Spaces:
Runtime error

Runtime error
Upload 47 files
Browse files- .gitattributes +0 -1
- .gitignore +145 -0
- LICENSE +201 -0
- app.py +37 -0
- documents/docs/1-搜索功能.md +0 -0
- documents/docs/2-总结功能.md +19 -0
- documents/docs/3-visualization.md +2 -0
- documents/docs/4-文献分析平台比较.md +56 -0
- documents/docs/index.md +43 -0
- documents/mkdocs.yml +3 -0
- inference_hf/__init__.py +1 -0
- inference_hf/_inference.py +53 -0
- lrt/__init__.py +3 -0
- lrt/academic_query/__init__.py +1 -0
- lrt/academic_query/academic.py +35 -0
- lrt/clustering/__init__.py +2 -0
- lrt/clustering/clustering_pipeline.py +108 -0
- lrt/clustering/clusters.py +91 -0
- lrt/clustering/config.py +11 -0
- lrt/clustering/models/__init__.py +1 -0
- lrt/clustering/models/adapter.py +25 -0
- lrt/clustering/models/keyBartPlus.py +411 -0
- lrt/lrt.py +144 -0
- lrt/utils/__init__.py +3 -0
- lrt/utils/article.py +412 -0
- lrt/utils/dimension_reduction.py +17 -0
- lrt/utils/functions.py +180 -0
- lrt/utils/union_find.py +55 -0
- lrt_instance/__init__.py +1 -0
- lrt_instance/instances.py +4 -0
- requirements.txt +15 -0
- scripts/inference/inference.py +17 -0
- scripts/inference/lrt.ipynb +310 -0
- scripts/queryAPI/API_Summary.ipynb +0 -0
- scripts/readme.md +5 -0
- scripts/tests/lrt_test_run.py +65 -0
- scripts/tests/model_test.py +103 -0
- scripts/train/KeyBartAdapter_train.ipynb +0 -0
- scripts/train/train.py +171 -0
- setup.py +38 -0
- templates/test.html +213 -0
- widgets/__init__.py +3 -0
- widgets/body.py +117 -0
- widgets/charts.py +80 -0
- widgets/sidebar.py +96 -0
- widgets/static/tum.png +0 -0
- widgets/utils.py +17 -0
.gitattributes
CHANGED
|
@@ -2,7 +2,6 @@
|
|
| 2 |
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
*.h5 filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 2 |
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 5 |
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 6 |
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
*.h5 filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
venv
|
| 2 |
+
test.py
|
| 3 |
+
.config.json
|
| 4 |
+
__pycache__
|
| 5 |
+
.idea
|
| 6 |
+
*.sh
|
| 7 |
+
|
| 8 |
+
# Byte-compiled / optimized / DLL files
|
| 9 |
+
__pycache__/
|
| 10 |
+
*.py[cod]
|
| 11 |
+
*$py.class
|
| 12 |
+
|
| 13 |
+
# C extensions
|
| 14 |
+
*.so
|
| 15 |
+
|
| 16 |
+
# Distribution / packaging
|
| 17 |
+
.config.json
|
| 18 |
+
test.py
|
| 19 |
+
pages
|
| 20 |
+
KeyBartAdapter
|
| 21 |
+
scripts/train/KeyBartAdapter/
|
| 22 |
+
docs/site
|
| 23 |
+
.Python
|
| 24 |
+
devenv
|
| 25 |
+
.idea
|
| 26 |
+
build/
|
| 27 |
+
develop-eggs/
|
| 28 |
+
dist/
|
| 29 |
+
downloads/
|
| 30 |
+
eggs/
|
| 31 |
+
.eggs/
|
| 32 |
+
lib/
|
| 33 |
+
lib64/
|
| 34 |
+
parts/
|
| 35 |
+
sdist/
|
| 36 |
+
var/
|
| 37 |
+
wheels/
|
| 38 |
+
pip-wheel-metadata/
|
| 39 |
+
share/python-wheels/
|
| 40 |
+
*.egg-info/
|
| 41 |
+
.installed.cfg
|
| 42 |
+
*.egg
|
| 43 |
+
MANIFEST
|
| 44 |
+
|
| 45 |
+
# PyInstaller
|
| 46 |
+
# Usually these files are written by a python script from a template
|
| 47 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 48 |
+
*.manifest
|
| 49 |
+
*.spec
|
| 50 |
+
|
| 51 |
+
# Installer logs
|
| 52 |
+
pip-log.txt
|
| 53 |
+
pip-delete-this-directory.txt
|
| 54 |
+
|
| 55 |
+
# Unit test / coverage reports
|
| 56 |
+
htmlcov/
|
| 57 |
+
.tox/
|
| 58 |
+
.nox/
|
| 59 |
+
.coverage
|
| 60 |
+
.coverage.*
|
| 61 |
+
.cache
|
| 62 |
+
nosetests.xml
|
| 63 |
+
coverage.xml
|
| 64 |
+
*.cover
|
| 65 |
+
*.py,cover
|
| 66 |
+
.hypothesis/
|
| 67 |
+
.pytest_cache/
|
| 68 |
+
|
| 69 |
+
# Translations
|
| 70 |
+
*.mo
|
| 71 |
+
*.pot
|
| 72 |
+
|
| 73 |
+
# Django stuff:
|
| 74 |
+
*.log
|
| 75 |
+
local_settings.py
|
| 76 |
+
db.sqlite3
|
| 77 |
+
db.sqlite3-journal
|
| 78 |
+
|
| 79 |
+
# Flask stuff:
|
| 80 |
+
instance/
|
| 81 |
+
.webassets-cache
|
| 82 |
+
|
| 83 |
+
# Scrapy stuff:
|
| 84 |
+
.scrapy
|
| 85 |
+
|
| 86 |
+
# Sphinx documentation
|
| 87 |
+
docs/_build/
|
| 88 |
+
|
| 89 |
+
# PyBuilder
|
| 90 |
+
target/
|
| 91 |
+
|
| 92 |
+
# Jupyter Notebook
|
| 93 |
+
.ipynb_checkpoints
|
| 94 |
+
|
| 95 |
+
# IPython
|
| 96 |
+
profile_default/
|
| 97 |
+
ipython_config.py
|
| 98 |
+
|
| 99 |
+
# pyenv
|
| 100 |
+
.python-version
|
| 101 |
+
|
| 102 |
+
# pipenv
|
| 103 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 104 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 105 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 106 |
+
# install all needed dependencies.
|
| 107 |
+
#Pipfile.lock
|
| 108 |
+
|
| 109 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 110 |
+
__pypackages__/
|
| 111 |
+
|
| 112 |
+
# Celery stuff
|
| 113 |
+
celerybeat-schedule
|
| 114 |
+
celerybeat.pid
|
| 115 |
+
|
| 116 |
+
# SageMath parsed files
|
| 117 |
+
*.sage.py
|
| 118 |
+
|
| 119 |
+
# Environments
|
| 120 |
+
.env
|
| 121 |
+
.venv
|
| 122 |
+
env/
|
| 123 |
+
venv/
|
| 124 |
+
ENV/
|
| 125 |
+
env.bak/
|
| 126 |
+
venv.bak/
|
| 127 |
+
|
| 128 |
+
# Spyder project settings
|
| 129 |
+
.spyderproject
|
| 130 |
+
.spyproject
|
| 131 |
+
|
| 132 |
+
# Rope project settings
|
| 133 |
+
.ropeproject
|
| 134 |
+
|
| 135 |
+
# mkdocs documentation
|
| 136 |
+
/site
|
| 137 |
+
|
| 138 |
+
# mypy
|
| 139 |
+
.mypy_cache/
|
| 140 |
+
.dmypy.json
|
| 141 |
+
dmypy.json
|
| 142 |
+
|
| 143 |
+
# Pyre type checker
|
| 144 |
+
.pyre/
|
| 145 |
+
*.py~
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
app.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from widgets import *
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# sidebar content
|
| 8 |
+
platforms, number_papers, start_year, end_year, hyperparams = render_sidebar()
|
| 9 |
+
|
| 10 |
+
# body head
|
| 11 |
+
with st.form("my_form",clear_on_submit=False):
|
| 12 |
+
st.markdown('''# 👋 Hi, enter your query here :)''')
|
| 13 |
+
query_input = st.text_input(
|
| 14 |
+
'Enter your query:',
|
| 15 |
+
placeholder='''e.g. "Machine learning"''',
|
| 16 |
+
# label_visibility='collapsed',
|
| 17 |
+
value=''
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
show_preview = st.checkbox('show paper preview')
|
| 21 |
+
|
| 22 |
+
# Every form must have a submit button.
|
| 23 |
+
submitted = st.form_submit_button("Search")
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
if submitted:
|
| 27 |
+
# body
|
| 28 |
+
render_body(platforms, number_papers, 5, query_input,
|
| 29 |
+
show_preview, start_year, end_year,
|
| 30 |
+
hyperparams,
|
| 31 |
+
hyperparams['standardization'])
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
documents/docs/1-搜索功能.md
ADDED
|
File without changes
|
documents/docs/2-总结功能.md
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 2 Research Trends Summarization
|
| 2 |
+
|
| 3 |
+
## Model Architecture
|
| 4 |
+

|
| 5 |
+
|
| 6 |
+
### 1 Baseline Configuration
|
| 7 |
+
1. pre-trained language model: `sentence-transformers/all-MiniLM-L6-v2`
|
| 8 |
+
2. dimension reduction: `None`
|
| 9 |
+
3. clustering algorithms: `kmeans`
|
| 10 |
+
4. keywords extraction model: `keyphrase-transformer`
|
| 11 |
+
|
| 12 |
+
[[example run](https://github.com/Mondkuchen/idp_LiteratureResearch_Tool/blob/main/example_run.py)] [[results](https://github.com/Mondkuchen/idp_LiteratureResearch_Tool/blob/main/examples/IDP.ipynb)]
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
### TODO:
|
| 16 |
+
1. clustering: using other clustering algorithms such as Gausian Mixture Model (GMM)
|
| 17 |
+
2. keywords extraction model: train another model
|
| 18 |
+
3. add dimension reduction
|
| 19 |
+
4. better PLM: sentence-transformers/sentence-t5-xxl
|
documents/docs/3-visualization.md
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 3 Visualization
|
| 2 |
+
[web app](https://huggingface.co/spaces/Adapting/literature-research-tool)
|
documents/docs/4-文献分析平台比较.md
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 4 Other Literature Research Tools
|
| 2 |
+
## 1 Citespace
|
| 3 |
+
|
| 4 |
+
> 作者:爱学习的毛里
|
| 5 |
+
> 链接:https://www.zhihu.com/question/27463829/answer/284247493
|
| 6 |
+
> 来源:知乎
|
| 7 |
+
> 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
|
| 8 |
+
|
| 9 |
+
一、工作原理
|
| 10 |
+
简单来讲,citespace主要基于“共现聚类”思想:
|
| 11 |
+
|
| 12 |
+
1. 首先对科学文献中的信息单元进行提取
|
| 13 |
+
- 包括文献层面上的参考文献,主题层面上的**关键词**、主题词、学科、领域分类等,主体层面上的作者、机构、国家、期刊等
|
| 14 |
+
2. 然后根据信息单元间的联系类型和强度进行重构,形成不同意义的网络结构
|
| 15 |
+
- 如关键词共现、作者合作、文献共被引等,
|
| 16 |
+
- 网络中的节点代表文献信息单元,连线代表节点间的联系(共现)
|
| 17 |
+
3. 最后通过对节点、连线及网络结构进行测度、统计分析(聚类、突现词检测等)和可视化,发现特定学科和领域知识结构的隐含模式和规律。
|
| 18 |
+
|
| 19 |
+
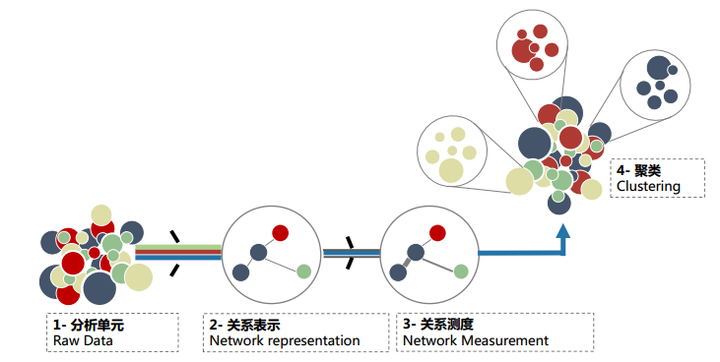*共现聚类思想*
|
| 20 |
+
|
| 21 |
+
二、主要用途
|
| 22 |
+
|
| 23 |
+
1. **<u>研究热点分析</u>**:一般利用关键词/主题词共现
|
| 24 |
+
2. 研究前沿探测:共被引、耦合、共词、突现词检测都有人使用,但因为对“研究前沿”的定义尚未统一,所以方法的选择和图谱结果的解读上众说纷纭
|
| 25 |
+
3. 研究演进路径分析:将时序维度与主题聚类结合,例如citespace中的时间线图和时区图
|
| 26 |
+
4. 研究群体发现:一般建立作者/机构合作、作者耦合等网络,可以发现研究小团体、核心作者/机构等
|
| 27 |
+
5. 学科/领域/知识交叉和流动分析:一般建立期刊/学科等的共现网络,可以研究学科之间的交叉、知识流动和融合等除分析 科学文献 外,citespace也可以用来分析 专利技术文献,用途与科学文献类似,包括技术研究热点、趋势、结构、核心专利权人或团体的识别等。
|
| 28 |
+
|
| 29 |
+
三、工作流程
|
| 30 |
+
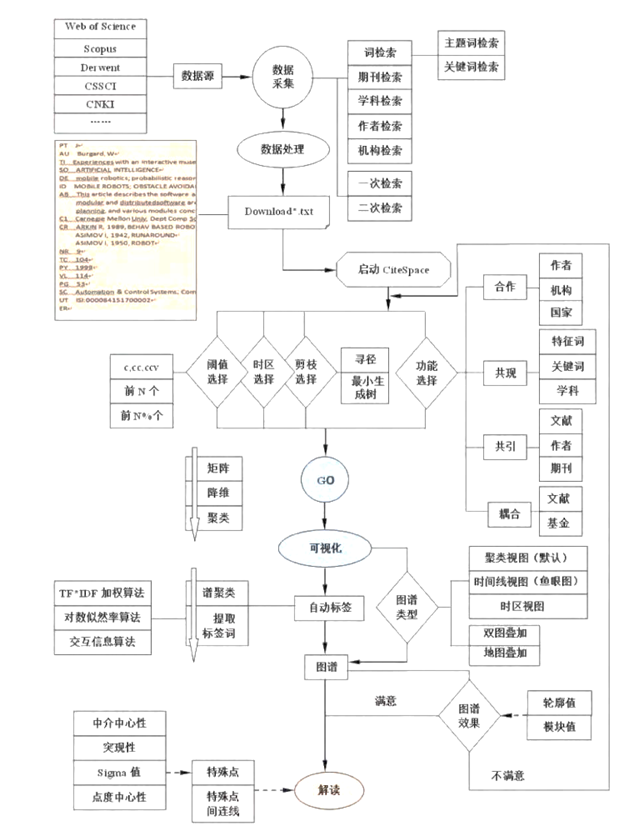
|
| 31 |
+
*摘自《引文空间分析原理与应用》*
|
| 32 |
+
|
| 33 |
+
### 聚类算法
|
| 34 |
+
|
| 35 |
+
CiteSpace提供的算法有3个,3个算法的名称分别是:
|
| 36 |
+
|
| 37 |
+
- LSI/LSA: Latent Semantic Indexing/Latent Semantic Analysis 浅语义索引
|
| 38 |
+
[intro](https://www.cnblogs.com/pinard/p/6805861.html)
|
| 39 |
+
|
| 40 |
+
- LLR: Log Likelihood Ratio 对数极大似然率
|
| 41 |
+
|
| 42 |
+
- MI: Mutual Information 互信息
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
对不同的数据,3种算法表现一样,可在实践中多做实践。
|
| 46 |
+
|
| 47 |
+
[paper](https://readpaper.com/paper/2613897633)
|
| 48 |
+
|
| 49 |
+
## 2 VOSviewer
|
| 50 |
+
|
| 51 |
+
VOSviewer的处理流程与大部分的科学知识图谱类软件类似,即文件导入——信息单元抽取(如作者、关键词等)——建立共现矩阵——利用相似度计算对关系进行标准化处理——统计分析(一般描述统计+聚类)——可视化展现(布局+其它图形属性映射)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
Normalization, mapping, and clustering
|
| 55 |
+
|
| 56 |
+
[paper](https://www.vosviewer.com/download/f-x2.pdf) (See Appendix)
|
documents/docs/index.md
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Intro
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
<!-- - [x] objective/Aim of the practical part
|
| 5 |
+
- [x] tasks/ work packages,
|
| 6 |
+
- [x] Timeline and Milestones
|
| 7 |
+
- [x] Brief introduction of the practice partner
|
| 8 |
+
- [x] Description of theoretical part and explanation of how the content of the lecture(s)/seminar(s) supports student in completing the practical part. -->
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
## IDP Theme
|
| 14 |
+
IDP Theme: Developing a Literature Research Tool that Automatically Search Literature and Summarize the Research Trends.
|
| 15 |
+
|
| 16 |
+
## Objective
|
| 17 |
+
In this IDP, we are going to develop a literature research tool that enables three functionalities:
|
| 18 |
+
1. Automatically search the most recent literature filtered by keywords on three literature platforms: Elvsier, IEEE and Google Scholar
|
| 19 |
+
2. Automatically summarize the most popular research directions and trends in the searched literature from step 1
|
| 20 |
+
3. visualize the results from step 1 and step 2
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Timeline & Milestones & Tasks
|
| 24 |
+

|
| 25 |
+
|
| 26 |
+
#### Tasks
|
| 27 |
+
| Label | Start | End | Duration | Description |
|
| 28 |
+
| ------- |------------| ---------- |----------| -------------------------------------------------------------------------------------------------------- |
|
| 29 |
+
| Task #1 | 15/11/2022 | 15/12/2022 | 30 days | Implement literature search by keywords on three literature platforms: Elvsier, IEEE, and Google Scholar |
|
| 30 |
+
| Task #2 | 15/12/2022 | 15/02/2023 | 60 days | Implement automatic summarization of research trends in the searched literature |
|
| 31 |
+
| Task #3 | 15/02/2022 | 15/03/2022 | 30 days | visualization of the tool (web app) |
|
| 32 |
+
| Task #4 | 01/03/2022 | 01/05/2022 | 60 days | write report and presentation |
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
## Correlation between the theoretical course and practical project
|
| 36 |
+
The accompanying theory courses *Machine Learning and Optimization* or *Machine Learning for Communication* teach basic and advanced machine learning (ML) and deep learning (DL) knowledge.
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
The core part of the project, in my opinion, is the automatic summarization of research trends/directions of the papers, which can be modeled as a **Topic Modeling** task in Natural Language Processing (NLP). This task requires machine learning and deep learning knowledge, such as word embeddings, transformers architecture, etc.
|
| 40 |
+
|
| 41 |
+
Therefore, I would like to take the Machine Learning and Optimization course or Machine learning for Communication course from EI department. And I think these theory courses should be necessary for a good ML/DL basis.
|
| 42 |
+
|
| 43 |
+
|
documents/mkdocs.yml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
site_name: LRT Document
|
| 2 |
+
theme: material
|
| 3 |
+
|
inference_hf/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from ._inference import InferenceHF
|
inference_hf/_inference.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import requests
|
| 3 |
+
from typing import Union,List
|
| 4 |
+
import aiohttp
|
| 5 |
+
from asyncio import run
|
| 6 |
+
|
| 7 |
+
class InferenceHF:
|
| 8 |
+
headers = {"Authorization": f"Bearer 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"}
|
| 9 |
+
API_URL = "https://api-inference.huggingface.co/models/"
|
| 10 |
+
|
| 11 |
+
@classmethod
|
| 12 |
+
def inference(cls, inputs: Union[List[str], str], model_name:str) ->dict:
|
| 13 |
+
payload = dict(
|
| 14 |
+
inputs = inputs,
|
| 15 |
+
options = dict(
|
| 16 |
+
wait_for_model=True
|
| 17 |
+
)
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
data = json.dumps(payload)
|
| 21 |
+
response = requests.request("POST", cls.API_URL+model_name, headers=cls.headers, data=data)
|
| 22 |
+
return json.loads(response.content.decode("utf-8"))
|
| 23 |
+
|
| 24 |
+
@classmethod
|
| 25 |
+
async def async_inference(cls, inputs: Union[List[str], str], model_name: str) -> dict:
|
| 26 |
+
payload = dict(
|
| 27 |
+
inputs=inputs,
|
| 28 |
+
options=dict(
|
| 29 |
+
wait_for_model=True
|
| 30 |
+
)
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
data = json.dumps(payload)
|
| 34 |
+
|
| 35 |
+
async with aiohttp.ClientSession() as session:
|
| 36 |
+
async with session.post(cls.API_URL + model_name, data=data, headers=cls.headers) as response:
|
| 37 |
+
return await response.json()
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
if __name__ == '__main__':
|
| 41 |
+
print(InferenceHF.inference(
|
| 42 |
+
inputs='hi how are you?',
|
| 43 |
+
model_name= 't5-small'
|
| 44 |
+
))
|
| 45 |
+
|
| 46 |
+
print(
|
| 47 |
+
run(InferenceHF.async_inference(
|
| 48 |
+
inputs='hi how are you?',
|
| 49 |
+
model_name='t5-small'
|
| 50 |
+
))
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
|
lrt/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .lrt import LiteratureResearchTool
|
| 2 |
+
from .clustering import Configuration
|
| 3 |
+
from .utils import Article, ArticleList
|
lrt/academic_query/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .academic import AcademicQuery
|
lrt/academic_query/academic.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from requests_toolkit import ArxivQuery,IEEEQuery,PaperWithCodeQuery
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
class AcademicQuery:
|
| 5 |
+
@classmethod
|
| 6 |
+
def arxiv(cls,
|
| 7 |
+
query: str,
|
| 8 |
+
max_results: int = 50
|
| 9 |
+
) -> List[dict]:
|
| 10 |
+
ret = ArxivQuery.query(query,'',0,max_results)
|
| 11 |
+
if not isinstance(ret,list):
|
| 12 |
+
return [ret]
|
| 13 |
+
return ret
|
| 14 |
+
|
| 15 |
+
@classmethod
|
| 16 |
+
def ieee(cls,
|
| 17 |
+
query: str,
|
| 18 |
+
start_year: int,
|
| 19 |
+
end_year: int,
|
| 20 |
+
num_papers: int = 200
|
| 21 |
+
) -> List[dict]:
|
| 22 |
+
IEEEQuery.__setup_api_key__('vpd9yy325enruv27zj2d353e')
|
| 23 |
+
ret = IEEEQuery.query(query,start_year,end_year,num_papers)
|
| 24 |
+
if not isinstance(ret,list):
|
| 25 |
+
return [ret]
|
| 26 |
+
return ret
|
| 27 |
+
|
| 28 |
+
@classmethod
|
| 29 |
+
def paper_with_code(cls,
|
| 30 |
+
query: str,
|
| 31 |
+
items_per_page = 50) ->List[dict]:
|
| 32 |
+
ret = PaperWithCodeQuery.query(query, 1,items_per_page)
|
| 33 |
+
if not isinstance(ret, list):
|
| 34 |
+
return [ret]
|
| 35 |
+
return ret
|
lrt/clustering/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .clustering_pipeline import ClusterPipeline, ClusterList
|
| 2 |
+
from .config import Configuration,BaselineConfig
|
lrt/clustering/clustering_pipeline.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from .config import BaselineConfig, Configuration
|
| 3 |
+
from ..utils import __create_model__
|
| 4 |
+
import numpy as np
|
| 5 |
+
# from sklearn.cluster import KMeans
|
| 6 |
+
from sklearn.preprocessing import StandardScaler
|
| 7 |
+
# from yellowbrick.cluster import KElbowVisualizer
|
| 8 |
+
from .clusters import ClusterList
|
| 9 |
+
from unsupervised_learning.clustering import GaussianMixture, Silhouette
|
| 10 |
+
|
| 11 |
+
class ClusterPipeline:
|
| 12 |
+
def __init__(self, config:Configuration = None):
|
| 13 |
+
if config is None:
|
| 14 |
+
self.__setup__(BaselineConfig())
|
| 15 |
+
else:
|
| 16 |
+
self.__setup__(config)
|
| 17 |
+
|
| 18 |
+
def __setup__(self, config:Configuration):
|
| 19 |
+
self.PTM = __create_model__(config.plm)
|
| 20 |
+
self.dimension_reduction = __create_model__(config.dimension_reduction)
|
| 21 |
+
self.clustering = __create_model__(config.clustering)
|
| 22 |
+
self.keywords_extraction = __create_model__(config.keywords_extraction)
|
| 23 |
+
|
| 24 |
+
def __1_generate_word_embeddings__(self, documents: List[str]):
|
| 25 |
+
'''
|
| 26 |
+
|
| 27 |
+
:param documents: a list of N strings:
|
| 28 |
+
:return: np.ndarray: Nx384 (sentence-transformers)
|
| 29 |
+
'''
|
| 30 |
+
print(f'>>> start generating word embeddings...')
