gt[j]).abs() # B, S, N, 2
|
| 57 |
+
i_loss = torch.mean(i_loss, dim=3) # B, S, N
|
| 58 |
+
flow_loss += i_weight * reduce_masked_mean(i_loss, valids[j])
|
| 59 |
+
flow_loss = flow_loss / n_predictions
|
| 60 |
+
total_flow_loss += flow_loss / float(N)
|
| 61 |
+
return total_flow_loss
|
cotracker/build/lib/models/core/embeddings.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import Tuple, Union
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_2d_sincos_pos_embed(
|
| 12 |
+
embed_dim: int, grid_size: Union[int, Tuple[int, int]]
|
| 13 |
+
) -> torch.Tensor:
|
| 14 |
+
"""
|
| 15 |
+
This function initializes a grid and generates a 2D positional embedding using sine and cosine functions.
|
| 16 |
+
It is a wrapper of get_2d_sincos_pos_embed_from_grid.
|
| 17 |
+
Args:
|
| 18 |
+
- embed_dim: The embedding dimension.
|
| 19 |
+
- grid_size: The grid size.
|
| 20 |
+
Returns:
|
| 21 |
+
- pos_embed: The generated 2D positional embedding.
|
| 22 |
+
"""
|
| 23 |
+
if isinstance(grid_size, tuple):
|
| 24 |
+
grid_size_h, grid_size_w = grid_size
|
| 25 |
+
else:
|
| 26 |
+
grid_size_h = grid_size_w = grid_size
|
| 27 |
+
grid_h = torch.arange(grid_size_h, dtype=torch.float)
|
| 28 |
+
grid_w = torch.arange(grid_size_w, dtype=torch.float)
|
| 29 |
+
grid = torch.meshgrid(grid_w, grid_h, indexing="xy")
|
| 30 |
+
grid = torch.stack(grid, dim=0)
|
| 31 |
+
grid = grid.reshape([2, 1, grid_size_h, grid_size_w])
|
| 32 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 33 |
+
return pos_embed.reshape(1, grid_size_h, grid_size_w, -1).permute(0, 3, 1, 2)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def get_2d_sincos_pos_embed_from_grid(
|
| 37 |
+
embed_dim: int, grid: torch.Tensor
|
| 38 |
+
) -> torch.Tensor:
|
| 39 |
+
"""
|
| 40 |
+
This function generates a 2D positional embedding from a given grid using sine and cosine functions.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
- embed_dim: The embedding dimension.
|
| 44 |
+
- grid: The grid to generate the embedding from.
|
| 45 |
+
|
| 46 |
+
Returns:
|
| 47 |
+
- emb: The generated 2D positional embedding.
|
| 48 |
+
"""
|
| 49 |
+
assert embed_dim % 2 == 0
|
| 50 |
+
|
| 51 |
+
# use half of dimensions to encode grid_h
|
| 52 |
+
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
|
| 53 |
+
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
|
| 54 |
+
|
| 55 |
+
emb = torch.cat([emb_h, emb_w], dim=2) # (H*W, D)
|
| 56 |
+
return emb
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def get_1d_sincos_pos_embed_from_grid(
|
| 60 |
+
embed_dim: int, pos: torch.Tensor
|
| 61 |
+
) -> torch.Tensor:
|
| 62 |
+
"""
|
| 63 |
+
This function generates a 1D positional embedding from a given grid using sine and cosine functions.
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
- embed_dim: The embedding dimension.
|
| 67 |
+
- pos: The position to generate the embedding from.
|
| 68 |
+
|
| 69 |
+
Returns:
|
| 70 |
+
- emb: The generated 1D positional embedding.
|
| 71 |
+
"""
|
| 72 |
+
assert embed_dim % 2 == 0
|
| 73 |
+
omega = torch.arange(embed_dim // 2, dtype=torch.double)
|
| 74 |
+
omega /= embed_dim / 2.0
|
| 75 |
+
omega = 1.0 / 10000**omega # (D/2,)
|
| 76 |
+
|
| 77 |
+
pos = pos.reshape(-1) # (M,)
|
| 78 |
+
out = torch.einsum("m,d->md", pos, omega) # (M, D/2), outer product
|
| 79 |
+
|
| 80 |
+
emb_sin = torch.sin(out) # (M, D/2)
|
| 81 |
+
emb_cos = torch.cos(out) # (M, D/2)
|
| 82 |
+
|
| 83 |
+
emb = torch.cat([emb_sin, emb_cos], dim=1) # (M, D)
|
| 84 |
+
return emb[None].float()
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def get_2d_embedding(xy: torch.Tensor, C: int, cat_coords: bool = True) -> torch.Tensor:
|
| 88 |
+
"""
|
| 89 |
+
This function generates a 2D positional embedding from given coordinates using sine and cosine functions.
|
| 90 |
+
|
| 91 |
+
Args:
|
| 92 |
+
- xy: The coordinates to generate the embedding from.
|
| 93 |
+
- C: The size of the embedding.
|
| 94 |
+
- cat_coords: A flag to indicate whether to concatenate the original coordinates to the embedding.
|
| 95 |
+
|
| 96 |
+
Returns:
|
| 97 |
+
- pe: The generated 2D positional embedding.
|
| 98 |
+
"""
|
| 99 |
+
B, N, D = xy.shape
|
| 100 |
+
assert D == 2
|
| 101 |
+
|
| 102 |
+
x = xy[:, :, 0:1]
|
| 103 |
+
y = xy[:, :, 1:2]
|
| 104 |
+
div_term = (
|
| 105 |
+
torch.arange(0, C, 2, device=xy.device, dtype=torch.float32) * (1000.0 / C)
|
| 106 |
+
).reshape(1, 1, int(C / 2))
|
| 107 |
+
|
| 108 |
+
pe_x = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
|
| 109 |
+
pe_y = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
|
| 110 |
+
|
| 111 |
+
pe_x[:, :, 0::2] = torch.sin(x * div_term)
|
| 112 |
+
pe_x[:, :, 1::2] = torch.cos(x * div_term)
|
| 113 |
+
|
| 114 |
+
pe_y[:, :, 0::2] = torch.sin(y * div_term)
|
| 115 |
+
pe_y[:, :, 1::2] = torch.cos(y * div_term)
|
| 116 |
+
|
| 117 |
+
pe = torch.cat([pe_x, pe_y], dim=2) # (B, N, C*3)
|
| 118 |
+
if cat_coords:
|
| 119 |
+
pe = torch.cat([xy, pe], dim=2) # (B, N, C*3+3)
|
| 120 |
+
return pe
|
cotracker/build/lib/models/core/model_utils.py
ADDED
|
@@ -0,0 +1,271 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from typing import Optional, Tuple
|
| 10 |
+
|
| 11 |
+
EPS = 1e-6
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def smart_cat(tensor1, tensor2, dim):
|
| 15 |
+
if tensor1 is None:
|
| 16 |
+
return tensor2
|
| 17 |
+
return torch.cat([tensor1, tensor2], dim=dim)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_points_on_a_grid(
|
| 21 |
+
size: int,
|
| 22 |
+
extent: Tuple[float, ...],
|
| 23 |
+
center: Optional[Tuple[float, ...]] = None,
|
| 24 |
+
device: Optional[torch.device] = torch.device("cpu"),
|
| 25 |
+
shift_grid: bool = False,
|
| 26 |
+
):
|
| 27 |
+
r"""Get a grid of points covering a rectangular region
|
| 28 |
+
|
| 29 |
+
`get_points_on_a_grid(size, extent)` generates a :attr:`size` by
|
| 30 |
+
:attr:`size` grid fo points distributed to cover a rectangular area
|
| 31 |
+
specified by `extent`.