|
| 31 |
+
print(f'>>> successfully generated word embeddings...')
|
| 32 |
+
return self.PTM.encode(documents)
|
| 33 |
+
|
| 34 |
+
def __2_dimenstion_reduction__(self, embeddings):
|
| 35 |
+
'''
|
| 36 |
+
|
| 37 |
+
:param embeddings: NxD
|
| 38 |
+
:return: Nxd, d<<D
|
| 39 |
+
'''
|
| 40 |
+
if self.dimension_reduction is None:
|
| 41 |
+
return embeddings
|
| 42 |
+
print(f'>>> start dimension reduction...')
|
| 43 |
+
embeddings = self.dimension_reduction.dimension_reduction(embeddings)
|
| 44 |
+
print(f'>>> finished dimension reduction...')
|
| 45 |
+
return embeddings
|
| 46 |
+
|
| 47 |
+
def __3_clustering__(self, embeddings, return_cluster_centers = False, max_k: int =10, standarization = False):
|
| 48 |
+
'''
|
| 49 |
+
|
| 50 |
+
:param embeddings: Nxd
|
| 51 |
+
:return:
|
| 52 |
+
'''
|
| 53 |
+
if self.clustering is None:
|
| 54 |
+
return embeddings
|
| 55 |
+
else:
|
| 56 |
+
print(f'>>> start clustering...')
|
| 57 |
+
|
| 58 |
+
######## new: standarization ########
|
| 59 |
+
if standarization:
|
| 60 |
+
print(f'>>> start standardization...')
|
| 61 |
+
scaler = StandardScaler()
|
| 62 |
+
embeddings = scaler.fit_transform(embeddings)
|
| 63 |
+
print(f'>>> finished standardization...')
|
| 64 |
+
######## new: standarization ########
|
| 65 |
+
|
| 66 |
+
best_k_algo = Silhouette(GaussianMixture,2,max_k)
|
| 67 |
+
best_k = best_k_algo.get_best_k(embeddings)
|
| 68 |
+
print(f'>>> The best K is {best_k}.')
|
| 69 |
+
|
| 70 |
+
labels, cluster_centers = self.clustering(embeddings, k=best_k)
|
| 71 |
+
clusters = ClusterList(best_k)
|
| 72 |
+
clusters.instantiate(labels)
|
| 73 |
+
print(f'>>> finished clustering...')
|
| 74 |
+
|
| 75 |
+
if return_cluster_centers:
|
| 76 |
+
return clusters, cluster_centers
|
| 77 |
+
return clusters
|
| 78 |
+
|
| 79 |
+
def __4_keywords_extraction__(self, clusters: ClusterList, documents: List[str]):
|
| 80 |
+
'''
|
| 81 |
+
|
| 82 |
+
:param clusters: N documents
|
| 83 |
+
:return: clusters, where each cluster has added keyphrases
|
| 84 |
+
'''
|
| 85 |
+
if self.keywords_extraction is None:
|
| 86 |
+
return clusters
|
| 87 |
+
else:
|
| 88 |
+
print(f'>>> start keywords extraction')
|
| 89 |
+
for cluster in clusters:
|
| 90 |
+
doc_ids = cluster.elements()
|
| 91 |
+
input_abstracts = [documents[i] for i in doc_ids] #[str]
|
| 92 |
+
keyphrases = self.keywords_extraction(input_abstracts) #[{keys...}]
|
| 93 |
+
cluster.add_keyphrase(keyphrases)
|
| 94 |
+
# for doc_id in doc_ids:
|
| 95 |
+
# keyphrases = self.keywords_extraction(documents[doc_id])
|
| 96 |
+
# cluster.add_keyphrase(keyphrases)
|
| 97 |
+
print(f'>>> finished keywords extraction')
|
| 98 |
+
return clusters
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def __call__(self, documents: List[str], max_k:int, standarization = False):
|
| 102 |
+
print(f'>>> pipeline starts...')
|
| 103 |
+
x = self.__1_generate_word_embeddings__(documents)
|
| 104 |
+
x = self.__2_dimenstion_reduction__(x)
|
| 105 |
+
clusters = self.__3_clustering__(x,max_k=max_k,standarization=standarization)
|
| 106 |
+
outputs = self.__4_keywords_extraction__(clusters, documents)
|
| 107 |
+
print(f'>>> pipeline finished!\n')
|
| 108 |
+
return outputs
|
lrt/clustering/clusters.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Iterable, Union
|
| 2 |
+
from pprint import pprint
|
| 3 |
+
|
| 4 |
+
class KeyphraseCount:
|
| 5 |
+
|
| 6 |
+
def __init__(self, keyphrase: str, count: int) -> None:
|
| 7 |
+
super().__init__()
|
| 8 |
+
self.keyphrase = keyphrase
|
| 9 |
+
self.count = count
|
| 10 |
+
|
| 11 |
+
@classmethod
|
| 12 |
+
def reduce(cls, kcs: list) :
|
| 13 |
+
'''
|
| 14 |
+
kcs: List[KeyphraseCount]
|
| 15 |
+
'''
|
| 16 |
+
keys = ''
|
| 17 |
+
count = 0
|
| 18 |
+
|
| 19 |
+
for i in range(len(kcs)-1):
|
| 20 |
+
kc = kcs[i]
|
| 21 |
+
keys += kc.keyphrase + '/'
|
| 22 |
+
count += kc.count
|
| 23 |
+
|
| 24 |
+
keys += kcs[-1].keyphrase
|
| 25 |
+
count += kcs[-1].count
|
| 26 |
+
return KeyphraseCount(keys, count)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class SingleCluster:
|
| 31 |
+
def __init__(self):
|
| 32 |
+
self.__container__ = []
|
| 33 |
+
self.__keyphrases__ = {}
|
| 34 |
+
def add(self, id:int):
|
| 35 |
+
self.__container__.append(id)
|
| 36 |
+
def __str__(self) -> str:
|
| 37 |
+
return str(self.__container__)
|
| 38 |
+
def elements(self) -> List:
|
| 39 |
+
return self.__container__
|
| 40 |
+
def get_keyphrases(self):
|
| 41 |
+
ret = []
|
| 42 |
+
for key, count in self.__keyphrases__.items():
|
| 43 |
+
ret.append(KeyphraseCount(key,count))
|
| 44 |
+
return ret
|
| 45 |
+
def add_keyphrase(self, keyphrase:Union[str,Iterable]):
|
| 46 |
+
if isinstance(keyphrase,str):
|
| 47 |
+
if keyphrase not in self.__keyphrases__.keys():
|
| 48 |
+
self.__keyphrases__[keyphrase] = 1
|
| 49 |
+
else:
|
| 50 |
+
self.__keyphrases__[keyphrase] += 1
|
| 51 |
+
elif isinstance(keyphrase,Iterable):
|
| 52 |
+
for i in keyphrase:
|
| 53 |
+
self.add_keyphrase(i)
|
| 54 |
+
|
| 55 |
+
def __len__(self):
|
| 56 |
+
return len(self.__container__)
|
| 57 |
+
|
| 58 |
+
def print_keyphrases(self):
|
| 59 |
+
pprint(self.__keyphrases__)
|
| 60 |
+
|
| 61 |
+
class ClusterList:
|
| 62 |
+
def __init__(self, k:int):
|
| 63 |
+
self.__clusters__ = [SingleCluster() for _ in range(k)]
|
| 64 |
+
|
| 65 |
+
# subscriptable and slice-able
|
| 66 |
+
def __getitem__(self, idx):
|
| 67 |
+
if isinstance(idx, int):
|
| 68 |
+
return self.__clusters__[idx]
|
| 69 |
+
if isinstance(idx, slice):
|
| 70 |
+
# return
|
| 71 |
+
return self.__clusters__[0 if idx.start is None else idx.start: idx.stop: 0 if idx.step is None else idx.step]
|
| 72 |
+
|
| 73 |
+
def instantiate(self, labels: Iterable):
|
| 74 |
+
for id, label in enumerate(labels):
|
| 75 |
+
self.__clusters__[label].add(id)
|
| 76 |
+
|
| 77 |
+
def __str__(self):
|
| 78 |
+
ret = f'There are {len(self.__clusters__)} clusters:\n'
|
| 79 |
+
for id,cluster in enumerate(self.__clusters__):
|
| 80 |
+
ret += f'cluster {id} contains: {cluster}.\n'
|
| 81 |
+
|
| 82 |
+
return ret
|
| 83 |
+
|
| 84 |
+
# return an iterator that can be used in for loop etc.
|
| 85 |
+
def __iter__(self):
|
| 86 |
+
return self.__clusters__.__iter__()
|
| 87 |
+
|
| 88 |
+
def __len__(self): return len(self.__clusters__)
|
| 89 |
+
|
| 90 |
+
def sort(self):
|
| 91 |
+
self.__clusters__.sort(key=len,reverse=True)
|
lrt/clustering/config.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class Configuration:
|
| 2 |
+
def __init__(self, plm:str, dimension_reduction:str,clustering:str,keywords_extraction:str):
|
| 3 |
+
self.plm = plm
|
| 4 |
+
self.dimension_reduction = dimension_reduction
|
| 5 |
+
self.clustering = clustering
|
| 6 |
+
self.keywords_extraction = keywords_extraction
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BaselineConfig(Configuration):
|
| 10 |
+
def __init__(self):
|
| 11 |
+
super().__init__('''all-mpnet-base-v2''', 'none', 'kmeans-euclidean', 'keyphrase-transformer')
|
lrt/clustering/models/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .keyBartPlus import KeyBartAdapter
|
lrt/clustering/models/adapter.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
class Adapter(nn.Module):
|
| 5 |
+
def __init__(self,input_dim:int, hidden_dim: int) -> None:
|
| 6 |
+
super().__init__()
|
| 7 |
+
self.input_dim = input_dim
|
| 8 |
+
self.hidden_dim = hidden_dim
|
| 9 |
+
self.layerNorm = nn.LayerNorm(input_dim)
|
| 10 |
+
self.down_proj = nn.Linear(input_dim,hidden_dim,False)
|
| 11 |
+
self.up_proj = nn.Linear(hidden_dim,input_dim,False)
|
| 12 |
+
|
| 13 |
+
def forward(self,x):
|
| 14 |
+
'''
|
| 15 |
+
|
| 16 |
+
:param x: N,L,D
|
| 17 |
+
:return: N,L,D
|
| 18 |
+
'''
|
| 19 |
+
output = x
|
| 20 |
+
x = self.layerNorm(x)
|
| 21 |
+
x = self.down_proj(x)
|
| 22 |
+
x = nn.functional.relu(x)
|
| 23 |
+
x = self.up_proj(x)
|
| 24 |
+
output = output + x # residual connection
|
| 25 |
+
return output
|
lrt/clustering/models/keyBartPlus.py
ADDED
|
@@ -0,0 +1,411 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, List, Union, Tuple
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import random
|
| 5 |
+
from torch.nn import CrossEntropyLoss
|
| 6 |
+
|
| 7 |
+
from transformers.utils import (
|
| 8 |
+
add_start_docstrings_to_model_forward,
|
| 9 |
+
add_end_docstrings,
|
| 10 |
+
replace_return_docstrings
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
from transformers import AutoModelForSeq2SeqLM
|
| 14 |
+
from transformers.models.bart.modeling_bart import (
|
| 15 |
+
BartForConditionalGeneration,
|
| 16 |
+
_expand_mask, logger,
|
| 17 |
+
shift_tokens_right,
|
| 18 |
+
BartPretrainedModel,
|
| 19 |
+
BART_INPUTS_DOCSTRING,
|
| 20 |
+
_CONFIG_FOR_DOC,
|
| 21 |
+
BART_GENERATION_EXAMPLE,
|
| 22 |
+
BartModel,
|
| 23 |
+
BartDecoder
|
| 24 |
+
|
| 25 |
+
)
|
| 26 |
+
from .adapter import Adapter
|
| 27 |
+
from transformers.modeling_outputs import (
|
| 28 |
+
BaseModelOutputWithPastAndCrossAttentions,
|
| 29 |
+
Seq2SeqModelOutput,
|
| 30 |
+
BaseModelOutput,
|
| 31 |
+
Seq2SeqLMOutput
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class KeyBartAdapter(BartForConditionalGeneration):
|
| 36 |
+
def __init__(self,adapter_hid_dim:int) -> None:
|
| 37 |
+
keyBart = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
|
| 38 |
+
self.__fix_weights__(keyBart)
|
| 39 |
+
|
| 40 |
+
super().__init__(keyBart.model.config)
|
| 41 |
+
self.lm_head = keyBart.lm_head
|
| 42 |
+
self.model = BartPlus(keyBart, adapter_hid_dim)
|
| 43 |
+
self.register_buffer("final_logits_bias", torch.zeros((1, self.model.shared.num_embeddings)))
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def __fix_weights__(self,keyBart:BartForConditionalGeneration):
|
| 47 |
+
for i in keyBart.model.parameters():
|
| 48 |
+
i.requires_grad = False
|
| 49 |
+
for i in keyBart.lm_head.parameters():
|
| 50 |
+
i.requires_grad = False
|
| 51 |
+
|
| 52 |
+
@add_start_docstrings_to_model_forward(BART_INPUTS_DOCSTRING)
|
| 53 |
+
@replace_return_docstrings(output_type=Seq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
|
| 54 |
+
@add_end_docstrings(BART_GENERATION_EXAMPLE)
|
| 55 |
+
def forward(
|
| 56 |
+
self,
|
| 57 |
+
input_ids: torch.LongTensor = None,
|
| 58 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 59 |
+
decoder_input_ids: Optional[torch.LongTensor] = None,
|
| 60 |
+
decoder_attention_mask: Optional[torch.LongTensor] = None,
|
| 61 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 62 |
+
decoder_head_mask: Optional[torch.Tensor] = None,
|
| 63 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 64 |
+
encoder_outputs: Optional[List[torch.FloatTensor]] = None,
|
| 65 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 66 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 67 |
+
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 68 |
+
labels: Optional[torch.LongTensor] = None,
|
| 69 |
+
use_cache: Optional[bool] = None,
|
| 70 |
+
output_attentions: Optional[bool] = None,
|
| 71 |
+
output_hidden_states: Optional[bool] = None,
|
| 72 |
+
return_dict: Optional[bool] = None,
|
| 73 |
+
) -> Union[Tuple, Seq2SeqLMOutput]:
|
| 74 |
+
r"""
|
| 75 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 76 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 77 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 78 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 79 |
+
Returns:
|
| 80 |
+
"""
|
| 81 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 82 |
+
|
| 83 |
+
if labels is not None:
|
| 84 |
+
if use_cache:
|
| 85 |
+
logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
|
| 86 |
+
use_cache = False
|
| 87 |
+
if decoder_input_ids is None and decoder_inputs_embeds is None:
|
| 88 |
+
decoder_input_ids = shift_tokens_right(
|
| 89 |
+
labels, self.config.pad_token_id, self.config.decoder_start_token_id
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
outputs = self.model(
|
| 93 |
+
input_ids,
|
| 94 |
+
attention_mask=attention_mask,
|
| 95 |
+
decoder_input_ids=decoder_input_ids,
|
| 96 |
+
encoder_outputs=encoder_outputs,
|
| 97 |
+
decoder_attention_mask=decoder_attention_mask,
|
| 98 |
+
head_mask=head_mask,
|
| 99 |
+
decoder_head_mask=decoder_head_mask,
|
| 100 |
+
cross_attn_head_mask=cross_attn_head_mask,
|
| 101 |
+
past_key_values=past_key_values,
|
| 102 |
+
inputs_embeds=inputs_embeds,
|
| 103 |
+
decoder_inputs_embeds=decoder_inputs_embeds,
|
| 104 |
+
use_cache=use_cache,
|
| 105 |
+
output_attentions=output_attentions,
|
| 106 |
+
output_hidden_states=output_hidden_states,
|
| 107 |
+
return_dict=return_dict,
|
| 108 |
+
)
|
| 109 |
+
lm_logits = self.lm_head(outputs[0]) + self.final_logits_bias
|
| 110 |
+
|
| 111 |
+
masked_lm_loss = None
|
| 112 |
+
if labels is not None:
|
| 113 |
+
loss_fct = CrossEntropyLoss()
|
| 114 |
+
masked_lm_loss = loss_fct(lm_logits.view(-1, self.config.vocab_size), labels.view(-1))
|
| 115 |
+
|
| 116 |
+
if not return_dict:
|
| 117 |
+
output = (lm_logits,) + outputs[1:]
|
| 118 |
+
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
|
| 119 |
+
|
| 120 |
+
return Seq2SeqLMOutput(
|
| 121 |
+
loss=masked_lm_loss,
|
| 122 |
+
logits=lm_logits,
|
| 123 |
+
past_key_values=outputs.past_key_values,
|
| 124 |
+
decoder_hidden_states=outputs.decoder_hidden_states,
|
| 125 |
+
decoder_attentions=outputs.decoder_attentions,
|
| 126 |
+
cross_attentions=outputs.cross_attentions,
|
| 127 |
+
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
|
| 128 |
+
encoder_hidden_states=outputs.encoder_hidden_states,
|
| 129 |
+
encoder_attentions=outputs.encoder_attentions,
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
class BartDecoderPlus(BartDecoder):
|
| 135 |
+
def __init__(self,keyBart:BartForConditionalGeneration,adapter_hid_dim: int) -> None:
|
| 136 |
+
super().__init__(keyBart.get_decoder().config)
|
| 137 |
+
self.decoder = keyBart.model.decoder
|
| 138 |
+
self.adapters = nn.ModuleList([Adapter(self.decoder.config.d_model,adapter_hid_dim) for _ in range(len(self.decoder.layers))])
|
| 139 |
+
self.config = self.decoder.config
|
| 140 |
+
self.dropout = self.decoder.dropout
|
| 141 |
+
self.layerdrop = self.decoder.layerdrop
|
| 142 |
+
self.padding_idx = self.decoder.padding_idx
|
| 143 |
+
self.max_target_positions = self.decoder.max_target_positions
|
| 144 |
+
self.embed_scale = self.decoder.embed_scale
|
| 145 |
+
self.embed_tokens = self.decoder.embed_tokens
|
| 146 |
+
self.embed_positions = self.decoder.embed_positions
|
| 147 |
+
self.layers = self.decoder.layers
|
| 148 |
+
self.layernorm_embedding = self.decoder.layernorm_embedding
|
| 149 |
+
self.gradient_checkpointing = self.decoder.gradient_checkpointing
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def forward(
|
| 153 |
+
self,
|
| 154 |
+
input_ids: torch.LongTensor = None,
|
| 155 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 156 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 157 |
+
encoder_attention_mask: Optional[torch.LongTensor] = None,
|
| 158 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 159 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 160 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 161 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 162 |
+
use_cache: Optional[bool] = None,
|
| 163 |
+
output_attentions: Optional[bool] = None,
|
| 164 |
+
output_hidden_states: Optional[bool] = None,
|
| 165 |
+
return_dict: Optional[bool] = None,
|
| 166 |
+
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
|
| 167 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 168 |
+
output_hidden_states = (
|
| 169 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 170 |
+
)
|
| 171 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 172 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 173 |
+
|
| 174 |
+
# retrieve input_ids and inputs_embeds
|
| 175 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 176 |
+
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
|
| 177 |
+
elif input_ids is not None:
|
| 178 |
+
input = input_ids
|
| 179 |
+
input_shape = input.shape
|
| 180 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 181 |
+
elif inputs_embeds is not None:
|
| 182 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 183 |
+
input = inputs_embeds[:, :, -1]
|
| 184 |
+
else:
|
| 185 |
+
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
|
| 186 |
+
|
| 187 |
+
# past_key_values_length
|
| 188 |
+
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
|
| 189 |
+
|
| 190 |
+
if inputs_embeds is None:
|
| 191 |
+
inputs_embeds = self.decoder.embed_tokens(input) * self.decoder.embed_scale
|
| 192 |
+
|
| 193 |
+
attention_mask = self.decoder._prepare_decoder_attention_mask(
|
| 194 |
+
attention_mask, input_shape, inputs_embeds, past_key_values_length
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
# expand encoder attention mask
|
| 198 |
+
if encoder_hidden_states is not None and encoder_attention_mask is not None:
|
| 199 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 200 |
+
encoder_attention_mask = _expand_mask(encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
|
| 201 |
+
|
| 202 |
+
# embed positions
|
| 203 |
+
positions = self.decoder.embed_positions(input, past_key_values_length)
|
| 204 |
+
|
| 205 |
+
hidden_states = inputs_embeds + positions
|
| 206 |
+
hidden_states = self.decoder.layernorm_embedding(hidden_states)
|
| 207 |
+
|
| 208 |
+
hidden_states = nn.functional.dropout(hidden_states, p=self.decoder.dropout, training=self.decoder.training)
|
| 209 |
+
|
| 210 |
+
# decoder layers
|
| 211 |
+
all_hidden_states = () if output_hidden_states else None
|
| 212 |
+
all_self_attns = () if output_attentions else None
|
| 213 |
+
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
|
| 214 |
+
next_decoder_cache = () if use_cache else None
|
| 215 |
+
|
| 216 |
+
# check if head_mask/cross_attn_head_mask has a correct number of layers specified if desired
|
| 217 |
+
for attn_mask, mask_name in zip([head_mask, cross_attn_head_mask], ["head_mask", "cross_attn_head_mask"]):
|
| 218 |
+
if attn_mask is not None:
|
| 219 |
+
if attn_mask.size()[0] != (len(self.decoder.layers)):
|
| 220 |
+
raise ValueError(
|
| 221 |
+
f"The `{mask_name}` should be specified for {len(self.decoder.layers)} layers, but it is for"
|
| 222 |
+
f" {head_mask.size()[0]}."