|
| 32 |
+
|
| 33 |
+
The `extent` is a pair of integer :math:`(H,W)` specifying the height
|
| 34 |
+
and width of the rectangle.
|
| 35 |
+
|
| 36 |
+
Optionally, the :attr:`center` can be specified as a pair :math:`(c_y,c_x)`
|
| 37 |
+
specifying the vertical and horizontal center coordinates. The center
|
| 38 |
+
defaults to the middle of the extent.
|
| 39 |
+
|
| 40 |
+
Points are distributed uniformly within the rectangle leaving a margin
|
| 41 |
+
:math:`m=W/64` from the border.
|
| 42 |
+
|
| 43 |
+
It returns a :math:`(1, \text{size} \times \text{size}, 2)` tensor of
|
| 44 |
+
points :math:`P_{ij}=(x_i, y_i)` where
|
| 45 |
+
|
| 46 |
+
.. math::
|
| 47 |
+
P_{ij} = \left(
|
| 48 |
+
c_x + m -\frac{W}{2} + \frac{W - 2m}{\text{size} - 1}\, j,~
|
| 49 |
+
c_y + m -\frac{H}{2} + \frac{H - 2m}{\text{size} - 1}\, i
|
| 50 |
+
\right)
|
| 51 |
+
|
| 52 |
+
Points are returned in row-major order.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
size (int): grid size.
|
| 56 |
+
extent (tuple): height and with of the grid extent.
|
| 57 |
+
center (tuple, optional): grid center.
|
| 58 |
+
device (str, optional): Defaults to `"cpu"`.
|
| 59 |
+
|
| 60 |
+
Returns:
|
| 61 |
+
Tensor: grid.
|
| 62 |
+
"""
|
| 63 |
+
if size == 1:
|
| 64 |
+
return torch.tensor([extent[1] / 2, extent[0] / 2], device=device)[None, None]
|
| 65 |
+
|
| 66 |
+
if center is None:
|
| 67 |
+
center = [extent[0] / 2, extent[1] / 2]
|
| 68 |
+
|
| 69 |
+
margin = extent[1] / 64
|
| 70 |
+
range_y = (margin - extent[0] / 2 + center[0], extent[0] / 2 + center[0] - margin)
|
| 71 |
+
range_x = (margin - extent[1] / 2 + center[1], extent[1] / 2 + center[1] - margin)
|
| 72 |
+
grid_y, grid_x = torch.meshgrid(
|
| 73 |
+
torch.linspace(*range_y, size, device=device),
|
| 74 |
+
torch.linspace(*range_x, size, device=device),
|
| 75 |
+
indexing="ij",
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
if shift_grid:
|
| 79 |
+
# shift the grid randomly
|
| 80 |
+
# grid_x: (10, 10)
|
| 81 |
+
# grid_y: (10, 10)
|
| 82 |
+
shift_x = (range_x[1] - range_x[0]) / (size - 1)
|
| 83 |
+
shift_y = (range_y[1] - range_y[0]) / (size - 1)
|
| 84 |
+
grid_x = grid_x + torch.randn_like(grid_x) / 3 * shift_x / 2
|
| 85 |
+
grid_y = grid_y + torch.randn_like(grid_y) / 3 * shift_y / 2
|
| 86 |
+
|
| 87 |
+
# stay within the bounds
|
| 88 |
+
grid_x = torch.clamp(grid_x, range_x[0], range_x[1])
|
| 89 |
+
grid_y = torch.clamp(grid_y, range_y[0], range_y[1])
|
| 90 |
+
|
| 91 |
+
return torch.stack([grid_x, grid_y], dim=-1).reshape(1, -1, 2)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def reduce_masked_mean(input, mask, dim=None, keepdim=False):
|
| 95 |
+
r"""Masked mean
|
| 96 |
+
|
| 97 |
+
`reduce_masked_mean(x, mask)` computes the mean of a tensor :attr:`input`
|
| 98 |
+
over a mask :attr:`mask`, returning
|
| 99 |
+
|
| 100 |
+
.. math::
|
| 101 |
+
\text{output} =
|
| 102 |
+
\frac
|
| 103 |
+
{\sum_{i=1}^N \text{input}_i \cdot \text{mask}_i}
|
| 104 |
+
{\epsilon + \sum_{i=1}^N \text{mask}_i}
|
| 105 |
+
|
| 106 |
+
where :math:`N` is the number of elements in :attr:`input` and
|
| 107 |
+
:attr:`mask`, and :math:`\epsilon` is a small constant to avoid
|
| 108 |
+
division by zero.