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
for idx, decoder_layer in enumerate(self.decoder.layers):
|
| 226 |
+
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
|
| 227 |
+
if output_hidden_states:
|
| 228 |
+
all_hidden_states += (hidden_states,)
|
| 229 |
+
dropout_probability = random.uniform(0, 1)
|
| 230 |
+
if self.decoder.training and (dropout_probability < self.decoder.layerdrop):
|
| 231 |
+
continue
|
| 232 |
+
|
| 233 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 234 |
+
|
| 235 |
+
if self.decoder.gradient_checkpointing and self.decoder.training:
|
| 236 |
+
|
| 237 |
+
if use_cache:
|
| 238 |
+
logger.warning(
|
| 239 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 240 |
+
)
|
| 241 |
+
use_cache = False
|
| 242 |
+
|
| 243 |
+
def create_custom_forward(module):
|
| 244 |
+
def custom_forward(*inputs):
|
| 245 |
+
# None for past_key_value
|
| 246 |
+
return module(*inputs, output_attentions, use_cache)
|
| 247 |
+
|
| 248 |
+
return custom_forward
|
| 249 |
+
|
| 250 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 251 |
+
create_custom_forward(decoder_layer),
|
| 252 |
+
hidden_states,
|
| 253 |
+
attention_mask,
|
| 254 |
+
encoder_hidden_states,
|
| 255 |
+
encoder_attention_mask,
|
| 256 |
+
head_mask[idx] if head_mask is not None else None,
|
| 257 |
+
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None,
|
| 258 |
+
None,
|
| 259 |
+
)
|
| 260 |
+
else:
|
| 261 |
+
|
| 262 |
+
layer_outputs = decoder_layer(
|
| 263 |
+
hidden_states,
|
| 264 |
+
attention_mask=attention_mask,
|
| 265 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 266 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 267 |
+
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
|
| 268 |
+
cross_attn_layer_head_mask=(
|
| 269 |
+
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None
|
| 270 |
+
),
|
| 271 |
+
past_key_value=past_key_value,
|
| 272 |
+
output_attentions=output_attentions,
|
| 273 |
+
use_cache=use_cache,
|
| 274 |
+
)
|
| 275 |
+
hidden_states = layer_outputs[0]
|
| 276 |
+
|
| 277 |
+
######################### new #################################
|
| 278 |
+
hidden_states = self.adapters[idx](hidden_states)
|
| 279 |
+
######################### new #################################
|
| 280 |
+
|
| 281 |
+
if use_cache:
|
| 282 |
+
next_decoder_cache += (layer_outputs[3 if output_attentions else 1],)
|
| 283 |
+
|
| 284 |
+
if output_attentions:
|
| 285 |
+
all_self_attns += (layer_outputs[1],)
|
| 286 |
+
|
| 287 |
+
if encoder_hidden_states is not None:
|
| 288 |
+
all_cross_attentions += (layer_outputs[2],)
|
| 289 |
+
|
| 290 |
+
# add hidden states from the last decoder layer
|
| 291 |
+
if output_hidden_states:
|
| 292 |
+
all_hidden_states += (hidden_states,)
|
| 293 |
+
|
| 294 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 295 |
+
if not return_dict:
|
| 296 |
+
return tuple(
|
| 297 |
+
v
|
| 298 |
+
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
|
| 299 |
+
if v is not None
|
| 300 |
+
)
|
| 301 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 302 |
+
last_hidden_state=hidden_states,
|
| 303 |
+
past_key_values=next_cache,
|
| 304 |
+
hidden_states=all_hidden_states,
|
| 305 |
+
attentions=all_self_attns,
|
| 306 |
+
cross_attentions=all_cross_attentions,
|
| 307 |
+
)
|
| 308 |
+
|
| 309 |
+
class BartPlus(BartModel):
|
| 310 |
+
def __init__(self,keyBart: BartForConditionalGeneration, adapter_hid_dim: int ) -> None:
|
| 311 |
+
super().__init__(keyBart.model.config)
|
| 312 |
+
self.config = keyBart.model.config
|
| 313 |
+
|
| 314 |
+
# self.shared = nn.Embedding(vocab_size, config.d_model, padding_idx)
|
| 315 |
+
self.shared = keyBart.model.shared
|
| 316 |
+
|
| 317 |
+
#self.encoder = BartEncoder(config, self.shared)
|
| 318 |
+
self.encoder = keyBart.model.encoder
|
| 319 |
+
|
| 320 |
+
#self.decoder = BartDecoder(config, self.shared)
|
| 321 |
+
#self.decoder = keyBart.model.decoder
|
| 322 |
+
self.decoder = BartDecoderPlus(keyBart,adapter_hid_dim=adapter_hid_dim)
|
| 323 |
+
|
| 324 |
+
def forward(
|
| 325 |
+
self,
|
| 326 |
+
input_ids: torch.LongTensor = None,
|
| 327 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 328 |
+
decoder_input_ids: Optional[torch.LongTensor] = None,
|
| 329 |
+
decoder_attention_mask: Optional[torch.LongTensor] = None,
|
| 330 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 331 |
+
decoder_head_mask: Optional[torch.Tensor] = None,
|
| 332 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 333 |
+
encoder_outputs: Optional[List[torch.FloatTensor]] = None,
|
| 334 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 335 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 336 |
+
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 337 |
+
use_cache: Optional[bool] = None,
|
| 338 |
+
output_attentions: Optional[bool] = None,
|
| 339 |
+
output_hidden_states: Optional[bool] = None,
|
| 340 |
+
return_dict: Optional[bool] = None,
|
| 341 |
+
) -> Union[Tuple, Seq2SeqModelOutput]:
|
| 342 |
+
|
| 343 |
+
# different to other models, Bart automatically creates decoder_input_ids from
|
| 344 |
+
# input_ids if no decoder_input_ids are provided
|
| 345 |
+
if decoder_input_ids is None and decoder_inputs_embeds is None:
|
| 346 |
+
if input_ids is None:
|
| 347 |
+
raise ValueError(
|
| 348 |
+
"If no `decoder_input_ids` or `decoder_inputs_embeds` are "
|
| 349 |
+
"passed, `input_ids` cannot be `None`. Please pass either "
|
| 350 |
+
"`input_ids` or `decoder_input_ids` or `decoder_inputs_embeds`."
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
decoder_input_ids = shift_tokens_right(
|
| 354 |
+
input_ids, self.config.pad_token_id, self.config.decoder_start_token_id
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 358 |
+
output_hidden_states = (
|
| 359 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 360 |
+
)
|
| 361 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 362 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 363 |
+
|
| 364 |
+
if encoder_outputs is None:
|
| 365 |
+
encoder_outputs = self.encoder(
|
| 366 |
+
input_ids=input_ids,
|
| 367 |
+
attention_mask=attention_mask,
|
| 368 |
+
head_mask=head_mask,
|
| 369 |
+
inputs_embeds=inputs_embeds,
|
| 370 |
+
output_attentions=output_attentions,
|
| 371 |
+
output_hidden_states=output_hidden_states,
|
| 372 |
+
return_dict=return_dict,
|
| 373 |
+
)
|
| 374 |
+
# If the user passed a tuple for encoder_outputs, we wrap it in a BaseModelOutput when return_dict=True
|
| 375 |
+
elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
|
| 376 |
+
encoder_outputs = BaseModelOutput(
|
| 377 |
+
last_hidden_state=encoder_outputs[0],
|
| 378 |
+
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
|
| 379 |
+
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
# decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
|
| 383 |
+
decoder_outputs = self.decoder(
|
| 384 |
+
input_ids=decoder_input_ids,
|
| 385 |
+
attention_mask=decoder_attention_mask,
|
| 386 |
+
encoder_hidden_states=encoder_outputs[0],
|
| 387 |
+
encoder_attention_mask=attention_mask,
|
| 388 |
+
head_mask=decoder_head_mask,
|
| 389 |
+
cross_attn_head_mask=cross_attn_head_mask,
|
| 390 |
+
past_key_values=past_key_values,
|
| 391 |
+
inputs_embeds=decoder_inputs_embeds,
|
| 392 |
+
use_cache=use_cache,
|
| 393 |
+
output_attentions=output_attentions,
|
| 394 |
+
output_hidden_states=output_hidden_states,
|
| 395 |
+
return_dict=return_dict,
|
| 396 |
+
)
|
| 397 |
+
|
| 398 |
+
if not return_dict:
|
| 399 |
+
return decoder_outputs + encoder_outputs
|
| 400 |
+
|
| 401 |
+
return Seq2SeqModelOutput(
|
| 402 |
+
last_hidden_state=decoder_outputs.last_hidden_state,
|
| 403 |
+
past_key_values=decoder_outputs.past_key_values,
|
| 404 |
+
decoder_hidden_states=decoder_outputs.hidden_states,
|
| 405 |
+
decoder_attentions=decoder_outputs.attentions,
|
| 406 |
+
cross_attentions=decoder_outputs.cross_attentions,
|
| 407 |
+
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
|
| 408 |
+
encoder_hidden_states=encoder_outputs.hidden_states,
|
| 409 |
+
encoder_attentions=encoder_outputs.attentions,
|
| 410 |
+
)
|
| 411 |
+
|
lrt/lrt.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .clustering import *
|
| 2 |
+
from typing import List
|
| 3 |
+
import textdistance as td
|
| 4 |
+
from .utils import UnionFind, ArticleList
|
| 5 |
+
from .academic_query import AcademicQuery
|
| 6 |
+
import streamlit as st
|
| 7 |
+
from tokenizers import Tokenizer
|
| 8 |
+
from .clustering.clusters import KeyphraseCount
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class LiteratureResearchTool:
|
| 13 |
+
def __init__(self, cluster_config: Configuration = None):
|
| 14 |
+
self.literature_search = AcademicQuery
|
| 15 |
+
self.cluster_pipeline = ClusterPipeline(cluster_config)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def __postprocess_clusters__(self, clusters: ClusterList,query: str) ->ClusterList:
|
| 19 |
+
'''
|
| 20 |
+
add top-5 keyphrases to each cluster
|
| 21 |
+
:param clusters:
|
| 22 |
+
:return: clusters
|
| 23 |
+
'''
|
| 24 |
+
def condition(x: KeyphraseCount, y: KeyphraseCount):
|
| 25 |
+
return td.ratcliff_obershelp(x.keyphrase, y.keyphrase) > 0.8
|
| 26 |
+
|
| 27 |
+
def valid_keyphrase(x:KeyphraseCount):
|
| 28 |
+
tmp = x.keyphrase
|
| 29 |
+
return tmp is not None and tmp != '' and not tmp.isspace() and len(tmp)!=1\
|
| 30 |
+
and tmp != query
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
for cluster in clusters:
|
| 34 |
+
|
| 35 |
+
keyphrases = cluster.get_keyphrases() # [kc]
|
| 36 |
+
keyphrases = list(filter(valid_keyphrase,keyphrases))
|
| 37 |
+
unionfind = UnionFind(keyphrases, condition)
|
| 38 |
+
unionfind.union_step()
|
| 39 |
+
|
| 40 |
+
tmp = unionfind.get_unions() # dict(root_id = [kc])
|
| 41 |
+
tmp = tmp.values() # [[kc]]
|
| 42 |
+
# [[kc]] -> [ new kc] -> sorted
|
| 43 |
+
tmp = [KeyphraseCount.reduce(x) for x in tmp]
|
| 44 |
+
keyphrases = sorted(tmp,key= lambda x: x.count,reverse=True)[:5]
|
| 45 |
+
keyphrases = [x.keyphrase for x in keyphrases]
|
| 46 |
+
|
| 47 |
+
# keyphrases = sorted(list(unionfind.get_unions().values()), key=len, reverse=True)[:5] # top-5 keyphrases: list
|
| 48 |
+
# for i in keyphrases:
|
| 49 |
+
# tmp = '/'.join(i)
|
| 50 |
+
# cluster.top_5_keyphrases.append(tmp)
|
| 51 |
+
cluster.top_5_keyphrases = keyphrases
|
| 52 |
+
|
| 53 |
+
return clusters
|
| 54 |
+
|
| 55 |
+
def __call__(self,
|
| 56 |
+
query: str,
|
| 57 |
+
num_papers: int,
|
| 58 |
+
start_year: int,
|
| 59 |
+
end_year: int,
|
| 60 |
+
max_k: int,
|
| 61 |
+
platforms: List[str] = ['IEEE', 'Arxiv', 'Paper with Code'],
|
| 62 |
+
loading_ctx_manager = None,
|
| 63 |
+
standardization = False
|
| 64 |
+
):
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
for platform in platforms:
|
| 68 |
+
if loading_ctx_manager:
|
| 69 |
+
with loading_ctx_manager():
|
| 70 |
+
clusters, articles = self.__platformPipeline__(platform,query,num_papers,start_year,end_year,max_k,standardization)
|
| 71 |
+
else:
|
| 72 |
+
clusters, articles = self.__platformPipeline__(platform, query, num_papers, start_year, end_year,max_k,standardization)
|
| 73 |
+
|
| 74 |
+
clusters.sort()
|
| 75 |
+
yield clusters,articles
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def __platformPipeline__(self,platforn_name:str,
|
| 80 |
+
query: str,
|
| 81 |
+
num_papers: int,
|
| 82 |
+
start_year: int,
|
| 83 |
+
end_year: int,
|
| 84 |
+
max_k: int,
|
| 85 |
+
standardization
|
| 86 |
+
) -> (ClusterList,ArticleList):
|
| 87 |
+
|
| 88 |
+
@st.cache(hash_funcs={Tokenizer: Tokenizer.__hash__},allow_output_mutation=True)
|
| 89 |
+
def ieee_process(
|
| 90 |
+
query: str,
|
| 91 |
+
num_papers: int,
|
| 92 |
+
start_year: int,
|
| 93 |
+
end_year: int,
|
| 94 |
+
):
|
| 95 |
+
articles = ArticleList.parse_ieee_articles(
|
| 96 |
+
self.literature_search.ieee(query, start_year, end_year, num_papers)) # ArticleList
|
| 97 |
+
abstracts = articles.getAbstracts() # List[str]
|
| 98 |
+
clusters = self.cluster_pipeline(abstracts,max_k,standardization)
|
| 99 |
+
clusters = self.__postprocess_clusters__(clusters,query)
|
| 100 |
+
return clusters, articles
|
| 101 |
+
|
| 102 |
+
@st.cache(hash_funcs={Tokenizer: Tokenizer.__hash__},allow_output_mutation=True)
|
| 103 |
+
def arxiv_process(
|
| 104 |
+
query: str,
|
| 105 |
+
num_papers: int,
|
| 106 |
+
):
|
| 107 |
+
articles = ArticleList.parse_arxiv_articles(
|
| 108 |
+
self.literature_search.arxiv(query, num_papers)) # ArticleList
|
| 109 |
+
abstracts = articles.getAbstracts() # List[str]
|
| 110 |
+
clusters = self.cluster_pipeline(abstracts,max_k,standardization)
|
| 111 |
+
clusters = self.__postprocess_clusters__(clusters,query)
|
| 112 |
+
return clusters, articles
|
| 113 |
+
|
| 114 |
+
@st.cache(hash_funcs={Tokenizer: Tokenizer.__hash__},allow_output_mutation=True)
|
| 115 |
+
def pwc_process(
|
| 116 |
+
query: str,
|
| 117 |
+
num_papers: int,
|
| 118 |
+
):
|
| 119 |
+
articles = ArticleList.parse_pwc_articles(
|
| 120 |
+
self.literature_search.paper_with_code(query, num_papers)) # ArticleList
|
| 121 |
+
abstracts = articles.getAbstracts() # List[str]
|
| 122 |
+
clusters = self.cluster_pipeline(abstracts,max_k,standardization)
|
| 123 |
+
clusters = self.__postprocess_clusters__(clusters,query)
|
| 124 |
+
return clusters, articles
|
| 125 |
+
|
| 126 |
+
if platforn_name == 'IEEE':
|
| 127 |
+
return ieee_process(query,num_papers,start_year,end_year)
|
| 128 |
+
elif platforn_name == 'Arxiv':
|
| 129 |
+
return arxiv_process(query,num_papers)
|
| 130 |
+
elif platforn_name == 'Paper with Code':
|
| 131 |
+
return pwc_process(query,num_papers)
|
| 132 |
+
else:
|
| 133 |
+
raise RuntimeError('This platform is not supported. Please open an issue on the GitHub.')
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
|
lrt/utils/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .functions import __create_model__
|
| 2 |
+
from .union_find import UnionFind
|
| 3 |
+
from .article import ArticleList, Article
|
lrt/utils/article.py
ADDED
|
@@ -0,0 +1,412 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Union, Optional
|
| 2 |
+
import pandas as pd
|
| 3 |
+
class Article:
|
| 4 |
+
'''
|
| 5 |
+
attributes:
|
| 6 |
+
- title: str
|
| 7 |
+
- authors: list of str
|
| 8 |
+
- abstract: str
|
| 9 |
+
- url: str
|
| 10 |
+
- publication_year: int
|
| 11 |
+
'''
|
| 12 |
+
def __init__(self,
|
| 13 |
+
title: str,
|
| 14 |
+
authors: List[str],
|
| 15 |
+
abstract: str,
|
| 16 |
+
url: str,
|
| 17 |
+
publication_year: int
|
| 18 |
+
) -> None:
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.title = title
|
| 21 |
+
self.authors = authors
|
| 22 |
+
self.url = url
|
| 23 |
+
self.publication_year = publication_year
|
| 24 |
+
self.abstract = abstract.replace('\n',' ')
|
| 25 |
+
def __str__(self):
|
| 26 |
+
ret = ''
|
| 27 |
+
ret +=self.title +'\n- '
|
| 28 |
+
ret +=f"authors: {';'.join(self.authors)}" + '\n- '
|
| 29 |
+
ret += f'''abstract: {self.abstract}''' + '\n- '
|
| 30 |
+
ret += f'''url: {self.url}'''+ '\n- '
|
| 31 |
+
ret += f'''publication year: {self.publication_year}'''+ '\n\n'
|
| 32 |
+
|
| 33 |
+
return ret
|
| 34 |
+
|
| 35 |
+
def getDict(self) -> dict:
|
| 36 |
+
return {
|
| 37 |
+
'title': self.title,
|
| 38 |
+
'authors': self.authors,
|
| 39 |
+
'abstract': self.abstract,
|
| 40 |
+
'url': self.url,
|
| 41 |
+
'publication_year': self.publication_year
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
class ArticleList:
|
| 45 |
+
'''
|
| 46 |
+
list of articles
|
| 47 |
+
'''
|
| 48 |
+
def __init__(self,articles:Optional[Union[Article, List[Article]]]=None) -> None:
|
| 49 |
+
super().__init__()
|
| 50 |
+
self.__list__ = [] # List[Article]
|
| 51 |
+
|
| 52 |
+
if articles is not None:
|
| 53 |
+
self.addArticles(articles)
|
| 54 |
+
|
| 55 |
+
def addArticles(self, articles:Union[Article, List[Article]]):
|
| 56 |
+
if isinstance(articles,Article):
|
| 57 |
+
self.__list__.append(articles)
|
| 58 |
+
elif isinstance(articles, list):
|
| 59 |
+
self.__list__ += articles
|
| 60 |
+
|
| 61 |
+
# subscriptable and slice-able
|
| 62 |
+
def __getitem__(self, idx):
|
| 63 |
+
if isinstance(idx, int):
|
| 64 |
+
return self.__list__[idx]
|
| 65 |
+
if isinstance(idx, slice):
|
| 66 |
+
# return
|
| 67 |
+
return self.__list__[0 if idx.start is None else idx.start: idx.stop: 0 if idx.step is None else idx.step]
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def __str__(self):
|
| 71 |
+
ret = f'There are {len(self.__list__)} articles:\n'
|
| 72 |
+
for id, article in enumerate(self.__list__):
|
| 73 |
+
ret += f'{id+1}) '
|
| 74 |
+
ret += f'{article}'