|
| 109 |
+
|
| 110 |
+
`reduced_masked_mean(x, mask, dim)` computes the mean of a tensor
|
| 111 |
+
:attr:`input` over a mask :attr:`mask` along a dimension :attr:`dim`.
|
| 112 |
+
Optionally, the dimension can be kept in the output by setting
|
| 113 |
+
:attr:`keepdim` to `True`. Tensor :attr:`mask` must be broadcastable to
|
| 114 |
+
the same dimension as :attr:`input`.
|
| 115 |
+
|
| 116 |
+
The interface is similar to `torch.mean()`.
|
| 117 |
+
|
| 118 |
+
Args:
|
| 119 |
+
inout (Tensor): input tensor.
|
| 120 |
+
mask (Tensor): mask.
|
| 121 |
+
dim (int, optional): Dimension to sum over. Defaults to None.
|
| 122 |
+
keepdim (bool, optional): Keep the summed dimension. Defaults to False.
|
| 123 |
+
|
| 124 |
+
Returns:
|
| 125 |
+
Tensor: mean tensor.
|
| 126 |
+
"""
|
| 127 |
+
|
| 128 |
+
mask = mask.expand_as(input)
|
| 129 |
+
|
| 130 |
+
prod = input * mask
|
| 131 |
+
|
| 132 |
+
if dim is None:
|
| 133 |
+
numer = torch.sum(prod)
|
| 134 |
+
denom = torch.sum(mask)
|
| 135 |
+
else:
|
| 136 |
+
numer = torch.sum(prod, dim=dim, keepdim=keepdim)
|
| 137 |
+
denom = torch.sum(mask, dim=dim, keepdim=keepdim)
|
| 138 |
+
|
| 139 |
+
mean = numer / (EPS + denom)
|
| 140 |
+
return mean
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def bilinear_sampler(input, coords, align_corners=True, padding_mode="border"):
|
| 144 |
+
r"""Sample a tensor using bilinear interpolation
|
| 145 |
+
|
| 146 |
+
`bilinear_sampler(input, coords)` samples a tensor :attr:`input` at
|
| 147 |
+
coordinates :attr:`coords` using bilinear interpolation. It is the same
|
| 148 |
+
as `torch.nn.functional.grid_sample()` but with a different coordinate
|
| 149 |
+
convention.
|
| 150 |
+
|
| 151 |
+
The input tensor is assumed to be of shape :math:`(B, C, H, W)`, where
|
| 152 |
+
:math:`B` is the batch size, :math:`C` is the number of channels,
|
| 153 |
+
:math:`H` is the height of the image, and :math:`W` is the width of the
|
| 154 |
+
image. The tensor :attr:`coords` of shape :math:`(B, H_o, W_o, 2)` is
|
| 155 |
+
interpreted as an array of 2D point coordinates :math:`(x_i,y_i)`.
|
| 156 |
+
|
| 157 |
+
Alternatively, the input tensor can be of size :math:`(B, C, T, H, W)`,
|
| 158 |
+
in which case sample points are triplets :math:`(t_i,x_i,y_i)`. Note
|
| 159 |
+
that in this case the order of the components is slightly different
|
| 160 |
+
from `grid_sample()`, which would expect :math:`(x_i,y_i,t_i)`.