|
| 75 |
+
|
| 76 |
+
return ret
|
| 77 |
+
|
| 78 |
+
# return an iterator that can be used in for loop etc.
|
| 79 |
+
def __iter__(self):
|
| 80 |
+
return self.__list__.__iter__()
|
| 81 |
+
|
| 82 |
+
def __len__(self):
|
| 83 |
+
return len(self.__list__)
|
| 84 |
+
|
| 85 |
+
def getDataFrame(self) ->pd.DataFrame:
|
| 86 |
+
return pd.DataFrame(
|
| 87 |
+
[x.getDict() for x in self.__list__]
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
@classmethod
|
| 92 |
+
def parse_ieee_articles(cls,items: Union[dict, List[dict]]):
|
| 93 |
+
if isinstance(items,dict):
|
| 94 |
+
items = [items]
|
| 95 |
+
|
| 96 |
+
ret = [
|
| 97 |
+
Article(
|
| 98 |
+
title=item['title'],
|
| 99 |
+
authors=[x['full_name'] for x in item['authors']['authors']],
|
| 100 |
+
abstract=item['abstract'],
|
| 101 |
+
url=item['html_url'],
|
| 102 |
+
publication_year=item['publication_year']
|
| 103 |
+
)
|
| 104 |
+
for item in items ] # List[Article]
|
| 105 |
+
|
| 106 |
+
ret = ArticleList(ret)
|
| 107 |
+
return ret
|
| 108 |
+
|
| 109 |
+
@classmethod
|
| 110 |
+
def parse_arxiv_articles(cls, items: Union[dict, List[dict]]):
|
| 111 |
+
if isinstance(items, dict):
|
| 112 |
+
items = [items]
|
| 113 |
+
|
| 114 |
+
def __getAuthors__(item):
|
| 115 |
+
if isinstance(item['author'],list):
|
| 116 |
+
return [x['name'] for x in item['author']]
|
| 117 |
+
else:
|
| 118 |
+
return [item['author']['name']]
|
| 119 |
+
|
| 120 |
+
ret = [
|
| 121 |
+
Article(
|
| 122 |
+
title=item['title'],
|
| 123 |
+
authors=__getAuthors__(item),
|
| 124 |
+
abstract=item['summary'],
|
| 125 |
+
url=item['id'],
|
| 126 |
+
publication_year=item['published'][:4]
|
| 127 |
+
)
|
| 128 |
+
for item in items] # List[Article]
|
| 129 |
+
|
| 130 |
+
ret = ArticleList(ret)
|
| 131 |
+
return ret
|
| 132 |
+
|
| 133 |
+
@classmethod
|
| 134 |
+
def parse_pwc_articles(cls, items: Union[dict, List[dict]]):
|
| 135 |
+
if isinstance(items, dict):
|
| 136 |
+
items = [items]
|
| 137 |
+
|
| 138 |
+
ret = [
|
| 139 |
+
Article(
|
| 140 |
+
title=item['title'],
|
| 141 |
+
authors=item['authors'],
|
| 142 |
+
abstract=item['abstract'],
|
| 143 |
+
url=item['url_abs'],
|
| 144 |
+
publication_year=item['published'][:4]
|
| 145 |
+
)
|
| 146 |
+
for item in items] # List[Article]
|
| 147 |
+
|
| 148 |
+
ret = ArticleList(ret)
|
| 149 |
+
return ret
|
| 150 |
+
|
| 151 |
+
def getAbstracts(self) -> List[str]:
|
| 152 |
+
return [x.abstract for x in self.__list__]
|
| 153 |
+
|
| 154 |
+
def getTitles(self) -> List[str]:
|
| 155 |
+
return [x.title for x in self.__list__]
|
| 156 |
+
|
| 157 |
+
def getArticles(self) -> List[Article]:
|
| 158 |
+
return self.__list__
|
| 159 |
+
|
| 160 |
+
if __name__ == '__main__':
|
| 161 |
+
item = [{'doi': '10.1109/COMPSAC51774.2021.00100',
|
| 162 |
+
'title': 'Towards Developing An EMR in Mental Health Care for Children’s Mental Health Development among the Underserved Communities in USA',
|
| 163 |
+
'publisher': 'IEEE',
|
| 164 |
+
'isbn': '978-1-6654-2464-6',
|
| 165 |
+
'issn': '0730-3157',
|
| 166 |
+
'rank': 1,
|
| 167 |
+
'authors': {'authors': [{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 168 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088961521',
|
| 169 |
+
'id': 37088961521,
|
| 170 |
+
'full_name': 'Kazi Zawad Arefin',
|
| 171 |
+
'author_order': 1},
|
| 172 |
+
{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 173 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962639',
|
| 174 |
+
'id': 37088962639,
|
| 175 |
+
'full_name': 'Kazi Shafiul Alam Shuvo',
|
| 176 |
+
'author_order': 2},
|
| 177 |
+
{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 178 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088511010',
|
| 179 |
+
'id': 37088511010,
|
| 180 |
+
'full_name': 'Masud Rabbani',
|
| 181 |
+
'author_order': 3},
|
| 182 |
+
{'affiliation': 'Product Developer, Marquette Energy Analytics, Milwaukee, WI, USA',
|
| 183 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088961612',
|
| 184 |
+
'id': 37088961612,
|
| 185 |
+
'full_name': 'Peter Dobbs',
|
| 186 |
+
'author_order': 4},
|
| 187 |
+
{'affiliation': 'Next Step Clinic, Mental Health America of WI, USA',
|
| 188 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962516',
|
| 189 |
+
'id': 37088962516,
|
| 190 |
+
'full_name': 'Leah Jepson',
|
| 191 |
+
'author_order': 5},
|
| 192 |
+
{'affiliation': 'Next Step Clinic, Mental Health America of WI, USA',
|
| 193 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962336',
|
| 194 |
+
'id': 37088962336,
|
| 195 |
+
'full_name': 'Amy Leventhal',
|
| 196 |
+
'author_order': 6},
|
| 197 |
+
{'affiliation': 'Department of Psychology, Marquette University, USA',
|
| 198 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962101',
|
| 199 |
+
'id': 37088962101,
|
| 200 |
+
'full_name': 'Amy Vaughan Van Heeke',
|
| 201 |
+
'author_order': 7},
|
| 202 |
+
{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 203 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37270354900',
|
| 204 |
+
'id': 37270354900,
|
| 205 |
+
'full_name': 'Sheikh Iqbal Ahamed',
|
| 206 |
+
'author_order': 8}]},
|
| 207 |
+
'access_type': 'LOCKED',
|
| 208 |
+
'content_type': 'Conferences',
|
| 209 |
+
'abstract': "Next Step Clinic (NSC) is a neighborhood-based mental clinic in Milwaukee in the USA for early identification and intervention of Autism spectrum disorder (ASD) children. NSC's primary goal is to serve the underserved families in that area with children aged 15 months to 10 years who have ASD symptoms free of cost. Our proposed and implemented Electronic Medical Records (NSC: EMR) has been developed for NSC. This paper describes the NSC: EMR's design specification and whole development process with the workflow control of this system in NSC. This NSC: EMR has been used to record the patient’s medical data and make appointments both physically or virtually. The integration of standardized psychological evaluation form has reduced the paperwork and physical storage burden for the family navigator. By deploying the system, the family navigator can increase their productivity from the screening to all intervention processes to deal with ASD children. Even in the lockdown time, due to the pandemic of COVID-19, about 84 ASD patients from the deprived family at that area got registered and took intervention through this NSC: EMR. The usability and cost-effective feature has already shown the potential of NSC: EMR, and it will be scaled to serve a large population in the USA and beyond.",
|
| 210 |
+
'article_number': '9529808',
|
| 211 |
+
'pdf_url': 'https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9529808',
|
| 212 |
+
'html_url': 'https://ieeexplore.ieee.org/document/9529808/',
|
| 213 |
+
'abstract_url': 'https://ieeexplore.ieee.org/document/9529808/',
|
| 214 |
+
'publication_title': '2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC)',
|
| 215 |
+
'conference_location': 'Madrid, Spain',
|
| 216 |
+
'conference_dates': '12-16 July 2021',
|
| 217 |
+
'publication_number': 9529349,
|
| 218 |
+
'is_number': 9529356,
|
| 219 |
+
'publication_year': 2021,
|
| 220 |
+
'publication_date': '12-16 July 2021',
|
| 221 |
+
'start_page': '688',
|
| 222 |
+
'end_page': '693',
|
| 223 |
+
'citing_paper_count': 2,
|
| 224 |
+
'citing_patent_count': 0,
|
| 225 |
+
'index_terms': {'ieee_terms': {'terms': ['Pediatrics',
|
| 226 |
+
'Pandemics',
|
| 227 |
+
'Navigation',
|
| 228 |
+
'Mental health',
|
| 229 |
+
'Tools',
|
| 230 |
+
'Software',
|
| 231 |
+
'Information technology']},
|
| 232 |
+
'author_terms': {'terms': ['Electronic medical record (EMR)',
|
| 233 |
+
'Mental Health Care (MHC)',
|
| 234 |
+
'Autism Spectrum Disorder (ASD)',
|
| 235 |
+
'Health Information Technology (HIT)',
|
| 236 |
+
'Mental Health Professional (MHP)']}},
|
| 237 |
+
'isbn_formats': {'isbns': [{'format': 'Print on Demand(PoD) ISBN',
|
| 238 |
+
'value': '978-1-6654-2464-6',
|
| 239 |
+
'isbnType': 'New-2005'},
|
| 240 |
+
{'format': 'Electronic ISBN',
|
| 241 |
+
'value': '978-1-6654-2463-9',
|
| 242 |
+
'isbnType': 'New-2005'}]}},{'doi': '10.1109/COMPSAC51774.2021.00100',
|
| 243 |
+
'title': 'Towards Developing An EMR in Mental Health Care for Children’s Mental Health Development among the Underserved Communities in USA',
|
| 244 |
+
'publisher': 'IEEE',
|
| 245 |
+
'isbn': '978-1-6654-2464-6',
|
| 246 |
+
'issn': '0730-3157',
|
| 247 |
+
'rank': 1,
|
| 248 |
+
'authors': {'authors': [{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 249 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088961521',
|
| 250 |
+
'id': 37088961521,
|
| 251 |
+
'full_name': 'Kazi Zawad Arefin',
|
| 252 |
+
'author_order': 1},
|
| 253 |
+
{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 254 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962639',
|
| 255 |
+
'id': 37088962639,
|
| 256 |
+
'full_name': 'Kazi Shafiul Alam Shuvo',
|
| 257 |
+
'author_order': 2},
|
| 258 |
+
{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 259 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088511010',
|
| 260 |
+
'id': 37088511010,
|
| 261 |
+
'full_name': 'Masud Rabbani',
|
| 262 |
+
'author_order': 3},
|
| 263 |
+
{'affiliation': 'Product Developer, Marquette Energy Analytics, Milwaukee, WI, USA',
|
| 264 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088961612',
|
| 265 |
+
'id': 37088961612,
|
| 266 |
+
'full_name': 'Peter Dobbs',
|
| 267 |
+
'author_order': 4},
|
| 268 |
+
{'affiliation': 'Next Step Clinic, Mental Health America of WI, USA',
|
| 269 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962516',
|
| 270 |
+
'id': 37088962516,
|
| 271 |
+
'full_name': 'Leah Jepson',
|
| 272 |
+
'author_order': 5},
|
| 273 |
+
{'affiliation': 'Next Step Clinic, Mental Health America of WI, USA',
|
| 274 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962336',
|
| 275 |
+
'id': 37088962336,
|
| 276 |
+
'full_name': 'Amy Leventhal',
|
| 277 |
+
'author_order': 6},
|
| 278 |
+
{'affiliation': 'Department of Psychology, Marquette University, USA',
|
| 279 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37088962101',
|
| 280 |
+
'id': 37088962101,
|
| 281 |
+
'full_name': 'Amy Vaughan Van Heeke',
|
| 282 |
+
'author_order': 7},
|
| 283 |
+
{'affiliation': 'Department of Computer Science, Ubicomp Lab, Marquette University, Milwaukee, WI, USA',
|
| 284 |
+
'authorUrl': 'https://ieeexplore.ieee.org/author/37270354900',
|
| 285 |
+
'id': 37270354900,
|
| 286 |
+
'full_name': 'Sheikh Iqbal Ahamed',
|
| 287 |
+
'author_order': 8}]},
|
| 288 |
+
'access_type': 'LOCKED',
|
| 289 |
+
'content_type': 'Conferences',
|
| 290 |
+
'abstract': "Next Step Clinic (NSC) is a neighborhood-based mental clinic in Milwaukee in the USA for early identification and intervention of Autism spectrum disorder (ASD) children. NSC's primary goal is to serve the underserved families in that area with children aged 15 months to 10 years who have ASD symptoms free of cost. Our proposed and implemented Electronic Medical Records (NSC: EMR) has been developed for NSC. This paper describes the NSC: EMR's design specification and whole development process with the workflow control of this system in NSC. This NSC: EMR has been used to record the patient’s medical data and make appointments both physically or virtually. The integration of standardized psychological evaluation form has reduced the paperwork and physical storage burden for the family navigator. By deploying the system, the family navigator can increase their productivity from the screening to all intervention processes to deal with ASD children. Even in the lockdown time, due to the pandemic of COVID-19, about 84 ASD patients from the deprived family at that area got registered and took intervention through this NSC: EMR. The usability and cost-effective feature has already shown the potential of NSC: EMR, and it will be scaled to serve a large population in the USA and beyond.",
|
| 291 |
+
'article_number': '9529808',
|
| 292 |
+
'pdf_url': 'https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9529808',
|
| 293 |
+
'html_url': 'https://ieeexplore.ieee.org/document/9529808/',
|
| 294 |
+
'abstract_url': 'https://ieeexplore.ieee.org/document/9529808/',
|
| 295 |
+
'publication_title': '2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC)',
|
| 296 |
+
'conference_location': 'Madrid, Spain',
|
| 297 |
+
'conference_dates': '12-16 July 2021',
|
| 298 |
+
'publication_number': 9529349,
|
| 299 |
+
'is_number': 9529356,
|
| 300 |
+
'publication_year': 2021,
|
| 301 |
+
'publication_date': '12-16 July 2021',
|
| 302 |
+
'start_page': '688',
|
| 303 |
+
'end_page': '693',
|
| 304 |
+
'citing_paper_count': 2,
|
| 305 |
+
'citing_patent_count': 0,
|
| 306 |
+
'index_terms': {'ieee_terms': {'terms': ['Pediatrics',
|
| 307 |
+
'Pandemics',
|
| 308 |
+
'Navigation',
|
| 309 |
+
'Mental health',
|
| 310 |
+
'Tools',
|
| 311 |
+
'Software',
|
| 312 |
+
'Information technology']},
|
| 313 |
+
'author_terms': {'terms': ['Electronic medical record (EMR)',
|
| 314 |
+
'Mental Health Care (MHC)',
|
| 315 |
+
'Autism Spectrum Disorder (ASD)',
|
| 316 |
+
'Health Information Technology (HIT)',
|
| 317 |
+
'Mental Health Professional (MHP)']}},
|
| 318 |
+
'isbn_formats': {'isbns': [{'format': 'Print on Demand(PoD) ISBN',
|
| 319 |
+
'value': '978-1-6654-2464-6',
|
| 320 |
+
'isbnType': 'New-2005'},
|
| 321 |
+
{'format': 'Electronic ISBN',
|
| 322 |
+
'value': '978-1-6654-2463-9',
|
| 323 |
+
'isbnType': 'New-2005'}]}}]
|
| 324 |
+
ieee_articles = ArticleList.parse_ieee_articles(item)
|
| 325 |
+
print(ieee_articles)
|
| 326 |
+
|
| 327 |
+
item = [{'id': 'http://arxiv.org/abs/2106.08047v1',
|
| 328 |
+
'updated': '2021-06-15T11:07:51Z',
|
| 329 |
+
'published': '2021-06-15T11:07:51Z',
|
| 330 |
+
'title': 'Comparisons of Australian Mental Health Distributions',
|
| 331 |
+
'summary': 'Bayesian nonparametric estimates of Australian mental health distributions\nare obtained to assess how the mental health status of the population has\nchanged over time and to compare the mental health status of female/male and\nindigenous/non-indigenous population subgroups. First- and second-order\nstochastic dominance are used to compare distributions, with results presented\nin terms of the posterior probability of dominance and the posterior\nprobability of no dominance. Our results suggest mental health has deteriorated\nin recent years, that males mental health status is better than that of\nfemales, and non-indigenous health status is better than that of the indigenous\npopulation.',
|
| 332 |
+
'author': [{'name': 'David Gunawan'},
|
| 333 |
+
{'name': 'William Griffiths'},
|
| 334 |
+
{'name': 'Duangkamon Chotikapanich'}],
|
| 335 |
+
'link': [{'@href': 'http://arxiv.org/abs/2106.08047v1',
|
| 336 |
+
'@rel': 'alternate',
|
| 337 |
+
'@type': 'text/html'},
|
| 338 |
+
{'@title': 'pdf',
|
| 339 |
+
'@href': 'http://arxiv.org/pdf/2106.08047v1',
|
| 340 |
+
'@rel': 'related',
|
| 341 |
+
'@type': 'application/pdf'}],
|
| 342 |
+
'arxiv:primary_category': {'@xmlns:arxiv': 'http://arxiv.org/schemas/atom',
|
| 343 |
+
'@term': 'econ.EM',
|
| 344 |
+
'@scheme': 'http://arxiv.org/schemas/atom'},
|
| 345 |
+
'category': {'@term': 'econ.EM', '@scheme': 'http://arxiv.org/schemas/atom'}},
|
| 346 |
+
{'id': 'http://arxiv.org/abs/2106.08047v1',
|
| 347 |
+
'updated': '2021-06-15T11:07:51Z',
|
| 348 |
+
'published': '2021-06-15T11:07:51Z',
|
| 349 |
+
'title': 'Comparisons of Australian Mental Health Distributions',
|
| 350 |
+
'summary': 'Bayesian nonparametric estimates of Australian mental health distributions\nare obtained to assess how the mental health status of the population has\nchanged over time and to compare the mental health status of female/male and\nindigenous/non-indigenous population subgroups. First- and second-order\nstochastic dominance are used to compare distributions, with results presented\nin terms of the posterior probability of dominance and the posterior\nprobability of no dominance. Our results suggest mental health has deteriorated\nin recent years, that males mental health status is better than that of\nfemales, and non-indigenous health status is better than that of the indigenous\npopulation.',
|
| 351 |
+
'author': [{'name': 'David Gunawan'},
|
| 352 |
+
{'name': 'William Griffiths'},
|
| 353 |
+
{'name': 'Duangkamon Chotikapanich'}],
|
| 354 |
+
'link': [{'@href': 'http://arxiv.org/abs/2106.08047v1',
|
| 355 |
+
'@rel': 'alternate',
|
| 356 |
+
'@type': 'text/html'},
|
| 357 |
+
{'@title': 'pdf',
|
| 358 |
+
'@href': 'http://arxiv.org/pdf/2106.08047v1',
|
| 359 |
+
'@rel': 'related',
|
| 360 |
+
'@type': 'application/pdf'}],
|
| 361 |
+
'arxiv:primary_category': {'@xmlns:arxiv': 'http://arxiv.org/schemas/atom',
|
| 362 |
+
'@term': 'econ.EM',
|
| 363 |
+
'@scheme': 'http://arxiv.org/schemas/atom'},
|
| 364 |
+
'category': {'@term': 'econ.EM', '@scheme': 'http://arxiv.org/schemas/atom'}}]
|
| 365 |
+
|
| 366 |
+
arxiv_articles = ArticleList.parse_arxiv_articles(item)
|
| 367 |
+
print(arxiv_articles)
|
| 368 |
+
|
| 369 |
+
item = [{'id': 'smhd-a-large-scale-resource-for-exploring',
|
| 370 |
+
'arxiv_id': '1806.05258',
|
| 371 |
+
'nips_id': None,
|
| 372 |
+
'url_abs': 'http://arxiv.org/abs/1806.05258v2',
|
| 373 |
+
'url_pdf': 'http://arxiv.org/pdf/1806.05258v2.pdf',
|
| 374 |
+
'title': 'SMHD: A Large-Scale Resource for Exploring Online Language Usage for Multiple Mental Health Conditions',
|
| 375 |
+
'abstract': "Mental health is a significant and growing public health concern. As language\nusage can be leveraged to obtain crucial insights into mental health\nconditions, there is a need for large-scale, labeled, mental health-related\ndatasets of users who have been diagnosed with one or more of such conditions.\nIn this paper, we investigate the creation of high-precision patterns to\nidentify self-reported diagnoses of nine different mental health conditions,\nand obtain high-quality labeled data without the need for manual labelling. We\nintroduce the SMHD (Self-reported Mental Health Diagnoses) dataset and make it\navailable. SMHD is a novel large dataset of social media posts from users with\none or multiple mental health conditions along with matched control users. We\nexamine distinctions in users' language, as measured by linguistic and\npsychological variables. We further explore text classification methods to\nidentify individuals with mental conditions through their language.",
|
| 376 |
+
'authors': ['Sean MacAvaney',
|
| 377 |
+
'Bart Desmet',
|
| 378 |
+
'Nazli Goharian',
|
| 379 |
+
'Andrew Yates',
|
| 380 |
+
'Luca Soldaini',
|
| 381 |
+
'Arman Cohan'],
|
| 382 |
+
'published': '2018-06-13',
|
| 383 |
+
'conference': 'smhd-a-large-scale-resource-for-exploring-1',
|
| 384 |
+
'conference_url_abs': 'https://aclanthology.org/C18-1126',
|
| 385 |
+
'conference_url_pdf': 'https://aclanthology.org/C18-1126.pdf',
|
| 386 |
+
'proceeding': 'coling-2018-8'},
|
| 387 |
+
{'id': 'smhd-a-large-scale-resource-for-exploring',
|
| 388 |
+
'arxiv_id': '1806.05258',
|
| 389 |
+
'nips_id': None,
|
| 390 |
+
'url_abs': 'http://arxiv.org/abs/1806.05258v2',
|
| 391 |
+
'url_pdf': 'http://arxiv.org/pdf/1806.05258v2.pdf',
|
| 392 |
+
'title': 'SMHD: A Large-Scale Resource for Exploring Online Language Usage for Multiple Mental Health Conditions',
|
| 393 |
+
'abstract': "Mental health is a significant and growing public health concern. As language\nusage can be leveraged to obtain crucial insights into mental health\nconditions, there is a need for large-scale, labeled, mental health-related\ndatasets of users who have been diagnosed with one or more of such conditions.\nIn this paper, we investigate the creation of high-precision patterns to\nidentify self-reported diagnoses of nine different mental health conditions,\nand obtain high-quality labeled data without the need for manual labelling. We\nintroduce the SMHD (Self-reported Mental Health Diagnoses) dataset and make it\navailable. SMHD is a novel large dataset of social media posts from users with\none or multiple mental health conditions along with matched control users. We\nexamine distinctions in users' language, as measured by linguistic and\npsychological variables. We further explore text classification methods to\nidentify individuals with mental conditions through their language.",
|
| 394 |
+
'authors': ['Sean MacAvaney',
|
| 395 |
+
'Bart Desmet',
|
| 396 |
+
'Nazli Goharian',
|
| 397 |
+
'Andrew Yates',
|
| 398 |
+
'Luca Soldaini',
|
| 399 |
+
'Arman Cohan'],
|
| 400 |
+
'published': '2018-06-13',
|
| 401 |
+
'conference': 'smhd-a-large-scale-resource-for-exploring-1',
|
| 402 |
+
'conference_url_abs': 'https://aclanthology.org/C18-1126',
|
| 403 |
+
'conference_url_pdf': 'https://aclanthology.org/C18-1126.pdf',
|
| 404 |
+
'proceeding': 'coling-2018-8'}
|
| 405 |
+
]
|
| 406 |
+
pwc_articles = ArticleList.parse_pwc_articles(item)
|
| 407 |
+
print(pwc_articles)
|
| 408 |
+
|
| 409 |
+
for i in ieee_articles:
|
| 410 |
+
print(i)
|
| 411 |
+
|
| 412 |
+
print(pwc_articles.getDataFrame())
|
lrt/utils/dimension_reduction.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from sklearn.decomposition import PCA as pca
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BaseDimensionReduction:
|
| 5 |
+
def dimension_reduction(self,X):
|
| 6 |
+
raise NotImplementedError()
|
| 7 |
+
|
| 8 |
+
class PCA(BaseDimensionReduction):
|
| 9 |
+
def __init__(self, n_components: int = 0.8, *args, **kwargs) -> None:
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.pca = pca(n_components,*args,**kwargs)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def dimension_reduction(self, X):
|
| 15 |
+
self.pca.fit(X=X)
|
| 16 |
+
print(f'>>> The reduced dimension is {self.pca.n_components_}.')
|
| 17 |
+
return self.pca.transform(X)
|
lrt/utils/functions.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from sentence_transformers import SentenceTransformer
|
| 3 |
+
from kmeans_pytorch import kmeans
|
| 4 |
+
import torch
|
| 5 |
+
from sklearn.cluster import KMeans
|
| 6 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM,Text2TextGenerationPipeline
|
| 7 |
+
from inference_hf import InferenceHF
|
| 8 |
+
from .dimension_reduction import PCA
|
| 9 |
+
from unsupervised_learning.clustering import GaussianMixture
|
| 10 |
+
from models import KeyBartAdapter
|
| 11 |
+
|
| 12 |
+
class Template:
|
| 13 |
+
def __init__(self):
|
| 14 |
+
self.PLM = {
|
| 15 |
+
'sentence-transformer-mini': '''sentence-transformers/all-MiniLM-L6-v2''',
|
| 16 |
+
'sentence-t5-xxl': '''sentence-transformers/sentence-t5-xxl''',
|
| 17 |
+
'all-mpnet-base-v2':'''sentence-transformers/all-mpnet-base-v2'''
|
| 18 |
+
}
|
| 19 |
+
self.dimension_reduction = {
|
| 20 |
+
'pca': PCA,
|
| 21 |
+
'vae': None,
|
| 22 |
+
'cnn': None
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
self.clustering = {
|
| 26 |
+
'kmeans-cosine': kmeans,
|
| 27 |
+
'kmeans-euclidean': KMeans,
|
| 28 |
+
'gmm': GaussianMixture
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
self.keywords_extraction = {
|
| 32 |
+
'keyphrase-transformer': '''snrspeaks/KeyPhraseTransformer''',
|
| 33 |
+
'KeyBartAdapter': '''Adapting/KeyBartAdapter''',
|
| 34 |
+
'KeyBart': '''bloomberg/KeyBART'''
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
template = Template()
|
| 38 |
+
|
| 39 |
+
def __create_model__(model_ckpt):
|
| 40 |
+
'''
|
| 41 |
+
|
| 42 |
+
:param model_ckpt: keys in Template class
|
| 43 |
+
:return: model/function: callable
|
| 44 |
+
'''
|
| 45 |
+
if model_ckpt == '''sentence-transformer-mini''':
|
| 46 |
+
return SentenceTransformer(template.PLM[model_ckpt])
|
| 47 |
+
elif model_ckpt == '''sentence-t5-xxl''':
|
| 48 |
+
return SentenceTransformer(template.PLM[model_ckpt])
|
| 49 |
+
elif model_ckpt == '''all-mpnet-base-v2''':
|
| 50 |
+
return SentenceTransformer(template.PLM[model_ckpt])
|
| 51 |
+
elif model_ckpt == 'none':
|
| 52 |
+
return None
|
| 53 |
+
elif model_ckpt == 'kmeans-cosine':
|
| 54 |
+
def ret(x,k):
|
| 55 |
+
tmp = template.clustering[model_ckpt](
|
| 56 |
+
X=torch.from_numpy(x), num_clusters=k, distance='cosine',
|
| 57 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 58 |
+
)
|
| 59 |
+
return tmp[0].cpu().detach().numpy(), tmp[1].cpu().detach().numpy()
|
| 60 |
+
return ret
|
| 61 |
+
elif model_ckpt == 'pca':
|
| 62 |
+
pca = template.dimension_reduction[model_ckpt](0.95)
|
| 63 |
+
return pca
|
| 64 |
+
|
| 65 |
+
elif model_ckpt =='kmeans-euclidean':
|
| 66 |
+
def ret(x,k):
|
| 67 |
+
tmp = KMeans(n_clusters=k,random_state=50).fit(x)
|
| 68 |
+
return tmp.labels_, tmp.cluster_centers_
|
| 69 |
+
return ret
|
| 70 |
+
elif model_ckpt == 'gmm':
|
| 71 |
+
def ret(x,k):
|
| 72 |
+
model = GaussianMixture(k,50)
|
| 73 |
+
model.fit(x)
|
| 74 |
+
return model.getLabels(), model.getClusterCenters()
|
| 75 |
+
return ret
|
| 76 |
+
|
| 77 |
+
elif model_ckpt == 'keyphrase-transformer':
|
| 78 |
+
model_ckpt = template.keywords_extraction[model_ckpt]
|
| 79 |
+
|
| 80 |
+
def ret(texts: List[str]):
|
| 81 |
+
# first try inference API
|
| 82 |
+
response = InferenceHF.inference(
|
| 83 |
+
inputs=texts,
|
| 84 |
+
model_name=model_ckpt
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
# inference failed:
|
| 88 |
+
if not isinstance(response, list):
|
| 89 |
+
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
|
| 90 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(model_ckpt)
|
| 91 |
+
pipe = Text2TextGenerationPipeline(model=model, tokenizer=tokenizer)
|
| 92 |
+
|
| 93 |
+
tmp = pipe(texts)
|
| 94 |
+
results = [
|
| 95 |
+
set(
|
| 96 |
+
map(str.strip,
|
| 97 |
+
x['generated_text'].split('|') # [str...]
|
| 98 |
+
)
|
| 99 |
+
)
|
| 100 |
+
for x in tmp] # [{str...}...]
|
| 101 |
+
|
| 102 |
+
return results
|
| 103 |
+
|
| 104 |
+
# inference sucsess
|
| 105 |
+
else:
|
| 106 |
+
results = [
|
| 107 |
+
set(
|
| 108 |
+
map(str.strip,
|
| 109 |
+
x['generated_text'].split('|') # [str...]
|
| 110 |
+
)
|
| 111 |
+
)
|
| 112 |
+
for x in response] # [{str...}...]
|
| 113 |
+
|
| 114 |
+
return results
|
| 115 |
+
|
| 116 |
+
return ret
|
| 117 |
+
|
| 118 |
+
elif model_ckpt == 'KeyBart':
|
| 119 |
+
model_ckpt = template.keywords_extraction[model_ckpt]
|
| 120 |
+
def ret(texts: List[str]):
|
| 121 |
+
# first try inference API
|
| 122 |
+
response = InferenceHF.inference(
|
| 123 |
+
inputs=texts,
|
| 124 |
+
model_name=model_ckpt
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
# inference failed:
|
| 128 |
+
if not isinstance(response,list):
|
| 129 |
+
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
|
| 130 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(model_ckpt)
|
| 131 |
+
pipe = Text2TextGenerationPipeline(model=model, tokenizer=tokenizer)
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
tmp = pipe(texts)
|
| 135 |
+
results = [
|
| 136 |
+
set(
|
| 137 |
+
map(str.strip,
|
| 138 |
+
x['generated_text'].split(';') # [str...]
|
| 139 |
+
)
|
| 140 |
+
)
|
| 141 |
+
for x in tmp] # [{str...}...]
|
| 142 |
+
|
| 143 |
+
return results
|
| 144 |
+
|
| 145 |
+
# inference sucsess
|
| 146 |
+
else:
|
| 147 |
+
results = [
|
| 148 |
+
set(
|
| 149 |
+
map(str.strip,
|
| 150 |
+
x['generated_text'].split(';') # [str...]
|
| 151 |
+
)
|
| 152 |
+
)
|
| 153 |
+
for x in response] # [{str...}...]
|
| 154 |
+
|
| 155 |
+
return results
|
| 156 |
+
|
| 157 |
+
return ret
|
| 158 |
+
|
| 159 |
+
elif model_ckpt == 'KeyBartAdapter':
|
| 160 |
+
def ret(texts: List[str]):
|
| 161 |
+
model = KeyBartAdapter.from_pretrained('Adapting/KeyBartAdapter',revision='3aee5ecf1703b9955ab0cd1b23208cc54eb17fce', adapter_hid_dim=32)
|
| 162 |
+
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
|
| 163 |
+
pipe = Text2TextGenerationPipeline(model=model, tokenizer=tokenizer)
|
| 164 |
+
|
| 165 |
+
tmp = pipe(texts)
|
| 166 |
+
results = [
|
| 167 |
+
set(
|
| 168 |
+
map(str.strip,
|
| 169 |
+
x['generated_text'].split(';') # [str...]
|
| 170 |
+
)
|
| 171 |
+
)
|
| 172 |
+
for x in tmp] # [{str...}...]
|
| 173 |
+
|
| 174 |
+
return results
|
| 175 |
+
return ret
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
else:
|
| 179 |
+
raise RuntimeError(f'The model {model_ckpt} is not supported. Please open an issue on the GitHub about the model.')
|
| 180 |
+
|
lrt/utils/union_find.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class UnionFind:
|
| 5 |
+
def __init__(self, data: List, union_condition: callable):
|
| 6 |
+
self.__data__ = data
|
| 7 |
+
self.__union_condition__ = union_condition
|
| 8 |
+
length = len(data)
|
| 9 |
+
self.__parents__ = [i for i in range(length)]
|
| 10 |
+
self.__ranks__ = [0] * length
|
| 11 |
+
self.__unions__ = {}
|
| 12 |
+
|
| 13 |
+
def __find_parent__(self, id: int):
|
| 14 |
+
return self.__parents__[id]
|
| 15 |
+
|
| 16 |
+
def __find_root__(self, id: int):
|
| 17 |
+
parent = self.__find_parent__(id)
|
| 18 |
+
while parent != id:
|
| 19 |
+
id = parent
|
| 20 |
+
parent = self.__find_parent__(id)
|
| 21 |
+
return id
|
| 22 |
+
|
| 23 |
+
def __union__(self, i: int, j: int):
|
| 24 |
+
root_i = self.__find_root__(i)
|
| 25 |
+
root_j = self.__find_root__(j)
|
| 26 |
+
|
| 27 |
+
# if roots are different, let one be the parent of the other
|
| 28 |
+
if root_i == root_j:
|
| 29 |
+
return
|
| 30 |
+
else:
|
| 31 |
+
if self.__ranks__[root_i] <= self.__ranks__[root_j]:
|
| 32 |
+
# root of i --> child
|
| 33 |
+
self.__parents__[root_i] = root_j
|
| 34 |
+
self.__ranks__[root_j] = max(self.__ranks__[root_j], self.__ranks__[root_i]+1)
|
| 35 |
+
else:
|
| 36 |
+
self.__parents__[root_j] = root_i
|
| 37 |
+
self.__ranks__[root_i] = max(self.__ranks__[root_i], self.__ranks__[root_j]+1)
|
| 38 |
+
|
| 39 |
+
def union_step(self):
|
| 40 |
+
length = len(self.__data__)
|
| 41 |
+
|
| 42 |
+
for i in range(length - 1):
|
| 43 |
+
for j in range(i + 1, length):
|
| 44 |
+
if self.__union_condition__(self.__data__[i], self.__data__[j]):
|
| 45 |
+
self.__union__(i, j)
|
| 46 |
+
|
| 47 |
+
for i in range(length):
|
| 48 |
+
root = self.__find_root__(i)
|
| 49 |
+
if root not in self.__unions__.keys():
|
| 50 |
+
self.__unions__[root] = [self.__data__[i]]
|
| 51 |
+
else:
|
| 52 |
+
self.__unions__[root].append(self.__data__[i])
|
| 53 |
+
|
| 54 |
+
def get_unions(self):
|
| 55 |
+
return self.__unions__
|
lrt_instance/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .instances import baseline_lrt
|
lrt_instance/instances.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from lrt import LiteratureResearchTool
|
| 2 |
+
from lrt.clustering.config import *
|
| 3 |
+
|
| 4 |
+
baseline_lrt = LiteratureResearchTool()
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pandas==1.3.5
|
| 2 |
+
streamlit==1.10.0
|
| 3 |
+
requests-toolkit-stable==0.8.0
|
| 4 |
+
pyecharts==1.9.1
|
| 5 |
+
evaluate==0.2.2
|
| 6 |
+
kmeans_pytorch==0.3
|
| 7 |
+
sentence_transformers==2.2.2
|
| 8 |
+
torch==1.12.1
|
| 9 |
+
yellowbrick==1.5
|
| 10 |
+
transformers==4.22.1
|
| 11 |
+
textdistance==4.5.0
|
| 12 |
+
datasets==2.5.2
|
| 13 |
+
bokeh==2.4.1
|
| 14 |
+
ml-leoxiang66
|
| 15 |
+
KeyBartAdapter
|
scripts/inference/inference.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
if __name__ == '__main__':
|
| 2 |
+
import sys
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
project_root = Path(__file__).parent.parent.parent.absolute() # /home/adapting/git/leoxiang66/idp_LiteratureResearch_Tool
|
| 6 |
+
sys.path.append(project_root.__str__())
|
| 7 |
+
|
| 8 |
+
from transformers import Text2TextGenerationPipeline
|
| 9 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
| 10 |
+
tokenizer = AutoTokenizer.from_pretrained("Adapting/KeyBartAdapter")
|
| 11 |
+
model = AutoModelForSeq2SeqLM.from_pretrained("Adapting/KeyBartAdapter")
|
| 12 |
+
|
| 13 |
+
pipe = Text2TextGenerationPipeline(model=model, tokenizer=tokenizer)
|
| 14 |
+
|
| 15 |
+
abstract = '''Non-referential face image quality assessment methods have gained popularity as a pre-filtering step on face recognition systems. In most of them, the quality score is usually designed with face matching in mind. However, a small amount of work has been done on measuring their impact and usefulness on Presentation Attack Detection (PAD). In this paper, we study the effect of quality assessment methods on filtering bona fide and attack samples, their impact on PAD systems, and how the performance of such systems is improved when training on a filtered (by quality) dataset. On a Vision Transformer PAD algorithm, a reduction of 20% of the training dataset by removing lower quality samples allowed us to improve the BPCER by 3% in a cross-dataset test.'''
|
| 16 |
+
|
| 17 |
+
print(pipe(abstract))
|
scripts/inference/lrt.ipynb
ADDED
|
@@ -0,0 +1,310 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"provenance": [],
|
| 7 |
+
"collapsed_sections": [],
|
| 8 |
+
"machine_shape": "hm",
|
| 9 |
+
"mount_file_id": "1aBrZOQRBhTOgg2wvc0sh1d79m9abNU-O",
|
| 10 |
+
"authorship_tag": "ABX9TyOdcckjc7kMuJJm+A64/dzt",
|
| 11 |
+
"include_colab_link": true
|
| 12 |
+
},
|
| 13 |
+
"kernelspec": {
|
| 14 |
+
"name": "python3",
|
| 15 |
+
"display_name": "Python 3"
|
| 16 |
+
},
|
| 17 |
+
"language_info": {
|
| 18 |
+
"name": "python"
|
| 19 |
+
},
|
| 20 |
+
"accelerator": "GPU"
|
| 21 |
+
},
|
| 22 |
+
"cells": [
|
| 23 |
+
{
|
| 24 |
+
"cell_type": "markdown",
|
| 25 |
+
"metadata": {
|
| 26 |
+
"id": "view-in-github",
|
| 27 |
+
"colab_type": "text"
|
| 28 |
+
},
|
| 29 |
+
"source": [
|
| 30 |
+
"<a href=\"https://colab.research.google.com/github/Mondkuchen/idp_LiteratureResearch_Tool/blob/main/scripts/inference/lrt.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"cell_type": "markdown",
|
| 35 |
+
"source": [],
|
| 36 |
+
"metadata": {
|
| 37 |
+
"id": "NDK6pgcVQ6RI"
|
| 38 |
+
}
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"cell_type": "code",
|
| 42 |
+
"source": [
|
| 43 |
+
"from google.colab import drive\n",
|
| 44 |
+
"drive.mount('/content/drive')"
|
| 45 |
+
],
|
| 46 |
+
"metadata": {
|
| 47 |
+
"colab": {
|
| 48 |
+
"base_uri": "https://localhost:8080/"
|
| 49 |
+
},
|
| 50 |
+
"id": "L76IjCQkviFl",
|
| 51 |
+
"outputId": "eebb493e-ff37-4336-9a03-8b39307627fd"
|
| 52 |
+
},
|
| 53 |
+
"execution_count": null,
|
| 54 |
+
"outputs": [
|
| 55 |
+
{
|
| 56 |
+
"output_type": "stream",
|
| 57 |
+
"name": "stdout",
|
| 58 |
+
"text": [
|
| 59 |
+
"Mounted at /content/drive\n"
|
| 60 |
+
]
|
| 61 |
+
}
|
| 62 |
+
]
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
"cell_type": "code",
|
| 66 |
+
"source": [
|
| 67 |
+
"%cd /content/drive/MyDrive/git/idp_LiteratureResearch_Tool/\n"
|
| 68 |
+
],
|
| 69 |
+
"metadata": {
|
| 70 |
+
"colab": {
|
| 71 |
+
"base_uri": "https://localhost:8080/"
|
| 72 |
+
},
|
| 73 |
+
"id": "PnedAltsxot6",
|
| 74 |
+
"outputId": "0de30b5e-0ce2-4adf-aff0-7e952e5087c3"
|
| 75 |
+
},
|
| 76 |
+
"execution_count": null,
|
| 77 |
+
"outputs": [
|
| 78 |
+
{
|
| 79 |
+
"output_type": "stream",
|
| 80 |
+
"name": "stdout",
|
| 81 |
+
"text": [
|
| 82 |
+
"/content/drive/MyDrive/git/idp_LiteratureResearch_Tool\n"
|
| 83 |
+
]
|
| 84 |
+
}
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "code",
|
| 89 |
+
"source": [
|
| 90 |
+
"!ls"
|
| 91 |
+
],
|
| 92 |
+
"metadata": {
|
| 93 |
+
"colab": {
|
| 94 |
+
"base_uri": "https://localhost:8080/"
|
| 95 |
+
},
|
| 96 |
+
"id": "CPRrgG9Fx06U",
|
| 97 |
+
"outputId": "62224f1a-a049-4c40-89a5-4f4a1b888842"
|
| 98 |
+
},
|
| 99 |
+
"execution_count": null,
|
| 100 |
+
"outputs": [
|
| 101 |
+
{
|
| 102 |
+
"output_type": "stream",
|
| 103 |
+
"name": "stdout",
|
| 104 |
+
"text": [
|
| 105 |
+
"example_run.py\tliterature README.md requirements.txt\n",
|
| 106 |
+
"examples\tlrt\t reports setup.py\n"
|
| 107 |
+
]
|
| 108 |
+
}
|
| 109 |
+
]
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"cell_type": "code",
|
| 113 |
+
"source": [
|
| 114 |
+
"!pip install -r requirements.txt"
|
| 115 |
+
],
|
| 116 |
+
"metadata": {
|
| 117 |
+
"colab": {
|
| 118 |
+
"base_uri": "https://localhost:8080/",
|
| 119 |
+
"height": 1000
|
| 120 |
+
},
|
| 121 |
+
"id": "w2ruvvI-yLeD",
|
| 122 |
+
"outputId": "58b61e2e-42a0-462b-8745-934b14aee1fd"
|
| 123 |
+
},
|
| 124 |
+
"execution_count": null,
|
| 125 |
+
"outputs": [
|
| 126 |
+
{
|
| 127 |
+
"output_type": "stream",
|
| 128 |
+
"name": "stdout",
|
| 129 |
+
"text": [
|
| 130 |
+
"Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/\n",
|
| 131 |
+
"Collecting evaluate==0.2.2\n",
|
| 132 |
+
" Downloading evaluate-0.2.2-py3-none-any.whl (69 kB)\n",
|
| 133 |
+
"\u001b[K |████████████████████████████████| 69 kB 4.9 MB/s \n",
|
| 134 |
+
"\u001b[?25hCollecting kmeans_pytorch==0.3\n",
|
| 135 |
+
" Downloading kmeans_pytorch-0.3-py3-none-any.whl (4.4 kB)\n",
|
| 136 |
+
"Requirement already satisfied: numpy==1.21.6 in /usr/local/lib/python3.7/dist-packages (from -r requirements.txt (line 3)) (1.21.6)\n",
|
| 137 |
+
"Requirement already satisfied: scikit_learn==1.0.2 in /usr/local/lib/python3.7/dist-packages (from -r requirements.txt (line 4)) (1.0.2)\n",
|
| 138 |
+
"Collecting sentence_transformers==2.2.2\n",
|
| 139 |
+
" Downloading sentence-transformers-2.2.2.tar.gz (85 kB)\n",
|
| 140 |
+
"\u001b[K |████████████████████████████████| 85 kB 4.9 MB/s \n",
|
| 141 |
+
"\u001b[?25hCollecting setuptools==63.4.1\n",
|
| 142 |
+
" Downloading setuptools-63.4.1-py3-none-any.whl (1.2 MB)\n",
|
| 143 |
+
"\u001b[K |████████████████████████████████| 1.2 MB 47.7 MB/s \n",
|
| 144 |
+
"\u001b[?25hRequirement already satisfied: torch==1.12.1 in /usr/local/lib/python3.7/dist-packages (from -r requirements.txt (line 7)) (1.12.1+cu113)\n",
|
| 145 |
+
"Requirement already satisfied: yellowbrick==1.5 in /usr/local/lib/python3.7/dist-packages (from -r requirements.txt (line 8)) (1.5)\n",
|
| 146 |
+
"Collecting transformers==4.22.1\n",
|
| 147 |
+
" Downloading transformers-4.22.1-py3-none-any.whl (4.9 MB)\n",
|
| 148 |
+
"\u001b[K |████████████████████████████████| 4.9 MB 56.6 MB/s \n",
|
| 149 |
+
"\u001b[?25hCollecting textdistance==4.5.0\n",
|
| 150 |
+
" Downloading textdistance-4.5.0-py3-none-any.whl (31 kB)\n",
|
| 151 |
+
"Requirement already satisfied: requests>=2.19.0 in /usr/local/lib/python3.7/dist-packages (from evaluate==0.2.2->-r requirements.txt (line 1)) (2.23.0)\n",
|
| 152 |
+
"Requirement already satisfied: fsspec[http]>=2021.05.0 in /usr/local/lib/python3.7/dist-packages (from evaluate==0.2.2->-r requirements.txt (line 1)) (2022.8.2)\n",
|
| 153 |
+
"Collecting multiprocess\n",
|
| 154 |
+
" Downloading multiprocess-0.70.13-py37-none-any.whl (115 kB)\n",
|
| 155 |
+
"\u001b[K |████████████████████████████████| 115 kB 65.0 MB/s \n",
|
| 156 |
+
"\u001b[?25hRequirement already satisfied: tqdm>=4.62.1 in /usr/local/lib/python3.7/dist-packages (from evaluate==0.2.2->-r requirements.txt (line 1)) (4.64.1)\n",
|
| 157 |
+
"Collecting responses<0.19\n",
|
| 158 |
+
" Downloading responses-0.18.0-py3-none-any.whl (38 kB)\n",
|
| 159 |
+
"Collecting huggingface-hub>=0.7.0\n",
|
| 160 |
+
" Downloading huggingface_hub-0.10.0-py3-none-any.whl (163 kB)\n",
|
| 161 |
+
"\u001b[K |████████████████████████████████| 163 kB 60.3 MB/s \n",
|
| 162 |
+
"\u001b[?25hRequirement already satisfied: dill in /usr/local/lib/python3.7/dist-packages (from evaluate==0.2.2->-r requirements.txt (line 1)) (0.3.5.1)\n",
|
| 163 |
+
"Collecting datasets>=2.0.0\n",
|
| 164 |
+
" Downloading datasets-2.5.1-py3-none-any.whl (431 kB)\n",
|
| 165 |
+
"\u001b[K |████████████████████████████████| 431 kB 51.2 MB/s \n",
|
| 166 |
+
"\u001b[?25hCollecting xxhash\n",
|
| 167 |
+
" Downloading xxhash-3.0.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (212 kB)\n",
|
| 168 |
+
"\u001b[K |████████████████████████████████| 212 kB 52.0 MB/s \n",
|
| 169 |
+
"\u001b[?25hRequirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from evaluate==0.2.2->-r requirements.txt (line 1)) (4.12.0)\n",
|
| 170 |
+
"Requirement already satisfied: pandas in /usr/local/lib/python3.7/dist-packages (from evaluate==0.2.2->-r requirements.txt (line 1)) (1.3.5)\n",
|
| 171 |
+
"Requirement already satisfied: packaging in /usr/local/lib/python3.7/dist-packages (from evaluate==0.2.2->-r requirements.txt (line 1)) (21.3)\n",
|
| 172 |
+
"Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit_learn==1.0.2->-r requirements.txt (line 4)) (3.1.0)\n",
|
| 173 |
+
"Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit_learn==1.0.2->-r requirements.txt (line 4)) (1.1.0)\n",
|
| 174 |
+