|
| 161 |
+
|
| 162 |
+
If `align_corners` is `True`, the coordinate :math:`x` is assumed to be
|
| 163 |
+
in the range :math:`[0,W-1]`, with 0 corresponding to the center of the
|
| 164 |
+
left-most image pixel :math:`W-1` to the center of the right-most
|
| 165 |
+
pixel.
|
| 166 |
+
|
| 167 |
+
If `align_corners` is `False`, the coordinate :math:`x` is assumed to
|
| 168 |
+
be in the range :math:`[0,W]`, with 0 corresponding to the left edge of
|
| 169 |
+
the left-most pixel :math:`W` to the right edge of the right-most
|
| 170 |
+
pixel.
|
| 171 |
+
|
| 172 |
+
Similar conventions apply to the :math:`y` for the range
|
| 173 |
+
:math:`[0,H-1]` and :math:`[0,H]` and to :math:`t` for the range
|
| 174 |
+
:math:`[0,T-1]` and :math:`[0,T]`.
|
| 175 |
+
|
| 176 |
+
Args:
|
| 177 |
+
input (Tensor): batch of input images.
|
| 178 |
+
coords (Tensor): batch of coordinates.
|
| 179 |
+
align_corners (bool, optional): Coordinate convention. Defaults to `True`.
|
| 180 |
+
padding_mode (str, optional): Padding mode. Defaults to `"border"`.
|
| 181 |
+
|
| 182 |
+
Returns:
|
| 183 |
+
Tensor: sampled points.
|
| 184 |
+
"""
|
| 185 |
+
|
| 186 |
+
sizes = input.shape[2:]
|
| 187 |
+
|
| 188 |
+
assert len(sizes) in [2, 3]
|
| 189 |
+
|
| 190 |
+
if len(sizes) == 3:
|
| 191 |
+
# t x y -> x y t to match dimensions T H W in grid_sample
|
| 192 |
+
coords = coords[..., [1, 2, 0]]
|
| 193 |
+
|
| 194 |
+
if align_corners:
|
| 195 |
+
coords = coords * torch.tensor(
|
| 196 |
+
[2 / max(size - 1, 1) for size in reversed(sizes)], device=coords.device
|
| 197 |
+
)
|
| 198 |
+
else:
|
| 199 |
+
coords = coords * torch.tensor([2 / size for size in reversed(sizes)], device=coords.device)
|
| 200 |
+
|
| 201 |
+
coords -= 1
|
| 202 |
+
|
| 203 |
+
return F.grid_sample(input, coords, align_corners=align_corners, padding_mode=padding_mode)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def sample_features4d(input, coords):
|
| 207 |
+
r"""Sample spatial features
|
| 208 |
+
|
| 209 |
+
`sample_features4d(input, coords)` samples the spatial features
|
| 210 |
+
:attr:`input` represented by a 4D tensor :math:`(B, C, H, W)`.
|
| 211 |
+
|
| 212 |
+
The field is sampled at coordinates :attr:`coords` using bilinear
|
| 213 |
+
interpolation. :attr:`coords` is assumed to be of shape :math:`(B, R,
|
| 214 |
+
3)`, where each sample has the format :math:`(x_i, y_i)`. This uses the
|
| 215 |
+
same convention as :func:`bilinear_sampler` with `align_corners=True`.
|
| 216 |
+
|
| 217 |
+
The output tensor has one feature per point, and has shape :math:`(B,
|
| 218 |
+
R, C)`.
|
| 219 |
+
|
| 220 |
+
Args:
|
| 221 |
+
input (Tensor): spatial features.
|
| 222 |
+
coords (Tensor): points.
|
| 223 |
+
|
| 224 |
+
Returns:
|
| 225 |
+
Tensor: sampled features.