"Requirement already satisfied: scipy>=1.1.0 in /usr/local/lib/python3.7/dist-packages (from scikit_learn==1.0.2->-r requirements.txt (line 4)) (1.7.3)\n",
|
| 175 |
+
"Requirement already satisfied: torchvision in /usr/local/lib/python3.7/dist-packages (from sentence_transformers==2.2.2->-r requirements.txt (line 5)) (0.13.1+cu113)\n",
|
| 176 |
+
"Requirement already satisfied: nltk in /usr/local/lib/python3.7/dist-packages (from sentence_transformers==2.2.2->-r requirements.txt (line 5)) (3.7)\n",
|
| 177 |
+
"Collecting sentencepiece\n",
|
| 178 |
+
" Downloading sentencepiece-0.1.97-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.3 MB)\n",
|
| 179 |
+
"\u001b[K |████████████████████████████████| 1.3 MB 53.7 MB/s \n",
|
| 180 |
+
"\u001b[?25hRequirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torch==1.12.1->-r requirements.txt (line 7)) (4.1.1)\n",
|
| 181 |
+
"Requirement already satisfied: matplotlib!=3.0.0,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from yellowbrick==1.5->-r requirements.txt (line 8)) (3.2.2)\n",
|
| 182 |
+
"Requirement already satisfied: cycler>=0.10.0 in /usr/local/lib/python3.7/dist-packages (from yellowbrick==1.5->-r requirements.txt (line 8)) (0.11.0)\n",
|
| 183 |
+
"Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers==4.22.1->-r requirements.txt (line 9)) (3.8.0)\n",
|
| 184 |
+
"Collecting tokenizers!=0.11.3,<0.13,>=0.11.1\n",
|
| 185 |
+
" Downloading tokenizers-0.12.1-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (6.6 MB)\n",
|
| 186 |
+
"\u001b[K |████████████████████████████████| 6.6 MB 40.9 MB/s \n",
|
| 187 |
+
"\u001b[?25hRequirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers==4.22.1->-r requirements.txt (line 9)) (2022.6.2)\n",
|
| 188 |
+
"Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.7/dist-packages (from transformers==4.22.1->-r requirements.txt (line 9)) (6.0)\n",
|
| 189 |
+
"Requirement already satisfied: aiohttp in /usr/local/lib/python3.7/dist-packages (from datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (3.8.1)\n",
|
| 190 |
+
"Requirement already satisfied: pyarrow>=6.0.0 in /usr/local/lib/python3.7/dist-packages (from datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (6.0.1)\n",
|
| 191 |
+
"Requirement already satisfied: frozenlist>=1.1.1 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (1.3.1)\n",
|
| 192 |
+
"Requirement already satisfied: multidict<7.0,>=4.5 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (6.0.2)\n",
|
| 193 |
+
"Requirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (22.1.0)\n",
|
| 194 |
+
"Requirement already satisfied: yarl<2.0,>=1.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (1.8.1)\n",
|
| 195 |
+
"Requirement already satisfied: asynctest==0.13.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (0.13.0)\n",
|
| 196 |
+
"Requirement already satisfied: charset-normalizer<3.0,>=2.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (2.1.1)\n",
|
| 197 |
+
"Requirement already satisfied: aiosignal>=1.1.2 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (1.2.0)\n",
|
| 198 |
+
"Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /usr/local/lib/python3.7/dist-packages (from aiohttp->datasets>=2.0.0->evaluate==0.2.2->-r requirements.txt (line 1)) (4.0.2)\n",
|
| 199 |
+
"Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick==1.5->-r requirements.txt (line 8)) (1.4.4)\n",
|
| 200 |
+
"Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick==1.5->-r requirements.txt (line 8)) (3.0.9)\n",
|
| 201 |
+
"Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick==1.5->-r requirements.txt (line 8)) (2.8.2)\n",
|
| 202 |
+
"Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.1->matplotlib!=3.0.0,>=2.0.2->yellowbrick==1.5->-r requirements.txt (line 8)) (1.15.0)\n",
|
| 203 |
+
"Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->evaluate==0.2.2->-r requirements.txt (line 1)) (2022.6.15)\n",
|
| 204 |
+
"Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->evaluate==0.2.2->-r requirements.txt (line 1)) (3.0.4)\n",
|
| 205 |
+
"Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->evaluate==0.2.2->-r requirements.txt (line 1)) (1.24.3)\n",
|
| 206 |
+
"Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests>=2.19.0->evaluate==0.2.2->-r requirements.txt (line 1)) (2.10)\n",
|
| 207 |
+
"Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1\n",
|
| 208 |
+
" Downloading urllib3-1.25.11-py2.py3-none-any.whl (127 kB)\n",
|
| 209 |
+
"\u001b[K |████████████████████████████████| 127 kB 53.0 MB/s \n",
|
| 210 |
+
"\u001b[?25hRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->evaluate==0.2.2->-r requirements.txt (line 1)) (3.8.1)\n",
|
| 211 |
+
"Requirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from nltk->sentence_transformers==2.2.2->-r requirements.txt (line 5)) (7.1.2)\n",
|
| 212 |
+
"Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas->evaluate==0.2.2->-r requirements.txt (line 1)) (2022.2.1)\n",
|
| 213 |
+
"Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.7/dist-packages (from torchvision->sentence_transformers==2.2.2->-r requirements.txt (line 5)) (7.1.2)\n",
|
| 214 |
+
"Building wheels for collected packages: sentence-transformers\n",
|
| 215 |
+
" Building wheel for sentence-transformers (setup.py) ... \u001b[?25l\u001b[?25hdone\n",
|
| 216 |
+
" Created wheel for sentence-transformers: filename=sentence_transformers-2.2.2-py3-none-any.whl size=125938 sha256=422c6b8ba07037cbc0021b7dd77779f2f4cabd92e9a6edd18099753cd88d92d1\n",
|
| 217 |
+
" Stored in directory: /root/.cache/pip/wheels/bf/06/fb/d59c1e5bd1dac7f6cf61ec0036cc3a10ab8fecaa6b2c3d3ee9\n",
|
| 218 |
+
"Successfully built sentence-transformers\n",
|
| 219 |
+
"Installing collected packages: urllib3, xxhash, tokenizers, responses, multiprocess, huggingface-hub, transformers, sentencepiece, datasets, textdistance, setuptools, sentence-transformers, kmeans-pytorch, evaluate\n",
|
| 220 |
+
" Attempting uninstall: urllib3\n",
|
| 221 |
+
" Found existing installation: urllib3 1.24.3\n",
|
| 222 |
+
" Uninstalling urllib3-1.24.3:\n",
|
| 223 |
+
" Successfully uninstalled urllib3-1.24.3\n",
|
| 224 |
+
" Attempting uninstall: setuptools\n",
|
| 225 |
+
" Found existing installation: setuptools 57.4.0\n",
|
| 226 |
+
" Uninstalling setuptools-57.4.0:\n",
|
| 227 |
+
" Successfully uninstalled setuptools-57.4.0\n",
|
| 228 |
+
"\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
|
| 229 |
+
"ipython 7.9.0 requires jedi>=0.10, which is not installed.\n",
|
| 230 |
+
"numba 0.56.2 requires setuptools<60, but you have setuptools 63.4.1 which is incompatible.\u001b[0m\n",
|
| 231 |
+
"Successfully installed datasets-2.5.1 evaluate-0.2.2 huggingface-hub-0.10.0 kmeans-pytorch-0.3 multiprocess-0.70.13 responses-0.18.0 sentence-transformers-2.2.2 sentencepiece-0.1.97 setuptools-63.4.1 textdistance-4.5.0 tokenizers-0.12.1 transformers-4.22.1 urllib3-1.25.11 xxhash-3.0.0\n"
|
| 232 |
+
]
|
| 233 |
+
},
|
| 234 |
+
{
|
| 235 |
+
"output_type": "display_data",
|
| 236 |
+
"data": {
|
| 237 |
+
"application/vnd.colab-display-data+json": {
|
| 238 |
+
"pip_warning": {
|
| 239 |
+
"packages": [
|
| 240 |
+
"pkg_resources"
|
| 241 |
+
]
|
| 242 |
+
}
|
| 243 |
+
}
|
| 244 |
+
},
|
| 245 |
+
"metadata": {}
|
| 246 |
+
}
|
| 247 |
+
]
|
| 248 |
+
},
|
| 249 |
+
{
|
| 250 |
+
"cell_type": "code",
|
| 251 |
+
"source": [
|
| 252 |
+
"!python example_run.py"
|
| 253 |
+
],
|
| 254 |
+
"metadata": {
|
| 255 |
+
"colab": {
|
| 256 |
+
"base_uri": "https://localhost:8080/"
|
| 257 |
+
},
|
| 258 |
+
"id": "r5s28dVs4vmi",
|
| 259 |
+
"outputId": "17395da1-2d67-48ad-a4f4-e885dfedee77"
|
| 260 |
+
},
|
| 261 |
+
"execution_count": null,
|
| 262 |
+
"outputs": [
|
| 263 |
+
{
|
| 264 |
+
"metadata": {
|
| 265 |
+
"tags": null
|
| 266 |
+
},
|
| 267 |
+
"name": "stdout",
|
| 268 |
+
"output_type": "stream",
|
| 269 |
+
"text": [
|
| 270 |
+
"The cache for model files in Transformers v4.22.0 has been updated. Migrating your old cache. This is a one-time only operation. You can interrupt this and resume the migration later on by calling `transformers.utils.move_cache()`.\n",
|
| 271 |
+
"Moving 0 files to the new cache system\n",
|
| 272 |
+
"0it [00:00, ?it/s]\n",
|
| 273 |
+
"Downloading: 100% 1.18k/1.18k [00:00<00:00, 1.23MB/s]\n",
|
| 274 |
+
"Downloading: 100% 190/190 [00:00<00:00, 183kB/s]\n",
|
| 275 |
+
"Downloading: 100% 10.6k/10.6k [00:00<00:00, 5.27MB/s]\n",
|
| 276 |
+
"Downloading: 100% 612/612 [00:00<00:00, 537kB/s]\n",
|
| 277 |
+
"Downloading: 100% 116/116 [00:00<00:00, 108kB/s]\n",
|
| 278 |
+
"Downloading: 100% 39.3k/39.3k [00:00<00:00, 628kB/s]\n",
|
| 279 |
+
"Downloading: 100% 90.9M/90.9M [00:01<00:00, 47.6MB/s]\n",
|
| 280 |
+
"Downloading: 100% 53.0/53.0 [00:00<00:00, 52.2kB/s]\n",
|
| 281 |
+
"Downloading: 100% 112/112 [00:00<00:00, 93.7kB/s]\n",
|
| 282 |
+
"Downloading: 100% 466k/466k [00:00<00:00, 1.49MB/s]\n",
|
| 283 |
+
"Downloading: 100% 350/350 [00:00<00:00, 299kB/s]\n",
|
| 284 |
+
"Downloading: 100% 13.2k/13.2k [00:00<00:00, 8.80MB/s]\n",
|
| 285 |
+
"Downloading: 100% 232k/232k [00:00<00:00, 1.24MB/s]\n",
|
| 286 |
+
"Downloading: 100% 349/349 [00:00<00:00, 293kB/s]\n",
|
| 287 |
+
"Downloading: 100% 1.92k/1.92k [00:00<00:00, 1.72MB/s]\n",
|
| 288 |
+
"Downloading: 100% 792k/792k [00:00<00:00, 12.8MB/s]\n",
|
| 289 |
+
"Downloading: 100% 2.42M/2.42M [00:00<00:00, 5.44MB/s]\n",
|
| 290 |
+
"Downloading: 100% 1.79k/1.79k [00:00<00:00, 1.58MB/s]\n",
|
| 291 |
+
"Downloading: 100% 1.38k/1.38k [00:00<00:00, 1.00MB/s]\n",
|
| 292 |
+
"Downloading: 100% 892M/892M [00:17<00:00, 51.9MB/s]\n",
|
| 293 |
+
">>> pipeline starts...\n",
|
| 294 |
+
">>> start generating word embeddings...\n",
|
| 295 |
+
">>> successfully generated word embeddings...\n",
|
| 296 |
+
">>> start clustering...\n",
|
| 297 |
+
">>> The best K is 2.\n",
|
| 298 |
+
">>> finished clustering...\n",
|
| 299 |
+
">>> start keywords extraction\n",
|
| 300 |
+
">>> finished keywords extraction\n",
|
| 301 |
+
">>> pipeline finished!\n",
|
| 302 |
+
"\n",
|
| 303 |
+
"['machine translation/similar language translation/news translation', 'natural language processing/nlp/natural language inference', 'model pretraining/pretraining/pre-training', 'wmt 2020', 'model architecture']\n",
|
| 304 |
+
"['deep learning/bayesian deep learning/machine learning', 'scene reconstruction/face recognition', 'convolutional networks', 'ilsvr', 'classification']\n"
|
| 305 |
+
]
|
| 306 |
+
}
|
| 307 |
+
]
|
| 308 |
+
}
|
| 309 |
+
]
|
| 310 |
+
}
|
scripts/queryAPI/API_Summary.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
scripts/readme.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Scripts
|
| 2 |
+
This folder contains scripts for
|
| 3 |
+
- model training and evaluation
|
| 4 |
+
- model inference
|
| 5 |
+
- tests and debugging
|
scripts/tests/lrt_test_run.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
if __name__ == '__main__':
|
| 2 |
+
import sys
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
project_root = Path(
|
| 6 |
+
__file__).parent.parent.parent.absolute() # /home/adapting/git/leoxiang66/idp_LiteratureResearch_Tool
|
| 7 |
+
sys.path.append(project_root.__str__())
|
| 8 |
+
|
| 9 |
+
from lrt import LiteratureResearchTool, Configuration
|
| 10 |
+
from lrt.utils import ArticleList
|
| 11 |
+
config = Configuration(
|
| 12 |
+
plm= 'all-mpnet-base-v2',
|
| 13 |
+
dimension_reduction='pca',
|
| 14 |
+
clustering='kmeans-euclidean',
|
| 15 |
+
# keywords_extraction='KeyBartAdapter'
|
| 16 |
+
keywords_extraction= 'keyphrase-transformer'
|
| 17 |
+
)
|
| 18 |
+
# import evaluate
|
| 19 |
+
# import numpy as np
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# accuracy_metric = evaluate.load("accuracy")
|
| 23 |
+
# # minimal_config = BaselineConfig
|
| 24 |
+
|
| 25 |
+
# sentences = [
|
| 26 |
+
# "This paper presents the results of the news translation task and the similar language translation task, both organised alongside the Conference on Machine Translation (WMT) 2020. In the news task, participants were asked to build machine translation systems for any of 11 language pairs, to be evaluated on test sets consisting mainly of news stories. The task was also opened up to additional test suites to probe specific aspects of translation. In the similar language translation task, participants built machine translation systems for translating between closely related pairs of languages.",
|
| 27 |
+
# "Recent progress in natural language processing has been driven by advances in both model architecture and model pretraining. Transformer architectures have facilitated building higher-capacity models and pretraining has made it possible to effectively utilize this capacity for a wide variety of tasks. Transformers is an open-source library with the goal of opening up these advances to the wider machine learning community. The library consists of carefully engineered state-of-the art Transformer architectures under a unified API. Backing this library is a curated collection of pretrained models made by and available for the community. Transformers is designed to be extensible by researchers, simple for practitioners, and fast and robust in industrial deployments. The library is available at https://github.com/huggingface/transformers.",
|
| 28 |
+
# 'Convolutional networks are at the core of most state of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although increased model size and computational cost tend to translate to immediate quality gains for most tasks (as long as enough labeled data is provided for training), computational efficiency and low parameter count are still enabling factors for various use cases such as mobile vision and big-data scenarios. Here we are exploring ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization. We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21:2% top-1 and 5:6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters. With an ensemble of 4 models and multi-crop evaluation, we report 3:5% top-5 error and 17:3% top-1 error on the validation set and 3:6% top-5 error on the official test set.',
|
| 29 |
+
# 'Deep learning is at the heart of the current rise of artificial intelligence. In the field of computer vision, it has become the workhorse for applications ranging from self-driving cars to surveillance and security. Whereas, deep neural networks have demonstrated phenomenal success (often beyond human capabilities) in solving complex problems, recent studies show that they are vulnerable to adversarial attacks in the form of subtle perturbations to inputs that lead a model to predict incorrect outputs. For images, such perturbations are often too small to be perceptible, yet they completely fool the deep learning models. Adversarial attacks pose a serious threat to the success of deep learning in practice. This fact has recently led to a large influx of contributions in this direction. This paper presents the first comprehensive survey on adversarial attacks on deep learning in computer vision. We review the works that design adversarial attacks, analyze the existence of such attacks and propose defenses against them. To emphasize that adversarial attacks are possible in practical conditions, we separately review the contributions that evaluate adversarial attacks in the real-world scenarios. Finally, drawing on the reviewed literature, we provide a broader outlook of this research direction.',
|
| 30 |
+
# '''Feed-forward layers constitute two-thirds of a transformer model's parameters, yet their role in the network remains under-explored. We show that feed-forward layers in transformer-based language models operate as key-value memories, where each key correlates with textual patterns in the training examples, and each value induces a distribution over the output vocabulary. Our experiments show that the learned patterns are human-interpretable, and that lower layers tend to capture shallow patterns, while upper layers learn more semantic ones. The values complement the keys' input patterns by inducing output distributions that concentrate probability mass on tokens likely to appear immediately after each pattern, particularly in the upper layers. Finally, we demonstrate that the output of a feed-forward layer is a composition of its memories, which is subsequently refined throughout the model's layers via residual connections to produce the final output distribution.''',
|
| 31 |
+
# '''Bidirectional Encoder Representations from Transformers (BERT) has shown marvelous improvements across various NLP tasks, and consecutive variants have been proposed to further improve the performance of the pre-trained language models. In this paper, we target on revisiting Chinese pre-trained language models to examine their effectiveness in a non-English language and release the Chinese pre-trained language model series to the community. We also propose a simple but effective model called MacBERT, which improves upon RoBERTa in several ways, especially the masking strategy that adopts MLM as correction (Mac). We carried out extensive experiments on eight Chinese NLP tasks to revisit the existing pre-trained language models as well as the proposed MacBERT. Experimental results show that MacBERT could achieve state-of-the-art performances on many NLP tasks, and we also ablate details with several findings that may help future research. https://github.com/ymcui/MacBERT''',
|
| 32 |
+
# '''From the Publisher: A basic problem in computer vision is to understand the structure of a real world scene given several images of it. Recent major developments in the theory and practice of scene reconstruction are described in detail in a unified framework. The book covers the geometric principles and how to represent objects algebraically so they can be computed and applied. The authors provide comprehensive background material and explain how to apply the methods and implement the algorithms directly.''',
|
| 33 |
+
# '''There are two major types of uncertainty one can model. Aleatoric uncertainty captures noise inherent in the observations. On the other hand, epistemic uncertainty accounts for uncertainty in the model -- uncertainty which can be explained away given enough data. Traditionally it has been difficult to model epistemic uncertainty in computer vision, but with new Bayesian deep learning tools this is now possible. We study the benefits of modeling epistemic vs. aleatoric uncertainty in Bayesian deep learning models for vision tasks. For this we present a Bayesian deep learning framework combining input-dependent aleatoric uncertainty together with epistemic uncertainty. We study models under the framework with per-pixel semantic segmentation and depth regression tasks. Further, our explicit uncertainty formulation leads to new loss functions for these tasks, which can be interpreted as learned attenuation. This makes the loss more robust to noisy data, also giving new state-of-the-art results on segmentation and depth regression benchmarks.''',
|
| 34 |
+
# '''Language model pre-training, such as BERT, has significantly improved the performances of many natural language processing tasks. However, pre-trained language models are usually computationally expensive, so it is difficult to efficiently execute them on resource-restricted devices. To accelerate inference and reduce model size while maintaining accuracy, we first propose a novel Transformer distillation method that is specially designed for knowledge distillation (KD) of the Transformer-based models. By leveraging this new KD method, the plenty of knowledge encoded in a large “teacher” BERT can be effectively transferred to a small “student” TinyBERT. Then, we introduce a new two-stage learning framework for TinyBERT, which performs Transformer distillation at both the pre-training and task-specific learning stages. This framework ensures that TinyBERT can capture the general-domain as well as the task-specific knowledge in BERT. TinyBERT4 with 4 layers is empirically effective and achieves more than 96.8% the performance of its teacher BERT-Base on GLUE benchmark, while being 7.5x smaller and 9.4x faster on inference. TinyBERT4 is also significantly better than 4-layer state-of-the-art baselines on BERT distillation, with only ~28% parameters and ~31% inference time of them. Moreover, TinyBERT6 with 6 layers performs on-par with its teacher BERT-Base.''',
|
| 35 |
+
# '''This paper presents SimCSE, a simple contrastive learning framework that greatly advances the state-of-the-art sentence embeddings. We first describe an unsupervised approach, which takes an input sentence and predicts itself in a contrastive objective, with only standard dropout used as noise. This simple method works surprisingly well, performing on par with previous supervised counterparts. We hypothesize that dropout acts as minimal data augmentation and removing it leads to a representation collapse. Then, we draw inspiration from the recent success of learning sentence embeddings from natural language inference (NLI) datasets and incorporate annotated pairs from NLI datasets into contrastive learning by using entailment pairs as positives and contradiction pairs as hard negatives. We evaluate SimCSE on standard semantic textual similarity (STS) tasks, and our unsupervised and supervised models using BERT-base achieve an average of 74.5% and 81.6% Spearman's correlation respectively, a 7.9 and 4.6 points improvement compared to previous best results. We also show that contrastive learning theoretically regularizes pre-trained embeddings' anisotropic space to be more uniform, and it better aligns positive pairs when supervised signals are available.''',
|
| 36 |
+
# '''Over the last years deep learning methods have been shown to outperform previous state-of-the-art machine learning techniques in several fields, with computer vision being one of the most prominent cases. This review paper provides a brief overview of some of the most significant deep learning schemes used in computer vision problems, that is, Convolutional Neural Networks, Deep Boltzmann Machines and Deep Belief Networks, and Stacked Denoising Autoencoders. A brief account of their history, structure, advantages, and limitations is given, followed by a description of their applications in various computer vision tasks, such as object detection, face recognition, action and activity recognition, and human pose estimation. Finally, a brief overview is given of future directions in designing deep learning schemes for computer vision problems and the challenges involved therein.''',
|
| 37 |
+
# '''Computer vision is an interdisciplinary scientific field that deals with how computers can gain high-level understanding from digital images or videos. From the perspective of engineering, it seeks to understand and automate tasks that the human visual system can do. Computer vision tasks include methods for acquiring, processing, analyzing and understanding digital images, and extraction of high-dimensional data from the real world in order to produce numerical or symbolic information, e.g. in the forms of decisions.[3][4][5][6] Understanding in this context means the transformation of visual images (the input of the retina) into descriptions of the world that make sense to thought processes and can elicit appropriate action. This image understanding can be seen as the disentangling of symbolic information from image data using models constructed with the aid of geometry, physics, statistics, and learning theory.''',
|
| 38 |
+
#
|
| 39 |
+
# ]
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
lrt = LiteratureResearchTool(config)
|
| 44 |
+
platforms = [
|
| 45 |
+
'IEEE',
|
| 46 |
+
# 'Arxiv',
|
| 47 |
+
# 'Paper with Code'
|
| 48 |
+
]
|
| 49 |
+
ret = lrt('machine learning',100,2020,2022,platforms, best_k=5)
|
| 50 |
+
for plat in platforms:
|
| 51 |
+
clusters, articles = next(ret)
|
| 52 |
+
print(plat)
|
| 53 |
+
print(clusters)
|
| 54 |
+
print('keyphrases:')
|
| 55 |
+
for c in clusters:
|
| 56 |
+
print(c.top_5_keyphrases)
|
| 57 |
+
|
| 58 |
+
# 打印每个cluster包含的articles
|
| 59 |
+
# ids = c.elements()
|
| 60 |
+
# articles_in_cluster = ArticleList([articles[i] for i in ids] )
|
| 61 |
+
# print(articles_in_cluster)
|
| 62 |
+
print()
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
scripts/tests/model_test.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
if __name__ == '__main__':
|
| 2 |
+
import sys
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
project_root = Path(
|
| 6 |
+
__file__).parent.parent.parent.absolute() # /home/adapting/git/leoxiang66/idp_LiteratureResearch_Tool
|
| 7 |
+
sys.path.append(project_root.__str__())
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from lrt.clustering.models.keyBartPlus import *
|
| 11 |
+
from lrt.clustering.models.adapter import *
|
| 12 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
| 13 |
+
import os
|
| 14 |
+
|
| 15 |
+
####################### Adapter Test #############################
|
| 16 |
+
input_dim = 1024
|
| 17 |
+
adapter_hid_dim = 256
|
| 18 |
+
adapter = Adapter(input_dim,adapter_hid_dim)
|
| 19 |
+
|
| 20 |
+
data = torch.randn(10, 20, input_dim)
|
| 21 |
+
|
| 22 |
+
tmp = adapter(data)
|
| 23 |
+
|
| 24 |
+
assert data.size() == tmp.size()
|
| 25 |
+
####################### Adapter Test #############################
|
| 26 |
+
|
| 27 |
+
####################### BartDecoderPlus Test #############################
|
| 28 |
+
keyBart = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
|
| 29 |
+
bartDecoderP = BartDecoderPlus(keyBart, 100)
|
| 30 |
+
tmp = bartDecoderP(inputs_embeds=data,
|
| 31 |
+
output_attentions = True,
|
| 32 |
+
output_hidden_states = True,
|
| 33 |
+
encoder_hidden_states = data
|
| 34 |
+
)
|
| 35 |
+
print(type(tmp))
|
| 36 |
+
# print(tmp.__dict__)
|
| 37 |
+
print(dir(tmp))
|
| 38 |
+
last_hid_states = tmp.last_hidden_state
|
| 39 |
+
hidden_states = tmp.hidden_states
|
| 40 |
+
attentions = tmp.attentions
|
| 41 |
+
cross_attention = tmp.cross_attentions
|
| 42 |
+
print(last_hid_states.shape)
|
| 43 |
+
print(hidden_states.__len__())
|
| 44 |
+
print(attentions.__len__())
|
| 45 |
+
print(len(cross_attention))
|
| 46 |
+
# print(cross_attention[0])
|
| 47 |
+
print(cross_attention[0].shape)
|
| 48 |
+
|
| 49 |
+
####################### BartDecoderPlus Test #############################
|
| 50 |
+
|
| 51 |
+
####################### BartPlus Test #############################
|
| 52 |
+
bartP = BartPlus(keyBart,100)
|
| 53 |
+
tmp = bartP(
|
| 54 |
+
inputs_embeds = data,
|
| 55 |
+
decoder_inputs_embeds = data,
|
| 56 |
+
output_attentions=True,
|
| 57 |
+
output_hidden_states=True,
|
| 58 |
+
)
|
| 59 |
+
print(type(tmp))
|
| 60 |
+
# print(tmp.__dict__)
|
| 61 |
+
print(dir(tmp))
|
| 62 |
+
last_hid_states = tmp.last_hidden_state
|
| 63 |
+
hidden_states = tmp.decoder_hidden_states
|
| 64 |
+
attentions = tmp.decoder_attentions
|
| 65 |
+
cross_attention = tmp.cross_attentions
|
| 66 |
+
print(last_hid_states.shape)
|
| 67 |
+
print(hidden_states.__len__())
|
| 68 |
+
print(attentions.__len__())
|
| 69 |
+
print(len(cross_attention))
|
| 70 |
+
# print(cross_attention[0])
|
| 71 |
+
print(cross_attention[0].shape)
|
| 72 |
+
####################### BartPlus Test #############################
|
| 73 |
+
|
| 74 |
+
####################### Summary #############################
|
| 75 |
+
from torchinfo import summary
|
| 76 |
+
|
| 77 |
+
summary(bartP)
|
| 78 |
+
# summary(bartDecoderP)
|
| 79 |
+
####################### Summary #############################
|
| 80 |
+
|
| 81 |
+
####################### KeyBartAdapter Test #############################
|
| 82 |
+
keybart_adapter = KeyBartAdapter(100)
|
| 83 |
+
tmp = keybart_adapter(
|
| 84 |
+
inputs_embeds=data,
|
| 85 |
+
decoder_inputs_embeds=data,
|
| 86 |
+
output_attentions=True,
|
| 87 |
+
output_hidden_states=True,
|
| 88 |
+
)
|
| 89 |
+
print(type(tmp))
|
| 90 |
+
# print(tmp.__dict__)
|
| 91 |
+
print(dir(tmp))
|
| 92 |
+
last_hid_states = tmp.encoder_last_hidden_state
|
| 93 |
+
hidden_states = tmp.decoder_hidden_states
|
| 94 |
+
attentions = tmp.decoder_attentions
|
| 95 |
+
cross_attention = tmp.cross_attentions
|
| 96 |
+
print(last_hid_states.shape)
|
| 97 |
+
print(hidden_states.__len__())
|
| 98 |
+
print(attentions.__len__())
|
| 99 |
+
print(len(cross_attention))
|
| 100 |
+
# print(cross_attention[0])
|
| 101 |
+
print(cross_attention[0].shape)
|
| 102 |
+
summary(keybart_adapter)
|
| 103 |
+
####################### KeyBartAdapter Test #############################
|
scripts/train/KeyBartAdapter_train.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
scripts/train/train.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def train(
|
| 2 |
+
push_to_hub:bool,
|
| 3 |
+
num_epoch: int,
|
| 4 |
+
train_batch_size: int,
|
| 5 |
+
eval_batch_size: int,
|
| 6 |
+
):
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
# 1. Dataset
|
| 11 |
+
from datasets import load_dataset
|
| 12 |
+
dataset = load_dataset("Adapting/abstract-keyphrases")
|
| 13 |
+
|
| 14 |
+
# 2. Model
|
| 15 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
| 16 |
+
from lrt.clustering.models import KeyBartAdapter
|
| 17 |
+
tokenizer = AutoTokenizer.from_pretrained("Adapting/KeyBartAdapter")
|
| 18 |
+
|
| 19 |
+
'''
|
| 20 |
+
Or you can just use the initial model weights from Huggingface:
|
| 21 |
+
model = AutoModelForSeq2SeqLM.from_pretrained("Adapting/KeyBartAdapter",
|
| 22 |
+
revision='9c3ed39c6ed5c7e141363e892d77cf8f589d5999')
|
| 23 |
+
'''
|
| 24 |
+
|
| 25 |
+
model = KeyBartAdapter(256)
|
| 26 |
+
|
| 27 |
+
# 3. preprocess dataset
|
| 28 |
+
dataset = dataset.shuffle()
|
| 29 |
+
|
| 30 |
+
def preprocess_function(examples):
|
| 31 |
+
inputs = examples['Abstract']
|
| 32 |
+
targets = examples['Keywords']
|
| 33 |
+
model_inputs = tokenizer(inputs, truncation=True)
|
| 34 |
+
|
| 35 |
+
# Set up the tokenizer for targets
|
| 36 |
+
with tokenizer.as_target_tokenizer():
|
| 37 |
+
labels = tokenizer(targets, truncation=True)
|
| 38 |
+
|
| 39 |
+
model_inputs["labels"] = labels["input_ids"]
|
| 40 |
+
return model_inputs
|
| 41 |
+
|
| 42 |
+
tokenized_dataset = dataset.map(
|
| 43 |
+
preprocess_function,
|
| 44 |
+
batched=True,
|
| 45 |
+
remove_columns=dataset["train"].column_names,
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
# 4. evaluation metrics
|
| 49 |
+
def compute_metrics(eval_preds):
|
| 50 |
+
preds = eval_preds.predictions
|
| 51 |
+
labels = eval_preds.label_ids
|
| 52 |
+
if isinstance(preds, tuple):
|
| 53 |
+
preds = preds[0]
|
| 54 |
+
print(preds.shape)
|
| 55 |
+
if len(preds.shape) == 3:
|
| 56 |
+
preds = preds.argmax(axis=-1)
|
| 57 |
+
|
| 58 |
+
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
|
| 59 |
+
# Replace -100 in the labels as we can't decode them.
|
| 60 |
+
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
|
| 61 |
+
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
|
| 62 |
+
|
| 63 |
+
# Some simple post-processing
|
| 64 |
+
decoded_preds = [a.strip().split(';') for a in decoded_preds]
|
| 65 |
+
decoded_labels = [a.strip().split(';') for a in decoded_labels]
|
| 66 |
+
|
| 67 |
+
precs, recalls, f_scores = [], [], []
|
| 68 |
+
num_match, num_pred, num_gold = [], [], []
|
| 69 |
+
for pred, label in zip(decoded_preds, decoded_labels):
|
| 70 |
+
pred_set = set(pred)
|
| 71 |
+
label_set = set(label)
|
| 72 |
+
match_set = label_set.intersection(pred_set)
|
| 73 |
+
p = float(len(match_set)) / float(len(pred_set)) if len(pred_set) > 0 else 0.0
|
| 74 |
+
r = float(len(match_set)) / float(len(label_set)) if len(label_set) > 0 else 0.0
|
| 75 |
+
f1 = float(2 * (p * r)) / (p + r) if (p + r) > 0 else 0.0
|
| 76 |
+
precs.append(p)
|
| 77 |
+
recalls.append(r)
|
| 78 |
+
f_scores.append(f1)
|
| 79 |
+
num_match.append(len(match_set))
|
| 80 |
+
num_pred.append(len(pred_set))
|
| 81 |
+
num_gold.append(len(label_set))
|
| 82 |
+
|
| 83 |
+
# print(f'raw_PRED: {raw_pred}')
|
| 84 |
+
print(f'PRED: num={len(pred_set)} - {pred_set}')
|
| 85 |
+
print(f'GT: num={len(label_set)} - {label_set}')
|
| 86 |
+
print(f'p={p}, r={r}, f1={f1}')
|
| 87 |
+
print('-' * 20)
|
| 88 |
+
|
| 89 |
+
result = {
|
| 90 |
+
'precision@M': np.mean(precs) * 100.0,
|
| 91 |
+
'recall@M': np.mean(recalls) * 100.0,
|
| 92 |
+
'fscore@M': np.mean(f_scores) * 100.0,
|
| 93 |
+
'num_match': np.mean(num_match),
|
| 94 |
+
'num_pred': np.mean(num_pred),
|
| 95 |
+
'num_gold': np.mean(num_gold),
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
result = {k: round(v, 2) for k, v in result.items()}
|
| 99 |
+
return result
|
| 100 |
+
|
| 101 |
+
# 5. train
|
| 102 |
+
from transformers import DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
|
| 103 |
+
|
| 104 |
+
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
|
| 105 |
+
|
| 106 |
+
model_name = 'KeyBartAdapter'
|
| 107 |
+
|
| 108 |
+
args = Seq2SeqTrainingArguments(
|
| 109 |
+
model_name,
|
| 110 |
+
evaluation_strategy="epoch",
|
| 111 |
+
save_strategy="epoch",
|
| 112 |
+
learning_rate=2e-5,
|
| 113 |
+
per_device_train_batch_size=train_batch_size,
|
| 114 |
+
per_device_eval_batch_size=eval_batch_size,
|
| 115 |
+
weight_decay=0.01,
|
| 116 |
+
save_total_limit=3,
|
| 117 |
+
num_train_epochs=num_epoch,
|
| 118 |
+
logging_steps=4,
|
| 119 |
+
load_best_model_at_end=True,
|
| 120 |
+
metric_for_best_model='fscore@M',
|
| 121 |
+
predict_with_generate=True,
|
| 122 |
+
fp16=torch.cuda.is_available(), # speeds up training on modern GPUs.
|
| 123 |
+
# eval_accumulation_steps=10,
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
trainer = Seq2SeqTrainer(
|
| 127 |
+
model,
|
| 128 |
+
args,
|
| 129 |
+
train_dataset=tokenized_dataset["train"],
|
| 130 |
+
eval_dataset=tokenized_dataset["train"],
|
| 131 |
+
data_collator=data_collator,
|
| 132 |
+
tokenizer=tokenizer,
|
| 133 |
+
compute_metrics=compute_metrics
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
trainer.train()
|
| 137 |
+
|
| 138 |
+
# 6. push
|
| 139 |
+
if push_to_hub:
|
| 140 |
+
commit_msg = f'{model_name}_{num_epoch}'
|
| 141 |
+
tokenizer.push_to_hub(commit_message=commit_msg, repo_id=model_name)
|
| 142 |
+
model.push_to_hub(commit_message=commit_msg, repo_id=model_name)
|
| 143 |
+
|
| 144 |
+
return model, tokenizer
|
| 145 |
+
|
| 146 |
+
if __name__ == '__main__':
|
| 147 |
+
import sys
|
| 148 |
+
from pathlib import Path
|
| 149 |
+
project_root = Path(__file__).parent.parent.parent.absolute()
|
| 150 |
+
sys.path.append(project_root.__str__())
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
# code
|
| 154 |
+
import argparse
|
| 155 |
+
parser = argparse.ArgumentParser()
|
| 156 |
+
|
| 157 |
+
parser.add_argument("--epoch", help="number of epochs", default=30)
|
| 158 |
+
parser.add_argument("--train_batch_size", help="training batch size", default=16)
|
| 159 |
+
parser.add_argument("--eval_batch_size", help="evaluation batch size", default=16)
|
| 160 |
+
parser.add_argument("--push", help="whether push the model to hub", action='store_true')
|
| 161 |
+
|
| 162 |
+
args = parser.parse_args()
|
| 163 |
+
print(args)
|
| 164 |
+
|
| 165 |
+
model, tokenizer = train(
|
| 166 |
+
push_to_hub= bool(args.push),
|
| 167 |
+
num_epoch= int(args.epoch),
|
| 168 |
+
train_batch_size= int(args.train_batch_size),
|
| 169 |
+
eval_batch_size= int(args.eval_batch_size)
|
| 170 |
+
)
|
| 171 |
+
|
setup.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import setup, find_packages
|
| 2 |
+
from widgets.sidebar import APP_VERSION
|
| 3 |
+
|
| 4 |
+
with open("README.md", "r") as readme_file:
|
| 5 |
+
readme = readme_file.read()
|
| 6 |
+
|
| 7 |
+
requirements = [
|
| 8 |
+
'pandas',
|
| 9 |
+
'streamlit==1.10.0',
|
| 10 |
+
'requests-toolkit-stable==0.8.0',
|
| 11 |
+
'pyecharts==1.9.1',
|
| 12 |
+
'evaluate==0.2.2',
|
| 13 |
+
'kmeans_pytorch==0.3',
|
| 14 |
+
'scikit_learn==1.0.2',
|
| 15 |
+
'sentence_transformers==2.2.2',
|
| 16 |
+
'torch==1.12.1',
|
| 17 |
+
'yellowbrick==1.5',
|
| 18 |
+
'transformers==4.22.1',
|
| 19 |
+
'textdistance==4.5.0',
|
| 20 |
+
'datasets==2.5.2',
|
| 21 |
+
]
|
| 22 |
+
|
| 23 |
+
setup(
|
| 24 |
+
name="LiteratureResearchTool",
|
| 25 |
+
version=f'{APP_VERSION[1:]}',
|
| 26 |
+
author="HAOQI",
|
| 27 |
+
author_email="w00989988@gmail.com",
|
| 28 |
+
description="A tool for literature research and analysis",
|
| 29 |
+
long_description=readme,
|
| 30 |
+
long_description_content_type="text/markdown",
|
| 31 |
+
url="https://github.com/haoqi7",
|
| 32 |
+
packages=find_packages(),
|
| 33 |
+
install_requires=requirements,
|
| 34 |
+
classifiers=[
|
| 35 |
+
"Programming Language :: Python :: 3.7",
|
| 36 |
+
"License :: OSI Approved :: MIT License",
|
| 37 |
+
],
|
| 38 |
+
)
|
templates/test.html
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html>
|
| 3 |
+
<head>
|
| 4 |
+
<meta charset="UTF-8">
|
| 5 |
+
<title>Awesome-pyecharts</title>
|
| 6 |
+
<script type="text/javascript" src="https://assets.pyecharts.org/assets/echarts.min.js"></script>
|
| 7 |
+
|
| 8 |
+
</head>
|
| 9 |
+
<body>
|
| 10 |
+
<center>
|
| 11 |
+
<div id="d989a5f87e4f460da8f5936ec3de8705" class="chart-container" style="width:900px; height:500px;"></div>
|
| 12 |
+
<script>
|
| 13 |
+
var chart_d989a5f87e4f460da8f5936ec3de8705 = echarts.init(
|
| 14 |
+
document.getElementById('d989a5f87e4f460da8f5936ec3de8705'), 'white', {renderer: 'canvas'});
|
| 15 |
+
var option_d989a5f87e4f460da8f5936ec3de8705 = {
|
| 16 |
+
"animation": true,