|
| 226 |
+
"""
|
| 227 |
+
|
| 228 |
+
B, _, _, _ = input.shape
|
| 229 |
+
|
| 230 |
+
# B R 2 -> B R 1 2
|
| 231 |
+
coords = coords.unsqueeze(2)
|
| 232 |
+
|
| 233 |
+
# B C R 1
|
| 234 |
+
feats = bilinear_sampler(input, coords)
|
| 235 |
+
|
| 236 |
+
return feats.permute(0, 2, 1, 3).view(
|
| 237 |
+
B, -1, feats.shape[1] * feats.shape[3]
|
| 238 |
+
) # B C R 1 -> B R C
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def sample_features5d(input, coords):
|
| 242 |
+
r"""Sample spatio-temporal features
|
| 243 |
+
|
| 244 |
+
`sample_features5d(input, coords)` works in the same way as
|
| 245 |
+
:func:`sample_features4d` but for spatio-temporal features and points:
|
| 246 |
+
:attr:`input` is a 5D tensor :math:`(B, T, C, H, W)`, :attr:`coords` is
|
| 247 |
+
a :math:`(B, R1, R2, 3)` tensor of spatio-temporal point :math:`(t_i,
|
| 248 |
+
x_i, y_i)`. The output tensor has shape :math:`(B, R1, R2, C)`.
|
| 249 |
+
|
| 250 |
+
Args:
|
| 251 |
+
input (Tensor): spatio-temporal features.
|
| 252 |
+
coords (Tensor): spatio-temporal points.
|
| 253 |
+
|
| 254 |
+
Returns:
|
| 255 |
+
Tensor: sampled features.
|
| 256 |
+
"""
|
| 257 |
+
|
| 258 |
+
B, T, _, _, _ = input.shape
|
| 259 |
+
|
| 260 |
+
# B T C H W -> B C T H W
|
| 261 |
+
input = input.permute(0, 2, 1, 3, 4)
|
| 262 |
+
|
| 263 |
+
# B R1 R2 3 -> B R1 R2 1 3
|
| 264 |
+
coords = coords.unsqueeze(3)
|
| 265 |
+
|
| 266 |
+
# B C R1 R2 1
|
| 267 |
+
feats = bilinear_sampler(input, coords)
|
| 268 |
+
|
| 269 |
+
return feats.permute(0, 2, 3, 1, 4).view(
|
| 270 |
+
B, feats.shape[2], feats.shape[3], feats.shape[1]
|
| 271 |
+
) # B C R1 R2 1 -> B R1 R2 C
|
cotracker/build/lib/models/evaluation_predictor.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from typing import Tuple
|
| 10 |
+
|
| 11 |
+
from cotracker.models.core.cotracker.cotracker import CoTracker2
|
| 12 |
+
from cotracker.models.core.model_utils import get_points_on_a_grid
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class EvaluationPredictor(torch.nn.Module):
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
cotracker_model: CoTracker2,
|
| 19 |
+
interp_shape: Tuple[int, int] = (384, 512),
|
| 20 |
+
grid_size: int = 5,
|
| 21 |
+
local_grid_size: int = 8,
|
| 22 |
+
single_point: bool = True,
|
| 23 |
+
n_iters: int = 6,
|
| 24 |
+
) -> None:
|
| 25 |
+
super(EvaluationPredictor, self).__init__()
|
| 26 |
+
self.grid_size = grid_size
|
| 27 |
+
self.local_grid_size = local_grid_size
|
| 28 |
+
self.single_point = single_point
|
| 29 |
+
self.interp_shape = interp_shape
|
| 30 |
+
self.n_iters = n_iters
|
| 31 |
+
|
| 32 |
+
self.model = cotracker_model
|
| 33 |
+
self.model.eval()
|
| 34 |
+
|
| 35 |
+
def forward(self, video, queries):
|
| 36 |
+
queries = queries.clone()
|
| 37 |
+
B, T, C, H, W = video.shape
|
| 38 |
+