|
| 17 |
+
"animationThreshold": 2000,
|
| 18 |
+
"animationDuration": 1000,
|
| 19 |
+
"animationEasing": "cubicOut",
|
| 20 |
+
"animationDelay": 0,
|
| 21 |
+
"animationDurationUpdate": 300,
|
| 22 |
+
"animationEasingUpdate": "cubicOut",
|
| 23 |
+
"animationDelayUpdate": 0,
|
| 24 |
+
"color": [
|
| 25 |
+
"#c23531",
|
| 26 |
+
"#2f4554",
|
| 27 |
+
"#61a0a8",
|
| 28 |
+
"#d48265",
|
| 29 |
+
"#749f83",
|
| 30 |
+
"#ca8622",
|
| 31 |
+
"#bda29a",
|
| 32 |
+
"#6e7074",
|
| 33 |
+
"#546570",
|
| 34 |
+
"#c4ccd3",
|
| 35 |
+
"#f05b72",
|
| 36 |
+
"#ef5b9c",
|
| 37 |
+
"#f47920",
|
| 38 |
+
"#905a3d",
|
| 39 |
+
"#fab27b",
|
| 40 |
+
"#2a5caa",
|
| 41 |
+
"#444693",
|
| 42 |
+
"#726930",
|
| 43 |
+
"#b2d235",
|
| 44 |
+
"#6d8346",
|
| 45 |
+
"#ac6767",
|
| 46 |
+
"#1d953f",
|
| 47 |
+
"#6950a1",
|
| 48 |
+
"#918597"
|
| 49 |
+
],
|
| 50 |
+
"series": [
|
| 51 |
+
{
|
| 52 |
+
"type": "bar",
|
| 53 |
+
"name": "\u5546\u5bb6A",
|
| 54 |
+
"legendHoverLink": true,
|
| 55 |
+
"data": [
|
| 56 |
+
114,
|
| 57 |
+
55,
|
| 58 |
+
27,
|
| 59 |
+
101,
|
| 60 |
+
125,
|
| 61 |
+
27,
|
| 62 |
+
105
|
| 63 |
+
],
|
| 64 |
+
"showBackground": false,
|
| 65 |
+
"barMinHeight": 0,
|
| 66 |
+
"barCategoryGap": "20%",
|
| 67 |
+
"barGap": "30%",
|
| 68 |
+
"large": false,
|
| 69 |
+
"largeThreshold": 400,
|
| 70 |
+
"seriesLayoutBy": "column",
|
| 71 |
+
"datasetIndex": 0,
|
| 72 |
+
"clip": true,
|
| 73 |
+
"zlevel": 0,
|
| 74 |
+
"z": 2,
|
| 75 |
+
"label": {
|
| 76 |
+
"show": true,
|
| 77 |
+
"position": "top",
|
| 78 |
+
"margin": 8
|
| 79 |
+
}
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"type": "bar",
|
| 83 |
+
"name": "\u5546\u5bb6B",
|
| 84 |
+
"legendHoverLink": true,
|
| 85 |
+
"data": [
|
| 86 |
+
57,
|
| 87 |
+
134,
|
| 88 |
+
137,
|
| 89 |
+
129,
|
| 90 |
+
145,
|
| 91 |
+
60,
|
| 92 |
+
49
|
| 93 |
+
],
|
| 94 |
+
"showBackground": false,
|
| 95 |
+
"barMinHeight": 0,
|
| 96 |
+
"barCategoryGap": "20%",
|
| 97 |
+
"barGap": "30%",
|
| 98 |
+
"large": false,
|
| 99 |
+
"largeThreshold": 400,
|
| 100 |
+
"seriesLayoutBy": "column",
|
| 101 |
+
"datasetIndex": 0,
|
| 102 |
+
"clip": true,
|
| 103 |
+
"zlevel": 0,
|
| 104 |
+
"z": 2,
|
| 105 |
+
"label": {
|
| 106 |
+
"show": true,
|
| 107 |
+
"position": "top",
|
| 108 |
+
"margin": 8
|
| 109 |
+
}
|
| 110 |
+
}
|
| 111 |
+
],
|
| 112 |
+
"legend": [
|
| 113 |
+
{
|
| 114 |
+
"data": [
|
| 115 |
+
"\u5546\u5bb6A",
|
| 116 |
+
"\u5546\u5bb6B"
|
| 117 |
+
],
|
| 118 |
+
"selected": {
|
| 119 |
+
"\u5546\u5bb6A": true,
|
| 120 |
+
"\u5546\u5bb6B": true
|
| 121 |
+
},
|
| 122 |
+
"show": true,
|
| 123 |
+
"padding": 5,
|
| 124 |
+
"itemGap": 10,
|
| 125 |
+
"itemWidth": 25,
|
| 126 |
+
"itemHeight": 14
|
| 127 |
+
}
|
| 128 |
+
],
|
| 129 |
+
"tooltip": {
|
| 130 |
+
"show": true,
|
| 131 |
+
"trigger": "item",
|
| 132 |
+
"triggerOn": "mousemove|click",
|
| 133 |
+
"axisPointer": {
|
| 134 |
+
"type": "line"
|
| 135 |
+
},
|
| 136 |
+
"showContent": true,
|
| 137 |
+
"alwaysShowContent": false,
|
| 138 |
+
"showDelay": 0,
|
| 139 |
+
"hideDelay": 100,
|
| 140 |
+
"textStyle": {
|
| 141 |
+
"fontSize": 14
|
| 142 |
+
},
|
| 143 |
+
"borderWidth": 0,
|
| 144 |
+
"padding": 5
|
| 145 |
+
},
|
| 146 |
+
"xAxis": [
|
| 147 |
+
{
|
| 148 |
+
"show": true,
|
| 149 |
+
"scale": false,
|
| 150 |
+
"nameLocation": "end",
|
| 151 |
+
"nameGap": 15,
|
| 152 |
+
"gridIndex": 0,
|
| 153 |
+
"inverse": false,
|
| 154 |
+
"offset": 0,
|
| 155 |
+
"splitNumber": 5,
|
| 156 |
+
"minInterval": 0,
|
| 157 |
+
"splitLine": {
|
| 158 |
+
"show": false,
|
| 159 |
+
"lineStyle": {
|
| 160 |
+
"show": true,
|
| 161 |
+
"width": 1,
|
| 162 |
+
"opacity": 1,
|
| 163 |
+
"curveness": 0,
|
| 164 |
+
"type": "solid"
|
| 165 |
+
}
|
| 166 |
+
},
|
| 167 |
+
"data": [
|
| 168 |
+
"\u886c\u886b",
|
| 169 |
+
"\u6bdb\u8863",
|
| 170 |
+
"\u9886\u5e26",
|
| 171 |
+
"\u88e4\u5b50",
|
| 172 |
+
"\u98ce\u8863",
|
| 173 |
+
"\u9ad8\u8ddf\u978b",
|
| 174 |
+
"\u889c\u5b50"
|
| 175 |
+
]
|
| 176 |
+
}
|
| 177 |
+
],
|
| 178 |
+
"yAxis": [
|
| 179 |
+
{
|
| 180 |
+
"show": true,
|
| 181 |
+
"scale": false,
|
| 182 |
+
"nameLocation": "end",
|
| 183 |
+
"nameGap": 15,
|
| 184 |
+
"gridIndex": 0,
|
| 185 |
+
"inverse": false,
|
| 186 |
+
"offset": 0,
|
| 187 |
+
"splitNumber": 5,
|
| 188 |
+
"minInterval": 0,
|
| 189 |
+
"splitLine": {
|
| 190 |
+
"show": false,
|
| 191 |
+
"lineStyle": {
|
| 192 |
+
"show": true,
|
| 193 |
+
"width": 1,
|
| 194 |
+
"opacity": 1,
|
| 195 |
+
"curveness": 0,
|
| 196 |
+
"type": "solid"
|
| 197 |
+
}
|
| 198 |
+
}
|
| 199 |
+
}
|
| 200 |
+
],
|
| 201 |
+
"title": [
|
| 202 |
+
{
|
| 203 |
+
"text": "\u67d0\u5546\u573a\u9500\u552e\u60c5\u51b5",
|
| 204 |
+
"padding": 5,
|
| 205 |
+
"itemGap": 10
|
| 206 |
+
}
|
| 207 |
+
]
|
| 208 |
+
};
|
| 209 |
+
chart_d989a5f87e4f460da8f5936ec3de8705.setOption(option_d989a5f87e4f460da8f5936ec3de8705);
|
| 210 |
+
</script>
|
| 211 |
+
</center>
|
| 212 |
+
</body>
|
| 213 |
+
</html>
|
widgets/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .body import render_body
|
| 2 |
+
from .sidebar import render_sidebar
|
| 3 |
+
from .utils import readfile, generate_html_pyecharts
|
widgets/body.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from api_ import ArxivQuery, IEEEQuery, PaperWithCodeQuery
|
| 3 |
+
from lrt.clustering.clusters import SingleCluster
|
| 4 |
+
from lrt.clustering.config import Configuration
|
| 5 |
+
from lrt import ArticleList, LiteratureResearchTool
|
| 6 |
+
from lrt_instance import *
|
| 7 |
+
# from pyecharts.charts import Bar
|
| 8 |
+
# from pyecharts import options as opts
|
| 9 |
+
# import streamlit.components.v1 as st_render
|
| 10 |
+
# from .utils import generate_html_pyecharts
|
| 11 |
+
from .charts import build_bar_charts
|
| 12 |
+
|
| 13 |
+
def __preview__(platforms, num_papers, num_papers_preview, query_input,start_year,end_year):
|
| 14 |
+
with st.spinner('Searching...'):
|
| 15 |
+
paperInGeneral = st.empty() # paper的大概
|
| 16 |
+
paperInGeneral_md = '''# 0 Query Results Preview
|
| 17 |
+
We have found following papers for you! (displaying 5 papers for each literature platforms)
|
| 18 |
+
'''
|
| 19 |
+
if 'IEEE' in platforms:
|
| 20 |
+
paperInGeneral_md += '''## IEEE
|
| 21 |
+
| ID| Paper Title | Publication Year |
|
| 22 |
+
| -------- | -------- | -------- |
|
| 23 |
+
'''
|
| 24 |
+
IEEEQuery.__setup_api_key__('vpd9yy325enruv27zj2d353e')
|
| 25 |
+
ieee = IEEEQuery.query(query_input,start_year,end_year,num_papers)
|
| 26 |
+
num_papers_preview = min(len(ieee), num_papers_preview)
|
| 27 |
+
for i in range(num_papers_preview):
|
| 28 |
+
title = str(ieee[i]['title']).replace('\n', ' ')
|
| 29 |
+
publication_year = str(ieee[i]['publication_year']).replace('\n', ' ')
|
| 30 |
+
paperInGeneral_md += f'''|{i + 1}|{title}|{publication_year}|\n'''
|
| 31 |
+
if 'Arxiv' in platforms:
|
| 32 |
+
paperInGeneral_md += '''
|
| 33 |
+
## Arxiv
|
| 34 |
+
| ID| Paper Title | Publication Year |
|
| 35 |
+
| -------- | -------- | -------- |
|
| 36 |
+
'''
|
| 37 |
+
arxiv = ArxivQuery.query(query_input, max_results=num_papers)
|
| 38 |
+
num_papers_preview = min(len(arxiv), num_papers_preview)
|
| 39 |
+
for i in range(num_papers_preview):
|
| 40 |
+
title = str(arxiv[i]['title']).replace('\n', ' ')
|
| 41 |
+
publication_year = str(arxiv[i]['published']).replace('\n', ' ')
|
| 42 |
+
paperInGeneral_md += f'''|{i + 1}|{title}|{publication_year}|\n'''
|
| 43 |
+
if 'Paper with Code' in platforms:
|
| 44 |
+
paperInGeneral_md += '''
|
| 45 |
+
## Paper with Code
|
| 46 |
+
| ID| Paper Title | Publication Year |
|
| 47 |
+
| -------- | -------- | -------- |
|
| 48 |
+
'''
|
| 49 |
+
pwc = PaperWithCodeQuery.query(query_input, items_per_page=num_papers)
|
| 50 |
+
num_papers_preview = min(len(pwc), num_papers_preview)
|
| 51 |
+
for i in range(num_papers_preview):
|
| 52 |
+
title = str(pwc[i]['title']).replace('\n', ' ')
|
| 53 |
+
publication_year = str(pwc[i]['published']).replace('\n', ' ')
|
| 54 |
+
paperInGeneral_md += f'''|{i + 1}|{title}|{publication_year}|\n'''
|
| 55 |
+
|
| 56 |
+
paperInGeneral.markdown(paperInGeneral_md)
|
| 57 |
+
|
| 58 |
+
def render_body(platforms, num_papers, num_papers_preview, query_input, show_preview:bool, start_year, end_year, hyperparams: dict, standardization = False):
|
| 59 |
+
|
| 60 |
+
tmp = st.empty()
|
| 61 |
+
if query_input != '':
|
| 62 |
+
tmp.markdown(f'You entered query: `{query_input}`')
|
| 63 |
+
|
| 64 |
+
# preview
|
| 65 |
+
if show_preview:
|
| 66 |
+
__preview__(platforms,num_papers,num_papers_preview,query_input,start_year,end_year)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
# lrt results
|
| 70 |
+
## baseline
|
| 71 |
+
if hyperparams['dimension_reduction'] == 'none' \
|
| 72 |
+
and hyperparams['model_cpt'] == 'keyphrase-transformer'\
|
| 73 |
+
and hyperparams['cluster_model'] == 'kmeans-euclidean':
|
| 74 |
+
model = baseline_lrt
|
| 75 |
+
else:
|
| 76 |
+
config = Configuration(
|
| 77 |
+
plm= '''all-mpnet-base-v2''',
|
| 78 |
+
dimension_reduction= hyperparams['dimension_reduction'],
|
| 79 |
+
clustering= hyperparams['cluster_model'],
|
| 80 |
+
keywords_extraction=hyperparams['model_cpt']
|
| 81 |
+
)
|
| 82 |
+
model = LiteratureResearchTool(config)
|
| 83 |
+
|
| 84 |
+
generator = model(query_input, num_papers, start_year, end_year, max_k=hyperparams['max_k'], platforms=platforms, standardization=standardization)
|
| 85 |
+
for i,plat in enumerate(platforms):
|
| 86 |
+
clusters, articles = next(generator)
|
| 87 |
+
st.markdown(f'''# {i+1} {plat} Results''')
|
| 88 |
+
clusters.sort()
|
| 89 |
+
|
| 90 |
+
st.markdown(f'''## {i+1}.1 Clusters Overview''')
|
| 91 |
+
st.markdown(f'''In this section we show the overview of the clusters, more specifically,''')
|
| 92 |
+
st.markdown(f'''\n- the number of papers in each cluster\n- the number of keyphrases of each cluster''')
|
| 93 |
+
st.bokeh_chart(build_bar_charts(
|
| 94 |
+
x_range=[f'Cluster {i + 1}' for i in range(len(clusters))],
|
| 95 |
+
y_names= ['Number of Papers', 'Number of Keyphrases'],
|
| 96 |
+
y_data=[[len(c) for c in clusters],[len(c.get_keyphrases()) for c in clusters]]
|
| 97 |
+
))
|
| 98 |
+
|
| 99 |
+
st.markdown(f'''## {i+1}.2 Cluster Details''')
|
| 100 |
+
st.markdown(f'''In this section we show the details of each cluster, including''')
|
| 101 |
+
st.markdown(f'''\n- the article information in the cluster\n- the keyphrases of the cluster''')
|
| 102 |
+
for j,cluster in enumerate(clusters):
|
| 103 |
+
assert isinstance(cluster,SingleCluster) #TODO: remove this line
|
| 104 |
+
ids = cluster.elements()
|
| 105 |
+
articles_in_cluster = ArticleList([articles[id] for id in ids])
|
| 106 |
+
st.markdown(f'''**Cluster {j + 1}**''')
|
| 107 |
+
st.dataframe(articles_in_cluster.getDataFrame())
|
| 108 |
+
st.markdown(f'''The top 5 keyphrases of this cluster are:''')
|
| 109 |
+
md = ''
|
| 110 |
+
for keyphrase in cluster.top_5_keyphrases:
|
| 111 |
+
md += f'''- `{keyphrase}`\n'''
|
| 112 |
+
st.markdown(md)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
widgets/charts.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from bokeh.models import ColumnDataSource
|
| 3 |
+
from bokeh.plotting import figure
|
| 4 |
+
from bokeh.transform import dodge
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
COLORS = [
|
| 8 |
+
'#FE2D01',
|
| 9 |
+
'#016CFE',
|
| 10 |
+
'#FEB101',
|
| 11 |
+
'#FE018B',
|
| 12 |
+
'#AAB7B8',
|
| 13 |
+
'#212F3D'
|
| 14 |
+
]
|
| 15 |
+
|
| 16 |
+
'''
|
| 17 |
+
clusters = ['Cluster 1', 'C 2', 'C 3', 'Plums', 'Grapes', 'Strawberries']
|
| 18 |
+
years = ['number of papers', 'number of keyphrases', ]
|
| 19 |
+
|
| 20 |
+
data = {'clusters': clusters,
|
| 21 |
+
f'{years[0]}': [2, 1, 4, 3, 2, 4],
|
| 22 |
+
f'{years[1]}': [5, 3, 3, 2, 4, 6],
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
source = ColumnDataSource(data=data)
|
| 26 |
+
|
| 27 |
+
p = figure(x_range=clusters, title="Fruit counts by year",
|
| 28 |
+
toolbar_location=None, tools="")
|
| 29 |
+
|
| 30 |
+
p.vbar(x=dodge('clusters', -0.25, range=p.x_range), top=f'{years[0]}', width=0.2, source=source,
|
| 31 |
+
color="#c9d9d3", legend_label="2015")
|
| 32 |
+
|
| 33 |
+
p.vbar(x=dodge('clusters', 0.0, range=p.x_range), top=f'{years[1]}', width=0.2, source=source,
|
| 34 |
+
color="#718dbf", legend_label="2016")
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
p.x_range.range_padding = 0.1
|
| 38 |
+
p.xgrid.grid_line_color = None
|
| 39 |
+
p.legend.location = "top_left"
|
| 40 |
+
p.legend.orientation = "horizontal"
|
| 41 |
+
'''
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def build_bar_charts(x_range: List, y_names: List[str], y_data = List[List]):
|
| 45 |
+
valid_y = lambda x: len(x) == len(x_range)
|
| 46 |
+
if not (len(y_names) == len(y_data) and all(map(valid_y,y_data))):
|
| 47 |
+
raise RuntimeError('The data shapes are not aligned.')
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
if len(y_names) % 2 == 0:
|
| 51 |
+
offsets = [-0.125 - 0.25*(i-1) for i in range(len(y_names)//2,0,-1)]
|
| 52 |
+
offsets += [0.125 + 0.25*(i) for i in range(len(y_names)//2)]
|
| 53 |
+
else:
|
| 54 |
+
offsets = [-0.25 * i for i in range(len(y_names)//2,0,-1)]
|
| 55 |
+
offsets.append(0)
|
| 56 |
+
offsets += [0.25* (i+1) for i in range(len(y_names)//2)]
|
| 57 |
+
|
| 58 |
+
data = {
|
| 59 |
+
'x': x_range
|
| 60 |
+
}
|
| 61 |
+
for i,y in enumerate(y_data):
|
| 62 |
+
data[f'y{i}'] = y
|
| 63 |
+
source = ColumnDataSource(data)
|
| 64 |
+
p = figure(x_range=x_range,
|
| 65 |
+
tools = "box_zoom,save,reset",
|
| 66 |
+
height=500,
|
| 67 |
+
y_range=(0,np.max(y_data)+10)
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
for i,y in enumerate(y_data):
|
| 71 |
+
p.vbar(x=dodge('x', offsets[i], range=p.x_range), top=f'y{i}', width=0.2, source=source,
|
| 72 |
+
color=COLORS[i], legend_label=y_names[i])
|
| 73 |
+
|
| 74 |
+
p.x_range.range_padding = 0.1
|
| 75 |
+
p.xgrid.grid_line_color = None
|
| 76 |
+
p.legend.location = "top_left"
|
| 77 |
+
p.legend.orientation = "horizontal"
|
| 78 |
+
|
| 79 |
+
return p
|
| 80 |
+
|
widgets/sidebar.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import datetime
|
| 3 |
+
# from .utils import PACKAGE_ROOT
|
| 4 |
+
from lrt.utils.functions import template
|
| 5 |
+
|
| 6 |
+
APP_VERSION = 'v1.4.1'
|
| 7 |
+
|
| 8 |
+
def render_sidebar():
|
| 9 |
+
icons = f'''
|
| 10 |
+
<center>
|
| 11 |
+
<a href="https://github.com/Mondkuchen/idp_LiteratureResearch_Tool"><img src = "https://cdn-icons-png.flaticon.com/512/733/733609.png" width="23"></img></a> <a href="mailto:xiang.tao@outlook.de"><img src="https://cdn-icons-png.flaticon.com/512/646/646094.png" alt="email" width = "27" ></a>
|
| 12 |
+
</center>
|
| 13 |
+
'''
|
| 14 |
+
|
| 15 |
+
sidebar_markdown = f'''
|
| 16 |
+
|
| 17 |
+
<center>
|
| 18 |
+
<img src="https://raw.githubusercontent.com/leoxiang66/streamlit-tutorial/IDP/widgets/static/tum.png" alt="TUM" width="150"/>
|
| 19 |
+
|
| 20 |
+
<h1>
|
| 21 |
+
Literature Research Tool
|
| 22 |
+
</h1>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
<code>
|
| 26 |
+
{APP_VERSION}
|
| 27 |
+
</code>
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
</center>
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
{icons}
|
| 34 |
+
|
| 35 |
+
---
|
| 36 |
+
|
| 37 |
+
## Choose the Paper Search Platforms'''
|
| 38 |
+
st.sidebar.markdown(sidebar_markdown,unsafe_allow_html=True)
|
| 39 |
+
# elvsier = st.sidebar.checkbox('Elvsier',value=True)
|
| 40 |
+
# IEEE = st.sidebar.checkbox('IEEE',value=False)
|
| 41 |
+
# google = st.sidebar.checkbox('Google Scholar')
|
| 42 |
+
platforms = st.sidebar.multiselect('Platforms',options=
|
| 43 |
+
[
|
| 44 |
+
# 'Elvsier',
|
| 45 |
+
'IEEE',
|
| 46 |
+
# 'Google Scholar',
|
| 47 |
+
'Arxiv',
|
| 48 |
+
'Paper with Code'
|
| 49 |
+
], default=[
|
| 50 |
+
# 'Elvsier',
|
| 51 |
+
'IEEE',
|
| 52 |
+
# 'Google Scholar',
|
| 53 |
+
'Arxiv',
|
| 54 |
+
'Paper with Code'
|
| 55 |
+
])
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
st.sidebar.markdown('## Choose the max number of papers to search')
|
| 60 |
+
number_papers=st.sidebar.slider('number', 10, 100, 20, 5)
|
| 61 |
+
|
| 62 |
+
st.sidebar.markdown('## Choose the start year of publication')
|
| 63 |
+
this_year = datetime.date.today().year
|
| 64 |
+
start_year = st.sidebar.slider('year start:', 2000, this_year, 2010, 1)
|
| 65 |
+
|
| 66 |
+
st.sidebar.markdown('## Choose the end year of publication')
|
| 67 |
+
end_year = st.sidebar.slider('year end:', 2000, this_year, this_year, 1)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
with st.sidebar:
|
| 71 |
+
st.markdown('## Adjust hyperparameters')
|
| 72 |
+
with st.expander('Clustering Options'):
|
| 73 |
+
standardization = st.selectbox('1) Standardization before clustering', options=['no', 'yes'], index=0 )
|
| 74 |
+
dr = st.selectbox('2) Dimension reduction', options=['none', 'pca'], index=0)
|
| 75 |
+
tmp = min(number_papers,15)
|
| 76 |
+
max_k = st.slider('3) Max number of clusters', 2,tmp , tmp//2)
|
| 77 |
+
cluster_model = st.selectbox('4) Clustering model', options=['Gaussian Mixture Model', 'K-means'], index=0)
|
| 78 |
+
|
| 79 |
+
with st.expander('Keyphrases Generation Options'):
|
| 80 |
+
model_cpt = st.selectbox(label='Model checkpoint', options=template.keywords_extraction.keys(),index=0)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
st.markdown('---')
|
| 84 |
+
st.markdown(icons,unsafe_allow_html=True)
|
| 85 |
+
st.markdown('''<center>Copyright © 2022 by Tao Xiang</center>''',unsafe_allow_html=True)
|
| 86 |
+
|
| 87 |
+
# st.sidebar.markdown('## Choose the number of clusters')
|
| 88 |
+
# k = st.sidebar.slider('number',1,10,3)
|
| 89 |
+
|
| 90 |
+
return platforms, number_papers, start_year, end_year, dict(
|
| 91 |
+
dimension_reduction= dr,
|
| 92 |
+
max_k = max_k,
|
| 93 |
+
model_cpt = model_cpt,
|
| 94 |
+
standardization = True if standardization == 'yes' else False,
|
| 95 |
+
cluster_model = 'gmm' if cluster_model == 'Gaussian Mixture Model' else 'kmeans-euclidean'
|
| 96 |
+
)
|
widgets/static/tum.png
ADDED

|
widgets/utils.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
import os
|
| 3 |
+
PACKAGE_ROOT = str(Path(__package__).absolute())
|
| 4 |
+
def readfile(path:str) -> str:
|
| 5 |
+
with open(path) as f:
|
| 6 |
+
ret = f.read()
|
| 7 |
+
return ret
|
| 8 |
+
|
| 9 |
+
def generate_html_pyecharts(chart, file_name) -> str:
|
| 10 |
+
if chart.render is None:
|
| 11 |
+
raise RuntimeError('Please pass a PyEchart chart object!')
|
| 12 |
+
|
| 13 |
+
path = f'./templates/{file_name}'
|
| 14 |
+
chart.render(path)
|
| 15 |
+
html = readfile(path).replace('<body>','<center><body>').replace('</body>','</body></center>')
|
| 16 |
+
os.remove(path)
|
| 17 |
+
return html
|