B, N, D = queries.shape
|
| 39 |
+
|
| 40 |
+
assert D == 3
|
| 41 |
+
|
| 42 |
+
video = video.reshape(B * T, C, H, W)
|
| 43 |
+
video = F.interpolate(video, tuple(self.interp_shape), mode="bilinear", align_corners=True)
|
| 44 |
+
video = video.reshape(B, T, 3, self.interp_shape[0], self.interp_shape[1])
|
| 45 |
+
|
| 46 |
+
device = video.device
|
| 47 |
+
|
| 48 |
+
queries[:, :, 1] *= (self.interp_shape[1] - 1) / (W - 1)
|
| 49 |
+
queries[:, :, 2] *= (self.interp_shape[0] - 1) / (H - 1)
|
| 50 |
+
|
| 51 |
+
if self.single_point:
|
| 52 |
+
traj_e = torch.zeros((B, T, N, 2), device=device)
|
| 53 |
+
vis_e = torch.zeros((B, T, N), device=device)
|
| 54 |
+
for pind in range((N)):
|
| 55 |
+
query = queries[:, pind : pind + 1]
|
| 56 |
+
|
| 57 |
+
t = query[0, 0, 0].long()
|
| 58 |
+
|
| 59 |
+
traj_e_pind, vis_e_pind = self._process_one_point(video, query)
|
| 60 |
+
traj_e[:, t:, pind : pind + 1] = traj_e_pind[:, :, :1]
|
| 61 |
+
vis_e[:, t:, pind : pind + 1] = vis_e_pind[:, :, :1]
|
| 62 |
+
else:
|
| 63 |
+
if self.grid_size > 0:
|
| 64 |
+
xy = get_points_on_a_grid(self.grid_size, video.shape[3:])
|
| 65 |
+
xy = torch.cat([torch.zeros_like(xy[:, :, :1]), xy], dim=2).to(device) #
|
| 66 |
+
queries = torch.cat([queries, xy], dim=1) #
|
| 67 |
+
|
| 68 |
+
traj_e, vis_e, __ = self.model(
|
| 69 |
+
video=video,
|
| 70 |
+
queries=queries,
|
| 71 |
+
iters=self.n_iters,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
traj_e[:, :, :, 0] *= (W - 1) / float(self.interp_shape[1] - 1)
|
| 75 |
+
traj_e[:, :, :, 1] *= (H - 1) / float(self.interp_shape[0] - 1)
|
| 76 |
+
return traj_e, vis_e
|
| 77 |
+
|
| 78 |
+
def _process_one_point(self, video, query):
|
| 79 |
+
t = query[0, 0, 0].long()
|
| 80 |
+
|
| 81 |
+
device = query.device
|
| 82 |
+
if self.local_grid_size > 0:
|
| 83 |
+
xy_target = get_points_on_a_grid(
|
| 84 |
+
self.local_grid_size,
|
| 85 |
+
(50, 50),
|
| 86 |
+
[query[0, 0, 2].item(), query[0, 0, 1].item()],
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
xy_target = torch.cat([torch.zeros_like(xy_target[:, :, :1]), xy_target], dim=2).to(
|
| 90 |
+
device
|
| 91 |
+
) #
|
| 92 |
+
query = torch.cat([query, xy_target], dim=1) #
|
| 93 |
+
|
| 94 |
+
if self.grid_size > 0:
|
| 95 |
+
xy = get_points_on_a_grid(self.grid_size, video.shape[3:])
|
| 96 |
+
xy = torch.cat([torch.zeros_like(xy[:, :, :1]), xy], dim=2).to(device) #
|
| 97 |
+
query = torch.cat([query, xy], dim=1) #
|
| 98 |
+
# crop the video to start from the queried frame
|
| 99 |
+
query[0, 0, 0] = 0
|
| 100 |
+
traj_e_pind, vis_e_pind, __ = self.model(
|
| 101 |
+
video=video[:, t:], queries=query, iters=self.n_iters
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
return traj_e_pind, vis_e_pind
|
cotracker/build/lib/utils/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|